Architecture
Aperçu de l’architecture.
Résumé
Chapitre 1. Aperçu de l’architecture
L’OpenShift Dedicated est une plateforme de conteneurs Kubernetes basée sur le cloud. La fondation d’OpenShift Dedicated est basée sur Kubernetes et partage donc la même technologie. En savoir plus sur OpenShift Dedicated et Kubernetes, consultez l’architecture des produits.
1.1. Glossaire des termes communs pour OpenShift Architecture dédiée
Ce glossaire définit des termes communs qui sont utilisés dans le contenu de l’architecture.
- les politiques d’accès
- Ensemble de rôles qui dictent la façon dont les utilisateurs, les applications et les entités d’un cluster interagissent les uns avec les autres. La politique d’accès augmente la sécurité des clusters.
- les plugins d’admission
- Les plugins d’admission appliquent des politiques de sécurité, des limitations de ressources ou des exigences de configuration.
- authentification
- Afin de contrôler l’accès à un cluster dédié OpenShift, un administrateur doté du rôle d’administrateur dédié peut configurer l’authentification de l’utilisateur pour s’assurer que seuls les utilisateurs approuvés accèdent au cluster. Afin d’interagir avec un cluster dédié OpenShift, vous devez vous authentifier avec l’API dédiée OpenShift. Dans vos demandes, vous pouvez vous authentifier en fournissant un jeton d’accès OAuth ou un certificat client X.509 à l’API dédiée OpenShift.
- Bootstrap
- Il s’agit d’une machine temporaire qui exécute un minimum de Kubernetes et déploie le plan de contrôle dédié OpenShift.
- demandes de signature de certificat (RSE)
- La ressource demande à un signataire désigné de signer un certificat. Cette demande peut être approuvée ou refusée.
- Gestionnaire de versions de cluster (CVO)
- Exploitant qui vérifie avec OpenShift Dedicated Update Service pour voir les mises à jour valides et les chemins de mise à jour basés sur les versions et informations actuelles des composants dans le graphique.
- calculer les nœuds
- Les nœuds responsables de l’exécution des charges de travail pour les utilisateurs de clusters. Les nœuds de calcul sont également connus sous le nom de nœuds ouvriers.
- dérive de configuration
- Dans une situation où la configuration sur un nœud ne correspond pas à ce que la configuration de la machine spécifie.
- conteneurs
- Des images légères et exécutables qui sont constituées de logiciels et de toutes ses dépendances. Comme les conteneurs virtualisent le système d’exploitation, vous pouvez exécuter des conteneurs n’importe où, tels que des centres de données, des clouds publics ou privés et des hôtes locaux.
- le moteur d’orchestration de conteneurs
- Logiciel qui automatise le déploiement, la gestion, la mise à l’échelle et la mise en réseau des conteneurs.
- charge de travail des conteneurs
- Applications qui sont emballées et déployées dans des conteneurs.
- groupes de contrôle (groupes)
- Ensembles de partitions de processus en groupes pour gérer et limiter les processus de ressources.
- le plan de contrôle
- Couche d’orchestration de conteneurs qui expose l’API et les interfaces pour définir, déployer et gérer le cycle de vie des conteneurs. Les plans de contrôle sont également connus sous le nom de machines de plan de contrôle.
- CRI-O
- Implémentation d’exécution de conteneur native Kubernetes qui s’intègre au système d’exploitation pour offrir une expérience Kubernetes efficace.
- déploiement
- Kubernetes objet ressource qui maintient le cycle de vie d’une application.
- Dockerfile
- Fichier texte contenant les commandes de l’utilisateur à effectuer sur un terminal pour assembler l’image.
- déploiements de cloud hybride
- Des déploiements qui fournissent une plate-forme cohérente dans les environnements cloud nus, virtuels, privés et publics. Cela offre vitesse, agilité et portabilité.
- Allumage
- L’utilitaire que RHCOS utilise pour manipuler les disques lors de la configuration initiale. Il complète les tâches de disque courantes, y compris le partitionnement des disques, le formatage des partitions, l’écriture de fichiers et la configuration des utilisateurs.
- infrastructure fournie par l’installateur
- Le programme d’installation déploie et configure l’infrastructure sur laquelle le cluster s’exécute.
- kubelet
- Agent de nœud primaire qui s’exécute sur chaque nœud du cluster pour s’assurer que les conteneurs s’exécutent dans une gousse.
- Kubernetes manifeste
- Caractéristiques d’un objet API Kubernetes au format JSON ou YAML. Le fichier de configuration peut inclure des déploiements, des cartes de configuration, des secrets, des ensembles de démons.
- Configurateur de machine Daemon (MCD)
- Daemon qui vérifie régulièrement les nœuds pour la dérive de configuration.
- Opérateur de configuration de machine (MCO)
- Exploitant qui applique la nouvelle configuration à vos machines à clusters.
- configuration de la machine pools (MCP)
- Ensemble de machines, telles que des composants de plan de contrôle ou des charges de travail des utilisateurs, qui sont basées sur les ressources qu’elles gèrent.
- les métadonnées
- Informations supplémentaires sur les artefacts de déploiement de clusters.
- les microservices
- Approche de l’écriture de logiciels. Les applications peuvent être séparées en composants les plus petits, indépendants les uns des autres en utilisant des microservices.
- registre miroir
- Le registre qui contient le miroir des images dédiées OpenShift.
- applications monolithiques
- Applications qui sont autonomes, construites et emballées en une seule pièce.
- espaces de noms
- L’espace de noms isole des ressources système spécifiques qui sont visibles pour tous les processus. À l’intérieur d’un espace de noms, seuls les processus qui sont membres de cet espace de noms peuvent voir ces ressources.
- le réseautage
- Informations de réseau du cluster dédié OpenShift.
- le nœud
- D’une machine ouvrier dans le cluster dédié OpenShift. Le nœud est soit une machine virtuelle (VM) soit une machine physique.
- CLI OpenShift (oc)
- L’outil de ligne de commande pour exécuter les commandes OpenShift Dédicated sur le terminal.
- Le service de mise à jour OpenShift (OSUS)
- En ce qui concerne les clusters avec accès à Internet, Red Hat Enterprise Linux (RHEL) fournit des mises à jour en direct en utilisant un service de mise à jour OpenShift en tant que service hébergé situé derrière les API publiques.
- Registre d’images OpenShift
- Le registre fourni par OpenShift dédié à la gestion des images.
- Exploitant
- La méthode préférée d’emballage, de déploiement et de gestion d’une application Kubernetes dans un cluster dédié OpenShift. L’opérateur utilise les connaissances opérationnelles humaines et l’encode dans un logiciel qui est emballé et partagé avec les clients.
- L’opérateurHub
- C’est une plate-forme qui contient divers opérateurs dédiés OpenShift à installer.
- Gestionnaire du cycle de vie de l’opérateur (OLM)
- Il vous aide à installer, mettre à jour et gérer le cycle de vie des applications natives Kubernetes. L’OLM est une boîte à outils open source conçue pour gérer les opérateurs de manière efficace, automatisée et évolutive.
- L’ostree
- Il s’agit d’un système de mise à niveau pour les systèmes d’exploitation Linux qui effectue des mises à niveau atomiques des arbres complets du système de fichiers. L’ostree suit les changements significatifs apportés à l’arborescence du système de fichiers à l’aide d’un magasin d’objets adressables, et est conçu pour compléter les systèmes de gestion de paquets existants.
- les mises à jour en direct (OTA)
- Le service de mise à jour dédié OpenShift (OSUS) fournit des mises à jour en direct à OpenShift Dedicated, y compris Red Hat Enterprise Linux CoreOS (RHCOS).
- la pod
- Il y a un ou plusieurs conteneurs avec des ressources partagées, telles que des adresses de volume et IP, qui s’exécutent dans votre cluster dédié OpenShift. Le pod est la plus petite unité de calcul définie, déployée et gérée.
- registre privé
- La société OpenShift Dedicated peut utiliser n’importe quel serveur mettant en œuvre l’API de registre d’images conteneur comme source de l’image qui permet aux développeurs de pousser et de tirer leurs images de conteneur privé.
- B) Registre public
- La société OpenShift Dedicated peut utiliser n’importe quel serveur mettant en œuvre l’API de registre d’images conteneur comme source de l’image qui permet aux développeurs de pousser et de tirer leurs images de conteneurs publics.
- Gestionnaire de cluster dédié RHEL OpenShift
- C’est un service géré où vous pouvez installer, modifier, exploiter et mettre à niveau vos clusters OpenShift dédiés.
- Registre des conteneurs RHEL Quay
- Le registre des conteneurs Quay.io sert la plupart des images de conteneurs et des opérateurs à OpenShift Dedicated clusters.
- contrôleurs de réplication
- Il s’agit d’un actif qui indique combien de répliques de pod doivent être exécutées à la fois.
- contrôle d’accès basé sur le rôle (RBAC)
- Contrôle de sécurité clé pour s’assurer que les utilisateurs de clusters et les charges de travail n’ont accès qu’aux ressources nécessaires à l’exécution de leurs rôles.
- itinéraire
- Les itinéraires exposent un service pour permettre l’accès au réseau aux pods des utilisateurs et des applications en dehors de l’instance OpenShift Dedicated.
- la mise à l’échelle
- L’augmentation ou la diminution de la capacité de ressources.
- le service
- Le service expose une application en cours d’exécution sur un ensemble de pods.
- Image source à image (S2I)
- Image créée en fonction du langage de programmation du code source de l’application dans OpenShift dédié au déploiement d’applications.
- le stockage
- Le logiciel OpenShift Dedicated prend en charge de nombreux types de stockage pour les fournisseurs de cloud. Dans un cluster dédié OpenShift, vous pouvez gérer le stockage de conteneurs pour des données persistantes et non persistantes.
- La télémétrie
- Composante permettant de recueillir des informations telles que la taille, la santé et l’état d’OpenShift Dedicated.
- le modèle
- Le modèle décrit un ensemble d’objets qui peuvent être paramétrés et traités pour produire une liste d’objets à créer par OpenShift Dedicated.
- console Web
- Interface utilisateur (UI) pour gérer OpenShift Dedicated.
- nœud de travailleur
- Les nœuds responsables de l’exécution des charges de travail pour les utilisateurs de clusters. Les nœuds ouvriers sont également connus sous le nom de nœuds de calcul.
1.2. Comprendre comment OpenShift Dedicated diffère de OpenShift Container Platform
La plateforme OpenShift Dedicated utilise la même base de code que OpenShift Container Platform, mais est installée de manière à être optimisée en termes de performances, d’évolutivité et de sécurité. Dedicated OpenShift est un service entièrement géré; par conséquent, de nombreux composants et paramètres dédiés OpenShift que vous avez configurés manuellement dans OpenShift Container Platform sont configurés pour vous par défaut.
Examinez les différences suivantes entre OpenShift Dedicated et une installation standard de OpenShift Container Platform sur votre propre infrastructure:
| La plate-forme OpenShift Container | Dédié à OpenShift |
|---|---|
| Le client installe et configure OpenShift Container Platform. | Le logiciel OpenShift Dedicated est installé via Red Hat OpenShift Cluster Manager et de manière normalisée, optimisée pour les performances, l’évolutivité et la sécurité. |
| Les clients peuvent choisir leurs ressources informatiques. | La société OpenShift Dedicated est hébergée et gérée dans un cloud public (Amazon Web Services ou Google Cloud Platform) appartenant à Red Hat ou fourni par le client. |
| Les clients ont un accès administratif de haut niveau à l’infrastructure. | Les clients ont un groupe d’administrateur intégré (admin dédié), bien que l’accès administratif de premier niveau soit disponible lorsque les comptes cloud sont fournis par le client. |
| Les clients peuvent utiliser toutes les fonctionnalités prises en charge et les paramètres de configuration disponibles dans OpenShift Container Platform. | Certaines fonctionnalités et paramètres de configuration OpenShift Container Platform peuvent ne pas être disponibles ou modifiables dans OpenShift Dedicated. |
| Configurez des composants de plan de contrôle tels que le serveur API et etcd sur les machines qui obtiennent le rôle de contrôle. Il est possible de modifier les composants du plan de contrôle, mais il est responsable de la sauvegarde, de la restauration et de la mise à disposition des données des plans de contrôle. | Le Red Hat configure le plan de contrôle et gère les composants du plan de contrôle pour vous. Le plan de contrôle est très disponible. |
| Il vous incombe de mettre à jour l’infrastructure sous-jacente du plan de contrôle et des nœuds de travail. La console Web OpenShift vous permet de mettre à jour les versions OpenShift Container Platform. | Le Red Hat avertit automatiquement le client lorsque des mises à jour sont disponibles. Il est possible de planifier manuellement ou automatiquement les mises à jour dans OpenShift Cluster Manager. |
| Le support est fourni en fonction des conditions de votre abonnement Red Hat ou de votre fournisseur de cloud. | Conçu, exploité et soutenu par Red Hat avec une couverture SLA de 99,95 % et une couverture 24x7. Consultez l’annexe 4 de l’accord d’entreprise Red Hat (Services d’abonnement en ligne). |
1.3. À propos de l’avion de contrôle
Le plan de contrôle gère les nœuds de travail et les pods dans votre cluster. Il est possible de configurer des nœuds avec l’utilisation de pools de configuration de machine (MCP). Les MCPS sont des groupes de machines, telles que des composants de plan de contrôle ou des charges de travail des utilisateurs, qui sont basées sur les ressources qu’elles gèrent. L’OpenShift Dedicated attribue différents rôles aux hôtes. Ces rôles définissent la fonction d’une machine dans un cluster. Le cluster contient des définitions pour le plan de contrôle standard et les types de rôles de travail.
