Authentification et autorisation
La sécurisation d’OpenShift Dédié.
Résumé
Chapitre 1. Aperçu de l’authentification et de l’autorisation
1.1. Glossaire des termes communs pour OpenShift Authentification et autorisation dédiées
Ce glossaire définit les termes communs qui sont utilisés dans OpenShift Dedicated Authentification et autorisation.
- authentification
- L’authentification détermine l’accès à un cluster dédié OpenShift et garantit que seuls les utilisateurs authentifiés accèdent au cluster dédié OpenShift.
- autorisation
- L’autorisation détermine si l’utilisateur identifié dispose d’autorisations pour effectuer l’action demandée.
- jeton au porteur
- Le jeton porteur est utilisé pour s’authentifier en API avec l’en-tête Autorisation: Bearer <token>.
- configuration de la carte
- La carte de configuration fournit un moyen d’injecter des données de configuration dans les pods. Les données stockées dans une carte de configuration peuvent être référencées dans un volume de type ConfigMap. Les applications qui s’exécutent dans un pod peuvent utiliser ces données.
- conteneurs
- Des images légères et exécutables qui sont constituées de logiciels et de toutes ses dépendances. Comme les conteneurs virtualisent le système d’exploitation, vous pouvez exécuter des conteneurs dans un centre de données, un cloud public ou privé ou votre hôte local.
- Les ressources personnalisées (CR)
- A CR est une extension de l’API Kubernetes.
- groupe de travail
- Le groupe est un ensemble d’utilisateurs. Le groupe est utile pour accorder des autorisations à plusieurs utilisateurs une fois.
- Htpasswd
- Htpasswd met à jour les fichiers qui stockent les noms d’utilisateur et le mot de passe pour l’authentification des utilisateurs HTTP.
- Keystone
- Keystone est un projet Red Hat OpenStack Platform (RHOSP) qui fournit des services d’identité, de jeton, de catalogue et de politique.
- Le protocole d’accès à l’annuaire léger (LDAP)
- LDAP est un protocole qui interroge les informations de l’utilisateur.
- espace de noms
- L’espace de noms isole des ressources système spécifiques qui sont visibles pour tous les processus. À l’intérieur d’un espace de noms, seuls les processus qui sont membres de cet espace de noms peuvent voir ces ressources.
- le nœud
- Le nœud est une machine ouvrier dans le cluster dédié OpenShift. Le nœud est soit une machine virtuelle (VM) soit une machine physique.
- Client OAuth
- Le client OAuth est utilisé pour obtenir un jeton au porteur.
- Le serveur OAuth
- Le plan de contrôle dédié OpenShift comprend un serveur OAuth intégré qui détermine l’identité de l’utilisateur à partir du fournisseur d’identité configuré et crée un jeton d’accès.
- Connexion d’OpenID
- L’OpenID Connect est un protocole permettant d’authentifier les utilisateurs à l’aide d’une connexion unique (SSO) pour accéder aux sites qui utilisent les fournisseurs OpenID.
- la pod
- La gousse est la plus petite unité logique de Kubernetes. La gousse est composée d’un ou de plusieurs contenants à utiliser dans un nœud ouvrier.
- les utilisateurs réguliers
- Les utilisateurs qui sont créés automatiquement dans le cluster lors de la première connexion ou via l’API.
- en-tête de demande
- L’en-tête de requête est un en-tête HTTP qui est utilisé pour fournir des informations sur le contexte de requête HTTP, afin que le serveur puisse suivre la réponse de la requête.
- contrôle d’accès basé sur le rôle (RBAC)
- Contrôle de sécurité clé pour s’assurer que les utilisateurs de clusters et les charges de travail n’ont accès qu’aux ressources nécessaires à l’exécution de leurs rôles.
- comptes de services
- Les comptes de service sont utilisés par les composants ou applications du cluster.
- les utilisateurs du système
- Les utilisateurs qui sont créés automatiquement lorsque le cluster est installé.
- les utilisateurs
- Les utilisateurs sont une entité qui peut faire des demandes à l’API.
1.2. À propos de l’authentification dans OpenShift Dedicated
Afin de contrôler l’accès à un cluster dédié OpenShift, un administrateur doté du rôle administrateur dédié peut configurer l’authentification de l’utilisateur et s’assurer que seuls les utilisateurs approuvés accèdent au cluster.
Afin d’interagir avec un cluster dédié OpenShift, les utilisateurs doivent d’abord s’authentifier auprès de l’API dédiée OpenShift d’une manière ou d’une autre. Dans vos demandes, vous pouvez vous authentifier en fournissant un jeton d’accès OAuth ou un certificat client X.509 à l’API dédiée OpenShift.
En cas de non-présentation d’un jeton d’accès valide ou d’un certificat, votre demande n’est pas authentifiée et vous recevez une erreur HTTP 401.
L’administrateur peut configurer l’authentification en configurant un fournisseur d’identité. Dans OpenShift Dedicated, vous pouvez définir n’importe quel fournisseur d’identité pris en charge et l’ajouter à votre cluster.
1.3. À propos de l’autorisation dans OpenShift Dedicated
L’autorisation consiste à déterminer si l’utilisateur identifié dispose d’autorisations pour effectuer l’action demandée.
Les administrateurs peuvent définir des autorisations et les attribuer aux utilisateurs en utilisant les objets RBAC, tels que les règles, les rôles et les liaisons. Afin de comprendre comment fonctionne l’autorisation dans OpenShift Dedicated, voir Évaluer l’autorisation.
Il est également possible de contrôler l’accès à un cluster dédié OpenShift par le biais de projets et d’espaces de noms.
En plus de contrôler l’accès de l’utilisateur à un cluster, vous pouvez également contrôler les actions qu’un pod peut effectuer et les ressources auxquelles il peut accéder en utilisant des contraintes de contexte de sécurité (SCC).
Il est possible de gérer l’autorisation d’OpenShift Dédiée à travers les tâches suivantes:
- Affichage des rôles et des liens locaux et de cluster.
- Créer un rôle local et l’attribuer à un utilisateur ou à un groupe.
- Attribution d’un rôle de cluster à un utilisateur ou à un groupe : OpenShift Dedicated inclut un ensemble de rôles de cluster par défaut. Il est possible de les ajouter à un utilisateur ou à un groupe.
- Accorder des privilèges d’administrateur aux utilisateurs : Vous pouvez accorder des privilèges d’administration dédiés aux utilisateurs.
- Création de comptes de service : Les comptes de service offrent un moyen flexible de contrôler l’accès à l’API sans partager les informations d’identification d’un utilisateur régulier. L’utilisateur peut créer et utiliser un compte de service dans des applications et aussi en tant que client OAuth.
- Jetons de portée : Un jeton à portée de main est un jeton qui s’identifie comme un utilisateur spécifique qui ne peut effectuer que des opérations spécifiques. Il est possible de créer des jetons expansés pour déléguer certaines de vos autorisations à un autre utilisateur ou à un compte de service.
- La synchronisation des groupes LDAP : Vous pouvez gérer les groupes d’utilisateurs en un seul endroit en synchronisant les groupes stockés dans un serveur LDAP avec les groupes d’utilisateurs dédiés OpenShift.
Chapitre 2. Comprendre l’authentification
Afin que les utilisateurs interagissent avec OpenShift Dedicated, ils doivent d’abord s’authentifier au cluster. La couche d’authentification identifie l’utilisateur associé aux requêtes à l’API dédiée OpenShift. La couche d’autorisation utilise ensuite des informations sur l’utilisateur demandeur pour déterminer si la demande est autorisée.
2.1. Les utilisateurs
L’utilisateur dans OpenShift Dedicated est une entité qui peut faire des demandes à l’API dédiée OpenShift. L’objet utilisateur dédié OpenShift représente un acteur qui peut recevoir des autorisations dans le système en ajoutant des rôles à eux ou à leurs groupes. En règle générale, cela représente le compte d’un développeur ou d’un administrateur qui interagit avec OpenShift Dedicated.
Différents types d’utilisateurs peuvent exister:
| Le type d’utilisateur | Description |
|---|---|
|
| C’est la façon dont les utilisateurs dédiés OpenShift les plus interactifs sont représentés. Les utilisateurs réguliers sont créés automatiquement dans le système lors de la première connexion ou peuvent être créés via l’API. Les utilisateurs réguliers sont représentés avec l’objet Utilisateur. Exemples: joe alice |
|
| Beaucoup d’entre eux sont créés automatiquement lorsque l’infrastructure est définie, principalement dans le but de permettre à l’infrastructure d’interagir en toute sécurité avec l’API. Ils comprennent un administrateur de cluster (avec accès à tout), un utilisateur par nœud, des utilisateurs pour les routeurs et les registres, et divers autres. Enfin, il y a un utilisateur système anonyme qui est utilisé par défaut pour les demandes non authentifiées. Exemples: system:admin system:openshift-registry system:node:node1.example.com |
|
| Il s’agit d’utilisateurs système spéciaux associés à des projets; certains sont créés automatiquement lorsque le projet est créé pour la première fois, tandis que les administrateurs de projet peuvent en créer davantage dans le but de définir l’accès au contenu de chaque projet. Les comptes de service sont représentés avec l’objet ServiceAccount. Exemples: system:serviceaccount:default:deployer system:serviceaccount:foo:builder |
Chaque utilisateur doit s’authentifier d’une manière ou d’une autre pour accéder à OpenShift Dedicated. Les requêtes API sans authentification ou authentification invalide sont authentifiées en tant que requêtes de l’utilisateur du système anonyme. Après l’authentification, la stratégie détermine ce que l’utilisateur est autorisé à faire.
2.2. Groupes
L’utilisateur peut être affecté à un ou plusieurs groupes, chacun représentant un certain ensemble d’utilisateurs. Les groupes sont utiles lors de la gestion des stratégies d’autorisation pour accorder des autorisations à plusieurs utilisateurs à la fois, par exemple permettre l’accès à des objets dans un projet, plutôt que de les accorder aux utilisateurs individuellement.
En plus des groupes explicitement définis, il y a aussi des groupes système, ou des groupes virtuels, qui sont automatiquement mis à disposition par le cluster.
Les groupes virtuels par défaut suivants sont les plus importants:
| Groupe virtuel | Description |
|---|---|
|
| Automatiquement associé à tous les utilisateurs authentifiés. |
|
| Automatiquement associé à tous les utilisateurs authentifiés avec un jeton d’accès OAuth. |
|
| Automatiquement associé à tous les utilisateurs non authentifiés. |
2.3. Authentification de l’API
Les demandes à l’API dédiée OpenShift sont authentifiées en utilisant les méthodes suivantes:
- Jetons d’accès OAuth
- Obtenu à partir du serveur OpenShift Dedicated OAuth à l’aide des points de terminaison <namespace_route>/oauth/autorisation et <namespace_route>/oauth/token.
- Envoyé en tant qu’autorisation: Bearer… en-tête.
- Envoyé comme un en-tête de sous-protocole websocket dans le formulaire base64url.bearer.authorization.k8s.io.<base64url-encoded-token> pour les requêtes websocket.
- Certificats de client x.509
- Nécessite une connexion HTTPS au serveur API.
- Vérifié par le serveur API par rapport à un ensemble d’autorités de certification de confiance.
- Le serveur API crée et distribue des certificats aux contrôleurs pour s’authentifier.
Chaque demande avec un jeton d’accès invalide ou un certificat invalide est rejetée par le calque d’authentification avec une erreur 401.
En l’absence de jeton d’accès ou de certificat, la couche d’authentification attribue le système: utilisateur virtuel anonyme et le groupe virtuel système:non authentifié à la demande. Cela permet à la couche d’autorisation de déterminer quelles requêtes, le cas échéant, un utilisateur anonyme est autorisé à faire.
2.3.1. Le serveur OAuth dédié à OpenShift
Le maître dédié OpenShift inclut un serveur OAuth intégré. Les utilisateurs obtiennent des jetons d’accès OAuth pour s’authentifier à l’API.
Lorsqu’une personne demande un nouveau jeton OAuth, le serveur OAuth utilise le fournisseur d’identité configuré pour déterminer l’identité de la personne qui fait la demande.
Il détermine ensuite à quel utilisateur cette identité cartographie, crée un jeton d’accès pour cet utilisateur, et retourne le jeton pour utilisation.
2.3.1.1. Demandes de jetons OAuth
Chaque demande de jeton OAuth doit spécifier le client OAuth qui recevra et utilisera le jeton. Les clients OAuth suivants sont automatiquement créés lors du démarrage de l’API dédiée OpenShift:
| Client OAuth | L’utilisation |
|---|---|
|
| Demande des jetons à <namespace_route>/oauth/token/request avec un agent utilisateur capable de gérer les connexions interactives. [1] |
|
| Demandes de jetons avec un agent utilisateur capable de gérer les défis WWW-Authenticate. |
<namespace_route> fait référence à la route de l’espace de noms. Ceci est trouvé en exécutant la commande suivante:
$ oc get route oauth-openshift -n openshift-authentication -o json | jq .spec.host
Les demandes de jetons OAuth impliquent une demande de <namespace_route>/oauth/autorisation. La plupart des intégrations d’authentification placent un proxy authentifiant devant ce point de terminaison, ou configurent OpenShift Dedicated pour valider les informations d’identification par rapport à un fournisseur d’identité de support. Les demandes de <namespace_route>/oauth/autorisation peuvent provenir d’agents utilisateurs qui ne peuvent pas afficher des pages de connexion interactives, telles que le CLI. Ainsi, OpenShift Dedicated prend en charge l’authentification à l’aide d’un défi WWW-Authenticate en plus des flux de connexion interactifs.
Lorsqu’un proxy authentifiant est placé devant le point de terminaison <namespace_route>/oauth/autoriser, il envoie des défis WWW-Authenticate non authentiques et non navigateurs, plutôt que d’afficher une page de connexion interactive ou de rediriger vers un flux de connexion interactif.
Afin d’éviter les attaques de faux de requêtes intersites (CSRF) contre les clients du navigateur, n’envoyer des défis d’authentification de base que si un en-tête X-CSRF-Token est sur la demande. Les clients qui s’attendent à recevoir les défis de base WWW-Authenticate doivent définir cette en-tête à une valeur non vide.
Lorsque le proxy d’authentification ne peut pas prendre en charge les défis WWW-Authenticate, ou si OpenShift Dedicated est configuré pour utiliser un fournisseur d’identité qui ne prend pas en charge les défis WWW-Authenticate, vous devez utiliser un navigateur pour obtenir manuellement un jeton à partir de <namespace_route>/oauth/token/request.
Chapitre 3. Gestion des jetons d’accès OAuth appartenant à l’utilisateur
Les utilisateurs peuvent revoir leurs propres jetons d’accès OAuth et supprimer tout ce qui n’est plus nécessaire.
3.1. Liste des jetons d’accès OAuth appartenant à l’utilisateur
Il est possible de répertorier vos jetons d’accès OAuth appartenant à l’utilisateur. Les noms de jetons ne sont pas sensibles et ne peuvent pas être utilisés pour se connecter.
Procédure
Liste de tous les jetons d’accès OAuth appartenant à l’utilisateur:
$ oc get useroauthaccesstokensExemple de sortie
NAME CLIENT NAME CREATED EXPIRES REDIRECT URI SCOPES <token1> openshift-challenging-client 2021-01-11T19:25:35Z 2021-01-12 19:25:35 +0000 UTC https://oauth-openshift.apps.example.com/oauth/token/implicit user:full <token2> openshift-browser-client 2021-01-11T19:27:06Z 2021-01-12 19:27:06 +0000 UTC https://oauth-openshift.apps.example.com/oauth/token/display user:full <token3> console 2021-01-11T19:26:29Z 2021-01-12 19:26:29 +0000 UTC https://console-openshift-console.apps.example.com/auth/callback user:fullListe des jetons d’accès OAuth appartenant à l’utilisateur pour un client particulier OAuth:
$ oc get useroauthaccesstokens --field-selector=clientName="console"Exemple de sortie
NAME CLIENT NAME CREATED EXPIRES REDIRECT URI SCOPES <token3> console 2021-01-11T19:26:29Z 2021-01-12 19:26:29 +0000 UTC https://console-openshift-console.apps.example.com/auth/callback user:full
3.2. Affichage des détails d’un jeton d’accès OAuth appartenant à l’utilisateur
Consultez les détails d’un jeton d’accès OAuth appartenant à l’utilisateur.
Procédure
Décrire les détails d’un jeton d’accès OAuth appartenant à l’utilisateur:
$ oc describe useroauthaccesstokens <token_name>Exemple de sortie
Name: <token_name>1 Namespace: Labels: <none> Annotations: <none> API Version: oauth.openshift.io/v1 Authorize Token: sha256~Ksckkug-9Fg_RWn_AUysPoIg-_HqmFI9zUL_CgD8wr8 Client Name: openshift-browser-client2 Expires In: 864003 Inactivity Timeout Seconds: 3174 Kind: UserOAuthAccessToken Metadata: Creation Timestamp: 2021-01-11T19:27:06Z Managed Fields: API Version: oauth.openshift.io/v1 Fields Type: FieldsV1 fieldsV1: f:authorizeToken: f:clientName: f:expiresIn: f:redirectURI: f:scopes: f:userName: f:userUID: Manager: oauth-server Operation: Update Time: 2021-01-11T19:27:06Z Resource Version: 30535 Self Link: /apis/oauth.openshift.io/v1/useroauthaccesstokens/<token_name> UID: f9d00b67-ab65-489b-8080-e427fa3c6181 Redirect URI: https://oauth-openshift.apps.example.com/oauth/token/display Scopes: user:full5 User Name: <user_name>6 User UID: 82356ab0-95f9-4fb3-9bc0-10f1d6a6a345 Events: <none>- 1
- Le nom du jeton, qui est le hachage sha256 du jeton. Les noms de jetons ne sont pas sensibles et ne peuvent pas être utilisés pour se connecter.
- 2
- Le nom du client, qui décrit d’où provient le jeton.
- 3
- La valeur en secondes du temps de création avant l’expiration de ce jeton.
- 4
- En cas d’inactivité du serveur OAuth, c’est la valeur en secondes du temps de création avant que ce jeton ne puisse plus être utilisé.
- 5
- Les portées de ce jeton.
- 6
- Le nom d’utilisateur associé à ce jeton.
3.3. La suppression des jetons d’accès OAuth appartenant à l’utilisateur
La commande oc logout invalide uniquement le jeton OAuth pour la session active. Il est possible d’utiliser la procédure suivante pour supprimer les jetons OAuth appartenant à l’utilisateur qui ne sont plus nécessaires.
La suppression d’un jeton d’accès OAuth déconnecte l’utilisateur de toutes les sessions qui utilisent le jeton.
Procédure
Effacer le jeton d’accès OAuth appartenant à l’utilisateur:
$ oc delete useroauthaccesstokens <token_name>Exemple de sortie
useroauthaccesstoken.oauth.openshift.io "<token_name>" deleted
3.4. Ajout de groupes non authentifiés aux rôles de cluster
En tant qu’administrateur de cluster, vous pouvez ajouter des utilisateurs non authentifiés aux rôles de cluster suivants dans OpenShift Dedicated en créant une liaison de rôle de cluster. Les utilisateurs non authentifiés n’ont pas accès à des rôles de cluster non publics. Cela ne devrait être fait que dans des cas d’utilisation spécifiques lorsque cela est nécessaire.
Il est possible d’ajouter des utilisateurs non authentifiés aux rôles de cluster suivants:
-
le système:scope-impersonation -
le système:webhook -
le système:oauth-token-deleter -
auto-réviseur d’accès
Assurez-vous toujours de respecter les normes de sécurité de votre organisation lors de la modification de l’accès non authentifié.
Conditions préalables
- En tant qu’utilisateur, vous avez accès au cluster avec le rôle cluster-admin.
- L’OpenShift CLI (oc) a été installé.
Procédure
Créez un fichier YAML nommé add-<cluster_role>-unauth.yaml et ajoutez le contenu suivant:
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "true" name: <cluster_role>access-unauthenticated roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: <cluster_role> subjects: - apiGroup: rbac.authorization.k8s.io kind: Group name: system:unauthenticatedAppliquer la configuration en exécutant la commande suivante:
$ oc apply -f add-<cluster_role>.yaml
Chapitre 4. Configuration des fournisseurs d’identité
Après la création de votre cluster OpenShift Dedicated, vous devez configurer des fournisseurs d’identité pour déterminer comment les utilisateurs se connectent pour accéder au cluster.
4.1. Comprendre les fournisseurs d’identité
Le serveur OpenShift Dedicated inclut un serveur OAuth intégré. Les développeurs et les administrateurs obtiennent des jetons d’accès OAuth pour s’authentifier à l’API. En tant qu’administrateur, vous pouvez configurer OAuth pour spécifier un fournisseur d’identité après avoir installé votre cluster. La configuration des fournisseurs d’identité permet aux utilisateurs de se connecter et d’accéder au cluster.
4.1.1. Fournisseurs d’identité pris en charge
Les types de fournisseurs d’identité suivants peuvent être configurés:
| Fournisseur d’identité | Description |
|---|---|
| GitHub ou GitHub Enterprise | Configurez un fournisseur d’identité GitHub pour valider les noms d’utilisateur et les mots de passe contre le serveur d’authentification OAuth de GitHub ou GitHub Enterprise. |
| GitLab | Configurez un fournisseur d’identité GitLab pour utiliser GitLab.com ou toute autre instance GitLab en tant que fournisseur d’identité. |
| | Configurez un fournisseur d’identité Google en utilisant l’intégration OpenID Connect de Google. |
| LDAP | Configurez un fournisseur d’identité LDAP pour valider les noms d’utilisateur et les mots de passe contre un serveur LDAPv3, en utilisant une simple authentification de liaison. |
| Connexion d’OpenID | Configurez un fournisseur d’identité OpenID Connect (OIDC) pour s’intégrer à un fournisseur d’identité OIDC à l’aide d’un flux de code d’autorisation. |
| htpasswd | Configurez un fournisseur d’identité htpasswd pour un seul utilisateur d’administration statique. En tant qu’utilisateur, vous pouvez vous connecter au cluster pour résoudre les problèmes. Important L’option fournisseur d’identité htpasswd n’est incluse que pour activer la création d’un seul utilisateur d’administration statique. htpasswd n’est pas pris en charge en tant que fournisseur d’identité à usage général pour OpenShift Dedicated. Les étapes pour configurer l’utilisateur unique, voir Configuration d’un fournisseur d’identité htpasswd. |
4.1.2. Les paramètres du fournisseur d’identité
Les paramètres suivants sont communs à tous les fournisseurs d’identité:
| Le paramètre | Description |
|---|---|
|
| Le nom du fournisseur est préfixé aux noms d’utilisateur du fournisseur pour former un nom d’identité. |
|
| Définit comment les nouvelles identités sont cartographiées aux utilisateurs lorsqu’ils se connectent. Entrez l’une des valeurs suivantes:
|
Lorsque vous ajoutez ou modifiez des fournisseurs d’identité, vous pouvez cartographier les identités du nouveau fournisseur aux utilisateurs existants en définissant le paramètre mappingMethod à ajouter.
4.2. Configuration d’un fournisseur d’identité GitHub
Configurez un fournisseur d’identité GitHub pour valider les noms d’utilisateur et les mots de passe contre le serveur d’authentification OAuth de GitHub ou GitHub Enterprise et accédez à votre cluster dédié OpenShift. L’OAuth facilite un flux d’échange de jetons entre OpenShift Dedicated et GitHub ou GitHub Enterprise.
La configuration de l’authentification GitHub permet aux utilisateurs de se connecter à OpenShift Dedicated avec leurs identifiants GitHub. Afin d’empêcher toute personne disposant d’un identifiant utilisateur GitHub de se connecter à votre cluster dédié OpenShift, vous devez restreindre l’accès à ceux qui se trouvent dans des organisations ou des équipes GitHub spécifiques.
Conditions préalables
- L’application OAuth doit être créée directement dans les paramètres d’organisation GitHub par l’administrateur de l’organisation GitHub.
- Les organisations ou les équipes GitHub sont configurées dans votre compte GitHub.
Procédure
- À partir d’OpenShift Cluster Manager, accédez à la page Liste des clusters et sélectionnez le cluster pour lequel vous devez configurer les fournisseurs d’identité.
- Cliquez sur l’onglet Contrôle d’accès.
Cliquez sur Ajouter un fournisseur d’identité.
NoteIl est également possible de cliquer sur le lien de configuration Ajouter Oauth dans le message d’avertissement affiché après la création du cluster pour configurer vos fournisseurs d’identité.
- Choisissez GitHub dans le menu déroulant.
Entrez un nom unique pour le fournisseur d’identité. Ce nom ne peut pas être changé plus tard.
L’URL de rappel OAuth est automatiquement générée dans le champ fourni. Ceci vous permettra d’enregistrer l’application GitHub.
https://oauth-openshift.apps.<cluster_name>.<cluster_domain>/oauth2callback/<idp_provider_name>À titre d’exemple:
https://oauth-openshift.apps.openshift-cluster.example.com/oauth2callback/github
- Enregistrez une demande sur GitHub.
- Cliquez sur OpenShift Dedicated et sélectionnez une méthode de cartographie dans le menu déroulant. La réclamation est recommandée dans la plupart des cas.
- Entrez l’ID Client et le secret du client fournis par GitHub.
- Entrez un nom d’hôte. Le nom d’hôte doit être saisi lors de l’utilisation d’une instance hébergée de GitHub Enterprise.
- Facultatif : Vous pouvez utiliser un fichier d’autorité de certification (CA) pour valider les certificats de serveur pour l’URL GitHub Enterprise configurée. Cliquez sur Parcourir pour localiser et joindre un fichier CA au fournisseur d’identité.
- Choisissez Utilisez des organisations ou Utilisez les équipes pour restreindre l’accès à une organisation GitHub particulière ou à une équipe GitHub.
