Chapter 2. Networking Operators
2.1. DNS Operator in OpenShift Dedicated
In OpenShift Dedicated, the DNS Operator deploys and manages a CoreDNS instance to provide a name resolution service to pods inside the cluster, enables DNS-based Kubernetes Service discovery, and resolves internal cluster.local names.
2.1.1. Checking the status of the DNS Operator
The DNS Operator implements the dns API from the operator.openshift.io API group. The Operator deploys CoreDNS using a daemon set, creates a service for the daemon set, and configures the kubelet to instruct pods to use the CoreDNS service IP address for name resolution.
Procedure
The DNS Operator is deployed during installation with a Deployment object.
Use the
oc getcommand to view the deployment status:oc get -n openshift-dns-operator deployment/dns-operator
$ oc get -n openshift-dns-operator deployment/dns-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example output
NAME READY UP-TO-DATE AVAILABLE AGE dns-operator 1/1 1 1 23h
NAME READY UP-TO-DATE AVAILABLE AGE dns-operator 1/1 1 1 23hCopy to Clipboard Copied! Toggle word wrap Toggle overflow Use the
oc getcommand to view the state of the DNS Operator:oc get clusteroperator/dns
$ oc get clusteroperator/dnsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example output
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE dns 4.1.15-0.11 True False False 92m
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE dns 4.1.15-0.11 True False False 92mCopy to Clipboard Copied! Toggle word wrap Toggle overflow AVAILABLE,PROGRESSING, andDEGRADEDprovide information about the status of the Operator.AVAILABLEisTruewhen at least 1 pod from the CoreDNS daemon set reports anAvailablestatus condition, and the DNS service has a cluster IP address.
2.1.2. View the default DNS
Every new OpenShift Dedicated installation has a dns.operator named default.
Procedure
Use the
oc describecommand to view the defaultdns:oc describe dns.operator/default
$ oc describe dns.operator/defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example output
Copy to Clipboard Copied! Toggle word wrap Toggle overflow To find the service CIDR range, such as
172.30.0.0/16, of your cluster, use theoc getcommand:oc get networks.config/cluster -o jsonpath='{$.status.serviceNetwork}'$ oc get networks.config/cluster -o jsonpath='{$.status.serviceNetwork}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.1.3. Using DNS forwarding
You can use DNS forwarding to override the default forwarding configuration in the /etc/resolv.conf file in the following ways:
Specify name servers (
spec.servers) for every zone. If the forwarded zone is the ingress domain managed by OpenShift Dedicated, then the upstream name server must be authorized for the domain.ImportantYou must specify at least one zone. Otherwise, your cluster can lose functionality.
-
Provide a list of upstream DNS servers (
spec.upstreamResolvers). - Change the default forwarding policy.
A DNS forwarding configuration for the default domain can have both the default servers specified in the /etc/resolv.conf file and the upstream DNS servers.
Procedure
Modify the DNS Operator object named
default:oc edit dns.operator/default
$ oc edit dns.operator/defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow After you issue the previous command, the Operator creates and updates the config map named
dns-defaultwith additional server configuration blocks based onspec.servers.ImportantWhen specifying values for the
zonesparameter, ensure that you only forward to specific zones, such as your intranet. You must specify at least one zone. Otherwise, your cluster can lose functionality.If none of the servers have a zone that matches the query, then name resolution falls back to the upstream DNS servers.
Configuring DNS forwarding
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- Must comply with the
rfc6335service name syntax. - 2
- Must conform to the definition of a subdomain in the
rfc1123service name syntax. The cluster domain,cluster.local, is an invalid subdomain for thezonesfield. - 3
- Defines the policy to select upstream resolvers listed in the
forwardPlugin. Default value isRandom. You can also use the valuesRoundRobin, andSequential. - 4
- A maximum of 15
upstreamsis allowed perforwardPlugin. - 5
- You can use
upstreamResolversto override the default forwarding policy and forward DNS resolution to the specified DNS resolvers (upstream resolvers) for the default domain. If you do not provide any upstream resolvers, the DNS name queries go to the servers declared in/etc/resolv.conf. - 6
- Determines the order in which upstream servers listed in
upstreamsare selected for querying. You can specify one of these values:Random,RoundRobin, orSequential. The default value isSequential. - 7
- When omitted, the platform chooses a default, normally the protocol of the original client request. Set to
TCPto specify that the platform should use TCP for all upstream DNS requests, even if the client request uses UDP. - 8
- Used to configure the transport type, server name, and optional custom CA or CA bundle to use when forwarding DNS requests to an upstream resolver.
- 9
- You can specify two types of
upstreams:SystemResolvConforNetwork.SystemResolvConfconfigures the upstream to use/etc/resolv.confandNetworkdefines aNetworkresolver. You can specify one or both. - 10
- If the specified type is
Network, you must provide an IP address. Theaddressfield must be a valid IPv4 or IPv6 address. - 11
- If the specified type is
Network, you can optionally provide a port. Theportfield must have a value between1and65535. If you do not specify a port for the upstream, the default port is 853.
2.1.4. Checking DNS Operator status
You can inspect the status and view the details of the DNS Operator using the oc describe command.
Procedure
View the status of the DNS Operator:
oc describe clusteroperators/dns
$ oc describe clusteroperators/dnsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Though the messages and spelling might vary in a specific release, the expected status output looks like:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.1.5. Viewing DNS Operator logs
You can view DNS Operator logs by using the oc logs command.
Procedure
View the logs of the DNS Operator:
oc logs -n openshift-dns-operator deployment/dns-operator -c dns-operator
$ oc logs -n openshift-dns-operator deployment/dns-operator -c dns-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.1.6. Setting the CoreDNS log level
Log levels for CoreDNS and the CoreDNS Operator are set by using different methods. You can configure the CoreDNS log level to determine the amount of detail in logged error messages. The valid values for CoreDNS log level are Normal, Debug, and Trace. The default logLevel is Normal.
The CoreDNS error log level is always enabled. The following log level settings report different error responses:
-
logLevel:Normalenables the "errors" class:log . { class error }. -
logLevel:Debugenables the "denial" class:log . { class denial error }. -
logLevel:Traceenables the "all" class:log . { class all }.
Procedure
To set
logLeveltoDebug, enter the following command:oc patch dnses.operator.openshift.io/default -p '{"spec":{"logLevel":"Debug"}}' --type=merge$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"logLevel":"Debug"}}' --type=mergeCopy to Clipboard Copied! Toggle word wrap Toggle overflow To set
logLeveltoTrace, enter the following command:oc patch dnses.operator.openshift.io/default -p '{"spec":{"logLevel":"Trace"}}' --type=merge$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"logLevel":"Trace"}}' --type=mergeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Verification
To ensure the desired log level was set, check the config map:
oc get configmap/dns-default -n openshift-dns -o yaml
$ oc get configmap/dns-default -n openshift-dns -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow For example, after setting the
logLeveltoTrace, you should see this stanza in each server block:errors log . { class all }errors log . { class all }Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.1.7. Viewing the CoreDNS logs
You can view CoreDNS logs by using the oc logs command.
Procedure
View the logs of a specific CoreDNS pod by entering the following command:
oc -n openshift-dns logs -c dns <core_dns_pod_name>
$ oc -n openshift-dns logs -c dns <core_dns_pod_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Follow the logs of all CoreDNS pods by entering the following command:
oc -n openshift-dns logs -c dns -l dns.operator.openshift.io/daemonset-dns=default -f --max-log-requests=<number>
$ oc -n openshift-dns logs -c dns -l dns.operator.openshift.io/daemonset-dns=default -f --max-log-requests=<number>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- Specifies the number of DNS pods to stream logs from. The maximum is 6.
2.1.8. Setting the CoreDNS Operator log level
Log levels for CoreDNS and CoreDNS Operator are set by using different methods. Cluster administrators can configure the Operator log level to more quickly track down OpenShift DNS issues. The valid values for operatorLogLevel are Normal, Debug, and Trace. Trace has the most detailed information. The default operatorlogLevel is Normal. There are seven logging levels for Operator issues: Trace, Debug, Info, Warning, Error, Fatal, and Panic. After the logging level is set, log entries with that severity or anything above it will be logged.
-
operatorLogLevel: "Normal"setslogrus.SetLogLevel("Info"). -
operatorLogLevel: "Debug"setslogrus.SetLogLevel("Debug"). -
operatorLogLevel: "Trace"setslogrus.SetLogLevel("Trace").
Procedure
To set
operatorLogLeveltoDebug, enter the following command:oc patch dnses.operator.openshift.io/default -p '{"spec":{"operatorLogLevel":"Debug"}}' --type=merge$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"operatorLogLevel":"Debug"}}' --type=mergeCopy to Clipboard Copied! Toggle word wrap Toggle overflow To set
operatorLogLeveltoTrace, enter the following command:oc patch dnses.operator.openshift.io/default -p '{"spec":{"operatorLogLevel":"Trace"}}' --type=merge$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"operatorLogLevel":"Trace"}}' --type=mergeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Verification
To review the resulting change, enter the following command:
oc get dnses.operator -A -oyaml
$ oc get dnses.operator -A -oyamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow You should see two log level entries. The
operatorLogLevelapplies to OpenShift DNS Operator issues, and thelogLevelapplies to the daemonset of CoreDNS pods:logLevel: Trace operatorLogLevel: Debug
logLevel: Trace operatorLogLevel: DebugCopy to Clipboard Copied! Toggle word wrap Toggle overflow To review the logs for the daemonset, enter the following command:
oc logs -n openshift-dns ds/dns-default
$ oc logs -n openshift-dns ds/dns-defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.1.9. Tuning the CoreDNS cache
For CoreDNS, you can configure the maximum duration of both successful or unsuccessful caching, also known respectively as positive or negative caching. Tuning the cache duration of DNS query responses can reduce the load for any upstream DNS resolvers.
Setting TTL fields to low values could lead to an increased load on the cluster, any upstream resolvers, or both.
