이 콘텐츠는 선택한 언어로 제공되지 않습니다.
Chapter 39. Troubleshooting OpenShift SDN
39.1. Overview
As described in the SDN documentation there are multiple layers of interfaces that are created to correctly pass the traffic from one container to another. In order to debug connectivity issues, you have to test the different layers of the stack to work out where the problem arises. This guide will help you dig down through the layers to identify the problem and how to fix it.
Part of the problem is that OpenShift Container Platform can be set up many ways, and the networking can be wrong in a few different places. So this document will work through some scenarios that, hopefully, will cover the majority of cases. If your problem is not covered, the tools and concepts that are introduced should help guide debugging efforts.
39.2. Nomenclature
- Cluster
- The set of machines in the cluster. i.e. the Masters and the Nodes.
- Master
- A controller of the OpenShift Container Platform cluster. Note that the master may not be a node in the cluster, and thus, may not have IP connectivity to the pods.
- Node
- Host in the cluster running OpenShift Container Platform that can host pods.
- Pod
- Group of containers running on a node, managed by OpenShift Container Platform.
- Service
- Abstraction that presents a unified network interface that is backed by one or more pods.
- Router
- A web proxy that can map various URLs and paths into OpenShift Container Platform services to allow external traffic to travel into the cluster.
- Node Address
- The IP address of a node. This is assigned and managed by the owner of the network to which the node is attached. Must be reachable from any node in the cluster (master and client).
- Pod Address
- The IP address of a pod. These are assigned and managed by OpenShift Container Platform. By default they are assigned out of the 10.128.0.0/14 network (or, in older versions, 10.1.0.0/16). Only reachable from the client nodes.
- Service Address
- An IP address that represents the service, and is mapped to a pod address internally. These are assigned and managed by OpenShift Container Platform. By default they are assigned out of the 172.30.0.0/16 network. Only reachable from the client nodes.
The following diagram shows all of the pieces involved with external access.
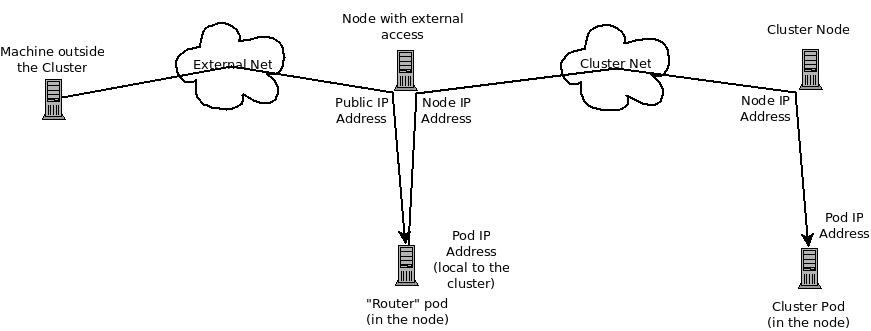
39.3. Debugging External Access to an HTTP Service
If you are on an machine outside the cluster and are trying to access a resource provided by the cluster there needs to be a process running in a pod that listens on a public IP address and "routes" that traffic inside the cluster. The OpenShift Container Platform router serves that purpose for HTTP, HTTPS (with SNI), WebSockets, or TLS (with SNI).
Assuming you can’t access an HTTP service from the outside of the cluster, let’s start by reproducing the problem on the command line of the machine where things are failing. Try:
curl -kv http://foo.example.com:8000/bar # But replace the argument with your URLIf that works, are you reproducing the bug from the right place? It is also possible that the service has some pods that work, and some that don’t. So jump ahead to the Section 39.4, “Debugging the Router” section.
If that failed, then let’s resolve the DNS name to an IP address (assuming it isn’t already one):
dig +short foo.example.com # But replace the hostname with yoursIf that doesn’t give back an IP address, it’s time to troubleshoot DNS, but that’s outside the scope of this guide.
Make sure that the IP address that you got back is one that you expect to be running the router. If it’s not, fix your DNS.
Next, use ping -c address and tracepath address to check that you can reach the router host. It is possible that they will not respond to ICMP packets, in which case those tests will fail, but the router machine may be reachable. In which case, try using the telnet command to access the port for the router directly:
telnet 1.2.3.4 8000You may get:
Trying 1.2.3.4...
Connected to 1.2.3.4.
Escape character is '^]'.
If so, there’s something listening on the port on the IP address. That’s good. Hit ctrl-] then hit the enter key and then type close to quit telnet. Move on to the Section 39.4, “Debugging the Router” section to check other things on the router.
