第3章 設計
本項では、Red Hat OpenStack Platform デプロイメントの設計における技術および運用面の考慮事項を記載します。
アーキテクチャー例はすべて、KVM ハイパーバイザーを使用する Red Hat Enterprise Linux 7.3 上に OpenStack Platform をデプロイすることを前提とします。
3.1. プランニングモデル
Red Hat OpenStack Platform デプロイメントを設計する際には、プロジェクトの期間がそのデプロイメントの設定とリソース割り当てに影響を及ぼす場合があります。各プランイングモデルは、異なる目標を達成することを目的としているため、異なる点を考慮する必要があります。
3.1.1. 短期モデル (3 カ月間)
短期間のキャパシティープランニングと予測を実行するには、以下のメトリックを取得することを検討してください。
- 仮想 CPU の合計数
- 割り当て済みの仮想メモリーの合計
- I/O の平均レイテンシー
- ネットワークトラフィック
- コンピュートの負荷
- ストレージの割り当て
仮想 CPU、仮想メモリー、およびレイテンシーのメトリックは、キャパシティープランニングで最も利用しやすい指標です。これらの詳細情報に対して、標準的な二次回帰を適用することで、向こう 3 カ月間のキャパシティー予測を得ることができます。この推定値を使用して、追加のハードウェアをデプロイする必要があるかどうかを判断してください。
3.1.2. 中期モデル (6 カ月間)
評価を繰り返し実施するモデルを採用し、トレンド予測と実際の使用率の偏差を推定する必要があります。この情報は、標準的な統計ツールや Nash-sutcliffe 係数などの特化した分析モデルを使用して分析することができます。トレンドは、先と同様に、二次回帰で計算することも可能です。
複数のインスタンスフレーバーが混在する利用環境では、仮想 CPU と仮想メモリーのメトリックを 1 つのメトリックとして考察すると、仮想メモリーと仮想 CPU の使用率の相関をより簡単に把握することができます。
3.1.3. 長期モデル (1 年間)
1 年の期間においては、全体的なリソース使用量が変動する可能性があり、元の長期的なキャパシティー予測との間には通常偏差が発生します。そのため、特に使用率がクリティカルなリソースについては、二次回帰によるキャパシティー予測は、指標として不十分な場合があります。
長期的なデプロイメントのプランニングを行う際には、1 年間にわたるデータに基づくキャパシティープランニングのモデルでは、少なくとも一次導関数のフィッティングが必要です。利用パターンによっては、頻度分析が必要となる場合もあります。
3.2. コンピュートリソース
コンピュートリソースは、OpenStack クラウドの中核です。このため、Red Hat OpenStack Platform デプロイメントを設計する際には、物理/仮想リソースの割り当て、分散、フェイルオーバー、および追加デバイスを考慮することを推奨します。
3.2.1. 一般的な考慮事項
- 各ハイパーバイザーのプロセッサー数、メモリー、ストレージ
プロセッサーのコアおよびスレッドの数は、コンピュートノードで実行可能なワーカースレッドの数に直接影響を及ぼします。このため、サービスに基づいて、全サービスでバランスの取れたインフラストラクチャーをベースとする設計を決定する必要があります。
ワークロードのプロファイルによっては、追加のコンピュートリソースをクラウドに後で追加することが可能です。特定のインスタンスのフレーバーに対する需要は、ハードウェアを個別に設計するための正当な理由にはならない場合があり、代わりにコモディティー化したシステムが優先されます。
いずれの場合も、一般的なインスタンスの要求に対応することのできるハードウェアリソースを割り当てることから設計を開始します。追加のハードウェア設計をアーキテクチャー全体に加えるには、この手順は後で実行することができます。
- プロセッサーの種別
プロセッサーの選択は、ハードウェアの設計における非常に重要な考慮事項です。特に、異なるプロセッサー間における機能とパフォーマンスの特性を比較する際に大切となります。
プロセッサーには、仮想化コンピュートホスト専用に、ハードウェア支援による仮想化、メモリーページング、EPT シャドウイングテクノロジーなどの機能を搭載することができます。これらの機能は、クラウド仮想マシンのパフォーマンスに大きな影響を及ぼします。
- リソースノード
- クラウド内のハイパーバイザー以外のリソースノードによるコンピュートに対する要求を考慮する必要があります。リソースノードには、コントローラーノードや Object Storage、Block Storage、Networking などのサービスを実行するノードが含まれます。
- リソースプール
オンデマンドで提供するリソースの複数のプールを割り当てる Compute の設計を使用します。この設計により、クラウド内のリソースの使用率が最大限に高められます。各リソースのプールは特定のインスタンスフレーバーまたはフレーバーグループに対応する必要があります。
複数のリソースプールを設計することにより、Compute ハイパーバイザーに対してインスタンスがスケジュールされると必ず各ノードリソースセットが割り当てられて、利用可能なハードウェアの使用率を最大限に高めるのに役立ちます。これは一般的にはビンパッキングと呼ばれます。
リソースプール内のノード間で一貫したハードウェア設計を採用すると、ビンパッキングにも役立ちます。Compute リソースプールに選択されたハードウェアノードは、共通のプロセッサー、メモリー、およびストレージレイアウトを共有する必要があります。共通のハードウェア設計を選択することにより、デプロイメント、サポート、ノードのライフサイクル管理が容易になります。
- オーバーコミット比
OpenStack では、コンピュートノードの CPU とメモリーをオーバーコミットすることができます。これは、クラウド内で実行するインスタンスの数を増やすのに役立ちます。ただし、オーバーコミットにより、インスタンスのパフォーマンスが低下する場合があります。
オーバーコミット比とは、利用可能な物理リソースと比較した利用可能な仮想リソースの比率です。
- デフォルトの CPU 割り当て比 16:1 は、スケジューラーが 1 つの物理コアに対して最大 16 の仮想コアを割り当てることを意味します。たとえば、物理ノードに 12 コアある場合には、スケジューラーは最大で 192 の仮想コアを割り当てることができます。標準的なフレーバーの定義では、1 インスタンスにつき 4 仮想コアなので、この比率では、1 物理ノードで 48 のインスタンスを提供することができます。
- デフォルトのメモリー割り当て比 1.5:1 とは、インスタンスに関連付けられているメモリーが物理ノードで利用可能なメモリー容量の 1.5 倍以下の場合に、スケジューラーがインスタンスを物理ノードに割り当てることを意味します。
CPU およびメモリーのオーバーコミット比は、コンピュートノードのハードウェアレイアウトに直接影響を及ぼすので、設計フェーズ中にチューニングしておくことが重要となります。Compute のリソースプールのようなインスタンスにサービスを提供するためのハードウェアノードを設計する際には、ノードで利用可能なプロセッサーコアの数とともに、フルキャパシティーで稼働するインスタンスにサービスを提供するのに必要なディスクとメモリーも考慮してください。
たとえば、m1.small のインスタンスは、1 仮想 CPU、20 GB の一時ストレージ、2048 MB のメモリーを使用します。10 コアの CPU が 2 つあり、ハイパースレッディングが有効化されたサーバーの場合には、次のようになります。
- デフォルトの CPU オーバーコミット比 16:1 で、合計 640 (2 × 10 × 2 × 16) の m1.small インスタンスを提供することが可能です。
- デフォルトのメモリーオーバーコミット 1.5:1 は、サーバーに最小で 853 GB (640 × 2048 MB / 1.5) のメモリーが必要なことを意味します。
