Chapter 5. Control plane backup and restore
5.1. Backing up etcd
etcd is the key-value store for OpenShift Container Platform, which persists the state of all resource objects.
Back up your cluster’s etcd data regularly and store in a secure location ideally outside the OpenShift Container Platform environment. Do not take an etcd backup before the first certificate rotation completes, which occurs 24 hours after installation, otherwise the backup will contain expired certificates. It is also recommended to take etcd backups during non-peak usage hours because the etcd snapshot has a high I/O cost.
Be sure to take an etcd backup after you upgrade your cluster. This is important because when you restore your cluster, you must use an etcd backup that was taken from the same z-stream release. For example, an OpenShift Container Platform 4.y.z cluster must use an etcd backup that was taken from 4.y.z.
Back up your cluster’s etcd data by performing a single invocation of the backup script on a control plane host. Do not take a backup for each control plane host.
After you have an etcd backup, you can restore to a previous cluster state.
5.1.1. Backing up etcd data
Follow these steps to back up etcd data by creating an etcd snapshot and backing up the resources for the static pods. This backup can be saved and used at a later time if you need to restore etcd.
Only save a backup from a single control plane host. Do not take a backup from each control plane host in the cluster.
Prerequisites
-
You have access to the cluster as a user with the
cluster-adminrole. You have checked whether the cluster-wide proxy is enabled.
TipYou can check whether the proxy is enabled by reviewing the output of
oc get proxy cluster -o yaml. The proxy is enabled if thehttpProxy,httpsProxy, andnoProxyfields have values set.
Procedure
Start a debug session as root for a control plane node:
$ oc debug --as-root node/<node_name>Change your root directory to
/hostin the debug shell:sh-4.4# chroot /hostIf the cluster-wide proxy is enabled, export the
NO_PROXY,HTTP_PROXY, andHTTPS_PROXYenvironment variables by running the following commands:$ export HTTP_PROXY=http://<your_proxy.example.com>:8080$ export HTTPS_PROXY=https://<your_proxy.example.com>:8080$ export NO_PROXY=<example.com>Run the
cluster-backup.shscript in the debug shell and pass in the location to save the backup to.TipThe
cluster-backup.shscript is maintained as a component of the etcd Cluster Operator and is a wrapper around theetcdctl snapshot savecommand.sh-4.4# /usr/local/bin/cluster-backup.sh /home/core/assets/backupExample script output
found latest kube-apiserver: /etc/kubernetes/static-pod-resources/kube-apiserver-pod-6 found latest kube-controller-manager: /etc/kubernetes/static-pod-resources/kube-controller-manager-pod-7 found latest kube-scheduler: /etc/kubernetes/static-pod-resources/kube-scheduler-pod-6 found latest etcd: /etc/kubernetes/static-pod-resources/etcd-pod-3 ede95fe6b88b87ba86a03c15e669fb4aa5bf0991c180d3c6895ce72eaade54a1 etcdctl version: 3.4.14 API version: 3.4 {"level":"info","ts":1624647639.0188997,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"/home/core/assets/backup/snapshot_2021-06-25_190035.db.part"} {"level":"info","ts":"2021-06-25T19:00:39.030Z","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"} {"level":"info","ts":1624647639.0301006,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"https://10.0.0.5:2379"} {"level":"info","ts":"2021-06-25T19:00:40.215Z","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"} {"level":"info","ts":1624647640.6032252,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"https://10.0.0.5:2379","size":"114 MB","took":1.584090459} {"level":"info","ts":1624647640.6047094,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"/home/core/assets/backup/snapshot_2021-06-25_190035.db"} Snapshot saved at /home/core/assets/backup/snapshot_2021-06-25_190035.db {"hash":3866667823,"revision":31407,"totalKey":12828,"totalSize":114446336} snapshot db and kube resources are successfully saved to /home/core/assets/backupIn this example, two files are created in the
/home/core/assets/backup/directory on the control plane host:-
snapshot_<datetimestamp>.db: This file is the etcd snapshot. Thecluster-backup.shscript confirms its validity. static_kuberesources_<datetimestamp>.tar.gz: This file contains the resources for the static pods. If etcd encryption is enabled, it also contains the encryption keys for the etcd snapshot.NoteIf etcd encryption is enabled, it is recommended to store this second file separately from the etcd snapshot for security reasons. However, this file is required to restore from the etcd snapshot.
Keep in mind that etcd encryption only encrypts values, not keys. This means that resource types, namespaces, and object names are unencrypted.
-
5.2. Replacing an unhealthy etcd member
This document describes the process to replace a single unhealthy etcd member.
This process depends on whether the etcd member is unhealthy because the machine is not running or the node is not ready, or whether it is unhealthy because the etcd pod is crashlooping.
If you have lost the majority of your control plane hosts, follow the disaster recovery procedure to restore to a previous cluster state instead of this procedure.
If the control plane certificates are not valid on the member being replaced, then you must follow the procedure to recover from expired control plane certificates instead of this procedure.
If a control plane node is lost and a new one is created, the etcd cluster Operator handles generating the new TLS certificates and adding the node as an etcd member.
5.2.1. Prerequisites
- Take an etcd backup prior to replacing an unhealthy etcd member.
5.2.2. Identifying an unhealthy etcd member
You can identify if your cluster has an unhealthy etcd member.
Prerequisites
-
Access to the cluster as a user with the
cluster-adminrole.
Procedure
Check the status of the
EtcdMembersAvailablestatus condition using the following command:$ oc get etcd -o=jsonpath='{range .items[0].status.conditions[?(@.type=="EtcdMembersAvailable")]}{.message}{"\n"}{end}'Review the output:
2 of 3 members are available, ip-10-0-131-183.ec2.internal is unhealthyThis example output shows that the
ip-10-0-131-183.ec2.internaletcd member is unhealthy.
5.2.3. Determining the state of the unhealthy etcd member
The steps to replace an unhealthy etcd member depend on which of the following states your etcd member is in:
- The machine is not running or the node is not ready
- The etcd pod is crashlooping
This procedure determines which state your etcd member is in. This enables you to know which procedure to follow to replace the unhealthy etcd member.
If you are aware that the machine is not running or the node is not ready, but you expect it to return to a healthy state soon, then you do not need to perform a procedure to replace the etcd member. The etcd cluster Operator will automatically sync when the machine or node returns to a healthy state.
Prerequisites
-
You have access to the cluster as a user with the
cluster-adminrole. - You have identified an unhealthy etcd member.
Procedure
Determine if the machine is not running:
$ oc get machines -A -ojsonpath='{range .items[*]}{@.status.nodeRef.name}{"\t"}{@.status.providerStatus.instanceState}{"\n"}' | grep -v runningExample output
ip-10-0-131-183.ec2.internal stopped1 - 1
- This output lists the node and the status of the node’s machine. If the status is anything other than
running, then the machine is not running.
If the machine is not running, then follow the Replacing an unhealthy etcd member whose machine is not running or whose node is not ready procedure.
Determine if the node is not ready.
If either of the following scenarios are true, then the node is not ready.
If the machine is running, then check whether the node is unreachable:
$ oc get nodes -o jsonpath='{range .items[*]}{"\n"}{.metadata.name}{"\t"}{range .spec.taints[*]}{.key}{" "}' | grep unreachableExample output
ip-10-0-131-183.ec2.internal node-role.kubernetes.io/master node.kubernetes.io/unreachable node.kubernetes.io/unreachable1 - 1
- If the node is listed with an
unreachabletaint, then the node is not ready.
If the node is still reachable, then check whether the node is listed as
NotReady:$ oc get nodes -l node-role.kubernetes.io/master | grep "NotReady"Example output
ip-10-0-131-183.ec2.internal NotReady master 122m v1.25.01 - 1
- If the node is listed as
NotReady, then the node is not ready.
If the node is not ready, then follow the Replacing an unhealthy etcd member whose machine is not running or whose node is not ready procedure.
Determine if the etcd pod is crashlooping.
If the machine is running and the node is ready, then check whether the etcd pod is crashlooping.
Verify that all control plane nodes are listed as
Ready:$ oc get nodes -l node-role.kubernetes.io/masterExample output
NAME STATUS ROLES AGE VERSION ip-10-0-131-183.ec2.internal Ready master 6h13m v1.25.0 ip-10-0-164-97.ec2.internal Ready master 6h13m v1.25.0 ip-10-0-154-204.ec2.internal Ready master 6h13m v1.25.0Check whether the status of an etcd pod is either
ErrororCrashloopBackoff:$ oc -n openshift-etcd get pods -l k8s-app=etcdExample output
etcd-ip-10-0-131-183.ec2.internal 2/3 Error 7 6h9m1 etcd-ip-10-0-164-97.ec2.internal 3/3 Running 0 6h6m etcd-ip-10-0-154-204.ec2.internal 3/3 Running 0 6h6m- 1
- Since this status of this pod is
Error, then the etcd pod is crashlooping.
If the etcd pod is crashlooping, then follow the Replacing an unhealthy etcd member whose etcd pod is crashlooping procedure.
5.2.4. Replacing the unhealthy etcd member
Depending on the state of your unhealthy etcd member, use one of the following procedures:
5.2.4.1. Replacing an unhealthy etcd member whose machine is not running or whose node is not ready
This procedure details the steps to replace an etcd member that is unhealthy either because the machine is not running or because the node is not ready.
If your cluster uses a control plane machine set, see "Recovering a degraded etcd Operator" in "Troubleshooting the control plane machine set" for an etcd recovery procedure.
Prerequisites
- You have identified the unhealthy etcd member.
You have verified that either the machine is not running or the node is not ready.
ImportantYou must wait if the other control plane nodes are powered off. The control plane nodes must remain powered off until the replacement of an unhealthy etcd member is complete.
-
You have access to the cluster as a user with the
cluster-adminrole. You have taken an etcd backup.
ImportantBefore you perform this procedure, take an etcd backup so that you can restore your cluster if you experience any issues.
Procedure
Remove the unhealthy member.
Choose a pod that is not on the affected node:
In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc -n openshift-etcd get pods -l k8s-app=etcdExample output
etcd-ip-10-0-131-183.ec2.internal 3/3 Running 0 123m etcd-ip-10-0-164-97.ec2.internal 3/3 Running 0 123m etcd-ip-10-0-154-204.ec2.internal 3/3 Running 0 124mConnect to the running etcd container, passing in the name of a pod that is not on the affected node:
In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc rsh -n openshift-etcd etcd-ip-10-0-154-204.ec2.internalView the member list:
sh-4.2# etcdctl member list -w tableExample output
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | 6fc1e7c9db35841d | started | ip-10-0-131-183.ec2.internal | https://10.0.131.183:2380 | https://10.0.131.183:2379 | | 757b6793e2408b6c | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | ca8c2990a0aa29d1 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+Take note of the ID and the name of the unhealthy etcd member because these values are needed later in the procedure. The
$ etcdctl endpoint healthcommand will list the removed member until the procedure of replacement is finished and a new member is added.Remove the unhealthy etcd member by providing the ID to the
etcdctl member removecommand:sh-4.2# etcdctl member remove 6fc1e7c9db35841dExample output
Member 6fc1e7c9db35841d removed from cluster ead669ce1fbfb346View the member list again and verify that the member was removed:
sh-4.2# etcdctl member list -w tableExample output
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | 757b6793e2408b6c | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | ca8c2990a0aa29d1 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+You can now exit the node shell.
Turn off the quorum guard by entering the following command:
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'This command ensures that you can successfully re-create secrets and roll out the static pods.
ImportantAfter you turn off the quorum guard, the cluster might be unreachable for a short time while the remaining etcd instances reboot to reflect the configuration change.
Noteetcd cannot tolerate any additional member failure when running with two members. Restarting either remaining member breaks the quorum and causes downtime in your cluster. The quorum guard protects etcd from restarts due to configuration changes that could cause downtime, so it must be disabled to complete this procedure.
Delete the affected node by running the following command:
$ oc delete node <node_name>Example command
$ oc delete node ip-10-0-131-183.ec2.internalRemove the old secrets for the unhealthy etcd member that was removed.
List the secrets for the unhealthy etcd member that was removed.
$ oc get secrets -n openshift-etcd | grep ip-10-0-131-183.ec2.internal1 - 1
- Pass in the name of the unhealthy etcd member that you took note of earlier in this procedure.
There is a peer, serving, and metrics secret as shown in the following output:
Example output
etcd-peer-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m etcd-serving-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m etcd-serving-metrics-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47mDelete the secrets for the unhealthy etcd member that was removed.
Delete the peer secret:
$ oc delete secret -n openshift-etcd etcd-peer-ip-10-0-131-183.ec2.internalDelete the serving secret:
$ oc delete secret -n openshift-etcd etcd-serving-ip-10-0-131-183.ec2.internalDelete the metrics secret:
$ oc delete secret -n openshift-etcd etcd-serving-metrics-ip-10-0-131-183.ec2.internal
Check whether a control plane machine set exists by entering the following command:
$ oc -n openshift-machine-api get controlplanemachinesetIf the control plane machine set exists, delete and re-create the control plane machine. After this machine is re-created, a new revision is forced and etcd scales up automatically. For more information, see "Replacing an unhealthy etcd member whose machine is not running or whose node is not ready".
If you are running installer-provisioned infrastructure, or you used the Machine API to create your machines, follow these steps. Otherwise, you must create the new control plane by using the same method that was used to originally create it.
Obtain the machine for the unhealthy member.
In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc get machines -n openshift-machine-api -o wideExample output
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-0 Running m4.xlarge us-east-1 us-east-1a 3h37m ip-10-0-131-183.ec2.internal aws:///us-east-1a/i-0ec2782f8287dfb7e stopped1 clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-154-204.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-164-97.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- This is the control plane machine for the unhealthy node,
ip-10-0-131-183.ec2.internal.
Delete the machine of the unhealthy member:
$ oc delete machine -n openshift-machine-api clustername-8qw5l-master-01 - 1
- Specify the name of the control plane machine for the unhealthy node.
A new machine is automatically provisioned after deleting the machine of the unhealthy member.
Verify that a new machine was created:
$ oc get machines -n openshift-machine-api -o wideExample output
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-154-204.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-164-97.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-master-3 Provisioning m4.xlarge us-east-1 us-east-1a 85s ip-10-0-133-53.ec2.internal aws:///us-east-1a/i-015b0888fe17bc2c8 running1 clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- The new machine,
clustername-8qw5l-master-3is being created and is ready once the phase changes fromProvisioningtoRunning.
It might take a few minutes for the new machine to be created. The etcd cluster Operator automatically syncs when the machine or node returns to a healthy state.
NoteVerify the subnet IDs that you are using for your machine sets to ensure that they end up in the correct availability zone.
