可扩展性和性能
扩展 OpenShift Container Platform 集群并调整产品环境的性能
摘要
第 1 章 OpenShift Container Platform 可扩展性和性能概述
OpenShift Container Platform 提供了最佳实践和工具,可帮助您优化集群的性能和规模。以下文档提供有关推荐的性能和可扩展性实践、参考设计规格、优化和低延迟调整的信息。
要联系红帽支持,请参阅获取支持。
有些性能和可扩展性 Operator 有独立于 OpenShift Container Platform 发行周期的发行周期。如需更多信息,请参阅 OpenShift Operator。
1.1. 推荐的性能和可扩展性实践
1.2. 电信参考设计规格
1.3. 规划、优化和测量
第 2 章 推荐的性能和可扩展性实践
2.1. 推荐的 control plane 实践
本主题为 OpenShift Container Platform 中的 control plane 提供推荐的性能和可扩展性实践。
2.1.1. 扩展集群的建议实践
本节中的指导信息仅与使用云供应商集成的安装相关。
应用以下最佳实践来扩展 OpenShift Container Platform 集群中的 worker 机器数量。您可以通过增加或减少 worker MachineSet 中定义的副本数量来扩展 worker 机器集。
将集群扩展到具有更多节点时:
- 将节点分散到所有可用区以获得更高的可用性。
- 同时扩展的机器数量不要超过 25 到 50 个。
- 考虑在每个可用区创建一个具有类似大小的替代实例类型的新计算机器集,以帮助缓解周期性供应商容量限制。例如,在 AWS 上,使用 m5.large 和 m5d.large。
云供应商可能会为 API 服务实施配额。因此,需要对集群逐渐进行扩展。
如果同时将计算机器集中的副本设置为更高数量,则控制器可能无法创建机器。部署 OpenShift Container Platform 的云平台可以处理的请求数量将会影响该进程。当尝试创建、检查和更新有状态的机器时,控制器会开始进行更多的查询。部署 OpenShift Container Platform 的云平台具有 API 请求限制,如果出现过量查询,则可能会因为云平台的限制而导致机器创建失败。
当扩展到具有大量节点时,启用机器健康检查。如果出现故障,健康检查会监控状况并自动修复不健康的机器。
当对大型且高密度的集群减少节点数时,可能需要大量时间,因为这个过程涉及排空或驱除在同时终止的节点上运行的对象。另外,如果要驱除的对象太多,对客户端的请求处理会出现瓶颈。默认客户端查询每秒(QPS)和突发率当前分别设置为 50 和 100。这些值无法在 OpenShift Container Platform 中修改。
2.1.2. Control plane 节点大小
控制平面节点资源要求取决于集群中的节点和对象的数量和类型。以下控制平面节点大小是基于控制平面密度测试的结果,或 Clusterdensity。此测试会在给定很多命名空间中创建以下对象:
- 1 个镜像流
- 1 个构建
-
5 个部署,其中 2 个 pod 副本处于
睡眠状态,每个状态都挂载 4 个 secret、4 个配置映射和 1 Downward API 卷 - 5 个服务,每个服务都指向前一个部署的 TCP/8080 和 TCP/8443 端口
- 1 个路由指向上一个服务的第一个路由
- 包含 2048 个随机字符串字符的 10 个 secret
- 10 个配置映射包含 2048 个随机字符串字符
| worker 节点数量 | 集群密度(命名空间) | CPU 内核 | 内存 (GB) |
|---|---|---|---|
| 24 | 500 | 4 | 16 |
| 120 | 1000 | 8 | 32 |
| 252 | 4000 | 16,但如果使用 OVN-Kubernetes 网络插件,则为 24 | 64,但在使用 OVN-Kubernetes 网络插件时为 128 |
| 501,但使用 OVN-Kubernetes 网络插件时未测试 | 4000 | 16 | 96 |
上表中的数据基于在 AWS 上运行的 OpenShift Container Platform,使用 r5.4xlarge 实例作为 control-plane 节点,m5.2xlarge 实例作为 worker 节点。
在具有三个 control plane 节点的大型高密度集群中,当其中一个节点停止、重启或失败时,CPU 和内存用量将会激增。故障可能是因为电源、网络、底层基础架构或意外情况造成意外问题,因为集群在关闭后重启,以节约成本。其余两个 control plane 节点必须处理负载才能高度可用,从而增加资源使用量。另外,在升级过程中还会有这个预期,因为 control plane 节点被封锁、排空并按顺序重新引导,以应用操作系统更新以及 control plane Operator 更新。为了避免级联失败,请将 control plane 节点上的总体 CPU 和内存资源使用量保留为最多 60% 的所有可用容量,以处理资源使用量激增。相应地增加 control plane 节点上的 CPU 和内存,以避免因为缺少资源而造成潜在的停机。
节点大小取决于集群中的节点和对象数量。它还取决于集群上是否正在主动创建这些对象。在创建对象时,control plane 在资源使用量方面与对象处于运行(Running)阶段的时间相比更活跃。
Operator Lifecycle Manager(OLM)在 control plane 节点上运行,其内存占用量取决于 OLM 在集群中管理的命名空间和用户安装的 operator 的数量。Control plane 节点需要相应地调整大小,以避免 OOM 终止。以下数据基于集群最大测试的结果。
| 命名空间数量 | 处于空闲状态的 OLM 内存(GB) | 安装了 5 个用户 operator 的 OLM 内存(GB) |
|---|---|---|
| 500 | 0.823 | 1.7 |
| 1000 | 1.2 | 2.5 |
| 1500 | 1.7 | 3.2 |
| 2000 | 2 | 4.4 |
| 3000 | 2.7 | 5.6 |
| 4000 | 3.8 | 7.6 |
| 5000 | 4.2 | 9.02 |
| 6000 | 5.8 | 11.3 |
| 7000 | 6.6 | 12.9 |
| 8000 | 6.9 | 14.8 |
| 9000 | 8 | 17.7 |
| 10,000 | 9.9 | 21.6 |
您只能为以下配置修改正在运行的 OpenShift Container Platform 4.20 集群中的 control plane 节点大小:
- 使用用户置备的安装方法安装的集群。
- 使用安装程序置备的基础架构安装方法安装的 AWS 集群。
- 使用 control plane 机器集管理 control plane 机器的集群。
对于所有其他配置,您必须估计节点总数并在安装过程中使用推荐的 control plane 节点大小。
在 OpenShift Container Platform 4.20 中,与 OpenShift Container Platform 3.11 及之前的版本相比,系统现在默认保留半个 CPU 内核(500 millicore)。确定大小时应该考虑这一点。
如果 Amazon Web Services (AWS) 集群中的 control plane 机器需要更多资源,您可以为 control plane 机器选择更大的 AWS 实例类型。
使用 control plane 机器集的集群的步骤与不使用 control plane 机器集的集群的步骤不同。
如果不确定集群中 ControlPlaneMachineSet CR 的状态,您可以验证 CR 状态。
您可以通过更新 control plane 机器集自定义资源 (CR) 中的规格来更改 control plane 机器使用的 Amazon Web Services (AWS) 实例类型。
先决条件
- 您的 AWS 集群使用 control plane 机器集。
流程
运行以下命令来编辑 control plane 机器集 CR:
$ oc --namespace openshift-machine-api edit controlplanemachineset.machine.openshift.io cluster编辑
providerSpec字段中的以下行:providerSpec: value: ... instanceType: <compatible_aws_instance_type>1 - 1
- 使用与之前选择相同的基础指定较大的 AWS 实例类型。例如,您可以将
m6i.xlarge更改为m6i.2xlarge或m6i.4xlarge。
保存您的更改。
-
对于使用默认
RollingUpdate更新策略的集群,Operator 会自动将更改传播到 control plane 配置。 -
对于配置为使用
OnDelete更新策略的集群,您必须手动替换 control plane 机器。
-
对于使用默认
2.1.2.1.2. 使用 AWS 控制台更改 Amazon Web Services 实例类型
您可以通过更新 AWS 控制台中的实例类型来更改 control plane 机器使用的 Amazon Web Services (AWS) 实例类型。
先决条件
- 您可以使用修改集群的 EC2 实例所需的权限访问 AWS 控制台。
-
您可以使用具有
cluster-admin角色的用户访问 OpenShift Container Platform 集群。
流程
- 打开 AWS 控制台并为 control plane 机器获取实例。
选择一个 control plane 机器实例。
- 对于所选 control plane 机器,通过创建 etcd 快照来备份 etcd 数据。如需更多信息,请参阅 "恢复 etcd"。
- 在 AWS 控制台中,停止 control plane 机器实例。
- 选择已停止的实例,然后点 Actions → Instance Settings → Change instance type。
-
将实例更改为较大的类型,确保类型与之前选择相同,并应用更改。例如,您可以将
m6i.xlarge更改为m6i.2xlarge或m6i.4xlarge。 - 启动实例。
-
如果您的 OpenShift Container Platform 集群具有实例对应的
Machine对象,请更新对象的实例类型以匹配 AWS 控制台中设置的实例类型。
- 为每个 control plane 机器重复此步骤。
2.2. 推荐的基础架构实践
本主题为 OpenShift Container Platform 中的基础架构提供推荐的性能和可扩展性实践。
2.2.1. 基础架构节点大小
基础架构节点是标记为运行 OpenShift Container Platform 环境组成部分的节点。基础架构节点的资源要求取决于集群中的集群年龄、节点和对象,因为这些因素可能会导致 Prometheus 的指标或时间序列增加。以下基础架构节点大小是基于在 Control plane 节点大小 部分中详述的集群密度测试中观察到的结果,其中监控堆栈和默认 ingress-controller 被移到这些节点。
| worker 节点数量 | 集群密度或命名空间数量 | CPU 内核 | 内存 (GB) |
|---|---|---|---|
| 27 | 500 | 4 | 24 |
| 120 | 1000 | 8 | 48 |
| 252 | 4000 | 16 | 128 |
| 501 | 4000 | 32 | 128 |
通常,建议每个集群有三个基础架构节点。
这些大小建议应用作指导行。Prometheus 是一个高内存密集型应用程序,资源使用量取决于各种因素,包括节点、对象、Prometheus 指标提取间隔、指标或时间序列以及集群的年龄。此外,路由器资源使用量也可以受到路由数量和入站请求的数量/类型的影响。
这些建议只适用于在集群创建过程中安装监控、Ingress 和 Registry 基础架构组件的基础架构节点。
在 OpenShift Container Platform 4.20 中,与 OpenShift Container Platform 3.11 及之前的版本相比,系统现在默认保留半个 CPU 内核(500 millicore)。这会影响缩放建议。
2.2.2. 扩展 Cluster Monitoring Operator
OpenShift Container Platform 会提供 Cluster Monitoring Operator 在基于 Prometheus 的监控堆栈中收集并存储的数据。作为管理员,您可以通过进入 Observe → Dashboards 来查看 OpenShift Container Platform Web 控制台中的系统资源、容器和组件指标的仪表板。
2.2.3. Prometheus 数据库存储要求
红帽对不同的扩展大小进行了各种测试。
- 以下 Prometheus 存储要求并不具有规定性,应该将它们视为参考信息。取决于具体的工作负载和资源的使用,集群中可能会出现高的资源消耗,包括 Prometheus 收集的指标,如 pod 、容器、路由或其他资源的数量。
- 您可以配置基于大小的数据保留策略,以满足您的存储要求。
| 节点数 | pod 数量(每个 pod 2 个容器) | 每天增加的 Prometheus 存储 | 每 15 天增加的 Prometheus 存储 | 网络(每个 tsdb 块) |
|---|---|---|---|---|
| 50 | 1800 | 6.3 GB | 94 GB | 16 MB |
| 100 | 3600 | 13 GB | 195 GB | 26 MB |
| 150 | 5400 | 19 GB | 283 GB | 36 MB |
| 200 | 7200 | 25 GB | 375 GB | 46 MB |
大约 20%的预期大小被添加为开销,以保证存储要求不会超过计算的值。
上面的计算用于默认的 OpenShift Container Platform Cluster Monitoring Operator。
CPU 利用率会有轻微影响。这个比例为在每 50 个节点和 1800 个 pod 的 40 个内核中大约有 1 个。
针对 OpenShift Container Platform 的建议
- 至少使用两个基础架构 (infra) 节点。
- 至少使用三个带有非易失性存储器 (SSD 或 NVMe) 驱动器的 openshift-container-storage 节点。
2.2.4. 配置集群监控
您可以为集群监控堆栈中的 Prometheus 组件增加存储容量。
流程
为 Prometheus 增加存储容量:
创建 YAML 配置文件
cluster-monitoring-config.yaml。例如:apiVersion: v1 kind: ConfigMap data: config.yaml: | prometheusK8s: retention: {{PROMETHEUS_RETENTION_PERIOD}}1 nodeSelector: node-role.kubernetes.io/infra: "" volumeClaimTemplate: spec: storageClassName: {{STORAGE_CLASS}}2 resources: requests: storage: {{PROMETHEUS_STORAGE_SIZE}}3 alertmanagerMain: nodeSelector: node-role.kubernetes.io/infra: "" volumeClaimTemplate: spec: storageClassName: {{STORAGE_CLASS}}4 resources: requests: storage: {{ALERTMANAGER_STORAGE_SIZE}}5 metadata: name: cluster-monitoring-config namespace: openshift-monitoring- 1
- Prometheus 保留的默认值为
PROMETHEUS_RETENTION_PERIOD=15d。时间单位使用以下后缀之一 : s 、m 、h 、d。 - 2 4
- 集群的存储类。
- 3
- 一个典型的值是
PROMETHEUS_STORAGE_SIZE=2000Gi。存储值可以是一个纯整数,也可以是带有以下后缀之一的整数: E 、P 、T 、G 、M 、K。您也可以使用以下效果相同的后缀:Ei 、Pi 、Ti 、Gi 、Mi 、Ki。 - 5
- 一个典型的值
是 alertmanager_STORAGE_SIZE=20Gi。存储值可以是一个纯整数,也可以是带有以下后缀之一的整数: E 、P 、T 、G 、M 、K。您也可以使用以下效果相同的后缀:Ei 、Pi 、Ti 、Gi 、Mi 、Ki。
- 为保留周期、存储类和存储大小添加值。
- 保存该文件。
运行以下命令应用这些更改:
$ oc create -f cluster-monitoring-config.yaml
第 3 章 电信核心参考设计规格
电信核心参考设计规格(RDS)配置在商业硬件上运行的 OpenShift Container Platform 集群,以托管电信核心工作负载。
3.1. 电信核心 RDS 4.20 使用模型概述
Telco 核心参考设计规格(RDS)描述了支持大型电信应用程序(包括 control plane 功能)的平台,如信号和聚合。它还包括一些集中式数据平面功能,如 user plane 功能 (UPF)。这些功能通常需要可扩展性、复杂的网络支持、弹性的软件定义存储并支持比 RAN 等远端部署限制的性能要求。
3.2. 关于电信核心集群使用模型
电信核心集群使用模型专为在商业硬件上运行的集群而设计。电信核心集群支持大规模电信应用程序,包括信号、聚合和会话边框控制器(SBC);以及集中式数据平面功能(UPF);以及中央化的 data plane,如 5G user plane functions (UPF)。电信核心集群功能需要可扩展性、复杂的网络支持、弹性软件定义存储和支持性能要求,比远边缘 RAN 部署更严格且受限制。
电信核心功能的网络要求因各种网络功能和性能点而异。IPv6 是一个要求,常见的是使用双栈。有些功能需要最大吞吐量和事务率,并需要支持 user-plane DPDK 网络。其他功能使用更为典型的云原生模式,并可以依赖 OVN-Kubernetes、内核网络和负载均衡。
电信核心集群配置为具有三个 control plane 的标准,以及配置了库存(非RT)内核的一个或多个 worker 节点。在支持具有不同网络和性能要求的工作负载中,您可以使用 MachineConfigPool 自定义资源(CR)对 worker 节点进行分段,例如,非用户数据平面或高吞吐量用例。为了支持所需的电信操作功能,核心集群安装了标准的第 2 天 OLM 管理的 Operator。
图 3.1. 电信核心 RDS 集群基于服务的架构和网络拓扑

3.3. 参考设计范围
电信核心和电信 RAN 参考规格(RDS)捕获了建议的、经过测试和支持的配置,以便为运行电信核心和电信 RAN 配置集的集群获得可靠和可重复的性能。
每个 RDS 包括已发布的功能及支持的配置,这些配置经过设计并验证,供集群运行各个配置集。配置提供了一个满足功能和 KPI 目标的基准 OpenShift Container Platform 安装。每个 RDS 还描述了每个单独配置的预期变化。每个 RDS 的验证包括很多长持续时间和大规模测试。
为 OpenShift Container Platform 的每个主要 Y-stream 版本更新经过验证的参考配置。z-stream 补丁版本会定期根据参考配置重新测试。
3.4. 来自参考设计的偏差
从经过验证的电信核心和电信 RAN DU 参考设计规范(RDS)中进行开发,在您更改的特定组件或功能之外可能会产生重大影响。开发需要在完整的解决方案上下文中分析和工程。
应使用明确的操作跟踪信息,分析来自 RDS 的所有偏差。预计将来自合作伙伴的尽职调查,以便了解如何通过参考设计来保持一致。这可能需要合作伙伴向红帽提供其他资源,以便其用例能够更好地与平台结果相联系。这对解决方案的支持性至关重要,并确保红帽与合作伙伴保持一致。
RDS 的偏差可以有一些或全部后果:
- 解决问题可能需要更长的时间。
- 缺少项目服务级别协议 (SLA)、项目期限、最终供应商性能要求等风险。
未批准的偏差可能需要在执行级别进行升级。
注意根据合作伙伴参与优先事项,红帽优先考虑为开发提供请求。
3.5. 电信核心常见基准模型
以下配置和使用模型适用于所有电信核心用例。电信核心用例基于这种常见功能基准进行构建。
- 集群拓扑
电信核心参考设计支持两个不同的集群配置变体:
- 非可调度 control plane 变体,其中用户工作负载严格禁止在 master 节点上运行。
一个可调度的 control plane 变体,允许用户工作负载在 master 节点上运行,以优化资源利用率。这个变体只适用于裸机 control plane 节点,且必须在安装时配置。
所有集群,无论变体如何,都必须符合以下要求:
- 由三个或更多节点组成的高可用性 control plane。
- 使用多个机器配置池。
- Storage
- 电信核心用例需要高度可用的持久性存储,如外部存储解决方案提供的。OpenShift Data Foundation 可用于管理对外部存储的访问。
- 网络
电信核心集群网络符合以下要求:
- 双堆栈 IPv4/IPv6 (IPv4 为主)。
- 完全断开连接的 - 集群在其生命周期中都无法访问公共网络。
- 支持多个网络。分段网络提供操作、管理和维护(OAM)、信号和存储流量之间的隔离。
- 集群网络类型是 OVN-Kubernetes,如 IPv6 支持需要。
电信核心集群具有由底层 RHCOS、SR-IOV Network Operator、Load Balancer 和其他组件支持的多个网络层。这些层包括以下内容:
集群网络层。通过安装配置定义并应用集群网络配置。使用 NMState Operator 在第 2 天操作过程中更新配置。使用初始配置建立以下内容:
- 主机接口配置。
- 主动/主动绑定(LACP)。
-
二级/额外网络层。通过网络
additionalNetwork或NetworkAttachmentDefinitionCR 配置 OpenShift Container Platform CNI。使用初始配置来配置 MACVLAN 虚拟网络接口。 - 应用程序工作负载层。User plane 网络在云原生网络功能(CNF)中运行。
- Service Mesh
- 电信 CNF 可以使用 Service Mesh。电信核心集群通常包括一个 Service Mesh 实现。选择实施和配置已超出此规格的范围。
3.6. 部署计划
MachineConfigPools (MCP)自定义资源(CR)根据客户计划参数,将电信核心集群中的 worker 节点划分为不同的节点组。使用 MCP 时要小心的部署计划对于尽量减少部署和升级时间至关重要,更重要的是,尽量减少集群升级过程中电信级服务的中断。
描述
电信核心集群可以使用 MachineConfigPools (MCP)将 worker 节点分成额外的独立角色,例如因为不同的硬件配置集。这允许为每个角色进行自定义性能优化,同时还可以加快电信核心集群部署或升级的关键功能。多个 MCP 可用于在一个或多个维护窗口间正确计划集群升级。这很重要,因为如果仔细考虑规划,则电信级服务可能会受到影响。
在集群升级过程中,您可以在升级 control plane 时暂停 MCP。如需更多信息,请参阅"绑定一个 Canary rollout 更新"。这样可确保 worker 节点不会被重启并运行工作负载,直到 MCP 取消暂停为止。
使用小心的 MCP 规划,您可以控制随时升级哪些节点的时间和顺序。有关如何使用 MCP 计划电信升级的更多信息,请参阅"在更新前将 MachineConfigPool 标签应用到节点"。
在开始初始部署前,请注意与 MCP 相关的以下工程注意事项:
PerformanceProfile 和 Tuned 配置集关联:
使用 PerformanceProfile 时,请记住每个 Machine Config Pool (MCP)必须只链接到一个 PerformanceProfile 或 Tuned 配置集定义。因此,即使多个 MCP 所需的配置是相同的,每个 MCP 仍然需要自己的专用 PerformanceProfile 定义。
规划您的 MCP 标签策略:
使用适当的策略规划 MCP 标签,以根据参数分割 worker 节点,例如:
- worker 节点类型:识别具有等效硬件配置集的一组节点,例如,用于 control plane 网络功能(NF) 的 worker 和用于用户 data plane NFs 的 worker。
- 每个 worker 节点类型的 worker 节点数量。
- 对等硬件配置集所需的最小 MCP 数量是 1,但对于较大的集群可能需要更多。例如,您可以为每个硬件配置集设计更多 MCP,以支持更精细的升级(每个步骤有较小的集群容量影响)。
MCP 中节点的更新策略取决于升级要求和所选的
maxUnavailable值:- 允许维护窗口的数量。
- 维护窗口持续的时间。
- worker 节点的总数。
-
所需
maxUnavailable(MCP 同时更新的节点数量)。
针对以下的 worker 节点的 CNF 要求:
- 升级过程中每个 Pod 所需的最小可用性,配置了 pod 中断预算(PDB)。PDB 在升级过程中维护电信服务级别协议(SLA)至关重要。有关 PDB 的更多信息,请参阅"了解如何使用 pod 中断预算来指定必须在线的 pod 数量"。
- 每个 Pod 所需的最小真正高可用性,因此每个副本都在单独的硬件上运行。
- pod 关联性和反关联性链接 :有关如何使用 pod 关联性和反关联性的更多信息,请参阅"使用关联性和反关联性规则相对于其他 pod 放置 pod"。
- 电信级服务可能会受到影响的持续时间和升级维护窗口数量。
3.7. 区域
设计集群以支持同时中断多个节点对于高可用性(HA)至关重要,并减少了升级时间。OpenShift Container Platform 和 Kubernetes 使用已知的标签 topology.kubernetes.io/zone 来创建受通用故障域的节点池。为拓扑(availability)区域注解节点允许高可用性工作负载分散,以便每个区域只包含一组 HA 复制 pod 中的一个副本。在这个版本中,单个区的丢失不会违反 HA 约束,将维护最小服务可用性。OpenShift Container Platform 和 Kubernetes 将默认 TopologySpreadConstraint 应用到所有副本结构(Service、ReplicaSet、StatefulSet 或 ReplicationController),它根据 topology.kubernetes.io/zone 标签来分散副本。此默认允许基于区的分布在不更改工作负载 pod 规格的情况下应用。
集群升级通常会在更新底层操作系统时造成节点中断。在大型集群中,需要同时更新多个节点以便快速、在几个维护窗口中完成升级。通过使用区来确保 pod 分布,可以同时将升级应用到区中的所有节点(假设有足够的备用容量),同时保持高可用性和服务可用性。推荐的集群设计是将节点分区到多个 MCP 中,并根据之前的注意事项将单个 MCP 中的所有节点标记为单个区,这与附加到其他 MCP 的区域不同。使用这个策略,可以同时更新 MCP 中的所有节点。
生命周期 hook (就绪、存活度、启动和预停止)在确保应用可用性方面发挥重要作用。对于特定预停止 hook 的升级,应用程序可以采取必要的步骤来准备中断,然后再从节点驱除。
- 限制和要求
- 默认 TopologySpreadConstraints (TSC)仅在未给出显式 TSC 时才适用。如果您的 pod 有明确的 TSC,请确保包含基于区的分布。
-
集群必须具有足够的备用容量,才能容忍同时更新 MCP。否则 MCP 的
maxUnavailable必须小于 100%。 - 更新 MCP 中所有节点的功能取决于工作负载设计和具有该中断级别的服务级别。
- 工程注意事项
- Pod 排空时间可能会影响节点更新时间。确保工作负载设计允许快速排空 pod。
PodDisruptionBudgets (PDB) 用于强制实施高可用性要求。
为确保持续应用可用性,集群设计必须使用足够的独立区域来分散工作负载的 pod。
- 如果 pod 分散到足够区域,则一个区域的丢失不会停机超过 Pod Disruption Budget (PDB)允许的 pod。
- 如果 pod 没有足够多的分布式,因为有太多的区域或限制调度限制,区域失败将违反 PDB,从而导致中断。
- 此外,这种较差的分布可能会强制并行运行升级,以按顺序执行缓慢和顺序(部分序列化),以避免违反 PDB,从而显著扩展维护时间。
- 具有 0 个中断的 pod 的 PDB 将阻止节点排空并需要管理员干预。在快速和自动升级时,应该避免使用此模式。
3.8. 电信核心集群常见使用模型工程注意事项
- 集群工作负载在"应用程序工作负载"中详细介绍。
Worker 节点应在以下任何 CPU 上运行:
- 当 OpenShift Container Platform 支持时,Intel 3rd Generation Xeon (IceLake) CPU 或具有 silicon 安全漏洞(Spectre 和类似)缓解的 CPU 被关闭。当启用 Spectre 和类似的缓解方案时,S Skylake 和旧的 CPU 可能会出现 40% 的事务性能下降。
- OpenShift Container Platform 支持 AMD EPYC Zen 4 CPU (Genoa、Bergamo) 或 AMD EPYC Zen 5 CPU (Turin)。
- OpenShift Container Platform 支持时的 Intel Sierra Forest CPU。
-
在 worker 节点上启用 IRQ 平衡。
PerformanceProfileCR 将globallyDisableIrqLoadBalancing参数设置为false的值。保证的 QoS pod 被注解以确保隔离,如"CPU 分区和性能调优"中所述。
所有集群节点应具有以下功能:
- 启用超线程
- 具有 x86_64 CPU 架构
- 启用了普通(非实时)内核
- 没有为工作负载分区配置
电源管理和最大性能之间的平衡因集群中的机器配置池而异。以下配置应该与机器配置池组中的所有节点一致。
- 集群扩展。如需更多信息,请参阅"可扩展性"。
- 集群应该可以扩展到至少 120 个节点。
-
CPU 分区使用
PerformanceProfileCR 配置,并应用于每个MachineConfigPool的节点。如需了解更多注意事项,请参阅"CPU 分区和性能调整"。 OpenShift Container Platform 的 CPU 要求取决于配置的功能集和应用程序工作负载特征。对于根据 kube-burner node-density 测试创建的 3000 pod 的模拟工作负载配置的集群,会验证以下 CPU 要求:
- control plane 和 worker 节点的最小保留 CPU 数量是每个 NUMA 节点 2 个 CPU (4 个超线程)。
- 用于非 DPDK 网络流量的 NIC 应配置为在最多 32 RX/TX 队列中使用。
具有大量 pod 或其他资源的节点可能需要额外的保留 CPU。剩余的 CPU 可用于用户工作负载。
注意OpenShift Container Platform 配置、工作负载大小和工作负载特征的不同需要额外分析,以确定对 OpenShift 平台所需 CPU 数量的影响。
3.8.1. 应用程序工作负载
在电信核心集群中运行的应用程序工作负载可包括高性能云原生网络功能(CNF)和传统的最佳 pod 工作负载。
保证因为性能或安全要求而需要专用或专用使用 CPU 的 pod 有保证的 QoS 调度可用。通常,使用 user plane 网络(如 DPDK)运行高性能或延迟敏感 CNF 的 pod 需要通过节点调整和保证 QoS 调度来独占使用专用的整个 CPU。在创建需要专用 CPU 的 pod 配置时,请注意超线程系统的潜在影响。当整个内核(2 超线程)必须分配给 pod 时,Pod 应该请求 2 个 CPU 的倍数。
运行不需要高吞吐量和低延迟网络的网络功能的 Pod 通常使用最佳或突发的 QoS pod 调度,且不需要专用或隔离的 CPU 内核。
- 工程考虑
使用以下信息来规划电信核心工作负载和集群资源:
-
从 OpenShift Container Platform 4.19 开始,
cgroup v1不再被支持并已被删除。现在,所有工作负载必须与cgroup v2兼容。如需更多信息,请参阅 Red Hat OpenShift 工作负载上下文中的 Red Hat Enterprise Linux 9 更改。 - CNF 应用程序应该符合 Kubernetes 的最新版本。
根据您的应用程序需要,使用最佳数量和突发的 QoS pod。
-
使用带有正确配置节点的
PerformanceProfileCR 中的保留或隔离 CPU 的保证 QoS pod。 - 保证的 QoS Pod 必须包含完全隔离 CPU 的注解。
- 最佳工作和突发 pod 无法保证专用 CPU 使用量。工作负载可能被其他工作负载、操作系统守护进程或内核任务抢占。
-
使用带有正确配置节点的
使用 exec probe 静默,且仅在没有其他合适的选项时才使用
-
如果 CNF 使用 CPU 固定,则不要使用 exec 探测。使用其他探测实施,如
httpGet或tcpSocket。 - 当您需要使用 exec 探测时,限制 exec 探测频率和数量。exec 探测的最大数量必须保持在 10 以下,且频率不得小于 10 秒。
- 您可以使用启动探测,因为它们不会在 steady-state 操作中使用大量资源。exec 探测的限制主要适用于存活度和就绪度探测。与其它探测类型相比,执行探测会导致管理内核 CPU 使用率高得多,因为它们需要进程分叉。
-
如果 CNF 使用 CPU 固定,则不要使用 exec 探测。使用其他探测实施,如
- 使用预停止 hook 允许应用程序工作负载在 pod 中断预算前执行必要的操作,比如在升级或节点维护过程中。hook 使 pod 能够将状态保存到持久性存储,从服务卸载流量,或向其他 Pod 卸载流量。
-
从 OpenShift Container Platform 4.19 开始,
3.8.2. 信号工作负载
信号工作负载通常使用 SCTP、REST、gRPC 或类似的 TCP 或 UDP 协议。信号工作负载支持使用配置为 MACVLAN 或 SR-IOV 接口的辅助 multus CNI 支持每秒数以千计的事务(TPS)。这些工作负载可以在带有保证或突发 QoS 的 pod 中运行。
3.9. 电信核心 RDS 组件
以下小节描述了用于配置和部署集群来运行电信核心工作负载的各种 OpenShift Container Platform 组件和配置。
3.9.1. CPU 分区和性能调整
- 这个版本中的新内容
- 禁用 RPS - 在应用程序 CPU 上应该考虑 pod 网络的资源使用
- 在可调度的 control-plane 节点上更好地隔离 control plane
- 支持 NUMA Resources Operator 中的可调度 control-plane
- 有关 Telco Core 集群的升级的其他指导
- 描述
- CPU 分区通过将敏感工作负载与通用任务、中断和驱动程序工作队列分离来提高性能并降低延迟。分配给这些辅助进程的 CPU 在以下部分中称为 reserved。在启用了超线程的系统中,CPU 是一个超线程。
- 限制和要求
操作系统需要一定数量的 CPU 来执行所有支持任务,包括内核网络。
- 仅具有 user plane 网络应用程序(DPDK)的系统至少需要为操作系统和基础架构组件保留一个核心(2 超线程)。
- 在启用了 Hyper-Threading 的系统中,内核同级线程必须始终处于相同的 CPU 池中。
- 保留和隔离的内核集合必须包含所有 CPU 内核。
- 每个 NUMA 节点的核心 0 必须包含在保留的 CPU 集中。
- 低延迟工作负载需要特殊配置,以避免受到平台中断、内核调度程序或其他部分影响。
如需更多信息,请参阅"创建性能配置集"。
- 工程考虑
-
从 OpenShift 4.19 开始,
cgroup v1不再被支持并已被删除。现在,所有工作负载必须与cgroup v2兼容。如需更多信息,请参阅 Red Hat OpenShift 工作负载上下文中的 Red Hat Enterprise Linux 9 更改。 -
所需的最少保留容量(
systemReserved) 的信息包括在在 OCP 4 节点上为系统保留量的 CPU和内存 - 对于可调度的 control plane,最低推荐保留容量至少为 16 个 CPU。
- 实际所需的保留 CPU 容量取决于集群配置和工作负载属性。
- 保留的 CPU 值必须向上舍入到完整内核(2 超线程)。
- 对 CPU 分区的更改会导致相关机器配置池中包含的节点排空并重启。
- 保留的 CPU 减少了 pod 密度,因为保留的 CPU 已从 OpenShift Container Platform 节点的可分配容量中删除。
应该为实时工作负载启用实时工作负载提示。
-
应用实时工作负载
Hint设置会导致应用nohz_full内核命令行参数来提高高性能应用程序的性能。当您应用workloadHint设置时,任何没有cpu-quota.crio.io: "disable"注解和正确的runtimeClassName值的隔离或 burstable pod 都会受到 CRI-O 速率限制。当您设置workloadHint参数时,请注意提高性能和 CRI-O 速率限制的潜在影响之间的权衡。确保正确注解所需的 pod。
-
应用实时工作负载
- 没有 IRQ 关联性支持的硬件会影响隔离的 CPU。所有服务器硬件都必须支持 IRQ 关联性,以确保具有保证 CPU QoS 的 pod 可以充分利用分配的 CPU。
-
OVS 动态管理其
cpuset条目,以适应网络流量的需求。您不需要保留额外的 CPU 来处理主 CNI 上的高网络吞吐量。 - 如果集群中运行的工作负载使用内核级别网络,则参与 NIC 的 RX/TX 队列数应设置为 16 或 32 个队列(如果硬件允许)。请注意默认队列计数。如果没有配置,每个在线 CPU 默认队列数是一个 RX/TX 队列,这可能会导致分配太多的中断。
irdma 内核模块可能会导致在具有高内核数的系统上分配太多中断向量。要防止这种情况,参考配置会阻止这个内核模块通过
PerformanceProfile资源中的内核命令行参数加载。通常,核心工作负载不需要这个内核模块。注意有些驱动程序在减少队列计数后也不会取消分配中断。
-
从 OpenShift 4.19 开始,
3.9.2. 可调度 control plane 上的工作负载
- 在 control plane 节点上启用工作负载
您可以启用可调度 control plane 在 control plane 节点上运行工作负载,利用裸机上的空闲 CPU 容量进行潜在的成本节省。此功能仅适用于带有裸机 control plane 节点的集群。
此功能有两个不同的部分:
- 在 control plane 节点上允许工作负载: 此功能可在初始集群安装后配置,允许您在需要在这些节点上运行工作负载时启用它。
- 启用工作负载分区 :这是一个关键隔离措施,保护 control plane 不受常规工作负载干扰,确保集群稳定性和可靠性。工作负载分区必须在初始的 "day zero" 集群安装过程中配置,且无法在以后启用。
如果您计划在 control plane 节点上运行工作负载,您必须首先在初始设置中启用工作负载分区。然后,您可以稍后启用可调度 control plane 功能。
- 工作负载特性和限制
您必须测试并验证工作负载,以确保应用程序不会影响核心集群功能。建议您从没有大量 CPU 或网络负载的轻量级容器开始。
由于集群稳定性的风险,在 control plane 节点上不允许某些工作负载。这包括重新配置内核参数或系统全局 sysctl 的任何工作负载,因为这可能导致集群无法预计的结果。
为确保稳定性,您必须遵循以下内容:
- 确保所有非预期的工作负载都定义了内存限值。这在出现内存泄漏时保护 control plane。
- 避免过度加载保留的 CPU,例如,大量使用 exec 探测。
- 避免大量基于内核的网络使用情况,因为它可以通过 OVS 等软件组件增加保留的 CPU 负载。
- NUMA Resources Operator 支持
- NUMA Resources Operator 支持在 control plane 节点上使用。Operator 的功能行为保持不变。
3.9.3. Service Mesh
- 描述
- 电信核心云原生功能(CNF)通常需要 Service Mesh 实现。特定的服务网格功能和性能要求取决于应用程序。服务网格实施和配置选择超出了本文档的范围。这个实现必须考虑服务网格对集群资源使用情况和性能的影响,包括在实现中 pod 网络中引入的额外延迟。
3.9.4. 网络
下图显示了电信核心参考设计网络配置。
图 3.2. 电信核心参考设计网络配置

- 这个版本中的新内容
- 这个版本没有参考设计更新
如果您在 metallb-system 命名空间中有自定义 FRRConfiguration CR,您必须将它们移到 openshift-network-operator 命名空间中。
- 描述
- 集群是为双栈 IP (IPv4 和 IPv6)配置的。
- 验证的物理网络配置由两个双端口 NIC 组成。一个 NIC 在主 CNI (OVN-Kubernetes)和 IPVLAN 和 MACVLAN 流量间共享,而第二个 NIC 专用于基于 SR-IOV VF 的 pod 流量。
-
Linux 绑定接口(
bond0)是在主动-主动 IEEE 802.3ad LACP 模式中创建的,并附加两个 NIC 端口。顶尖网络设备必须支持,并为多机链路聚合 (mLAG) 技术进行配置。 -
VLAN 接口在
bond0上创建,包括用于主 CNI。 -
在安装过程的网络配置阶段,会在集群安装过程中创建绑定和 VLAN 接口。除了主 CNI 使用的
vlan0VLAN 外,其它所有 VLAN 可以在第 2 天活动期间使用 Kubernetes NMstate Operator 创建。 - MACVLAN 和 IPVLAN 接口使用对应的 CNI 创建。它们不共享相同的基本接口。如需更多信息,请参阅"Cluster Network Operator"。
- SR-IOV VF 由 SR-IOV Network Operator 管理。
-
为确保 LoadBalancer Service 后面的 pod 一致源 IP 地址,请配置
EgressIPCR 并指定podSelector参数。EgressIP 在 "Cluster Network Operator" 部分进一步讨论。 您可以通过执行以下操作实现服务流量分离:
-
使用
NodeNetworkConfigurationPolicyCR 在节点上配置 VLAN 接口和特定内核 IP 路由。 -
为每个 VLAN 创建一个 MetalLB
BGPPeerCR,以与远程 BGP 路由器建立对等。 -
定义 MetalLB
BGPAdvertisementCR,以指定哪些 IP 地址池应公告为所选BGPPeer资源列表。下图演示了如何通过特定的 VLAN 接口从外部公告特定的服务 IP 地址。服务路由在BGPAdvertisementCR 中定义,并使用IPAddressPool1和BGPPeer1字段的值进行配置。
-
使用
图 3.3. 电信核心参考设计 MetalLB 服务分离

3.9.4.1. Cluster Network Operator
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
Cluster Network Operator (CNO)会在集群安装过程中部署和管理集群网络组件,包括默认的 OVN-Kubernetes 网络插件。CNO 允许配置主接口 MTU 设置,OVN 网关模式可为 pod 出口使用节点路由表,以及 MACVLAN 等其他二级网络。
支持网络流量分离,通过 CNO 配置多个网络接口。定向到这些接口的流量通过使用 NMState Operator 应用的静态路由来配置。为确保 pod 流量被正确路由,OVN-K 被配置为启用了
routingViaHost选项。此设置使用内核路由表,以及应用的静态路由,而不是 OVN 用于 pod 出口流量。Whereabouts CNI 插件用于为其他 pod 网络接口提供动态 IPv4 和 IPv6 寻址,而无需使用 DHCP 服务器。
- 限制和要求
- IPv6 支持需要 OVN-Kubernetes。
- 大型 MTU 集群支持需要将连接的网络设备设置为相同的或更大值。支持 MTU 大小最多 8900。
MACVLAN 和 IPVLAN 无法在同一主接口上并置,因为它们依赖于相同的底层内核机制,特别是
rx_handler。此处理程序允许第三方模块处理传入的数据包,主机处理它们之前,每个网络接口只能注册一个这样的处理程序。由于 MACVLAN 和 IPVLAN 都需要注册自己的rx_handler才能正常工作,所以它们不会冲突,且无法在同一接口上共存。查看源代码了解更多详情:- 备用 NIC 配置包括将共享 NIC 拆分为多个 NIC 或使用一个双端口 NIC,尽管它们尚未经过测试和验证。
- 带有单堆栈 IP 配置的集群不会被验证。
EgressIP
-
EgressIP 故障转移时间取决于
NetworkCR 中的reachabilityTotalTimeoutSeconds参数。这个参数决定了在所选出口节点无法访问时用于检测的探测的频率。此参数的建议值为1秒。 - 当将 EgressIP 配置为多个出口节点时,故障转移时间应该以秒数或更长的时间为准。
- 在具有额外网络接口 EgressIP 流量的节点上,将通过分配 EgressIP 地址的接口出口。请参阅"配置出口 IP 地址"。
-
EgressIP 故障转移时间取决于
-
Pod 级别 SR-IOV 绑定模式必须设置为
active-backup,并且必须设置miimon的值(建议使用100)。
- 工程考虑
-
Pod 出口流量由内核路由表使用
routingViaHost选项处理。主机上必须配置适当的静态路由。
-
Pod 出口流量由内核路由表使用
3.9.4.2. 负载均衡器
- 这个版本中的新内容
- 这个版本没有参考设计更新。
如果您在 metallb-system 命名空间中有自定义 FRRConfiguration CR,您必须将它们移到 openshift-network-operator 命名空间中。
- 描述
- MetalLB 是使用标准路由协议的裸机 Kubernetes 集群的负载均衡器实现。它可让 Kubernetes 服务获取外部 IP 地址,该地址也添加到集群中的主机网络中。MetalLB Operator 部署并管理集群中 MetalLB 实例的生命周期。有些用例可能需要 MetalLB 中没有提供的功能,如有状态负载均衡。如有必要,您可以使用外部第三方负载均衡器。外部负载均衡器的选择和配置已超出此规格的范围。使用外部第三方负载均衡器时,集成工作必须包含足够的分析,以确保满足所有性能和资源利用率要求。
- 限制和要求
- MetalLB 不支持有状态负载均衡。如果这是工作负载 CNF 的要求,则必须使用备用负载均衡器实现。
- 您必须确保外部 IP 地址可以从客户端路由到集群的主机网络。
- 工程考虑
- MetalLB 仅在 BGP 模式下用于电信内核使用模型。
-
对于电信内核使用模型,MetalLB 仅支持本地网关模式中使用的 OVN-Kubernetes 网络供应商。请参阅 "Cluster Network Operator" 中的
routingViaHost。 MetalLB 中的 BGP 配置应该根据网络和对等点的要求而有所不同。
- 您可以使用地址、聚合长度、自动分配等变化来配置地址池。
-
MetalLB 仅将 BGP 用于公告路由。只有
transmitInterval和minimumTtl参数在此模式中相关。BFD 配置集中的其他参数应保持接近默认值,因为较短的值可能会导致假的负值并影响性能。
3.9.4.3. SR-IOV
- 这个版本中的新内容
- 这个版本没有参考设计更新。
- 描述
- SR-IOV 允许将物理功能(PF)划分为多个虚拟功能(VF)。然后 VF 可以分配给多个 pod,以实现更高的吞吐量性能,同时使 pod 保持隔离。SR-IOV Network Operator 置备并管理 SR-IOV CNI、网络设备插件和 SR-IOV 堆栈的其他组件。
- 限制和要求
- 仅支持某些网络接口。如需更多信息,请参阅"支持设备"。
- 启用 SR-IOV 和 IOMMU :SR-IOV Network Operator 会在内核命令行中自动启用 IOMMU。
- SR-IOV VF 不会从 PF 接收链路状态更新。如果需要链接降级检测,它必须在协议级别进行。
-
MultiNetworkPolicyCR 只能应用到netdevice网络。这是因为,实施使用 iptables,它无法管理 vfio 接口。
- 工程考虑
-
vfio模式中的 SR-IOV 接口通常用于为需要高吞吐量或低延迟的应用程序启用额外的二级网络。 -
必须明确创建
SriovOperatorConfigCR。此 CR 包含在引用配置策略中,这会导致在初始部署期间创建它。 - 不支持使用 UEFI 安全引导或内核锁定进行固件更新的 NIC 必须预先配置,并启用了足够的虚拟功能(VF)来支持应用程序工作负载所需的 VF 数量。对于 Mellanox NIC,您必须在 SR-IOV Network Operator 中禁用 Mellanox vendor 插件。如需更多信息,请参阅"配置 SR-IOV 网络设备"。
-
要在 pod 启动后更改 VF 的 MTU 值,请不要配置
SriovNetworkNodePolicyMTU 字段。反之,使用 Kubernetes NMState Operator 设置相关 PF 的 MTU。
-
3.9.4.4. NMState Operator
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
- Kubernetes NMState Operator 提供了一个 Kubernetes API,用于在集群节点中执行状态驱动的网络配置。它在二级接口上启用网络接口配置、静态 IP 和 DNS、VLAN、中继、绑定、静态路由、MTU 并启用混杂模式。集群节点定期向 API 服务器报告每个节点的网络接口状态。
- 限制和要求
- Not applicable
- 工程考虑
-
初始网络配置是使用安装 CR 中的
NMStateConfig内容应用。NMState Operator 仅在网络更新需要时才使用。 -
当 SR-IOV 虚拟功能用于主机网络时,使用 NMState Operator (通过
nodeNetworkConfigurationPolicyCR)来配置 VF 接口,如 VLAN 和 MTU。
-
初始网络配置是使用安装 CR 中的
3.9.5. 日志记录
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
- Cluster Logging Operator 启用收集并提供与节点相关的日志,以进行远程归档和分析。参考配置使用 Kafka 将审核和基础架构日志发送到远程归档。
- 限制和要求
- Not applicable
- 工程考虑
- 集群 CPU 使用的影响取决于生成的日志的数量或大小以及配置的日志过滤量。
- 参考配置不包括应用程序日志的发布。将应用程序日志包含在配置中,需要评估应用程序日志记录率以及分配给保留集合的足够额外 CPU 资源。
3.9.6. 电源管理
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
- 使用 Performance Profile 配置具有高电源模式、低电源模式或混合模式的集群。电源模式的选择取决于集群中运行的工作负载的特征,特别是对延迟敏感度。使用每个 pod 电源管理 C-states 功能,为低延迟 pod 配置最大延迟。
- 限制和要求
- 电源配置依赖于适当的 BIOS 配置,例如启用 C-states 和 P-states。配置因硬件供应商而异。
- 工程考虑
- 延迟 :为了确保对延迟敏感的工作负载满足要求,您需要一个高电源或每个 pod 电源管理配置。每个 pod 电源管理仅适用于具有专用固定 CPU 的 Guaranteed QoS pod。
3.9.7. Storage
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
云原生存储服务可由 OpenShift Data Foundation 或其他第三方解决方案提供。
OpenShift Data Foundation 是面向容器的基于 Red Hat Ceph Storage 的存储解决方案。它提供块存储、文件系统存储和内部对象存储,可针对持久性和非持久性数据要求动态置备。电信核心应用程序需要持久性存储。
注意所有存储数据可能无法加密。要降低风险,请将存储网络与其他集群网络隔离。存储网络不能从其他集群网络访问或路由。只有直接附加到存储网络的节点才应允许访问它。
3.9.7.1. OpenShift Data Foundation
- 这个版本中的新内容
- 这个版本没有参考设计更新。
- 描述
OpenShift Data Foundation 是容器的软件定义的存储服务。OpenShift Data Foundation 可使用两种模式之一部署:
- 内部模式,OpenShift Data Foundation 软件组件作为软件容器直接部署到 OpenShift Container Platform 集群节点上,以及其他容器化应用程序。
- 外部模式,其中 OpenShift Data Foundation 部署到专用存储集群中,通常是在 Red Hat Enterprise Linux (RHEL)上运行的独立 Red Hat Ceph Storage 集群。
这些存储服务在应用程序工作负载集群外部运行。
对于电信核心集群,存储支持由 OpenShift Data Foundation 存储服务在外部模式中运行,原因如下:
- 在 OpenShift Container Platform 和 Ceph 操作间分离依赖项允许独立的 OpenShift Container Platform 和 OpenShift Data Foundation 更新。
- 分离存储和 OpenShift Container Platform 基础架构层的操作功能是电信核心用例的典型客户要求。
- 外部 Red Hat Ceph Storage 集群可由在同一区域部署的多个 OpenShift Container Platform 集群重新使用。
OpenShift Data Foundation 支持使用二级 CNI 网络来分离存储流量。
- 限制和要求
- 在 IPv4/IPv6 双栈网络环境中,OpenShift Data Foundation 使用 IPv4 地址。如需更多信息,请参阅 IPv6 支持。
- 工程考虑
- OpenShift Data Foundation 网络流量应该与专用网络上的其他流量隔离,例如使用 VLAN 隔离。
- 在将多个 OpenShift Container Platform 集群附加到外部 OpenShift Data Foundation 集群前,必须有范围,以确保有足够的吞吐量、带宽和性能 KPI。
3.9.7.2. 其他存储解决方案
您可以使用其他存储解决方案为电信核心集群提供持久性存储。这些解决方案的配置和集成超出了参考设计规格(RDS)的范围。
将存储解决方案集成至电信核心集群必须包含正确的大小和性能分析,以确保存储满足整体性能和资源使用量要求。
3.9.8. 电信核心部署组件
以下小节描述了您使用 Red Hat Advanced Cluster Management (RHACM) 配置 hub 集群的各种 OpenShift Container Platform 组件和配置。
3.9.8.1. Red Hat Advanced Cluster Management
- 这个版本中的新内容
- 使用 RHACM 和 PolicyGenerator CR 是管理和部署策略的建议方法。这将替换 PolicyGenTemplate CR 用于此目的。
- 描述
RHACM 为部署的集群提供多集群引擎(MCE)安装和持续 GitOps ZTP 生命周期管理。您可以通过在维护窗口期间将
Policy自定义资源 (CR) 应用到集群来声明管理集群配置和升级。您可以使用 RHACM 策略控制器应用策略,由 TALM 管理。配置、升级和集群状态通过策略控制器进行管理。
安装受管集群时,RHACM 将标签和初始 ignition 配置应用到各个节点,以支持自定义磁盘分区、分配角色和分配到机器配置池。您可以使用
SiteConfig或ClusterInstanceCR 定义这些配置。- 限制和要求
- 工程考虑
- 当管理每个安装、站点或部署具有唯一内容的集群时,强烈建议使用 RHACM hub 模板。RHACM hub 模板允许您在为每个安装提供唯一值时对集群应用一致的策略集合。
3.9.8.2. Topology Aware Lifecycle Manager
- 这个版本中的新内容
- 这个版本没有参考设计更新。
- 描述
TALM 是一个仅在 hub 集群上运行的 Operator。TALM 管理如何将集群和 Operator 升级、配置等更改部署到网络中的受管集群。TALM 具有以下核心功能:
- 提供由集群策略定义的集群配置和升级(OpenShift Container Platform 和 Operator)的序列更新。
- 提供用于延迟集群更新的应用程序。
- 支持对用户可配置的批处理中的集群集合进行策略更新进度发布。
-
通过在集群中添加
ztp-done或类似用户定义的标签来允许针对每个集群的操作。
- 限制和要求
- 支持以 400 批处理中的并发集群部署
- 工程考虑
-
在初始集群安装过程中,TALM 只应用带有
ran.openshift.io/ztp-deploy-wave注解的策略。 -
TALM 控制用户创建的
ClusterGroupUpgradeCR 时可以修复任何策略。 在集群升级维护窗口中将
MachineConfigPool(mcp) CRpaused字段设置为 true,并将maxUnavailable字段设置为最大可容忍的值。这可防止在升级过程中重启多个集群节点,这会使整体升级较短。当您取消暂停mcpCR 时,所有配置更改都使用一次重启来应用。注意在安装过程中,自定义
mcpCR 可以暂停,并将maxUnavailable设置为 100% 以改进安装时间。可以使用包含这些更新的策略的
ClusterGroupUpgrade(CGU) CR 编配(包括 OpenShift Container Platform、day-2 OLM operator 和自定义配置)。- 可以使用链的 CGU CR 编配 EUS 到 EUS 升级
- MCP 暂停的控制可以通过 CGU CR 中的策略来管理,用于完整 control plane 和 worker 节点推出部署。
-
在初始集群安装过程中,TALM 只应用带有
3.9.8.3. GitOps Operator 和 ZTP 插件
- 这个版本中的新内容
- 这个版本没有参考设计更新。
- 描述
GitOps Operator 提供了一个 GitOps 驱动的基础架构,用于管理集群部署和配置。集群定义和配置在 Git 仓库中维护。
ZTP 插件支持从
SiteConfigCR 生成InstallationCR,并根据 RHACMPolicyGeneratorCR 在策略中自动嵌套配置 CR。SiteConfig Operator 改进了从
ClusterInstanceCR 生成InstallationCR 的支持。重要使用
ClusterInstanceCR 进行集群安装优先于使用 ZTP 插件方法的SiteConfig自定义资源。您应该根据发行版本构建 Git 仓库,其中包含所有必要的工件(
SiteConfig、ClusterInstance、PolicyGenerator和PolicyGenTemplate,并支持引用 CR)。这可让同时部署和管理多个 OpenShift Container Platform 版本和配置版本。推荐的 Git 结构将引用 CR 保留在独立于客户或合作伙伴提供的内容的目录中。这意味着,您可以通过只覆盖现有内容来导入引用更新。客户或合作伙伴提供的 CR 可以在参考 CR 的并行目录中提供,以便轻松包含在生成的配置策略中。
- 限制和要求
- 每个 ArgoCD 应用程序都支持最多 1000 个节点。可以使用多个 ArgoCD 应用程序来实现单个 hub 集群支持的最大集群数量。
SiteConfigCR 必须使用extraManifests.searchPaths字段来引用引用清单。注意从 OpenShift Container Platform 4.15 开始,
spec.extraManifestPath字段已弃用。
- 工程考虑
在集群升级维护窗口中将
MachineConfigPool(MCP) CRpaused字段设置为 true,并将maxUnavailable字段设置为最大可容忍的值。这可防止在升级过程中重启多个集群节点,这会使整体升级较短。当您取消暂停mcpCR 时,所有配置更改都使用一次重启来应用。注意在安装过程中,自定义
MCPCR 可以暂停,并将maxUnavailable设置为 100% 以改进安装时间。-
为了避免在更新内容时造成混淆或意外覆盖,您应该在 core-overlay 和 extra manifests 下的
reference-crs/目录中的自定义 CR 使用唯一的和可分辨名称。 -
SiteConfigCR 允许多个 extra-manifest 路径。当文件名在多个目录路径中有重叠时,目录顺序列表中的最后一个文件将具有优先权。
3.9.9. 监控
- 这个版本中的新内容
- 这个版本没有参考设计更新。
- 描述
Cluster Monitoring Operator (CMO) 默认包含在 OpenShift Container Platform 中,并为平台组件和可选用户项目提供监控(指标、仪表板和警报)。您可以自定义默认日志保留周期、自定义警报规则等。
监控堆栈的配置通过 cluster-monitoring-config ConfigMap 中的单个字符串值来完成。参考调优调优会合并两个要求的内容:
- Prometheus 配置被扩展,将警报转发到 ACM hub 集群,以进行警报聚合。如果需要进行此配置,可以扩展到额外的位置。
Prometheus 保留周期从默认值中减少。集群外部的主要指标存储应该是外部的。Core 集群中的指标存储应该是一个备份到中央存储,并可用于本地故障排除。
除了默认配置外,还应该为电信核心集群配置以下指标:
- 用户工作负载的 Pod CPU 和内存指标和警报
- 工程考虑
- Prometheus 保留周期由用户指定。使用的值是根据 CPU 和存储资源维护集群中的历史数据的操作要求之间的权衡。保留周期较长,增加存储需求,并需要额外的 CPU 来管理数据的索引。
3.9.10. 调度
- 这个版本中的新内容
- 这个版本没有参考设计更新。
- 描述
调度程序是一个集群范围的组件,负责为给定工作负载选择正确的节点。它是平台的核心部分,不需要在常见部署场景中进行任何特定的配置。但是,在以下部分中描述了一些特定的用例。
可以通过 NUMA Resources Operator 启用 NUMA 感知调度。如需更多信息,请参阅"有效的 NUMA 感知工作负载"。
- 限制和要求
默认调度程序不了解工作负载的 NUMA 本地性。它仅了解 worker 节点上所有可用资源的总和。当调度到将拓扑管理器策略设置为 single-numa-node 或 restricted 的节点时,这可能会导致工作负载被拒绝。如需更多信息,请参阅"Topology Manager 策略"。
- 例如,考虑请求 6 个 CPU 的 pod,并调度到每个 NUMA 节点有 4 个 CPU 的空节点。节点的可分配容量总数为 8 个 CPU。调度程序将 pod 放置到空节点上。但是,节点本地准入将失败,因为每个 NUMA 节点中只有 4 个 CPU 可用。
-
具有多 NUMA 节点的所有集群都需要使用 NUMA Resources Operator。如需更多信息,请参阅"安装 NUMA Resources Operator"。使用
KubeletConfigCR 中的machineConfigPoolSelector字段选择需要 NUMA 校准调度的所有节点。 - 所有机器配置池都必须具有一致的硬件配置。例如,所有节点都应该具有相同的 NUMA 区域计数。
- 工程考虑
- Pod 可能需要注解才能正确调度和隔离。有关注解的更多信息,请参阅"CPU 分区和性能调优"。
-
您可以通过在
SriovNetworkNodePolicyCR 中使用 excludeTopology 字段,将 SR-IOV 虚拟功能 NUMA 关联性配置为在调度期间被忽略。
3.9.11. 节点配置
- 这个版本中的新内容
- 这个版本没有参考设计更新。
- 限制和要求
分析其他内核模块,以确定对 CPU 负载、系统性能以及满足 KPI 的能力的影响。
Expand 表 3.1. 其他内核模块 功能 描述 其他内核模块
使用
MachineConfigCR 安装以下内核模块,为 CNFs 提供扩展的内核功能。- sctp
- ip_gre
- nf_tables
- nf_conntrack
- nft_ct
- nft_limit
- nft_log
- nft_nat
- nft_chain_nat
- nf_reject_ipv4
- nf_reject_ipv6
- nfnetlink_log
容器挂载命名空间隐藏
减少 kubelet 内务处理和驱除监控的频率,以减少 CPU 用量。创建容器挂载命名空间,对 kubelet 和 CRI-O 可见,以减少系统挂载扫描资源使用情况。
kdump 启用
可选配置(默认为启用)
3.9.12. 主机固件和引导装载程序配置
- 这个版本中的新内容
- 这个版本没有参考设计更新。
- 工程考虑
启用安全引导是推荐的配置。
注意启用安全引导后,内核只载入签名的内核模块。不支持树外驱动程序。
3.9.13. kubelet 设置
有些 CNF 工作负载使用 sysctl,这些 sysctl 不在系统范围的安全 sysctl 列表中。通常网络 sysctl 是命名空间,可以使用 PerformanceProfile 中的 kubeletconfig.experimental 注解作为 JSON 字符串启用,格式为 allowedUnsafeSysctls。
显示 allowedUnsafeSysctls 的片段示例
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
name: {{ .metadata.name }}
annotations:kubeletconfig.experimental: |
{"allowedUnsafeSysctls":["net.ipv6.conf.all.accept_ra"]}
# ...虽然这些具有命名空间,但可能允许 pod 使用内存或其他资源,超过 pod 描述中指定的任何限制。您必须确保这些 sysctl 不会耗尽平台资源。
3.9.14. 断开连接的环境
- 这个版本中的新内容
- 这个版本没有参考设计更新。
- 描述
电信核心集群预期会在网络中安装,而无需直接访问互联网。安装、配置和操作集群所需的所有容器镜像都必须在断开连接的 registry 中提供。这包括 OpenShift Container Platform 镜像、第 2 天 OLM Operator 镜像和应用程序工作负载镜像。断开连接的环境的使用提供多种优点,包括:
- 安全 - 限制对集群的访问
- 策展的内容 - registry 根据集群的策展和批准更新填充
- 限制和要求
-
所有自定义
CatalogSource资源都需要一个唯一名称。不要重复使用默认目录名称。
-
所有自定义
- 工程考虑
- 必须将有效的时间源配置为集群安装的一部分
3.9.15. 基于代理的安装程序
- 这个版本中的新内容
- 这个版本没有参考设计更新。
- 描述
推荐的 Telco Core 集群安装方法是使用 Red Hat Advanced Cluster Management。基于代理的安装程序(ABI)是在没有运行集群部署的现有基础架构的环境中为 Openshift 的独立安装流。使用 ABI 在裸机服务器上安装 OpenShift Container Platform,无需额外的服务器或虚拟机来管理安装,但不提供持续生命周期管理、监控或自动化。ABI 可以在任何系统上运行,例如笔记本电脑来生成 ISO 安装镜像。ISO 用作集群 control plane 节点的安装介质。您可以使用任何带有与 control plane 节点的 API 接口的网络连接的系统中的 ABI 来监控进度。
ABI 支持以下内容:
- 从声明性 CR 安装
- 在断开连接的环境中安装
- 不需要额外的服务器来支持安装,例如,不再需要堡垒节点
- 限制和要求
- 断开连接的安装需要一个 registry,其中包含所有需要的内容,并可从安装的主机访问。
- 工程考虑
- 网络配置应在安装过程中作为 NMState 配置应用,而不是使用 NMState Operator 的第 2 天配置。
3.9.16. 安全性
- 这个版本中的新内容
- 这个版本没有参考设计更新。
- 描述
电信客户安全隐患,需要针对多个攻击向量强化集群。在 OpenShift Container Platform 中,没有单一组件或功能用来负责保护集群。以下是电信核心 RDS 中涵盖的使用模型的各种面向安全特性和配置。
-
SecurityContextConstraints (SCC):所有工作负载 Pod 都应使用
restricted-v2或restrictedSCC 运行。 -
Seccomp :所有 pod 都应使用
RuntimeDefault(或更强大的)seccomp 配置集运行。 - Rootless DPDK pod: 许多用户-plane 网络(DPDK) CNFs 需要 pod 使用 root 权限运行。使用此功能,可在不需要 root 特权的情况下运行符合 DPDK pod。Rootless DPDK pod 在 rootless pod 中创建 tap 设备,将 DPDK 应用程序的流量注入内核。
- 存储:存储网络应该被隔离且不可路由到其他集群网络。详情请查看 "Storage" 部分。
如需了解在 OpenShift Container Platform 集群节点中实施自定义 nftables 防火墙规则的支持方法,请参阅 OpenShift 中的自定义 nftable 防火墙规则。本文面向在 OpenShift Container Platform 环境中管理网络安全策略的集群管理员。
在部署此方法前,请仔细考虑操作影响,包括:
- 早期应用程序 :规则在引导时应用,在网络完全运行之前。确保规则不会意外阻止引导过程中所需的必要服务。
- 错误配置的风险 :自定义规则中的错误可能会导致意外的结果,这可能会导致性能影响或阻止合法流量或隔离节点。在将规则部署到主集群之前,在非生产环境中完全测试您的规则。
- 外部端点 :OpenShift Container Platform 需要访问外部端点才能正常工作。如需有关防火墙允许列表的更多信息,请参阅"为 OpenShift Container Platform 配置防火墙"。确保集群节点有权访问这些端点。确保集群节点有权访问这些端点。
节点重新引导 :配置了无盘节点中断策略,使用所需防火墙设置应用
MachineConfigCR 会导致节点重新引导。请注意,这个影响并相应地调度维护窗口。如需更多信息,请参阅使用节点中断策略来最大程度降低机器配置变化的中断。注意OpenShift Container Platform 4.17 及更新的版本中提供了节点中断策略。
- 网络流列表 :有关管理入口流量的更多信息,请参阅"OpenShift Container Platform 网络流列表"。您可以将入口流量限制为基本流以提高网络安全性。该列表提供了对基础集群服务的见解,但排除 day-2 Operator 生成的流量。
- 集群版本更新和升级 :在更新或升级 OpenShift Container Platform 集群时非常谨慎。对平台防火墙要求的最新更改可能需要调整网络端口权限。虽然文档提供了指南,但请注意这些要求可能会随着时间而演变。要最小化中断,您应该在生产环境中测试任何更新或升级,然后再在生产环境中应用它们。这有助于您识别并解决与防火墙配置更改相关的潜在兼容性问题。
-
SecurityContextConstraints (SCC):所有工作负载 Pod 都应使用
- 限制和要求
Rootless DPDK pod 需要以下额外配置:
-
为 tap 插件配置
container_tSELinux 上下文。 -
为集群主机启用
container_use_devicesSELinux 布尔值。
-
为 tap 插件配置
- 工程考虑
-
对于无根 DPDK pod 支持,请在主机上启用 SELinux
container_use_devices布尔值,以允许创建 tap 设备。这会带来可接受的安全风险。
-
对于无根 DPDK pod 支持,请在主机上启用 SELinux
3.9.17. 可扩展性
- 这个版本中的新内容
- 这个版本没有参考设计更新。
- 描述
- 扩展集群,如 "Limits and requirements" 所述。"应用程序工作负载"中描述了工作负载扩展。
- 限制和要求
- 集群可以扩展到至少 120 个节点。
3.10. 电信核心参考配置 CR
使用以下自定义资源(CR)来使用电信核心配置集配置和部署 OpenShift Container Platform 集群。使用 CR 组成所有特定使用模型中使用的通用基准,除非另有说明。
3.10.1. 提取电信核心引用设计 CR
您可以从 telco-core-rds-rhel9 容器镜像中提取电信核心配置集的完整自定义资源(CR)集合。容器镜像具有电信核心配置集所需的 CR 和可选 CR。
先决条件
-
已安装
podman。
流程
运行以下命令,使用凭证登录到容器镜像 registry:
$ podman login registry.redhat.io运行以下命令,从
lecommunications-core-rds-rhel9容器镜像中提取内容:$ mkdir -p ./out$ podman run -it registry.redhat.io/openshift4/openshift-telco-core-rds-rhel9:v4.19 | base64 -d | tar xv -C out
验证
out目录具有以下目录结构:您可以运行以下命令来查看out/telco-core-rds/目录中的电信核心 CR:$ tree -L 4输出示例
. ├── configuration │ ├── compare.sh │ ├── core-baseline.yaml │ ├── core-finish.yaml │ ├── core-overlay.yaml │ ├── core-upgrade.yaml │ ├── kustomization.yaml │ ├── Makefile │ ├── ns.yaml │ ├── README.md │ ├── reference-crs │ │ ├── custom-manifests │ │ │ ├── mcp-worker-1.yaml │ │ │ ├── mcp-worker-2.yaml │ │ │ ├── mcp-worker-3.yaml │ │ │ └── README.md │ │ ├── optional │ │ │ ├── logging │ │ │ ├── networking │ │ │ ├── other │ │ │ └── tuning │ │ └── required │ │ ├── networking │ │ ├── other │ │ ├── performance │ │ ├── scheduling │ │ └── storage │ ├── reference-crs-kube-compare │ │ ├── compare_ignore │ │ ├── comparison-overrides.yaml │ │ ├── metadata.yaml │ │ ├── optional │ │ │ ├── logging │ │ │ ├── networking │ │ │ ├── other │ │ │ └── tuning │ │ ├── ReferenceVersionCheck.yaml │ │ ├── required │ │ │ ├── networking │ │ │ ├── other │ │ │ ├── performance │ │ │ ├── scheduling │ │ │ └── storage │ │ ├── unordered_list.tmpl │ │ └── version_match.tmpl │ └── template-values │ ├── hw-types.yaml │ └── regional.yaml ├── install │ ├── custom-manifests │ │ ├── mcp-worker-1.yaml │ │ ├── mcp-worker-2.yaml │ │ └── mcp-worker-3.yaml │ ├── example-standard.yaml │ ├── extra-manifests │ │ ├── control-plane-load-kernel-modules.yaml │ │ ├── kdump-master.yaml │ │ ├── kdump-worker.yaml │ │ ├── mc_rootless_pods_selinux.yaml │ │ ├── mount_namespace_config_master.yaml │ │ ├── mount_namespace_config_worker.yaml │ │ ├── sctp_module_mc.yaml │ │ └── worker-load-kernel-modules.yaml │ └── README.md └── README.md
3.10.2. 将集群与电信核心参考配置进行比较
在部署了电信核心集群后,您可以使用 cluster-compare 插件评估集群与电信核心参考设计规格 (RDS) 的合规性。cluster-compare 插件是一个 OpenShift CLI (oc) 插件。该插件使用电信核心参考配置来验证具有电信 RAN DU 自定义资源(CR)的集群。
电信核心的特定于插件的引用配置打包在带有 Telco 核心 CR 的容器镜像中。
有关 cluster-compare 插件的更多信息,请参阅"了解 cluster-compare 插件"。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。 -
有访问
registry.redhat.io容器镜像 registry 的凭证。 -
已安装
cluster-compare插件。
流程
运行以下命令,使用凭证登录到容器镜像 registry:
$ podman login registry.redhat.io运行以下命令,从
lecommunications-core-rds-rhel9容器镜像中提取内容:$ mkdir -p ./out$ podman run -it registry.redhat.io/openshift4/openshift-telco-core-rds-rhel9:v4.20 | base64 -d | tar xv -C out您可以运行以下命令来查看
out/telco-core-rds/configuration/reference-crs-kube-compare目录中的引用配置:$ tree -L 2输出示例
. ├── compare_ignore ├── comparison-overrides.yaml ├── metadata.yaml1 ├── optional2 │ ├── logging │ ├── networking │ ├── other │ └── tuning ├── ReferenceVersionCheck.yaml ├── required3 │ ├── networking │ ├── other │ ├── performance │ ├── scheduling │ └── storage ├── unordered_list.tmpl └── version_match.tmpl运行以下命令,将集群的配置与电信核心参考配置进行比较:
$ oc cluster-compare -r out/telco-core-rds/configuration/reference-crs-kube-compare/metadata.yaml输出示例
