第 2 章 网络配置参考
网络配置对于构建高性能 Red Hat Ceph Storage 集群至关重要。Ceph 存储集群不代表 Ceph 客户端执行请求路由或分配请求。相反,Ceph 客户端直接向 Ceph OSD 守护进程发出请求。Ceph OSD 代表 Ceph 客户端执行数据复制,这意味着复制和其他因素对 Ceph 存储集群的网络造成额外的负载。
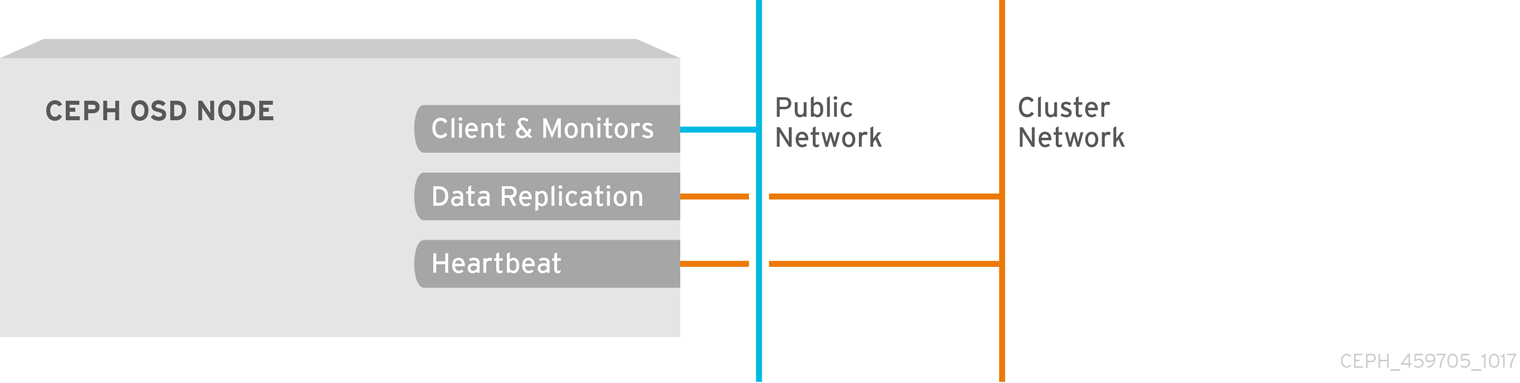
所有 Ceph 集群都必须使用公共网络。但是,除非指定了一个集群(内部)网络,Ceph 假定有一个公共网络。Ceph 可以在只有一个公共网络的情况下运行,但对于大型集群,如果还有第二个 "cluster" 网络,则性能会显著提高。
红帽建议运行具有两个网络的 Ceph 存储集群:
- 公共网络
- 以及集群网络。
要支持两个网络,每个 Ceph 节点都需要有一个以上的网络接口卡 (NIC) 。

需要考虑操作两个独立网络的原因有很多:
- 性能: Ceph OSD 处理 Ceph 客户端的数据复制。当 Ceph OSD 多次复制数据时,Ceph OSD 之间网络负载可轻松地在 Ceph 客户端和 Ceph 存储集群之间分配网络负载。这会引入延迟并创建性能问题。恢复和重新平衡还在公共网络上引入大量延迟。
-
安全 :虽然大多数人用户都会正常使用资源,但有些人可能会参与所谓的拒绝服务 (DoS) 攻击。当 Ceph OSD 之间的流量中断时,peering 可能会失败,放置组可能无法反映
活跃的 + clean状态,这可能会阻止用户读取和写入数据。缓解这类攻击的一个好方法是,维护一个完全独立的、不直接连接到互联网的集群网络。
2.1. 网络配置设置
不需要网络配置设置。Ceph 可只用于公共网络,假定在运行 Ceph 守护进程的所有主机上都配置了公共网络。但是,Ceph 允许您建立更加具体的标准,包括用于公共网络的多个 IP 网络和子网掩码。您还可以建立一个单独的集群网络来处理 OSD 心跳、对象复制和恢复流量。
不要将您在配置中设置的 IP 地址与面向公共的 IP 地址网络客户端混淆。典型的内部 IP 网络通常为 192.168.0.0 或 10.0.0.0。
如果您为公共或集群网络指定多个 IP 地址和子网掩码,则网络中的子网必须能够相互路由。另外,请确保在 IP 表中包括每个 IP 地址/子网,并根据需要打开端口。
Ceph 使用 CIDR 表示法作为子网(例如,1 0.0.0.0/24)。
当配置网络时,您可以重启集群或重启每个守护进程。Ceph 守护进程动态绑定,因此如果更改网络配置,不必一次重启整个集群。
2.1.1. 公共网络
要配置公共网络,请在 Ceph 配置文件的 [global] 部分添加以下选项:
[global]
...
