虚拟化
OpenShift Virtualization 安装、使用和发行注记
摘要
第 1 章 关于 OpenShift virtualization
OpenShift Virtualization 的功能与支持范围。
1.1. OpenShift Virtualization 的作用
OpenShift 虚拟化(OpenShift virtualization)是 OpenShift Container Platform 的一个附加组件,可用于运行和管理虚拟机工作负载以及容器工作负载。
OpenShift Virtualization 通过 Kubernetes 自定义资源添加新对象至 OpenShift Container Platform 集群中,以启用虚拟化任务。这些任务包括:
- 创建和管理 Linux 和 Windows 虚拟机 (VM)
- 在集群中运行 pod 和虚拟机工作负载
- 通过各种控制台和 CLI 工具连接至虚拟机
- 导入和克隆现有虚拟机
- 管理虚拟机上附加的网络接口控制器和存储磁盘
- 在节点间实时迁移虚拟机
增强版 web 控制台提供了一个图形化的门户界面 来管理虚拟化资源以及 OpenShift Container Platform 集群容器和基础架构。
OpenShift Virtualization 的设计和测试,可与 Red Hat OpenShift Data Foundation 功能配合工作。
在部署带有 OpenShift Data Foundation 的 OpenShift Virtualization 时,您必须为 Windows 虚拟机磁盘创建一个专用存储类。详情请参阅为 Windows 虚拟机优化 ODF PersistentVolume。
您可以将 OpenShift Virtualization 与 OVN-Kubernetes、OpenShift SDN 或 认证的 OpenShift CNI 插件 中列出的其他认证网络插件一起使用。
您可以通过安装 Compliance Operator 并运行带有 ocp4-moderate 和 ocp4-moderate-node 配置集的扫描来检查您的 OpenShift Virtualization 集群的合规性。Compliance Operator 使用 NIST 认证工具 OpenSCAP 扫描并执行安全策略。
1.1.1. OpenShift Virtualization 支持的集群版本
OpenShift Virtualization 4.13 的最新稳定版本是 4.13.11。
OpenShift Virtualization 4.13 支持在 OpenShift Container Platform 4.13 集群中使用。要使用 OpenShift Virtualization 的最新 z-stream 版本,您需要首先升级到 OpenShift Container Platform 的最新版本。
1.2. 关于虚拟机磁盘的存储卷
如果您将存储 API 与已知的存储供应商搭配使用,则会自动选择卷和访问模式。但是,如果您使用没有存储配置集的存储类,则必须选择卷和访问模式。
要获得最佳结果,请使用 accessMode: ReadWriteMany 和 volumeMode: Block。这一点非常重要:
- 实时迁移需要 ReadWriteMany (RWX) 访问模式。
与
Filesystem卷模式相比,Block卷模式性能有显著提高。这是因为Filesystem卷模式使用更多存储层,包括文件系统层和磁盘镜像文件。对于虚拟机磁盘存储,并不需要这些层。例如,如果您使用 Red Hat OpenShift Data Foundation,Ceph RBD 卷优先于 CephFS 卷。
重要您无法实时迁移使用以下配置的虚拟机:
- 具有 ReadWriteOnce (RWO) 访问模式的存储卷
- 具有透传功能,比如 GPU
对于这些虚拟机,不要将
evictionStrategy字段设置为LiveMigrate。
1.3. 单节点 Openshift 的不同
您可以在单节点 OpenShift 上安装 OpenShift Virtualization。
但请注意,单节点 OpenShift 不支持以下功能:
- 高可用性
- Pod disruption
- Live migration(实时迁移)
- 配置了驱除策略的虚拟机或模板
第 2 章 支持的限制
您可以在为 OpenShift Virtualization 规划 OpenShift Container Platform 环境时引用测试的对象最大值。但是,接近最大值可以降低性能并增加延迟。确保您的计划适用于您的特定用例,并考虑可能会影响集群扩展的所有因素。
有关影响性能的集群配置和选项的更多信息,请参阅红帽知识库中的 OpenShift Virtualization - 调优和扩展指南。
2.1. 为 OpenShift Virtualization 测试的最大值
以下限制适用于大规模 OpenShift Virtualization 4.x 环境。它们基于最大可能大小的单一集群。在计划环境时,请记住多个较小的集群可能是您的用例的最佳选择。
2.1.1. 虚拟机最大值
以下最大值适用于 OpenShift Virtualization 上运行的虚拟机 (VM)。这些值取决于使用 KVM 的 Red Hat Enterprise Linux 的虚拟化限制中指定的限制。
| 目标(每个虚拟机) | 经过测试的限制 | 理论上的限制 |
|---|---|---|
| 虚拟 CPU | 216 个 vCPU | 255 个 vCPU |
| 内存 | 6 TB | 16 TB |
| 单个磁盘大小 | 20 TB | 100 TB |
| 热插磁盘 | 255 个磁盘 | N/A |
每个虚拟机必须具有至少 512 MB 内存。
2.1.2. 主机最大值
以下最大值适用于用于 OpenShift Virtualization 的 OpenShift Container Platform 主机。
| 目标(每个主机) | 经过测试的限制 | 理论上的限制 |
|---|---|---|
| 逻辑 CPU 内核或线程 | 与 Red Hat Enterprise Linux (RHEL) 相同 | N/A |
| RAM | 与 RHEL 相同 | N/A |
| 同时实时迁移 | 默认为每个节点 2 个出站迁移,每个集群 5 个并发迁移 | 取决于 NIC 带宽 |
| 实时迁移带宽 | 没有默认限制 | 取决于 NIC 带宽 |
2.1.3. 集群最大限制
以下最大值应用到 OpenShift Virtualization 中定义的对象。
| 目标(每个集群) | 经过测试的限制 | 理论上的限制 |
|---|---|---|
| 每个节点附加的 PV 数量 | N/A | CSI 存储供应商依赖 |
| 最大 PV 大小 | N/A | CSI 存储供应商依赖 |
| 主机 | 500 个主机(推荐使用 100 个或更少)[1] | 与 OpenShift Container Platform 相同 |
| 定义的虚拟机 | 10,000 个 VM [2] | 与 OpenShift Container Platform 相同 |
如果使用超过 100 个节点,请考虑使用 Red Hat Advanced Cluster Management (RHACM) 来管理多个集群,而不是扩展单个 control plane。较大的集群增加了复杂性,需要更长的更新,并根据节点大小和对象密度增加,它们可以增加 control plane 压力。
使用多个集群对于如按集群隔离和高可用性等区域很有用。
每个节点的最大虚拟机数量取决于主机硬件和资源容量。它还受以下参数的限制:
-
限制可调度到节点的 pod 数量的设置。例如:
maxPods。 -
默认 KVM 设备数。例如:
devices.kubevirt.io/kvm: 1k。
-
限制可调度到节点的 pod 数量的设置。例如:
第 3 章 OpenShift Virtualization 架构
了解 OpenShift Virtualization 架构。
3.1. OpenShift Virtualization 架构如何工作
安装 OpenShift Virtualization 后,Operator Lifecycle Manager(OLM)会为 OpenShift Virtualization 的每个组件部署 operator pod:
-
Compute:
virt-operator -
Storage:
cdi-operator -
Network:
cluster-network-addons-operator -
Scaling:
ssp-operator -
Templating:
tekton-tasks-operator
OLM 还会部署 hyperconverged-cluster-operator pod,它负责其他组件的部署、配置和生命周期,以及几个 helper pod: hco-webhook 和 hyperconverged-cluster-cli-download。
成功部署所有 Operator pod 后,您应该创建 HyperConverged 自定义资源 (CR)。HyperConverged CR 中的配置充当 OpenShift Virtualization 的单一的信任源和进入点,并指导 CR 的行为。
HyperConverged CR 为其协调范围中的所有其他组件的 operator 创建对应的 CR。然后,每个 Operator 会为 OpenShift Virtualization control plane 创建资源,如守护进程集、配置映射和其他组件。例如,当 hco-operator 创建 KubeVirt CR 时,virt-operator 会协调它并创建其他资源,如 virt-controller、virt-handler 和 virt-api。
OLM 部署 hostpath-provisioner-operator,但在创建 hostpath provisioner (HPP)CR 之前,它无法正常工作。

3.2. 关于 hco-operator
hco-operator (HCO)提供了一个单一入口点,用于部署和管理 OpenShift Virtualization 以及一些带有建议的默认值的 helper operator。它还会为这些操作器创建自定义资源(CR)。
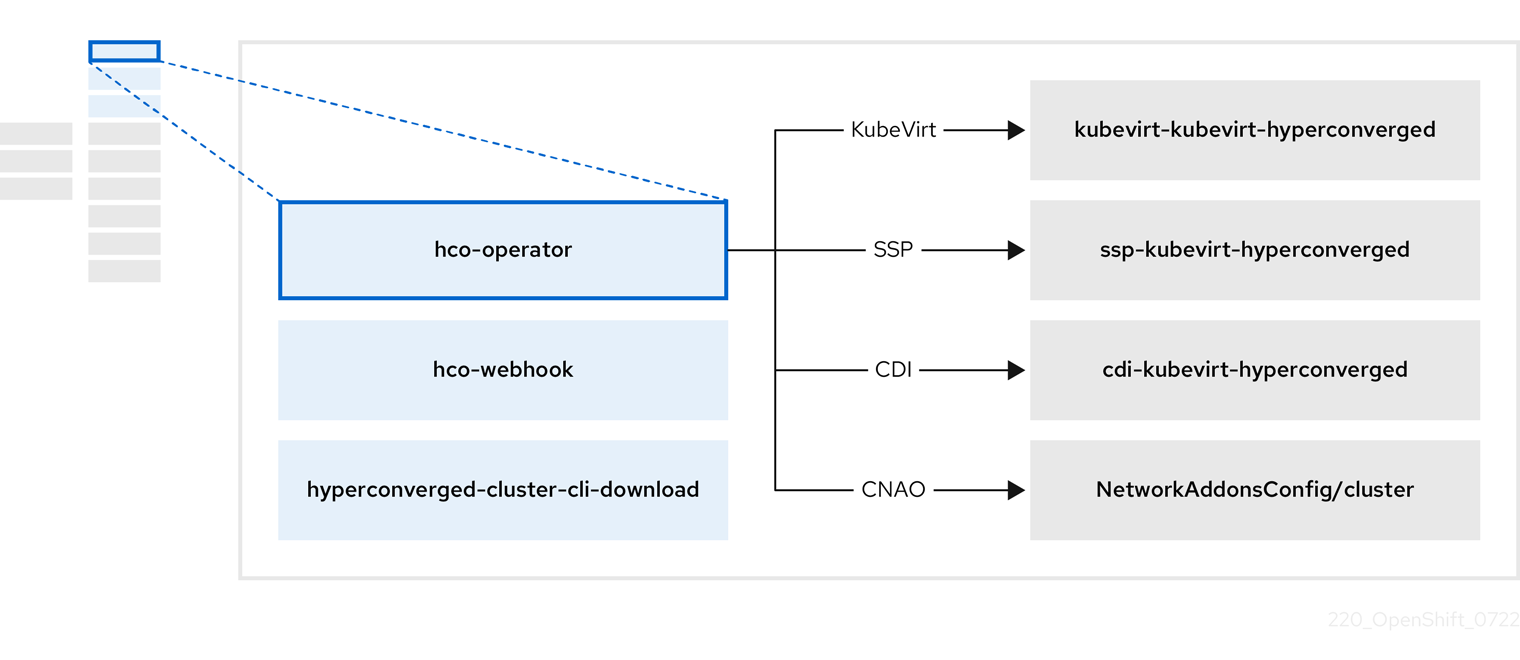
| 组件 | 描述 |
|---|---|
|
|
验证 |
|
|
提供 |
|
| 包含 OpenShift Virtualization 需要的所有 operator、CR 和对象。 |
|
| SSP CR。这由 HCO 自动创建。 |
|
| CDI CR。这由 HCO 自动创建。 |
|
|
指示并由 |
3.3. 关于 cdi-operator
cdi-operator 管理 Containerized Data Importer(CDI)及其相关资源,它使用数据卷将虚拟机(VM)镜像导入到持久性卷声明(PVC)。

| 组件 | 描述 |
|---|---|
|
| 管理将虚拟机磁盘上传到 PVC 的授权过程,它会发布安全上传令牌。 |
|
| 将外部磁盘上传流量定向到适当的上传服务器 pod,以便将其写入正确的 PVC。需要一个有效的上传令牌。 |
|
| helper(帮助程序)Pod,在创建数据卷时将虚拟机镜像导入到 PVC 中。 |
3.4. 关于 cluster-network-addons-operator
cluster-network-addons-operator 在集群中部署网络组件,并管理相关资源以了解扩展网络功能。
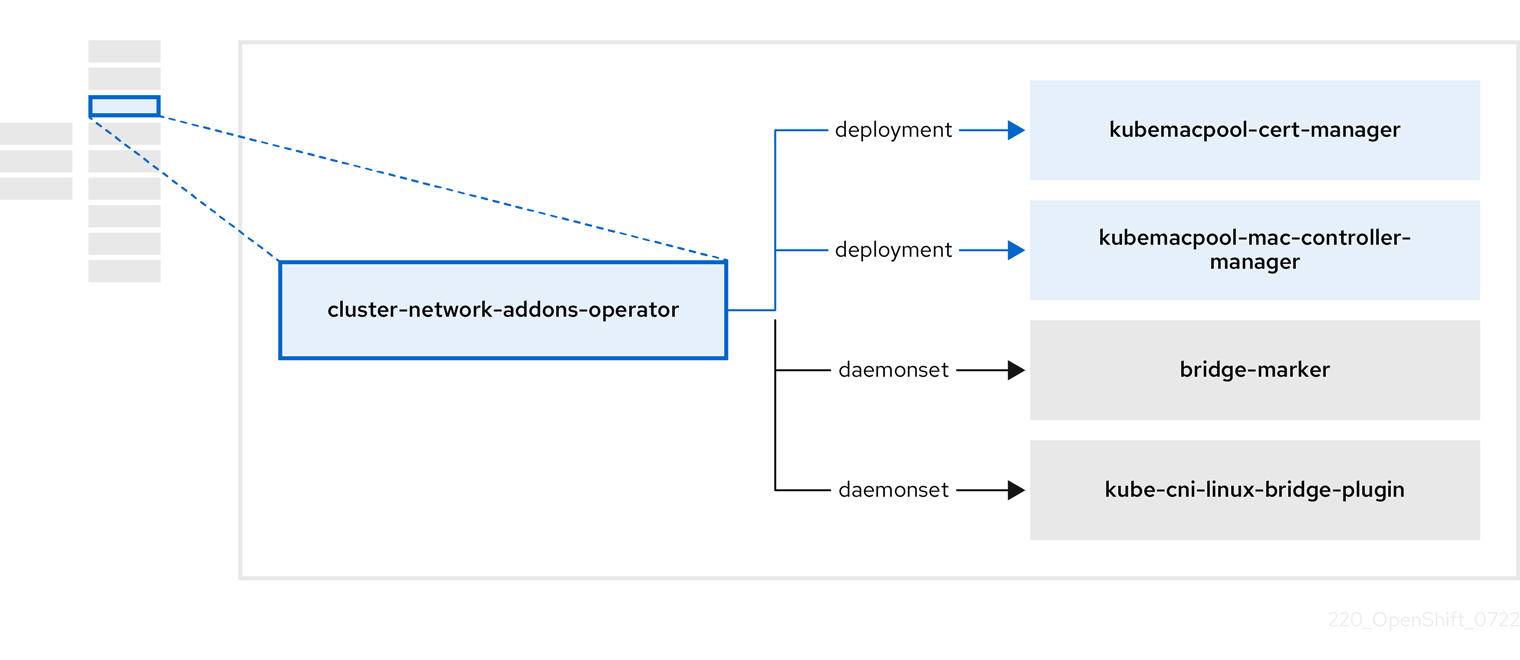
| 组件 | 描述 |
|---|---|
|
| 管理 Kubemacpool 的 webhook 的 TLS 证书。 |
|
| 为虚拟机 (VM) 网络接口卡 (NIC) 提供 MAC 地址池服务。 |
|
| 将节点上可用的网络桥接标记为节点资源。 |
|
| 在集群节点上安装 CNI 插件,通过网络附加定义将虚拟机附加到 Linux 网桥。 |
3.5. 关于 hostpath-provisioner-operator
hostpath-provisioner-operator 部署并管理多节点 hostpath 置备程序(HPP)和相关资源。
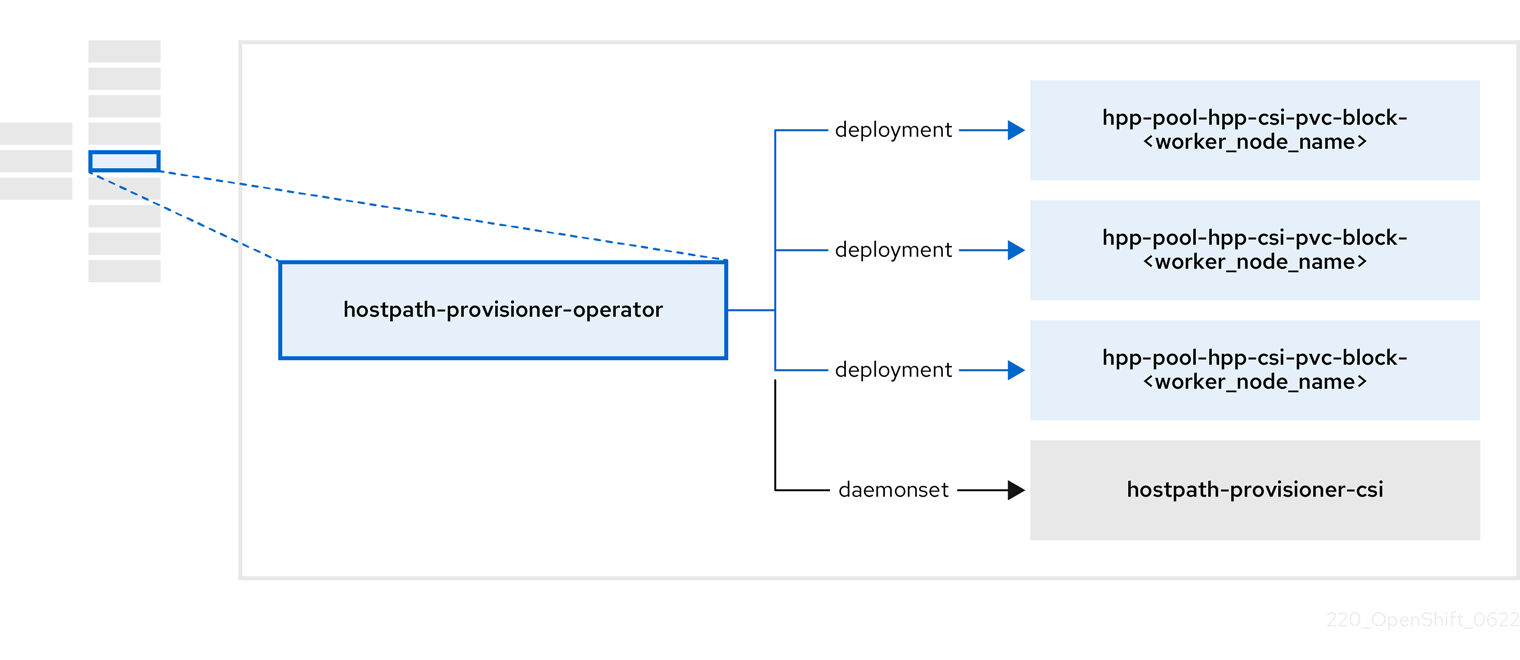
| 组件 | 描述 |
|---|---|
|
| 为指定 hostpath 置备程序(HPP)的每个节点提供一个 worker。pod 在节点上挂载指定的后备存储。 |
|
| 实现 HPP 的容器存储接口(CSI)驱动程序接口。 |
|
| 实现 HPP 的传统驱动程序接口。 |
3.6. 关于 ssp-operator
ssp-operator 部署通用模板、相关默认引导源和模板验证器。

| 组件 | 描述 |
|---|---|
|
|
检查从模板创建的虚拟机上 |
3.7. 关于 tekton-tasks-operator
tekton-tasks-operator 部署示例管道,显示 OpenShift Pipelines 用于虚拟机的情况。它还部署额外的 OpenShift Pipeline 任务,允许用户从模板创建虚拟机、复制和修改模板,以及创建数据卷。
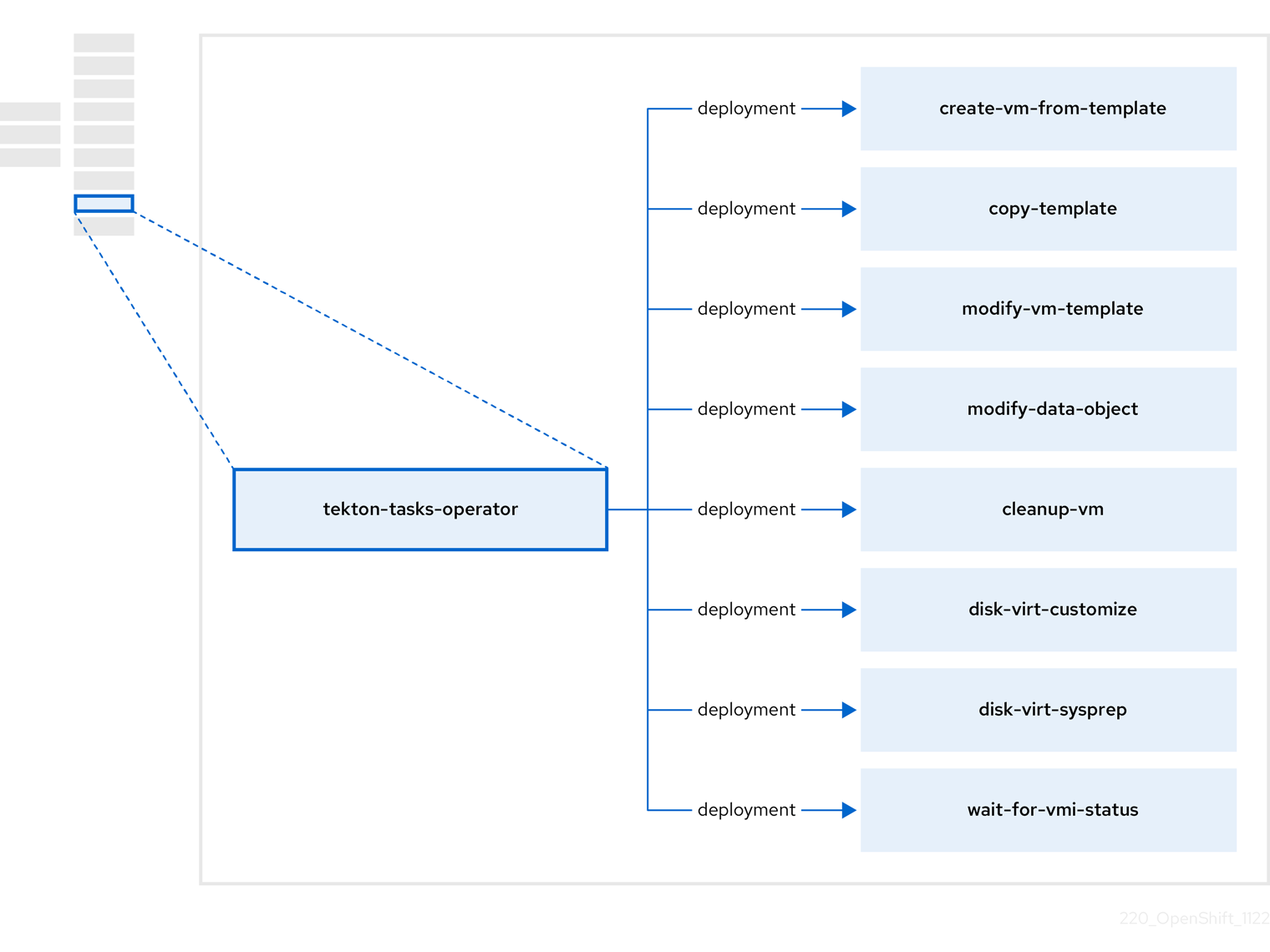
| 组件 | 描述 |
|---|---|
|
| 从模板创建虚拟机。 |
|
| 复制虚拟机模板。 |
|
| 创建和删除虚拟机模板。 |
|
| 创建和删除数据卷或数据源。 |
|
| 在虚拟机上运行脚本或命令,然后在之后停止或删除虚拟机。 |
|
|
使用 |
|
|
使用 |
|
| 等待特定 VMI 状态,然后根据该状态失败或成功。 |
3.8. 关于 virt-operator
virt-operator 在不影响当前虚拟机(VM)工作负载的情况下部署、升级和管理 OpenShift Virtualization。
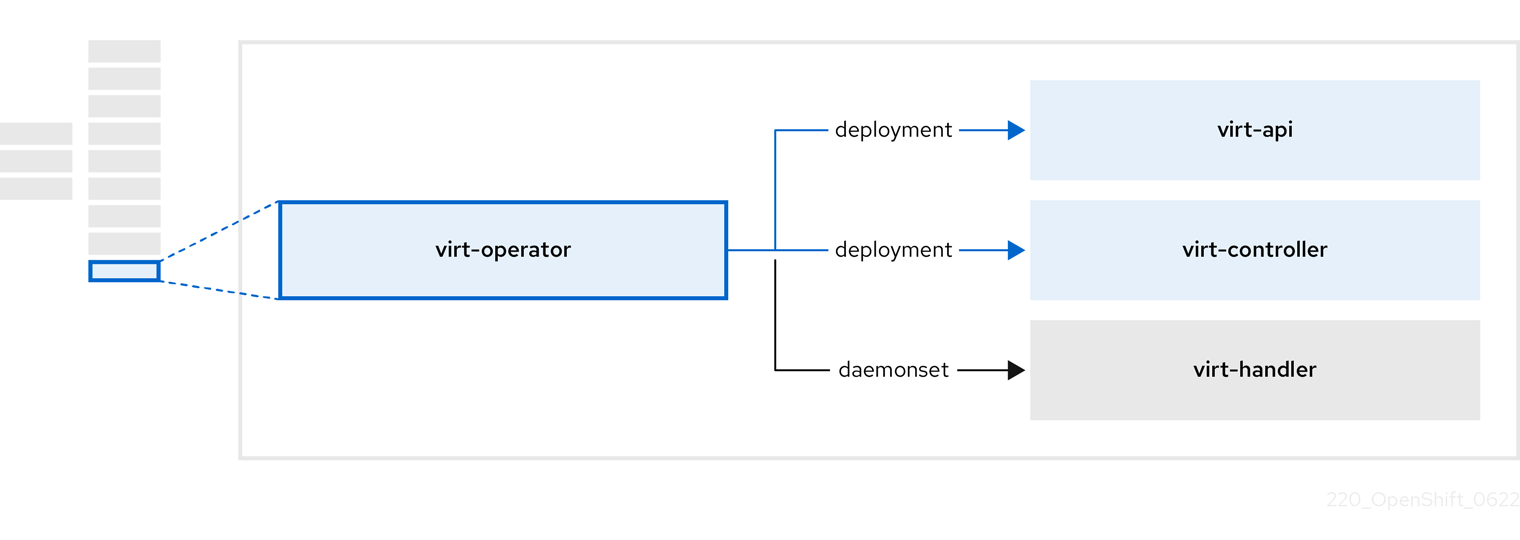
| 组件 | 描述 |
|---|---|
|
| HTTP API 服务器,用作所有与虚拟化相关的流的入口点。 |
|
|
观察创建新虚拟机实例对象,并创建对应的 pod。当 pod 被调度到某个节点上时, |
|
|
监控对虚拟机的任何更改,并指示 |
|
|
包含由 |
第 4 章 OpenShift Virtualization 入门
您可以通过安装和配置基本环境来探索 OpenShift Virtualization 的功能和功能。
集群配置过程需要 cluster-admin 权限。
4.1. 规划和安装 OpenShift Virtualization
在 OpenShift Container Platform 集群中计划并安装 OpenShift Virtualization:
规划和安装资源
4.2. 创建和管理虚拟机
使用 web 控制台创建虚拟机 (VM):
连接到虚拟机:
- 使用 web 控制台连接至虚拟机的串行控制台或 VNC控制台。
- 使用 SSH 连接到虚拟机。
- 使用 RDP 连接到 Windows 虚拟机。
管理虚拟机:
4.3. 后续步骤
将虚拟机连接到二级网络:
- 将虚拟机连接到 Linux 网桥网络。
- 注意
默认情况下,虚拟机连接到 pod 网络。您必须配置二级网络,如 Linux 网桥或 SR-IOV,然后将网络添加到虚拟机配置中。
- 实时迁移虚拟机.
- 备份和恢复虚拟机。
- 调整和扩展集群
第 5 章 Web 控制台概述
OpenShift Container Platform Web 控制台的 Virtualization 部分包含以下页面来管理和监控 OpenShift Virtualization 环境。
| 页面 | 描述 |
|---|---|
| 管理和监控 OpenShift Virtualization 环境。 | |
| 从模板目录创建 VirtualMachines。 | |
| 配置和监控 VirtualMachines。 | |
| 创建和管理模板。 | |
| 为 VirtualMachine 引导源创建和管理数据源。 | |
| 为工作负载创建和管理 MigrationPolicies。 |
| 图标 | 描述 |
|---|---|
|
| 编辑图标 |
|
| 链接图标 |
5.1. 概述页面
Overview 页面显示资源、指标、迁移进度和集群级别设置。
例 5.1. 概述页面
| 元素 | 描述 |
|---|---|
|
下载 virtctl |
下载 |
| 资源、使用量、警报和状态 | |
| CPU、内存和存储资源的主要使用者 | |
| 实时迁移状态 | |
| 集群范围的设置,包括实时迁移限制和用户权限 |
5.1.1. 概述标签
Overview 选项卡显示资源、使用情况、警报和状态。
例 5.2. 概述标签页
| 元素 | 描述 |
|---|---|
| 入门资源卡 |
|
| VirtualMachines 标题 | VirtualMachines 数量,带有图表,显示最后 7 天的趋势 |
| vCPU 使用标题 | vCPU 使用量,图表显示最后 7 天的趋势 |
| 内存标题 | 内存用量,图表显示最后 7 天的趋势 |
| 存储标题 | 存储使用,图表显示最后 7 天的趋势 |
| 警报标题 | OpenShift Virtualization 警报,按严重性分组 |
| VirtualMachine 状态标题 | VirtualMachines 数量,按状态分组 |
| 每个模板的 VirtualMachines 图标 | 从模板创建的 VirtualMachines 数量,按模板名称分组 |
5.1.2. 顶级消费者选项卡
Top consumers 选项卡显示 CPU、内存和存储的主要使用者。
例 5.3. 顶级消费者选项卡
| 元素 | 描述 |
|---|---|
|
查看虚拟化仪表板 | 到 Observe → Dashboards 的链接,显示 OpenShift Virtualization 的顶部用户 |
| 时间周期列表 | 选择过滤结果的时间周期。 |
| 顶级消费者列表 | 选择顶级消费者的数量来过滤结果。 |
| CPU chart | 带有最高 CPU 使用率的 VirtualMachines |
| 内存图表 | 带有最高内存用量的 VirtualMachines |
| 内存交换流量图表 | 带有最高内存交换流量的 VirtualMachines |
| vCPU 等待图表 | 带有最高 vCPU 等待周期的 VirtualMachines |
| 存储吞吐量图表 | 带有最高存储吞吐量使用量的 VirtualMachines |
| 存储 IOPS图表 | 带有最高存储输入/输出操作的 VirtualMachines 每秒使用。 |
5.1.3. Migration 标签页
Migrations 选项卡显示 VirtualMachineInstance 迁移的状态。
例 5.4. Migration 标签页
| 元素 | 描述 |
|---|---|
| 时间周期列表 | 选择一个时间段来过滤 VirtualMachineInstanceMigrations。 |
| VirtualMachineInstanceMigrations 表 | VirtualMachineInstance 迁移列表 |
5.1.4. 设置标签页
Settings 选项卡在以下标签页中显示集群范围的设置:
| 标签页 | 描述 |
|---|---|
| OpenShift Virtualization 版本和更新状态 | |
| 实时迁移限制和网络设置。 | |
| 红帽模板项目 | |
| 集群范围的用户权限 |
5.1.4.1. 常规标签页
General 选项卡显示 OpenShift Virtualization 版本和更新状态。
例 5.5. 常规 标签页
| 标签 | 描述 |
|---|---|
| 服务名称 | OpenShift Virtualization |
| 供应商 | Red Hat |
| 已安装的版本 | 4.13.11 |
| 更新状态 |
例如: |
| Channel | 为更新选择的频道 |
5.1.4.2. 实时迁移标签页
您可以在实时迁移选项卡中配置实时迁移。
例 5.6. 实时迁移标签页
| 元素 | 描述 |
|---|---|
| Max. migration per cluster 字段 | 选择每个集群的最大实时迁移数量。 |
| Max. migrations per node 字段 | 选择每个节点的最大实时迁移数量。 |
| 实时迁移网络列表 | 为实时迁移选择专用的二级网络。 |
5.1.4.3. templates project 标签页
您可以在 Templates project 选项卡中为模板选择一个项目。
例 5.7. templates project 标签页
| 元素 | 描述 |
|---|---|
| 项目列表 |
选择要在其中存储红帽模板的项目。默认模板项目为 如果要定义多个模板项目,您必须在每个项目的 Templates 页面中克隆模板。 |
5.1.4.4. 用户权限标签页
User permissions 选项卡显示集群范围的用户权限。
例 5.8. 用户权限标签页
| 元素 | 描述 |
|---|---|
| 用户权限表 | 任务列表,如共享模板和权限 |
5.2. 目录页面
您可以通过在 Catalog 页面中选择一个模板或引导源来创建 VirtualMachine。
例 5.9. 目录页面
| 元素 | 描述 |
|---|---|
| 模板目录标签页 | 选择要从中创建 VirtualMachine 的模板。 |
5.2.1. 模板目录标签页
| 元素 | 描述 |
|---|---|
| 模板项目列表 | 选择模板所在的项目。
默认情况下,红帽模板存储在 |
| All items|Default templates | 点 Default templates 以仅显示默认模板。 |
| Boot source available 复选框 | 选中复选框以显示带有可用引导源的模板。 |
| 操作系统 复选框 | 选中复选框以显示带有所选操作系统的模板。 |
| 工作负载 复选框 | 选中复选框以显示带有所选工作负载的模板。 |
| 搜索字段 | 按关键字搜索模板。 |
| 模板标题 | 点模板标题查看模板详情并创建 VirtualMachine。 |
5.3. VirtualMachines 页面
您可以在 VirtualMachines 页面中创建和管理 VirtualMachines。
例 5.10. VirtualMachines 页面
| 元素 | 描述 |
|---|---|
| Create → From template | 在 Catalog 页 → Template catalog 选项卡中创建一个 VirtualMachine。 |
| Create → From YAML | 通过编辑 YAML 配置文件来创建 VirtualMachine。 |
| Filter 字段 | 根据状态、模板、操作系统或节点过滤 VirtualMachines。 |
| 搜索字段 | 根据名称或标签搜索 VirtualMachines。 |
| VirtualMachines 表 | VirtualMachines 列表
点 VirtualMachine 旁边的 Options 菜单
点 VirtualMachine 进入 VirtualMachine 详情页面。 |
5.3.1. VirtualMachine 详情页面
您可以在 VirtualMachine 详情页面中配置 VirtualMachine。
例 5.11. VirtualMachine 详情页面
| 元素 | 描述 |
|---|---|
| 操作菜单 | 点 Actions 菜单,选择 Stop, Restart, Pause, Clone, Migrate, Copy SSH command, Edit labels, Edit annotations, 或 Delete。 |
| 资源使用情况、警报、磁盘和设备 | |
| VirtualMachine 详情和配置 | |
| 内存、CPU、存储、网络和迁移指标 | |
| VirtualMachine YAML 配置文件 | |
| 包含 调度、环境、网络接口、磁盘和脚本选项卡 | |
| 调度 VirtualMachine 以便在特定节点上运行 | |
| 配置映射、secret 和服务帐户管理 | |
| 网络接口 | |
| 磁盘 | |
| cloud-init 设置、Linux VirtualMachines 的 SSH 密钥、Windows VirtualMachines 的 Sysprep 回答文件 | |
| VirtualMachine 事件流 | |
| 控制台会话管理 | |
| 快照管理 | |
| 状态条件和卷快照状态 |
5.3.1.1. 概述标签
Overview 选项卡显示资源使用情况、警报和配置信息。
例 5.12. 概述标签
| 元素 | 描述 |
|---|---|
| 详情标题 | 常规 VirtualMachine 信息 |
| 使用标题 | CPU, Memory, Storage, 和 Network transfer 图。默认情况下,Network transfer 显示所有网络的总和。要查看特定网络的分类,请点 Breakdown by network。 |
| 硬件设备标题 | GPU 和主机设备 |
| 警报标题 | OpenShift Virtualization 警报,按严重性分组 |
| 快照标题 |
进行快照 |
| 网络接口标题 | 网络接口表 |
| 磁盘标题 | 磁盘表 |
5.3.1.2. 详情标签页
您可以查看 VirtualMachine 的信息,并编辑标签、注解和其他元数据以及 Details 标签页中。
例 5.13. 详情标签页
| 元素 | 描述 |
|---|---|
| YAML 开关 | 设置为 ON,以在 YAML 配置文件中查看您的实时更改。 |
| Name | VirtualMachine 名称 |
| Namespace | VirtualMachine 命名空间 |
| 标签 | 点编辑图标编辑标签。 |
| 注解 | 点编辑图标编辑注解。 |
| 描述 | 点编辑图标,以输入描述。 |
| 操作系统 | 操作系统名称 |
| CPU|内存 | 点编辑图标编辑 CPU|Memory 请求。
CPU 数量通过以下公式来计算: |
| 机器类型 | VirtualMachine 集群类型 |
| 引导模式 | 点编辑图标编辑引导模式。 |
| 以 pause 模式启动 | 点编辑图标启用此设置。 |
| 模板 | 用于创建 VirtualMachine 的模板的名称 |
| 创建于 | VirtualMachine 创建日期 |
| 所有者 | VirtualMachine 所有者 |
| Status | VirtualMachine 状态 |
| Pod |
|
| VirtualMachineInstance | VirtualMachineInstance 名称 |
| 引导顺序 | 点编辑图标选择引导源。 |
| IP 地址 | VirtualMachine 的 IP 地址 |
| 主机名 | VirtualMachine 的主机名 |
| 时区 | VirtualMachine 的时区 |
| 节点 | 运行 VirtualMachine 的节点 |
| Workload 配置集 | 点编辑图标编辑工作负载配置集。 |
| 使用 virtctl 进行 SSH |
点复制图标将 |
| SSH 服务类型选项 | 选择 SSH over LoadBalancer 或 SSH over NodePort。 |
| GPU 设备 | 点编辑图标添加 GPU 设备。 |
| 主机设备 | 点编辑图标添加主机设备。 |
| 无头模式 | 点编辑图标启用无头模式。 |
| Services 部分 | 如果安装了 QEMU 客户机代理,则显示服务。 |
| 活跃用户部分 | 如果安装了 QEMU 客户机代理,则显示活动用户。 |
5.3.1.3. Metrics 标签页
Metrics 选项卡显示内存、CPU、存储、网络和迁移使用图表。
例 5.14. Metrics 标签页
| 元素 | 描述 |
|---|---|
| 时间范围列表 | 选择一个时间范围来过滤结果。 |
|
虚拟化仪表板 | 链接到当前项目的 Workloads 选项卡 |
| 使用率部分 | 内存和 CPU 图标 |
| 存储部分 | 存储总读/写和存储 IOPS 总读/写图表 |
| 网络部分 | Network in,Network out,Network bandwidth, 和 Network interface 图表。从网络接口下拉菜单中选择所有网络或一个特定的网络。 |
| 迁移部分 | Migration 和 KV data transfer rate 图。 |
5.3.1.4. YAML 标签页
您可以通过编辑 YAML 选项卡上的 YAML 文件来配置 VirtualMachine。
例 5.15. YAML 标签页
| 元素 | 描述 |
|---|---|
| 保存按钮 | 保存对 YAML 文件的更改。 |
| 重新加载按钮 | 丢弃您的更改并重新载入 YAML 文件。 |
| 取消 按钮 | 退出 YAML 选项卡。 |
| 下载 按钮 | 将 YAML 文件下载到您的本地计算机。 |
5.3.1.5. 配置标签页
您可以在 Configuration 选项卡中配置调度、网络接口、磁盘和其他选项。
例 5.16. Configuration 选项卡上的标签页
| 标签页 | 描述 |
|---|---|
| 调度 VirtualMachine 以便在特定节点上运行 | |
| 配置映射、secret 和服务帐户 | |
| 网络接口 | |
| 磁盘 | |
| cloud-init 设置、Linux VirtualMachines 的 SSH 密钥、Windows VirtualMachines 的 Sysprep 回答文件 |
5.3.1.5.1. 调度标签
您可以将 VirtualMachines 配置为在 Scheduling 选项卡上的特定节点上运行。
例 5.17. 调度标签
| 设置 | 描述 |
|---|---|
| YAML 开关 | 设置为 ON,以在 YAML 配置文件中查看您的实时更改。 |
| 节点选择器 | 点编辑图标添加标签来指定合格节点。 |
| 容限(Tolerations) | 点编辑图标,以添加容限来指定合格节点。 |
| 关联性规则 | 点编辑图标来添加关联性规则。 |
| Descheduler 交换机 | 启用或禁用 descheduler。descheduler 驱除正在运行的 pod,以便可将 pod 重新调度到更合适的节点上。 |
| 专用资源 | 点编辑图标,选择 Schedule this workload with dedicated resources (guaranteed policy)。 |
| 驱除策略 | 点编辑图标选择 LiveMigrate 作为 VirtualMachineInstance 驱除策略。 |
5.3.1.5.2. Environment 标签页
您可以在 Environment 标签页中管理配置映射、secret 和服务帐户。
例 5.18. Environment 标签页
| 元素 | 描述 |
|---|---|
| YAML 开关 | 设置为 ON,以在 YAML 配置文件中查看您的实时更改。 |
|
添加配置映射、Secret 或服务帐户 | 点链接,然后从资源列表中选择配置映射、secret 或服务帐户。 |
5.3.1.5.3. 网络接口选项卡
您可以在 Network interfaces 选项卡上管理网络接口。
例 5.19. 网络接口选项卡
| 设置 | 描述 |
|---|---|
| YAML 开关 | 设置为 ON,以在 YAML 配置文件中查看您的实时更改。 |
| 添加网络接口按钮 | 在 VirtualMachine 中添加网络接口。 |
| Filter 字段 | 按接口类型过滤。 |
| 搜索字段 | 根据名称或标签搜索网络接口。 |
| 网络接口表 | 网络接口列表
点击网络接口
|
5.3.1.5.4. Disk 标签页
您可以在 Disks 选项卡上管理磁盘。
例 5.20. Disk 标签页
| 设置 | 描述 |
|---|---|
| YAML 开关 | 设置为 ON,以在 YAML 配置文件中查看您的实时更改。 |
| 添加磁盘按钮 | 在 VirtualMachine 中添加磁盘。 |
| Filter 字段 | 按磁盘类型过滤。 |
| 搜索字段 | 按名称搜索磁盘。 |
| 挂载 Windows 驱动程序磁盘 复选框 | 选择将临时容器磁盘挂载为 CD-ROM。 |
| 磁盘表 | VirtualMachine 磁盘列表
点磁盘
|
| 文件系统表 | 如果安装了 QEMU 客户机代理,则 VirtualMachine 文件系统列表 |
5.3.1.5.5. Script 标签页
您可以配置 cloud-init,为 Linux VirtualMachine 添加 SSH 密钥,并在 Scripts 选项卡中为 Windows VirtualMachine 上传 Sysprep 回答文件。
例 5.21. Script 标签页
| 元素 | 描述 |
|---|---|
| YAML 开关 | 设置为 ON,以在 YAML 配置文件中查看您的实时更改。 |
| Cloud-init | 点编辑图标来编辑 cloud-init 设置。 |
| 授权 SSH 密钥 | 点 edit 图标创建新 secret 或附加现有 secret。 |
| Sysprep |
点编辑图标上传 |
5.3.1.6. Events 标签页
Events 选项卡显示 VirtualMachine 事件列表。
5.3.1.7. 控制台标签页
您可以在 Console 选项卡中打开到 VirtualMachine 的控制台会话。
例 5.22. 控制台标签页
| 元素 | 描述 |
|---|---|
| 客户机登录凭证部分 |
展开 Guest login credentials 以查看使用 |
| 控制台列表 | 选择 VNC console 或 Serial console。 您可以选择 Desktop viewer 来使用 Remote Desktop Protocol (RDP) 连接到 Windows VirtualMachines。您必须在同一网络的机器上安装 RDP 客户端。 |
| send key 列表 | 选择要发送到控制台的键组合。 |
| Disconnect 按钮 | 断开控制台连接。 如果您打开新的控制台会话,则必须手动断开控制台连接。否则,第一个控制台会话会在后台继续运行。 |
| 粘贴 按钮 | 在使用 VNC 控制台时,您可以从客户端的剪贴板中粘贴字符串到客户机中。 |
5.3.1.8. 快照选项卡
您可以从 Snapshots 选项卡上的快照中创建快照并恢复 VirtualMachines。
例 5.23. 快照选项卡
| 元素 | 描述 |
|---|---|
| 创建快照按钮 | 创建快照。 |
| Filter 字段 | 根据状态过滤快照。 |
| 搜索字段 | 根据名称或标签搜索快照。 |
| 快照表 | 快照列表 点快照名称编辑标签或注解。
点击快照旁边的 Options 菜单
|
5.3.1.9. 诊断标签页
您可以在诊断选项卡中查看状态条件和卷快照状态。
例 5.24. 诊断标签页
| 元素 | 描述 |
|---|---|
| 状态条件表 | 显示为虚拟机的所有方面报告的条件列表。 |
| Filter 字段 | 根据类别和条件过滤状态条件。 |
| Search 字段 | 按原因搜索状态条件。 |
| 管理列 图标 | 要显示的列。 |
| 卷快照 表 | 卷列表、快照启用状态和原因 |
5.4. 模板页
您可以在 Templates 页中创建、编辑和克隆 VirtualMachine 模板。
您不能编辑红帽模板。您可以克隆红帽模板并编辑它来创建自定义模板。
例 5.25. 模板页
| 元素 | 描述 |
|---|---|
| 创建模板按钮 | 通过编辑 YAML 配置文件创建模板。 |
| Filter 字段 | 根据类型、引导源、模板供应商或操作系统过滤模板。 |
| 搜索字段 | 根据名称或标签搜索模板。 |
| 模板表 | 模板列表
点击模板旁边的 Options 菜单
|
5.4.1. 模板详情页面
您可以查看模板设置并在 Template 详情页面中编辑自定义模板。
例 5.26. 模板详情页面
5.4.1.1. 详情标签页
您可以在 Details 标签页中配置自定义模板。
例 5.27. 详情标签页
| 元素 | 描述 |
|---|---|
| YAML 开关 | 设置为 ON,以在 YAML 配置文件中查看您的实时更改。 |
| Name | 模板名称 |
| Namespace | 模板命名空间 |
| 标签 | 点编辑图标编辑标签。 |
| 注解 | 点编辑图标编辑注解。 |
| 显示名称 | 点编辑图标编辑显示名称。 |
| 描述 | 点编辑图标,以输入描述。 |
| 操作系统 | 操作系统名称 |
| CPU|内存 | 点编辑图标编辑 CPU|Memory 请求。
CPU 数量通过以下公式来计算: |
| 机器类型 | 模板机器类型 |
| 引导模式 | 点编辑图标编辑引导模式。 |
| 基本模板 | 用于创建此模板的基本模板的名称 |
| 创建于 | 模板创建日期 |
| 所有者 | 模板所有者 |
| 引导顺序 | 模板引导顺序 |
| 引导源 | 引导源可用性 |
| 供应商 | 模板供应商 |
| 支持 | 模板支持级别 |
| GPU 设备 | 点编辑图标添加 GPU 设备。 |
| 主机设备 | 点编辑图标添加主机设备。 |
5.4.1.2. YAML 标签页
您可以通过编辑 YAML 选项卡上的 YAML 文件来配置 自定义模板。
例 5.28. YAML 标签页
| 元素 | 描述 |
|---|---|
| 保存按钮 | 保存对 YAML 文件的更改。 |
| 重新加载按钮 | 丢弃您的更改并重新载入 YAML 文件。 |
| 取消 按钮 | 退出 YAML 选项卡。 |
| 下载 按钮 | 将 YAML 文件下载到您的本地计算机。 |
5.4.1.3. 调度标签
您可以在 Scheduling 选项卡中配置调度。
例 5.29. 调度标签
| 设置 | 描述 |
|---|---|
| YAML 开关 | 设置为 ON,以在 YAML 配置文件中查看您的实时更改。 |
| 节点选择器 | 点编辑图标添加标签来指定合格节点。 |
| 容限(Tolerations) | 点编辑图标,以添加容限来指定合格节点。 |
| 关联性规则 | 点编辑图标来添加关联性规则。 |
| Descheduler 交换机 | 启用或禁用 descheduler。descheduler 驱除正在运行的 pod,以便可将 pod 重新调度到更合适的节点上。 |
| 专用资源 | 点编辑图标,选择 Schedule this workload with dedicated resources (guaranteed policy)。 |
| 驱除策略 | 点编辑图标选择 LiveMigrate 作为 VirtualMachineInstance 驱除策略。 |
5.4.1.4. 网络接口选项卡
您可以在 Network interfaces 选项卡上管理网络接口。
例 5.30. 网络接口选项卡
| 设置 | 描述 |
|---|---|
| YAML 开关 | 设置为 ON,以在 YAML 配置文件中查看您的实时更改。 |
| 添加网络接口按钮 | 向模板添加网络接口。 |
| Filter 字段 | 按接口类型过滤。 |
| 搜索字段 | 根据名称或标签搜索网络接口。 |
| 网络接口表 | 网络接口列表
点击网络接口
|
5.4.1.5. Disk 标签页
您可以在 Disks 选项卡上管理磁盘。
例 5.31. Disk 标签页
| 设置 | 描述 |
|---|---|
| YAML 开关 | 设置为 ON,以在 YAML 配置文件中查看您的实时更改。 |
| 添加磁盘按钮 | 向模板添加磁盘。 |
| Filter 字段 | 按磁盘类型过滤。 |
| 搜索字段 | 按名称搜索磁盘。 |
| 磁盘表 | 模板磁盘列表
点磁盘
|
5.4.1.6. Script 标签页
您可以在 Scripts 选项卡上管理 cloud-init 设置、SSH 密钥和 Sysprep 回答文件。
例 5.32. Script 标签页
| 元素 | 描述 |
|---|---|
| YAML 开关 | 设置为 ON,以在 YAML 配置文件中查看您的实时更改。 |
| Cloud-init | 点编辑图标来编辑 cloud-init 设置。 |
| 授权 SSH 密钥 | 点 edit 图标创建新 secret 或附加现有 secret。 |
| Sysprep |
点编辑图标上传 |
5.4.1.7. 参数标签页
您可以在 Parameters 选项卡中编辑所选模板设置。
例 5.33. 参数标签页
| 元素 | 描述 |
|---|---|
| YAML 开关 | 设置为 ON,以在 YAML 配置文件中查看您的实时更改。 |
| 虚拟机名称 | 为生成的值选择 Generated (expression),Value 设置一个默认值,或从 Default value type 列表中选择 None。 |
| 数据源名称 | 为生成的值选择 Generated (expression),Value 设置一个默认值,或从 Default value type 列表中选择 None。 |
| 数据源命名空间 | 为生成的值选择 Generated (expression),Value 设置一个默认值,或从 Default value type 列表中选择 None。 |
| 云用户密码 | 为生成的值选择 Generated (expression),Value 设置一个默认值,或从 Default value type 列表中选择 None。 |
5.5. 数据源页
您可以在 DataSources 页面中为 VirtualMachine 引导源创建和配置 DataSources。
当您创建 DataSource 时,DataImportCron 资源定义了一个 cron 作业来轮询和导入磁盘镜像,除非您禁用自动引导源更新。
例 5.34. 数据源页
| 元素 | 描述 |
|---|---|
| Create DataSource → With form | 通过输入 registry URL、磁盘大小、修订版本数和 cron 表达式来创建 DataSource。 |
| Create DataSources → With YAML | 通过编辑 YAML 配置文件创建数据源。 |
| Filter 字段 | 根据可用属性(例如 DataImportCron 等)过滤 DataSources。 |
| Search 字段 | 根据名称或标签搜索 DataSource。 |
| DataSources 表 | 数据源列表
点 DataSource 旁边的 Options 菜单
|
点 DataSource 查看 DataSource 详情页面。
5.5.1. 数据源详情页面
您可以在 DataSource 详情页面中配置数据源。
例 5.35. 数据源详情页面
| 元素 | 描述 |
|---|---|
| 详情标签页 | 通过编辑表单来配置数据源。 |
| YAML 标签页 | 通过编辑 YAML 配置文件来配置数据源。 |
| 操作菜单 | 选择 Edit labels,Edit annotations,Delete, 或 Manage source. |
| Name | 数据源名称 |
| Namespace | 数据源命名空间 |
| DataImportCron | DataSource DataImportCron |
| 标签 | 点编辑图标编辑标签。 |
| 注解 | 点编辑图标编辑注解。 |
| Conditions | 显示 DataSource 的状态条件。 |
| 创建于 | 数据源创建日期 |
| 所有者 | 数据源所有者 |
5.6. MigrationPolicies 页面
您可以在 MigrationPolicies 页面中为您的工作负载管理 MigrationPolicies。
例 5.36. MigrationPolicies 页面
| 元素 | 描述 |
|---|---|
| Create MigrationPolicy → With form | 通过以表单输入配置和标签来创建 MigrationPolicy。 |
| Create MigrationPolicy → With YAML | 通过编辑 YAML 配置文件创建 MigrationPolicy。 |
| Name | Label 搜索字段 | 根据名称或标签搜索 MigrationPolicy。 |
| MigrationPolicies 表 | MigrationPolicies 列表
点 MigrationPolicy 旁边的 Options 菜单
|
点 MigrationPolicy 查看 MigrationPolicy 详情页面。
5.6.1. MigrationPolicy 详情页面
您可以在 MigrationPolicy 详情页面中配置 MigrationPolicy。
例 5.37. MigrationPolicy 详情页面
| 元素 | 描述 |
|---|---|
| 详情标签页 | 通过编辑表单来配置 MigrationPolicy。 |
| YAML 标签页 | 通过编辑 YAML 配置文件来配置 MigrationPolicy。 |
| 操作菜单 | 选择 Edit 或 Delete。 |
| Name | MigrationPolicy 名称 |
| 描述 | MigrationPolicy 描述 |
| 配置 | 点编辑图标更新 MigrationPolicy 配置。 |
| 每个迁移的带宽 |
每个迁移的带宽请求。对于无限带宽,请将值设为 |
| 自动聚合 | 自动聚合策略 |
| Post-copy | 后复制策略 |
| 完成超时 | 完成超时值(以秒为单位) |
| 项目标签 | 点 Edit 以编辑项目标签。 |
| VirtualMachine 标签 | 点 Edit 以编辑 VirtualMachine 标签。 |
第 6 章 OpenShift Virtualization 发行注记
6.1. 关于 Red Hat OpenShift Virtualization
Red Hat OpenShift Virtualization 可让您将传统虚拟机(VM)放入 OpenShift Container Platform 中,与容器一同运行,并作为原生 Kubernetes 对象进行管理。
OpenShift Virtualization 由
![]() 图标表示。
图标表示。
OpenShift Virtualization 可以与 OVN-Kubernetes 或 OpenShiftSDN 默认 Container Network Interface(CNI)网络供应商一起使用。
了解更多有关 OpenShift Virtualization 的作用。
了解更多有关 OpenShift Virtualization 架构和部署 的信息。
为 OpenShift Virtualization 准备集群。
6.1.1. OpenShift Virtualization 支持的集群版本
OpenShift Virtualization 4.13 的最新稳定版本是 4.13.11。
OpenShift Virtualization 4.13 支持在 OpenShift Container Platform 4.13 集群中使用。要使用 OpenShift Virtualization 的最新 z-stream 版本,您必须首先升级到 OpenShift Container Platform 的最新版本。
不支持从 OpenShift Virtualization 4.12.2 升级到 OpenShift Virtualization 4.13。
6.1.2. 支持的客户端操作系统
要查看 OpenShift Virtualization 支持的客户机操作系统,请参阅 Red Hat OpenStack Platform、Red Hat Virtualization、OpenShift Virtualization 和带有 KVM 的 Red Hat Enterprise Linux 中的认证的客户机操作系统。
6.2. 新增和改变的功能
- OpenShift Virtualization 是 FIPS 就绪的。但是,OpenShift Container Platform 4.13 基于 Red Hat Enterprise Linux (RHEL) 9.2。RHEL 9.2 尚未提交用于 FIPS 验证。红帽计划获取 RHEL 9.0 和 RHEL 9.2 以及以后的 RHEL 9.x 偶数的次版本模块的 FIPS 验证,但没有具体的时间表。更新将包括在 Compliance Activities and Government Standards 中。
OpenShift Virtualization 已在 Microsoft 的 Windows Server Virtualization Validation Program (SVVP) 中认证来运行 Windows Server 的工作负载。
SVVP 认证适用于:
- Red Hat Enterprise Linux CoreOS worker。在 Microsoft SVVP Catalog 中,它们名为 Red Hat OpenShift Container Platform 4.13。
- Intel 和 AMD CPU。
-
OpenShift Virtualization 现在遵循
restrictedKubernetes pod 安全标准 配置集。如需更多信息,请参阅 OpenShift Virtualization 安全策略文档。
OpenShift Virtualization 现在基于 Red Hat Enterprise Linux (RHEL) 9。
虚拟机有新的 RHEL 9 机器类型:
machineType: pc-q35-rhel9.2.0。OpenShift Virtualization 中包含的所有虚拟机模板现在都默认使用此机器类型。
- 如需更多信息,请参阅 RHEL 9 上的 OpenShift Virtualization。
-
现在,您可以在导出虚拟机或快照后从导出服务器获取
VirtualMachine、ConfigMap和Secret清单。如需更多信息,请参阅访问导出的虚拟机清单。
- "Logging、事件和监控"文档现在被称为支持。监控工具文档已移至 Monitoring。
- 您可以使用 LokiStack 在 web 控制台中查看并过滤聚合的 OpenShift Virtualization 日志。
6.2.1. 快速启动
-
有几个 OpenShift Virtualization 功能提供快速入门导览。要查看导览,请点击 OpenShift Virtualization 控制台标题菜单栏中的 Help 图标 ?,然后选择 Quick Starts。您可以通过在 Filter 字段中输入
virtualization关键字来过滤可用的导览。
6.2.2. 网络
- 现在,在使用 OVN-Kubernetes CNI 插件时,您可以在默认 pod 网络连接的两个虚拟机间发送未分片帧数据包。
6.2.3. Storage
- OpenShift Virtualization 存储资源现在会自动迁移到 beta API 版本。alpha API 版本不再被支持。
6.2.4. Web 控制台
- 在 VirtualMachine details 页中,Scheduling, Environment, Network interfaces, Disks, 和 Scripts 标签页包括在新的 Configuration 标签页中。
- 您可以从客户端的剪贴板中粘贴字符串到客户机中。
- VirtualMachine details → Details 选项卡现在提供了一个新的 SSH 服务类型 SSH over LoadBalancer,以通过负载均衡器公开 SSH 服务。
- 使热插拔卷的选项添加到 Disks 选项卡的 Disks 选项卡中。
- 现在,有一个 VirtualMachine details →\":\" s 选项卡,您可以在其中查看虚拟机的状态条件以及卷的快照状态。
- 现在,您可以在 web 控制台中为高性能虚拟机启用无头模式。
6.3. 弃用和删除的功能
6.3.1. 已弃用的功能
弃用的功能在当前发行版本中包括并被支持。但是,它们将在以后的发行版本中删除,且不建议用于新部署。
-
RPM 对 Red Hat Enterprise Linux (RHEL) 7 和 RHEL 9 的
virtctl命令行工具安装的支持已弃用,计划在以后的发行版本中删除。
6.3.2. 删除的功能
当前版本不支持删除的功能。
- OpenShift Virtualization 不再支持 Red Hat Enterprise Linux 6。
- 所有新部署都删除了对旧的 HPP 自定义资源和关联的存储类的支持。在 OpenShift Virtualization 4.13 中,HPP Operator 使用 Kubernetes Container Storage Interface (CSI) 驱动程序来配置本地存储。只有在以前的 OpenShift Virtualization 版本上安装了旧的 HPP 自定义资源时,才支持它。
6.4. 技术预览功能
这个版本中的一些功能当前还处于技术预览状态。它们并不适用于在生产环境中使用。请参阅红帽门户网站中关于对技术预览功能支持范围的信息:
现在,您可以使用 Prometheus 监控以下指标:
-
kubevirt_vmi_cpu_system_usage_seconds返回虚拟机监控程序消耗的物理系统 CPU 时间。 -
kubevirt_vmi_cpu_user_usage_seconds返回虚拟机监控程序消耗的物理用户 CPU 时间。 -
kubevirt_vmi_cpu_usage_seconds通过计算 vCPU 和虚拟机监控程序使用量的总和,返回 CPU 时间(以秒为单位)。
-
- 现在,您可以运行一个 checkup 来验证 OpenShift Container Platform 集群节点是否可以运行带有零数据包丢失的 Data Plane Development Kit (DPDK) 工作负载的虚拟机。
- 您可以将 虚拟机配置为运行 DPDK 工作负载,以实现较低延迟和更高的吞吐量,以便在用户空间中更快地处理数据包。
- 现在,您可以使用其完全限定域名 (FQDN) 从集群外部访问附加到二级网络接口的虚拟机。
- 现在,您可以使用 OpenShift Virtualization 虚拟机托管的 worker 节点创建 OpenShift Container Platform 集群。如需更多信息,请参阅 Red Hat Advanced Cluster Management (RHACM) 文档中的在 OpenShift Virtualization 上管理托管的 control plane 集群。
- 现在,您可以使用 Microsoft Windows 11 作为客户机操作系统。但是,OpenShift Virtualization 4.13 不支持 USB 磁盘,它们是 BitLocker 恢复的关键功能所必需的。要保护恢复密钥,请使用 BitLocker 恢复指南中的其他方法。
6.5. 程序错误修复
- 由于一些由 Containerized Data Importer (CDI) 创建的持久性卷声明 (PVC) 注解,虚拟机快照恢复操作不再会无限期挂起。(BZ#2070366)
6.6. 已知问题
随着 RHSA-2023:3722 公告的发布,在启用了 FIPS 的 RHEL 9 系统上,对 TLS 1.2 连接强制
Extended Master Secret(EMS)扩展 (RFC 7627) 。这符合 FIPS-140-3 要求。TLS 1.3 不受影响。不支持 EMS 或 TLS 1.3 的旧的 OpenSSL 客户端现在无法连接到运行在 RHEL 9 上的 FIPS 服务器。同样,FIPS 模式下的 RHEL 9 客户端无法连接到只支持没有 EMS 的 TLS 1.2 服务器。在实践中意味着这些客户端无法连接到 RHEL 6、RHEL 7 和非 RHEL 传统操作系统上的服务器。这是因为传统的 OpenSSL 1.0.x 版本不支持 EMS 或 TLS 1.3。如需更多信息,请参阅 使用 Red Hat Enterprise Linux 9.2 强制执行的 TLS 扩展 "Extended Master Secret" 。
作为临时解决方案,将旧的 OpenSSL 客户端升级到支持 TLS 1.3 的版本,并将 OpenShift Virtualization 配置为使用 TLS 1.3,为 FIPS 模式使用
ModernTLS 安全配置集类型。
如果您通过编辑 OpenShift Virtualization 4.12.4 中的
HyperConverged自定义资源启用了DisableMDEVConfiguration功能门,您必须在升级到 4.13.0 或 4.13.1 版本后重新启用功能门,方法是创建一个 JSON Patch 注解 (BZ#2184439):$ oc annotate --overwrite -n openshift-cnv hyperconverged kubevirt-hyperconverged \ kubevirt.kubevirt.io/jsonpatch='[{"op": "add","path": "/spec/configuration/developerConfiguration/featureGates/-", \ "value": "DisableMDEVConfiguration"}]'
OpenShift Virtualization 版本 4.12.2 及更早版本与 OpenShift Container Platform 4.13 不兼容。OpenShift Virtualization 4.12.1 和 4.12.2 中的设计会阻止将 OpenShift Container Platform 更新至 4.13,但这个限制不能添加到 OpenShift Virtualization 4.12.0 中。如果您有 OpenShift Virtualization 4.12.0,请确保没有将 OpenShift Container Platform 更新至 4.13。
重要如果您运行不兼容的 OpenShift Container Platform 和 OpenShift Virtualization 版本,您的集群将不被支持。
- 在虚拟机上启用 descheduler 驱除是一个技术预览功能,可能会导致迁移失败和不稳定的调度。
- 您无法在单堆栈 IPv6 集群上运行 OpenShift Virtualization。(BZ#2193267)
当您使用具有不同 SELinux 上下文的两个 pod 时,带有
ocs-storagecluster-cephfs存储类的虚拟机无法迁移,虚拟机状态变为Paused。这是因为两个 pod 会尝试同时访问共享ReadWriteManyCephFS 卷。(BZ#2092271)-
作为临时解决方案,使用
ocs-storagecluster-ceph-rbd存储类在使用 Red Hat Ceph Storage 的集群上实时迁移虚拟机。
-
作为临时解决方案,使用
如果您使用
csi-clone克隆策略克隆超过 100 个虚拟机,则 Ceph CSI 可能无法清除克隆。手动删除克隆也可能会失败。(BZ#2055595)-
作为临时解决方案,您可以重启
ceph-mgr来清除虚拟机克隆。
-
作为临时解决方案,您可以重启
- 如果您停止集群中的节点,然后使用 Node Health Check Operator 来启动节点,到 Multus 的连接可能会丢失。(OCPBUGS-8398)
OpenShift Virtualization 4.12 中更改了
TopoLVM置备程序名称字符串。因此,自动导入操作系统镜像可能会失败,并显示以下错误消息(BZ39) 2158521):DataVolume.storage spec is missing accessMode and volumeMode, cannot get access mode from StorageProfile.作为临时解决方案:
更新存储配置文件的
claimPropertySets数组:$ oc patch storageprofile <storage_profile> --type=merge -p '{"spec": {"claimPropertySets": [{"accessModes": ["ReadWriteOnce"], "volumeMode": "Block"}, \ {"accessModes": ["ReadWriteOnce"], "volumeMode": "Filesystem"}]}}'-
删除
openshift-virtualization-os-images命名空间中的受影响的数据卷。它们通过更新的存储配置集的访问模式和卷模式重新创建。
当为绑定模式为
WaitForFirstConsumer的存储恢复虚拟机快照时,恢复的 PVC 会处于Pending状态,恢复操作不会进行。-
作为临时解决方案,启动恢复的虚拟机,停止它,然后再次启动它。将调度虚拟机,PVC 将处于
Bound状态,恢复操作将完成。(BZ#2149654)
-
作为临时解决方案,启动恢复的虚拟机,停止它,然后再次启动它。将调度虚拟机,PVC 将处于
-
从单一节点 OpenShift (SNO) 集群上的通用模板创建的虚拟机会显示一个
VMCannotBeEvicted警报,因为模板的默认驱除策略是LiveMigrate。您可以通过更新虚拟机的驱除策略来忽略此警报或删除警报。(BZ#2092412)
-
卸载 OpenShift Virtualization 不会删除 OpenShift Virtualization 创建的
feature.node.kubevirt.io节点标签。您必须手动删除标签。(CNV-22036)
-
Windows 11 虚拟机不会在以 FIPS 模式运行的集群上引导。Windows 11 默认需要一个 TPM (可信平台模块)设备。但是,
swtpm(软件 TPM 模拟器)软件包与 FIPS 不兼容。(BZ#2089301)
如果您的 OpenShift Container Platform 集群使用 OVN-Kubernetes 作为默认 Container Network Interface(CNI)供应商,则无法将 Linux 网桥或绑定设备附加到主机的默认接口,因为 OVN-Kubernetes 的主机网络拓扑发生了变化。(BZ#1885605)
- 作为临时解决方案,您可以使用连接到主机的二级网络接口,或切换到 OpenShift SDN 默认 CNI 供应商。
在某些情况下,多个虚拟机可以以读写模式挂载相同的 PVC,这可能会导致数据崩溃。(BZ#1992753)
- 作为临时解决方案,请避免在使用多个虚拟机的读写模式中使用单个 PVC。
Pod Disruption Budget(PDB)可防止 pod 意外中断。如果 PDB 检测到 pod 中断,则
openshift-monitoring会每 60 分钟发送PodDisruptionBudgetAtLimit警报,以使用LiveMigrate驱除策略。(BZ#2026733)- 作为临时解决方案,静默警报。
OpenShift Virtualization 将 pod 使用的服务帐户令牌链接到该特定 pod。OpenShift Virtualization 通过创建包含令牌的磁盘镜像来实施服务帐户卷。如果您迁移虚拟机,则服务帐户卷无效。(BZ#2037611)
- 作为临时解决方案,使用用户帐户而不是服务帐户,因为用户帐户令牌没有绑定到特定 pod。
- 在具有不同计算节点的异构集群中,启用了 HyperV Reenlightenment 的虚拟机无法调度到不支持时间戳扩展 (TSC) 或具有适当 TSC 频率的节点。(BZ#2151169)
- 如果使用 Red Hat OpenShift Data Foundation 部署 OpenShift Virtualization,您必须为 Windows 虚拟机磁盘创建一个专用存储类。详情请参阅为 Windows 虚拟机优化 ODF PersistentVolume。
使用带有块存储设备的逻辑卷管理 (LVM) 的虚拟机需要额外的配置,以避免与 Red Hat Enterprise Linux CoreOS (RHCOS) 主机冲突。
-
作为临时解决方案,您可以创建一个虚拟机、置备 LVM 并重启虚拟机。这会创建一个空的
system.lvmdevices文件。(OCPBUGS-5223)
-
作为临时解决方案,您可以创建一个虚拟机、置备 LVM 并重启虚拟机。这会创建一个空的
第 7 章 安装
7.1. 为 OpenShift Virtualization 准备集群
在安装 OpenShift Virtualization 前,参阅这个部分以确保集群满足要求。
您可以使用任何安装方法(包括用户置备的、安装程序置备或辅助安装程序)来部署 OpenShift Container Platform。但是,安装方法和集群拓扑可能会影响 OpenShift Virtualization 功能,如快照或实时迁移。
IPv6
您无法在单堆栈 IPv6 集群上运行 OpenShift Virtualization。(BZ#2193267)
7.1.1. 硬件和操作系统要求
查看 OpenShift Virtualization 的以下硬件和操作系统要求。
支持的平台
- 内部裸机服务器
- Amazon Web Services 裸机实例。详情请参阅在 AWS 裸机节点上部署 OpenShift Virtualization。
- IBM Cloud 裸机服务器。详情请参阅在 IBM Cloud Bare Metal 节点上部署 OpenShift Virtualization。
在 AWS 裸机实例或 IBM Cloud Bare Metal 服务器上安装 OpenShift Virtualization 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
- 不支持由其他云供应商提供的裸机实例或服务器。
CPU 要求
- Red Hat Enterprise Linux(RHEL) 9 支持
- 支持 AMD 和 Intel 64 位架构 (x86-64-v2)
- 支持 Intel 64 或 AMD64 CPU 扩展
- 启用 Intel VT 或 AMD-V 硬件虚拟化扩展
- 启用 NX(无执行)标记
存储要求
- OpenShift Container Platform 支持
如果使用 Red Hat OpenShift Data Foundation 部署 OpenShift Virtualization,您必须为 Windows 虚拟机磁盘创建一个专用存储类。详情请参阅为 Windows 虚拟机优化 ODF PersistentVolume。
操作系统要求
在 worker 节点上安装的 Red Hat Enterprise Linux CoreOS(RHCOS)
注意不支持 RHEL worker 节点。
- 如果您的集群使用具有不同 CPU 的 worker 节点,则可能会出现实时迁移失败,因为不同的 CPU 具有不同的容量。为了避免这种故障,请为每个节点使用适当的容量,并在虚拟机上设置节点关联性以确保迁移成功。如需更多信息,请参阅配置所需的节点关联性规则。
7.1.2. 物理资源开销要求
OpenShift Virtualization 是 OpenShift Container Platform 的一个附加组件,它会带来额外的开销。除了 OpenShift Container Platform 要求外,每个集群机器都必须满足以下开销要求。覆盖集群中的物理资源可能会影响性能。
本文档中给出的数字基于红帽的测试方法和设置。这些数字会根据您自己的设置和环境而有所不同。
7.1.2.1. 内存开销
使用以下因素计算 OpenShift Virtualization 的内存开销值。
集群内存开销
Memory overhead per infrastructure node ≈ 150 MiBMemory overhead per worker node ≈ 360 MiB另外,OpenShift Virtualization 环境资源需要总计 2179 MiB 的内存,分布到所有基础架构节点。
虚拟机内存开销
Memory overhead per virtual machine ≈ (1.002 × requested memory) \
+ 218 MiB \
+ 8 MiB × (number of vCPUs) \
+ 16 MiB × (number of graphics devices) \
+ (additional memory overhead) 7.1.2.2. CPU 开销
使用以下内容计算 OpenShift Virtualization 的集群处理器开销要求。每个虚拟机的 CPU 开销取决于您的单独设置。
集群 CPU 开销
CPU overhead for infrastructure nodes ≈ 4 coresOpenShift Virtualization 增加集群级别服务的整体使用,如日志记录、路由和监控。要考虑这个工作负载,请确保托管基础架构组件的节点分配了用于不同节点的 4 个额外内核(4000 毫秒)的容量。
CPU overhead for worker nodes ≈ 2 cores + CPU overhead per virtual machine除了虚拟机工作负载所需的 CPU 外,每个托管虚拟机的 worker 节点都必须有 2 个额外内核(2000 毫秒)用于 OpenShift Virtualization 管理工作负载。
虚拟机 CPU 开销
如果请求专用 CPU,则会对集群 CPU 开销要求有 1:1 影响。否则,没有有关虚拟机所需 CPU 数量的具体规则。
7.1.2.3. 存储开销
使用以下指南来估算 OpenShift Virtualization 环境的存储开销要求。
集群存储开销
Aggregated storage overhead per node ≈ 10 GiB10 GiB 在安装 OpenShift Virtualization 时,集群中每个节点的磁盘存储影响估计值。
虚拟机存储开销
每个虚拟机的存储开销取决于虚拟机内的具体资源分配请求。该请求可能用于集群中其他位置托管的节点或存储资源的临时存储。OpenShift Virtualization 目前不会为正在运行的容器本身分配任何额外的临时存储。
7.1.2.4. Example
作为集群管理员,如果您计划托管集群中的 10 个虚拟机,每个虚拟机都有 1 GiB RAM 和 2 个 vCPU,集群中的内存影响为 11.68 GiB。集群中每个节点的磁盘存储影响估算为 10 GiB,托管虚拟机工作负载的 worker 节点的 CPU 影响最小 2 个内核。
7.1.3. 关于虚拟机磁盘的存储卷
如果您将存储 API 与已知的存储供应商搭配使用,则会自动选择卷和访问模式。但是,如果您使用没有存储配置集的存储类,则必须选择卷和访问模式。
要获得最佳结果,请使用 accessMode: ReadWriteMany 和 volumeMode: Block。这一点非常重要:
- 实时迁移需要 ReadWriteMany (RWX) 访问模式。
与
Filesystem卷模式相比,Block卷模式性能有显著提高。这是因为Filesystem卷模式使用更多存储层,包括文件系统层和磁盘镜像文件。虚拟机磁盘存储不需要这些层。例如,如果您使用 Red Hat OpenShift Data Foundation,Ceph RBD 卷优先于 CephFS 卷。
重要您无法实时迁移使用以下配置的虚拟机:
- 具有 ReadWriteOnce (RWO) 访问模式的存储卷
- 透传功能,比如 GPU
对于这些虚拟机,不要将
evictionStrategy字段设置为LiveMigrate。
7.1.4. 对象最大值
在规划集群时,您必须考虑以下测试的对象最大值:
7.1.5. 受限网络环境
如果在没有互联网连接的受限环境中安装 OpenShift Virtualization,您必须为受限网络配置 Operator Lifecycle Manager。
如果您拥有有限的互联网连接,您可以在 Operator Lifecycle Manager 中配置代理支持 以访问红帽提供的 OperatorHub。
7.1.6. 实时迁移
实时迁移有以下要求:
-
使用
ReadWriteMany(RWX)访问模式的共享存储. - 足够的 RAM 和网络带宽。
- 如果虚拟机使用主机型号 CPU,则节点必须支持虚拟机的主机型号 CPU。
您必须确保集群中有足够的内存请求容量来支持节点排空会导致实时迁移。您可以使用以下计算来确定大约所需的备用内存:
Product of (Maximum number of nodes that can drain in parallel) and (Highest total VM memory request allocations across nodes)集群中可以并行运行的迁移数量的默认值为 5。
7.1.7. 集群高可用性选项
您可以为集群配置以下高可用性(HA)选项之一:
通过 部署机器健康检查,可以使用 安装程序置备的基础架构 (IPI)自动高可用性。
注意在使用安装程序置备的基础架构安装并正确配置 MachineHealthCheck 的 OpenShift Container Platform 集群中,如果节点上的 MachineHealthCheck 失败且对集群不可用,则该节点可以被回收使用。在故障节点上运行的虚拟机之后会发生什么,这取决于一系列条件。如需了解更多有关潜在结果以及 RunStrategies 如何影响这些结果的信息,请参阅虚拟机的 RunStrategies。
-
通过在 OpenShift Container Platform 集群上使用 Node Health Check Operator 来部署
NodeHealthCheck控制器,可以使用 IPI 和非 IPI 自动高可用性。控制器识别不健康的节点并使用补救供应商,如 Self Node Remediation Operator 或 Fence Agents Remediation Operator 来修复不健康的节点。如需有关补救、隔离和维护节点的更多信息,请参阅 Red Hat OpenShift 文档中的工作负载可用性。 任何平台的高可用性可通过使用监控系统或合格的人类监控节点可用性来实现。当节点丢失时,关闭并运行
oc delete node <lost_node>。注意如果没有外部监控系统或合格的人类监控节点运行状况,虚拟机就失去高可用性。
7.2. 为 OpenShift Virtualization 组件指定节点
通过配置节点放置规则来指定要部署 OpenShift Virtualization Operator、工作负载和控制器的节点。
您可以在安装 OpenShift Virtualization 后为一些组件配置节点放置,但如果要为工作负载配置节点放置,则一定不能存在虚拟机。
7.2.1. 关于虚拟化组件的节点放置
您可能想要自定义 OpenShift Virtualization 在什么位置部署其组件,以确保:
- 虚拟机仅部署到设计为用于虚拟化工作负载的节点上。
- Operator 仅在基础架构节点上部署。
- 某些节点不会受到 OpenShift Virtualization 的影响。例如,您有与集群中运行的虚拟化不相关的工作负载,希望这些工作负载与 OpenShift Virtualization 分离。
7.2.1.1. 如何将节点放置规则应用到虚拟化组件
您可以通过直接编辑对应对象或使用 Web 控制台为组件指定节点放置规则。
-
对于 Operator Lifecycle Manager(OLM)部署的 OpenShift Virtualization Operator,直接编辑 OLM
Subscription对象。目前,您无法使用 Web 控制台为Subscription对象配置节点放置规则。 -
对于 OpenShift Virtualization Operator 部署的组件,直接编辑
HyperConverged对象,或在 OpenShift Virtualization 安装过程中使用 Web 控制台进行配置。 对于 hostpath 置备程序,直接编辑
HostPathProvisioner对象,或使用 web 控制台进行配置。警告您必须将 hostpath 置备程序和虚拟化组件调度到同一节点上。否则,使用 hostpath 置备程序的虚拟化 pod 无法运行。
根据对象,您可以使用以下一个或多个规则类型:
nodeSelector- 允许将 Pod 调度到使用您在此字段中指定的键值对标记的节点上。节点必须具有与所有列出的对完全匹配的标签。
关联性- 可让您使用更宽松的语法来设置与 pod 匹配的规则。关联性也允许在规则应用方面更加精细。例如,您可以指定规则是首选项,而不是硬要求,因此如果不满足该规则,仍可以调度 pod。
容限(tolerations)- 允许将 pod 调度到具有匹配污点的节点。如果某个节点有污点(taint),则该节点只接受容许该污点的 pod。
7.2.1.2. 放置在 OLM 订阅对象中的节点
要指定 OLM 部署 OpenShift Virtualization Operator 的节点,在 OpenShift Virtualization 安装过程中编辑 Subscription 对象。您可以在 spec.config 字段中包含节点放置规则,如下例所示:
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: hco-operatorhub
namespace: openshift-cnv
spec:
source: redhat-operators
sourceNamespace: openshift-marketplace
name: kubevirt-hyperconverged
startingCSV: kubevirt-hyperconverged-operator.v4.13.11
channel: "stable"
config: - 1
config字段支持nodeSelector和tolerations,但它不支持关联性。
7.2.1.3. HyperConverged 对象中的节点放置
要指定 OpenShift Virtualization 部署其组件的节点,您可以在 OpenShift Virtualization 安装过程中创建的 HyperConverged Cluster 自定义资源(CR)文件中包含 nodePlacement 对象。您可以在 spec.infra 和 spec.workloads 字段中包含 nodePlacement,如下例所示:
apiVersion: hco.kubevirt.io/v1beta1
kind: HyperConverged
metadata:
name: kubevirt-hyperconverged
namespace: openshift-cnv
spec:
infra:
nodePlacement:
...