If the control plane machine set does not exist, delete and re-create the control plane machine. After this machine is re-created, a new revision is forced and etcd scales up automatically.
If you are running installer-provisioned infrastructure, or you used the Machine API to create your machines, follow these steps. Otherwise, you must create the new control plane by using the same method that was used to originally create it.
Obtain the machine for the unhealthy member.
In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc get machines -n openshift-machine-api -o wideExample output
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-0 Running m4.xlarge us-east-1 us-east-1a 3h37m ip-10-0-131-183.ec2.internal aws:///us-east-1a/i-0ec2782f8287dfb7e stopped1 clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-154-204.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-164-97.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- This is the control plane machine for the unhealthy node,
ip-10-0-131-183.ec2.internal.
Save the machine configuration to a file on your file system:
$ oc get machine clustername-8qw5l-master-0 \1 -n openshift-machine-api \ -o yaml \ > new-master-machine.yaml- 1
- Specify the name of the control plane machine for the unhealthy node.
Edit the
new-master-machine.yamlfile that was created in the previous step to assign a new name and remove unnecessary fields.Remove the entire
statussection:status: addresses: - address: 10.0.131.183 type: InternalIP - address: ip-10-0-131-183.ec2.internal type: InternalDNS - address: ip-10-0-131-183.ec2.internal type: Hostname lastUpdated: "2020-04-20T17:44:29Z" nodeRef: kind: Node name: ip-10-0-131-183.ec2.internal uid: acca4411-af0d-4387-b73e-52b2484295ad phase: Running providerStatus: apiVersion: awsproviderconfig.openshift.io/v1beta1 conditions: - lastProbeTime: "2020-04-20T16:53:50Z" lastTransitionTime: "2020-04-20T16:53:50Z" message: machine successfully created reason: MachineCreationSucceeded status: "True" type: MachineCreation instanceId: i-0fdb85790d76d0c3f instanceState: stopped kind: AWSMachineProviderStatusChange the
metadata.namefield to a new name.Keep the same base name as the old machine and change the ending number to the next available number. In this example,
clustername-8qw5l-master-0is changed toclustername-8qw5l-master-3.For example:
apiVersion: machine.openshift.io/v1beta1 kind: Machine metadata: ... name: clustername-8qw5l-master-3 ...Remove the
spec.providerIDfield:providerID: aws:///us-east-1a/i-0fdb85790d76d0c3f
Delete the machine of the unhealthy member:
$ oc delete machine -n openshift-machine-api clustername-8qw5l-master-01 - 1
- Specify the name of the control plane machine for the unhealthy node.
Verify that the machine was deleted:
$ oc get machines -n openshift-machine-api -o wideExample output
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-154-204.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-164-97.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a runningCreate the new machine by using the
new-master-machine.yamlfile:$ oc apply -f new-master-machine.yamlVerify that the new machine was created:
$ oc get machines -n openshift-machine-api -o wideExample output
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-154-204.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-164-97.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-master-3 Provisioning m4.xlarge us-east-1 us-east-1a 85s ip-10-0-133-53.ec2.internal aws:///us-east-1a/i-015b0888fe17bc2c8 running1 clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- The new machine,
clustername-8qw5l-master-3is being created and is ready once the phase changes fromProvisioningtoRunning.
It might take a few minutes for the new machine to be created. The etcd cluster Operator automatically syncs when the machine or node returns to a healthy state.
Turn the quorum guard back on by entering the following command:
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'You can verify that the
unsupportedConfigOverridessection is removed from the object by entering this command:$ oc get etcd/cluster -oyamlIf you are using single-node OpenShift, restart the node. Otherwise, you might encounter the following error in the etcd cluster Operator:
Example output
EtcdCertSignerControllerDegraded: [Operation cannot be fulfilled on secrets "etcd-peer-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-metrics-sno-0": the object has been modified; please apply your changes to the latest version and try again]
Verification
Verify that all etcd pods are running properly.
In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc -n openshift-etcd get pods -l k8s-app=etcdExample output
etcd-ip-10-0-133-53.ec2.internal 3/3 Running 0 7m49s etcd-ip-10-0-164-97.ec2.internal 3/3 Running 0 123m etcd-ip-10-0-154-204.ec2.internal 3/3 Running 0 124mIf the output from the previous command only lists two pods, you can manually force an etcd redeployment. In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge1 - 1
- The
forceRedeploymentReasonvalue must be unique, which is why a timestamp is appended.
Verify that there are exactly three etcd members.
Connect to the running etcd container, passing in the name of a pod that was not on the affected node:
In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc rsh -n openshift-etcd etcd-ip-10-0-154-204.ec2.internalView the member list:
sh-4.2# etcdctl member list -w tableExample output
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | 5eb0d6b8ca24730c | started | ip-10-0-133-53.ec2.internal | https://10.0.133.53:2380 | https://10.0.133.53:2379 | | 757b6793e2408b6c | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | ca8c2990a0aa29d1 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+If the output from the previous command lists more than three etcd members, you must carefully remove the unwanted member.
WarningBe sure to remove the correct etcd member; removing a good etcd member might lead to quorum loss.
5.2.4.2. Replacing an unhealthy etcd member whose etcd pod is crashlooping
This procedure details the steps to replace an etcd member that is unhealthy because the etcd pod is crashlooping.
Prerequisites
- You have identified the unhealthy etcd member.
- You have verified that the etcd pod is crashlooping.
-
You have access to the cluster as a user with the
cluster-adminrole. You have taken an etcd backup.
ImportantIt is important to take an etcd backup before performing this procedure so that your cluster can be restored if you encounter any issues.
Procedure
Stop the crashlooping etcd pod.
Debug the node that is crashlooping.
In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc debug node/ip-10-0-131-183.ec2.internal1 - 1
- Replace this with the name of the unhealthy node.
Change your root directory to
/host:sh-4.2# chroot /hostMove the existing etcd pod file out of the kubelet manifest directory:
sh-4.2# mkdir /var/lib/etcd-backupsh-4.2# mv /etc/kubernetes/manifests/etcd-pod.yaml /var/lib/etcd-backup/Move the etcd data directory to a different location:
sh-4.2# mv /var/lib/etcd/ /tmpYou can now exit the node shell.
Remove the unhealthy member.
Choose a pod that is not on the affected node.
In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc -n openshift-etcd get pods -l k8s-app=etcdExample output
etcd-ip-10-0-131-183.ec2.internal 2/3 Error 7 6h9m etcd-ip-10-0-164-97.ec2.internal 3/3 Running 0 6h6m etcd-ip-10-0-154-204.ec2.internal 3/3 Running 0 6h6mConnect to the running etcd container, passing in the name of a pod that is not on the affected node.
In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc rsh -n openshift-etcd etcd-ip-10-0-154-204.ec2.internalView the member list:
sh-4.2# etcdctl member list -w tableExample output
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | 62bcf33650a7170a | started | ip-10-0-131-183.ec2.internal | https://10.0.131.183:2380 | https://10.0.131.183:2379 | | b78e2856655bc2eb | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | d022e10b498760d5 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+Take note of the ID and the name of the unhealthy etcd member, because these values are needed later in the procedure.
Remove the unhealthy etcd member by providing the ID to the
etcdctl member removecommand:sh-4.2# etcdctl member remove 62bcf33650a7170aExample output
Member 62bcf33650a7170a removed from cluster ead669ce1fbfb346View the member list again and verify that the member was removed:
sh-4.2# etcdctl member list -w tableExample output
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | b78e2856655bc2eb | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | d022e10b498760d5 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+You can now exit the node shell.
Turn off the quorum guard by entering the following command:
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'This command ensures that you can successfully re-create secrets and roll out the static pods.
Remove the old secrets for the unhealthy etcd member that was removed.
List the secrets for the unhealthy etcd member that was removed.
$ oc get secrets -n openshift-etcd | grep ip-10-0-131-183.ec2.internal1 - 1
- Pass in the name of the unhealthy etcd member that you took note of earlier in this procedure.
There is a peer, serving, and metrics secret as shown in the following output:
Example output
etcd-peer-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m etcd-serving-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m etcd-serving-metrics-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47mDelete the secrets for the unhealthy etcd member that was removed.
Delete the peer secret:
$ oc delete secret -n openshift-etcd etcd-peer-ip-10-0-131-183.ec2.internalDelete the serving secret:
$ oc delete secret -n openshift-etcd etcd-serving-ip-10-0-131-183.ec2.internalDelete the metrics secret:
$ oc delete secret -n openshift-etcd etcd-serving-metrics-ip-10-0-131-183.ec2.internal
Force etcd redeployment.
In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "single-master-recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge1 - 1
- The
forceRedeploymentReasonvalue must be unique, which is why a timestamp is appended.
When the etcd cluster Operator performs a redeployment, it ensures that all control plane nodes have a functioning etcd pod.
Turn the quorum guard back on by entering the following command:
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'You can verify that the
unsupportedConfigOverridessection is removed from the object by entering this command:$ oc get etcd/cluster -oyamlIf you are using single-node OpenShift, restart the node. Otherwise, you might encounter the following error in the etcd cluster Operator:
Example output
EtcdCertSignerControllerDegraded: [Operation cannot be fulfilled on secrets "etcd-peer-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-metrics-sno-0": the object has been modified; please apply your changes to the latest version and try again]
Verification
Verify that the new member is available and healthy.
Connect to the running etcd container again.
In a terminal that has access to the cluster as a cluster-admin user, run the following command:
$ oc rsh -n openshift-etcd etcd-ip-10-0-154-204.ec2.internalVerify that all members are healthy:
sh-4.2# etcdctl endpoint healthExample output
https://10.0.131.183:2379 is healthy: successfully committed proposal: took = 16.671434ms https://10.0.154.204:2379 is healthy: successfully committed proposal: took = 16.698331ms https://10.0.164.97:2379 is healthy: successfully committed proposal: took = 16.621645ms
5.2.4.3. Replacing an unhealthy bare metal etcd member whose machine is not running or whose node is not ready
This procedure details the steps to replace a bare metal etcd member that is unhealthy either because the machine is not running or because the node is not ready.
If you are running installer-provisioned infrastructure or you used the Machine API to create your machines, follow these steps. Otherwise you must create the new control plane node using the same method that was used to originally create it.
Prerequisites
- You have identified the unhealthy bare metal etcd member.
- You have verified that either the machine is not running or the node is not ready.
-
You have access to the cluster as a user with the
cluster-adminrole. You have taken an etcd backup.
ImportantYou must take an etcd backup before performing this procedure so that your cluster can be restored if you encounter any issues.
Procedure
Verify and remove the unhealthy member.
Choose a pod that is not on the affected node:
In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc -n openshift-etcd get pods -l k8s-app=etcd -o wideExample output
etcd-openshift-control-plane-0 5/5 Running 11 3h56m 192.168.10.9 openshift-control-plane-0 <none> <none> etcd-openshift-control-plane-1 5/5 Running 0 3h54m 192.168.10.10 openshift-control-plane-1 <none> <none> etcd-openshift-control-plane-2 5/5 Running 0 3h58m 192.168.10.11 openshift-control-plane-2 <none> <none>Connect to the running etcd container, passing in the name of a pod that is not on the affected node:
In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc rsh -n openshift-etcd etcd-openshift-control-plane-0View the member list:
sh-4.2# etcdctl member list -w tableExample output
+------------------+---------+--------------------+---------------------------+---------------------------+---------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+--------------------+---------------------------+---------------------------+---------------------+ | 7a8197040a5126c8 | started | openshift-control-plane-2 | https://192.168.10.11:2380/ | https://192.168.10.11:2379/ | false | | 8d5abe9669a39192 | started | openshift-control-plane-1 | https://192.168.10.10:2380/ | https://192.168.10.10:2379/ | false | | cc3830a72fc357f9 | started | openshift-control-plane-0 | https://192.168.10.9:2380/ | https://192.168.10.9:2379/ | false | +------------------+---------+--------------------+---------------------------+---------------------------+---------------------+Take note of the ID and the name of the unhealthy etcd member, because these values are required later in the procedure. The
etcdctl endpoint healthcommand will list the removed member until the replacement procedure is completed and the new member is added.Remove the unhealthy etcd member by providing the ID to the
etcdctl member removecommand:WarningBe sure to remove the correct etcd member; removing a good etcd member might lead to quorum loss.
sh-4.2# etcdctl member remove 7a8197040a5126c8Example output
Member 7a8197040a5126c8 removed from cluster b23536c33f2cdd1bView the member list again and verify that the member was removed:
sh-4.2# etcdctl member list -w tableExample output
+------------------+---------+--------------------+---------------------------+---------------------------+-------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+--------------------+---------------------------+---------------------------+-------------------------+ | cc3830a72fc357f9 | started | openshift-control-plane-2 | https://192.168.10.11:2380/ | https://192.168.10.11:2379/ | false | | 8d5abe9669a39192 | started | openshift-control-plane-1 | https://192.168.10.10:2380/ | https://192.168.10.10:2379/ | false | +------------------+---------+--------------------+---------------------------+---------------------------+-------------------------+You can now exit the node shell.
ImportantAfter you remove the member, the cluster might be unreachable for a short time while the remaining etcd instances reboot.
Turn off the quorum guard by entering the following command:
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'This command ensures that you can successfully re-create secrets and roll out the static pods.
Remove the old secrets for the unhealthy etcd member that was removed by running the following commands.
List the secrets for the unhealthy etcd member that was removed.
$ oc get secrets -n openshift-etcd | grep openshift-control-plane-2Pass in the name of the unhealthy etcd member that you took note of earlier in this procedure.
There is a peer, serving, and metrics secret as shown in the following output:
etcd-peer-openshift-control-plane-2 kubernetes.io/tls 2 134m etcd-serving-metrics-openshift-control-plane-2 kubernetes.io/tls 2 134m etcd-serving-openshift-control-plane-2 kubernetes.io/tls 2 134mDelete the secrets for the unhealthy etcd member that was removed.
Delete the peer secret:
$ oc delete secret etcd-peer-openshift-control-plane-2 -n openshift-etcd secret "etcd-peer-openshift-control-plane-2" deletedDelete the serving secret:
$ oc delete secret etcd-serving-metrics-openshift-control-plane-2 -n openshift-etcd secret "etcd-serving-metrics-openshift-control-plane-2" deletedDelete the metrics secret:
$ oc delete secret etcd-serving-openshift-control-plane-2 -n openshift-etcd secret "etcd-serving-openshift-control-plane-2" deleted
Obtain the machine for the unhealthy member.