public_network = <public-network/netmask>
公共网络配置允许您为公共网络定义 IP 地址和子网。您可以使用特定守护进程的 设置。
公共 addr 设置特别分配静态 IP 地址或覆盖公共网络
- public_network
- 描述
-
公共(前端)网络的 IP 地址和子网掩码(例如,
192.168.0.0/24)。在[global]中设置。您可以指定以逗号分隔的子网。 - 类型
-
<ip-address>/<netmask> [, <ip-address>/<netmask>] - 必填
- 否
- 默认
- N/A
- public_addr
- 描述
- 公共(前端)网络的 IP 地址。为每个守护进程设置。
- 类型
- IP 地址
- 必填
- 否
- 默认
- N/A
2.1.2. 集群网络
如果您创建集群网络,OSD 会通过集群网络路由心跳、对象复制和恢复流量。与使用单个网络相比,这可以提高性能。要配置集群网络,请在 Ceph 配置文件的 [global] 部分添加以下选项:
[global]
...
cluster_network = <cluster-network/netmask>最好的情况是,不能从公共网络或互联网访问集群网络以提高安全性。
集群网络配置允许您声明集群网络,并具体为集群网络定义 IP 地址和子网。您可以使用特定 OSD 守护进程的集群 addr 设置来具体分配静态 IP 地址或覆盖 。
集群 网络设置
- cluster_network
- 描述
-
集群网络的 IP 地址和子网掩码(例如
10.0.0.0/24)。在[global]中设置。您可以指定以逗号分隔的子网。 - 类型
-
<ip-address>/<netmask> [, <ip-address>/<netmask>] - 必填
- 否
- 默认
- N/A
- cluster_addr
- 描述
- 集群网络的 IP 地址。为每个守护进程设置。
- 类型
- 地址
- 必填
- 否
- 默认
- N/A
2.1.3. 验证并配置 MTU 值
最大传输单元 (MTU) 值是链路层上发送的最大数据包的大小(以字节为单位)。默认的 MTU 值为 1500 字节。红帽建议将巨型帧( MTU 值为 9000 字节)用于 Red Hat Ceph Storage 集群。
Red Hat Ceph Storage 在通信路径的所有网络设备中,公共和集群网络需要相同的 MTU 值。在在生产环境中使用 Red Hat Ceph Storage 集群之前,验证环境中所有节点和网络设备上的 MTU 值相同。
将网络接口绑定在一起时,MTU 值只需要在绑定接口上设置。新的 MTU 值从绑定设备传播到底层网络设备。
先决条件
- 节点的根级别访问权限。
流程
验证当前的 MTU 值:
示例
[root@mon ~]# ip link list 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: enp22s0f0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000在本例中,网络接口是
enp22s0f0,其 MTU 值为1500。临时更改 在线 MTU 值:
语法
ip link set dev NET_INTERFACE mtu NEW_MTU_VALUE示例
[root@mon ~]# ip link set dev enp22s0f0 mtu 9000以永久更改 MTU 值。
打开针对特点网络接口的网络配置文件进行编辑:
语法
vim /etc/sysconfig/network-scripts/ifcfg-NET_INTERFACE示例
[root@mon ~]# vim /etc/sysconfig/network-scripts/ifcfg-enp22s0f0在新行中添加
MTU=9000选项:示例
NAME="enp22s0f0" DEVICE="enp22s0f0" MTU=90001 ONBOOT=yes NETBOOT=yes UUID="a8c1f1e5-bd62-48ef-9f29-416a102581b2" IPV6INIT=yes BOOTPROTO=dhcp TYPE=Ethernet重启网络服务:
示例
[root@mon ~]# systemctl restart network
其它资源
- 详情请查看 Red Hat Enterprise Linux 7 的 网络指南。
2.1.4. 消息传递
messenger 是 Ceph 网络层实施。红帽支持两种 messenger 类型:
-
simple -
async
在 RHCS 2 及更早的版本中,简单 是默认的 mesenger 类型。在 RHCS 3 中,async 是默认的 messenger 类型。要更改 messenger 类型,请在 Ceph 配置文件的 [global] 部分中指定 ms_type 配置设置。
对于 async messenger,红帽支持 posix 传输类型,但目前不支持 rdma 或 dpdk。默认情况下,RHCS 3 中的 ms_type 设置应反映 async+posix,其中 async 是 messenger 类型,posix 传输类型。
关于 SimpleMessenger
SimpleMessenger 实施使用每个套接字有两个线程的 TCP 套接字。Ceph 将每个逻辑会话与连接相关联。管道处理连接,包括每个消息的输入和输出。尽管 SimpleMessenger 对 posix 传输类型有效,但它不适用于 rdma 或 dpdk 等其他传输类型。因此,AsyncMessenger 是 RHCS 3 及更新的版本的默认 mesenger 类型。
关于 AsyncMessenger
对于 RHCS 3,AsyncMessenger 实现使用带有固定大小的线程池的 TCP 套接字进行连接,这应该等于最大副本数或纠删代码区块。如果性能因为 CPU 数量较低或每个服务器有大量 OSD,可以将线程数设置为较低值。
红帽目前不支持其他传输类型,如 rdma 或 dpdk。
messenger Type Settings
- ms_type
- 描述
-
网络传输层的 messenger 类型。红帽支持使用
posix语义的simple和asyncmessenger 类型。 - 类型
- 字符串.
