第4章 CPU
central processing unit (中央処理装置) を表す CPU という言葉は、実体とかけ離れた呼称です。というのも、central は single (シングル) を意味しますが、ほとんどの最近のシステムには 2 つ以上の処理装置、コア、があるからです。物理的には、CPU は マザーボードに取り付けられているパッケージのソケット内に格納されています。マザーボード上の各ソケットには、様々な接続があります。例えば、別の CPU ソケット、メモリコントローラー、割り込みコントローラー、他の周辺機器への接続といったものです。オペレーティングシステムへのソケットは CPU および関連リソースの論理グループ化です。この概念は、CPU チューニングの議論の中心となります。
Red Hat Enterprise Linux は、システム CPU イベントについての多大な統計を保持します。これらの統計は、CPU パフォーマンス改善のためのチューニング戦略を考える際に有用なものです。「CPU パフォーマンスのチューニング」 では、特に有益な統計、それらが見つかる場所、パフォーマンスチューニングのためにそれらを分析する方法について説明します。
トポロジー
古いコンピューターではシステムあたりの CPU 数が比較的少なく、Symmetric Multi-Processor (SMP) と呼ばれるアーキテクチャーを可能にしていました。つまり、システム内の各 CPU には利用可能なメモリに対して同様の (またはそれに釣り合った) アクセスがありました。最近では、ソケットあたりの CPU 数が非常に多くなったので、システム内の全 RAM に対して釣り合いのとれたアクセスを与えることは非常に高価なことになってしまいます。CPU 数の多いシステムのほとんどでは今日、 SMP ではなく Non-Uniform Memory Access (NUMA) と呼ばれるアーキテクチャーが使われています。
AMD プロセッサーは Hyper Transport (HT) 相互接続にこのタイプのアーキテクチャーを使っており、Intel は Quick Path Interconnect (QPI) 設計で NUMA の実装を開始しました。アプリケーションにリソースを配分する際にはシステムのトポロジーを占める必要があるので、NUMA と SMP のチューニング方法は違うものになります。
スレッド
Linux オペレーティングシステムでは、実行の単位は スレッド と呼ばれます。スレッドには、レジスタコンテキスト、スタック、実行可能なコードのセグメントがあり、これらは CPU 上で実行されます。利用可能な CPU でこれらのスレッドのスケジュール管理をするのがオペレーティングシステムの役割です。
OS は、利用可能なコアにまたがってスレッドの負荷を分散させることで、CPU 使用率を最大化します。OS が最も注意を払うのは CPU を稼働させることなので、アプリケーションのパフォーマンスに関しては最適な判断をしません。アプリケーションスレッドを別のソケットにある CPU に移動することで、単に現行 CPU が利用可能になるまで待機するよりもパフォーマンスが落ちる場合があります。これは、メモリアクセス操作がソケット全域で大幅に遅くなる可能性があるからです。高パフォーマンスアプリケーションの場合、通常はスレッドの格納場所については設計者が判断した方がよいとされています。「CPU のスケジューリング」 では、アプリケーションスレッドの実行における CPU とメモリの最善の配分方法を説明しています。
割り込み
アプリケーションのパフォーマンスに影響を与えるシステムイベントのうちで、あまり明確でないもの (ただし重要なもの) に割り込み (Linux では IRQ とも呼ぶ) があります。これらのイベントは OS が処理し、データの到着や、ネットワークを介した書き込みやタイマーイベントなどの操作の完了を知らせるために周辺機器が使用します。
アプリケーションコードを実行する OS や CPU が割り込みを扱う手法がアプリケーションの機能性に影響を与えることはありません。しかし、アプリケーションのパフォーマンスに影響を与える可能性があります。本章では、割り込みがアプリケーションのパフォーマンスにマイナスの影響を与えないようにするヒントについても説明します。
4.1. CPUトポロジー
リンクのコピーリンクがクリップボードにコピーされました!
4.1.1. CPU と NUMA トポロジー
リンクのコピーリンクがクリップボードにコピーされました!
