Chapter 3. Understanding OpenShift updates
3.1. Introduction to OpenShift updates
With OpenShift Container Platform 4, you can update an OpenShift Container Platform cluster with a single operation by using the web console or the OpenShift CLI (oc). Platform administrators can view new update options either by going to Administration oc adm upgrade command.
Red Hat hosts a public OpenShift Update Service (OSUS), which serves a graph of update possibilities based on the OpenShift Container Platform release images in the official registry. The graph contains update information for any public OCP release. OpenShift Container Platform clusters are configured to connect to the OSUS by default, and the OSUS responds to clusters with information about known update targets.
An update begins when either a cluster administrator or an automatic update controller edits the custom resource (CR) of the Cluster Version Operator (CVO) with a new version. To reconcile the cluster with the newly specified version, the CVO retrieves the target release image from an image registry and begins to apply changes to the cluster.
Operators previously installed through Operator Lifecycle Manager (OLM) follow a different process for updates. See Updating installed Operators for more information.
The target release image contains manifest files for all cluster components that form a specific OCP version. When updating the cluster to a new version, the CVO applies manifests in separate stages called Runlevels. Most, but not all, manifests support one of the cluster Operators. As the CVO applies a manifest to a cluster Operator, the Operator might perform update tasks to reconcile itself with its new specified version.
The CVO monitors the state of each applied resource and the states reported by all cluster Operators. The CVO only proceeds with the update when all manifests and cluster Operators in the active Runlevel reach a stable condition. After the CVO updates the entire control plane through this process, the Machine Config Operator (MCO) updates the operating system and configuration of every node in the cluster.
3.1.1. Common questions about update availability
There are several factors that affect if and when an update is made available to an OpenShift Container Platform cluster. The following list provides common questions regarding the availability of an update:
What are the differences between each of the update channels?
-
A new release is initially added to the
candidatechannel. -
After successful final testing, a release on the
candidatechannel is promoted to thefastchannel, an errata is published, and the release is now fully supported. After a delay, a release on the
fastchannel is finally promoted to thestablechannel. This delay represents the only difference between thefastandstablechannels.NoteFor the latest z-stream releases, this delay may generally be a week or two. However, the delay for initial updates to the latest minor version may take much longer, generally 45-90 days.
-
Releases promoted to the
stablechannel are simultaneously promoted to theeuschannel. The primary purpose of theeuschannel is to serve as a convenience for clusters performing an EUS-to-EUS update.
Is a release on the stable channel safer or more supported than a release on the fast channel?
-
If a regression is identified for a release on a
fastchannel, it will be resolved and managed to the same extent as if that regression was identified for a release on thestablechannel. -
The only difference between releases on the
fastandstablechannels is that a release only appears on thestablechannel after it has been on thefastchannel for some time, which provides more time for new update risks to be discovered.
What does it mean if an update is supported but not recommended?
- Red Hat continuously evaluates data from multiple sources to determine whether updates from one version to another lead to issues. If an issue is identified, an update path may no longer be recommended to users. However, even if the update path is not recommended, customers are still supported if they perform the update.
Red Hat does not block users from updating to a certain version. Red Hat may declare conditional update risks, which may or may not apply to a particular cluster.
- Declared risks provide cluster administrators more context about a supported update. Cluster administrators can still accept the risk and update to that particular target version. This update is always supported despite not being recommended in the context of the conditional risk.
What if I see that an update to a particular release is no longer recommended?
- If Red Hat removes update recommendations from any supported release due to a regression, a superseding update recommendation will be provided to a future version that corrects the regression. There may be a delay while the defect is corrected, tested, and promoted to your selected channel.
How long until the next z-stream release is made available on the fast and stable channels?
While the specific cadence can vary based on a number of factors, new z-stream releases for the latest minor version are typically made available about every week. Older minor versions, which have become more stable over time, may take much longer for new z-stream releases to be made available.
ImportantThese are only estimates based on past data about z-stream releases. Red Hat reserves the right to change the release frequency as needed. Any number of issues could cause irregularities and delays in this release cadence.
-
Once a z-stream release is published, it also appears in the
fastchannel for that minor version. After a delay, the z-stream release may then appear in that minor version’sstablechannel.
