第24章 永続ストレージの設定
24.1. 概要
Kubernetes の永続ボリュームフレームワークにより、お使いの環境で利用可能なネットワークストレージを使用して、OpenShift Container Platform クラスターに永続ストレージをプロビジョニングできます。これは、アプリケーションのニーズに応じて初回 OpenShift Container Platform インストールの完了後に行うことができ、ユーザーは基礎となるインフラストラクチャーの知識がなくてもこれらのリソースを要求できるようになります。
このトピックでは、以下のサポートされるボリュームプラグインを使って永続ボリュームを OpenShift Container Platform で設定する方法を説明します。
24.2. NFS を使用した永続ストレージ
24.2.1. 概要
OpenShift Container Platform クラスターは、NFS を使用している永続ストレージを使ってプロビジョニングすることが可能です。永続ボリューム (PV) および Persistent Volume Claim (永続ボリューム要求、PVC) は、プロジェクト全体でボリュームを共有するための便利な方法を提供します。PV 定義に含まれる NFS に固有の情報は、Pod 定義で直接定義することも可能ですが、この方法の場合にはボリュームが一意のクラスターリソースとして作成されされないため、ボリュームが競合の影響を受けやすくなります。
このトピックでは、NFS 永続ストレージタイプの具体的な使用方法について説明します。OpenShift Container Platform と NFS についてある程度理解していることを前提とします。OpenShift Container Platform 永続ボリューム (PV) の一般的なフレームワークの詳細は永続ストレージの概念に関するトピックを参照してください。
24.2.2. プロビジョニング
OpenShift Container Platform でストレージをボリュームとしてマウントするには、ストレージがあらかじめ基礎となるインフラストラクチャーに存在している必要があります。NFS ボリュームをプロビジョニングするには、NFS サーバーの一覧とエクスポートパスのみが必要です。
最初に、PV のオブジェクト定義を作成します。
例24.1 NFS を使用した PV オブジェクト定義
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0001
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
nfs:
path: /tmp
server: 172.17.0.2
persistentVolumeReclaimPolicy: Recycle - 1
- ボリュームの名前。これは、各種の
oc <command> podコマンドの PV アイデンティティーです。 - 2
- このボリュームに割り当てられるストレージの量。
- 3
- これはボリュームへのアクセスの制御に関連するように見えますが、実際はラベルの場合と同様に、PVC を PV に一致させるために使用されます。現時点では、
accessModesに基づくアクセスルールは適用されていません。 - 4
- 使用されているボリュームタイプ。この場合は nfs プラグインです。
- 5
- NFS サーバーがエクスポートしているパス。
- 6
- NFS サーバーのホスト名または IP アドレス
- 7
- PV の回収ポリシー。ボリュームが要求から解放されるタイミングでボリュームで実行されることを定義します。有効な選択肢は Retain (デフォルト) と Recycle です。「リソースの回収」を参照してください。
各 NFS ボリュームは、クラスター内のスケジュール可能なすべてのノードによってマウント可能でなければなりません。
定義をファイル (nfs-pv.yaml など) に保存し、PV を作成します。
$ oc create -f nfs-pv.yaml
persistentvolume "pv0001" createdPV が作成されたことを確認します。
# oc get pv
NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
pv0001 <none> 5368709120 RWO Available 31s以下の手順で PVC が作成されます。これは新規 PV にバインドされます。
例24.2 PVC オブジェクト定義
定義をファイル (nfs-claim.yaml など) に保存し、PVC を作成します。
# oc create -f nfs-claim.yaml24.2.3. ディスククォータの実施
ディスクパーティションを使用して、ディスククォータとサイズ制限を実施することができます。それぞれのパーティションを独自のエクスポートとすることができ、それぞれのエクスポートは 1 つの PV になります。OpenShift Container Platform は PV に固有の名前を適用しますが、NFS ボリュームのサーバーとパスの一意性については管理者に委ねられています。
この方法でクォータを有効にすると、開発者は永続ストレージを具体的な量 (10Gi など) を指定して要求し、この容量以上が設定されている対応のボリュームに適合できます。
24.2.4. NFS ボリュームのセキュリティー
このセクションでは、一致するパーミッションや SELinux の考慮点を含む、NFS ボリュームのセキュリティーについて説明します。ユーザーは、POSIX パーミッションやプロセス UID、補助グループおよび SELinux の基礎的な点を理解している必要があります。
NFS ボリュームを実装する前に 「ボリュームのセキュリティー」のトピックをすべてお読みください。
開発者は、Pod 定義の volumes セクションで、PVC を名前で参照するか、または NFS ボリュームのプラグインを直接参照して NFS ストレージを要求します。
NFS サーバーの /etc/exports ファイルにはアクセス可能な NFS ディレクトリーが含まれています。ターゲットの NFS ディレクトリーには、POSIX の所有者とグループ ID があります。OpenShift Container Platform NFS プラグインは、同じ POSIX の所有者とエクスポートされる NFS ディレクトリーにあるパーミッションを使って、コンテナーの NFS ディレクトリーをマウントします。ただし、コンテナーは NFS マウントの所有者と同等の実効 UID では実行されません。これは期待される動作です。
ターゲットの NFS ディレクトリーが NFS サーバーに表示される場合を例に取って見てみましょう。
# ls -lZ /opt/nfs -d
drwxrws---. nfsnobody 5555 unconfined_u:object_r:usr_t:s0 /opt/nfs
# id nfsnobody
uid=65534(nfsnobody) gid=65534(nfsnobody) groups=65534(nfsnobody)コンテナーは SELinux ラベルと一致している必要があり、ディレクトリーにアクセスするために UID 65534 (nfsnobody 所有者) か、または補助グループの 5555 のいずれかを使って実行する必要があります。
ここで、所有者 ID 65534 は一例として使用されています。NFS の root_squash が root (0) を nfsnobody (65534) にマップしても、NFS エクスポートは任意の所有者 ID を持つことができます。所有者 65534 は NFS エクスポートには必要ありません。
24.2.4.1. グループ ID
NFS アクセスに対応する際の推奨される方法として、補助グループを使用することができます (NFS エクスポートのパーミッションを変更するオプションがないことを前提としています)。OpenShift Container Platform の補助グループは共有ストレージに使用されます (例: NFS)。これとは対照的に、Ceph RBD や iSCSI などのブロックストレージは、Pod の securityContext で fsGroup SCC ストラテジーと fsGroup の値を使用します。
一般的に、永続ストレージへのアクセスを取得する場合、ユーザー ID ではなく補助グループ ID を使用することが推奨されます。補助グループについては「ボリュームのセキュリティー」トピックで詳しく説明されています。
上記のターゲット NFS ディレクトリーの例で使用したグループ ID は 5555 なので、Pod は、supplementalGroups を使用してグループ ID を Pod レベルの securityContext 定義の下で定義することができます。以下は例になります。
spec:
containers:
- name:
...
securityContext:
supplementalGroups: [5555]
Pod の要件を満たすカスタム SCC が存在しない場合、Pod は 制限付きの SCC に一致する可能性があります。この SCC では、supplementalGroups ストラテジーが RunAsAny に設定されています。これは、指定されるグループ ID は範囲のチェックなしに受け入れられることを意味します。
その結果、上記の Pod は受付をパスして起動します。しかし、グループ ID の範囲をチェックすることが望ましい場合は、「Pod のセキュリティーとカスタム SCC」で説明されているようにカスタム SCC の使用が推奨されます。カスタム SCC は、最小および最大のグループ ID が定義され、グループ ID の範囲チェックが実施され、グループ ID 5555 が許可されるように作成できます。
カスタム SCC を使用するには、最初にそこに適切なサービスアカウントを追加しておく必要があります。たとえば、所定のプロジェクトでは、Pod 仕様において別のサービスアカウントが指定されていない限り、default のサービスアカウントを使用してください。詳細は、「SCC のユーザー、グループまたはプロジェクトへの追加」を参照してください。
24.2.4.2. ユーザー ID
ユーザー ID は、コンテナーイメージまたは Pod 定義で定義できます。ユーザー ID に基づいてストレージアクセスを制御する方法については、「ボリュームのセキュリティー」のトピックで説明されています。NFS 永続ストレージをセットアップする前に、必ず読んでおいてください。
永続ストレージへのアクセスを取得する場合、通常はユーザー ID ではなく 補助グループ ID を使用することが推奨されます。
上記の ターゲット NFS ディレクトリーの例 では、コンテナーは UID を 65534 (ここではグループ ID を省略します) に設定する必要があります。したがって以下を Pod 定義に追加することができます。
spec:
containers:
- name:
...