- Entrez le nom de l’organisation ou de l’équipe à laquelle vous souhaitez restreindre l’accès. Cliquez sur Ajouter plus pour spécifier plusieurs organisations ou équipes dont les utilisateurs peuvent être membres.
- Cliquez sur Confirmer.
La vérification
- Le fournisseur d’identité configuré est maintenant visible dans l’onglet Contrôle d’accès de la page Liste des clusters.
4.3. Configuration d’un fournisseur d’identité GitLab
Configurez un fournisseur d’identité GitLab pour utiliser GitLab.com ou toute autre instance GitLab en tant que fournisseur d’identité.
Conditions préalables
- Lorsque vous utilisez la version 7.7.0 à 11.0 de GitLab, vous vous connectez à l’intégration OAuth. En utilisant la version 11.1 ou ultérieure de GitLab, vous pouvez utiliser OpenID Connect (OIDC) pour vous connecter au lieu d’OAuth.
Procédure
- À partir d’OpenShift Cluster Manager, accédez à la page Liste des clusters et sélectionnez le cluster pour lequel vous devez configurer les fournisseurs d’identité.
- Cliquez sur l’onglet Contrôle d’accès.
Cliquez sur Ajouter un fournisseur d’identité.
NoteIl est également possible de cliquer sur le lien de configuration Ajouter Oauth dans le message d’avertissement affiché après la création du cluster pour configurer vos fournisseurs d’identité.
- Choisissez GitLab dans le menu déroulant.
Entrez un nom unique pour le fournisseur d’identité. Ce nom ne peut pas être changé plus tard.
L’URL de rappel OAuth est automatiquement générée dans le champ fourni. Cette URL est fournie à GitLab.
https://oauth-openshift.apps.<cluster_name>.<cluster_domain>/oauth2callback/<idp_provider_name>À titre d’exemple:
https://oauth-openshift.apps.openshift-cluster.example.com/oauth2callback/gitlab
- Ajouter une nouvelle application dans GitLab.
- Cliquez sur OpenShift Dedicated et sélectionnez une méthode de cartographie dans le menu déroulant. La réclamation est recommandée dans la plupart des cas.
- Entrez l’ID Client et le secret client fournis par GitLab.
- Entrez l’URL de votre fournisseur GitLab.
- Facultatif : Vous pouvez utiliser un fichier d’autorité de certification (CA) pour valider les certificats de serveur pour l’URL GitLab configurée. Cliquez sur Parcourir pour localiser et joindre un fichier CA au fournisseur d’identité.
- Cliquez sur Confirmer.
La vérification
- Le fournisseur d’identité configuré est maintenant visible dans l’onglet Contrôle d’accès de la page Liste des clusters.
4.4. Configuration d’un fournisseur d’identité Google
Configurez un fournisseur d’identité Google pour permettre aux utilisateurs de s’authentifier avec leurs identifiants Google.
L’utilisation de Google comme fournisseur d’identité permet à tout utilisateur de Google de s’authentifier auprès de votre serveur. Il est possible de limiter l’authentification aux membres d’un domaine hébergé spécifique avec l’attribut de configuration hostDomain.
Procédure
- À partir d’OpenShift Cluster Manager, accédez à la page Liste des clusters et sélectionnez le cluster pour lequel vous devez configurer les fournisseurs d’identité.
- Cliquez sur l’onglet Contrôle d’accès.
Cliquez sur Ajouter un fournisseur d’identité.
NoteIl est également possible de cliquer sur le lien de configuration Ajouter Oauth dans le message d’avertissement affiché après la création du cluster pour configurer vos fournisseurs d’identité.
- Choisissez Google dans le menu déroulant.
Entrez un nom unique pour le fournisseur d’identité. Ce nom ne peut pas être changé plus tard.
L’URL de rappel OAuth est automatiquement générée dans le champ fourni. Cette URL sera fournie à Google.
https://oauth-openshift.apps.<cluster_name>.<cluster_domain>/oauth2callback/<idp_provider_name>À titre d’exemple:
https://oauth-openshift.apps.openshift-cluster.example.com/oauth2callback/google
- Configurez un fournisseur d’identité Google en utilisant l’intégration OpenID Connect de Google.
- Cliquez sur OpenShift Dedicated et sélectionnez une méthode de cartographie dans le menu déroulant. La réclamation est recommandée dans la plupart des cas.
- Entrez l’ID Client d’un projet Google enregistré et le secret client émis par Google.
- Entrez un domaine hébergé pour restreindre les utilisateurs à un domaine Google Apps.
- Cliquez sur Confirmer.
La vérification
- Le fournisseur d’identité configuré est maintenant visible dans l’onglet Contrôle d’accès de la page Liste des clusters.
4.5. Configuration d’un fournisseur d’identité LDAP
Configurez le fournisseur d’identité LDAP pour valider les noms d’utilisateur et les mots de passe contre un serveur LDAPv3, en utilisant une simple authentification de liaison.
Conditions préalables
Lorsque vous configurez un fournisseur d’identité LDAP, vous devrez entrer une URL LDAP configurée. L’URL configurée est une URL RFC 2255, qui spécifie l’hôte LDAP et les paramètres de recherche à utiliser. La syntaxe de l’URL est:
ldap://host:port/basedn?attribute?scope?filterExpand Composant URL Description LDAPDans le cas d’un LDAP régulier, utilisez la corde ldap. Dans le cas d’un LDAP sécurisé (LDAPS), utilisez plutôt ldaps.
hôte:portLe nom et le port du serveur LDAP. Défaut à localhost:389 pour ldap et localhost:636 pour LDAPS.
baseDNLe DN de la branche du répertoire où toutes les recherches devraient commencer. À tout le moins, cela doit être le haut de votre arbre de répertoire, mais il pourrait également spécifier un sous-arbre dans le répertoire.
attributL’attribut à rechercher. Bien que la RFC 2255 autorise une liste d’attributs séparés par des virgules, seul le premier attribut sera utilisé, peu importe le nombre d’attributs fournis. En l’absence d’attributs, la valeur par défaut est d’utiliser uid. Il est recommandé de choisir un attribut qui sera unique dans toutes les entrées dans le sous-arbre que vous utiliserez.
champ d’applicationLa portée de la recherche. Il peut être un ou sous. Dans le cas où la portée n’est pas fournie, la valeur par défaut est d’utiliser une portée de sub.
filtrerFiltre de recherche LDAP valide. Dans le cas contraire, par défaut (objectClass=*)
Lorsque vous effectuez des recherches, l’attribut, le filtre et le nom d’utilisateur fourni sont combinés pour créer un filtre de recherche qui ressemble à:
(&(<filter>)(<attribute>=<username>))ImportantLorsque le répertoire LDAP nécessite une authentification pour rechercher, spécifiez un bindDN et bindPassword à utiliser pour effectuer la recherche d’entrée.
Procédure
- À partir d’OpenShift Cluster Manager, accédez à la page Liste des clusters et sélectionnez le cluster pour lequel vous devez configurer les fournisseurs d’identité.
- Cliquez sur l’onglet Contrôle d’accès.
Cliquez sur Ajouter un fournisseur d’identité.
NoteIl est également possible de cliquer sur le lien de configuration Ajouter Oauth dans le message d’avertissement affiché après la création du cluster pour configurer vos fournisseurs d’identité.
- Choisissez LDAP dans le menu déroulant.
- Entrez un nom unique pour le fournisseur d’identité. Ce nom ne peut pas être changé plus tard.
- Choisissez une méthode de cartographie dans le menu déroulant. La réclamation est recommandée dans la plupart des cas.
- Entrez une URL LDAP pour spécifier les paramètres de recherche LDAP à utiliser.
- Facultatif: Entrez un mot de passe Bind DN et Bind.
Entrez les attributs qui mapperont les attributs LDAP aux identités.
- Entrez un attribut ID dont la valeur doit être utilisée comme ID utilisateur. Cliquez sur Ajouter plus pour ajouter plusieurs attributs d’identification.
- Facultatif: Entrez un attribut de nom d’utilisateur préféré dont la valeur doit être utilisée comme nom d’affichage. Cliquez sur Ajouter plus pour ajouter plusieurs attributs de nom d’utilisateur préférés.
- Facultatif: Entrez un attribut Email dont la valeur doit être utilisée comme adresse e-mail. Cliquez sur Ajouter plus pour ajouter plusieurs attributs de messagerie.
- Facultatif: Cliquez sur Afficher les options avancées pour ajouter un fichier d’autorité de certificat (CA) à votre fournisseur d’identité LDAP pour valider les certificats de serveur pour l’URL configurée. Cliquez sur Parcourir pour localiser et joindre un fichier CA au fournisseur d’identité.
Facultatif: Dans le cadre des options avancées, vous pouvez choisir de rendre le fournisseur LDAP non sécurisé. Dans le cas où vous sélectionnez cette option, un fichier CA ne peut pas être utilisé.
ImportantLorsque vous utilisez une connexion LDAP non sécurisée (ldap:/ ou port 389), vous devez vérifier l’option Insecure dans l’assistant de configuration.
- Cliquez sur Confirmer.
La vérification
- Le fournisseur d’identité configuré est maintenant visible dans l’onglet Contrôle d’accès de la page Liste des clusters.
4.6. Configuration d’un fournisseur d’identité OpenID
Configurez un fournisseur d’identité OpenID pour s’intégrer à un fournisseur d’identité OpenID Connect à l’aide d’un flux de code d’autorisation.
L’opérateur d’authentification dans OpenShift Dedicated exige que le fournisseur d’identité OpenID Connect configuré implémente la spécification OpenID Connect Discovery.
Les réclamations sont lues à partir du JWT id_token retourné par le fournisseur d’identité OpenID et, si spécifié, à partir du JSON retourné par l’URL de l’émetteur.
Au moins une revendication doit être configurée pour être utilisée comme identité de l’utilisateur.
Il est également possible d’indiquer les revendications à utiliser comme nom d’utilisateur, nom d’affichage et adresse e-mail préférés de l’utilisateur. Lorsque plusieurs revendications sont spécifiées, la première avec une valeur non vide est utilisée. Les revendications standard sont les suivantes:
| Demande d ' indemnisation | Description |
|---|---|
|
| Le nom d’utilisateur préféré lors du provisionnement d’un utilisateur. C’est un nom abrégé que l’utilisateur veut appeler, tel que janedoe. Généralement une valeur correspondant au nom d’utilisateur ou au nom d’utilisateur dans le système d’authentification, tel que le nom d’utilisateur ou l’email. |
|
| Adresse e-mail. |
|
| Afficher le nom. |
Consultez la documentation sur les demandes OpenID pour plus d’informations.
Conditions préalables
- Avant de configurer OpenID Connect, vérifiez les prérequis d’installation pour tout produit ou service Red Hat que vous souhaitez utiliser avec votre cluster OpenShift Dedicated.
Procédure
- À partir d’OpenShift Cluster Manager, accédez à la page Liste des clusters et sélectionnez le cluster pour lequel vous devez configurer les fournisseurs d’identité.
- Cliquez sur l’onglet Contrôle d’accès.
Cliquez sur Ajouter un fournisseur d’identité.
NoteIl est également possible de cliquer sur le lien de configuration Ajouter Oauth dans le message d’avertissement affiché après la création du cluster pour configurer vos fournisseurs d’identité.
- Choisissez OpenID dans le menu déroulant.
Entrez un nom unique pour le fournisseur d’identité. Ce nom ne peut pas être changé plus tard.
L’URL de rappel OAuth est automatiquement générée dans le champ fourni.
https://oauth-openshift.apps.<cluster_name>.<cluster_domain>/oauth2callback/<idp_provider_name>À titre d’exemple:
https://oauth-openshift.apps.openshift-cluster.example.com/oauth2callback/openid
- Enregistrez un nouveau client OpenID Connect dans le fournisseur d’identité OpenID en suivant les étapes pour créer une demande d’autorisation.
- Cliquez sur OpenShift Dedicated et sélectionnez une méthode de cartographie dans le menu déroulant. La réclamation est recommandée dans la plupart des cas.
- Entrez un identifiant client et un secret client fourni à partir d’OpenID.
- Entrez une URL de l’émetteur. C’est l’URL que le fournisseur OpenID affirme comme l’identifiant de l’émetteur. Il doit utiliser le schéma https sans paramètres de requête d’URL ou fragments.
- Entrez un attribut Email dont la valeur doit être utilisée comme adresse e-mail. Cliquez sur Ajouter plus pour ajouter plusieurs attributs de messagerie.
- Entrez un attribut Nom dont la valeur doit être utilisée comme nom d’utilisateur préféré. Cliquez sur Ajouter plus pour ajouter plusieurs noms d’utilisateur préférés.
- Entrez un attribut de nom d’utilisateur préféré dont la valeur doit être utilisée comme nom d’affichage. Cliquez sur Ajouter plus pour ajouter plusieurs noms d’affichage.
- Facultatif: Cliquez sur Afficher les options avancées pour ajouter un fichier d’autorité de certificat (CA) à votre fournisseur d’identité OpenID.
- Facultatif: Sous les options avancées, vous pouvez ajouter des zones supplémentaires. La portée OpenID est demandée par défaut.
- Cliquez sur Confirmer.
La vérification
- Le fournisseur d’identité configuré est maintenant visible dans l’onglet Contrôle d’accès de la page Liste des clusters.
4.7. Configuration d’un fournisseur d’identité htpasswd
Configurez un fournisseur d’identité htpasswd pour créer un seul utilisateur statique avec des privilèges d’administration de clusters. Connectez-vous à votre cluster en tant qu’utilisateur pour résoudre les problèmes.
L’option fournisseur d’identité htpasswd n’est incluse que pour activer la création d’un seul utilisateur d’administration statique. htpasswd n’est pas pris en charge en tant que fournisseur d’identité à usage général pour OpenShift Dedicated.
Procédure
- À partir d’OpenShift Cluster Manager, accédez à la page Liste des clusters et sélectionnez votre cluster.
- Choisissez Contrôle d’accès → Fournisseurs d’identité.
- Cliquez sur Ajouter un fournisseur d’identité.
- Choisissez HTPasswd dans le menu déroulant fournisseur d’identité.
- Ajoutez un nom unique dans le champ Nom du fournisseur d’identité.
Utilisez le nom d’utilisateur et le mot de passe suggérés pour l’utilisateur statique, ou créez le vôtre.
NoteLes informations d’identification définies dans cette étape ne sont pas visibles après avoir sélectionné Ajouter à l’étape suivante. Lorsque vous perdez les informations d’identification, vous devez recréer le fournisseur d’identité et définir à nouveau les informations d’identification.
- Cliquez sur Ajouter pour créer le fournisseur d’identité htpasswd et l’utilisateur unique et statique.
Accordez l’autorisation de l’utilisateur statique pour gérer le cluster:
- Dans Contrôle d’accès → Rôles de cluster et Accès, sélectionnez Ajouter un utilisateur.
- Entrez l’identifiant utilisateur de l’utilisateur statique que vous avez créé à l’étape précédente.
- Choisissez Ajouter un utilisateur pour accorder les privilèges d’administration à l’utilisateur.
La vérification
Le fournisseur d’identité htpasswd configuré est visible sur la page Contrôle d’accès → Fournisseurs d’identité.
NoteAprès avoir créé le fournisseur d’identité, la synchronisation se termine généralement en deux minutes. Lorsque le fournisseur d’identité htpasswd est disponible, vous pouvez vous connecter au cluster en tant qu’utilisateur.
- Le seul utilisateur administratif est visible sur la page Access Control → Cluster Roles and Access. L’adhésion du groupe d’administration de l’utilisateur est également affichée.
4.8. Accéder à votre cluster
Après avoir configuré vos fournisseurs d’identité, les utilisateurs peuvent accéder au cluster à partir de Red Hat OpenShift Cluster Manager.
Conditions préalables
- Connectez-vous à OpenShift Cluster Manager.
- Création d’un cluster OpenShift dédié.
- Configuration d’un fournisseur d’identité pour votre cluster.
- Ajout de votre compte utilisateur au fournisseur d’identité configuré.
Procédure
- À partir d’OpenShift Cluster Manager, cliquez sur le cluster auquel vous souhaitez accéder.
- Cliquez sur Ouvrir la console.
- Cliquez sur votre fournisseur d’identité et fournissez vos informations d’identification pour vous connecter au cluster.
- Cliquez sur Ouvrir la console pour ouvrir la console Web de votre cluster.
- Cliquez sur votre fournisseur d’identité et fournissez vos informations d’identification pour vous connecter au cluster. Complétez toute demande d’autorisation présentée par votre fournisseur.
Chapitre 5. Annuler les privilèges et l’accès à un cluster dédié OpenShift
En tant que propriétaire de cluster, vous pouvez révoquer les privilèges d’administrateur et l’accès de l’utilisateur à un cluster dédié OpenShift.
5.1. Annuler les privilèges d’administrateur d’un utilisateur
Suivez les étapes de cette section pour révoquer les privilèges d’administration dédié d’un utilisateur.
Conditions préalables
- Connectez-vous à OpenShift Cluster Manager.
- Création d’un cluster OpenShift dédié.
- « vous avez configuré un fournisseur d’identité GitHub pour votre cluster et ajouté un utilisateur de fournisseur d’identité.
- « vous avez accordé des privilèges dédiés à l’administration à un utilisateur.
Procédure
- Accédez à OpenShift Cluster Manager et sélectionnez votre cluster.
- Cliquez sur l’onglet Contrôle d’accès.
- Dans l’onglet Rôles de cluster et Accès, sélectionnez à côté d’un utilisateur et cliquez sur Supprimer.
La vérification
- Après avoir révoqué les privilèges, l’utilisateur n’est plus listé dans le groupe admins dédiés sous Contrôle d’accès → Rôles de cluster et Accès sur la page OpenShift Cluster Manager pour votre cluster.
5.2. Annuler l’accès de l’utilisateur à un cluster
Il est possible de révoquer l’accès au cluster d’un utilisateur du fournisseur d’identité en les supprimant de votre fournisseur d’identité configuré.
Il est possible de configurer différents types de fournisseurs d’identité pour votre cluster OpenShift dédié. L’exemple suivant révoque l’accès au cluster pour un membre d’une organisation ou d’une équipe GitHub qui est configuré pour la fourniture d’identité au cluster.
Conditions préalables
- Il y a un cluster dédié OpenShift.
- Il y a un compte utilisateur GitHub.
- « vous avez configuré un fournisseur d’identité GitHub pour votre cluster et ajouté un utilisateur de fournisseur d’identité.
Procédure
- Accédez à github.com et connectez-vous à votre compte GitHub.
Enlevez l’utilisateur de votre organisation ou équipe GitHub:
- Lorsque la configuration de votre fournisseur d’identité utilise une organisation GitHub, suivez les étapes de la suppression d’un membre de votre organisation dans la documentation GitHub.
- Lorsque la configuration de votre fournisseur d’identité utilise une équipe au sein d’une organisation GitHub, suivez les étapes dans Retirer les membres de l’organisation d’une équipe dans la documentation GitHub.
La vérification
- Après avoir retiré l’utilisateur de votre fournisseur d’identité, l’utilisateur ne peut pas s’authentifier dans le cluster.
Chapitre 6. Gestion des rôles d’administration et des utilisateurs
6.1. Comprendre les rôles administratifs
6.1.1. Le rôle de cluster-admin
En tant qu’administrateur d’un cluster dédié OpenShift avec abonnements cloud client (CCS), vous avez accès au rôle cluster-admin. L’utilisateur qui a créé le cluster peut ajouter le rôle d’utilisateur cluster-admin à un compte pour avoir le maximum de privilèges d’administrateur. Ces privilèges ne sont pas automatiquement attribués à votre compte utilisateur lorsque vous créez le cluster. Alors qu’ils sont connectés à un compte avec le rôle de cluster-admin, les utilisateurs ont pour la plupart un accès illimité au contrôle et à la configuration du cluster. Il y a certaines configurations qui sont bloquées avec des webhooks pour empêcher la déstabilisation du cluster, ou parce qu’elles sont gérées dans OpenShift Cluster Manager et tout changement dans l’inclusion serait écrasé. L’utilisation du rôle de cluster-admin est soumise aux restrictions énumérées dans votre accord de l’Annexe 4 avec Red Hat. En tant que meilleure pratique, limiter le nombre d’utilisateurs de cluster-admin au plus petit nombre possible.
6.1.2. Le rôle dédié-admin
En tant qu’administrateur d’un cluster dédié OpenShift, votre compte dispose d’autorisations supplémentaires et d’un accès à tous les projets créés par l’utilisateur dans le cluster de votre organisation. Alors qu’il est connecté à un compte avec le rôle dédié-admin, les commandes CLI développeur (sous la commande oc) vous permettent d’augmenter la visibilité et les capacités de gestion sur les objets à travers les projets, tandis que les commandes CLI administrateur (sous la commande oc adm) vous permettent de compléter des opérations supplémentaires.
Bien que votre compte ait ces autorisations accrues, la maintenance réelle du cluster et la configuration de l’hôte sont toujours effectuées par l’équipe des opérations OpenShift.
6.2. Gestion des administrateurs dédiés à OpenShift
Les rôles d’administrateur sont gérés à l’aide d’un cluster-admin ou d’un groupe dédié-admin sur le cluster. Les membres existants de ce groupe peuvent modifier l’adhésion via OpenShift Cluster Manager.
6.2.1. Ajout d’un utilisateur
Procédure
- Accédez à la page Détails du cluster et à l’onglet Contrôle d’accès.
- Choisissez l’onglet Rôles de cluster et Accès et cliquez sur Ajouter un utilisateur.
- Entrez le nom d’utilisateur et sélectionnez le groupe.
- Cliquez sur Ajouter un utilisateur.
L’ajout d’un utilisateur au groupe cluster-admin peut prendre plusieurs minutes.
6.2.2. La suppression d’un utilisateur
Procédure
- Accédez à la page Détails du cluster et à l’onglet Contrôle d’accès.
- Cliquez sur le menu Options à droite de la combinaison utilisateur et groupe et cliquez sur Supprimer.
Chapitre 7. En utilisant RBAC pour définir et appliquer des autorisations
7.1. Aperçu du RBAC
Les objets de contrôle d’accès basés sur les rôles (RBAC) déterminent si un utilisateur est autorisé à effectuer une action donnée au sein d’un projet.
Les administrateurs dotés du rôle d’administrateur dédié peuvent utiliser les rôles de cluster et les liaisons pour contrôler qui a différents niveaux d’accès à la plate-forme OpenShift Dedicated elle-même et à tous les projets.
Les développeurs peuvent utiliser des rôles et des liens locaux pour contrôler qui a accès à leurs projets. À noter que l’autorisation est une étape distincte de l’authentification, qui consiste davantage à déterminer l’identité de qui prend l’action.
L’autorisation est gérée en utilisant:
| L’objet d’autorisation | Description |
|---|---|
| Les règles | Ensembles de verbes autorisés sur un ensemble d’objets. À titre d’exemple, si un compte d’utilisateur ou de service peut créer des pods. |
| Les rôles | Collections de règles. Il est possible d’associer ou de lier des utilisateurs et des groupes à plusieurs rôles. |
| Fixations | Associations entre utilisateurs et/ou groupes ayant un rôle. |
Il y a deux niveaux de rôles et de liaisons RBAC qui contrôlent l’autorisation:
| Le niveau RBAC | Description |
|---|---|
| Cluster RBAC | Les rôles et les liens qui s’appliquent à tous les projets. Les rôles de cluster existent à l’échelle du groupe, et les liens de rôle de cluster ne peuvent référencer que les rôles de cluster. |
| Local RBAC | Les rôles et les liens qui s’appliquent à un projet donné. Bien que les rôles locaux n’existent que dans un seul projet, les liens de rôle locaux peuvent référencer à la fois les rôles de cluster et les rôles locaux. |
La liaison entre les rôles de cluster est une obligation qui existe au niveau des clusters. Il existe un rôle contraignant au niveau du projet. La vue de rôle de cluster doit être liée à un utilisateur en utilisant une liaison de rôle locale pour que cet utilisateur puisse voir le projet. Créer des rôles locaux uniquement si un rôle de cluster ne fournit pas l’ensemble des autorisations nécessaires à une situation particulière.
Cette hiérarchie à deux niveaux permet de réutiliser plusieurs projets via les rôles de cluster tout en permettant la personnalisation à l’intérieur des projets individuels via des rôles locaux.
Au cours de l’évaluation, on utilise à la fois les liaisons de rôle de groupe et les liaisons locales pour les rôles. À titre d’exemple:
- Les règles «permis» à l’échelle du cluster sont vérifiées.
- Les règles "d’autorisation" locales sont vérifiées.
- Déni par défaut.
7.1.1. Les rôles de cluster par défaut
Le programme OpenShift Dedicated inclut un ensemble de rôles de cluster par défaut que vous pouvez lier aux utilisateurs et aux groupes à l’échelle du cluster ou localement.