メモリーでノードのサイズ指定する際には、オペレーティングシステムとサービスのニーズに対応する必要な追加メモリーを考慮することも重要です。
3.2.2. フレーバー
作成される各インスタンスには、フレーバーまたはリソーステンプレートが適用され、それによってインスタンスのサイズと容量が決定します。フレーバーは、第 2 の一時ストレージ、スワップディスク、メタデータを指定して、使用量や特別なプロジェクトへのアクセスを制限することができます。デフォルトのフレーバーには、これらの追加の属性は定義されていません。インスタンスのフレーバーにより、一般的なユースケースは、予測可能なサイズに設定され、場当たり的に決定されるわけではないので、キャパシティー予測を立てることができます。
物理ホストへの仮想マシンのパッキングを円滑にするために、デフォルトでは、2 番目に大きなフレーバーが選択されます。このフレーバーは、すべてのサイズが最も大きなフレーバーの半分で、仮想 CPU の数、仮想メモリー容量、一時ディスクの容量がそれぞれ半分となります。それ以降の各サイズは、それよりも 1 サイズ大きなフレーバーの半分のサイズとなります。
以下の図には、汎用のコンピューティング設計と CPU を最適化した、パックされたサーバーでのフレーバーの割り当てを図解しています。
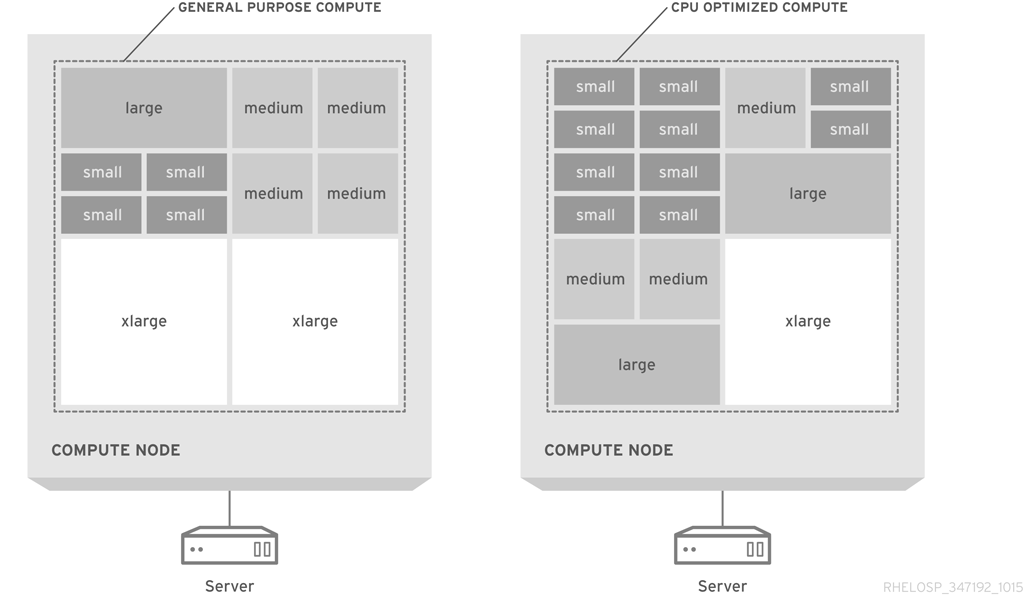
デフォルトのフレーバーは、コモディティーサーバーハードウェアの標準的な設定に推奨されます。使用率を最大限に高めるには、フレーバーをカスタマイズするか、新規フレーバーを作成して、インスタンスのサイズを利用可能なハードウェアに合わせる必要がある場合があります。
可能な場合には、1 フレーバーにつき 1 仮想 CPU の設定に制限してください。種別 1 のハイパーバイザーは、1 仮想 CPU で設定されている仮想マシンにはより簡単に CPU 時間をスケジュールできる点に注意することが重要です。たとえば、4 仮想 CPU で設定された仮想マシンに CPU 時間をスケジュールするハイパーバイザーは、実行するタスクに 1 仮想 CPU しか必要でない場合でも、4 つの物理コアが利用可能となるまで待つ必要があります。
ワークロードの特性がハードウェアの選択とフレーバーの設定に影響を及ぼす場合もあります。これは、特にタスクで CPU、メモリー、ハードディスクドライブの要件の比が異なる場合に著明です。フレーバーに関する情報は、『インスタンス&イメージガイド』の「フレーバーの管理」を参照してください。
3.2.3. 仮想 CPU コア対物理 CPU コアの比
Red Hat OpenStack Platform のデフォルトの割り当て比は 1 物理コアまたは 1 ハイパースレッドコアにつき 16 仮想 CPU です。
以下の表には、システム用に確保される 4 GB を含む使用可能なメモリーの合計に基づいて、1 物理ホストに適した実行可能な仮想マシンの最大数をまとめています。
| メモリーの合計 | 仮想マシン | 仮想 CPU の合計 |
|---|---|---|
|
64 GB |
14 |
56 |
|
96 GB |
20 |
80 |
|
128 GB |
29 |
116 |
たとえば、60 インスタンスの初期展開をプランニングする場合には、4 つ (3+1) のコンピュートノードが必要になります。通常は、メモリーのボトルネックは CPU のボトルネックよりも一般的ですが、必要な場合には、割り当て比を 1 物理コアあたり 8 仮想 CPU に下げることができます。
3.2.4. メモリーオーバーヘッド
KVM ハイパーバイザーには少量の仮想マシンメモリーオーバーヘッドが必要です。これには、共有可能でないメモリーが含まれます。QEMU/KVM システムの共有可能なメモリーは、ハイパーバイザーにつき 200 MB に丸めることができます。
| 仮想メモリー | 物理メモリーの使用量 (平均) |
|---|---|
|
256 |
310 |
|
512 |
610 |
|
1024 |
1080 |
|
2048 |
2120 |
|
4096 |
4180 |
通常は、仮想マシン 1 つあたり 100 MB のハイパーバイザーオーバーヘッドを推定することができます。
3.2.5. オーバーサブスクリプション
メモリーは、ハイパーバイザーのデプロイメントを制限する一要素です。各物理ホスト上で実行できる仮想マシンは、そのホストがアクセス可能なメモリー容量によって制限されます。たとえば、クワッドコア CPU で 256 GB のメモリーを搭載したマシンで 200 を超える 1 GB のインスタンスを実行すると、パフォーマンスが低くなります。このため、CPU コアとメモリーの最適な比率は慎重に決定して、全インスタンス間で分散する必要があります。
3.2.6. 密度
- インスタンスの密度
- コンピュートを重視したアーキテクチャーでは、インスタンスの密度は低く、CPU とメモリーのオーバーサブスクリプション比も低くなります。特に設計にデュアルソケットハードウェアを使用している場合には、インスタンスの密度が低いと、予想されるスケールをサポートするホストがより多く必要になる可能性があります。
- ホストの密度
- クワッドソケットプラットフォームを使用することにより、ホスト数が多いデュアルソケット設計に対応できます。このプラットフォームは、ホストの密度を低くし、ラック数を増やします。この設定は、電源接続数などのネットワークの要件や冷却の要件にも影響を及ぼす場合があります。
- 電源と冷却の密度
- 電源と冷却の密度を低くすることは、古いインフラストラクチャーを使用するデータセンターでは重要な考慮事項です。たとえば、2U、3U、4U のサーバー設計の電源と冷却の密度の要件は、ホストの密度が低いため、ブレード、スレッド、IU のサーバー設計よりも低くなる場合があります。
3.2.7. コンピュートのハードウェア
- ブレードサーバー
- 大半のブレードサーバーは、デュアルソケット、マルチコアの CPU をサポートしています。CPU の上限を超えないようにするには、フルワイド または フルハイト のブレードを選択してください。これらのブレードタイプは、サーバーの密度を低くすることもできます。たとえば、HP BladeSystem や Dell PowerEdge M1000e などの高密度のブレードサーバーは、10 ラックユニットのみで 16 台のサーバーをサポートします。ハーフハイトのブレードは、フルハイトのブレードの 2 倍の密度で、10 ラックユニットにつき 8 台のみとなります。
- 1U サーバー
単一のラックユニットを占有する 1U ラックマウント型サーバーは、ブレードサーバーのソリューションよりもサーバーの密度が高い場合があります。1 ラックに 1U サーバーを 40 ユニット使用して、Top-of-Rack (ToR) スイッチ用のスペースを提供することができます。これに対して、フルワイドのブレードサーバーは、1 ラックで 32 台しか使用することができません。
ただし、大手ベンダーの 1U サーバーは、デュアルソケット、マルチコアの CPU 設定のみとなっており、1U ラックマウントのフォームファクターでそれよりも高い CPU 設定をサポートするには、ODM (相手先ブランド設計製造業者) または二次製造業者からシステムを購入してください。
- 2U サーバー
- 2U ラックマウント型サーバーは、クワッドソケット、マルチコアの CPU をサポートしますが、それに応じてサーバーの密度が低減します。2U ラックマウント型サーバーの密度は、1U ラックマウントサーバーが提供する密度の半分となります。
- 大型サーバー
- 4U サーバーのような大型のラックマウント型サーバーは、多くの場合、より高い CPU キャパシティーを提供し、通常は 4 または 8 もの CPU ソケットをサポートします。これらのサーバーは、拡張性は高いですが、サーバー密度がはるかに低く、大抵は高額です。
- スレッドサーバー
スレッドサーバーは、ラックマウント型のサーバーで、複数の独立したサーバーを単一の 2U または 3U 筐体でサポートします。これらのサーバーは、通常の 1U または 2U のラックマウント型サーバーよりも高い密度を提供します。
