第1章 コンポーネント
Red Hat OpenStack Platform IaaS クラウドは、コンピューティング、ストレージ、ネットワークのリソースを制御するために相互に対話するサービスのコレクションとして実装されます。クラウドは、Web ベースのダッシュボードまたはコマンドラインクライアントで管理されます。これにより、管理者は OpenStack リソースの制御、プロビジョニング、自動化を行うことができます。OpenStack は、クラウドの全ユーザーが利用できる豊富な API も提供しています。
以下の図は、OpenStack のコアサービスとそれらの相互関係の俯瞰的な概要を示しています。
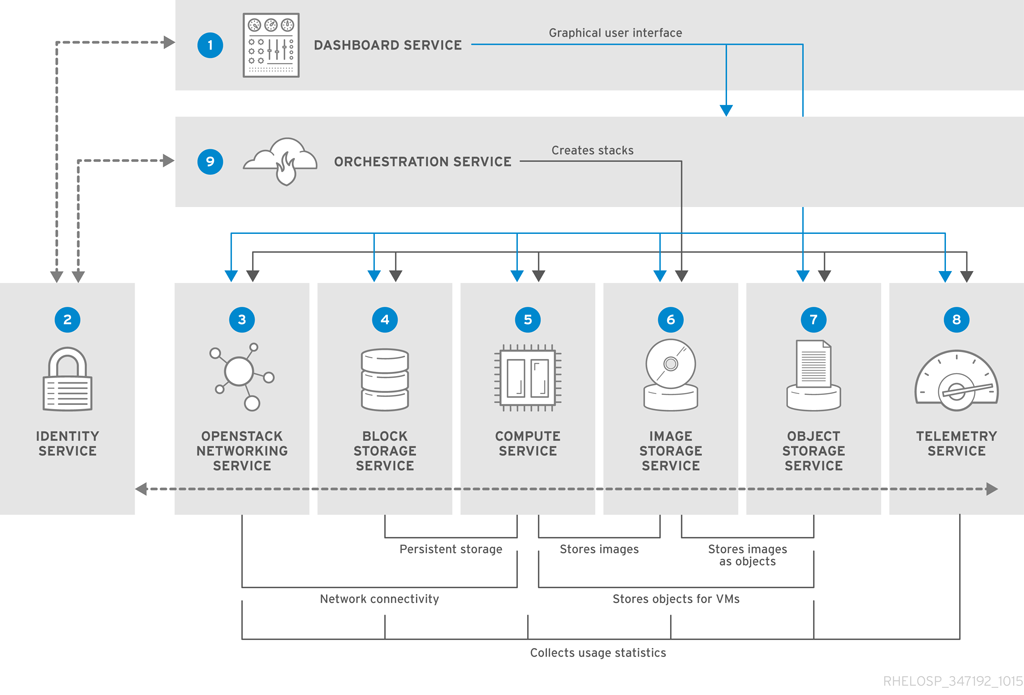
以下の表には、上図に示した各コンポーネントについての簡単な説明と、それぞれのセクションへのリンクをまとめています。
| サービス | コード | 説明 | リンク | |
|---|---|---|---|---|
|
|
Dashboard |
horizon |
OpenStack の各サービスの管理に使用する Web ブラウザーベースのダッシュボード | |
|
|
Identity |
keystone |
OpenStack サービスを認証および承認し、ユーザー/プロジェクト/ロールを管理する一元化されたサービス | |
|
|
OpenStack Networking |
neutron |
OpenStack サービスのインターフェース間の接続性を提供します。 | |
|
|
Block Storage |
cinder |
仮想マシン用の永続的な Block Storage ボリュームを管理します。 | |
|
|
Compute |
nova |
ハイパーバイザーノードで実行されている仮想マシンの管理とプロビジョニングを行います。 | |
|
|
Image |
glance |
仮想マシンイメージやボリュームのスナップショットなどのリソースの保管に使用するレジストリーサービス | |
|
|
Object Storage |
swift |
ユーザーによるファイルおよび任意のデータの保管/取得を可能にします。 | |
|
|
Telemetry |
ceilometer |
クラウドリソースの計測値を提供します。 | |
|
|
Orchestration |
heat |
リソーススタックの自動作成をサポートする、テンプレートベースのオーケストレーションエンジン |









各 OpenStack サービスには、Linux サービスおよびその他のコンポーネントの機能グループが含まれています。たとえば、glance-api および glance-registry Linux サービスは MariaDB データベースとともに Image サービスを実装します。OpenStack サービスに含まれるサードパーティーコンポーネントに関する詳しい情報は、「サードパーティーのコンポーネント」を参照してください。
その他のサービス:
- 「OpenStack Bare Metal Provisioning (ironic)」: さまざまなハードウェアベンダーの物理マシン (ベアメタル) のプロビジョニングを可能にします。
- 「OpenStack Data Processing (sahara)」: OpenStack で Hadoop クラスターのプロビジョニングと管理を行うことができるようになります。
1.1. ネットワーク
1.1.1. OpenStack Networking (neutron)
OpenStack Networking は、OpenStack クラウド内の仮想ネットワークインフラストラクチャーの作成と管理を処理します。インフラストラクチャー要素にはネットワーク、サブネット、ルーターなどが含まれます。また、ファイアウォールや仮想プライベートネットワーク (VPN) などの高度なサービスもデプロイすることができます。
OpenStack Networking は、クラウド管理者が、個々のサービスをどの物理システムで実行するかを決定する柔軟性を提供します。評価目的の場合には、全サービスデーモンを単一の物理ホストで実行することが可能です。また、各サービスに独自の物理ホストを使用したり、複数のホストにわたって複製して冗長化を行ったりすることもできます。
OpenStack Networking はソフトウェア定義型なので、新規 IP アドレスの作成や割り当てなど、変化するネットワークのニーズにリアルタイムで対応することができます。
OpenStack Networking には、次のような利点があります。
- ユーザーは、ネットワークの作成やトラフィックの制御を行ったり、サーバーおよびデバイスを単一または複数のネットワークに接続したりすることができます。
- ボリュームとテナンシーに適応可能な柔軟性の高いネットワークモデルを提供します。
- IP アドレスは、専用または Floating IP を使用することができます。Floating IP により、動的なトラフィックルーティングが可能となります。
- VLAN ネットワークを使用する場合には、最大で 4094 の VLAN (4094 のネットワーク) を使用することが可能です。この場合、4094 = 2^12 (この値から使用不可な 2 つを差し引いた) ネットワークアドレスです。これは、12 ビットのヘッダーで課せられる制限です。
- VXLAN トンネルベースのネットワークを使用する場合には、VNI (Virtual Network Identifier) は 24 ビットのヘッダーを使用することができます。これは、実質的には 1600 万の一意なアドレス/ネットワークを使用できることになります。
| コンポーネント | 説明 |
|---|---|
|
ネットワークエージェント |