Procedure
Edit the DNS Operator object named
defaultby running the following command:oc edit dns.operator.openshift.io/default
$ oc edit dns.operator.openshift.io/defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow Modify the time-to-live (TTL) caching values:
Configuring DNS caching
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- The string value
1his converted to its respective number of seconds by CoreDNS. If this field is omitted, the value is assumed to be0sand the cluster uses the internal default value of900sas a fallback. - 2
- The string value can be a combination of units such as
0.5h10mand is converted to its respective number of seconds by CoreDNS. If this field is omitted, the value is assumed to be0sand the cluster uses the internal default value of30sas a fallback.
Verification
To review the change, look at the config map again by running the following command:
oc get configmap/dns-default -n openshift-dns -o yaml
$ oc get configmap/dns-default -n openshift-dns -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Verify that you see entries that look like the following example:
cache 3600 { denial 9984 2400 }cache 3600 { denial 9984 2400 }Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.1.10. Advanced tasks
2.1.10.1. Changing the DNS Operator managementState
The DNS Operator manages the CoreDNS component to provide a name resolution service for pods and services in the cluster. The managementState of the DNS Operator is set to Managed by default, which means that the DNS Operator is actively managing its resources. You can change it to Unmanaged, which means the DNS Operator is not managing its resources.
The following are use cases for changing the DNS Operator managementState:
-
You are a developer and want to test a configuration change to see if it fixes an issue in CoreDNS. You can stop the DNS Operator from overwriting the configuration change by setting the
managementStatetoUnmanaged. -
You are a cluster administrator and have reported an issue with CoreDNS, but need to apply a workaround until the issue is fixed. You can set the
managementStatefield of the DNS Operator toUnmanagedto apply the workaround.
Procedure
Change
managementStatetoUnmanagedin the DNS Operator:oc patch dns.operator.openshift.io default --type merge --patch '{"spec":{"managementState":"Unmanaged"}}'oc patch dns.operator.openshift.io default --type merge --patch '{"spec":{"managementState":"Unmanaged"}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow Review
managementStateof the DNS Operator by using thejsonpathcommand-line JSON parser:oc get dns.operator.openshift.io default -ojsonpath='{.spec.managementState}'$ oc get dns.operator.openshift.io default -ojsonpath='{.spec.managementState}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow NoteYou cannot upgrade while the
managementStateis set toUnmanaged.
2.1.10.2. Controlling DNS pod placement
The DNS Operator has two daemon sets: one for CoreDNS called dns-default and one for managing the /etc/hosts file called node-resolver.
You can assign and run CoreDNS pods on specified nodes. For example, if the cluster administrator has configured security policies that prohibit communication between pairs of nodes, you can configure CoreDNS pods to run on a restricted set of nodes.
DNS service is available to all pods if the following circumstances are true:
- DNS pods are running on some nodes in the cluster.
- The nodes on which DNS pods are not running have network connectivity to nodes on which DNS pods are running,
The node-resolver daemon set must run on every node host because it adds an entry for the cluster image registry to support pulling images. The node-resolver pods have only one job: to look up the image-registry.openshift-image-registry.svc service’s cluster IP address and add it to /etc/hosts on the node host so that the container runtime can resolve the service name.
As a cluster administrator, you can use a custom node selector to configure the daemon set for CoreDNS to run or not run on certain nodes.
Prerequisites
-
You installed the
ocCLI. -
You are logged in to the cluster as a user with
cluster-adminprivileges. -
Your DNS Operator
managementStateis set toManaged.
Procedure
To allow the daemon set for CoreDNS to run on certain nodes, configure a taint and toleration:
Set a taint on the nodes that you want to control DNS pod placement by entering the following command:
oc adm taint nodes <node_name> dns-only=abc:NoExecute
$ oc adm taint nodes <node_name> dns-only=abc:NoExecute1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- Replace
<node_name>with the actual name of the node.
Modify the DNS Operator object named
defaultto include the corresponding toleration by entering the following command:oc edit dns.operator/default
$ oc edit dns.operator/defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow Specify a taint key and a toleration for the taint. The following toleration matches the taint set on the nodes.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Optional: To specify node placement using a node selector, modify the default DNS Operator:
Edit the DNS Operator object named
defaultto include a node selector:spec: nodePlacement: nodeSelector: node-role.kubernetes.io/control-plane: ""spec: nodePlacement: nodeSelector:1 node-role.kubernetes.io/control-plane: ""Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- This node selector ensures that the CoreDNS pods run only on control plane nodes.
2.1.10.3. Configuring DNS forwarding with TLS
When working in a highly regulated environment, you might need the ability to secure DNS traffic when forwarding requests to upstream resolvers so that you can ensure additional DNS traffic and data privacy.
Be aware that CoreDNS caches forwarded connections for 10 seconds. CoreDNS will hold a TCP connection open for those 10 seconds if no request is issued. With large clusters, ensure that your DNS server is aware that it might get many new connections to hold open because you can initiate a connection per node. Set up your DNS hierarchy accordingly to avoid performance issues.
When specifying values for the zones parameter, ensure that you only forward to specific zones, such as your intranet. You must specify at least one zone. Otherwise, your cluster can lose functionality.
Procedure
Modify the DNS Operator object named
default:oc edit dns.operator/default
$ oc edit dns.operator/defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow Cluster administrators can configure transport layer security (TLS) for forwarded DNS queries.
Configuring DNS forwarding with TLS
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- Must comply with the
rfc6335service name syntax. - 2
- Must conform to the definition of a subdomain in the
rfc1123service name syntax. The cluster domain,cluster.local, is an invalid subdomain for thezonesfield. The cluster domain,cluster.local, is an invalidsubdomainforzones. - 3
- When configuring TLS for forwarded DNS queries, set the
transportfield to have the valueTLS. - 4
- When configuring TLS for forwarded DNS queries, this is a mandatory server name used as part of the server name indication (SNI) to validate the upstream TLS server certificate.
- 5
- Defines the policy to select upstream resolvers. Default value is
Random. You can also use the valuesRoundRobin, andSequential. - 6
- Required. Use it to provide upstream resolvers. A maximum of 15
upstreamsentries are allowed perforwardPluginentry. - 7
- Optional. You can use it to override the default policy and forward DNS resolution to the specified DNS resolvers (upstream resolvers) for the default domain. If you do not provide any upstream resolvers, the DNS name queries go to the servers in
/etc/resolv.conf. - 8
- Only the
Networktype is allowed when using TLS and you must provide an IP address.Networktype indicates that this upstream resolver should handle forwarded requests separately from the upstream resolvers listed in/etc/resolv.conf. - 9
- The
addressfield must be a valid IPv4 or IPv6 address. - 10
- You can optionally provide a port. The
portmust have a value between1and65535. If you do not specify a port for the upstream, the default port is 853.
NoteIf
serversis undefined or invalid, the config map only contains the default server.
Verification
View the config map:
oc get configmap/dns-default -n openshift-dns -o yaml
$ oc get configmap/dns-default -n openshift-dns -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Sample DNS ConfigMap based on TLS forwarding example
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- Changes to the
forwardPlugintriggers a rolling update of the CoreDNS daemon set.
2.2. Ingress Operator in OpenShift Dedicated
The Ingress Operator implements the IngressController API and is the component responsible for enabling external access to OpenShift Dedicated cluster services.
2.2.1. OpenShift Dedicated Ingress Operator
When you create your OpenShift Dedicated cluster, pods and services running on the cluster are each allocated their own IP addresses. The IP addresses are accessible to other pods and services running nearby but are not accessible to outside clients.
The Ingress Operator makes it possible for external clients to access your service by deploying and managing one or more HAProxy-based Ingress Controllers to handle routing. Red Hat Site Reliability Engineers (SRE) manage the Ingress Operator for OpenShift Dedicated clusters. While you cannot alter the settings for the Ingress Operator, you may view the default Ingress Controller configurations, status, and logs as well as the Ingress Operator status.
2.2.2. The Ingress configuration asset
The installation program generates an asset with an Ingress resource in the config.openshift.io API group, cluster-ingress-02-config.yml.
YAML Definition of the Ingress resource
The installation program stores this asset in the cluster-ingress-02-config.yml file in the manifests/ directory. This Ingress resource defines the cluster-wide configuration for Ingress. This Ingress configuration is used as follows:
- The Ingress Operator uses the domain from the cluster Ingress configuration as the domain for the default Ingress Controller.
-
The OpenShift API Server Operator uses the domain from the cluster Ingress configuration. This domain is also used when generating a default host for a
Routeresource that does not specify an explicit host.
2.2.3. Ingress Controller configuration parameters
The IngressController custom resource (CR) includes optional configuration parameters that you can configure to meet specific needs for your organization.
| Parameter | Description |
|---|---|
|
|
The
If empty, the default value is |
|
|
|
|
|
For cloud environments, use the
You can configure the following
If not set, the default value is based on
For most platforms, the
If you need to update the
|
|
|
The
The secret must contain the following keys and data: *
If not set, a wildcard certificate is automatically generated and used. The certificate is valid for the Ingress Controller The in-use certificate, whether generated or user-specified, is automatically integrated with OpenShift Dedicated built-in OAuth server. |
|
|
|
|
|
|
|
|
If not set, the defaults values are used. Note
The |
|
|
If not set, the default value is based on the
When using the
The minimum TLS version for Ingress Controllers is Note
Ciphers and the minimum TLS version of the configured security profile are reflected in the Important
The Ingress Operator converts the TLS |
|
|
The
The |
|
|
|
|
|
|
|
|
By setting the
By default, the policy is set to
By setting These adjustments are only applied to cleartext, edge-terminated, and re-encrypt routes, and only when using HTTP/1.
