14.3. 高可用性の実装
高可用性 (HA) を実装することでその信頼性を強化し、ブローカークラスターは 1 つ以上のブローカーがオフラインになっても機能し続けます。
HA の実装には、複数のステップが関係します。
- 「ブローカークラスターの作成」 の説明に従って、HA 実装のブローカークラスターを設定します。
- ライブバックアップグループの概要を理解し、要件に最も適した HA ポリシーを選択する必要があります。Understanding how HA works in AMQ Broker を参照してください。
適切な HA ポリシーを選択したら、クラスター内の各ブローカーに HA ポリシーを設定します。以下を参照してください。
- フェイルオーバーを使用するようにクライアントアプリケーションを設定します。
高可用性用に設定されたブローカークラスターをトラブルシューティングする必要がある場合は、クラスターでブローカーを実行している各 Java Virtual Machine (JVM) インスタンスにガベージコレクション (GC) ログを有効にすることが推奨されます。JVM で GC ログを有効にする方法については、JVM で使用される Java Development Kit (JDK) バージョンの公式ドキュメントを参照してください。AMQ Broker がサポートする JVM バージョンの詳細は、Red Hat AMQ 7 Supported Configurations を参照してください。
14.3.1. High Availability Deployment and Usage
AMQ Broker では、クラスターでブローカーを ライブバックアップグループ にグループ化して、高可用性 (HA) を実装します。ライブバックアップグループでは、ライブブローカーはバックアップブローカーにリンクされ、失敗した場合はライブブローカーを引き継ぐことができます。AMQ Broker は、ライブバックアップグループ内のフェイルオーバー ( HA ポリシー と呼ばれる ) にいくつかの異なるストラテジーも提供します。
14.3.1.1. ライブバックアップグループがどのように高可用性を提供するか
AMQ Broker では、クラスターにブローカーをリンクして高可用性 (HA) を実装し、ライブバックアップグループ を形成します。ライブバックアップグループは フェイルオーバー を提供します。つまり、1 つのブローカーが失敗すると、別のブローカーがメッセージ処理を引き継ぐことができます。
ライブバックアップグループは、1 つ以上のバックアップブローカー ( スレーブ ブローカーとも呼ばれる ) にリンクされた 1 つのライブブローカー ( マスター ブローカーとも呼ばれる ) で設定されます。ライブブローカーはクライアント要求に対応し、バックアップブローカーはパッシブモードで待機します。ライブブローカーが失敗すると、バックアップブローカーはライブブローカーに置き換わり、クライアントが再接続し、作業を続行します。
14.3.1.2. 高可用性ポリシー
高可用性 ( HA ) ポリシーは、ライブバックアップグループでのフェイルオーバーの発生方法を定義します。AMQ Broker では、複数の HA ポリシーが提供されます。
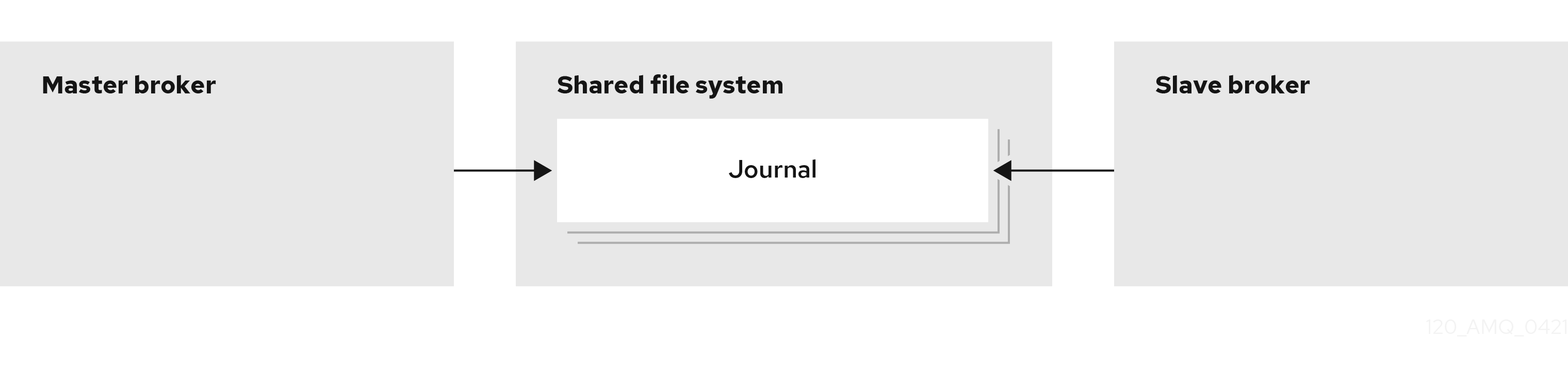
- 共有ストア ( 推奨 )
ライブおよびバックアップブローカーは、メッセージングデータを共有ファイルシステム上の共通ディレクトリー ( 通常は Storage Area Network (SAN) または Network File System (NFS) サーバー ) に保存します。また、JDBC ベースの永続を設定している場合は、ブローカーデータを指定されたデータベースに保存することもできます。共有ストアでは、ライブブローカーが失敗すると、バックアップブローカーは共有ストアからメッセージデータを読み込み、失敗したライブブローカーに対して引き継ぎします。
ほとんどの場合、レプリケーションの代わりに共有ストアを使用する必要があります。共有ストアはネットワーク経由でデータを複製しないため、通常はレプリケーションよりもパフォーマンスが向上します。共有ストアは、ライブブローカーとそのバックアップが同時に行われるという問題である、ネットワーク分離 (スプリットブレインとも呼ばれる) を回避します。
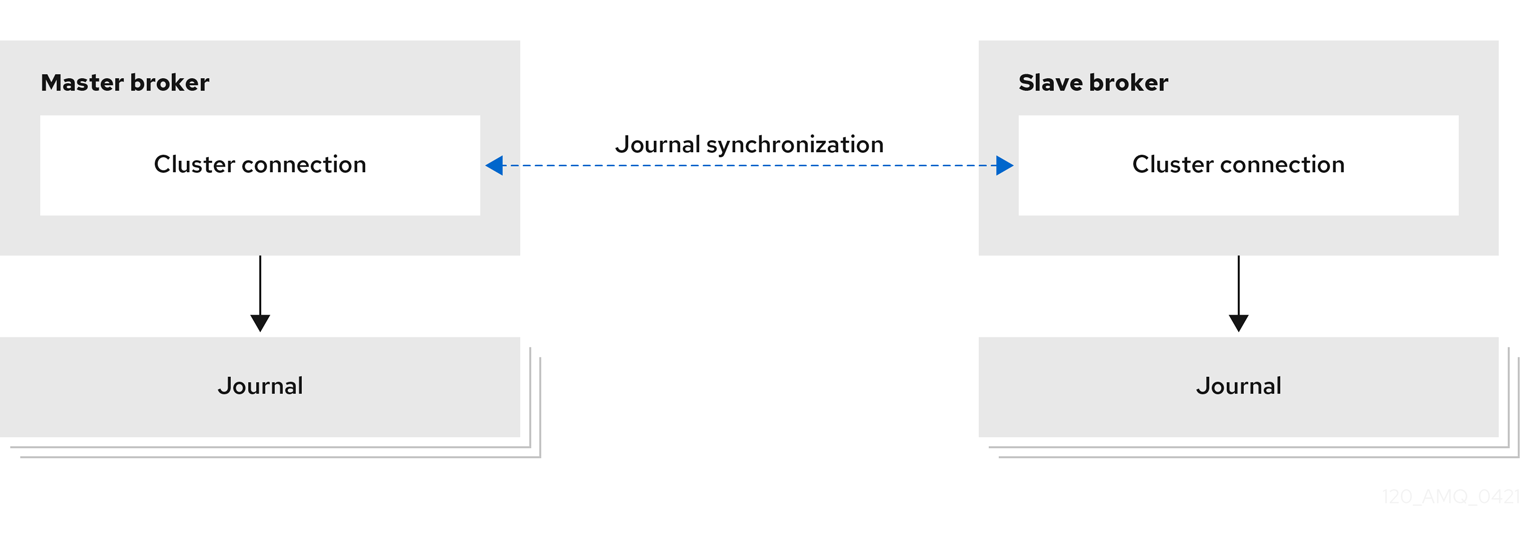
- レプリケーション
ライブおよびバックアップブローカーは、そのメッセージングデータをネットワーク経由で継続的に同期します。ライブブローカーが失敗すると、バックアップブローカーは同期データを読み込み、失敗したライブブローカーに対して引き継ぎます。
ライブブローカーとバックアップブローカー間のデータ同期により、ライブブローカーが失敗してもメッセージングデータが失われないようにします。ライブブローカーおよびバックアップブローカーが最初に結合すると、ライブブローカーはネットワーク経由ですべての既存データをバックアップブローカーに複製します。この最初のフェーズが完了すると、ライブブローカーは永続データを、ライブブローカーが受信時にバックアップブローカーに複製します。つまり、ライブブローカーがネットワークから切断されると、バックアップブローカーには、ライブブローカーが受信したすべての永続データが含まれます。
レプリケーションはネットワーク経由でデータを同期するため、ネットワーク障害により、ライブブローカーとそのバックアップが同時に存続するネットワーク分離が発生する可能性があります。
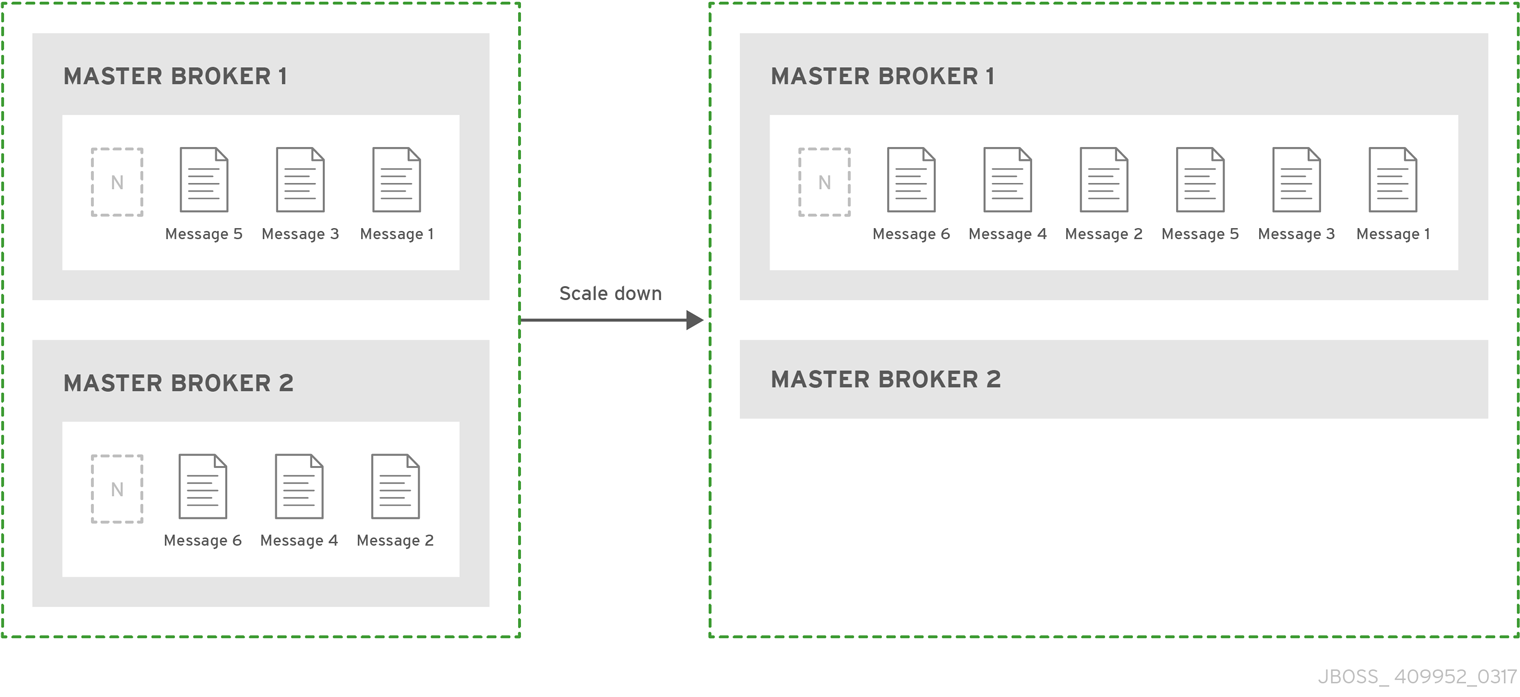
- ライブのみ ( 限定 HA)
ライブブローカーが正常に停止されると、メッセージとトランザクションの状態を別のライブブローカーにコピーし、シャットダウンします。その後、クライアントは他のブローカーに再接続し、メッセージの送受信を続行します。
関連情報
- ライブバックアップグループのブローカー間で共有される永続メッセージデータの詳細は、「ジャーナルでのメッセージデータの永続化」 を参照してください。
14.3.1.3. レプリケーションポリシーの制限
レプリケーションを使用して高可用性を提供する場合、ライブブローカーとバックアップブローカーの両方が同時にライブになるリスクが存在します。これはスプリットブレインと呼ばれます。
ライブブローカーとそのバックアップが接続を失うと、スプリットブレインが発生する可能性があります。この場合、ライブブローカーとそのバックアップの両方を同時にアクティブにすることができます。この状況では、ブローカー間でメッセージレプリケーションがないため、各ブローカーはクライアントとプロセスメッセージに、他のメッセージを認識せずに提供します。この場合、各ブローカーは完全に異なるジャーナルを持ちます。この状況からの復元は非常に困難であり、場合によっては不可能です。
- スプリットブレインの可能性を 排除 するには、共有ストア HA ポリシーを使用します。