各 OpenStack ノード上で稼働し、そのノードの仮想マシンとネットワークサービスのローカルネットワーク設定を行うサービス (例: Open vSwitch) |
|
neutron-dhcp-agent |
テナントネットワークに対して DHCP サービスを提供するエージェント |
|
neutron-ml2 |
ネットワークドライバーを管理して、Open vSwitch や Ryu ネットワークなどのネットワークサービスのルーティングおよびスイッチングサービスを提供するプラグイン |
|
neutron-server |
ユーザー要求を管理し、Networking API を公開する Python デーモン。デフォルトのサーバー設定では、特定のネットワークメカニズムが装備されたプラグインを使用して Networking API を実装します。 openvswitch や linuxbridge などの特定のプラグインは、ネイティブの Linux ネットワークメカニズムを使用しますが、その他のプラグインは外部のデバイスや SDN コントローラーと連動します。 |
|
neutron |
API にアクセスするためのコマンドラインクライアント |
OpenStack Networking サービスおよびエージェントの配置は、ネットワーク要件によって異なります。以下の図には、コントローラーを使用しない、一般的なデプロイメントモデルを示しています。このモデルでは、専用の OpenStack Networking ノードとテナントネットワークを使用します。
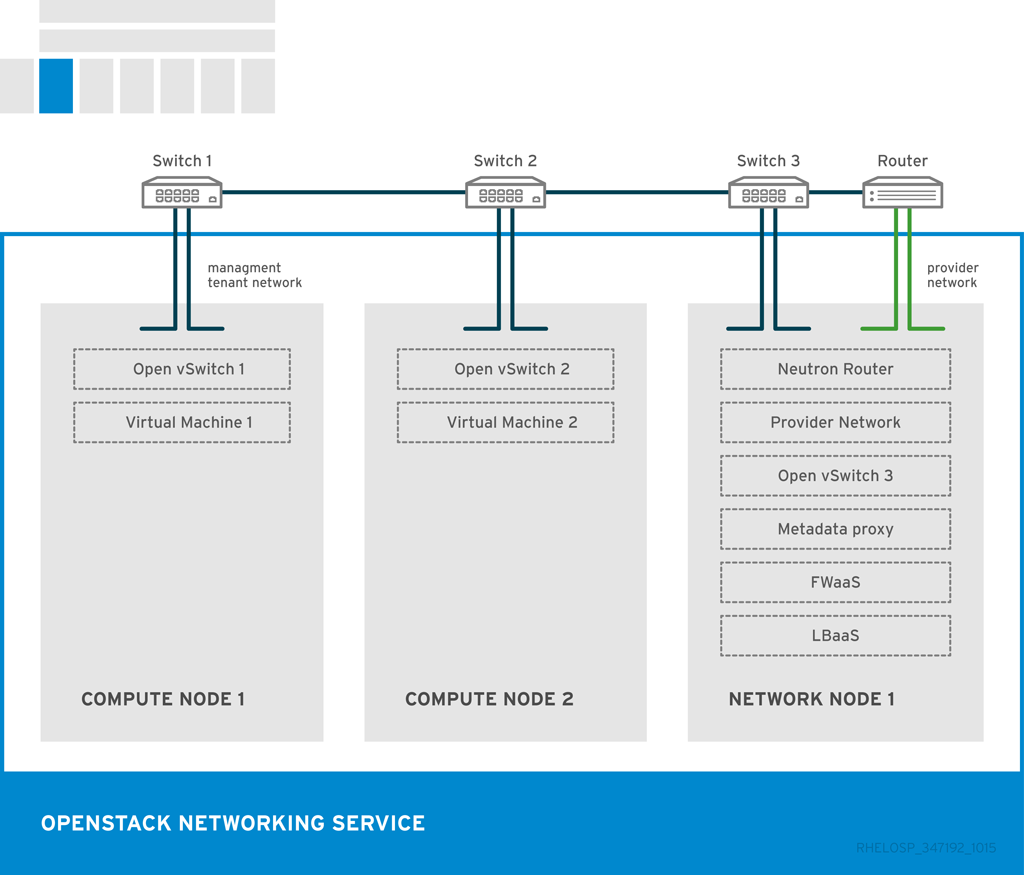
上記の例は、以下のネットワークサービス構成を示しています。
2 つのコンピュートノードで Open vSwitch (ovs-agent) を実行し、1 つの OpenStack Networking ノードで、次のネットワーク機能を実行します。
- L3 ルーティング
- DHCP
- FWaaS や LBaaS などのサービスを含む NAT
- コンピュートノードには、2 枚の物理ネットワークカードを装備します。一方はテナントトラフィックを処理し、もう一方は接続性を管理します。
- OpenStack Networking ノードには、プロバイダートラフィック専用に 3 枚目のネットワークカードを装備します。
1.2. ストレージ
「OpenStack Block Storage (cinder)」
「OpenStack Object Storage (swift)」
1.2.1. OpenStack Block Storage (cinder)
Block Storage サービスは、仮想ハードドライブの永続的なブロックストレージ管理機能を提供します。Block Storage により、ユーザーはブロックデバイスの作成/削除やサーバーへの Block Device の接続を管理することができます。
デバイスの実際の接続/切断は、Compute サービスとの統合により処理されます。分散ブロックストレージホストの処理には、リージョンとゾーンの両方を使用することができます。
Block Storage は、データベースストレージや、拡張可能なファイルシステムなど、パフォーマンスが要求されるシナリオに使用することができます。また、RAW ブロックレベルストレージにアクセス可能なサーバーとして使用することもできます。加えて、ボリュームのスナップショットを作成して、データの復元や新規ブロックストレージボリュームの作成も可能です。スナップショットは、ドライバーのサポートに依存します。
OpenStack Block Storage には、次のような利点があります。
- ボリュームとスナップショットの作成、一覧表示、削除
- 実行中の仮想マシンへのボリュームの接続/切断
実稼働環境で Block Storage の主要なサービス (ボリューム、スケジューラー、API) を併置することは可能ですが、ボリュームサービスのインスタンスを複数デプロイして、API およびスケジューラーサービスのインスタンス (単一または複数) でそれらを管理する構成の方がより一般的です。
| コンポーネント | 説明 |
|---|---|
|
openstack-cinder-api |
要求に応答し、メッセージキューに配置します。API サービスは Block Storage 要求のための HTTP エンドポイントを提供します。受信要求を受け取ると、API はアイデンティティー要件が満たされているかどうかを確認し、その要求を、必要とされる Block Storage のアクションを含むメッセージに変換します。このメッセージは、次にメッセージブローカーに送信され、他の Block Storage サービスによって処理されます。 |
|
openstack-cinder-backup |
Block Storage ボリュームを外部のストレージリポジトリーにバックアップします。デフォルトでは、OpenStack は Object Storage サービスを使用してバックアップを保管します。Ceph または NFS のバックエンドをバックアップ用のストレージリポジトリーとして使用することも可能です。 |
|
openstack-cinder-scheduler |
タスクをキューに割り当て、プロビジョニングするボリュームサーバーを決定します。スケジューラーサービスは、メッセージキューから要求を読み取り、要求されたアクションを実行する Block Storage ホストを判断します。スケジューラーは次に選択したホスト上の openstack-cinder-volume サービスと通信し、要求を処理します。 |
|
openstack-cinder-volume |
