Chapter 3. Recommended Host Practices
3.1. Recommended Practices for OpenShift Container Platform Master Hosts
In addition to pod traffic, the most-used data-path in an OpenShift Container Platform infrastructure is between the OpenShift Container Platform master hosts and etcd. The OpenShift Container Platform API server (part of the master binary) consults etcd for node status, network configuration, secrets, and more.
Optimize this traffic path by:
- Running etcd on master hosts. By default, etcd runs in a static pod on all master hosts.
- Ensuring an uncongested, low latency LAN communication link between master hosts.
The OpenShift Container Platform master caches deserialized versions of resources aggressively to ease CPU load. However, in smaller clusters of less than 1000 pods, this cache can waste a lot of memory for negligible CPU load reduction. The default cache size is 50,000 entries, which, depending on the size of your resources, can grow to occupy 1 to 2 GB of memory. This cache size can be reduced using the following setting the in /etc/origin/master/master-config.yaml:
kubernetesMasterConfig:
apiServerArguments:
deserialization-cache-size:
- "1000"3.2. Recommended Practices for OpenShift Container Platform Node Hosts
The OpenShift Container Platform node configuration file contains important options, such as the iptables synchronization period, the Maximum Transmission Unit (MTU) of the SDN network, and the proxy-mode. To configure your nodes, modify the appropriate node configuration map.
Do not edit the node-config.yaml file directly.
The node configuration file allows you to pass arguments to the kubelet (node) process. You can view a list of possible options by running kubelet --help.
Not all kubelet options are supported by OpenShift Container Platform, and are used in the upstream Kubernetes. This means certain options are in limited support.
See the Cluster Limits page for the maximum supported limits for each version of OpenShift Container Platform.
In the /etc/origin/node/node-config.yaml file, two parameters control the maximum number of pods that can be scheduled to a node: pods-per-core and max-pods. When both options are in use, the lower of the two limits the number of pods on a node. Exceeding these values can result in:
- Increased CPU utilization on both OpenShift Container Platform and Docker.
- Slow pod scheduling.
- Potential out-of-memory scenarios (depends on the amount of memory in the node).
- Exhausting the pool of IP addresses.
- Resource overcommitting, leading to poor user application performance.
In Kubernetes, a pod that is holding a single container actually uses two containers. The second container is used to set up networking prior to the actual container starting. Therefore, a system running 10 pods will actually have 20 containers running.
pods-per-core sets the number of pods the node can run based on the number of processor cores on the node. For example, if pods-per-core is set to 10 on a node with 4 processor cores, the maximum number of pods allowed on the node will be 40.
kubeletArguments:
pods-per-core:
- "10"
Setting pods-per-core to 0 disables this limit.
max-pods sets the number of pods the node can run to a fixed value, regardless of the properties of the node. Cluster Limits documents maximum supported values for max-pods.
kubeletArguments:
max-pods:
- "250"
Using the above example, the default value for pods-per-core is 10 and the default value for max-pods is 250. This means that unless the node has 25 cores or more, by default, pods-per-core will be the limiting factor.
See the Sizing Considerations section in the installation documentation for the recommended limits for an OpenShift Container Platform cluster. The recommended sizing accounts for OpenShift Container Platform and Docker coordination for container status updates. This coordination puts CPU pressure on the master and docker processes, which can include writing a large amount of log data.
3.3. Recommended Practices for OpenShift Container Platform etcd Hosts
etcd is a distributed key-value store that OpenShift Container Platform uses for configuration.
| OpenShift Container Platform Version | etcd version | storage schema version |
| 3.3 and earlier | 2.x | v2 |
| 3.4 and 3.5 | 3.x | v2 |
| 3.6 | 3.x | v2 (upgrades) |
| 3.6 | 3.x | v3 (new installations) |
etcd 3.x introduces important scalability and performance improvements that reduce CPU, memory, network, and disk requirements for any size cluster. etcd 3.x also implements a backwards compatible storage API that facilitates a two-step migration of the on-disk etcd database. For migration purposes, the storage mode used by etcd 3.x in OpenShift Container Platform 3.5 remained in v2 mode. As of OpenShift Container Platform 3.6, new installs will use storage mode v3. Upgrades from previous versions of OpenShift Container Platform will not automatically migrate data from v2 to v3. You must use the supplied playbooks and follow the documented process to migrate the data.