securityContext:
runAsUser: 65534 デフォルトのプロジェクトと制限付き SCC を前提とする場合は、Pod が要求するユーザー ID 65534 は許可されず、Pod は失敗します。Pod が失敗する理由は以下の通りです。
- 65534 をユーザー ID として要求している。
- ユーザー ID 65534 を許可する SCC を確認するために Pod で利用できるすべての SCC が検査される (実際は SCC のすべてのポリシーがチェックされますが、ここでのフォーカスはユーザー ID になります)。
-
利用可能なすべての SCC は
runAsUserストラテジーに MustRunAsRange を使用するため、UID の範囲チェックが必要である。 - 65534 は SCC またはプロジェクトのユーザー ID 範囲に含まれていない。
一般に、事前定義された SCC は変更しないことが勧められています。ただし、この状況を改善するには、「ボリュームのセキュリティー」のトピックで説明されているようにカスタム SCC を作成することが推奨されます。カスタム SCC は、最小および最大のユーザー ID が定義され、UID 範囲のチェックの実施が設定されており、UID 65534 が許可されるように作成できます。
カスタム SCC を使用するには、最初にそこに適切なサービスアカウントを追加しておく必要があります。たとえば、所定のプロジェクトでは、Pod 仕様において別のサービスアカウントが指定されていない限り、default のサービスアカウントを使用してください。詳細は、「SCC のユーザー、グループまたはプロジェクトへの追加」を参照してください。
24.2.4.3. SELinux
SELinux を使用してストレージアクセスを制御する方法についての詳細は、「ボリュームのセキュリティー」を参照してください。
デフォルトでは、SELinux は Pod からリモートの NFS サーバーへの書き込みを許可していません。NFS ボリュームは正常にマウントされますが、読み取り専用です。
SELinux を各ノードで有効にした状態で NFS ボリュームへの書き込みを有効にするには、以下を実行します。
# setsebool -P virt_use_nfs 1
上記の -P オプションは、ブール値をリブート間で継続させます。
virt_use_nfs ブール値は docker-selinux パッケージで定義されます。このブール値が定義されていないことを示すエラーが表示された場合は、このパッケージがインストールされていることを確認してください。
24.2.4.4. エクスポート設定
任意のコンテナーユーザーにボリュームの読み取りと書き出しを許可するには、NFS サーバーにエクスポートされる各ボリュームは以下の条件を満たしている必要があります。
各エクスポートを以下のように指定します。
/<example_fs> *(rw,root_squash)ファイアウォールは、マウントポイントへのトラフィックを許可するように設定する必要があります。
NFSv4 の場合、デフォルトのポート
2049(nfs) とポート111(portmapper) を設定します。NFSv4
# iptables -I INPUT 1 -p tcp --dport 2049 -j ACCEPT # iptables -I INPUT 1 -p tcp --dport 111 -j ACCEPTNFSv3 の場合、以下の 3 つのポートを設定します。
2049(nfs)、20048(mountd)、111(portmapper)。NFSv3
# iptables -I INPUT 1 -p tcp --dport 2049 -j ACCEPT # iptables -I INPUT 1 -p tcp --dport 20048 -j ACCEPT # iptables -I INPUT 1 -p tcp --dport 111 -j ACCEPT
-
NFS エクスポートとディレクトリーは、ターゲット Pod からアクセスできるようにセットアップされる必要があります。この場合、エクスポートをコンテナーのプライマリー UID で所有されるように設定するか、または上記の「グループ ID」で説明したように、
supplementalGroupsを使用して Pod にグループアクセスを付与します。Pod のセキュリティーに関する追加情報は、「ボリュームのセキュリティー」のトピックを参照してください。
24.2.5. リソースの回収
NFS は OpenShift Container Platform の 再利用可能な プラグインインターフェースを実装します。回収タスクは、それぞれの永続ボリュームに設定されるポリシーに基づいて自動プロセスによって処理されます。
デフォルトでは、PV は Retain に設定されます。Recycle に設定される NFS ボリュームは、要求からの解放後 (このボリュームにバインドされるユーザーの PersistentVolumeClaim の削除後) に除去されます ( rm -rf がこのボリュームで実行されます)。リサイクルされた NFS ボリュームは新規の要求にバインドさせることができます。
PV への要求が解除される (PVC が削除される) と、PV オブジェクトは再利用できません。代わりに、新規の PV が元のボリュームと同じ基本ボリューム情報を使って作成されます。
たとえば、管理者は nfs1 という名前の PV を作成するとします。
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs1
spec:
capacity:
storage: 1Mi
accessModes:
- ReadWriteMany
nfs:
server: 192.168.1.1
path: "/"
ユーザーは、nfs1 にバインドされる PVC1 を作成します。次にユーザーは PVC1 を削除し、nfs1 への要求を解除します。これにより、nfs1 は Released になります。管理者が同じ NFS 共有を利用可能にする必要がある場合には、同じ NFS サーバー情報を使って新規 PV を作成する必要があります。この場合、PV の名前は元の名前とは異なる名前にします。
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs2
spec:
capacity:
storage: 1Mi
accessModes:
- ReadWriteMany
nfs:
server: 192.168.1.1
path: "/"
元の PV を削除して、PV を同じ名前で再作成することは推奨されません。PV のステータスを Released から Available に手動で変更しようとすると、エラーが発生してデータが失われる可能性があります。
Recycle の保持ポリシーを持つ PV はデータを除去 (rm -rf を実行) し、要求について Available というマークを付けます。Recycle の保持ポリシーは、OpenShift Container Platform 3.6 以降で非推奨となっています。Recycler を利用しているユーザーは、代わりに動的プロビジョニングとボリュームの削除機能を使用してください。
24.2.6. 自動化
クラスターは、NFS を使用している永続ストレージを使って以下の方法でプロビジョニングすることができます。
- ディスクパーティションを使ってストレージクォータを実施する。
- 要求を持つプロジェクトにボリュームを制限してセキュリティーを実施する。
- 破棄されたリソースの回収を各 PV に設定する。
スクリプトを使って上記タスクを自動化する方法は多数あります。まずは Ansible Playbook のサンプルを使用して開始することができます。
24.2.7. その他の設定とトラブルシューティング
適切なエクスポートとセキュリティーマッピングを行うため、使用している NFS のバージョンおよびその設定方法に応じて追加の設定が必要になることがあります。以下は例になります。
|
NFSv4 のマウントにすべてのファイルの所有者が nobody:nobody と誤って表示される。 |
|
|
NFSv4 の ID マッピングが無効になっている |
|
24.3. Red Hat Gluster Storage を使用する永続ストレージ
24.3.1. 概要
Red Hat Gluster Storage は、OpenShift Container Platform の永続ストレージと動的プロビジョニングを提供するように設定でき、OpenShift Container Platform 内のコンテナー化ストレージ (コンバージドモード) としても、独自のノード上の非コンテナー化ストレージ (インデペンデントモード) としても使用できます。
24.3.1.1. コンバージドモード
コンバージドモードの場合には、Red Hat Gluster Storage は、コンテナー化されたディレクトリーを OpenShift Container Platform ノードで直接実行します。それにより、コンピュートおよびストレージインスタンスをスケジュールでき、同じハードウェアのセットから実行することができます。
図24.1 アーキテクチャー - コンバージドモード
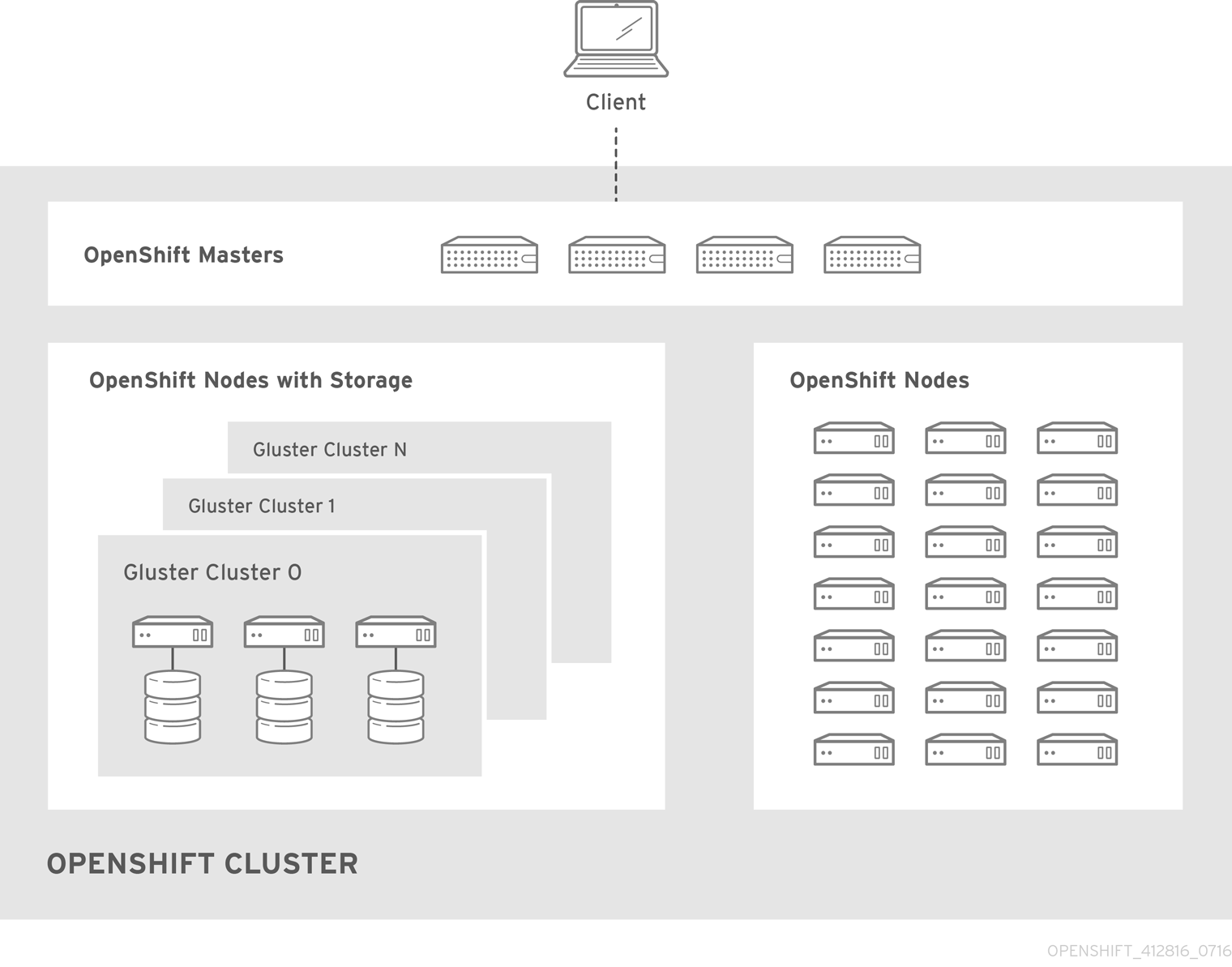
コンバージドモードは Red Hat Gluster Storage 3.1 update 3 より利用できます。詳細については、「converged mode for OpenShift Container Platform」を参照してください。
24.3.1.2. インデペンデントモード
インデペンデントモードの場合、Container-Ready Storage を使用することで、Red Hat Gluster Storage は独自の専用ノードで実行され、GlusterFS のボリューム管理 REST サービスの heketi のインスタンスによって管理されます。heketi サービスは、スタンドアロンまたはコンテナー化のいずれかで実行できます。コンテナー化の場合、簡単なメカニズムで高可用性をサービスに提供できます。ここでは、heketi をコンテナー化した場合の設定に焦点を当てます。
24.3.1.3. スタンドアロンの Red Hat Gluster Storage
スタンドアロンの Red Hat Gluster Storage クラスターが環境で使用できる場合、OpenShift Container Platform の GlusterFS ボリュームプラグインを使用してそのクラスター上でボリュームを使用することができます。この方法は、アプリケーションが専用のコンピュートノード、OpenShift Container Platform クラスターで実行され、ストレージはその専用ノードから提供される従来のデプロイメントです。
図24.2 アーキテクチャー - OpenShift Container Platform の GlusterFS ボリュームプラグインを使用したスタンドアロンの Red Hat Gluster Storage クラスター
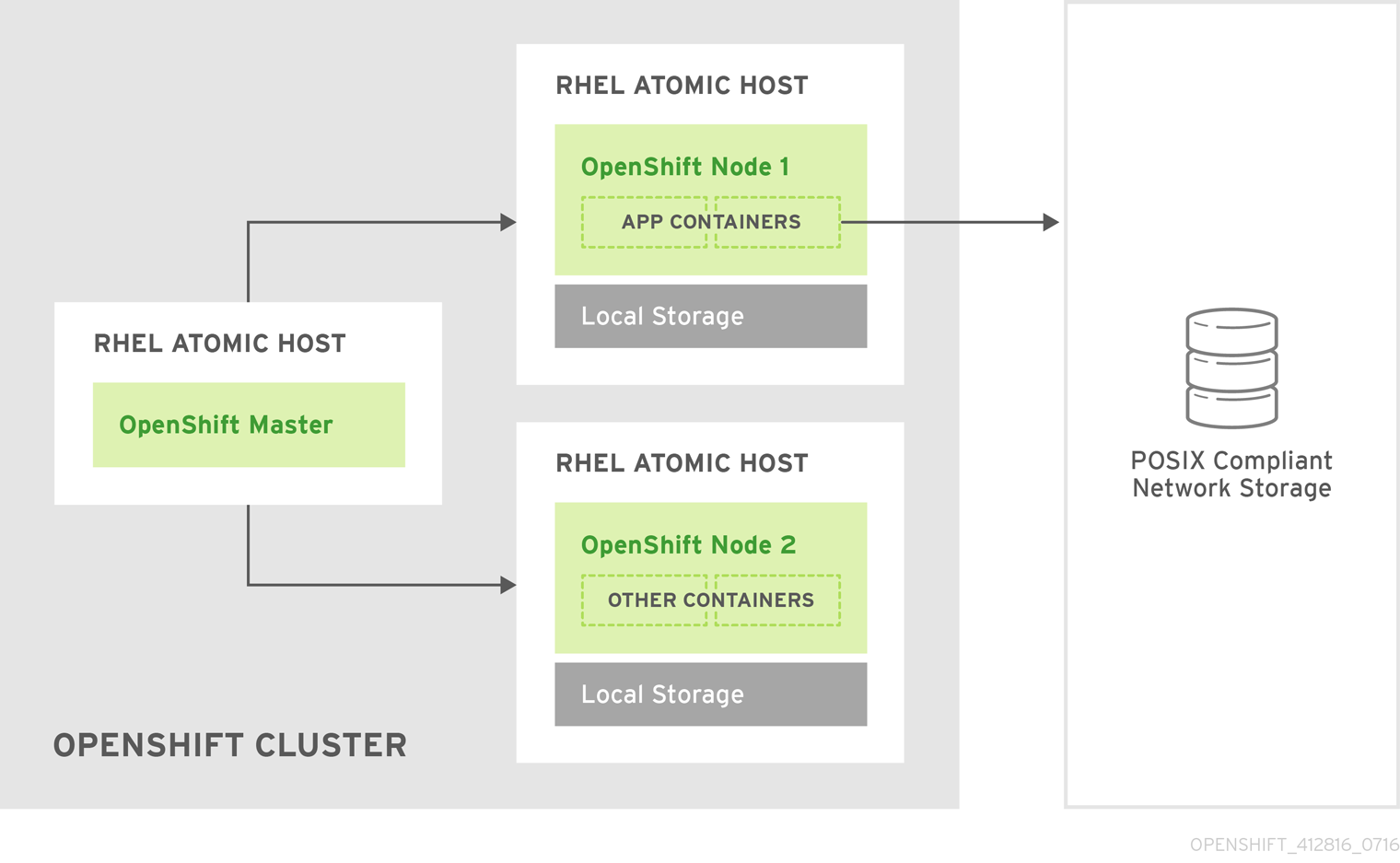
Red Hat Gluster Storage の詳細については、『Red Hat Gluster Storage Installation Guide』および『Red Hat Gluster Storage Administration Guide』を参照してください。
インフラストラクチャーにおけるストレージの高可用性は、基礎となるストレージのプロバイダーに委ねられています。
24.3.1.4. GlusterFS ボリューム
GlusterFS ボリュームは、POSIX に準拠したファイルシステムを提供し、クラスター上の 1 つ以上のノードにまたがる 1 つ以上の「ブリック」から構成されます。このブリックは所定のストレージノード上のディレクトリーであり、一般的にブロックストレージデバイスのマウントポイントになります。GlusterFS はボリュームの設定に応じて、所定のボリュームのブリック間でファイルの分散および複製を処理します。
heketi は、ボリューム管理において、作成、削除、サイズ変更といった一般的な操作に使用することが推奨されます。OpenShift Container Platform は、GlusterFS プロビジョナーを使用する際に heketi が存在していることを前提としています。heketi はデフォルトで、レプリカ数が 3 のボリュームを作成します。このボリュームの各ファイルには 3 つの異なるノードをまたがる 3 つのコピーがあります。したがって、heketi が使用する Red Hat Gluster Storage クラスターでは 3 つ以上のノードを利用可能にすることが推奨されます。
GlusterFS ボリュームに使用可能な機能は多数ありますが、これらについては本書では扱いません。
24.3.1.5. gluster-block ボリューム
gluster-block ボリュームは、iSCSI 上にマウントすることが可能なボリュームです。既存の GlusterFS ボリュームにファイルを作成し、そのファイルをブロックデバイスとして iSCSI ターゲットを介して提供することでマウントできます。このような GlusterFS ボリュームは、ブロックホスティングボリュームと呼ばれます。
gluster-block ボリュームにはトレードオフもあります。iSCSI ターゲットとして使用される場合、複数のノード/クライアントでマウントできる GlusterFS ボリュームとは対照的に、gluster-block ボリュームをマウントできるのは 1 回に 1 つのノード/クライアントのみです。ただし、バックエンドのファイルであるため、GlusterFS ボリュームでは一般にコストのかかる操作 (メタデータの参照など) を、GlusterFS ボリュームでの一般的により高速な操作 (読み取り、書き込みなど) に変換することが可能です。それにより、特定の負荷に対するパフォーマンスを大幅に改善できる可能性があります。
現時点では、gluster-block ボリュームは OpenShift ロギングと OpenShift メトリクスストレージにのみを使用することが推奨されます。
24.3.1.6. Gluster S3 ストレージ
Gluster S3 サービスは、ユーザーアプリケーションが S3 インターフェースを介して GlusterFS ストレージへアクセスすることを可能にします。このサービスは GlusterFS の、オブジェクトデータ用とオブジェクトメタデータ用の 2 つのボリュームにバインドされ、受信する S3 REST 要求をボリューム上のファイルシステム操作に変換します。このサービスは OpenShift Container Platform 内の Pod として実行することが推奨されます。
現時点では、Gluster S3 サービスの使用およびインストールはテクノロジープレビューの段階にあります。
24.3.2. 考慮事項
このセクションでは、Red Hat Gluster Storage を OpenShift Container Platform で使用する際に考慮すべきトピックについて取り上げます。
