Introduction à OpenShift dédié
Aperçu de l’architecture dédiée à OpenShift
Résumé
Chapitre 1. Comprendre OpenShift dédié
Avec sa fondation à Kubernetes, OpenShift Dedicated est un cluster complet OpenShift Container Platform fourni en tant que service cloud, configuré pour une haute disponibilité et dédié à un seul client.
1.1. Aperçu d’OpenShift Dedicated
La société OpenShift Dedicated est gérée professionnellement par Red Hat et hébergée sur Amazon Web Services (AWS) ou Google Cloud Platform (GCP). Chaque cluster OpenShift Dedicated est livré avec un plan de contrôle entièrement géré (nœuds de contrôle et d’infrastructure), des nœuds d’application, de l’installation et de la gestion par Red Hat Site Reliability Engineers (SRE), un support Red Hat premium et des services de cluster tels que l’enregistrement, les métriques, la surveillance, le portail de notifications et un portail de clusters.
La société OpenShift Dedicated fournit des améliorations prêtes à l’entreprise à Kubernetes, y compris les améliorations suivantes:
- Les clusters dédiés OpenShift sont déployés sur des environnements AWS ou GCP et peuvent être utilisés dans le cadre d’une approche hybride pour la gestion des applications.
- La technologie Red Hat intégrée. Les principaux composants d’OpenShift Dedicated proviennent de Red Hat Enterprise Linux et des technologies Red Hat associées. La société OpenShift Dedicated bénéficie des initiatives intenses de tests et de certification du logiciel de qualité d’entreprise de Red Hat.
- Le modèle de développement open source. Le développement est terminé en ouvert, et le code source est disponible auprès des référentiels de logiciels publics. Cette collaboration ouverte favorise l’innovation et le développement rapides.
Afin d’en savoir plus sur les options d’actifs que vous pouvez créer lorsque vous créez et déployez des applications Kubernetes conteneurisées dans OpenShift Container Platform, voir Comprendre le développement de la plate-forme de conteneurs OpenShift.
1.1.1. Le système d’exploitation personnalisé
Le système d’exploitation OpenShift Dedicated utilise Red Hat Enterprise Linux CoreOS (RHCOS), un système d’exploitation orienté conteneur qui combine certaines des meilleures fonctionnalités et fonctions des systèmes d’exploitation CoreOS et Red Hat Atomic Host. Le RHCOS est spécialement conçu pour exécuter des applications conteneurisées à partir d’OpenShift Dedicated et travaille avec de nouveaux outils pour fournir une installation rapide, une gestion basée sur l’opérateur et des mises à niveau simplifiées.
Le RHCOS comprend:
- Allumage, que OpenShift Dedicated utilise comme première configuration du système de démarrage pour la mise en place et la configuration initiales des machines.
- CRI-O, une implémentation d’exécution de conteneurs native Kubernetes qui s’intègre étroitement avec le système d’exploitation pour offrir une expérience Kubernetes efficace et optimisée. CRI-O fournit des installations pour l’exécution, l’arrêt et le redémarrage des conteneurs.
- Kubelet, le principal agent de nœud pour Kubernetes qui est responsable du lancement et de la surveillance des conteneurs.
1.1.2. Autres caractéristiques clés
Les opérateurs sont à la fois l’unité fondamentale de la base de code dédiée OpenShift et un moyen pratique de déployer des applications et des composants logiciels pour vos applications à utiliser. Dans OpenShift Dedicated, les opérateurs servent de base de la plate-forme et éliminent le besoin de mises à niveau manuelles des systèmes d’exploitation et des applications de plan de contrôle. Les opérateurs dédiés OpenShift tels que l’opérateur de version de cluster et l’opérateur de configuration de machine permettent une gestion simplifiée et à l’échelle du cluster de ces composants critiques.
Gestionnaire du cycle de vie de l’opérateur (OLM) et OperatorHub fournissent des installations pour stocker et distribuer des opérateurs aux personnes qui développent et déploient des applications.
Le registre des conteneurs Red Hat Quay est un registre de conteneurs Quay.io qui sert la plupart des images de conteneurs et des opérateurs à OpenShift Dedicated clusters. Le Quay.io est une version de registre public de Red Hat Quay qui stocke des millions d’images et de balises.
D’autres améliorations apportées à Kubernetes dans OpenShift Dedicated incluent des améliorations dans le réseau défini par logiciel (SDN), l’authentification, l’agrégation de journal, la surveillance et le routage. L’OpenShift Dedicated propose également une console Web complète et l’interface personnalisée OpenShift CLI (oc).
1.1.3. Accès Internet et télémétrie pour OpenShift dédié
Dans OpenShift Dedicated, vous avez besoin d’accès à Internet pour installer et mettre à niveau votre cluster.
Grâce au service de télémétrie, des informations sont envoyées à Red Hat à partir de clusters dédiés OpenShift pour permettre l’automatisation de la gestion des abonnements, surveiller la santé des clusters, aider avec le support et améliorer l’expérience client.
Le service Télémétrie s’exécute automatiquement et votre cluster est enregistré sur Red Hat OpenShift Cluster Manager. Dans OpenShift Dedicated, les rapports de santé à distance sont toujours activés et vous ne pouvez pas vous retirer. L’équipe de Red Hat Site Reliability Engineering (SRE) nécessite l’information pour fournir un support efficace pour votre cluster OpenShift dédié.
Chapitre 2. Définition des politiques et des services
2.1. Définition de service dédié à OpenShift
2.1.1. Gestion des comptes
2.1.1.1. Les options de facturation
Les clients ont la possibilité d’acheter des abonnements annuels d’OpenShift Dedicated (OSD) ou de consommer à la demande via des places de marché en nuage. Les clients peuvent décider d’apporter leur propre compte d’infrastructure cloud, appelé Customer Cloud Subscription (CCS), ou de déployer dans des comptes de fournisseurs de cloud appartenant à Red Hat. Le tableau ci-dessous fournit des informations supplémentaires sur la facturation, ainsi que les options de déploiement prises en charge correspondantes.
| Abonnement OSD-type | Compte d’infrastructure cloud | Facturé à travers |
|---|---|---|
| Abonnements annuels à capacité fixe via Red Hat | Compte cloud Red Hat | Chapeau rouge pour la consommation des abonnements OSD et de l’infrastructure cloud |
| Compte cloud du client | Chapeau rouge pour la consommation des abonnements OSD Fournisseur de cloud pour la consommation d’infrastructures cloud | |
| Consommation basée sur l’utilisation à la demande via Google Cloud Marketplace | Compte Google Cloud du client | Google Cloud pour l’infrastructure cloud et les abonnements Red Hat OSD |
| Consommation basée sur l’utilisation à la demande via Red Hat Marketplace | Compte cloud du client | Chapeau rouge pour la consommation des abonnements OSD Fournisseur de cloud pour la consommation d’infrastructures cloud |
Les clients qui utilisent leur propre compte d’infrastructure cloud, appelé Customer Cloud Subscription (CSS), sont responsables de pré-achat ou de fournir des instances de calcul d’instance réservée (RI) afin d’assurer la réduction des coûts d’infrastructure cloud.
Des ressources supplémentaires peuvent être achetées pour un cluster OpenShift dédié, y compris:
- Les nœuds supplémentaires (peuvent être différents types et tailles grâce à l’utilisation de pools de machines)
- Middleware (JBoss EAP, JBoss Fuse, etc.) - prix supplémentaire basé sur un composant de middleware spécifique
- Stockage supplémentaire par incréments de 500 Go (non-CCS seulement; 100 Go inclus)
- 12 autres E/S réseau TiB (non-CCS seulement; 12 To inclus)
- Les balanceurs de charge pour les services sont disponibles en paquets de 4; permet le trafic non-HTTP/SNI ou des ports non standard (non-CCS seulement)
2.1.1.2. Cluster en libre-service
Les clients peuvent créer, adapter et supprimer leurs clusters à partir d’OpenShift Cluster Manager, à condition qu’ils aient déjà acheté les abonnements nécessaires.
Les actions disponibles dans Red Hat OpenShift Cluster Manager ne doivent pas être exécutées directement à partir du cluster car cela pourrait causer des effets indésirables, y compris le retour automatique de toutes les actions.
2.1.1.3. Fournisseurs de cloud
L’OpenShift Dedicated propose des clusters OpenShift Container Platform en tant que service géré sur les fournisseurs de cloud suivants:
- Amazon Web Services (AWS)
- Google Cloud Platform (GCP)
2.1.1.4. Les types d’instances
Les clusters de zone de disponibilité unique nécessitent un minimum de 2 nœuds de travail pour les clusters d’abonnement au cloud client (CCS) déployés dans une seule zone de disponibilité. Au moins 4 nœuds de travail sont requis pour les clusters non-CCS. Ces 4 nœuds ouvriers sont inclus dans l’abonnement de base.
Les clusters de zones de disponibilité multiples nécessitent un minimum de 3 nœuds de travail pour les clusters d’abonnement au cloud client (CCS), 1 déployé dans chacune des 3 zones de disponibilité. Au moins 9 nœuds de travailleurs sont requis pour les clusters non-CCS. Ces 9 nœuds de travail sont inclus dans l’abonnement de base, et des nœuds supplémentaires doivent être achetés en multiples de 3 pour maintenir une bonne distribution des nœuds.
Les nœuds d’ouvrier dans un seul pool de machines dédié OpenShift doivent être du même type et de la même taille. Cependant, les nœuds de travail à travers plusieurs pools de machines au sein d’un cluster dédié OpenShift peuvent être de différents types et tailles.
Les nœuds d’avion de contrôle et d’infrastructure sont déployés et gérés par Red Hat. Il y a au moins 3 nœuds de plan de contrôle qui gèrent les charges de travail etcd et API. Il y a au moins 2 nœuds d’infrastructure qui gèrent les métriques, le routage, la console Web et d’autres charges de travail. Il ne faut pas exécuter de charge de travail sur le plan de contrôle et les nœuds d’infrastructure. Les charges de travail que vous avez l’intention d’exécuter doivent être déployées sur les nœuds des travailleurs.
La fermeture de l’infrastructure sous-jacente via la console fournisseur de cloud n’est pas prise en charge et peut entraîner une perte de données.
Consultez la section support de Red Hat ci-dessous pour plus d’informations sur les charges de travail de Red Hat qui doivent être déployées sur les nœuds des travailleurs.
Environ 1 noyau vCPU et 1 GiB de mémoire sont réservés sur chaque nœud de travail et retirés des ressources allocatables. Ceci est nécessaire pour exécuter les processus requis par la plate-forme sous-jacente. Cela inclut les démons système tels que udev, kubelet, le temps d’exécution du conteneur, etc., ainsi que les comptes pour les réservations du noyau. Les systèmes de base OpenShift Container Platform tels que l’agrégation des journaux d’audit, la collecte des métriques, le DNS, le registre d’images, le SDN, etc., pourraient consommer des ressources allocatables supplémentaires pour maintenir la stabilité et la maintenabilité du cluster. Les ressources supplémentaires consommées peuvent varier en fonction de l’utilisation.
À partir de OpenShift Dedicated 4.11, la limite PID par défaut par-pod est 4096. Lorsque vous souhaitez activer cette limite de PID, vous devez mettre à niveau vos clusters OpenShift Dedicated vers cette version ou ultérieure. Les clusters dédiés qui exécutent des versions antérieures à 4.11 utilisent une limite PID par défaut de 1024.
Il est impossible de configurer la limite PID par pod sur un cluster dédié OpenShift.
Ressources supplémentaires
2.1.1.5. Les types d’instance AWS pour les clusters d’abonnement au cloud client
Le logiciel OpenShift Dedicated offre les types et tailles d’instances de nœuds de travail suivants sur AWS:
Exemple 2.1. But général
- ajouter au panier M5.metal (96† vCPU, 384 GiB)
- format M5.xlarge (4 vCPU, 16 GiB)
- format M5.2xlarge (8 vCPU, 32 GiB)
- format M5.4xlarge (16 vCPU, 64 GiB)
- format M5.8xlarge (32 vCPU, 128 GiB)
- format M5.12xlarge (48 vCPU, 192 GiB)
- format M5.16xlarge (64 vCPU, 256 GiB)
- format M5.24xlarge (96 vCPU, 384 GiB)
- ajouter au panier M5a.xlarge (4 vCPU, 16 GiB)
- format M5a.2xlarge (8 vCPU, 32 GiB)
- format M5a.4xlarge (16 vCPU, 64 GiB)
- format M5a.8xlarge (32 vCPU, 128 GiB)
- format M5a.12xlarge (48 vCPU, 192 GiB)
- format M5a.16xlarge (64 vCPU, 256 GiB)
- format M5a.24xlarge (96 vCPU, 384 GiB)
- ajouter au panier M5ad.xlarge (4 vCPU, 16 GiB)
- ajouter au panier M5ad.2xlarge (8 vCPU, 32 GiB)
- ajouter au panier M5ad.4xlarge (16 vCPU, 64 GiB)
- format M5ad.8xlarge (32 vCPU, 128 GiB)
- ajouter au panier M5ad.12xlarge (48 vCPU, 192 GiB)
- format M5ad.16xlarge (64 vCPU, 256 GiB)
- ajouter au panier M5ad.24xlarge (96 vCPU, 384 GiB)
- ajouter au panier M5d.metal (96† vCPU, 384 GiB)
- ajouter au panier M5d.xlarge (4 vCPU, 16 GiB)
- format M5d.2xlarge (8 vCPU, 32 GiB)
- format M5d.4xlarge (16 vCPU, 64 GiB)
- format M5d.8xlarge (32 vCPU, 128 GiB)
- format M5d.12xlarge (48 vCPU, 192 GiB)
- format M5d.16xlarge (64 vCPU, 256 GiB)
- format M5d.24xlarge (96 vCPU, 384 GiB)
- ajouter au panier M5n.metal (96 vCPU, 384 GiB)
- ajouter au panier M5n.xlarge (4 vCPU, 16 GiB)
- format M5n.2xlarge (8 vCPU, 32 GiB)
- format M5n.4xlarge (16 vCPU, 64 GiB)
- format M5n.8xlarge (32 vCPU, 128 GiB)
- format M5n.12xlarge (48 vCPU, 192 GiB)
- format M5n.16xlarge (64 vCPU, 256 GiB)
- format M5n.24xlarge (96 vCPU, 384 GiB)
- ajouter au panier M5dn.metal (96 vCPU, 384 GiB)
- ajouter au panier M5dn.xlarge (4 vCPU, 16 GiB)
- ajouter au panier M5dn.2xlarge (8 vCPU, 32 GiB)
- format M5dn.4xlarge (16 vCPU, 64 GiB)
- format M5dn.8xlarge (32 vCPU, 128 GiB)
- format M5dn.12xlarge (48 vCPU, 192 GiB)
- format M5dn.16xlarge (64 vCPU, 256 GiB)
- format M5dn.24xlarge (96 vCPU, 384 GiB)
- ajouter au panier M5zn.metal (48 vCPU, 192 GiB)
- ajouter au panier M5zn.xlarge (4 vCPU, 16 GiB)
- ajouter au panier M5zn.2xlarge (8 vCPU, 32 GiB)
- format M5zn.3xlarge (12 vCPU, 48 GiB)
- format M5zn.6xlarge (24 vCPU, 96 GiB)
- format M5zn.12xlarge (48 vCPU, 192 GiB)
- ajouter au panier M6a.xlarge (4 vCPU, 16 GiB)
- format M6a.2xlarge (8 vCPU, 32 GiB)
- format M6a.4xlarge (16 vCPU, 64 GiB)
- format M6a.8xlarge (32 vCPU, 128 GiB)
- format M6a.12xlarge (48 vCPU, 192 GiB)
- format M6a.16xlarge (64 vCPU, 256 GiB)
- format M6a.24xlarge (96 vCPU, 384 GiB)
- format M6a.32xlarge (128 vCPU, 512 GiB)
- format M6a.48xlarge (192 vCPU, 768 GiB)
- ajouter au panier M6i.metal (128 vCPU, 512 GiB)
- ajouter au panier M6i.xlarge (4 vCPU, 16 GiB)
- ajouter au panier M6i.2xlarge (8 vCPU, 32 GiB)
- format M6i.4xlarge (16 vCPU, 64 GiB)
- format M6i.8xlarge (32 vCPU, 128 GiB)
- format M6i.12xlarge (48 vCPU, 192 GiB)
- format M6i.16xlarge (64 vCPU, 256 GiB)
- format M6i.24xlarge (96 vCPU, 384 GiB)
- format M6i.32xlarge (128 vCPU, 512 GiB)
- ajouter au panier M6id.xlarge (4 vCPU, 16 GiB)
- ajouter au panier M6id.2xlarge (8 vCPU, 32 GiB)
- format M6id.4xlarge (16 vCPU, 64 GiB)
- format M6id.8xlarge (32 vCPU, 128 GiB)
- format M6id.12xlarge (48 vCPU, 192 GiB)
- format M6id.16xlarge (64 vCPU, 256 GiB)
- format M6id.24xlarge (96 vCPU, 384 GiB)
- format M6id.32xlarge (128 vCPU, 512 GiB)
- ajouter au panier M7i.xlarge (4 vCPU, 16 GiB)
- format M7i.2xlarge (8 vCPU, 32 GiB)
- format M7i.4xlarge (16 vCPU, 64 GiB)
- format M7i.8xlarge (32 vCPU, 128 GiB)
- format M7i.12xlarge (48 vCPU, 192 GiB)
- format M7i.16xlarge (64 vCPU, 256 GiB)
- format M7i.24xlarge (96 vCPU, 384 GiB)
- format M7i.48xlarge (192 vCPU, 768 GiB)
- ajouter au panier M7i.metal-24xl (96 vCPU, 384 GiB)
- ajouter au panier M7i.metal-48xl (192 vCPU, 768 GiB)
- ajouter au panier M7i-flex.xlarge (4 vCPU, 16 GiB)
- ajouter au panier M7i-flex.2xlarge (8 vCPU, 32 GiB)
- format M7i-flex.4xlarge (16 vCPU, 64 GiB)
- format M7i-flex.8xlarge (32 vCPU, 128 GiB)
- ajouter au panier M7a.xlarge (4 vCPU, 16 GiB)
- format M7a.2xlarge (8 vCPU, 32 GiB)
- format M7a.4xlarge (16 vCPU, 64 GiB)
- format M7a.8xlarge (32 vCPU, 128 GiB)
- format M7a.12xlarge (48 vCPU, 192 GiB)
- format M7a.16xlarge (64 vCPU, 256 GiB)
- format M7a.24xlarge (96 vCPU, 384 GiB)
- format M7a.32xlarge (128 vCPU, 512 GiB)
- format M7a.48xlarge (192 vCPU, 768 GiB)
- ajouter au panier M7a.metal-48xl (192 vCPU, 768 GiB)
† Ces types d’instances fournissent 96 processeurs logiques sur 48 cœurs physiques. Ils fonctionnent sur des serveurs uniques avec deux sockets Intel physiques.