workloads:
nodePlacement:
...- 1
nodePlacement字段支持nodeSelector、affinity和tolerations字段。
7.2.1.4. HostPathProvisioner 对象中的节点放置
您可以在安装 hostpath 置备程序时创建的 HostPathProvisioner 对象的 spec.workload 字段中配置节点放置规则。
apiVersion: hostpathprovisioner.kubevirt.io/v1beta1
kind: HostPathProvisioner
metadata:
name: hostpath-provisioner
spec:
imagePullPolicy: IfNotPresent
pathConfig:
path: "</path/to/backing/directory>"
useNamingPrefix: false
workload: - 1
workload字段支持nodeSelector、affinity和tolerations字段。
7.2.2. 清单示例
以下示例 YAML 文件使用 nodePlacement、affinity(关联性) 和 tolerations(容限)对象为 OpenShift Virtualization 组件自定义节点放置。
7.2.2.1. Operator Lifecycle Manager Subscription 对象
7.2.2.1.1. 示例:在 OLM 订阅对象中使用 nodeSelector 的节点放置
在本例中,配置了 nodeSelector,OLM 将 OpenShift Virtualization Operator 放置到标记为 example.io/example-infra-key = example-infra-value 的节点上。
apiVersion: operators.coreos.com/v1beta1
kind: Subscription
metadata:
name: hco-operatorhub
namespace: openshift-cnv
spec:
source: redhat-operators
sourceNamespace: openshift-marketplace
name: kubevirt-hyperconverged
startingCSV: kubevirt-hyperconverged-operator.v4.13.11
channel: "stable"
config:
nodeSelector:
example.io/example-infra-key: example-infra-value7.2.2.1.2. 示例:将容限放置在 OLM 订阅对象中
在本例中,为 OLM 部署 OpenShift Virtualization Operator 保留的节点使用 key=virtualization:NoSchedule 污点标记。只有具有与容限匹配的 pod 才会调度到这些节点。
apiVersion: operators.coreos.com/v1beta1
kind: Subscription
metadata:
name: hco-operatorhub
namespace: openshift-cnv
spec:
source: redhat-operators
sourceNamespace: openshift-marketplace
name: kubevirt-hyperconverged
startingCSV: kubevirt-hyperconverged-operator.v4.13.11
channel: "stable"
config:
tolerations:
- key: "key"
operator: "Equal"
value: "virtualization"
effect: "NoSchedule"7.2.2.2. HyperConverged 对象
在本例中,配置了 nodeSelector,将基础架构资源放置在带有 example.io/example-infra-key = example-infra-value = example-infra-value 的节点上,把工作负载放置在带有 example.io/example-workloads-key = example-workloads-value 的节点上。
apiVersion: hco.kubevirt.io/v1beta1
kind: HyperConverged
metadata:
name: kubevirt-hyperconverged
namespace: openshift-cnv
spec:
infra:
nodePlacement:
nodeSelector:
example.io/example-infra-key: example-infra-value
workloads:
nodePlacement:
nodeSelector:
example.io/example-workloads-key: example-workloads-value7.2.2.2.2. 示例:在 HyperConverged Cluster CR 中使用关联性进行节点放置
在本例中,配置了 affinity,将基础架构资源放置在带有 example.io/example-infra-key = example-value 的节点上,把工作负载放置在带有 example.io/example-workloads-key = example-workloads-value 的节点上。对于工作负载,最好使用八个以上 CPU 的节点,但如果它们不可用,仍可调度 pod。
apiVersion: hco.kubevirt.io/v1beta1
kind: HyperConverged
metadata:
name: kubevirt-hyperconverged
namespace: openshift-cnv
spec:
infra:
nodePlacement:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: example.io/example-infra-key
operator: In
values:
- example-infra-value
workloads:
nodePlacement:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: example.io/example-workloads-key
operator: In
values:
- example-workloads-value
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: example.io/num-cpus
operator: Gt
values:
- 87.2.2.2.3. 示例:在 HyperConverged Cluster CR 中使用容限进行节点放置
在本例中,为 OpenShift Virtualization 组件保留的节点使用 key=virtualization:NoSchedule 污点标记。只有具有与容限匹配的 pod 才会调度到这些节点。
apiVersion: hco.kubevirt.io/v1beta1
kind: HyperConverged
metadata:
name: kubevirt-hyperconverged
namespace: openshift-cnv
spec:
workloads:
nodePlacement:
tolerations:
- key: "key"
operator: "Equal"
value: "virtualization"
effect: "NoSchedule"7.2.2.3. HostPathProvisioner 对象
在本例中,配置了 nodeSelector,以便将工作负载放置到带有 example.io/example-workloads-key = example-workloads-value 的节点上。
apiVersion: hostpathprovisioner.kubevirt.io/v1beta1
kind: HostPathProvisioner
metadata:
name: hostpath-provisioner
spec:
imagePullPolicy: IfNotPresent
pathConfig:
path: "</path/to/backing/directory>"
useNamingPrefix: false
workload:
nodeSelector:
example.io/example-workloads-key: example-workloads-value7.3. 使用 Web 控制台安装 OpenShift Virtualization
安装 OpenShift Virtualization 以便在 OpenShift Container Platform 集群中添加虚拟化功能。
您可以使用 OpenShift Container Platform 4.13 web 控制台来订阅和部署 OpenShift Virtualization Operator。
7.3.1. 安装 OpenShift Virtualization Operator
您可以从 OpenShift Container Platform Web 控制台安装 OpenShift Virtualization Operator。
先决条件
- 在集群上安装 OpenShift Container Platform 4.13。
-
以具有
cluster-admin权限的用户身份登录到 OpenShift Container Platform web 控制台。
流程
- 从 Administrator 视角中,点 Operators → OperatorHub。
- 在 Filter by keyword 字段中,键入 Virtualization。
- 选择带有 Red Hat source 标签的 OpenShift Virtualization Operator 标题。
- 阅读 Operator 信息并单击 Install。
在 Install Operator 页面中:
- 从可用 Update Channel 选项列表中选择 stable。这样可确保安装与 OpenShift Container Platform 版本兼容的 OpenShift Virtualization 版本。
对于安装的命名空间,请确保选择了 Operator 推荐的命名空间选项。这会在
openshift-cnv命名空间中安装 Operator,该命名空间在不存在时自动创建。警告尝试在
openshift-cnv以外的命名空间中安装 OpenShift Virtualization Operator 会导致安装失败。对于 Approval Strategy,强烈建议您选择 Automatic (默认值),以便在 stable 更新频道中提供新版本时 OpenShift Virtualization 会自动更新。
虽然可以选择 Manual 批准策略,但这不可取,因为它会给集群提供支持和功能带来高风险。只有在您完全了解这些风险且无法使用 Automatic 时,才选择 Manual。
警告因为 OpenShift Virtualization 只在与对应的 OpenShift Container Platform 版本搭配使用时被支持,所以缺少的 OpenShift Virtualization 更新可能会导致您的集群不被支持。
-
点击 Install 使 Operator 可供
openshift-cnv命名空间使用。 - 当 Operator 成功安装时,点 Create HyperConverged。
- 可选: 为 OpenShift Virtualization 组件配置 Infra 和 Workloads 节点放置选项。
- 点击 Create 启动 OpenShift Virtualization。
验证
- 导航到 Workloads → Pods 页面,并监控 OpenShift Virtualization Pod,直至全部处于 Running 状态。在所有 pod 都处于 Running 状态后,您可以使用 OpenShift Virtualization。
7.3.2. 后续步骤
您可能还需要额外配置以下组件:
- hostpath 置备程序是设计用于 OpenShift Virtualization 的本地存储置备程序。如果要为虚拟机配置本地存储,您必须首先启用 hostpath 置备程序。
7.4. 使用 CLI 安装 OpenShift Virtualization
安装 OpenShift Virtualization 以便在 OpenShift Container Platform 集群中添加虚拟化功能。您可以使用命令行将清单应用到集群,以订阅和部署 OpenShift Virtualization Operator。
要指定 OpenShift Virtualization 安装其组件的节点,请配置节点放置规则。
7.4.1. 先决条件
- 在集群上安装 OpenShift Container Platform 4.13。
-
安装 OpenShift CLI (
oc) 。 -
以具有
cluster-admin特权的用户身份登录。
7.4.2. 使用 CLI 订阅 OpenShift virtualization 目录
在安装 OpenShift Virtualization 前,需要订阅到 OpenShift Virtualization catalog。订阅会授予 OpenShift virtualization Operator 对 openshift-cnv 命名空间的访问权限。
为了订阅,在您的集群中应用一个单独的清单(manifest)来配置 Namespace、OperatorGroup 和 Subscription 对象。
先决条件
- 在集群上安装 OpenShift Container Platform 4.13。
-
安装 OpenShift CLI (
oc) 。 -
以具有
cluster-admin特权的用户身份登录。
流程
创建一个包含以下清单的 YAML 文件:
apiVersion: v1 kind: Namespace metadata: name: openshift-cnv --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: kubevirt-hyperconverged-group namespace: openshift-cnv spec: targetNamespaces: - openshift-cnv --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: hco-operatorhub namespace: openshift-cnv spec: source: redhat-operators sourceNamespace: openshift-marketplace name: kubevirt-hyperconverged startingCSV: kubevirt-hyperconverged-operator.v4.13.11 channel: "stable"1 - 1
- 使用
stable频道可确保您安装与 OpenShift Container Platform 版本兼容的 OpenShift Virtualization 版本。
运行以下命令,为 OpenShift Virtualization 创建所需的
Namespace、OperatorGroup和Subscription对象:$ oc apply -f <filename>.yaml
验证
您必须验证订阅创建是否成功,然后才能安装 OpenShift Virtualization。
检查
ClusterServiceVersion(CSV)对象是否已成功创建。运行以下命令并验证输出:$ oc get csv -n openshift-cnv如果成功创建 CSV,输出会显示一个条目,其中包含
kubevirt-hyperconverged-operatorchannel、DISPLAY值、OpenShift Virtualization的 DISPLAY 值和PHASE值Succeeded,如下例所示:输出示例
NAME DISPLAY VERSION REPLACES PHASE kubevirt-hyperconverged-operator.v4.13.11 OpenShift Virtualization 4.13.11 kubevirt-hyperconverged-operator.v4.12.0 Succeeded检查
HyperConverged自定义资源(CR)是否具有正确的版本。运行以下命令并验证输出:$ oc get hco -n openshift-cnv kubevirt-hyperconverged -o json | jq .status.versions输出示例
{ "name": "operator", "version": "4.13.11" }验证
HyperConvergedCR 条件。运行以下命令并检查输出:$ oc get hco kubevirt-hyperconverged -n openshift-cnv -o json | jq -r '.status.conditions[] | {type,status}'输出示例
{ "type": "ReconcileComplete", "status": "True" } { "type": "Available", "status": "True" } { "type": "Progressing", "status": "False" } { "type": "Degraded", "status": "False" } { "type": "Upgradeable", "status": "True" }
您可以在 YAML 文件中配置证书轮转参数。
7.4.3. 使用 CLI 部署 OpenShift Virtualization Operator
您可以使用 oc CLI 部署 OpenShift Virtualization Operator。
先决条件
-
在
openshift-cnv命名空间中的一个有效的 OpenShift virtualization 目录订阅。
流程
创建一个包含以下清单的 YAML 文件:
apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec:运行以下命令来部署 OpenShift Virtualization Operator:
$ oc apply -f <file_name>.yaml
验证
通过观察
openshift-cnv命名空间中集群服务版本(CSV)的PHASE来确保 OpenShift Virtualization 已被成功部署。运行以下命令:$ watch oc get csv -n openshift-cnv如果部署成功,则会显示以下输出:
输出示例
NAME DISPLAY VERSION REPLACES PHASE kubevirt-hyperconverged-operator.v4.13.11 OpenShift Virtualization 4.13.11 Succeeded
7.4.4. 后续步骤
您可能还需要额外配置以下组件:
- hostpath 置备程序是设计用于 OpenShift Virtualization 的本地存储置备程序。如果要为虚拟机配置本地存储,您必须首先启用 hostpath 置备程序。
7.5. 卸载 OpenShift Virtualization
您可以使用 Web 控制台或命令行界面(CLI)卸载 OpenShift Virtualization,以删除 OpenShift Virtualization 工作负载、Operator 及其资源。
7.5.1. 使用 Web 控制台卸载 OpenShift Virtualization
您可以使用 Web 控制台卸载 OpenShift Virtualization 来执行以下任务:
7.5.1.1. 删除 HyperConverged 自定义资源
要卸载 OpenShift Virtualization,首先删除 HyperConverged 自定义资源 (CR)。
先决条件
-
可以使用具有
cluster-admin权限的账户访问 OpenShift Container Platform 集群。
流程
- 进入到 Operators → Installed Operators 页面。
- 选择 OpenShift Virtualization Operator。
- 点 OpenShift Virtualization Deployment 选项卡。
-
点
kubevirt-hyperconverged旁边的 Options 菜单 ,然后选择 Delete HyperConverged。
,然后选择 Delete HyperConverged。
- 在确认窗口中点击 Delete。
7.5.1.2. 使用 Web 控制台从集群中删除 Operator
集群管理员可以使用 Web 控制台从所选命名空间中删除已安装的 Operator。
先决条件
-
您可以使用具有
cluster-admin权限的账户访问 OpenShift Container Platform 集群 Web 控制台。
流程
- 进入到 Operators → Installed Operators 页面。
- 在 Filter by name 字段中滚动或输入关键字以查找您要删除的 Operator。然后点它。
在 Operator Details 页面右侧,从 Actions 列表中选择 Uninstall Operator。
此时会显示 Uninstall Operator? 对话框。
选择 Uninstall 来删除 Operator、Operator 部署和 pod。按照此操作,Operator 将停止运行,不再接收更新。
注意此操作不会删除 Operator 管理的资源,包括自定义资源定义 (CRD) 和自定义资源 (CR) 。Web 控制台和继续运行的集群资源启用的仪表板和导航项可能需要手动清理。要在卸载 Operator 后删除这些,您可能需要手动删除 Operator CRD。
7.5.1.3. 使用 web 控制台删除命令空间
您可以使用 OpenShift Container Platform web 控制台删除一个命名空间。
先决条件
-
可以使用具有
cluster-admin权限的账户访问 OpenShift Container Platform 集群。
流程
- 导航至 Administration → Namespaces。
- 在命名空间列表中找到您要删除的命名空间。
-
在命名空间列表的右侧,从 Options 菜单
中选择 Delete Namespace。
- 当 Delete Namespace 页打开时,在相关项中输入您要删除的命名空间的名称。
- 点击 Delete。
7.5.1.4. 删除 OpenShift Virtualization 自定义资源定义
您可以使用 Web 控制台删除 OpenShift Virtualization 自定义资源定义 (CRD)。
先决条件
-
可以使用具有
cluster-admin权限的账户访问 OpenShift Container Platform 集群。
流程
- 进入到 Administration → CustomResourceDefinitions。
-
选择 Label 过滤器,并在 Search 字段中输入
operators.coreos.com/kubevirt-hyperconverged.openshift-cnv,以显示 OpenShift Virtualization CRD。 -
点每个 CRD 旁边的 Options 菜单
,然后选择 Delete CustomResourceDefinition。
7.5.2. 使用 CLI 卸载 OpenShift Virtualization
您可以使用 OpenShift CLI (oc) 卸载 OpenShift Virtualization。
先决条件
-
可以使用具有
cluster-admin权限的账户访问 OpenShift Container Platform 集群。 -
已安装 OpenShift CLI(
oc)。 - 您已删除所有虚拟机和虚拟机实例。当其工作负载保留在集群中时,您无法卸载 OpenShift Virtualization。
流程
删除
HyperConverged自定义资源:$ oc delete HyperConverged kubevirt-hyperconverged -n openshift-cnv删除 OpenShift Virtualization Operator 订阅:
$ oc delete subscription hco-operatorhub -n openshift-cnv删除 OpenShift Virtualization
ClusterServiceVersion资源:$ oc delete csv -n openshift-cnv -l operators.coreos.com/kubevirt-hyperconverged.openshift-cnv删除 OpenShift Virtualization 命名空间:
$ oc delete namespace openshift-cnv使用
dry-run选项运行oc delete crd命令列出 OpenShift Virtualization 自定义资源定义 (CRD):$ oc delete crd --dry-run=client -l operators.coreos.com/kubevirt-hyperconverged.openshift-cnv输出示例
customresourcedefinition.apiextensions.k8s.io "cdis.cdi.kubevirt.io" deleted (dry run) customresourcedefinition.apiextensions.k8s.io "hostpathprovisioners.hostpathprovisioner.kubevirt.io" deleted (dry run) customresourcedefinition.apiextensions.k8s.io "hyperconvergeds.hco.kubevirt.io" deleted (dry run) customresourcedefinition.apiextensions.k8s.io "kubevirts.kubevirt.io" deleted (dry run) customresourcedefinition.apiextensions.k8s.io "networkaddonsconfigs.networkaddonsoperator.network.kubevirt.io" deleted (dry run) customresourcedefinition.apiextensions.k8s.io "ssps.ssp.kubevirt.io" deleted (dry run) customresourcedefinition.apiextensions.k8s.io "tektontasks.tektontasks.kubevirt.io" deleted (dry run)运行
oc delete crd命令来删除 CRD,而无需dry-run选项:$ oc delete crd -l operators.coreos.com/kubevirt-hyperconverged.openshift-cnv
第 8 章 更新 OpenShift Virtualization
了解 Operator Lifecycle Manager (OLM) 如何为 OpenShift Virtualization 提供 z-stream 和次要版本更新。
不支持从 OpenShift Virtualization 4.12.2 升级到 OpenShift Virtualization 4.13。
8.1. RHEL 9 上的 OpenShift Virtualization
OpenShift Virtualization 4.13 基于 Red Hat Enterprise Linux (RHEL) 9。您可以按照标准 OpenShift Virtualization 更新过程,从基于 RHEL 8 的版本升级到 OpenShift Virtualization 4.13。不需要额外的步骤。
与之前的版本一样,您可以在不中断运行工作负载的情况下执行更新。OpenShift Virtualization 4.13 支持从 RHEL 8 节点实时迁移到 RHEL 9 节点。
8.1.1. 新的 RHEL 9 机器类型
这个版本还为虚拟机引进了新的 RHEL 9 机器类型: machineType: pc-q35-rhel9.2.0。OpenShift Virtualization 中包含的所有虚拟机模板现在都默认使用此机器类型。
更新 OpenShift Virtualization 不会更改任何现有虚拟机的 machineType 值。这些虚拟机在更新前继续正常工作。
虽然不需要,但您可能想要将虚拟机的机器类型改为 pc-q35-rhel9.2.0,以便它可从 RHEL 9 的改进中受益。
在更改虚拟机的 machineType 值前,您必须关闭虚拟机。
8.2. 关于更新 OpenShift Virtualization
- Operator Lifecycle Manager (OLM) 管理 OpenShift Virtualization Operator 的生命周期。Marketplace Operator 在 OpenShift Container Platform 安装过程中部署,使外部 Operator 可供集群使用。
- OLM 为 OpenShift Virtualization 提供 z-stream 和次要版本更新。在将 OpenShift Container Platform 更新至下一个次版本时,次版本更新将变为可用。在不先更新 OpenShift Container Platform 的情况下,您无法将 OpenShift Virtualization 更新至下一个次版本。
- OpenShift Virtualization 订阅使用一个名为 stable 的单一更新频道。stable 频道确保 OpenShift Virtualization 和 OpenShift Container Platform 版本兼容。
如果您的订阅的批准策略被设置为 Automatic,则当 stable 频道中提供新版本的 Operator 时,更新过程就会马上启动。强烈建议您使用 Automatic(自动) 批准策略来维护可支持的环境。只有在运行对应的 OpenShift Container Platform 版本时,才会支持 OpenShift Virtualization 的每个次要版本。例如,您必须在 OpenShift Container Platform 4.13 上运行 OpenShift Virtualization 4.13。
- 虽然可以选择 Manual(手工) 批准策略,但并不建议这样做,因为它存在集群的支持性和功能风险。使用 Manual 批准策略时,您必须手动批准每个待处理的更新。如果 OpenShift Container Platform 和 OpenShift Virtualization 更新不同步,您的集群将无法被支持。
- 更新完成所需时间取决于您的网络连接情况。大部分自动更新可在十五分钟内完成。
- 更新 OpenShift Virtualization 不会中断网络连接。
- 数据卷及其关联的持久性卷声明会在更新过程中保留。
如果您的虚拟机正在运行,使用 hostpath 置备程序存储,则无法实时迁移,并可能会阻止 OpenShift Container Platform 集群更新。
作为临时解决方案,您可以重新配置虚拟机以便在集群更新过程中自动关闭它们。删除 evictionStrategy: LiveMigrate 字段,并将 runStrategy 字段设置为 Always。
8.2.1. 关于工作负载更新
更新 OpenShift Virtualization 时,虚拟机工作负载(包括 libvirt、virt-launcher )和 qemu (如果支持实时迁移)会自动更新。
每个虚拟机均有一个 virt-launcher pod,用于运行虚拟机实例(VMI)。virt-launcher pod 运行一个 libvirt 实例,用于管理虚拟机(VM)进程。
您可以通过编辑 HyperConverged 自定义资源 (CR) 的 spec.workloadUpdateStrategy 小节来配置工作负载的更新方式。可用的工作负载更新方法有两种: LiveMigrate 和 Evict。
因为 Evict 方法关闭 VMI pod,所以只启用 LiveMigrate 更新策略。
当 LiveMigrate 是唯一启用的更新策略时:
- 支持实时迁移的 VMI 会在更新过程中进行迁移。VM 客户机会进入启用了更新组件的新 pod。
不支持实时迁移的 VMI 不会中断或更新。
-
如果 VMI 有
LiveMigrate驱除策略,但没有支持实时迁移。
-
如果 VMI 有
如果您同时启用 LiveMigrate 和 Evict :
-
支持实时迁移的 VMI 使用
LiveMigrate更新策略。 -
不支持实时迁移的 VMI 使用
Evict更新策略。如果 VMI 由具有always的runStrategy值的VirtualMachine对象控制,则会在带有更新组件的新 pod 中创建一个新的 VMI。
迁移尝试和超时
更新工作负载时,如果 pod 在以下时间段内处于 Pending 状态,实时迁移会失败:
- 5 分钟
-
如果 pod 因为是
Unschedulable而处于 pending 状态。 - 15 分钟
- 如果 pod 因任何原因处于 pending 状态。
当 VMI 无法迁移时,virt-controller 会尝试再次迁移它。它会重复这个过程,直到所有可可迁移的 VMI 在新的 virt-launcher Pod 上运行。如果 VMI 没有被正确配置,这些尝试可能会无限期重复。
每次尝试都会对应于一个迁移对象。只有最近五个尝试才在缓冲区中。这可防止迁移对象在系统上进行积累,同时保留用于调试的信息。
8.2.2. 关于 EUS 到 EUS 更新
每个 OpenShift Container Platform 的次版本号为偶数(包括 4.10 和 4.12)都是延长更新支持(EUS)版本。但是,由于 Kubernetes 设计了串行次版本更新,所以您无法直接从一个 EUS 版本更新到下一个版本。
从源 EUS 版本升级到下一个奇数次版本后,您必须按顺序将 OpenShift Virtualization 更新至更新路径中的所有次版本的 z-stream 版本。当您升级到最新的适用 z-stream 版本时,您可以将 OpenShift Container Platform 更新至目标 EUS 次版本。
当 OpenShift Container Platform 更新成功时,OpenShift Virtualization 的对应更新将变为可用。现在,您可以将 OpenShift Virtualization 更新至目标 EUS 版本。
8.2.2.1. 准备更新
在开始 EUS 到 EUS 更新前,您必须:
- 在启动 EUS 到 EUS 更新前,暂停 worker 节点的机器配置池,以便 worker 不会重启两次。
- 在开始更新过程前禁用自动工作负载更新。这是为了防止 OpenShift Virtualization 迁移或驱除虚拟机(VM),直到您升级到目标 EUS 版本。
默认情况下,当您更新 OpenShift Virtualization Operator 时,OpenShift Virtualization 会自动更新工作负载,如 virt-launcher pod。您可以在 HyperConverged 自定义资源的 spec.workloadUpdateStrategy 小节中配置此行为。
了解有关准备执行 EUS 到 EUS 更新的更多信息。
8.3. 防止在 EUS 到 EUS 更新过程中进行工作负载更新
当您从一个延长更新支持(EUS)版本升级到下一个版本时,您必须手动禁用自动工作负载更新,以防止 OpenShift Virtualization 在更新过程中迁移或驱除工作负载。
先决条件
- 您正在运行 EUS 版本 OpenShift Container Platform,并希望升级到下一个 EUS 版本。还没有同时更新至奇数版本。
- 您可以阅读"准备执行 EUS 到 EUS 更新",并了解到与 OpenShift Container Platform 集群相关的注意事项和要求。
- 按照 OpenShift Container Platform 文档的指示暂停 worker 节点的机器配置池。
- 建议您使用默认的 Automatic 批准策略。如果使用 Manual 批准策略,您必须批准 web 控制台中的所有待处理的更新。如需了解更多详细信息,请参阅"需要批准待处理的 Operator 更新"部分。
流程
运行以下命令备份当前的
workloadUpdateMethods配置:$ WORKLOAD_UPDATE_METHODS=$(oc get kv kubevirt-kubevirt-hyperconverged -n openshift-cnv -o jsonpath='{.spec.workloadUpdateStrategy.workloadUpdateMethods}')运行以下命令关闭所有工作负载更新方法:
$ oc patch hco kubevirt-hyperconverged -n openshift-cnv --type json -p '[{"op":"replace","path":"/spec/workloadUpdateStrategy/workloadUpdateMethods", "value":[]}]'输出示例
hyperconverged.hco.kubevirt.io/kubevirt-hyperconverged patched在继续操作前,请确保
HyperConvergedOperator 为Upgradeable。输入以下命令并监控输出:$ oc get hco kubevirt-hyperconverged -n openshift-cnv -o json | jq ".status.conditions"例 8.1. 输出示例
[ { "lastTransitionTime": "2022-12-09T16:29:11Z", "message": "Reconcile completed successfully", "observedGeneration": 3, "reason": "ReconcileCompleted", "status": "True", "type": "ReconcileComplete" }, { "lastTransitionTime": "2022-12-09T20:30:10Z", "message": "Reconcile completed successfully", "observedGeneration": 3, "reason": "ReconcileCompleted", "status": "True", "type": "Available" }, { "lastTransitionTime": "2022-12-09T20:30:10Z", "message": "Reconcile completed successfully", "observedGeneration": 3, "reason": "ReconcileCompleted", "status": "False", "type": "Progressing" }, { "lastTransitionTime": "2022-12-09T16:39:11Z", "message": "Reconcile completed successfully", "observedGeneration": 3, "reason": "ReconcileCompleted", "status": "False", "type": "Degraded" }, { "lastTransitionTime": "2022-12-09T20:30:10Z", "message": "Reconcile completed successfully", "observedGeneration": 3, "reason": "ReconcileCompleted", "status": "True", "type": "Upgradeable"1 } ]- 1
- OpenShift Virtualization Operator 具有
Upgradeable状态。
手动将集群从源 EUS 版本升级到下一个 OpenShift Container Platform 次要版本:
$ oc adm upgrade验证
运行以下命令检查当前版本:
$ oc get clusterversion注意将 OpenShift Container Platform 更新至下一版本是更新 OpenShift Virtualization 的先决条件。如需了解更多详细信息,请参阅 OpenShift Container Platform 文档中的"更新集群"部分。
更新 OpenShift Virtualization。
- 使用默认的 Automatic 批准策略,OpenShift Virtualization 会在更新 OpenShift Container Platform 后自动更新到对应的版本。
- 如果使用 Manual 批准策略,请使用 Web 控制台批准待处理的更新。
运行以下命令监控 OpenShift Virtualization 更新:
$ oc get csv -n openshift-cnv- 将 OpenShift Virtualization 更新至可用于非 EUS 次版本的每个 z-stream 版本,通过运行上一步中显示的命令来监控每个更新。
运行以下命令,确认 OpenShift Virtualization 已成功更新至非 EUS 版本的最新 z-stream 版本:
$ oc get hco kubevirt-hyperconverged -n openshift-cnv -o json | jq ".status.versions"输出示例
[ { "name": "operator", "version": "4.13.11" } ]等待
HyperConvergedOperator 在执行下一次更新前具有Upgradeable状态。输入以下命令并监控输出:$ oc get hco kubevirt-hyperconverged -n openshift-cnv -o json | jq ".status.conditions"- 将 OpenShift Container Platform 更新至目标 EUS 版本。
通过检查集群版本确认更新是否成功:
$ oc get clusterversion将 OpenShift Virtualization 更新至目标 EUS 版本。
- 使用默认的 Automatic 批准策略,OpenShift Virtualization 会在更新 OpenShift Container Platform 后自动更新到对应的版本。
- 如果使用 Manual 批准策略,请使用 Web 控制台批准待处理的更新。
运行以下命令监控 OpenShift Virtualization 更新:
$ oc get csv -n openshift-cnv当
VERSION字段与目标 EUS 版本匹配并且PHASE字段显示为Succeeded时,更新已完成。恢复您备份的工作负载更新方法配置:
$ oc patch hco kubevirt-hyperconverged -n openshift-cnv --type json -p "[{\"op\":\"add\",\"path\":\"/spec/workloadUpdateStrategy/workloadUpdateMethods\", \"value\":$WORKLOAD_UPDATE_METHODS}]"输出示例
hyperconverged.hco.kubevirt.io/kubevirt-hyperconverged patched验证
运行以下命令检查虚拟机迁移的状态:
$ oc get vmim -A
后续步骤
- 现在,您可以取消暂停 worker 节点的机器配置池。
8.4. 配置工作负载更新方法
您可以通过编辑 HyperConverged 自定义资源(CR)来配置工作负载更新方法。
先决条件
要使用实时迁移作为更新方法,您必须首先在集群中启用实时迁移。
注意如果
VirtualMachineInstanceCR 包含evictionStrategy: LiveMigrate,且虚拟机实例(VMI)不支持实时迁移,则 VMI 将不会更新。
流程
要在默认编辑器中打开
HyperConvergedCR,请运行以下命令:$ oc edit hco -n openshift-cnv kubevirt-hyperconverged编辑
HyperConvergedCR 的workloadUpdateStrategy小节。例如:apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: workloadUpdateStrategy: workloadUpdateMethods:1 - LiveMigrate2 - Evict3 batchEvictionSize: 104 batchEvictionInterval: "1m0s"5 # ...- 1
- 可用于执行自动化工作负载更新的方法。可用值为
LiveMigrate和Evict。如果您如本例所示启用这两个选项,则更新会为不支持实时迁移的 VMI 使用LiveMigrate,对于不支持实时迁移的 VMI 使用Evict。要禁用自动工作负载更新,您可以删除workloadUpdateStrategy小节,或设置workloadUpdateMethods: []将数组留空。 - 2
- 具有最低破坏性的更新方法。支持实时迁移的 VMI 通过将虚拟机 (VM) 客户机迁移到启用了更新组件的新 pod 中来更新。如果
LiveMigrate是唯一列出的工作负载更新方法,不支持实时迁移的 VMI 不会中断或更新。 - 3
- 在升级过程中关闭 VMI pod 是一个有破坏性的方法。如果在集群中没有启用实时迁移,
Evict是唯一可用的更新方法。如果 VMI 由已配置了runStrategy: always的VirtualMachine对象控制,新的 VMI 会在带有更新组件的新 pod 中创建。 - 4
- 使用
Evict方法每次可以强制更新的 VMI 数量。这不适用于LiveMigrate方法。 - 5
- 驱除下一批工作负载前等待的时间间隔。这不适用于
LiveMigrate方法。
注意您可以通过编辑
HyperConvergedCR 的spec.liveMigrationConfig小节来配置实时迁移限制和超时。- 若要应用您的更改,请保存并退出编辑器。
8.5. 批准待处理的 Operator 更新
8.5.1. 手动批准待处理的 Operator 更新
如果已安装的 Operator 的订阅被设置为 Manual,则当其当前更新频道中发布新更新时,在开始安装前必须手动批准更新。
先决条件
- 之前使用 Operator Lifecycle Manager(OLM)安装的 Operator。
流程
- 在 OpenShift Container Platform Web 控制台的 Administrator 视角中,进入 Operators → Installed Operators。
- 处于待定更新的 Operator 会显示 Upgrade available 状态。点您要更新的 Operator 的名称。
- 点 Subscription 标签页。任何需要批准的更新都会在 Upgrade status 旁边显示。例如:它可能会显示 1 requires approval。
- 点 1 requires approval,然后点 Preview Install Plan。
- 检查列出可用于更新的资源。在满意后,点 Approve。
- 返回到 Operators → Installed Operators 页面,以监控更新的进度。完成后,状态会变为 Succeeded 和 Up to date。
8.6. 监控更新状态
8.6.1. 监控 OpenShift Virtualization 升级状态
要监控 OpenShift Virtualization Operator 升级的状态,请观察集群服务版本 (CSV) PHASE。此外您还可在 web 控制台中,或运行此处提供的命令来监控 CSV 状况。
PHASE 和状况值均是基于可用信息的近似值。
先决条件
-
以具有
cluster-admin角色的用户身份登录集群。 -
安装 OpenShift CLI(
oc)。
流程
运行以下命令:
$ oc get csv -n openshift-cnv查看输出,检查
PHASE字段。例如:输出示例
VERSION REPLACES PHASE 4.9.0 kubevirt-hyperconverged-operator.v4.8.2 Installing 4.9.0 kubevirt-hyperconverged-operator.v4.9.0 Replacing可选:运行以下命令来监控所有 OpenShift Virtualization 组件状况的聚合状态:
$ oc get hco -n openshift-cnv kubevirt-hyperconverged \ -o=jsonpath='{range .status.conditions[*]}{.type}{"\t"}{.status}{"\t"}{.message}{"\n"}{end}'成功升级后会输出以下内容:
输出示例
ReconcileComplete True Reconcile completed successfully Available True Reconcile completed successfully Progressing False Reconcile completed successfully Degraded False Reconcile completed successfully Upgradeable True Reconcile completed successfully
8.6.2. 查看过时的 OpenShift Virtualization 工作负载
您可以使用 CLI 查看过时的工作负载列表。
如果集群中存在过时的虚拟化 pod,OutdatedVirtualMachineInstanceWorkloads 警报会触发。
流程
要查看过时的虚拟机实例 (VMI) 列表,请运行以下命令:
$ oc get vmi -l kubevirt.io/outdatedLauncherImage --all-namespaces
配置工作负载更新以确保 VMI 自动更新。
第 9 章 安全策略
了解 OpenShift Virtualization 安全和授权。
关键点
-
OpenShift Virtualization 遵循
restrictedKubernetes pod security standards 配置集,旨在强制实施 Pod 安全性的当前最佳实践。 - 虚拟机 (VM) 工作负载作为非特权 pod 运行。
-
为
kubevirt-controller服务帐户定义 安全性上下文约束 (SCC)。
9.1. 关于工作负载安全性
默认情况下,虚拟机 (VM) 工作负载在 OpenShift Virtualization 中不会使用 root 权限运行,且支持的 OpenShift Virtualization 功能都不需要 root 权限。
对于每个虚拟机,都会有一个 virt-launcher pod,它以会话模式(session mode)运行一个 libvirt 实例,用于管理 VM 进程。在会话模式中,libvirt 守护进程是以非 root 用户帐户运行的,它只允许来自使用同一用户标识符 (UID) 运行的客户端的连接。这样,虚拟机就可以作为非特权 pod 运行,遵循了最小特权的安全原则。
Pod 的安全上下文约束(SCC)控制权限。这些权限包括 Pod(容器集合)可以执行的操作以及它们可以访问的资源。您可以使用 SCC 定义 Pod 运行必须满足的一组条件,以便其能被系统接受。
virt-controller 是一个集群控制器,可为集群中的虚拟机创建 virt-launcher pod。这些 pod 由 kubevirt-controller 服务帐户授予权限。
kubevirt-controller 服务帐户被授予额外的 SCC 和 Linux 功能,以便能够创建具有适当权限的 virt-launcher Pod。这些扩展权限允许虚拟机使用超出典型 pod 范围的 OpenShift Virtualization 功能。
kubevirt-controller 服务帐户被授予以下 SCC:
-
scc.AllowHostDirVolumePlugin = true
这允许虚拟机使用 hostpath 卷插件。 -
scc.AllowPrivilegedContainer = false
可确保 virt-launcher pod 不是作为特权容器运行。 scc.AllowedCapabilities = []corev1.Capability{"SYS_NICE", "NET_BIND_SERVICE"}
-
SYS_NICE允许设置 CPU 关联性。 -
NET_BIND_SERVICE允许 DHCP 和 Slirp 操作。
-
9.2.1. 查看 kubevirt-controller 的 SCC 和 RBAC 定义
您可以使用 oc 工具查看 kubevirt-controller 的 SecurityContextConstraints 定义:
$ oc get scc kubevirt-controller -o yaml
您可以使用 oc 工具查看 kubevirt-controller clusterrole 的 RBAC 定义:
$ oc get clusterrole kubevirt-controller -o yaml9.3. 授权
OpenShift Virtualization 使用基于角色的访问控制 (RBAC) 进行授权。例如,管理员可以创建一个 RBAC 角色,它提供启动虚拟机所需的权限。然后,管理员可以通过将角色绑定到特定用户来限制对该功能的访问。
9.3.1. OpenShift Virtualization 的默认集群角色
通过使用集群角色聚合,OpenShift Virtualization 会扩展默认的 OpenShift Container Platform 集群角色,使其包含访问虚拟化对象的权限。
| 默认集群角色 | OpenShift Virtualization 集群角色 | OpenShift Virtualization 集群角色描述 |
|---|---|---|
|
|
| 此用户可以查看集群中的所有 OpenShift Virtualization 资源,但不能创建、删除、修改或访问它们。例如,用户可以看到虚拟机 (VM) 正在运行,但不能将其关闭或访问其控制台。 |
|
|
| 可以修改集群中的所有 OpenShift Virtualization 资源。例如,用户可以创建虚拟机、访问虚拟机控制台和删除虚拟机。 |
|
|
|
具有所有 OpenShift Virtualization 资源的完整权限,包括删除资源集合。用户也可以查看和修改 OpenShift Virtualization 运行时配置,该配置位于 |
第 10 章 使用 virtctl 和 libguestfs CLI 工具
您可使用 virtctl 命令行工具管理 OpenShift Virtualization 资源。
您还可以使用 virtctl 部署 libguestfs-tools 容器。libguestfs 是一组用于访问和修改虚拟机(VM)磁盘镜像的工具。
10.1. 安装 virtctl
要在 Linux、Windows 和 MacOS 操作系统上安装 virtctl,您可以下载并安装 virtctl 二进制文件。
要在 Red Hat Enterprise Linux (RHEL) 上安装 virtctl,您可以启用 OpenShift Virtualization 仓库,然后安装 kubevirt-virtctl 软件包。
10.1.1. 在 RHEL 9、Linux、Windows 或 macOS 上安装 virtctl 二进制文件
您可以从 OpenShift Container Platform web 控制台下载适用于操作系统的 virtctl 二进制文件,然后安装它。
流程
- 在 web 控制台中进入到 Virtualization → Overview 页面。
-
点 Download virtctl 链接为您的操作系统下载
virtctl二进制文件。 安装
virtctl:对于 RHEL 9 和其他 Linux 操作系统:
解压缩存档文件:
$ tar -xvf <virtctl-version-distribution.arch>.tar.gz运行以下命令使
virtctl二进制可执行文件:$ chmod +x <path/virtctl-file-name>将
virtctl二进制文件移到PATH环境变量中的目录中。您可以运行以下命令来检查您的路径:
$ echo $PATH设置
KUBECONFIG环境变量:$ export KUBECONFIG=/home/<user>/clusters/current/auth/kubeconfig
对于 Windows:
- 解压缩存档文件。
-
进入解压的目录中,双击
virtctl可执行文件来安装客户端。 将
virtctl二进制文件移到PATH环境变量中的目录中。您可以运行以下命令来检查您的路径:
C:\> path
macOS:
- 解压缩存档文件。
将
virtctl二进制文件移到PATH环境变量中的目录中。您可以运行以下命令来检查您的路径:
echo $PATH
10.1.2. 在 RHEL 8 上安装 virtctl RPM
您可以通过启用 OpenShift Virtualization 仓库并安装 kubevirt-virtctl 软件包,在 Red Hat Enterprise Linux (RHEL) 8 上安装 virtctl RPM 软件包。
先决条件
- 集群中的每个主机都必须通过 Red Hat Subscription Manager (RHSM) 注册,并具有有效的 OpenShift Container Platform 订阅。
流程
使用
subscription-managerCLI 工具为操作系统启用 OpenShift Virtualization 仓库,以运行以下命令:# subscription-manager repos --enable cnv-4.13-for-rhel-8-x86_64-rpms运行以下命令安装
kubevirt-virtctl软件包:# yum install kubevirt-virtctl
10.2. virtctl 命令
virtctl 客户端是用于管理 OpenShift Virtualization 资源的命令行实用程序。
除非另有指定,否则虚拟机 (VM) 命令也适用于虚拟机实例。
10.2.1. virtctl 信息命令
您可使用 virtctl 信息命令查看 virtctl 客户端的信息。
| 命令 | 描述 |
|---|---|
|
|
查看 |
|
|
查看 |
|
| 查看特定命令的选项列表。 |
|
|
查看任何 |
10.2.2. VM 信息命令
您可使用 virtctl 查看有关虚拟机和 VMI 的信息。
| 命令 | 描述 |
|---|---|
|
| 查看客户机机器上可用的文件系统。 |
|
| 查看客户机机器上操作系统的信息。 |
|
| 查看客户机机器上的登录用户。 |
10.2.3. VM 管理命令
您可使用 virtctl 虚拟机 (VM) 管理命令管理和迁移虚拟机和 VMI。
| 命令 | 描述 |
|---|---|
|
|
创建 |
|
| 启动虚拟机。 |
|
| 以暂停状态启动虚拟机。这个选项可让您从 VNC 控制台中断引导过程。 |
|
| 停止虚拟机。 |
|
| 强制停止虚拟机。这个选项可能会导致数据不一致或数据丢失。 |
|
| 暂停虚拟机。机器状态保存在内存中。 |
|
| 取消暂停虚拟机。 |
|
| 迁移虚拟机。 |
|
| 重启虚拟机。 |
10.2.4. VM 连接命令
您可使用 virtctl 连接命令来公开端口并连接到虚拟机和 VMI。
| 命令 | 描述 |
|---|---|
|
| 连接到虚拟机的串行控制台。 |
|
| 创建转发虚拟机的指定端口的服务,并在节点的指定端口上公开服务。 |
|
| 将文件从机器复制到虚拟机。此命令使用 SSH 密钥对的私钥。虚拟机必须配置有公钥。 |
|
| 将文件从虚拟机复制到您的机器中。此命令使用 SSH 密钥对的私钥。虚拟机必须配置有公钥。 |
|
| 与虚拟机打开 SSH 连接。此命令使用 SSH 密钥对的私钥。虚拟机必须配置有公钥。 |
|
| 连接到虚拟机的 VNC 控制台。 通过 VNC 访问 VMI 的图形控制台需要在本地机器上有一个远程查看器。 |
|
| 显示端口号,并使用任何查看器通过 VNC 连接手动连接到 VMI。 |
|
| 如果该端口可用,则指定端口号用于在指定端口上运行代理。 如果没有指定端口号,代理会在随机端口上运行。 |
10.2.5. VM 导出命令
您可使用 virtctl vmexport 命令来创建、下载或删除从虚拟机、虚拟机快照或持久性卷声明 (PVC) 导出的卷。
| 命令 | 描述 |
|---|---|
|
|
创建一个
|
|
|
手动删除 |
|
|
下载在
可选:
|
|
|
创建一个 |
10.2.6. VM 内存转储命令
您可使用 virtctl memory-dump 命令在 PVC 上输出虚拟机 (VM) 内存转储。您可以指定现有的 PVC,或使用 --create-claim 标志来创建新 PVC。
先决条件
-
PVC 卷模式必须是
FileSystem。 PVC 必须足够大以保存内存转储。
计算 PVC 大小的公式为
(VMMemorySize + 100Mi)* FileSystemOverhead,其中100Mi是内存转储开销。您必须运行以下命令来在
HyperConverged自定义资源中启用热插功能:$ oc patch hco kubevirt-hyperconverged -n openshift-cnv \ --type json -p '[{"op": "add", "path": "/spec/featureGates", \ "value": "HotplugVolumes"}]'
下载内存转储
您必须使用 virtctl vmexport download 命令下载内存转储:
$ virtctl vmexport download <vmexport_name> --vm\|pvc=<object_name> \
--volume=<volume_name> --output=<output_file>| 命令 | 描述 |
|---|---|
|
|
在 PVC 上保存虚拟机的内存转储。内存转储状态显示在 可选:
|
|
|
使用相同的 PVC 重新运行 这个命令覆盖以前的内存转储。 |
|
| 删除内存转储。 如果要更改目标 PVC,则必须手动删除内存转储。
这个命令会删除虚拟机和 PVC 之间的关联,以便在 |
10.2.7. 热插和热拔命令
您可使用 virtctl 从正在运行的虚拟机和 VMI 中添加或删除资源。
| 命令 | 描述 |
|---|---|
|
| 热插数据卷或持久性卷声明 (PVC)。 可选:
|
|
| 热拔虚拟磁盘。 |
10.2.8. 镜像上传命令
您可使用 virtctl image-upload 命令将虚拟机镜像上传到数据卷中。
| 命令 | 描述 |
|---|---|
|
| 将虚拟机镜像上传到已存在的数据卷中。 |
|
| 将虚拟机镜像上传到指定请求大小的新数据卷中。 |
10.3. 使用 libguestfs
10.3.1. 使用 virtctl 部署 libguestfs-tools 容器
您可以使用 virtctl guestfs 命令部署带有 libguestfs-tools 以及附加到它的持久性卷声明 (PVC) 的交互式容器。
流程
要部署一个带有
libguestfs-tools的容器,挂载 PVC 并为其附加一个 shell,运行以下命令:$ virtctl guestfs -n <namespace> <pvc_name>1 - 1
- PVC 名称是必需的参数。如果没有包括它,则会出现错误消息。
10.3.2. libguestfs 和 virtctl guestfs 命令
libguestfs 工具可帮助您访问和修改虚拟机 (VM) 磁盘镜像。您可以使用 libguestfs 工具查看和编辑客户机中的文件、克隆和构建虚拟机,以及格式化和调整磁盘大小。
您还可以使用 virtctl guestfs 命令及其子命令在 PVC 上修改、检查和调试虚拟机磁盘。要查看子命令的完整列表,请在命令行中输入 virt- 并按 Tab 键。例如:
| 命令 | 描述 |
|---|---|
|
| 在终端中以交互方式编辑文件。 |
|
| 将 ssh 密钥注入客户系统并创建登录。 |
|
| 查看虚拟机使用了多少磁盘空间。 |
|
| 通过创建包含完整列表的输出文件,查看虚拟客户机上安装的所有 RPM 的完整列表。 |
|
|
在终端中使用 |
|
| 封装要用作模板的虚拟机磁盘镜像。 |
默认情况下,virtctl guestfs 会创建一个会话,其中包含管理 VM 磁盘所需的一切内容。但是,如果想要自定义行为,该命令还支持几个标志选项:
| 标记选项 | 描述 |
|---|---|
|
|
为 |
|
带有 | 使用特定命名空间中的 PVC。
如果不使用
如果没有包括 |
|
|
列出
您可以使用 |
|
|
代表
默认情况下,
如果群集没有任何
如果没有设置, |
|
|
显示
您还可以通过设置 |
这个命令还会检查 PVC 是否被另一个 pod 使用,这时会出现错误消息。但是,libguestfs-tools 进程启动后,设置无法避免使用相同的 PVC 的新 pod。在启动虚拟机访问同一 PVC 前,您必须先验证没有活跃的 virtctl guestfs pod。
virtctl guestfs 命令只接受附加到交互式 pod 的单个 PVC。
第 11 章 虚拟机
11.1. 创建虚拟机
使用以下其中一个流程来创建虚拟机:
- 快速入门指南
- 从目录快速创建
- 使用虚拟机向导来粘贴预先配置的 YAML 文件
- 使用 CLI
不要在 openshift-* 命名空间中创建虚拟机 。相反,创建一个新命名空间或使用没有 openshift 前缀的现有命名空间。
从 web 控制台创建虚拟机时,请选择配置了引导源的虚拟机模板。具有引导源的虚拟机模板标记为 Available boot source,或者它们显示自定义标签文本。使用有可用引导源的模板可促进创建虚拟机的过程。
没有引导源的模板被标记为 Boot source required。如果完成了向虚拟机中添加引导源的步骤,您可以使用这些模板。
由于存储行为的区别,一些虚拟机模板与单节点 OpenShift 不兼容。为确保兼容性,请不要为使用数据卷或存储配置集的任何模板或虚拟机设置 evictionStrategy 字段。
11.1.1. 使用快速入门创建虚拟机
web 控制台为创建虚拟机提供指导指导快速入门。您可以通过在 Administrator 视角中选择 Help 菜单来查看 Quick Starts 目录来访问 Quick Starts 目录。当您点快速入门标题并开始使用时,系统会帮助您完成这个过程。
快速入门中的任务以选择红帽模板开始。然后,您可以添加一个引导源并导入操作系统镜像。最后,您可以保存自定义模板,并使用它来创建虚拟机。
先决条件
- 访问您可以下载操作系统镜像的 URL 链接的网站。
流程
- 在 web 控制台中,从 Help 菜单中选择 Quick Starts。
- 点 Quick Starts 目录里的一个标题。例如:Creating a Red Hat Linux Enterprise Linux virtual machine。
- 按照教程中的说明,完成导入操作系统镜像并创建虚拟机的任务。Virtualization → VirtualMachines 页面显示虚拟机。
11.1.2. 快速创建虚拟机
您可以使用有可用引导源的模板快速创建虚拟机(VM)。
流程
- 在侧边菜单中点 Virtualization → Catalog。
点 Boot source available 来使用引导源过滤模板。
注意默认情况下,模板列表将仅显示默认模板。过滤时点 All Items,以查看您选择的过滤器的所有可用模板。
- 点模板查看其详情。
点 Quick Create VirtualMachine 从模板创建虚拟机。
虚拟机 Details 页面会显示 provisioning 状态。
验证
- 点 Events 在虚拟机被置备时查看事件流。
- 点 Console 以验证虚拟机是否已成功引导。
11.1.3. 从自定义模板创建虚拟机
有些模板需要额外的参数,例如使用引导源的 PVC。您可以自定义模板的选择参数来创建虚拟机(VM)。
流程
在 web 控制台中选择一个模板:
- 在侧边菜单中点 Virtualization → Catalog。
- 可选:按项目、关键字、操作系统或工作负载配置集过滤模板。
- 点您要自定义的模板。
- 点 Customize VirtualMachine。
- 指定虚拟机的参数,包括其 Name 和 Disk source。您可选择指定要克隆的数据源。
验证
- 点 Events 在虚拟机被置备时查看事件流。
- 点 Console 以验证虚拟机是否已成功引导。
从 web 控制台创建虚拟机时,请参考虚拟机字段部分。
11.1.3.1. 网络字段
| 名称 | 描述 |
|---|---|
| Name | 网络接口控制器的名称。 |
| model | 指明网络接口控制器的型号。支持的值有 e1000e 和 virtio。 |
| 网络 | 可用网络附加定义的列表。 |
| 类型 | 可用绑定方法列表。选择适合网络接口的绑定方法:
|
| MAC 地址 | 网络接口控制器的 MAC 地址。如果没有指定 MAC 地址,则会自动分配一个。 |
11.1.3.2. 存储字段
| 名称 | 选择 | 描述 |
|---|---|---|
| Source | 空白(创建 PVC) | 创建一个空磁盘。 |
| 通过 URL 导入(创建 PVC) | 通过 URL(HTTP 或 HTTPS 端点)导入内容。 | |
| 使用现有的 PVC | 使用集群中已可用的 PVC。 | |
| 克隆现有的 PVC(创建 PVC) | 选择集群中可用的现有 PVC 并克隆它。 | |
| 通过 Registry 导入(创建 PVC) | 通过容器 registry 导入内容。 | |
| 容器(临时) | 从集群可以访问的 registry 中的容器上传内容。容器磁盘应只用于只读文件系统,如 CD-ROM 或临时虚拟机。 | |
| 名称 |
磁盘的名称。名称可包含小写字母 ( | |
| Size | GiB 中磁盘的大小。 | |
| 类型 | 磁盘类型。示例:磁盘或光盘 | |
| Interface | 磁盘设备的类型。支持的接口包括 virtIO、SATA 和 SCSI。 | |
| Storage class | 用于创建磁盘的存储类。 |
高级存储设置
以下高级存储设置是可选的,对 Blank, Import via URL, and Clone existing PVC 磁盘可用。在 OpenShift Virtualization 4.11 之前,如果您没有指定这些参数,系统将使用 kubevirt-storage-class-defaults 配置映射中的默认值。在 OpenShift Virtualization 4.11 及更高版本中,系统使用存储配置集中的默认值。
使用存储配置集来确保在为 OpenShift Virtualization 置备存储时一致的高级存储设置。
要手动指定 卷模式 和 访问模式,您必须清除 Apply optimized StorageProfile settings 复选框,该复选框被默认选择。
| Name | 模式描述 | 参数 | 参数描述 |
|---|---|---|---|
| 卷模式 | 定义持久性卷是否使用格式化的文件系统或原始块状态。默认为 Filesystem。 | Filesystem | 在基于文件系统的卷中保存虚拟磁盘。 |
| Block |
直接将虚拟磁盘存储在块卷中。只有底层存储支持时才使用 | ||
| 访问模式 | 持久性卷访问模式。 | ReadWriteOnce (RWO) | 卷可以被一个节点以读写模式挂载。 |
| ReadWriteMany (RWX) | 卷可以被多个节点以读写模式挂载。 注意 对于一些功能(如虚拟机在节点间实时迁移)需要这个权限。 | ||
| ReadOnlyMany (ROX) | 卷可以被多个节点以只读形式挂载。 |
11.1.3.3. Cloud-init 字段
| 名称 | 描述 |
|---|---|
| 授权 SSH 密钥 | 复制到虚拟机上 ~/.ssh/authorized_keys 的用户公钥。 |
| 自定义脚本 | 将其他选项替换为您粘贴自定义 cloud-init 脚本的字段。 |
要配置存储类默认设置,请使用存储配置集。如需更多信息,请参阅自定义存储配置集。
11.1.3.4. 粘贴至预先配置的 YAML 文件中以创建虚拟机
通过写入或粘贴 YAML 配置文件来创建虚拟机。每当您打开 YAML 编辑屏幕,默认会提供一个有效的 example 虚拟机配置。
如果您点击 Create 时 YAML 配置无效,则错误消息会指示出错的参数。一次仅显示一个错误。
编辑时离开 YAML 屏幕会取消您对配置做出的任何更改。
流程
- 在侧边菜单中点 Virtualization → VirtualMachines。
- 点 Create 并选择 With YAML。
在可编辑窗口写入或粘贴您的虚拟机配置。
-
或者,使用 YAML 屏幕中默认提供的
example虚拟机。
-
或者,使用 YAML 屏幕中默认提供的
- 可选:点 Download 以下载当前状态下的 YAML 配置文件。
- 点击 Create 以创建虚拟机。
虚拟机在 VirtualMachines 页面中列出。
11.1.4. 使用 CLI 创建虚拟机
您可以从 virtualMachine 清单创建虚拟机。
流程
编辑虚拟机的
VirtualMachine清单。例如,以下清单配置 Red Hat Enterprise Linux(RHEL)虚拟机:例 11.1. RHEL 虚拟机的清单示例
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: labels: app: <vm_name>1 name: <vm_name> spec: dataVolumeTemplates: - apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: <vm_name> spec: sourceRef: kind: DataSource name: rhel9 namespace: openshift-virtualization-os-images storage: resources: requests: storage: 30Gi running: false template: metadata: labels: kubevirt.io/domain: <vm_name> spec: domain: cpu: cores: 1 sockets: 2 threads: 1 devices: disks: - disk: bus: virtio name: rootdisk - disk: bus: virtio name: cloudinitdisk interfaces: - masquerade: {} name: default rng: {} features: smm: enabled: true firmware: bootloader: efi: {} resources: requests: memory: 8Gi evictionStrategy: LiveMigrate networks: - name: default pod: {} volumes: - dataVolume: name: <vm_name> name: rootdisk - cloudInitNoCloud: userData: |- #cloud-config user: cloud-user password: '<password>'2 chpasswd: { expire: False } name: cloudinitdisk使用清单文件创建虚拟机:
$ oc create -f <vm_manifest_file>.yaml可选:启动虚拟机:
$ virtctl start <vm_name>
11.1.5. 虚拟机存储卷类型
| 存储卷类型 | 描述 |
|---|---|
| ephemeral | 将网络卷用作只读后备存储的本地写时复制 (COW) 镜像。后备卷必须为 PersistentVolumeClaim。当虚拟机启动并在本地存储所有写入数据时,便会创建临时镜像。当虚拟机停止、重启或删除时,便会丢弃临时镜像。其底层的卷 (PVC) 不会以任何方式发生变化。 |
| persistentVolumeClaim | 将可用 PV 附加到虚拟机。附加 PV 可确保虚拟机数据在会话之间保持。 将现有虚拟机导入到 OpenShift Container Platform 中的建议方法是,使用 CDI 将现有虚拟机磁盘导入到 PVC 中,然后将 PVC 附加到虚拟机实例。在 PVC 中使用磁盘需要满足一些要求。 |
| dataVolume |
通过导入、克隆或上传操作来管理虚拟机磁盘的准备过程,以此在
指定 |
| cloudInitNoCloud | 附加包含所引用的 cloud-init NoCloud 数据源的磁盘,从而向虚拟机提供用户数据和元数据。虚拟机磁盘内部需要安装 cloud-init。 |
| containerDisk | 引用容器镜像 registry 中存储的镜像,如虚拟机磁盘。镜像从 registry 中拉取,并在虚拟机启动时作为磁盘附加到虚拟机。
注意
|
| emptyDisk | 创建额外的稀疏 QCOW2 磁盘,与虚拟机接口的生命周期相关联。当虚拟机中的客户端初始化重启后,数据保留下来,但当虚拟机停止或从 web 控制台重启时,数据将被丢弃。空磁盘用于存储应用程序依赖项和数据,否则这些依赖项和数据会超出临时磁盘有限的临时文件系统。 此外还必须提供磁盘容量大小。 |
11.1.6. 关于虚拟机的 RunStrategies
虚拟机的 RunStrategy 会根据一系列条件,决定虚拟机实例(VMI)的行为。spec.runStrategy 设置存在于虚拟机配置过程中,作为 spec.running 设置的替代方案。spec.runStrategy 设置为创建和管理 VMI 提供了更大的灵活性。而 spec.running 设置只能有 true 或 false 响应。但是,这两种设置是相互排斥的。只能同时使用 spec.running 或 spec.runStrategy 之一。如果两者都存在,则会出现错误。
有四个定义的 RunStrategies。
Always-
在创建虚拟机时,始终会存在 VMI。如果因为任何原因造成原始的 VMI 停止运行,则会创建一个新的 VMI,这与
spec.running: true的行为相同。 RerunOnFailure- 如果上一个实例因为错误而失败,则会重新创建一个 VMI。如果虚拟机成功停止(例如虚拟机正常关机),则不会重新创建实例。
Manual-
start、stop和restartvirtctl 客户端命令可以被用来控制 VMI 的状态。 Halted-
创建虚拟机时没有 VMI,这与
spec.running: false的行为相同。
start、stop 和 restart virtctl 命令的不同组合会影响到使用哪个 RunStrategy。
下表是虚拟机从不同状态过渡的列表。第一栏显示了 VM 的初始 RunStrategy。每个额外的栏都显示一个 virtctl 命令以及在运行该命令后的新的 RunStrategy。
| 初始 RunStrategy | 开始 | 停止 | 重启 |
|---|---|---|---|
| Always | - | Halted | Always |
| RerunOnFailure | - | Halted | RerunOnFailure |
| Manual | Manual | Manual | Manual |
| Halted | Always | - | - |
在使用安装程序置备的基础架构安装的 OpenShift Virtualization 集群中,当节点的 MachineHealthCheck 失败且集群不可用时,,带有 Always 或 RerunOnFailure 的 RunStrategy 的虚拟机会被重新调度到一个新的节点上。
apiVersion: kubevirt.io/v1
kind: VirtualMachine
spec:
RunStrategy: Always
template:
# ...- 1
- VMI 的当前
RunStrategy设置。
11.2. 编辑虚拟机
您可以使用 web 控制台中的 YAML 编辑器或命令行上的 OpenShift CLI 来更新虚拟机配置。您还可以更新 Virtual Machine Details 屏幕中的参数子集。
11.2.1. 在 web 控制台中编辑虚拟机
您可以使用 OpenShift Container Platform web 控制台或命令行界面编辑虚拟机。
流程
- 在 web 控制台中进入到 Virtualization → VirtualMachines。
- 选择虚拟机以打开 VirtualMachine 详情页面。
- 点具有铅笔图标的字段,这表示该字段可编辑。例如,点当前的 引导模式 设置(如 BIOS 或 UEFI)打开 引导模式 窗口并从列表中选择一个选项。
- 点击 Save。
如果虚拟机正在运行,对 Boot Order 或 Flavor 的更改在重启虚拟机后才会生效。
您可以点击相关字段右侧的 View Pending Changes 来查看待处理的更改。页面顶部的 Pending Changes 标题显示虚拟机重启时将应用的所有更改列表。
11.2.2. 使用 web 控制台编辑虚拟机 YAML 配置
您可以在 web 控制台中编辑虚拟机的 YAML 配置。某些参数无法修改。如果在有无效配置时点 Save,则会出现一个错误消息指示无法更改的参数。
编辑时离开 YAML 屏幕会取消您对配置做出的任何更改。
流程
- 在侧边菜单中点 Virtualization → VirtualMachines。
- 选择虚拟机。
- 点击 YAML 选项卡以显示可编辑的配置。
- (可选):您可点击 Download,在本地下载当前状态的 YAML 文件。
- 编辑该文件并点击 Save。
确认消息显示修改已成功,其中包含对象的更新版本号。
11.2.3. 使用 CLI 编辑虚拟机 YAML 配置
使用这个步骤,通过 CLI 编辑虚拟机 YAML 配置。
先决条件
- 已使用 YAML 对象配置文件配置了虚拟机。
-
已安装
ocCLI。
流程
运行以下命令以更新虚拟机配置:
$ oc edit <object_type> <object_ID>- 打开对象配置。
- 编辑 YAML。
如果要编辑正在运行的虚拟机,您需要执行以下任一操作:
- 重启虚拟机。
运行以下命令使新配置生效:
$ oc apply <object_type> <object_ID>
11.2.4. 将虚拟磁盘添加到虚拟机
使用这个流程在虚拟机中添加虚拟磁盘。
流程
- 在侧边菜单中点 Virtualization → VirtualMachines。
- 选择虚拟机以打开 VirtualMachine 详情页面。
- 在 Configuration → Disks 选项卡中,点 Add disk。
指定 Source、Name、Size、Type、Interface 和 Storage Class。
- 可选:如果您使用空磁盘源并在创建数据卷时要求最大写入性能,则可以启用预分配。如果要这样做,可选中启用预分配复选框。
-
可选:您可以清除 Apply optimized StorageProfile 设置,以更改虚拟磁盘的卷模式和访问模式。如果没有指定这些参数,系统将使用
kubevirt-storage-class-defaults配置映射中的默认值。
- 点 Add。
如果虚拟机正在运行,新磁盘处于 pending restart 状态,且不会在重启虚拟机前附加。
页面顶部的 Pending Changes 标题显示虚拟机重启时将应用的所有更改列表。
要配置存储类默认设置,请使用存储配置集。如需更多信息,请参阅自定义存储配置集。
11.2.4.1. 存储字段
| 名称 | 选择 | 描述 |
|---|---|---|
| Source | 空白(创建 PVC) | 创建一个空磁盘。 |
| 通过 URL 导入(创建 PVC) | 通过 URL(HTTP 或 HTTPS 端点)导入内容。 | |
| 使用现有的 PVC | 使用集群中已可用的 PVC。 | |
| 克隆现有的 PVC(创建 PVC) | 选择集群中可用的现有 PVC 并克隆它。 | |
| 通过 Registry 导入(创建 PVC) | 通过容器 registry 导入内容。 | |
| 容器(临时) | 从集群可以访问的 registry 中的容器上传内容。容器磁盘应只用于只读文件系统,如 CD-ROM 或临时虚拟机。 | |
| 名称 |
磁盘的名称。名称可包含小写字母 ( | |
| Size | GiB 中磁盘的大小。 | |
| 类型 | 磁盘类型。示例:磁盘或光盘 | |
| Interface | 磁盘设备的类型。支持的接口包括 virtIO、SATA 和 SCSI。 | |
| Storage class | 用于创建磁盘的存储类。 |
高级存储设置
以下高级存储设置是可选的,对 Blank, Import via URL, and Clone existing PVC 磁盘可用。在 OpenShift Virtualization 4.11 之前,如果您没有指定这些参数,系统将使用 kubevirt-storage-class-defaults 配置映射中的默认值。在 OpenShift Virtualization 4.11 及更高版本中,系统使用存储配置集中的默认值。
使用存储配置集来确保在为 OpenShift Virtualization 置备存储时一致的高级存储设置。
要手动指定 卷模式 和 访问模式,您必须清除 Apply optimized StorageProfile settings 复选框,该复选框被默认选择。
| Name | 模式描述 | 参数 | 参数描述 |
|---|---|---|---|
| 卷模式 | 定义持久性卷是否使用格式化的文件系统或原始块状态。默认为 Filesystem。 | Filesystem | 在基于文件系统的卷中保存虚拟磁盘。 |
| Block |
直接将虚拟磁盘存储在块卷中。只有底层存储支持时才使用 | ||
| 访问模式 | 持久性卷访问模式。 | ReadWriteOnce (RWO) | 卷可以被一个节点以读写模式挂载。 |
| ReadWriteMany (RWX) | 卷可以被多个节点以读写模式挂载。 注意 对于一些功能(如虚拟机在节点间实时迁移)需要这个权限。 | ||
| ReadOnlyMany (ROX) | 卷可以被多个节点以只读形式挂载。 |
11.2.5. 将 secret、配置映射或服务帐户添加到虚拟机
使用 OpenShift Container Platform Web 控制台向虚拟机添加 secret、配置映射或服务帐户。
这些资源作为磁盘添加到虚拟机中。您可在挂载任何其他磁盘时挂载 secret、配置映射或服务帐户。
如果虚拟机正在运行,则更改在重启虚拟机之后才会生效。新添加的资源在页面的顶部被标记为待处理更改。
先决条件
- 要添加的 secret、配置映射或服务帐户必须与目标虚拟机位于同一命名空间中。
流程
- 在侧边菜单中点 Virtualization → VirtualMachines。
- 选择虚拟机以打开 VirtualMachine 详情页面。
- 点 Configuration → Environment。
- 点 Add Config Map、Secret 或 Service Account。
- 点 Select a resource,从列表中选择一个资源。为所选资源自动生成带有六个字符的序列号。
- 可选:点 Reload 将环境恢复到其上次保存的状态。
- 点击 Save。
验证
- 在 VirtualMachine 详情页面中,点 Configuration → Disks 并验证资源是否在磁盘列表中显示。
- 点 Actions → Restart 重启虚拟机。
现在,您可以在挂载任何其他磁盘时挂载 secret、配置映射或服务帐户。
配置映射、secret 和服务帐户的其他资源
11.2.6. 将网络接口添加到虚拟机
将网络接口添加到虚拟机.
