Chapter 5. Prometheus Cluster Monitoring
5.1. Overview
OpenShift Container Platform ships with a pre-configured and self-updating monitoring stack that is based on the Prometheus open source project and its wider eco-system. It provides monitoring of cluster components and ships with a set of alerts to immediately notify the cluster administrator about any occurring problems and a set of Grafana dashboards.
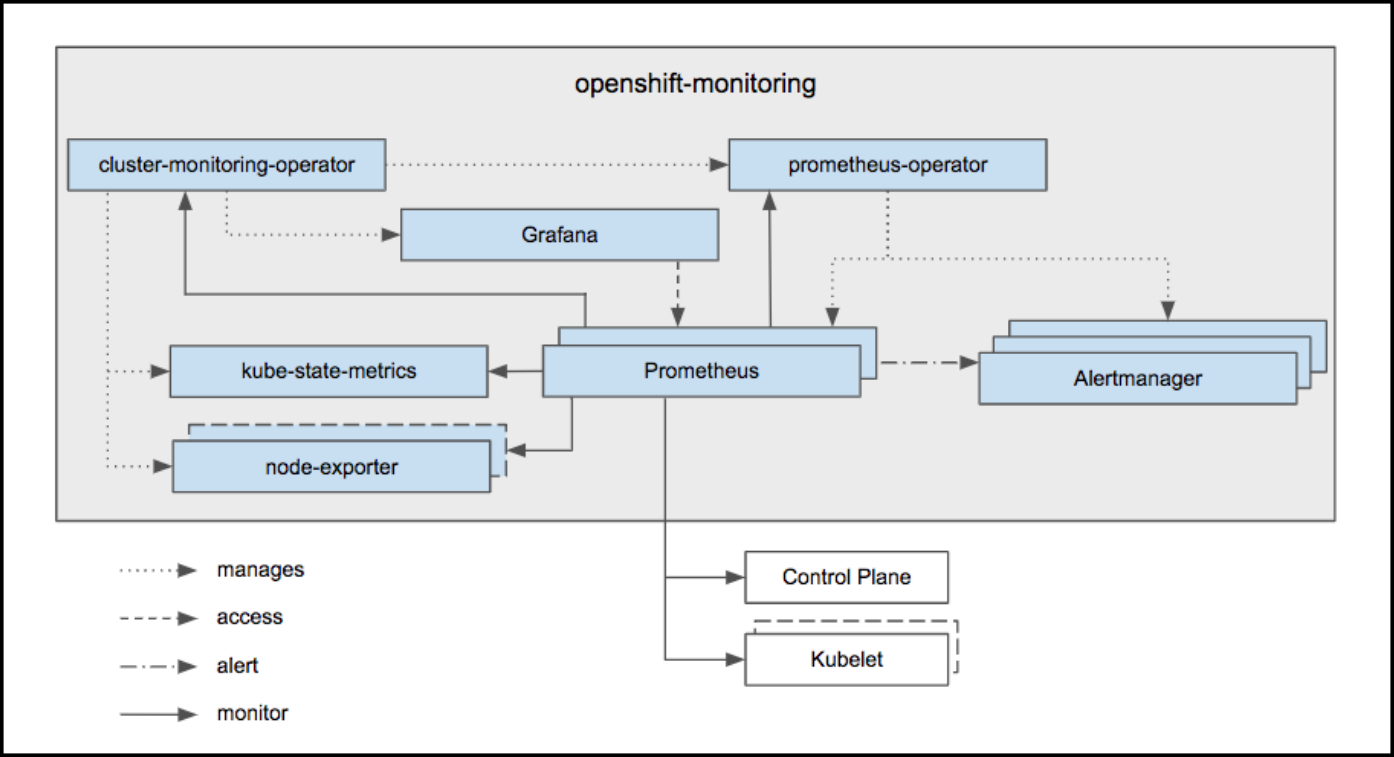
Highlighted in the diagram above, at the heart of the monitoring stack sits the OpenShift Container Platform Cluster Monitoring Operator (CMO), which watches over the deployed monitoring components and resources, and ensures that they are always up to date.