Il n’est pas recommandé de modifier manuellement les rôles de cluster par défaut. Les modifications apportées à ces rôles du système peuvent empêcher un cluster de fonctionner correctement.
| Le rôle du cluster par défaut | Description |
|---|---|
|
| Chef de projet. En cas d’utilisation dans une liaison locale, un administrateur a le droit de visualiser toute ressource dans le projet et de modifier toute ressource dans le projet, à l’exception du quota. |
|
| D’un utilisateur qui peut obtenir des informations de base sur les projets et les utilisateurs. |
|
| C’est un super-utilisateur qui peut effectuer n’importe quelle action dans n’importe quel projet. Lorsqu’ils sont liés à un utilisateur avec une liaison locale, ils ont un contrôle total sur le quota et chaque action sur chaque ressource du projet. |
|
| D’un utilisateur qui peut obtenir des informations de base sur l’état du cluster. |
|
| D’un utilisateur qui peut obtenir ou visualiser la plupart des objets, mais qui ne peut pas les modifier. |
|
| L’utilisateur qui peut modifier la plupart des objets d’un projet mais qui n’a pas le pouvoir d’afficher ou de modifier des rôles ou des liaisons. |
|
| L’utilisateur qui peut créer ses propres projets. |
|
| L’utilisateur qui ne peut apporter aucune modification, mais qui peut voir la plupart des objets dans un projet. Ils ne peuvent pas voir ou modifier les rôles ou les liaisons. |
Gardez à l’esprit la différence entre les liaisons locales et les regroupements. À titre d’exemple, si vous liez le rôle cluster-admin à un utilisateur en utilisant une liaison de rôle locale, il peut sembler que cet utilisateur a les privilèges d’un administrateur de cluster. Ce n’est pas le cas. Lier le cluster-admin à un utilisateur dans un projet accorde des privilèges de super administrateur pour seulement ce projet à l’utilisateur. Cet utilisateur a les autorisations de l’administrateur de rôle de cluster, plus quelques permissions supplémentaires comme la possibilité de modifier les limites de taux, pour ce projet. Cette liaison peut être déroutante via l’interface utilisateur de la console Web, qui ne répertorie pas les liaisons de rôle de cluster qui sont liées à de vrais administrateurs de clusters. Cependant, il répertorie les liaisons de rôle locales que vous pouvez utiliser pour lier localement cluster-admin.
Les relations entre les rôles de cluster, les rôles locaux, les liens de rôle de cluster, les liens locaux de rôle, les utilisateurs, les groupes et les comptes de services sont illustrés ci-dessous.
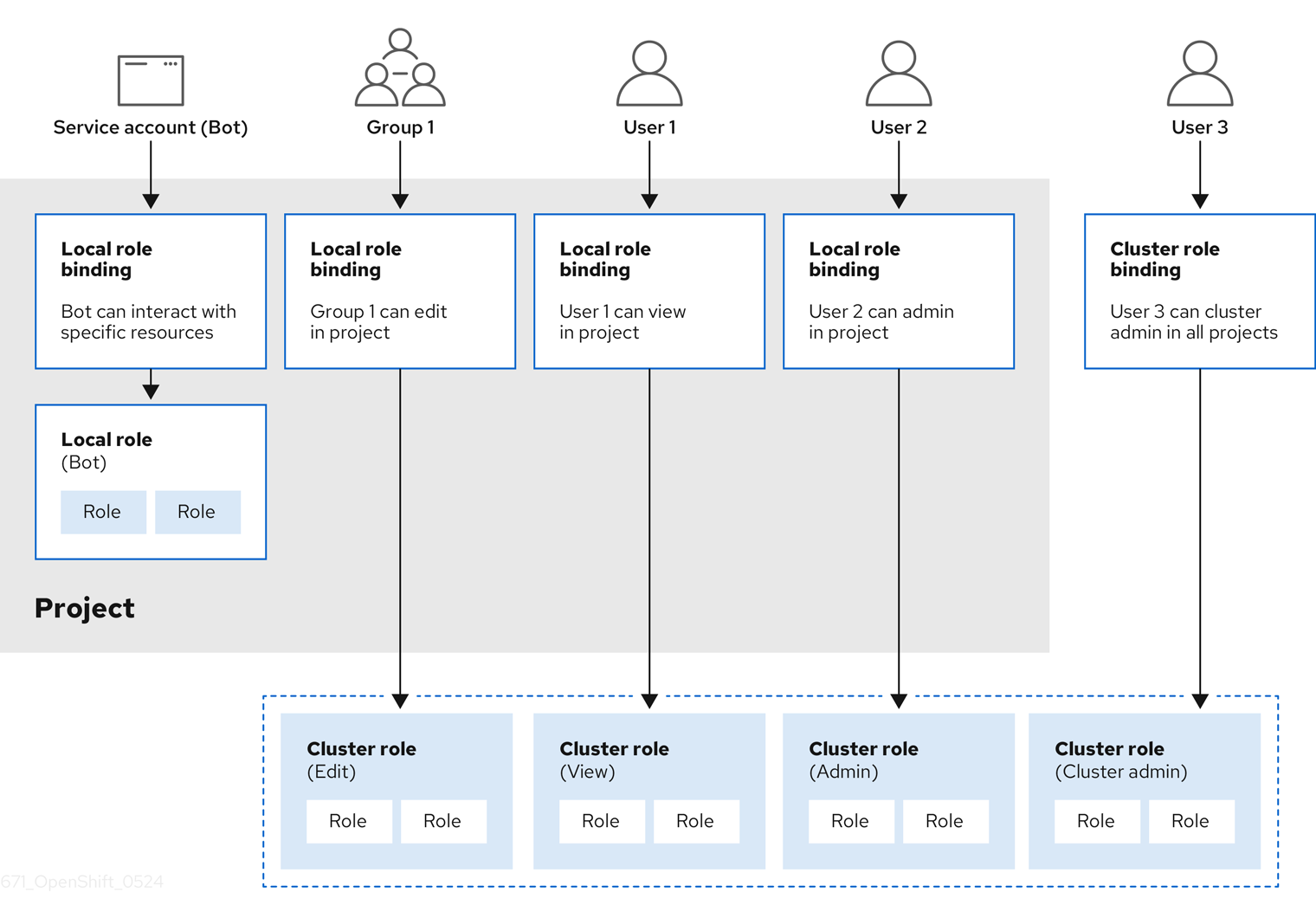
Les get pods/exec, get pods/*, et obtenir * règles accordent des privilèges d’exécution lorsqu’ils sont appliqués à un rôle. Appliquez le principe du moindre privilège et n’attribuez que les droits minimaux RBAC requis pour les utilisateurs et les agents. Les règles RBAC autorisent les privilèges d’exécution.
7.1.2. Évaluation de l’autorisation
La société OpenShift Dedicated évalue l’autorisation en utilisant:
- Identité
- Le nom d’utilisateur et la liste des groupes auxquels l’utilisateur appartient.
- À l’action
L’action que vous effectuez. Dans la plupart des cas, il s’agit de:
- Le projet auquel vous accédez. Il s’agit d’un espace de noms Kubernetes avec des annotations supplémentaires qui permet à une communauté d’utilisateurs d’organiser et de gérer leur contenu indépendamment des autres communautés.
- L’action elle-même : obtenir, répertorier, créer, mettre à jour, supprimer, supprimer, supprimer ou regarder.
- Le nom de la ressource : le point de terminaison API auquel vous accédez.
- Fixations
- La liste complète des liens, les associations entre utilisateurs ou groupes ayant un rôle.
La société OpenShift Dedicated évalue l’autorisation en utilisant les étapes suivantes:
- L’identité et l’action à portée de projet sont utilisées pour trouver toutes les liaisons qui s’appliquent à l’utilisateur ou à ses groupes.
- Les liaisons sont utilisées pour localiser tous les rôles qui s’appliquent.
- Les rôles sont utilisés pour trouver toutes les règles qui s’appliquent.
- L’action est vérifiée par rapport à chaque règle pour trouver un match.
- En cas d’absence de règle de correspondance, l’action est alors refusée par défaut.
Gardez à l’esprit que les utilisateurs et les groupes peuvent être associés ou liés à plusieurs rôles en même temps.
Les administrateurs de projet peuvent utiliser le CLI pour afficher les rôles et les liens locaux, y compris une matrice des verbes et des ressources auxquels chacun est associé.
Le rôle de cluster lié à l’administrateur du projet est limité dans un projet par le biais d’une liaison locale. Il n’est pas lié à l’ensemble du cluster comme les rôles de cluster attribués au cluster-admin ou system:admin.
Les rôles de cluster sont des rôles définis au niveau du cluster, mais peuvent être liés soit au niveau du cluster, soit au niveau du projet.
7.1.2.1. Agrégation des rôles de cluster
L’administrateur, l’édition, la vue et les rôles de cluster par défaut prennent en charge l’agrégation des rôles de cluster, où les règles de cluster pour chaque rôle sont mises à jour dynamiquement à mesure que de nouvelles règles sont créées. Cette fonctionnalité n’est pertinente que si vous étendez l’API Kubernetes en créant des ressources personnalisées.
7.2. Les projets et espaces de noms
L’espace de noms Kubernetes fournit un mécanisme permettant d’étendre les ressources d’un cluster. La documentation Kubernetes contient plus d’informations sur les espaces de noms.
Les espaces de noms offrent une possibilité unique pour:
- Les ressources nommées pour éviter les collisions de base.
- Délégation du pouvoir de gestion aux utilisateurs de confiance.
- La capacité de limiter la consommation de ressources communautaires.
La plupart des objets du système sont encadrés par l’espace de noms, mais certains sont exceptés et n’ont pas d’espace de noms, y compris les nœuds et les utilisateurs.
Le projet est un espace de noms Kubernetes avec des annotations supplémentaires et est le véhicule central par lequel l’accès aux ressources pour les utilisateurs réguliers est géré. Le projet permet à une communauté d’utilisateurs d’organiser et de gérer leur contenu indépendamment des autres communautés. Les utilisateurs doivent avoir accès aux projets par les administrateurs ou, s’ils sont autorisés à créer des projets, ont automatiquement accès à leurs propres projets.
Les projets peuvent avoir un nom, un nom d’affichage et une description séparés.
- Le nom obligatoire est un identifiant unique pour le projet et est plus visible lors de l’utilisation des outils CLI ou API. La longueur maximale du nom est de 63 caractères.
- Le nom optionnel d’affichage est la façon dont le projet est affiché dans la console Web (par défaut de nom).
- La description optionnelle peut être une description plus détaillée du projet et est également visible dans la console Web.
Chaque projet porte sur son propre ensemble de:
| L’objet | Description |
|---|---|
|
| Des pods, des services, des contrôleurs de réplication, etc. |
|
| Les règles pour lesquelles les utilisateurs peuvent ou ne peuvent pas effectuer des actions sur des objets. |
|
| Quotas pour chaque type d’objet qui peut être limité. |
|
| Les comptes de service agissent automatiquement avec l’accès désigné aux objets du projet. |
Les administrateurs ayant le rôle d’administrateur dédié peuvent créer des projets et déléguer des droits administratifs pour le projet à tout membre de la communauté d’utilisateurs. Les administrateurs ayant un rôle d’administrateur dédié peuvent également permettre aux développeurs de créer leurs propres projets.
Les développeurs et les administrateurs peuvent interagir avec des projets en utilisant le CLI ou la console Web.
7.3. Les projets par défaut
Les projets OpenShift Dedicated sont livrés avec un certain nombre de projets par défaut, et les projets commençant par openshift- sont les plus essentiels pour les utilisateurs. Ces projets hébergent des composants maîtres qui fonctionnent comme des pods et d’autres composants d’infrastructure. Les pods créés dans ces espaces de noms qui ont une annotation critique de pod sont considérés comme critiques, et l’admission garantie par kubelet. Les pods créés pour les composants maîtres dans ces espaces de noms sont déjà marqués comme critiques.
Évitez d’exécuter des charges de travail ou de partager l’accès aux projets par défaut. Les projets par défaut sont réservés à l’exécution de composants de cluster de base.
Les projets par défaut suivants sont considérés comme hautement privilégiés: par défaut, kube-public, kube-system, openshift, openshift-infra, openshift-node, et d’autres projets créés par système qui ont l’étiquette openshift.io / run-level définie à 0 ou 1. La fonctionnalité qui repose sur des plugins d’admission, tels que l’admission de sécurité pod, les contraintes de contexte de sécurité, les quotas de ressources de cluster et la résolution de référence d’image, ne fonctionne pas dans des projets hautement privilégiés.
7.4. Affichage des rôles et des liens de cluster
Il est possible d’utiliser le CLI oc pour afficher les rôles et les liaisons de cluster à l’aide de la commande de description oc.
Conditions préalables
- Installez le CLI oc.
- Demandez l’autorisation d’afficher les rôles et les liaisons du cluster.
Procédure
Afficher les rôles de cluster et leurs ensembles de règles associés:
$ oc describe clusterrole.rbacExemple de sortie
Name: admin Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate: true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- .packages.apps.redhat.com [] [] [* create update patch delete get list watch] imagestreams [] [] [create delete deletecollection get list patch update watch create get list watch] imagestreams.image.openshift.io [] [] [create delete deletecollection get list patch update watch create get list watch] secrets [] [] [create delete deletecollection get list patch update watch get list watch create delete deletecollection patch update] buildconfigs/webhooks [] [] [create delete deletecollection get list patch update watch get list watch] buildconfigs [] [] [create delete deletecollection get list patch update watch get list watch] buildlogs [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs/scale [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamimages [] [] [create delete deletecollection get list patch update watch get list watch] imagestreammappings [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamtags [] [] [create delete deletecollection get list patch update watch get list watch] processedtemplates [] [] [create delete deletecollection get list patch update watch get list watch] routes [] [] [create delete deletecollection get list patch update watch get list watch] templateconfigs [] [] [create delete deletecollection get list patch update watch get list watch] templateinstances [] [] [create delete deletecollection get list patch update watch get list watch] templates [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs.apps.openshift.io/scale [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs.apps.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] buildconfigs.build.openshift.io/webhooks [] [] [create delete deletecollection get list patch update watch get list watch] buildconfigs.build.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] buildlogs.build.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamimages.image.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] imagestreammappings.image.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamtags.image.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] routes.route.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] processedtemplates.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] templateconfigs.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] templateinstances.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] templates.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] serviceaccounts [] [] [create delete deletecollection get list patch update watch impersonate create delete deletecollection patch update get list watch] imagestreams/secrets [] [] [create delete deletecollection get list patch update watch] rolebindings [] [] [create delete deletecollection get list patch update watch] roles [] [] [create delete deletecollection get list patch update watch] rolebindings.authorization.openshift.io [] [] [create delete deletecollection get list patch update watch] roles.authorization.openshift.io [] [] [create delete deletecollection get list patch update watch] imagestreams.image.openshift.io/secrets [] [] [create delete deletecollection get list patch update watch] rolebindings.rbac.authorization.k8s.io [] [] [create delete deletecollection get list patch update watch] roles.rbac.authorization.k8s.io [] [] [create delete deletecollection get list patch update watch] networkpolicies.extensions [] [] [create delete deletecollection patch update create delete deletecollection get list patch update watch get list watch] networkpolicies.networking.k8s.io [] [] [create delete deletecollection patch update create delete deletecollection get list patch update watch get list watch] configmaps [] [] [create delete deletecollection patch update get list watch] endpoints [] [] [create delete deletecollection patch update get list watch] persistentvolumeclaims [] [] [create delete deletecollection patch update get list watch] pods [] [] [create delete deletecollection patch update get list watch] replicationcontrollers/scale [] [] [create delete deletecollection patch update get list watch] replicationcontrollers [] [] [create delete deletecollection patch update get list watch] services [] [] [create delete deletecollection patch update get list watch] daemonsets.apps [] [] [create delete deletecollection patch update get list watch] deployments.apps/scale [] [] [create delete deletecollection patch update get list watch] deployments.apps [] [] [create delete deletecollection patch update get list watch] replicasets.apps/scale [] [] [create delete deletecollection patch update get list watch] replicasets.apps [] [] [create delete deletecollection patch update get list watch] statefulsets.apps/scale [] [] [create delete deletecollection patch update get list watch] statefulsets.apps [] [] [create delete deletecollection patch update get list watch] horizontalpodautoscalers.autoscaling [] [] [create delete deletecollection patch update get list watch] cronjobs.batch [] [] [create delete deletecollection patch update get list watch] jobs.batch [] [] [create delete deletecollection patch update get list watch] daemonsets.extensions [] [] [create delete deletecollection patch update get list watch] deployments.extensions/scale [] [] [create delete deletecollection patch update get list watch] deployments.extensions [] [] [create delete deletecollection patch update get list watch] ingresses.extensions [] [] [create delete deletecollection patch update get list watch] replicasets.extensions/scale [] [] [create delete deletecollection patch update get list watch] replicasets.extensions [] [] [create delete deletecollection patch update get list watch] replicationcontrollers.extensions/scale [] [] [create delete deletecollection patch update get list watch] poddisruptionbudgets.policy [] [] [create delete deletecollection patch update get list watch] deployments.apps/rollback [] [] [create delete deletecollection patch update] deployments.extensions/rollback [] [] [create delete deletecollection patch update] catalogsources.operators.coreos.com [] [] [create update patch delete get list watch] clusterserviceversions.operators.coreos.com [] [] [create update patch delete get list watch] installplans.operators.coreos.com [] [] [create update patch delete get list watch] packagemanifests.operators.coreos.com [] [] [create update patch delete get list watch] subscriptions.operators.coreos.com [] [] [create update patch delete get list watch] buildconfigs/instantiate [] [] [create] buildconfigs/instantiatebinary [] [] [create] builds/clone [] [] [create] deploymentconfigrollbacks [] [] [create] deploymentconfigs/instantiate [] [] [create] deploymentconfigs/rollback [] [] [create] imagestreamimports [] [] [create] localresourceaccessreviews [] [] [create] localsubjectaccessreviews [] [] [create] podsecuritypolicyreviews [] [] [create] podsecuritypolicyselfsubjectreviews [] [] [create] podsecuritypolicysubjectreviews [] [] [create] resourceaccessreviews [] [] [create] routes/custom-host [] [] [create] subjectaccessreviews [] [] [create] subjectrulesreviews [] [] [create] deploymentconfigrollbacks.apps.openshift.io [] [] [create] deploymentconfigs.apps.openshift.io/instantiate [] [] [create] deploymentconfigs.apps.openshift.io/rollback [] [] [create] localsubjectaccessreviews.authorization.k8s.io [] [] [create] localresourceaccessreviews.authorization.openshift.io [] [] [create] localsubjectaccessreviews.authorization.openshift.io [] [] [create] resourceaccessreviews.authorization.openshift.io [] [] [create] subjectaccessreviews.authorization.openshift.io [] [] [create] subjectrulesreviews.authorization.openshift.io [] [] [create] buildconfigs.build.openshift.io/instantiate [] [] [create] buildconfigs.build.openshift.io/instantiatebinary [] [] [create] builds.build.openshift.io/clone [] [] [create] imagestreamimports.image.openshift.io [] [] [create] routes.route.openshift.io/custom-host [] [] [create] podsecuritypolicyreviews.security.openshift.io [] [] [create] podsecuritypolicyselfsubjectreviews.security.openshift.io [] [] [create] podsecuritypolicysubjectreviews.security.openshift.io [] [] [create] jenkins.build.openshift.io [] [] [edit view view admin edit view] builds [] [] [get create delete deletecollection get list patch update watch get list watch] builds.build.openshift.io [] [] [get create delete deletecollection get list patch update watch get list watch] projects [] [] [get delete get delete get patch update] projects.project.openshift.io [] [] [get delete get delete get patch update] namespaces [] [] [get get list watch] pods/attach [] [] [get list watch create delete deletecollection patch update] pods/exec [] [] [get list watch create delete deletecollection patch update] pods/portforward [] [] [get list watch create delete deletecollection patch update] pods/proxy [] [] [get list watch create delete deletecollection patch update] services/proxy [] [] [get list watch create delete deletecollection patch update] routes/status [] [] [get list watch update] routes.route.openshift.io/status [] [] [get list watch update] appliedclusterresourcequotas [] [] [get list watch] bindings [] [] [get list watch] builds/log [] [] [get list watch] deploymentconfigs/log [] [] [get list watch] deploymentconfigs/status [] [] [get list watch] events [] [] [get list watch] imagestreams/status [] [] [get list watch] limitranges [] [] [get list watch] namespaces/status [] [] [get list watch] pods/log [] [] [get list watch] pods/status [] [] [get list watch] replicationcontrollers/status [] [] [get list watch] resourcequotas/status [] [] [get list watch] resourcequotas [] [] [get list watch] resourcequotausages [] [] [get list watch] rolebindingrestrictions [] [] [get list watch] deploymentconfigs.apps.openshift.io/log [] [] [get list watch] deploymentconfigs.apps.openshift.io/status [] [] [get list watch] controllerrevisions.apps [] [] [get list watch] rolebindingrestrictions.authorization.openshift.io [] [] [get list watch] builds.build.openshift.io/log [] [] [get list watch] imagestreams.image.openshift.io/status [] [] [get list watch] appliedclusterresourcequotas.quota.openshift.io [] [] [get list watch] imagestreams/layers [] [] [get update get] imagestreams.image.openshift.io/layers [] [] [get update get] builds/details [] [] [update] builds.build.openshift.io/details [] [] [update] Name: basic-user Labels: <none> Annotations: openshift.io/description: A user that can get basic information about projects. rbac.authorization.kubernetes.io/autoupdate: true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- selfsubjectrulesreviews [] [] [create] selfsubjectaccessreviews.authorization.k8s.io [] [] [create] selfsubjectrulesreviews.authorization.openshift.io [] [] [create] clusterroles.rbac.authorization.k8s.io [] [] [get list watch] clusterroles [] [] [get list] clusterroles.authorization.openshift.io [] [] [get list] storageclasses.storage.k8s.io [] [] [get list] users [] [~] [get] users.user.openshift.io [] [~] [get] projects [] [] [list watch] projects.project.openshift.io [] [] [list watch] projectrequests [] [] [list] projectrequests.project.openshift.io [] [] [list] Name: cluster-admin Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate: true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- *.* [] [] [*] [*] [] [*] ...Afficher l’ensemble actuel de liaisons de rôles de cluster, qui montre les utilisateurs et les groupes qui sont liés à divers rôles:
$ oc describe clusterrolebinding.rbacExemple de sortie
Name: alertmanager-main Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: alertmanager-main Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount alertmanager-main openshift-monitoring Name: basic-users Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate: true Role: Kind: ClusterRole Name: basic-user Subjects: Kind Name Namespace ---- ---- --------- Group system:authenticated Name: cloud-credential-operator-rolebinding Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: cloud-credential-operator-role Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount default openshift-cloud-credential-operator Name: cluster-admin Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate: true Role: Kind: ClusterRole Name: cluster-admin Subjects: Kind Name Namespace ---- ---- --------- Group system:masters Name: cluster-admins Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate: true Role: Kind: ClusterRole Name: cluster-admin Subjects: Kind Name Namespace ---- ---- --------- Group system:cluster-admins User system:admin Name: cluster-api-manager-rolebinding Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: cluster-api-manager-role Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount default openshift-machine-api ...
7.5. Affichage des rôles et des liens locaux
Il est possible d’utiliser le CLI oc pour afficher les rôles et les liaisons locaux à l’aide de la commande de description oc.
Conditions préalables
- Installez le CLI oc.
Obtenir la permission d’afficher les rôles et les liens locaux:
- Les utilisateurs avec le rôle de cluster par défaut d’administrateur lié localement peuvent afficher et gérer les rôles et les liaisons dans ce projet.
Procédure
Afficher l’ensemble actuel de liaisons de rôles locales, qui montrent les utilisateurs et les groupes qui sont liés à divers rôles pour le projet en cours:
$ oc describe rolebinding.rbacAfin d’afficher les liaisons de rôle locales pour un projet différent, ajoutez le drapeau -n à la commande:
$ oc describe rolebinding.rbac -n joe-projectExemple de sortie
Name: admin Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- User kube:admin Name: system:deployers Labels: <none> Annotations: openshift.io/description: Allows deploymentconfigs in this namespace to rollout pods in this namespace. It is auto-managed by a controller; remove subjects to disa... Role: Kind: ClusterRole Name: system:deployer Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount deployer joe-project Name: system:image-builders Labels: <none> Annotations: openshift.io/description: Allows builds in this namespace to push images to this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-builder Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount builder joe-project Name: system:image-pullers Labels: <none> Annotations: openshift.io/description: Allows all pods in this namespace to pull images from this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-puller Subjects: Kind Name Namespace ---- ---- --------- Group system:serviceaccounts:joe-project
7.6. Ajout de rôles aux utilisateurs
Il est possible d’utiliser l’administrateur oc adm CLI pour gérer les rôles et les liaisons.
La liaison ou l’ajout d’un rôle aux utilisateurs ou aux groupes donne à l’utilisateur ou au groupe l’accès accordé par le rôle. Il est possible d’ajouter et de supprimer des rôles vers et à partir d’utilisateurs et de groupes à l’aide de commandes de stratégie adm oc.
Il est possible de lier n’importe lequel des rôles de cluster par défaut aux utilisateurs locaux ou aux groupes de votre projet.
Procédure
Ajouter un rôle à un utilisateur dans un projet spécifique:
$ oc adm policy add-role-to-user <role> <user> -n <project>À titre d’exemple, vous pouvez ajouter le rôle d’administrateur à l’utilisateur alice dans le projet joe en exécutant:
$ oc adm policy add-role-to-user admin alice -n joeAstuceAlternativement, vous pouvez appliquer le YAML suivant pour ajouter le rôle à l’utilisateur:
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: admin-0 namespace: joe roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: admin subjects: - apiGroup: rbac.authorization.k8s.io kind: User name: aliceConsultez les liaisons locales des rôles et vérifiez l’ajout dans la sortie:
$ oc describe rolebinding.rbac -n <project>À titre d’exemple, voir les liens de rôle locaux pour le projet joe:
$ oc describe rolebinding.rbac -n joeExemple de sortie
Name: admin Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- User kube:admin Name: admin-0 Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- User alice1 Name: system:deployers Labels: <none> Annotations: openshift.io/description: Allows deploymentconfigs in this namespace to rollout pods in this namespace. It is auto-managed by a controller; remove subjects to disa... Role: Kind: ClusterRole Name: system:deployer Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount deployer joe Name: system:image-builders Labels: <none> Annotations: openshift.io/description: Allows builds in this namespace to push images to this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-builder Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount builder joe Name: system:image-pullers Labels: <none> Annotations: openshift.io/description: Allows all pods in this namespace to pull images from this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-puller Subjects: Kind Name Namespace ---- ---- --------- Group system:serviceaccounts:joe- 1
- L’utilisateur alice a été ajouté aux administrateurs RoleBinding.
