확장 및 성능
프로덕션 환경에서 OpenShift Container Platform 클러스터 스케일링 및 성능 튜닝
초록
1장. OpenShift Container Platform 확장성 및 성능 개요
OpenShift Container Platform은 클러스터의 성능 및 규모를 최적화하는 데 도움이 되는 모범 사례와 툴을 제공합니다. 다음 문서에서는 권장 성능 및 확장성 사례, 참조 설계 사양, 최적화 및 짧은 대기 시간 튜닝에 대한 정보를 제공합니다.
Red Hat 지원에 문의하려면 지원 받기를 참조하십시오.
일부 성능 및 확장성 Operator에는 OpenShift Container Platform 릴리스 사이클과 독립적인 릴리스 사이클이 있습니다. 자세한 내용은 OpenShift Operator 를 참조하십시오.
권장 성능 및 확장성 사례
Telco 참조 설계 사양
계획, 최적화 및 측정
IBM Z 및 IBM LinuxONE에 대한 권장 사례
클러스터 안정성 및 파티셔닝 워크로드를 개선하기 위한 짧은 대기 시간 튜닝
2장. 권장 성능 및 확장성 사례
2.1. 컨트롤 플레인 권장 사례
이 주제에서는 OpenShift Container Platform의 컨트롤 플레인에 대한 권장 성능 및 확장성 사례를 설명합니다.
2.1.1. 클러스터 스케일링에 대한 권장 사례
이 섹션의 지침은 클라우드 공급자 통합을 통한 설치에만 관련이 있습니다.
다음 모범 사례를 적용하여 OpenShift Container Platform 클러스터의 작업자 머신 수를 스케일링하십시오. 작업자 머신 세트에 정의된 복제본 수를 늘리거나 줄여 작업자 머신을 스케일링합니다.
노드 수가 많아지도록 클러스터를 확장하는 경우 다음을 수행합니다.
- 고가용성을 위해 모든 사용 가능한 영역으로 노드를 분산합니다.
- 한 번에 확장하는 머신 수가 25~50개를 넘지 않도록 합니다.
- 주기적인 공급자 용량 제약 조건을 완화하는 데 도움이 되도록 유사한 크기의 대체 인스턴스 유형을 사용하여 사용 가능한 각 영역에 새 컴퓨팅 머신 세트를 생성하는 것이 좋습니다. 예를 들어 AWS에서 m5.large 및 m5d.large를 사용합니다.
클라우드 제공자는 API 서비스 할당량을 구현할 수 있습니다. 따라서 점진적으로 클러스터를 스케일링하십시오.
컴퓨팅 머신 세트의 복제본이 한 번에 모두 더 높은 숫자로 설정된 경우 컨트롤러가 머신을 생성하지 못할 수 있습니다. OpenShift Container Platform이 배포된 클라우드 플랫폼에서 처리할 수 있는 요청 수는 프로세스에 영향을 미칩니다. 컨트롤러는 상태를 사용하여 머신을 생성하고, 점검하고, 업데이트하는 동안 더 많이 쿼리하기 시작합니다. OpenShift Container Platform이 배포된 클라우드 플랫폼에는 API 요청 제한이 있습니다. 과도한 쿼리로 인해 클라우드 플랫폼 제한으로 인해 머신 생성 오류가 발생할 수 있습니다.
노드 수가 많아지도록 스케일링하는 경우 머신 상태 점검을 활성화하십시오. 실패가 발생하면 상태 점검에서 상태를 모니터링하고 비정상 머신을 자동으로 복구합니다.
대규모 및 밀도가 높은 클러스터의 노드 수를 줄이는 경우 프로세스에서 동시에 종료되는 노드에서 실행되는 오브젝트를 드레이닝하거나 제거해야 하므로 많은 시간이 걸릴 수 있습니다. 또한 제거할 개체가 너무 많으면 클라이언트 요청 처리에 병목 현상이 발생할 수 있습니다. 기본 클라이언트 쿼리(QPS) 및 버스트 비율은 각각 50 및 100 으로 설정됩니다. 이러한 값은 OpenShift Container Platform에서 수정할 수 없습니다.
2.1.2. 컨트롤 플레인 노드 크기 조정
컨트롤 플레인 노드 리소스 요구 사항은 클러스터의 노드 및 오브젝트 수와 유형에 따라 다릅니다. 다음 컨트롤 플레인 노드 크기 권장 사항은 컨트롤 플레인 밀도 중심 테스트 또는 Cluster-density 결과를 기반으로 합니다. 이 테스트에서는 지정된 수의 네임스페이스에서 다음 오브젝트를 생성합니다.
- 이미지 스트림 1개
- 빌드 1개
-
5개의 배포,
절전상태에 2개의 Pod 복제본이 있는 배포, 4개의 시크릿 마운트, 4개의 구성 맵, 각각 1개의 Downward API 볼륨 - 5개의 서비스, 각각 이전 배포 중 하나의 TCP/8080 및 TCP/8443 포트를 가리킵니다.
- 이전 서비스 중 첫 번째를 가리키는 1 경로
- 2048 임의의 문자열 문자가 포함된 10개의 보안
- 2048 임의의 문자열 문자가 포함된 10개의 구성 맵
| 작업자 노드 수 | cluster-density(네임스페이스) | CPU 코어 수 | 메모리(GB) |
|---|---|---|---|
| 24 | 500 | 4 | 16 |
| 120 | 1000 | 8 | 32 |
| 252 | 4000 | 16, 그러나 24 OVN-Kubernetes 네트워크 플러그인을 사용하는 경우 | OVN-Kubernetes 네트워크 플러그인을 사용하는 경우 64이지만 128 |
| 501 그러나 OVN-Kubernetes 네트워크 플러그인으로 테스트되지 않음 | 4000 | 16 | 96 |
위의 표의 데이터는 r5.4xlarge 인스턴스를 컨트롤 플레인 노드로 사용하고 m5.2xlarge 인스턴스를 작업자 노드로 사용하여 AWS에서 실행되는 OpenShift Container Platform을 기반으로 합니다.
컨트롤 플레인 노드가 3개인 대규모 및 밀도가 높은 클러스터에서는 노드 중 하나가 중지, 재부팅 또는 실패할 때 CPU 및 메모리 사용량이 증가합니다. 비용 절감을 위해 전원, 네트워크, 기본 인프라 또는 의도적인 경우 클러스터를 종료한 후 클러스터를 다시 시작하는 예기치 않은 문제로 인해 오류가 발생할 수 있습니다. 나머지 두 컨트롤 플레인 노드는 고가용성이 되기 위해 부하를 처리하여 리소스 사용량을 늘려야 합니다. 이는 컨트롤 플레인 노드가 직렬로 연결, 드레이닝, 재부팅되어 운영 체제 업데이트를 적용하고 컨트롤 플레인 Operator 업데이트를 적용하기 때문에 업그레이드 중에도 이 문제가 발생할 수 있습니다. 단계적 오류를 방지하려면 컨트롤 플레인 노드에서 전체 CPU 및 메모리 리소스 사용량을 사용 가능한 모든 용량의 최대 60 %로 유지하여 리소스 사용량 급증을 처리합니다. 리소스 부족으로 인한 다운타임을 방지하기 위해 컨트롤 플레인 노드에서 CPU 및 메모리를 늘립니다.
노드 크기 조정은 클러스터의 노드 수와 개체 수에 따라 달라집니다. 또한 클러스터에서 개체가 현재 생성되는지에 따라 달라집니다. 개체 생성 중에 컨트롤 플레인은 개체가 running 단계에 있을 때보다 리소스 사용량 측면에서 더 활성화됩니다.
OLM(Operator Lifecycle Manager)은 컨트롤 플레인 노드에서 실행되며 해당 메모리 공간은 OLM이 클러스터에서 관리해야 하는 네임스페이스 및 사용자 설치된 Operator 수에 따라 다릅니다. OOM이 종료되지 않도록 컨트를 플레인 노드의 크기를 적절하게 조정해야 합니다. 다음 데이터 지점은 클러스터 최대값 테스트 결과를 기반으로 합니다.
| 네임스페이스 수 | 유휴 상태의 OLM 메모리(GB) | 5명의 사용자 operator가 설치된 OLM 메모리(GB) |
|---|---|---|
| 500 | 0.823 | 1.7 |
| 1000 | 1.2 | 2.5 |
| 1500 | 1.7 | 3.2 |
| 2000 | 2 | 4.4 |
| 3000 | 2.7 | 5.6 |
| 4000 | 3.8 | 7.6 |
| 5000 | 4.2 | 9.02 |
| 6000 | 5.8 | 11.3 |
| 7000 | 6.6 | 12.9 |
| 8000 | 6.9 | 14.8 |
| 9000 | 8 | 17.7 |
| 10,000 | 9.9 | 21.6 |
다음 구성에서만 실행 중인 OpenShift Container Platform 4.15 클러스터에서 컨트롤 플레인 노드 크기를 수정할 수 있습니다.
- 사용자 프로비저닝 설치 방법으로 설치된 클러스터입니다.
- 설치 관리자 프로비저닝 인프라 설치 방법을 사용하여 설치된 AWS 클러스터
- 컨트롤 플레인 머신 세트를 사용하여 컨트롤 플레인 시스템을 관리하는 클러스터입니다.
다른 모든 구성의 경우 총 노드 수를 추정하고 설치 중에 제안된 컨트롤 플레인 노드 크기를 사용해야 합니다.
권장 사항은 OpenShift SDN이 있는 OpenShift Container Platform 클러스터에서 네트워크 플러그인으로 캡처된 데이터 포인트를 기반으로 합니다.
OpenShift Container Platform 4.15에서는 기본적으로 OpenShift Container Platform 3.11 및 이전 버전과 비교하여 CPU 코어의 절반(500밀리코어)이 시스템에 의해 예약되어 있습니다. 이러한 점을 고려하여 크기가 결정됩니다.
2.1.2.1. 컨트롤 플레인 시스템에 대한 대규모 Amazon Web Services 인스턴스 유형 선택
AWS(Amazon Web Services) 클러스터의 컨트롤 플레인 시스템에 더 많은 리소스가 필요한 경우 컨트롤 플레인 시스템에서 사용할 더 큰 AWS 인스턴스 유형을 선택할 수 있습니다.
컨트롤 플레인 머신 세트를 사용하는 클러스터의 절차는 컨트롤 플레인 머신 세트를 사용하지 않는 클러스터의 절차와 다릅니다.
클러스터에서 ControlPlaneMachineSet CR의 상태에 대해 확신이 있는 경우 CR 상태를 확인할 수 있습니다.
2.1.2.1.1. 컨트롤 플레인 머신 세트를 사용하여 Amazon Web Services 인스턴스 유형 변경
컨트롤 플레인 머신 세트 CR(사용자 정의 리소스)에서 사양을 업데이트하여 컨트롤 플레인 시스템에서 사용하는 AWS(Amazon Web Services) 인스턴스 유형을 변경할 수 있습니다.
사전 요구 사항
- AWS 클러스터는 컨트롤 플레인 머신 세트를 사용합니다.
프로세스
다음 명령을 실행하여 컨트롤 플레인 머신 세트 CR을 편집합니다.
oc --namespace openshift-machine-api edit controlplanemachineset.machine.openshift.io cluster
$ oc --namespace openshift-machine-api edit controlplanemachineset.machine.openshift.io clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow providerSpec필드 아래의 다음 행을 편집합니다.providerSpec: value: ... instanceType: <compatible_aws_instance_type>providerSpec: value: ... instanceType: <compatible_aws_instance_type>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 이전 선택과 동일한 기준으로 더 큰 AWS 인스턴스 유형을 지정합니다. 예를 들어
m6i.xlarge를m6i.2xlarge또는m6i.4xlarge로 변경할 수 있습니다.
변경 사항을 저장하십시오.
-
기본
RollingUpdate업데이트 전략을 사용하는 클러스터의 경우 Operator는 변경 사항을 컨트롤 플레인 구성에 자동으로 전파합니다. -
OnDelete업데이트 전략을 사용하도록 구성된 클러스터의 경우 컨트롤 플레인 시스템을 수동으로 교체해야 합니다.
-
기본
2.1.2.1.2. AWS 콘솔을 사용하여 Amazon Web Services 인스턴스 유형 변경
AWS 콘솔에서 인스턴스 유형을 업데이트하여 컨트롤 플레인 시스템에서 사용하는 AWS(Amazon Web Services) 인스턴스 유형을 변경할 수 있습니다.
사전 요구 사항
- 클러스터의 EC2 인스턴스를 수정하는 데 필요한 권한이 있는 AWS 콘솔에 액세스할 수 있습니다.
-
cluster-admin역할의 사용자로 OpenShift Container Platform 클러스터에 액세스할 수 있습니다.
프로세스
- AWS 콘솔을 열고 컨트롤 플레인 시스템의 인스턴스를 가져옵니다.
컨트롤 플레인 머신 인스턴스 1개를 선택합니다.
- 선택한 컨트롤 플레인 시스템의 경우 etcd 스냅샷을 생성하여 etcd 데이터를 백업하십시오. 자세한 내용은 " etcd 백업"을 참조하십시오.
- AWS 콘솔에서 컨트롤 플레인 머신 인스턴스를 중지합니다.
- 중지된 인스턴스를 선택하고 작업 → 인스턴스 설정 → 인스턴스 유형 변경을 클릭합니다.
-
인스턴스를 더 큰 유형으로 변경하고 유형이 이전 선택과 동일한 기본 유형인지 확인하고 변경 사항을 적용합니다. 예를 들어
m6i.xlarge를m6i.2xlarge또는m6i.4xlarge로 변경할 수 있습니다. - 인스턴스를 시작합니다.
-
OpenShift Container Platform 클러스터에 인스턴스에 대한 해당
Machine오브젝트가 있는 경우 AWS 콘솔에 설정된 인스턴스 유형과 일치하도록 오브젝트의 인스턴스 유형을 업데이트합니다.
- 각 컨트롤 플레인 시스템에 대해 이 프로세스를 반복합니다.
2.2. 인프라 관련 권장 사례
이 주제에서는 OpenShift Container Platform의 인프라에 대한 권장 성능 및 확장성 사례를 제공합니다.
2.2.1. 인프라 노드 크기 조정
인프라 노드는 OpenShift Container Platform 환경의 일부를 실행하도록 레이블이 지정된 노드입니다. 인프라 노드 리소스 요구사항은 클러스터 사용 기간, 노드, 클러스터의 오브젝트에 따라 달라집니다. 이러한 요인으로 인해 Prometheus의 지표 또는 시계열 수가 증가할 수 있기 때문입니다. 다음 인프라 노드 크기 권장 사항은 모니터링 스택 및 기본 ingress-controller가 이러한 노드로 이동되는 컨트롤 플레인 노드 크기 조정 섹션에 자세히 설명된 클러스터 밀도 테스트에서 관찰된 결과를 기반으로 합니다.
| 작업자 노드 수 | 클러스터 밀도 또는 네임스페이스 수 | CPU 코어 수 | 메모리(GB) |
|---|---|---|---|
| 27 | 500 | 4 | 24 |
| 120 | 1000 | 8 | 48 |
| 252 | 4000 | 16 | 128 |
| 501 | 4000 | 32 | 128 |
일반적으로 클러스터당 세 개의 인프라 노드를 사용하는 것이 좋습니다.
이러한 크기 조정 권장 사항은 지침으로 사용해야 합니다. Prometheus는 고도의 메모리 집약적 애플리케이션입니다. 리소스 사용량은 노드 수, 오브젝트, Prometheus 지표 스크래핑 간격, 지표 또는 시계열, 클러스터 사용 기간 등 다양한 요인에 따라 달라집니다. 또한 라우터 리소스 사용은 경로 수 및 인바운드 요청의 양/유형의 영향을 받을 수 있습니다.
이러한 권장 사항은 클러스터 생성 중에 설치된 인프라 인프라 구성 요소를 호스팅하는 인프라 노드에만 적용됩니다.
OpenShift Container Platform 4.15에서는 기본적으로 OpenShift Container Platform 3.11 및 이전 버전과 비교하여 CPU 코어의 절반(500밀리코어)이 시스템에 의해 예약되어 있습니다. 명시된 크기 조정 권장 사항은 이러한 요인의 영향을 받습니다.
2.2.2. Cluster Monitoring Operator 스케일링
OpenShift Container Platform은CMO(Cluster Monitoring Operator)가 수집하여 Prometheus 기반 모니터링 스택에 저장하는 지표를 노출합니다. 관리자는 Observe → Dashboards 로 이동하여 OpenShift Container Platform 웹 콘솔에서 시스템 리소스, 컨테이너 및 구성 요소에 대한 대시보드를 볼 수 있습니다.
2.2.3. Prometheus 데이터베이스 스토리지 요구사항
Red Hat은 다양한 규모에 대해 다양한 테스트를 수행했습니다.
- 다음 Prometheus 스토리지 요구 사항은 규범이 아니며 참조로 사용해야 합니다. Prometheus에서 수집한 메트릭을 노출하는 Pod, 컨테이너, 경로 또는 기타 리소스 수를 포함하여 워크로드 활동 및 리소스 밀도에 따라 클러스터에서 리소스 사용량이 증가할 수 있습니다.
- 스토리지 요구 사항에 맞게 크기 기반 데이터 보존 정책을 구성할 수 있습니다.
| 노드 수 | Pod 수 (2 Pod당 컨테이너) | Prometheus 스토리지 증가(1일당) | Prometheus 스토리지 증가(15일당) | 네트워크(tsdb 청크당) |
|---|---|---|---|---|
| 50 | 1800 | 6.3GB | 94GB | 16MB |
| 100 | 3600 | 13GB | 195GB | 26MB |
| 150 | 5400 | 19GB | 283GB | 36MB |
| 200 | 7200 | 25GB | 375GB | 46MB |
스토리지 요구사항이 계산된 값을 초과하지 않도록 예상 크기의 약 20%가 오버헤드로 추가되었습니다.
위의 계산은 기본 OpenShift Container Platform Cluster Monitoring Operator용입니다.
CPU 사용률은 약간의 영향을 미칩니다. 50개 노드 및 1,800개 Pod당 비율이 약 40개 중 1개 코어입니다.
OpenShift Container Platform 권장 사항
- 인프라(infra) 노드를 두 개 이상 사용합니다.
- SSD 또는 NVMe(Non-volatile Memory express) 드라이브를 사용하여 openshift-container-storage 노드를 3개 이상 사용합니다.
2.2.4. 클러스터 모니터링 구성
클러스터 모니터링 스택에서 Prometheus 구성 요소의 스토리지 용량을 늘릴 수 있습니다.
프로세스
Prometheus의 스토리지 용량을 늘리려면 다음을 수행합니다.
YAML 구성 파일
cluster-monitoring-config.yaml을 생성합니다. 예를 들면 다음과 같습니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- Prometheus 보존의 기본값은
PROMETHEUS_RETENTION_PERIOD=15d입니다. 단위는 s, m, h, d 접미사 중 하나를 사용하는 시간으로 측정됩니다. - 2 4
- 클러스터의 스토리지 클래스입니다.
- 3
- 일반적인 값은
PROMETHEUS_STORAGE_SIZE=2000Gi입니다. 스토리지 값은 일반 정수 또는 E, P, T, G, M, K 접미사 중 하나를 사용하는 고정 지점 정수일 수 있습니다. Ei, Pi, Ti, Gi, Mi, Ki의 power-of-two를 사용할 수도 있습니다. - 5
- 일반적인 값은
ALERTMANAGER_STORAGE_SIZE=20Gi입니다. 스토리지 값은 일반 정수 또는 E, P, T, G, M, K 접미사 중 하나를 사용하는 고정 지점 정수일 수 있습니다. Ei, Pi, Ti, Gi, Mi, Ki의 power-of-two를 사용할 수도 있습니다.
- 보존 기간, 스토리지 클래스 및 스토리지 크기에 대한 값을 추가합니다.
- 파일을 저장합니다.
다음을 실행하여 변경사항을 적용합니다.
oc create -f cluster-monitoring-config.yaml
$ oc create -f cluster-monitoring-config.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.3. etcd 관련 권장 사례
이 주제에서는 OpenShift Container Platform의 etcd에 대한 권장 성능 및 확장성 사례를 제공합니다.
2.3.1. etcd 관련 권장 사례
etcd는 디스크에 데이터를 작성하고 디스크에 제안을 유지하므로 성능은 디스크 성능에 따라 다릅니다. etcd는 특히 I/O 집약적이지만 최적의 성능과 안정성을 위해 짧은 대기 시간 블록 장치가 필요합니다. etcd의 접합성 프로토콜은 메타데이터를 로그(WAL)에 영구적으로 저장하는 데 따라 다르기 때문에 etcd는 디스크 쓰기 대기 시간에 민감합니다. 다른 프로세스의 디스크 및 디스크 활동이 느리면 fsync 대기 시간이 길어질 수 있습니다.