In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc get machines -n openshift-machine-api -o wideExample output
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE examplecluster-control-plane-0 Running 3h11m openshift-control-plane-0 baremetalhost:///openshift-machine-api/openshift-control-plane-0/da1ebe11-3ff2-41c5-b099-0aa41222964e externally provisioned1 examplecluster-control-plane-1 Running 3h11m openshift-control-plane-1 baremetalhost:///openshift-machine-api/openshift-control-plane-1/d9f9acbc-329c-475e-8d81-03b20280a3e1 externally provisioned examplecluster-control-plane-2 Running 3h11m openshift-control-plane-2 baremetalhost:///openshift-machine-api/openshift-control-plane-2/3354bdac-61d8-410f-be5b-6a395b056135 externally provisioned examplecluster-compute-0 Running 165m openshift-compute-0 baremetalhost:///openshift-machine-api/openshift-compute-0/3d685b81-7410-4bb3-80ec-13a31858241f provisioned examplecluster-compute-1 Running 165m openshift-compute-1 baremetalhost:///openshift-machine-api/openshift-compute-1/0fdae6eb-2066-4241-91dc-e7ea72ab13b9 provisioned- 1
- This is the control plane machine for the unhealthy node,
examplecluster-control-plane-2.
Ensure that the Bare Metal Operator is available by running the following command:
$ oc get clusteroperator baremetalExample output
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE baremetal 4.12.0 True False False 3d15hRemove the old
BareMetalHostobject by running the following command:$ oc delete bmh openshift-control-plane-2 -n openshift-machine-apiExample output
baremetalhost.metal3.io "openshift-control-plane-2" deletedDelete the machine of the unhealthy member by running the following command:
$ oc delete machine -n openshift-machine-api examplecluster-control-plane-2After you remove the
BareMetalHostandMachineobjects, then theMachinecontroller automatically deletes theNodeobject.If deletion of the machine is delayed for any reason or the command is obstructed and delayed, you can force deletion by removing the machine object finalizer field.
ImportantDo not interrupt machine deletion by pressing
Ctrl+c. You must allow the command to proceed to completion. Open a new terminal window to edit and delete the finalizer fields.A new machine is automatically provisioned after deleting the machine of the unhealthy member.
Edit the machine configuration by running the following command:
$ oc edit machine -n openshift-machine-api examplecluster-control-plane-2Delete the following fields in the
Machinecustom resource, and then save the updated file:finalizers: - machine.machine.openshift.ioExample output
machine.machine.openshift.io/examplecluster-control-plane-2 edited
Verify that the machine was deleted by running the following command:
$ oc get machines -n openshift-machine-api -o wideExample output
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE examplecluster-control-plane-0 Running 3h11m openshift-control-plane-0 baremetalhost:///openshift-machine-api/openshift-control-plane-0/da1ebe11-3ff2-41c5-b099-0aa41222964e externally provisioned examplecluster-control-plane-1 Running 3h11m openshift-control-plane-1 baremetalhost:///openshift-machine-api/openshift-control-plane-1/d9f9acbc-329c-475e-8d81-03b20280a3e1 externally provisioned examplecluster-compute-0 Running 165m openshift-compute-0 baremetalhost:///openshift-machine-api/openshift-compute-0/3d685b81-7410-4bb3-80ec-13a31858241f provisioned examplecluster-compute-1 Running 165m openshift-compute-1 baremetalhost:///openshift-machine-api/openshift-compute-1/0fdae6eb-2066-4241-91dc-e7ea72ab13b9 provisionedVerify that the node has been deleted by running the following command:
$ oc get nodes NAME STATUS ROLES AGE VERSION openshift-control-plane-0 Ready master 3h24m v1.25.0 openshift-control-plane-1 Ready master 3h24m v1.25.0 openshift-compute-0 Ready worker 176m v1.25.0 openshift-compute-1 Ready worker 176m v1.25.0Create the new
BareMetalHostobject and the secret to store the BMC credentials:$ cat <<EOF | oc apply -f - apiVersion: v1 kind: Secret metadata: name: openshift-control-plane-2-bmc-secret namespace: openshift-machine-api data: password: <password> username: <username> type: Opaque --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: openshift-control-plane-2 namespace: openshift-machine-api spec: automatedCleaningMode: disabled bmc: address: redfish://10.46.61.18:443/redfish/v1/Systems/1 credentialsName: openshift-control-plane-2-bmc-secret disableCertificateVerification: true bootMACAddress: 48:df:37:b0:8a:a0 bootMode: UEFI externallyProvisioned: false online: true rootDeviceHints: deviceName: /dev/sda userData: name: master-user-data-managed namespace: openshift-machine-api EOFNoteThe username and password can be found from the other bare metal host’s secrets. The protocol to use in
bmc:addresscan be taken from other bmh objects.ImportantIf you reuse the
BareMetalHostobject definition from an existing control plane host, do not leave theexternallyProvisionedfield set totrue.Existing control plane
BareMetalHostobjects may have theexternallyProvisionedflag set totrueif they were provisioned by the OpenShift Container Platform installation program.After the inspection is complete, the
BareMetalHostobject is created and available to be provisioned.Verify the creation process using available
BareMetalHostobjects:$ oc get bmh -n openshift-machine-api NAME STATE CONSUMER ONLINE ERROR AGE openshift-control-plane-0 externally provisioned examplecluster-control-plane-0 true 4h48m openshift-control-plane-1 externally provisioned examplecluster-control-plane-1 true 4h48m openshift-control-plane-2 available examplecluster-control-plane-3 true 47m openshift-compute-0 provisioned examplecluster-compute-0 true 4h48m openshift-compute-1 provisioned examplecluster-compute-1 true 4h48mVerify that a new machine has been created:
$ oc get machines -n openshift-machine-api -o wideExample output
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE examplecluster-control-plane-0 Running 3h11m openshift-control-plane-0 baremetalhost:///openshift-machine-api/openshift-control-plane-0/da1ebe11-3ff2-41c5-b099-0aa41222964e externally provisioned1 examplecluster-control-plane-1 Running 3h11m openshift-control-plane-1 baremetalhost:///openshift-machine-api/openshift-control-plane-1/d9f9acbc-329c-475e-8d81-03b20280a3e1 externally provisioned examplecluster-control-plane-2 Running 3h11m openshift-control-plane-2 baremetalhost:///openshift-machine-api/openshift-control-plane-2/3354bdac-61d8-410f-be5b-6a395b056135 externally provisioned examplecluster-compute-0 Running 165m openshift-compute-0 baremetalhost:///openshift-machine-api/openshift-compute-0/3d685b81-7410-4bb3-80ec-13a31858241f provisioned examplecluster-compute-1 Running 165m openshift-compute-1 baremetalhost:///openshift-machine-api/openshift-compute-1/0fdae6eb-2066-4241-91dc-e7ea72ab13b9 provisioned- 1
- The new machine,
clustername-8qw5l-master-3is being created and is ready after the phase changes fromProvisioningtoRunning.
It should take a few minutes for the new machine to be created. The etcd cluster Operator will automatically sync when the machine or node returns to a healthy state.
Verify that the bare metal host becomes provisioned and no error reported by running the following command:
$ oc get bmh -n openshift-machine-apiExample output
$ oc get bmh -n openshift-machine-api NAME STATE CONSUMER ONLINE ERROR AGE openshift-control-plane-0 externally provisioned examplecluster-control-plane-0 true 4h48m openshift-control-plane-1 externally provisioned examplecluster-control-plane-1 true 4h48m openshift-control-plane-2 provisioned examplecluster-control-plane-3 true 47m openshift-compute-0 provisioned examplecluster-compute-0 true 4h48m openshift-compute-1 provisioned examplecluster-compute-1 true 4h48mVerify that the new node is added and in a ready state by running this command:
$ oc get nodesExample output
$ oc get nodes NAME STATUS ROLES AGE VERSION openshift-control-plane-0 Ready master 4h26m v1.25.0 openshift-control-plane-1 Ready master 4h26m v1.25.0 openshift-control-plane-2 Ready master 12m v1.25.0 openshift-compute-0 Ready worker 3h58m v1.25.0 openshift-compute-1 Ready worker 3h58m v1.25.0
Turn the quorum guard back on by entering the following command:
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'You can verify that the
unsupportedConfigOverridessection is removed from the object by entering this command:$ oc get etcd/cluster -oyamlIf you are using single-node OpenShift, restart the node. Otherwise, you might encounter the following error in the etcd cluster Operator:
Example output
EtcdCertSignerControllerDegraded: [Operation cannot be fulfilled on secrets "etcd-peer-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-metrics-sno-0": the object has been modified; please apply your changes to the latest version and try again]
Verification
Verify that all etcd pods are running properly.
In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc -n openshift-etcd get pods -l k8s-app=etcdExample output
etcd-openshift-control-plane-0 5/5 Running 0 105m etcd-openshift-control-plane-1 5/5 Running 0 107m etcd-openshift-control-plane-2 5/5 Running 0 103mIf the output from the previous command only lists two pods, you can manually force an etcd redeployment. In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge1 - 1
- The
forceRedeploymentReasonvalue must be unique, which is why a timestamp is appended.
To verify there are exactly three etcd members, connect to the running etcd container, passing in the name of a pod that was not on the affected node. In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc rsh -n openshift-etcd etcd-openshift-control-plane-0View the member list:
sh-4.2# etcdctl member list -w tableExample output
+------------------+---------+--------------------+---------------------------+---------------------------+-----------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+--------------------+---------------------------+---------------------------+-----------------+ | 7a8197040a5126c8 | started | openshift-control-plane-2 | https://192.168.10.11:2380 | https://192.168.10.11:2379 | false | | 8d5abe9669a39192 | started | openshift-control-plane-1 | https://192.168.10.10:2380 | https://192.168.10.10:2379 | false | | cc3830a72fc357f9 | started | openshift-control-plane-0 | https://192.168.10.9:2380 | https://192.168.10.9:2379 | false | +------------------+---------+--------------------+---------------------------+---------------------------+-----------------+NoteIf the output from the previous command lists more than three etcd members, you must carefully remove the unwanted member.
Verify that all etcd members are healthy by running the following command:
# etcdctl endpoint health --clusterExample output
https://192.168.10.10:2379 is healthy: successfully committed proposal: took = 8.973065ms https://192.168.10.9:2379 is healthy: successfully committed proposal: took = 11.559829ms https://192.168.10.11:2379 is healthy: successfully committed proposal: took = 11.665203msValidate that all nodes are at the latest revision by running the following command:
$ oc get etcd -o=jsonpath='{range.items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'AllNodesAtLatestRevision
5.3. Backing up and restoring etcd on a hosted cluster
If you use hosted control planes on OpenShift Container Platform, the process to back up and restore etcd is different from the usual etcd backup process.
Hosted control planes is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
For more information about the support scope of Red Hat Technology Preview features, see Technology Preview Features Support Scope.
5.3.1. Taking a snapshot of etcd on a hosted cluster
As part of the process to back up etcd for a hosted cluster, you take a snapshot of etcd. After you take the snapshot, you can restore it, for example, as part of a disaster recovery operation.
This procedure requires API downtime.
Procedure
Pause reconciliation of the hosted cluster by entering this command:
$ oc patch -n clusters hostedclusters/${CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=mergeStop all etcd-writer deployments by entering this command:
$ oc scale deployment -n ${HOSTED_CLUSTER_NAMESPACE} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserverTake an etcd snapshot by using the
execcommand in each etcd container:$ oc exec -it etcd-0 -n ${HOSTED_CLUSTER_NAMESPACE} -- env ETCDCTL_API=3 /usr/bin/etcdctl --cacert /etc/etcd/tls/client/etcd-client-ca.crt --cert /etc/etcd/tls/client/etcd-client.crt --key /etc/etcd/tls/client/etcd-client.key --endpoints=localhost:2379 snapshot save /var/lib/data/snapshot.db $ oc exec -it etcd-0 -n ${HOSTED_CLUSTER_NAMESPACE} -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/data/snapshot.dbCopy the snapshot data to a location where you can retrieve it later, such as an S3 bucket, as shown in the following example.
NoteThe following example uses signature version 2. If you are in a region that supports signature version 4, such as the us-east-2 region, use signature version 4. Otherwise, if you use signature version 2 to copy the snapshot to an S3 bucket, the upload fails and signature version 2 is deprecated.
Example
BUCKET_NAME=somebucket FILEPATH="/${BUCKET_NAME}/${CLUSTER_NAME}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" ACCESS_KEY=accesskey SECRET_KEY=secret SIGNATURE_HASH=`echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac ${SECRET_KEY} -binary | base64` oc exec -it etcd-0 -n ${HOSTED_CLUSTER_NAMESPACE} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${CLUSTER_NAME}-snapshot.dbIf you want to be able to restore the snapshot on a new cluster later, save the encryption secret that the hosted cluster references, as shown in this example:
Example
oc get hostedcluster $CLUSTER_NAME -o=jsonpath='{.spec.secretEncryption.aescbc}' {"activeKey":{"name":"CLUSTER_NAME-etcd-encryption-key"}} # Save this secret, or the key it contains so the etcd data can later be decrypted oc get secret ${CLUSTER_NAME}-etcd-encryption-key -o=jsonpath='{.data.key}'
Next steps
Restore the etcd snapshot.
5.3.2. Restoring an etcd snapshot on a hosted cluster
If you have a snapshot of etcd from your hosted cluster, you can restore it. Currently, you can restore an etcd snapshot only during cluster creation.
To restore an etcd snapshot, you modify the output from the create cluster --render command and define a restoreSnapshotURL value in the etcd section of the HostedCluster specification.
Prerequisites
You took an etcd snapshot on a hosted cluster.
Procedure
On the
awscommand-line interface (CLI), create a pre-signed URL so that you can download your etcd snapshot from S3 without passing credentials to the etcd deployment:ETCD_SNAPSHOT=${ETCD_SNAPSHOT:-"s3://${BUCKET_NAME}/${CLUSTER_NAME}-snapshot.db"} ETCD_SNAPSHOT_URL=$(aws s3 presign ${ETCD_SNAPSHOT})Modify the
HostedClusterspecification to refer to the URL:spec: etcd: managed: storage: persistentVolume: size: 4Gi type: PersistentVolume restoreSnapshotURL: - "${ETCD_SNAPSHOT_URL}" managementType: Managed-
Ensure that the secret that you referenced from the
spec.secretEncryption.aescbcvalue contains the same AES key that you saved in the previous steps.
5.4. Disaster recovery
5.4.1. About disaster recovery
The disaster recovery documentation provides information for administrators on how to recover from several disaster situations that might occur with their OpenShift Container Platform cluster. As an administrator, you might need to follow one or more of the following procedures to return your cluster to a working state.
Disaster recovery requires you to have at least one healthy control plane host.
