Chapter 27. Configuring Persistent Storage
27.1. Overview
The Kubernetes persistent volume framework allows you to provision an OpenShift Container Platform cluster with persistent storage using networked storage available in your environment. This can be done after completing the initial OpenShift Container Platform installation depending on your application needs, giving users a way to request those resources without having any knowledge of the underlying infrastructure.
These topics show how to configure persistent volumes in OpenShift Container Platform using the following supported volume plug-ins:
27.2. Persistent Storage Using NFS
27.2.1. Overview
OpenShift Container Platform clusters can be provisioned with persistent storage using NFS. Persistent volumes (PVs) and persistent volume claims (PVCs) provide a convenient method for sharing a volume across a project. While the NFS-specific information contained in a PV definition could also be defined directly in a pod definition, doing so does not create the volume as a distinct cluster resource, making the volume more susceptible to conflicts.
This topic covers the specifics of using the NFS persistent storage type. Some familiarity with OpenShift Container Platform and NFS is beneficial. See the Persistent Storage concept topic for details on the OpenShift Container Platform persistent volume (PV) framework in general.
27.2.2. Provisioning
Storage must exist in the underlying infrastructure before it can be mounted as a volume in OpenShift Container Platform. To provision NFS volumes, a list of NFS servers and export paths are all that is required.
You must first create an object definition for the PV:
Example 27.1. PV Object Definition Using NFS
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0001
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
nfs:
path: /tmp
server: 172.17.0.2
persistentVolumeReclaimPolicy: Retain - 1
- The name of the volume. This is the PV identity in various
oc <command> podcommands. - 2
- The amount of storage allocated to this volume.
- 3
- Though this appears to be related to controlling access to the volume, it is actually used similarly to labels and used to match a PVC to a PV. Currently, no access rules are enforced based on the
accessModes. - 4
- The volume type being used, in this case the nfs plug-in.
- 5
- The path that is exported by the NFS server.
- 6
- The host name or IP address of the NFS server.
- 7
- The reclaim policy for the PV. This defines what happens to a volume when released from its claim. See Reclaiming Resources.
Each NFS volume must be mountable by all schedulable nodes in the cluster.
Save the definition to a file, for example nfs-pv.yaml, and create the PV:
$ oc create -f nfs-pv.yaml
persistentvolume "pv0001" createdVerify that the PV was created:
# oc get pv
NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
pv0001 <none> 5368709120 RWO Available 31sThe next step can be to create a PVC, which binds to the new PV:
Example 27.2. PVC Object Definition
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-claim1
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi Save the definition to a file, for example nfs-claim.yaml, and create the PVC:
# oc create -f nfs-claim.yaml27.2.3. Enforcing Disk Quotas
You can use disk partitions to enforce disk quotas and size constraints. Each partition can be its own export. Each export is one PV. OpenShift Container Platform enforces unique names for PVs, but the uniqueness of the NFS volume’s server and path is up to the administrator.
Enforcing quotas in this way allows the developer to request persistent storage by a specific amount (for example, 10Gi) and be matched with a corresponding volume of equal or greater capacity.
27.2.4. NFS Volume Security
This section covers NFS volume security, including matching permissions and SELinux considerations. The user is expected to understand the basics of POSIX permissions, process UIDs, supplemental groups, and SELinux.
See the full Volume Security topic before implementing NFS volumes.
Developers request NFS storage by referencing, in the volumes section of their pod definition, either a PVC by name or the NFS volume plug-in directly.
The /etc/exports file on the NFS server contains the accessible NFS directories. The target NFS directory has POSIX owner and group IDs. The OpenShift Container Platform NFS plug-in mounts the container’s NFS directory with the same POSIX ownership and permissions found on the exported NFS directory. However, the container is not run with its effective UID equal to the owner of the NFS mount, which is the desired behavior.
As an example, if the target NFS directory appears on the NFS server as:
# ls -lZ /opt/nfs -d
drwxrws---. nfsnobody 5555 unconfined_u:object_r:usr_t:s0 /opt/nfs
# id nfsnobody
uid=65534(nfsnobody) gid=65534(nfsnobody) groups=65534(nfsnobody)Then the container must match SELinux labels, and either run with a UID of 65534 (nfsnobody owner) or with 5555 in its supplemental groups in order to access the directory.
The owner ID of 65534 is used as an example. Even though NFS’s root_squash maps root (0) to nfsnobody (65534), NFS exports can have arbitrary owner IDs. Owner 65534 is not required for NFS exports.
27.2.4.1. Group IDs
The recommended way to handle NFS access (assuming it is not an option to change permissions on the NFS export) is to use supplemental groups. Supplemental groups in OpenShift Container Platform are used for shared storage, of which NFS is an example. In contrast, block storage, such as Ceph RBD or iSCSI, use the fsGroup SCC strategy and the fsGroup value in the pod’s securityContext.
It is generally preferable to use supplemental group IDs to gain access to persistent storage versus using user IDs. Supplemental groups are covered further in the full Volume Security topic.
Because the group ID on the example target NFS directory shown above is 5555, the pod can define that group ID using supplementalGroups under the pod-level securityContext definition. For example:
spec:
containers:
- name:
...
securityContext:
supplementalGroups: [5555]
Assuming there are no custom SCCs that might satisfy the pod’s requirements, the pod likely matches the restricted SCC. This SCC has the supplementalGroups strategy set to RunAsAny, meaning that any supplied group ID is accepted without range checking.
As a result, the above pod passes admissions and is launched. However, if group ID range checking is desired, a custom SCC, as described in pod security and custom SCCs, is the preferred solution. A custom SCC can be created such that minimum and maximum group IDs are defined, group ID range checking is enforced, and a group ID of 5555 is allowed.
To use a custom SCC, you must first add it to the appropriate service account. For example, use the default service account in the given project unless another has been specified on the pod specification. See Add an SCC to a User, Group, or Project for details.
27.2.4.2. User IDs
User IDs can be defined in the container image or in the pod definition. The full Volume Security topic covers controlling storage access based on user IDs, and should be read prior to setting up NFS persistent storage.
It is generally preferable to use supplemental group IDs to gain access to persistent storage versus using user IDs.
In the example target NFS directory shown above, the container needs its UID set to 65534 (ignoring group IDs for the moment), so the following can be added to the pod definition:
spec:
containers:
- name:
...
securityContext:
runAsUser: 65534 Assuming the default project and the restricted SCC, the pod’s requested user ID of 65534 is not allowed, and therefore the pod fails. The pod fails for the following reasons:
- It requests 65534 as its user ID.
- All SCCs available to the pod are examined to see which SCC allows a user ID of 65534 (actually, all policies of the SCCs are checked but the focus here is on user ID).
-
Because all available SCCs use MustRunAsRange for their
runAsUserstrategy, UID range checking is required. - 65534 is not included in the SCC or project’s user ID range.
It is generally considered a good practice not to modify the predefined SCCs. The preferred way to fix this situation is to create a custom SCC, as described in the full Volume Security topic. A custom SCC can be created such that minimum and maximum user IDs are defined, UID range checking is still enforced, and the UID of 65534 is allowed.
To use a custom SCC, you must first add it to the appropriate service account. For example, use the default service account in the given project unless another has been specified on the pod specification. See Add an SCC to a User, Group, or Project for details.
27.2.4.3. SELinux
See the full Volume Security topic for information on controlling storage access in conjunction with using SELinux.
By default, SELinux does not allow writing from a pod to a remote NFS server. The NFS volume mounts correctly, but is read-only.
To enable writing to NFS volumes with SELinux enforcing on each node, run:
# setsebool -P virt_use_nfs 1
The -P option above makes the bool persistent between reboots.
The virt_use_nfs boolean is defined by the docker-selinux package. If an error is seen indicating that this bool is not defined, ensure this package has been installed.
27.2.4.4. Export Settings
In order to enable arbitrary container users to read and write the volume, each exported volume on the NFS server should conform to the following conditions:
Each export must be:
/<example_fs> *(rw,root_squash)The firewall must be configured to allow traffic to the mount point.
For NFSv4, configure the default port
2049(nfs).NFSv4
# iptables -I INPUT 1 -p tcp --dport 2049 -j ACCEPTFor NFSv3, there are three ports to configure:
2049(nfs),20048(mountd), and111(portmapper).NFSv3
# iptables -I INPUT 1 -p tcp --dport 2049 -j ACCEPT # iptables -I INPUT 1 -p tcp --dport 20048 -j ACCEPT # iptables -I INPUT 1 -p tcp --dport 111 -j ACCEPT
-
The NFS export and directory must be set up so that it is accessible by the target pods. Either set the export to be owned by the container’s primary UID, or supply the pod group access using
supplementalGroups, as shown in Group IDs above. See the full Volume Security topic for additional pod security information as well.
27.2.5. Reclaiming Resources
NFS implements the OpenShift Container Platform Recyclable plug-in interface. Automatic processes handle reclamation tasks based on policies set on each persistent volume.
By default, PVs are set to Retain.
Once claim to a PV is released (that is, the PVC is deleted), the PV object should not be re-used. Instead, a new PV should be created with the same basic volume details as the original.
For example, the administrator creates a PV named nfs1:
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs1
spec:
capacity:
storage: 1Mi
accessModes:
- ReadWriteMany
nfs:
server: 192.168.1.1
path: "/"
The user creates PVC1, which binds to nfs1. The user then deletes PVC1, releasing claim to nfs1, which causes nfs1 to be Released. If the administrator wishes to make the same NFS share available, they should create a new PV with the same NFS server details, but a different PV name:
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs2
spec:
capacity:
storage: 1Mi
accessModes:
- ReadWriteMany
nfs:
server: 192.168.1.1
path: "/"
Deleting the original PV and re-creating it with the same name is discouraged. Attempting to manually change the status of a PV from Released to Available causes errors and potential data loss.
27.2.6. Automation
Clusters can be provisioned with persistent storage using NFS in the following ways:
- Enforce storage quotas using disk partitions.
- Enforce security by restricting volumes to the project that has a claim to them.
- Configure reclamation of discarded resources for each PV.
There are many ways that you can use scripts to automate the preceding tasks. You can use an example Ansible playbook that is associated with the OpenShift Container Platform 3.11 release to help you get started.
27.2.7. Additional Configuration and Troubleshooting
Depending on what version of NFS is being used and how it is configured, there may be additional configuration steps needed for proper export and security mapping. The following are some that may apply:
| NFSv4 mount incorrectly shows all files with ownership of nobody:nobody |
|
| Disabling ID mapping on NFSv4 |
|
27.3. Persistent Storage Using Red Hat Gluster Storage
27.3.1. Overview
Red Hat Gluster Storage can be configured to provide persistent storage and dynamic provisioning for OpenShift Container Platform. It can be used both containerized within OpenShift Container Platform (converged mode) and non-containerized on its own nodes (independent mode).
27.3.1.1. converged mode
With converged mode, Red Hat Gluster Storage runs containerized directly on OpenShift Container Platform nodes. This allows for compute and storage instances to be scheduled and run from the same set of hardware.
Figure 27.1. Architecture - converged mode
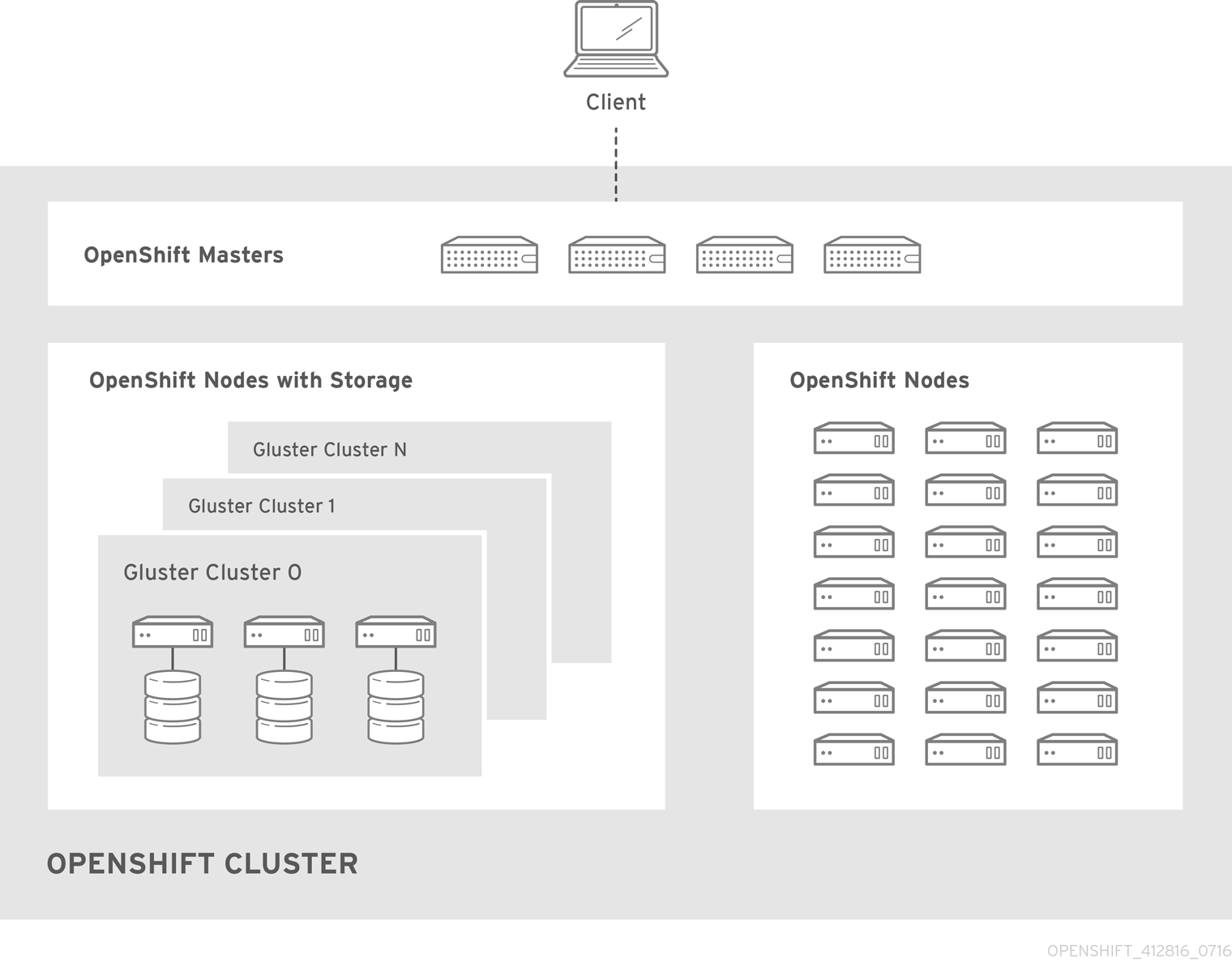
converged mode is available in Red Hat Gluster Storage 3.4. See converged mode for OpenShift Container Platform for additional documentation.
27.3.1.2. independent mode
With independent mode, Red Hat Gluster Storage runs on its own dedicated nodes and is managed by an instance of heketi, the GlusterFS volume management REST service. This heketi service must run as containerized, and not as standalone. Containerization allows for an easy mechanism to provide high-availability to the service. This documentation focuses on the containerized heketi configuration.
27.3.1.3. Standalone Red Hat Gluster Storage
If you have a standalone Red Hat Gluster Storage cluster available in your environment, you can make use of volumes on that cluster using OpenShift Container Platform’s GlusterFS volume plug-in. This solution is a conventional deployment where applications run on dedicated compute nodes, an OpenShift Container Platform cluster, and storage is provided from its own dedicated nodes.
Figure 27.2. Architecture - Standalone Red Hat Gluster Storage Cluster Using OpenShift Container Platform's GlusterFS Volume Plug-in

See the Red Hat Gluster Storage Installation Guide and the Red Hat Gluster Storage Administration Guide for more on Red Hat Gluster Storage.
High availability of storage in the infrastructure is left to the underlying storage provider.
27.3.1.4. GlusterFS Volumes
GlusterFS volumes present a POSIX-compliant filesystem and are comprised of one or more "bricks" across one or more nodes in their cluster. A brick is just a directory on a given storage node and is typically the mount point for a block storage device. GlusterFS handles distribution and replication of files across a given volume’s bricks per that volume’s configuration.
It is recommended to use heketi for most common volume management operations such as create, delete, and resize. OpenShift Container Platform expects heketi to be present when using the GlusterFS provisioner. heketi by default will create volumes that are three-ray replica, that is volumes where each file has three copies across three different nodes. As such it is recommended that any Red Hat Gluster Storage clusters which will be used by heketi have at least three nodes available.
There are many features available for GlusterFS volumes, but they are beyond the scope of this documentation.
27.3.1.5. gluster-block Volumes
gluster-block volumes are volumes that can be mounted over iSCSI. This is done by creating a file on an existing GlusterFS volume and then presenting that file as a block device via an iSCSI target. Such GlusterFS volumes are called block-hosting volumes.
gluster-block volumes present a sort of trade-off. Being consumed as iSCSI targets, gluster-block volumes can only be mounted by one node/client at a time which is in contrast to GlusterFS volumes which can be mounted by multiple nodes/clients. Being files on the backend, however, allows for operations which are typically costly on GlusterFS volumes (e.g. metadata lookups) to be converted to ones which are typically much faster on GlusterFS volumes (e.g. reads and writes). This leads to potentially substantial performance improvements for certain workloads.
For more information about OpenShift Container Storage and OpenShift Container Platform interoperability, see link: OpenShift Container Storage and OpenShift Container Platform interoperability matrix.
27.3.1.6. Gluster S3 Storage
The Gluster S3 service allows user applications to access GlusterFS storage via an S3 interface. The service binds to two GlusterFS volumes, one for object data and one for object metadata, and translates incoming S3 REST requests into filesystem operations on the volumes. It is recommended to run the service as a pod inside OpenShift Container Platform.
At this time, use and installation of the Gluster S3 service is in tech preview.
27.3.2. Considerations
This section covers a few topics that should be taken into consideration when using Red Hat Gluster Storage with OpenShift Container Platform.
27.3.2.1. Software Prerequisites
To access GlusterFS volumes, the mount.glusterfs command must be available on all schedulable nodes. For RPM-based systems, the glusterfs-fuse package must be installed:
# yum install glusterfs-fuseThis package comes installed on every RHEL system. However, it is recommended to update to the latest available version from Red Hat Gluster Storage if your servers use x86_64 architecture. To do this, the following RPM repository must be enabled:
# subscription-manager repos --enable=rh-gluster-3-client-for-rhel-7-server-rpmsIf glusterfs-fuse is already installed on the nodes, ensure that the latest version is installed:
# yum update glusterfs-fuse27.3.2.2. Hardware Requirements
Any nodes used in a converged mode or independent mode cluster are considered storage nodes. Storage nodes can be grouped into distinct cluster groups, though a single node can not be in multiple groups. For each group of storage nodes:
- A minimum of one or more storage nodes per group is required based on storage gluster volumetype option.
Each storage node must have a minimum of 8 GB of RAM. This is to allow running the Red Hat Gluster Storage pods, as well as other applications and the underlying operating system.
- Each GlusterFS volume also consumes memory on every storage node in its storage cluster, which is about 30 MB. The total amount of RAM should be determined based on how many concurrent volumes are desired or anticipated.
Each storage node must have at least one raw block device with no present data or metadata. These block devices will be used in their entirety for GlusterFS storage. Make sure the following are not present:
- Partition tables (GPT or MSDOS)
- Filesystems or residual filesystem signatures
- LVM2 signatures of former Volume Groups and Logical Volumes
- LVM2 metadata of LVM2 physical volumes
If in doubt,
wipefs -a <device>should clear any of the above.
It is recommended to plan for two clusters: one dedicated to storage for infrastructure applications (such as an OpenShift Container Registry) and one dedicated to storage for general applications. This would require a total of six storage nodes. This recommendation is made to avoid potential impacts on performance in I/O and volume creation.
27.3.2.3. Storage Sizing
Every GlusterFS cluster must be sized based on the needs of the anticipated applications that will use its storage. For example, there are sizing guides available for both OpenShift Logging and OpenShift Metrics.
Some additional things to consider are:
For each converged mode or independent mode cluster, the default behavior is to create GlusterFS volumes with three-way replication. As such, the total storage to plan for should be the desired capacity times three.
-
As an example, each heketi instance creates a
heketidbstoragevolume that is 2 GB in size, requiring a total of 6 GB of raw storage across three nodes in the storage cluster. This capacity is always required and should be taken into consideration for sizing calculations. - Applications like an integrated OpenShift Container Registry share a single GlusterFS volume across multiple instances of the application.
-
As an example, each heketi instance creates a
gluster-block volumes require the presence of a GlusterFS block-hosting volume with enough capacity to hold the full size of any given block volume’s capacity.
- By default, if no such block-hosting volume exists, one will be automatically created at a set size. The default for this size is 100 GB. If there is not enough space in the cluster to create the new block-hosting volume, the creation of the block volume will fail. Both the auto-create behavior and the auto-created volume size are configurable.
- Applications with multiple instances that use gluster-block volumes, such as OpenShift Logging and OpenShift Metrics, will use one volume per instance.
- The Gluster S3 service binds to two GlusterFS volumes. In a default cluster installation, these volumes are 1 GB each, consuming a total of 6 GB of raw storage.
27.3.2.4. Volume Operation Behaviors
Volume operations, such as create and delete, can be impacted by a variety of environmental circumstances and can in turn affect applications as well.
If the application pod requests a dynamically provisioned GlusterFS persistent volume claim (PVC), then extra time might have to be considered for the volume to be created and bound to the corresponding PVC. This effects the startup time for an application pod.
NoteCreation time of GlusterFS volumes scales linearly depending on the number of volumes. As an example, given 100 volumes in a cluster using recommended hardware specifications, each volume took approximately 6 seconds to be created, allocated, and bound to a pod.
When a PVC is deleted, that action will trigger the deletion of the underlying GlusterFS volume. While PVCs will disappear immediately from the
oc get pvcoutput, this does not mean the volume has been fully deleted. A GlusterFS volume can only be considered deleted when it does not show up in the command-line outputs forheketi-cli volume listandgluster volume list.NoteThe time to delete the GlusterFS volume and recycle its storage depends on and scales linearly with the number of active GlusterFS volumes. While pending volume deletes do not affect running applications, storage administrators should be aware of and be able to estimate how long they will take, especially when tuning resource consumption at scale.