3.1.2. About the OpenShift Update Service
The OpenShift Update Service (OSUS) provides update recommendations to OpenShift Container Platform, including Red Hat Enterprise Linux CoreOS (RHCOS). It provides a graph, or diagram, that contains the vertices of component Operators and the edges that connect them. The edges in the graph show which versions you can safely update to. The vertices are update payloads that specify the intended state of the managed cluster components.
The Cluster Version Operator (CVO) in your cluster checks with the OpenShift Update Service to see the valid updates and update paths based on current component versions and information in the graph. When you request an update, the CVO uses the corresponding release image to update your cluster. The release artifacts are hosted in Quay as container images.
To allow the OpenShift Update Service to provide only compatible updates, a release verification pipeline drives automation. Each release artifact is verified for compatibility with supported cloud platforms and system architectures, as well as other component packages. After the pipeline confirms the suitability of a release, the OpenShift Update Service notifies you that it is available.
The OpenShift Update Service displays all recommended updates for your current cluster. If an update path is not recommended by the OpenShift Update Service, it might be because of a known issue with the update or the target release.
Two controllers run during continuous update mode. The first controller continuously updates the payload manifests, applies the manifests to the cluster, and outputs the controlled rollout status of the Operators to indicate whether they are available, upgrading, or failed. The second controller polls the OpenShift Update Service to determine if updates are available.
Only updating to a newer version is supported. Reverting or rolling back your cluster to a previous version is not supported. If your update fails, contact Red Hat support.
During the update process, the Machine Config Operator (MCO) applies the new configuration to your cluster machines. The MCO cordons the number of nodes specified by the maxUnavailable field on the machine configuration pool and marks them unavailable. By default, this value is set to 1. The MCO then applies the new configuration and reboots the machine.
If you use Red Hat Enterprise Linux (RHEL) machines as workers, the MCO does not update the kubelet because you must update the OpenShift API on the machines first.
With the specification for the new version applied to the old kubelet, the RHEL machine cannot return to the Ready state. You cannot complete the update until the machines are available. However, the maximum number of unavailable nodes is set to ensure that normal cluster operations can continue with that number of machines out of service.
The OpenShift Update Service is composed of an Operator and one or more application instances.
3.1.3. Common terms
- Control plane
- The control plane, which is composed of control plane machines, manages the OpenShift Container Platform cluster. The control plane machines manage workloads on the compute machines, which are also known as worker machines.
- Cluster Version Operator
- The Cluster Version Operator (CVO) starts the update process for the cluster. It checks with OSUS based on the current cluster version and retrieves the graph which contains available or possible update paths.
- Machine Config Operator
- The Machine Config Operator (MCO) is a cluster-level Operator that manages the operating system and machine configurations. Through the MCO, platform administrators can configure and update systemd, CRI-O and Kubelet, the kernel, NetworkManager, and other system features on the worker nodes.
- OpenShift Update Service
- The OpenShift Update Service (OSUS) provides over-the-air updates to OpenShift Container Platform, including to Red Hat Enterprise Linux CoreOS (RHCOS). It provides a graph, or diagram, that contains the vertices of component Operators and the edges that connect them.
- Channels
- Channels declare an update strategy tied to minor versions of OpenShift Container Platform. The OSUS uses this configured strategy to recommend update edges consistent with that strategy.
- Recommended update edge
- A recommended update edge is a recommended update between OpenShift Container Platform releases. Whether a given update is recommended can depend on the cluster’s configured channel, current version, known bugs, and other information. OSUS communicates the recommended edges to the CVO, which runs in every cluster.
- Extended Update Support
All post-4.7 even-numbered minor releases are labeled as Extended Update Support (EUS) releases. These releases introduce a verified update path between EUS releases, permitting customers to streamline updates of worker nodes and formulate update strategies of EUS-to-EUS OpenShift Container Platform releases that result in fewer reboots of worker nodes.
For more information, see Red Hat OpenShift Extended Update Support (EUS) Overview.
3.2. How cluster updates work
The following sections describe each major aspect of the OpenShift Container Platform (OCP) update process in detail. For a general overview of how updates work, see the Introduction to OpenShift updates.