Exemple 2.2. Rafale à usage général
- ajouter au panier T3.xlarge (4 vCPU, 16 GiB)
- format T3.2xlarge (8 vCPU, 32 GiB)
- ajouter au panier T3a.xlarge (4 vCPU, 16 GiB)
- ajouter au panier T3a.2xlarge (8 vCPU, 32 GiB)
Exemple 2.3. Intensité de mémoire
- format x1.16xlarge (64 vCPU, 976 GiB)
- format x1.32xlarge (128 vCPU, 1952 GiB)
- ajouter au panier x1e.xlarge (4 vCPU, 122 GiB)
- ajouter au panier x1e.2xlarge (8 vCPU, 244 GiB)
- ajouter au panier x1e.4xlarge (16 vCPU, 488 GiB)
- format x1e.8xlarge (32 vCPU, 976 GiB)
- format x1e.16xlarge (64 vCPU, 1,952 GiB)
- format x1e.32xlarge (128 vCPU, 3 904 GiB)
- ajouter au panier x2idn.16xlarge (64 vCPU, 1024 GiB)
- ajouter au panier x2idn.24xlarge (96 vCPU, 1536 GiB)
- format x2idn.32xlarge (128 vCPU, 2048 GiB)
- ajouter au panier x2iedn.xlarge (4 vCPU, 128 GiB)
- ajouter au panier x2iedn.2xlarge (8 vCPU, 256 GiB)
- ajouter au panier x2iedn.4xlarge (16 vCPU, 512 GiB)
- format x2iedn.8xlarge (32 vCPU, 1024 GiB)
- ajouter au panier x2iedn.16xlarge (64 vCPU, 2048 GiB)
- ajouter au panier x2iedn.24xlarge (96 vCPU, 3072 GiB)
- format x2iedn.32xlarge (128 vCPU, 4096 GiB)
- ajouter au panier x2iezn.2xlarge (8 vCPU, 256 GiB)
- ajouter au panier x2iezn.4xlarge (16vCPU, 512 GiB)
- ajouter au panier x2iezn.6xlarge (24vCPU, 768 GiB)
- ajouter au panier x2iezn.8xlarge (32vCPU, 1 024 GiB)
- ajouter au panier x2iezn.12xlarge (48vCPU, 1.536 GiB)
- ajouter au panier x2idn.metal (128vCPU, 2,048 GiB)
- ajouter au panier x2iedn.metal (128vCPU, 4,096 GiB)
- ajouter au panier x2iezn.metal (48 vCPU, 1 536 GiB)
Exemple 2.4. La mémoire optimisée
- ajouter au panier R4.xlarge (4 vCPU, 30.5 GiB)
- ajouter au panier R4.2xlarge (8 vCPU, 61 GiB)
- ajouter au panier R4.4xlarge (16 vCPU, 122 GiB)
- largeur de r4.8xlarge (32 vCPU, 244 GiB)
- largeur (64 vCPU, 488 GiB)
- (96† vCPU, 768 GiB)
- ajouter au panier R5.xlarge (4 vCPU, 32 GiB)
- ajouter au panier R5.2xlarge (8 vCPU, 64 GiB)
- longueur d’écran (16 vCPU, 128 GiB)
- largeur de r5.8xlarge (32 vCPU, 256 GiB)
- largeur de r5.12xlarge (48 vCPU, 384 GiB)
- largeur de r5.16xlarge (64 vCPU, 512 GiB)
- 5,54xlarge (96 vCPU, 768 GiB)
- ajouter au panier R5a.xlarge (4 vCPU, 32 GiB)
- ajouter au panier R5a.2xlarge (8 vCPU, 64 GiB)
- ajouter au panier R5a.4xlarge (16 vCPU, 128 GiB)
- largeur (32 vCPU, 256 GiB)
- ajouter au panier R5a.12xlarge (48 vCPU, 384 GiB)
- 5a.16xlarge (64 vCPU, 512 GiB)
- largeur de r5a.24xlarge (96 vCPU, 768 GiB)
- ajouter au panier R5ad.xlarge (4 vCPU, 32 GiB)
- ajouter au panier R5ad.2xlarge (8 vCPU, 64 GiB)
- ajouter au panier R5ad.4xlarge (16 vCPU, 128 GiB)
- ajouter au panier R5ad.8xlarge (32 vCPU, 256 GiB)
- ajouter au panier R5ad.12xlarge (48 vCPU, 384 GiB)
- ajouter au panier R5ad.16xlarge (64 vCPU, 512 GiB)
- ajouter au panier R5ad.24xlarge (96 vCPU, 768 GiB)
- le r5d.metal (96† vCPU, 768 GiB)
- ajouter au panier R5d.xlarge (4 vCPU, 32 GiB)
- ajouter au panier R5d.2xlarge (8 vCPU, 64 GiB)
- ajouter au panier R5d.4xlarge (16 vCPU, 128 GiB)
- largeur de r5d.8xlarge (32 vCPU, 256 GiB)
- largeur de r5d.12xlarge (48 vCPU, 384 GiB)
- 5d.16xlarge (64 vCPU, 512 GiB)
- largeur de r5d.24xlarge (96 vCPU, 768 GiB)
- C5n.metal (96 vCPU, 768 GiB)
- ajouter au panier R5n.xlarge (4 vCPU, 32 GiB)
- ajouter au panier R5n.2xlarge (8 vCPU, 64 GiB)
- ajouter au panier R5n.4xlarge (16 vCPU, 128 GiB)
- largeur (32 vCPU, 256 GiB)
- ajouter au panier R5n.12xlarge (48 vCPU, 384 GiB)
- 5n.16xlarge (64 vCPU, 512 GiB)
- largeur de r5n.24xlarge (96 vCPU, 768 GiB)
- a) R5dn.metal (96 vCPU, 768 GiB)
- ajouter au panier R5dn.xlarge (4 vCPU, 32 GiB)
- ajouter au panier R5dn.2xlarge (8 vCPU, 64 GiB)
- ajouter au panier R5dn.4xlarge (16 vCPU, 128 GiB)
- largeur de r5dn.8xlarge (32 vCPU, 256 GiB)
- ajouter au panier R5dn.12xlarge (48 vCPU, 384 GiB)
- 5dn.16xlarge (64 vCPU, 512 GiB)
- largeur de r5dn.24xlarge (96 vCPU, 768 GiB)
- ajouter au panier R6a.xlarge (4 vCPU, 32 GiB)
- ajouter au panier R6a.2xlarge (8 vCPU, 64 GiB)
- ajouter au panier R6a.4xlarge (16 vCPU, 128 GiB)
- largeur (32 vCPU, 256 GiB)
- ajouter au panier R6a.12xlarge (48 vCPU, 384 GiB)
- 6a.16xlarge (64 vCPU, 512 GiB)
- 6a.24xlarge (96 vCPU, 768 GiB)
- largeur de r6a.32xlarge (128 vCPU, 1 024 GiB)
- ajouter au panier R6a.48xlarge (192 vCPU, 1 536 GiB)
- (128 vCPU, 1 024 GiB)
- ajouter au panier R6i.xlarge (4 vCPU, 32 GiB)
- ajouter au panier R6i.2xlarge (8 vCPU, 64 GiB)
- ajouter au panier R6i.4xlarge (16 vCPU, 128 GiB)
- largeur (32 vCPU, 256 GiB)
- ajouter au panier R6i.12xlarge (48 vCPU, 384 GiB)
- 6i.16xlarge (64 vCPU, 512 GiB)
- 6i.24xlarge (96 vCPU, 768 GiB)
- largeur de r6i.32xlarge (128 vCPU, 1 024 GiB)
- ajouter au panier R6id.xlarge (4 vCPU, 32 GiB)
- ajouter au panier R6id.2xlarge (8 vCPU, 64 GiB)
- ajouter au panier R6id.4xlarge (16 vCPU, 128 GiB)
- largeur (32 vCPU, 256 GiB)
- ajouter au panier R6id.12xlarge (48 vCPU, 384 GiB)
- 6id.16xlarge (64 vCPU, 512 GiB)
- largeur de r6id.24xlarge (96 vCPU, 768 GiB)
- largeur de r6id.32xlarge (128 vCPU, 1 024 GiB)
- ajouter au panier z1d.metal (48^ vCPU, 384 GiB)
- ajouter au panier z1d.xlarge (4 vCPU, 32 GiB)
- ajouter au panier z1d.2xlarge (8 vCPU, 64 GiB)
- ajouter au panier z1d.3xlarge (12 vCPU, 96 GiB)
- ajouter au panier z1d.6xlarge (24 vCPU, 192 GiB)
- format z1d.12xlarge (48 vCPU, 384 GiB)
- ajouter au panier R7a.xlarge (4 vCPU, 32 GiB)
- ajouter au panier R7a.2xlarge (8 vCPU, 64 GiB)
- ajouter au panier R7a.4xlarge (16 vCPU, 128 GiB)
- largeur de r7a.8xlarge (32 vCPU, 256 GiB)
- ajouter au panier R7a.12xlarge (48 vCPU, 384 GiB)
- largeur de r7a.16xlarge (64 vCPU, 512 GiB)
- largeur de r7a.24xlarge (96 vCPU, 768 GiB)
- largeur de r7a.32xlarge (128 vCPU, 1024 GiB)
- ajouter au panier R7a.48xlarge (192 vCPU, 1536 GiB)
- ajouter au panier R7a.metal-48xl (192 vCPU, 1536 GiB)
- ajouter au panier R7i.xlarge (4 vCPU, 32 GiB)
- ajouter au panier R7i.2xlarge (8 vCPU, 64 GiB)
- ajouter au panier R7i.4xlarge (16 vCPU, 128 GiB)
- largeur de r7i.8xlarge (32 vCPU, 256 GiB)
- ajouter au panier R7i.12xlarge (48 vCPU, 384 GiB)
- largeur de r7i.16xlarge (64 vCPU, 512 GiB)
- largeur de r7i.24xlarge (96 vCPU, 768 GiB)
- a) R7i.metal-24xl (96 vCPU, 768 GiB)
- ajouter au panier R7iz.xlarge (4 vCPU, 32 GiB)
- ajouter au panier R7iz.2xlarge (8 vCPU, 64 GiB)
- ajouter au panier R7iz.4xlarge (16 vCPU, 128 GiB)
- largeur de r7iz.8xlarge (32 vCPU, 256 GiB)
- ajouter au panier R7iz.12xlarge (48 vCPU, 384 GiB)
- largeur de r7iz.16xlarge (64 vCPU, 512 GiB)
- largeur de r7iz.32xlarge (128 vCPU, 1024 GiB)
- ajouter au panier R7iz.metal-16xl (64 vCPU, 512 GiB)
- le R7iz.metal-32xl (128 vCPU, 1024 GiB)
† Ces types d’instances fournissent 96 processeurs logiques sur 48 cœurs physiques. Ils fonctionnent sur des serveurs uniques avec deux sockets Intel physiques.
Ce type d’instance fournit 48 processeurs logiques sur 24 cœurs physiques.
Exemple 2.5. Calcul accéléré
- ajouter au panier P3.2xlarge (8 vCPU, 61 GiB)
- largeur de p3.8xlarge (32 vCPU, 244 GiB)
- largeur de p3.16xlarge (64 vCPU, 488 GiB)
- format p3dn.24xlarge (96 vCPU, 768 GiB)
- format p4d.24xlarge (96 vCPU, 152 GiB)
- ajouter au panier P4de.24xlarge (96 vCPU, 152 GiB)
- format P5.48xlarge (192 vCPU, 2,048 GiB)
- g4ad.xlarge (4 vCPU, 16 GiB)
- g4ad.2xlarge (8 vCPU, 32 GiB)
- g4ad.4xlarge (16 vCPU, 64 GiB)
- g4ad.8xlarge (32 vCPU, 128 GiB)
- g4ad.16xlarge (64 vCPU, 256 GiB)
- g4dn.xlarge (4 vCPU, 16 GiB)
- g4dn.2xlarge (8 vCPU, 32 GiB)
- g4dn.4xlarge (16 vCPU, 64 GiB)
- g4dn.8xlarge (32 vCPU, 128 GiB)
- g4dn.12xlarge (48 vCPU, 192 GiB)
- g4dn.16xlarge (64 vCPU, 256 GiB)
- g4dn.metal (96 vCPU, 384 GiB)
- g5.xlarge (4 vCPU, 16 GiB)
- G5.2xlarge (8 vCPU, 32 GiB)
- g5.4xlarge (16 vCPU, 64 GiB)
- G5.8xlarge (32 vCPU, 128 GiB)
- G5.16xlarge (64 vCPU, 256 GiB)
- g5.12xlarge (48 vCPU, 192 GiB)
- G5.24xlarge (96 vCPU, 384 GiB)
- g5.48xlarge (192 vCPU, 768 GiB)
- dl1.24xlarge (96 vCPU, 768 GiB)†
- g6.xlarge (4 vCPU, 16 GiB)
- G6.2xlarge (8 vCPU, 32 GiB)
- g6.4xlarge (16 vCPU, 64 GiB)
- G6.8xlarge (32 vCPU, 128 GiB)
- g6.12xlarge (48 vCPU, 192 GiB)
- G6.16xlarge (64 vCPU, 256 GiB)
- G6.24xlarge (96 vCPU, 384 GiB)
- g6.48xlarge (192 vCPU, 768 GiB)
- g6e.xlarge (4 vCPU, 32 GiB)
- g6e.2xlarge (8 vCPU, 64 GiB)
- g6e.4xlarge (16 vCPU, 128 GiB)
- g6e.8xlarge (32 vCPU, 256 GiB)
- g6e.12xlarge (48 vCPU, 384 GiB)
- g6e.16xlarge (64 vCPU, 512 GiB)
- g6e.24xlarge (96 vCPU, 768 GiB)
- g6e.48xlarge (192 vCPU, 1 536 GiB)
- gr6.4xlarge (16 vCPU, 128 GiB)
- gr6.8xlarge (32 vCPU, 256 GiB)
† Intel spécifique; non couvert par Nvidia
La prise en charge de la pile logicielle de type d’instance GPU est fournie par AWS. Assurez-vous que vos quotas de service AWS peuvent accueillir les types d’instances GPU souhaités.
