第2章 Kamelets を使用した Kafka への接続
Apache Kafka は、耐障害性のあるリアルタイムデータフィードを作成する、オープンソースの分散型 publish/subscribe メッセージングシステムです。Kafka はデータを素早く保存し、多数のコンシューマー (外部コネクション) 用にデータを複製します。
Kafka は、ストリーミングイベントを処理するソリューションの構築に役立ちます。分散されたイベント駆動型のアーキテクチャーでは、イベントをキャプチャーし、通信し、処理するのに役立つ「バックボーン」が必要です。Kafka は、データソースとイベントをアプリケーションに接続する通信バックボーンとして機能します。
kamelets を使用して Kafka と外部リソースとの間の通信を設定できます。Kamelets を使用すると、コードを作成せずに、Kafka stream-processing フレームワークでデータをあるエンドポイントから別のエンドポイントに移動する方法を設定できます。Kamelets は、パラメーター値を指定して設定するルートテンプレートです。
たとえば、Kafka はデータをバイナリー形式で保存します。kamelets を使用すると、外部接続との間で送受信するためにデータをシリアライズおよびデシリアライズすることができます。kamelets を使用すると、スキーマを検証し、追加、フィルタリング、マスクなどのデータ変更を行うことができます。Kamelets はエラーを処理できます。問題が発生した場合は、エラーが処理される必要があります。
2.1. kamelets を使用した Kafka への接続の概要
Apache Kafka stream-processing フレームワークを使用する場合は、kamelets を使用してサービスおよびアプリケーションを Kafka トピックに接続できます。Kamelet Catalog は、Kafka トピックへの接続専用に、以下の kamelets を提供します。
-
kafka-sink: イベントをデータプロデューサーから Kafka トピックに移動します。kamelet バインディングでは、kafka-sink kamelet をシンクとして指定します。 -
kafka-source: イベントを Kafka トピックからデータコンシューマーに移動します。kamelet バインディングでは、kafka-source kamelet をソースとして指定します。
図 2.1 では、ソースとシンク kamelets を Kafka トピックに接続するフローを示します。
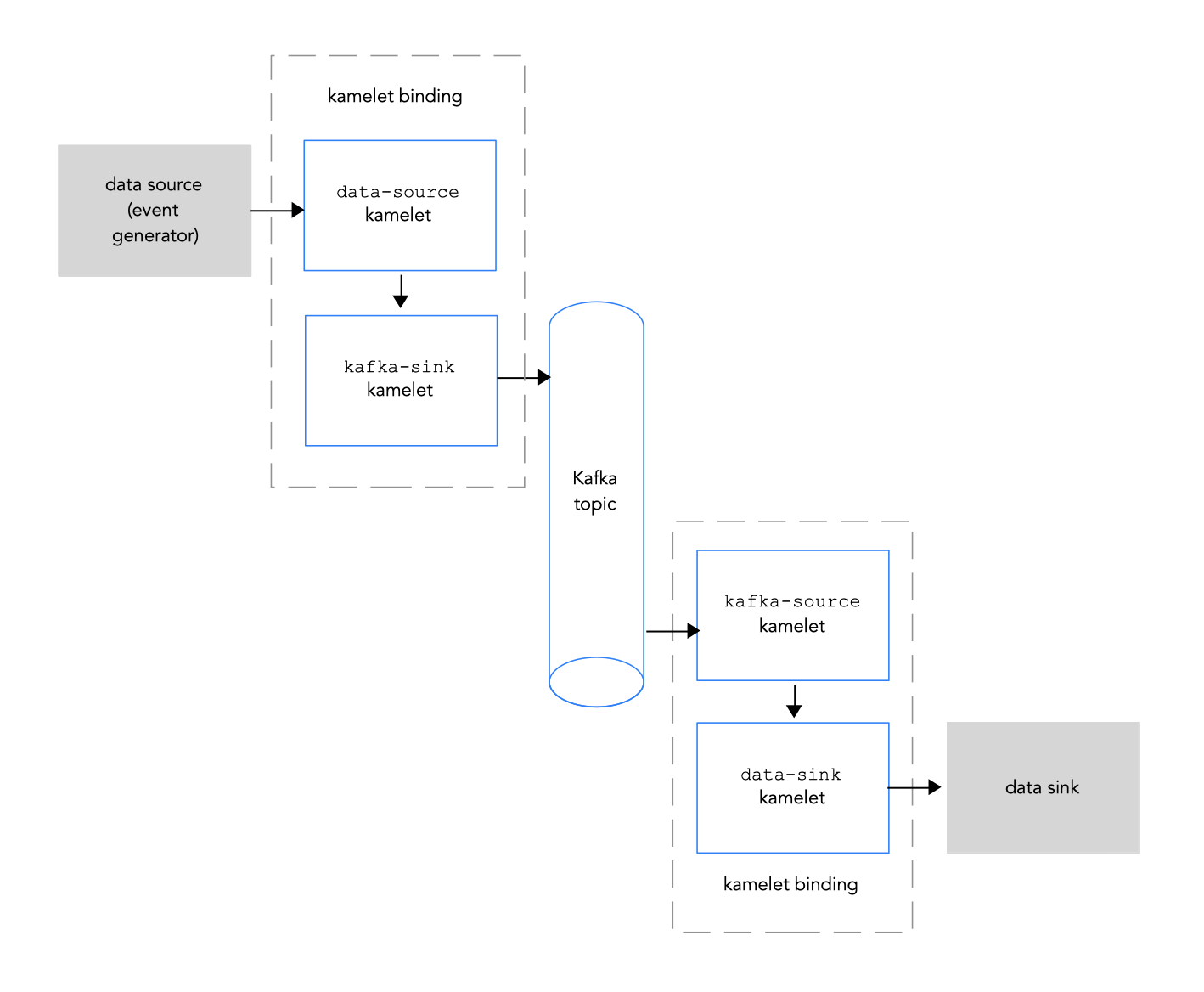