24.3.2.1. ソフトウェア要件
GlusterFS ボリュームにアクセスするには、すべてのスケジュール可能なノードで mount.glusterfs コマンドを利用できる必要があります。RPM ベースのシステムの場合は、glusterfs-fuse パッケージがインストールされている必要があります。
# yum install glusterfs-fuseこのパッケージはすべての RHEL システムにインストールされています。ただし、サーバーが x86_64 アーキテクチャーを使用する場合は Red Hat Gluster Storage の最新バージョンに更新することを推奨します。そのためには、以下の RPM リポジトリーを有効にする必要があります。
# subscription-manager repos --enable=rh-gluster-3-client-for-rhel-7-server-rpmsglusterfs-fuse がノードにすでにインストールされている場合、最新バージョンがインストールされていることを確認します。
# yum update glusterfs-fuse24.3.2.2. ハードウェア要件
コンバージドモード (converged mode) またはインデペンデントモード (independent mode) のクラスターで使用されるノードはストレージノードとみなされます。単一ノードは複数のグループに分割できませんが、ストレージノードはそれぞれ別個のクラスターグループに分類できます。ストレージノードの各グループについては、以下が当てはまります。
- 1 グループあたり 3 つ以上のストレージノードが必要です。
各ストレージノードには 8 GB 以上の RAM が必要です。これにより、Red Hat Gluster Storage Pod、その他のアプリケーションおよび基礎となる OS を実行できます。
- 各 GlusterFS ボリュームはストレージクラスターにあるすべてのストレージノードのメモリー (約 30 MB) も消費します。RAM の合計量は、コンカレントボリュームがいくつ求められているか、またはいくつ予想されるかによって決める必要があります。
各ストレージノードには、現在のデータまたはメタデータを含まない 1 つ以上の raw ブロックデバイスが必要です。それらのブロックデバイス全体は GlusterFS ストレージで使用されます。以下が存在しないことを確認してください。
- パーティションテーブル (GPT または MSDOS)
- ファイルシステムまたは未処理のファイルシステムの署名
- 以前のボリュームグループの LVM2 署名および論理ボリューム
- LVM2 物理ボリュームの LVM2 メタデータ
不確かな場合には、
wipefs -a <device>で上記のすべてを消去する必要があります。
2 つのクラスター、つまりインフラストラクチャーアプリケーション (OpenShift Container レジストリーなど) のストレージ専用のクラスターと一般的なアプリケーションのストレージ専用のクラスターについて計画することをお勧めします。これには、合計で 6 つのストレージノードが必要となりますが、この設定は I/O およびボリューム作成のパフォーマンスへの潜在的な影響を回避するために推奨されます。
24.3.2.3. ストレージのサイジング
GlusterFS クラスターはすべて、そのストレージを利用するアプリケーションで想定される要件に基づいてサイズを決定する必要があります。たとえば、「OpenShift ロギング」と「OpenShift メトリクス」の両方に対して、サイジングガイドが提供されています。
その他考慮すべき事項:
コンバージドモードまたはインデペンデントモードのクラスターでは、デフォルトの動作により 3 通りのレプリケーションを持つ GlusterFS ボリュームが作成されます。そのため、合計のストレージの計画を立てる際には、必要な容量の 3 倍にする必要があります。
-
例として、各 heketi インスタンスは 2 GB の
heketidbstorageボリュームを作成する場合、ストレージクラスター内の 3 つのノードに合計で 6 GB の raw ストレージが必要になります。この容量は常に必要となり、これをサイジングの際に考慮する必要があります。 - 統合 OpenShift Container レジストリーなどのアプリケーションでは、GlusterFS の単一ボリュームがアプリケーションの複数インスタンスで共有されます。
-
例として、各 heketi インスタンスは 2 GB の
gluster-block ボリュームを使用する場合は、所定のブロックのボリューム容量をフルサイズで保持するための十分な容量を備えた GlusterFS ブロックホスティングボリュームがなければなりません。
- デフォルトでは、このようなブロックホスティングボリュームが存在しない場合、これが設定されたサイズで自動的に 1 つ作成されます。デフォルトのサイズは 100 GB です。クラスター内に新しいブロックホスティングボリュームを作成するための十分なスペースがない場合、ブロックボリュームの作成は失敗します。自動作成の動作、および自動作成されるボリュームのサイズはどちらも設定することが可能です。
- OpenShift ロギングや OpenShift メトリクスなどの gluster-block ボリュームを使用する複数のインスタンスを持つアプリケーションは、各インスタンスにつき 1 つのボリュームを使用します。
- Gluster S3 サービスは、2 つの GlusterFS ボリュームにバインドされます。デフォルトのクラスターインストールでは、ボリュームはそれぞれ 1 GB となり、合計 6 GB の raw ストレージを使用します。
24.3.2.4. ボリューム操作の動作
作成や削除などのボリューム操作は、さまざまな環境条件の影響を受けることもあれば、アプリケーションに影響を与えることもあります。
アプリケーション Pod が動的にプロビジョニングされた GlusterFS の Persistent Volume Claim (永続ボリューム要求、PVC) を要求する場合は、ボリュームの作成と対応する PVC へのバインドにかかる追加の時間を考慮する必要があります。これはアプリケーション Pod の起動時間に影響します。
注記GlusterFS ボリュームの作成時間は、ボリュームの数に応じて直線的に増加します。たとえば、クラスター内に推奨されるハードウェア仕様を使用する 100 のボリュームがある場合、各ボリュームの作成、割り当て、Pod へのバインドに約 6 秒の時間がかかりました。
PVC が削除されると、基礎となる GlusterFS ボリュームの削除がトリガーされます。PVC は
oc get pvcの出力からすぐに消えますが、ボリュームが完全に削除される訳ではありません。GlusterFS ボリュームは、heketi-cli volume listおよびgluster volume listのコマンドライン出力に表示されなくなったときにのみ削除されていると見なされます。注記GlusterFS ボリュームの削除とそのストレージのリサイクルの時間は、アクティブな GlusterFS ボリュームの数に応じて直線的に増加します。保留中のボリューム削除は実行中のアプリケーションに影響しませんが、ストレージ管理者は、特にリソース消費を大きな規模で調整している場合には、ボリュームの削除にかかる時間を認識し、それを見積もることができるようにしておく必要があります。
24.3.2.5. ボリュームのセキュリティー
このセクションでは、Portable Operating System Interface [Unix 向け] (POSIX) パーミッションや SELinux に関する考慮事項を含む、Red Hat Gluster Storage ボリュームのセキュリティーについて説明します。ボリュームのセキュリティー、POSIX パーミッションおよび SELinux に関する基本を理解していることを前提とします。
24.3.2.5.1. POSIX パーミッション
Red Hat Gluster Storage ボリュームは POSIX 準拠のファイルシステムを表します。そのため、chmod や chown などの標準コマンドラインツールを使用してアクセスパーミッションを管理できます。
コンバージドモードとインデペンデントモードでは、ボリュームの作成時に、ボリュームの Root を所有するグループ ID を指定することも可能です。静的なプロビジョニングでは、これは、heketi-cli ボリュームの作成コマンドの一部として指定します。
$ heketi-cli volume create --size=100 --gid=10001000このボリュームに関連付けられる PersistentVolume には、PersistentVolume を使用する Pod がファイルシステムにアクセスできるように、グループ ID をアノテーションとして付加する必要があります。このアノテーションは以下の形式で指定します。
pv.beta.kubernetes.io/gid: "<GID>" ---
動的プロビジョニングの場合は、プロビジョナーがグループ ID を自動的に生成し、これを適用します。gidMin および gidMax StorageClass パラメーターを使用してこのグループ ID の選択範囲を制御できます (「動的プロビジョニング」を参照してください)。プロビジョナーは、生成される PersistentVolume にグループ ID をアノテーションとして付ける処理も行います。
24.3.2.5.2. SELinux
デフォルトでは、SELinux は Pod からリモート Red Hat Gluster Storage サーバーへの書き込みを許可しません。SELinux が有効な状態で Red Hat Gluster Storage ボリュームへの書き込みを有効にするには、GlusterFS を実行する各ノードで以下のコマンドを実行します。
$ sudo setsebool -P virt_sandbox_use_fusefs on
$ sudo setsebool -P virt_use_fusefs on- 1
-Pオプションを使用すると、再起動した後もブール値が永続化されます。
virt_sandbox_use_fusefs ブール値は、docker-selinux パッケージによって定義されます。このブール値が定義されていないというエラーが表示される場合は、このパッケージがインストールされていることを確認してください。
Atomic Host を使用している場合に、Atomic Host をアップグレードすると、SELinux のブール値が消去されるので、Atomic Host をアップグレードする場合には、これらのブール値を設定し直す必要があります。
24.3.3. サポート要件
Red Hat Gluster Storage と OpenShift Container Platform のサポートされる統合を作成するには、以下の要件が満たされている必要があります。
インデペンデントモードまたは スタンドアロンの Red Hat Gluster Storage の場合:
- 最小バージョン: Red Hat Gluster Storage 3.1.3
- すべての Red Hat Gluster Storage ノードに Red Hat Network チャンネルとサブスクリプションマネージャーリポジトリーへの有効なサブスクリプションが必要です。
- Red Hat Gluster Storage ノードは、「Planning Red Hat Gluster Storage Installation」に記載されている要件に準拠している必要があります。
- Red Hat Gluster Storage ノードは、最新のパッチとアップグレードが適用された完全に最新の状態でなければなりません。最新バージョンへのアップグレードについては、『Red Hat Gluster Storage Installation Guide』を参照してください。
- 各 Red Hat Gluster Storage ノードには、完全修飾ドメイン名 (FQDN) が設定されている必要があります。適切な DNS レコードが存在すること、および FQDN が正引きと逆引きの両方の DNS ルックアップで解決できることを確認してください。
24.3.4. インストール
スタンドアロンの Red Hat Gluster Storage の場合、OpenShift Container Platform で使用するためにインストールする必要があるコンポーネントはありません。OpenShift Container Platform には組み込み GlusterFS ボリュームドライバーが付属しており、これを使用して既存のボリュームを既存のクラスターで活用できます。既存のボリュームの使用方法については、「プロビジョニング」を参照してください。
コンバージドモードおよびインデペンデントモードでは、「クラスターインストールプロセスを使用して、必要なコンポーネントをインストールすることを推奨します。
24.3.4.1. インデペンデントモード: Red Hat Gluster Storage ノードのインストール
インデペンデントモードの場合は、Red Hat Gluster Storage ノードに適切なシステム設定 (ファイアウォールポートやカーネルモジュールなど) が設定されており、Red Hat Gluster Storage サービスが実行されている必要があります。このサービスは追加で設定できず、Trusted Storage Pool を作成することはできません。
Red Hat Gluster Storage ノードのインストールは本書の対象外です。詳細については、「インデペンデントモードの設定」を参照してください。
24.3.4.2. インストーラーの使用
クラスターインストールプロセスを使用すると、2 つの GlusterFS ノードグループの 1 つまたは両方をインストールできます。
-
glusterfs: ユーザーアプリケーション用の汎用ストレージクラスター。 -
glusterfs-registry: 統合 OpenShift Container レジストリーなどのインフラストラクチャーアプリケーション用の専用ストレージクラスター。
I/O およびボリューム作成のパフォーマンスに対する潜在的影響を回避するため、両方のグループをデプロイすることを推奨します。これらはどちらもインベントリーホストファイルで定義されます。
クラスターを定義するには、[OSEv3:children] グループに該当する名前を追加し、類似した名前付きグループを作成して、グループにノード情報を設定します。その後、[OSEv3:vars] グループのさまざまな変数を使用してクラスターを定義できます。glusterfs 変数は openshift_storage_glusterfs_ から、glusterfs-registry 変数は openshift_storage_glusterfs_registry_ からそれぞれ始まります。openshift_hosted_registry_storage_kind などのその他のいくつかの変数は GlusterFS クラスターと対話します。