最初のコンピュータープロセッサーは uniprocessors、つまりシステムには 1 つの CPU があるだけでした。単一の CPU を 1 つの実行 (プロセス) スレッドから別のスレッドに迅速にスイッチすることで、オペレーティングシステムはプロセスの並列処理という幻想を作り出していました。システムパフォーマンスを高めるために、設計者は指示を実行するためのクロック率を高めても、これが機能するのはある地点まで (通常は、現在の技術で安定的なクロック波形を作成できる限界) であることに気付きました。システムパフォーマンス全体を高めるために、設計者はもう 1 つの CPU をシステムに追加して、指示を 2 つの並列ストリームで実行できるようにしました。プロセッサーを追加するというこのトレンドが長らく続くことになります。
初期のマルチプロセッサーシステムでは、各 CPU がメモリ位置へ同一の論理パスを持っている場合がほとんどでした (通常はパラレルバス)。これにより、CPU はシステム内の他の CPU と同じ時間でメモリにアクセスすることができました。このタイプのアーキテクチャーは、Symmetric Multi-Processor (SMP) と呼ばれます。SMP は CPU の数が少ない場合はうまく機能しましたが、一定数 (8 または 16) を超えると、メモリへの同等アクセスに必要な並列トレースの数がボード面積を使い過ぎてしまい、周辺機器のスペースが不足してしまいました。
2 つの新しい概念が組み合わされて、システム内で多数の CPU が可能になりました。
- シリアルバス
- NUMA トポロジー
シリアルバスは、クロック率が非常に高い、単一ワイヤーパスで、データをパッケージ化されたバーストとして移動します。ハードウェア設計者は、シリアルバスを CPU 間や CPU とメモリコントローラー、他の周辺機器との間の高速の相互接続として使用し始めました。つまり、ボード上で 各 CPU からメモリサブシステムへ 32 から 64 のトレースを必要とする代わりに、1 つのトレースを必要とするので、ボード上での必要なスペースが大幅に削減されました。
同時に、ハードウェア設計者はダイサイズを小さくすることで、より多くのトランジスタを同一スペースにまとめました。メインボードに直接個別の CPU を載せるのではなく、マルチコアプロセッサーとして 1 つのプロセッサーパッケージに CPU をまとめ始めたのです。そして、各プロセッサーパッケージからメモリへの同じアクセスを提供するのではなく、Non-Uniform Memory Access (NUMA) 戦略という手段に訴えました。つまり、各パッケージ/ソケットの組み合わせに高速アクセスの専用メモリ領域が 1 つ以上あることになります。各ソケットには他のソケットへの相互接続もあり、遅いアクセスはこれらの他のソケットのメモリにアクセスすることになります。
簡単な NUMA の例として、ソケットが 2 つあるマザーボードを想定してみましょう。各ソケットには、クアッドコアのパッケージが設定されています。つまり、システムには合計 8 つの CPU があり、各ソケットに 4 つずつあることになります。各ソケットには、4 GB の RAM のメモリバンクもあり、システム全体のメモリは 8 GB になります。ここでは、CPU 0-3 はソケット 0 にあり、CPU 4-7 はソケット 1 にあるとします。各ソケットは、NUMA ノードにも対応することにします。
