5.6. Creating Replicated Volumes
Replicated volume creates copies of files across multiple bricks in the volume. Use replicated volumes in environments where high-availability and high-reliability are critical.
Use
gluster volume create to create different types of volumes, and gluster volume info to verify successful volume creation.
Prerequisites
- A trusted storage pool has been created, as described in Section 4.1, “Adding Servers to the Trusted Storage Pool”.
- Understand how to start and stop volumes, as described in Section 5.11, “Starting Volumes”.
5.6.1. Creating Two-way Replicated Volumes (Deprecated)
Copy linkLink copied to clipboard!
Warning
As of Red Hat Gluster Storage 3.4, two-way replication without arbiter bricks is considered deprecated. Existing volumes that use two-way replication without arbiter bricks remain supported for this release. New volumes with this configuration are not supported. Red Hat no longer recommends the use of two-way replication without arbiter bricks, and plans to remove support entirely in future versions of Red Hat Gluster Storage. This change affects both replicated and distributed-replicated volumes that do not use arbiter bricks.
Two-way replication without arbiter bricks is being deprecated because it does not provide adequate protection from split-brain conditions. Even in distributed-replicated configurations, two-way replication cannot ensure that the correct copy of a conflicting file is selected without the use of a tie-breaking node.
While a dummy node can be used as an interim solution for this problem, Red Hat strongly recommends that all volumes that currently use two-way replication without arbiter bricks are migrated to use either arbitrated replication or three-way replication.
Instructions for migrating a two-way replicated volume without arbiter bricks to an arbitrated replicated volume are available in the Red Hat Gluster Storage 3.4 Administration Guide: https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3.4/html-single/administration_guide/#sect-Convert_Rep_to_Arbiter.
Information about three-way replication is available in Section 5.6.2, “Creating Three-way Replicated Volumes” and Section 5.7.2, “Creating Three-way Distributed Replicated Volumes”.
Two-way replicated volume creates two copies of files across the bricks in the volume. The number of bricks must be multiple of two for a replicated volume. To protect against server and disk failures, it is recommended that the bricks of the volume are from different servers.
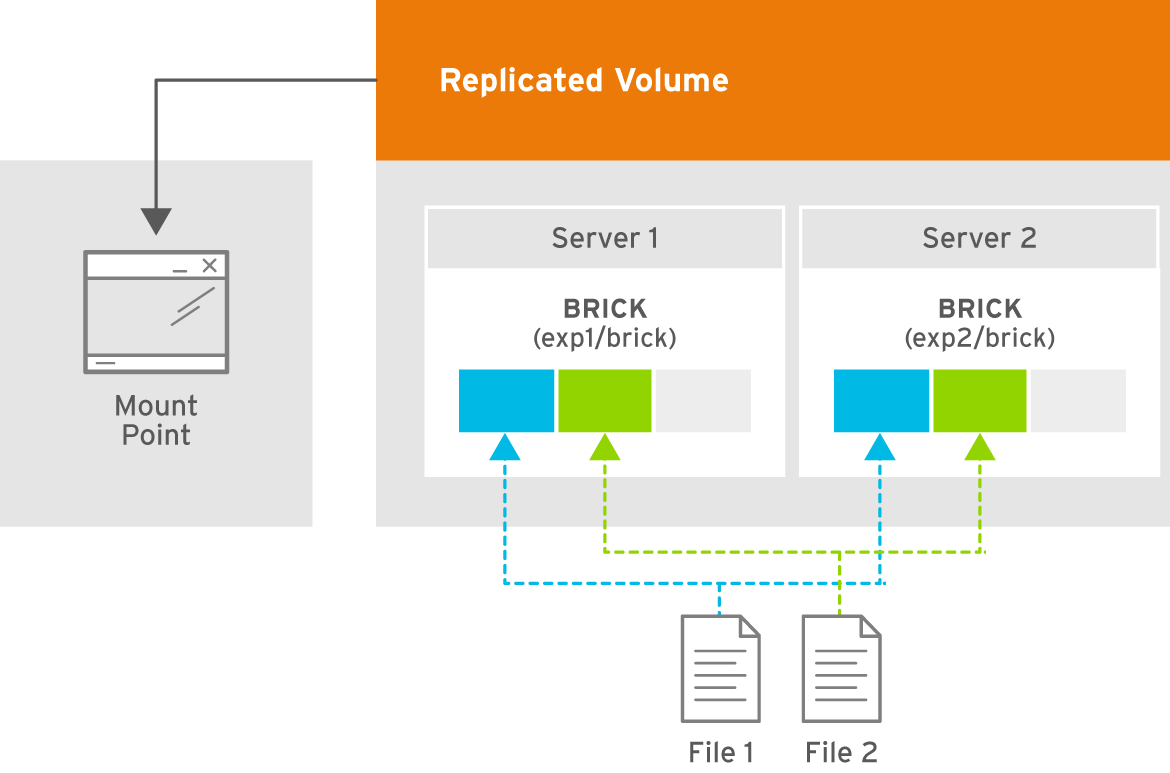
Figure 5.3. Illustration of a Two-way Replicated Volume
Creating two-way replicated volumes
- Run the
gluster volume createcommand to create the replicated volume.The syntax is# gluster volume create NEW-VOLNAME [replica COUNT] [transport tcp | rdma | tcp,rdma] NEW-BRICK...The default value for transport istcp. Other options can be passed such asauth.alloworauth.reject. See Section 11.1, “Configuring Volume Options” for a full list of parameters.Example 5.3. Replicated Volume with Two Storage Servers
The order in which bricks are specified determines how they are replicated with each other. For example, every2bricks, where2is the replica count, forms a replica set. This is illustrated in Figure 5.3, “Illustration of a Two-way Replicated Volume” .# gluster volume create test-volume replica 2 transport tcp server1:/rhgs/brick1 server2:/rhgs/brick2 Creation of test-volume has been successful Please start the volume to access data. - Run
# gluster volume start VOLNAMEto start the volume.# gluster volume start test-volume Starting test-volume has been successful - Run
gluster volume infocommand to optionally display the volume information.