仮想マシン用にストレージを指定します。ボリュームサービスは、ブロックストレージデバイスとの対話を管理します。スケジューラーからの要求を受け取ると、ボリュームサービスはボリュームの作成、変更、削除を行います。ボリュームサービスには、NFS、Red Hat Storage、Dell EqualLogic などのブロックストレージデバイスと対話するための複数のドライバーが同梱されています。 |
|
cinder |
Block Storage API にアクセスするためのコマンドラインクライアント |
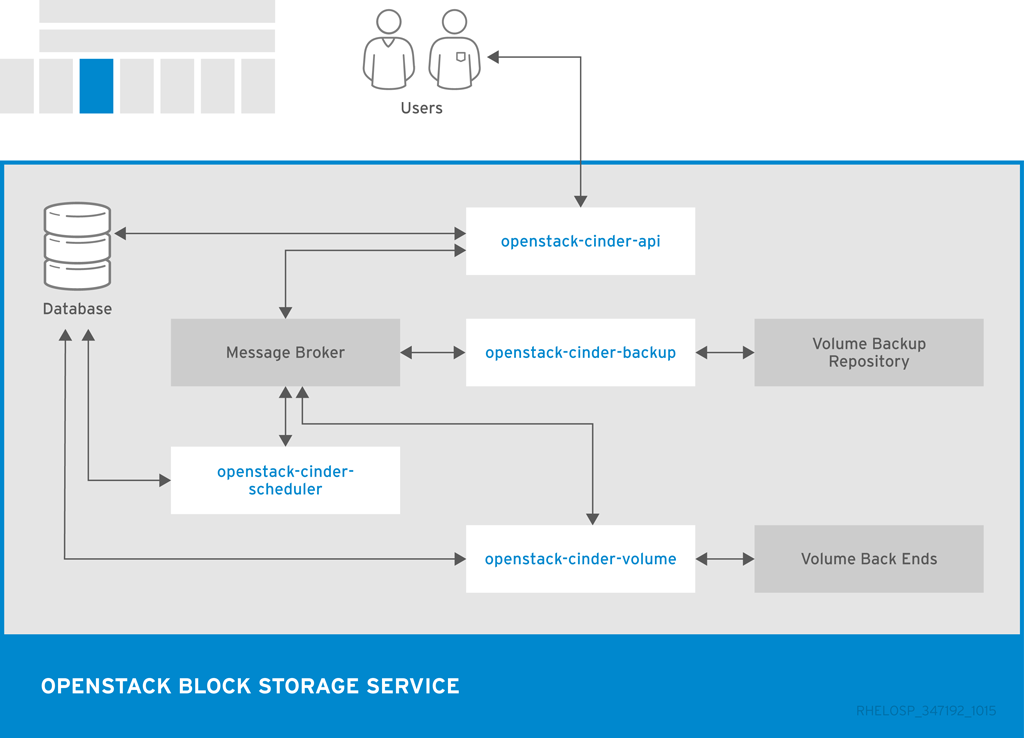
以下の図には、Blocck Storage API、スケジューラー、ボリュームサービス、その他の OpenStack コンポーネントの関係を示しています。
1.2.2. OpenStack Object Storage (swift)
Object Storage サービスは、HTTP 経由でアクセス可能な、大量データ用のストレージシステムを提供します。ビデオ、イメージ、メールのメッセージ、ファイル、仮想マシンイメージなどの静的エンティティーをすべて保管することができます。オブジェクトは、各ファイルの拡張属性に保管されているメタデータとともに、下層のファイルシステムにバイナリーとして保管されます。
Object Storage の分散アーキテクチャーは、水平スケーリングに加えて、ソフトウェアベースのデータ複製を使用したフェイルオーバーのための冗長化をサポートします。このサービスは、非同期で結果整合性のある複製をサポートするので、複数のデータセンターで構成されるデプロイメントに使用することができます。
OpenStack Object Storage には、次のような利点があります。
- ストレージのレプリカにより、障害発生時にオブジェクトの状態が維持されます。最低でも 3 つ以上のレプリカが推奨されます。
- ストレージゾーンにより、レプリカがホストされます。ゾーンを使用することにより、任意のオブジェクトの各レプリカを個別に格納することができます。ゾーンは、個別のディスクドライブ、アレイ、サーバー、サーバーラック、あるいはデータセンター全体を指すこともあります。
- ストレージリージョンでゾーンをグループ化することができます。リージョンには、通常同じ地理的地域に配置されているサーバーやサーバーファームなどを含めることができます。リージョンには、Object Storage サービスをインストールしたシステムごとに個別の API エンドポイントがあり、サービスを分離することができます。
Object Storage は、データベースおよび設定ファイルとして機能するリング .gz ファイルを使用します。これらのファイルには、全ストレージデバイスの詳細情報と、保管されているエンティティーから各ファイルの物理的な場所へのマッピングが含まれているので、特定のデータの場所を決定するのに使用することができます。プロジェクト、アカウント、コンテナーサーバーにはそれぞれ固有のリングファイルがあります。
Object Storage サービスは、他の OpenStack サービスおよびコンポーネントに依存してアクションを実行します。たとえば、Identity サービス (keystone)、rsync デーモン、ロードバランサーはすべて必要です。
| コンポーネント | 説明 |
|---|---|
|
openstack-swift-account |
アカウントデータベースを使用して、コンテナーのリストを処理します。 |
|
openstack-swift-container |
コンテナーデータベースを使用して、特定のコンテナーに含まれているオブジェクトのリストを処理します。 |
|
openstack-swift-object |
オブジェクトを保管、取得、削除します。 |
|
openstack-swift-proxy |
パブリック API の公開、認証、要求のルーティングを行います。オブジェクトは、スプールせずに、プロキシーサーバーを介してユーザーにストリーミングされます。 |
|
swift |
Object Storage API にアクセスするためのコマンドラインクライアント |
| ハウスキーピング | コンポーネント | 説明 |
|---|---|---|
|
監査 |
|
Object Storage のアカウント、コンテナー、オブジェクトの整合性を検証し、データの破損から保護します。 |
|
レプリケーション |
|
Object Storage クラスター全体でレプリケーションの一貫性と可用性を確保します (ガベージコレクションを含む)。 |
|
更新 |
|
失敗した更新を特定し、再試行します。 |
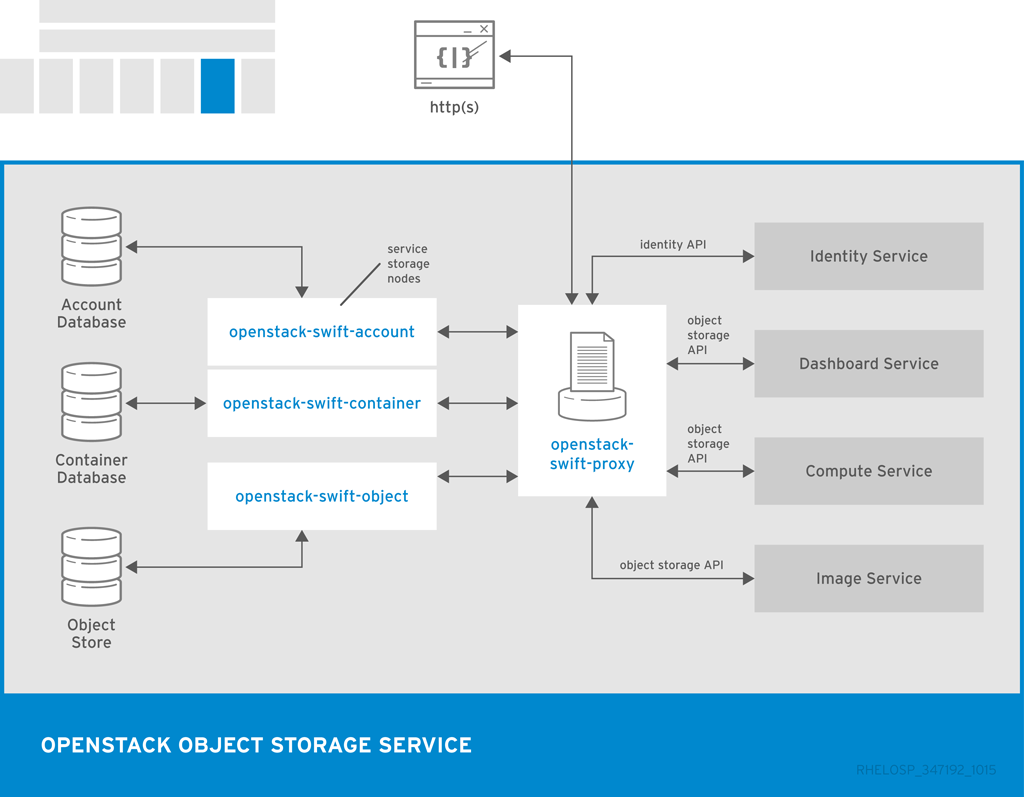
以下の図には、Object Storage が他の OpenStack サービス、データベース、ブローカーと対話するのに使用する主要なインターフェースを示しています。
1.3. 仮想マシン、イメージ、テンプレート
「OpenStack Bare Metal Provisioning (ironic)」
「OpenStack Orchestration (heat)」
「OpenStack Data Processing (sahara)」
1.3.1. OpenStack Compute (nova)
OpenStack Compute サービスは、オンデマンドで仮想マシンを提供する、OpenStack クラウドの中核です。Compute は、下層の仮想化メカニズムと対話するドライバーを定義し、他の OpenStack コンポーネントに機能を公開することにより、仮想マシンが一式のノード上で実行されるようにスケジュールします。
Compute は、KVM をハイパーバイザーとして使用する libvirt ドライバー libvirtd をサポートしています。ハイパーバイザーは、仮想マシンを作成し、ノード間でのライブマイグレーションを可能にします。ベアメタルマシンのプロビジョニングには、「OpenStack Bare Metal Provisioning (ironic)」 を使用することもできます。