Red Hat Gluster Storage Pod が、サービス停止後に、異なるバージョンの Red Hat Gluster Storage が含まれるクラスターにアップグレードされないようにするには、すべてのコンテナー化コンポーネントに、イメージ名とバージョンタグを指定することを推奨します。関連のある変数は以下のとおりです。
-
openshift_storage_glusterfs_image -
openshift_storage_glusterfs_block_image -
openshift_storage_glusterfs_s3_image -
openshift_storage_glusterfs_heketi_image -
openshift_storage_glusterfs_registry_image -
openshift_storage_glusterfs_registry_block_image -
openshift_storage_glusterfs_registry_s3_image -
openshift_storage_glusterfs_registry_heketi_image
gluster-block および gluster-s3 のイメージ変数は、適切なデプロイメント変数 (末尾が _block_deploy および _s3_deploy の変数) が True の場合のみ必要です。
以下は、このバージョンの OpenShift Container Platform で推奨される値です。
-
openshift_storage_glusterfs_image=registry.access.redhat.com/rhgs3/rhgs-server-rhel7:v3.10 -
openshift_storage_glusterfs_block_image=registry.access.redhat.com/rhgs3/rhgs-gluster-block-prov-rhel7:v3.10 -
openshift_storage_glusterfs_s3_image=registry.access.redhat.com/rhgs3/rhgs-s3-server-rhel7:v3.10 -
openshift_storage_glusterfs_heketi_image=registry.access.redhat.com/rhgs3/rhgs-volmanager-rhel7:v3.10
これらの値は、対応する registry 変数と同じです。
変数の詳細な一覧については、GitHub の GlusterFS ロールに関する README を参照してください。
変数を設定したら、インストールの環境に応じていくつかの Playbook が利用可能になります。
クラスターインストールのメイン Playbook を使用すると、OpenShift Container Platform の初期インストールと並行して GlusterFS クラスターをデプロイできます。
- これには、GlusterFS ストレージを使用する統合 OpenShift Container レジストリーのデプロイが含まれます。
- OpenShift ロギングや OpenShift メトリクスは含まれません。現時点では、これは別の手順で扱われるためです。詳細については、「OpenShift ロギングおよびメトリクス用のコンバージドモード」を参照してください。
-
playbooks/openshift-glusterfs/config.ymlを使用して、クラスターを既存の OpenShift Container Platform インストールにデプロイできます。 playbooks/openshift-glusterfs/registry.ymlを使用して、クラスターを既存の OpenShift Container Platform インストールにデプロイできます。さらに、GlusterFS ストレージを使用する統合 OpenShift Container レジストリーもデプロイされます。重要OpenShift Container Platform クラスターに既存のレジストリーがない状態でなければなりません。
playbooks/openshift-glusterfs/uninstall.ymlを使用して、インベントリーホストファイルの設定に一致する既存のクラスターを削除できます。これは、設定エラーによってデプロイメントが失敗した場合に OpenShift Container Platform 環境をクリーンアップするのに便利です。注記GlusterFS Playbook では、必ず冪等性を確保できるわけではありません。
注記GlusterFS インストール全体 (ディスクデータを含む) を削除してインストールし直すことなく、特定のインストールに対して Playbook を複数回実行することは、現在はサポートされていません。
24.3.4.2.1. 例: 基本的なコンバージドモードのインストール
インベントリーファイルの
[OSEv3:vars]セクションに次の変数を追加し、設定に合わせてそれらを調整します。[OSEv3:vars] ... openshift_storage_glusterfs_namespace=app-storage openshift_storage_glusterfs_storageclass=true openshift_storage_glusterfs_storageclass_default=false openshift_storage_glusterfs_block_deploy=true openshift_storage_glusterfs_block_host_vol_size=100 openshift_storage_glusterfs_block_storageclass=true openshift_storage_glusterfs_block_storageclass_default=false[OSEv3:children]セクションにglusterfsを追加して、[glusterfs]グループを有効にします。[OSEv3:children] masters nodes glusterfsGlusterFS ストレージをホストする各ストレージノードのエントリーを含む
[glusterfs]セクションを追加します。ノードごとに、glusterfs_devicesを GlusterFS クラスターの一部として完全に管理される raw ブロックデバイスの一覧に設定します。少なくとも 1 つのデバイスを一覧に含める必要があります。各デバイスは、パーティションや LVM PV がないベアでなければなりません。変数は以下の形式で指定します。<hostname_or_ip> glusterfs_devices='[ "</path/to/device1/>", "</path/to/device2>", ... ]'以下は例を示しています。
[glusterfs] node11.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node12.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node13.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]'[glusterfs]の下に一覧表示されているホストを[nodes]グループに追加します。[nodes] ... node11.example.com openshift_node_group_name="node-config-compute" node12.example.com openshift_node_group_name="node-config-compute" node13.example.com openshift_node_group_name="node-config-compute"注記前述の手順では、インベントリーファイルに追加する必要のある一部のオプションのみを指定しています。Red Hat Gluster Storage をデプロイするには、完全なインベントリーファイルを使用します。
インストール Playbook を実行します。インベントリーファイルの相対パスをオプションとして指定します。
OpenShift Container Platform の新規インストール:
ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/prerequisites.yml ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/deploy_cluster.yml既存の OpenShift Container Platform クラスターへのインストール:
ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/openshift-glusterfs/config.yml
24.3.4.2.2. 例: 基本的なインデペンデントモードのインストール
インベントリーファイルの
[OSEv3:vars]セクションに次の変数を追加し、設定に合わせてそれらを調整します。[OSEv3:vars] ... openshift_storage_glusterfs_namespace=app-storage openshift_storage_glusterfs_storageclass=true openshift_storage_glusterfs_storageclass_default=false openshift_storage_glusterfs_block_deploy=true openshift_storage_glusterfs_block_host_vol_size=100 openshift_storage_glusterfs_block_storageclass=true openshift_storage_glusterfs_block_storageclass_default=false openshift_storage_glusterfs_is_native=false openshift_storage_glusterfs_heketi_is_native=true openshift_storage_glusterfs_heketi_executor=ssh openshift_storage_glusterfs_heketi_ssh_port=22 openshift_storage_glusterfs_heketi_ssh_user=root openshift_storage_glusterfs_heketi_ssh_sudo=false openshift_storage_glusterfs_heketi_ssh_keyfile="/root/.ssh/id_rsa"[OSEv3:children]セクションにglusterfsを追加して、[glusterfs]グループを有効にします。[OSEv3:children] masters nodes glusterfsGlusterFS ストレージをホストする各ストレージノードのエントリーを含む
[glusterfs]セクションを追加します。ノードごとに、glusterfs_devicesを GlusterFS クラスターの一部として完全に管理される raw ブロックデバイスの一覧に設定します。少なくと も 1 つのデバイスを一覧に含める必要があります。各デバイスはパーティションや LVM PV がないベアでなければなりません。また、glusterfs_ipをノードの IP アドレスに設定します。変数は以下の形式で指定します。<hostname_or_ip> glusterfs_ip=<ip_address> glusterfs_devices='[ "</path/to/device1/>", "</path/to/device2>", ... ]'以下は例を示しています。
[glusterfs] gluster1.example.com glusterfs_ip=192.168.10.11 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' gluster2.example.com glusterfs_ip=192.168.10.12 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' gluster3.example.com glusterfs_ip=192.168.10.13 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]'注記前述の手順では、インベントリーファイルに追加する必要のある一部のオプションのみを指定しています。Red Hat Gluster Storage をデプロイするには、完全なインベントリーファイルを使用します。
インストール Playbook を実行します。インベントリーファイルの相対パスをオプションとして指定します。
OpenShift Container Platform の新規インストール:
ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/prerequisites.yml ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/deploy_cluster.yml既存の OpenShift Container Platform クラスターへのインストール:
ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/openshift-glusterfs/config.yml
24.3.4.2.3. 例: 統合 OpenShift Container レジストリーを使用するコンバージドモード
インベントリーファイルの
[OSEv3:vars]セクションに次の変数を追加し、設定に合わせてそれらを調整します。[OSEv3:vars] ... openshift_hosted_registry_storage_kind=glusterfs1 openshift_hosted_registry_storage_volume_size=5Gi openshift_hosted_registry_selector='node-role.kubernetes.io/infra=true'- 1
- 統合 OpenShift Container レジストリーをインフラストラクチャーノードで実行することが推奨されます。インフラストラクチャーノードは、OpenShift Container Platform クラスターのサービスを提供するために管理者がデプロイするアプリケーションを実行する専用ノードです。
[OSEv3:children]セクションにglusterfs_registryを追加して、[glusterfs_registry]グループを有効にします。[OSEv3:children] masters nodes glusterfs_registryGlusterFS ストレージをホストする各ストレージノードのエントリーを含む