For request headers, these adjustments are applied only for routes that have the
|
|
|
|
|
|
|
|
|
For any cookie that you want to capture, the following parameters must be in your
For example: httpCaptureCookies:
- matchType: Exact
maxLength: 128
name: MYCOOKIE
|
|
|
|
|
|
|
|
|
The
|
|
|
The
These connections come from load balancer health probes or web browser speculative connections (preconnect) and can be safely ignored. However, these requests can be caused by network errors, so setting this field to |
2.2.3.1. Ingress Controller TLS security profiles
TLS security profiles provide a way for servers to regulate which ciphers a connecting client can use when connecting to the server.
2.2.3.1.1. Understanding TLS security profiles
You can use a TLS (Transport Layer Security) security profile to define which TLS ciphers are required by various OpenShift Dedicated components. The OpenShift Dedicated TLS security profiles are based on Mozilla recommended configurations.
You can specify one of the following TLS security profiles for each component:
| Profile | Description |
|---|---|
|
| This profile is intended for use with legacy clients or libraries. The profile is based on the Old backward compatibility recommended configuration.
The Note For the Ingress Controller, the minimum TLS version is converted from 1.0 to 1.1. |
|
| This profile is the default TLS security profile for the Ingress Controller, kubelet, and control plane. The profile is based on the Intermediate compatibility recommended configuration.
The Note This profile is the recommended configuration for the majority of clients. |
|
| This profile is intended for use with modern clients that have no need for backwards compatibility. This profile is based on the Modern compatibility recommended configuration.
The |
|
| This profile allows you to define the TLS version and ciphers to use. Warning
Use caution when using a |
When using one of the predefined profile types, the effective profile configuration is subject to change between releases. For example, given a specification to use the Intermediate profile deployed on release X.Y.Z, an upgrade to release X.Y.Z+1 might cause a new profile configuration to be applied, resulting in a rollout.
2.2.3.1.2. Configuring the TLS security profile for the Ingress Controller
To configure a TLS security profile for an Ingress Controller, edit the IngressController custom resource (CR) to specify a predefined or custom TLS security profile. If a TLS security profile is not configured, the default value is based on the TLS security profile set for the API server.
Sample IngressController CR that configures the Old TLS security profile
The TLS security profile defines the minimum TLS version and the TLS ciphers for TLS connections for Ingress Controllers.
You can see the ciphers and the minimum TLS version of the configured TLS security profile in the IngressController custom resource (CR) under Status.Tls Profile and the configured TLS security profile under Spec.Tls Security Profile. For the Custom TLS security profile, the specific ciphers and minimum TLS version are listed under both parameters.
The HAProxy Ingress Controller image supports TLS 1.3 and the Modern profile.
The Ingress Operator also converts the TLS 1.0 of an Old or Custom profile to 1.1.
Prerequisites
-
You have access to the cluster as a user with the
cluster-adminrole.
Procedure
Edit the
IngressControllerCR in theopenshift-ingress-operatorproject to configure the TLS security profile:oc edit IngressController default -n openshift-ingress-operator
$ oc edit IngressController default -n openshift-ingress-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow Add the
spec.tlsSecurityProfilefield:Sample
IngressControllerCR for aCustomprofileCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Save the file to apply the changes.
Verification
Verify that the profile is set in the
IngressControllerCR:oc describe IngressController default -n openshift-ingress-operator
$ oc describe IngressController default -n openshift-ingress-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example output
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.3.1.3. Configuring mutual TLS authentication
You can configure the Ingress Controller to enable mutual TLS (mTLS) authentication by setting a spec.clientTLS value. The clientTLS value configures the Ingress Controller to verify client certificates. This configuration includes setting a clientCA value, which is a reference to a config map. The config map contains the PEM-encoded CA certificate bundle that is used to verify a client’s certificate. Optionally, you can also configure a list of certificate subject filters.
If the clientCA value specifies an X509v3 certificate revocation list (CRL) distribution point, the Ingress Operator downloads and manages a CRL config map based on the HTTP URI X509v3 CRL Distribution Point specified in each provided certificate. The Ingress Controller uses this config map during mTLS/TLS negotiation. Requests that do not provide valid certificates are rejected.
Prerequisites
-
You have access to the cluster as a user with the
cluster-adminrole. - You have a PEM-encoded CA certificate bundle.
If your CA bundle references a CRL distribution point, you must have also included the end-entity or leaf certificate to the client CA bundle. This certificate must have included an HTTP URI under
CRL Distribution Points, as described in RFC 5280. For example:Issuer: C=US, O=Example Inc, CN=Example Global G2 TLS RSA SHA256 2020 CA1 Subject: SOME SIGNED CERT X509v3 CRL Distribution Points: Full Name: URI:http://crl.example.com/example.crlIssuer: C=US, O=Example Inc, CN=Example Global G2 TLS RSA SHA256 2020 CA1 Subject: SOME SIGNED CERT X509v3 CRL Distribution Points: Full Name: URI:http://crl.example.com/example.crlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Procedure
In the
openshift-confignamespace, create a config map from your CA bundle:oc create configmap \ router-ca-certs-default \ --from-file=ca-bundle.pem=client-ca.crt \ -n openshift-config
$ oc create configmap \ router-ca-certs-default \ --from-file=ca-bundle.pem=client-ca.crt \1 -n openshift-configCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- The config map data key must be
ca-bundle.pem, and the data value must be a CA certificate in PEM format.
Edit the
IngressControllerresource in theopenshift-ingress-operatorproject:oc edit IngressController default -n openshift-ingress-operator
$ oc edit IngressController default -n openshift-ingress-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow Add the
spec.clientTLSfield and subfields to configure mutual TLS:Sample
IngressControllerCR for aclientTLSprofile that specifies filtering patternsCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
Optional, get the Distinguished Name (DN) for
allowedSubjectPatternsby entering the following command.
openssl x509 -in custom-cert.pem -noout -subject
$ openssl x509 -in custom-cert.pem -noout -subject
subject= /CN=example.com/ST=NC/C=US/O=Security/OU=OpenShift2.2.4. View the default Ingress Controller
The Ingress Operator is a core feature of OpenShift Dedicated and is enabled out of the box.
Every new OpenShift Dedicated installation has an ingresscontroller named default. It can be supplemented with additional Ingress Controllers. If the default ingresscontroller is deleted, the Ingress Operator will automatically recreate it within a minute.
Procedure
View the default Ingress Controller:
oc describe --namespace=openshift-ingress-operator ingresscontroller/default
$ oc describe --namespace=openshift-ingress-operator ingresscontroller/defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.5. View Ingress Operator status
You can view and inspect the status of your Ingress Operator.
Procedure
View your Ingress Operator status:
oc describe clusteroperators/ingress
$ oc describe clusteroperators/ingressCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.6. View Ingress Controller logs
You can view your Ingress Controller logs.
Procedure
View your Ingress Controller logs:
oc logs --namespace=openshift-ingress-operator deployments/ingress-operator -c <container_name>
$ oc logs --namespace=openshift-ingress-operator deployments/ingress-operator -c <container_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.7. View Ingress Controller status
Your can view the status of a particular Ingress Controller.
Procedure
View the status of an Ingress Controller:
oc describe --namespace=openshift-ingress-operator ingresscontroller/<name>
$ oc describe --namespace=openshift-ingress-operator ingresscontroller/<name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.8. Creating a custom Ingress Controller
As a cluster administrator, you can create a new custom Ingress Controller. Because the default Ingress Controller might change during OpenShift Dedicated updates, creating a custom Ingress Controller can be helpful when maintaining a configuration manually that persists across cluster updates.
This example provides a minimal spec for a custom Ingress Controller. To further customize your custom Ingress Controller, see "Configuring the Ingress Controller".
Prerequisites
-
Install the OpenShift CLI (
oc). -
Log in as a user with
cluster-adminprivileges.
Procedure
Create a YAML file that defines the custom
IngressControllerobject:Example
custom-ingress-controller.yamlfileCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- Specify the a custom
namefor theIngressControllerobject. - 2
- Specify the name of the secret with the custom wildcard certificate.
- 3
- Minimum replica needs to be ONE
- 4
- Specify the domain to your domain name. The domain specified on the IngressController object and the domain used for the certificate must match. For example, if the domain value is "custom_domain.mycompany.com", then the certificate must have SAN *.custom_domain.mycompany.com (with the
*.added to the domain).
Create the object by running the following command:
oc create -f custom-ingress-controller.yaml
$ oc create -f custom-ingress-controller.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.9. Configuring the Ingress Controller
2.2.9.1. Setting a custom default certificate
As an administrator, you can configure an Ingress Controller to use a custom certificate by creating a Secret resource and editing the IngressController custom resource (CR).
Prerequisites
- You must have a certificate/key pair in PEM-encoded files, where the certificate is signed by a trusted certificate authority or by a private trusted certificate authority that you configured in a custom PKI.
Your certificate meets the following requirements:
- The certificate is valid for the ingress domain.
-
The certificate uses the
subjectAltNameextension to specify a wildcard domain, such as*.apps.ocp4.example.com.
You must have an
IngressControllerCR, which includes just having thedefaultIngressControllerCR. You can run the following command to check that you have anIngressControllerCR:oc --namespace openshift-ingress-operator get ingresscontrollers
$ oc --namespace openshift-ingress-operator get ingresscontrollersCopy to Clipboard Copied! Toggle word wrap Toggle overflow
If you have intermediate certificates, they must be included in the tls.crt file of the secret containing a custom default certificate. Order matters when specifying a certificate; list your intermediate certificate(s) after any server certificate(s).
Procedure
The following assumes that the custom certificate and key pair are in the tls.crt and tls.key files in the current working directory. Substitute the actual path names for tls.crt and tls.key. You also may substitute another name for custom-certs-default when creating the Secret resource and referencing it in the IngressController CR.
This action will cause the Ingress Controller to be redeployed, using a rolling deployment strategy.