The Prometheus Operator (PO) creates, configures, and manages Prometheus and Alertmanager instances. It also automatically generates monitoring target configurations based on familiar Kubernetes label queries.
In addition to Prometheus and Alertmanager, OpenShift Container Platform Monitoring also includes node-exporter and kube-state-metrics. Node-exporter is an agent deployed on every node to collect metrics about it. The kube-state-metrics exporter agent converts Kubernetes objects to metrics consumable by Prometheus.
The targets monitored as part of the cluster monitoring are:
- Prometheus itself
- Prometheus-Operator
- cluster-monitoring-operator
- Alertmanager cluster instances
- Kubernetes apiserver
- kubelets (the kubelet embeds cAdvisor for per container metrics)
- kube-controllers
- kube-state-metrics
- node-exporter
- etcd (if etcd monitoring is enabled)
All these components are automatically updated.
For more information about the OpenShift Container Platform Cluster Monitoring Operator, see the Cluster Monitoring Operator GitHub project.
In order to be able to deliver updates with guaranteed compatibility, configurability of the OpenShift Container Platform Monitoring stack is limited to the explicitly available options.
5.2. Configuring OpenShift Container Platform cluster monitoring
The OpenShift Container Platform Ansible openshift_cluster_monitoring_operator role configures and deploys the Cluster Monitoring Operator using the variables from the inventory file.
| Variable | Description |
|---|---|
|
|
Deploy the Cluster Monitoring Operator if |
|
|
The persistent volume claim size for each of the Prometheus instances. This variable applies only if |
|
|
The persistent volume claim size for each of the Alertmanager instances. This variable applies only if |
|
|
Set to the desired, existing node selector to ensure that pods are placed onto nodes with specific labels. Defaults to |
|
| Configures Alertmanager. |
|
|
Enable persistent storage of Prometheus' time-series data. This variable is set to |
|
|
Enable persistent storage of Alertmanager notifications and silences. This variable is set to |
|
|
If you enabled the |
|
|
If you enabled the |
5.2.1. Monitoring prerequisites
The monitoring stack imposes additional resource requirements. See computing resources recommendations for details.
5.2.2. Installing monitoring stack
The Monitoring stack is installed with OpenShift Container Platform by default. You can prevent it from being installed. To do that, set this variable to false in the Ansible inventory file:
openshift_cluster_monitoring_operator_install
You can do it by running:
$ ansible-playbook [-i </path/to/inventory>] <OPENSHIFT_ANSIBLE_DIR>/playbooks/openshift-monitoring/config.yml \
-e openshift_cluster_monitoring_operator_install=False
A common path for the Ansible directory is /usr/share/ansible/openshift-ansible/. In this case, the path to the configuration file is /usr/share/ansible/openshift-ansible/playbooks/openshift-monitoring/config.yml.
5.2.3. Persistent storage
Running cluster monitoring with persistent storage means that your metrics are stored to a persistent volume and can survive a pod being restarted or recreated. This is ideal if you require your metrics or alerting data to be guarded from data loss. For production environments, it is highly recommended to configure persistent storage using block storage technology.
5.2.3.1. Enabling persistent storage
By default, persistent storage is disabled for both Prometheus time-series data and for Alertmanager notifications and silences. You can configure the cluster to persistently store any one of them or both.
To enable persistent storage of Prometheus time-series data, set this variable to
truein the Ansible inventory file:openshift_cluster_monitoring_operator_prometheus_storage_enabledTo enable persistent storage of Alertmanager notifications and silences, set this variable to
truein the Ansible inventory file:openshift_cluster_monitoring_operator_alertmanager_storage_enabled
5.2.3.2. Determining how much storage is necessary
How much storage you need depends on the number of pods. It is administrator’s responsibility to dedicate sufficient storage to ensure that the disk does not become full. For information on system requirements for persistent storage, see Capacity Planning for Cluster Monitoring Operator.