Exemple 2.6. Calcul optimisé
- c5.métal (96 vCPU, 192 GiB)
- c5.xlarge (4 vCPU, 8 GiB)
- c5.2xlarge (8 vCPU, 16 GiB)
- c5.4xlarge (16 vCPU, 32 GiB)
- c5.9xlarge (36 vCPU, 72 GiB)
- c5.12xlarge (48 vCPU, 96 GiB)
- c5.18xlarge (72 vCPU, 144 GiB)
- c5.24xlarge (96 vCPU, 192 GiB)
- c5d.metal (96 vCPU, 192 GiB)
- c5d.xlarge (4 vCPU, 8 GiB)
- c5d.2xlarge (8 vCPU, 16 GiB)
- c5d.4xlarge (16 vCPU, 32 GiB)
- c5d.9xlarge (36 vCPU, 72 GiB)
- c5d.12xlarge (48 vCPU, 96 GiB)
- c5d.18xlarge (72 vCPU, 144 GiB)
- c5d.24xlarge (96 vCPU, 192 GiB)
- c5a.xlarge (4 vCPU, 8 GiB)
- c5a.2xlarge (8 vCPU, 16 GiB)
- c5a.4xlarge (16 vCPU, 32 GiB)
- c5a.8xlarge (32 vCPU, 64 GiB)
- c5a.12xlarge (48 vCPU, 96 GiB)
- c5a.16xlarge (64 vCPU, 128 GiB)
- c5a.24xlarge (96 vCPU, 192 GiB)
- c5ad.xlarge (4 vCPU, 8 GiB)
- c5ad.2xlarge (8 vCPU, 16 GiB)
- c5ad.4xlarge (16 vCPU, 32 GiB)
- c5ad.8xlarge (32 vCPU, 64 GiB)
- c5ad.12xlarge (48 vCPU, 96 GiB)
- c5ad.16xlarge (64 vCPU, 128 GiB)
- c5ad.24xlarge (96 vCPU, 192 GiB)
- c5n.metal (72 vCPU, 192 GiB)
- c5n.xlarge (4 vCPU, 10.5 GiB)
- c5n.2xlarge (8 vCPU, 21 GiB)
- c5n.4xlarge (16 vCPU, 42 GiB)
- c5n.9xlarge (36 vCPU, 96 GiB)
- c5n.18xlarge (72 vCPU, 192 GiB)
- c6a.xlarge (4 vCPU, 8 GiB)
- c6a.2xlarge (8 vCPU, 16 GiB)
- c6a.4xlarge (16 vCPU, 32 GiB)
- c6a.8xlarge (32 vCPU, 64 GiB)
- c6a.12xlarge (48 vCPU, 96 GiB)
- c6a.16xlarge (64 vCPU, 128 GiB)
- c6a.24xlarge (96 vCPU, 192 GiB)
- c6a.32xlarge (128 vCPU, 256 GiB)
- c6a.48xlarge (192 vCPU, 384 GiB)
- c6i.metal (128 vCPU, 256 GiB)
- c6i.xlarge (4 vCPU, 8 GiB)
- c6i.2xlarge (8 vCPU, 16 GiB)
- c6i.4xlarge (16 vCPU, 32 GiB)
- c6i.8xlarge (32 vCPU, 64 GiB)
- c6i.12xlarge (48 vCPU, 96 GiB)
- c6i.16xlarge (64 vCPU, 128 GiB)
- c6i.24xlarge (96 vCPU, 192 GiB)
- c6i.32xlarge (128 vCPU, 256 GiB)
- c6id.xlarge (4 vCPU, 8 GiB)
- c6id.2xlarge (8 vCPU, 16 GiB)
- c6id.4xlarge (16 vCPU, 32 GiB)
- c6id.8xlarge (32 vCPU, 64 GiB)
- c6id.12xlarge (48 vCPU, 96 GiB)
- c6id.16xlarge (64 vCPU, 128 GiB)
- c6id.24xlarge (96 vCPU, 192 GiB)
- c6id.32xlarge (128 vCPU, 256 GiB)
- c7a.xlarge (4 vCPU, 8 GiB)
- c7a.2xlarge (8 vCPU, 16 GiB)
- c7a.4xlarge (16 vCPU, 32 GiB)
- c7a.8xlarge (32 vCPU, 64 GiB)
- c7a.12xlarge (48 vCPU, 96 GiB)
- c7a.16xlarge (64 vCPU, 128 GiB)
- c7a.24xlarge (96 vCPU, 192 GiB)
- c7a.32xlarge (128 vCPU, 256 GiB)
- c7a.48xlarge (192 vCPU, 384 GiB)
- c7a.metal-48xl (192 vCPU, 384 GiB)
- c7i.xlarge (4 vCPU, 8 GiB)
- c7i.2xlarge (8 vCPU, 16 GiB)
- c7i.4xlarge (16 vCPU, 32 GiB)
- c7i.8xlarge (32 vCPU, 64 GiB)
- c7i.12xlarge (48 vCPU, 96 GiB)
- c7i.16xlarge (64 vCPU, 128 GiB)
- c7i.24xlarge (96 vCPU, 192 GiB)
- c7i.48xlarge (192 vCPU, 384 GiB)
- c7i.metal-24xl (96 vCPU, 192 GiB)
- c7i.metal-48xl (192 vCPU, 384 GiB)
- hpc6a.48xlarge (96 vCPU, 384 GiB)
- hpc6id.32xlarge (64 vCPU, 1024 GiB)
- hpc7a.12xlarge (24 vCPU, 768 GiB)
- hpc7a.24xlarge (48 vCPU, 768 GiB)
- hpc7a.48xlarge (96 vCPU, 768 GiB)
- hpc7a.96xlarge (192 vCPU, 768 GiB)
Exemple 2.7. Le stockage optimisé
- i3.metal (72† vCPU, 512 GiB)
- i3.xlarge (4 vCPU, 30.5 GiB)
- i3.2xlarge (8 vCPU, 61 GiB)
- i3.4xlarge (16 vCPU, 122 GiB)
- i3.8xlarge (32 vCPU, 244 GiB)
- i3.16xlarge (64 vCPU, 488 GiB)
- i3en.metal (96 vCPU, 768 GiB)
- i3en.xlarge (4 vCPU, 32 GiB)
- i3en.2xlarge (8 vCPU, 64 GiB)
- i3en.3xlarge (12 vCPU, 96 GiB)
- i3en.6xlarge (24 vCPU, 192 GiB)
- i3en.12xlarge (48 vCPU, 384 GiB)
- i3en.24xlarge (96 vCPU, 768 GiB)
- i4i.xlarge (4 vCPU, 32 GiB)
- i4i.2xlarge (8 vCPU, 64 GiB)
- i4i.4xlarge (16 vCPU, 128 GiB)
- i4i.8xlarge (32 vCPU, 256 GiB)
- i4i.12xlarge (48 vCPU, 384 GiB)
- i4i.16xlarge (64 vCPU, 512 GiB)
- i4i.24xlarge (96 vCPU, 768 GiB)
- i4i.32xlarge (128 vCPU, 1024 GiB)
- i4i.metal (128 vCPU, 1024 GiB)
† Ce type d’instance fournit 72 processeurs logiques sur 36 cœurs physiques.
Les types d’instances virtuelles initialisent plus rapidement que les types d’instances ".metal".
Exemple 2.8. Haute mémoire
- agrandir U-3tb1.56xlarge (224 vCPU, 3 072 GiB)
- format U-6tb1.56xlarge (224 vCPU, 6,144 GiB)
- ajouter au panier U-6tb1.112xlarge (448 vCPU, 6,144 GiB)
- ajouter au panier U-6tb1.metal (448 vCPU, 6,144 GiB)
- ajouter au panier U-9tb1.112xlarge (448 vCPU, 9,216 GiB)
- ajouter au panier U-9tb1.metal (448 vCPU, 9,216 GiB)
- ajouter au panier U-12tb1.112xlarge (448 vCPU, 12,288 GiB)
- ajouter au panier U-12tb1.metal (448 vCPU, 12 288 GiB)
- ajouter au panier U-18tb1.metal (448 vCPU, 18,432 GiB)
- ajouter au panier U-24tb1.metal (448 vCPU, 24 576 GiB)
2.1.1.6. Les types d’instance AWS pour les clusters non-CCS
La société OpenShift Dedicated offre les types et tailles de nœuds de travail suivants sur AWS:
Exemple 2.9. But général
- format M5.xlarge (4 vCPU, 16 GiB)
- format M5.2xlarge (8 vCPU, 32 GiB)
- format M5.4xlarge (16 vCPU, 64 GiB)
Exemple 2.10. La mémoire optimisée
- ajouter au panier R5.xlarge (4 vCPU, 32 GiB)
- ajouter au panier R5.2xlarge (8 vCPU, 64 GiB)
- longueur d’écran (16 vCPU, 128 GiB)
Exemple 2.11. Calcul optimisé
- c5.2xlarge (8 vCPU, 16 GiB)
- c5.4xlarge (16 vCPU, 32 GiB)
2.1.1.7. Les types d’instances Google Cloud
L’OpenShift Dedicated propose les types et tailles de nœuds de travail suivants sur Google Cloud qui sont choisis pour avoir un CPU et une capacité de mémoire communs qui sont les mêmes que les autres types d’instances cloud:
les types d’instances e2, a2 et a3 sont disponibles uniquement pour le CSC.
Exemple 2.12. But général
- Custom-4-16384 (4 vCPU, 16 GiB)
- Custom-8-32768 (8 vCPU, 32 GiB)
- Custom-16-65536 (16 vCPU, 64 GiB)
- Custom-32-131072 (32 vCPU, 128 GiB)
- Custom-48-199608 (48 vCPU, 192 GiB)
- Custom-64-262144 (64 vCPU, 256 GiB)
- Custom-96-393216 (96 vCPU, 384 GiB)
- e2-standard-4 (4 vCPU, 16 GiB)
- format N2-standard-4 (4 vCPU, 16 GiB)
- e2-standard-8 (8 vCPU, 32 GiB)
- le N2-standard-8 (8 vCPU, 32 GiB)
- e2-standard-16 (16 vCPU, 64 GiB)
- format N2-standard-16 (16 vCPU, 64 GiB)
- e2-standard-32 (32 vCPU, 128 GiB)
- le n2-standard-32 (32 vCPU, 128 GiB)
- en savoir plus N2-standard-48 (48 vCPU, 192 GiB)
- le n2-standard-64 (64 vCPU, 256 GiB)
- la N2-standard-80 (80 vCPU, 320 GiB)
- le n2-standard-96 (96 vCPU, 384 GiB)
- 2-standard-128 (128 vCPU, 512 GiB)
Exemple 2.13. La mémoire optimisée
- Custom-4-32768-ext (4 vCPU, 32 GiB)
- Custom-8-65536-ext (8 vCPU, 64 GiB)
- Custom-16-131072-ext (16 vCPU, 128 GiB)
- e2-highmem-4 (4 vCPU, 32 GiB)
- e2-highmem-8 (8 vCPU, 64 GiB)
- e2-highmem-16 (16 vCPU, 128 GiB)
- haut-mem-4 (4 vCPU, 32 GiB)
- le N2-highmem-8 (8 vCPU, 64 GiB)
- ajouter au panier N2-highmem-16 (16 vCPU, 128 GiB)
- le n2-highmem-32 (32 vCPU, 256 GiB)
- le n2-highmem-48 (48 vCPU, 384 GiB)
- le n2-highmem-64 (64 vCPU, 512 GiB)
- le n2-highmem-80 (80 vCPU, 640 GiB)
- le n2-highmem-96 (96 vCPU, 768 GiB)
- le n2-highmem-128 (128 vCPU, 864 GiB)
Exemple 2.14. Calcul optimisé
- Custom-8-16384 (8 vCPU, 16 GiB)
- Custom-16-32768 (16 vCPU, 32 GiB)
- Custom-36-73728 (36 vCPU, 72 GiB)
- Custom-48-98304 (48 vCPU, 96 GiB)
- Custom-72-147456 (72 vCPU, 144 GiB)
- Custom-96-196608 (96 vCPU, 192 GiB)
- c2-standard-4 (4 vCPU, 16 GiB)
- c2-standard-8 (8 vCPU, 32 GiB)
- c2-standard-16 (16 vCPU, 64 GiB)
- c2-standard-30 (30 vCPU, 120 GiB)
- c2-standard-60 (60 vCPU, 240 GiB)
- e2-highcpu-8 (8 vCPU, 8 GiB)
- e2-highcpu-16 (16 vCPU, 16 GiB)
- e2-highcpu-32 (32 vCPU, 32 GiB)
- ajouter au panier N2-highcpu-8 (8 vCPU, 8 GiB)
- ajouter au panier N2-highcpu-16 (16 vCPU, 16 GiB)
- le n2-highcpu-32 (32 vCPU, 32 GiB)
- 48-highcpu-48 (48 vCPU, 48 GiB)
- le n2-highcpu-64 (64 vCPU, 64 GiB)
- 80-highcpu-80 (80 vCPU, 80 GiB)
- le n2-highcpu-96 (96 vCPU, 96 GiB)
Exemple 2.15. Calcul accéléré
- a2-highgpu-1g (12 vCPU, 85 GiB)
- a2-highgpu-2g (24 vCPU, 170 GiB)
- a2-highgpu-4g (48 vCPU, 340 GiB)
- a2-highgpu-8g (96 vCPU, 680 GiB)
- a2-megagpu-16g (96 vCPU, 1.33 TiB)
- a2-ultragpu-1g (12 vCPU, 170 GiB)
- a2-ultragpu-2g (24 vCPU, 340 GiB)
- a2-ultragpu-4g (48 vCPU, 680 GiB)
- a2-ultragpu-8g (96 vCPU, 1360 GiB)
- a3-highgpu-1g (26 vCPU, 234 GiB)
- a3-highgpu-2g (52 vCPU, 468 GiB)
- a3-highgpu-4g (104 vCPU, 936 GiB)
- a3-highgpu-8g (208 vCPU, 1872 GiB)
- a3-megagpu-8g (208 vCPU, 1872 GiB)
- a3-edgegpu-8g (208 vCPU, 1872 GiB)
2.1.1.8. Les régions et les zones de disponibilité
Les régions suivantes sont prises en charge par OpenShift Container Platform 4 et sont prises en charge pour OpenShift Dedicated.
2.1.1.8.1. Les régions AWS et les zones de disponibilité
Les régions AWS suivantes sont prises en charge par OpenShift Container Platform 4 et sont prises en charge pour OpenShift Dedicated:
- AF-south-1 (Cape Town, AWS opt-in requis)
- AP-east-1 (Hong Kong, AWS opt-in requis)
- AP-northeast-1 (Tokyo)
- AP-northeast-2 (Seoul)
- AP-northeast-3 (Osaka)
- AP-sud-1 (Mumbai)
- AP-south-2 (Hyderabad, AWS opt-in requis)
- AP-sud-est-1 (Singapour)
- AP-sud-est-2 (Sydney)
- AP-sud-est-3 (Jakarta, AWS opt-in requis)
- AP-sud-est-4 (Melbourne, AWS opt-in requis)
- ca-central-1 (Centre du Canada)
- EU-central-1 (Francfort)
- EU-central-2 (Zurich, AWS opt-in requis)
- EU-north-1 (Stockholm)
- EU-Sud-1 (Milan, AWS opt-in requis)
- EU-Sudth-2 (Espagne, AWS opt-in requis)
- UE-Ouest-1 (Irlande)
- EU-west-2 (Londres)
- EU-west-3 (Paris)
- le me-central-1 (UAE, AWS opt-in requis)
- le me-sud-1 (Bahrain, AWS opt-in requis)
- hôtels proches de la SA-east-1 (São Paulo)
- États-Unis-Est-1 (N. Virginie)
- C’est nous-Est-2 (Ohio)
- États-Unis-Ouest-1 (N.-Californie)
- l’ouest-2 (Oregon)
2.1.1.8.2. Google Cloud régions et zones de disponibilité
Les régions Google Cloud suivantes sont actuellement prises en charge:
- Asie-Est1, comté de Changhua, Taïwan
- Asie-Est2, Hong Kong
- Asie-nord-est1, Tokyo, Japon
- Asie-nord-est2, Osaka, Japon
- Asie-sud1, Mumbai, Inde
- Asie-sud2, Delhi, Inde
- Asie-sud-Est1, Jurong Ouest, Singapour
- Australie-sud-est1, Sydney, Australie
- Australie-sud-est2, Melbourne, Australie
- Europe-Nord1, Hamina, Finlande
- Europe-Ouest1, St. Ghislain, Belgique
- Europe-Ouest2, Londres, Angleterre, Royaume-Uni
- Europe-Ouest3, Francfort, Allemagne
- Europe-Ouest4, Eemshaven, Pays-Bas
- Europe-Ouest6, Zurich, Suisse
- Europe-Ouest8, Milan, Italie
- Europe-Ouest12, Turin, Italie
- Europe-sud-Ouest1, Madrid, Espagne
- Amérique du Nord-nord-est1, Montréal, Québec, Canada
- Amérique du Sud-Est1, Osasco (São Paulo), Brésil
- Amérique du Sud-Ouest1, Santiago, Chili
- central1, Conseil Bluffs, Iowa, États-Unis
- US-east1, Moncks Corner, Caroline du Sud, États-Unis
- Ashburn, Virginie du Nord, États-Unis
- les Dalles, Oregon, États-Unis
- États-Unis d’Amérique, Los Angeles, Californie, États-Unis
- centre 1, Doha, Qatar
- central2, Dammam, Arabie saoudite
Les clusters multi-AZ ne peuvent être déployés que dans les régions avec au moins 3 zones de disponibilité (voir AWS et Google Cloud).