レプリケーション HA ポリシーを使用する場合は、次の手順を実行して、スプリットブレインが発生するリスクを軽減してください。
ブローカーが ZooKeeper Coordination Service を使用してブローカーを調整するようにする場合は、少なくとも 3 つのノードに ZooKeeper をデプロイします。ブローカーが 1 つの ZooKeeper ノードへの接続を失った場合、少なくとも 3 つのノードを使用することで、ライブバックアップブローカーペアでレプリケーションの中断が発生したときに、ノードの過半数をブローカー調整のために使用できるようになります。
クラスター内の他の使用可能なブローカーを使用してクォーラムの投票を提供する埋め込みブローカー調整を使用する場合、3 つ以上のライブ/バックアップペア を使用することで、スプリットブレインが発生する可能性を減らすことができます (なくすことはできません)。3 つ以上のライブ/バックアップペアを使用することで、ライブ/バックアップのブローカーのペアでレプリケーションが中断された場合に発生するクォーラム票で過半数の結果を得ることができます。
レプリケーション HA ポリシーを使用する場合の追加に関する考慮事項は以下のとおりです。
- ライブブローカーが失敗し、バックアップがライブに移行すると、新しいバックアップブローカーがライブに割り当てられるまで、または元のライブブローカーへのフェイルバックが発生するまでレプリケーションは行われません。
- ライブバックアップグループでバックアップブローカーが失敗すると、ライブブローカーはメッセージを提供します。ただし、メッセージは別のブローカーがバックアップとして追加されるか、元のバックアップブローカーが再起動されるまで複製されません。この間、メッセージはライブブローカーにのみ永続化されます。
- ブローカが埋め込みブローカー調整を使用し、ライブ/バックアップペアの両方のブローカがシャットダウンされている場合、メッセージロスを避けるために、最後にアクティブだったブローカを最初に再起動する必要があります。最近アクティブなブローカーがバックアップブローカーであった場合は、このブローカーをマスターブローカーとして手動で再設定し、最初に再起動できるようにする必要があります。
14.3.3. Configuring replication high availability
レプリケーション高可用性 (HA) ポリシーを使用して HA をブローカークラスターに実装できます。レプリケーションでは、永続データはライブブローカーとバックアップブローカー間で同期されます。ライブブローカーが障害に遭遇すると、メッセージデータはバックアップブローカーに同期され、失敗したライブブローカーに対して引き継ぎされます。
共有ファイルシステムがない場合は、共有ストアの代わりにレプリケーションを使用する必要があります。ただし、レプリケーションにより、ライブブローカーとそのバックアップが同時にライブになるシナリオが発生する可能性があります。
ライブおよびバックアップブローカーは、ネットワーク経由でメッセージングデータを同期する必要があるため、レプリケーションによりパフォーマンスのオーバーヘッドが追加されます。この同期プロセスでは、ジャーナル操作がブロックされますが、クライアントはブロックされません。データの同期のためにジャーナル操作がブロックできる最大時間を設定できます。
ライブ/バックアップブローカーペア間のレプリケーション接続が中断された場合、ブローカーには、ライブブローカがまだアクティブであるかどうか、または使用できず、バックアップブローカへのフェイルオーバーが必要かどうかを判断するための調整方法が必要です。この調整を提供するために、次のいずれかを使用するようにブローカーを設定できます。
- Apache ZooKeeper 調整サービス。
- クラスター内の他のブローカーを使用してクォーラム投票を提供する組み込み型のブローカー調整。
14.3.3.1. 調整方法の選択
レプリケーションの中断が発生したときにフェイルオーバーが必要かどうかを判断するために、ZooKeeper 調整サービスまたは組み込みブローカー調整を使用するようにブローカーを設定できます。このセクションでは、インフラストラクチャーの要件と、両方の方法におけるデータの一貫性を管理する方法の違いについて説明します。これは、調整方法を選択する際の考慮事項となる可能性があります。
インフラストラクチャーの要件
- ブローカーで ZooKeeper 調整サービスを使用する場合は、ブローカーを少なくとも 3 つの Apache ZooKeeper ノードに接続する必要があります。3 つ以上の ZooKeeper ノードがあれば、ブローカーが 1 つのノードへの接続を失った場合でも、ブローカーは機能し続けることができます。ブローカーに調整サービスを提供するために、他のアプリケーションで使用されている既存の ZooKeeper ノードを共有できます。Apache ZooKeeper の設定の詳細については、Apache ZooKeeper のドキュメントを参照してください。
- クラスター内の他の使用可能なブローカーを使用してクォーラムの投票を提供する組み込みブローカー調整を使用する場合は、少なくとも 3 つのライブ/バックアップブローカーペアが必要です。3 つ以上のライブ/バックアップペアを使用することで、ライブ/バックアップのブローカーのペアでレプリケーションが中断された場合に発生するクォーラム票で過半数の結果を得ることができます。
データの整合性
- Apache ZooKeeper 調整サービスを使用する場合、ZooKeeper は各ブローカー上のデータのバージョンを追跡するため、レプリケーションの目的でブローカーがプライマリーまたはバックアップのどちらとして設定されているかに関係なく、最新のジャーナルデータを持つブローカーだけがライブブローカーとして起動することが可能です。バージョンの追跡により、ブローカーが期限切れのジャーナルでアクティブ化され、クライアントへのサービスを開始する可能性がなくなります。
- 組み込みのブローカー調整を使用する場合、最新のジャーナルを持つブローカーのみがライブブローカーになることができるように、各ブローカーのデータのバージョンを追跡するメカニズムはありません。したがって、期限切れのジャーナルを持つブローカーが稼働してクライアントへのサービスを開始する可能性があり、これによりジャーナルに相違が生じます。
14.3.3.2. レプリケーションの中断後にブローカーが調整する方法
このセクションでは、レプリケーション接続が中断された後、両方の調整方法がどのように機能するかについて説明します。
ZooKeeper 調整サービスの使用
ZooKeeper 調整サービスを使用してレプリケーションの中断を管理する場合、両方のブローカーが複数の Apache ZooKeeper ノードに接続されている必要があります。