7.7. Créer un rôle local
Il est possible de créer un rôle local pour un projet, puis de le lier à un utilisateur.
Procédure
Afin de créer un rôle local pour un projet, exécutez la commande suivante:
$ oc create role <name> --verb=<verb> --resource=<resource> -n <project>Dans cette commande, spécifiez:
- <nom>, le nom du rôle local
- <verb>, une liste séparée par virgule des verbes à appliquer au rôle
- <Resource>, les ressources auxquelles le rôle s’applique
- <projet>, le nom du projet
À titre d’exemple, pour créer un rôle local qui permet à un utilisateur d’afficher des pods dans le projet bleu, exécutez la commande suivante:
$ oc create role podview --verb=get --resource=pod -n blueAfin de lier le nouveau rôle à un utilisateur, exécutez la commande suivante:
$ oc adm policy add-role-to-user podview user2 --role-namespace=blue -n blue
7.8. Commandes locales de liaison des rôles
Lorsque vous gérez les rôles associés d’un utilisateur ou d’un groupe pour les liaisons de rôles locales en utilisant les opérations suivantes, un projet peut être spécifié avec l’indicateur -n. Dans le cas contraire, le projet en cours est utilisé.
Les commandes suivantes peuvent être utilisées pour la gestion RBAC locale.
| Commande | Description |
|---|---|
|
| Indique quels utilisateurs peuvent effectuer une action sur une ressource. |
|
| Lie un rôle spécifié aux utilisateurs spécifiés dans le projet en cours. |
|
| Élimine un rôle donné des utilisateurs spécifiés dans le projet en cours. |
|
| Élimine les utilisateurs spécifiés et tous leurs rôles dans le projet en cours. |
|
| Lie un rôle donné à des groupes spécifiés dans le projet en cours. |
|
| Élimine un rôle donné des groupes spécifiés dans le projet en cours. |
|
| Élimine les groupes spécifiés et tous leurs rôles dans le projet en cours. |
7.9. Commandes de liaison de rôle de cluster
En outre, vous pouvez gérer les liaisons de rôles de cluster à l’aide des opérations suivantes. Le drapeau -n n’est pas utilisé pour ces opérations parce que les liaisons de rôle de cluster utilisent des ressources non-nombrées.
| Commande | Description |
|---|---|
|
| Lie un rôle donné aux utilisateurs spécifiés pour tous les projets du cluster. |
|
| Élimine un rôle donné des utilisateurs spécifiés pour tous les projets du cluster. |
|
| Lie un rôle donné à des groupes spécifiés pour tous les projets du cluster. |
|
| Élimine un rôle donné des groupes spécifiés pour tous les projets du cluster. |
7.10. Accorder des privilèges d’administrateur à un utilisateur
Après avoir configuré un fournisseur d’identité pour votre cluster et ajouté un utilisateur au fournisseur d’identité, vous pouvez accorder des privilèges de cluster dédié-admin à l’utilisateur.
Conditions préalables
- Connectez-vous à OpenShift Cluster Manager.
- Création d’un cluster OpenShift dédié.
- Configuration d’un fournisseur d’identité pour votre cluster.
Procédure
- Accédez à OpenShift Cluster Manager et sélectionnez votre cluster.
- Cliquez sur l’onglet Contrôle d’accès.
- Dans l’onglet Rôles de cluster et Accès, cliquez sur Ajouter un utilisateur.
- Entrez l’identifiant utilisateur d’un utilisateur fournisseur d’identité.
- Cliquez sur Ajouter un utilisateur pour accorder des privilèges de cluster dédié-admin à l’utilisateur.
La vérification
- Après avoir accordé les privilèges, l’utilisateur est listé dans le groupe admins dédié sous Contrôle d’accès → Rôles de cluster et Accès sur la page OpenShift Cluster Manager pour votre cluster.
7.11. Liaisons de rôles de cluster pour les groupes non authentifiés
Avant OpenShift Dedicated 4.17, les groupes non authentifiés étaient autorisés à accéder à certains rôles de cluster. Les clusters mis à jour à partir des versions avant OpenShift Dedicated 4.17 conservent cet accès pour les groupes non authentifiés.
Et pour des raisons de sécurité, OpenShift Dedicated 4 ne permet pas aux groupes non authentifiés d’avoir un accès par défaut aux rôles de cluster.
Il y a des cas d’utilisation où il pourrait être nécessaire d’ajouter system:inauthenticated à un rôle de cluster.
Les administrateurs de clusters peuvent ajouter des utilisateurs non authentifiés aux rôles de cluster suivants:
-
le système:scope-impersonation -
le système:webhook -
le système:oauth-token-deleter -
auto-réviseur d’accès
Assurez-vous toujours de respecter les normes de sécurité de votre organisation lors de la modification de l’accès non authentifié.
Chapitre 8. Comprendre et créer des comptes de services
8.1. Aperçu des comptes de services
Le compte de service est un compte dédié OpenShift qui permet à un composant d’accéder directement à l’API. Les comptes de service sont des objets API qui existent dans chaque projet. Les comptes de service offrent un moyen flexible de contrôler l’accès à l’API sans partager les informations d’identification d’un utilisateur régulier.
Lorsque vous utilisez le CLI dédié OpenShift ou la console Web, votre jeton API vous authentifie vers l’API. Il est possible d’associer un composant à un compte de service afin qu’il puisse accéder à l’API sans utiliser les informations d’identification d’un utilisateur régulier.
Le nom d’utilisateur de chaque compte de service est dérivé de son projet et de son nom:
system:serviceaccount:<project>:<name>Chaque compte de service est également membre de deux groupes:
| Groupe de travail | Description |
|---|---|
| le système:comptes de service | Inclut tous les comptes de service dans le système. |
| les comptes de service:<projet> | Inclut tous les comptes de service dans le projet spécifié. |
8.1.1. Les secrets d’attraction d’image générés automatiquement
Par défaut, OpenShift Dedicated crée un secret d’attraction d’image pour chaque compte de service.
Avant OpenShift Dedicated 4.16, un secret de jeton API de compte de service de longue durée a également été généré pour chaque compte de service créé. À partir de OpenShift Dedicated 4.16, le secret de jetons de compte de service n’est plus créé.
Après la mise à niveau à 4, tous les secrets de jetons de compte de service de longue durée existants ne sont pas supprimés et continueront à fonctionner. Afin d’obtenir des informations sur la détection des jetons API de longue durée qui sont utilisés dans votre cluster ou de les supprimer s’ils ne sont pas nécessaires, consultez l’article Red Hat Knowledgebase des jetons API de compte de service longue durée dans OpenShift Container Platform.
Ce secret d’attraction d’image est nécessaire pour intégrer le registre d’images OpenShift dans le système d’authentification et d’autorisation de l’utilisateur du cluster.
Cependant, si vous n’activez pas la fonction ImageRegistry ou si vous désactivez le registre d’images OpenShift intégré dans la configuration de l’opérateur de registre d’images du cluster, un secret d’attraction d’image n’est pas généré pour chaque compte de service.
Lorsque le registre d’images OpenShift intégré est désactivé sur un cluster qui l’avait précédemment activé, les secrets d’extraction d’images générés précédemment sont supprimés automatiquement.
8.2. Création de comptes de service
Il est possible de créer un compte de service dans un projet et de lui accorder des autorisations en le liant à un rôle.
Procédure
Facultatif: Pour visualiser les comptes de service dans le projet en cours:
$ oc get saExemple de sortie
NAME SECRETS AGE builder 1 2d default 1 2d deployer 1 2dCréer un nouveau compte de service dans le projet en cours:
$ oc create sa <service_account_name>1 - 1
- Afin de créer un compte de service dans un projet différent, spécifiez -n <project_name>.
Exemple de sortie
serviceaccount "robot" createdAstuceAlternativement, vous pouvez appliquer le YAML suivant pour créer le compte de service:
apiVersion: v1 kind: ServiceAccount metadata: name: <service_account_name> namespace: <current_project>Facultatif: Voir les secrets pour le compte de service:
$ oc describe sa robotExemple de sortie
Name: robot Namespace: project1 Labels: <none> Annotations: openshift.io/internal-registry-pull-secret-ref: robot-dockercfg-qzbhb Image pull secrets: robot-dockercfg-qzbhb Mountable secrets: robot-dockercfg-qzbhb Tokens: <none> Events: <none>
8.3. Accorder des rôles aux comptes de services
Il est possible d’accorder des rôles aux comptes de service de la même manière que vous accordez des rôles à un compte utilisateur régulier.
Il est possible de modifier les comptes de service pour le projet en cours. À titre d’exemple, ajouter le rôle de vue au compte de service robot dans le projet top-secret:
$ oc policy add-role-to-user view system:serviceaccount:top-secret:robotAstuceAlternativement, vous pouvez appliquer le YAML suivant pour ajouter le rôle:
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: view namespace: top-secret roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: view subjects: - kind: ServiceAccount name: robot namespace: top-secretIl est également possible d’accorder l’accès à un compte de service spécifique dans un projet. À partir du projet auquel appartient le compte de service, utilisez le drapeau -z et spécifiez le <service_account_name>
$ oc policy add-role-to-user <role_name> -z <service_account_name>ImportantDans le cas où vous souhaitez autoriser l’accès à un compte de service spécifique dans un projet, utilisez le drapeau -z. L’utilisation de ce drapeau permet d’éviter les typos et garantit que l’accès est accordé uniquement au compte de service spécifié.
AstuceAlternativement, vous pouvez appliquer le YAML suivant pour ajouter le rôle:
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: <rolebinding_name> namespace: <current_project_name> roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: <role_name> subjects: - kind: ServiceAccount name: <service_account_name> namespace: <current_project_name>Afin de modifier un espace de noms différent, vous pouvez utiliser l’option -n pour indiquer l’espace de noms du projet auquel il s’applique, comme indiqué dans les exemples suivants.
À titre d’exemple, permettre à tous les comptes de services de tous les projets d’afficher les ressources du projet de mon projet:
$ oc policy add-role-to-group view system:serviceaccounts -n my-projectAstuceAlternativement, vous pouvez appliquer le YAML suivant pour ajouter le rôle:
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: view namespace: my-project roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: view subjects: - apiGroup: rbac.authorization.k8s.io kind: Group name: system:serviceaccountsDe permettre à tous les comptes de services du projet des gestionnaires d’éditer des ressources dans le projet de mon projet:
$ oc policy add-role-to-group edit system:serviceaccounts:managers -n my-projectAstuceAlternativement, vous pouvez appliquer le YAML suivant pour ajouter le rôle:
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: edit namespace: my-project roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: edit subjects: - apiGroup: rbac.authorization.k8s.io kind: Group name: system:serviceaccounts:managers
Chapitre 9. L’utilisation des comptes de service dans les applications
9.1. Aperçu des comptes de services
Le compte de service est un compte dédié OpenShift qui permet à un composant d’accéder directement à l’API. Les comptes de service sont des objets API qui existent dans chaque projet. Les comptes de service offrent un moyen flexible de contrôler l’accès à l’API sans partager les informations d’identification d’un utilisateur régulier.
Lorsque vous utilisez le CLI dédié OpenShift ou la console Web, votre jeton API vous authentifie vers l’API. Il est possible d’associer un composant à un compte de service afin qu’il puisse accéder à l’API sans utiliser les informations d’identification d’un utilisateur régulier.
Le nom d’utilisateur de chaque compte de service est dérivé de son projet et de son nom:
system:serviceaccount:<project>:<name>Chaque compte de service est également membre de deux groupes:
| Groupe de travail | Description |
|---|---|
| le système:comptes de service | Inclut tous les comptes de service dans le système. |
| les comptes de service:<projet> | Inclut tous les comptes de service dans le projet spécifié. |
9.2. Comptes de service par défaut
Le cluster dédié OpenShift contient des comptes de service par défaut pour la gestion de clusters et génère plus de comptes de service pour chaque projet.
9.2.1. Comptes de service cluster par défaut
De nombreux contrôleurs d’infrastructure s’exécutent à l’aide d’informations d’identification de compte de service. Les comptes de service suivants sont créés dans le projet d’infrastructure dédié OpenShift (openshift-infra) au début du serveur, et compte tenu des rôles suivants à l’échelle du cluster:
| Compte de service | Description |
|---|---|
|
| Assigné le rôle système: réplication-contrôleur |
|
| Assigné au rôle système:déploiement-contrôleur |
|
| Assigné le rôle système:build-controller. De plus, le compte de service build-controller est inclus dans la contrainte privilégiée du contexte de sécurité pour créer des pods de build privilégiés. |
9.2.2. Comptes et rôles de service de projet par défaut
Les trois comptes de services sont créés automatiquement dans chaque projet:
| Compte de service | L’utilisation |
|---|---|
|
| Il est utilisé par les gousses de construction. Il est donné le rôle system: image-builder, qui permet de pousser des images vers n’importe quel flux d’images dans le projet en utilisant le registre interne Docker. Note Le compte de service constructeur n’est pas créé si la capacité du cluster Build n’est pas activée. |
|
| Utilisé par les pods de déploiement et étant donné le rôle system:deployer, qui permet de visualiser et de modifier les contrôleurs de réplication et les pods dans le projet. Note Le compte de service de déploiement n’est pas créé si la fonctionnalité de cluster DeploymentConfig n’est pas activée. |
|
| Utilisé pour exécuter tous les autres pods à moins qu’ils spécifient un compte de service différent. |
L’ensemble des comptes de service d’un projet reçoivent le rôle système: image-puller, qui permet de tirer des images de n’importe quel flux d’images dans le projet à l’aide du registre interne des images conteneur.
9.2.3. Les secrets d’attraction d’image générés automatiquement
Par défaut, OpenShift Dedicated crée un secret d’attraction d’image pour chaque compte de service.
Avant OpenShift Dedicated 4.16, un secret de jeton API de compte de service de longue durée a également été généré pour chaque compte de service créé. À partir de OpenShift Dedicated 4.16, le secret de jetons de compte de service n’est plus créé.
Après la mise à niveau à 4, tous les secrets de jetons de compte de service de longue durée existants ne sont pas supprimés et continueront à fonctionner. Afin d’obtenir des informations sur la détection des jetons API de longue durée qui sont utilisés dans votre cluster ou de les supprimer s’ils ne sont pas nécessaires, consultez l’article Red Hat Knowledgebase des jetons API de compte de service longue durée dans OpenShift Container Platform.
Ce secret d’attraction d’image est nécessaire pour intégrer le registre d’images OpenShift dans le système d’authentification et d’autorisation de l’utilisateur du cluster.
Cependant, si vous n’activez pas la fonction ImageRegistry ou si vous désactivez le registre d’images OpenShift intégré dans la configuration de l’opérateur de registre d’images du cluster, un secret d’attraction d’image n’est pas généré pour chaque compte de service.
Lorsque le registre d’images OpenShift intégré est désactivé sur un cluster qui l’avait précédemment activé, les secrets d’extraction d’images générés précédemment sont supprimés automatiquement.
9.3. Création de comptes de service
Il est possible de créer un compte de service dans un projet et de lui accorder des autorisations en le liant à un rôle.
Procédure
Facultatif: Pour visualiser les comptes de service dans le projet en cours:
$ oc get saExemple de sortie
NAME SECRETS AGE builder 1 2d default 1 2d deployer 1 2dCréer un nouveau compte de service dans le projet en cours:
$ oc create sa <service_account_name>1 - 1
- Afin de créer un compte de service dans un projet différent, spécifiez -n <project_name>.
Exemple de sortie
serviceaccount "robot" createdAstuceAlternativement, vous pouvez appliquer le YAML suivant pour créer le compte de service:
apiVersion: v1 kind: ServiceAccount metadata: name: <service_account_name> namespace: <current_project>Facultatif: Voir les secrets pour le compte de service:
$ oc describe sa robotExemple de sortie
Name: robot Namespace: project1 Labels: <none> Annotations: openshift.io/internal-registry-pull-secret-ref: robot-dockercfg-qzbhb Image pull secrets: robot-dockercfg-qzbhb Mountable secrets: robot-dockercfg-qzbhb Tokens: <none> Events: <none>
Chapitre 10. En utilisant un compte de service en tant que client OAuth
10.1. Comptes de service en tant que clients OAuth
Il est possible d’utiliser un compte de service comme une forme restreinte de client OAuth. Les comptes de service ne peuvent demander qu’un sous-ensemble de portées qui permettent l’accès à certaines informations utilisateur de base et à la puissance basée sur les rôles à l’intérieur du propre espace de noms du compte de service:
-
l’utilisateur:info -
accès utilisateur:check-access -
le rôle:<any_role>:<service_account_namespace> -
le rôle:<any_role>:<service_account_namespace>:!
Lors de l’utilisation d’un compte de service en tant que client OAuth:
- client_id est system:serviceaccount:<service_account_namespace>:<service_account_name>.
client_secret peut être l’un des jetons API pour ce compte de service. À titre d’exemple:
$ oc sa get-token <service_account_name>- Afin d’obtenir les défis WWW-Authenticate, définissez une annotation de serviceaccounts.openshift.io/oauth-want-want-challenges sur le compte de service à true.
- redirect_uri doit correspondre à une annotation sur le compte de service.
10.1.1. Rediriger les URI pour les comptes de service en tant que clients OAuth
Les clés d’annotation doivent avoir le préfixe serviceaccounts.openshift.io/oauth-redirecturi. ou serviceaccounts.openshift.io/oauth-redirectreference.
serviceaccounts.openshift.io/oauth-redirecturi.<name>Dans sa forme la plus simple, l’annotation peut être utilisée pour spécifier directement les URI de redirection valides. À titre d’exemple:
"serviceaccounts.openshift.io/oauth-redirecturi.first": "https://example.com"
"serviceaccounts.openshift.io/oauth-redirecturi.second": "https://other.com"Les premier et deuxième postfixes de l’exemple ci-dessus sont utilisés pour séparer les deux URI de redirection valides.
Dans les configurations plus complexes, les URI de redirection statiques peuvent ne pas suffire. À titre d’exemple, vous voulez peut-être que toutes les Ingresses soient considérées comme valides. C’est là que la redirection dynamique des URIs via le préfixe serviceaccounts.openshift.io/oauth-redirectreference.
À titre d’exemple:
"serviceaccounts.openshift.io/oauth-redirectreference.first": "{\"kind\":\"OAuthRedirectReference\",\"apiVersion\":\"v1\",\"reference\":{\"kind\":\"Route\",\"name\":\"jenkins\"}}"Étant donné que la valeur de cette annotation contient des données JSON sérialisées, il est plus facile de voir dans un format élargi:
{
"kind": "OAuthRedirectReference",
"apiVersion": "v1",
"reference": {
"kind": "Route",
"name": "jenkins"
}
}Désormais, vous pouvez voir qu’une OAuthRedirectReference nous permet de faire référence à l’itinéraire nommé jenkins. Ainsi, toutes les Ingresses pour cette route seront désormais considérées comme valides. La spécification complète d’une OAuthRedirectReference est:
{
"kind": "OAuthRedirectReference",
"apiVersion": "v1",
"reference": {
"kind": ...,
"name": ...,
"group": ...
}
}- 1
- genre fait référence au type de l’objet référencé. Actuellement, seule la route est prise en charge.
- 2
- le nom fait référence au nom de l’objet. L’objet doit être dans le même espace de noms que le compte de service.
- 3
- le groupe fait référence au groupe de l’objet. Laissez ce vide, car le groupe pour un itinéraire est la chaîne vide.
Les deux préfixes d’annotation peuvent être combinés pour remplacer les données fournies par l’objet de référence. À titre d’exemple:
"serviceaccounts.openshift.io/oauth-redirecturi.first": "custompath"
"serviceaccounts.openshift.io/oauth-redirectreference.first": "{\"kind\":\"OAuthRedirectReference\",\"apiVersion\":\"v1\",\"reference\":{\"kind\":\"Route\",\"name\":\"jenkins\"}}"Le premier postfix est utilisé pour lier les annotations ensemble. En supposant que la route des jenkins avait un Ingress de https://example.com, maintenant https://example.com/custompath est considéré comme valide, mais https://example.com ne l’est pas. Le format pour fournir partiellement des données de substitution est le suivant:
| Le type | Syntaxe |
|---|---|
| Le plan d’action | "HTTPS://" |
| Le nom d’hôte | "//site.com" |
| Le port | "//:8000" |
| Le chemin | « exemple » |
La spécification d’un nom d’hôte remplace les données du nom d’hôte de l’objet référencé, ce qui n’est pas susceptible d’être un comportement souhaité.
Chaque combinaison de la syntaxe ci-dessus peut être combinée en utilisant le format suivant:
<Scheme:>//<nom d’hôte><:port>/<path>
Le même objet peut être référencé plus d’une fois pour plus de flexibilité:
"serviceaccounts.openshift.io/oauth-redirecturi.first": "custompath"
"serviceaccounts.openshift.io/oauth-redirectreference.first": "{\"kind\":\"OAuthRedirectReference\",\"apiVersion\":\"v1\",\"reference\":{\"kind\":\"Route\",\"name\":\"jenkins\"}}"
"serviceaccounts.openshift.io/oauth-redirecturi.second": "//:8000"
"serviceaccounts.openshift.io/oauth-redirectreference.second": "{\"kind\":\"OAuthRedirectReference\",\"apiVersion\":\"v1\",\"reference\":{\"kind\":\"Route\",\"name\":\"jenkins\"}}"En supposant que l’itinéraire nommé jenkins dispose d’un Ingress de https://example.com, alors https://example.com:8000 et ▲ sont considérés comme valides.
Les annotations statiques et dynamiques peuvent être utilisées en même temps pour atteindre le comportement souhaité:
"serviceaccounts.openshift.io/oauth-redirectreference.first": "{\"kind\":\"OAuthRedirectReference\",\"apiVersion\":\"v1\",\"reference\":{\"kind\":\"Route\",\"name\":\"jenkins\"}}"
"serviceaccounts.openshift.io/oauth-redirecturi.second": "https://other.com"Chapitre 11. Jetons de cadrage
11.1. À propos des jetons de cadrage
Il est possible de créer des jetons expansés pour déléguer certaines de vos autorisations à un autre compte d’utilisateur ou de service. À titre d’exemple, un administrateur de projet pourrait vouloir déléguer le pouvoir de créer des pods.
Il s’agit d’un jeton qui s’identifie en tant qu’utilisateur donné, mais qui se limite à certaines actions par sa portée. Il n’y a qu’un utilisateur doté du rôle d’administrateur dédié qui peut créer des jetons à portée.
Les portées sont évaluées en convertissant l’ensemble de portées d’un jeton en un ensemble de règles de politique. Ensuite, la demande est assortie de ces règles. Les attributs de requête doivent correspondre à au moins une des règles de portée à transmettre à l’autorisant « normal » pour d’autres vérifications d’autorisation.
11.1.1. Champ d’application de l’utilisateur
Les portées des utilisateurs sont axées sur l’obtention d’informations sur un utilisateur donné. Ils sont basés sur l’intention, de sorte que les règles sont automatiquement créées pour vous:
- l’utilisateur:full - Permet l’accès complet à l’API avec toutes les autorisations de l’utilisateur.
- l’utilisateur:info - Permet l’accès en lecture seule aux informations sur l’utilisateur, tels que le nom et les groupes.
- accès utilisateur:check-access - Permet l’accès à des avis d’auto-localisation et à des examens d’auto-sujet. Ce sont les variables où vous passez un utilisateur vide et des groupes dans votre objet de demande.
- les projets User:list-projects - Permet l’accès en lecture seule à la liste des projets auxquels l’utilisateur a accès.
11.1.2. Champ d’application du rôle
La portée des rôles vous permet d’avoir le même niveau d’accès qu’un rôle donné filtré par l’espace de noms.
le rôle:<cluster-role name>:<namespace ou * pour tous> - Limite la portée aux règles spécifiées par le cluster-rôle, mais seulement dans l’espace de noms spécifié.
NoteAvertissement: Cela empêche l’accès croissant. Bien que le rôle permette l’accès à des ressources telles que des secrets, des obligations de rôle et des rôles, cette portée refusera l’accès à ces ressources. Cela aide à prévenir les escalades inattendues. Beaucoup de gens ne pensent pas à un rôle comme l’édition comme étant un rôle croissant, mais avec l’accès à un secret, il est.
- le rôle:<cluster-role name>:<namespace ou * pour tous>:! - Ceci est similaire à l’exemple ci-dessus, sauf que l’inclusion du bang provoque cette portée pour permettre un accès croissant.
11.2. Ajout de groupes non authentifiés aux rôles de cluster
En tant qu’administrateur de cluster, vous pouvez ajouter des utilisateurs non authentifiés aux rôles de cluster suivants dans OpenShift Dedicated en créant une liaison de rôle de cluster. Les utilisateurs non authentifiés n’ont pas accès à des rôles de cluster non publics. Cela ne devrait être fait que dans des cas d’utilisation spécifiques lorsque cela est nécessaire.
Il est possible d’ajouter des utilisateurs non authentifiés aux rôles de cluster suivants:
-
le système:scope-impersonation -
le système:webhook -
le système:oauth-token-deleter -
auto-réviseur d’accès
Assurez-vous toujours de respecter les normes de sécurité de votre organisation lors de la modification de l’accès non authentifié.
Conditions préalables
- En tant qu’utilisateur, vous avez accès au cluster avec le rôle cluster-admin.
- L’OpenShift CLI (oc) a été installé.