W1212 14:13:06.281590 36629 compare.go:425] Reference Contains Templates With Types (kind) Not Supported By Cluster: BFDProfile, BGPAdvertisement, BGPPeer, ClusterLogForwarder, Community, IPAddressPool, MetalLB, MultiNetworkPolicy, NMState, NUMAResourcesOperator, NUMAResourcesScheduler, NodeNetworkConfigurationPolicy, SriovNetwork, SriovNetworkNodePolicy, SriovOperatorConfig, StorageCluster ... ********************************** Cluster CR: config.openshift.io/v1_OperatorHub_cluster1 Reference File: required/other/operator-hub.yaml2 Diff Output: diff -u -N /tmp/MERGED-2801470219/config-openshift-io-v1_operatorhub_cluster /tmp/LIVE-2569768241/config-openshift-io-v1_operatorhub_cluster --- /tmp/MERGED-2801470219/config-openshift-io-v1_operatorhub_cluster 2024-12-12 14:13:22.898756462 +0000 +++ /tmp/LIVE-2569768241/config-openshift-io-v1_operatorhub_cluster 2024-12-12 14:13:22.898756462 +0000 @@ -1,6 +1,6 @@ apiVersion: config.openshift.io/v1 kind: OperatorHub metadata: + annotations:3 + include.release.openshift.io/hypershift: "true" name: cluster -spec: - disableAllDefaultSources: true ********************************** Summary4 CRs with diffs: 3/45 CRs in reference missing from the cluster: 226 other: other: Missing CRs:7 - optional/other/control-plane-load-kernel-modules.yaml - optional/other/worker-load-kernel-modules.yaml required-networking: networking-root: Missing CRs: - required/networking/nodeNetworkConfigurationPolicy.yaml networking-sriov: Missing CRs: - required/networking/sriov/sriovNetwork.yaml - required/networking/sriov/sriovNetworkNodePolicy.yaml - required/networking/sriov/SriovOperatorConfig.yaml - required/networking/sriov/SriovSubscription.yaml - required/networking/sriov/SriovSubscriptionNS.yaml - required/networking/sriov/SriovSubscriptionOperGroup.yaml required-other: scheduling: Missing CRs: - required/other/catalog-source.yaml - required/other/icsp.yaml required-performance: performance: Missing CRs: - required/performance/PerformanceProfile.yaml required-scheduling: scheduling: Missing CRs: - required/scheduling/nrop.yaml - required/scheduling/NROPSubscription.yaml - required/scheduling/NROPSubscriptionNS.yaml - required/scheduling/NROPSubscriptionOperGroup.yaml - required/scheduling/sched.yaml required-storage: storage-odf: Missing CRs: - required/storage/odf-external/01-rook-ceph-external-cluster-details.secret.yaml - required/storage/odf-external/02-ocs-external-storagecluster.yaml - required/storage/odf-external/odfNS.yaml - required/storage/odf-external/odfOperGroup.yaml - required/storage/odf-external/odfSubscription.yaml No CRs are unmatched to reference CRs8 Metadata Hash: fe41066bac56517be02053d436c815661c9fa35eec5922af25a1be359818f2979 No patched CRs10
3.10.3. 节点配置参考 CR
| 组件 | 参考 CR | 描述 | 选填 |
|---|---|---|---|
| 其他内核模块 |
| 可选。为 control plane 节点配置内核模块。 | 否 |
| 其他内核模块 |
| 可选。在 worker 节点中载入 SCTP 内核模块。 | 否 |
| 其他内核模块 |
| 可选。为 worker 节点配置内核模块。 | 否 |
| 容器挂载命名空间隐藏 |
| 配置挂载命名空间,以便在 control plane 节点上的 kubelet 和 CRI-O 之间共享特定容器的挂载。 | 否 |
| 容器挂载命名空间隐藏 |
| 配置挂载命名空间,以便在 worker 节点上在 kubelet 和 CRI-O 之间共享特定于容器的挂载。 | 否 |
| kdump 启用 |
| 在 master 节点上配置 kdump 崩溃报告。 | 否 |
| kdump 启用 |
| 在 worker 节点上配置 kdump 崩溃报告。 | 否 |
3.10.4. 集群基础架构引用 CR
| 组件 | 参考 CR | 描述 | 选填 |
|---|---|---|---|
| 集群日志记录 |
| 使用指定服务帐户配置日志转发实例,并验证配置是否有效。 | 是 |
| 集群日志记录 |
| 配置集群日志记录命名空间。 | 是 |
| 集群日志记录 |
| 在 openshift-logging 命名空间中创建 Operator 组,允许 Cluster Logging Operator 监视和管理资源。 | 是 |
| 集群日志记录 |
| 配置集群日志记录服务帐户。 | 是 |
| 集群日志记录 |
| 将 collect-audit-logs 集群角色授予 logs 收集器服务帐户。 | 是 |
| 集群日志记录 |
| 允许收集器服务帐户从基础架构资源收集日志。 | 是 |
| 集群日志记录 |
| 使用手动批准为 Cluster Logging Operator 创建订阅资源,以进行安装计划。 | 是 |
| 断开连接的配置 |
| 定义断开连接的 Red Hat Operator 目录。 | 否 |
| 断开连接的配置 |
| 为断开连接的 registry 定义已镜像存储库摘要列表。 | 否 |
| 断开连接的配置 |
| 定义禁用所有默认源的 OperatorHub 配置。 | 否 |
| 监控和可观察性 |
| 为 Prometheus 和 Alertmanager 配置存储和保留。 | 是 |
| 电源管理 |
| 定义性能配置集资源,指定 CPU 隔离、巨页配置和工作负载提示,以便在所选节点上进行性能优化。 | 否 |
3.10.5. 资源调优引用 CR
| 组件 | 参考 CR | 描述 | 选填 |
|---|---|---|---|
| 系统保留容量 |
| 可选。配置 kubelet,为 control plane 节点池启用自动保留资源。 | 是 |
3.10.6. 网络引用 CR
| 组件 | 参考 CR | 描述 | 选填 |
|---|---|---|---|
| Baseline |
| 配置默认集群网络,指定 OVN Kubernetes 设置,如通过主机的路由。它还允许定义额外网络,包括自定义 CNI 配置,并允许在多个网络间对网络策略使用 MultiNetworkPolicy CR。 | 否 |
| Baseline |
| 可选。定义 NetworkAttachmentDefinition 资源,指定网络配置详情,如节点选择器和 CNI 配置。 | 是 |
| Load Balancer |
| 配置 MetalLB,以管理启用了 auto-assign 的 IP 地址池,以便从指定范围内动态分配 IP。 | 否 |
| Load Balancer |
| 使用自定义间隔、检测倍数和模式配置双向转发检测(BFD),以加快网络故障检测和负载平衡故障转移。 | 否 |
| Load Balancer |
| 为 MetalLB 定义 BGP 广告资源,指定 IP 地址池如何公告给 BGP 对等点。这可对流量路由和公告进行精细控制。 | 否 |
| Load Balancer |
| 在 MetalLB 中定义 BGP peer,代表用于动态路由的 BGP 邻居。 | 否 |
| Load Balancer |
| 定义一个 MetalLB 社区,将一个或多个 BGP 社区分组到指定资源下。社区可以应用到 BGP 公告,以控制路由策略并更改流量路由。 | 否 |
| Load Balancer |
| 定义集群中的 MetalLB 资源。 | 否 |
| Load Balancer |
| 定义集群中的 metallb-system 命名空间。 | 否 |
| Load Balancer |
| 为 MetalLB Operator 定义 Operator 组。 | 否 |
| Load Balancer |
| 为 MetalLB Operator 创建订阅资源,并带有手动批准的安装计划。 | 否 |
| Multus - 用于无根 DPDK pod 的 Tap CNI |
| 配置 MachineConfig 资源,为 worker 节点上的 tap CNI 插件设置 SELinux 布尔值。 | 是 |
| NMState Operator |
| 定义 NMState Operator 用来管理节点网络配置的 NMState 资源。 | 否 |
| NMState Operator |
| 创建 NMState Operator 命名空间。 | 否 |
| NMState Operator |
| 在 openshift-nmstate 命名空间中创建 Operator 组,允许 NMState Operator 监视和管理资源。 | 否 |
| NMState Operator |
| 为 NMState Operator 创建订阅,通过 OLM 管理。 | 否 |
| Cluster Network Operator |
| 定义一个 SR-IOV 网络,指定网络功能、IP 地址管理(ipam)和关联的网络命名空间和资源。 | 否 |
| Cluster Network Operator |
| 针对特定节点上的 SR-IOV 设备配置网络策略,包括自定义设备选择、VF 分配(numVfs)、特定于节点的设置(nodeSelector)和优先级。 | 否 |
| Cluster Network Operator |
| 为 SR-IOV Operator 配置各种设置,包括启用注入程序和 Operator Webhook,禁用 pod 排空,并为配置守护进程定义节点选择器。 | 否 |
| Cluster Network Operator |
| 为通过 OLM 管理的 SR-IOV Network Operator 创建订阅。 | 否 |
| Cluster Network Operator |
| 创建 SR-IOV Network Operator 订阅命名空间。 | 否 |
| Cluster Network Operator |
| 为 SR-IOV Network Operator 创建 Operator 组,允许它监视和管理目标命名空间中的资源。 | 否 |
3.10.7. 调度引用 CR
| 组件 | 参考 CR | 描述 | 选填 |
|---|---|---|---|
| NUMA 感知调度程序 |
| 启用 NUMA Resources Operator,将工作负载与特定的 NUMA 节点配置保持一致。具有多 NUMA 节点的集群是必需的。 | 否 |
| NUMA 感知调度程序 |
| 为通过 OLM 管理的 NUMA Resources Operator 创建订阅。具有多 NUMA 节点的集群是必需的。 | 否 |
| NUMA 感知调度程序 |
| 创建 NUMA Resources Operator 订阅命名空间。具有多 NUMA 节点的集群是必需的。 | 否 |
| NUMA 感知调度程序 |
| 在 numaresources-operator 命名空间中创建 Operator 组,允许 NUMA Resources Operator 监视和管理资源。具有多 NUMA 节点的集群是必需的。 | 否 |
| NUMA 感知调度程序 |
| 在集群中配置拓扑感知调度程序,该调度程序可以处理 NUMA 感知型节点调度 pod。 | 否 |
| NUMA 感知调度程序 |
| 将 control plane 节点配置为工作负载的不可调度。 | 否 |
3.10.8. 存储引用 CR
| 组件 | 参考 CR | 描述 | 选填 |
|---|---|---|---|
| 外部 ODF 配置 |
|
定义包含 | 否 |
| 外部 ODF 配置 |
| 定义一个 OpenShift Container Storage (OCS) 存储资源,该资源将集群配置为使用外部存储后端。 | 否 |
| 外部 ODF 配置 |
|
为 OpenShift Data Foundation Operator 创建受监控的 | 否 |
| 外部 ODF 配置 |
|
在 | 否 |
3.11. 电信核心参考配置软件规格
Red Hatlecommunications core 4.20 解决方案已使用 OpenShift Container Platform 集群的以下红帽软件产品进行验证。
| 组件 | 软件版本 |
|---|---|
| Red Hat Advanced Cluster Management (RHACM) | 2.14 |
| Red Hat OpenShift GitOps | 1.18 |
| Cluster Logging Operator | 6.2 |
| OpenShift Data Foundation | 4.19 |
| Cluster Network Operator | 4.20 |
| MetalLB | 4.20 |
| NMState Operator | 4.20 |
| NUMA 感知调度程序 | 4.20 |
- 当发布一致的 Red Hat Advanced Cluster Management (RHACM) 版本时,Red Hat Advanced Cluster Management (RHACM) 将更新至 2.15。
- 当发布一致的 OpenShift Data Foundation 版本(4.20) 时,OpenShift Data Foundation 将更新至 4.20。
第 4 章 Telco RAN DU 参考规格
电信 RAN DU 参考规格(RDS)描述了在商业硬件上运行的集群配置,以托管 Radio 访问网络(RAN)中的 5G 工作负载。它捕获了推荐的、经过测试和支持的配置,以便为运行电信 RAN DU 配置集的集群获取可靠和可重复的性能。
使用模型和系统级信息来规划电信 RAN DU 工作负载、集群资源以及受管单节点 OpenShift 集群的最小硬件规格。
后续小节中详细介绍了各个组件的具体限制、要求和工程考虑。
4.1. 电信 RAN DU 5G 部署的参考设计规范
红帽和认证合作伙伴为在 OpenShift Container Platform 4.20 集群上运行电信应用程序所需的网络和操作功能提供深厚的专业技术和支持。
红帽的电信合作伙伴需要一个经过精心设计、经过充分测试且稳定的环境,可大规模地复制企业 5G 解决方案。电信核心和 RAN DU 参考规范(RDS)根据特定的 OpenShift Container Platform 版本概述推荐的解决方案架构。每个 RDS 均描述了电信核心和 RAN DU 使用模型的经过测试和验证的平台配置。RDS 通过定义电信 5G 内核和 RAN DU 的关键 KPI 集合来确保运行应用程序时的最佳体验。按照 RDS 最小化高严重性升级并提高了应用程序稳定性。
5G 用例不断演变,您的工作负载正在不断变化。红帽致力于迭代电信核心和 RAN DU RDS,以支持根据客户和合作伙伴的不断演变要求。
参考配置包括边缘集群和 hub 集群组件的配置。
本文档中的参考配置使用中央受管 hub 集群基础架构进行部署,如下图所示。
图 4.1. Telco RAN DU 部署架构

4.1.1. RAN DU 支持的 CPU 架构
| 架构 | 实时内核 | 非实时内核 |
|---|---|---|
| x86_64 | 是 | 是 |
| aarch64 | 否 | 是 |
4.2. 参考设计范围
电信核心和电信 RAN 参考规格(RDS)捕获了建议的、经过测试和支持的配置,以便为运行电信核心和电信 RAN 配置集的集群获得可靠和可重复的性能。
每个 RDS 包括已发布的功能及支持的配置,这些配置经过设计并验证,供集群运行各个配置集。配置提供了一个满足功能和 KPI 目标的基准 OpenShift Container Platform 安装。每个 RDS 还描述了每个单独配置的预期变化。每个 RDS 的验证包括很多长持续时间和大规模测试。
为 OpenShift Container Platform 的每个主要 Y-stream 版本更新经过验证的参考配置。z-stream 补丁版本会定期根据参考配置重新测试。
4.3. 来自参考设计的偏差
从经过验证的电信核心和电信 RAN DU 参考设计规范(RDS)中进行开发,在您更改的特定组件或功能之外可能会产生重大影响。开发需要在完整的解决方案上下文中分析和工程。
应使用明确的操作跟踪信息,分析来自 RDS 的所有偏差。预计将来自合作伙伴的尽职调查,以便了解如何通过参考设计来保持一致。这可能需要合作伙伴向红帽提供其他资源,以便其用例能够更好地与平台结果相联系。这对解决方案的支持性至关重要,并确保红帽与合作伙伴保持一致。
RDS 的偏差可以有一些或全部后果:
- 解决问题可能需要更长的时间。
- 缺少项目服务级别协议 (SLA)、项目期限、最终供应商性能要求等风险。
未批准的偏差可能需要在执行级别进行升级。
注意根据合作伙伴参与优先事项,红帽优先考虑为开发提供请求。
4.4. RAN DU 使用模型的工程注意事项
RAN DU 使用模型配置在商业硬件上运行的 OpenShift Container Platform 集群,用于托管 RAN 分布式单元(DU)工作负载。型号和系统级别注意事项如下所述。后续小节中详细介绍了各个组件的具体限制、要求和工程考虑。
有关电信 RAN DU RDS KPI 测试结果的详情,请查看电信 RAN DU 4.20 参考规范 KPI 测试结果。此信息仅适用于客户和合作伙伴。
- 集群拓扑
RAN DU 工作负载的建议拓扑是单节点 OpenShift。DU 工作负载可以在其他集群拓扑上运行,如 3 节点紧凑集群、高可用性(3 control plane + n worker 节点)或 SNO+1。建议多个 SNO 集群或高度可用的 3 节点紧凑集群,而不是 SNO+1 拓扑。
在标准集群拓扑问题单(3+n)下,只有以下情况允许混合架构集群:
- 所有 control plane 节点都是 x86_64。
- 所有 worker 节点都是 aarch64。
不建议或包含此参考设计规格下的远程 worker 节点(RWN)集群拓扑。对于具有高服务级别协议要求的工作负载,如 RAN DU,以下缺陷将排除 RWN:
- 不支持基于镜像构建以及该功能提供的好处,如更快的升级和回滚功能。
- 第 2 天 Operator 的更新同时会影响所有 RWN,而无需执行滚动更新。
- 由于 control plane 提供的站点数量较多,control plane (灾难)丢失会对整个服务可用性产生重大影响。
- 在超过监控宽限期和容限超时的期间内丢失 RWN 和 control plane 之间的网络连接可能会导致 pod 驱除,并导致服务中断。
- 不支持容器镜像预缓存。
- 工作负载相关性中的其他复杂性。
- RAN DU 支持的集群拓扑
Expand 表 4.2. RAN DU 支持的集群拓扑 架构 SNO SNO+1 3-node Standard RWN x86_64
是
是
是
是
否
aarch64
是
否
否
否
否
mixed
N/A
否
否
是
否
- 工作负载
- DU 工作负载在 Telco RAN DU 应用程序工作负载中描述。
- DU worker 节点是 Intel 3rd Generation Xeon (IceLake) 2.20 GHz 或更好地调整主机固件,以获得最佳性能。
- Resources
- 系统上运行的最大 pod 数量(包括应用程序工作负载和 OpenShift Container Platform pod)是 160。
- 资源利用率
OpenShift Container Platform 资源利用率根据包括应用程序工作负载特性的许多因素而有所不同,例如:
- Pod 数量
- 探测的类型和频率
- 带有内核网络的主或二级 CNI 的消息传递率
- API 访问率
- 日志记录率
- 存储 IOPS
为配置的集群测量资源利用率,如下所示:
- 集群是安装了单节点 OpenShift 的单个主机。
- 集群运行 "参考应用程序 workload characteristics" 中描述的代表应用程序工作负载。
- 集群按照 "Hub cluster management characteristics" 中详述的约束进行管理。
- 在使用模型配置中作为"可选"组件不会被包括。
注意不满足这些条件的 RAN DU RDS 范围以外的配置需要额外的分析,以确定对资源利用率和满足 KPI 目标的能力的影响。您可能需要分配额外的集群资源来满足这些要求。
- 参考应用程序工作负载特性
- 每个 pod 用于 vRAN 应用,在 5 个命名空间中使用 75 个 pod,包括其管理和控制功能
-
为每个命名空间创建 30 个
ConfigMapCR 和 30 个SecretCR - 使用 no exec 探测
使用二级网络
注意您可以从平台指标中提取 CPU 负载。例如:
$ query=avg_over_time(pod:container_cpu_usage:sum{namespace="openshift-kube-apiserver"}[30m])- 平台日志收集器不会收集应用程序日志。
- 主 CNI 上的聚合流量最多为 30 Mbps,最多在二级网络上 5 Gbps
- hub 集群管理特征
RHACM 是推荐的集群管理解决方案,并配置为这些限制:
- 使用最多 10 个 RHACM 配置策略,包括 5 个红帽提供的策略和最多 5 个自定义配置策略,兼容评估间隔小于 10 分钟。
- 在集群策略中,使用受管集群模板的最小数量(最多 10)。使用 hub 侧模板。
-
禁用 RHACM 附加组件,但
policyController除外,并使用默认配置配置可观察性。
下表描述了应用程序负载下的资源利用率。
Expand 表 4.3. 引用应用程序负载下的资源利用率 指标 Limits 注 OpenShift 平台 CPU 用量
小于 4000mc - 2 个内核(4HT)
平台 CPU 固定到保留内核,包括每个保留内核的超线程。系统设计为使用 steady-state 的 3 个 CPU (3000mc),以允许定期的系统任务和激增。
OpenShift Platform 内存
少于 16G
4.5. Telco RAN DU 应用程序工作负载
开发符合以下要求的 RAN DU 应用程序:
- 描述和限制
- 开发符合 Kubernetes 最新版本的红帽最佳实践的云原生网络功能(CNF)。
- 使用 SR-IOV 进行高性能网络。
使用 exec probe 静默,且仅在没有其他合适的选项时才使用
-
如果 CNF 使用 CPU 固定,则不要使用 exec 探测。使用其他探测实施,如
httpGet或tcpSocket。 当您需要使用 exec 探测时,限制 exec 探测频率和数量。exec 探测的最大数量必须保持在 10 以下,且频率不得小于 10 秒。与其它探测类型相比,执行探测会导致管理内核 CPU 使用率高得多,因为它们需要进程分叉。
注意在 steady-state 操作过程中启动探测需要最少的资源。exec 探测的限制主要适用于存活度和就绪度探测。
-
如果 CNF 使用 CPU 固定,则不要使用 exec 探测。使用其他探测实施,如
注意符合参考 DU 应用程序工作负载的尺寸测试工作负载可在 openshift-kni/du-test-workloads 中找到。
4.6. Telco RAN DU 参考组件
以下小节描述了用于配置和部署集群来运行 RAN DU 工作负载的各种 OpenShift Container Platform 组件和配置。
图 4.2. Telco RAN DU 参考组件
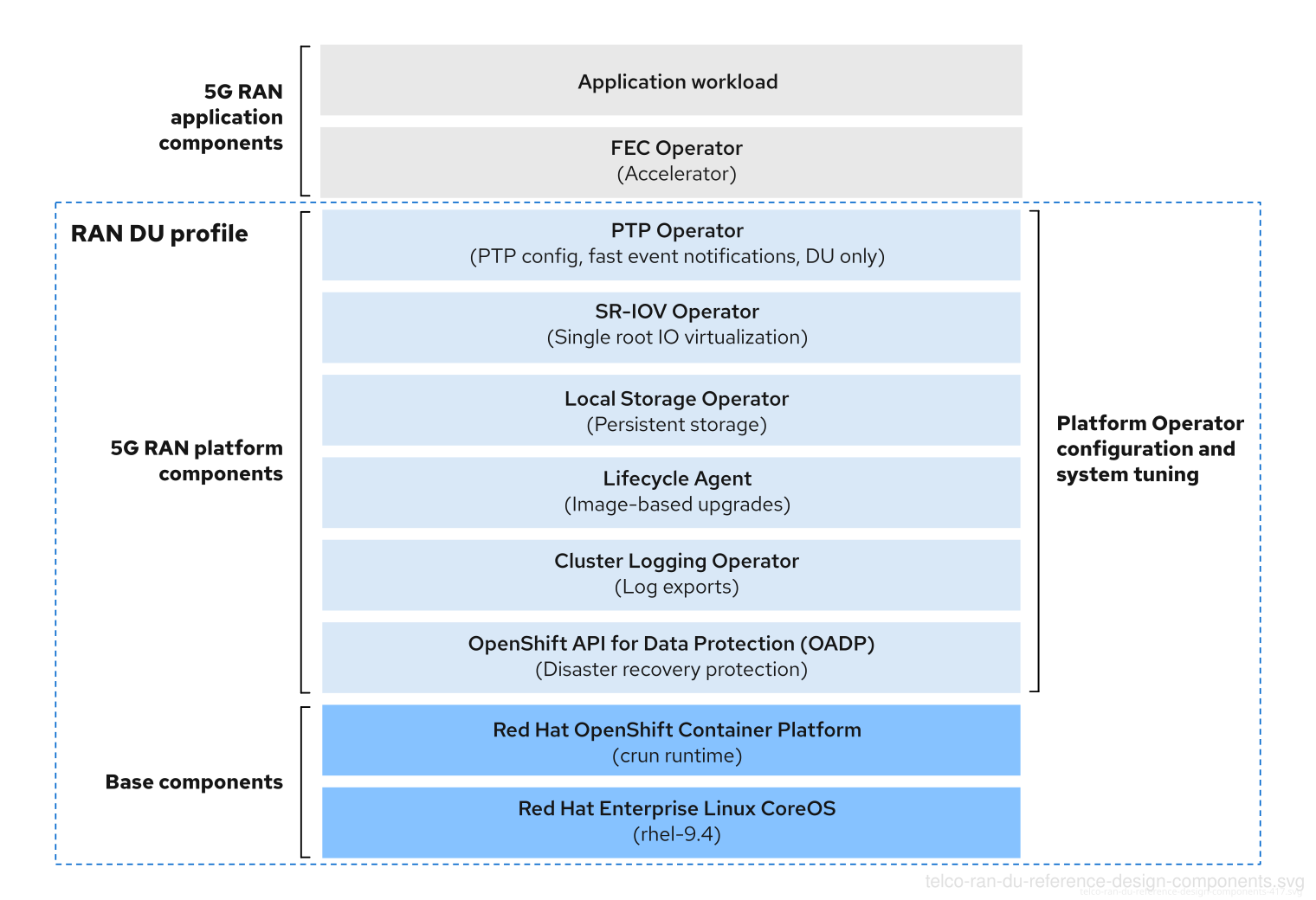
确保没有在电信 RAN DU 配置集中指定的其他组件不会影响分配给工作负载应用程序的 CPU 资源。
不支持在树外驱动程序中。5g RAN 应用程序组件不包含在 RAN DU 配置集中,必须针对分配给应用程序的资源(CPU)进行设计。
4.6.1. 主机固件调整
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
在初始集群部署期间调优主机固件设置以获得最佳的性能。如需更多信息,请参阅"为 vDU 应用程序工作负载推荐单节点 OpenShift 集群配置"。在初始部署期间应用主机固件中的调优设置。如需更多信息,请参阅“使用 GitOps ZTP 管理主机固件设置”。受管集群主机固件设置在 hub 集群中作为使用
ClusterInstanceCR 和 GitOps ZTP 部署受管集群时创建的独立BareMetalHost自定义资源(CR)提供。注意根据提供的参考
example-sno.yamlCR 创建ClusterInstanceCR。- 限制和要求
- 您必须在主机固件设置中启用 Hyper-Threading
- 工程考虑
- 调优所有固件设置以获得最佳性能。
- 除非需要针对节能进行调优,否则所有设置都是针对实现最大性能而设计的。
- 如果需要,您可以针对实现节能目的而对主机固件进行调优,这会牺牲性能。
- 启用安全引导。启用安全引导后,内核只载入签名的内核模块。不支持树外驱动程序。
4.6.2. kubelet 设置
有些 CNF 工作负载使用 sysctl,这些 sysctl 不在系统范围的安全 sysctl 列表中。通常,网络 sysctl 具有命名空间,您可以使用 PerformanceProfile 自定义资源(CR) 中的 kubeletconfig.experimental 注解作为以下形式的 JSON 字符串来启用它们:
显示 allowedUnsafeSysctls 的片段示例
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
name: {{ .metadata.name }}
annotations:kubeletconfig.experimental: |
{"allowedUnsafeSysctls":["net.ipv6.conf.all.accept_ra"]}
# ...虽然这些 sysctl 具有命名空间的限制,但可能允许 pod 使用内存或其他资源,超过 pod 描述中指定的任何限制。您必须确保这些 sysctl 不会耗尽平台资源。
如需更多信息,请参阅"在容器中使用 sysctl"。
4.6.3. CPU 分区和性能调整
- 这个版本中的新内容
PerformanceProfile和Tuned PerformancePatch对象已更新,以完全支持 aarch64 架构。-
如果您之前已将额外的补丁应用到
Tuned PerformancePatch对象,则必须将这些补丁转换为包括ran-du-performance配置集的新性能配置集。请参阅"引擎注意事项"部分。
-
如果您之前已将额外的补丁应用到
- 描述
-
RAN DU 使用模型包括集群性能调优,使用
PerformanceProfileCR 进行低延迟性能,以及添加其他特定于 RAN 的调优的Tuned PerformancePatchCR。为 x86_64 和 aarch64 CPU 架构提供了一个参考PerformanceProfile。提供的单个Tuned PerformancePatch对象自动检测 CPU 架构并执行所需的额外调整。RAN DU 用例需要针对低延迟性能调整集群。Node Tuning Operator 协调PerformanceProfile和TunedPerformancePatchCR。
有关使用 PerformanceProfile CR 进行节点调整的详情,请参阅"使用性能配置集为低延迟的节点"。
- 限制和要求
您必须在 Tel RAN DU 配置集
PerformanceProfileCR 中配置以下设置:在 x86_64 上设置为 4 个或更多个保留的
cpuset(相当于 4 个超线程(2 个内核),或将 aarch64 上的 4 个内核用于以下 CPU:- Intel 3rd Generation Xeon (IceLake) 2.20 GHz 或更好的 CPU,带有调整主机固件以获得最大性能
- AMD EPYC Zen 4 CPU (Genoa、Bergamo)。
ARM CPU (Neoverse)
注意建议评估功能,如每个 pod 电源管理,以确定对性能的潜在影响。
x86_64:
-
将保留的
cpuset设置为包括每个包含的内核的超线程同级功能。Unreserved 内核可作为可分配 CPU 用于调度工作负载。 - 确保超线程不会跨保留和隔离的内核进行分割。
- 确保保留和隔离的 CPU 包括 CPU 中所有内核的所有线程。
- 在保留 CPU 集中包含每个 NUMA 节点的 Core 0。
- 将巨页大小设置为 1G。
-
将保留的
aarch64:
- 将前 4 个内核用于保留 CPU 集(或更多)。
- 将巨页大小设置为 512M。
- 仅固定 OpenShift Container Platform pod,这些 pod 配置为管理工作负载分区的一部分到保留内核。
-
当硬件厂商建议时,使用
hardwareTuning部分为保留和隔离的 CPU 设置最大 CPU 频率。
- 工程考虑
RealTime (RT) 内核
在 x86_64 下,若要访问完整的性能指标,您必须使用 RT 内核,它是
x86_64/PerformanceProfile.yaml配置中的默认设置。- 如果需要,您可以使用非 RT 内核,这会对集群性能产生相应的影响。
-
在 aarch64 下,只会为 RAN DU 用例使用 64k-pagesize 非 RT 内核,这是
aarch64/PerformanceProfile.yaml配置中的默认设置。
- 您配置的巨页数量取决于应用程序工作负载要求。这个参数中的变化是正常的,并允许。
- 根据所选硬件和系统中使用的其他组件,预计在保留和隔离的 CPU 集的配置中有变化。变体必须仍然符合指定的限制。
- 没有 IRQ 关联性支持的硬件会影响隔离的 CPU。为确保具有保证整个 CPU QoS 的 pod 完全使用分配的 CPU,服务器中的所有硬件都必须支持 IRQ 关联性。
-
要启用工作负载分区,请在部署过程中将
cpuPartitioningMode设置为AllNodes,然后使用PerformanceProfileCR 分配足够的 CPU 来支持操作系统、中断和 OpenShift Container Platform pod。 -
在 x86_64 下,
PerformanceProfileCR 包含vfio_pci的额外内核参数设置。包括这些参数以支持设备,如 FEC 加速器。如果您的工作负载不需要,可以省略它们。 在 aarch64 下,必须根据平台的需求调整
PerformanceProfile:对于 Grace Hopper 系统,需要以下内核命令行参数:
-
acpi_power_meter.force_cap_on=y -
module_blacklist=nouveau -
pci=realloc=off -
pci=pcie_bus_safe
-
-
对于其他 ARM 平台,您可能需要启用
iommu.passthrough=1或pci=realloc
扩展和增强
Tuned PerformancePatch.yaml:-
TunedPerformancePatch.yaml引入了一个名为ran-du-performance的默认顶级调优配置集,以及名为ran-du-performance-architecture-common的构架感知 RAN 调优配置文件,以及其他特定于 archichitecture 的子策略,由通用策略自动选择。 -
默认情况下,
ran-du-performance配置集被设置为priority级别18,其中包括 PerformanceProfile-created 配置集openshift-node-performance-openshift-node-performance-profile和ran-du-performance-architecture-common 如果您自定义了
PerformanceProfile对象的名称,您必须创建一个新的 tuned 对象,其中包含由PerformanceProfileCR 创建的 tuned 配置集的名称更改,以及ran-du-performance-architecture-commonRAN 调优配置集。priority必须小于 18。例如,如果 PerformanceProfile 对象命名为change-this-name:apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: custom-performance-profile-override namespace: openshift-cluster-node-tuning-operator spec: profile: - name: custom-performance-profile-x data: | [main] summary=Override of the default ran-du performance tuning to adjust for our renamed PerformanceProfile include=openshift-node-performance-change-this-name,ran-du-performance-architecture-common recommend: - machineConfigLabels: machineconfiguration.openshift.io/role: "master" priority: 15 profile: custom-performance-profile-x-
要进一步覆盖,可选的
TunedPowerCustom.yaml配置文件如何扩展所提供的Tuned PerformancePatch.yaml,而无需直接覆盖或编辑它。创建额外的调优配置集,其中包含名为ran-du-performance的顶级 tuned 配置集,并在recommend部分中具有较低priority,可以轻松地添加额外的设置。 - 如需有关 Node Tuning Operator 的更多信息,请参阅"使用 Node Tuning Operator"。
-
4.6.4. PTP Operator
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
- 在集群节点中配置精确时间协议(PTP)。与其它时钟同步协议(如 NTP)相比,PTP 在 RAN 环境中确保精确的时间和可靠性。
- 支持包括
- Grandmaster 时钟 (T-GM):使用 GPS 来同步本地时钟,并提供与其他设备的时间同步
- 边界时钟 (T-BC):从另一个 PTP 源接收时间并将其重新分发到其它设备
- 普通时钟 (T-TSC):同步另一个 PTP 时间源的本地时钟
配置变化允许多个 NIC 配置提高时间分布和高可用性(HA),并通过 HTTP 提供可选快速事件通知。
- 限制和要求
为以下电信用例支持 PTP G.8275.1 配置集:
T-GM 用例:
- 限制为最多 3 个 Westport 频道 NIC
- 需要 GNSS 输入到一个 NIC 卡,以及 SMA 连接来同步其他 NIC
- HA 支持 N/A
T-BC 用例:
- 限制为最多 2 个 NIC
- 系统时钟 HA 支持在 2-NIC 配置中是可选的。
T-TSC 用例:
- 仅限于单个 NIC
- 系统时钟 HA 支持在 active/standby 2-port 配置中是可选的。
-
日志缩减必须使用
true或enhanced启用。
- 工程考虑
* 为以下提供了 RAN DU RDS 示例:
- T-GM、T-BC 和 T-TSC
- 带有和不使用 HA 的变体
-
PTP 快速事件通知使用
ConfigMapCR 来持久保留订阅者详情。 - PTP 事件不支持在 O-RAN 规格中所述的分级事件订阅。
- PTP fast 事件 REST API v1 是生命周期结束。
4.6.5. SR-IOV Operator
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
-
SR-IOV Operator 置备并配置 SR-IOV CNI 和设备插件。
netdevice(内核 VF)和vfio(DPDK) 设备都被支持,并适用于 RAN DU 使用模型。 - 限制和要求
- 使用 OpenShift Container Platform 支持的设备。如需更多信息,请参阅"支持设备"。
- 主机固件设置中的 SR-IOV 和 IOMMU 启用 :SR-IOV Network Operator 会在内核命令行中自动启用 IOMMU。
- SR-IOV VF 不会从 PF 接收链路状态更新。如果需要链接检测,则必须在协议级别进行配置。
- 工程考虑
-
带有
vfio驱动程序类型的 SR-IOV 接口通常用于为需要高吞吐量或低延迟的应用程序启用额外的二级网络。 -
期望客户对
SriovNetwork和SriovNetworkNodePolicy自定义资源 (CR) 的配置和数量变化。 -
IOMMU 内核命令行设置会在安装时使用
MachineConfigCR 应用。这样可确保SriovOperatorCR 在添加节点时不会导致节点重启。 - SR-IOV 支持并行排空节点,不适用于单节点 OpenShift 集群。
-
您必须在部署中包含
SriovOperatorConfigCR;不会自动创建 CR。此 CR 包含在初始部署期间应用的引用配置策略中。 - 如果您将工作负载固定到特定的节点,SR-IOV 并行节点排空功能不会重新调度 pod。在这些情况下,SR-IOV Operator 会禁用并行节点排空功能。
- 不支持使用安全引导或内核锁定进行固件更新的 NIC 必须预先配置足够的虚拟功能(VF),以支持应用程序工作负载所需的 VF 数量。对于 Mellanox NIC,您必须在 SR-IOV Network Operator 中禁用 Mellanox vendor 插件。如需更多信息,请参阅"启用安全引导时在 Mellanox 卡中配置 SR-IOV Network Operator"。
要在 pod 启动后更改虚拟功能的 MTU 值,请不要在
SriovNetworkNodePolicyCR 中配置 MTU 字段。相反,请配置网络管理器,或使用自定义systemd脚本将物理功能的 MTU 设置为适当的值。例如:# ip link set dev <physical_function> mtu 9000
-
带有
4.6.6. 日志记录
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
- 使用日志记录从最边缘节点收集日志进行远程分析。推荐的日志收集器是 Vector。
- 工程考虑
- 例如,处理基础架构和审计日志以外的日志,例如,应用程序工作负载会根据额外的日志记录率需要额外的 CPU 和网络带宽。
- 从 OpenShift Container Platform 4.14 开始,Vector 是引用日志收集器。在 RAN 使用模型中使用 fluentd 已被弃用。
4.6.7. SRIOV-FEC Operator
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
- SRIOV-FEC Operator 是一个可选的第三方认证 Operator,支持 FEC 加速器硬件。
- 限制和要求
从 FEC Operator v2.7.0 开始:
- 支持安全引导
-
PF 的
vfio驱动程序需要使用注入 pod 的vfio-token。pod 中的应用程序可以使用 EAL 参数--vfio-vf-token将 VF 令牌传递给 DPDK。
- 工程考虑
- SRIOV-FEC Operator 使用隔离 CPU 集合的 CPU 内核。
- 您可以作为应用程序部署的预检查的一部分来验证 FEC 就绪,例如通过扩展验证策略。
4.6.8. 生命周期代理
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
- Lifecycle Agent 为基于单节点 OpenShift 集群的基于镜像的升级提供本地生命周期管理服务。基于镜像的升级是单节点 OpenShift 集群的建议升级方法。
- 限制和要求
- Lifecycle Agent 不适用于带有额外 worker 的多节点集群或单节点 OpenShift 集群。
- Lifecycle Agent 需要您在安装集群时创建的持久性卷。
有关分区要求的更多信息,请参阅"在使用 GitOps ZTP 时在 ostree stateroot 之间配置共享容器目录"。
4.6.9. Local Storage Operator
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
-
您可以使用 Local Storage Operator 创建可用作
PVC资源的持久性卷。您创建的PV资源的数量和类型取决于您的要求。 - 工程考虑
-
在创建
PV之前,为PVCR 创建后备存储。这可以是分区、本地卷、LVM 卷或完整磁盘。 -
请参阅
LocalVolumeCR 中的设备列表,访问每个设备以确保正确分配磁盘和分区,例如/dev/disk/by-path/<id>。无法保证在节点重启后逻辑名称(例如/dev/sda)一致。
-
在创建
4.6.10. 逻辑卷管理器存储
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
-
逻辑卷管理器 (LVM) 存储是一个可选组件。它通过从本地设备创建逻辑卷来提供块存储和文件存储的动态置备,这些逻辑卷可以被应用程序用作持久性卷声明(PVC)资源。也可以进行卷扩展和快照。RDS 中提供了带有
StorageLVMCluster.yaml文件的示例配置。 - 限制和要求
- 在单节点 OpenShift 集群中,持久性存储必须由 LVM Storage 或本地存储提供,不能同时由这两个存储提供。
- 参考配置中排除卷快照。
- 工程考虑
- LVM 存储可用作 RAN DU 用例的本地存储实现。当 LVM 存储用作存储解决方案时,它会替换 Local Storage Operator,并将所需的 CPU 分配给管理分区作为平台开销。参考配置必须包含这些存储解决方案中的一个,但不能同时包含这两个解决方案。
- 确保有足够的磁盘或分区来满足存储要求。
4.6.11. 工作负载分区
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
-
工作负载分区将作为 DU 配置集一部分的 OpenShift Container Platform 和第 2 天 Operator pod 固定到保留的 CPU 集,并从节点核算中删除保留的 CPU。这会保留所有非保留 CPU 内核供用户工作负载使用。这会保留所有非保留 CPU 内核供用户工作负载使用。工作负载分区通过安装参数中设置的能力启用:
cpuPartitioningMode: AllNodes。使用您在PerformanceProfileCR 中配置的保留 CPU 集设置管理分区内核。 - 限制和要求
-
必须注解
Namespace和PodCR,以允许将 pod 应用到管理分区 - 具有 CPU 限制的 Pod 无法分配给分区。这是因为 mutation 可以更改 pod QoS。
- 有关可分配给管理分区的最小 CPU 数量的更多信息,请参阅"Node Tuning Operator"。
-
必须注解
- 工程考虑
- 工作负载分区将所有管理 pod 固定到保留内核。必须将足够数量的内核分配给保留集以考虑操作系统、管理 pod,以及工作负载启动时发生 CPU 使用的预期激增、节点重启或其他系统事件。
4.6.12. 集群调整
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
- 有关使用集群功能功能禁用的组件的完整列表,请参阅"集群功能"。
- 限制和要求
- 集群功能不适用于安装程序置备的安装方法。
下表列出了所需的平台调优配置:
| 功能 | 描述 |
|---|---|
| 删除可选集群功能 | 通过在单节点 OpenShift 集群上禁用可选集群 Operator 来减少 OpenShift Container Platform 占用空间。
|
| 配置集群监控 | 通过执行以下操作配置监控堆栈以减少占用空间:
|
| 禁用网络诊断 | 为单节点 OpenShift 禁用网络诊断,因为它们不是必需的。 |
| 配置单个 OperatorHub 目录源 |
将集群配置为使用单个目录源,它只包含 RAN DU 部署所需的 Operator。每个目录源会增加集群中的 CPU 使用量。使用单个 |
| 禁用 Console Operator |
如果集群在禁用控制台的情况下部署,则不需要 |
- 工程考虑
- 从 OpenShift Container Platform 4.19 开始,cgroup v1 不再被支持并已被删除。现在,所有工作负载必须与 cgroup v2 兼容。如需更多信息,请参阅 Red Hat OpenShift 工作负载上下文中的 Red Hat Enterprise Linux 9 更改。
4.6.13. 机器配置
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 限制和要求
-
CRI-O 擦除禁用
MachineConfigCR 假设磁盘上的镜像是静态的镜像,而不是在定义的维护窗口中调度的维护期间使用。为确保镜像是静态的,请不要将 podimagePullPolicy字段设置为Always。 - 此表中的配置 CR 是必需的组件,除非另有说明。
-
CRI-O 擦除禁用
| 功能 | 描述 |
|---|---|
| 容器运行时 |
将所有节点角色的容器运行时设为 |
| kubelet 配置和容器挂载命名空间隐藏 | 减少 kubelet 内务和驱除监控的频率,从而减少 CPU 用量 |
| SCTP | 可选配置(默认为启用) |
| Kdump | 可选配置(默认启用)启用 kdump 在内核 panic 发生时捕获调试信息。启用 kdump 的参考 CR 根据参考配置中包含的驱动程序和内核模块集合增加内存保留。 |
| CRI-O 擦除禁用 | 在未清除关闭后禁用 CRI-O 镜像缓存的自动擦除。 |
| 与 SR-IOV 相关的内核参数 | 在内核命令行中包括额外的 SR-IOV 相关参数。 |
| 设置 RCU Normal |
在系统完成启动后设置 |
| 一次性时间同步 | 为 control plane 或 worker 节点运行一次性 NTP 系统时间同步作业。 |
4.7. Telco RAN DU 部署组件
以下小节描述了您使用 RHACM 配置 hub 集群的各种 OpenShift Container Platform 组件和配置。
4.7.1. Red Hat Advanced Cluster Management
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
RHACM 为部署的集群提供多集群引擎(MCE)安装和持续生命周期管理功能。您可以通过在维护窗口期间将
Policy自定义资源 (CR) 应用到集群来声明管理集群配置和升级。RHACM 提供以下功能:
- 在 RHACM 中使用 MCE 组件的集群零接触置备(ZTP)。
- 通过 RHACM 策略控制器配置、升级和集群状态。
-
在受管集群安装过程中,RHACM 可以对通过
ClusterInstanceCR 配置的单个节点应用标签。
单节点 OpenShift 集群安装的建议方法是基于镜像的安装方法,在 MCE 中使用
ClusterInstanceCR 进行集群定义。基于镜像的升级是单节点 OpenShift 集群升级的建议方法。
- 限制和要求
-
单个 hub 集群支持最多 3500 部署的单节点 OpenShift 集群,其中包含绑定到每个集群的 5 个
PolicyCR。
-
单个 hub 集群支持最多 3500 部署的单节点 OpenShift 集群,其中包含绑定到每个集群的 5 个
- 工程考虑
- 使用 RHACM 策略 hub 侧模板来更好地扩展集群配置。您可以使用单个组策略或少量常规组策略(其中组和每个集群值替换)来显著减少策略数量。
-
集群特定的配置:受管集群通常具有一些特定于单个集群的配置值。这些配置应该使用 RHACM 策略 hub 侧模板来管理,其值基于集群名称从
ConfigMapCR 中拉取。 - 要在受管集群中保存 CPU 资源,在集群安装 GitOps ZTP 后,应用静态配置的策略应该从受管集群绑定。
4.7.2. SiteConfig Operator
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
SiteConfig Operator 是一个模板驱动的解决方案,旨在通过不同的安装方法置备集群。它引进了统一
ClusterInstanceAPI,它替换了已弃用的SiteConfigAPI。通过利用ClusterInstanceAPI,SiteConfig Operator 通过提供以下内容来提高集群置备:- 更好地隔离安装方法的定义
- 取消验证 Git 和非 Git 工作流
- 安装方法的一致性 API
- 增强的可扩展性
- 使用自定义安装模板提高灵活性
- 对部署问题进行故障排除的宝贵见解
SiteConfig Operator 提供经过验证的默认安装模板,以便通过 Assisted Installer 和基于 Image 的安装程序置备方法进行集群部署:
- Assisted Installer 通过利用预定义的配置和验证的主机设置来自动部署 OpenShift Container Platform 集群。它确保目标基础架构满足 OpenShift Container Platform 要求。与手动设置相比,辅助安装程序可以简化安装过程,同时最大程度减少时间和复杂性。
- 基于镜像的安装程序 利用预配置和验证的 OpenShift Container Platform 认为镜像可以加快单节点 OpenShift 集群的部署。seed 镜像在目标主机上预装,可启用快速重新配置和部署。基于镜像的安装程序特别适用于远程或断开连接的环境,因为它简化了集群创建过程,并显著减少部署时间。
- 限制和要求
- 单个 hub 集群支持最多 3500 部署的单节点 OpenShift 集群。
4.7.3. Topology Aware Lifecycle Manager
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
Topology Aware Lifecycle Manager(TALM)是一个仅在 hub 集群上运行的 Operator,用于管理集群升级、Operator 升级和集群配置等更改如何应用到网络。TALM 支持以下功能:
- 在用户可配置的批处理中,对集群团队进行进度发布。
-
针对每个集群操作,在对受管集群的配置更改后添加
ztp-done标签或其他 user-configurable 标签。 预缓存单节点 OpenShift 集群镜像 :TALM 支持在启动升级前支持可选的 OpenShift、OLM Operator 和其他用户镜像到单节点 OpenShift 集群。当使用推荐的基于镜像的升级方法升级单节点 OpenShift 集群时,预缓存功能不适用。
-
使用
PreCachingConfigCR 指定可选预缓存配置。如需更多信息,请参阅示例参考PreCachingConfigCR。 - 使用可配置的过滤排除未使用的镜像。
- 使用可配置的空间必需参数在预缓存存储空间验证前后启用。
-
使用
- 限制和要求
- 支持以 400 批处理中的并发集群部署
- 预缓存和备份仅限于单节点 OpenShift 集群
- 工程考虑
-
PreCachingConfigCR 是可选的,如果您只需要预缓存平台相关的 OpenShift 和 OLM Operator 镜像,则不需要创建它。 -
在
ClusterGroupUpgradeCR 中引用PreCachingConfigCR 之前,必须应用 PreCachingConfig CR。 -
只有带有
ran.openshift.io/ztp-deploy-wave注解的策略才会在集群安装过程中自动应用。 -
TALM 控制用户创建的
ClusterGroupUpgradeCR 时可以修复任何策略。
-
4.7.4. GitOps Operator 和 GitOps ZTP
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
GitOps Operator 和 GitOps ZTP 提供了一个基于 GitOps 的基础架构,用于管理集群部署和配置。集群定义和配置在 Git 中作为声明状态进行维护。您可以将
ClusterInstanceCR 应用到 hub 集群,其中SiteConfigOperator 会将它们呈现为安装 CR。在以前的版本中,GitOps ZTP 插件支持从SiteConfigCR 生成安装 CR。此插件现已弃用。单独的 GitOps ZTP 插件可以根据PolicyGenerator或PolicyGenTemplateCR 启用自动将配置 CR 嵌套到策略中。您可以使用基准引用配置 CR 在受管集群中部署和管理多个 OpenShift Container Platform 版本。您可以使用自定义 CR 和基线(baseline)CR。要同时维护多个每个版本策略,请使用 Git 使用
PolicyGenerator或PolicyGenTemplateCR 管理源 CR 的版本。RHACMPolicyGenerator是从 OpenShift Container Platform 4.19 发行版本开始的建议生成器插件。- 限制和要求
-
每个 ArgoCD 应用程序 1000 个
ClusterInstanceCR。多个应用程序可以用来达到单个 hub 集群支持的最大集群数 -
Git 中
source-crs/目录中的内容会覆盖 ZTP 插件容器中提供的内容,因为 Git 在搜索路径中具有优先权。 -
source-crs/目录必须与kustomization.yaml文件位于同一个目录中,其中包括PolicyGeneratorCR 作为生成器。此上下文中不支持source-crs/目录的备用位置。
-
每个 ArgoCD 应用程序 1000 个
- 工程考虑
-
对于多节点集群升级,您可以通过将
paused字段设置为true,在维护窗口期间暂停MachineConfigPool(MCP) CR。您可以通过在MCPCR 中配置maxUnavailable设置来增加每个MCPCR 同时更新的节点数量。MaxUnavailable字段定义了,在MachineConfig更新期间,池中可以同时不可用的节点的百分比。将maxUnavailable设置为最大可容忍的值。这可减少升级过程中的重启次数,从而缩短升级时间。当您最终取消暂停MCPCR 时,所有更改的配置都会使用单个重启来应用。 -
在集群安装过程中,您可以通过将 paused 字段设置为 true 并将
maxUnavailable设置为 100% 以改进安装时间来暂停自定义 MCP CR。 将引用 CR 和自定义 CR 保留在不同的目录中。这样,您可以通过简单的替换所有目录内容来修补和更新引用 CR,而无需涉及自定义 CR。在管理多个版本时,建议采用以下最佳实践:
- 在 Git 存储库中保留所有源 CR 和策略创建 CR,以确保每个 OpenShift Container Platform 版本只根据 Git 中的内容生成策略。
- 将引用源 CR 保留在与自定义 CR 的独立目录中。这有助于根据需要轻松更新引用 CR。
-
为了避免在更新内容时造成混淆或意外覆盖,强烈建议您在
source-crs/目录中对自定义 CR 使用唯一且可分辨名称,并在 Git 中使用额外的清单。 -
ClusterInstanceCR 中通过ConfigMapCR 引用额外的安装清单。ConfigMapCR 应该与 Git 中的ClusterInstanceCR 一起存储,作为集群的单个数据源。如果需要,您可以使用ConfigMap生成器来创建ConfigMapCR。
-
对于多节点集群升级,您可以通过将
4.7.5. 基于代理的安装程序
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
- 可选的基于代理的安装程序组件提供没有集中基础架构的安装功能。安装程序会创建一个挂载到服务器的 ISO 镜像。当服务器引导时,它会安装 OpenShift Container Platform 并提供额外的清单。基于代理的安装程序允许您在没有 hub 集群的情况下安装 OpenShift Container Platform。集群安装需要容器镜像 registry。
- 限制和要求
- 您可在安装时提供一组有限的额外清单。
-
您必须包含 RAN DU 用例所需的
MachineConfigurationCR。
- 工程考虑
- 基于代理的安装程序提供了一个 OpenShift Container Platform 基础基准安装。
- 安装后,您要安装第 2 天 Operator 和 RAN DU 用例配置的其余部分。
4.8. Telco RAN DU 参考配置 CR
使用以下自定义资源(CR)使用 Telco RAN DU 配置集配置和部署 OpenShift Container Platform 集群。使用 CR 组成所有特定使用模型中使用的通用基准,除非另有说明。
您可以从 ztp-site-generate 容器镜像中提取一组 RAN DU CR。如需更多信息,请参阅准备 GitOps ZTP 站点配置存储库。
4.8.1. 集群调优参考 CR
| 组件 | 参考 CR | 描述 | 选填 |
|---|---|---|---|
| 集群功能 |
| 代表 SiteConfig CR,使用 RAN DU 配置集安装单节点 OpenShift | 否 |
| 控制台禁用 |
| 禁用 Console Operator。 | 否 |
| 断开连接的 registry |
| 定义用于管理 OpenShift Operator Marketplace 的专用命名空间。 | 否 |
| 断开连接的 registry |
| 为断开连接的 registry 配置目录源。 | 否 |
| 断开连接的 registry |
| 禁用 OLM 的性能配置集。 | 否 |
| 断开连接的 registry |
| 配置断开连接的 registry 镜像内容源策略。 | 否 |
| 断开连接的 registry |
| 可选,仅适用于多节点集群。在 OpenShift 中配置 OperatorHub,禁用所有默认 Operator 源。在禁用了 marketplace 功能的单节点 OpenShift 安装中不需要。 | 否 |
| 监控配置 |
| 禁用 Alertmanager 和 Telemeter 减少监控空间,并将 Prometheus 保留设置为 24 小时 | 否 |
| 网络诊断禁用 |
| 配置集群网络设置,以禁用内置网络故障排除和诊断功能。 | 否 |
4.8.2. 第 2 天 Operator 参考 CR
| 组件 | 参考 CR | 描述 | 选填 |
|---|---|---|---|
| Cluster Logging Operator |
| 为集群配置日志转发。 | 否 |
| Cluster Logging Operator |
| 配置集群日志记录的命名空间。 | 否 |
| Cluster Logging Operator |
| 为集群日志记录配置 Operator 组。 | 否 |
| Cluster Logging Operator |
| 4.18 中的新功能。配置集群日志记录服务帐户。 | 否 |
| Cluster Logging Operator |
| 4.18 中的新功能。配置集群日志记录服务帐户。 | 否 |
| Cluster Logging Operator |
| 4.18 中的新功能。配置集群日志记录服务帐户。 | 否 |
| Cluster Logging Operator |
| 管理 Cluster Logging Operator 的安装和更新。 | 否 |
| 生命周期代理 |
| 在 OpenShift 中管理基于镜像的升级过程。 | 是 |
| 生命周期代理 |
| 管理 LCA Operator 的安装和更新。 | 是 |
| 生命周期代理 |
| 为 LCA 订阅配置命名空间。 | 是 |
| 生命周期代理 |
| 为 LCA 订阅配置 Operator 组。 | 是 |
| Local Storage Operator |
| 定义带有 Delete reclaim 策略的存储类,且集群中没有动态置备。 | 否 |
| Local Storage Operator |
| 为 openshift-local-storage 命名空间中的 example-storage-class 配置本地存储设备,指定设备路径和文件系统类型。 | 否 |
| Local Storage Operator |
| 使用工作负载管理注解创建命名空间,并为 Local Storage Operator 部署 wave。 | 否 |
| Local Storage Operator |
| 为 Local Storage Operator 创建 Operator 组。 | 否 |
| Local Storage Operator |
| 为 Local Storage Operator 创建命名空间,其中包含用于工作负载管理和部署的注解。 | 否 |
| LVM Operator |
| 验证 LVM Storage Operator 的安装或升级。 | 是 |
| LVM Operator |
| 定义 LVM 集群配置,其占位符用于存储设备类和卷组设置。Local Storage Operator 的可选替换。 | 否 |
| LVM Operator |
| 管理 LVMS Operator 的安装和更新。Local Storage Operator 的可选替换。 | 否 |
| LVM Operator |
| 使用集群监控和工作负载管理的标签和注解为 LVMS Operator 创建命名空间。Local Storage Operator 的可选替换。 | 否 |
| LVM Operator |
| 定义 LVMS Operator 的目标命名空间。Local Storage Operator 的可选替换。 | 否 |
| Node Tuning Operator |
| 在 OpenShift 集群中配置节点性能设置,针对 aarch64 CPU 的低延迟和实时工作负载优化。 | 否 |
| Node Tuning Operator |
| 在 OpenShift 集群中配置节点性能设置,针对 x86_64 CPU 的低延迟和实时工作负载优化。 | 否 |
| Node Tuning Operator |
| 应用性能调优设置,包括特定命名空间中节点的调度程序组和服务配置。 | 否 |
| Node Tuning Operator |
| 在 Tuned PerformancePatch 之上应用额外的节能模式调整作为覆盖。 | 否 |
| PTP 快速事件通知 |
| 使用事件同步的额外选项为 PTP 边界时钟配置 PTP 设置。依赖于集群角色。 | 否 |
| PTP 快速事件通知 |
| 使用额外的 PTP 快速事件设置为高可用边界时钟配置 PTP。依赖于集群角色。 | 否 |
| PTP 快速事件通知 |
| 使用额外的 PTP 快速事件设置为 PTP grandmaster 时钟配置 PTP。依赖于集群角色。 | 否 |
| PTP 快速事件通知 |
| 使用额外的 PTP 快速事件设置为 PTP 普通时钟配置 PTP。依赖于集群角色。 | 否 |
| PTP 快速事件通知 |
| 覆盖默认的 OperatorConfig。配置 PTP Operator 指定在 openshift-ptp 命名空间中运行 PTP 守护进程的节点选择条件。 | 否 |
| PTP Operator |
| 为 PTP 边界时钟配置 PTP 设置。依赖于集群角色。 | 否 |
| PTP Operator |
| 为具有双 NIC 的主机配置 PTP grandmaster 时钟设置。依赖于集群角色。 | 否 |
| PTP Operator |
| 为具有 3 个 NIC 的主机配置 PTP grandmaster 时钟设置。依赖于集群角色。 | 否 |
| PTP Operator |
| 为具有单个 NIC 的主机配置 PTP grandmaster 时钟设置。依赖于集群角色。 | 否 |
| PTP Operator |
| 为 PTP 普通时钟配置 PTP 设置。依赖于集群角色。 | 否 |
| PTP Operator |
| 使用 active/standby 配置中的 2 接口为 PTP 普通时钟配置 PTP 设置。依赖于集群角色。 | 否 |
| PTP Operator |
| 配置 PTP Operator 设置,指定在 openshift-ptp 命名空间中运行 PTP 守护进程的节点选择条件。 | 否 |
| PTP Operator |
| 在 openshift-ptp 命名空间中管理 PTP Operator 的安装和更新。 | 否 |
| PTP Operator |
| 为 PTP Operator 配置命名空间。 | 否 |
| PTP Operator |
| 为 PTP Operator 配置 Operator 组。 | 否 |
| PTP Operator (高可用性) |
| 为高可用性 PTP 边界时钟配置 PTP 设置。 | 否 |
| PTP Operator (高可用性) |
| 为高可用性 PTP 边界时钟配置 PTP 设置。 | 否 |
| SR-IOV FEC Operator |
| 为 VRAN Acceleration Operator 配置命名空间。应用程序工作负载的可选部分。 | 是 |
| SR-IOV FEC Operator |
| 为 VRAN Acceleration Operator 配置 Operator 组。应用程序工作负载的可选部分。 | 是 |
| SR-IOV FEC Operator |
| 管理 VRAN Acceleration Operator 的安装和更新。应用程序工作负载的可选部分。 | 是 |
| SR-IOV FEC Operator |
| 为节点配置 SR-IOV FPGA 以太网控制器(FEC)设置,指定驱动程序、VF 数量和节点选择。 | 是 |
| SR-IOV Operator |
| 定义 SR-IOV 网络配置,其中包含各种网络设置的占位符。 | 否 |
| SR-IOV Operator |
| 为特定节点配置 SR-IOV 网络设置,包括设备类型、RDMA 支持、物理功能名称和虚拟功能的数量。 | 否 |
| SR-IOV Operator |
| 配置 SR-IOV Network Operator 设置,包括节点选择、注入器和 Webhook 选项。 | 否 |
| SR-IOV Operator |
| 在 openshift-sriov-network-operator 命名空间中为 Single Node OpenShift (SNO) 配置 SR-IOV Network Operator 设置,包括节点选择、注入器、webhook 选项和禁用节点排空。 | 否 |
| SR-IOV Operator |
| 管理 SR-IOV Network Operator 的安装和更新。 | 否 |
| SR-IOV Operator |
| 为 SR-IOV Network Operator 创建命名空间,其中包含工作负载管理和部署的特定注解。 | 否 |
| SR-IOV Operator |
| 定义 SR-IOV Network Operator 的目标命名空间,在此命名空间中启用其管理和部署。 | 否 |
4.8.3. 机器配置引用 CR
| 组件 | 参考 CR | 描述 | 选填 |
|---|---|---|---|
| 容器运行时 (crun) |
| 为 control plane 节点配置容器运行时(crun)。 | 否 |
| 容器运行时 (crun) |
| 为 worker 节点配置容器运行时(crun)。 | 否 |
| CRI-O 擦除禁用 |
| 在 control plane 节点上为重启后禁用自动 CRI-O 缓存擦除。 | 否 |
| CRI-O 擦除禁用 |
| 在 worker 节点上为重启后禁用自动 CRI-O 缓存擦除。 | 否 |
| kdump 启用 |
| 在 master 节点上配置 kdump 崩溃报告。 | 否 |
| kdump 启用 |
| 在 worker 节点上配置 kdump 崩溃报告。 | 否 |
| kubelet 配置和容器挂载隐藏 |
| 配置挂载命名空间,以便在 control plane 节点上的 kubelet 和 CRI-O 之间共享特定容器的挂载。 | 否 |
| kubelet 配置和容器挂载隐藏 |
| 配置挂载命名空间,以便在 worker 节点上在 kubelet 和 CRI-O 之间共享特定于容器的挂载。 | 否 |
| 一次性时间同步 |
| 在 master 节点上同步一次的时间。 | 否 |
| 一次性时间同步 |
| 在 worker 节点上同步一次的时间。 | 否 |
| SCTP |
| 在 master 节点上载入 SCTP 内核模块。 | 是 |
| SCTP |
| 在 worker 节点上载入 SCTP 内核模块。 | 是 |
| 设置 RCU normal |
| 通过在 control plane 节点引导后设置 rcu_normal 来禁用 rcu_expedited。 | 否 |
| 设置 RCU normal |
| 通过在 worker 节点引导后设置 rcu_normal 来禁用 rcu_expedited。 | 否 |
| 与 SRIOV 相关的内核参数 |
| 在 master 节点上启用 SR-IOV 支持。 | 否 |
| 与 SRIOV 相关的内核参数 |
| 在 worker 节点上启用 SR-IOV 支持。 | 否 |
4.9. 比较带有电信 RAN DU 参考配置的集群
在部署了电信 RAN DU 集群后,您可以使用 cluster-compare 插件来评估集群的电信 RAN DU 参考设计规格 (RDS) 的合规性。cluster-compare 插件是一个 OpenShift CLI (oc) 插件。该插件使用电信 RAN DU 参考配置来验证具有电信 RAN DU 自定义资源(CR)的集群。
电信 RAN DU 的特定于插件的引用配置打包在带有 Telco RAN DU CR 的容器镜像中。
有关 cluster-compare 插件的更多信息,请参阅"了解 cluster-compare 插件"。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。 -
有访问
registry.redhat.io容器镜像 registry 的凭证。 -
已安装
cluster-compare插件。
流程
运行以下命令,使用凭证登录到容器镜像 registry:
$ podman login registry.redhat.io运行以下命令,从
ztp-site-generate-rhel8容器镜像中提取内容:$ podman pull registry.redhat.io/openshift4/ztp-site-generate-rhel8:v4.20$ mkdir -p ./out$ podman run --log-driver=none --rm registry.redhat.io/openshift4/ztp-site-generate-rhel8:v4.20 extract /home/ztp --tar | tar x -C ./out运行以下命令,将集群的配置与引用配置进行比较:
$ oc cluster-compare -r out/reference/metadata.yaml输出示例
... ********************************** Cluster CR: config.openshift.io/v1_OperatorHub_cluster1 Reference File: required/other/operator-hub.yaml2 Diff Output: diff -u -N /tmp/MERGED-2801470219/config-openshift-io-v1_operatorhub_cluster /tmp/LIVE-2569768241/config-openshift-io-v1_operatorhub_cluster --- /tmp/MERGED-2801470219/config-openshift-io-v1_operatorhub_cluster 2024-12-12 14:13:22.898756462 +0000 +++ /tmp/LIVE-2569768241/config-openshift-io-v1_operatorhub_cluster 2024-12-12 14:13:22.898756462 +0000 @@ -1,6 +1,6 @@ apiVersion: config.openshift.io/v1 kind: OperatorHub metadata: + annotations:3 + include.release.openshift.io/hypershift: "true" name: cluster -spec: - disableAllDefaultSources: true ********************************** Summary4 CRs with diffs: 11/125 CRs in reference missing from the cluster: 406 optional-image-registry: image-registry: Missing CRs:7 - optional/image-registry/ImageRegistryPV.yaml optional-ptp-config: ptp-config: One of the following is required: - optional/ptp-config/PtpConfigBoundary.yaml - optional/ptp-config/PtpConfigGmWpc.yaml - optional/ptp-config/PtpConfigDualCardGmWpc.yaml - optional/ptp-config/PtpConfigForHA.yaml - optional/ptp-config/PtpConfigMaster.yaml - optional/ptp-config/PtpConfigSlave.yaml - optional/ptp-config/PtpConfigSlaveForEvent.yaml - optional/ptp-config/PtpConfigForHAForEvent.yaml - optional/ptp-config/PtpConfigMasterForEvent.yaml - optional/ptp-config/PtpConfigBoundaryForEvent.yaml ptp-operator-config: One of the following is required: - optional/ptp-config/PtpOperatorConfig.yaml - optional/ptp-config/PtpOperatorConfigForEvent.yaml optional-storage: storage: Missing CRs: - optional/local-storage-operator/StorageLV.yaml ... No CRs are unmatched to reference CRs8 Metadata Hash: 09650c31212be9a44b99315ec14d2e7715ee194a5d68fb6d24f65fd5ddbe3c3c9 No patched CRs10
4.10. Telco RAN DU 4.20 验证软件组件
Red Hatlecommunications RAN DU 4.20 解决方案已使用以下红帽软件产品用于 OpenShift Container Platform 受管集群。
| 组件 | 软件版本 |
|---|---|
| 受管集群版本 | 4.19 |
| Cluster Logging Operator | 6.2 |
| Local Storage Operator | 4.20 |
| OpenShift API for Data Protection (OADP) | 1.5 |
| PTP Operator | 4.20 |
| SR-IOV Operator | 4.20 |
| SRIOV-FEC Operator | 2.11 |
| 生命周期代理 | 4.20 |
第 5 章 电信 hub 参考设计规格
电信 hub 参考设计规格(RDS)描述了 hub 集群的配置,该集群的配置在电信环境中部署和运行 OpenShift Container Platform 集群。
5.1. 参考设计范围
电信核心和电信 RAN 参考规格(RDS)捕获了建议的、经过测试和支持的配置,以便为运行电信核心和电信 RAN 配置集的集群获得可靠和可重复的性能。
每个 RDS 包括已发布的功能及支持的配置,这些配置经过设计并验证,供集群运行各个配置集。配置提供了一个满足功能和 KPI 目标的基准 OpenShift Container Platform 安装。每个 RDS 还描述了每个单独配置的预期变化。每个 RDS 的验证包括很多长持续时间和大规模测试。
为 OpenShift Container Platform 的每个主要 Y-stream 版本更新经过验证的参考配置。z-stream 补丁版本会定期根据参考配置重新测试。
5.2. 来自参考设计的偏差
从经过验证的电信核心和电信 RAN DU 参考设计规范(RDS)中进行开发,在您更改的特定组件或功能之外可能会产生重大影响。开发需要在完整的解决方案上下文中分析和工程。
应使用明确的操作跟踪信息,分析来自 RDS 的所有偏差。预计将来自合作伙伴的尽职调查,以便了解如何通过参考设计来保持一致。这可能需要合作伙伴向红帽提供其他资源,以便其用例能够更好地与平台结果相联系。这对解决方案的支持性至关重要,并确保红帽与合作伙伴保持一致。
RDS 的偏差可以有一些或全部后果:
- 解决问题可能需要更长的时间。
- 缺少项目服务级别协议 (SLA)、项目期限、最终供应商性能要求等风险。
未批准的偏差可能需要在执行级别进行升级。
注意根据合作伙伴参与优先事项,红帽优先考虑为开发提供请求。
5.3. hub 集群架构概述
使用管理 hub 集群上运行的功能和组件来管理 hub 和spoke 拓扑中的许多其他集群。hub 集群提供了一个高可用性和集中式接口,用于管理已部署集群的配置、生命周期和可观察性。
所有管理 hub 功能都可以部署到专用 OpenShift Container Platform 集群中,也可以作为与现有集群中共同运行的应用程序部署。
- 受管集群生命周期
- 通过使用第 2 天 Operator 的组合,hub 集群使用 GitOps 方法提供必要的基础架构来部署和配置集群。在部署集群的生命周期内,进一步管理升级,扩展集群、节点替换和其他生命周期管理功能的数量可以被声明并推出。您可以控制跨团队推出部署的时间和进度。
- 监控
- hub 集群通过 RHACM Operator 的 Observability pillar 为受管集群提供监控和状态报告。这包括通过监管策略框架聚合的指标、警报和合规性监控。
电信管理 hub 参考设计规格(RDS)和相关的参考自定义资源(CR)描述电信工程和 QE 验证方法,用于部署、配置和管理电信受管集群基础架构的生命周期。参考配置包括 OpenShift Container Platform 上的 hub 集群组件的安装和配置。
图 5.1. hub 集群参考设计组件

图 5.2. hub 集群参考架构
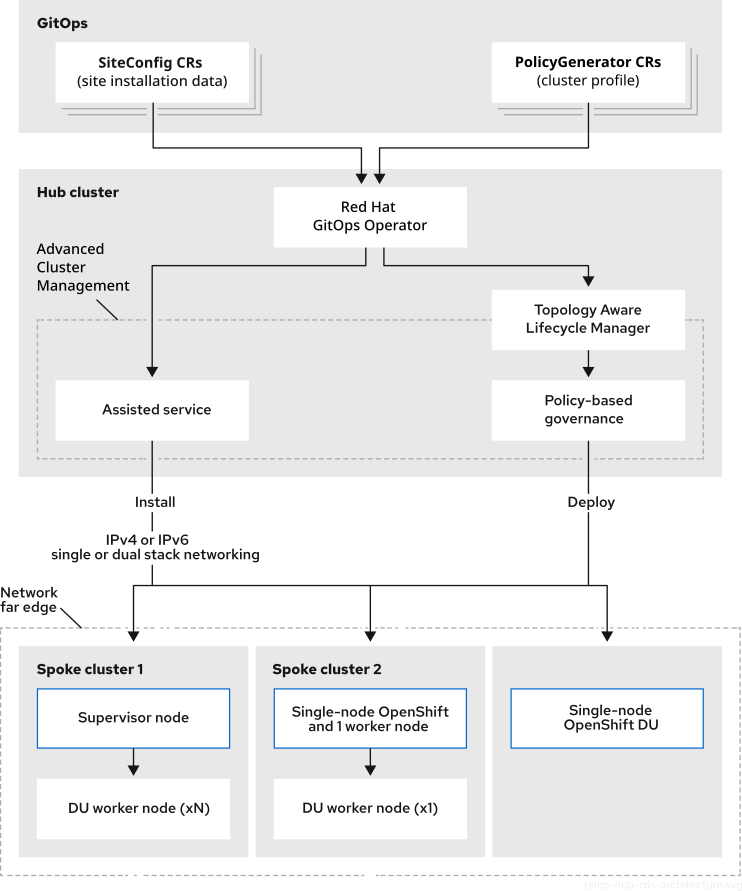
5.4. 电信管理 hub 集群使用模型
hub 集群为电信应用程序和工作负载集群提供受管集群安装、配置、可观察性和持续生命周期管理。
5.5. hub 集群扩展目标
hub 集群的资源要求直接取决于 hub 管理的集群数量、每个受管集群的策略数量,以及 Red Hat Advanced Cluster Management (RHACM) 中配置的一组功能。
hub 集群引用配置在以下情况下最多支持 3500 个受管单节点 OpenShift 集群:
- 每个配置了 hub-side 模板的集群的 5 个策略,间隔为 10 分钟。
仅启用以下 RHACM 附加组件:
- 策略控制器
- 带有默认配置的可观察性
- 您可以使用 GitOps ZTP 一次在最多 500 个集群的批处理中使用 GitOps ZTP 部署受管集群。
另外,还会验证引用配置以部署和管理受管集群拓扑混合。具体限制取决于集群拓扑、启用的 RHACM 功能等混合。在混合拓扑场景中,使用 1200 个单节点 OpenShift 集群、400 个紧凑集群(3 节点组合了 control plane 和计算节点)和 230 标准集群(3 control plane 和 2 个 worker 节点)验证引用 hub 配置。
符合此参考规格的 hub 集群可以支持每个 ArgoCD 应用程序的 1000 个单节点 ClusterInstance CR 同步。您可以使用多个应用程序来实现单个 hub 集群支持的最大集群数量。
特定的维度要求高度依赖于集群拓扑和工作负载。如需更多信息,请参阅"存储要求"。根据您的受管集群的特定特征调整集群维度。
5.6. hub 集群资源使用率
在以下情况下,为部署 hub 集群测量资源利用率:
- 在引用管理 3500 单节点 OpenShift 集群下。
- 3 节点紧凑集群,用于在双插槽裸机服务器上运行的管理 hub。
- 网络降低 50 ms 往返延迟、100 Mbps 带宽限制和 0.02% 数据包丢失。
- Observability (可观察性)没有被启用。
- 仅使用本地存储。
| 指标 | 峰值测量 |
|---|---|
| OpenShift Platform CPU | 106 cores (52 cores peak per node) |
| OpenShift Platform 内存 | 504 G (168 G peak per node) |
5.7. hub 集群拓扑
在生产环境中,OpenShift Container Platform hub 集群必须高度可用,才能维护管理功能的高可用性。
- 限制和要求
为 hub 集群使用高可用性集群拓扑,例如:
- Compact (3 节点组合 control plane 和计算节点)
- Standard (3 control plane 节点 + N 计算节点)
- 工程考虑
- 在非生产环境中,单节点 OpenShift 集群可用于有限的 hub 集群功能。
- 单节点 OpenShift 不支持某些功能,如 Red Hat OpenShift Data Foundation。在这个配置中,一些 hub 集群功能可能不可用。
- 可选计算节点的数量可能会因特定用例的规模而异。
- 可以根据需要稍后添加计算节点。
5.8. hub 集群网络