たとえば、多くのスレッドサーバーは、2U で 4 つの独立したデュアルノードを提供し、合計 CPU ソケットは 8 となります。ただし、各ノードがデュアルソケットに制限されているため、追加のコストや設定の複雑さを補うには十分でない可能性があります。
3.2.8. 追加のデバイス
コンピュートノードに以下のデバイスを追加するかどうかを検討します。
- ハイパフォーマンスなコンピューティングジョブのためのグラフィックス処理装置 (GPU)
-
暗号化ルーチンでエントロピーのスターベーションが発生するのを回避するためのハードウェアベースの乱数生成器。乱数生成器は、インスタンスのイメージプロパティーを使用して、インスタンスに追加することができます。デフォルトのエントロピーソースは
/dev/randomです。 - データベース管理システムの読み取り/書き込み時間を最大限にするための一時ストレージ用 SSD
- ホストアグリゲートは、同じ特性 (例: ハードウェアの類似性など) を共有するホストをグループ化することによって機能します。クラウドデプロイメントに特化したハードウェアを追加すると、各ノードのコストが高くなる場合があるので、追加のカスタマイズが必要なのが全コンピュートノードか、サブセットのみかを検討してください。
3.3. ストレージのリソース
クラウドを設計する際には、選択するストレージソリューションは、パフォーマンス、キャパシティー、可用性、相互運用性などのデプロイメントの重要な面に影響を及ぼします。
ストレージソリューションを選択する際には、以下の要素を考慮してください。
3.3.1. 一般的な考慮事項
- アプリケーション
クラウドストレージソリューションを効果的に使用するには、アプリケーションが下層のストレージサブシステムを認識する必要があります。ネイティブで利用可能なレプリケーションが使用できない場合には、オペレーターがアプリケーションを設定してレプリケーションサービスを提供するようにできる必要があります。
下層のストレージシステムを検出できるアプリケーションは、多様なインフラストラクチャーで機能することが可能です。インフラストラクチャーの違いにかかわらず、基本的な操作は変わりません。
- I/O
入出力パフォーマンスのベンチマークは、予想されるパフォーマンス水準のベースラインを提供します。ベンチマークの結果データは、異なる負荷がかかった状態の動作をモデリングして、適切なアーキテクチャーを設計するのに役立ちます。
アーキテクチャーのライフサイクル中には、異なる時点におけるシステムの健全性を記録するのに、より小さな、スクリプト化されたベンチマークが役立ちます。スクリプト化されたベンチマークから取得したデータは、スコープを定義し、組織のニーズをより深く理解するのに役立ちます。
- 相互運用性
- ハードウェアまたはストレージ管理プラットフォームが OpenStack のコンポーネント (KVM ハイパーバイザーなど) と相互運用可能であることを確認してください。これは、インスタンスの短期ストレージに使用できるかどうかに影響を及ぼします。
- セキュリティー
- データセキュリティー設計は、SLA、法律上の要件、業界の規制、担当者またはシステムに必要な認定に基づいて異なる面に重点を置くことができます。データのタイプに応じて、HIPPA、ISO9000、SOX のコンプライアンスを検討してください。組織によっては、アクセス制御レベルも考慮する必要があります。
3.3.2. OpenStack Object Storage (swift)
- 可用性
対象となるオブジェクトデータに必要な可用性レベルを提供するオブジェクトストレージリソースプールを設計します。必要なレプリカ数に対応するラックレベルとゾーンレベルの設計を考慮してください。デフォルトのレプリカ数は 3 です。各データレプリカは、特定のゾーンに対応する電源、冷却、ネットワークリソースを備えた別々のアベイラビリティーゾーンに配置する必要があります。
OpenStack Object Storage サービスは、特定数のデータレプリカをオブジェクトとしてリソースノードに配置します。これらのレプリカは、クラスター内の全ノード上に存在するコンシステントハッシュリングに基づいてクラスター全体で分散されます。また、オブジェクトノードに保管されたデータへのアクセスを提供する Object Storage プロキシーサーバーのプールは各アベイラビリティーゾーンにサービスを提供する必要があります。
レプリカ数に対し必要最小の正常な応答を提供するのに十分な数のゾーンで Object Storage システムを設計してください。たとえば、Swift クラスターに 3 つのレプリカを設定する場合、Object Storage クラスター内に設定するゾーンの推奨される数は 5 です。
より少ないゾーンを使用するソリューションをデプロイすることはできますが、一部のデータが利用できなくなる可能性があり、クラスター内に保管されている一部のオブジェクトに対する API 要求が失敗する場合があります。このため、Object Storage クラスター内のゾーン数を必ず考慮に入れるようにしてください。
各リージョンのオブジェクトプロキシーは、ローカルの読み取り/書き込みアフィニティーを活用して、可能な場合にはローカルストレージリソースがオブジェクトへのアクセスを円滑化するようにすべきです。アップストリームの負荷分散機能をデプロイして、プロキシーサービスが複数のゾーン間で分散されるようにするとよいでしょう。サービスの地理的分散を補助するサードパーティーのソリューションが必要な場合もあります。
Object Storage クラスター内のゾーンは、論理的な分割で、 単一のディスク、単一のノード、ノードのコレクション、複数のラック、複数の DC で構成することができます。 Object Storage クラスターが利用可能な冗長ストレージシステムを提供中にスケーリングができるようにする必要があります。レプリカ、保有期間、および特定のゾーンのストレージの設計に影響を及ぼすその他の要素に応じて異なるストレージポリシーを設定する必要がある場合があります。
- ノードストレージ
OpenStack Object Storage 用のハードウェアリソースを設計する際の主要な目的は、各リソースノードのストレージ容量を最大限に増やしつつ、テラバイトあたりのコストを最小限に抑えることです。これには多くの場合、 多数のスピニングディスクを保持することが可能なサーバーを活用する必要があります。ストレージがアタッチ済みの 2U サーバーフォームファクターや、多数のドライブを保持することが可能な外部シャーシを使用することができます。
OpenStack Object Storage の一貫性と分断耐性の特性により、データが最新の状態に維持され、ハードウェアの障害発生時にも特別なデータレプリケーションデバイスの必要なく存続します。
- パフォーマンス
- Object Storage のノードは、要求数によってクラスターのパフォーマンスが妨げられないように設計すべきです。Object Storage サービスは、通信の多いプロトコルです。このため、コア数の高い複数のプロセッサーを使用して、I/O 要求がサーバーに殺到しないようにします。
- 重み付けとコスト
OpenStack Object Storage は、Swift のリング内での重み付けによりドライブを組み合わせることができます。Swift のストレージクラスターを設計する際には、費用対効果が最も高いストレージソリューションを使用することができます。
多くのサーバーシャーシは、4U のラックスペースで 60 以上のドライブを収容することができます。このため、テラバイトあたりのコストを最低限に抑えて、ストレージの容量を最大化することができます。ただし、Object Storage ノードには、RAID コントローラーの使用はお勧めできません。
- スケーリング
ストレージソリューションを設計する際には、Object Storage サービスが必要とする partition power を決定した上で作成可能なパーティション数を決定します。Object Storage は全ストレージクラスターデータを分散しますが、各パーティションは複数のディスクにまたがることはできないので、最大パーティション数は、ディスクの数より大きくすることはできません。