Or you could get:
Trying 1.2.3.4...
telnet: connect to address 1.2.3.4: Connection refusedWhich tells us that the router is not listening on that port. See the Section 39.4, “Debugging the Router” section for more pointers on how to configure the router.
Or if you see:
Trying 1.2.3.4...
telnet: connect to address 1.2.3.4: Connection timed outWhich tells us that you can’t talk to anything on that IP address. Check your routing, firewalls, and that you have a router listening on that IP address. To debug the router, see the Section 39.4, “Debugging the Router” section. For IP routing and firewall issues, debugging that is beyond the purview of this guide.
39.4. Debugging the Router
Now that you have an IP address, we need to ssh to that machine and check that the router software is running on that machine and configured correctly. So let’s ssh there and get administrative OpenShift Container Platform credentials.
If you have access to administrator credentials but are no longer logged in as the default system user system:admin, you can log back in as this user at any time as long as the credentials are still present in your CLI configuration file. The following command logs in and switches to the default project:
$ oc login -u system:admin -n defaultCheck that the router is running:
# oc get endpoints --namespace=default --selector=router
NAMESPACE NAME ENDPOINTS
default router 10.128.0.4:80If that command fails, then your OpenShift Container Platform configuration is broken. Fixing that is outside the scope of this document.
You should see one or more router endpoints listed, but that won’t tell you if they are running on the machine with the given external IP address, since the endpoint IP address will be one of the pod addresses that is internal to the cluster. To get the list of router host IP addresses, run:
# oc get pods --all-namespaces --selector=router --template='{{range .items}}HostIP: {{.status.hostIP}} PodIP: {{.status.podIP}}{{end}}{{"\n"}}'
HostIP: 192.168.122.202 PodIP: 10.128.0.4You should see the host IP that corresponds to your external address. If you do not, refer to the router documentation to configure the router pod to run on the right node (by setting the affinity correctly) or update your DNS to match the IP addresses where the routers are running.
At this point in the guide, you should be on a node, running your router pod, but you still cannot get the HTTP request to work. First we need to make sure that the router is mapping the external URL to the correct service, and if that works, we need to dig into that service to make sure that all endpoints are reachable.
Let’s list all of the routes that OpenShift Container Platform knows about:
# oc get route --all-namespaces
NAME HOST/PORT PATH SERVICE LABELS TLS TERMINATION
route-unsecured www.example.com /test service-nameIf the host name and path from your URL don’t match anything in the list of returned routes, then you need to add a route. See the router documentation.
If your route is present, then you need to debug access to the endpoints. That’s the same as if you were debugging problems with a service, so continue on with the next Section 39.5, “Debugging a Service” section.
39.5. Debugging a Service
If you can’t communicate with a service from inside the cluster (either because your services can’t communicate directly, or because you are using the router and everything works until you get into the cluster) then you need to work out what endpoints are associated with a service and debug them.
First, let’s get the services:
# oc get services --all-namespaces
NAMESPACE NAME LABELS SELECTOR IP(S) PORT(S)
default docker-registry docker-registry=default docker-registry=default 172.30.243.225 5000/TCP
default kubernetes component=apiserver,provider=kubernetes <none> 172.30.0.1 443/TCP
default router router=router router=router 172.30.213.8 80/TCPYou should see your service in the list. If not, then you need to define your service.
The IP addresses listed in the service output are the Kubernetes service IP addresses that Kubernetes will map to one of the pods that backs that service. So you should be able to talk to that IP address. But, unfortunately, even if you can, it doesn’t mean all pods are reachable; and if you can’t, it doesn’t mean all pods aren’t reachable. It just tells you the status of the one that kubeproxy hooked you up to.
Let’s test the service anyway. From one of your nodes:
curl -kv http://172.30.243.225:5000/bar # Replace the argument with your service IP address and port
Then, let’s work out what pods are backing our service (replace docker-registry with the name of the broken service):
# oc get endpoints --selector=docker-registry
NAME ENDPOINTS
docker-registry 10.128.2.2:5000From this, we can see that there’s only one endpoint. So, if your service test succeeded, and the router test succeeded, then something really odd is going on. But if there’s more than one endpoint, or the service test failed, try the following for each endpoint. Once you identify what endpoints aren’t working, then proceed to the next section.
First, test each endpoint (change the URL to have the right endpoint IP, port, and path):
curl -kv http://10.128.2.2:5000/barIf that works, great, try the next one. If it failed, make a note of it and we’ll work out why, in the next section.