参考 hub 集群设计为在无法直接访问互联网的断开连接的环境中运行。与所有 OpenShift Container Platform 集群一样,hub 集群需要访问托管所有 OpenShift 和第 2 天 Operator Lifecycle Manager (OLM)镜像的镜像 registry。
hub 集群支持 IPv6 和 IPv4 网络的双栈网络。IPv6 通常用于边缘或边缘网络段,而 IPv4 更适合与数据中心中的传统设备一起使用。
- 限制和要求
无论安装方法如何,您必须为 hub 集群配置以下网络类型:
-
clusterNetwork -
serviceNetwork -
machineNetwork
-
您必须为 hub 集群配置以下 IP 地址:
-
apiVIP -
ingressVIP
-
注意对于上述网络配置,需要一些值,或者根据所选的架构和 DHCP 配置自动分配值。
- 您必须使用默认 OpenShift Container Platform 网络供应商 OVN-Kubernetes。
受管集群和 hub 集群之间的网络必须满足 Red Hat Advanced Cluster Management (RHACM) 文档中的网络要求,例如:
- hub 集群访问受管集群 API 服务、Ironic Python 代理和基板管理控制器(BMC)端口。
- 受管集群对 hub 集群 API 服务、入口 IP 和 control plane 节点 IP 地址的访问。
- 受管集群 BMC 访问 hub 集群 control plane 节点 IP 地址。
镜像 registry 必须可在 hub 集群生命周期内访问。
- 所有需要的容器镜像都必须镜像到断开连接的 registry 中。
- hub 集群必须配置为使用断开连接的 registry。
- hub 集群无法托管自己的镜像 registry。例如,在电源故障影响所有群集节点的情况下,registry 必须可用。
- 工程考虑
- 在部署 hub 集群时,请确定您定义了正确大小的 CIDR 范围定义。
5.9. hub 集群内存和 CPU 要求
hub 集群的内存和 CPU 要求因 hub 集群的配置、集群中的资源数量和受管集群数量而有所不同。
- 限制和要求
- 确保 hub 集群满足 OpenShift Container Platform 和 Red Hat Advanced Cluster Management (RHACM) 的底层内存和 CPU 要求。
- 工程考虑
- 在部署电信 hub 集群前,请确保集群主机满足集群要求。
有关扩展受管集群数量的更多信息,请参阅 "Hub cluster scaling target"。
5.10. hub 集群存储要求
管理 hub 集群所需的存储总量取决于集群中部署的每个应用程序的存储要求。以下部分介绍了通过高可用性 PersistentVolume 资源进行存储的主要组件。
底层 OpenShift Container Platform 安装所需的存储与以下要求分开。
5.10.1. 支持的服务
Assisted Service 使用多集群引擎和 Red Hat Advanced Cluster Management (RHACM) 部署。
| 持久性卷资源 | 大小(GB) |
|---|---|
|
| 50 |
|
| 700 |
|
| 20 |
5.10.2. RHACM Observability
Cluster Observability 由多集群引擎和 Red Hat Advanced Cluster Management (RHACM)提供。
-
Observability 存储需要几个
PV资源和一个 S3 兼容存储桶存储,才能长期保留指标。 -
存储要求计算非常复杂,并依赖于受管集群的特定工作负载和特征。
PV资源和 S3 存储桶的要求取决于很多方面,包括数据保留、受管集群数量、受管集群工作负载等。 - 使用 RHACM 容量规划存储库中的 observability 大小计算器估算可观察性所需的存储。有关使用计算器估算可观察性存储要求的说明,请参阅红帽知识库文章在 电信环境中计算 存储需求。下表使用来自电信 RAN DU RDS 和 hub 集群 RDS 作为代表值的输入。
估计以下数字:调优值以获得更准确的结果。将工程利润(如 +20%)添加到潜在估算不准确的结果中。
| 容量规划器输入 | 数据源 | 示例值 |
|---|---|---|
| control plane 节点数量 | hub 集群 RDS (scale) 和电信 RAN DU RDS (topology) | 3500 |
| 额外 worker 节点数量 | hub 集群 RDS (scale) 和电信 RAN DU RDS (topology) | 0 |
| 存储数据的天数 | hub 集群 RDS | 15 |
| 每个集群的 pod 总数 | Telco RAN DU RDS | 120 |
| 命名空间数量(不包括 OpenShift Container Platform) | Telco RAN DU RDS | 4 |
| 每小时的指标样本数 | 默认值 | 12 |
| 接收器持久性卷(PV)中保留小时数 | 默认值 | 24 |
使用这些输入值,大小计算器,如红帽知识库文章 计算存储需求在电信环境中对 MultiClusterHub Observability 的需求 所示,表示以下存储需求:
alertmanager PV | thanos receive PV | thanos compact PV | |||
|---|---|---|---|---|---|
| Per replica | 总计 | Per replica | 总计 | 总计 | |
| 10 GiB | 30 GiB | 10 GiB | 30 GiB | 100 GiB | |
thanos rule PV | thanos store PV | 对象存储桶[1] | |||
|---|---|---|---|---|---|
| Per replica | 总计 | Per replica | 总计 | Per day | 总计 |
| 30 GiB | 90 GiB | 100 GiB | 300 GiB | 15 GiB | 101 GiB |
[1] 对于对象存储桶,假定禁用降级,以便只为存储要求计算原始数据。
5.10.3. 存储注意事项
- 限制和要求
- 最低 OpenShift Container Platform 和 Red Hat Advanced Cluster Management (RHACM)限制应用
- 高可用性应该通过存储后端提供。hub 集群引用配置通过 Red Hat OpenShift Data Foundation 提供存储。
- 对象存储桶存储通过 OpenShift Data Foundation 提供。
- 工程考虑
- 使用低延迟的 SSD 或 NVMe 磁盘,为 etcd 存储使用高吞吐量。
电信 hub 集群的存储解决方案是 OpenShift Data Foundation。
- Local Storage Operator 支持 OpenShift Data Foundation 使用的存储类提供 hub 集群上的其他组件所需的块、文件和对象存储。
-
Local Storage Operator
LocalVolume配置包括设置forceWipeDevicesAndDestroyAllData: true,以支持之前使用 OpenShift Data Foundation 的 hub 集群节点重新安装。
5.10.4. Git 存储库
电信管理 hub 集群支持通过 GitOps 驱动方法为各种电信应用程序安装和管理 OpenShift 集群的配置。此方法需要一个可访问的 Git 存储库,充当集群定义和配置工件的权威来源。
红帽不提供商业支持的 Git 服务器。生产环境中提供的现有 Git 服务器可以使用。Gitea 和 Gogs 是您可以使用的自托管 Git 服务器的示例。
Git 存储库通常在 hub 集群外部的 production 网络中提供。在大型部署中,多个 hub 集群可以使用同一 Git 存储库来维护受管集群的定义。使用此方法,您可以轻松地检查完整网络的状态。作为集群定义的真实来源,Git 存储库应当高度可用,并在灾难场景中恢复。
对于灾难恢复和多 hub 注意事项,请独立于 hub 集群运行 Git 存储库。
- 限制和要求
- 需要 Git 存储库来支持 hub 集群的 GitOps ZTP 功能,包括受管集群的安装、配置和生命周期管理。
- Git 存储库必须可从管理集群访问。
- 工程考虑
- GitOps Operator 使用 Git 存储库来确保持续部署以及应用的配置的单一数据源。
5.11. 在 hub 集群上安装 OpenShift Container Platform
- 描述
为 hub 集群安装 OpenShift Container Platform 的参考方法是通过基于代理的安装程序。
基于代理的安装程序提供安装功能,而无需额外的集中式基础架构。基于代理的安装程序会创建一个 ISO 镜像,您要挂载到要安装的服务器。当您引导服务器时,OpenShift Container Platform 会与可选提供的额外清单一起安装,如 Red Hat OpenShift GitOps Operator。
注意您还可以使用其他安装方法在 hub 集群中安装 OpenShift Container Platform。
如果 hub 集群功能应用到现有的 OpenShift Container Platform 集群,则不需要基于代理的安装程序安装。安装第 2 天 Operator 的剩余步骤并为这些功能配置集群保持不变。当 OpenShift Container Platform 安装完成后,必须在 hub 集群上安装一组额外 Operator 及其配置。
参考配置包括所有这些自定义资源(CR),您可以手动应用它们,例如:
$ oc apply -f <reference_cr>您还可以将引用配置添加到 Git 存储库,并使用 ArgoCD 应用它。
注意如果手动应用 CR,请确保按照依赖项的顺序应用 CR。例如,在 Operator 前应用命名空间,并在配置前应用 Operator。
- 限制和要求
- 基于代理的安装程序需要一个可访问的镜像仓库,其中包含所有所需的 OpenShift Container Platform 和第 2 天 Operator 镜像。
- 基于代理的安装程序根据特定的 OpenShift 发行版本和特定集群详情构建 ISO 镜像。安装第二个 hub 需要构建一个单独的 ISO 镜像。
- 工程考虑
- 基于代理的安装程序提供 OpenShift Container Platform 基础安装。您可以在安装集群后应用第 2 天 Operator 和其他配置 CR。
- 参考配置支持在断开连接的环境中的基于代理的安装程序安装。
- 在安装时可以提供有限的附加清单集合。
5.12. hub 集群中的第 2 天 Operator
管理 hub 集群依赖于一组第 2 天 Operator 来提供关键管理服务和基础架构。使用与团队中的一组受管集群版本匹配的 Operator 版本。
使用 Operator Lifecycle Manager (OLM) 和 Subscription 自定义资源 (CR) 安装第 2 天 Operator。Subscription CR 识别要安装的第 2 天 Operator、找到 Operator 的目录以及 Operator 的适当版本频道。默认情况下,OLM 安装并尝试使用频道中提供的最新 z-stream 版本来保持 Operator 更新。默认情况下,所有订阅都使用 installPlanApproval: Automatic 值进行设置。在这个模式中,OLM 会在目录和频道中可用时会自动安装新的 Operator 版本。
将 installPlanApproval 设置为在定义的维护窗口外自动更新 Operator 的风险(如果目录索引被更新为包含较新的 Operator 版本)。在断开连接的环境中,您要在目录中构建和维护一组策展的 Operator 和版本,如果您遵循为更新版本创建新目录索引的策略,则 Operator 被意外更新的风险将很大删除。但是,如果您想要进一步防止这个风险,可以把 Subscription CR 设置为 installPlanApproval: Manual,这会阻止 Operator 在没有显式管理员批准的情况下进行更新。
- 限制和要求
- 当升级电信 hub 集群时,OpenShift Container Platform 和 Operator 的版本必须满足所有相关兼容性列表的要求。
5.13. Observability(可观察性)
Red Hat Advanced Cluster Management (RHACM) 多集群引擎 Observability 组件为所有受管集群提供指标和警报的集中聚合和视觉化。为了平衡性能和数据分析,监控服务维护以 downsampled 间隔收集的聚合指标的子集。这些指标可以通过一组不同的预配置仪表板在 hub 上访问。
- Observability 安装
启用和配置 Observability 服务的主要 CR 是
MulticlusterObservabilityCR,它定义以下设置:要启用和配置可观察性服务的主自定义资源(CR)是MulticlusterObservabilityCR,它定义了以下设置:- 可配置的保留设置。
-
不同组件的存储:
thanos receive,thanos compact,thanos rule,thanos storesharding,alertmanager。 metadata.annotations.mco-disable-alerting="true"注解,它允许在受管集群中调整监控配置。注意如果没有设置 Observability 组件,则尝试配置受管集群监控配置。使用这个值集,您可以将所需的配置与必要的 Observability 配置合并,将警报转发到受管集群监控
ConfigMap对象中。当 Observability 服务启用 RHACM 时,将部署到每个受管集群,以将本地 Monitoring 生成的指标和警报推送到 hub 集群。要从受管集群转发到 hub 的指标和警报由open-cluster-management-addon-observability命名空间中的ConfigMapCR 定义。您也可以指定自定义指标,如需更多信息,请参阅添加自定义指标。
- Alertmananger 配置
- hub 集群提供了一个 Observability Alertmanager,它可以配置为将警报推送到外部系统,如电子邮件。Alertmanager 默认启用。
- 您必须配置警报转发。
- 当 Alertmanager 启用但没有配置时,hub Alertmanager 不会向外部转发警报。
- 启用 Observability 后,可将受管集群配置为将警报发送到包括 hub Alertmanager 在内的任何端点。
- 当受管集群配置为将警报转发到外部源时,不会通过 hub 集群 Alertmanager 路由警报。
- 警报状态作为指标可用。
- 启用可观察性后,受管集群警报状态会包含在转发到 hub 集群的指标子集中,并通过 Observability 仪表板获得。
- 限制和要求
- Observability 需要持久性对象存储用于长期指标。如需更多信息,请参阅"存储要求"。
- 工程考虑
-
指标的转发是完整指标数据的子集。它只包含
observability-metrics-allowlist配置映射中定义的指标,以及用户添加的任何自定义指标。 -
指标以 downsampled 率转发。指标通过取 5 分钟间隔的最新数据点(或由
MultiClusterObservabilityCR 配置定义)来转发。 - 网络中断可能会导致在该时间段内转发给 hub 集群的指标丢失。如果指标也直接从受管集群转发到提供商网络中的外部指标收集器,则可以缓解这个问题。受管集群上提供了完整解析指标。
- 除了 hub 上的默认指标仪表板外,用户还可定义自定义仪表板。
- 引用配置的大小基于 hub 集群为 3500 单节点 OpenShift 集群的指标存储 15 天。如果需要更长的保留或其他受管集群拓扑或大小,则必须更新存储计算并有足够的存储容量。有关计算新值的更多信息,请参阅"存储要求"。
-
指标的转发是完整指标数据的子集。它只包含
5.14. 受管集群生命周期管理
要在网络边缘置备和管理站点,请在 hub 和spoke 架构中使用 GitOps ZTP,其中单个 hub 集群管理许多受管集群。
spoke 集群的生命周期管理可分为两个不同的阶段:集群部署,包括 OpenShift Container Platform 安装和集群配置。
5.14.1. 受管集群部署
- 描述
-
从 Red Hat Advanced Cluster Management (RHACM) 2.12 开始,使用 SiteConfig Operator 是部署受管集群的推荐方法。SiteConfig Operator 引入了一个统一的 ClusterInstance API,它将参数与部署集群的方式分离。SiteConfig Operator 使用一组集群模板,这些模板使用
ClusterInstance自定义资源(CR)的数据实例化来动态生成安装清单。根据 GitOps 方法,ClusterInstanceCR 通过 ArgoCD 从 Git 存储库提供。ClusterInstanceCR 可以用来使用 Assisted Installer 启动集群安装,或者在多集群引擎中可用基于镜像的安装。 - 限制和要求
-
处理 SiteConfig CR 的
SiteConfigArgoCD 插件已从 OpenShift Container Platform 4.18 中弃用。
-
处理 SiteConfig CR 的
- 工程考虑
-
您必须使用集群基板管理控制器(BMC)的登录信息创建一个
SecretCR。然后,在SiteConfigCR 中引用此SecretCR。可以使用 Vault 等机密存储集成来管理机密。 - 除了提供 Git 和非 Git 工作流的部署方法隔离和取消验证外,SiteConfig Operator 还为使用自定义模板提供了更好的可扩展性、更大的灵活性以及增强的故障排除体验。
-
您必须使用集群基板管理控制器(BMC)的登录信息创建一个
5.14.2. 受管集群更新
- 描述
您可以通过在以要升级集群的
Policy自定义资源(CR)中声明所需的版本来升级 OpenShift Container Platform、第 2 天 Operator 和受管集群配置的版本。策略控制器定期检查策略合规性。如果结果为负数,则创建一个违反报告。如果将策略补救操作设置为
enforce根据更新的策略修复违反情况。如果将策略补救操作设置为inform,则进程以不合规的状态报告结束,并且由用户启动升级负责在适当的维护窗口期间执行。Topology Aware Lifecycle Manager (TALM)扩展 Red Hat Advanced Cluster Management (RHACM),其功能在集群生命周期中管理升级或配置的推出。它以集群进度、有限大小批处理运行。当需要升级到 OpenShift Container Platform 或第 2 天 Operator 时,TALM 会逐渐推出更新,方法是逐步完成一组策略并将其切换到 "enforce" 策略以将配置推送到受管集群。
TALM 用来构建补救计划的自定义资源(CR)是
ClusterGroupUpgradeCR。您可以将基于镜像的升级(IBU)与生命周期代理一起使用,作为单节点 OpenShift 集群平台版本的替代升级路径。IBU 使用从专用 seed 集群生成的 OCI 镜像在目标集群上安装单节点 OpenShift。
TALM 使用
ImageBasedGroupUpgradeCR 将基于镜像的升级发布到一组已识别的集群。- 限制和要求
-
您可以使用基于镜像的升级来对单节点 OpenShift 集群之间进行升级,从 OpenShift Container Platform
<4.y>升级到<4.y+2>,从<4.y.z>到<4.y.z+n>。 - 基于镜像的升级使用特定于集群运行的硬件平台的自定义镜像。不同的硬件平台需要单独的 seed 镜像。
-
您可以使用基于镜像的升级来对单节点 OpenShift 集群之间进行升级,从 OpenShift Container Platform
- 工程考虑
-
在边缘部署中,您可以通过管理时间和推出更改来最小化受管集群的中断。将所有策略设置为
inform以监控合规性,而不触发自动强制。同样,将第 2 天 Operator 订阅配置为 manual,以防止在调度的维护窗口外进行更新。 - 推荐的单节点 OpenShift 集群的升级升级是基于镜像的升级。
对于多节点集群升级,请考虑以下
MachineConfigPoolCR 配置来减少升级时间:-
通过将
paused字段设置为true,在维护窗口期间暂停配置部署到节点。 -
调整
maxUnavailable字段,以控制池中可以同时更新多少个节点。MaxUnavailable字段定义池中节点在MachineConfig对象更新期间可同时不可用的百分比。将maxUnavailable设置为最大可容忍的值。这可减少升级过程中的重启次数,从而缩短升级时间。 -
通过将
paused字段设置为false来恢复配置部署。配置更改在单个重启中应用。
-
通过将
-
在集群安装过程中,您可以通过将
paused字段设置为true并将maxUnavailable设置为 100% 以改进安装时间来暂停MachineConfigPoolCR。
-
在边缘部署中,您可以通过管理时间和推出更改来最小化受管集群的中断。将所有策略设置为
5.15. hub 集群灾难恢复
请注意,丢失 hub 集群通常不会在受管集群中创建服务中断。hub 集群提供的功能将会丢失,如可观察性、配置、生命周期管理更新通过 hub 集群驱动的,等等。
- 限制和要求
- Backup、restore 和 disaster recovery 由集群备份和恢复 Operator 提供,它依赖于 OpenShift API for Data Protection (OADP) Operator。
- 工程考虑
- 您可以根据配置将集群备份和恢复 Operator 扩展至 hub 集群的第三方资源。
- 在 Red Hat Advanced Cluster Management (RHACM) 中不默认启用集群备份和恢复 Operator。参考配置启用此功能。
5.16. hub 集群组件
5.16.1. Red Hat Advanced Cluster Management (RHACM)
- 这个版本中的新内容
- 这个版本没有参考设计更新。
- 描述
Red Hat Advanced Cluster Management (RHACM) 为部署的集群提供 Multi Cluster Engine (MCE) 安装和持续生命周期管理功能。您可以通过在维护窗口期间将
Policy自定义资源 (CR) 应用到集群来声明管理集群配置和升级。RHACM 提供如下功能:
- 在 RHACM 中使用多集群引擎组件的集群零接触置备(ZTP)和持续扩展。
- 通过 RHACM 策略控制器配置、升级和集群状态。
-
在受管集群安装过程中,RHACM 可以对通过
ClusterInstanceCR 配置的单个节点应用标签。 - RHACM 的 Topology Aware Lifecycle Manager 组件提供对受管集群的配置更改的分阶段部署。
- RHACM 多集群引擎 Observability 组件提供选择性监控、仪表板、警报和指标。
推荐的单节点 OpenShift 集群安装方法是使用多集群引擎中的基于镜像的安装方法,它使用
ClusterInstanceCR 进行集群定义。单节点 OpenShift 升级的建议方法是基于镜像的升级方法。
注意RHACM 多集群引擎 Observability 组件可让您集中查看所有受管集群的健康和状态。默认情况下,每个受管集群都启用来发送由 Cluster Monitoring Operator (CMO)创建的指标和警报,返回到 Observability。如需更多信息,请参阅"Observability"。
- 限制和要求
- 如需有关单个 hub 集群管理的集群数量的更多信息,请参阅"Telco management hub 集群使用 model"。
hub 有效地管理的受管集群数量取决于不同的因素,包括:
- 每个受管集群的资源可用性
- 策略复杂性和集群大小
- 网络利用率
- 工作负载需求和分布
- hub 和受管集群必须维护足够的双向连接。
- 工程考虑
- 您可以配置集群备份和恢复 Operator,使其包含第三方资源。
- 强烈建议您在通过策略定义配置时使用 RHACM hub 侧模板。此功能通过为每个集群或每个组启用来管理团队所需的策略数量。例如,要在策略中模板的区域或硬件类型内容,并根据集群或组替换。
-
受管集群通常具有一些特定于单个集群的配置值。它们应该使用 RHACM 策略 hub 侧模板,以及基于集群名称从
ConfigMapCR 中拉取的值来管理。
5.16.2. Topology Aware Lifecycle Manager
- 这个版本中的新内容
- 这个版本没有参考设计更新。
- 描述
Topology Aware Lifecycle Manager(TALM)是一个仅在 hub 集群上运行的 Operator,用于管理集群升级、Operator 升级和集群配置等更改如何应用到网络。TALM 支持以下功能:
- 在用户可配置的批处理中,对集群团队进行进度发布。
-
针对每个集群操作,在对受管集群的配置更改后添加
ztp-done标签或其他 user-configurable 标签。 TALM 在启动升级前,支持可选的 OpenShift Container Platform、OLM Operator 和其他用户镜像到单节点 OpenShift 集群。当使用推荐的基于镜像的升级方法升级单节点 OpenShift 集群时,预缓存功能不适用。
-
使用
PreCachingConfigCR 指定可选预缓存配置。 - 可配置镜像过滤以排除未使用的内容。
- 使用定义的空间要求参数在预缓存之前和之后存储验证。
-
使用
- 限制和要求
- TALM 支持以 500 批量进行并发集群升级。
- 预缓存仅限于单节点 OpenShift 集群拓扑。
- 工程考虑
-
PreCachingConfig自定义资源 (CR) 是可选的。如果您只想预缓存平台相关的镜像,如 OpenShift Container Platform 和 OLM,则不需要创建它。 - TALM 支持在 Red Hat Advanced Cluster Management 策略中使用 hub 侧模板。
-
5.16.3. GitOps Operator 和 GitOps ZTP
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
GitOps Operator 和 GitOps ZTP 提供了一个基于 GitOps 的基础架构,用于管理集群部署和配置。集群定义和配置在 Git 中作为声明状态进行维护。您可以将
ClusterInstance自定义资源(CR)应用到 hub 集群,其中SiteConfigOperator 会将它们呈现为安装 CR。在以前的版本中,GitOps ZTP 插件支持从SiteConfigCR 生成安装 CR。此插件现已弃用。单独的 GitOps ZTP 插件可根据PolicyGenerator或PolicyGenTemplateCR 启用自动将配置 CR 嵌套到策略中。您可以使用基准引用配置 CR 在受管集群中部署和管理多个 OpenShift Container Platform 版本。您可以使用自定义 CR 和基线(baseline)CR。要同时维护多个每个版本策略,请使用 Git 使用
PolicyGenerator或PolicyGenTemplateCR 管理源 CR 的版本。- 限制和要求
- 为确保在集群或节点删除过程中对受管集群及其相关资源进行一致并完成清理,您必须将 ArgoCD 配置为使用后台删除模式。
- 工程考虑
-
为了避免在更新内容时造成混淆或意外覆盖,请在
source-crs目录和额外清单中对自定义 CR 使用唯一的和可分辨名称。 - 将引用源 CR 保留在与自定义 CR 的独立目录中。这有助于根据需要轻松更新引用 CR。
- 为了帮助多个版本,请将所有源 CR 和策略创建 CR 保留在 Git 存储库中,以确保每个 OpenShift Container Platform 版本生成策略的一致性。
-
为了避免在更新内容时造成混淆或意外覆盖,请在
5.16.4. Local Storage Operator
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
-
您可以使用 Local Storage Operator 创建可用作
PVC资源的持久性卷。您创建的PV资源的数量和类型取决于您的要求。 - 工程考虑
-
在创建持久性卷前,为
PVCR 创建后备存储。这可以是分区、本地卷、LVM 卷或完整磁盘。 -
请参阅
LocalVolumeCR 中的设备列表,访问每个设备以确保正确分配磁盘和分区,例如/dev/disk/by-path/<id>。无法保证在节点重启后逻辑名称(例如/dev/sda)一致。
-
在创建持久性卷前,为
5.16.5. Red Hat OpenShift Data Foundation
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
- Red Hat OpenShift Data Foundation 为 hub 集群提供文件、块和对象存储服务。
- 限制和要求
- 内部模式中的 Red Hat OpenShift Data Foundation (ODF) 需要 Local Storage Operator 定义提供所需底层存储的存储类。
- 在为电信管理集群规划时,请考虑 ODF 基础架构和网络要求。
- 双堆栈支持有限。在双栈集群中支持 ODF IPv4。
- 工程考虑
- 当存储容量耗尽时,因为恢复可及时解决容量警告会比较困难,请参阅容量规划。
5.16.6. 日志记录
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
- 使用 Cluster Logging Operator 从节点中收集并发送日志以进行远程归档和分析。参考配置使用 Kafka 将审核和基础架构日志发送到远程归档。
- 限制和要求
- 参考配置不包括本地日志存储。
- 引用配置不包括在 hub 集群中受管集群日志的聚合。
- 工程考虑
- 集群 CPU 使用的影响取决于生成的日志的数量或大小以及配置的日志过滤量。
- 参考配置不包括应用程序日志的发布。将应用程序日志包含在配置中,需要评估应用程序日志记录率以及分配给保留集合的足够额外 CPU 资源。
5.16.7. OpenShift API for Data Protection
- 这个版本中的新内容
- 这个版本没有参考设计更新
- 描述
启用备份功能时,由 Red Hat Advanced Cluster Management (RHACM) 自动安装和管理的 OpenShift API for Data Protection (OADP) Operator。
OADP Operator 有助于在 OpenShift Container Platform 集群中备份和恢复工作负载。根据上游的开源项目 Velero,它允许您为给定项目(包括持久性卷)备份和恢复所有 Kubernetes 资源。
虽然在 hub 集群中不需要它,但强烈建议您对 hub 集群进行集群备份、灾难恢复和高可用性架构。必须启用 OADP Operator,以便为 RHACM 使用灾难恢复解决方案。参考配置通过 RHACM Operator 提供的
MultiClusterHub自定义资源(CR)启用备份(OADP)。- 限制和要求
- 集群中只能安装一个 OADP 版本。RHACM 安装的版本必须用于 RHACM 灾难恢复功能。
- 工程考虑
- 这个版本没有工程考虑更新。
5.17. 提取电信 hub 引用设计 CR
您可以从 openshift-telco-hub-rds-rhel9 容器镜像提取电信 hub 配置集的完整自定义资源(CR)集合。容器镜像具有电信 hub 配置集所需的 CR 和可选 CR。
先决条件
-
已安装
podman。
流程
运行以下命令,使用凭证登录到容器镜像 registry:
$ podman login registry.redhat.io运行以下命令,从
openshift-telco-hub-rds-rhel9容器镜像中提取内容:$ mkdir -p ./out$ podman run -it registry.redhat.io/openshift4/openshift-telco-hub-rds-rhel9:v4.19 | base64 -d | tar xv -C out
验证
out目录具有以下目录结构:您可以运行以下命令来查看out/telco-hub-rds/目录中的电信 hub CR:$ tree -L 4 out/telco-hub-rds/输出示例
out/telco-hub-rds/ ├── configuration │ ├── example-overlays-config │ │ ├── acm │ │ │ ├── acmMirrorRegistryCM-patch.yaml │ │ │ ├── kustomization.yaml │ │ │ ├── options-agentserviceconfig-patch.yaml │ │ │ └── storage-mco-patch.yaml │ │ ├── gitops │ │ │ ├── argocd-tls-certs-cm-patch.yaml │ │ │ ├── init-argocd-app.yaml │ │ │ └── kustomization.yaml │ │ ├── logging │ │ │ ├── cluster-log-forwarder-patch.yaml │ │ │ ├── kustomization.yaml │ │ │ └── README.md │ │ ├── lso │ │ │ ├── kustomization.yaml │ │ │ └── local-storage-disks-patch.yaml │ │ ├── odf │ │ │ ├── kustomization.yaml │ │ │ └── options-storage-cluster.yaml │ │ └── registry │ │ ├── catalog-source-image-patch.yaml │ │ ├── idms-operator-mirrors-patch.yaml │ │ ├── idms-release-mirrors-patch.yaml │ │ ├── itms-generic-mirrors-patch.yaml │ │ ├── itms-release-mirrors-patch.yaml │ │ ├── kustomization.yaml │ │ └── registry-ca-patch.yaml │ ├── kustomization.yaml │ ├── README.md │ └── reference-crs │ ├── kustomization.yaml │ ├── optional │ │ ├── logging │ │ ├── lso │ │ └── odf-internal │ └── required │ ├── acm │ ├── gitops │ ├── registry │ └── talm ├── install │ ├── mirror-registry │ │ ├── imageset-config.yaml │ │ └── README.md │ └── openshift │ ├── agent-config.yaml │ └── install-config.yaml └── scripts └── check_current_versions.sh
5.18. hub 集群引用配置 CR
以下小节在 4.19 中简要描述电信管理 hub 引用配置的每个自定义资源 (CR)。
5.19. Red Hat Advanced Cluster Management (RHACM) CR
| 组件 | 参考 CR | 描述 | 选填 |
|---|---|---|---|
| RHACM |
| 创建一个策略来管理从对象存储桶声明复制数据到 secret 中,以便 Observability 连接到 Thanos。 | 否 |
| RHACM |
| 定义 ACM 所需的 MultiCluster Engine 配置。 | 否 |
| RHACM |
|
配置具有高可用性的 | 否 |
| RHACM |
|
为 | 否 |
| RHACM |
|
定义 | 否 |
| RHACM |
|
为 | 否 |
| RHACM |
| 通过定义各种参数和 API 设置来配置 Open Cluster Management 搜索。 | 否 |
| RHACM |
| 在 metal3.io/v1alpha1 API 版本中配置 provisioning 资源,以监视所有命名空间。 | 否 |
| RHACM |
| 使用自动安装计划批准订阅 RHACM Operator。 | 否 |
| RHACM |
|
配置 | 否 |
| RHACM |
|
创建一个 | 否 |
| RHACM |
|
在 | 否 |
| RHACM |
|
在 | 否 |
| RHACM |
| 创建一个策略,将全局 pull secret 复制到 observability 命名空间中。 | 否 |
| RHACM |
| 创建一个策略,将对象存储桶声明中的数据复制到 secret 中,以便可观察性连接到 Thanos。 | 否 |
| TALM |
|
为 TALM 创建 | 否 |
5.20. 存储引用 CR
| 组件 | 参考 CR | 描述 | 选填 |
|---|---|---|---|
| Local Storage Operator |
|
定义指定本地存储配置和节点选择条件的 | 是 |
| Local Storage Operator |
|
定义 | 是 |
| Local Storage Operator |
|
为 | 是 |
| Local Storage Operator |
|
为 Local Storage Operator 定义 | 是 |
| OpenShift Data Foundation |
|
使用特定注解和标签定义 | 是 |
| OpenShift Data Foundation |
|
为 | 是 |
| OpenShift Data Foundation |
| 定义用于验证 ODF 部署的就绪状态的资源。 | 是 |
| OpenShift Data Foundation |
| 为 OpenShift Data Foundation Operator 配置 OpenShift Container Platform 订阅,指定安装详情,如 Operator 的名称、命名空间、频道和批准策略。 | 是 |
| OpenShift Data Foundation |
|
使用 Argo CD 同步的特定资源请求和限值、存储设备集和注解定义 | 否 |
5.21. GitOps Zero Touch Provisioning (ZTP) 参考 CR
| 组件 | 参考 CR | 描述 | 选填 |
|---|---|---|---|
| GitOps Operator |
|
定义 | 否 |
| GitOps Operator |
| 定义将 ArgoCD 自定义插件添加到 GitOps 控制器的策略。 | 否 |
| GitOps Operator |
| 定义用于 GitOps 管理的 ArgoCD 应用程序。 | 否 |
| GitOps Operator |
|
为 ArgoCD TLS 证书管理定义 | 否 |
| GitOps Operator |
|
定义向 GitOps Operator 授予权限的 | 否 |
| GitOps Operator |
|
将 | 否 |
| GitOps Operator |
|
定义 | 否 |
| GitOps Operator |
|
使用默认升级策略在 | 否 |
| GitOps Operator |
| 为 OpenShift Container Platform GitOps Operator 定义订阅,指定自动安装计划批准和源详情。 | 否 |
| GitOps Operator |
| 定义 ZTP 清单和配置的 Git 存储库。 | 否 |
| GitOps 应用程序 |
|
定义 ArgoCD | 否 |
| GitOps 应用程序 |
| 定义命名空间和 ArgoCD 应用程序,以管理指定 Git 存储库中的集群配置部署。 | 否 |
| GitOps 应用程序 |
|
定义一个 | 否 |
| GitOps 应用程序 |
|
将 | 否 |
| GitOps 应用程序 |
| 为 GitOps ZTP 应用程序安装定义 Kustomization 配置,列出应包含的各种 YAML 资源。 | 否 |
| GitOps 应用程序 |
| 定义 Argo CD AppProject 资源,指定集群和命名空间资源白名单和目的地。 | 否 |
| GitOps 应用程序 |
|
定义用于策略管理的 ArgoCD | 否 |
5.22. 日志记录引用 CR
| 组件 | 参考 CR | 描述 | 选填 |
|---|---|---|---|
| Cluster Logging Operator |
|
定义 | 是 |
| Cluster Logging Operator |
| 为 Cluster Logging Operator 配置命名空间。 | 是 |
| Cluster Logging Operator |
| 为 Cluster Logging Operator 配置 Operator 组。 | 是 |
| Cluster Logging Operator |
|
定义 Cluster Logging Operator 组件使用的 | 是 |
| Cluster Logging Operator |
|
将 Cluster Logging | 是 |
| Cluster Logging Operator |
|
将 Cluster Logging | 是 |
| Cluster Logging Operator |
| 定义用于安装和管理 Cluster Logging Operator 的订阅。 | 是 |
5.23. 容器 registry 引用 CR
| 组件 | 参考 CR | 描述 | 选填 |
|---|---|---|---|
| Registry |
|
为镜像 Operator 目录定义 | 否 |
| Registry |
|
为镜像的 Operator 镜像定义镜像摘要 | 否 |
| Registry |
|
为 OpenShift Container Platform 发行镜像定义镜像摘要 | 否 |
| Registry |
| 定义用于管理镜像 registry 和策略的镜像配置 CR。 | 否 |
| Registry |
|
为断开连接的 registry 中的镜像定义镜像标签 | 否 |
| Registry |
|
为 OpenShift Container Platform 发行镜像定义镜像标签 | 否 |
| Registry |
|
为 registry 相关的 CR 定义 | 否 |
| Registry |
|
为离线目录源配置 | 否 |
| Registry |
|
定义包含 registry CA 证书的 | 否 |
5.24. 镜像镜像引用 CR
| 组件 | 参考 CR | 描述 | 选填 |
|---|---|---|---|
| 镜像配置 CR |
|
定义 | 否 |
5.25. 安装引用 CR
| 组件 | 参考 CR | 描述 | 选填 |
|---|---|---|---|
| 基于代理的安装 |
|
使用此示例模板 | 否 |
| 基于代理的安装 |
|
使用此示例 | 否 |
5.26. 电信 hub 参考配置软件规格
电信 hub 4.19 解决方案已为 OpenShift Container Platform 集群使用以下红帽软件产品进行验证。
| 组件 | 软件版本 |
|---|---|
| OpenShift Container Platform | 4.19 |
| Local Storage Operator | 4.19 |
| Red Hat OpenShift Data Foundation (ODF) | 4.18 |
| Red Hat Advanced Cluster Management (RHACM) | 2.13 |
| Red Hat OpenShift GitOps | 1.16 |
| GitOps Zero Touch Provisioning (ZTP) 插件 | 4.19 |
| 多集群引擎 Operator PolicyGenerator 插件 | 2.13 |
| Topology Aware Lifecycle Manager (TALM) | 4.19 |
| Cluster Logging Operator | 6.2 |
| OpenShift API for Data Protection (OADP) | 与 RHACM 版本一致的版本。 |
第 6 章 比较集群配置
6.1. 了解 cluster-compare 插件
cluster-compare 插件是一个 OpenShift CLI (oc) 插件,它将集群配置与参考配置进行比较。该插件报告配置差异,同时通过使用可配置的验证规则和模板来抑制预期的变化。
在开发、生产和支持场景中使用 cluster-compare 插件来确保集群遵循引用配置,并快速识别并排除相关配置差异。
6.1.1. cluster-compare 插件概述
以大规模部署的集群通常使用一组经过验证的基准自定义资源(CR)来配置集群来满足用例要求,并确保在不同环境中部署时的一致性。
在实时集群中,预期来自经过验证的 CR 集合的一些变化。例如,配置可能会因为变量替换、可选组件或特定于硬件的字段而有所不同。这种变化使得集群是否符合基准配置变得困难。
将 cluster-compare 插件与 oc 命令搭配使用,您可以将实时集群中的配置与参考配置进行比较。参考配置代表基准配置,但使用各种插件功能在比较期间阻止预期的变化。例如,您可以应用验证规则,指定可选和所需资源,并定义资源之间的关系。通过减少不相关的差异,插件可以更轻松地评估集群与基准配置以及跨环境的合规性。
智能地将集群的配置与参考配置进行比较的功能如下:
Production: 确保遵守服务更新间的参考配置、升级和更改参考配置。
Development: 确保遵守测试管道中的参考配置。
Design: 与合作伙伴实验室参考配置保持一致,以确保一致性。
Support: 比较实时集群中的 must-gather 数据的引用配置,以排除配置问题。
图 6.1. cluster-compare 插件概述

6.1.2. 了解参考配置
cluster-compare 插件使用参考配置从实时集群验证配置。参考配置由名为 metadata.yaml 的 YAML 文件组成,该文件引用一组代表基准配置的模板。
参考配置的目录结构示例
├── metadata.yaml
├── optional
│ ├── optionalTemplate1.yaml
│ └── optionalTemplate2.yaml
├── required
│ ├── requiredTemplate3.yaml
│ └── requiredTemplate4.yaml
└── baselineClusterResources
├── clusterResource1.yaml
├── clusterResource2.yaml
├── clusterResource3.yaml
└── clusterResource4.yaml
在比较过程中,插件会将每个模板与集群中的配置资源匹配。该插件使用 Golang 模板语法和内联正则表达式验证等功能评估模板中的可选或必填字段。metadata.yaml 文件应用额外的验证规则,以确定模板是否是可选的或需要,并评估模板依赖关系关系。
使用这些功能,插件标识集群和参考配置之间的相关配置差异。例如,插件可以突出显示不匹配的字段值、缺失的资源、额外资源、字段类型不匹配或版本差异。
有关配置参考配置的更多信息,请参阅"创建参考配置"。
6.2. 安装 cluster-compare 插件
您可以从红帽容器目录中的容器镜像提取 cluster-compare 插件,并将其用作 oc 命令的插件。
6.2.1. 安装 cluster-compare 插件
安装 cluster-compare 插件,将引用配置与来自 live 集群或 must-gather 数据的集群配置进行比较。
先决条件
-
已安装 OpenShift CLI(
oc)。 -
已安装
podman。 - 您可以访问红帽容器目录。
流程
运行以下命令登录到红帽容器目录:
$ podman login registry.redhat.io运行以下命令,为
cluster-compare镜像创建容器:$ podman create --name cca registry.redhat.io/openshift4/kube-compare-artifacts-rhel9:latest运行以下命令,将
cluster-compare插件复制到PATH环境变量中包含的目录中:$ podman cp cca:/usr/share/openshift/<arch>/kube-compare.<rhel_version> <directory_on_path>/kubectl-cluster_comparearch是您的机器的架构。有效值为:-
linux_amd64 -
linux_arm64 -
linux_ppc64le -
linux_s390x
-
-
<rhel_version>是您机器上的 RHEL 的版本。有效值为rhel8或rhel9。 -
<directory_on_path>是PATH环境变量中包含的目录的路径。
验证
运行以下命令,查看插件的帮助信息:
$ oc cluster-compare -h输出示例
Compare a known valid reference configuration and a set of specific cluster configuration CRs. ... Usage: compare -r <Reference File> Examples: # Compare a known valid reference configuration with a live cluster: kubectl cluster-compare -r ./reference/metadata.yaml ...
6.3. 使用 cluster-compare 插件
您可以使用 cluster-compare 插件将参考配置与来自 live 集群或 must-gather 数据的配置进行比较。
6.3.1. 将 cluster-compare 插件与实时集群一起使用
您可以使用 cluster-compare 插件将引用配置与来自 live 集群的配置自定义资源(CR)进行比较。
验证实时集群配置,以确保在设计、开发或测试场景中遵守引用配置。
在非生产环境中,将 cluster-compare 插件与 live 集群一起使用。对于生产环境,请使用带有 must-gather 数据的插件。
先决条件
-
已安装 OpenShift CLI(
oc)。 -
您可以使用具有
cluster-admin角色的用户访问集群。 -
您下载了
cluster-compare插件,并将其包含在PATH环境变量中。 - 您可以访问参考配置。
流程
使用以下命令运行
cluster-compare插件:$ oc cluster-compare -r <path_to_reference_config>/metadata.yaml-r指定引用配置的metadata.yaml文件的路径。您可以指定本地目录或 URI。输出示例
... ********************************** Cluster CR: operator.openshift.io/v1_Console_cluster1 Reference File: optional/console-disable/ConsoleOperatorDisable.yaml2 Diff Output: diff -u -N /tmp/MERGED-622469311/operator-openshift-io-v1_console_cluster /tmp/LIVE-2358803347/operator-openshift-io-v1_console_cluster /tmp/MERGED-622469311/operator-openshift-io-v1_console_cluster 2024-11-20 15:43:42.888633602 +0000 +++ /tmp/LIVE-2358803347/operator-openshift-io-v1_console_cluster 2024-11-20 15:43:42.888633602 +0000 @@ -4,5 +4,5 @@ name: cluster spec: logLevel: Normal - managementState: Removed3 + managementState: Managed operatorLogLevel: Normal ********************************** … Summary4 CRs with diffs: 5/495 CRs in reference missing from the cluster: 16 required-cluster-tuning: cluster-tuning: Missing CRs:7 - required/cluster-tuning/disabling-network-diagnostics/DisableSnoNetworkDiag.yaml No CRs are unmatched to reference CRs8 Metadata Hash: 512a9bf2e57fd5a5c44bbdea7abb3ffd7739d4a1f14ef9021f6793d5cdf868f09 No patched CRs10
通过将 -o junit 添加到命令,以 junit 格式获取输出。例如:
$ oc cluster-compare -r <path_to_reference_config>/metadata.yaml -o junit
junit 输出包括以下结果类型:
- 为每个完全匹配模板传递的结果。
- 找到或缺少所需自定义资源(CR)的不同结果失败。
- 跳过使用用户覆盖机制修补的结果。
6.3.2. 将 cluster-compare 插件与 must-gather 数据一起使用
您可以使用 cluster-compare 插件将引用配置与 must-gather 数据的配置自定义资源(CR)进行比较。
使用 must-gather 数据来在生产环境中排除配置问题来验证集群配置。
对于生产环境,仅将 cluster-compare 插件与 must-gather 数据一起使用。
-
您可以从目标集群访问
must-gather数据。 -
已安装 OpenShift CLI(
oc)。 -
您已下载了
cluster-compare插件,并将其包含在PATH环境变量中。 - 您可以访问参考配置。
流程
运行以下命令,将
must-gather数据与参考配置进行比较:$ oc cluster-compare -r <path_to_reference_config>/metadata.yaml -f "must-gather*/*/cluster-scoped-resources","must-gather*/*/namespaces" -R-
-r指定引用配置的metadata.yaml文件的路径。您可以指定本地目录或 URI。 -
-f指定must-gather数据目录的路径。您可以指定本地目录或 URI。这个示例限制了相关集群配置目录的比较。 -R递归搜索目标目录。输出示例
... ********************************** Cluster CR: operator.openshift.io/v1_Console_cluster1 Reference File: optional/console-disable/ConsoleOperatorDisable.yaml2 Diff Output: diff -u -N /tmp/MERGED-622469311/operator-openshift-io-v1_console_cluster /tmp/LIVE-2358803347/operator-openshift-io-v1_console_cluster /tmp/MERGED-622469311/operator-openshift-io-v1_console_cluster 2024-11-20 15:43:42.888633602 +0000 +++ /tmp/LIVE-2358803347/operator-openshift-io-v1_console_cluster 2024-11-20 15:43:42.888633602 +0000 @@ -4,5 +4,5 @@ name: cluster spec: logLevel: Normal - managementState: Removed3 + managementState: Managed operatorLogLevel: Normal ********************************** … Summary4 CRs with diffs: 5/495 CRs in reference missing from the cluster: 16 required-cluster-tuning: cluster-tuning: Missing CRs:7 - required/cluster-tuning/disabling-network-diagnostics/DisableSnoNetworkDiag.yaml No CRs are unmatched to reference CRs8 Metadata Hash: 512a9bf2e57fd5a5c44bbdea7abb3ffd7739d4a1f14ef9021f6793d5cdf868f09 No patched CRs10
-
通过将 -o junit 添加到命令,以 junit 格式获取输出。例如:
$ oc cluster-compare -r <path_to_reference_config>/metadata.yaml -f "must-gather*/*/cluster-scoped-resources","must-gather*/*/namespaces" -R -o junit
junit 输出包括以下结果类型:
- 为每个完全匹配模板传递的结果。
- 找到或缺少所需自定义资源(CR)的不同结果失败。
- 跳过使用用户覆盖机制修补的结果。
6.3.3. 参考 cluster-compare 插件选项
以下内容描述了 cluster-compare 插件的选项。
| 选项 | 描述 |
|---|---|
|
| 当与 live 集群一起使用时,尝试匹配集群中与引用配置中类型匹配的所有资源。与本地文件一起使用时,会尝试与参考配置中类型匹配的本地文件中的所有资源匹配。 |
|
|
在与来自 live 版本的资源进行比较时,为要并行处理的模板数量指定一个整数值。较大的数字会增加速度,但同时也会增加内存、I/O 和 CPU 的用量。默认值为 |
|
| 指定用户配置文件的路径。 |
|
| 指定与参考配置进行比较的配置自定义资源的文件名、目录或 URL。 |
|
| 指定需要补丁的模板路径。 |
|
| 显示可用的模板功能。 注意
您必须使用相对于 |
|
| 显示帮助信息。 |
|
|
指定处理 |
|
|
指定输出格式。选项包括 |
|
| 指定生成覆盖的原因。 |
|
| 为参考配置指定补丁覆盖文件的路径。 |
|
|
处理以递归方式在 |
|
|
指定引用配置 |
|
|
指定 |
|
| 增加插件输出的详细程度。 |
6.3.4. 示例:比较带有电信内核参考配置的集群
您可以使用 cluster-compare 插件将参考配置与来自 live 集群或 must-gather 数据的配置进行比较。
这个示例将实时集群的配置与电信核心参考配置进行比较。电信核心参考配置源自电信核心参考设计规范(RDS)。电信核心 RDS 专为集群设计,以支持大规模电信应用程序,包括控制平面和一些集中式数据平面功能。
参考配置打包在带有电信核心 RDS 的容器镜像中。
有关将 cluster-compare 插件与电信核心和电信 RAN 分布式单元(DU)配置文件一起使用的更多信息,请参阅"添加资源"部分。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。 -
有访问
registry.redhat.io容器镜像 registry 的凭证。 -
已安装
cluster-compare插件。
流程
运行以下命令,使用凭证登录到容器镜像 registry:
$ podman login registry.redhat.io运行以下命令,从
lecommunications-core-rds-rhel9容器镜像中提取内容:$ mkdir -p ./out$ podman run -it registry.redhat.io/openshift4/openshift-telco-core-rds-rhel9:v4.18 | base64 -d | tar xv -C out您可以在
reference-crs-kube-compare/目录中查看引用配置。out/telco-core-rds/configuration/reference-crs-kube-compare/ ├── metadata.yaml1 ├── optional2 │ ├── logging │ ├── networking │ ├── other │ └── tuning └── required3 ├── networking ├── other ├── performance ├── scheduling └── storage运行以下命令,将集群的配置与电信核心参考配置进行比较:
$ oc cluster-compare -r out/telco-core-rds/configuration/reference-crs-kube-compare/metadata.yaml输出示例
W1212 14:13:06.281590 36629 compare.go:425] Reference Contains Templates With Types (kind) Not Supported By Cluster: BFDProfile, BGPAdvertisement, BGPPeer, ClusterLogForwarder, Community, IPAddressPool, MetalLB, MultiNetworkPolicy, NMState, NUMAResourcesOperator, NUMAResourcesScheduler, NodeNetworkConfigurationPolicy, SriovNetwork, SriovNetworkNodePolicy, SriovOperatorConfig, StorageCluster ... ********************************** Cluster CR: config.openshift.io/v1_OperatorHub_cluster1 Reference File: required/other/operator-hub.yaml2 Diff Output: diff -u -N /tmp/MERGED-2801470219/config-openshift-io-v1_operatorhub_cluster /tmp/LIVE-2569768241/config-openshift-io-v1_operatorhub_cluster --- /tmp/MERGED-2801470219/config-openshift-io-v1_operatorhub_cluster 2024-12-12 14:13:22.898756462 +0000 +++ /tmp/LIVE-2569768241/config-openshift-io-v1_operatorhub_cluster 2024-12-12 14:13:22.898756462 +0000 @@ -1,6 +1,6 @@ apiVersion: config.openshift.io/v1 kind: OperatorHub metadata: + annotations:3 + include.release.openshift.io/hypershift: "true" name: cluster -spec: - disableAllDefaultSources: true ********************************** Summary4 CRs with diffs: 3/45 CRs in reference missing from the cluster: 226 other: other: Missing CRs:7 - optional/other/control-plane-load-kernel-modules.yaml - optional/other/worker-load-kernel-modules.yaml required-networking: networking-root: Missing CRs: - required/networking/nodeNetworkConfigurationPolicy.yaml networking-sriov: Missing CRs: - required/networking/sriov/sriovNetwork.yaml - required/networking/sriov/sriovNetworkNodePolicy.yaml - required/networking/sriov/SriovOperatorConfig.yaml - required/networking/sriov/SriovSubscription.yaml - required/networking/sriov/SriovSubscriptionNS.yaml - required/networking/sriov/SriovSubscriptionOperGroup.yaml required-other: scheduling: Missing CRs: - required/other/catalog-source.yaml - required/other/icsp.yaml required-performance: performance: Missing CRs: - required/performance/PerformanceProfile.yaml required-scheduling: scheduling: Missing CRs: - required/scheduling/nrop.yaml - required/scheduling/NROPSubscription.yaml - required/scheduling/NROPSubscriptionNS.yaml - required/scheduling/NROPSubscriptionOperGroup.yaml - required/scheduling/sched.yaml required-storage: storage-odf: Missing CRs: - required/storage/odf-external/01-rook-ceph-external-cluster-details.secret.yaml - required/storage/odf-external/02-ocs-external-storagecluster.yaml - required/storage/odf-external/odfNS.yaml - required/storage/odf-external/odfOperGroup.yaml - required/storage/odf-external/odfSubscription.yaml No CRs are unmatched to reference CRs8 Metadata Hash: fe41066bac56517be02053d436c815661c9fa35eec5922af25a1be359818f2979 No patched CRs10
通过将 -o junit 添加到命令,以 junit 格式获取输出。例如:
$ oc cluster-compare -r out/telco-core-rds/configuration/reference-crs-kube-compare/metadata.yaml -o junit
junit 输出包括以下结果类型:
- 为每个完全匹配模板传递的结果。
- 找到或缺少所需自定义资源(CR)的不同结果失败。
- 跳过使用用户覆盖机制修补的结果。
6.4. 创建参考配置
配置引用配置以验证集群中的配置资源。
6.4.1. metadata.yaml 文件的结构
metadata.yaml 文件提供了一个中央配置点,用于在参考配置中定义和配置模板。该文件具有 parts 和 components 的层次结构。parts 是 components 组,components 是模版组。在每个组件下,您可以配置模板依赖项、验证规则并添加描述性元数据。
metadata.yaml 文件示例
apiVersion: v2
parts:
- name: Part1
components:
- name: Component1
<component1_configuration>
- name: Part2
- name: Component2
<component2_configuration>6.4.2. 配置模板关系
通过在参考配置中定义模板之间的关系,您可以支持复杂依赖项的用例。例如,您可以将组件配置为需要特定的模板,需要组中的一个模板,或者允许来自组的任何模板等。
流程
创建
metadata.yaml文件以匹配您的用例。使用以下结构作为示例:metadata.yaml 文件示例
apiVersion: v2 parts: - name: Part1 components: - name: Component1 allOf:1 - path: RequiredTemplate1.yaml - path: RequiredTemplate2.yaml - name: Component2 allOrNoneOf:2 - path: OptionalBlockTemplate1.yaml - path: OptionalBlockTemplate2.yaml - name: Component3 anyOf:3 - path: OptionalTemplate1.yaml - path: OptionalTemplate2.yaml - name: Component4 noneOf:4 - path: BannedTemplate1.yaml - path: BannedTemplate2.yaml - name: Component5 oneOf:5 - path: RequiredExclusiveTemplate1.yaml - path: RequiredExclusiveTemplate2.yaml - name: Component6 anyOneOf:6 - path: OptionalExclusiveTemplate1.yaml - path: OptionalExclusiveTemplate2.yaml #...
6.4.3. 在模板中配置预期的变体
您可以使用 Golang 模板语法处理模板中的变量内容。使用这个语法,您可以配置处理模板中可选、必要和条件内容的验证逻辑。
-
cluster-compare插件要求所有模板呈现为有效的 YAML。为了避免解析缺失字段的错误,请在实施模板语法时使用条件模板语法,如{{- if .spec.<optional_field> }}。此条件逻辑可确保模板正常处理缺少的字段,并保持有效的 YAML 格式。 - 您可以将 Golang 模板语法与自定义和内置功能用于复杂用例。所有 Golang 内置功能都支持,包括 Sprig 库中的函数。
流程
创建
metadata.yaml文件以匹配您的用例。使用以下结构作为示例:apiVersion: v2 kind: Service metadata: name: frontend1 namespace: {{ .metadata.namespace }}2 labels: app: guestbook tier: frontend spec: {{- if and .spec.type (eq (.spec.type) "NodePort" "LoadBalancer") }} type: {{.spec.type }}3 {{- else }} type: should be NodePort or LoadBalancer {{- end }} ports: - port: 80 selector: app: guestbook {{- if .spec.selector.tier }}4 tier: frontend {{- end }}
6.4.3.1. 参考模板功能
cluster-compare 插件支持所有 sprig 库函数,但 env 和 expandenv 功能除外。有关 sprig 库函数的完整列表,请参阅"Sprig Function 文档"。
下表描述了 cluster-compare 插件的额外模板功能:
| 功能 | 描述 | Example |
|---|---|---|
|
| 将传入字符串解析为结构化 JSON 对象。 |
|
|
| 将传入字符串解析为结构化 JSON 数组。 |
|
|
| 将传入字符串解析为结构化的 YAML 对象。 |
|
|
| 将传入的字符串解析为结构化的 YAML 数组。 |
|
|
| 在保留对象类型时将传入的数据呈现为 JSON。 |
|
|
| 将传入字符串呈现为结构化的 TOML 数据。 |
|
|
| 将传入的数据呈现为 YAML,同时保留对象类型。 |
对于简单的 scalar 值:
对于 list 或dict: |
|
|
防止模板与集群资源匹配,即使它通常匹配。您可以在模板中使用此功能,以有条件地将某些资源从关联中排除。使用
当模板没有指定固定名称或命名空间时,此功能特别有用。在这些情况下,您可以使用 |
|
|
|
返回与指定参数匹配的对象数组。例如:
如果
如果 | - |
|
|
返回与参数匹配的单个对象。如果多个对象匹配,则函数返回任何内容。此功能使用与 | - |
以下示例演示了如何使用 lookupCR 功能从多个匹配资源检索和呈现值:
使用 lookupCRs 的配置映射示例
kind: ConfigMap
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-settings
namespace: kubernetes-dashboard
data:
dashboard: {{ index (lookupCR "apps/v1" "Deployment" "kubernetes-dashboard" "kubernetes-dashboard") "metadata" "name" \| toYaml }}
metrics: {{ (lookupCR "apps/v1" "Deployment" "kubernetes-dashboard" "dashboard-metrics-scraper").metadata.name \| toYaml }}
以下示例演示了如何使用 lookupCR 功能从单个匹配资源检索和使用特定值:
使用 lookupCR 的配置映射示例
kind: ConfigMap
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-settings
namespace: kubernetes-dashboard
data:
{{- $objlist := lookupCRs "apps/v1" "Deployment" "kubernetes-dashboard" "*" }}
{{- $dashboardName := "unknown" }}
{{- $metricsName := "unknown" }}
{{- range $obj := $objlist }}
{{- $appname := index $obj "metadata" "labels" "k8s-app" }}
{{- if contains "metrics" $appname }}
{{- $metricsName = $obj.metadata.name }}
{{- end }}
{{- if eq "kubernetes-dashboard" $appname }}
{{- $dashboardName = $obj.metadata.name }}
{{- end }}
{{- end }}
dashboard: {{ $dashboardName }}
metrics: {{ $metricsName }}6.4.4. 配置 metadata.yaml 文件以排除模板字段
您可以配置 metadata.yaml 文件,以从比较中排除字段。排除与比较不相关的字段,如与集群配置不相关的注解或标签。
您可以使用以下方法在 metadata.yaml 文件中配置排除项:
- 排除模板中未指定的自定义资源中的所有字段。
排除使用
pathToKey字段定义的特定字段。注意pathToKey是一个以句点分隔的路径。使用引号来转义带有句点的键值。
6.4.4.1. 排除模板中未指定的所有字段
在比较过程中,cluster-compare 插件通过将字段与对应的自定义资源(CR)合并来呈现模板。如果将 ignore-unspecified-fields 配置为 true,则 CR 中存在的但没有在模版中的所有字段都不包括在合并中。当您只想比较模板中指定的字段时,请使用这个方法。
流程
创建
metadata.yaml文件以匹配您的用例。使用以下结构作为示例:apiVersion: v2 parts: - name: Part1 components: - name: Namespace allOf: - path: namespace.yaml config: ignore-unspecified-fields: true1 #...- 1
- 指定
true从比较所有字段中排除没有在对应的namespace.yaml模板中明确配置的 CR。
6.4.4.2. 通过设置默认排除字段来排除特定字段
您可以通过在 defaultOmitRef 字段中为 fieldsToOmitRefs 定义一个默认值来排除字段。此默认排除适用于所有模板,除非被特定模板的 config.fieldsToOmitRefs 字段覆盖。
6.4.4.3. 排除特定字段
您可以通过定义字段的路径来指定要排除的字段,然后在模板的 config 部分中引用定义。
流程
创建
metadata.yaml文件以匹配您的用例。使用以下结构作为示例:metadata.yaml 文件示例
apiVersion: v2 parts: - name: Part1 components: - name: Component1 - path: deployment.yaml config: fieldsToOmitRefs: - deployments1 #... fieldsToOmit: items: deployments: - pathToKey: spec.selector.matchLabels.k8s-app2 注意设置
fieldsToOmitRefs替换默认值。
6.4.4.4. 通过设置默认排除组来排除特定字段
您可以创建要排除的默认字段组。组排除项可以引用另一个组,以避免在定义排除时重复。
流程
创建
metadata.yaml文件以匹配您的用例。使用以下结构作为示例:metadata.yaml 文件示例
apiVersion: v2 parts: #... fieldsToOmit: defaultOmitRef: default items: common: - pathToKey: metadata.annotations."kubernetes.io/metadata.name" - pathToKey: metadata.annotations."kubernetes.io/metadata.name" - pathToKey: metadata.annotations."kubectl.kubernetes.io/last-applied-configuration" - pathToKey: metadata.creationTimestamp - pathToKey: metadata.generation - pathToKey: spec.ownerReferences - pathToKey: metadata.ownerReferences default: - include: common1 - pathToKey: status- 1
common组包含在 default 组中。
6.4.5. 为模板字段配置内联验证
您可以启用内联正则表达式来验证模板字段,特别是在 Golang 模板语法难以维护或过于复杂的情况下。使用内联正则表达式可简化模板,提高可读性,并可以使用更高级的验证逻辑。
cluster-compare 插件为内联验证提供两个功能:
-
regex:使用正则表达式验证字段中的内容。 -
capturegroups:通过将非捕获组文本处理为完全匹配来增强多行文本比较功能,仅在指定捕获组中应用正则表达式匹配,并确保重复捕获组的一致性。
当您使用 regex 或 capturegroups 功能进行内联验证时,cluster-compare 插件会强制执行相同的命名的捕获组在模板中的多个字段中具有相同的值。这意味着,如果命名的捕获组(如 (?<username>[a-z0-9]+)) 出现在多个字段中,则该组的值必须在整个模板中保持一致。
6.4.5.1. 使用 regex 功能配置内联验证
使用 regex 内联功能,使用正则表达式验证字段。
流程
创建
metadata.yaml文件以匹配您的用例。使用以下结构作为示例:apiVersion: v2 parts: - name: Part1 components: - name: Example allOf: - path: example.yaml config: perField: - pathToKey: spec.bigTextBlock1 inlineDiffFunc: regex2 使用正则表达式验证关联模板中的字段:
apiVersion: v1 kind: ConfigMap metadata: namespace: dashboard data: username: "(?<username>[a-z0-9]+)" bigTextBlock: |- This is a big text block with some static content, like this line. It also has a place where (?<username>[a-z0-9]+) would put in their own name. (?<username>[a-z0-9]+) would put in their own name.