- いつでも、ライブブローカーが ZooKeeper ノードの大部分への接続を失った場合、「スプリットブレイン」が発生するリスクを回避するためにシャットダウンします。
- いつでも、バックアップブローカーが ZooKeeper ノードの大部分への接続を失った場合、レプリケーションデータの受信を停止し、ZooKeeper ノードの大部分に接続できるようになるまで待機してから、バックアップブローカーとして再び機能します。接続が ZooKeeper ノードの大部分に復元されると、バックアップブローカーは ZooKeeper を使用して、データを破棄し、複製元のライブブローカーを検索する必要があるかどうか、または現在のデータでライブブローカーになることができるかどうかを判断します。
ZooKeeper は、以下の制御メカニズムを使用してフェイルオーバープロセスを管理します。
- いつでも単一のライブブローカーによってのみ所有することができる共有リースロック。
- ブローカーデータの最新バージョンを追跡する起動シーケンスカウンター。各ブローカーは、NodeID とともに、サーバーロックファイルに保存されているローカルカウンター内のジャーナルデータのバージョンを追跡します。また、ライブブローカーは、ZooKeeper の調整されたアクティベーションシーケンスカウンターでそのバージョンを共有します。
ライブブローカーとバックアップブローカー間のレプリケーション接続が失われた場合、ライブブローカーは、ZooKeeper のローカルアクティベーションシーケンスカウンター値と調整されたアクティベーションシーケンスカウンター値の両方を 1 増やして、最新のデータがあることをアドバタイズします。バックアップブローカーのデータは古くなったと見なされ、レプリケーション接続が復元されて最新のデータが同期されるまで、ブローカーはライブブローカーになることはできません。
レプリケーション接続が失われた後、バックアップブローカは ZooKeeper のロックがライブブローカによって所有されているか、ZooKeeper 上の調整されたアクティベーションシーケンスカウンターがそのローカルカウンター値と一致するかを確認します。
- ロックがライブブローカーによって所有されている場合、バックアップブローカーは、レプリケーション接続が失われたときに、ZooKeeper 上のアクティベーションシーケンスカウンターがライブブローカーによって更新されたことを検出します。これは、ライブブローカーが実行中であることを示すので、バックアップブローカーはフェイルオーバーを試みない。バックアップブローカーは、データを複製するライブブローカーを検索し、最新のデータを取得します。
- ロックがライブブローカーによって所有されていない場合、ライブブローカーは動作していません。バックアップブローカーのアクティベーションシーケンスカウンターの値が、ZooKeeper の調整されたアクティベーションシーケンスカウンターの値と同じである場合、バックアップブローカーに最新のデータがあることを示し、バックアップブローカーはフェイルオーバーします。
- ロックがライブブローカーによって所有されていないが、バックアップブローカーのアクティベーションシーケンスカウンターの値が ZooKeeper のカウンター値よりも小さい場合、バックアップブローカーのデータは最新ではなく、バックアップブローカーはフェイルオーバーできません。
組み込みブローカー調整の使用
ライブバックアップブローカーペアが、組み込みブローカー調整を使用してレプリケーションの中断を調整する場合、次の 2 種類のクォーラム評価を開始することができます。
| 投票タイプ | 説明 | イニシエーター | 必要な設定 | 参加者 | 投票の結果に基づくアクション |
|---|---|---|---|---|---|
| バックアップ投票 | バックアップブローカーがライブブローカーへのレプリケーション接続を失うと、バックアップブローカーはこの投票の結果に基づいて開始するかどうかを決定します。 | バックアップブローカー | なし。バックアップブローカーがレプリケーションパートナーへの接続を失った際に、バックアップ評価が自動的に行われます。 ただし、これらのパラメーターにカスタムの値を指定すると、バックアップ評価のプロパティーを制御できます。
| クラスターの他のライブブローカー | バックアップブローカーは、クラスター内の他のライブブローカーから過半数 ( クォーラム ) 票を受信すると開始します。これは、レプリケーションパートナーが利用可能でなくなったことを示しています。 |
| ライブ評価 | ライブブローカーがレプリケーションパートナーへの接続を失った場合、ライブブローカーはこの投票に基づいて実行を継続するかどうかを決定します。 | ライブブローカー |
ライブ評価は、ライブブローカーがレプリケーションパートナーへの接続を失い、 | クラスターの他のライブブローカー | ライブブローカーは、クラスターの他のライブブローカーから過半数を受け取ら ない 場合はシャットダウンします。これは、クラスター接続がまだアクティブであることを示します。 |
以下は、ブローカークラスターの設定がクォーラム投票の動作にどのように影響するかについて留意すべき重要な事項になります。
- クォーラム評価を成功させるには、クラスターのサイズで、過半数の結果が得られる必要があります。したがって、クラスターには 少なくとも 3 つ のライブバックアップブローカーペアが必要です。
- クラスターに追加するその他のライブバックアップブローカーのペア。クラスターのフォールトトレランス全体を増やすことができます。たとえば、ライブ / バックアップのペアが 3 つあるとします。完全なライブバックアップペアがなくなると、残りの 2 つのライブ / バックアップペアが、後続のクォーラムの投票で最大数に達することができません。この状況では、クラスターでさらにレプリケーションが中断されると、ライブブローカーがシャットダウンし、バックアップブローカーが起動しない可能性があります。例えば 5 組のブローカペアでクラスターを設定することで、クラスターでは少なくとも 2 つの障害が発生することができますが、それでもクォーラム投票で過半数の結果を得ることができます。
- クラスター内のライブバックアップブローカーのペアの数を意図的に 減らす と、過半数に以前に設定されたしきい値は自動的に減らされません。この間、レプリケーション接続が失われたためにトリガーされたクォーラムの評価は成功せず、クラスターがスプリットブレインに対してより脆弱になります。クラスターがクォーラム票の過半数を再計算するには、まずクラスターから削除するライブバックアップのペアをシャットダウンします。次に、クラスター内の残りのライブバックアップペアを再起動します。残りのブローカーがすべて再起動すると、クラスターはクォーラム評価しきい値を再計算します。
14.3.3.3. ZooKeeper 調整サービスを使用したレプリケーションの高可用性のためのブローカークラスターの設定