If all of them failed, then it is possible that the local node is not working, jump to the Section 39.7, “Debugging Local Networking” section.
If all of them worked, then jump to the Section 39.11, “Debugging Kubernetes” section to work out why the service IP address isn’t working.
39.6. Debugging Node to Node Networking
Using our list of non-working endpoints, we need to test connectivity to the node.
Make sure that all nodes have the expected IP addresses:
# oc get hostsubnet NAME HOST HOST IP SUBNET rh71-os1.example.com rh71-os1.example.com 192.168.122.46 10.1.1.0/24 rh71-os2.example.com rh71-os2.example.com 192.168.122.18 10.1.2.0/24 rh71-os3.example.com rh71-os3.example.com 192.168.122.202 10.1.0.0/24If you are using DHCP they could have changed. Ensure the host names, IP addresses, and subnets match what you expect. If any node details have changed, use
oc edit hostsubnetto correct the entries.After ensuring the node addresses and host names are correct, list the endpoint IPs and node IPs:
# oc get pods --selector=docker-registry \ --template='{{range .items}}HostIP: {{.status.hostIP}} PodIP: {{.status.podIP}}{{end}}{{"\n"}}' HostIP: 192.168.122.202 PodIP: 10.128.0.4Find the endpoint IP address you made note of before and look for it in the
PodIPentry, and find the correspondingHostIPaddress. Then test connectivity at the node host level using the address fromHostIP:-
ping -c 3 <IP_address>: No response could mean that an intermediate router is eating the ICMP traffic. tracepath <IP_address>: Shows the IP route taken to the target, if ICMP packets are returned by all hops.If both
tracepathandpingfail, then look for connectivity issues with your local or virtual network.
-
For local networking, check the following:
Check the route the packet takes out of the box to the target address:
# ip route get 192.168.122.202 192.168.122.202 dev ens3 src 192.168.122.46 cacheIn the above example, it will go out the interface named
ens3with the source address of192.168.122.46and go directly to the target. If that is what you expected, useip a show dev ens3to get the interface details and make sure that is the expected interface.An alternate result may be the following:
# ip route get 192.168.122.202 1.2.3.4 via 192.168.122.1 dev ens3 src 192.168.122.46It will pass through the
viaIP value to route appropriately. Ensure that the traffic is routing correctly. Debugging route traffic is beyond the scope of this guide.
Other debugging options for node to node networking can be solved with the following:
-
Do you have ethernet link on both ends? Look for
Link detected: yesin the output fromethtool <network_interface>. -
Are your duplex settings, and ethernet speeds right on both ends? Look through the rest of the
ethtool <network_interface>information. - Are the cables plugged in correctly? To the correct ports?
- Are the switches configured correctly?
Once you have ascertained that the node to node connectivity is fine, we need to look at the SDN configuration on both ends.
39.7. Debugging Local Networking
At this point we should have a list of one or more endpoints that you can’t communicate with, but that have node to node connectivity. For each one, we need to work out what is wrong, but first you need to understand how the SDN sets up the networking on a node for the different pods.
39.7.1. The Interfaces on a Node
These are the interfaces that the OpenShift SDN creates:
-
br0: The OVS bridge device that containers will be attached to. OpenShift SDN also configures a set of non-subnet-specific flow rules on this bridge. -
tun0: An OVS internal port (port 2 onbr0). This gets assigned the cluster subnet gateway address, and is used for external network access. OpenShift SDN configuresnetfilterand routing rules to enable access from the cluster subnet to the external network via NAT. -
vxlan_sys_4789: The OVS VXLAN device (port 1 onbr0), which provides access to containers on remote nodes. Referred to asvxlan0in the OVS rules. -
vethX(in the main netns): A Linux virtual ethernet peer ofeth0in the Docker netns. It will be attached to the OVS bridge on one of the other ports.