Procédure
Créez un fichier YAML nommé add-<cluster_role>-unauth.yaml et ajoutez le contenu suivant:
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "true" name: <cluster_role>access-unauthenticated roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: <cluster_role> subjects: - apiGroup: rbac.authorization.k8s.io kind: Group name: system:unauthenticatedAppliquer la configuration en exécutant la commande suivante:
$ oc apply -f add-<cluster_role>.yaml
Chapitre 12. En utilisant des jetons de compte de service liés
Il est possible d’utiliser des jetons de compte de service liés, ce qui améliore la capacité d’intégration avec les services de gestion de l’accès à l’identité des fournisseurs de cloud (IAM), tels que OpenShift Dedicated sur AWS IAM ou Google Cloud Platform IAM.
12.1. À propos des jetons de compte de service lié
Il est possible d’utiliser des jetons de compte de service liés pour limiter la portée des autorisations d’un jeton de compte de service donné. Ces jetons sont l’audience et le temps. Cela facilite l’authentification d’un compte de service à un rôle IAM et la génération d’informations d’identification temporaires montées sur un pod. Il est possible de demander des jetons de compte de service liés en utilisant la projection de volume et l’API TokenRequest.
12.2. Configuration des jetons de compte de service liés en utilisant la projection de volume
En utilisant la projection de volume, vous pouvez configurer des pods pour demander des jetons de compte de service liés.
Conditions préalables
- En tant qu’utilisateur, vous avez accès au cluster avec le rôle d’administrateur dédié.
- C’est vous qui avez créé un compte de service. Cette procédure suppose que le compte de service est nommé build-robot.
Procédure
Configurez un pod pour utiliser un jeton de compte de service lié en utilisant la projection de volume.
Créez un fichier appelé pod-projected-svc-token.yaml avec les contenus suivants:
apiVersion: v1 kind: Pod metadata: name: nginx spec: securityContext: runAsNonRoot: true1 seccompProfile: type: RuntimeDefault2 containers: - image: nginx name: nginx volumeMounts: - mountPath: /var/run/secrets/tokens name: vault-token securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] serviceAccountName: build-robot3 volumes: - name: vault-token projected: sources: - serviceAccountToken: path: vault-token4 expirationSeconds: 72005 audience: vault6 - 1
- Empêche les conteneurs de fonctionner comme racine pour minimiser les risques de compromis.
- 2
- Définit le profil seccomp par défaut, limitant les appels système essentiels, afin de réduire les risques.
- 3
- La référence à un compte de service existant.
- 4
- Le chemin relatif au point de montage du fichier pour projeter le jeton dans.
- 5
- Définissez en option l’expiration du jeton de compte de service, en quelques secondes. La valeur par défaut est de 3600 secondes (1 heure), et cette valeur doit être d’au moins 600 secondes (10 minutes). Le kubelet commence à essayer de faire pivoter le jeton si le jeton est supérieur à 80% de son temps à vivre ou si le jeton est plus de 24 heures.
- 6
- Définissez en option l’audience prévue du jeton. Le destinataire d’un jeton doit vérifier que l’identité du destinataire correspond à la revendication d’audience du jeton, et devrait autrement rejeter le jeton. L’audience par défaut à l’identifiant du serveur API.
NoteAfin d’éviter les échecs inattendus, OpenShift Dedicated remplace la valeur d’expirationSeconds pour être un an à partir de la génération de jetons initiale avec la valeur --service-account-extend-token-expiration de true. Il n’est pas possible de modifier ce paramètre.
Créer le pod:
$ oc create -f pod-projected-svc-token.yamlLe kubelet demande et stocke le jeton pour le compte du pod, met le jeton à la disposition du pod sur un chemin de fichier configurable, et actualise le jeton à mesure qu’il approche de l’expiration.
L’application qui utilise le jeton lié doit gérer le rechargement du jeton lorsqu’il tourne.
Le kubelet tourne le jeton s’il est plus de 80 pour cent de son temps de vivre, ou si le jeton est plus de 24 heures.
12.3. Création de jetons de compte de service liés en dehors du pod
Conditions préalables
- C’est vous qui avez créé un compte de service. Cette procédure suppose que le compte de service est nommé build-robot.
Procédure
Créez le jeton de compte de service lié en dehors du pod en exécutant la commande suivante:
$ oc create token build-robotExemple de sortie
eyJhbGciOiJSUzI1NiIsImtpZCI6IkY2M1N4MHRvc2xFNnFSQlA4eG9GYzVPdnN3NkhIV0tRWmFrUDRNcWx4S0kifQ.eyJhdWQiOlsiaHR0cHM6Ly9pc3N1ZXIyLnRlc3QuY29tIiwiaHR0cHM6Ly9pc3N1ZXIxLnRlc3QuY29tIiwiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjIl0sImV4cCI6MTY3OTU0MzgzMCwiaWF0IjoxNjc5NTQwMjMwLCJpc3MiOiJodHRwczovL2lzc3VlcjIudGVzdC5jb20iLCJrdWJlcm5ldGVzLmlvIjp7Im5hbWVzcGFjZSI6ImRlZmF1bHQiLCJzZXJ2aWNlYWNjb3VudCI6eyJuYW1lIjoidGVzdC1zYSIsInVpZCI6ImM3ZjA4MjkwLWIzOTUtNGM4NC04NjI4LTMzMTM1NTVhNWY1OSJ9fSwibmJmIjoxNjc5NTQwMjMwLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6ZGVmYXVsdDp0ZXN0LXNhIn0.WyAOPvh1BFMUl3LNhBCrQeaB5wSynbnCfojWuNNPSilT4YvFnKibxwREwmzHpV4LO1xOFZHSi6bXBOmG_o-m0XNDYL3FrGHd65mymiFyluztxa2lgHVxjw5reIV5ZLgNSol3Y8bJqQqmNg3rtQQWRML2kpJBXdDHNww0E5XOypmffYkfkadli8lN5QQD-MhsCbiAF8waCYs8bj6V6Y7uUKTcxee8sCjiRMVtXKjQtooERKm-CH_p57wxCljIBeM89VdaR51NJGued4hVV5lxvVrYZFu89lBEAq4oyQN_d6N1vBWGXQMyoihnt_fQjn-NfnlJWk-3NSZDIluDJAv7e-MTEk3geDrHVQKNEzDei2-Un64hSzb-n1g1M0Vn0885wQBQAePC9UlZm8YZlMNk1tq6wIUKQTMv3HPfi5HtBRqVc2eVs0EfMX4-x-PHhPCasJ6qLJWyj6DvyQ08dP4DW_TWZVGvKlmId0hzwpg59TTcLR0iCklSEJgAVEEd13Aa_M0-faD11L3MhUGxw0qxgOsPczdXUsolSISbefs7OKymzFSIkTAn9sDQ8PHMOsuyxsK8vzfrR-E0z7MAeguZ2kaIY7cZqbN6WFy0caWgx46hrKem9vCKALefElRYbCg3hcBmowBcRTOqaFHLNnHghhU1LaRpoFzH7OUarqX9SGQ
Chapitre 13. Gestion des contraintes de contexte de sécurité
Dans OpenShift Dedicated, vous pouvez utiliser des contraintes de contexte de sécurité (SCC) pour contrôler les autorisations pour les pods de votre cluster.
Les CSC par défaut sont créés pendant l’installation et lorsque vous installez certains opérateurs ou d’autres composants. En tant qu’administrateur de cluster, vous pouvez également créer vos propres SCC en utilisant l’OpenShift CLI (oc).
Il ne faut pas modifier les CCN par défaut. La personnalisation des SCC par défaut peut entraîner des problèmes lorsque certains pods de plate-forme se déploient ou OpenShift Dedicated est mis à niveau. De plus, les valeurs SCC par défaut sont réinitialisées aux valeurs par défaut lors de certaines mises à niveau de cluster, ce qui élimine toutes les personnalisations de ces SCC.
Au lieu de modifier les CSC par défaut, créez et modifiez vos propres CSC au besoin. En ce qui concerne les étapes détaillées, voir Créer des contraintes de contexte de sécurité.
Dans les déploiements dédiés à OpenShift, vous pouvez créer vos propres SCC uniquement pour les clusters utilisant le modèle d’abonnement au cloud client (CCS). Il est impossible de créer des SCC pour les clusters dédiés OpenShift qui utilisent un compte cloud Red Hat, car la création de ressources SCC nécessite des privilèges d’administration de cluster.
13.1. À propos des contraintes de contexte de sécurité
À l’instar de la façon dont les ressources RBAC contrôlent l’accès des utilisateurs, les administrateurs peuvent utiliser des contraintes de contexte de sécurité (SCC) pour contrôler les autorisations pour les pods. Ces autorisations déterminent les actions qu’un pod peut effectuer et les ressources auxquelles il peut accéder. Il est possible d’utiliser les CSC pour définir un ensemble de conditions avec lesquelles un pod doit fonctionner pour être accepté dans le système.
Les contraintes de contexte de sécurité permettent à un administrateur de contrôler:
- La possibilité d’exécuter des conteneurs privilégiés avec le drapeau AuthorPrivilegedContainer
- La question de savoir si un pod est limité avec le drapeau AuthorPrivilegeEscalation
- Les capacités qu’un conteneur peut demander
- L’utilisation des répertoires hôtes comme volumes
- Le contexte SELinux du conteneur
- L’identifiant de l’utilisateur du conteneur
- L’utilisation d’espaces de noms d’hôte et de mise en réseau
- L’attribution d’un groupe FS qui possède les volumes de pod
- La configuration des groupes complémentaires admissibles
- La question de savoir si un conteneur nécessite un accès par écrit à son système de fichiers racine
- L’utilisation des types de volume
- La configuration des profils seccomp admissibles
Il ne faut pas définir l’étiquette de niveau openshift.io/run sur les espaces de noms d’OpenShift Dedicated. Ce label est destiné à être utilisé par les composants internes OpenShift dédiés pour gérer le démarrage des grands groupes d’API, tels que le serveur API Kubernetes et le serveur API OpenShift. Lorsque l’étiquette openshift.io/run-level est définie, aucun SCC n’est appliqué aux pods dans cet espace de noms, ce qui fait que les charges de travail qui s’exécutent dans cet espace de noms sont hautement privilégiées.
13.1.1. Contraintes du contexte de sécurité par défaut
Le cluster contient plusieurs contraintes de contexte de sécurité par défaut (SCC) comme décrit dans le tableau ci-dessous. Des SCC supplémentaires peuvent être installés lorsque vous installez des Opérateurs ou d’autres composants sur OpenShift Dedicated.
Il ne faut pas modifier les CCN par défaut. La personnalisation des SCC par défaut peut entraîner des problèmes lorsque certains pods de plate-forme se déploient ou OpenShift Dedicated est mis à niveau. De plus, les valeurs SCC par défaut sont réinitialisées aux valeurs par défaut lors de certaines mises à niveau de cluster, ce qui élimine toutes les personnalisations de ces SCC.
Au lieu de modifier les CSC par défaut, créez et modifiez vos propres CSC au besoin. En ce qui concerne les étapes détaillées, voir Créer des contraintes de contexte de sécurité.
| Contrainte du contexte de sécurité | Description |
|---|---|
|
| Fournit toutes les fonctionnalités du SCC restreint, mais permet aux utilisateurs de fonctionner avec n’importe quel UID et n’importe quel GID. |
|
| Fournit toutes les fonctionnalités du SCC restreint, mais permet aux utilisateurs de fonctionner avec n’importe quel UID non-root. L’utilisateur doit spécifier l’UID ou il doit être spécifié dans le manifeste de l’exécution du conteneur. |
|
| Comme le CCN non racine, mais avec les différences suivantes:
|
|
| Il refuse l’accès à toutes les fonctionnalités de l’hôte et nécessite que les pods soient exécutés avec un UID et un contexte SELinux qui sont attribués à l’espace de noms. Le CCN restreint:
Dans les clusters qui ont été mis à niveau à partir d’OpenShift Dedicated 4.10 ou antérieur, ce SCC est disponible pour utilisation par tout utilisateur authentifié. Le SCC restreint n’est plus disponible pour les utilisateurs de nouvelles installations OpenShift Dedicated 4.11 ou ultérieures, sauf si l’accès est explicitement accordé. |
|
| Comme le CCN restreint, mais avec les différences suivantes:
Il s’agit du SCC le plus restrictif fourni par une nouvelle installation et sera utilisé par défaut pour les utilisateurs authentifiés. Note Le CCN restreint-v2 est le plus restrictif des CSC qui est inclus par défaut avec le système. Cependant, vous pouvez créer un CSC personnalisé qui est encore plus restrictif. À titre d’exemple, vous pouvez créer un SCC qui limite readOnlyRootFilesystem à true. |
13.1.2. Configuration des contraintes du contexte de sécurité
Les contraintes de contexte de sécurité (SCC) sont composées de paramètres et de stratégies qui contrôlent les fonctionnalités de sécurité auxquelles un pod a accès. Ces paramètres se répartissent en trois catégories:
| Catégorie | Description |
|---|---|
| Contrôlé par un booléen | Les champs de ce type par défaut à la valeur la plus restrictive. À titre d’exemple, AllowPrivilegedContainer est toujours mis à faux s’il n’est pas spécifié. |
| Contrôlé par un ensemble admissible | Les champs de ce type sont vérifiés par rapport à l’ensemble pour s’assurer que leur valeur est autorisée. |
| Contrôlé par une stratégie | Les éléments qui ont une stratégie pour générer une valeur fournissent:
|
CRI-O a la liste par défaut suivante des capacités qui sont autorisées pour chaque conteneur d’un pod:
-
CHOWN -
DAC_OVERRIDE -
FSETID -
FOWNER -
À PROPOS DE SETGID -
♪ SETUID ♪ -
LE SETPCAP -
ACCUEIL NET_BIND_SERVICE -
♪ TUE ♪
Les conteneurs utilisent les capacités de cette liste par défaut, mais les auteurs de manifestes de pod peuvent modifier la liste en demandant des capacités supplémentaires ou en supprimant certains des comportements par défaut. Employez les paramètres AutoriséCapities, defaultAddCapities et NeedDropCapities pour contrôler ces requêtes à partir des pods. Avec ces paramètres, vous pouvez spécifier quelles capacités peuvent être demandées, celles qui doivent être ajoutées à chaque conteneur, et celles qui doivent être interdites, ou abandonnées, de chaque conteneur.
Il est possible de supprimer tous les capabilites des conteneurs en réglant le paramètre DropCapities requis sur TOUS. C’est ce que fait le CCN limité-v2.
13.1.3. Contraintes du contexte de sécurité
RunAsUser
Il faut qu’un runAsUser soit configuré. Utilise le runAsUser configuré par défaut. Il valide par rapport au runAsUser configuré.
Exemple MustRunAs snippet
... runAsUser: type: MustRunAs uid: <id> ...Les valeurs minimales et maximales doivent être définies si elles n’utilisent pas des valeurs préaffectées. Utilise le minimum par défaut. Il valide par rapport à l’ensemble de la gamme autorisée.
Exemple MustRunAsRange snippet
... runAsUser: type: MustRunAsRange uidRangeMax: <maxvalue> uidRangeMin: <minvalue> ...MustRunAsNonRoot - exige que le pod soit soumis avec un runasUser non nul ou que la directive UTILISATEUR soit définie dans l’image. Aucun défaut fourni.
Exemple MustRunAsNonRoot snippet
... runAsUser: type: MustRunAsNonRoot ...RunAsAny - Aucune valeur par défaut n’est fournie. Permet de spécifier n’importe quel runAsUser.
Exemple RunAsAny snippet
... runAsUser: type: RunAsAny ...
À propos de SELinuxContext
- Il faut configurer seLinuxOptions s’il n’utilise pas de valeurs préaffectées. Utilise seLinuxOptions par défaut. Il valide contre seLinuxOptions.
- RunAsAny - Aucune valeur par défaut n’est fournie. Permet de spécifier toutes les options seLinux.
Groupes complémentaires
- MustRunAs - exige qu’au moins une plage soit spécifiée si elle n’utilise pas de valeurs préaffectées. Utilise la valeur minimale de la première plage comme valeur par défaut. Il valide toutes les gammes.
- RunAsAny - Aucune valeur par défaut n’est fournie. Permet de spécifier tout groupe supplémentaire.
Groupe FS
- MustRunAs - exige qu’au moins une plage soit spécifiée si elle n’utilise pas de valeurs préaffectées. Utilise la valeur minimale de la première plage comme valeur par défaut. Il valide par rapport au premier ID de la première gamme.
- RunAsAny - Aucune valeur par défaut n’est fournie. Permet de spécifier n’importe quel ID fsGroup.
13.1.4. Contrôle des volumes pour les clusters CCS
L’utilisation de types de volume spécifiques pour OpenShift Dedicated with Customer Cloud Subscription (CCS) peut être contrôlée en définissant le champ de volumes du SCC.
Les valeurs admissibles de ce champ correspondent aux sources de volume définies lors de la création d’un volume:
-
awsElasticBlockStore -
azureDisk -
azureFile -
CephFS -
cinder -
ConfigMap -
CSI -
API vers le bas -
le videDir -
FC -
Flexvolume -
Flocker -
gcePersistentDisk -
éphémère -
Gitrepo -
GlusterFS -
HostPath -
ISCSI -
les NFS -
à propos de PersistVolumeClaim -
fiche de photonPersistentDisk -
à propos de PortworxVolume -
a) Prévisions -
à propos de Quobyte -
le RBD -
ScaleIO -
le secret -
à propos de StorageOS -
à propos de vsphereVolume - * (Une valeur spéciale pour permettre l’utilisation de tous les types de volume.)
- aucune (une valeur spéciale pour refuser l’utilisation de tous les types de volumes. Existe uniquement pour la rétrocompatibilité.)
L’ensemble minimum recommandé de volumes autorisés pour les nouveaux CCN est configMap, downAPI, emptyDir, persistantVolumeClaim, secret et projeté.
Cette liste de types de volume autorisés n’est pas exhaustive car de nouveaux types sont ajoutés à chaque version d’OpenShift Dedicated.
En cas de rétrocompatibilité, l’utilisation de allowHostDirVolumePlugin remplace les paramètres dans le champ des volumes. À titre d’exemple, si l’autorisationHostDirVolumePlugin est définie sur false mais autorisée dans le champ volumes, la valeur hostPath sera supprimée des volumes.
13.1.5. Contrôle d’admission
Le contrôle d’admission avec les CCN permet de contrôler la création de ressources en fonction des capacités accordées à un utilisateur.
En ce qui concerne les CSC, cela signifie qu’un contrôleur d’admission peut inspecter les informations de l’utilisateur mises à disposition dans le contexte pour récupérer un ensemble approprié de CSC. Cela garantit que le pod est autorisé à faire des demandes sur son environnement d’exploitation ou à générer un ensemble de contraintes à appliquer à la gousse.
L’ensemble de CSC que l’admission utilise pour autoriser un pod sont déterminés par l’identité de l’utilisateur et les groupes auxquels l’utilisateur appartient. De plus, si la pod spécifie un compte de service, l’ensemble des CSC admissibles comprend toutes les contraintes accessibles au compte de service.
Lorsque vous créez une ressource de charge de travail, comme le déploiement, seul le compte de service est utilisé pour trouver les CCN et admettre les pods lorsqu’ils sont créés.
L’admission utilise l’approche suivante pour créer le contexte de sécurité final pour le pod:
- Découvrez tous les CCN disponibles pour l’utilisation.
- Générez des valeurs de champ pour les paramètres de contexte de sécurité qui n’ont pas été spécifiés sur la demande.
- Validez les paramètres finaux par rapport aux contraintes disponibles.
Lorsqu’un ensemble de contraintes est trouvé, le pod est accepté. Dans le cas où la demande ne peut pas être appariée à une CSC, le pod est rejeté.
La gousse doit valider tous les champs par rapport au CCN. Ce qui suit sont des exemples pour seulement deux des champs qui doivent être validés:
Ces exemples sont dans le contexte d’une stratégie utilisant les valeurs préaffectées.
La stratégie FSGroup SCC de MustRunAs
Lorsque le pod définit un ID fsGroup, cet ID doit être égal à l’ID fsGroup par défaut. Dans le cas contraire, le pod n’est pas validé par ce CCN et le prochain CSC est évalué.
Lorsque le champ SecurityContextConstraints.fsGroup a une valeur RunAsAny et que la spécification de pod omet le Pod.spec.securityContext.fsGroup, ce champ est considéré comme valide. Il est possible que lors de la validation, d’autres paramètres SCC rejettent d’autres champs de pod et causent ainsi l’échec de la dose.
La stratégie du CCN des groupes complémentaires de MustRunAs
Dans le cas où la spécification du pod définit un ou plusieurs IDs de groupes supplémentaires, les identifiants du pod doivent être égaux à l’un des ID de l’annotation openshift.io/sa.scc.supplémental-groups de l’espace de noms. Dans le cas contraire, le pod n’est pas validé par ce CCN et le prochain CSC est évalué.
Lorsque le champ SecurityContextConstraints.supplementalGroups a une valeur RunAsAny et que la spécification de pod omet le Pod.spec.securityContext.supplementalGroups, ce champ est considéré comme valide. Il est possible que lors de la validation, d’autres paramètres SCC rejettent d’autres champs de pod et causent ainsi l’échec de la dose.
13.1.6. Contraintes liées au contexte de sécurité
Les contraintes de contexte de sécurité (SCC) ont un champ prioritaire qui affecte la commande lorsque vous tentez de valider une demande du contrôleur d’admission.
La valeur prioritaire de 0 est la priorité la plus faible possible. La priorité zéro est considérée comme une priorité 0 ou inférieure. Les CCN prioritaires sont déplacés vers l’avant de l’ensemble lors du tri.
Lorsque l’ensemble complet des CSC disponibles est déterminé, les CSC sont ordonnés de la manière suivante:
- Les CCN prioritaires sont commandés en premier.
- Lorsque les priorités sont égales, les CSC sont classés de la plus restrictive à la moins restrictive.
- Lorsque les priorités et les restrictions sont égales, les CSC sont triés par nom.
Le CCN en tout état de cause accordé aux administrateurs de clusters par défaut est donné la priorité dans leur ensemble de CSC. Cela permet aux administrateurs de clusters d’exécuter des pods comme n’importe quel utilisateur en spécifiant RunAsUser dans SecurityContext du pod.
13.2. À propos des valeurs préaffectées de contraintes de contexte de sécurité
Le contrôleur d’admission est conscient de certaines conditions dans les contraintes de contexte de sécurité (SCC) qui le déclenchent pour rechercher des valeurs préaffectées à partir d’un espace de noms et peupler le SCC avant de traiter le pod. Chaque stratégie SCC est évaluée indépendamment des autres stratégies, avec les valeurs pré-affectées, lorsque cela est permis, pour chaque politique agrégée avec des valeurs de spécification de pod pour faire les valeurs finales pour les différents ID définis dans le pod en cours d’exécution.
Les CCN suivants font en sorte que le contrôleur d’admission recherche des valeurs préaffectées lorsqu’aucune plage n’est définie dans la spécification du pod:
- La stratégie RunAsUser de MustRunAsRange n’est pas définie au minimum ou au maximum. Admission recherche l’annotation openshift.io/sa.scc.uid-range pour peupler les champs de gamme.
- La stratégie SELinuxContext de MustRunAs sans définition de niveau. L’admission recherche l’annotation openshift.io/sa.scc.mcs pour peupler le niveau.
- La stratégie FSGroup de MustRunAs. L’admission recherche l’annotation openshift.io/sa.scc.supplémental-groups.
- La stratégie des groupes supplémentaires de MustRunAs. L’admission recherche l’annotation openshift.io/sa.scc.supplémental-groups.
Au cours de la phase de génération, le fournisseur de contexte de sécurité utilise des valeurs par défaut pour toutes les valeurs de paramètres qui ne sont pas spécifiquement définies dans le pod. Les valeurs par défaut sont basées sur la stratégie sélectionnée:
- Les stratégies RunAsAny et MustRunAsNonRoot ne fournissent pas de valeurs par défaut. Lorsque le pod a besoin d’une valeur de paramètre, comme un ID de groupe, vous devez définir la valeur dans la spécification de pod.
- Les stratégies MustRunAs (valeur unique) fournissent une valeur par défaut qui est toujours utilisée. À titre d’exemple, pour les ID de groupe, même si la spécification de pod définit sa propre valeur ID, la valeur du paramètre par défaut de l’espace de noms apparaît également dans les groupes du pod.
- Les stratégies MustRunAsRange et MustRunAs (basées sur la plage) fournissent la valeur minimale de la plage. Comme pour une seule stratégie MustRunAs, la valeur par défaut de l’espace de noms apparaît dans le pod en cours d’exécution. Lorsqu’une stratégie basée sur une plage est configurable avec plusieurs plages, elle fournit la valeur minimale de la première plage configurée.
Les stratégies FSGroup et SupplementalGroups reviennent à l’annotation openshift.io/scc.uid-range si l’annotation openshift.io/scc.supplémental-groups n’existe pas sur l’espace de noms. Dans le cas contraire, la CSC n’est pas créée.
La stratégie FSGroup basée sur l’annotation se configure par défaut avec une seule plage basée sur la valeur minimale pour l’annotation. Ainsi, si votre annotation lit 1/3, la stratégie FSGroup se configure avec une valeur minimale et maximale de 1. Lorsque vous souhaitez que plus de groupes soient acceptés pour le champ FSGroup, vous pouvez configurer un SCC personnalisé qui n’utilise pas l’annotation.
L’annotation openshift.io/sa.scc.supplémental-groups accepte une liste de blocs délimitée par virgule dans le format <start>/<longueur ou <start>-<end>. L’annotation openshift.io/sa.scc.uid-range n’accepte qu’un seul bloc.