- 必需
- No.
- 默认
-
async+posix
- ms_public_type
- 描述
-
公共网络的网络传输层的 messenger 类型。它的工作方式与
ms_type相同,但仅适用于公共网络或前端网络。此设置可让 Ceph 为公共或前端和集群或后端网络使用不同的 mesenger 类型。 - 类型
- 字符串.
- 必需
- No.
- 默认
- 无。
- ms_cluster_type
- 描述
-
集群网络的网络传输层的 messenger 类型。它的工作方式与
ms_type相同,但仅适用于集群或后端网络。此设置可让 Ceph 为公共或前端和集群或后端网络使用不同的 mesenger 类型。 - 类型
- 字符串.
- 必需
- No.
- 默认
- 无。
2.1.5. AsyncMessenger 设置
- ms_async_transport_type
- 描述
-
AsyncMessenger使用的传输类型。红帽支持posix设置,但目前不支持dpdk或rdma设置。POSIX 使用标准 TCP/IP 网络,它是默认值。其他传输类型是实验性的,因此不被支持。 - 类型
- 字符串
- 必需
- 否
- 默认
-
posix
- ms_async_op_threads
- 描述
-
每个
AsyncMessenger实例使用的初始 worker 线程数。此配置设置 SHOULD 等于副本或纠删代码区块的数量。但如果 CPU 内核数量较低或单个服务器上的 OSD 数量很高,则可设置它。 - 类型
- 64-bit Unsigned 整数
- 必需
- 否
- 默认
-
3
- ms_async_max_op_threads
- 描述
-
每个
AsyncMessenger实例使用的最大 worker 线程数量。如果 OSD 主机具有有限 CPU 数量,并且如果 Ceph 利用率不足,则设置为较低值。 - 类型
- 64-bit Unsigned 整数
- 必需
- 否
- 默认
-
5
- ms_async_set_affinity
- 描述
-
设置为
true,将AsyncMessengerworker 绑定到特定的 CPU 内核。 - 类型
- 布尔值
- 必需
- 否
- 默认
-
true
- ms_async_affinity_cores
- 描述
-
当
ms_async_set_affinity为true时,该字符串指定了将AsyncMessengerworker 绑定到 CPU 内核的方式。例如:0,2会将 worker #1 和 #2 分别绑定到 CPU 内核 #0 和 #2。注意: 在手动设置关联性时,确保不将 worker 分配给创建的虚拟 CPU,作为超线程或类似技术的影响,因为它们比物理 CPU 内核慢。 - 类型
- 字符串
- 必需
- 否
- 默认
-
(empty)
- ms_async_send_inline
- 描述
-
直接从生成它们的线程中直接发送消息,而不是排队并从
AsyncMessenger线程发送发送。这个选项已知可以降低具有大量 CPU 内核的系统的性能,因此默认禁用它。 - 类型
- 布尔值
- 必需
- 否
- 默认
-
false
2.1.6. 绑定
BIND 设置设置 Ceph OSD 守护进程使用的默认端口范围。默认范围为 6800:7100。确保防火墙配置允许您使用配置的端口范围。
您还可以启用 Ceph 守护进程来绑定到 IPv6 地址。
- ms_bind_port_min
- 描述
- OSD 守护进程要绑定到的最低端口号。
- 类型
- 32 位整数
- 默认
-
6800 - 必填
- 否
- ms_bind_port_max
- 描述
- OSD 守护进程要绑定到的最大端口号。
- 类型
- 32 位整数
- 默认
-
7300 - 必需
- No.