39.7.2. SDN Flows Inside a Node
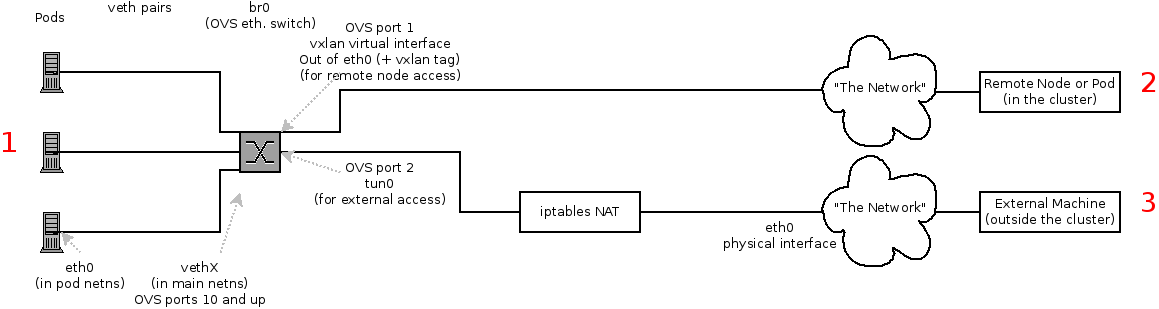
Depending on what you are trying to access (or be accessed from) the path will vary. There are four different places the SDN connects (inside a node). They are labeled in red on the diagram above.
- Pod: Traffic is going from one pod to another on the same machine (1 to a different 1)
- Remote Node (or Pod): Traffic is going from a local pod to a remote node or pod in the same cluster (1 to 2)
- External Machine: Traffic is going from a local pod outside the cluster (1 to 3)
Of course the opposite traffic flows are also possible.
39.7.3. Debugging Steps
39.7.3.1. Is IP Forwarding Enabled?
Check that sysctl net.ipv4.ip_forward is set to 1 (and check the host if this is a VM)
39.7.3.2. Are your routes correct?
Check the route tables with ip route:
# ip route
default via 192.168.122.1 dev ens3
10.128.0.0/14 dev tun0 proto kernel scope link # This sends all pod traffic into OVS
10.128.2.0/23 dev tun0 proto kernel scope link src 10.128.2.1 # This is traffic going to local pods, overriding the above
169.254.0.0/16 dev ens3 scope link metric 1002 # This is for Zeroconf (may not be present)
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.42.1 # Docker's private IPs... used only by things directly configured by docker; not OpenShift
192.168.122.0/24 dev ens3 proto kernel scope link src 192.168.122.46 # The physical interface on the local subnetYou should see the 10.128.x.x lines (assuming you have your pod network set to the default range in your configuration). If you do not, check the OpenShift Container Platform logs (see the Section 39.10, “Reading the Logs” section)
39.7.4. Is the Open vSwitch configured correctly?
Check the Open vSwitch bridges on both sides:
# ovs-vsctl list-br
br0
This should be br0.
You can list all of the ports that ovs knows about:
# ovs-ofctl -O OpenFlow13 dump-ports-desc br0
OFPST_PORT_DESC reply (OF1.3) (xid=0x2):
1(vxlan0): addr:9e:f1:7d:4d:19:4f
config: 0
state: 0
speed: 0 Mbps now, 0 Mbps max
2(tun0): addr:6a:ef:90:24:a3:11
config: 0
state: 0
speed: 0 Mbps now, 0 Mbps max
8(vethe19c6ea): addr:1e:79:f3:a0:e8:8c
config: 0
state: 0
current: 10GB-FD COPPER
speed: 10000 Mbps now, 0 Mbps max
LOCAL(br0): addr:0a:7f:b4:33:c2:43
config: PORT_DOWN
state: LINK_DOWN
speed: 0 Mbps now, 0 Mbps max
In particular, the vethX devices for all of the active pods should be listed as ports.
Next, list the flows that are configured on that bridge:
# ovs-ofctl -O OpenFlow13 dump-flows br0The results will vary slightly depending on whether you are using the ovs-subnet or ovs-multitenant plug-in, but there are certain general things you can look for:
-
Every remote node should have a flow matching
tun_src=<node_IP_address>(for incoming VXLAN traffic from that node) and another flow including the actionset_field:<node_IP_address>->tun_dst(for outgoing VXLAN traffic to that node). -
Every local pod should have flows matching
arp_spa=<pod_IP_address>andarp_tpa=<pod_IP_address>(for incoming and outgoing ARP traffic for that pod), and flows matchingnw_src=<pod_IP_address>andnw_dst=<pod_IP_address>(for incoming and outgoing IP traffic for that pod).
If there are flows missing, look in the Section 39.10, “Reading the Logs” section.
39.7.4.1. Is the iptables configuration correct?
Check the output from iptables-save to make sure you are not filtering traffic. However, OpenShift Container Platform sets up iptables rules during normal operation, so do not be surprised to see entries there.
39.7.4.2. Is your external network correct?
Check external firewalls, if any, allow traffic to the target address (this is site-dependent, and beyond the purview of this guide).