- Restoring to a previous cluster state
This solution handles situations where you want to restore your cluster to a previous state, for example, if an administrator deletes something critical. This also includes situations where you have lost the majority of your control plane hosts, leading to etcd quorum loss and the cluster going offline. As long as you have taken an etcd backup, you can follow this procedure to restore your cluster to a previous state.
If applicable, you might also need to recover from expired control plane certificates.
WarningRestoring to a previous cluster state is a destructive and destablizing action to take on a running cluster. This procedure should only be used as a last resort.
Prior to performing a restore, see About restoring cluster state for more information on the impact to the cluster.
NoteIf you have a majority of your masters still available and have an etcd quorum, then follow the procedure to replace a single unhealthy etcd member.
- Recovering from expired control plane certificates
- This solution handles situations where your control plane certificates have expired. For example, if you shut down your cluster before the first certificate rotation, which occurs 24 hours after installation, your certificates will not be rotated and will expire. You can follow this procedure to recover from expired control plane certificates.
5.4.2. Restoring to a previous cluster state
To restore the cluster to a previous state, you must have previously backed up the etcd data by creating a snapshot. You will use this snapshot to restore the cluster state. For more information, see "Backing up etcd data".
5.4.2.1. About restoring cluster state
You can use an etcd backup to restore your cluster to a previous state. This can be used to recover from the following situations:
- The cluster has lost the majority of control plane hosts (quorum loss).
- An administrator has deleted something critical and must restore to recover the cluster.
Restoring to a previous cluster state is a destructive and destablizing action to take on a running cluster. This should only be used as a last resort.
If you are able to retrieve data using the Kubernetes API server, then etcd is available and you should not restore using an etcd backup.
Restoring etcd effectively takes a cluster back in time and all clients will experience a conflicting, parallel history. This can impact the behavior of watching components like kubelets, Kubernetes controller managers, SDN controllers, and persistent volume controllers.
It can cause Operator churn when the content in etcd does not match the actual content on disk, causing Operators for the Kubernetes API server, Kubernetes controller manager, Kubernetes scheduler, and etcd to get stuck when files on disk conflict with content in etcd. This can require manual actions to resolve the issues.
In extreme cases, the cluster can lose track of persistent volumes, delete critical workloads that no longer exist, reimage machines, and rewrite CA bundles with expired certificates.
5.4.2.2. Restoring to a previous cluster state
You can use a saved etcd backup to restore a previous cluster state or restore a cluster that has lost the majority of control plane hosts.
If your cluster uses a control plane machine set, see "Recovering a degraded etcd Operator" in "Troubleshooting the control plane machine set" for an etcd recovery procedure.
When you restore your cluster, you must use an etcd backup that was taken from the same z-stream release. For example, an OpenShift Container Platform 4.7.2 cluster must use an etcd backup that was taken from 4.7.2.
Prerequisites
-
Access to the cluster as a user with the
cluster-adminrole through a certificate-basedkubeconfigfile, like the one that was used during installation. - A healthy control plane host to use as the recovery host.
- SSH access to control plane hosts.
-
A backup directory containing both the etcd snapshot and the resources for the static pods, which were from the same backup. The file names in the directory must be in the following formats:
snapshot_<datetimestamp>.dbandstatic_kuberesources_<datetimestamp>.tar.gz.
For non-recovery control plane nodes, it is not required to establish SSH connectivity or to stop the static pods. You can delete and recreate other non-recovery, control plane machines, one by one.
Procedure
- Select a control plane host to use as the recovery host. This is the host that you will run the restore operation on.
Establish SSH connectivity to each of the control plane nodes, including the recovery host.
kube-apiserverbecomes inaccessible after the restore process starts, so you cannot access the control plane nodes. For this reason, it is recommended to establish SSH connectivity to each control plane host in a separate terminal.ImportantIf you do not complete this step, you will not be able to access the control plane hosts to complete the restore procedure, and you will be unable to recover your cluster from this state.
Copy the
etcdbackup directory to the recovery control plane host.This procedure assumes that you copied the
backupdirectory containing theetcdsnapshot and the resources for the static pods to the/home/core/directory of your recovery control plane host.Stop the static pods on any other control plane nodes.
NoteYou do not need to stop the static pods on the recovery host.
- Access a control plane host that is not the recovery host.
Move the existing
etcdpod file out of the kubelet manifest directory by running:$ sudo mv -v /etc/kubernetes/manifests/etcd-pod.yaml /tmpVerify that the
etcdpods are stopped by using:$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"If the output of this command is not empty, wait a few minutes and check again.
Move the existing Kubernetes API server pod file out of the kubelet manifest directory by running:
$ sudo mv -v /etc/kubernetes/manifests/kube-apiserver-pod.yaml /tmpVerify that the
kube-apiservercontainers are stopped by running:$ sudo crictl ps | grep kube-apiserver | egrep -v "operator|guard"If the output of this command is not empty, wait a few minutes and check again.
Move the existing
kube-controller-managerfile out of the kubelet manifest directory by using:$ sudo mv -v /etc/kubernetes/manifests/kube-controller-manager-pod.yaml /tmpVerify that the
kube-controller-managercontainers are stopped by running:$ sudo crictl ps | grep kube-controller-manager | egrep -v "operator|guard"If the output of this command is not empty, wait a few minutes and check again.
Move the existing
kube-schedulerfile out of the kubelet manifest directory by using:$ sudo mv -v /etc/kubernetes/manifests/kube-scheduler-pod.yaml /tmpVerify that the
kube-schedulercontainers are stopped by using:$ sudo crictl ps | grep kube-scheduler | egrep -v "operator|guard"Move the etcd data directory to a different location with the following example:
$ sudo mv -v /var/lib/etcd/ /tmpIf the
/etc/kubernetes/manifests/keepalived.yamlfile exists and the node is deleted, follow these steps:Move the
/etc/kubernetes/manifests/keepalived.yamlfile out of the kubelet manifest directory:$ sudo mv -v /etc/kubernetes/manifests/keepalived.yaml /tmpVerify that any containers managed by the
keepaliveddaemon are stopped:$ sudo crictl ps --name keepalivedThe output of this command should be empty. If it is not empty, wait for a few minutes and check again.
Check if the control plane has any Virtual IPs (VIPs) assigned to it:
$ ip -o address | egrep '<api_vip>|<ingress_vip>'For each reported VIP, run the following command to remove it:
$ ip -o address | grep <api_vip>
- Repeat this step on each of the other control plane hosts that is not the recovery host.
- Access the recovery control plane host.
If the
keepaliveddaemon is in use, verify that the recovery control plane node owns the VIP by using the following:$ ip -o address | grep <api_vip>The address of the VIP is highlighted in the output if it exists. This command returns an empty string if the VIP is not set or configured incorrectly.
If the cluster-wide proxy is enabled, be sure that you have exported the
NO_PROXY,HTTP_PROXY, andHTTPS_PROXYenvironment variables.TipYou can check whether the proxy is enabled by reviewing the output of
oc get proxy cluster -o yaml. The proxy is enabled if thehttpProxy,httpsProxy, andnoProxyfields have values set.Run the restore script on the recovery control plane host and pass in the path to the
etcdbackup directory:$ sudo -E /usr/local/bin/cluster-restore.sh /home/core/assets/backupExample script output
...stopping kube-scheduler-pod.yaml ...stopping kube-controller-manager-pod.yaml ...stopping etcd-pod.yaml ...stopping kube-apiserver-pod.yaml Waiting for container etcd to stop .complete Waiting for container etcdctl to stop .............................complete Waiting for container etcd-metrics to stop complete Waiting for container kube-controller-manager to stop complete Waiting for container kube-apiserver to stop ..........................................................................................complete Waiting for container kube-scheduler to stop complete Moving etcd data-dir /var/lib/etcd/member to /var/lib/etcd-backup starting restore-etcd static pod starting kube-apiserver-pod.yaml static-pod-resources/kube-apiserver-pod-7/kube-apiserver-pod.yaml starting kube-controller-manager-pod.yaml static-pod-resources/kube-controller-manager-pod-7/kube-controller-manager-pod.yaml starting kube-scheduler-pod.yaml static-pod-resources/kube-scheduler-pod-8/kube-scheduler-pod.yamlThe cluster-restore.sh script must show that
etcd,kube-apiserver,kube-controller-manager, andkube-schedulerpods are stopped and then started at the end of the restore process.NoteThe restore process can cause nodes to enter the
NotReadystate if the node certificates were updated after the last etcd backup.Check the nodes to ensure they are in the
Readystate.Run the following command:
$ oc get nodes -wSample output
NAME STATUS ROLES AGE VERSION host-172-25-75-28 Ready master 3d20h v1.25.0 host-172-25-75-38 Ready infra,worker 3d20h v1.25.0 host-172-25-75-40 Ready master 3d20h v1.25.0 host-172-25-75-65 Ready master 3d20h v1.25.0 host-172-25-75-74 Ready infra,worker 3d20h v1.25.0 host-172-25-75-79 Ready worker 3d20h v1.25.0 host-172-25-75-86 Ready worker 3d20h v1.25.0 host-172-25-75-98 Ready infra,worker 3d20h v1.25.0It can take several minutes for all nodes to report their state.
If any nodes are in the
NotReadystate, log in to the nodes and remove all of the PEM files from the/var/lib/kubelet/pkidirectory on each node. You can SSH into the nodes or use the terminal window in the web console.$ ssh -i <ssh-key-path> core@<master-hostname>Sample
pkidirectorysh-4.4# pwd /var/lib/kubelet/pki sh-4.4# ls kubelet-client-2022-04-28-11-24-09.pem kubelet-server-2022-04-28-11-24-15.pem kubelet-client-current.pem kubelet-server-current.pem
Restart the kubelet service on all control plane hosts.
From the recovery host, run the following command:
$ sudo systemctl restart kubelet.service- Repeat this step on all other control plane hosts.
Approve the pending CSRs:
NoteClusters with no worker nodes, such as single-node clusters or clusters consisting of three schedulable control plane nodes, will not have any pending CSRs to approve. You can skip all the commands listed in this step.
Get the list of current CSRs:
$ oc get csrExample output
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-2s94x 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending1 csr-4bd6t 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending2 csr-4hl85 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending3 csr-zhhhp 3m8s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending4 ...Review the details of a CSR to verify that it is valid by running:
$ oc describe csr <csr_name>1 - 1
<csr_name>is the name of a CSR from the list of current CSRs.
Approve each valid
node-bootstrapperCSR:$ oc adm certificate approve <csr_name>For user-provisioned installations, approve each valid kubelet service CSR by running:
$ oc adm certificate approve <csr_name>
Verify that the single member control plane has started successfully.
From the recovery host, verify that the
etcdcontainer is running by using:$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"Example output
3ad41b7908e32 36f86e2eeaaffe662df0d21041eb22b8198e0e58abeeae8c743c3e6e977e8009 About a minute ago Running etcd 0 7c05f8af362f0From the recovery host, verify that the etcd pod is running by using:
$ oc -n openshift-etcd get pods -l k8s-app=etcdExample output
NAME READY STATUS RESTARTS AGE etcd-ip-10-0-143-125.ec2.internal 1/1 Running 1 2m47sIf the status is
Pending, or the output lists more than one runningetcdpod, wait a few minutes and check again.
If you are using the
OVNKubernetesnetwork plugin, delete the node objects that are associated with control plane hosts that are not the recovery control plane host by using the following command:$ oc delete node <non-recovery-controlplane-host-1> <non-recovery-controlplane-host-2>Verify that the Cluster Network Operator (CNO) redeploys the OVN-Kubernetes control plane and that it no longer references the non-recovery controller IP addresses. To verify this result, regularly check the output of the following command. Wait until it returns an empty result before you proceed to restart the Open Virtual Network (OVN) Kubernetes pods on all of the hosts in the next step:
$ oc -n openshift-ovn-kubernetes get ds/ovnkube-master -o yaml | grep -E '<non-recovery_controller_ip_1>|<non-recovery_controller_ip_2>'NoteIt can take at least 5-10 minutes for the OVN-Kubernetes control plane to be redeployed and the previous command to return empty output.
Restart the Open Virtual Network (OVN) Kubernetes pods on all the hosts.
NoteValidating and mutating admission webhooks can reject pods. If you add any additional webhooks with the
failurePolicyset toFail, then they can reject pods and the restoration process can fail. You can avoid this by saving and deleting webhooks while restoring the cluster state. After the cluster state is restored successfully, you can enable the webhooks again.Alternatively, you can temporarily set the
failurePolicytoIgnorewhile restoring the cluster state. After the cluster state is restored successfully, you can set thefailurePolicytoFail.Remove the northbound database (nbdb) and southbound database (sbdb). Access the recovery host and the remaining control plane nodes by using Secure Shell (SSH) and run the following command:
$ sudo rm -f /var/lib/ovn/etc/*.dbDelete all OVN-Kubernetes control plane pods by running the following command:
$ oc delete pods -l app=ovnkube-master -n openshift-ovn-kubernetesEnsure that any OVN-Kubernetes control plane pods are deployed again and are in a
Runningstate by running the following command:$ oc get pods -l app=ovnkube-master -n openshift-ovn-kubernetesExample output
NAME READY STATUS RESTARTS AGE ovnkube-master-nb24h 4/4 Running 0 48sDelete all
ovnkube-nodepods by running the following command:$ oc get pods -n openshift-ovn-kubernetes -o name | grep ovnkube-node | while read p ; do oc delete $p -n openshift-ovn-kubernetes ; doneEnsure that all the
ovnkube-nodepods are deployed again and are in aRunningstate by running the following command:$ oc get pods -n openshift-ovn-kubernetes | grep ovnkube-node
Delete and re-create other non-recovery, control plane machines, one by one. After the machines are re-created, a new revision is forced and etcd automatically scales up.
If you use a user-provisioned bare metal installation, you can re-create a control plane machine by using the same method that you used to originally create it. For more information, see "Installing a user-provisioned cluster on bare metal".
WarningDo not delete and re-create the machine for the recovery host.
If you are running installer-provisioned infrastructure, or you used the Machine API to create your machines, follow these steps:
WarningDo not delete and re-create the machine for the recovery host.
For bare metal installations on installer-provisioned infrastructure, control plane machines are not re-created. For more information, see "Replacing a bare-metal control plane node".
Obtain the machine for one of the lost control plane hosts.
In a terminal that has access to the cluster as a cluster-admin user, run the following command:
$ oc get machines -n openshift-machine-api -o wideExample output:
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-0 Running m4.xlarge us-east-1 us-east-1a 3h37m ip-10-0-131-183.ec2.internal aws:///us-east-1a/i-0ec2782f8287dfb7e stopped1 clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- This is the control plane machine for the lost control plane host,
ip-10-0-131-183.ec2.internal.