[glusterfs_registry]セクションを追加します。ノードごとに、glusterfs_devicesを GlusterFS クラスターの一部として完全に管理される raw ブロックデバイスの一覧に設定します。少なくとも 1 つのデバイスを一覧に含める必要があります。各デバイスはパーティションや LVM PV がないベアでなければなりません。変数は次の形式で指定します。<hostname_or_ip> glusterfs_devices='[ "</path/to/device1/>", "</path/to/device2>", ... ]'以下は例を示しています。
[glusterfs_registry] node11.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node12.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node13.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]'[glusterfs_registry]の下に一覧表示されているホストを[nodes]グループに追加します。[nodes] ... node11.example.com openshift_node_group_name="node-config-infra" node12.example.com openshift_node_group_name="node-config-infra" node13.example.com openshift_node_group_name="node-config-infra"注記前述の手順では、インベントリーファイルに追加する必要のある一部のオプションのみを指定しています。Red Hat Gluster Storage をデプロイするには、完全なインベントリーファイルを使用します。
インストール Playbook を実行します。インベントリーファイルの相対パスをオプションとして指定します。
OpenShift Container Platform の新規インストール:
ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/prerequisites.yml ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/deploy_cluster.yml既存の OpenShift Container Platform クラスターへのインストール:
ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/openshift-glusterfs/config.yml
24.3.4.2.4. 例: OpenShift ロギングおよびメトリクス用のコンバージドモード
インベントリーファイルの
[OSEv3:vars]セクションに次の変数を追加し、設定に合わせてそれらを調整します。[OSEv3:vars] ... openshift_metrics_install_metrics=true openshift_metrics_hawkular_nodeselector={"node-role.kubernetes.io/infra": "true"}1 openshift_metrics_cassandra_nodeselector={"node-role.kubernetes.io/infra": "true"}2 openshift_metrics_heapster_nodeselector={"node-role.kubernetes.io/infra": "true"}3 openshift_metrics_storage_kind=dynamic openshift_metrics_storage_volume_size=10Gi openshift_metrics_cassandra_pvc_storage_class_name="glusterfs-registry-block"4 openshift_logging_install_logging=true openshift_logging_kibana_nodeselector={"node-role.kubernetes.io/infra": "true"}5 openshift_logging_curator_nodeselector={"node-role.kubernetes.io/infra": "true"}6 openshift_logging_es_nodeselector={"node-role.kubernetes.io/infra": "true"}7 openshift_logging_storage_kind=dynamic openshift_logging_es_pvc_size=10Gi8 openshift_logging_es_pvc_storage_class_name="glusterfs-registry-block"9 openshift_storage_glusterfs_registry_namespace=infra-storage openshift_storage_glusterfs_registry_block_deploy=true openshift_storage_glusterfs_registry_block_host_vol_size=100 openshift_storage_glusterfs_registry_block_storageclass=true openshift_storage_glusterfs_registry_block_storageclass_default=false- 1 2 3 5 6 7
- 統合 OpenShift Container レジストリー、ロギングおよびメトリクスは、管理者が OpenShift Container Platform クラスターにサービスを提供するためにデプロイしたアプリケーションである「インフラストラクチャー」アプリケーション専用のノードで実行することを推奨します。
- 4 9
- ロギングとメトリクスに使用する StorageClass を指定します。この名前は、ターゲットの GlusterFS クラスター (例:
glusterfs-<name>-block) 名から生成されます。この例ではregistryにデフォルト設定されています。 - 8
- OpenShift ロギングでは、PVC のサイズを指定する必要があります。ここで指定される値は単なる例であり、推奨される値ではありません。
注記これらの変数とその他の変数の詳細については、GlusterFS ロールに関する README を参照してください。
[OSEv3:children]セクションにglusterfs_registryを追加して、[glusterfs_registry]グループを有効にします。[OSEv3:children] masters nodes glusterfs_registryGlusterFS ストレージをホストする各ストレージノードのエントリーを含む
[glusterfs_registry]セクションを追加します。ノードごとに、glusterfs_devicesを GlusterFS クラスターの一部として完全に管理される raw ブロックデバイスの一覧に設定します。少なくとも 1 つのデバイスを一覧に含める必要があります。各デバイスはパーティションや LVM PV がないベアでなければなりません。変数は次の形式で指定します。<hostname_or_ip> glusterfs_devices='[ "</path/to/device1/>", "</path/to/device2>", ... ]'以下は例を示しています。
[glusterfs_registry] node11.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node12.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node13.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]'[glusterfs_registry]の下に一覧表示されているホストを[nodes]グループに追加します。[nodes] ... node11.example.com openshift_node_group_name="node-config-infra" node12.example.com openshift_node_group_name="node-config-infra" node13.example.com openshift_node_group_name="node-config-infra"注記前述の手順では、インベントリーファイルに追加する必要のある一部のオプションのみを指定しています。Red Hat Gluster Storage をデプロイするには、完全なインベントリーファイルを使用します。
インストール Playbook を実行します。インベントリーファイルの相対パスをオプションとして指定します。
OpenShift Container Platform の新規インストール:
ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/prerequisites.yml ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/deploy_cluster.yml既存の OpenShift Container Platform クラスターへのインストール:
ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/openshift-glusterfs/config.yml
24.3.4.2.5. 例: アプリケーション、レジストリー、ロギングおよびメトリクス用のコンバージドモード
インベントリーファイルの
[OSEv3:vars]セクションに次の変数を追加し、設定に合わせてそれらを調整します。[OSEv3:vars] ... openshift_hosted_registry_storage_kind=glusterfs1 openshift_hosted_registry_storage_volume_size=5Gi openshift_hosted_registry_selector='node-role.kubernetes.io/infra=true' openshift_metrics_install_metrics=true openshift_metrics_hawkular_nodeselector={"node-role.kubernetes.io/infra": "true"}2 openshift_metrics_cassandra_nodeselector={"node-role.kubernetes.io/infra": "true"}3 openshift_metrics_heapster_nodeselector={"node-role.kubernetes.io/infra": "true"}4 openshift_metrics_storage_kind=dynamic openshift_metrics_storage_volume_size=10Gi openshift_metrics_cassandra_pvc_storage_class_name="glusterfs-registry-block"5 openshift_logging_install_logging=true openshift_logging_kibana_nodeselector={"node-role.kubernetes.io/infra": "true"}6 openshift_logging_curator_nodeselector={"node-role.kubernetes.io/infra": "true"}7 openshift_logging_es_nodeselector={"node-role.kubernetes.io/infra": "true"}8 openshift_logging_storage_kind=dynamic openshift_logging_es_pvc_size=10Gi9 openshift_logging_es_pvc_storage_class_name="glusterfs-registry-block"10 openshift_storage_glusterfs_namespace=app-storage openshift_storage_glusterfs_storageclass=true openshift_storage_glusterfs_storageclass_default=false openshift_storage_glusterfs_block_deploy=true openshift_storage_glusterfs_block_host_vol_size=100 openshift_storage_glusterfs_block_storageclass=true openshift_storage_glusterfs_block_storageclass_default=false openshift_storage_glusterfs_registry_namespace=infra-storage openshift_storage_glusterfs_registry_block_deploy=true openshift_storage_glusterfs_registry_block_host_vol_size=100 openshift_storage_glusterfs_registry_block_storageclass=true openshift_storage_glusterfs_registry_block_storageclass_default=false- 1 2 3 4 6 7 8
- 統合 OpenShift Container レジストリー、ロギングおよびメトリクスをインフラストラクチャーノードで実行することが推奨されます。インフラストラクチャーノードは、OpenShift Container Platform クラスターのサービスを提供するために管理者がデプロイするアプリケーションを実行する専用ノードです。
- 5 10
- ロギングとメトリクスに使用する StorageClass を指定します。この名前は、ターゲットの GlusterFS クラスター (例:
glusterfs-<name>-block) 名から生成されます。この例では<name>はregistryにデフォルト設定されています。 - 9
- OpenShift ロギングでは、PVC サイズを指定する必要があります。ここで指定される値は単なる例であり、推奨される値ではありません。
[OSEv3:children]セクションにglusterfsとglusterfs_registryを追加し、[glusterfs]グループと[glusterfs_registry]グループを有効にします。[OSEv3:children] ... glusterfs glusterfs_registry[glusterfs]セクションと[glusterfs_registry]セクションを追加し、両セクションに GlusterFS ストレージをホストするストレージノードを入力します。ノードごとにglusterfs_devicesを、GlusterFS クラスターの一部として完全に管理される raw ブロックデバイスの一覧に設定します。少なくとも 1 つのデバイスを一覧に含める必要があります。各デバイスは、パーティションや LVM PV がないベアでなければなりません。変数は以下の形式で指定します。<hostname_or_ip> glusterfs_devices='[ "</path/to/device1/>", "</path/to/device2>", ... ]'以下は例を示しています。