Compute は、インスタンスおよびデータベースへのアクセス認証には Identity サービス、イメージへのアクセスとインスタンスの起動には Image サービス、ユーザーおよび管理用のインターフェースの提供には Dashboard サービスと対話します。
イメージへのアクセスは、プロジェクトまたはユーザー別に制限することが可能です。また、プロジェクトとユーザーのクォータ (例: 単一のユーザーが作成可能なインスタンス数など) を指定することができます。
Red Hat OpenStack Platform クラウドをデプロイする際には、以下のような異なるカテゴリーでクラウドを分割することができます。
- リージョン
Identity サービスでカタログ化されている各サービスは、サービスリージョン別に特定されます。サービスリージョンとは、通常地理的な場所およびサービスエンドポイントのことを示します。複数のコンピュートノードを使用するクラウドでは、リージョンによりサービスを別々に分けることができます。
また、リージョンを使用すると、コンピュートをインストールしたシステム間でインフラストラクチャーを共有しつつ、高度の耐障害性を維持することもできます。
- セル (テクノロジープレビュー)
Compute ホストは、セルと呼ばれるグループに分割して、大型のデプロイメントや地理的に分離されたインストールを処理することができます。セルは、木構造に構成されています。最上位のセルは API セルと呼ばれ、nova-api サービスを実行しますが、nova-compute サービスは実行しません。
各子セルは、その他すべての標準的な nova-* サービスを実行しますが、nova-api サービスは実行しません。各セルには、個別のメッセージキューとデータベースサービスがあり、API と子セルの間の通信を管理する nova-cells サービスも実行します。
セルには以下のような利点があります。
- 単一の API サーバーを使用して、Compute がインストールされた複数のシステムへのアクセスを制御することができます。
- セルレベルで追加のスケジューリングレベルが利用できます。ホストのスケジューリングとは異なり、仮想マシンの実行時により高い柔軟性と制御を提供します。
この機能は、本リリースではテクノロジープレビューとして提供しているため、Red Hat では全面的にはサポートしていません。これは、テスト目的のみでご利用いただく機能で、実稼働環境にデプロイすべきではありません。 テクノロジープレビューについての詳しい情報は 「対象範囲の詳細」を参照してください。
- ホストアグリゲートとアベイラビリティーゾーン
単一のコンピュートのデプロイメントは、複数の論理グループに分割することが可能です。ストレージやネットワークなどの共通のリソースを共有する複数のグループやトラステッドコンピューティングハードウェアなどの特殊なプロパティーを共有するグループなどを複数作成することができます。
このグループは、管理者には、割り当て済みのコンピュートノードと関連メタデータとともにホストアグリゲートとして表示されます。ホストアグリゲートのメタデータは通常、ホストのサブネットに特定のフレーバーやイメージを制限するなどの openstack-nova-scheduler のアクションに向けた情報を提供するのに使用されます。
ユーザーに対しては、グループはアベイラビリティーゾーンとして表示されます。ユーザーはグループメタデータを表示したり、ゾーン内のホスト一覧を確認したりすることはできません。
アグリゲート/ゾーンには、以下のような利点があります。
- ロードバランシングおよびインスタンスの分散
- 別々の電源とネットワーク機器を使用して実装される、ゾーン間における物理的な分離および冗長性
- 共通の属性を持つサーバーグループのラベル
- 異なるハードウェアクラスの分離
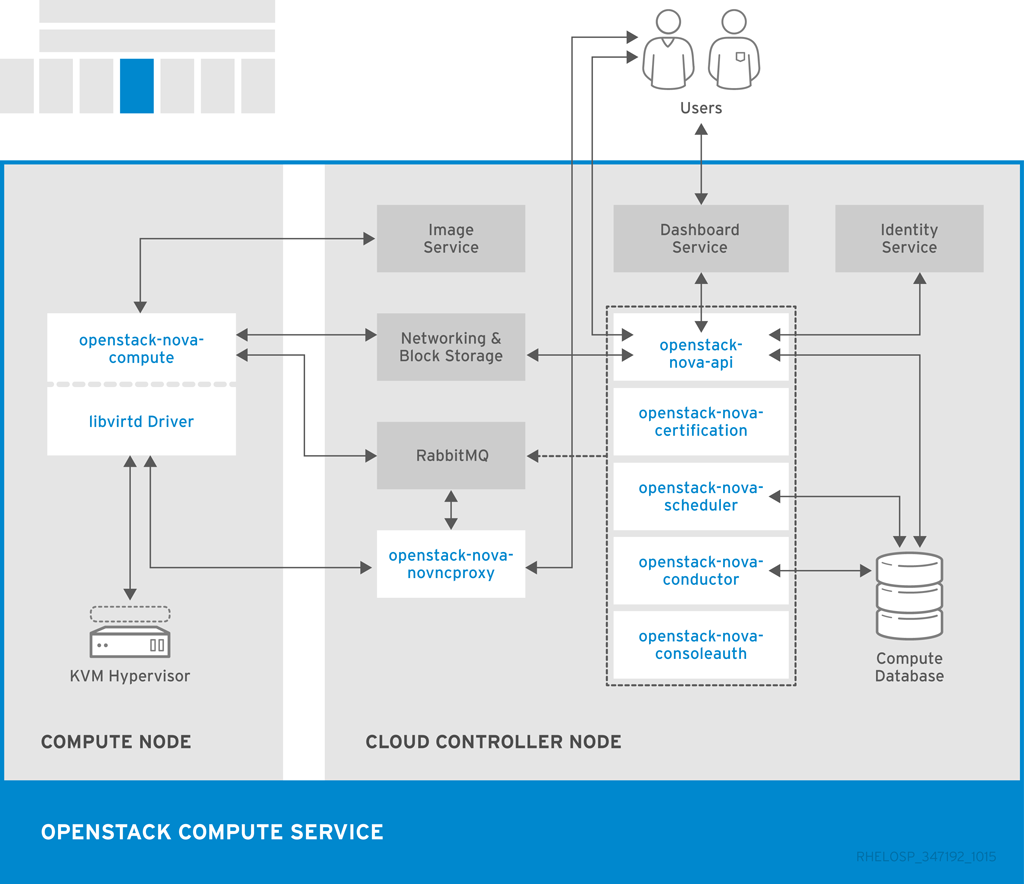
| コンポーネント | 説明 |
|---|---|
|
openstack-nova-api |
要求を処理し、Compute サービス (例: インスタンスの起動など) へのアクセスを提供します。 |
|
openstack-nova-cert |
証明書マネージャーを提供します。 |
|
openstack-nova-compute |
仮想マシンの作成および削除を行うために、各ノード上で実行されます。Compute サービスはハイパーバイザーと対話して新規インスタンスを起動し、Compute のデータベースでインスタンスの状態が維持管理されるようにします。 |
|
openstack-nova-conductor |
コンピュートノードのデータベースアクセスのサポートを提供し、セキュリティーリスクを軽減します。 |
|
openstack-nova-consoleauth |
コンソールの認証を処理します。 |
|
openstack-nova-novncproxy |
ブラウザー用の VNC プロキシーを提供して、VNC コンソールが仮想マシンにアクセスできるようにします。 |
|
openstack-nova-scheduler |
設定済みの重みとフィルターに基づいて、 新規仮想マシンに対する要求を正しいノードに割り当てます。 |
|
nova |
Compute API にアクセスするためのコマンドラインクライアント |
以下の図は、Compute サービスとその他の OpenStack コンポーネントの間の関係を示しています。
1.3.2. OpenStack Bare Metal Provisioning (ironic)
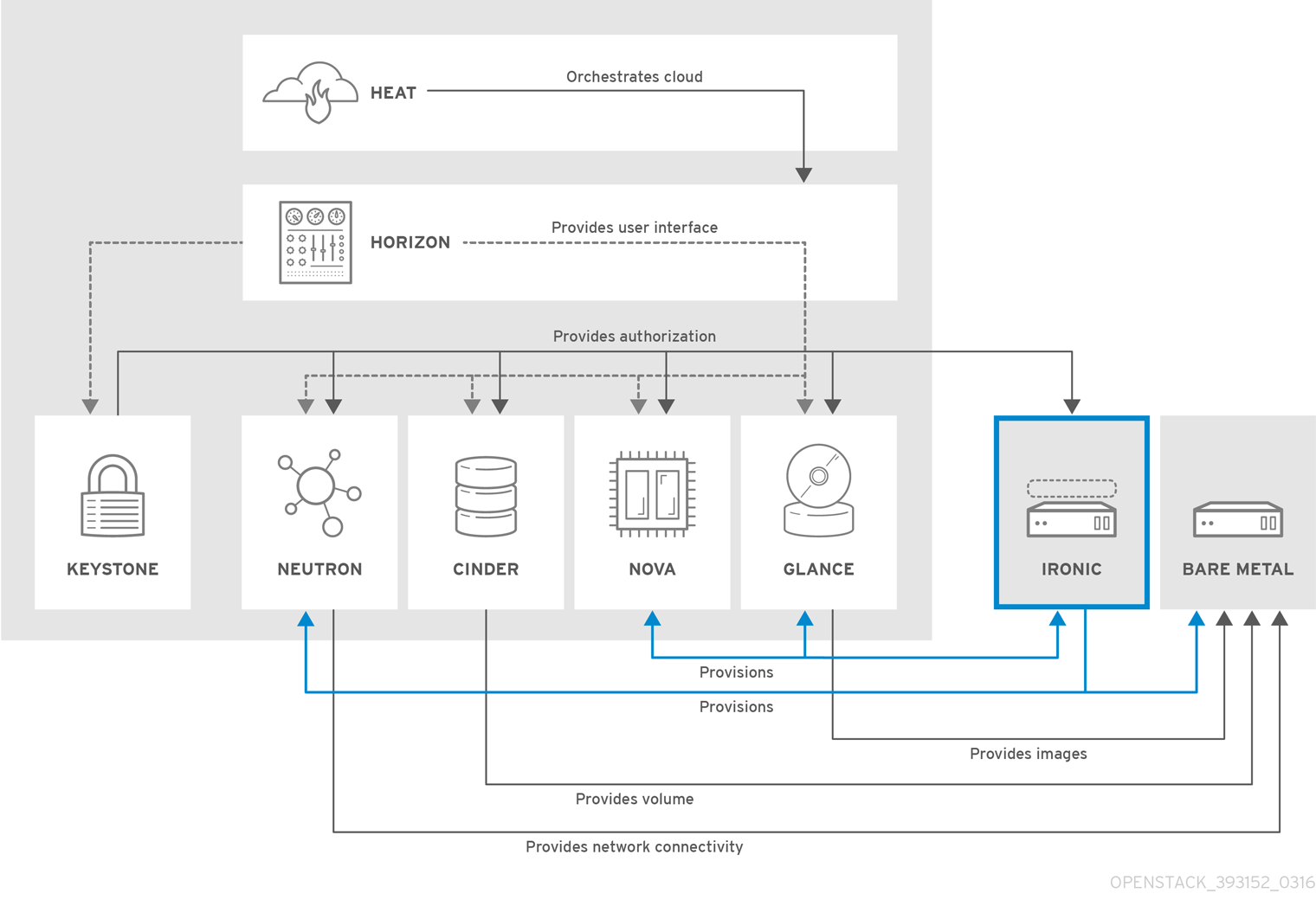