以下の手順では、Apache ZooKeeper 調整サービスを使用するブローカクラスターに対して、レプリケーションの高可用性 (HA) を設定する方法を説明します。
前提条件
- ブローカーが 1 つのノードとの接続を失った場合でも操作を継続できるように、3 つ以上の Apache ZooKeeper ノードを用意します。
- ZooKeeper は、一時停止時間が ZooKeeper サーバーの ティック時間より大幅に短くなるように、十分なリソースを確保する必要があります。ブローカーの予想される負荷に応じて、ブローカーと ZooKeeper ノードが同じノードを共有するかどうか慎重に検討してください。詳細は、https://zookeeper.apache.org/ を参照してください。
手順
ZooKeeper 調整サービスを使用したレプリケーションの高可用性を使用するようにライブブローカーを設定します。
-
ライブブローカーの
<broker_instance_dir> /etc/broker.xml設定ファイルを開きます。 HA ポリシーのレプリケーションを使用するようにライブブローカーを設定します。
<configuration> <core> ... <ha-policy> <replication> <primary> <manager> ... </manager> <group-name>my-group-1</group-name> </primary> </replication> </ha-policy> ... </core> </configuration>プライマリー- 初期設定後、このブローカーがライブブローカーとして起動することを示します。
group-name- このライブバックアップグループの名前 (オプション)。ライブバックアップグループを形成するには、ライブおよびバックアップブローカーを同じグループ名で設定する必要があります。group-name を指定しない場合、バックアップブローカーは任意のライブブローカーとレプリケーションを行うことができます。
managerセクションで、ライブブローカーを ZooKeeper ノードに接続するためのプロパティーを設定します。<configuration> <core> ... <ha-policy> <replication> <primary> <manager> <class-name>org.apache.activemq.artemis.quorum.zookeeper.CuratorDistributedPrimitiveManager</class-name> <properties> <property key="connect-string" value="192.168.1.10:6666,192.168.2.10:6667,192.168.3.10:6668"/> </properties> </manager> ... </primary> </replication> </ha-policy> ... </core> </configuration>class-name-
ZooKeeper 調整サービスのクラス名:
org.apache.activemq.artemis.quorum.zookeeper.CuratorDistributedPrimitiveManager。Apache Curator がデフォルトのマネージャーであるため、この要素はオプションです。 propertiesproperty要素を指定します。この要素内で一連のキーと値のペアを指定して、ZooKeeper ノードの接続の詳細を提供できます。Expand キー 値 connect-string
ライブブローカー用の ZooKeeper ノードの IP アドレスとポート番号のコンマ区切りリストを指定します。たとえば、
value="192.168.1.10:6666,192.168.2.10:6667,192.168.3.10:6668"です。session-ms
ライブブローカーが ZooKeeper の大半のノードとの接続を失ってシャットダウンするまでの待ち時間。デフォルト値は
18000ミリ秒です。有効な値は、ZooKeeper サーバーのティック時間の 2 倍から 20 倍までの間です。注記ZooKeeper のハートビートが確実に機能するためには、ガベージコレクションのための ZooKeeper の一時停止時間を
session-msプロパティー値の 0.33 未満にする必要があります。一時停止時間をこの制限よりも短くすることができない場合は、各ブローカーのsession-msプロパティー値を増やし、より遅いフェイルオーバーを受け入れます。重要ブローカーレプリケーションパートナーは、2 秒ごとに自動的に "ping" パケットを交換し、パートナーブローカーが利用可能であることを確認します。バックアップブローカーがライブブローカーから応答を受信しない場合、バックアップはブローカーの接続 Time-to-live (TTL) が期限切れになるまで応答を待ちます。デフォルトの connection-ttl は
60000ミリ秒です。これは、バックアップブローカが 60 秒後にフェイルオーバーを試みることを意味します。フェイルオーバーを高速化するために、connection-ttl 値をsession-msプロパティー値と同様の値に設定することを推奨します。新しい connection-ttl を設定するには、connection-ttl-overrideプロパティーを設定します。namespace (オプション)
ブローカーが他のアプリケーションと ZooKeeper ノードを共有する場合、ブローカーに調整サービスを提供するファイルを格納する ZooKeeper namespace を作成することができます。バックアップブローカーに namespace を指定した場合、ライブブローカーにも同じ namespace を指定する必要があります。
ライブブローカーの追加の HA プロパティーを設定します。
これらの追加の HA プロパティーには、最も一般的なユースケースに適したデフォルト値があります。そのため、デフォルト動作が必要ない場合のみこのプロパティーを設定する必要があります。詳細は、付録F 追加のレプリケーションの高可用性設定要素 を参照してください。
-
ライブブローカーの
ZooKeeper 調整サービスを使用したレプリケーションの高可用性を使用するようにバックアップブローカーを設定します。
-
バックアップブローカーの
<broker_instance_dir> /etc/broker.xml設定ファイルを開きます。 HA ポリシーのレプリケーションを使用するようにバックアップブローカーを設定します。
<configuration> <core> ... <ha-policy> <replication> <backup> <manager> ... </manager> <group-name>my-group-1</group-name> <allow-failback>true</allow-failback> </backup> </replication> </ha-policy> ... </core> </configuration>backup- 初期設定後、このブローカーがバックアップブローカーとして起動することを示します。