Version 3 of etcd implements a backwards compatible storage API that facilitates a two-step migration of the on-disk etcd database. For migration purposes, the storage mode used by etcd 3.x in OpenShift Container Platform 3.5 remained in v2 mode. As of OpenShift Container Platform 3.6, new installs will use storage mode v3. In order to provide customers time to prepare for migrating the etcd schema from v2 to v3 (and associated downtime and verification), OpenShift Container Platform 3.6 does not enforce this upgrade. However, based on extensive test results Red Hat strongly recommends migrating existing OpenShift Container Platform clusters to etcd 3.x storage mode v3. This is particularly relevant in larger clusters, or in scenarios where SSD storage is not available.
etcd schema migration will be required by future OpenShift Container Platform upgrades.
In addition to changing the storage mode for new installs to v3, OpenShift Container Platform 3.6 also begins enforcing quorum reads for all OpenShift Container Platform types. This is done to ensure that queries against etcd do not return stale data. In single-node etcd clusters, stale data is not a concern. In highly available etcd deployments typically found in production clusters, quorum reads ensure valid query results. A quorum read is linearizable in database terms - every client sees the latest updated state of the cluster, and all clients see the same sequence of reads and writes. See the etcd 3.1 announcement for more information on performance improvements.
It is important to note that OpenShift Container Platform uses etcd for storing additional information beyond what Kubernetes itself requires. For example, OpenShift Container Platform stores information about images, builds, and other components in etcd, as is required by features that OpenShift Container Platform adds on top of Kubernetes. Ultimately, this means that guidance around performance and sizing for etcd hosts will differ from Kubernetes and other recommendations in salient ways. Red Hat tests etcd scalability and performance with the OpenShift Container Platform use-case and parameters in mind to generate the most accurate recommendations.
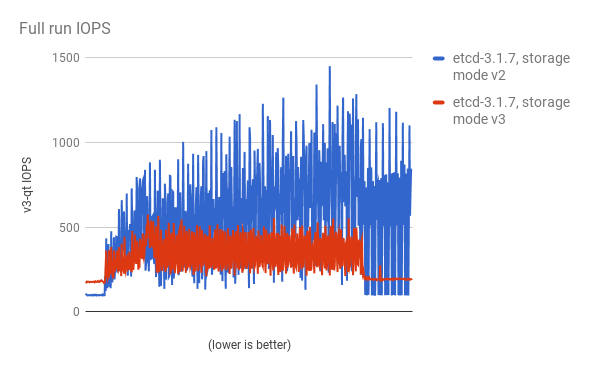
Performance improvements were quantified using a 300-node OpenShift Container Platform 3.6 cluster using the cluster-loader utility. Comparing etcd 3.x (storage mode v2) versus etcd 3.x (storage mode v3), clear improvements are identified in the charts below.