Chaque nouveau cluster dédié OpenShift Dedicated est installé dans un Cloud privé virtuel (VPC) dédié dans une seule région, avec la possibilité de se déployer dans une zone de disponibilité unique (Single-AZ) ou sur plusieurs zones de disponibilité (Multi-AZ). Cela permet d’isoler le réseau et les ressources au niveau du cluster, et permet les paramètres VPC fournisseurs de cloud, tels que les connexions VPN et VPC Peering. Les volumes persistants sont soutenus par le stockage de blocs cloud et sont spécifiques à la zone de disponibilité dans laquelle ils sont approvisionnés. Les volumes persistants ne se lient pas à un volume tant que la ressource de pod associée n’est pas affectée dans une zone de disponibilité spécifique afin d’éviter les pods imprévus. Les ressources spécifiques à la zone de disponibilité ne sont utilisables que par des ressources dans la même zone de disponibilité.
La région et le choix d’une zone de disponibilité unique ou multiple ne peuvent pas être modifiés une fois qu’un cluster a été déployé.
2.1.1.9. Accord de niveau de service (SLA)
Les SLA du service lui-même sont définies à l’annexe 4 de l’Annexe 4 de l’Accord d’entreprise Red Hat (Services d’abonnement en ligne).
2.1.1.10. Le statut de soutien limité
Lorsqu’un cluster passe à un statut de support limité, Red Hat ne surveille plus de manière proactive le cluster, le SLA n’est plus applicable et les crédits demandés contre l’ALS sont refusés. Cela ne signifie pas que vous n’avez plus de support produit. Dans certains cas, le cluster peut revenir à un statut entièrement pris en charge si vous corrigez les facteurs de violation. Cependant, dans d’autres cas, vous devrez peut-être supprimer et recréer le cluster.
Il est possible qu’un cluster passe à un statut de support limité pour de nombreuses raisons, y compris les scénarios suivants:
- Lorsque vous ne mettez pas à niveau un cluster vers une version prise en charge avant la date de fin de vie
Le Red Hat ne fait aucune garantie d’exécution ou de SLA pour les versions après leur date de fin de vie. Afin de recevoir un soutien continu, mettre à niveau le cluster vers une version prise en charge avant la date de fin de vie. Lorsque vous ne mettez pas à niveau le cluster avant la date de fin de vie, le cluster passe à un statut de support limité jusqu’à ce qu’il soit mis à niveau vers une version prise en charge.
Le Red Hat fournit un support commercialement raisonnable pour passer d’une version non prise en charge à une version prise en charge. Cependant, si un chemin de mise à niveau pris en charge n’est plus disponible, vous devrez peut-être créer un nouveau cluster et migrer vos charges de travail.
- Dans le cas où vous supprimez ou remplacez des composants natifs OpenShift dédiés ou tout autre composant installé et géré par Red Hat
- En cas d’utilisation des autorisations d’administrateur de clusters, Red Hat n’est pas responsable des actions de vos utilisateurs autorisés ou de vos utilisateurs autorisés, y compris celles qui affectent les services d’infrastructure, la disponibilité des services ou la perte de données. Dans le cas où Red Hat détecte de telles actions, le cluster pourrait passer à un statut de support limité. Le Red Hat vous informe du changement d’état et vous devriez soit inverser l’action, soit créer un cas de support pour explorer les étapes d’assainissement qui pourraient vous obliger à supprimer et à recréer le cluster.
Lorsque vous avez des questions sur une action spécifique qui pourrait faire passer un cluster à un statut de support limité ou avoir besoin d’une assistance supplémentaire, ouvrez un ticket de support.
2.1.1.11. Le soutien
Le service OpenShift Dedicated inclut le support Red Hat Premium, auquel vous pouvez accéder en utilisant le portail client Red Hat.
Consultez la page Portée de couverture pour plus de détails sur ce qui est couvert avec le support inclus pour OpenShift Dedicated.
Consultez les SLA dédiés OpenShift pour les temps de réponse de support.
2.1.2. L’exploitation forestière
En option, OpenShift Dedicated fournit un transfert de journal intégré vers Amazon CloudWatch (sur AWS) ou Google Cloud Logging (sur GCP).
Consultez À propos de la collecte et de la transmission des journaux pour plus d’informations.
2.1.2.1. Enregistrement de l’audit en grappes
Les journaux d’audit en cluster sont disponibles via Amazon CloudWatch (sur AWS) ou Google Cloud Logging (sur GCP), si l’intégration est activée. Lorsque l’intégration n’est pas activée, vous pouvez demander les journaux d’audit en ouvrant un dossier d’assistance. Les demandes de journaux d’audit doivent préciser une date et une période ne dépassant pas 21 jours. Lorsque vous demandez des journaux d’audit, les clients doivent savoir que les journaux d’audit sont de nombreux GB par jour en taille.
2.1.2.2. Enregistrement des applications
Les journaux d’application envoyés à STDOUT sont transmis à Amazon CloudWatch (sur AWS) ou Google Cloud Logging (sur GCP) via la pile de journalisation des clusters, s’il est installé.
2.1.3. Le suivi
2.1.3.1. Les métriques des clusters
Les clusters dédiés OpenShift sont livrés avec une pile Prometheus/Grafana intégrée pour la surveillance des clusters, y compris les métriques CPU, mémoire et réseau. Ceci est accessible via la console Web et peut également être utilisé pour afficher l’état et la capacité / utilisation au niveau du cluster via un tableau de bord Grafana. Ces métriques permettent également un autoscaling de pod horizontal basé sur des métriques CPU ou mémoire fournies par un utilisateur dédié OpenShift.
2.1.3.2. Les notifications de cluster
Les notifications de cluster sont des messages sur l’état, la santé ou les performances de votre cluster.
Les notifications de cluster sont la principale façon dont Red Hat Site Reliability Engineering (SRE) communique avec vous sur la santé de votre cluster géré. Le SRE peut également utiliser des notifications de cluster pour vous inviter à effectuer une action afin de résoudre ou d’empêcher un problème avec votre cluster.
Les propriétaires de clusters et les administrateurs doivent régulièrement examiner et agir les notifications de clusters pour s’assurer que les clusters restent en bonne santé et pris en charge.
Dans l’onglet Historique des clusters de votre cluster, vous pouvez afficher les notifications de cluster dans la console de cloud hybride Red Hat. Par défaut, seul le propriétaire du cluster reçoit des notifications de cluster sous forme d’e-mails. Lorsque d’autres utilisateurs doivent recevoir des e-mails de notification en cluster, ajoutez chaque utilisateur comme contact de notification pour votre cluster.
2.1.4. Le réseautage
2.1.4.1. Domaines personnalisés pour les applications
En commençant par OpenShift Dedicated 4.14, l’opérateur de domaine personnalisé est obsolète. Afin de gérer Ingress dans OpenShift Dedicated 4.14 ou ultérieur, utilisez l’opérateur Ingress. La fonctionnalité est inchangée pour OpenShift Dedicated 4.13 et versions antérieures.
Afin d’utiliser un nom d’hôte personnalisé pour un itinéraire, vous devez mettre à jour votre fournisseur DNS en créant un enregistrement de nom canonique (CNAME). L’enregistrement CNAME doit cartographier le nom d’hôte du routeur canonique OpenShift à votre domaine personnalisé. Le nom d’hôte du routeur canonique OpenShift est affiché sur la page Détails de l’itinéraire après la création d’une Route. Alternativement, un enregistrement générique CNAME peut être créé une fois pour acheminer tous les sous-domaines d’un nom d’hôte donné vers le routeur du cluster.
2.1.4.2. Domaines personnalisés pour les services de cluster
Les domaines et sous-domaines personnalisés ne sont pas disponibles pour les routes de service de la plate-forme, par exemple, les routes API ou console Web, ou pour les routes d’application par défaut.
2.1.4.3. Certificats validés par domaine
Le programme OpenShift Dedicated inclut les certificats de sécurité TLS nécessaires à la fois pour les services internes et externes sur le cluster. Dans le cas des routes externes, il y a deux certificats de wildcard TLS distincts qui sont fournis et installés sur chaque cluster, un pour la console Web et les noms d’hôte par défaut d’itinéraire et le second pour le point de terminaison API. Let's Encrypt est l’autorité de certification utilisée pour les certificats. Les itinéraires au sein du cluster, par exemple, le point de terminaison interne de l’API, utilisent les certificats TLS signés par l’autorité de certification intégrée du cluster et exigent le paquet CA disponible dans chaque pod pour faire confiance au certificat TLS.
2.1.4.4. Autorités de certification personnalisées pour les constructions
Le logiciel OpenShift Dedicated prend en charge l’utilisation d’autorités de certification personnalisées à utiliser par les builds lors de l’extraction d’images à partir d’un registre d’images.
2.1.4.5. Balanceurs de charge
L’OpenShift Dedicated utilise jusqu’à 5 balanceurs de charge différents:
- Balanceur de charge de plan de contrôle interne qui est interne au cluster et utilisé pour équilibrer le trafic pour les communications internes de cluster.
- Balanceur de charge de plan de contrôle externe utilisé pour accéder aux API OpenShift Container Platform et Kubernetes. Cet équilibreur de charge peut être désactivé dans Red Hat OpenShift Cluster Manager. Lorsque cet équilibreur de charge est désactivé, Red Hat reconfigure le DNS API pour pointer vers l’équilibreur de charge de contrôle interne.
- Balanceur de charge de plan de contrôle externe pour Red Hat qui est réservé à la gestion des clusters par Red Hat. L’accès est strictement contrôlé, et la communication n’est possible que par les hôtes de bastion autorisés.
- Balanceur de charge routeur / ingère par défaut qui est l’équilibreur de charge par défaut de l’application, indiqué par les applications dans l’URL. L’équilibreur de charge par défaut peut être configuré dans OpenShift Cluster Manager pour être soit accessible au public sur Internet, soit uniquement accessible en privé via une connexion privée préexistante. L’ensemble des itinéraires d’application du cluster sont exposés sur cet équilibreur de charge de routeur par défaut, y compris les services de cluster tels que l’interface utilisateur de journalisation, l’API métrique et le registre.
- Facultatif: l’équilibreur de charge secondaire de routeur / ingère qui est un équilibreur de charge d’application secondaire, indiqué par les applications2 dans l’URL. L’équilibreur de charge secondaire peut être configuré dans OpenShift Cluster Manager pour être soit accessible au public sur Internet, soit uniquement accessible en privé via une connexion privée préexistante. En cas de configuration d’un 'Label Match' pour cet équilibreur de charge de routeur, seuls les itinéraires d’application correspondant à cette étiquette seront exposés sur cet équilibreur de charge du routeur, sinon tous les itinéraires d’application sont également exposés sur cet équilibreur de charge du routeur.
- Facultatif: Les équilibreurs de charge pour les services qui peuvent être mappés à un service fonctionnant sur OpenShift Dedicated pour activer des fonctionnalités avancées d’entrée, telles que le trafic non-HTTP/SNI ou l’utilisation de ports non standard. Ceux-ci peuvent être achetés en groupes de 4 pour les clusters non-CCS, ou ils peuvent être fournis via la console fournisseur de cloud dans les clusters d’abonnement au cloud client (CCS); cependant, chaque compte AWS dispose d’un quota qui limite le nombre d’équilibreurs de charge classiques pouvant être utilisés dans chaque cluster.
2.1.4.6. L’utilisation du réseau
Dans le cas des clusters dédiés à OpenShift non-CCS, l’utilisation du réseau est mesurée en fonction du transfert de données entre le trafic entrant, VPC peering, VPN et AZ. Dans un cluster de base non-CCS OpenShift dédié, 12 To d’E/S réseau sont fournis. Des E/S supplémentaires de réseau peuvent être achetées par incréments de 12 To. Dans le cas des clusters dédiés à CCS OpenShift, l’utilisation du réseau n’est pas surveillée et est facturée directement par le fournisseur de cloud.
2.1.4.7. Entrée de cluster
Les administrateurs de projet peuvent ajouter des annotations d’itinéraire à de nombreuses fins différentes, y compris le contrôle d’entrée grâce à la liste d’autorisations IP.
Les stratégies d’entrée peuvent également être modifiées en utilisant les objets NetworkPolicy, qui exploitent le plugin ovs-networkpolicy. Cela permet un contrôle total de la stratégie réseau d’entrée jusqu’au niveau pod, y compris entre les pods sur le même cluster et même dans le même espace de noms.
L’ensemble du trafic d’entrée de cluster passe par les équilibreurs de charge définis. L’accès direct à tous les nœuds est bloqué par la configuration du cloud.
2.1.4.8. Egress de cluster
Le contrôle du trafic par le biais d’objets EgressNetworkPolicy peut être utilisé pour prévenir ou limiter le trafic sortant dans OpenShift Dedicated.
Le trafic public sortant du plan de contrôle et des nœuds d’infrastructure est nécessaire pour maintenir la sécurité de l’image de cluster et la surveillance des clusters. Cela nécessite que l’itinéraire 0.0.0.0/0 appartienne uniquement à la passerelle Internet; il n’est pas possible d’acheminer cette gamme sur des connexions privées.
Les clusters dédiés à OpenShift utilisent les passerelles NAT pour présenter une IP publique statique pour tout trafic public sortant du cluster. Chaque sous-réseau dans lequel un cluster est déployé reçoit une passerelle NAT distincte. Dans le cas des clusters déployés sur AWS avec plusieurs zones de disponibilité, jusqu’à 3 adresses IP statiques uniques peuvent exister pour le trafic de sortie de cluster. Dans le cas des clusters déployés sur Google Cloud, quelle que soit la topologie de la zone de disponibilité, il y aura 1 adresse IP statique pour le trafic de nœuds de travail. Le trafic qui reste à l’intérieur du cluster ou qui ne sort pas vers l’Internet public ne passera pas par la passerelle NAT et aura une adresse IP source appartenant au nœud d’origine du trafic. Les adresses IP des nœuds sont dynamiques et, par conséquent, un client ne devrait pas compter sur l’autorisation d’une adresse IP individuelle lors de l’accès aux ressources privées.
Les clients peuvent déterminer leurs adresses IP statiques publiques en exécutant un pod sur le cluster, puis en interrogeant un service externe. À titre d’exemple:
$ oc run ip-lookup --image=busybox -i -t --restart=Never --rm -- /bin/sh -c "/bin/nslookup -type=a myip.opendns.com resolver1.opendns.com | grep -E 'Address: [0-9.]+'"2.1.4.9. Configuration du réseau cloud
L’OpenShift Dedicated permet la configuration d’une connexion réseau privée via plusieurs technologies gérées par des fournisseurs de cloud:
- Connexions VPN
- AWS VPC peering
- AWS Transit Gateway
- AWS Direct Connect
- Google Cloud VPC Network peering
- Google Cloud Classic VPN
- Google Cloud HA VPN
Les SRE Red Hat ne surveillent pas les connexions réseau privées. La surveillance de ces connexions relève de la responsabilité du client.
2.1.4.10. Envoi DNS
Dans le cas des clusters dédiés à OpenShift qui ont une configuration de réseau cloud privé, un client peut spécifier des serveurs DNS internes disponibles sur cette connexion privée qui devraient être interrogés pour les domaines explicitement fournis.
2.1.4.11. La vérification du réseau
Les vérifications réseau s’exécutent automatiquement lorsque vous déployez un cluster dédié OpenShift dans un cloud privé virtuel (VPC) existant ou créez un pool de machines supplémentaire avec un sous-réseau qui est nouveau à votre cluster. Les vérifications valident votre configuration réseau et mettent en évidence les erreurs, vous permettant de résoudre les problèmes de configuration avant le déploiement.