13.3. Exemple de contraintes de contexte de sécurité
Les exemples suivants montrent le format et les annotations du contexte de sécurité (SCC):
CCN privilégié annoté
allowHostDirVolumePlugin: true
allowHostIPC: true
allowHostNetwork: true
allowHostPID: true
allowHostPorts: true
allowPrivilegedContainer: true
allowedCapabilities:
- '*'
apiVersion: security.openshift.io/v1
defaultAddCapabilities: []
fsGroup:
type: RunAsAny
groups:
- system:cluster-admins
- system:nodes
kind: SecurityContextConstraints
metadata:
annotations:
kubernetes.io/description: 'privileged allows access to all privileged and host
features and the ability to run as any user, any group, any fsGroup, and with
any SELinux context. WARNING: this is the most relaxed SCC and should be used
only for cluster administration. Grant with caution.'
creationTimestamp: null
name: privileged
priority: null
readOnlyRootFilesystem: false
requiredDropCapabilities: null
runAsUser:
type: RunAsAny
seLinuxContext:
type: RunAsAny
seccompProfiles:
- '*'
supplementalGroups:
type: RunAsAny
users:
- system:serviceaccount:default:registry
- system:serviceaccount:default:router
- system:serviceaccount:openshift-infra:build-controller
volumes:
- '*'- 1
- Liste des capacités qu’un pod peut demander. La liste vide signifie qu’aucune des capacités ne peut être demandée alors que le symbole spécial * autorise des capacités.
- 2
- Liste des capacités supplémentaires qui sont ajoutées à n’importe quel pod.
- 3
- La stratégie FSGroup, qui dicte les valeurs admissibles pour le contexte de sécurité.
- 4
- Les groupes qui peuvent accéder à ce CSC.
- 5
- Liste des capacités à supprimer d’un pod. Indiquez TOUT pour laisser tomber toutes les capacités.
- 6
- Le type de stratégie runAsUser, qui dicte les valeurs autorisées pour le contexte de sécurité.
- 7
- Le type de stratégie seLinuxContext, qui dicte les valeurs autorisées pour le contexte de sécurité.
- 8
- La stratégie de groupe complémentaire, qui dicte les groupes supplémentaires admissibles pour le contexte de sécurité.
- 9
- Les utilisateurs qui peuvent accéder à ce SCC.
- 10
- Les types de volume admissibles pour le contexte de sécurité. Dans l’exemple, * permet l’utilisation de tous les types de volume.
Les utilisateurs et les groupes s’affichent sur le contrôle du CCN auquel les utilisateurs peuvent accéder au CCN. Les administrateurs de clusters, les nœuds et le contrôleur de construction bénéficient par défaut d’un accès au SCC privilégié. Les utilisateurs authentifiés bénéficient d’un accès au CCN restreint-v2.
Configuration sans runAsUser explicite
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo
spec:
securityContext:
containers:
- name: sec-ctx-demo
image: gcr.io/google-samples/node-hello:1.0- 1
- Lorsqu’un conteneur ou un pod ne demande pas d’identifiant d’utilisateur sous lequel il doit être exécuté, l’UID efficace dépend du CCN qui émet ce pod. Étant donné que le SCC restreint-v2 est accordé à tous les utilisateurs authentifiés par défaut, il sera disponible pour tous les utilisateurs et comptes de service et utilisés dans la plupart des cas. Le SCC restrictif-v2 utilise la stratégie MustRunAsRange pour limiter et par défaut les valeurs possibles du champ securityContext.runAsUser. Le plugin d’admission cherchera l’annotation de plage openshift.io/sa.scc.uid sur le projet actuel pour peupler les champs de gamme, car il ne fournit pas cette plage. En fin de compte, un conteneur aura runAsUser égal à la première valeur de la gamme qui est difficile à prédire parce que chaque projet a des gammes différentes.
Avec le paramètre runAsUser explicite
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo
spec:
securityContext:
runAsUser: 1000
containers:
- name: sec-ctx-demo
image: gcr.io/google-samples/node-hello:1.0- 1
- Le conteneur ou la pod qui demande un identifiant d’utilisateur spécifique ne sera accepté par OpenShift Dedicated que lorsqu’un compte de service ou un utilisateur se voit accorder l’accès à un SCC qui permet un tel identifiant d’utilisateur. Le SCC peut autoriser des ID arbitraires, un ID qui tombe dans une plage, ou l’identifiant d’utilisateur exact spécifique à la demande.
Cette configuration est valable pour les groupes SELinux, fsGroup et Supplémentaires.
13.4. Créer des contraintes de contexte de sécurité pour les clusters CCS
Lorsque les contraintes du contexte de sécurité par défaut (SCC) ne répondent pas aux exigences de charge de travail de votre application, vous pouvez créer un SCC personnalisé à l’aide de l’OpenShift CLI (oc).
La création et la modification de vos propres SCC sont des opérations avancées qui pourraient causer de l’instabilité à votre cluster. Contactez Red Hat Support Si vous avez des questions sur l’utilisation de vos propres CSC, contactez Red Hat Support. En savoir plus sur la prise en charge de Red Hat, consultez l’aide d’Accueil.
Dans les déploiements dédiés à OpenShift, vous pouvez créer vos propres SCC uniquement pour les clusters utilisant le modèle d’abonnement au cloud client (CCS). Il est impossible de créer des SCC pour les clusters dédiés OpenShift qui utilisent un compte cloud Red Hat, car la création de ressources SCC nécessite des privilèges d’administration de cluster.
Conditions préalables
- Installez le OpenShift CLI (oc).
- Connectez-vous au cluster en tant qu’utilisateur avec le rôle cluster-admin.
Procédure
Définissez le SCC dans un fichier YAML nommé scc-admin.yaml:
kind: SecurityContextConstraints apiVersion: security.openshift.io/v1 metadata: name: scc-admin allowPrivilegedContainer: true runAsUser: type: RunAsAny seLinuxContext: type: RunAsAny fsGroup: type: RunAsAny supplementalGroups: type: RunAsAny users: - my-admin-user groups: - my-admin-groupEn option, vous pouvez supprimer des capacités spécifiques pour un SCC en définissant le champ Capacités de dépôt requise avec les valeurs souhaitées. Les capacités spécifiées sont supprimées du conteneur. Afin de supprimer toutes les capacités, spécifiez TOUT. À titre d’exemple, pour créer un SCC qui laisse tomber les capacités KILL, MKNOD et SYS_CHROOT, ajoutez ce qui suit à l’objet SCC:
requiredDropCapabilities: - KILL - MKNOD - SYS_CHROOTNoteIl n’est pas possible de répertorier une capacité dans les capacités autorisées et les capacités de dépôt requises.
CRI-O prend en charge la même liste de valeurs de capacités que celles que l’on trouve dans la documentation Docker.
Créer le SCC en passant dans le fichier:
$ oc create -f scc-admin.yamlExemple de sortie
securitycontextconstraints "scc-admin" created
La vérification
Assurez-vous que le CCN a été créé:
$ oc get scc scc-adminExemple de sortie
NAME PRIV CAPS SELINUX RUNASUSER FSGROUP SUPGROUP PRIORITY READONLYROOTFS VOLUMES scc-admin true [] RunAsAny RunAsAny RunAsAny RunAsAny <none> false [awsElasticBlockStore azureDisk azureFile cephFS cinder configMap downwardAPI emptyDir fc flexVolume flocker gcePersistentDisk gitRepo glusterfs iscsi nfs persistentVolumeClaim photonPersistentDisk quobyte rbd secret vsphere]
13.5. Configuration d’une charge de travail pour nécessiter un SCC spécifique
Il est possible de configurer une charge de travail pour exiger une certaine contrainte contextuelle de sécurité (SCC). Ceci est utile dans les scénarios où vous souhaitez épingler un CSC spécifique à la charge de travail ou si vous voulez empêcher votre CSC requis d’être préempté par un autre CSC dans le cluster.
Afin d’exiger un SCC spécifique, définissez l’annotation openshift.io/required-scc sur votre charge de travail. Cette annotation peut être définie sur n’importe quelle ressource pouvant définir un modèle de manifeste de pod, tel qu’un déploiement ou un jeu de démons.
La CSC doit exister dans le cluster et doit s’appliquer à la charge de travail, sinon l’admission de pod échoue. Le SCC est considéré comme applicable à la charge de travail si l’utilisateur qui crée le pod ou le compte de service du pod utilise des autorisations pour le SCC dans l’espace de noms du pod.
Il ne faut pas modifier l’annotation openshift.io/requis-scc dans le manifeste de la gousse vivante, car cela provoque l’échec de l’admission de la gousse. Afin de modifier le SCC requis, mettre à jour l’annotation dans le modèle de pod sous-jacent, ce qui entraîne la suppression et la recréation de la pod.
Conditions préalables
- La CSC doit exister dans le cluster.
Procédure
Créez un fichier YAML pour le déploiement et spécifiez un SCC requis en définissant l’annotation openshift.io/required-scc:
Exemple de déploiement.yaml
apiVersion: config.openshift.io/v1 kind: Deployment apiVersion: apps/v1 spec: # ... template: metadata: annotations: openshift.io/required-scc: "my-scc"1 # ...- 1
- Indiquez le nom de la CSC à exiger.
Créez la ressource en exécutant la commande suivante:
$ oc create -f deployment.yaml
La vérification
Assurez-vous que le déploiement a utilisé le SCC spécifié:
Afficher la valeur de l’annotation openshift.io/scc du pod en exécutant la commande suivante:
$ oc get pod <pod_name> -o jsonpath='{.metadata.annotations.openshift\.io\/scc}{"\n"}'1 - 1
- <pod_name> par le nom de votre pod de déploiement.
Examinez la sortie et confirmez que le SCC affiché correspond au CCN que vous avez défini dans le déploiement:
Exemple de sortie
my-scc
13.6. Accès basé sur le rôle aux contraintes du contexte de sécurité
Il est possible de spécifier les CCN comme ressources gérées par RBAC. Cela vous permet d’étendre l’accès à vos CCN à un certain projet ou à l’ensemble du cluster. L’attribution de comptes d’utilisateurs, de groupes ou de services directement à un CCN conserve la portée du cluster.
Évitez d’exécuter des charges de travail ou de partager l’accès aux projets par défaut. Les projets par défaut sont réservés à l’exécution de composants de cluster de base.
Les projets par défaut suivants sont considérés comme hautement privilégiés: par défaut, kube-public, kube-system, openshift, openshift-infra, openshift-node, et d’autres projets créés par système qui ont l’étiquette openshift.io / run-level définie à 0 ou 1. La fonctionnalité qui repose sur des plugins d’admission, tels que l’admission de sécurité pod, les contraintes de contexte de sécurité, les quotas de ressources de cluster et la résolution de référence d’image, ne fonctionne pas dans des projets hautement privilégiés.
Afin d’inclure l’accès aux CSC pour votre rôle, spécifiez la ressource scc lors de la création d’un rôle.
$ oc create role <role-name> --verb=use --resource=scc --resource-name=<scc-name> -n <namespace>Il en résulte la définition de rôle suivante:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
...
name: role-name
namespace: namespace
...
rules:
- apiGroups:
- security.openshift.io
resourceNames:
- scc-name
resources:
- securitycontextconstraints
verbs:
- use- 1
- Le nom du rôle.
- 2
- Espace de noms du rôle défini. Défaut par défaut s’il n’est pas spécifié.
- 3
- Le groupe API qui inclut la ressource SecurityContextConstraints. Défini automatiquement lorsque scc est spécifié comme une ressource.
- 4
- Exemple de nom d’un CCN auquel vous souhaitez avoir accès.
- 5
- Le nom du groupe de ressources qui permet aux utilisateurs de spécifier les noms SCC dans le champ resourceNames.
- 6
- Liste des verbes à appliquer au rôle.
Le rôle local ou cluster avec une telle règle permet aux sujets qui lui sont liés par une liaison de rôle ou un rôle de cluster d’utiliser le SCC défini par l’utilisateur appelé scc-name.
Étant donné que RBAC est conçu pour prévenir l’escalade, même les administrateurs de projet ne sont pas en mesure d’accorder l’accès à un CSC. Ils ne sont pas autorisés par défaut à utiliser le verbe sur les ressources du CCN, y compris le CCN restreint-v2.
13.7. La référence des commandes de contraintes de contexte de sécurité
Dans votre instance, vous pouvez gérer les contraintes de contexte de sécurité (SCC) en tant qu’objets API normaux à l’aide de l’OpenShift CLI (oc).
13.7.1. Énumérer les contraintes du contexte de sécurité
Afin d’obtenir une liste actuelle des CCN:
$ oc get sccExemple de sortie
NAME PRIV CAPS SELINUX RUNASUSER FSGROUP SUPGROUP PRIORITY READONLYROOTFS VOLUMES
anyuid false <no value> MustRunAs RunAsAny RunAsAny RunAsAny 10 false ["configMap","downwardAPI","emptyDir","persistentVolumeClaim","projected","secret"]
hostaccess false <no value> MustRunAs MustRunAsRange MustRunAs RunAsAny <no value> false ["configMap","downwardAPI","emptyDir","hostPath","persistentVolumeClaim","projected","secret"]
hostmount-anyuid false <no value> MustRunAs RunAsAny RunAsAny RunAsAny <no value> false ["configMap","downwardAPI","emptyDir","hostPath","nfs","persistentVolumeClaim","projected","secret"]
hostnetwork false <no value> MustRunAs MustRunAsRange MustRunAs MustRunAs <no value> false ["configMap","downwardAPI","emptyDir","persistentVolumeClaim","projected","secret"]
hostnetwork-v2 false ["NET_BIND_SERVICE"] MustRunAs MustRunAsRange MustRunAs MustRunAs <no value> false ["configMap","downwardAPI","emptyDir","persistentVolumeClaim","projected","secret"]
node-exporter true <no value> RunAsAny RunAsAny RunAsAny RunAsAny <no value> false ["*"]
nonroot false <no value> MustRunAs MustRunAsNonRoot RunAsAny RunAsAny <no value> false ["configMap","downwardAPI","emptyDir","persistentVolumeClaim","projected","secret"]
nonroot-v2 false ["NET_BIND_SERVICE"] MustRunAs MustRunAsNonRoot RunAsAny RunAsAny <no value> false ["configMap","downwardAPI","emptyDir","persistentVolumeClaim","projected","secret"]
privileged true ["*"] RunAsAny RunAsAny RunAsAny RunAsAny <no value> false ["*"]
restricted false <no value> MustRunAs MustRunAsRange MustRunAs RunAsAny <no value> false ["configMap","downwardAPI","emptyDir","persistentVolumeClaim","projected","secret"]
restricted-v2 false ["NET_BIND_SERVICE"] MustRunAs MustRunAsRange MustRunAs RunAsAny <no value> false ["configMap","downwardAPI","emptyDir","persistentVolumeClaim","projected","secret"]13.7.2. Examen des contraintes liées au contexte de sécurité
Il est possible d’afficher des informations sur un CCN en particulier, y compris les utilisateurs, les comptes de service et les groupes auxquels la CSC est appliquée.
À titre d’exemple, examiner le CCN restreint:
$ oc describe scc restrictedExemple de sortie
Name: restricted
Priority: <none>
Access:
Users: <none>
Groups: <none>
Settings:
Allow Privileged: false
Allow Privilege Escalation: true
Default Add Capabilities: <none>
Required Drop Capabilities: KILL,MKNOD,SETUID,SETGID
Allowed Capabilities: <none>
Allowed Seccomp Profiles: <none>
Allowed Volume Types: configMap,downwardAPI,emptyDir,persistentVolumeClaim,projected,secret
Allowed Flexvolumes: <all>
Allowed Unsafe Sysctls: <none>
Forbidden Sysctls: <none>
Allow Host Network: false
Allow Host Ports: false
Allow Host PID: false
Allow Host IPC: false
Read Only Root Filesystem: false
Run As User Strategy: MustRunAsRange
UID: <none>
UID Range Min: <none>
UID Range Max: <none>
SELinux Context Strategy: MustRunAs
User: <none>
Role: <none>
Type: <none>
Level: <none>
FSGroup Strategy: MustRunAs
Ranges: <none>
Supplemental Groups Strategy: RunAsAny
Ranges: <none>Chapitre 14. Comprendre et gérer l’admission à la sécurité des pod
L’admission à la sécurité de Pod est une mise en œuvre des normes de sécurité des pod Kubernetes. Il faut utiliser l’admission de sécurité de pod pour restreindre le comportement des gousses.
14.1. À propos de l’admission à la sécurité de pod
Le programme OpenShift Dedicated inclut l’admission à la sécurité des pod Kubernetes. Les pods qui ne sont pas conformes à l’admission de sécurité pod définie globalement ou au niveau de l’espace de noms ne sont pas admis au cluster et ne peuvent pas s’exécuter.
À l’échelle mondiale, le profil privilégié est appliqué et le profil restreint est utilisé pour les avertissements et les audits.
Il est également possible de configurer les paramètres d’entrée de sécurité pod au niveau de l’espace de noms.
Évitez d’exécuter des charges de travail ou de partager l’accès aux projets par défaut. Les projets par défaut sont réservés à l’exécution de composants de cluster de base.
Les projets par défaut suivants sont considérés comme hautement privilégiés: par défaut, kube-public, kube-system, openshift, openshift-infra, openshift-node, et d’autres projets créés par système qui ont l’étiquette openshift.io / run-level définie à 0 ou 1. La fonctionnalité qui repose sur des plugins d’admission, tels que l’admission de sécurité pod, les contraintes de contexte de sécurité, les quotas de ressources de cluster et la résolution de référence d’image, ne fonctionne pas dans des projets hautement privilégiés.
14.1.1. Les modes d’admission à la sécurité de Pod
Les modes d’admission de sécurité pod suivants peuvent être configurés pour un espace de noms:
| Le mode | Étiquette | Description |
|---|---|---|
|
|
| Il rejette un pod d’admission s’il ne se conforme pas au profil défini |
|
|
| Enregistre les événements d’audit si un pod ne se conforme pas au profil défini |
|
|
| Affiche les avertissements si un pod ne se conforme pas au profil défini |
14.1.2. Les profils d’admission à la sécurité de Pod
Chacun des modes d’admission à la sécurité de pod peut être défini sur l’un des profils suivants:
| Le profil | Description |
|---|---|
|
| La politique la moins restrictive; permet une escalade connue des privilèges |
|
| La politique minimalement restrictive; empêche les escalades de privilèges connues |
|
| La politique la plus restrictive; suit les meilleures pratiques actuelles de durcissement de la pod |
14.1.3. Espaces de noms privilégiés
Les espaces de noms système suivants sont toujours définis sur le profil d’admission de sécurité de pod privilégié:
-
défaut par défaut -
Kube-public -
Kube-système
Il est impossible de modifier le profil de sécurité des pod pour ces espaces de noms privilégiés.
14.1.4. Conditions d’admission en matière de sécurité et contraintes liées au contexte de sécurité
Les normes d’admission en matière de sécurité de Pod et les contraintes liées au contexte de sécurité sont réconciliées et appliquées par deux contrôleurs indépendants. Les deux contrôleurs travaillent indépendamment en utilisant les processus suivants pour appliquer les politiques de sécurité:
- Le contrôleur de contrainte du contexte de sécurité peut muter certains champs de contexte de sécurité selon le SCC assigné par le pod. À titre d’exemple, si le profil seccomp est vide ou non défini et si le champ SCC assigné par le pod applique le champ seccompProfiles pour être runtime/default, le contrôleur définit le type par défaut sur RuntimeDefault.
- Le contrôleur de contrainte du contexte de sécurité valide le contexte de sécurité de la pod par rapport au SCC correspondant.
- Le contrôleur d’admission de sécurité de pod valide le contexte de sécurité du pod par rapport à la norme de sécurité de pod assignée à l’espace de noms.
14.2. À propos de la synchronisation de l’admission de sécurité de pod
En plus de la configuration globale de contrôle d’admission de sécurité de pod, un contrôleur applique les étiquettes de contrôle d’admission de sécurité pod aux espaces de noms selon les autorisations SCC des comptes de service qui se trouvent dans un espace de noms donné.
Le contrôleur examine les autorisations d’objet ServiceAccount pour utiliser les contraintes de contexte de sécurité dans chaque espace de noms. Les contraintes de contexte de sécurité (SCC) sont cartographiées pour pod des profils de sécurité en fonction de leurs valeurs de champ; le contrôleur utilise ces profils traduits. Les étiquettes d’admission de sécurité Pod et les étiquettes d’audit sont définies sur le profil de sécurité de pod le plus privilégié dans l’espace de noms pour empêcher l’affichage des avertissements et les événements d’audit de journalisation lorsque des pods sont créés.
L’étiquetage de l’espace de noms est basé sur la prise en compte des privilèges de compte de service local-nomspace.
Appliquer des pods directement pourrait utiliser les privilèges SCC de l’utilisateur qui exécute le pod. Cependant, les privilèges de l’utilisateur ne sont pas pris en compte lors de l’étiquetage automatique.
14.2.1. Exclusions de l’espace de noms de synchronisation de l’entrée de Pod en matière de sécurité
La synchronisation de l’entrée de sécurité Pod est désactivée de façon permanente sur les espaces de noms créés par le système et les espaces de noms préfixés openshift-*.
Les espaces de noms qui sont définis comme faisant partie de la charge utile du cluster ont mis en place une synchronisation d’admission de sécurité désactivée de façon permanente. Les espaces de noms suivants sont désactivés de façon permanente:
-
défaut par défaut -
location de Kube-node -
Kube-système -
Kube-public -
à propos de OpenShift - L’ensemble des espaces de noms créés par le système qui sont préfixés avec openshift-
14.3. Contrôle de la synchronisation de l’admission de sécurité des pod
Il est possible d’activer ou de désactiver la synchronisation automatique de l’entrée de sécurité pod pour la plupart des espaces de noms.
Il est impossible d’activer la synchronisation de l’entrée de sécurité pod sur les espaces de noms créés par le système. Cliquez ici pour plus d’informations, consultez les exclusions de l’espace de noms d’entrée de sécurité Pod.
Procédure
Dans chaque espace de noms que vous souhaitez configurer, définissez une valeur pour le label security.openshift.io/scc.podSecurityLabelSync:
Afin de désactiver la synchronisation des étiquettes d’admission de sécurité pod dans un espace de noms, définissez la valeur de l’étiquette security.openshift.io/scc.podSecurityLabelSync sur false.
Exécutez la commande suivante:
$ oc label namespace <namespace> security.openshift.io/scc.podSecurityLabelSync=falseAfin d’activer la synchronisation des étiquettes de sécurité de pod dans un espace de noms, définissez la valeur du label security.openshift.io/scc.podSecurityLabelSync sur true.
Exécutez la commande suivante:
$ oc label namespace <namespace> security.openshift.io/scc.podSecurityLabelSync=true
NoteUtilisez le drapeau --overwrite pour écraser la valeur si cette étiquette est déjà définie sur l’espace de noms.
Ressources supplémentaires
14.4. Configuration de l’admission de sécurité de pod pour un espace de noms
Les paramètres d’entrée de sécurité de pod peuvent être configurés au niveau de l’espace de noms. Dans chacun des modes d’admission de sécurité pod sur l’espace de noms, vous pouvez définir le profil d’admission de sécurité à utiliser.
Procédure
Exécutez la commande suivante pour chaque mode d’admission de sécurité de pod que vous souhaitez définir sur un espace de noms:
$ oc label namespace <namespace> \1 pod-security.kubernetes.io/<mode>=<profile> \2 --overwrite
14.5. À propos des alertes d’admission de sécurité de pod
L’alerte PodSecurityViolation est déclenchée lorsque le serveur API Kubernetes signale qu’il y a un refus de pod au niveau d’audit du contrôleur d’admission de sécurité de pod. Cette alerte persiste pendant une journée.
Consultez les journaux d’audit du serveur de l’API Kubernetes pour enquêter sur les alertes déclenchées. À titre d’exemple, une charge de travail est susceptible d’échouer si l’application de la loi mondiale est fixée au niveau de sécurité des pod restreints.
Dans la documentation Kubernetes, consultez les annotations dans la documentation de Kubernetes.
Chapitre 15. La synchronisation des groupes LDAP
En tant qu’administrateur avec le rôle d’administrateur dédié, vous pouvez utiliser des groupes pour gérer les utilisateurs, modifier leurs autorisations et améliorer la collaboration. Il se peut que votre organisation ait déjà créé des groupes d’utilisateurs et les stocké dans un serveur LDAP. La fonction OpenShift Dedicated peut synchroniser ces enregistrements LDAP avec des enregistrements internes OpenShift dédiés, ce qui vous permet de gérer vos groupes en un seul endroit. Actuellement, OpenShift Dedicated prend en charge la synchronisation de groupe avec les serveurs LDAP en utilisant trois schémas communs pour définir l’appartenance au groupe : RFC 2307, Active Directory et Active Directory augmentée.
Consultez Configuration d’un fournisseur d’identité LDAP pour plus d’informations sur la configuration de LDAP.
Il faut avoir des privilèges dédiés-admin pour synchroniser des groupes.
15.1. À propos de la configuration de la synchronisation LDAP
Avant de pouvoir exécuter la synchronisation LDAP, vous avez besoin d’un fichier de configuration de synchronisation. Ce fichier contient les détails de configuration du client LDAP suivants:
- Configuration pour se connecter à votre serveur LDAP.
- Les options de configuration de synchronisation qui dépendent du schéma utilisé dans votre serveur LDAP.
- Liste définie par l’administrateur de mappages de noms qui mappe les noms de groupe OpenShift dédiés à des groupes dans votre serveur LDAP.
Le format du fichier de configuration dépend du schéma que vous utilisez : RFC 2307, Active Directory ou Active Directory augmentée.
- Configuration client LDAP
- La section de configuration client LDAP de la configuration définit les connexions à votre serveur LDAP.
La section de configuration client LDAP de la configuration définit les connexions à votre serveur LDAP.
Configuration client LDAP
url: ldap://10.0.0.0:389
bindDN: cn=admin,dc=example,dc=com
bindPassword: <password>
insecure: false
ca: my-ldap-ca-bundle.crt - 1
- Le protocole de connexion, l’adresse IP du serveur LDAP hébergeant votre base de données, et le port à connecter, formaté comme schéma://host:port.