図 2.1: kamelets と Kafka トピックによるデータフロー
以下は、kamelets および kamelet バインディングを使用してアプリケーションやサービスを Kafka トピックに接続するための基本的な手順の概要です。
Kafka を設定します。
必要な OpenShift Operator をインストールします。
- OpenShift Streams for Apache Kafka では、RHOAS および Camel K Operator をインストールします。
- AMQ Streams では、Camel K および AMQ Streams の operator をインストールします。
- Kafka インスタンスを作成します。Kafka インスタンスはメッセージブローカーとして動作します。ブローカーにはトピックが含まれ、ストレージとメッセージの渡しをオーケストレーションします。
- Kafka トピックを作成します。トピックは、データの保存先を提供します。
- Kafka 認証クレデンシャルを取得します。
- Kafka トピックに接続するサービスまたはアプリケーションを決定します。
- kamelet カタログを表示し、インテグレーションに追加するソースおよびシンクコンポーネントの kamelets を見つけます。使用する各 kamelet に必要な設定パラメーターも決定します。
kamelet バインディングを作成します。
-
データソース (データを生成するコンポーネント) を Kafka トピックに接続する kamelet バインディングを作成します (
kafka-sinkkamelet を使用します)。 -
kafka トピックをデータシンク (データを消費するコンポーネント) に接続する kamelet バインディングを作成します (
kafka-sourcekamelet を使用します)。
-
データソース (データを生成するコンポーネント) を Kafka トピックに接続する kamelet バインディングを作成します (
- オプションとして、kamelet バインディング内の中間ステップとして 1 つまたは複数のアクション kamelets を追加して、kafka トピックおよびデータソース/シンク間で渡されるデータを操作します。
- 必要に応じて、kamelet バインディング内でエラーを処理する方法を定義します。
kamelet バインディングをリソースとしてプロジェクトに適用します。
Camel K Operator は、kamelet バインディングごとに個別の Camel K インテグレーションを生成します。