6.4.5.2. 使用 capturegroups 功能配置内联验证
使用 capturegroups 内联功能来更加精确地验证带有多行字符串的字段。此功能还确保同名的捕获组在多个字段之间具有相同的值。
流程
创建
metadata.yaml文件以匹配您的用例。使用以下结构作为示例:apiVersion: v2 parts: - name: Part1 components: - name: Example allOf: - path: example.yaml config: perField: - pathToKey: data.username1 inlineDiffFunc: regex2 - pathToKey: spec.bigTextBlock3 inlineDiffFunc: capturegroups4 使用正则表达式验证关联模板中的字段:
apiVersion: v1 kind: ConfigMap metadata: namespace: dashboard data: username: "(?<username>[a-z0-9]+)"1 bigTextBlock: |- This static content outside of a capture group should match exactly. Here is a username capture group: (?<username>[a-z0-9]+). It should match this capture group: (?<username>[a-z0-9]+).- 1
- 如果
data.username字段中的用户名值和bigTextBlock中捕获的值不匹配,cluster-compare插件会警告您不一致的匹配。
带有与不一致的匹配警告的输出示例:
WARNING: Capturegroup (?<username>…) matched multiple values: « mismatchuser | exampleuser »
6.4.6. 配置输出的描述
每个部分、组件或模板都可以包含描述来提供额外的上下文、说明或文档链接。这些描述有助于说明需要特定模板或结构的原因。
流程
创建
metadata.yaml文件以匹配您的用例。使用以下结构作为示例:apiVersion: v2 parts: - name: Part1 description: |- General text for every template under this part, unless overridden. components: - name: Component1 # With no description set, this inherits the description from the part above. OneOf: - path: Template1.yaml # This inherits the component description, if set. - path: Template2.yaml - path: Template3.yaml description: |- This template has special instructions that don't apply to the others. - name: Component2 description: |- This overrides the part text with something more specific. Multi-line text is supported, at all levels. allOf: - path: RequiredTemplate1.yaml - path: RequiredTemplate2.yaml description: |- Required for important reasons. - path: RequiredTemplate3.yaml
6.5. 执行高级参考配置自定义
对于您要从参考设计中临时开发的情况,您可以应用更高级的自定义。
这些自定义覆盖 cluster-compare 插件在比较过程中使用的默认匹配过程。在应用这些高级自定义时请小心,因为它可能会导致意外的结果,如从集群比较中排除后续信息。
用于动态自定义参考配置的一些高级任务包括:
- 手动匹配 :配置用户配置文件,以手动将自定义资源从集群与参考配置中的模板匹配。
-
Patching the reference:在
cluster-compare命令中使用 patch 选项对一个参考进行补丁来配置参考配置。
6.5.1. 配置 CR 和模板之间的手动匹配
在某些情况下,cluster-compare 插件的默认匹配可能无法按预期工作。您可以使用用户配置文件手动定义自定义资源(CR)如何映射到模板。
默认情况下,插件会根据 apiversion、kind、name 和 namespace 字段将 CR 映射到模板。但是,多个模板可能与一个 CR 匹配。例如,在以下情况下可能会发生这种情况:
-
有多个模板有相同的
apiversion、kind、name和namespace字段。 -
模板将任何带有特定
apiversion和kind的 CR 匹配,无论其namespace或name。
当一个 CR 匹配多个模板时,插件会使用一个 tie-breaking 机制来选择一个差异最小的模板。要明确控制插件选择的模板,您可以创建一个定义手动匹配规则的用户配置 YAML 文件。您可以将此配置文件传递给 cluster-compare 命令,以强制执行所需的模板选择。
流程
创建用户配置文件以定义手动匹配标准:
user-config.yaml文件示例correlationSettings:1 manualCorrelation:2 correlationPairs:3 ptp.openshift.io/v1_PtpConfig_openshift-ptp_grandmaster: optional/ptp-config/PtpOperatorConfig.yaml4 ptp.openshift.io/v1_PtpOperatorConfig_openshift-ptp_default: optional/ptp-config/PtpOperatorConfig.yaml运行以下命令,在
cluster-compare命令中引用用户配置文件:$ oc cluster-compare -r <path_to_reference_config>/metadata.yaml -c <path_to_user_config>/user-config.yaml1 - 1
- 使用
-c选项指定user-config.yaml文件。
6.5.2. 修补参考配置
在某些情况下,您可能需要修补参考配置来处理集群配置中的预期偏差。该插件在比较过程中应用补丁,修改补丁文件中定义的指定资源字段。
例如,您可能需要临时修补模板,因为集群使用了最新的参考配置已弃用的字段。在比较输出概述中报告补丁文件。
您可以通过两种方式创建补丁文件:
-
使用
cluster-compare插件生成补丁 YAML 文件。 - 创建您自己的补丁文件。
6.5.2.1. 使用 cluster-compare 插件生成补丁
您可以使用 cluster-compare 插件为特定模板文件生成补丁。该插件调整模板,以确保它与集群自定义资源(CR)匹配。补丁模板中的任何有效差异都不会报告。该插件在输出中突出显示补丁文件。
流程
运行以下命令,为模板生成补丁:
$ oc cluster-compare -r <path_to_reference_config>/metadata.yaml -o 'generate-patches' --override-reason "A valid reason for the override" --generate-override-for "<template1_path>" --generate-override-for "<template2_path>" > <path_to_patches_file>-
-r指定仓库配置的 metadata.yaml 文件的路径。 -
-o指定输出格式。要生成补丁输出,您必须使用generate-patches值。 -
--override-reason描述了补丁的原因。 --generate-override-for指定需要补丁的模板的路径。注意您必须使用相对于
metadata.yaml文件的目标模板的文件路径。例如,如果metadata.yaml文件的文件路径是./compare/metadata.yaml,则模板的相对文件路径可能是optional/my-template.yaml。-
<path_to_patches_file>指定补丁的文件名和路径。
-
可选:在应用到引用配置前查看补丁文件:
patch-config文件示例- apiVersion: storage.k8s.io/v1 kind: StorageClass name: crc-csi-hostpath-provisioner patch: '{"provisioner":"kubevirt.io.hostpath-provisioner"}'1 reason: A valid reason for the override templatePath: optional/local-storage-operator/StorageClass.yaml2 type: mergepatch3 运行以下命令,将补丁应用到引用配置:
$ oc cluster-compare -r <referenceConfigurationDirectory> -p <path_to_patches_file>-
-r指定仓库配置的 metadata.yaml 文件的路径。 -p指定补丁文件的路径。输出示例
... Cluster CR: storage.k8s.io/v1_StorageClass_crc-csi-hostpath-provisioner Reference File: optional/local-storage-operator/StorageClass.yaml Description: Component description Diff Output: None Patched with patch Patch Reasons: - A valid reason for the override ... No CRs are unmatched to reference CRs Metadata Hash: bb2165004c496b32e0c8509428fb99c653c3cf4fba41196ea6821bd05c3083ab Cluster CRs with patches applied: 1
-
6.5.2.2. 手动创建补丁文件
您可以编写补丁文件来处理集群配置中的预期偏差。
对于 type 字段,补丁有三个可能的值:
-
mergepatch- 将 JSON 合并到目标模板中。未指定的字段保持不变。 -
rfc6902- 使用add,remove,replace,move, 和copy操作在目标模板中合并 JSON。每个操作都以特定路径为目标。 -
go-template- 定义 Golang 模板。该插件使用集群自定义资源(CR)作为输入呈现模板,并为目标模板生成mergepatch或rfc6902补丁。
以下示例显示了使用所有三个不同格式相同的补丁。
流程
创建一个补丁文件来与您的用例匹配。使用以下结构作为示例:
patch-config示例- apiVersion: v11 kind: Namespace name: openshift-storage reason: known deviation templatePath: namespace.yaml type: mergepatch patch: '{"metadata":{"annotations":{"openshift.io/sa.scc.mcs":"s0:c29,c14","openshift.io/sa.scc.supplemental-groups":"1000840000/10000","openshift.io/sa.scc.uid-range":"1000840000/10000","reclaimspace.csiaddons.openshift.io/schedule":"@weekly","workload.openshift.io/allowed":null},"labels":{"kubernetes.io/metadata.name":"openshift-storage","olm.operatorgroup.uid/ffcf3f2d-3e37-4772-97bc-983cdfce128b":"","openshift.io/cluster-monitoring":"false","pod-security.kubernetes.io/audit":"privileged","pod-security.kubernetes.io/audit-version":"v1.24","pod-security.kubernetes.io/warn":"privileged","pod-security.kubernetes.io/warn-version":"v1.24","security.openshift.io/scc.podSecurityLabelSync":"true"}},"spec":{"finalizers":["kubernetes"]}}' - name: openshift-storage apiVersion: v1 kind: Namespace templatePath: namespace.yaml type: rfc6902 reason: known deviation patch: '[ {"op": "add", "path": "/metadata/annotations/openshift.io~1sa.scc.mcs", "value": "s0:c29,c14"}, {"op": "add", "path": "/metadata/annotations/openshift.io~1sa.scc.supplemental-groups", "value": "1000840000/10000"}, {"op": "add", "path": "/metadata/annotations/openshift.io~1sa.scc.uid-range", "value": "1000840000/10000"}, {"op": "add", "path": "/metadata/annotations/reclaimspace.csiaddons.openshift.io~1schedule", "value": "@weekly"}, {"op": "remove", "path": "/metadata/annotations/workload.openshift.io~1allowed"}, {"op": "add", "path": "/metadata/labels/kubernetes.io~1metadata.name", "value": "openshift-storage"}, {"op": "add", "path": "/metadata/labels/olm.operatorgroup.uid~1ffcf3f2d-3e37-4772-97bc-983cdfce128b", "value": ""}, {"op": "add", "path": "/metadata/labels/openshift.io~1cluster-monitoring", "value": "false"}, {"op": "add", "path": "/metadata/labels/pod-security.kubernetes.io~1audit", "value": "privileged"}, {"op": "add", "path": "/metadata/labels/pod-security.kubernetes.io~1audit-version", "value": "v1.24"}, {"op": "add", "path": "/metadata/labels/pod-security.kubernetes.io~1warn", "value": "privileged"}, {"op": "add", "path": "/metadata/labels/pod-security.kubernetes.io~1warn-version", "value": "v1.24"}, {"op": "add", "path": "/metadata/labels/security.openshift.io~1scc.podSecurityLabelSync", "value": "true"}, {"op": "add", "path": "/spec", "value": {"finalizers": ["kubernetes"]}} ]' - apiVersion: v1 kind: Namespace name: openshift-storage reason: "known deviation" templatePath: namespace.yaml type: go-template patch: | { "type": "rfc6902", "patch": '[ {"op": "add", "path": "/metadata/annotations/openshift.io~1sa.scc.mcs", "value": "s0:c29,c14"}, {"op": "add", "path": "/metadata/annotations/openshift.io~1sa.scc.supplemental-groups", "value": "1000840000/10000"}, {"op": "add", "path": "/metadata/annotations/openshift.io~1sa.scc.uid-range", "value": "1000840000/10000"}, {"op": "add", "path": "/metadata/annotations/reclaimspace.csiaddons.openshift.io~1schedule", "value": "@weekly"}, {"op": "remove", "path": "/metadata/annotations/workload.openshift.io~1allowed"}, {"op": "add", "path": "/metadata/labels/kubernetes.io~1metadata.name", "value": "openshift-storage"}, {"op": "add", "path": "/metadata/labels/olm.operatorgroup.uid~1ffcf3f2d-3e37-4772-97bc-983cdfce128b", "value": ""}, {"op": "add", "path": "/metadata/labels/openshift.io~1cluster-monitoring", "value": "false"}, {"op": "add", "path": "/metadata/labels/pod-security.kubernetes.io~1audit", "value": "privileged"}, {"op": "add", "path": "/metadata/labels/pod-security.kubernetes.io~1audit-version", "value": "v1.24"}, {"op": "add", "path": "/metadata/labels/pod-security.kubernetes.io~1warn", "value": "privileged"}, {"op": "add", "path": "/metadata/labels/pod-security.kubernetes.io~1warn-version", "value": "v1.24"}, {"op": "add", "path": "/metadata/labels/security.openshift.io~1scc.podSecurityLabelSync", "value": "true"}, {"op": "add", "path": "/spec", "value": {"finalizers": {{ .spec.finalizers | toJson }} }} ]' }- 1
- 补丁使用
kind,apiVersion,name, andnamespace字段来将补丁与正确的集群 CR 匹配。
运行以下命令,将补丁应用到参考配置:
$ oc cluster-compare -r <referenceConfigurationDirectory> -p <path_to_patches_file>-
-r指定仓库配置的 metadata.yaml 文件的路径。 p指定补丁文件的路径。输出示例
... Cluster CR: storage.k8s.io/v1_StorageClass_crc-csi-hostpath-provisioner Reference File: namespace.yaml Description: Component description Diff Output: None Patched with patch Patch Reasons: - known deviation - known deviation - known deviation ... No CRs are unmatched to reference CRs Metadata Hash: bb2165004c496b32e0c8509428fb99c653c3cf4fba41196ea6821bd05c3083ab Cluster CRs with patches applied: 1
-
6.6. 集群比较故障排除
使用 cluster-compare 插件时,您可能会看到意外结果,如存在多个集群自定义资源(CR)时的假正或冲突。
6.6.1. 对缺少资源的误报进行故障排除
即使集群中存在集群自定义资源(CR),插件也会报告缺少的资源。
流程
-
确保您使用最新版本的
cluster-compare插件。如需更多信息,请参阅"安装 cluster-compare 插件"。 - 确保您在使用参考配置的最新版本。
-
确保模板具有与集群 CR 相同的
apiVersion、kind、name和namespace字段。
6.6.2. 对同一 CR 的多个模板匹配的故障排除
在某些情况下,多个集群 CR 可以与一个模板匹配,因为它们具有相同的 apiVersion、namespace 和 kind。插件的默认匹配比较具有最低差异的 CR。
您可以选择配置引用配置以避免这种情况。
流程
-
确保模板具有不同的
apiVersion、namespace和kind值,以确保不会重复模板匹配。 - 使用用户配置文件手动将模板与 CR 匹配。如需更多信息,请参阅"在 CR 和模板之间手动配置手动匹配"。
第 7 章 根据对象限制规划您的环境
在规划 OpenShift Container Platform 集群时,请考虑以下对象限制。
这些限制基于最大可能的集群。对于较小的集群,最大值限制会较低。很多因素会影响指定的阈值,包括 etcd 版本或者存储数据格式。
在大多数情况下,超过这些限制会降低整体性能。它不一定意味着集群会出现错误。
对于快速变化的集群(如集群中包括多个启动和停止的 pod)可能会有比记录中小的实际最大大小。
7.1. OpenShift Container Platform 为主发行版本测试了集群最大值
红帽不提供针对 OpenShift Container Platform 集群大小调整的直接指导。这是因为,判断集群是否在 OpenShift Container Platform 支持的边界内,需要仔细考虑限制集群扩展的所有多维因素。
OpenShift Container Platform 支持测试的集群最大值,而不是绝对集群最大值。并非所有 OpenShift Container Platform 版本、control plane 工作负载和网络插件的组合都会被测试,因此下表并不表示所有部署的扩展绝对预期。可能无法同时扩展到所有维度上的最大值。表包含特定工作负载和部署配置的测试的最大值,并充当扩展指南,如类似部署的预期内容。
| 最大类型 | 4.x 测试的最大值 |
|---|---|
| 节点数 | 2,000 [1] |
| pod 数量 [2] | 150,000 |
| 每个节点的 pod 数量 | 2,500 [3] |
| 命名空间数量 [4] | 10,000 |
| 构建(build)数 | 10,000(默认 pod RAM 512 Mi)- Source-to-Image (S2I) 构建策略 |
| 每个命名空间的 pod 数量 [5] | 25,000 |
| 每个默认 2-router 部署的路由数 | 9,000 |
| secret 的数量 | 80,000 |
| 配置映射数量 | 90,000 |
| 服务数 [6] | 10,000 |
| 每个命名空间的服务数 | 5,000 |
| 每个服务中的后端数 | 5,000 |
| 每个命名空间的部署数量 [5] | 2,000 |
| 构建配置数 | 12,000 |
| 自定义资源定义 (CRD) 的数量 | 1,024 [7] |
- 部署暂停 Pod 以在 2000 个节点规模下对 OpenShift Container Platform 的 control plane 组件进行压力测试。扩展至类似数量的功能会根据特定的部署和工作负载参数而有所不同。
- 这里的 pod 数量是 test pod 的数量。实际的 pod 数量取决于应用程序的内存、CPU 和存储要求。
-
在具有 31 个服务器的集群中测试:3 个 control plane、2 个基础架构节点和 26 个 worker 节点。如果您需要 2,500 个用户 pod,则需要
hostPrefix为20,它为每个节点分配一个足够大的网络,以便每个节点包含 2000 个 pod,并将maxPods设置为2500的自定义 kubelet 配置。如需更多信息,请参阅在 OCP 4.13 上每个节点运行 2500 个 pod。 - 当有大量活跃的项目时,如果键空间增长过大并超过空间配额,etcd 的性能将会受到影响。强烈建议您定期维护 etcd 存储(包括整理碎片)来释放 etcd 存储。
- 系统中有一些控制循环必须迭代给定命名空间中的所有对象,作为对一些状态更改的响应。在单一命名空间中有大量给定类型的对象可使这些循环的运行成本变高,并降低对给定状态变化的处理速度。限制假设系统有足够的 CPU 、内存和磁盘来满足应用程序的要求。
-
每个服务端口和每个服务后端在
iptables中都有对应条目。给定服务的后端数量会影响端点对象的大小,这会影响到整个系统发送的数据大小。 -
在具有 29 个服务器的集群中测试:3 个 control plane、2 个基础架构节点和 24 个 worker 节点。集群有 500 个命名空间。OpenShift Container Platform 的限制是 1,024 个总自定义资源定义(CRD),其中包括由 OpenShift Container Platform 安装的产品、与 OpenShift Container Platform 集成并创建了 CRD 的产品。如果创建超过 1,024 CRD,则
oc命令请求可能会节流。
7.1.1. 示例情境
例如,500 个 worker 节点(m5.2xl)经过测试,并被支持,使用 OpenShift Container Platform 4.20、OVN-Kubernetes 网络插件和以下工作负载对象:
- 除默认值外,200 个命名空间
- 每个节点 60 个 pod;30 个服务器和 30 个客户端 pod (总计 30k)
- 57 镜像流/ns (11.4k 总计)
- 15 services/ns 被服务器 pod 支持 (共 3k)
- 15 routes/ns 被以前的服务支持 (共 3k)
- 20 secrets/ns (共 4k)
- 10 config maps/ns (共 2k)
- 6 个网络策略/ns,包括 deny-all、allow-from ingress 和 in-namespace 规则
- 57 builds/ns
以下因素已知会对集群工作负载扩展有影响(正面的影响或负面的影响),在规划部署时应进行考虑。如需其他信息和指导,请联络您的销售代表或 红帽支持。
- 每个节点的 pod 数量
- 每个 pod 的容器数量
- 使用的探测类型(如 liveness/readiness、exec/http)
- 网络策略数量
- 项目或命名空间数量
- 每个项目的镜像流数
- 项目的构建数
- 服务/日期和类型数
- 路由数
- 分片数量
- secret 的数量
- 配置映射数量
API 调用率或集群 "churn",这是集群配置中快速变化的估算。
-
Prometheus 查询每秒 5 分钟窗口的 pod 创建请求:
sum(irate(apiserver_request_count{resource="pods",verb="POST"}[5m])) -
在 5 分钟的时间内 Prometheus 每秒查询所有 API 请求:
sum(irate(apiserver_request_count{}[5m]))
-
Prometheus 查询每秒 5 分钟窗口的 pod 创建请求:
- CPU 的集群节点资源消耗
- 集群节点资源消耗
7.2. 测试集群最大值的 OpenShift Container Platform 环境和配置
7.2.1. AWS 云平台
| 节点 | Flavor | vCPU | RAM(GiB) | 磁盘类型 | 磁盘大小(GiB)/IOS | 数量 | 区域 |
|---|---|---|---|---|---|---|---|
| control plane/etcd [1] | r5.4xlarge | 16 | 128 | gp3 | 220 | 3 | us-west-2 |
| Infra [2] | m5.12xlarge | 48 | 192 | gp3 | 100 | 3 | us-west-2 |
| Workload [3] | m5.4xlarge | 16 | 64 | gp3 | 500 [4] | 1 | us-west-2 |
| Compute | m5.2xlarge | 8 | 32 | gp3 | 100 | 3/25/250/500 [5] | us-west-2 |
- 带有基准性能为 3000 IOPS 和 125 MiB 每秒的 gp3 磁盘用于 control plane/etcd 节点,因为 etcd 对延迟敏感。gp3 卷不使用突发性能。
- Infra 节点用于托管 Monitoring、Ingress 和 Registry 组件,以确保它们有足够资源可大规模运行。
- 工作负载节点专用于运行性能和可扩展工作负载生成器。
- 使用更大的磁盘,以便有足够的空间存储在运行性能和可扩展性测试期间收集的大量数据。
- 在迭代中扩展了集群,且性能和可扩展性测试是在指定节点数中执行的。
7.2.2. IBM Power 平台
| 节点 | vCPU | RAM(GiB) | 磁盘类型 | 磁盘大小(GiB)/IOS | 数量 |
|---|---|---|---|---|---|
| control plane/etcd [1] | 16 | 32 | io1 | 每个 GiB 120 / 10 IOPS | 3 |
| Infra [2] | 16 | 64 | gp2 | 120 | 2 |
| Workload [3] | 16 | 256 | gp2 | 120 [4] | 1 |
| Compute | 16 | 64 | gp2 | 120 | 2 到 100 [5] |
- 带有 120 / 10 IOPS 的 io1 磁盘用于 control plane/etcd 节点,因为 etcd 非常大,且敏感延迟。
- Infra 节点用于托管 Monitoring、Ingress 和 Registry 组件,以确保它们有足够资源可大规模运行。
- 工作负载节点专用于运行性能和可扩展工作负载生成器。
- 使用更大的磁盘,以便有足够的空间存储在运行性能和可扩展性测试期间收集的大量数据。
- 在迭代中扩展了集群。
7.2.3. IBM Z 平台
| 节点 | vCPU [4] | RAM(GiB)[5] | 磁盘类型 | 磁盘大小(GiB)/IOS | 数量 |
|---|---|---|---|---|---|
| Control plane/etcd [1,2] | 8 | 32 | ds8k | 300 / LCU 1 | 3 |
| Compute [1,3] | 8 | 32 | ds8k | 150 / LCU 2 | 4 节点(每个节点扩展到 100/250/500 pod) |
- 节点在两个逻辑控制单元 (LCU) 之间分发,以优化 control plane/etcd 节点的磁盘 I/O 负载,因为 etcd 非常大,且对延迟敏感。etcd I/O 需求不应干扰其他工作负载。
- 四个计算节点用于运行同时具有 100/250/500 pod 的多个迭代的测试。首先,使用闲置 pod 来评估 pod 是否可以实例。接下来,使用网络和 CPU 要求客户端/服务器工作负载来评估系统在压力下的稳定性。客户端和服务器 pod 是部署范围,每个对分布在两个计算节点上。
- 没有单独的工作负载节点。工作负载在两个计算节点之间模拟微服务工作负载。
- 使用的物理处理器数量是 6 个用于 Linux (IFL)的集成设施。
- 使用的总物理内存为 512 GiB。
7.3. 如何根据经过测试的集群限制规划您的环境
在节点中过度订阅物理资源会影响在 pod 放置过程中对 Kubernetes 调度程序的资源保证。了解可以采取什么措施避免内存交换。
某些限制只在单一维度中扩展。当很多对象在集群中运行时,它们会有所不同。
本文档中给出的数字基于红帽的测试方法、设置、配置和调整。这些数字会根据您自己的设置和环境而有所不同。
在规划您的环境时,请确定每个节点会运行多少 个 pod :
required pods per cluster / pods per node = total number of nodes needed每个节点的默认最多 pod 数为 250。而在某个节点中运行的 pod 的具体数量取决于应用程序本身。请参阅“如何根据应用程序要求规划您的环境”中的内容来计划应用程序的内存、CPU 和存储要求。
示例情境
如果您计划把集群的规模限制在有 2200 个 pod,则需要至少有五个节点,假设每个节点最多有 500 个 pod:
2200 / 500 = 4.4如果将节点数量增加到 20,那么 pod 的分布情况将变为每个节点有 110 个 pod:
2200 / 20 = 110其中:
required pods per cluster / total number of nodes = expected pods per nodeOpenShift Container Platform 附带几个系统 pod,如 OVN-Kubernetes、DNS、Operator 等,这些 pod 默认在每个 worker 节点上运行。因此,以上公式的结果可能会有所不同。
7.4. 如何根据应用程序要求规划您的环境
考虑应用程序环境示例:
| pod 类型 | pod 数量 | 最大内存 | CPU 内核 | 持久性存储 |
|---|---|---|---|---|
| Apache | 100 | 500 MB | 0.5 | 1 GB |
| node.js | 200 | 1 GB | 1 | 1 GB |
| postgresql | 100 | 1 GB | 2 | 10 GB |
| JBoss EAP | 100 | 1 GB | 1 | 1 GB |
推断的要求: 550 个 CPU 内核、450GB RAM 和 1.4TB 存储。
根据您的具体情况,节点的实例大小可以被增大或降低。在节点上通常会使用资源过度分配。在这个部署场景中,您可以选择运行多个额外的较小节点,或数量更少的较大节点来提供同样数量的资源。在做出决定前应考虑一些因素,如操作的灵活性以及每个实例的成本。
| 节点类型 | 数量 | CPU | RAM (GB) |
|---|---|---|---|
| 节点(选择 1) | 100 | 4 | 16 |
| 节点(选择 2) | 50 | 8 | 32 |
| 节点(选择 3) | 25 | 16 | 64 |
有些应用程序很适合于过度分配的环境,有些则不适合。大多数 Java 应用程序以及使用巨页的应用程序都不允许使用过度分配功能。它们的内存不能用于其他应用程序。在上面的例子中,环境大约会出现 30% 过度分配的情况,这是一个常见的比例。
应用程序 pod 可以使用环境变量或 DNS 访问服务。如果使用环境变量,当 pod 在节点上运行时,对于每个活跃服务,则 kubelet 的变量都会注入。集群感知 DNS 服务器监视 Kubernetes API 提供了新服务,并为每个服务创建一组 DNS 记录。如果整个集群中启用了 DNS,则所有 pod 都应自动根据其 DNS 名称解析服务。如果您必须超过 5000 服务,可以使用 DNS 进行服务发现。当使用环境变量进行服务发现时,参数列表超过了命名空间中 5000 服务后允许的长度,则 pod 和部署将失败。要解决这个问题,请禁用部署的服务规格文件中的服务链接:
---
apiVersion: template.openshift.io/v1
kind: Template
metadata:
name: deployment-config-template
creationTimestamp:
annotations:
description: This template will create a deploymentConfig with 1 replica, 4 env vars and a service.
tags: ''
objects:
- apiVersion: apps.openshift.io/v1
kind: DeploymentConfig
metadata:
name: deploymentconfig${IDENTIFIER}
spec:
template:
metadata:
labels:
name: replicationcontroller${IDENTIFIER}
spec:
enableServiceLinks: false
containers:
- name: pause${IDENTIFIER}
image: "${IMAGE}"
ports:
- containerPort: 8080
protocol: TCP
env:
- name: ENVVAR1_${IDENTIFIER}
value: "${ENV_VALUE}"
- name: ENVVAR2_${IDENTIFIER}
value: "${ENV_VALUE}"
- name: ENVVAR3_${IDENTIFIER}
value: "${ENV_VALUE}"
- name: ENVVAR4_${IDENTIFIER}
value: "${ENV_VALUE}"
resources: {}
imagePullPolicy: IfNotPresent
capabilities: {}
securityContext:
capabilities: {}
privileged: false
restartPolicy: Always
serviceAccount: ''
replicas: 1
selector:
name: replicationcontroller${IDENTIFIER}
triggers:
- type: ConfigChange
strategy:
type: Rolling
- apiVersion: v1
kind: Service
metadata:
name: service${IDENTIFIER}
spec:
selector:
name: replicationcontroller${IDENTIFIER}
ports:
- name: serviceport${IDENTIFIER}
protocol: TCP
port: 80
targetPort: 8080
clusterIP: ''
type: ClusterIP
sessionAffinity: None
status:
loadBalancer: {}
parameters:
- name: IDENTIFIER
description: Number to append to the name of resources
value: '1'
required: true
- name: IMAGE
description: Image to use for deploymentConfig
value: gcr.io/google-containers/pause-amd64:3.0
required: false
- name: ENV_VALUE
description: Value to use for environment variables
generate: expression
from: "[A-Za-z0-9]{255}"
required: false
labels:
template: deployment-config-template
可在命名空间中运行的应用程序 pod 数量取决于服务数量以及环境变量用于服务发现时的服务名称长度。系统上的 ARG_MAX 定义新进程的最大参数长度,默认设置为 2097152 字节 (2 MiB)。Kubelet 将环境变量注入到要在命名空间中运行的每个 pod 中,包括:
-
<SERVICE_NAME>_SERVICE_HOST=<IP> -
<SERVICE_NAME>_SERVICE_PORT=<PORT> -
<SERVICE_NAME>_PORT=tcp://<IP>:<PORT> -
<SERVICE_NAME>_PORT_<PORT>_TCP=tcp://<IP>:<PORT> -
<SERVICE_NAME>_PORT_<PORT>_TCP_PROTO=tcp -
<SERVICE_NAME>_PORT_<PORT>_TCP_PORT=<PORT> -
<SERVICE_NAME>_PORT_<PORT>_TCP_ADDR=<ADDR>
如果参数长度超过允许的值,服务名称中的字符数会受到影响,命名空间中的 pod 将开始失败。例如,在一个带有 5000 服务的命名空间中,服务名称的限制为 33 个字符,它可让您在命名空间中运行 5000 个 Pod。
第 8 章 配额和限值范围
资源配额由 ResourceQuota 对象定义,提供约束来限制各个项目的聚合资源消耗。它可根据类型限制项目中创建的对象数量,以及该项目中资源可以消耗的计算资源和存储的总和。
通过使用配额和限值范围,集群管理员可以设置限制来限制项目中所用计算资源的数量或计算资源的数量。这有助于集群管理员更好地管理和分配所有项目的资源,并确保没有项目不适合于集群大小。
配额由集群管理员设置,并可限定到给定项目。OpenShift Container Platform 项目所有者可以更改其项目的配额,但不能更改限制范围。OpenShift Container Platform 用户无法修改配额或限制范围。
以下小节帮助您了解如何检查配额和限值范围设置、它们可能会限制哪些类型,以及如何在自己的 pod 和容器中请求或限制计算资源。
8.1. 由配额管理的资源
资源配额由 ResourceQuota 对象定义,提供约束来限制各个项目的聚合资源消耗。它可根据类型限制项目中创建的对象数量,以及该项目中资源可以消耗的计算资源和存储的总和。
下文描述了可能通过配额管理的计算资源和对象类型的集合。
如果 status.phase 为 Failed 或 Succeeded, 则 pod 处于终端状态。
| 资源名称 | 描述 |
|---|---|
|
|
非终端状态的所有 Pod 的 CPU 请求总和不能超过这个值。 |
|
|
非终端状态的所有 Pod 的 内存请求总和不能超过这个值。 |
|
|
非终端状态的所有本地临时存储请求总和不能超过这个值。 |
|
|
非终端状态的所有 Pod 的 CPU 请求总和不能超过这个值。 |
|
|
非终端状态的所有 Pod 的 内存请求总和不能超过这个值。 |
|
|
非终端状态的所有临时存储请求总和不能超过这个值。 |
|
| 非终端状态的所有 Pod 的 CPU 限值总和不能超过这个值。 |
|
| 非终端状态的所有 Pod 的内存限值总和不能超过这个值。 |
|
| 非终端状态的所有 Pod 的临时存储限值总和不能超过这个值。只有在您启用了临时存储技术预览时,此资源才可用。此功能默认为禁用。 |
| 资源名称 | 描述 |
|---|---|
|
| 处于任何状态的所有持久性卷声明的存储请求总和不能超过这个值。 |
|
| 项目中可以存在的持久性卷声明的总数。 |
|
| 在处于任何状态且具有匹配存储类的所有持久性卷声明中,存储请求总和不能超过这个值。 |
|
| 项目中可以存在的具有匹配存储类的持久性卷声明的总数。 |
| 资源名称 | 描述 |
|---|---|
|
| 项目中可以存在的处于非终端状态的 Pod 总数。 |
|
| 项目中可以存在的复制控制器的总数。 |
|
| 项目中可以存在的资源配额总数。 |
|
| 项目中可以存在的服务总数。 |
|
| 项目中可以存在的 secret 的总数。 |
|
|
项目中可以存在的 |
|
| 项目中可以存在的持久性卷声明的总数。 |
|
| 项目中可以存在的镜像流的总数。 |
您可以为这些命名空间的资源类型使用 count/<resource>.<group> 语法配置一个对象数配额。
$ oc create quota <name> --hard=count/<resource>.<group>=<quota> - 1
<resource>是资源名称,<group>则是 API 组(若适用)。使用oc api-resources命令可以列出资源及其关联的 API 组。
8.1.1. 为扩展资源设定资源配额
扩展资源不允许过量使用资源,因此您必须在配额中为相同扩展资源指定 requests 和 limits。目前,扩展资源只允许使用带有前缀 requests. 配额项。以下是如何为 GPU 资源 nvidia.com/gpu 设置资源配额的示例场景。
流程
要确定集群中的一个节点中有多少可用 GPU,使用以下命令:
$ oc describe node ip-172-31-27-209.us-west-2.compute.internal | egrep 'Capacity|Allocatable|gpu'输出示例
openshift.com/gpu-accelerator=true Capacity: nvidia.com/gpu: 2 Allocatable: nvidia.com/gpu: 2 nvidia.com/gpu: 0 0本例中有 2 个 GPU 可用。
在命名空间
nvidia中设置配额。本例中配额为1:$ cat gpu-quota.yaml输出示例
apiVersion: v1 kind: ResourceQuota metadata: name: gpu-quota namespace: nvidia spec: hard: requests.nvidia.com/gpu: 1使用以下命令创建 pod:
$ oc create -f gpu-quota.yaml输出示例
resourcequota/gpu-quota created使用以下命令验证命名空间是否设置了正确的配额:
$ oc describe quota gpu-quota -n nvidia输出示例
Name: gpu-quota Namespace: nvidia Resource Used Hard -------- ---- ---- requests.nvidia.com/gpu 0 1运行以下命令,运行一个请求单个 GPU 的 pod:
$ oc create pod gpu-pod.yaml输出示例
apiVersion: v1 kind: Pod metadata: generateName: gpu-pod-s46h7 namespace: nvidia spec: restartPolicy: OnFailure containers: - name: rhel7-gpu-pod image: rhel7 env: - name: NVIDIA_VISIBLE_DEVICES value: all - name: NVIDIA_DRIVER_CAPABILITIES value: "compute,utility" - name: NVIDIA_REQUIRE_CUDA value: "cuda>=5.0" command: ["sleep"] args: ["infinity"] resources: limits: nvidia.com/gpu: 1使用以下命令验证 pod 是否正在运行:
$ oc get pods输出示例
NAME READY STATUS RESTARTS AGE gpu-pod-s46h7 1/1 Running 0 1m运行以下命令,检查配额
Used计数是否正确:$ oc describe quota gpu-quota -n nvidia输出示例
Name: gpu-quota Namespace: nvidia Resource Used Hard -------- ---- ---- requests.nvidia.com/gpu 1 1使用以下命令,尝试在
nvidia命名空间中创建第二个 GPU pod。从技术上讲这是可行的,因为它有 2 个 GPU:$ oc create -f gpu-pod.yaml输出示例
Error from server (Forbidden): error when creating "gpu-pod.yaml": pods "gpu-pod-f7z2w" is forbidden: exceeded quota: gpu-quota, requested: requests.nvidia.com/gpu=1, used: requests.nvidia.com/gpu=1, limited: requests.nvidia.com/gpu=1应该会显示此
Forbidden错误消息,因为您有设为 1 个 GPU 的配额,但这一 Pod 试图分配第二个 GPU,而这超过了配额。
8.1.2. 配额范围
每个配额都有一组关联的范围。配额只在与枚举的范围交集匹配时才会测量资源的使用量。
为配额添加范围会限制该配额可应用的资源集合。指定允许的集合之外的资源会导致验证错误。
| 影响范围 | 描述 |
|---|---|
|
|
匹配 |
|
|
匹配 |
|
|
匹配 |
|
|
匹配 |
BestEffort 范围将配额仅限为限制以下资源:
-
pods
Terminating、NotTerminating 和 NotBestEffort 范围将配额仅限为跟踪以下资源:
-
pods -
memory -
requests.memory -
limits.memory -
cpu -
requests.cpu -
limits.cpu -
ephemeral-storage -
requests.ephemeral-storage -
limits.ephemeral-storage
只有在启用了临时存储技术预览功能时,才会应用临时存储请求和限值。此功能默认为禁用。
其他资源
有关计算资源的更多信息,请参阅配额管理的资源。
如需更多提交计算资源,请参阅 服务质量类。
8.2. 管理配额使用量
8.2.1. 配额强制
在项目中首次创建资源配额后,项目会限制您创建可能会违反配额约束的新资源,直到它计算了更新后的使用量统计。
在创建了配额并且更新了使用量统计后,项目会接受创建新的内容。当您创建或修改资源时,配额使用量会在请求创建或修改资源时立即递增。
在您删除资源时,配额使用量在下一次完整重新计算项目的配额统计时才会递减。
可配置的时间量决定了将配额使用量统计降低到其当前观察到的系统值所需的时间。
如果项目修改超过配额使用量限值,服务器会拒绝该操作,并将对应的错误消息返回给用户,解释违反了配额约束,并说明系统中目前观察到的使用量统计。
8.2.2. 与限值相比的请求
在分配计算资源时,每个容器可能会为 CPU、内存和临时存储各自指定请求和限制值。配额可以限制任何这些值。
如果配额具有为 requests.cpu 或 requests.memory 指定的值,那么它要求每个传入的容器都明确请求那些资源。如果配额具有为 limits.cpu 或 limits.memory 指定的值,那么它要求每个传入的容器为那些资源指定一个显性限值。
8.2.3. 资源配额定义示例
core-object-counts.yaml 示例
apiVersion: v1
kind: ResourceQuota
metadata:
name: core-object-counts
spec:
hard:
configmaps: "10"
persistentvolumeclaims: "4"
replicationcontrollers: "20"
secrets: "10"
services: "10" openshift-object-counts.yaml 示例
apiVersion: v1
kind: ResourceQuota
metadata:
name: openshift-object-counts
spec:
hard:
openshift.io/imagestreams: "10" - 1
- 项目中可以存在的镜像流的总数。
compute-resources.yaml 示例
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
spec:
hard:
pods: "4"
requests.cpu: "1"
requests.memory: 1Gi
requests.ephemeral-storage: 2Gi
limits.cpu: "2"
limits.memory: 2Gi
limits.ephemeral-storage: 4Gi besteffort.yaml 示例
apiVersion: v1
kind: ResourceQuota
metadata:
name: besteffort
spec:
hard:
pods: "1"
scopes:
- BestEffort compute-resources-long-running.yaml 示例
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources-long-running
spec:
hard:
pods: "4"
limits.cpu: "4"
limits.memory: "2Gi"
limits.ephemeral-storage: "4Gi"
scopes:
- NotTerminating compute-resources-time-bound.yaml 示例
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources-time-bound
spec:
hard:
pods: "2"
limits.cpu: "1"
limits.memory: "1Gi"
limits.ephemeral-storage: "1Gi"
scopes:
- Terminating storage-consumption.yaml 示例
apiVersion: v1
kind: ResourceQuota
metadata:
name: storage-consumption
spec:
hard:
persistentvolumeclaims: "10"
requests.storage: "50Gi"
gold.storageclass.storage.k8s.io/requests.storage: "10Gi"
silver.storageclass.storage.k8s.io/requests.storage: "20Gi"
silver.storageclass.storage.k8s.io/persistentvolumeclaims: "5"
bronze.storageclass.storage.k8s.io/requests.storage: "0"
bronze.storageclass.storage.k8s.io/persistentvolumeclaims: "0" 8.2.4. 创建配额
要创建配额,首先在一个文件中定义配额。然后,使用该文件将它应用到项目中。有关对其描述的链接,请参阅附加资源部分。
$ oc create -f <resource_quota_definition> [-n <project_name>]
以下是一个使用 core-object-counts.yaml 资源配额定义和 demoproject 项目名称的示例:
$ oc create -f core-object-counts.yaml -n demoproject8.2.5. 创建对象数配额
您可以针对所有 OpenShift Container Platform 标准命名空间资源类型创建对象数配额,如 BuildConfig和 DeploymentConfig。对象配额数将定义的配额施加于所有标准命名空间资源类型。
在使用资源配额时,如果服务器存储中存在某一对象,则从其配额中扣减。这些类型的配额对防止耗尽存储资源很有用处。
要为资源配置对象数配额,请运行以下命令:
$ oc create quota <name> --hard=count/<resource>.<group>=<quota>,count/<resource>.<group>=<quota>显示对象数配额示例:
$ oc create quota test --hard=count/deployments.extensions=2,count/replicasets.extensions=4,count/pods=3,count/secrets=4
resourcequota "test" created$ oc describe quota test输出示例
Name: test
Namespace: quota
Resource Used Hard
-------- ---- ----
count/deployments.extensions 0 2
count/pods 0 3
count/replicasets.extensions 0 4
count/secrets 0 4本例将列出的资源限制为集群中各个项目的硬限值。
8.2.6. 查看配额
您可以在 Web 控制台导航到项目的 Quota 页面,查看与项目配额中定义的硬限值相关的使用量统计。
您还可以使用 CLI 查看配额详情:
首先,获取项目中定义的配额列表。例如,对于名为
demoproject的项目:$ oc get quota -n demoproject输出示例
NAME AGE besteffort 11m compute-resources 2m core-object-counts 29m描述您关注的配额,如
core-object-counts配额:$ oc describe quota core-object-counts -n demoproject输出示例
Name: core-object-counts Namespace: demoproject Resource Used Hard -------- ---- ---- configmaps 3 10 persistentvolumeclaims 0 4 replicationcontrollers 3 20 secrets 9 10 services 2 10
8.2.7. 配置配额同步周期
删除一组资源时,资源的同步时间帧由 /etc/origin/master/master-config.yaml 文件中的 resource-quota-sync-period 设置决定。
在恢复配额使用量前,用户在尝试重复使用资源时可能会遇到问题。您可以更改 resource-quota-sync-period 设置,使其在所需时间内重新生成一组资源,以便资源再次可用:
resource-quota-sync-period 设置示例
kubernetesMasterConfig:
apiLevels:
- v1beta3
- v1
apiServerArguments: null
controllerArguments:
resource-quota-sync-period:
- "10s"进行任何更改后,重启控制器服务以应用它们。
$ master-restart api$ master-restart controllers在使用自动化时,调整重新生成时间对创建资源和决定资源使用量很有帮助。
resource-quota-sync-period 设置平衡系统性能。减少同步周期可能会导致控制器出现大量负载。
8.2.8. 消耗资源的明确配额
如果资源不受配额管理,用户可以消耗的资源量就不会有限制。例如,如果没有与金级存储类相关的存储配额,则项目可以创建的金级存储量没有限制。
对于高成本计算或存储资源,管理员可以授予显式配额来消耗资源。譬如,如果某个项目没有显式赋予与金级存储类有关的存储配额,则该项目的用户将无法创建该类型的存储。
为了要求显式配额消耗特定资源,应将以下小节添加到 master-config.yaml 中。
admissionConfig:
pluginConfig:
ResourceQuota:
configuration:
apiVersion: resourcequota.admission.k8s.io/v1alpha1
kind: Configuration
limitedResources:
- resource: persistentvolumeclaims
matchContains:
- gold.storageclass.storage.k8s.io/requests.storage
在上例中,配额系统会拦截创建或更新 persistentVolumeClaim 的每个操作。它会检查要消耗的配额控制的资源。如果项目中没有涵盖这些资源的配额,则请求将被拒绝。在本例中,如果用户创建的 PersistentVolumeClaim 使用与金级存储类关联的存储,并且项目中没有匹配的配额,请求会被拒绝。
其他资源
有关如何创建设置配额所需的文件的示例,请参阅配额管理的资源。
如何分配由配额管理的计算资源的描述。
有关管理项目资源限制和配额的详情,请参阅使用项目。
如果为项目定义了配额,请参阅了解集群配置中的注意事项。
8.3. 设置限制范围
LimitRange 对象定义的限值范围在 pod、容器、镜像、镜像流和持久性卷声明级别上定义计算资源约束。限制范围指定 pod、容器、镜像、镜像流或持久性卷声明可以消耗的资源量。
要创建和修改资源的所有请求都会针对项目中的每个 LimitRange 对象进行评估。如果资源违反了任何限制,则会拒绝该资源。如果资源没有设置显式值,如果约束支持默认值,则默认值将应用到资源。
对于 CPU 和内存限值,如果您指定一个最大值,但没有指定最小限制,资源会消耗超过最大值的 CPU 和内存资源。
核心限制范围对象定义
apiVersion: "v1"
kind: "LimitRange"
metadata:
name: "core-resource-limits"
spec:
limits:
- type: "Pod"
max:
cpu: "2"
memory: "1Gi"
min:
cpu: "200m"
memory: "6Mi"
- type: "Container"
max:
cpu: "2"
memory: "1Gi"
min:
cpu: "100m"
memory: "4Mi"
default:
cpu: "300m"
memory: "200Mi"
defaultRequest:
cpu: "200m"
memory: "100Mi"
maxLimitRequestRatio:
cpu: "10" - 1
- 限制范围对象的名称。
- 2
- pod 可在所有容器间请求的最大 CPU 量。
- 3
- pod 可在所有容器间请求的最大内存量。
- 4
- pod 可在所有容器间请求的最小 CPU 量。如果没有设置
min值,或者将min设置为0,则结果为没有限制,pod 消耗的消耗可能会超过maxCPU 值。 - 5
- pod 可在所有容器间请求的最小内存量。如果没有设置
min值,或者将min设置为0,则结果为没有限制,pod 消耗的消耗可能会超过max内存的值。 - 6
- pod 中单个容器可以请求的最大 CPU 量。
- 7
- pod 中单个容器可以请求的最大内存量。
- 8
- pod 中单个容器可以请求的最小 CPU 量。如果没有设置
min值,或者将min设置为0,则结果为没有限制,pod 消耗的消耗可能会超过maxCPU 值。 - 9
- pod 中单个容器可以请求的最小内存量。如果没有设置
min值,或者将min设置为0,则结果为没有限制,pod 消耗的消耗可能会超过max内存的值。 - 10
- 如果没有在 pod 规格中指定限制,则容器的默认 CPU 限值。
- 11
- 如果没有在 pod 规格中指定限制,则容器的默认内存限值。
- 12
- 如果您没有在 pod 规格中指定请求,则容器的默认 CPU 请求。
- 13
- 如果您没有在 pod 规格中指定请求,则容器的默认内存请求。
- 14
- 容器最大的限制与请求的比率。
OpenShift Container Platform Limit 范围对象定义
apiVersion: "v1"
kind: "LimitRange"
metadata:
name: "openshift-resource-limits"
spec:
limits:
- type: openshift.io/Image
max:
storage: 1Gi
- type: openshift.io/ImageStream
max:
openshift.io/image-tags: 20
openshift.io/images: 30
- type: "Pod"
max:
cpu: "2"
memory: "1Gi"
ephemeral-storage: "1Gi"
min:
cpu: "1"
memory: "1Gi" 您可以在一个限制范围对象中指定 core 和 OpenShift Container Platform 资源。
8.3.1. 容器限制
支持的资源:
- CPU
- 内存
支持的限制
根据容器,如果指定,则必须满足以下条件:
Container
| 约束 | 行为 |
|---|---|
|
|
如果配置定义了 |
|
|
如果配置定义了 |
|
|
如果限制范围定义了
例如,如果容器的 |
支持的默认值:
Default[<resource>]-
如果没有,则默认将
container.resources.limit[resource]设置为指定的值。 Default Requests[<resource>]-
如果无,则默认为
container.resources.requests[<resource>]作为指定的值。
8.3.2. Pod 限值
支持的资源:
- CPU
- 内存
支持的限制:
在 pod 中的所有容器中,需要满足以下条件:
| 约束 | 强制行为 |
|---|---|
|
|
|
|
|
|
|
|
|
8.3.3. 镜像限制
支持的资源:
- Storage
资源类型名称:
-
openshift.io/Image
根据镜像,如果指定,则必须满足以下条件:
| 约束 | 行为 |
|---|---|
|
|
|
要防止超过限制的 Blob 上传到 registry,则必须将 registry 配置为强制实施配额。REGISTRY_MIDDLEWARE_REPOSITORY_OPENSHIFT_ENFORCEQUOTA 环境变量必须设置为 true。默认情况下,新部署的环境变量设为 true。
8.3.4. 镜像流限值
支持的资源:
-
openshift.io/image-tags -
openshift.io/images
资源类型名称:
-
openshift.io/ImageStream
根据镜像,如果指定,则必须满足以下条件:
| 约束 | 行为 |
|---|---|
|
|
|
|
|
|
8.3.5. 镜像引用计数
openshift.io/image-tags 资源代表唯一的流限制。可能的引用是 ImageStreamTag、ImageStreamImage 或 DockerImage。可以使用 oc tag 和 oc import-image 命令或使用镜像流来创建标签。内部和外部引用之间没有区别。但是,镜像流规格中标记的每个唯一引用仅计算一次。它不以任何方式限制推送到内部容器镜像 registry,但对标签限制很有用。
openshift.io/images 资源代表在镜像流状态中记录的唯一镜像名称。它有助于限制可推送到内部 registry 的多个镜像。内部和外部引用无法区分。
8.3.6. PersistentVolumeClaim 限制
支持的资源:
- 存储
支持的限制:
在一个项目中的所有持久性卷声明中,必须满足以下条件:
| 约束 | 强制行为 |
|---|---|
|
| Min[<resource>] <= claim.spec.resources.requests[<resource>] (必须) |
|
| Min[resource] <= claim.spec.resources.requests[resource] (必须) |
限制范围对象定义
{
"apiVersion": "v1",
"kind": "LimitRange",
"metadata": {
"name": "pvcs"
},
"spec": {
"limits": [{
"type": "PersistentVolumeClaim",
"min": {
"storage": "2Gi"
},
"max": {
"storage": "50Gi"
}
}
]
}
}其他资源
有关流限制的详情,请参考管理镜像流。
有关流限制的信息。
有关计算资源约束的更多信息。
有关如何测量 CPU 和内存的更多信息,请参阅推荐的 control plane 实践。
您可以为临时存储指定限值和请求。有关此功能的更多信息,请参阅了解临时存储。
8.4. 限制范围操作
8.4.1. 创建限制范围
以下是创建限值范围所遵循的示例流程。
流程
创建对象:
$ oc create -f <limit_range_file> -n <project>
8.4.2. 查看限制
您可以通过在 Web 控制台中导航到项目的 Quota 页面来查看项目中定义的任何限值范围。您还可以通过执行以下步骤来使用 CLI 查看限制范围详情:
流程
获取项目中定义的限值范围对象列表。例如,名为
demoproject的项目:$ oc get limits -n demoproject输出示例
NAME AGE resource-limits 6d描述限值范围。例如,对于名为
resource-limits的限制范围:$ oc describe limits resource-limits -n demoproject输出示例
Name: resource-limits Namespace: demoproject Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio ---- -------- --- --- --------------- ------------- ----------------------- Pod cpu 200m 2 - - - Pod memory 6Mi 1Gi - - - Container cpu 100m 2 200m 300m 10 Container memory 4Mi 1Gi 100Mi 200Mi - openshift.io/Image storage - 1Gi - - - openshift.io/ImageStream openshift.io/image - 12 - - - openshift.io/ImageStream openshift.io/image-tags - 10 - - -
8.4.3. 删除限制范围
要删除限制范围,请运行以下命令:
$ oc delete limits <limit_name>其他资源
有关对用户可以在项目资源上创建、管理限值和配额的项目数量实施不同的限值的信息,请参阅每个项目的资源配额。
第 9 章 IBM Z 和 IBM LinuxONE 环境的推荐主机实践
本主题为 IBM Z® 和 IBM® LinuxONE 上的 OpenShift Container Platform 提供推荐的主机实践。
s390x 架构在很多方面都是唯一的。因此,此处提出的一些建议可能不适用于其他平台。
除非另有说明,否则这些实践适用于 IBM Z® 和 IBM® LinuxONE 上的 z/VM 和 Red Hat Enterprise Linux (RHEL) KVM 安装。
9.1. 管理 CPU 过量使用
在高度虚拟化的 IBM Z® 环境中,您必须仔细规划基础架构的设置和大小。虚拟化最重要的功能之一是能够进行资源过量使用,从而将更多资源分配给虚拟机,而不是在管理程序级别实际可用。这主要依赖于具体的工作负载,并没有适用于所有环境的“黄金法则”。
根据您的设置,在设计 CPU 过量使用 时请考虑这些最佳实践:
- 在 LPAR 级别 (PR/SM hypervisor),避免将所有可用物理内核 (IFL) 分配给每个 LPAR。例如,当有四个物理 IFL 可用时,您不应该定义三个 LPAR,每个都带有四个逻辑 IFL。
- 检查并了解 LPAR 共享和权重.
- 过多的虚拟 CPU 会对性能造成负面影响。不要将比逻辑处理器定义为 LPAR 更多的虚拟处理器。
- 为峰值工作负载配置每个客户机的虚拟处理器数量,而不是配置更多.
- 从一个小的数量开始,并监控工作负载。如有必要,逐步增加 vCPU 数量。
- 并非所有工作负载都适合适用高过量使用比率。如果工作负载是 CPU 密集型的,那么您可能无法在不对性能造成影响的情况下使用高的比率。对于高 I/O 密集型工作负载,即便具有较高的过量使用比率,也能保持一致的性能。
9.2. 禁用透明巨页
Transparent Huge Pages (THP) 会试图自动执行创建、管理和使用巨页的大部分方面。由于 THP 自动管理巨页,因此并不始终对所有类型的工作负载进行最佳处理。THP 可能会导致性能下降,因为许多应用程序都自行处理巨页。因此,请考虑禁用 THP。
9.3. 使用 Receive Flow Steering(RFS)提高网络性能
通过进一步减少网络延迟,Receive Flow Steering (RFS) 进一步扩展了 Receive Packet Steering (RPS)。RFS 在技术上基于 RPS,通过增加 CPU 缓存命中率来提高数据包处理的效率。RFS 通过确定计算最方便的 CPU,以便缓存命中更有可能在 CPU 中发生,增加了对队列长度的考虑。因此,会减少 CPU 缓存无效的频率,从而只需要较少的循环来重建缓存。这有助于缩短数据包处理运行时间。
9.3.1. 使用 Machine Config Operator (MCO) 激活 RFS
流程
将以下 MCO 示例配置集复制到 YAML 文件中。例如,
enable-rfs.yaml:apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 50-enable-rfs spec: config: ignition: version: 2.2.0 storage: files: - contents: source: data:text/plain;charset=US-ASCII,%23%20turn%20on%20Receive%20Flow%20Steering%20%28RFS%29%20for%20all%20network%20interfaces%0ASUBSYSTEM%3D%3D%22net%22%2C%20ACTION%3D%3D%22add%22%2C%20RUN%7Bprogram%7D%2B%3D%22/bin/bash%20-c%20%27for%20x%20in%20/sys/%24DEVPATH/queues/rx-%2A%3B%20do%20echo%208192%20%3E%20%24x/rps_flow_cnt%3B%20%20done%27%22%0A filesystem: root mode: 0644 path: /etc/udev/rules.d/70-persistent-net.rules - contents: source: data:text/plain;charset=US-ASCII,%23%20define%20sock%20flow%20enbtried%20for%20%20Receive%20Flow%20Steering%20%28RFS%29%0Anet.core.rps_sock_flow_entries%3D8192%0A filesystem: root mode: 0644 path: /etc/sysctl.d/95-enable-rps.conf创建 MCO 配置集:
$ oc create -f enable-rfs.yaml验证是否列出了名为
50-enable-rfs的条目:$ oc get mc要取消激活,请输入:
$ oc delete mc 50-enable-rfs
9.4. 选择您的网络设置
网络堆栈是 OpenShift Container Platform 等基于 Kubernetes 的产品最重要的组件之一。对于 IBM Z® 设置,网络设置取决于您选择的虚拟机监控程序。取决于具体的工作负载和应用,最佳实践通常需要根据用例和流量模式进行更改。
根据您的设置,考虑以下最佳实践:
- 考虑有关网络设备的所有选项,以优化您的流量模式。探索 OSA-Express、RoCE Express、HiperSockets、z/VM VSwitch、Linux 网桥 (KVM) 的优势,以确定哪个选项为您的设置带来最大好处。
- 始终使用最新可用的 NIC 版本。例如,OSA Express 7S 10 GbE 与带有事务工作负载类型的 OSA Express 6S 10 GbE 相比有显著改进,尽管两者都是 10 GbE 适配器。
- 每个虚拟交换机都添加了额外的延迟层。
- 负载平衡器在集群外的网络通信中扮演重要角色。如果这对应用程序至关重要,请考虑使用生产环境级的硬件负载平衡器。
- OpenShift Container Platform OVN-Kubernetes 网络插件引入了流和规则,这会影响网络性能。确保对 pod 关联性和放置进行考虑,以便至关重要的服务会受益于本地通信的优势。
- 平衡性能和功能之间的权衡.
9.5. 确保 z/VM 上使用 HyperPAV 的高磁盘性能
DASD 和 ECKD 设备通常在 IBM Z® 环境中使用的磁盘类型。在 z/VM 环境中的典型 OpenShift Container Platform 设置中,DASD 磁盘通常用于支持节点的本地存储。您可以设置 HyperPAV 别名设备,以便为支持 z/VM 客户机的 DASD 磁盘提供更多吞吐量和总体更好的 I/O 性能。
将 HyperPAV 用于本地存储设备可带来显著的性能优势。但是,您必须考虑吞吐量和 CPU 成本之间有一个权衡。
对于使用 full-pack minidisk 的基于 z/VM 的 OpenShift Container Platform 设置,您可以通过在所有节点中激活 HyperPAV 别名来利用 MCO 配置集的优势。您必须为 control plane 和计算节点添加 YAML 配置。
流程
将以下 MCO 示例配置集复制到 control plane 节点的 YAML 文件中。例如,
05-master-kernelarg-hpav.yaml:$ cat 05-master-kernelarg-hpav.yaml apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 05-master-kernelarg-hpav spec: config: ignition: version: 3.1.0 kernelArguments: - rd.dasd=800-805将以下 MCO 示例配置集复制到计算节点的 YAML 文件中。例如,
05-worker-kernelarg-hpav.yaml:$ cat 05-worker-kernelarg-hpav.yaml apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 05-worker-kernelarg-hpav spec: config: ignition: version: 3.1.0 kernelArguments: - rd.dasd=800-805注意您必须修改
rd.dasd参数以适合设备 ID。创建 MCO 配置集:
$ oc create -f 05-master-kernelarg-hpav.yaml$ oc create -f 05-worker-kernelarg-hpav.yaml要取消激活,请输入:
$ oc delete -f 05-master-kernelarg-hpav.yaml$ oc delete -f 05-worker-kernelarg-hpav.yaml
9.6. IBM Z 主机上的 RHEL KVM 建议
优化 KVM 虚拟服务器环境很大程度上取决于虚拟服务器的工作负载和可用资源。增强一个环境中性能的相同操作可能会对另一种环境产生负面影响。为特定设置找到最佳平衡可能是一项挑战,通常需要进行各种试验。
下面的部分介绍了在 IBM Z® 和 IBM® LinuxONE 环境中将 OpenShift Container Platform 与 RHEL KVM 搭配使用时的一些最佳实践。
9.6.1. 对虚拟块设备使用 I/O 线程
要使虚拟块设备使用 I/O 线程,您必须为虚拟服务器和每个虚拟块设备配置一个或多个 I/O 线程,以使用其中一个 I/O 线程。
以下示例指定了 <iothreads>3</iothreads> 来配置三个 I/O 线程,带有连续十进制线程 ID 1、2 和 3。iothread="2" 参数指定要使用 ID 为 2 的 I/O 线程的磁盘设备的驱动程序元素。
I/O 线程规格示例
...
<domain>
<iothreads>3</iothreads>
...
<devices>
...
<disk type="block" device="disk">
<driver ... iothread="2"/>
</disk>
...
</devices>
...
</domain>线程可以提高磁盘设备的 I/O 操作性能,但也可使用内存和 CPU 资源。您可以将多个设备配置为使用同一线程。线程到设备的最佳映射取决于可用资源和工作负载。
从少量 I/O 线程开始。通常,为所有磁盘设备使用单个 I/O 线程就足够了。不要配置超过虚拟 CPU 数量的线程,也不要配置空闲线程。
您可以使用 virsh iothreadadd 命令将具有特定线程 ID 的 I/O 线程添加到正在运行的虚拟服务器。
9.6.2. 避免虚拟 SCSI 设备
仅在需要通过 SCSI 特定的接口解决设备时配置虚拟 SCSI 设备。将磁盘空间配置为虚拟块设备,而非虚拟 SCSI 设备,无论主机上的支持是什么。
但是,您可能需要以下特定于 SCSI 的接口:
- 主机上 SCSI 附加磁带驱动器的 LUN。
- 在主机文件系统中挂载在虚拟 DVD 驱动器中的 DVD ISO 文件。
9.6.3. 为磁盘配置客户机缓存
将磁盘设备配置为由客户机而不是主机执行缓存。
确保磁盘设备的 driver 元素包含 cache="none" 和 io="native" 参数。
<disk type="block" device="disk">
<driver name="qemu" type="raw" cache="none" io="native" iothread="1"/>
...
</disk>9.6.4. 排除内存气球(Balloon)设备
除非您需要动态内存大小,否则请不要定义内存气球设备,并确保 libvirt 不会为您创建。将 memballoon 参数作为设备元素的子项包含在您的域配置 XML 文件中。
检查活跃配置集列表:
<memballoon model="none"/>
9.6.5. 调整主机调度程序的 CPU 迁移算法
除非您非常了解相关的影响,请不要更改调度程序设置。在进行完整的测试并确定相关的影响前,不要对生产系统应用更改。
kernel.sched_migration_cost_ns 参数指定以纳秒为单位的时间间隔。任务最后一次执行后,CPU 缓存被视为具有有用内容,直到此间隔过期为止。增加这个间隔会导致任务迁移减少。默认值为 500000 ns。
如果存在可运行的进程时 CPU 空闲时间高于预期的间隔,请尝试缩短这个间隔。如果任务非常频繁地在 CPU 或节点之间进行转换,请尝试增加它。
要动态将间隔设置为 60000 ns,请输入以下命令:
# sysctl kernel.sched_migration_cost_ns=60000
要将值永久更改为 60000 ns,在 /etc/sysctl.conf 中添加以下条目:
kernel.sched_migration_cost_ns=600009.6.6. 禁用 cpuset cgroup 控制器
此设置仅适用于使用 cgroups 版本 1 的 KVM 主机。要在主机上启用 CPU 热插拔,请禁用 cgroup 控制器。
流程
-
使用您选择的编辑器打开
/etc/libvirt/qemu.conf。 -
转至
cgroup_controllers行。 - 复制整行并从副本中删除前导编号符号(#)。
删除
cpuset条目,如下所示:cgroup_controllers = [ "cpu", "devices", "memory", "blkio", "cpuacct" ]要使新设置生效,您必须重启 libvirtd 守护进程:
- 停止所有虚拟机。
运行以下命令:
# systemctl restart libvirtd- 重新启动虚拟机。
此设置在主机重新引导后保留。
9.6.7. 为空闲的虚拟 CPU 调整轮询周期
当虚拟 CPU 空闲时,KVM 会轮询虚拟 CPU 的唤醒条件,然后再分配主机资源。您可以指定时间间隔,在间隔期间在 /sys/module/kvm/parameters/halt_poll_ns 的 sysfs 中进行轮询。在指定时间内,轮询可减少虚拟 CPU 的唤醒延迟,但会牺牲资源使用量。根据工作负载,更长或更短的轮询时间可能很有用。时间间隔以纳秒为单位指定。默认值为 50000 ns。
要针对低 CPU 消耗进行优化,请输入一个小的值或写入 0 来禁用轮询:
# echo 0 > /sys/module/kvm/parameters/halt_poll_ns要针对低延迟进行优化(例如,用于事务的工作负载),请输入一个大的值:
# echo 80000 > /sys/module/kvm/parameters/halt_poll_ns
第 10 章 使用 Node Tuning Operator
了解 Node Tuning Operator,以及如何使用它通过编排 tuned 守护进程以管理节点级别的性能优化。
10.1. 关于 Node Tuning Operator
Node Tuning Operator 可以帮助您通过编排 TuneD 守护进程来管理节点级别的性能优化,并使用 Performance Profile 控制器获得低延迟性能。大多数高性能应用程序都需要一定程度的内核级性能优化。Node Tuning Operator 为用户提供了一个统一的、节点一级的 sysctl 管理接口,并可以根据具体用户的需要灵活地添加自定义性能优化设置。
Operator 将为 OpenShift Container Platform 容器化 TuneD 守护进程作为一个 Kubernetes 守护进程集进行管理。它保证了自定义性能优化设置以可被守护进程支持的格式传递到在集群中运行的所有容器化的 TuneD 守护进程中。相应的守护进程会在集群的所有节点上运行,每个节点上运行一个。
在发生触发配置集更改的事件时,或通过接收和处理终止信号安全终止容器化 TuneD 守护进程时,容器化 TuneD 守护进程所应用的节点级设置将被回滚。
Node Tuning Operator 使用 Performance Profile 控制器来实现自动性能优化,从而实现 OpenShift Container Platform 应用程序的低延迟性能。
集群管理员配置了性能配置集以定义节点级别的设置,例如:
- 将内核更新至 kernel-rt。
- 为内务选择 CPU。
- 为运行工作负载选择 CPU。
在版本 4.1 及更高版本中,OpenShift Container Platform 标准安装中包含了 Node Tuning Operator。
在早期版本的 OpenShift Container Platform 中,Performance Addon Operator 用来实现自动性能优化,以便为 OpenShift 应用程序实现低延迟性能。在 OpenShift Container Platform 4.11 及更新的版本中,这个功能是 Node Tuning Operator 的一部分。
10.2. 访问 Node Tuning Operator 示例规格
使用此流程来访问 Node Tuning Operator 的示例规格。
流程
运行以下命令以访问 Node Tuning Operator 示例规格:
oc get tuned.tuned.openshift.io/default -o yaml -n openshift-cluster-node-tuning-operator
默认 CR 旨在为 OpenShift Container Platform 平台提供标准的节点级性能优化,它只能被修改来设置 Operator Management 状态。Operator 将覆盖对默认 CR 的任何其他自定义更改。若进行自定义性能优化,请创建自己的 Tuned CR。新创建的 CR 将与默认的 CR 合并,并基于节点或 pod 标识和配置文件优先级对节点应用自定义调整。
虽然在某些情况下,对 pod 标识的支持可以作为自动交付所需调整的一个便捷方式,但我们不鼓励使用这种方法,特别是在大型集群中。默认 Tuned CR 并不带有 pod 标识匹配。如果创建了带有 pod 标识匹配的自定义配置集,则该功能将在此时启用。在以后的 Node Tuning Operator 版本中将弃用 pod 标识功能。
10.3. 在集群中设置默认配置集
以下是在集群中设置的默认配置集。
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: default
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Optimize systems running OpenShift (provider specific parent profile)
include=-provider-${f:exec:cat:/var/lib/ocp-tuned/provider},openshift
name: openshift
recommend:
- profile: openshift-control-plane
priority: 30
match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
- profile: openshift-node
priority: 40
从 OpenShift Container Platform 4.9 开始,所有 OpenShift TuneD 配置集都随 TuneD 软件包一起提供。您可以使用 oc exec 命令查看这些配置集的内容:
$ oc exec $tuned_pod -n openshift-cluster-node-tuning-operator -- find /usr/lib/tuned/openshift{,-control-plane,-node} -name tuned.conf -exec grep -H ^ {} \;10.4. 验证是否应用了 TuneD 配置集
验证应用到集群节点的 TuneD 配置集。
$ oc get profile.tuned.openshift.io -n openshift-cluster-node-tuning-operator输出示例
NAME TUNED APPLIED DEGRADED AGE
master-0 openshift-control-plane True False 6h33m
master-1 openshift-control-plane True False 6h33m
master-2 openshift-control-plane True False 6h33m
worker-a openshift-node True False 6h28m
worker-b openshift-node True False 6h28m-
NAME:配置集(Profile)对象的名称。每个节点有一个 Profile 对象,其名称相互匹配。 -
TUNED:要应用的 TuneD 配置集的名称。 -
APPLIED:如果 TuneD 守护进程应用了所需的配置集,则为True。(True/False/Unknown)。 -
DEGRADED:如果在应用 TuneD 配置集时报告了任何错误则为True(True/False/Unknown)。 -
AGE:创建 Profile 对象后经过的时间。
ClusterOperator/node-tuning 对象还包含有关 Operator 及其节点代理健康状况的有用信息。例如,ClusterOperator /node-tuning 状态消息报告 Operator 错误配置。
要获取 ClusterOperator/node-tuning 对象的状态信息,请运行以下命令:
$ oc get co/node-tuning -n openshift-cluster-node-tuning-operator输出示例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE
node-tuning 4.20.1 True False True 60m 1/5 Profiles with bootcmdline conflict
如果 ClusterOperator/node-tuning 或配置集对象的状态是 DEGRADED,则 Operator 或操作对象日志中会提供额外的信息。
10.5. 自定义调整规格
Operator 的自定义资源 (CR) 包含两个主要部分。第一部分是 profile:,这是 TuneD 配置集及其名称的列表。第二部分是 recommend:,用来定义配置集选择逻辑。
多个自定义调优规格可以共存,作为 Operator 命名空间中的多个 CR。Operator 会检测到是否存在新 CR 或删除了旧 CR。所有现有的自定义性能优化设置都会合并,同时更新容器化 TuneD 守护进程的适当对象。
管理状态
通过调整默认的 Tuned CR 来设置 Operator Management 状态。默认情况下,Operator 处于 Managed 状态,默认的 Tuned CR 中没有 spec.managementState 字段。Operator Management 状态的有效值如下:
- Managed: Operator 会在配置资源更新时更新其操作对象
- Unmanaged: Operator 将忽略配置资源的更改
- Removed: Operator 将移除 Operator 置备的操作对象和资源
配置集数据
profile: 部分列出了 TuneD 配置集及其名称。
profile:
- name: tuned_profile_1
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_1 profile
[sysctl]
net.ipv4.ip_forward=1
# ... other sysctl's or other TuneD daemon plugins supported by the containerized TuneD
# ...
- name: tuned_profile_n
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_n profile
# tuned_profile_n profile settings建议的配置集
profile: 选择逻辑通过 CR 的 recommend: 部分来定义。recommend: 部分是根据选择标准推荐配置集的项目列表。
recommend:
<recommend-item-1>
# ...
<recommend-item-n>列表中的独立项:
- machineConfigLabels:
<mcLabels>
match:
<match>
priority: <priority>
profile: <tuned_profile_name>
operand:
debug: <bool>
tunedConfig:
reapply_sysctl: <bool> - 1
- 可选。
- 2
MachineConfig标签的键/值字典。键必须是唯一的。- 3
- 如果省略,则会假设配置集匹配,除非设置了优先级更高的配置集,或设置了
machineConfigLabels。 - 4
- 可选列表。
- 5
- 配置集排序优先级。较低数字表示优先级更高(
0是最高优先级)。 - 6
- 在匹配项中应用的 TuneD 配置集。例如
tuned_profile_1。 - 7
- 可选操作对象配置。
- 8
- 为 TuneD 守护进程打开或关闭调试。
true为打开,false为关闭。默认值为false。 - 9
- 为 TuneD 守护进程打开或关闭
reapply_sysctl功能。选择true代表开启,false代表关闭。
<match> 是一个递归定义的可选数组,如下所示:
- label: <label_name>
value: <label_value>
type: <label_type>
<match>
如果不省略 <match>,则所有嵌套的 <match> 部分也必须评估为 true。否则会假定 false,并且不会应用或建议具有对应 <match> 部分的配置集。因此,嵌套(子级 <match> 部分)会以逻辑 AND 运算来运作。反之,如果匹配 <match> 列表中任何一项,整个 <match> 列表评估为 true。因此,该列表以逻辑 OR 运算来运作。
如果定义 了 machineConfigLabels,基于机器配置池的匹配会对给定的 recommend: 列表项打开。<mcLabels> 指定机器配置标签。机器配置会自动创建,以在配置集 <tuned_profile_name> 中应用主机设置,如内核引导参数。这包括使用与 <mcLabels> 匹配的机器配置选择器查找所有机器配置池,并在分配了找到的机器配置池的所有节点上设置配置集 <tuned_profile_name>。要针对同时具有 master 和 worker 角色的节点,您必须使用 master 角色。
列表项 match 和 machineConfigLabels 由逻辑 OR 操作符连接。match 项首先以短电路方式评估。因此,如果它被评估为 true,则不考虑 MachineConfigLabels 项。
当使用基于机器配置池的匹配时,建议将具有相同硬件配置的节点分组到同一机器配置池中。不遵循这个原则可能会导致在共享同一机器配置池的两个或者多个节点中 TuneD 操作对象导致内核参数冲突。
示例:基于节点或 pod 标签的匹配
- match:
- label: tuned.openshift.io/elasticsearch
match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
type: pod
priority: 10
profile: openshift-control-plane-es
- match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
priority: 20
profile: openshift-control-plane
- priority: 30
profile: openshift-node
根据配置集优先级,以上 CR 针对容器化 TuneD 守护进程转换为 recommend.conf 文件。优先级最高 (10) 的配置集是 openshift-control-plane-es,因此会首先考虑它。在给定节点上运行的容器化 TuneD 守护进程会查看同一节点上是否在运行设有 tuned.openshift.io/elasticsearch 标签的 pod。如果没有,则整个 <match> 部分评估为 false。如果存在具有该标签的 pod,为了让 <match> 部分评估为 true,节点标签也需要是 node-role.kubernetes.io/master 或 node-role.kubernetes.io/infra。
如果这些标签对优先级为 10 的配置集而言匹配,则应用 openshift-control-plane-es 配置集,并且不考虑其他配置集。如果节点/pod 标签组合不匹配,则考虑优先级第二高的配置集 (openshift-control-plane)。如果容器化 TuneD Pod 在具有标签 node-role.kubernetes.io/master 或 node-role.kubernetes.io/infra 的节点上运行,则应用此配置集。
最后,配置集 openshift-node 的优先级最低 (30)。它没有 <match> 部分,因此始终匹配。如果给定节点上不匹配任何优先级更高的配置集,它会作为一个适用于所有节点的配置集来设置 openshift-node 配置集。

示例:基于机器配置池的匹配
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: openshift-node-custom
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Custom OpenShift node profile with an additional kernel parameter
include=openshift-node
[bootloader]
cmdline_openshift_node_custom=+skew_tick=1
name: openshift-node-custom
recommend:
- machineConfigLabels:
machineconfiguration.openshift.io/role: "worker-custom"
priority: 20
profile: openshift-node-custom为尽量减少节点的重新引导情况,为目标节点添加机器配置池将匹配的节点选择器标签,然后创建上述 Tuned CR,最后创建自定义机器配置池。
特定于云供应商的 TuneD 配置集
使用此功能,所有针对于 OpenShift Container Platform 集群上的云供应商都可以方便地分配 TuneD 配置集。这可实现,而无需添加额外的节点标签或将节点分组到机器配置池中。
这个功能会利用 spec.providerID 节点对象值(格式为 <cloud-provider>://<cloud-provider-specific-id>),并在 NTO operand 容器中写带有 <cloud-provider> 值的文件 /var/lib/ocp-tuned/provider。然后,TuneD 会使用这个文件的内容来加载 provider-<cloud-provider> 配置集(如果这个配置集存在)。
openshift 配置集(openshift-control-plane 和 openshift-node 配置集都从其中继承设置)现在被更新来使用这个功能(通过使用条件配置集加载)。NTO 或 TuneD 目前不包含任何特定于云供应商的配置集。但是,您可以创建一个自定义配置集 provider-<cloud-provider>,它将适用于所有针对于所有云供应商的集群节点。
GCE 云供应商配置集示例
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: provider-gce
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=GCE Cloud provider-specific profile
# Your tuning for GCE Cloud provider goes here.
name: provider-gce
由于配置集的继承,provider-<cloud-provider> 配置集中指定的任何设置都会被 openshift 配置集及其子配置集覆盖。
10.6. 自定义调整示例
从默认 CR 中使用 TuneD 配置集
以下 CR 对带有标签 tuned.openshift.io/ingress-node-label 的 OpenShift Container Platform 节点应用节点一级的自定义调整。
示例:使用 openshift-control-plane TuneD 配置集进行自定义性能优化
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: ingress
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=A custom OpenShift ingress profile
include=openshift-control-plane
[sysctl]
net.ipv4.ip_local_port_range="1024 65535"
net.ipv4.tcp_tw_reuse=1
name: openshift-ingress
recommend:
- match:
- label: tuned.openshift.io/ingress-node-label
priority: 10
profile: openshift-ingress
对于开发自定义配置集的人员。我们强烈建议包括在默认 Tuned CR 中提供的默认 TuneD 守护进程配置集。上面的示例使用默认 openshift-control-plane 配置集。
使用内置 TuneD 配置集
由于 NTO 管理的守护进程集已被成功推出,TuneD 操作对象会管理 TuneD 守护进程的同一版本。要列出守护进程支持的内置 TuneD 配置集,请以以下方式查询任何 TuneD pod:
$ oc exec $tuned_pod -n openshift-cluster-node-tuning-operator -- find /usr/lib/tuned/ -name tuned.conf -printf '%h\n' | sed 's|^.*/||'您可以使用自定义调优规格中检索的配置集名称。
示例:使用内置 hpc-compute TuneD 配置集
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: openshift-node-hpc-compute
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Custom OpenShift node profile for HPC compute workloads
include=openshift-node,hpc-compute
name: openshift-node-hpc-compute
recommend:
- match:
- label: tuned.openshift.io/openshift-node-hpc-compute
priority: 20
profile: openshift-node-hpc-compute
除了内置的 hpc-compute 配置集外,上面的示例还包括默认 Tuned CR 中提供的 openshift-node TuneD 守护进程配置集,以对计算节点使用特定于 OpenShift 的调优。
覆盖主机级别 sysctl
可以使用 /run/sysctl.d/、/etc/sysctl.d/ 和 / etc/sysctl.conf 主机配置文件在运行时更改各种内核参数。OpenShift Container Platform 添加几个主机配置文件,在运行时设置内核参数;例如 net.ipv[4-6].、fs.inotify., 和 vm.max_map_count。这些运行时参数在 kubelet 和 Operator 启动前为系统提供基本功能调整。
除非 reapply_sysctl 选项设置为 false,否则 Operator 不会覆盖这些设置。将这个选项设置为 false 会导致 TuneD 在应用其自定义配置集后不会应用主机配置文件中的设置。
示例:覆盖主机级别 sysctl
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: openshift-no-reapply-sysctl
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Custom OpenShift profile
include=openshift-node
[sysctl]
vm.max_map_count=>524288
name: openshift-no-reapply-sysctl
recommend:
- match:
- label: tuned.openshift.io/openshift-no-reapply-sysctl
priority: 15
profile: openshift-no-reapply-sysctl
operand:
tunedConfig:
reapply_sysctl: false10.7. 延迟应用程序的调优更改
作为管理员,使用 Node Tuning Operator (NTO)更新正在运行的系统上的自定义资源(CR)并进行更改。例如,他们可以更新 sysctl 参数,或添加调优对象的 [sysctl] 部分。当管理员应用调优更改时,NTO 会提示 TuneD 重新处理所有配置,从而导致 tuned 进程回滚所有调整,然后重新应用它。
对延迟敏感的应用程序可能无法容忍 tuned 配置集的删除和重新应用,因为它可能会降低性能。对于分区 CPU 和管理使用性能配置集的进程或中断关联性的配置,这尤其重要。为了避免这个问题,OpenShift Container Platform 引入了应用调整更改的新方法。在 OpenShift Container Platform 4.17 之前,唯一可用的方法(即时)应用更改,通常会立即触发 tuned 重启。
支持以下附加方法:
-
always: 每个更改都会在下次节点重启时应用。 -
update:当调优更改修改 tuned 配置集时,它会被默认立即应用,并尽快生效。当调优更改不会导致 tuned 配置集更改,并且修改其值时,它将被视为 always。
通过添加 tuned.openshift.io/deferred 注解来启用此功能。下表总结了注解的可能值:
| 注解值 | 描述 |
|---|---|
| missing | 更改会立即应用。 |
| always | 更改在下次节点重启时应用。 |
| update | 如果造成配置集更改,则立即应用更改,否则在下次节点重启时。 |
以下示例演示了如何使用 always 方法将更改应用到 kernel.shmmni sysctl 参数:
Example
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: performance-patch
namespace: openshift-cluster-node-tuning-operator
annotations:
tuned.openshift.io/deferred: "always"
spec:
profile:
- name: performance-patch
data: |
[main]
summary=Configuration changes profile inherited from performance created tuned
include=openshift-node-performance-performance
[sysctl]
kernel.shmmni=8192
recommend:
- machineConfigLabels:
machineconfiguration.openshift.io/role: worker-cnf
priority: 19
profile: performance-patch您可以使用 Topology Aware Lifecycle Manager 在一组 spoke 集群上执行受控的重启,以应用延迟调整更改。有关协调重启的更多信息,请参阅"协调重启以了解配置更改"。
10.7.1. 延迟调优更改的应用程序:一个示例
以下工作示例描述了如何使用 Node Tuning Operator 延迟调整应用程序的调整更改。
先决条件
-
有
cluster-admin角色访问权限。 - 您已将性能配置集应用到集群。
-
一个
MachineConfigPool资源,如worker-cnf,以确保配置集只应用到指定的节点。
流程
运行以下命令,检查当前应用到集群的配置集:
$ oc -n openshift-cluster-node-tuning-operator get tuned输出示例
NAME AGE default 63m openshift-node-performance-performance 21m运行以下命令,检查集群中的机器配置池:
$ oc get mcp输出示例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-79a26af9f78ced61fa8ccd309d3c859c True False False 3 3 3 0 157m worker rendered-worker-d9352e91a1b14de7ef453fa54480ce0e True False False 2 2 2 0 157m worker-cnf rendered-worker-cnf-f398fc4fcb2b20104a51e744b8247272 True False False 1 1 1 0 92m运行以下命令来描述当前应用的性能配置集:
$ oc describe performanceprofile performance | grep Tuned输出示例
Tuned: openshift-cluster-node-tuning-operator/openshift-node-performance-performance验证
kernel.shmmnisysctl 参数的现有值:运行以下命令以显示节点名称:
$ oc get nodes输出示例
NAME STATUS ROLES AGE VERSION ip-10-0-26-151.ec2.internal Ready worker,worker-cnf 116m v1.30.6 ip-10-0-46-60.ec2.internal Ready worker 115m v1.30.6 ip-10-0-52-141.ec2.internal Ready control-plane,master 123m v1.30.6 ip-10-0-6-97.ec2.internal Ready control-plane,master 121m v1.30.6 ip-10-0-86-145.ec2.internal Ready worker 117m v1.30.6 ip-10-0-92-228.ec2.internal Ready control-plane,master 123m v1.30.6运行以下命令,在节点
ip-10-0-32-74.ec2.internal中显示kernel.shmmnisysctl 参数的当前值:$ oc debug node/ip-10-0-26-151.ec2.internal -q -- chroot host sysctl kernel.shmmni输出示例
kernel.shmmni = 4096
创建一个配置集补丁,如
perf-patch.yaml,它将kernel.shmmnisysctl 参数改为8192。通过应用以下配置,使用always方法将更改延迟到新的手动重启:apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: performance-patch namespace: openshift-cluster-node-tuning-operator annotations: tuned.openshift.io/deferred: "always" spec: profile: - name: performance-patch data: | [main] summary=Configuration changes profile inherited from performance created tuned include=openshift-node-performance-performance1 [sysctl] kernel.shmmni=81922 recommend: - machineConfigLabels: machineconfiguration.openshift.io/role: worker-cnf3 priority: 19 profile: performance-patch运行以下命令来应用配置集补丁:
$ oc apply -f perf-patch.yaml运行以下命令,以验证配置集补丁正在等待下一个节点重启:
$ oc -n openshift-cluster-node-tuning-operator get profile输出示例
NAME TUNED APPLIED DEGRADED MESSAGE AGE ip-10-0-26-151.ec2.internal performance-patch False True The TuneD daemon profile is waiting for the next node restart: performance-patch 126m ip-10-0-46-60.ec2.internal openshift-node True False TuneD profile applied. 125m ip-10-0-52-141.ec2.internal openshift-control-plane True False TuneD profile applied. 130m ip-10-0-6-97.ec2.internal openshift-control-plane True False TuneD profile applied. 130m ip-10-0-86-145.ec2.internal openshift-node True False TuneD profile applied. 126m ip-10-0-92-228.ec2.internal openshift-control-plane True False TuneD profile applied. 130m在重启前确认
kernel.shmmnisysctl 参数的值保持不变:运行以下命令以确认,不会应用对节点
ip-10-0-26-151.ec2.internal上的kernel.shmmnisysctl 参数的应用程序更改:$ oc debug node/ip-10-0-26-151.ec2.internal -q -- chroot host sysctl kernel.shmmni输出示例
kernel.shmmni = 4096
运行以下命令重启节点
ip-10-0-26-151.ec2.internal以应用所需的更改:$ oc debug node/ip-10-0-26-151.ec2.internal -q -- chroot host reboot&在另一个终端窗口中,运行以下命令验证节点是否已重启:
$ watch oc get nodes等待节点
ip-10-0-26-151.ec2.internal过渡到Ready状态。运行以下命令,以验证配置集补丁正在等待下一个节点重启:
$ oc -n openshift-cluster-node-tuning-operator get profile输出示例
NAME TUNED APPLIED DEGRADED MESSAGE AGE ip-10-0-20-251.ec2.internal performance-patch True False TuneD profile applied. 3h3m ip-10-0-30-148.ec2.internal openshift-control-plane True False TuneD profile applied. 3h8m ip-10-0-32-74.ec2.internal openshift-node True True TuneD profile applied. 179m ip-10-0-33-49.ec2.internal openshift-control-plane True False TuneD profile applied. 3h8m ip-10-0-84-72.ec2.internal openshift-control-plane True False TuneD profile applied. 3h8m ip-10-0-93-89.ec2.internal openshift-node True False TuneD profile applied. 179m重启后,检查
kernel.shmmnisysctl 参数的值是否已改变:运行以下命令,以验证
kernel.shmmnisysctl 参数更改已在节点ip-10-0-32-74.ec2.internal上应用:$ oc debug node/ip-10-0-32-74.ec2.internal -q -- chroot host sysctl kernel.shmmni输出示例
kernel.shmmni = 8192
额外的重启会导致恢复 kernel.shmmni sysctl 参数的原始值。
10.8. 支持的 TuneD 守护进程插件
在使用 Tuned CR 的 profile: 部分中定义的自定义配置集时,以下 TuneD 插件都受到支持,但 [main] 部分除外:
- audio
- cpu
- disk
- eeepc_she
- modules
- mounts
- net
- scheduler
- scsi_host
- selinux
- sysctl
- sysfs
- usb
- video
- vm
- bootloader
其中一些插件提供了不受支持的动态性能优化功能。目前不支持以下 TuneD 插件:
- script
- systemd
TuneD bootloader 插件只支持 Red Hat Enterprise Linux CoreOS (RHCOS) worker 节点。
其他资源
10.9. 在托管集群中配置节点性能优化
要在托管集群中的节点上设置节点级别性能优化,您可以使用 Node Tuning Operator。在托管的 control plane 中,您可以通过创建包含 Tuned 对象并在节点池中引用这些配置映射的配置映射来配置节点调整。
流程
创建包含有效 tuned 清单的配置映射,并引用节点池中的清单。在以下示例中,
Tuned清单定义了一个配置文件,在包含tuned-1-node-label节点标签的节点上将vm.dirty_ratio设为 55。将以下ConfigMap清单保存到名为tuned-1.yaml的文件中:apiVersion: v1 kind: ConfigMap metadata: name: tuned-1 namespace: clusters data: tuning: | apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: tuned-1 namespace: openshift-cluster-node-tuning-operator spec: profile: - data: | [main] summary=Custom OpenShift profile include=openshift-node [sysctl] vm.dirty_ratio="55" name: tuned-1-profile recommend: - priority: 20 profile: tuned-1-profile注意如果您没有将任何标签添加到 Tuned spec 的
spec.recommend部分中的条目中,则假定基于 node-pool 的匹配,因此spec.recommend部分中的最高优先级配置集应用于池中的节点。虽然您可以通过在 Tuned.spec.recommend.match部分中设置标签值来实现更精细的节点标记匹配,除非您将节点池的.spec.management.upgradeType值设置为InPlace。在管理集群中创建
ConfigMap对象:$ oc --kubeconfig="$MGMT_KUBECONFIG" create -f tuned-1.yaml通过编辑节点池或创建节点池的
spec.tuningConfig字段中引用ConfigMap对象。在本例中,假设您只有一个NodePool,名为nodepool-1,它含有 2 个节点。apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: ... name: nodepool-1 namespace: clusters ... spec: ... tuningConfig: - name: tuned-1 status: ...注意您可以在多个节点池中引用同一配置映射。在托管的 control plane 中,Node Tuning Operator 会将节点池名称和命名空间的哈希值附加到 Tuned CR 的名称中,以区分它们。在这种情况下,请不要为同一托管集群在不同的 Tuned CR 中创建多个名称相同的 TuneD 配置集。
验证
现在,您已创建包含 Tuned 清单的 ConfigMap 对象并在 NodePool 中引用它,Node Tuning Operator 会将 Tuned 对象同步到托管集群中。您可以验证定义了 Tuned 对象,以及将 TuneD 配置集应用到每个节点。
列出托管的集群中的
Tuned对象:$ oc --kubeconfig="$HC_KUBECONFIG" get tuned.tuned.openshift.io \ -n openshift-cluster-node-tuning-operator输出示例
NAME AGE default 7m36s rendered 7m36s tuned-1 65s列出托管的集群中的
Profile对象:$ oc --kubeconfig="$HC_KUBECONFIG" get profile.tuned.openshift.io \ -n openshift-cluster-node-tuning-operator输出示例
NAME TUNED APPLIED DEGRADED AGE nodepool-1-worker-1 tuned-1-profile True False 7m43s nodepool-1-worker-2 tuned-1-profile True False 7m14s注意如果没有创建自定义配置集,则默认应用
openshift-node配置集。要确认正确应用了调整,请在节点上启动一个 debug shell,并检查 sysctl 值:
$ oc --kubeconfig="$HC_KUBECONFIG" \ debug node/nodepool-1-worker-1 -- chroot /host sysctl vm.dirty_ratio输出示例
vm.dirty_ratio = 55
10.10. 通过设置内核引导参数来对托管集群进行高级节点调整
对于托管 control plane 中的高级性能优化(需要设置内核引导参数),您还可以使用 Node Tuning Operator。以下示例演示了如何创建保留巨页的节点池。
流程
创建一个
ConfigMap对象,其中包含一个Tuned对象清单,用于创建大小为 2 MB 的 10 个巨页。将此ConfigMap清单保存到名为tuned-hugepages.yaml的文件中:apiVersion: v1 kind: ConfigMap metadata: name: tuned-hugepages namespace: clusters data: tuning: | apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: hugepages namespace: openshift-cluster-node-tuning-operator spec: profile: - data: | [main] summary=Boot time configuration for hugepages include=openshift-node [bootloader] cmdline_openshift_node_hugepages=hugepagesz=2M hugepages=50 name: openshift-node-hugepages recommend: - priority: 20 profile: openshift-node-hugepages注意.spec.recommend.match字段被有意留空。在本例中,这个Tuned对象应用到引用此ConfigMap对象的节点池中的所有节点。将具有相同硬件配置的节点分组到同一节点池中。否则,TuneD 操作对象可以为共享同一节点池的两个或多个节点计算冲突的内核参数。在管理集群中创建
ConfigMap对象:$ oc --kubeconfig="<management_cluster_kubeconfig>" create -f tuned-hugepages.yaml1 - 1
- 将
<management_cluster_kubeconfig>替换为管理集群kubeconfig文件的名称。
创建
NodePool清单 YAML 文件,自定义NodePool的升级类型,并引用您在spec.tuningConfig部分中创建的ConfigMap对象。创建NodePool清单,并使用hcpCLI 将其保存到名为hugepages-nodepool.yaml的文件中:$ hcp create nodepool aws \ --cluster-name <hosted_cluster_name> \1 --name <nodepool_name> \2 --node-count <nodepool_replicas> \3 --instance-type <instance_type> \4 --render > hugepages-nodepool.yaml注意在
hcp create命令中使用--render标志将不会呈现 secret。要呈现 secret,您必须在hcp create命令中使用--render和--render-sensitive标志。在
hugepages-nodepool.yaml文件中,将.spec.management.upgradeType设置为InPlace,并将.spec.tuningConfig设置为引用您创建的tuned-hugepagesConfigMap对象。apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: name: hugepages-nodepool namespace: clusters ... spec: management: ... upgradeType: InPlace ... tuningConfig: - name: tuned-hugepages注意要避免应用新的
MachineConfig对象时不必要的重新创建节点,请将.spec.management.upgradeType设置为InPlace。如果使用Replace升级类型,则节点会被完全删除,当应用 TuneD 操作对象计算的新内核引导参数时,新节点可以替换它们。在管理集群中创建
NodePool:$ oc --kubeconfig="<management_cluster_kubeconfig>" create -f hugepages-nodepool.yaml
验证
节点可用后,容器化 TuneD 守护进程会根据应用的 TuneD 配置集计算所需的内核引导参数。在节点就绪并重新引导以应用生成的 MachineConfig 对象后,您可以验证是否已应用 TuneD 配置集,并且设置了内核引导参数。
列出托管的集群中的
Tuned对象:$ oc --kubeconfig="<hosted_cluster_kubeconfig>" get tuned.tuned.openshift.io \ -n openshift-cluster-node-tuning-operator输出示例
NAME AGE default 123m hugepages-8dfb1fed 1m23s rendered 123m列出托管的集群中的
Profile对象:$ oc --kubeconfig="<hosted_cluster_kubeconfig>" get profile.tuned.openshift.io \ -n openshift-cluster-node-tuning-operator输出示例
NAME TUNED APPLIED DEGRADED AGE nodepool-1-worker-1 openshift-node True False 132m nodepool-1-worker-2 openshift-node True False 131m hugepages-nodepool-worker-1 openshift-node-hugepages True False 4m8s hugepages-nodepool-worker-2 openshift-node-hugepages True False 3m57s新
NodePool中的两个 worker 节点都应用了openshift-node-hugepages配置集。要确认正确应用了调整,请在节点上启动一个 debug shell 并检查
/proc/cmdline。$ oc --kubeconfig="<hosted_cluster_kubeconfig>" \ debug node/nodepool-1-worker-1 -- chroot /host cat /proc/cmdline输出示例
BOOT_IMAGE=(hd0,gpt3)/ostree/rhcos-... hugepagesz=2M hugepages=50
第 11 章 使用 CPU Manager 和拓扑管理器
CPU Manager 管理 CPU 组并限制特定 CPU 的负载。
CPU Manager 对于有以下属性的负载有用:
- 需要尽可能多的 CPU 时间。
- 对处理器缓存丢失非常敏感。
- 低延迟网络应用程序。
- 需要与其他进程协调,并从共享一个处理器缓存中受益。
拓扑管理器(Topology Manager)从 CPU Manager、设备管理器和其他 Hint 提供者收集提示信息,以匹配相同非统一 内存访问(NUMA)节点上的所有 QoS 类的 pod 资源(如 CPU、SR-IOV VF 和其他设备资源)。
拓扑管理器使用收集来的提示信息中获得的拓扑信息,根据配置的 Topology Manager 策略以及请求的 Pod 资源,决定节点是否被节点接受或拒绝。
拓扑管理器对希望使用硬件加速器来支持对工作延迟有极高要求的操作及高吞吐并发计算的负载很有用。
要使用拓扑管理器,您必须使用 静态 策略配置 CPU Manager。
11.1. 设置 CPU Manager
要配置 CPU Manager,请创建一个 KubeletConfig 自定义资源 (CR) 并将其应用到所需的一组节点。
流程
运行以下命令来标记节点:
# oc label node perf-node.example.com cpumanager=true要为所有计算节点启用 CPU Manager,请运行以下命令来编辑 CR:
# oc edit machineconfigpool worker将
custom-kubelet: cpumanager-enabled标签添加到metadata.labels部分。metadata: creationTimestamp: 2020-xx-xxx generation: 3 labels: custom-kubelet: cpumanager-enabled创建
KubeletConfig,cpumanager-kubeletconfig.yaml,自定义资源 (CR) 。请参阅上一步中创建的标签,以便使用新的 kubelet 配置更新正确的节点。请参见MachineConfigPoolSelector部分:apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cpumanager-enabled spec: machineConfigPoolSelector: matchLabels: custom-kubelet: cpumanager-enabled kubeletConfig: cpuManagerPolicy: static1 cpuManagerReconcilePeriod: 5s2 运行以下命令来创建动态 kubelet 配置:
# oc create -f cpumanager-kubeletconfig.yaml这会在 kubelet 配置中添加 CPU Manager 功能,如果需要,Machine Config Operator(MCO)将重启节点。要启用 CPU Manager,则不需要重启。
运行以下命令,检查合并的 kubelet 配置:
# oc get machineconfig 99-worker-XXXXXX-XXXXX-XXXX-XXXXX-kubelet -o json | grep ownerReference -A7输出示例
"ownerReferences": [ { "apiVersion": "machineconfiguration.openshift.io/v1", "kind": "KubeletConfig", "name": "cpumanager-enabled", "uid": "7ed5616d-6b72-11e9-aae1-021e1ce18878" } ]运行以下命令,检查更新的
kubelet.conf文件的计算节点:# oc debug node/perf-node.example.com sh-4.2# cat /host/etc/kubernetes/kubelet.conf | grep cpuManager输出示例
cpuManagerPolicy: static1 cpuManagerReconcilePeriod: 5s2 运行以下命令来创建项目:
$ oc new-project <project_name>创建请求一个或多个内核的 pod。限制和请求都必须将其 CPU 值设置为一个整数。这是专用于此 pod 的内核数:
# cat cpumanager-pod.yaml输出示例
apiVersion: v1 kind: Pod metadata: generateName: cpumanager- spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: cpumanager image: gcr.io/google_containers/pause:3.2 resources: requests: cpu: 1 memory: "1G" limits: cpu: 1 memory: "1G" securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] nodeSelector: cpumanager: "true"创建 pod:
# oc create -f cpumanager-pod.yaml
验证
运行以下命令,验证 pod 是否已调度到您标记的节点:
# oc describe pod cpumanager输出示例
Name: cpumanager-6cqz7 Namespace: default Priority: 0 PriorityClassName: <none> Node: perf-node.example.com/xxx.xx.xx.xxx ... Limits: cpu: 1 memory: 1G Requests: cpu: 1 memory: 1G ... QoS Class: Guaranteed Node-Selectors: cpumanager=true运行以下命令,验证 CPU 是否已完全分配给 pod:
# oc describe node --selector='cpumanager=true' | grep -i cpumanager- -B2输出示例
NAMESPACE NAME CPU Requests CPU Limits Memory Requests Memory Limits Age cpuman cpumanager-mlrrz 1 (28%) 1 (28%) 1G (13%) 1G (13%) 27m确认正确配置了
cgroups。运行以下命令,获取cluster进程的进程 ID (PID):# oc debug node/perf-node.example.comsh-4.2# systemctl status | grep -B5 pause注意如果输出返回多个暂停进程条目,您必须识别正确的暂停进程。
输出示例
# ├─init.scope │ └─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 17 └─kubepods.slice ├─kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice │ ├─crio-b5437308f1a574c542bdf08563b865c0345c8f8c0b0a655612c.scope │ └─32706 /pause运行以下命令,验证 pod 服务质量(QoS)等级
Guaranteed是否在kubepods.slice子目录中:# cd /sys/fs/cgroup/kubepods.slice/kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice/crio-b5437308f1ad1a7db0574c542bdf08563b865c0345c86e9585f8c0b0a655612c.scope# for i in `ls cpuset.cpus cgroup.procs` ; do echo -n "$i "; cat $i ; done注意其他 QoS 等级的 Pod 会位于父
kubepods的子cgroups中。输出示例
cpuset.cpus 1 tasks 32706运行以下命令,检查任务允许的 CPU 列表:
# grep ^Cpus_allowed_list /proc/32706/status输出示例
Cpus_allowed_list: 1验证系统中的另一个 pod 无法在为
Guaranteedpod 分配的内核中运行。例如,要验证besteffortQoS 层中的 pod,请运行以下命令:# cat /sys/fs/cgroup/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-podc494a073_6b77_11e9_98c0_06bba5c387ea.slice/crio-c56982f57b75a2420947f0afc6cafe7534c5734efc34157525fa9abbf99e3849.scope/cpuset.cpus# oc describe node perf-node.example.com输出示例
... Capacity: attachable-volumes-aws-ebs: 39 cpu: 2 ephemeral-storage: 124768236Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 8162900Ki pods: 250 Allocatable: attachable-volumes-aws-ebs: 39 cpu: 1500m ephemeral-storage: 124768236Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 7548500Ki pods: 250 ------- ---- ------------ ---------- --------------- ------------- --- default cpumanager-6cqz7 1 (66%) 1 (66%) 1G (12%) 1G (12%) 29m Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 1440m (96%) 1 (66%)这个 VM 有两个 CPU 内核。
system-reserved设置保留 500 millicores,这代表一个内核中的一半被从节点的总容量中减小,以达到Node Allocatable的数量。您可以看到Allocatable CPU是 1500 毫秒。这意味着您可以运行一个 CPU Manager pod,因为每个 pod 需要一个完整的内核。一个完整的内核等于 1000 毫秒。如果您尝试调度第二个 pod,系统将接受该 pod,但不会调度它:NAME READY STATUS RESTARTS AGE cpumanager-6cqz7 1/1 Running 0 33m cpumanager-7qc2t 0/1 Pending 0 11s
11.2. 拓扑管理器策略
拓扑管理器通过从 Hint 提供者(如 CPU Manager 和设备管理器)收集拓扑提示来调整所有级别服务质量(QoS)的 Pod 资源,并使用收集的提示来匹配 Pod 资源。
拓扑管理器支持四个分配策略,这些策略在名为 cpumanager-enabled 的 KubeletConfig 自定义资源 (CR) 中分配:
none策略- 这是默认策略,不执行任何拓扑对齐调整。
best-effort策略-
对于带有
best-effort拓扑管理策略的 pod 中的每个容器,kubelet 会尝试根据该容器的首选 NUMA 节点关联性来匹配 NUMA 节点上的所有所需资源。即使因为资源不足而无法分配,Topology Manager 仍然接受 pod,但分配会与其他 NUMA 节点共享。 restricted策略-
对于带有
restricted拓扑管理策略的 pod 中的每个容器,kubelet 决定理论上可以满足请求的 NUMA 节点数量。如果实际分配需要超过该数量的 NUMA 节点,则拓扑管理器会拒绝准入,将 pod 置于Terminated状态。如果 NUMA 节点数量可以满足请求,则拓扑管理器会接受 pod 和 pod 开始运行。 single-numa-node策略-
对于带有
single-numa-node拓扑管理策略的 pod 中的每个容器,如果 pod 所需的所有资源可以在同一 NUMA 节点上分配,kubelet 会接受 pod。如果无法使用单一 NUMA 节点关联性,则拓扑管理器会拒绝来自节点的 pod。这会导致 pod 处于Terminated状态,且 pod 准入失败。
11.3. 设置拓扑管理器
要使用拓扑管理器,您必须在名为 cpumanager-enabled 的 KubeletConfig 自定义资源 (CR) 中配置分配策略。如果您设置了 CPU Manager,则该文件可能会存在。如果这个文件不存在,您可以创建该文件。
先决条件
-
将 CPU Manager 策略配置为
static。
流程
激活拓扑管理器:
在自定义资源中配置拓扑管理器分配策略。
$ oc edit KubeletConfig cpumanager-enabledapiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cpumanager-enabled spec: machineConfigPoolSelector: matchLabels: custom-kubelet: cpumanager-enabled kubeletConfig: cpuManagerPolicy: static1 cpuManagerReconcilePeriod: 5s topologyManagerPolicy: single-numa-node2
11.4. Pod 与拓扑管理器策略的交互
以下的 Pod specs 示例演示了 Pod 与 Topology Manager 的交互。
因为没有指定资源请求或限制,以下 pod 以 BestEffort QoS 类运行。
spec:
containers:
- name: nginx
image: nginx
因为请求小于限制,下一个 pod 以 Burstable QoS 类运行。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
如果所选策略不是 none,则拓扑管理器将处理所有 pod,并且仅针对 Guaranteed Qos Pod 规格强制实施资源校准。当拓扑管理器策略设置为 none 时,相关的容器会被固定到任何可用的 CPU 中,而不考虑 NUMA 关联性。这是默认行为,不会针对性能敏感的工作负载进行优化。其他值支持使用来自设备插件核心资源(如 CPU 和内存)的拓扑感知信息。当策略设置为不是 none 的其他值时,拓扑管理器会尝试根据节点的拓扑匹配 CPU、内存和设备分配。有关可用值的更多信息,请参阅拓扑管理器策略。
以下示例 pod 以 Guaranteed QoS 类运行,因为请求等于限制。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"拓扑管理器将考虑这个 pod。拓扑管理器会参考 Hint 提供者,即 CPU Manager、设备管理器和 Memory Manager,以获取 pod 的拓扑提示。
拓扑管理器将使用此信息存储该容器的最佳拓扑。在本 pod 中,CPU Manager 和设备管理器将在资源分配阶段使用此存储的信息。
第 12 章 调度 NUMA 感知工作负载
了解 NUMA 感知调度以及如何使用它来在 OpenShift Container Platform 集群中部署高性能工作负载。
NUMA Resources Operator 允许您在相同的 NUMA 区域中调度高性能工作负载。它部署一个节点资源导出代理,该代理在可用的集群节点 NUMA 资源以及管理工作负载的辅助调度程序上报告。
12.1. 关于 NUMA
非统一内存访问(NUMA)架构是一个多处理器架构模型,其中 CPU 不在同一速度访问所有位置中的所有内存。相反,CPU 可以更快地访问距离近的或是本地的内存,但对较远的内存访问会较慢。
允许有多个内存控制器的 CPU 在 CPU 复杂间使用任何可用内存,无论内存所处的位置。但是,这种增长的灵活性会牺牲性能。
NUMA 资源拓扑 引用 CPU、内存和 PCI 设备的物理位置,相对于 NUMA 区域中的每个设备。在 NUMA 架构中,NUMA 区域是一组具有其自身处理器和内存的 CPU。colocated 资源表示在同一 NUMA 区域中,并且区域的 CPU 比该区域以外的 CPU 更快地访问同一本地内存。使用位于 NUMA 区域以外的内存的 CPU 处理工作负载的速度比单个 NUMA 区域处理的工作负载要慢。对于对 I/O 有限制的工作负载,在远程的 NUMA 区域中的网络接口会减慢访问应用程序的速度。
通过在同一 NUMA 区域内包含数据和处理,应用程序可以提高性能。对于高性能工作负载和应用程序,如电信工作负载,集群必须处理单个 NUMA 区域中的 pod 工作负载,以便工作负载可以操作规格。
12.2. 关于 NUMA 感知调度
NUMA 感知调度会调整同一 NUMA 区域中请求的集群计算资源(CPU、内存、设备),以有效地处理对延迟敏感的工作负责或高性能工作负载。NUMA 感知调度还提高了每个计算节点的 pod 密度,以提高资源效率。
12.2.1. 与 Node Tuning Operator 集成
通过将 Node Tuning Operator 的性能配置集与 NUMA 感知调度集成,您可以进一步配置 CPU 关联性来优化对延迟敏感的工作负载的性能。
12.2.2. 默认调度逻辑
默认的 OpenShift Container Platform pod 调度程序调度逻辑考虑整个计算节点的可用资源,而不是单个 NUMA 区域。如果在 kubelet 拓扑管理器中请求最严格的资源协调,则会在将 pod 传递给节点时出现错误条件。相反,如果没有请求限制性最严格的资源协调,则 pod 可以在没有正确的资源协调的情况下被节点接受,从而导致性能更差或无法达到预期。例如,当 pod 调度程序通过不知道 pod 请求的资源可用而导致做出非最佳的调度决定时,pod 创建可能会出现 Topology Affinity Error 状态。调度不匹配决策可能会导致 pod 启动延迟。另外,根据集群状态和资源分配,pod 调度决策可能会因为启动失败而对集群造成额外的负载。
12.2.3. NUMA 感知 pod 调度图
NUMA Resources Operator 部署了一个自定义 NUMA 资源辅助调度程序和其他资源,以缓解默认 OpenShift Container Platform pod 调度程序的缩写。下图显示了 NUMA 感知 pod 调度的高级概述。
图 12.1. NUMA 感知调度概述

- NodeResourceTopology API
-
NodeResourceTopologyAPI 描述了每个计算节点上可用的 NUMA 区资源。 - NUMA 感知调度程序
-
NUMA 感知辅助调度程序从
NodeResourceTopologyAPI 接收有关可用 NUMA 区域的信息,并在可以最佳处理的节点上调度高性能工作负载。 - 节点拓扑 exporter
-
节点拓扑 exporter 会公开每个计算节点的可用 NUMA 区资源到
NodeResourceTopologyAPI。节点拓扑 exporter 守护进程使用PodResourcesAPI 跟踪来自 kubelet 的资源分配。 - PodResources API
对于每个节点,
PodResourcesAPI 是本地的,并向 kubelet 公开资源拓扑和可用资源。注意PodResourcesAPI 的List端点公开分配给特定容器的专用 CPU。API 不会公开属于共享池的 CPU。GetAllocatableResources端点公开节点上可用的可分配资源。
12.3. NUMA 资源调度策略
在调度高性能工作负载时,二级调度程序可以使用不同的策略来确定所选 worker 节点中的哪些 NUMA 节点将处理工作负载。OpenShift Container Platform 中支持的策略包括 LeastAllocated、mostAllocated 和 BalancedAllocation。了解这些策略有助于优化工作负载放置,以提高性能和资源利用率。
当在 NUMA 感知集群中调度高性能工作负载时,会执行以下步骤:
- 调度程序首先根据集群范围的标准选择合适的 worker 节点。例如污点、标签或资源可用性。
- 选择了 worker 节点后,调度程序会评估其 NUMA 节点,并应用评分策略来确定哪个 NUMA 节点将处理工作负载。
- 调度工作负载后,所选 NUMA 节点的资源会更新,以反映分配。
应用的默认策略是 LeastAllocated 策略。这会为 NUMA 节点分配具有最少使用的 NUMA 节点最多可用资源的工作负载。此策略的目标是将工作负载分散到 NUMA 节点之间,以减少争用并避免热点。
下表总结了不同的策略及其结果:
Scoring 策略概述
| 策略 | 描述 | 结果 |
|---|---|---|
|
| 优先选择具有最多可用资源的 NUMA 节点。 | 分散工作负载,以减少竞争,并确保工作空间用于高优先级任务。 |
|
| 优先选择具有最少可用资源的 NUMA 节点。 | 在更少的 NUMA 节点上整合工作负载,从而释放其他工作负载,从而获得能源效率。 |
|
| 优先选择 CPU 和内存使用情况均衡的 NUMA 节点。 | 确保即使资源利用率,防止使用模式。 |
LeastAllocated 策略示例
LeastAllocated 是默认策略。此策略将工作负载分配给具有最多可用资源的 NUMA 节点,从而最大程度减少资源争用并将工作负载分散到 NUMA 节点上。这可减少热点,并确保有足够的保留空间来处理高优先级任务。假设 worker 节点有两个 NUMA 节点,工作负载需要 4 个 vCPU 和 8 GB 内存:
| NUMA 节点 | CPU 总数 | 使用的 CPU | 内存总量 (GB) | 已用内存(GB) | 可用资源 |
|---|---|---|---|---|---|
| NUMA 1 | 16 | 12 | 64 | 56 | 4 个 CPU,8 GB 内存 |
| NUMA 2 | 16 | 6 | 64 | 24 | 10 个 CPU,40 GB 内存 |
由于 NUMA 2 与 NUMA 1 相比具有更多可用资源,因此工作负载将分配给 NUMA 2。
MostAllocated 策略示例
MostAllocated 策略通过将工作负载分配给具有最少可用资源的 NUMA 节点来整合工作负载,这是最常用的 NUMA 节点。这种方法有助于释放其他 NUMA 节点,以实现能源效率或关键工作负载,需要完全隔离。本例使用 LeastAllocated 部分中列出的 "Example initial NUMA nodes state" 值。
工作负载需要 4 个 vCPU 和 8 GB 内存。与 NUMA 2 相比,NUMA 1 的可用资源较少,因此调度程序会将工作负载分配给 NUMA 1,在保持 NUMA 2 空闲或最小加载时进一步利用其资源。
BalancedAllocation 策略示例
BalancedAllocation 策略将工作负载分配给 NUMA 节点,并在 CPU 和内存之间平衡资源利用率。目标是防止不平衡使用量,如 CPU 利用率低下内存。假设 worker 节点具有以下 NUMA 节点状态:
| NUMA 节点 | CPU 用量 | 内存用量 | BalancedAllocation score |
|---|---|---|---|
| NUMA 1 | 60% | 55% | 高(更均衡) |
| NUMA 2 | 80% | 20% | 低(不均衡) |
与 NUMA 2 相比,NUMA 1 的 CPU 和内存使用率更为平衡,因此,BalancedAllocation 策略被分配为 NUMA 1。
12.4. 安装 NUMA Resources Operator
NUMA Resources Operator 部署资源,供您调度 NUMA 感知工作负载和部署。您可以使用 OpenShift Container Platform CLI 或 Web 控制台安装 NUMA Resources Operator。
12.4.1. 使用 CLI 安装 NUMA Resources Operator
作为集群管理员,您可以使用 CLI 安装 Operator。
先决条件
-
安装 OpenShift CLI(
oc)。 -
以具有
cluster-admin特权的用户身份登录。
流程
为 NUMA Resources Operator 创建命名空间:
将以下 YAML 保存到
nro-namespace.yaml文件中:apiVersion: v1 kind: Namespace metadata: name: openshift-numaresources运行以下命令来创建
NamespaceCR:$ oc create -f nro-namespace.yaml
为 NUMA Resources Operator 创建 operator 组:
在
nro-operatorgroup.yaml文件中保存以下 YAML:apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: numaresources-operator namespace: openshift-numaresources spec: targetNamespaces: - openshift-numaresources运行以下命令来创建
OperatorGroupCR:$ oc create -f nro-operatorgroup.yaml
为 NUMA Resources Operator 创建订阅:
将以下 YAML 保存到
nro-sub.yaml文件中:apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: numaresources-operator namespace: openshift-numaresources spec: channel: "4.20" name: numaresources-operator source: redhat-operators sourceNamespace: openshift-marketplace运行以下命令来创建
SubscriptionCR:$ oc create -f nro-sub.yaml
验证
通过检查
openshift-numaresources命名空间中的 CSV 资源来验证安装是否成功。运行以下命令:$ oc get csv -n openshift-numaresources输出示例
NAME DISPLAY VERSION REPLACES PHASE numaresources-operator.v4.20.2 numaresources-operator 4.20.2 Succeeded
12.4.2. 使用 Web 控制台安装 NUMA Resources Operator
作为集群管理员,您可以使用 Web 控制台安装 NUMA Resources Operator。
流程
为 NUMA Resources Operator 创建命名空间:
- 在 OpenShift Container Platform web 控制台中,点 Administration → Namespaces。
-
点 Create Namespace,在 Name 字段中输入
openshift-numaresources,然后点 Create。
安装 NUMA Resources Operator:
- 在 OpenShift Container Platform Web 控制台中,点 Ecosystem → Software Catalog。
- 从可用的 Operator 列表中选择 numaresources-operator,然后点 Install。
-
在 Installed Namespaces 字段中,选择
openshift-numaresources命名空间,然后点 Install。
可选:验证 NUMA Resources Operator 是否已成功安装:
- 切换到 Ecosystem → Installed Operators 页。
确保
openshift-numaresources命名空间中列出 NUMA Resources Operator,Status 为 InstallSucceeded。注意在安装过程中,Operator 可能会显示 Failed 状态。如果安装过程结束后有 InstallSucceeded 信息,您可以忽略这个 Failed 信息。
如果 Operator 没有被成功安装,请按照以下步骤进行故障排除:
- 进入 Ecosystem → Installed Operators 页,检查 Operator Subscriptions 和 Install Plans 选项卡中的 Status 项中是否有任何错误。
-
进入 Workloads → Pods 页面,检查
default项目中的 pod 的日志。
12.5. 配置单个 NUMA 节点策略
NUMA Resources Operator 要求在集群中配置单个 NUMA 节点策略。这可以通过创建并应用性能配置集或配置 KubeletConfig 来实现。
配置单个 NUMA 节点策略的首选方法是应用性能配置集。您可以使用 Performance Profile Creator (PPC) 工具来创建性能配置集。如果在集群中创建了性能配置集,它会自动创建 KubeletConfig 和 tuned 配置集等其他调优组件。
有关创建性能配置集的更多信息,请参阅"添加资源"部分中的"关于 Performance Profile Creator"。
12.5.1. 为 NUMA 感知调度程序管理高可用性(HA)
管理高可用性只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅以下链接:
NUMA Resources Operator 根据 NUMAResourcesScheduler 自定义资源(CR)中的 spec.replicas 字段管理 NUMA 感知二级调度程序的高可用性。默认情况下,NUMA Resources Operator 会自动为每个 control plane 节点创建一个调度程序副本来启用 HA 模式,最多有三个副本。
以下清单演示了这种默认行为。要自动启用副本检测,请省略 replicas 字段。
apiVersion: nodetopology.openshift.io/v1
kind: NUMAResourcesScheduler
metadata:
name: example-auto-ha
spec:
imageSpec: 'registry.redhat.io/openshift4/noderesourcetopology-scheduler-rhel9:v4.20'
# The 'replicas' field is not included, enabling auto-detection.您可以使用以下选项之一控制调度程序行为:
- 自定义副本数量。
- 禁用 NUMA 感知调度。
12.5.1.1. 自定义调度程序副本
通过更新 NUMAResourcesScheduler 自定义资源中的 spec.replicas 字段来设置特定数量的调度程序副本。这会覆盖默认的 HA 行为。
流程
使用以下 YAML 创建
NUMAResourcesSchedulerCR,如custom-ha.yaml,将副本数设置为 2:apiVersion: nodetopology.openshift.io/v1 kind: NUMAResourcesScheduler metadata: name: example-custom spec: imageSpec: 'registry.redhat.io/openshift4/noderesourcetopology-scheduler-rhel9:v4.20' replicas: 2运行以下命令部署 NUMA 感知 pod 调度程序:
$ oc apply -f custom-ha.yaml
12.5.1.2. 禁用 NUMA 感知调度
禁用 NUMA 感知调度程序,停止所有正在运行的调度程序 pod,并防止新调度程序启动。
流程
在
nro-disable-scheduler.yaml文件中保存以下最小所需的 YAML。通过将spec.replicas字段设置为0来禁用调度程序。apiVersion: nodetopology.openshift.io/v1 kind: NUMAResourcesScheduler metadata: name: example-disable spec: imageSpec: 'registry.redhat.io/openshift4/noderesourcetopology-scheduler-rhel9:v4.20' replicas: 0运行以下命令禁用 NUMA 感知 pod 调度程序:
$ oc apply -f nro-disable-scheduler.yaml
12.5.1.3. 验证调度程序高可用性(HA)状态
验证 NUMA 感知调度程序的状态,以确保它根据您的配置使用预期的副本数。
流程
运行以下命令仅列出调度程序 pod:
$ oc get pods -n openshift-numaresources -l app=secondary-scheduler预期输出
使用默认 HA 模式,pod 数量等于 control-plane 节点的数量。标准 HA OpenShift Container Platform 集群通常有三个 control-plane 节点,因此显示三个 pod:
NAME READY STATUS RESTARTS AGE secondary-scheduler-5b8c9d479d-2r4p5 1/1 Running 0 5m secondary-scheduler-5b8c9d479d-k2f3p 1/1 Running 0 5m secondary-scheduler-5b8c9d479d-q8c7b 1/1 Running 0 5m- 如果自定义副本,则 pod 的数量与您设置的值匹配。
如果您禁用了调度程序,则不会有正在运行的带有此标签的 pod。
注意对 NUMA 感知调度程序强制执行 3 个副本的限制。在托管的 control plane 集群中,调度程序 pod 在 hosted-cluster 的 worker 节点上运行。
运行以下命令,验证副本数及其状态:
$ oc get deployment secondary-scheduler -n openshift-numaresources输出示例
NAME READY UP-TO-DATE AVAILABLE AGE secondary-scheduler 3/3 3 3 5m在这个输出中,3/3 表示 3 个副本已经从预期的 3 个副本中就绪。
如需更详细的信息,请运行以下命令:
$ oc describe deployment secondary-scheduler -n openshift-numaresources输出示例
Replicas行显示为 3 个副本配置的部署,所有 3 个更新且可用。Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
12.5.2. 性能配置集示例
此 YAML 示例显示使用性能配置集创建器(PPC) 工具创建的性能配置集:
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
name: performance
spec:
cpu:
isolated: "3"
reserved: 0-2
machineConfigPoolSelector:
pools.operator.machineconfiguration.openshift.io/worker: ""
nodeSelector:
node-role.kubernetes.io/worker: ""
numa:
topologyPolicy: single-numa-node
realTimeKernel:
enabled: true
workloadHints:
highPowerConsumption: true
perPodPowerManagement: false
realTime: true- 1
- 这个值需要与您要配置 NUMA Resources Operator 的
MachineConfigPool值匹配。例如,您可以创建一个名为worker-cnf的MachineConfigPool对象,它指定电信工作负载在其中运行的一组节点。MachineConfigPool的值必须与稍后在"创建 NUMAResourcesOperator 自定义资源"中配置的NUMAResourcesOperatorCR 中的machineConfigPoolSelector值匹配。 - 2
- 确保
topologyPolicy字段被设置为single-numa-node,方法是在运行 PPC 工具时将topology-manager-policy参数设置为single-numa-node。注意对于托管的 control plane 集群,
MachineConfigPoolSelector并没有任何功能上的效果。节点关联由特定的NodePool对象决定。
12.5.3. 创建 KubeletConfig CR
配置单个 NUMA 节点策略的建议方法是应用性能配置集。另一种方法是创建并应用 KubeletConfig 自定义资源 (CR),如下所示。
流程
创建
KubeletConfig自定义资源 (CR) 来为机器配置集配置 pod admittance 策略:将以下 YAML 保存到
nro-kubeletconfig.yaml文件中:apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: worker-tuning spec: machineConfigPoolSelector: matchLabels: pools.operator.machineconfiguration.openshift.io/worker: ""1 kubeletConfig: cpuManagerPolicy: "static"2 cpuManagerReconcilePeriod: "5s" reservedSystemCPUs: "0,1"3 memoryManagerPolicy: "Static"4 evictionHard: memory.available: "100Mi" kubeReserved: memory: "512Mi" reservedMemory: - numaNode: 0 limits: memory: "1124Mi" systemReserved: memory: "512Mi" topologyManagerPolicy: "single-numa-node"5 注意对于托管的 control plane 集群,
MachineConfigPoolSelector设置并没有任何功能上的效果。节点关联由特定的NodePool对象决定。要为托管的 control plane 集群应用KubeletConfig,您必须创建一个包含配置的ConfigMap,然后在NodePool的spec.config字段中引用该ConfigMap。运行以下命令来创建
KubeletConfigCR:$ oc create -f nro-kubeletconfig.yaml注意应用性能配置集或
KubeletConfig会自动触发节点重新引导。如果没有触发重启,您可以通过查看处理节点组的KubeletConfig中的标签来排除此问题。
12.6. 调度 NUMA 感知工作负载
运行对延迟敏感工作负载的集群通常具有性能配置集,以帮助最小化工作负载延迟并优化性能。NUMA 感知调度程序根据可用的节点 NUMA 资源部署工作负载,并遵循应用到节点的任何性能配置集设置。NUMA 感知部署和工作负载的性能配置集相结合,确保以最大化性能的方式调度工作负载。
要使 NUMA Resources Operator 完全可正常工作,您必须部署 NUMAResourcesOperator 自定义资源和 NUMA 感知辅助 pod 调度程序。
12.6.1. 创建 NUMAResourcesOperator 自定义资源
安装 NUMA Resources Operator 后,创建 NUMAResourcesOperator 自定义资源 (CR) 来指示 NUMA Resources Operator 安装支持 NUMA 感知调度程序所需的所有集群基础架构,包括守护进程集和 API。
先决条件
-
安装 OpenShift CLI(
oc)。 -
以具有
cluster-admin特权的用户身份登录。 - 安装 NUMA Resources Operator。
流程
创建
NUMAResourcesOperator自定义资源:将以下最小所需的 YAML 文件示例保存为
nrop.yaml:apiVersion: nodetopology.openshift.io/v1 kind: NUMAResourcesOperator metadata: name: numaresourcesoperator spec: nodeGroups: - machineConfigPoolSelector: matchLabels: pools.operator.machineconfiguration.openshift.io/worker: ""1 - 1
- 这必须与您要配置 NUMA Resources Operator 的
MachineConfigPool资源匹配。例如,您可能已创建了名为worker-cnf的MachineConfigPool资源,它指定了一组应该运行电信工作负载的节点。每个NodeGroup必须与一个MachineConfigPool完全匹配。不支持NodeGroup匹配多个MachineConfigPool的配置。
运行以下命令来创建
NUMAResourcesOperatorCR:$ oc create -f nrop.yaml
可选: 要为多个机器配置池(MCP)启用 NUMA 感知调度,请为每个池定义单独的
NodeGroup。例如,在NUMAResourcesOperatorCR 中为worker-cnf、worker-ht和worker-other定义三个NodeGroups,如下例所示:具有多个
NodeGroups的NUMAResourcesOperatorCR 的 YAML 定义示例apiVersion: nodetopology.openshift.io/v1 kind: NUMAResourcesOperator metadata: name: numaresourcesoperator spec: logLevel: Normal nodeGroups: - machineConfigPoolSelector: matchLabels: machineconfiguration.openshift.io/role: worker-ht - machineConfigPoolSelector: matchLabels: machineconfiguration.openshift.io/role: worker-cnf - machineConfigPoolSelector: matchLabels: machineconfiguration.openshift.io/role: worker-other
验证
运行以下命令,验证 NUMA Resources Operator 是否已成功部署:
$ oc get numaresourcesoperators.nodetopology.openshift.io输出示例
NAME AGE numaresourcesoperator 27s几分钟后,运行以下命令验证所需资源是否已成功部署:
$ oc get all -n openshift-numaresources输出示例
NAME READY STATUS RESTARTS AGE pod/numaresources-controller-manager-7d9d84c58d-qk2mr 1/1 Running 0 12m pod/numaresourcesoperator-worker-7d96r 2/2 Running 0 97s pod/numaresourcesoperator-worker-crsht 2/2 Running 0 97s pod/numaresourcesoperator-worker-jp9mw 2/2 Running 0 97s
12.6.2. 为托管 control plane 创建 NUMAResourcesOperator 自定义资源
安装 NUMA Resources Operator 后,创建 NUMAResourcesOperator 自定义资源 (CR)。CR 指示 NUMA Resources Operator 安装支持在托管 control plane 上的 NUMA 感知调度程序所需的所有集群基础架构,包括守护进程集和 API。
为托管 control plane 创建 NUMAResourcesOperator 自定义资源只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅以下链接:
先决条件
-
安装 OpenShift CLI(
oc)。 -
以具有
cluster-admin特权的用户身份登录。 - 安装 NUMA Resources Operator。
流程
运行以下命令导出管理集群 kubeconfig 文件:
$ export KUBECONFIG=<path-to-management-cluster-kubeconfig>运行以下命令,为您的集群查找
node-pool-name:$ oc --kubeconfig="$MGMT_KUBECONFIG" get np -A输出示例
NAMESPACE NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE clusters democluster-us-east-1a democluster 1 1 False False 4.20.0 False Falsenode-pool-name是输出中的NAME字段。在本例中,node-pool-name是democluster-us-east-1a。创建名为
nrop-hcp.yaml的 YAML 文件,至少包含以下内容:apiVersion: nodetopology.openshift.io/v1 kind: NUMAResourcesOperator metadata: name: numaresourcesoperator spec: nodeGroups: - poolName: democluster-us-east-1a1 - 1
poolName是在第 2 步中获取的node-pool-name。
在受管集群中,运行以下命令来列出可用的 secret:
$ oc get secrets -n clusters输出示例
NAME TYPE DATA AGE builder-dockercfg-25qpp kubernetes.io/dockercfg 1 128m default-dockercfg-mkvlz kubernetes.io/dockercfg 1 128m democluster-admin-kubeconfig Opaque 1 127m democluster-etcd-encryption-key Opaque 1 128m democluster-kubeadmin-password Opaque 1 126m democluster-pull-secret Opaque 1 128m deployer-dockercfg-8lfpd kubernetes.io/dockercfg 1 128m运行以下命令,提取托管集群的
kubeconfig文件:$ oc get secret <SECRET_NAME> -n clusters -o jsonpath='{.data.kubeconfig}' | base64 -d > hosted-cluster-kubeconfigExample
$ oc get secret democluster-admin-kubeconfig -n clusters -o jsonpath='{.data.kubeconfig}' | base64 -d > hosted-cluster-kubeconfig运行以下命令导出托管集群
kubeconfig文件:$ export HC_KUBECONFIG=<path_to_hosted-cluster-kubeconfig>通过在托管集群中运行以下命令来创建
NUMAResourcesOperatorCR:$ oc create -f nrop-hcp.yaml
验证
运行以下命令,验证 NUMA Resources Operator 是否已成功部署:
$ oc get numaresourcesoperators.nodetopology.openshift.io输出示例
NAME AGE numaresourcesoperator 27s几分钟后,运行以下命令验证所需资源是否已成功部署:
$ oc get all -n openshift-numaresources输出示例
NAME READY STATUS RESTARTS AGE pod/numaresources-controller-manager-7d9d84c58d-qk2mr 1/1 Running 0 12m pod/numaresourcesoperator-democluster-7d96r 2/2 Running 0 97s pod/numaresourcesoperator-democluster-crsht 2/2 Running 0 97s pod/numaresourcesoperator-democluster-jp9mw 2/2 Running 0 97s
12.6.3. 部署 NUMA 感知辅助 pod 调度程序
安装 NUMA Resources Operator 后,按照以下步骤部署 NUMA 感知二级 pod 调度程序。
流程
创建
NUMAResourcesScheduler自定义资源来部署 NUMA 感知自定义 pod 调度程序:将以下最小 YAML 保存到
nro-scheduler.yaml文件中:apiVersion: nodetopology.openshift.io/v1 kind: NUMAResourcesScheduler metadata: name: numaresourcesscheduler spec: imageSpec: "registry.redhat.io/openshift4/noderesourcetopology-scheduler-rhel9:v4.20"1 - 1
- 在断开连接的环境中,请确保通过以下方法配置此镜像的解析:
-
创建
ImageTagMirrorSet自定义资源 (CR)。如需更多信息,请参阅"添加资源"部分中的"配置镜像 registry 存储库镜像"。 - 将 URL 设置为断开连接的 registry。
-
创建
运行以下命令来创建
NUMAResourcesSchedulerCR:$ oc create -f nro-scheduler.yaml注意在托管的 control plane 集群中,在托管的 control plane 节点上运行这个命令。
几秒钟后,运行以下命令确认已成功部署所需资源:
$ oc get all -n openshift-numaresources输出示例
NAME READY STATUS RESTARTS AGE pod/numaresources-controller-manager-7d9d84c58d-qk2mr 1/1 Running 0 12m pod/numaresourcesoperator-worker-7d96r 2/2 Running 0 97s pod/numaresourcesoperator-worker-crsht 2/2 Running 0 97s pod/numaresourcesoperator-worker-jp9mw 2/2 Running 0 97s pod/secondary-scheduler-847cb74f84-9whlm 1/1 Running 0 10m NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/numaresourcesoperator-worker 3 3 3 3 3 node-role.kubernetes.io/worker= 98s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/numaresources-controller-manager 1/1 1 1 12m deployment.apps/secondary-scheduler 1/1 1 1 10m NAME DESIRED CURRENT READY AGE replicaset.apps/numaresources-controller-manager-7d9d84c58d 1 1 1 12m replicaset.apps/secondary-scheduler-847cb74f84 1 1 1 10m
12.6.4. 使用 NUMA 感知调度程序调度工作负载
现在,安装了 topo-aware-scheduler,会应用 NUMAResourcesOperator 和 NUMAResourcesScheduler CR,并且集群具有匹配的性能配置集或 kubeletconfig,您可以使用部署 CR 使用 NUMA 感知调度程序来调度工作负载,该 CR 可以指定最低所需的资源来处理工作负载。
以下示例部署使用 NUMA 感知调度示例工作负载。
先决条件
-
安装 OpenShift CLI(
oc)。 -
以具有
cluster-admin特权的用户身份登录。
流程
运行以下命令,获取集群中部署的 NUMA 感知调度程序名称:
$ oc get numaresourcesschedulers.nodetopology.openshift.io numaresourcesscheduler -o json | jq '.status.schedulerName'输出示例
"topo-aware-scheduler"创建一个
DeploymentCR,它使用名为topo-aware-scheduler的调度程序,例如:将以下 YAML 保存到
nro-deployment.yaml文件中:apiVersion: apps/v1 kind: Deployment metadata: name: numa-deployment-1 namespace: openshift-numaresources spec: replicas: 1 selector: matchLabels: app: test template: metadata: labels: app: test spec: schedulerName: topo-aware-scheduler1 containers: - name: ctnr image: quay.io/openshifttest/hello-openshift:openshift imagePullPolicy: IfNotPresent resources: limits: memory: "100Mi" cpu: "10" requests: memory: "100Mi" cpu: "10" - name: ctnr2 image: registry.access.redhat.com/rhel:latest imagePullPolicy: IfNotPresent command: ["/bin/sh", "-c"] args: [ "while true; do sleep 1h; done;" ] resources: limits: memory: "100Mi" cpu: "8" requests: memory: "100Mi" cpu: "8"- 1
schedulerName必须与集群中部署的 NUMA 感知调度程序的名称匹配,如topo-aware-scheduler。
运行以下命令来创建
DeploymentCR:$ oc create -f nro-deployment.yaml
验证
验证部署是否成功:
$ oc get pods -n openshift-numaresources输出示例
NAME READY STATUS RESTARTS AGE numa-deployment-1-6c4f5bdb84-wgn6g 2/2 Running 0 5m2s numaresources-controller-manager-7d9d84c58d-4v65j 1/1 Running 0 18m numaresourcesoperator-worker-7d96r 2/2 Running 4 43m numaresourcesoperator-worker-crsht 2/2 Running 2 43m numaresourcesoperator-worker-jp9mw 2/2 Running 2 43m secondary-scheduler-847cb74f84-fpncj 1/1 Running 0 18m运行以下命令,验证
topo-aware-scheduler是否在调度部署的 pod:$ oc describe pod numa-deployment-1-6c4f5bdb84-wgn6g -n openshift-numaresources输出示例
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 4m45s topo-aware-scheduler Successfully assigned openshift-numaresources/numa-deployment-1-6c4f5bdb84-wgn6g to worker-1注意请求的资源超过可用于调度的部署将失败,并显示
MinimumReplicasUnavailable错误。当所需资源可用时,部署会成功。Pod 会一直处于Pending状态,直到所需资源可用。验证是否为节点列出了预期的分配资源。
运行以下命令,识别运行部署 pod 的节点:
$ oc get pods -n openshift-numaresources -o wide输出示例
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES numa-deployment-1-6c4f5bdb84-wgn6g 0/2 Running 0 82m 10.128.2.50 worker-1 <none> <none>运行以下命令,使用运行部署 Pod 的节点的名称。
$ oc describe noderesourcetopologies.topology.node.k8s.io worker-1输出示例
... Zones: Costs: Name: node-0 Value: 10 Name: node-1 Value: 21 Name: node-0 Resources: Allocatable: 39 Available: 211 Capacity: 40 Name: cpu Allocatable: 6442450944 Available: 6442450944 Capacity: 6442450944 Name: hugepages-1Gi Allocatable: 134217728 Available: 134217728 Capacity: 134217728 Name: hugepages-2Mi Allocatable: 262415904768 Available: 262206189568 Capacity: 270146007040 Name: memory Type: Node- 1
- 由于已分配给有保证 pod 的资源,
可用的容量会减少。
通过保证 pod 使用的资源从
noderesourcetopologies.topology.node.k8s.io中列出的可用节点资源中减去。
对具有
Best-effort或Burstable服务质量 (qosClass) 的pod 的资源分配不会反映在noderesourcetopologies.topology.node.k8s.io下的 NUMA 节点资源中。如果 pod 消耗的资源没有反映在节点资源计算中,请验证 pod 的Guaranteed具有qosClass,且 CPU 请求是一个整数值,而不是十进制值。您可以运行以下命令来验证 pod 是否具有Guaranteed的qosClass:$ oc get pod numa-deployment-1-6c4f5bdb84-wgn6g -n openshift-numaresources -o jsonpath="{ .status.qosClass }"输出示例
Guaranteed
12.7. NUMA Resources Operator 支持可调度的 control-plane 节点
您可以启用可调度 control plane 节点来运行用户定义的 pod,从而有效地将节点转换为混合 Control Plane 和 Worker 节点。此配置在资源约束的环境中特别有用,如紧凑集群。启用后,NUMA Resources Operator 可以将其拓扑感知调度应用到节点以获得保证工作负载,确保根据最佳的 NUMA 关联性来放置 Pod。
通常,OpenShift Container Platform 中的 control plane 节点专用于运行关键集群服务。启用可调度的 control plane 节点允许将用户定义的 Pod 调度到节点上。
您可以通过在 schedulers.config.openshift.io 资源中将 mastersSchedulable 字段设置为 true 来提高 control plane 节点调度。
当您启用可调度的 control plane 节点时,强烈建议启用工作负载分区来保护关键基础架构 pod 不受资源不足的影响。这个过程将基础架构组件(如 ovnkube-node 进程)限制为专用保留 CPU。但是,OVS 动态固定功能依赖于 ovnkube-node 可以访问为 bustable/best-effort pod 指定的 CPU,以正确识别和使用非固定 CPU。当工作负载分区为保留 CPU 配置 ovnkube-node 进程时,这个动态固定机制会破坏。
NUMA Resources Operator 为需要特定 NUMA 关联性的工作负载提供拓扑感知调度。当 control plane 节点可以调度时,Operator 的管理功能可以应用到它们,就像它们应用到 worker 节点一样。这样可确保 NUMA 感知 pod 放置到具有最佳 NUMA 拓扑的节点上,无论它是 control plane 节点还是 worker 节点。
在配置 NUMA Resources Operator 时,其管理范围由其自定义资源(CR)中的 nodeGroups 字段决定。这个原则适用于紧凑和多节点集群。
- 紧凑集群
- 在紧凑集群中,所有节点都被配置为可调度的 control plane 节点。NUMA Resources Operator 可以配置为管理集群中的所有节点。有关流程的更多详细信息,请按照部署说明进行操作。
- 多节点 OpenShift (MNO)集群
-
在多节点 OpenShift Container Platform 集群中,除了现有 worker 节点外,control plane 节点也会可以调度。要管理这些节点,您可以通过在 control plane 和 worker 节点的
NUMAResourcesOperatorCR 中定义单独的nodeGroups来配置 NUMA Resources Operator。这样可确保 NUMA Resources Operator 根据资源可用性和 NUMA 拓扑在两组节点上正确调度 pod。
修改性能配置集通常会触发 control plane 节点重启。由于 control plane 节点上有更严格的 Pod Disruption Budgets (PDB),集群的弹性机制会被激活。这些机制可防止强制驱除受保护但不健康的 pod,如 CrashLoopBackOff 中的那些 pod,这会导致重启过程中出现 Machine Config Pool (MCP)停滞。
如果 MCP 因此行为而卡住,则需要干预来解决这个问题,并允许 control plane 升级完成。
要解决这个问题,管理员有两个选项:
- 临时放松 PDB 限制,以允许进行必要的驱除。
- 手动删除不健康的 pod,以强制 MCP 协调并继续排空过程。
此流程描述了如何配置 NUMA Resources Operator (NROP)来管理用户配置为可以调度的 control plane 节点。这在 control plane 节点也充当 worker 节点的紧凑集群中特别有用,或者在 control plane 节点配置为运行工作负载的多节点 OpenShift (MNO)集群中特别有用。
先决条件
-
安装 OpenShift CLI(
oc)。 -
以具有
cluster-admin特权的用户身份登录。 - 安装 NUMA Resources Operator。
流程
要在 control plane 节点上启用 Topology Aware Scheduling (TAS),首先将节点配置为可以调度。这允许 NUMA Resources Operator 部署和管理它们上的 pod。如果没有此操作,Operator 无法部署从这些节点收集 NUMA 拓扑信息所需的 pod。按照以下步骤使 control plane 节点可以调度:
运行以下命令来编辑
schedulers.config.openshift.io资源:$ oc edit schedulers.config.openshift.io cluster在编辑器中,将
mastersSchedulable字段设置为true,然后保存并退出编辑器。apiVersion: config.openshift.io/v1 kind: Scheduler metadata: creationTimestamp: "2019-09-10T03:04:05Z" generation: 1 name: cluster resourceVersion: "433" selfLink: /apis/config.openshift.io/v1/schedulers/cluster uid: a636d30a-d377-11e9-88d4-0a60097bee62 spec: mastersSchedulable: true status: {} #...
要配置 NUMA Resources Operator,您必须在集群中创建单个 NUMAResourcesOperator 自定义资源(CR)。此 CR 中的
nodeGroups配置指定 Operator 必须管理的节点池。注意在配置
nodeGroups之前,请确保指定节点池满足 12.5 节中详述的所有先决条件,"配置单个 NUMA 节点策略"。NUMA Resources Operator 要求组内的所有节点都相同。不合规的节点可防止 NUMA Resources Operator 为整个池执行预期的拓扑感知调度。您可以为 NUMA Resources Operator 指定多个非重叠节点集。每个集合都应该对应于不同的机器配置池(MCP)。然后,NUMA Resources Operator 管理这些指定节点组中的可调度 control plane 节点。
对于紧凑集群,紧凑集群的 master 节点也是可调度的节点,因此只指定 master 池。在
NUMAResourcesOperatorCR 中创建以下nodeGroups配置:apiVersion: nodetopology.openshift.io/v1 kind: NUMAResourcesOperator metadata: name: numaresourcesoperator spec: nodeGroups: - poolName: master注意除了
master池外,应该避免使用 worker 池的紧凑集群。虽然此设置不会破坏集群或影响 Operator 功能,但可能会导致冗余或重复的 pod 在系统中创建不必要的操作。worker 池基本上是一个无点的、在此上下文中的空 MCP,它不提供任何目的。对于 control plane 和 worker 节点的 MNO 集群,您可以选择配置 NUMA Resources Operator 来管理多个
nodeGroups。您可以通过将对应的 MCP 添加到NUMAResourcesOperatorCR 中的nodeGroups列表中来指定要包含哪些节点。配置完全取决于您的具体要求。例如,要管理master和worker-cnf池,请在 NUMAResourcesOperator CR 中创建以下nodeGroups配置:apiVersion: nodetopology.openshift.io/v1 kind: NUMAResourcesOperator metadata: name: numaresourcesoperator spec: nodeGroups: - poolName: master - poolName: worker-cnf注意您可以自定义此列表,使其包含通过 Topology-Aware 调度进行管理的 nodeGroups 的任意组合。要防止重复、待处理的 pod,您必须确保配置中的每个
poolName都对应于带有唯一节点选择器标签的 MachineConfigPool (MCP)。该标签必须仅应用到该特定池中的节点,且不得与集群中的任何其他节点上的标签重叠。worker-cnfMCP 指定一组运行电信工作负载的节点。在更新了
NUMAResourcesOperatorCR 中的nodeGroups字段以反映集群的配置后,运行以下命令应用更改:$ oc apply -f <filename>.yaml注意将
<filename>.yaml替换为配置文件的名称。
验证
应用配置后,通过执行以下检查来验证 NUMA Resources Operator 是否已正确管理可调度 control plane 节点:
运行以下命令确认 control plane 节点具有 worker 角色,并可以调度:
$ oc get nodes输出示例:
NAME STATUS ROLES AGE VERSION worker-0 Ready worker,worker-cnf 100m v1.33.3 worker-1 Ready worker 93m v1.33.3 master-0 Ready control-plane,master,worker 108m v1.33.3 master-1 Ready control-plane,master,worker 107m v1.33.3 master-2 Ready control-plane,master,worker 107m v1.33.3 worker-2 Ready worker 100m v1.33.3运行以下命令,验证 NUMA Resources Operator 的 pod 是否在预期节点上运行。您应该为您在 CR 中指定的每个节点组群看到 numaresourcesoperator pod:
$ oc get pods -n openshift-numaresources -o wide输出示例:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES numaresources-controller-manager-bdbdd574-xx6bw 1/1 Running 0 49m 10.130.0.17 master-0 <none> <none> numaresourcesoperator-master-lprrh 2/2 Running 0 20m 10.130.0.20 master-0 <none> 2/2 numaresourcesoperator-master-qk6k4 2/2 Running 0 20m 10.129.0.50 master-2 <none> 2/2 numaresourcesoperator-master-zm79n 2/2 Running 0 20m 10.128.0.44 master-1 <none> 2/2 numaresourcesoperator-worker-cnf-gqlmd 2/2 Running 0 4m27s 10.128.2.21 worker-0 <none> 2/2运行以下命令,确认 NUMA Resources Operator 已收集并报告指定组中所有节点的 NUMA 拓扑数据:
$ oc get noderesourcetopologies.topology.node.k8s.io输出示例:
NAME AGE worker-0 6m11s master-0 22m master-1 21m master-2 21m节点的
NodeResourceTopology资源存在确认 NUMA Resources Operator 能够在其上调度 pod 以收集数据,从而启用拓扑感知调度。运行以下命令检查单个节点资源拓扑:
$ oc get noderesourcetopologies <master_node_name> -o yaml输出示例:
apiVersion: topology.node.k8s.io/v1alpha2 attributes: - name: nodeTopologyPodsFingerprint value: pfp0v001ef46db3751d8e999 - name: nodeTopologyPodsFingerprintMethod value: with-exclusive-resources - name: topologyManagerScope value: container - name: topologyManagerPolicy value: single-numa-node kind: NodeResourceTopology metadata: annotations: k8stopoawareschedwg/rte-update: periodic topology.node.k8s.io/fingerprint: pfp0v001ef46db3751d8e999 creationTimestamp: "2025-09-23T10:18:34Z" generation: 1 name: master-0 resourceVersion: "58173" uid: 35c0d27e-7d9f-43d3-bab9-2ebc0d385861 zones: - costs: - name: node-0 value: 10 name: node-0 resources: - allocatable: "3" available: "2" capacity: "4" name: cpu - allocatable: "1476189952" available: "1378189952" capacity: "1576189952" name: memory type: Node具有 master 角色的节点存在此资源可证明 NUMA Resources Operator 能够将其发现 pod 部署到该节点上。这些 pod 是收集 NUMA 拓扑数据的内容,它们只能调度到被视为可以调度的节点上。
输出确认 master 节点可以调度的步骤成功,因为 NUMA Resources Operator 现已收集并报告该特定 control plane 节点的 NUMA 相关信息。
12.8. 可选:为 NUMA 资源更新配置轮询操作
由 NUMA Resources Operator 控制的守护进程在其 nodeGroup 轮询资源以检索有关可用 NUMA 资源的更新。您可以通过在 NUMAResourcesOperator 自定义资源 (CR) 中配置 spec.nodeGroups 规格来微调这些守护进程的轮询操作。这提供了对轮询操作的高级控制。配置这些规格,以改进调度行为,并对子优化调度决策进行故障排除。
配置选项如下:
-
infoRefreshMode:确定轮询 kubelet 的触发器条件。NUMA Resources Operator 向 API 服务器报告生成的信息。 -
infoRefreshPeriod:确定轮询更新之间的持续时间。 podsFingerprinting: 确定节点上当前运行的当前 pod 集合的时间点信息是否公开,以轮询更新。注意podsFingerprinting的默认值为EnabledExclusiveResources。要优化调度程序性能,请将podFingerprinting设置为EnabledExclusiveResources或Enabled。另外,在NUMAResourcesScheduler自定义资源(CR) 中将cacheResyncPeriod配置为大于 0 的值。cacheResyncPeriod规格有助于通过监控节点上的待处理资源来报告更准确的资源可用性。
先决条件
-
安装 OpenShift CLI(
oc)。 -
以具有
cluster-admin特权的用户身份登录。 - 安装 NUMA Resources Operator。
流程
在
NUMAResourcesOperatorCR 中配置spec.nodeGroups规格:apiVersion: nodetopology.openshift.io/v1 kind: NUMAResourcesOperator metadata: name: numaresourcesoperator spec: nodeGroups: - config: infoRefreshMode: Periodic1 infoRefreshPeriod: 10s2 podsFingerprinting: Enabled3 name: worker- 1
- 有效值为
Periodic、Event、PeriodicAndEvents。使用Periodic根据您在infoRefreshPeriod中定义的间隔轮询 kubelet。使用Events在每个 pod 生命周期事件时轮询 kubelet。使用PeriodicAndEvents启用这两种方法。 - 2
- 为
Periodic或PeriodicAndEvents刷新模式定义轮询间隔。如果刷新模式是Events,则忽略该字段。 - 3
- 有效值为
Enabled,Disabled, 和EnabledExclusiveResources。设置为Enabled或EnabledExclusiveResources是NUMAResourcesScheduler中的cacheResyncPeriod规格的要求。
验证
部署 NUMA Resources Operator 后,运行以下命令来验证节点组配置是否已应用:
$ oc get numaresop numaresourcesoperator -o json | jq '.status'输出示例
... "config": { "infoRefreshMode": "Periodic", "infoRefreshPeriod": "10s", "podsFingerprinting": "Enabled" }, "name": "worker" ...