たとえば、最初のディスクが 1 つと partition power が 3 のシステムの場合には 8 パーティション (23) を設けることができます。2 番目のディスクを追加すると、各ディスクに 4 パーティションに分割できることになります。1 パーティションにつき 1 ディスクの制限により、このシステムでは、8 よりも多いディスクを使用できず、スケーラビリティーが制限されますが、最初のディスクが 1 つで partition power が 10 のシステムでは、最大で 1024 (210) パーティションを設けることができます。
システムバックエンドストレージの容量を増やす場合には必ず、パーティションマップが全ストレージノードにデータを再分散します。このレプリケーションは極めて大量のデータセットで構成されることがあり、その場合には、テナントからのデータへのアクセスと競合が発生しないバックエンドレプリケーションリンクを使用すべきです。
より多くのテナントがクラスター内でデータにアクセスし、データセットが拡大している場合には、フロントエンドの帯域幅を追加して、データアクセス要求に対応できるようにする必要があります。Object Storage クラスターに フロントエンドの帯域幅を追加するには、テナントがデータへのアクセスに使用できる Object Storage プロキシーとともに、プロキシー層のスケーリングを可能にする高可用性ソリューションを設計する必要があります。
テナントとコンシューマーがクラスター内に保管されているデータにアクセスするために使用するフロントエンドの負荷分散層を設計するべきです。この負荷分散層は、複数のゾーン/リージョンにわたって、あるいは地理的な境界を越えても分散することができます。
場合によっては、プロキシーサーバーとストレージノードの間の要求に対応するネットワークリソースに帯域幅と容量を追加する必要があります。このため、ストレージノードとプロキシーサーバーへのアクセスを提供するネットワークアーキテクチャーは、スケーラブルである必要があります。
3.3.3. OpenStack Block Storage (cinder)
- 可用性と冗長性
アプリケーションに必要な入出力毎秒 (IOPS) により、RAID コントローラーを使用すべきかどうかと、必要な RAID レベルが決定します。冗長性については、RAID の冗長設定 (RAID 5、RAID 6 など) を使用すべきです。ブロックストレージボリュームの自動レプリケーションのような一部の特殊な機能には、より高い要求を処理するのにサードパーティーのプラグインまたはエンタープライズブロックストレージソリューションが必要となる場合があります。
Block Storage に対する要求が極めて高い環境では、複数のストレージプールを使用すべきです。 各デバイスプール内の全ハードウェアノードに同様のハードウェア設計とディスク設定を適用すべきです。このような設計により、アプリケーションは多様な冗長性、可用性、パフォーマンス特性を提供する幅広い Block Storage プールにアクセスできるようになります。
ネットワークアーキテクチャーには、インスタンスが利用可能なストレージリソースを使用するための East-West (水平方向) の帯域幅も考慮すべきです。選択するネットワークデバイスは、大型のデータブロックを転送するためのジャンボフレームをサポートするべきです。場合によっては、インスタンスと Block Storage リソースの間の接続性を提供してネットワークリソースにかかる負荷を軽減するための追加の専用バックエンドストレージネットワークを作成する必要がある可能性があります。
複数のストレージプールをデプロイする場合には、複数のリソースノードにストレージをプロビジョニングする Block Storage スケジューラーに対する影響を考慮する必要があります。アプリケーションが、特定のネットワーク、電源、冷却用のインフラストラクチャーを使用して、複数のリージョンのボリュームをスケジューリングできるようにします。この設計により、テナントは、複数のアベイラビリティーゾーンに分散する耐障害性のアプリケーションをビルドすることが可能となります。
Block Storage リソースノードに加えて、ストレージノードをプロビジョニングしてそのノードへのアクセスを提供する機能を果す API および関連サービスの高可用性と冗長性に対応する設計を行うことも重要となります。高可用性の REST API サービスを提供してサービスが中断されないようにするには、ハードウェアまたはソフトウェアのロードバランサーの層を設計すべきです。
Block Storage ボリュームにサービスを提供し、状態を保存する機能を果すバックエンドストレージサービスへのアクセスを提供する追加の負荷分散層をデプロイする必要がある場合があります。MariaDB や Galera などの Block Storage データベースを保管するには、高可用性ソリューションを設計すべきです。
- アタッチするストレージ
Block Storage サービスは、ハードウェアベンダーによって開発されたプラグインドライバーを使用するエンタープライズストレージソリューションを活用することができます。エンタープライズプラグインの多くには、OpenStack Block Storage がそのまま使用できる状態で同梱されており、それ以外ではサードパーティーチャンネルから入手できるようになっています。
汎用クラウドは通常、大半の Block Storage ノードでダイレクトアタッチストレージを使用します。 このため、テナントに追加のサービスレベルを提供する必要がある場合があります。このようなレベルは、エンタープライズストレージソリューションしか提供できない可能性があります。
- パフォーマンス
- より高いパフォーマンスが要求される場合には、ハイパフォーマンス RAID ボリュームを使用することができます。極限のパフォーマンスを実現するには、高速のソリッドステートドライブ (SSD) ディスクを使用することができます。
- プール
- Block Storage プールでは、テナントがアプリケーション用に適切なストレージソリューションを選択できるようにすべきです。異なる種別のストレージプールを複数作成して、Block Storage サービス向けの高度なストレージスケジューラーを設定することにより、さまざまなパフォーマンスレベルと冗長性のオプションを備えたストレージサービスの大きなカタログをテナントに提供することができます。
- スケーリング
Block Storage プールをアップグレードして、Block Storage サービス全体を中断せずにストレージ容量を追加することができます。適切なハードウェアとソフトウェアをインストール/設定して、プールにノードを追加します。この後に、新規ノードがメッセージバスを使用して適切なストレージプールにレポーティングするように設定することができます。
Block Storage ノードは、新規ノードがオンラインで利用可能な場合にスケジューラーサービスへノードが稼動中であることをレポーティングするので、テナントは新規ストレージリソースを即時に使用することができます。
場合によっては、インスタンスからの Block Storage への要求によって利用可能なネットワーク帯域幅がすべて使い果たされてしまうことがあります。このため、ネットワークインフラストラクチャーが Block Storage リソースに対応し、容量と帯域幅をシームレスに追加できるように設計すべきです。
これには大抵、動的なルーティングプロトコルまたはダウンストリームのデバイスに容量を追加するための高度なネットワーキングソリューションが必要となります。フロントエンドおよび バックエンドのストレージネットワーク設計には、容量と帯域幅を迅速かつ容易に追加するための機能を含めるべきです。
3.3.4. ストレージハードウェア
- 容量
ノードのハードウェアは、クラウドサービス用に十分なストレージに対応し、かつデプロイ後に容量を追加できるようにする必要があります。ハードウェアノードは、RAID コントローラーカードに依存せずに、安価なディスクを多数サポートするべきです。