流程
- 在侧边菜单中点 Virtualization → VirtualMachines。
- 选择虚拟机以打开 VirtualMachine 详情页面。
- 在 Configuration → Network interfaces 选项卡中,点 Add Network Interface。
- 在 Add Network Interface 窗口中,指定网络接口的 Name、Model、Network、Type 和 MAC Address。
- 点 Add。
如果虚拟机正在运行,新的网络接口处于 pending restart 状态,且更改在重启虚拟机后才会生效。
页面顶部的 Pending Changes 标题显示虚拟机重启时将应用的所有更改列表。
11.2.6.1. 网络字段
| 名称 | 描述 |
|---|---|
| Name | 网络接口控制器的名称。 |
| model | 指明网络接口控制器的型号。支持的值有 e1000e 和 virtio。 |
| 网络 | 可用网络附加定义的列表。 |
| 类型 | 可用绑定方法列表。选择适合网络接口的绑定方法:
|
| MAC 地址 | 网络接口控制器的 MAC 地址。如果没有指定 MAC 地址,则会自动分配一个。 |
11.3. 编辑引导顺序
您可以使用 Web 控制台或 CLI 更新引导顺序列表的值。
通过 Virtual Machine Overview 页面中的 Boot Order ,您可以:
- 选择磁盘或网络接口控制器 (NIC) 并将其添加到引导顺序列表中。
- 编辑引导顺序列表中磁盘或 NIC 的顺序。
- 从引导顺序列表中移除磁盘或者 NIC,然后将其返回到可引导源清单。
11.3.1. 向 web 控制台的引导顺序列表中添加项目
使用 web 控制台将项目添加到引导顺序列表中。
流程
- 在侧边菜单中点 Virtualization → VirtualMachines。
- 选择虚拟机以打开 VirtualMachine 详情页面。
- 点 Details 标签页。
- 点击位于 Boot Order 右侧的铅笔图标。如果 YAML 配置不存在,或者是首次创建引导顺序列表时,会显示以下消息: No resource selected.虚拟机会根据在 YAML 文件中的顺序从磁盘引导。
- 点 Add Source,为虚拟机选择一个可引导磁盘或网络接口控制器 (NIC)。
- 在引导顺序列表中添加附加磁盘或者 NIC。
- 点 Save。
如果虚拟机正在运行,在重启虚拟机后对 Boot Order 的更改不会生效。
您可以点 Boot Order 字段右侧的 View Pending Changes 查看待处理的修改。页面顶部的 Pending Changes 标题显示虚拟机重启时将应用的所有更改列表。
11.3.2. 在 web 控制台中编辑引导顺序列表
在 web 控制台中编辑引导顺序列表。
流程
- 在侧边菜单中点 Virtualization → VirtualMachines。
- 选择虚拟机以打开 VirtualMachine 详情页面。
- 点 Details 标签页。
- 点击位于 Boot Order 右侧的铅笔图标。
选择适当的方法来移动引导顺序列表中的项目:
- 如果您没有使用屏幕阅读器,请在您想要移动的项目旁的箭头图标上切换,拖动或下移项目,然后将其放到您选择的位置。
- 如果您使用屏幕阅读器,请按上箭头或者下箭头键移动引导顺序列表中的项目。然后,按 Tab 键将项目放到您选择的位置。
- 点 Save。
如果虚拟机正在运行,对引导顺序列表的更改将在重启虚拟机后才会生效。
您可以点 Boot Order 字段右侧的 View Pending Changes 查看待处理的修改。页面顶部的 Pending Changes 标题显示虚拟机重启时将应用的所有更改列表。
11.3.3. 在 YAML 配置文件中编辑引导顺序列表
使用 CLI 编辑 YAML 配置文件中的引导顺序列表。
流程
运行以下命令为虚拟机打开 YAML 配置文件:
$ oc edit vm example编辑 YAML 文件并修改与磁盘或网络接口控制器 (NIC) 关联的引导顺序值。例如:
disks: - bootOrder: 11 disk: bus: virtio name: containerdisk - disk: bus: virtio name: cloudinitdisk - cdrom: bus: virtio name: cd-drive-1 interfaces: - boot Order: 22 macAddress: '02:96:c4:00:00' masquerade: {} name: default- 保存 YAML 文件。
- 点 reload the content,使 YAML 文件中更新的引导顺序值应用到 web 控制台的引导顺序列表中。
11.3.4. 从 web 控制台中的引导顺序列表中删除项目
使用 Web 控制台从引导顺序列表中移除项目。
流程
- 在侧边菜单中点 Virtualization → VirtualMachines。
- 选择虚拟机以打开 VirtualMachine 详情页面。
- 点 Details 标签页。
- 点击位于 Boot Order 右侧的铅笔图标。
-
点击项
 旁边的 Remove 图标。该项目从引导顺序列表中删除,可用引导源列表的内容被保存。如果您从引导顺序列表中删除所有项目,则会显示以下消息: No resource selected.虚拟机会根据在 YAML 文件中的顺序从磁盘引导。
旁边的 Remove 图标。该项目从引导顺序列表中删除,可用引导源列表的内容被保存。如果您从引导顺序列表中删除所有项目,则会显示以下消息: No resource selected.虚拟机会根据在 YAML 文件中的顺序从磁盘引导。
如果虚拟机正在运行,在重启虚拟机后对 Boot Order 的更改不会生效。
您可以点 Boot Order 字段右侧的 View Pending Changes 查看待处理的修改。页面顶部的 Pending Changes 标题显示虚拟机重启时将应用的所有更改列表。
11.4. 删除虚拟机
您可从 web 控制台或使用 oc 命令行删除虚拟机。
11.4.1. 使用 web 控制台删除虚拟机
删除虚拟机会将其从集群中永久移除。
流程
- 在 OpenShift Container Platform 控制台中,从侧边菜单中点 Virtualization → VirtualMachines。
点虚拟机旁边的 Options 菜单
并选择 Delete。
或者,击虚拟机名称,打开 VirtualMachine 详情页面并点击 Actions → Delete。
- 可选: 选择 With grace period 或清除 Delete disks。
- 点 Delete 以永久删除虚拟机。
11.4.2. 使用 CLI 删除虚拟机
您可以使用 oc 命令行接口 (CLI) 删除虚拟机。oc 客户端允许您在多个虚拟机上执行操作。
先决条件
- 找到要删除的虚拟机名称。
流程
运行以下命令以删除虚拟机:
$ oc delete vm <vm_name>注意此命令只删除当前项目中的虚拟机。如果您要删除其他项目或命名空间中的虚拟机,请使用
-n <project_name>选项。
11.5. 导出虚拟机
您可以导出虚拟机 (VM) 及其关联的磁盘,以将虚拟机导入到另一个集群或分析卷以备备目的。
您可以使用命令行界面创建一个 VirtualMachineExport 自定义资源 (CR)。
另外,您可以使用 virtctl vmexport 命令创建一个 VirtualMachineExport CR 并下载导出的卷。
11.5.1. 创建 VirtualMachineExport 自定义资源
您可以创建一个 VirtualMachineExport 自定义资源 (CR) 来导出以下对象:
- 虚拟机 (VM):导出指定虚拟机的持久性卷声明 (PVC)。
-
VM 快照:导出
VirtualMachineSnapshotCR 中包含的 PVC。 -
PVC :导出 PVC。如果 PVC 被另一个 pod (如
virt-launcherpod)使用,则导出会一直处于Pending状态,直到 PVC 不再使用为止。
VirtualMachineExport CR 为导出的卷创建内部和外部链接。内部链接在集群中有效。可以使用 Ingress 或 Route 访问外部链接。
导出服务器支持以下文件格式:
-
raw: 原始磁盘镜像文件。 -
gzip:压缩的磁盘镜像文件. -
dir:PVC 目录和文件。 -
tar.gz:压缩的 PVC 文件。
先决条件
- 必须为虚拟机导出关闭虚拟机。
流程
创建一个
VirtualMachineExport清单,根据以下示例从VirtualMachine、VirtualMachineSnapshot或PersistentVolumeClaimCR 导出卷,并将其保存为example-export.yaml:VirtualMachineExport示例apiVersion: export.kubevirt.io/v1alpha1 kind: VirtualMachineExport metadata: name: example-export spec: source: apiGroup: "kubevirt.io"1 kind: VirtualMachine2 name: example-vm ttlDuration: 1h3 创建
VirtualMachineExportCR:$ oc create -f example-export.yaml获取
VirtualMachineExportCR:$ oc get vmexport example-export -o yaml导出的卷的内部和外部链接显示在
status小节中:输出示例
apiVersion: export.kubevirt.io/v1alpha1 kind: VirtualMachineExport metadata: name: example-export namespace: example spec: source: apiGroup: "" kind: PersistentVolumeClaim name: example-pvc tokenSecretRef: example-token status: conditions: - lastProbeTime: null lastTransitionTime: "2022-06-21T14:10:09Z" reason: podReady status: "True" type: Ready - lastProbeTime: null lastTransitionTime: "2022-06-21T14:09:02Z" reason: pvcBound status: "True" type: PVCReady links: external:1 cert: |- -----BEGIN CERTIFICATE----- ... -----END CERTIFICATE----- volumes: - formats: - format: raw url: https://vmexport-proxy.test.net/api/export.kubevirt.io/v1alpha1/namespaces/example/virtualmachineexports/example-export/volumes/example-disk/disk.img - format: gzip url: https://vmexport-proxy.test.net/api/export.kubevirt.io/v1alpha1/namespaces/example/virtualmachineexports/example-export/volumes/example-disk/disk.img.gz name: example-disk internal:2 cert: |- -----BEGIN CERTIFICATE----- ... -----END CERTIFICATE----- volumes: - formats: - format: raw url: https://virt-export-example-export.example.svc/volumes/example-disk/disk.img - format: gzip url: https://virt-export-example-export.example.svc/volumes/example-disk/disk.img.gz name: example-disk phase: Ready serviceName: virt-export-example-export
11.5.2. 访问导出的虚拟机清单
导出虚拟机 (VM) 或快照后,您可以从导出服务器获取 VirtualMachine 清单和相关信息。
先决条件
您可以通过创建一个
VirtualMachineExport自定义资源 (CR) 来导出虚拟机或虚拟机快照。注意具有
spec.source.kind: PersistentVolumeClaim参数的VirtualMachineExport对象不会生成虚拟机清单。
流程
要访问清单,您必须首先将证书从源集群复制到目标集群。
- 登录到源集群。
运行以下命令,将证书保存到
cacert.crt文件中:$ oc get vmexport <export_name> -o jsonpath={.status.links.external.cert} > cacert.crt1 - 1
- 使用
VirtualMachineExport对象中的metadata.name值替换<export_name>。
-
将
cacert.crt文件复制到目标集群。
运行以下命令,解码源集群中的令牌并将其保存到
token_decode文件中:$ oc get secret export-token-<export_name> -o jsonpath={.data.token} | base64 --decode > token_decode1 - 1
- 使用
VirtualMachineExport对象中的metadata.name值替换<export_name>。
-
将
token_decode文件复制到目标集群。 运行以下命令来获取
VirtualMachineExport自定义资源:$ oc get vmexport <export_name> -o yaml查看
status.links小节,该小节被分为external和internal部分。请注意每个部分中的manifests.url字段:输出示例
apiVersion: export.kubevirt.io/v1alpha1 kind: VirtualMachineExport metadata: name: example-export spec: source: apiGroup: "kubevirt.io" kind: VirtualMachine name: example-vm tokenSecretRef: example-token status: #... links: external: #... manifests: - type: all url: https://vmexport-proxy.test.net/api/export.kubevirt.io/v1alpha1/namespaces/example/virtualmachineexports/example-export/external/manifests/all1 - type: auth-header-secret url: https://vmexport-proxy.test.net/api/export.kubevirt.io/v1alpha1/namespaces/example/virtualmachineexports/example-export/external/manifests/secret2 internal: #... manifests: - type: all url: https://virt-export-export-pvc.default.svc/internal/manifests/all3 - type: auth-header-secret url: https://virt-export-export-pvc.default.svc/internal/manifests/secret phase: Ready serviceName: virt-export-example-export- 登录到目标集群。
运行以下命令来获取
Secret清单:$ curl --cacert cacert.crt <secret_manifest_url> -H \1 "x-kubevirt-export-token:token_decode" -H \2 "Accept:application/yaml"例如:
$ curl --cacert cacert.crt https://vmexport-proxy.test.net/api/export.kubevirt.io/v1alpha1/namespaces/example/virtualmachineexports/example-export/external/manifests/secret -H "x-kubevirt-export-token:token_decode" -H "Accept:application/yaml"运行以下命令,获取
type: all清单,如ConfigMap和VirtualMachine清单:$ curl --cacert cacert.crt <all_manifest_url> -H \1 "x-kubevirt-export-token:token_decode" -H \2 "Accept:application/yaml"例如:
$ curl --cacert cacert.crt https://vmexport-proxy.test.net/api/export.kubevirt.io/v1alpha1/namespaces/example/virtualmachineexports/example-export/external/manifests/all -H "x-kubevirt-export-token:token_decode" -H "Accept:application/yaml"
后续步骤
-
现在,您可以使用导出的清单在目标集群中创建
ConfigMap和VirtualMachine对象。
11.6. 管理虚拟机实例
如果您在 OpenShift Virtualization 环境之外创建独立虚拟机实例(VMI),您可以使用 web 控制台或使用命令行界面(CLI)使用 oc 或 virtctl 命令管理它们。
virtctl 命令提供比 oc 命令更多的虚拟化选项。例如,您可以使用 virtctl 暂停虚拟机或公开端口。
11.6.1. 关于虚拟机实例
虚拟机实例(VMI)代表正在运行的虚拟机(VM)。当某个 VMI 属于某个虚拟机或者其他对象,您可通过 web 控制台中的拥有者或使用 oc 命令行界面(CLI)来管理它。
通过自动化或其他 CLI 的方法使用脚本创建并启动独立 VMI。在您的环境中,您可能会在 OpenShift Virtualization 环境之外开发并启动的独立 VMI。您可以使用 CLI 继续管理这些独立的 VMI。您还可以将 Web 控制台用于与独立 VMI 关联的特定任务:
- 列出独立 VMI 及其详情。
- 编辑独立 VMI 的标签和注解。
- 删除独立 VMI。
当删除虚拟机时,相关的 VMI 会被自动删除。您直接删除一个独立的 VMI,因为它不归 VM 或其他对象所有。
在卸载 OpenShift Virtualization 前,使用 CLI 或 Web 控制台列出并查看独立 VMI。然后,删除所有未完成的 VMI。
11.6.2. 使用 CLI 列出所有虚拟机实例
您可以使用 oc 命令行界面(CLI)列出集群中的所有虚拟机实例(VMI),包括独立 VMI 和虚拟机拥有的实例。
流程
运行以下命令列出所有 VMI:
$ oc get vmis -A
11.6.3. 使用 web 控制台列出独立虚拟机实例
使用 web 控制台,您可以列出并查看集群中不属于虚拟机(VM)的独立虚拟机实例(VMI)。
受 VM 或其他对象拥有的 VMI 不会被显示在 web 控制台中。web 控制台仅显示独立 VMI。如果要列出集群中的所有 VMI,则必须使用 CLI。
流程
在侧边菜单中点 Virtualization → VirtualMachines。
您可以在名称旁使用黑色徽标识别独立 VMI。
11.6.4. 使用 web 控制台编辑独立虚拟机实例
您可以使用 web 控制台编辑独立虚拟机实例(VMI)的注解和标签。其他字段不可编辑。
流程
- 在 OpenShift Container Platform 控制台中,从侧边菜单中点 Virtualization → VirtualMachines。
- 选择独立 VMI 以打开 VirtualMachineInstance 详情页面。
- 在 Details 标签页中,点 Annotations 或 Labels 旁边的铅笔图标。
- 进行相关的更改并点击 Save。
11.6.5. 使用 CLI 删除独立虚拟机实例
您可以使用 oc CLI 删除独立虚拟机实例。
先决条件
- 找出要删除的 VMI 的名称。
流程
运行以下命令来创建 VMI:
$ oc delete vmi <vmi_name>
11.6.6. 使用 web 控制台删除独立虚拟机实例
从 web 控制台删除独立虚拟机实例(VMI)。
流程
- 在 OpenShift Container Platform web 控制台中,从侧边菜单中点 Virtualization → VirtualMachines。
- 点 Actions → Delete VirtualMachineInstance。
- 在弹出的确认窗口中点击 Delete 永久删除独立的 VMI。
11.7. 控制虚拟机状态
您可从 web 控制台来停止、启动和重启虚拟机。
您可使用 virtctl 管理虚拟机状态并从 CLI 执行其他操作。例如,您可以使用 virtctl 来强制停止虚拟机或公开端口。
11.7.1. 启动虚拟机
您可从 web 控制台启动虚拟机。
流程
- 在侧边菜单中点 Virtualization → VirtualMachines。
- 找到包含要启动的虚拟机的行。
导航到适合您的用例的菜单:
要保留此页面(您可以在其中对多个虚拟机执行操作):
-
点击
位于行右边的 Options 菜单。
-
点击
在启动虚拟机前,要查看有关所选虚拟机的综合信息:
- 点虚拟机名称访问 VirtualMachine 详情页面。
- 点 Actions。
- 选择 Restart。
- 在确认窗口中,点 Start 启动虚拟机。
首次启动从 URL 源置备的虚拟机时,当 OpenShift Virtualization 从 URL 端点导入容器时,虚拟机将处于 Importing 状态。根据镜像大小,该过程可能需要几分钟时间。
11.7.2. 重启虚拟机
您可从 web 控制台重启正在运行的虚拟机。
为了避免错误,不要重启状态为 Importing 的虚拟机。
流程
- 在侧边菜单中点 Virtualization → VirtualMachines。
- 找到包含要启动的虚拟机的行。
导航到适合您的用例的菜单:
要保留此页面(您可以在其中对多个虚拟机执行操作):
-
点击
位于行右边的 Options 菜单。
-
点击
要在重启前查看有关所选虚拟机的综合信息:
- 点虚拟机名称访问 VirtualMachine 详情页面。
- 点 Actions → Restart。
- 在确认窗口中,点击 Restart 重启虚拟机。
11.7.3. 停止虚拟机
您可从 web 控制台停止虚拟机。
流程
- 在侧边菜单中点 Virtualization → VirtualMachines。
- 找到包含您要停止的虚拟机的行。
导航到适合您的用例的菜单:
要保留此页面(您可以在其中对多个虚拟机执行操作):
-
点击
位于行右边的 Options 菜单。
-
点击
在停止之前,查看所选虚拟机的综合信息:
- 点虚拟机名称访问 VirtualMachine 详情页面。
- 点 Actions → Stop。
- 在确认窗口中,点击 Stop 停止虚拟机。
11.7.4. 取消暂停虚拟机
您可从 web 控制台取消暂停一个正暂停的虚拟机。
先决条件
至少一个虚拟机的状态是 Paused。
注意您可以使用
virtctl客户端暂停虚拟机。
流程
- 在侧边菜单中点 Virtualization → VirtualMachines。
- 找到包含您要取消暂停的虚拟机的行。
导航到适合您的用例的菜单:
要保留此页面(您可以在其中对多个虚拟机执行操作):
- 在 Status 栏中点 Paused。
要在取消暂停之前查看所选虚拟机的综合信息:
- 点虚拟机名称访问 VirtualMachine 详情页面。
- 点击位于 Status 右侧的铅笔图标。
- 在确认窗口中,点击 Unpause 来取消暂停虚拟机。
11.8. 访问虚拟机控制台
OpenShift Virtualization 提供不同的虚拟机控制台,您可使用这些控制台来完成不同的产品任务。您可以使用 CLI 命令通过 OpenShift Container Platform Web 控制台和访问这些控制台。
目前不支持运行到单个虚拟机的并发 VNC 连接。
11.8.1. 在 OpenShift Container Platform web 控制台中访问虚拟机控制台
您可以使用 OpenShift Container Platform web 控制台中的串口控制台或 VNC 控制台连接至虚拟机。
您可以使用 OpenShift Container Platform Web 控制台中的 desktop viewer 控制台(使用 RDP(远程桌面协议)连接到 Windows 虚拟机。
11.8.1.1. 连接至串行控制台
从 web 控制台的 VirtualMachine 详情页中的 Console 选项卡连接至正在运行的虚拟机的串行控制台。
流程
- 在 OpenShift Container Platform 控制台中,从侧边菜单中点 Virtualization → VirtualMachines。
- 选择虚拟机以打开 VirtualMachine 详情页面。
- 点击 Console 选项卡。默认会打开 VNC 控制台。
- 点 Disconnect 以确保一次只打开一个控制台会话。否则,VNC 控制台会话会在后台保持活跃。
- 点击 VNC Console 下拉菜单并选择 Serial Console。
- 点 Disconnect 结束控制台会话。
- 可选:点 Open Console in New Window 在一个单独的窗口中打开串口控制台。
11.8.1.2. 连接至 VNC 控制台
从 web 控制台的 VirtualMachine 详情页中的 Console 选项卡连接至正在运行的虚拟机的 VNC 控制台。
流程
- 在 OpenShift Container Platform 控制台中,从侧边菜单中点 Virtualization → VirtualMachines。
- 选择虚拟机以打开 VirtualMachine 详情页面。
- 点击 Console 选项卡。默认会打开 VNC 控制台。
- 可选:点 Open Console in New Window 在一个单独的窗口中打开 VNC 控制台。
- 可选:点 Send Key 将密钥组合发送到虚拟机。
- 点控制台窗口外,然后点 Disconnect 结束会话。
11.8.1.3. 通过 RDP 连接至 Windows 虚拟机
Desktop viewer 控制台利用远程桌面协议 (RDP),为连接至 Windows 虚拟机提供更好的控制台体验。
要使用 RDP 连接至 Windows 虚拟机,请从 web 控制台上 Virtual Machine Details 屏幕中的 Consoles 选项卡下载虚拟机的 console.rdp 文件,并将其提供给您首选的 RDP 客户端。
先决条件
-
正在运行的 Windows 虚拟机装有 QEMU 客户机代理。VirtIO 驱动程序中包含
qemu-guest-agent。 - 与 Windows 虚拟机处于相同网络的机器上装有 RDP 客户端。
流程
- 在 OpenShift Container Platform 控制台中,从侧边菜单中点 Virtualization → VirtualMachines。
- 点 Windows 虚拟机打开 VirtualMachine 详情页。
- 点击 Console 选项卡。
- 从控制台列表中,选择 Desktop viewer。
-
点击 Launch Remote Desktop 下载
console.rdp文件。 -
参考您首选的 RDP 客户端中的
console.rdp文件,以连接到 Windows 虚拟机。
11.8.1.4. 在虚拟机间切换显示
如果您的 Windows 虚拟机附加了 vGPU,您可以使用 web 控制台在默认显示和 vGPU 显示间切换。
先决条件
-
介质设备在
HyperConverged自定义资源中配置,并分配给虚拟机。 - 虚拟机正在运行。
流程
- 在 OpenShift Container Platform 控制台中点 Virtualization → VirtualMachines
- 选择 Windows 虚拟机以打开 Overview 屏幕。
- 点击 Console 选项卡。
- 从控制台列表中,选择 VNC 控制台。
从 Send Key 列表选择适当的组合:
-
要访问默认虚拟机显示,请选择
Ctl + Alt+ 1。 -
要访问 vGPU 显示,请选择
Ctl + Alt + 2。
-
要访问默认虚拟机显示,请选择
11.8.1.5. 使用 Web 控制台复制 SSH 命令
复制命令,以通过 SSH 连接到虚拟机 (VM) 终端。
流程
- 在 OpenShift Container Platform 控制台中,从侧边菜单中点 Virtualization → VirtualMachines。
-
点虚拟机的 Options 菜单
,然后选择 Copy SSH 命令。
- 将其粘贴到终端中以访问虚拟机。
11.8.2. 使用 CLI 命令访问虚拟机控制台
11.8.2.1. 使用 virtctl 通过 SSH 访问虚拟机
您可使用 virtctl ssh 命令,使用本地 SSH 客户端将 SSH 流量转发到虚拟机 (VM)。如果您之前使用虚拟机配置了 SSH 密钥身份验证,请跳至步骤 2,因为不需要第 1 步。
control plane 上的高 SSH 流量可能会减慢 API 服务器的速度。如果您定期需要大量连接,请使用专用的 Kubernetes Service 对象来访问虚拟机。
先决条件
-
已安装 OpenShift CLI(
oc)。 -
已安装
virtctl客户端。 - 您要访问的虚拟机正在运行。
- 您与虚拟机位于同一个项目中。
流程
配置 SSH 密钥身份验证:
使用
ssh-keygen命令生成 SSH 公钥对:$ ssh-keygen -f <key_file>1 - 1
- 指定要存储密钥的文件。
创建一个 SSH 身份验证 secret,其中包含用于访问虚拟机的 SSH 公钥:
$ oc create secret generic my-pub-key --from-file=key1=<key_file>.pub在
VirtualMachine清单中添加对 secret 的引用。例如:apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: testvm spec: running: true template: spec: accessCredentials: - sshPublicKey: source: secret: secretName: my-pub-key1 propagationMethod: configDrive: {}2 # ...- 重启虚拟机以应用您的更改。
通过 SSH 连接到虚拟机:
运行以下命令通过 SSH 访问虚拟机:
$ virtctl ssh -i <key_file> <vm_username>@<vm_name>可选: 要安全地向虚拟机或虚拟机传输文件,请使用以下命令:
将文件从机器复制到虚拟机
$ virtctl scp -i <key_file> <filename> <vm_username>@<vm_name>:将文件从虚拟机复制到您的机器中
$ virtctl scp -i <key_file> <vm_username@<vm_name>:<filename> .
11.8.2.2. 使用 OpenSSH 和 virtctl port-forward
您可以使用本地 OpenSSH 客户端和 virtctl port-forward 命令连接到正在运行的虚拟机 (VM)。您可以将此方法与 Ansible 配合使用,以自动配置虚拟机。
对于低流量应用程序,建议使用这个方法,因为端口转发流量通过 control plane 发送。对于 Rsync 或 Remote Desktop 协议等高流量应用程序(如 Rsync 或 Remote Desktop 协议)使用这个方法,因为它对 API 服务器造成大量负担。
先决条件
-
已安装
virtctl客户端。 - 您要访问的虚拟机正在运行。
-
安装
virtctl工具的环境具有访问虚拟机所需的集群权限。例如,运行oc login或设置了KUBECONFIG环境变量。
流程
在客户端机器上的
~/.ssh/config文件中添加以下文本:Host vm/* ProxyCommand virtctl port-forward --stdio=true %h %p运行以下命令来连接到虚拟机:
$ ssh <user>@vm/<vm_name>.<namespace>
11.8.2.3. 访问虚拟机实例的串行控制台
virtctl console 命令可打开特定虚拟机实例的串行控制台。
先决条件
-
必须安装
virt-viewer软件包。 - 您要访问的虚拟机实例必须正在运行。
流程
使用
virtctl连接至串行控制台:$ virtctl console <VMI>
11.8.2.4. 使用 VNC 访问虚拟机实例的图形控制台
virtctl 客户端实用程序可使用 remote-viewer 功能打开正在运行的虚拟机实例的图形控制台。该功能包含在 virt-viewer 软件包中。
先决条件
-
必须安装
virt-viewer软件包。 - 您要访问的虚拟机实例必须正在运行。
如果要通过 SSH 在远程机器上使用 virtctl,您必须将 X 会话转发至您的机器。
流程
使用
virtctl实用程序连接至图形界面:$ virtctl vnc <VMI>如果命令失败,请尝试使用
-v标志来收集故障排除信息:$ virtctl vnc <VMI> -v 4
11.8.2.5. 通过 RDP 控制台连接至 Windows 虚拟机
使用本地远程桌面协议 (RDP) 客户端创建 Kubernetes Service 对象以连接到 Windows 虚拟机(VM)。
先决条件
-
正在运行的 Windows 虚拟机装有 QEMU 客户机代理。VirtIO 驱动程序中包含
qemu-guest-agent对象。 - 在本地机器上安装了 RDP 客户端。
流程
编辑
VirtualMachine清单,为创建服务添加标签:apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: vm-ephemeral namespace: example-namespace spec: running: false template: metadata: labels: special: key1 # ...- 1
- 在
spec.template.metadata.labels部分添加标签special: key。
注意虚拟机上的标签会传递到 pod。
special: key标签必须与Service清单的spec.selector属性中的标签匹配。-
保存
VirtualMachine清单文件以应用更改。 创建
Service清单以公开虚拟机:apiVersion: v1 kind: Service metadata: name: rdpservice1 namespace: example-namespace2 spec: ports: - targetPort: 33893 protocol: TCP selector: special: key4 type: NodePort5 # ...-
保存
Service清单文件。 运行以下命令来创建服务:
$ oc create -f <service_name>.yaml- 启动虚拟机。如果虚拟机已在运行,重启它。
查询
Service对象以验证它是否可用:$ oc get service -n example-namespaceNodePort服务的输出示例NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE rdpservice NodePort 172.30.232.73 <none> 3389:30000/TCP 5m运行以下命令来获取节点的 IP 地址:
$ oc get node <node_name> -o wide输出示例
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP node01 Ready worker 6d22h v1.24.0 192.168.55.101 <none>- 在首选的 RDP 客户端中指定节点 IP 地址和分配的端口。
- 输入用户名和密码以连接到 Windows 虚拟机。
11.9. 使用 sysprep 自动执行 Windows 安装
您可以使用 Microsoft DVD 镜像和 sysprep 自动安装、设置和软件置备 Windows 虚拟机。
11.9.1. 使用 Windows DVD 创建虚拟机磁盘镜像
Microsoft 不提供下载的磁盘镜像,但您可以使用 Windows DVD 创建磁盘镜像。然后,可以使用此磁盘镜像来创建虚拟机。
流程
- 在 OpenShift Virtualization web 控制台中,点 Storage → PersistentVolumeClaims → Create PersistentVolumeClaim With Data upload form。
- 选择预期的项目。
- 设置 持久性卷声明名称。
- 从 Windows DVD 上传虚拟机磁盘镜像。该镜像现在可作为引导源来创建新的 Windows 虚拟机。
11.9.2. 使用磁盘镜像安装 Windows
您可以使用磁盘镜像在虚拟机上安装 Windows。
先决条件
- 您必须使用 Windows DVD 创建磁盘镜像。
-
您必须创建一个
autounattend.xml回答文件。详情请查看 Microsoft 文档。
流程
- 在 OpenShift Container Platform 控制台中,从侧边菜单中点 Virtualization → Catalog。
- 选择 Windows 模板并点 Customize VirtualMachine。
- 从 Disk source 列表中选择 Upload(Upload a new file to a PVC),并浏览 DVD 镜像。
- 点 Review and create VirtualMachine。
- 清除 Clone available operating system source to this Virtual Machine。
- 清除 Start this VirtualMachine after creation。
- 在 Scripts 选项卡的 Sysprep 部分,点 Edit。
-
浏览到
autounattend.xml回答文件,然后点保存。 - 点 Create VirtualMachine。
-
在 YAML 标签页中,将
running:false替换为runStrategy: RerunOnFailure,点 Save。
虚拟机将从包含 autounattend.xml 回答文件的 sysprep 磁盘开始。
11.9.3. 使用 sysprep 常规调整 Windows 虚拟机
常规化镜像允许该镜像在部署虚拟机上时删除所有特定于系统的配置数据。
在常规调整虚拟机前,您必须确保 sysprep 工具在无人值守的 Windows 安装后无法检测到应答文件。
先决条件
- 正在运行的 Windows 虚拟机装有 QEMU 客户机代理。
流程
- 在 OpenShift Container Platform 控制台中点 Virtualization → VirtualMachines。
- 选择 Windows 虚拟机以打开 VirtualMachine 详情页。
- 点 Configuration → Disks。
-
点
sysprep磁盘的 Options 菜单
,然后选择 Detach。
- 单击 Detach。
-
重命名
C:\Windows\Panther\unattend.xml以避免sysprep工具对其进行检测。 运行以下命令启动
sysprep程序:%WINDIR%\System32\Sysprep\sysprep.exe /generalize /shutdown /oobe /mode:vm-
sysprep工具完成后,Windows 虚拟机将关闭。VM 的磁盘镜像现在可作为 Windows 虚拟机的安装镜像使用。
现在,您可以对虚拟机进行特殊化。
11.9.4. 专用 Windows 虚拟机
专用虚拟机(VM)将配置从常规化 Windows 镜像到虚拟机中的计算机特定信息。
先决条件
- 您必须有一个通用的 Windows 磁盘镜像。
-
您必须创建一个
unattend.xml回答文件。详情请查看 Microsoft 文档。
流程
- 在 OpenShift Container Platform 控制台中点 Virtualization → Catalog。
- 选择 Windows 模板并点 Customize VirtualMachine。
- 从 Disk source 列表中选择 PVC(clone PVC)。
- 指定通用 Windows 镜像的持久性卷声明项目和持久性卷声明名称。
- 点 Review and create VirtualMachine。
- 点 Scripts 选项卡。
-
在 Sysprep 部分中,点 Edit,浏览到
unattend.xml回答文件,然后点保存。 - 点 Create VirtualMachine。
在初次启动过程中,Windows 使用 unattend.xml 回答文件来专注于虚拟机。虚拟机现在可供使用。
11.10. 解决故障节点来触发虚拟机故障切换
如果节点失败,并且没有在集群中部署 机器健康检查,则带有 RunStrategy: Always 配置的虚拟机(VM)不会被自动重新定位到健康的节点上。要触发虚拟机故障切换,您必须手动删除 Node 对象。
如果使用安装程序置备的基础架构安装集群,并且正确地配置了机器健康检查: https://docs.redhat.com/en/documentation/openshift_container_platform/4.13/html-single/deploying_installer-provisioned_clusters_on_bare_metal/#ipi-install-overview
- 故障节点会被自动回收。
-
RunStrategy被设置为Always或RerunOnFailure的虚拟机会自动调度到健康的节点上。
11.10.1. 先决条件
-
运行虚拟机的节点具有
NotReady条件。 -
在故障节点中运行的虚拟机的
RunStrategy设置为Always。 -
已安装 OpenShift CLI(
oc)。
11.10.2. 从裸机集群中删除节点
当您使用 CLI 删除节点时,节点对象会从 Kubernetes 中删除,但该节点上存在的 pod 不会被删除。任何未由复制控制器支持的裸机 pod 都无法从 OpenShift Container Platform 访问。由复制控制器支持的 Pod 会重新调度到其他可用的节点。您必须删除本地清单 pod。
流程
通过完成以下步骤,从裸机上运行的 OpenShift Container Platform 集群中删除节点:
将节点标记为不可调度:
$ oc adm cordon <node_name>排空节点上的所有 pod:
$ oc adm drain <node_name> --force=true如果节点离线或者无响应,此步骤可能会失败。即使节点没有响应,它仍然在运行写入共享存储的工作负载。为了避免数据崩溃,请在进行操作前关闭物理硬件。
从集群中删除节点:
$ oc delete node <node_name>虽然节点对象现已从集群中删除,但它仍然可在重启后或 kubelet 服务重启后重新加入集群。要永久删除该节点及其所有数据,您必须弃用该节点。
- 如果您关闭了物理硬件,请重新打开它以便节点可以重新加入集群。
11.10.3. 验证虚拟机故障切换
在不健康节点上终止所有资源后,会为每个重新定位的虚拟机在健康的节点上自动创建新虚拟机实例(VMI)。要确认已创建了 VMI,使用 oc CLI 查看所有 VMI。
11.10.3.1. 使用 CLI 列出所有虚拟机实例
您可以使用 oc 命令行界面(CLI)列出集群中的所有虚拟机实例(VMI),包括独立 VMI 和虚拟机拥有的实例。
流程
运行以下命令列出所有 VMI:
$ oc get vmis -A
11.11. 安装 QEMU 客户机代理和 VirtIO 驱动程序
QEMU 客户机代理是在虚拟机上运行的一个守护进程,它会将有关虚拟机、用户、文件系统和从属网络的信息传递给主机。
11.11.1. 安装 QEMU 客户机代理
11.11.1.1. 在 Linux 虚拟机上安装 QEMU 客户机代理
qemu-guest-agent 广泛可用,默认在 Red Hat Enterprise Linux (RHEL) 虚拟机 (VM) 中可用。安装代理并启动服务。
要为具有最高完整性的在线(Running 状态)虚拟机创建快照,请安装 QEMU 客户机代理。
QEMU 客户机代理通过尝试静止虚拟机的文件系统来尽可能取一个一致的快照,具体取决于系统工作负载。这样可确保在进行快照前将 in-flight I/O 写入磁盘。如果没有客户机代理,则无法静止并生成最佳快照。执行快照的条件反映在 web 控制台或 CLI 中显示的快照声明中。
流程
- 通过其中一个控制台或通过 SSH 访问虚拟机命令行。
在虚拟机上安装 QEMU 客户机代理:
$ yum install -y qemu-guest-agent确保服务持久并启动它:
$ systemctl enable --now qemu-guest-agent
验证
运行以下命令,以验证
AgentConnected是否列在 VM spec 中:$ oc get vm <vm_name>
11.11.1.2. 在 Windows 虚拟机上安装 QEMU 客户机代理
对于 Windows 虚拟机,QEMU 客户机代理包含在 VirtIO 驱动程序中。在现有或者新的 Windows 安装上安装驱动程序。
要为具有最高完整性的在线(Running 状态)虚拟机创建快照,请安装 QEMU 客户机代理。
QEMU 客户机代理通过尝试静止虚拟机的文件系统来尽可能取一个一致的快照,具体取决于系统工作负载。这样可确保在进行快照前将 in-flight I/O 写入磁盘。如果没有客户机代理,则无法静止并生成最佳快照。执行快照的条件反映在 web 控制台或 CLI 中显示的快照声明中。
流程
-
在 Windows Guest Operating System (OS) 中,使用 File Explorer 导航到
virtio-winCD 驱动器中的guest-agent目录。 -
运行
qemu-ga-x86_64.msi安装程序。
验证
运行以下命令以验证输出是否包含
QEMU 客户机代理:$ net start
11.11.2. 安装 VirtIO 驱动程序
11.11.2.1. Microsoft Windows 虚拟机支持的 VirtIO 驱动程序
| 驱动程序名称 | 硬件 ID | 描述 |
|---|---|---|
| viostor |
VEN_1AF4&DEV_1001 | 块驱动程序。有时会在 Other devices 组中显示为 SCSI Controller。 |
| viorng |
VEN_1AF4&DEV_1005 | 熵源(entropy)驱动程序。有时会在 Other devices 组中显示为 PCI Device。 |
| NetKVM |
VEN_1AF4&DEV_1000 | 网络驱动程序。有时会在 Other devices 组中显示为 Ethernet Controller。仅在配置了 VirtIO NIC 时可用。 |
11.11.2.2. 关于 VirtIO 驱动程序
VirtIO 驱动程序是 Microsoft Windows 虚拟机在 OpenShift Virtualization 中运行时所需的半虚拟化设备驱动程序。受支持的驱动程序可在 红帽生态系统目录的 container-native-virtualization/virtio-win 容器磁盘中找到。
必须将 container-native-virtualization/virtio-win 容器磁盘作为 SATA CD 驱动器附加到虚拟机,以启用驱动程序安装。您可在虚拟机安装 Windows 期间安装 VirtIO 驱动程序,或将其附加到现有 Windows 安装。
安装完驱动程序后,可从虚拟机中移除 container-native-virtualization/virtio-win 容器磁盘。
11.11.2.3. 在现有 Windows 虚拟机上安装 VirtIO 驱动程序
从附加的 SATA CD 驱动器将 VirtIO 驱动程序安装到现有 Windows 虚拟机。
该流程使用通用方法为 Windows 添加驱动。具体流程可能会因 Windows 版本而稍有差异。有关具体安装步骤,请参阅您的 Windows 版本安装文档。
流程
- 启动虚拟机并连接至图形控制台。
- 登录 Windows 用户会话。
打开 Device Manager 并展开 Other devices 以列出所有 Unknown device。
-
打开
Device Properties以识别未知设备。右击设备并选择 Properties。 - 单击 Details 选项卡,并在 Property 列表中选择 Hardware Ids。
- 将 Hardware Ids 的 Value 与受支持的 VirtIO 驱动程序相比较。
-
打开
- 右击设备并选择 Update Driver Software。
- 点击 Browse my computer for driver software 并浏览所附加的 VirtIO 驱动程序所在 SATA CD 驱动器。驱动程序将按照其驱动程序类型、操作系统和 CPU 架构分层排列。
- 点击 Next 以安装驱动程序。
- 对所有必要 VirtIO 驱动程序重复这一过程。
- 安装完驱动程序后,点击 Close 关闭窗口。
- 重启虚拟机以完成驱动程序安装。
11.11.2.4. 在 Windows 安装过程中安装 VirtIO 驱动程序
在 Windows 安装过程中或之后安装 virtio 驱动程序。
该流程使用通用方法安装 Windows,且安装方法可能因 Windows 版本而异。有关您要安装的 Windows 版本,请参阅相关文档。
先决条件
-
包含
virtio驱动程序的存储设备必须附加到虚拟机。
流程
-
在 Windows 客户机操作系统中,使用
File Explorer导航到virtio-winCD 驱动器。 双击来为您的虚拟机运行适当的安装程序:
-
对于 64 位 vCPU,请使用
virtio-win-gt-x64安装程序。不再支持 32 位 vCPU。
-
对于 64 位 vCPU,请使用
- 可选:在安装程序的 Custom Setup 步骤中,选择您要安装的设备驱动程序。推荐的驱动程序集会被默认选择。
- 安装完成后,选择 Finish。
- 重启虚拟机。
验证
-
在 PC 上打开系统磁盘。这通常是
C:。 - 进入到 Program Files → Virtio-Win。
如果 Virtio-Win 目录存在并包含每个驱动程序的子目录,则安装可以成功。
11.11.2.5. 将 VirtIO 驱动程序容器磁盘添加到虚拟机中
针对 Microsoft Windows 的 OpenShift Virtualization VirtIO 驱动程序作为一个容器磁盘提供,可在 Red Hat Ecosystem Catalog 中找到。要为 Windows 虚拟机安装这些驱动程序,请在虚拟机配置文件中将 container-native-virtualization/virtio-win 容器磁盘作为 SATA CD 驱动器附加到虚拟机。
先决条件
-
从 Red Hat Ecosystem Catalog 下载
container-native-virtualization/virtio-win容器磁盘。这一步并非强制要求,因为如果集群中不存在容器磁盘,将从 Red Hat registry 中下载,但通过此步下载可节省安装时间。
流程
将
container-native-virtualization/virtio-win容器磁盘作为cdrom磁盘添加到 Windows 虚拟机配置文件中。如果集群中还没有容器磁盘,将从 registry 中下载。spec: domain: devices: disks: - name: virtiocontainerdisk bootOrder: 21 cdrom: bus: sata volumes: - containerDisk: image: container-native-virtualization/virtio-win name: virtiocontainerdisk- 1
- OpenShift Virtualization 按照
VirtualMachine配置文件中定义的顺序启动虚拟机磁盘。您可将虚拟机的其他磁盘定义到container-native-virtualization/virtio-win容器磁盘前面,也可使用bootOrder可选参数来确保虚拟机从正确磁盘启动。如果为一个磁盘指定bootOrder,则必须为配置中的所有磁盘指定。
虚拟机启动后,磁盘随即可用:
-
如果要将容器磁盘添加到正在运行的虚拟机,请在 CLI 中执行
oc apply -f <vm.yaml>,或重启虚拟机,以使更改生效。 -
如果虚拟机还未运行,则使用
virtctl start <vm>。
-
如果要将容器磁盘添加到正在运行的虚拟机,请在 CLI 中执行
虚拟机启动后,可从附加的 SATA CD 驱动器安装 VirtIO 驱动程序。
11.12. 查看虚拟机的 QEMU 客户机代理信息
当 QEMU 客户机代理在虚拟机上运行时,您可以使用 web 控制台查看有关虚拟机、用户、文件系统和从属网络的信息。
如果没有安装 QEMU 客户机代理,Overview 和 Details 选项卡将显示有关创建虚拟机时指定的操作系统的信息。
11.12.1. 在 web 控制台中查看 QEMU 客户机代理信息
您可以使用 web 控制台查看由 QEMU 客户机代理传递给主机的虚拟机信息。
先决条件
- 在虚拟机上安装 QEMU 客户机代理。
流程
- 在侧边菜单中点 Virtualization → VirtualMachines。
- 选择虚拟机名称以打开 VirtualMachine 详情页。
- 点 Details 选项卡查看活跃用户。
- 点 Configuration → Disks 选项卡查看文件系统的信息。
11.13. 使用虚拟可信平台模块设备
通过编辑 VirtualMachine (VM)或 VirtualMachineInstance (VMI)清单,将虚拟 Trusted Platform 模块(vTPM)设备添加到新的或现有虚拟机中。
11.13.1. 关于 vTPM 设备
虚拟可信平台模块(vTPM)设备功能,如物理信任平台模块(TPM)硬件芯片。
您可以将 vTPM 设备与任何操作系统一起使用,但 Windows 11 需要存在 TPM 芯片用来安装或引导的 TPM 芯片。vTPM 设备允许从 Windows 11 镜像创建的虚拟机在没有物理 TPM 芯片的情况下正常工作。
如果没有启用 vTPM,则虚拟机无法识别 TPM 设备,即使节点有一个。
vTPM 设备还可通过在没有物理硬件的情况下暂时存储 secret 来保护虚拟机。但是,当前不支持将 vTPM 用于持久性 secret 存储。vTPM 在虚拟机关闭后丢弃存储的 secret。
11.13.2. 将 vTPM 设备添加到虚拟机
将虚拟 Trusted Platform 模块(vTPM)设备添加到虚拟机(VM)可让您从 Windows 11 镜像创建的虚拟机,而无需物理 TPM 设备。vTPM 设备还会为该虚拟机临时存储 secret。
流程
运行以下命令以更新虚拟机配置:
$ oc edit vm <vm_name>编辑 VM
spec,使其包含tpm: {}行。例如:apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: example-vm spec: template: spec: domain: devices: tpm: {}1 # ...- 1
- 在虚拟机中添加 TPM 设备。
- 若要应用您的更改,请保存并退出编辑器。
- 可选:如果编辑了正在运行的虚拟机,您必须重启它才能使更改生效。
11.14. 使用 OpenShift Pipelines 管理虚拟机
Red Hat OpenShift Pipelines 是一个 Kubernetes 原生 CI/CD 框架,允许开发人员在其自己的容器中设计和运行 CI/CD 管道的每个步骤。
Tekton Tasks Operator (TTO) 将 OpenShift Virtualization 与 OpenShift Pipelines 集成。TTO 包含集群任务和示例管道,允许您:
- 创建和管理虚拟机 (VM)、持久性卷声明 (PVC) 和数据卷
- 在虚拟机中运行命令
-
使用
libguestfs工具操作磁盘镜像
使用 Red Hat OpenShift Pipelines 管理虚拟机只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
11.14.1. 先决条件
-
您可以使用
cluster-admin权限访问 OpenShift Container Platform 集群。 -
已安装 OpenShift CLI(
oc)。 - 已安装 OpenShift Pipelines。
11.14.2. 部署 Tekton Tasks Operator 资源
安装 OpenShift Virtualization 时,默认不会部署 Tekton Tasks Operator (TTO) 集群任务和示例管道。要部署 TTO 资源,请在 HyperConverged 自定义资源 (CR) 中启用 deployTektonTaskResources 功能门。
流程
运行以下命令,在默认编辑器中打开
HyperConvergedCR:$ oc edit hco -n openshift-cnv kubevirt-hyperconverged将
spec.featureGates.deployTektonTaskResources字段设置为true。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: kubevirt-hyperconverged spec: tektonPipelinesNamespace: <user_namespace>1 featureGates: deployTektonTaskResources: true2 # ...注意即使稍后禁用功能门,集群任务和示例管道仍可用。
- 保存更改并退出编辑器。
11.14.3. Tekton Tasks Operator 支持的虚拟机任务
下表显示了作为 Tekton Tasks Operator 一部分的集群任务。
| 任务 | 描述 |
|---|---|
|
| 从模板创建虚拟机。 |
|
| 复制虚拟机模板。 |
|
| 修改虚拟机模板。 |
|
| 创建和删除数据卷或数据源。 |
|
| 在虚拟机上运行脚本或命令,并在之后停止或删除虚拟机。 |
|
|
使用 |
|
|
使用 |
|
| 等待虚拟机实例的特定状态,并根据状态失败或成功。 |
11.14.4. 管道示例
Tekton Tasks Operator 包含以下 Pipeline 清单示例。您可以使用 Web 控制台或 CLI 运行示例管道。
如果需要多个 Windows 版本,您可能需要运行多个安装程序传送线。如果您运行多个安装程序管道,每个管道都需要唯一的参数,如 autounattend 配置映射和基础镜像名称。例如,如果您需要 Windows 10 和 Windows 11 或 Windows Server 2022 镜像,则必须运行 Windows efi 安装程序管道和 Windows bios 安装程序管道。但是,如果您需要 Windows 11 和 Windows Server 2022 镜像,则必须只运行 Windows efi 安装程序管道。
- Windows EFI 安装程序管道
- 此管道将 Windows 11 或 Windows Server 2022 安装到 Windows 安装镜像 (ISO 文件) 的新数据卷中。自定义应答文件用于运行安装过程。
- Windows BIOS 安装程序管道
- 此管道将 Windows 10 安装到 Windows 安装镜像(也称为 ISO 文件)的新数据卷中。自定义应答文件用于运行安装过程。
- Windows 自定义管道
- 此管道克隆基本 Windows 10、11 或 Windows Server 2022 安装的数据卷,安装 Microsoft SQL Server Express 或 Microsoft Visual Studio Code,然后创建一个新镜像和模板。
11.14.4.1. 使用 Web 控制台运行示例管道
您可以从 web 控制台中的 Pipelines 菜单运行示例管道。
流程
- 在侧边菜单中点 Pipelines → Pipelines。
- 选择一个管道以打开 Pipeline 详情页面。
- 从 Actions 列表中,选择 Start。此时会显示 Start Pipeline 对话框。
- 保留参数的默认值,然后点 Start 运行管道。Details 选项卡跟踪每个任务的进度,并显示管道状态。
11.14.4.2. 使用 CLI 运行示例管道
使用 PipelineRun 资源来运行示例管道。PipelineRun 对象是管道的运行实例。它使用集群上的特定输入、输出和执行参数来实例化 Pipeline 执行。它还为管道中的每个任务创建一个 TaskRun 对象。
流程
要运行 Windows 10 安装程序管道,请创建以下
PipelineRun清单:apiVersion: tekton.dev/v1beta1 kind: PipelineRun metadata: generateName: windows10-installer-run- labels: pipelinerun: windows10-installer-run spec: params: - name: winImageDownloadURL value: <link_to_windows_10_iso>1 pipelineRef: name: windows10-installer taskRunSpecs: - pipelineTaskName: copy-template taskServiceAccountName: copy-template-task - pipelineTaskName: modify-vm-template taskServiceAccountName: modify-vm-template-task - pipelineTaskName: create-vm-from-template taskServiceAccountName: create-vm-from-template-task - pipelineTaskName: wait-for-vmi-status taskServiceAccountName: wait-for-vmi-status-task - pipelineTaskName: create-base-dv taskServiceAccountName: modify-data-object-task - pipelineTaskName: cleanup-vm taskServiceAccountName: cleanup-vm-task status: {}- 1
- 指定 Windows 10 64 位 ISO 文件的 URL。产品语言必须是 English (United States)。
应用
PipelineRun清单:$ oc apply -f windows10-installer-run.yaml要运行 Windows 10 自定义管道,请创建以下
PipelineRun清单:apiVersion: tekton.dev/v1beta1 kind: PipelineRun metadata: generateName: windows10-customize-run- labels: pipelinerun: windows10-customize-run spec: params: - name: allowReplaceGoldenTemplate value: true - name: allowReplaceCustomizationTemplate value: true pipelineRef: name: windows10-customize taskRunSpecs: - pipelineTaskName: copy-template-customize taskServiceAccountName: copy-template-task - pipelineTaskName: modify-vm-template-customize taskServiceAccountName: modify-vm-template-task - pipelineTaskName: create-vm-from-template taskServiceAccountName: create-vm-from-template-task - pipelineTaskName: wait-for-vmi-status taskServiceAccountName: wait-for-vmi-status-task - pipelineTaskName: create-base-dv taskServiceAccountName: modify-data-object-task - pipelineTaskName: cleanup-vm taskServiceAccountName: cleanup-vm-task - pipelineTaskName: copy-template-golden taskServiceAccountName: copy-template-task - pipelineTaskName: modify-vm-template-golden taskServiceAccountName: modify-vm-template-task status: {}应用
PipelineRun清单:$ oc apply -f windows10-customize-run.yaml
11.15. 高级虚拟机管理
11.15.1. 为虚拟机使用资源配额
为虚拟机创建和管理资源配额。
11.15.1.1. 为虚拟机设置资源配额限制
只有使用请求自动用于虚拟机 (VM) 的资源配额。如果您的资源配额使用限制,则必须为虚拟机手动设置资源限值。资源限值必须至少大于资源请求的 100 MiB。
流程
通过编辑
VirtualMachine清单来为虚拟机设置限值。例如:apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: with-limits spec: running: false template: spec: domain: # ... resources: requests: memory: 128Mi limits: memory: 256Mi1 - 1
- 这个配置被支持,因为
limits.memory值至少比requests.memory的值大100Mi。
-
保存
VirtualMachine清单。
11.15.2. 为虚拟机指定节点
您可以使用节点放置规则将虚拟机放置到特定的节点上。
11.15.2.1. 关于虚拟机的节点放置
要确保虚拟机在适当的节点上运行,您可以配置节点放置规则。如果出现以下情况,您可能需要进行此操作:
- 您有多台虚拟机。为确保容错,您希望它们在不同节点上运行。
- 您有两个 chatty 虚拟机。为了避免冗余节点间路由,您希望虚拟机在同一节点上运行。
- 您的虚拟机需要所有可用节点上不存在的特定硬件功能。
- 您有一个 pod 可以向节点添加功能,并想将虚拟机放置到该节点上,以便它可以使用这些功能。
虚拟机放置依赖于工作负载的现有节点放置规则。如果组件级别上的特定节点排除工作负载,则虚拟机无法放置在这些节点上。
您可以在 VirtualMachine 清单的 spec 字段中使用以下规则类型:
nodeSelector- 允许将虚拟机调度到使用此字段中指定的键值对标记的节点上。节点必须具有与所有列出的对完全匹配的标签。
关联性这可让您使用更具表达力的语法来设置与虚拟机匹配的规则。例如,您可以指定规则是首选项,而非硬要求,因此在规则不满足时仍然可以调度虚拟机。虚拟机放置支持 Pod 关联性、pod 反关联性和节点关联性。Pod 关联性适用于虚拟机,因为
VirtualMachine工作负载类型基于Pod对象。注意关联性规则仅在调度期间应用。如果不再满足限制,OpenShift Container Platform 不会重新调度正在运行的工作负载。
容限(tolerations)- 允许将虚拟机调度到具有匹配污点的节点。如果污点应用到某个节点,则该节点只接受容许该污点的虚拟机。
11.15.2.2. 节点放置示例
以下示例 YAML 文件片断使用 nodePlacement、affinity 和 tolerations 字段为虚拟机自定义节点放置。
11.15.2.2.1. 示例:使用 nodeSelector 放置虚拟机节点
在本例中,虚拟机需要一个包含 example-key-1 = example-value-1 和 example-key-2 = example-value-2 标签的元数据的节点。
如果没有节点适合此描述,则不会调度虚拟机。
VM 清单示例
metadata:
name: example-vm-node-selector
apiVersion: kubevirt.io/v1
kind: VirtualMachine
spec:
template:
spec:
nodeSelector:
example-key-1: example-value-1
example-key-2: example-value-2
# ...11.15.2.2.2. 示例:使用 pod 关联性和 pod 反关联性的虚拟机节点放置
在本例中,虚拟机必须调度到具有标签 example-key-1 = example-value-1 的正在运行的 pod 的节点上。如果没有在任何节点上运行这样的 pod,则不会调度虚拟机。
如果可能,虚拟机不会调度到具有标签 example-key-2 = example-value-2 的 pod 的节点上。但是,如果所有候选节点都有具有此标签的 pod,调度程序会忽略此约束。
VM 清单示例
metadata:
name: example-vm-pod-affinity
apiVersion: kubevirt.io/v1
kind: VirtualMachine
spec:
template:
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: example-key-1
operator: In
values:
- example-value-1
topologyKey: kubernetes.io/hostname
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: example-key-2
operator: In
values:
- example-value-2
topologyKey: kubernetes.io/hostname
# ...11.15.2.2.3. 示例:使用节点关联性进行虚拟机节点放置
在本例中,虚拟机必须调度到具有标签 example.io/example-key = example-value-1 或标签 example.io/example-key = example-value-2 的节点上。如果节点上只有一个标签,则会满足约束。如果没有标签,则不会调度虚拟机。
若有可能,调度程序会避免具有标签 example-node-label-key = example-node-label-value 的节点。但是,如果所有候选节点都具有此标签,调度程序会忽略此限制。
VM 清单示例
metadata:
name: example-vm-node-affinity
apiVersion: kubevirt.io/v1
kind: VirtualMachine
spec:
template:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: example.io/example-key
operator: In
values:
- example-value-1
- example-value-2
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: example-node-label-key
operator: In
values:
- example-node-label-value
# ...11.15.2.2.4. 示例:带有容限的虚拟机节点放置
在本例中,为虚拟机保留的节点已使用 key=virtualization:NoSchedule 污点标记。由于此虚拟机具有匹配的容限,它可以调度到污点节点上。
容许污点的虚拟机不需要调度到具有该污点的节点。
VM 清单示例
metadata:
name: example-vm-tolerations
apiVersion: kubevirt.io/v1
kind: VirtualMachine
spec:
tolerations:
- key: "key"
operator: "Equal"
value: "virtualization"
effect: "NoSchedule"
# ...11.15.3. 配置证书轮转
配置证书轮转参数以替换现有证书。
11.15.3.1. 配置证书轮转
您可以在 web 控制台中的 OpenShift Virtualization 安装过程中,或者在安装 HyperConverged 自定义资源(CR)后完成此操作。
流程
运行以下命令打开
HyperConvergedCR:$ oc edit hco -n openshift-cnv kubevirt-hyperconverged按照以下示例所示,编辑
spec.certConfig字段。要避免系统过载,请确保所有值都大于或等于 10 分钟。将所有值显示为符合 golangParseDuration格式的字符串。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: certConfig: ca: duration: 48h0m0s renewBefore: 24h0m0s1 server: duration: 24h0m0s2 renewBefore: 12h0m0s3 - 将 YAML 文件应用到集群。
11.15.3.2. 证书轮转参数故障排除
删除一个或多个 certConfig 值会导致它们恢复到默认值,除非默认值与以下条件之一冲突:
-
ca.renewBefore的值必须小于或等于ca.duration的值。 -
server.duration的值必须小于或等于ca.duration的值。 -
server.renewBefore的值必须小于或等于server.duration的值。
如果默认值与这些条件冲突,您将收到错误。
如果您删除了以下示例中的 server.duration 值,则默认值 24h0m0s 大于 ca.duration 的值,并与指定条件冲突。
Example
certConfig:
ca:
duration: 4h0m0s
renewBefore: 1h0m0s
server:
duration: 4h0m0s
renewBefore: 4h0m0s这会生成以下出错信息:
error: hyperconvergeds.hco.kubevirt.io "kubevirt-hyperconverged" could not be patched: admission webhook "validate-hco.kubevirt.io" denied the request: spec.certConfig: ca.duration is smaller than server.duration错误消息仅提及第一个冲突。在继续操作前,查看所有 certConfig 值。
11.15.4. 配置默认 CPU 型号
使用 HyperConverged 自定义资源 (CR) 中的 defaultCPUModel 设置来定义集群范围的默认 CPU 模型。
虚拟机 (VM) CPU 模型取决于虚拟机和集群中的 CPU 模型的可用性。
如果虚拟机没有定义的 CPU 模型:
-
defaultCPUModel使用在集群范围级别上定义的 CPU 模型自动设置。
-
如果虚拟机和集群都有定义的 CPU 模型:
- 虚拟机的 CPU 模型具有优先权。
如果虚拟机或集群都没有定义的 CPU 模型:
- host-model 使用主机级别上定义的 CPU 模型自动设置。
11.15.4.1. 配置默认 CPU 型号
通过更新 HyperConverged 自定义资源(CR) 来配置 defaultCPUModel。您可以在 OpenShift Virtualization 运行时更改 defaultCPUModel。
defaultCPUModel 是区分大小写的。
先决条件
- 安装 OpenShift CLI(oc)。
流程
运行以下命令打开
HyperConvergedCR:$ oc edit hco -n openshift-cnv kubevirt-hyperconverged将
defaultCPUModel字段添加到 CR,并将值设置为集群中存在的 CPU 模型的名称:apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: defaultCPUModel: "EPYC"- 将 YAML 文件应用到集群。
11.15.5. 为虚拟机使用 UEFI 模式
您可以使用统一可扩展固件接口(UEFI)模式引导虚拟机(VM)。
11.15.5.1. 关于虚拟机的 UEFI 模式
像旧的 BIOS 一样,统一可扩展固件接口(UEFI)在计算机启动时初始化硬件组件和操作系统镜像文件。与 BIOS 相比,UEFI 支持更现代的功能和自定义选项,从而加快启动速度。
它将初始化和启动的所有信息保存在带有 .efi 扩展的文件中,该扩展被保存在名为 EFI 系统分区(ESP)的特殊分区中。ESP 还包含安装在计算机上的操作系统的引导装载程序程序。
11.15.5.2. 在 UEFI 模式中引导虚拟机
您可以通过编辑 VirtualMachine 清单,将虚拟机配置为在 UEFI 模式中引导。
先决条件
-
安装 OpenShift CLI (
oc) 。
流程
编辑或创建
VirtualMachine清单文件。使用spec.firmware.bootloader小节来配置 UEFI 模式:使用安全引导活跃在 UEFI 模式中引导
apiversion: kubevirt.io/v1 kind: VirtualMachine metadata: labels: special: vm-secureboot name: vm-secureboot spec: template: metadata: labels: special: vm-secureboot spec: domain: devices: disks: - disk: bus: virtio name: containerdisk features: acpi: {} smm: enabled: true1 firmware: bootloader: efi: secureBoot: true2 # ...运行以下命令,将清单应用到集群:
$ oc create -f <file_name>.yaml
11.15.6. 为虚拟机配置 PXE 启动
OpenShift Virtualization 中提供 PXE 启动或网络启动。网络启动支持计算机启动和加载操作系统或其他程序,无需本地连接的存储设备。例如,在部署新主机时,您可使用 PXE 启动从 PXE 服务器中选择所需操作系统镜像。
11.15.6.1. 先决条件
- Linux 网桥必须已连接。
- PXE 服务器必须作为网桥连接至相同 VLAN。
11.15.6.2. 使用指定的 MAC 地址的 PXE 引导
作为管理员,您可首先为您的 PXE 网络创建 NetworkAttachmentDefinition 对象,以此通过网络引导客户端。然后在启动虚拟机实例前,在您的虚拟机实例配置文件中引用网络附加定义。如果 PXE 服务器需要,您还可在虚拟机实例配置文件中指定 MAC 地址。
先决条件
- 必须已连接 Linux 网桥。
- PXE 服务器必须作为网桥连接至相同 VLAN。
流程
在集群上配置 PXE 网络:
为 PXE 网络
pxe-net-conf创建网络附加定义文件:apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: pxe-net-conf spec: config: '{ "cniVersion": "0.3.1", "name": "pxe-net-conf", "plugins": [ { "type": "cnv-bridge", "bridge": "br1", "vlan": 11 }, { "type": "cnv-tuning"2 } ] }'注意虚拟机实例将通过所请求的 VLAN 的访问端口附加到网桥
br1。
使用您在上一步中创建的文件创建网络附加定义:
$ oc create -f pxe-net-conf.yaml编辑虚拟机实例配置文件以包括接口和网络的详情。
如果 PXE 服务器需要,请指定网络和 MAC 地址。如果未指定 MAC 地址,则会自动分配一个值。
请确保
bootOrder设置为1,以便该接口先启动。在本例中,该接口连接到了名为<pxe-net>的网络中:interfaces: - masquerade: {} name: default - bridge: {} name: pxe-net macAddress: de:00:00:00:00:de bootOrder: 1注意启动顺序对于接口和磁盘全局通用。
为磁盘分配一个启动设备号,以确保置备操作系统后能够正确启动。
将磁盘
bootOrder值设置为2:devices: disks: - disk: bus: virtio name: containerdisk bootOrder: 2指定网络连接到之前创建的网络附加定义。在这种情况下,
<pxe-net>连接到名为<pxe-net-conf>的网络附加定义:networks: - name: default pod: {} - name: pxe-net multus: networkName: pxe-net-conf
创建虚拟机实例:
$ oc create -f vmi-pxe-boot.yaml
输出示例
virtualmachineinstance.kubevirt.io "vmi-pxe-boot" created等待虚拟机实例运行:
$ oc get vmi vmi-pxe-boot -o yaml | grep -i phase phase: Running使用 VNC 查看虚拟机实例:
$ virtctl vnc vmi-pxe-boot- 查看启动屏幕,验证 PXE 启动是否成功。
登录虚拟机实例:
$ virtctl console vmi-pxe-boot验证虚拟机上的接口和 MAC 地址,并验证连接到网桥的接口是否具有指定的 MAC 地址。在本例中,我们使用了
eth1进行 PXE 启动,无需 IP 地址。另一接口eth0从 OpenShift Container Platform 获取 IP 地址。$ ip addr
输出示例
...