Create a Secret resource containing the custom certificate in the
openshift-ingressnamespace using thetls.crtandtls.keyfiles.oc --namespace openshift-ingress create secret tls custom-certs-default --cert=tls.crt --key=tls.key
$ oc --namespace openshift-ingress create secret tls custom-certs-default --cert=tls.crt --key=tls.keyCopy to Clipboard Copied! Toggle word wrap Toggle overflow Update the IngressController CR to reference the new certificate secret:
oc patch --type=merge --namespace openshift-ingress-operator ingresscontrollers/default \ --patch '{"spec":{"defaultCertificate":{"name":"custom-certs-default"}}}'$ oc patch --type=merge --namespace openshift-ingress-operator ingresscontrollers/default \ --patch '{"spec":{"defaultCertificate":{"name":"custom-certs-default"}}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow Verify the update was effective:
echo Q |\ openssl s_client -connect console-openshift-console.apps.<domain>:443 -showcerts 2>/dev/null |\ openssl x509 -noout -subject -issuer -enddate
$ echo Q |\ openssl s_client -connect console-openshift-console.apps.<domain>:443 -showcerts 2>/dev/null |\ openssl x509 -noout -subject -issuer -enddateCopy to Clipboard Copied! Toggle word wrap Toggle overflow where:
<domain>- Specifies the base domain name for your cluster.
Example output
subject=C = US, ST = NC, L = Raleigh, O = RH, OU = OCP4, CN = *.apps.example.com issuer=C = US, ST = NC, L = Raleigh, O = RH, OU = OCP4, CN = example.com notAfter=May 10 08:32:45 2022 GM
subject=C = US, ST = NC, L = Raleigh, O = RH, OU = OCP4, CN = *.apps.example.com issuer=C = US, ST = NC, L = Raleigh, O = RH, OU = OCP4, CN = example.com notAfter=May 10 08:32:45 2022 GMCopy to Clipboard Copied! Toggle word wrap Toggle overflow TipYou can alternatively apply the following YAML to set a custom default certificate:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow The certificate secret name should match the value used to update the CR.
Once the IngressController CR has been modified, the Ingress Operator updates the Ingress Controller’s deployment to use the custom certificate.
2.2.9.2. Removing a custom default certificate
As an administrator, you can remove a custom certificate that you configured an Ingress Controller to use.
Prerequisites
-
You have access to the cluster as a user with the
cluster-adminrole. -
You have installed the OpenShift CLI (
oc). - You previously configured a custom default certificate for the Ingress Controller.
Procedure
To remove the custom certificate and restore the certificate that ships with OpenShift Dedicated, enter the following command:
oc patch -n openshift-ingress-operator ingresscontrollers/default \ --type json -p $'- op: remove\n path: /spec/defaultCertificate'
$ oc patch -n openshift-ingress-operator ingresscontrollers/default \ --type json -p $'- op: remove\n path: /spec/defaultCertificate'Copy to Clipboard Copied! Toggle word wrap Toggle overflow There can be a delay while the cluster reconciles the new certificate configuration.
Verification
To confirm that the original cluster certificate is restored, enter the following command:
echo Q | \ openssl s_client -connect console-openshift-console.apps.<domain>:443 -showcerts 2>/dev/null | \ openssl x509 -noout -subject -issuer -enddate
$ echo Q | \ openssl s_client -connect console-openshift-console.apps.<domain>:443 -showcerts 2>/dev/null | \ openssl x509 -noout -subject -issuer -enddateCopy to Clipboard Copied! Toggle word wrap Toggle overflow where:
<domain>- Specifies the base domain name for your cluster.
Example output
subject=CN = *.apps.<domain> issuer=CN = ingress-operator@1620633373 notAfter=May 10 10:44:36 2023 GMT
subject=CN = *.apps.<domain> issuer=CN = ingress-operator@1620633373 notAfter=May 10 10:44:36 2023 GMTCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.9.3. Autoscaling an Ingress Controller
You can automatically scale an Ingress Controller to dynamically meet routing performance or availability requirements, such as the requirement to increase throughput.
The following procedure provides an example for scaling up the default Ingress Controller.
Prerequisites
-
You have the OpenShift CLI (
oc) installed. -
You have access to an OpenShift Dedicated cluster as a user with the
cluster-adminrole. You installed the Custom Metrics Autoscaler Operator and an associated KEDA Controller.
-
You can install the Operator by using OperatorHub on the web console. After you install the Operator, you can create an instance of
KedaController.
-
You can install the Operator by using OperatorHub on the web console. After you install the Operator, you can create an instance of
Procedure
Create a service account to authenticate with Thanos by running the following command:
oc create -n openshift-ingress-operator serviceaccount thanos && oc describe -n openshift-ingress-operator serviceaccount thanos
$ oc create -n openshift-ingress-operator serviceaccount thanos && oc describe -n openshift-ingress-operator serviceaccount thanosCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example output
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Manually create the service account secret token with the following command:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Define a
TriggerAuthenticationobject within theopenshift-ingress-operatornamespace by using the service account’s token.Create the
TriggerAuthenticationobject and pass the value of thesecretvariable to theTOKENparameter:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Create and apply a role for reading metrics from Thanos:
Create a new role,
thanos-metrics-reader.yaml, that reads metrics from pods and nodes:thanos-metrics-reader.yaml
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Apply the new role by running the following command:
oc apply -f thanos-metrics-reader.yaml
$ oc apply -f thanos-metrics-reader.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Add the new role to the service account by entering the following commands:
oc adm policy -n openshift-ingress-operator add-role-to-user thanos-metrics-reader -z thanos --role-namespace=openshift-ingress-operator
$ oc adm policy -n openshift-ingress-operator add-role-to-user thanos-metrics-reader -z thanos --role-namespace=openshift-ingress-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc adm policy -n openshift-ingress-operator add-cluster-role-to-user cluster-monitoring-view -z thanos
$ oc adm policy -n openshift-ingress-operator add-cluster-role-to-user cluster-monitoring-view -z thanosCopy to Clipboard Copied! Toggle word wrap Toggle overflow NoteThe argument
add-cluster-role-to-useris only required if you use cross-namespace queries. The following step uses a query from thekube-metricsnamespace which requires this argument.Create a new
ScaledObjectYAML file,ingress-autoscaler.yaml, that targets the default Ingress Controller deployment:Example
ScaledObjectdefinitionCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- The custom resource that you are targeting. In this case, the Ingress Controller.
- 2
- Optional: The maximum number of replicas. If you omit this field, the default maximum is set to 100 replicas.
- 3
- The Thanos service endpoint in the
openshift-monitoringnamespace. - 4
- The Ingress Operator namespace.
- 5
- This expression evaluates to however many worker nodes are present in the deployed cluster.
ImportantIf you are using cross-namespace queries, you must target port 9091 and not port 9092 in the
serverAddressfield. You also must have elevated privileges to read metrics from this port.Apply the custom resource definition by running the following command:
oc apply -f ingress-autoscaler.yaml
$ oc apply -f ingress-autoscaler.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Verification
Verify that the default Ingress Controller is scaled out to match the value returned by the
kube-state-metricsquery by running the following commands:Use the
grepcommand to search the Ingress Controller YAML file for the number of replicas:oc get -n openshift-ingress-operator ingresscontroller/default -o yaml | grep replicas:
$ oc get -n openshift-ingress-operator ingresscontroller/default -o yaml | grep replicas:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Get the pods in the
openshift-ingressproject:oc get pods -n openshift-ingress
$ oc get pods -n openshift-ingressCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example output
NAME READY STATUS RESTARTS AGE router-default-7b5df44ff-l9pmm 2/2 Running 0 17h router-default-7b5df44ff-s5sl5 2/2 Running 0 3d22h router-default-7b5df44ff-wwsth 2/2 Running 0 66s
NAME READY STATUS RESTARTS AGE router-default-7b5df44ff-l9pmm 2/2 Running 0 17h router-default-7b5df44ff-s5sl5 2/2 Running 0 3d22h router-default-7b5df44ff-wwsth 2/2 Running 0 66sCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.9.4. Scaling an Ingress Controller
Manually scale an Ingress Controller to meeting routing performance or availability requirements such as the requirement to increase throughput. oc commands are used to scale the IngressController resource. The following procedure provides an example for scaling up the default IngressController.
Scaling is not an immediate action, as it takes time to create the desired number of replicas.
Procedure
View the current number of available replicas for the default
IngressController:oc get -n openshift-ingress-operator ingresscontrollers/default -o jsonpath='{$.status.availableReplicas}'$ oc get -n openshift-ingress-operator ingresscontrollers/default -o jsonpath='{$.status.availableReplicas}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow Scale the default
IngressControllerto the desired number of replicas by using theoc patchcommand. The following example scales the defaultIngressControllerto 3 replicas.oc patch -n openshift-ingress-operator ingresscontroller/default --patch '{"spec":{"replicas": 3}}' --type=merge$ oc patch -n openshift-ingress-operator ingresscontroller/default --patch '{"spec":{"replicas": 3}}' --type=mergeCopy to Clipboard Copied! Toggle word wrap Toggle overflow Verify that the default
IngressControllerscaled to the number of replicas that you specified:oc get -n openshift-ingress-operator ingresscontrollers/default -o jsonpath='{$.status.availableReplicas}'$ oc get -n openshift-ingress-operator ingresscontrollers/default -o jsonpath='{$.status.availableReplicas}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow TipYou can alternatively apply the following YAML to scale an Ingress Controller to three replicas:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- If you need a different amount of replicas, change the
replicasvalue.
2.2.9.5. Configuring Ingress access logging
You can configure the Ingress Controller to enable access logs. If you have clusters that do not receive much traffic, then you can log to a sidecar. If you have high traffic clusters, to avoid exceeding the capacity of the logging stack or to integrate with a logging infrastructure outside of OpenShift Dedicated, you can forward logs to a custom syslog endpoint. You can also specify the format for access logs.
Container logging is useful to enable access logs on low-traffic clusters when there is no existing Syslog logging infrastructure, or for short-term use while diagnosing problems with the Ingress Controller.
Syslog is needed for high-traffic clusters where access logs could exceed the OpenShift Logging stack’s capacity, or for environments where any logging solution needs to integrate with an existing Syslog logging infrastructure. The Syslog use-cases can overlap.