OpenStack Bare Metal Provisioning により、ハードウェア固有のドライバーを使用するさまざまなハードウェアベンダーの製品で物理マシンまたはベアメタルマシンのプロビジョニングを行うことができます。Bare Metal Provisioning は Compute サービスと統合して、仮想マシンのプロビジョニングと同じ方法で、ベアメタルマシンのプロビジョニングを行い、bare-metal-to-trusted-tenant ユースケースの解決策を提供します。
OpenStack Baremetal Provisioning には以下のような利点があります。
- Hadoop クラスターをベアメタルマシン上にデプロイすることができます。
- ハイパースケールおよびハイパフォーマンスコンピューティング (HPC) のクラスターをデプロイすることが可能です。
- 仮想マシンの影響を受けるアプリケーション用のデータベースホスティングを使用することが可能です。
Bare Metal Provisioning は、スケジューリングとクォータの管理に Compute サービスを使用します。また認証には Identity サービスを使用します。インスタンスのイメージは、KVM ではなく Bare Metal Provisioning をサポートするように設定する必要があります。
以下の図は、物理サーバーがプロビジョニングされた際に Ironic とその他の OpenStack サービスがどのように対話するかを示しています。
| コンポーネント | 説明 |
|---|---|
|
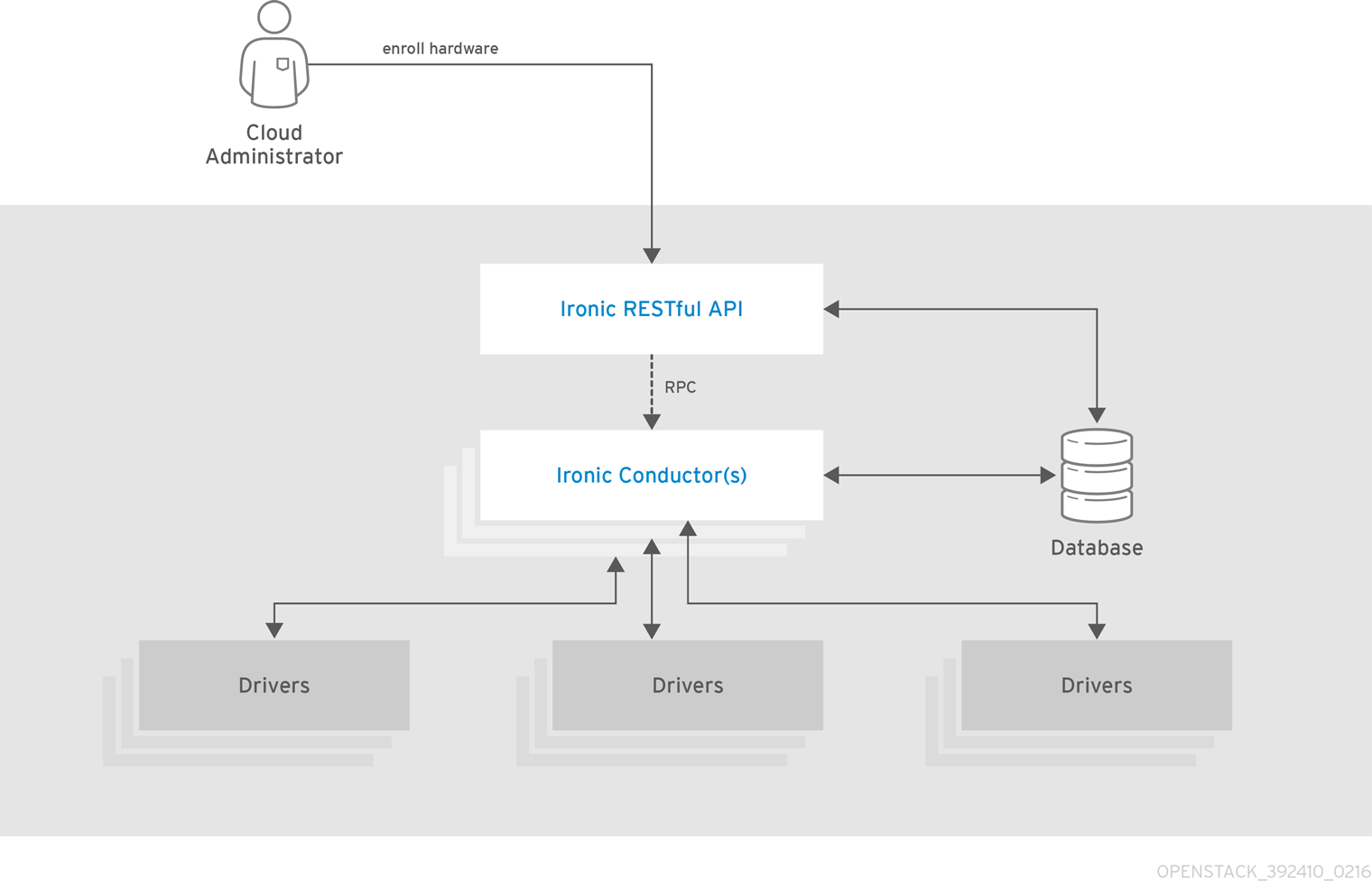
openstack-ironic-api |
ベアメタルノード上のコンピュートリソースに対する要求を処理し、アクセスを提供します。 |
|
openstack-ironic-conductor |
ハードウェアおよび ironic のデータベースと直接対話して、要求されたアクションおよび定期的なアクションを処理します。異なるハードウェアドライバーと対話するには、複数のコンダクターを作成してください。 |
|
ironic |
Bare Metal Provisioning API にアクセスするためのコマンドラインクライアント |
以下の図は、Ironic API、コンダクター、ドライバー、その他の OpenStack コンポーネントの間の関係を示しています。
1.3.3. OpenStack Image (glance)
OpenStack Image は、仮想ディスクイメージのレジストリーとして機能します。ユーザーは、新規イメージを追加したり、既存のサーバーのスナップショットを作成して直ちに保存したりすることができます。スナップショットはバックアップ用、またはサーバーを新規作成するためのテンプレートとして使用できます。
登録したイメージは、Object Storage サービスまたは別の場所 (例: シンプルなファイルシステムや外部の Web サーバー) に保管することができます。
以下のイメージディスク形式がサポートされています。
- aki/ami/ari (Amazon のカーネル、RAM ディスク、またはマシンイメージ)
- iso (CD などの光学ディスクのアーカイブ形式)
- qcow2 (Copy On Write をサポートする Qemu/KVM)
- raw (非構造化の形式)
- vhd (VMware、Xen、Microsoft、VirtualBox などのベンダーの仮想マシンモニターで一般的な Hyper-V)
- vdi (Qemu/VirtualBox)
- vmdk (VMware)
コンテナーの形式は、Image サービスにより登録することも可能です。コンテナーの形式により、イメージに保管される仮想マシンのメタデータの種別と詳細レベルが決定されます。
以下のコンテナー形式がサポートされています。
- bare (メタデータなし)
- ova (OVA tar アーカイブ)
- ovf (OVF 形式)
- aki/ami/ari (Amazon のカーネル、RAM ディスク、またはマシンイメージ)
| コンポーネント | 説明 |
|---|---|
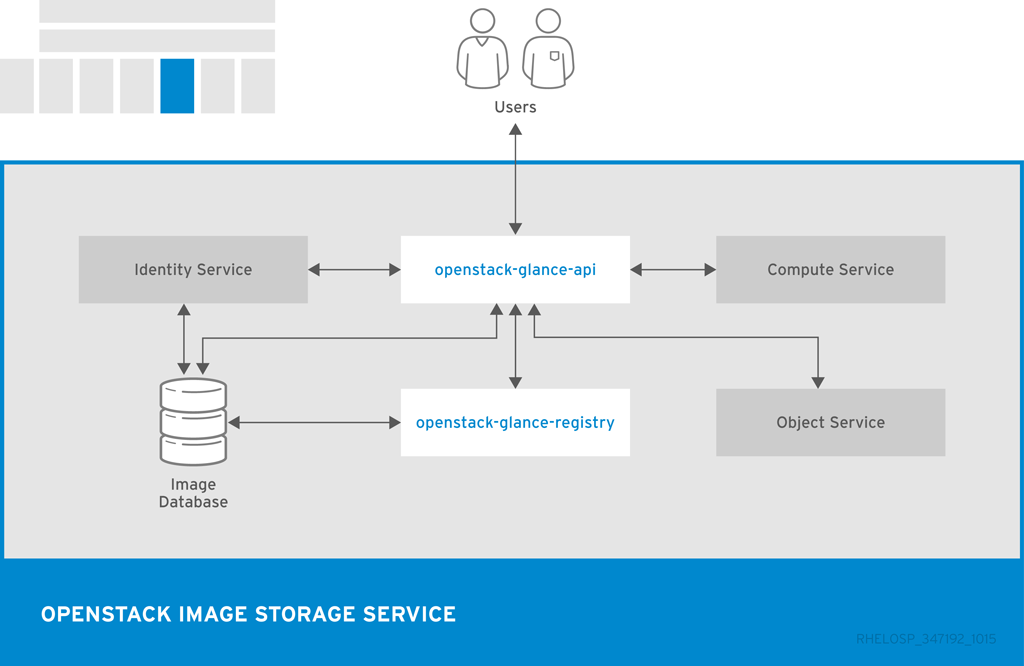
|
openstack-glance-api |
ストレージバックエンドと対話して、イメージの取得と保管の要求を処理します。API は openstack-glance-registry を使用してイメージの情報を取得します。レジストリーサービスには直接アクセスしてはなりません。 |
|
openstack-glance-registry |
各イメージの全メタデータを管理します。 |
|
glance |
Image API にアクセスするためのコマンドラインクライアント |
以下の図には、Image データベースからイメージを登録/取得するのに Image サービスが使用する主要なインターフェースを示しています。
1.3.4. OpenStack Orchestration (heat)
OpenStack Orchestration は、ストレージ、ネットワーク、インスタンス、アプリケーションなどのクラウドリソースを作成および管理するためのテンプレートを提供します。テンプレートは、リソースのコレクションであるスタックの作成に使用されます。
たとえば、インスタンス、Floating IP、ボリューム、セキュリティーグループ、ユーザーのテンプレートを作成することができます。Orchestration は、単一のモジュール型テンプレートを使用した OpenStack の全コアサービスへのアクセスに加えて、自動スケーリングや高可用性などの機能を提供します。
OpenStack Orchestration には以下のような利点があります。
- 単一のテンプレートで下層の全サービス API へのアクセスを提供します。