5.2.3.3. Setting persistent storage size
To specify the size of the persistent volume claim for Prometheus and Alertmanager, change these Ansible variables:
-
openshift_cluster_monitoring_operator_prometheus_storage_capacity(default: 50Gi) -
openshift_cluster_monitoring_operator_alertmanager_storage_capacity(default: 2Gi)
Each of these variables applies only if its corresponding storage_enabled variable is set to true.
5.2.3.4. Allocating enough persistent volumes
Unless you use dynamically-provisioned storage, you need to make sure you have a persistent volume (PV) ready to be claimed by the PVC, one PV for each replica. Prometheus has two replicas and Alertmanager has three replicas, which amounts to five PVs.
5.2.3.5. Enabling dynamically-provisioned storage
Instead of statically-provisioned storage, you can use dynamically-provisioned storage. See Dynamic Volume Provisioning for details.
To enable dynamic storage for Prometheus and Alertmanager, set the following parameters to true in the Ansible inventory file:
-
openshift_cluster_monitoring_operator_prometheus_storage_enabled(Default: false) -
openshift_cluster_monitoring_operator_alertmanager_storage_enabled(Default: false)
After you enable dynamic storage, you can also set the storageclass for the persistent volume claim for each component in the following parameters in the Ansible inventory file:
-
openshift_cluster_monitoring_operator_prometheus_storage_class_name(default: "") -
openshift_cluster_monitoring_operator_alertmanager_storage_class_name(default: "")
Each of these variables applies only if its corresponding storage_enabled variable is set to true.
5.2.4. Supported configuration
The supported way of configuring OpenShift Container Platform Monitoring is by configuring it using the options described in this guide. Beyond those explicit configuration options, it is possible to inject additional configuration into the stack. However this is unsupported, as configuration paradigms might change across Prometheus releases, and such cases can only be handled gracefully if all configuration possibilities are controlled.
Explicitly unsupported cases include:
-
Creating additional
ServiceMonitorobjects in theopenshift-monitoringnamespace, thereby extending the targets the cluster monitoring Prometheus instance scrapes. This can cause collisions and load differences that cannot be accounted for, therefore the Prometheus setup can be unstable. -
Creating additional
ConfigMapobjects, that cause the cluster monitoring Prometheus instance to include additional alerting and recording rules. Note that this behavior is known to cause a breaking behavior if applied, as Prometheus 2.0 will ship with a new rule file syntax.
5.3. Configuring Alertmanager
The Alertmanager manages incoming alerts; this includes silencing, inhibition, aggregation, and sending out notifications through methods such as email, PagerDuty, and HipChat.
The default configuration of the OpenShift Container Platform Monitoring Alertmanager cluster is:
global:
resolve_timeout: 5m
route:
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: default
routes:
- match:
alertname: DeadMansSwitch
repeat_interval: 5m
receiver: deadmansswitch
receivers:
- name: default
- name: deadmansswitch
This configuration can be overwritten using the Ansible variable openshift_cluster_monitoring_operator_alertmanager_config from the openshift_cluster_monitoring_operator role.
The following example configures PagerDuty for notifications. See the PagerDuty documentation for Alertmanager to learn how to retrieve the service_key.
openshift_cluster_monitoring_operator_alertmanager_config: |+
global:
resolve_timeout: 5m
route:
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: default
routes:
- match:
alertname: DeadMansSwitch
repeat_interval: 5m
receiver: deadmansswitch
- match:
service: example-app
routes:
- match:
severity: critical
receiver: team-frontend-page
receivers:
- name: default
- name: deadmansswitch
- name: team-frontend-page
pagerduty_configs:
- service_key: "<key>"
The sub-route matches only on alerts that have a severity of critical and sends them using the receiver called team-frontend-page. As the name indicates, someone should be paged for alerts that are critical. See Alertmanager configuration for configuring alerting through different alert receivers.
5.3.1. Dead man’s switch
OpenShift Container Platform Monitoring ships with a dead man’s switch to ensure the availability of the monitoring infrastructure.
The dead man’s switch is a simple Prometheus alerting rule that always triggers. The Alertmanager continuously sends notifications for the dead man’s switch to the notification provider that supports this functionality. This also ensures that communication between the Alertmanager and the notification provider is working.