ハードウェアベースのストレージパフォーマンスと冗長性を提供するには、ハードウェアノードが高速ストレージソリューションと RAID コントローラーカードもサポート可能であるべきです。破損したアレイを自動修正するハードウェア RAID コントローラーを選択すると、劣化または破損したストレージデバイスの取り替えや修復に役立ちます。
- 接続性
- ストレージソリューションにイーサネット以外のストレージプロトコルを使用する場合は、 ハードウェアがそのプロトコルに対応可能であることを確認してください。中央集中型ストレージアレイを選択する場合には、ハイパーバイザーがそのイメージストレージ用のストレージアレイに接続可能であることを確認してください。
- コスト
- ストレージは、全システムコストの中で高い割合を占めます。ベンダーのサポートが必要な場合には、商用ストレージソリューションが推奨されますが、より高額な費用を伴います。初期投資額を最小限に抑える必要がある場合には、コモディティーハードウェアをベースとしたシステムを設計することができます。ただし、初期費用で節約しても、継続的なサポート費用と非互換性のリスクが高くなる可能性があります。
- ダイレクトアタッチストレージ
- ダイレクトアタッチストレージ (DAS) は、サーバーのハードウェア選択を左右し、ホストの密度、インスタンスの密度、電源の密度、ハイパーバイザー、および管理ツールに影響を及ぼします。
- スケーラビリティー
- スケーラビリティーは、どの OpenStack クラウドにおいても重要な考慮事項です。実装の最終的な想定サイズを予測するのが難しい場合があります。 将来の拡張およびユーザーの需要に対応するには、初期デプロイメントを大きく設計することを検討してください。
- 拡張性
拡張性は、ストレージソリューションの主要なアーキテクチャー要素です。50 PB にまで拡張するストレージソリューションは、10 PB までにしか拡張できないソリューションよりも拡張性が高いと見なされます。このメトリックは、ワークロードの増加に応じたソリューションのパフォーマンスの尺度であるスケーラビリティーとは異なります。
たとえば、開発プラットフォーム用クラウドのストレージアーキテクチャーには、商用のクラウドと同じ拡張性とスケーラビリティーは必要ない場合があります。
- 耐障害性
Object Storage リソースノードには、ハードウェアの耐障害性や RAID コントローラーは必要ありません。Object Storage サービスはゾーン間でのレプリケーションをデフォルトで提供するので、Object Storage のハードウェアには、耐障害性の計画は必要ありません。
ブロックストレージノード、コンピュートノード、およびクラウドコントローラーには、ハードウェア RAID コントローラーやさまざまなレベルの RAID 設定を使用してハードウェアレベルで耐障害性を組込むべきです。RAID レベルは、クラウドのパフォーマンスおよび可用性の要件と一貫している必要があります。
- リンク
- インスタンスおよびイメージのストレージの地理的な場所は、アーキテクチャー設計に影響を及ぼす場合があります。
- パフォーマンス
Object Storage サービスを実行するディスクは、高速なパフォーマンスのディスクである必要はありません。このため、ストレージのテラバイトあたりの費用対効果を最大限に高めることができます。ただし、Block Storage サービスを実行するディスクには、パフォーマンスを強化する機能を使用すべきです。これには、 高パフォーマンスの Block Storage プールを提供するための SSD やフラッシュストレージが必要な場合があります。
インスタンス用に短期間使用するディスクのストレージパフォーマンスも考慮すべきです。コンピュートプールに高使用率の短期ストレージが必要な場合や、極めて高いパフォーマンスが要求される場合には、Block Storage 用にデプロイするのを同様のハードウェアソリューションをデプロイすべきです。
- サーバーの種別
- DAS を含むスケールアウト型のストレージアーキテクチャーは、サーバーのハードウェア選択を左右します。また、このアーキテクチャーは、ホストの密度、インスタンスの密度、電源の密度、ハイパーバイザー、管理ツールなどにも影響を及ぼします。
3.3.5. Ceph Storage
外部ストレージに Ceph を検討している場合には、Ceph クラスターバックエンドは、妥当なレイテンシーで、並行稼動に必要とされる仮想マシン数を処理できるようにサイジングする必要があります。I/O 操作の 99% を書き込み 20 ミリ秒以下、読み取り 10 ミリ秒以下に維持できることが、サービスレベルの許容範囲となっています。
Rados Block Device (RBD) あたりの最大帯域幅を設定するか、保証される最小コミットメントを指定することにより、I/O スパイクを他の仮想マシンから分離することが可能です。
3.4. ネットワークリソース
ネットワークの可用性は、クラウドデプロイメント内のハイパーバイザーにとって極めて重要です。たとえば、ハイパーバイザーが各ノードで数台の仮想マシンのみをサポートする場合には、 アプリケーションには高速のネットワークは必要なく、1 GB のイーサネットリンクを 1 つまたは 2 つ使用することができますが、アプリケーションが高速のネットワークを必要とする場合や、ハイパーバイザーが各ノードで多数の仮想マシンをサポートする場合には、10 GB のイーサネットリンクを 1 つまたは 2 つ使用することを推奨します。
標準的なクラウドのデプロイメントは、従来のコアネットワークトポロジーが通常必要とする量を上回る P2P 通信を使用します。仮想マシンはクラスター全体で無作為にプロビジョンされますが、同じネットワーク上にあるかのように相互通信する必要があります。この要件により、ネットワークの境界とコアの間のリンクがオーバーサブスクライブされるので、従来のコアネットワークトポロジーではネットワーク速度の低下やパケット損失が発生する可能性があります。
3.4.1. サービスの分離
OpenStack クラウドには、従来複数のネットワークセグメントがあります。各セグメントは、クラウド内のリソースへのアクセスをオペレーターやテナントに提供します。ネットワークサービスにも、他のネットワークから分離したネットワーク通信パスが必要です。サービスを分離してネットワークを分けると、機密データをセキュリティー保護して、サービスへの不正なアクセスから守るのに役立ちます。
推奨される最小限の分離を行うには、以下のネットワークセグメントが必要です。
- クラウドの REST API にアクセスするのにテナントとオペレーターが使用するパブリックネットワークセグメント。通常このネットワークセグメントに接続する必要があるのは、クラウド内のコントローラーノードと swift プロキシーのみです。場合によっては、このネットワークセグメントはハードウェアのロードバランサーやその他のネットワークデバイスによりサービスが提供されることもあります。
クラウド管理者がハードウェアリソースを管理し、設定管理ツールが新しいハードウェアにソフトウェアとサービスをデプロイするために使用する管理ネットワークセグメント。場合によっては、このネットワークセグメントは、相互通信が必要なメッセージバスやデータベースサービスなどの内部サービスにも使用されることがあります。
セキュリティー要件により、このネットワークセグメントは不正アクセスから保護することを推奨します。このネットワークセグメントは、通常クラウド内の全ハードウェアノードと通信する必要があります。
アプリケーションおよびコンシューマーが物理ネットワークへのアクセスを提供し、ユーザーがクラウド内で稼働中のアプリケーションにアクセスするために使用するアプリケーションネットワークセグメント。このネットワークは、物理ネットワークから分離して、クラウド内のハードウェアリソースとは直接通信しないようにする必要があります。
このネットワークセグメントは、アプリケーションデータをクラウド外部の物理ネットワークに転送するコンピュートのリソースノードとネットワークゲートウェイサービスが通信に使用することができます。
3.4.2. 一般的な考慮事項
- セキュリティー