CPU 0 がバンク 0 からメモリにアクセスするには、3 クロックサイクルが必要になります。まず、メモリコントローラーにアドレスを提示するサイクル。次に、メモリの位置へのアクセスを設定するサイクル。そして、その位置への読み取り/書き込みサイクル、です。しかし、CPU 4 が同じ位置からメモリにアクセスするには、6 クロックサイクルが必要になります。別のソケット上にあることで、ソケット 1 のローカルメモリコントローラーとソケット 0 のリモートメモリコントローラーという 2 つのメモリコントローラーを通過する必要があるからです。その位置にあるメモリが争われた場合 (つまり、2 つ以上の CPU が同一位置のメモリに同時にアクセスしようとした場合) は、メモリコントローラーがメモリへのアクセスを仲裁して順番を付けることで、メモリアクセスの時間が長くかかることになります。キャッシュの一貫性を加えると (ローカル CPU キャッシュで、同一メモリ位置には同一データがあることを確認する)、プロセスはさらに複雑になります。
Intel (Xeon) および AMD (Opteron) の最新のハイエンドプロセッサーには、NUMA トポロジーがあります。AMD プロセッサーは HyperTransport™ または HT と呼ばれる相互接続を使用し、Intel は QuickPath Interconnect™ または QPI と呼ばれる相互接続を使用しています。相互接続は、他の相互接続やメモリー、周辺機器への物理的な接続方法で異なりますが、実質的には、ある接続済みデバイスから別の接続済みデバイスへの透過的なアクセスを可能にするスイッチです。このケースでは、「透過的」とは「コストゼロ」のオプションではなく、相互接続に特別なプログラミング API を必要としないことを指します。
システムアーキテクチャーは非常に多様なので、非ローカルメモリにアクセスすることで課せられるパフォーマンスペナルティーを具体的に表すことは現実的ではありません。相互接続上の各ホップが、ホップにつき少なくとも比較的一定のパフォーマンスペナルティーを課している、ということは言えます。現行 CPU から 2 つの相互接続先にあるメモリ位置を参照すると少なくとも 2N + メモリサイクル時間 のユニットをアクセス時間に課すことになります。ここでの N は、ホップあたりのペナルティーになります。
このパフォーマンスペナルティーを考慮すると、パフォーマンス依存型のアプリケーションは NUMA トポロジーシステムのリモートメモリへの定期的アクセスは避けるべきです。このようなアプリケーションは、特定のノードに留まり、そのノードからメモリを割り当てるような設定にするべきです。
これを行うには、アプリケーションは以下の点を知る必要があります。
- システムのトポロジーは何か?
- アプリケーションは現在、どこで実行中か?
- 一番近いメモリバンクはどこか?
4.1.2. CPU パフォーマンスのチューニング
リンクのコピーリンクがクリップボードにコピーされました!
このセクションでは、CPU パフォーマンスのチューニング方法とこのプロセスに役立つツールの導入方法を説明します。
NUMA は当初、単一プロセッサーを複数のメモリバンクに接続するために使われました。CPU の製造企業がプロセスの正確性を高め、ダイサイズが縮小されるにつれて、複数の CPU コアが 1 つのパッケージに収まるようになりました。この CPU コアはクラスター化され、それぞれのローカルメモリバンクへのアクセス時間が同一になり、コア間でキャッシュの共有が可能になりました。しかし、相互接続のコア、メモリ、キャッシュ間での「ホップ」には、わずかなパフォーマンスペナルティーが発生しました。
図4.1「NUMA トポロジーにおけるローカルおよびリモートのメモリアクセス」 の例のシステムには、2 つの NUMA ノードがあります。各ノードには 4 つの CPU とメモリバンク、メモリコントローラーがあります。CPU は同じノード上のメモリバンクへの直接のアクセスがあります。ノード 1 の矢印にしたがって、以下のようなステップになります。
- CPU (0-3 のいずれか) がメモリアドレスをローカルのメモリコントローラーに提示します。
- メモリコントローラーがメモリアドレスへのアクセスを設定します。
- そのメモリアドレス上で、CPU が読み取り/書き込み操作を実行します。
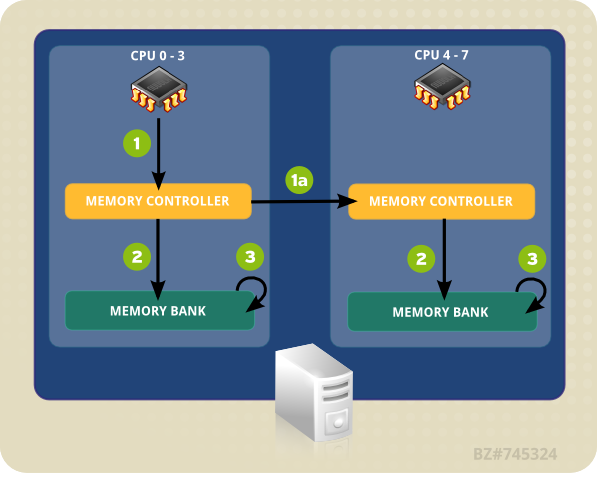