- 2
- En option nom distingué (DN) à utiliser comme le Bind DN. La fonction OpenShift Dedicated est utilisée si un privilège élevé est nécessaire pour récupérer les entrées pour l’opération de synchronisation.
- 3
- Le mot de passe optionnel à utiliser pour lier. C’est ce que OpenShift Dedicated utilise si un privilège élevé est nécessaire pour récupérer les entrées pour l’opération de synchronisation. Cette valeur peut également être fournie dans une variable d’environnement, un fichier externe ou un fichier chiffré.
- 4
- Lorsque les URL LDAP (ldaps://) sécurisées se connectent à l’aide de TLS, et les URL LDAP (ldap://) non sécurisées sont mises à niveau vers TLS. Lorsqu’il est vrai, aucune connexion TLS n’est faite au serveur et vous ne pouvez pas utiliser les schémas d’URL ldaps://.
- 5
- Le paquet de certificats à utiliser pour valider les certificats de serveur pour l’URL configurée. En cas de vide, OpenShift Dedicated utilise des racines fiables du système. Cela ne s’applique que si l’insécurité est définie sur false.
- Définition de requête LDAP
- Les configurations de synchronisation consistent en définitions de requête LDAP pour les entrées qui sont nécessaires à la synchronisation. La définition spécifique d’une requête LDAP dépend du schéma utilisé pour stocker les informations d’adhésion dans le serveur LDAP.
Définition de requête LDAP
baseDN: ou=users,dc=example,dc=com
scope: sub
derefAliases: never
timeout: 0
filter: (objectClass=person)
pageSize: 0 - 1
- Le nom distingué (DN) de la branche du répertoire où toutes les recherches commenceront. Il est nécessaire que vous spécifiiez le haut de l’arborescence de votre répertoire, mais vous pouvez également spécifier un sous-arbre dans le répertoire.
- 2
- La portée de la recherche. Les valeurs valides sont base, un ou sous. Lorsque cela n’est pas défini, une portée de sub est assumée. Les descriptions des options de portée se trouvent dans le tableau ci-dessous.
- 3
- Le comportement de la recherche par rapport aux alias dans l’arbre LDAP. Les valeurs valides ne sont jamais, recherche, base, ou toujours. Dans le cas où cela n’est pas défini, la valeur par défaut est toujours de déroférer les alias. Les descriptions des comportements de déréférencement se trouvent dans le tableau ci-dessous.
- 4
- Le délai autorisé pour la recherche par le client, en secondes. La valeur 0 n’impose aucune limite côté client.
- 5
- Filtre de recherche LDAP valide. Dans le cas où cela n’est pas défini, la valeur par défaut est (objectClass=*).
- 6
- La taille maximale facultative des pages de réponse du serveur, mesurée dans les entrées LDAP. En cas de définition de 0, aucune restriction de taille ne sera imposée sur les pages de réponses. La configuration des tailles de mise en page est nécessaire lorsque les requêtes renvoient plus d’entrées que le client ou le serveur le permettent par défaut.
| Champ de recherche LDAP | Description |
|---|---|
|
| Considérez uniquement l’objet spécifié par la base DN donnée pour la requête. |
|
| Considérez tous les objets au même niveau dans l’arbre que le DN de base pour la requête. |
|
| Considérez l’ensemble du sous-arbre enraciné à la base DN donnée pour la requête. |
| Comportement de déréférencement | Description |
|---|---|
|
| Jamais ne dérober les alias trouvés dans l’arbre LDAP. |
|
| Déréférence seulement les alias trouvés lors de la recherche. |
|
| Déréférence seulement les alias lors de la recherche de l’objet de base. |
|
| Déroulez toujours tous les alias trouvés dans l’arbre LDAP. |
- Cartographie des noms définis par l’utilisateur
- Le mappage de nom défini par l’utilisateur mappe explicitement les noms des groupes OpenShift dédiés à des identifiants uniques qui trouvent des groupes sur votre serveur LDAP. La cartographie utilise la syntaxe YAML normale. Le mappage défini par l’utilisateur peut contenir une entrée pour chaque groupe de votre serveur LDAP ou seulement un sous-ensemble de ces groupes. Lorsqu’il y a des groupes sur le serveur LDAP qui n’ont pas de mappage de nom défini par l’utilisateur, le comportement par défaut pendant la synchronisation est d’utiliser l’attribut spécifié comme nom du groupe OpenShift Dedicated.
Cartographie des noms définis par l’utilisateur
groupUIDNameMapping:
"cn=group1,ou=groups,dc=example,dc=com": firstgroup
"cn=group2,ou=groups,dc=example,dc=com": secondgroup
"cn=group3,ou=groups,dc=example,dc=com": thirdgroup15.1.1. À propos du fichier de configuration RFC 2307
Le schéma RFC 2307 exige que vous fournissiez une définition de requête LDAP pour les entrées d’utilisateur et de groupe, ainsi que les attributs avec lesquels les représenter dans les enregistrements internes OpenShift Dedicated.
Le groupe que vous créez dans OpenShift Dedicated doit utiliser des attributs autres que le nom distingué lorsque cela est possible pour les champs orientés vers l’utilisateur ou l’administrateur. À titre d’exemple, identifiez les utilisateurs d’un groupe dédié OpenShift par leur e-mail et utilisez le nom du groupe comme nom commun. Le fichier de configuration suivant crée ces relations:
En utilisant des mappages de noms définis par l’utilisateur, votre fichier de configuration sera différent.
Configuration de synchronisation LDAP utilisant le schéma RFC 2307: rfc2307_config.yaml
kind: LDAPSyncConfig
apiVersion: v1
url: ldap://LDAP_SERVICE_IP:389
insecure: false
bindDN: cn=admin,dc=example,dc=com
bindPassword:
file: "/etc/secrets/bindPassword"
rfc2307:
groupsQuery:
baseDN: "ou=groups,dc=example,dc=com"
scope: sub
derefAliases: never
pageSize: 0
groupUIDAttribute: dn
groupNameAttributes: [ cn ]
groupMembershipAttributes: [ member ]
usersQuery:
baseDN: "ou=users,dc=example,dc=com"
scope: sub
derefAliases: never
pageSize: 0
userUIDAttribute: dn
userNameAttributes: [ mail ]
tolerateMemberNotFoundErrors: false
tolerateMemberOutOfScopeErrors: false- 1
- L’adresse IP et l’hôte du serveur LDAP où l’enregistrement de ce groupe est stocké.
- 2
- Lorsque les URL LDAP (ldaps://) sécurisées se connectent à l’aide de TLS, et les URL LDAP (ldap://) non sécurisées sont mises à niveau vers TLS. Lorsqu’il est vrai, aucune connexion TLS n’est faite au serveur et vous ne pouvez pas utiliser les schémas d’URL ldaps://.
- 3
- L’attribut qui identifie de manière unique un groupe sur le serveur LDAP. Lorsque vous utilisez DN pour groupUIDAttribute, vous ne pouvez pas spécifier les filtres groupUIDAttribute. Dans le cas d’un filtrage à grains fins, utilisez la méthode de la liste blanche/liste noire.
- 4
- L’attribut à utiliser comme nom du groupe.
- 5
- L’attribut sur le groupe qui stocke les informations d’adhésion.
- 6
- L’attribut qui identifie de manière unique un utilisateur sur le serveur LDAP. Il est impossible de spécifier les filtres UserQuery lors de l’utilisation de DN pour userUIDAttribute. Dans le cas d’un filtrage à grains fins, utilisez la méthode de la liste blanche/liste noire.
- 7
- L’attribut à utiliser comme nom de l’utilisateur dans l’enregistrement du groupe OpenShift Dedicated.
15.1.2. À propos du fichier de configuration Active Directory
Le schéma Active Directory vous oblige à fournir une définition de requête LDAP pour les entrées d’utilisateur, ainsi que les attributs pour les représenter dans les enregistrements internes du groupe OpenShift Dedicated.
Le groupe que vous créez dans OpenShift Dedicated doit utiliser des attributs autres que le nom distingué lorsque cela est possible pour les champs orientés vers l’utilisateur ou l’administrateur. À titre d’exemple, identifiez les utilisateurs d’un groupe dédié OpenShift par leur e-mail, mais définissez le nom du groupe par le nom du groupe sur le serveur LDAP. Le fichier de configuration suivant crée ces relations:
Configuration de synchronisation LDAP qui utilise le schéma Active Directory: active_directory_config.yaml
kind: LDAPSyncConfig
apiVersion: v1
url: ldap://LDAP_SERVICE_IP:389
activeDirectory:
usersQuery:
baseDN: "ou=users,dc=example,dc=com"
scope: sub
derefAliases: never
filter: (objectclass=person)
pageSize: 0
userNameAttributes: [ mail ]
groupMembershipAttributes: [ memberOf ] 15.1.3. À propos du fichier de configuration Active Directory augmenté
Le schéma Active Directory augmenté vous oblige à fournir une définition de requête LDAP pour les entrées d’utilisateur et les entrées de groupe, ainsi que les attributs avec lesquels les représenter dans les enregistrements internes de groupe OpenShift Dedicated.
Le groupe que vous créez dans OpenShift Dedicated doit utiliser des attributs autres que le nom distingué lorsque cela est possible pour les champs orientés vers l’utilisateur ou l’administrateur. À titre d’exemple, identifiez les utilisateurs d’un groupe dédié OpenShift par leur e-mail et utilisez le nom du groupe comme nom commun. Le fichier de configuration suivant crée ces relations.
Configuration de synchronisation LDAP qui utilise le schéma Active Directory augmenté: augmentéed_active_directory_config.yaml
kind: LDAPSyncConfig
apiVersion: v1
url: ldap://LDAP_SERVICE_IP:389
augmentedActiveDirectory:
groupsQuery:
baseDN: "ou=groups,dc=example,dc=com"
scope: sub
derefAliases: never
pageSize: 0
groupUIDAttribute: dn
groupNameAttributes: [ cn ]
usersQuery:
baseDN: "ou=users,dc=example,dc=com"
scope: sub
derefAliases: never
filter: (objectclass=person)
pageSize: 0
userNameAttributes: [ mail ]
groupMembershipAttributes: [ memberOf ] - 1
- L’attribut qui identifie de manière unique un groupe sur le serveur LDAP. Lorsque vous utilisez DN pour groupUIDAttribute, vous ne pouvez pas spécifier les filtres groupUIDAttribute. Dans le cas d’un filtrage à grains fins, utilisez la méthode de la liste blanche/liste noire.
- 2
- L’attribut à utiliser comme nom du groupe.
- 3
- L’attribut à utiliser comme nom de l’utilisateur dans l’enregistrement du groupe OpenShift Dedicated.
- 4
- L’attribut sur l’utilisateur qui stocke les informations d’adhésion.
15.2. Exécution de la synchronisation LDAP
Lorsque vous avez créé un fichier de configuration de synchronisation, vous pouvez commencer à synchroniser. La fonction OpenShift Dedicated permet aux administrateurs d’effectuer un certain nombre de types de synchronisation différents avec le même serveur.
15.2.1. La synchronisation du serveur LDAP avec OpenShift Dedicated
Il est possible de synchroniser tous les groupes à partir du serveur LDAP avec OpenShift Dedicated.
Conditions préalables
- Créer un fichier de configuration de synchronisation.
- En tant qu’utilisateur, vous avez accès au cluster avec le rôle d’administrateur dédié.
Procédure
Afin de synchroniser tous les groupes à partir du serveur LDAP avec OpenShift Dedicated:
$ oc adm groups sync --sync-config=config.yaml --confirmNotePar défaut, toutes les opérations de synchronisation de groupe sont exécutées à sec, de sorte que vous devez définir l’indicateur --confirmer sur la commande de synchronisation des groupes adm oc pour apporter des modifications aux enregistrements de groupe dédiés OpenShift.
15.2.2. La synchronisation des groupes OpenShift dédiés avec le serveur LDAP
Il est possible de synchroniser tous les groupes déjà dans OpenShift Dedicated qui correspondent à des groupes dans le serveur LDAP spécifié dans le fichier de configuration.
Conditions préalables
- Créer un fichier de configuration de synchronisation.
- En tant qu’utilisateur, vous avez accès au cluster avec le rôle d’administrateur dédié.
Procédure
Afin de synchroniser les groupes OpenShift dédiés avec le serveur LDAP:
$ oc adm groups sync --type=openshift --sync-config=config.yaml --confirmNotePar défaut, toutes les opérations de synchronisation de groupe sont exécutées à sec, de sorte que vous devez définir l’indicateur --confirmer sur la commande de synchronisation des groupes adm oc pour apporter des modifications aux enregistrements de groupe dédiés OpenShift.
15.2.3. La synchronisation des sous-groupes à partir du serveur LDAP avec OpenShift Dedicated
Il est possible de synchroniser un sous-ensemble de groupes LDAP avec OpenShift Dedicated en utilisant des fichiers de liste blanche, des fichiers de liste noire ou les deux.
Il est possible d’utiliser n’importe quelle combinaison de fichiers de liste noire, de fichiers de liste blanche ou de lettres de liste blanche. Les fichiers de liste blanche et de liste noire doivent contenir un identifiant de groupe unique par ligne, et vous pouvez inclure des lettres de liste blanche directement dans la commande elle-même. Ces directives s’appliquent aux groupes trouvés sur les serveurs LDAP ainsi qu’aux groupes déjà présents dans OpenShift Dedicated.
Conditions préalables
- Créer un fichier de configuration de synchronisation.
- En tant qu’utilisateur, vous avez accès au cluster avec le rôle d’administrateur dédié.
Procédure
Afin de synchroniser un sous-ensemble de groupes LDAP avec OpenShift Dedicated, utilisez les commandes suivantes:
$ oc adm groups sync --whitelist=<whitelist_file> \ --sync-config=config.yaml \ --confirm$ oc adm groups sync --blacklist=<blacklist_file> \ --sync-config=config.yaml \ --confirm$ oc adm groups sync <group_unique_identifier> \ --sync-config=config.yaml \ --confirm$ oc adm groups sync <group_unique_identifier> \ --whitelist=<whitelist_file> \ --blacklist=<blacklist_file> \ --sync-config=config.yaml \ --confirm$ oc adm groups sync --type=openshift \ --whitelist=<whitelist_file> \ --sync-config=config.yaml \ --confirmNotePar défaut, toutes les opérations de synchronisation de groupe sont exécutées à sec, de sorte que vous devez définir l’indicateur --confirmer sur la commande de synchronisation des groupes adm oc pour apporter des modifications aux enregistrements de groupe dédiés OpenShift.
15.3. Exécution d’un travail d’élagage en groupe
L’administrateur peut également choisir de supprimer des groupes des enregistrements dédiés OpenShift si les enregistrements sur le serveur LDAP qui les ont créés ne sont plus présents. Le travail de taille acceptera le même fichier de configuration de synchronisation et les listes blanches ou les listes noires utilisées pour le travail de synchronisation.
À titre d’exemple:
$ oc adm prune groups --sync-config=/path/to/ldap-sync-config.yaml --confirm$ oc adm prune groups --whitelist=/path/to/whitelist.txt --sync-config=/path/to/ldap-sync-config.yaml --confirm$ oc adm prune groups --blacklist=/path/to/blacklist.txt --sync-config=/path/to/ldap-sync-config.yaml --confirm15.4. Exemples de synchronisation de groupe LDAP
Cette section contient des exemples pour les schémas RFC 2307, Active Directory et Active Directory augmentés.
Ces exemples supposent que tous les utilisateurs sont des membres directs de leurs groupes respectifs. En particulier, aucun groupe n’a d’autres groupes en tant que membres. Consultez l’exemple de Sync d’adhésion imbriquée pour obtenir des informations sur la façon de synchroniser les groupes imbriqués.
15.4.1. La synchronisation des groupes à l’aide du schéma RFC 2307
En ce qui concerne le schéma RFC 2307, les exemples suivants synchronisent un groupe nommé admins qui compte deux membres : Jane et Jim. Les exemples expliquent:
- Comment le groupe et les utilisateurs sont ajoutés au serveur LDAP.
- Ce que l’enregistrement du groupe résultant dans OpenShift Dedicated sera après synchronisation.
Ces exemples supposent que tous les utilisateurs sont des membres directs de leurs groupes respectifs. En particulier, aucun groupe n’a d’autres groupes en tant que membres. Consultez l’exemple de Sync d’adhésion imbriquée pour obtenir des informations sur la façon de synchroniser les groupes imbriqués.
Dans le schéma RFC 2307, les utilisateurs (Jane et Jim) et les groupes existent sur le serveur LDAP en tant qu’entrées de première classe, et l’adhésion au groupe est stockée dans des attributs du groupe. L’extrait suivant de ldif définit les utilisateurs et le groupe pour ce schéma:
Entrées LDAP utilisant le schéma RFC 2307: rfc2307.ldif
dn: ou=users,dc=example,dc=com
objectClass: organizationalUnit
ou: users
dn: cn=Jane,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
cn: Jane
sn: Smith
displayName: Jane Smith
mail: jane.smith@example.com
dn: cn=Jim,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
cn: Jim
sn: Adams
displayName: Jim Adams
mail: jim.adams@example.com
dn: ou=groups,dc=example,dc=com
objectClass: organizationalUnit
ou: groups
dn: cn=admins,ou=groups,dc=example,dc=com
objectClass: groupOfNames
cn: admins
owner: cn=admin,dc=example,dc=com
description: System Administrators
member: cn=Jane,ou=users,dc=example,dc=com
member: cn=Jim,ou=users,dc=example,dc=comConditions préalables
- Créer le fichier de configuration.
- En tant qu’utilisateur, vous avez accès au cluster avec le rôle d’administrateur dédié.
Procédure
Exécutez la synchronisation avec le fichier rfc2307_config.yaml:
$ oc adm groups sync --sync-config=rfc2307_config.yaml --confirmÀ la suite de l’opération de synchronisation ci-dessus, OpenShift Dedicated crée l’enregistrement de groupe suivant:
Groupe dédié créé à l’aide du fichier rfc2307_config.yaml
apiVersion: user.openshift.io/v1 kind: Group metadata: annotations: openshift.io/ldap.sync-time: 2015-10-13T10:08:38-04001 openshift.io/ldap.uid: cn=admins,ou=groups,dc=example,dc=com2 openshift.io/ldap.url: LDAP_SERVER_IP:3893 creationTimestamp: name: admins4 users:5 - jane.smith@example.com - jim.adams@example.com- 1
- La dernière fois que ce groupe dédié OpenShift a été synchronisé avec le serveur LDAP, au format ISO 6801.
- 2
- L’identifiant unique pour le groupe sur le serveur LDAP.
- 3
- L’adresse IP et l’hôte du serveur LDAP où l’enregistrement de ce groupe est stocké.
- 4
- Le nom du groupe tel que spécifié par le fichier de synchronisation.
- 5
- Les utilisateurs qui sont membres du groupe, nommés comme spécifié par le fichier de synchronisation.
15.4.2. La synchronisation des groupes à l’aide du schéma RFC2307 avec des mappages de noms définis par l’utilisateur
Lorsque vous synchronisez des groupes avec des mappages de noms définis par l’utilisateur, le fichier de configuration change pour contenir ces mappages comme indiqué ci-dessous.
Configuration de synchronisation LDAP qui utilise le schéma RFC 2307 avec des mappages de noms définis par l’utilisateur: rfc2307_config_user_defined.yaml
kind: LDAPSyncConfig
apiVersion: v1
groupUIDNameMapping:
"cn=admins,ou=groups,dc=example,dc=com": Administrators
rfc2307:
groupsQuery:
baseDN: "ou=groups,dc=example,dc=com"
scope: sub
derefAliases: never
pageSize: 0
groupUIDAttribute: dn
groupNameAttributes: [ cn ]
groupMembershipAttributes: [ member ]
usersQuery:
baseDN: "ou=users,dc=example,dc=com"
scope: sub
derefAliases: never
pageSize: 0
userUIDAttribute: dn
userNameAttributes: [ mail ]
tolerateMemberNotFoundErrors: false
tolerateMemberOutOfScopeErrors: false- 1
- Le mappage de nom défini par l’utilisateur.
- 2
- L’attribut identifiant unique qui est utilisé pour les clés dans le mappage de nom défini par l’utilisateur. Lorsque vous utilisez DN pour groupUIDAttribute, vous ne pouvez pas spécifier les filtres groupUIDAttribute. Dans le cas d’un filtrage à grains fins, utilisez la méthode de la liste blanche/liste noire.
- 3
- L’attribut pour nommer OpenShift Groupes dédiés avec si leur identifiant unique n’est pas dans le mappage de nom défini par l’utilisateur.
- 4
- L’attribut qui identifie de manière unique un utilisateur sur le serveur LDAP. Il est impossible de spécifier les filtres UserQuery lors de l’utilisation de DN pour userUIDAttribute. Dans le cas d’un filtrage à grains fins, utilisez la méthode de la liste blanche/liste noire.
Conditions préalables
- Créer le fichier de configuration.
- En tant qu’utilisateur, vous avez accès au cluster avec le rôle d’administrateur dédié.
Procédure
Exécutez la synchronisation avec le fichier rfc2307_config_user_defined.yaml:
$ oc adm groups sync --sync-config=rfc2307_config_user_defined.yaml --confirmÀ la suite de l’opération de synchronisation ci-dessus, OpenShift Dedicated crée l’enregistrement de groupe suivant:
Groupe dédié créé à l’aide du fichier rfc2307_config_user_defined.yaml
apiVersion: user.openshift.io/v1 kind: Group metadata: annotations: openshift.io/ldap.sync-time: 2015-10-13T10:08:38-0400 openshift.io/ldap.uid: cn=admins,ou=groups,dc=example,dc=com openshift.io/ldap.url: LDAP_SERVER_IP:389 creationTimestamp: name: Administrators1 users: - jane.smith@example.com - jim.adams@example.com- 1
- Le nom du groupe tel que spécifié par le mappage de nom défini par l’utilisateur.
15.4.3. La synchronisation des groupes à l’aide de la RFC 2307 avec des tolérances d’erreur définies par l’utilisateur
Par défaut, si les groupes synchronisés contiennent des membres dont les entrées sont en dehors de la portée définie dans la requête membre, la synchronisation du groupe échoue avec une erreur:
Error determining LDAP group membership for "<group>": membership lookup for user "<user>" in group "<group>" failed because of "search for entry with dn="<user-dn>" would search outside of the base dn specified (dn="<base-dn>")".Cela indique souvent une baseDN mal configurée dans le champ UserQuery. Cependant, dans les cas où la baseDN ne contient pas intentionnellement certains des membres du groupe, le réglage tolèreMemberOutOfScopeErrors: true permet au groupe de se synchroniser. Les membres hors de portée seront ignorés.
De même, lorsque le processus de synchronisation de groupe ne parvient pas à localiser un membre pour un groupe, il échoue carrément avec des erreurs:
Error determining LDAP group membership for "<group>": membership lookup for user "<user>" in group "<group>" failed because of "search for entry with base dn="<user-dn>" refers to a non-existent entry".
Error determining LDAP group membership for "<group>": membership lookup for user "<user>" in group "<group>" failed because of "search for entry with base dn="<user-dn>" and filter "<filter>" did not return any results".Cela indique souvent un champ utilisateur mal configuré. Cependant, dans les cas où le groupe contient des entrées de membres qui sont connues pour être manquantes, la configuration tolèreMemberNotFoundErrors: true permet au groupe de se synchroniser. Les membres problématiques seront ignorés.
L’activation des tolérances d’erreur pour la synchronisation du groupe LDAP fait que le processus de synchronisation ignore les entrées de membres problématiques. Dans le cas où la synchronisation du groupe LDAP n’est pas configurée correctement, cela pourrait entraîner la synchronisation de groupes OpenShift Dédiés manquants.
Entrées LDAP qui utilisent le schéma RFC 2307 avec l’adhésion à un groupe problématique: rfc2307_problematic_users.ldif
dn: ou=users,dc=example,dc=com
objectClass: organizationalUnit
ou: users
dn: cn=Jane,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
cn: Jane
sn: Smith
displayName: Jane Smith
mail: jane.smith@example.com
dn: cn=Jim,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
cn: Jim
sn: Adams
displayName: Jim Adams
mail: jim.adams@example.com
dn: ou=groups,dc=example,dc=com
objectClass: organizationalUnit
ou: groups
dn: cn=admins,ou=groups,dc=example,dc=com
objectClass: groupOfNames
cn: admins
owner: cn=admin,dc=example,dc=com
description: System Administrators
member: cn=Jane,ou=users,dc=example,dc=com
member: cn=Jim,ou=users,dc=example,dc=com
member: cn=INVALID,ou=users,dc=example,dc=com
member: cn=Jim,ou=OUTOFSCOPE,dc=example,dc=com Afin de tolérer les erreurs dans l’exemple ci-dessus, les ajouts suivants à votre fichier de configuration de synchronisation doivent être effectués:
Configuration de synchronisation LDAP qui utilise les erreurs de tolérance du schéma RFC 2307: rfc2307_config_tolerating.yaml
kind: LDAPSyncConfig
apiVersion: v1
url: ldap://LDAP_SERVICE_IP:389
rfc2307:
groupsQuery:
baseDN: "ou=groups,dc=example,dc=com"
scope: sub
derefAliases: never
groupUIDAttribute: dn
groupNameAttributes: [ cn ]
groupMembershipAttributes: [ member ]
usersQuery:
baseDN: "ou=users,dc=example,dc=com"
scope: sub
derefAliases: never
userUIDAttribute: dn
userNameAttributes: [ mail ]
tolerateMemberNotFoundErrors: true
tolerateMemberOutOfScopeErrors: true - 1
- L’attribut qui identifie de manière unique un utilisateur sur le serveur LDAP. Il est impossible de spécifier les filtres UserQuery lors de l’utilisation de DN pour userUIDAttribute. Dans le cas d’un filtrage à grains fins, utilisez la méthode de la liste blanche/liste noire.