3. eth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether de:00:00:00:00:de brd ff:ff:ff:ff:ff:ff11.15.6.3. OpenShift Virtualization 术语表
OpenShift Virtualization 使用自定义资源和插件提供高级联网功能。
以下是整个 OpenShift Virtualization 文档中使用的术语:
- Container Network Interface (CNI)
- 一个 Cloud Native Computing Foundation 项目,侧重容器网络连接。OpenShift Virtualization 使用 CNI 插件基于基本 Kubernetes 网络功能进行构建。
- Multus
- 一个“meta”CNI 插件,支持多个 CNI 共存,以便 pod 或虚拟机可使用其所需的接口。
- 自定义资源定义(CRD)
- 一种 Kubernetes API 资源,用于定义自定义资源,或使用 CRD API 资源定义的对象。
- 网络附加定义(NAD)
- 由 Multus 项目引入的 CRD,允许您将 Pod、虚拟机和虚拟机实例附加到一个或多个网络。
- 节点网络配置策略(NNCP)
-
节点上请求的网络配置的描述。您可以通过将
NodeNetworkConfigurationPolicy清单应用到集群来更新节点网络配置,包括添加和删除网络接口 。 - 预启动执行环境 (PXE)
- 一种接口,让管理员能够通过网络从服务器启动客户端机器。网络启动可用于为客户端远程加载操作系统和其他软件。
11.15.7. 在虚拟机中使用巨页
您可以使用巨页作为集群中虚拟机的后备内存。
11.15.7.1. 先决条件
- 节点必须配置预分配的巨页。
11.15.7.2. 巨页的作用
内存在块(称为页)中进行管理。在大多数系统中,页的大小为 4Ki。1Mi 内存相当于 256 个页,1Gi 内存相当于 256,000 个页。CPU 有内置的内存管理单元,可在硬件中管理这些页的列表。Translation Lookaside Buffer (TLB) 是虚拟页到物理页映射的小型硬件缓存。如果在硬件指令中包括的虚拟地址可以在 TLB 中找到,则其映射信息可以被快速获得。如果没有包括在 TLN 中,则称为 TLB miss。系统将会使用基于软件的,速度较慢的地址转换机制,从而出现性能降低的问题。因为 TLB 的大小是固定的,因此降低 TLB miss 的唯一方法是增加页的大小。
巨页指一个大于 4Ki 的内存页。在 x86_64 构架中,有两个常见的巨页大小: 2Mi 和 1Gi。在其它构架上的大小会有所不同。要使用巨页,必须写相应的代码以便应用程序了解它们。Transparent Huge Pages(THP)试图在应用程序不需要了解的情况下自动管理巨页,但这个技术有一定的限制。特别是,它的页大小会被限为 2Mi。当有较高的内存使用率时,THP 可能会导致节点性能下降,或出现大量内存碎片(因为 THP 的碎片处理)导致内存页被锁定。因此,有些应用程序可能更适用于(或推荐)使用预先分配的巨页,而不是 THP。
在 OpenShift Virtualization 中,可将虚拟机配置为消耗预先分配的巨页。
11.15.7.3. 为虚拟机配置巨页
您可以在虚拟机配置中包括 memory.hugepages.pageSize 和 resources.requests.memory 参数来配置虚拟机来使用预分配的巨页。
内存请求必须按页大小分离。例如,您不能对大小为 1Gi 的页请求 500Mi 内存。
主机的内存布局和客户端操作系统不相关。虚拟机清单中请求的巨页适用于 QEMU。客户端中的巨页只能根据虚拟机实例的可用内存量来配置。
如果您编辑了正在运行的虚拟机,则必须重启虚拟机才能使更改生效。
先决条件
- 节点必须配置预先分配的巨页。
流程
在虚拟机配置中,把
resources.requests.memory和memory.hugepages.pageSize参数添加到spec.domain。以下配置片段适用于请求总计4Gi内存的虚拟机,页面大小为1Gi:kind: VirtualMachine # ... spec: domain: resources: requests: memory: "4Gi"1 memory: hugepages: pageSize: "1Gi"2 # ...应用虚拟机配置:
$ oc apply -f <virtual_machine>.yaml
11.15.8. 为虚拟机启用专用资源
要提高性能,您可以将节点的资源(如 CPU)专用于特定的一个虚拟机。
11.15.8.1. 关于专用资源
当为您的虚拟机启用专用资源时,您的工作负载将会在不会被其他进程使用的 CPU 上调度。通过使用专用资源,您可以提高虚拟机性能以及延迟预测的准确性。
11.15.8.2. 先决条件
-
节点上必须配置 CPU Manager。在调度虚拟机工作负载前,请确认节点具有
cpumanager = true标签。 - 虚拟机必须关机。
11.15.8.3. 为虚拟机启用专用资源
您可以在 Details 选项卡中为虚拟机启用专用资源。从红帽模板创建的虚拟机可以使用专用资源进行配置。
流程
- 在 OpenShift Container Platform 控制台中,从侧边菜单中点 Virtualization → VirtualMachines。
- 选择虚拟机以打开 VirtualMachine 详情页面。
- 在 Configuration → Scheduling 选项卡中,点 Dedicated Resources 旁边的编辑图标。
- 选择 Schedule this workload with dedicated resources (guaranteed policy)。
- 点 Save。
11.15.9. 调度虚拟机
在确保虚拟机的 CPU 模型和策略属性与节点支持的 CPU 模型和策略属性兼容的情况下,可在节点上调度虚拟机(VM)。
11.15.9.1. 策略属性
您可以指定策略属性和在虚拟机调度到节点上时匹配的 CPU 功能来调度虚拟机(VM)。为虚拟机指定的策略属性决定了如何在节点上调度该虚拟机。
| 策略属性 | 描述 |
|---|---|
| force | VM 被强制调度到某个节点上。即使主机 CPU 不支持虚拟机的 CPU,也是如此。 |
| require | 在虚拟机没有使用特定 CPU 模型和功能规格配置时,应用于虚拟机的默认策略。如果节点没有配置为支持使用此默认策略属性或其他策略属性的 CPU 节点发现,则虚拟机不会调度到该节点上。主机 CPU 必须支持虚拟机的 CPU,或者虚拟机监控程序必须可以模拟支持的 CPU 模型。 |
| optional | 如果主机物理机器 CPU 支持该虚拟机,则虚拟机会被添加到节点。 |
| disable | 无法通过 CPU 节点发现调度虚拟机。 |
| forbid | 即使主机 CPU 支持该功能,且启用了 CPU 节点发现,也不会调度虚拟机。 |
11.15.9.2. 设置策略属性和 CPU 功能
您可以为每个虚拟机(VM)设置策略属性和 CPU 功能,以确保根据策略和功能在节点上调度该功能。验证您设置的 CPU 功能以确保主机 CPU 支持或者虚拟机监控程序模拟该功能。
11.15.9.3. 使用支持的 CPU 型号调度虚拟机
您可以为虚拟机 (VM) 配置 CPU 模型,将其调度到支持其 CPU 模型的节点。
流程
编辑虚拟机配置文件的
domainspec。以下示例显示了为虚拟机定义的特定 CPU 模型:apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: myvm spec: template: spec: domain: cpu: model: Conroe1 - 1
- 虚拟机的 CPU 模型.
11.15.9.4. 使用主机模型调度虚拟机
当将虚拟机(VM)的 CPU 模型设置为 host-model 时,虚拟机会继承调度节点的 CPU 模型。
流程
编辑虚拟机配置文件的
domainspec。以下示例演示了为虚拟机指定host-model:apiVersion: kubevirt/v1alpha3 kind: VirtualMachine metadata: name: myvm spec: template: spec: domain: cpu: model: host-model1 - 1
- 继承调度节点的 CPU 模型的虚拟机。
11.15.10. 配置 PCI 透传
借助 Peripheral Component Interconnect(PCI)透传功能,您可以从虚拟机访问和管理硬件设备。配置 PCI 透传后,PCI 设备的功能就如同它们实际上附加到客户机操作系统上一样。
集群管理员可以使用 oc CLI 来公开和管理集群中允许在集群中使用的主机设备。
11.15.10.1. 关于为 PCI 透传准备主机设备
要使用 CLI 为 PCI 透传准备主机设备,请创建一个 MachineConfig 对象并添加内核参数,以启用输入输出内存管理单元(IOMMU)。将 PCI 设备绑定到虚拟功能 I/O(VFIO)驱动程序,然后通过编辑 HyperConverged 自定义资源(CR)的 allowedHostDevices 字段在集群中公开它。首次安装 OpenShift Virtualization Operator 时,allowedHostDevices 列表为空。
要使用 CLI 从集群中删除 PCI 主机设备,可从 HyperConverged CR 中删除 PCI 设备信息。
11.15.10.1.1. 添加内核参数以启用 IOMMU 驱动程序
要在内核中启用 IOMMU(Input-Output Memory Management Unit)驱动程序,请创建 MachineConfig 对象并添加内核参数。
先决条件
- 正常运行的 OpenShift 容器平台集群的管理特权。
- Intel 或 AMD CPU 硬件。
- 启用用于直接 I/O 扩展的 Intel 虚拟化技术或 BIOS 中的 AMD IOMMU(基本输入/输出系统)。
流程
创建用于标识内核参数的
MachineConfig对象。以下示例显示了 Intel CPU 的内核参数。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker1 name: 100-worker-iommu2 spec: config: ignition: version: 3.2.0 kernelArguments: - intel_iommu=on3 # ...创建新的
MachineConfig对象:$ oc create -f 100-worker-kernel-arg-iommu.yaml
验证
验证是否添加了新的
MachineConfig对象。$ oc get MachineConfig
11.15.10.1.2. 将 PCI 设备绑定到 VFIO 驱动程序
要将 PCI 设备绑定到 VFIO(虚拟功能 I/O)驱动程序,请从每个设备获取 vendor-ID 和 device-ID 的值,并创建值的列表。将这个列表添加到 MachineConfig 对象。MachineConfig Operator 在带有 PCI 设备的节点上生成 /etc/modprobe.d/vfio.conf,并将 PCI 设备绑定到 VFIO 驱动程序。
先决条件
- 您添加了内核参数来为 CPU 启用 IOMMU。
流程
运行
lspci命令,以获取 PCI 设备的vendor-ID和device-ID。$ lspci -nnv | grep -i nvidia输出示例
02:01.0 3D controller [0302]: NVIDIA Corporation GV100GL [Tesla V100 PCIe 32GB] [10de:1eb8] (rev a1)创建 Butane 配置文件
100-worker-vfiopci.bu,将 PCI 设备绑定到 VFIO 驱动程序。注意您在 配置文件中指定的 Butane 版本 应与 OpenShift Container Platform 版本匹配,并且始终以
0结尾。例如:4.13.0。有关 Butane 的信息,请参阅"使用 Butane 创建机器配置"。Example
variant: openshift version: 4.13.0 metadata: name: 100-worker-vfiopci labels: machineconfiguration.openshift.io/role: worker1 storage: files: - path: /etc/modprobe.d/vfio.conf mode: 0644 overwrite: true contents: inline: | options vfio-pci ids=10de:1eb82 - path: /etc/modules-load.d/vfio-pci.conf3 mode: 0644 overwrite: true contents: inline: vfio-pci使用 Butane 生成
MachineConfig对象文件100-worker-vfiopci.yaml,包含要发送到 worker 节点的配置:$ butane 100-worker-vfiopci.bu -o 100-worker-vfiopci.yaml将
MachineConfig对象应用到 worker 节点:$ oc apply -f 100-worker-vfiopci.yaml验证
MachineConfig对象是否已添加。$ oc get MachineConfig输出示例
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 00-master d3da910bfa9f4b599af4ed7f5ac270d55950a3a1 3.2.0 25h 00-worker d3da910bfa9f4b599af4ed7f5ac270d55950a3a1 3.2.0 25h 01-master-container-runtime d3da910bfa9f4b599af4ed7f5ac270d55950a3a1 3.2.0 25h 01-master-kubelet d3da910bfa9f4b599af4ed7f5ac270d55950a3a1 3.2.0 25h 01-worker-container-runtime d3da910bfa9f4b599af4ed7f5ac270d55950a3a1 3.2.0 25h 01-worker-kubelet d3da910bfa9f4b599af4ed7f5ac270d55950a3a1 3.2.0 25h 100-worker-iommu 3.2.0 30s 100-worker-vfiopci-configuration 3.2.0 30s
验证
验证是否已加载 VFIO 驱动程序。
$ lspci -nnk -d 10de:输出确认使用了 VFIO 驱动程序。
输出示例
04:00.0 3D controller [0302]: NVIDIA Corporation GP102GL [Tesla P40] [10de:1eb8] (rev a1) Subsystem: NVIDIA Corporation Device [10de:1eb8] Kernel driver in use: vfio-pci Kernel modules: nouveau
11.15.10.1.3. 使用 CLI 在集群中公开 PCI 主机设备
要在集群中公开 PCI 主机设备,将 PCI 设备的详细信息添加到 HyperConverged 自定义资源(CR)的 spec.permittedHostDevices.pciHostDevices 数组中。
流程
运行以下命令,在默认编辑器中编辑
HyperConvergedCR:$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv将 PCI 设备信息添加到
spec.percommitHostDevices.pciHostDevices数组。例如:配置文件示例
apiVersion: hco.kubevirt.io/v1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: permittedHostDevices:1 pciHostDevices:2 - pciDeviceSelector: "10DE:1DB6"3 resourceName: "nvidia.com/GV100GL_Tesla_V100"4 - pciDeviceSelector: "10DE:1EB8" resourceName: "nvidia.com/TU104GL_Tesla_T4" - pciDeviceSelector: "8086:6F54" resourceName: "intel.com/qat" externalResourceProvider: true5 # ...注意上例代码片段显示有两个 PCI 主机设备,名为
nvidia.com/GV100GL_Tesla_V100和nvidia.com/TU104GL_Tesla_Tesla_T4。它们被添加到HyperConvergedCR 中的允许主机设备列表中。这些设备已经过测试和验证以用于 OpenShift Virtualization。- 保存更改并退出编辑器。
验证
运行以下命令,验证 PCI 主机设备是否已添加到节点。示例输出显示,每个设备都与
nvidia.com/GV100GL_Tesla_V100、nvidia.com/TU104GL_Tesla_T4和intel.com/qat资源名称关联。$ oc describe node <node_name>输出示例
Capacity: cpu: 64 devices.kubevirt.io/kvm: 110 devices.kubevirt.io/tun: 110 devices.kubevirt.io/vhost-net: 110 ephemeral-storage: 915128Mi hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 131395264Ki nvidia.com/GV100GL_Tesla_V100 1 nvidia.com/TU104GL_Tesla_T4 1 intel.com/qat: 1 pods: 250 Allocatable: cpu: 63500m devices.kubevirt.io/kvm: 110 devices.kubevirt.io/tun: 110 devices.kubevirt.io/vhost-net: 110 ephemeral-storage: 863623130526 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 130244288Ki nvidia.com/GV100GL_Tesla_V100 1 nvidia.com/TU104GL_Tesla_T4 1 intel.com/qat: 1 pods: 250
11.15.10.1.4. 使用 CLI 从集群中删除 PCI 主机设备
要从集群中删除 PCI 主机设备,请从 HyperConverged 自定义资源(CR)中删除该设备的信息。
流程
运行以下命令,在默认编辑器中编辑
HyperConvergedCR:$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv通过删除相应设备的
pciDeviceSelector、resourceName和externalResourceProvider(如果适用)字段来从spec.permittedHostDevices.pciHostDevices阵列中删除 PCI 设备信息。在本例中,intel.com/qat资源已被删除。配置文件示例
apiVersion: hco.kubevirt.io/v1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: permittedHostDevices: pciHostDevices: - pciDeviceSelector: "10DE:1DB6" resourceName: "nvidia.com/GV100GL_Tesla_V100" - pciDeviceSelector: "10DE:1EB8" resourceName: "nvidia.com/TU104GL_Tesla_T4" # ...- 保存更改并退出编辑器。
验证
运行以下命令,验证 PCI 主机设备已从节点移除。示例输出显示,与
intel.com/qat资源名称关联的设备为零。$ oc describe node <node_name>输出示例
Capacity: cpu: 64 devices.kubevirt.io/kvm: 110 devices.kubevirt.io/tun: 110 devices.kubevirt.io/vhost-net: 110 ephemeral-storage: 915128Mi hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 131395264Ki nvidia.com/GV100GL_Tesla_V100 1 nvidia.com/TU104GL_Tesla_T4 1 intel.com/qat: 0 pods: 250 Allocatable: cpu: 63500m devices.kubevirt.io/kvm: 110 devices.kubevirt.io/tun: 110 devices.kubevirt.io/vhost-net: 110 ephemeral-storage: 863623130526 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 130244288Ki nvidia.com/GV100GL_Tesla_V100 1 nvidia.com/TU104GL_Tesla_T4 1 intel.com/qat: 0 pods: 250
11.15.10.2. 为 PCI 透传配置虚拟机
将 PCI 设备添加到集群中后,您可以将它们分配到虚拟机。PCI 设备现在可用。就像它们被物理地连接到虚拟机一样。
11.15.10.2.1. 为虚拟机分配 PCI 设备
当集群中有 PCI 设备时,您可以将其分配到虚拟机并启用 PCI 透传。
流程
将 PCI 设备分配到虚拟机作为主机设备。
Example
apiVersion: kubevirt.io/v1 kind: VirtualMachine spec: domain: devices: hostDevices: - deviceName: nvidia.com/TU104GL_Tesla_T41 name: hostdevices1- 1
- 集群中作为主机设备允许的 PCI 设备的名称。虚拟机可以访问此主机设备。
验证
使用以下命令,验证主机设备可从虚拟机使用。
$ lspci -nnk | grep NVIDIA输出示例
$ 02:01.0 3D controller [0302]: NVIDIA Corporation GV100GL [Tesla V100 PCIe 32GB] [10de:1eb8] (rev a1)
11.15.11. 配置 vGPU 透传
您的虚拟机可以访问虚拟 GPU(vGPU)硬件。通过为虚拟机分配 vGPU,您可以执行以下操作:
- 访问底层硬件的 GPU 以达到虚拟机中的高性能优势。
- 简化资源密集型 I/O 操作。
vGPU 透传只能分配给连接到裸机环境中运行的集群的设备。
11.15.11.1. 为虚拟机分配 vGPU 透传设备
使用 OpenShift Container Platform web 控制台为虚拟机分配 vGPU 透传设备。
先决条件
- 必须停止虚拟机。
流程
- 在 OpenShift Container Platform web 控制台中,从侧边菜单中点 Virtualization → VirtualMachines。
- 选择您要为其分配该设备的虚拟机。
在 Details 标签页中,点 GPU 设备。
如果将 vGPU 设备添加为主机设备,则无法使用 VNC 控制台访问该设备。
- 点 Add GPU 设备,输入名称并从设备名称列表中选择 设备。
- 点击 Save。
-
点 YAML 选项卡,验证
hostDevices部分中的新设备是否已添加到集群配置中。
您可以将硬件设备添加到从自定义模板或 YAML 文件创建的虚拟机中。您不能将设备添加到特定操作系统的预先提供的引导源模板,如 Windows 10 或 RHEL 7。
要显示连接到集群的资源,请从侧边菜单中点 Compute → Hardware Devices。
11.15.12. 配置介质设备
如果您在 HyperConverged 自定义资源(CR)中提供设备列表,OpenShift Virtualization 会自动创建介质设备,如虚拟 GPU(vGPU)。
介质(mediated)设备的声明配置只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
11.15.12.1. 关于使用 NVIDIA GPU Operator
NVIDIA GPU Operator 在 OpenShift Container Platform 集群中管理 NVIDIA GPU 资源,并自动执行与引导 GPU 节点相关的任务。由于 GPU 是集群中的一个特殊资源,所以您必须先安装一些组件,然后才能将应用程序工作负载部署到 GPU。这些组件包括 NVIDIA 驱动程序,启用计算统一设备架构(CUDA)、Kubernetes 设备插件、容器运行时和其他功能,如自动节点标签、监控等。
NVIDIA GPU Operator 仅支持 NVIDIA。有关从 NVIDIA 获取支持的更多信息,请参阅 NVIDIA 支持。
使用 OpenShift Container Platform OpenShift Virtualization 启用 GPU 有两种方法:这里介绍了 OpenShift Container Platform 原生方法,并使用 NVIDIA GPU Operator。
NVIDIA GPU Operator 是一个 Kubernetes Operator,它使用 OpenShift Container Platform OpenShift Virtualization 为在 OpenShift Container Platform 上运行的虚拟化工作负载置备 GPU。使用 Operator,您可以轻松地置备和管理启用了 GPU 的虚拟机,以便在与其他工作负载相同的平台上运行复杂的人工智能/机器学习(AI/ML)工作负载。Operator 还提供了扩展其基础架构的 GPU 容量的简单方法,从而可以快速增长基于 GPU 的工作负载。
有关使用 NVIDIA GPU Operator 为运行 GPU 加速虚拟机置备 worker 节点的更多信息,请参阅使用 OpenShift Virtualization 的 NVIDIA GPU Operator。
11.15.12.2. 关于在 OpenShift Virtualization 中使用虚拟 GPU
有些图形处理单元(GPU)卡支持创建虚拟 GPU(vGPU)。如果管理员在 HyperConverged 自定义资源(CR)中提供配置详情,则 OpenShift Virtualization 可以自动创建 vGPU 和其他介质设备。这个自动化对大型集群特别有用。
有关功能和支持详情,请参考您的硬件供应商文档。
- 介质设备
- 划分为一个或多个虚拟设备的物理设备。vGPU 是一个介质设备(mdev)类型,物理 GPU 的性能会被划分到各个虚拟设备中。您可以将介质设备分配给一个或多个虚拟机(VM),但客户机数量必须与您的 GPU 兼容。有些 GPU 不支持多个虚拟机。
11.15.12.2.1. 先决条件
如果您的硬件厂商提供驱动程序,您可以在要创建介质设备的节点上安装它们。
- 如果您使用 NVIDIA 卡,则 安装了 NVIDIA GRID 驱动程序。
11.15.12.2.2. 配置概述
在配置介质设备时,管理员必须完成以下任务:
- 创建介质设备。
- 在集群中公开介质设备。
HyperConverged CR 包含可以实现这两个任务的 API。
创建介质设备
# ...
spec:
mediatedDevicesConfiguration:
mediatedDevicesTypes:
- <device_type>
nodeMediatedDeviceTypes:
- mediatedDevicesTypes:
- <device_type>
nodeSelector:
<node_selector_key>: <node_selector_value>
# ...在集群中公开介质设备
# ...
permittedHostDevices:
mediatedDevices:
- mdevNameSelector: GRID T4-2Q
resourceName: nvidia.com/GRID_T4-2Q
# ...- 1
- 公开映射到主机上这个值的介质设备。注意
您可以通过
/sys/bus/pci/devices/<slot>:<bus>:<domain>.<function>/mdev_supported_types/<type>/name(使用您的具体系统信息替换相关部分)查看您的设备支持的介质设备类型。例如,
nvidia-231类型的名称文件包含选择器字符串GRID T4-2Q。使用GRID T4-2Q作为mdevNameSelector值,允许节点使用nvidia-231类型。 - 2
resourceName应该与节点上分配的匹配。使用以下命令查找resourceName:$ oc get $NODE -o json \ | jq '.status.allocatable \ | with_entries(select(.key | startswith("nvidia.com/"))) \ | with_entries(select(.value != "0"))'
11.15.12.2.3. vGPU 如何分配给节点
对于每个物理设备,OpenShift Virtualization 配置以下值:
- 单个 mdev 类型。
-
所选
mdev类型的最大实例数量。
集群架构会影响创建设备并分配到节点的方式。
- 每个节点具有多个卡的大型集群
在支持多个 vGPU 类型的节点上,以轮循方式创建相关设备类型。例如:
# ... mediatedDevicesConfiguration: mediatedDevicesTypes: - nvidia-222 - nvidia-228 - nvidia-105 - nvidia-108 # ...在这种情况下,每个节点有两个卡,它们支持以下 vGPU 类型:
nvidia-105 # ... nvidia-108 nvidia-217 nvidia-299 # ...在每个节点上,OpenShift Virtualization 会创建以下 vGPU:
- 在第一个卡上,16 个类型为 nvidia-105 的 vGPU。
- 第二卡上的 2 个类型为 nvidia-108 的 vGPU。
- 一个节点有一个卡,它支持多个请求的 vGPU 类型
OpenShift Virtualization 使用最先在
mediatedDevicesTypes列表中提供的支持类型。例如,节点卡中的卡支持
nvidia-223和nvidia-224。以下mediatedDevicesTypes列表已配置:# ... mediatedDevicesConfiguration: mediatedDevicesTypes: - nvidia-22 - nvidia-223 - nvidia-224 # ...在本例中,OpenShift Virtualization 使用
nvidia-223类型。
11.15.12.2.4. 关于更改和删除介质设备
集群的介质设备配置可使用 OpenShift Virtualization 更新:
-
编辑
HyperConvergedCR 并更改mediatedDevicesTypes小节的内容。 -
更改与
nodeMediatedDeviceTypes节点选择器匹配的节点标签。 从
HyperConvergedCR 的spec.mediatedDevicesConfiguration和spec.permittedHostDevices小节中删除设备信息。注意如果您在
spec.permittedHostDevices小节中删除设备信息,且没有将其从spec.mediatedDevicesConfiguration小节中移除,则无法在同一节点上创建新的介质设备类型。要正确删除介质设备,请从两个段中删除设备信息。
根据具体更改,这些操作会导致 OpenShift Virtualization 重新配置介质设备或从集群节点中删除它们。
11.15.12.2.5. 为介质设备准备主机
在配置介质设备前,您必须启用输入输出内存管理单元 (IOMMU) 驱动程序。
11.15.12.2.5.1. 添加内核参数以启用 IOMMU 驱动程序
要在内核中启用 IOMMU(Input-Output Memory Management Unit)驱动程序,请创建 MachineConfig 对象并添加内核参数。
先决条件
- 正常运行的 OpenShift 容器平台集群的管理特权。
- Intel 或 AMD CPU 硬件。
- 启用用于直接 I/O 扩展的 Intel 虚拟化技术或 BIOS 中的 AMD IOMMU(基本输入/输出系统)。
流程
创建用于标识内核参数的
MachineConfig对象。以下示例显示了 Intel CPU 的内核参数。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker1 name: 100-worker-iommu2 spec: config: ignition: version: 3.2.0 kernelArguments: - intel_iommu=on3 # ...创建新的
MachineConfig对象:$ oc create -f 100-worker-kernel-arg-iommu.yaml
验证
验证是否添加了新的
MachineConfig对象。$ oc get MachineConfig
11.15.12.2.6. 添加和删除介质设备
您可以添加或删除介质设备。
11.15.12.2.6.1. 创建并公开介质设备
您可以通过编辑 HyperConverged 自定义资源(CR)来公开和创建介质设备,如虚拟 GPU(vGPU)。
先决条件
- 已启用 IOMMU(Input-Output Memory Management Unit)驱动程序。
流程
运行以下命令,在默认编辑器中编辑
HyperConvergedCR:$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv将介质设备信息添加到
HyperConvergedCRspec中,确保包含mediatedDevicesConfiguration和 allowedHostDevices小节。例如:配置文件示例
apiVersion: hco.kubevirt.io/v1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: mediatedDevicesConfiguration: <.> mediatedDevicesTypes: <.> - nvidia-231 nodeMediatedDeviceTypes: <.> - mediatedDevicesTypes: <.> - nvidia-233 nodeSelector: kubernetes.io/hostname: node-11.redhat.com permittedHostDevices: <.> mediatedDevices: - mdevNameSelector: GRID T4-2Q resourceName: nvidia.com/GRID_T4-2Q - mdevNameSelector: GRID T4-8Q resourceName: nvidia.com/GRID_T4-8Q # ...<.> 创建介质设备。<.> 必需: 全局
mediatedDevicesTypes配置。<.> 可选:覆盖特定节点的全局配置。<.> 如果使用nodeMediatedDeviceTypes是必需的。<.> 向集群公开介质设备。- 保存更改并退出编辑器。
验证
您可以运行以下命令来验证设备是否已添加到特定节点:
$ oc describe node <node_name>
11.15.12.2.6.2. 使用 CLI 从集群中删除介质设备
要从集群中删除介质设备,请从 HyperConverged 自定义资源(CR)中删除该设备的信息。
流程
运行以下命令,在默认编辑器中编辑
HyperConvergedCR:$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv从
HyperConvergedCR 的spec.mediatedDevicesConfiguration和spec.permittedHostDevices小节中删除设备信息。删除这两个条目可确保您稍后在同一节点上创建新的介质设备类型。例如:配置文件示例
apiVersion: hco.kubevirt.io/v1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: mediatedDevicesConfiguration: mediatedDevicesTypes:1 - nvidia-231 permittedHostDevices: mediatedDevices:2 - mdevNameSelector: GRID T4-2Q resourceName: nvidia.com/GRID_T4-2Q- 保存更改并退出编辑器。
11.15.12.3. 使用介质设备
vGPU 是介质设备的类型;物理 GPU 的性能被划分到虚拟设备中。您可以将介质设备分配给一个或多个虚拟机。
11.15.12.3.1. 为虚拟机分配介质设备
为虚拟机分配介质设备,如虚拟 GPU(vGPU)。
先决条件
-
介质设备在
HyperConverged自定义资源中配置。
流程
通过编辑
VirtualMachine清单的spec.domain.devices.gpus小节,将介质设备分配给虚拟机(VM):虚拟机清单示例
apiVersion: kubevirt.io/v1 kind: VirtualMachine spec: domain: devices: gpus: - deviceName: nvidia.com/TU104GL_Tesla_T41 name: gpu12 - deviceName: nvidia.com/GRID_T4-1Q name: gpu2
验证
要验证该设备在虚拟机中可用,运行以下命令,将
<device_name>替换为VirtualMachine清单中的deviceName值:$ lspci -nnk | grep <device_name>
11.15.13. 在虚拟机上启用 descheduler 驱除
您可以使用 descheduler 来驱除 pod,以便可将 pod 重新调度到更合适的节点上。如果 pod 是虚拟机,pod 驱除会导致虚拟机实时迁移到另一节点。
虚拟机的 descheduler 驱除功能只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
11.15.13.1. Descheduler 配置集
使用技术预览 DevPreviewLifecycle 配置集为虚拟机启用 descheduler。这是当前可用于 OpenShift Virtualization 的 descheduler 配置集。为确保正确调度,请创建带有 CPU 和内存请求的虚拟机用于预期的负载。
DevPreviewLongLifecycle此配置集在节点间平衡资源使用量并启用以下策略:
-
RemovePodsHavingTooManyRestarts:删除其容器重启次数太多的 pod,以及其中所有容器(包括 Init 容器)重启的总数超过 100 的 pod。重启虚拟机客户端操作系统不会增加这个计数。 LowNodeUtilization:在存在没有被充分利用的节点时,将 pod 从过度使用的节点上驱除。被驱除的 pod 的目标节点将由调度程序决定。- 如果节点的用量低于 20%(CPU、内存和 pod 的数量),则该节点将被视为使用率不足。
- 如果节点的用量超过 50%(CPU、内存和 pod 的数量),则该节点将被视为过量使用。
-
11.15.13.2. 安装 descheduler
在默认情况下,不提供 descheduler。要启用 descheduler,您必须从 OperatorHub 安装 Kube Descheduler Operator,并启用一个或多个 descheduler 配置集。
默认情况下,descheduler 以预测模式运行,这意味着它只模拟 pod 驱除。您必须将 descheduler 的模式更改为自动进行 pod 驱除。
如果您在集群中启用了托管的 control plane,设置自定义优先级阈值,以降低托管 control plane 命名空间中的 pod 被驱除。将优先级阈值类名称设置为 hypershift-control-plane,因为它有托管的 control plane 优先级类的最低优先级值(100000000)。
先决条件
-
以具有
cluster-admin角色的用户身份登录到 OpenShift Container Platform。 - 访问 OpenShift Container Platform Web 控制台。
流程
- 登陆到 OpenShift Container Platform Web 控制台。
为 Kube Descheduler Operator 创建所需的命名空间。
- 进行 Administration → Namespaces,点 Create Namespace。
-
在 Name 字段中输入
openshift-kube-descheduler-operator,在 Labels 字段中输入openshift.io/cluster-monitoring=true来启用 descheduler 指标,然后点击 Create。
安装 Kube Descheduler Operator。
- 进入 Operators → OperatorHub。
- 在过滤框中输入 Kube Descheduler Operator。
- 选择 Kube Descheduler Operator 并点 Install。
- 在 Install Operator 页面中,选择 A specific namespace on the cluster。从下拉菜单中选择 openshift-kube-descheduler-operator 。
- 将 Update Channel 和 Approval Strategy 的值调整为所需的值。
- 点击 Install。
创建 descheduler 实例。
- 在 Operators → Installed Operators 页面中,点 Kube Descheduler Operator。
- 选择 Kube Descheduler 标签页并点 Create KubeDescheduler。
根据需要编辑设置。
- 要驱除 pod 而不是模拟驱除,请将 Mode 字段更改为 Automatic。
展开 Profiles 部分,再选择
DevPreviewLongLifecycle。AffinityAndTaints配置集默认为启用。重要当前仅适用于 OpenShift Virtualization 的配置集是
DevPreviewLongLifecycle。
您还可以稍后使用 OpenShift CLI(oc)为 descheduler 配置配置集和设置。
11.15.13.3. 在虚拟机(VM)上启用 descheduler 驱除
安装 descheduler 后,您可以通过在 VirtualMachine 自定义资源(CR)中添加注解来在虚拟机上启用 descheduler 驱除。
先决条件
-
在 OpenShift Container Platform Web 控制台或 OpenShift CLI(
oc)中安装 descheduler。 - 确保虚拟机没有运行。
流程
在启动虚拟机前,将
descheduler.alpha.kubernetes.io/evict注解添加到VirtualMachineCR:apiVersion: kubevirt.io/v1 kind: VirtualMachine spec: template: metadata: annotations: descheduler.alpha.kubernetes.io/evict: "true"如果您还没有在安装过程中在 web 控制台中设置
DevPreviewLongLifecycle配置集,请在KubeDescheduler对象的spec.profile部分指定DevPreviewLongLifecycle:apiVersion: operator.openshift.io/v1 kind: KubeDescheduler metadata: name: cluster namespace: openshift-kube-descheduler-operator spec: deschedulingIntervalSeconds: 3600 profiles: - DevPreviewLongLifecycle mode: Predictive1 - 1
- 默认情况下,descheduler 不会驱除 pod。要驱除 pod,请将
mode设置为Automatic。
现在在虚拟机上启用了 descheduler。
11.16. 导入虚拟机
11.16.1. 数据卷导入的 TLS 证书
11.16.1.1. 添加用于身份验证数据卷导入的 TLS 证书
registry 或 HTTPS 端点的 TLS 证书必须添加到配置映射中,才能从这些源导入数据。此配置映射必须存在于目标数据卷的命名空间中。
通过引用 TLS 证书的相对文件路径来创建配置映射。
流程
确定您处于正确的命名空间中。配置映射只能被数据卷引用(如果位于同一命名空间中)。
$ oc get ns创建配置映射:
$ oc create configmap <configmap-name> --from-file=</path/to/file/ca.pem>
11.16.1.2. 示例:从 TLS 证书创建的配置映射
以下示例是从 ca.pem TLS 证书创建的配置映射。
apiVersion: v1
kind: ConfigMap
metadata:
name: tls-certs
data:
ca.pem: |
-----BEGIN CERTIFICATE-----
... <base64 encoded cert> ...