ネットワークサービスを分離し、トラフィックが不要な場所を経由せずに正しい送信先に流れるようにします。
以下に例示する要素を考慮してください。
- ファイアウォール
- 分離されたテナントネットワークを結合するためのオーバーレイの相互接続
- 特定のネットワークを経由または回避
ネットワークをハイパーバイザーにアタッチする方法により、セキュリティーの脆弱性にさらされる場合があります。ハイパーバイザーのセキュリティーホールが悪用されるリスクを軽減するには、他のシステムからのネットワークを分離して、 そのネットワークのインスタンスは専用のコンピュートノードにスケジューリングします。このような分離により、セキュリティーが侵害されたインスタンスから攻撃者がネットワークに侵入するのを防ぎます。
- キャパシティープランニング
- クラウドのネットワークには、キャパシティーと拡張の管理が必要です。キャパシープランニングには、ネットワークサーキットとハードウェアの購入と、月/年単位で測定可能なリードタイムが含まれます。
- 複雑性
- 複雑なネットワーク設計は、メンテナンスとトラブルシューティングが難しくなる場合があります。デバイスレベルの設定でメンテナンスに関する懸念を軽減し、自動化ツールでオーバーレイネットワークの処理を行うことができますが、機能と特化したハードウェア間で従来とは異なる相互接続を避けるか文書化して、サービスの停止を防いでください。
- 設定エラー
- 誤った IP アドレス、VLAN、またはルーターを設定すると、ネットワークのエリアまたはクラウドインフラストラクチャー全体でもサービス停止の原因となる場合があります。ネットワーク設定を自動化して、ネットワークの可用性を中断させる可能性のあるオペレーターのエラーを最小限に抑えてください。
- 非標準の機能
クラウドネットワークを設定して、ベンダー固有の機能を利用するとリスクが高くなる可能性があります。
たとえば、マルチリンクアグリゲーション (MLAG) を使用して、ネットワークのアグリゲータースイッチレベルで冗長性を提供します。MLAG は標準のアグリゲーション形式ではなく、各ベンダーが機能の専用フレーバーを実装しています。MLAG アーキテクチャーは、全スイッチベンダー間で相互運用可能ではないため、ベンダーロックインに陥り、ネットワークコンポーネントのアップグレード時に遅延や問題が発生する場合があります。
- 単一障害点
- アップストリームのリンクまたは電源が 1 つしかないために、ネットワークに単一障害点 (SPOF) がある場合には、障害の発生時にネットワークが停止する可能性があります。
- チューニング
- クラウドネットワークを設定して、リンク損失、パケット損失、パケットストーム、ブロードキャストストーム、ループを最小限に抑えます。
3.4.3. ネットワークハードウェア
OpenStack クラウドをサポートするネットワークハードウェアのアーキテクチャーには、すべての実装に適用可能な単一のベストプラクティスはありません。ネットワークハードウェアの選択における重要な考慮事項には以下の点が含まれます。
- 可用性
クラウドノードのアクセスが中断されないようにするには、ネットワークアーキテクチャーで単一障害点を特定し、適切な冗長性や耐障害性を提供する必要があります。
- ネットワークの冗長性は、冗長電源またはペアのスイッチを追加することによって提供することができます。
- ネットワークインフラストラクチャーには、LACP や VRRP などのネットワークプロトコルを使用して、高可用性のネットワーク接続を実現することができます。
- OpenStack API およびクラウド内のその他のサービスを高可用性で提供するには、ネットワークアーキテクチャー内に負荷分散ソリューションを設計するべきです。
- 接続性
- OpenStack クラウド内の全ノードにはネットワーク接続が必要です。ノードが複数のネットワークセグメントにアクセスする必要がある場合もあります。クラウド内のすべての垂直/水平方向のトラフィックに十分なリソースを使用できるようにするには、設計に十分なネットワーク容量と帯域幅を組み入れる必要があります。
- ポート
どのような設計にも、必要なポートを備えたネットワーク用ハードウェアが必要です。
- ポートを提供するのに必要な物理的なスペースがあることを確認します。Compute やストレージコンポーネント用のラックスペースが残るので、ポートの密度が高いほど望ましいですが、適切な可用性のポートを提供することにより、障害ドメインを防ぎ、電源密度に役立ちます。スイッチの密度が高いほど、費用が高額となり、必要がない場合にはネットワークを過剰設計しないことが重要となる点も考慮に入れるべきです。
- ネットワーク用のハードウェアは、予定されているネットワークスピードをサポートする必要があります。例: 1 GbE、10 GbE、40 GbE (または 100 GbE)
- 電源
- 選択したネットワークハードウェアに必要な電源を物理データセンターが提供するようにします。たとえば、リーフ/スパイン型ファブリック内のスパインスイッチまたは End of Row (EoR) スイッチは、十分な電源を供給しない可能性があります。
- スケーラビリティー
- ネットワーク設計には、スケーラブルな物理/論理ネットワークを組込むべきです。ネットワークハードウエアは、ハードウェアノードが必要とするインターフェースタイプとスピードを提供するべきです。
3.5. パフォーマンス
OpenStack デプロイメントのパフォーマンスは、インフラストラクチャーとコントローラーサービスに関連する複数の要素によって左右されます。ユーザーの要件は、全般的なネットワークパフォーマンス、Compute リソースのパフォーマンス、ストレージシステムのパフォーマンスに分けることができます
システムがスピードダウンせず、一貫して動作しているときでも、パフォーマンスのベースラインの履歴を保持するようにします。ベースラインの情報が利用できると、パフォーマンス問題の発生時に比較するためのデータが必要な場合に参照するのに役立ちます。
「OpenStack Telemetry (ceilometer)」 以外にも、外部のソフトウェアを使用してパフォーマンスをトラッキングすることができます。Red Hat OpenStack Platform の運用ツールリポジトリーには、次のツールが含まれています。
3.5.1. ネットワークのパフォーマンス
ネットワーク要件はパフォーマンス能力を決定するのに役立ちます。たとえば、小型のデプロイメントでは、1 ギガビットイーサネット (GbE) のネットワークを採用し、複数の部署/多数のユーザーにサービスを提供する大型のデプロイメントでは 10 GbE のネットワークを使用するとよいでしょう。
インスタンスを実行するパフォーマンスは、これらのネットワークスピードによって左右されます。異なるネットワーク機能を実行する OpenStack 環境を設計することが可能です。異なるインターフェース速度を使用することにより、OpenStack 環境のユーザーは、自分の目的に適したネットワークを選択することができます。
たとえば、Web アプリケーションのインスタンスは、1 GbE 対応の OpenStack Networking を使用するパブリックネットワーク上で実行することができ、バックエンドデータベースには、10GbE 対応の OpenStack Networking を使用してデータのレプリケーションを行うことができます。場合によっては、設計にリンクアグリゲートを組み込んでスループットを拡大することが可能です。
ネットワークのパフォーマンスは、クラウド API にフロントエンドサービスを提供するハードウェアロードバランサーを実装することによって強化することができます。ハードウェアロードバランサーは、必要な場合に SSL 終了を実行することができます。SSL オフロードを実装する場合には、選択したデバイスの SSL オフロード機能を確認することが重要となります。
3.5.2. コンピュートノードのパフォーマンス
CPU、メモリー、ディスクの種別など、コンピュートノードに使用するハードウェア仕様は、インスタンスのパフォーマンスに直接影響します。OpenStack サービスの調整可能パラメーターもパフォーマンスに直接影響する場合があります。