12.9. 对 NUMA 感知调度进行故障排除
要排除 NUMA 感知 pod 调度的常见问题,请执行以下步骤。
先决条件
-
安装 OpenShift Container Platform CLI(
oc)。 - 以具有 cluster-admin 权限的用户身份登录。
- 安装 NUMA Resources Operator 并部署 NUMA 感知辅助调度程序。
流程
运行以下命令,验证
noderesourcetopologiesCRD 是否已在集群中部署:$ oc get crd | grep noderesourcetopologies输出示例
NAME CREATED AT noderesourcetopologies.topology.node.k8s.io 2022-01-18T08:28:06Z运行以下命令,检查 NUMA-aware 调度程序名称是否与 NUMA 感知工作负载中指定的名称匹配:
$ oc get numaresourcesschedulers.nodetopology.openshift.io numaresourcesscheduler -o json | jq '.status.schedulerName'输出示例
topo-aware-scheduler验证 NUMA-aware schedulable 节点是否应用了
noderesourcetopologiesCR。运行以下命令:$ oc get noderesourcetopologies.topology.node.k8s.io输出示例
NAME AGE compute-0.example.com 17h compute-1.example.com 17h注意节点数应该等于机器配置池 (
mcp) worker 定义中配置的 worker 节点数量。运行以下命令,验证所有 schedulable 节点的 NUMA 区粒度:
$ oc get noderesourcetopologies.topology.node.k8s.io -o yaml输出示例
apiVersion: v1 items: - apiVersion: topology.node.k8s.io/v1 kind: NodeResourceTopology metadata: annotations: k8stopoawareschedwg/rte-update: periodic creationTimestamp: "2022-06-16T08:55:38Z" generation: 63760 name: worker-0 resourceVersion: "8450223" uid: 8b77be46-08c0-4074-927b-d49361471590 topologyPolicies: - SingleNUMANodeContainerLevel zones: - costs: - name: node-0 value: 10 - name: node-1 value: 21 name: node-0 resources: - allocatable: "38" available: "38" capacity: "40" name: cpu - allocatable: "134217728" available: "134217728" capacity: "134217728" name: hugepages-2Mi - allocatable: "262352048128" available: "262352048128" capacity: "270107316224" name: memory - allocatable: "6442450944" available: "6442450944" capacity: "6442450944" name: hugepages-1Gi type: Node - costs: - name: node-0 value: 21 - name: node-1 value: 10 name: node-1 resources: - allocatable: "268435456" available: "268435456" capacity: "268435456" name: hugepages-2Mi - allocatable: "269231067136" available: "269231067136" capacity: "270573244416" name: memory - allocatable: "40" available: "40" capacity: "40" name: cpu - allocatable: "1073741824" available: "1073741824" capacity: "1073741824" name: hugepages-1Gi type: Node - apiVersion: topology.node.k8s.io/v1 kind: NodeResourceTopology metadata: annotations: k8stopoawareschedwg/rte-update: periodic creationTimestamp: "2022-06-16T08:55:37Z" generation: 62061 name: worker-1 resourceVersion: "8450129" uid: e8659390-6f8d-4e67-9a51-1ea34bba1cc3 topologyPolicies: - SingleNUMANodeContainerLevel zones:1 - costs: - name: node-0 value: 10 - name: node-1 value: 21 name: node-0 resources:2 - allocatable: "38" available: "38" capacity: "40" name: cpu - allocatable: "6442450944" available: "6442450944" capacity: "6442450944" name: hugepages-1Gi - allocatable: "134217728" available: "134217728" capacity: "134217728" name: hugepages-2Mi - allocatable: "262391033856" available: "262391033856" capacity: "270146301952" name: memory type: Node - costs: - name: node-0 value: 21 - name: node-1 value: 10 name: node-1 resources: - allocatable: "40" available: "40" capacity: "40" name: cpu - allocatable: "1073741824" available: "1073741824" capacity: "1073741824" name: hugepages-1Gi - allocatable: "268435456" available: "268435456" capacity: "268435456" name: hugepages-2Mi - allocatable: "269192085504" available: "269192085504" capacity: "270534262784" name: memory type: Node kind: List metadata: resourceVersion: "" selfLink: ""
12.9.1. 报告的资源可用性更精确
启用 cacheResyncPeriod 规格,以帮助 NUMA Resource Operator 通过监控节点上的待处理资源,并在调度程序缓存中同步此信息,以帮助 NUMA Resource Operator 报告更准确的资源可用性。这也有助于减少 Topology Affinity Error 错误,因为未优化调度决策。间隔越低,网络负载越大。cacheResyncPeriod 规格默认禁用。
先决条件
-
安装 OpenShift CLI(
oc)。 -
以具有
cluster-admin特权的用户身份登录。
流程
删除当前运行的
NUMAResourcesScheduler资源:运行以下命令来获取活跃的
NUMAResourcesScheduler:$ oc get NUMAResourcesScheduler输出示例
NAME AGE numaresourcesscheduler 92m运行以下命令来删除二级调度程序资源:
$ oc delete NUMAResourcesScheduler numaresourcesscheduler输出示例
numaresourcesscheduler.nodetopology.openshift.io "numaresourcesscheduler" deleted
将以下 YAML 保存到文件
nro-scheduler-cacheresync.yaml中。本例将日志级别更改为Debug:apiVersion: nodetopology.openshift.io/v1 kind: NUMAResourcesScheduler metadata: name: numaresourcesscheduler spec: imageSpec: "registry.redhat.io/openshift4/noderesourcetopology-scheduler-container-rhel8:v4.20" cacheResyncPeriod: "5s"1 - 1
- 为调度程序缓存同步输入间隔值(以秒为单位)。值
5s通常用于大多数实现。
运行以下命令来创建更新的
NUMAResourcesScheduler资源:$ oc create -f nro-scheduler-cacheresync.yaml输出示例
numaresourcesscheduler.nodetopology.openshift.io/numaresourcesscheduler created
验证步骤
检查 NUMA-aware 调度程序是否已成功部署:
运行以下命令检查 CRD 是否已成功创建:
$ oc get crd | grep numaresourcesschedulers输出示例
NAME CREATED AT numaresourcesschedulers.nodetopology.openshift.io 2022-02-25T11:57:03Z运行以下命令,检查新的自定义调度程序是否可用:
$ oc get numaresourcesschedulers.nodetopology.openshift.io输出示例
NAME AGE numaresourcesscheduler 3h26m
检查调度程序的日志是否显示增加的日志级别:
运行以下命令,获取在
openshift-numaresources命名空间中运行的 pod 列表:$ oc get pods -n openshift-numaresources输出示例
NAME READY STATUS RESTARTS AGE numaresources-controller-manager-d87d79587-76mrm 1/1 Running 0 46h numaresourcesoperator-worker-5wm2k 2/2 Running 0 45h numaresourcesoperator-worker-pb75c 2/2 Running 0 45h secondary-scheduler-7976c4d466-qm4sc 1/1 Running 0 21m运行以下命令,获取二级调度程序 pod 的日志:
$ oc logs secondary-scheduler-7976c4d466-qm4sc -n openshift-numaresources输出示例
... I0223 11:04:55.614788 1 reflector.go:535] k8s.io/client-go/informers/factory.go:134: Watch close - *v1.Namespace total 11 items received I0223 11:04:56.609114 1 reflector.go:535] k8s.io/client-go/informers/factory.go:134: Watch close - *v1.ReplicationController total 10 items received I0223 11:05:22.626818 1 reflector.go:535] k8s.io/client-go/informers/factory.go:134: Watch close - *v1.StorageClass total 7 items received I0223 11:05:31.610356 1 reflector.go:535] k8s.io/client-go/informers/factory.go:134: Watch close - *v1.PodDisruptionBudget total 7 items received I0223 11:05:31.713032 1 eventhandlers.go:186] "Add event for scheduled pod" pod="openshift-marketplace/certified-operators-thtvq" I0223 11:05:53.461016 1 eventhandlers.go:244] "Delete event for scheduled pod" pod="openshift-marketplace/certified-operators-thtvq"
12.9.2. 更改高性能工作负载运行的位置
NUMA 感知辅助调度程序负责在 worker 节点上调度高性能工作负载,并在可以最佳处理工作负载的 NUMA 节点上调度。默认情况下,二级调度程序将工作负载分配给所选 worker 节点(具有最多可用资源)中的 NUMA 节点。
如果要更改工作负载的运行位置,您可以将 scoringStrategy 设置添加到 NUMAResourcesScheduler 自定义资源中,并将其值设为 MostAllocated 或 BalancedAllocation。
先决条件
-
安装 OpenShift CLI(
oc)。 -
以具有
cluster-admin特权的用户身份登录。
流程
使用以下步骤删除当前运行的
NUMAResourcesScheduler资源:运行以下命令来获取活跃的
NUMAResourcesScheduler:$ oc get NUMAResourcesScheduler输出示例
NAME AGE numaresourcesscheduler 92m运行以下命令来删除二级调度程序资源:
$ oc delete NUMAResourcesScheduler numaresourcesscheduler输出示例
numaresourcesscheduler.nodetopology.openshift.io "numaresourcesscheduler" deleted
将以下 YAML 保存到文件
nro-scheduler-mostallocated.yaml中。这个示例将scoringStrategy改为MostAllocated:apiVersion: nodetopology.openshift.io/v1 kind: NUMAResourcesScheduler metadata: name: numaresourcesscheduler spec: imageSpec: "registry.redhat.io/openshift4/noderesourcetopology-scheduler-container-rhel8:v{product-version}" scoringStrategy: type: "MostAllocated"1 - 1
- 如果省略
scoringStrategy配置,则应用默认的LeastAllocated。
运行以下命令来创建更新的
NUMAResourcesScheduler资源:$ oc create -f nro-scheduler-mostallocated.yaml输出示例
numaresourcesscheduler.nodetopology.openshift.io/numaresourcesscheduler created
验证
使用以下步骤检查 NUMA 感知调度程序是否已成功部署:
运行以下命令检查自定义资源定义(CRD)是否已成功创建:
$ oc get crd | grep numaresourcesschedulers输出示例
NAME CREATED AT numaresourcesschedulers.nodetopology.openshift.io 2022-02-25T11:57:03Z运行以下命令,检查新的自定义调度程序是否可用:
$ oc get numaresourcesschedulers.nodetopology.openshift.io输出示例
NAME AGE numaresourcesscheduler 3h26m
运行以下命令,检查调度程序的相关
ConfigMap资源,验证ScoringStrategy是否已正确应用:$ oc get -n openshift-numaresources cm topo-aware-scheduler-config -o yaml | grep scoring -A 1输出示例
scoringStrategy: type: MostAllocated
12.9.3. 检查 NUMA 感知调度程序日志
通过查看日志来排除 NUMA 感知调度程序的问题。如果需要,可以通过修改 NUMAResourcesScheduler 资源的 spec.logLevel 字段来增加调度程序日志级别。可接受值为 Normal、Debug 和 Trace,其中 Trace 是最详细的选项。
要更改辅助调度程序的日志级别,请删除正在运行的调度程序资源,并使用更改后的日志级别重新部署它。在此停机期间,调度程序无法调度新的工作负载。
先决条件
-
安装 OpenShift CLI(
oc)。 -
以具有
cluster-admin特权的用户身份登录。
流程
删除当前运行的
NUMAResourcesScheduler资源:运行以下命令来获取活跃的
NUMAResourcesScheduler:$ oc get NUMAResourcesScheduler输出示例
NAME AGE numaresourcesscheduler 90m运行以下命令来删除二级调度程序资源:
$ oc delete NUMAResourcesScheduler numaresourcesscheduler输出示例
numaresourcesscheduler.nodetopology.openshift.io "numaresourcesscheduler" deleted
将以下 YAML 保存到文件
nro-scheduler-debug.yaml中。本例将日志级别更改为Debug:apiVersion: nodetopology.openshift.io/v1 kind: NUMAResourcesScheduler metadata: name: numaresourcesscheduler spec: imageSpec: "registry.redhat.io/openshift4/noderesourcetopology-scheduler-container-rhel8:v4.20" logLevel: Debug运行以下命令,创建更新的
DebugloggingNUMAResourcesScheduler资源:$ oc create -f nro-scheduler-debug.yaml输出示例
numaresourcesscheduler.nodetopology.openshift.io/numaresourcesscheduler created
验证步骤
检查 NUMA-aware 调度程序是否已成功部署:
运行以下命令检查 CRD 是否已成功创建:
$ oc get crd | grep numaresourcesschedulers输出示例
NAME CREATED AT numaresourcesschedulers.nodetopology.openshift.io 2022-02-25T11:57:03Z运行以下命令,检查新的自定义调度程序是否可用:
$ oc get numaresourcesschedulers.nodetopology.openshift.io输出示例
NAME AGE numaresourcesscheduler 3h26m
检查调度程序的日志是否显示增加的日志级别:
运行以下命令,获取在
openshift-numaresources命名空间中运行的 pod 列表:$ oc get pods -n openshift-numaresources输出示例
NAME READY STATUS RESTARTS AGE numaresources-controller-manager-d87d79587-76mrm 1/1 Running 0 46h numaresourcesoperator-worker-5wm2k 2/2 Running 0 45h numaresourcesoperator-worker-pb75c 2/2 Running 0 45h secondary-scheduler-7976c4d466-qm4sc 1/1 Running 0 21m运行以下命令,获取二级调度程序 pod 的日志:
$ oc logs secondary-scheduler-7976c4d466-qm4sc -n openshift-numaresources输出示例
... I0223 11:04:55.614788 1 reflector.go:535] k8s.io/client-go/informers/factory.go:134: Watch close - *v1.Namespace total 11 items received I0223 11:04:56.609114 1 reflector.go:535] k8s.io/client-go/informers/factory.go:134: Watch close - *v1.ReplicationController total 10 items received I0223 11:05:22.626818 1 reflector.go:535] k8s.io/client-go/informers/factory.go:134: Watch close - *v1.StorageClass total 7 items received I0223 11:05:31.610356 1 reflector.go:535] k8s.io/client-go/informers/factory.go:134: Watch close - *v1.PodDisruptionBudget total 7 items received I0223 11:05:31.713032 1 eventhandlers.go:186] "Add event for scheduled pod" pod="openshift-marketplace/certified-operators-thtvq" I0223 11:05:53.461016 1 eventhandlers.go:244] "Delete event for scheduled pod" pod="openshift-marketplace/certified-operators-thtvq"
12.9.4. 对资源拓扑 exporter 进行故障排除
通过检查对应的 resource-topology-exporter 日志,对发生意外结果的 noderesourcetopologlogies 对象进行故障排除。
建议为它们引用的节点命名 NUMA 资源拓扑导出器实例。例如,名为 worker 的 worker 节点应具有对应的 noderesourcetopologies 对象,称为 worker。
先决条件
-
安装 OpenShift CLI(
oc)。 -
以具有
cluster-admin特权的用户身份登录。
流程
获取由 NUMA Resources Operator 管理的守护进程集(daemonset)。每个守护进程在
NUMAResourcesOperatorCR 中有一个对应的nodeGroup。运行以下命令:$ oc get numaresourcesoperators.nodetopology.openshift.io numaresourcesoperator -o jsonpath="{.status.daemonsets[0]}"输出示例
{"name":"numaresourcesoperator-worker","namespace":"openshift-numaresources"}使用上一步中的
name值获取所需的守护进程集的标签:$ oc get ds -n openshift-numaresources numaresourcesoperator-worker -o jsonpath="{.spec.selector.matchLabels}"输出示例
{"name":"resource-topology"}运行以下命令,使用
resource-topology标签获取 pod:$ oc get pods -n openshift-numaresources -l name=resource-topology -o wide输出示例
NAME READY STATUS RESTARTS AGE IP NODE numaresourcesoperator-worker-5wm2k 2/2 Running 0 2d1h 10.135.0.64 compute-0.example.com numaresourcesoperator-worker-pb75c 2/2 Running 0 2d1h 10.132.2.33 compute-1.example.com检查与您要故障排除的节点对应的 worker pod 上运行的
resource-topology-exporter容器的日志。运行以下命令:$ oc logs -n openshift-numaresources -c resource-topology-exporter numaresourcesoperator-worker-pb75c输出示例
I0221 13:38:18.334140 1 main.go:206] using sysinfo: reservedCpus: 0,1 reservedMemory: "0": 1178599424 I0221 13:38:18.334370 1 main.go:67] === System information === I0221 13:38:18.334381 1 sysinfo.go:231] cpus: reserved "0-1" I0221 13:38:18.334493 1 sysinfo.go:237] cpus: online "0-103" I0221 13:38:18.546750 1 main.go:72] cpus: allocatable "2-103" hugepages-1Gi: numa cell 0 -> 6 numa cell 1 -> 1 hugepages-2Mi: numa cell 0 -> 64 numa cell 1 -> 128 memory: numa cell 0 -> 45758Mi numa cell 1 -> 48372Mi
12.9.5. 更正缺少的资源拓扑 exporter 配置映射
如果您在配置了集群设置的集群中安装 NUMA Resources Operator,在有些情况下,Operator 会显示为 active,但资源拓扑 exporter (RTE) 守护进程集 pod 的日志显示 RTE 的配置缺失,例如:
Info: couldn't find configuration in "/etc/resource-topology-exporter/config.yaml"
此日志消息显示集群中未正确应用带有所需配置的 kubeletconfig,从而导致缺少 RTE configmap。例如,以下集群缺少 numaresourcesoperator-worker configmap 自定义资源 (CR):
$ oc get configmap输出示例
NAME DATA AGE
0e2a6bd3.openshift-kni.io 0 6d21h
kube-root-ca.crt 1 6d21h
openshift-service-ca.crt 1 6d21h
topo-aware-scheduler-config 1 6d18h
在正确配置的集群中,oc get configmap 也会返回一个 numaresourcesoperator-worker configmap CR。
先决条件
-
安装 OpenShift Container Platform CLI(
oc)。 - 以具有 cluster-admin 权限的用户身份登录。
- 安装 NUMA Resources Operator 并部署 NUMA 感知辅助调度程序。
流程
使用以下命令,比较
kubeletconfig中的spec.machineConfigPoolSelector.matchLabels值和MachineConfigPool(mcp) worker CR 中的metadata.labels的值:运行以下命令来检查
kubeletconfig标签:$ oc get kubeletconfig -o yaml输出示例
machineConfigPoolSelector: matchLabels: cnf-worker-tuning: enabled运行以下命令来检查
mcp标签:$ oc get mcp worker -o yaml输出示例
labels: machineconfiguration.openshift.io/mco-built-in: "" pools.operator.machineconfiguration.openshift.io/worker: ""cnf-worker-tuning: enabled标签没有存在于MachineConfigPool对象中。
编辑
MachineConfigPoolCR 使其包含缺少的标签,例如:$ oc edit mcp worker -o yaml输出示例
labels: machineconfiguration.openshift.io/mco-built-in: "" pools.operator.machineconfiguration.openshift.io/worker: "" cnf-worker-tuning: enabled- 应用标签更改并等待集群应用更新的配置。运行以下命令:
验证
检查是否应用了缺少的
numaresourcesoperator-workerconfigmapCR:$ oc get configmap输出示例
NAME DATA AGE 0e2a6bd3.openshift-kni.io 0 6d21h kube-root-ca.crt 1 6d21h numaresourcesoperator-worker 1 5m openshift-service-ca.crt 1 6d21h topo-aware-scheduler-config 1 6d18h
12.9.6. 收集 NUMA Resources Operator 数据
您可以使用 oc adm must-gather CLI 命令来收集有关集群的信息,包括与 NUMA Resources Operator 关联的功能和对象。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。 -
已安装 OpenShift CLI(
oc)。
流程
要使用
must-gather来收集 NUMA Resources Operator 数据,您必须指定 NUMA Resources Operatormust-gather镜像。$ oc adm must-gather --image=registry.redhat.io/openshift4/numaresources-must-gather-rhel9:v4.20
第 13 章 可扩展性和性能优化
13.1. 优化存储
优化存储有助于最小化所有资源中的存储使用。通过优化存储,管理员可帮助确保现有存储资源以高效的方式工作。
13.1.1. 可用的持久性存储选项
了解持久性存储选项,以便可以优化 OpenShift Container Platform 环境。
| 存储类型 | 描述 | 例子 |
|---|---|---|
| Block |
| AWS EBS 和 VMware vSphere 支持在 OpenShift Container Platform 中的原生动态持久性卷 (PV) 置备 。 |
| File |
| RHEL NFS、NetApp NFS [1] 和供应商 NFS |
| 对象 |
| AWS S3 |
- NetApp NFS 在使用 Trident 插件时支持动态 PV 置备。
13.1.2. 推荐的可配置存储技术
下表总结了为给定的 OpenShift Container Platform 集群应用程序推荐的可配置存储技术。
| 存储类型 | Block | File | 对象 |
|---|---|---|---|
|
1
2 3 Prometheus 是用于指标数据的底层技术。 4 这不适用于物理磁盘、虚拟机物理磁盘、VMDK 、NFS 回送、AWS EBS 和 Azure 磁盘。
5 对于指标数据,使用 6 用于日志记录,请参阅为日志存储配置持久性存储中的推荐存储解决方案。使用 NFS 存储作为持久性卷或通过 NAS (如 Gluster)可能会破坏数据。因此,OpenShift Container Platform Logging 中的 Elasticsearch 存储和 LokiStack 日志存储不支持 NFS。您必须为每个日志存储使用一个持久性卷类型。 7 对象存储不会通过 OpenShift Container Platform 的 PV 或 PVC 使用。应用程序必须与对象存储 REST API 集成。 | |||
| ROX1 | Yes4 | Yes4 | 是 |
| RWX2 | 否 | 是 | 是 |
| Registry | 可配置 | 可配置 | 推荐的 |
| 扩展的 registry | 无法配置 | 可配置 | 推荐的 |
| Metrics3 | 推荐的 | Configurable5 | 无法配置 |
| Elasticsearch Logging | 推荐的 | Configurable6 | 不支持6 |
| Loki Logging | 无法配置 | 无法配置 | 推荐的 |
| Apps | 推荐的 | 推荐的 | Not configurable7 |
扩展的容器镜像仓库(registry)是一个 OpenShift 镜像 registry,它有两个或更多个 pod 运行副本。
13.1.2.1. 特定应用程序存储建议
测试显示在 Red Hat Enterprise Linux(RHEL) 中使用 NFS 服务器作为核心服务的存储后端的问题。这包括 OpenShift Container Registry 和 Quay,Prometheus 用于监控存储,以及 Elasticsearch 用于日志存储。因此,不建议使用 RHEL NFS 作为 PV 后端用于核心服务。
市场上的其他 NFS 实现可能没有这些问题。如需了解更多与此问题相关的信息,请联络相关的 NFS 厂商。
13.1.2.1.1. Registry
在非扩展的/高可用性 (HA) OpenShift 镜像 registry 集群部署中:
- 存储技术不需要支持 RWX 访问模式。
- 存储技术必须保证读写一致性。
- 首选存储技术是对象存储,然后是块存储。
- 对于应用于生产环境工作负载的 OpenShift 镜像 Registry 集群部署,我们不推荐使用文件存储。
13.1.2.1.2. 扩展的 registry
在扩展的/HA OpenShift 镜像 registry 集群部署中:
- 存储技术必须支持 RWX 访问模式。
- 存储技术必须保证读写一致性。
- 首选存储技术是对象存储。
- 支持 Red Hat OpenShift Data Foundation, Amazon Simple Storage Service (Amazon S3), Google Cloud Storage (GCS), Microsoft Azure Blob Storage, 和 OpenStack Swift。
- 对象存储应该兼容 S3 或 Swift。
- 对于非云平台,如 vSphere 和裸机安装,唯一可配置的技术是文件存储。
- 块存储是不可配置的。
- 支持将网络文件系统(NFS)存储与 OpenShift Container Platform 搭配使用。但是,将 NFS 存储与扩展 registry 搭配使用可能会导致已知问题。如需更多信息,请参阅红帽知识库解决方案,是否在生产阶段中对 OpenShift 集群内部组件支持 NFS?
13.1.2.1.3. 指标
在 OpenShift Container Platform 托管的 metrics 集群部署中:
- 首选存储技术是块存储。
- 对象存储是不可配置的。
在带有生产环境负载的托管 metrics 集群部署中不推荐使用文件存储。
13.1.2.1.4. 日志记录
在 OpenShift Container Platform 托管的日志集群部署中:
Loki Operator:
- 首选存储技术是 S3 兼容对象存储。
- 块存储是不可配置的。
OpenShift Elasticsearch Operator:
- 首选存储技术是块存储。
- 不支持对象存储。
自日志记录版本 5.4.3 起,OpenShift Elasticsearch Operator 已被弃用,计划在以后的发行版本中删除。红帽将在当前发行生命周期中提供对这个功能的程序漏洞修复和支持,但这个功能将不再获得改进,并将被删除。您可以使用 Loki Operator 作为 OpenShift Elasticsearch Operator 的替代方案来管理默认日志存储。
13.1.2.1.5. 应用程序
应用程序的用例会根据不同应用程序而不同,如下例所示:
- 支持动态 PV 部署的存储技术的挂载时间延迟较低,且不与节点绑定来支持一个健康的集群。
- 应用程序开发人员需要了解应用程序对存储的要求,以及如何与所需的存储一起工作以确保应用程序扩展或者与存储层交互时不会出现问题。
13.1.2.2. 其他特定的应用程序存储建议
不建议在 Write 密集型工作负载(如 etcd )中使用 RAID 配置。如果您使用 RAID 配置运行 etcd,您可能会遇到工作负载性能问题的风险。
- Red Hat OpenStack Platform(RHOSP)Cinder: RHOSP Cinder 倾向于在 ROX 访问模式用例中使用。
- 数据库:数据库(RDBMS 、nosql DBs 等等)倾向于使用专用块存储来获得最好的性能。
- etcd 数据库必须具有足够的存储和适当的性能容量才能启用大型集群。有关监控和基准测试工具的信息,以建立基本存储和高性能环境,请参阅 推荐 etcd 实践。
13.1.3. 数据存储管理
下表总结了 OpenShift Container Platform 组件写入数据的主要目录。
| 目录 | 备注 | 大小 | 预期增长 |
|---|---|---|---|
| /var/log | 所有组件的日志文件。 | 10 到 30 GB。 | 日志文件可能会快速增长 ; 大小可以通过增加磁盘或使用日志轮转来管理。 |
| /var/lib/etcd | 用于存储数据库的 etcd 存储。 | 小于 20 GB。 数据库可增大到 8 GB。 | 随着环境增长会缓慢增长。只存储元数据。 每多加 8 GB 内存需要额外 20-25 GB。 |
| /var/lib/containers | 这是 CRI-O 运行时的挂载点。用于活跃容器运行时的存储,包括 Pod 和本地镜像存储。不适用于 registry 存储。 | 有 16 GB 内存的节点需要 50 GB。请注意,这个大小不应该用于决定最小集群要求。 每多加 8 GB 内存需要额外 20-25 GB。 | 增长受运行容器容量的限制。 |
| /var/lib/kubelet | pod 的临时卷(Ephemeral volume)存储。这包括在运行时挂载到容器的任何外部存储。包括环境变量、kube secret 和不受持久性卷支持的数据卷。 | 可变 | 如果需要存储的 pod 使用持久性卷,则最小。如果使用临时存储,可能会快速增长。 |
13.1.4. 为 Microsoft Azure 优化存储性能
OpenShift Container Platform 和 Kubernetes 对磁盘性能敏感,建议使用更快的存储,特别是 control plane 节点上的 etcd。
对于生产环境 Azure 集群和带有密集型工作负载的集群,control plane 机器的虚拟机操作系统磁盘应该可以保持经过测试和推荐的最小吞吐量 5000 IOPS / 200MBps。此吞吐量可以通过至少 1 TiB Premium SSD (P30) 提供。在 Azure 和 Azure Stack Hub 中,磁盘性能直接依赖于 SSD 磁盘大小。要达到 Standard_D8s_v3 虚拟机或者其它类似机器类型,目标为 5000 IOPS,至少需要 P30 磁盘。
在读取数据时,主机缓存必须设置为 ReadOnly,以实现低延迟和高 IOPS 和吞吐量。从缓存中读取数据(在虚拟机内存或本地 SSD 磁盘上)比从磁盘读取速度要快得多,而这在 blob 存储中。
13.2. 优化路由
OpenShift Container Platform HAProxy 路由器可以扩展或配置以优化性能。
13.2.1. Ingress Controller(router)性能的基线
OpenShift Container Platform Ingress Controller 或路由器是使用路由和入口配置的应用程序和服务的入口流量的入站点。
当根据每秒处理的 HTTP 请求来评估单个 HAProxy 路由器性能时,其性能取决于多个因素。特别是:
- HTTP keep-alive/close 模式
- 路由类型
- 对 TLS 会话恢复客户端的支持
- 每个目标路由的并行连接数
- 目标路由数
- 后端服务器页面大小
- 底层基础架构(网络、CPU 等)
具体环境中的性能会有所不同,红帽实验室在一个有 4 个 vCPU/16GB RAM 的公有云实例中进行测试。一个 HAProxy 路由器处理由后端终止的 100 个路由服务提供 1kB 静态页面,每秒处理以下传输数。
在 HTTP 的 keep-alive 模式下:
| Encryption | LoadBalancerService | HostNetwork |
|---|---|---|
| none | 21515 | 29622 |
| edge | 16743 | 22913 |
| passthrough | 36786 | 53295 |
| re-encrypt | 21583 | 25198 |
在 HTTP 关闭(无 keep-alive)情境中:
| Encryption | LoadBalancerService | HostNetwork |
|---|---|---|
| none | 5719 | 8273 |
| edge | 2729 | 4069 |
| passthrough | 4121 | 5344 |
| re-encrypt | 2320 | 2941 |
默认 Ingress Controller 配置用于将 spec.tuningOptions.threadCount 字段设置为 4。测试了两个不同的端点发布策略: Load Balancer Service 和 Host Network。TLS 会话恢复用于加密路由。使用 HTTP keep-alive 设置,单个 HAProxy 路由器可在页面大小小到 8 kB 时充满 1 Gbit NIC。
当在使用现代处理器的裸机中运行时,性能可以期望达到以上公有云实例测试性能的大约两倍。这个开销是由公有云的虚拟化层造成的,基于私有云虚拟化的环境也会有类似的开销。下表是有关在路由器后面的应用程序数量的指导信息:
| 应用程序数量 | 应用程序类型 |
|---|---|
| 5-10 | 静态文件/web 服务器或者缓存代理 |
| 100-1000 | 生成动态内容的应用程序 |
取决于所使用的技术,HAProxy 通常可支持最多 1000 个程序的路由。Ingress Controller 性能可能会受其后面的应用程序的能力和性能的限制,如使用的语言,静态内容或动态内容。
如果有多个服务于应用程序的 Ingress 或路由器,则应该使用路由器分片(router sharding)以帮助横向扩展路由层。
如需有关 Ingress 分片的更多信息,请参阅 使用路由标签和使用命名空间标签和配置 Ingress Controller 分片。
您可以修改 Ingress Controller 部署,根据 Setting Ingress Controller thread count(对于线程)和 Ingress Controller configuration parameters(对于超时)的内容,以及其他 Ingress Controller 规格中的其他调优配置。
13.2.2. 配置 Ingress Controller 存活度、就绪度和启动探测
集群管理员可为由 OpenShift Container Platform Ingress Controller(路由器)管理的路由器部署配置 kubelet 存活度、就绪度和启动探测的超时值。路由器的存活度和就绪度探测使用默认值 1 秒,这在网络或运行时性能严重降级时太短。探测超时可能会导致中断应用程序连接的路由器重启。设置较大的超时值可以降低不必要的和不需要的重启的风险。
您可以更新路由器容器的 livenessProbe、readinessProbe 和 startProbe 参数上的 timeoutSeconds 值。
| 参数 | 描述 |
|---|---|
|
|
|
|
|
|
|
|
|
timeout 配置选项是一个高级调优技术,可用于解决问题。但是,最终应该诊断这些问题,并可能为导致探测超时的所有问题打开支持问题单或 JIRA 问题。
以下示例演示了如何直接修补默认路由器部署来为存活度和就绪度探测设置 5 秒超时:
$ oc -n openshift-ingress patch deploy/router-default --type=strategic --patch='{"spec":{"template":{"spec":{"containers":[{"name":"router","livenessProbe":{"timeoutSeconds":5},"readinessProbe":{"timeoutSeconds":5}}]}}}}'验证
$ oc -n openshift-ingress describe deploy/router-default | grep -e Liveness: -e Readiness:
Liveness: http-get http://:1936/healthz delay=0s timeout=5s period=10s #success=1 #failure=3
Readiness: http-get http://:1936/healthz/ready delay=0s timeout=5s period=10s #success=1 #failure=313.2.3. 配置 HAProxy 重新加载间隔
当您更新路由或与路由关联的端点时,OpenShift Container Platform 路由器会更新 HAProxy 的配置。然后,HAProxy 重新加载更新后的配置以使这些更改生效。当 HAProxy 重新加载时,它会生成一个使用更新的配置来处理新连接的新进程。
HAProxy 保持旧进程正在运行,以处理现有连接,直到这些连接都关闭。当旧进程有长期连接时,这些进程可能会累积并消耗资源。
默认最小 HAProxy 重新加载间隔为 5 秒。您可以使用 spec.tuningOptions.reloadInterval 字段配置 Ingress Controller,以设置较长的重新载入间隔。
为最低 HAProxy 重新加载间隔设置较大的值可能会导致观察路由及其端点更新产生延迟。要降低风险,请避免设置值超过更新可容忍的延迟。
流程
运行以下命令,将默认 Ingress Controller 的最小 HAProxy 重新加载间隔改为 15 秒:
$ oc -n openshift-ingress-operator patch ingresscontrollers/default --type=merge --patch='{"spec":{"tuningOptions":{"reloadInterval":"15s"}}}'
13.3. 优化网络
OVN-Kubernetes 使用 Generic Network Virtualization Encapsulation (Geneve),一个类似于 Geneve 的协议,用于在节点间为流量提供隧道。可以使用网络接口控制器 (NIC) 卸载来调优此网络。
Geneve 提供了比 VLAN 更多的好处,如网络从 4096 增加到一千六百万,以及跨物理网络的第 2 层连接。这允许服务后的所有 pod 相互通信,即使它们在不同系统中运行也是如此。
运行 OpenShift Container Platform 的云、虚拟和裸机环境可在进行最少调优配置的情况下获得高的 NIC 功能百分比。使用带有 Geneve 隧道的 OVN-Kubernetes 可以有效地处理高吞吐量的流量并扩展(例如,使用 100 Gbps NIC),并进行扩展(例如,添加更多 NIC),而无需特殊配置。
在最大效率至关重要的某些高性能场景中,目标性能调优可帮助优化 CPU 使用量、减少开销并确保您完全使用 NIC 的功能。
对于最大吞吐量和 CPU 效率至关重要的环境,您可以使用以下策略进一步优化性能:
-
使用
iPerf3和k8s-netperf等工具验证网络性能。这些工具允许您跨 pod 和节点接口对每秒吞吐量、延迟和数据包每秒(PPS)进行基准测试。 - 评估 OVN-Kubernetes 用户定义的网络(UDN)路由技术,如边框网关协议(BGP)。
- 使用 Geneve-offload 功能的网络适配器。Geneve-offload 将数据包校验和相关的 CPU 开销从系统 CPU 移动到网络适配器的专用硬件中。这会释放 Pod 和应用程序使用的 CPU 周期,并允许用户利用其网络基础架构的全部带宽。
13.3.1. 为您的网络优化 MTU
有两个重要的最大传输单元 (MTU):网络接口控制器 (NIC) MTU 和集群网络 MTU。
NIC MTU 在 OpenShift Container Platform 安装时配置,您也可以将集群的 MTU 更改为安装后任务。如需更多信息,请参阅"删除集群网络 MTU"。
对于使用 OVN-Kubernetes 插件的集群,MTU 必须小于 100 字节,以获得网络 NIC 的最大支持值。如果您要优化吞吐量,请选择最大可能的值,如 8900。如果您要优化最小延迟,请选择一个较低值。
如果您的集群使用 OVN-Kubernetes 插件,并且网络使用 NIC 来通过网络发送和接收未碎片的巨型巨型帧数据包,则必须将 9000 字节指定为 NIC 的 MTU 值,以便 pod 不会失败。
13.3.2. 安装大型集群的实践建议
在安装大型集群或将现有的集群扩展到较大规模时,请在安装集群在 install-config.yaml 文件中相应地设置集群网络 cidr :
带有大量节点数的集群的网络配置的 install-config.yaml 文件示例
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
machineNetwork:
- cidr: 10.0.0.0/16
networkType: OVNKubernetes
serviceNetwork:
- 172.30.0.0/16
如果集群的节点数超过 500 个,则无法使用默认的集群网络 cidr 10.128.0.0/14。cidr 必须设置为 10.128.0.0/12 或 10.128.0.0/10,以达到超过 500 个节点的更大的节点数。
13.3.3. IPsec 的影响
因为加密和解密节点主机使用 CPU 电源,所以启用加密时,无论使用的 IP 安全系统是什么,性能都会影响节点上的吞吐量和 CPU 使用量。
IPsec 在到达 NIC 前,会在 IP 有效负载级别加密流量,以保护用于 NIC 卸载的字段。这意味着,在启用 IPSec 时,一些 NIC 加速功能可能无法使用,并可能导致吞吐量降低并增加 CPU 用量。
13.4. 使用挂载命名空间封装优化 CPU 使用量
您可以使用 mount 命名空间封装来优化 OpenShift Container Platform 集群中的 CPU 使用量,以便为 kubelet 和 CRI-O 进程提供私有命名空间。这可减少 systemd 使用的集群 CPU 资源,且功能没有差别。
挂载命名空间封装只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅以下链接:
13.4.1. 封装挂载命名空间
挂载命名空间用于隔离挂载点,以便不同命名空间中的进程无法查看彼此的文件。封装是将 Kubernetes 挂载命名空间移到备选位置的过程,这些位置不会由主机操作系统不断扫描。
主机操作系统使用 systemd 持续扫描所有挂载命名空间:标准 Linux 挂载和 Kubernetes 用来操作的大量挂载。kubelet 和 CRI-O 的当前实现都使用所有容器运行时和 kubelet 挂载点的顶级命名空间。但是,在私有命名空间中封装这些特定于容器的挂载点可减少 systemd 开销,且功能没有差别。为 CRI-O 和 kubelet 使用单独的挂载命名空间可以封装来自任何 systemd 或其他主机操作系统交互的容器特定挂载。
现在,所有 OpenShift Container Platform 管理员都可以获得潜在的 CPU 优化功能。封装也可以通过将 Kubernetes 特定的挂载点存储在非特权用户安全检查的位置来提高安全性。
下图显示了封装之前和之后的 Kubernetes 安装。这两种场景演示了具有双向、主机到容器和 none 挂载传播设置的示例容器。
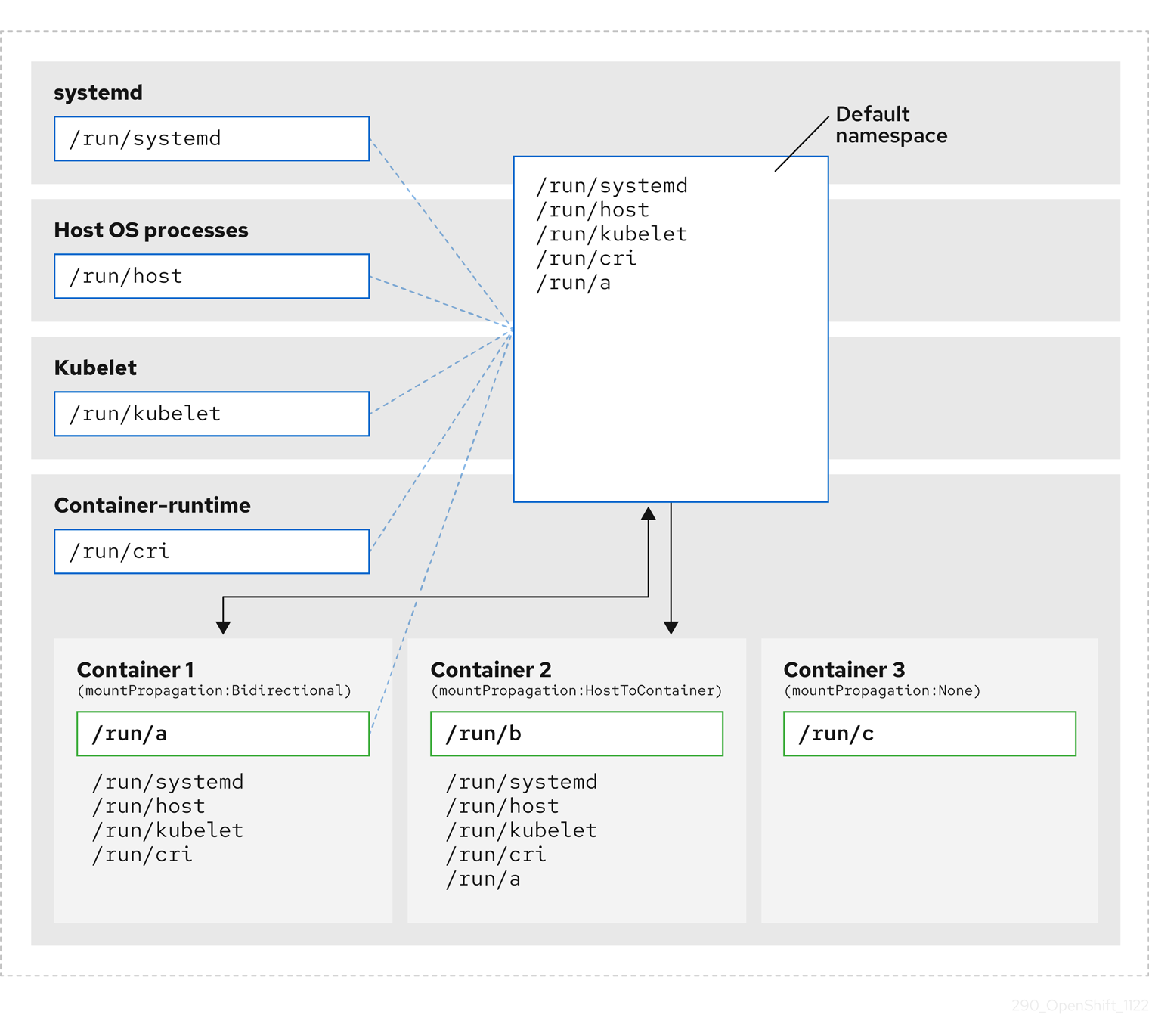
在这里,我们看到 systemd、主机操作系统进程、kubelet 和容器运行时共享单个挂载命名空间。
- systemd、主机操作系统进程、kubelet 和容器运行时都可以访问所有挂载点和可见性。
-
容器 1 (使用双向挂载传播配置)可以访问 systemd 和主机挂载、kubelet 和 CRI-O 挂载。源自容器 1 的挂载(如
/run/a)对于 systemd、主机操作系统进程、kubelet、容器运行时和其他配置了主机的容器或双向挂载传播(如在容器 2 中)可见。 -
容器 2 (使用 host-to-container 挂载传播配置)可以访问 systemd 和主机挂载、kubelet 和 CRI-O 挂载。源自容器 2 的挂载(如
/run/b)对任何其他上下文都不可见。 -
容器 3 没有配置挂载传播,对外部挂载点没有可见性。源自容器 3 的挂载(如
/run/c)对任何其他上下文都不可见。
下图演示了封装后的系统状态。
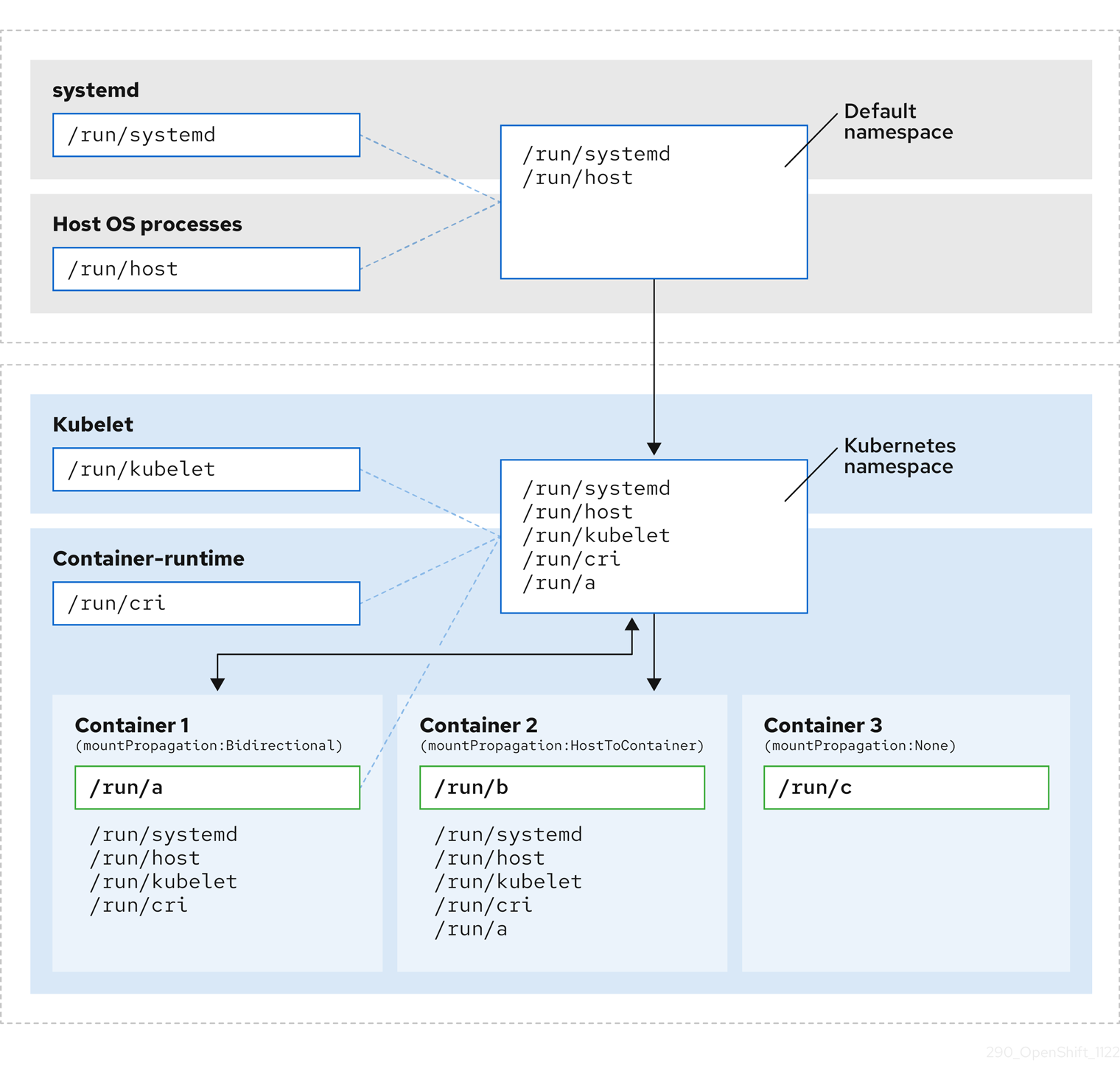
- 主 systemd 进程不再被禁止对特定于 Kubernetes 的挂载点进行不必要的扫描。它仅监控特定于 systemd 和主机挂载点。
- 主机操作系统进程只能访问 systemd 和主机挂载点。
- 为 CRI-O 和 kubelet 使用单独的挂载命名空间,可将所有特定于容器的挂载完全独立于任何 systemd 或其他主机操作系统交互。
-
容器 1 的行为保持不变,但它创建的挂载(如
/run/a)不再对 systemd 或主机操作系统进程可见。仍然对 kubelet、CRI-O 和其他配置了主机到容器或双向挂载传播的容器(如 Container 2)可见。 - 容器 2 和容器 3 的行为不会改变。
13.4.2. 配置挂载命名空间封装
您可以配置挂载命名空间封装,以便集群以较少的资源开销运行。
挂载命名空间封装是一个技术预览功能,它默认是禁用的。要使用它,您必须手动启用该功能。
先决条件
-
已安装 OpenShift CLI(
oc)。 -
您已以具有
cluster-admin权限的用户身份登录。
流程
使用以下 YAML 创建名为
mount_namespace_config.yaml的文件:apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 99-kubens-master spec: config: ignition: version: 3.2.0 systemd: units: - enabled: true name: kubens.service --- apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 99-kubens-worker spec: config: ignition: version: 3.2.0 systemd: units: - enabled: true name: kubens.service运行以下命令来应用挂载命名空间
MachineConfigCR:$ oc apply -f mount_namespace_config.yaml输出示例
machineconfig.machineconfiguration.openshift.io/99-kubens-master created machineconfig.machineconfiguration.openshift.io/99-kubens-worker createdMachineConfigCR 最多可能需要 30 分钟才能完成在集群中应用。您可以运行以下命令来检查MachineConfigCR 的状态:$ oc get mcp输出示例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-03d4bc4befb0f4ed3566a2c8f7636751 False True False 3 0 0 0 45m worker rendered-worker-10577f6ab0117ed1825f8af2ac687ddf False True False 3 1 1运行以下命令,等待所有 control plane 和 worker 节点成功应用
MachineConfigCR:$ oc wait --for=condition=Updated mcp --all --timeout=30m输出示例
machineconfigpool.machineconfiguration.openshift.io/master condition met machineconfigpool.machineconfiguration.openshift.io/worker condition met
验证
要验证集群主机的封装,请运行以下命令:
打开集群主机的默认 shell:
$ oc debug node/<node_name>打开
chroot会话:sh-4.4# chroot /host检查 systemd 挂载命名空间:
sh-4.4# readlink /proc/1/ns/mnt输出示例
mnt:[4026531953]检查 kubelet 挂载命名空间:
sh-4.4# readlink /proc/$(pgrep kubelet)/ns/mnt输出示例
mnt:[4026531840]检查 CRI-O 挂载命名空间:
sh-4.4# readlink /proc/$(pgrep crio)/ns/mnt输出示例
mnt:[4026531840]
这些命令返回与 systemd、kubelet 和容器运行时关联的挂载命名空间。在 OpenShift Container Platform 中,容器运行时是 CRI-O。
如果 systemd 位于 kubelet 和 CRI-O 的挂载命名空间中,则封装生效,如上例中所示。如果所有三个进程都位于同一挂载命名空间中,则封装无效。
13.4.3. 检查封装的命名空间
您可以使用 Red Hat Enterprise Linux CoreOS (RHCOS) 中的 kubensenter 脚本检查集群主机操作系统中特定于 Kubernetes 的挂载点以进行调试或审核目的。
到集群主机的 SSH shell 会话位于 default 命名空间中。要在 SSH shell 提示符中检查特定于 Kubernetes 的挂载点,您需要以 root 用户身份运行 kubensenter 脚本。kubensenter 脚本了解挂载封装的状态,即使未启用封装,也可以安全地运行。
默认情况下,oc debug 远程 shell 会话在 Kubernetes 命名空间内启动。使用 oc debug 时,您不需要运行 kubensenter 来检查挂载点。
如果没有启用封装功能,kubensenter findmnt 和 findmnt 命令会返回相同的输出,无论它们是否在 oc debug 会话或 SSH shell 提示符中运行。
先决条件
-
已安装 OpenShift CLI(
oc)。 -
您已以具有
cluster-admin权限的用户身份登录。 - 您已配置了到集群主机的 SSH 访问。
流程
打开到集群主机的远程 SSH shell。例如:
$ ssh core@<node_name>以 root 用户身份使用提供的
kubensenter脚本运行命令。要在 Kubernetes 命名空间中运行单个命令,请为kubensenter脚本提供命令和任何参数。例如,要在 Kubernetes 命名空间中运行findmnt命令,请运行以下命令:[core@control-plane-1 ~]$ sudo kubensenter findmnt输出示例
kubensenter: Autodetect: kubens.service namespace found at /run/kubens/mnt TARGET SOURCE FSTYPE OPTIONS / /dev/sda4[/ostree/deploy/rhcos/deploy/32074f0e8e5ec453e56f5a8a7bc9347eaa4172349ceab9c22b709d9d71a3f4b0.0] | xfs rw,relatime,seclabel,attr2,inode64,logbufs=8,logbsize=32k,prjquota shm tmpfs ...要在 Kubernetes 命名空间中启动新的交互式 shell,请运行没有任何参数的
kubensenter脚本:[core@control-plane-1 ~]$ sudo kubensenter输出示例
kubensenter: Autodetect: kubens.service namespace found at /run/kubens/mnt
13.4.4. 在封装的命名空间中运行额外的服务
任何依赖于可以在主机操作系统中运行的能力,以及由 kubelet、CRI-O 或容器本身创建的挂载点的监控工具,都必须输入容器挂载命名空间来查看这些挂载点。OpenShift Container Platform 提供的 kubensenter 脚本在 Kubernetes 挂载点中执行另一个命令,并可用于适配任何现有工具。
kubensenter 脚本了解挂载封装功能状态,即使未启用封装功能,也可以安全地运行。在这种情况下,脚本会在默认挂载命名空间中执行提供的命令。
例如,如果 systemd 服务需要在新的 Kubernetes 挂载命名空间中运行,请编辑服务文件,并使用带有 kubensenter 的 ExecStart= 命令行。
[Unit]
Description=Example service
[Service]
ExecStart=/usr/bin/kubensenter /path/to/original/command arg1 arg2第 14 章 管理裸机主机
在裸机集群中安装 OpenShift Container Platform 时,您可以使用机器(machine)和机器集(machineset)自定义资源(CR)为集群中存在的裸机主机置备和管理裸机节点。
14.1. 关于裸机主机和节点
要将 Red Hat Enterprise Linux CoreOS(RHCOS)裸机主机置备为集群中的节点,首先创建一个与裸机主机硬件对应的 MachineSet 自定义资源(CR)对象。裸机主机计算机器集描述了特定于您的配置的基础架构组件。将特定的 Kubernetes 标签应用于这些计算机器集,然后将基础架构组件更新为仅在那些机器上运行。
当您扩展包含 metal3.io/autoscale-to-hosts 注解的相关 MachineSet 时,Machine CR 会被自动创建。OpenShift Container Platform 使用 Machine CR 来置备与 MachineSet CR 中指定的主机对应的裸机节点。
14.2. 维护裸机主机
您可从 OpenShift Container Platform Web 控制台维护集群中的裸机主机详情。导航到 Compute → Bare Metal Hosts,然后从 Actions 下拉菜单中选择一个任务。您可以在此处管理诸如 BMC 详情、主机的引导 MAC 地址、启用电源管理等项目。您还可以查看主机的网络接口和驱动器详情。
您可以将裸机主机移入维护模式。当您将主机移入维护模式时,调度程序会将所有受管工作负载从对应的裸机节点中移出。在处于维护模式时不会调度新的工作负载。
您可以在 web 控制台中取消置备裸机主机。取消置备主机执行以下操作:
-
使用
cluster.k8s.io/delete-machine: true注解裸机主机 CR - 缩减相关的计算机器集
在不先将守护进程集和未管理的静态 pod 移动到另一节点的情况下,关闭主机电源可能会导致服务中断和数据丢失。
14.2.1. 使用 web 控制台在集群中添加裸机主机
您可以在 web 控制台中在集群中添加裸机主机。
先决条件
- 在裸机上安装 RHCOS 集群。
-
以具有
cluster-admin特权的用户身份登录。
流程
- 在 web 控制台中,导航到 Compute → Bare Metal Hosts。
- 选择 Add Host → New with Dialog。
- 为新的裸机主机指定唯一名称。
- 设置 引导 MAC 地址。
- 设置 基板管理控制台(BMC)地址.