3.2.1. Evaluation of update availability
The Cluster Version Operator (CVO) periodically queries the OpenShift Update Service (OSUS) for the most recent data about update possibilities. This data is based on the cluster’s subscribed channel. The CVO then saves information about update recommendations into either the availableUpdates or conditionalUpdates field of its ClusterVersion resource.
The CVO periodically checks the conditional updates for update risks. These risks are conveyed through the data served by the OSUS, which contains information for each version about known issues that might affect a cluster updated to that version. Most risks are limited to clusters with specific characteristics, such as clusters with a certain size or clusters that are deployed in a particular cloud platform.
The CVO continuously evaluates its cluster characteristics against the conditional risk information for each conditional update. If the CVO finds that the cluster matches the criteria, the CVO stores this information in the conditionalUpdates field of its ClusterVersion resource. If the CVO finds that the cluster does not match the risks of an update, or that there are no risks associated with the update, it stores the target version in the availableUpdates field of its ClusterVersion resource.
The user interface, either the web console or the OpenShift CLI (oc), presents this information in sectioned headings to the administrator. Each supported but not recommended update recommendation contains a link to further resources about the risk so that the administrator can make an informed decision about the update.
You can inspect all available updates with the following command:
$ oc adm upgrade --include-not-recommended
The additional --include-not-recommended parameter includes updates that are available but not recommended due to a known risk that applies to the cluster.
Example output
Cluster version is 4.10.22
Upstream is unset, so the cluster will use an appropriate default.
Channel: fast-4.11 (available channels: candidate-4.10, candidate-4.11, eus-4.10, fast-4.10, fast-4.11, stable-4.10)
Recommended updates:
VERSION IMAGE
4.10.26 quay.io/openshift-release-dev/ocp-release@sha256:e1fa1f513068082d97d78be643c369398b0e6820afab708d26acda2262940954
4.10.25 quay.io/openshift-release-dev/ocp-release@sha256:ed84fb3fbe026b3bbb4a2637ddd874452ac49c6ead1e15675f257e28664879cc
4.10.24 quay.io/openshift-release-dev/ocp-release@sha256:aab51636460b5a9757b736a29bc92ada6e6e6282e46b06e6fd483063d590d62a
4.10.23 quay.io/openshift-release-dev/ocp-release@sha256:e40e49d722cb36a95fa1c03002942b967ccbd7d68de10e003f0baa69abad457b
Supported but not recommended updates:
Version: 4.11.0
Image: quay.io/openshift-release-dev/ocp-release@sha256:300bce8246cf880e792e106607925de0a404484637627edf5f517375517d54a4
Recommended: False
Reason: RPMOSTreeTimeout
Message: Nodes with substantial numbers of containers and CPU contention may not reconcile machine configuration https://bugzilla.redhat.com/show_bug.cgi?id=2111817#c22
One way to inspect the underlying availability data created by the CVO is by querying the ClusterVersion resource with the following command:
$ oc get clusterversion version -o json | jq '.status.availableUpdates'Example output
[
{
"channels": [
"candidate-4.11",
"candidate-4.12",
"fast-4.11",
"fast-4.12"
],
"image": "quay.io/openshift-release-dev/ocp-release@sha256:400267c7f4e61c6bfa0a59571467e8bd85c9188e442cbd820cc8263809be3775",
"url": "https://access.redhat.com/errata/RHBA-2023:3213",
"version": "4.11.41"
},
...
]A similar command can be used to check conditional updates:
$ oc get clusterversion version -o json | jq '.status.conditionalUpdates'Example output
[
{
"conditions": [
{
"lastTransitionTime": "2023-05-30T16:28:59Z",
"message": "The 4.11.36 release only resolves an installation issue https://issues.redhat.com//browse/OCPBUGS-11663 , which does not affect already running clusters. 4.11.36 does not include fixes delivered in recent 4.11.z releases and therefore upgrading from these versions would cause fixed bugs to reappear. Red Hat does not recommend upgrading clusters to 4.11.36 version for this reason. https://access.redhat.com/solutions/7007136",
"reason": "PatchesOlderRelease",
"status": "False",
"type": "Recommended"
}
],
"release": {
"channels": [...],
"image": "quay.io/openshift-release-dev/ocp-release@sha256:8c04176b771a62abd801fcda3e952633566c8b5ff177b93592e8e8d2d1f8471d",
"url": "https://access.redhat.com/errata/RHBA-2023:1733",
"version": "4.11.36"
},
"risks": [...]