Important
You must set client-side quorum on replicated volumes to prevent split-brain scenarios. For more information on setting client-side quorum, see Section 11.15.1.2, “Configuring Client-Side Quorum”
5.6.2. Creating Three-way Replicated Volumes
Copy linkLink copied to clipboard!
Three-way replicated volume creates three copies of files across multiple bricks in the volume. The number of bricks must be equal to the replica count for a replicated volume. To protect against server and disk failures, it is recommended that the bricks of the volume are from different servers.
Synchronous three-way replication is now fully supported in Red Hat Gluster Storage. It is recommended that three-way replicated volumes use JBOD, but use of hardware RAID with three-way replicated volumes is also supported.
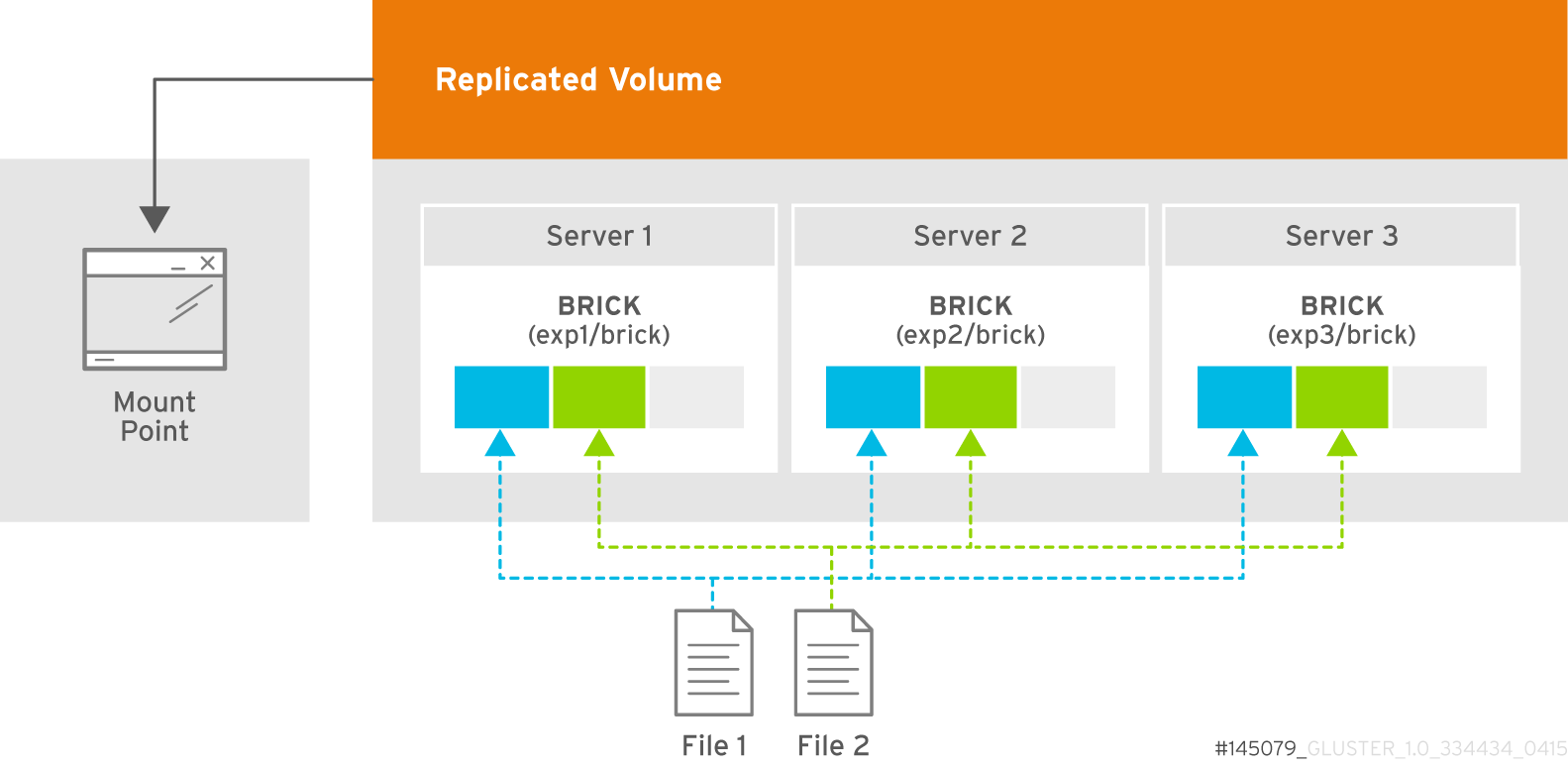
Figure 5.4. Illustration of a Three-way Replicated Volume
Creating three-way replicated volumes
- Run the
gluster volume createcommand to create the replicated volume.The syntax is# gluster volume create NEW-VOLNAME [replica COUNT] [transport tcp | rdma | tcp,rdma] NEW-BRICK...The default value for transport istcp. Other options can be passed such asauth.alloworauth.reject. See Section 11.1, “Configuring Volume Options” for a full list of parameters.Example 5.4. Replicated Volume with Three Storage Servers
The order in which bricks are specified determines how bricks are replicated with each other. For example, everynbricks, where3is the replica count forms a replica set. This is illustrated in Figure 5.4, “Illustration of a Three-way Replicated Volume”.# gluster volume create test-volume replica 3 transport tcp server1:/rhgs/brick1 server2:/rhgs/brick2 server3:/rhgs/brick3 Creation of test-volume has been successful Please start the volume to access data. - Run
# gluster volume start VOLNAMEto start the volume.# gluster volume start test-volume Starting test-volume has been successful - Run
gluster volume infocommand to optionally display the volume information.
Important
By default, the client-side quorum is enabled on three-way replicated volumes to minimize split-brain scenarios. For more information on client-side quorum, see Section 11.15.1.2, “Configuring Client-Side Quorum”
5.6.3. Creating Sharded Replicated Volumes
Copy linkLink copied to clipboard!
Sharding breaks files into smaller pieces so that they can be distributed across the bricks that comprise a volume. This is enabled on a per-volume basis.
When sharding is enabled, files written to a volume are divided into pieces. The size of the pieces depends on the value of the volume's features.shard-block-size parameter. The first piece is written to a brick and given a GFID like a normal file. Subsequent pieces are distributed evenly between bricks in the volume (sharded bricks are distributed by default), but they are written to that brick's
.shard directory, and are named with the GFID and a number indicating the order of the pieces. For example, if a file is split into four pieces, the first piece is named GFID and stored normally. The other three pieces are named GFID.1, GFID.2, and GFID.3 respectively. They are placed in the .shard directory and distributed evenly between the various bricks in the volume.