- 输入主机的基板管理控制器(BMC)的用户凭据。
- 选择在创建后打开主机电源,然后选择 Create。
- 向上扩展副本数,以匹配可用的裸机主机数量。导航到 Compute → MachineSets,然后从 Actions 下拉菜单中选择 Edit Machine count 来增加集群中的机器副本数量。
您还可以使用 oc scale 命令和适当的裸机计算机器集来管理裸机节点的数量。
14.2.2. 在 web 控制台中使用 YAML 在集群中添加裸机主机
您可以使用描述裸机主机的 YAML 文件在 web 控制台中在集群中添加裸机主机。
先决条件
- 在裸机基础架构上安装 RHCOS 计算机器,以便在集群中使用。
-
以具有
cluster-admin特权的用户身份登录。 -
为裸机主机创建
SecretCR。
流程
- 在 web 控制台中,导航到 Compute → Bare Metal Hosts。
- 选择 Add Host → New from YAML。
复制并粘贴以下 YAML,使用您的主机详情修改相关字段:
apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: <bare_metal_host_name> spec: online: true bmc: address: <bmc_address> credentialsName: <secret_credentials_name>1 disableCertificateVerification: True2 bootMACAddress: <host_boot_mac_address>- 选择 Create 以保存 YAML 并创建新的裸机主机。
向上扩展副本数,以匹配可用的裸机主机数量。导航到 Compute → MachineSets,然后从 Actions 下拉菜单中选择 Edit Machine count 来增加集群中的机器数量。
注意您还可以使用
oc scale命令和适当的裸机计算机器集来管理裸机节点的数量。
14.2.3. 自动将机器扩展到可用的裸机主机数量
要自动创建与可用 BareMetalHost 对象数量匹配的 Machine 对象数量,请在 MachineSet 对象中添加 metal3.io/autoscale-to-hosts 注解。
先决条件
-
安装 RHCOS 裸机计算机器以在集群中使用,并创建对应的
BareMetalHost对象。 -
安装 OpenShift Container Platform CLI(
oc)。 -
以具有
cluster-admin特权的用户身份登录。
流程
通过添加
metal3.io/autoscale-to-hosts注解来注解您要配置的用于自动扩展的计算机器集。将<machineset>替换为计算机器设置的名称。$ oc annotate machineset <machineset> -n openshift-machine-api 'metal3.io/autoscale-to-hosts=<any_value>'等待新的缩放计算机启动。
当您使用 BareMetalHost 对象在集群中创建机器时,BareMetalHost 上更改了标签或选择器,BareMetalHost 对象仍然会根据创建 Machine 对象的 MachineSet 进行计数。
14.2.4. 从 provisioner 节点中删除裸机主机
在某些情况下,您可能想要从 provisioner 节点临时删除裸机主机。例如,在使用 OpenShift Container Platform 管理控制台或机器配置池更新触发裸机主机重启时,OpenShift Container Platform 日志会登录到集成的 Dell Remote Access Controller (iDrac),并发出删除作业队列。
要防止管理与可用 BareMetalHost 对象数量匹配的 Machine 对象数量,请在 MachineSet 对象中添加 baremetalhost.metal3.io/detached 注解。
这个注解只适用于处于 Provisioned, ExternallyProvisioned 或 Ready/Available 状态的 BareMetalHost 对象。
先决条件
-
安装 RHCOS 裸机计算机器以在集群中使用,并创建对应的
BareMetalHost对象。 -
安装 OpenShift Container Platform CLI(
oc)。 -
以具有
cluster-admin特权的用户身份登录。
流程
通过添加
baremetalhost.metal3.io/detached注解来注解您要从 provisioner 节点中删除的计算机器集。$ oc annotate machineset <machineset> -n openshift-machine-api 'baremetalhost.metal3.io/detached'等待新机器启动。
注意当您使用
BareMetalHost对象在集群中创建机器时,BareMetalHost上更改了标签或选择器,BareMetalHost对象仍然会根据创建Machine对象的MachineSet进行计数。在置备用例中,使用以下命令在重启完成后删除注解:
$ oc annotate machineset <machineset> -n openshift-machine-api 'baremetalhost.metal3.io/detached-'
14.2.5. 关闭裸机主机电源
您可以在 web 控制台中关闭裸机集群主机,或使用 OpenShift CLI (oc)应用集群中的补丁。在关闭主机前,您应该将节点标记为不可调度,并排空节点上的所有 pod 和工作负载。
先决条件
- 您已在裸机基础架构上安装了 RHCOS 计算机器,以便在集群中使用。
-
您已以具有
cluster-admin权限的用户身份登录。 -
您已将主机配置为 managed,并为集群主机添加了 BMC 凭证。您可以通过在集群中应用
Secret自定义资源(CR)或登录到 web 控制台并配置裸机主机,来添加 BMC 凭证。
流程
在 Web 控制台中,将您要关闭的节点标记为不可调度。执行以下步骤:
- 进入到 Nodes,再选择您要关闭的节点。展开 Actions 菜单,再选择 Mark as unschedulable。
- 通过调整 pod 部署或将节点上的工作负载缩减为零,手动删除或重新定位节点上运行 pod。等待排空过程完成。
- 进入到 Compute → Bare Metal Hosts。
- 展开您要关闭的裸机主机的 Options 菜单,然后选择 Power Off。选择 Immediate power off。
另外,您可以使用
oc修补您要关闭的主机的BareMetalHost资源。获取受管裸机主机的名称。运行以下命令:
$ oc get baremetalhosts -n openshift-machine-api -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.provisioning.state}{"\n"}{end}'输出示例
master-0.example.com managed master-1.example.com managed master-2.example.com managed worker-0.example.com managed worker-1.example.com managed worker-2.example.com managed将节点标记为不可调度:
$ oc adm cordon <bare_metal_host>1 - 1
<bare_metal_host>是您要关闭的主机,如worker-2.example.com。
排空节点上的所有 pod:
$ oc adm drain <bare_metal_host> --force=true由复制控制器支持的 Pod 会重新调度到集群中的其他可用节点。
安全关闭裸机主机。运行以下命令:
$ oc patch <bare_metal_host> --type json -p '[{"op": "replace", "path": "/spec/online", "value": false}]'打开主机后,使节点可为工作负载调度。运行以下命令:
$ oc adm uncordon <bare_metal_host>
第 15 章 巨页的作用及应用程序如何使用它们
15.1. 巨页的作用
内存在块(称为页)中进行管理。在大多数系统中,页的大小为 4Ki。1Mi 内存相当于 256 个页,1Gi 内存相当于 256,000 个页。CPU 有内置的内存管理单元,可在硬件中管理这些页的列表。Translation Lookaside Buffer (TLB) 是虚拟页到物理页映射的小型硬件缓存。如果在硬件指令中包括的虚拟地址可以在 TLB 中找到,则其映射信息可以被快速获得。如果没有包括在 TLN 中,则称为 TLB miss。系统将会使用基于软件的,速度较慢的地址转换机制,从而出现性能降低的问题。因为 TLB 的大小是固定的,因此降低 TLB miss 的唯一方法是增加页的大小。
巨页指一个大于 4Ki 的内存页。在 x86_64 构架中,有两个常见的巨页大小: 2Mi 和 1Gi。在其它构架上的大小会有所不同。要使用巨页,必须写相应的代码以便应用程序了解它们。Transparent Huge Pages(THP)试图在应用程序不需要了解的情况下自动管理巨页,但这个技术有一定的限制。特别是,它的页大小会被限为 2Mi。当有较高的内存使用率时,THP 可能会导致节点性能下降,或出现大量内存碎片(因为 THP 的碎片处理)导致内存页被锁定。因此,有些应用程序可能更适用于(或推荐)使用预先分配的巨页,而不是 THP。
在 OpenShift Container Platform 中,pod 中的应用程序可以分配并消耗预先分配的巨页。
15.2. 应用程序如何使用巨页
节点必须预先分配巨页以便节点报告其巨页容量。一个节点只能预先分配一个固定大小的巨页。
巨页可以使用名为 hugepages-<size> 的容器一级的资源需求被消耗。其中 size 是特定节点上支持的整数值的最精简的二进制标记。例如:如果某个节点支持 2048KiB 页大小,它将会有一个可调度的资源 hugepages-2Mi。与 CPU 或者内存不同,巨页不支持过量分配。
apiVersion: v1
kind: Pod
metadata:
generateName: hugepages-volume-
spec:
containers:
- securityContext:
privileged: true
image: rhel7:latest
command:
- sleep
- inf
name: example
volumeMounts:
- mountPath: /dev/hugepages
name: hugepage
resources:
limits:
hugepages-2Mi: 100Mi
memory: "1Gi"
cpu: "1"
volumes:
- name: hugepage
emptyDir:
medium: HugePages- 1
- 为
巨页指定要分配的准确内存数量。不要将这个值指定为巨页内存大小乘以页的大小。例如,巨页的大小为 2MB,如果应用程序需要使用由巨页组成的 100MB 的内存,则需要分配 50 个巨页。OpenShift Container Platform 会进行相应的计算。如上例所示,您可以直接指定100MB。
分配特定大小的巨页
有些平台支持多个巨页大小。要分配指定大小的巨页,在巨页引导命令参数前使用巨页大小选择参数hugepagesz=<size>。<size> 的值必须以字节为单位,并可以使用一个可选的后缀 [kKmMgG]。默认的巨页大小可使用 default_hugepagesz=<size> 引导参数定义。
巨页要求
- 巨页面请求必须等于限制。如果指定了限制,则它是默认的,但请求不是。
- 巨页在 pod 范围内被隔离。容器隔离功能计划在以后的版本中推出。
-
后端为巨页的
EmptyDir卷不能消耗大于 pod 请求的巨页内存。 -
通过带有
SHM_HUGETLB的shmget()来使用巨页的应用程序,需要运行一个匹配 proc/sys/vm/hugetlb_shm_group 的 supplemental 组。
15.3. 使用 Downward API 消耗巨页资源
您可以使用 Downward API 注入容器消耗的巨页资源的信息。
您可以将资源分配作为环境变量、卷插件或两者都注入。您在容器中开发和运行的应用可以通过读取指定卷中的环境变量或文件来确定可用的资源。
流程
创建一个类似以下示例的
hugepages-volume-pod.yaml文件:apiVersion: v1 kind: Pod metadata: generateName: hugepages-volume- labels: app: hugepages-example spec: containers: - securityContext: capabilities: add: [ "IPC_LOCK" ] image: rhel7:latest command: - sleep - inf name: example volumeMounts: - mountPath: /dev/hugepages name: hugepage - mountPath: /etc/podinfo name: podinfo resources: limits: hugepages-1Gi: 2Gi memory: "1Gi" cpu: "1" requests: hugepages-1Gi: 2Gi env: - name: REQUESTS_HUGEPAGES_1GI \1 valueFrom: resourceFieldRef: containerName: example resource: requests.hugepages-1Gi volumes: - name: hugepage emptyDir: medium: HugePages - name: podinfo downwardAPI: items: - path: "hugepages_1G_request" \2 resourceFieldRef: containerName: example resource: requests.hugepages-1Gi divisor: 1Gi从
hugepages-volume-pod.yaml文件创建 pod:$ oc create -f hugepages-volume-pod.yaml
验证
检查
REQUESTS_HUGEPAGES_1GI环境变量的值:$ oc exec -it $(oc get pods -l app=hugepages-example -o jsonpath='{.items[0].metadata.name}') \ -- env | grep REQUESTS_HUGEPAGES_1GI输出示例
REQUESTS_HUGEPAGES_1GI=2147483648检查
/etc/podinfo/hugepages_1G_request文件的值:$ oc exec -it $(oc get pods -l app=hugepages-example -o jsonpath='{.items[0].metadata.name}') \ -- cat /etc/podinfo/hugepages_1G_request输出示例
2
15.4. 在引导时配置巨页
节点必须预先分配在 OpenShift Container Platform 集群中使用的巨页。保留巨页的方法有两种: 在引导时和在运行时。在引导时进行保留会增加成功的可能性,因为内存还没有很大的碎片。Node Tuning Operator 目前支持在特定节点上分配巨页。
流程
要减少节点重启的情况,请按照以下步骤顺序进行操作:
通过标签标记所有需要相同巨页设置的节点。
$ oc label node <node_using_hugepages> node-role.kubernetes.io/worker-hp=创建一个包含以下内容的文件,并把它命名为
hugepages_tuning.yaml:apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: hugepages1 namespace: openshift-cluster-node-tuning-operator spec: profile:2 - data: | [main] summary=Boot time configuration for hugepages include=openshift-node [bootloader] cmdline_openshift_node_hugepages=hugepagesz=2M hugepages=503 name: openshift-node-hugepages recommend: - machineConfigLabels:4 machineconfiguration.openshift.io/role: "worker-hp" priority: 30 profile: openshift-node-hugepages创建 Tuned
hugepages对象$ oc create -f hugepages-tuned-boottime.yaml创建一个带有以下内容的文件,并把它命名为
hugepages-mcp.yaml:apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: worker-hp labels: worker-hp: "" spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,worker-hp]} nodeSelector: matchLabels: node-role.kubernetes.io/worker-hp: ""创建机器配置池:
$ oc create -f hugepages-mcp.yaml
因为有足够的非碎片内存,worker-hp 机器配置池中的所有节点现在都应分配 50 个 2Mi 巨页。
$ oc get node <node_using_hugepages> -o jsonpath="{.status.allocatable.hugepages-2Mi}"
100MiTuneD bootloader 插件只支持 Red Hat Enterprise Linux CoreOS (RHCOS) worker 节点。
15.5. 禁用透明巨页
Transparent Huge Pages (THP) 会试图自动执行创建、管理和使用巨页的大部分方面。由于 THP 自动管理巨页,因此并不始终对所有类型的工作负载进行最佳处理。THP 可能会导致性能下降,因为许多应用程序都自行处理巨页。因此,请考虑禁用 THP。以下步骤描述了如何使用 Node Tuning Operator (NTO)禁用 THP。
流程
使用以下内容创建文件,并将其命名为
thp-disable-tuned.yaml:apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: thp-workers-profile namespace: openshift-cluster-node-tuning-operator spec: profile: - data: | [main] summary=Custom tuned profile for OpenShift to turn off THP on worker nodes include=openshift-node [vm] transparent_hugepages=never name: openshift-thp-never-worker recommend: - match: - label: node-role.kubernetes.io/worker priority: 25 profile: openshift-thp-never-worker创建 Tuned 对象:
$ oc create -f thp-disable-tuned.yaml检查活跃配置集列表:
$ oc get profile -n openshift-cluster-node-tuning-operator
验证
登录到其中一个节点,并执行常规 THP 检查来验证节点是否成功应用了配置集:
$ cat /sys/kernel/mm/transparent_hugepage/enabled输出示例
always madvise [never]
第 16 章 了解集群节点的低延迟调整
边缘计算在降低延迟和拥塞问题方面具有关键作用,提高了电信和 5G 网络应用程序的应用程序性能。维护具有最低延迟的网络架构是满足 5G 的网络性能要求的关键。对于 4G 技术,平均延迟为 50 ms,5G 的目标是达到 1 ms 或更小的延迟。这个对延迟的降低会将无线网络的吞吐量提高 10 倍。
16.1. 关于低延迟
很多在 Telco 空间部署的应用程序都需要低延迟,它们只能容忍零数据包丢失。针对零数据包丢失进行调节有助于缓解降低网络性能的固有问题。如需更多信息,请参阅 Red Hat OpenStack Platform(RHOSP)中的 Zero Packet Los 调节。
Edge 计算也可用于降低延迟率。将其想象成云边缘,并更接近用户。这可大大减少用户和远程数据中心之间的距离,从而减少应用程序响应时间和性能延迟。
管理员必须能够集中管理多个 Edge 站点和本地服务,以便所有部署都可以以最低的管理成本运行。它们还需要一个简便的方法来部署和配置其集群的某些节点,以实现实时低延迟和高性能目的。低延迟节点对于如 Cloud-native Network Functions(CNF)和 Data Plane Development Kit(DPDK) 等应用程序非常有用。
OpenShift Container Platform 目前提供在 OpenShift Container Platform 集群上调整软件的机制,以获取实时运行和低延迟时间(响应时间小于 20 微秒)。这包括调整内核和 OpenShift Container Platform 设置值、安装内核和重新配置机器。但是这个方法需要设置四个不同的 Operator,并执行很多配置,这些配置在手动完成时比较复杂,并容易出错。
OpenShift Container Platform 使用 Node Tuning Operator 实现自动性能优化,以实现 OpenShift Container Platform 应用程序的低延迟性能。集群管理员使用此性能配置集配置,这有助于以更可靠的方式进行更改。管理员可以指定是否要将内核更新至 kernel-rt,为集群和操作系统日常任务保留 CPU(包括 pod infra 容器),以及隔离 CPU,以便应用程序容器运行工作负载。
OpenShift Container Platform 还支持 Node Tuning Operator 的工作负载提示,它可以微调 PerformanceProfile 以满足不同行业环境的需求。工作负载提示可用于 highPowerConsumption(以增加功耗为代价已实现非常低的延迟),以及 realtime(实现最佳延迟具有高优先级)。对于这些提示使用 true/false 设置的组合来处理特定于应用程序的工作负载配置文件和要求。
工作负载提示简化了行业扇区设置的性能微调。工作负载提示可以满足所有"大小"方法,而是可以将工作负载提示满足使用模式,例如将优先级放在:
- 低延迟
- 实时功能
- 有效地使用电源
理想情况下,所有前面列出的项目都会被优先选择。然而,优先其中一些项目可能会牺牲其他项目的优先级。Node Tuning Operator 现在可以了解工作负载预期并更好地满足工作负载的需求。集群管理员现在可以指定工作负载进入的用例。Node Tuning Operator 使用 PerformanceProfile 来微调工作负载的性能设置。
运行应用程序的环境会影响其行为。对于没有严格的延迟要求的典型数据中心,只需要最小默认调整,它会为某些高性能工作负载 pod 启用 CPU 分区。对于延迟具有更高的优先级的数据中心和工作负载,仍然会采取措施来优化功耗。最复杂的情况是接近对延迟非常敏感的设备的集群,如工厂中的制造设备,以及软件定义的无线电。最后一类部署通常被称为远边缘(Far edge)。对于远边缘部署,以下延迟是最终优先级,且牺牲电源管理。
16.2. 关于低延迟和实时应用程序的超线程
超线程是一个 Intel 处理器技术,它允许物理 CPU 处理器内核作为两个逻辑内核同时执行两个独立的线程。超线程可以为并行处理很有用的某些工作负载类型的系统吞吐量提供更好的系统吞吐量。默认的 OpenShift Container Platform 配置需要启用 Hyper-Threading。
对于电信领域的应用程序,设计您的应用程序架构非常重要,以尽量减小延迟。超线程会降低性能,并严重影响需要低延迟的计算负载的吞吐量。禁用超线程可确保性能的可预测性,并可减少这些工作负载的处理时间。
超线程实现和配置会因运行 OpenShift Container Platform 的硬件而异。如需了解特定于该硬件的超线程实现的更多详情,请参考相关的主机硬件调节信息。禁用超线程可以增加集群的每个内核的成本。
第 17 章 使用性能配置集调整节点以实现低延迟
使用集群性能配置集调整节点以实现低延迟。您可以限制 infra 和应用程序容器的 CPU,配置巨页、Hyper-Threading,并为对延迟敏感的进程配置 CPU 分区。
17.1. 创建性能配置集
您可以使用 Performance Profile Creator (PPC) 工具创建集群性能配置集。PPC 是 Node Tuning Operator 的功能。
PPC 将有关集群的信息与用户提供的配置相结合,以生成适合您的硬件、拓扑和用例的性能配置集。
性能配置集只适用于集群直接访问底层硬件资源的裸机环境。您可以为单节点 OpenShift 和多节点集群配置性能配置集。
以下是在集群中创建和应用性能配置集的高级工作流:
-
为您要使用性能配置为目标的节点创建机器配置池 (MCP)。在单节点 OpenShift 集群中,您必须使用
masterMCP,因为集群中只有一个节点。 -
使用
must-gather命令收集有关集群的信息。 使用 PPC 工具使用以下方法之一创建性能配置集:
- 使用 Podman 运行 PPC 工具。
- 使用 wrapper 脚本运行 PPC 工具。
- 为您的用例配置性能配置集,并将性能配置集应用到集群。
17.1.1. 关于性能配置集创建器
Performance Profile Creator (PPC) 是一个命令行工具,由 Node Tuning Operator 提供,它可帮助您为集群创建性能配置集。
最初,您可以使用 PPC 工具处理 must-gather 数据来显示集群的关键性能配置,包括以下信息:
- 使用分配的 CPU ID 进行 NUMA 单元分区
- 超线程节点配置
您可以使用这些信息来帮助配置性能配置集。
运行 PPC
为 PPC 工具指定性能配置参数,以生成适合您的硬件、拓扑和用例的推荐性能配置集。
您可以使用以下方法之一运行 PPC:
- 使用 Podman 运行 PPC
- 使用 wrapper 脚本运行 PPC
使用 wrapper 脚本将一些更精细的 Podman 任务抽象到可执行脚本中。例如,wrapper 脚本处理诸如拉取和运行所需容器镜像、将目录挂载到容器等任务,并通过 Podman 直接向容器提供参数。两种方法都获得相同的结果。
17.1.2. 为性能调整创建机器配置池到目标节点
对于多节点集群,您可以定义机器配置池 (MCP) 来识别您要使用性能配置集配置的目标节点。
在单节点 OpenShift 集群中,您必须使用 master MCP,因为集群中只有一个节点。您不需要为单节点 OpenShift 集群创建单独的 MCP。
先决条件
-
有
cluster-admin角色访问权限。 -
已安装 OpenShift CLI(
oc)。
流程
运行以下命令为配置标记目标节点:
$ oc label node <node_name> node-role.kubernetes.io/worker-cnf=""1 - 1
- 将
<node_name>替换为节点的名称。本例应用worker-cnf标签。
创建包含目标节点的
MachineConfigPool资源:创建定义
MachineConfigPool资源的 YAML 文件:mcp-worker-cnf.yaml文件示例apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: worker-cnf1 labels: machineconfiguration.openshift.io/role: worker-cnf2 spec: machineConfigSelector: matchExpressions: - { key: machineconfiguration.openshift.io/role, operator: In, values: [worker, worker-cnf], } paused: false nodeSelector: matchLabels: node-role.kubernetes.io/worker-cnf: ""3 运行以下命令来应用
MachineConfigPool资源:$ oc apply -f mcp-worker-cnf.yaml输出示例
machineconfigpool.machineconfiguration.openshift.io/worker-cnf created
验证
运行以下命令,检查集群中的机器配置池:
$ oc get mcp输出示例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-58433c7c3c1b4ed5ffef95234d451490 True False False 3 3 3 0 6h46m worker rendered-worker-168f52b168f151e4f853259729b6azc4 True False False 2 2 2 0 6h46m worker-cnf rendered-worker-cnf-168f52b168f151e4f853259729b6azc4 True False False 1 1 1 0 73s
17.1.3. 为 PPC 收集集群数据
Performance Profile Creator(PPC)工具需要 must-gather 数据。作为集群管理员,运行 must-gather 命令来捕获集群的信息。
先决条件
-
使用具有
cluster-admin角色的用户访问集群。 -
已安装 OpenShift CLI(
oc)。 - 您识别要使用性能配置集配置的目标 MCP。
流程
-
进入存储
must-gather数据的目录。 运行以下命令来收集集群信息:
$ oc adm must-gather该命令在本地目录中创建带有
must-gather数据的文件夹,其命名格式类似如下:must-gather.local.1971646453781853027。可选:从
must-gather目录创建一个压缩文件:$ tar cvaf must-gather.tar.gz <must_gather_folder>1 - 1
- 使用
must-gather数据文件夹的名称替换。
注意如果您正在运行性能配置集 Creator wrapper 脚本,则需要压缩输出。
17.1.4. 使用 Podman 运行 Performance Profile Creator
作为集群管理员,您可以使用带有 Performance Profile Creator (PPC) 的 Podman 来创建性能配置集。
有关 PPC 参数的更多信息,请参阅 "Performance Profile Creator 参数" 部分。
PPC 使用集群中的 must-gather 数据来创建性能配置集。如果您对集群进行任何更改,如重新标记针对性能配置的节点,则必须在再次运行 PPC 前重新创建 must-gather 数据。
先决条件
-
使用具有
cluster-admin角色的用户访问集群。 - 在裸机硬件上安装的集群。
-
已安装
podman和 OpenShift CLI (oc)。 - 访问 Node Tuning Operator 镜像。
- 您识别包含用于配置的目标节点的机器配置池。
-
您可以访问集群的
must-gather数据。
流程
运行以下命令检查机器配置池:
$ oc get mcp输出示例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-58433c8c3c0b4ed5feef95434d455490 True False False 3 3 3 0 8h worker rendered-worker-668f56a164f151e4a853229729b6adc4 True False False 2 2 2 0 8h worker-cnf rendered-worker-cnf-668f56a164f151e4a853229729b6adc4 True False False 1 1 1 0 79m运行以下命令,使用 Podman 向
registry.redhat.io进行身份验证:$ podman login registry.redhat.ioUsername: <user_name> Password: <password>可选:运行以下命令来显示 PPC 工具的帮助信息:
$ podman run --rm --entrypoint performance-profile-creator registry.redhat.io/openshift4/ose-cluster-node-tuning-rhel9-operator:v4.20 -h输出示例
A tool that automates creation of Performance Profiles Available Commands: completion Generate the autocompletion script for the specified shell help Help about any command info requires --must-gather-dir-path, ignores other arguments. [Valid values: log,json] Usage: performance-profile-creator [flags] performance-profile-creator [command] Flags: --disable-ht Disable Hyperthreading --enable-hardware-tuning Enable setting maximum cpu frequencies -h, --help help for performance-profile-creator --mcp-name string MCP name corresponding to the target machines (required) --must-gather-dir-path string Must gather directory path (default "must-gather") --offlined-cpu-count int Number of offlined CPUs --per-pod-power-management Enable Per Pod Power Management --power-consumption-mode string The power consumption mode. [Valid values: default, low-latency, ultra-low-latency] (default "default") --profile-name string Name of the performance profile to be created (default "performance") --reserved-cpu-count int Number of reserved CPUs (required) --rt-kernel Enable Real Time Kernel (required) --split-reserved-cpus-across-numa Split the Reserved CPUs across NUMA nodes --topology-manager-policy string Kubelet Topology Manager Policy of the performance profile to be created. [Valid values: single-numa-node, best-effort, restricted] (default "restricted") --user-level-networking Run with User level Networking(DPDK) enabled Use "performance-profile-creator [command] --help" for more information about a command.要显示集群的信息,请运行以下命令使用
log参数运行 PPC 工具:$ podman run --entrypoint performance-profile-creator -v <path_to_must_gather>:/must-gather:z registry.redhat.io/openshift4/ose-cluster-node-tuning-rhel9-operator:v4.20 info --must-gather-dir-path /must-gather-
--entrypoint performance-profile-creator将性能配置集创建者定义为podman的新入口点。 -v <path_to_must_gather>指定到以下组件之一的路径:-
包含
must-gather数据的目录。 包含
must-gather解压缩的 .tar 文件的现有目录。输出示例
level=info msg="Nodes names targeted by master pool are: " level=info msg="Nodes names targeted by worker-cnf pool are: host2.example.com " level=info msg="Nodes names targeted by worker pool are: host.example.com host1.example.com " level=info msg="Cluster info:" level=info msg="MCP 'master' nodes:" level=info msg=--- level=info msg="MCP 'worker' nodes:" level=info msg="Node: host.example.com (NUMA cells: 1, HT: true)" level=info msg="NUMA cell 0 : [0 1 2 3]" level=info msg="CPU(s): 4" level=info msg="Node: host1.example.com (NUMA cells: 1, HT: true)" level=info msg="NUMA cell 0 : [0 1 2 3]" level=info msg="CPU(s): 4" level=info msg=--- level=info msg="MCP 'worker-cnf' nodes:" level=info msg="Node: host2.example.com (NUMA cells: 1, HT: true)" level=info msg="NUMA cell 0 : [0 1 2 3]" level=info msg="CPU(s): 4" level=info msg=---
-
包含
-
运行以下命令来创建性能配置集。这个示例使用示例 PPC 参数和值:
$ podman run --entrypoint performance-profile-creator -v <path_to_must_gather>:/must-gather:z registry.redhat.io/openshift4/ose-cluster-node-tuning-rhel9-operator:v4.20 --mcp-name=worker-cnf --reserved-cpu-count=1 --rt-kernel=true --split-reserved-cpus-across-numa=false --must-gather-dir-path /must-gather --power-consumption-mode=ultra-low-latency --offlined-cpu-count=1 > my-performance-profile.yaml-v <path_to_must_gather>指定到以下组件之一的路径:-
包含
must-gather数据的目录。 -
包含
must-gather解压缩的 .tar 文件的目录。
-
包含
-
--mcp-name=worker-cnf指定worker-=cnf机器配置池。 -
--reserved-cpu-count=1指定一个保留 CPU。 -
--rt-kernel=true启用实时内核。 -
--split-reserved-cpus-across-numa=false禁用跨 NUMA 节点的保留 CPU 分割。 -
--power-consumption-mode=ultra-low-latency指定最大延迟,这会增加功耗。 --offlined-cpu-count=1指定一个离线 CPU。注意本例中的
mcp-name参数根据oc get mcp命令的输出设置为worker-cnf。对于单节点 OpenShift,请使用--mcp-name=master。输出示例
level=info msg="Nodes targeted by worker-cnf MCP are: [worker-2]" level=info msg="NUMA cell(s): 1" level=info msg="NUMA cell 0 : [0 1 2 3]" level=info msg="CPU(s): 4" level=info msg="1 reserved CPUs allocated: 0 " level=info msg="2 isolated CPUs allocated: 2-3" level=info msg="Additional Kernel Args based on configuration: []"
运行以下命令,查看创建的 YAML 文件:
$ cat my-performance-profile.yaml输出示例
--- apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: cpu: isolated: 2-3 offlined: "1" reserved: "0" machineConfigPoolSelector: machineconfiguration.openshift.io/role: worker-cnf net: userLevelNetworking: false nodeSelector: node-role.kubernetes.io/worker-cnf: "" numa: topologyPolicy: restricted realTimeKernel: enabled: true workloadHints: highPowerConsumption: true perPodPowerManagement: false realTime: true应用生成的配置集:
$ oc apply -f my-performance-profile.yaml输出示例
performanceprofile.performance.openshift.io/performance created
17.1.5. 运行性能配置集 Creator wrapper 脚本
wrapper 脚本简化了使用 Performance Profile Creator (PPC) 工具创建性能配置集的过程。脚本处理诸如拉取和运行所需容器镜像、将目录挂载到容器等任务,并通过 Podman 直接向容器提供参数。
有关 Performance Profile Creator 参数的更多信息,请参阅 "Performance Profile Creator 参数" 部分。
PPC 使用集群中的 must-gather 数据来创建性能配置集。如果您对集群进行任何更改,如重新标记针对性能配置的节点,则必须在再次运行 PPC 前重新创建 must-gather 数据。
先决条件
-
使用具有
cluster-admin角色的用户访问集群。 - 在裸机硬件上安装的集群。
-
已安装
podman和 OpenShift CLI (oc)。 - 访问 Node Tuning Operator 镜像。
- 您识别包含用于配置的目标节点的机器配置池。
-
访问
must-gathertarball。
流程
在本地机器上创建一个文件,例如
run-perf-profile-creator.sh:$ vi run-perf-profile-creator.sh将以下代码粘贴到文件中:
#!/bin/bash readonly CONTAINER_RUNTIME=${CONTAINER_RUNTIME:-podman} readonly CURRENT_SCRIPT=$(basename "$0") readonly CMD="${CONTAINER_RUNTIME} run --entrypoint performance-profile-creator" readonly IMG_EXISTS_CMD="${CONTAINER_RUNTIME} image exists" readonly IMG_PULL_CMD="${CONTAINER_RUNTIME} image pull" readonly MUST_GATHER_VOL="/must-gather" NTO_IMG="registry.redhat.io/openshift4/ose-cluster-node-tuning-rhel9-operator:v4.20" MG_TARBALL="" DATA_DIR="" usage() { print "Wrapper usage:" print " ${CURRENT_SCRIPT} [-h] [-p image][-t path] -- [performance-profile-creator flags]" print "" print "Options:" print " -h help for ${CURRENT_SCRIPT}" print " -p Node Tuning Operator image" print " -t path to a must-gather tarball" ${IMG_EXISTS_CMD} "${NTO_IMG}" && ${CMD} "${NTO_IMG}" -h } function cleanup { [ -d "${DATA_DIR}" ] && rm -rf "${DATA_DIR}" } trap cleanup EXIT exit_error() { print "error: $*" usage exit 1 } print() { echo "$*" >&2 } check_requirements() { ${IMG_EXISTS_CMD} "${NTO_IMG}" || ${IMG_PULL_CMD} "${NTO_IMG}" || \ exit_error "Node Tuning Operator image not found" [ -n "${MG_TARBALL}" ] || exit_error "Must-gather tarball file path is mandatory" [ -f "${MG_TARBALL}" ] || exit_error "Must-gather tarball file not found" DATA_DIR=$(mktemp -d -t "${CURRENT_SCRIPT}XXXX") || exit_error "Cannot create the data directory" tar -zxf "${MG_TARBALL}" --directory "${DATA_DIR}" || exit_error "Cannot decompress the must-gather tarball" chmod a+rx "${DATA_DIR}" return 0 } main() { while getopts ':hp:t:' OPT; do case "${OPT}" in h) usage exit 0 ;; p) NTO_IMG="${OPTARG}" ;; t) MG_TARBALL="${OPTARG}" ;; ?) exit_error "invalid argument: ${OPTARG}" ;; esac done shift $((OPTIND - 1)) check_requirements || exit 1 ${CMD} -v "${DATA_DIR}:${MUST_GATHER_VOL}:z" "${NTO_IMG}" "$@" --must-gather-dir-path "${MUST_GATHER_VOL}" echo "" 1>&2 } main "$@"为这个脚本中的每个人添加执行权限:
$ chmod a+x run-perf-profile-creator.sh运行以下命令,使用 Podman 向
registry.redhat.io进行身份验证:$ podman login registry.redhat.ioUsername: <user_name> Password: <password>可选:运行以下命令来显示 PPC 工具的帮助信息:
$ ./run-perf-profile-creator.sh -h输出示例
Wrapper usage: run-perf-profile-creator.sh [-h] [-p image][-t path] -- [performance-profile-creator flags] Options: -h help for run-perf-profile-creator.sh -p Node Tuning Operator image -t path to a must-gather tarball A tool that automates creation of Performance Profiles Usage: performance-profile-creator [flags] Flags: --disable-ht Disable Hyperthreading -h, --help help for performance-profile-creator --info string Show cluster information; requires --must-gather-dir-path, ignore the other arguments. [Valid values: log, json] (default "log") --mcp-name string MCP name corresponding to the target machines (required) --must-gather-dir-path string Must gather directory path (default "must-gather") --offlined-cpu-count int Number of offlined CPUs --per-pod-power-management Enable Per Pod Power Management --power-consumption-mode string The power consumption mode. [Valid values: default, low-latency, ultra-low-latency] (default "default") --profile-name string Name of the performance profile to be created (default "performance") --reserved-cpu-count int Number of reserved CPUs (required) --rt-kernel Enable Real Time Kernel (required) --split-reserved-cpus-across-numa Split the Reserved CPUs across NUMA nodes --topology-manager-policy string Kubelet Topology Manager Policy of the performance profile to be created. [Valid values: single-numa-node, best-effort, restricted] (default "restricted") --user-level-networking Run with User level Networking(DPDK) enabled --enable-hardware-tuning Enable setting maximum CPU frequencies注意您可以选择使用
-p选项为 Node Tuning Operator 镜像设置路径。如果您没有设置路径,wrapper 脚本使用默认镜像:registry.redhat.io/openshift4/ose-cluster-node-tuning-rhel9-operator:v4.20。要显示集群的信息,请运行以下命令使用
log参数运行 PPC 工具:$ ./run-perf-profile-creator.sh -t /<path_to_must_gather_dir>/must-gather.tar.gz -- --info=log-t /<path_to_must_gather_dir>/must-gather.tar.gz指定包含 must-gather tarball 的目录的路径。这是 wrapper 脚本的必要参数。输出示例
level=info msg="Cluster info:" level=info msg="MCP 'master' nodes:" level=info msg=--- level=info msg="MCP 'worker' nodes:" level=info msg="Node: host.example.com (NUMA cells: 1, HT: true)" level=info msg="NUMA cell 0 : [0 1 2 3]" level=info msg="CPU(s): 4" level=info msg="Node: host1.example.com (NUMA cells: 1, HT: true)" level=info msg="NUMA cell 0 : [0 1 2 3]" level=info msg="CPU(s): 4" level=info msg=--- level=info msg="MCP 'worker-cnf' nodes:" level=info msg="Node: host2.example.com (NUMA cells: 1, HT: true)" level=info msg="NUMA cell 0 : [0 1 2 3]" level=info msg="CPU(s): 4" level=info msg=---
运行以下命令来创建性能配置集。
$ ./run-perf-profile-creator.sh -t /path-to-must-gather/must-gather.tar.gz -- --mcp-name=worker-cnf --reserved-cpu-count=1 --rt-kernel=true --split-reserved-cpus-across-numa=false --power-consumption-mode=ultra-low-latency --offlined-cpu-count=1 > my-performance-profile.yaml本例使用示例 PPC 参数和值。
-
--mcp-name=worker-cnf指定worker-=cnf机器配置池。 -
--reserved-cpu-count=1指定一个保留 CPU。 -
--rt-kernel=true启用实时内核。 -
--split-reserved-cpus-across-numa=false禁用跨 NUMA 节点的保留 CPU 分割。 -
--power-consumption-mode=ultra-low-latency指定最大延迟,这会增加功耗。 --offlined-cpu-count=1指定一个离线 CPU。注意本例中的
mcp-name参数根据oc get mcp命令的输出设置为worker-cnf。对于单节点 OpenShift,请使用--mcp-name=master。
-
运行以下命令,查看创建的 YAML 文件:
$ cat my-performance-profile.yaml输出示例
--- apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: cpu: isolated: 2-3 offlined: "1" reserved: "0" machineConfigPoolSelector: machineconfiguration.openshift.io/role: worker-cnf nodeSelector: node-role.kubernetes.io/worker-cnf: "" numa: topologyPolicy: restricted realTimeKernel: enabled: true workloadHints: highPowerConsumption: true perPodPowerManagement: false realTime: true应用生成的配置集:
$ oc apply -f my-performance-profile.yaml输出示例
performanceprofile.performance.openshift.io/performance created
17.1.6. Performance Profile Creator 参数
| 参数 | 描述 |
|---|---|
|
|
MCP 的名称;例如,与目标机器对应的 |
|
| must gather 目录的路径。
只有在使用 Podman 运行 PPC 工具时才需要此参数。如果您将 PPC 与 wrapper 脚本搭配使用,请不要使用此参数。反之,使用 wrapper 脚本的 |
|
| 保留 CPU 的数量。使用大于零的一个自然数字。 |
|
| 启用实时内核。
可能的值: |
| 参数 | 描述 |
|---|---|
|
| 禁用超线程。
可能的值:
默认值: 警告
如果此参数设为 |
| enable-hardware-tuning | 启用最大 CPU 频率的设置。 要启用此功能,请在以下两个字段中为隔离和保留 CPU 上运行的应用程序设置最大频率:
这是一个高级功能。如果您配置硬件性能优化,则生成的 |
|
|
这会捕获集群信息。这个参数还需要 可能的值:
默认: |
|
| 离线 CPU 数量。 注意 使用大于零的一个自然数字。如果没有足够的逻辑处理器离线,则会记录错误消息。信息是: |
|
| 电源功耗模式。 可能的值:
默认: |
|
|
为每个 pod 电源管理启用。如果您将
可能的值:
默认值: |
|
| 要创建的性能配置集的名称。
默认: |
|
| 将保留的 CPU 划分到 NUMA 节点。
可能的值:
默认值: |
|
| 要创建的性能配置集的 kubelet Topology Manager 策略。 可能的值:
默认: |
|
| 在启用了用户级别网络(DPDK)的情况下运行。
可能的值:
默认值: |
17.1.7. 参考性能配置集
使用以下引用性能配置集作为开发您自己的自定义配置集的基础。
17.1.7.1. 在 OpenStack 上使用 OVS-DPDK 的集群的性能配置集模板
要最大化使用 Open vSwitch 和 Red Hat OpenStack Platform(RHOSP)上的 Data Plane Development Kit(OVS-DPDK)的机器性能,您可以使用性能配置集。
您可以使用以下性能配置集模板为您的部署创建配置集。
使用 OVS-DPDK 的集群的性能配置集模板
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
name: cnf-performanceprofile
spec:
additionalKernelArgs:
- nmi_watchdog=0
- audit=0
- mce=off
- processor.max_cstate=1
- idle=poll
- intel_idle.max_cstate=0
- default_hugepagesz=1GB
- hugepagesz=1G
- intel_iommu=on
cpu:
isolated: <CPU_ISOLATED>
reserved: <CPU_RESERVED>
hugepages:
defaultHugepagesSize: 1G
pages:
- count: <HUGEPAGES_COUNT>
node: 0
size: 1G
nodeSelector:
node-role.kubernetes.io/worker: ''
realTimeKernel:
enabled: false
globallyDisableIrqLoadBalancing: true
插入适用于 CPU_ISOLATED、CPU_RESERVED 和 HUGEPAGES_COUNT 密钥的配置的值。
17.1.7.2. Telco RAN DU 参考设计性能配置集
以下性能配置集在商业硬件上配置 OpenShift Container Platform 集群的节点级性能设置,以托管电信 RAN DU 工作负载。
Telco RAN DU 参考设计性能配置集
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
# if you change this name make sure the 'include' line in TunedPerformancePatch.yaml
# matches this name: include=openshift-node-performance-${PerformanceProfile.metadata.name}
# Also in file 'validatorCRs/informDuValidator.yaml':
# name: 50-performance-${PerformanceProfile.metadata.name}
name: openshift-node-performance-profile
annotations:
ran.openshift.io/reference-configuration: "ran-du.redhat.com"
spec:
additionalKernelArgs:
- "rcupdate.rcu_normal_after_boot=0"
- "efi=runtime"
- "vfio_pci.enable_sriov=1"
- "vfio_pci.disable_idle_d3=1"
- "module_blacklist=irdma"
cpu:
isolated: $isolated
reserved: $reserved
hugepages:
defaultHugepagesSize: $defaultHugepagesSize
pages:
- size: $size
count: $count
node: $node
machineConfigPoolSelector:
pools.operator.machineconfiguration.openshift.io/$mcp: ""
nodeSelector:
node-role.kubernetes.io/$mcp: ''
numa:
topologyPolicy: "restricted"
# To use the standard (non-realtime) kernel, set enabled to false
realTimeKernel:
enabled: true
workloadHints:
# WorkloadHints defines the set of upper level flags for different type of workloads.
# See https://github.com/openshift/cluster-node-tuning-operator/blob/master/docs/performanceprofile/performance_profile.md#workloadhints
# for detailed descriptions of each item.
# The configuration below is set for a low latency, performance mode.
realTime: true
highPowerConsumption: false
perPodPowerManagement: false17.1.7.3. 电信核心参考设计性能配置集
以下性能配置集在商业硬件上为 OpenShift Container Platform 集群配置节点级别的性能设置,以托管电信核心工作负载。
电信核心参考设计性能配置集
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
# if you change this name make sure the 'include' line in TunedPerformancePatch.yaml
# matches this name: include=openshift-node-performance-${PerformanceProfile.metadata.name}
# Also in file 'validatorCRs/informDuValidator.yaml':
# name: 50-performance-${PerformanceProfile.metadata.name}
name: openshift-node-performance-profile
annotations:
ran.openshift.io/reference-configuration: "ran-du.redhat.com"
spec:
additionalKernelArgs:
- "rcupdate.rcu_normal_after_boot=0"
- "efi=runtime"
- "vfio_pci.enable_sriov=1"
- "vfio_pci.disable_idle_d3=1"
- "module_blacklist=irdma"
cpu:
isolated: $isolated
reserved: $reserved
hugepages:
defaultHugepagesSize: $defaultHugepagesSize
pages:
- size: $size
count: $count
node: $node
machineConfigPoolSelector:
pools.operator.machineconfiguration.openshift.io/$mcp: ""
nodeSelector:
node-role.kubernetes.io/$mcp: ''
numa:
topologyPolicy: "restricted"
# To use the standard (non-realtime) kernel, set enabled to false
realTimeKernel:
enabled: true
workloadHints:
# WorkloadHints defines the set of upper level flags for different type of workloads.
# See https://github.com/openshift/cluster-node-tuning-operator/blob/master/docs/performanceprofile/performance_profile.md#workloadhints
# for detailed descriptions of each item.
# The configuration below is set for a low latency, performance mode.
realTime: true
highPowerConsumption: false
perPodPowerManagement: false17.2. 支持的性能配置集 API 版本
Node Tuning Operator 在性能配置集 apiVersion 字段中支持 v2、v1 和 v1alpha1。v1 和 v1alpha1 API 相同。v2 API 包括一个可选的布尔值项 globallyDisableIrqLoadBalancing,默认值为 false。
升级性能配置集以使用设备中断处理
当您将 Node Tuning Operator 性能配置集自定义资源定义(CRD)从 v1 或 v1alpha1 升级到 v2 时,现有配置集会将 globallyDisableIrqLoadBalancing 设置为 true。
globallyDisableIrqLoadBalancing 切换用于 Isolated CPU 集是否禁用了 IRQ 负载均衡。当选项设置为 true 时,它会禁用 Isolated CPU 集的 IRQ 负载均衡。将选项设置为 false 允许在所有 CPU 之间平衡 IRQ。
将 Node Tuning Operator API 从 v1alpha1 升级到 v1
当将 Node Tuning Operator API 版本从 v1alpha1 升级到 v1 时,,v1alpha1 性能配置集会通过"None" Conversion 策略自行转换,并提供给带有 API 版本 v1 的 Performance Addon Operator。
将 Node Tuning Operator API 从 v1alpha1 或 v1 升级到 v2
当从旧的 Node Tuning Operator API 版本升级时,现有的 v1 和 v1alpha1 性能配置集将使用转换 Webhook 转换,它将注入 globallyDisableIrqLoadBalancing 字段,值为 true。
17.3. 使用工作负载提示配置节点功耗和实时处理
流程
-
使用
Performance ProfileCreator (PPC) 工具创建适合环境的硬件和拓扑的 PerformanceProfile。下表描述了为与 PPC 工具关联的power-consumption-mode标志设置的可能值,以及应用的工作负载提示。
| 性能配置集创建器设置 | 提示 | 环境 | 描述 |
|---|---|---|---|
| Default(默认) |
| 没有延迟要求的高吞吐量集群 | 仅通过 CPU 分区实现的性能。 |
| Low-latency |
| 地区数据中心 | 节能和低延迟都需要考虑的:在电源管理、延迟和吞吐量之间进行妥当调节。 |
| Ultra-low-latency |
| 对于远边缘集群,对延迟非常敏感的工作负载 | 实现最小延迟和最大确定性会增加电源消耗的成本。 |
| 每个 pod 电源管理 |
| 关键和非关键工作负载 | 允许每个 pod 进行电源管理。 |
Example
以下配置通常在电信 RAN DU 部署中使用。
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
name: workload-hints
spec:
...
workloadHints:
realTime: true
highPowerConsumption: false
perPodPowerManagement: false - 1
- 禁用一些可能会影响系统延迟的调试和监控功能。
当在性能配置集中将 realTime 工作负载 hint 标志设置为 true 时,将 cpu-quota.crio.io: disable 注解添加到带有固定 CPU 的每个保证 pod。此注解是防止 pod 中进程性能降级所必需的。如果没有明确设置 realTime 工作负载提示,则默认为 true。
有关如何将功耗和实时设置组合会影响延迟的更多信息,请参阅了解工作负载提示。
17.4. 为运行 colocated 高和低优先级工作负载的节点配置节能
您可以为带有低优先级工作负载的节点实现节能,而不影响高优先级工作负载的延迟或吞吐量。无需修改工作负载本身即可进行节能。
Intel Ice Lake 及更新的 Intel CPU 支持该功能。处理器的功能可能会影响高优先级工作负载的延迟和吞吐量。
先决条件
- 您在 BIOS 中启用了 C-states 和操作系统控制的 P-states
流程
将
per-pod-power-management参数设置为true来生成PerformanceProfile:$ podman run --entrypoint performance-profile-creator -v \ /must-gather:/must-gather:z registry.redhat.io/openshift4/ose-cluster-node-tuning-rhel9-operator:v4.20 \ --mcp-name=worker-cnf --reserved-cpu-count=20 --rt-kernel=true \ --split-reserved-cpus-across-numa=false --topology-manager-policy=single-numa-node \ --must-gather-dir-path /must-gather --power-consumption-mode=low-latency \1 --per-pod-power-management=true > my-performance-profile.yaml- 1
- 当
per-pod-power-management参数设置为true时,power-consumption-mode参数必须是default或low-latency。
带有
perPodPowerManagement的PerformanceProfile示例apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: [.....] workloadHints: realTime: true highPowerConsumption: false perPodPowerManagement: true在
PerformanceProfile自定义资源(CR) 中将默认cpufreq调控器设置为附加内核参数:apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: ... additionalKernelArgs: - cpufreq.default_governor=schedutil1 - 1
- 建议使用
schedutil管理器,但您可以使用其他监管器,如ondemand或powersavegovernors。
在
Tuned PerformancePatchCR 中设置最大 CPU 频率:spec: profile: - data: | [sysfs] /sys/devices/system/cpu/intel_pstate/max_perf_pct = <x>1 - 1
max_perf_pct控制cpufreq驱动程序的最大频率,以最大百分比的形式设置支持的 cpu 频率。这个值适用于所有 CPU。您可以检查/sys/devices/system/cpu/cpu0/cpufreq/cpuinfo_max_freq中的最大支持频率。作为起点,您可以使用以All Cores Turbo频率封装所有 CPU 的百分比。All Cores Turbo频率是所有内核在运行的频率,当内核完全占用时。
17.5. 为 infra 和应用程序容器限制 CPU
通用内务处理和工作负载任务使用 CPU 的方式可能会影响对延迟敏感的进程。默认情况下,容器运行时使用所有在线 CPU 一起运行所有容器,这可能导致上下文切换和延迟激增。对 CPU 进行分区可防止无状态进程通过相互分离来干扰对延迟敏感的进程。下表描述了在使用 Node Tuning Operator 调整节点后在 CPU 上运行的进程:
| 进程类型 | 详情 |
|---|---|
|
| 在除了运行低延迟工作负载外的任意 CPU 上运行 |
| 基础架构 pod | 在除了运行低延迟工作负载外的任意 CPU 上运行 |
| 中断 | 重定向到保留的 CPU(OpenShift Container Platform 4.7 及更新的版本中的可选) |
| 内核进程 | 固定保留的 CPU |
| 对延迟敏感的工作负载 pod | 固定到隔离池中的特定专用 CPU |
| OS 进程/systemd 服务 | 固定保留的 CPU |
在一个节点上的对于所有 QoS 进程类型( Burstable、BestEffort 或 Guaranteed )的 pod 的可分配容量等于隔离池的容量。保留池的容量已从节点的总内核容量中删除,供集群和操作系统日常任务使用。
示例 1
节点具有 100 个内核的容量。通过使用性能配置集,集群管理员将 50 个内核分配给隔离池,将 50 个内核分配给保留池。集群管理员为 QoS 为 BestEffort 或 Burstable 的 pod 分配 25 个内核,为 Guaranteed 的 pod 分配 25 个内核。这与隔离池的容量匹配。
示例 2
节点具有 100 个内核的容量。通过使用性能配置集,集群管理员将 50 个内核分配给隔离池,将 50 个内核分配给保留池。集群管理员为 QoS 为 BestEffort 或 Burstable 的 pod 分配一个内核,为 Guaranteed 的 pod 分配 50 个内核。这超过了隔离池容量一个内核。Pod 调度因为 CPU 容量不足而失败。
使用的确切分区模式取决于许多因素,如硬件、工作负载特性和预期的系统负载。以下是一些用例示例:
- 如果对延迟敏感的工作负载使用特定的硬件,如网络接口控制器(NIC),请确保隔离池中的 CPU 尽可能地与这个硬件接近。至少,您应该将工作负载放在同一个非统一内存访问 (NUMA) 节点中。
- 保留的池用于处理所有中断。根据系统网络,分配一个足够大小的保留池来处理所有传入的数据包中断。在 4.20 及更新的版本中,工作负载可以选择性地被标记为敏感版本。
在决定哪些特定 CPU 用于保留和隔离分区时,需要详细分析和测量。设备和内存的 NUMA 紧密度等因素扮演了角色。选择也取决于工作负载架构和具体的用例。
保留和隔离的 CPU 池不得重叠,并且必须一起跨越 worker 节点中的所有可用内核。
为确保内务处理任务和工作负载不会相互干扰,请在性能配置集的 spec 部分指定两组 CPU。
-
isolated- 指定应用程序容器工作负载的 CPU。这些 CPU 的延迟最低。这个组中的进程没有中断,例如,可以达到更高的 DPDK 零数据包丢失带宽。 -
reserved- 为集群和操作系统日常任务指定 CPU。reserved组中的线程经常会比较繁忙。不要在reserved组中运行对延迟敏感的应用程序。对延迟敏感的应用程序在isolated组中运行。
流程
- 创建适合环境硬件和拓扑的性能配置集。
使用您想要为 infra 和应用程序容器保留和隔离的 CPU 添加
reserved和isolated参数:apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: infra-cpus spec: cpu: reserved: "0-4,9"1 isolated: "5-8"2 nodeSelector:3 node-role.kubernetes.io/worker: ""
17.6. 为集群配置超线程
要为 OpenShift Container Platform 集群配置超线程,请将性能配置集中的 CPU 线程设置为为保留或隔离的 CPU 池配置的相同内核。
如果您配置了性能配置集,然后更改主机的超线程配置,请确保更新 PerformanceProfile YAML 中的 CPU isolated 和 reserved字段以匹配新配置。
禁用之前启用的主机超线程配置可能会导致 PerformanceProfile YAML 中列出的 CPU 内核 ID 错误。此不正确的配置可能会导致节点不可用,因为无法找到列出的 CPU。
先决条件
-
使用具有
cluster-admin角色的用户访问集群。 - 安装 OpenShift CLI(oc)。
流程
确定在您要配置的主机的 CPU 上运行哪些线程。
您可以通过登录到集群并运行以下命令来查看在主机 CPU 上运行哪些线程:
$ lscpu --all --extended输出示例
CPU NODE SOCKET CORE L1d:L1i:L2:L3 ONLINE MAXMHZ MINMHZ 0 0 0 0 0:0:0:0 yes 4800.0000 400.0000 1 0 0 1 1:1:1:0 yes 4800.0000 400.0000 2 0 0 2 2:2:2:0 yes 4800.0000 400.0000 3 0 0 3 3:3:3:0 yes 4800.0000 400.0000 4 0 0 0 0:0:0:0 yes 4800.0000 400.0000 5 0 0 1 1:1:1:0 yes 4800.0000 400.0000 6 0 0 2 2:2:2:0 yes 4800.0000 400.0000 7 0 0 3 3:3:3:0 yes 4800.0000 400.0000在这个示例中,在四个物理 CPU 内核中运行了八个逻辑 CPU 内核。CPU0 和 CPU4 在物理 Core0 中运行,CPU1 和 CPU5 在物理 Core 1 中运行,以此类推。
另外要查看为特定物理 CPU 内核设定的线程(以下示例中的
cpu0),打开命令提示符并运行以下命令:$ cat /sys/devices/system/cpu/cpu0/topology/thread_siblings_list输出示例
0-4在
PerformanceProfileYAML 中应用隔离和保留的 CPU。例如,您可以将逻辑内核 CPU0 和 CPU4 设置为isolated;将逻辑内核 CPU1 到 CPU3 以及 CPU5 到 CPU7 设置为reserved。当您配置保留的和隔离的 CPU 时,pod 中的 infra 容器将使用保留的 CPU,应用程序容器则使用隔离的 CPU。... cpu: isolated: 0,4 reserved: 1-3,5-7 ...注意保留和隔离的 CPU 池不得重叠,并且必须一起跨越 worker 节点中的所有可用内核。
大多数 Intel 处理器上默认启用超线程。如果启用超线程,特定内核处理的所有线程都必须被隔离或者在同一个内核中处理。
启用超线程后,所有保证的 pod 都必须使用多个 SMT (simultaneous multi-threading)级别,以避免造成 "noisy neighbor" 的情况并导致 pod 失败。如需更多信息,请参阅静态策略选项。
17.6.1. 为低延迟应用程序禁用超线程
在为低延迟进程配置集群时,请考虑是否要在部署集群前禁用超线程。要禁用 Hyper-Threading,请执行以下步骤:
- 创建一个适合您的硬件和拓扑的性能配置集。
将
nosmt设为附加内核参数。以下示例的性能配置集演示了此设置:apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: example-performanceprofile spec: additionalKernelArgs: - nmi_watchdog=0 - audit=0 - mce=off - processor.max_cstate=1 - idle=poll - intel_idle.max_cstate=0 - nosmt cpu: isolated: 2-3 reserved: 0-1 hugepages: defaultHugepagesSize: 1G pages: - count: 2 node: 0 size: 1G nodeSelector: node-role.kubernetes.io/performance: '' realTimeKernel: enabled: true注意当您配置保留的和隔离的 CPU 时,pod 中的 infra 容器将使用保留的 CPU,应用程序容器则使用隔离的 CPU。
17.7. 管理设备中断处理保证 pod 隔离 CPU
Node Tuning Operator 可以通过将主机 CPU 划分为保留的 CPU 来管理主机 CPU,以进行集群和操作系统日常任务(包括 pod infra 容器),以及用于应用程序容器运行工作负载的隔离 CPU。这可让您将低延迟工作负载的 CPU 设置为隔离状态。
设备中断在所有隔离和保留 CPU 之间平衡负载,以避免出现 CPU 超载问题,但运行有保证 pod 的 CPU 除外。当为 pod 设置相关注解时,保证 pod CPU 无法处理设备中断。
在性能配置集中,globallyDisableIrqLoadBalancing 用于管理设备中断是否被处理。对于某些工作负载,保留 CPU 并不总是足以处理设备中断,因此不会在隔离的 CPU 上禁用设备中断。默认情况下,Node Tuning Operator 不会禁用隔离 CPU 上的设备中断。
17.7.1. 为节点查找有效的 IRQ 关联性设置
有些 IRQ 控制器缺少对 IRQ 关联性设置的支持,并将始终将所有在线 CPU 公开为 IRQ 掩码。这些 IRQ 控制器在 CPU 0 上运行。
以下是红帽了解对 IRQ 关联性设置的支持的驱动程序和硬件示例。以下是相关的列表(并没有包括所有):
-
一些 RAID 控制器驱动程序,如
megaraid_sas - 许多非易失性内存表达 (NVMe) 驱动程序
- 主板 (LOM) 网络控制器上的一些 LAN
-
驱动程序使用
managed_irqs
不支持 IRQ 关联性设置的原因可能与主板中的处理器类型、IRI 控制器或断路器连接等因素相关。
如果任何 IRQ 的有效关联性被设置为一个隔离的 CPU,则可能代表一些硬件或驱动程序不支持 IRQ 关联性设置。要查找有效的关联性,请登录到主机并运行以下命令:
$ find /proc/irq -name effective_affinity -printf "%p: " -exec cat {} \;输出示例
/proc/irq/0/effective_affinity: 1
/proc/irq/1/effective_affinity: 8
/proc/irq/2/effective_affinity: 0
/proc/irq/3/effective_affinity: 1
/proc/irq/4/effective_affinity: 2
/proc/irq/5/effective_affinity: 1
/proc/irq/6/effective_affinity: 1
/proc/irq/7/effective_affinity: 1
/proc/irq/8/effective_affinity: 1
/proc/irq/9/effective_affinity: 2
/proc/irq/10/effective_affinity: 1
/proc/irq/11/effective_affinity: 1
/proc/irq/12/effective_affinity: 4
/proc/irq/13/effective_affinity: 1
/proc/irq/14/effective_affinity: 1
/proc/irq/15/effective_affinity: 1
/proc/irq/24/effective_affinity: 2
/proc/irq/25/effective_affinity: 4
/proc/irq/26/effective_affinity: 2
/proc/irq/27/effective_affinity: 1
/proc/irq/28/effective_affinity: 8
/proc/irq/29/effective_affinity: 4
/proc/irq/30/effective_affinity: 4
/proc/irq/31/effective_affinity: 8
/proc/irq/32/effective_affinity: 8
/proc/irq/33/effective_affinity: 1
/proc/irq/34/effective_affinity: 2
有些驱动程序使用 managed_irqs,其关联性由内核在内部管理,用户空间无法更改关联性。在某些情况下,这些 IRQ 可能会分配给隔离的 CPU。有关 managed_irqs 的更多信息,请参阅 无法更改受管中断的关联性,即使它们目标隔离 CPU。
17.7.2. 配置节点中断关联性
为 IRQ 动态负载平衡配置集群节点,以控制哪些内核可以接收设备中断请求 (IRQ)。
先决条件
- 对于内核隔离,所有服务器硬件组件都必须支持 IRQ 关联性。要检查服务器的硬件组件是否支持 IRQ 关联性,请查看服务器的硬件规格或联系您的硬件供应商。
流程
- 以具有 cluster-admin 权限的用户身份登录 OpenShift Container Platform 集群。
-
将性能配置集
apiVersion设置为使用performance.openshift.io/v2。 -
删除
globallyDisableIrqLoadBalancing字段,或把它设置为false。 设置适当的隔离 CPU 和保留的 CPU。以下片段演示了保留 2 个 CPU 的配置集。对于在
isolatedCPU 集中运行的 pod,启用 IRQ 负载均衡:apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: dynamic-irq-profile spec: cpu: isolated: 2-5 reserved: 0-1 ...注意当您配置保留和隔离的 CPU、操作系统进程、内核进程和 systemd 服务在保留 CPU 上运行时。基础架构 pod 在任何 CPU 上运行,但运行低延迟工作负载除外。低延迟工作负载 pod 在隔离池中的专用 CPU 上运行。如需更多信息,请参阅"为 infra 和应用程序容器限制 CPU"。
17.8. 配置内存页面大小
通过配置内存页面大小,系统管理员可以在特定节点上实施更高效的内存管理,以适应工作负载要求。Node Tuning Operator 提供了使用性能配置集配置巨页和内核页面大小的方法。
17.8.1. 配置内核页面大小
使用性能配置集中的 kernelPageSize 规格在特定节点上配置内核页面大小。为内存密集型高性能工作负载指定较大的内核页面大小。
对于具有 x86_64 或 AMD64 架构的节点,您只能为 kernelPageSize 规格指定 4k。对于具有 AArch64 架构的节点,您可以为 kernelPageSize 规格指定 4k 或 64k。在使用 64k 选项前,您必须禁用实时内核。默认值为 4k。
先决条件
-
使用具有
cluster-admin角色的用户访问集群。 -
安装 OpenShift CLI(
oc)。
流程
通过创建一个定义
PerformanceProfile资源的 YAML 文件,为要配置内核页面大小的目标节点创建一个性能配置集:pp-kernel-pages.yaml文件示例apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: example-performance-profile #... spec: kernelPageSize: "64k"1 realTimeKernel: enabled: false2 nodeSelector: node-role.kubernetes.io/worker: ""3 将性能配置集应用到集群:
$ oc create -f pp-kernel-pages.yaml输出示例
performanceprofile.performance.openshift.io/example-performance-profile created
验证
运行以下命令,在应用性能配置集的节点上启动 debug 会话:
$ oc debug node/<node_name>1 - 1
- 将
<node_name>替换为节点的名称,并应用了性能配置集。
运行以下命令,验证内核页面大小是否已设置为您在性能配置集中指定的值:
$ getconf PAGESIZE输出示例
65536
17.8.2. 配置巨页
节点必须预先分配在 OpenShift Container Platform 集群中使用的巨页。使用 Node Tuning Operator 在特定节点中分配巨页。
OpenShift Container Platform 提供了创建和分配巨页的方法。Node Tuning Operator 提供了一种更易于使用性能配置集的方法。
例如,在性能配置集的 hugepages pages 部分,您可以指定多个块的 size、count 以及可选的 node:
hugepages:
defaultHugepagesSize: "1G"
pages:
- size: "1G"
count: 4
node: 0 - 1
node是分配巨页的 NUMA 节点。如果省略了node,该页面将平均分布在所有 NUMA 节点中。
等待显示更新已完成的相关机器配置池状态。
这些是分配巨页的唯一配置步骤。
验证
要验证配置,请查看节点上的
/proc/meminfo文件:$ oc debug node/ip-10-0-141-105.ec2.internal# grep -i huge /proc/meminfo输出示例
AnonHugePages: ###### ## ShmemHugePages: 0 kB HugePages_Total: 2 HugePages_Free: 2 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: #### ## Hugetlb: #### ##使用
oc describe报告新大小:$ oc describe node worker-0.ocp4poc.example.com | grep -i huge输出示例
hugepages-1g=true hugepages-###: ### hugepages-###: ###
17.8.3. 分配多个巨页大小
您可以在同一容器下请求具有不同大小的巨页。这样,您可以定义由具有不同巨页大小的容器组成的更复杂的 pod。
例如,您可以把大小定义为 1G 和 2M,Node Tuning Operator 会在节点上配置这两个大小,如下所示:
spec:
hugepages:
defaultHugepagesSize: 1G
pages:
- count: 1024
node: 0
size: 2M
- count: 4
node: 1
size: 1G17.9. 使用 Node Tuning Operator 减少 NIC 队列
Node Tuning Operator 有助于减少 NIC 队列以提高性能。使用性能配置集进行调整,允许为不同的网络设备自定义队列。
17.9.1. 使用性能配置集调整 NIC 队列
通过性能配置集,您可以调整每个网络设备的队列计数。
支持的网络设备:
- 非虚拟网络设备
- 支持多个队列的网络设备(通道)
不支持的网络设备:
- 纯软件网络接口
- 块设备
- Intel DPDK 虚拟功能
先决条件
-
使用具有
cluster-admin角色的用户访问集群。 -
安装 OpenShift CLI(
oc)。
流程
-
以具有
cluster-admin权限的用户身份登录运行 Node Tuning Operator 的 OpenShift Container Platform 集群。 - 创建并应用适合您的硬件和拓扑的性能配置集。有关创建配置集的指南,请参阅"创建性能配置集"部分。
编辑这个创建的性能配置集:
$ oc edit -f <your_profile_name>.yaml使用
net对象填充spec字段。对象列表可以包含两个字段:-
userLevelNetworking是一个必需字段,指定为布尔值标记。如果userLevelNetworking为true,则队列数将设置为所有支持设备的保留 CPU 计数。默认值为false。 devices是一个可选字段,指定队列设置为保留 CPU 数的设备列表。如果设备列表为空,则配置适用于所有网络设备。配置如下:interfaceName:此字段指定接口名称,并支持 shell 样式的通配符,可以是正数或负数。-
通配符语法示例如下:
<string> .* -
负规则的前缀为感叹号。要将网络队列更改应用到排除列表以外的所有设备,请使用
!<device>。例如!eno1。
-
通配符语法示例如下:
-
vendorID:网络设备供应商 ID,以带有0x前缀的 16 位十六进制数字代表。 deviceID:网络设备 ID(model),以带有0x前缀的 16 位十六进制数字代表。注意当指定
deviceID时,还必须定义vendorID。与设备条目interfaceName、vendorID或vendorID加deviceID中指定的所有设备标识符相匹配的设备会被视为一个网络设备。然后,此网络设备的 net 队列数设置为保留的 CPU 计数。当指定了两个或多个设备时,网络队列数将设置为与其中一个设备匹配的任何网络设备。
-
使用此示例性能配置集将所有设备的队列数设置为保留的 CPU 计数:
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,55-103 reserved: 0-2,52-54 net: userLevelNetworking: true nodeSelector: node-role.kubernetes.io/worker-cnf: ""使用这个示例性能配置集,将所有与任何定义的设备标识符匹配的保留 CPU 数设置为保留的 CPU 计数:
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,55-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: "eth0" - interfaceName: "eth1" - vendorID: "0x1af4" deviceID: "0x1000" nodeSelector: node-role.kubernetes.io/worker-cnf: ""使用这个示例性能配置集,将所有以接口名称
eth开头的设备的队列数设置为保留的 CPU 计数:apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,55-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: "eth*" nodeSelector: node-role.kubernetes.io/worker-cnf: ""使用这个示例性能配置集。将所有设备的队列数设置为保留的 CPU 计数,该接口具有
eno1以外的任何接口:apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,55-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: "!eno1" nodeSelector: node-role.kubernetes.io/worker-cnf: ""使用这个示例性能配置集,将所有具有接口名称
eth0,vendorID为0x1af4、deviceID为0x1000的设备的队列数设置为保留 CPU 数:apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,55-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: "eth0" - vendorID: "0x1af4" deviceID: "0x1000" nodeSelector: node-role.kubernetes.io/worker-cnf: ""应用更新的性能配置集:
$ oc apply -f <your_profile_name>.yaml
17.9.2. 验证队列状态
在这一部分中,一些示例演示了不同的性能配置集以及如何验证是否应用了更改。
示例 1
在本例中,网络队列数为所有支持的设备设置为保留 CPU 数(2)。
性能配置集中的相关部分是:
apiVersion: performance.openshift.io/v2
metadata:
name: performance
spec:
kind: PerformanceProfile
spec:
cpu:
reserved: 0-1 #total = 2
isolated: 2-8
net:
userLevelNetworking: true
# ...使用以下命令显示与设备关联的队列状态:
注意在应用了性能配置集的节点中运行这个命令。
$ ethtool -l <device>在应用配置集前验证队列状态:
$ ethtool -l ens4输出示例
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 4应用配置集后验证队列状态:
$ ethtool -l ens4输出示例
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 21
- 1
- 该组合通道显示为所有支持的设备保留 CPU 的总数为 2。这与性能配置集中配置的内容匹配。
示例 2
在本例中,针对具有特定 vendorID 的所有受支持的网络设备,网络队列数设置为保留 CPU 数(2)。
性能配置集中的相关部分是:
apiVersion: performance.openshift.io/v2
metadata:
name: performance
spec:
kind: PerformanceProfile
spec:
cpu:
reserved: 0-1 #total = 2
isolated: 2-8
net:
userLevelNetworking: true
devices:
- vendorID = 0x1af4
# ...使用以下命令显示与设备关联的队列状态:
注意在应用了性能配置集的节点中运行这个命令。
$ ethtool -l <device>应用配置集后验证队列状态:
$ ethtool -l ens4输出示例
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 21
- 1
- 带有
vendorID=0x1af4的所有支持设备的预留 CPU 总数为 2。例如,如果存在另一个网络设备ens2,其vendorID=0x1af4也具有总计的网络队列为 2。这与性能配置集中配置的内容匹配。
示例 3
在本例中,针对与任何定义的设备标识符匹配的所有受支持网络设备,网络队列数设置为保留 CPU 数(2)。
命令 udevadm info 提供了有关设备的详细报告。在这个示例中,设备是:
# udevadm info -p /sys/class/net/ens4
...
E: ID_MODEL_ID=0x1000
E: ID_VENDOR_ID=0x1af4
E: INTERFACE=ens4
...# udevadm info -p /sys/class/net/eth0
...
E: ID_MODEL_ID=0x1002
E: ID_VENDOR_ID=0x1001
E: INTERFACE=eth0
...对于
interfaceName等于eth0的设备,以及具有vendorID=0x1af4的设备,并使用以下性能配置集,将网络队列设置为 2:apiVersion: performance.openshift.io/v2 metadata: name: performance spec: kind: PerformanceProfile spec: cpu: reserved: 0-1 #total = 2 isolated: 2-8 net: userLevelNetworking: true devices: - interfaceName = eth0 - vendorID = 0x1af4 ...应用配置集后验证队列状态:
$ ethtool -l ens4输出示例
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 21 - 1
- 带有
vendorID=0x1af4的所有支持设备的预留 CPU 总数设置为 2。例如,如果存在另一个带有vendorID=0x1af4的网络设备ens2,则其总子网队列也将设置为 2。类似地,interfaceName等于eth0的设备会将总网络队列设置为 2。
17.9.3. 与调整 NIC 队列关联的日志记录
详细说明所分配设备的日志消息记录在相应的 Tuned 守护进程日志中。以下信息可能会记录到 /var/log/tuned/tuned.log 文件中:
记录了一个
INFO信息,详细描述了成功分配的设备:INFO tuned.plugins.base: instance net_test (net): assigning devices ens1, ens2, ens3如果无法分配任何设备,则会记录
WARNING信息:WARNING tuned.plugins.base: instance net_test: no matching devices available
第 18 章 使用性能配置集调整托管的 control plane 以实现低延迟
通过应用性能配置集来调整托管 control plane 以实现低延迟。使用性能配置集,您可以限制基础架构和应用程序容器的 CPU,并为对延迟敏感的进程配置巨页、Hyper-Threading 和 CPU 分区。
18.1. 为托管 control plane 创建性能配置集
您可以使用 Performance Profile Creator (PPC) 工具创建集群性能配置集。PPC 是 Node Tuning Operator 的功能。
PPC 将有关集群的信息与用户提供的配置相结合,以生成适合您的硬件、拓扑和用例的性能配置集。
以下是在集群中创建和应用性能配置集的高级工作流:
-
使用
must-gather命令收集有关集群的信息。 - 使用 PPC 工具创建性能配置集。
- 将性能配置集应用到集群。
18.1.1. 为 PPC 收集托管 control plane 集群的数据
Performance Profile Creator(PPC)工具需要 must-gather 数据。作为集群管理员,运行 must-gather 命令来捕获集群的信息。
先决条件
-
有对管理集群的
cluster-admin角色访问权限。 -
已安装 OpenShift CLI(
oc)。
流程
运行以下命令导出管理集群
kubeconfig文件:$ export MGMT_KUBECONFIG=<path_to_mgmt_kubeconfig>运行以下命令,列出所有命名空间中的所有节点池:
$ oc --kubeconfig="$MGMT_KUBECONFIG" get np -A输出示例
NAMESPACE NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE clusters democluster-us-east-1a democluster 1 1 False False 4.17.0 False True-
输出显示了定义
NodePool资源的管理集群中的命名空间集群。 -
NodePool资源的名称,如democluster-us-east-1a。 -
此
NodePool所属的HostedCluster。例如,democluster。
-
输出显示了定义
在受管集群中,运行以下命令来列出可用的 secret:
$ oc get secrets -n clusters输出示例
NAME TYPE DATA AGE builder-dockercfg-25qpp kubernetes.io/dockercfg 1 128m default-dockercfg-mkvlz kubernetes.io/dockercfg 1 128m democluster-admin-kubeconfig Opaque 1 127m democluster-etcd-encryption-key Opaque 1 128m democluster-kubeadmin-password Opaque 1 126m democluster-pull-secret Opaque 1 128m deployer-dockercfg-8lfpd kubernetes.io/dockercfg 1 128m运行以下命令,提取托管集群的
kubeconfig文件:$ oc get secret <secret_name> -n <cluster_namespace> -o jsonpath='{.data.kubeconfig}' | base64 -d > hosted-cluster-kubeconfigExample
$ oc get secret democluster-admin-kubeconfig -n clusters -o jsonpath='{.data.kubeconfig}' | base64 -d > hosted-cluster-kubeconfig要为托管集群创建
must-gather捆绑包,请打开终端窗口并运行以下命令:导出托管的集群
kubeconfig文件:$ export HC_KUBECONFIG=<path_to_hosted_cluster_kubeconfig>Example
$ export HC_KUBECONFIG=~/hostedcpkube/hosted-cluster-kubeconfig-
进入存储
must-gather数据的目录。 为托管集群收集故障排除数据:
$ oc --kubeconfig="$HC_KUBECONFIG" adm must-gather从工作目录中刚刚创建的
must-gather目录创建一个压缩文件。例如,在使用 Linux 操作系统的计算机上运行以下命令:$ tar -czvf must-gather.tar.gz must-gather.local.1203869488012141147
18.1.2. 使用 Podman 在托管集群中运行 Performance Profile Creator
作为集群管理员,您可以使用带有 Performance Profile Creator (PPC) 工具的 Podman 来创建性能配置集。
有关 PPC 参数的更多信息,请参阅"Performance Profile Creator 参数"。
PPC 工具被设计为托管的集群感知。当它检测到来自 must-gather 数据的托管集群时,它会自动执行以下操作:
- 识别没有机器配置池(MCP)。
- 使用节点池作为计算节点配置的真实来源,而不是 MCP。
-
除非要以特定池为目标,否则不需要明确指定
node-pool-name值。
PPC 使用托管集群中的 must-gather 数据来创建性能配置集。如果您对集群进行任何更改,如重新标记针对性能配置的节点,则必须在再次运行 PPC 前重新创建 must-gather 数据。
先决条件
-
使用具有
cluster-admin角色的用户访问集群。 - 已安装托管集群。
-
安装 Podman 和 OpenShift CLI (
oc)。 - 访问 Node Tuning Operator 镜像。
-
访问集群的
must-gather数据。
流程
在托管的集群中,运行以下命令使用 Podman 向
registry.redhat.io进行身份验证:$ podman login registry.redhat.ioUsername: <user_name> Password: <password>运行以下命令,在托管集群上创建性能配置集。这个示例使用示例 PPC 参数和值:
$ podman run --entrypoint performance-profile-creator \ -v /path/to/must-gather:/must-gather:z \1 registry.redhat.io/openshift4/ose-cluster-node-tuning-rhel9-operator:v4.20 \ --must-gather-dir-path /must-gather \ --reserved-cpu-count=2 \2 --rt-kernel=false \3 --split-reserved-cpus-across-numa=false \4 --topology-manager-policy=single-numa-node \5 --node-pool-name=democluster-us-east-1a \ --power-consumption-mode=ultra-low-latency \6 --offlined-cpu-count=1 \7 > my-hosted-cp-performance-profile.yaml输出示例
level=info msg="Nodes names targeted by democluster-us-east-1a pool are: ip-10-0-129-110.ec2.internal " level=info msg="NUMA cell(s): 1" level=info msg="NUMA cell 0 : [0 2 1 3]" level=info msg="CPU(s): 4" level=info msg="2 reserved CPUs allocated: 0,2 " level=info msg="1 isolated CPUs allocated: 1" level=info msg="Additional Kernel Args based on configuration: []运行以下命令,查看创建的 YAML 文件:
$ cat my-hosted-cp-performance-profile输出示例
--- apiVersion: v1 data: tuning: | apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: creationTimestamp: null name: performance spec: cpu: isolated: "1" offlined: "3" reserved: 0,2 net: userLevelNetworking: false nodeSelector: node-role.kubernetes.io/worker: "" numa: topologyPolicy: single-numa-node realTimeKernel: enabled: false workloadHints: highPowerConsumption: true perPodPowerManagement: false realTime: true status: {} kind: ConfigMap metadata: name: performance namespace: clusters
18.1.3. 在托管集群中配置低延迟性能优化
要使用托管集群中的节点中的性能配置集设置低延迟,您可以使用 Node Tuning Operator。在托管的 control plane 中,您可以通过创建包含 Tuned 对象并在节点池中引用这些配置映射的配置映射来配置低延迟性能优化。在这种情况下,tuned 对象是一个 PerformanceProfile 对象,它定义了您要应用到节点池中的节点的性能配置集。
流程
运行以下命令导出管理集群
kubeconfig文件:$ export MGMT_KUBECONFIG=<path_to_mgmt_kubeconfig>运行以下命令,在管理集群中创建
ConfigMap对象:$ oc --kubeconfig="$MGMT_KUBECONFIG" apply -f my-hosted-cp-performance-profile.yaml运行以下命令,编辑
clusters命名空间中的NodePool对象,添加spec.tuningConfig字段和在该字段中创建性能配置集的名称:$ oc edit np -n clustersapiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: annotations: hypershift.openshift.io/nodePoolCurrentConfig: 2f752a2c hypershift.openshift.io/nodePoolCurrentConfigVersion: 998aa3ce hypershift.openshift.io/nodePoolPlatformMachineTemplate: democluster-us-east-1a-3dff55ec creationTimestamp: "2025-04-09T09:41:55Z" finalizers: - hypershift.openshift.io/finalizer generation: 1 labels: hypershift.openshift.io/auto-created-for-infra: democluster name: democluster-us-east-1a namespace: clusters ownerReferences: - apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster name: democluster uid: af77e390-c289-433c-9d29-3aee8e5dc76f resourceVersion: "53056" uid: 11efa47c-5a7b-476c-85cf-a274f748a868 spec: tuningConfig: - name: performance arch: amd64 clusterName: democluster management:注意您可以在多个节点池中引用同一配置集。在托管的 control plane 中,Node Tuning Operator 会将节点池名称和命名空间的哈希值附加到
Tuned自定义资源的名称中,以区分它们。进行更改后,系统会检测到需要配置更改,并启动该池中节点的滚动更新以应用新配置。
验证
运行以下命令,列出所有命名空间中的所有节点池:
$ oc --kubeconfig="$MGMT_KUBECONFIG" get np -A输出示例
NAMESPACE NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE clusters democluster-us-east-1a democluster 1 1 False False 4.17.0 False True注意UPDATINGCONFIG字段指示节点池是否在更新其配置过程中。在更新过程中,节点池状态中的UPDATINGCONFIG字段将变为True。只有在UPDATINGCONFIG字段返回到False时,新配置才会被视为完全应用。运行以下命令,列出
clusters-democluster命名空间中的所有配置映射:$ oc --kubeconfig="$MGMT_KUBECONFIG" get cm -n clusters-democluster输出示例
NAME DATA AGE aggregator-client-ca 1 69m auth-config 1 68m aws-cloud-config 1 68m aws-ebs-csi-driver-trusted-ca-bundle 1 66m ... 1 67m kubelet-client-ca 1 69m kubeletconfig-performance-democluster-us-east-1a 1 22m ... ovnkube-identity-cm 2 66m performance-democluster-us-east-1a 1 22m ... tuned-performance-democluster-us-east-1a 1 22m输出显示 kubeletconfig
kubeletconfig-performance-democluster-us-east-1a和性能配置集performance-democluster-us-east-1a。Node Tuning Operator 将Tuned对象同步到托管的集群中。您可以验证定义了哪些Tuned对象,以及将哪些配置集应用到每个节点。运行以下命令,列出管理集群中的可用 secret:
$ oc get secrets -n clusters输出示例
NAME TYPE DATA AGE builder-dockercfg-25qpp kubernetes.io/dockercfg 1 128m default-dockercfg-mkvlz kubernetes.io/dockercfg 1 128m democluster-admin-kubeconfig Opaque 1 127m democluster-etcd-encryption-key Opaque 1 128m democluster-kubeadmin-password Opaque 1 126m democluster-pull-secret Opaque 1 128m deployer-dockercfg-8lfpd kubernetes.io/dockercfg 1 128m运行以下命令,提取托管集群的
kubeconfig文件:$ oc get secret <secret_name> -n clusters -o jsonpath='{.data.kubeconfig}' | base64 -d > hosted-cluster-kubeconfigExample
$ oc get secret democluster-admin-kubeconfig -n clusters -o jsonpath='{.data.kubeconfig}' | base64 -d > hosted-cluster-kubeconfig运行以下命令导出托管集群 kubeconfig :
$ export HC_KUBECONFIG=<path_to_hosted-cluster-kubeconfig>运行以下命令,验证 kubeletconfig 是否在托管集群中镜像:
$ oc --kubeconfig="$HC_KUBECONFIG" get cm -n openshift-config-managed | grep kubelet输出示例
kubelet-serving-ca 1 79m kubeletconfig-performance-democluster-us-east-1a 1 15m运行以下命令,验证在托管集群中是否设置了
single-numa-node策略:$ oc --kubeconfig="$HC_KUBECONFIG" get cm kubeletconfig-performance-democluster-us-east-1a -o yaml -n openshift-config-managed | grep single输出示例
topologyManagerPolicy: single-numa-node
第 19 章 置备实时和低延迟工作负载
许多企业需要高性能计算和低可预测延迟,特别是在金融和电信行业中。
OpenShift Container Platform 提供 Node Tuning Operator 来实现自动性能优化,以便为 OpenShift Container Platform 应用程序实现低延迟性能和响应时间。您可以使用性能配置集配置进行这些更改。您可以将内核更新至 kernel-rt,为集群和操作系统日常任务保留 CPU,包括 pod infra 容器,为应用程序容器隔离 CPU 来运行工作负载,并禁用未使用的 CPU 来减少功耗。
在编写应用程序时,请遵循 RHEL for Real Time 进程和线程中介绍的常规建议。
19.1. 将低延迟工作负载调度到具有实时功能的 worker
您可以将低延迟工作负载调度到应用实时功能的 worker 节点上。
要将工作负载调度到特定的节点上,请使用 Pod 自定义资源(CR)中的标签选择器。标签选择器必须与附加到机器配置池的节点匹配,这些池是为低延迟配置的。
先决条件
-
已安装 OpenShift CLI(
oc)。 -
您已以具有
cluster-admin权限的用户身份登录。 - 您已在集群中应用了性能配置集,用于针对低延迟工作负载调整 worker 节点。
流程
为低延迟工作负载创建
PodCR,并在集群中应用它,例如:配置为使用实时处理的
Pod规格示例apiVersion: v1 kind: Pod metadata: name: dynamic-low-latency-pod annotations: cpu-quota.crio.io: "disable"1 cpu-load-balancing.crio.io: "disable"2 irq-load-balancing.crio.io: "disable"3 spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: dynamic-low-latency-pod image: "registry.redhat.io/openshift4/cnf-tests-rhel8:v4.20" command: ["sleep", "10h"] resources: requests: cpu: 2 memory: "200M" limits: cpu: 2 memory: "200M" securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] nodeSelector: node-role.kubernetes.io/worker-cnf: ""4 runtimeClassName: performance-dynamic-low-latency-profile5 # ...-
以 performance-<profile_name> 格式输入 pod
runtimeClassName,其中 <profile_name> 是来自PerformanceProfileYAML 中的名称。在上例中,名称是performance-dynamic-low-latency-profile。 确保 pod 正确运行。状态应该为
running,并应正确设置了 cnf-worker 节点:$ oc get pod -o wide预期输出
NAME READY STATUS RESTARTS AGE IP NODE dynamic-low-latency-pod 1/1 Running 0 5h33m 10.131.0.10 cnf-worker.example.com获取为 IRQ 动态负载均衡配置的 pod 运行 CPU:
$ oc exec -it dynamic-low-latency-pod -- /bin/bash -c "grep Cpus_allowed_list /proc/self/status | awk '{print $2}'"预期输出
Cpus_allowed_list: 2-3
验证
确保正确应用节点配置。
登录节点以验证配置。
$ oc debug node/<node-name>验证可以使用节点文件系统:
sh-4.4# chroot /host预期输出
sh-4.4#确保默认系统 CPU 关联性掩码不包括
dynamic-low-latency-podCPU,如 CPU 2 和 3。sh-4.4# cat /proc/irq/default_smp_affinity输出示例
33确定系统 IRQ 没有配置为在
dynamic-low-latency-podCPU 上运行:sh-4.4# find /proc/irq/ -name smp_affinity_list -exec sh -c 'i="$1"; mask=$(cat $i); file=$(echo $i); echo $file: $mask' _ {} \;输出示例
/proc/irq/0/smp_affinity_list: 0-5 /proc/irq/1/smp_affinity_list: 5 /proc/irq/2/smp_affinity_list: 0-5 /proc/irq/3/smp_affinity_list: 0-5 /proc/irq/4/smp_affinity_list: 0 /proc/irq/5/smp_affinity_list: 0-5 /proc/irq/6/smp_affinity_list: 0-5 /proc/irq/7/smp_affinity_list: 0-5 /proc/irq/8/smp_affinity_list: 4 /proc/irq/9/smp_affinity_list: 4 /proc/irq/10/smp_affinity_list: 0-5 /proc/irq/11/smp_affinity_list: 0 /proc/irq/12/smp_affinity_list: 1 /proc/irq/13/smp_affinity_list: 0-5 /proc/irq/14/smp_affinity_list: 1 /proc/irq/15/smp_affinity_list: 0 /proc/irq/24/smp_affinity_list: 1 /proc/irq/25/smp_affinity_list: 1 /proc/irq/26/smp_affinity_list: 1 /proc/irq/27/smp_affinity_list: 5 /proc/irq/28/smp_affinity_list: 1 /proc/irq/29/smp_affinity_list: 0 /proc/irq/30/smp_affinity_list: 0-5
当您调整节点以实现低延迟时,执行探测与需要保证 CPU 的应用程序一起使用可能会导致延迟激增。使用其他探测(如正确配置的一组网络探测作为替代方案)。
19.2. 创建具有保证 QoS 类的 pod
您可以创建一个 pod,其服务质量(QoS)类为 Guaranteed,用于高性能工作负载。使用 Guaranteed 类的 QoS 类配置 pod 可确保 pod 具有对指定 CPU 和内存资源的优先级访问权限。
要创建带有 Guaranteed 类 QoS 类的 pod,您必须应用以下规格:
- 为 pod 中每个容器的内存限值和内存请求字段设置相同的值。
- 为 pod 中每个容器的 CPU 限制和 CPU 请求字段设置相同的值。
通常,带有 Guaranteed 类 QoS 类的 pod 不会从节点中驱除。一个例外是,在由超过保留资源的系统守护进程导致的资源争用过程中。在这种情况下,kubelet 可能会驱除 pod 以保持节点稳定性,从最低优先级 pod 开始。
先决条件
-
使用具有
cluster-admin角色的用户访问集群 -
OpenShift CLI (
oc)
流程
运行以下命令,为 pod 创建命名空间:
$ oc create namespace qos-example1 - 1
- 本例使用
qos-example命名空间。
输出示例
namespace/qos-example created创建
Pod资源:创建定义
Pod资源的 YAML 文件:qos-example.yaml文件示例apiVersion: v1 kind: Pod metadata: name: qos-demo namespace: qos-example spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: qos-demo-ctr image: quay.io/openshifttest/hello-openshift:openshift1 resources: limits: memory: "200Mi"2 cpu: "1"3 requests: memory: "200Mi"4 cpu: "1"5 securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL]运行以下命令来创建
Pod资源:$ oc apply -f qos-example.yaml --namespace=qos-example输出示例
pod/qos-demo created
验证
运行以下命令,查看 pod 的
qosClass值:$ oc get pod qos-demo --namespace=qos-example --output=yaml | grep qosClass输出示例
qosClass: Guaranteed
19.3. 在 Pod 中禁用 CPU 负载均衡
禁用或启用 CPU 负载均衡的功能在 CRI-O 级别实现。CRI-O 下的代码仅在满足以下要求时禁用或启用 CPU 负载均衡。
pod 必须使用
performance-<profile-name>运行时类。您可以通过查看性能配置集的状态来获得正确的名称,如下所示:apiVersion: performance.openshift.io/v2 kind: PerformanceProfile ... status: ... runtimeClass: performance-manual
Node Tuning Operator 负责在相关节点下创建高性能运行时处理器配置片断,并在集群下创建高性能运行时类。它将具有与默认运行时处理程序相同的内容,但它启用了 CPU 负载均衡配置功能。
要禁用 pod 的 CPU 负载均衡,Pod 规格必须包括以下字段:
apiVersion: v1
kind: Pod
metadata:
#...
annotations:
#...
cpu-load-balancing.crio.io: "disable"
#...