Save the machine configuration to a file on your file system by running:
$ oc get machine clustername-8qw5l-master-0 \1 -n openshift-machine-api \ -o yaml \ > new-master-machine.yaml- 1
- Specify the name of the control plane machine for the lost control plane host.
Edit the
new-master-machine.yamlfile that was created in the previous step to assign a new name and remove unnecessary fields.Remove the entire
statussection:status: addresses: - address: 10.0.131.183 type: InternalIP - address: ip-10-0-131-183.ec2.internal type: InternalDNS - address: ip-10-0-131-183.ec2.internal type: Hostname lastUpdated: "2020-04-20T17:44:29Z" nodeRef: kind: Node name: ip-10-0-131-183.ec2.internal uid: acca4411-af0d-4387-b73e-52b2484295ad phase: Running providerStatus: apiVersion: awsproviderconfig.openshift.io/v1beta1 conditions: - lastProbeTime: "2020-04-20T16:53:50Z" lastTransitionTime: "2020-04-20T16:53:50Z" message: machine successfully created reason: MachineCreationSucceeded status: "True" type: MachineCreation instanceId: i-0fdb85790d76d0c3f instanceState: stopped kind: AWSMachineProviderStatusChange the
metadata.namefield to a new name.It is recommended to keep the same base name as the old machine and change the ending number to the next available number. In this example,
clustername-8qw5l-master-0is changed toclustername-8qw5l-master-3:apiVersion: machine.openshift.io/v1beta1 kind: Machine metadata: ... name: clustername-8qw5l-master-3 ...Remove the
spec.providerIDfield by running:providerID: aws:///us-east-1a/i-0fdb85790d76d0c3fRemove the
metadata.annotationsandmetadata.generationfields by running:annotations: machine.openshift.io/instance-state: running ... generation: 2Remove the
metadata.resourceVersionandmetadata.uidfields:resourceVersion: "13291" uid: a282eb70-40a2-4e89-8009-d05dd420d31a
Delete the machine of the lost control plane host by running:
$ oc delete machine -n openshift-machine-api clustername-8qw5l-master-01 - 1
- Specify the name of the control plane machine for the lost control plane host.
Verify that the machine was deleted:
$ oc get machines -n openshift-machine-api -o wideExample output:
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a runningCreate a machine by using the
new-master-machine.yamlfile by running:$ oc apply -f new-master-machine.yamlVerify that the new machine has been created by running:
$ oc get machines -n openshift-machine-api -o wideExample output:
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-master-3 Provisioning m4.xlarge us-east-1 us-east-1a 85s ip-10-0-173-171.ec2.internal aws:///us-east-1a/i-015b0888fe17bc2c8 running1 clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- The new machine,
clustername-8qw5l-master-3is being created and is ready after the phase changes fromProvisioningtoRunning.
It might take a few minutes for the new machine to be created. The
etcdcluster Operator automatically syncs when the machine or node returns to a healthy state.- Repeat these steps for each lost control plane host that is not the recovery host.
Turn off the quorum guard by entering the following command:
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'This command ensures that you can successfully re-create secrets and roll out the static pods.
In a separate terminal window within the recovery host, export the recovery
kubeconfigfile by running the following command:$ export KUBECONFIG=/etc/kubernetes/static-pod-resources/kube-apiserver-certs/secrets/node-kubeconfigs/localhost-recovery.kubeconfigForce
etcdredeployment.In the same terminal window where you exported the recovery
kubeconfigfile, run the following command:$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge1 - 1
- The
forceRedeploymentReasonvalue must be unique, which is why a timestamp is appended.
When the etcd cluster Operator performs a redeployment, the existing nodes are started with new pods similar to the initial bootstrap scale up.
Turn the quorum guard back on by entering the following command:
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'You can verify that the
unsupportedConfigOverridessection is removed from the object by entering this command:$ oc get etcd/cluster -oyamlVerify all nodes are updated to the latest revision.
In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc get etcd -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Review the
NodeInstallerProgressingstatus condition foretcdto verify that all nodes are at the latest revision. The output showsAllNodesAtLatestRevisionupon successful update:AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- In this example, the latest revision number is
7.
If the output includes multiple revision numbers, such as
2 nodes are at revision 6; 1 nodes are at revision 7, this means that the update is still in progress. Wait a few minutes and try again.After etcd is redeployed, force new rollouts for the control plane.
kube-apiserverreinstalls itself on the other nodes because the kubelet is connected to API servers using an internal load balancer.In a terminal that has access to the cluster as a
cluster-adminuser, run the following commands.Force a new rollout for the kube-apiserver:
$ oc patch kubeapiserver cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeVerify all nodes are updated to the latest revision.
$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Review the
NodeInstallerProgressingstatus condition to verify that all nodes are at the latest revision. The output showsAllNodesAtLatestRevisionupon successful update:AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- In this example, the latest revision number is
7.
If the output includes multiple revision numbers, such as
2 nodes are at revision 6; 1 nodes are at revision 7, this means that the update is still in progress. Wait a few minutes and try again.Force a new rollout for the
kubecontrollermanagerby running:$ oc patch kubecontrollermanager cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeVerify all nodes are updated to the latest revision by running:
$ oc get kubecontrollermanager -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Review the
NodeInstallerProgressingstatus condition to verify that all nodes are at the latest revision. The output showsAllNodesAtLatestRevisionupon successful update:AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- In this example, the latest revision number is
7.
If the output includes multiple revision numbers, such as
2 nodes are at revision 6; 1 nodes are at revision 7, this means that the update is still in progress. Wait a few minutes and try again.Force a new rollout for the
kube-schedulerby running:$ oc patch kubescheduler cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeVerify all nodes are updated to the latest revision.
$ oc get kubescheduler -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Review the
NodeInstallerProgressingstatus condition to verify that all nodes are at the latest revision. The output showsAllNodesAtLatestRevisionupon successful update:AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- In this example, the latest revision number is
7.
If the output includes multiple revision numbers, such as
2 nodes are at revision 6; 1 nodes are at revision 7, this means that the update is still in progress. Wait a few minutes and try again.
Verify that all control plane hosts have started and joined the cluster.
In a terminal that has access to the cluster as a
cluster-adminuser, run the following command:$ oc -n openshift-etcd get pods -l k8s-app=etcdExample output
etcd-ip-10-0-143-125.ec2.internal 2/2 Running 0 9h etcd-ip-10-0-154-194.ec2.internal 2/2 Running 0 9h etcd-ip-10-0-173-171.ec2.internal 2/2 Running 0 9h-
To ensure that all workloads return to normal operation following a recovery procedure, restart each pod that stores
kube-apiserverinformation. This includes OpenShift Container Platform components such as routers, Operators, and third-party components.
On completion of the previous procedural steps, you might need to wait a few minutes for all services to return to their restored state. For example, authentication by using oc login might not immediately work until the OAuth server pods are restarted.
Consider using the system:admin kubeconfig file for immediate authentication. This method basis its authentication on SSL/TLS client certificates as against OAuth tokens. You can authenticate with this file by issuing the following command:
$ export KUBECONFIG=<installation_directory>/auth/kubeconfigIssue the following command to display your authenticated user name:
$ oc whoami5.4.2.3. Restoring a cluster manually from an etcd backup
The restore procedure described in the section "Restoring to a previous cluster state":
-
Requires the complete recreation of 2 control plane nodes, which might be a complex procedure for clusters installed with the UPI installation method, since an UPI installation does not create any
MachineorControlPlaneMachinesetfor the control plane nodes. - Uses the script /usr/local/bin/cluster-restore.sh, which starts a new single-member etcd cluster and then scales it to three members.
In contrast, this procedure:
- Does not require recreating any control plane nodes.
- Directly starts a three-member etcd cluster.
If the cluster uses a MachineSet for the control plane, it is suggested to use the "Restoring to a previous cluster state" for a simpler etcd recovery procedure.
When you restore your cluster, you must use an etcd backup that was taken from the same z-stream release. For example, an OpenShift Container Platform 4.7.2 cluster must use an etcd backup that was taken from 4.7.2.
Prerequisites
-
Access to the cluster as a user with the
cluster-adminrole; for example, thekubeadminuser. -
SSH access to all control plane hosts, with a host user allowed to become
root; for example, the defaultcorehost user. -
A backup directory containing both a previous etcd snapshot and the resources for the static pods from the same backup. The file names in the directory must be in the following formats:
snapshot_<datetimestamp>.dbandstatic_kuberesources_<datetimestamp>.tar.gz.
Procedure
Use SSH to connect to each of the control plane nodes.
The Kubernetes API server becomes inaccessible after the restore process starts, so you cannot access the control plane nodes. For this reason, it is recommended to use a SSH connection for each control plane host you are accessing in a separate terminal.
ImportantIf you do not complete this step, you will not be able to access the control plane hosts to complete the restore procedure, and you will be unable to recover your cluster from this state.
Copy the etcd backup directory to each control plane host.
This procedure assumes that you copied the
backupdirectory containing the etcd snapshot and the resources for the static pods to the/home/core/assetsdirectory of each control plane host. You might need to create suchassetsfolder if it does not exist yet.Stop the static pods on all the control plane nodes; one host at a time.
Move the existing Kubernetes API Server static pod manifest out of the kubelet manifest directory.
$ mkdir -p /root/manifests-backup $ mv /etc/kubernetes/manifests/kube-apiserver-pod.yaml /root/manifests-backup/Verify that the Kubernetes API Server containers have stopped with the command:
$ crictl ps | grep kube-apiserver | grep -E -v "operator|guard"The output of this command should be empty. If it is not empty, wait a few minutes and check again.
If the Kubernetes API Server containers are still running, terminate them manually with the following command:
$ crictl stop <container_id>Repeat the same steps for
kube-controller-manager-pod.yaml,kube-scheduler-pod.yamland finallyetcd-pod.yaml.Stop the
kube-controller-managerpod with the following command:$ mv /etc/kubernetes/manifests/kube-controller-manager-pod.yaml /root/manifests-backup/Check if the containers are stopped using the following command:
$ crictl ps | grep kube-controller-manager | grep -E -v "operator|guard"Stop the
kube-schedulerpod using the following command:$ mv /etc/kubernetes/manifests/kube-scheduler-pod.yaml /root/manifests-backup/Check if the containers are stopped using the following command:
$ crictl ps | grep kube-scheduler | grep -E -v "operator|guard"Stop the
etcdpod using the following command:$ mv /etc/kubernetes/manifests/etcd-pod.yaml /root/manifests-backup/Check if the containers are stopped using the following command:
$ crictl ps | grep etcd | grep -E -v "operator|guard"
On each control plane host, save the current
etcddata, by moving it into thebackupfolder:$ mkdir /home/core/assets/old-member-data $ mv /var/lib/etcd/member /home/core/assets/old-member-dataThis data will be useful in case the
etcdbackup restore does not work and theetcdcluster must be restored to the current state.Find the correct etcd parameters for each control plane host.
The value for
<ETCD_NAME>is unique for the each control plane host, and it is equal to the value of theETCD_NAMEvariable in the manifest/etc/kubernetes/static-pod-resources/etcd-certs/configmaps/restore-etcd-pod/pod.yamlfile in the specific control plane host. It can be found with the command:RESTORE_ETCD_POD_YAML="/etc/kubernetes/static-pod-resources/etcd-certs/configmaps/restore-etcd-pod/pod.yaml" cat $RESTORE_ETCD_POD_YAML | \ grep -A 1 $(cat $RESTORE_ETCD_POD_YAML | grep 'export ETCD_NAME' | grep -Eo 'NODE_.+_ETCD_NAME') | \ grep -Po '(?<=value: ").+(?=")'The value for
<UUID>can be generated in a control plane host with the command:$ uuidgenNoteThe value for
<UUID>must be generated only once. After generatingUUIDon one control plane host, do not generate it again on the others. The sameUUIDwill be used in the next steps on all control plane hosts.The value for
ETCD_NODE_PEER_URLshould be set like the following example:https://<IP_CURRENT_HOST>:2380The correct IP can be found from the
<ETCD_NAME>of the specific control plane host, with the command:$ echo <ETCD_NAME> | \ sed -E 's/[.-]/_/g' | \ xargs -I {} grep {} /etc/kubernetes/static-pod-resources/etcd-certs/configmaps/etcd-scripts/etcd.env | \ grep "IP" | grep -Po '(?<=").+(?=")'The value for
<ETCD_INITIAL_CLUSTER>should be set like the following, where<ETCD_NAME_n>is the<ETCD_NAME>of each control plane host.NoteThe port used must be 2380 and not 2379. The port 2379 is used for etcd database management and is configured directly in etcd start command in container.
Example output
<ETCD_NAME_0>=<ETCD_NODE_PEER_URL_0>,<ETCD_NAME_1>=<ETCD_NODE_PEER_URL_1>,<ETCD_NAME_2>=<ETCD_NODE_PEER_URL_2>1 - 1
- Specifies the
ETCD_NODE_PEER_URLvalues from each control plane host.
The
<ETCD_INITIAL_CLUSTER>value remains same across all control plane hosts. The same value is required in the next steps on every control plane host.
Regenerate the etcd database from the backup.
Such operation must be executed on each control plane host.
Copy the
etcdbackup to/var/lib/etcddirectory with the command:$ cp /home/core/assets/backup/<snapshot_yyyy-mm-dd_hhmmss>.db /var/lib/etcdIdentify the correct
etcdctlimage before proceeding. Use the following command to retrieve the image from the backup of the pod manifest:$ jq -r '.spec.containers[]|select(.name=="etcdctl")|.image' /root/manifests-backup/etcd-pod.yaml$ podman run --rm -it --entrypoint="/bin/bash" -v /var/lib/etcd:/var/lib/etcd:z <image-hash>Check that the version of the
etcdctltool is the version of theetcdserver where the backup was created:$ etcdctl versionRun the following command to regenerate the
etcddatabase, using the correct values for the current host:$ ETCDCTL_API=3 /usr/bin/etcdctl snapshot restore /var/lib/etcd/<snapshot_yyyy-mm-dd_hhmmss>.db \ --name "<ETCD_NAME>" \ --initial-cluster="<ETCD_INITIAL_CLUSTER>" \ --initial-cluster-token "openshift-etcd-<UUID>" \ --initial-advertise-peer-urls "<ETCD_NODE_PEER_URL>" \ --data-dir="/var/lib/etcd/restore-<UUID>" \ --skip-hash-check=trueNoteThe quotes are mandatory when regenerating the
etcddatabase.