Il est possible d’utiliser les opérateurs pour emballer, déployer et gérer des services sur le plan de contrôle. Les opérateurs sont des composants importants d’OpenShift dédiés parce qu’ils fournissent les services suivants:
- Effectuer des contrôles de santé
- Fournir des moyens de regarder les applications
- Gérer les mises à jour en direct
- Assurez-vous que les applications restent dans l’état spécifié
1.4. À propos des applications conteneurisées pour les développeurs
En tant que développeur, vous pouvez utiliser différents outils, méthodes et formats pour développer votre application conteneurisée en fonction de vos exigences uniques, par exemple:
- Employez diverses options de build-tool, d’image de base et de registre pour construire une application de conteneur simple.
- Utilisez des composants de support tels que OperatorHub et des modèles pour développer votre application.
- Emballez et déployez votre application en tant qu’opérateur.
Il est également possible de créer un manifeste Kubernetes et de le stocker dans un dépôt Git. Kubernetes fonctionne sur des unités de base appelées pods. Le pod est une instance unique d’un processus en cours d’exécution dans votre cluster. Les gousses peuvent contenir un ou plusieurs contenants. Il est possible de créer un service en regroupant un ensemble de pods et leurs stratégies d’accès. Les services fournissent des adresses IP internes permanentes et des noms d’hôte pour d’autres applications à utiliser comme pods sont créés et détruits. Kubernetes définit les charges de travail en fonction du type de votre application.
1.5. À propos des plugins d’admission
Il est possible d’utiliser des plugins d’admission pour réguler les fonctions d’OpenShift Dedicated. Après qu’une demande de ressource soit authentifiée et autorisée, les plugins d’admission interceptent la demande de ressource à l’API principale pour valider les demandes de ressources et pour s’assurer que les politiques de mise à l’échelle sont respectées. Les plugins d’admission sont utilisés pour appliquer des politiques de sécurité, des limitations de ressources, des exigences de configuration et d’autres paramètres.
Chapitre 2. Architecture dédiée à OpenShift
2.1. Introduction à OpenShift dédié
L’OpenShift Dedicated est une plate-forme pour le développement et l’exécution d’applications conteneurisées. Il est conçu pour permettre aux applications et aux centres de données qui les soutiennent de passer de quelques machines et applications à des milliers de machines qui servent des millions de clients.
Avec sa fondation à Kubernetes, OpenShift Dedicated intègre la même technologie qui sert de moteur pour les télécommunications massives, le streaming vidéo, les jeux, les banques et d’autres applications. Grâce à sa mise en œuvre dans les technologies ouvertes de Red Hat, vous pouvez étendre vos applications conteneurisées au-delà d’un seul cloud vers des environnements sur site et multicloud.
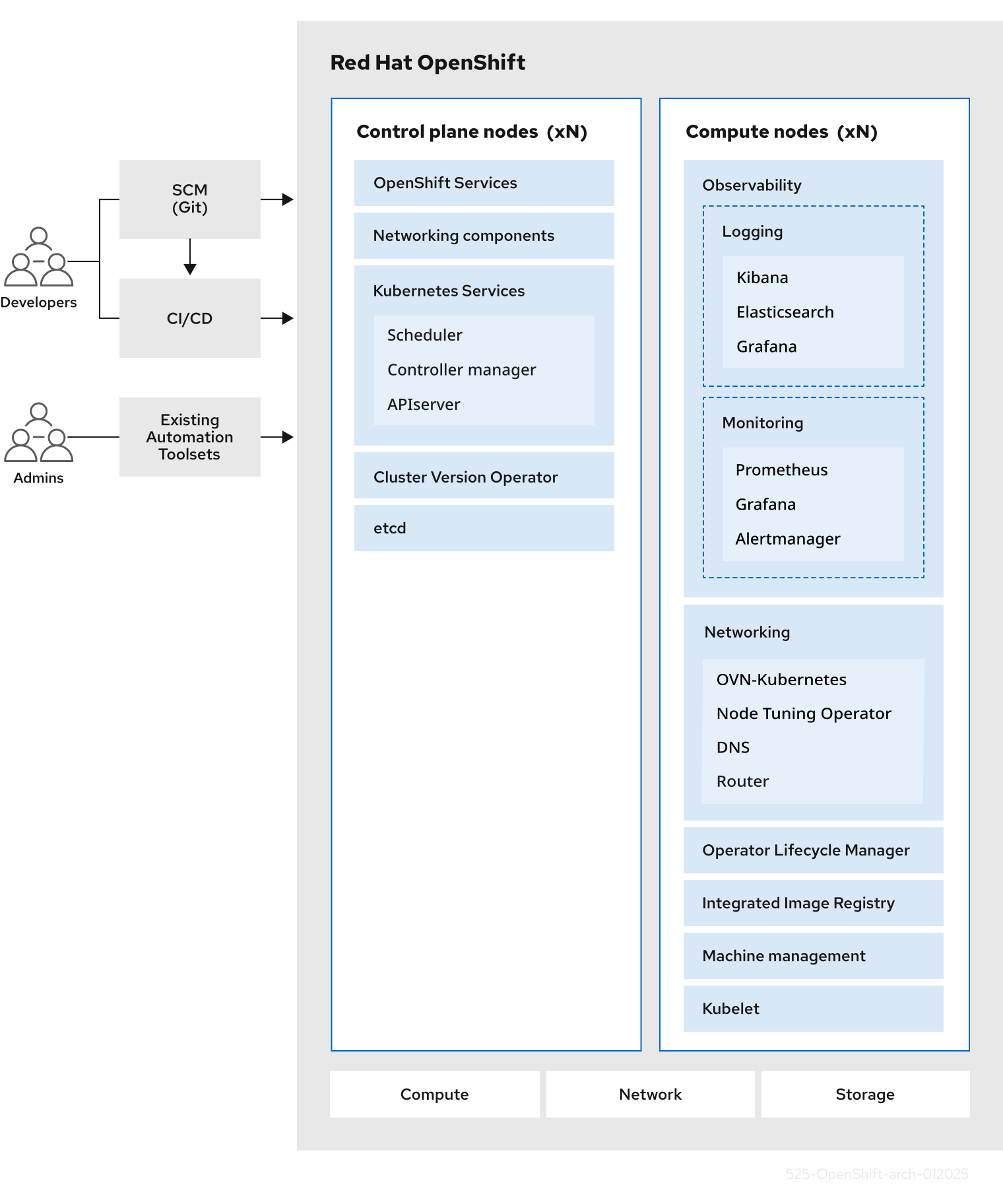
2.1.1. À propos de Kubernetes
Bien que les images de conteneurs et les conteneurs qui s’en sortent soient les principaux éléments de base du développement d’applications modernes, les exécuter à grande échelle nécessite un système de distribution fiable et flexible. Kubernetes est la norme de facto pour l’orchestration des conteneurs.
Kubernetes est un moteur d’orchestration de conteneurs open source pour automatiser le déploiement, l’échelle et la gestion des applications conteneurisées. Le concept général de Kubernetes est assez simple:
- Commencez avec un ou plusieurs nœuds de travail pour exécuter les charges de travail du conteneur.
- Gérez le déploiement de ces charges de travail à partir d’un ou de plusieurs nœuds d’avion de contrôle.
- Enveloppez des conteneurs dans une unité de déploiement appelée un pod. À l’aide de pods fournit des métadonnées supplémentaires avec le conteneur et offre la possibilité de regrouper plusieurs conteneurs dans une seule entité de déploiement.
- Créer des types spéciaux d’actifs. À titre d’exemple, les services sont représentés par un ensemble de pods et une politique qui définit la manière dont ils sont accessibles. Cette politique permet aux conteneurs de se connecter aux services dont ils ont besoin même s’ils n’ont pas les adresses IP spécifiques pour les services. Les contrôleurs de réplication sont un autre actif spécial qui indique combien de répliques de pod sont nécessaires pour exécuter à la fois. Cette capacité permet d’adapter automatiquement votre application à sa demande actuelle.
En seulement quelques années, Kubernetes a connu une adoption massive de cloud et sur site. Le modèle de développement open source permet à de nombreuses personnes d’étendre Kubernetes en mettant en œuvre différentes technologies pour des composants tels que le réseau, le stockage et l’authentification.
2.1.2. Les avantages des applications conteneurisées
L’utilisation d’applications conteneurisées offre de nombreux avantages par rapport aux méthodes de déploiement traditionnelles. Lorsque les applications devaient autrefois être installées sur des systèmes d’exploitation comprenant toutes leurs dépendances, les conteneurs permettent à une application de transporter ses dépendances avec eux. La création d’applications conteneurisées offre de nombreux avantages.
2.1.2.1. Avantages du système d’exploitation
Les conteneurs utilisent de petits systèmes d’exploitation Linux dédiés sans noyau. Leur système de fichiers, leur réseau, leurs groupes, leurs tables de processus et leurs espaces de noms sont séparés du système Linux hôte, mais les conteneurs peuvent s’intégrer aux hôtes de manière transparente si nécessaire. Être basé sur Linux permet aux conteneurs d’utiliser tous les avantages associés au modèle de développement open source d’innovation rapide.
Comme chaque conteneur utilise un système d’exploitation dédié, vous pouvez déployer des applications qui nécessitent des dépendances logicielles contradictoires sur le même hôte. Chaque conteneur possède son propre logiciel dépendant et gère ses propres interfaces, telles que le réseau et les systèmes de fichiers, de sorte que les applications n’ont jamais besoin de rivaliser pour ces actifs.
2.1.2.2. Avantages pour le déploiement et la mise à l’échelle
Lorsque vous utilisez des mises à niveau progressives entre les versions majeures de votre application, vous pouvez continuellement améliorer vos applications sans temps d’arrêt et maintenir votre compatibilité avec la version actuelle.
Il est également possible de déployer et de tester une nouvelle version d’une application parallèlement à la version existante. Lorsque le conteneur passe vos tests, il suffit de déployer plus de nouveaux conteneurs et de supprimer les anciens.
Étant donné que toutes les dépendances logicielles pour une application sont résolues dans le conteneur lui-même, vous pouvez utiliser un système d’exploitation standardisé sur chaque hôte de votre centre de données. Il n’est pas nécessaire de configurer un système d’exploitation spécifique pour chaque hôte d’application. Lorsque votre centre de données a besoin de plus de capacité, vous pouvez déployer un autre système hôte générique.
De même, la mise à l’échelle des applications conteneurisées est simple. L’OpenShift Dedicated offre une méthode simple et standard de mise à l’échelle de n’importe quel service conteneurisé. Ainsi, si vous construisez des applications comme un ensemble de microservices plutôt que comme de grandes applications monolithiques, vous pouvez mettre à l’échelle les microservices individuels pour répondre à la demande. Cette capacité vous permet de ne mettre à l’échelle que les services requis au lieu de l’ensemble de l’application, ce qui peut vous permettre de répondre aux demandes d’application tout en utilisant des ressources minimales.
2.1.3. Aperçu dédié à OpenShift
La société OpenShift Dedicated fournit des améliorations prêtes à l’entreprise à Kubernetes, y compris les améliorations suivantes:
- La technologie Red Hat intégrée. Les principaux composants d’OpenShift Dedicated proviennent de Red Hat Enterprise Linux (RHEL) et des technologies Red Hat associées. La société OpenShift Dedicated bénéficie des initiatives intenses de tests et de certification du logiciel de qualité d’entreprise de Red Hat.
- Le modèle de développement open source. Le développement est terminé en ouvert, et le code source est disponible auprès des référentiels de logiciels publics. Cette collaboration ouverte favorise l’innovation et le développement rapides.
Bien que Kubernetes excelle dans la gestion de vos applications, il ne spécifie ni ne gère les exigences au niveau de la plate-forme ou les processus de déploiement. Les outils et processus de gestion de plate-forme puissants et flexibles sont des avantages importants qu’offre OpenShift Dedicated 4. Les sections suivantes décrivent certaines caractéristiques et avantages uniques d’OpenShift Dedicated.
2.1.3.1. Le système d’exploitation personnalisé
Le système d’exploitation OpenShift Dedicated utilise Red Hat Enterprise Linux CoreOS (RHCOS) comme système d’exploitation pour tous les nœuds de plan de contrôle et de travail.
Le RHCOS comprend:
- Allumage, que OpenShift Dedicated utilise comme première configuration du système de démarrage pour la mise en place et la configuration initiales des machines.
- CRI-O, une implémentation d’exécution de conteneurs native Kubernetes qui s’intègre étroitement avec le système d’exploitation pour offrir une expérience Kubernetes efficace et optimisée. CRI-O fournit des installations pour l’exécution, l’arrêt et le redémarrage des conteneurs. Il remplace entièrement le Docker Container Engine, qui a été utilisé dans OpenShift Dedicated 3.
- Kubelet, le principal agent de nœud pour Kubernetes qui est responsable du lancement et de la surveillance des conteneurs.
2.1.3.2. Le processus de mise à jour simplifié
La mise à jour, ou la mise à jour, OpenShift Dedicated est un processus simple et hautement automatisé. Étant donné qu’OpenShift Dedicated contrôle complètement les systèmes et services qui fonctionnent sur chaque machine, y compris le système d’exploitation lui-même, à partir d’un plan de contrôle central, les mises à niveau sont conçues pour devenir des événements automatiques.
2.1.3.3. Autres caractéristiques clés
Les opérateurs sont à la fois l’unité fondamentale de la base de code OpenShift Dedicated 4 et un moyen pratique de déployer des applications et des composants logiciels pour vos applications à utiliser. Dans OpenShift Dedicated, les opérateurs servent de base de la plate-forme et éliminent le besoin de mises à niveau manuelles des systèmes d’exploitation et des applications de plan de contrôle. Les opérateurs dédiés OpenShift tels que l’opérateur de version de cluster et l’opérateur de configuration de machine permettent une gestion simplifiée et à l’échelle du cluster de ces composants critiques.