図4.1 NUMA トポロジーにおけるローカルおよびリモートのメモリアクセス
しかし、一方のノード上にある CPU が別の NUMA ノードのメモリバンク上に存在するコードにアクセスする必要がある場合、パスは直接的なものではなくなります。
- CPU (0-3 のいずれか) がリモートのメモリアドレスをローカルのメモリコントローラーに提示します。
- このリモートのメモリアドレスに対する CPU の要請は、そのメモリアドレスがあるノードがローカルである、リモートのメモリコントローラーに渡されます。
- リモートのメモリコントローラーがリモートのメモリアドレスへのアクセスを設定します。
- そのリモートメモリアドレス上で、CPU が読み取り/書き込み操作を実行します。
リモートのメモリアドレスにアクセスしようとすると、すべてのアクションが複数のメモリコントローラーを経由しなくてはならないので、アクセスに 2 倍以上の時間がかかる可能性があります。このため、マルチコアシステムでのパフォーマンスの主な関心事は、情報が最短、最速のパスでできるだけ効率的に移動できるようにすることです。
最善の CPU パフォーマンスを発揮するようにアプリケーションを設定するには、以下の点を知る必要があります。
- システムのトポロジー (コンポーネントの接続方法)
- アプリケーションを実行するコア
- 一番近いメモリバンクの位置
Red Hat Enterprise Linux 6 は、これらの情報をみつけ、それに応じてシステムをチューニングする際に役立つ多くのツールと出荷されています。以下のセクションでは、CPU パフォーマンスのチューニングに有用なツールの概要を説明します。
4.1.2.1. taskset を使った CPU アフィニティの設定
リンクのコピーリンクがクリップボードにコピーされました!
taskset は、実行中のプロセスの CPU アフィニティを (プロセス ID で) 取得、設定します。特定の CPU アフィニティを使ってプロセスを開始することも可能で、この場合はこの指定されたプロセスは特定の CPU または CPU セットにバインドされます。しかし、taskset はローカルメモリの割り当てを保証するわけではありません。ローカルメモリの割り当てによるパフォーマンスの向上を必要とする場合は、taskset ではなく numactl を使用することが推奨されます。詳細については 「numactl を使った NUMA ポリシーのコントロール」 を参照してください。
CPU アフィニティはビットマスクで表されます。順序の一番低いビットは最初の論理 CPU に対応し、順序の一番高いビットは最後の論理 CPU 対応します。これらのマスクは通常 16 進数で提供され、
0x00000001 はプロセッサー 0 を、0x00000003 はプロセッサー 0 および 1 を表します。
実行中のプロセスの CPU アフィニティを設定するには、以下のコマンドを実行します。mask はプロセスを結び付けたいプロセッサーのマスクに置き換え、pid はアフィニティを変更するプロセスのプロセス ID に置き換えます。
# taskset -p mask pid
あるアフィニティでプロセスを開始するには、以下のコマンドを実行します。mask はプロセスを結び付けたいプロセッサーのマスクに置き換え、program は実行するプログラムおよびプログラムの引数 に置き換えます。
# taskset mask -- program
プロセスをビットマスクで指定する代わりに、
-c オプションを使って別個のプロセッサーのコンマ区切りの一覧表やプロセッサーの範囲を提供することもできます。
# taskset -c 0,5,7-9 -- myprogram
taskset の詳細は man ページ:
man taskset を参照してください。
4.1.2.2. numactl を使った NUMA ポリシーのコントロール
リンクのコピーリンクがクリップボードにコピーされました!