- テンプレートは、モジュール型でリソース指向です。
- テンプレートは、ネストされたスタックのように、再帰的に定義/再利用することができます。クラウドインフラストラクチャーはモジュール式に定義/再利用されます。
- リソースの実装はプラグ可能なので、カスタムリソースを利用することができます。
- リソースは自動スケーリングが可能なので、使用状況に応じてクラスターに追加/削除されます。
- 基本的な高可用性機能を利用することができます。
| コンポーネント | 説明 |
|---|---|
|
openstack-heat-api |
OpenStack のネイティブの REST API。RPC を使用して openstack-heat-engine サービスへの要求を送信することにより、API 要求を処理します。 |
|
openstack-heat-api-cfn |
AWS CloudFormation との互換性があるオプションの AWS-Query API。RPC を使用して openstack-heat-engine サービスへの要求を送信することにより、API 要求を処理します。 |
|
openstack-heat-engine |
テンプレートの起動をオーケストレーションして、API コンシューマーに対してイベントを生成します。 |
|
openstack-heat-cfntools |
ヘルパースクリプトのパッケージ (例: メタデータの更新を処理し、カスタムフックを実行する cfn-hup) |
|
heat |
Orchestration API と通信して AWS CloudFormation API を実行するコマンドラインツール |
以下の図には、Orchestration サービスが 2 つの新規インスタンスと 1 つのローカルネットワークを使用して新規スタックを作成する場合の主要なインターフェースを示しています。
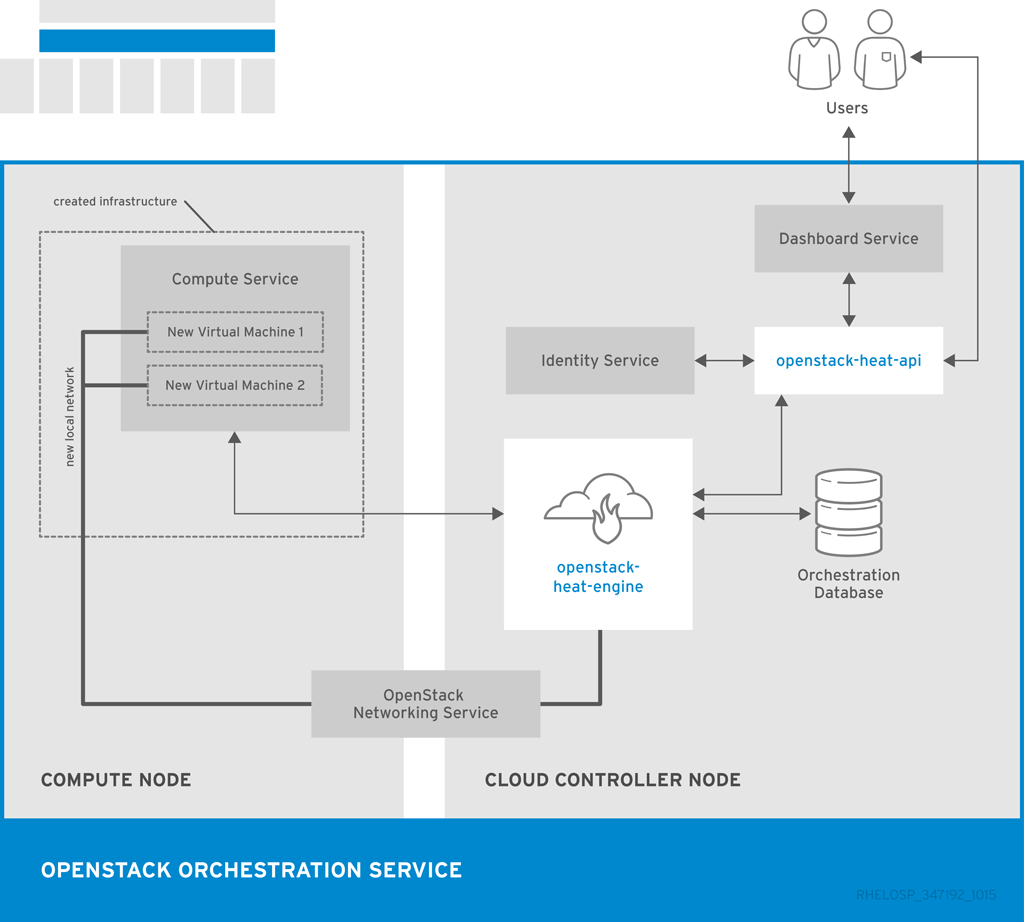
1.3.5. OpenStack Data Processing (sahara)
OpenStack Data Processing により、OpenStack 上の Hadoop クラスターのプロビジョニングと管理を行うことができます。Hadoop は、クラスター内の大量の構造化/非構造化データを保管および分析します。
Hadoop クラスターは、Hadoop Distributed File System (HDFS) を実行するストレージサーバー、Hadoop の MapReduce (MR) フレームワークを実行するコンピュートサーバー、またはそれらの両方として機能することができるサーバーグループです。
Hadoop クラスター内のサーバーは、同じネットワーク内に配置されている必要がありますが、メモリーやディスクを共有する必要はありません。このため、既存のサーバーとの互換性に影響を及ぼすことなく、サーバーとクラスターの追加/削除を行うことができます。
Hadoop のコンピュートサーバーとストレージサーバーは併置されるので、保管されているデータの分析を高速に行うことができます。タスクはすべてサーバー間で分散され、サーバーのローカルリソースを使用します。
OpenStack Data Processing には以下のような利点があります。
- Identity サービスがユーザーを認証して、Hadoop クラスター内におけるユーザーセキュリティーを提供することができます。
- Compute サービスがクラスターのインスタンスをプロビジョニングすることができます。
- Image サービスがクラスターのインスタンスを保管することができます。各インスタンスにはオペレーティングシステムとHDFS が含まれます。
- Object Storage サービスを使用して Hadoop ジョブプロセスのデータを格納することができます。
- クラスターの作成と設定にテンプレートを使用することができます。ユーザーは、カスタムテンプレートを作成して設定パラメーターを変更したり、クラスターの作成中にパラメーターを上書きすることができます。ノードはノードグループテンプレートを使用してグループ化され、ノードグループはクラスターテンプレートによりが統合されます。
- ジョブを使用して、Hadoop クラスター上のタスクを実行することができます。ジョブバイナリーには、実行可能コードが保管されます。また、データソースに入出力の場所や必要な認証情報が保管されます。
Data Processing は Cloudera (CDH) プラグインと、ベンダー固有の管理ツール (例: Apache Ambari) をサポートしています。OpenStack Dashboard またはコマンドラインツールを使用してクラスターのプロビジョニングと管理を行うことができます。
| コンポーネント | 説明 |
|---|---|
|
openstack-sahara-all |
API とエンジンサービスを処理するレガシーパッケージ |
|
openstack-sahara-api |
API 要求を処理して、Data Processing サービスへのアクセスを提供します。 |
|
openstack-sahara-engine |
クラスターの要求とデータ配信を処理するプロビジョニングエンジン |
|
sahara |
Data Processing API にアクセスするためのコマンドラインクライアント |
以下の図には、Data Processing サービスが Hadoop クラスターのプロビジョニングと管理に使用する主要なインターフェースを示しています。
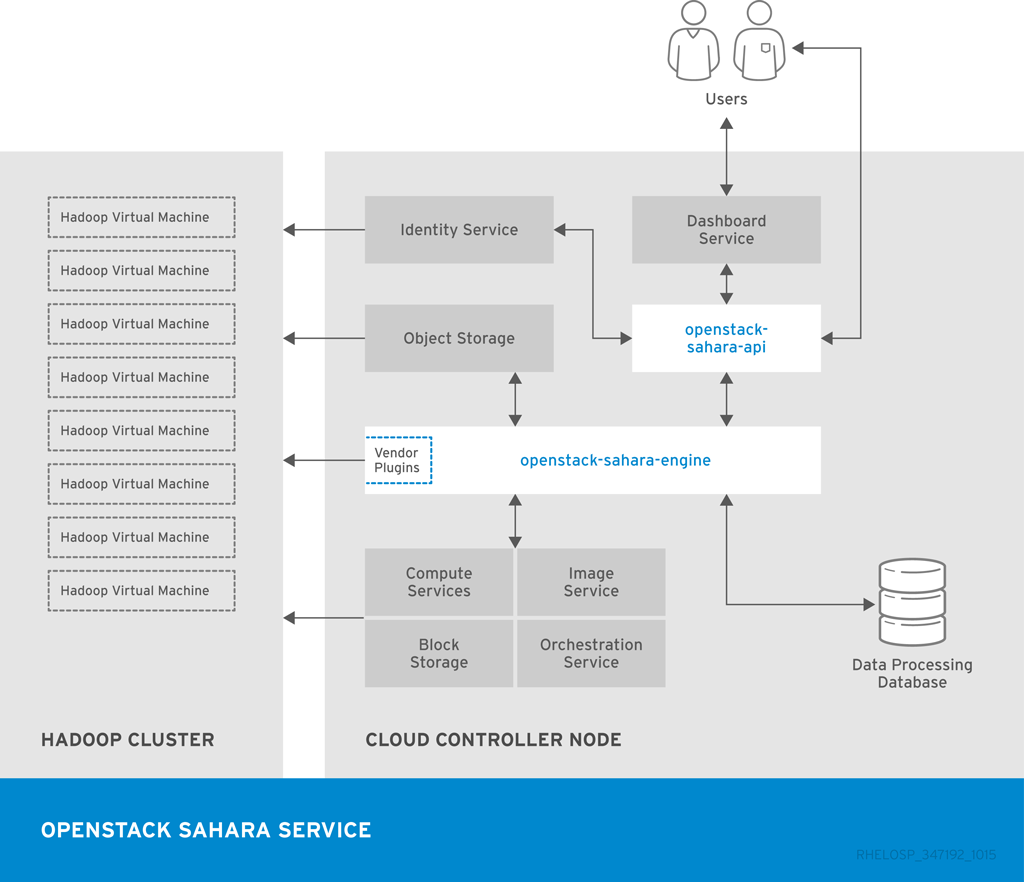
1.4. アイデンティティー管理
1.4.1. OpenStack Identity (keystone)