Gestionnaire du cycle de vie de l’opérateur (OLM) et OperatorHub fournissent des installations pour stocker et distribuer des opérateurs aux personnes qui développent et déploient des applications.
Le registre des conteneurs Red Hat Quay est un registre de conteneurs Quay.io qui sert la plupart des images de conteneurs et des opérateurs à OpenShift Dedicated clusters. Le Quay.io est une version de registre public de Red Hat Quay qui stocke des millions d’images et de balises.
D’autres améliorations apportées à Kubernetes dans OpenShift Dedicated incluent des améliorations dans le réseau défini par logiciel (SDN), l’authentification, l’agrégation de journal, la surveillance et le routage. L’OpenShift Dedicated propose également une console Web complète et l’interface personnalisée OpenShift CLI (oc).
Chapitre 3. Dédié sur les modèles d’architecture Google Cloud Platform (GCP)
Avec OpenShift Dedicated on Google Cloud Platform (GCP), vous pouvez créer des clusters accessibles via des réseaux publics ou privés.
3.1. Dédié sur l’architecture Google Cloud Platform (GCP) sur les réseaux publics et privés
En choisissant l’un des types de configuration réseau suivants, vous pouvez personnaliser les modèles d’accès pour votre point de terminaison de serveur API et la gestion de Red Hat SRE:
- Cluster privé avec Private Service Connect (PSC).
- Cluster privé sans CFP
- Groupe de travail public
Le Red Hat recommande d’utiliser PSC lors du déploiement d’un cluster privé OpenShift dédié sur Google Cloud Platform (GCP). La CFP s’assure qu’il existe une connectivité privée sécurisée entre l’infrastructure Red Hat, l’ingénierie de fiabilité du site (SRE) et les clusters privés OpenShift.
3.2. Comprendre la connexion du service privé
Le Private Service Connect (PSC), une capacité de mise en réseau Google Cloud, permet la communication privée entre les services de différents projets ou organisations au sein de GCP. Les utilisateurs qui implémentent PSC dans le cadre de leur connectivité réseau peuvent déployer des clusters OpenShift dédiés dans un environnement privé et sécurisé au sein de Google Cloud Platform (GCP) sans aucune ressource cloud accessible au public.
Consultez la section Private Service Connect pour obtenir de plus amples renseignements sur la CFP.
La CFP n’est disponible que sur OpenShift Dedicated version 4.17 et ultérieure, et n’est prise en charge que par le type d’infrastructure d’abonnement au cloud client (CCS).
3.2.1. Architecture de connexion de service privé
L’architecture de la CFP comprend les services aux producteurs et les services aux consommateurs. En utilisant la CFP, les consommateurs peuvent accéder aux services aux producteurs en privé à partir de l’intérieur de leur réseau VPC. De même, il permet aux producteurs d’héberger des services dans leurs propres réseaux VPC séparés et d’offrir une connexion privée à leurs consommateurs.
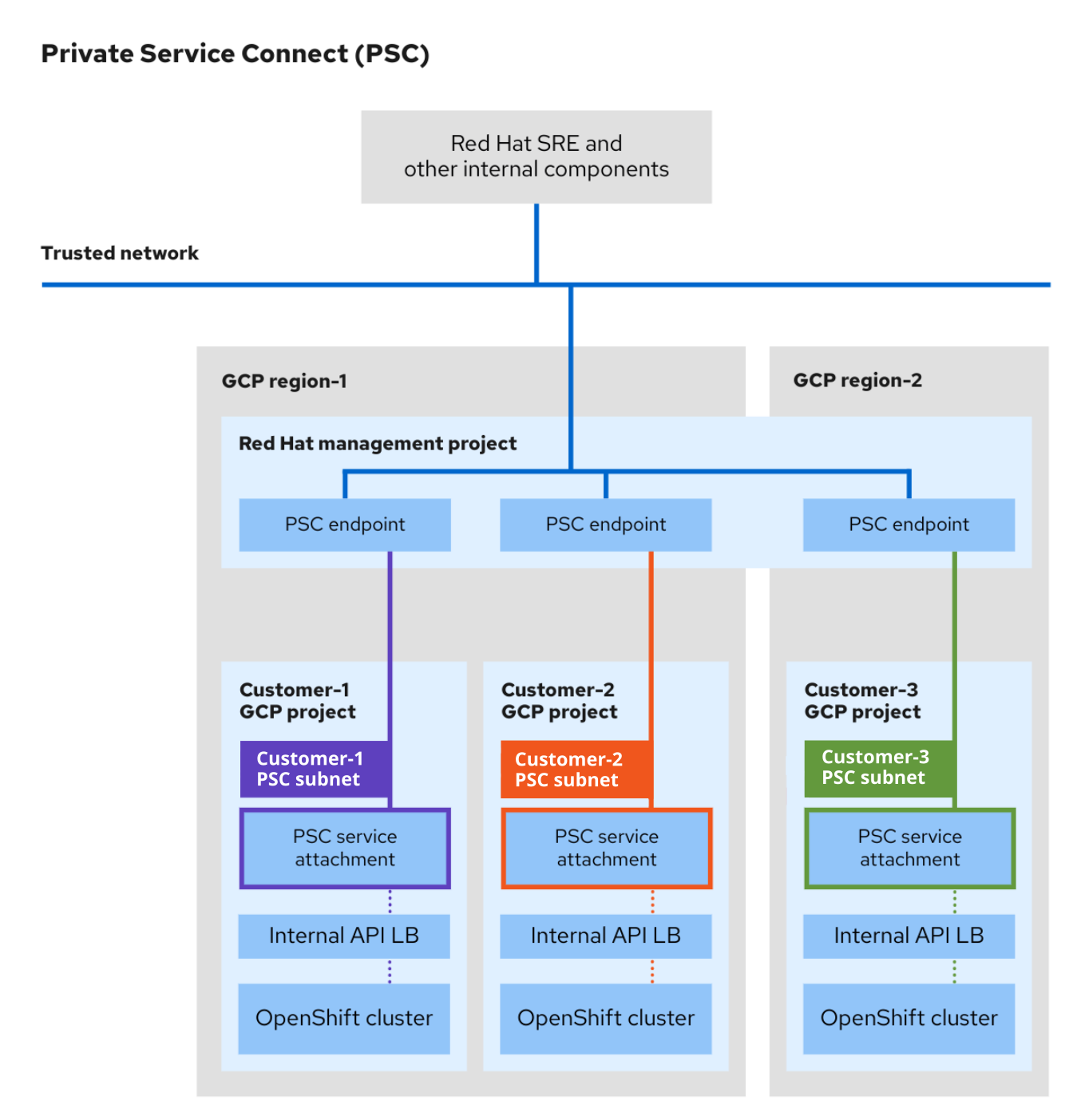
L’image suivante illustre la façon dont les SRE Red HAT et d’autres grappes internes d’accès aux ressources et de soutien ont été créées à l’aide de la CFP.
- Chaque cluster OSD du projet GCP client crée une pièce jointe de service PSC unique. La pièce jointe du service PSC pointe vers l’équilibreur de charge du serveur API cluster créé dans le projet GCP client.
- Comme les pièces jointes de service, un point de terminaison PSC unique est créé dans le projet Red Hat Management GCP pour chaque cluster OSD.
- Le sous-réseau dédié à GCP Private Service Connect est créé dans le réseau du cluster au sein du projet GCP client. Il s’agit d’un type de sous-réseau spécial où les services de producteurs sont publiés via des pièces jointes de service de la CFP. Ce sous-réseau est utilisé pour Source NAT (SNAT) requêtes entrantes au serveur API cluster. De plus, le sous-réseau de la CFP doit se trouver dans la plage CIDR Machine et ne peut pas être utilisé dans plus d’une pièce jointe de service.
- Les ressources internes Red Hat et les SRE accèdent à des clusters OSD privés en utilisant la connectivité entre un point de terminaison PSC et une pièce jointe du service. Bien que le trafic transite plusieurs réseaux VPC, il reste entièrement dans Google Cloud.
- L’accès aux pièces jointes du service de la CFP n’est possible que via le projet Red Hat Management.
Figure 3.1. Aperçu de l’architecture de la CFP
3.3. Dédié sur Google Cloud Platform (GCP) avec le modèle d’architecture Private Service Connect
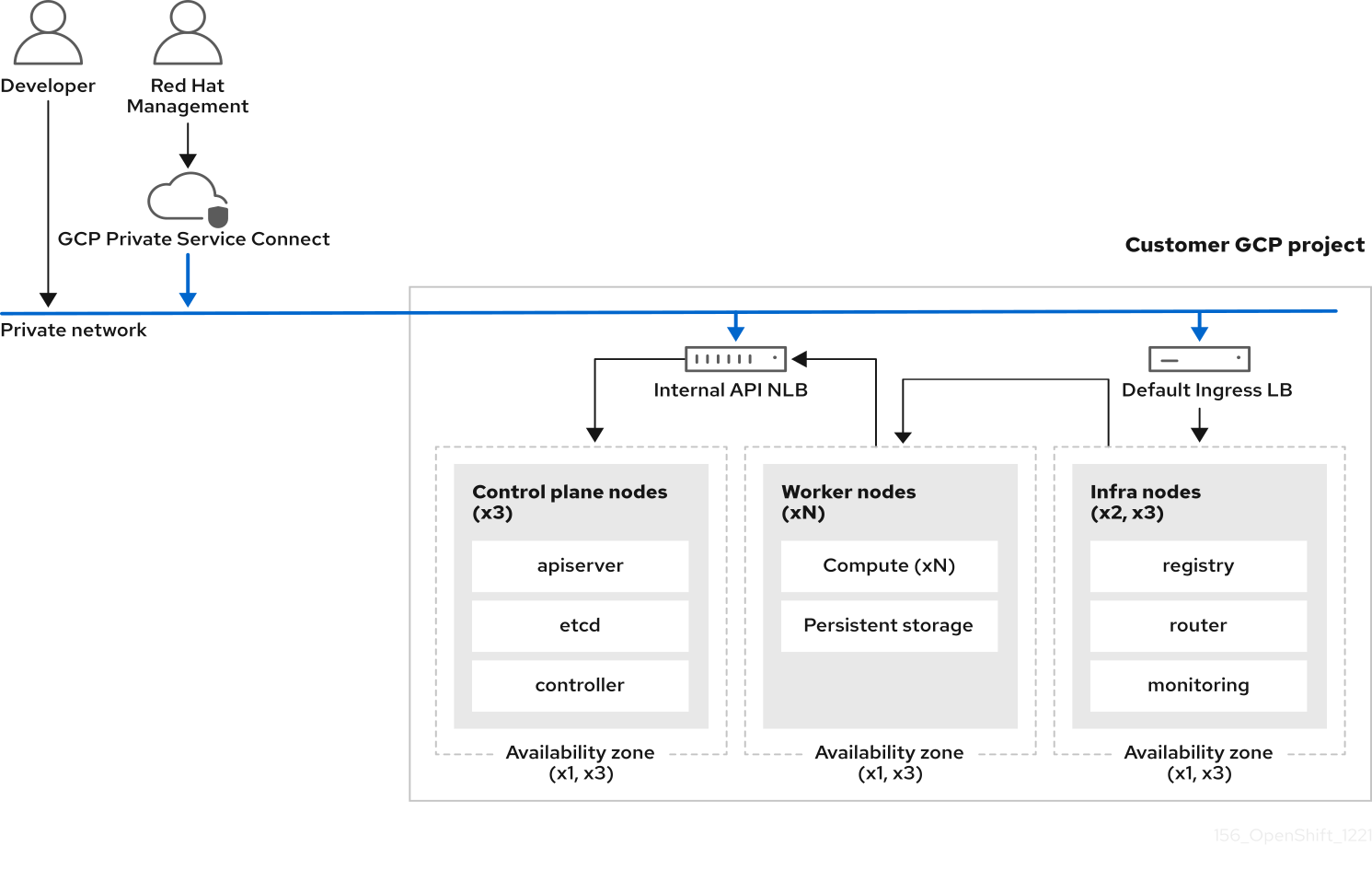
Avec une configuration de réseau privée GCP Private Service Connect (PSC), votre point de terminaison de serveur API cluster et vos itinéraires d’application sont privés. Les sous-réseaux publics ou les passerelles NAT ne sont pas requis dans votre VPC pour la sortie. La direction de Red Hat SRE accède au cluster via la connectivité privée de GCP PSC. Le contrôleur d’entrée par défaut est privé. Les contrôleurs d’entrée supplémentaires peuvent être publics ou privés. Le diagramme suivant montre la connectivité réseau d’un cluster privé avec la CFP.
Figure 3.2. Dédié sur Google Cloud Platform (GCP) déployé sur un réseau privé avec PSC
3.4. Dédié sur Google Cloud Platform (GCP) sans modèle d’architecture Private Service Connect (PSC)
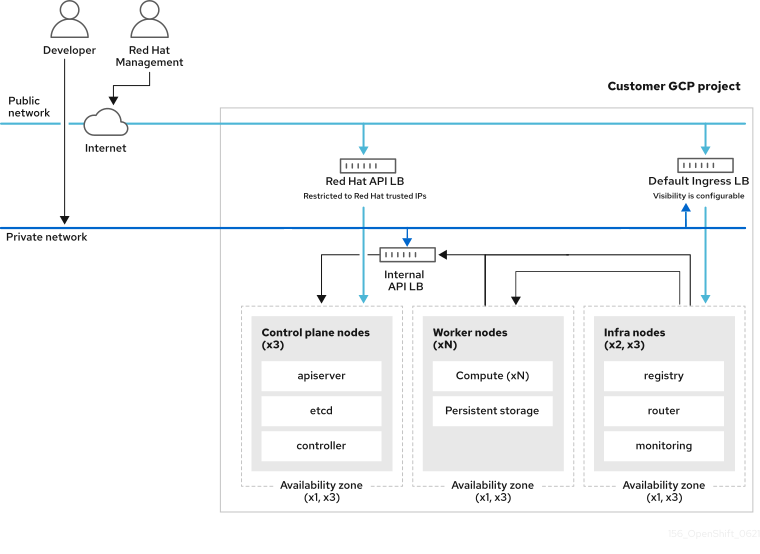
Avec une configuration réseau privé, votre point de terminaison de serveur API cluster et vos itinéraires d’application sont privés. Dédié aux clusters GCP, nous utilisons certains sous-réseaux publics, mais aucun avion de contrôle ou nœud de travail n’est déployé dans des sous-réseaux publics.