이러한 대기 시간으로 인해 etcd가 하트비트를 놓치고 새 제안을 제 시간에 디스크에 커밋하지 않고 궁극적으로 요청 시간 초과 및 임시 리더 손실이 발생할 수 있습니다. 쓰기 대기 시간이 길어지면 OpenShift API 속도가 느려서 클러스터 성능에 영향을 미칩니다. 이러한 이유로 I/O 민감하거나 집약적이며 동일한 기본 I/O 인프라를 공유하는 컨트롤 플레인 노드에서 다른 워크로드를 배치하지 마십시오.
대기 시간 측면에서 8000바이트의 최소 50 IOPS를 순차적으로 작성할 수 있는 블록 장치 상단에서 etcd를 실행합니다. 즉, 대기 시간이 10ms인 경우 fdatasync를 사용하여 WAL의 각 쓰기를 동기화합니다. 로드가 많은 클러스터의 경우 8000바이트(2ms)의 순차적 500 IOPS를 권장합니다. 이러한 숫자를 측정하려면 fio와 같은 벤치마킹 툴을 사용할 수 있습니다.
이러한 성능을 달성하려면 대기 시간이 짧고 처리량이 높은 SSD 또는 NVMe 디스크에서 지원하는 머신에서 etcd를 실행합니다. 메모리 셀당 1비트를 제공하는 SSD(Single-level cell) SSD(Solid-State Drive)는 Cryostat 및 reliable이며 쓰기 집약적인 워크로드에 이상적입니다.
etcd의 로드는 노드 및 Pod 수와 같은 정적 요인과 Pod 자동 스케일링, Pod 재시작, 작업 실행 및 기타 워크로드 관련 이벤트로 인한 끝점 변경 등 동적 요인에서 발생합니다. etcd 설정의 크기를 정확하게 조정하려면 워크로드의 특정 요구 사항을 분석해야 합니다. etcd의 로드에 영향을 미치는 노드, 포드 및 기타 관련 요인을 고려하십시오.
다음 하드 드라이브 사례는 최적의 etcd 성능을 제공합니다.
- 전용 etcd 드라이브를 사용합니다. iSCSI와 같이 네트워크를 통해 통신하는 드라이브를 방지합니다. etcd 드라이브에 로그 파일 또는 기타 많은 워크로드를 배치하지 마십시오.
- 빠른 읽기 및 쓰기 작업을 지원하기 위해 대기 시간이 짧은 드라이브를 선호합니다.
- 더 빠른 압축 및 조각 모음을 위해 고 대역폭 쓰기를 선호합니다.
- 실패에서 더 빠른 복구를 위해 고 대역폭 읽기를 선호합니다.
- 솔리드 스테이트 드라이브를 최소 선택으로 사용하십시오. 프로덕션 환경에 대한 NVMe 드라이브를 선호합니다.
- 안정성 향상을 위해 서버 수준 하드웨어를 사용하십시오.
NAS 또는 SAN 설정 및 회전 드라이브를 방지합니다. Ceph Rados Block Device(RBD) 및 기타 유형의 네트워크 연결 스토리지로 인해 네트워크 대기 시간이 예측할 수 없습니다. 대규모 etcd 노드에 빠른 스토리지를 제공하려면 PCI 패스스루를 사용하여 NVM 장치를 노드에 직접 전달합니다.
항상 fio와 같은 유틸리티를 사용하여 벤치마크합니다. 이러한 유틸리티를 사용하여 증가에 따라 클러스터 성능을 지속적으로 모니터링할 수 있습니다.
NFS(Network File System) 프로토콜 또는 기타 네트워크 기반 파일 시스템을 사용하지 마십시오.
배포된 OpenShift Container Platform 클러스터에서 모니터링할 몇 가지 주요 지표는 etcd 디스크 쓰기 전 로그 기간과 etcd 리더 변경 횟수입니다. 이러한 지표를 추적하려면 Prometheus를 사용하십시오.
etcd 멤버 데이터베이스 크기는 정상적인 작업 중에 클러스터에서 다를 수 있습니다. 이 차이점은 리더 크기가 다른 멤버와 다른 경우에도 클러스터 업그레이드에는 영향을 미치지 않습니다.
OpenShift Container Platform 클러스터를 생성하기 전이나 후에 etcd의 하드웨어를 검증하려면 fio를 사용할 수 있습니다.
사전 요구 사항
- Podman 또는 Docker와 같은 컨테이너 런타임은 테스트 중인 시스템에 설치됩니다.
-
데이터는
/var/lib/etcd경로에 기록됩니다.
프로세스
Fio를 실행하고 결과를 분석합니다.
Podman을 사용하는 경우 다음 명령을 실행합니다.
sudo podman run --volume /var/lib/etcd:/var/lib/etcd:Z quay.io/cloud-bulldozer/etcd-perf
$ sudo podman run --volume /var/lib/etcd:/var/lib/etcd:Z quay.io/cloud-bulldozer/etcd-perfCopy to Clipboard Copied! Toggle word wrap Toggle overflow Docker를 사용하는 경우 다음 명령을 실행합니다.
sudo docker run --volume /var/lib/etcd:/var/lib/etcd:Z quay.io/cloud-bulldozer/etcd-perf
$ sudo docker run --volume /var/lib/etcd:/var/lib/etcd:Z quay.io/cloud-bulldozer/etcd-perfCopy to Clipboard Copied! Toggle word wrap Toggle overflow
출력에서는 실행에서 캡처된 fsync 지표의 99번째 백분위수를 비교하여 디스크가 etcd를 호스트할 수 있을 만큼 빠른지 여부를 보고하여 10ms 미만인지 확인합니다. I/O 성능의 영향을 받을 수 있는 가장 중요한 etcd 지표 중 일부는 다음과 같습니다.
-
etcd_disk_wal_fsync_duration_seconds_bucket지표에서 etcd의 WAL fsync 기간을 보고합니다. -
etcd_disk_backend_commit_duration_seconds_bucket지표에서 etcd 백엔드 커밋 대기 시간 보고 -
etcd_server_leader_changes_seen_total메트릭에서 리더 변경 사항을 보고합니다.
etcd는 모든 멤버 간에 요청을 복제하므로 성능은 네트워크 입력/출력(I/O) 대기 시간에 따라 달라집니다. 네트워크 대기 시간이 길어지면 etcd 하트비트가 선택 시간 초과보다 오래 걸리므로 리더 선택이 발생하여 클러스터가 손상될 수 있습니다. 배포된 OpenShift Container Platform 클러스터에서 모니터링되는 주요 메트릭은 각 etcd 클러스터 멤버에서 etcd 네트워크 피어 대기 시간의 99번째 백분위 수입니다. 이러한 메트릭을 추적하려면 Prometheus를 사용하십시오.
히스토그램_quantile(0.99, rate(etcd_network_peer_round_trip_time_seconds_bucket[2m])) 메트릭은 etcd가 멤버 간 클라이언트 요청을 복제하는 것을 완료하기 위한 왕복 시간을 보고합니다. 50ms 미만이어야 합니다.
2.3.2. etcd를 다른 디스크로 이동
etcd를 공유 디스크에서 별도의 디스크로 이동하여 성능 문제를 방지하거나 해결할 수 있습니다.
MCO(Machine Config Operator)는 OpenShift Container Platform 4.15 컨테이너 스토리지를 위한 보조 디스크를 마운트합니다.
이 인코딩된 스크립트는 다음 장치 유형에 대한 장치 이름만 지원합니다.
- SCSI 또는 SATA
-
/dev/sd* - 가상 장치
-
/dev/vd* - NVMe
-
/dev/nvme*[0-9]*n*
제한
-
새 디스크가 클러스터에 연결되면 etcd 데이터베이스가 root 마운트의 일부입니다. 기본 노드가 다시 생성되는 경우 보조 디스크 또는 의도한 디스크의 일부가 아닙니다. 결과적으로 기본 노드는 별도의
/var/lib/etcd마운트를 생성하지 않습니다.
사전 요구 사항
- 클러스터의 etcd 데이터 백업이 있습니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
cluster-admin권한이 있는 클러스터에 액세스할 수 있습니다. - 머신 구성을 업로드하기 전에 디스크를 추가합니다.
-
MachineConfigPool은metadata.labels[machineconfiguration.openshift.io/role]과 일치해야 합니다. 이는 컨트롤러, 작업자 또는 사용자 지정 풀에 적용됩니다.
이 절차에서는 루트 파일 시스템의 부분(예: /var/ )을 설치된 노드의 다른 디스크 또는 파티션으로 이동하지 않습니다.
컨트롤 플레인 머신 세트를 사용할 때 이 절차는 지원되지 않습니다.
프로세스
새 디스크를 클러스터에 연결하고 디버그 쉘에서
lsblk명령을 실행하여 노드에서 디스크가 감지되었는지 확인합니다.oc debug node/<node_name>
$ oc debug node/<node_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow lsblk
# lsblkCopy to Clipboard Copied! Toggle word wrap Toggle overflow lsblk명령에서 보고한 새 디스크의 장치 이름을 확인합니다.다음 스크립트를 생성하고 이름을
etcd-find-secondary-device.sh로 지정합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- &
lt;device_type_glob>를 블록 장치 유형의 쉘 글로 바꿉니다. SCSI 또는 SATA 드라이브의 경우/dev/sd*를 사용합니다. 가상 드라이브의 경우/dev/vd*를 사용합니다. NVMe 드라이브의 경우/dev/nvme*[0-9]*를 사용합니다.
etcd-find-secondary-device.sh스크립트에서 base64로 인코딩된 문자열을 생성하고 해당 내용을 확인합니다.base64 -w0 etcd-find-secondary-device.sh
$ base64 -w0 etcd-find-secondary-device.shCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음과 같은 콘텐츠를 사용하여
etcd-mc.yml이라는MachineConfigYAML 파일을 만듭니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- &
lt;encoded_etcd_find_secondary_device_script>를 사용자가 언급한 인코딩된 스크립트 콘텐츠로 바꿉니다.
검증 단계
노드의 디버그 쉘에서
grep /var/lib/etcd /proc/mounts명령을 실행하여 디스크가 마운트되었는지 확인합니다.oc debug node/<node_name>
$ oc debug node/<node_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow grep -w "/var/lib/etcd" /proc/mounts
# grep -w "/var/lib/etcd" /proc/mountsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 출력 예
/dev/sdb /var/lib/etcd xfs rw,seclabel,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
/dev/sdb /var/lib/etcd xfs rw,seclabel,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.3.3. etcd 데이터 조각 모음
대규모 및 밀도가 높은 클러스터의 경우 키 공간이 너무 커져서 공간 할당량을 초과하면 etcd 성능이 저하될 수 있습니다. etcd를 정기적으로 유지 관리하고 조각 모음하여 데이터 저장소의 공간을 확보합니다. Prometheus에 대해 etcd 지표를 모니터링하고 필요한 경우 조각 모음합니다. 그러지 않으면 etcd에서 키 읽기 및 삭제만 허용하는 유지 관리 모드로 클러스터를 만드는 클러스터 전체 알람을 발생시킬 수 있습니다.
다음 주요 메트릭을 모니터링합니다.
-
etcd_server_quota_backend_bytes(현재 할당량 제한) -
etcd_mvcc_db_total_size_in_use_in_bytes에서는 기록 압축 후 실제 데이터베이스 사용량을 나타냅니다. -
etcd_mvcc_db_total_size_in_bytes: 조각 모음 대기 여유 공간을 포함하여 데이터베이스 크기를 표시합니다.
etcd 기록 압축과 같은 디스크 조각화를 초래하는 이벤트 후 디스크 공간을 회수하기 위해 etcd 데이터를 조각 모음합니다.
기록 압축은 5분마다 자동으로 수행되며 백엔드 데이터베이스에서 공백이 남습니다. 이 분할된 공간은 etcd에서 사용할 수 있지만 호스트 파일 시스템에서 사용할 수 없습니다. 호스트 파일 시스템에서 이 공간을 사용할 수 있도록 etcd 조각을 정리해야 합니다.
조각 모음이 자동으로 수행되지만 수동으로 트리거할 수도 있습니다.
etcd Operator는 클러스터 정보를 사용하여 사용자에게 가장 효율적인 작업을 결정하기 때문에 자동 조각 모음은 대부분의 경우에 적합합니다.
2.3.3.1. 자동 조각 모음
etcd Operator는 디스크 조각 모음을 자동으로 수행합니다. 수동 조작이 필요하지 않습니다.
다음 로그 중 하나를 확인하여 조각 모음 프로세스가 성공했는지 확인합니다.
- etcd 로그
- cluster-etcd-operator Pod
- Operator 상태 오류 로그
자동 조각 모음으로 인해 Kubernetes 컨트롤러 관리자와 같은 다양한 OpenShift 핵심 구성 요소에서 리더 선택 실패가 발생하여 실패한 구성 요소를 다시 시작할 수 있습니다. 재시작은 무해하며 다음 실행 중인 인스턴스로 장애 조치를 트리거하거나 다시 시작한 후 구성 요소가 작업을 다시 시작합니다.
성공적으로 조각 모음을 위한 로그 출력 예
etcd member has been defragmented: <member_name>, memberID: <member_id>
etcd member has been defragmented: <member_name>, memberID: <member_id>실패한 조각 모음에 대한 로그 출력 예
failed defrag on member: <member_name>, memberID: <member_id>: <error_message>
failed defrag on member: <member_name>, memberID: <member_id>: <error_message>2.3.3.2. 수동 조각 모음
Prometheus 경고는 수동 조각 모음을 사용해야 하는 시기를 나타냅니다. 경고는 다음 두 가지 경우에 표시됩니다.
- etcd에서 사용 가능한 공간의 50% 이상을 10분 이상 사용하는 경우
- etcd가 10분 이상 전체 데이터베이스 크기의 50% 미만을 적극적으로 사용하는 경우
PromQL 표현식의 조각 모음으로 해제될 etcd 데이터베이스 크기를 MB 단위로 확인하여 조각 모음이 필요한지 여부를 확인할 수도 있습니다. (etcd_mvcc_db_total_size_in_bytes - etcd_mvcc_db_total_size_in_bytes)/1024/1024
etcd를 분리하는 것은 차단 작업입니다. 조각 모음이 완료될 때까지 etcd 멤버는 응답하지 않습니다. 따라서 각 pod의 조각 모음 작업 간에 클러스터가 정상 작동을 재개할 수 있도록 1분 이상 대기해야 합니다.
각 etcd 멤버의 etcd 데이터 조각 모음을 수행하려면 다음 절차를 따릅니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다.
프로세스
리더가 최종 조각화 처리를 수행하므로 어떤 etcd 멤버가 리더인지 확인합니다.
etcd pod 목록을 가져옵니다.
oc -n openshift-etcd get pods -l k8s-app=etcd -o wide
$ oc -n openshift-etcd get pods -l k8s-app=etcd -o wideCopy to Clipboard Copied! Toggle word wrap Toggle overflow 출력 예
etcd-ip-10-0-159-225.example.redhat.com 3/3 Running 0 175m 10.0.159.225 ip-10-0-159-225.example.redhat.com <none> <none> etcd-ip-10-0-191-37.example.redhat.com 3/3 Running 0 173m 10.0.191.37 ip-10-0-191-37.example.redhat.com <none> <none> etcd-ip-10-0-199-170.example.redhat.com 3/3 Running 0 176m 10.0.199.170 ip-10-0-199-170.example.redhat.com <none> <none>
etcd-ip-10-0-159-225.example.redhat.com 3/3 Running 0 175m 10.0.159.225 ip-10-0-159-225.example.redhat.com <none> <none> etcd-ip-10-0-191-37.example.redhat.com 3/3 Running 0 173m 10.0.191.37 ip-10-0-191-37.example.redhat.com <none> <none> etcd-ip-10-0-199-170.example.redhat.com 3/3 Running 0 176m 10.0.199.170 ip-10-0-199-170.example.redhat.com <none> <none>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Pod를 선택하고 다음 명령을 실행하여 어떤 etcd 멤버가 리더인지 확인합니다.
oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.com etcdctl endpoint status --cluster -w table
$ oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.com etcdctl endpoint status --cluster -w tableCopy to Clipboard Copied! Toggle word wrap Toggle overflow 출력 예
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 출력의
ISLEADER 열에 따르면https://10.0.199.170:2379엔드 포인트가 리더입니다. 이전 단계의 출력과 이 앤드 포인트가 일치하면 리더의 Pod 이름은etcd-ip-10-0199-170.example.redhat.com입니다.
etcd 멤버를 분리합니다.
실행중인 etcd 컨테이너에 연결하고 리더가 아닌 pod 이름을 전달합니다.
oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.com
$ oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow ETCDCTL_ENDPOINTS환경 변수를 설정 해제합니다.unset ETCDCTL_ENDPOINTS
sh-4.4# unset ETCDCTL_ENDPOINTSCopy to Clipboard Copied! Toggle word wrap Toggle overflow etcd 멤버를 분리합니다.
etcdctl --command-timeout=30s --endpoints=https://localhost:2379 defrag
sh-4.4# etcdctl --command-timeout=30s --endpoints=https://localhost:2379 defragCopy to Clipboard Copied! Toggle word wrap Toggle overflow 출력 예
Finished defragmenting etcd member[https://localhost:2379]
Finished defragmenting etcd member[https://localhost:2379]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 시간 초과 오류가 발생하면 명령이 성공할 때까지
--command-timeout의 값을 늘립니다.데이터베이스 크기가 감소되었는지 확인합니다.
etcdctl endpoint status -w table --cluster
sh-4.4# etcdctl endpoint status -w table --clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 출력 예
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예에서는 etcd 멤버의 데이터베이스 크기가 시작 크기인 104MB와 달리 현재 41MB임을 보여줍니다.
다음 단계를 반복하여 다른 etcd 멤버에 연결하고 조각 모음을 수행합니다. 항상 리더의 조각 모음을 마지막으로 수행합니다.
etcd pod가 복구될 수 있도록 조각 모음 작업에서 1분 이상 기다립니다. etcd pod가 복구될 때까지 etcd 멤버는 응답하지 않습니다.
공간 할당량을 초과하여
NOSPACE경고가 발생하는 경우 이를 지우십시오.NOSPACE경고가 있는지 확인합니다.etcdctl alarm list
sh-4.4# etcdctl alarm listCopy to Clipboard Copied! Toggle word wrap Toggle overflow 출력 예
memberID:12345678912345678912 alarm:NOSPACE
memberID:12345678912345678912 alarm:NOSPACECopy to Clipboard Copied! Toggle word wrap Toggle overflow 경고를 지웁니다.
etcdctl alarm disarm
sh-4.4# etcdctl alarm disarmCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.3.4. etcd의 튜닝 매개변수 설정
컨트롤 플레인 하드웨어 속도를 "Standard", "Slower" 또는 기본값인 "" 로 설정할 수 있습니다.
기본 설정을 사용하면 시스템에서 사용할 속도를 결정할 수 있습니다. 이 값을 사용하면 시스템에서 이전 버전에서 값을 선택할 수 있으므로 이 기능이 존재하지 않는 버전에서 업그레이드할 수 있습니다.
다른 값 중 하나를 선택하면 기본값을 덮어씁니다. 시간 초과 또는 누락된 하트비트로 인해 리더 선택이 많이 표시되고 시스템이 "" 또는 "표준" 으로 설정된 경우 하드웨어 속도를 "Slower" 로 설정하여 시스템의 대기 시간을 늘리도록 합니다.
etcd 대기 오차 튜닝은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
2.3.4.1. 하드웨어 속도 내결함성 변경
etcd의 하드웨어 속도 내결함성을 변경하려면 다음 단계를 완료합니다.
사전 요구 사항
-
TechPreviewNoUpgrade기능을 활성화하기 위해 클러스터 인스턴스를 편집했습니다. 자세한 내용은 추가 리소스 의 "기능 게이트 이해"를 참조하십시오.
프로세스
다음 명령을 입력하여 현재 값이 무엇인지 확인합니다.
oc describe etcd/cluster | grep "Control Plane Hardware Speed"
$ oc describe etcd/cluster | grep "Control Plane Hardware Speed"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 출력 예
Control Plane Hardware Speed: <VALUE>
Control Plane Hardware Speed: <VALUE>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고출력이 비어 있으면 필드가 설정되지 않았으며 기본값으로 간주해야 합니다.
다음 명령을 입력하여 값을 변경합니다. &
lt;value>를"","Standard"또는"Slower": 유효한 값 중 하나로 바꿉니다.oc patch etcd/cluster --type=merge -p '{"spec": {"controlPlaneHardwareSpeed": "<value>"}}'$ oc patch etcd/cluster --type=merge -p '{"spec": {"controlPlaneHardwareSpeed": "<value>"}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 표는 각 프로필에 대한 하트비트 간격 및 리더 선택 시간 초과를 나타냅니다. 이러한 값은 변경될 수 있습니다.
Expand 프로필
ETCD_HEARTBEAT_INTERVAL
ETCD_LEADER_ELECTION_TIMEOUT
""플랫폼에 따라 다릅니다.