27.3.2.5. Volume Security
This section covers Red Hat Gluster Storage volume security, including Portable Operating System Interface [for Unix] (POSIX) permissions and SELinux considerations. Understanding the basics of Volume Security, POSIX permissions, and SELinux is presumed.
In OpenShift Container Storage 3.11, you must enable SSL encryption to ensure secure access control to persistent volumes.
For more information, see the Red Hat OpenShift Container Storage 3.11 Operations Guide.
27.3.2.5.1. POSIX Permissions
Red Hat Gluster Storage volumes present POSIX-compliant file systems. As such, access permissions can be managed using standard command-line tools such as chmod and chown.
For converged mode and independent mode, it is also possible to specify a group ID that will own the root of the volume at volume creation time. For static provisioning, this is specified as part of the heketi-cli volume creation command:
$ heketi-cli volume create --size=100 --gid=10001000The PersistentVolume that will be associated with this volume must be annotated with the group ID so that pods consuming the PersistentVolume can have access to the file system. This annotation takes the form of:
pv.beta.kubernetes.io/gid: "<GID>" ---
For dynamic provisioning, the provisioner automatically generates and applies a group ID. It is possible to control the range from which this group ID is selected using the gidMin and gidMax StorageClass parameters (see Dynamic Provisioning). The provisioner also takes care of annotating the generated PersistentVolume with the group ID.
27.3.2.5.2. SELinux
By default, SELinux does not allow writing from a pod to a remote Red Hat Gluster Storage server. To enable writing to Red Hat Gluster Storage volumes with SELinux on, run the following on each node running GlusterFS:
$ sudo setsebool -P virt_sandbox_use_fusefs on
$ sudo setsebool -P virt_use_fusefs on- 1
- The
-Poption makes the boolean persistent between reboots.
The virt_sandbox_use_fusefs boolean is defined by the docker-selinux package. If you get an error saying it is not defined, ensure that this package is installed.
If you use Atomic Host, the SELinux booleans are cleared when you upgrade Atomic Host. When you upgrade Atomic Host, you must set these boolean values again.
27.3.3. Support Requirements
The following requirements must be met to create a supported integration of Red Hat Gluster Storage and OpenShift Container Platform.
For independent mode or standalone Red Hat Gluster Storage:
- Minimum version: Red Hat Gluster Storage 3.4
- All Red Hat Gluster Storage nodes must have valid subscriptions to Red Hat Network channels and Subscription Manager repositories.
- Red Hat Gluster Storage nodes must adhere to the requirements specified in the Planning Red Hat Gluster Storage Installation.
- Red Hat Gluster Storage nodes must be completely up to date with the latest patches and upgrades. Refer to the Red Hat Gluster Storage Installation Guide to upgrade to the latest version.
- A fully-qualified domain name (FQDN) must be set for each Red Hat Gluster Storage node. Ensure that correct DNS records exist, and that the FQDN is resolvable via both forward and reverse DNS lookup.
27.3.4. Installation
For standalone Red Hat Gluster Storage, there is no component installation required to use it with OpenShift Container Platform. OpenShift Container Platform comes with a built-in GlusterFS volume driver, allowing it to make use of existing volumes on existing clusters. See provisioning for more on how to make use of existing volumes.
For converged mode and independent mode, it is recommended to use the cluster installation process to install the required components.
27.3.4.1. independent mode: Installing Red Hat Gluster Storage Nodes
For independent mode, each Red Hat Gluster Storage node must have the appropriate system configurations (e.g. firewall ports, kernel modules) and the Red Hat Gluster Storage services must be running. The services should not be further configured, and should not have formed a Trusted Storage Pool.
The installation of Red Hat Gluster Storage nodes is beyond the scope of this documentation. For more information, see Setting Up independent mode.
27.3.4.2. Using the Installer
Use separate nodes for glusterfs and glusterfs_registry node groups. Each instance must be a separate gluster instance as they are managed independently. Using the same node for glusterfs and glusterfs_registry node groups causes deployment failure.
The cluster installation process can be used to install one or both of two GlusterFS node groups:
-
glusterfs: A general storage cluster for use by user applications. -
glusterfs_registry: A dedicated storage cluster for use by infrastructure applications such as an integrated OpenShift Container Registry.
It is recommended to deploy both groups to avoid potential impacts on performance in I/O and volume creation. Both of these are defined in the inventory hosts file.
To define the storage clusters, include the relevant names in the [OSEv3:children] group, creating similarly named groups. Then populate the groups with the node information.
In the [OSEv3:children] group, you add the masters, nodes, etcd, and the glusterfs and glusterfs_registry storage clusters.
After the groups are created and populated, you then configure the clusters by defining more parameter values in the [OSEv3:vars] group. The variables interact with the GlusterFS clusters. and are stored in the inventory file, as shown in the following example.
-
glusterfsvariables begin withopenshift_storage_glusterfs_. -
glusterfs_registryvariables begin withopenshift_storage_glusterfs_registry_.
The following example of an inventory file illustrates the use of variables when deploying the two GlusterFS node groups:
`[OSEv3:children]
masters
nodes
etcd
glusterfs
glusterfs_registry`
[OSEv3:vars]
install_method=rpm
os_update=false
install_update_docker=true
docker_storage_driver=devicemapper
ansible_ssh_user=root
openshift_release=v3.11
oreg_url=registry.access.redhat.com/openshift3/ose-${component}:v3.11
#openshift_cockpit_deployer_image='registry.redhat.io/openshift3/registry-console:v3.11'
openshift_docker_insecure_registries=registry.access.redhat.com
openshift_deployment_type=openshift-enterprise
openshift_web_console_install=true
openshift_enable_service_catalog=false
osm_use_cockpit=false
osm_cockpit_plugins=['cockpit-kubernetes']
debug_level=5
openshift_set_hostname=true
openshift_override_hostname_check=true
openshift_disable_check=docker_image_availability
openshift_check_min_host_disk_gb=2
openshift_check_min_host_memory_gb=1
openshift_portal_net=172.31.0.0/16
openshift_master_cluster_method=native
openshift_clock_enabled=true
openshift_use_openshift_sdn=true
openshift_master_dynamic_provisioning_enabled=true
# logging
openshift_logging_install_logging=true
openshift_logging_es_pvc_dynamic=true
openshift_logging_kibana_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_logging_curator_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_logging_es_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_logging_es_pvc_size=20Gi
openshift_logging_es_pvc_storage_class_name="glusterfs-registry-block"
# metrics
openshift_metrics_install_metrics=true
openshift_metrics_storage_kind=dynamic
openshift_metrics_hawkular_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_metrics_cassandra_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_metrics_heapster_nodeselector={"node-role.kubernetes.io/infra": "true"}
openshift_metrics_storage_volume_size=20Gi
openshift_metrics_cassandra_pvc_storage_class_name="glusterfs-registry-block"
# glusterfs
openshift_storage_glusterfs_timeout=900
openshift_storage_glusterfs_namespace=glusterfs
openshift_storage_glusterfs_storageclass=true
openshift_storage_glusterfs_storageclass_default=false
openshift_storage_glusterfs_block_storageclass=true
openshift_storage_glusterfs_block_storageclass_default=false
openshift_storage_glusterfs_block_deploy=true
openshift_storage_glusterfs_block_host_vol_create=true
openshift_storage_glusterfs_block_host_vol_size=100
# glusterfs_registry
openshift_storage_glusterfs_registry_namespace=glusterfs-registry
openshift_storage_glusterfs_registry_storageclass=true
openshift_storage_glusterfs_registry_storageclass_default=false
openshift_storage_glusterfs_registry_block_storageclass=true
openshift_storage_glusterfs_registry_block_storageclass_default=false
openshift_storage_glusterfs_registry_block_deploy=true
openshift_storage_glusterfs_registry_block_host_vol_create=true
openshift_storage_glusterfs_registry_block_host_vol_size=100
# glusterfs_registry_storage
openshift_hosted_registry_storage_kind=glusterfs
openshift_hosted_registry_storage_volume_size=20Gi
openshift_hosted_registry_selector="node-role.kubernetes.io/infra=true"
openshift_storage_glusterfs_heketi_admin_key='adminkey'
openshift_storage_glusterfs_heketi_user_key='heketiuserkey'
openshift_storage_glusterfs_image='registry.access.redhat.com/rhgs3/rhgs-server-rhel7:v3.11'
openshift_storage_glusterfs_heketi_image='registry.access.redhat.com/rhgs3/rhgs-volmanager-rhel7:v3.11'
openshift_storage_glusterfs_block_image='registry.access.redhat.com/rhgs3/rhgs-gluster-block-prov-rhel7:v3.11'
openshift_master_cluster_hostname=node101.redhat.com
openshift_master_cluster_public_hostname=node101.redhat.com
[masters]
node101.redhat.com
[etcd]
node101.redhat.com
[nodes]
node101.redhat.com openshift_node_group_name="node-config-master"
node102.redhat.com openshift_node_group_name="node-config-infra"
node103.redhat.com openshift_node_group_name="node-config-compute"
node104.redhat.com openshift_node_group_name="node-config-compute"
node105.redhat.com openshift_node_group_name="node-config-compute"
node106.redhat.com openshift_node_group_name="node-config-compute"
node107.redhat.com openshift_node_group_name="node-config-compute"
node108.redhat.com openshift_node_group_name="node-config-compute"
[glusterfs]
node103.redhat.com glusterfs_zone=1 glusterfs_devices='["/dev/sdd"]'
node104.redhat.com glusterfs_zone=2 glusterfs_devices='["/dev/sdd"]'
node105.redhat.com glusterfs_zone=3 glusterfs_devices='["/dev/sdd"]'
[glusterfs_registry]
node106.redhat.com glusterfs_zone=1 glusterfs_devices='["/dev/sdd"]'
node107.redhat.com glusterfs_zone=2 glusterfs_devices='["/dev/sdd"]'
node108.redhat.com glusterfs_zone=3 glusterfs_devices='["/dev/sdd"]'27.3.4.2.1. Host variables
Each host in the glusterfs and glusterfs_registry groups must have the glusterfs_devices variable defined. This variable defines the list of block devices that will be managed as part of the GlusterFS cluster. You must have at least one device, which must be bare, with no partitions or LVM PVs.
You can also define the following variables for each host. If they are defined, these variables further control the host configuration as a GlusterFS node:
-
glusterfs_cluster: The ID of the cluster this node belongs to. -
glusterfs_hostname: A host name or IP address to be used for internal GlusterFS communication. -
glusterfs_ip: The IP address that the pods use to communicate with the GlusterFS node. -
glusterfs_zone: A zone number for the node. Within the cluster, zones determine how to distribute the bricks of GlusterFS volumes.
27.3.4.2.2. Role variables
To control the integration of a GlusterFS cluster into a new or existing OpenShift Container Platform cluster, you can also define a number of role variables, which are stored in the inventory file. Each role variable also has a corresponding variable to optionally configure a separate GlusterFS cluster for use as storage for an integrated Docker registry.
27.3.4.2.3. Image name and version tag variables
To prevent OpenShift Container Platform pods from upgrading after an outage leading to a cluster with different OpenShift Container Platform versions, it is recommended that you specify the image name and version tags for all containerized components. These variables are:
-
openshift_storage_glusterfs_image -
openshift_storage_glusterfs_block_image -
openshift_storage_glusterfs_s3_image -
openshift_storage_glusterfs_heketi_image
The image variables for gluster-block and gluster-s3 are only necessary if the corresponding deployment variables (the variables ending in _block_deploy and _s3_deploy) are true.
A valid image tag is required for your deployment to succeed. Replace <tag> with the version of Red Hat Gluster Storage that is compatible with OpenShift Container Platform 3.11 as described in the interoperability matrix for the following variables in your inventory file:
-
openshift_storage_glusterfs_image=registry.redhat.io/rhgs3/rhgs-server-rhel7:<tag> -
openshift_storage_glusterfs_block_image=registry.redhat.io/rhgs3/rhgs-gluster-block-prov-rhel7:<tag> -
openshift_storage_glusterfs_s3_image=registry.redhat.io/rhgs3/rhgs-s3-server-rhel7:<tag> -
openshift_storage_glusterfs_heketi_image=registry.redhat.io/rhgs3/rhgs-volmanager-rhel7:<tag> -
openshift_storage_glusterfs_registry_image=registry.redhat.io/rhgs3/rhgs-server-rhel7:<tag> -
openshift_storage_glusterfs_block_registry_image=registry.redhat.io/rhgs3/rhgs-gluster-block-prov-rhel7:<tag> -
openshift_storage_glusterfs_s3_registry_image=registry.redhat.io/rhgs3/rhgs-s3-server-rhel7:<tag> -
openshift_storage_glusterfs_heketi_registry_image=registry.redhat.io/rhgs3/rhgs-volmanager-rhel7:<tag>
For a complete list of variables, see the GlusterFS role README on GitHub.
Once the variables are configured, there are several playbooks available depending on the circumstances of the installation:
The main playbook for cluster installations can be used to deploy the GlusterFS clusters in tandem with an initial installation of OpenShift Container Platform.
- This includes deploying an integrated OpenShift Container Registry that uses GlusterFS storage.
- This does not include OpenShift Logging or OpenShift Metrics, as that is currently still a separate step. See converged mode for OpenShift Logging and Metrics for more information.
-
playbooks/openshift-glusterfs/config.ymlcan be used to deploy the clusters onto an existing OpenShift Container Platform installation. playbooks/openshift-glusterfs/registry.ymlcan be used to deploy the clusters onto an existing OpenShift Container Platform installation. In addition, this will deploy an integrated OpenShift Container Registry which uses GlusterFS storage.ImportantThere must not be a pre-existing registry in the OpenShift Container Platform cluster.
playbooks/openshift-glusterfs/uninstall.ymlcan be used to remove existing clusters matching the configuration in the inventory hosts file. This is useful for cleaning up the OpenShift Container Platform environment in the case of a failed deployment due to configuration errors.NoteThe GlusterFS playbooks are not guaranteed to be idempotent.
NoteRunning the playbooks more than once for a given installation is currently not supported without deleting the entire GlusterFS installation (including disk data) and starting over.
27.3.4.2.4. Example: Basic converged mode Installation
In your inventory file, include the following variables in the
[OSEv3:vars]section, and adjust them as required for your configuration:[OSEv3:vars] ... openshift_storage_glusterfs_namespace=app-storage openshift_storage_glusterfs_storageclass=true openshift_storage_glusterfs_storageclass_default=false openshift_storage_glusterfs_block_deploy=true openshift_storage_glusterfs_block_host_vol_size=100 openshift_storage_glusterfs_block_storageclass=true openshift_storage_glusterfs_block_storageclass_default=falseAdd
glusterfsin the[OSEv3:children]section to enable the[glusterfs]group:[OSEv3:children] masters nodes glusterfsAdd a
[glusterfs]section with entries for each storage node that will host the GlusterFS storage. For each node, setglusterfs_devicesto a list of raw block devices that will be completely managed as part of a GlusterFS cluster. There must be at least one device listed. Each device must be bare, with no partitions or LVM PVs. Specifying the variable takes the form:<hostname_or_ip> glusterfs_devices='[ "</path/to/device1/>", "</path/to/device2>", ... ]'For example:
[glusterfs] node11.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node12.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node13.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]'Add the hosts listed under
[glusterfs]to the[nodes]group:[nodes] ... node11.example.com openshift_node_group_name="node-config-compute" node12.example.com openshift_node_group_name="node-config-compute" node13.example.com openshift_node_group_name="node-config-compute"NoteThe preceding steps only provide some of the options that must be added to the inventory file. Use the complete inventory file to deploy Red Hat Gluster Storage.
Change to the playbook directory and run the installation playbook. Provide the relative path for the inventory file as an option.
For a new OpenShift Container Platform installation:
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/prerequisites.yml $ ansible-playbook -i <path_to_inventory_file> playbooks/deploy_cluster.ymlFor an installation onto an existing OpenShift Container Platform cluster:
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/openshift-glusterfs/config.yml
27.3.4.2.5. Example: Basic independent mode Installation
In your inventory file, include the following variables in the
[OSEv3:vars]section, and adjust them as required for your configuration:[OSEv3:vars] ... openshift_storage_glusterfs_namespace=app-storage openshift_storage_glusterfs_storageclass=true openshift_storage_glusterfs_storageclass_default=false openshift_storage_glusterfs_block_deploy=true openshift_storage_glusterfs_block_host_vol_size=100 openshift_storage_glusterfs_block_storageclass=true openshift_storage_glusterfs_block_storageclass_default=false openshift_storage_glusterfs_is_native=false openshift_storage_glusterfs_heketi_is_native=true openshift_storage_glusterfs_heketi_executor=ssh openshift_storage_glusterfs_heketi_ssh_port=22 openshift_storage_glusterfs_heketi_ssh_user=root openshift_storage_glusterfs_heketi_ssh_sudo=false openshift_storage_glusterfs_heketi_ssh_keyfile="/root/.ssh/id_rsa"Add
glusterfsin the[OSEv3:children]section to enable the[glusterfs]group:[OSEv3:children] masters nodes glusterfsAdd a
[glusterfs]section with entries for each storage node that will host the GlusterFS storage. For each node, setglusterfs_devicesto a list of raw block devices that will be completely managed as part of a GlusterFS cluster. There must be at least one device listed. Each device must be bare, with no partitions or LVM PVs. Also, setglusterfs_ipto the IP address of the node. Specifying the variable takes the form:<hostname_or_ip> glusterfs_ip=<ip_address> glusterfs_devices='[ "</path/to/device1/>", "</path/to/device2>", ... ]'For example:
[glusterfs] gluster1.example.com glusterfs_ip=192.168.10.11 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' gluster2.example.com glusterfs_ip=192.168.10.12 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' gluster3.example.com glusterfs_ip=192.168.10.13 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]'NoteThe preceding steps only provide some of the options that must be added to the inventory file. Use the complete inventory file to deploy Red Hat Gluster Storage.
Change to the playbook directory and run the installation playbook. Provide the relative path for the inventory file as an option.
For a new OpenShift Container Platform installation:
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/prerequisites.yml $ ansible-playbook -i <path_to_inventory_file> playbooks/deploy_cluster.ymlFor an installation onto an existing OpenShift Container Platform cluster:
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/openshift-glusterfs/config.yml
27.3.4.2.6. Example: converged mode with an Integrated OpenShift Container Registry
In your inventory file, set the following variable under
[OSEv3:vars]section, and adjust them as required for your configuration:[OSEv3:vars] ... openshift_hosted_registry_storage_kind=glusterfs1 openshift_hosted_registry_storage_volume_size=5Gi openshift_hosted_registry_selector='node-role.kubernetes.io/infra=true'- 1
- Running the integrated OpenShift Container Registry, on infrastructure nodes is recommended. Infrastructure node are nodes dedicated to running applications deployed by administrators to provide services for the OpenShift Container Platform cluster.
Add
glusterfs_registryin the[OSEv3:children]section to enable the[glusterfs_registry]group:[OSEv3:children] masters nodes glusterfs_registryAdd a
[glusterfs_registry]section with entries for each storage node that will host the GlusterFS storage. For each node, setglusterfs_devicesto a list of raw block devices that will be completely managed as part of a GlusterFS cluster. There must be at least one device listed. Each device must be bare, with no partitions or LVM PVs. Specifying the variable takes the form:<hostname_or_ip> glusterfs_devices='[ "</path/to/device1/>", "</path/to/device2>", ... ]'For example:
[glusterfs_registry] node11.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node12.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node13.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]'Add the hosts listed under
[glusterfs_registry]to the[nodes]group:[nodes] ... node11.example.com openshift_node_group_name="node-config-infra" node12.example.com openshift_node_group_name="node-config-infra" node13.example.com openshift_node_group_name="node-config-infra"NoteThe preceding steps only provide some of the options that must be added to the inventory file. Use the complete inventory file to deploy Red Hat Gluster Storage.
Change to the playbook directory and run the installation playbook. Provide the relative path for the inventory file as an option.
For a new OpenShift Container Platform installation:
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/prerequisites.yml $ ansible-playbook -i <path_to_inventory_file> playbooks/deploy_cluster.ymlFor an installation onto an existing OpenShift Container Platform cluster:
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/openshift-glusterfs/config.yml
27.3.4.2.7. Example: converged mode for OpenShift Logging and Metrics
In your inventory file, set the following variables under
[OSEv3:vars]section, and adjust them as required for your configuration:[OSEv3:vars] ... openshift_metrics_install_metrics=true openshift_metrics_hawkular_nodeselector={"node-role.kubernetes.io/infra": "true"}1 openshift_metrics_cassandra_nodeselector={"node-role.kubernetes.io/infra": "true"}2 openshift_metrics_heapster_nodeselector={"node-role.kubernetes.io/infra": "true"}3 openshift_metrics_storage_kind=dynamic openshift_metrics_storage_volume_size=10Gi openshift_metrics_cassandra_pvc_storage_class_name="glusterfs-registry-block"4 openshift_logging_install_logging=true openshift_logging_kibana_nodeselector={"node-role.kubernetes.io/infra": "true"}5 openshift_logging_curator_nodeselector={"node-role.kubernetes.io/infra": "true"}6 openshift_logging_es_nodeselector={"node-role.kubernetes.io/infra": "true"}7 openshift_logging_storage_kind=dynamic openshift_logging_es_pvc_size=10Gi8 openshift_logging_elasticsearch_storage_type=pvc9 openshift_logging_es_pvc_storage_class_name="glusterfs-registry-block"10 openshift_storage_glusterfs_registry_namespace=infra-storage openshift_storage_glusterfs_registry_block_deploy=true openshift_storage_glusterfs_registry_block_host_vol_size=100 openshift_storage_glusterfs_registry_block_storageclass=true openshift_storage_glusterfs_registry_block_storageclass_default=false- 1 2 3 5 6 7
- It is recommended to run the integrated OpenShift Container Registry, Logging, and Metrics on nodes dedicated to "infrastructure" applications, that is applications deployed by administrators to provide services for the OpenShift Container Platform cluster.
