第3章 AMQ Streams での Kafka のデプロイメント
Apache Kafka コンポーネントは、AMQ Streams ディストリビューションを使用して OpenShift にデプロイするために提供されます。Kafka コンポーネントは通常、クラスターとして実行され、可用性を確保します。
Kafka コンポーネントが組み込まれた通常のデプロイメントには以下が含まれます。
- ブローカーノードの Kafka クラスター
- レプリケートされた ZooKeeper インスタンスの zookeeper クラスター
- 外部データ接続用の Kafka Connect クラスター
- セカンダリークラスターで Kafka クラスターをミラーリングする Kafka MirrorMaker クラスター
- 監視用に追加のKafka メトリクスデータを抽出する Kafka Exporter
- Kafka クラスターに対して HTTP ベースの要求を行う Kafka Bridge
少なくとも Kafka および ZooKeeper は必要ですが、上記のコンポーネントがすべて必須なわけではありません。MirrorMaker や Kafka Connect など、一部のコンポーネントでは Kafka なしでデプロイできます。
3.1. Kafka コンポーネントのアーキテクチャー
Kafka ブローカーのクラスターはメッセージの配信を処理します。
ブローカーは、設定データの保存やクラスターの調整に Apache ZooKeeper を使用します。Apache Kafka の実行前に、Apache ZooKeeper クラスターを用意する必要があります。
他の Kafka コンポーネントはそれぞれ Kafka クラスターと対話し、特定のロールを実行します。
Kafka コンポーネントの操作
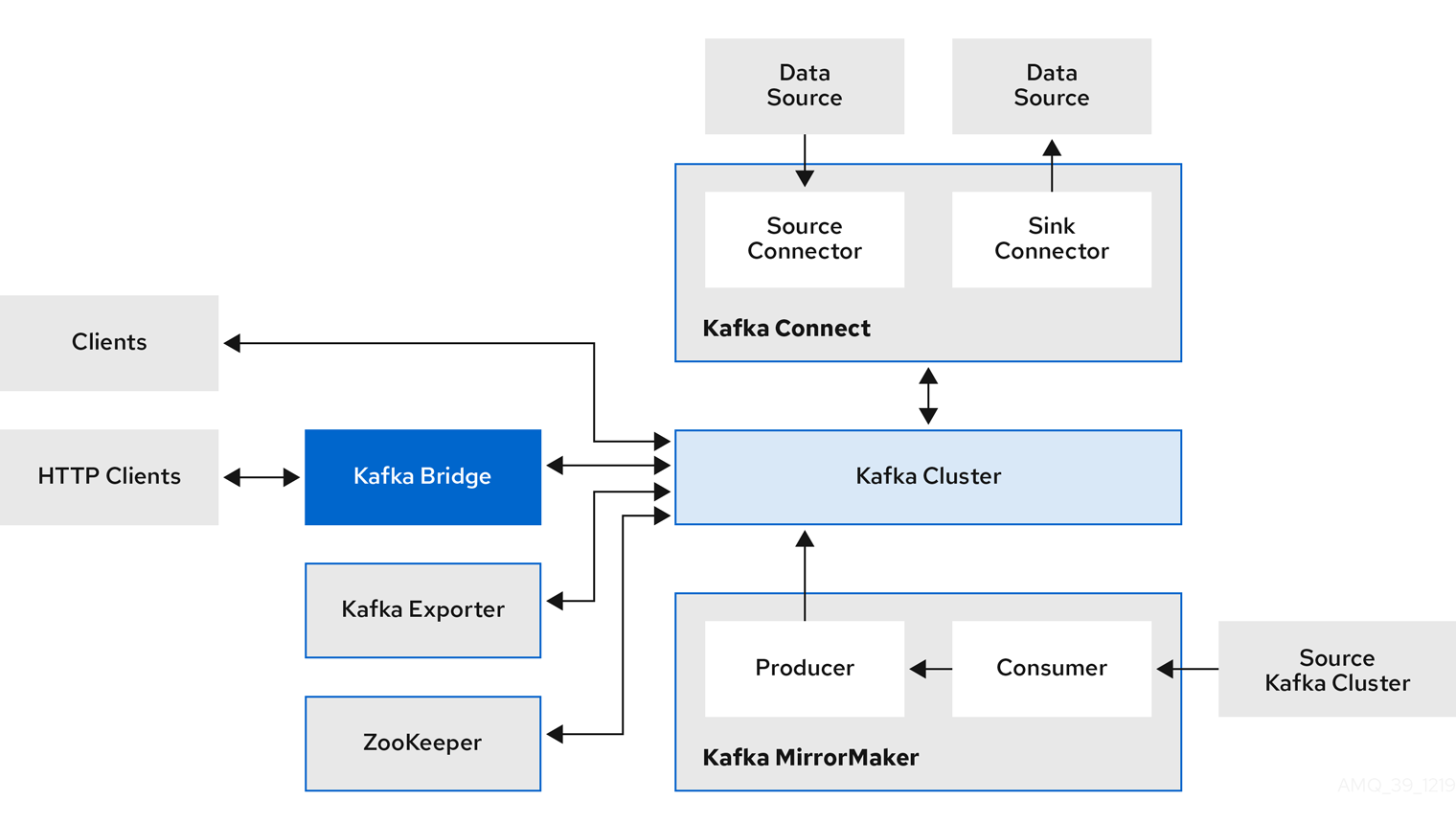
- Apache ZooKeeper
- Apache ZooKeeper はクラスター調整サービスを提供し、ブローカーおよびコンシューマーのステータスを保存して追跡するので、Kafka のコアとなる依存関係です。Zookeeper は、パーティションのリーダー選択にも使用されます。
- Kafka Connect
Kafka Connect は、Connector プラグインを使用して Kafka ブローカーと他のシステムの間でデータをストリーミングする統合ツールです。Kafka Connect は、Kafka と、データベースなどの外部データソースまたはターゲットと統合するためのフレームワークを提供し、コネクターを使用してデータをインポートまたはエクスポートします。コネクターは、必要な接続設定を提供するプラグインです。
- ソース コネクターは、外部データを Kafka にプッシュします。
sink コネクターは Kafka からデータを抽出します。
外部データは適切な形式に変換されます。
データコネクションに必要なコネクタープラグインでコンテナーイメージを自動的にビルドする
build設定にて、Kafka Connect をデプロイできます。
- Kafka MirrorMaker
Kafka MirrorMaker は、データセンター内またはデータセンター全体の 2 台の Kafka クラスター間でデータをレプリケーションします。
MirrorMaker はソースの Kafka クラスターからメッセージを取得して、ターゲットの Kafka クラスターに書き込みます。
- Kafka Bridge
- Kafka Bridge には、HTTP ベースのクライアントと Kafka クラスターを統合する API が含まれています。
- Kafka Exporter
- Kafka Exporter は、Prometheus メトリクス (主にオフセット、コンシューマーグループ、コンシューマーラグおよびトピックに関連するデータ) として分析用にデータを抽出します。コンシューマーラグとは、パーティションに最後に書き込まれたメッセージと、そのパーティションからコンシューマーが現在取得中のメッセージとの間の遅延を指します。