Record the values printed in the
added memberlogs; for example:Example output
2022-06-28T19:52:43Z info membership/cluster.go:421 added member {"cluster-id": "c5996b7c11c30d6b", "local-member-id": "0", "added-peer-id": "56cd73b614699e7", "added-peer-peer-urls": ["https://10.0.91.5:2380"], "added-peer-is-learner": false} 2022-06-28T19:52:43Z info membership/cluster.go:421 added member {"cluster-id": "c5996b7c11c30d6b", "local-member-id": "0", "added-peer-id": "1f63d01b31bb9a9e", "added-peer-peer-urls": ["https://10.0.90.221:2380"], "added-peer-is-learner": false} 2022-06-28T19:52:43Z info membership/cluster.go:421 added member {"cluster-id": "c5996b7c11c30d6b", "local-member-id": "0", "added-peer-id": "fdc2725b3b70127c", "added-peer-peer-urls": ["https://10.0.94.214:2380"], "added-peer-is-learner": false}- Exit from the container.
-
Repeat these steps on the other control plane hosts, checking that the values printed in the
added memberlogs are the same for all control plane hosts.
Move the regenerated
etcddatabase to the default location.Such operation must be executed on each control plane host.
Move the regenerated database (the
memberfolder created by the previousetcdctl snapshot restorecommand) to the default etcd location/var/lib/etcd:$ mv /var/lib/etcd/restore-<UUID>/member /var/lib/etcdRestore the SELinux context for
/var/lib/etcd/memberfolder on/var/lib/etcddirectory:$ restorecon -vR /var/lib/etcd/Remove the leftover files and directories:
$ rm -rf /var/lib/etcd/restore-<UUID>$ rm /var/lib/etcd/<snapshot_yyyy-mm-dd_hhmmss>.dbImportantWhen you are finished the
/var/lib/etcddirectory must contain only the foldermember.- Repeat these steps on the other control plane hosts.
Restart the etcd cluster.
- The following steps must be executed on all control plane hosts, but one host at a time.
Move the
etcdstatic pod manifest back to the kubelet manifest directory, in order to make kubelet start the related containers :$ mv /root/manifests-backup/etcd-pod.yaml /etc/kubernetes/manifestsVerify that all the
etcdcontainers have started:$ crictl ps | grep etcd | grep -v operatorExample output
38c814767ad983 f79db5a8799fd2c08960ad9ee22f784b9fbe23babe008e8a3bf68323f004c840 28 seconds ago Running etcd-health-monitor 2 fe4b9c3d6483c e1646b15207c6 9d28c15860870e85c91d0e36b45f7a6edd3da757b113ec4abb4507df88b17f06 About a minute ago Running etcd-metrics 0 fe4b9c3d6483c 08ba29b1f58a7 9d28c15860870e85c91d0e36b45f7a6edd3da757b113ec4abb4507df88b17f06 About a minute ago Running etcd 0 fe4b9c3d6483c 2ddc9eda16f53 9d28c15860870e85c91d0e36b45f7a6edd3da757b113ec4abb4507df88b17f06 About a minute ago Running etcdctlIf the output of this command is empty, wait a few minutes and check again.
Check the status of the
etcdcluster.On any of the control plane hosts, check the status of the
etcdcluster with the following command:$ crictl exec -it $(crictl ps | grep etcdctl | awk '{print $1}') etcdctl endpoint status -w tableExample output
+--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://10.0.89.133:2379 | 682e4a83a0cec6c0 | 3.5.0 | 67 MB | true | false | 2 | 218 | 218 | | | https://10.0.92.74:2379 | 450bcf6999538512 | 3.5.0 | 67 MB | false | false | 2 | 218 | 218 | | | https://10.0.93.129:2379 | 358efa9c1d91c3d6 | 3.5.0 | 67 MB | false | false | 2 | 218 | 218 | | +--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
Restart the other static pods.
The following steps must be executed on all control plane hosts, but one host at a time.
Move the Kubernetes API Server static pod manifest back to the kubelet manifest directory to make kubelet start the related containers with the command:
$ mv /root/manifests-backup/kube-apiserver-pod.yaml /etc/kubernetes/manifestsVerify that all the Kubernetes API Server containers have started:
$ crictl ps | grep kube-apiserver | grep -v operatorNoteif the output of the following command is empty, wait a few minutes and check again.
Repeat the same steps for
kube-controller-manager-pod.yamlandkube-scheduler-pod.yamlfiles.Restart the kubelets in all nodes using the following command:
$ systemctl restart kubeletStart the remaining control plane pods using the following command:
$ mv /root/manifests-backup/kube-* /etc/kubernetes/manifests/Check if the
kube-apiserver,kube-schedulerandkube-controller-managerpods start correctly:$ crictl ps | grep -E 'kube-(apiserver|scheduler|controller-manager)' | grep -v -E 'operator|guard'Wipe the OVN databases using the following commands:
for NODE in $(oc get node -o name | sed 's:node/::g') do oc debug node/${NODE} -- chroot /host /bin/bash -c 'rm -f /var/lib/ovn-ic/etc/ovn*.db && systemctl restart ovs-vswitchd ovsdb-server' oc -n openshift-ovn-kubernetes delete pod -l app=ovnkube-node --field-selector=spec.nodeName=${NODE} --wait oc -n openshift-ovn-kubernetes wait pod -l app=ovnkube-node --field-selector=spec.nodeName=${NODE} --for condition=ContainersReady --timeout=600s done
5.4.2.5. Issues and workarounds for restoring a persistent storage state
If your OpenShift Container Platform cluster uses persistent storage of any form, a state of the cluster is typically stored outside etcd. It might be an Elasticsearch cluster running in a pod or a database running in a StatefulSet object. When you restore from an etcd backup, the status of the workloads in OpenShift Container Platform is also restored. However, if the etcd snapshot is old, the status might be invalid or outdated.
The contents of persistent volumes (PVs) are never part of the etcd snapshot. When you restore an OpenShift Container Platform cluster from an etcd snapshot, non-critical workloads might gain access to critical data, or vice-versa.
The following are some example scenarios that produce an out-of-date status:
- MySQL database is running in a pod backed up by a PV object. Restoring OpenShift Container Platform from an etcd snapshot does not bring back the volume on the storage provider, and does not produce a running MySQL pod, despite the pod repeatedly attempting to start. You must manually restore this pod by restoring the volume on the storage provider, and then editing the PV to point to the new volume.
- Pod P1 is using volume A, which is attached to node X. If the etcd snapshot is taken while another pod uses the same volume on node Y, then when the etcd restore is performed, pod P1 might not be able to start correctly due to the volume still being attached to node Y. OpenShift Container Platform is not aware of the attachment, and does not automatically detach it. When this occurs, the volume must be manually detached from node Y so that the volume can attach on node X, and then pod P1 can start.
- Cloud provider or storage provider credentials were updated after the etcd snapshot was taken. This causes any CSI drivers or Operators that depend on the those credentials to not work. You might have to manually update the credentials required by those drivers or Operators.
A device is removed or renamed from OpenShift Container Platform nodes after the etcd snapshot is taken. The Local Storage Operator creates symlinks for each PV that it manages from
/dev/disk/by-idor/devdirectories. This situation might cause the local PVs to refer to devices that no longer exist.To fix this problem, an administrator must:
- Manually remove the PVs with invalid devices.
- Remove symlinks from respective nodes.
-
Delete
LocalVolumeorLocalVolumeSetobjects (see StorageConfiguring persistent storage Persistent storage using local volumes Deleting the Local Storage Operator Resources).
5.4.3. Recovering from expired control plane certificates
5.4.3.1. Recovering from expired control plane certificates
The cluster can automatically recover from expired control plane certificates.
However, you must manually approve the pending node-bootstrapper certificate signing requests (CSRs) to recover kubelet certificates. For user-provisioned installations, you might also need to approve pending kubelet serving CSRs.
Use the following steps to approve the pending CSRs:
Procedure
Get the list of current CSRs:
$ oc get csrExample output
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-2s94x 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending1 csr-4bd6t 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending csr-4hl85 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending2 csr-zhhhp 3m8s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...Review the details of a CSR to verify that it is valid:
$ oc describe csr <csr_name>1 - 1
<csr_name>is the name of a CSR from the list of current CSRs.
Approve each valid
node-bootstrapperCSR:$ oc adm certificate approve <csr_name>For user-provisioned installations, approve each valid kubelet serving CSR:
$ oc adm certificate approve <csr_name>
5.4.4. Disaster recovery for a hosted cluster within an AWS region
In a situation where you need disaster recovery (DR) for a hosted cluster, you can recover a hosted cluster to the same region within AWS. For example, you need DR when the upgrade of a management cluster fails and the hosted cluster is in a read-only state.
Hosted control planes is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
For more information about the support scope of Red Hat Technology Preview features, see Technology Preview Features Support Scope.
The DR process involves three main steps:
- Backing up the hosted cluster on the source management cluster
- Restoring the hosted cluster on a destination management cluster
- Deleting the hosted cluster from the source management cluster
Your workloads remain running during the process. The Cluster API might be unavailable for a period, but that will not affect the services that are running on the worker nodes.
Both the source management cluster and the destination management cluster must have the --external-dns flags to maintain the API server URL, as shown in this example:
Example: External DNS flags
--external-dns-provider=aws \
--external-dns-credentials=<AWS Credentials location> \
--external-dns-domain-filter=<DNS Base Domain>
That way, the server URL ends with https://api-sample-hosted.sample-hosted.aws.openshift.com.
If you do not include the --external-dns flags to maintain the API server URL, the hosted cluster cannot be migrated.
5.4.4.1. Example environment and context
Consider an scenario where you have three clusters to restore. Two are management clusters, and one is a hosted cluster. You can restore either the control plane only or the control plane and the nodes. Before you begin, you need the following information:
- Source MGMT Namespace: The source management namespace
- Source MGMT ClusterName: The source management cluster name
-
Source MGMT Kubeconfig: The source management
kubeconfigfile -
Destination MGMT Kubeconfig: The destination management
kubeconfigfile -
HC Kubeconfig: The hosted cluster
kubeconfigfile - SSH key file: The SSH public key
- Pull secret: The pull secret file to access the release images
- AWS credentials
- AWS region
- Base domain: The DNS base domain to use as an external DNS
- S3 bucket name: The bucket in the AWS region where you plan to upload the etcd backup
This information is shown in the following example environment variables.
Example environment variables
SSH_KEY_FILE=${HOME}/.ssh/id_rsa.pub
BASE_PATH=${HOME}/hypershift
BASE_DOMAIN="aws.sample.com"
PULL_SECRET_FILE="${HOME}/pull_secret.json"
AWS_CREDS="${HOME}/.aws/credentials"
AWS_ZONE_ID="Z02718293M33QHDEQBROL"
CONTROL_PLANE_AVAILABILITY_POLICY=SingleReplica
HYPERSHIFT_PATH=${BASE_PATH}/src/hypershift
HYPERSHIFT_CLI=${HYPERSHIFT_PATH}/bin/hypershift
HYPERSHIFT_IMAGE=${HYPERSHIFT_IMAGE:-"quay.io/${USER}/hypershift:latest"}
NODE_POOL_REPLICAS=${NODE_POOL_REPLICAS:-2}
# MGMT Context
MGMT_REGION=us-west-1
MGMT_CLUSTER_NAME="${USER}-dev"
MGMT_CLUSTER_NS=${USER}
MGMT_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT_CLUSTER_NS}-${MGMT_CLUSTER_NAME}"
MGMT_KUBECONFIG="${MGMT_CLUSTER_DIR}/kubeconfig"
# MGMT2 Context
MGMT2_CLUSTER_NAME="${USER}-dest"
MGMT2_CLUSTER_NS=${USER}
MGMT2_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT2_CLUSTER_NS}-${MGMT2_CLUSTER_NAME}"
MGMT2_KUBECONFIG="${MGMT2_CLUSTER_DIR}/kubeconfig"
# Hosted Cluster Context
HC_CLUSTER_NS=clusters
HC_REGION=us-west-1
HC_CLUSTER_NAME="${USER}-hosted"
HC_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}"
HC_KUBECONFIG="${HC_CLUSTER_DIR}/kubeconfig"
BACKUP_DIR=${HC_CLUSTER_DIR}/backup
BUCKET_NAME="${USER}-hosted-${MGMT_REGION}"
# DNS
AWS_ZONE_ID="Z07342811SH9AA102K1AC"
EXTERNAL_DNS_DOMAIN="hc.jpdv.aws.kerbeross.com"5.4.4.2. Overview of the backup and restore process
The backup and restore process works as follows:
On management cluster 1, which you can think of as the source management cluster, the control plane and workers interact by using the external DNS API. The external DNS API is accessible, and a load balancer sits between the management clusters.