- 4 10
- Specify the StorageClass to be used for Logging and Metrics. This name is generated from the name of the target GlusterFS cluster (e.g.,
glusterfs-<name>-block). In this example, this defaults toregistry. - 8
- OpenShift Logging requires that a PVC size be specified. The supplied value is only an example, not a recommendation.
- 9
- If using Persistent Elasticsearch Storage, set the storage type to
pvc.
NoteSee the GlusterFS role README for details on these and other variables.
Add
glusterfs_registryin the[OSEv3:children]section to enable the[glusterfs_registry]group:[OSEv3:children] masters nodes glusterfs_registryAdd a
[glusterfs_registry]section with entries for each storage node that will host the GlusterFS storage. For each node, setglusterfs_devicesto a list of raw block devices that will be completely managed as part of a GlusterFS cluster. There must be at least one device listed. Each device must be bare, with no partitions or LVM PVs. Specifying the variable takes the form:<hostname_or_ip> glusterfs_devices='[ "</path/to/device1/>", "</path/to/device2>", ... ]'For example:
[glusterfs_registry] node11.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node12.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node13.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]'Add the hosts listed under
[glusterfs_registry]to the[nodes]group:[nodes] ... node11.example.com openshift_node_group_name="node-config-infra" node12.example.com openshift_node_group_name="node-config-infra" node13.example.com openshift_node_group_name="node-config-infra"NoteThe preceding steps only provide some of the options that must be added to the inventory file. Use the complete inventory file to deploy Red Hat Gluster Storage.
Change to the playbook directory and run the installation playbook. Provide the relative path for the inventory file as an option.
For a new OpenShift Container Platform installation:
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/prerequisites.yml $ ansible-playbook -i <path_to_inventory_file> playbooks/deploy_cluster.ymlFor an installation onto an existing OpenShift Container Platform cluster:
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/openshift-glusterfs/config.yml
27.3.4.2.8. Example: converged mode for Applications, Registry, Logging, and Metrics
In your inventory file, set the following variables under
[OSEv3:vars]section, and adjust them as required for your configuration:[OSEv3:vars] ... openshift_hosted_registry_storage_kind=glusterfs1 openshift_hosted_registry_storage_volume_size=5Gi openshift_hosted_registry_selector='node-role.kubernetes.io/infra=true' openshift_metrics_install_metrics=true openshift_metrics_hawkular_nodeselector={"node-role.kubernetes.io/infra": "true"}2 openshift_metrics_cassandra_nodeselector={"node-role.kubernetes.io/infra": "true"}3 openshift_metrics_heapster_nodeselector={"node-role.kubernetes.io/infra": "true"}4 openshift_metrics_storage_kind=dynamic openshift_metrics_storage_volume_size=10Gi openshift_metrics_cassandra_pvc_storage_class_name="glusterfs-registry-block"5 openshift_logging_install_logging=true openshift_logging_kibana_nodeselector={"node-role.kubernetes.io/infra": "true"}6 openshift_logging_curator_nodeselector={"node-role.kubernetes.io/infra": "true"}7 openshift_logging_es_nodeselector={"node-role.kubernetes.io/infra": "true"}8 openshift_logging_storage_kind=dynamic openshift_logging_es_pvc_size=10Gi9 openshift_logging_elasticsearch_storage_type=pvc10 openshift_logging_es_pvc_storage_class_name="glusterfs-registry-block"11 openshift_storage_glusterfs_namespace=app-storage openshift_storage_glusterfs_storageclass=true openshift_storage_glusterfs_storageclass_default=false openshift_storage_glusterfs_block_deploy=true openshift_storage_glusterfs_block_host_vol_size=10012 openshift_storage_glusterfs_block_storageclass=true openshift_storage_glusterfs_block_storageclass_default=false openshift_storage_glusterfs_registry_namespace=infra-storage openshift_storage_glusterfs_registry_block_deploy=true openshift_storage_glusterfs_registry_block_host_vol_size=100 openshift_storage_glusterfs_registry_block_storageclass=true openshift_storage_glusterfs_registry_block_storageclass_default=false- 1 2 3 4 6 7 8
- Running the integrated OpenShift Container Registry, Logging, and Metrics on infrastructure nodes is recommended. Infrastructure node are nodes dedicated to running applications deployed by administrators to provide services for the OpenShift Container Platform cluster.
- 5 11
- Specify the StorageClass to be used for Logging and Metrics. This name is generated from the name of the target GlusterFS cluster, for example
glusterfs-<name>-block. In this example,<name>defaults toregistry. - 9
- Specifying a PVC size is required for OpenShift Logging. The supplied value is only an example, not a recommendation.
- 10
- If using Persistent Elasticsearch Storage, set the storage type to
pvc. - 12
- Size, in GB, of GlusterFS volumes that will be automatically created to host glusterblock volumes. This variable is used only if there is not enough space is available for a glusterblock volume create request. This value represents an upper limit on the size of glusterblock volumes unless you manually create larger GlusterFS block-hosting volumes.
Add
glusterfsandglusterfs_registryin the[OSEv3:children]section to enable the[glusterfs]and[glusterfs_registry]groups:[OSEv3:children] ... glusterfs glusterfs_registryAdd
[glusterfs]and[glusterfs_registry]sections with entries for each storage node that will host the GlusterFS storage. For each node, setglusterfs_devicesto a list of raw block devices that will be completely managed as part of a GlusterFS cluster. There must be at least one device listed. Each device must be bare, with no partitions or LVM PVs. Specifying the variable takes the form:<hostname_or_ip> glusterfs_devices='[ "</path/to/device1/>", "</path/to/device2>", ... ]'For example:
[glusterfs] node11.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node12.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node13.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' [glusterfs_registry] node14.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node15.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node16.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]'Add the hosts listed under
[glusterfs]and[glusterfs_registry]to the[nodes]group:[nodes] ... node11.example.com openshift_node_group_name='node-config-compute'1 node12.example.com openshift_node_group_name='node-config-compute'2 node13.example.com openshift_node_group_name='node-config-compute'3 node14.example.com openshift_node_group_name='node-config-infra'"4 node15.example.com openshift_node_group_name='node-config-infra'"5 node16.example.com openshift_node_group_name='node-config-infra'"6 NoteThe preceding steps only provide some of the options that must be added to the inventory file. Use the complete inventory file to deploy Red Hat Gluster Storage.
Change to the playbook directory and run the installation playbook. Provide the relative path for the inventory file as an option.
For a new OpenShift Container Platform installation:
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/prerequisites.yml $ ansible-playbook -i <path_to_inventory_file> playbooks/deploy_cluster.ymlFor an installation onto an existing OpenShift Container Platform cluster:
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/openshift-glusterfs/config.yml
27.3.4.2.9. Example: independent mode for Applications, Registry, Logging, and Metrics
In your inventory file, set the following variables under
[OSEv3:vars]section, and adjust them as required for your configuration:[OSEv3:vars] ... openshift_hosted_registry_storage_kind=glusterfs1 openshift_hosted_registry_storage_volume_size=5Gi openshift_hosted_registry_selector='node-role.kubernetes.io/infra=true' openshift_metrics_install_metrics=true openshift_metrics_hawkular_nodeselector={"node-role.kubernetes.io/infra": "true"}2 openshift_metrics_cassandra_nodeselector={"node-role.kubernetes.io/infra": "true"}3 openshift_metrics_heapster_nodeselector={"node-role.kubernetes.io/infra": "true"}4 openshift_metrics_storage_kind=dynamic openshift_metrics_storage_volume_size=10Gi openshift_metrics_cassandra_pvc_storage_class_name="glusterfs-registry-block"5 openshift_logging_install_logging=true openshift_logging_kibana_nodeselector={"node-role.kubernetes.io/infra": "true"}6 openshift_logging_curator_nodeselector={"node-role.kubernetes.io/infra": "true"}7 openshift_logging_es_nodeselector={"node-role.kubernetes.io/infra": "true"}8 openshift_logging_storage_kind=dynamic openshift_logging_es_pvc_size=10Gi9 openshift_logging_elasticsearch_storage_type10 openshift_logging_es_pvc_storage_class_name="glusterfs-registry-block"11 openshift_storage_glusterfs_namespace=app-storage openshift_storage_glusterfs_storageclass=true openshift_storage_glusterfs_storageclass_default=false openshift_storage_glusterfs_block_deploy=true openshift_storage_glusterfs_block_host_vol_size=10012 openshift_storage_glusterfs_block_storageclass=true openshift_storage_glusterfs_block_storageclass_default=false openshift_storage_glusterfs_is_native=false openshift_storage_glusterfs_heketi_is_native=true openshift_storage_glusterfs_heketi_executor=ssh openshift_storage_glusterfs_heketi_ssh_port=22 openshift_storage_glusterfs_heketi_ssh_user=root openshift_storage_glusterfs_heketi_ssh_sudo=false openshift_storage_glusterfs_heketi_ssh_keyfile="/root/.ssh/id_rsa" openshift_storage_glusterfs_registry_namespace=infra-storage openshift_storage_glusterfs_registry_block_deploy=true openshift_storage_glusterfs_registry_block_host_vol_size=100 openshift_storage_glusterfs_registry_block_storageclass=true openshift_storage_glusterfs_registry_block_storageclass_default=false openshift_storage_glusterfs_registry_is_native=false openshift_storage_glusterfs_registry_heketi_is_native=true openshift_storage_glusterfs_registry_heketi_executor=ssh openshift_storage_glusterfs_registry_heketi_ssh_port=22 openshift_storage_glusterfs_registry_heketi_ssh_user=root openshift_storage_glusterfs_registry_heketi_ssh_sudo=false openshift_storage_glusterfs_registry_heketi_ssh_keyfile="/root/.ssh/id_rsa"- 1 2 3 4 6 7 8
- It is recommended to run the integrated OpenShift Container Registry on nodes dedicated to "infrastructure" applications, that is applications deployed by administrators to provide services for the OpenShift Container Platform cluster. It is up to the administrator to select and label nodes for infrastructure applications.
- 5 11
- Specify the StorageClass to be used for Logging and Metrics. This name is generated from the name of the target GlusterFS cluster (e.g.,
glusterfs-<name>-block). In this example, this defaults toregistry. - 9
- OpenShift Logging requires that a PVC size be specified. The supplied value is only an example, not a recommendation.
- 10
- If using Persistent Elasticsearch Storage, set the storage type to
pvc. - 12
- Size, in GB, of GlusterFS volumes that will be automatically created to host glusterblock volumes. This variable is used only if there is not enough space is available for a glusterblock volume create request. This value represents an upper limit on the size of glusterblock volumes unless you manually create larger GlusterFS block-hosting volumes.
Add
glusterfsandglusterfs_registryin the[OSEv3:children]section to enable the[glusterfs]and[glusterfs_registry]groups:[OSEv3:children] ... glusterfs glusterfs_registryAdd
[glusterfs]and[glusterfs_registry]sections with entries for each storage node that will host the GlusterFS storage. For each node, setglusterfs_devicesto a list of raw block devices that will be completely managed as part of a GlusterFS cluster. There must be at least one device listed. Each device must be bare, with no partitions or LVM PVs. Also, setglusterfs_ipto the IP address of the node. Specifying the variable takes the form:<hostname_or_ip> glusterfs_ip=<ip_address> glusterfs_devices='[ "</path/to/device1/>", "</path/to/device2>", ... ]'For example:
[glusterfs] gluster1.example.com glusterfs_ip=192.168.10.11 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' gluster2.example.com glusterfs_ip=192.168.10.12 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' gluster3.example.com glusterfs_ip=192.168.10.13 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' [glusterfs_registry] gluster4.example.com glusterfs_ip=192.168.10.14 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' gluster5.example.com glusterfs_ip=192.168.10.15 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' gluster6.example.com glusterfs_ip=192.168.10.16 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]'NoteThe preceding steps only provide some of the options that must be added to the inventory file. Use the complete inventory file to deploy Red Hat Gluster Storage.
Change to the playbook directory and run the installation playbook. Provide the relative path for the inventory file as an option.
For a new OpenShift Container Platform installation:
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/prerequisites.yml $ ansible-playbook -i <path_to_inventory_file> playbooks/deploy_cluster.ymlFor an installation onto an existing OpenShift Container Platform cluster:
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i <path_to_inventory_file> playbooks/openshift-glusterfs/config.yml
27.3.5. Uninstall converged mode
For converged mode, an OpenShift Container Platform install comes with a playbook to uninstall all resources and artifacts from the cluster. To use the playbook, provide the original inventory file that was used to install the target instance of converged mode, change to the playbook directory, and run the following playbook:
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -i <path_to_inventory_file> playbooks/openshift-glusterfs/uninstall.yml
In addition, the playbook supports the use of a variable called openshift_storage_glusterfs_wipe which, when enabled, destroys any data on the block devices that were used for Red Hat Gluster Storage backend storage. To use the openshift_storage_glusterfs_wipe variable, change to the playbook directory and run the following playbook:
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -i <path_to_inventory_file> -e \
"openshift_storage_glusterfs_wipe=true" \
playbooks/openshift-glusterfs/uninstall.ymlThis procedure destroys data. Proceed with caution.
27.3.6. Provisioning
GlusterFS volumes can be provisioned either statically or dynamically. Static provisioning is available with all configurations. Only converged mode and independent mode support dynamic provisioning.
27.3.6.1. Static Provisioning
-
To enable static provisioning, first create a GlusterFS volume. See the Red Hat Gluster Storage Administration Guide for information on how to do this using the
glustercommand-line interface or the heketi project site for information on how to do this usingheketi-cli. For this example, the volume will be namedmyVol1. Define the following Service and Endpoints in
gluster-endpoints.yaml:--- apiVersion: v1 kind: Service metadata: name: glusterfs-cluster1 spec: ports: - port: 1 --- apiVersion: v1 kind: Endpoints metadata: name: glusterfs-cluster2 subsets: - addresses: - ip: 192.168.122.2213 ports: - port: 14 - addresses: - ip: 192.168.122.2225 ports: - port: 16 - addresses: - ip: 192.168.122.2237 ports: - port: 18 From the OpenShift Container Platform master host, create the Service and Endpoints:
$ oc create -f gluster-endpoints.yaml service "glusterfs-cluster" created endpoints "glusterfs-cluster" createdVerify that the Service and Endpoints were created:
$ oc get services NAME CLUSTER_IP EXTERNAL_IP PORT(S) SELECTOR AGE glusterfs-cluster 172.30.205.34 <none> 1/TCP <none> 44s $ oc get endpoints NAME ENDPOINTS AGE docker-registry 10.1.0.3:5000 4h glusterfs-cluster 192.168.122.221:1,192.168.122.222:1,192.168.122.223:1 11s kubernetes 172.16.35.3:8443 4dNoteEndpoints are unique per project. Each project accessing the GlusterFS volume needs its own Endpoints.
In order to access the volume, the container must run with either a user ID (UID) or group ID (GID) that has access to the file system on the volume. This information can be discovered in the following manner:
$ mkdir -p /mnt/glusterfs/myVol1 $ mount -t glusterfs 192.168.122.221:/myVol1 /mnt/glusterfs/myVol1 $ ls -lnZ /mnt/glusterfs/ drwxrwx---. 592 590 system_u:object_r:fusefs_t:s0 myVol11 2 Define the following PersistentVolume (PV) in
gluster-pv.yaml:apiVersion: v1 kind: PersistentVolume metadata: name: gluster-default-volume1 annotations: pv.beta.kubernetes.io/gid: "590"2 spec: capacity: storage: 2Gi3 accessModes:4 - ReadWriteMany glusterfs: endpoints: glusterfs-cluster5 path: myVol16 readOnly: false persistentVolumeReclaimPolicy: Retain- 1
- The name of the volume.
- 2
- The GID on the root of the GlusterFS volume.
- 3
- The amount of storage allocated to this volume.
- 4
accessModesare used as labels to match a PV and a PVC. They currently do not define any form of access control.- 5
- The Endpoints resource previously created.
- 6
- The GlusterFS volume that will be accessed.
From the OpenShift Container Platform master host, create the PV:
$ oc create -f gluster-pv.yamlVerify that the PV was created:
$ oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE gluster-default-volume <none> 2147483648 RWX Available 2sCreate a PersistentVolumeClaim (PVC) that will bind to the new PV in
gluster-claim.yaml:apiVersion: v1 kind: PersistentVolumeClaim metadata: name: gluster-claim1 spec: accessModes: - ReadWriteMany2 resources: requests: storage: 1Gi3 From the OpenShift Container Platform master host, create the PVC:
$ oc create -f gluster-claim.yamlVerify that the PV and PVC are bound:
$ oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE gluster-pv <none> 1Gi RWX Available gluster-claim 37s $ oc get pvc NAME LABELS STATUS VOLUME CAPACITY ACCESSMODES AGE gluster-claim <none> Bound gluster-pv 1Gi RWX 24s
PVCs are unique per project. Each project accessing the GlusterFS volume needs its own PVC. PVs are not bound to a single project, so PVCs across multiple projects may refer to the same PV.
27.3.6.2. Dynamic Provisioning
To enable dynamic provisioning, first create a
StorageClassobject definition. The definition below is based on the minimum requirements needed for this example to work with OpenShift Container Platform. See Dynamic Provisioning and Creating Storage Classes for additional parameters and specification definitions.kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: glusterfs provisioner: kubernetes.io/glusterfs parameters: resturl: "http://10.42.0.0:8080"1 restauthenabled: "false"2 From the OpenShift Container Platform master host, create the StorageClass:
# oc create -f gluster-storage-class.yaml storageclass "glusterfs" createdCreate a PVC using the newly-created StorageClass. For example:
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: gluster1 spec: accessModes: - ReadWriteMany resources: requests: storage: 30Gi storageClassName: glusterfsFrom the OpenShift Container Platform master host, create the PVC:
# oc create -f glusterfs-dyn-pvc.yaml persistentvolumeclaim "gluster1" createdView the PVC to see that the volume was dynamically created and bound to the PVC:
# oc get pvc NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE gluster1 Bound pvc-78852230-d8e2-11e6-a3fa-0800279cf26f 30Gi RWX glusterfs 42s
27.4. Persistent Storage Using OpenStack Cinder
27.4.1. Overview
You can provision your OpenShift Container Platform cluster with persistent storage using OpenStack Cinder. Some familiarity with Kubernetes and OpenStack is assumed.
Before you create persistent volumes (PVs) using Cinder, configured OpenShift Container Platform for OpenStack.
The Kubernetes persistent volume framework allows administrators to provision a cluster with persistent storage and gives users a way to request those resources without having any knowledge of the underlying infrastructure. You can provision OpenStack Cinder volumes dynamically.
Persistent volumes are not bound to a single project or namespace; they can be shared across the OpenShift Container Platform cluster. Persistent volume claims, however, are specific to a project or namespace and can be requested by users.
High-availability of storage in the infrastructure is left to the underlying storage provider.
27.4.2. Provisioning Cinder PVs
Storage must exist in the underlying infrastructure before it can be mounted as a volume in OpenShift Container Platform. After ensuring that OpenShift Container Platform is configured for OpenStack, all that is required for Cinder is a Cinder volume ID and the PersistentVolume API.
27.4.2.1. Creating the Persistent Volume
You must define your PV in an object definition before creating it in OpenShift Container Platform:
Save your object definition to a file, for example cinder-pv.yaml:
apiVersion: "v1" kind: "PersistentVolume" metadata: name: "pv0001"1 spec: capacity: storage: "5Gi"2 accessModes: - "ReadWriteOnce" cinder:3 fsType: "ext3"4 volumeID: "f37a03aa-6212-4c62-a805-9ce139fab180"5 ImportantDo not change the
fstypeparameter value after the volume is formatted and provisioned. Changing this value can result in data loss and pod failure.Create the persistent volume:
# oc create -f cinder-pv.yaml persistentvolume "pv0001" createdVerify that the persistent volume exists:
# oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE pv0001 <none> 5Gi RWO Available 2s
Users can then request storage using persistent volume claims, which can now utilize your new persistent volume.
Persistent volume claims exist only in the user’s namespace and can be referenced by a pod within that same namespace. Any attempt to access a persistent volume claim from a different namespace causes the pod to fail.
27.4.2.2. Cinder PV format
Before OpenShift Container Platform mounts the volume and passes it to a container, it checks that it contains a file system as specified by the fsType parameter in the persistent volume definition. If the device is not formatted with the file system, all data from the device is erased and the device is automatically formatted with the given file system.
This allows using unformatted Cinder volumes as persistent volumes, because OpenShift Container Platform formats them before the first use.
27.4.2.3. Cinder volume security
If you use Cinder PVs in your application, configure security for their deployment configurations.
Review the Volume Security information before implementing Cinder volumes.
-
Create an SCC that uses the appropriate
fsGroupstrategy. Create a service account and add it to the SCC:
[source,bash] $ oc create serviceaccount <service_account> $ oc adm policy add-scc-to-user <new_scc> -z <service_account> -n <project>In your application’s deployment configuration, provide the service account name and
securityContext:apiVersion: v1 kind: ReplicationController metadata: name: frontend-1 spec: replicas: 11 selector:2 name: frontend template:3 metadata: labels:4 name: frontend5 spec: containers: - image: openshift/hello-openshift name: helloworld ports: - containerPort: 8080 protocol: TCP restartPolicy: Always serviceAccountName: <service_account>6 securityContext: fsGroup: 77777 - 1
- The number of copies of the pod to run.
- 2
- The label selector of the pod to run.
- 3
- A template for the pod the controller creates.
- 4
- The labels on the pod must include labels from the label selector.
- 5
- The maximum name length after expanding any parameters is 63 characters.
- 6
- Specify the service account you created.
- 7
- Specify an
fsGroupfor the pods.
27.4.2.4. Cinder volume limit
By default, a maximum of 256 Cinder volumes can be attached to each node in a cluster. To change this limit:
Set the
KUBE_MAX_PD_VOLSenvironment variable to an integer. For example, in/etc/origin/master/master.env:KUBE_MAX_PD_VOLS=26From a command line, restart the API service:
# master-restart apiFrom a command line, restart the controllers service:
# master-restart controllers
27.5. Persistent Storage Using Ceph Rados Block Device (RBD)
27.5.1. Overview
OpenShift Container Platform clusters can be provisioned with persistent storage using Ceph RBD.