- 2
- Lorsque c’est vrai, le travail de synchronisation tolère les groupes pour lesquels certains membres n’ont pas été trouvés, et les membres dont les entrées LDAP ne sont pas trouvées sont ignorés. Le comportement par défaut de la tâche de synchronisation est d’échouer si un membre d’un groupe n’est pas trouvé.
- 3
- Lorsque c’est vrai, la tâche de synchronisation tolère les groupes pour lesquels certains membres sont en dehors de la portée de l’utilisateur donnée dans la base DN UserQuery, et les membres en dehors de la portée de requête des membres sont ignorés. Le comportement par défaut de la tâche de synchronisation est d’échouer si un membre d’un groupe est hors de portée.
Conditions préalables
- Créer le fichier de configuration.
- En tant qu’utilisateur, vous avez accès au cluster avec le rôle d’administrateur dédié.
Procédure
Exécutez la synchronisation avec le fichier rfc2307_config_tolerating.yaml:
$ oc adm groups sync --sync-config=rfc2307_config_tolerating.yaml --confirmÀ la suite de l’opération de synchronisation ci-dessus, OpenShift Dedicated crée l’enregistrement de groupe suivant:
Groupe dédié créé à l’aide du fichier rfc2307_config.yaml
apiVersion: user.openshift.io/v1 kind: Group metadata: annotations: openshift.io/ldap.sync-time: 2015-10-13T10:08:38-0400 openshift.io/ldap.uid: cn=admins,ou=groups,dc=example,dc=com openshift.io/ldap.url: LDAP_SERVER_IP:389 creationTimestamp: name: admins users:1 - jane.smith@example.com - jim.adams@example.com- 1
- Les utilisateurs qui sont membres du groupe, comme spécifié par le fichier de synchronisation. Les membres pour lesquels la recherche a rencontré des erreurs tolérées sont absents.
15.4.4. La synchronisation des groupes à l’aide du schéma Active Directory
Dans le schéma Active Directory, les deux utilisateurs (Jane et Jim) existent dans le serveur LDAP en tant qu’entrées de première classe, et l’adhésion au groupe est stockée dans des attributs de l’utilisateur. L’extrait suivant de ldif définit les utilisateurs et le groupe pour ce schéma:
Entrées LDAP utilisant le schéma Active Directory: active_directory.ldif
dn: ou=users,dc=example,dc=com
objectClass: organizationalUnit
ou: users
dn: cn=Jane,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: testPerson
cn: Jane
sn: Smith
displayName: Jane Smith
mail: jane.smith@example.com
memberOf: admins
dn: cn=Jim,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: testPerson
cn: Jim
sn: Adams
displayName: Jim Adams
mail: jim.adams@example.com
memberOf: admins- 1
- Les adhésions de groupe d’utilisateur sont répertoriées comme attributs sur l’utilisateur, et le groupe n’existe pas en tant qu’entrée sur le serveur. L’attribut MemberOf n’a pas besoin d’être un attribut littéral sur l’utilisateur; dans certains serveurs LDAP, il est créé lors de la recherche et retourné au client, mais pas engagé dans la base de données.
Conditions préalables
- Créer le fichier de configuration.
- En tant qu’utilisateur, vous avez accès au cluster avec le rôle d’administrateur dédié.
Procédure
Exécutez la synchronisation avec le fichier active_directory_config.yaml:
$ oc adm groups sync --sync-config=active_directory_config.yaml --confirmÀ la suite de l’opération de synchronisation ci-dessus, OpenShift Dedicated crée l’enregistrement de groupe suivant:
Groupe dédié créé à l’aide du fichier active_directory_config.yaml
apiVersion: user.openshift.io/v1 kind: Group metadata: annotations: openshift.io/ldap.sync-time: 2015-10-13T10:08:38-04001 openshift.io/ldap.uid: admins2 openshift.io/ldap.url: LDAP_SERVER_IP:3893 creationTimestamp: name: admins4 users:5 - jane.smith@example.com - jim.adams@example.com- 1
- La dernière fois que ce groupe dédié OpenShift a été synchronisé avec le serveur LDAP, au format ISO 6801.
- 2
- L’identifiant unique pour le groupe sur le serveur LDAP.
- 3
- L’adresse IP et l’hôte du serveur LDAP où l’enregistrement de ce groupe est stocké.
- 4
- Le nom du groupe tel qu’indiqué dans le serveur LDAP.
- 5
- Les utilisateurs qui sont membres du groupe, nommés comme spécifié par le fichier de synchronisation.
15.4.5. La synchronisation des groupes à l’aide du schéma Active Directory augmenté
Dans le schéma Active Directory augmenté, les utilisateurs (Jane et Jim) et les groupes existent dans le serveur LDAP en tant qu’entrées de première classe, et l’adhésion au groupe est stockée dans des attributs sur l’utilisateur. L’extrait suivant de ldif définit les utilisateurs et le groupe pour ce schéma:
Entrées LDAP qui utilisent le schéma Active Directory augmenté: augmentéed_active_directory.ldif
dn: ou=users,dc=example,dc=com
objectClass: organizationalUnit
ou: users
dn: cn=Jane,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: testPerson
cn: Jane
sn: Smith
displayName: Jane Smith
mail: jane.smith@example.com
memberOf: cn=admins,ou=groups,dc=example,dc=com
dn: cn=Jim,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: testPerson
cn: Jim
sn: Adams
displayName: Jim Adams
mail: jim.adams@example.com
memberOf: cn=admins,ou=groups,dc=example,dc=com
dn: ou=groups,dc=example,dc=com
objectClass: organizationalUnit
ou: groups
dn: cn=admins,ou=groups,dc=example,dc=com
objectClass: groupOfNames
cn: admins
owner: cn=admin,dc=example,dc=com
description: System Administrators
member: cn=Jane,ou=users,dc=example,dc=com
member: cn=Jim,ou=users,dc=example,dc=comConditions préalables
- Créer le fichier de configuration.
- En tant qu’utilisateur, vous avez accès au cluster avec le rôle d’administrateur dédié.
Procédure
Exécutez la synchronisation avec le fichier Augd_active_directory_config.yaml:
$ oc adm groups sync --sync-config=augmented_active_directory_config.yaml --confirmÀ la suite de l’opération de synchronisation ci-dessus, OpenShift Dedicated crée l’enregistrement de groupe suivant:
Groupe dédié créé à l’aide du fichier Augmentd_active_directory_config.yaml
apiVersion: user.openshift.io/v1 kind: Group metadata: annotations: openshift.io/ldap.sync-time: 2015-10-13T10:08:38-04001 openshift.io/ldap.uid: cn=admins,ou=groups,dc=example,dc=com2 openshift.io/ldap.url: LDAP_SERVER_IP:3893 creationTimestamp: name: admins4 users:5 - jane.smith@example.com - jim.adams@example.com- 1
- La dernière fois que ce groupe dédié OpenShift a été synchronisé avec le serveur LDAP, au format ISO 6801.
- 2
- L’identifiant unique pour le groupe sur le serveur LDAP.
- 3
- L’adresse IP et l’hôte du serveur LDAP où l’enregistrement de ce groupe est stocké.
- 4
- Le nom du groupe tel que spécifié par le fichier de synchronisation.
- 5
- Les utilisateurs qui sont membres du groupe, nommés comme spécifié par le fichier de synchronisation.
15.4.5.1. Exemple de synchronisation de l’adhésion imbriquée LDAP
Les groupes dans OpenShift Dedicated ne nichent pas. Le serveur LDAP doit aplatir l’adhésion au groupe avant que les données puissent être consommées. Le serveur Active Directory de Microsoft prend en charge cette fonctionnalité via la règle LDAP_MATCHING_RULE_IN_CHAIN, qui a l’OID 1.2.840.113556.1.4.1941. En outre, seuls les groupes explicitement inscrits sur la liste blanche peuvent être synchronisés lors de l’utilisation de cette règle de correspondance.
Cette section a un exemple pour le schéma Active Directory augmenté, qui synchronise un groupe nommé admins qui a un utilisateur Jane et un groupe d’autres administrateurs en tant que membres. L’autre groupe admins a un membre utilisateur: Jim. Cet exemple explique:
- Comment le groupe et les utilisateurs sont ajoutés au serveur LDAP.
- À quoi ressemble le fichier de configuration de synchronisation LDAP.
- Ce que l’enregistrement du groupe résultant dans OpenShift Dedicated sera après synchronisation.
Dans le schéma Active Directory augmenté, les utilisateurs (Jane et Jim) et les groupes existent dans le serveur LDAP en tant qu’entrées de première classe, et l’adhésion au groupe est stockée dans des attributs sur l’utilisateur ou le groupe. L’extrait suivant de ldif définit les utilisateurs et les groupes pour ce schéma:
Entrées LDAP qui utilisent le schéma Active Directory augmenté avec des membres imbriqués: augmentéed_active_directory_nested.ldif
dn: ou=users,dc=example,dc=com
objectClass: organizationalUnit
ou: users
dn: cn=Jane,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: testPerson
cn: Jane
sn: Smith
displayName: Jane Smith
mail: jane.smith@example.com
memberOf: cn=admins,ou=groups,dc=example,dc=com
dn: cn=Jim,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: testPerson
cn: Jim
sn: Adams
displayName: Jim Adams
mail: jim.adams@example.com
memberOf: cn=otheradmins,ou=groups,dc=example,dc=com
dn: ou=groups,dc=example,dc=com
objectClass: organizationalUnit
ou: groups
dn: cn=admins,ou=groups,dc=example,dc=com
objectClass: group
cn: admins
owner: cn=admin,dc=example,dc=com
description: System Administrators
member: cn=Jane,ou=users,dc=example,dc=com
member: cn=otheradmins,ou=groups,dc=example,dc=com
dn: cn=otheradmins,ou=groups,dc=example,dc=com
objectClass: group
cn: otheradmins
owner: cn=admin,dc=example,dc=com
description: Other System Administrators
memberOf: cn=admins,ou=groups,dc=example,dc=com
member: cn=Jim,ou=users,dc=example,dc=comLorsque vous synchronisez des groupes imbriqués avec Active Directory, vous devez fournir une définition de requête LDAP pour les entrées d’utilisateur et les entrées de groupe, ainsi que les attributs avec lesquels les représenter dans les enregistrements internes de groupe OpenShift Dedicated. En outre, certaines modifications sont nécessaires dans cette configuration:
- La commande de synchronisation des groupes adm oc doit explicitement des groupes de liste blanche.
- Les attributs de groupe de l’utilisateur doivent inclure "memberOf:1.2.840.113556.1.4.1941:" pour se conformer à la règle LDAP_MATCHING_RULE_IN_CHAIN.
- Le groupeUIDAttribute doit être défini sur dn.
Les groupesQuery:
- Il ne faut pas définir le filtre.
- Doit définir une derefAliases valide.
- Il ne faut pas définir baseDN car cette valeur est ignorée.
- Il ne faut pas définir la portée car cette valeur est ignorée.
Le groupe que vous créez dans OpenShift Dedicated doit utiliser des attributs autres que le nom distingué lorsque cela est possible pour les champs orientés vers l’utilisateur ou l’administrateur. À titre d’exemple, identifiez les utilisateurs d’un groupe dédié OpenShift par leur e-mail et utilisez le nom du groupe comme nom commun. Le fichier de configuration suivant crée ces relations:
Configuration de synchronisation LDAP qui utilise le schéma Active Directory augmenté avec des membres imbriqués: Augmentd_active_directory_config_nested.yaml
kind: LDAPSyncConfig
apiVersion: v1
url: ldap://LDAP_SERVICE_IP:389
augmentedActiveDirectory:
groupsQuery:
derefAliases: never
pageSize: 0
groupUIDAttribute: dn
groupNameAttributes: [ cn ]
usersQuery:
baseDN: "ou=users,dc=example,dc=com"
scope: sub
derefAliases: never
filter: (objectclass=person)
pageSize: 0
userNameAttributes: [ mail ]
groupMembershipAttributes: [ "memberOf:1.2.840.113556.1.4.1941:" ] - 1
- les filtres GroupQuery ne peuvent pas être spécifiés. Les valeurs DN et scope de base groupsQuery sont ignorées. groupsQuery doit définir une derefAliases valide.
- 2
- L’attribut qui identifie de manière unique un groupe sur le serveur LDAP. Il doit être réglé sur dn.
- 3
- L’attribut à utiliser comme nom du groupe.
- 4
- L’attribut à utiliser comme nom de l’utilisateur dans l’enregistrement du groupe OpenShift Dedicated. courrier ou sAMAccountName sont des choix préférés dans la plupart des installations.
- 5
- L’attribut sur l’utilisateur qui stocke les informations d’adhésion. A noter l’utilisation de LDAP_MATCHING_RULE_IN_CHAIN.
Conditions préalables
- Créer le fichier de configuration.
- En tant qu’utilisateur, vous avez accès au cluster avec le rôle d’administrateur dédié.
Procédure
Exécutez la synchronisation avec le fichier Augd_active_directory_config_nested.yaml:
$ oc adm groups sync \ 'cn=admins,ou=groups,dc=example,dc=com' \ --sync-config=augmented_active_directory_config_nested.yaml \ --confirmNoteLe groupe cn=admins,ou=groups, dc=example, dc=com doit être explicitement inscrit sur la liste blanche.
À la suite de l’opération de synchronisation ci-dessus, OpenShift Dedicated crée l’enregistrement de groupe suivant:
Groupe dédié créé à l’aide du fichier Augd_active_directory_config_nested.yaml
apiVersion: user.openshift.io/v1 kind: Group metadata: annotations: openshift.io/ldap.sync-time: 2015-10-13T10:08:38-04001 openshift.io/ldap.uid: cn=admins,ou=groups,dc=example,dc=com2 openshift.io/ldap.url: LDAP_SERVER_IP:3893 creationTimestamp: name: admins4 users:5 - jane.smith@example.com - jim.adams@example.com- 1
- La dernière fois que ce groupe dédié OpenShift a été synchronisé avec le serveur LDAP, au format ISO 6801.
- 2
- L’identifiant unique pour le groupe sur le serveur LDAP.
- 3
- L’adresse IP et l’hôte du serveur LDAP où l’enregistrement de ce groupe est stocké.
- 4
- Le nom du groupe tel que spécifié par le fichier de synchronisation.
- 5
- Les utilisateurs qui sont membres du groupe, nommés comme spécifié par le fichier de synchronisation. Il est à noter que les membres des groupes imbriqués sont inclus puisque l’adhésion au groupe a été aplatie par Microsoft Active Directory Server.
15.5. Caractéristiques de configuration de synchronisation LDAP
La spécification de l’objet pour le fichier de configuration est ci-dessous. Il est à noter que les différents objets de schéma ont des champs différents. Ainsi, v1.ActiveDirectoryConfig n’a pas de champ groupsQuery alors que v1.RFC2307Config et v1.AugmentedActiveDirectoryConfig le font tous deux.
Il n’y a pas de support pour les attributs binaires. Les données d’attribut provenant du serveur LDAP doivent être au format d’une chaîne encodée UTF-8. À titre d’exemple, ne jamais utiliser un attribut binaire, tel que objectGUID, comme attribut ID. À la place, vous devez utiliser des attributs de chaîne, tels que sAMAccountName ou userPrincipalName.
15.5.1. 1.LDAPSyncConfig
LDAPSyncConfig détient les options de configuration nécessaires pour définir une synchronisation de groupe LDAP.
| Le nom | Description | Le schéma |
|---|---|---|
|
| Chaîne de valeur représentant la ressource REST que représente cet objet. Les serveurs peuvent déduire cela à partir du point de terminaison auquel le client soumet des demandes. Impossible d’être mis à jour. Dans CamelCase. En savoir plus: https://github.com/kubernetes/community/blob/master/contributors/devel/sig-architecture/api-conventions.md#types-kinds | chaîne de caractères |
|
| Définit le schéma versionné de cette représentation d’un objet. Les serveurs doivent convertir des schémas reconnus en valeur interne la plus récente, et peuvent rejeter des valeurs non reconnues. En savoir plus: https://github.com/kubernetes/community/blob/master/contributors/devel/sig-architecture/api-conventions.md#resources | chaîne de caractères |
|
| Host est le schéma, l’hôte et le port du serveur LDAP pour se connecter à: Scheme://host:port | chaîne de caractères |
|
| DN optionnel pour se lier au serveur LDAP avec. | chaîne de caractères |
|
| Le mot de passe optionnel pour se lier pendant la phase de recherche. | la v1.StringSource |
|
| Le cas échéant, indique que la connexion ne doit pas utiliser TLS. En cas de faux, les URL ldaps:// se connectent à l’aide de TLS, et les URL ldap:// sont mises à niveau vers une connexion TLS en utilisant StartTLS comme spécifié dans https://tools.ietf.org/html/rfc2830. En cas de configuration non sécurisée sur true, vous ne pouvez pas utiliser les schémas d’URL ldaps://. | booléen |
|
| Ensemble optionnel d’autorité de certification de confiance à utiliser lors de la présentation de demandes au serveur. En cas de vide, les racines du système par défaut sont utilisées. | chaîne de caractères |
|
| Cartographie directe optionnelle des UID du groupe LDAP à OpenShift Noms de groupe dédiés. | l’objet |
|
| Contient la configuration pour extraire des données à partir d’un serveur LDAP configuré d’une manière similaire à RFC2307: entrées de groupe et d’utilisateur de première classe, avec l’adhésion au groupe déterminée par un attribut multi-valeur sur l’entrée de groupe listant ses membres. | le v1.RFC2307Config |
|
| Contient la configuration pour extraire des données à partir d’un serveur LDAP configuré d’une manière similaire à celle utilisée dans Active Directory: entrées utilisateur de première classe, avec une adhésion de groupe déterminée par un attribut multi-valeur sur les groupes de membres dont ils sont membres. | la v1.ActiveDirectoryConfig |
|
| Contient la configuration pour extraire des données à partir d’un serveur LDAP configuré d’une manière similaire à celle utilisée dans Active Directory comme décrit ci-dessus, avec une addition: les entrées de groupe de première classe existent et sont utilisées pour contenir des métadonnées mais pas l’adhésion au groupe. | la version 1.AugmentedActiveDirectoryConfig |
15.5.2. la v1.StringSource
StringSource permet de spécifier une chaîne en ligne, ou en externe via une variable d’environnement ou un fichier. Lorsqu’il ne contient qu’une valeur de chaîne, il se dirige vers une simple chaîne JSON.
| Le nom | Description | Le schéma |
|---|---|---|
|
| Indique la valeur de texte clair, ou une valeur cryptée si keyFile est spécifié. | chaîne de caractères |
|
| Indique une variable d’environnement contenant la valeur de texte clair, ou une valeur cryptée si le fichier clé est spécifié. | chaîne de caractères |
|
| Fait référence à un fichier contenant la valeur de texte clair, ou une valeur cryptée si un fichier clé est spécifié. | chaîne de caractères |
|
| Fait référence à un fichier contenant la clé à utiliser pour déchiffrer la valeur. | chaîne de caractères |
15.5.3. la v1.LDAPQuery
LDAPQuery détient les options nécessaires pour construire une requête LDAP.
| Le nom | Description | Le schéma |
|---|---|---|
|
| DN de la branche du répertoire où toutes les recherches devraient commencer. | chaîne de caractères |
|
| La portée facultative de la recherche. Il peut être base: seul l’objet de base, un: tous les objets au niveau de la base, sous: l’ensemble du sous-arbre. Défaut de sous-sous si elle n’est pas définie. | chaîne de caractères |
|
| Le comportement optionnel de la recherche en ce qui concerne les alias. Impossible de ne jamais: ne jamais déréférer les alias, la recherche: seulement la déréférence dans la recherche, base: seulement la déréférence dans la recherche de l’objet de base, toujours: toujours la déréférence. Défaut à toujours si elle n’est pas définie. | chaîne de caractères |
|
| Conserve la limite de temps en secondes que toute demande au serveur peut rester en suspens avant que l’attente d’une réponse soit abandonnée. Dans le cas de 0, aucune limite côté client n’est imposée. | entier |
|
| Filtre de recherche LDAP valide qui récupère toutes les entrées pertinentes du serveur LDAP avec le DN de base. | chaîne de caractères |
|
| La taille maximale de la page préférée, mesurée dans les entrées LDAP. La taille de la page 0 signifie qu’aucune mise en page ne sera effectuée. | entier |
15.5.4. le v1.RFC2307Config
Le RFC2307Config contient les options de configuration nécessaires pour définir comment un groupe LDAP synchronise avec un serveur LDAP en utilisant le schéma RFC2307.
| Le nom | Description | Le schéma |
|---|---|---|
|
| Contient le modèle d’une requête LDAP qui renvoie les entrées de groupe. | la v1.LDAPQuery |
|
| Définit quel attribut sur une entrée de groupe LDAP sera interprété comme son identifiant unique. (ldapGroupUID) | chaîne de caractères |
|
| Définit quels attributs sur une entrée de groupe LDAP seront interprétés comme son nom à utiliser pour un groupe dédié OpenShift. | chaîne de chaîne |
|
| Définit quels attributs sur une entrée de groupe LDAP seront interprétés comme ses membres. Les valeurs contenues dans ces attributs doivent être interrogeables par votre UserUIDAttribute. | chaîne de chaîne |
|
| Contient le modèle d’une requête LDAP qui renvoie les entrées de l’utilisateur. | la v1.LDAPQuery |
|
| Définit quel attribut sur une entrée utilisateur LDAP sera interprété comme son identifiant unique. Il doit correspondre à des valeurs que l’on trouvera dans le GroupMembershipAttributes. | chaîne de caractères |
|
| Définit quels attributs sur une entrée d’utilisateur LDAP seront utilisés, dans l’ordre, comme son nom d’utilisateur dédié OpenShift. Le premier attribut avec une valeur non vide est utilisé. Cela devrait correspondre à votre paramètre PreferredUsername pour votre LDAPPasswordIdentityProvider. L’attribut à utiliser comme nom de l’utilisateur dans l’enregistrement du groupe OpenShift Dedicated. courrier ou sAMAccountName sont des choix préférés dans la plupart des installations. | chaîne de chaîne |
|
| Détermine le comportement du travail de synchronisation LDAP lorsque des entrées utilisateur manquantes sont rencontrées. Dans l’affirmative, une requête LDAP pour les utilisateurs qui n’en trouvent pas sera tolérée et une seule et une erreur seront enregistrées. En cas de faux, le travail de synchronisation LDAP échoue si une requête pour les utilisateurs n’en trouve pas. La valeur par défaut est false. Les tâches de synchronisation LDAP mal configurées avec cet ensemble d’indicateurs peuvent entraîner la suppression de l’adhésion au groupe, il est donc recommandé d’utiliser ce drapeau avec prudence. | booléen |
|
| Détermine le comportement du travail de synchronisation LDAP lorsque des entrées d’utilisateur hors champ sont rencontrées. Dans l’affirmative, une requête LDAP pour un utilisateur qui tombe en dehors de la base DN donnée pour l’ensemble de la requête utilisateur sera tolérée et seule une erreur sera enregistrée. En cas de faux, la tâche de synchronisation LDAP échoue si une requête utilisateur recherche en dehors du DN de base spécifié par l’ensemble de la requête utilisateur. Les tâches de synchronisation LDAP mal configurées avec cet ensemble d’indicateurs peuvent entraîner des groupes d’utilisateurs manquants, il est donc recommandé d’utiliser ce drapeau avec prudence. | booléen |
15.5.5. la v1.ActiveDirectoryConfig
ActiveDirectoryConfig détient les options de configuration nécessaires pour définir comment un groupe LDAP synchronise avec un serveur LDAP à l’aide du schéma Active Directory.
| Le nom | Description | Le schéma |
|---|---|---|
|
| Contient le modèle d’une requête LDAP qui renvoie les entrées de l’utilisateur. | la v1.LDAPQuery |
|
| Définit quels attributs sur une entrée d’utilisateur LDAP seront interprétés comme son nom d’utilisateur dédié OpenShift. L’attribut à utiliser comme nom de l’utilisateur dans l’enregistrement du groupe OpenShift Dedicated. courrier ou sAMAccountName sont des choix préférés dans la plupart des installations. | chaîne de chaîne |
|
| Définit quels attributs sur une entrée d’utilisateur LDAP seront interprétés comme les groupes dont il est membre. | chaîne de chaîne |
15.5.6. la version 1.AugmentedActiveDirectoryConfig
AugmentedActiveDirectoryConfig détient les options de configuration nécessaires pour définir comment un groupe LDAP synchronise avec un serveur LDAP à l’aide du schéma Active Directory augmenté.
| Le nom | Description | Le schéma |
|---|---|---|
|
| Contient le modèle d’une requête LDAP qui renvoie les entrées de l’utilisateur. | la v1.LDAPQuery |
|
| Définit quels attributs sur une entrée d’utilisateur LDAP seront interprétés comme son nom d’utilisateur dédié OpenShift. L’attribut à utiliser comme nom de l’utilisateur dans l’enregistrement du groupe OpenShift Dedicated. courrier ou sAMAccountName sont des choix préférés dans la plupart des installations. | chaîne de chaîne |
|
| Définit quels attributs sur une entrée d’utilisateur LDAP seront interprétés comme les groupes dont il est membre. | chaîne de chaîne |
|
| Contient le modèle d’une requête LDAP qui renvoie les entrées de groupe. | la v1.LDAPQuery |
|
| Définit quel attribut sur une entrée de groupe LDAP sera interprété comme son identifiant unique. (ldapGroupUID) | chaîne de caractères |
|
| Définit quels attributs sur une entrée de groupe LDAP seront interprétés comme son nom à utiliser pour un groupe dédié OpenShift. | chaîne de chaîne |
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.