-----END CERTIFICATE-----11.16.2. 使用数据卷导入虚拟机镜像
您可以将现有虚拟机镜像导入到 OpenShift Container Platform 集群存储中。使用 Containerized Data Importer (CDI),您可以使用数据卷将镜像导入到持久性卷声明(PVC)。OpenShift Virtualization 使用一个或多个数据卷来自动导入数据并创建底层 PVC。您可以将数据卷附加到虚拟机以获取持久性存储。
虚拟机镜像可以托管在 HTTP 或 HTTPS 端点上,也可以内嵌在容器磁盘中,并存储在容器镜像仓库中。
当您将磁盘镜像导入到 PVC 中时,磁盘镜像扩展为使用 PVC 中请求的全部存储容量。要使用该空间,可能需要扩展虚拟机中的磁盘分区和文件系统。
调整大小的流程因虚拟机上安装的操作系统而异。详情请查看操作系统文档。
11.16.2.1. 先决条件
- 如果端点需要 TLS 证书,该证书必须 包含在与数据卷相同的命名空间中的配置映射 中,并在数据卷配置中引用。
导入容器磁盘:
- 您可能需要从虚拟机镜像准备容器磁盘,并在导入前将其存储在容器镜像仓库中。
-
如果容器镜像仓库没有 TLS,您必须将 registry 添加到
HyperConverged自定义资源的insecureRegistries字段中,然后才能从中导入容器磁盘。
- 您可能需要定义存储类或准备 CDI 涂销空间才能成功完成此操作。
如果要使用数据卷将虚拟机镜像导入到块存储中,则必须有一个可用的本地块持久性卷。
11.16.2.2. CDI 支持的操作列表
此列表针对端点显示内容类型支持的 CDI 操作,以及哪些操作需要涂销空间(scratch space)。
| 内容类型 | HTTP | HTTPS | HTTP 基本身份验证 | Registry | 上传 |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) |
✓ QCOW2 |
✓ QCOW2** |
✓ QCOW2 |
✓ QCOW2* |
✓ QCOW2* |
| KubeVirt (RAW) |
✓ RAW |
✓ RAW |
✓ RAW |
✓ RAW* |
✓ RAW* |
✓ 支持的操作
□ 不支持的操作
* 需要涂销空间
** 如果需要自定义证书颁发机构,则需要涂销空间
CDI 现在使用 OpenShift Container Platform 集群范围的代理配置。
11.16.2.3. 关于数据卷
DataVolume 对象是 Containerized Data Importer (CDI) 项目提供的自定义资源。DataVolume 编配与底层持久性卷声明(PVC)关联的导入、克隆和上传操作。您可以将数据卷创建为独立资源,也可以使用虚拟机 (VM) 规格中的 dataVolumeTemplate 字段。
-
使用独立数据卷准备的虚拟机磁盘 PVC,维护虚拟机的独立生命周期。如果您使用虚拟机规格中的
dataVolumeTemplate字段准备 PVC,PVC 会共享与虚拟机相同的生命周期。
11.16.2.4. 本地块持久性卷
如果要使用数据卷将虚拟机镜像导入到块存储中,则必须有一个可用的本地块持久性卷。
11.16.2.4.1. 关于块持久性卷
块持久性卷(PV)是一个受原始块设备支持的 PV。这些卷没有文件系统,可以通过降低开销来为虚拟机提供性能优势。
原始块卷可以通过在 PV 和持久性卷声明(PVC)规格中指定 volumeMode: Block 来置备。
11.16.2.4.2. 创建本地块持久性卷
如果要使用数据卷将虚拟机镜像导入到块存储中,则必须有一个可用的本地块持久性卷。
通过填充文件并将其挂载为循环设备,在节点上创建本地块持久性卷(PV)。然后,您可以在 PV 清单中将该循环设备作为 Block(块)卷引用,并将其用作虚拟机镜像的块设备。
流程
-
以
root身份登录节点,在其上创建本地 PV。本流程以node01为例。 创建一个文件并用空字符填充,以便可将其用作块设备。以下示例创建
loop10文件,大小为 2Gb(20,100 Mb 块):$ dd if=/dev/zero of=<loop10> bs=100M count=20将
loop10文件挂载为 loop 设备。$ losetup </dev/loop10>d3 <loop10>1 2 创建引用所挂载 loop 设备的
PersistentVolume清单。kind: PersistentVolume apiVersion: v1 metadata: name: <local-block-pv10> annotations: spec: local: path: </dev/loop10>1 capacity: storage: <2Gi> volumeMode: Block2 storageClassName: local3 accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Delete nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - <node01>4 创建块 PV。
# oc create -f <local-block-pv10.yaml>1 - 1
- 上一步中创建的持久性卷的文件名。
11.16.2.5. 使用数据卷将虚拟机镜像导入到存储中
您可以使用数据卷将虚拟机镜像导入到存储中。
虚拟机镜像可以托管在 HTTP 或 HTTPS 端点上,或者镜像可以构建到容器磁盘中,并存储在容器镜像仓库中。
您可以在 VirtualMachine 配置文件中为镜像指定数据源。创建虚拟机时,包含虚拟机镜像的数据卷将导入到存储中。
先决条件
要导入虚拟机镜像,必须有以下内容:
-
RAW、ISO 或 QCOW2 格式的虚拟机磁盘镜像,可选择使用
xz或gz进行压缩。 - 托管镜像的 HTTP 或 HTTPS 端点,以及访问数据源所需的任何身份验证凭证。
-
RAW、ISO 或 QCOW2 格式的虚拟机磁盘镜像,可选择使用
- 要导入容器磁盘,您必须将虚拟机镜像构建到容器磁盘中,并存储在容器镜像仓库中,以及访问数据源所需的任何身份验证凭证。
- 如果虚拟机必须与未由系统 CA 捆绑包签名的证书的服务器通信,则必须在与数据卷相同的命名空间中创建一个配置映射。
流程
如果您的数据源需要身份验证,请创建一个
Secret清单,指定数据源凭证,并将其保存为endpoint-secret.yaml:apiVersion: v1 kind: Secret metadata: name: endpoint-secret1 labels: app: containerized-data-importer type: Opaque data: accessKeyId: ""2 secretKey: ""3 应用
Secret清单:$ oc apply -f endpoint-secret.yaml编辑
VirtualMachine清单,为要导入的虚拟机镜像指定数据源,并将其保存为vm-fedora-datavolume.yaml:apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: creationTimestamp: null labels: kubevirt.io/vm: vm-fedora-datavolume name: vm-fedora-datavolume1 spec: dataVolumeTemplates: - metadata: creationTimestamp: null name: fedora-dv2 spec: storage: volumeMode: Block3 resources: requests: storage: 10Gi storageClassName: local source:4 http: url: "https://mirror.arizona.edu/fedora/linux/releases/35/Cloud/x86_64/images/Fedora-Cloud-Base-35-1.2.x86_64.qcow2"5 secretRef: endpoint-secret6 certConfigMap: ""7 # To use a registry source, uncomment the following lines and delete the preceding HTTP source block # registry: # url: "docker://kubevirt/fedora-cloud-container-disk-demo:latest" # secretRef: registry-secret8 # certConfigMap: ""9 status: {} running: true template: metadata: creationTimestamp: null labels: kubevirt.io/vm: vm-fedora-datavolume spec: domain: devices: disks: - disk: bus: virtio name: datavolumedisk1 machine: type: "" resources: requests: memory: 1.5Gi terminationGracePeriodSeconds: 180 volumes: - dataVolume: name: fedora-dv name: datavolumedisk1 status: {}创建虚拟机:
$ oc create -f vm-fedora-datavolume.yaml注意oc create命令创建数据卷和虚拟机。CDI 控制器创建一个带有正确注解和导入过程的底层 PVC。导入完成后,数据卷状态变为Succeeded。您可以启动虚拟机。数据卷置备在后台进行,因此无需监控进程。
验证
importer pod 从指定的 URL 下载虚拟机镜像或容器磁盘,并将其存储在置备的 PV 上。运行以下命令,查看 importer pod 的状态:
$ oc get pods运行以下命令监控数据卷,直到其状态为
Succeeded:$ oc describe dv fedora-dv1 - 1
- 指定您在
VirtualMachine清单中定义的数据卷名称。
通过访问其串行控制台来验证置备是否已完成,并且虚拟机是否已启动:
$ virtctl console vm-fedora-datavolume
11.17. 克隆虚拟机
11.17.1. 启用用户权限跨命名空间克隆数据卷
命名空间的隔离性质意味着用户默认无法在命名空间之间克隆资源。
要让用户将虚拟机克隆到另一个命名空间,具有 cluster-admin 角色的用户必须创建新的集群角色。将此集群角色绑定到用户,以便其将虚拟机克隆到目标命名空间。
11.17.1.1. 先决条件
-
只有具有
cluster-admin角色的用户才能创建集群角色。
11.17.1.2. 关于数据卷
DataVolume 对象是 Containerized Data Importer (CDI) 项目提供的自定义资源。DataVolume 编配与底层持久性卷声明(PVC)关联的导入、克隆和上传操作。您可以将数据卷创建为独立资源,也可以使用虚拟机 (VM) 规格中的 dataVolumeTemplate 字段。
-
使用独立数据卷准备的虚拟机磁盘 PVC,维护虚拟机的独立生命周期。如果您使用虚拟机规格中的
dataVolumeTemplate字段准备 PVC,PVC 会共享与虚拟机相同的生命周期。
11.17.1.3. 创建用于克隆数据卷的 RBAC 资源
创建一个新的集群角色,为 datavolumes 资源的所有操作启用权限。
流程
创建
ClusterRole清单:apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: <datavolume-cloner>1 rules: - apiGroups: ["cdi.kubevirt.io"] resources: ["datavolumes/source"] verbs: ["*"]- 1
- 集群角色的唯一名称。
在集群中创建集群角色:
$ oc create -f <datavolume-cloner.yaml>1 - 1
- 上一步中创建的
ClusterRole清单的文件名。
创建应用于源和目标命名空间的
RoleBinding清单,并引用上一步中创建的集群角色。apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: <allow-clone-to-user>1 namespace: <Source namespace>2 subjects: - kind: ServiceAccount name: default namespace: <Destination namespace>3 roleRef: kind: ClusterRole name: datavolume-cloner4 apiGroup: rbac.authorization.k8s.io在集群中创建角色绑定:
$ oc create -f <datavolume-cloner.yaml>1 - 1
- 上一步中创建的
RoleBinding清单的文件名。
11.17.2. 将虚拟机磁盘克隆到新数据卷中
您可以通过引用数据卷配置文件中的源 PVC 来将虚拟机磁盘的持久性卷声明(PVC)克隆到新数据卷中。
支持在不同卷模式间克隆操作,比如从带有 volumeMode: Block 的持久性卷(PV)克隆到带有 volumeMode: Filesystem 的 PV。
但是,只有在不同的卷模式中存在contentType: kubevirt 时才可以克隆它们。
当您全局启用预分配或单个数据卷时,Containerized Data Importer(CDI)会在克隆过程中预分配磁盘空间。预分配可提高写入性能。如需更多信息,请参阅对数据卷使用预分配。
11.17.2.1. 先决条件
- 用户需要额外权限才能将虚拟机磁盘的 PVC 克隆到另一个命名空间中。
11.17.2.2. 关于数据卷
DataVolume 对象是 Containerized Data Importer (CDI) 项目提供的自定义资源。DataVolume 编配与底层持久性卷声明(PVC)关联的导入、克隆和上传操作。您可以将数据卷创建为独立资源,也可以使用虚拟机 (VM) 规格中的 dataVolumeTemplate 字段。
-
使用独立数据卷准备的虚拟机磁盘 PVC,维护虚拟机的独立生命周期。如果您使用虚拟机规格中的
dataVolumeTemplate字段准备 PVC,PVC 会共享与虚拟机相同的生命周期。
11.17.2.3. 将虚拟机磁盘的持久性卷声明克隆到新数据卷中
您可以将现有虚拟机磁盘的持久性卷声明(PVC)克隆到新数据卷中。新的数据卷可用于新虚拟机。
当独立于虚拟机创建数据卷时,数据卷的生命周期与虚拟机是独立的。如果删除了虚拟机,数据卷及其相关 PVC 都不会被删除。
先决条件
- 确定要使用的现有虚拟机磁盘的 PVC。克隆之前,必须关闭与 PVC 关联的虚拟机。
-
安装 OpenShift CLI(
oc)。
流程
- 检查您要克隆的虚拟机磁盘,以识别关联 PVC 的名称和命名空间。
为数据卷创建一个 YAML 文件,用于指定新数据卷的名称、源 PVC 的名称和命名空间,以及新数据卷的大小。
例如:
apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: <cloner-datavolume>1 spec: source: pvc: namespace: "<source-namespace>"2 name: "<my-favorite-vm-disk>"3 pvc: accessModes: - ReadWriteOnce resources: requests: storage: <2Gi>4 通过创建数据卷开始克隆 PVC:
$ oc create -f <cloner-datavolume>.yaml注意在 PVC 就绪前,DataVolume 会阻止虚拟机启动,以便您可以在 PVC 克隆期间创建引用新数据卷的虚拟机。
11.17.2.4. CDI 支持的操作列表
此列表针对端点显示内容类型支持的 CDI 操作,以及哪些操作需要涂销空间(scratch space)。
| 内容类型 | HTTP | HTTPS | HTTP 基本身份验证 | Registry | 上传 |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) |
✓ QCOW2 |
✓ QCOW2** |
✓ QCOW2 |
✓ QCOW2* |
✓ QCOW2* |
| KubeVirt (RAW) |
✓ RAW |
✓ RAW |
✓ RAW |
✓ RAW* |
✓ RAW* |
✓ 支持的操作
□ 不支持的操作
* 需要涂销空间
** 如果需要自定义证书颁发机构,则需要涂销空间
11.17.3. 使用数据卷模板克隆虚拟机
您可以通过克隆现有虚拟机的持久性卷声明(PVC)来创建新虚拟机。在虚拟机配置文件中包括 dataVolumeTemplate,即可从原始 PVC 创建新数据卷。
支持在不同卷模式间克隆操作,比如从带有 volumeMode: Block 的持久性卷(PV)克隆到带有 volumeMode: Filesystem 的 PV。
但是,只有在不同的卷模式中存在contentType: kubevirt 时才可以克隆它们。
当您全局启用预分配或单个数据卷时,Containerized Data Importer(CDI)会在克隆过程中预分配磁盘空间。预分配可提高写入性能。如需更多信息,请参阅对数据卷使用预分配。
11.17.3.1. 先决条件
- 用户需要额外权限才能将虚拟机磁盘的 PVC 克隆到另一个命名空间中。
11.17.3.2. 关于数据卷
DataVolume 对象是 Containerized Data Importer (CDI) 项目提供的自定义资源。DataVolume 编配与底层持久性卷声明(PVC)关联的导入、克隆和上传操作。您可以将数据卷创建为独立资源,也可以使用虚拟机 (VM) 规格中的 dataVolumeTemplate 字段。
-
使用独立数据卷准备的虚拟机磁盘 PVC,维护虚拟机的独立生命周期。如果您使用虚拟机规格中的
dataVolumeTemplate字段准备 PVC,PVC 会共享与虚拟机相同的生命周期。
11.17.3.3. 使用数据卷模板从克隆的持久性卷声明创建新虚拟机
您可以创建一个虚拟机,将现有虚拟机的持久性卷声明(PVC)克隆到数据卷中。在虚拟机清单中引用 dataVolumeTemplate,并将源 PVC 克隆到数据卷中,然后自动用于创建虚拟机。
当作为虚拟机的数据卷模板创建数据卷时,数据卷的生命周期依赖于虚拟机。如果删除了虚拟机,数据卷和相关 PVC 也会被删除。
先决条件
- 确定要使用的现有虚拟机磁盘的 PVC。克隆之前,必须关闭与 PVC 关联的虚拟机。
-
安装 OpenShift CLI(
oc)。
流程
- 检查您要克隆的虚拟机,以识别关联 PVC 的名称和命名空间。
为
VirtualMachine对象创建 YAML 文件。以下虚拟机示例克隆my-favorite-vm-disk,该磁盘位于source-name命名空间中。从my-favorite-vm-disk创建的名为favorite-clone的2Gi数据卷 。例如:
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: labels: kubevirt.io/vm: vm-dv-clone name: vm-dv-clone1 spec: running: false template: metadata: labels: kubevirt.io/vm: vm-dv-clone spec: domain: devices: disks: - disk: bus: virtio name: root-disk resources: requests: memory: 64M volumes: - dataVolume: name: favorite-clone name: root-disk dataVolumeTemplates: - metadata: name: favorite-clone spec: storage: accessModes: - ReadWriteOnce resources: requests: storage: 2Gi source: pvc: namespace: "source-namespace" name: "my-favorite-vm-disk"- 1
- 要创建的虚拟机。
使用 PVC 克隆的数据卷创建虚拟机:
$ oc create -f <vm-clone-datavolumetemplate>.yaml
11.17.3.4. CDI 支持的操作列表
此列表针对端点显示内容类型支持的 CDI 操作,以及哪些操作需要涂销空间(scratch space)。
| 内容类型 | HTTP | HTTPS | HTTP 基本身份验证 | Registry | 上传 |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) |
✓ QCOW2 |
✓ QCOW2** |
✓ QCOW2 |
✓ QCOW2* |
✓ QCOW2* |
| KubeVirt (RAW) |
✓ RAW |
✓ RAW |
✓ RAW |
✓ RAW* |
✓ RAW* |
✓ 支持的操作
□ 不支持的操作
* 需要涂销空间
** 如果需要自定义证书颁发机构,则需要涂销空间
11.17.4. 将虚拟机磁盘克隆到新块存储持久性卷声明中
您可以通过引用克隆目标数据卷配置文件中的源 PVC 来将虚拟机磁盘的持久性卷声明(PVC)克隆到新块 PVC 中。
支持在不同卷模式间克隆操作,比如从带有 volumeMode: Block 的持久性卷(PV)克隆到带有 volumeMode: Filesystem 的 PV。
但是,只有在不同的卷模式中存在contentType: kubevirt 时才可以克隆它们。
当您全局启用预分配或单个数据卷时,Containerized Data Importer(CDI)会在克隆过程中预分配磁盘空间。预分配可提高写入性能。如需更多信息,请参阅对数据卷使用预分配。
11.17.4.1. 先决条件
- 用户需要额外权限才能将虚拟机磁盘的 PVC 克隆到另一个命名空间中。
11.17.4.2. 关于数据卷
DataVolume 对象是 Containerized Data Importer (CDI) 项目提供的自定义资源。DataVolume 编配与底层持久性卷声明(PVC)关联的导入、克隆和上传操作。您可以将数据卷创建为独立资源,也可以使用虚拟机 (VM) 规格中的 dataVolumeTemplate 字段。
-
使用独立数据卷准备的虚拟机磁盘 PVC,维护虚拟机的独立生命周期。如果您使用虚拟机规格中的
dataVolumeTemplate字段准备 PVC,PVC 会共享与虚拟机相同的生命周期。
11.17.4.3. 关于块持久性卷
块持久性卷(PV)是一个受原始块设备支持的 PV。这些卷没有文件系统,可以通过降低开销来为虚拟机提供性能优势。
原始块卷可以通过在 PV 和持久性卷声明(PVC)规格中指定 volumeMode: Block 来置备。
11.17.4.4. 创建本地块持久性卷
如果要使用数据卷将虚拟机镜像导入到块存储中,则必须有一个可用的本地块持久性卷。
通过填充文件并将其挂载为循环设备,在节点上创建本地块持久性卷(PV)。然后,您可以在 PV 清单中将该循环设备作为 Block(块)卷引用,并将其用作虚拟机镜像的块设备。
流程
-
以
root身份登录节点,在其上创建本地 PV。本流程以node01为例。 创建一个文件并用空字符填充,以便可将其用作块设备。以下示例创建
loop10文件,大小为 2Gb(20,100 Mb 块):$ dd if=/dev/zero of=<loop10> bs=100M count=20将
loop10文件挂载为 loop 设备。$ losetup </dev/loop10>d3 <loop10>1 2 创建引用所挂载 loop 设备的
PersistentVolume清单。kind: PersistentVolume apiVersion: v1 metadata: name: <local-block-pv10> annotations: spec: local: path: </dev/loop10>1 capacity: storage: <2Gi> volumeMode: Block2 storageClassName: local3 accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Delete nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - <node01>4 创建块 PV。
# oc create -f <local-block-pv10.yaml>1 - 1
- 上一步中创建的持久性卷的文件名。
11.17.4.5. 将虚拟机磁盘的持久性卷声明克隆到新数据卷中
您可以将现有虚拟机磁盘的持久性卷声明(PVC)克隆到新数据卷中。新的数据卷可用于新虚拟机。
当独立于虚拟机创建数据卷时,数据卷的生命周期与虚拟机是独立的。如果删除了虚拟机,数据卷及其相关 PVC 都不会被删除。
先决条件
- 确定要使用的现有虚拟机磁盘的 PVC。克隆之前,必须关闭与 PVC 关联的虚拟机。
-
安装 OpenShift CLI(
oc)。 - 至少一个可用块持久性卷(PV)大小不低于源 PVC。
流程
- 检查您要克隆的虚拟机磁盘,以识别关联 PVC 的名称和命名空间。
为数据卷创建一个 YAML 文件,用于指定新数据卷的名称、源 PVC 的名称和命名空间、
volumeMode: Block,以便使用可用块 PV,以及新数据卷的大小。例如:
apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: <cloner-datavolume>1 spec: source: pvc: namespace: "<source-namespace>"2 name: "<my-favorite-vm-disk>"3 pvc: accessModes: - ReadWriteOnce resources: requests: storage: <2Gi>4 volumeMode: Block5 通过创建数据卷开始克隆 PVC:
$ oc create -f <cloner-datavolume>.yaml注意在 PVC 就绪前,DataVolume 会阻止虚拟机启动,以便您可以在 PVC 克隆期间创建引用新数据卷的虚拟机。
11.17.4.6. CDI 支持的操作列表
此列表针对端点显示内容类型支持的 CDI 操作,以及哪些操作需要涂销空间(scratch space)。
| 内容类型 | HTTP | HTTPS | HTTP 基本身份验证 | Registry | 上传 |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) |
✓ QCOW2 |
✓ QCOW2** |
✓ QCOW2 |
✓ QCOW2* |
✓ QCOW2* |
| KubeVirt (RAW) |
✓ RAW |
✓ RAW |
✓ RAW |
✓ RAW* |
✓ RAW* |
✓ 支持的操作
□ 不支持的操作
* 需要涂销空间
** 如果需要自定义证书颁发机构,则需要涂销空间
11.18. 虚拟机网络
11.18.1. 为默认 pod 网络配置虚拟机
您可以通过将其网络接口配置为使用 masquerade 绑定模式,将虚拟机连接到默认的内部 pod 网络。
附加到默认 pod 网络的虚拟网络接口卡 (vNIC) 上的流量在实时迁移过程中中断。
11.18.1.1. 从命令行配置伪装模式
您可以使用伪装模式将虚拟机的外发流量隐藏在 pod IP 地址后。伪装模式使用网络地址转换 (NAT) 来通过 Linux 网桥将虚拟机连接至 pod 网络后端。
启用伪装模式,并通过编辑虚拟机配置文件让流量进入虚拟机。
先决条件
- 虚拟机必须配置为使用 DHCP 来获取 IPv4 地址。以下示例配置为使用 DHCP。
流程
编辑虚拟机配置文件的
interfaces规格:kind: VirtualMachine spec: domain: devices: interfaces: - name: default masquerade: {}1 ports:2 - port: 80 networks: - name: default pod: {}注意端口 49152 和 49153 保留供 libvirt 平台使用,这些端口的所有其他传入流量将被丢弃。
创建虚拟机:
$ oc create -f <vm-name>.yaml
11.18.1.2. 使用双栈(IPv4 和 IPv6)配置伪装模式
您可以使用 cloud-init 将新虚拟机配置为在默认 pod 网络上同时使用 IPv6 和 IPv4。
虚拟机实例配置中的 Network.pod.vmIPv6NetworkCIDR 字段决定虚拟机的静态 IPv6 地址和网关 IP 地址。virt-launcher Pod 使用它们将 IPv6 流量路由到虚拟机,而不在外部使用。Network.pod.vmIPv6NetworkCIDR 字段在无类别域间路由(CIDR)标记中指定一个 IPv6 地址块。默认值为 fd10:0:2::2/120。您可以根据网络要求编辑这个值。
当虚拟机运行时,虚拟机的传入和传出流量将路由到 IPv4 地址和 virt-launcher Pod 的唯一 IPv6 地址。virt-launcher pod 随后将 IPv4 流量路由到虚拟机的 DHCP 地址,并将 IPv6 流量路由到虚拟机的静态设置 IPv6 地址。
先决条件
- OpenShift Container Platform 集群必须使用为双栈配置的 OVN-Kubernetes Container Network Interface (CNI) 网络插件。
流程
在新的虚拟机配置中,包含具有
masquerade的接口,并使用 cloud-init 配置 IPv6 地址和默认网关。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: example-vm-ipv6 # ... interfaces: - name: default masquerade: {}1 ports: - port: 802 networks: - name: default pod: {} volumes: - cloudInitNoCloud: networkData: | version: 2 ethernets: eth0: dhcp4: true addresses: [ fd10:0:2::2/120 ]3 gateway6: fd10:0:2::14 在命名空间中创建虚拟机:
$ oc create -f example-vm-ipv6.yaml
验证
- 要验证 IPv6 是否已配置,启动虚拟机并查看虚拟机实例的接口状态,以确保它具有 IPv6 地址:
$ oc get vmi <vmi-name> -o jsonpath="{.status.interfaces[*].ipAddresses}"11.18.1.3. 关于巨型帧支持
使用 OVN-Kubernetes CNI 插件时,您可以在默认 pod 网络上连接的两个虚拟机 (VM) 之间发送未分片的巨型帧数据包。巨型帧有一个大于 1500 字节的最大传输单元 (MTU) 值。
虚拟机自动获得集群网络的 MTU 值,由集群管理员设置,如下所示:
-
libvirt:如果客户机操作系统具有 VirtIO 驱动程序的最新版本,该驱动程序可通过模拟设备中的 Peripheral Component Interconnect (PCI) 配置寄存器来解释传入的数据。 - DHCP :如果客户机 DHCP 客户端可以从 DHCP 服务器响应中读取 MTU 值。
对于没有 VirtIO 驱动程序的 Windows 虚拟机,您必须使用 netsh 或类似的工具手动设置 MTU。这是因为 Windows DHCP 客户端没有读取 MTU 值。
11.18.2. 创建服务以公开虚拟机
您可以使用 Service 对象在集群内或集群外部公开虚拟机。
11.18.2.1. 关于服务
一个 Kubernetes 服务 向在一组 pod 上运行的应用程序公开客户端访问。服务提供了抽象、负载均衡功能,在 NodePort 和 LoadBalancer 的情况下用于向外部公开。
服务可以在 web 控制台的 VirtualMachine details → Details 选项卡中公开,也可以在 Service 对象中指定 spec.type :
- ClusterIP
-
在内部 IP 地址上公开服务,并将 DNS 名称公开给集群中的其他应用程序。单个服务可映射到多个虚拟机。当客户端尝试连接到服务时,客户端请求会在可用后端之间平衡负载。
ClusterIP是默认服务类型。 - NodePort
-
在集群中每个所选节点的同一端口上公开该服务。
NodePort使服务可从集群外部访问。 - LoadBalancer
- 在当前云中创建外部负载均衡器(如果支持),并为该服务分配固定的外部 IP 地址。
对于内部集群,您可以通过部署 MetalLB Operator 来配置负载均衡服务。
11.18.2.1.1. 双栈支持
如果为集群启用了 IPv4 和 IPv6 双栈网络,您可以通过定义 Service 对象中的 spec.ipFamilyPolicy 和 spec.ipFamilies 字段来创建使用 IPv4、IPv6 或两者的服务。
spec.ipFamilyPolicy 字段可以设置为以下值之一:
- SingleStack
- control plane 根据配置的第一个服务集群 IP 范围为该服务分配集群 IP 地址。
- PreferDualStack
- control plane 为配置了双栈的集群中的服务分配 IPv4 和 IPv6 集群 IP 地址。
- RequireDualStack
-
对于没有启用双栈网络的集群,这个选项会失败。对于配置了双栈的集群,其行为与将值设置为
PreferDualStack时相同。control plane 从 IPv4 和 IPv6 地址范围分配集群 IP 地址。
您可以通过将 spec.ipFamilies 字段设置为以下数组值之一来定义用于单堆栈的 IP 系列,或者定义双栈 IP 系列的顺序:
-
[IPv4] -
[IPv6] -
[IPv4, IPv6] -
[IPv6, IPv4]
11.18.2.2. 将虚拟机作为服务公开
创建 ClusterIP、NodePort 或 LoadBalancer 服务,以便从集群内部或外部连接到正在运行的虚拟机 (VM)。
流程
编辑
VirtualMachine清单,为创建服务添加标签:apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: vm-ephemeral namespace: example-namespace spec: running: false template: metadata: labels: special: key1 # ...- 1
- 在
spec.template.metadata.labels部分添加标签special: key。
注意虚拟机上的标签会传递到 pod。
special: key标签必须与Service清单的spec.selector属性中的标签匹配。-
保存
VirtualMachine清单文件以应用更改。 创建
Service清单以公开虚拟机:apiVersion: v1 kind: Service metadata: name: vmservice1 namespace: example-namespace2 spec: externalTrafficPolicy: Cluster3 ports: - nodePort: 300004 port: 27017 protocol: TCP targetPort: 225 selector: special: key6 type: NodePort7 - 1
Service对象的名称。- 2
Service对象所在的命名空间。这必须与VirtualMachine清单的metadata.namespace字段匹配。- 3
- 可选:指定节点如何分发在外部 IP 地址上接收的服务流量。这只适用于
NodePort和LoadBalancer服务类型。默认值为Cluster,它将流量平均路由到所有集群端点。 - 4
- 可选:设置后,
nodePort值必须在所有服务间是唯一的。如果没有指定,则会动态分配以上30000范围中的值。 - 5
- 可选:由服务公开的虚拟机端口。如果虚拟机清单中定义了端口列表,则必须引用打开端口。如果没有指定
targetPort,它将采用与port相同的值。 - 6
- 对您在
VirtualMachine清单的spec.template.metadata.labels小节中添加的标签的引用。 - 7
- 服务的类型。可能的值有
ClusterIP、NodePort和LoadBalancer。
-
保存
Service清单文件。 运行以下命令来创建服务:
$ oc create -f <service_name>.yaml- 启动虚拟机。如果虚拟机已在运行,重启它。
验证
查询
Service对象以验证它是否可用:$ oc get service -n example-namespaceClusterIP服务的输出示例NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE vmservice ClusterIP 172.30.3.149 <none> 27017/TCP 2mNodePort服务的输出示例NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE vmservice NodePort 172.30.232.73 <none> 27017:30000/TCP 5mLoadBalancer服务的输出示例NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE vmservice LoadBalancer 172.30.27.5 172.29.10.235,172.29.10.235 27017:31829/TCP 5s选择连接到虚拟机的适当方法:
对于
ClusterIP服务,使用服务 IP 地址和服务端口从集群内部连接到虚拟机。例如:$ ssh fedora@172.30.3.149 -p 27017对于
NodePort服务,通过指定节点 IP 地址和集群网络之外的节点端口来连接到虚拟机。例如:$ ssh fedora@$NODE_IP -p 30000-
对于
LoadBalancer服务,使用vinagre客户端使用公共 IP 地址和端口连接到虚拟机。外部端口是动态分配的。
11.18.3. 将虚拟机连接到 Linux 网桥网络
默认情况下,OpenShift Virtualization 安装了一个内部 pod 网络。
您必须创建一个 Linux 网桥网络附加定义(NAD)以连接到额外网络。
将虚拟机附加到额外网络:
- 创建 Linux 网桥节点网络配置策略。
- 创建 Linux 网桥网络附加定义。
- 配置虚拟机,使虚拟机能够识别网络附加定义。
有关调度、接口类型和其他节点网络活动的更多信息,请参阅节点网络部分。
11.18.3.1. 通过网络附加定义连接到网络
11.18.3.1.1. 创建 Linux 网桥节点网络配置策略
使用 NodeNetworkConfigurationPolicy 清单 YAML 文件来创建 Linux 网桥。
先决条件
- 已安装 Kubernetes NMState Operator。
流程
创建
NodeNetworkConfigurationPolicy清单。本例包含示例值,您必须替换为您自己的信息。apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: name: br1-eth1-policy1 spec: desiredState: interfaces: - name: br12 description: Linux bridge with eth1 as a port3 type: linux-bridge4 state: up5 ipv4: enabled: false6 bridge: options: stp: enabled: false7 port: - name: eth18
11.18.3.2. 创建 Linux 网桥网络附加定义
不支持在虚拟机的网络附加定义中配置 IP 地址管理(IPAM)。
11.18.3.2.1. 在 web 控制台中创建 Linux 网桥网络附加定义
您可以创建网络附加定义,为 pod 和虚拟机提供第 2 层网络。
Linux 网桥网络附加定义是将虚拟机连接至 VLAN 的最有效方法。
流程
- 在 Web 控制台中,点 Networking → NetworkAttachmentDefinitions。
点 Create Network Attachment Definition。
注意网络附加定义必须与 pod 或虚拟机位于同一个命名空间中。
- 输入唯一 Name 和可选 Description。
- 从 Network Type 列表中选择 CNV Linux 网桥。
- 在 Bridge Name 字段输入网桥名称。
- 可选:如果资源配置了 VLAN ID,请在 VLAN Tag Number 字段中输入 ID 号。
- 可选: 选择 MAC Spoof Check 来启用 MAC spoof 过滤。此功能只允许单个 MAC 地址退出 pod,从而可以防止使用 MAC 欺骗进行的安全攻击。
- 点 Create。
11.18.3.2.2. 在 CLI 中创建 Linux 网桥网络附加定义
作为网络管理员,您可以配置 cnv-bridge 类型的网络附加定义,为 Pod 和虚拟机提供第 2 层网络。
先决条件
-
节点必须支持 nftables,必须部署
nft二进制文件才能启用 MAC 欺骗检查。
流程
- 在与虚拟机相同的命名空间中创建网络附加定义。
在网络附加定义中添加虚拟机,如下例所示:
apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: <bridge-network>1 annotations: k8s.v1.cni.cncf.io/resourceName: bridge.network.kubevirt.io/<bridge-interface>2 spec: config: '{ "cniVersion": "0.3.1", "name": "<bridge-network>",3 "type": "cnv-bridge",4 "bridge": "<bridge-interface>",5 "macspoofchk": true,6 "vlan": 100,7 "preserveDefaultVlan": false8 }'- 1
NetworkAttachmentDefinition对象的名称。- 2
- 可选:为节点选择注解键值对,其中
bridge-interface必须与某些节点上配置的桥接名称匹配。如果在网络附加定义中添加此注解,您的虚拟机实例将仅在连接bridge-interface网桥的节点中运行。 - 3
- 配置的名称。建议您将配置名称与网络附加定义的
name值匹配。 - 4
- 为这个网络附加定义的 Container Network Interface(CNI)插件的实际名称。不要更改此字段,除非要使用不同的 CNI。
- 5
- 节点上配置的 Linux 网桥名称。
- 6
- 可选:启用 MAC 欺骗检查。当设置为
true时,您无法更改 pod 或客户机接口的 MAC 地址。此属性仅允许单个 MAC 地址退出容器集,从而防止 MAC 欺骗攻击。 - 7
- 可选: VLAN 标签。节点网络配置策略不需要额外的 VLAN 配置。
- 8
- 可选:指示虚拟机是否通过默认 VLAN 连接到网桥。默认值为
true。
注意Linux 网桥网络附加定义是将虚拟机连接至 VLAN 的最有效方法。
创建网络附加定义:
$ oc create -f <network-attachment-definition.yaml>1 - 1
- 其中
<network-attachment-definition.yaml>是网络附加定义清单的文件名。
验证
运行以下命令验证网络附加定义是否已创建:
$ oc get network-attachment-definition <bridge-network>
11.18.3.3. 为 Linux 网桥网络配置虚拟机
11.18.3.3.1. 在 web 控制台中为虚拟机创建 NIC
从 web 控制台创建并附加额外 NIC。
先决条件
- 网络附加定义必须可用。
流程
- 在 OpenShift Container Platform 控制台的正确项目中,从侧边菜单中点 Virtualization → VirtualMachines。
- 选择虚拟机以打开 VirtualMachine 详情页面。
- 点 Configuration → Network Interface 查看已附加到虚拟机的 NIC。
- 点 Add Network Interface 在列表中创建新插槽。
- 从 Network 列表中选择额外网络的网络附加定义。
- 填写新 NIC 的 Name、Model、Type 和 MAC Address。
- 点 Save 保存并附加 NIC 到虚拟机。
11.18.3.3.2. 网络字段
| 名称 | 描述 |
|---|---|
| Name | 网络接口控制器的名称。 |
| model | 指明网络接口控制器的型号。支持的值有 e1000e 和 virtio。 |
| 网络 | 可用网络附加定义的列表。 |
| 类型 | 可用绑定方法列表。选择适合网络接口的绑定方法:
|
| MAC 地址 | 网络接口控制器的 MAC 地址。如果没有指定 MAC 地址,则会自动分配一个。 |
11.18.3.3.3. 在 CLI 中将虚拟机附加到额外网络
通过添加桥接接口并在虚拟机配置中指定网络附加定义,将虚拟机附加到额外网络。
此流程使用 YAML 文件来演示编辑配置,并将更新的文件应用到集群。您还可以使用 oc edit <object> <name> 命令编辑现有虚拟机。
先决条件
- 在编辑配置前关闭虚拟机。如果编辑正在运行的虚拟机,您必须重启虚拟机才能使更改生效。
流程
- 创建或编辑您要连接到桥接网络的虚拟机的配置。
将网桥接口添加到
spec.template.spec.domain.devices.interfaces列表中,把网络附加定义添加到spec.template.spec.networks列表中。这个示例添加了名为bridge-net的桥接接口,它连接到a-bridge-network网络附加定义:apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: <example-vm> spec: template: spec: domain: devices: interfaces: - masquerade: {} name: <default> - bridge: {} name: <bridge-net>1 # ... networks: - name: <default> pod: {} - name: <bridge-net>2 multus: networkName: <network-namespace>/<a-bridge-network>3 # ...应用配置:
$ oc apply -f <example-vm.yaml>- 可选:如果编辑了正在运行的虚拟机,您必须重启它才能使更改生效。
11.18.3.4. 后续步骤
11.18.4. 将虚拟机连接到 SR-IOV 网络
您可以通过执行以下步骤将虚拟机 (VM) 连接到单根 I/O 虚拟化 (SR-IOV) 网络:
- 配置 SR-IOV 网络设备。
- 配置 SR-IOV 网络。
- 将虚拟机连接到 SR-IOV 网络。
11.18.4.1. 先决条件
11.18.4.2. 配置 SR-IOV 网络设备
SR-IOV Network Operator 把 SriovNetworkNodePolicy.sriovnetwork.openshift.io CRD 添加到 OpenShift Container Platform。您可以通过创建一个 SriovNetworkNodePolicy 自定义资源 (CR) 来配置 SR-IOV 网络设备。
在应用由 SriovNetworkNodePolicy 对象中指定的配置时,SR-IOV Operator 可能会排空节点,并在某些情况下会重启节点。
它可能需要几分钟时间来应用配置更改。
先决条件
-
已安装 OpenShift CLI(
oc)。 -
您可以使用具有
cluster-admin角色的用户访问集群。 - 已安装 SR-IOV Network Operator。
- 集群中有足够的可用节点,用于处理从排空节点中驱除的工作负载。
- 您还没有为 SR-IOV 网络设备配置选择任何 control plane 节点。
流程
创建一个
SriovNetworkNodePolicy对象,然后在<name>-sriov-node-network.yaml文件中保存 YAML。使用配置的实际名称替换<name>。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: <name>1 namespace: openshift-sriov-network-operator2 spec: resourceName: <sriov_resource_name>3 nodeSelector: feature.node.kubernetes.io/network-sriov.capable: "true"4 priority: <priority>5 mtu: <mtu>6 numVfs: <num>7 nicSelector:8 vendor: "<vendor_code>"9 deviceID: "<device_id>"10 pfNames: ["<pf_name>", ...]11 rootDevices: ["<pci_bus_id>", "..."]12 deviceType: vfio-pci13 isRdma: false14 - 1
- 为 CR 对象指定一个名称。
- 2
- 指定 SR-IOV Operator 安装到的命名空间。
- 3
- 指定 SR-IOV 设备插件的资源名称。您可以为一个资源名称创建多个
SriovNetworkNodePolicy对象。 - 4
- 指定节点选择器来选择要配置哪些节点。只有所选节点上的 SR-IOV 网络设备才会被配置。SR-IOV Container Network Interface(CNI)插件和设备插件仅在所选节点上部署。
- 5
- 可选:指定一个
0到99之间的整数。较小的数值具有较高的优先权,优先级10高于优先级99。默认值为99。 - 6
- 可选:为虚拟功能(VF)的最大传输单位 (MTU) 指定一个值。最大 MTU 值可能因不同的 NIC 型号而有所不同。
- 7
- 为 SR-IOV 物理网络设备指定要创建的虚拟功能 (VF) 的数量。对于 Intel 网络接口控制器(NIC),VF 的数量不能超过该设备支持的 VF 总数。对于 Mellanox NIC,VF 的数量不能超过
127。 - 8
nicSelector映射为 Operator 选择要配置的以太网设备。您不需要为所有参数指定值。注意建议您以足够的准确度来识别以太网适配器,以便尽量减小意外选择其他以太网设备的可能性。如果指定了
rootDevices,则必须同时为vendor、deviceID或pfNames指定一个值。如果同时指定了
pfNames和rootDevices,请确保它们指向同一个设备。- 9
- 可选:指定 SR-IOV 网络设备的厂商十六进制代码。允许的值只能是
8086或15b3。 - 10
- 可选:指定 SR-IOV 网络设备的设备十六进制代码。允许的值只能是
158b、1015、1017。 - 11
- 可选:参数接受包括以太网设备的一个或多个物理功能 (PF) 的数组。
- 12
- 参数接受一个包括一个或多个 PCI 总线地址,用于以太网设备的物理功能的数组。使用以下格式提供地址:
0000:02:00.1。 - 13
- OpenShift Virtualization 中的虚拟功能需要
vfio-pci驱动程序类型。 - 14
- 可选:指定是否启用远程直接访问(RDMA)模式。对于 Mellanox 卡,请将
isRdma设置为false。默认值为false。注意如果将
RDMA标记设定为true,您可以继续使用启用了 RDMA 的 VF 作为普通网络设备。设备可在其中的一个模式中使用。
-
可选:将 SR-IOV 功能的集群节点标记为
SriovNetworkNodePolicy.Spec.NodeSelector(如果它们还没有标记)。有关标记节点的更多信息,请参阅"了解如何更新节点上的标签"。 创建
SriovNetworkNodePolicy对象:$ oc create -f <name>-sriov-node-network.yaml其中
<name>指定这个配置的名称。在应用配置更新后,
sriov-network-operator命名空间中的所有 Pod 都会变为Running状态。要验证是否已配置了 SR-IOV 网络设备,请输入以下命令。将
<node_name>替换为带有您刚才配置的 SR-IOV 网络设备的节点名称。$ oc get sriovnetworknodestates -n openshift-sriov-network-operator <node_name> -o jsonpath='{.status.syncStatus}'
11.18.4.3. 配置 SR-IOV 额外网络
您可以通过创建一个 SriovNetwork 对象来配置使用 SR-IOV 硬件的额外网络。
创建 SriovNetwork 对象时,SR-IOV Network Operator 会自动创建一个 NetworkAttachmentDefinition 对象。
如果一个 SriovNetwork 对象已被附加到状态为 running 的 Pod 或虚拟机上,则不能修改或删除它。
先决条件
-
安装 OpenShift CLI(
oc)。 -
以具有
cluster-admin特权的用户身份登录。
流程
-
创建以下
SriovNetwork对象,然后在<name>-sriov-network.yaml文件中保存 YAML。用这个额外网络的名称替换<name>。
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetwork
metadata:
name: <name>
namespace: openshift-sriov-network-operator
spec:
resourceName: <sriov_resource_name>
networkNamespace: <target_namespace>
vlan: <vlan>
spoofChk: "<spoof_check>"
linkState: <link_state>
maxTxRate: <max_tx_rate>
minTxRate: <min_rx_rate>
vlanQoS: <vlan_qos>
trust: "<trust_vf>"
capabilities: <capabilities> - 1
- 将
<name>替换为对象的名称。SR-IOV Network Operator 创建一个名称相同的NetworkAttachmentDefinition对象。 - 2
- 指定 SR-IOV Network Operator 安装到的命名空间。
- 3
- 将
<sriov_resource_name>替换为来自为这个额外网络定义 SR-IOV 硬件的SriovNetworkNodePolicy对象的.spec.resourceName参数的值。 - 4
- 将
<target_namespace>替换为 SriovNetwork 的目标命名空间。只有目标命名空间中的 pod 或虚拟机可以附加到 SriovNetwork。 - 5
- 可选:使用额外网络的虚拟 LAN (VLAN) ID 替换
<vlan>。它需要是一个从0到4095范围内的一个整数值。默认值为0。 - 6
- 可选:将
<spoof_check>替换为 VF 的 spoof 检查模式。允许的值是字符串"on"和"off"。重要指定的值必须由引号包括,否则 SR-IOV Network Operator 将拒绝 CR。
- 7
- 可选:将
<link_state>替换为 Virtual Function (VF) 的链接状态。允许的值是enable、disable和auto。 - 8
- 可选:将
<max_tx_rate>替换为 VF 的最大传输率(以 Mbps 为单位)。 - 9
- 可选:将
<min_tx_rate>替换为 VF 的最小传输率(以 Mbps 为单位)。这个值应该总是小于或等于最大传输率。注意Intel NIC 不支持
minTxRate参数。如需更多信息,请参阅 BZ#1772847。 - 10
- 可选:将
<vlan_qos>替换为 VF 的 IEEE 802.1p 优先级级别。默认值为0。 - 11
- 可选:将
<trust_vf>替换为 VF 的信任模式。允许的值是字符串"on"和"off"。重要指定的值必须由引号包括,否则 SR-IOV Network Operator 将拒绝 CR。
- 12
- 可选:将
<capabilities>替换为为这个网络配置的功能。
运行以下命令来创建对象。用这个额外网络的名称替换
<name>。$ oc create -f <name>-sriov-network.yaml可选: 要确认与您在上一步中创建的
SriovNetwork对象关联的NetworkAttachmentDefinition对象是否存在,请输入以下命令。将<namespace>替换为您在SriovNetwork对象中指定的命名空间。$ oc get net-attach-def -n <namespace>
11.18.4.4. 将虚拟机连接到 SR-IOV 网络
您可以通过在虚拟机配置中包含网络详情将虚拟机 (VM) 连接到 SR-IOV 网络。
流程
在虚拟机配置的
spec.domain.devices.interfaces和spec.networks中包含 SR-IOV 网络详情:kind: VirtualMachine # ... spec: domain: devices: interfaces: - name: <default>1 masquerade: {}2 - name: <nic1>3 sriov: {} networks: - name: <default>4 pod: {} - name: <nic1>5 multus: networkName: <sriov-network>6 # ...应用虚拟机配置:
$ oc apply -f <vm-sriov.yaml>1 - 1
- 虚拟机 YAML 文件的名称。
11.18.4.5. 为 DPDK 工作负载配置集群
您可以使用以下步骤配置 OpenShift Container Platform 集群来运行 Data Plane Development Kit (DPDK) 工作负载。
为 DPDK 工作负载配置集群只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
先决条件
-
您可以使用具有
cluster-admin权限的用户访问集群。 -
已安装 OpenShift CLI(
oc)。 - 已安装 SR-IOV Network Operator。
- 已安装 Node Tuning Operator。
流程
- 映射计算节点拓扑,以确定为 DPDK 应用程序隔离哪些非统一内存访问 (NUMA) CPU,以及为操作系统 (OS) 保留哪些非一致性内存访问 (NUMA) CPU。
使用自定义角色标记计算节点的子集,例如
worker-dpdk:$ oc label node <node_name> node-role.kubernetes.io/worker-dpdk=""创建一个新的
MachineConfigPool清单,其中包含spec.machineConfigSelector对象中的worker-dpdk标签:MachineConfigPool清单示例apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: worker-dpdk labels: machineconfiguration.openshift.io/role: worker-dpdk spec: machineConfigSelector: matchExpressions: - key: machineconfiguration.openshift.io/role operator: In values: - worker - worker-dpdk nodeSelector: matchLabels: node-role.kubernetes.io/worker-dpdk: ""创建一个
PerformanceProfile清单,它应用到标记的节点以及您在上一步中创建的机器配置池。性能配置集指定为 DPDK 应用程序隔离的 CPU,以及用于保留保留而保留的 CPU。PerformanceProfile清单示例apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: profile-1 spec: cpu: isolated: 4-39,44-79 reserved: 0-3,40-43 hugepages: defaultHugepagesSize: 1G pages: - count: 32 node: 0 size: 1G net: userLevelNetworking: true nodeSelector: node-role.kubernetes.io/worker-dpdk: "" numa: topologyPolicy: single-numa-node注意应用
MachineConfigPool和PerformanceProfile清单后,计算节点会自动重启。从
PerformanceProfile对象的status.runtimeClass字段检索生成的RuntimeClass资源的名称:$ oc get performanceprofiles.performance.openshift.io profile-1 -o=jsonpath='{.status.runtimeClass}{"\n"}'通过在
HyperConverged自定义资源 (CR)中添加以下注解,将之前获取的RuntimeClass名称设置为virt-launcherpod 的默认容器运行时类:$ oc annotate --overwrite -n openshift-cnv hco kubevirt-hyperconverged \ kubevirt.kubevirt.io/jsonpatch='[{"op": "add", "path": "/spec/configuration/defaultRuntimeClass", "value": <runtimeclass_name>}]'注意将注解添加到
HyperConvergedCR 会更改一个全局设置,该设置会影响应用注解后创建的所有虚拟机。设置此注解会破坏 OpenShift Virtualization 实例的支持,且必须仅在测试集群中使用。为获得最佳性能,适用于支持例外。创建一个
SriovNetworkNodePolicy对象,并将spec.deviceType字段设置为vfio-pci:SriovNetworkNodePolicy清单示例apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: policy-1 namespace: openshift-sriov-network-operator spec: resourceName: intel_nics_dpdk deviceType: vfio-pci mtu: 9000 numVfs: 4 priority: 99 nicSelector: vendor: "8086" deviceID: "1572" pfNames: - eno3 rootDevices: - "0000:19:00.2" nodeSelector: feature.node.kubernetes.io/network-sriov.capable: "true"
11.18.4.6. 为 DPDK 工作负载配置项目
您可以将项目配置为在 SR-IOV 硬件中运行 DPDK 工作负载。
先决条件
- 集群被配置为运行 DPDK 工作负载。
流程
为您的 DPDK 应用程序创建一个命名空间:
$ oc create ns dpdk-checkup-ns创建一个
SriovNetwork对象来引用SriovNetworkNodePolicy对象。创建SriovNetwork对象时,SR-IOV Network Operator 会自动创建一个NetworkAttachmentDefinition对象。SriovNetwork清单示例apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: dpdk-sriovnetwork namespace: openshift-sriov-network-operator spec: ipam: | { "type": "host-local", "subnet": "10.56.217.0/24", "rangeStart": "10.56.217.171", "rangeEnd": "10.56.217.181", "routes": [{ "dst": "0.0.0.0/0" }], "gateway": "10.56.217.1" } networkNamespace: dpdk-checkup-ns1 resourceName: intel_nics_dpdk2 spoofChk: "off" trust: "on" vlan: 1019- 可选:运行虚拟机延迟检查以验证网络是否已正确配置。
- 可选:运行 DPDK 检查,以验证命名空间是否已准备好 DPDK 工作负载。
11.18.4.7. 为 DPDK 工作负载配置虚拟机
您可以在虚拟机 (VM) 上运行 Data Packet Development Kit (DPDK) 工作负载,以实现较低延迟和更高的吞吐量,以便在用户空间中更快地处理数据包。DPDK 使用 SR-IOV 网络进行基于硬件的 I/O 共享。
先决条件
- 集群被配置为运行 DPDK 工作负载。
- 您已创建并配置了运行虚拟机的项目。
流程
编辑
VirtualMachine清单,使其包含 SR-IOV 网络接口、CPU 拓扑、CRI-O 注解和巨页的信息:VirtualMachine清单示例apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: rhel-dpdk-vm spec: running: true template: metadata: annotations: cpu-load-balancing.crio.io: disable1 cpu-quota.crio.io: disable2 irq-load-balancing.crio.io: disable3 spec: domain: cpu: sockets: 14 cores: 55 threads: 2 dedicatedCpuPlacement: true isolateEmulatorThread: true interfaces: - masquerade: {} name: default - model: virtio name: nic-east pciAddress: '0000:07:00.0' sriov: {} networkInterfaceMultiqueue: true rng: {} memory: hugepages: pageSize: 1Gi6 guest: 8Gi networks: - name: default pod: {} - multus: networkName: dpdk-net7 name: nic-east # ...- 1
- 此注解指定为容器使用的 CPU 禁用负载均衡。
- 2
- 此注解指定容器使用的 CPU 配额被禁用。
- 3
- 此注解指定,容器使用的 CPU 禁用中断请求 (IRQ) 负载均衡。
- 4
- 虚拟机中的插槽数。此字段必须设置为
1,才能从相同的 Non-Uniform Memory Access (NUMA) 节点调度 CPU。 - 5
- 虚拟机中的内核数。这必须大于或等于
1。在本例中,虚拟机被调度有 5 个超线程或 10 个 CPU。 - 6
- 巨页的大小。x86-64 构架的可能值为 1Gi 和 2Mi。在这个示例中,请求大小为 1Gi 的 8 个巨页。
- 7
- SR-IOV
NetworkAttachmentDefinition对象的名称。
- 保存并退出编辑器。
应用
VirtualMachine清单:$ oc apply -f <file_name>.yaml配置客户机操作系统。以下示例显示了 RHEL 8 OS 的配置步骤:
使用 GRUB 引导装载程序命令行界面配置巨页。在以下示例中,指定了 8 个 1G 巨页。
$ grubby --update-kernel=ALL --args="default_hugepagesz=1GB hugepagesz=1G hugepages=8"要使用 TuneD 应用程序中的
cpu-partitioning配置集来实现低延迟性能优化,请运行以下命令:$ dnf install -y tuned-profiles-cpu-partitioning$ echo isolated_cores=2-9 > /etc/tuned/cpu-partitioning-variables.conf前两个 CPU (0 和 1) 被设置,用于保存任务,其余则隔离 DPDK 应用程序。
$ tuned-adm profile cpu-partitioning使用
driverctl设备驱动程序控制工具覆盖 SR-IOV NIC 驱动程序:$ dnf install -y driverctl$ driverctl set-override 0000:07:00.0 vfio-pci
- 重启虚拟机以应用更改。
11.18.4.8. 后续步骤
11.18.5. 将虚拟机连接到服务网格
OpenShift Virtualization 现在与 OpenShift Service Mesh 集成。您可以使用 IPv4 监控、视觉化和控制在默认 pod 网络上运行虚拟机工作负载的 pod 之间的流量。
11.18.5.1. 先决条件
- 您必须已安装了 Service Mesh Operator 并部署了服务网格 control plane。
- 您必须已将创建虚拟机的命名空间添加到 服务网格 member roll 中。
-
您必须将
masquerade绑定方法用于默认 pod 网络。
11.18.5.2. 为服务网格配置虚拟机
要将虚拟机 (VM) 工作负载添加到服务网格中,请在虚拟机配置文件中启用自动 sidecar 注入,方法是将 sidecar.istio.io/inject 注解设置为 true。然后,将虚拟机公开为服务,以便在网格中查看应用程序。
先决条件
- 为了避免端口冲突,请不要使用 Istio sidecar 代理使用的端口。它们包括 15000、15001、15006、15008、15020、15021 和 15090。
流程
编辑虚拟机配置文件以添加
sidecar.istio.io/inject: "true"注解。配置文件示例
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: labels: kubevirt.io/vm: vm-istio name: vm-istio spec: runStrategy: Always template: metadata: labels: kubevirt.io/vm: vm-istio app: vm-istio1 annotations: sidecar.istio.io/inject: "true"2 spec: domain: devices: interfaces: - name: default masquerade: {}3 disks: - disk: bus: virtio name: containerdisk - disk: bus: virtio name: cloudinitdisk resources: requests: memory: 1024M networks: - name: default pod: {} terminationGracePeriodSeconds: 180 volumes: - containerDisk: image: registry:5000/kubevirt/fedora-cloud-container-disk-demo:devel name: containerdisk应用 VM 配置:
$ oc apply -f <vm_name>.yaml1 - 1
- 虚拟机 YAML 文件的名称。
创建一个
Service对象,将虚拟机公开给服务网格。apiVersion: v1 kind: Service metadata: name: vm-istio spec: selector: app: vm-istio1 ports: - port: 8080 name: http protocol: TCP- 1
- 服务选择器,决定服务的目标 pod 集合。此属性对应于虚拟机配置文件中的
spec.metadata.labels字段。在上例中,名为vm-istio的Service对象在任何带有标签app=vm-istio的 pod 上都以 TCP 端口 8080 为目标。
创建服务:
$ oc create -f <service_name>.yaml1 - 1
- 服务 YAML 文件的名称。
11.18.6. 为虚拟机配置 IP 地址
您可以为虚拟机配置静态和动态 IP 地址。
11.18.6.1. 使用 cloud-init 为新虚拟机配置 IP 地址
在创建虚拟机时,您可以使用 cloud-init 配置二级 NIC 的 IP 地址。IP 地址可以动态部署,也可以静态置备。
如果虚拟机连接到 pod 网络,pod 网络接口是默认路由,除非您更新它。
先决条件
- 虚拟机连接到第二个网络。
- 在二级网络上有一个 DHCP 服务器,用于为虚拟机配置动态 IP。
流程
编辑虚拟机配置的
spec.template.spec.volumes.cloudInitNoCloud.networkData小节:要配置动态 IP 地址,请指定接口名称并启用 DHCP:
kind: VirtualMachine spec: # ... template: # ... spec: volumes: - cloudInitNoCloud: networkData: | version: 2 ethernets: eth1:1 dhcp4: true- 1
- 指定接口名称。
要配置静态 IP,请指定接口名称和 IP 地址:
kind: VirtualMachine spec: # ... template: # ... spec: volumes: - cloudInitNoCloud: networkData: | version: 2 ethernets: eth1:1 addresses: - 10.10.10.14/242
11.18.7. 在虚拟机上查看 NIC 的 IP 地址
您可以使用 Web 控制台或 oc 客户端查看网络接口控制器 (NIC) 的 IP 地址。QEMU 客户机代理显示有关虚拟机辅助网络的附加信息。
11.18.7.1. 先决条件
- 在虚拟机上安装 QEMU 客户机代理。
11.18.7.2. 在 CLI 中查看虚拟机接口的 IP 地址
oc describe vmi <vmi_name> 命令中包含网络接口配置。
您还可通过在虚拟机上运行 ip addr 或通过运行 oc get vmi <vmi_name> -o yaml 来查看 IP 地址信息。
流程
使用
oc describe命令来显示虚拟机接口配置:$ oc describe vmi <vmi_name>输出示例
# ... Interfaces: Interface Name: eth0 Ip Address: 10.244.0.37/24 Ip Addresses: 10.244.0.37/24 fe80::858:aff:fef4:25/64 Mac: 0a:58:0a:f4:00:25 Name: default Interface Name: v2 Ip Address: 1.1.1.7/24 Ip Addresses: 1.1.1.7/24 fe80::f4d9:70ff:fe13:9089/64 Mac: f6:d9:70:13:90:89 Interface Name: v1 Ip Address: 1.1.1.1/24 Ip Addresses: 1.1.1.1/24 1.1.1.2/24 1.1.1.4/24 2001:de7:0:f101::1/64 2001:db8:0:f101::1/64 fe80::1420:84ff:fe10:17aa/64 Mac: 16:20:84:10:17:aa
11.18.7.3. 在 web 控制台中查看虚拟机接口的 IP 地址
IP 信息显示在虚拟机的 VirtualMachine Details 页面中。
流程
- 在 OpenShift Container Platform 控制台中,从侧边菜单中点 Virtualization → VirtualMachines。
- 选择虚拟机名称以打开 VirtualMachine 详情页。
每个附加 NIC 的信息会显示在 Details 标签页中的 IP Address 下。
11.18.8. 使用集群域名访问二级网络上的虚拟机
您可以使用集群的完全限定域名 (FQDN) 从集群外部访问附加到二级网络接口的虚拟机 (VM)。
使用集群 FQDN 访问虚拟机只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
11.18.8.1. 为二级网络配置 DNS 服务器
当您在 HyperConverged 自定义资源 (CR)中启用 KubeSecondaryDNS 功能门时,Cluster Network Addons Operator (CNAO) 部署域名服务器 (DNS) 服务器和监控组件。
先决条件
-
已安装 OpenShift CLI(
oc)。 -
您可以使用
cluster-admin权限访问 OpenShift Container Platform 集群。
流程
使用 MetalLB 或其他负载均衡器创建
LoadBalancer服务,以在集群外公开 DNS 服务器。该服务侦听端口 53,目标端口 5353。例如:$ oc expose -n openshift-cnv deployment/secondary-dns --name=dns-lb --type=LoadBalancer --port=53 --target-port=5353 --protocol='UDP'通过查询
Service对象来检索服务的公共 IP 地址:$ oc get service -n openshift-cnv输出示例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE dns-lb LoadBalancer 172.30.27.5 10.46.41.94 53:31829/TCP 5s通过编辑
HyperConvergedCR 部署 DNS 服务器和监控组件:apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: featureGates: deployKubeSecondaryDNS: true1 kubeSecondaryDNSNameServerIP: "10.46.41.94"2 # ...使用以下命令,检索 OpenShift Container Platform 集群的 FQDN:
$ oc get dnses.config.openshift.io cluster -o json | jq .spec.baseDomain输出示例
openshift.example.com使用以下方法之一指向 DNS 服务器:
将
kubeSecondaryDNSNameServerIP值添加到本地机器的resolv.conf文件中。注意编辑
resolv.conf文件会覆盖任何现有的 DNS 设置。将
kubeSecondaryDNSNameServerIP值和集群 FQDN 添加到企业 DNS 服务器记录中。例如:vm.<FQDN>. IN NS ns.vm.<FQDN>.ns.vm.<FQDN>. IN A 10.46.41.94
11.18.8.2. 使用集群 FQDN 连接到二级网络上的虚拟机
您可以使用集群的完全限定域名 (FQDN) 从集群外部访问附加到二级网络接口的虚拟机 (VM)。
先决条件
- QEMU 客户机代理必须在虚拟机上运行。
- 要使用 DNS 客户端(您要使用 DNS 客户端)要连接的虚拟机的 IP 地址必须是公共的。
- 您已为二级网络配置 DNS 服务器。
- 您已获取集群的完全限定域名 (FQDN)。
流程
使用以下命令检索虚拟机配置:
$ oc get vm -n <namespace> <vm_name> -o yaml输出示例
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: labels: kubevirt.io/vm: example-vm name: example-vm namespace: example-namespace spec: running: true template: metadata: labels: kubevirt.io/vm: example-vm spec: domain: devices: # ... interfaces: - bridge: {} name: example-nic # ... networks: - multus: networkName: bridge-conf name: example-nic1 # ...- 1
- 指定二级网络接口的名称。
使用
ssh命令连接到虚拟机:$ ssh <user_name>@<interface_name>.<vm_name>.<namespace>.vm.<FQDN>1 - 1
- 指定用户名、接口名称、虚拟机名称、虚拟机名称、虚拟机名称和 FQDN。
Example
$ ssh you@example-nic.example-vm.example-namespace.vm.openshift.example.com
11.18.9. 为虚拟机使用 MAC 地址池
KubeMacPool 组件为命名空间中的虚拟机 NIC 提供 MAC 地址池服务。
11.18.9.1. 关于 KubeMacPool
KubeMacPool 为每个命名空间提供一个 MAC 地址池,并从池中为虚拟机 NIC 分配 MAC 地址。这样可确保为 NIC 分配一 个唯一的 MAC 地址,该地址与另一个虚拟机的 MAC 地址不会有冲突。
从该虚拟机创建的虚拟机实例会在重启后保留分配的 MAC 地址。
KubeMacPool 不处理独立于虚拟机创建的虚拟机实例。
安装 OpenShift Virtualization 时, KubeMacPool 会被默认启用。您可以通过将 mutatevirtualmachines.kubemacpool.io=ignore 标签添加到命名空间来在命名空间中禁用一个 MAC 地址池。通过删除标签为命名空间重新启用 KubeMacPool。
11.18.9.2. 在 CLI 中为命名空间禁用 MAC 地址池
通过将 mutatevirtualmachines.kubemacpool.io=ignore 标签添加到命名空间来禁用命名空间中虚拟机的 MAC 地址池。
流程
将
mutatevirtualmachines.kubemacpool.io=ignore标签添加到命名空间。以下示例为<namespace1>和<namespace2>这两个命名空间禁用 KubeMacPool:$ oc label namespace <namespace1> <namespace2> mutatevirtualmachines.kubemacpool.io=ignore
11.18.9.3. 在 CLI 中为命名空间重新启用 MAC 地址池
如果您为命名空间禁用 KubeMacPool 并希望重新启用它,请从命名空间中删除 mutatevirtualmachines.kubemacpool.io=ignore 标签。
早期版本的 OpenShift Virtualization 使用标签 mutatevirtualmachines.kubemacpool.io=allocate 为命名空间启用 KubeMacPool。这仍然被支持,但是冗余的,因为 KubeMacPool 现在被默认启用。
流程
从命名空间中删除 KubeMacPool 标签。以下示例为
<namespace1>和<namespace2>这两个命名空间重新启用 KubeMacPool:$ oc label namespace <namespace1> <namespace2> mutatevirtualmachines.kubemacpool.io-
11.19. 虚拟机磁盘
11.19.1. 为虚拟机配置本地存储
您可以使用 hostpath 置备程序(HPP)为虚拟机配置本地存储。
安装 OpenShift Virtualization Operator 时,会自动安装 Hostpath Provisioner(HPP)Operator。HPP 是一个本地存储置备程序,用于由 Hostpath Provisioner Operator 创建的 OpenShift Virtualization。要使用 HPP,您必须创建一个 HPP 自定义资源(CR)。
11.19.1.1. 使用基本存储池创建 hostpath 置备程序
您可以使用 storagePools 小节创建 HPP 自定义资源(CR),以使用基本存储池配置 hostpath 置备程序(HPP)。存储池指定 CSI 驱动程序使用的名称和路径。
先决条件
-
在
spec.storagePools.path中指定的目录必须具有读/写访问权限。 - 存储池不能与操作系统位于同一个分区。否则,操作系统分区可能会被填充到容量中,这会影响性能或导致节点不稳定或不可用。
流程
使用
storagePools小节创建一个hpp_cr.yaml文件,如下例所示:apiVersion: hostpathprovisioner.kubevirt.io/v1beta1 kind: HostPathProvisioner metadata: name: hostpath-provisioner spec: imagePullPolicy: IfNotPresent storagePools:1 - name: any_name path: "/var/myvolumes"2 workload: nodeSelector: kubernetes.io/os: linux- 保存文件并退出。
运行以下命令来创建 HPP:
$ oc create -f hpp_cr.yaml
11.19.1.1.1. 关于创建存储类
当您创建存储类时,您将设置参数,它们会影响属于该存储类的持久性卷(PV)的动态置备。您不能在创建 StorageClass 对象后更新其参数。
要使用 hostpath 置备程序(HPP),您必须使用 storagePools 小节为 CSI 驱动程序创建关联的存储类。
虚拟机使用基于本地 PV 的数据卷。本地 PV 与特定节点绑定。虽然磁盘镜像准备供虚拟机消耗,但可能不会将虚拟机调度到之前固定本地存储 PV 的节点。
要解决这个问题,使用 Kubernetes pod 调度程序将持久性卷声明(PVC)绑定到正确的节点上的 PV。通过使用 volumeBindingMode 参数设置为 WaitForFirstConsumer 的 StorageClass 值,PV 的绑定和置备会延迟到 pod 使用 PVC。
11.19.1.1.2. 使用 storagePools 小节为 CSI 驱动程序创建存储类
您可以为 hostpath 置备程序(HPP)CSI 驱动程序创建存储类自定义资源(CR)。
流程
创建
storageclass_csi.yaml文件来定义存储类:apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: hostpath-csi provisioner: kubevirt.io.hostpath-provisioner reclaimPolicy: Delete1 volumeBindingMode: WaitForFirstConsumer2 parameters: storagePool: my-storage-pool3
11.19.1.2. 关于使用 PVC 模板创建的存储池
如果您有单个大持久性卷(PV),可以通过在 hostpath 置备程序(HPP)自定义资源(CR)中定义 PVC 模板来创建存储池。
使用 PVC 模板创建的存储池可以包含多个 HPP 卷。将 PV 拆分为较小的卷,可为数据分配提供更大的灵活性。
PVC 模板基于 PersistentVolumeClaim 对象的 spec 小节:
PersistentVolumeClaim 对象示例
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: iso-pvc
spec:
volumeMode: Block
storageClassName: my-storage-class
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi- 1
- 这个值只适用于块卷模式 PV。
您可以使用 HPP CR 中的 pvcTemplate 规格来定义存储池。Operator 从包含 HPP CSI 驱动程序的每个节点中创建一个 PVC。从 PVC 模板创建的 PVC 使用单个大 PV,允许 HPP 创建较小的动态卷。
您可以将基本存储池与从 PVC 模板中创建的存储池合并。
11.19.1.2.1. 使用 PVC 模板创建存储池
您可以通过在 HPP 自定义资源(CR)中指定 PVC 模板,为多个 hostpath 置备程序(HPP)卷创建存储池。
先决条件
-
在
spec.storagePools.path中指定的目录必须具有读/写访问权限。 - 存储池不能与操作系统位于同一个分区。否则,操作系统分区可能会被填充到容量中,这会影响性能或导致节点不稳定或不可用。
流程
为 HPP CR 创建
hpp_pvc_template_pool.yaml文件,该文件指定storagePools小节中的持久性卷(PVC)模板,如下例所示:apiVersion: hostpathprovisioner.kubevirt.io/v1beta1 kind: HostPathProvisioner metadata: name: hostpath-provisioner spec: imagePullPolicy: IfNotPresent storagePools:1 - name: my-storage-pool path: "/var/myvolumes"2 pvcTemplate: volumeMode: Block3 storageClassName: my-storage-class4 accessModes: - ReadWriteOnce resources: requests: storage: 5Gi5 workload: nodeSelector: kubernetes.io/os: linux- 1
storagePools小节是一个可包含基本和 PVC 模板存储池的数组。- 2
- 指定此节点路径下的存储池目录。
- 3
- 可选:
volumeMode参数可以是Block或Filesystem,只要它与置备的卷格式匹配。如果没有指定值,则默认为Filesystem。如果volumeMode是Block,挂载 pod 会在挂载前在块卷中创建一个 XFS 文件系统。 - 4
- 如果省略
storageClassName参数,则使用默认存储类来创建 PVC。如果省略storageClassName,请确保 HPP 存储类不是默认存储类。 - 5
- 您可以指定静态或动态置备的存储。在这两种情况下,确保请求的存储大小适合您要虚拟分割的卷,或者 PVC 无法绑定到大型 PV。如果您使用的存储类使用动态置备的存储,请选择与典型请求大小匹配的分配大小。
- 保存文件并退出。
运行以下命令,使用存储池创建 HPP:
$ oc create -f hpp_pvc_template_pool.yaml
11.19.2. 创建数据卷
您可以使用 PVC 或存储 API 创建数据卷。
在 OpenShift Container Platform Container Storage 中使用 OpenShift Virtualization 时,指定创建虚拟机磁盘时 RBD 块模式持久性卷声明(PVC)。使用虚拟机磁盘时,RBD 块模式卷更高效,并且比 Ceph FS 或 RBD 文件系统模式 PVC 提供更好的性能。
要指定 RBD 块模式 PVC,请使用 'ocs-storagecluster-ceph-rbd' 存储类和 VolumeMode: Block。
在可能的情况下,使用存储 API 来优化空间分配并最大限度地提高性能。
存储配置集是 CDI 管理的自定义资源。它根据关联的存储类提供推荐的存储设置。为每个存储类分配一个存储配置文件。
存储配置集可让您快速创建数据卷,同时减少编码并最大程度减少潜在的错误。
对于可识别的存储类型,CDI 提供优化 PVC 创建的值。但是,如果您自定义存储配置集,您可以为存储类配置自动设置。
11.19.2.1. 关于数据卷
DataVolume 对象是 Containerized Data Importer (CDI) 项目提供的自定义资源。DataVolume 编配与底层持久性卷声明(PVC)关联的导入、克隆和上传操作。您可以将数据卷创建为独立资源,也可以使用虚拟机 (VM) 规格中的 dataVolumeTemplate 字段。
-
使用独立数据卷准备的虚拟机磁盘 PVC,维护虚拟机的独立生命周期。如果您使用虚拟机规格中的
dataVolumeTemplate字段准备 PVC,PVC 会共享与虚拟机相同的生命周期。
11.19.2.2. 使用存储 API 创建数据卷
当您使用存储 API 创建数据卷时,Containerized Data Interface(CDI)会根据所选存储类支持的存储类型优化持久性卷声明(PVC)分配。您只需要指定数据卷名称、命名空间和要分配的存储量。
例如:
-
使用 Ceph RBD 时,
accessModes会自动设置为ReadWriteMany,这将启用实时迁移。volumeMode设置为Block以最大化性能。 -
当使用
volumeMode: Filesystem时,如果需要满足文件系统开销,CDI 将自动请求更多空间。
在以下 YAML 中,使用存储 API 请求具有 2G 可用空间的数据卷。用户不需要知道 volumeMode 就可正确估算所需的持久性卷声明(PVC)大小。CDI 自动选择 accessModes 和 volumeMode 属性的最佳组合。这些最佳值基于存储类型或您在存储配置文件中定义的默认值。如果要提供自定义值,它们会覆盖系统计算的值。
DataVolume 定义示例
apiVersion: cdi.kubevirt.io/v1beta1
kind: DataVolume
metadata:
name: <datavolume>
spec:
source:
pvc:
namespace: "<source_namespace>"
name: "<my_vm_disk>"
storage:
resources:
requests:
storage: 2Gi
storageClassName: <storage_class> 11.19.2.3. 使用 PVC API 创建数据卷
当使用 PVC API 创建数据卷时,Containerized Data Interface(CDI)会根据您为以下字段指定的内容创建数据卷:
-
accessModes(ReadWriteOnce、ReadWriteMany或ReadOnlyMany) -
volumeMode(Filesystem或Block) -
capacityofstorage(例如,5Gi)
在以下 YAML 中,使用 PVC API 分配存储容量为 2GB 的数据卷。您可以指定 ReadWriteMany 访问模式来启用实时迁移。因为您知道系统可以支持的值,所以可以指定 Block 存储而不是默认的 Filesystem。
DataVolume 定义示例
apiVersion: cdi.kubevirt.io/v1beta1
kind: DataVolume
metadata:
name: <datavolume>
spec:
source:
pvc:
namespace: "<source_namespace>"
name: "<my_vm_disk>"
pvc:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 2Gi
volumeMode: Block
storageClassName: <storage_class>
当您使用 PVC API 明确分配数据卷且没有使用 volumeMode: Block 时,请考虑文件系统开销。
文件系统开销是文件系统维护其元数据所需的空间量。文件系统元数据所需的空间量取决于文件系统。无法考虑存储容量请求中的文件系统开销会导致底层持久性卷声明(PVC)不足以容纳您的虚拟机磁盘。
如果您使用存储 API,CDI 将包含在文件系统开销中,并请求更大的持久性卷声明(PVC)以确保您的分配请求成功。
11.19.2.4. 自定义存储配置集
您可以通过编辑置备程序存储类的 StorageProfile 对象来指定默认参数。这些默认参数只有在 DataVolume 对象中没有配置持久性卷声明 (PVC) 时才适用。
存储配置文件中的空 status 部分表示存储置备程序不被 Containerized Data Interface(CDI)识别。如果您有一个存储置备程序无法被 CDI 识别,则需要自定义存储配置集。在这种情况下,管理员在存储配置集中设置适当的值以确保分配成功。
如果您创建数据卷并省略 YAML 属性,且存储配置集中没有定义这些属性,则不会分配请求的存储,也不会创建底层持久性卷声明(PVC)。
先决条件
- 确保存储类及其供应商支持您计划的配置。在存储配置集中指定不兼容的配置会导致卷置备失败。
流程
编辑存储配置文件。在本例中,CDI 不支持置备程序:
$ oc edit -n openshift-cnv storageprofile <storage_class>存储配置集示例
apiVersion: cdi.kubevirt.io/v1beta1 kind: StorageProfile metadata: name: <unknown_provisioner_class> # ... spec: {} status: provisioner: <unknown_provisioner> storageClass: <unknown_provisioner_class>在存储配置集中提供所需的属性值:
存储配置集示例
apiVersion: cdi.kubevirt.io/v1beta1 kind: StorageProfile metadata: name: <unknown_provisioner_class> # ... spec: claimPropertySets: - accessModes: - ReadWriteOnce1 volumeMode: Filesystem2 status: provisioner: <unknown_provisioner> storageClass: <unknown_provisioner_class>保存更改后,所选值将显示在存储配置集的
status项中。
11.19.2.4.1. 使用存储配置集设置默认克隆策略
您可以使用存储配置集为存储类设置默认克隆方法,从而创建 克隆策略。例如,如果您的存储供应商只支持某些克隆方法,设置克隆策略会很有用。它还允许您选择一个限制资源使用或最大化性能的方法。
可以通过将存储配置集中的 cloneStrategy 属性设置为以下值之一来指定克隆策略:
-
配置快照时,默认使用
snapshot。此克隆策略使用临时卷快照来克隆卷。存储置备程序必须支持 Container Storage Interface (CSI) 快照。 -
copy使用源 pod 和目标 pod 将数据从源卷复制到目标卷。主机辅助克隆是最有效的克隆方法。 -
csi-clone使用 CSI 克隆 API 在不使用临时卷快照的情况下高效地克隆现有卷。与snapshot或copy不同(它们在没有定义存储配置集时被默认使用),只有在StorageProfile对象中为置备程序存储类指定它时,才会使用 CSI 卷克隆。
您还可以在不修改 YAML spec 部分中的默认 claimPropertySets 的情况下使用 CLI 设置克隆策略。
存储配置集示例
apiVersion: cdi.kubevirt.io/v1beta1
kind: StorageProfile
metadata:
name: <provisioner_class>
# ...
spec:
claimPropertySets:
- accessModes:
- ReadWriteOnce
volumeMode:
Filesystem
cloneStrategy: csi-clone
status:
provisioner: <provisioner>
storageClass: <provisioner_class>11.19.3. 为文件系统开销保留 PVC 空间
默认情况下,OpenShift Virtualization 在使用 Filesystem 卷模式的持久性卷声明 (PVC) 中为文件系统开销数据保留空间。您可以设置在全局范围内保留空间的百分比,以及为特定存储类保留空间。
11.19.3.1. 文件系统的开销对虚拟机磁盘空间的影响
当您向使用 Filesystem 卷模式的持久性卷声明(PVC)添加虚拟机磁盘时,必须确保 PVC 中有足够的空间用于:
- 虚拟机磁盘。
- 为文件系统开销保留的空间,如元数据
默认情况下,OpenShift Virtualization 为开销保留 5.5% 的 PVC 空间,从而减少了虚拟机磁盘的可用空间。
您可以通过编辑 HCO 对象来配置不同的开销值。您可以在全局范围内更改值,也可以为特定存储类指定值。
11.19.3.2. 覆盖默认文件系统开销值
通过编辑 HCO 对象的 spec.filesystemOverhead 属性来更改 OpenShift Virtualization 为文件系统开销保留的持久性卷声明 (PVC) 空间量。
先决条件
-
安装 OpenShift CLI (
oc) 。
流程
运行以下命令,打开
HCO对象进行编辑:$ oc edit hco -n openshift-cnv kubevirt-hyperconverged编辑
spec.filesystemOverhead字段,使用您选择的值填充它们:# ... spec: filesystemOverhead: global: "<new_global_value>"1 storageClass: <storage_class_name>: "<new_value_for_this_storage_class>"2 -
保存并退出编辑器以更新
HCO对象。
验证
运行以下命令之一查看
CDIConfig状态并验证您的更改:通常验证
CDIConfig的更改:$ oc get cdiconfig -o yaml查看您对
CDIConfig的具体更改:$ oc get cdiconfig -o jsonpath='{.items..status.filesystemOverhead}'
11.19.4. 配置 CDI 以使用具有计算资源配额的命名空间
您可以使用 Containerized Data Importer(CDI)将虚拟机磁盘导入、上传并克隆到命名空间中,这可能受 CPU 和内存资源限制。
11.19.4.1. 关于命名空间中的 CPU 和内存配额
资源配额 由 ResourceQuota 对象定义,对一个命名空间实施限制,该命名空间限制可被该命名空间中资源消耗的计算资源总量。
HyperConverged 自定义资源(CR)定义了 Containerized Data Importer(CDI)的用户配置。CPU 和内存请求和限制值设置为默认值 0。这样可确保由 CDI 创建的无需计算资源要求的 Pod 具有默认值,并允许在使用配额限制的命名空间中运行。
11.19.4.2. 覆盖 CPU 和内存默认值
通过将 spec.resourceRequirements.storageWorkloads 小节添加到 HyperConverged 自定义资源(CR),为您的用例修改 CPU 和内存请求和限值的默认设置。
先决条件
-
安装 OpenShift CLI (
oc) 。
流程
运行以下命令来编辑
HyperConvergedCR:$ oc edit hco -n openshift-cnv kubevirt-hyperconverged将
spec.resourceRequirements.storageWorkloads小节添加到 CR,根据您的用例设置值。例如:apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: resourceRequirements: storageWorkloads: limits: cpu: "500m" memory: "2Gi" requests: cpu: "250m" memory: "1Gi"-
保存并退出编辑器以更新
HyperConvergedCR。
11.19.5. 管理数据卷注解
数据卷(DV)注解允许您管理 pod 行为。您可以将一个或多个注解添加到数据卷,然后将其传播到创建的导入程序 pod。
11.19.5.1. 示例:数据卷注解
本例演示了如何配置数据卷(DV)注解来控制 importer pod 使用的网络。v1.multus-cni.io/default-network: bridge-network 注解会导致 pod 使用名为 bridge-network 的 multus 网络作为其默认网络。如果您希望 importer pod 使用集群中的默认网络和从属 multus 网络,请使用 k8s.v1.cni.cncf.io/networks: <network_name> 注解。
Multus 网络注解示例
apiVersion: cdi.kubevirt.io/v1beta1
kind: DataVolume
metadata:
name: dv-ann
annotations:
v1.multus-cni.io/default-network: bridge-network
spec:
source:
http:
url: "example.exampleurl.com"
pvc:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi- 1
- Multus 网络注解
11.19.6. 对数据卷使用预分配
Containerized Data Importer 可以预先分配磁盘空间,以便在创建数据卷时提高写入性能。
您可以为特定数据卷启用预分配。
11.19.6.1. 关于预分配
Containerized Data Importer(CDI)可以使用 QEMU 预先分配数据卷模式来提高写入性能。您可以使用预分配模式导入和上传操作,并在创建空白数据卷时使用。
如果启用了预分配,CDI 根据底层文件系统和设备类型使用更好的预分配方法:
fallocate-
如果文件系统支持它,CDI 通过使用
posix_fallocate功能(它分配块并将其标记为未初始化),来使用操作系统本身的(fallocate调用来预分配空间。 full-
如果无法使用
fallocate模式,则会使用full模式通过将数据写入底层存储来为镜像分配空间。根据存储位置,所有空分配的空间都可能会为零。
11.19.6.2. 为数据卷启用预分配
您可以通过在数据卷清单中包含 spec.preallocation 字段来为特定数据卷启用预分配。您可以在 web 控制台中或使用 OpenShift CLI (oc) 启用预分配模式。
所有 CDI 源类型都支持 Preallocation 模式。
11.19.7. 使用 Web 控制台上传本地磁盘镜像
您可以使用 web 控制台上传本地存储的磁盘镜像文件。
11.19.7.1. 先决条件
- 您必须有 IMG、ISO 或 QCOW2 格式的虚拟机镜像文件。
- 如果您根据 CDI 支持的操作列表要求涂销空间,您必须首先定义一个 StorageClass 或准备 CDI 涂销空间才能成功完成此操作。
11.19.7.2. CDI 支持的操作列表
此列表针对端点显示内容类型支持的 CDI 操作,以及哪些操作需要涂销空间(scratch space)。
| 内容类型 | HTTP | HTTPS | HTTP 基本身份验证 | Registry | 上传 |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) |
✓ QCOW2 |
✓ QCOW2** |
✓ QCOW2 |
✓ QCOW2* |
✓ QCOW2* |
| KubeVirt (RAW) |
✓ RAW |
✓ RAW |
✓ RAW |
✓ RAW* |
✓ RAW* |
✓ 支持的操作
□ 不支持的操作
* 需要涂销空间
** 如果需要自定义证书颁发机构,则需要涂销空间
11.19.7.3. 使用 Web 控制台上传镜像文件
使用 Web 控制台将镜像文件上传到新持久性卷声明(PVC)。之后,您可以使用此 PVC 将镜像附加到新虚拟机。
先决条件
您必须有以下之一:
- 原始虚拟机镜像文件,可以是 ISO 或 IMG 格式。
- 虚拟机镜像文件(QCOW2 格式)。
要获得最佳结果,先根据以下方法压缩您的镜像文件:
使用
xz或gzip压缩原始映像文件。注意使用压缩的原始镜像文件的上传效果最佳。
使用为您的客户端推荐的方法压缩 QCOW2 镜像文件:
- 如果使用 Linux 客户端,使用 virt-sparsify 工具对 QCOW2 文件进行 sparsify。
-
如果您使用 Windows 客户端。使用
xz或者gzip压缩 QCOW2 文件。
流程
- 在 web 控制台的侧边菜单中点击 Storage → Persistent Volume Claims。
- 点 Create Persistent Volume Claim 下拉列表展开它。
- 点 With Data Upload Form 打开 Upload Data to Persistent Volume Claim 页面。
- 点 Browse 打开文件管理器并选择要上传的镜像,或者将文件拖到 Drag a file here or browse to upload 项中。
可选:将此镜像设置为特定操作系统的默认镜像。
- 选择 Attach this data to a virtual machine operating system 复选框。
- 从列表中选择一个操作系统。
- Persistent Volume Claim Name 字段自动填充唯一名称,且无法编辑。记录分配给 PVC 的名称,以便以后根据需要指定它。
- 从 Storage Class 列表中选择存储类。
在 Size 字段中输入 PVC 的大小值。从下拉列表中选择对应的度量单位。
警告PVC 大小必须大于未压缩的虚拟磁盘的大小。
- 选择与您选择的存储类匹配的 Access Mode。
- 点 Upload。
11.19.8. 使用 virtctl 工具上传本地磁盘镜像
您可使用 virtctl 命令行工具将本地存储的磁盘镜像上传到新的或现有的持久性卷声明 (PVC) 中。
11.19.8.1. 先决条件
-
安装
virtctl。 - 您可能需要定义存储类或准备 CDI 涂销空间才能成功完成此操作。
11.19.8.2. 关于数据卷
DataVolume 对象是 Containerized Data Importer (CDI) 项目提供的自定义资源。DataVolume 编配与底层持久性卷声明(PVC)关联的导入、克隆和上传操作。您可以将数据卷创建为独立资源,也可以使用虚拟机 (VM) 规格中的 dataVolumeTemplate 字段。
-
使用独立数据卷准备的虚拟机磁盘 PVC,维护虚拟机的独立生命周期。如果您使用虚拟机规格中的
dataVolumeTemplate字段准备 PVC,PVC 会共享与虚拟机相同的生命周期。
11.19.8.3. 创建上传数据卷
您可以使用 upload 数据源手动创建数据源,用于上传本地磁盘镜像。
流程
创建指定
spec: source: upload{}的数据卷配置:apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: <upload-datavolume>1 spec: source: upload: {} pvc: accessModes: - ReadWriteOnce resources: requests: storage: <2Gi>2 运行以下命令来创建数据卷:
$ oc create -f <upload-datavolume>.yaml
11.19.8.4. 上传本地磁盘镜像至数据卷
您可使用 virtctl CLI 实用程序将客户端机器中的本地磁盘镜像上传到集群中的数据卷(DV)。您可以使用集群中已存在的 DV,也可以在此过程中创建新的 DV。
上传本地磁盘镜像后,您可将其添加到虚拟机中。
先决条件
您必须有以下之一:
- 原始虚拟机镜像文件,可以是 ISO 或 IMG 格式。
- 虚拟机镜像文件(QCOW2 格式)。
要获得最佳结果,先根据以下方法压缩您的镜像文件:
使用
xz或gzip压缩原始映像文件。注意使用压缩的原始镜像文件的上传效果最佳。
使用为您的客户端推荐的方法压缩 QCOW2 镜像文件:
- 如果使用 Linux 客户端,使用 virt-sparsify 工具对 QCOW2 文件进行 sparsify。
-
如果您使用 Windows 客户端。使用
xz或者gzip压缩 QCOW2 文件。
-
kubevirt-virtctl软件包必须安装在客户端机器上。 - 客户端机器必须配置为信任 OpenShift Container Platform 路由器的证书。
流程
确定以下各项:
- 要使用的上传数据卷的名称。如果这个数据卷不存在,则会自动创建。
- 在上传过程中创建数据卷的大小。大小必须大于或等于磁盘镜像的大小。
- 要上传的虚拟机磁盘镜像的文件位置。
运行
virtctl image-upload命令上传磁盘镜像。指定您在上一步中获得的参数。例如:$ virtctl image-upload dv <datavolume_name> \1 --size=<datavolume_size> \2 --image-path=</path/to/image> \3 注意-
如果您不想创建新数据卷,请省略
--size参数,并包含--no-create标志。 - 将磁盘镜像上传到 PVC 时,PVC 大小必须大于未压缩的虚拟磁盘的大小。
-
若要在使用 HTTPS 时允许不安全的服务器连接,请使用
--insecure参数。注意,在使用--insecure标志时,不会验证上传端点的真实性。
-
如果您不想创建新数据卷,请省略
可选。要验证数据卷是否已创建,运行以下命令来查看所有数据卷:
$ oc get dvs
11.19.8.5. CDI 支持的操作列表
此列表针对端点显示内容类型支持的 CDI 操作,以及哪些操作需要涂销空间(scratch space)。
| 内容类型 | HTTP | HTTPS | HTTP 基本身份验证 | Registry | 上传 |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) |
✓ QCOW2 |
✓ QCOW2** |
✓ QCOW2 |
✓ QCOW2* |
✓ QCOW2* |
| KubeVirt (RAW) |
✓ RAW |
✓ RAW |
✓ RAW |
✓ RAW* |
✓ RAW* |
✓ 支持的操作
□ 不支持的操作
* 需要涂销空间
** 如果需要自定义证书颁发机构,则需要涂销空间
11.19.9. 上传本地磁盘镜像至块存储持久性卷声明
您可使用 virtctl 命令行实用程序将本地磁盘镜像上传到块持久性卷声明 (PVC) 中。
在此工作流中,您会创建一个本地块设备用作 PV,将此块卷与 upload 数据卷关联,并使用 virtctl 将本地磁盘镜像上传至 PVC 中。
11.19.9.1. 先决条件
-
安装
virtctl。 - 您可能需要定义存储类或准备 CDI 涂销空间才能成功完成此操作。
11.19.9.2. 关于数据卷
DataVolume 对象是 Containerized Data Importer (CDI) 项目提供的自定义资源。DataVolume 编配与底层持久性卷声明(PVC)关联的导入、克隆和上传操作。您可以将数据卷创建为独立资源,也可以使用虚拟机 (VM) 规格中的 dataVolumeTemplate 字段。
-
使用独立数据卷准备的虚拟机磁盘 PVC,维护虚拟机的独立生命周期。如果您使用虚拟机规格中的
dataVolumeTemplate字段准备 PVC,PVC 会共享与虚拟机相同的生命周期。
11.19.9.3. 关于块持久性卷
块持久性卷(PV)是一个受原始块设备支持的 PV。这些卷没有文件系统,可以通过降低开销来为虚拟机提供性能优势。
原始块卷可以通过在 PV 和持久性卷声明(PVC)规格中指定 volumeMode: Block 来置备。
11.19.9.4. 创建本地块持久性卷
如果要使用数据卷将虚拟机镜像导入到块存储中,则必须有一个可用的本地块持久性卷。
通过填充文件并将其挂载为循环设备,在节点上创建本地块持久性卷(PV)。然后,您可以在 PV 清单中将该循环设备作为 Block(块)卷引用,并将其用作虚拟机镜像的块设备。
流程
-
以
root身份登录节点,在其上创建本地 PV。本流程以node01为例。 创建一个文件并用空字符填充,以便可将其用作块设备。以下示例创建
loop10文件,大小为 2Gb(20,100 Mb 块):$ dd if=/dev/zero of=<loop10> bs=100M count=20将
loop10文件挂载为 loop 设备。$ losetup </dev/loop10>d3 <loop10>1 2 创建引用所挂载 loop 设备的
PersistentVolume清单。kind: PersistentVolume apiVersion: v1 metadata: name: <local-block-pv10> annotations: spec: local: path: </dev/loop10>1 capacity: storage: <2Gi> volumeMode: Block2 storageClassName: local3 accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Delete nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - <node01>4 创建块 PV。
# oc create -f <local-block-pv10.yaml>1 - 1
- 上一步中创建的持久性卷的文件名。
11.19.9.5. 创建上传数据卷
您可以使用 upload 数据源手动创建数据源,用于上传本地磁盘镜像。
流程
创建指定
spec: source: upload{}的数据卷配置:apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: <upload-datavolume>1 spec: source: upload: {} pvc: accessModes: - ReadWriteOnce resources: requests: storage: <2Gi>2 运行以下命令来创建数据卷:
$ oc create -f <upload-datavolume>.yaml
11.19.9.6. 上传本地磁盘镜像至数据卷
您可使用 virtctl CLI 实用程序将客户端机器中的本地磁盘镜像上传到集群中的数据卷(DV)。您可以使用集群中已存在的 DV,也可以在此过程中创建新的 DV。
上传本地磁盘镜像后,您可将其添加到虚拟机中。
先决条件
您必须有以下之一:
- 原始虚拟机镜像文件,可以是 ISO 或 IMG 格式。
- 虚拟机镜像文件(QCOW2 格式)。
要获得最佳结果,先根据以下方法压缩您的镜像文件:
使用
xz或gzip压缩原始映像文件。注意使用压缩的原始镜像文件的上传效果最佳。
使用为您的客户端推荐的方法压缩 QCOW2 镜像文件:
- 如果使用 Linux 客户端,使用 virt-sparsify 工具对 QCOW2 文件进行 sparsify。
-
如果您使用 Windows 客户端。使用
xz或者gzip压缩 QCOW2 文件。
-
kubevirt-virtctl软件包必须安装在客户端机器上。 - 客户端机器必须配置为信任 OpenShift Container Platform 路由器的证书。
流程
确定以下各项:
- 要使用的上传数据卷的名称。如果这个数据卷不存在,则会自动创建。
- 在上传过程中创建数据卷的大小。大小必须大于或等于磁盘镜像的大小。
- 要上传的虚拟机磁盘镜像的文件位置。
运行
virtctl image-upload命令上传磁盘镜像。指定您在上一步中获得的参数。例如:$ virtctl image-upload dv <datavolume_name> \1 --size=<datavolume_size> \2 --image-path=</path/to/image> \3 注意-
如果您不想创建新数据卷,请省略
--size参数,并包含--no-create标志。 - 将磁盘镜像上传到 PVC 时,PVC 大小必须大于未压缩的虚拟磁盘的大小。
-
若要在使用 HTTPS 时允许不安全的服务器连接,请使用
--insecure参数。注意,在使用--insecure标志时,不会验证上传端点的真实性。
-
如果您不想创建新数据卷,请省略
可选。要验证数据卷是否已创建,运行以下命令来查看所有数据卷:
$ oc get dvs
11.19.9.7. CDI 支持的操作列表
此列表针对端点显示内容类型支持的 CDI 操作,以及哪些操作需要涂销空间(scratch space)。
| 内容类型 | HTTP | HTTPS | HTTP 基本身份验证 | Registry | 上传 |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) |
✓ QCOW2 |
✓ QCOW2** |
✓ QCOW2 |
✓ QCOW2* |
✓ QCOW2* |
| KubeVirt (RAW) |
✓ RAW |
✓ RAW |
✓ RAW |
✓ RAW* |
✓ RAW* |
✓ 支持的操作
□ 不支持的操作
* 需要涂销空间
** 如果需要自定义证书颁发机构,则需要涂销空间
11.19.10. 管理虚拟机快照
您可以为虚拟机创建和删除虚拟机快照,无论是关闭(离线)还是(在线)虚拟机。您只能恢复到已关机(脱机)虚拟机。OpenShift Virtualization 支持以下虚拟机快照:
- Red Hat OpenShift Data Foundation
- 使用支持 Kubernetes 卷快照 API 的 Container Storage Interface(CSI)驱动程序的任何其他云存储供应商
在线快照的默认时间期限为五分钟(5m),可根据需要进行更改。
具有热插虚拟磁盘的虚拟机支持在线快照。但是,没有在虚拟机规格中的热插磁盘不会包含在快照中。
要为具有最高完整性的在线(Running 状态)虚拟机创建快照,请安装 QEMU 客户机代理。
QEMU 客户机代理通过尝试静止虚拟机的文件系统来尽可能取一个一致的快照,具体取决于系统工作负载。这样可确保在进行快照前将 in-flight I/O 写入磁盘。如果没有客户机代理,则无法静止并生成最佳快照。执行快照的条件反映在 web 控制台或 CLI 中显示的快照声明中。
11.19.10.1. 关于虚拟机快照
快照 代表虚拟机(VM)在特定时间点的状态和数据。您可以使用快照将现有虚拟机恢复到以前的状态(由快照代表)进行备份和恢复,或者快速回滚到以前的开发版本。
虚拟机快照从关机(停止状态)或 powred on(Running 状态)上的虚拟机创建。
在为正在运行的虚拟机执行快照时,控制器将检查 QEMU 客户机代理是否已安装并在运行。如果是这样,它会在拍摄快照前冻结虚拟机文件系统,并在拍摄快照后修改文件系统。
快照存储附加到虚拟机的每个 Container Storage Interface(CSI)卷的副本以及虚拟机规格和元数据的副本。创建后无法更改快照。
借助 VM 快照功能,集群管理员和应用程序开发人员可以:
- 创建新快照
- 列出附加到特定虚拟机的所有快照
- 从快照恢复虚拟机
- 删除现有虚拟机快照
11.19.10.1.1. 虚拟机快照控制器和自定义资源定义(CRD)
VM 快照功能引入了三个新的 API 对象,定义为 CRD,用于管理快照:
-
VirtualMachineSnapshot:代表创建快照的用户请求。它包含有关虚拟机当前状态的信息。 -
VirtualMachineSnapshotContent:代表集群中置备的资源(快照)。它由虚拟机快照控制器创建,其中包含恢复虚拟机所需的所有资源的引用。 -
VirtualMachineRestore:代表从快照中恢复虚拟机的用户请求。
VM 快照控制器会把一个 VirtualMachineSnapshotContent 对象与创建它的 VirtualMachineSnapshotContent 对象绑定,并具有一对一的映射。
11.19.10.2. 在 Linux 虚拟机上安装 QEMU 客户机代理
qemu-guest-agent 广泛可用,默认在 Red Hat Enterprise Linux (RHEL) 虚拟机 (VM) 中可用。安装代理并启动服务。
要为具有最高完整性的在线(Running 状态)虚拟机创建快照,请安装 QEMU 客户机代理。
QEMU 客户机代理通过尝试静止虚拟机的文件系统来尽可能取一个一致的快照,具体取决于系统工作负载。这样可确保在进行快照前将 in-flight I/O 写入磁盘。如果没有客户机代理,则无法静止并生成最佳快照。执行快照的条件反映在 web 控制台或 CLI 中显示的快照声明中。
流程
- 通过其中一个控制台或通过 SSH 访问虚拟机命令行。
在虚拟机上安装 QEMU 客户机代理:
$ yum install -y qemu-guest-agent确保服务持久并启动它:
$ systemctl enable --now qemu-guest-agent
验证
运行以下命令,以验证
AgentConnected是否列在 VM spec 中:$ oc get vm <vm_name>
11.19.10.3. 在 Windows 虚拟机上安装 QEMU 客户机代理
对于 Windows 虚拟机,QEMU 客户机代理包含在 VirtIO 驱动程序中。在现有或者新的 Windows 安装上安装驱动程序。
要为具有最高完整性的在线(Running 状态)虚拟机创建快照,请安装 QEMU 客户机代理。
QEMU 客户机代理通过尝试静止虚拟机的文件系统来尽可能取一个一致的快照,具体取决于系统工作负载。这样可确保在进行快照前将 in-flight I/O 写入磁盘。如果没有客户机代理,则无法静止并生成最佳快照。执行快照的条件反映在 web 控制台或 CLI 中显示的快照声明中。
流程
-
在 Windows Guest Operating System (OS) 中,使用 File Explorer 导航到
virtio-winCD 驱动器中的guest-agent目录。 -
运行
qemu-ga-x86_64.msi安装程序。
验证
运行以下命令以验证输出是否包含
QEMU 客户机代理:$ net start
11.19.10.3.1. 在现有 Windows 虚拟机上安装 VirtIO 驱动程序
从附加的 SATA CD 驱动器将 VirtIO 驱动程序安装到现有 Windows 虚拟机。
该流程使用通用方法为 Windows 添加驱动。具体流程可能会因 Windows 版本而稍有差异。有关具体安装步骤,请参阅您的 Windows 版本安装文档。
流程
- 启动虚拟机并连接至图形控制台。
- 登录 Windows 用户会话。
打开 Device Manager 并展开 Other devices 以列出所有 Unknown device。
-
打开
Device Properties以识别未知设备。右击设备并选择 Properties。 - 单击 Details 选项卡,并在 Property 列表中选择 Hardware Ids。
- 将 Hardware Ids 的 Value 与受支持的 VirtIO 驱动程序相比较。
-
打开
- 右击设备并选择 Update Driver Software。
- 点击 Browse my computer for driver software 并浏览所附加的 VirtIO 驱动程序所在 SATA CD 驱动器。驱动程序将按照其驱动程序类型、操作系统和 CPU 架构分层排列。
- 点击 Next 以安装驱动程序。
- 对所有必要 VirtIO 驱动程序重复这一过程。
- 安装完驱动程序后,点击 Close 关闭窗口。
- 重启虚拟机以完成驱动程序安装。
11.19.10.4. 在 web 控制台中创建虚拟机快照
您可以使用 web 控制台创建虚拟机(VM)快照。
要为具有最高完整性的在线(Running 状态)虚拟机创建快照,请安装 QEMU 客户机代理。
QEMU 客户机代理通过尝试静止虚拟机的文件系统来尽可能取一个一致的快照,具体取决于系统工作负载。这样可确保在进行快照前将 in-flight I/O 写入磁盘。如果没有客户机代理,则无法静止并生成最佳快照。执行快照的条件反映在 web 控制台或 CLI 中显示的快照声明中。
VM 快照只包含满足以下要求的磁盘:
- 必须是数据卷或持久性卷声明
- 属于支持容器存储接口(CSI)卷快照的存储类
流程
- 在侧边菜单中点 Virtualization → VirtualMachines。
- 选择虚拟机以打开 VirtualMachine 详情页面。
- 如果虚拟机正在运行,点 Actions → Stop 关闭它。
- 点 Snapshots 标签页,然后点 Take Snapshot。
- 填写 Snapshot Name 和可选的 Description 字段。
- 扩展 Disks included in this Snapshot 以查看快照中包含的存储卷。
- 如果您的虚拟机磁盘无法包含在快照中,并且您仍然希望继续,请选择 I am aware of this warning and wish to proceed 复选框。
- 点击 Save。
11.19.10.5. 通过 CLI 创建虚拟机快照
您可以通过创建一个 VirtualMachineSnapshot 对象来为离线或在线虚拟机创建虚拟机快照。kubevirt 与 QEMU 客户机代理协调,以创建在线虚拟机的快照。
要为具有最高完整性的在线(Running 状态)虚拟机创建快照,请安装 QEMU 客户机代理。
QEMU 客户机代理通过尝试静止虚拟机的文件系统来尽可能取一个一致的快照,具体取决于系统工作负载。这样可确保在进行快照前将 in-flight I/O 写入磁盘。如果没有客户机代理,则无法静止并生成最佳快照。执行快照的条件反映在 web 控制台或 CLI 中显示的快照声明中。
先决条件
- 确保持久性卷声明(PVC)位于支持 Container Storage Interface(CSI)卷快照的存储类中。
-
安装 OpenShift CLI (
oc) 。 - 可选:关闭您要为其创建快照的虚拟机。
流程
创建一个 YAML 文件来定义
VirtualMachineSnapshot对象,以指定新VirtualMachineSnapshot的名称和源虚拟机的名称。例如:
apiVersion: snapshot.kubevirt.io/v1beta1 kind: VirtualMachineSnapshot metadata: name: my-vmsnapshot1 spec: source: apiGroup: kubevirt.io kind: VirtualMachine name: my-vm2 创建
VirtualMachineSnapshot资源。快照控制器会创建一个VirtualMachineSnapshotContent对象,将其绑定到VirtualMachineSnapshot并更新VirtualMachineSnapshot对象的status和readyToUse字段。$ oc create -f <my-vmsnapshot>.yaml可选: 如果要执行在线快照,您可以使用
wait命令并监控快照的状态:输入以下命令:
$ oc wait my-vm my-vmsnapshot --for condition=Ready验证快照的状态:
-
InProgress- 在线快照操作仍在进行中。 -
succeeded- 在线快照操作成功完成。 Failed- 在线快照操作失败。注意在线快照的默认时间期限为五分钟(
5m)。如果快照在五分钟内没有成功完成,其状态将设为failed。之后,文件系统将被”解冻”,虚拟机将取消冻结,但状态会一直failed,直到您删除失败的快照镜像。要更改默认时间期限,在 VM 快照 spec 中添加
FailureDeadline属性,指定在快照超时前的时间,以分钟(m)或秒(s)为单位。要设置截止时间,您可以指定
0,但通常不建议这样做,因为它可能会导致虚拟机没有响应。如果您没有指定时间单位,如
m或s,则默认为 秒(s)。
-
验证
验证
VirtualMachineSnapshot对象是否已创建并绑定到VirtualMachineSnapshotContent。readyToUse标志必须设为true。$ oc describe vmsnapshot <my-vmsnapshot>输出示例
apiVersion: snapshot.kubevirt.io/v1beta1 kind: VirtualMachineSnapshot metadata: creationTimestamp: "2020-09-30T14:41:51Z" finalizers: - snapshot.kubevirt.io/vmsnapshot-protection generation: 5 name: mysnap namespace: default resourceVersion: "3897" selfLink: /apis/snapshot.kubevirt.io/v1beta1/namespaces/default/virtualmachinesnapshots/my-vmsnapshot uid: 28eedf08-5d6a-42c1-969c-2eda58e2a78d spec: source: apiGroup: kubevirt.io kind: VirtualMachine name: my-vm status: conditions: - lastProbeTime: null lastTransitionTime: "2020-09-30T14:42:03Z" reason: Operation complete status: "False"1 type: Progressing - lastProbeTime: null lastTransitionTime: "2020-09-30T14:42:03Z" reason: Operation complete status: "True"2 type: Ready creationTime: "2020-09-30T14:42:03Z" readyToUse: true3 sourceUID: 355897f3-73a0-4ec4-83d3-3c2df9486f4f virtualMachineSnapshotContentName: vmsnapshot-content-28eedf08-5d6a-42c1-969c-2eda58e2a78d4 -
检查
VirtualMachineSnapshotContent资源的spec:volumeBackups属性,以验证快照中包含了预期的 PVC。
11.19.10.6. 使用快照声明验证在线快照创建
快照表示是有关在线虚拟机 (VM) 快照操作的上下文信息。对于离线虚拟机 (VM) 快照操作,提示不可用。暗示有助于描述在线快照创建的详细信息。
先决条件
- 要查看提示信息,您必须已尝试使用 CLI 或 Web 控制台创建在线虚拟机快照。
流程
通过执行以下操作之一来显示快照的输出:
-
对于使用 CLI 创建的快照,请查看
VirtualMachineSnapshot对象 YAML 中的 status 字段中的指示器输出。 - 对于使用 Web 控制台创建的快照,请点击 Snapshot details 屏幕中的 VirtualMachineSnapshot > Status。
-
对于使用 CLI 创建的快照,请查看
验证在线虚拟机快照的状态:
-
Online代表虚拟机在在线快照创建期间运行。 -
NoGuestAgent表示 QEMU 客户机代理在在线快照创建过程中没有运行。QEMU 客户机代理无法用于冻结和构建文件系统,要么因为 QEMU 客户机代理尚未安装或正在运行,要么是因为另一个错误。
-
11.19.10.7. 在 web 控制台中从快照中恢复虚拟机
您可以将虚拟机(VM)恢复到 web 控制台中由快照表示的以前的配置。
流程
- 在侧边菜单中点 Virtualization → VirtualMachines。
- 选择虚拟机以打开 VirtualMachine 详情页面。
- 如果虚拟机正在运行,点 Actions → Stop 关闭它。
- 点 Snapshots 标签页。该页面显示与虚拟机关联的快照列表。
选择以下方法之一恢复虚拟机快照:
- 对于您要用作恢复虚拟机的源的快照,点 Restore。
- 选择快照以打开 Snapshot Details 屏幕,然后点 Actions → Restore VirtualMachineSnapshot。
- 在确认弹出窗口中,点 Restore 可将虚拟机恢复到快照代表的以前的配置中。
11.19.10.8. 通过 CLI 从快照中恢复虚拟机
您可以使用虚拟机快照将现有虚拟机 (VM) 恢复到以前的配置。您只能从离线虚拟机快照中恢复。
先决条件
-
安装 OpenShift CLI(
oc)。 - 关闭您要恢复到之前状态的虚拟机。
流程
创建一个 YAML 文件来定义
VirtualMachineRestore对象,它指定您要恢复的虚拟机的名称以及要用作源的快照名称。例如:
apiVersion: snapshot.kubevirt.io/v1beta1 kind: VirtualMachineRestore metadata: name: my-vmrestore1 spec: target: apiGroup: kubevirt.io kind: VirtualMachine name: my-vm2 virtualMachineSnapshotName: my-vmsnapshot3 创建
VirtualMachineRestore资源。快照控制器更新了VirtualMachineRestore对象的 status 字段,并将现有虚拟机配置替换为快照内容。$ oc create -f <my-vmrestore>.yaml
验证
验证虚拟机是否已恢复到快照代表的以前的状态。
complete标志需要被设置为true。$ oc get vmrestore <my-vmrestore>输出示例
apiVersion: snapshot.kubevirt.io/v1beta1 kind: VirtualMachineRestore metadata: creationTimestamp: "2020-09-30T14:46:27Z" generation: 5 name: my-vmrestore namespace: default ownerReferences: - apiVersion: kubevirt.io/v1 blockOwnerDeletion: true controller: true kind: VirtualMachine name: my-vm uid: 355897f3-73a0-4ec4-83d3-3c2df9486f4f resourceVersion: "5512" selfLink: /apis/snapshot.kubevirt.io/v1beta1/namespaces/default/virtualmachinerestores/my-vmrestore uid: 71c679a8-136e-46b0-b9b5-f57175a6a041 spec: target: apiGroup: kubevirt.io kind: VirtualMachine name: my-vm virtualMachineSnapshotName: my-vmsnapshot status: complete: true1 conditions: - lastProbeTime: null lastTransitionTime: "2020-09-30T14:46:28Z" reason: Operation complete status: "False"2 type: Progressing - lastProbeTime: null lastTransitionTime: "2020-09-30T14:46:28Z" reason: Operation complete status: "True"3 type: Ready deletedDataVolumes: - test-dv1 restoreTime: "2020-09-30T14:46:28Z" restores: - dataVolumeName: restore-71c679a8-136e-46b0-b9b5-f57175a6a041-datavolumedisk1 persistentVolumeClaim: restore-71c679a8-136e-46b0-b9b5-f57175a6a041-datavolumedisk1 volumeName: datavolumedisk1 volumeSnapshotName: vmsnapshot-28eedf08-5d6a-42c1-969c-2eda58e2a78d-volume-datavolumedisk1
11.19.10.9. 删除 web 控制台中的虚拟机快照
您可以使用 web 控制台删除现有虚拟机快照。
流程
- 在侧边菜单中点 Virtualization → VirtualMachines。
- 选择虚拟机以打开 VirtualMachine 详情页面。
- 点 Snapshots 标签页。该页面显示与虚拟机关联的快照列表。
-
点您要删除的虚拟机快照
的 Options 菜单,然后选择 Delete Virtual Machine Snapshot。
- 在确认弹出窗口中点 Delete 删除快照。
11.19.10.10. 通过 CLI 删除虚拟机快照
您可以通过删除正确的 VirtualMachineSnapshot 对象来删除现有虚拟机(VM)快照。
先决条件
-
安装 OpenShift CLI (
oc) 。
流程
删除
VirtualMachineSnapshot对象。快照控制器会删除VirtualMachineSnapshot和关联的VirtualMachineSnapshotContent对象。$ oc delete vmsnapshot <my-vmsnapshot>
验证
验证快照是否已删除,且不再附加到此虚拟机:
$ oc get vmsnapshot
11.19.11. 将本地虚拟机磁盘移动到不同的节点中
使用本地卷存储的虚拟机可被移动,以便在特定节点中运行。
因为以下原因,您可能想要将该虚拟机移动到特定的节点上:
- 当前节点对本地存储配置有限制。
- 新节点对那个虚拟机的工作负载进行了更好的优化。
要移动使用本地存储的虚拟机,您必须使用数据卷克隆基础卷。克隆操作完成后,您可以 编辑虚拟机配置,以便使用新数据卷,或 将新数据卷添加到其他虚拟机。
当您全局启用预分配或单个数据卷时,Containerized Data Importer(CDI)会在克隆过程中预分配磁盘空间。预分配可提高写入性能。如需更多信息,请参阅对数据卷使用预分配。
没有 cluster-admin 角色的用户需要额外的用户权限才能在 命名空间间克隆卷。
11.19.11.1. 克隆本地卷到另一个节点
您可以通过克隆底层 PVC,移动虚拟机磁盘使其在特定节点上运行。
要确保虚拟机磁盘克隆到正确的节点,您必须创建新的持久性卷(PV)或在正确的节点上识别它。对 PV 应用一个唯一标签,以便数据卷可以引用它。
目标 PV 的大小不得小于源 PVC。如果目标 PV 小于源 PVC,克隆操作会失败。
先决条件
- 虚拟机不能正在运行。在克隆虚拟机磁盘前关闭虚拟机。
流程
在节点上创建新本地 PV,或使用已有的本地 PV:
创建包含
nodeAffinity.nodeSelectorTerms参数的本地 PV。以下 manifest 在node01上创建了一个10Gi的本地 PV。kind: PersistentVolume apiVersion: v1 metadata: name: <destination-pv>1 annotations: spec: accessModes: - ReadWriteOnce capacity: storage: 10Gi2 local: path: /mnt/local-storage/local/disk13 nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - node014 persistentVolumeReclaimPolicy: Delete storageClassName: local volumeMode: Filesystem已存在于节点上的一个 PV。您可以通过查看其配置中的
nodeAffinity字段来标识置备 PV 的节点:$ oc get pv <destination-pv> -o yaml以下输出显示 PV 位于
node01:输出示例
# ... spec: nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname1 operator: In values: - node012 # ...
为 PV 添加唯一标签:
$ oc label pv <destination-pv> node=node01创建引用以下内容的数据卷清单:
- 虚拟机的 PVC 名称和命名空间。
- 应用上一步中的 PV 标签。
目标 PV 的大小。
apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: <clone-datavolume>1 spec: source: pvc: name: "<source-vm-disk>"2 namespace: "<source-namespace>"3 pvc: accessModes: - ReadWriteOnce selector: matchLabels: node: node014 resources: requests: storage: <10Gi>5
通过将数据卷清单应用到集群来开始克隆操作:
$ oc apply -f <clone-datavolume.yaml>
数据卷将虚拟机的 PVC 克隆到特定节点上的 PV 中。
11.19.12. 通过添加空白磁盘镜像扩展虚拟存储
您可向 OpenShift Virtualization 添加空白磁盘镜像来提高存储容量或创建新数据分区。
11.19.12.1. 关于数据卷
DataVolume 对象是 Containerized Data Importer (CDI) 项目提供的自定义资源。DataVolume 编配与底层持久性卷声明(PVC)关联的导入、克隆和上传操作。您可以将数据卷创建为独立资源,也可以使用虚拟机 (VM) 规格中的 dataVolumeTemplate 字段。
-
使用独立数据卷准备的虚拟机磁盘 PVC,维护虚拟机的独立生命周期。如果您使用虚拟机规格中的
dataVolumeTemplate字段准备 PVC,PVC 会共享与虚拟机相同的生命周期。
11.19.12.2. 使用数据卷创建空白磁盘镜像
您可以通过自定义和部署数据卷配置文件在持久性卷声明中创建新空白磁盘镜像。
先决条件
- 至少一个可用持久性卷。
-
安装 OpenShift CLI(
oc)。
流程
编辑
DataVolume清单:apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: blank-image-datavolume spec: source: blank: {} pvc: storageClassName: "hostpath"1 accessModes: - ReadWriteOnce resources: requests: storage: 500Mi- 1
- 可选:如果没有指定存储类,则会应用默认存储类。
运行以下命令,创建空白磁盘镜像:
$ oc create -f <blank-image-datavolume>.yaml
11.19.13. 使用 smart-cloning(智能克隆) 克隆数据卷
Smart-cloning(智能克隆)是 Red Hat OpenShift Data Foundation 的内置功能。与主机辅助克隆相比,智能克隆速度更快、效率更高。
您不需要执行任何操作来启用智能克隆功能,但需要确保您的存储环境与智能克隆兼容。
使用持久性卷声明(PVC)源创建数据卷时,会自动启动克隆过程。如果您的环境支持智能克隆,则始终会收到数据卷的克隆。但是,只有存储供应商支持智能克隆时,才会获得智能克隆的性能优势。
11.19.13.1. 关于数据卷
DataVolume 对象是 Containerized Data Importer (CDI) 项目提供的自定义资源。DataVolume 编配与底层持久性卷声明(PVC)关联的导入、克隆和上传操作。您可以将数据卷创建为独立资源,也可以使用虚拟机 (VM) 规格中的 dataVolumeTemplate 字段。
-
使用独立数据卷准备的虚拟机磁盘 PVC,维护虚拟机的独立生命周期。如果您使用虚拟机规格中的
dataVolumeTemplate字段准备 PVC,PVC 会共享与虚拟机相同的生命周期。
11.19.13.2. 关于智能克隆
当一个数据卷被智能克隆时,会出现以下情况:
- 创建源持久性卷声明(PVC)的快照。
- 从快照创建一个 PVC。
- 快照被删除。
11.19.13.3. 克隆数据卷
先决条件
要实现智能克隆,需要满足以下条件:
- 您的存储供应商必须支持快照。
- 源和目标 PVC 必须定义为相同的存储类。
- 源和目标 PVC 共享相同的 volumeMode。
-
VolumeSnapshotClass对象必须引用定义为源和目标 PVC 的存储类。
流程
启动数据卷克隆:
为
DataVolume对象创建一个 YAML 文件,用于指定新数据卷的名称以及源 PVC 的名称和命名空间。在这个示例中,因为指定了 storage API,因此不需要指定 accessModes 或 volumeMode。将自动为您计算最佳值。apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: <cloner-datavolume>1 spec: source: pvc: namespace: "<source-namespace>"2 name: "<my-favorite-vm-disk>"3 storage:4 resources: requests: storage: <2Gi>5 通过创建数据卷开始克隆 PVC:
$ oc create -f <cloner-datavolume>.yaml注意在 PVC 就绪前,DataVolume 会阻止虚拟机启动,以便您可以在 PVC 克隆期间创建引用新数据卷的虚拟机。
11.19.14. 热插虚拟磁盘
您可以在不停止虚拟机(VM)或虚拟机实例(VMI)的情况下添加或删除虚拟磁盘。
11.19.14.1. 关于热插虚拟磁盘
当您热插拔虚拟磁盘时,可以在虚拟机运行时将虚拟磁盘附加到虚拟机实例中。
当热拔虚拟磁盘时,您可以在虚拟机运行时从虚拟机实例分离虚拟磁盘。
只有数据卷和持久性卷声明(PVC)才能热插和热拔。您不能热插或热拔容器磁盘。
热插虚拟磁盘后,它会保持附加状态,直到分离它,即使您重启虚拟机。
在 web 控制台中,热插卷在磁盘列表中由磁盘列表中的 "persistent hotplug" 标签标记(VirtualMachine Details → Configuration → Disks 选项卡)。要将热插卷改为持久性卷,请点 Options 菜单
并选择 Make persistent。删除 "persistent hotplug" 标签,并在下次重启后应用更改。
11.19.14.2. 关于 virtio-scsi
在 OpenShift Virtualization 中,每个虚拟机 (VM) 都有一个 virtio-scsi 控制器,以便热插磁盘可以使用 scsi 总线。virtio-scsi 控制器克服了 virtio 的限制,同时保持其性能优势。它高度可扩展,支持超过 400 万个磁盘的热插拔。
常规 virtio 不适用于热插磁盘,因为它无法扩展:每个 virtio 磁盘使用虚拟机中的有限 PCI Express (PCIe) 插槽。PCIe 插槽也被其他设备使用,必须提前保留,因此插槽可能按需提供。
11.19.14.3. 使用 CLI 热插虚拟磁盘
在虚拟机运行时热插要附加到虚拟机实例(VMI)的虚拟磁盘。
先决条件
- 您必须有一个正在运行的虚拟机才能热插虚拟磁盘。
- 您必须至少有一个数据卷或持久性卷声明(PVC)可用于热插。
流程
运行以下命令来热插虚拟磁盘:
$ virtctl addvolume <virtual-machine|virtual-machine-instance> --volume-name=<datavolume|PVC> \ [--persist] [--serial=<label-name>]-
使用可选
--persist标志,将热插磁盘作为永久挂载的虚拟磁盘添加到虚拟机规格中。停止、重新启动或重新启动虚拟机以永久挂载虚拟磁盘。指定--persist标志后,您无法再热插或热拔虚拟磁盘。Persist标志适用于虚拟机,不适用于虚拟机实例。 -
可选
--serial标志允许您添加您选择的字母数字字符串标签。这有助于您识别客户机虚拟机中的热插磁盘。如果没有指定这个选项,则标签默认为热插数据卷或 PVC 的名称。
-
使用可选
11.19.14.4. 使用 CLI 热拔虚拟磁盘
在虚拟机运行时,热拔您想要从虚拟机实例(VMI)断开的虚拟磁盘。
先决条件
- 您的虚拟机必须正在运行。
- 您必须至少有一个数据卷或持久性卷声明(PVC)可用并为热插。
流程
运行以下命令来热拔虚拟磁盘:
$ virtctl removevolume <virtual-machine|virtual-machine-instance> --volume-name=<datavolume|PVC>
11.19.14.5. 使用 web 控制台热插虚拟磁盘
在虚拟机运行时热插要附加到虚拟机实例(VMI)的虚拟磁盘。当您热插虚拟磁盘时,它会一直附加到 VMI 中,直到您拔出为止。
先决条件
- 您必须有一个正在运行的虚拟机才能热插虚拟磁盘。
流程
- 在侧边菜单中点 Virtualization → VirtualMachines。
- 选择您要热插虚拟磁盘的虚拟机。
- 在 VirtualMachine 详情页面中,点 Configuration → Disks。
- 点 Add disk。
- 在 Add disk(hot plugged) 窗口中,填写您要热插的虚拟磁盘的信息。
- 点击 Save。
11.19.14.6. 使用 web 控制台热拔出虚拟磁盘
在虚拟机运行时,热拔您想要从虚拟机实例(VMI)断开的虚拟磁盘。
先决条件
- 虚拟机必须在连接热插拔磁盘的情况下运行。
流程
- 在侧边菜单中点 Virtualization → VirtualMachines。
- 使用您要热拔的磁盘选择正在运行的虚拟机以打开 VirtualMachine 详情页面。
- 点 Configuration → Disks。
-
点您要热拔的虚拟磁盘旁边的 Options 菜单
,然后选择 Detach。
- 单击 Detach。
11.19.15. 将容器磁盘与虚拟机搭配使用
您可以将虚拟机镜像构建到容器磁盘中,并将其存储在容器 registry 中。然后,您可以将容器磁盘导入虚拟机的持久性存储中,或者将其直接附加到虚拟机临时存储。
如果您使用大型容器磁盘,则 I/O 流量可能会增加,影响 worker 节点。这可能导致不可用的节点。您可以通过以下方法解决这个问题:
11.19.15.1. 关于容器磁盘
容器磁盘是一个虚拟机镜像,它作为容器镜像存储在容器镜像 registry 中。您可以使用容器磁盘将同一磁盘镜像传送到多个虚拟机,并创建大量虚拟机克隆。
容器磁盘可以使用附加到虚拟机的数据卷导入到持久性卷声明(PVC),也可以作为临时 containerDisk 卷直接附加到虚拟机。
11.19.15.1.1. 使用数据卷将容器磁盘导入到 PVC 中
通过 Containerized Data Importer(CDI)使用数据卷将容器磁盘导入到 PVC 中。然后,您可以将数据卷附加到虚拟机以获取持久性存储。
11.19.15.1.2. 将容器磁盘作为 containerDisk 卷附加到虚拟机
containerDisk 卷是临时的。将在虚拟机停止、重启或删除时丢弃。当一个带有 containerDisk 卷的虚拟机启动时,容器镜像从 registry 中拉取,并托管在托管虚拟机的节点上。
将 containerDisk 卷用于只读文件系统,如 CD-ROM 或可处理的虚拟机。
不建议将 containerDisk 卷用于读写文件系统,因为数据是临时写入托管节点上的本地存储。这会减慢虚拟机的实时迁移速度,如节点维护,因为数据必须迁移到目标节点。另外,如果节点断电或者意外关闭,则所有数据都会丢失。
11.19.15.2. 为虚拟机准备容器磁盘
您必须使用虚拟机镜像构建容器磁盘,并将其推送到容器 registry,然后才能用于虚拟机。然后,您可以使用数据卷将容器磁盘导入到 PVC 中,并将其附加到虚拟机,或者将容器磁盘作为临时 containerDisk 卷直接附加到虚拟机。
容器磁盘中磁盘镜像的大小受托管容器磁盘的 registry 的最大层大小的限制。
对于 Red Hat Quay,您可以通过编辑首次部署 Red Hat Quay 时创建的 YAML 配置文件来更改最大层大小。
先决条件
-
如果还没有安装,安装
podman。 - 虚拟机镜像必须是 QCOW2 或 RAW 格式。
流程
创建一个 Dockerfile 以将虚拟机镜像构建到容器镜像中。虚拟机镜像必须属于 QEMU,其 UID 为
107,并放置在容器的/disk/目录中。/disk/目录的权限必须设为0440。以下示例在第一阶段使用 Red Hat Universal Base Image(UBI)来处理这些配置更改,并使用第二阶段中的最小
scratch镜像存储结果:$ cat > Dockerfile << EOF FROM registry.access.redhat.com/ubi8/ubi:latest AS builder ADD --chown=107:107 <vm_image>.qcow2 /disk/1 RUN chmod 0440 /disk/* FROM scratch COPY --from=builder /disk/* /disk/ EOF- 1
- 其中,<vm_image> 是 QCOW2 或 RAW 格式的虚拟机镜像。
要使用远程虚拟机镜像,将<vm_image>.qcow2替换为远程镜像的完整 url。
构建和标记容器:
$ podman build -t <registry>/<container_disk_name>:latest .将容器镜像推送到 registry:
$ podman push <registry>/<container_disk_name>:latest
如果容器镜像敞开没有 TLS,您必须将其添加为一个不安全的容器镜像仓库,然后才能将容器磁盘导入持久性存储。
11.19.15.3. 禁用容器镜像仓库的 TLS,以用作不安全的容器镜像仓库
您可以通过编辑 HyperConverged 自定义资源的 insecureRegistries 字段来禁用一个或多个容器 registry 的 TLS(传输层安全)。
先决条件
-
以具有
cluster-admin角色的用户身份登录集群。
流程
编辑
HyperConverged自定义资源,将不安全 registry 列表添加到spec.storageImport.insecureRegistries字段中。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: storageImport: insecureRegistries:1 - "private-registry-example-1:5000" - "private-registry-example-2:5000"- 1
- 将此列表中的示例替换为有效的 registry 主机名。
11.19.15.4. 后续步骤
- 将容器磁盘导入虚拟机的持久性存储中。
-
创建一个虚拟机,它使用一个
containerDisk卷作为临时存储。
11.19.16. 准备 CDI 涂销空间
11.19.16.1. 关于数据卷
DataVolume 对象是 Containerized Data Importer (CDI) 项目提供的自定义资源。DataVolume 编配与底层持久性卷声明(PVC)关联的导入、克隆和上传操作。您可以将数据卷创建为独立资源,也可以使用虚拟机 (VM) 规格中的 dataVolumeTemplate 字段。
-
使用独立数据卷准备的虚拟机磁盘 PVC,维护虚拟机的独立生命周期。如果您使用虚拟机规格中的
dataVolumeTemplate字段准备 PVC,PVC 会共享与虚拟机相同的生命周期。
11.19.16.2. 关于涂销空间
Containerized Data Importer (CDI) 需要涂销空间(临时存储)来完成一些操作,如导入和上传虚拟机镜像。在此过程中,CDI 会提供一个与支持目标数据卷(DV)的 PVC 大小相等的涂销空间 PVC。该涂销空间 PVC 将在操作完成或中止后删除。
您可以在 HyperConverged 自定义资源的 spec.scratchSpaceStorageClass 字段中定义绑定涂销空间 PVC 的存储类。
如果定义的存储类与集群中的存储类不匹配,则会使用为集群定义的默认存储类。如果没有在集群中定义默认存储类,则会使用置备原始 DV 或 PVC 的存储类。
CDI 需要通过 file 卷模式来请求涂销空间,与支持原始数据卷的 PVC 无关。如果 block 卷模式支持原始 PVC,则您必须定义一个能够置备 file 卷模式 PVC 的 StorageClass。
手动调配
如果没有存储类,CDI 将使用项目中与镜像的大小要求匹配的任何 PVC。如果没有与这些要求匹配的 PVC,则 CDI 导入 Pod 将保持 Pending 状态,直至有适当的 PVC 可用或直至超时功能关闭 Pod。
11.19.16.3. 需要涂销空间的 CDI 操作
| 类型 | 原因 |
|---|---|
| registry 导入 | CDI 必须下载镜像至涂销空间,并对层进行提取,以查找镜像文件。然后镜像文件传递至 QEMU-IMG 以转换成原始磁盘。 |
| 上传镜像 | QEMU-IMG 不接受来自 STDIN 的输入。相反,要上传的镜像保存到涂销空间中,然后才可传递至 QEMU-IMG 进行转换。 |
| 存档镜像的 HTTP 导入 | QEMU-IMG 不知道如何处理 CDI 支持的存档格式。相反,镜像取消存档并保存到涂销空间中,然后再传递至 QEMU-IMG。 |
| 经过身份验证的镜像的 HTTP 导入 | QEMU-IMG 未充分处理身份验证。相反,镜像保存到涂销空间中并进行身份验证,然后再传递至 QEMU-IMG。 |
| 自定义证书的 HTTP 导入 | QEMU-IMG 未充分处理 HTTPS 端点的自定义证书。相反,CDI 下载镜像到涂销空间,然后再将文件传递至 QEMU-IMG。 |
11.19.16.4. 定义存储类
您可以通过将 spec.scratchSpaceStorageClass 字段添加到 HyperConverged 自定义资源(CR)来定义 Containerized Data Importer(CDI)在分配涂销空间时使用的存储类。
先决条件
-
安装 OpenShift CLI (
oc) 。
流程
运行以下命令来编辑
HyperConvergedCR:$ oc edit hco -n openshift-cnv kubevirt-hyperconverged将
spec.scratchSpaceStorageClass字段添加到 CR,将值设置为集群中存在的存储类的名称:apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: scratchSpaceStorageClass: "<storage_class>"1 - 1
- 如果您没有指定存储类,CDI 将使用正在填充的持久性卷声明的存储类。
-
保存并退出默认编辑器以更新
HyperConvergedCR。
11.19.16.5. CDI 支持的操作列表
此列表针对端点显示内容类型支持的 CDI 操作,以及哪些操作需要涂销空间(scratch space)。
| 内容类型 | HTTP | HTTPS | HTTP 基本身份验证 | Registry | 上传 |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) |
✓ QCOW2 |
✓ QCOW2** |
✓ QCOW2 |
✓ QCOW2* |
✓ QCOW2* |
| KubeVirt (RAW) |
✓ RAW |
✓ RAW |
✓ RAW |
✓ RAW* |
✓ RAW* |
✓ 支持的操作
□ 不支持的操作
* 需要涂销空间
** 如果需要自定义证书颁发机构,则需要涂销空间
11.19.17. 重新使用持久性卷
要重新使用静态置备的持久性卷(PV),,您必须首先重新声明该卷。这涉及删除 PV,以便重新使用存储配置。
11.19.17.1. 关于重新声明静态置备的持久性卷
当重新声明持久性卷(PV)时,您从持久性卷声明(PVC)中卸载 PV 并删除 PV。根据底层存储,您可能需要手动删除共享存储。
然后,您可以重新使用 PV 配置来创建具有不同名称的 PV。
静态置备的 PV 必须具有 Retain 的重新声明策略才能重新声明。如果没有,则当 PVC 取消和 PV 的绑定后,PV 将进入失败的状态。
在 OpenShift Container Platform 4 中, Recycle 重新声明策略已被弃用。
11.19.17.2. 重新声明静态置备的持久性卷
通过取消绑定持久性卷声明(PVC)并删除 PV 重新声明静态置备的持久性卷(PV)。您可能还需要手动删除共享存储。
重新声明静态置备的 PV 依赖于底层存储。此流程提供一般方法,可能需要根据您的存储进行调整。
流程
确保 PV 的 reclaim 策略被设置为
Retain:检查 PV 上的 reclaim 策略:
$ oc get pv <pv_name> -o yaml | grep 'persistentVolumeReclaimPolicy'如果
persistentVolumeReclaimPolicy没有设置为Retain,使用以下命令编辑 reclaim 策略:$ oc patch pv <pv_name> -p '{"spec":{"persistentVolumeReclaimPolicy":"Retain"}}'
确保没有资源在使用 PV:
$ oc describe pvc <pvc_name> | grep 'Mounted By:'在继续操作前,删除所有使用 PVC 的资源。
删除 PVC 以释放 PV:
$ oc delete pvc <pvc_name>可选:将 PV 配置导出到 YAML 文件。如果在稍后手动删除共享存储,您可以参考此配置。您还可以使用该文件中的
spec参数作为基础,在重新声明 PV 后创建具有相同存储配置的新 PV:$ oc get pv <pv_name> -o yaml > <file_name>.yaml删除 PV:
$ oc delete pv <pv_name>可选:根据存储类型,您可能需要删除共享存储文件夹的内容:
$ rm -rf <path_to_share_storage>可选:创建一个使用与删除 PV 相同的存储配置的 PV。如果您之前导出了重新声明的 PV 配置,您可以使用该文件的
spec参数作为新 PV 清单的基础:注意为了避免可能的冲突,最好为新 PV 对象赋予与您删除的名称不同的名称。
$ oc create -f <new_pv_name>.yaml
11.19.18. 扩展虚拟机磁盘
您可以通过调整磁盘持久性卷声明(PVC)大小来扩大虚拟机(VM)磁盘的大小,以提供更大的存储容量。
但是,您无法缩小虚拟机磁盘的大小。
11.19.18.1. 划分虚拟机磁盘
虚拟机 (VM) 磁盘放大功能可以为虚拟机提供更多空间。但是,虚拟机所有者负责决定如何使用存储。
如果磁盘是一个 Filesystem PVC,则匹配的文件会扩展到剩余大小,同时为文件系统开销保留一些空间。
流程
编辑您要扩展的虚拟机磁盘的
PersistentVolumeClaim清单:$ oc edit pvc <pvc_name>更新磁盘大小:
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: vm-disk-expand spec: accessModes: - ReadWriteMany resources: requests: storage: 3Gi1 # ...- 1
- 指定新磁盘大小。
第 12 章 虚拟机模板
12.1. 创建虚拟机模板
12.1.1. 关于虚拟机模板
Virtualization → Templates 页面中列出了预先配置的红帽虚拟机模板。这些模板适用于 Red Hat Enterprise Linux、Fedora、微软 Windows 10 和 Microsoft Windows Servers 的不同版本。每个红帽虚拟机模板都预先配置了操作系统镜像、操作系统的默认设置、类型(CPU 和内存)以及工作负载类型(server)。
Templates 页面中显示四个类型的虚拟机模板:
- 红帽支持的模板完全被红帽模板。
- 用户支持的模板 红帽支持的 模板,但由用户克隆并创建。
- 红帽提供的模板,红帽会提供有限的支持。
- 用户提供的模板是由 红帽提供的,但由用户克隆和创建的模板。
您可以使用模板目录中的过滤器,按照引导源可用性、操作系统和工作负载等属性对模板进行排序。
您不能编辑或删除 Red Hat Supported 或 Red Hat Provided 模板。您可以克隆模板,将其保存为自定义虚拟机模板,然后编辑该模板。
您还可以通过编辑 YAML 文件示例来创建自定义虚拟机模板。
12.1.2. 关于虚拟机和引导源
虚拟机由虚拟机定义以及由数据卷支持的一个或多个磁盘组成。虚拟机模板允许您使用预定义的虚拟机规格创建虚拟机。
每个虚拟机模板都需要一个引导源,它是一个完全配置的虚拟机磁盘镜像,包括配置的驱动程序。每个虚拟机模板包含一个虚拟机定义,其中包含指向引导源的指针。每个引导源都有一个预定义的名称和命名空间。对于某些操作系统,会自动提供一个引导源。如果没有提供,管理员必须准备自定义引导源。
提供的引导源会自动更新至操作系统的最新版本。对于自动更新的引导源,持久性卷声明(PVC)使用集群的默认存储类创建。如果在配置后选择了不同的默认存储类,您必须删除使用之前的默认存储类配置的集群命名空间中的现有数据卷。
要使用引导源功能,请安装 OpenShift Virtualization 的最新版本。命名空间 openshift-virtualization-os-images 启用该功能,并安装 OpenShift Virtualization Operator。安装引导源功能后,您可以创建引导源,将它们附加到模板,并从模板创建虚拟机。
使用通过上传本地文件、克隆现有 PVC、从 registry 或 URL 导入的持久性卷声明(PVC)定义引导源。使用 web 控制台将引导源附加到虚拟机模板。在启动源附加到虚拟机模板后,您可从模板创建任意数量的已完全配置的可随时使用虚拟机。
12.1.3. 在 web 控制台中创建虚拟机模板
您可以通过编辑 OpenShift Container Platform web 控制台中的 YAML 文件示例来创建虚拟机模板。
流程
- 在 web 控制台中,在侧边菜单中点 Virtualization → Templates。
-
可选:使用 Project 下拉菜单更改与新模板关联的项目。所有模板都默认保存到
openshift项目中。 - 点 Create Template。
- 通过编辑 YAML 文件来指定模板参数。
点 Create。
模板显示在 Templates 页面中。
- 可选:点 Download 下载并保存 YAML 文件。
12.1.4. 为虚拟机模板添加引导源
对于您要用于创建虚拟机或自定义模板的任何虚拟机模板,可以配置引导源。当使用引导源配置虚拟机模板时,会在 Templates 页面中被标记为 Source。在向模板中添加引导源后,您可以使用该模板创建新虚拟机。
在 web 控制台中选择和添加引导源有四个方法:
- 上传本地文件(创建 PVC)
- URL(创建 PVC)
- Clone(创建 PVC)
- Registry(创建 PVC)
先决条件
-
要添加引导源,您必须以具有
os-images.kubevirt.io:editRBAC 角色或管理员的用户身份登录。您不需要特殊权限才能从附加了引导源的模板创建虚拟机。 - 要上传本地文件,操作系统镜像文件必须存在于本地机器中。
- 要通过 URL 导入,您需要访问带操作系统镜像的 web 服务器。例如:带有镜像的 Red Hat Enterprise Linux 网页。
- 要克隆现有的 PVC,需要使用 PVC 访问项目。
- 要通过 registry 导入,需要访问容器 registry。
流程
- 在 OpenShift Container Platform 控制台中,从侧边菜单中点 Virtualization → Templates。
- 点模板旁边的选项菜单,然后选择 Edit boot source。
- 点 Add disk。
- 在 Add disk 窗口中,选择 Use this disk 作为引导源。
- 输入磁盘名称并选择 Source,例如 Blank (创建 PVC)。
- 为 持久性卷声明大小 输入一个值,以指定适合未压缩镜像的 PVC 大小,以及任何需要的额外空间。
- 选择一个 类型,如 Disk。
可选:点 Storage class 并选择用于创建磁盘的存储类。通常,这个存储类是创建供所有 PVC 使用的默认存储类。
注意提供的引导源会自动更新至操作系统的最新版本。对于自动更新的引导源,持久性卷声明(PVC)使用集群的默认存储类创建。如果在配置后选择了不同的默认存储类,您必须删除使用之前的默认存储类配置的集群命名空间中的现有数据卷。
- 可选:清除 Apply optimized StorageProfile settings,以编辑访问模式或卷模式。
选择保存引导源的适当方法:
- 如果您上传一个本地文件,请点击 Save and upload。
- 如果从 URL 或 registry 中导入内容,点 Save and import。
- 如果克隆现有的 PVC,点 Save and clone。
Catalog 页面中列出了带有引导源的自定义虚拟机模板。您可以使用此模板创建虚拟机。
12.1.4.1. 用于添加引导源的虚拟机模板字段
下表描述了在 模板窗口中添加引导源的字段。当您点 Virtualization → Templates 页面中的虚拟机模板的 Add source 时会显示此窗口。
| Name | 参数 | 描述 |
|---|---|---|
| 引导源类型 | 上传本地文件(创建 PVC) | 从本地设备上传文件。支持的文件类型包括 gz、xz、tar 和 qcow2。 |
| URL(创建 PVC) | 从 HTTP 或 HTTPS 端点提供的镜像导入内容。从镜像下载可用的网页中获取下载链接 URL,并在 Import URL 字段中输入该 URL 链接。示例:对于 Red Hat Enterprise Linux 镜像,登录到红帽客户门户网站,访问进行下载页面,并复制 KVM 客户机镜像的下载链接 URL。 | |
| PVC(创建 PVC) | 使用集群中已可用的 PVC 并克隆它。 | |
| Registry(创建 PVC) | 指定位于 registry 中并可从集群访问的可引导操作系统容器。示例: kubevirt/cirros-registry-dis-demo。 | |
| 源供应商 | 可选字段。添加有关模板源的描述性文本,或者创建模板的用户名称。例如:Red Hat。 | |
| 高级存储设置 | StorageClass | 用于创建磁盘的存储类。 |
| 访问模式 |
持久性卷访问模式。支持的访问模式有: 单用户(RWO)、 共享访问(RWX) 和 只读(ROX)。如果选择了 Single User(RWO),则该磁盘可以被单一节点以读写模式挂载。如果选择了 Shared Access(RWX),则该磁盘可以被多个节点以读写模式挂载。 注意 对一些功能(如虚拟机在节点间实时迁移)需要共享访问(RWX)。 | |
| 卷模式 |
定义持久性卷是否使用格式化的文件系统或原始块状态。支持的模式是 Block 和 Filesystem。 |
12.2. 编辑虚拟机模板
您可在 web 控制台中编辑虚拟机模板。
您不能编辑 Red Hat Virtualization Operator 提供的模板。如果克隆模板,您可以编辑该模板。
12.2.1. 在 web 控制台中编辑虚拟机模板
您可以使用 OpenShift Container Platform web 控制台或命令行界面编辑虚拟机模板。
编辑虚拟机模板不会影响已经从该模板中创建的虚拟机。
流程
- 在 web 控制台中进入到 Virtualization → Templates。
-
点虚拟机模板旁边的
Options 菜单并选择要编辑的对象。
要编辑红帽模板,点
Options 菜单,选择 Clone 来创建自定义模板,然后编辑自定义模板。
注意如果模板的数据源由
DataImportCron自定义资源管理,或者模板没有数据卷引用,则 编辑引导源 引用被禁用。- 点击 Save。
12.2.1.1. 将网络接口添加到虚拟机模板
将网络接口添加到虚拟机模板。
流程
- 从侧边菜单中点 Virtualization → Templates。
- 选择虚拟机模板以打开 Template 详情页面。
- 在 Network interfaces 选项卡中,点 Add Network Interface。
- 在 Add Network Interface 窗口中,指定网络接口的 Name、Model、Network、Type 和 MAC Address。
- 点击 Add。
12.2.1.2. 将虚拟磁盘添加到虚拟机模板
使用这个步骤将虚拟磁盘添加到虚拟机模板。
流程
- 从侧边菜单中点 Virtualization → Templates。
- 选择虚拟机模板以打开 Template 详情页面。
- 在 Disks 选项卡上,点 Add disk。
指定 Source、Name、Size、Type、Interface 和 Storage Class。
- 可选:如果您使用空磁盘源并在创建数据卷时要求最大写入性能,则可以启用预分配。如果要这样做,可选中启用预分配复选框。
-
可选:您可以清除 Apply optimized StorageProfile 设置,以更改虚拟磁盘的卷模式和访问模式。如果没有指定这些参数,系统将使用
kubevirt-storage-class-defaults配置映射中的默认值。
- 点击 Add。
12.3. 为虚拟机模板启用专用资源
虚拟机可以具有一个节点的资源,比如 CPU,以便提高性能。
12.3.1. 关于专用资源
当为您的虚拟机启用专用资源时,您的工作负载将会在不会被其他进程使用的 CPU 上调度。通过使用专用资源,您可以提高虚拟机性能以及延迟预测的准确性。
12.3.2. 先决条件
-
节点上必须配置 CPU Manager。在调度虚拟机工作负载前,请确认节点具有
cpumanager=true标签。
12.3.3. 为虚拟机模板启用专用资源
您可以在 Details 选项卡中为虚拟机模板启用专用资源。从红帽模板创建的虚拟机可以使用专用资源进行配置。
流程
- 在 OpenShift Container Platform 控制台中,从侧边菜单中点 Virtualization → Templates。
- 选择虚拟机模板以打开 Template 详情页面。
- 在 Scheduling 选项卡中,点 Dedicated Resources 旁边的编辑图标。
- 选择 Schedule this workload with dedicated resources (guaranteed policy)。
- 点击 Save。
12.4. 将虚拟机模板部署到自定义命名空间
红帽提供在 openshift 命名空间中安装的预配置虚拟机模板。默认情况下,ssp-operator 将虚拟机模板部署到 openshift 命名空间。openshift 命名空间中的模板可公开供所有用户使用。这些模板列在不同操作系统的 Virtualization → Templates 页面中。
12.4.1. 为模板创建自定义命名空间
您可以创建一个自定义命名空间,用于部署虚拟机模板,供具有访问这些模板权限的任何人使用。要将模板添加到自定义命名空间,请编辑 HyperConverged 自定义资源(CR),将 commonTemplatesNamespace 添加到 spec,并为虚拟机模板指定自定义命名空间。修改了 HyperConverged CR 后,ssp-operator 会填充自定义命名空间中的模板。
先决条件
-
安装 OpenShift Container Platform CLI
oc。 - 以具有 cluster-admin 权限的用户身份登录。
流程
使用以下命令创建自定义命名空间:
$ oc create namespace <mycustomnamespace>
12.4.2. 将模板添加到自定义命名空间中
默认情况下,ssp-operator 将虚拟机模板部署到 openshift 命名空间。openshift 命名空间中的模板对所有用户都公开。当创建自定义命名空间并添加到该命名空间中时,您可以修改或删除 openshift 命名空间中的虚拟机模板。要将模板添加到自定义命名空间,请编辑包含 ssp-operator 的 HyperConverged 自定义资源(CR)。
流程
查看
openshift命名空间中可用的虚拟机模板列表。$ oc get templates -n openshift运行以下命令,在默认编辑器中编辑
HyperConvergedCR:$ oc edit hco -n openshift-cnv kubevirt-hyperconverged查看自定义命名空间中可用的虚拟机模板列表。
$ oc get templates -n customnamespace添加
commonTemplatesNamespace属性并指定自定义命名空间。Example:apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: commonTemplatesNamespace: customnamespace1 - 1
- 用于部署模板的自定义命名空间。
-
保存更改并退出编辑器。
ssp-operator将默认openshift命名空间中存在的虚拟机模板添加到自定义命名空间中。
12.4.2.1. 从自定义命名空间中删除模板
要从自定义命名空间中删除虚拟机模板,请从 HyperConverged 自定义资源(CR)中删除 commonTemplateNamespace 属性,并从那个自定义命名空间中删除每个模板。
流程
运行以下命令,在默认编辑器中编辑
HyperConvergedCR:$ oc edit hco -n openshift-cnv kubevirt-hyperconverged删除
commonTemplateNamespace属性。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: commonTemplatesNamespace: customnamespace1 - 1
- 要删除的
commonTemplatesNamespace属性。
从已删除的自定义命名空间中删除特定模板。
$ oc delete templates -n customnamespace <template_name>
验证
验证模板是否已从自定义命名空间中删除。
$ oc get templates -n customnamespace
12.5. 删除虚拟机模板
您可以使用 web 控制台删除基于红帽模板的自定义虚拟机模板。
您不能删除红帽模板。
12.5.1. 删除 web 控制台中的虚拟机模板
删除虚拟机模板会将其从集群中永久移除。
您可以删除自定义虚拟机模板。您不能删除红帽提供的模板。
流程
- 在 OpenShift Container Platform 控制台中,从侧边菜单中点 Virtualization → Templates。
-
点模板的 Options 菜单
并选择 Delete template。
- 点击 Delete。
12.6. 创建并使用引导源
引导源包含可引导操作系统(OS)以及操作系统的所有配置设置,如驱动程序。
您可以使用引导源创建带有特定配置的虚拟机模板。这些模板可用于创建任意数量的可用虚拟机。
OpenShift Container Platform Web 控制台提供了快速入门导览,可帮助您创建自定义引导源、上传引导源和其他任务。从 Help 菜单中选择 Quick Starts 以查看快速入门。
12.6.1. 关于虚拟机和引导源
虚拟机由虚拟机定义以及由数据卷支持的一个或多个磁盘组成。虚拟机模板允许您使用预定义的虚拟机规格创建虚拟机。
每个虚拟机模板都需要一个引导源,它是一个完全配置的虚拟机磁盘镜像,包括配置的驱动程序。每个虚拟机模板包含一个虚拟机定义,其中包含指向引导源的指针。每个引导源都有一个预定义的名称和命名空间。对于某些操作系统,会自动提供一个引导源。如果没有提供,管理员必须准备自定义引导源。
提供的引导源会自动更新至操作系统的最新版本。对于自动更新的引导源,持久性卷声明(PVC)使用集群的默认存储类创建。如果在配置后选择了不同的默认存储类,您必须删除使用之前的默认存储类配置的集群命名空间中的现有数据卷。
要使用引导源功能,请安装 OpenShift Virtualization 的最新版本。命名空间 openshift-virtualization-os-images 启用该功能,并安装 OpenShift Virtualization Operator。安装引导源功能后,您可以创建引导源,将它们附加到模板,并从模板创建虚拟机。
使用通过上传本地文件、克隆现有 PVC、从 registry 或 URL 导入的持久性卷声明(PVC)定义引导源。使用 web 控制台将引导源附加到虚拟机模板。在启动源附加到虚拟机模板后,您可从模板创建任意数量的已完全配置的可随时使用虚拟机。
12.6.2. 将 RHEL 镜像导入为引导源
您可以通过指定镜像的 URL 来导入 Red Hat Enterprise Linux(RHEL)镜像作为引导源。
先决条件
- 您必须有权访问带有操作系统镜像的网页。例如:使用镜像下载 Red Hat Enterprise Linux 网页。
流程
- 在 OpenShift Container Platform 控制台中,从侧边菜单中点 Virtualization → Templates。
- 找到您要为其配置引导源的 RHEL 模板并点 Add source。
- 在 Add boot source to template 窗口中,从 Boot source type 列表中选择 URL(creates PVC)。
- 点击 RHEL 下载页面 访问红帽客户门户。下载 Red Hat Enterprise Linux 页面中显示可用安装程序和镜像的列表。
- 确定您要下载的 Red Hat Enterprise Linux KVM 客户机镜像。右键单击 Download Now,再复制镜像的 URL。
- 在 Add boot source to template 窗口中,将 URL 粘贴到 Import URL 字段中,然后点 Save and import。
验证
- 验证模板在 Templates 页面上的 Boot source 列中显示绿色勾号。
现在,您可以使用此模板创建 RHEL 虚拟机。
12.6.3. 为虚拟机模板添加引导源
对于您要用于创建虚拟机或自定义模板的任何虚拟机模板,可以配置引导源。当使用引导源配置虚拟机模板时,会在 Templates 页面中被标记为 Source。在向模板中添加引导源后,您可以使用该模板创建新虚拟机。
在 web 控制台中选择和添加引导源有四个方法:
- 上传本地文件(创建 PVC)
- URL(创建 PVC)
- Clone(创建 PVC)
- Registry(创建 PVC)
先决条件
-
要添加引导源,您必须以具有
os-images.kubevirt.io:editRBAC 角色或管理员的用户身份登录。您不需要特殊权限才能从附加了引导源的模板创建虚拟机。 - 要上传本地文件,操作系统镜像文件必须存在于本地机器中。
- 要通过 URL 导入,您需要访问带操作系统镜像的 web 服务器。例如:带有镜像的 Red Hat Enterprise Linux 网页。
- 要克隆现有的 PVC,需要使用 PVC 访问项目。
- 要通过 registry 导入,需要访问容器 registry。
流程
- 在 OpenShift Container Platform 控制台中,从侧边菜单中点 Virtualization → Templates。
- 点模板旁边的选项菜单,然后选择 Edit boot source。
- 点 Add disk。
- 在 Add disk 窗口中,选择 Use this disk 作为引导源。
- 输入磁盘名称并选择 Source,例如 Blank (创建 PVC)。
- 为 持久性卷声明大小 输入一个值,以指定适合未压缩镜像的 PVC 大小,以及任何需要的额外空间。
- 选择一个 类型,如 Disk。
可选:点 Storage class 并选择用于创建磁盘的存储类。通常,这个存储类是创建供所有 PVC 使用的默认存储类。
注意提供的引导源会自动更新至操作系统的最新版本。对于自动更新的引导源,持久性卷声明(PVC)使用集群的默认存储类创建。如果在配置后选择了不同的默认存储类,您必须删除使用之前的默认存储类配置的集群命名空间中的现有数据卷。
- 可选:清除 Apply optimized StorageProfile settings,以编辑访问模式或卷模式。
选择保存引导源的适当方法:
- 如果您上传一个本地文件,请点击 Save and upload。
- 如果从 URL 或 registry 中导入内容,点 Save and import。
- 如果克隆现有的 PVC,点 Save and clone。
Catalog 页面中列出了带有引导源的自定义虚拟机模板。您可以使用此模板创建虚拟机。
12.6.4. 从带有附加引导源的模板创建虚拟机
将引导源添加到模板后,即可从模板创建虚拟机。
流程
- 在 OpenShift Container Platform web 控制台中,在侧边菜单中点 Virtualization → Catalog。
- 选择更新的模板并点 Quick create VirtualMachine。
VirtualMachine 详情会显示状态为 Starting。
12.7. 管理自动引导源更新
管理自动引导源更新。
12.7.1. 关于自动引导源更新
通过引导源,可让虚拟机 (VM) 的创建更容易和高效。如果启用了自动引导源更新,Containerized Data Importer (CDI) 导入、轮询和更新镜像,以便为新虚拟机克隆它们。默认情况下,CDI 自动更新 OpenShift Virtualization 提供的系统定义的引导源。
您可以通过禁用 enableCommonBootImageImport 功能门,选择对所有系统定义的引导源的自动更新。如果您禁用这个功能门,则所有 DataImportCron 对象都会被删除。这不会删除之前导入的 PersistentVolumeClaim (PVC) 对象来存储操作系统镜像,但管理员可以手动删除它们。
当禁用 enableCommonBootImageImport 功能门时,DataSource 对象会被重置,以便它们不再指向原始 PVC。管理员可以通过为 DataSource 对象创建新 PVC,并使用操作系统镜像填充 PVC 来手动提供引导源。
不是由 OpenShift Virtualization 提供的自定义引导源不受功能门控制。您必须通过编辑 HyperConverged 自定义资源 (CR) 来单独管理它们。您还可以使用此方法管理各个系统定义的引导源。
12.7.2. 为所有系统引导源启用或禁用自动更新
使用功能门控制所有系统定义的引导源的自动更新。
12.7.2.1. 为所有系统定义的引导源管理自动更新
禁用自动引导源导入和更新可能会降低资源使用量。在断开连接的环境中,禁用自动引导源更新可防止 CDIDataImportCronOutdated 警报填满日志。
要禁用所有系统定义的引导源的自动更新,请通过将值设为 false 来关闭 enableCommonBootImageImport 功能门。将此值设置为 true 可重新启用功能门并重新打开自动更新。
自定义引导源不受此设置的影响。
流程
通过编辑
HyperConverged自定义资源 (CR) 为自动引导源更新切换功能门。要禁用自动引导源更新,请将
HyperConvergedCR 中的spec.featureGates.enableCommonBootImageImport字段设置为false。例如:$ oc patch hco kubevirt-hyperconverged -n openshift-cnv \ --type json -p '[{"op": "replace", "path": \ "/spec/featureGates/enableCommonBootImageImport", \ "value": false}]'要重新启用自动引导源更新,请将
HyperConvergedCR 中的spec.featureGates.enableCommonBootImageImport字段设置为true。例如:$ oc patch hco kubevirt-hyperconverged -n openshift-cnv \ --type json -p '[{"op": "replace", "path": \ "/spec/featureGates/enableCommonBootImageImport", \ "value": true}]'
12.7.3. 为自定义引导源启用自动更新
确保集群具有默认存储类。然后,为自定义引导源启用自动更新。
12.7.3.1. 为自定义引导源更新配置存储类
在 HyperConverged 自定义资源 (CR) 中指定新的默认存储类。
引导源使用默认存储类从存储创建。如果您的集群没有默认存储类,则必须在为自定义引导源配置自动更新前定义一个。
流程
运行以下命令,在默认编辑器中打开
HyperConvergedCR:$ oc edit hco -n openshift-cnv kubevirt-hyperconverged通过在
storageClassName字段中输入值来定义新的存储类:apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: dataImportCronTemplates: - metadata: name: rhel8-image-cron spec: template: spec: storageClassName: <new_storage_class>1 #...- 1
- 定义存储类。
从当前的默认存储类中删除
storageclass.kubernetes.io/is-default-class注解。运行以下命令,检索当前默认存储类的名称:
$ oc get sc输出示例
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE csi-manila-ceph manila.csi.openstack.org Delete Immediate false 11d hostpath-csi-basic (default) kubevirt.io.hostpath-provisioner Delete WaitForFirstConsumer false 11d1 ...- 1
- 在本例中,当前的默认存储类名为
hostpath-csi-basic。
运行以下命令,从当前默认存储类中删除注解:
$ oc patch storageclass <current_default_storage_class> -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'1 - 1
- 将
<current_default_storage_class>替换为默认存储类的storageClassName值。
运行以下命令,将新存储类设置为默认值:
$ oc patch storageclass <new_storage_class> -p '{"metadata":{"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'1 - 1
- 将
<new_storage_class>替换为添加到HyperConvergedCR 中的storageClassName值。
12.7.3.2. 为自定义引导源启用自动更新
OpenShift Virtualization 默认自动更新系统定义的引导源,但不会自动更新自定义引导源。您必须通过编辑 HyperConverged 自定义资源 (CR) 手动启用自动更新。
先决条件
- 集群有一个默认存储类。
流程
运行以下命令,在默认编辑器中打开
HyperConvergedCR:$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv编辑
HyperConvergedCR,在dataImportCronTemplates部分添加适当的模板和引导源。例如:自定义资源示例
apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: dataImportCronTemplates: - metadata: name: centos7-image-cron annotations: cdi.kubevirt.io/storage.bind.immediate.requested: "true"1 spec: schedule: "0 */12 * * *"2 template: spec: source: registry:3 url: docker://quay.io/containerdisks/centos:7-2009 storage: resources: requests: storage: 10Gi managedDataSource: centos74 retentionPolicy: "None"5 - 1
- 对于将
volumeBindingMode设置为WaitForFirstConsumer的存储类来说,这个注解是必需的。 - 2
- 以 cron 格式指定的作业调度计划。
- 3
- 用于从 registry 源创建数据卷。使用默认
podpullMethod而不是节点pullMethod,这基于节点docker 缓存。当 registry 镜像通过Container.Image可用时,节点docker 缓存很有用,但 CDI 导入程序没有授权访问它。 - 4
- 要使自定义镜像被检测到为可用的引导源,镜像的
managedDataSource的名称必须与模板的DataSource的名称匹配,它在 VM 模板 YAML 文件中的spec.dataVolumeTemplates.spec.sourceRef.name下找到。 - 5
- 在删除 cron 作业时,使用
All来保留数据卷和数据源。删除 cron 作业时,使用None删除数据卷和数据源。
- 保存该文件。
12.7.4. 禁用特定引导源的自动更新
禁用单个引导源的自动更新。
12.7.4.1. 为单个引导源禁用自动更新
您可以通过编辑 HyperConverged 自定义资源 (CR) 禁用单个引导源的自动更新,无论是自定义还是系统定义。
流程
运行以下命令,在默认编辑器中打开
HyperConvergedCR:$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv通过编辑
spec.dataImportCronTemplates字段来禁用单个引导源的自动更新。- 自定义引导源
-
从
spec.dataImportCronTemplates字段删除引导源。在默认情况下,自定义引导源禁用了自动更新。
-
从
- 系统定义的引导源
将引导源添加到
spec.dataImportCronTemplates。注意对于系统定义的引导源,默认启用自动更新,但除非添加它们,否则这些引导源不会在 CR 中列出。
将
dataimportcrontemplate.kubevirt.io/enable注解的值设置为'false'。例如:
apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: dataImportCronTemplates: - metadata: annotations: dataimportcrontemplate.kubevirt.io/enable: 'false' name: rhel8-image-cron # ...