플랫폼에 따라 다릅니다.
Standard100
1000
느림500
2500
출력을 확인합니다.
출력 예
etcd.operator.openshift.io/cluster patched
etcd.operator.openshift.io/cluster patchedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 유효한 값 이외의 값을 입력하면 오류 출력이 표시됩니다. 예를 들어 값으로
"Faster"를 입력하면 출력은 다음과 같습니다.출력 예
The Etcd "cluster" is invalid: spec.controlPlaneHardwareSpeed: Unsupported value: "Faster": supported values: "", "Standard", "Slower"
The Etcd "cluster" is invalid: spec.controlPlaneHardwareSpeed: Unsupported value: "Faster": supported values: "", "Standard", "Slower"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 명령을 입력하여 값이 변경되었는지 확인합니다.
oc describe etcd/cluster | grep "Control Plane Hardware Speed"
$ oc describe etcd/cluster | grep "Control Plane Hardware Speed"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 출력 예
Control Plane Hardware Speed: ""
Control Plane Hardware Speed: ""Copy to Clipboard Copied! Toggle word wrap Toggle overflow etcd pod가 롤아웃될 때까지 기다립니다.
oc get pods -n openshift-etcd -w
$ oc get pods -n openshift-etcd -wCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 출력은 master-0에 대한 예상 항목을 보여줍니다. 계속하기 전에 모든 마스터에
실행 중인 4/4상태가 표시될 때까지 기다립니다.출력 예
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 명령을 입력하여 값을 검토합니다.
oc describe -n openshift-etcd pod/<ETCD_PODNAME> | grep -e HEARTBEAT_INTERVAL -e ELECTION_TIMEOUT
$ oc describe -n openshift-etcd pod/<ETCD_PODNAME> | grep -e HEARTBEAT_INTERVAL -e ELECTION_TIMEOUTCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고이러한 값은 기본값에서 변경되지 않을 수 있습니다.
3장. 참조 설계 사양
3.1. Telco core 및 RAN DU 참조 설계 사양
Telco 코어 참조 설계 사양(RDS)은 컨트롤 플레인 및 일부 중앙 집중식 데이터 플레인 기능을 포함하여 대규모 통신 애플리케이션을 지원할 수 있는 상용 하드웨어에서 실행되는 OpenShift Container Platform 4.15 클러스터를 설명합니다.
Telco RAN RDS는 RAN(Radio Access Network)에서 5G 워크로드를 호스팅하기 위해 상용 하드웨어에서 실행되는 클러스터의 구성을 설명합니다.
3.1.1. 통신 5G 배포를 위한 참조 설계 사양
Red Hat 및 인증된 파트너는 OpenShift Container Platform 4.15 클러스터에서 telco 애플리케이션을 실행하는 데 필요한 네트워킹 및 운영 기능에 대한 깊은 기술 전문 지식 및 지원을 제공합니다.
Red Hat의 통신 파트너는 엔터프라이즈 5G 솔루션을 위해 대규모로 복제할 수 있는 잘 통합되고 테스트되고 안정적인 환경이 필요합니다. Telco 코어 및 RAN DU 참조 설계 사양(RDS)은 특정 OpenShift Container Platform 버전을 기반으로 하는 권장 솔루션 아키텍처를 간략하게 설명합니다. 각 RDS는 telco 코어 및 RAN DU 모델을 사용하기 위한 테스트되고 검증된 플랫폼 구성을 설명합니다. RDS는 통신 5G 코어 및 RAN DU에 대한 중요한 KPI 세트를 정의하여 애플리케이션을 실행할 때 최적의 환경을 보장합니다. RDS는 높은 심각도의 에스컬레이션을 최소화하고 애플리케이션 안정성을 향상시킵니다.
5G 사용 사례는 계속 증가하고 있으며 워크로드는 지속적으로 변하고 있습니다. Red Hat은 telco 코어 및 RAN DU RDS를 통해 고객 및 파트너 피드백을 기반으로 진화하는 요구 사항을 지원하기 위해 최선을 다하고 있습니다.
3.1.2. 참조 설계 범위
Telco core 및 telco RAN 참조 설계 사양(RDS)은 권장, 테스트 및 지원되는 구성을 캡처하여 Telco core 및 telco RAN 프로필을 실행하는 클러스터에 대해 안정적이고 반복 가능한 성능을 제공합니다.
각 RDS에는 클러스터가 개별 프로필을 실행할 수 있도록 설계 및 검증되는 릴리스된 기능 및 지원되는 구성이 포함되어 있습니다. 이 구성은 기능 및 KPI 대상을 충족하는 기본 OpenShift Container Platform 설치를 제공합니다. 각 RDS는 개별 구성에 대해 예상되는 변형도 설명합니다. 각 RDS의 검증에는 긴 기간과 대규모 테스트가 포함되어 있습니다.
검증된 참조 구성은 OpenShift Container Platform의 각 주요 Y-stream 릴리스에 대해 업데이트됩니다. Z-stream 패치 릴리스는 참조 구성에 대해 주기적으로 다시 테스트됩니다.
3.1.3. 참조 설계의 편차
검증된 Telco 코어 및 telco RAN DU 참조 설계 사양(RDS)을 벗어나면 변경되는 특정 구성 요소 또는 기능 이외의 중요한 영향을 미칠 수 있습니다. 편차는 전체 솔루션의 맥락에서 분석 및 엔지니어링이 필요합니다.
RDS의 모든 편차는 명확한 작업 추적 정보로 분석 및 문서화되어야 합니다. 실사실은 파트너로부터 참조 설계에 맞춰 편차를 가져오는 방법을 이해할 것으로 예상됩니다. 이를 위해서는 파트너사가 Red Hat과 협력하여 플랫폼에서 최상의 결과를 얻을 수 있도록 활용 사례를 제공하기 위해 추가 리소스를 제공해야 할 수 있습니다. 이는 솔루션의 지원 가능성과 Red Hat 및 파트너 간의 조정을 보장하는 데 매우 중요합니다.
RDS의 편차는 다음과 같은 결과 중 일부 또는 모두를 가질 수 있습니다.
- 문제를 해결하는 데 시간이 더 걸릴 수 있습니다.
- 프로젝트 서비스 수준 계약(SLA), 프로젝트 기한, 최종 공급자 성능 요구 사항이 누락될 위험이 있습니다.
승인되지 않은 편차는 행정 수준에서 에스컬레이션이 필요할 수 있습니다.
참고Red Hat은 파트너 참여 우선 순위에 따라 편차 요청의 우선 순위를 지정합니다.
3.2. Telco RAN DU 참조 설계 사양
3.2.1. Telco RAN DU 4.15 참조 설계 개요
Telco RAN distributed unit (DU) 4.15 참조 설계는 상용 하드웨어에서 실행되는 OpenShift Container Platform 4.15 클러스터를 구성하여 Telco RAN DU 워크로드를 호스팅합니다. Telco RAN DU 프로필을 실행하는 클러스터에 대해 안정적이고 반복 가능한 성능을 얻기 위해 권장, 테스트 및 지원되는 구성을 캡처합니다.
3.2.1.1. telco RAN DU를 위한 OpenShift Container Platform 4.15 기능
Telco RAN DU 참조 설계 사양 (RDS)의 4.15 버전에는 telco RAN DU RDS의 4.14 버전과 동일한 기능 세트가 있습니다.
자세한 내용은 OpenShift Container Platform 4.14 telco RAN DU 기능을 참조하십시오.
3.2.1.2. 배포 아키텍처 개요
중앙 집중식 관리형 RHACM 허브 클러스터에서 관리되는 클러스터에 telco RAN DU 4.15 참조 구성을 배포합니다. 참조 설계 사양(RDS)에는 관리 클러스터 및 허브 클러스터 구성 요소가 포함되어 있습니다.
그림 3.1. Telco RAN DU 배포 아키텍처 개요

3.2.2. Ttelco RAN DU 사용 모델 개요
다음 정보를 사용하여 허브 클러스터 및 관리형 단일 노드 OpenShift 클러스터에 대한 통신 RAN DU 워크로드, 클러스터 리소스 및 하드웨어 사양을 계획합니다.
3.2.2.1. Telco RAN DU 애플리케이션 워크로드
DU 작업자 노드에는 최대 성능을 위해 조정된 펌웨어가 있는 3세대 Xeon(Ice Lake) 2.20 Cryostat 또는 더 나은 CPU가 있어야 합니다.
5G RAN DU 사용자 애플리케이션 및 워크로드는 다음과 같은 모범 사례 및 애플리케이션 제한을 준수해야 합니다.
- CNF 모범 사례 가이드의 최신 버전을 준수하는 클라우드 네이티브 네트워크 기능(CNF )을 개발합니다.
- 고성능 네트워킹을 위해 SR-IOV를 사용합니다.
exec 프로브를 사용하여 다른 적절한 옵션을 사용할 수 없는 경우에만 사용
-
CNF에서 CPU 고정을 사용하는 경우 exec 프로브를 사용하지 마십시오. 다른 프로브 구현(예:
httpGet또는tcpSocket)을 사용합니다. - exec 프로브를 사용해야 하는 경우 exec 프로브 빈도 및 수량을 제한합니다. 최대 exec 프로브 수는 10초 미만으로 유지해야 하며 빈도를 10초 미만으로 설정하지 않아야 합니다.
-
CNF에서 CPU 고정을 사용하는 경우 exec 프로브를 사용하지 마십시오. 다른 프로브 구현(예:
시작 프로브에는 지속적인 상태 작업 중에 최소한의 리소스가 필요합니다. exec 프로브의 제한은 주로 liveness 및 readiness 프로브에 적용됩니다.
3.2.2.2. Telco RAN DU 대표 참조 애플리케이션 워크로드 특성
대표적인 참조 애플리케이션 워크로드에는 다음과 같은 특징이 있습니다.
- 관리 및 제어 기능을 포함하여 vRAN 애플리케이션에 대한 최대 15개의 Pod 및 30개의 컨테이너가 있습니다.
-
Pod당 최대 2개의
ConfigMap및 4개의SecretCR 사용 - 10초 미만의 빈도로 최대 10 exec 프로브 사용
kube-apiserver에서의 증분 애플리케이션 로드는 클러스터 플랫폼 사용의 10% 미만입니다.참고플랫폼 지표에서 CPU 로드를 추출할 수 있습니다. 예를 들면 다음과 같습니다.
query=avg_over_time(pod:container_cpu_usage:sum{namespace="openshift-kube-apiserver"}[30m])query=avg_over_time(pod:container_cpu_usage:sum{namespace="openshift-kube-apiserver"}[30m])Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 애플리케이션 로그는 플랫폼 로그 수집기에 의해 수집되지 않습니다.
- 기본 CNI의 집계 트래픽은 1MBps 미만입니다.
3.2.2.3. Telco RAN 작업자 노드 클러스터 리소스 사용률
애플리케이션 워크로드 및 OpenShift Container Platform Pod를 포함하여 시스템에서 실행 중인 최대 Pod 수는 120입니다.
- 리소스 사용률
OpenShift Container Platform 리소스 사용률은 다음과 같은 애플리케이션 워크로드 특성을 포함한 다양한 요인에 따라 다릅니다.
- Pod 수
- 프로브 유형 및 빈도
- 커널 네트워킹을 통한 기본 CNI 또는 보조 CNI의 메시징 속도
- API 액세스 속도
- 로깅 속도
- 스토리지 IOPS
클러스터 리소스 요구 사항은 다음 조건에 따라 적용할 수 있습니다.
- 클러스터는 설명된 대표 애플리케이션 워크로드를 실행하고 있습니다.
- 클러스터는 "Telco RAN DU 작업자 노드 클러스터 리소스 사용률"에 설명된 제약 조건으로 관리됩니다.
- RAN DU 사용 모델 구성에서 선택 사항으로 명시된 구성 요소는 적용되지 않습니다.
리소스 사용률에 미치는 영향 및 Telco RAN DU 참조 디자인 범위를 벗어난 구성에 대한 KPI 대상을 충족하기 위해 추가 분석을 수행해야 합니다. 요구 사항에 따라 클러스터에서 추가 리소스를 할당해야 할 수 있습니다.
3.2.2.4. hub 클러스터 관리 특성
RHACM(Red Hat Advanced Cluster Management)은 권장되는 클러스터 관리 솔루션입니다. hub 클러스터에서 다음 제한으로 구성합니다.
- 규정 준수 평가 간격을 10분 이상 사용하여 최대 5개의 RHACM 정책을 구성합니다.
- 정책에서 최대 10개의 관리형 클러스터 템플릿을 사용합니다. 가능한 경우 hub-side template을 사용하십시오.
policy-controller및observability-controller애드온을 제외한 모든 RHACM 애드온을 비활성화합니다.Observability를 기본 구성으로 설정합니다.중요선택적 구성 요소 또는 추가 기능을 구성하면 리소스 사용량이 추가되고 전체 시스템 성능이 저하될 수 있습니다.
자세한 내용은 참조 설계 배포 구성 요소를 참조하십시오.
| 지표 | 제한 | 참고 |
|---|---|---|
| CPU 사용량 | 4000 mc 미만 - 2 코어 (4 하이퍼스레드) | 플랫폼 CPU는 예약된 각 코어의 두 하이퍼스레드를 포함하여 예약된 코어에 고정되어 있습니다. 시스템은 주기적인 시스템 작업 및 급증을 허용하도록 안정적인 상태에서 3개의 CPU (3000mc)를 사용하도록 설계되었습니다. |
| 사용된 메모리 | 16G 미만 |
3.2.2.5. Telco RAN DU RDS 구성 요소
다음 섹션에서는 telco RAN DU 워크로드를 실행하기 위해 클러스터를 구성하고 배포하는 데 사용하는 다양한 OpenShift Container Platform 구성 요소 및 구성에 대해 설명합니다.
그림 3.2. Telco RAN DU 참조 구성 요소

telco RAN DU 프로필에 포함되지 않은 구성 요소가 워크로드 애플리케이션에 할당된 CPU 리소스에 영향을 미치지 않도록 합니다.
트리 부족 드라이버는 지원되지 않습니다.
3.2.3. Telco RAN DU 4.15 참조 설계 구성 요소
다음 섹션에서는 RAN DU 워크로드를 실행하기 위해 클러스터를 구성하고 배포하는 데 사용하는 다양한 OpenShift Container Platform 구성 요소 및 구성에 대해 설명합니다.
3.2.3.1. 호스트 펌웨어 튜닝
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
시스템 수준 성능 구성. 권장 설정은 짧은 대기 시간과 고성능은 호스트 펌웨어 구성 을 참조하십시오.
Ironic 검사가 활성화되면 hub 클러스터의 클러스터별
BareMetalHostCR에서 펌웨어 설정 값을 사용할 수 있습니다. 클러스터를 설치하는 데 사용하는SiteConfigCR의spec.clusters.nodes필드에 라벨을 사용하여 Ironic 검사를 활성화합니다. 예를 들면 다음과 같습니다.nodes: - hostName: "example-node1.example.com" ironicInspect: "enabled"nodes: - hostName: "example-node1.example.com" ironicInspect: "enabled"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고Ttelco RAN DU 참조
SiteConfig는 기본적으로ironicInspect필드를 활성화하지 않습니다.- 제한 및 요구사항
- 하이퍼 스레딩을 활성화해야 합니다.
- 엔지니어링 고려 사항
최대 성능을 위해 모든 설정 조정
참고필요에 따라 성능 저하를 위해 펌웨어 선택을 조정할 수 있습니다.
3.2.3.2. Node Tuning Operator
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
성능 프로파일을 생성하여 클러스터 성능을 조정합니다. 성능 프로필을 사용하여 구성하는 설정은 다음과 같습니다.
- 실시간 또는 비실시간 커널 선택.
-
예약된 또는 분리된
cpuset에 코어 할당. 관리 워크로드 파티션에 할당된 OpenShift Container Platform 프로세스는 예약된 세트에 고정됩니다. - kubelet 기능 활성화(CPU 관리자, 토폴로지 관리자, 메모리 관리자).
- 대규모 페이지 구성.
- 추가 커널 인수 설정.
- 코어당 전원 튜닝 및 최대 CPU 빈도 설정.
- 제한 및 요구사항
Node Tuning Operator는
PerformanceProfileCR을 사용하여 클러스터를 구성합니다. RAN DU 프로파일PerformanceProfileCR에서 다음 설정을 구성해야 합니다.- 예약 및 분리된 코어를 선택하고 Intel 3rd Generation Xeon (Ice Lake) 2.20 Cryostat CPU에서 최소 4개의 하이퍼스레드(각주 2개 코어)를 할당하거나 최대 성능을 위해 펌웨어를 튜닝했는지 확인합니다.
-
포함된 각 코어에 대해 두 개의 하이퍼스레드 형제를 모두 포함하도록 예약된
cpuset을 설정합니다. 예약되지 않은 코어는 워크로드 예약에 할당 가능한 CPU로 사용할 수 있습니다. 하이퍼스레드 형제가 예약된 코어와 분리된 코어 간에 분할되지 않도록 합니다. - 예약 및 분리된 CPU로 설정된 내용에 따라 모든 코어에 모든 스레드를 포함하도록 예약 및 분리된 CPU를 구성합니다.
- 예약된 CPU 세트에 포함할 각 NUMA 노드의 코어 0을 설정합니다.
- 대규모 페이지 크기를 1G로 설정합니다.
관리 파티션에 워크로드를 추가해서는 안 됩니다. OpenShift 관리 플랫폼의 일부인 포드만 관리 파티션에 주석을 달아야 합니다.
- 엔지니어링 고려 사항
RT 커널을 사용하여 성능 요구 사항을 충족해야 합니다.
참고필요한 경우 RT가 아닌 커널을 사용할 수 있습니다.
- 구성하는 대규모 페이지 수는 애플리케이션 워크로드 요구 사항에 따라 다릅니다. 이 매개변수의 변형은 예상되고 허용됩니다.
- 선택한 하드웨어 및 시스템에서 사용 중인 추가 구성 요소를 기반으로 예약 및 격리된 CPU 세트 구성에서 변동이 예상됩니다. 변형은 지정된 제한을 충족해야 합니다.
- IRQ 선호도 지원이 없는 하드웨어는 분리된 CPU에 영향을 미칩니다. 보장된 전체 CPU QoS가 있는 Pod가 할당된 CPU를 완전히 사용하도록 하려면 서버의 모든 하드웨어가 IRQ 선호도를 지원해야 합니다. 자세한 내용은 IRQ 선호도 설정 지원 정보를 참조하십시오.
OpenShift Container Platform 4.15에서 클러스터에 구성된 모든 PerformanceProfile CR로 인해 Node Tuning Operator가 cgroup v1을 사용하도록 모든 클러스터 노드를 자동으로 설정합니다.
cgroup에 대한 자세한 내용은 Linux cgroup 구성을 참조하십시오.
3.2.3.3. PTP Operator
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
클러스터 노드에서 PTP의 지원 및 구성에 대한 자세한 내용은 PTP 타이밍 을 참조하십시오. DU 노드는 다음 모드에서 실행할 수 있습니다.
- 일반 클럭 (OC)은 할 마스터 클록 또는 경계 클록 (T-BC)에 동기화됩니다.
- 단일 또는 듀얼 카드 E810 Westport 채널 NIC를 지원하는 GPS에서 동기화된 마스터 클럭
E810 Westport 채널 NIC를 지원하는 이중 경계 클럭( NIC당 하나씩)으로
참고고가용성 경계 클록은 지원되지 않습니다.
- 선택 사항: 라디오 단위(RU)의 경계 클럭
마스터 클록에 대한 이벤트 및 메트릭은 4.14 telco RAN DU RDS에 추가된 기술 프리뷰 기능입니다. 자세한 내용은 PTP 하드웨어 빠른 이벤트 알림 프레임워크 사용을 참조하십시오.
DU 애플리케이션이 실행 중인 노드에서 발생하는 PTP 이벤트에 애플리케이션을 구독할 수 있습니다.
- 제한 및 요구사항
- 듀얼 NIC 구성에서 고가용성은 지원되지 않습니다.
- E810 Westport 채널 NIC에서는 DPDK(digital Phase-Locked Cryostat) 클럭 동기화가 지원되지 않습니다.
- GPS 오프셋은 보고되지 않습니다. 기본 오프셋을 5 미만으로 사용합니다.
- DPLL 오프셋이 보고되지 않습니다. 기본 오프셋을 5 미만으로 사용합니다.
- 엔지니어링 고려 사항
- 일반 클럭, 경계 클럭 또는 마스터 클록에 대한 구성이 제공됩니다.
-
PTP 빠른 이벤트 알림은
ConfigMapCR을 사용하여 PTP 이벤트 서브스크립션을 저장 - GPS 타이밍과 최소 펌웨어 버전 4.40인 PTP 할 마스터 클록에 대해 Intel E810-XXV-4T Westport Channel NIC를 사용하십시오.