Persistent volumes (PVs) and persistent volume claims (PVCs) can share volumes across a single project. While the Ceph RBD-specific information contained in a PV definition could also be defined directly in a pod definition, doing so does not create the volume as a distinct cluster resource, making the volume more susceptible to conflicts.
This topic presumes some familiarity with OpenShift Container Platform and Ceph RBD. See the Persistent Storage concept topic for details on the OpenShift Container Platform persistent volume (PV) framework in general.
Project and namespace are used interchangeably throughout this document. See Projects and Users for details on the relationship.
High-availability of storage in the infrastructure is left to the underlying storage provider.
27.5.2. Provisioning
To provision Ceph volumes, the following are required:
- An existing storage device in your underlying infrastructure.
- The Ceph key to be used in an OpenShift Container Platform secret object.
- The Ceph image name.
- The file system type on top of the block storage (e.g., ext4).
ceph-common installed on each schedulable OpenShift Container Platform node in your cluster:
# yum install ceph-common
27.5.2.1. Creating the Ceph Secret
Define the authorization key in a secret configuration, which is then converted to base64 for use by OpenShift Container Platform.
In order to use Ceph storage to back a persistent volume, the secret must be created in the same project as the PVC and pod. The secret cannot simply be in the default project.
Run
ceph auth get-keyon a Ceph MON node to display the key value for theclient.adminuser:apiVersion: v1 kind: Secret metadata: name: ceph-secret data: key: QVFBOFF2SlZheUJQRVJBQWgvS2cwT1laQUhPQno3akZwekxxdGc9PQ== type: kubernetes.io/rbdSave the secret definition to a file, for example ceph-secret.yaml, then create the secret:
$ oc create -f ceph-secret.yamlVerify that the secret was created:
# oc get secret ceph-secret NAME TYPE DATA AGE ceph-secret kubernetes.io/rbd 1 23d
27.5.2.2. Creating the Persistent Volume
Developers request Ceph RBD storage by referencing either a PVC, or the Gluster volume plug-in directly in the volumes section of a pod specification. A PVC exists only in the user’s namespace and can be referenced only by pods within that same namespace. Any attempt to access a PV from a different namespace causes the pod to fail.
Define the PV in an object definition before creating it in OpenShift Container Platform:
Example 27.3. Persistent Volume Object Definition Using Ceph RBD
apiVersion: v1 kind: PersistentVolume metadata: name: ceph-pv1 spec: capacity: storage: 2Gi2 accessModes: - ReadWriteOnce3 rbd:4 monitors:5 - 192.168.122.133:6789 pool: rbd image: ceph-image user: admin secretRef: name: ceph-secret6 fsType: ext47 readOnly: false persistentVolumeReclaimPolicy: Retain- 1
- The name of the PV that is referenced in pod definitions or displayed in various
ocvolume commands. - 2
- The amount of storage allocated to this volume.
- 3
accessModesare used as labels to match a PV and a PVC. They currently do not define any form of access control. All block storage is defined to be single user (non-shared storage).- 4
- The volume type being used, in this case the rbd plug-in.
- 5
- An array of Ceph monitor IP addresses and ports.
- 6
- The Ceph secret used to create a secure connection from OpenShift Container Platform to the Ceph server.
- 7
- The file system type mounted on the Ceph RBD block device.
ImportantChanging the value of the
fstypeparameter after the volume has been formatted and provisioned can result in data loss and pod failure.Save your definition to a file, for example ceph-pv.yaml, and create the PV:
# oc create -f ceph-pv.yamlVerify that the persistent volume was created:
# oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE ceph-pv <none> 2147483648 RWO Available 2sCreate a PVC that will bind to the new PV:
Example 27.4. PVC Object Definition
kind: PersistentVolumeClaim apiVersion: v1 metadata: name: ceph-claim spec: accessModes:1 - ReadWriteOnce resources: requests: storage: 2Gi2 Save the definition to a file, for example ceph-claim.yaml, and create the PVC:
# oc create -f ceph-claim.yaml
27.5.3. Ceph Volume Security
See the full Volume Security topic before implementing Ceph RBD volumes.
A significant difference between shared volumes (NFS and GlusterFS) and block volumes (Ceph RBD, iSCSI, and most cloud storage), is that the user and group IDs defined in the pod definition or container image are applied to the target physical storage. This is referred to as managing ownership of the block device. For example, if the Ceph RBD mount has its owner set to 123 and its group ID set to 567, and if the pod defines its runAsUser set to 222 and its fsGroup to be 7777, then the Ceph RBD physical mount’s ownership will be changed to 222:7777.
Even if the user and group IDs are not defined in the pod specification, the resulting pod may have defaults defined for these IDs based on its matching SCC, or its project. See the full Volume Security topic which covers storage aspects of SCCs and defaults in greater detail.
A pod defines the group ownership of a Ceph RBD volume using the fsGroup stanza under the pod’s securityContext definition:
27.6. Persistent Storage Using AWS Elastic Block Store
27.6.1. Overview
OpenShift Container Platform supports AWS Elastic Block Store volumes (EBS). You can provision your OpenShift Container Platform cluster with persistent storage using AWS EC2. Some familiarity with Kubernetes and AWS is assumed.
Before creating persistent volumes using AWS, OpenShift Container Platform must first be properly configured for AWS ElasticBlockStore.
The Kubernetes persistent volume framework allows administrators to provision a cluster with persistent storage and gives users a way to request those resources without having any knowledge of the underlying infrastructure. AWS Elastic Block Store volumes can be provisioned dynamically. Persistent volumes are not bound to a single project or namespace; they can be shared across the OpenShift Container Platform cluster. Persistent volume claims, however, are specific to a project or namespace and can be requested by users.
High-availability of storage in the infrastructure is left to the underlying storage provider.
27.6.2. Provisioning
Storage must exist in the underlying infrastructure before it can be mounted as a volume in OpenShift Container Platform. After ensuring OpenShift is configured for AWS Elastic Block Store, all that is required for OpenShift and AWS is an AWS EBS volume ID and the PersistentVolume API.
27.6.2.1. Creating the Persistent Volume
You must define your persistent volume in an object definition before creating it in OpenShift Container Platform:
Example 27.5. Persistent Volume Object Definition Using AWS
apiVersion: "v1"
kind: "PersistentVolume"
metadata:
name: "pv0001"
spec:
capacity:
storage: "5Gi"
accessModes:
- "ReadWriteOnce"
awsElasticBlockStore:
fsType: "ext4"
volumeID: "vol-f37a03aa" - 1
- The name of the volume. This will be how it is identified via persistent volume claims or from pods.
- 2
- The amount of storage allocated to this volume.
- 3
- This defines the volume type being used, in this case the awsElasticBlockStore plug-in.
- 4
- File system type to mount.
- 5
- This is the AWS volume that will be used.
Changing the value of the fstype parameter after the volume has been formatted and provisioned can result in data loss and pod failure.
Save your definition to a file, for example aws-pv.yaml, and create the persistent volume:
# oc create -f aws-pv.yaml
persistentvolume "pv0001" createdVerify that the persistent volume was created:
# oc get pv
NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
pv0001 <none> 5Gi RWO Available 2sUsers can then request storage using persistent volume claims, which can now utilize your new persistent volume.
Persistent volume claims only exist in the user’s namespace and can only be referenced by a pod within that same namespace. Any attempt to access a persistent volume from a different namespace causes the pod to fail.
27.6.2.2. Volume Format
Before OpenShift Container Platform mounts the volume and passes it to a container, it checks that it contains a file system as specified by the fsType parameter in the persistent volume definition. If the device is not formatted with the file system, all data from the device is erased and the device is automatically formatted with the given file system.
This allows using unformatted AWS volumes as persistent volumes, because OpenShift Container Platform formats them before the first use.
27.6.2.3. Maximum Number of EBS Volumes on a Node
By default, OpenShift Container Platform supports a maximum of 39 EBS volumes attached to one node. This limit is consistent with the AWS Volume Limits.
OpenShift Container Platform can be configured to have a higher limit by setting the environment variable KUBE_MAX_PD_VOLS. However, AWS requires a particular naming scheme (AWS Device Naming) for attached devices, which only supports a maximum of 52 volumes. This limits the number of volumes that can be attached to a node via OpenShift Container Platform to 52.
27.7. Persistent Storage Using GCE Persistent Disk
27.7.1. Overview
OpenShift Container Platform supports GCE Persistent Disk volumes (gcePD). You can provision your OpenShift Container Platform cluster with persistent storage using GCE. Some familiarity with Kubernetes and GCE is assumed.
Before creating persistent volumes using GCE, OpenShift Container Platform must first be properly configured for GCE Persistent Disk.
The Kubernetes persistent volume framework allows administrators to provision a cluster with persistent storage and gives users a way to request those resources without having any knowledge of the underlying infrastructure. GCE Persistent Disk volumes can be provisioned dynamically. Persistent volumes are not bound to a single project or namespace; they can be shared across the OpenShift Container Platform cluster. Persistent volume claims, however, are specific to a project or namespace and can be requested by users.
High-availability of storage in the infrastructure is left to the underlying storage provider.
27.7.2. Provisioning
Storage must exist in the underlying infrastructure before it can be mounted as a volume in OpenShift Container Platform. After ensuring OpenShift Container Platform is configured for GCE PersistentDisk, all that is required for OpenShift Container Platform and GCE is an GCE Persistent Disk volume ID and the PersistentVolume API.
27.7.2.1. Creating the Persistent Volume
You must define your persistent volume in an object definition before creating it in OpenShift Container Platform:
Example 27.6. Persistent Volume Object Definition Using GCE
apiVersion: "v1"
kind: "PersistentVolume"
metadata:
name: "pv0001"
spec:
capacity:
storage: "5Gi"
accessModes:
- "ReadWriteOnce"
gcePersistentDisk:
fsType: "ext4"
pdName: "pd-disk-1" - 1
- The name of the volume. This will be how it is identified via persistent volume claims or from pods.
- 2
- The amount of storage allocated to this volume.
- 3
- This defines the volume type being used, in this case the gcePersistentDisk plug-in.
- 4
- File system type to mount.
- 5
- This is the GCE Persistent Disk volume that will be used.
Changing the value of the fstype parameter after the volume has been formatted and provisioned can result in data loss and pod failure.
Save your definition to a file, for example gce-pv.yaml, and create the persistent volume:
# oc create -f gce-pv.yaml
persistentvolume "pv0001" createdVerify that the persistent volume was created:
# oc get pv
NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
pv0001 <none> 5Gi RWO Available 2sUsers can then request storage using persistent volume claims, which can now utilize your new persistent volume.
Persistent volume claims only exist in the user’s namespace and can only be referenced by a pod within that same namespace. Any attempt to access a persistent volume from a different namespace causes the pod to fail.
27.7.2.2. Volume Format
Before OpenShift Container Platform mounts the volume and passes it to a container, it checks that it contains a file system as specified by the fsType parameter in the persistent volume definition. If the device is not formatted with the file system, all data from the device is erased and the device is automatically formatted with the given file system.
This allows using unformatted GCE volumes as persistent volumes, because OpenShift Container Platform formats them before the first use.
27.8. Persistent Storage Using iSCSI
27.8.1. Overview
You can provision your OpenShift Container Platform cluster with persistent storage using iSCSI. Some familiarity with Kubernetes and iSCSI is assumed.
The Kubernetes persistent volume framework allows administrators to provision a cluster with persistent storage and gives users a way to request those resources without having any knowledge of the underlying infrastructure.
High-availability of storage in the infrastructure is left to the underlying storage provider.
27.8.2. Provisioning
Verify that the storage exists in the underlying infrastructure before mounting it as a volume in OpenShift Container Platform. All that is required for the iSCSI is the iSCSI target portal, a valid iSCSI Qualified Name (IQN), a valid LUN number, the filesystem type, and the PersistentVolume API.
Optionally, multipath portals and Challenge Handshake Authentication Protocol (CHAP) configuration can be provided.
Example 27.7. Persistent Volume Object Definition
apiVersion: v1
kind: PersistentVolume
metadata:
name: iscsi-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
iscsi:
targetPortal: 10.16.154.81:3260
portals: ['10.16.154.82:3260', '10.16.154.83:3260']
iqn: iqn.2014-12.example.server:storage.target00
lun: 0
fsType: 'ext4'
readOnly: false
chapAuthDiscovery: true
chapAuthSession: true
secretRef:
name: chap-secret27.8.2.1. Enforcing Disk Quotas
Use LUN partitions to enforce disk quotas and size constraints. Each LUN is one persistent volume. Kubernetes enforces unique names for persistent volumes.
Enforcing quotas in this way allows the end user to request persistent storage by a specific amount (e.g, 10Gi) and be matched with a corresponding volume of equal or greater capacity.
27.8.2.2. iSCSI Volume Security
Users request storage with a PersistentVolumeClaim. This claim only lives in the user’s namespace and can only be referenced by a pod within that same namespace. Any attempt to access a persistent volume across a namespace causes the pod to fail.
Each iSCSI LUN must be accessible by all nodes in the cluster.
27.8.2.3. iSCSI Multipathing
For iSCSI-based storage, you can configure multiple paths by using the same IQN for more than one target portal IP address. Multipathing ensures access to the persistent volume when one or more of the components in a path fail.
To specify multi-paths in pod specification use the portals field. For example:
apiVersion: v1
kind: PersistentVolume
metadata:
name: iscsi-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
iscsi:
targetPortal: 10.0.0.1:3260
portals: ['10.0.2.16:3260', '10.0.2.17:3260', '10.0.2.18:3260']
iqn: iqn.2016-04.test.com:storage.target00
lun: 0
fsType: ext4
readOnly: false- 1
- Add additional target portals using the
portalsfield.
27.8.2.4. iSCSI Custom Initiator IQN
Configure the custom initiator iSCSI Qualified Name (IQN) if the iSCSI targets are restricted to certain IQNs, but the nodes that the iSCSI PVs are attached to are not guaranteed to have these IQNs.
To specify custom initiator IQN, use initiatorName field.
apiVersion: v1
kind: PersistentVolume
metadata:
name: iscsi-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
iscsi:
targetPortal: 10.0.0.1:3260
portals: ['10.0.2.16:3260', '10.0.2.17:3260', '10.0.2.18:3260']
iqn: iqn.2016-04.test.com:storage.target00
lun: 0
initiatorName: iqn.2016-04.test.com:custom.iqn
fsType: ext4
readOnly: false- 1
- To add an additional custom initiator IQN, use
initiatorNamefield.
27.9. Persistent Storage Using Fibre Channel
27.9.1. Overview
You can provision your OpenShift Container Platform cluster with persistent storage using Fibre Channel (FC). Some familiarity with Kubernetes and FC is assumed.
The Kubernetes persistent volume framework allows administrators to provision a cluster with persistent storage and gives users a way to request those resources without having any knowledge of the underlying infrastructure.
High-availability of storage in the infrastructure is left to the underlying storage provider.
27.9.2. Provisioning
Storage must exist in the underlying infrastructure before it can be mounted as a volume in OpenShift Container Platform. All that is required for FC persistent storage is the PersistentVolume API, the wwids or the targetWWNs with a valid lun number, and the fsType. Persistent volume and a LUN have one-to-one mapping between them.
Persistent Volume Object Definition
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0001
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
fc:
wwids: [scsi-3600508b400105e210000900000490000]
targetWWNs: ['500a0981891b8dc5', '500a0981991b8dc5']
lun: 2
fsType: ext4- 1
- Optional: World wide identifiers (WWIDs). Either FC
wwidsor a combination of FCtargetWWNsandlunmust be set, but not both simultaneously. The FC WWID identifier is recommended over the WWNs target because it is guaranteed to be unique for every storage device, and independent of the path that is used to access the device. The WWID identifier can be obtained by issuing a SCSI Inquiry to retrieve the Device Identification Vital Product Data (page 0x83) or Unit Serial Number (page 0x80). FC WWIDs are identified as/dev/disk/by-id/to reference the data on the disk, even if the path to the device changes and even when accessing the device from different systems. - 2 3
- Optional: World wide names (WWNs). Either FC
wwidsor a combination of FCtargetWWNsandlunmust be set, but not both simultaneously. The FC WWID identifier is recommended over the WWNs target because it is guaranteed to be unique for every storage device, and independent of the path that is used to access the device. FC WWNs are identified as/dev/disk/by-path/pci-<identifier>-fc-0x<wwn>-lun-<lun_#>, but you do not need to provide any part of the path leading up to the<wwn>, including the0x, and anything after, including the-(hyphen).
Changing the value of the fstype parameter after the volume has been formatted and provisioned can result in data loss and pod failure.
27.9.2.1. Enforcing Disk Quotas
Use LUN partitions to enforce disk quotas and size constraints. Each LUN is one persistent volume. Kubernetes enforces unique names for persistent volumes.
Enforcing quotas in this way allows the end user to request persistent storage by a specific amount, such as 10 Gi, and be matched with a corresponding volume of equal or greater capacity.
27.9.2.2. Fibre Channel Volume Security
Users request storage with a PersistentVolumeClaim. This claim only lives in the namespace of the user and can only be referenced by a pod within that same namespace. Any attempt to access a persistent volume claim across a namespace causes the pod to fail.
Each FC LUN must be accessible by all nodes in the cluster.
27.10. Persistent Storage Using Azure Disk
27.10.1. Overview
OpenShift Container Platform supports Microsoft Azure Disk volumes. You can provision your OpenShift Container Platform cluster with persistent storage using Azure. Some familiarity with Kubernetes and Azure is assumed.
The Kubernetes persistent volume framework allows administrators to provision a cluster with persistent storage and gives users a way to request those resources without having any knowledge of the underlying infrastructure.
Azure Disk volumes can be provisioned dynamically. Persistent volumes are not bound to a single project or namespace; they can be shared across the OpenShift Container Platform cluster. Persistent volume claims, however, are specific to a project or namespace and can be requested by users.
High availability of storage in the infrastructure is left to the underlying storage provider.
27.10.2. Prerequisites
Before creating persistent volumes using Azure, ensure your OpenShift Container Platform cluster meets the following requirements:
- OpenShift Container Platform must first be configured for Azure Disk.
- Each node host in the infrastructure must match the Azure virtual machine name.
- Each node host must be in the same resource group.
27.10.3. Provisioning
Storage must exist in the underlying infrastructure before it can be mounted as a volume in OpenShift Container Platform. After ensuring OpenShift Container Platform is configured for Azure Disk, all that is required for OpenShift Container Platform and Azure is an Azure Disk Name and Disk URI and the PersistentVolume API.
27.10.4. Configuring Azure Disk for regional cloud
Azure has multiple regions on which to deploy an instance. To specify a desired region, add the following to the azure.conf file:
cloud: <region>The region can be any of the following:
-
German cloud:
AZUREGERMANCLOUD -
China cloud:
AZURECHINACLOUD -
Public cloud:
AZUREPUBLICCLOUD -
US cloud:
AZUREUSGOVERNMENTCLOUD
27.10.4.1. Creating the Persistent Volume
You must define your persistent volume in an object definition before creating it in OpenShift Container Platform:
Example 27.8. Persistent Volume Object Definition Using Azure
apiVersion: "v1"
kind: "PersistentVolume"
metadata:
name: "pv0001"
spec:
capacity:
storage: "5Gi"
accessModes:
- "ReadWriteOnce"
azureDisk:
diskName: test2.vhd
diskURI: https://someacount.blob.core.windows.net/vhds/test2.vhd
cachingMode: ReadWrite
fsType: ext4
readOnly: false - 1
- The name of the volume. This will be how it is identified via persistent volume claims or from pods.
- 2
- The amount of storage allocated to this volume.
- 3
- This defines the volume type being used (azureDisk plug-in, in this example).
- 4
- The name of the data disk in the blob storage.
- 5
- The URI of the data disk in the blob storage.
- 6
- Host caching mode: None, ReadOnly, or ReadWrite.
- 7
- File system type to mount (for example,
ext4,xfs, and so on). - 8
- Defaults to
false(read/write).ReadOnlyhere will force theReadOnlysetting inVolumeMounts.
Changing the value of the fsType parameter after the volume is formatted and provisioned can result in data loss and pod failure.
Save your definition to a file, for example azure-pv.yaml, and create the persistent volume:
# oc create -f azure-pv.yaml persistentvolume "pv0001" createdVerify that the persistent volume was created:
# oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE pv0001 <none> 5Gi RWO Available 2s
Now you can request storage using persistent volume claims, which can now use your new persistent volume.
For a pod that has a mounted volume through an Azure disk PVC, scheduling the pod to a new node takes a few minutes. Wait for two to three minutes to complete the Disk Detach operation, and then start a new deployment. If a new pod creation request is started before completing the Disk Detach operation, the Disk Attach operation initiated by the pod creation fails, resulting in pod creation failure.
Persistent volume claims only exist in the user’s namespace and can only be referenced by a pod within that same namespace. Any attempt to access a persistent volume from a different namespace causes the pod to fail.
27.10.4.2. Volume Format
Before OpenShift Container Platform mounts the volume and passes it to a container, it checks that it contains a file system as specified by the fsType parameter in the persistent volume definition. If the device is not formatted with the file system, all data from the device is erased and the device is automatically formatted with the given file system.
This allows unformatted Azure volumes to be used as persistent volumes because OpenShift Container Platform formats them before the first use.
27.11. Persistent Storage Using Azure File
27.11.1. Overview
OpenShift Container Platform supports Microsoft Azure File volumes. You can provision your OpenShift Container Platform cluster with persistent storage using Azure. Some familiarity with Kubernetes and Azure is assumed.
High availability of storage in the infrastructure is left to the underlying storage provider.
27.11.2. Before you begin
Install
samba-client,samba-common, andcifs-utilson all nodes:$ sudo yum install samba-client samba-common cifs-utilsEnable SELinux booleans on all nodes:
$ /usr/sbin/setsebool -P virt_use_samba on $ /usr/sbin/setsebool -P virt_sandbox_use_samba onRun the
mountcommand to checkdir_modeandfile_modepermissions, for example:$ mount
If the dir_mode and file_mode permissions are set to 0755, change the default value 0755 to 0777 or 0775. This manual step is required because the default dir_mode and file_mode permissions changed from 0777 to 0755 in OpenShift Container Platform 3.9. The following examples show configuration files with the changed values.