[glusterfs] node11.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node12.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node13.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' [glusterfs_registry] node14.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node15.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' node16.example.com glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]'[glusterfs]と[glusterfs_registry]に一覧表示されているホストを[nodes]グループに追加します。[nodes] ... node11.example.com openshift_node_group_name='node-config-compute'1 node12.example.com openshift_node_group_name='node-config-compute'2 node13.example.com openshift_node_group_name='node-config-compute'3 node14.example.com openshift_node_group_name='node-config-infra'"4 node15.example.com openshift_node_group_name='node-config-infra'"5 node16.example.com openshift_node_group_name='node-config-infra'"6 注記前述の手順では、インベントリーファイルに追加する必要のある一部のオプションのみを指定しています。Red Hat Gluster Storage をデプロイするには、完全なインベントリーファイルを使用します。
インストール Playbook を実行します。インベントリーファイルの相対パスをオプションとして指定します。
OpenShift Container Platform の新規インストール:
ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/prerequisites.yml ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/deploy_cluster.yml既存の OpenShift Container Platform クラスターへのインストール:
ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/openshift-glusterfs/config.yml
24.3.4.2.6. 例: アプリケーション、レジストリー、ロギングおよびメトリクス用のインデペンデントモード
インベントリーファイルの
[OSEv3:vars]セクションに次の変数を追加し、設定に合わせてそれらを調整します。[OSEv3:vars] ... openshift_hosted_registry_storage_kind=glusterfs1 openshift_hosted_registry_storage_volume_size=5Gi openshift_hosted_registry_selector='node-role.kubernetes.io/infra=true' openshift_metrics_install_metrics=true openshift_metrics_hawkular_nodeselector={"node-role.kubernetes.io/infra": "true"}2 openshift_metrics_cassandra_nodeselector={"node-role.kubernetes.io/infra": "true"}3 openshift_metrics_heapster_nodeselector={"node-role.kubernetes.io/infra": "true"}4 openshift_metrics_storage_kind=dynamic openshift_metrics_storage_volume_size=10Gi openshift_metrics_cassandra_pvc_storage_class_name="glusterfs-registry-block"5 openshift_logging_install_logging=true openshift_logging_kibana_nodeselector={"node-role.kubernetes.io/infra": "true"}6 openshift_logging_curator_nodeselector={"node-role.kubernetes.io/infra": "true"}7 openshift_logging_es_nodeselector={"node-role.kubernetes.io/infra": "true"}8 openshift_logging_storage_kind=dynamic openshift_logging_es_pvc_size=10Gi9 openshift_logging_es_pvc_storage_class_name="glusterfs-registry-block"10 openshift_storage_glusterfs_namespace=app-storage openshift_storage_glusterfs_storageclass=true openshift_storage_glusterfs_storageclass_default=false openshift_storage_glusterfs_block_deploy=true openshift_storage_glusterfs_block_host_vol_size=100 openshift_storage_glusterfs_block_storageclass=true openshift_storage_glusterfs_block_storageclass_default=false openshift_storage_glusterfs_is_native=false openshift_storage_glusterfs_heketi_is_native=true openshift_storage_glusterfs_heketi_executor=ssh openshift_storage_glusterfs_heketi_ssh_port=22 openshift_storage_glusterfs_heketi_ssh_user=root openshift_storage_glusterfs_heketi_ssh_sudo=false openshift_storage_glusterfs_heketi_ssh_keyfile="/root/.ssh/id_rsa" openshift_storage_glusterfs_registry_namespace=infra-storage openshift_storage_glusterfs_registry_block_deploy=true openshift_storage_glusterfs_registry_block_host_vol_size=100 openshift_storage_glusterfs_registry_block_storageclass=true openshift_storage_glusterfs_registry_block_storageclass_default=false openshift_storage_glusterfs_registry_is_native=false openshift_storage_glusterfs_registry_heketi_is_native=true openshift_storage_glusterfs_registry_heketi_executor=ssh openshift_storage_glusterfs_registry_heketi_ssh_port=22 openshift_storage_glusterfs_registry_heketi_ssh_user=root openshift_storage_glusterfs_registry_heketi_ssh_sudo=false openshift_storage_glusterfs_registry_heketi_ssh_keyfile="/root/.ssh/id_rsa"- 1 2 3 4 6 7 8
- 統合 OpenShift Container レジストリーは、管理者が OpenShift Container Platform クラスターにサービスを提供するためにデプロイしたアプリケーションである「インフラストラクチャー」アプリケーション専用のノードで実行することが推奨されます。インフラストラクチャーアプリケーション用のノードは、管理者が選択し、それにラベルを付けます。
- 5 10
- ロギングとメトリクスに使用する StorageClass を指定します。この名前は、ターゲットの GlusterFS クラスター (例:
glusterfs-<name>-block) 名から生成されます。この例ではregistryにデフォルト設定されています。 - 9
- OpenShift ロギングでは、PVC のサイズを指定する必要があります。ここで指定される値は単なる例であり、推奨される値ではありません。
[OSEv3:children]セクションにglusterfsとglusterfs_registryを追加し、[glusterfs]グループと[glusterfs_registry]グループを有効にします。[OSEv3:children] ... glusterfs glusterfs_registry[glusterfs]セクションと[glusterfs_registry]セクションを追加し、両セクションに GlusterFS ストレージをホストするストレージノードを入力します。ノードごとに、glusterfs_devicesを、GlusterFS クラスターの一部として完全に管理される raw ブロックデバイスの一覧に設定します。少なくと も 1 つのデバイスを一覧に含める必要があります。各デバイスは、パーティションや LVM PV がないベアでなければなりません。また、glusterfs_ipをノードの IP アドレスに設定します。変数は以下の形式で指定します。<hostname_or_ip> glusterfs_ip=<ip_address> glusterfs_devices='[ "</path/to/device1/>", "</path/to/device2>", ... ]'以下は例を示しています。
[glusterfs] gluster1.example.com glusterfs_ip=192.168.10.11 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' gluster2.example.com glusterfs_ip=192.168.10.12 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' gluster3.example.com glusterfs_ip=192.168.10.13 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' [glusterfs_registry] gluster4.example.com glusterfs_ip=192.168.10.14 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' gluster5.example.com glusterfs_ip=192.168.10.15 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]' gluster6.example.com glusterfs_ip=192.168.10.16 glusterfs_devices='[ "/dev/xvdc", "/dev/xvdd" ]'注記前述の手順では、インベントリーファイルに追加する必要のある一部のオプションのみを指定しています。Red Hat Gluster Storage をデプロイするには、完全なインベントリーファイルを使用します。
インストール Playbook を実行します。インベントリーファイルの相対パスをオプションとして指定します。
OpenShift Container Platform の新規インストール:
ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/prerequisites.yml ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/deploy_cluster.yml既存の OpenShift Container Platform クラスターへのインストール:
ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/openshift-glusterfs/config.yml
24.3.5. コンバージドモードのアンイストール
コンバージドモードの場合、OpenShift Container Platform のインストールには、クラスターから全リソースおよびアーティファクトをアンイストールするための Playbook が同梱されています。この Playbook を使用するには、コンバージドモードのターゲットインスタンスをインストールするのに使用した元のインベントリーファイルを指定して、以下の Playbook を実行します。
# ansible-playbook -i <path_to_inventory_file> /usr/share/ansible/openshift-ansible/playbooks/openshift-glusterfs/uninstall.yml
さらに、Playbook は、openshift_storage_glusterfs_wipe と呼ばれる変数の使用をサポートします。これは、有効化されている場合には、Red Hat Gluster Storage バックエンドストレージに使用されていたブロックデバイス上のデータを破棄します。openshift_storage_glusterfs_wipe 変数を使用するには、以下を実行します。