Prerequisites
-
Log in as a user with
cluster-adminprivileges.
Procedure
Configure Ingress access logging to a sidecar.
To configure Ingress access logging, you must specify a destination using
spec.logging.access.destination. To specify logging to a sidecar container, you must specifyContainerspec.logging.access.destination.type. The following example is an Ingress Controller definition that logs to aContainerdestination:Copy to Clipboard Copied! Toggle word wrap Toggle overflow When you configure the Ingress Controller to log to a sidecar, the operator creates a container named
logsinside the Ingress Controller Pod:oc -n openshift-ingress logs deployment.apps/router-default -c logs
$ oc -n openshift-ingress logs deployment.apps/router-default -c logsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example output
2020-05-11T19:11:50.135710+00:00 router-default-57dfc6cd95-bpmk6 router-default-57dfc6cd95-bpmk6 haproxy[108]: 174.19.21.82:39654 [11/May/2020:19:11:50.133] public be_http:hello-openshift:hello-openshift/pod:hello-openshift:hello-openshift:10.128.2.12:8080 0/0/1/0/1 200 142 - - --NI 1/1/0/0/0 0/0 "GET / HTTP/1.1"
2020-05-11T19:11:50.135710+00:00 router-default-57dfc6cd95-bpmk6 router-default-57dfc6cd95-bpmk6 haproxy[108]: 174.19.21.82:39654 [11/May/2020:19:11:50.133] public be_http:hello-openshift:hello-openshift/pod:hello-openshift:hello-openshift:10.128.2.12:8080 0/0/1/0/1 200 142 - - --NI 1/1/0/0/0 0/0 "GET / HTTP/1.1"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Configure Ingress access logging to a Syslog endpoint.
To configure Ingress access logging, you must specify a destination using
spec.logging.access.destination. To specify logging to a Syslog endpoint destination, you must specifySyslogforspec.logging.access.destination.type. If the destination type isSyslog, you must also specify a destination endpoint usingspec.logging.access.destination.syslog.addressand you can specify a facility usingspec.logging.access.destination.syslog.facility. The following example is an Ingress Controller definition that logs to aSyslogdestination:Copy to Clipboard Copied! Toggle word wrap Toggle overflow NoteThe
syslogdestination port must be UDP.The
syslogdestination address must be an IP address. It does not support DNS hostname.
Configure Ingress access logging with a specific log format.
You can specify
spec.logging.access.httpLogFormatto customize the log format. The following example is an Ingress Controller definition that logs to asyslogendpoint with IP address 1.2.3.4 and port 10514:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Disable Ingress access logging.
To disable Ingress access logging, leave
spec.loggingorspec.logging.accessempty:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Allow the Ingress Controller to modify the HAProxy log length when using a sidecar.
Use
spec.logging.access.destination.syslog.maxLengthif you are usingspec.logging.access.destination.type: Syslog.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Use
spec.logging.access.destination.container.maxLengthif you are usingspec.logging.access.destination.type: Container.Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
To view the original client source IP address by using the
X-Forwarded-Forheader in theIngressaccess logs, see the "Capturing Original Client IP from the X-Forwarded-For Header in Ingress and Application Logs" Red Hat Knowledgebase solution.
2.2.9.6. Setting Ingress Controller thread count
A cluster administrator can set the thread count to increase the amount of incoming connections a cluster can handle. You can patch an existing Ingress Controller to increase the amount of threads.
Prerequisites
- The following assumes that you already created an Ingress Controller.
Procedure
Update the Ingress Controller to increase the number of threads:
oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"threadCount": 8}}}'$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"threadCount": 8}}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow NoteIf you have a node that is capable of running large amounts of resources, you can configure
spec.nodePlacement.nodeSelectorwith labels that match the capacity of the intended node, and configurespec.tuningOptions.threadCountto an appropriately high value.
2.2.9.7. Configuring an Ingress Controller to use an internal load balancer
When creating an Ingress Controller on cloud platforms, the Ingress Controller is published by a public cloud load balancer by default. As an administrator, you can create an Ingress Controller that uses an internal cloud load balancer.
If you want to change the scope for an IngressController, you can change the .spec.endpointPublishingStrategy.loadBalancer.scope parameter after the custom resource (CR) is created.
Figure 2.1. Diagram of LoadBalancer
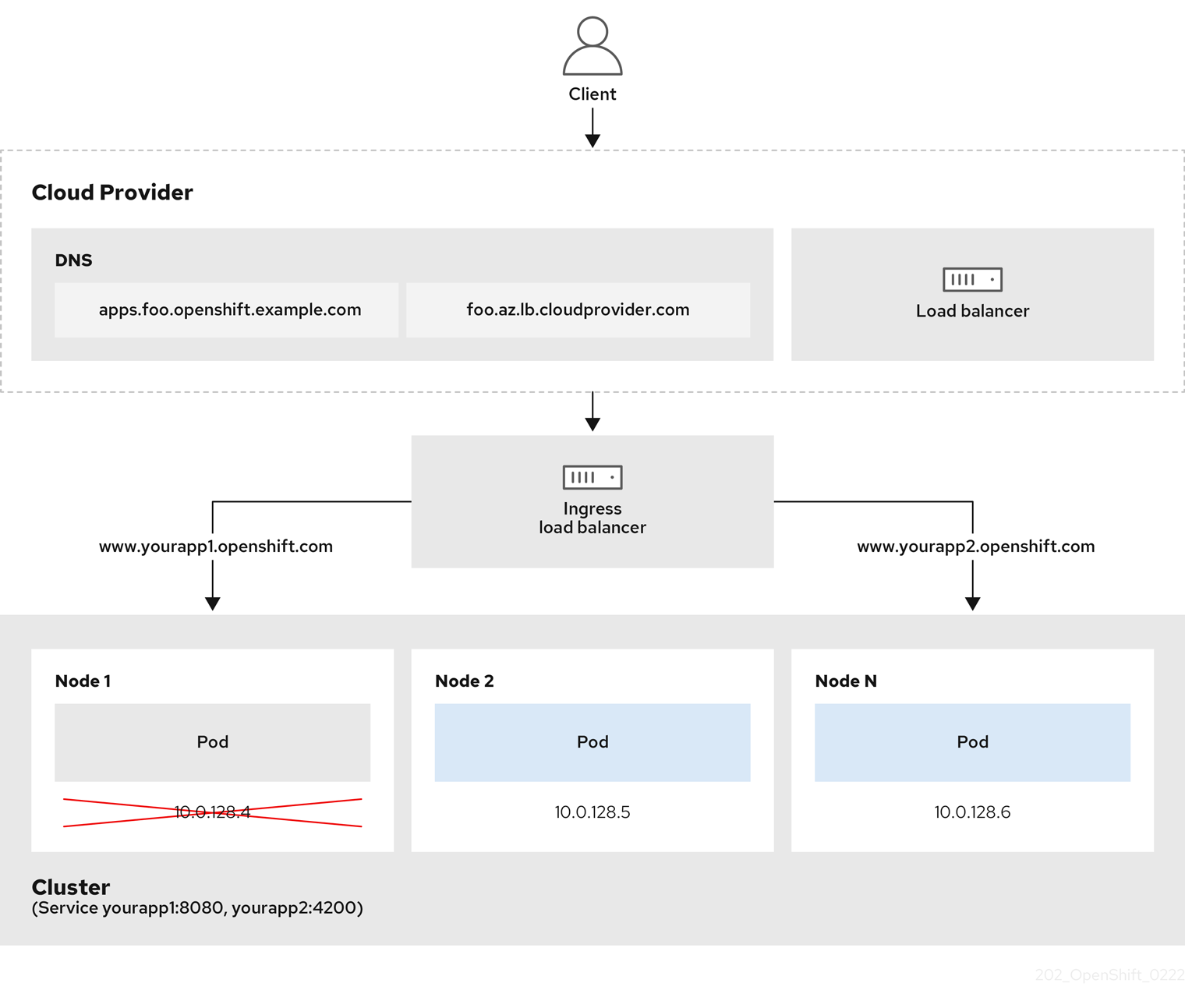
The preceding graphic shows the following concepts pertaining to OpenShift Dedicated Ingress LoadBalancerService endpoint publishing strategy:
- You can load balance externally, using the cloud provider load balancer, or internally, using the OpenShift Ingress Controller Load Balancer.
- You can use the single IP address of the load balancer and more familiar ports, such as 8080 and 4200 as shown on the cluster depicted in the graphic.
- Traffic from the external load balancer is directed at the pods, and managed by the load balancer, as depicted in the instance of a down node. See the Kubernetes Services documentation for implementation details.
Prerequisites
-
Install the OpenShift CLI (
oc). -
Log in as a user with
cluster-adminprivileges.
Procedure
Create an
IngressControllercustom resource (CR) in a file named<name>-ingress-controller.yaml, such as in the following example:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Create the Ingress Controller defined in the previous step by running the following command:
oc create -f <name>-ingress-controller.yaml
$ oc create -f <name>-ingress-controller.yaml1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- Replace
<name>with the name of theIngressControllerobject.
Optional: Confirm that the Ingress Controller was created by running the following command:
oc --all-namespaces=true get ingresscontrollers
$ oc --all-namespaces=true get ingresscontrollersCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.9.8. Setting the Ingress Controller health check interval
A cluster administrator can set the health check interval to define how long the router waits between two consecutive health checks. This value is applied globally as a default for all routes. The default value is 5 seconds.
Prerequisites
- The following assumes that you already created an Ingress Controller.
Procedure
Update the Ingress Controller to change the interval between back end health checks:
oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"healthCheckInterval": "8s"}}}'$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"healthCheckInterval": "8s"}}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow NoteTo override the
healthCheckIntervalfor a single route, use the route annotationrouter.openshift.io/haproxy.health.check.interval
2.2.9.9. Configuring the default Ingress Controller for your cluster to be internal
You can configure the default Ingress Controller for your cluster to be internal by deleting and recreating it.