numactl は、指定されたスケジュールまたはメモリプレースメントポリシーでプロセスを実行します。選択されたポリシーは、そのプロセスとその子プロセスすべてに設定されます。numactl は共有メモリセグメントもしくはファイル向けに維持するポリシーも設定でき、プロセスの CPU アフィニティおよびメモリアフィニティも設定できます。 /sys ファイルシステムを使ってシステムトポロジーを決定します。
/sys ファイルシステムには、CPU とメモリ、周辺機器が NUMA 相互接続経由でどのように接続されているかについての情報が含まれています。特に、/sys/devices/system/cpu ディレクトリーには、システムの CPU がそれぞれどのように接続されているかについての情報が含まれています。/sys/devices/system/node ディレクトリーには、システム内の NUMA ノードとノード間の相対距離についての情報が含まれています。
NUMA システムでは、プロセッサーとメモリバンク間の距離が長ければ長いほど、プロセッサーのメモリへのアクセスは遅くなります。このため、パフォーマンス依存型のアプリケーションは、一番近いメモリバンクからのメモリを割り当てるような設定にするべきです。
また、パフォーマンス依存型のアプリケーションは、特定のコア数で実行する設定が推奨されます。マルチスレッドのアプリケーションは、特にこれが当てはまります。最初のレベルのキャッシュは通常少ないため、複数スレッドが 1 つのコアで実行すると、各スレッドは以前のスレッドがアクセスしたキャッシュ済みのデータを削除する可能性があります。オペレーティングシステムがこれらのスレッド間でマルチタスクを試みる際に、スレッドが互いのキャッシュ済みデータを削除し続けると、実行時間の多くがキャッシュラインの置換に費やされてしまいます。この問題は、キャッシュスラッシング (cache thrashing) と呼ばれています。このため、マルチスレッドのアプリケーションを単一コアではなく、ノードに結び付けることが推奨されます。これによって、スレッドは複数レベル (最初、2 番目、最終レベルのキャッシュ) でキャッシュラインの共有ができ、キャッシュを満たす操作の必要性が最小限に抑えられるからです。しかし、スレッドすべてが同一のキャッシュ済みデータにアクセスしている場合は、アプリケーションの単一コアへのバインディングは永続的なものになる場合があります。
numactl を使うとアプリケーションを特定のコアもしくは NUMA ノードにバインドできるようになり、そのアプリケーションにコアもしくはコアのセットに関連したメモリを割り当てられるようになります。numactl には以下の便利なオプションがあります。
--show- 現行プロセスの NUMA ポリシー設定を表示します。このパラメーターにはさらなるパラメーターは必要なく、以下のように使用できます。
numactl --show --hardware- システム上で利用可能なノードのインベントリーを表示します。
--membind- 指定のノードからのメモリのみを割り当てます。これを使用中は、このノード上のメモリが不足すると割り当ては失敗します。このパラメーターの使用方法は、
numactl --membind=nodes programです。ここでは、nodes はメモリの割り当て元となるノードのリストで、program はそのノードからメモリを割り当てられる必要のあるプログラムのことです。ノード番号は、コンマ区切りの一覧表か範囲、もしくはこの 2 つの組み合わせになります。詳細は、numactl の man ページ:man numactlを参照してください。 --cpunodebind- 指定ノードに属する CPU上のコマンド (およびその子プロセス) のみを実行します。このパラメーターの使用方法は、
numactl --cpunodebind=nodes programです。ここでは、nodes は指定プログラム (program) をバインドする CPU のあるノード一覧のことです。ノード番号は、コンマ区切りの一覧表か範囲、もしくはこの 2 つの組み合わせになります。詳細は、numactl の man ページ:man numactlを参照してください。 --physcpubind- 指定ノード上のコマンド (およびその子プロセス) のみを実行します。このパラメーターの使用方法は、
numactl --physcpubind=cpu programです。ここでは、cpu は/proc/cpuinfoのプロセッサーフィード内で表示されている物理 CPU番号のコンマ区切り一覧で、program はこれらの CPU 上でのみ実行するプログラムです。CPU は、現行cpusetに相対的にも指定できます。詳細は、numactl の man ページ:man numactlを参照してください。 --localalloc- 現行ノード上に常に割り当てられるメモリを指定します。
--preferred- 可能な場合、メモリは指定のノードに割り当てられます。指定ノードへのメモリ割り当てができない場合、別のノードにフォールバックします。このオプションでは以下のように 1 つのノード番号のみを使います。
numactl --preferred=node。詳細は numactl の man ページ:man numactlを参照してください。
numactl にパッケージに含まれている libnuma ライブラリは、カーネルがサポートしている NUMA ポリシーへの簡潔なプログラミングインターフェースを提供します。これは、より詳細なチューニングの際に numactl ユーティリティーよりも便利なものです。詳細情報は man ページ:
man numa(7) を参照してください。
4.1.3. ハードウェアパフォーマンスポリシー (x86_energy_perf_policy)
リンクのコピーリンクがクリップボードにコピーされました!