# ansible-playbook -i <path_to_inventory_file> -e
"openshift_storage_glusterfs_wipe=true"
/usr/share/ansible/openshift-ansible/playbooks/openshift-glusterfs/uninstall.ymlこの手順ではデータが破棄されるので、注意して進めてください。
24.3.6. プロビジョニング
GlusterFS ボリュームは、静的または動的にプロビジョニングできます。静的プロビジョニングは、すべての設定で使用できます。動的プロビジョニングは、コンバージドモードおよびインデペンデントモードでサポートされます。
24.3.6.1. 静的プロビジョニング
-
静的プロビジョニングを有効にするには、最初に GlusterFS ボリュームを作成します。
glusterコマンドラインインターフェースを使用してこれを行う方法については、『Red Hat Gluster Storage Administration Guide』を参照してください。また、heketi-cliを使用してこれを行う方法については、heketi プロジェクトサイトを参照してください。この例では、ボリュームにmyVol1という名前を付けます。 gluster-endpoints.yamlで以下のサービスとエンドポイントを定義します。--- apiVersion: v1 kind: Service metadata: name: glusterfs-cluster1 spec: ports: - port: 1 --- apiVersion: v1 kind: Endpoints metadata: name: glusterfs-cluster2 subsets: - addresses: - ip: 192.168.122.2213 ports: - port: 14 - addresses: - ip: 192.168.122.2225 ports: - port: 16 - addresses: - ip: 192.168.122.2237 ports: - port: 18 OpenShift Container Platform マスターホストからサービスとエンドポイントを作成します。
$ oc create -f gluster-endpoints.yaml service "glusterfs-cluster" created endpoints "glusterfs-cluster" createdサービスとエンドポイントが作成されたことを確認します。
$ oc get services NAME CLUSTER_IP EXTERNAL_IP PORT(S) SELECTOR AGE glusterfs-cluster 172.30.205.34 <none> 1/TCP <none> 44s $ oc get endpoints NAME ENDPOINTS AGE docker-registry 10.1.0.3:5000 4h glusterfs-cluster 192.168.122.221:1,192.168.122.222:1,192.168.122.223:1 11s kubernetes 172.16.35.3:8443 4d注記エンドポイントはプロジェクトごとに一意です。GlusterFS にアクセスする各プロジェクトには独自のエンドポイントが必要です。
ボリュームにアクセスするには、ボリューム上のファイルシステムにアクセスできるユーザー ID (UID) またはグループ ID (GID) でコンテナーを実行する必要があります。この情報は以下の方法で取得できます。
$ mkdir -p /mnt/glusterfs/myVol1 $ mount -t glusterfs 192.168.122.221:/myVol1 /mnt/glusterfs/myVol1 $ ls -lnZ /mnt/glusterfs/ drwxrwx---. 592 590 system_u:object_r:fusefs_t:s0 myVol11 2 gluster-pv.yamlで以下の PersistentVolume (PV) を定義します。apiVersion: v1 kind: PersistentVolume metadata: name: gluster-default-volume1 annotations: pv.beta.kubernetes.io/gid: "590"2 spec: capacity: storage: 2Gi3 accessModes:4 - ReadWriteMany glusterfs: endpoints: glusterfs-cluster5 path: myVol16 readOnly: false persistentVolumeReclaimPolicy: RetainOpenShift Container Platform マスターホストから PV を作成します。
$ oc create -f gluster-pv.yamlPV が作成されたことを確認します。
$ oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE gluster-default-volume <none> 2147483648 RWX Available 2sgluster-claim.yamlで、新規 PV にバインドする PersistentVolumeClaim (PVC) を作成します。apiVersion: v1 kind: PersistentVolumeClaim metadata: name: gluster-claim1 spec: accessModes: - ReadWriteMany2 resources: requests: storage: 1Gi3 OpenShift Container Platform マスターホストから PVC を作成します。
$ oc create -f gluster-claim.yamlPV と PVC がバインドされていることを確認します。
$ oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE gluster-pv <none> 1Gi RWX Available gluster-claim 37s $ oc get pvc NAME LABELS STATUS VOLUME CAPACITY ACCESSMODES AGE gluster-claim <none> Bound gluster-pv 1Gi RWX 24s
PVC はプロジェクトごとに一意です。GlusterFS ボリュームにアクセスする各プロジェクトには独自の PVC が必要です。PV は単一のプロジェクトにバインドされないため、複数のプロジェクトにまたがる PVC が同じ PV を参照する場合があります。
24.3.6.2. 動的プロビジョニング
動的プロビジョニングを有効にするには、最初に
StorageClassオブジェクト定義を作成します。以下の定義は、OpenShift Container Platform でこの例を使用するために必要な最小要件に基づいています。その他のパラメーターと仕様定義については、「動的プロビジョニングとストレージクラスの作成」を参照してください。kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: glusterfs provisioner: kubernetes.io/glusterfs parameters: resturl: "http://10.42.0.0:8080"1 restauthenabled: "false"2 OpenShift Container Platform マスターホストから StorageClass を作成します。
# oc create -f gluster-storage-class.yaml storageclass "glusterfs" created新たに作成される StorageClass を使用して PVC を作成します。以下は例になります。
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: gluster1 spec: accessModes: - ReadWriteMany resources: requests: storage: 30Gi storageClassName: glusterfsOpenShift Container Platform マスターホストから PVC を作成します。
# oc create -f glusterfs-dyn-pvc.yaml persistentvolumeclaim "gluster1" createdPVC を表示し、ボリュームが動的に作成され、PVC にバインドされていることを確認します。
# oc get pvc NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE gluster1 Bound pvc-78852230-d8e2-11e6-a3fa-0800279cf26f 30Gi RWX gluster-dyn 42s
24.4. OpenStack Cinder を使用した永続ストレージ
24.4.1. 概要
OpenStack Cinder を使用して、OpenShift Container Platform クラスターに永続ストレージをプロビジョニングできます。これには、Kubernetes と OpenStack についてある程度の理解があることが前提となります。
Cinder を使用して永続ボリューム (PV) を作成する前に、OpenStack 向けに OpenShft Container Platform を設定してください。
Kubernetes の 永続ボリュームフレームワークは、管理者がクラスターに永続ストレージをプロビジョニングできるようにします。ユーザーが基礎となるインフラストラクチャーの知識がなくてもこれらのリソースを要求できるようにします。OpenStack Cinder ボリュームを動的にプロビジョニングできます。
永続ボリュームは、単一のプロジェクトまたは namespace にバインドされず、OpenShift Container Platform クラスター全体で共有できます。ただし、Persistent Volume Claim (永続ボリューム要求) は、プロジェクトまたは namespace に固有で、ユーザーが要求できます。
インフラストラクチャーにおけるストレージの高可用性は、基礎となるストレージのプロバイダーに委ねられています。
24.4.2. Cinder PV のプロビジョニング
OpenShift Container Platform でストレージをボリュームとしてマウントするには、ストレージが基礎となるインフラストラクチャーに存在している必要があります。OpenShift Container Platform が OpenStack 用に設定されていることを確認した後、Cinder に必要なのは、Cinder ボリューム ID と PersistentVolume API のみになります。
24.4.2.1. 永続ボリュームの作成
Cinder では、「リサイクル」回収ポリシーはサポートされません。
OpenShift Container Platform に PV を作成する前に、PV をオブジェクト定義に定義する必要があります。
オブジェクト定義を cinder-pv.yaml などのファイルに保存します。
apiVersion: "v1" kind: "PersistentVolume" metadata: name: "pv0001"1 spec: capacity: storage: "5Gi"2 accessModes: - "ReadWriteOnce" cinder:3 fsType: "ext3"4 volumeID: "f37a03aa-6212-4c62-a805-9ce139fab180"5 重要ボリュームをフォーマットしてプロビジョニングした後には、
fstypeパラメーターの値は変更しないでください。この値を変更すると、データの損失や、Pod の障害につながる可能性があります。永続ボリュームを作成します。
# oc create -f cinder-pv.yaml persistentvolume "pv0001" created永続ボリュームの存在を確認します。
# oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE pv0001 <none> 5Gi RWO Available 2s
次に、ユーザーは永続ボリューム要求 (Persistent Volume Claim) を使用してストレージを要求できるので、この新規の永続ボリュームを活用できます。
Persistent Volume Claim (永続ボリューム要求) は、ユーザーの namespace にのみ存在し、同じ namespace 内の Pod からしか参照できません。別の namespace から Persistent Volume Claim (永続ボリューム要求) にアクセスしようとすると、Pod にエラーが発生します。
24.4.2.2. Cinder の PV 形式
OpenShift Container Platform は、ボリュームをマウントしてコンテナーに渡す前に、永続ボリューム定義の fsType パラメーターで指定されたファイルシステムがボリュームにあるかどうか確認します。デバイスが指定されたファイルシステムでフォーマットされていない場合、デバイスのデータはすべて消去され、デバイスはそのファイルシステムで自動的にフォーマットされます。
これにより、OpenShift Container Platform がフォーマットされていない Cinder ボリュームを初回の使用前にフォーマットするため、それらを永続ボリュームとして使用することが可能になります。
24.4.2.3. Cinder ボリュームのセキュリティー
お使いのアプリケーションで Cinder PV を使用する場合に、そのデプロイメント設定にセキュリティーを追加します。
Cinder ボリュームを実装する前に、ボリュームのセキュリティーを確認します。
-
適切な
fsGroupストラテジーを使用するSCC を作成します。 サービスアカウントを作成して、そのアカウントを SCC に追加します。
[source,bash] $ oc create serviceaccount <service_account> $ oc adm policy add-scc-to-user <new_scc> -z <service_account> -n <project>アプリケーションのデプロイ設定で、サービスアカウント名と