},
...
]3.2.2. Release images
A release image is the delivery mechanism for a specific OpenShift Container Platform (OCP) version. It contains the release metadata, a Cluster Version Operator (CVO) binary matching the release version, every manifest needed to deploy individual OpenShift cluster Operators, and a list of SHA digest-versioned references to all container images that make up this OpenShift version.
You can inspect the content of a specific release image by running the following command:
$ oc adm release extract <release image>Example output
$ oc adm release extract quay.io/openshift-release-dev/ocp-release:4.12.6-x86_64
Extracted release payload from digest sha256:800d1e39d145664975a3bb7cbc6e674fbf78e3c45b5dde9ff2c5a11a8690c87b created at 2023-03-01T12:46:29Z
$ ls
0000_03_authorization-openshift_01_rolebindingrestriction.crd.yaml
0000_03_config-operator_01_proxy.crd.yaml
0000_03_marketplace-operator_01_operatorhub.crd.yaml
0000_03_marketplace-operator_02_operatorhub.cr.yaml
0000_03_quota-openshift_01_clusterresourcequota.crd.yaml
...
0000_90_service-ca-operator_02_prometheusrolebinding.yaml
0000_90_service-ca-operator_03_servicemonitor.yaml
0000_99_machine-api-operator_00_tombstones.yaml
image-references
release-metadata3.2.3. Update process workflow
The following steps represent a detailed workflow of the OpenShift Container Platform (OCP) update process:
-
The target version is stored in the
spec.desiredUpdate.versionfield of theClusterVersionresource, which may be managed through the web console or the CLI. -
The Cluster Version Operator (CVO) detects that the
desiredUpdatein theClusterVersionresource differs from the current cluster version. Using graph data from the OpenShift Update Service, the CVO resolves the desired cluster version to a pull spec for the release image. - The CVO validates the integrity and authenticity of the release image. Red Hat publishes cryptographically-signed statements about published release images at predefined locations by using image SHA digests as unique and immutable release image identifiers. The CVO utilizes a list of built-in public keys to validate the presence and signatures of the statement matching the checked release image.
-
The CVO creates a job named
version-$version-$hashin theopenshift-cluster-versionnamespace. This job uses containers that are executing the release image, so the cluster downloads the image through the container runtime. The job then extracts the manifests and metadata from the release image to a shared volume that is accessible to the CVO. - The CVO validates the extracted manifests and metadata.
- The CVO checks some preconditions to ensure that no problematic condition is detected in the cluster. Certain conditions can prevent updates from proceeding. These conditions are either determined by the CVO itself, or reported by individual cluster Operators that detect some details about the cluster that the Operator considers problematic for the update.
-
The CVO records the accepted release in
status.desiredand creates astatus.historyentry about the new update. - The CVO begins applying the manifests from the release image. Cluster Operators are updated in separate stages called Runlevels, and the CVO ensures that all Operators in a Runlevel finish updating before it proceeds to the next level.
- Manifests for the CVO itself are applied early in the process. When the CVO deployment is applied, the current CVO pod terminates, and a CVO pod using the new version starts. The new CVO proceeds to apply the remaining manifests.
-
The update proceeds until the entire control plane is updated to the new version. Individual cluster Operators might perform update tasks on their domain of the cluster, and while they do so, they report their state through the
Progressing=Truecondition. - The Machine Config Operator (MCO) manifests are applied towards the end of the process. The updated MCO then begins updating the system configuration and operating system of every node. Each node might be drained, updated, and rebooted before it starts to accept workloads again.
The cluster reports as updated after the control plane update is finished, usually before all nodes are updated. After the update, the CVO maintains all cluster resources to match the state delivered in the release image.
3.2.4. Understanding how manifests are applied during an update
Some manifests supplied in a release image must be applied in a certain order because of the dependencies between them. For example, the CustomResourceDefinition resource must be created before the matching custom resources. Additionally, there is a logical order in which the individual cluster Operators must be updated to minimize disruption in the cluster. The Cluster Version Operator (CVO) implements this logical order through the concept of Runlevels.