cpupowerutils パッケージには、x86_energy_perf_policy が含まれます。このツールを使うと、管理者はエネルギー効率に対してパフォーマンスの相対的な重要性を定義することができます。この情報はその後、この機能に対応しているプロセッサーがパフォーマンスとエネルギー効率を交換するオプションを選択する際に、そのプロセッサーに影響を及ぼすために使用できます。プロセッサーのサポートは
CPUID.06H.ECX.bit3 で示されます。
x86_energy_perf_policy は root 権限を必要とし、デフォルトですべての CPU で実行できます。
現行ポリシーを表示するには、以下のコマンドを実行します。
# x86_energy_perf_policy -r
新たなポリシーを設定するには、以下のコマンドを実行します。
# x86_energy_perf_policy profile_name
profile_name を以下のいずれかのプロファイルで置き換えます。
performance- プロセッサーは省エネルギーのためにパフォーマンスを犠牲にすることを嫌がります。これがデフォルト値です。
normal- 大幅な省エネルギーの可能性がある場合、プロセッサーはマイナーなパフォーマンス低下を許可します。これは、ほとんどのデスクトップおよびサーバーで妥当な設定です。
powersave- プロセッサーは、エネルギー効率を最大化するために大幅なパフォーマンス低下の可能性を受け入れます。
このツールについての詳細情報は、man ページ:
man x86_energy_perf_policy を参照してください。
4.1.4. turbostat
リンクのコピーリンクがクリップボードにコピーされました!
turbostat ツールは cpupowerutils パッケージの一部です。これは、Intel 64 プロセッサー上のプロセッサートポロジー、周波数、アイドル電源状態の統計数字、温度、および電力使用量をレポートします。
Turbostat を使うと管理者は必要以上に電力を消費しているサーバーや本来スリープ状態に入っているはずなのに入っていないサーバー、またはプラットホームがすぐに利用可能な場合に仮想化を検討すべき (つまり、物理サーバーを使用停止にできる) アイドル状態にあるサーバーを特定することができます。また、システム管理の割り込み (SMI) の比率や SMI を不必要にプロンプトしている、遅延を区別するアプリケーションの特定に役立ちます。Turbostat は powertop ユーティリティーと併せて使用することでプロセッサーがスリープ状態に入ることを妨げている可能性のあるサービスを特定することもできます。
Turbostat を実行するには
root 権限が必要になります。また、不変タイムスタンプカウンターをサポートしているプロセッサーと、APERF および MPERF のモデル固有レジスタが必要になります。
デフォルトでは、turbostat はシステム全体のカウンター結果の概要と、それに続いて以下の見出しの下にカウンター結果を 5 秒ごとにプリントします。
- pkg
- プロセッサーのパッケージ番号。
- core
- プロセッサーのコア番号。
- CPU
- Linux CPU (論理プロセッサー) 番号。
- %c0
- CPU リタイヤ状態の指示の間隔のパーセント。
- GHz
- CPU が c0 状態にあった間の平均クロック速度。この数値が TSC の値よりも高い場合は、CPU はターボモードになります。
- TSC
- 間隔全体にわたる平均クロック速度。この数値が TSC の値よりも低い場合は、CPU はターボモードになります。
- %c1、%c3、および %c6
- プロセッサーが c1、c3、または c6 の各状態だった間隔のパーセント。
- %pc3 または %pc6
- プロセッサーが pc3 または pc6 の各状態だった間隔のパーセント。
-i オプションを使ってカウンター結果の間の異なる期間を指定します。たとえば、turbostat -i 10 を実行すると、10 秒ごとに結果がプリントされます。
注記
今後発売される Intel プロセッサーは、新たな C 状態を追加する可能性があります。Red Hat Enterprise Linux 6.5 では、turbostat は c7、c8、c9、および c10 の状態をサポートしています。
turbostat についての詳細情報は、man ページ:
man turbostat を参照してください。
4.1.5. numastat
リンクのコピーリンクがクリップボードにコピーされました!