3.2.3.4. SR-IOV Operator
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
-
SR-IOV Operator는 SR-IOV CNI 및 장치 플러그인을 프로비저닝하고 구성합니다.
netdevice(커널 VF) 및 DPDK(Vfio) 장치가 모두 지원됩니다. - 엔지니어링 고려 사항
-
구성 및
SriovNetworkNodePolicy -
IOMMU 커널 명령줄 설정은 설치 시
MachineConfigCR과 함께 적용됩니다. 이렇게 하면SriovOperatorCR에서 노드를 추가할 때 노드가 재부팅되지 않습니다.
-
구성 및
3.2.3.5. 로깅
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
- 로깅을 사용하여 원격 분석을 위해 far edge 노드에서 로그를 수집합니다. 권장되는 로그 수집기는 Vector입니다.
- 엔지니어링 고려 사항
- 예를 들어, 인프라 및 감사 로그 이외의 로그를 처리하려면 추가 로깅 속도를 기반으로 하는 추가 CPU 및 네트워크 대역폭이 필요합니다.
OpenShift Container Platform 4.14부터 Vector는 참조 로그 수집기입니다.
참고RAN 사용 모델에서 fluentd 사용은 더 이상 사용되지 않습니다.
3.2.3.6. SRIOV-FEC Operator
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
- SRIOV-FEC Operator는 FEC 액셀러레이터 하드웨어를 지원하는 선택적 타사 Certified Operator입니다.
- 제한 및 요구사항
FEC Operator v2.7.0부터 다음을 수행합니다.
-
SecureBoot지원 -
PF의vfio드라이버를 사용하려면 Pod에 삽입되는vfio-token을 사용해야 합니다.VF토큰은 EAL 매개변수--vfio-vf-token을 사용하여 DPDK에 전달할 수 있습니다.
-
- 엔지니어링 고려 사항
-
SRIOV-FEC Operator는
분리된CPU 세트의 CPU 코어를 사용합니다. - 예를 들어 검증 정책을 확장하여 FEC 준비 상태를 사전 점검의 일부로 검증할 수 있습니다.
-
SRIOV-FEC Operator는
3.2.3.7. Local Storage Operator
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
-
Local Storage Operator를 사용하여 애플리케이션에서
PVC리소스로 사용할 수 있는 영구 볼륨을 생성할 수 있습니다. 생성하는PV리소스의 수 및 유형은 요구 사항에 따라 다릅니다. - 엔지니어링 고려 사항
-
PV를 생성하기 전에PVCR에 대한 백업 스토리지를 생성합니다. 파티션, 로컬 볼륨, LVM 볼륨 또는 전체 디스크일 수 있습니다. 디스크 및 파티션을 올바르게 할당하도록 각 장치에 액세스하는 데 사용되는 하드웨어 경로에서
LocalVolumeCR의 장치 목록을 참조하십시오. 논리 이름(예:/dev/sda)은 노드를 재부팅해도 일관성이 보장되지 않습니다.자세한 내용은 장치 식별자에 대한 RHEL 9 설명서 를 참조하십시오.
-
3.2.3.8. LVMS Operator
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 이번 릴리스의 새로운 기능
-
간소화된 LVMS
deviceSelector논리 -
ext4및PV리소스가 포함된 LVM 스토리지
-
간소화된 LVMS
LVMS Operator는 선택적 구성 요소입니다.
- 설명
LVMS Operator는 블록 및 파일 스토리지에 대한 동적 프로비저닝을 제공합니다. LVMS Operator는 애플리케이션에서
PVC리소스로 사용할 수 있는 로컬 장치에서 논리 볼륨을 생성합니다. 볼륨 확장 및 스냅샷도 가능합니다.다음 예제 구성은 설치 디스크
를 제외한 노드에서 사용 가능한 모든 디스크를 활용하는 Cryostat1볼륨 그룹을 생성합니다.StorageLVMCluster.yaml
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 제한 및 요구사항
- 노드가 3개 미만인 클러스터 토폴로지에 사용되는 경우 Ceph가 제외됩니다. 예를 들어 Ceph는 단일 작업자 노드가 있는 단일 노드 OpenShift 클러스터 또는 단일 노드 OpenShift 클러스터에서 제외됩니다.
- 단일 노드 OpenShift 클러스터에서 영구 스토리지는 둘 다 아닌 LVMS 또는 로컬 스토리지에서 제공해야 합니다.
- 엔지니어링 고려 사항
- LVMS Operator는 DU 사용 사례에 대한 참조 스토리지 솔루션이 아닙니다. 애플리케이션 워크로드에 LVMS Operator가 필요한 경우 애플리케이션 코어에 대해 리소스 사용을 고려합니다.
- 스토리지 요구 사항에 충분한 디스크 또는 파티션을 사용할 수 있는지 확인합니다.
3.2.3.9. 워크로드 파티셔닝
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
워크로드 파티셔닝은 DU 프로파일의 일부인 OpenShift 플랫폼과 Day 2 Operator Pod를 예약된
cpuset에 고정하고 노드 회계에서 예약된 CPU를 제거합니다. 이렇게 하면 사용자 워크로드에서 예약되지 않은 모든 CPU 코어를 사용할 수 있습니다.OpenShift Container Platform 4.14에서 워크로드 파티셔닝을 활성화하고 구성하는 방법입니다.
- 4.14 이상
설치 매개변수를 설정하여 파티션을 구성합니다.
cpuPartitioningMode: AllNodes
cpuPartitioningMode: AllNodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
PerformanceProfileCR에 예약된 CPU 세트를 사용하여 관리 파티션 코어 구성
- 4.13 및 이전 버전
-
설치 시 적용된 추가
MachineConfigurationCR을 사용하여 파티션 구성
-
설치 시 적용된 추가
- 제한 및 요구사항
-
Pod를 관리 파티션에 적용할 수 있도록네임스페이스및 Pod CR에 주석을 달 수 있어야 합니다. - CPU 제한이 있는 Pod는 파티션에 할당할 수 없습니다. 변경으로 Pod QoS를 변경할 수 있기 때문입니다.
- 관리 파티션에 할당할 수 있는 최소 CPU 수에 대한 자세한 내용은 Node Tuning Operator 를 참조하십시오.
-
- 엔지니어링 고려 사항
- 워크로드 파티셔닝은 모든 관리 Pod를 예약된 코어에 고정합니다. 워크로드 시작, 노드 재부팅 또는 기타 시스템 이벤트가 발생할 때 발생하는 CPU 사용 급증을 고려하여 예약된 세트에 코어 수를 할당해야 합니다.
3.2.3.10. 클러스터 튜닝
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
클러스터 기능 기능에는 제외 시 클러스터에서 다음 Operator 및 해당 리소스를 비활성화하는
MachineAPI구성 요소가 포함되어 있습니다.-
openshift/cluster-autoscaler-operator -
openshift/cluster-control-plane-machine-set-operator -
openshift/machine-api-operator
-
클러스터 기능을 사용하여 이미지 레지스트리 Operator를 제거합니다.
- 제한 및 요구사항
- 설치 관리자가 프로비저닝한 설치 방법에서는 클러스터 기능을 사용할 수 없습니다.
모든 플랫폼 튜닝 구성을 적용해야 합니다. 다음 표에는 필요한 플랫폼 튜닝 구성이 나열되어 있습니다.
Expand 표 3.2. 클러스터 기능 구성 기능 설명 선택적 클러스터 기능 제거
단일 노드 OpenShift 클러스터에서만 선택적 클러스터 Operator를 비활성화하여 OpenShift Container Platform 풋프린트를 줄입니다.
- Marketplace 및 Node Tuning Operator를 제외한 모든 선택적 Operator를 제거합니다.
클러스터 모니터링 구성
다음을 수행하여 공간 절약을 위해 모니터링 스택을 구성합니다.
-
로컬
alertmanager및 Telemeter 구성요소를 비활성화합니다. -
RHACM 관찰 기능을 사용하는 경우 경고를 허브 클러스터에 전달하려면 적절한
additionalAlertManagerConfigsCR로 CR을 보강해야 합니다. Prometheus보존 기간을 24시간으로 줄입니다.참고RHACM 허브 클러스터는 관리되는 클러스터 메트릭을 집계합니다.
네트워킹 진단 비활성화
필요하지 않으므로 단일 노드 OpenShift에 대한 네트워킹 진단을 비활성화합니다.
단일 OperatorHub 카탈로그 소스 구성
RAN DU 배포에 필요한 Operator만 포함하는 단일 카탈로그 소스를 사용하도록 클러스터를 구성합니다. 각 카탈로그 소스는 클러스터에서 CPU 사용을 늘립니다. 단일
CatalogSource를 사용하면 플랫폼 CPU 예산에 적합합니다.
3.2.3.11. 머신 구성
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 제한 및 요구사항
CRI-O wipe disable
MachineConfig는 디스크의 이미지가 정의된 유지 관리 창에서 예약된 유지 관리 중이 아닌 정적이라고 가정합니다. 이미지가 정적임을 확인하려면 PodimagePullPolicy필드를Always로 설정하지 마십시오.Expand 표 3.3. 머신 구성 옵션 기능 설명 컨테이너 런타임
모든 노드 역할에 대해 컨테이너 런타임을
crun으로 설정합니다.kubelet 구성 및 컨테이너 마운트 숨기기
kubelet 하우스키핑 및 제거 모니터링의 빈도를 줄여 CPU 사용량을 줄입니다. kubelet 및 CRI-O에 표시되는 컨테이너 마운트 네임스페이스를 생성하여 시스템 마운트 검사 리소스 사용량을 줄입니다.
SCTP
선택적 구성(기본적으로 활성화)은 SCTP를 활성화합니다. SCTP는 RAN 애플리케이션에 필요하지만 RHCOS에서 기본적으로 비활성화되어 있습니다.
kdump
선택적 설정(기본적으로 사용)을 사용하면 커널 패닉이 발생할 때 kdump에서 디버그 정보를 캡처할 수 있습니다.
CRI-O wipe disable
클린 종료 후 CRI-O 이미지 캐시 자동 제거 기능을 비활성화합니다.
SR-IOV 관련 커널 인수
커널 명령줄에 추가 SR-IOV 관련 인수가 포함됩니다.
RCU 일반 systemd 서비스
시스템이 완전히 시작된 후
rcu_normal를 설정합니다.일회성 시간 동기화
컨트롤 플레인 또는 작업자 노드에 대한 일회성 시스템 시간 동기화 작업을 실행합니다.
3.2.3.12. 참조 설계 배포 구성 요소
다음 섹션에서는 RHACM(Red Hat Advanced Cluster Management)을 사용하여 허브 클러스터를 구성하는 데 사용하는 다양한 OpenShift Container Platform 구성 요소 및 구성에 대해 설명합니다.
3.2.3.12.1. Red Hat Advanced Cluster Management(RHACM)
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
RHACM은 배포된 클러스터에 대한 MCE(Multi Cluster Engine) 설치 및 지속적인 라이프사이클 관리 기능을 제공합니다.
PolicyCR을 사용하여 구성 및 업그레이드를 선언적으로 지정하고 토폴로지 Aware Lifecycle Manager에서 관리하는 대로 RHACM 정책 컨트롤러를 사용하여 클러스터에 정책을 적용합니다.- ZTP(ZTP)는 RHACM의 MCE 기능을 사용합니다.
- 구성, 업그레이드 및 클러스터 상태는 RHACM 정책 컨트롤러로 관리됩니다.
설치 중 RHACM은 site
ConfigCR(사용자 정의 리소스)에 구성된 개별 노드에 레이블을 적용할 수 있습니다.- 제한 및 요구사항
-
단일 허브 클러스터는 5
PolicyCR이 각 클러스터에 바인딩된 최대 3500개의 배포된 단일 노드 OpenShift 클러스터를 지원합니다.
-
단일 허브 클러스터는 5
- 엔지니어링 고려 사항
- RHACM 정책 허브 측 템플릿을 사용하여 클러스터 구성을 보다 효과적으로 확장할 수 있습니다. 단일 그룹 정책 또는 그룹과 클러스터별 값이 템플릿으로 대체되는 일반 그룹 정책 수를 사용하여 정책 수를 크게 줄일 수 있습니다.
-
클러스터별 구성: 관리 클러스터에는 일반적으로 개별 클러스터에 고유한 몇 가지 구성 값이 있습니다. 이러한 구성은 클러스터 이름을 기반으로
ConfigMapCR에서 가져온 값을 사용하여 RHACM 정책 허브 쪽 템플릿을 사용하여 관리해야 합니다. - 관리 클러스터에 CPU 리소스를 저장하려면 클러스터의 GitOps ZTP 설치 후 정적 구성을 적용하는 정책을 관리 클러스터에서 바인딩해야 합니다. 자세한 내용은 영구 볼륨 릴리스를 참조하십시오.
3.2.3.12.2. 토폴로지 인식 라이프사이클 관리자(TALM)
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
- 관리형 업데이트
TALM은 변경 사항(클러스터 및 Operator 업그레이드, 구성 등)이 네트워크에 롤아웃되는 방식을 관리하기 위해 hub 클러스터에서만 실행되는 Operator입니다. TALM은 다음을 수행합니다.
-
PolicyCR을 사용하여 사용자 구성 가능한 일괄 처리의 클러스터에 점진적으로 업데이트를 적용합니다. -
클러스터별로
ztp-done레이블 또는 기타 사용자 구성 가능 라벨 추가
-
- 단일 노드 OpenShift 클러스터 사전 연결
TALM은 업그레이드를 시작하기 전에 OpenShift Container Platform, OLM Operator 및 추가 사용자 이미지의 선택적 사전 처리를 단일 노드 OpenShift 클러스터에 지원합니다.
- 단일 노드 OpenShift의 백업 및 복원
- TALM은 로컬 디스크의 전용 파티션으로 클러스터 운영 체제 및 구성의 스냅샷을 작성할 수 있습니다. 클러스터를 백업 상태로 반환하는 복원 스크립트가 제공됩니다.
- 제한 및 요구사항
- TALM은 400개의 배치로 동시 클러스터 배포를 지원
- 사전 캐싱 및 백업 기능은 단일 노드 OpenShift 클러스터에만 사용할 수 있습니다.
- 엔지니어링 고려 사항
-
PreCachingConfigCR은 선택 사항이며 플랫폼 관련 (OpenShift 및 OLM Operator) 이미지를 사전 캐시하려는 경우 생성할 필요가 없습니다.PreCachingConfigCR은ClusterGroupUpgradeCR에서 참조하기 전에 적용해야 합니다. - TALM 백업 및 복원 기능을 사용하도록 선택한 경우 설치 중에 복구 파티션을 만듭니다.
-
3.2.3.12.3. GitOps 및 GitOps ZTP 플러그인
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
GitOps 및 GitOps ZTP 플러그인은 클러스터 배포 및 구성을 관리하기 위한 GitOps 기반 인프라를 제공합니다. 클러스터 정의 및 구성은 Git에서 선언적 상태로 유지됩니다. ZTP 플러그인은 site
ConfigCR에서 설치 CR을 생성하고PolicyGenTemplateCR을 기반으로 정책의 구성 CR을 자동으로 래핑할 수 있도록 지원합니다.기준 참조 구성 CR을 사용하여 관리형 클러스터에서 여러 버전의 OpenShift Container Platform을 배포하고 관리할 수 있습니다. 기본 CR과 함께 사용자 정의 CR을 사용할 수도 있습니다.
- 제한
-
ArgoCD 애플리케이션당 300개의 site
ConfigCR. 여러 애플리케이션을 사용하여 단일 허브 클러스터에서 지원하는 최대 클러스터 수를 달성할 수 있습니다. -
Git의
/source-crs폴더의 콘텐츠는 GitOps ZTP 플러그인 컨테이너에 제공된 콘텐츠를 덮어씁니다. Git이 검색 경로에서 우선합니다. PolicyGenTemplate을 생성기로 포함하는kustomization.yaml파일과 동일한 디렉터리에/source-crs폴더를 추가합니다.참고이 컨텍스트에서
/source-crs디렉터리의 대체 위치는 지원되지 않습니다.
-
ArgoCD 애플리케이션당 300개의 site
- 엔지니어링 고려 사항
-
콘텐츠를 업데이트할 때 파일의 혼동 또는 의도하지 않은 덮어쓰기를 방지하려면
/source-crs폴더 및 Git의 추가 매니페스트에서 사용자 제공 CR에 대해 고유하고 구분 가능한 이름을 사용합니다. -
SiteConfigCR을 사용하면 여러 추가 경로가 허용됩니다. 동일한 이름의 파일이 여러 디렉토리 경로에 있는 경우 마지막으로 발견된 파일이 우선합니다. 이를 통해 Git에 버전별 Day 0 매니페스트(extra-manifests)의 전체 세트를 배치하고 siteConfig CR에서 참조할수 있습니다. 이 기능을 사용하면 여러 OpenShift Container Platform 버전을 관리 클러스터에 동시에 배포할 수 있습니다. -
SiteConfigCR의extraManifestPath필드는 OpenShift Container Platform 4.15 이상에서 더 이상 사용되지 않습니다. 대신 새로운extraManifests.searchPaths필드를 사용합니다.
-
콘텐츠를 업데이트할 때 파일의 혼동 또는 의도하지 않은 덮어쓰기를 방지하려면
3.2.3.12.4. 에이전트 기반 설치 프로그램
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
에이전트 기반 설치 관리자(ABI)는 중앙 집중식 인프라 없이 설치 기능을 제공합니다. 설치 프로그램은 서버에 마운트하는 ISO 이미지를 생성합니다. 서버를 부팅하면 OpenShift Container Platform을 설치하고 추가 매니페스트를 제공했습니다.
참고ABI를 사용하여 허브 클러스터 없이 OpenShift Container Platform 클러스터를 설치할 수도 있습니다. 이러한 방식으로 ABI를 사용할 때 이미지 레지스트리가 계속 필요합니다.
에이전트 기반 설치 관리자(ABI)는 선택적 구성 요소입니다.
- 제한 및 요구사항
- 설치 시 제한된 추가 매니페스트 세트를 제공할 수 있습니다.
-
RAN DU 사용 사례에 필요한
MachineConfigurationCR을 포함해야 합니다.
- 엔지니어링 고려 사항
- ABI는 기본 OpenShift Container Platform 설치를 제공합니다.
- 설치 후 Day 2 Operator 및 RAN DU 사용 사례 구성을 설치합니다.
3.2.3.13. 추가 구성 요소
3.2.3.13.1. Bare Metal Event Relay
Bare Metal Event Relay는 관리형 spoke 클러스터에서 독점적으로 실행되는 선택적 Operator입니다. Redfish 하드웨어 이벤트를 클러스터 애플리케이션으로 릴레이합니다.
베어 메탈 이벤트 릴레이는 RAN DU에 포함되지 않으며 모델 참조 구성에 포함되어 있으며 선택적 기능입니다. Bare Metal Event Relay를 사용하려면 애플리케이션 CPU 예산에서 추가 CPU 리소스를 할당합니다.
3.2.4. Ttelco RAN distributed unit (DU) 참조 구성 CR
다음 CR(사용자 정의 리소스)을 사용하여 telco RAN DU 프로필을 사용하여 OpenShift Container Platform 클러스터를 구성하고 배포합니다. 일부 CR은 요구 사항에 따라 선택 사항입니다. 변경할 수 있는 CR 필드에는 YAML 주석을 사용하여 CR에 주석이 추가됩니다.
ztp-site-generate 컨테이너 이미지에서 RAN DU CR의 전체 세트를 추출할 수 있습니다. 자세한 내용은 GitOps ZTP 사이트 구성 리포지토리 준비를 참조하십시오.
3.2.4.1. 2일차 Operator 참조 CR
| Component | 참조 CR | 선택 사항 | 이번 릴리스의 새로운 기능 |
|---|---|---|---|
| 클러스터 로깅 | 없음 | 없음 | |
| 클러스터 로깅 | 없음 | 없음 | |
| 클러스터 로깅 | 없음 | 없음 | |
| 클러스터 로깅 | 없음 | 없음 | |
| 클러스터 로깅 | 없음 | 없음 | |
| Local Storage Operator | 제공됨 | 없음 | |
| Local Storage Operator | 제공됨 | 없음 | |
| Local Storage Operator | 제공됨 | 없음 | |
| Local Storage Operator | 제공됨 | 없음 | |
| Local Storage Operator | 제공됨 | 없음 | |
| Node Tuning Operator | 없음 | 없음 | |
| Node Tuning Operator | 없음 | 없음 | |
| PTP 빠른 이벤트 알림 | 제공됨 | 없음 | |
| PTP Operator | 없음 | 없음 | |
| PTP Operator | 없음 | 없음 | |
| PTP Operator | 없음 | 없음 | |
| PTP Operator | 없음 | 없음 | |
| PTP Operator |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 제공됨 | 없음 | |
| SR-IOV Operator | 없음 | 없음 | |
| SR-IOV Operator | 없음 | 없음 | |
| SR-IOV Operator | 없음 | 없음 | |
| SR-IOV Operator | 없음 | 없음 | |
| SR-IOV Operator | 없음 | 없음 | |
| SR-IOV Operator | 없음 | 없음 |
3.2.4.2. 클러스터 튜닝 참조 CR
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.2.4.3.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.2.4.4.