- ms_bind_ipv6
- 描述
- 启用 Ceph 守护进程来绑定到 IPv6 地址。
- 类型
- 布尔值
- 默认
-
false - 必填
- 否
2.1.7. 主机
Ceph 预期在 Ceph 配置文件中至少声明了一个 monitor,每个声明的 monitor 下都有一个 mon addr 设置。Ceph 预期 Ceph 在 Ceph 配置文件中每个声明的 monitor、元数据服务器和 OSD 下的 host 设置。
- mon_addr
- 描述
-
客户端可用于连接到 Ceph 监视器的
<hostname>:<port>条目列表。如果没有设置,Ceph 会搜索[mon.*]部分。 - 类型
- 字符串
- 必需
- 否
- 默认
- N/A
- 主机
- 描述
-
主机名。对特定的守护进程实例使用此设置(例如,
[osd.0])。 - 类型
- 字符串
- 必填
- 是,对于守护进程实例。
- 默认
-
localhost
不要使用 localhost。要获得您的主机名,请执行 hostname -s 命令并使用您的主机名到第一个句点,而不是完全限定域名。
在使用检索您的 主机名 的第三方部署系统时,不要为主机指定任何值。
2.1.8. TCP
Ceph 默认禁用 TCP 缓冲。
- ms_tcp_nodelay
- 描述
-
Ceph 启用
ms_tcp_nodelay,使每个请求立即发送(无缓冲区)。禁用 Nagle 的算法会增加网络流量,它可以造成拥塞问题。如果您遇到大量小数据包,您可以尝试禁用ms_tcp_nodelay,但请注意,禁用它通常会增加延迟。 - 类型
- 布尔值
- 必需
- 否
- 默认
-
true
- ms_tcp_rcvbuf
- 描述
- 网络连接结尾的套接字缓冲区的大小。默认禁用。
- 类型
- 32 位整数
- 必填
- 否
- 默认
-
0
- ms_tcp_read_timeout
- 描述
-
如果客户端或守护进程向另一个 Ceph 守护进程发出请求且不丢弃未使用的连接,则
tcp read timeout会在指定秒数后将连接定义为 idle。 - 类型
- unsigned 64 位整数
- 必填
- 否
- 默认
-
90015 分钟。
2.1.9. firewall
默认情况下,守护进程绑定到 6800:7100 范围内的端口。您可自行配置此范围。在配置防火墙前,检查默认防火墙配置。您可自行配置此范围。
sudo iptables -L
对于 firewalld 守护进程,以 root 用户身份执行以下命令:
# firewall-cmd --list-all-zones一些 Linux 发行版包含拒绝除来自所有网络接口的 SSH 之外的所有入站请求的规则。例如:
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited2.1.9.1. 监控防火墙
Ceph 监视器默认侦听端口 6789。此外,Ceph 监视器始终对公共网络运行。当使用以下示例添加规则时,请确保将 <iface> 替换为公共网络接口(如 eth0、eth1 等等),将 <ip-address> 替换为公共网络的 IP 地址,将 <netmask> 替换为公共网络的子网掩码。
sudo iptables -A INPUT -i <iface> -p tcp -s <ip-address>/<netmask> --dport 6789 -j ACCEPT
对于 firewalld 守护进程,以 root 用户身份执行以下命令:
# firewall-cmd --zone=public --add-port=6789/tcp
# firewall-cmd --zone=public --add-port=6789/tcp --permanent2.1.9.2. OSD 防火墙
默认情况下,Ceph OSD 绑定到从 6800 端口开始的 Ceph 节点上第一个可用端口。确保为主机上运行的每个 OSD 最少打开三个端口,使其以端口 6800 开始:
- 个用于与客户端和服务器(公共网络)对话。
- 个用于将数据发送到其他 OSD(集群网络)。
- 个用于发送 heartbeat 数据包(集群网络)。
端口特定于节点。但是,如果进程重启并且绑定端口没有释放绑定端口,您可能需要打开比该 Ceph 节点上运行的端口所需的端口数量。当守护进程失败并重启而不释放端口,以便重启的守护进程绑定到新端口时,请考虑打开一些额外的端口。另外,请考虑在每个 OSD 主机上打开 6800:7300 端口范围。
如果设置了单独的公共和集群网络,您必须同时为公共网络和集群网络添加规则,因为客户端将使用公共网络连接,其他 Ceph OSD 守护进程将使用集群网络进行连接。
当使用以下示例添加规则时,请确保将 < iface> 替换为网络接口(如 eth0 或 eth1), '<ip-address & gt; 替换为公共或集群网络的子网掩码。例如:
sudo iptables -A INPUT -i <iface> -m multiport -p tcp -s <ip-address>/<netmask> --dports 6800:6810 -j ACCEPT
对于 firewalld 守护进程,以 root 用户身份执行以下命令:
# firewall-cmd --zone=public --add-port=6800-6810/tcp
# firewall-cmd --zone=public --add-port=6800-6810/tcp --permanent如果将集群网络放在另一个区中,请根据需要在该区中打开端口。