- 保存该文件。
12.7.5. 验证引导源的状态
您可以通过查看 HyperConverged 自定义资源(CR)来确定引导源是否为系统定义或自定义。
流程
运行以下命令,查看
HyperConvergedCR 的内容:$ oc get hco -n openshift-cnv kubevirt-hyperconverged -o yaml输出示例
apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: # ... status: # ... dataImportCronTemplates: - metadata: annotations: cdi.kubevirt.io/storage.bind.immediate.requested: "true" name: centos-7-image-cron spec: garbageCollect: Outdated managedDataSource: centos7 schedule: 55 8/12 * * * template: metadata: {} spec: source: registry: url: docker://quay.io/containerdisks/centos:7-2009 storage: resources: requests: storage: 30Gi status: {} status: commonTemplate: true1 # ... - metadata: annotations: cdi.kubevirt.io/storage.bind.immediate.requested: "true" name: user-defined-dic spec: garbageCollect: Outdated managedDataSource: user-defined-centos-stream8 schedule: 55 8/12 * * * template: metadata: {} spec: source: registry: pullMethod: node url: docker://quay.io/containerdisks/centos-stream:8 storage: resources: requests: storage: 30Gi status: {} status: {}2 # ...通过查看
status.dataImportCronTemplates.status字段来验证引导源的状态。-
如果字段包含
commonTemplate: true,则它是一个系统定义的引导源。 -
如果
status.dataImportCronTemplates.status字段的值为{},则它是一个自定义引导源。
-
如果字段包含
第 13 章 实时迁移
13.1. 虚拟机实时迁移
13.1.1. 关于实时迁移
实时迁移是在不中断虚拟工作负载或访问的情况下,将正在运行的虚拟机实例(VMI)迁移到集群中另一节点的过程。如果 VMI 使用 LiveMigrate 驱除策略,它会在 VMI 运行的节点置于维护模式时自动迁移。您还可以选择要迁移的 VMI 手动启动实时迁移。
如果满足以下条件,您可以使用实时迁移:
-
使用
ReadWriteMany(RWX)访问模式的共享存储. - 足够的 RAM 和网络带宽。
- 如果虚拟机使用主机型号 CPU,则节点必须支持虚拟机的主机型号 CPU。
默认情况下,实时迁移流量使用传输层安全 (TLS) 加密。
13.2. 实时迁移限制和超时
应用实时迁移限制和超时,以便迁移过程不会给集群造成负担。通过编辑 HyperConverged 自定义资源(CR)来配置这些设置。
13.2.1. 配置实时迁移限制和超时
通过更新位于 openshift-cnv 命名空间中的 HyperConverged 自定义资源(CR)为集群配置实时迁移限制和超时。
流程
编辑
HyperConvergedCR 并添加必要的实时迁移参数。$ oc edit hco -n openshift-cnv kubevirt-hyperconverged配置文件示例
apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: liveMigrationConfig:1 bandwidthPerMigration: 64Mi completionTimeoutPerGiB: 800 parallelMigrationsPerCluster: 5 parallelOutboundMigrationsPerNode: 2 progressTimeout: 150- 1
- 在本例中,
spec.liveMigrationConfig数组包含每个字段的默认值。
注意您可以通过删除该键/值对并保存文件来恢复任何
spec.liveMigrationConfig字段的默认值。例如,删除progressTimeout: <value>以恢复默认的progressTimeout: 150。
13.2.2. 集群范围内的实时迁移限制和超时
| 参数 | 描述 | 默认 |
|---|---|---|
|
| 集群中并行运行的迁移数。 | 5 |
|
| 每个节点的最大出站迁移数。 | 2 |
|
|
每个迁移的带宽限制,其中值为每秒字节数。例如, | 0 [1] |
|
|
如果迁移未能在此时间内完成则会取消,以每 GiB 内存秒数为单位。例如,如果 6GiB 内存的虚拟机实例未能在 4800 秒内完成,该虚拟机实例将超时。如果 | 800 |
|
| 如果内存复制未能在此时间内取得进展,则会取消迁移,以秒为单位。 | 150 |
-
默认值
0代表没有限制。
13.3. 迁移虚拟机实例到另一节点
使用 web 控制台或 CLI 手动将虚拟机实例实时迁移到另一节点。
如果虚拟机使用主机模型 CPU,则只能在支持其主机 CPU 模型的节点之间进行实时迁移。
13.3.1. 在 web 控制台中启动虚拟机实例的实时迁移
将正在运行的虚拟机实例迁移到集群中的不同节点。
Migrate 操作对所有用户可见,但只有 admin 用户可以启动虚拟机迁移。
流程
- 在 OpenShift Container Platform 控制台中,从侧边菜单中点 Virtualization → VirtualMachines。
您可从此页面启动迁移,这有助于在同一页面上对多个虚拟机执行操作,也可从 VirtualMachine 详情页面(您可以在其中查看所选虚拟机的综合详情):
-
点虚拟机旁边的 Options 菜单
并选择 Migrate。
- 点虚拟机名称,打开 VirtualMachine 详情页面,然后点击 Actions → Migrate。
-
点虚拟机旁边的 Options 菜单
- 点击 Migrate 把虚拟机迁移到另一节点。
13.3.1.1. 使用 Web 控制台监控实时迁移
您可以在 web 控制台Overview → Migrations 选项卡中监控所有实时迁移的进度。
您可以在 web 控制台的 VirtualMachine details → Metrics 选项卡中查看虚拟机的迁移指标。
13.3.2. 在 CLI 中启动虚拟机实例的实时迁移
通过在集群中创建 VirtualMachineInstanceMigration 对象并引用虚拟机实例的名称来启动正在运行的虚拟机实例的实时迁移。
流程
为要迁移的虚拟机实例创建
VirtualMachineInstanceMigration配置文件。例如VMI-migrate.yaml:apiVersion: kubevirt.io/v1 kind: VirtualMachineInstanceMigration metadata: name: migration-job spec: vmiName: vmi-fedora运行以下命令在集群中创建对象:
$ oc create -f vmi-migrate.yaml
VirtualMachineInstanceMigration 对象触发虚拟机实例的实时迁移。只要虚拟机实例在运行,该对象便始终存在于集群中,除非手动删除。
13.3.2.1. 在 CLI 中监控虚拟机实例的实时迁移
虚拟机迁移的状态保存在 VirtualMachineInstance 配置的 Status 组件中。
流程
在正在迁移的虚拟机实例上使用
oc describe命令:$ oc describe vmi vmi-fedora输出示例
# ... Status: Conditions: Last Probe Time: <nil> Last Transition Time: <nil> Status: True Type: LiveMigratable Migration Method: LiveMigration Migration State: Completed: true End Timestamp: 2018-12-24T06:19:42Z Migration UID: d78c8962-0743-11e9-a540-fa163e0c69f1 Source Node: node2.example.com Start Timestamp: 2018-12-24T06:19:35Z Target Node: node1.example.com Target Node Address: 10.9.0.18:43891 Target Node Domain Detected: true
13.4. 在专用额外网络中迁移虚拟机
您可以为实时迁移配置专用 Multus 网络。专用的网络可最小化实时迁移期间对租户工作负载的网络饱和影响。
13.4.1. 为虚拟机实时迁移配置专用的二级网络
要为实时迁移配置专用的二级网络,您必须首先使用 CLI 为 openshift-cnv 命名空间创建一个桥接网络附加定义。然后,将 NetworkAttachmentDefinition 对象的名称添加到 HyperConverged 自定义资源(CR)。
先决条件
-
已安装 OpenShift CLI(
oc)。 -
您以具有
cluster-admin角色的用户身份登录到集群。 - Multus Container Network Interface (CNI) 插件已安装在集群中。
- 集群中的每个节点至少有两个网络接口卡(NIC),用于实时迁移的 NIC 则连接到同一个 VLAN。
-
虚拟机(VM)使用
LiveMigrate驱除策略运行。
流程
创建
NetworkAttachmentDefinition清单。配置文件示例
apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: my-secondary-network1 namespace: openshift-cnv2 spec: config: '{ "cniVersion": "0.3.1", "name": "migration-bridge", "type": "macvlan", "master": "eth1",3 "mode": "bridge", "ipam": { "type": "whereabouts",4 "range": "10.200.5.0/24"5 } }'运行以下命令,在默认编辑器中打开
HyperConvergedCR:oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv将
NetworkAttachmentDefinition对象的名称添加到HyperConvergedCR 的spec.liveMigrationConfig小节中。例如:配置文件示例
apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: liveMigrationConfig: completionTimeoutPerGiB: 800 network: my-secondary-network1 parallelMigrationsPerCluster: 5 parallelOutboundMigrationsPerNode: 2 progressTimeout: 150 # ...- 1
- 用于实时迁移的 Multus
NetworkAttachmentDefinition对象的名称。
-
保存更改并退出编辑器。
virt-handlerPod 会重启并连接到二级网络。
验证
当运行虚拟机的节点置于维护模式时,虚拟机会自动迁移到集群中的另一个节点。您可以通过检查虚拟机实例(VMI)元数据中的目标 IP 地址,验证迁移是否在二级网络中发生,而不是默认 pod 网络。
oc get vmi <vmi_name> -o jsonpath='{.status.migrationState.targetNodeAddress}'
13.4.2. 使用 Web 控制台选择专用网络
您可以使用 OpenShift Container Platform Web 控制台为实时迁移选择一个专用网络。
先决条件
- 为实时迁移配置了 Multus 网络。
流程
- 在 OpenShift Container Platform web 控制台中进入到 Virtualization > Overview。
- 点 Settings 选项卡,然后点 Live migration。
- 从 Live migration network 列表中选择网络。
13.4.3. 其他资源
13.5. 取消虚拟机实例的实时迁移
取消实时迁移,以便虚拟机实例保留在原始节点上。
您可通过 web 控制台或 CLI 取消实时迁移。
13.5.1. 在 web 控制台中取消虚拟机实例的实时迁移
您可以在 web 控制台中取消虚拟机实例的实时迁移。
流程
- 在 OpenShift Container Platform 控制台中,从侧边菜单中点 Virtualization → VirtualMachines。
-
点虚拟机旁边的 Options 菜单
并选择 Cancel Migration。
13.5.2. 在 CLI 中取消虚拟机实例的实时迁移
通过删除与迁移关联的 VirtualMachineInstanceMigration 对象来取消虚拟机实例的实时迁移。
流程
删除触发实时迁移的
VirtualMachineInstanceMigration对象,本例中为migration-job:$ oc delete vmim migration-job
13.6. 配置虚拟机驱除策略
LiveMigrate 驱除策略可确保当节点置于维护中或排空时,虚拟机实例不会中断。具有驱除策略的虚拟机实例将实时迁移到另一节点。
13.6.1. 使用 LiveMigration 驱除策略配置自定义虚拟机
您只需在自定义虚拟机上配置 LiveMigration 驱除策略。通用模板默认已配置该驱除策略。
流程
将
evictionStrategy: LiveMigrate选项添加到虚拟机配置文件的spec.template.spec部分。本例使用oc edit来更新VirtualMachine配置文件中的相关片段:$ oc edit vm <custom-vm> -n <my-namespace>apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: custom-vm spec: template: spec: evictionStrategy: LiveMigrate # ...重启虚拟机以使更新生效:
$ virtctl restart <custom-vm> -n <my-namespace>
13.7. 配置实时迁移策略
您可以使用实时迁移策略为指定虚拟机实例 (VMI) 组定义不同的迁移配置。
实时迁移策略只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
要使用 Web 控制台配置实时迁移策略,请参阅 MigrationPolicies 页面文档。
13.7.1. 使用命令行配置实时迁移策略
使用 MigrationPolicy 自定义资源定义 (CRD) 为一个或多个所选虚拟机实例 (VMI) 定义迁移策略。
您可以使用以下任一组合指定 VMI 组:
-
虚拟机实例标签,如
size,os,gpu, 和其他 VMI 标签。 -
命名空间标签,如
priority,bandwidth,hpc-workload, 和其他命名空间标签。
要使策略应用到特定 VMI 组,VMI 组的所有标签都必须与策略中的标签匹配。
如果多个实时迁移策略应用到 VMI,则具有最高匹配标签的策略会优先使用。如果有多个策略满足此条件,策略会按照字典的顺序匹配标签键,第一个有最高的优先级。
流程
为指定 VMI 组创建一个
MigrationPolicyCRD。以下示例 YAML 使用标签hpc-workloads:true,xyz-workloads-type: "",workload-type: db, 和operating-system: ""配置组:apiVersion: migrations.kubevirt.io/v1beta1 kind: MigrationPolicy metadata: name: my-awesome-policy spec: # Migration Configuration allowAutoConverge: true bandwidthPerMigration: 217Ki completionTimeoutPerGiB: 23 allowPostCopy: false # Matching to VMIs selectors: namespaceSelector:1 hpc-workloads: "True" xyz-workloads-type: "" virtualMachineInstanceSelector:2 workload-type: "db" operating-system: ""
第 14 章 节点维护
14.1. 关于节点维护
14.1.1. 关于节点维护模式
节点可以使用 oc adm 实用程序或者使用 NodeMaintenance 自定义资源(CR)置于维护模式。
OpenShift Virtualization 不再提供 node-maintenance-operator (NMO)。现在,它可以被部署为 OpenShift Container Platform Web 控制台中的 OperatorHub 的独立 Operator,或使用 OpenShift CLI (oc)。
将节点置于维护中可将节点标记为不可调度,并排空其中的所有虚拟机和 pod。具有 LiveMigrate 驱除策略的虚拟机实例实时迁移到另一节点不会丢失服务。在从通用模板创建的虚拟机中默认配置此驱除策略,而自定义虚拟机则必须手动更配置。
没有驱除策略的虚拟机实例将被关闭。具有 Running 或 RerunOnFailure 的 RunStrategy 的虚拟机会在另一节点上重新创建。带有 Manual 的 RunStrategy 虚拟机不会被自动重启。
虚拟机必须具有一个采用共享 ReadWriteMany(RWX)访问模式的 PVC 才能实时迁移。
Node Maintenance Operator 监视是否有新的或删除的 NodeMaintenance CR。当检测到新的 NodeMaintenance CR 时,不会调度新的工作负载,并且该节点从集群的其余部分中分离。所有可被驱除的 pod 都会从节点上驱除。删除 NodeMaintenance CR 时,CR 中引用的节点将可用于新工作负载。
使用 NodeMaintenance CR 进行节点维护任务可实现与 oc adm cordon 和 oc adm drain 命令相同的结果,使用标准 OpenShift Container Platform 自定义资源处理。
14.1.2. 维护裸机节点
当您在裸机基础架构上部署 OpenShift Container Platform 时,与在云基础架构上部署相比,还需要考虑其他的注意事项。与集群节点被视为临时的云环境中不同,重新置备裸机节点需要大量时间和精力进行维护任务。
当裸机节点出现故障时,例如,如果发生致命内核错误或发生 NIC 卡硬件故障,在修复或替换问题节点时,故障节点上的工作负载需要重启。节点维护模式允许集群管理员安全关闭节点,将工作负载移到集群的其它部分,并确保工作负载不会中断。详细进度和节点状态详情会在维护过程中提供。
14.2. 自动续订 TLS 证书
OpenShift Virtualization 组件的所有 TLS 证书都会被更新并自动轮转。您不需要手动刷新它们。
14.2.1. TLS 证书自动续订计划
TLS 证书会根据以下调度被自动删除并替换:
- KubeVirt 证书每天都会被更新。
- Containerized Data Importer controller (CDI) 证书每 15 天更新一次。
- MAC 池证书每年更新一次。
自动 TLS 证书轮转不会影响任何操作。例如,以下操作可在没有任何中断的情况下继续工作:
- 迁移
- 镜像上传
- VNC 和控制台连接
14.3. 为过时的 CPU 型号管理节点标签
只要节点支持 VM CPU 模型和策略,您可以在节点上调度虚拟机(VM)。
14.3.1. 关于过时 CPU 型号的节点标签
OpenShift Virtualization Operator 使用预定义的过时 CPU 型号列表来确保节点只支持调度的虚拟机的有效 CPU 型号。
默认情况下,从为节点生成的标签列表中删除了以下 CPU 型号:
例 14.1. 过时的 CPU 型号
"486"
Conroe
athlon
core2duo
coreduo
kvm32
kvm64
n270
pentium
pentium2
pentium3
pentiumpro
phenom
qemu32
qemu64
在 HyperConverged CR 中无法看到这个预定义列表。您无法从此列表中删除 CPU 型号,但您可以通过编辑 HyperConverged CR 的 spec.obsoleteCPUs.cpuModels 字段来添加到列表中。
14.3.2. 关于 CPU 功能的节点标签
在迭代过程中,从为节点生成的标签列表中删除最小 CPU 模型中的基本 CPU 功能。
例如:
-
一个环境可能有两个支持的 CPU 型号:
Penryn和Haswell。 如果将
Penryn指定为minCPU的 CPU 型号,Penryn的每个基本 CPU 功能都会与Haswell支持的 CPU 功能列表进行比较。例 14.2.
Penryn支持的 CPU 功能apic clflush cmov cx16 cx8 de fpu fxsr lahf_lm lm mca mce mmx msr mtrr nx pae pat pge pni pse pse36 sep sse sse2 sse4.1 ssse3 syscall tsc例 14.3.
Haswell支持的 CPU 功能aes apic avx avx2 bmi1 bmi2 clflush cmov cx16 cx8 de erms fma fpu fsgsbase fxsr hle invpcid lahf_lm lm mca mce mmx movbe msr mtrr nx pae pat pcid pclmuldq pge pni popcnt pse pse36 rdtscp rtm sep smep sse sse2 sse4.1 sse4.2 ssse3 syscall tsc tsc-deadline x2apic xsave如果
Penryn和Haswell都支持特定的 CPU 功能,则不会为该功能创建一个标签。为仅受Haswell支持且不受Penryn支持的 CPU 功能生成标签。例 14.4. 迭代后为 CPU 功能创建的节点标签
aes avx avx2 bmi1 bmi2 erms fma fsgsbase hle invpcid movbe pcid pclmuldq popcnt rdtscp rtm sse4.2 tsc-deadline x2apic xsave
14.3.3. 配置过时的 CPU 型号
您可以通过编辑 HyperConverged 自定义资源(CR)来配置过时的 CPU 型号列表。
流程
编辑
HyperConverged自定义资源,在obsoleteCPUs阵列中指定过时的 CPU 型号。例如:apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: obsoleteCPUs: cpuModels:1 - "<obsolete_cpu_1>" - "<obsolete_cpu_2>" minCPUModel: "<minimum_cpu_model>"2
14.4. 防止节点协调
使用 skip-node 注解来防止 node-labeller 协调节点。
14.4.1. 使用 skip-node 注解
如果您希望 node-labeller 跳过节点,请使用 oc CLI 注解该节点。
先决条件
-
已安装 OpenShift CLI(
oc)。
流程
运行以下命令来注解您要跳过的节点:
$ oc annotate node <node_name> node-labeller.kubevirt.io/skip-node=true1 - 1
- 将
<node_name>替换为要跳过的相关节点的名称。
在节点注解被删除或设置为 false 后,协调会在下一个周期中恢复。
第 15 章 支持
15.1. 支持概述
您可以收集有关环境的数据,监控集群和虚拟机 (VM) 的健康状态,并使用以下工具对 OpenShift Virtualization 资源进行故障排除。
15.1.1. Web 控制台
OpenShift Container Platform Web 控制台显示集群和 OpenShift Virtualization 组件和资源的资源使用、警报、事件和趋势。
| 页面 | 描述 |
|---|---|
| 概述页面 | 集群详情、状态、警报、清单和资源使用情况 |
| Virtualization → Overview 标签页 | OpenShift Virtualization 资源、使用量、警报和状态 |
| Virtualization → Top consumers 标签页 | CPU、内存和存储的主要使用者 |
| Virtualization → Migrations 标签页 | 实时迁移的进度 |
| VirtualMachines → VirtualMachine → VirtualMachine details → Metrics 标签页 | VM 资源使用情况、存储、网络和迁移 |
| VirtualMachines → VirtualMachine → VirtualMachine details → Events 标签页 | VM 事件列表 |
| VirtualMachines → VirtualMachine → VirtualMachine details → Diagnostics 标签页 | 虚拟机状态条件和卷快照状态 |
15.1.2. 为红帽支持收集数据
当您向红帽支持提交支持问题单时,提供调试信息会很有帮助。您可以执行以下步骤来收集调试信息:
- 收集有关环境的数据
-
配置 Prometheus 和 Alertmanager,并为 OpenShift Container Platform 和 OpenShift Virtualization 收集
must-gather数据。 - 收集虚拟机的数据
-
从虚拟机收集
must-gather数据和内存转储。 - OpenShift Virtualization 的
must-gather工具 -
配置和使用
must-gather工具。
15.1.3. 监控
您可以监控集群和虚拟机的健康状况。有关监控工具的详情,请查看监控概述。
15.1.4. 故障排除
对 OpenShift Virtualization 组件和虚拟机进行故障排除,并解决在 web 控制台中触发警报的问题。
15.2. 为红帽支持收集数据
当您向红帽支持 提交支持问题单 时,使用以下工具为 OpenShift Container Platform 和 OpenShift Virtualization 提供调试信息会很有帮助:
- must-gather 工具
-
must-gather工具收集诊断信息,包括资源定义和服务日志。 - Prometheus
- Prometheus 是一个时间序列数据库和用于指标的规则评估引擎。Prometheus 将警报发送到 Alertmanager 进行处理。
- Alertmanager
- Alertmanager 服务处理从 Prometheus 接收的警报。Alertmanager 还负责将警报发送到外部通知系统。
如需有关 OpenShift Container Platform 监控堆栈的信息,请参阅关于 OpenShift Container Platform 监控。
15.2.1. 收集有关环境的数据
收集有关环境的数据可最小化分析和确定根本原因所需的时间。
先决条件
- 将 Prometheus 指标数据的保留时间设置为最少 7 天。
- 配置 Alertmanager 以捕获相关的警报并将其发送到专用邮箱,以便可以在集群外部查看和保留它们。
- 记录受影响的节点和虚拟机的确切数量。
15.2.2. 收集虚拟机的数据
收集有关出现故障的虚拟机 (VM) 的数据可最小化分析和确定根本原因所需的时间。
先决条件
- Linux 虚拟机: 安装最新的 QEMU 客户机代理。
Windows 虚拟机:
- 记录 Windows 补丁更新详情。
- 安装最新的 VirtIO 驱动程序。
- 安装最新的 QEMU 客户机代理。
- 如果启用了远程桌面协议(RDP),请尝试使用 Web 控制台或命令行通过 RDP 连接到虚拟机,以确定连接软件是否存在问题。
流程
-
使用
/usr/bin/gather脚本为虚拟机收集 must-gather 数据。 - 收集在重启前崩溃的虚拟机截图。
- 在修复尝试前,从虚拟机收集内存转储。
- 记录出现故障的虚拟机通常具有的因素。例如,虚拟机具有相同的主机或网络。
15.2.3. 为 OpenShift Virtualization 使用 must-gather 工具
您可以使用 OpenShift Virtualization 镜像运行 must-gather 命令收集有关 OpenShift Virtualization 资源的数据。
默认数据收集包含有关以下资源的信息:
- OpenShift Virtualization Operator 命名空间,包括子对象
- OpenShift Virtualization 自定义资源定义
- 包含虚拟机的命名空间
- 基本虚拟机定义
流程
运行以下命令来收集有关 OpenShift Virtualization 的数据:
$ oc adm must-gather \ --image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel9:v4.13.11 \ -- /usr/bin/gather
15.2.3.1. must-gather 工具选项
您可以为以下选项指定脚本和环境变量组合:
- 从命名空间收集详细虚拟机 (VM) 信息
- 收集指定虚拟机的详细信息
- 收集镜像、image-stream 和 image-stream-tags 信息
-
限制
must-gather工具使用的最大并行进程数
15.2.3.1.1. 参数
环境变量
您可以为兼容脚本指定环境变量。
NS=<namespace_name>-
从您指定的命名空间中收集虚拟机信息,包括
virt-launcherpod 详情。为所有命名空间收集VirtualMachine和VirtualMachineInstanceCR 数据。 VM=<vm_name>-
收集特定虚拟机的详情。要使用这个选项,还必须使用
NS环境变量指定命名空间。 PROS=<number_of_processes>修改
must-gather工具使用的最大并行进程数。默认值为5。重要使用太多的并行进程可能会导致性能问题。不建议增加并行进程的最大数量。
脚本
每个脚本仅与某些环境变量组合兼容。
/usr/bin/gather-
使用默认
must-gather脚本,从所有命名空间中收集集群数据,且仅包含基本的虚拟机信息。此脚本只与PROS变量兼容。 /usr/bin/gather --vms_details-
收集属于 OpenShift Virtualization 资源的虚拟机日志文件、虚拟机定义、control-plane 日志和命名空间。指定命名空间包括其子对象。如果您在指定命名空间或虚拟机的情况下使用这个参数,
must-gather工具会为集群中的所有虚拟机收集这个数据。此脚本与所有环境变量兼容,但是如果使用VM变量,则必须指定一个命名空间。 /usr/bin/gather --images-
收集镜像、image-stream 和 image-stream-tags 自定义资源信息。此脚本只与
PROS变量兼容。
15.2.3.1.2. 使用和示例
环境变量是可选的。您可以自行运行脚本,也可以使用一个或多个兼容环境变量来运行脚本。
| 脚本 | 兼容环境变量 |
|---|---|
|
|
|
|
|
|
|
|
|
语法
$ oc adm must-gather \
--image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel9:v4.13.11 \
-- <environment_variable_1> <environment_variable_2> <script_name>默认数据收集并行进程
默认情况下,五个进程并行运行。
$ oc adm must-gather \
--image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel9:v4.13.11 \
-- PROS=5 /usr/bin/gather - 1
- 您可以通过更改默认值来修改并行进程的数量。
详细虚拟机信息
以下命令在 mynamespace 命名空间中收集 my-vm 虚拟机的详细虚拟机信息:
$ oc adm must-gather \
--image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel9:v4.13.11 \
-- NS=mynamespace VM=my-vm /usr/bin/gather --vms_details - 1
- 如果您使用
VM环境变量,则需要NS环境变量。
image、image-stream 和 image-stream-tags 信息
以下命令从集群中收集镜像、image-stream 和 image-stream-tags 信息:
$ oc adm must-gather \
--image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel9:v4.13.11 \
/usr/bin/gather --images15.3. 监控
15.3.1. 监控概述
您可以使用以下工具监控集群和虚拟机 (VM) 的健康状况:
- OpenShift Container Platform 集群检查框架
使用 OpenShift Container Platform 集群检查框架在集群中运行自动测试,以检查以下条件:
- 附加到二级网络接口的两个虚拟机之间的网络连接和延迟
- 运行带有零数据包丢失的 Data Plane Development Kit (DPDK) 工作负载的虚拟机
OpenShift Container Platform 集群检查框架只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
- Prometheus 对虚拟资源的查询
- 查询 vCPU、网络、存储和客户机内存交换使用情况和实时迁移进度。
- VM 自定义指标
-
配置
node-exporter服务,以公开内部虚拟机指标和进程。 - xref:[VM health checks]
- 为虚拟机配置就绪度、存活度和客户机代理 ping 探测和 watchdog。
客户机代理 ping 探测只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
15.3.2. OpenShift Container Platform 集群检查框架
OpenShift Virtualization 包括预定义的检查,可用于集群维护和故障排除。
OpenShift Container Platform 集群检查框架只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
15.3.2.1. 关于 OpenShift Container Platform 集群检查框架
checkup 是一个自动测试工作负载,可让您验证特定的集群功能是否按预期工作。集群检查框架使用原生 Kubernetes 资源来配置和执行检查。
通过使用预定义的检查,集群管理员和开发人员可以提高集群可维护性,排除意外行为,最小化错误并节省时间。还可以检查结果并与专家分享,以进一步进行分析。供应商可以编写和发布它们所提供的功能或服务的检查,并验证其客户环境是否已正确配置。
在现有命名空间中运行预定义的检查涉及为检查设置服务帐户,为服务帐户创建 Role 和 RoleBinding 对象,启用检查权限,以及创建输入配置映射和检查作业。您可以多次运行检查。
您必须始终:
- 在应用之前,验证检查镜像是否来自可信源。
-
在创建
Role和RoleBinding对象前,查看检查权限。
15.3.2.2. 虚拟机延迟检查
您可以使用预定义的检查来验证附加到二级网络接口的两个虚拟机 (VM) 之间的网络连接和测量延迟。延迟检查使用 ping 工具。
您可以执行以下步骤来运行延迟检查:
- 创建服务帐户、角色和 rolebindings,以便为延迟检查提供集群访问权限。
- 创建配置映射以提供运行检查并存储结果的输入。
- 创建用于运行检查的作业。
- 查看配置映射中的结果。
- 可选: 要重新运行检查,请删除现有的配置映射和作业,然后创建新的配置映射和作业。
- 完成后,删除延迟检查资源。
先决条件
-
已安装 OpenShift CLI(
oc)。 - 集群至少有两个 worker 节点。
- Multus Container Network Interface (CNI) 插件已安装在集群中。
- 为命名空间配置了网络附加定义。
流程
为延迟检查创建一个
ServiceAccount、Role和RoleBinding清单:例 15.1. 角色清单文件示例
--- apiVersion: v1 kind: ServiceAccount metadata: name: vm-latency-checkup-sa --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: kubevirt-vm-latency-checker rules: - apiGroups: ["kubevirt.io"] resources: ["virtualmachineinstances"] verbs: ["get", "create", "delete"] - apiGroups: ["subresources.kubevirt.io"] resources: ["virtualmachineinstances/console"] verbs: ["get"] - apiGroups: ["k8s.cni.cncf.io"] resources: ["network-attachment-definitions"] verbs: ["get"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: kubevirt-vm-latency-checker subjects: - kind: ServiceAccount name: vm-latency-checkup-sa roleRef: kind: Role name: kubevirt-vm-latency-checker apiGroup: rbac.authorization.k8s.io --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: kiagnose-configmap-access rules: - apiGroups: [ "" ] resources: [ "configmaps" ] verbs: ["get", "update"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: kiagnose-configmap-access subjects: - kind: ServiceAccount name: vm-latency-checkup-sa roleRef: kind: Role name: kiagnose-configmap-access apiGroup: rbac.authorization.k8s.io应用
ServiceAccount、Role和RoleBinding清单:$ oc apply -n <target_namespace> -f <latency_sa_roles_rolebinding>.yaml1 - 1
<target_namespace>是要运行检查的命名空间。这必须是NetworkAttachmentDefinition对象所在的现有命名空间。
创建包含检查的输入参数的
ConfigMap清单:输入配置映射示例
apiVersion: v1 kind: ConfigMap metadata: name: kubevirt-vm-latency-checkup-config data: spec.timeout: 5m spec.param.networkAttachmentDefinitionNamespace: <target_namespace> spec.param.networkAttachmentDefinitionName: "blue-network"1 spec.param.maxDesiredLatencyMilliseconds: "10"2 spec.param.sampleDurationSeconds: "5"3 spec.param.sourceNode: "worker1"4 spec.param.targetNode: "worker2"5 应用目标命名空间中的配置映射清单:
$ oc apply -n <target_namespace> -f <latency_config_map>.yaml创建一个
Job清单以运行检查:任务清单示例
apiVersion: batch/v1 kind: Job metadata: name: kubevirt-vm-latency-checkup spec: backoffLimit: 0 template: spec: serviceAccountName: vm-latency-checkup-sa restartPolicy: Never containers: - name: vm-latency-checkup image: registry.redhat.io/container-native-virtualization/vm-network-latency-checkup-rhel9:v4.13.0 securityContext: allowPrivilegeEscalation: false capabilities: drop: ["ALL"] runAsNonRoot: true seccompProfile: type: "RuntimeDefault" env: - name: CONFIGMAP_NAMESPACE value: <target_namespace> - name: CONFIGMAP_NAME value: kubevirt-vm-latency-checkup-config - name: POD_UID valueFrom: fieldRef: fieldPath: metadata.uid应用
Job清单:$ oc apply -n <target_namespace> -f <latency_job>.yaml等待作业完成:
$ oc wait job kubevirt-vm-latency-checkup -n <target_namespace> --for condition=complete --timeout 6m运行以下命令,检查延迟检查的结果。如果测量的最大延迟大于
spec.param.maxDesiredLatencyMilliseconds属性的值,则检查会失败并返回错误。$ oc get configmap kubevirt-vm-latency-checkup-config -n <target_namespace> -o yaml输出配置映射(成功)示例
apiVersion: v1 kind: ConfigMap metadata: name: kubevirt-vm-latency-checkup-config namespace: <target_namespace> data: spec.timeout: 5m spec.param.networkAttachmentDefinitionNamespace: <target_namespace> spec.param.networkAttachmentDefinitionName: "blue-network" spec.param.maxDesiredLatencyMilliseconds: "10" spec.param.sampleDurationSeconds: "5" spec.param.sourceNode: "worker1" spec.param.targetNode: "worker2" status.succeeded: "true" status.failureReason: "" status.completionTimestamp: "2022-01-01T09:00:00Z" status.startTimestamp: "2022-01-01T09:00:07Z" status.result.avgLatencyNanoSec: "177000" status.result.maxLatencyNanoSec: "244000"1 status.result.measurementDurationSec: "5" status.result.minLatencyNanoSec: "135000" status.result.sourceNode: "worker1" status.result.targetNode: "worker2"- 1
- 以纳秒为单位的最大测量延迟。
可选: 要在检查失败时查看详细作业日志,请使用以下命令:
$ oc logs job.batch/kubevirt-vm-latency-checkup -n <target_namespace>运行以下命令删除之前创建的作业和配置映射:
$ oc delete job -n <target_namespace> kubevirt-vm-latency-checkup$ oc delete config-map -n <target_namespace> kubevirt-vm-latency-checkup-config可选:如果您不计划运行另一个检查,请删除角色清单:
$ oc delete -f <latency_sa_roles_rolebinding>.yaml
15.3.2.3. DPDK 检查
使用预定义的检查来验证 OpenShift Container Platform 集群节点是否可以运行带有零数据包丢失的 Data Plane Development Kit (DPDK) 工作负载的虚拟机 (VM)。DPDK 检查运行流量生成器 pod 和运行测试 DPDK 应用程序的虚拟机之间的流量。
您可以执行以下步骤来运行 DPDK 检查:
- 为 DPDK 检查创建服务帐户、角色和角色绑定,以及用于流量生成器 pod 的服务帐户。
- 为流量生成器 pod 创建安全性上下文约束资源。
- 创建配置映射以提供运行检查并存储结果的输入。
- 创建用于运行检查的作业。
- 查看配置映射中的结果。
- 可选: 要重新运行检查,请删除现有的配置映射和作业,然后创建新的配置映射和作业。
- 完成后,删除 DPDK 检查资源。
先决条件
-
您可以使用具有
cluster-admin权限的用户访问集群。 -
已安装 OpenShift CLI(
oc)。 - 您已将计算节点配置为在有零数据包丢失的虚拟机上运行 DPDK 应用程序。
检查创建的流量生成器 pod 有升级的权限:
- 它以 root 用户身份运行。
- 它有一个绑定挂载到节点的文件系统。
流量生成器的容器镜像是从上游 Project Quay 容器 registry 中拉取的。
流程
为 DPDK 检查和流量生成器 pod 创建
ServiceAccount、Role和RoleBinding清单:例 15.2. 服务帐户、角色和 rolebinding 清单文件示例
--- apiVersion: v1 kind: ServiceAccount metadata: name: dpdk-checkup-sa --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: kiagnose-configmap-access rules: - apiGroups: [ "" ] resources: [ "configmaps" ] verbs: [ "get", "update" ] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: kiagnose-configmap-access subjects: - kind: ServiceAccount name: dpdk-checkup-sa roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: kiagnose-configmap-access --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: kubevirt-dpdk-checker rules: - apiGroups: [ "kubevirt.io" ] resources: [ "virtualmachineinstances" ] verbs: [ "create", "get", "delete" ] - apiGroups: [ "subresources.kubevirt.io" ] resources: [ "virtualmachineinstances/console" ] verbs: [ "get" ] - apiGroups: [ "" ] resources: [ "pods" ] verbs: [ "create", "get", "delete" ] - apiGroups: [ "" ] resources: [ "pods/exec" ] verbs: [ "create" ] - apiGroups: [ "k8s.cni.cncf.io" ] resources: [ "network-attachment-definitions" ] verbs: [ "get" ] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: kubevirt-dpdk-checker subjects: - kind: ServiceAccount name: dpdk-checkup-sa roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: kubevirt-dpdk-checker --- apiVersion: v1 kind: ServiceAccount metadata: name: dpdk-checkup-traffic-gen-sa应用
ServiceAccount、Role和RoleBinding清单:$ oc apply -n <target_namespace> -f <dpdk_sa_roles_rolebinding>.yaml为流量生成器 pod 创建
SecurityContextConstraints清单:安全性上下文约束清单示例
apiVersion: security.openshift.io/v1 kind: SecurityContextConstraints metadata: name: dpdk-checkup-traffic-gen allowHostDirVolumePlugin: true allowHostIPC: false allowHostNetwork: false allowHostPID: false allowHostPorts: false allowPrivilegeEscalation: false allowPrivilegedContainer: false allowedCapabilities: - IPC_LOCK - NET_ADMIN - NET_RAW - SYS_RESOURCE defaultAddCapabilities: null fsGroup: type: RunAsAny groups: [] readOnlyRootFilesystem: false requiredDropCapabilities: null runAsUser: type: RunAsAny seLinuxContext: type: RunAsAny seccompProfiles: - runtime/default - unconfined supplementalGroups: type: RunAsAny users: - system:serviceaccount:dpdk-checkup-ns:dpdk-checkup-traffic-gen-sa应用
SecurityContextConstraints清单:$ oc apply -f <dpdk_scc>.yaml创建包含检查的输入参数的
ConfigMap清单:输入配置映射示例
apiVersion: v1 kind: ConfigMap metadata: name: dpdk-checkup-config data: spec.timeout: 10m spec.param.networkAttachmentDefinitionName: <network_name>1 spec.param.trafficGeneratorRuntimeClassName: <runtimeclass_name>2 spec.param.trafficGeneratorImage: "quay.io/kiagnose/kubevirt-dpdk-checkup-traffic-gen:v0.1.1"3 spec.param.vmContainerDiskImage: "quay.io/kiagnose/kubevirt-dpdk-checkup-vm:v0.1.1"4 应用目标命名空间中的
ConfigMap清单:$ oc apply -n <target_namespace> -f <dpdk_config_map>.yaml创建一个
Job清单以运行检查:任务清单示例
apiVersion: batch/v1 kind: Job metadata: name: dpdk-checkup spec: backoffLimit: 0 template: spec: serviceAccountName: dpdk-checkup-sa restartPolicy: Never containers: - name: dpdk-checkup image: registry.redhat.io/container-native-virtualization/kubevirt-dpdk-checkup-rhel9:v4.13.0 imagePullPolicy: Always securityContext: allowPrivilegeEscalation: false capabilities: drop: ["ALL"] runAsNonRoot: true seccompProfile: type: "RuntimeDefault" env: - name: CONFIGMAP_NAMESPACE value: <target-namespace> - name: CONFIGMAP_NAME value: dpdk-checkup-config - name: POD_UID valueFrom: fieldRef: fieldPath: metadata.uid应用
Job清单:$ oc apply -n <target_namespace> -f <dpdk_job>.yaml等待作业完成:
$ oc wait job dpdk-checkup -n <target_namespace> --for condition=complete --timeout 10m运行以下命令,查看检查的结果:
$ oc get configmap dpdk-checkup-config -n <target_namespace> -o yaml输出配置映射(成功)示例
apiVersion: v1 kind: ConfigMap metadata: name: dpdk-checkup-config data: spec.timeout: 1h2m spec.param.NetworkAttachmentDefinitionName: "mlx-dpdk-network-1" spec.param.trafficGeneratorRuntimeClassName: performance-performance-zeus10 spec.param.trafficGeneratorImage: "quay.io/kiagnose/kubevirt-dpdk-checkup-traffic-gen:v0.1.1" spec.param.vmContainerDiskImage: "quay.io/kiagnose/kubevirt-dpdk-checkup-vm:v0.1.1" status.succeeded: true status.failureReason: " " status.startTimestamp: 2022-12-21T09:33:06+00:00 status.completionTimestamp: 2022-12-21T11:33:06+00:00 status.result.actualTrafficGeneratorTargetNode: worker-dpdk1 status.result.actualDPDKVMTargetNode: worker-dpdk2 status.result.dropRate: 0运行以下命令删除之前创建的作业和配置映射:
$ oc delete job -n <target_namespace> dpdk-checkup$ oc delete config-map -n <target_namespace> dpdk-checkup-config可选:如果您不计划运行另一个检查,请删除
ServiceAccount、Role和RoleBinding清单:$ oc delete -f <dpdk_sa_roles_rolebinding>.yaml
15.3.2.3.1. DPDK 检查配置映射参数
下表显示了在运行集群 DPDK 就绪度检查时,您可以在输入 ConfigMap 清单的 data 小节中设置的强制参数和可选参数:
| 参数 | 描述 | 是必须的 |
|---|---|---|
|
| 检查失败前的时间(以分钟为单位)。 | True |
|
|
连接 SR-IOV NIC 的 | True |
|
| 流量生成器 pod 使用的 RuntimeClass 资源。 | True |
|
|
流量生成器的容器镜像。默认值为 | False |
|
| 要在其上调度流量生成器 pod 的节点。节点应配置为允许 DPDK 流量。 | False |
|
| 每秒数据包数量,单位为(k)或500万(m)。默认值为 14m。 | False |
|
|
连接到流量生成器 pod 或虚拟机的 NIC 的 MAC 地址。默认值为随机 MAC 地址,格式为 | False |
|
|
连接到流量生成器 pod 或虚拟机的 NIC 的 MAC 地址。默认值为随机 MAC 地址,格式为 | False |
|
|
虚拟机的容器磁盘镜像。默认值为 | False |
|
| 运行虚拟机的节点标签。节点应配置为允许 DPDK 流量。 | False |
|
|
连接到虚拟机的 NIC 的 MAC 地址。默认值为随机 MAC 地址,格式为 | False |
|
|
连接到虚拟机的 NIC 的 MAC 地址。默认值为随机 MAC 地址,格式为 | False |
|
| 流量生成器运行的持续时间(以分钟为单位)。默认值为 5 分钟。 | False |
|
| SR-IOV NIC 的最大带宽。默认值为 10GB。 | False |
|
|
当设置为 | False |
15.3.2.3.2. 为 RHEL 虚拟机构建容器磁盘镜像
您可以使用 qcow2 格式构建自定义 Red Hat Enterprise Linux (RHEL) 8 OS 镜像,并使用它来创建容器磁盘镜像。您可以将容器磁盘镜像存储在集群中可访问的 registry 中,并在 DPDK 检查配置映射的 spec.param.vmContainerDiskImage 属性中指定镜像位置。
要构建容器镜像,您必须创建一个镜像构建器虚拟机 (VM)。镜像构建器虚拟机 是一个 RHEL 8 虚拟机,可用于构建自定义 RHEL 镜像。
先决条件
-
镜像构建器虚拟机必须运行 RHEL 8.7,且必须至少在
/var目录中有 2 个 CPU 内核、4 GiB RAM 和 20 GB 的可用空间。 -
您已在虚拟机上安装了镜像构建器工具及其 CLI (
composer-cli)。 已安装
virt-customize工具:# dnf install libguestfs-tools-
已安装 Podman CLI 工具 (
podman)。
流程
验证您可以构建 RHEL 8.7 镜像:
# composer-cli distros list注意要以非 root 身份运行
composer-cli命令,请将您的用户添加到weldr或root组中:# usermod -a -G weldr user$ newgrp weldr输入以下命令以 TOML 格式创建镜像蓝图文件,其中包含要安装的软件包、内核自定义和服务,以及在引导时要禁用的服务:
$ cat << EOF > dpdk-vm.toml name = "dpdk_image" description = "Image to use with the DPDK checkup" version = "0.0.1" distro = "rhel-87" [[packages]] name = "dpdk" [[packages]] name = "dpdk-tools" [[packages]] name = "driverctl" [[packages]] name = "tuned-profiles-cpu-partitioning" [customizations.kernel] append = "default_hugepagesz=1GB hugepagesz=1G hugepages=8 isolcpus=2-7" [customizations.services] disabled = ["NetworkManager-wait-online", "sshd"] EOF运行以下命令,将蓝图文件推送到镜像构建器工具中:
# composer-cli blueprints push dpdk-vm.toml通过指定蓝图名称和输出文件格式来生成系统镜像。在开始 compose 过程时,会显示镜像的通用唯一标识符(UUID)。
# composer-cli compose start dpdk_image qcow2等待 compose 进程完成。compose 状态必须先显示
FINISHED,然后才能继续下一步。# composer-cli compose status输入以下命令通过指定其 UUID 来下载
qcow2镜像文件:# composer-cli compose image <UUID>运行以下命令来创建自定义脚本:
$ cat <<EOF >customize-vm echo isolated_cores=2-7 > /etc/tuned/cpu-partitioning-variables.conf tuned-adm profile cpu-partitioning echo "options vfio enable_unsafe_noiommu_mode=1" > /etc/modprobe.d/vfio-noiommu.conf EOF$ cat <<EOF >first-boot driverctl set-override 0000:06:00.0 vfio-pci driverctl set-override 0000:07:00.0 vfio-pci mkdir /mnt/huge mount /mnt/huge --source nodev -t hugetlbfs -o pagesize=1GB EOF使用
virt-customize工具自定义镜像构建器工具生成的镜像:$ virt-customize -a <UUID>.qcow2 --run=customize-vm --firstboot=first-boot --selinux-relabel要创建包含构建容器镜像的所有命令的 Dockerfile,请输入以下命令:
$ cat << EOF > Dockerfile FROM scratch COPY <uuid>-disk.qcow2 /disk/ EOF其中:
- <uuid>-disk.qcow2
-
以
qcow2格式指定自定义镜像的名称。
运行以下命令构建并标记容器:
$ podman build . -t dpdk-rhel:latest运行以下命令,将容器磁盘镜像推送到集群可访问的 registry:
$ podman push dpdk-rhel:latest-
在 DPDK 检查配置映射中的
spec.param.vmContainerDiskImage属性中提供容器磁盘镜像的链接。
15.3.3. Prometheus 对虚拟资源的查询
OpenShift Virtualization 提供用于监控集群基础架构资源消耗的指标,包括 vCPU、网络、存储和客户机内存交换。您还可以使用指标查询实时迁移状态。
使用 OpenShift Container Platform 监控仪表板查询虚拟化指标。
15.3.3.1. 先决条件
-
要使用 vCPU 指标,必须将
schedstats=enable内核参数应用到MachineConfig对象。此内核参数启用用于调试和性能调优的调度程序统计,并为调度程序添加较小的额外负载。如需更多信息,请参阅向节点添加内核参数。 - 要进行客户机内存交换查询以返回数据,必须在虚拟客户机上启用内存交换。
15.3.3.2. 查询指标
OpenShift Container Platform 监控仪表板可供您运行 Prometheus Query Language (PromQL) 查询来查看图表中呈现的指标。此功能提供有关集群以及要监控的任何用户定义工作负载的状态信息。
作为集群管理员,您可以查询所有 OpenShift Container Platform 核心项目和用户定义的项目的指标。
作为开发者,您必须在查询指标时指定项目名称。您必须具有所需权限才能查看所选项目的指标。
15.3.3.2.1. 以集群管理员身份查询所有项目的指标
作为集群管理员,或具有所有项目的查看权限的用户,您可以在 Metrics UI 中访问所有 OpenShift Container Platform 默认项目和用户定义的项目的指标。
先决条件
-
您可以使用具有
cluster-admin集群角色的用户访问集群,或者具有所有项目的查看权限。 -
已安装 OpenShift CLI(
oc)。
流程
- 从 OpenShift Container Platform Web 控制台中的 Administrator 视角,选择 Observe → Metrics。
要添加一个或多个查询,请执行以下操作之一:
Expand 选项 描述 创建自定义查询。
将 Prometheus Query Language (PromQL) 查询添加到 Expression 字段中。
当您输入 PromQL 表达式时,自动完成建议会出现在下拉列表中。这些建议包括功能、指标、标签和时间令牌。您可以使用键盘箭头选择其中一项建议的项目,然后按 Enter 将项目添加到您的表达式中。您还可以将鼠标指针移到建议的项目上,以查看该项目的简短描述。
添加多个查询。
选择 Add query。
复制现有的查询。
选择查询旁边的 Options 菜单
,然后选择 Duplicate 查询。
禁用查询正在运行。
选择查询旁边的 Options 菜单
并选择 Disable query。
要运行您创建的查询,请选择 Run queries。图表中会直观呈现查询的指标。如果查询无效,则 UI 会显示错误消息。
注意如果查询对大量数据进行运算,这可能会在绘制时序图时造成浏览器超时或过载。要避免这种情况,请选择 Hide graph 并且仅使用指标表来校准查询。然后,在找到可行的查询后,启用图表来绘制图形。
注意默认情况下,查询表会显示一个展开的视图,列出每个指标及其当前值。您可以选择 ˅ 来最小化查询的展开视图。
- 可选:页面 URL 现在包含您运行的查询。要在以后再次使用这一组查询,请保存这个 URL。
探索视觉化指标。最初,图表中显示所有启用的查询中的所有指标。您可以通过执行以下操作来选择显示哪些指标:
Expand 选项 描述 隐藏查询中的所有指标。
点查询的 Options 菜单
并点 Hide all series。
隐藏特定指标。
前往查询表,再点指标名称旁边的带颜色的方格。
放大图表并更改时间范围。
任一:
- 点击图表并在水平方向上拖动,以可视化方式选择时间范围。
- 使用左上角的菜单来选择时间范围。
重置时间范围。
选择 Reset zoom。
在特定时间点显示所有查询的输出。
将鼠标光标悬停在图表上。弹出框中会显示查询输出。
隐藏图表。
选择 Hide graph。
15.3.3.2.2. 以开发者身份查询用户定义的项目的指标
您可以以开发者或具有项目查看权限的用户身份访问用户定义项目的指标。
在 Developer 视角中, Metrics UI 包括所选项目的一些预定义 CPU、内存、带宽和网络数据包查询。您还可以对项目的 CPU、内存、带宽、网络数据包和应用程序指标运行自定义 Prometheus Query Language (PromQL) 查询。
开发者只能使用 Developer 视角,而不能使用 Administrator 视角。作为开发者,您一次只能查询一个项目的指标。
先决条件
- 对于您要查看指标的项目,您可以作为开发者或具有查看权限的用户访问集群。
- 您已为用户定义的项目启用了监控。
- 您已在用户定义的项目中部署了服务。
-
您已为该服务创建了
ServiceMonitor自定义资源定义(CRD),以定义如何监控该服务。
流程
- 在 OpenShift Container Platform web 控制台中的 Developer 视角中,选择 Observe → Metrics。
- 在 Project: 列表中选择您要查看指标的项目。
从 Select query 列表中选择查询,或者通过选择 Show PromQL 根据所选查询创建自定义 PromQL 查询。图表中会直观呈现查询的指标。
注意在 Developer 视角中,您一次只能运行一个查询。
通过执行以下操作来探索视觉化的指标:
Expand 选项 描述 放大图表并更改时间范围。
任一:
- 点击图表并在水平方向上拖动,以可视化方式选择时间范围。
- 使用左上角的菜单来选择时间范围。
重置时间范围。
选择 Reset zoom。
在特定时间点显示所有查询的输出。
将鼠标光标悬停在图表上。查询输出会出现在弹出窗口中。
15.3.3.3. 虚拟化指标
以下指标描述包括示例 Prometheus Query Language(PromQL)查询。这些指标不是 API,可能在不同版本之间有所变化。
以下示例使用 topk 查询来指定时间段。如果在那个时间段内删除虚拟机,它们仍然会显示在查询输出中。
15.3.3.3.1. vCPU 指标
以下查询可以识别等待输入/输出 (I/O) 的虚拟机:
kubevirt_vmi_vcpu_wait_seconds- 返回虚拟机的 vCPU 等待时间(以秒为单位)。类型:计数器。
高于"0" 的值表示 vCPU 要运行,但主机调度程序还无法运行它。无法运行代表 I/O 存在问题。
要查询 vCPU 指标,必须首先将 schedstats=enable 内核参数应用到 MachineConfig 对象。此内核参数启用用于调试和性能调优的调度程序统计,并为调度程序添加较小的额外负载。
vCPU 等待时间查询示例
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_vcpu_wait_seconds[6m]))) > 0 - 1
- 此查询会返回在六分钟内每次都等待 I/O 的 3 台虚拟机。
15.3.3.3.2. 网络指标
以下查询可以识别正在饱和网络的虚拟机:
kubevirt_vmi_network_receive_bytes_total- 返回虚拟机网络中接收的流量总数(以字节为单位)。类型:计数器。
kubevirt_vmi_network_transmit_bytes_total- 返回虚拟机网络上传输的流量总数(以字节为单位)。类型:计数器。
网络流量查询示例
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_network_receive_bytes_total[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_network_transmit_bytes_total[6m]))) > 0 - 1
- 此查询会返回每给定时间在六分钟内传输最多流量的 3 台虚拟机。
15.3.3.3.3. 存储指标
15.3.3.3.3.1. 与存储相关的流量
以下查询可以识别正在写入大量数据的虚拟机:
kubevirt_vmi_storage_read_traffic_bytes_total- 返回虚拟机与存储相关的流量的总量(以字节为单位)。类型:计数器。
kubevirt_vmi_storage_write_traffic_bytes_total- 返回虚拟机与存储相关的流量的存储写入总量(以字节为单位)。类型:计数器。
与存储相关的流量查询示例
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_storage_read_traffic_bytes_total[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_storage_write_traffic_bytes_total[6m]))) > 0 - 1
- 此查询会返回在六分钟内每给定时间执行最多存储流量的 3 台虚拟机。
15.3.3.3.3.2. 存储快照数据
kubevirt_vmsnapshot_disks_restored_from_source_total- 返回从源虚拟机中恢复的虚拟机磁盘总数。类型:Gauge。
kubevirt_vmsnapshot_disks_restored_from_source_bytes- 返回从源虚拟机恢复的字节空间量。类型:Gauge。
存储快照数据查询示例
kubevirt_vmsnapshot_disks_restored_from_source_total{vm_name="simple-vm", vm_namespace="default"} - 1
- 此查询返回从源虚拟机恢复的虚拟机磁盘总数。
kubevirt_vmsnapshot_disks_restored_from_source_bytes{vm_name="simple-vm", vm_namespace="default"} - 1
- 此查询返回源虚拟机恢复的空间大小,以字节为单位。
15.3.3.3.3.3. I/O 性能
以下查询可决定存储设备的 I/O 性能:
kubevirt_vmi_storage_iops_read_total- 返回虚拟机每秒执行的写入 I/O 操作量。类型:计数器。
kubevirt_vmi_storage_iops_write_total- 返回虚拟机每秒执行的读取 I/O 操作量。类型:计数器。
I/O 性能查询示例
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_storage_iops_read_total[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_storage_iops_write_total[6m]))) > 0 - 1
- 此查询返回在六分钟内每给定时间每秒执行最多 I/O 操作数的 3 台虚拟机。
15.3.3.3.4. 客户机内存交换指标
以下查询可识别启用了交换最多的客户端执行内存交换最多:
kubevirt_vmi_memory_swap_in_traffic_bytes_total- 返回虚拟客户机交换的内存总量(以字节为单位)。类型:Gauge。
kubevirt_vmi_memory_swap_out_traffic_bytes_total- 返回虚拟 guest 正在交换的内存总量(以字节为单位)。类型:Gauge。
内存交换查询示例
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_memory_swap_in_traffic_bytes_total[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_memory_swap_out_traffic_bytes_total[6m]))) > 0 - 1
- 此查询返回前 3 台虚拟机,其中客户机在六分钟内执行每个给定时间段内每个给定时间最多的内存交换。
内存交换表示虚拟机面临内存压力。增加虚拟机的内存分配可以缓解此问题。
15.3.3.3.5. 实时迁移指标
可以查询以下指标来显示实时迁移状态:
kubevirt_migrate_vmi_data_processed_bytes- 迁移到新虚拟机(VM)的客户机操作系统数据量。类型:Gauge。
kubevirt_migrate_vmi_data_remaining_bytes- 要迁移的客户机操作系统数据量。类型:Gauge。
kubevirt_migrate_vmi_dirty_memory_rate_bytes- 在客户端操作系统中达到脏的速率。脏内存是已更改但还没有写入磁盘的数据。类型:Gauge。
kubevirt_migrate_vmi_pending_count- 待处理的迁移数量。类型:Gauge。
kubevirt_migrate_vmi_scheduling_count- 调度迁移的数量。类型:Gauge。
kubevirt_migrate_vmi_running_count- 正在运行的迁移数量。类型:Gauge。
kubevirt_migrate_vmi_succeeded- 成功完成迁移的数量。类型:Gauge。
kubevirt_migrate_vmi_failed- 失败的迁移数量。类型:Gauge。
15.3.4. 为虚拟机公开自定义指标
OpenShift Container Platform 包括一个预配置、预安装和自我更新的监控堆栈,可为核心平台组件提供监控。此监控堆栈基于 Prometheus 监控系统。Prometheus 是一个时间序列数据库和用于指标的规则评估引擎。
除了使用 OpenShift Container Platform 监控堆栈外,您还可以使用 CLI 启用对用户定义的项目的监控,并查询通过 node-exporter 服务为虚拟机公开的自定义指标。
15.3.4.1. 配置节点导出器服务
node-exporter 代理部署在您要从中收集指标的集群中的每个虚拟机上。将 node-exporter 代理配置为服务,以公开与虚拟机关联的内部指标和进程。
先决条件
-
安装 OpenShift Container Platform CLI
oc。 -
以具有
cluster-admin权限的用户身份登录集群。 -
在
openshift-monitoring项目中创建cluster-monitoring-configConfigMap对象。 -