If you want to change the scope for an IngressController, you can change the .spec.endpointPublishingStrategy.loadBalancer.scope parameter after the custom resource (CR) is created.
Prerequisites
-
Install the OpenShift CLI (
oc). -
Log in as a user with
cluster-adminprivileges.
Procedure
Configure the
defaultIngress Controller for your cluster to be internal by deleting and recreating it.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.9.10. Configuring the route admission policy
Administrators and application developers can run applications in multiple namespaces with the same domain name. This is for organizations where multiple teams develop microservices that are exposed on the same hostname.
Allowing claims across namespaces should only be enabled for clusters with trust between namespaces, otherwise a malicious user could take over a hostname. For this reason, the default admission policy disallows hostname claims across namespaces.
Prerequisites
- Cluster administrator privileges.
Procedure
Edit the
.spec.routeAdmissionfield of theingresscontrollerresource variable using the following command:oc -n openshift-ingress-operator patch ingresscontroller/default --patch '{"spec":{"routeAdmission":{"namespaceOwnership":"InterNamespaceAllowed"}}}' --type=merge$ oc -n openshift-ingress-operator patch ingresscontroller/default --patch '{"spec":{"routeAdmission":{"namespaceOwnership":"InterNamespaceAllowed"}}}' --type=mergeCopy to Clipboard Copied! Toggle word wrap Toggle overflow Sample Ingress Controller configuration
spec: routeAdmission: namespaceOwnership: InterNamespaceAllowed ...spec: routeAdmission: namespaceOwnership: InterNamespaceAllowed ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow TipYou can alternatively apply the following YAML to configure the route admission policy:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.9.11. Using wildcard routes
The HAProxy Ingress Controller has support for wildcard routes. The Ingress Operator uses wildcardPolicy to configure the ROUTER_ALLOW_WILDCARD_ROUTES environment variable of the Ingress Controller.
The default behavior of the Ingress Controller is to admit routes with a wildcard policy of None, which is backwards compatible with existing IngressController resources.
Procedure
Configure the wildcard policy.
Use the following command to edit the
IngressControllerresource:oc edit IngressController
$ oc edit IngressControllerCopy to Clipboard Copied! Toggle word wrap Toggle overflow Under
spec, set thewildcardPolicyfield toWildcardsDisallowedorWildcardsAllowed:spec: routeAdmission: wildcardPolicy: WildcardsDisallowed # or WildcardsAllowedspec: routeAdmission: wildcardPolicy: WildcardsDisallowed # or WildcardsAllowedCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.9.12. HTTP header configuration
OpenShift Dedicated provides different methods for working with HTTP headers. When setting or deleting headers, you can use specific fields in the Ingress Controller or an individual route to modify request and response headers. You can also set certain headers by using route annotations. The various ways of configuring headers can present challenges when working together.
You can only set or delete headers within an IngressController or Route CR, you cannot append them. If an HTTP header is set with a value, that value must be complete and not require appending in the future. In situations where it makes sense to append a header, such as the X-Forwarded-For header, use the spec.httpHeaders.forwardedHeaderPolicy field, instead of spec.httpHeaders.actions.
2.2.9.12.1. Order of precedence
When the same HTTP header is modified both in the Ingress Controller and in a route, HAProxy prioritizes the actions in certain ways depending on whether it is a request or response header.
- For HTTP response headers, actions specified in the Ingress Controller are executed after the actions specified in a route. This means that the actions specified in the Ingress Controller take precedence.
- For HTTP request headers, actions specified in a route are executed after the actions specified in the Ingress Controller. This means that the actions specified in the route take precedence.
For example, a cluster administrator sets the X-Frame-Options response header with the value DENY in the Ingress Controller using the following configuration:
Example IngressController spec
A route owner sets the same response header that the cluster administrator set in the Ingress Controller, but with the value SAMEORIGIN using the following configuration:
Example Route spec
When both the IngressController spec and Route spec are configuring the X-Frame-Options response header, then the value set for this header at the global level in the Ingress Controller takes precedence, even if a specific route allows frames. For a request header, the Route spec value overrides the IngressController spec value.
This prioritization occurs because the haproxy.config file uses the following logic, where the Ingress Controller is considered the front end and individual routes are considered the back end. The header value DENY applied to the front end configurations overrides the same header with the value SAMEORIGIN that is set in the back end:
Additionally, any actions defined in either the Ingress Controller or a route override values set using route annotations.
2.2.9.12.2. Special case headers
The following headers are either prevented entirely from being set or deleted, or allowed under specific circumstances:
| Header name | Configurable using IngressController spec | Configurable using Route spec | Reason for disallowment | Configurable using another method |
|---|---|---|---|---|
|
| No | No |
The | No |
|
| No | Yes |
When the | No |
|
| No | No |
The |
Yes: the |
|
| No | No | The cookies that HAProxy sets are used for session tracking to map client connections to particular back-end servers. Allowing these headers to be set could interfere with HAProxy’s session affinity and restrict HAProxy’s ownership of a cookie. | Yes:
|
2.2.9.13. Setting or deleting HTTP request and response headers in an Ingress Controller
You can set or delete certain HTTP request and response headers for compliance purposes or other reasons. You can set or delete these headers either for all routes served by an Ingress Controller or for specific routes.
For example, you might want to migrate an application running on your cluster to use mutual TLS, which requires that your application checks for an X-Forwarded-Client-Cert request header, but the OpenShift Dedicated default Ingress Controller provides an X-SSL-Client-Der request header.
The following procedure modifies the Ingress Controller to set the X-Forwarded-Client-Cert request header, and delete the X-SSL-Client-Der request header.
Prerequisites
-
You have installed the OpenShift CLI (
oc). -
You have access to an OpenShift Dedicated cluster as a user with the
cluster-adminrole.
Procedure
Edit the Ingress Controller resource:
oc -n openshift-ingress-operator edit ingresscontroller/default
$ oc -n openshift-ingress-operator edit ingresscontroller/defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow Replace the X-SSL-Client-Der HTTP request header with the X-Forwarded-Client-Cert HTTP request header:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- The list of actions you want to perform on the HTTP headers.
- 2
- The type of header you want to change. In this case, a request header.
- 3
- The name of the header you want to change. For a list of available headers you can set or delete, see HTTP header configuration.
- 4
- The type of action being taken on the header. This field can have the value
SetorDelete. - 5
- When setting HTTP headers, you must provide a
value. The value can be a string from a list of available directives for that header, for exampleDENY, or it can be a dynamic value that will be interpreted using HAProxy’s dynamic value syntax. In this case, a dynamic value is added.
NoteFor setting dynamic header values for HTTP responses, allowed sample fetchers are
res.hdrandssl_c_der. For setting dynamic header values for HTTP requests, allowed sample fetchers arereq.hdrandssl_c_der. Both request and response dynamic values can use thelowerandbase64converters.- Save the file to apply the changes.
2.2.9.14. Using X-Forwarded headers
You configure the HAProxy Ingress Controller to specify a policy for how to handle HTTP headers including Forwarded and X-Forwarded-For. The Ingress Operator uses the HTTPHeaders field to configure the ROUTER_SET_FORWARDED_HEADERS environment variable of the Ingress Controller.
Procedure
Configure the
HTTPHeadersfield for the Ingress Controller.Use the following command to edit the
IngressControllerresource:oc edit IngressController
$ oc edit IngressControllerCopy to Clipboard Copied! Toggle word wrap Toggle overflow Under
spec, set theHTTPHeaderspolicy field toAppend,Replace,IfNone, orNever:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Example use cases
As a cluster administrator, you can:
Configure an external proxy that injects the
X-Forwarded-Forheader into each request before forwarding it to an Ingress Controller.To configure the Ingress Controller to pass the header through unmodified, you specify the
neverpolicy. The Ingress Controller then never sets the headers, and applications receive only the headers that the external proxy provides.Configure the Ingress Controller to pass the
X-Forwarded-Forheader that your external proxy sets on external cluster requests through unmodified.To configure the Ingress Controller to set the
X-Forwarded-Forheader on internal cluster requests, which do not go through the external proxy, specify theif-nonepolicy. If an HTTP request already has the header set through the external proxy, then the Ingress Controller preserves it. If the header is absent because the request did not come through the proxy, then the Ingress Controller adds the header.
As an application developer, you can:
Configure an application-specific external proxy that injects the
X-Forwarded-Forheader.To configure an Ingress Controller to pass the header through unmodified for an application’s Route, without affecting the policy for other Routes, add an annotation
haproxy.router.openshift.io/set-forwarded-headers: if-noneorhaproxy.router.openshift.io/set-forwarded-headers: neveron the Route for the application.NoteYou can set the
haproxy.router.openshift.io/set-forwarded-headersannotation on a per route basis, independent from the globally set value for the Ingress Controller.
2.2.9.15. Enable or disable HTTP/2 on Ingress Controllers
You can enable or disable transparent end-to-end HTTP/2 connectivity in HAProxy. Application owners can use HTTP/2 protocol capabilities, including single connection, header compression, binary streams, and more.
You can enable or disable HTTP/2 connectivity for an individual Ingress Controller or for the entire cluster.
If you enable or disable HTTP/2 connectivity for an individual Ingress Controller and for the entire cluster, the HTTP/2 configuration for the Ingress Controller takes precedence over the HTTP/2 configuration for the cluster.
To enable the use of HTTP/2 for a connection from the client to an HAProxy instance, a route must specify a custom certificate. A route that uses the default certificate cannot use HTTP/2. This restriction is necessary to avoid problems from connection coalescing, where the client re-uses a connection for different routes that use the same certificate.
Consider the following use cases for an HTTP/2 connection for each route type:
- For a re-encrypt route, the connection from HAProxy to the application pod can use HTTP/2 if the application supports using Application-Level Protocol Negotiation (ALPN) to negotiate HTTP/2 with HAProxy. You cannot use HTTP/2 with a re-encrypt route unless the Ingress Controller has HTTP/2 enabled.