OpenStack Identity は、全 OpenStack コンポーネントに対してユーザーの認証と承認を提供します。Identity は、ユーザー名/パスワード認証情報、トークンベースのシステム、AWS 式のログインなど複数の認証メカニズムをサポートしています。
デフォルトでは、Identity サービスはトークン、カタログ、ポリシー、アイデンティティー情報に MariaDB バックエンドを使用します。このバックエンドは、開発環境や小規模なユーザーセットを認証する場合に推奨されます。また、LDAP、SQL などの複数の Identity バックエンドの併用や、memcache や Redis によるトークンの永続化も可能です。
Identity は SAML によるフェデレーションをサポートしています。フェデレーション対応の Identity により、Identity Provider (IdP) とIdentity がエンドユーザーに提供するサービスとの間で信頼関係が確立されます。
フェデレーション対応の Identity および複数のバックエンドの併用には、Eventlet デプロイメントの代わりに Identity API v3 と Apache HTTPD デプロイメントが必要です。
OpenStack Identity には以下のような利点があります。
- 名前やパスワードなどの関連情報を含むユーザーアカウント管理。カスタムユーザーに加えて、カタログ化された各サービス用にユーザーを定義する必要があります。たとえば、glance ユーザーは、Image サービス用に定義する必要があります。
- テナント/プロジェクトの管理。ユーザーグループ、プロジェクト、組織をテナントすることができます。
- ロール管理。ロールは、ユーザーのパーミッションを決定します。たとえば、ロールを使用して、営業担当者とマネージャーのパーミッションを区別することができます。
- ドメイン管理。ドメインは、Identity サービスエンティティーの管理上の境界線を決定し、1 つのドメインがユーザー、グループ、テナントのグループを示すマルチテナンシーをサポートします。1 つのドメインには複数のテナントを含めることができます。複数のアイデンティティープロバイダーを併用する場合には、プロバイダーにつき 1 ドメインとなります。
| コンポーネント | 説明 |
|---|---|
|
openstack-keystone |
Identity のサービスおよび管理/パブリック用の API を提供します。Identity API v2 と API v3 の両方がサポートされています。 |
|
keystone |
Identity API にアクセスするためのコマンドラインクライアント |
以下の図には、Identity が他の OpenStack コンポーネントとのユーザー認証で使用する基本的な認証フローを示してます。
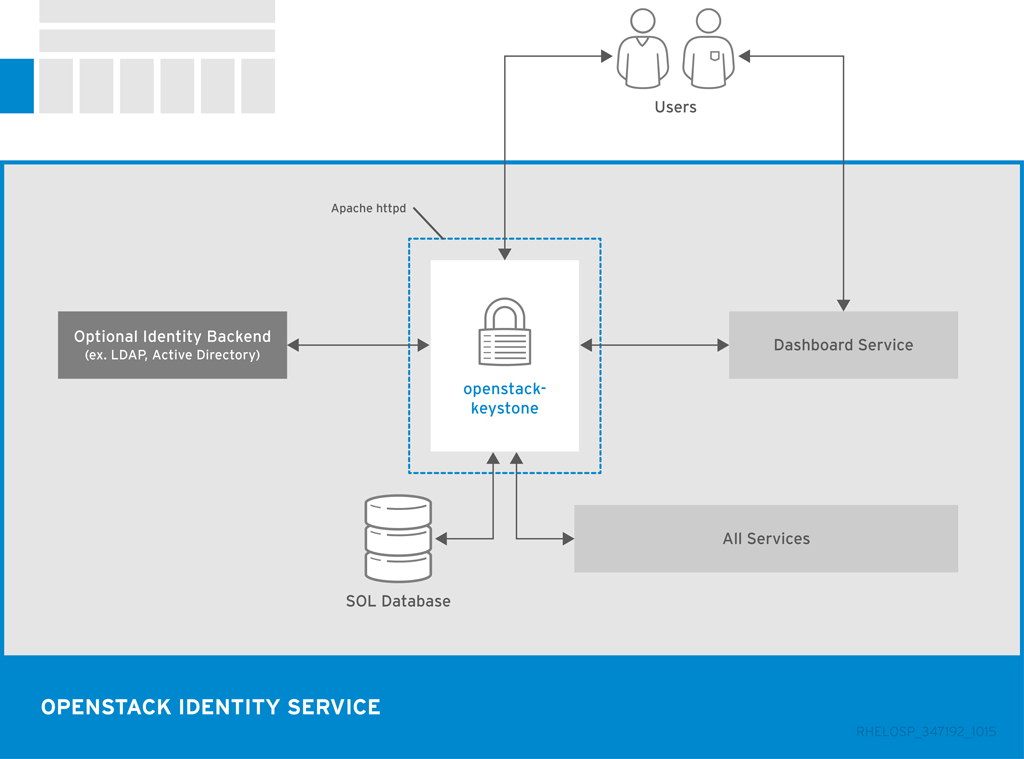
1.5. ユーザーインターフェース
「OpenStack Dashboard (horizon)」
「OpenStack Telemetry (ceilometer)」
1.5.1. OpenStack Dashboard (horizon)
OpenStack Dashboard は、ユーザーおよび管理者がインスタンスの作成/起動やネットワークの管理、アクセス制御の設定などの操作を行うためのグラフィカルユーザーインターフェースを提供します。
Dashboard サービスは、プロジェクト、管理、設定のデフォルトダッシュボードを提供します。Dashboard は、モジュール型設計により、課金、モニタリング、追加の管理ツールなどの他の製品と連結することができます。
以下の画像は、管理ダッシュボードの Compute パネルの例を示しています。
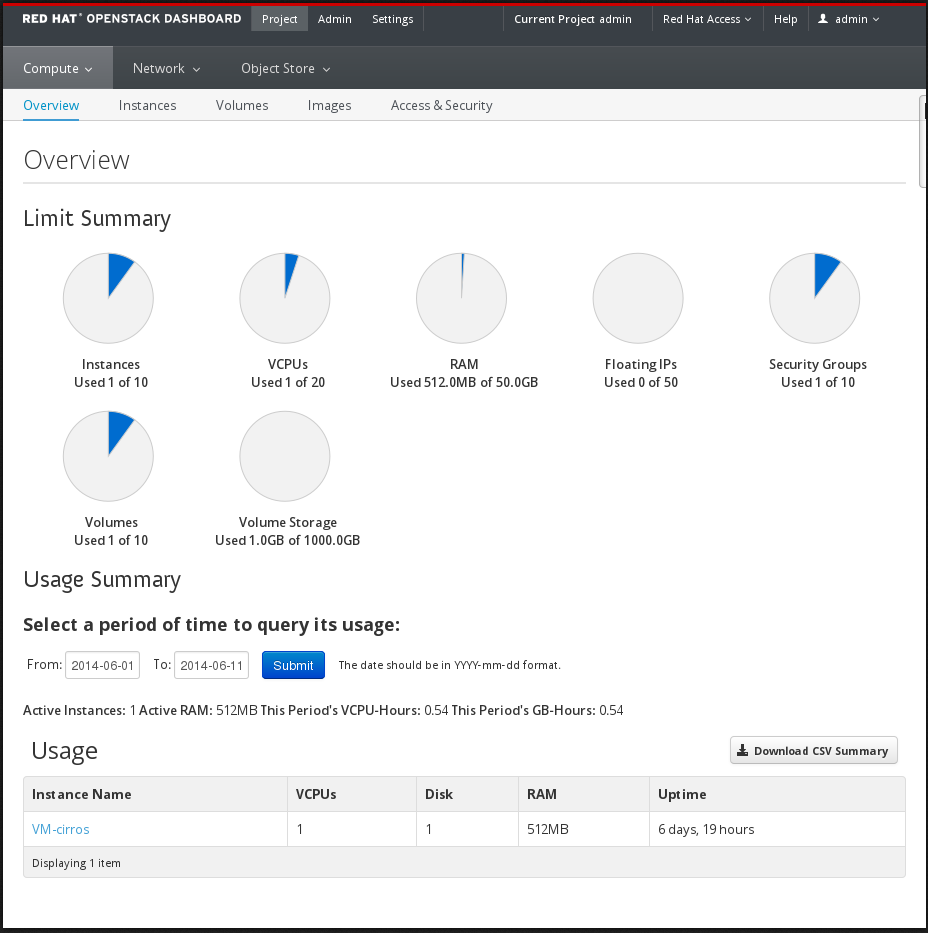
Dashboard にログインするユーザーのロールによって、表示されるダッシュボードとパネルが異なります。
| コンポーネント | 説明 |
|---|---|
|
openstack-dashboard |
Web ブラウザーから Dashboard へのアクセスを提供する Django Web アプリケーション |
|
Apache HTTP サーバー (httpd サービス) |
アプリケーションをホストします。 |
以下の図には、Dashboard のアーキテクチャーの概観を示しています。
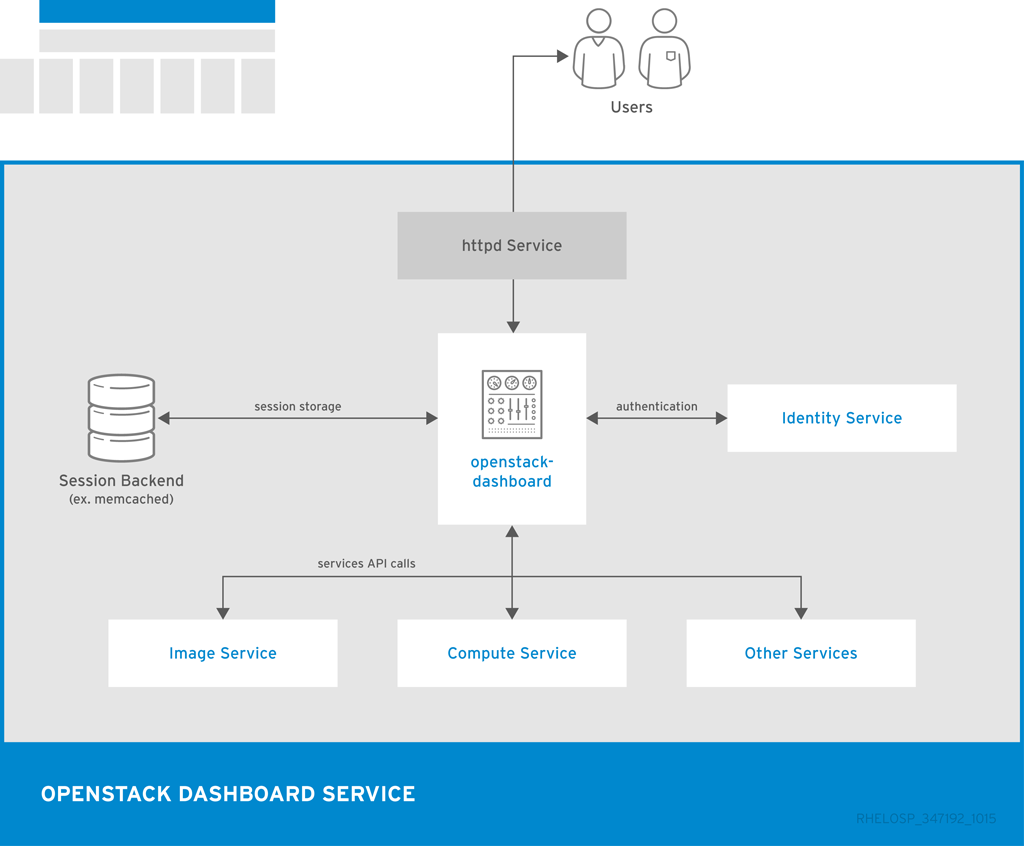
上記の例には、以下の対話を示しています。
- OpenStack Identity サービスがユーザーの認証および承認を行います。
- セッションバックエンドがデータベースサービスを提供します。
- httpd サービスは、Web アプリケーションおよび API コールのためのその他すべての OpenStack サービスをホストします。
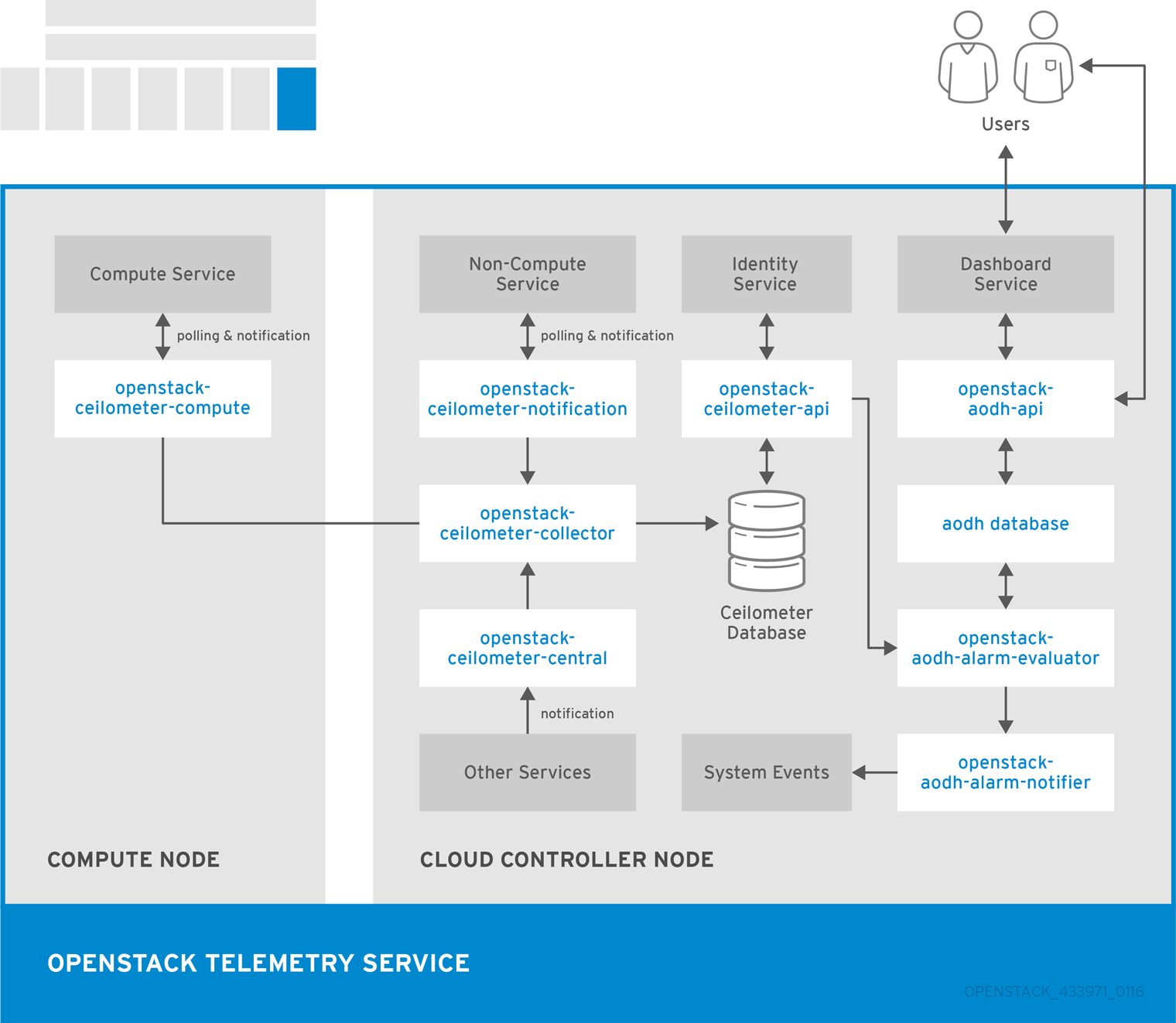
1.5.2. OpenStack Telemetry (ceilometer)
OpenStack Telemetry は、OpenStack をベースとするクラウドのユーザーレベルの使用状況データを提供します。データは、顧客の課金、システムの監視、警告に使用することができます。Telemetry は既存の OpenStack コンポーネント (例: Compute の使用イベント) や libvirt などの OpenStack インフラストラクチャーリソースのポーリングにより送信される通知からデータを収集することができます。
Telemetry には、信頼済みのメッセージングシステムを介して認証済みのエージェントと通信し、データを収集/集計するストレージデーモンが含まれています。また、サービスは、新規モニターを追加するのに使用可能なプラグインシステムを使用します。API サーバー、中央エージェント、データストアサービス、コレクターエージェントを異なるホストにデプロイすることができます。