重要
以前の numastat ツールは、Andi Kleen 氏が記述した Perl スクリプトでした。Red Hat Enterprise Linux 6.4 向けには、これが大幅に書き換えられています。
デフォルトのコマンド (
numastat でオプションやパラメーターなし) はツールのこれまでのバージョンと厳密な互換性を維持していますが、オプションやパラメーターが加えられるとこのコマンドの出力コンテンツとフォーマットが大幅に変わることに注意してください。
numastat は、プロセスとオペレーティングシステムのメモリ統計 (割り当てのヒットとミスなど) を NUMA ノードあたりで表示します。デフォルトでは、
numastat を実行すると、各ノードの以下のイベントカテゴリーごとに占有されているメモリのページ数を表示します。
numa_miss および numa_foreign の値が低いと、CPU パフォーマンスが優れていることを示します。
numastat の更新バージョンも、プロセスメモリがシステム全体に拡散しているかもしくは numactl を使用している特定ノード上に集中しているかを表示します。
メモリが割り当てられているノードと同一ノード上でプロセススレッドが実行中かどうかを検証するために、CPU あたりの top 出力を使って numastat 出力を相互参照します。
デフォルトの追跡カテゴリー
- numa_hit
- 当該ノードに割り当てを試みたもので成功した数。
- numa_miss
- 別のノードに割り当てを試みたもので、当初の意図されたノードがメモリ不足だったために当該ノードに割り当てられた数。各
numa_missイベントには、対応するnuma_foreignイベントが別のノード上にあります。 - numa_foreign
- 当初は当該ノードへの割り当てを意図したもので、別のノードに割り当てられた数。
numa_foreignイベントには対応するnuma_missイベントが別のノード上にあります。 - interleave_hit
- 当該ノードに試みたインターリーブポリシーの割り当てで成功した数。
- local_node
- 当該ノード上のプロセスが当該ノード上へのメモリ割り当てに成功した回数。
- other_node
- 別のノード上のプロセスが当該ノード上にメモリを割り当てた回数。
以下のオプションのいずれかを適用すると、メモリの表示単位がメガバイトに変更され (四捨五入で小数点第 2 位まで)、以下のように他の特定の numastat 動作に変更を加えます。
-c- 表示情報の表を横方向に縮小します。これは、NUMA ノード数が多いシステムでは有用ですが、コラムの幅とコラム間の間隔はあまり予測可能ではありません。このオプションが使用されると、メモリ量は一番近いメガバイトに切り上げ/下げられます。
-m- ノードあたりでのシステム全体のメモリ使用量を表示します。
/proc/meminfoにある情報に類似したものです。 -n- オリジナルの
numastatコマンド (numa_hit、numa_miss、numa_foreign、interleave_hit、local_node、other_node) と同一情報を表示しますが、測定単位にメガバイトを使用した更新フォーマットが使われます。 -p pattern- 指定されたパターンのノードごとのメモリー情報を表示します。pattern の値が数字の場合は、numastat は数値プロセス識別子とみなされます。それ以外の場合は、numastat は指定されたパターンのプロセスコマンドラインを検索します。
-pオプションの値の後に入力されるコマンドライン引数は、フィルターにかける追加のパターンとみなされます。追加のパターンは、フィルターを絞り込むのではなく拡張します。 -s- 表示データを降順に並び替えるので、(
totalコラムの) メモリ消費量の多いものが最初に来ます。オプションで node を指定すると、表は node コラムにしたがって並び替えられます。このオプションの使用時には、以下のように node 値は-sオプションのすぐあとに来る必要があります。numastat -s2このオプションと値の間に空白スペースを入れないでください。 -v- 詳細情報を表示します。つまり、複数プロセスのプロセス情報が各プロセスの詳細情報を表示します。
-V- numastat のバージョン情報を表示します。
-z- 情報情報から値が 0 の行と列のみを省略します。表示目的で 0 に切り下げられている 0 に近い値は、表示出力から省略されません。
4.1.6. NUMA アフィニティ管理デーモン (numad)
リンクのコピーリンクがクリップボードにコピーされました!