#...
spec:
#...
runtimeClassName: performance-<profile_name>
#...仅在启用了 CPU 管理器静态策略,以及带有保证 QoS 使用整个 CPU 的 pod 时,禁用 CPU 负载均衡。否则,禁用 CPU 负载均衡会影响集群中其他容器的性能。
19.4. 为高优先级 pod 禁用节能模式
您可以配置 pod,以确保在为工作负载运行的节点配置节能时,高优先级工作负载不受影响。
当您使用节能配置配置节点时,您必须使用 pod 级别的性能配置高优先级工作负载,这意味着配置适用于 pod 使用的所有内核。
通过在 pod 级别上禁用 P-states 和 C-states,您可以配置高优先级工作负载以获得最佳性能和最低延迟。
| 注解 | 可能的值 | 描述 |
|---|---|---|
|
|
|
此注解允许您为每个 CPU 启用或禁用 C-states。另外,您还可以为 C-states 指定最大延迟(以微秒为单位)。例如,启用最大延迟为 10 微秒的 C-states,设置 |
|
|
任何支持的 |
为每个 CPU 设置 |
先决条件
- 您已为调度高优先级工作负载 pod 的节点在性能配置集中配置了节能。
流程
将所需的注解添加到高优先级工作负载 pod。注解会覆盖
默认设置。高优先级工作负载注解示例
apiVersion: v1 kind: Pod metadata: #... annotations: #... cpu-c-states.crio.io: "disable" cpu-freq-governor.crio.io: "performance" #... #... spec: #... runtimeClassName: performance-<profile_name> #...- 重启 pod 以应用注解。
19.5. 禁用 CPU CFS 配额
要消除固定 pod 的 CPU 节流,请使用 cpu-quota.crio.io: "disable" 注解创建一个 pod。此注解在 pod 运行时禁用 CPU 完全公平调度程序(CFS)配额。
禁用 cpu-quota.crio.io 的 pod 规格示例
apiVersion: v1
kind: Pod
metadata:
annotations:
cpu-quota.crio.io: "disable"
spec:
runtimeClassName: performance-<profile_name>
#...仅在启用了 CPU 管理器静态策略,以及带有保证 QoS 使用整个 CPU 的 pod 时禁用 CPU CFS 配额。例如,包含 CPU 固定容器的 pod。否则,禁用 CPU CFS 配额可能会影响集群中其他容器的性能。
19.6. 为固定容器运行的 CPU 禁用中断处理
为实现低延迟,一些容器需要固定的 CPU 不处理设备中断。pod 注解 irq-load-balancing.crio.io 用于定义在固定容器运行的 CPU 上是否处理设备中断。配置后,CRI-O 禁用运行 pod 容器的设备中断。
要禁用属于各个 pod 的容器的中断处理,请确保在性能配置集中将 globallyDisableIrqLoadBalancing 设置为 false。然后,在 pod 规格中,将 irq-load-balancing.crio.io pod 注解设置为 disable。
以下 pod 规格包含此注解:
apiVersion: performance.openshift.io/v2
kind: Pod
metadata:
annotations:
irq-load-balancing.crio.io: "disable"
spec:
runtimeClassName: performance-<profile_name>
...第 20 章 调试低延迟节点调整状态
使用 PerformanceProfile 自定义资源(CR)状态字段来报告集群节点中的调优状态和调试延迟问题。
20.1. 调试低延迟 CNF 调整状态
PerformanceProfile 自定义资源(CR)包含报告调整状态和调试延迟降级问题的状态字段。这些字段报告描述 Operator 协调功能状态的条件。
当附加到性能配置集的机器配置池处于降级状态时会出现一个典型的问题,从而导致 PerformanceProfile 状态降级。在这种情况下,机器配置池会给出一个失败信息。
Node Tuning Operator 包含 performanceProfile.spec.status.Conditions 状态字段:
Status:
Conditions:
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: True
Type: Available
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: True
Type: Upgradeable
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: False
Type: Progressing
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: False
Type: Degraded
Status 字段包含指定 Type 值来指示性能配置集状态的 Conditions:
Available- 所有机器配置和 Tuned 配置集都已被成功创建,且集群组件可用于处理它们(NTO、MCO、Kubelet)。
Upgradeable- 代表 Operator 维护的资源是否处于可安全升级的状态。
Progressing- 表示已从性能配置集启动部署过程。
Degraded如果出现以下情况代表错误:
- 验证性能配置集失败。
- 创建所有相关组件未能成功完成。
每个类型都包括以下字段:
状态-
特定类型的状态(
true或false)。 Timestamp- 事务的时间戳。
Reason string- 机器可读的原因。
Message string- 描述状态和错误详情的人类可读的原因信息(如果存在)。
20.1.1. 机器配置池
性能配置集及其创建的产品会根据关联的机器配置池(MCP)应用到节点。MCP 包含有关应用由性能配置集创建的机器配置的有价值的信息,它包括了内核 arg、Kube 配置、巨页分配和 rt-kernel 部署。Performance Profile 控制器监控 MCP 中的更改,并相应地更新性能配置集状态。
MCP 返回到性能配置集状态的唯一条件是 MCP 处于 Degraded 状态,这会导致 performaceProfile.status.condition.Degraded = true。
Example
以下示例是创建关联机器配置池(worker-cnf)的性能配置集:
关联的机器配置池处于降级状态:
# oc get mcp输出示例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-2ee57a93fa6c9181b546ca46e1571d2d True False False 3 3 3 0 2d21h worker rendered-worker-d6b2bdc07d9f5a59a6b68950acf25e5f True False False 2 2 2 0 2d21h worker-cnf rendered-worker-cnf-6c838641b8a08fff08dbd8b02fb63f7c False True True 2 1 1 1 2d20hMCP 的
describe部分包括了原因:# oc describe mcp worker-cnf输出示例
Message: Node node-worker-cnf is reporting: "prepping update: machineconfig.machineconfiguration.openshift.io \"rendered-worker-cnf-40b9996919c08e335f3ff230ce1d170\" not found" Reason: 1 nodes are reporting degraded status on sync降级状态也应该出现在标记为
degraded = true的性能配置集的status字段中:# oc describe performanceprofiles performance输出示例
Message: Machine config pool worker-cnf Degraded Reason: 1 nodes are reporting degraded status on sync. Machine config pool worker-cnf Degraded Message: Node yquinn-q8s5v-w-b-z5lqn.c.openshift-gce-devel.internal is reporting: "prepping update: machineconfig.machineconfiguration.openshift.io \"rendered-worker-cnf-40b9996919c08e335f3ff230ce1d170\" not found". Reason: MCPDegraded Status: True Type: Degraded
20.2. 为红帽支持收集调试数据延迟
在提交问题单时同时提供您的集群信息,可以帮助红帽支持为您进行排除故障。
您可使用 must-gather 工具来收集有关 OpenShift Container Platform 集群的诊断信息,包括节点调整、NUMA 拓扑和其他调试延迟设置问题所需的信息。
为了获得快速支持,请提供 OpenShift Container Platform 和低延迟调整的诊断信息。
20.2.1. 关于 must-gather 工具
oc adm must-gather CLI 命令可收集最有助于解决问题的集群信息,如:
- 资源定义
- 审计日志
- 服务日志
您在运行该命令时,可通过包含 --image 参数来指定一个或多个镜像。指定镜像后,该工具便会收集有关相应功能或产品的信息。在运行 oc adm must-gather 时,集群上会创建一个新 pod。在该 pod 上收集数据,并保存至以 must-gather.local 开头的一个新目录中。该目录在当前工作目录中创建。
20.2.2. 收集低延迟数据
使用 oc adm must-gather CLI 命令来收集有关集群的信息,包括与低延迟性能优化相关的功能和对象,包括:
- Node Tuning Operator 命名空间和子对象。
-
MachineConfigPool和关联的MachineConfig对象。 - Node Tuning Operator 和关联的 Tuned 对象。
- Linux 内核命令行选项。
- CPU 和 NUMA 拓扑
- 基本 PCI 设备信息和 NUMA 本地性。
先决条件
-
使用具有
cluster-admin角色的用户访问集群。 - 安装了 OpenShift Container Platform CLI(oc)。
流程
-
进入要存储
must-gather数据的目录。 运行以下命令来收集调试信息:
$ oc adm must-gather输出示例
[must-gather ] OUT Using must-gather plug-in image: quay.io/openshift-release When opening a support case, bugzilla, or issue please include the following summary data along with any other requested information: ClusterID: 829er0fa-1ad8-4e59-a46e-2644921b7eb6 ClusterVersion: Stable at "<cluster_version>" ClusterOperators: All healthy and stable [must-gather ] OUT namespace/openshift-must-gather-8fh4x created [must-gather ] OUT clusterrolebinding.rbac.authorization.k8s.io/must-gather-rhlgc created [must-gather-5564g] POD 2023-07-17T10:17:37.610340849Z Gathering data for ns/openshift-cluster-version... [must-gather-5564g] POD 2023-07-17T10:17:38.786591298Z Gathering data for ns/default... [must-gather-5564g] POD 2023-07-17T10:17:39.117418660Z Gathering data for ns/openshift... [must-gather-5564g] POD 2023-07-17T10:17:39.447592859Z Gathering data for ns/kube-system... [must-gather-5564g] POD 2023-07-17T10:17:39.803381143Z Gathering data for ns/openshift-etcd... ... Reprinting Cluster State: When opening a support case, bugzilla, or issue please include the following summary data along with any other requested information: ClusterID: 829er0fa-1ad8-4e59-a46e-2644921b7eb6 ClusterVersion: Stable at "<cluster_version>" ClusterOperators: All healthy and stable从工作目录中创建的
must-gather目录创建一个压缩文件。例如,在使用 Linux 操作系统的计算机上运行以下命令:$ tar cvaf must-gather.tar.gz must-gather-local.54213423446277122891 - 1
- 将
must-gather-local.5421342344627712289//替换为must-gather工具创建的目录名称。
注意创建压缩文件以将数据附加到支持问题单中,或者在创建性能配置集时与 Performance Profile Creator wrapper 脚本一起使用。
- 在红帽客户门户中为您的问题单附上压缩文件。
第 21 章 为平台验证执行延迟测试
您可以使用 Cloud-native Network Function (CNF) 测试镜像在启用了 CNF 的 OpenShift Container Platform 集群上运行延迟测试,其中安装了运行 CNF 工作负载所需的所有组件。运行延迟测试以验证工作负载的节点调整。
cnf-tests 容器镜像位于 registry.redhat.io/openshift4/cnf-tests-rhel9:v4.20 中。
21.1. 运行延迟测试的先决条件
运行延迟测试前,集群必须满足以下要求:
-
您已应用所有所需的 CNF 配置。这包括
PerformanceProfile集群和其他配置,具体取决于参考设计规格(RDS)或您的特定要求。 -
已使用
podman login命令,使用客户门户网站凭证登录到registry.redhat.io。
21.2. 测量延迟
cnf-tests 镜像使用三种工具来测量系统的延迟:
-
hwlatdetect -
cyclictest -
oslat
每个工具都有特定的用途。按顺序使用工具来获取可靠的测试结果。
- hwlatdetect
-
测量裸机硬件可达到的基准。在继续执行下一个延迟测试前,请确保
hwlatdetect报告的延迟满足所需的阈值,因为您无法通过操作系统调整来修复硬件延迟高峰。 - cyclictest
-
在
hwlatdetect验证后验证实时内核调度程序延迟。cyclictest工具调度重复的计时器,并测量所需与实际触发时间之间的差别。这种差别可以发现与中断或进程优先级导致的调优相关的基本问题。该工具必须在实时内核中运行。 - oslat
- 行为与 CPU 密集型 DPDK 应用程序类似,并测量模拟 CPU 繁重数据处理的忙碌循环和中断。
测试引入了以下环境变量:
| 环境变量 | 描述 |
|---|---|
|
| 指定测试开始运行的时间(以秒为单位)。您可以使用变量来允许 CPU 管理器协调循环来更新默认的 CPU 池。默认值为 0。 |
|
| 指定运行延迟测试的 pod 使用的 CPU 数量。如果没有设置变量,则默认配置包含所有隔离的 CPU。 |
|
| 指定延迟测试必须运行的时间(以秒为单位)。默认值为 300 秒。 注意
要防止 Ginkgo 2.0 测试套件在延迟测试完成前超时,请将 |
|
|
指定工作负载和操作系统的最大可接受硬件延迟(微秒)。如果您没有设置 |
|
|
指定 |
|
|
指定 |
|
| 指定以微秒为单位的最大可接受的延迟的统一变量。适用于所有可用延迟工具。 |
特定于延迟工具的变量优先于统一变量。例如,如果 OSLAT_MAXIMUM_LATENCY 设置为 30 微秒,而 MAXIMUM_LATENCY 被设置为 10 微秒,则 oslat 测试将以最大可接受的延迟 30 微秒运行。
21.3. 运行延迟测试
运行集群延迟测试,以验证 Cloud-native Network Function (CNF) 工作负载的节点调整。
当以非 root 用户或非特权用户执行 podman 命令时,挂载路径可能会失败,错误为 permission denied。根据您的本地操作系统和 SELinux 配置,您可能从主目录运行这些命令时也会遇到问题。要使 podman 命令正常工作,请从不属于 home/<username> 目录的文件夹运行命令,并将 :Z 附加到卷创建。例如, -v $(pwd)/:/kubeconfig:Z。这允许 podman 进行正确的 SELinux 重新标记。
此流程运行三个单独的测试 hwlatdetect、cyclictest 和 oslat。有关这些独立测试的详情,请查看它们的独立部分。
流程
在包含
kubeconfig文件的目录中打开 shell 提示符。您可以在当前目录中为测试镜像提供
kubeconfig文件,及其相关的$KUBECONFIG环境变量(通过卷挂载)。这允许运行的容器使用容器内的kubeconfig文件。注意在以下命令中,您的本地
kubeconfig挂载到 cnf-tests 容器中的 kubeconfig/kubeconfig,允许访问集群。要运行延迟测试,请运行以下命令,并根据情况替换变量值:
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUNTIME=600\ -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel9:v4.20 /usr/bin/test-run.sh \ --ginkgo.v --ginkgo.timeout="24h"LATENCY_TEST_RUNTIME 以秒为单位,本例中为 600 秒 (10 分钟)。当最观察到的延迟低于 MAXIMUM_LATENCY (20 μs) 时,测试会成功运行。
如果结果超过延迟阈值,测试会失败。
-
可选:使用
--ginkgo.dry-run标志,以 dry-run 模式运行延迟测试。这可用于检查测试会运行哪些命令。 -
可选:使用
--ginkgo.v标志来运行测试并增加输出详细程度。 可选: 使用
--ginkgo.timeout="24h"标志,以确保在延迟测试完成前 Ginkgo 2.0 测试套件不会超时。重要在测试更短的时间段内,可用于运行测试。但是,对于最终验证和有效结果,测试应至少运行 12 小时 (43200 秒)。
21.3.1. 运行 hwlatdetect
hwlatdetect 工具位于 rt-kernel 软件包中,带有常规订阅 Red Hat Enterprise Linux (RHEL) 9.x。
当以非 root 用户或非特权用户执行 podman 命令时,挂载路径可能会失败,错误为 permission denied。根据您的本地操作系统和 SELinux 配置,您可能从主目录运行这些命令时也会遇到问题。要使 podman 命令正常工作,请从不属于 home/<username> 目录的文件夹运行命令,并将 :Z 附加到卷创建。例如, -v $(pwd)/:/kubeconfig:Z。这允许 podman 进行正确的 SELinux 重新标记。
先决条件
- 您已查看了运行延迟测试的先决条件。
流程
要运行
hwlatdetect测试,请运行以下命令,并根据情况替换变量值:$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel9:v4.20 \ /usr/bin/test-run.sh --ginkgo.focus="hwlatdetect" --ginkgo.v --ginkgo.timeout="24h"hwlatdetect测试运行了 10 分钟 (600 秒)。当最观察到的延迟低于MAXIMUM_LATENCY(20 FORWARD) 时,测试会成功运行。如果结果超过延迟阈值,测试会失败。
重要在测试更短的时间段内,可用于运行测试。但是,对于最终验证和有效结果,测试应至少运行 12 小时 (43200 秒)。
失败输出示例
running /usr/bin/cnftests -ginkgo.v -ginkgo.focus=hwlatdetect I0908 15:25:20.023712 27 request.go:601] Waited for 1.046586367s due to client-side throttling, not priority and fairness, request: GET:https://api.hlxcl6.lab.eng.tlv2.redhat.com:6443/apis/imageregistry.operator.openshift.io/v1?timeout=32s Running Suite: CNF Features e2e integration tests ================================================= Random Seed: 1662650718 Will run 1 of 3 specs [...] • Failure [283.574 seconds] [performance] Latency Test /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:62 with the hwlatdetect image /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:228 should succeed [It] /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:236 Log file created at: 2022/09/08 15:25:27 Running on machine: hwlatdetect-b6n4n Binary: Built with gc go1.17.12 for linux/amd64 Log line format: [IWEF]mmdd hh:mm:ss.uuuuuu threadid file:line] msg I0908 15:25:27.160620 1 node.go:39] Environment information: /proc/cmdline: BOOT_IMAGE=(hd1,gpt3)/ostree/rhcos-c6491e1eedf6c1f12ef7b95e14ee720bf48359750ac900b7863c625769ef5fb9/vmlinuz-4.18.0-372.19.1.el8_6.x86_64 random.trust_cpu=on console=tty0 console=ttyS0,115200n8 ignition.platform.id=metal ostree=/ostree/boot.1/rhcos/c6491e1eedf6c1f12ef7b95e14ee720bf48359750ac900b7863c625769ef5fb9/0 ip=dhcp root=UUID=5f80c283-f6e6-4a27-9b47-a287157483b2 rw rootflags=prjquota boot=UUID=773bf59a-bafd-48fc-9a87-f62252d739d3 skew_tick=1 nohz=on rcu_nocbs=0-3 tuned.non_isolcpus=0000ffff,ffffffff,fffffff0 systemd.cpu_affinity=4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79 intel_iommu=on iommu=pt isolcpus=managed_irq,0-3 nohz_full=0-3 tsc=nowatchdog nosoftlockup nmi_watchdog=0 mce=off skew_tick=1 rcutree.kthread_prio=11 + + I0908 15:25:27.160830 1 node.go:46] Environment information: kernel version 4.18.0-372.19.1.el8_6.x86_64 I0908 15:25:27.160857 1 main.go:50] running the hwlatdetect command with arguments [/usr/bin/hwlatdetect --threshold 1 --hardlimit 1 --duration 100 --window 10000000us --width 950000us] F0908 15:27:10.603523 1 main.go:53] failed to run hwlatdetect command; out: hwlatdetect: test duration 100 seconds detector: tracer parameters: Latency threshold: 1us1 Sample window: 10000000us Sample width: 950000us Non-sampling period: 9050000us Output File: None Starting test test finished Max Latency: 326us2 Samples recorded: 5 Samples exceeding threshold: 5 ts: 1662650739.017274507, inner:6, outer:6 ts: 1662650749.257272414, inner:14, outer:326 ts: 1662650779.977272835, inner:314, outer:12 ts: 1662650800.457272384, inner:3, outer:9 ts: 1662650810.697273520, inner:3, outer:2 [...] JUnit report was created: /junit.xml/cnftests-junit.xml Summarizing 1 Failure: [Fail] [performance] Latency Test with the hwlatdetect image [It] should succeed /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:476 Ran 1 of 194 Specs in 365.797 seconds FAIL! -- 0 Passed | 1 Failed | 0 Pending | 2 Skipped --- FAIL: TestTest (366.08s) FAIL
hwlatdetect 测试结果示例
您可以捕获以下类型的结果:
- 在每次运行后收集的粗略结果,以便对整个测试过程中所做的任何更改产生影响的历史记录。
- 基本测试和配置设置的组合。
良好结果的示例
hwlatdetect: test duration 3600 seconds
detector: tracer
parameters:
Latency threshold: 10us
Sample window: 1000000us
Sample width: 950000us
Non-sampling period: 50000us
Output File: None
Starting test
test finished
Max Latency: Below threshold
Samples recorded: 0
hwlatdetect 工具仅在示例超过指定阈值时提供输出。
错误结果的示例
hwlatdetect: test duration 3600 seconds
detector: tracer
parameters:Latency threshold: 10usSample window: 1000000us
Sample width: 950000usNon-sampling period: 50000usOutput File: None
Starting tests:1610542421.275784439, inner:78, outer:81
ts: 1610542444.330561619, inner:27, outer:28
ts: 1610542445.332549975, inner:39, outer:38
ts: 1610542541.568546097, inner:47, outer:32
ts: 1610542590.681548531, inner:13, outer:17
ts: 1610543033.818801482, inner:29, outer:30
ts: 1610543080.938801990, inner:90, outer:76
ts: 1610543129.065549639, inner:28, outer:39
ts: 1610543474.859552115, inner:28, outer:35
ts: 1610543523.973856571, inner:52, outer:49
ts: 1610543572.089799738, inner:27, outer:30
ts: 1610543573.091550771, inner:34, outer:28
ts: 1610543574.093555202, inner:116, outer:63
hwlatdetect 的输出显示多个样本超过阈值。但是,相同的输出可能会根据以下因素显示不同的结果:
- 测试的持续时间
- CPU 内核数
- 主机固件设置
在继续执行下一个延迟测试前,请确保 hwlatdetect 报告的延迟满足所需的阈值。修复硬件带来的延迟可能需要您联系系统厂商支持。
并非所有延迟高峰都与硬件相关。确保调整主机固件以满足您的工作负载要求。如需更多信息,请参阅为系统调整设置固件参数。
21.3.2. 运行 cyclictest
cyclictest 工具测量指定 CPU 上的实时内核调度程序延迟。
当以非 root 用户或非特权用户执行 podman 命令时,挂载路径可能会失败,错误为 permission denied。根据您的本地操作系统和 SELinux 配置,您可能从主目录运行这些命令时也会遇到问题。要使 podman 命令正常工作,请从不属于 home/<username> 目录的文件夹运行命令,并将 :Z 附加到卷创建。例如, -v $(pwd)/:/kubeconfig:Z。这允许 podman 进行正确的 SELinux 重新标记。
先决条件
- 您已查看了运行延迟测试的先决条件。
流程
要执行
cyclictest,请运行以下命令,并根据情况替换变量值:$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_CPUS=10 -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel9:v4.20 \ /usr/bin/test-run.sh --ginkgo.focus="cyclictest" --ginkgo.v --ginkgo.timeout="24h"该命令运行
cyclictest工具 10 分钟(600 秒)。当观察到的延迟低于MAXIMUM_LATENCY时,测试会成功运行(在本例中,20 TOKENs)。对于电信 RAN 工作负载,对 20 个以上延迟的激增通常并不能接受。如果结果超过延迟阈值,测试会失败。
重要在测试更短的时间段内,可用于运行测试。但是,对于最终验证和有效结果,测试应至少运行 12 小时 (43200 秒)。
失败输出示例
running /usr/bin/cnftests -ginkgo.v -ginkgo.focus=cyclictest I0908 13:01:59.193776 27 request.go:601] Waited for 1.046228824s due to client-side throttling, not priority and fairness, request: GET:https://api.compute-1.example.com:6443/apis/packages.operators.coreos.com/v1?timeout=32s Running Suite: CNF Features e2e integration tests ================================================= Random Seed: 1662642118 Will run 1 of 3 specs [...] Summarizing 1 Failure: [Fail] [performance] Latency Test with the cyclictest image [It] should succeed /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:220 Ran 1 of 194 Specs in 161.151 seconds FAIL! -- 0 Passed | 1 Failed | 0 Pending | 2 Skipped --- FAIL: TestTest (161.48s) FAIL
cyclictest 结果示例
相同的输出可能会显示不同工作负载的结果。例如,spikes 最长为 18μs 对 4G DU 工作负载是可以接受的,但对于 5G DU 工作负载不能接受。
良好结果的示例
running cmd: cyclictest -q -D 10m -p 1 -t 16 -a 2,4,6,8,10,12,14,16,54,56,58,60,62,64,66,68 -h 30 -i 1000 -m
# Histogram
000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000
000001 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000
000002 579506 535967 418614 573648 532870 529897 489306 558076 582350 585188 583793 223781 532480 569130 472250 576043
More histogram entries ...
# Total: 000600000 000600000 000600000 000599999 000599999 000599999 000599998 000599998 000599998 000599997 000599997 000599996 000599996 000599995 000599995 000599995
# Min Latencies: 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002
# Avg Latencies: 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002
# Max Latencies: 00005 00005 00004 00005 00004 00004 00005 00005 00006 00005 00004 00005 00004 00004 00005 00004
# Histogram Overflows: 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000
# Histogram Overflow at cycle number:
# Thread 0:
# Thread 1:
# Thread 2:
# Thread 3:
# Thread 4:
# Thread 5:
# Thread 6:
# Thread 7:
# Thread 8:
# Thread 9:
# Thread 10:
# Thread 11:
# Thread 12:
# Thread 13:
# Thread 14:
# Thread 15:错误结果的示例
running cmd: cyclictest -q -D 10m -p 1 -t 16 -a 2,4,6,8,10,12,14,16,54,56,58,60,62,64,66,68 -h 30 -i 1000 -m
# Histogram
000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000
000001 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000
000002 564632 579686 354911 563036 492543 521983 515884 378266 592621 463547 482764 591976 590409 588145 589556 353518
More histogram entries ...
# Total: 000599999 000599999 000599999 000599997 000599997 000599998 000599998 000599997 000599997 000599996 000599995 000599996 000599995 000599995 000599995 000599993
# Min Latencies: 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002
# Avg Latencies: 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002
# Max Latencies: 00493 00387 00271 00619 00541 00513 00009 00389 00252 00215 00539 00498 00363 00204 00068 00520
# Histogram Overflows: 00001 00001 00001 00002 00002 00001 00000 00001 00001 00001 00002 00001 00001 00001 00001 00002
# Histogram Overflow at cycle number:
# Thread 0: 155922
# Thread 1: 110064
# Thread 2: 110064
# Thread 3: 110063 155921
# Thread 4: 110063 155921
# Thread 5: 155920
# Thread 6:
# Thread 7: 110062
# Thread 8: 110062
# Thread 9: 155919
# Thread 10: 110061 155919
# Thread 11: 155918
# Thread 12: 155918
# Thread 13: 110060
# Thread 14: 110060
# Thread 15: 110059 15591721.3.3. 运行 oslat
oslat 测试模拟 CPU 密集型 DPDK 应用程序,并测量所有中断和中断来测试集群处理 CPU 大量数据处理的方式。
当以非 root 用户或非特权用户执行 podman 命令时,挂载路径可能会失败,错误为 permission denied。根据您的本地操作系统和 SELinux 配置,您可能从主目录运行这些命令时也会遇到问题。要使 podman 命令正常工作,请从不属于 home/<username> 目录的文件夹运行命令,并将 :Z 附加到卷创建。例如, -v $(pwd)/:/kubeconfig:Z。这允许 podman 进行正确的 SELinux 重新标记。
先决条件
- 您已查看了运行延迟测试的先决条件。
流程
要执行
oslat测试,请运行以下命令,根据需要替换变量值:$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_CPUS=10 -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel9:v4.20 \ /usr/bin/test-run.sh --ginkgo.focus="oslat" --ginkgo.v --ginkgo.timeout="24h"LATENCY_TEST_CPUS指定使用oslat命令测试的 CPU 数量。命令运行
oslat工具 10 分钟(600 秒)。当最观察到的延迟低于MAXIMUM_LATENCY(20 FORWARD) 时,测试会成功运行。如果结果超过延迟阈值,测试会失败。
重要在测试更短的时间段内,可用于运行测试。但是,对于最终验证和有效结果,测试应至少运行 12 小时 (43200 秒)。
失败输出示例
running /usr/bin/cnftests -ginkgo.v -ginkgo.focus=oslat I0908 12:51:55.999393 27 request.go:601] Waited for 1.044848101s due to client-side throttling, not priority and fairness, request: GET:https://compute-1.example.com:6443/apis/machineconfiguration.openshift.io/v1?timeout=32s Running Suite: CNF Features e2e integration tests ================================================= Random Seed: 1662641514 Will run 1 of 3 specs [...] • Failure [77.833 seconds] [performance] Latency Test /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:62 with the oslat image /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:128 should succeed [It] /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:153 The current latency 304 is bigger than the expected one 1 :1 [...] Summarizing 1 Failure: [Fail] [performance] Latency Test with the oslat image [It] should succeed /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:177 Ran 1 of 194 Specs in 161.091 seconds FAIL! -- 0 Passed | 1 Failed | 0 Pending | 2 Skipped --- FAIL: TestTest (161.42s) FAIL- 1
- 在本例中,测量的延迟超出了最大允许的值。
21.4. 生成延迟测试失败报告
使用以下步骤生成 JUnit 延迟测试输出和测试失败报告。
先决条件
-
已安装 OpenShift CLI(
oc)。 -
您已以具有
cluster-admin权限的用户身份登录。
流程
使用集群状态和资源的信息创建测试失败报告,通过传递
--report参数并使用报告转储的路径来进行故障排除:$ podman run -v $(pwd)/:/kubeconfig:Z -v $(pwd)/reportdest:<report_folder_path> \ -e KUBECONFIG=/kubeconfig/kubeconfig registry.redhat.io/openshift4/cnf-tests-rhel9:v4.20 \ /usr/bin/test-run.sh --report <report_folder_path> --ginkgo.v其中:
- <report_folder_path>
- 是生成报告的文件夹的路径。
21.5. 生成 JUnit 延迟测试报告
使用以下步骤生成 JUnit 延迟测试输出和测试失败报告。
先决条件
-
已安装 OpenShift CLI(
oc)。 -
您已以具有
cluster-admin权限的用户身份登录。
流程
通过传递
--junit参数和转储报告的路径来创建兼容 JUnit 的 XML 报告:注意您必须先创建
junit文件夹,然后才能运行此命令。$ podman run -v $(pwd)/:/kubeconfig:Z -v $(pwd)/junit:/junit \ -e KUBECONFIG=/kubeconfig/kubeconfig registry.redhat.io/openshift4/cnf-tests-rhel9:v4.20 \ /usr/bin/test-run.sh --ginkgo.junit-report junit/<file_name>.xml --ginkgo.v其中:
file_name- XML 报告文件的名称。
21.6. 在单节点 OpenShift 集群上运行延迟测试
您可以在单节点 OpenShift 集群上运行延迟测试。
当以非 root 用户或非特权用户执行 podman 命令时,挂载路径可能会失败,错误为 permission denied。要使 podman 命令正常工作,请将 :Z 附加到卷创建中,例如 -v $(pwd)/:/kubeconfig:Z。这允许 podman 进行正确的 SELinux 重新标记。
先决条件
-
已安装 OpenShift CLI(
oc)。 -
您已以具有
cluster-admin权限的用户身份登录。 - 已使用 Node Tuning Operator 应用了集群性能配置集。
流程
要在单节点 OpenShift 集群上运行延迟测试,请运行以下命令:
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUNTIME=<time_in_seconds> registry.redhat.io/openshift4/cnf-tests-rhel9:v4.20 \ /usr/bin/test-run.sh --ginkgo.v --ginkgo.timeout="24h"注意每个测试的默认运行时为 300 秒。如需有效的延迟测试结果,通过更新
LATENCY_TEST_RUNTIME变量,对至少 12 小时运行测试。要运行存储桶延迟验证步骤,您必须指定最大延迟。有关最大延迟变量的详情,请查看 "Measuring latency" 部分中的表。运行测试套件后,,清理所有悬停的资源。
21.7. 在断开连接的集群中运行延迟测试
CNF 测试镜像可在无法访问外部 registry 的断开连接的集群中运行测试。这需要两个步骤:
-
将
cnf-tests镜像镜像到自定义断开连接的 registry。 - 指示测试使用来自自定义断开连接的 registry 的镜像。
将镜像镜像(mirror)到集群可访问的自定义 registry
mirror 中提供了镜像可执行文件,以提供 oc 需要的输入来镜像运行测试到本地 registry 所需的镜像。
从可访问集群和 registry.redhat.io 的中间机器运行这个命令:
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel9:v4.20 \ /usr/bin/mirror -registry <disconnected_registry> | oc image mirror -f -其中:
- <disconnected_registry>
-
是您配置的断开连接的镜像 registry,如
my.local.registry:5000/。
当您将
cnf-tests镜像 mirror 到断开连接的 registry 中时,您必须覆盖用于运行测试时用来获取镜像的原始 registry,例如:podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e IMAGE_REGISTRY="<disconnected_registry>" \ -e CNF_TESTS_IMAGE="cnf-tests-rhel9:v4.20" \ -e LATENCY_TEST_RUNTIME=<time_in_seconds> \ <disconnected_registry>/cnf-tests-rhel9:v4.20 /usr/bin/test-run.sh --ginkgo.v --ginkgo.timeout="24h"
配置测试以使用自定义 registry 中的镜像
您可以使用 CNF_TESTS_IMAGE 和 IMAGE_REGISTRY 变量来使用自定义测试镜像和镜像 registry 运行延迟测试。
要将延迟测试配置为使用自定义测试镜像和镜像 registry,请运行以下命令:
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e IMAGE_REGISTRY="<custom_image_registry>" \ -e CNF_TESTS_IMAGE="<custom_cnf-tests_image>" \ -e LATENCY_TEST_RUNTIME=<time_in_seconds> \ registry.redhat.io/openshift4/cnf-tests-rhel9:v4.20 /usr/bin/test-run.sh --ginkgo.v --ginkgo.timeout="24h"其中:
- <custom_image_registry>
-
是自定义镜像 registry,如
custom.registry:5000/。 - <custom_cnf-tests_image>
-
是自定义 cnf-tests 镜像,如
custom-cnf-tests-image:latest。
将镜像镜像 (mirror) 到集群 OpenShift 镜像 registry
OpenShift Container Platform 提供了一个内建的容器镜像 registry,它作为一个标准的工作负载在集群中运行。
流程
通过使用路由公开到 registry 的外部访问权限:
$ oc patch configs.imageregistry.operator.openshift.io/cluster --patch '{"spec":{"defaultRoute":true}}' --type=merge运行以下命令来获取 registry 端点:
$ REGISTRY=$(oc get route default-route -n openshift-image-registry --template='{{ .spec.host }}')创建用于公开镜像的命名空间:
$ oc create ns cnftests使镜像流可供用于测试的所有命名空间使用。这需要允许 test 命名空间从
cnf-tests镜像流中获取镜像。运行以下命令:$ oc policy add-role-to-user system:image-puller system:serviceaccount:cnf-features-testing:default --namespace=cnftests$ oc policy add-role-to-user system:image-puller system:serviceaccount:performance-addon-operators-testing:default --namespace=cnftests运行以下命令,检索 docker secret 名称和 auth 令牌:
$ SECRET=$(oc -n cnftests get secret | grep builder-docker | awk {'print $1'}$ TOKEN=$(oc -n cnftests get secret $SECRET -o jsonpath="{.data['\.dockercfg']}" | base64 --decode | jq '.["image-registry.openshift-image-registry.svc:5000"].auth')创建
dockerauth.json文件,例如:$ echo "{\"auths\": { \"$REGISTRY\": { \"auth\": $TOKEN } }}" > dockerauth.json对镜像进行 mirror:
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel9:v4.20 \ /usr/bin/mirror -registry $REGISTRY/cnftests | oc image mirror --insecure=true \ -a=$(pwd)/dockerauth.json -f -运行测试:
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUNTIME=<time_in_seconds> \ -e IMAGE_REGISTRY=image-registry.openshift-image-registry.svc:5000/cnftests cnf-tests-local:latest /usr/bin/test-run.sh --ginkgo.v --ginkgo.timeout="24h"
对不同的测试镜像进行镜像(mirror)
您可以选择更改对延迟测试镜像的默认上游镜像。
流程
mirror命令默认尝试对上游镜像进行 mirror。这可以通过向镜像传递带有以下格式的文件来覆盖:[ { "registry": "public.registry.io:5000", "image": "imageforcnftests:4.20" } ]将文件传递给
mirror命令,例如将其在本地保存为images.json。使用以下命令,本地路径挂载到容器内的/kubeconfig中,并可传递给 mirror 命令。$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel9:v4.20 /usr/bin/mirror \ --registry "my.local.registry:5000/" --images "/kubeconfig/images.json" \ | oc image mirror -f -
21.8. 对 cnf-tests 容器的错误进行故障排除
要运行延迟测试,集群必须从 cnf-tests 容器中访问。
先决条件
-
已安装 OpenShift CLI(
oc)。 -
您已以具有
cluster-admin权限的用户身份登录。
流程
运行以下命令,验证可以从
cnf-tests容器中访问集群:$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel9:v4.20 \ oc get nodes如果这个命令无法正常工作,则可能会出现与跨 DNS、MTU 大小或防火墙访问相关的错误。
第 22 章 使用 worker 延迟配置集提高高延迟环境中的集群稳定性
如果集群管理员为平台验证执行了延迟测试,他们可以发现需要调整集群的操作,以确保高延迟的情况的稳定性。集群管理员只需要更改一个参数,该参数记录在一个文件中,它控制了 Supervisory 进程读取状态并解释集群的运行状况的四个参数。仅更改一个参数可以以方便、可支持的方式提供集群调整。
Kubelet 进程提供监控集群运行状况的起点。Kubelet 为 OpenShift Container Platform 集群中的所有节点设置状态值。Kubernetes Controller Manager (kube controller) 默认每 10 秒读取状态值。如果 kube 控制器无法读取节点状态值,它会在配置的时间后丢失与该节点联系。默认行为是:
-
control plane 上的节点控制器将节点健康状况更新为
Unhealthy,并奖节点Ready的条件标记为 'Unknown'。 - 因此,调度程序会停止将 pod 调度到该节点。
-
Node Lifecycle Controller 添加了一个
node.kubernetes.io/unreachable污点,对节点具有NoExecute效果,默认在五分钟后调度节点上的任何 pod 进行驱除。
如果您的网络容易出现延迟问题,尤其是在网络边缘中有节点时,此行为可能会造成问题。在某些情况下,Kubernetes Controller Manager 可能会因为网络延迟而从健康的节点接收更新。Kubelet 会从节点中驱除 pod,即使节点处于健康状态。
要避免这个问题,您可以使用 worker 延迟配置集调整 kubelet 和 Kubernetes Controller Manager 在执行操作前等待状态更新的频率。如果在控制平面和 worker 节点间存在网络延迟,worker 节点没有处于最近状态,这个调整有助于集群可以正常工作。
这些 worker 延迟配置集包含预定义的三组参数,它们带有经过仔细调优的值,以控制集群对增加的延迟进行适当地响应。不需要手动进行实验以查找最佳值。
您可在安装集群时配置 worker 延迟配置集,或当您发现集群网络中的延迟增加时。
22.1. 了解 worker 延迟配置集
worker 延迟配置集带有四个不同的、包括经过仔细调优的参数的类别。实现这些值的四个参数是 node-status-update-frequency、node-monitor-grace-period、default-not-ready-toleration-seconds 和 default-unreachable-toleration-seconds。这些参数可让您使用这些值来控制集群对延迟问题的响应,而无需手动确定最佳值。
不支持手动设置这些参数。参数设置不正确会影响集群的稳定性。
所有 worker 延迟配置集配置以下参数:
- node-status-update-frequency
- 指定 kubelet 将节点状态发布到 API 服务器的频率。
- node-monitor-grace-period
-
指定 Kubernetes Controller Manager 在节点不健康前等待更新的时间(以秒为单位),并将
node.kubernetes.io/not-ready或node.kubernetes.io/unreachable污点添加到节点。 - default-not-ready-toleration-seconds
- 指定在标记节点不健康后,Kube API Server Operator 在从该节点驱除 pod 前等待的时间(以秒为单位)。
- default-unreachable-toleration-seconds
- 指定在节点无法访问后,Kube API Server Operator 在从该节点驱除 pod 前等待的时间(以秒为单位)。
以下 Operator 监控 worker 延迟配置集的更改并相应地响应:
-
Machine Config Operator (MCO) 更新 worker 节点上的
node-status-update-frequency参数。 -
Kubernetes Controller Manager 更新 control plane 节点上的
node-monitor-grace-period参数。 -
Kubernetes API Server Operator 更新 control plane 节点上的
default-not-ready-toleration-seconds和default-unreachable-toleration-seconds参数。
虽然默认配置在大多数情况下可以正常工作,但 OpenShift Container Platform 会为网络遇到比通常更高的延迟的情况提供两个其他 worker 延迟配置集。以下部分描述了三个 worker 延迟配置集:
- 默认 worker 延迟配置集
使用
Default配置集时,每个Kubelet每 10 秒更新其状态(node-status-update-frequency)。Kube Controller Manager每 5 秒检查Kubelet的状态。在认为
Kubelet不健康前,Kubernetes Controller Manager 会等待 40 秒(node-monitor-grace-period)以获取来自Kubelet的状态更新。如果没有可用于 Kubernetes Controller Manager 的使用状态,它会使用node.kubernetes.io/not-ready或node.kubernetes.io/unreachable污点标记节点,并驱除该节点上的 pod。如果 pod 位于具有
NoExecute污点的节点上,则 pod 根据tolerationSeconds运行。如果节点没有污点,它将在 300 秒内被驱除(Kube API Server的default-not-ready-toleration-seconds和default-unreachable-toleration-seconds设置)。Expand profile 组件 参数 值 Default(默认)
kubelet
node-status-update-frequency10s
kubelet Controller Manager
node-monitor-grace-period40s
Kubernetes API Server Operator
default-not-ready-toleration-seconds300s
Kubernetes API Server Operator
default-unreachable-toleration-seconds300s
- 中型 worker 延迟配置集
如果网络延迟比通常稍高,则使用
MediumUpdateAverageReaction配置集。MediumUpdateAverageReaction配置集减少了 kubelet 更新频率为 20 秒,并将 Kubernetes Controller Manager 等待这些更新的时间更改为 2 分钟。该节点上的 pod 驱除周期会减少到 60 秒。如果 pod 具有tolerationSeconds参数,则驱除会等待该参数指定的周期。Kubernetes Controller Manager 会先等待 2 分钟时间,才会认为节点不健康。另一分钟后,驱除过程会启动。
Expand profile 组件 参数 值 MediumUpdateAverageReaction
kubelet
node-status-update-frequency20s
kubelet Controller Manager
node-monitor-grace-period2m
Kubernetes API Server Operator
default-not-ready-toleration-seconds60s
Kubernetes API Server Operator
default-unreachable-toleration-seconds60s
- 低 worker 延迟配置集
如果网络延迟非常高,请使用
LowUpdateSlowReaction配置集。LowUpdateSlowReaction配置集将 kubelet 更新频率减少为 1 分钟,并将 Kubernetes Controller Manager 等待这些更新的时间更改为 5 分钟。该节点上的 pod 驱除周期会减少到 60 秒。如果 pod 具有tolerationSeconds参数,则驱除会等待该参数指定的周期。Kubernetes Controller Manager 在认为节点不健康前会等待 5 分钟。另一分钟后,驱除过程会启动。
Expand profile 组件 参数 值 LowUpdateSlowReaction
kubelet
node-status-update-frequency1m
kubelet Controller Manager
node-monitor-grace-period5m
Kubernetes API Server Operator
default-not-ready-toleration-seconds60s
Kubernetes API Server Operator
default-unreachable-toleration-seconds60s
延迟配置集不支持自定义机器配置池,只有默认的 worker 机器配置池。
22.2. 在集群创建时实现 worker 延迟配置集
要编辑安装程序的配置,首先使用 openshift-install create manifests 命令创建默认节点清单和其他清单 YAML 文件。在添加 workerLatencyProfile 之前,该文件结构必须存在。您要安装的平台可能具有不同的要求。有关特定平台,请参阅文档中的安装部分。
workerLatencyProfile 必须按以下顺序添加到清单中:
- 使用适合您安装的文件夹名称,创建构建集群所需的清单。
-
创建 YAML 文件以定义
config.node。该文件必须位于manifests目录中。 -
第一次在清单中定义
workerLatencyProfile时,在集群创建时指定任何配置集:Default,MediumUpdateAverageReaction或LowUpdateSlowReaction。
验证
以下是一个清单创建示例,显示清单文件中的
spec.workerLatencyProfileDefault值:$ openshift-install create manifests --dir=<cluster-install-dir>编辑清单并添加值。在本例中,我们使用
vi显示添加了 "Default"workerLatencyProfile值的示例清单文件:$ vi <cluster-install-dir>/manifests/config-node-default-profile.yaml输出示例
apiVersion: config.openshift.io/v1 kind: Node metadata: name: cluster spec: workerLatencyProfile: "Default"
22.3. 使用和更改 worker 延迟配置集
要更改 worker 延迟配置集以处理网络延迟,请编辑 node.config 对象以添加配置集的名称。当延迟增加或减少时,您可以随时更改配置集。
您必须一次移动一个 worker 延迟配置集。例如,您无法直接从 Default 配置集移到 LowUpdateSlowReaction worker 延迟配置集。您必须首先从 Default worker 延迟配置集移到 MediumUpdateAverageReaction 配置集,然后再移到 LowUpdateSlowReaction。同样,当返回到 Default 配置集时,您必须首先从低配置集移到中配置集,然后移到 Default。
您还可以在安装 OpenShift Container Platform 集群时配置 worker 延迟配置集。
流程
将默认的 worker 延迟配置集改为:
中 worke worker 延迟配置集:
编辑
node.config对象:$ oc edit nodes.config/cluster添加
spec.workerLatencyProfile: MediumUpdateAverageReaction:node.config对象示例apiVersion: config.openshift.io/v1 kind: Node metadata: annotations: include.release.openshift.io/ibm-cloud-managed: "true" include.release.openshift.io/self-managed-high-availability: "true" include.release.openshift.io/single-node-developer: "true" release.openshift.io/create-only: "true" creationTimestamp: "2022-07-08T16:02:51Z" generation: 1 name: cluster ownerReferences: - apiVersion: config.openshift.io/v1 kind: ClusterVersion name: version uid: 36282574-bf9f-409e-a6cd-3032939293eb resourceVersion: "1865" uid: 0c0f7a4c-4307-4187-b591-6155695ac85b spec: workerLatencyProfile: MediumUpdateAverageReaction1 # ...- 1
- 指定中 worker 延迟策略。
随着更改被应用,每个 worker 节点上的调度都会被禁用。
可选:改为低 worker 延迟配置集:
编辑
node.config对象:$ oc edit nodes.config/cluster将
spec.workerLatencyProfile值更改为LowUpdateSlowReaction:node.config对象示例apiVersion: config.openshift.io/v1 kind: Node metadata: annotations: include.release.openshift.io/ibm-cloud-managed: "true" include.release.openshift.io/self-managed-high-availability: "true" include.release.openshift.io/single-node-developer: "true" release.openshift.io/create-only: "true" creationTimestamp: "2022-07-08T16:02:51Z" generation: 1 name: cluster ownerReferences: - apiVersion: config.openshift.io/v1 kind: ClusterVersion name: version uid: 36282574-bf9f-409e-a6cd-3032939293eb resourceVersion: "1865" uid: 0c0f7a4c-4307-4187-b591-6155695ac85b spec: workerLatencyProfile: LowUpdateSlowReaction1 # ...- 1
- 指定使用低 worker 延迟策略。
随着更改被应用,每个 worker 节点上的调度都会被禁用。
验证
当所有节点都返回到
Ready条件时,您可以使用以下命令查看 Kubernetes Controller Manager 以确保应用它:$ oc get KubeControllerManager -o yaml | grep -i workerlatency -A 5 -B 5输出示例
# ... - lastTransitionTime: "2022-07-11T19:47:10Z" reason: ProfileUpdated status: "False" type: WorkerLatencyProfileProgressing - lastTransitionTime: "2022-07-11T19:47:10Z"1 message: all static pod revision(s) have updated latency profile reason: ProfileUpdated status: "True" type: WorkerLatencyProfileComplete - lastTransitionTime: "2022-07-11T19:20:11Z" reason: AsExpected status: "False" type: WorkerLatencyProfileDegraded - lastTransitionTime: "2022-07-11T19:20:36Z" status: "False" # ...- 1
- 指定配置集被应用并激活。
要将中配置集改为默认,或将默认改为中,编辑 node.config 对象,并将 spec.workerLatencyProfile 参数设置为适当的值。
22.4. 显示 workerLatencyProfile 生成的值的步骤示例
您可以使用以下命令显示 workerLatencyProfile 中的值。
验证
检查 Kube API Server 的
default-not-ready-toleration-seconds和default-unreachable-toleration-seconds字段输出:$ oc get KubeAPIServer -o yaml | grep -A 1 default-输出示例
default-not-ready-toleration-seconds: - "300" default-unreachable-toleration-seconds: - "300"从 Kube Controller Manager 检查
node-monitor-grace-period字段的值:$ oc get KubeControllerManager -o yaml | grep -A 1 node-monitor输出示例
node-monitor-grace-period: - 40s检查 Kubelet 中的
nodeStatusUpdateFrequency值。将目录/host设置为 debug shell 中的根目录。将根目录改为/host,您可以运行主机可执行路径中包含的二进制文件:$ oc debug node/<worker-node-name>$ chroot /host# cat /etc/kubernetes/kubelet.conf|grep nodeStatusUpdateFrequency输出示例
“nodeStatusUpdateFrequency”: “10s”
这些输出验证 Worker Latency Profile 的计时变量集合。
第 23 章 工作负载分区
工作负载分区将计算节点 CPU 资源划分为不同的 CPU 集。主要目标是将平台 pod 保留在指定的内核中,以避免中断客户工作负载的 CPU。
使用工作负载分区隔离 OpenShift Container Platform 服务、集群管理工作负载和基础架构 pod,以便在保留的一组 CPU 上运行。这样可确保集群部署中剩余的 CPU 没有被修改,并只可用于非平台工作负载。集群管理所需的最小保留 CPU 数量是 4 个 CPU Hyper-Threads (HT)。
在启用工作负载分区和管理 CPU 资源的情况下,没有正确配置的节点不允许通过节点准入 Webhook 加入集群。启用工作负载分区功能时,control plane 和 worker 的机器配置池将提供要使用的节点配置。向这些池添加新节点可确保在加入集群前正确配置它们。
目前,每个机器配置池必须具有统一配置,以确保在该池中的所有节点中正确设置了正确的 CPU 关联性。准入后,集群中的节点将自己识别为支持名为 management.workload.openshift.io/cores 的新资源类型,并准确报告其 CPU 容量。工作负载分区只能在集群安装过程中启用,方法是将额外的字段 cpuPartitioningMode 添加到 install-config.yaml 文件中。
启用工作负载分区后,management.workload.openshift.io/cores 资源允许调度程序根据主机的 cpushares 容量正确分配 pod,而不只是默认的 cpuset。这样可确保为工作负载分区场景更精确地分配资源。
工作负载分区确保 pod 配置中指定的 CPU 请求和限值被遵守。在 OpenShift Container Platform 4.16 或更高版本中,通过 CPU 分区为平台 pod 设置准确的 CPU 用量限制。因为工作负载分区使用 management.workload.openshift.io/cores 的自定义资源类型,因此请求和限制的值相同,因为 Kubernetes 对扩展资源的要求相同。但是,工作负载分区修改的注解可以正确地反映所需的限制。
扩展资源无法过量使用,因此如果容器规格中存在扩展资源,则请求和限制必须相等。
23.1. 启用工作负载分区
使用工作负载分区时,集群管理 pod 被标注,以便将其正确分区到指定的 CPU 关联性中。这些 pod 通常在 Performance Profile 中保留值指定的最小大小 CPU 配置内运行。在计算应该为平台设置多少个保留 CPU 内核时,应考虑使用工作负载分区的额外第 2 天 Operator。
工作负载分区使用标准 Kubernetes 调度功能将用户工作负载与平台工作负载隔离。
您只能在集群安装过程中启用工作负载分区。您不能在安装后禁用工作负载分区。但是,您可以在安装后更改 reserved 和 isolated CPU 配置。
使用这个流程在集群范围内启用工作负载分区:
流程
在
install-config.yaml文件中,添加额外的cpuPartitioningMode字段,并将其设置为AllNodes。apiVersion: v1 baseDomain: devcluster.openshift.com cpuPartitioningMode: AllNodes1 compute: - architecture: amd64 hyperthreading: Enabled name: worker platform: {} replicas: 3 controlPlane: architecture: amd64 hyperthreading: Enabled name: master platform: {} replicas: 3- 1
- 在安装时为 CPU 分区设置集群。默认值为
None。
23.2. 性能配置集和工作负载分区
通过应用性能配置集,您可以使用工作负载分区功能。适当配置的性能配置集指定isolated和reserved CPU。创建性能配置集的建议方法是使用 Performance Profile Creator (PPC) 工具创建性能配置集。
23.3. 性能配置集配置示例
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
# if you change this name make sure the 'include' line in TunedPerformancePatch.yaml
# matches this name: include=openshift-node-performance-${PerformanceProfile.metadata.name}
# Also in file 'validatorCRs/informDuValidator.yaml':
# name: 50-performance-${PerformanceProfile.metadata.name}
name: openshift-node-performance-profile
annotations:
ran.openshift.io/reference-configuration: "ran-du.redhat.com"
spec:
additionalKernelArgs:
- "rcupdate.rcu_normal_after_boot=0"
- "efi=runtime"
- "vfio_pci.enable_sriov=1"
- "vfio_pci.disable_idle_d3=1"
- "module_blacklist=irdma"
cpu:
isolated: $isolated
reserved: $reserved
hugepages:
defaultHugepagesSize: $defaultHugepagesSize
pages:
- size: $size
count: $count
node: $node
machineConfigPoolSelector:
pools.operator.machineconfiguration.openshift.io/$mcp: ""
nodeSelector:
node-role.kubernetes.io/$mcp: ''
numa:
topologyPolicy: "restricted"
# To use the standard (non-realtime) kernel, set enabled to false
realTimeKernel:
enabled: true
workloadHints:
# WorkloadHints defines the set of upper level flags for different type of workloads.
# See https://github.com/openshift/cluster-node-tuning-operator/blob/master/docs/performanceprofile/performance_profile.md#workloadhints
# for detailed descriptions of each item.
# The configuration below is set for a low latency, performance mode.
realTime: true
highPowerConsumption: false
perPodPowerManagement: false| PerformanceProfile CR 字段 | 描述 |
|---|---|
|
|
确保
|
|
|
|
|
| 设置隔离的 CPU。确保所有 Hyper-Threading 对都匹配。 重要 保留和隔离的 CPU 池不得重叠,并且必须一起跨越所有可用的内核。未考虑导致系统中未定义的 CPU 内核。 |
|
| 设置保留的 CPU。启用工作负载分区时,系统进程、内核线程和系统容器线程仅限于这些 CPU。所有不是隔离的 CPU 都应保留。 |
|
|
|
|
|
将 |
|
|
使用 |
第 24 章 使用 Node Observability Operator
Node Observability Operator 从计算节点脚本收集并存储 CRI-O 和 Kubelet 分析或指标。
使用 Node Observability Operator,您可以查询性能分析数据,从而分析 CRI-O 和 Kubelet 中的性能趋势。它支持调试与性能相关的问题,并使用自定义资源定义中的 run 字段为网络指标执行内嵌脚本。要启用 CRI-O 和 Kubelet 分析或脚本,您可以在自定义资源定义中配置 type 字段。
Node Observability Operator 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅以下链接:
24.1. Node Observability Operator 的工作流
以下工作流概述了如何使用 Node Observability Operator 查询分析数据:
- 在 OpenShift Container Platform 集群中安装 Node Observability Operator。
- 创建 NodeObservability 自定义资源,在您选择的 worker 节点上启用 CRI-O 分析。
- 运行性能分析查询,以生成分析数据。
24.2. 安装 Node Observability Operator
默认情况下,OpenShift Container Platform 中不会安装 Node Observability Operator。您可以使用 OpenShift Container Platform CLI 或 Web 控制台安装 Node Observability Operator。
24.2.1. 使用 CLI 安装 Node Observability Operator
您可以使用 OpenShift CLI(oc)安装 Node Observability Operator。
先决条件
- 已安装 OpenShift CLI(oc)。
-
您可以使用
cluster-admin权限访问集群。
流程
运行以下命令确认 Node Observability Operator 可用:
$ oc get packagemanifests -n openshift-marketplace node-observability-operator输出示例
NAME CATALOG AGE node-observability-operator Red Hat Operators 9h运行以下命令来创建
node-observability-operator命名空间:$ oc new-project node-observability-operator创建
OperatorGroup对象 YAML 文件:cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: node-observability-operator namespace: node-observability-operator spec: targetNamespaces: [] EOF创建一个
Subscription对象 YAML 文件,以便为 Operator 订阅一个命名空间:cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: node-observability-operator namespace: node-observability-operator spec: channel: alpha name: node-observability-operator source: redhat-operators sourceNamespace: openshift-marketplace EOF
验证
运行以下命令来查看安装计划名称:
$ oc -n node-observability-operator get sub node-observability-operator -o yaml | yq '.status.installplan.name'输出示例
install-dt54w运行以下命令验证安装计划状态:
$ oc -n node-observability-operator get ip <install_plan_name> -o yaml | yq '.status.phase'<install_plan_name>是您从上一命令的输出中获取的安装计划名称。输出示例
COMPLETE验证 Node Observability Operator 是否正在运行:
$ oc get deploy -n node-observability-operator输出示例
NAME READY UP-TO-DATE AVAILABLE AGE node-observability-operator-controller-manager 1/1 1 1 40h
24.2.2. 使用 Web 控制台安装 Node Observability Operator
您可从 OpenShift Container Platform Web 控制台安装 Node Observability Operator。
先决条件
-
您可以使用
cluster-admin权限访问集群。 - 访问 OpenShift Container Platform web 控制台。
流程
- 登陆到 OpenShift Container Platform Web 控制台。
- 在 Administrator 的导航面板中,选择 Ecosystem → Software Catalog。
- 在 All items 字段中,输入 Node Observability Operator 并选择 Node Observability Operator 标题。
- 点 Install。
在 Install Operator 页面中,配置以下设置:
- 在 Update 频道区中,点 alpha。
- 在 Installation 模式 区中,点 A specific namespace on the cluster。
- 在 Installed Namespace 列表中,从列表中选择 node-observability-operator。
- 在 Update approval 区中,选择 Automatic。
- 点 Install。
验证
- 在 Administrator 的导航面板中,展开 Ecosystem → Installed Operators。
- 验证 Node Observability Operator 是否列在 Operators 列表中。
创建 Node Observability 自定义资源来收集 CRI-O 和 Kubelet 分析数据。
24.3.1. 创建 Node Observability 自定义资源
在运行性能分析查询前,您必须创建并运行 NodeObservability 自定义资源 (CR)。运行 NodeObservability CR 时,它会创建所需的机器配置和机器配置池 CR,以便在与 nodeSelector 匹配的 worker 节点上启用 CRI-O 分析。
如果 worker 节点上没有启用 CRI-O 分析,则会创建 NodeObservabilityMachineConfig 资源。与 NodeObservability CR 中指定的 nodeSelector 匹配的 worker 节点。这可能需要 10 分钟或更长时间来完成。
kubelet 分析被默认启用。
节点的 CRI-O unix 套接字挂载在代理 pod 上,允许代理与 CRI-O 通信来运行 pprof 请求。同样,kubelet-serving-ca 证书链被挂载到代理 pod 上,允许在代理和节点的 kubelet 端点之间进行安全通信。
先决条件
- 已安装 Node Observability Operator。
- 已安装 OpenShift CLI(oc)。
-
您可以使用
cluster-admin权限访问集群。
流程
运行以下命令登录到 OpenShift Container Platform CLI:
$ oc login -u kubeadmin https://<HOSTNAME>:6443运行以下命令切换回
node-observability-operator命名空间:$ oc project node-observability-operator创建名为
nodeobservability.yaml的 CR 文件,其中包含以下文本:apiVersion: nodeobservability.olm.openshift.io/v1alpha2 kind: NodeObservability metadata: name: cluster1 spec: nodeSelector: kubernetes.io/hostname: <node_hostname>2 type: crio-kubelet运行
NodeObservabilityCR:oc apply -f nodeobservability.yaml输出示例
nodeobservability.olm.openshift.io/cluster created运行以下命令,检查
NodeObservabilityCR 的状态:$ oc get nob/cluster -o yaml | yq '.status.conditions'输出示例
conditions: conditions: - lastTransitionTime: "2022-07-05T07:33:54Z" message: 'DaemonSet node-observability-ds ready: true NodeObservabilityMachineConfig ready: true' reason: Ready status: "True" type: Ready当原因为
Ready且状态为True时,NodeObservabilityCR 运行已完成。
24.3.2. 运行性能分析查询
要运行性能分析查询,您必须创建一个 NodeObservabilityRun 资源。分析查询是一个阻止操作,用于在 30 秒内获取 CRI-O 和 Kubelet 分析数据。分析查询完成后,您必须检索容器文件系统 /run/node-observability 目录中的性能分析数据。数据生命周期通过 emptyDir 卷绑定到代理 pod,因此您可以在代理 pod 处于 running 状态时访问性能分析数据。
您可以在任何时间点上请求一个性能分析查询。
先决条件
- 已安装 Node Observability Operator。
-
您已创建了
NodeObservability自定义资源(CR)。 -
您可以使用
cluster-admin权限访问集群。
流程
创建名为
nodeobservabilityrun.yaml的NodeObservabilityRun资源文件,其中包含以下文本:apiVersion: nodeobservability.olm.openshift.io/v1alpha2 kind: NodeObservabilityRun metadata: name: nodeobservabilityrun spec: nodeObservabilityRef: name: cluster运行
NodeObservabilityRun资源来触发性能分析查询:$ oc apply -f nodeobservabilityrun.yaml运行以下命令,检查
NodeObservabilityRun的状态:$ oc get nodeobservabilityrun nodeobservabilityrun -o yaml | yq '.status.conditions'输出示例
conditions: - lastTransitionTime: "2022-07-07T14:57:34Z" message: Ready to start profiling reason: Ready status: "True" type: Ready - lastTransitionTime: "2022-07-07T14:58:10Z" message: Profiling query done reason: Finished status: "True" type: Finished分析查询在状态变为
True后完成,类型为Finished。通过运行以下 bash 脚本,从容器的
/run/node-observability路径中检索配置集数据:for a in $(oc get nodeobservabilityrun nodeobservabilityrun -o yaml | yq .status.agents[].name); do echo "agent ${a}" mkdir -p "/tmp/${a}" for p in $(oc exec "${a}" -c node-observability-agent -- bash -c "ls /run/node-observability/*.pprof"); do f="$(basename ${p})" echo "copying ${f} to /tmp/${a}/${f}" oc exec "${a}" -c node-observability-agent -- cat "${p}" > "/tmp/${a}/${f}" done done
24.4. Node Observability Operator 脚本
脚本允许您使用当前的 Node Observability Operator 和 Node Observability 代理运行预先配置的 bash 脚本。
这些脚本监控 CPU 负载、内存压力和 worker 节点问题等关键指标。它们还收集 sar 报告和自定义性能指标。
24.4.1. 为脚本创建 Node Observability 自定义资源
在运行脚本前,您必须创建并运行 NodeObservability 自定义资源 (CR)。运行 NodeObservability CR 时,它会在与 nodeSelector 标签匹配的计算节点上以脚本模式启用代理。
先决条件
- 已安装 Node Observability Operator。
-
已安装 OpenShift CLI(
oc)。 -
您可以使用
cluster-admin权限访问集群。
流程
运行以下命令登录到 OpenShift Container Platform 集群:
$ oc login -u kubeadmin https://<host_name>:6443运行以下命令切换到
node-observability-operator命名空间:$ oc project node-observability-operator创建名为
nodeobservability.yaml的文件,其中包含以下内容:apiVersion: nodeobservability.olm.openshift.io/v1alpha2 kind: NodeObservability metadata: name: cluster1 spec: nodeSelector: kubernetes.io/hostname: <node_hostname>2 type: scripting3 运行以下命令来创建
NodeObservabilityCR:$ oc apply -f nodeobservability.yaml输出示例
nodeobservability.olm.openshift.io/cluster created运行以下命令,检查
NodeObservabilityCR 的状态:$ oc get nob/cluster -o yaml | yq '.status.conditions'输出示例
conditions: conditions: - lastTransitionTime: "2022-07-05T07:33:54Z" message: 'DaemonSet node-observability-ds ready: true NodeObservabilityScripting ready: true' reason: Ready status: "True" type: Ready当
reason为Ready,status为"True"时代表NodeObservabilityCR 运行完成。
24.4.2. 配置 Node Observability Operator 脚本
先决条件
- 已安装 Node Observability Operator。
-
您已创建了
NodeObservability自定义资源(CR)。 -
您可以使用
cluster-admin权限访问集群。
流程
创建一个名为
nodeobservabilityrun-script.yaml的文件,其中包含以下内容:apiVersion: nodeobservability.olm.openshift.io/v1alpha2 kind: NodeObservabilityRun metadata: name: nodeobservabilityrun-script namespace: node-observability-operator spec: nodeObservabilityRef: name: cluster type: scripting重要您只能请求以下脚本:
-
metrics.sh -
network-metrics.sh(使用monitor.sh)
-
使用以下命令创建
NodeObservabilityRun资源来触发脚本:$ oc apply -f nodeobservabilityrun-script.yaml运行以下命令,查看
NodeObservabilityRun脚本的状态:$ oc get nodeobservabilityrun nodeobservabilityrun-script -o yaml | yq '.status.conditions'输出示例
Status: Agents: Ip: 10.128.2.252 Name: node-observability-agent-n2fpm Port: 8443 Ip: 10.131.0.186 Name: node-observability-agent-wcc8p Port: 8443 Conditions: Conditions: Last Transition Time: 2023-12-19T15:10:51Z Message: Ready to start profiling Reason: Ready Status: True Type: Ready Last Transition Time: 2023-12-19T15:11:01Z Message: Profiling query done Reason: Finished Status: True Type: Finished Finished Timestamp: 2023-12-19T15:11:01Z Start Timestamp: 2023-12-19T15:10:51Z当
Status为True,Type为Finished时代表脚本完成。运行以下 bash 脚本,从容器的 root 路径检索脚本数据:
#!/bin/bash RUN=$(oc get nodeobservabilityrun --no-headers | awk '{print $1}') for a in $(oc get nodeobservabilityruns.nodeobservability.olm.openshift.io/${RUN} -o json | jq .status.agents[].name); do echo "agent ${a}" agent=$(echo ${a} | tr -d "\"\'\`") base_dir=$(oc exec "${agent}" -c node-observability-agent -- bash -c "ls -t | grep node-observability-agent" | head -1) echo "${base_dir}" mkdir -p "/tmp/${agent}" for p in $(oc exec "${agent}" -c node-observability-agent -- bash -c "ls ${base_dir}"); do f="/${base_dir}/${p}" echo "copying ${f} to /tmp/${agent}/${p}" oc exec "${agent}" -c node-observability-agent -- cat ${f} > "/tmp/${agent}/${p}" done done
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.