group-name- このバックアップが接続するライブブローカーのグループ名。バックアップブローカーは、同じグループ名を共有するライブブローカーにのみ接続します。group-name を指定しない場合、バックアップブローカーは任意のライブブローカーとレプリケーションを行うことができます。
allow-failbacktrueに設定すると、現在ライブブローカーであるバックアップブローカーが、プライマリーブローカーとして設定されているレプリケーションパートナーにライブのロールを返すことができるようになります。ライブ (プライマリー) ブローカーとして設定されているブローカーは、起動時に、最新のデータがあり、ライブブローカーとして実行できるかどうかを確認します。データが最新でないと判断した場合、ブローカーは空のジャーナルで再起動し、現在稼働中のブローカーに接続して最新データをレプリケートするのを待ちます。プライマリーブローカーとして設定されたブローカーは、データを複製した後、現在稼働中のバックアップブローカーに再起動を要求し、フェイルオーバーして再びライブブローカーになることができるようにします。
allow-failbackがtrueに設定されている場合、バックアップブローカーは再起動して、レプリケーションパートナーが再びライブになることを許可します。allow-failbackがfalseに設定されている場合、バックアップブローカーは再起動しないため、両方のブローカーが現在のロールを維持します。
managerセクション内で、バックアップブローカーを ZooKeeper ノードに接続するためのプロパティーを設定します。<configuration> <core> ... <ha-policy> <replication> <backup> <manager> <class-name>org.apache.activemq.artemis.quorum.zookeeper.CuratorDistributedPrimitiveManager</class-name> <properties> <property key="connect-string" value="192.168.1.10:6666,192.168.2.10:6667,192.168.3.10:6668"/> </properties> </manager> ... </backup> </replication> </ha-policy> ... </core> </configuration>class-name-
ZooKeeper 調整サービスのクラス名:
org.apache.activemq.artemis.quorum.zookeeper.CuratorDistributedPrimitiveManager。Apache Curator がデフォルトのマネージャーであるため、この要素はオプションです。 propertiespropertyセクションを指定します。このセクションでは、キーと値のペアのセットを指定して、ZooKeeper ノードの接続の詳細を提供できます。Expand キー 値 connect-string
バックアップブローカー用の ZooKeeper ノードの IP アドレスとポート番号のコンマ区切りリストを指定します。たとえば、
value="192.168.1.10:6666,192.168.2.10:6667,192.168.3.10:6668"です。session-ms
ライブブローカーが ZooKeeper の大半のノードとの接続を失ってシャットダウンするまでの待ち時間。デフォルト値は
18000ミリ秒です。有効な値は、ZooKeeper サーバーのティック時間の 2 倍から 20 倍までの間です。注記ZooKeeper のハートビートが確実に機能するためには、ガベージコレクションのための ZooKeeper の一時停止時間を
session-msプロパティー値の 0.33 未満にする必要があります。一時停止時間をこの制限よりも短くすることができない場合は、各ブローカーのsession-msプロパティー値を増やし、より遅いフェイルオーバーを受け入れます。重要ブローカーレプリケーションパートナーは、2 秒ごとに自動的に "ping" パケットを交換し、パートナーブローカーが利用可能であることを確認します。バックアップブローカーがライブブローカーから応答を受信しない場合、バックアップはブローカーの接続 Time-to-live (TTL) が期限切れになるまで応答を待ちます。デフォルトの connection-ttl は
60000ミリ秒です。これは、バックアップブローカが 60 秒後にフェイルオーバーを試みることを意味します。フェイルオーバーを高速化するために、connection-ttl 値をsession-msプロパティー値と同様の値に設定することを推奨します。新しい connection-ttl を設定するには、connection-ttl-overrideプロパティーを設定します。namespace (オプション)
ブローカーが他のアプリケーションと ZooKeeper ノードを共有する場合、ブローカーに調整サービスを提供するファイルを格納する ZooKeeper namespace を作成することができます。バックアップブローカーに namespace を指定した場合、ライブブローカーにも同じ namespace を指定する必要があります。
バックアップブローカーの追加の HA プロパティーを設定します。
これらの追加の HA プロパティーには、最も一般的なユースケースに適したデフォルト値があります。そのため、デフォルト動作が必要ない場合のみこのプロパティーを設定する必要があります。詳細は、付録F 追加のレプリケーションの高可用性設定要素 を参照してください。
-
バックアップブローカーの
- ステップ 1 と 2 を繰り返して、クラスターの追加のライブバックアップブローカーペアをそれぞれ設定します。
関連情報
- HA のレプリケーションを使用するブローカークラスターの例については、HA サンプルプログラム を参照してください。
- ノード ID の詳細は、Understanding node IDs を参照してください。
14.3.3.4. 組み込みのブローカー調整を使用したレプリケーションの高可用性のためのブローカークラスターの設定
組み込みのブローカー調整を使用したレプリケーションでは、「スプリットブレイン」のリスクを軽減する (ただし、排除するわけではない) ために、少なくとも 3 つのライブバックアップペアが必要です。
以下の手順では、6 つのブローカークラスターにレプリケーションの高可用性 (HA) を設定する方法を説明します。このトポロジーでは、6 つのブローカーはライブバックアップのペアにグループ化されます。3 つのライブブローカーは、専用のバックアップブローカーとペアになります。