39.8. Debugging Virtual Networking
39.8.1. Builds on a Virtual Network are Failing
If you are installing OpenShift Container Platform using a virtual network (for example, OpenStack), and a build is failing, the maximum transmission unit (MTU) of the target node host might not be compatible with the MTU of the primary network interface (for example, eth0).
For a build to complete successfully, the MTU of an SDN must be less than the eth0 network MTU in order to pass data to between node hosts.
Check the MTU of your network by running the
ip addrcommand:# ip addr --- 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether fa:16:3e:56:4c:11 brd ff:ff:ff:ff:ff:ff inet 172.16.0.0/24 brd 172.16.0.0 scope global dynamic eth0 valid_lft 168sec preferred_lft 168sec inet6 fe80::f816:3eff:fe56:4c11/64 scope link valid_lft forever preferred_lft forever ---The MTU of the above network is 1500.
The MTU in your node configuration must be lower than the network value. Check the
mtuin the node configuration of the targeted node host:# cat /etc/origin/node/node-config.yaml ... networkConfig: mtu: 1450 networkPluginName: company/openshift-ovs-subnet ...In the above node configuration file, the
mtuvalue is lower than the network MTU, so no configuration is needed. If themtuvalue was higher, edit the file and lower the value to at least 50 units fewer than the MTU of the primary network interface, then restart the node service. This would allow larger packets of data to pass between nodes.
39.9. Debugging Pod Egress
If you are trying to access an external service from a pod, e.g.:
curl -kv github.comMake sure that the DNS is resolving correctly:
dig +search +noall +answer github.comThat should return the IP address for the github server, but check that you got back the correct address. If you get back no address, or the address of one of your machines, then you may be matching the wildcard entry in your local DNS server.
To fix that, you either need to make sure that DNS server that has the wildcard entry is not listed as a nameserver in your /etc/resolv.conf or you need to make sure that the wildcard domain is not listed in the search list.
If the correct IP address was returned, then try the debugging advice listed above in Section 39.7, “Debugging Local Networking”. Your traffic should leave the Open vSwitch on port 2 to pass through the iptables rules, then out the route table normally.
39.10. Reading the Logs
Run: journalctl -u atomic-openshift-node.service --boot | less
Look for the Output of setup script: line. Everything starting with '+' below that are the script steps. Look through that for obvious errors.
Following the script you should see lines with Output of adding table=0. Those are the OVS rules, and there should be no errors.
39.11. Debugging Kubernetes
Check iptables -t nat -L to make sure that the service is being NAT’d to the right port on the local machine for the kubeproxy.
This is all changing soon… Kubeproxy is being eliminated and replaced with an iptables-only solution.
39.12. Finding Network Issues Using the Diagnostics Tool
As a cluster administrator, run the diagnostics tool to diagnose common network issues:
# oc adm diagnostics NetworkCheckThe diagnostics tool runs a series of checks for error conditions for the specified component. See the Diagnostics Tool section for more information.
Currently, the diagnostics tool cannot diagnose IP failover issues. As a workaround, you can run the script at https://raw.githubusercontent.com/openshift/openshift-sdn/master/hack/ipf-debug.sh on the master (or from another machine with access to the master) to generate useful debugging information. However, this script is unsupported.
By default, oc adm diagnostics NetworkCheck logs errors into /tmp/openshift/. This can be configured with the --network-logdir option:
# oc adm diagnostics NetworkCheck --network-logdir=<path/to/directory>39.13. Miscellaneous Notes
39.13.1. Other clarifications on ingress
- Kube - declare a service as NodePort and it will claim that port on all machines in the cluster (on what interface?) and then route into kube-proxy and then to a backing pod. See https://kubernetes.io/docs/concepts/services-networking/service/#type-nodeport (some node must be accessible from outside)
- Kube - declare as a LoadBalancer and something you have to write does the rest
- OS/AE - Both use the router
39.13.2. TLS Handshake Timeout
When a pod fails to deploy, check its docker log for a TLS handshake timeout:
$ docker log <container_id>
...
[...] couldn't get deployment [...] TLS handshake timeout
...This condition, and generally, errors in establishing a secure connection, may be caused by a large difference in the MTU values between tun0 and the primary interface (e.g., eth0), such as when tun0 MTU is 1500 and eth0 MTU is 9000 (jumbo frames).
39.13.3. Other debugging notes
-
Peer interfaces (of a Linux virtual ethernet pair) can be determined with
ethtool -S ifname -
Driver type:
ethtool -i ifname