Il est également possible d’exécuter manuellement les vérifications réseau pour valider la configuration d’un cluster existant.
2.1.5. Le stockage
2.1.5.1. Stockage crypté du système d’exploitation/node
Les nœuds de plan de contrôle utilisent le stockage crypté au repos-EBS.
2.1.5.2. Crypté au repos PV
Les volumes EBS utilisés pour les volumes persistants (PV) sont cryptés au repos par défaut.
2.1.5.3. Bloc de stockage (RWO)
Les volumes persistants (PV) sont soutenus par AWS EBS et Google Cloud, qui utilise le mode d’accès ReadWriteOnce (RWO). Dans un cluster de base non-CCS OpenShift dédié, 100 Go de stockage par bloc sont fournis pour les PV, qui sont fournis dynamiquement et recyclés en fonction des demandes d’application. Le stockage persistant supplémentaire peut être acheté par incréments de 500 Go.
Les PVS ne peuvent être attachés qu’à un seul nœud à la fois et sont spécifiques à la zone de disponibilité dans laquelle ils ont été fournis, mais ils peuvent être attachés à n’importe quel nœud dans la zone de disponibilité.
Chaque fournisseur de cloud a ses propres limites pour combien de PV peuvent être attachés à un seul nœud. Consultez les limites de type d’instance AWS ou les types de machines personnalisées de Google Cloud Platform pour plus de détails.
2.1.6. La plate-forme
2.1.6.1. La stratégie de sauvegarde des clusters
Il est essentiel que les clients disposent d’un plan de sauvegarde pour leurs applications et leurs données d’application.
Les sauvegardes de données d’application et d’application ne font pas partie du service dédié OpenShift. Dans chaque cluster dédié OpenShift, tous les objets Kubernetes sont sauvegardés pour faciliter une récupération rapide dans le cas peu probable qu’un cluster devienne irréparable.
Les sauvegardes sont stockées dans un seau de stockage d’objets sécurisé (Multi-AZ) dans le même compte que le cluster. Les volumes racine des nœuds ne sont pas sauvegardés parce que Red Hat Enterprise Linux CoreOS est entièrement géré par le cluster OpenShift Container Platform et qu’aucune donnée étatique ne doit être stockée sur le volume racine d’un nœud.
Le tableau suivant montre la fréquence des sauvegardes:
| Composante | Fréquence de capture d’écran | La rétention | Les notes |
|---|---|---|---|
| Sauvegarde complète du magasin d’objets | Chaque jour à 0100 UTC | 7 jours | Il s’agit d’une sauvegarde complète de tous les objets Kubernetes. Aucun volume persistant (PV) n’est sauvegardé dans ce calendrier de sauvegarde. |
| Sauvegarde complète du magasin d’objets | Hebdomadaire le lundi à 0200 UTC | 30 jours | Il s’agit d’une sauvegarde complète de tous les objets Kubernetes. Aucun PV n’est sauvegardé dans ce calendrier de sauvegarde. |
| Sauvegarde complète du magasin d’objets | Heure à 17 minutes après l’heure | 24 heures | Il s’agit d’une sauvegarde complète de tous les objets Kubernetes. Aucun PV n’est sauvegardé dans ce calendrier de sauvegarde. |
2.1.6.2. Autoscaling
La mise à l’échelle automatique des nœuds est disponible sur OpenShift Dedicated. Consultez À propos des nœuds autoscaling sur un cluster pour plus d’informations sur les nœuds autoscaling sur un cluster.
2.1.6.3. Ensembles de démons
Les clients peuvent créer et exécuter DaemonSets sur OpenShift Dedicated. Afin de limiter DaemonSets à fonctionner uniquement sur les nœuds de travail, utilisez le nodeSelector suivant:
...
spec:
nodeSelector:
role: worker
...2.1.6.4. La zone de disponibilité multiple
Dans un cluster de zones de disponibilité multiple, les nœuds de contrôle sont répartis entre les zones de disponibilité et au moins trois nœuds de travail sont requis dans chaque zone de disponibilité.
2.1.6.5. Étiquettes des nœuds
Les étiquettes de nœuds personnalisés sont créées par Red Hat lors de la création de nœuds et ne peuvent pas être modifiées sur les clusters dédiés OpenShift pour le moment.
2.1.6.6. La version OpenShift
Le service OpenShift Dedicated est mis à jour avec la dernière version OpenShift Container Platform.
2.1.6.7. Des mises à niveau
Consultez le cycle de vie dédié OpenShift pour plus d’informations sur la politique et les procédures de mise à niveau.
2.1.6.8. Conteneurs Windows
Les conteneurs Windows ne sont pas disponibles sur OpenShift Dedicated pour le moment.
2.1.6.9. Conteneur moteur
L’OpenShift Dedicated fonctionne sur OpenShift 4 et utilise CRI-O comme seul moteur de conteneur disponible.
2.1.6.10. Le système d’exploitation
Le système OpenShift Dedicated fonctionne sur OpenShift 4 et utilise Red Hat Enterprise Linux CoreOS comme système d’exploitation pour tous les nœuds de plan de contrôle et de travail.
2.1.6.11. Assistance de Red Hat Operator
Les charges de travail Red Hat se réfèrent généralement aux opérateurs fournis par Red Hat mis à disposition par l’intermédiaire de l’opérateur Hub. Les charges de travail Red Hat ne sont pas gérées par l’équipe Red Hat SRE et doivent être déployées sur les nœuds des travailleurs. Ces opérateurs peuvent nécessiter des abonnements supplémentaires à Red Hat et peuvent entraîner des coûts d’infrastructure cloud supplémentaires. Des exemples de ces opérateurs fournis par Red Hat sont:
- Chapeau rouge Quay
- Gestion avancée des clusters Red Hat
- Ajouter au panier Red Hat Advanced Cluster Security
- Chapeau rouge OpenShift Service Mesh
- Informations sur OpenShift Serverless
- Coupe rouge OpenShift Logging
- Chapeau rouge OpenShift Pipelines
2.1.6.12. Assistance de l’opérateur Kubernetes
Les opérateurs inscrits sur le marché OperatorHub devraient être disponibles pour l’installation. Les opérateurs installés à partir de OperatorHub, y compris Red Hat Operators, ne sont pas gérés SRE dans le cadre du service dédié OpenShift. Consultez le portail client Red Hat pour plus d’informations sur la compatibilité d’un opérateur donné.
2.1.7. La sécurité
Cette section fournit des informations sur la définition du service pour la sécurité dédiée à OpenShift.
2.1.7.1. Fournisseur d’authentification
L’authentification pour le cluster est configurée dans le cadre du processus de création de clusters Red Hat OpenShift Cluster Manager. « OpenShift n’est pas un fournisseur d’identité, et tout accès au cluster doit être géré par le client dans le cadre de sa solution intégrée. Le provisionnement de plusieurs fournisseurs d’identité fournis en même temps est pris en charge. Les fournisseurs d’identité suivants sont pris en charge:
- GitHub ou GitHub Enterprise OAuth
- GitLab OAuth
- Google OAuth
- LDAP
- Connexion OpenID
2.1.7.2. Conteneurs privilégiés
Les conteneurs privilégiés ne sont pas disponibles par défaut sur OpenShift Dedicated. Les contraintes de contexte de sécurité anyuid et non racine sont disponibles pour les membres du groupe admins dédiés, et devraient traiter de nombreux cas d’utilisation. Les conteneurs privilégiés ne sont disponibles que pour les utilisateurs de cluster-admin.
2.1.7.3. Administrateur client utilisateur
En plus des utilisateurs normaux, OpenShift Dedicated fournit l’accès à un groupe dédié OpenShift spécifique appelé dédié-admin. Les utilisateurs du cluster qui sont membres du groupe admin dédié:
- Avoir un accès administrateur à tous les projets créés par le client sur le cluster.
- Gérer les quotas de ressources et les limites du cluster.
- Il peut ajouter et gérer des objets NetworkPolicy.
- Ils sont capables d’afficher des informations sur des nœuds spécifiques et des PV dans le cluster, y compris les informations sur les planificateurs.
- Accéder au projet admin réservé sur le cluster, ce qui permet la création de comptes de service avec des privilèges élevés et permet également de mettre à jour les limites et les quotas par défaut pour les projets sur le cluster.
- Il peut installer des Opérateurs à partir de OperatorHub (* verbes dans tous les groupes d’API *.operators.coreos.com).
2.1.7.4. Le rôle de l’administration des clusters
En tant qu’administrateur d’OpenShift Dedicated with Customer Cloud Subscriptions (CCS), vous avez accès au rôle cluster-admin. Alors qu’ils sont connectés à un compte avec le rôle de cluster-admin, les utilisateurs ont pour la plupart un accès illimité au contrôle et à la configuration du cluster. Il y a certaines configurations qui sont bloquées avec des webhooks pour empêcher le désétablissement du cluster, ou parce qu’elles sont gérées dans OpenShift Cluster Manager et tout changement dans l’inclusion serait écrasé.
2.1.7.5. Libre-service de projet
L’ensemble des utilisateurs, par défaut, ont la possibilité de créer, mettre à jour et supprimer leurs projets. Cela peut être restreint si un membre du groupe admin dédié supprime le rôle d’auto-fournisseur des utilisateurs authentifiés:
$ oc adm policy remove-cluster-role-from-group self-provisioner system:authenticated:oauthLes restrictions peuvent être annulées en appliquant:
$ oc adm policy add-cluster-role-to-group self-provisioner system:authenticated:oauth2.1.7.6. Conformité réglementaire
La société OpenShift Dedicated suit les meilleures pratiques courantes de l’industrie en matière de sécurité et de contrôle. Les certifications sont décrites dans le tableau suivant.
| Conformité | Dédié à OpenShift sur AWS | Dédié à OpenShift sur GCP |
|---|---|---|
| HIPAA Qualifié | (abonnements uniquement au cloud client) | (abonnements uniquement au cloud client) |
| ISO 27001 | ♪ oui ♪ | ♪ oui ♪ |
| DSS PCI | ♪ oui ♪ | ♪ oui ♪ |
| Le SOC 2 de type 2 | ♪ oui ♪ | ♪ oui ♪ |
2.1.7.7. La sécurité du réseau
Chaque cluster dédié OpenShift est protégé par une configuration réseau sécurisée au niveau de l’infrastructure cloud en utilisant les règles de pare-feu (AWS Security Groups ou Google Cloud Compute Engine). Les clients dédiés sur AWS sont également protégés contre les attaques DDoS avec AWS Shield Standard. De même, tous les équilibreurs de charge GCP et les adresses IP publiques utilisées par OpenShift Dedicated on GCP sont protégés contre les attaques DDoS avec Google Cloud Armor Standard.
2.1.7.8. chiffrement etcd
Dans OpenShift Dedicated, le stockage du plan de contrôle est crypté au repos par défaut et cela inclut le cryptage des volumes etcd. Ce chiffrement de niveau de stockage est fourni via la couche de stockage du fournisseur de cloud.
Il est également possible d’activer le chiffrement etcd, qui chiffre les valeurs clés dans etcd, mais pas les clés. Lorsque vous activez le cryptage etcd, les ressources suivantes du serveur API Kubernetes et OpenShift API sont cryptées:
- Les secrets
- Configuration des cartes
- Itinéraires
- Jetons d’accès OAuth
- Autoriser les jetons OAuth
La fonction de chiffrement etcd n’est pas activée par défaut et ne peut être activée qu’au moment de l’installation du cluster. Bien que le chiffrement etcd soit activé, les valeurs clés etcd sont accessibles à toute personne ayant accès aux nœuds de plan de contrôle ou aux privilèges cluster-admin.
En activant le chiffrement etcd pour les valeurs clés dans etcd, vous subirez un surcharge de performance d’environ 20%. Les frais généraux sont le résultat de l’introduction de cette deuxième couche de chiffrement, en plus du chiffrement de stockage de plan de contrôle par défaut qui crypte les volumes etcd. Le Red Hat vous recommande d’activer le chiffrement etc. uniquement si vous en avez spécifiquement besoin pour votre cas d’utilisation.
2.2. Matrice d’affectation des responsabilités
Comprendre le Red Hat, le fournisseur de cloud et les responsabilités des clients pour le service géré OpenShift Dedicated.
2.2.1. Aperçu des responsabilités d’OpenShift dédié
Alors que Red Hat gère le service OpenShift Dedicated, le client partage la responsabilité de certains aspects. Les services OpenShift Dedicated sont accessibles à distance, hébergés sur des ressources cloud publiques, créés dans les comptes de Red Hat ou de fournisseurs de services cloud appartenant à des clients, et ont une plate-forme sous-jacente et une sécurité des données qui appartient à Red Hat.
Lorsque le rôle de cluster-administrateur est activé sur un cluster, consultez les notes de responsabilité et d’exclusion dans l’Annexe 4 de l’Accord d’entreprise Red Hat (Services d’abonnement en ligne).
| A) Ressources | Gestion des incidents et des opérations | Gestion du changement | Accès et autorisation d’identité | Conformité à la sécurité et à la réglementation | La reprise après sinistre |
|---|---|---|---|---|---|
| Données du client | Client | Client | Client | Client | Client |
| Applications client | Client | Client | Client | Client | Client |
| Les services des développeurs | Client | Client | Client | Client | Client |
| La surveillance de la plate-forme | Chapeau rouge | Chapeau rouge | Chapeau rouge | Chapeau rouge | Chapeau rouge |
| L’exploitation forestière | Chapeau rouge | Le partage | Le partage | Le partage | Chapeau rouge |
| La mise en réseau des applications | Le partage | Le partage | Le partage | Chapeau rouge | Chapeau rouge |
| La mise en réseau de clusters | Chapeau rouge | Le partage | Le partage | Chapeau rouge | Chapeau rouge |
| Le réseau virtuel | Le partage | Le partage | Le partage | Le partage | Le partage |
| Avion de contrôle et nœuds d’infrastructure | Chapeau rouge | Chapeau rouge | Chapeau rouge | Chapeau rouge | Chapeau rouge |
| Les nœuds ouvriers | Chapeau rouge | Chapeau rouge | Chapeau rouge | Chapeau rouge | Chapeau rouge |
| La version du cluster | Chapeau rouge | Le partage | Chapeau rouge | Chapeau rouge | Chapeau rouge |
| Gestion des capacités | Chapeau rouge | Le partage | Chapeau rouge | Chapeau rouge | Chapeau rouge |
| Le stockage virtuel | Fournisseur Red Hat et cloud | Fournisseur Red Hat et cloud | Fournisseur Red Hat et cloud | Fournisseur Red Hat et cloud | Fournisseur Red Hat et cloud |
| Infrastructure physique et sécurité | Fournisseur de cloud | Fournisseur de cloud | Fournisseur de cloud | Fournisseur de cloud | Fournisseur de cloud |
2.2.3. Les responsabilités des clients en matière de données et d’applications
Le client est responsable des applications, des charges de travail et des données qu’il déploie sur OpenShift Dedicated. Cependant, Red Hat fournit divers outils pour aider le client à gérer les données et les applications sur la plateforme.
| A) Ressources | Les responsabilités de Red Hat | Les responsabilités du client |
|---|---|---|
| Données du client |
| Gardez la responsabilité de toutes les données client stockées sur la plateforme et de la façon dont les applications client consomment et exposent ces données. |
| Applications client |
|
|
2.3. Comprendre le processus et la sécurité pour OpenShift Dédié
2.3.1. Examen et notifications des groupes d’action
Les notifications de cluster sont des messages sur l’état, la santé ou les performances de votre cluster.
Les notifications de cluster sont la principale façon dont Red Hat Site Reliability Engineering (SRE) communique avec vous sur la santé de votre cluster géré. Le SRE peut également utiliser des notifications de cluster pour vous inviter à effectuer une action afin de résoudre ou d’empêcher un problème avec votre cluster.
Les propriétaires de clusters et les administrateurs doivent régulièrement examiner et agir les notifications de clusters pour s’assurer que les clusters restent en bonne santé et pris en charge.
Dans l’onglet Historique des clusters de votre cluster, vous pouvez afficher les notifications de cluster dans la console de cloud hybride Red Hat. Par défaut, seul le propriétaire du cluster reçoit des notifications de cluster sous forme d’e-mails. Lorsque d’autres utilisateurs doivent recevoir des e-mails de notification en cluster, ajoutez chaque utilisateur comme contact de notification pour votre cluster.
2.3.1.1. La politique de notification par groupe
Les notifications de cluster sont conçues pour vous tenir informé de la santé de votre cluster et des événements à fort impact qui l’affectent.