たとえば、OpenStack Compute のデフォルトのオーバーコミット比は CPU が 16:1、メモリーが 1.5 です。これらの高い比によって、「noisy-neighbor」アクティビティーが増える可能性があります。Compute 環境のサイズは、慎重に設定して、このようなシナリオを回避し、使用率が高くなった場合には、必ず環境をモニタリングする必要があります。
3.5.3. Block Storage ホストのパフォーマンス
Block Storage では、NetApp や EMC などのエンタープライズバックエンドシステム、または Ceph などのスケールアウトストレージを使用したり、Block Storage ノード内でストレージを直接アタッチしたりする機能を活用することができます。
Block Storage は、トラフィックがホストネットワークを通過できるようにデプロイすることが可能です。このような構成は、フロントサイドの API トラフィックのパフォーマンスに影響を及ぼす可能性があります。またホストネットワークのトラフィックがフロントサイドの API トラフィックによって悪影響を受ける場合もあります。このため、コントローラーおよびコンピュートホストでは、専用のインターフェースを備えたデータストレージネットワークを使用すること検討してください。
3.5.4. Object Storage ホストのパフォーマンス
ユーザーは通常、ハードウェアロードバランサーの背後で動作するプロキシーサービスを使用して Object Storage にアクセスします。デフォルトでは、耐障害性の高いストレージシステムが保管されているデータを複製し、これによりシステム全体のパフォーマンスが影響を受けます。この場合、ストレージネットワークアーキテクチャー全体にわたってネットワーク容量を 10 GbE 以上に設定することを推奨します。
3.5.5. コントローラーノード
コントローラーノードは、エンドユーザーに管理サービスを提供し、クラウド運用のためのサービスを内部で提供します。コントローラーのインフラストラクチャーに使用するハードウェアの設計は慎重に行うことが重要となります。
コントローラーは、サービス間のシステムメッセージ用にメッセージキューサービスを実行します。インスタンスメッセージングにおけるパフォーマンス上の問題により、インスタンスのスピンアップ/削除、新規ストレージボリュームのプロビジョニング、ネットワークリソースの管理などの運用機能に遅延が発生する場合があります。このような遅延は、特に自動スケーリング機能を使用している場合に、一部の条件に対してアプリケーションが反応する能力に影響を及ぼす可能性があります。
コントローラーノードは、複数の同時ユーザーのワークロードを処理できるようにする必要もあります。API と Horizon のサービスのロードテストを予め行って、顧客のサービス信頼性を向上するようにしてください。
クラウド内で OpenStack およびエンドユーザーに全サービスの認証と承認を提供する OpenStack Identity サービス (keystone) について考慮することが重要です。このサービスのサイズを適切に設定していない場合には、全体的なパフォーマンスの低下をもたらす可能性があります。
モニタリングすべき極めて重要なメトリックには以下が含まれます。
- イメージディスクの使用率
- Compute API の応答時間
3.6. メンテナンスとサポート
環境のサポートとメンテナンスを行うために、OpenStack クラウドの管理には、運用スタッフがアーキテクチャー設計を理解している必要があります。運用スタッフとエンジニアリングスタッフのスキルレベルおよび役割分担はその環境のサイズと目的によって異なります。
- 大手のクラウドサービスプロバイダーまたは電気通信プロバイダーでは、特別に訓練を受けた専用の運用組織が管理を行う傾向があります。
- 小規模な実装は、エンジニアリング、設計、運用の機能を併せて担う必要のあるサポートスタッフに依存する傾向があります。
設計の運用オーバーヘッドを低減するための機能を組み込んだ場合には、一部の運用機能を自動化することができます。
設計は、サービスレベルアグリーメント (SLA) の条件によって直接の影響を受けます。SLA はサービスの可用性のレベルを定義し、契約上の義務を果たさない場合には、通常ペナルティーがあります。設計に影響を及ぼす SLA の条件には、以下が含まれます。
- 複数のインフラストラクチャーサービスと高可用性のロードバランサーを意味する、API の可用性の保証
- スイッチの設計に影響を及ぼし、冗長のスイッチまたは電源が必要な可能性のあるネットワークのアップタイムの保証
- ネットワークの分離または追加のセキュリティーメカニズムを暗示する、ネットワークセキュリティーポリシー要件
3.6.1. バックアップ
バックアップと復元のストラテジー、データの評価、階層型のストレージ管理、保持ストラテジー、データの配置、ワークフローの自動化によって設計が影響を受ける場合があります。
3.6.2. ダウンタイム
有効なクラウドアーキテクチャーは、以下をサポートする必要があります。
- 計画的なダウンタイム (メンテナンス)
- 計画外のダウンタイム (システムの障害)
たとえば、コンピュートホストで障害が発生した場合に、スナップショットからインスタンスを復元したり、インスタンスを再起動したりすることができます。ただし、高可用性には、共有ストレージなどの追加のサポートサービスをデプロイするか、信頼できるマイグレーションパスを設計する必要がある場合があります。
3.7. 可用性
OpenStack は、少なくとも 2 台のサーバーを使用している場合に高可用性のデプロイメントを提供することができます。サーバーは、RabbitMQ メッセージキューサービスおよび MariaDB データベースサービスからの全サービスを実行することが可能です。
クラウド内のサービスをスケーリングする際には、バックエンドサービスもスケーリングする必要があります。サーバーの使用率と応答時間のモニタリング/レポーティングに加えて、システムの付加テストを行うとスケーリングについての意思決定に役立てることができます。
- 単一障害点が生じないようにするには、OpenStack サービスを複数のサーバーにわたってデプロイするべきです。API の可用性は、複数の OpenStack サーバーをメンバーとする高可用性のロードバランサーの背後に配置することによって実現することができます。
- デプロイメントに適切なバックアップ機能を実装するようにします。たとえば、高可用性機能を使用する 2 つのインフラストラクチャーコントローラーノードで構成されるデプロイメントでは、1 つのコントローラーを失っても、もう 1 つのコントローラーからクラウドサービスを実行することが可能です。
- OpenStack のインフラストラクチャーは、サービスの提供に不可欠なので、常に稼働している必要があります。これは、特に SLA に基づいて運用している場合に重要となります。コアインフラストラクチャーに必要なスイッチ数、ルート、電源の冗長性に加え、それらに付随して、高可用性スイッチインフラストラクチャーに多様なルートを提供するためのネットワークボンディングも考慮してください。
- Compute ホストがライブマイグレーションに対応するように設定されていない場合には、1 台の Compute ホストでエラーが発生した際に Compute のインスタンスとそのインスタンスに保管されているデータが失われる可能性があります。Compute ホストのアップタイムを維持するには、エンタープライズストレージまたは OpenStack Block Storage 上で共有ファイルシステムを使用することができます。
サービスの可用性や閾値の制限をチェックして適切な警告を設定するのに外部のソフトウェアを使用することができます。Red Hat OpenStack Platform の運用ツールリポジトリーには、以下のツールが含まれています。
OpenStack で高可用性を使用するためのリファレンスアーキテクチャーは、「Deploying Highly Available Red Hat OpenStack Platform 6 with Ceph Storage」の記事を参照してください。