This mechanism is supported by PagerDuty to issue alerts when the monitoring system itself is down. For more information, see Dead man’s switch PagerDuty below.
5.3.2. Grouping alerts
After alerts are firing against the Alertmanager, it must be configured to know how to logically group them.
For this example, a new route is added to reflect alert routing of the frontend team.
Procedure
Add new routes. Multiple routes may be added beneath the original route, typically to define the receiver for the notification. The following example uses a matcher to ensure that only alerts coming from the service
example-appare used:global: resolve_timeout: 5m route: group_wait: 30s group_interval: 5m repeat_interval: 12h receiver: default routes: - match: alertname: DeadMansSwitch repeat_interval: 5m receiver: deadmansswitch - match: service: example-app routes: - match: severity: critical receiver: team-frontend-page receivers: - name: default - name: deadmansswitchThe sub-route matches only on alerts that have a severity of
critical, and sends them using the receiver calledteam-frontend-page. As the name indicates, someone should be paged for alerts that are critical.
5.3.3. Dead man’s switch PagerDuty
PagerDuty supports this mechanism through an integration called Dead Man’s Snitch. Simply add a PagerDuty configuration to the default deadmansswitch receiver. Use the process described above to add this configuration.
Configure Dead Man’s Snitch to page the operator if the Dead man’s switch alert is silent for 15 minutes. With the default Alertmanager configuration, the Dead man’s switch alert is repeated every five minutes. If Dead Man’s Snitch triggers after 15 minutes, it indicates that the notification has been unsuccessful at least twice.
Learn how to configure Dead Man’s Snitch for PagerDuty.
5.3.4. Alerting rules
OpenShift Container Platform Cluster Monitoring ships with the following alerting rules configured by default. Currently you cannot add custom alerting rules.
Some alerting rules have identical names. This is intentional. They are alerting about the same event with different thresholds, with different severity, or both. With the inhibition rules, the lower severity is inhibited when the higher severity is firing.
For more details on the alerting rules, see the configuration file.
| Alert | Severity | Description |
|---|---|---|
|
|
| Cluster Monitoring Operator is experiencing X% errors. |
|
|
| Alertmanager has disappeared from Prometheus target discovery. |
|
|
| ClusterMonitoringOperator has disappeared from Prometheus target discovery. |
|
|
| KubeAPI has disappeared from Prometheus target discovery. |
|
|
| KubeControllerManager has disappeared from Prometheus target discovery. |
|
|
| KubeScheduler has disappeared from Prometheus target discovery. |
|
|
| KubeStateMetrics has disappeared from Prometheus target discovery. |
|
|
| Kubelet has disappeared from Prometheus target discovery. |
|
|
| NodeExporter has disappeared from Prometheus target discovery. |
|
|
| Prometheus has disappeared from Prometheus target discovery. |
|
|
| PrometheusOperator has disappeared from Prometheus target discovery. |
|
|
| Namespace/Pod (Container) is restarting times / second |
|
|
| Namespace/Pod is not ready. |
|
|
| Deployment Namespace/Deployment generation mismatch |
|
|
| Deployment Namespace/Deployment replica mismatch |
|
|
| StatefulSet Namespace/StatefulSet replica mismatch |
|
|
| StatefulSet Namespace/StatefulSet generation mismatch |
|
|
| Only X% of desired pods scheduled and ready for daemon set Namespace/DaemonSet |
|
|
| A number of pods of daemonset Namespace/DaemonSet are not scheduled. |
|
|
| A number of pods of daemonset Namespace/DaemonSet are running where they are not supposed to run. |
|
|
| CronJob Namespace/CronJob is taking more than 1h to complete. |
|
|
| Job Namespaces/Job is taking more than 1h to complete. |
|
|
| Job Namespaces/Job failed to complete. |
|
|
| Overcommited CPU resource requests on Pods, cannot tolerate node failure. |
|
|
| Overcommited Memory resource requests on Pods, cannot tolerate node failure. |
|
|
| Overcommited CPU resource request quota on Namespaces. |
|
|
| Overcommited Memory resource request quota on Namespaces. |
|
|
| X% usage of Resource in namespace Namespace. |
|
|
| The persistent volume claimed by PersistentVolumeClaim in namespace Namespace has X% free. |