Considerations when using Azure File
The following file system features are not supported by Azure File:
- Symlinks
- Hard links
- Extended attributes
- Sparse files
- Named pipes
Additionally, the owner user identifier (UID) of the Azure File mounted directory is different from the process UID of the container.
You might experience instability in your environment if you use any container images that use unsupported file system features. Containers for PostgreSQL and MySQL are known to have issues when used with Azure File.
Workaround for using MySQL with Azure File
If you use MySQL containers, you must modify the PV configuration as a workaround to a file ownership mismatch between the mounted directory UID and the container process UID. Make the following changes to your PV configuration file:
Specify the Azure File mounted directory UID in the
runAsUservariable in the PV configuration file:spec: containers: ... securityContext: runAsUser: <mounted_dir_uid>Specify the container process UID under
mountOptionsin the PV configuration file:mountOptions: - dir_mode=0700 - file_mode=0600 - uid=<container_process_uid> - gid=0
27.11.3. Example configuration files
The following example configuration file displays a PV configuration using Azure File:
PV configuration file example
apiVersion: "v1"
kind: "PersistentVolume"
metadata:
name: "azpv"
spec:
capacity:
storage: "1Gi"
accessModes:
- "ReadWriteMany"
azureFile:
secretName: azure-secret
shareName: azftest
readOnly: false
mountOptions:
- dir_mode=0777
- file_mode=0777The following example configuration file displays a storage class using Azure File:
Storage class configuration file example
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: azurefile
provisioner: kubernetes.io/azure-file
mountOptions:
- dir_mode=0777
- file_mode=0777
parameters:
storageAccount: ocp39str
location: centralus27.11.4. Configuring Azure File for regional cloud
While Azure Disk is compatible with multiple regional clouds, Azure File supports only the Azure public cloud, because the endpoint is hard-coded.
27.11.5. Creating the Azure Storage Account secret
Define the Azure Storage Account name and key in a secret configuration, which is then converted to base64 for use by OpenShift Container Platform.
Obtain an Azure Storage Account name and key and encode to base64:
apiVersion: v1 kind: Secret metadata: name: azure-secret type: Opaque data: azurestorageaccountname: azhzdGVzdA== azurestorageaccountkey: eElGMXpKYm5ub2pGTE1Ta0JwNTBteDAyckhzTUsyc2pVN21GdDRMMTNob0I3ZHJBYUo4akQ2K0E0NDNqSm9nVjd5MkZVT2hRQ1dQbU02WWFOSHk3cWc9PQ==Save the secret definition to a file, for example azure-secret.yaml, then create the secret:
$ oc create -f azure-secret.yamlVerify that the secret was created:
$ oc get secret azure-secret NAME TYPE DATA AGE azure-secret Opaque 1 23dDefine the PV in an object definition before creating it in OpenShift Container Platform:
PV object definition using Azure File example
apiVersion: "v1" kind: "PersistentVolume" metadata: name: "pv0001"1 spec: capacity: storage: "5Gi"2 accessModes: - "ReadWriteMany" azureFile:3 secretName: azure-secret4 shareName: example5 readOnly: false6 - 1
- The name of the volume. This is how it is identified via PV claims or from pods.
- 2
- The amount of storage allocated to this volume.
- 3
- This defines the volume type being used: azureFile plug-in.
- 4
- The name of the secret used.
- 5
- The name of the file share.
- 6
- Defaults to
false(read/write).ReadOnlyhere forces theReadOnlysetting inVolumeMounts.
Save your definition to a file, for example azure-file-pv.yaml, and create the PV:
$ oc create -f azure-file-pv.yaml persistentvolume "pv0001" createdVerify that the PV was created:
$ oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE pv0001 <none> 5Gi RWM Available 2s
You can now request storage using PV claims, which can now use your new PV.
PV claims only exist in the user’s namespace and can only be referenced by a pod within that same namespace. Any attempt to access a PV from a different namespace causes the pod to fail.
27.12. Persistent Storage Using FlexVolume Plug-ins
27.12.1. Overview
OpenShift Container Platform has built-in volume plug-ins to use different storage technologies. To use storage from a back-end that does not have a built-in plug-in, you can extend OpenShift Container Platform through FlexVolume drivers and provide persistent storage to applications.
27.12.2. FlexVolume drivers
A FlexVolume driver is an executable file that resides in a well-defined directory on all machines in the cluster, both masters and nodes. OpenShift Container Platform calls the FlexVolume driver whenever it needs to attach, detach, mount, or unmount a volume represented by a PersistentVolume with flexVolume as the source.
The first command-line argument of the driver is always an operation name. Other parameters are specific to each operation. Most of the operations take a JavaScript Object Notation (JSON) string as a parameter. This parameter is a complete JSON string, and not the name of a file with the JSON data.
The FlexVolume driver contains:
-
All
flexVolume.options. -
Some options from
flexVolumeprefixed bykubernetes.io/, such asfsTypeandreadwrite. -
The content of the referenced secret, if specified, prefixed by
kubernetes.io/secret/.
FlexVolume driver JSON input example
{
"fooServer": "192.168.0.1:1234",
"fooVolumeName": "bar",
"kubernetes.io/fsType": "ext4",
"kubernetes.io/readwrite": "ro",
"kubernetes.io/secret/<key name>": "<key value>",
"kubernetes.io/secret/<another key name>": "<another key value>",
}OpenShift Container Platform expects JSON data on standard output of the driver. When not specified, the output describes the result of the operation.
FlexVolume Driver Default Output
{
"status": "<Success/Failure/Not supported>",
"message": "<Reason for success/failure>"
}
Exit code of the driver should be 0 for success and 1 for error.
Operations should be idempotent, which means that the attachment of an already attached volume or the mounting of an already mounted volume should result in a successful operation.
The FlexVolume driver can work in two modes:
- with the master-initated attach/detach operation, or
- without the master-initated attach/detach operation.
The attach/detach operation is used by the OpenShift Container Platform master to attach a volume to a node and to detach it from a node. This is useful when a node becomes unresponsive for any reason. Then, the master can kill all pods on the node, detach all volumes from it, and attach the volumes to other nodes to resume the applications while the original node is still not reachable.
Not all storage back-end supports master-initiated detachment of a volume from another machine.
27.12.2.1. FlexVolume drivers with master-initiated attach/detach
A FlexVolume driver that supports master-controlled attach/detach must implement the following operations:
initInitializes the driver. It is called during initialization of masters and nodes.
- Arguments: none
- Executed on: master, node
- Expected output: default JSON
getvolumenameReturns the unique name of the volume. This name must be consistent among all masters and nodes, because it is used in subsequent
detachcall as<volume-name>. Any/characters in the<volume-name>are automatically replaced by~.-
Arguments:
<json> - Executed on: master, node
Expected output: default JSON +
volumeName:{ "status": "Success", "message": "", "volumeName": "foo-volume-bar"1 }- 1
- The unique name of the volume in storage back-end
foo.
-
Arguments:
attachAttaches a volume represented by the JSON to a given node. This operation should return the name of the device on the node if it is known, that is, if it has been assigned by the storage back-end before it runs. If the device is not known, the device must be found on the node by the subsequent
waitforattachoperation.-
Arguments:
<json><node-name> - Executed on: master
Expected output: default JSON +
device, if known:{ "status": "Success", "message": "", "device": "/dev/xvda"1 }- 1
- The name of the device on the node, if known.
-
Arguments:
waitforattachWaits until a volume is fully attached to a node and its device emerges. If the previous
attachoperation has returned<device-name>, it is provided as an input parameter. Otherwise,<device-name>is empty and the operation must find the device on the node.-
Arguments:
<device-name><json> - Executed on: node
Expected output: default JSON +
device{ "status": "Success", "message": "", "device": "/dev/xvda"1 }- 1
- The name of the device on the node.
-
Arguments:
detachDetaches the given volume from a node.
<volume-name>is the name of the device returned by thegetvolumenameoperation. Any/characters in the<volume-name>are automatically replaced by~.-
Arguments:
<volume-name><node-name> - Executed on: master
- Expected output: default JSON
-
Arguments:
isattachedChecks that a volume is attached to a node.
-
Arguments:
<json><node-name> - Executed on: master
Expected output: default JSON +
attached{ "status": "Success", "message": "", "attached": true1 }- 1
- The status of attachment of the volume to the node.
-
Arguments:
mountdeviceMounts a volume’s device to a directory.
<device-name>is name of the device as returned by the previouswaitforattachoperation.-
Arguments:
<mount-dir><device-name><json> - Executed on: node
- Expected output: default JSON
-
Arguments:
unmountdeviceUnmounts a volume’s device from a directory.
-
Arguments:
<mount-dir> - Executed on: node
-
Arguments:
All other operations should return JSON with {"status": "Not supported"} and exit code 1.
Master-initiated attach/detach operations are enabled by default. When not enabled, the attach/detach operations are initiated by a node where the volume should be attached to or detached from. Syntax and all parameters of FlexVolume driver invocations are the same in both cases.
27.12.2.2. FlexVolume drivers without master-initiated attach/detach
FlexVolume drivers that do not support master-controlled attach/detach are executed only on the node and must implement these operations:
initInitializes the driver. It is called during initialization of all nodes.
- Arguments: none
- Executed on: node
- Expected output: default JSON
mountMounts a volume to directory. This can include anything that is necessary to mount the volume, including attaching the volume to the node, finding the its device, and then mounting the device.
-
Arguments:
<mount-dir><json> - Executed on: node
- Expected output: default JSON
-
Arguments:
unmountUnmounts a volume from a directory. This can include anything that is necessary to clean up the volume after unmounting, such as detaching the volume from the node.
-
Arguments:
<mount-dir> - Executed on: node
- Expected output: default JSON
-
Arguments:
All other operations should return JSON with {"status": "Not supported"} and exit code 1.
27.12.3. Installing FlexVolume drivers
To install the FlexVolume driver:
- Ensure that the executable file exists on all masters and nodes in the cluster.
- Place the executable file at the volume plug-in path: /usr/libexec/kubernetes/kubelet-plugins/volume/exec/<vendor>~<driver>/<driver>.
For example, to install the FlexVolume driver for the storage foo, place the executable file at: /usr/libexec/kubernetes/kubelet-plugins/volume/exec/openshift.com~foo/foo.
In OpenShift Container Platform 3.11, since controller-manager runs as a static pod, the FlexVolume binary file that performs the attach and detach operations must be a self-contained executable file with no external dependencies.
On Atomic hosts, the default location of the FlexVolume plug-in directory is /etc/origin/kubelet-plugins/. You must place the FlexVolume executable file in the /etc/origin/kubelet-plugins/volume/exec/<vendor>~<driver>/<driver> directory on all master and nodes in the cluster.
27.12.4. Consuming storage using FlexVolume drivers
Use the PersistentVolume object to reference the installed storage. Each PersistentVolume object in OpenShift Container Platform represents one storage asset, typically a volume, in the storage back-end.
Persistent volume object definition using FlexVolume drivers example
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0001
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
flexVolume:
driver: openshift.com/foo
fsType: "ext4"
secretRef: foo-secret
readOnly: true
options:
fooServer: 192.168.0.1:1234
fooVolumeName: bar- 1
- The name of the volume. This is how it is identified through persistent volume claims or from pods. This name can be different from the name of the volume on back-end storage.
- 2
- The amount of storage allocated to this volume.
- 3
- The name of the driver. This field is mandatory.
- 4
- The file system that is present on the volume. This field is optional.
- 5
- The reference to a secret. Keys and values from this secret are provided to the FlexVolume driver on invocation. This field is optional.
- 6
- The read-only flag. This field is optional.
- 7
- The additional options for the FlexVolume driver. In addition to the flags specified by the user in the
optionsfield, the following flags are also passed to the executable:
"fsType":"<FS type>",
"readwrite":"<rw>",
"secret/key1":"<secret1>"
...
"secret/keyN":"<secretN>"Secrets are passed only to mount/unmount call-outs.
27.13. Using VMware vSphere volumes for persistent storage
27.13.1. Overview
OpenShift Container Platform supports VMware vSphere’s Virtual Machine Disk (VMDK) volumes. You can provision your OpenShift Container Platform cluster with persistent storage using VMware vSphere. Some familiarity with Kubernetes and VMware vSphere is assumed.
OpenShift Container Platform creates the disk in vSphere and attaches the disk to the correct instance.
The OpenShift Container Platform persistent volume (PV) framework allows administrators to provision a cluster with persistent storage and gives users a way to request those resources without having any knowledge of the underlying infrastructure. vSphere VMDK volumes can be provisioned dynamically.
PVs are not bound to a single project or namespace; they can be shared across the OpenShift Container Platform cluster. PV claims, however, are specific to a project or namespace and can be requested by users.
High availability of storage in the infrastructure is left to the underlying storage provider.
Prerequisites
Before creating PVs using vSphere, ensure your OpenShift Container Platform cluster meets the following requirements:
- OpenShift Container Platform must first be configured for vSphere.
- Each node host in the infrastructure must match the vSphere VM name.
- Each node host must be in the same resource group.
27.13.2. Dynamically Provisioning VMware vSphere volumes
Dynamically provisioning VMware vSphere volumes is the preferred provisioning method.
If you did not specify the
openshift_cloudprovider_kind=vsphereandopenshift_vsphere_*variables in the Ansible inventory file when you provisioned the cluster, you must manually create the followingStorageClassto use thevsphere-volumeprovisioner:$ oc get --export storageclass vsphere-standard -o yaml kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: "vsphere-standard"1 provisioner: kubernetes.io/vsphere-volume2 parameters: diskformat: thin3 datastore: "YourvSphereDatastoreName"4 reclaimPolicy: DeleteAfter you request a PV, using the StorageClass shown in the previous step, OpenShift Container Platform automatically creates VMDK disks in the vSphere infrastructure. To verify that the disks were created, use the Datastore browser in vSphere.
NotevSphere-volume disks are
ReadWriteOnceaccess mode, which means the volume can be mounted as read-write by a single node. See the Access modes section of the Architecture guide for more information.
27.13.3. Statically Provisioning VMware vSphere volumes
Storage must exist in the underlying infrastructure before it can be mounted as a volume in OpenShift Container Platform. After ensuring OpenShift Container Platform is configured for vSphere, all that is required for OpenShift Container Platform and vSphere is a VM folder path, file system type, and the PersistentVolume API.
27.13.3.1. Create the VMDKs
Create VMDK using one of the following methods before using them.
Create using
vmkfstools:Access ESX through Secure Shell (SSH) and then use following command to create a VMDK volume:
vmkfstools -c 40G /vmfs/volumes/DatastoreName/volumes/myDisk.vmdkCreate using
vmware-vdiskmanager:shell vmware-vdiskmanager -c -t 0 -s 40GB -a lsilogic myDisk.vmdk
27.13.3.2. Creating PersistentVolumes
Define a PV object definition, for example vsphere-pv.yaml:
apiVersion: v1 kind: PersistentVolume metadata: name: pv00011 spec: capacity: storage: 2Gi2 accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain vsphereVolume:3 volumePath: "[datastore1] volumes/myDisk"4 fsType: ext45 - 1
- The name of the volume. This must be how it is identified by PV claims or from pods.
- 2
- The amount of storage allocated to this volume.
- 3
- The volume type being used. This example uses
vsphereVolume. The label is used to mount a vSphere VMDK volume into pods. The contents of a volume are preserved when it is unmounted. The volume type supports VMFS and VSAN datastore. - 4
- The existing VMDK volume to use. You must enclose the datastore name in square brackets ([]) in the volume definition, as shown.
- 5
- The file system type to mount. For example,
ext4,xfs, or other file-systems.
ImportantChanging the value of the
fsTypeparameter after the volume is formatted and provisioned can result in data loss and pod failure.Create the PV:
$ oc create -f vsphere-pv.yaml persistentvolume "pv0001" createdVerify that the PV was created:
$ oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE pv0001 <none> 2Gi RWO Available 2s
Now you can request storage using PV claims, which can now use your PV.
PV claims only exist in the user’s namespace and can only be referenced by a pod within that same namespace. Any attempt to access a PV from a different namespace causes the pod to fail.
27.13.3.3. Formatting VMware vSphere volumes
Before OpenShift Container Platform mounts the volume and passes it to a container, it checks that the volume contains a file system as specified by the fsType parameter in the PV definition. If the device is not formatted with the file system, all data from the device is erased, and the device is automatically formatted with the given file system.
Because OpenShift Container Platform formats them before the first use, you can use unformatted vSphere volumes as PVs.
27.14. Persistent Storage Using Local Volume
27.14.1. Overview
OpenShift Container Platform clusters can be provisioned with persistent storage by using local volumes. Local persistent volume allows you to access local storage devices such as a disk, partition or directory by using the standard PVC interface.
Local volumes can be used without manually scheduling pods to nodes, because the system is aware of the volume’s node constraints. However, local volumes are still subject to the availability of the underlying node and are not suitable for all applications.
Local volumes is an alpha feature and may change in a future release of OpenShift Container Platform. See Feature Status(Local Volume) section for details on known issues and workarounds.
Local volumes can only be used as a statically created Persistent Volume.
27.14.2. Provisioning
Storage must exist in the underlying infrastructure before it can be mounted as a volume in OpenShift Container Platform. Ensure that OpenShift Container Platform is configured for Local Volumes, before using the PersistentVolume API.
27.14.3. Creating Local Persistent Volume
Define the persistent volume in an object definition.
apiVersion: v1
kind: PersistentVolume
metadata:
name: example-local-pv
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /mnt/disks/ssd1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- my-node27.14.4. Creating Local Persistent Volume Claim
Define the persistent volume claim in an object definition.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: example-local-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: local-storage 27.14.5. Feature Status
What Works:
- Creating a PV by specifying a directory with node affinity.
- A Pod using the PVC that is bound to the previously mentioned PV always get scheduled to that node.
- External static provisioner daemonset that discovers local directories, creates, cleans up and deletes PVs.
What does not work:
- Multiple local PVCs in a single pod.
PVC binding does not consider pod scheduling requirements and may make sub-optimal or incorrect decisions.
Workarounds:
- Run those pods first, which requires local volume.
- Give the pods high priority.
- Run a workaround controller that unbinds PVCs for pods that are stuck pending.
If mounts are added after the external provisioner is started, then external provisioner cannot detect the correct capcity of mounts.
Workarounds:
- Before adding any new mount points, first stop the daemonset, add the new mount points, and then start the daemonset.
-
fsgroupconflict occurs if multiple pods using the same PVC specify differentfsgroup's.
27.15. Persistent Storage Using Container Storage Interface (CSI)
27.15.1. Overview
Container Storage Interface (CSI) allows OpenShift Container Platform to consume storage from storage backends that implement the CSI interface as persistent storage.
CSI volumes are currently in Technology Preview and not for production workloads. CSI volumes may change in a future release of OpenShift Container Platform. Technology Preview features are not supported with Red Hat production service level agreements (SLAs), might not be functionally complete, and Red Hat does not recommend to use them for production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
See the link:https://access.redhat.com/support/offerings/techpreview/[Red Hat
OpenShift Container Platform does not ship with any CSI drivers. It is recommended to use the CSI drivers provided by community or storage vendors.
OpenShift Container Platform 3.11 supports version 0.2.0 of the CSI specification.
27.15.2. Architecture
CSI drivers are typically shipped as container images. These containers are not aware of OpenShift Container Platform where they run. To use CSI-compatible storage backend in OpenShift Container Platform, the cluster administrator must deploy several components that serve as a bridge between OpenShift Container Platform and the storage driver.
The following diagram provides a high-level overview about the components running in pods in the OpenShift Container Platform cluster.
It is possible to run multiple CSI drivers for different storage backends. Each driver needs its own external controllers' deployment and DaemonSet with the driver and CSI registrar.
27.15.2.1. External CSI Controllers
External CSI Controllers is a deployment that deploys one or more pods with three containers:
-
External CSI attacher container that translates
attachanddetachcalls from OpenShift Container Platform to respectiveControllerPublishandControllerUnpublishcalls to CSI driver -
External CSI provisioner container that translates
provisionanddeletecalls from OpenShift Container Platform to respectiveCreateVolumeandDeleteVolumecalls to CSI driver - CSI driver container
The CSI attacher and CSI provisioner containers talk to the CSI driver container using UNIX Domain Sockets, ensuring that no CSI communication leaves the pod. The CSI driver is not accessible from outside of the pod.
attach, detach, provision, and delete operations typically require the CSI driver to use credentials to the storage backend. Run the CSI controller pods on infrastructure nodes so the credentials never leak to user processes, even in the event of a catastrophic security breach on a compute node.
The external attacher must also run for CSI drivers that do not support third-party attach/detach operations. The external attacher will not issue any ControllerPublish or ControllerUnpublish operations to the CSI driver. However, it still must run to implement the necessary OpenShift Container Platform attachment API.
27.15.2.2. CSI Driver DaemonSet
Finally, the CSI driver DaemonSet runs a pod on every node that allows OpenShift Container Platform to mount storage provided by the CSI driver to the node and use it in user workloads (pods) as persistent volumes (PVs). The pod with the CSI driver installed contains the following containers:
-
CSI driver registrar, which registers the CSI driver into the
openshift-nodeservice running on the node. Theopenshift-nodeprocess running on the node then directly connects with the CSI driver using the UNIX Domain Socket available on the node. - CSI driver.
The CSI driver deployed on the node should have as few credentials to the storage backend as possible. OpenShift Container Platform will only use the node plug-in set of CSI calls such as NodePublish/NodeUnpublish and NodeStage/NodeUnstage (if implemented).
27.15.3. Example Deployment
Since OpenShift Container Platform does not ship with any CSI driver installed, this example shows how to deploy a community driver for OpenStack Cinder in OpenShift Container Platform.
Create a new project where the CSI components will run and a new service account that will run the components. Explicit node selector is used to run the Daemonset with the CSI driver also on master nodes.
# oc adm new-project csi --node-selector="" Now using project "csi" on server "https://example.com:8443". # oc create serviceaccount cinder-csi serviceaccount "cinder-csi" created # oc adm policy add-scc-to-user privileged system:serviceaccount:csi:cinder-csi scc "privileged" added to: ["system:serviceaccount:csi:cinder-csi"]Apply this YAML file to create the deployment with the external CSI attacher and provisioner and DaemonSet with the CSI driver.