前提条件
6 つ以上のブローカーを持つブローカークラスターが必要です。
6 つのブローカーは 3 つのライブバックアップペアに設定されます。ブローカーのクラスターへの追加に関する詳細は、14章ブローカークラスターの設定 を参照してください。
手順
クラスターのブローカーをライブバックアップグループにグループ化します。
ほとんどの場合、ライブバックアップグループは、ライブブローカーとバックアップブローカーという 2 つのブローカーで設定される必要があります。クラスターに 6 つのブローカーがある場合は、3 つのライブバックアップグループが必要です。
1 つのライブブローカーと 1 つのバックアップブローカーで設定される最初のライブバックアップグループを作成します。
-
ライブブローカーの
<broker_instance_dir> /etc/broker.xml設定ファイルを開きます。 HA ポリシーのレプリケーションを使用するようにライブブローカーを設定します。
<configuration> <core> ... <ha-policy> <replication> <master> <check-for-live-server>true</check-for-live-server> <group-name>my-group-1</group-name> <vote-on-replication-failure>true</vote-on-replication-failure> ... </master> </replication> </ha-policy> ... </core> </configuration>check-for-live-serverライブブローカーが失敗すると、このプロパティーは、再起動時にクライアントがフェイルバックするかどうかを制御します。
このプロパティーを
trueに設定すると、以前のフェイルオーバー後にライブブローカーが再起動すると、同じノード ID を持つクラスター内の別のブローカーを検索します。ライブブローカーが同じノード ID を持つ別のブローカーを見つけると、ライブブローカーの失敗時にバックアップブローカーが正常に起動することを示しています。この場合、ライブブローカーはデータをバックアップブローカーと同期します。その後、ライブブローカーはバックアップブローカーにシャットダウンするよう要求します。以下に示すように、バックアップブローカーがフェイルバック用に設定されている場合、シャットダウンします。その後、ライブブローカーはアクティブなロールを再開します。そして、クライアントはこれに再接続します。警告ライブブローカーで
check-for-live-serverをtrueに設定しない場合、以前のフェイルオーバー後にライブブローカーを再起動すると、重複したメッセージング処理が発生する可能性があります。具体的には、このプロパティーをfalseに設定してライブブローカーを再起動すると、ライブブローカーはバックアップブローカーとデータを同期しません。この場合、ライブブローカーはバックアップブローカーがすでに処理された同じメッセージを処理し、重複が発生する可能性があります。group-name- このライブバックアップグループの名前 (オプション)。ライブバックアップグループを形成するには、ライブおよびバックアップブローカーを同じグループ名で設定する必要があります。group-name を指定しない場合、バックアップブローカーは任意のライブブローカーとレプリケーションを行うことができます。
vote-on-replication-failureこのプロパティーは、レプリケーション接続が中断された場合に、ライブブローカーが ライブ評価 と呼ばれるクォーラム評価を開始するかどうかを制御します。
ライブ評価は、ライブブローカーで、それまたはパートナーが中断されたレプリケーション接続の原因であるかどうかを判断する方法です。評価の結果に基づいて、ライブブローカーは稼働またはシャットダウンします。
重要クォーラム評価を成功させるには、クラスターのサイズで、過半数の結果が得られる必要があります。そのため、レプリケーション HA ポリシーを使用する場合、クラスターには少なくとも 3 つのライブバックアップブローカーのペアが必要です。
クラスターに設定するブローカーのペアが多いほど、クラスターの全体的なフォールトトレランスが向上します。たとえば、3 つのライブバックアップブローカーのペアがあるとします。完全なライブバックアップペアへの接続を失った場合、残りの 2 つのライブ / バックアップペアが、クォーラムの投票で過半数に達しなくなります。この状況では、後続のレプリケーションが中断されると、ライブブローカーがシャットダウンし、バックアップブローカーが起動しない可能性があります。例えば 5 組のブローカペアでクラスターを設定することで、クラスターでは少なくとも 2 つの障害が発生することができますが、それでもクォーラム投票で過半数の結果を得ることができます。
ライブブローカーの追加の HA プロパティーを設定します。
これらの追加の HA プロパティーには、最も一般的なユースケースに適したデフォルト値があります。そのため、デフォルト動作が必要ない場合のみこのプロパティーを設定する必要があります。詳細は、付録F 追加のレプリケーションの高可用性設定要素 を参照してください。
-
バックアップブローカーの
<broker_instance_dir> /etc/broker.xml設定ファイルを開きます。 HA ポリシーのレプリケーションを使用するようにバックアップブローカーを設定します。
<configuration> <core> ... <ha-policy> <replication> <slave> <allow-failback>true</allow-failback> <group-name>my-group-1</group-name> <vote-on-replication-failure>true</vote-on-replication-failure> ... </slave> </replication> </ha-policy> ... </core> </configuration>allow-failbackフェイルオーバーが発生し、バックアップブローカがライブブローカを引き継いだ場合、このプロパティーは、バックアップブローカが再起動してクラスターに再接続したときに、元のライブブローカにフェイルバックするかどうかを制御します。
注記フェイルバックは、ライブバックアップのペア (単一のバックアップブローカーとペアの 1 つのライブブローカー) を対象としています。ライブブローカーが複数のバックアップで設定されている場合、フェイルバックは発生しません。代わりに、フェイルオーバーイベントが発生すると、バックアップブローカーはライブになり、次のバックアップがバックアップになります。元のライブブローカーがオンラインに戻ると、現在のブローカーにバックアップがすでにあるため、フェイルバックを開始できなくなります。