|
|
| Based on recent sampling, the persistent volume claimed by PersistentVolumeClaim in namespace Namespace is expected to fill up within four days. Currently X bytes are available. |
|
|
| Node has been unready for more than an hour |
|
|
| There are X different versions of Kubernetes components running. |
|
|
| Kubernetes API server client 'Job/Instance' is experiencing X% errors.' |
|
|
| Kubernetes API server client 'Job/Instance' is experiencing X errors / sec.' |
|
|
| Kubelet Instance is running X pods, close to the limit of 110. |
|
|
| The API server has a 99th percentile latency of X seconds for Verb Resource. |
|
|
| The API server has a 99th percentile latency of X seconds for Verb Resource. |
|
|
| API server is erroring for X% of requests. |
|
|
| API server is erroring for X% of requests. |
|
|
| Kubernetes API certificate is expiring in less than 7 days. |
|
|
| Kubernetes API certificate is expiring in less than 1 day. |
|
|
|
Summary: Configuration out of sync. Description: The configuration of the instances of the Alertmanager cluster |
|
|
| Summary: Alertmanager’s configuration reload failed. Description: Reloading Alertmanager’s configuration has failed for Namespace/Pod. |
|
|
| Summary: Targets are down. Description: X% of Job targets are down. |
|
|
| Summary: Alerting DeadMansSwitch. Description: This is a DeadMansSwitch meant to ensure that the entire Alerting pipeline is functional. |
|
|
| Device Device of node-exporter Namespace/Pod is running full within the next 24 hours. |
|
|
| Device Device of node-exporter Namespace/Pod is running full within the next 2 hours. |
|
|
| Summary: Reloading Prometheus' configuration failed. Description: Reloading Prometheus' configuration has failed for Namespace/Pod |
|
|
| Summary: Prometheus' alert notification queue is running full. Description: Prometheus' alert notification queue is running full for Namespace/Pod |
|
|
| Summary: Errors while sending alert from Prometheus. Description: Errors while sending alerts from Prometheus Namespace/Pod to Alertmanager Alertmanager |
|
|
| Summary: Errors while sending alerts from Prometheus. Description: Errors while sending alerts from Prometheus Namespace/Pod to Alertmanager Alertmanager |
|
|
| Summary: Prometheus is not connected to any Alertmanagers. Description: Prometheus Namespace/Pod is not connected to any Alertmanagers |
|
|
| Summary: Prometheus has issues reloading data blocks from disk. Description: Job at Instance had X reload failures over the last four hours. |
|
|
| Summary: Prometheus has issues compacting sample blocks. Description: Job at Instance had X compaction failures over the last four hours. |
|
|
| Summary: Prometheus write-ahead log is corrupted. Description: Job at Instance has a corrupted write-ahead log (WAL). |
|
|
| Summary: Prometheus isn’t ingesting samples. Description: Prometheus Namespace/Pod isn’t ingesting samples. |
|
|
| Summary: Prometheus has many samples rejected. Description: Namespace/Pod has many samples rejected due to duplicate timestamps but different values |
|
|
| Etcd cluster "Job": insufficient members (X). |
|
|
| Etcd cluster "Job": member Instance has no leader. |
|
|
| Etcd cluster "Job": instance Instance has seen X leader changes within the last hour. |
|
|
| Etcd cluster "Job": X% of requests for GRPC_Method failed on etcd instance Instance. |
|
|
| Etcd cluster "Job": X% of requests for GRPC_Method failed on etcd instance Instance. |
|
|
| Etcd cluster "Job": gRPC requests to GRPC_Method are taking X_s on etcd instance _Instance. |
|
|
| Etcd cluster "Job": member communication with To is taking X_s on etcd instance _Instance. |
|
|
| Etcd cluster "Job": X proposal failures within the last hour on etcd instance Instance. |
|
|
| Etcd cluster "Job": 99th percentile fync durations are X_s on etcd instance _Instance. |
|
|
| Etcd cluster "Job": 99th percentile commit durations X_s on etcd instance _Instance. |
|
|
| Job instance Instance will exhaust its file descriptors soon |
|
|
| Job instance Instance will exhaust its file descriptors soon |
5.4. Configuring etcd monitoring
If the etcd service does not run correctly, successful operation of the whole OpenShift Container Platform cluster is in danger. Therefore, it is reasonable to configure monitoring of etcd.