3.8. セキュリティー
セキュリティードメインには、単一のシステム内で共通する信頼の要件と予測を共有するユーザー、アプリケーション、サーバー、ネットワークが含まれます。セキュリティードメインは、通常同じ認証/承認要件およびユーザーを使用します。
標準的なセキュリティードメインのカテゴリーには、Public、Guest、Management、Data です。ドメインは、OpenStack デプロイメントに個別または統合してマッピングすることができます。たとえば、ゲストとデータのドメインを 1 つの物理ネットワーク内に統合するデプロイメントトポロジーもあれば、ネットワークを物理的に分離するデプロイメントトポロジーもあります。いずれの場合も、クラウドオペレーターは関連するセキュリティー問題について認識している必要があります。
セキュリティードメインは、特定の OpenStack デプロイメントトポロジーにマッピングする必要があります。ドメインおよびドメイン信頼要件は、インスタンスがパブリック、プライベート、ハイブリッドであるかによって異なります。
- パブリックドメイン
- クラウドインフラストラクチャーの完全に信頼されない領域です。パブリックドメインは、インターネット全体または権限のない複数のネットワークのことを指します。このドメインは、常に信頼できないものと見なす必要があります。
- ゲストドメイン
通常は、インスタンス間のトラフィックに使用され、クラウド上でインスタンスによって生成された Compute のデータを処理しますが、API コールなどのクラウドの運用をサポートするサービスによって生成されるデータは対象ではありません。
インスタンスの使用を厳格に制御しない、またはインスタンスに制限なしのインターネットアクセスを許可しているパブリッククラウドプロバイダーおよびプライベートクラウドプロバイダーは、このドメインを信頼できないものと見なすべきです。プライベートクラウドのプロバイダーは、このネットワークを内部と見なす場合があり、インスタンスおよび全クラウドテナント内で信頼をアサートする制御を使用する場合のみ信頼されます。
- ドメインの管理
- サービスが相互に対話するドメイン。このドメインは、コントロールプレーンとしても知られています。このドメイン内のネットワークは、設定パラメーター、ユーザー名、パスワードなどの機密データを転送します。大半のデプロイメントでは、このドメインは信頼されているものと見なされます。
- データドメイン
- ストレージサービスがデータを転送するドメイン。このドメインを通過するデータの大半は、整合性と機密性の要件が高く、デプロイメントの種別によっては、高可用性が要求される場合があります。このネットワークの信頼レベルは、デプロイメントの他の決定事項によって左右されます。
企業内のプライベートクラウドとして OpenStack をデプロイする場合には、デプロイメントは通常ファイアウォールの背後で、既存のシステムを使用する信頼済みのネットワーク内に設定します。クラウドのユーザーは、通常その企業が定義したセキュリティー要件に拘束される従業員です。このようなデプロイメントでは、大半のセキュリティードメインを信頼できます。
ただし、一般向けのロールに OpenStack をデプロイする場合には、ドメインの信頼レベルに関して何も想定することができず、攻撃ベクトルが大幅に増大します。たとえば、API エンドポイントと下層にあるソフトウェアは不正にアクセスしようとしたり、サービスへのアクセスを妨害しようとする悪意のある者に対して脆弱になります。このような攻撃により、データ、機能、評判を失う可能性があります。このようなサービスは、監査や適切なフィルタリングを使用して保護する必要があります。
パブリッククラウドとプライベートクラウドの両方のシステムのユーザーを管理する際にも注意を払う必要があります。Identity サービスは、LDAP などの外部のアイデンティティーバックエンドを使用することができます。これにより、OpenStack 内部でのユーザー管理の負担が軽減されます。ユーザー認証要求には、ユーザー名、パスワード、認証トークンなどの機密情報が含まれるので、API サービスは、SSL 終了を実行するハードウェアの背後に配置すべきです。
3.9. 追加のソフトウェア
標準的な OpenStack デプロイメントには OpenStack 固有のコンポーネントと 「サードパーティーのコンポーネント」が含まれます。追加のソフトウェアにはクラスタリング、ロギング、監視、警告などのソフトウェアが含まれます。このため、デプロイメントの設計は、CPU、メモリー、ストレージ、ネットワーク帯域幅などの追加のリソース消費を考慮に入れる必要があります。
クラウドの設計時には、以下の要素を考慮してください。
- データベースとメッセージング
下層にあるメッセージキュープロバイダーにより、コントローラーサービスの必要数や耐障害性の高いデータベース機能を提供する技術が影響を受ける場合があります。たとえば、MariaDB と Galera を併用する場合には、レプリケーションサービスは定足数によって左右されます。このため、下層のデータベースは、少なくとも 3 つのノードで構成して、障害が発生した Galera ノードのリカバリーに対応するべきです。
ソフトウェアの機能をサポートするためにノードの数を増やす場合には、ラックのスペースとスイッチポートの密度の両方を考慮してください。
- 外部のキャッシュ
Memcached は、分散型メモリーオブジェクトキャッシュシステムで、Redis はキーバリューストアです。いずれのシステムも、クラウド内にデプロイして、Identity サービスの負荷を軽減することができます。たとえば、memcached サービスは、トークンをキャッシュし、分散型キャッシュシステムを使用して下層の認証システムからの一部のボトルネックを軽減します。
memcached または Redis を使用しても、アーキテクチャー全体の設計には影響はありません。これらのサービスは通常、OpenStack サービスを提供するインフラストラクチャーノードにデプロイされるのが理由です。
- ロードバランシング
多くの汎用デプロイメントは、ハードウェアロードバランサーを使用して高可用性の API アクセスと SSL 終了を提供しますが、HAProxy のようなソフトウェアソリューションも検討することができます。ソフトウェア定義のロードバランシング実装も高可用性を確保する必要があります。
Keepalived または Pacemaker と Corosync を併用するソリューションでソフトウェア定義の高可用性を設定することができます。Pacemaker と Corosync は、OpenStack 環境内の特定のサービスをベースとする active-active または active-passive の高可用性構成を提供することができます。
これらのアプリケーションには少なくとも 2 コントローラーノードで構成されるデプロイメントで、そのうちの 1 つのコントローラーノードがスタンバイモードでサービスを実行可能である必要があるので、設計に影響を及ぼす可能性があります。
- ロギングとモニタリング
ログは、容易に分析できるように一元的に保管するべきです。ログデータの解析エンジンは、一般的な問題を警告/修正するメカニズムを使用して、自動化と問題通知機能を提供することができます。
ツールがアーキテクチャー設計内の既存のソフトウェアおよびハードウェアがツールをサポートしている限りは、基本的な OpenStack のログに加えて外部のロギングまたはモニタリング用ソフトウェアを使用することができます。Red Hat OpenStack Platform の運用ツールリポジトリーには、以下のツールが含まれています。
3.10. プランニングツール
Cloud Resource Calculator は、キャパシティー要件の計算に役立つルールです。
このツールを使用するには、ハードウェアの詳細をスプレッドシートに入力します。ツールは次に利用可能なインスタンス数の推定値を算出して表示します。これには、フレーバー別の概算も含まれます。
このツールは、お客様の便宜のためのみに提供されており、Red Hat では正式にサポートされていません。