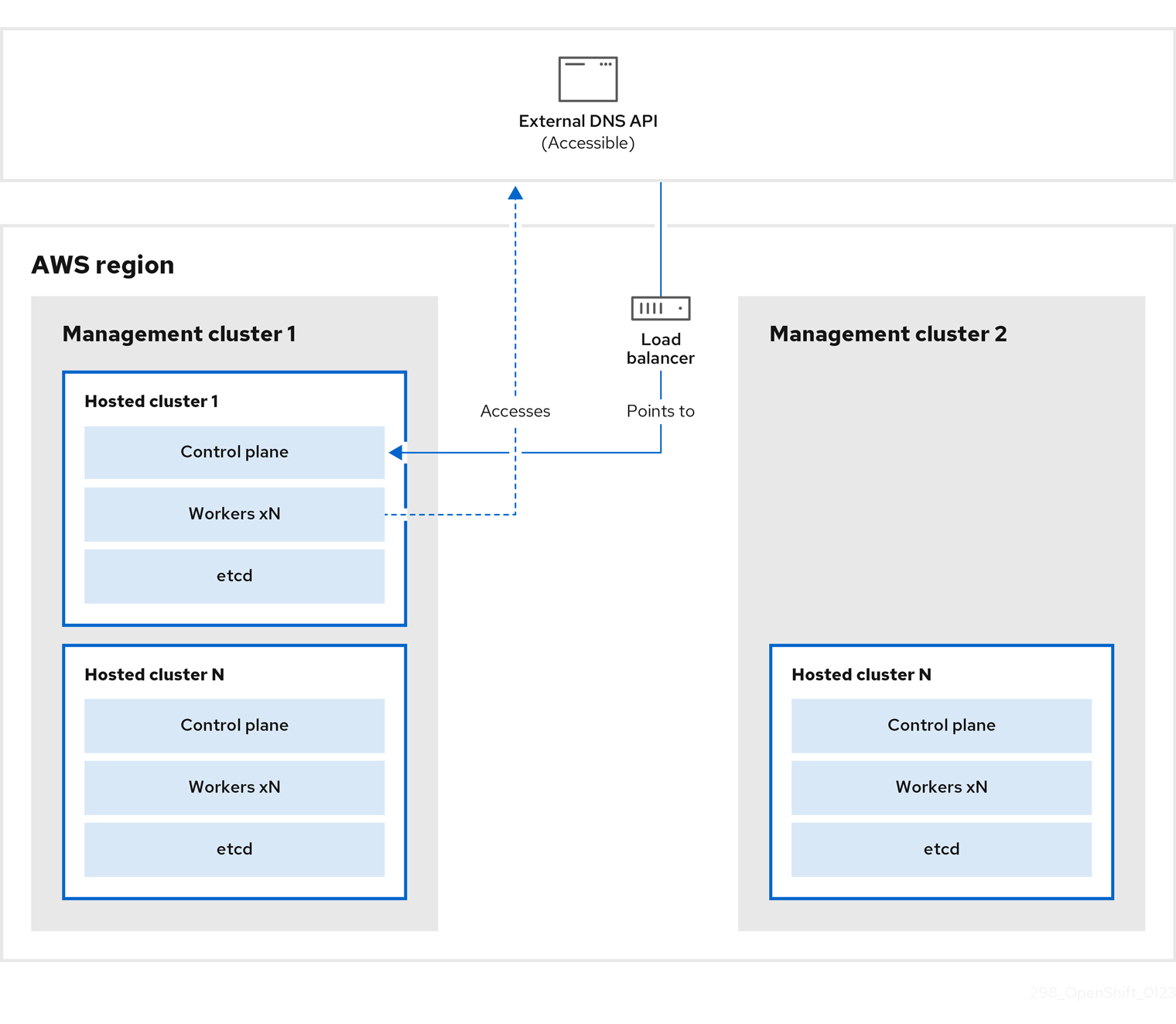
You take a snapshot of the hosted cluster, which includes etcd, the control plane, and the worker nodes. During this process, the worker nodes continue to try to access the external DNS API even if it is not accessible, the workloads are running, the control plane is saved in a local manifest file, and etcd is backed up to an S3 bucket. The data plane is active and the control plane is paused.
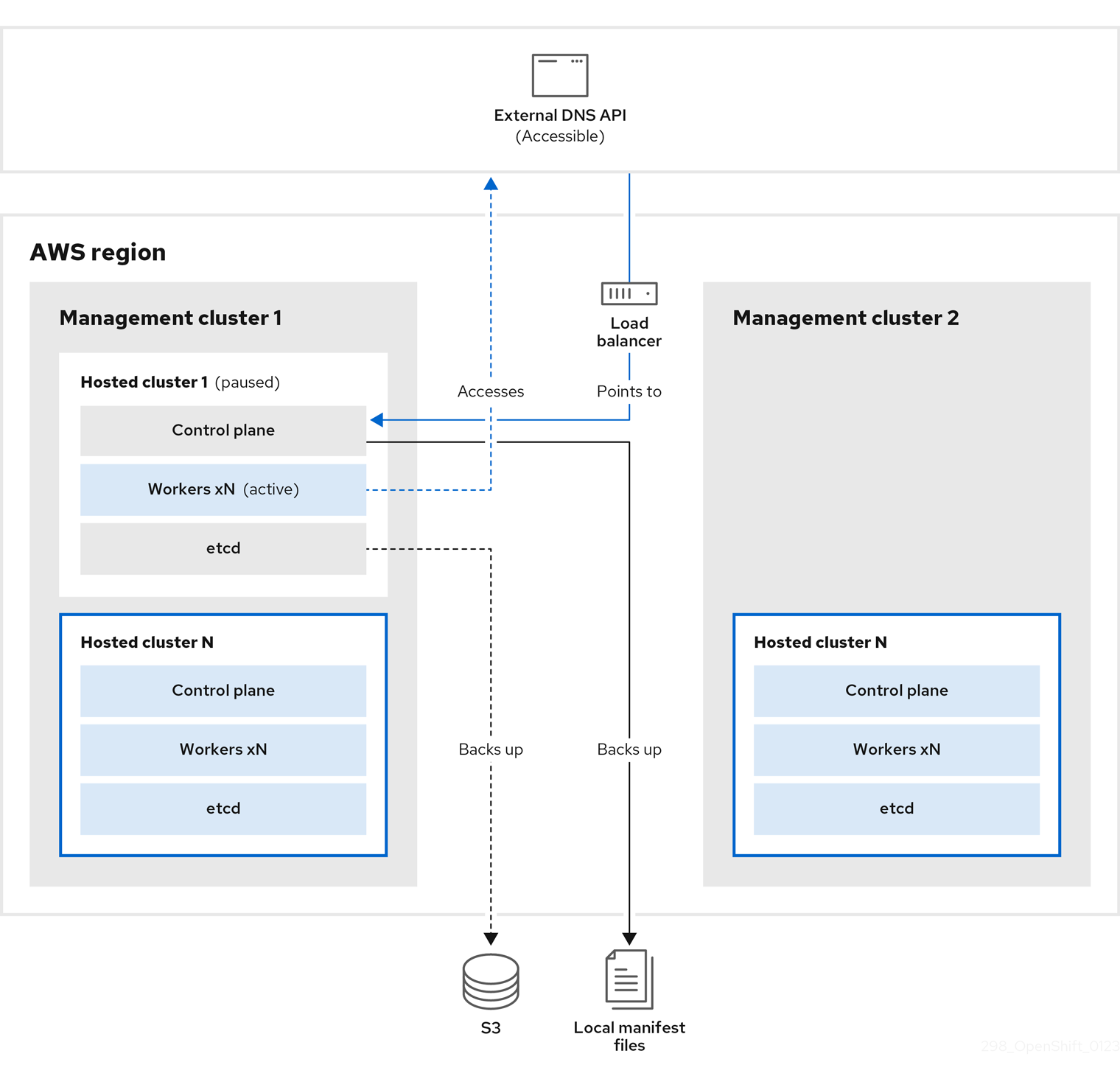
On management cluster 2, which you can think of as the destination management cluster, you restore etcd from the S3 bucket and restore the control plane from the local manifest file. During this process, the external DNS API is stopped, the hosted cluster API becomes inaccessible, and any workers that use the API are unable to update their manifest files, but the workloads are still running.
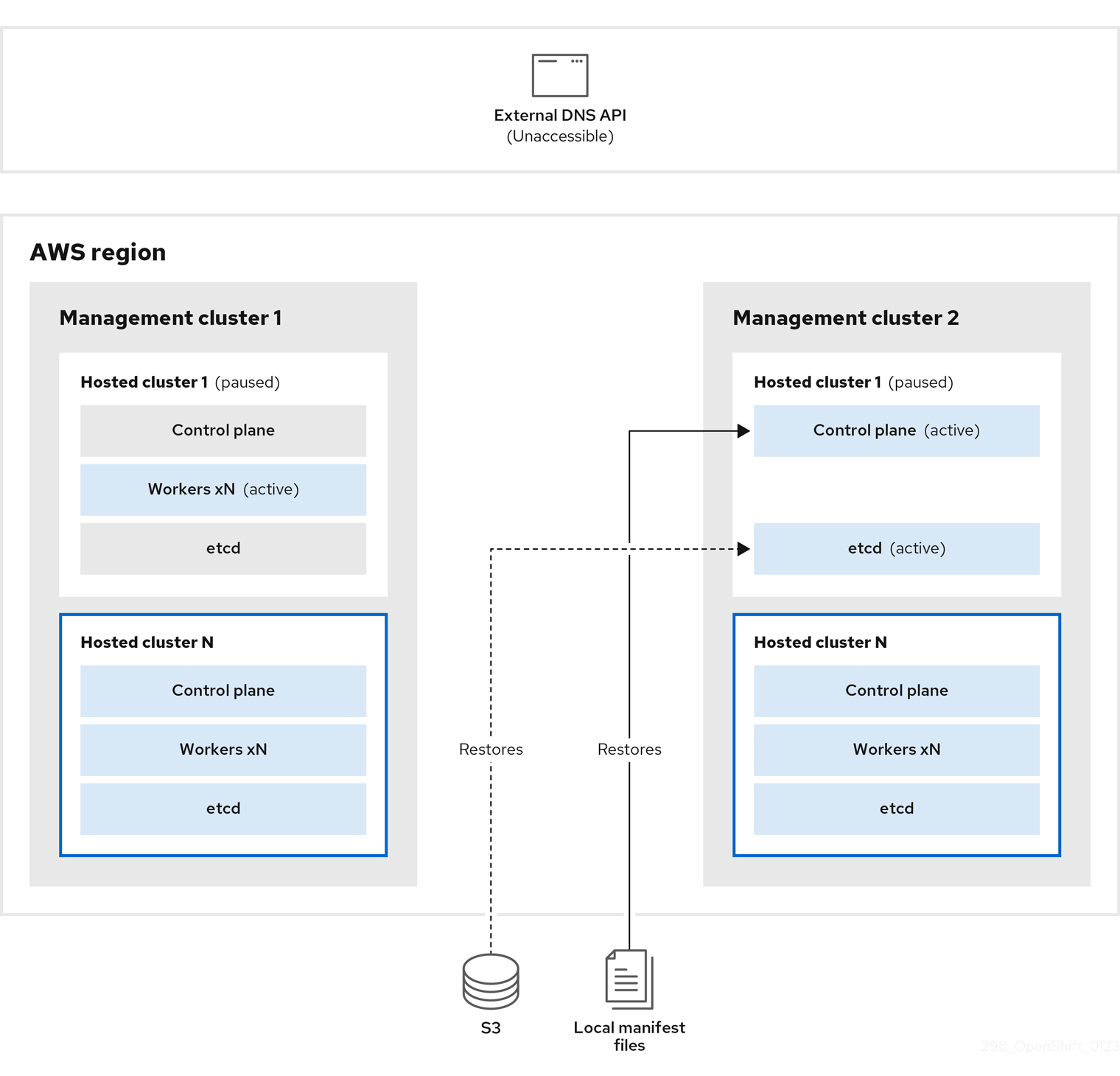
The external DNS API is accessible again, and the worker nodes use it to move to management cluster 2. The external DNS API can access the load balancer that points to the control plane.

On management cluster 2, the control plane and worker nodes interact by using the external DNS API. The resources are deleted from management cluster 1, except for the S3 backup of etcd. If you try to set up the hosted cluster again on mangagement cluster 1, it will not work.
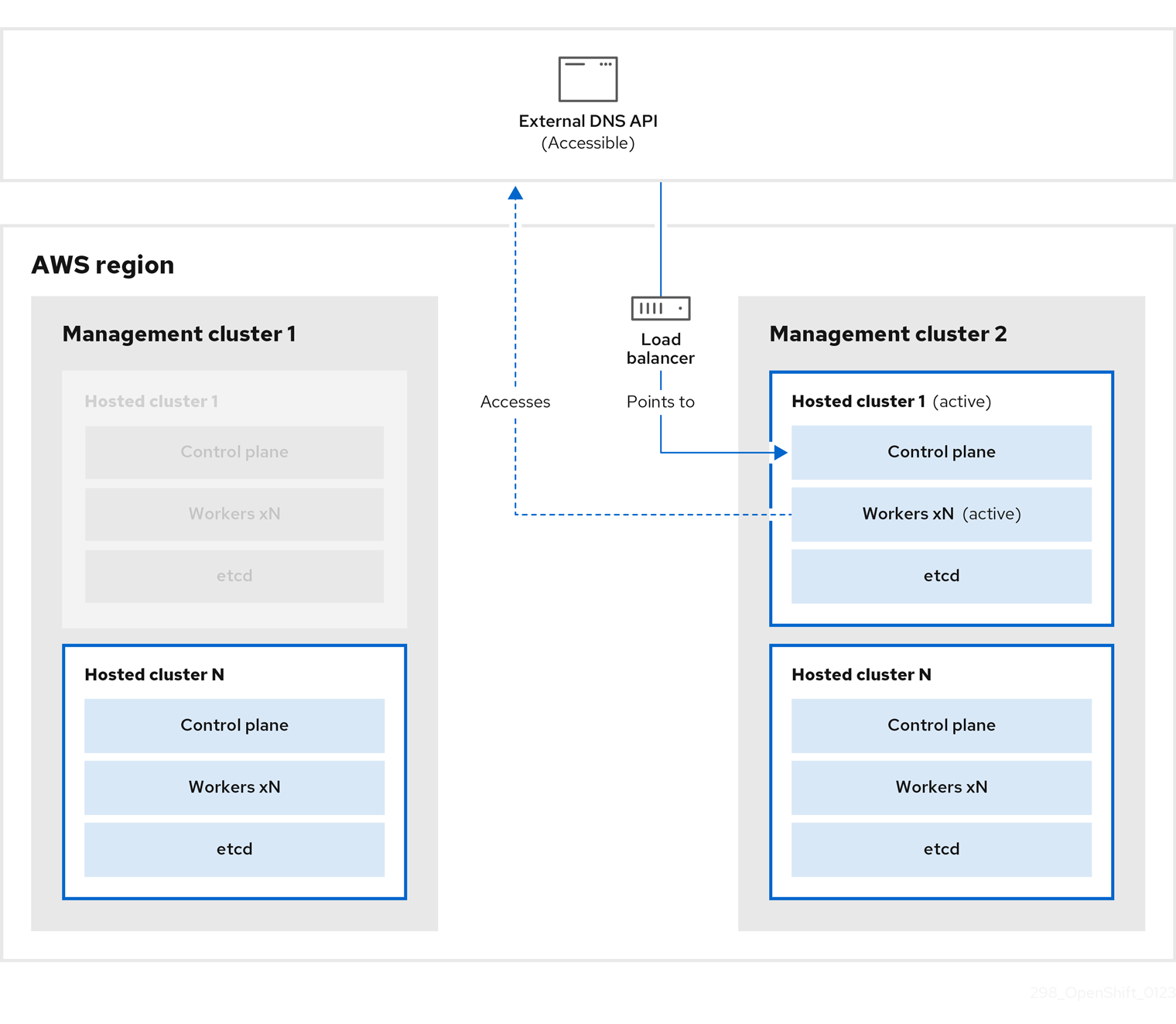
You can manually back up and restore your hosted cluster, or you can run a script to complete the process. For more information about the script, see "Running a script to back up and restore a hosted cluster".
5.4.4.3. Backing up a hosted cluster
To recover your hosted cluster in your target management cluster, you first need to back up all of the relevant data.