Follow these steps to configure etcd monitoring:
Procedure
Verify that the monitoring stack is running:
$ oc -n openshift-monitoring get pods NAME READY STATUS RESTARTS AGE alertmanager-main-0 3/3 Running 0 34m alertmanager-main-1 3/3 Running 0 33m alertmanager-main-2 3/3 Running 0 33m cluster-monitoring-operator-67b8797d79-sphxj 1/1 Running 0 36m grafana-c66997f-pxrf7 2/2 Running 0 37s kube-state-metrics-7449d589bc-rt4mq 3/3 Running 0 33m node-exporter-5tt4f 2/2 Running 0 33m node-exporter-b2mrp 2/2 Running 0 33m node-exporter-fd52p 2/2 Running 0 33m node-exporter-hfqgv 2/2 Running 0 33m prometheus-k8s-0 4/4 Running 1 35m prometheus-k8s-1 0/4 ContainerCreating 0 21s prometheus-operator-6c9fddd47f-9jfgk 1/1 Running 0 36mOpen the configuration file for the cluster monitoring stack:
$ oc -n openshift-monitoring edit configmap cluster-monitoring-configUnder
config.yaml: |+, add theetcdsection.If you run
etcdin static pods on your master nodes, you can specify theetcdnodes using the selector:... data: config.yaml: |+ ... etcd: targets: selector: openshift.io/component: etcd openshift.io/control-plane: "true"If you run
etcdon separate hosts, you need to specify the nodes using IP addresses:... data: config.yaml: |+ ... etcd: targets: ips: - "127.0.0.1" - "127.0.0.2" - "127.0.0.3"If the IP addresses for
etcdnodes change, you must update this list.
Verify that the
etcdservice monitor is now running:$ oc -n openshift-monitoring get servicemonitor NAME AGE alertmanager 35m etcd 1m1 kube-apiserver 36m kube-controllers 36m kube-state-metrics 34m kubelet 36m node-exporter 34m prometheus 36m prometheus-operator 37m- 1
- The
etcdservice monitor.
It might take up to a minute for the
etcdservice monitor to start.Now you can navigate to the web interface to see more information about the status of
etcdmonitoring.To get the URL, run:
$ oc -n openshift-monitoring get routes NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD ... prometheus-k8s prometheus-k8s-openshift-monitoring.apps.msvistun.origin-gce.dev.openshift.com prometheus-k8s web reencrypt None-
Using
https, navigate to the URL listed forprometheus-k8s. Log in.