- For a passthrough route, the connection can use HTTP/2 if the application supports using ALPN to negotiate HTTP/2 with the client. You can use HTTP/2 with a passthrough route if the Ingress Controller has HTTP/2 enabled or disabled.
-
For an edge-terminated secure route, the connection uses HTTP/2 if the service specifies only
appProtocol: kubernetes.io/h2c. You can use HTTP/2 with an edge-terminated secure route if the Ingress Controller has HTTP/2 enabled or disabled. -
For an insecure route, the connection uses HTTP/2 if the service specifies only
appProtocol: kubernetes.io/h2c. You can use HTTP/2 with an insecure route if the Ingress Controller has HTTP/2 enabled or disabled.
For non-passthrough routes, the Ingress Controller negotiates its connection to the application independently of the connection from the client. This means a client might connect to the Ingress Controller and negotiate HTTP/1.1. The Ingress Controller might then connect to the application, negotiate HTTP/2, and forward the request from the client HTTP/1.1 connection by using the HTTP/2 connection to the application.
This sequence of events causes an issue if the client subsequently tries to upgrade its connection from HTTP/1.1 to the WebSocket protocol. Consider that if you have an application that is intending to accept WebSocket connections, and the application attempts to allow for HTTP/2 protocol negotiation, the client fails any attempt to upgrade to the WebSocket protocol.
2.2.9.15.1. Enabling HTTP/2
You can enable HTTP/2 on a specific Ingress Controller, or you can enable HTTP/2 for the entire cluster.
Procedure
To enable HTTP/2 on a specific Ingress Controller, enter the
oc annotatecommand:oc -n openshift-ingress-operator annotate ingresscontrollers/<ingresscontroller_name> ingress.operator.openshift.io/default-enable-http2=true
$ oc -n openshift-ingress-operator annotate ingresscontrollers/<ingresscontroller_name> ingress.operator.openshift.io/default-enable-http2=true1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- Replace
<ingresscontroller_name>with the name of an Ingress Controller to enable HTTP/2.
To enable HTTP/2 for the entire cluster, enter the
oc annotatecommand:oc annotate ingresses.config/cluster ingress.operator.openshift.io/default-enable-http2=true
$ oc annotate ingresses.config/cluster ingress.operator.openshift.io/default-enable-http2=trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Alternatively, you can apply the following YAML code to enable HTTP/2:
2.2.9.15.2. Disabling HTTP/2
You can disable HTTP/2 on a specific Ingress Controller, or you can disable HTTP/2 for the entire cluster.
Procedure
To disable HTTP/2 on a specific Ingress Controller, enter the
oc annotatecommand:oc -n openshift-ingress-operator annotate ingresscontrollers/<ingresscontroller_name> ingress.operator.openshift.io/default-enable-http2=false
$ oc -n openshift-ingress-operator annotate ingresscontrollers/<ingresscontroller_name> ingress.operator.openshift.io/default-enable-http2=false1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- Replace
<ingresscontroller_name>with the name of an Ingress Controller to disable HTTP/2.
To disable HTTP/2 for the entire cluster, enter the
oc annotatecommand:oc annotate ingresses.config/cluster ingress.operator.openshift.io/default-enable-http2=false
$ oc annotate ingresses.config/cluster ingress.operator.openshift.io/default-enable-http2=falseCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Alternatively, you can apply the following YAML code to disable HTTP/2:
2.2.9.16. Configuring the PROXY protocol for an Ingress Controller
A cluster administrator can configure the PROXY protocol when an Ingress Controller uses either the HostNetwork, NodePortService, or Private endpoint publishing strategy types. The PROXY protocol enables the load balancer to preserve the original client addresses for connections that the Ingress Controller receives. The original client addresses are useful for logging, filtering, and injecting HTTP headers. In the default configuration, the connections that the Ingress Controller receives only contain the source address that is associated with the load balancer.
The default Ingress Controller with installer-provisioned clusters on non-cloud platforms that use a Keepalived Ingress Virtual IP (VIP) do not support the PROXY protocol.
The PROXY protocol enables the load balancer to preserve the original client addresses for connections that the Ingress Controller receives. The original client addresses are useful for logging, filtering, and injecting HTTP headers. In the default configuration, the connections that the Ingress Controller receives contain only the source IP address that is associated with the load balancer.
For a passthrough route configuration, servers in OpenShift Dedicated clusters cannot observe the original client source IP address. If you need to know the original client source IP address, configure Ingress access logging for your Ingress Controller so that you can view the client source IP addresses.
For re-encrypt and edge routes, the OpenShift Dedicated router sets the Forwarded and X-Forwarded-For headers so that application workloads check the client source IP address.
For more information about Ingress access logging, see "Configuring Ingress access logging".
Configuring the PROXY protocol for an Ingress Controller is not supported when using the LoadBalancerService endpoint publishing strategy type. This restriction is because when OpenShift Dedicated runs in a cloud platform, and an Ingress Controller specifies that a service load balancer should be used, the Ingress Operator configures the load balancer service and enables the PROXY protocol based on the platform requirement for preserving source addresses.
You must configure both OpenShift Dedicated and the external load balancer to use either the PROXY protocol or TCP.
This feature is not supported in cloud deployments. This restriction is because when OpenShift Dedicated runs in a cloud platform, and an Ingress Controller specifies that a service load balancer should be used, the Ingress Operator configures the load balancer service and enables the PROXY protocol based on the platform requirement for preserving source addresses.
You must configure both OpenShift Dedicated and the external load balancer to either use the PROXY protocol or to use Transmission Control Protocol (TCP).
Prerequisites
- You created an Ingress Controller.
Procedure
Edit the Ingress Controller resource by entering the following command in your CLI:
oc -n openshift-ingress-operator edit ingresscontroller/default
$ oc -n openshift-ingress-operator edit ingresscontroller/defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow Set the PROXY configuration:
If your Ingress Controller uses the
HostNetworkendpoint publishing strategy type, set thespec.endpointPublishingStrategy.hostNetwork.protocolsubfield toPROXY:Sample
hostNetworkconfiguration toPROXYCopy to Clipboard Copied! Toggle word wrap Toggle overflow If your Ingress Controller uses the
NodePortServiceendpoint publishing strategy type, set thespec.endpointPublishingStrategy.nodePort.protocolsubfield toPROXY:Sample
nodePortconfiguration toPROXYCopy to Clipboard Copied! Toggle word wrap Toggle overflow If your Ingress Controller uses the
Privateendpoint publishing strategy type, set thespec.endpointPublishingStrategy.private.protocolsubfield toPROXY:Sample
privateconfiguration toPROXYCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.9.17. Specifying an alternative cluster domain using the appsDomain option
As a cluster administrator, you can specify an alternative to the default cluster domain for user-created routes by configuring the appsDomain field. The appsDomain field is an optional domain for OpenShift Dedicated to use instead of the default, which is specified in the domain field. If you specify an alternative domain, it overrides the default cluster domain for the purpose of determining the default host for a new route.
For example, you can use the DNS domain for your company as the default domain for routes and ingresses for applications running on your cluster.
Prerequisites
- You deployed an OpenShift Dedicated cluster.
-
You installed the
occommand-line interface.
Procedure
Configure the
appsDomainfield by specifying an alternative default domain for user-created routes.Edit the ingress
clusterresource:oc edit ingresses.config/cluster -o yaml
$ oc edit ingresses.config/cluster -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Edit the YAML file:
Sample
appsDomainconfiguration totest.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Verify that an existing route contains the domain name specified in the
appsDomainfield by exposing the route and verifying the route domain change:NoteWait for the
openshift-apiserverfinish rolling updates before exposing the route.Expose the route by entering the following command. The command outputs
route.route.openshift.io/hello-openshift exposedto designate exposure of the route.oc expose service hello-openshift
$ oc expose service hello-openshiftCopy to Clipboard Copied! Toggle word wrap Toggle overflow Get a list of routes by running the following command:
oc get routes
$ oc get routesCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example output
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD hello-openshift hello_openshift-<my_project>.test.example.com hello-openshift 8080-tcp None
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD hello-openshift hello_openshift-<my_project>.test.example.com hello-openshift 8080-tcp NoneCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.9.18. Converting HTTP header case
HAProxy lowercases HTTP header names by default; for example, changing Host: xyz.com to host: xyz.com. If legacy applications are sensitive to the capitalization of HTTP header names, use the Ingress Controller spec.httpHeaders.headerNameCaseAdjustments API field for a solution to accommodate legacy applications until they can be fixed.
OpenShift Dedicated includes HAProxy 2.8. If you want to update to this version of the web-based load balancer, ensure that you add the spec.httpHeaders.headerNameCaseAdjustments section to your cluster’s configuration file.
As a cluster administrator, you can convert the HTTP header case by entering the oc patch command or by setting the HeaderNameCaseAdjustments field in the Ingress Controller YAML file.
Prerequisites
-
You have installed the OpenShift CLI (
oc). -
You have access to the cluster as a user with the
cluster-adminrole.
Procedure
Capitalize an HTTP header by using the
oc patchcommand.Change the HTTP header from
hosttoHostby running the following command:oc -n openshift-ingress-operator patch ingresscontrollers/default --type=merge --patch='{"spec":{"httpHeaders":{"headerNameCaseAdjustments":["Host"]}}}'$ oc -n openshift-ingress-operator patch ingresscontrollers/default --type=merge --patch='{"spec":{"httpHeaders":{"headerNameCaseAdjustments":["Host"]}}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow Create a
Routeresource YAML file so that the annotation can be applied to the application.Example of a route named
my-applicationCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- Set
haproxy.router.openshift.io/h1-adjust-caseso that the Ingress Controller can adjust thehostrequest header as specified.
Specify adjustments by configuring the
HeaderNameCaseAdjustmentsfield in the Ingress Controller YAML configuration file.The following example Ingress Controller YAML file adjusts the
hostheader toHostfor HTTP/1 requests to appropriately annotated routes:Example Ingress Controller YAML
Copy to Clipboard Copied! Toggle word wrap Toggle overflow The following example route enables HTTP response header name case adjustments by using the
haproxy.router.openshift.io/h1-adjust-caseannotation:Example route YAML
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- Set
haproxy.router.openshift.io/h1-adjust-caseto true.