3.2.4.4.1.
apiVersion: v1
kind: Namespace
metadata:
name: vran-acceleration-operators
annotations: {}
apiVersion: v1
kind: Namespace
metadata:
name: vran-acceleration-operators
annotations: {}
3.2.4.4.2.
3.2.4.4.3.
3.2.5.
3.2.5.1.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.3.
3.3.1.
3.3.1.1.
|
|
|
3.3.2.
3.3.2.1.
3.3.2.1.1.
3.3.2.1.2.
- 참고
3.3.3.
3.3.3.1.
cpu-load-balancing.crio.io: "disable" cpu-quota.crio.io: "disable" irq-load-balancing.crio.io: "disable"
cpu-load-balancing.crio.io: "disable" cpu-quota.crio.io: "disable" irq-load-balancing.crio.io: "disable"Copy to Clipboard Copied! Toggle word wrap Toggle overflow cpu-c-states.crio.io: "disable" cpu-freq-governor.crio.io: "performance"
cpu-c-states.crio.io: "disable" cpu-freq-governor.crio.io: "performance"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3.3.2.
3.3.3.3.
3.3.3.3.1.
3.3.3.3.2.
3.3.3.3.3.
3.3.3.3.4.
3.3.3.4.
3.3.3.5.
3.3.3.6.
- 참고
3.3.3.6.1.
3.3.3.6.2.
3.3.3.7.
3.3.3.8.
3.3.3.9.
- ,
3.3.3.10.
3.3.3.11.
3.3.3.12.
3.3.3.12.1.
3.3.3.12.2.
- 참고
3.3.4.
3.3.4.1.
|
|
|
|
|
|
|
|
|
|
3.3.4.2.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.3.4.3.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.3.4.4.
|
|
|
|
|
|
|
|
|
|
3.3.4.5.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.3.4.6.
3.3.4.6.1.
3.3.4.6.2.
3.3.4.6.3.
apiVersion: nmstate.io/v1
kind: NMState
metadata:
name: nmstate
spec: {}
apiVersion: nmstate.io/v1
kind: NMState
metadata:
name: nmstate
spec: {}
3.3.4.6.4.
3.3.4.6.5.
4장.
4.1.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4.1.1.
4.2.
4.2.1.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4.2.2.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4.2.3.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4.3.
required pods per cluster / pods per node = total number of nodes needed
required pods per cluster / pods per node = total number of nodes needed
2200 / 500 = 4.4
2200 / 500 = 4.4
2200 / 20 = 110
2200 / 20 = 110
required pods per cluster / total number of nodes = expected pods per node
required pods per cluster / total number of nodes = expected pods per node
4.4.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5장.
5.1.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
oc create quota <name> --hard=count/<resource>.<group>=<quota>
$ oc create quota <name> --hard=count/<resource>.<group>=<quota> 5.1.1.
oc describe node ip-172-31-27-209.us-west-2.compute.internal | egrep 'Capacity|Allocatable|gpu'
$ oc describe node ip-172-31-27-209.us-west-2.compute.internal | egrep 'Capacity|Allocatable|gpu'Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow cat gpu-quota.yaml
$ cat gpu-quota.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f gpu-quota.yaml
$ oc create -f gpu-quota.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow resourcequota/gpu-quota created
resourcequota/gpu-quota createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc describe quota gpu-quota -n nvidia
$ oc describe quota gpu-quota -n nvidiaCopy to Clipboard Copied! Toggle word wrap Toggle overflow Name: gpu-quota Namespace: nvidia Resource Used Hard -------- ---- ---- requests.nvidia.com/gpu 0 1
Name: gpu-quota Namespace: nvidia Resource Used Hard -------- ---- ---- requests.nvidia.com/gpu 0 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create pod gpu-pod.yaml
$ oc create pod gpu-pod.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc get pods
$ oc get podsCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME READY STATUS RESTARTS AGE gpu-pod-s46h7 1/1 Running 0 1m
NAME READY STATUS RESTARTS AGE gpu-pod-s46h7 1/1 Running 0 1mCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc describe quota gpu-quota -n nvidia
$ oc describe quota gpu-quota -n nvidiaCopy to Clipboard Copied! Toggle word wrap Toggle overflow Name: gpu-quota Namespace: nvidia Resource Used Hard -------- ---- ---- requests.nvidia.com/gpu 1 1
Name: gpu-quota Namespace: nvidia Resource Used Hard -------- ---- ---- requests.nvidia.com/gpu 1 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f gpu-pod.yaml
$ oc create -f gpu-pod.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Error from server (Forbidden): error when creating "gpu-pod.yaml": pods "gpu-pod-f7z2w" is forbidden: exceeded quota: gpu-quota, requested: requests.nvidia.com/gpu=1, used: requests.nvidia.com/gpu=1, limited: requests.nvidia.com/gpu=1
Error from server (Forbidden): error when creating "gpu-pod.yaml": pods "gpu-pod-f7z2w" is forbidden: exceeded quota: gpu-quota, requested: requests.nvidia.com/gpu=1, used: requests.nvidia.com/gpu=1, limited: requests.nvidia.com/gpu=1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.1.2.
|
|
|
|
|
|
|
|
|
|
|
|
5.2.
5.2.1.
5.2.2.
5.2.3.
5.2.4.
oc create -f <resource_quota_definition> [-n <project_name>]
$ oc create -f <resource_quota_definition> [-n <project_name>]
oc create -f core-object-counts.yaml -n demoproject
$ oc create -f core-object-counts.yaml -n demoproject5.2.5.
oc create quota <name> --hard=count/<resource>.<group>=<quota>,count/<resource>.<group>=<quota>
$ oc create quota <name> --hard=count/<resource>.<group>=<quota>,count/<resource>.<group>=<quota>
5.2.6.
oc get quota -n demoproject
$ oc get quota -n demoproject NAME AGE besteffort 11m compute-resources 2m core-object-counts 29mCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.2.7.
master-restart api master-restart controllers
$ master-restart api
$ master-restart controllers
5.2.8.
5.3.
5.3.1.
|
|
|
|
|
|
|
|
|
5.3.2.
|
|
|
|
|
|
|
|
|
5.3.3.
|
|
|
5.3.4.
|
|
|
|
|
|
5.3.5.
5.3.6.
|
|
|
|
|
|
5.4.
5.4.1.
oc create -f <limit_range_file> -n <project>
$ oc create -f <limit_range_file> -n <project>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.4.2.
oc get limits -n demoproject
$ oc get limits -n demoprojectCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME AGE resource-limits 6d
NAME AGE resource-limits 6dCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc describe limits resource-limits -n demoproject
$ oc describe limits resource-limits -n demoprojectCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.4.3.
oc delete limits <limit_name>
$ oc delete limits <limit_name>
6장.
6.1.
6.2.
6.3.
6.3.1.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f enable-rfs.yaml
$ oc create -f enable-rfs.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get mc
$ oc get mcCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc delete mc 50-enable-rfs
$ oc delete mc 50-enable-rfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.4.
6.5.
6.5.1.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고oc create -f 05-master-kernelarg-hpav.yaml
$ oc create -f 05-master-kernelarg-hpav.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f 05-worker-kernelarg-hpav.yaml
$ oc create -f 05-worker-kernelarg-hpav.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc delete -f 05-master-kernelarg-hpav.yaml
$ oc delete -f 05-master-kernelarg-hpav.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc delete -f 05-worker-kernelarg-hpav.yaml
$ oc delete -f 05-worker-kernelarg-hpav.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.6.
6.6.1.
6.6.2.
6.6.3.
<disk type="block" device="disk">
<driver name="qemu" type="raw" cache="none" io="native" iothread="1"/>
...
</disk>
<disk type="block" device="disk">
<driver name="qemu" type="raw" cache="none" io="native" iothread="1"/>
...
</disk>6.6.4.
<memballoon model="none"/>
<memballoon model="none"/>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.6.5.
sysctl kernel.sched_migration_cost_ns=60000
# sysctl kernel.sched_migration_cost_ns=60000
kernel.sched_migration_cost_ns=60000
kernel.sched_migration_cost_ns=600006.6.6.
cgroup_controllers = [ "cpu", "devices", "memory", "blkio", "cpuacct" ]
cgroup_controllers = [ "cpu", "devices", "memory", "blkio", "cpuacct" ]Copy to Clipboard Copied! Toggle word wrap Toggle overflow systemctl restart libvirtd
# systemctl restart libvirtdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.6.7.
echo 0 > /sys/module/kvm/parameters/halt_poll_ns
# echo 0 > /sys/module/kvm/parameters/halt_poll_nsCopy to Clipboard Copied! Toggle word wrap Toggle overflow echo 80000 > /sys/module/kvm/parameters/halt_poll_ns
# echo 80000 > /sys/module/kvm/parameters/halt_poll_nsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
7장.
7.1.
7.2.
oc get tuned.tuned.openshift.io/default -o yaml -n openshift-cluster-node-tuning-operator
oc get tuned.tuned.openshift.io/default -o yaml -n openshift-cluster-node-tuning-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow
7.3.
oc exec $tuned_pod -n openshift-cluster-node-tuning-operator -- find /usr/lib/tuned/openshift{,-control-plane,-node} -name tuned.conf -exec grep -H ^ {} \;
$ oc exec $tuned_pod -n openshift-cluster-node-tuning-operator -- find /usr/lib/tuned/openshift{,-control-plane,-node} -name tuned.conf -exec grep -H ^ {} \;7.4.
oc get profile.tuned.openshift.io -n openshift-cluster-node-tuning-operator
$ oc get profile.tuned.openshift.io -n openshift-cluster-node-tuning-operator
oc get co/node-tuning -n openshift-cluster-node-tuning-operator
$ oc get co/node-tuning -n openshift-cluster-node-tuning-operator
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE node-tuning 4.15.1 True False True 60m 1/5 Profiles with bootcmdline conflict
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE
node-tuning 4.15.1 True False True 60m 1/5 Profiles with bootcmdline conflict
7.5.
recommend: <recommend-item-1> # ... <recommend-item-n>
recommend:
<recommend-item-1>
# ...
<recommend-item-n>
- label: <label_name>
value: <label_value>
type: <label_type>
<match>
- label: <label_name>
value: <label_value>
type: <label_type>
<match>
7.6.
oc exec $tuned_pod -n openshift-cluster-node-tuning-operator -- find /usr/lib/tuned/ -name tuned.conf -printf '%h\n' | sed 's|^.*/||'
$ oc exec $tuned_pod -n openshift-cluster-node-tuning-operator -- find /usr/lib/tuned/ -name tuned.conf -printf '%h\n' | sed 's|^.*/||'
7.7.
7.8.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고oc --kubeconfig="$MGMT_KUBECONFIG" create -f tuned-1.yaml
$ oc --kubeconfig="$MGMT_KUBECONFIG" create -f tuned-1.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고
oc --kubeconfig="$HC_KUBECONFIG" get tuned.tuned.openshift.io -n openshift-cluster-node-tuning-operator
$ oc --kubeconfig="$HC_KUBECONFIG" get tuned.tuned.openshift.io -n openshift-cluster-node-tuning-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME AGE default 7m36s rendered 7m36s tuned-1 65s
NAME AGE default 7m36s rendered 7m36s tuned-1 65sCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc --kubeconfig="$HC_KUBECONFIG" get profile.tuned.openshift.io -n openshift-cluster-node-tuning-operator
$ oc --kubeconfig="$HC_KUBECONFIG" get profile.tuned.openshift.io -n openshift-cluster-node-tuning-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME TUNED APPLIED DEGRADED AGE nodepool-1-worker-1 tuned-1-profile True False 7m43s nodepool-1-worker-2 tuned-1-profile True False 7m14s
NAME TUNED APPLIED DEGRADED AGE nodepool-1-worker-1 tuned-1-profile True False 7m43s nodepool-1-worker-2 tuned-1-profile True False 7m14sCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고oc --kubeconfig="$HC_KUBECONFIG" debug node/nodepool-1-worker-1 -- chroot /host sysctl vm.dirty_ratio
$ oc --kubeconfig="$HC_KUBECONFIG" debug node/nodepool-1-worker-1 -- chroot /host sysctl vm.dirty_ratioCopy to Clipboard Copied! Toggle word wrap Toggle overflow vm.dirty_ratio = 55
vm.dirty_ratio = 55Copy to Clipboard Copied! Toggle word wrap Toggle overflow
7.9.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고oc --kubeconfig="<management_cluster_kubeconfig>" create -f tuned-hugepages.yaml
$ oc --kubeconfig="<management_cluster_kubeconfig>" create -f tuned-hugepages.yaml1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고oc --kubeconfig="<management_cluster_kubeconfig>" create -f hugepages-nodepool.yaml
$ oc --kubeconfig="<management_cluster_kubeconfig>" create -f hugepages-nodepool.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
oc --kubeconfig="<hosted_cluster_kubeconfig>" get tuned.tuned.openshift.io -n openshift-cluster-node-tuning-operator
$ oc --kubeconfig="<hosted_cluster_kubeconfig>" get tuned.tuned.openshift.io -n openshift-cluster-node-tuning-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME AGE default 123m hugepages-8dfb1fed 1m23s rendered 123m
NAME AGE default 123m hugepages-8dfb1fed 1m23s rendered 123mCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc --kubeconfig="<hosted_cluster_kubeconfig>" get profile.tuned.openshift.io -n openshift-cluster-node-tuning-operator
$ oc --kubeconfig="<hosted_cluster_kubeconfig>" get profile.tuned.openshift.io -n openshift-cluster-node-tuning-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME TUNED APPLIED DEGRADED AGE nodepool-1-worker-1 openshift-node True False 132m nodepool-1-worker-2 openshift-node True False 131m hugepages-nodepool-worker-1 openshift-node-hugepages True False 4m8s hugepages-nodepool-worker-2 openshift-node-hugepages True False 3m57s
NAME TUNED APPLIED DEGRADED AGE nodepool-1-worker-1 openshift-node True False 132m nodepool-1-worker-2 openshift-node True False 131m hugepages-nodepool-worker-1 openshift-node-hugepages True False 4m8s hugepages-nodepool-worker-2 openshift-node-hugepages True False 3m57sCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc --kubeconfig="<hosted_cluster_kubeconfig>" debug node/nodepool-1-worker-1 -- chroot /host cat /proc/cmdline
$ oc --kubeconfig="<hosted_cluster_kubeconfig>" debug node/nodepool-1-worker-1 -- chroot /host cat /proc/cmdlineCopy to Clipboard Copied! Toggle word wrap Toggle overflow BOOT_IMAGE=(hd0,gpt3)/ostree/rhcos-... hugepagesz=2M hugepages=50
BOOT_IMAGE=(hd0,gpt3)/ostree/rhcos-... hugepagesz=2M hugepages=50Copy to Clipboard Copied! Toggle word wrap Toggle overflow
8장.
8.1.
oc label node perf-node.example.com cpumanager=true
# oc label node perf-node.example.com cpumanager=trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc edit machineconfigpool worker
# oc edit machineconfigpool workerCopy to Clipboard Copied! Toggle word wrap Toggle overflow metadata: creationTimestamp: 2020-xx-xxx generation: 3 labels: custom-kubelet: cpumanager-enabledmetadata: creationTimestamp: 2020-xx-xxx generation: 3 labels: custom-kubelet: cpumanager-enabledCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f cpumanager-kubeletconfig.yaml
# oc create -f cpumanager-kubeletconfig.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get machineconfig 99-worker-XXXXXX-XXXXX-XXXX-XXXXX-kubelet -o json | grep ownerReference -A7
# oc get machineconfig 99-worker-XXXXXX-XXXXX-XXXX-XXXXX-kubelet -o json | grep ownerReference -A7Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc debug node/perf-node.example.com
# oc debug node/perf-node.example.com sh-4.2# cat /host/etc/kubernetes/kubelet.conf | grep cpuManagerCopy to Clipboard Copied! Toggle word wrap Toggle overflow cpuManagerPolicy: static cpuManagerReconcilePeriod: 5s
cpuManagerPolicy: static1 cpuManagerReconcilePeriod: 5s2 Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc new-project <project_name>
$ oc new-project <project_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow cat cpumanager-pod.yaml
# cat cpumanager-pod.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f cpumanager-pod.yaml
# oc create -f cpumanager-pod.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
oc describe pod cpumanager
# oc describe pod cpumanagerCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc describe node --selector='cpumanager=true' | grep -i cpumanager- -B2
# oc describe node --selector='cpumanager=true' | grep -i cpumanager- -B2Copy to Clipboard Copied! Toggle word wrap Toggle overflow NAMESPACE NAME CPU Requests CPU Limits Memory Requests Memory Limits Age cpuman cpumanager-mlrrz 1 (28%) 1 (28%) 1G (13%) 1G (13%) 27m
NAMESPACE NAME CPU Requests CPU Limits Memory Requests Memory Limits Age cpuman cpumanager-mlrrz 1 (28%) 1 (28%) 1G (13%) 1G (13%) 27mCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc debug node/perf-node.example.com
# oc debug node/perf-node.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow systemctl status | grep -B5 pause
sh-4.2# systemctl status | grep -B5 pauseCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고Copy to Clipboard Copied! Toggle word wrap Toggle overflow cd /sys/fs/cgroup/kubepods.slice/kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice/crio-b5437308f1ad1a7db0574c542bdf08563b865c0345c86e9585f8c0b0a655612c.scope
# cd /sys/fs/cgroup/kubepods.slice/kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice/crio-b5437308f1ad1a7db0574c542bdf08563b865c0345c86e9585f8c0b0a655612c.scopeCopy to Clipboard Copied! Toggle word wrap Toggle overflow for i in `ls cpuset.cpus cgroup.procs` ; do echo -n "$i "; cat $i ; done
# for i in `ls cpuset.cpus cgroup.procs` ; do echo -n "$i "; cat $i ; doneCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고cpuset.cpus 1 tasks 32706
cpuset.cpus 1 tasks 32706Copy to Clipboard Copied! Toggle word wrap Toggle overflow grep ^Cpus_allowed_list /proc/32706/status
# grep ^Cpus_allowed_list /proc/32706/statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow Cpus_allowed_list: 1
Cpus_allowed_list: 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow cat /sys/fs/cgroup/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-podc494a073_6b77_11e9_98c0_06bba5c387ea.slice/crio-c56982f57b75a2420947f0afc6cafe7534c5734efc34157525fa9abbf99e3849.scope/cpuset.cpus
# cat /sys/fs/cgroup/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-podc494a073_6b77_11e9_98c0_06bba5c387ea.slice/crio-c56982f57b75a2420947f0afc6cafe7534c5734efc34157525fa9abbf99e3849.scope/cpuset.cpusCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc describe node perf-node.example.com
# oc describe node perf-node.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow NAME READY STATUS RESTARTS AGE cpumanager-6cqz7 1/1 Running 0 33m cpumanager-7qc2t 0/1 Pending 0 11s
NAME READY STATUS RESTARTS AGE cpumanager-6cqz7 1/1 Running 0 33m cpumanager-7qc2t 0/1 Pending 0 11sCopy to Clipboard Copied! Toggle word wrap Toggle overflow
8.2.
8.3.
8.4.
spec:
containers:
- name: nginx
image: nginx
spec:
containers:
- name: nginx
image: nginx
9장.
9.1.
그림 9.1.