La plupart des notifications de cluster sont générées et envoyées automatiquement pour vous assurer que vous êtes immédiatement informé des problèmes ou des changements importants à l’état de votre cluster.
Dans certaines situations, Red Hat Site Reliability Engineering (SRE) crée et envoie des notifications de cluster pour fournir un contexte supplémentaire et des conseils pour un problème complexe.
Les notifications de cluster ne sont pas envoyées pour les événements à faible impact, les mises à jour de sécurité à faible risque, les opérations et la maintenance de routine, ou les problèmes transitoires mineurs qui sont rapidement résolus par SRE.
Les services Red Hat envoient automatiquement des notifications lorsque:
- Les contrôles de surveillance de la santé ou de vérification de l’environnement à distance détectent un problème dans votre cluster, par exemple lorsqu’un nœud de travail a peu d’espace disque.
- Des événements importants du cycle de vie des clusters se produisent, par exemple, lorsque la maintenance ou les mises à niveau programmées commencent, ou que les opérations de cluster sont touchées par un événement, mais ne nécessitent pas d’intervention du client.
- D’importants changements de gestion des clusters se produisent, par exemple, lorsque la propriété de clusters ou le contrôle administratif est transféré d’un utilisateur à un autre.
- L’abonnement à votre cluster est modifié ou mis à jour, par exemple lorsque Red Hat met à jour les conditions d’abonnement ou les fonctionnalités disponibles pour votre cluster.
La SRE crée et envoie des notifications lorsque:
- L’incident entraîne une dégradation ou une panne qui affecte la disponibilité ou les performances de votre cluster, par exemple, votre fournisseur de cloud a une panne régionale. La SRE envoie des notifications ultérieures pour vous informer de l’état d’avancement de la résolution des incidents et lorsque l’incident est résolu.
- Des failles de sécurité, des failles de sécurité ou des activités inhabituelles sont détectées sur votre cluster.
- Le Red Hat détecte que les changements que vous avez apportés sont en train de créer ou peuvent entraîner une instabilité des clusters.
- Le Red Hat détecte que vos charges de travail causent une dégradation des performances ou une instabilité dans votre cluster.
2.3.2. Gestion des incidents et des opérations
Cette documentation détaille les responsabilités de Red Hat pour le service géré OpenShift Dedicated. Le fournisseur de cloud est responsable de la protection de l’infrastructure matérielle qui gère les services offerts par le fournisseur de cloud. Le client est responsable de la gestion des incidents et des opérations des données d’application client et de tout réseau personnalisé que le client a configuré pour le réseau cluster ou le réseau virtuel.
2.3.2.1. La surveillance de la plate-forme
Le Red Hat Site Reliability Engineer (SRE) maintient un système de surveillance et d’alerte centralisé pour tous les composants de cluster dédiés OpenShift, les services SRE et les comptes de fournisseurs cloud sous-jacents. Les journaux d’audit de plate-forme sont transmis en toute sécurité à un système centralisé SIEM (Security Information and Event Monitoring), où ils peuvent déclencher des alertes configurées à l’équipe SRE et sont également soumis à un examen manuel. Les journaux d’audit sont conservés dans le SIEM pendant un an. Les journaux d’audit d’un cluster donné ne sont pas supprimés au moment où le cluster est supprimé.
2.3.2.2. Gestion des incidents
L’incident est un événement qui entraîne une dégradation ou une panne d’un ou de plusieurs services Red Hat. L’incident peut être soulevé par un client ou un membre de l’Expérience client et de l’engagement (CEE) par le biais d’un dossier d’assistance, directement par le système centralisé de surveillance et d’alerte, ou directement par un membre de l’équipe SRE.
En fonction de l’impact sur le service et le client, l’incident est classé en termes de gravité.
Le flux de travail général de la façon dont un nouvel incident est géré par Red Hat:
- Le premier intervenant de SRE est alerté d’un nouvel incident et commence une enquête initiale.
- Après l’enquête initiale, l’incident est assigné à un responsable de l’incident, qui coordonne les efforts de rétablissement.
- Le responsable de l’incident gère toute communication et coordination autour de la récupération, y compris toute notification pertinente ou toute mise à jour de cas d’assistance.
- L’incident est récupéré.
- L’incident est documenté et une analyse des causes profondes est effectuée dans les 5 jours ouvrables suivant l’incident.
- Le projet de document d’analyse des causes profondes (RCA) est communiqué au client dans les 7 jours ouvrables suivant l’incident.
2.3.2.3. Sauvegarde et récupération
Les clusters dédiés OpenShift sont sauvegardés à l’aide de snapshots des fournisseurs de cloud. En particulier, cela n’inclut pas les données clients stockées sur des volumes persistants (PV). Les snapshots sont pris à l’aide des API instantanées appropriées du fournisseur de cloud et sont téléchargés sur un seau de stockage d’objets sécurisé (S3 dans AWS et GCS dans Google Cloud) dans le même compte que le cluster.
| Composante | Fréquence de prise de vue | La rétention | Les notes |
|---|---|---|---|
| Sauvegarde complète du magasin d’objets | Au quotidien | 7 jours | Il s’agit d’une sauvegarde complète de tous les objets Kubernetes comme etcd. Aucun PV n’est sauvegardé dans ce calendrier de sauvegarde. |
| Chaque semaine | 30 jours | ||
| Sauvegarde complète du magasin d’objets | Horaire | 24 heures | Il s’agit d’une sauvegarde complète de tous les objets Kubernetes comme etcd. Aucun PV n’est sauvegardé dans ce calendrier de sauvegarde. |
| Le volume de racine des nœuds | Jamais jamais | C) N/A | Les nœuds sont considérés comme à court terme. Aucune critique ne doit être stockée sur le volume racine d’un nœud. |
- Le Red Hat ne s’engage à aucun objectif de point de récupération (RPO) ou objectif de temps de récupération (RTO).
- Les clients sont responsables de prendre régulièrement des sauvegardes de leurs données
- Les clients devraient déployer des clusters multiAZ avec des charges de travail qui suivent les meilleures pratiques de Kubernetes afin d’assurer une disponibilité élevée dans une région.
- Lorsqu’une région cloud entière n’est pas disponible, les clients doivent installer un nouveau cluster dans une autre région et restaurer leurs applications à l’aide de leurs données de sauvegarde.
2.3.2.4. Capacité des clusters
L’évaluation et la gestion de la capacité des clusters est une responsabilité partagée entre Red Hat et le client. Le Red Hat SRE est responsable de la capacité de tous les nœuds d’avion de contrôle et d’infrastructure sur le cluster.
Le Red Hat SRE évalue également la capacité des clusters lors des mises à niveau et en réponse aux alertes de clusters. L’impact d’une mise à niveau du cluster sur la capacité est évalué dans le cadre du processus d’essai de mise à niveau afin de s’assurer que la capacité n’est pas affectée négativement par de nouveaux ajouts au cluster. Lors d’une mise à niveau de cluster, des nœuds de travail supplémentaires sont ajoutés pour s’assurer que la capacité totale du cluster est maintenue pendant le processus de mise à niveau.
Les évaluations des capacités du personnel de SRE ont également lieu en réponse aux alertes du groupe, une fois que les seuils d’utilisation sont dépassés pendant une certaine période. De telles alertes peuvent également entraîner une notification au client.
2.3.3. Gestion du changement
Cette section décrit les stratégies sur la façon dont les changements de cluster et de configuration, les correctifs et les versions sont gérés.
2.3.3.1. Changements initiés par le client
Il est possible d’initier des modifications en utilisant des fonctionnalités en libre-service telles que le déploiement de clusters, la mise à l’échelle des nœuds de travail ou la suppression de clusters.
L’historique des changements est capturé dans la section Historique des clusters dans l’onglet Aperçu OpenShift Cluster Manager, et est disponible pour vous. L’historique des changements comprend, sans s’y limiter, les journaux des changements suivants:
- Ajout ou suppression de fournisseurs d’identité
- Ajout ou suppression d’utilisateurs vers ou à partir du groupe admins dédiés
- Dimensionnement des nœuds de calcul du cluster
- Dimensionnement de l’équilibreur de charge du cluster
- Dimensionnement du stockage persistant du cluster
- Amélioration du cluster
Il est possible d’implémenter une exclusion de maintenance en évitant les changements dans OpenShift Cluster Manager pour les composants suivants:
- La suppression d’un cluster
- Ajout, modification ou suppression de fournisseurs d’identité
- Ajout, modification ou suppression d’un utilisateur d’un groupe élevé
- Installation ou suppression des add-ons
- La modification des configurations de réseau de clusters
- Ajout, modification ou suppression de pools de machines
- Activer ou désactiver la surveillance de la charge de travail des utilisateurs
- Lancement d’une mise à niveau
Afin de faire respecter l’exclusion de la maintenance, assurez-vous que les politiques d’autoscaling ou de mise à niveau automatique du pool de machines ont été désactivées. Après que l’exclusion de maintenance a été levée, procéder à l’activation automatique de la mise à l’échelle de la machine ou des politiques de mise à niveau automatique comme souhaité.
2.3.3.2. Changements initiés par Red Hat
L’ingénierie de fiabilité du site Red Hat (SRE) gère l’infrastructure, le code et la configuration d’OpenShift Dedicated à l’aide d’un flux de travail GitOps et de pipelines CI/CD entièrement automatisés. Ce processus permet à Red Hat d’introduire en toute sécurité des améliorations de service sur une base continue sans impact négatif sur les clients.
Chaque changement proposé fait l’objet d’une série de vérifications automatisées dès l’enregistrement. Les changements sont ensuite déployés dans un environnement de mise en scène où ils subissent des tests d’intégration automatisés. Enfin, des changements sont déployés dans l’environnement de production. Chaque étape est entièrement automatisée.
L’examinateur autorisé doit approuver l’avancement à chaque étape. L’examinateur ne peut pas être la même personne qui a proposé le changement. Les modifications et approbations sont entièrement vérifiables dans le cadre du flux de travail GitOps.
Certaines modifications sont publiées à la production progressivement, en utilisant des drapeaux de fonctionnalités pour contrôler la disponibilité de nouvelles fonctionnalités pour des clusters ou des clients spécifiés.
2.3.3.3. Gestion des patchs
Le logiciel OpenShift Container Platform et l’image immuable du système d’exploitation Red Hat Enterprise Linux CoreOS (RHCOS) sont corrigées pour les bogues et les vulnérabilités dans les mises à niveau régulières du flux z. En savoir plus sur l’architecture RHCOS dans la documentation OpenShift Container Platform.
2.3.3.4. Gestion des libérations
Le Red Hat ne met pas automatiquement à niveau vos clusters. Il est possible de programmer la mise à niveau des clusters à intervalles réguliers (mise à niveau récurrente) ou une seule fois (mise à niveau individuelle) à l’aide de la console Web OpenShift Cluster Manager. Le Red Hat pourrait mettre à niveau avec force un cluster vers une nouvelle version z-stream seulement si le cluster est affecté par un CVE d’impact critique. Consultez l’historique de tous les événements de mise à niveau de cluster dans la console Web OpenShift Cluster Manager. Consultez la politique sur le cycle de vie pour plus d’informations sur les communiqués.
2.3.4. Conformité à la sécurité et à la réglementation
La conformité à la sécurité et à la réglementation comprend des tâches telles que la mise en œuvre de contrôles de sécurité et la certification de conformité.
2.3.4.1. Classification des données
Red Hat définit et suit une norme de classification des données pour déterminer la sensibilité des données et mettre en évidence le risque inhérent à la confidentialité et à l’intégrité de ces données lors de leur collecte, de leur utilisation, de leur transmission et de leur traitement. Les données appartenant au client sont classées au plus haut niveau de sensibilité et d’exigences de manipulation.
2.3.4.2. Gestion des données
Le service OpenShift Dedicated utilise des services de fournisseurs de cloud tels qu’AWS Key Management Service (KMS) et Google Cloud KMS pour aider à gérer en toute sécurité les clés de chiffrement pour les données persistantes. Ces clés sont utilisées pour chiffrer tous les volumes racine des plans de contrôle, de l’infrastructure et des nœuds de travail. Les clients peuvent spécifier leur propre clé KMS pour chiffrer les volumes racine au moment de l’installation. Les volumes persistants (PV) utilisent également KMS pour la gestion des clés. Les clients peuvent spécifier leur propre clé KMS pour chiffrer les PV en créant une nouvelle StorageClass faisant référence à la clé KMS Amazon Resource Name (ARN) ou ID.
Lorsqu’un client supprime son cluster dédié OpenShift, toutes les données de cluster sont définitivement supprimées, y compris les volumes de données de plan de contrôle et les volumes de données d’application client, un tel volume persistant (PV).
2.3.4.3. Gestion de la vulnérabilité
Le Red Hat effectue une analyse périodique de vulnérabilité d’OpenShift Dedicated à l’aide d’outils standard de l’industrie. Les vulnérabilités identifiées sont suivies de leur assainissement en fonction des échéanciers en fonction de la gravité. Les activités d’analyse et d’assainissement des vulnérabilités sont documentées aux fins de vérification par des tiers évaluateurs dans le cadre d’audits de certification de conformité.
2.3.4.4. La sécurité du réseau
2.3.4.4.1. Coupe-feu et protection DDoS
Chaque cluster dédié OpenShift est protégé par une configuration réseau sécurisée au niveau de l’infrastructure cloud en utilisant les règles de pare-feu (AWS Security Groups ou Google Cloud Compute Engine). Les clients dédiés sur AWS sont également protégés contre les attaques DDoS avec AWS Shield Standard. De même, tous les équilibreurs de charge GCP et les adresses IP publiques utilisées par OpenShift Dedicated on GCP sont protégés contre les attaques DDoS avec Google Cloud Armor Standard.
2.3.4.4.2. Clusters privés et connectivité réseau
Les clients peuvent éventuellement configurer leurs points de terminaison OpenShift Dedicated cluster (console Web, API et routeur d’applications) pour être rendus privés de sorte que le plan de contrôle du cluster ou les applications ne soient pas accessibles à partir d’Internet.
Dans le cas d’AWS, les clients peuvent configurer une connexion réseau privée à leur cluster dédié OpenShift via AWS VPC peering, AWS VPN ou AWS Direct Connect.
2.3.4.4.3. Contrôles d’accès au réseau cluster
Les règles de contrôle d’accès réseau fines peuvent être configurées par les clients par projet.
2.3.4.5. Essais de pénétration
Le Red Hat effectue des tests de pénétration périodiques contre OpenShift Dedicated. Les tests sont effectués par une équipe interne indépendante à l’aide d’outils standard de l’industrie et de meilleures pratiques.
Les problèmes qui sont découverts sont prioritaires en fonction de la gravité. Les problèmes constatés dans le cadre de projets open source sont partagés avec la communauté aux fins de résolution.
2.3.4.6. Conformité
La société OpenShift Dedicated suit les meilleures pratiques courantes de l’industrie en matière de sécurité et de contrôle. Les certifications sont décrites dans le tableau suivant.
| Conformité | Dédié à OpenShift sur AWS | Dédié à OpenShift sur GCP |
|---|---|---|
| HIPAA Qualifié | (abonnements uniquement au cloud client) | (abonnements uniquement au cloud client) |
| ISO 27001 | ♪ oui ♪ | ♪ oui ♪ |
| DSS 4.0 PCI | ♪ oui ♪ | ♪ oui ♪ |
| Le SOC 2 de type 2 | ♪ oui ♪ | ♪ oui ♪ |
2.3.5. La reprise après sinistre
L’OpenShift Dedicated fournit une reprise après sinistre pour les défaillances qui se produisent au niveau de la pod, du nœud de travail, du nœud d’infrastructure, du nœud d’avion de contrôle et des niveaux de zone de disponibilité.
La récupération après sinistre exige que le client utilise les meilleures pratiques pour le déploiement d’applications, de stockage et d’architecture de clusters hautement disponibles (par exemple, déploiement d’une zone unique contre déploiement multizone) pour tenir compte du niveau de disponibilité souhaité.
En cas de panne d’une zone ou d’une zone de disponibilité, un groupe unique n’assurera pas d’évitement ou de reprise en cas de catastrophe. De multiples clusters à zone unique avec basculement entretenu par le client peuvent tenir compte des pannes au niveau de la zone ou de la région.
En cas de panne totale de la région, un groupe multizones ne permettra pas d’éviter les catastrophes ou de se remettre en état. De multiples clusters multizones avec basculement entretenu par le client peuvent tenir compte des pannes au niveau de la région.
2.4. Accès au compte SRE et service
2.4.1. Gestion de l’identité et des accès
La plupart des accès par les équipes d’ingénierie de fiabilité du site de Red Hat (SRE) se font en utilisant des opérateurs de clusters par le biais d’une gestion automatisée de la configuration.