このサービスは、MongoDB データベースを使用して、収集したデータを格納します。データベースにアクセスできるのは、コレクターエージェントと API サーバーのみです。
アラームと通知は、新たに aodh サービスによって処理/制御されます。
| コンポーネント | 説明 |
|---|---|
|
openstack-aodh-api |
データストアに保管されているアラームの情報へのアクセスを提供します。 |
|
openstack-aodh-alarm-evaluator |
スライディング時間枠の閾値超過に関連する統計の傾向に基づいて、どのような場合にアラームを生成するかを決定します。 |
|
openstack-aodh-alarm-notifier |
アラームのトリガー時にアクションを実行します。 |
|
openstack-aodh-alarm-listener |
事前に定義したイベントパターンが発生した場合にアラームを生成します。 |
|
openstack-ceilometer-api |
中央管理サーバー (単一または複数) で実行して、データベース内のデータへのアクセスを提供します。 |
|
openstack-ceilometer-central |
中央管理サーバーで実行して、インスタンスやコンピュートノードには依存しないリソースについての使用状況の統計をポーリングします。エージェントは水平スケーリングはできないので、このサービスのインスタンスは 1 回に 1 つしか実行できません。 |
|
openstack-ceilometer-collector |
1 つまたは複数の中央管理サーバーを実行してメッセージキューをモニタリングします。各コレクターは処理を行い、通知メッセージを Telemetry メッセージに変換し、メッセージバスに対して適切なトピックでメッセージを送信します。 Telemetry メッセージは、変更なしでデータストアに書き込まれます。エージェント内の通信はすべて、ceilometer-alarm-evaluator サービスと同様の ceilometer-api サービスに対する AMQP/REST コールをベースとするので、これらのエージェントを実行する場所を選択することができます。 |
|
openstack-ceilometer-compute |
各コンピュートノードで実行して、リソース使用状況の統計をポーリングします。各 nova-compute ノードでは ceilometer-compute エージェントがデプロイ済みで実行されている必要があります。 |
|
openstack-ceilometer-notification |
さまざまな OpenStack サービスからメトリックをコレクターサービスにプッシュします。 |
|
ceilometer |
Telemetry API にアクセスするためのコマンドラインクライアント |
以下の図には、Telemetry サービスが使用するインターフェースを示しています。
1.6. サードパーティーのコンポーネント
1.6.1. サードパーティーのコンポーネント
一部の Red Hat OpenStack Platform コンポーネントは、サードパーティーのデータベース、サービス、ツールを使用します。
1.6.1.1. データベース
- MariaDB は、Red Hat Enterprise Linux に同梱されているデフォルトのデータベースです。MariaDB により、Red Hat はオープンソースコミュニティーで開発されたソフトウェアを完全にサポートすることができます。Telemetry を除く各 OpenStack コンポーネントは、MariaDB サービスを実行する必要があるため、完全な OpenStack クラウドサービスをデプロイする前や、スタンドアロンの OpenStack コンポーネントをインストールする前には、MariaDB をデプロイしておく必要があります。
- Telemetry サービスは MongoDB データベースを使用して、コレクターエージェントから収集した使用状況のデータを保管します。データベースにアクセスできるのは、コレクターエージェントと API サーバーのみです。
1.6.1.2. メッセージング
RabbitMQ は、AMQP 基準に基づいた、オープンソースの頑強なメッセージングシステムです。RabbitMQ は、数多くのエンタープライズシステムで使用され、商用に幅広くサポートされているハイパフォーマンスなメッセージブローカーです。Red Hat OpenStack Platform では、RabbitMQ はデフォルトの推奨メッセージブローカーです。
RabbitMQ はキューイング、配信、セキュリティー、管理、クラスタリング、フェデレーションなどの OpenStack のトランザクションを管理します。また、高可用性とクラスタリングのシナリオで主要な役割を担います。
1.6.1.3. 外部キャッシュ
memcached や Redis などの外部のキャッシュ用アプリケーションは永続的な共有ストレージを提供し、データベースの負荷を軽減することにより動的な Web アプリケーションを迅速化します。外部キャッシュは、さまざまな OpenStack コンポーネントで使用されます。以下に例を示します。
- Object Storage サービスは、対話をするたびに各クライアントに再承認を要求する代わりに、memcached を使用して認証済みのクライアントをキャッシュします。
- デフォルトでは、Dashboard はセッションストレージに memcached を使用します。
- Identity サービスはトークンの永続化に Redis または memcached を使用します。