Ensure the user belongs to the
cluster-monitoring-viewrole. This role provides access to viewing cluster monitoring UIs.For example, to add user
developerto thecluster-monitoring-viewrole, run:$ oc adm policy add-cluster-role-to-user cluster-monitoring-view developer-
In the web interface, log in as the user belonging to the
cluster-monitoring-viewrole. Click Status, then Targets. If you see an
etcdentry,etcdis being monitored.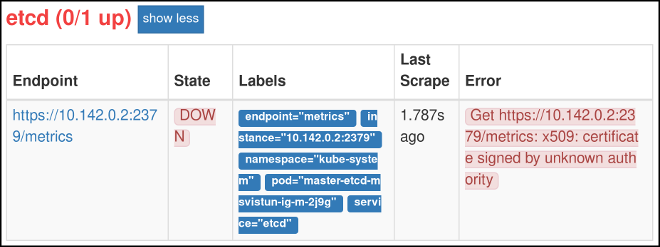
While
etcdis now being monitored, Prometheus is not yet able to authenticate againstetcd, and so cannot gather metrics.To configure Prometheus authentication against
etcd:Copy the
/etc/etcd/ca/ca.crtand/etc/etcd/ca/ca.keycredentials files from the master node to the local machine:$ ssh -i gcp-dev/ssh-privatekey cloud-user@35.237.54.213Create the
openssl.cnffile with these contents:[ req ] req_extensions = v3_req distinguished_name = req_distinguished_name [ req_distinguished_name ] [ v3_req ] basicConstraints = CA:FALSE keyUsage = nonRepudiation, keyEncipherment, digitalSignature extendedKeyUsage=serverAuth, clientAuthGenerate the
etcd.keyprivate key file:$ openssl genrsa -out etcd.key 2048Generate the
etcd.csrcertificate signing request file:$ openssl req -new -key etcd.key -out etcd.csr -subj "/CN=etcd" -config openssl.cnfGenerate the
etcd.crtcertificate file:$ openssl x509 -req -in etcd.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out etcd.crt -days 365 -extensions v3_req -extfile openssl.cnfPut the credentials into format used by OpenShift Container Platform:
$ cat <<-EOF > etcd-cert-secret.yaml apiVersion: v1 data: etcd-client-ca.crt: "$(cat ca.crt | base64 --wrap=0)" etcd-client.crt: "$(cat etcd.crt | base64 --wrap=0)" etcd-client.key: "$(cat etcd.key | base64 --wrap=0)" kind: Secret metadata: name: kube-etcd-client-certs namespace: openshift-monitoring type: Opaque EOFThis creates the etcd-cert-secret.yaml file
Apply the credentials file to the cluster:
$ oc apply -f etcd-cert-secret.yaml
Now that you have configured authentication, visit the Targets page of the web interface again. Verify that
etcdis now being correctly monitored. It might take several minutes for changes to take effect.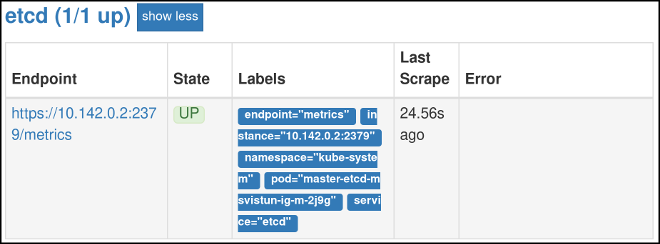
If you want
etcdmonitoring to be automatically updated when you update OpenShift Container Platform, set this variable in the Ansible inventory file totrue:openshift_cluster_monitoring_operator_etcd_enabled=trueIf you run
etcdon separate hosts, specify the nodes by IP addresses using this Ansible variable:openshift_cluster_monitoring_operator_etcd_hosts=[<address1>, <address2>, ...]If the IP addresses of the
etcdnodes change, you must update this list.
5.5. Accessing Prometheus, Alertmanager, and Grafana
OpenShift Container Platform Monitoring ships with a Prometheus instance for cluster monitoring and a central Alertmanager cluster. In addition to Prometheus and Alertmanager, OpenShift Container Platform Monitoring also includes a Grafana instance as well as pre-built dashboards for cluster monitoring troubleshooting. The Grafana instance that is provided with the monitoring stack, along with its dashboards, is read-only.
To get the addresses for accessing Prometheus, Alertmanager, and Grafana web UIs:
Procedure
Run the following command:
$ oc -n openshift-monitoring get routes NAME HOST/PORT alertmanager-main alertmanager-main-openshift-monitoring.apps._url_.openshift.com grafana grafana-openshift-monitoring.apps._url_.openshift.com prometheus-k8s prometheus-k8s-openshift-monitoring.apps._url_.openshift.comMake sure to prepend
https://to these addresses. You cannot access web UIs using unencrypted connections.-
Authentication is performed against the OpenShift Container Platform identity and uses the same credentials or means of authentication as is used elsewhere in OpenShift Container Platform. You must use a role that has read access to all namespaces, such as the
cluster-monitoring-viewcluster role.