group-name- このライブバックアップグループの名前 (オプション)。ライブバックアップグループを形成するには、ライブおよびバックアップブローカーを同じグループ名で設定する必要があります。group-name を指定しない場合、バックアップブローカーは任意のライブブローカーとレプリケーションを行うことができます。
vote-on-replication-failureこのプロパティーは、レプリケーション接続が中断された場合に、ライブブローカーが ライブ評価 と呼ばれるクォーラム評価を開始するかどうかを制御します。アクティブになったバックアップブローカーはライブブローカーと見なされ、ライブ評価を開始できます。
ライブ評価は、ライブブローカーで、それまたはパートナーが中断されたレプリケーション接続の原因であるかどうかを判断する方法です。評価の結果に基づいて、ライブブローカーは稼働またはシャットダウンします。
( 任意設定 ) バックアップブローカーが開始するクォーラム票のプロパティーを設定します。
<configuration> <core> ... <ha-policy> <replication> <slave> ... <vote-retries>12</vote-retries> <vote-retry-wait>5000</vote-retry-wait> ... </slave> </replication> </ha-policy> ... </core> </configuration>vote-retries- このプロパティーは、バックアップブローカーの起動を可能にする大部分の結果を受信するために、バックアップブローカーがクォーラム評価を再試行する回数を制御します。
vote-retry-wait- このプロパティーは、バックアップブローカーがクォーラム評価の再試行ごとに待機する期間 ( ミリ秒単位 ) を制御します。
バックアップブローカーの追加の HA プロパティーを設定します。
これらの追加の HA プロパティーには、最も一般的なユースケースに適したデフォルト値があります。そのため、デフォルト動作が必要ない場合のみこのプロパティーを設定する必要があります。詳細は、付録F 追加のレプリケーションの高可用性設定要素 を参照してください。
-
ライブブローカーの
クラスター内の追加のライブバックアップグループごとに、手順 2 を繰り返します。
クラスターに 6 つのブローカーがある場合は、この手順を 2 回ずつ繰り返し、残りのライブバックアップグループごとに 1 回ずつ繰り返します。
関連情報
- HA のレプリケーションを使用するブローカークラスターの例については、HA サンプルプログラム を参照してください。
- ノード ID の詳細は、Understanding node IDs を参照してください。
14.3.4. Configuring limited high availability with live-only
ライブのみの HA ポリシーを使用すると、メッセージを失わずにクラスターのブローカーをシャットダウンすることができます。ライブのみでは、ライブブローカーが正常に停止されると、メッセージとトランザクションの状態を別のライブブローカーにコピーし、シャットダウンします。その後、クライアントは他のブローカーに再接続し、メッセージの送受信を続行します。
ライブのみの HA ポリシーは、ブローカーが正常に停止された場合にのみケースを処理します。予期しないブローカーの失敗を処理しません。
ライブのみの HA はメッセージの損失を防ぎますが、メッセージの順序は保持されない可能性があります。ライブのみの HA で設定されたブローカーが停止すると、そのメッセージは別のブローカーのキューの最後に追加されます。
ブローカーがスケールダウンする準備時に、接続が切断される前に、新しいブローカーがメッセージを処理する準備ができていることを通知する前に、メッセージをクライアントに送信します。ただし、クライアントは、初期ブローカーがスケールダウンされた後にのみ新しいブローカーに再接続する必要があります。これにより、キューやトランザクションなどの状態が、クライアントが再接続する際に他のブローカーで利用可能になります。通常の再接続設定はクライアントが再接続する際に適用されるため、スケールダウンに必要な時間を処理するのに十分な時間を設定する必要があります。
この手順では、クラスター内の各ブローカーをスケールダウンするように設定する方法を説明します。この手順を完了すると、ブローカーが正常に停止されるたびに、メッセージとトランザクションの状態がクラスター内の別のブローカーにコピーされます。
手順
-
最初のブローカーの
<broker_instance_dir> /etc/broker.xml設定ファイルを開きます。 ライブのみの HA ポリシーを使用するようにブローカーを設定します。
<configuration> <core> ... <ha-policy> <live-only> </live-only> </ha-policy> ... </core> </configuration>ブローカークラスターをスケールダウンする方法を設定します。
このブローカーがスケールダウンするブローカーのブローカーまたはグループを指定します。
Expand スケールダウン 以下を行います クラスター内の特定のブローカー
スケールダウンするブローカーのコネクターを指定します。
<live-only> <scale-down> <connectors> <connector-ref>broker1-connector</connector-ref> </connectors> </scale-down> </live-only>クラスター内のすべてのブローカー
ブローカークラスターの検出グループを指定します。
<live-only> <scale-down> <discovery-group-ref discovery-group-name="my-discovery-group"/> </scale-down> </live-only>特定のブローカーグループのブローカー
ブローカーグループを指定します。
<live-only> <scale-down> <group-name>my-group-name</group-name> </scale-down> </live-only>- クラスター内の残りのブローカーごとに、この手順を繰り返します。
関連情報
- クラスターをスケールダウンするためにライブのみを使用するブローカークラスターの例については、scale-down example programs を参照してください。
14.3.5. Configuring high availability with colocated backups
ライブバックアップグループを設定するのではなく、バックアップブローカーを別のライブブローカーと同じ JVM にコロケートできます。この設定では、各ライブブローカーは別のライブブローカーを要求し、その JVM でバックアップブローカーを作成し、開始します。