Procedure
Create a configmap file to declare the source management cluster by entering this command:
$ oc create configmap mgmt-parent-cluster -n default --from-literal=from=${MGMT_CLUSTER_NAME}Shut down the reconciliation in the hosted cluster and in the node pools by entering these commands:
$ PAUSED_UNTIL="true" $ oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge $ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator$ PAUSED_UNTIL="true" $ oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge $ oc patch -n ${HC_CLUSTER_NS} nodepools/${NODEPOOLS} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge $ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operatorBack up etcd and upload the data to an S3 bucket by running this bash script:
TipWrap this script in a function and call it from the main function.
# ETCD Backup ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi for POD in ${ETCD_PODS}; do # Create an etcd snapshot oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl --cacert /etc/etcd/tls/client/etcd-client-ca.crt --cert /etc/etcd/tls/client/etcd-client.crt --key /etc/etcd/tls/client/etcd-client.key --endpoints=localhost:2379 snapshot save /var/lib/data/snapshot.db oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/data/snapshot.db FILEPATH="/${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" set +x ACCESS_KEY=$(grep aws_access_key_id ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SECRET_KEY=$(grep aws_secret_access_key ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SIGNATURE_HASH=$(echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac "${SECRET_KEY}" -binary | base64) set -x # FIXME: this is pushing to the OIDC bucket oc exec -it etcd-0 -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${HC_CLUSTER_NAME}-${POD}-snapshot.db doneFor more information about backing up etcd, see "Backing up and restoring etcd on a hosted cluster".
Back up Kubernetes and OpenShift Container Platform objects by entering the following commands. You need to back up the following objects:
-
HostedClusterandNodePoolobjects from the HostedCluster namespace -
HostedClustersecrets from the HostedCluster namespace -
HostedControlPlanefrom the Hosted Control Plane namespace -
Clusterfrom the Hosted Control Plane namespace -
AWSCluster,AWSMachineTemplate, andAWSMachinefrom the Hosted Control Plane namespace -
MachineDeployments,MachineSets, andMachinesfrom the Hosted Control Plane namespace ControlPlanesecrets from the Hosted Control Plane namespace$ mkdir -p ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS} ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $ chmod 700 ${BACKUP_DIR}/namespaces/ # HostedCluster $ echo "Backing Up HostedCluster Objects:" $ oc get hc ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml $ echo "--> HostedCluster" $ sed -i '' -e '/^status:$/,$d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml # NodePool $ oc get np ${NODEPOOLS} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml $ echo "--> NodePool" $ sed -i '' -e '/^status:$/,$ d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml # Secrets in the HC Namespace $ echo "--> HostedCluster Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS} | grep "^${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-${s}.yaml done # Secrets in the HC Control Plane Namespace $ echo "--> HostedCluster ControlPlane Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} | egrep -v "docker|service-account-token|oauth-openshift|NAME|token-${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-${s}.yaml done # Hosted Control Plane $ echo "--> HostedControlPlane:" $ oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-${HC_CLUSTER_NAME}.yaml # Cluster $ echo "--> Cluster:" $ CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) $ oc get cluster ${CL_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-${HC_CLUSTER_NAME}.yaml # AWS Cluster $ echo "--> AWS Cluster:" $ oc get awscluster ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-${HC_CLUSTER_NAME}.yaml # AWS MachineTemplate $ echo "--> AWS Machine Template:" $ oc get awsmachinetemplate ${NODEPOOLS} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-${HC_CLUSTER_NAME}.yaml # AWS Machines $ echo "--> AWS Machine:" $ CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) for s in $(oc get awsmachines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --no-headers | grep ${CL_NAME} | cut -f1 -d\ ); do oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} awsmachines $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-${s}.yaml done # MachineDeployments $ echo "--> HostedCluster MachineDeployments:" for s in $(oc get machinedeployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do mdp_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-${mdp_name}.yaml done # MachineSets $ echo "--> HostedCluster MachineSets:" for s in $(oc get machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do ms_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-${ms_name}.yaml done # Machines $ echo "--> HostedCluster Machine:" for s in $(oc get machine -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do m_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-${m_name}.yaml done
-
Clean up the
ControlPlaneroutes by entering this command:$ oc delete routes -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --allBy entering that command, you enable the ExternalDNS Operator to delete the Route53 entries.
Verify that the Route53 entries are clean by running this script:
function clean_routes() { if [[ -z "${1}" ]];then echo "Give me the NS where to clean the routes" exit 1 fi # Constants if [[ -z "${2}" ]];then echo "Give me the Route53 zone ID" exit 1 fi ZONE_ID=${2} ROUTES=10 timeout=40 count=0 # This allows us to remove the ownership in the AWS for the API route oc delete route -n ${1} --all while [ ${ROUTES} -gt 2 ] do echo "Waiting for ExternalDNS Operator to clean the DNS Records in AWS Route53 where the zone id is: ${ZONE_ID}..." echo "Try: (${count}/${timeout})" sleep 10 if [[ $count -eq timeout ]];then echo "Timeout waiting for cleaning the Route53 DNS records" exit 1 fi count=$((count+1)) ROUTES=$(aws route53 list-resource-record-sets --hosted-zone-id ${ZONE_ID} --max-items 10000 --output json | grep -c ${EXTERNAL_DNS_DOMAIN}) done } # SAMPLE: clean_routes "<HC ControlPlane Namespace>" "<AWS_ZONE_ID>" clean_routes "${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" "${AWS_ZONE_ID}"
Verification
Check all of the OpenShift Container Platform objects and the S3 bucket to verify that everything looks as expected.
Next steps
Restore your hosted cluster.
5.4.4.4. Restoring a hosted cluster
Gather all of the objects that you backed up and restore them in your destination management cluster.
Prerequisites
You backed up the data from your source management cluster.
Ensure that the kubeconfig file of the destination management cluster is placed as it is set in the KUBECONFIG variable or, if you use the script, in the MGMT2_KUBECONFIG variable. Use export KUBECONFIG=<Kubeconfig FilePath> or, if you use the script, use export KUBECONFIG=${MGMT2_KUBECONFIG}.
Procedure
Verify that the new management cluster does not contain any namespaces from the cluster that you are restoring by entering these commands:
$ export KUBECONFIG=${MGMT2_KUBECONFIG}$ BACKUP_DIR=${HC_CLUSTER_DIR}/backupNamespace deletion in the destination Management cluster
$ oc delete ns ${HC_CLUSTER_NS} || true$ oc delete ns ${HC_CLUSTER_NS}-{HC_CLUSTER_NAME} || trueRe-create the deleted namespaces by entering these commands:
Namespace creation commands
$ oc new-project ${HC_CLUSTER_NS}$ oc new-project ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}Restore the secrets in the HC namespace by entering this command:
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-*Restore the objects in the
HostedClustercontrol plane namespace by entering these commands:Restore secret command
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-*Cluster restore commands
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-*If you are recovering the nodes and the node pool to reuse AWS instances, restore the objects in the HC control plane namespace by entering these commands:
Commands for AWS
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-*Commands for machines
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-*Restore the etcd data and the hosted cluster by running this bash script:
ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi HC_RESTORE_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-restore.yaml HC_BACKUP_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml HC_NEW_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-new.yaml cat ${HC_BACKUP_FILE} > ${HC_NEW_FILE} cat > ${HC_RESTORE_FILE} <<EOF restoreSnapshotURL: EOF for POD in ${ETCD_PODS}; do # Create a pre-signed URL for the etcd snapshot ETCD_SNAPSHOT="s3://${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" ETCD_SNAPSHOT_URL=$(AWS_DEFAULT_REGION=${MGMT2_REGION} aws s3 presign ${ETCD_SNAPSHOT}) # FIXME no CLI support for restoreSnapshotURL yet cat >> ${HC_RESTORE_FILE} <<EOF - "${ETCD_SNAPSHOT_URL}" EOF done cat ${HC_RESTORE_FILE} if ! grep ${HC_CLUSTER_NAME}-snapshot.db ${HC_NEW_FILE}; then sed -i '' -e "/type: PersistentVolume/r ${HC_RESTORE_FILE}" ${HC_NEW_FILE} sed -i '' -e '/pausedUntil:/d' ${HC_NEW_FILE} fi HC=$(oc get hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} -o name || true) if [[ ${HC} == "" ]];then echo "Deploying HC Cluster: ${HC_CLUSTER_NAME} in ${HC_CLUSTER_NS} namespace" oc apply -f ${HC_NEW_FILE} else echo "HC Cluster ${HC_CLUSTER_NAME} already exists, avoiding step" fiIf you are recovering the nodes and the node pool to reuse AWS instances, restore the node pool by entering this command:
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-*
Verification
To verify that the nodes are fully restored, use this function:
timeout=40 count=0 NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 while [ ${NODE_POOL_REPLICAS} != ${NODE_STATUS} ] do echo "Waiting for Nodes to be Ready in the destination MGMT Cluster: ${MGMT2_CLUSTER_NAME}" echo "Try: (${count}/${timeout})" sleep 30 if [[ $count -eq timeout ]];then echo "Timeout waiting for Nodes in the destination MGMT Cluster" exit 1 fi count=$((count+1)) NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 done
Next steps
Shut down and delete your cluster.
5.4.4.5. Deleting a hosted cluster from your source management cluster
After you back up your hosted cluster and restore it to your destination management cluster, you shut down and delete the hosted cluster on your source management cluster.
Prerequisites
You backed up your data and restored it to your source management cluster.
Ensure that the kubeconfig file of the destination management cluster is placed as it is set in the KUBECONFIG variable or, if you use the script, in the MGMT_KUBECONFIG variable. Use export KUBECONFIG=<Kubeconfig FilePath> or, if you use the script, use export KUBECONFIG=${MGMT_KUBECONFIG}.
Procedure
Scale the
deploymentandstatefulsetobjects by entering these commands:$ export KUBECONFIG=${MGMT_KUBECONFIG}Scale down deployment commands
$ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all$ oc scale statefulset.apps -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all$ sleep 15Delete the
NodePoolobjects by entering these commands:NODEPOOLS=$(oc get nodepools -n ${HC_CLUSTER_NS} -o=jsonpath='{.items[?(@.spec.clusterName=="'${HC_CLUSTER_NAME}'")].metadata.name}') if [[ ! -z "${NODEPOOLS}" ]];then oc patch -n "${HC_CLUSTER_NS}" nodepool ${NODEPOOLS} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' oc delete np -n ${HC_CLUSTER_NS} ${NODEPOOLS} fiDelete the
machineandmachinesetobjects by entering these commands:# Machines for m in $(oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done$ oc delete machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all || trueDelete the cluster object by entering these commands:
$ C_NAME=$(oc get cluster -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name)$ oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${C_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'$ oc delete cluster.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --allDelete the AWS machines (Kubernetes objects) by entering these commands. Do not worry about deleting the real AWS machines. The cloud instances will not be affected.
for m in $(oc get awsmachine.infrastructure.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name) do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true doneDelete the
HostedControlPlaneandControlPlaneHC namespace objects by entering these commands:Delete HCP and ControlPlane HC NS commands
$ oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} hostedcontrolplane.hypershift.openshift.io ${HC_CLUSTER_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'$ oc delete hostedcontrolplane.hypershift.openshift.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all$ oc delete ns ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} || trueDelete the
HostedClusterand HC namespace objects by entering these commands:Delete HC and HC Namespace commands
$ oc -n ${HC_CLUSTER_NS} patch hostedclusters ${HC_CLUSTER_NAME} -p '{"metadata":{"finalizers":null}}' --type merge || true$ oc delete hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} || true$ oc delete ns ${HC_CLUSTER_NS} || true
Verification
To verify that everything works, enter these commands:
Validations commands
$ export KUBECONFIG=${MGMT2_KUBECONFIG}$ oc get hc -n ${HC_CLUSTER_NS}$ oc get np -n ${HC_CLUSTER_NS}$ oc get pod -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}$ oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}Commands for inside the HostedCluster
$ export KUBECONFIG=${HC_KUBECONFIG}$ oc get clusterversion$ oc get nodes
Next steps
Delete the OVN pods in the hosted cluster so that you can connect to the new OVN control plane that runs in the new management cluster:
-
Load the
KUBECONFIGenvironment variable with the hosted cluster’s kubeconfig path. Enter this command:
$ oc delete pod -n openshift-ovn-kubernetes --all
5.4.4.6. Running a script to back up and restore a hosted cluster
To expedite the process to back up a hosted cluster and restore it within the same region on AWS, you can modify and run a script.
Procedure
Replace the variables in the following script with your information:
# Fill the Common variables to fit your environment, this is just a sample SSH_KEY_FILE=${HOME}/.ssh/id_rsa.pub BASE_PATH=${HOME}/hypershift BASE_DOMAIN="aws.sample.com" PULL_SECRET_FILE="${HOME}/pull_secret.json" AWS_CREDS="${HOME}/.aws/credentials" CONTROL_PLANE_AVAILABILITY_POLICY=SingleReplica HYPERSHIFT_PATH=${BASE_PATH}/src/hypershift HYPERSHIFT_CLI=${HYPERSHIFT_PATH}/bin/hypershift HYPERSHIFT_IMAGE=${HYPERSHIFT_IMAGE:-"quay.io/${USER}/hypershift:latest"} NODE_POOL_REPLICAS=${NODE_POOL_REPLICAS:-2} # MGMT Context MGMT_REGION=us-west-1 MGMT_CLUSTER_NAME="${USER}-dev" MGMT_CLUSTER_NS=${USER} MGMT_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT_CLUSTER_NS}-${MGMT_CLUSTER_NAME}" MGMT_KUBECONFIG="${MGMT_CLUSTER_DIR}/kubeconfig" # MGMT2 Context MGMT2_CLUSTER_NAME="${USER}-dest" MGMT2_CLUSTER_NS=${USER} MGMT2_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT2_CLUSTER_NS}-${MGMT2_CLUSTER_NAME}" MGMT2_KUBECONFIG="${MGMT2_CLUSTER_DIR}/kubeconfig" # Hosted Cluster Context HC_CLUSTER_NS=clusters HC_REGION=us-west-1 HC_CLUSTER_NAME="${USER}-hosted" HC_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" HC_KUBECONFIG="${HC_CLUSTER_DIR}/kubeconfig" BACKUP_DIR=${HC_CLUSTER_DIR}/backup BUCKET_NAME="${USER}-hosted-${MGMT_REGION}" # DNS AWS_ZONE_ID="Z026552815SS3YPH9H6MG" EXTERNAL_DNS_DOMAIN="guest.jpdv.aws.kerbeross.com"- Save the script to your local file system.
Run the script by entering the following command:
source <env_file>where:
env_fileis the name of the file where you saved the script.The migration script is maintained at the following repository: https://github.com/openshift/hypershift/blob/main/contrib/migration/migrate-hcp.sh.