Les clusters OpenShift dédiés aux clusters Google Cloud Platform (GCP) créés avec le type d’authentification WIF (Workload Identify Federation) n’utilisent pas les opérateurs pour l’accès SRE. Au lieu de cela, les rôles nécessaires à l’accès au compte SRE sont attribués au groupe d’accès sd-sre-platform-gcp-access dans le cadre de la création de la configuration WIF et sont validés avant le déploiement du cluster par le gestionnaire de cluster OpenShift. Consultez les ressources supplémentaires pour plus d’informations sur les configurations WIF.
2.4.1.1. Les sous-traitants
Dans la liste des sous-traitants disponibles, consultez la liste des sous-processeurs Red Hat sur le portail client Red Hat.
2.4.1.2. Accès SRE à tous les clusters dédiés OpenShift
Accès SRES aux clusters dédiés à OpenShift via un proxy. Le proxy crée un compte de service dans un cluster OpenShift dédié pour les SREs lorsqu’ils se connectent. Comme aucun fournisseur d’identité n’est configuré pour les clusters dédiés OpenShift, les SRE accèdent au proxy en exécutant un conteneur de console Web local. Le SRES n’accède pas directement à la console web cluster. Le SRES doit s’authentifier en tant qu’utilisateurs individuels afin d’assurer l’auditabilité. Les tentatives d’authentification sont enregistrées sur un système de gestion des informations de sécurité et des événements (SIEM).
2.4.1.3. Contrôles d’accès privilégiés dans OpenShift Dedicated
Le Red Hat SRE adhère au principe du moindre privilège lors de l’accès aux composants OpenShift Dedicated et des fournisseurs de cloud public. Il existe quatre catégories de base d’accès SRE manuels:
- Accès administrateur SRE via le portail client Red Hat avec une authentification normale à deux facteurs et aucune élévation privilégiée.
- L’administrateur SRE accède par l’intermédiaire du SSO d’entreprise Red Hat avec une authentification normale à deux facteurs et aucune élévation privilégiée.
- Élévation OpenShift, qui est une élévation manuelle utilisant Red Hat SSO. Il fait l’objet d’une vérification complète et l’approbation de la direction est requise pour chaque opération SRE.
- Accès ou élévation des fournisseurs de cloud, qui est une élévation manuelle pour la console fournisseur de cloud ou l’accès CLI. L’accès est limité à 60 minutes et est entièrement audité.
Chacun de ces types d’accès a différents niveaux d’accès aux composants:
| Composante | Accès administrateur SRE typique (Portail client Red Hat) | Accès administrateur SRE typique (Red Hat SSO) | Élévation de OpenShift | Accès aux fournisseurs de cloud |
|---|---|---|---|---|
| Gestionnaire de cluster OpenShift | DE R/W | Aucun accès | Aucun accès | Aucun accès |
| Console Web OpenShift | Aucun accès | DE R/W | DE R/W | Aucun accès |
| Le système d’exploitation des nœuds | Aucun accès | Liste spécifique des autorisations élevées du système d’exploitation et du réseau. | Liste spécifique des autorisations élevées du système d’exploitation et du réseau. | Aucun accès |
| Console AWS | Aucun accès | Aucun accès, mais il s’agit du compte utilisé pour demander l’accès aux fournisseurs de cloud. | Aucun accès | L’ensemble des autorisations des fournisseurs de cloud utilisant l’identité SRE. |
2.4.1.4. Accès SRE aux comptes d’infrastructure cloud
Le personnel de Red Hat n’a pas accès aux comptes d’infrastructure cloud dans le cadre des opérations courantes d’OpenShift Dedicated. À des fins de dépannage d’urgence, Red Hat SRE dispose de procédures bien définies et vérifiables pour accéder aux comptes d’infrastructure cloud.
Dans AWS, les SRE génèrent un jeton AWS de courte durée pour l’utilisateur BYOCAdminAccess à l’aide du service de jetons de sécurité AWS (STS). L’accès au jeton STS est enregistré et traçable pour les utilisateurs individuels. Le BYOCAdminAccess a la politique AdministratorAccess IAM jointe.
Dans Google Cloud, les SRE accèdent aux ressources après avoir été authentifiées contre un fournisseur d’identité Red Hat SAML (IDP). Le PDI autorise les jetons qui ont des expirations de temps à vie. L’émission du jeton est vérifiable par Red Hat IT d’entreprise et liée à un utilisateur individuel.
2.4.1.5. Accès au support Red Hat
Les membres de l’équipe de Red Hat CEE ont généralement accès en lecture seule à certaines parties du cluster. En particulier, CEE a un accès limité aux espaces de noms de cœur et de produits et n’a pas accès aux espaces de noms des clients.
| Le rôle | Espace de noms de base | Espace de noms de produit en couches | Espace de noms du client | Compte infrastructure cloud* |
|---|---|---|---|---|
| À propos de OpenShift SRE | Lire: Tout Écrire: Très Limité [1] | Lire: Tout Écrire: Aucun | Lire: Aucune[2] Écrire: Aucun | Lire: Tout [3] Ecrire : Tout [3] |
| CEE | Lire: Tout Écrire: Aucun | Lire: Tout Écrire: Aucun | Lire: Aucune[2] Écrire: Aucun | Lire: Aucun Écrire: Aucun |
| Administrateur client | Lire: Aucun Écrire: Aucun | Lire: Aucun Écrire: Aucun | Lire: Tout Ecrire: Tous | Lire: Limitée[4] Ecrire: Limited[4] |
| Client utilisateur | Lire: Aucun Écrire: Aucun | Lire: Aucun Écrire: Aucun | Lire: Limitée[5] Ecrire: Limited[5] | Lire: Aucun Écrire: Aucun |
| Les autres | Lire: Aucun Écrire: Aucun | Lire: Aucun Écrire: Aucun | Lire: Aucun Écrire: Aucun | Lire: Aucun Écrire: Aucun |
Le compte Infrastructure Cloud fait référence au compte AWS ou Google Cloud sous-jacent
- Limité à traiter les cas d’utilisation courante tels que les déploiements défaillants, la mise à niveau d’un cluster et le remplacement des nœuds de mauvais travailleurs.
- Les associés Red Hat n’ont pas accès aux données client par défaut.
- L’accès SRE au compte d’infrastructure cloud est une procédure de dépannage exceptionnelle lors d’un incident documenté.
- L’administrateur client a un accès limité à la console de compte d’infrastructure cloud via Cloud Infrastructure Access.
- Limité à ce qui est accordé par RBAC par l’administrateur client, ainsi que les espaces de noms créés par l’utilisateur.
2.4.1.6. Accès client
L’accès du client est limité aux espaces de noms créés par le client et aux autorisations accordées par RBAC par le rôle d’administrateur client. L’accès à l’infrastructure sous-jacente ou aux espaces de noms de produits n’est généralement pas autorisé sans accès cluster-admin. De plus amples informations sur l’accès et l’authentification des clients se trouvent dans la section Compréhension de l’authentification de la documentation.
2.4.1.7. Approbation et examen de l’accès
L’accès aux nouveaux utilisateurs SRE nécessite l’approbation de la direction. Les comptes SRE séparés ou transférés sont supprimés en tant qu’utilisateurs autorisés par le biais d’un processus automatisé. En outre, SRE effectue un examen périodique des accès, y compris la signature par la direction des listes d’utilisateurs autorisées.
2.4.2. Accès au cluster SRE
L’accès SRE aux clusters dédiés OpenShift est contrôlé par plusieurs couches d’authentification requise, qui sont toutes gérées par une politique stricte de l’entreprise. Les tentatives d’authentification pour accéder à un cluster et les modifications apportées au sein d’un cluster sont enregistrées dans les journaux d’audit, ainsi que l’identité spécifique du compte du SRE responsable de ces actions. Ces journaux d’audit permettent de s’assurer que toutes les modifications apportées par les SRE au cluster d’un client respectent les politiques et procédures strictes qui composent les lignes directrices sur les services gérés de Red Hat.
L’information présentée ci-dessous est un aperçu du processus qu’une SRE doit effectuer pour accéder au cluster d’un client.
- Le SRE demande un jeton d’identification actualisé de la Red Hat SSO (Cloud Services). Cette demande est authentifiée. Le jeton est valable quinze minutes. Après l’expiration du jeton, vous pouvez rafraîchir le jeton à nouveau et recevoir un nouveau jeton. La capacité de se rafraîchir à un nouveau jeton est indéfinie; cependant, la capacité de se rafraîchir à un nouveau jeton est révoquée après 30 jours d’inactivité.
- Le SRE se connecte au VPN Red Hat. L’authentification au VPN est complétée par le système Red Hat Corporate Identity and Access Management (RH IAM). Avec RH IAM, les SRE sont multifactorielles et peuvent être gérées en interne par les groupes et les processus existants d’intégration et de hors-bord. Après qu’un SRE soit authentifié et connecté, le SRE peut accéder à l’avion de gestion de flotte de services cloud. Les modifications apportées au plan de gestion de la flotte de services cloud nécessitent de nombreuses couches d’approbation et sont maintenues par une politique stricte de l’entreprise.
- Après la fin de l’autorisation, le SRE se connecte à l’avion de gestion de flotte et reçoit un compte de service que l’avion de gestion de flotte a créé. Le jeton est valable pendant 15 minutes. Après que le jeton n’est plus valide, il est supprimé.
Avec l’accès accordé au plan de gestion de flotte, SRE utilise diverses méthodes pour accéder aux clusters, en fonction de la configuration du réseau.
- Accès à un cluster privé ou public : Demande est envoyée via un balanceur de charge réseau spécifique (NLB) à l’aide d’une connexion HTTP chiffrée sur le port 6443.
- Accès à un cluster PrivateLink : Demande est envoyée à la passerelle Red Hat Transit, qui se connecte ensuite à un PCV Red Hat par région. Le VPC qui reçoit la demande dépendra de la région du cluster privé cible. Dans le VPC, il y a un sous-réseau privé qui contient le point de terminaison PrivateLink au cluster PrivateLink du client.
- Accès à un cluster Private Service Connect (PSC) : Demande est envoyée à l’infrastructure de backend interne de Red Hat, qui dirige le trafic via un réseau sécurisé et fiable vers le projet de gestion de Red Hat dans GCP. Le projet Red Hat Management comprend VPC, qui est configuré avec des sous-réseaux dans plusieurs régions, chacune contenant un point de terminaison PSC qui fournit un accès privé au cluster du client dans la région respective. Le trafic est acheminé par le sous-réseau régional approprié, assurant un accès sécurisé et privé au cluster sans traverser l’Internet public.
2.4.3. Comment les comptes de services assument les rôles AWS IAM dans les projets appartenant à SRE
Lorsque vous installez un cluster dédié OpenShift qui utilise le service de jetons de sécurité AWS (STS), des rôles AWS Identity and Access Management (IAM) spécifiques au cluster sont créés. Ces rôles IAM permettent aux opérateurs de clusters dédiés d’OpenShift d’exécuter la fonctionnalité principale d’OpenShift.
Les opérateurs de cluster utilisent les comptes de service pour assumer des rôles IAM. Lorsqu’un compte de service assume un rôle IAM, des informations d’identification STS temporaires sont fournies pour que le compte de service puisse être utilisé dans la pod de l’opérateur du cluster. Lorsque le rôle assumé dispose des privilèges AWS nécessaires, le compte de service peut exécuter les opérations SDK AWS dans la pod.
Flux de travail pour assumer les rôles AWS IAM dans les projets appartenant à SRE
Le diagramme suivant illustre le flux de travail pour assumer les rôles AWS IAM dans les projets appartenant à SRE:
Figure 2.1. Flux de travail pour assumer les rôles AWS IAM dans les projets appartenant à SRE
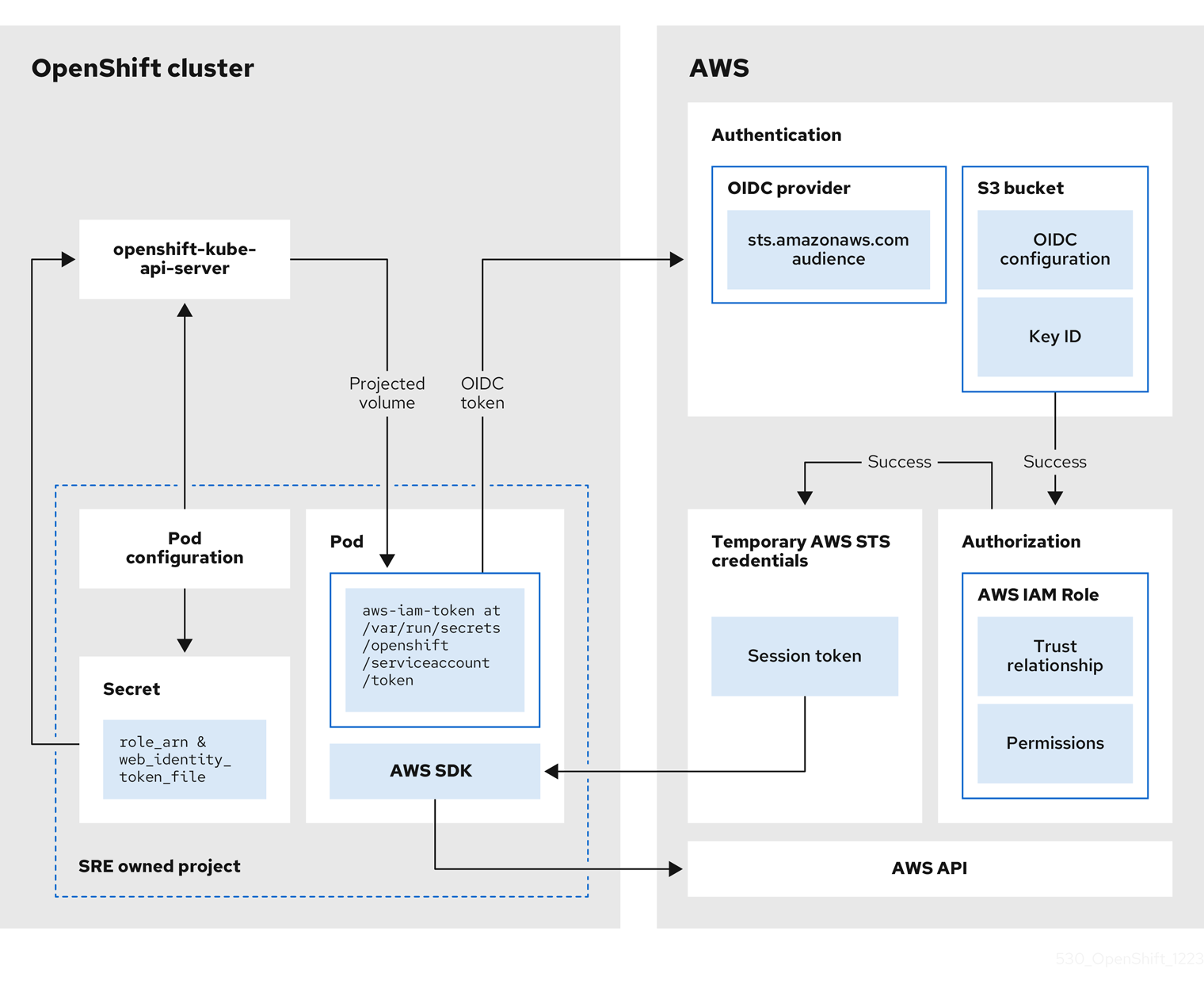
Le flux de travail comporte les étapes suivantes:
Dans chaque projet qu’un opérateur de cluster exécute, la spécification de déploiement de l’opérateur dispose d’une monture de volume pour le jeton de compte de service projeté, et d’un secret contenant une configuration d’identification AWS pour le pod. Le jeton est lié à l’audience et au temps. Chaque heure, OpenShift Dedicated génère un nouveau jeton, et le SDK AWS lit le secret monté contenant la configuration d’identification AWS. Cette configuration a un chemin vers le jeton monté et le rôle AWS IAM ARN. La configuration d’identification du secret comprend les éléments suivants:
- La variable $AWS_ARN_ROLE possède l’ARN pour le rôle IAM qui possède les autorisations requises pour exécuter les opérations SDK AWS.
- * une variable $AWS_WEB_IDENTITY_TOKEN_FILE qui a le chemin complet dans le pod vers le jeton OpenID Connect (OIDC) pour le compte de service. Le chemin complet est /var/run/secrets/openshift/serviceaccount/token.