# This YAML file contains all API objects that are necessary to run Cinder CSI # driver. # # In production, this needs to be in separate files, e.g. service account and # role and role binding needs to be created once. # # It serves as an example of how to use external attacher and external provisioner # images that are shipped with OpenShift Container Platform with a community CSI driver. kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: cinder-csi-role rules: - apiGroups: [""] resources: ["persistentvolumes"] verbs: ["create", "delete", "get", "list", "watch", "update", "patch"] - apiGroups: [""] resources: ["events"] verbs: ["create", "get", "list", "watch", "update", "patch"] - apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update", "patch"] - apiGroups: [""] resources: ["nodes"] verbs: ["get", "list", "watch", "update", "patch"] - apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"] - apiGroups: ["storage.k8s.io"] resources: ["volumeattachments"] verbs: ["get", "list", "watch", "update", "patch"] - apiGroups: [""] resources: ["configmaps"] verbs: ["get", "list", "watch", "create", "update", "patch"] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: cinder-csi-role subjects: - kind: ServiceAccount name: cinder-csi namespace: csi roleRef: kind: ClusterRole name: cinder-csi-role apiGroup: rbac.authorization.k8s.io --- apiVersion: v1 data: cloud.conf: W0dsb2JhbF0KYXV0aC11cmwgPSBodHRwczovL2V4YW1wbGUuY29tOjEzMDAwL3YyLjAvCnVzZXJuYW1lID0gYWxhZGRpbgpwYXNzd29yZCA9IG9wZW5zZXNhbWUKdGVuYW50LWlkID0gZTBmYTg1YjZhMDY0NDM5NTlkMmQzYjQ5NzE3NGJlZDYKcmVnaW9uID0gcmVnaW9uT25lCg==1 kind: Secret metadata: creationTimestamp: null name: cloudconfig --- kind: Deployment apiVersion: apps/v1 metadata: name: cinder-csi-controller spec: replicas: 2 selector: matchLabels: app: cinder-csi-controllers template: metadata: labels: app: cinder-csi-controllers spec: serviceAccount: cinder-csi containers: - name: csi-attacher image: registry.redhat.io/openshift3/csi-attacher:v3.11 args: - "--v=5" - "--csi-address=$(ADDRESS)" - "--leader-election" - "--leader-election-namespace=$(MY_NAMESPACE)" - "--leader-election-identity=$(MY_NAME)" env: - name: MY_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: MY_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: ADDRESS value: /csi/csi.sock volumeMounts: - name: socket-dir mountPath: /csi - name: csi-provisioner image: registry.redhat.io/openshift3/csi-provisioner:v3.11 args: - "--v=5" - "--provisioner=csi-cinderplugin" - "--csi-address=$(ADDRESS)" env: - name: ADDRESS value: /csi/csi.sock volumeMounts: - name: socket-dir mountPath: /csi - name: cinder-driver image: quay.io/jsafrane/cinder-csi-plugin command: [ "/bin/cinder-csi-plugin" ] args: - "--nodeid=$(NODEID)" - "--endpoint=unix://$(ADDRESS)" - "--cloud-config=/etc/cloudconfig/cloud.conf" env: - name: NODEID valueFrom: fieldRef: fieldPath: spec.nodeName - name: ADDRESS value: /csi/csi.sock volumeMounts: - name: socket-dir mountPath: /csi - name: cloudconfig mountPath: /etc/cloudconfig volumes: - name: socket-dir emptyDir: - name: cloudconfig secret: secretName: cloudconfig --- kind: DaemonSet apiVersion: apps/v1 metadata: name: cinder-csi-ds spec: selector: matchLabels: app: cinder-csi-driver template: metadata: labels: app: cinder-csi-driver spec:2 serviceAccount: cinder-csi containers: - name: csi-driver-registrar image: registry.redhat.io/openshift3/csi-driver-registrar:v3.11 securityContext: privileged: true args: - "--v=5" - "--csi-address=$(ADDRESS)" env: - name: ADDRESS value: /csi/csi.sock - name: KUBE_NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName volumeMounts: - name: socket-dir mountPath: /csi - name: cinder-driver securityContext: privileged: true capabilities: add: ["SYS_ADMIN"] allowPrivilegeEscalation: true image: quay.io/jsafrane/cinder-csi-plugin command: [ "/bin/cinder-csi-plugin" ] args: - "--nodeid=$(NODEID)" - "--endpoint=unix://$(ADDRESS)" - "--cloud-config=/etc/cloudconfig/cloud.conf" env: - name: NODEID valueFrom: fieldRef: fieldPath: spec.nodeName - name: ADDRESS value: /csi/csi.sock volumeMounts: - name: socket-dir mountPath: /csi - name: cloudconfig mountPath: /etc/cloudconfig - name: mountpoint-dir mountPath: /var/lib/origin/openshift.local.volumes/pods/ mountPropagation: "Bidirectional" - name: cloud-metadata mountPath: /var/lib/cloud/data/ - name: dev mountPath: /dev volumes: - name: cloud-metadata hostPath: path: /var/lib/cloud/data/ - name: socket-dir hostPath: path: /var/lib/kubelet/plugins/csi-cinderplugin type: DirectoryOrCreate - name: mountpoint-dir hostPath: path: /var/lib/origin/openshift.local.volumes/pods/ type: Directory - name: cloudconfig secret: secretName: cloudconfig - name: dev hostPath: path: /dev- 1
- Replace with
cloud.conffor your OpenStack deployment, as described in OpenStack configuration. For example, the Secret can be generated using theoc create secret generic cloudconfig --from-file cloud.conf --dry-run -o yaml. - 2
- Optionally, add
nodeSelectorto the CSI driver pod template to configure the nodes on which the CSI driver starts. Only nodes matching the selector run pods that use volumes that are served by the CSI driver. WithoutnodeSelector, the driver runs on all nodes in the cluster.
27.15.4. Dynamic Provisioning
Dynamic provisioning of persistent storage depends on the capabilities of the CSI driver and underlying storage backend. The provider of the CSI driver should document how to create a StorageClass in OpenShift Container Platform and the parameters available for configuration.
As seen in the OpenStack Cinder example, you can deploy this StorageClass to enable dynamic provisioning. The following example creates a new default storage class that ensures that all PVCs that do not require any special storage class are provisioned by the installed CSI driver:
# oc create -f - << EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: cinder
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: csi-cinderplugin
parameters:
EOF27.15.5. Usage
Once the CSI driver is deployed and the StorageClass for dynamic provisioning is created, OpenShift Container Platform is ready to use CSI. The following example installs a default MySQL template without any changes to the template:
# oc new-app mysql-persistent
--> Deploying template "openshift/mysql-persistent" to project default
...
# oc get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql Bound kubernetes-dynamic-pv-3271ffcb4e1811e8 1Gi RWO cinder 3s27.16. Persistent Storage Using OpenStack Manila
27.16.1. Overview
Persistent volume (PV) provisioning using OpenStack Manila is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs), might not be functionally complete, and Red Hat does not recommend to use them for production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
For more information on Red Hat Technology Preview features support scope, see https://access.redhat.com/support/offerings/techpreview/.
OpenShift Container Platform is capable of provisioning PVs using the OpenStack Manila shared file system service.
It is assumed the OpenStack Manila service has been correctly set up and is accessible from the OpenShift Container Platform cluster. Only the NFS share types can be provisioned.
Familiarity with PVs, persistent volume claims (PVCs), dynamic provisioning, and RBAC authorization is recommended.
27.16.2. Installation and Setup
The feature is provided by an external provisioner. You must install and configure it in the OpenShift Container Platform cluster.
27.16.2.1. Starting the External Provisioner
The external provisioner service is distributed as a container image and can be run in the OpenShift Container Platform cluster as usual.
To allow the containers managing the API objects, configure the required role-based access control (RBAC) rules as a cluster administrator:
Create a
ServiceAccount:apiVersion: v1 kind: ServiceAccount metadata: name: manila-provisioner-runnerCreate a
ClusterRole:kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: manila-provisioner-role rules: - apiGroups: [""] resources: ["persistentvolumes"] verbs: ["get", "list", "watch", "create", "delete"] - apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update"] - apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["events"] verbs: ["list", "watch", "create", "update", "patch"]Bind the rules via
ClusterRoleBinding:apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: manila-provisioner roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: manila-provisioner-role subjects: - kind: ServiceAccount name: manila-provisioner-runner namespace: defaultCreate a new
StorageClass:apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: "manila-share" provisioner: "externalstorage.k8s.io/manila" parameters: type: "default"1 zones: "nova"2 - 1
- The Manila share type the provisioner will create for the volume.
- 2
- Set of Manila availability zones that the volume might be created in.
Configure the provisioner to connect, authenticate, and authorize to the Manila servic using environment variables. Select the appropriate combination of environment variables for your installation from the following list:
OS_USERNAME
OS_PASSWORD
OS_AUTH_URL
OS_DOMAIN_NAME
OS_TENANT_NAMEOS_USERID
OS_PASSWORD
OS_AUTH_URL
OS_TENANT_IDOS_USERNAME
OS_PASSWORD
OS_AUTH_URL
OS_DOMAIN_ID
OS_TENANT_NAMEOS_USERNAME
OS_PASSWORD
OS_AUTH_URL
OS_DOMAIN_ID
OS_TENANT_ID
To pass the variables to the provisioner, use a Secret. The following example shows a Secret configured for the first variables combination
apiVersion: v1
kind: Secret
metadata:
name: manila-provisioner-env
type: Opaque
data:
os_username: <base64 encoded Manila username>
os_password: <base64 encoded password>
os_auth_url: <base64 encoded OpenStack Keystone URL>
os_domain_name: <base64 encoded Manila service Domain>
os_tenant_name: <base64 encoded Manila service Tenant/Project name>
Newer OpenStack versions use "project" instead of "tenant." However, the environment variables used by the provisioner must use TENANT in their names.
The last step is to start the provisioner itself, for example, using a deployment:
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: manila-provisioner
spec:
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: manila-provisioner
spec:
serviceAccountName: manila-provisioner-runner
containers:
- image: "registry.redhat.io/openshift3/manila-provisioner:latest"
imagePullPolicy: "IfNotPresent"
name: manila-provisioner
env:
- name: "OS_USERNAME"
valueFrom:
secretKeyRef:
name: manila-provisioner-env
key: os_username
- name: "OS_PASSWORD"
valueFrom:
secretKeyRef:
name: manila-provisioner-env
key: os_password
- name: "OS_AUTH_URL"
valueFrom:
secretKeyRef:
name: manila-provisioner-env
key: os_auth_url
- name: "OS_DOMAIN_NAME"
valueFrom:
secretKeyRef:
name: manila-provisioner-env
key: os_domain_name
- name: "OS_TENANT_NAME"
valueFrom:
secretKeyRef:
name: manila-provisioner-env
key: os_tenant_name27.16.3. Usage
After the provisioner is running, you can provision PVs using a PVC and the corresponding StorageClass:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: manila-nfs-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2G
storageClassName: manila-share
The PersistentVolumeClaim is then bound to a PersistentVolume backed by the newly provisioned Manila share. When the PersistentVolumeClaim and subsequently the PersistentVolume are deleted, the provisioner deletes and unexports the Manila share.
27.17. Dynamic provisioning and creating storage classes
27.17.1. Overview
The StorageClass resource object describes and classifies storage that can be requested, as well as provides a means for passing parameters for dynamically provisioned storage on demand. StorageClass objects can also serve as a management mechanism for controlling different levels of storage and access to the storage. Cluster Administrators (cluster-admin) or Storage Administrators (storage-admin) define and create the StorageClass objects that users can request without needing any intimate knowledge about the underlying storage volume sources.
The OpenShift Container Platform persistent volume framework enables this functionality and allows administrators to provision a cluster with persistent storage. The framework also gives users a way to request those resources without having any knowledge of the underlying infrastructure.
Many storage types are available for use as persistent volumes in OpenShift Container Platform. While all of them can be statically provisioned by an administrator, some types of storage are created dynamically using the built-in provider and plug-in APIs.
To enable dynamic provisioning, add the openshift_master_dynamic_provisioning_enabled variable to the [OSEv3:vars] section of the Ansible inventory file and set its value to True.
[OSEv3:vars]
openshift_master_dynamic_provisioning_enabled=True27.17.2. Available dynamically provisioned plug-ins
OpenShift Container Platform provides the following provisioner plug-ins, which have generic implementations for dynamic provisioning that use the cluster’s configured provider’s API to create new storage resources:
| Storage Type | Provisioner Plug-in Name | Required Configuration | Notes |
|---|---|---|---|
| OpenStack Cinder |
| ||
| AWS Elastic Block Store (EBS) |
|
For dynamic provisioning when using multiple clusters in different zones, tag each node with | |
| GCE Persistent Disk (gcePD) |
| In multi-zone configurations, it is advisable to run one Openshift cluster per GCE project to avoid PVs from getting created in zones where no node from current cluster exists. | |
| GlusterFS |
| ||
| Ceph RBD |
| ||
| Trident from NetApp |
| Storage orchestrator for NetApp ONTAP, SolidFire, and E-Series storage. | |
|
| |||
| Azure Disk |
|
Any chosen provisioner plug-in also requires configuration for the relevant cloud, host, or third-party provider as per the relevant documentation.
27.17.3. Defining a StorageClass
StorageClass objects are currently a globally scoped object and need to be created by cluster-admin or storage-admin users.
For GCE and AWS, a default StorageClass is created during OpenShift Container Platform installation. You can change the default StorageClass or delete it.
There are currently six plug-ins that are supported. The following sections describe the basic object definition for a StorageClass and specific examples for each of the supported plug-in types.
27.17.3.1. Basic StorageClass object definition
StorageClass Basic object definition
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: foo
annotations:
...
provisioner: kubernetes.io/plug-in-type
parameters:
param1: value
...
paramN: value- 1
- (required) The API object type.
- 2
- (required) The current apiVersion.
- 3
- (required) The name of the StorageClass.
- 4
- (optional) Annotations for the StorageClass
- 5
- (required) The type of provisioner associated with this storage class.
- 6
- (optional) The parameters required for the specific provisioner, this will change from plug-in to plug-in.
27.17.3.2. StorageClass annotations
To set a StorageClass as the cluster-wide default:
storageclass.kubernetes.io/is-default-class: "true"This enables any Persistent Volume Claim (PVC) that does not specify a specific volume to automatically be provisioned through the default StorageClass
Beta annotation storageclass.beta.kubernetes.io/is-default-class is still working. However it will be removed in a future release.
To set a StorageClass description:
kubernetes.io/description: My StorageClass Description27.17.3.3. OpenStack Cinder object definition
cinder-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: gold
provisioner: kubernetes.io/cinder
parameters:
type: fast
availability: nova
fsType: ext4 - 1
- Volume type created in Cinder. Default is empty.
- 2
- Availability Zone. If not specified, volumes are generally round-robined across all active zones where the OpenShift Container Platform cluster has a node.
- 3
- File system that is created on dynamically provisioned volumes. This value is copied to the
fsTypefield of dynamically provisioned persistent volumes and the file system is created when the volume is mounted for the first time. The default value isext4.
27.17.3.4. AWS ElasticBlockStore (EBS) object definition
aws-ebs-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: slow
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
zone: us-east-1d
iopsPerGB: "10"
encrypted: "true"
kmsKeyId: keyvalue
fsType: ext4 - 1
- Select from
io1,gp2,sc1,st1. The default isgp2. See AWS documentation for valid Amazon Resource Name (ARN) values. - 2
- AWS zone. If no zone is specified, volumes are generally round-robined across all active zones where the OpenShift Container Platform cluster has a node. Zone and zones parameters must not be used at the same time.
- 3
- Only for io1 volumes. I/O operations per second per GiB. The AWS volume plug-in multiplies this with the size of the requested volume to compute IOPS of the volume. The value cap is 20,000 IOPS, which is the maximum supported by AWS. See AWS documentation for further details.
- 4
- Denotes whether to encrypt the EBS volume. Valid values are
trueorfalse. - 5
- Optional. The full ARN of the key to use when encrypting the volume. If none is supplied, but
encyptedis set totrue, then AWS generates a key. See AWS documentation for a valid ARN value. - 6
- File system that is created on dynamically provisioned volumes. This value is copied to the
fsTypefield of dynamically provisioned persistent volumes and the file system is created when the volume is mounted for the first time. The default value isext4.
27.17.3.5. GCE PersistentDisk (gcePD) object definition
gce-pd-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: slow
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
zone: us-central1-a
zones: us-central1-a, us-central1-b, us-east1-b
fsType: ext4 - 1
- Select either
pd-standardorpd-ssd. The default ispd-ssd. - 2
- GCE zone. If no zone is specified, volumes are generally round-robined across all active zones where the OpenShift Container Platform cluster has a node. Zone and zones parameters must not be used at the same time.
- 3
- A comma-separated list of GCE zone(s). If no zone is specified, volumes are generally round-robined across all active zones where the OpenShift Container Platform cluster has a node. Zone and zones parameters must not be used at the same time.
- 4
- File system that is created on dynamically provisioned volumes. This value is copied to the
fsTypefield of dynamically provisioned persistent volumes and the file system is created when the volume is mounted for the first time. The default value isext4.
27.17.3.6. GlusterFS object definition
glusterfs-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: slow
provisioner: kubernetes.io/glusterfs
parameters:
resturl: http://127.0.0.1:8081
restuser: admin
secretName: heketi-secret
secretNamespace: default
gidMin: "40000"
gidMax: "50000"
volumeoptions: group metadata-cache, nl-cache on
volumetype: replicate:3
volumenameprefix: custom - 1
- Listed are mandatory and a few optional parameters. Please refer to Registering a Storage Class for additional parameters.
- 2
- heketi (volume management REST service for Gluster) URL that provisions GlusterFS volumes on demand. The general format should be
{http/https}://{IPaddress}:{Port}. This is a mandatory parameter for the GlusterFS dynamic provisioner. If the heketi service is exposed as a routable service in the OpenShift Container Platform, it will have a resolvable fully qualified domain name (FQDN) and heketi service URL. - 3
- heketi user who has access to create volumes. Usually "admin".
- 4
- Identification of a Secret that contains a user password to use when talking to heketi. Optional; an empty password will be used when both
secretNamespaceandsecretNameare omitted. The provided secret must be of type"kubernetes.io/glusterfs". - 5
- The namespace of mentioned
secretName. Optional; an empty password will be used when bothsecretNamespaceandsecretNameare omitted. The provided secret must be of type"kubernetes.io/glusterfs". - 6
- Optional. The minimum value of the GID range for volumes of this StorageClass.
- 7
- Optional. The maximum value of the GID range for volumes of this StorageClass.
- 8
- Optional. Options for newly created volumes. It allows for performance tuning. See Tuning Volume Options for more GlusterFS volume options.
- 9
- Optional. The type of volume to use.
- 10
- Optional. Enables custom volume name support using the following format:
<volumenameprefix>_<namespace>_<claimname>_UUID. If you create a new PVC calledmyclaimin your projectproject1using this storageClass, the volume name will becustom-project1-myclaim-UUID.
When the gidMin and gidMax values are not specified, their defaults are 2000 and 2147483647, respectively. Each dynamically provisioned volume will be given a GID in this range (gidMin-gidMax). This GID is released from the pool when the respective volume is deleted. The GID pool is per StorageClass. If two or more storage classes have GID ranges that overlap there may be duplicate GIDs dispatched by the provisioner.
When heketi authentication is used, a Secret containing the admin key should also exist:
heketi-secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: heketi-secret
namespace: default
data:
key: bXlwYXNzd29yZA==
type: kubernetes.io/glusterfs- 1
- base64 encoded password, for example:
echo -n "mypassword" | base64
When the PVs are dynamically provisioned, the GlusterFS plug-in automatically creates an Endpoints and a headless Service named gluster-dynamic-<claimname>. When the PVC is deleted, these dynamic resources are deleted automatically.
27.17.3.7. Ceph RBD object definition
ceph-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast
provisioner: kubernetes.io/rbd
parameters:
monitors: 10.16.153.105:6789
adminId: admin
adminSecretName: ceph-secret
adminSecretNamespace: kube-system
pool: kube
userId: kube
userSecretName: ceph-secret-user
fsType: ext4 - 1
- Ceph monitors, comma-delimited. It is required.
- 2
- Ceph client ID that is capable of creating images in the pool. Default is "admin".
- 3
- Secret Name for
adminId. It is required. The provided secret must have type "kubernetes.io/rbd". - 4
- The namespace for
adminSecret. Default is "default". - 5
- Ceph RBD pool. Default is "rbd".
- 6
- Ceph client ID that is used to map the Ceph RBD image. Default is the same as
adminId. - 7
- The name of Ceph Secret for
userIdto map Ceph RBD image. It must exist in the same namespace as PVCs. It is required. - 8
- File system that is created on dynamically provisioned volumes. This value is copied to the
fsTypefield of dynamically provisioned persistent volumes and the file system is created when the volume is mounted for the first time. The default value isext4.
27.17.3.8. Trident object definition
trident.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: gold
provisioner: netapp.io/trident
parameters:
media: "ssd"
provisioningType: "thin"
snapshots: "true"Trident uses the parameters as selection criteria for the different pools of storage that are registered with it. Trident itself is configured separately.
- 1
- For more information about installing Trident with OpenShift Container Platform, see the Trident documentation.
- 2
- For more information about supported parameters, see the storage attributes section of the Trident documentation.
27.17.3.9. VMware vSphere object definition
vsphere-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1beta1
metadata:
name: slow
provisioner: kubernetes.io/vsphere-volume
parameters:
diskformat: thin - 1
- For more information about using VMWare vSphere with OpenShift Container Platform, see the VMWare vSphere documentation.