Le Red Hat recommande d’utiliser Private Service Connect (PSC) lors du déploiement d’un cluster privé OpenShift dédié sur Google Cloud Platform (GCP). La CFP s’assure qu’il existe une connectivité privée sécurisée entre l’infrastructure Red Hat, l’ingénierie de fiabilité du site (SRE) et les clusters privés OpenShift.
La gestion Red Hat SRE accède au cluster via un point de terminaison public d’équilibre de charge qui est limité aux IP Red Hat. Le point de terminaison du serveur API est privé. Le point d’extrémité de l’API Red Hat distinct est public (mais limité aux adresses IP de confiance de Red Hat). Le contrôleur d’entrée par défaut peut être public ou privé. L’image suivante montre la connectivité réseau d’un cluster privé sans Private Service Connect (PSC).
Figure 3.3. Dédié sur Google Cloud Platform (GCP) déployé sur un réseau privé sans PSC
3.5. Dédié sur le modèle d’architecture Google Cloud Platform (GCP)
Avec une configuration de réseau public, le point de terminaison de votre serveur API cluster et les itinéraires d’application sont orientés sur Internet. Le contrôleur d’entrée par défaut peut être public ou privé. L’image suivante montre la connectivité réseau d’un cluster public.
Figure 3.4. Dédié sur Google Cloud Platform (GCP) déployé sur un réseau public

Chapitre 4. Architecture de l’avion de contrôle
Le plan de contrôle, qui est composé de machines de plan de contrôle, gère le cluster OpenShift dédié. Les machines à plan de contrôle gèrent les charges de travail sur les machines de calcul, qui sont également connues sous le nom de machines de travail. Le cluster gère lui-même toutes les mises à niveau vers les machines par les actions de l’opérateur de versions de cluster (CVO), et un ensemble d’opérateurs individuels.
4.1. Les rôles de machine dans OpenShift Dedicated
La fonction OpenShift Dedicated assigne différents rôles. Ces rôles définissent la fonction de la machine dans le cluster. Le cluster contient des définitions pour les types de rôles standard de maître et de travailleur.
4.1.1. Les travailleurs des clusters
Dans un cluster Kubernetes, les nœuds de travail exécutent et gèrent les charges de travail réelles demandées par les utilisateurs de Kubernetes. Les nœuds de travail annoncent leur capacité et le planificateur, qui est un service d’avion de contrôle, détermine sur quels nœuds commencer les pods et les conteneurs. Les services importants suivants s’appliquent à chaque nœud de travail:
- CRI-O, qui est le moteur de conteneur.
- kubelet, qui est le service qui accepte et répond aux demandes d’exécution et d’arrêt des charges de travail des conteneurs.
- Le proxy de service, qui gère la communication pour les pods entre les travailleurs.
- L’exécution de conteneurs crun ou runC de bas niveau, qui crée et exécute des conteneurs.
Consultez la documentation pour créer un ContainerRuntimeConfig CR pour obtenir des informations sur la façon d’activer runC au lieu du cron par défaut.
Dans OpenShift Dedicated, les ensembles de machines de calcul contrôlent les machines de calcul, qui sont assignées au rôle de la machine de travail. Les machines avec le rôle du travailleur propulsent les charges de travail qui sont régies par un pool de machines spécifique qui les met à l’échelle automatique. Étant donné qu’OpenShift Dedicated a la capacité de prendre en charge plusieurs types de machines, les machines ayant le rôle de travailleur sont classées comme machines de calcul. Dans cette version, les termes machine de travail et machine de calcul sont utilisés de manière interchangeable parce que le seul type par défaut de machine de calcul est la machine ouvrier. Dans les versions futures d’OpenShift Dedicated, différents types de machines de calcul, telles que les machines d’infrastructure, pourraient être utilisés par défaut.
Les ensembles de machines de calcul sont des regroupements de ressources de la machine de calcul sous l’espace de noms machine-api. Les ensembles de machines de calcul sont des configurations conçues pour démarrer de nouvelles machines de calcul sur un fournisseur de cloud spécifique. Inversement, les pools de configuration de machine (MCP) font partie de l’espace de noms de l’opérateur de configuration de machine (MCO). Le MCP est utilisé pour regrouper les machines afin que l’AGC puisse gérer leurs configurations et faciliter leurs mises à niveau.
4.1.2. Les plans de contrôle des clusters
Dans un cluster Kubernetes, les nœuds maîtres exécutent des services qui sont nécessaires pour contrôler le cluster Kubernetes. Dans OpenShift Dedicated, le plan de contrôle est composé de machines de plan de contrôle qui ont un rôle maître de machine. Ils contiennent plus que les services Kubernetes pour la gestion du cluster OpenShift dédié.
Dans la plupart des clusters dédiés à OpenShift, les machines de plan de contrôle sont définies par une série de ressources d’API automatiques autonomes. Les plans de contrôle sont gérés avec des ensembles de machines de plan de contrôle. Des contrôles supplémentaires s’appliquent aux machines de plan de contrôle pour vous empêcher de supprimer toutes les machines de plan de contrôle et de casser votre cluster.
Les clusters de zone de disponibilité unique et plusieurs clusters de zones de disponibilité nécessitent un minimum de trois nœuds de plan de contrôle.
Les services qui relèvent de la catégorie Kubernetes sur le plan de contrôle comprennent le serveur API Kubernetes, etcd, le gestionnaire du contrôleur Kubernetes et le planificateur Kubernetes.
| Composante | Description |
|---|---|
| Kubernetes serveur API | Le serveur API Kubernetes valide et configure les données pour les pods, les services et les contrôleurs de réplication. Il fournit également un point focal pour l’état partagé du cluster. |
| etc. | etcd stocke l’état persistant du plan de contrôle tandis que d’autres composants surveillent, etc., les changements à apporter dans l’état spécifié. |
| Gestionnaire de contrôleur Kubernetes | Le gestionnaire du contrôleur Kubernetes veille etcd pour les modifications d’objets tels que les objets de réplication, d’espace de noms et de contrôleur de compte de service, puis utilise l’API pour appliquer l’état spécifié. De nombreux processus de ce type créent un cluster avec un leader actif à la fois. |
| Kubernetes planificateur | Le planificateur Kubernetes montre les pods nouvellement créés sans nœud assigné et sélectionne le meilleur nœud pour héberger le pod. |
Il existe également des services OpenShift qui s’exécutent sur le plan de contrôle, qui comprennent le serveur API OpenShift, le gestionnaire de contrôleur OpenShift, le serveur OpenShift OAuth API et le serveur OpenShift OAuth.
| Composante | Description |
|---|---|
| Le serveur d’API OpenShift | Le serveur API OpenShift valide et configure les données pour les ressources OpenShift, telles que des projets, des itinéraires et des modèles. Le serveur d’API OpenShift est géré par l’opérateur de serveur d’API OpenShift. |
| Gestionnaire de contrôleur OpenShift | Le gestionnaire de contrôleur OpenShift veille etcd pour les modifications apportées aux objets OpenShift, tels que les objets de projet, d’itinéraire et de contrôleur de modèle, puis utilise l’API pour appliquer l’état spécifié. Le gestionnaire de contrôleur OpenShift est géré par l’opérateur OpenShift Controller Manager. |
| Le serveur de l’API OpenShift OAuth | Le serveur API OpenShift OAuth valide et configure les données pour s’authentifier auprès d’OpenShift Dedicated, tels que les utilisateurs, les groupes et les jetons OAuth. Le serveur de l’API OpenShift OAuth est géré par l’opérateur d’authentification du cluster. |
| Le serveur OpenShift OAuth | Les utilisateurs demandent des jetons au serveur OpenShift OAuth pour s’authentifier à l’API. Le serveur OpenShift OAuth est géré par l’opérateur d’authentification du cluster. |
Certains de ces services sur les machines de plan de contrôle fonctionnent comme des services système, tandis que d’autres fonctionnent comme des gousses statiques.
Les services système sont appropriés pour les services dont vous avez besoin pour toujours proposer ce système en particulier peu de temps après son démarrage. Dans le cas des machines de contrôle, celles-ci incluent sshd, ce qui permet la connexion à distance. Il comprend également des services tels que:
- Le moteur de conteneur CRI-O (crio), qui fonctionne et gère les conteneurs. L’OpenShift Dedicated 4 utilise CRI-O au lieu du moteur Docker Container.
- Kubelet (kubelet), qui accepte les demandes de gestion des conteneurs sur la machine à partir des services d’avion de contrôle.
CRI-O et Kubelet doivent fonctionner directement sur l’hôte en tant que services système, car ils doivent être exécutés avant de pouvoir exécuter d’autres conteneurs.
Les pods de plan de contrôle installateur* et révision-pruner-* doivent s’exécuter avec des autorisations root car ils écrivent dans le répertoire /etc/kubernetes, qui appartient à l’utilisateur root. Ces pods se trouvent dans les espaces de noms suivants:
-
à propos de OpenShift-etcd -
comment utiliser OpenShift-kube-apiserver? -
le gestionnaire OpenShift-kube-controller-manager -
horaires OpenShift-kube-scheduler
4.2. Les opérateurs dans OpenShift dédiés
Les opérateurs sont parmi les composants les plus importants d’OpenShift Dedicated. Ils sont la méthode préférée d’emballage, de déploiement et de gestion des services sur le plan de contrôle. Ils peuvent également fournir des avantages aux applications que les utilisateurs exécutent.
Les opérateurs s’intègrent aux API Kubernetes et aux outils CLI tels que kubectl et OpenShift CLI (oc). Ils fournissent les moyens de surveiller les applications, d’effectuer des contrôles de santé, de gérer les mises à jour en direct (OTA) et de s’assurer que les applications restent dans votre état spécifié.
Les opérateurs offrent également une expérience de configuration plus granulaire. Configurez chaque composant en modifiant l’API que l’opérateur expose au lieu de modifier un fichier de configuration global.
Comme le CRI-O et le Kubelet fonctionnent sur tous les nœuds, presque toutes les autres fonctions de cluster peuvent être gérées sur le plan de contrôle en utilisant des opérateurs. Les composants qui sont ajoutés au plan de contrôle en utilisant les opérateurs comprennent des services de réseautage et d’identification critiques.
Bien que les deux suivent des concepts et des objectifs similaires, les opérateurs dans OpenShift Dedicated sont gérés par deux systèmes différents, en fonction de leur objectif:
- Les opérateurs de clusters
- Géré par l’opérateur de versions de cluster (CVO) et installé par défaut pour effectuer des fonctions de cluster.
- Opérateurs complémentaires optionnels
- Géré par Operator Lifecycle Manager (OLM) et peut être rendu accessible pour les utilisateurs à exécuter dans leurs applications. Également connu sous le nom d’opérateurs basés sur OLM.
4.2.1. Opérateurs d’extensions
Le gestionnaire de cycle de vie de l’opérateur (OLM) et OperatorHub sont des composants par défaut dans OpenShift Dedicated qui aident à gérer les applications natives Kubernetes en tant qu’opérateurs. Ensemble, ils fournissent le système de découverte, d’installation et de gestion des opérateurs complémentaires optionnels disponibles sur le cluster.
En utilisant OperatorHub dans la console Web dédiée OpenShift, les administrateurs ayant le rôle d’administrateur dédié et les utilisateurs autorisés peuvent sélectionner Opérateurs à installer à partir des catalogues d’opérateurs. Après avoir installé un opérateur depuis OperatorHub, il peut être mis à disposition dans le monde entier ou dans des espaces de noms spécifiques pour s’exécuter dans des applications utilisateur.
Des sources de catalogue par défaut sont disponibles qui incluent les opérateurs Red Hat, les opérateurs certifiés et les opérateurs communautaires. Les administrateurs dotés du rôle d’administrateur dédié peuvent également ajouter leurs propres sources de catalogue personnalisées, qui peuvent contenir un ensemble personnalisé d’opérateurs.
Les opérateurs inscrits sur le marché du hub opérateur devraient être disponibles pour l’installation. Ces opérateurs sont considérés comme des charges de travail des clients et ne sont pas surveillés par Red Hat Site Reliability Engineering (SRE).
Les développeurs peuvent utiliser le SDK de l’opérateur pour aider les opérateurs personnalisés qui profitent également des fonctionnalités OLM. Leur opérateur peut ensuite être groupé et ajouté à une source de catalogue personnalisée, qui peut être ajoutée à un cluster et mise à la disposition des utilisateurs.
L’OLM ne gère pas les opérateurs de clusters qui composent l’architecture dédiée OpenShift.
4.3. Aperçu de etcd
etcd est un magasin de valeur clé cohérent et distribué qui contient de petites quantités de données qui peuvent s’intégrer entièrement dans la mémoire. Bien que etcd soit un élément central de nombreux projets, c’est le principal magasin de données pour Kubernetes, qui est le système standard pour l’orchestration des conteneurs.
