3.2.5. 存储容量
当 Red Hat Ceph Storage 集群接近其最大容量时(通过 mon_osd_full_ratio 参数显示),Ceph 会阻止您写入或读取 Ceph OSD 的安全措施,以防止数据丢失。因此,让一个生产用 Red Hat Ceph Storage 集群方法使其全满比率不是一个好的做法,因为它降低了高可用性。默认全满比率为 .95 或 95% 的容量。对于具有多个 OSD 的测试集群来说,这是一个非常积极的设置。
监控集群时,请注意与 nearfull 比率相关的警告。这意味着,一些 OSD 故障可能会导致临时服务中断,如果一个或多个 OSD 出现故障。考虑添加更多 OSD 以增加存储容量。
测试集群的常见场景涉及系统管理员从 Red Hat Ceph Storage 集群中删除 Ceph OSD,以观察集群重新平衡。然后,删除另一个 Ceph OSD,直到 Red Hat Ceph Storage 集群最终达到完全的比例并锁定。
红帽建议在一个测试集群中仍然有点的容量规划。通过规划,您可以量化您需要的备用容量来保持高可用性。理想情况下,您要规划一系列 Ceph OSD 失败的情况,集群可以在不立即替换这些 Ceph OSD 的情况下恢复到 active + clean 状态。您可以运行状态为 active + degraded 的集群,但这对正常操作并不是一个理想的状态。
下图显示了一个简化的 Red Hat Ceph Storage 集群,其中包含每个主机有一个 Ceph OSD 的 33 Ceph 节点,每个 Ceph OSD 守护进程从中读取并写入 3TB 驱动器。因此,这一 exemplary Red Hat Ceph Storage 集群具有最大 99TB 的实际容量。当 mon osd full ratio 为 0.95,如果 Red Hat Ceph Storage 集群达到 5TB 的容量,集群不允许 Ceph 客户端读取和写入数据。因此,Red Hat Ceph Storage 集群的操作容量为 95 TB,而不是 99 TB。
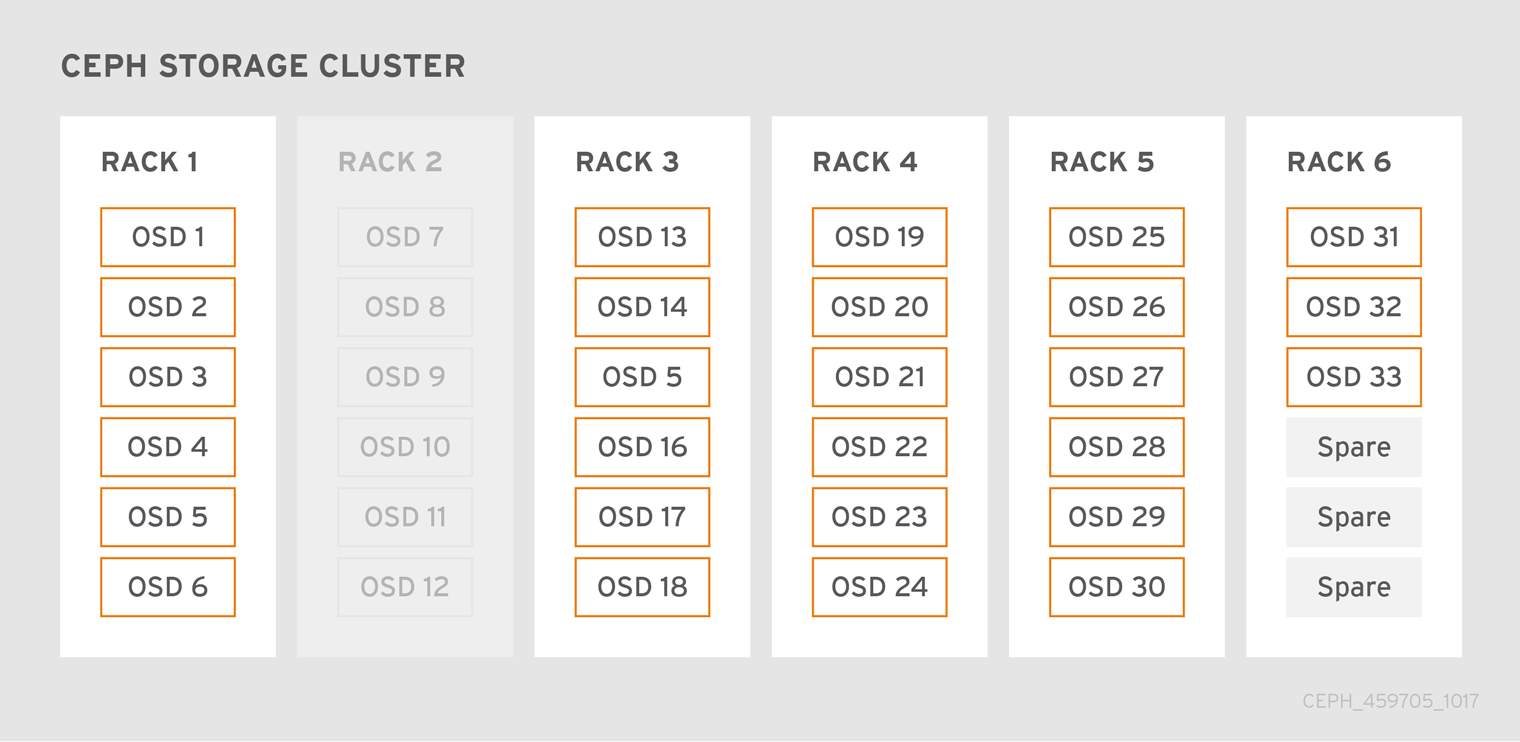
在这样的集群中,一个或多个 OSD 无法正常使用。较为频繁但合理的方案涉及机架的路由器或电源故障,例如同时导致多个 OSD 下线,例如 OSDs 7-12。在这种情况下,保持集群正常运行并处于 active + clean 状态仍会为您带来更大益处,即使这需要在短时间内添加具有额外 OSD 的主机。如果您的容量利用率太高,可能不会丢失数据,但您仍然可能会牺牲数据可用性,同时在故障域内解决集群的容量利用率超过完整的比例。因此,红帽建议至少使用一些最小容量规划。
识别集群的两个值:
- OSD 数量
- 集群的总容量
要确定集群中的 OSD 的平均容量,请将集群的总容量除以集群中的 OSD 数量。考虑将这个数量乘以您希望在正常操作期间同时出现故障的 OSD 数量(相对较小的数)。最后,通过满比例将集群的容量乘以达到最大操作容量。然后,从 OSD 中减去您希望无法达到合理的全满比率的 OSD 的数据量。重复处理数量较高的 OSD 故障(例如,一个 OSD 机架),以达到接近的全满比率的合理数量。
[global]
...
mon_osd_full_ratio = .80
mon_osd_nearfull_ratio = .70- mon_osd_full_ratio
- 描述
-
在 OSD 被视为
full之前使用的磁盘空间百分比。 - 类型
- 浮点值:
- 默认
-
.95
- mon_osd_nearfull_ratio
- 描述
-
在 OSD 视为
nearfull之前使用的磁盘空间百分比。 - 类型
- 浮点值
- 默认
-
.85
如果某些 OSD 接近满,但其他 OSD 具有容量量,则可能对 OSD 的 CRUSH 权重出现问题。
nearfull