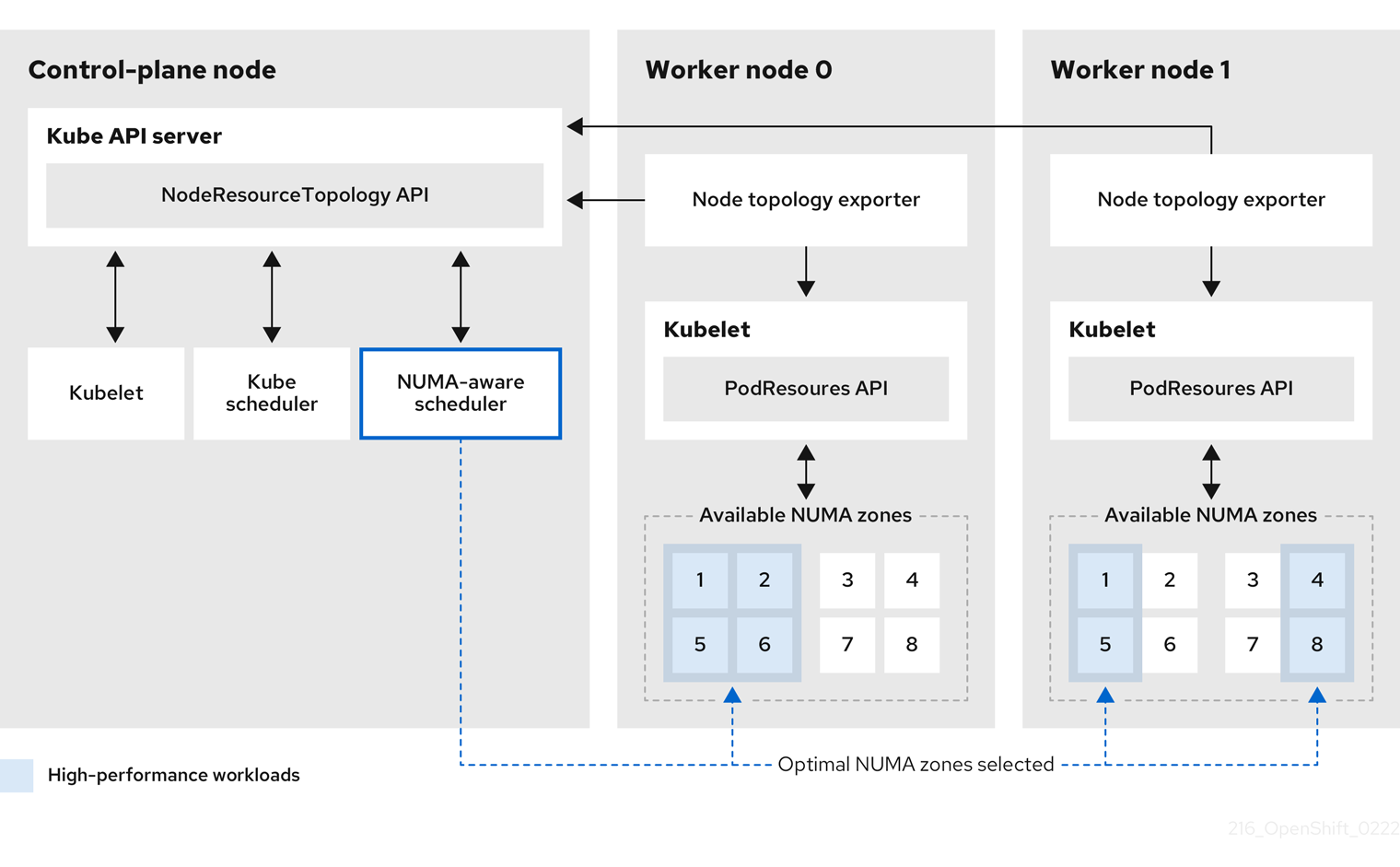
- 참고
9.2.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
9.3.
9.3.1.
apiVersion: v1 kind: Namespace metadata: name: openshift-numaresources
apiVersion: v1 kind: Namespace metadata: name: openshift-numaresourcesCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f nro-namespace.yaml
$ oc create -f nro-namespace.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f nro-operatorgroup.yaml
$ oc create -f nro-operatorgroup.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f nro-sub.yaml
$ oc create -f nro-sub.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
oc get csv -n openshift-numaresources
$ oc get csv -n openshift-numaresourcesCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME DISPLAY VERSION REPLACES PHASE numaresources-operator.v4.15.2 numaresources-operator 4.15.2 Succeeded
NAME DISPLAY VERSION REPLACES PHASE numaresources-operator.v4.15.2 numaresources-operator 4.15.2 SucceededCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3.2.
- 참고
9.4.
9.4.1.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f nrop.yaml
$ oc create -f nrop.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
oc get numaresourcesoperators.nodetopology.openshift.io
$ oc get numaresourcesoperators.nodetopology.openshift.ioCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME AGE numaresourcesoperator 27s
NAME AGE numaresourcesoperator 27sCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get all -n openshift-numaresources
$ oc get all -n openshift-numaresourcesCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME READY STATUS RESTARTS AGE pod/numaresources-controller-manager-7d9d84c58d-qk2mr 1/1 Running 0 12m pod/numaresourcesoperator-worker-7d96r 2/2 Running 0 97s pod/numaresourcesoperator-worker-crsht 2/2 Running 0 97s pod/numaresourcesoperator-worker-jp9mw 2/2 Running 0 97s
NAME READY STATUS RESTARTS AGE pod/numaresources-controller-manager-7d9d84c58d-qk2mr 1/1 Running 0 12m pod/numaresourcesoperator-worker-7d96r 2/2 Running 0 97s pod/numaresourcesoperator-worker-crsht 2/2 Running 0 97s pod/numaresourcesoperator-worker-jp9mw 2/2 Running 0 97sCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.4.2.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f nro-scheduler.yaml
$ oc create -f nro-scheduler.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
oc get all -n openshift-numaresources
$ oc get all -n openshift-numaresourcesCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.4.3.
9.4.4.
9.4.5.
9.4.6.
oc get numaresourcesschedulers.nodetopology.openshift.io numaresourcesscheduler -o json | jq '.status.schedulerName'
$ oc get numaresourcesschedulers.nodetopology.openshift.io numaresourcesscheduler -o json | jq '.status.schedulerName'Copy to Clipboard Copied! Toggle word wrap Toggle overflow "topo-aware-scheduler"
"topo-aware-scheduler"Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f nro-deployment.yaml
$ oc create -f nro-deployment.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
oc get pods -n openshift-numaresources
$ oc get pods -n openshift-numaresourcesCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc describe pod numa-deployment-1-6c4f5bdb84-wgn6g -n openshift-numaresources
$ oc describe pod numa-deployment-1-6c4f5bdb84-wgn6g -n openshift-numaresourcesCopy to Clipboard Copied! Toggle word wrap Toggle overflow Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 4m45s topo-aware-scheduler Successfully assigned openshift-numaresources/numa-deployment-1-6c4f5bdb84-wgn6g to worker-1
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 4m45s topo-aware-scheduler Successfully assigned openshift-numaresources/numa-deployment-1-6c4f5bdb84-wgn6g to worker-1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고oc get pods -n openshift-numaresources -o wide
$ oc get pods -n openshift-numaresources -o wideCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES numa-deployment-1-6c4f5bdb84-wgn6g 0/2 Running 0 82m 10.128.2.50 worker-1 <none> <none>
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES numa-deployment-1-6c4f5bdb84-wgn6g 0/2 Running 0 82m 10.128.2.50 worker-1 <none> <none>Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc describe noderesourcetopologies.topology.node.k8s.io worker-1
$ oc describe noderesourcetopologies.topology.node.k8s.io worker-1Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
oc get pod numa-deployment-1-6c4f5bdb84-wgn6g -n openshift-numaresources -o jsonpath="{ .status.qosClass }"$ oc get pod numa-deployment-1-6c4f5bdb84-wgn6g -n openshift-numaresources -o jsonpath="{ .status.qosClass }"Copy to Clipboard Copied! Toggle word wrap Toggle overflow Guaranteed
GuaranteedCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.5.
- 참고
oc get numaresop numaresourcesoperator -o json | jq '.status'
$ oc get numaresop numaresourcesoperator -o json | jq '.status'Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.6.
oc get crd | grep noderesourcetopologies
$ oc get crd | grep noderesourcetopologiesCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME CREATED AT noderesourcetopologies.topology.node.k8s.io 2022-01-18T08:28:06Z
NAME CREATED AT noderesourcetopologies.topology.node.k8s.io 2022-01-18T08:28:06ZCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get numaresourcesschedulers.nodetopology.openshift.io numaresourcesscheduler -o json | jq '.status.schedulerName'
$ oc get numaresourcesschedulers.nodetopology.openshift.io numaresourcesscheduler -o json | jq '.status.schedulerName'Copy to Clipboard Copied! Toggle word wrap Toggle overflow topo-aware-scheduler
topo-aware-schedulerCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get noderesourcetopologies.topology.node.k8s.io
$ oc get noderesourcetopologies.topology.node.k8s.ioCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME AGE compute-0.example.com 17h compute-1.example.com 17h
NAME AGE compute-0.example.com 17h compute-1.example.com 17hCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고oc get noderesourcetopologies.topology.node.k8s.io -o yaml
$ oc get noderesourcetopologies.topology.node.k8s.io -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.6.1.
oc get NUMAResourcesScheduler
$ oc get NUMAResourcesSchedulerCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME AGE numaresourcesscheduler 92m
NAME AGE numaresourcesscheduler 92mCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc delete NUMAResourcesScheduler numaresourcesscheduler
$ oc delete NUMAResourcesScheduler numaresourcesschedulerCopy to Clipboard Copied! Toggle word wrap Toggle overflow numaresourcesscheduler.nodetopology.openshift.io "numaresourcesscheduler" deleted
numaresourcesscheduler.nodetopology.openshift.io "numaresourcesscheduler" deletedCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f nro-scheduler-cacheresync.yaml
$ oc create -f nro-scheduler-cacheresync.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow numaresourcesscheduler.nodetopology.openshift.io/numaresourcesscheduler created
numaresourcesscheduler.nodetopology.openshift.io/numaresourcesscheduler createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
oc get crd | grep numaresourcesschedulers
$ oc get crd | grep numaresourcesschedulersCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME CREATED AT numaresourcesschedulers.nodetopology.openshift.io 2022-02-25T11:57:03Z
NAME CREATED AT numaresourcesschedulers.nodetopology.openshift.io 2022-02-25T11:57:03ZCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get numaresourcesschedulers.nodetopology.openshift.io
$ oc get numaresourcesschedulers.nodetopology.openshift.ioCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME AGE numaresourcesscheduler 3h26m
NAME AGE numaresourcesscheduler 3h26mCopy to Clipboard Copied! Toggle word wrap Toggle overflow
oc get pods -n openshift-numaresources
$ oc get pods -n openshift-numaresourcesCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME READY STATUS RESTARTS AGE numaresources-controller-manager-d87d79587-76mrm 1/1 Running 0 46h numaresourcesoperator-worker-5wm2k 2/2 Running 0 45h numaresourcesoperator-worker-pb75c 2/2 Running 0 45h secondary-scheduler-7976c4d466-qm4sc 1/1 Running 0 21m
NAME READY STATUS RESTARTS AGE numaresources-controller-manager-d87d79587-76mrm 1/1 Running 0 46h numaresourcesoperator-worker-5wm2k 2/2 Running 0 45h numaresourcesoperator-worker-pb75c 2/2 Running 0 45h secondary-scheduler-7976c4d466-qm4sc 1/1 Running 0 21mCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc logs secondary-scheduler-7976c4d466-qm4sc -n openshift-numaresources
$ oc logs secondary-scheduler-7976c4d466-qm4sc -n openshift-numaresourcesCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.6.2.
oc get NUMAResourcesScheduler
$ oc get NUMAResourcesSchedulerCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME AGE numaresourcesscheduler 92m
NAME AGE numaresourcesscheduler 92mCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc delete NUMAResourcesScheduler numaresourcesscheduler
$ oc delete NUMAResourcesScheduler numaresourcesschedulerCopy to Clipboard Copied! Toggle word wrap Toggle overflow numaresourcesscheduler.nodetopology.openshift.io "numaresourcesscheduler" deleted
numaresourcesscheduler.nodetopology.openshift.io "numaresourcesscheduler" deletedCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f nro-scheduler-mostallocated.yaml
$ oc create -f nro-scheduler-mostallocated.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow numaresourcesscheduler.nodetopology.openshift.io/numaresourcesscheduler created
numaresourcesscheduler.nodetopology.openshift.io/numaresourcesscheduler createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
oc get crd | grep numaresourcesschedulers
$ oc get crd | grep numaresourcesschedulersCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME CREATED AT numaresourcesschedulers.nodetopology.openshift.io 2022-02-25T11:57:03Z
NAME CREATED AT numaresourcesschedulers.nodetopology.openshift.io 2022-02-25T11:57:03ZCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get numaresourcesschedulers.nodetopology.openshift.io
$ oc get numaresourcesschedulers.nodetopology.openshift.ioCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME AGE numaresourcesscheduler 3h26m
NAME AGE numaresourcesscheduler 3h26mCopy to Clipboard Copied! Toggle word wrap Toggle overflow
oc get -n openshift-numaresources cm topo-aware-scheduler-config -o yaml | grep scoring -A 1
$ oc get -n openshift-numaresources cm topo-aware-scheduler-config -o yaml | grep scoring -A 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow scoringStrategy: type: MostAllocated
scoringStrategy: type: MostAllocatedCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.6.3.
oc get NUMAResourcesScheduler
$ oc get NUMAResourcesSchedulerCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME AGE numaresourcesscheduler 90m
NAME AGE numaresourcesscheduler 90mCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc delete NUMAResourcesScheduler numaresourcesscheduler
$ oc delete NUMAResourcesScheduler numaresourcesschedulerCopy to Clipboard Copied! Toggle word wrap Toggle overflow numaresourcesscheduler.nodetopology.openshift.io "numaresourcesscheduler" deleted
numaresourcesscheduler.nodetopology.openshift.io "numaresourcesscheduler" deletedCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f nro-scheduler-debug.yaml
$ oc create -f nro-scheduler-debug.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow numaresourcesscheduler.nodetopology.openshift.io/numaresourcesscheduler created
numaresourcesscheduler.nodetopology.openshift.io/numaresourcesscheduler createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
oc get crd | grep numaresourcesschedulers
$ oc get crd | grep numaresourcesschedulersCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME CREATED AT numaresourcesschedulers.nodetopology.openshift.io 2022-02-25T11:57:03Z
NAME CREATED AT numaresourcesschedulers.nodetopology.openshift.io 2022-02-25T11:57:03ZCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get numaresourcesschedulers.nodetopology.openshift.io
$ oc get numaresourcesschedulers.nodetopology.openshift.ioCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME AGE numaresourcesscheduler 3h26m
NAME AGE numaresourcesscheduler 3h26mCopy to Clipboard Copied! Toggle word wrap Toggle overflow
oc get pods -n openshift-numaresources
$ oc get pods -n openshift-numaresourcesCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME READY STATUS RESTARTS AGE numaresources-controller-manager-d87d79587-76mrm 1/1 Running 0 46h numaresourcesoperator-worker-5wm2k 2/2 Running 0 45h numaresourcesoperator-worker-pb75c 2/2 Running 0 45h secondary-scheduler-7976c4d466-qm4sc 1/1 Running 0 21m
NAME READY STATUS RESTARTS AGE numaresources-controller-manager-d87d79587-76mrm 1/1 Running 0 46h numaresourcesoperator-worker-5wm2k 2/2 Running 0 45h numaresourcesoperator-worker-pb75c 2/2 Running 0 45h secondary-scheduler-7976c4d466-qm4sc 1/1 Running 0 21mCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc logs secondary-scheduler-7976c4d466-qm4sc -n openshift-numaresources
$ oc logs secondary-scheduler-7976c4d466-qm4sc -n openshift-numaresourcesCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.6.4.
oc get numaresourcesoperators.nodetopology.openshift.io numaresourcesoperator -o jsonpath="{.status.daemonsets[0]}"$ oc get numaresourcesoperators.nodetopology.openshift.io numaresourcesoperator -o jsonpath="{.status.daemonsets[0]}"Copy to Clipboard Copied! Toggle word wrap Toggle overflow {"name":"numaresourcesoperator-worker","namespace":"openshift-numaresources"}{"name":"numaresourcesoperator-worker","namespace":"openshift-numaresources"}Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc get ds -n openshift-numaresources numaresourcesoperator-worker -o jsonpath="{.spec.selector.matchLabels}"$ oc get ds -n openshift-numaresources numaresourcesoperator-worker -o jsonpath="{.spec.selector.matchLabels}"Copy to Clipboard Copied! Toggle word wrap Toggle overflow {"name":"resource-topology"}{"name":"resource-topology"}Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc get pods -n openshift-numaresources -l name=resource-topology -o wide
$ oc get pods -n openshift-numaresources -l name=resource-topology -o wideCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME READY STATUS RESTARTS AGE IP NODE numaresourcesoperator-worker-5wm2k 2/2 Running 0 2d1h 10.135.0.64 compute-0.example.com numaresourcesoperator-worker-pb75c 2/2 Running 0 2d1h 10.132.2.33 compute-1.example.com
NAME READY STATUS RESTARTS AGE IP NODE numaresourcesoperator-worker-5wm2k 2/2 Running 0 2d1h 10.135.0.64 compute-0.example.com numaresourcesoperator-worker-pb75c 2/2 Running 0 2d1h 10.132.2.33 compute-1.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc logs -n openshift-numaresources -c resource-topology-exporter numaresourcesoperator-worker-pb75c
$ oc logs -n openshift-numaresources -c resource-topology-exporter numaresourcesoperator-worker-pb75cCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.6.5.
Info: couldn't find configuration in "/etc/resource-topology-exporter/config.yaml"
Info: couldn't find configuration in "/etc/resource-topology-exporter/config.yaml"
oc get configmap
$ oc get configmap
NAME DATA AGE 0e2a6bd3.openshift-kni.io 0 6d21h kube-root-ca.crt 1 6d21h openshift-service-ca.crt 1 6d21h topo-aware-scheduler-config 1 6d18h
NAME DATA AGE
0e2a6bd3.openshift-kni.io 0 6d21h
kube-root-ca.crt 1 6d21h
openshift-service-ca.crt 1 6d21h
topo-aware-scheduler-config 1 6d18h
oc get kubeletconfig -o yaml
$ oc get kubeletconfig -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow machineConfigPoolSelector: matchLabels: cnf-worker-tuning: enabledmachineConfigPoolSelector: matchLabels: cnf-worker-tuning: enabledCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get mcp worker -o yaml
$ oc get mcp worker -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow labels: machineconfiguration.openshift.io/mco-built-in: "" pools.operator.machineconfiguration.openshift.io/worker: ""
labels: machineconfiguration.openshift.io/mco-built-in: "" pools.operator.machineconfiguration.openshift.io/worker: ""Copy to Clipboard Copied! Toggle word wrap Toggle overflow
oc edit mcp worker -o yaml
$ oc edit mcp worker -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow labels: machineconfiguration.openshift.io/mco-built-in: "" pools.operator.machineconfiguration.openshift.io/worker: "" cnf-worker-tuning: enabled
labels: machineconfiguration.openshift.io/mco-built-in: "" pools.operator.machineconfiguration.openshift.io/worker: "" cnf-worker-tuning: enabledCopy to Clipboard Copied! Toggle word wrap Toggle overflow
oc get configmap
$ oc get configmapCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.6.6.
oc adm must-gather --image=registry.redhat.io/numaresources-must-gather/numaresources-must-gather-rhel9:v4.15
$ oc adm must-gather --image=registry.redhat.io/numaresources-must-gather/numaresources-must-gather-rhel9:v4.15Copy to Clipboard Copied! Toggle word wrap Toggle overflow
10장.
10.1.
10.1.1.
|
| |
|
|
| |
|
|
| |
|
10.1.2.
|
| |||
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10.1.2.1.
10.1.2.1.1.
10.1.2.1.2.
10.1.2.1.3.
10.1.2.1.4.
10.1.2.1.5.
10.1.2.2.
10.1.3.
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10.1.4.
10.2.
10.2.1.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10.2.2.
|
|
|
|
|
|
|
|
|
oc -n openshift-ingress patch deploy/router-default --type=strategic --patch='{"spec":{"template":{"spec":{"containers":[{"name":"router","livenessProbe":{"timeoutSeconds":5},"readinessProbe":{"timeoutSeconds":5}}]}}}}'
$ oc -n openshift-ingress patch deploy/router-default --type=strategic --patch='{"spec":{"template":{"spec":{"containers":[{"name":"router","livenessProbe":{"timeoutSeconds":5},"readinessProbe":{"timeoutSeconds":5}}]}}}}'
oc -n openshift-ingress describe deploy/router-default | grep -e Liveness: -e Readiness:
$ oc -n openshift-ingress describe deploy/router-default | grep -e Liveness: -e Readiness:
Liveness: http-get http://:1936/healthz delay=0s timeout=5s period=10s #success=1 #failure=3
Readiness: http-get http://:1936/healthz/ready delay=0s timeout=5s period=10s #success=1 #failure=310.2.3.
oc -n openshift-ingress-operator patch ingresscontrollers/default --type=merge --patch='{"spec":{"tuningOptions":{"reloadInterval":"15s"}}}'$ oc -n openshift-ingress-operator patch ingresscontrollers/default --type=merge --patch='{"spec":{"tuningOptions":{"reloadInterval":"15s"}}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
10.3.
10.3.1.
10.3.2.
10.3.3.
10.4.
10.4.1.