4.3.1. Avantages de l’utilisation etcd
En utilisant etcd, vous pouvez bénéficier de plusieurs façons:
- Conservez des temps de disponibilité cohérents pour vos applications cloud natives et maintenez-les en fonction même si les serveurs individuels échouent
- Conserver et reproduire tous les états de cluster pour Kubernetes
- Distribuer les données de configuration pour fournir la redondance et la résilience pour la configuration des nœuds
4.3.2. Comment fonctionne etcd
Afin d’assurer une approche fiable de la configuration et de la gestion des clusters, etcd utilise l’opérateur etcd. L’opérateur simplifie l’utilisation de etcd sur une plate-forme de conteneurs Kubernetes comme OpenShift Dedicated. Avec l’opérateur etcd, vous pouvez créer ou supprimer des membres etcd, redimensionner des clusters, effectuer des sauvegardes et mettre à niveau etcd.
L’opérateur etcd observe, analyse et agit:
- Il observe l’état du cluster en utilisant l’API Kubernetes.
- Il analyse les différences entre l’état actuel et l’état que vous voulez.
- Il corrige les différences à travers les API de gestion de cluster etcd, l’API Kubernetes, ou les deux.
etcd détient l’état du cluster, qui est constamment mis à jour. Cet état est constamment persisté, ce qui conduit à un nombre élevé de petits changements à haute fréquence. En conséquence, Red Hat Site Reliability Engineering (SRE) soutient le membre du cluster etcd avec des E/S rapides et à faible latence.
4.4. Des mises à jour automatiques de la configuration du plan de contrôle
Dans les clusters dédiés à OpenShift, les réglages de plan de commande propagent automatiquement les modifications à la configuration de votre plan de contrôle. Lorsqu’une machine de plan de commande doit être remplacée, l’opérateur de jeu de machines de plan de contrôle crée une machine de remplacement basée sur la configuration spécifiée par la ressource personnalisée ControlPlaneMachineSet (CR). Lorsque la nouvelle machine de plan de contrôle est prête, l’opérateur draine et met fin en toute sécurité à l’ancienne machine de plan de contrôle d’une manière qui atténue tout effet négatif potentiel sur l’API de cluster ou la disponibilité de la charge de travail.
Il est impossible de demander que les remplacements d’appareils de commande se produisent uniquement pendant les fenêtres de maintenance. L’opérateur d’ensemble de machines de plan de contrôle agit pour assurer la stabilité du cluster. L’attente d’une fenêtre de maintenance pourrait compromettre la stabilité des clusters.
La machine à plan de commande peut être marquée pour être remplacée à tout moment, généralement parce que la machine est tombée hors de la spécification ou est entrée dans un état malsain. Ces remplacements sont une partie normale du cycle de vie d’un cluster et ne sont pas une source de préoccupation. Le SRE sera automatiquement alerté du problème en cas de défaillance d’une partie d’un nœud de contrôle.
En fonction du moment où le cluster dédié OpenShift a été créé à l’origine, l’introduction de jeux de machines de plan de contrôle peut laisser un ou deux nœuds de plan de contrôle avec des étiquettes ou des noms de machines qui sont incompatibles avec les autres nœuds de plan de contrôle. A titre d’exemple clustername-master-0, clustername-master-1, et clustername-master-2-abcxyz. De telles incohérences de dénomination n’affectent pas le fonctionnement du groupe et ne sont pas une source de préoccupation.
4.5. La récupération des machines de plan de contrôle défaillantes
L’opérateur d’ensemble de machines de plan de contrôle automatise la récupération des machines de plan de contrôle. Lorsqu’une machine de plan de contrôle est supprimée, l’opérateur crée un remplacement par la configuration spécifiée dans la ressource personnalisée ControlPlaneMachineSet (CR).
Chapitre 5. Aperçu de l’architecture GPU NVIDIA
La NVIDIA prend en charge l’utilisation des ressources de l’unité de traitement graphique (GPU) sur OpenShift Dedicated. La plateforme OpenShift Dedicated est une plateforme Kubernetes axée sur la sécurité et développée et prise en charge par Red Hat pour déployer et gérer des clusters Kubernetes à grande échelle. Le logiciel OpenShift Dedicated inclut des améliorations à Kubernetes afin que les utilisateurs puissent facilement configurer et utiliser les ressources GPU NVIDIA pour accélérer les charges de travail.
L’opérateur GPU NVIDIA exploite le cadre Opérateur d’OpenShift dédié pour gérer le cycle de vie complet des composants logiciels NVIDIA nécessaires pour exécuter des charges de travail accélérées par GPU.
Ces composants incluent les pilotes NVIDIA (pour activer CUDA), le plugin de périphérique Kubernetes pour les GPU, la boîte à outils NVIDIA Container Toolkit, le marquage automatique des nœuds utilisant la découverte de fonctionnalités GPU (GFD), la surveillance basée sur DCGM, et d’autres.
L’opérateur GPU NVIDIA n’est pris en charge que par NVIDIA. En savoir plus sur l’obtention d’un support auprès de NVIDIA, consultez Obtain Support de NVIDIA.
5.1. Conditions préalables du GPU NVIDIA
- Cluster OpenShift fonctionnant avec au moins un nœud de travail GPU.
- Accès au cluster OpenShift en tant que cluster-admin pour effectuer les étapes requises.
- Le CLI OpenShift (oc) est installé.
- L’opérateur de découverte de fonctionnalités de nœud (NFD) est installé et une instance de découverte de nodefeature est créée.
5.2. GPU et OSD
Il est possible de déployer OpenShift Dedicated sur les types d’instances NVIDIA GPU.
Il est important que cette instance de calcul soit une instance de calcul accélérée par GPU et que le type GPU corresponde à la liste des GPU pris en charge de NVIDIA AI Enterprise. À titre d’exemple, T4, V100 et A100 font partie de cette liste.
Choisissez l’une des méthodes suivantes pour accéder aux GPU conteneurisés:
- GPU passe par l’accès et l’utilisation du matériel GPU au sein d’une machine virtuelle (VM).
- GPU (vGPU) tranchant le temps lorsque l’ensemble du GPU n’est pas requis.
5.3. Les méthodes de partage GPU
« Red Hat et NVIDIA ont développé des mécanismes de concurrence et de partage GPU pour simplifier l’informatique accélérée par GPU sur un cluster dédié OpenShift au niveau de l’entreprise.
Les applications ont généralement des exigences de calcul différentes qui peuvent laisser les GPU sous-utilisés. Fournir le bon nombre de ressources de calcul pour chaque charge de travail est essentiel pour réduire les coûts de déploiement et maximiser l’utilisation du GPU.
Il existe des mécanismes de concurrence pour améliorer l’utilisation des GPU, allant des API de programmation aux logiciels système et au partitionnement matériel, y compris la virtualisation. La liste suivante montre les mécanismes de concurrence du GPU:
- Calcul des flux d’architecture de dispositifs unifiés (CUDA)
- Tranchant du temps
- CUDA Multi-Process Service (MPS)
- GPU multi-instance (MIG)
- La virtualisation avec vGPU
Ressources supplémentaires
5.3.1. Flux CUDA
Compute Unified Device Architecture (CUDA) est une plate-forme informatique parallèle et un modèle de programmation développé par NVIDIA pour l’informatique générale sur les GPU.
Le flux est une séquence d’opérations qui s’exécute en ordre de problème sur le GPU. Les commandes CUDA sont généralement exécutées de manière séquentielle dans un flux par défaut et une tâche ne démarre pas tant qu’une tâche précédente n’est pas terminée.
Le traitement asynchrone des opérations sur différents flux permet l’exécution parallèle des tâches. La tâche émise dans un flux s’exécute avant, pendant ou après qu’une autre tâche soit émise dans un autre flux. Cela permet au GPU d’exécuter plusieurs tâches simultanément dans aucun ordre prescrit, ce qui permet d’améliorer les performances.
Ressources supplémentaires
5.3.2. Tranchant du temps
GPU time-slicing interleva les charges de travail programmées sur les GPU surchargés lorsque vous exécutez plusieurs applications CUDA.
Il est possible de définir un ensemble de répliques pour un GPU, chacun pouvant être distribué indépendamment à un pod pour exécuter des charges de travail. Contrairement au GPU multiinstance (MIG), il n’y a pas d’isolement de mémoire ou de défaut entre les répliques, mais pour certaines charges de travail, c’est mieux que de ne pas partager du tout. En interne, le chronométrage GPU est utilisé pour multiplexer les charges de travail à partir de répliques du même GPU sous-jacent.
Il est possible d’appliquer une configuration par défaut à l’échelle du cluster. Il est également possible d’appliquer des configurations spécifiques aux nœuds. À titre d’exemple, vous pouvez appliquer une configuration de découpage de temps uniquement aux nœuds dotés de GPU Tesla T4 et ne pas modifier les nœuds avec d’autres modèles GPU.
Il est possible de combiner ces deux approches en appliquant une configuration par défaut à l’échelle du cluster, puis d’étiqueter les nœuds pour donner à ces nœuds une configuration spécifique à chaque nœud.
5.3.3. CUDA Multi-Process Service
CUDA Multi-Process Service (MPS) permet à un seul GPU d’utiliser plusieurs processus CUDA. Les processus s’exécutent en parallèle sur le GPU, éliminant ainsi la saturation des ressources de calcul GPU. Le MPS permet également l’exécution simultanée, ou le chevauchement, des opérations du noyau et de la copie de mémoire à partir de différents processus pour améliorer l’utilisation.
Ressources supplémentaires
5.3.4. GPU multi-instance
En utilisant le GPU Multi-instance (MIG), vous pouvez diviser les unités de calcul GPU et la mémoire en plusieurs instances MIG. Chacune de ces instances représente un périphérique GPU autonome du point de vue du système et peut être connectée à n’importe quelle application, conteneur ou machine virtuelle fonctionnant sur le nœud. Le logiciel qui utilise le GPU traite chacune de ces instances MIG comme un GPU individuel.
Le MIG est utile lorsque vous avez une application qui ne nécessite pas la pleine puissance d’un GPU entier. La fonctionnalité MIG de la nouvelle architecture NVIDIA Ampere vous permet de diviser vos ressources matérielles en plusieurs instances GPU, dont chacune est disponible pour le système d’exploitation en tant que GPU indépendant compatible CUDA.
La version 1.7.0 et supérieure de NVIDIA GPU Operator fournit une prise en charge MIG pour les cartes A100 et A30 Ampere. Ces instances GPU sont conçues pour prendre en charge jusqu’à sept applications CUDA indépendantes afin qu’elles fonctionnent complètement isolées avec des ressources matérielles dédiées.
Ressources supplémentaires
5.3.5. La virtualisation avec vGPU
Les machines virtuelles (VM) peuvent accéder directement à un seul GPU physique à l’aide de NVIDIA vGPU. Il est possible de créer des GPU virtuels qui peuvent être partagés par des machines virtuelles à travers l’entreprise et accessibles par d’autres appareils.
Cette capacité combine la puissance des performances GPU avec les avantages de gestion et de sécurité fournis par vGPU. Les avantages supplémentaires fournis par vGPU comprennent la gestion proactive et la surveillance de votre environnement de VM, l’équilibrage de la charge de travail pour les charges de travail mixtes VDI et calcul, et le partage des ressources sur plusieurs machines virtuelles.
Ressources supplémentaires
5.4. Fonctionnalités GPU NVIDIA pour OpenShift Dedicated
- Boîte à outils NVIDIA Container
- La boîte à outils NVIDIA Container vous permet de créer et d’exécuter des conteneurs accélérés par GPU. La boîte à outils comprend une bibliothèque d’exécution de conteneurs et des utilitaires pour configurer automatiquement les conteneurs pour utiliser les GPU NVIDIA.
- Entreprise NVIDIA AI
La NVIDIA AI Enterprise est une suite complète de logiciels d’analyse de données et d’IA optimisés, certifiés et pris en charge avec les systèmes certifiés NVIDIA.
La NVIDIA AI Enterprise prend en charge Red Hat OpenShift Dedicated. Les méthodes d’installation suivantes sont prises en charge:
- Dédié sur le métal nu ou VMware vSphere avec GPU Passthrough.
- Dédié sur VMware vSphere avec NVIDIA vGPU.
- Découverte de fonctionnalités GPU
Découverte de fonctionnalités GPU NVIDIA pour Kubernetes est un composant logiciel qui vous permet de générer automatiquement des étiquettes pour les GPU disponibles sur un nœud. GPU Feature Discovery utilise la découverte de fonctionnalités de nœud (NFD) pour effectuer cette étiquette.
Le Node Feature Discovery Operator (NFD) gère la découverte des fonctionnalités matérielles et des configurations dans un cluster OpenShift Container Platform en étiquetant des nœuds avec des informations spécifiques au matériel. Le NFD étiquete l’hôte avec des attributs spécifiques aux nœuds, tels que les cartes PCI, le noyau, la version OS, etc.
Il est possible de trouver l’opérateur NFD dans le hub opérateur en recherchant "Node Feature Discovery".
- Opérateur GPU NVIDIA avec virtualisation OpenShift
Jusqu’à présent, l’opérateur GPU n’a fourni que des nœuds de travail pour exécuter des conteneurs accélérés par GPU. Désormais, l’opérateur GPU peut également être utilisé pour fournir des nœuds de travail pour l’exécution de machines virtuelles accélérées par GPU (VM).
Il est possible de configurer l’opérateur GPU pour déployer différents composants logiciels sur les nœuds de travail en fonction de la charge de travail GPU configurée pour s’exécuter sur ces nœuds.
- GPU Surveillance du tableau de bord
- Il est possible d’installer un tableau de bord de surveillance pour afficher les informations d’utilisation du GPU sur la page Observer le cluster dans la console Web dédiée OpenShift. Les informations sur l’utilisation du GPU comprennent le nombre de GPU disponibles, la consommation d’énergie (en watts), la température (en degrés Celsius), l’utilisation (en pourcentage) et d’autres mesures pour chaque GPU.