Storage IOPS under load is significantly reduced:
Storage IOPS in steady state is also significantly reduced:
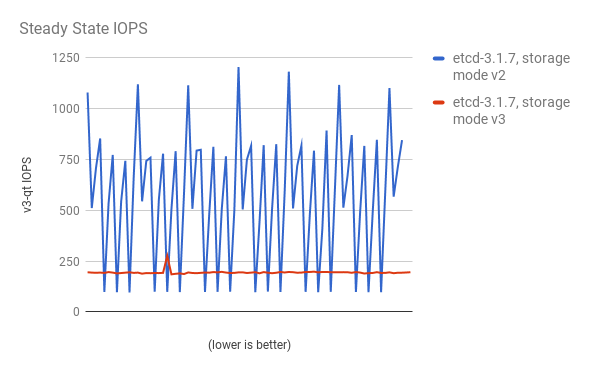
Viewing the same I/O data, plotting the average IOPS in both modes:

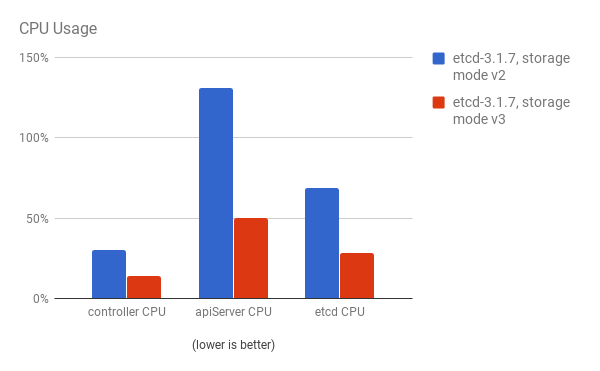
CPU utilization by both the API server (master) and etcd processes is reduced:
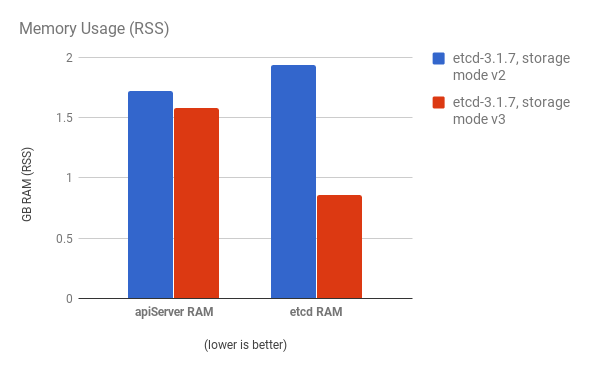
Memory utilization by both the API server (master) and etcd processes is also reduced:
After profiling etcd under OpenShift Container Platform, etcd frequently performs small amounts of storage input and output. Using etcd with storage that handles small read/write operations quickly, such as SSD, is highly recommended.
Looking at the size I/O operations done by a 3-node cluster of etcd 3.1 (using storage v3 mode and with quorum reads enforced), read sizes are as follows:
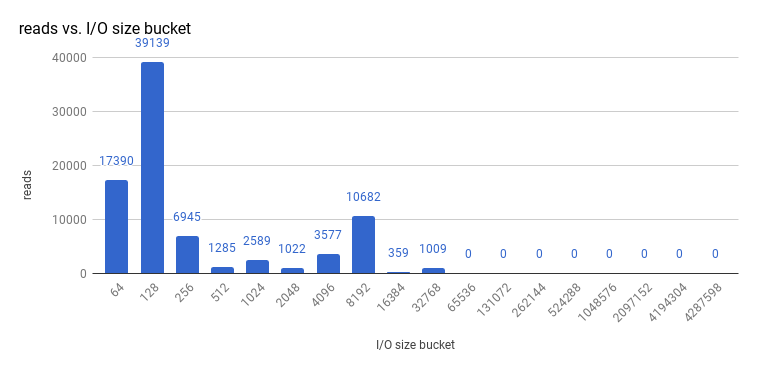
And writes:
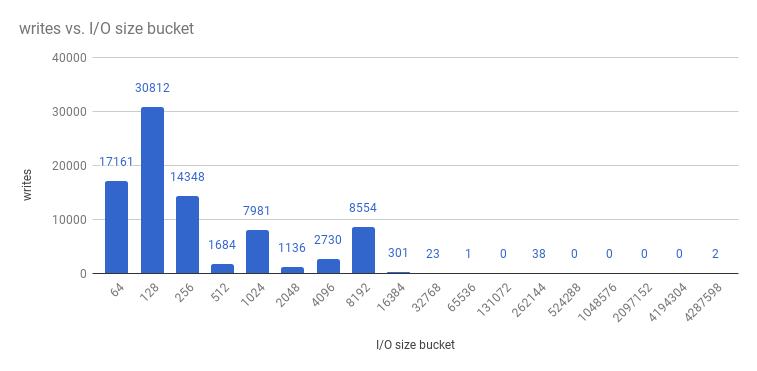
etcd processes are typically memory intensive. Master / API server processes are CPU intensive. This makes them a reasonable co-location pair within a single machine or virtual machine (VM). Optimize communication between etcd and master hosts either by co-locating them on the same host, or providing a dedicated network.