These dependencies are encoded in the filenames of the manifests in the release image:
0000_<runlevel>_<component>_<manifest-name>.yamlFor example:
0000_03_config-operator_01_proxy.crd.yamlThe CVO internally builds a dependency graph for the manifests, where the CVO obeys the following rules:
- During an update, manifests at a lower Runlevel are applied before those at a higher Runlevel.
- Within one Runlevel, manifests for different components can be applied in parallel.
- Within one Runlevel, manifests for a single component are applied in lexicographic order.
The CVO then applies manifests following the generated dependency graph.
For some resource types, the CVO monitors the resource after its manifest is applied, and considers it to be successfully updated only after the resource reaches a stable state. Achieving this stable state can take some time. This is especially true for cluster Operators, which might perform their own update actions in the cluster after the CVO deploys their new versions. While the additional update actions take place, these cluster Operators temporarily set their Progressing condition to True.
The CVO waits until all cluster Operators in the Runlevel meet the following conditions before it proceeds to the next Runlevel:
-
The cluster Operators have an
Available=Truecondition. -
The cluster Operators have a
Degraded=Falsecondition. - The cluster Operators declare they have achieved the desired version in their ClusterOperator resource.
Some actions can take significant time to finish. The CVO waits for the actions to complete in order to ensure the subsequent Runlevels can proceed safely. The process of applying all manifests is expected to take 60 to 120 minutes in total; see Understanding OpenShift Container Platform update duration for more information about factors that influence update duration.
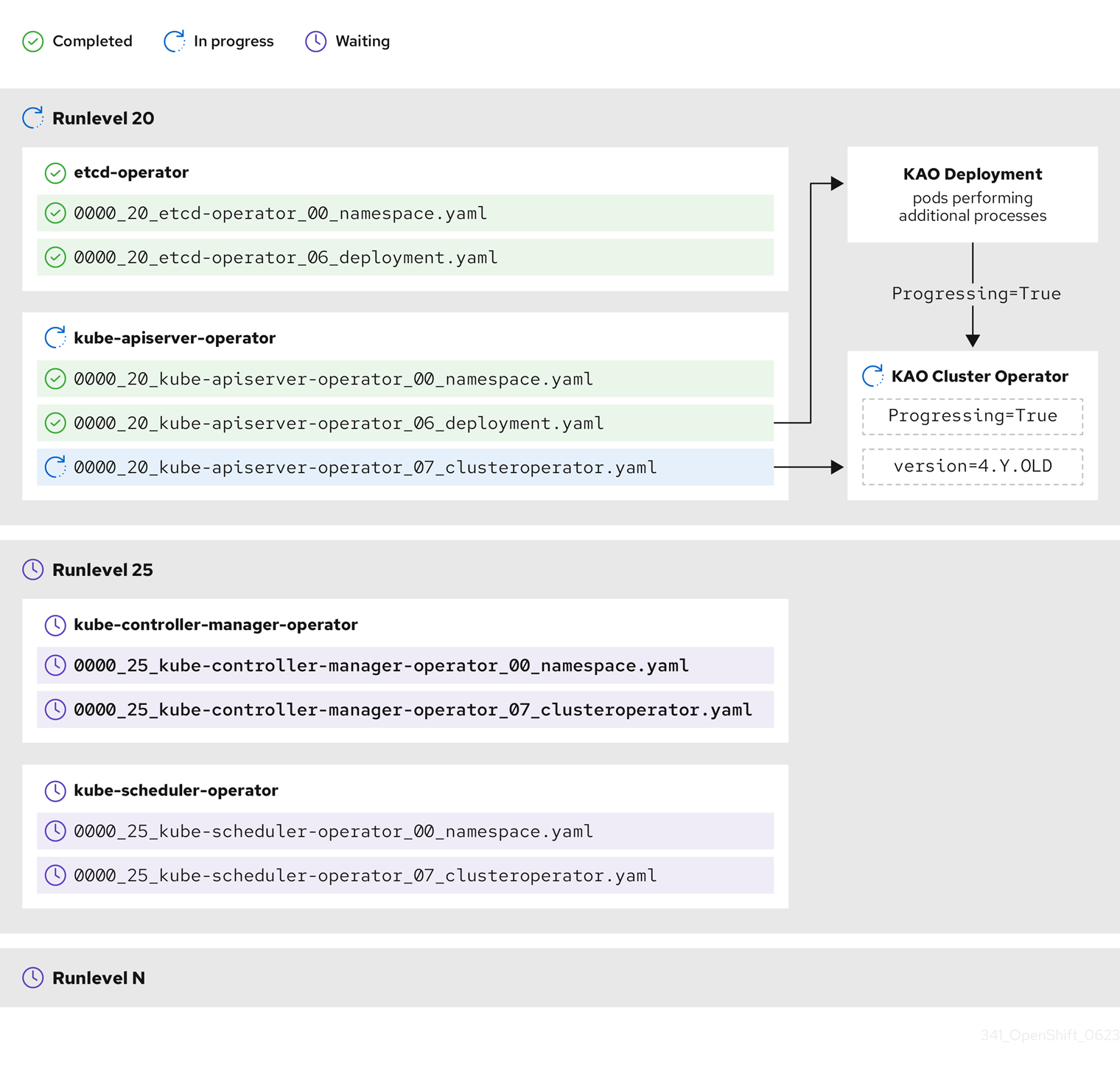
In the previous example diagram, the CVO is waiting until all work is completed at Runlevel 20. The CVO has applied all manifests to the Operators in the Runlevel, but the kube-apiserver-operator ClusterOperator performs some actions after its new version was deployed. The kube-apiserver-operator ClusterOperator declares this progress through the Progressing=True condition and by not declaring the new version as reconciled in its status.versions. The CVO waits until the ClusterOperator reports an acceptable status, and then it will start applying manifests at Runlevel 25.
3.2.5. Understanding how the Machine Config Operator updates nodes