Chapitre 6. Comprendre le développement dédié d’OpenShift
Afin de tirer pleinement parti de la capacité des conteneurs lors du développement et de l’exécution d’applications de qualité d’entreprise, assurez-vous que votre environnement est pris en charge par des outils qui permettent aux conteneurs d’être:
- Créé sous forme de microservices discrets pouvant être connectés à d’autres services conteneurisés et non conteneurisés. À titre d’exemple, vous voudrez peut-être joindre votre application à une base de données ou y joindre une application de surveillance.
- Donc, si un serveur se bloque ou doit descendre pour la maintenance ou pour être déclassé, les conteneurs peuvent démarrer sur une autre machine.
- Automatisé pour récupérer automatiquement les modifications de code, puis démarrer et déployer de nouvelles versions d’eux-mêmes.
- À l’échelle, ou répliquée, pour avoir plus d’instances au service des clients à mesure que la demande augmente, puis réduite à moins de cas à mesure que la demande diminue.
- Exécutez de différentes manières, en fonction du type d’application. À titre d’exemple, une application peut s’exécuter une fois par mois pour produire un rapport puis sortir. Il se peut qu’une autre application ait besoin de fonctionner constamment et d’être très disponible pour les clients.
- Géré afin que vous puissiez surveiller l’état de votre application et réagir lorsque quelque chose va mal.
L’acceptation généralisée des conteneurs et les exigences qui en découlent pour les outils et les méthodes pour les rendre prêts à l’entreprise ont donné lieu à de nombreuses options pour eux.
Le reste de cette section explique les options pour les actifs que vous pouvez créer lorsque vous créez et déployez des applications Kubernetes conteneurisées dans OpenShift Dedicated. Il décrit également les approches que vous pourriez utiliser pour différents types d’applications et d’exigences de développement.
6.1. À propos du développement d’applications conteneurisées
Il est possible d’aborder le développement d’applications avec des conteneurs de plusieurs façons, et différentes approches pourraient être plus appropriées pour différentes situations. Afin d’illustrer une partie de cette variété, la série d’approches qui est présentée commence par le développement d’un seul conteneur et, en fin de compte, le déploiement de ce conteneur en tant qu’application critique pour une grande entreprise. Ces approches montrent différents outils, formats et méthodes que vous pouvez utiliser avec le développement d’applications conteneurisées. Ce sujet décrit:
- Construire un simple conteneur et le stocker dans un registre
- Créer un Kubernetes se manifeste et l’enregistrer dans un dépôt Git
- Faire un opérateur pour partager votre application avec d’autres personnes
6.2. Construire un conteneur simple
« vous avez une idée pour une application et vous voulez la conteneuriser.
D’abord, vous avez besoin d’un outil pour construire un conteneur, comme buildah ou docker, et un fichier qui décrit ce qui se passe dans votre conteneur, qui est généralement un Dockerfile.
Ensuite, vous avez besoin d’un emplacement pour pousser l’image du conteneur résultant afin que vous puissiez l’utiliser pour exécuter n’importe où vous voulez qu’elle s’exécute. Cet emplacement est un registre de conteneurs.
Certains exemples de chacun de ces composants sont installés par défaut sur la plupart des systèmes d’exploitation Linux, à l’exception du Dockerfile, que vous fournissez vous-même.
Le diagramme suivant affiche le processus de construction et de poussée d’une image:
Figure 6.1. Créez une application conteneurisée simple et poussez-la vers un registre
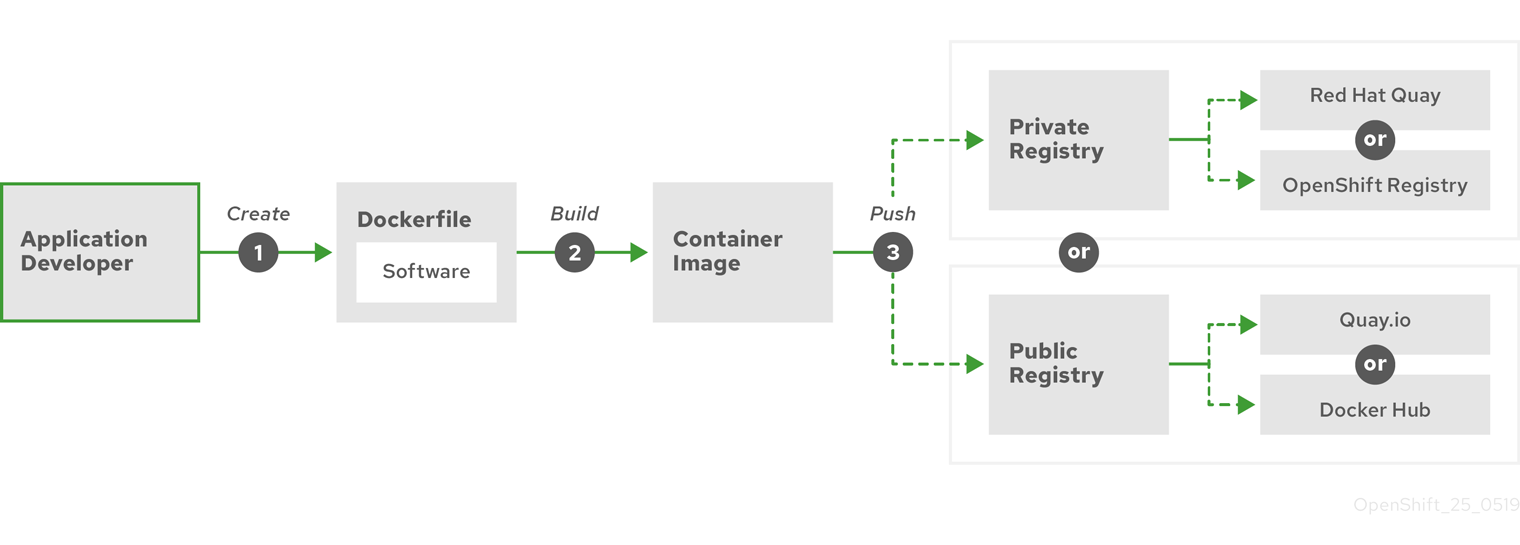
Lorsque vous utilisez un ordinateur qui exécute Red Hat Enterprise Linux (RHEL) comme système d’exploitation, le processus de création d’une application conteneurisée nécessite les étapes suivantes:
- Installer des outils de construction de conteneurs: RHEL contient un ensemble d’outils qui incluent podman, buildah et skopeo que vous utilisez pour construire et gérer des conteneurs.
- Créez un Dockerfile pour combiner l’image de base et le logiciel: Les informations sur la construction de votre conteneur vont dans un fichier nommé Dockerfile. Dans ce fichier, vous identifiez l’image de base à partir de laquelle vous créez, les paquets logiciels que vous installez et le logiciel que vous copiez dans le conteneur. De plus, vous identifiez les valeurs de paramètres comme les ports réseau que vous exposez en dehors du conteneur et les volumes que vous montez à l’intérieur du conteneur. Installez votre Dockerfile et le logiciel que vous souhaitez conteneuriser dans un répertoire sur votre système RHEL.
- Exécutez buildah ou docker build: exécutez le buildah build-using-dockerfile ou la commande docker build pour tirer l’image de base choisie vers le système local et créer une image conteneur qui est stockée localement. Il est également possible de construire des images de conteneurs sans Dockerfile en utilisant buildah.
- Balisez et poussez vers un registre: ajoutez une balise à votre nouvelle image de conteneur qui identifie l’emplacement du registre dans lequel vous souhaitez stocker et partager votre conteneur. Ensuite, poussez cette image vers le registre en exécutant la commande podman push ou docker push.
- Tirez et exécutez l’image: À partir de n’importe quel système qui dispose d’un outil client conteneur, tel que podman ou docker, exécutez une commande qui identifie votre nouvelle image. À titre d’exemple, exécutez la commande podman run <image_name> ou docker run <image_name>. Ici <image_name> est le nom de votre nouvelle image de conteneur, qui ressemble à quay.io/myrepo/myapp:lastest. Le registre peut nécessiter des informations d’identification pour pousser et tirer des images.
6.2.1. Les options d’outil de construction de conteneurs
La construction et la gestion de conteneurs avec buildah, podman et skopeo se traduit par des images de conteneurs standard de l’industrie qui incluent des fonctionnalités spécifiquement réglées pour le déploiement de conteneurs dans les environnements OpenShift Dedicated ou autres Kubernetes. Ces outils sont sans démon et peuvent fonctionner sans privilèges root, nécessitant moins de frais généraux pour les exécuter.
La prise en charge de Docker Container Engine en tant que temps d’exécution du conteneur est dépréciée dans Kubernetes 1.20 et sera supprimée dans une version ultérieure. Cependant, les images produites par Docker continueront à fonctionner dans votre cluster avec tous les temps d’exécution, y compris CRI-O. Consultez l’annonce du blog Kubernetes pour plus d’informations.
Lorsque vous exécutez finalement vos conteneurs dans OpenShift Dedicated, vous utilisez le moteur de conteneur CRI-O. CRI-O fonctionne sur chaque machine d’avion de travail et de contrôle dans un cluster dédié OpenShift, mais CRI-O n’est pas encore pris en charge en tant que temps d’exécution autonome en dehors d’OpenShift Dedicated.
6.2.2. Les options d’image de base
L’image de base sur laquelle vous choisissez de construire votre application contient un ensemble de logiciels qui ressemble à un système Linux à votre application. Lorsque vous construisez votre propre image, votre logiciel est placé dans ce système de fichiers et voit ce système de fichiers comme s’il regardait son système d’exploitation. Le choix de cette image de base a un impact majeur sur la sécurité, l’efficacité et la mise à niveau de votre conteneur à l’avenir.
Le Red Hat fournit un nouvel ensemble d’images de base appelées Red Hat Universal Base Images (UBI). Ces images sont basées sur Red Hat Enterprise Linux et sont similaires aux images de base offertes par Red Hat dans le passé, avec une différence majeure : elles sont librement redistribuables sans abonnement Red Hat. En conséquence, vous pouvez construire votre application sur des images UBI sans avoir à vous soucier de la façon dont elles sont partagées ou de la nécessité de créer différentes images pour différents environnements.
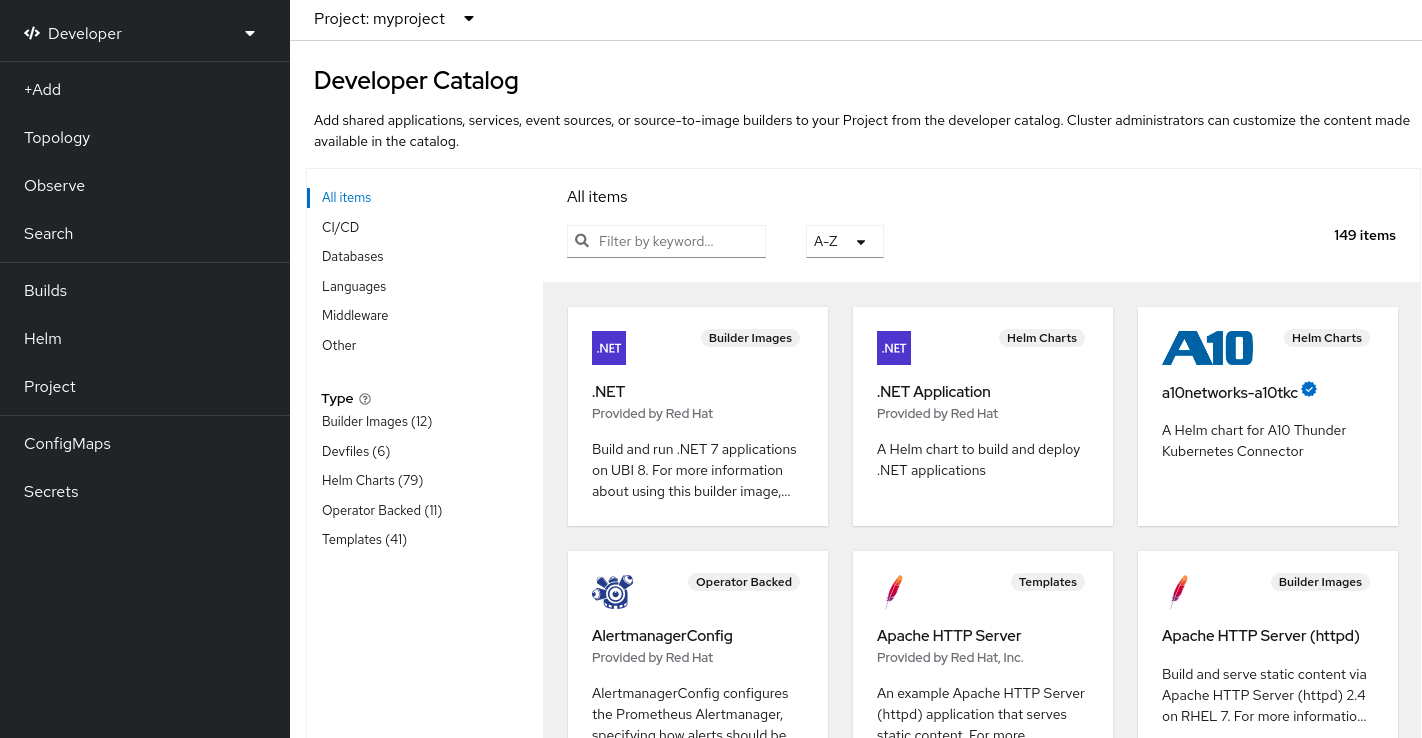
Ces images UBI ont des versions standard, init et minimales. Il est également possible d’utiliser les images Red Hat Software Collections comme base pour les applications qui s’appuient sur des environnements d’exécution spécifiques tels que Node.js, Perl ou Python. Les versions spéciales de certaines de ces images de base d’exécution sont appelées images Source-à-Image (S2I). Avec les images S2I, vous pouvez insérer votre code dans un environnement d’image de base prêt à exécuter ce code.