10.4.2.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc apply -f mount_namespace_config.yaml
$ oc apply -f mount_namespace_config.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow machineconfig.machineconfiguration.openshift.io/99-kubens-master created machineconfig.machineconfiguration.openshift.io/99-kubens-worker created
machineconfig.machineconfiguration.openshift.io/99-kubens-master created machineconfig.machineconfiguration.openshift.io/99-kubens-worker createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get mcp
$ oc get mcpCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-03d4bc4befb0f4ed3566a2c8f7636751 False True False 3 0 0 0 45m worker rendered-worker-10577f6ab0117ed1825f8af2ac687ddf False True False 3 1 1
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-03d4bc4befb0f4ed3566a2c8f7636751 False True False 3 0 0 0 45m worker rendered-worker-10577f6ab0117ed1825f8af2ac687ddf False True False 3 1 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc wait --for=condition=Updated mcp --all --timeout=30m
$ oc wait --for=condition=Updated mcp --all --timeout=30mCopy to Clipboard Copied! Toggle word wrap Toggle overflow machineconfigpool.machineconfiguration.openshift.io/master condition met machineconfigpool.machineconfiguration.openshift.io/worker condition met
machineconfigpool.machineconfiguration.openshift.io/master condition met machineconfigpool.machineconfiguration.openshift.io/worker condition metCopy to Clipboard Copied! Toggle word wrap Toggle overflow
oc debug node/<node_name>
$ oc debug node/<node_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow chroot /host
sh-4.4# chroot /hostCopy to Clipboard Copied! Toggle word wrap Toggle overflow readlink /proc/1/ns/mnt
sh-4.4# readlink /proc/1/ns/mntCopy to Clipboard Copied! Toggle word wrap Toggle overflow mnt:[4026531953]
mnt:[4026531953]Copy to Clipboard Copied! Toggle word wrap Toggle overflow readlink /proc/$(pgrep kubelet)/ns/mnt
sh-4.4# readlink /proc/$(pgrep kubelet)/ns/mntCopy to Clipboard Copied! Toggle word wrap Toggle overflow mnt:[4026531840]
mnt:[4026531840]Copy to Clipboard Copied! Toggle word wrap Toggle overflow readlink /proc/$(pgrep crio)/ns/mnt
sh-4.4# readlink /proc/$(pgrep crio)/ns/mntCopy to Clipboard Copied! Toggle word wrap Toggle overflow mnt:[4026531840]
mnt:[4026531840]Copy to Clipboard Copied! Toggle word wrap Toggle overflow
10.4.3.
ssh core@<node_name>
$ ssh core@<node_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow sudo kubensenter findmnt
[core@control-plane-1 ~]$ sudo kubensenter findmntCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow sudo kubensenter
[core@control-plane-1 ~]$ sudo kubensenterCopy to Clipboard Copied! Toggle word wrap Toggle overflow kubensenter: Autodetect: kubens.service namespace found at /run/kubens/mnt
kubensenter: Autodetect: kubens.service namespace found at /run/kubens/mntCopy to Clipboard Copied! Toggle word wrap Toggle overflow
10.4.4.
[Unit] Description=Example service [Service] ExecStart=/usr/bin/kubensenter /path/to/original/command arg1 arg2
[Unit]
Description=Example service
[Service]
ExecStart=/usr/bin/kubensenter /path/to/original/command arg1 arg211장.
11.1.
11.2.
11.2.1.
11.2.2.
11.2.3.
oc annotate machineset <machineset> -n openshift-machine-api 'metal3.io/autoscale-to-hosts=<any_value>'
$ oc annotate machineset <machineset> -n openshift-machine-api 'metal3.io/autoscale-to-hosts=<any_value>'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
11.2.4.
oc annotate machineset <machineset> -n openshift-machine-api 'baremetalhost.metal3.io/detached'
$ oc annotate machineset <machineset> -n openshift-machine-api 'baremetalhost.metal3.io/detached'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고oc annotate machineset <machineset> -n openshift-machine-api 'baremetalhost.metal3.io/detached-'
$ oc annotate machineset <machineset> -n openshift-machine-api 'baremetalhost.metal3.io/detached-'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
11.2.5.
oc get baremetalhosts -n openshift-machine-api -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.provisioning.state}{"\n"}{end}'$ oc get baremetalhosts -n openshift-machine-api -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.provisioning.state}{"\n"}{end}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc adm cordon <bare_metal_host>
$ oc adm cordon <bare_metal_host>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc adm drain <bare_metal_host> --force=true
$ oc adm drain <bare_metal_host> --force=trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc patch <bare_metal_host> --type json -p '[{"op": "replace", "path": "/spec/online", "value": false}]'$ oc patch <bare_metal_host> --type json -p '[{"op": "replace", "path": "/spec/online", "value": false}]'Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc adm uncordon <bare_metal_host>
$ oc adm uncordon <bare_metal_host>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
12장.
12.1.
12.2.
12.2.1.
그림 12.1.
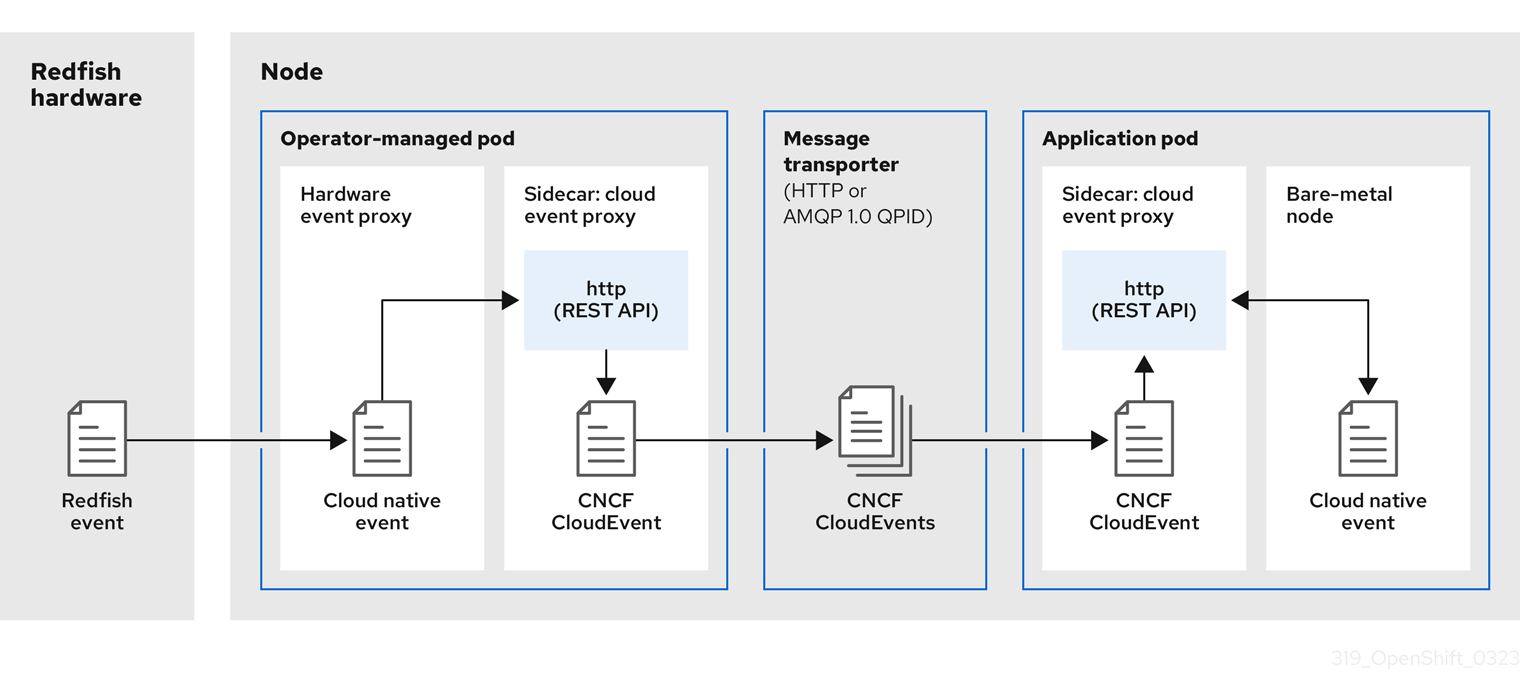
12.2.1.1.
12.2.1.2.
12.2.1.3.
12.2.1.4.
12.2.1.5.
12.2.1.6.
12.2.2.
12.2.3.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f bare-metal-events-namespace.yaml
$ oc create -f bare-metal-events-namespace.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f bare-metal-events-operatorgroup.yaml
$ oc create -f bare-metal-events-operatorgroup.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f bare-metal-events-sub.yaml
$ oc create -f bare-metal-events-sub.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
oc get csv -n openshift-bare-metal-events -o custom-columns=Name:.metadata.name,Phase:.status.phase
$ oc get csv -n openshift-bare-metal-events -o custom-columns=Name:.metadata.name,Phase:.status.phase12.2.4.
- 참고
12.3.
oc get pods -n amq-interconnect
$ oc get pods -n amq-interconnectCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME READY STATUS RESTARTS AGE amq-interconnect-645db76c76-k8ghs 1/1 Running 0 23h interconnect-operator-5cb5fc7cc-4v7qm 1/1 Running 0 23h
NAME READY STATUS RESTARTS AGE amq-interconnect-645db76c76-k8ghs 1/1 Running 0 23h interconnect-operator-5cb5fc7cc-4v7qm 1/1 Running 0 23hCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get pods -n openshift-bare-metal-events
$ oc get pods -n openshift-bare-metal-eventsCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME READY STATUS RESTARTS AGE hw-event-proxy-operator-controller-manager-74d5649b7c-dzgtl 2/2 Running 0 25s
NAME READY STATUS RESTARTS AGE hw-event-proxy-operator-controller-manager-74d5649b7c-dzgtl 2/2 Running 0 25sCopy to Clipboard Copied! Toggle word wrap Toggle overflow
12.4.
12.4.1.
- 참고
curl https://<bmc_ip_address>/redfish/v1/EventService --insecure -H 'Content-Type: application/json' -u "<bmc_username>:<password>"
$ curl https://<bmc_ip_address>/redfish/v1/EventService --insecure -H 'Content-Type: application/json' -u "<bmc_username>:<password>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc get route -n openshift-bare-metal-events
$ oc get route -n openshift-bare-metal-eventsCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD hw-event-proxy hw-event-proxy-openshift-bare-metal-events.apps.compute-1.example.com hw-event-proxy-service 9087 edge None
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD hw-event-proxy hw-event-proxy-openshift-bare-metal-events.apps.compute-1.example.com hw-event-proxy-service 9087 edge NoneCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc delete -f bmc_sub.yaml
$ oc delete -f bmc_sub.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow curl -i -k -X POST -H "Content-Type: application/json" -d '{"Destination": "https://<proxy_service_url>", "Protocol" : "Redfish", "EventTypes": ["Alert"], "Context": "root"}' -u <bmc_username>:<password> 'https://<bmc_ip_address>/redfish/v1/EventService/Subscriptions' –v$ curl -i -k -X POST -H "Content-Type: application/json" -d '{"Destination": "https://<proxy_service_url>", "Protocol" : "Redfish", "EventTypes": ["Alert"], "Context": "root"}' -u <bmc_username>:<password> 'https://<bmc_ip_address>/redfish/v1/EventService/Subscriptions' –vCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
12.4.2.
curl --globoff -H "Content-Type: application/json" -k -X GET --user <bmc_username>:<password> https://<bmc_ip_address>/redfish/v1/EventService/Subscriptions
$ curl --globoff -H "Content-Type: application/json" -k -X GET --user <bmc_username>:<password> https://<bmc_ip_address>/redfish/v1/EventService/SubscriptionsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow curl --globoff -L -w "%{http_code} %{url_effective}\n" -k -u <bmc_username>:<password >-H "Content-Type: application/json" -d '{}' -X DELETE https://<bmc_ip_address>/redfish/v1/EventService/Subscriptions/1$ curl --globoff -L -w "%{http_code} %{url_effective}\n" -k -u <bmc_username>:<password >-H "Content-Type: application/json" -d '{}' -X DELETE https://<bmc_ip_address>/redfish/v1/EventService/Subscriptions/1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
12.4.3.
- 참고
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f hw-event-bmc-secret.yaml
$ oc create -f hw-event-bmc-secret.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
12.5.
|
|
|
{
"uriLocation": "http://localhost:8089/api/ocloudNotifications/v1/subscriptions",
"resource": "/cluster/node/openshift-worker-0.openshift.example.com/redfish/event"
}
{
"uriLocation": "http://localhost:8089/api/ocloudNotifications/v1/subscriptions",
"resource": "/cluster/node/openshift-worker-0.openshift.example.com/redfish/event"
}
|
|
|
OK
OK12.6.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
13장.
13.1.
13.2.
13.3.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f hugepages-volume-pod.yaml
$ oc create -f hugepages-volume-pod.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
oc exec -it $(oc get pods -l app=hugepages-example -o jsonpath='{.items[0].metadata.name}') \ -- env | grep REQUESTS_HUGEPAGES_1GI$ oc exec -it $(oc get pods -l app=hugepages-example -o jsonpath='{.items[0].metadata.name}') \ -- env | grep REQUESTS_HUGEPAGES_1GICopy to Clipboard Copied! Toggle word wrap Toggle overflow REQUESTS_HUGEPAGES_1GI=2147483648
REQUESTS_HUGEPAGES_1GI=2147483648Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc exec -it $(oc get pods -l app=hugepages-example -o jsonpath='{.items[0].metadata.name}') \ -- cat /etc/podinfo/hugepages_1G_request$ oc exec -it $(oc get pods -l app=hugepages-example -o jsonpath='{.items[0].metadata.name}') \ -- cat /etc/podinfo/hugepages_1G_requestCopy to Clipboard Copied! Toggle word wrap Toggle overflow 2
2Copy to Clipboard Copied! Toggle word wrap Toggle overflow
13.4.
oc label node <node_using_hugepages> node-role.kubernetes.io/worker-hp=
$ oc label node <node_using_hugepages> node-role.kubernetes.io/worker-hp=Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f hugepages-tuned-boottime.yaml
$ oc create -f hugepages-tuned-boottime.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f hugepages-mcp.yaml
$ oc create -f hugepages-mcp.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
oc get node <node_using_hugepages> -o jsonpath="{.status.allocatable.hugepages-2Mi}"
$ oc get node <node_using_hugepages> -o jsonpath="{.status.allocatable.hugepages-2Mi}"
100Mi
13.5.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create -f thp-disable-tuned.yaml
$ oc create -f thp-disable-tuned.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get profile -n openshift-cluster-node-tuning-operator
$ oc get profile -n openshift-cluster-node-tuning-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow
cat /sys/kernel/mm/transparent_hugepage/enabled
$ cat /sys/kernel/mm/transparent_hugepage/enabledCopy to Clipboard Copied! Toggle word wrap Toggle overflow always madvise [never]
always madvise [never]Copy to Clipboard Copied! Toggle word wrap Toggle overflow
14장.
14.1.
14.2.
15장.
15.1.
15.1.1.
15.1.2.
oc label node <node_name> node-role.kubernetes.io/worker-cnf=""
$ oc label node <node_name> node-role.kubernetes.io/worker-cnf=""1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc apply -f mcp-worker-cnf.yaml
$ oc apply -f mcp-worker-cnf.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow machineconfigpool.machineconfiguration.openshift.io/worker-cnf created
machineconfigpool.machineconfiguration.openshift.io/worker-cnf createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
oc get mcp
$ oc get mcpCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-58433c7c3c1b4ed5ffef95234d451490 True False False 3 3 3 0 6h46m worker rendered-worker-168f52b168f151e4f853259729b6azc4 True False False 2 2 2 0 6h46m worker-cnf rendered-worker-cnf-168f52b168f151e4f853259729b6azc4 True False False 1 1 1 0 73s
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-58433c7c3c1b4ed5ffef95234d451490 True False False 3 3 3 0 6h46m worker rendered-worker-168f52b168f151e4f853259729b6azc4 True False False 2 2 2 0 6h46m worker-cnf rendered-worker-cnf-168f52b168f151e4f853259729b6azc4 True False False 1 1 1 0 73sCopy to Clipboard Copied! Toggle word wrap Toggle overflow
15.1.3.
oc adm must-gather
$ oc adm must-gatherCopy to Clipboard Copied! Toggle word wrap Toggle overflow tar cvaf must-gather.tar.gz <must_gather_folder>
$ tar cvaf must-gather.tar.gz <must_gather_folder>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고
15.1.4.
oc get mcp
$ oc get mcpCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-58433c8c3c0b4ed5feef95434d455490 True False False 3 3 3 0 8h worker rendered-worker-668f56a164f151e4a853229729b6adc4 True False False 2 2 2 0 8h worker-cnf rendered-worker-cnf-668f56a164f151e4a853229729b6adc4 True False False 1 1 1 0 79m
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-58433c8c3c0b4ed5feef95434d455490 True False False 3 3 3 0 8h worker rendered-worker-668f56a164f151e4a853229729b6adc4 True False False 2 2 2 0 8h worker-cnf rendered-worker-cnf-668f56a164f151e4a853229729b6adc4 True False False 1 1 1 0 79mCopy to Clipboard Copied! Toggle word wrap Toggle overflow podman login registry.redhat.io
$ podman login registry.redhat.ioCopy to Clipboard Copied! Toggle word wrap Toggle overflow Username: <user_name> Password: <password>
Username: <user_name> Password: <password>Copy to Clipboard Copied! Toggle word wrap Toggle overflow podman run --rm --entrypoint performance-profile-creator registry.redhat.io/openshift4/ose-cluster-node-tuning-rhel9-operator:v4.15 -h
$ podman run --rm --entrypoint performance-profile-creator registry.redhat.io/openshift4/ose-cluster-node-tuning-rhel9-operator:v4.15 -hCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow podman run --entrypoint performance-profile-creator -v <path_to_must_gather>:/must-gather:z registry.redhat.io/openshift4/ose-cluster-node-tuning-rhel9-operator:v4.15 --info log --must-gather-dir-path /must-gather
$ podman run --entrypoint performance-profile-creator -v <path_to_must_gather>:/must-gather:z registry.redhat.io/openshift4/ose-cluster-node-tuning-rhel9-operator:v4.15 --info log --must-gather-dir-path /must-gatherCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
podman run --entrypoint performance-profile-creator -v <path_to_must_gather>:/must-gather:z registry.redhat.io/openshift4/ose-cluster-node-tuning-rhel9-operator:v4.15 --mcp-name=worker-cnf --reserved-cpu-count=1 --rt-kernel=true --split-reserved-cpus-across-numa=false --must-gather-dir-path /must-gather --power-consumption-mode=ultra-low-latency --offlined-cpu-count=1 > my-performance-profile.yaml
$ podman run --entrypoint performance-profile-creator -v <path_to_must_gather>:/must-gather:z registry.redhat.io/openshift4/ose-cluster-node-tuning-rhel9-operator:v4.15 --mcp-name=worker-cnf --reserved-cpu-count=1 --rt-kernel=true --split-reserved-cpus-across-numa=false --must-gather-dir-path /must-gather --power-consumption-mode=ultra-low-latency --offlined-cpu-count=1 > my-performance-profile.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 참고
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
cat my-performance-profile.yaml
$ cat my-performance-profile.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc apply -f my-performance-profile.yaml
$ oc apply -f my-performance-profile.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow performanceprofile.performance.openshift.io/performance created
performanceprofile.performance.openshift.io/performance createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
15.1.5.
vi run-perf-profile-creator.sh
$ vi run-perf-profile-creator.shCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow chmod a+x run-perf-profile-creator.sh
$ chmod a+x run-perf-profile-creator.shCopy to Clipboard Copied! Toggle word wrap Toggle overflow podman login registry.redhat.io
$ podman login registry.redhat.ioCopy to Clipboard Copied! Toggle word wrap Toggle overflow Username: <user_name> Password: <password>
Username: <user_name> Password: <password>Copy to Clipboard Copied! Toggle word wrap Toggle overflow ./run-perf-profile-creator.sh -h
$ ./run-perf-profile-creator.sh -hCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고./run-perf-profile-creator.sh -t /<path_to_must_gather_dir>/must-gather.tar.gz -- --info=log
$ ./run-perf-profile-creator.sh -t /<path_to_must_gather_dir>/must-gather.tar.gz -- --info=logCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
./run-perf-profile-creator.sh -t /path-to-must-gather/must-gather.tar.gz -- --mcp-name=worker-cnf --reserved-cpu-count=1 --rt-kernel=true --split-reserved-cpus-across-numa=false --power-consumption-mode=ultra-low-latency --offlined-cpu-count=1 > my-performance-profile.yaml
$ ./run-perf-profile-creator.sh -t /path-to-must-gather/must-gather.tar.gz -- --mcp-name=worker-cnf --reserved-cpu-count=1 --rt-kernel=true --split-reserved-cpus-across-numa=false --power-consumption-mode=ultra-low-latency --offlined-cpu-count=1 > my-performance-profile.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 참고
cat my-performance-profile.yaml
$ cat my-performance-profile.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc apply -f my-performance-profile.yaml
$ oc apply -f my-performance-profile.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow performanceprofile.performance.openshift.io/performance created
performanceprofile.performance.openshift.io/performance createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
15.1.6.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
주의
|
|
|
|
|
|
참고
Error: failed to compute the reserved and isolated CPUs: please ensure that reserved-cpu-count plus offlined-cpu-count should be in the range [0,1] Error: failed to compute the reserved and isolated CPUs: please specify the offlined CPU count in the range [0,1] |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
15.1.7.