numad は自動の NUMA 管理デーモンです。システム内の NUMA トポロジーとリソース使用量を監視して、動的に NUMA リソース割り当ておよび管理 (つまりシステムパフォーマンス) を改善します。
システムのワークロードによって、numad はベンチマークパフォーマンスを最大 50% 改善します。このパフォーマンス改善を達成するため、numad は定期的に
/proc ファイルシステムからの情報にアクセスし、ノードごとに利用可能なシステムリソースを監視します。その後はデーモンが、十分な配置メモリと最適な NUMA パフォーマンスのための CPU リソースがある NUMA ノード上に重要なプロセスを配置します。プロセス管理の最新のしきい値は 1 つの CPU の少なくとも 50%と 300 MB のメモリです。numad はリソース使用量のレベルの維持を図り、割り当ての再バランス化が必要な場合は NUMA ノード間でプロセスを移動します。
numad は、様々なジョブ管理システムが質問できる配置前のアドバイスサービスも提供しており、プロセスにおける CPU とメモリリソースの初期バインディングの手助けをします。この配置前アドバイスサービスは、numad がシステム上でデーモンとして実行中かどうかにかかわらず、利用可能です。
-w オプションで配置前アドバイスを使用する方法については、man ページ: man numad を参照してください。
4.1.6.1. numad の利点
リンクのコピーリンクがクリップボードにコピーされました!
numad は主に、多大な量のリソースを消費する、長期間実行のシステムに利益をもたらします。これらのプロセスがトータルシステムリソースのサブセットに含まれる場合は、特にそうです。
numad は、複数の NUMA ノード分のリソースを消費するアプリケーションにも有用です。しかし、numad のもたらす利点は、システム上で消費されるリソースの割合が高まるにつれて低下します。
プロセスの実行時間がほんの数分であったり、多くのリソースが消費されない場合は、numad はパフォーマンスを改善しない可能性が高くなります。大型のメモリ内データベースなど、継続的に予想できないメモリアクセスのパターンがあるシステムも、numad の使用で恩恵を得る可能性は低くなります。
4.1.6.2. オペレーションモード
リンクのコピーリンクがクリップボードにコピーされました!
注記
KSM を使用する場合は、
/sys/kernel/mm/ksm/merge_nodes の調整可能な値を 0 に変更して NUMA にまたがるページのマージを回避します。カーネルメモリーが計算した統計は、大量のクロスノードのマージ後にはそれぞれの間で相反する場合があります。そのため、KSM デーモンが大量のメモリーをマージすると、numad は混乱する可能性があります。システムに未使用のメモリーが大量にあると、KSM デーモンをオフにして無効にすることでパフォーマンスが高まる場合があります。
numad には 2 つの使用方法があります。
- サービスとして使用
- 実行可能ファイルとして使用
4.1.6.2.1. numad をサービスとして使用
リンクのコピーリンクがクリップボードにコピーされました!
numad サービスの実行中に、ワークロードに基づいてシステムを動的にチューニングしようとします。
サービスを開始するには、以下のコマンドを実行します。
# service numad start
リブート後もサービスを維持するには、以下のコマンドを実行します。
# chkconfig numad on4.1.6.2.2. numad を実行可能ファイルとして使用
リンクのコピーリンクがクリップボードにコピーされました!
numad を実行可能ファイルとして使用するには、単に以下のコマンドを実行します。
# numad
numad は停止されるまで実行し続けます。実行中は、アクティビティが
/var/log/numad.log にログ記録されます。
numad 管理を特定プロセスに限定するには、以下のオプションで開始します。
# numad -S 0 -p pid-p pid- 指定の pid を明示的な対象一覧に加えます。指定されたプロセスは、 numad プロセスの重要度しきい値に達するまで管理されません。
-S mode-Sパラメーターはプロセススキャニングのタイプを指定します。例のように0に設定すると numad 管理を明示的に付加プロセスに限定します。
numad を停止するには、以下のコマンドを実行します。
# numad -i 0
numad を停止しても NUMA アフィニティの改善のためになされた変更は削除されません。システムの使用方法が大幅に変わる場合は、numad を再度実行することでアフィニティが調整され、新たな条件の下でパフォーマンスが改善されます。
利用可能な numad オプションについては、numad man ページ:
man numad を参照してください。