Les images S2I sont disponibles pour vous à utiliser directement à partir de l’interface Web dédiée OpenShift. Dans la perspective Développeur, accédez à la vue +Ajouter et dans la tuile du catalogue des développeurs, visualisez tous les services disponibles dans le catalogue des développeurs.
Figure 6.2. Choisissez des images de base S2I pour les applications qui ont besoin d’exécutions spécifiques
6.2.3. Les options de registre
Les registres de conteneurs sont l’endroit où vous stockez des images de conteneurs afin que vous puissiez les partager avec d’autres et les mettre à la disposition de la plate-forme où ils finissent par fonctionner. Il est possible de sélectionner de grands registres de conteneurs publics qui offrent des comptes gratuits ou une version premium offrant plus de stockage et de fonctionnalités spéciales. En outre, vous pouvez installer votre propre registre qui peut être exclusif à votre organisation ou partagé de manière sélective avec d’autres personnes.
Afin d’obtenir des images Red Hat et des images de partenaires certifiés, vous pouvez tirer du Registre Red Hat. Le Registre Red Hat est représenté par deux emplacements: Registry.access.redhat.com, qui n’est pas authentifié et déprécié, et Registry.redhat.io, qui nécessite une authentification. En savoir plus sur les images Red Hat et les images partenaires dans le Registre Red Hat à partir de la section Images Container du catalogue de l’écosystème Red Hat. En plus de la liste des images de conteneurs Red Hat, il montre également des informations détaillées sur le contenu et la qualité de ces images, y compris les scores de santé basés sur les mises à jour de sécurité appliquées.
Les grands registres publics comprennent Docker Hub et Quay.io. Le registre Quay.io est détenu et géré par Red Hat. De nombreux composants utilisés dans OpenShift Dedicated sont stockés dans Quay.io, y compris les images de conteneurs et les opérateurs qui sont utilisés pour déployer OpenShift Dedicated lui-même. Le Quay.io offre également les moyens de stocker d’autres types de contenu, y compris les graphiques Helm.
Dans le cas où vous voulez votre propre registre de conteneurs privé, OpenShift Dedicated comprend un registre de conteneurs privé qui est installé avec OpenShift Dedicated et fonctionne sur son cluster. Le Red Hat propose également une version privée du registre Quay.io appelé Red Hat Quay. Le Red Hat Quay inclut la réplication géographique, les déclencheurs Git build, le balayage d’image clair et de nombreuses autres fonctionnalités.
L’ensemble des registres mentionnés ici peut nécessiter des informations d’identification pour télécharger des images à partir de ces registres. Certaines de ces informations d’identification sont présentées à l’échelle du cluster à partir d’OpenShift Dedicated, tandis que d’autres informations d’identification peuvent être attribuées à des individus.
6.3. Création d’un manifeste Kubernetes pour OpenShift Dedicated
Alors que l’image du conteneur est le bloc de base d’une application conteneurisée, plus d’informations sont nécessaires pour gérer et déployer cette application dans un environnement Kubernetes tel que OpenShift Dedicated. Les étapes suivantes typiques après la création d’une image sont les suivantes:
- Comprendre les différentes ressources avec lesquelles vous travaillez dans Kubernetes se manifeste
- Faites quelques décisions sur le type d’application que vous exécutez
- Rassembler les composants de support
- Créez un manifeste et un magasin qui se manifestent dans un dépôt Git afin que vous puissiez le stocker dans un système de version source, l’auditer, le suivre, le promouvoir et le déployer dans l’environnement suivant, le retourner aux versions antérieures, si nécessaire, et le partager avec d’autres personnes.
6.3.1. À propos de Kubernetes pods et services
Alors que l’image du conteneur est l’unité de base avec docker, les unités de base avec lesquelles Kubernetes fonctionne sont appelées pods. Les pods représentent la prochaine étape dans la création d’une application. La gousse peut contenir un ou plusieurs contenants. La clé est que le pod est l’unité unique que vous déployez, mettez à l’échelle et gérez.
L’évolutivité et les espaces de noms sont probablement les principaux éléments à considérer lors de la détermination de ce qui se passe dans un pod. Afin de faciliter votre déploiement, vous voudrez peut-être déployer un conteneur dans un pod et inclure son propre conteneur d’enregistrement et de surveillance dans le pod. Ensuite, lorsque vous exécutez la pod et que vous devez mettre à l’échelle une instance supplémentaire, ces autres conteneurs sont mis à l’échelle avec elle. Dans le cas des espaces de noms, les conteneurs d’un pod partagent les mêmes interfaces réseau, volumes de stockage partagés et limitations de ressources, tels que la mémoire et le CPU, ce qui facilite la gestion du contenu du pod en tant qu’unité unique. Les conteneurs dans un pod peuvent également communiquer les uns avec les autres en utilisant des communications inter-processus standard, telles que les sémaphores du système V ou la mémoire partagée POSIX.
Alors que les gousses individuelles représentent une unité évolutive dans Kubernetes, un service fournit un moyen de regrouper un ensemble de gousses pour créer une application complète et stable qui peut accomplir des tâches telles que l’équilibrage de charge. Le service est également plus permanent qu’un pod car le service reste disponible à partir de la même adresse IP jusqu’à ce que vous le supprimiez. Lorsque le service est utilisé, il est demandé par nom et le cluster OpenShift Dedicated résout ce nom dans les adresses IP et les ports où vous pouvez atteindre les pods qui composent le service.
De par leur nature, les applications conteneurisées sont séparées des systèmes d’exploitation où elles s’exécutent et, par extension, de leurs utilisateurs. Dans une partie de votre manifeste Kubernetes décrit comment exposer l’application à des réseaux internes et externes en définissant des politiques réseau qui permettent un contrôle fin sur la communication avec vos applications conteneurisées. Afin de connecter les requêtes entrantes pour HTTP, HTTPS et d’autres services de l’extérieur de votre cluster à des services à l’intérieur de votre cluster, vous pouvez utiliser une ressource Ingress.
Lorsque votre conteneur nécessite un stockage sur disque au lieu d’un stockage de base de données, qui peut être fourni via un service, vous pouvez ajouter des volumes à vos manifestes pour que ce stockage soit disponible à vos pods. Configurez les manifestes pour créer des volumes persistants (PV) ou créer dynamiquement des volumes qui sont ajoutés à vos définitions Pod.
Après avoir défini un groupe de pods qui composent votre application, vous pouvez définir ces pods dans les objets Déploiement et DéploiementConfig.
6.3.2. Les types d’application
Ensuite, considérez comment votre type d’application influence comment l’exécuter.
Kubernetes définit différents types de charges de travail qui conviennent à différents types d’applications. Afin de déterminer la charge de travail appropriée pour votre demande, considérez si la demande est:
- Destiné à courir jusqu’à l’achèvement et être fait. Exemple est une application qui commence à produire un rapport et sort lorsque le rapport est terminé. L’application pourrait ne pas fonctionner à nouveau pendant un mois. Les objets dédiés OpenShift pour ces types d’applications incluent les objets Job et CronJob.
- Je m’attendais à courir en continu. Dans le cas des applications de longue date, vous pouvez écrire un déploiement.
- Il faut être très disponible. Lorsque votre application nécessite une disponibilité élevée, vous souhaitez dimensionner votre déploiement pour avoir plus d’une instance. L’objet Déploiement ou DéploiementConfig peut incorporer un ensemble de répliques pour ce type d’application. Avec les ensembles de répliques, les pods courent sur plusieurs nœuds pour s’assurer que l’application est toujours disponible, même si un travailleur descend.
- Il faut courir sur tous les nœuds. Certains types d’applications Kubernetes sont destinés à s’exécuter dans le cluster lui-même sur chaque nœud maître ou travailleur. DNS et les applications de surveillance sont des exemples d’applications qui doivent fonctionner en continu sur chaque nœud. Il est possible d’exécuter ce type d’application sous la forme d’un jeu de démons. Il est également possible d’exécuter un démon sur un sous-ensemble de nœuds, basé sur des étiquettes de nœuds.
- Besoin d’une gestion du cycle de vie. Lorsque vous souhaitez distribuer votre application pour que d’autres puissent l’utiliser, envisagez de créer un opérateur. Les opérateurs vous permettent de construire l’intelligence, afin qu’il puisse gérer des choses comme les sauvegardes et les mises à niveau automatiquement. Couplés avec le gestionnaire de cycle de vie de l’opérateur (OLM), les gestionnaires de clusters peuvent exposer les opérateurs à des espaces de noms sélectionnés afin que les utilisateurs du cluster puissent les exécuter.
- Avoir des exigences d’identité ou de numérotation. La demande peut avoir des exigences d’identité ou de numérotation. À titre d’exemple, vous devrez peut-être exécuter exactement trois instances de l’application et nommer les instances 0, 1 et 2. Cet ensemble est adapté à cette application. Les ensembles d’état sont les plus utiles pour les applications qui nécessitent un stockage indépendant, tels que les bases de données et les clusters de gardiens de zoo.
6.3.3. Composants de support disponibles
L’application que vous écrivez peut avoir besoin de composants de support, comme une base de données ou un composant de journalisation. Afin de répondre à ce besoin, vous pourriez être en mesure d’obtenir le composant requis à partir des catalogues suivants qui sont disponibles dans la console Web dédiée OpenShift:
- OperatorHub, qui est disponible dans chaque cluster OpenShift Dedicated 4. Le OperatorHub met les Opérateurs à la disposition de Red Hat, des partenaires certifiés Red Hat et des membres de la communauté à l’opérateur de cluster. L’opérateur de cluster peut rendre ces opérateurs disponibles dans tous les espaces de noms ou sélectionnés dans le cluster, afin que les développeurs puissent les lancer et les configurer avec leurs applications.
- Les modèles, qui sont utiles pour un type d’application unique, où le cycle de vie d’un composant n’est pas important après son installation. Le modèle fournit un moyen facile de commencer à développer une application Kubernetes avec un minimum de frais généraux. Le modèle peut être une liste de définitions de ressources, qui pourraient être le déploiement, le service, la route ou d’autres objets. Lorsque vous souhaitez modifier des noms ou des ressources, vous pouvez définir ces valeurs en tant que paramètres dans le modèle.
Les opérateurs et les modèles supportés peuvent être configurés selon les besoins spécifiques de votre équipe de développement, puis les rendre disponibles dans les espaces de noms dans lesquels vos développeurs travaillent. Beaucoup de gens ajoutent des modèles partagés à l’espace de noms openshift car il est accessible depuis tous les autres espaces de noms.
6.3.4. Appliquer le manifeste
Les manifestes de Kubernetes vous permettent de créer une image plus complète des composants qui composent vos applications Kubernetes. Ecrire ces manifestes sous forme de fichiers YAML et les déployer en les appliquant au cluster, par exemple en exécutant la commande oc application.
6.3.5. Les prochaines étapes
À ce stade, envisagez des moyens d’automatiser votre processus de développement de conteneurs. Idéalement, vous avez une sorte de pipeline CI qui construit les images et les pousse vers un registre. En particulier, un pipeline GitOps intègre le développement de vos conteneurs aux dépôts Git que vous utilisez pour stocker le logiciel nécessaire à la construction de vos applications.
Le flux de travail à ce stade pourrait ressembler à:
- Jour 1: Vous écrivez un peu de YAML. Ensuite, vous exécutez la commande oc appliquer pour appliquer ce YAML sur le cluster et tester qu’il fonctionne.
- Jour 2: Vous mettez votre fichier de configuration de conteneur YAML dans votre propre dépôt Git. À partir de là, les personnes qui veulent installer cette application, ou vous aider à l’améliorer, peuvent retirer le YAML et l’appliquer à leur cluster pour exécuter l’application.
- Jour 3: envisagez d’écrire un opérateur pour votre demande.
6.4. Développer pour les opérateurs
L’emballage et le déploiement de votre application en tant qu’opérateur peuvent être préférés si vous mettez votre application à la disposition des autres à exécuter. Comme indiqué précédemment, les opérateurs ajoutent un composant de cycle de vie à votre application qui reconnaît que le travail d’exécution d’une demande n’est pas terminé dès qu’il est installé.
Lorsque vous créez une application en tant qu’opérateur, vous pouvez construire dans votre propre connaissance de la façon d’exécuter et de maintenir l’application. Il est possible de créer des fonctionnalités pour mettre à niveau l’application, la sauvegarder, la mettre à l’échelle ou garder une trace de son état. Lorsque vous configurez correctement l’application, les tâches de maintenance, comme la mise à jour de l’opérateur, peuvent se produire automatiquement et de manière invisible pour les utilisateurs de l’opérateur.
L’exemple d’un opérateur utile est celui qui est configuré pour sauvegarder automatiquement les données à des moments particuliers. Le fait d’avoir un opérateur gérer la sauvegarde d’une application à des heures définies peut sauver un administrateur système de se souvenir pour le faire.
La maintenance des applications qui a été traditionnellement terminée manuellement, comme la sauvegarde de données ou les certificats tournants, peut être effectuée automatiquement avec un opérateur.
Chapitre 7. Les plugins d’admission
Les plugins d’admission sont utilisés pour aider à réguler les fonctions d’OpenShift Dedicated.