- Lorsqu’un opérateur de cluster doit assumer un rôle AWS IAM pour accéder à un service AWS (tel qu’EC2), le code client AWS SDK s’exécutant sur l’opérateur invoque l’appel de l’API AssumeRoleWithWebIdentity.
Le jeton OIDC est transmis du pod au fournisseur OIDC. Le fournisseur authentifie l’identité du compte de service si les exigences suivantes sont remplies:
- La signature d’identité est valide et signée par la clé privée.
L’audience sts.amazonaws.com est listée dans le jeton OIDC et correspond à l’audience configurée dans le fournisseur OIDC.
NoteDans OpenShift Dedicated with STS clusters, le fournisseur OIDC est créé lors de l’installation et défini comme émetteur de compte de service par défaut. L’audience sts.amazonaws.com est définie par défaut dans le fournisseur OIDC.
- Le jeton OIDC n’a pas expiré.
- La valeur de l’émetteur dans le jeton a l’URL pour le fournisseur OIDC.
- Lorsque le compte de projet et de service est dans le champ d’application de la politique de confiance pour le rôle de l’IAM qui est assumé, l’autorisation réussit.
- Après une authentification et une autorisation réussies, les informations d’identification AWS STS temporaires sous la forme d’un jeton d’accès AWS, d’une clé secrète et d’un jeton de session sont transmises à la pod pour utilisation par le compte de service. En utilisant les informations d’identification, le compte de service reçoit temporairement les autorisations AWS activées dans le rôle IAM.
- Lorsque l’opérateur de cluster s’exécute, l’opérateur qui utilise le SDK AWS dans la pod consomme le secret qui a le chemin vers le compte de service projeté et le rôle AWS IAM ARN pour s’authentifier contre le fournisseur OIDC. Le fournisseur OIDC retourne des informations d’identification STS temporaires pour l’authentification par rapport à l’API AWS.
2.4.4. Ressources supplémentaires
En savoir plus sur la configuration WIF et les rôles d’accès SRE, voir Création d’une configuration WIF.
2.5. Comprendre la disponibilité pour OpenShift Dedicated
La disponibilité et l’évitement des catastrophes sont des aspects extrêmement importants de toute plate-forme d’application. « OpenShift Dedicated fournit de nombreuses protections contre les défaillances à plusieurs niveaux, mais les applications déployées par le client doivent être configurées de manière appropriée pour une haute disponibilité. En outre, pour tenir compte des pannes des fournisseurs de cloud qui pourraient survenir, d’autres options sont disponibles, telles que le déploiement d’un cluster sur plusieurs zones de disponibilité ou la maintenance de plusieurs clusters avec des mécanismes de basculement.
2.5.1. Les points d’échec potentiels
La plateforme OpenShift Container offre de nombreuses fonctionnalités et options pour protéger vos charges de travail contre les temps d’arrêt, mais les applications doivent être conçues de manière appropriée pour tirer parti de ces fonctionnalités.
Le logiciel OpenShift Dedicated peut vous protéger davantage contre de nombreux problèmes Kubernetes communs en ajoutant le support de Red Hat Site Reliability Engineer (SRE) et l’option de déployer un cluster multizones, mais il existe un certain nombre de façons dont un conteneur ou une infrastructure peut encore échouer. En comprenant les points d’échec potentiels, vous pouvez comprendre les risques et concevoir de manière appropriée vos applications et vos clusters pour être aussi résilients que nécessaire à chaque niveau spécifique.
La panne peut se produire à plusieurs niveaux d’infrastructures et de composants de clusters.
2.5.1.1. Défaillance du conteneur ou de la gousse
D’après la conception, les gousses sont censées exister pendant une courte période. La mise à l’échelle appropriée des services de sorte que plusieurs instances de vos pods d’application sont en cours d’exécution protège contre les problèmes avec n’importe quel pod ou conteneur individuel. Le programmeur de nœuds peut également s’assurer que ces charges de travail sont réparties entre différents nœuds de travail afin d’améliorer encore la résilience.
Lors de la prise en compte des éventuelles défaillances de pod, il est également important de comprendre comment le stockage est attaché à vos applications. Les volumes persistants uniques attachés à des pods uniques ne peuvent pas tirer parti de tous les avantages de la mise à l’échelle des pod, tandis que les bases de données reproduites, les services de base de données ou le stockage partagé peuvent.
Afin d’éviter les perturbations de vos applications lors de la maintenance planifiée, comme les mises à niveau, il est important de définir un budget de perturbation de pod. Ceux-ci font partie de l’API Kubernetes et peuvent être gérés avec l’OpenShift CLI (oc) comme d’autres types d’objets. Ils permettent la spécification des contraintes de sécurité sur les gousses pendant les opérations, telles que l’évacuation d’un nœud pour l’entretien.
2.5.1.2. Défaillance du nœud ouvrier
Les nœuds ouvriers sont les machines virtuelles qui contiennent vos pods d’application. Par défaut, un cluster dédié OpenShift dispose d’un minimum de quatre nœuds de travail pour un cluster de zone de disponibilité unique. En cas de défaillance d’un nœud ouvrier, les gousses sont transférées vers des nœuds de travail fonctionnels, tant qu’il y a suffisamment de capacité, jusqu’à ce que tout problème avec un nœud existant soit résolu ou que le nœud soit remplacé. Le plus grand nombre de nœuds de travail signifie plus de protection contre les pannes de nœuds uniques et assure une capacité de cluster appropriée pour les gousses reprogrammées en cas de défaillance du nœud.
Lors de la prise en compte des défaillances possibles des nœuds, il est également important de comprendre comment le stockage est affecté.
2.5.1.3. Défaillance du cluster
Les clusters dédiés OpenShift ont au moins trois nœuds de plan de contrôle et trois nœuds d’infrastructure préconfigurés pour une haute disponibilité, soit dans une seule zone, soit sur plusieurs zones en fonction du type de cluster que vous avez sélectionné. Cela signifie que l’avion de contrôle et les nœuds d’infrastructure ont la même résilience des nœuds ouvriers, avec l’avantage supplémentaire d’être entièrement géré par Red Hat.
Dans le cas d’une panne complète des nœuds de plan de contrôle, les API OpenShift ne fonctionneront pas, et les pods de nœuds de travail existants ne seront pas affectés. Cependant, s’il y a aussi une panne de gousse ou de nœud en même temps, les nœuds de plan de contrôle devront récupérer avant que de nouveaux gousses ou nœuds puissent être ajoutés ou programmés.
L’ensemble des services fonctionnant sur les nœuds d’infrastructure sont configurés par Red Hat pour être hautement disponibles et distribués à travers les nœuds d’infrastructure. En cas de panne complète de l’infrastructure, ces services ne seront pas disponibles jusqu’à ce que ces nœuds aient été récupérés.
2.5.1.4. Défaillance de la zone
La défaillance d’une zone d’un fournisseur de cloud public affecte tous les composants virtuels, tels que les nœuds de travail, le blocage ou le stockage partagé, et les équilibreurs de charge spécifiques à une seule zone de disponibilité. Afin de se protéger contre une défaillance de zone, OpenShift Dedicated offre l’option pour les clusters qui sont répartis sur trois zones de disponibilité, appelées clusters de zone multidisponibilité. Les charges de travail apatrides existantes sont redistribuées dans des zones non affectées en cas de panne, tant qu’il y a suffisamment de capacité.
2.5.1.5. Défaillance de stockage
Lorsque vous avez déployé une application étatique, le stockage est un composant essentiel et doit être pris en compte lors de la réflexion sur la haute disponibilité. Le PV de stockage d’un seul bloc est incapable de résister aux pannes même au niveau de la pod. Les meilleurs moyens de maintenir la disponibilité du stockage sont d’utiliser des solutions de stockage répliquées, un stockage partagé qui n’est pas affecté par des pannes, ou un service de base de données indépendant du cluster.
2.6. Cycle de vie de la mise à jour dédiée
2.6.1. Aperçu général
Le Red Hat fournit un cycle de vie de produit publié pour OpenShift Dedicated afin que les clients et les partenaires puissent planifier, déployer et soutenir efficacement leurs applications en cours d’exécution sur la plateforme. Le Red Hat publie ce cycle de vie pour offrir autant de transparence que possible et pourrait faire des exceptions à ces politiques lorsque des conflits surgissent.
La société OpenShift Dedicated est une instance gérée de Red Hat OpenShift et maintient un calendrier de sortie indépendant. De plus amples détails sur l’offre gérée peuvent être trouvés dans la définition de service dédié OpenShift. La disponibilité des avis de sécurité et des avis de correction de bogues pour une version spécifique dépend de la politique de cycle de vie de Red Hat OpenShift Container Platform et est soumise au calendrier de maintenance dédié à OpenShift.
2.6.2. Définitions
| Format de version | A) Majeur | Le mineur | Le patch | Le major.minor.patch |
|---|---|---|---|---|
| a) x | C) Y | à Z | à propos de x.y.z | |
| Exemple : | 4 | 5 | 21 | 4.5.21 |
- Les versions majeures ou X- Releases
Désignés uniquement comme des versions majeures ou X- Releases (X.y.z).
Exemples
- « Grande version 5 » → 5.y.z
- « Grande version 4 » → 4.y.z
- « Version majeure 3 » → 3.y.z
- Libérations mineures ou sorties Y
Désignés uniquement comme des libérations mineures ou des versions Y (x.Y.z).
Exemples
- "Liminor release 4" → 4.4.z
- "La libération mineure 5" → 4.5.z
- "Liminor release 6" → 4.6.z
- Lancements de patchs ou Z- Releases
Désigne uniquement les versions de patch ou Z- Releases (x.y.Z).
Exemples
- « Patch release 14 de la libération mineure 5 » → 4.5.14
- « Patch release 25 of minor release 5 » → 4.5.25
- « Patch release 26 of minor release 6 » → 4.6.26
2.6.3. Les versions majeures (X.y.z)
Les versions majeures d’OpenShift Dedicated, par exemple la version 4, sont prises en charge pendant un an après la sortie d’une version majeure ultérieure ou la retraite du produit.
Exemple :
- Dans le cas où la version 5 était disponible sur OpenShift Dedicated le 1er janvier, la version 4 serait autorisée à continuer à fonctionner sur les clusters gérés pendant 12 mois, jusqu’au 31 décembre. Après cette période, les clusters devront être mis à niveau ou migrés vers la version 5.
2.6.4. Les versions mineures (x.Y.z)
À partir de la version mineure de 4.8 OpenShift Container Platform, Red Hat prend en charge toutes les versions mineures pendant au moins 16 mois après la disponibilité générale de la version mineure donnée. Les versions de patch ne sont pas affectées par la période de support.
Les clients sont informés 60, 30 et 15 jours avant la fin de la période d’assistance. Les clusters doivent être mis à niveau vers la dernière version de patch de la version mineure la plus ancienne prise en charge avant la fin de la période de support, ou le cluster entrera un statut « Support limité ».
Exemple :
- Le cluster d’un client est actuellement en cours d’exécution sur 4.13.8. La version 4.13 mineure est devenue généralement disponible le 17 mai 2023.
- Le 19 juillet, le 16 août et le 2 septembre 2024, le client est informé que son cluster entrera dans le statut « Support limité » le 17 septembre 2024 si le cluster n’a pas déjà été mis à niveau vers une version mineure prise en charge.
- Le cluster doit être mis à niveau à 4.14 ou plus tard d’ici le 17 septembre 2024.
- Dans le cas où la mise à jour n’a pas été effectuée, le cluster sera marqué comme étant dans un état de « Support limité ».
2.6.5. Correction des versions (x.y.Z)
Au cours de la période pendant laquelle une version mineure est prise en charge, Red Hat prend en charge toutes les versions de patch OpenShift Container Platform sauf indication contraire.
En raison de la sécurité et de la stabilité de la plate-forme, une version de correctif peut être dépréciée, ce qui empêcherait les installations de cette version et déclencherait des mises à niveau obligatoires de cette version.
Exemple :
- 4.7.6 contient un CVE critique.
- Les versions affectées par le CVE seront supprimées de la liste de diffusion des correctifs pris en charge. De plus, tous les clusters fonctionnant en 4.7.6 seront programmés pour des mises à niveau automatiques dans les 48 heures.
2.6.6. Le statut de soutien limité
Lorsqu’un cluster passe à un statut de support limité, Red Hat ne surveille plus de manière proactive le cluster, le SLA n’est plus applicable et les crédits demandés contre l’ALS sont refusés. Cela ne signifie pas que vous n’avez plus de support produit. Dans certains cas, le cluster peut revenir à un statut entièrement pris en charge si vous corrigez les facteurs de violation. Cependant, dans d’autres cas, vous devrez peut-être supprimer et recréer le cluster.
Il est possible qu’un cluster passe à un statut de support limité pour de nombreuses raisons, y compris les scénarios suivants:
- Lorsque vous ne mettez pas à niveau un cluster vers une version prise en charge avant la date de fin de vie
Le Red Hat ne fait aucune garantie d’exécution ou de SLA pour les versions après leur date de fin de vie. Afin de recevoir un soutien continu, mettez le cluster à une version prise en charge avant la date de fin de vie. Lorsque vous ne mettez pas à niveau le cluster avant la date de fin de vie, le cluster passe à un statut de support limité jusqu’à ce qu’il soit mis à niveau vers une version prise en charge.
Le Red Hat fournit un support commercialement raisonnable pour passer d’une version non prise en charge à une version prise en charge. Cependant, si un chemin de mise à niveau pris en charge n’est plus disponible, vous devrez peut-être créer un nouveau cluster et migrer vos charges de travail.
- Dans le cas où vous supprimez ou remplacez des composants natifs OpenShift dédiés ou tout autre composant installé et géré par Red Hat
- En cas d’utilisation des autorisations d’administrateur de clusters, Red Hat n’est pas responsable des actions de vos utilisateurs autorisés ou de vos utilisateurs autorisés, y compris celles qui affectent les services d’infrastructure, la disponibilité des services ou la perte de données. Dans le cas où Red Hat détecte de telles actions, le cluster pourrait passer à un statut de support limité. Le Red Hat vous informe du changement d’état et vous devriez soit inverser l’action, soit créer un cas de support pour explorer les étapes d’assainissement qui pourraient vous obliger à supprimer et à recréer le cluster.
Lorsque vous avez des questions sur une action spécifique qui pourrait faire passer un cluster à un statut de support limité ou avoir besoin d’une assistance supplémentaire, ouvrez un ticket de support.
2.6.7. La politique d’exception des versions prises en charge
Le Red Hat se réserve le droit d’ajouter ou de supprimer des versions nouvelles ou existantes, ou de retarder les versions mineures à venir, qui ont été identifiées comme ayant un ou plusieurs problèmes de production critiques ayant un impact sur les bogues ou les problèmes de sécurité sans préavis.
2.6.8. La politique d’installation
Alors que Red Hat recommande l’installation de la dernière version de support, OpenShift Dedicated prend en charge l’installation de toute version prise en charge comme couvert par la politique précédente.
2.6.9. Des mises à niveau obligatoires
Lorsqu’un CVE critique ou important, ou un autre bug identifié par Red Hat, a un impact significatif sur la sécurité ou la stabilité du cluster, le client doit passer à la prochaine version du correctif pris en charge dans les deux jours ouvrables.
Dans des circonstances extrêmes et sur la base de l’évaluation par Red Hat de la criticité CVE pour l’environnement, Red Hat informera les clients qu’ils disposent de deux jours ouvrables pour planifier ou mettre à jour manuellement leur cluster vers la dernière version sécurisée du patch. Dans le cas où une mise à jour n’est pas effectuée après deux jours ouvrables, Red Hat mettra automatiquement à jour le cluster vers la dernière version de correctif sécurisé afin d’atténuer les failles de sécurité potentielles ou l’instabilité. À sa propre discrétion, Red Hat peut retarder temporairement une mise à jour automatisée si un client le demande par le biais d’un dossier d’assistance.
2.6.10. Dates du cycle de vie
| La version | Disponibilité générale | Fin de vie |
|---|---|---|
| 4.17 | 14 octobre 2024 | 14 février 2026 |
| 4.16 | Juil 2, 2024 | 2 novembre 2025 |
| 4.15 | Fév 27, 2024 | 30 juin 2025 |
| 4.14 | 31 octobre 2023 | 1er mai 2025 |
| 4.13 | 17 mai 2023 | 17 septembre 2024 |
| 4.12 | 17 janv. 2023 | 17 juil. 2024 |
| 4.11 | Août 10, 2022 | Déc 10, 2023 |
| 4.10 | 10 mars 2022 | 10 septembre, 2023 |
| 4.9 | 18 oct 2021 | Décembre 18, 2022 |
| 4.8 | 27 juil. 2021 | 27 septembre 2022 |
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.