Because sharding distributes files across the bricks in a volume, it lets you store files with a larger aggregate size than any individual brick in the volume. Because the file pieces are smaller, heal operations are faster, and geo-replicated deployments can sync the small pieces of a file that have changed, rather than syncing the entire aggregate file.
Sharding also lets you increase volume capacity by adding bricks to a volume in an ad-hoc fashion.
5.6.3.1. Supported use cases
Copy linkLink copied to clipboard!
Sharding has one supported use case: in the context of providing Red Hat Gluster Storage as a storage domain for Red Hat Enterprise Virtualization, to provide storage for live virtual machine images. Note that sharding is also a requirement for this use case, as it provides significant performance improvements over previous implementations.
Important
Quotas are not compatible with sharding.
Important
Sharding is supported in new deployments only, as there is currently no upgrade path for this feature.
Example 5.5. Example: Three-way replicated sharded volume
- Set up a three-way replicated volume, as described in the Red Hat Gluster Storage Administration Guide: https://access.redhat.com/documentation/en-US/red_hat_gluster_storage/3.4/html/Administration_Guide/sect-Creating_Replicated_Volumes.html#Creating_Three-way_Replicated_Volumes.
- Before you start your volume, enable sharding on the volume.
# gluster volume set test-volume features.shard enable - Start the volume and ensure it is working as expected.
# gluster volume test-volume start # gluster volume info test-volume
5.6.3.2. Configuration Options
Copy linkLink copied to clipboard!
Sharding is enabled and configured at the volume level. The configuration options are as follows.
-
features.shard - Enables or disables sharding on a specified volume. Valid values are
enableanddisable. The default value isdisable.# gluster volume set volname features.shard enableNote that this only affects files created after this command is run; files created before this command is run retain their old behaviour. -
features.shard-block-size - Specifies the maximum size of the file pieces when sharding is enabled. The supported value for this parameter is 512MB.
# gluster volume set volname features.shard-block-size 32MBNote that this only affects files created after this command is run; files created before this command is run retain their old behaviour.
5.6.3.3. Finding the pieces of a sharded file
Copy linkLink copied to clipboard!
When you enable sharding, you might want to check that it is working correctly, or see how a particular file has been sharded across your volume.
To find the pieces of a file, you need to know that file's GFID. To obtain a file's GFID, run:
# getfattr -d -m. -e hex path_to_file
Once you have the GFID, you can run the following command on your bricks to see how this file has been distributed:
# ls /rhgs/*/.shard -lh | grep GFID