図14.4 コロケートされたライブブローカーおよびバックアップブローカー
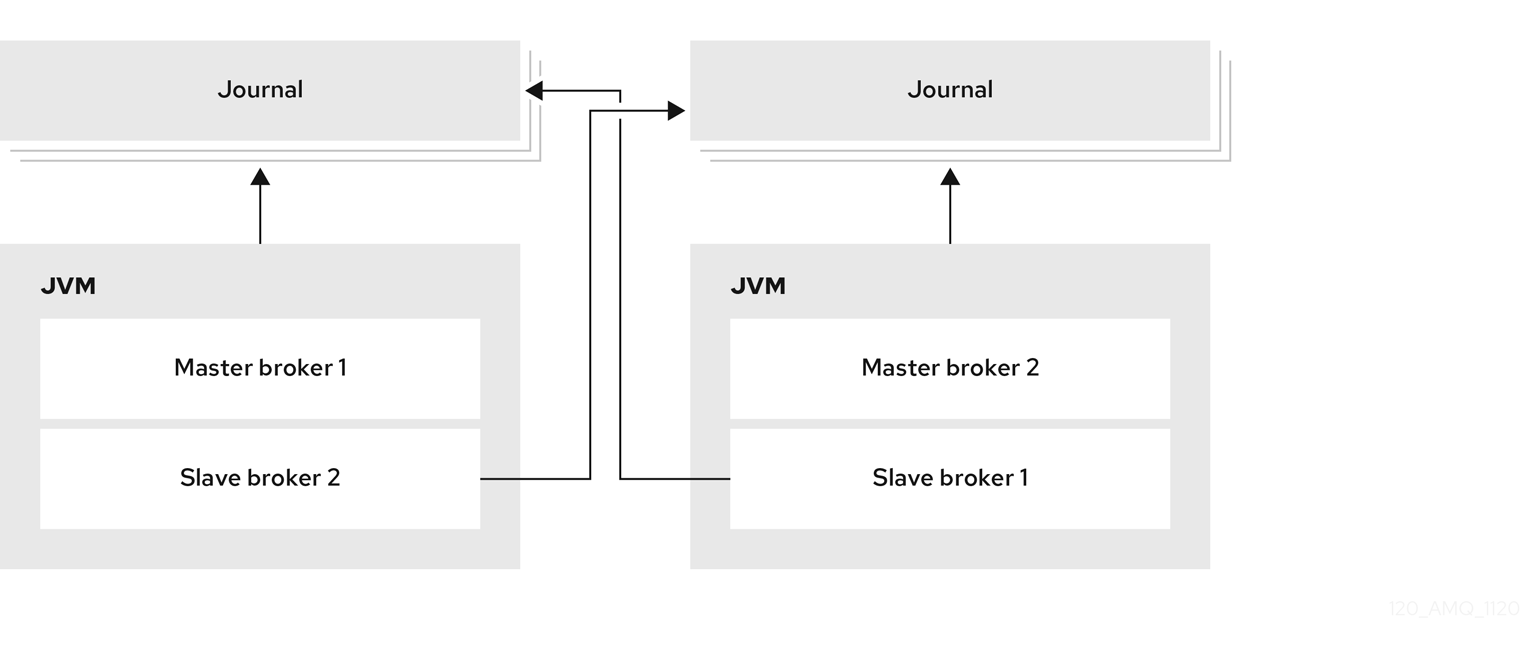
コロケーションは、共有ストアまたはレプリケーションのいずれかを高可用性 (HA) ポリシーとして使用できます。新しいバックアップブローカーは、これを作成するライブブローカーからその設定を継承します。バックアップの名前は、colocated_backup_n に設定されます。n は、ライブブローカーが作成したバックアップの数です。
さらに、バックアップブローカーは、コネクターと、これを作成するライブブローカーからアクセプターの設定を継承します。デフォルトでは、ポートオフセット 100 がそれぞれに適用されます。たとえば、ライブブローカーにポート 61616 のアクセプターがある場合、作成される最初のバックアップブローカーはポート 61716 を使用し、2 番目のバックアップは 61816 を使用します。
ジャーナル、大きなメッセージ、ページングのディレクトリーは、選択した HA ポリシーに従って設定されます。共有ストアを選択する場合、要求ブローカーはターゲットブローカーに対し、使用するディレクトリーについて通知します。レプリケーションが選択されている場合、ディレクトリーは作成ブローカーから継承され、新しいバックアップの名前が追加されます。
この手順では、共有のストア HA を使用するようにクラスター内の各ブローカーを設定し、バックアップを作成してクラスター内の別のブローカーと共存させるよう要求します。
手順
-
最初のブローカーの
<broker_instance_dir> /etc/broker.xml設定ファイルを開きます。 HA ポリシーとコロケーションを使用するようにブローカーを設定します。
この例では、ブローカーは共有ストア HA およびコロケーションで設定されます。
<configuration> <core> ... <ha-policy> <shared-store> <colocated> <request-backup>true</request-backup> <max-backups>1</max-backups> <backup-request-retries>-1</backup-request-retries> <backup-request-retry-interval>5000</backup-request-retry-interval/> <backup-port-offset>150</backup-port-offset> <excludes> <connector-ref>remote-connector</connector-ref> </excludes> <master> <failover-on-shutdown>true</failover-on-shutdown> </master> <slave> <failover-on-shutdown>true</failover-on-shutdown> <allow-failback>true</allow-failback> <restart-backup>true</restart-backup> </slave> </colocated> </shared-store> </ha-policy> ... </core> </configuration>request-backup-
このプロパティーを
trueに設定すると、このブローカーはクラスター内の別のライブブローカーによって作成されるバックアップブローカーを要求します。 max-backups-
このブローカーが作成できるバックアップブローカーの数。このプロパティーを
0に設定すると、このブローカーはクラスターの他のブローカーからのバックアップ要求を受け入れません。 backup-request-retries-
このブローカーがバックアップブローカーの作成を要求する回数。デフォルトは、無制限を意味する
-1です。 backup-request-retry-interval-
バックアップブローカーを作成する要求を再試行する前にブローカーが待機する時間 ( ミリ秒単位 )。デフォルトは
5000(5 秒) です。 backup-port-offset-
新しいバックアップブローカーにアクセプターおよびコネクターに使用するポートオフセット。このブローカーがクラスター内の別のブローカーのバックアップを作成する要求を受信すると、この量によってポートオフセットでバックアップブローカーが作成されます。デフォルトは
100です。 excludes( オプション )-
バックアップポートのオフセットからコネクターを除外します。バックアップポートのオフセットから除外する必要のある外部ブローカーのコネクターを設定している場合は、コネクターごとに
<connector-ref>を追加します。 master- このブローカーの共有ストアまたはレプリケーションフェイルオーバーの設定。
slave- このブローカーのバックアップの共有ストアまたはレプリケーションのフェイルオーバー設定。
- クラスター内の残りのブローカーごとに、この手順を繰り返します。
関連情報
- コロケートバックアップを使用するブローカークラスターの例については、HA example programs を参照してください。
14.3.6. フェイルオーバーするクライアントの設定
ブローカークラスターで高可用性を設定したら、クライアントがフェイルオーバーするように設定します。クライアントのフェイルオーバーにより、ブローカーが失敗すると、接続したクライアントは最小限のダウンタイムでクラスター内の別のブローカーに再接続できます。
一時的なネットワークの問題が発生すると、AMQ Broker は同じブローカーへの接続を自動的に再割り当てします。これは、クライアントが同じブローカーに再接続する以外は failover と似ています。
2 種類のクライアントフェイルオーバーを設定できます。
- 自動クライアントフェイルオーバー
- クライアントは、初回接続時にブローカークラスターに関する情報を受け取ります。接続先のブローカーが失敗すると、クライアントはブローカーのバックアップに自動的に再接続し、バックアップブローカーはフェイルオーバーの前に各接続に存在するセッションおよびコンシューマーを再作成します。
- アプリケーションレベルのクライアントフェイルオーバー
- 自動クライアントのフェイルオーバーの代わりに、障害ハンドラーで独自のカスタム再接続ロジックを使用してクライアントアプリケーションをコーディングすることもできます。
手順
AMQ Core Protocol JMS を使用して、自動またはアプリケーションレベルのフェイルオーバーでクライアントアプリケーションを設定します。
詳細は、Using the AMQ Core Protocol JMS Client を参照してください。