3.3.1. Providing Storage to an etcd Node Using PCI Passthrough with OpenStack
To provide fast storage to an etcd node so that etcd is stable at large scale, use PCI passthrough to pass a non-volatile memory express (NVMe) device directly to the etcd node. To set this up with Red Hat OpenStack 11 or later, complete the following on the OpenStack compute nodes where the PCI device exists.
- Ensure Intel Vt-x is enabled in BIOS.
-
Enable the input–output memory management unit (IOMMU). In the /etc/sysconfig/grub file, add
intel_iommu=on iommu=ptto the end of theGRUB_CMDLINX_LINUXline, within the quotation marks. Regenerate /etc/grub2.cfg by running:
$ grub2-mkconfig -o /etc/grub2.cfg- Reboot the system.
On controllers in /etc/nova.conf:
[filter_scheduler] enabled_filters=RetryFilter,AvailabilityZoneFilter,RamFilter,DiskFilter,ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,ServerGroupAntiAffinityFilter,ServerGroupAffinityFilter,PciPassthroughFilter available_filters=nova.scheduler.filters.all_filters [pci] alias = { "vendor_id":"144d", "product_id":"a820", "device_type":"type-PCI", "name":"nvme" }-
Restart
nova-apiandnova-scheduleron the controllers. On compute nodes in /etc/nova/nova.conf:
[pci] passthrough_whitelist = { "address": "0000:06:00.0" } alias = { "vendor_id":"144d", "product_id":"a820", "device_type":"type-PCI", "name":"nvme" }To retrieve the required
address,vendor_id, andproduct_idvalues of the NVMe device you want to passthrough, run:# lspci -nn | grep devicename-
Restart
nova-computeon the compute nodes. - Configure the OpenStack version you are running to use the NVMe and launch the etcd node.
3.4. Scaling Hosts Using the Tuned Profile
Tuned is a tuning profile delivery mechanism enabled by default in Red Hat Enterprise Linux (RHEL) and other Red Hat products. Tuned customizes Linux settings, such as sysctls, power management, and kernel command line options, to optimize the operating system for different workload performance and scalability requirements.
OpenShift Container Platform leverages the tuned daemon and includes Tuned profiles called openshift, openshift-node and openshift-control-plane. These profiles safely increase some of the commonly encountered vertical scaling limits present in the kernel, and are automatically applied to your system during installation.
The Tuned profiles support inheritance between profiles. They also support an auto-parent functionality which selects a parent profile based on whether the profile is used in a virtual environment. The openshift profile uses both of these features and is a parent of openshift-node and openshift-control-plane profiles. It contains tuning relevant to both OpenShift Container Platform application nodes and control plane nodes respectively. The openshift-node and openshift-control-plane profiles are set on application and control plane nodes respectively.
The profile hierarchy with the openshift profile as a parent ensures the tuning delivered to the OpenShift Container Platform system is a union of throughput-performance (the default for RHEL) for bare metal hosts and virtual-guest for RHEL and atomic-guest for RHEL Atomic Host nodes.
To see which Tuned profile is enabled on your system, run:
# tuned-adm active
Current active profile: openshift-nodeSee the Red Hat Enterprise Linux Performance Tuning Guide for more information about Tuned.