The Machine Config Operator (MCO) applies a new machine configuration to each control plane node and compute node. During the machine configuration update, control plane nodes and compute nodes are organized into their own machine config pools, where the pools of machines are updated in parallel. The .spec.maxUnavailable parameter, which has a default value of 1, determines how many nodes in a machine config pool can simultaneously undergo the update process.
When the machine configuration update process begins, the MCO checks the amount of currently unavailable nodes in a pool. If there are fewer unavailable nodes than the value of .spec.maxUnavailable, the MCO initiates the following sequence of actions on available nodes in the pool:
Cordon and drain the node
NoteWhen a node is cordoned, workloads cannot be scheduled to it.
- Update the system configuration and operating system (OS) of the node
- Reboot the node
- Uncordon the node
A node undergoing this process is unavailable until it is uncordoned and workloads can be scheduled to it again. The MCO begins updating nodes until the number of unavailable nodes is equal to the value of .spec.maxUnavailable.
As a node completes its update and becomes available, the number of unavailable nodes in the machine config pool is once again fewer than .spec.maxUnavailable. If there are remaining nodes that need to be updated, the MCO initiates the update process on a node until the .spec.maxUnavailable limit is once again reached. This process repeats until each control plane node and compute node has been updated.
The following example workflow describes how this process might occur in a machine config pool with 5 nodes, where .spec.maxUnavailable is 3 and all nodes are initially available:
- The MCO cordons nodes 1, 2, and 3, and begins to drain them.
- Node 2 finishes draining, reboots, and becomes available again. The MCO cordons node 4 and begins draining it.
- Node 1 finishes draining, reboots, and becomes available again. The MCO cordons node 5 and begins draining it.
- Node 3 finishes draining, reboots, and becomes available again.
- Node 5 finishes draining, reboots, and becomes available again.
- Node 4 finishes draining, reboots, and becomes available again.
Because the update process for each node is independent of other nodes, some nodes in the example above finish their update out of the order in which they were cordoned by the MCO.
You can check the status of the machine configuration update by running the following command:
$ oc get mcpExample output
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE
master rendered-master-acd1358917e9f98cbdb599aea622d78b True False False 3 3 3 0 22h
worker rendered-worker-1d871ac76e1951d32b2fe92369879826 False True False 2 1 1 0 22h