15.1.7.1.
15.1.7.2.
15.1.7.3.
15.2.
15.3.
|
|
workloadHints: highPowerConsumption: false realTime: false |
|
|
|
|
workloadHints: highPowerConsumption: false realTime: true |
|
|
|
|
workloadHints: highPowerConsumption: true realTime: true |
|
|
|
|
workloadHints: realTime: true highPowerConsumption: false perPodPowerManagement: true |
|
|
15.4.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow spec: profile: - data: | [sysfs] /sys/devices/system/cpu/intel_pstate/max_perf_pct = <x>spec: profile: - data: | [sysfs] /sys/devices/system/cpu/intel_pstate/max_perf_pct = <x>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow
15.5.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
15.6.
lscpu --all --extended
$ lscpu --all --extendedCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow cat /sys/devices/system/cpu/cpu0/topology/thread_siblings_list
$ cat /sys/devices/system/cpu/cpu0/topology/thread_siblings_listCopy to Clipboard Copied! Toggle word wrap Toggle overflow 0-4
0-4Copy to Clipboard Copied! Toggle word wrap Toggle overflow ... cpu: isolated: 0,4 reserved: 1-3,5-7 ...... cpu: isolated: 0,4 reserved: 1-3,5-7 ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고
15.6.1.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고
15.7.
15.7.1.
find /proc/irq -name effective_affinity -printf "%p: " -exec cat {} \;
$ find /proc/irq -name effective_affinity -printf "%p: " -exec cat {} \;
15.7.2.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고
15.8.
oc debug node/ip-10-0-141-105.ec2.internal
$ oc debug node/ip-10-0-141-105.ec2.internalCopy to Clipboard Copied! Toggle word wrap Toggle overflow grep -i huge /proc/meminfo
# grep -i huge /proc/meminfoCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc describe node worker-0.ocp4poc.example.com | grep -i huge
$ oc describe node worker-0.ocp4poc.example.com | grep -i hugeCopy to Clipboard Copied! Toggle word wrap Toggle overflow hugepages-1g=true hugepages-###: ### hugepages-###: ###
hugepages-1g=true hugepages-###: ### hugepages-###: ###Copy to Clipboard Copied! Toggle word wrap Toggle overflow
15.8.1.
15.9.
15.9.1.
oc edit -f <your_profile_name>.yaml
$ oc edit -f <your_profile_name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 참고
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc apply -f <your_profile_name>.yaml
$ oc apply -f <your_profile_name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
15.9.2.
- 참고
ethtool -l <device>
$ ethtool -l <device>Copy to Clipboard Copied! Toggle word wrap Toggle overflow ethtool -l ens4
$ ethtool -l ens4Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow ethtool -l ens4
$ ethtool -l ens4Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- 참고
ethtool -l <device>
$ ethtool -l <device>Copy to Clipboard Copied! Toggle word wrap Toggle overflow ethtool -l ens4
$ ethtool -l ens4Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Copy to Clipboard Copied! Toggle word wrap Toggle overflow ethtool -l ens4
$ ethtool -l ens4Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
15.9.3.
INFO tuned.plugins.base: instance net_test (net): assigning devices ens1, ens2, ens3
INFO tuned.plugins.base: instance net_test (net): assigning devices ens1, ens2, ens3Copy to Clipboard Copied! Toggle word wrap Toggle overflow WARNING tuned.plugins.base: instance net_test: no matching devices available
WARNING tuned.plugins.base: instance net_test: no matching devices availableCopy to Clipboard Copied! Toggle word wrap Toggle overflow
16장.
16.1.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc get pod -o wide
$ oc get pod -o wideCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME READY STATUS RESTARTS AGE IP NODE dynamic-low-latency-pod 1/1 Running 0 5h33m 10.131.0.10 cnf-worker.example.com
NAME READY STATUS RESTARTS AGE IP NODE dynamic-low-latency-pod 1/1 Running 0 5h33m 10.131.0.10 cnf-worker.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc exec -it dynamic-low-latency-pod -- /bin/bash -c "grep Cpus_allowed_list /proc/self/status | awk '{print $2}'"$ oc exec -it dynamic-low-latency-pod -- /bin/bash -c "grep Cpus_allowed_list /proc/self/status | awk '{print $2}'"Copy to Clipboard Copied! Toggle word wrap Toggle overflow Cpus_allowed_list: 2-3
Cpus_allowed_list: 2-3Copy to Clipboard Copied! Toggle word wrap Toggle overflow
oc debug node/<node-name>
$ oc debug node/<node-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow chroot /host
sh-4.4# chroot /hostCopy to Clipboard Copied! Toggle word wrap Toggle overflow sh-4.4#
sh-4.4#Copy to Clipboard Copied! Toggle word wrap Toggle overflow cat /proc/irq/default_smp_affinity
sh-4.4# cat /proc/irq/default_smp_affinityCopy to Clipboard Copied! Toggle word wrap Toggle overflow 33
33Copy to Clipboard Copied! Toggle word wrap Toggle overflow find /proc/irq/ -name smp_affinity_list -exec sh -c 'i="$1"; mask=$(cat $i); file=$(echo $i); echo $file: $mask' _ {} \;sh-4.4# find /proc/irq/ -name smp_affinity_list -exec sh -c 'i="$1"; mask=$(cat $i); file=$(echo $i); echo $file: $mask' _ {} \;Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
16.2.
oc apply -f qos-pod.yaml --namespace=qos-example
$ oc apply -f qos-pod.yaml --namespace=qos-exampleCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get pod qos-demo --namespace=qos-example --output=yaml
$ oc get pod qos-demo --namespace=qos-example --output=yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow spec: containers: ... status: qosClass: Guaranteedspec: containers: ... status: qosClass: GuaranteedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고
16.3.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
16.4.
|
| |
|
|
|
|
|
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
16.5.
16.6.
17장.
17.1.
17.1.1.
oc get mcp
# oc get mcpCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-2ee57a93fa6c9181b546ca46e1571d2d True False False 3 3 3 0 2d21h worker rendered-worker-d6b2bdc07d9f5a59a6b68950acf25e5f True False False 2 2 2 0 2d21h worker-cnf rendered-worker-cnf-6c838641b8a08fff08dbd8b02fb63f7c False True True 2 1 1 1 2d20h
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-2ee57a93fa6c9181b546ca46e1571d2d True False False 3 3 3 0 2d21h worker rendered-worker-d6b2bdc07d9f5a59a6b68950acf25e5f True False False 2 2 2 0 2d21h worker-cnf rendered-worker-cnf-6c838641b8a08fff08dbd8b02fb63f7c False True True 2 1 1 1 2d20hCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc describe mcp worker-cnf
# oc describe mcp worker-cnfCopy to Clipboard Copied! Toggle word wrap Toggle overflow Message: Node node-worker-cnf is reporting: "prepping update: machineconfig.machineconfiguration.openshift.io \"rendered-worker-cnf-40b9996919c08e335f3ff230ce1d170\" not found" Reason: 1 nodes are reporting degraded status on syncMessage: Node node-worker-cnf is reporting: "prepping update: machineconfig.machineconfiguration.openshift.io \"rendered-worker-cnf-40b9996919c08e335f3ff230ce1d170\" not found" Reason: 1 nodes are reporting degraded status on syncCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc describe performanceprofiles performance
# oc describe performanceprofiles performanceCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
17.2.
17.2.1.
17.2.2.
oc adm must-gather
$ oc adm must-gatherCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow tar cvaf must-gather.tar.gz must-gather-local.5421342344627712289
$ tar cvaf must-gather.tar.gz must-gather-local.54213423446277122891 Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고
18장.
18.1.
18.2.
|
|
|
|
|
|
|
|
참고
|
|
|
|
|
|
|
|
|
|
|
|
|
18.3.
- 참고
podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUNTIME=600\ -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 /usr/bin/test-run.sh \ --ginkgo.v --ginkgo.timeout="24h"
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUNTIME=600\ -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 /usr/bin/test-run.sh \ --ginkgo.v --ginkgo.timeout="24h"Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 중요
18.3.1.
podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/test-run.sh --ginkgo.focus="hwlatdetect" --ginkgo.v --ginkgo.timeout="24h"
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/test-run.sh --ginkgo.focus="hwlatdetect" --ginkgo.v --ginkgo.timeout="24h"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 중요Copy to Clipboard Copied! Toggle word wrap Toggle overflow
18.3.2.
podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_CPUS=10 -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/test-run.sh --ginkgo.focus="cyclictest" --ginkgo.v --ginkgo.timeout="24h"
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_CPUS=10 -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/test-run.sh --ginkgo.focus="cyclictest" --ginkgo.v --ginkgo.timeout="24h"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 중요Copy to Clipboard Copied! Toggle word wrap Toggle overflow
18.3.3.
podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_CPUS=10 -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/test-run.sh --ginkgo.focus="oslat" --ginkgo.v --ginkgo.timeout="24h"
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_CPUS=10 -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/test-run.sh --ginkgo.focus="oslat" --ginkgo.v --ginkgo.timeout="24h"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 중요Copy to Clipboard Copied! Toggle word wrap Toggle overflow
18.4.
podman run -v $(pwd)/:/kubeconfig:Z -v $(pwd)/reportdest:<report_folder_path> \ -e KUBECONFIG=/kubeconfig/kubeconfig registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/test-run.sh --report <report_folder_path> --ginkgo.v
$ podman run -v $(pwd)/:/kubeconfig:Z -v $(pwd)/reportdest:<report_folder_path> \ -e KUBECONFIG=/kubeconfig/kubeconfig registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/test-run.sh --report <report_folder_path> --ginkgo.vCopy to Clipboard Copied! Toggle word wrap Toggle overflow
18.5.
- 참고
podman run -v $(pwd)/:/kubeconfig:Z -v $(pwd)/junit:/junit \ -e KUBECONFIG=/kubeconfig/kubeconfig registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/test-run.sh --ginkgo.junit-report junit/<file-name>.xml --ginkgo.v
$ podman run -v $(pwd)/:/kubeconfig:Z -v $(pwd)/junit:/junit \ -e KUBECONFIG=/kubeconfig/kubeconfig registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/test-run.sh --ginkgo.junit-report junit/<file-name>.xml --ginkgo.vCopy to Clipboard Copied! Toggle word wrap Toggle overflow
18.6.
podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUNTIME=<time_in_seconds> registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/test-run.sh --ginkgo.v --ginkgo.timeout="24h"
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUNTIME=<time_in_seconds> registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/test-run.sh --ginkgo.v --ginkgo.timeout="24h"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고
18.7.
podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/mirror -registry <disconnected_registry> | oc image mirror -f -
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/mirror -registry <disconnected_registry> | oc image mirror -f -Copy to Clipboard Copied! Toggle word wrap Toggle overflow podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e IMAGE_REGISTRY="<disconnected_registry>" \ -e CNF_TESTS_IMAGE="cnf-tests-rhel8:v4.15" \ -e LATENCY_TEST_RUNTIME=<time_in_seconds> \ <disconnected_registry>/cnf-tests-rhel8:v4.15 /usr/bin/test-run.sh --ginkgo.v --ginkgo.timeout="24h"
podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e IMAGE_REGISTRY="<disconnected_registry>" \ -e CNF_TESTS_IMAGE="cnf-tests-rhel8:v4.15" \ -e LATENCY_TEST_RUNTIME=<time_in_seconds> \ <disconnected_registry>/cnf-tests-rhel8:v4.15 /usr/bin/test-run.sh --ginkgo.v --ginkgo.timeout="24h"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e IMAGE_REGISTRY="<custom_image_registry>" \ -e CNF_TESTS_IMAGE="<custom_cnf-tests_image>" \ -e LATENCY_TEST_RUNTIME=<time_in_seconds> \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 /usr/bin/test-run.sh --ginkgo.v --ginkgo.timeout="24h"
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e IMAGE_REGISTRY="<custom_image_registry>" \ -e CNF_TESTS_IMAGE="<custom_cnf-tests_image>" \ -e LATENCY_TEST_RUNTIME=<time_in_seconds> \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 /usr/bin/test-run.sh --ginkgo.v --ginkgo.timeout="24h"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
oc patch configs.imageregistry.operator.openshift.io/cluster --patch '{"spec":{"defaultRoute":true}}' --type=merge$ oc patch configs.imageregistry.operator.openshift.io/cluster --patch '{"spec":{"defaultRoute":true}}' --type=mergeCopy to Clipboard Copied! Toggle word wrap Toggle overflow REGISTRY=$(oc get route default-route -n openshift-image-registry --template='{{ .spec.host }}')$ REGISTRY=$(oc get route default-route -n openshift-image-registry --template='{{ .spec.host }}')Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc create ns cnftests
$ oc create ns cnftestsCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc policy add-role-to-user system:image-puller system:serviceaccount:cnf-features-testing:default --namespace=cnftests
$ oc policy add-role-to-user system:image-puller system:serviceaccount:cnf-features-testing:default --namespace=cnftestsCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc policy add-role-to-user system:image-puller system:serviceaccount:performance-addon-operators-testing:default --namespace=cnftests
$ oc policy add-role-to-user system:image-puller system:serviceaccount:performance-addon-operators-testing:default --namespace=cnftestsCopy to Clipboard Copied! Toggle word wrap Toggle overflow SECRET=$(oc -n cnftests get secret | grep builder-docker | awk {'print $1'}$ SECRET=$(oc -n cnftests get secret | grep builder-docker | awk {'print $1'}Copy to Clipboard Copied! Toggle word wrap Toggle overflow TOKEN=$(oc -n cnftests get secret $SECRET -o jsonpath="{.data['\.dockercfg']}" | base64 --decode | jq '.["image-registry.openshift-image-registry.svc:5000"].auth')$ TOKEN=$(oc -n cnftests get secret $SECRET -o jsonpath="{.data['\.dockercfg']}" | base64 --decode | jq '.["image-registry.openshift-image-registry.svc:5000"].auth')Copy to Clipboard Copied! Toggle word wrap Toggle overflow echo "{\"auths\": { \"$REGISTRY\": { \"auth\": $TOKEN } }}" > dockerauth.json$ echo "{\"auths\": { \"$REGISTRY\": { \"auth\": $TOKEN } }}" > dockerauth.jsonCopy to Clipboard Copied! Toggle word wrap Toggle overflow podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:4.15 \ /usr/bin/mirror -registry $REGISTRY/cnftests | oc image mirror --insecure=true \ -a=$(pwd)/dockerauth.json -f -
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:4.15 \ /usr/bin/mirror -registry $REGISTRY/cnftests | oc image mirror --insecure=true \ -a=$(pwd)/dockerauth.json -f -Copy to Clipboard Copied! Toggle word wrap Toggle overflow podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUNTIME=<time_in_seconds> \ -e IMAGE_REGISTRY=image-registry.openshift-image-registry.svc:5000/cnftests cnf-tests-local:latest /usr/bin/test-run.sh --ginkgo.v --ginkgo.timeout="24h"
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUNTIME=<time_in_seconds> \ -e IMAGE_REGISTRY=image-registry.openshift-image-registry.svc:5000/cnftests cnf-tests-local:latest /usr/bin/test-run.sh --ginkgo.v --ginkgo.timeout="24h"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Copy to Clipboard Copied! Toggle word wrap Toggle overflow podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 /usr/bin/mirror \ --registry "my.local.registry:5000/" --images "/kubeconfig/images.json" \ | oc image mirror -f -
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 /usr/bin/mirror \ --registry "my.local.registry:5000/" --images "/kubeconfig/images.json" \ | oc image mirror -f -Copy to Clipboard Copied! Toggle word wrap Toggle overflow
18.8.
podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ oc get nodes
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
19장.
19.1.
Expand Expand Expand
19.2.
openshift-install create manifests --dir=<cluster-install-dir>
$ openshift-install create manifests --dir=<cluster-install-dir>Copy to Clipboard Copied! Toggle word wrap Toggle overflow vi <cluster-install-dir>/manifests/config-node-default-profile.yaml
$ vi <cluster-install-dir>/manifests/config-node-default-profile.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
19.3.
oc edit nodes.config/cluster
$ oc edit nodes.config/clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
oc edit nodes.config/cluster
$ oc edit nodes.config/clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
oc get KubeControllerManager -o yaml | grep -i workerlatency -A 5 -B 5
$ oc get KubeControllerManager -o yaml | grep -i workerlatency -A 5 -B 5Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
19.4.
oc get KubeAPIServer -o yaml | grep -A 1 default-
$ oc get KubeAPIServer -o yaml | grep -A 1 default-Copy to Clipboard Copied! Toggle word wrap Toggle overflow default-not-ready-toleration-seconds: - "300" default-unreachable-toleration-seconds: - "300"
default-not-ready-toleration-seconds: - "300" default-unreachable-toleration-seconds: - "300"Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc get KubeControllerManager -o yaml | grep -A 1 node-monitor
$ oc get KubeControllerManager -o yaml | grep -A 1 node-monitorCopy to Clipboard Copied! Toggle word wrap Toggle overflow node-monitor-grace-period: - 40s
node-monitor-grace-period: - 40sCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc debug node/<worker-node-name> chroot /host cat /etc/kubernetes/kubelet.conf|grep nodeStatusUpdateFrequency
$ oc debug node/<worker-node-name> $ chroot /host # cat /etc/kubernetes/kubelet.conf|grep nodeStatusUpdateFrequencyCopy to Clipboard Copied! Toggle word wrap Toggle overflow “nodeStatusUpdateFrequency”: “10s”
“nodeStatusUpdateFrequency”: “10s”Copy to Clipboard Copied! Toggle word wrap Toggle overflow
20장.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 표 20.1. 중요
21장.
21.1.
21.2.
21.2.1.
oc get packagemanifests -n openshift-marketplace node-observability-operator
$ oc get packagemanifests -n openshift-marketplace node-observability-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME CATALOG AGE node-observability-operator Red Hat Operators 9h
NAME CATALOG AGE node-observability-operator Red Hat Operators 9hCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc new-project node-observability-operator
$ oc new-project node-observability-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
oc -n node-observability-operator get sub node-observability-operator -o yaml | yq '.status.installplan.name'
$ oc -n node-observability-operator get sub node-observability-operator -o yaml | yq '.status.installplan.name'Copy to Clipboard Copied! Toggle word wrap Toggle overflow install-dt54w
install-dt54wCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc -n node-observability-operator get ip <install_plan_name> -o yaml | yq '.status.phase'
$ oc -n node-observability-operator get ip <install_plan_name> -o yaml | yq '.status.phase'Copy to Clipboard Copied! Toggle word wrap Toggle overflow COMPLETE
COMPLETECopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get deploy -n node-observability-operator
$ oc get deploy -n node-observability-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME READY UP-TO-DATE AVAILABLE AGE node-observability-operator-controller-manager 1/1 1 1 40h
NAME READY UP-TO-DATE AVAILABLE AGE node-observability-operator-controller-manager 1/1 1 1 40hCopy to Clipboard Copied! Toggle word wrap Toggle overflow
21.2.2.
21.3.
21.3.1.
oc login -u kubeadmin https://<HOSTNAME>:6443
$ oc login -u kubeadmin https://<HOSTNAME>:6443Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc project node-observability-operator
$ oc project node-observability-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc apply -f nodeobservability.yaml
oc apply -f nodeobservability.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow nodeobservability.olm.openshift.io/cluster created
nodeobservability.olm.openshift.io/cluster createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get nob/cluster -o yaml | yq '.status.conditions'
$ oc get nob/cluster -o yaml | yq '.status.conditions'Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
21.3.2.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc apply -f nodeobservabilityrun.yaml
$ oc apply -f nodeobservabilityrun.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get nodeobservabilityrun nodeobservabilityrun -o yaml | yq '.status.conditions'
$ oc get nodeobservabilityrun nodeobservabilityrun -o yaml | yq '.status.conditions'Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
21.4.
21.4.1.
oc login -u kubeadmin https://<host_name>:6443
$ oc login -u kubeadmin https://<host_name>:6443Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc project node-observability-operator
$ oc project node-observability-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc apply -f nodeobservability.yaml
$ oc apply -f nodeobservability.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow nodeobservability.olm.openshift.io/cluster created
nodeobservability.olm.openshift.io/cluster createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get nob/cluster -o yaml | yq '.status.conditions'
$ oc get nob/cluster -o yaml | yq '.status.conditions'Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
21.4.2.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 중요oc apply -f nodeobservabilityrun-script.yaml
$ oc apply -f nodeobservabilityrun-script.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get nodeobservabilityrun nodeobservabilityrun-script -o yaml | yq '.status.conditions'
$ oc get nodeobservabilityrun nodeobservabilityrun-script -o yaml | yq '.status.conditions'Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Legal Notice
Copyright © 2025 Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of Joyent. Red Hat Software Collections is not formally related to or endorsed by the official Joyent Node.js open source or commercial project.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.