通过将
enableUserWorkload设置为true,配置openshift-user-workload-monitoring项目中的user-workload-monitoring-configConfigMap对象。
流程
创建
ServiceYAML 文件。在以下示例中,该文件名为node-exporter-service.yaml。kind: Service apiVersion: v1 metadata: name: node-exporter-service1 namespace: dynamation2 labels: servicetype: metrics3 spec: ports: - name: exmet4 protocol: TCP port: 91005 targetPort: 91006 type: ClusterIP selector: monitor: metrics7 创建 node-exporter 服务:
$ oc create -f node-exporter-service.yaml
15.3.4.2. 配置使用节点 exporter 服务的虚拟机
将 node-exporter 文件下载到虚拟机。然后,创建一个在虚拟机引导时运行 node-exporter 服务的 systemd 服务。
先决条件
-
该组件的 Pod 在
openshift-user-workload-monitoring项目中运行。 -
向需要监控此用户定义的项目的用户授予
monitoring-edit角色。
流程
- 登录虚拟机。
使用应用到
node-exporter文件的目录的路径,将node-exporter文件下载到虚拟机。$ wget https://github.com/prometheus/node_exporter/releases/download/v1.3.1/node_exporter-1.3.1.linux-amd64.tar.gz提取可执行文件并将其放置在
/usr/bin目录中。$ sudo tar xvf node_exporter-1.3.1.linux-amd64.tar.gz \ --directory /usr/bin --strip 1 "*/node_exporter"在此目录路径中创建
node_exporter.service文件:/etc/systemd/system。此systemd服务文件在虚拟机重启时运行 node-exporter 服务。[Unit] Description=Prometheus Metrics Exporter After=network.target StartLimitIntervalSec=0 [Service] Type=simple Restart=always RestartSec=1 User=root ExecStart=/usr/bin/node_exporter [Install] WantedBy=multi-user.target启用并启动
systemd服务。$ sudo systemctl enable node_exporter.service $ sudo systemctl start node_exporter.service
验证
验证 node-exporter 代理是否已报告虚拟机的指标。
$ curl http://localhost:9100/metrics输出示例
go_gc_duration_seconds{quantile="0"} 1.5244e-05 go_gc_duration_seconds{quantile="0.25"} 3.0449e-05 go_gc_duration_seconds{quantile="0.5"} 3.7913e-05
15.3.4.3. 为虚拟机创建自定义监控标签
要启用来自单个服务的多个虚拟机的查询,请在虚拟机的 YAML 文件中添加自定义标签。
先决条件
-
安装 OpenShift Container Platform CLI
oc。 -
以具有
cluster-admin特权的用户身份登录。 - 访问 web 控制台以停止和重启虚拟机。
流程
编辑虚拟机配置文件的
模板spec。在本例中,标签monitor具有值metrics。spec: template: metadata: labels: monitor: metrics-
停止并重启虚拟机,以创建具有与
monitor标签给定标签名称的新 pod。
15.3.4.3.1. 查询 node-exporter 服务以获取指标
指标通过 /metrics 规范名称下的 HTTP 服务端点公开。当您查询指标时,Prometheus 会直接从虚拟机公开的指标端点中提取指标,并展示这些指标来查看。
先决条件
-
您可以使用具有
cluster-admin特权或monitoring-edit角色的用户访问集群。 - 您已通过配置 node-exporter 服务为用户定义的项目启用了监控。
流程
通过为服务指定命名空间来获取 HTTP 服务端点:
$ oc get service -n <namespace> <node-exporter-service>要列出 node-exporter 服务的所有可用指标,请查询
metrics资源。$ curl http://<172.30.226.162:9100>/metrics | grep -vE "^#|^$"输出示例
node_arp_entries{device="eth0"} 1 node_boot_time_seconds 1.643153218e+09 node_context_switches_total 4.4938158e+07 node_cooling_device_cur_state{name="0",type="Processor"} 0 node_cooling_device_max_state{name="0",type="Processor"} 0 node_cpu_guest_seconds_total{cpu="0",mode="nice"} 0 node_cpu_guest_seconds_total{cpu="0",mode="user"} 0 node_cpu_seconds_total{cpu="0",mode="idle"} 1.10586485e+06 node_cpu_seconds_total{cpu="0",mode="iowait"} 37.61 node_cpu_seconds_total{cpu="0",mode="irq"} 233.91 node_cpu_seconds_total{cpu="0",mode="nice"} 551.47 node_cpu_seconds_total{cpu="0",mode="softirq"} 87.3 node_cpu_seconds_total{cpu="0",mode="steal"} 86.12 node_cpu_seconds_total{cpu="0",mode="system"} 464.15 node_cpu_seconds_total{cpu="0",mode="user"} 1075.2 node_disk_discard_time_seconds_total{device="vda"} 0 node_disk_discard_time_seconds_total{device="vdb"} 0 node_disk_discarded_sectors_total{device="vda"} 0 node_disk_discarded_sectors_total{device="vdb"} 0 node_disk_discards_completed_total{device="vda"} 0 node_disk_discards_completed_total{device="vdb"} 0 node_disk_discards_merged_total{device="vda"} 0 node_disk_discards_merged_total{device="vdb"} 0 node_disk_info{device="vda",major="252",minor="0"} 1 node_disk_info{device="vdb",major="252",minor="16"} 1 node_disk_io_now{device="vda"} 0 node_disk_io_now{device="vdb"} 0 node_disk_io_time_seconds_total{device="vda"} 174 node_disk_io_time_seconds_total{device="vdb"} 0.054 node_disk_io_time_weighted_seconds_total{device="vda"} 259.79200000000003 node_disk_io_time_weighted_seconds_total{device="vdb"} 0.039 node_disk_read_bytes_total{device="vda"} 3.71867136e+08 node_disk_read_bytes_total{device="vdb"} 366592 node_disk_read_time_seconds_total{device="vda"} 19.128 node_disk_read_time_seconds_total{device="vdb"} 0.039 node_disk_reads_completed_total{device="vda"} 5619 node_disk_reads_completed_total{device="vdb"} 96 node_disk_reads_merged_total{device="vda"} 5 node_disk_reads_merged_total{device="vdb"} 0 node_disk_write_time_seconds_total{device="vda"} 240.66400000000002 node_disk_write_time_seconds_total{device="vdb"} 0 node_disk_writes_completed_total{device="vda"} 71584 node_disk_writes_completed_total{device="vdb"} 0 node_disk_writes_merged_total{device="vda"} 19761 node_disk_writes_merged_total{device="vdb"} 0 node_disk_written_bytes_total{device="vda"} 2.007924224e+09 node_disk_written_bytes_total{device="vdb"} 0
15.3.4.4. 为节点 exporter 服务创建 ServiceMonitor 资源
您可以使用 Prometheus 客户端库和从 /metrics 端点中提取指标来访问和查看 node-exporter 服务公开的指标。使用 ServiceMonitor 自定义资源定义(CRD)来监控节点 exporter 服务。
先决条件
-
您可以使用具有
cluster-admin特权或monitoring-edit角色的用户访问集群。 - 您已通过配置 node-exporter 服务为用户定义的项目启用了监控。
流程
为
ServiceMonitor资源配置创建一个 YAML 文件。在本例中,服务监控器与带有标签metrics的任意服务匹配,每 30 秒对exmet端口进行查询。apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: k8s-app: node-exporter-metrics-monitor name: node-exporter-metrics-monitor1 namespace: dynamation2 spec: endpoints: - interval: 30s3 port: exmet4 scheme: http selector: matchLabels: servicetype: metrics为 node-exporter 服务创建
ServiceMonitor配置。$ oc create -f node-exporter-metrics-monitor.yaml
15.3.4.4.1. 访问集群外的节点导出服务
您可以访问集群外的 node-exporter 服务,并查看公开的指标。
先决条件
-
您可以使用具有
cluster-admin特权或monitoring-edit角色的用户访问集群。 - 您已通过配置 node-exporter 服务为用户定义的项目启用了监控。
流程
公开 node-exporter 服务。
$ oc expose service -n <namespace> <node_exporter_service_name>获取路由的 FQDN(全限定域名)。
$ oc get route -o=custom-columns=NAME:.metadata.name,DNS:.spec.host输出示例
NAME DNS node-exporter-service node-exporter-service-dynamation.apps.cluster.example.org使用
curl命令显示 node-exporter 服务的指标。$ curl -s http://node-exporter-service-dynamation.apps.cluster.example.org/metrics输出示例
go_gc_duration_seconds{quantile="0"} 1.5382e-05 go_gc_duration_seconds{quantile="0.25"} 3.1163e-05 go_gc_duration_seconds{quantile="0.5"} 3.8546e-05 go_gc_duration_seconds{quantile="0.75"} 4.9139e-05 go_gc_duration_seconds{quantile="1"} 0.000189423
15.3.5. 虚拟机健康检查
您可以通过在 VirtualMachine 资源中定义就绪度和存活度探测来配置虚拟机 (VM) 健康检查。
15.3.5.1. 关于就绪度和存活度探测
使用就绪度和存活度探测来检测和处理不健康的虚拟机 (VM)。您可以在虚拟机规格中包含一个或多个探测,以确保流量无法访问未就绪的虚拟机,并在虚拟机变得无响应时创建新虚拟机。
就绪度探测决定 VMI 是否准备好接受服务请求。如果探测失败,则 VMI 会从可用端点列表中移除,直到 VMI 就绪为止。
存活度探测决定 VMI 是否响应。如果探测失败,则会删除虚拟机并创建一个新的虚拟机来恢复响应性。
您可以通过设置 VirtualMachine 对象的 spec.readinessProbe 和 spec.livenessProbe 字段来配置就绪度和存活度探测。这些字段支持以下测试:
- HTTP GET
- 该探测使用 Web hook 确定 VMI 的健康状况。如果 HTTP 响应代码介于 200 和 399 之间,则测试成功。您可以将 HTTP GET 测试用于在完全初始化时返回 HTTP 状态代码的应用程序。
- TCP 套接字
- 该探测尝试为 VMI 打开一个套接字。只有在探测可以建立连接时,VMI 才被视为健康。对于在初始化完成前不会开始监听的应用程序,可以使用 TCP 套接字测试。
- 客户机代理 ping
-
该探测使用
guest-ping命令来确定 QEMU 客户机代理是否在虚拟机上运行。
15.3.5.1.1. 定义 HTTP 就绪度探测
通过设置虚拟机配置的 spec.readinessProbe.httpGet 字段来定义 HTTP 就绪度探测。
流程
在虚拟机配置文件中包括就绪度探测的详细信息。
使用 HTTP GET 测试就绪度探测示例
# ... spec: readinessProbe: httpGet:1 port: 15002 path: /healthz3 httpHeaders: - name: Custom-Header value: Awesome initialDelaySeconds: 1204 periodSeconds: 205 timeoutSeconds: 106 failureThreshold: 37 successThreshold: 38 # ...- 1
- 执行的 HTTP GET 请求以连接 VM。
- 2
- 探测查询的虚拟机端口。在上例中,探测查询端口 1500。
- 3
- 在 HTTP 服务器上访问的路径。在上例中,如果服务器的 /healthz 路径的处理程序返回成功代码,则 VMI 被视为健康。如果处理程序返回失败代码,则虚拟机将从可用端点列表中移除。
- 4
- 虚拟机启动就绪度探测前的时间(以秒为单位)。
- 5
- 执行探测之间的延迟(以秒为单位)。默认延迟为 10 秒。这个值必须大于
timeoutSeconds。 - 6
- 在不活跃的时间(以秒为单位)超过这个值时探测会超时,且假定 VM 失败。默认值为 1。这个值必须小于
periodSeconds。 - 7
- 探测允许失败的次数。默认值为 3。在进行了指定数量的尝试后,pod 被标记为
Unready。 - 8
- 在失败后,在探测报告成功的次数达到这个值时才能被视为成功。默认值为 1。
运行以下命令来创建虚拟机:
$ oc create -f <file_name>.yaml
15.3.5.1.2. 定义 TCP 就绪度探测
通过设置虚拟机 (VM) 配置的 spec.readinessProbe.tcpSocket 字段来定义 TCP 就绪度探测。
流程
在虚拟机配置文件中包括 TCP 就绪度探测的详细信息。
使用 TCP 套接字测试的就绪度探测示例
# ... spec: readinessProbe: initialDelaySeconds: 1201 periodSeconds: 202 tcpSocket:3 port: 15004 timeoutSeconds: 105 # ...运行以下命令来创建虚拟机:
$ oc create -f <file_name>.yaml
15.3.5.1.3. 定义 HTTP 存活度探测
通过设置虚拟机 (VM) 配置的 spec.livenessProbe.httpGet 字段来定义 HTTP 存活度探测。您可以按照与就绪度探测相同的方式为存活度探测定义 HTTP 和 TCP 测试。此流程使用 HTTP GET 测试配置示例存活度探测。
流程
在虚拟机配置文件中包括 HTTP 存活度探测的详细信息。
使用 HTTP GET 测试的存活度探测示例
# ... spec: livenessProbe: initialDelaySeconds: 1201 periodSeconds: 202 httpGet:3 port: 15004 path: /healthz5 httpHeaders: - name: Custom-Header value: Awesome timeoutSeconds: 106 # ...- 1
- 虚拟机启动存活度探测前的时间(以秒为单位)。
- 2
- 执行探测之间的延迟(以秒为单位)。默认延迟为 10 秒。这个值必须大于
timeoutSeconds。 - 3
- 执行的 HTTP GET 请求以连接 VM。
- 4
- 探测查询的虚拟机端口。在上例中,探测查询端口 1500。VM 通过 cloud-init 在端口 1500 上安装并运行最小 HTTP 服务器。
- 5
- 在 HTTP 服务器上访问的路径。在上例中,如果服务器的
/healthz路径的处理程序返回成功代码,则 VMI 被视为健康。如果处理程序返回失败代码,则会删除虚拟机并创建新虚拟机。 - 6
- 在不活跃的时间(以秒为单位)超过这个值时探测会超时,且假定 VM 失败。默认值为 1。这个值必须小于
periodSeconds。
运行以下命令来创建虚拟机:
$ oc create -f <file_name>.yaml
15.3.5.2. 定义 watchdog
您可以通过执行以下步骤来定义 watchdog 来监控客户端操作系统的健康状态:
- 为虚拟机配置 watchdog 设备。
- 在客户机上安装 watchdog 代理。
watchdog 设备监控代理,并在客户机操作系统不响应时执行以下操作之一:
-
poweroff:虚拟机立即关闭。如果spec.running设为true或spec.runStrategy没有设置为manual,则虚拟机将重启。 reset:虚拟机重新启动,客户机操作系统无法响应。注意重启时间可能会导致存活度探测超时。如果集群级别的保护检测到失败的存活度探测,则虚拟机可能会被强制重新调度,从而增加重启时间。
-
shutdown:通过停止所有服务来正常关闭虚拟机。
watchdog 不适用于 Windows 虚拟机。
15.3.5.2.1. 为虚拟机配置 watchdog 设备
您可以为虚拟机配置 watchdog 设备。
先决条件
-
虚拟机必须具有对
i6300esbwatchdog 设备的内核支持。Red Hat Enterprise Linux (RHEL) 镜像支持i6300esb。
流程
创建包含以下内容的
YAML文件:apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: labels: kubevirt.io/vm: vm2-rhel84-watchdog name: <vm-name> spec: running: false template: metadata: labels: kubevirt.io/vm: vm2-rhel84-watchdog spec: domain: devices: watchdog: name: <watchdog> i6300esb: action: "poweroff"1 # ...- 1
- 指定
poweroff,reset, 或shutdown.
上面的示例使用 poweroff 操作配置 RHEL8 虚拟机上的
i6300esbwatchdog 设备,并将设备公开为/dev/watchdog。现在,watchdog 二进制文件可以使用这个设备。
运行以下命令,将 YAML 文件应用到集群:
$ oc apply -f <file_name>.yaml
此流程仅用于测试 watchdog 功能,且不得在生产环境中运行。
运行以下命令来验证虚拟机是否已连接到 watchdog 设备:
$ lspci | grep watchdog -i运行以下命令之一以确认 watchdog 处于活跃状态:
触发内核 panic:
# echo c > /proc/sysrq-trigger停止 watchdog 服务:
# pkill -9 watchdog
15.3.5.2.2. 在客户机上安装 watchdog 代理
您可以在客户机上安装 watchdog 代理并启动 watchdog 服务。
流程
- 以 root 用户身份登录虚拟机。
安装
watchdog软件包及其依赖项:# yum install watchdog在
/etc/watchdog.conf文件中取消注释以下行并保存更改:#watchdog-device = /dev/watchdog在引导时启用
watchdog服务:# systemctl enable --now watchdog.service
15.3.5.3. 定义客户机代理 ping 探测
通过设置虚拟机 (VM) 配置的 spec.readinessProbe.guestAgentPing 字段来定义客户机代理 ping 探测。
客户机代理 ping 探测只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
先决条件
- 必须在虚拟机上安装并启用 QEMU 客户机代理。
流程
在虚拟机配置文件中包括客户机代理 ping 探测的详情。例如:
客户机代理 ping 探测示例
# ... spec: readinessProbe: guestAgentPing: {}1 initialDelaySeconds: 1202 periodSeconds: 203 timeoutSeconds: 104 failureThreshold: 35 successThreshold: 36 # ...运行以下命令来创建虚拟机:
$ oc create -f <file_name>.yaml
15.4. 故障排除
OpenShift Virtualization 提供用于对虚拟机和虚拟化组件进行故障排除的工具和日志。
您可以使用 web 控制台中提供的工具 或使用 oc CLI 工具排除 OpenShift Virtualization 组件。
15.4.1. 事件
OpenShift Container Platform 事件是重要生命周期信息的记录,有助于监控虚拟机、命名空间和资源问题。
15.4.2. 日志
您可以查看以下日志进行故障排除:
15.4.2.1. 使用 web 控制台查看虚拟机日志
您可以使用 OpenShift Container Platform web 控制台查看虚拟机日志。
流程
- 进入到 Virtualization → VirtualMachines。
- 选择虚拟机以打开 VirtualMachine 详情页面。
- 在 Details 标签页中,点 pod 名称以打开 Pod 详情页面。
- 点 Logs 选项卡查看日志。
15.4.2.2. 查看 OpenShift Virtualization pod 日志
您可以使用 oc CLI 工具查看 OpenShift Virtualization pod 的日志。
您可以通过编辑 HyperConverged 自定义资源 (CR) 来配置日志的详细程度。
15.4.2.2.1. 使用 CLI 查看 OpenShift Virtualization pod 日志
您可以使用 oc CLI 工具查看 OpenShift Virtualization pod 的日志。
流程
运行以下命令,查看 OpenShift Virtualization 命名空间中的 pod 列表:
$ oc get pods -n openshift-cnv例 15.3. 输出示例
NAME READY STATUS RESTARTS AGE disks-images-provider-7gqbc 1/1 Running 0 32m disks-images-provider-vg4kx 1/1 Running 0 32m virt-api-57fcc4497b-7qfmc 1/1 Running 0 31m virt-api-57fcc4497b-tx9nc 1/1 Running 0 31m virt-controller-76c784655f-7fp6m 1/1 Running 0 30m virt-controller-76c784655f-f4pbd 1/1 Running 0 30m virt-handler-2m86x 1/1 Running 0 30m virt-handler-9qs6z 1/1 Running 0 30m virt-operator-7ccfdbf65f-q5snk 1/1 Running 0 32m virt-operator-7ccfdbf65f-vllz8 1/1 Running 0 32m运行以下命令来查看 pod 日志:
$ oc logs -n openshift-cnv <pod_name>注意如果 pod 无法启动,您可以使用
--previous选项查看最后一次尝试的日志。要实时监控日志输出,请使用
-f选项。例 15.4. 输出示例
{"component":"virt-handler","level":"info","msg":"set verbosity to 2","pos":"virt-handler.go:453","timestamp":"2022-04-17T08:58:37.373695Z"} {"component":"virt-handler","level":"info","msg":"set verbosity to 2","pos":"virt-handler.go:453","timestamp":"2022-04-17T08:58:37.373726Z"} {"component":"virt-handler","level":"info","msg":"setting rate limiter to 5 QPS and 10 Burst","pos":"virt-handler.go:462","timestamp":"2022-04-17T08:58:37.373782Z"} {"component":"virt-handler","level":"info","msg":"CPU features of a minimum baseline CPU model: map[apic:true clflush:true cmov:true cx16:true cx8:true de:true fpu:true fxsr:true lahf_lm:true lm:true mca:true mce:true mmx:true msr:true mtrr:true nx:true pae:true pat:true pge:true pni:true pse:true pse36:true sep:true sse:true sse2:true sse4.1:true ssse3:true syscall:true tsc:true]","pos":"cpu_plugin.go:96","timestamp":"2022-04-17T08:58:37.390221Z"} {"component":"virt-handler","level":"warning","msg":"host model mode is expected to contain only one model","pos":"cpu_plugin.go:103","timestamp":"2022-04-17T08:58:37.390263Z"} {"component":"virt-handler","level":"info","msg":"node-labeller is running","pos":"node_labeller.go:94","timestamp":"2022-04-17T08:58:37.391011Z"}
15.4.2.2.2. 配置 OpenShift Virtualization pod 日志详细程度
您可以通过编辑 HyperConverged 自定义资源 (CR) 来配置 OpenShift Virtualization pod 日志的详细程度。
流程
要为特定组件设置日志详细程度,请运行以下命令在默认文本编辑器中打开
HyperConvergedCR:$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv通过编辑
spec.logVerbosityConfig小节,为一个或多个组件设置日志级别。例如:apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: logVerbosityConfig: kubevirt: virtAPI: 51 virtController: 4 virtHandler: 3 virtLauncher: 2 virtOperator: 6- 1
- 日志详细程度值必须是范围
1-9中的一个整数,其中较高的数字表示更详细的日志。在本例中,如果优先级级别为5或更高版本,则virtAPI组件日志会公开。
- 通过保存并退出编辑器来应用您的更改。
15.4.2.2.3. 常见错误消息
OpenShift Virtualization 日志中可能会出现以下出错信息:
ErrImagePull或ImagePullBackOff- 表示引用镜像的部署配置或问题。
15.4.2.3. 使用 LokiStack 查看聚合的 OpenShift Virtualization 日志
您可以使用 web 控制台中的 LokiStack 查看 OpenShift Virtualization pod 和容器的聚合日志。
先决条件
- 您已部署了 LokiStack。
流程
- 在 web 控制台中进入 Observe → Logs。
-
从日志类型列表中选择 应用程序,对于
virt-launcherpod 日志或基础架构,为 OpenShift Virtualization control plane pod 和容器选择应用程序。 - 点 Show Query 以显示查询字段。
- 在查询字段中输入 LogQL 查询,然后点 Run Query 以显示过滤的日志。
15.4.2.3.1. OpenShift Virtualization LogQL 查询
您可以通过在 web 控制台的 Observe → Logs 页面中运行 Loki Query Language (LogQL) 查询来查看和过滤 OpenShift Virtualization 组件的聚合日志。
默认日志类型是 infrastructure。virt-launcher 日志类型是 application。
可选: 您可以使用行过滤器表达式来包含或排除字符串或正则表达式。
如果查询与大量日志匹配,查询可能会超时。
| 组件 | LogQL 查询 |
|---|---|
| All |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Container |
|
|
| 在运行此查询前,您必须从日志类型列表中选择 应用程序。 |
您可以使用行过滤器表达式过滤日志行使其包含或排除字符串或正则表达式。
| 行过滤器表达式 | 描述 |
|---|---|
|
| 日志行包含字符串 |
|
| 日志行不包含字符串 |
|
| 日志行包含正则表达式 |
|
| 日志行不包含正则表达式 |
行过滤器表达式示例
{log_type=~".+"}|json
|kubernetes_labels_app_kubernetes_io_part_of="hyperconverged-cluster"
|= "error" != "timeout"15.4.3. 数据卷故障排除
您可以检查 DataVolume 对象的 Conditions 和 Events 部分,以分析并解决问题。
15.4.3.1. 关于数据卷条件和事件
您可以通过检查命令生成的 Conditions 和 Events 部分的输出来诊断数据卷的问题:
$ oc describe dv <DataVolume>
Conditions 部分显示以下 类型 :
-
Bound -
Running -
Ready
Events 部分提供以下额外信息:
-
事件
类型 -
日志
原因 -
事件
源 -
包含其他诊断信息的
消息。
oc describe 的输出并不总是包含 Events。
当 Status、Reason 或 Message 改变时会产生一个事件。条件和事件均响应数据卷状态的变化。
例如,在导入操作中错误拼写了 URL,则导入会生成 404 信息。该消息的更改会生成一个带有原因的事件。Conditions 部分中的输出也会更新。
15.4.3.2. 分析数据卷条件和事件
通过检查 describe 命令生成的 Conditions 和 Events 部分,您可以确定与 PVC相关的数据卷的状态,以及某个操作是否正在主动运行或完成。您可能还会收到信息,它们提供了有关数据卷状态的特定详情,以及如何处于当前状态。
有多种条件的组合。对每个条件组合的评估都必须其特定的环境下进行。
下面是各种组合的例子。
Bound- 本示例中会显示成功绑定 PVC。请注意,
Type是Bound,所以Status为True。如果 PVC 没有绑定,Status为False。当 PVC 被绑定时,会生成一个事件声明 PVC 已被绑定。在本例中,
Reason为Bound,Status为True。Message指明了哪个 PVC 拥有数据卷。在
Events部分,Message提供了更多详细信息,包括 PVC 被绑定的时间(Age)和它的源(From),在本例中是datavolume-controller:输出示例
Status: Conditions: Last Heart Beat Time: 2020-07-15T03:58:24Z Last Transition Time: 2020-07-15T03:58:24Z Message: PVC win10-rootdisk Bound Reason: Bound Status: True Type: Bound ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Bound 24s datavolume-controller PVC example-dv BoundRunning- 在本例中,请注意Type是Running,Status为False。这表示发生事件导致尝试的操作失败,将 Status 从True改为False。然而,请注意
Reason是Completed,Message显示Import Complete。在
Events部分,Reason和Message包含有关失败操作的额外故障排除信息。在这个示例中,Message显示因为404无法连接,这在Events部分的第一个Warning中列出。根据这些信息,您认为导入操作正在运行,并为试图访问数据卷的其他操作创建竞争:
输出示例
Status: Conditions: Last Heart Beat Time: 2020-07-15T04:31:39Z Last Transition Time: 2020-07-15T04:31:39Z Message: Import Complete Reason: Completed Status: False Type: Running ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning Error 12s (x2 over 14s) datavolume-controller Unable to connect to http data source: expected status code 200, got 404. Status: 404 Not FoundReady- 如果Type是Ready,Status为True,则代表数据卷已就绪,如下例所示。如果数据卷未就绪,则Status为False:输出示例
Status: Conditions: Last Heart Beat Time: 2020-07-15T04:31:39Z Last Transition Time: 2020-07-15T04:31:39Z Status: True Type: Ready
15.5. OpenShift Virtualization runbooks
OpenShift Virtualization Operator 的 runbooks 在 openshift/runbooks Git 存储库中维护,您可以在 GitHub 上查看它们。要诊断并解决触发 OpenShift Virtualization 警报的问题,请按照 runbooks 中的步骤操作。
OpenShift Virtualization 警报显示在 web 控制台的 Virtualization → Overview 选项卡中。
15.5.1. CDIDataImportCronOutdated
15.5.2. CDIDataVolumeUnusualRestartCount
15.5.3. CDIDefaultStorageClassDegraded
15.5.4. CDIMultipleDefaultVirtStorageClasses
15.5.5. CDINoDefaultStorageClass
15.5.6. CDINotReady
15.5.7. CDIOperatorDown
15.5.8. CDIStorageProfilesIncomplete
15.5.9. CnaoDown
15.5.10. CnaoNMstateMigration
15.5.11. HCOInstallationIncomplete
15.5.12. HPPNotReady
15.5.13. HPPOperatorDown
15.5.14. HPPSharingPoolPathWithOS
15.5.15. KubemacpoolDown
15.5.16. KubeMacPoolDuplicateMacsFound
15.5.17. KubeVirtComponentExceedsRequestedCPU
-
KubeVirtComponentExceedsRequestedCPU警报已弃用。
15.5.18. KubeVirtComponentExceedsRequestedMemory
-
KubeVirtComponentExceedsRequestedMemory警报已弃用。
15.5.19. KubeVirtCRModified
15.5.20. KubeVirtDeprecatedAPIRequested
15.5.21. KubeVirtNoAvailableNodesToRunVMs
15.5.22. KubevirtVmHighMemoryUsage
15.5.23. KubeVirtVMIExcessiveMigrations
15.5.24. LowKVMNodesCount
15.5.25. LowReadyVirtControllersCount
15.5.26. LowReadyVirtOperatorsCount
15.5.27. LowVirtAPICount
15.5.28. LowVirtControllersCount
15.5.29. LowVirtOperatorCount
15.5.30. NetworkAddonsConfigNotReady
15.5.31. NoLeadingVirtOperator
15.5.32. NoReadyVirtController
15.5.33. NoReadyVirtOperator
15.5.34. OrphanedVirtualMachineInstances
15.5.35. OutdatedVirtualMachineInstanceWorkloads
15.5.36. SingleStackIPv6Unsupported
15.5.37. SSPCommonTemplatesModificationReverted
15.5.38. SSPDown
15.5.39. SSPFailingToReconcile
15.5.40. SSPHighRateRejectedVms
15.5.41. SSPTemplateValidatorDown
15.5.42. UnsupportedHCOModification
15.5.43. VirtAPIDown
15.5.44. VirtApiRESTErrorsBurst
15.5.45. VirtApiRESTErrorsHigh
15.5.46. VirtControllerDown
15.5.47. VirtControllerRESTErrorsBurst
15.5.48. VirtControllerRESTErrorsHigh
15.5.49. VirtHandlerDaemonSetRolloutFailing
15.5.50. VirtHandlerRESTErrorsBurst
15.5.51. VirtHandlerRESTErrorsHigh
15.5.52. VirtOperatorDown
15.5.53. VirtOperatorRESTErrorsBurst
15.5.54. VirtOperatorRESTErrorsHigh
15.5.55. VirtualMachineCRCErrors
VirtualMachineCRCErrors警报的 runbook 已被弃用,因为警报已重命名为VMStorageClassWarning。
15.5.56. VMCannotBeEvicted
15.5.57. VMStorageClassWarning
第 16 章 备份和恢复
16.1. 安装和配置 OADP
作为集群管理员,您可以通过安装 OADP Operator 来为数据保护(OADP)安装 OpenShift API。Operator 安装 Velero 1.14。
您可以为备份存储供应商创建一个默认 Secret,然后安装数据保护应用程序。
16.1.1. 安装 OADP Operator
您可以使用 Operator Lifecycle Manager(OLM)在 OpenShift Container Platform 4.13 上安装 Data Protection(OADP)Operator 的 OpenShift API。
OADP Operator 安装 Velero 1.14。
先决条件
-
您必须以具有
cluster-admin权限的用户身份登录。
流程
- 在 OpenShift Container Platform Web 控制台中,点击 Operators → OperatorHub。
- 使用 Filter by keyword 字段查找 OADP Operator。
- 选择 OADP Operator 并点 Install。
-
点 Install 在
openshift-adp项目中安装 Operator。 - 点 Operators → Installed Operators 来验证安装。
16.1.2. 关于备份和恢复位置及其 secret
您可以在 DataProtectionApplication 自定义资源(CR)中指定备份和快照位置及其 secret。
备份位置
您可以将 AWS S3 兼容对象存储指定为备份位置,如 Multicloud Object Gateway;Red Hat Container Storage;Ceph RADOS 网关,也称为 Ceph 对象网关;Red Hat OpenShift Data Foundation;或 MinIO。
Velero 将 OpenShift Container Platform 资源、Kubernetes 对象和内部镜像备份为对象存储上的存档文件。
快照位置
如果使用云供应商的原生快照 API 备份持久性卷,您必须将云供应商指定为快照位置。
如果使用 Container Storage Interface(CSI)快照,则不需要指定快照位置,因为您要创建一个 VolumeSnapshotClass CR 来注册 CSI 驱动程序。
如果您使用文件系统备份 (FSB),则不需要指定快照位置,因为 FSB 在对象存储上备份文件系统。
Secrets
如果备份和快照位置使用相同的凭证,或者不需要快照位置,请创建一个默认 Secret。
如果备份和恢复位置使用不同的凭证,您可以创建两个 secret 对象:
-
您在
DataProtectionApplicationCR 中指定的备份位置的自定义Secret。 -
快照位置的默认
Secret,在DataProtectionApplicationCR 中没有引用。
数据保护应用程序需要一个默认的 Secret。否则,安装将失败。
如果您不想在安装过程中指定备份或快照位置,您可以使用空 credentials-velero 文件创建默认 Secret。
16.1.2.1. 创建默认 Secret
如果您的备份和快照位置使用相同的凭证,或者不需要快照位置,则创建一个默认 Secret。
DataProtectionApplication 自定义资源(CR)需要一个默认的 Secret。否则,安装将失败。如果没有指定备份位置 Secret 的名称,则会使用默认名称。
如果您不想在安装过程中使用备份位置凭证,您可以使用空 credentials-velero 文件创建带有默认名称的 Secret。
先决条件
- 您的对象存储和云存储(若有)必须使用相同的凭证。
- 您必须为 Velero 配置对象存储。
流程
-
为您的云供应商为备份存储位置创建一个
credentials-velero文件。 使用默认名称创建
Secret自定义资源(CR):$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero
在安装 Data Protection Application 时,secret 会在 DataProtectionApplication CR 的 spec.backupLocations.credential 块中引用。
16.1.3. 配置数据保护应用程序
您可以通过设置 Velero 资源分配或启用自签名 CA 证书来配置数据保护应用程序。
16.1.3.1. 设置 Velero CPU 和内存分配
您可以通过编辑 DataProtectionApplication 自定义资源(CR)清单来为 Velero pod 设置 CPU 和内存分配。
先决条件
- 您必须安装了 OpenShift API for Data Protection(OADP)Operator。
流程
编辑
DataProtectionApplicationCR 清单的spec.configuration.velero.podConfig.ResourceAllocations块中的值,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node_selector>1 resourceAllocations:2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
Kopia 是 OADP 1.3 及之后的版本中的一个选项。您可以使用 Kopia 进行文件系统备份,Kopia 是 Data Mover 的唯一选择,并带有内置数据 Mover。
和 Restic 相比,Kopia 需要更多资源,您可能需要相应地调整 CPU 和内存要求。
16.1.3.2. 启用自签名 CA 证书
您必须通过编辑 DataProtectionApplication 自定义资源(CR)清单来为对象存储启用自签名 CA 证书,以防止由未知颁发机构签名的证书。
先决条件
- 您必须安装了 OpenShift API for Data Protection(OADP)Operator。
流程
编辑
DataProtectionApplicationCR 清单的spec.backupLocations.velero.objectStorage.caCert参数和spec.backupLocations.velero.config参数:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket> prefix: <prefix> caCert: <base64_encoded_cert_string>1 config: insecureSkipTLSVerify: "false"2 ...
16.1.3.2.1. 使用带有用于 velero 部署的 velero 命令的 CA 证书
如果您望使用 Velero CLI 而又不想在您的系统中安装它,可以为它创建一个别名。
先决条件
-
您必须使用具有
cluster-admin角色的用户登录到 OpenShift Container Platform 集群。 已安装 OpenShift CLI (
oc)。要使用别名的 Velero 命令,请运行以下命令:
$ alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'运行以下命令检查别名是否正常工作:
Example
$ velero version Client: Version: v1.12.1-OADP Git commit: - Server: Version: v1.12.1-OADP要使用这个命令来使用 CA 证书,您可以运行以下命令在 Velero 部署中添加证书:
$ CA_CERT=$(oc -n openshift-adp get dataprotectionapplications.oadp.openshift.io <dpa-name> -o jsonpath='{.spec.backupLocations[0].velero.objectStorage.caCert}') $ [[ -n $CA_CERT ]] && echo "$CA_CERT" | base64 -d | oc exec -n openshift-adp -i deploy/velero -c velero -- bash -c "cat > /tmp/your-cacert.txt" || echo "DPA BSL has no caCert"$ velero describe backup <backup_name> --details --cacert /tmp/<your_cacert>.txt要获取备份日志,请运行以下命令:
$ velero backup logs <backup_name> --cacert /tmp/<your_cacert.txt>您可以使用这些日志来查看无法备份的资源的失败和警告。
-
如果 Velero pod 重启,
/tmp/your-cacert.txt文件会消失,您需要通过重新运行上一步中的命令来重新创建/tmp/your-cacert.txt文件。 您可以运行以下命令来检查
/tmp/your-cacert.txt文件是否存在(在存储它的文件位置中):$ oc exec -n openshift-adp -i deploy/velero -c velero -- bash -c "ls /tmp/your-cacert.txt" /tmp/your-cacert.txt
在以后的 OpenShift API for Data Protection (OADP) 发行版本中,我们计划将证书挂载到 Velero pod,以便不需要这一步。
16.1.4. 安装数据保护应用程序 1.2 及更早版本
您可以通过创建 DataProtectionApplication API 的实例来安装数据保护应用程序(DPA)。
先决条件
- 您必须安装 OADP Operator。
- 您必须将对象存储配置为备份位置。
- 如果使用快照来备份 PV,云供应商必须支持原生快照 API 或 Container Storage Interface(CSI)快照。
如果备份和快照位置使用相同的凭证,您必须创建带有默认名称
cloud-credentials的Secret。注意如果您不想在安装过程中指定备份或快照位置,您可以使用空
credentials-velero文件创建默认Secret。如果没有默认Secret,安装将失败。注意Velero 在 OADP 命名空间中创建一个名为
velero-repo-credentials的 secret,其中包含默认的备份存储库密码。在运行第一个面向备份存储库的备份之前,您可以使用自己的密码更新 secret,以 base64 编码。要更新的键值是Data[repository-password]。创建 DPA 后,第一次运行指向备份存储库的备份时,Velero 会创建一个备份存储库,其 secret 为
velero-repo-credentials,其中包含默认密码或您替换它。如果在首次备份之后更新 secret 密码,新密码将与velero-repo-credentials中的密码不匹配,因此 Velero 将无法与旧的备份连接。
流程
- 点 Operators → Installed Operators 并选择 OADP Operator。
- 在 Provided APIs 下,点 DataProtectionApplication 框中的 Create 实例。
-
点 YAML View 并更新
DataProtectionApplication清单的参数: - 点 Create。
验证
运行以下命令,查看 OpenShift API for Data Protection (OADP) 资源来验证安装:
$ oc get all -n openshift-adp输出示例
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/restic-9cq4q 1/1 Running 0 94s pod/restic-m4lts 1/1 Running 0 94s pod/restic-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/restic 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s运行以下命令,验证
DataProtectionApplication(DPA) 是否已协调:$ oc get dpa dpa-sample -n openshift-adp -o jsonpath='{.status}'输出示例
{"conditions":[{"lastTransitionTime":"2023-10-27T01:23:57Z","message":"Reconcile complete","reason":"Complete","status":"True","type":"Reconciled"}]}-
验证
type被设置为Reconciled。 运行以下命令,验证备份存储位置并确认
PHASE为Available:$ oc get backupstoragelocations.velero.io -n openshift-adp输出示例
NAME PHASE LAST VALIDATED AGE DEFAULT dpa-sample-1 Available 1s 3d16h true
16.1.5. 安装数据保护应用程序
您可以通过创建 DataProtectionApplication API 的实例来安装数据保护应用程序(DPA)。
先决条件
- 您必须安装 OADP Operator。
- 您必须将对象存储配置为备份位置。
- 如果使用快照来备份 PV,云供应商必须支持原生快照 API 或 Container Storage Interface(CSI)快照。
如果备份和快照位置使用相同的凭证,您必须创建带有默认名称
cloud-credentials的Secret。注意如果您不想在安装过程中指定备份或快照位置,您可以使用空
credentials-velero文件创建默认Secret。如果没有默认Secret,安装将失败。
流程
- 点 Operators → Installed Operators 并选择 OADP Operator。
- 在 Provided APIs 下,点 DataProtectionApplication 框中的 Create 实例。
-
点 YAML View 并更新
DataProtectionApplication清单的参数: - 点 Create。
验证
运行以下命令,查看 OpenShift API for Data Protection (OADP) 资源来验证安装:
$ oc get all -n openshift-adp输出示例
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/node-agent-9cq4q 1/1 Running 0 94s pod/node-agent-m4lts 1/1 Running 0 94s pod/node-agent-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s service/openshift-adp-velero-metrics-svc ClusterIP 172.30.10.0 <none> 8085/TCP 8h NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/node-agent 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s运行以下命令,验证
DataProtectionApplication(DPA) 是否已协调:$ oc get dpa dpa-sample -n openshift-adp -o jsonpath='{.status}'输出示例
{"conditions":[{"lastTransitionTime":"2023-10-27T01:23:57Z","message":"Reconcile complete","reason":"Complete","status":"True","type":"Reconciled"}]}-
验证
type被设置为Reconciled。 运行以下命令,验证备份存储位置并确认
PHASE为Available:$ oc get backupstoragelocations.velero.io -n openshift-adp输出示例
NAME PHASE LAST VALIDATED AGE DEFAULT dpa-sample-1 Available 1s 3d16h true
16.1.5.1. 在 DataProtectionApplication CR 中启用 CSI
您可以在 DataProtectionApplication 自定义资源(CR)中启用 Container Storage Interface(CSI)来备份持久性卷,以使用 CSI 快照备份持久性卷。
先决条件
- 云供应商必须支持 CSI 快照。
流程
编辑
DataProtectionApplicationCR,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... spec: configuration: velero: defaultPlugins: - openshift - csi1 - 1
- 添加
csi默认插件。
16.1.6. 卸载 OADP
您可以通过删除 OADP Operator 来卸载 OpenShift API for Data Protection(OADP)。详情请参阅从集群中删除 Operator。
16.2. 备份和恢复虚拟机
OADP for OpenShift Virtualization 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
您可以使用 OpenShift API 进行数据保护(OADP) 来备份和恢复虚拟机。
先决条件
-
使用具有
cluster-admin角色的用户访问集群。
流程
- 根据您的存储供应商说明安装 OADP Operator。
-
使用
kubevirt和openshift插件 安装 数据保护应用程序。 -
通过创建
Backup自定义资源(CR) 来备份虚拟机。 -
通过创建一个
RestoreCR 来恢复BackupCR。
16.3. 备份虚拟机
OADP for OpenShift Virtualization 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
您可以通过创建一个 Backup 自定义资源 (CR) 来备份虚拟机(VM)
Backup CR 执行以下操作:
- 通过在 S3 兼容对象存储上创建存档文件来备份 OpenShift Virtualization 资源,如 Multicloud Object Gateway、Noobaa 或 Minio。
使用以下选项之一备份虚拟机磁盘:
- 启用 CSI 的云存储上的 容器存储接口(CSI)快照,如 Ceph RBD 或 Ceph FS。
- 在对象存储中,使用文件系统备份备份应用程序:Kopia 或 Restic。
OADP 提供备份 hook,以便在备份操作前冻结虚拟机文件系统,并在备份完成后取消解冻。
kubevirt-controller 使用注解创建 virt-launcher pod,使 Velero 可以在备份操作前和之后运行 virt-freezer 二进制文件。
freeze 和 unfreeze API 是虚拟机快照 API 的子资源。有关详细信息,请参阅关于虚拟机快照。
您可以在 Backup CR 中添加 hook,以便在备份操作前或之后在特定虚拟机上运行命令。
您可以通过创建一个 Schedule CR 而不是 Backup CR 来调度备份。
16.3.1. 创建备份 CR
要备份 Kubernetes 资源、内部镜像和持久性卷(PV),请创建一个 Backup 自定义资源(CR)。
先决条件
- 您必须安装用于数据保护(OADP)Operator 的 OpenShift API。
-
DataProtectionApplicationCR 必须处于Ready状态。 备份位置先决条件:
- 您必须为 Velero 配置 S3 对象存储。
-
您必须在
DataProtectionApplicationCR 中配置了一个备份位置。
快照位置先决条件:
- 您的云供应商必须具有原生快照 API 或支持 Container Storage Interface(CSI)快照。
-
对于 CSI 快照,您必须创建一个
VolumeSnapshotClassCR 来注册 CSI 驱动程序。 -
您必须在
DataProtectionApplicationCR 中配置了一个卷位置。
流程
输入以下命令来检索
backupStorageLocationsCR:$ oc get backupstoragelocations.velero.io -n openshift-adp输出示例
NAMESPACE NAME PHASE LAST VALIDATED AGE DEFAULT openshift-adp velero-sample-1 Available 11s 31m创建一个
BackupCR,如下例所示:apiVersion: velero.io/v1 kind: Backup metadata: name: <backup> labels: velero.io/storage-location: default namespace: openshift-adp spec: hooks: {} includedNamespaces: - <namespace>1 includedResources: []2 excludedResources: []3 storageLocation: <velero-sample-1>4 ttl: 720h0m0s labelSelector:5 matchLabels: app=<label_1> app=<label_2> app=<label_3> orLabelSelectors:6 - matchLabels: app=<label_1> app=<label_2> app=<label_3>验证
BackupCR 的状态是否为Completed:$ oc get backups.velero.io -n openshift-adp <backup> -o jsonpath='{.status.phase}'
16.3.1.1. 使用 CSI 快照备份持久性卷
在创建 Backup CR 前,您可以编辑云存储的 VolumeSnapshotClass 自定义资源(CR)来备份持久性卷(CSI)快照。
先决条件
- 云供应商必须支持 CSI 快照。
-
您必须在
DataProtectionApplicationCR 中启用 CSI。
流程
将
metadata.labels.velero.io/csi-volumesnapshot-class: "true"键值对添加到VolumeSnapshotClassCR:配置文件示例
apiVersion: snapshot.storage.k8s.io/v1 kind: VolumeSnapshotClass metadata: name: <volume_snapshot_class_name> labels: velero.io/csi-volumesnapshot-class: "true"1 annotations: snapshot.storage.kubernetes.io/is-default-class: true2 driver: <csi_driver> deletionPolicy: <deletion_policy_type>3
后续步骤
-
现在,您可以创建一个
BackupCR。
16.3.1.2. 使用 Restic 备份应用程序
您可以通过编辑备份自定义资源(CR)来使用 Restic Backup 资源、内部镜像和持久性卷备份 Kubernetes 资源。
您不需要在 DataProtectionApplication CR 中指定快照位置。
Restic 不支持备份 hostPath 卷。如需更多信息,请参阅额外的 Restic 限制。
先决条件
- 您必须安装用于数据保护(OADP)Operator 的 OpenShift API。
-
您不能将
DataProtectionApplicationCR 中的spec.configuration.restic.enable设置为false来禁用默认的 Restic 安装。 -
DataProtectionApplicationCR 必须处于Ready状态。
流程
编辑
BackupCR,如下例所示:apiVersion: velero.io/v1 kind: Backup metadata: name: <backup> labels: velero.io/storage-location: default namespace: openshift-adp spec: defaultVolumesToFsBackup: true1 ...- 1
- 在 OADP 版本 1.2 及更高版本中,在
spec块中添加defaultVolumesToFsBackup: true设置。在 OADP 版本 1.1 中,添加defaultVolumesToRestic: true。
16.3.1.3. 创建备份 hook
您可以通过编辑备份自定义资源(CR)来创建 Backup hook 以在 pod 中运行的容器中运行命令。
在 pod 备份前运行 Pre hook。在备份后运行 Post hook。
流程
在
BackupCR 的spec.hooks块中添加 hook,如下例所示:apiVersion: velero.io/v1 kind: Backup metadata: name: <backup> namespace: openshift-adp spec: hooks: resources: - name: <hook_name> includedNamespaces: - <namespace>1 excludedNamespaces:2 - <namespace> includedResources: [] - pods3 excludedResources: []4 labelSelector:5 matchLabels: app: velero component: server pre:6 - exec: container: <container>7 command: - /bin/uname8 - -a onError: Fail9 timeout: 30s10 post:11 ...- 1
- 可选:您可以指定 hook 应用的命名空间。如果没有指定这个值,则 hook 适用于所有命名空间。
- 2
- 可选:您可以指定 hook 不应用到的命名空间。
- 3
- 目前,pod 是唯一可以应用 hook 的支持的资源。
- 4
- 可选:您可以指定 hook 不应用到的资源。
- 5
- 可选:此 hook 仅适用于与标签匹配的对象。如果没有指定这个值,则 hook 适用于所有命名空间。
- 6
- 备份前要运行的 hook 数组。
- 7
- 可选:如果没有指定容器,该命令将在 pod 的第一个容器中运行。
- 8
- 这是正在添加的 init 容器的入口点。
- 9
- 错误处理允许的值是
Fail和Continue。默认值为Fail。 - 10
- 可选:等待命令运行的时间。默认值为
30s。 - 11
- 此块定义了在备份后运行的一组 hook,其参数与 pre-backup hook 相同。
16.3.2. 其他资源
16.4. 恢复虚拟机
您可以通过创建一个 Restore CR 来恢复一个 OpenShift API for Data Protection (OADP) Backup 自定义资源 (CR)。
您可以在 Restore CR 中添加 hook,以便在应用程序容器启动前,在初始(init)容器中运行命令,或在应用程序容器中运行命令。
16.4.1. 创建恢复 CR
您可以通过创建一个 Restore CR 来恢复 Backup 自定义资源(CR)。
先决条件
- 您必须安装用于数据保护(OADP)Operator 的 OpenShift API。
-
DataProtectionApplicationCR 必须处于Ready状态。 -
您必须具有 Velero
BackupCR。 - 持久性卷 (PV) 容量必须与备份时请求的大小匹配。如果需要,调整请求的大小。
流程
创建一个
RestoreCR,如下例所示:apiVersion: velero.io/v1 kind: Restore metadata: name: <restore> namespace: openshift-adp spec: backupName: <backup>1 includedResources: []2 excludedResources: - nodes - events - events.events.k8s.io - backups.velero.io - restores.velero.io - resticrepositories.velero.io restorePVs: true3 输入以下命令验证
RestoreCR 的状态是否为Completed:$ oc get restores.velero.io -n openshift-adp <restore> -o jsonpath='{.status.phase}'输入以下命令验证备份资源是否已恢复:
$ oc get all -n <namespace>1 - 1
- 备份的命名空间。
如果您使用卷恢复
DeploymentConfig,或使用 post-restore hook,请输入以下命令运行dc-post-restore.shcleanup 脚本:$ bash dc-restic-post-restore.sh -> dc-post-restore.sh注意在恢复过程中,OADP Velero 插件会缩减
DeploymentConfig对象,并将 pod 恢复为独立 pod。这是为了防止集群在恢复时立即删除恢复的DeploymentConfigpod,并允许 restore 和 post-restore hook 在恢复的 pod 上完成其操作。下面显示的清理脚本会删除这些断开连接的 pod,并将任何DeploymentConfig对象扩展至适当的副本数。例 16.1.
dc-restic-post-restore.sh → dc-post-restore.shcleanup 脚本#!/bin/bash set -e # if sha256sum exists, use it to check the integrity of the file if command -v sha256sum >/dev/null 2>&1; then CHECKSUM_CMD="sha256sum" else CHECKSUM_CMD="shasum -a 256" fi label_name () { if [ "${#1}" -le "63" ]; then echo $1 return fi sha=$(echo -n $1|$CHECKSUM_CMD) echo "${1:0:57}${sha:0:6}" } if [[ $# -ne 1 ]]; then echo "usage: ${BASH_SOURCE} restore-name" exit 1 fi echo "restore: $1" label=$(label_name $1) echo "label: $label" echo Deleting disconnected restore pods oc delete pods --all-namespaces -l oadp.openshift.io/disconnected-from-dc=$label for dc in $(oc get dc --all-namespaces -l oadp.openshift.io/replicas-modified=$label -o jsonpath='{range .items[*]}{.metadata.namespace}{","}{.metadata.name}{","}{.metadata.annotations.oadp\.openshift\.io/original-replicas}{","}{.metadata.annotations.oadp\.openshift\.io/original-paused}{"\n"}') do IFS=',' read -ra dc_arr <<< "$dc" if [ ${#dc_arr[0]} -gt 0 ]; then echo Found deployment ${dc_arr[0]}/${dc_arr[1]}, setting replicas: ${dc_arr[2]}, paused: ${dc_arr[3]} cat <<EOF | oc patch dc -n ${dc_arr[0]} ${dc_arr[1]} --patch-file /dev/stdin spec: replicas: ${dc_arr[2]} paused: ${dc_arr[3]} EOF fi done
16.4.1.1. 创建恢复 hook
您可以通过编辑 Restore 自定义资源 (CR)创建恢复 hook,以便在 pod 中的容器中运行命令。
您可以创建两种类型的恢复 hook:
inithook 将 init 容器添加到 pod,以便在应用程序容器启动前执行设置任务。如果您恢复 Restic 备份,则会在恢复 hook init 容器前添加
restic-waitinit 容器。-
exechook 在恢复的 pod 的容器中运行命令或脚本。
流程
在
RestoreCR 的spec.hooks块中添加 hook,如下例所示:apiVersion: velero.io/v1 kind: Restore metadata: name: <restore> namespace: openshift-adp spec: hooks: resources: - name: <hook_name> includedNamespaces: - <namespace>1 excludedNamespaces: - <namespace> includedResources: - pods2 excludedResources: [] labelSelector:3 matchLabels: app: velero component: server postHooks: - init: initContainers: - name: restore-hook-init image: alpine:latest volumeMounts: - mountPath: /restores/pvc1-vm name: pvc1-vm command: - /bin/ash - -c timeout:4 - exec: container: <container>5 command: - /bin/bash6 - -c - "psql < /backup/backup.sql" waitTimeout: 5m7 execTimeout: 1m8 onError: Continue9 - 1
- 可选: hook 应用的命名空间数组。如果没有指定这个值,则 hook 适用于所有命名空间。
- 2
- 目前,pod 是唯一可以应用 hook 的支持的资源。
- 3
- 可选:此 hook 仅适用于与标签选择器匹配的对象。
- 4
- 可选:超时指定 Velero 等待
initContainers完成的最大时间长度。 - 5
- 可选:如果没有指定容器,该命令将在 pod 的第一个容器中运行。
- 6
- 这是正在添加的 init 容器的入口点。
- 7
- 可选:等待容器就绪的时间。这应该足够长,以便容器可以启动,在相同容器中的任何以前的 hook 可以完成。如果没有设置,恢复过程会无限期等待。
- 8
- 可选:等待命令运行的时间。默认值为
30s。 - 9
- 错误处理的允许值为
Fail和Continue:-
Continue: 只记录命令失败。 -
Fail: 任何 pod 中的任何容器中没有更多恢复 hook 运行。RestoreCR 的状态将是PartiallyFailed。
-
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.