- 2
diskformat:thin,zeroedthickandeagerzeroedthick. See vSphere docs for details. Default:thin
27.17.3.10. Azure File object definition
To configure Azure file dynamic provisioning:
Create the role in the user’s project:
$ cat azf-role.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: system:controller:persistent-volume-binder namespace: <user's project name> rules: - apiGroups: [""] resources: ["secrets"] verbs: ["create", "get", "delete"]Create the role binding to the
persistent-volume-binderservice account in thekube-systemproject:$ cat azf-rolebind.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: system:controller:persistent-volume-binder namespace: <user's project> roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: system:controller:persistent-volume-binder subjects: - kind: ServiceAccount name: persistent-volume-binder namespace: kube-systemAdd the service account as
adminto the user’s project:$ oc policy add-role-to-user admin system:serviceaccount:kube-system:persistent-volume-binder -n <user's project>Create a storage class for the Azure file:
$ cat azfsc.yaml | oc create -f - kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: azfsc provisioner: kubernetes.io/azure-file mountOptions: - dir_mode=0777 - file_mode=0777
The user can now create a PVC that uses this storage class.
27.17.3.11. Azure Disk object definition
azure-advanced-disk-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: slow
provisioner: kubernetes.io/azure-disk
parameters:
storageAccount: azure_storage_account_name
storageaccounttype: Standard_LRS
kind: Dedicated - 1
- Azure storage account name. This must reside in the same resource group as the cluster. If a storage account is specified, the
locationis ignored. If a storage account is not specified, a new storage account gets created in the same resource group as the cluster. If you are specifying astorageAccount, the value forkindmust beDedicated. - 2
- Azure storage account SKU tier. Default is empty. Note: Premium VM can attach both Standard_LRS and Premium_LRS disks, Standard VM can only attach Standard_LRS disks, Managed VM can only attach managed disks, and unmanaged VM can only attach unmanaged disks.
- 3
- Possible values are
Shared(default),Dedicated, andManaged.-
If
kindis set toShared, Azure creates all unmanaged disks in a few shared storage accounts in the same resource group as the cluster. -
If
kindis set toManaged, Azure creates new managed disks. If
kindis set toDedicatedand astorageAccountis specified, Azure uses the specified storage account for the new unmanaged disk in the same resource group as the cluster. For this to work:- The specified storage account must be in the same region.
- Azure Cloud Provider must have a write access to the storage account.
-
If
kindis set toDedicatedand astorageAccountis not specified, Azure creates a new dedicated storage account for the new unmanaged disk in the same resource group as the cluster.
-
If
Azure StorageClass is revised in OpenShift Container Platform version 3.7. If you upgraded from a previous version, either:
-
specify the property
kind: dedicatedto continue using the Azure StorageClass created before the upgrade. Or, -
add the location parameter (for example,
"location": "southcentralus",) in the azure.conf file to use the default propertykind: shared. Doing this creates new storage accounts for future use.
27.17.4. Changing the default StorageClass
If you are using GCE and AWS, use the following process to change the default StorageClass:
List the StorageClass:
$ oc get storageclass NAME TYPE gp2 (default) kubernetes.io/aws-ebs1 standard kubernetes.io/gce-pd- 1
(default)denotes the default StorageClass.
Change the value of the annotation
storageclass.kubernetes.io/is-default-classtofalsefor the default StorageClass:$ oc patch storageclass gp2 -p '{"metadata": {"annotations": \ {"storageclass.kubernetes.io/is-default-class": "false"}}}'Make another StorageClass the default by adding or modifying the annotation as
storageclass.kubernetes.io/is-default-class=true.$ oc patch storageclass standard -p '{"metadata": {"annotations": \ {"storageclass.kubernetes.io/is-default-class": "true"}}}'
If more than one StorageClass is marked as default, a PVC can only be created if the storageClassName is explicitly specified. Therefore, only one StorageClass should be set as the default.
Verify the changes:
$ oc get storageclass NAME TYPE gp2 kubernetes.io/aws-ebs standard (default) kubernetes.io/gce-pd
27.17.5. Additional information and examples
27.18. Volume Security
27.18.1. Overview
This topic provides a general guide on pod security as it relates to volume security. For information on pod-level security in general, see Managing Security Context Constraints (SCC) and the Security Context Constraint concept topic. For information on the OpenShift Container Platform persistent volume (PV) framework in general, see the Persistent Storage concept topic.
Accessing persistent storage requires coordination between the cluster and/or storage administrator and the end developer. The cluster administrator creates PVs, which abstract the underlying physical storage. The developer creates pods and, optionally, PVCs, which bind to PVs, based on matching criteria, such as capacity.
Multiple persistent volume claims (PVCs) within the same project can bind to the same PV. However, once a PVC binds to a PV, that PV cannot be bound by a claim outside of the first claim’s project. If the underlying storage needs to be accessed by multiple projects, then each project needs its own PV, which can point to the same physical storage. In this sense, a bound PV is tied to a project. For a detailed PV and PVC example, see the example for Deploying WordPress and MySQL with Persistent Volumes.
For the cluster administrator, granting pods access to PVs involves:
- knowing the group ID and/or user ID assigned to the actual storage,
- understanding SELinux considerations, and
- ensuring that these IDs are allowed in the range of legal IDs defined for the project and/or the SCC that matches the requirements of the pod.
Group IDs, the user ID, and SELinux values are defined in the SecurityContext section in a pod definition. Group IDs are global to the pod and apply to all containers defined in the pod. User IDs can also be global, or specific to each container. Four sections control access to volumes:
27.18.2. SCCs, Defaults, and Allowed Ranges
SCCs influence whether or not a pod is given a default user ID, fsGroup ID, supplemental group ID, and SELinux label. They also influence whether or not IDs supplied in the pod definition (or in the image) will be validated against a range of allowable IDs. If validation is required and fails, then the pod will also fail.
SCCs define strategies, such as runAsUser, supplementalGroups, and fsGroup. These strategies help decide whether the pod is authorized. Strategy values set to RunAsAny are essentially stating that the pod can do what it wants regarding that strategy. Authorization is skipped for that strategy and no OpenShift Container Platform default is produced based on that strategy. Therefore, IDs and SELinux labels in the resulting container are based on container defaults instead of OpenShift Container Platform policies.
For a quick summary of RunAsAny:
- Any ID defined in the pod definition (or image) is allowed.
- Absence of an ID in the pod definition (and in the image) results in the container assigning an ID, which is root (0) for Docker.
- No SELinux labels are defined, so Docker will assign a unique label.
For these reasons, SCCs with RunAsAny for ID-related strategies should be protected so that ordinary developers do not have access to the SCC. On the other hand, SCC strategies set to MustRunAs or MustRunAsRange trigger ID validation (for ID-related strategies), and cause default values to be supplied by OpenShift Container Platform to the container when those values are not supplied directly in the pod definition or image.
Allowing access to SCCs with a RunAsAny FSGroup strategy can also prevent users from accessing their block devices. Pods need to specify an fsGroup in order to take over their block devices. Normally, this is done when the SCC FSGroup strategy is set to MustRunAs. If a user’s pod is assigned an SCC with a RunAsAny FSGroup strategy, then the user may face permission denied errors until they discover that they need to specify an fsGroup themselves.
SCCs may define the range of allowed IDs (user or groups). If range checking is required (for example, using MustRunAs) and the allowable range is not defined in the SCC, then the project determines the ID range. Therefore, projects support ranges of allowable ID. However, unlike SCCs, projects do not define strategies, such as runAsUser.
Allowable ranges are helpful not only because they define the boundaries for container IDs, but also because the minimum value in the range becomes the default value for the ID in question. For example, if the SCC ID strategy value is MustRunAs, the minimum value of an ID range is 100, and the ID is absent from the pod definition, then 100 is provided as the default for this ID.
As part of pod admission, the SCCs available to a pod are examined (roughly, in priority order followed by most restrictive) to best match the requests of the pod. Setting a SCC’s strategy type to RunAsAny is less restrictive, whereas a type of MustRunAs is more restrictive. All of these strategies are evaluated. To see which SCC was assigned to a pod, use the oc get pod command:
# oc get pod <pod_name> -o yaml
...
metadata:
annotations:
openshift.io/scc: nfs-scc
name: nfs-pod1
namespace: default
...- 1
- Name of the SCC that the pod used (in this case, a custom SCC).
- 2
- Name of the pod.
- 3
- Name of the project. "Namespace" is interchangeable with "project" in OpenShift Container Platform. See Projects and Users for details.
It may not be immediately obvious which SCC was matched by a pod, so the command above can be very useful in understanding the UID, supplemental groups, and SELinux relabeling in a live container.
Any SCC with a strategy set to RunAsAny allows specific values for that strategy to be defined in the pod definition (and/or image). When this applies to the user ID (runAsUser) it is prudent to restrict access to the SCC to prevent a container from being able to run as root.
Because pods often match the restricted SCC, it is worth knowing the security this entails. The restricted SCC has the following characteristics:
-
User IDs are constrained due to the
runAsUserstrategy being set to MustRunAsRange. This forces user ID validation. -
Because a range of allowable user IDs is not defined in the SCC (see oc get -o yaml --export scc restricted` for more details), the project’s
openshift.io/sa.scc.uid-rangerange will be used for range checking and for a default ID, if needed. -
A default user ID is produced when a user ID is not specified in the pod definition and the matching SCC’s
runAsUseris set to MustRunAsRange. -
An SELinux label is required (
seLinuxContextset to MustRunAs), which uses the project’s default MCS label. -
fsGroupIDs are constrained to a single value due to theFSGroupstrategy being set to MustRunAs, which dictates that the value to use is the minimum value of the first range specified. -
Because a range of allowable
fsGroupIDs is not defined in the SCC, the minimum value of the project’sopenshift.io/sa.scc.supplemental-groupsrange (or the same range used for user IDs) will be used for validation and for a default ID, if needed. -
A default
fsGroupID is produced when afsGroupID is not specified in the pod and the matching SCC’sFSGroupis set to MustRunAs. -
Arbitrary supplemental group IDs are allowed because no range checking is required. This is a result of the
supplementalGroupsstrategy being set to RunAsAny. - Default supplemental groups are not produced for the running pod due to RunAsAny for the two group strategies above. Therefore, if no groups are defined in the pod definition (or in the image), the container(s) will have no supplemental groups predefined.
The following shows the default project and a custom SCC (my-custom-scc), which summarizes the interactions of the SCC and the project:
$ oc get project default -o yaml
...
metadata:
annotations:
openshift.io/sa.scc.mcs: s0:c1,c0
openshift.io/sa.scc.supplemental-groups: 1000000000/10000
openshift.io/sa.scc.uid-range: 1000000000/10000
$ oc get scc my-custom-scc -o yaml
...
fsGroup:
type: MustRunAs
ranges:
- min: 5000
max: 6000
runAsUser:
type: MustRunAsRange
uidRangeMin: 1000100000
uidRangeMax: 1000100999
seLinuxContext:
type: MustRunAs
SELinuxOptions:
user: <selinux-user-name>
role: ...
type: ...
level: ...
supplementalGroups:
type: MustRunAs
ranges:
- min: 5000
max: 6000- 1
- default is the name of the project.
- 2
- Default values are only produced when the corresponding SCC strategy is not RunAsAny.
- 3
- SELinux default when not defined in the pod definition or in the SCC.
- 4
- Range of allowable group IDs. ID validation only occurs when the SCC strategy is RunAsAny. There can be more than one range specified, separated by commas. See below for supported formats.
- 5
- Same as <4> but for user IDs. Also, only a single range of user IDs is supported.
- 6 10
- MustRunAs enforces group ID range checking and provides the container’s groups default. Based on this SCC definition, the default is 5000 (the minimum ID value). If the range was omitted from the SCC, then the default would be 1000000000 (derived from the project). The other supported type, RunAsAny, does not perform range checking, thus allowing any group ID, and produces no default groups.
- 7
- MustRunAsRange enforces user ID range checking and provides a UID default. Based on this SCC, the default UID is 1000100000 (the minimum value). If the minimum and maximum range were omitted from the SCC, the default user ID would be 1000000000 (derived from the project). MustRunAsNonRoot and RunAsAny are the other supported types. The range of allowed IDs can be defined to include any user IDs required for the target storage.
- 8
- When set to MustRunAs, the container is created with the SCC’s SELinux options, or the MCS default defined in the project. A type of RunAsAny indicates that SELinux context is not required, and, if not defined in the pod, is not set in the container.
- 9
- The SELinux user name, role name, type, and labels can be defined here.
Two formats are supported for allowed ranges:
-
M/N, whereMis the starting ID andNis the count, so the range becomesMthrough (and including)M+N-1. -
M-N, whereMis again the starting ID andNis the ending ID. The default group ID is the starting ID in the first range, which is1000000000in this project. If the SCC did not define a minimum group ID, then the project’s default ID is applied.
27.18.3. Supplemental Groups
Read SCCs, Defaults, and Allowed Ranges before working with supplemental groups.
Supplemental groups are regular Linux groups. When a process runs in Linux, it has a UID, a GID, and one or more supplemental groups. These attributes can be set for a container’s main process. The supplementalGroups IDs are typically used for controlling access to shared storage, such as NFS and GlusterFS, whereas fsGroup is used for controlling access to block storage, such as Ceph RBD and iSCSI.
The OpenShift Container Platform shared storage plug-ins mount volumes such that the POSIX permissions on the mount match the permissions on the target storage. For example, if the target storage’s owner ID is 1234 and its group ID is 5678, then the mount on the host node and in the container will have those same IDs. Therefore, the container’s main process must match one or both of those IDs in order to access the volume.
For example, consider the following NFS export.
On an OpenShift Container Platform node:
showmount requires access to the ports used by rpcbind and rpc.mount on the NFS server
# showmount -e <nfs-server-ip-or-hostname>
Export list for f21-nfs.vm:
/opt/nfs *On the NFS server:
# cat /etc/exports
/opt/nfs *(rw,sync,root_squash)
...
# ls -lZ /opt/nfs -d
drwx------. 1000100001 5555 unconfined_u:object_r:usr_t:s0 /opt/nfsThe /opt/nfs/ export is accessible by UID 1000100001 and the group 5555. In general, containers should not run as root. So, in this NFS example, containers which are not run as UID 1000100001 and are not members the group 5555 will not have access to the NFS export.
Often, the SCC matching the pod does not allow a specific user ID to be specified, thus using supplemental groups is a more flexible way to grant storage access to a pod. For example, to grant NFS access to the export above, the group 5555 can be defined in the pod definition:
apiVersion: v1
kind: Pod
...
spec:
containers:
- name: ...
volumeMounts:
- name: nfs
mountPath: /usr/share/...
securityContext:
supplementalGroups: [5555]
volumes:
- name: nfs
nfs:
server: <nfs_server_ip_or_host>
path: /opt/nfs - 1
- Name of the volume mount. Must match the name in the
volumessection. - 2
- NFS export path as seen in the container.
- 3
- Pod global security context. Applies to all containers inside the pod. Each container can also define its
securityContext, however group IDs are global to the pod and cannot be defined for individual containers. - 4
- Supplemental groups, which is an array of IDs, is set to 5555. This grants group access to the export.
- 5
- Name of the volume. Must match the name in the
volumeMountssection. - 6
- Actual NFS export path on the NFS server.
All containers in the above pod (assuming the matching SCC or project allows the group 5555) will be members of the group 5555 and have access to the volume, regardless of the container’s user ID. However, the assumption above is critical. Sometimes, the SCC does not define a range of allowable group IDs but instead requires group ID validation (a result of supplementalGroups set to MustRunAs). Note that this is not the case for the restricted SCC. The project will not likely allow a group ID of 5555, unless the project has been customized to access this NFS export. So, in this scenario, the above pod will fail because its group ID of 5555 is not within the SCC’s or the project’s range of allowed group IDs.
Supplemental Groups and Custom SCCs
To remedy the situation in the previous example, a custom SCC can be created such that:
- a minimum and max group ID are defined,
- ID range checking is enforced, and
- the group ID of 5555 is allowed.
It is often better to create a new SCC rather than modifying a predefined SCC, or changing the range of allowed IDs in the predefined projects.
The easiest way to create a new SCC is to export an existing SCC and customize the YAML file to meet the requirements of the new SCC. For example:
Use the restricted SCC as a template for the new SCC:
$ oc get -o yaml --export scc restricted > new-scc.yaml- Edit the new-scc.yaml file to your desired specifications.
Create the new SCC:
$ oc create -f new-scc.yaml
The oc edit scc command can be used to modify an instantiated SCC.
Here is a fragment of a new SCC named nfs-scc:
$ oc get -o yaml --export scc nfs-scc
allowHostDirVolumePlugin: false
...
kind: SecurityContextConstraints
metadata:
...
name: nfs-scc
priority: 9
...
supplementalGroups:
type: MustRunAs
ranges:
- min: 5000
max: 6000
...- 1
- The
allowbooleans are the same as for the restricted SCC. - 2
- Name of the new SCC.
- 3
- Numerically larger numbers have greater priority. Nil or omitted is the lowest priority. Higher priority SCCs sort before lower priority SCCs and thus have a better chance of matching a new pod.
- 4
supplementalGroupsis a strategy and it is set to MustRunAs, which means group ID checking is required.- 5
- Multiple ranges are supported. The allowed group ID range here is 5000 through 5999, with the default supplemental group being 5000.
When the same pod shown earlier runs against this new SCC (assuming, of course, the pod matches the new SCC), it will start because the group 5555, supplied in the pod definition, is now allowed by the custom SCC.
27.18.4. fsGroup
Read SCCs, Defaults, and Allowed Ranges before working with supplemental groups.
It is generally preferable to use group IDs (supplemental or fsGroup) to gain access to persistent storage versus using user IDs.
fsGroup defines a pod’s "file system group" ID, which is added to the container’s supplemental groups. The supplementalGroups ID applies to shared storage, whereas the fsGroup ID is used for block storage.
Block storage, such as Ceph RBD, iSCSI, and various cloud storage, is typically dedicated to a single pod which has requested the block storage volume, either directly or using a PVC. Unlike shared storage, block storage is taken over by a pod, meaning that user and group IDs supplied in the pod definition (or image) are applied to the actual, physical block device. Typically, block storage is not shared.
A fsGroup definition is shown below in the following pod definition fragment:
kind: Pod
...
spec:
containers:
- name: ...
securityContext:
fsGroup: 5555
...
As with supplementalGroups, all containers in the above pod (assuming the matching SCC or project allows the group 5555) will be members of the group 5555, and will have access to the block volume, regardless of the container’s user ID. If the pod matches the restricted SCC, whose fsGroup strategy is MustRunAs, then the pod will fail to run. However, if the SCC has its fsGroup strategy set to RunAsAny, then any fsGroup ID (including 5555) will be accepted. Note that if the SCC has its fsGroup strategy set to RunAsAny and no fsGroup ID is specified, the "taking over" of the block storage does not occur and permissions may be denied to the pod.
fsGroups and Custom SCCs
To remedy the situation in the previous example, a custom SCC can be created such that:
- a minimum and maximum group ID are defined,
- ID range checking is enforced, and
- the group ID of 5555 is allowed.
It is better to create new SCCs versus modifying a predefined SCC, or changing the range of allowed IDs in the predefined projects.
Consider the following fragment of a new SCC definition:
# oc get -o yaml --export scc new-scc
...
kind: SecurityContextConstraints
...
fsGroup:
type: MustRunAs
ranges:
- max: 6000
min: 5000
...- 1
- MustRunAs triggers group ID range checking, whereas RunAsAny does not require range checking.
- 2
- The range of allowed group IDs is 5000 through, and including, 5999. Multiple ranges are supported but not used. The allowed group ID range here is 5000 through 5999, with the default
fsGroupbeing 5000. - 3
- The minimum value (or the entire range) can be omitted from the SCC, and thus range checking and generating a default value will defer to the project’s
openshift.io/sa.scc.supplemental-groupsrange.fsGroupandsupplementalGroupsuse the same group field in the project; there is not a separate range forfsGroup.
When the pod shown above runs against this new SCC (assuming, of course, the pod matches the new SCC), it will start because the group 5555, supplied in the pod definition, is allowed by the custom SCC. Additionally, the pod will "take over" the block device, so when the block storage is viewed by a process outside of the pod, it will actually have 5555 as its group ID.
A list of volumes supporting block ownership include:
- AWS Elastic Block Store
- OpenStack Cinder
- Ceph RBD
- GCE Persistent Disk
- iSCSI
- emptyDir
This list is potentially incomplete.
27.18.5. User IDs
Read SCCs, Defaults, and Allowed Ranges before working with supplemental groups.
It is generally preferable to use group IDs (supplemental or fsGroup) to gain access to persistent storage versus using user IDs.
User IDs can be defined in the container image or in the pod definition. In the pod definition, a single user ID can be defined globally to all containers, or specific to individual containers (or both). A user ID is supplied as shown in the pod definition fragment below:
spec:
containers:
- name: ...
securityContext:
runAsUser: 1000100001
ID 1000100001 in the above is container-specific and matches the owner ID on the export. If the NFS export’s owner ID was 54321, then that number would be used in the pod definition. Specifying securityContext outside of the container definition makes the ID global to all containers in the pod.
Similar to group IDs, user IDs may be validated according to policies set in the SCC and/or project. If the SCC’s runAsUser strategy is set to RunAsAny, then any user ID defined in the pod definition or in the image is allowed.
This means even a UID of 0 (root) is allowed.
If, instead, the runAsUser strategy is set to MustRunAsRange, then a supplied user ID will be validated against a range of allowed IDs. If the pod supplies no user ID, then the default ID is set to the minimum value of the range of allowable user IDs.
Returning to the earlier NFS example, the container needs its UID set to 1000100001, which is shown in the pod fragment above. Assuming the default project and the restricted SCC, the pod’s requested user ID of 1000100001 will not be allowed, and therefore the pod will fail. The pod fails because:
- it requests 1000100001 as its user ID,
-
all available SCCs use MustRunAsRange for their
runAsUserstrategy, so UID range checking is required, and - 1000100001 is not included in the SCC or in the project’s user ID range.
To remedy this situation, a new SCC can be created with the appropriate user ID range. A new project could also be created with the appropriate user ID range defined. There are also other, less-preferred options:
- The restricted SCC could be modified to include 1000100001 within its minimum and maximum user ID range. This is not recommended as you should avoid modifying the predefined SCCs if possible.
-
The restricted SCC could be modified to use RunAsAny for the
runAsUservalue, thus eliminating ID range checking. This is strongly not recommended, as containers could run as root. - The default project’s UID range could be changed to allow a user ID of 1000100001. This is not generally advisable because only a single range of user IDs can be specified, and thus other pods may not run if the range is altered.