2.2.9.19. Using router compression
You configure the HAProxy Ingress Controller to specify router compression globally for specific MIME types. You can use the mimeTypes variable to define the formats of MIME types to which compression is applied. The types are: application, image, message, multipart, text, video, or a custom type prefaced by "X-". To see the full notation for MIME types and subtypes, see RFC1341.
Memory allocated for compression can affect the max connections. Additionally, compression of large buffers can cause latency, like heavy regex or long lists of regex.
Not all MIME types benefit from compression, but HAProxy still uses resources to try to compress if instructed to. Generally, text formats, such as html, css, and js, formats benefit from compression, but formats that are already compressed, such as image, audio, and video, benefit little in exchange for the time and resources spent on compression.
Procedure
Configure the
httpCompressionfield for the Ingress Controller.Use the following command to edit the
IngressControllerresource:oc edit -n openshift-ingress-operator ingresscontrollers/default
$ oc edit -n openshift-ingress-operator ingresscontrollers/defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow Under
spec, set thehttpCompressionpolicy field tomimeTypesand specify a list of MIME types that should have compression applied:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.9.20. Exposing router metrics
You can expose the HAProxy router metrics by default in Prometheus format on the default stats port, 1936. The external metrics collection and aggregation systems such as Prometheus can access the HAProxy router metrics. You can view the HAProxy router metrics in a browser in the HTML and comma separated values (CSV) format.
Prerequisites
- You configured your firewall to access the default stats port, 1936.
Procedure
Get the router pod name by running the following command:
oc get pods -n openshift-ingress
$ oc get pods -n openshift-ingressCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example output
NAME READY STATUS RESTARTS AGE router-default-76bfffb66c-46qwp 1/1 Running 0 11h
NAME READY STATUS RESTARTS AGE router-default-76bfffb66c-46qwp 1/1 Running 0 11hCopy to Clipboard Copied! Toggle word wrap Toggle overflow Get the router’s username and password, which the router pod stores in the
/var/lib/haproxy/conf/metrics-auth/statsUsernameand/var/lib/haproxy/conf/metrics-auth/statsPasswordfiles:Get the username by running the following command:
oc rsh <router_pod_name> cat metrics-auth/statsUsername
$ oc rsh <router_pod_name> cat metrics-auth/statsUsernameCopy to Clipboard Copied! Toggle word wrap Toggle overflow Get the password by running the following command:
oc rsh <router_pod_name> cat metrics-auth/statsPassword
$ oc rsh <router_pod_name> cat metrics-auth/statsPasswordCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Get the router IP and metrics certificates by running the following command:
oc describe pod <router_pod>
$ oc describe pod <router_pod>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Get the raw statistics in Prometheus format by running the following command:
curl -u <user>:<password> http://<router_IP>:<stats_port>/metrics
$ curl -u <user>:<password> http://<router_IP>:<stats_port>/metricsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Access the metrics securely by running the following command:
curl -u user:password https://<router_IP>:<stats_port>/metrics -k
$ curl -u user:password https://<router_IP>:<stats_port>/metrics -kCopy to Clipboard Copied! Toggle word wrap Toggle overflow Access the default stats port, 1936, by running the following command:
curl -u <user>:<password> http://<router_IP>:<stats_port>/metrics
$ curl -u <user>:<password> http://<router_IP>:<stats_port>/metricsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example 2.1. Example output
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Launch the stats window by entering the following URL in a browser:
http://<user>:<password>@<router_IP>:<stats_port>
http://<user>:<password>@<router_IP>:<stats_port>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Optional: Get the stats in CSV format by entering the following URL in a browser:
http://<user>:<password>@<router_ip>:1936/metrics;csv
http://<user>:<password>@<router_ip>:1936/metrics;csvCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.9.21. Customizing HAProxy error code response pages
As a cluster administrator, you can specify a custom error code response page for either 503, 404, or both error pages. The HAProxy router serves a 503 error page when the application pod is not running or a 404 error page when the requested URL does not exist. For example, if you customize the 503 error code response page, then the page is served when the application pod is not running, and the default 404 error code HTTP response page is served by the HAProxy router for an incorrect route or a non-existing route.
Custom error code response pages are specified in a config map then patched to the Ingress Controller. The config map keys have two available file names as follows: error-page-503.http and error-page-404.http.
Custom HTTP error code response pages must follow the HAProxy HTTP error page configuration guidelines. Here is an example of the default OpenShift Dedicated HAProxy router http 503 error code response page. You can use the default content as a template for creating your own custom page.
By default, the HAProxy router serves only a 503 error page when the application is not running or when the route is incorrect or non-existent. This default behavior is the same as the behavior on OpenShift Dedicated 4.8 and earlier. If a config map for the customization of an HTTP error code response is not provided, and you are using a custom HTTP error code response page, the router serves a default 404 or 503 error code response page.
If you use the OpenShift Dedicated default 503 error code page as a template for your customizations, the headers in the file require an editor that can use CRLF line endings.
Procedure
Create a config map named
my-custom-error-code-pagesin theopenshift-confignamespace:oc -n openshift-config create configmap my-custom-error-code-pages \ --from-file=error-page-503.http \ --from-file=error-page-404.http
$ oc -n openshift-config create configmap my-custom-error-code-pages \ --from-file=error-page-503.http \ --from-file=error-page-404.httpCopy to Clipboard Copied! Toggle word wrap Toggle overflow ImportantIf you do not specify the correct format for the custom error code response page, a router pod outage occurs. To resolve this outage, you must delete or correct the config map and delete the affected router pods so they can be recreated with the correct information.
Patch the Ingress Controller to reference the
my-custom-error-code-pagesconfig map by name:oc patch -n openshift-ingress-operator ingresscontroller/default --patch '{"spec":{"httpErrorCodePages":{"name":"my-custom-error-code-pages"}}}' --type=merge$ oc patch -n openshift-ingress-operator ingresscontroller/default --patch '{"spec":{"httpErrorCodePages":{"name":"my-custom-error-code-pages"}}}' --type=mergeCopy to Clipboard Copied! Toggle word wrap Toggle overflow The Ingress Operator copies the
my-custom-error-code-pagesconfig map from theopenshift-confignamespace to theopenshift-ingressnamespace. The Operator names the config map according to the pattern,<your_ingresscontroller_name>-errorpages, in theopenshift-ingressnamespace.Display the copy:
oc get cm default-errorpages -n openshift-ingress
$ oc get cm default-errorpages -n openshift-ingressCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example output
NAME DATA AGE default-errorpages 2 25s
NAME DATA AGE default-errorpages 2 25s1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- The example config map name is
default-errorpagesbecause thedefaultIngress Controller custom resource (CR) was patched.
Confirm that the config map containing the custom error response page mounts on the router volume where the config map key is the filename that has the custom HTTP error code response:
For 503 custom HTTP custom error code response:
oc -n openshift-ingress rsh <router_pod> cat /var/lib/haproxy/conf/error_code_pages/error-page-503.http
$ oc -n openshift-ingress rsh <router_pod> cat /var/lib/haproxy/conf/error_code_pages/error-page-503.httpCopy to Clipboard Copied! Toggle word wrap Toggle overflow For 404 custom HTTP custom error code response:
oc -n openshift-ingress rsh <router_pod> cat /var/lib/haproxy/conf/error_code_pages/error-page-404.http
$ oc -n openshift-ingress rsh <router_pod> cat /var/lib/haproxy/conf/error_code_pages/error-page-404.httpCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Verification
Verify your custom error code HTTP response:
Create a test project and application:
oc new-project test-ingress
$ oc new-project test-ingressCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc new-app django-psql-example
$ oc new-app django-psql-exampleCopy to Clipboard Copied! Toggle word wrap Toggle overflow For 503 custom http error code response:
- Stop all the pods for the application.
Run the following curl command or visit the route hostname in the browser:
curl -vk <route_hostname>
$ curl -vk <route_hostname>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
For 404 custom http error code response:
- Visit a non-existent route or an incorrect route.
Run the following curl command or visit the route hostname in the browser:
curl -vk <route_hostname>
$ curl -vk <route_hostname>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Check if the
errorfileattribute is properly in thehaproxy.configfile:oc -n openshift-ingress rsh <router> cat /var/lib/haproxy/conf/haproxy.config | grep errorfile
$ oc -n openshift-ingress rsh <router> cat /var/lib/haproxy/conf/haproxy.config | grep errorfileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.9.22. Setting the Ingress Controller maximum connections
A cluster administrator can set the maximum number of simultaneous connections for OpenShift router deployments. You can patch an existing Ingress Controller to increase the maximum number of connections.
Prerequisites
- The following assumes that you already created an Ingress Controller
Procedure
Update the Ingress Controller to change the maximum number of connections for HAProxy:
oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"maxConnections": 7500}}}'$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"maxConnections": 7500}}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow WarningIf you set the
spec.tuningOptions.maxConnectionsvalue greater than the current operating system limit, the HAProxy process will not start. See the table in the "Ingress Controller configuration parameters" section for more information about this parameter.
2.2.10. OpenShift Dedicated Ingress Operator configurations
The following table details the components of the Ingress Operator and if Red Hat Site Reliability Engineers (SRE) maintains this component on OpenShift Dedicated clusters.
| Ingress component | Managed by | Default configuration? |
|---|---|---|
| Scaling Ingress Controller | SRE | Yes |
| Ingress Operator thread count | SRE | Yes |
| Ingress Controller access logging | SRE | Yes |
| Ingress Controller sharding | SRE | Yes |
| Ingress Controller route admission policy | SRE | Yes |
| Ingress Controller wildcard routes | SRE | Yes |
| Ingress Controller X-Forwarded headers | SRE | Yes |
| Ingress Controller route compression | SRE | Yes |