7.1. À propos des plugins d’admission
Les plugins d’admission interceptent les requêtes à l’API principale pour valider les demandes de ressources. Après qu’une demande soit authentifiée et autorisée, les plugins d’admission s’assurent que toutes les politiques associées sont suivies. Ils sont par exemple couramment utilisés pour appliquer la politique de sécurité, les limitations de ressources ou les exigences de configuration.
Les plugins d’admission s’exécutent en séquence comme une chaîne d’admission. Lorsqu’un plugin d’admission dans la séquence rejette une demande, toute la chaîne est avortée et une erreur est retournée.
Le module OpenShift Dedicated dispose d’un ensemble de plugins d’admission par défaut activés pour chaque type de ressource. Ceux-ci sont nécessaires au bon fonctionnement du cluster. Les plugins d’admission ignorent les ressources dont ils ne sont pas responsables.
En plus des paramètres par défaut, la chaîne d’admission peut être étendue dynamiquement par le biais de plugins d’entrée Webhook qui appellent à des serveurs webhook personnalisés. Il existe deux types de plugins d’admission webhook: un plugin d’admission mutant et un plugin d’admission valide. Le plugin d’admission mutant s’exécute en premier et peut à la fois modifier les ressources et valider les demandes. Le plugin d’admission valide les requêtes et s’exécute après le plugin d’admission mutant afin que les modifications déclenchées par le plugin d’admission mutant puissent également être validées.
Appeler des serveurs webhook via un plugin d’admission mutant peut produire des effets secondaires sur les ressources liées à l’objet cible. Dans de telles situations, vous devez prendre des mesures pour valider que le résultat final est comme prévu.
L’admission dynamique doit être utilisée avec prudence car elle a un impact sur les opérations des avions de contrôle en grappes. Lorsque vous appelez des serveurs Webhook via des plugins d’admission Webhook dans OpenShift Dedicated 4, assurez-vous que vous avez lu la documentation complètement et testé pour les effets secondaires des mutations. Inclure des étapes pour restaurer les ressources dans leur état d’origine avant la mutation, dans le cas où une demande ne passe pas dans toute la chaîne d’admission.
7.2. Les plugins d’admission par défaut
Les plugins de validation et d’admission par défaut sont activés dans OpenShift Dedicated 4. Ces plugins par défaut contribuent à la fonctionnalité fondamentale du plan de contrôle, telles que la politique d’entrée, le dépassement de ressources de cluster et la politique de quota.
Évitez d’exécuter des charges de travail ou de partager l’accès aux projets par défaut. Les projets par défaut sont réservés à l’exécution de composants de cluster de base.
Les projets par défaut suivants sont considérés comme hautement privilégiés: par défaut, kube-public, kube-system, openshift, openshift-infra, openshift-node, et d’autres projets créés par système qui ont l’étiquette openshift.io / run-level définie à 0 ou 1. La fonctionnalité qui repose sur des plugins d’admission, tels que l’admission de sécurité pod, les contraintes de contexte de sécurité, les quotas de ressources de cluster et la résolution de référence d’image, ne fonctionne pas dans des projets hautement privilégiés.
Les listes suivantes contiennent les plugins d’admission par défaut:
Exemple 7.1. Validation des plugins d’admission
-
LimiteRanger -
Compte de ServiceAccount -
À propos de PodNodeSelector -
La priorité -
La restriction de PodTolerationRestriction -
Le propriétaireReferencesPermissionEnforcement -
Accueil > PersistentVolumeClaimResize -
Cours d’exécution -
CertificatApproval -
CertificatSigning -
CertificateSubjectRestriction -
autoscaling.openshift.io/ManagementCPUsOverride -
Autorisation.openshift.io/RestrictSubjectBindings -
calendrier.openshift.io/OriginPodNodeEnvironnement -
le réseau.openshift.io/ExternalIPRanger -
accès à Network.openshift.io/RestrictedEndpointsAdmission -
image.openshift.io/ImagePolicy -
accueil > Security.openshift.io/SecurityContextConstraint -
conditions de sécurité.openshift.io/SCCExecRestrictions -
itinéraire.openshift.io/IngressAdmission -
config.openshift.io/ValidateAPIServer -
config.openshift.io/ValidateAuthentication -
config.openshift.io/ValidateFeatureGate -
config.openshift.io/ValidateConsole -
l’opérateur.openshift.io/ValidateDNS -
config.openshift.io/ValidateImage -
config.openshift.io/ValidateOAuth -
config.openshift.io/ValidateProject -
config.openshift.io/DenyDeleteClusterConfiguration -
config.openshift.io/ValidateScheduler -
quota.openshift.io/ValidateClusterResourceQuota -
accueil > Security.openshift.io/ValidateSecurityContextConstraints -
Autorisation.openshift.io/ValidateRoleBindingRestriction -
config.openshift.io/ValidateNetwork -
opérateur.openshift.io/ValidateKubeControllerManager -
Comment validerAdmissionWebhook -
À propos de ResourceQuota -
quota.openshift.io/ClusterResourceQuota
Exemple 7.2. La mutation des plugins d’admission
-
Le NamespaceLifecycle -
LimiteRanger -
Compte de ServiceAccount -
Limite de Node -
Ajouter au panier TaintNodesByCondition -
À propos de PodNodeSelector -
La priorité -
DefaultTolerationDeuxièmes -
La restriction de PodTolerationRestriction -
DefaultStorageClass -
StorageObjectInUseProtection -
Cours d’exécution -
DefaultIngressClass -
autoscaling.openshift.io/ManagementCPUsOverride -
calendrier.openshift.io/OriginPodNodeEnvironnement -
image.openshift.io/ImagePolicy -
accueil > Security.openshift.io/SecurityContextConstraint -
accueil > Security.openshift.io/DefaultSecurityContextConstraints -
À propos de MutatingAdmissionWebhook
7.3. Les plugins d’admission Webhook
En plus des plugins d’admission par défaut OpenShift Dedicated, l’admission dynamique peut être implémentée via des plugins d’admission Webhook qui appellent des serveurs webhook, afin d’étendre les fonctionnalités de la chaîne d’admission. Les serveurs Webhook sont appelés HTTP à des points de terminaison définis.
Il existe deux types de plugins d’admission webhook dans OpenShift Dedicated:
- Au cours du processus d’admission, le plugin d’admission mutant peut effectuer des tâches, telles que l’injection d’étiquettes d’affinité.
- À la fin du processus d’admission, le plugin d’admission de validation peut être utilisé pour s’assurer qu’un objet est configuré correctement, par exemple en veillant à ce que les étiquettes d’affinité soient comme prévu. Lorsque la validation passe, OpenShift Dedicated programme l’objet tel qu’il est configuré.
Lorsqu’une demande d’API intervient, muter ou valider les plugins d’admission utilisent la liste des webhooks externes dans la configuration et les appellent en parallèle:
- Lorsque tous les webhooks approuvent la demande, la chaîne d’admission se poursuit.
- Lorsque l’un des webhooks refuse la demande, la demande d’admission est refusée et le motif de ce refus est fondé sur le premier refus.
- Lorsque plus d’un webhook refuse la demande d’admission, seule la première raison de refus est renvoyée à l’utilisateur.
- En cas d’erreur lors de l’appel d’un webhook, la demande est refusée ou le webhook est ignoré en fonction de l’ensemble de la stratégie d’erreur. Lorsque la politique d’erreur est définie sur Ignore, la demande est acceptée sans condition en cas de défaillance. En cas d’échec de la politique, les demandes manquées sont refusées. L’utilisation d’Ignore peut entraîner un comportement imprévisible pour tous les clients.
Le diagramme suivant illustre le processus de chaîne d’admission séquentiel dans lequel plusieurs serveurs webhook sont appelés.
Figure 7.1. Chaîne d’admission API avec mutation et validation des plugins d’admission
Exemple de cas d’utilisation du plugin d’admission webhook est où tous les pods doivent avoir un ensemble commun d’étiquettes. Dans cet exemple, le plugin d’admission mutant peut injecter des étiquettes et le plugin d’admission de validation peut vérifier que les étiquettes sont comme prévu. L’OpenShift Dedicated programmerait par la suite les pods qui incluent les étiquettes requises et rejetterait ceux qui ne le font pas.
Certains cas d’utilisation du plugin d’admission Webhook courants incluent:
- La réservation de l’espace de noms.
- Limiter les ressources réseau personnalisées gérées par le plugin de périphérique réseau SR-IOV.
- La validation de classe prioritaire de pod.
La valeur maximale de timeout par défaut de webhook dans OpenShift Dedicated est de 13 secondes, et elle ne peut pas être modifiée.
7.4. Les types de plugins d’admission webhook
Les administrateurs de cluster peuvent appeler vers des serveurs webhook via le plugin d’admission mutant ou le plugin d’admission validant dans la chaîne d’admission du serveur API.
7.4.1. La mutation du plugin d’admission
Le plugin d’admission mutant est invoqué pendant la phase de mutation du processus d’admission, ce qui permet de modifier le contenu de la ressource avant qu’il ne soit persisté. La fonction Pod Node Selector, qui utilise une annotation sur un espace de noms pour trouver un sélecteur d’étiquettes et l’ajouter à la spécification du pod, est un exemple de webhook qui peut être appelé via le plugin d’admission mutant.
Exemple mutant la configuration du plugin d’admission
apiVersion: admissionregistration.k8s.io/v1beta1
kind: MutatingWebhookConfiguration
metadata:
name: <webhook_name>
webhooks:
- name: <webhook_name>
clientConfig:
service:
namespace: default
name: kubernetes
path: <webhook_url>
caBundle: <ca_signing_certificate>
rules:
- operations:
- <operation>
apiGroups:
- ""
apiVersions:
- "*"
resources:
- <resource>
failurePolicy: <policy>
sideEffects: None- 1
- Indique une configuration mutante du plugin d’admission.
- 2
- Le nom de l’objet MutatingWebhookConfiguration. <webhook_name> par la valeur appropriée.
- 3
- Le nom du webhook à appeler. <webhook_name> par la valeur appropriée.
- 4
- Informations sur la façon de se connecter, de faire confiance et d’envoyer des données au serveur webhook.
- 5
- L’espace de noms où le service front-end est créé.
- 6
- Le nom du service front-end.
- 7
- L’URL Webhook utilisée pour les demandes d’admission. <webhook_url> par la valeur appropriée.
- 8
- Certificat CA codé PEM qui signe le certificat de serveur utilisé par le serveur webhook. <ca_signing_certificate> par le certificat approprié au format base64.
- 9
- Les règles qui définissent quand le serveur API doit utiliser ce plugin d’admission webhook.
- 10
- Il y a une ou plusieurs opérations qui déclenchent le serveur API pour appeler ce plugin d’admission webhook. Les valeurs possibles sont la création, la mise à jour, la suppression ou la connexion. De remplacer <opération> et <resource> par les valeurs appropriées.
- 11
- Indique comment la politique doit se dérouler si le serveur webhook n’est pas disponible. * remplacer <policy> par Ignorer (pour accepter inconditionnellement la demande en cas d’échec) ou l’échec (pour refuser la demande rejetée). L’utilisation d’Ignore peut entraîner un comportement imprévisible pour tous les clients.
Dans OpenShift Dedicated 4, les objets créés par les utilisateurs ou les boucles de contrôle via un plugin d’admission mutant peuvent retourner des résultats inattendus, surtout si les valeurs définies dans une requête initiale sont écrasées, ce qui n’est pas recommandé.
7.4.2. La validation du plugin d’admission
La validation d’un plugin d’admission est invoquée pendant la phase de validation du processus d’admission. Cette phase permet l’application des invariants sur des ressources API particulières pour s’assurer que la ressource ne change plus. Le Pod Node Selector est également un exemple de webhook qui est appelé par le plugin d’admission de validation, pour s’assurer que tous les champs nodeSelector sont limités par les restrictions du sélecteur de nœuds sur l’espace de noms.
Exemple de validation de la configuration du plugin d’admission
apiVersion: admissionregistration.k8s.io/v1beta1
kind: ValidatingWebhookConfiguration
metadata:
name: <webhook_name>
webhooks:
- name: <webhook_name>
clientConfig:
service:
namespace: default
name: kubernetes
path: <webhook_url>
caBundle: <ca_signing_certificate>
rules:
- operations:
- <operation>
apiGroups:
- ""
apiVersions:
- "*"
resources:
- <resource>
failurePolicy: <policy>
sideEffects: Unknown- 1
- Indique une configuration de plugin d’admission valide.
- 2
- Le nom de l’objet ValidatingWebhookConfiguration. <webhook_name> par la valeur appropriée.
- 3
- Le nom du webhook à appeler. <webhook_name> par la valeur appropriée.
- 4
- Informations sur la façon de se connecter, de faire confiance et d’envoyer des données au serveur webhook.
- 5
- L’espace de noms où le service front-end est créé.
- 6
- Le nom du service front-end.
- 7
- L’URL Webhook utilisée pour les demandes d’admission. <webhook_url> par la valeur appropriée.
- 8
- Certificat CA codé PEM qui signe le certificat de serveur utilisé par le serveur webhook. <ca_signing_certificate> par le certificat approprié au format base64.
- 9
- Les règles qui définissent quand le serveur API doit utiliser ce plugin d’admission webhook.
- 10
- Il y a une ou plusieurs opérations qui déclenchent le serveur API pour appeler ce plugin d’admission webhook. Les valeurs possibles sont la création, la mise à jour, la suppression ou la connexion. De remplacer <opération> et <resource> par les valeurs appropriées.
- 11
- Indique comment la politique doit se dérouler si le serveur webhook n’est pas disponible. * remplacer <policy> par Ignorer (pour accepter inconditionnellement la demande en cas d’échec) ou l’échec (pour refuser la demande rejetée). L’utilisation d’Ignore peut entraîner un comportement imprévisible pour tous les clients.
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.