User IDs and Custom SCCs
It is good practice to avoid modifying the predefined SCCs if possible. The preferred approach is to create a custom SCC that better fits an organization’s security needs, or create a new project that supports the desired user IDs.
To remedy the situation in the previous example, a custom SCC can be created such that:
- a minimum and maximum user ID is defined,
- UID range checking is still enforced, and
- the UID of 1000100001 is allowed.
For example:
$ oc get -o yaml --export scc nfs-scc
allowHostDirVolumePlugin: false
...
kind: SecurityContextConstraints
metadata:
...
name: nfs-scc
priority: 9
requiredDropCapabilities: null
runAsUser:
type: MustRunAsRange
uidRangeMax: 1000100001
uidRangeMin: 1000100001
...- 1
- The
allowXXbools are the same as for the restricted SCC. - 2
- The name of this new SCC is nfs-scc.
- 3
- Numerically larger numbers have greater priority. Nil or omitted is the lowest priority. Higher priority SCCs sort before lower priority SCCs, and thus have a better chance of matching a new pod.
- 4
- The
runAsUserstrategy is set to MustRunAsRange, which means UID range checking is enforced. - 5
- The UID range is 1000100001 through 1000100001 (a range of one value).
Now, with runAsUser: 1000100001 shown in the previous pod definition fragment, the pod matches the new nfs-scc and is able to run with a UID of 1000100001.
27.18.6. SELinux Options
All predefined SCCs, except for the privileged SCC, set the seLinuxContext to MustRunAs. So the SCCs most likely to match a pod’s requirements will force the pod to use an SELinux policy. The SELinux policy used by the pod can be defined in the pod itself, in the image, in the SCC, or in the project (which provides the default).
SELinux labels can be defined in a pod’s securityContext.seLinuxOptions section, and supports user, role, type, and level:
Level and MCS label are used interchangeably in this topic.
...
securityContext:
seLinuxOptions:
level: "s0:c123,c456"
...Here are fragments from an SCC and from the default project:
$ oc get -o yaml --export scc scc-name
...
seLinuxContext:
type: MustRunAs
# oc get -o yaml --export namespace default
...
metadata:
annotations:
openshift.io/sa.scc.mcs: s0:c1,c0
...
All predefined SCCs, except for the privileged SCC, set the seLinuxContext to MustRunAs. This forces pods to use MCS labels, which can be defined in the pod definition, the image, or provided as a default.
The SCC determines whether or not to require an SELinux label and can provide a default label. If the seLinuxContext strategy is set to MustRunAs and the pod (or image) does not define a label, OpenShift Container Platform defaults to a label chosen from the SCC itself or from the project.
If seLinuxContext is set to RunAsAny, then no default labels are provided, and the container determines the final label. In the case of Docker, the container will use a unique MCS label, which will not likely match the labeling on existing storage mounts. Volumes which support SELinux management will be relabeled so that they are accessible by the specified label and, depending on how exclusionary the label is, only that label.
This means two things for unprivileged containers:
-
The volume is given a type that is accessible by unprivileged containers. This type is usually
container_file_tin Red Hat Enterprise Linux (RHEL) version 7.5 and later. This type treats volumes as container content. In previous RHEL versions, RHEL 7.4, 7.3, and so forth, the volume is given thesvirt_sandbox_file_ttype. -
If a
levelis specified, the volume is labeled with the given MCS label.
For a volume to be accessible by a pod, the pod must have both categories of the volume. So a pod with s0:c1,c2 will be able to access a volume with s0:c1,c2. A volume with s0 will be accessible by all pods.
If pods fail authorization, or if the storage mount is failing due to permissions errors, then there is a possibility that SELinux enforcement is interfering. One way to check for this is to run:
# ausearch -m avc --start recentThis examines the log file for AVC (Access Vector Cache) errors.
27.19. Selector-Label Volume Binding
27.19.1. Overview
This guide provides the steps necessary to enable binding of persistent volume claims (PVCs) to persistent volumes (PVs) via selector and label attributes. By implementing selectors and labels, regular users are able to target provisioned storage by identifiers defined by a cluster administrator.
27.19.2. Motivation
In cases of statically provisioned storage, developers seeking persistent storage are required to know a handful of identifying attributes of a PV in order to deploy and bind a PVC. This creates several problematic situations. Regular users might have to contact a cluster administrator to either deploy the PVC or provide the PV values. PV attributes alone do not convey the intended use of the storage volumes, nor do they provide methods by which volumes can be grouped.
Selector and label attributes can be used to abstract away PV details from the user while providing cluster administrators with a way of identifying volumes by a descriptive and customizable tag. Through the selector-label method of binding, users are only required to know which labels are defined by the administrator.
The selector-label feature is currently only available for statically provisioned storage and is currently not implemented for storage provisioned dynamically.
27.19.3. Deployment
This section reviews how to define and deploy PVCs.
27.19.3.1. Prerequisites
- A running OpenShift Container Platform 3.3+ cluster
- A volume provided by a supported storage provider
- A user with a cluster-admin role binding
27.19.3.2. Define the Persistent Volume and Claim
As the cluster-admin user, define the PV. For this example, we will be using a GlusterFS volume. See the appropriate storage provider for your provider’s configuration.
Example 27.9. Persistent Volume with Labels
apiVersion: v1 kind: PersistentVolume metadata: name: gluster-volume labels:1 volume-type: ssd aws-availability-zone: us-east-1 spec: capacity: storage: 2Gi accessModes: - ReadWriteMany glusterfs: endpoints: glusterfs-cluster path: myVol1 readOnly: false persistentVolumeReclaimPolicy: Retain- 1
- A PVC whose selectors match all of a PV’s labels will be bound, assuming a PV is available.
Define the PVC:
Example 27.10. Persistent Volume Claim with Selectors
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: gluster-claim spec: accessModes: - ReadWriteMany resources: requests: storage: 1Gi selector:1 matchLabels:2 volume-type: ssd aws-availability-zone: us-east-1
27.19.3.3. Optional: Bind a PVC to a specific PV
A PVC that does not specify a PV name or selector will match any PV.
To bind a PVC to a specific PV as a cluster administrator:
-
Use
pvc.spec.volumeNameif you know the PV name. Use
pvc.spec.selectorif you know the PV labels.By specifying a selector, the PVC requires the PV to have specific labels.
27.19.3.4. Optional: Reserve a PV to a specific PVC
To reserve a PV for specific tasks, you have two options: create a specific storage class, or pre-bind the PV to your PVC.
Request a specific storage class for the PV by specifying the storage class’s name.
The following resource shows the required values that you use to configure a StorageClass. This example uses the AWS ElasticBlockStore (EBS) object definition.
Example 27.11. StorageClass definition for EBS
kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: kafka provisioner: kubernetes.io/aws-ebs ...ImportantIf necessary in a multi-tenant environment, use a quota definition to reserve the storage class and PV(s) only to a specific namespace.
Pre-bind the PV to your PVC using the PVC namespace and name. A PV defined as such will bind only to the specified PVC and to nothing else, as shown in the following example:
Example 27.12. claimRef in PV definition
apiVersion: v1 kind: PersistentVolume metadata: name: mktg-ops--kafka--kafka-broker01 spec: capacity: storage: 15Gi accessModes: - ReadWriteOnce claimRef: apiVersion: v1 kind: PersistentVolumeClaim name: kafka-broker01 namespace: default ...
27.19.3.5. Deploy the Persistent Volume and Claim
As the cluster-admin user, create the persistent volume:
Example 27.13. Create the Persistent Volume
# oc create -f gluster-pv.yaml
persistentVolume "gluster-volume" created
# oc get pv
NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
gluster-volume map[] 2147483648 RWX Available 2sOnce the PV is created, any user whose selectors match all its labels can create their PVC.
Example 27.14. Create the Persistent Volume Claim
# oc create -f gluster-pvc.yaml
persistentVolumeClaim "gluster-claim" created
# oc get pvc
NAME LABELS STATUS VOLUME
gluster-claim Bound gluster-volume27.20. Enabling Controller-managed Attachment and Detachment
27.20.1. Overview
By default, the controller running on the cluster’s master manages volume attach and detach operations on behalf of a set of nodes, as opposed to letting them manage their own volume attach and detach operations.
Controller-managed attachment and detachment has the following benefits:
- If a node is lost, volumes that were attached to it can be detached by the controller and reattached elsewhere.
- Credentials for attaching and detaching do not need to be made present on every node, improving security.
27.20.2. Determining What Is Managing Attachment and Detachment
If a node has set the annotation volumes.kubernetes.io/controller-managed-attach-detach on itself, then its attach and detach operations are being managed by the controller. The controller will automatically inspect all nodes for this annotation and act according to whether it is present or not. Therefore, you may inspect the node for this annotation to determine if it has enabled controller-managed attach and detach.
To further ensure that the node is opting for controller-managed attachment and detachment, its logs can be searched for the following line:
Setting node annotation to enable volume controller attach/detachIf the above line is not found, the logs should instead contain:
Controller attach/detach is disabled for this node; Kubelet will attach and detach volumes
To check from the controller’s end that it is managing a particular node’s attach and detach operations, the logging level must first be set to at least 4. Then, the following line should be found:
processVolumesInUse for node <node_hostname>For information on how to view logs and configure logging levels, see Configuring Logging Levels.
27.20.3. Configuring Nodes to Enable Controller-managed Attachment and Detachment
Enabling controller-managed attachment and detachment is done by configuring individual nodes to opt in and disable their own node-level attachment and detachment management. See Node Configuration Files for information on what node configuration file to edit and add the following:
kubeletArguments:
enable-controller-attach-detach:
- "true"Once a node is configured, it must be restarted for the setting to take effect.
27.21. Persistent Volume Snapshots
27.21.1. Overview
Persistent Volume Snapshots are a Technology Preview feature. Technology Preview features are not supported with Red Hat production service level agreements (SLAs), might not be functionally complete, and Red Hat does not recommend to use them for production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
For more information on Red Hat Technology Preview features support scope, see https://access.redhat.com/support/offerings/techpreview/.
Many storage systems provide the ability to create "snapshots" of a persistent volume (PV) to protect against data loss. The external snapshot controller and provisioner provide means to use the feature in the OpenShift Container Platform cluster and handle volume snapshots through the OpenShift Container Platform API.
This document describes the current state of volume snapshot support in OpenShift Container Platform. Familiarity with PVs, persistent volume claims (PVCs), and dynamic provisioning is recommended.
27.21.2. Features
-
Create snapshot of a
PersistentVolumebound to aPersistentVolumeClaim -
List existing
VolumeSnapshots -
Delete existing
VolumeSnapshot -
Create a new
PersistentVolumefrom an existingVolumeSnapshot Supported
PersistentVolumetypes:- AWS Elastic Block Store (EBS)
- Google Compute Engine (GCE) Persistent Disk (PD)
27.21.3. Installation and Setup
The external controller and provisioner are the external components that provide volume snapshotting. These external components run in the cluster. The controller is responsible for creating, deleting, and reporting events on volume snapshots. The provisioner creates new PersistentVolumes from the volume snapshots. See Create Snapshot and Restore Snapshot for more information.
27.21.3.1. Starting the External Controller and Provisioner
The external controller and provisioner services are distributed as container images and can be run in the OpenShift Container Platform cluster as usual. There are also RPM versions for the controller and provisioner.
To allow the containers managing the API objects, the necessary role-based access control (RBAC) rules need to be configured by the administrator:
Create a
ServiceAccountandClusterRole:apiVersion: v1 kind: ServiceAccount metadata: name: snapshot-controller-runner kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: snapshot-controller-role rules: - apiGroups: [""] resources: ["persistentvolumes"] verbs: ["get", "list", "watch", "create", "delete"] - apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update"] - apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["events"] verbs: ["list", "watch", "create", "update", "patch"] - apiGroups: ["apiextensions.k8s.io"] resources: ["customresourcedefinitions"] verbs: ["create", "list", "watch", "delete"] - apiGroups: ["volumesnapshot.external-storage.k8s.io"] resources: ["volumesnapshots"] verbs: ["get", "list", "watch", "create", "update", "patch", "delete"] - apiGroups: ["volumesnapshot.external-storage.k8s.io"] resources: ["volumesnapshotdatas"] verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]Bind the rules via
ClusterRoleBinding:apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: snapshot-controller roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: snapshot-controller-role subjects: - kind: ServiceAccount name: snapshot-controller-runner namespace: default
If the external controller and provisioner are deployed in Amazon Web Services (AWS), they must be able to authenticate using the access key. To provide the credential to the pod, the administrator creates a new secret:
apiVersion: v1
kind: Secret
metadata:
name: awskeys
type: Opaque
data:
access-key-id: <base64 encoded AWS_ACCESS_KEY_ID>
secret-access-key: <base64 encoded AWS_SECRET_ACCESS_KEY>The AWS deployment of the external controller and provisioner containers (note that both pod containers use the secret to access the AWS cloud provider API):
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: snapshot-controller
spec:
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: snapshot-controller
spec:
serviceAccountName: snapshot-controller-runner
containers:
- name: snapshot-controller
image: "registry.redhat.io/openshift3/snapshot-controller:latest"
imagePullPolicy: "IfNotPresent"
args: ["-cloudprovider", "aws"]
env:
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: awskeys
key: access-key-id
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: awskeys
key: secret-access-key
- name: snapshot-provisioner
image: "registry.redhat.io/openshift3/snapshot-provisioner:latest"
imagePullPolicy: "IfNotPresent"
args: ["-cloudprovider", "aws"]
env:
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: awskeys
key: access-key-id
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: awskeys
key: secret-access-keyFor GCE, there is no need to use secrets to access the GCE cloud provider API. The administrator can proceed with the deployment:
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: snapshot-controller
spec:
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: snapshot-controller
spec:
serviceAccountName: snapshot-controller-runner
containers:
- name: snapshot-controller
image: "registry.redhat.io/openshift3/snapshot-controller:latest"
imagePullPolicy: "IfNotPresent"
args: ["-cloudprovider", "gce"]
- name: snapshot-provisioner
image: "registry.redhat.io/openshift3/snapshot-provisioner:latest"
imagePullPolicy: "IfNotPresent"
args: ["-cloudprovider", "gce"]27.21.3.2. Managing Snapshot Users
Depending on the cluster configuration, it might be necessary to allow non-administrator users to manipulate the VolumeSnapshot objects on the API server. This can be done by creating a ClusterRole bound to a particular user or group.
For example, assume the user 'alice' needs to work with snapshots in the cluster. The cluster administrator completes the following steps:
Define a new
ClusterRole:apiVersion: v1 kind: ClusterRole metadata: name: volumesnapshot-admin rules: - apiGroups: - "volumesnapshot.external-storage.k8s.io" attributeRestrictions: null resources: - volumesnapshots verbs: - create - delete - deletecollection - get - list - patch - update - watchBind the cluster role to the user 'alice' by creating a
ClusterRoleBindingobject:apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: volumesnapshot-admin roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: volumesnapshot-admin subjects: - kind: User name: alice
This is only an example of API access configuration. The VolumeSnapshot objects behave similar to other OpenShift Container Platform API objects. See the API access control documentation for more information on managing the API RBAC.
27.21.4. Lifecycle of a Volume Snapshot and Volume Snapshot Data
27.21.4.1. Persistent Volume Claim and Persistent Volume
The PersistentVolumeClaim is bound to a PersistentVolume. The PersistentVolume type must be one of the snapshot supported persistent volume types.
27.21.4.1.1. Snapshot Promoter
To create a StorageClass:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: snapshot-promoter
provisioner: volumesnapshot.external-storage.k8s.io/snapshot-promoter
This StorageClass is necessary to restore a PersistentVolume from a VolumeSnapshot that was previously created.
27.21.4.2. Create Snapshot
To take a snapshot of a PV, create a new VolumeSnapshot object:
apiVersion: volumesnapshot.external-storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: snapshot-demo
spec:
persistentVolumeClaimName: ebs-pvc
persistentVolumeClaimName is the name of the PersistentVolumeClaim bound to a PersistentVolume. This particular PV is snapshotted.
A VolumeSnapshotData object is then automatically created based on the VolumeSnapshot. The relationship between VolumeSnapshot and VolumeSnapshotData is similar to the relationship between PersistentVolumeClaim and PersistentVolume.
Depending on the PV type, the operation might go through several phases, which are reflected by the VolumeSnapshot status:
-
The new
VolumeSnapshotobject is created. -
The controller starts the snapshot operation. The snapshotted
PersistentVolumemight need to be frozen and the applications paused. -
The storage system finishes creating the snapshot (the snapshot is "cut") and the snapshotted
PersistentVolumemight return to normal operation. The snapshot itself is not yet ready. The last status condition is ofPendingtype with status valueTrue. A newVolumeSnapshotDataobject is created to represent the actual snapshot. -
The newly created snapshot is complete and ready to use. The last status condition is of
Readytype with status valueTrue.
It is the user’s responsibility to ensure data consistency (stop the pod/application, flush caches, freeze the file system, and so on).
In case of error, the VolumeSnapshot status is appended with an Error condition.
To display the VolumeSnapshot status:
$ oc get volumesnapshot -o yamlThe status is displayed.
apiVersion: volumesnapshot.external-storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
clusterName: ""
creationTimestamp: 2017-09-19T13:58:28Z
generation: 0
labels:
Timestamp: "1505829508178510973"
name: snapshot-demo
namespace: default
resourceVersion: "780"
selfLink: /apis/volumesnapshot.external-storage.k8s.io/v1/namespaces/default/volumesnapshots/snapshot-demo
uid: 9cc5da57-9d42-11e7-9b25-90b11c132b3f
spec:
persistentVolumeClaimName: ebs-pvc
snapshotDataName: k8s-volume-snapshot-9cc8813e-9d42-11e7-8bed-90b11c132b3f
status:
conditions:
- lastTransitionTime: null
message: Snapshot created successfully
reason: ""
status: "True"
type: Ready
creationTimestamp: null27.21.4.3. Restore Snapshot
To restore a PV from a VolumeSnapshot, create a PVC:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: snapshot-pv-provisioning-demo
annotations:
snapshot.alpha.kubernetes.io/snapshot: snapshot-demo
spec:
storageClassName: snapshot-promoter
annotations: snapshot.alpha.kubernetes.io/snapshot is the name of the VolumeSnapshot to be restored. storageClassName: StorageClass is created by the administrator for restoring VolumeSnapshots.
A new PersistentVolume is created and bound to the PersistentVolumeClaim. The process may take several minutes depending on the PV type.
27.21.4.4. Delete Snapshot
To delete a snapshot-demo:
$ oc delete volumesnapshot/snapshot-demo
The VolumeSnapshotData bound to the VolumeSnapshot is automatically deleted.
27.22. Using hostPath
A hostPath volume in an OpenShift Container Platform cluster mounts a file or directory from the host node’s file system into your pod. Most pods do not need a hostPath volume, but it does offer a quick option for testing should an application require it.
The cluster administrator must configure pods to run as privileged. This grants access to pods in the same node.
27.22.1. Overview
OpenShift Container Platform supports hostPath mounting for development and testing on a single-node cluster.
In a production cluster, you would not use hostPath. Instead, a cluster administrator provisions a network resource, such as a GCE Persistent Disk volume or an Amazon EBS volume. Network resources support the use of storage classes to set up dynamic provisioning.
A hostPath volume must be provisioned statically.
27.22.2. Configuring hostPath volumes in the Pod specification
You can use hostPath volumes to access read-write files on nodes. This can be useful for pods that can configure and monitor the host from the inside. You can also use hostPath volumes to mount volumes on the host using mountPropagation.
Using hostPath volumes can be dangerous, as they allow pods to read and write any file on the host. Proceed with caution.
It is recommended that you specify hostPath volumes directly in the Pod specification, rather than in a PersistentVolume object. This is useful because the pod already knows the path it needs to access when configuring nodes.
Procedure
Create a privileged pod:
apiVersion: v1 kind: Pod metadata: name: pod-name spec: containers: ... securityContext: privileged: true volumeMounts: - mountPath: /host/etc/motd.confg1 name: hostpath-privileged ... volumes: - name: hostpath-privileged hostPath: path: /etc/motd.confg2
In this example, the pod can see the path of the host inside /etc/motd.confg as /host/etc/motd.confg. As a result, the motd can be configured without accessing the host directly.
27.22.3. Statically provisioning hostPath volumes
A pod that uses a hostPath volume must be referenced by manual, or static, provisioning.
Using persistent volumes with hostPath should only be used when there is no persistent storage available.
Procedure
Define the persistent volume (PV). Create a
pv.yamlfile with thePersistentVolumeobject definition:apiVersion: v1 kind: PersistentVolume metadata: name: task-pv-volume1 labels: type: local spec: storageClassName: manual2 capacity: storage: 5Gi accessModes: - ReadWriteOnce3 persistentVolumeReclaimPolicy: Retain hostPath: path: "/mnt/data"4 - 1
- The name of the volume. This name is how it is identified by persistent volume claims or pods.
- 2
- Used to bind persistent volume claim requests to this persistent volume.
- 3
- The volume can be mounted as
read-writeby a single node. - 4
- The configuration file specifies that the volume is at
/mnt/dataon the cluster’s node.
Create the PV from the file:
$ oc create -f pv.yamlDefine the persistent volume claim (PVC). Create a
pvc.yamlfile with thePersistentVolumeClaimobject definition:apiVersion: v1 kind: PersistentVolumeClaim metadata: name: task-pvc-volume spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi storageClassName: manualCreate the PVC from the file:
$ oc create -f pvc.yaml
27.22.4. Mounting the hostPath share in a privileged pod
After the persistent volume claim has been created, it can be used inside of a pod by an application. The following example demonstrates mounting this share inside of a pod.
Prerequisites
-
A persistent volume claim exists that is mapped to the underlying
hostPathshare.
Procedure
Create a privileged pod that mounts the existing persistent volume claim:
apiVersion: v1 kind: Pod metadata: name: pod-name1 spec: containers: ... securityContext: privileged: true2 volumeMounts: - mountPath: /data3 name: hostpath-privileged ... securityContext: {} volumes: - name: hostpath-privileged persistentVolumeClaim: claimName: task-pvc-volume4