securityContextを指定します。apiVersion: v1 kind: ReplicationController metadata: name: frontend-1 spec: replicas: 11 selector:2 name: frontend template:3 metadata: labels:4 name: frontend5 spec: containers: - image: openshift/hello-openshift name: helloworld ports: - containerPort: 8080 protocol: TCP restartPolicy: Always serviceAccountName: <service_account>6 securityContext: fsGroup: 77777
24.5. Ceph Rados ブロックデバイス (RBD) を使用した永続ストレージ
24.5.1. 概要
OpenShift Container Platform クラスターでは、Ceph RBD を使用して永続ストレージをプロビジョニングできます。
永続ボリューム (PV) と Persistent Volume Claim (永続ボリューム要求、PVC)は、単一プロジェクトでボリュームを共有できます。PV 定義に含まれている Ceph RBD 固有の情報は Pod 定義で直接定義することも可能ですが、この方法だとボリュームが一意のクラスターリソースとして作成されず、競合の影響を受けやすくなります。
このトピックでは、OpenShift Container Platform と Ceph RBD についてある程度理解していることを前提とします。OpenShift Container Platform 永続ボリューム (PV) の一般的なフレームワークについての詳細は、永続ストレージの概念に関するトピックを参照してください。
本書では、プロジェクトと namespace は区別せずに使用されています。両者の関係については、「プロジェクトおよびユーザー」を参照してください。
インフラストラクチャーにおけるストレージの高可用性は、基礎となるストレージのプロバイダーに委ねられています。
24.5.2. プロビジョニング
Ceph ボリュームをプロビジョニングするには、以下が必要になります。
- 基礎となるインフラストラクチャーの既存ストレージデバイス。
- OpenShift Container Platform シークレットオブジェクトで使用される Ceph キー。
- Ceph イメージ名。
- ブロックストレージ上部のファイルシステムタイプ (ext4 など)。
クラスター内のスケジュール可能な各 OpenShift Container Platform ノードにインストールされた ceph-common。
# yum install ceph-common
24.5.2.1. Ceph シークレットの作成
承認キーをシークレット設定に定義します。これは後に OpenShift Container Platform で使用できるように base64 に変換されます。
Ceph ストレージを使用して永続ボリュームをサポートするには、シークレットを PVC や Pod と同じプロジェクトに作成する必要があります。シークレットは、単にデフォルトプロジェクトに置くことはできません。
Ceph MON ノードで
ceph auth get-keyを実行し、client.adminユーザーのキー値を表示します。apiVersion: v1 kind: Secret metadata: name: ceph-secret data: key: QVFBOFF2SlZheUJQRVJBQWgvS2cwT1laQUhPQno3akZwekxxdGc9PQ==シークレット定義を ceph-secret.yaml などのファイルに保存し、シークレットを作成します。
$ oc create -f ceph-secret.yamlシークレットが作成されたことを確認します。
# oc get secret ceph-secret NAME TYPE DATA AGE ceph-secret Opaque 1 23d
24.5.2.2. 永続ボリュームの作成
Ceph RBD では、「リサイクル」回収ポリシーはサポートされません。
開発者は、PVC を参照するか、Pod 仕様の volumes セクションにある Gluster ボリュームプラグインを直接参照することによって Ceph RBD ストレージを要求します。PVC は、ユーザーの namespace にのみ存在し、同じ namespace 内の Pod からしか参照できません。別の namespace から PV にアクセスしようとすると、Pod エラーが発生します。
OpenShift Container Platform に PV を作成する前に、PV をオブジェクト定義に定義します。
例24.3 Ceph RBD を使用した永続ボリュームオブジェクトの定義
apiVersion: v1 kind: PersistentVolume metadata: name: ceph-pv1 spec: capacity: storage: 2Gi2 accessModes: - ReadWriteOnce3 rbd:4 monitors:5 - 192.168.122.133:6789 pool: rbd image: ceph-image user: admin secretRef: name: ceph-secret6 fsType: ext47 readOnly: false persistentVolumeReclaimPolicy: Retain- 1
- Pod 定義で参照されるか、または各種の
ocボリュームコマンドで表示される PV の名前。 - 2
- このボリュームに割り当てられるストレージの量。
- 3
accessModesは、PV と PVC を一致させるためのラベルとして使用されます。現時点で、これらはいずれの形式のアクセス制御も定義しません。すべてのブロックストレージは単一ユーザーに対して定義されます (非共有ストレージ)。- 4
- 使用されるボリュームタイプ。この場合は、rbd プラグインです。
- 5
- Ceph モニターの IP アドレスとポートの配列。
- 6
- OpenShift Container Platform から Ceph サーバーへのセキュアな接続を作成するために使用される Ceph シークレット。
- 7
- Ceph RBD ブロックデバイスにマウントされるファイルシステムタイプ。
重要ボリュームをフォーマットしてプロビジョニングした後に
fstypeパラメーターの値を変更すると、データ損失や Pod エラーが発生する可能性があります。定義を ceph-pv.yaml などのファイルに保存し、PV を作成します。
# oc create -f ceph-pv.yaml永続ボリュームが作成されたことを確認します。
# oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE ceph-pv <none> 2147483648 RWO Available 2s新規 PV にバインドされる PVC を作成します。
定義をファイル (ceph-claim.yaml など) に保存し、PVC を作成します。
# oc create -f ceph-claim.yaml
24.5.3. Ceph ボリュームのセキュリティー
Ceph RBD ボリュームを実装する前に、「ボリュームのセキュリティー」トピックの詳細を参照してください。
共有ボリューム (NFS および GlusterFS) とブロックボリューム (Ceph RBD、iSCSI、およびほとんどのクラウドストレージ) の大きな違いは、Pod 定義またはコンテナーイメージで定義されたユーザー ID とグループ ID がターゲットの物理ストレージに適用されることです。これはブロックデバイスの所有権の管理と呼ばれます。たとえば、Ceph RBD マウントで所有者が 123 に、グループ ID が 567 に設定されていて、Pod で runAsUser が 222 に、fsGroup が 7777 に定義されている場合、Ceph RBD 物理マウントの所有権は 222:7777 に変更されます。
ユーザー ID とグループ ID が Pod 仕様で定義されていない場合でも、生成される Pod では、これらの ID のデフォルト値が一致する SCC またはプロジェクトに基づいて定義されることがあります。詳細については、「ボリュームのセキュリティー」トピックの詳細を参照してください。このトピックでは、SCC のストレージの側面とデフォルト値について説明しています。
Pod の securityContext 定義で fsGroup スタンザを使用して、Pod で Ceph RBD ボリュームのグループ所有権を定義します。
24.6. AWS Elastic Block Store を使用した永続ストレージ
24.6.1. 概要
OpenShift Container Platform では、AWS Elastic Block Store ボリューム (EBS) がサポートされます。AWS EC2 を使用して、OpenShift Container Platform クラスターに永続ストレージをプロビジョニングできます。これには、Kubernetes と AWS についてある程度の理解があることが前提となります。
AWS を使用して永続ボリュームを作成する前に、まず OpenShift Container Platform を AWS ElasticBlockStore 用に適切に設定する必要があります。
Kubernetes 永続ボリュームフレームワークは、管理者がクラスターに永続ストレージをプロビジョニングできるようにします。ユーザーが基礎となるインフラストラクチャーの知識がなくてもこれらのリソースを要求できるようになります。AWS Elastic Block Store ボリュームは、動的にプロビジョニングできます。永続ボリュームは、単一のプロジェクトまたは namespace にバインドされず、OpenShift Container Platform クラスター全体で共有できます。ただし、Persistent Volume Claim (永続ボリューム要求)は、プロジェクトまたは namespace に固有で、ユーザーが要求できます。
インフラストラクチャーにおけるストレージの高可用性は、基礎となるストレージのプロバイダーに委ねられています。
24.6.2. プロビジョニング
OpenShift Container Platform でストレージをボリュームとしてマウントするには、基礎となるインフラストラクチャーにストレージが存在している必要があります。OpenShift Container Platform が AWS Elastic Block Store 用に設定されていることを確認した後、OpenShift と AWS に必要になるのは、AWS EBS ボリューム ID と PersistentVolume API のみです。
24.6.2.1. 永続ボリュームの作成
AWS では、「リサイクル」回収ポリシーはサポートされません。
OpenShift Container Platform に永続ボリュームを作成する前に、永続ボリュームをオブジェクト定義で定義する必要があります。
例24.5 AWS を使用した永続ボリュームオブジェクトの定義
apiVersion: "v1"
kind: "PersistentVolume"
metadata:
name: "pv0001"
spec:
capacity:
storage: "5Gi"
accessModes:
- "ReadWriteOnce"
awsElasticBlockStore:
fsType: "ext4"
volumeID: "vol-f37a03aa"
ボリュームをフォーマットしてプロビジョニングした後に fstype パラメーターの値を変更すると、データ損失や Pod エラーが発生する可能性があります。
定義を aws-pv.yaml などのファイルに保存し、永続ボリュームを作成します。
# oc create -f aws-pv.yaml
persistentvolume "pv0001" created永続ボリュームが作成されたことを確認します。
# oc get pv
NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
pv0001 <none> 5Gi RWO Available 2s次に、ユーザーは永続ボリューム要求 (Persistent Volume Claim) を使用してストレージを要求できるので、この新規の永続ボリュームを活用できます。
Persistent Volume Claim (永続ボリューム要求) は、ユーザーの namespace にのみ存在し、同じ namespace 内の Pod からしか参照できません。別の namespace から永続ボリュームにアクセスしようとすると、Pod にエラーが発生します。
24.6.2.2. ボリュームのフォーマット
OpenShift Container Platform は、ボリュームをマウントしてコンテナーに渡す前に、永続ボリューム定義の fsType パラメーターで指定されたファイルシステムがボリュームにあるかどうか確認します。デバイスが指定されたファイルシステムでフォーマットされていない場合、デバイスのデータはすべて消去され、デバイスはそのファイルシステムで自動的にフォーマットされます。
これにより、OpenShift Container Platform がフォーマットされていない AWS ボリュームを初回の使用前にフォーマットするため、それらを永続ボリュームとして使用することが可能になります。
24.6.2.3. ノード上の EBS ボリュームの最大数
OpenShift Container Platform では、デフォルトで 1 つのノードに最大 39 の EBS ボリュームを割り当てることができます。この制限は、AWS ボリュームの制限に合致します。
OpenShift Container Platform では、環境変数 KUBE_MAX_PD_VOLS を設定することで、より大きな制限値を設定できます。ただし、AWS では、割り当てられるデバイスに特定の命名スキーム (AWS デバイスの命名) を使用する必要があります。この命名スキームでは、最大で 52 のボリュームしかサポートされません。これにより、OpenShift Container Platform 経由でノードに割り当てることができるボリュームの数が 52 に制限されます。
24.7. GCE Persistent Disk を使用した永続ストレージ
24.7.1. 概要
OpenShift Container Platform では、GCE Persistent Disk ボリューム (gcePD) がサポートされます。GCE を使用して、OpenShift Container Platform クラスターに永続ストレージをプロビジョニングできます。これには、Kubernetes と GCE についてある程度の理解があることが前提となります。
GCE を使用して永続ボリュームを作成する前に、まず OpenShift Container Platform を GCE Persistent Disk 用に適切に設定する必要があります。
Kubernetes の 永続ボリュームフレームワークは、管理者がクラスターに永続ストレージをプロビジョニングできるようにします。また、ユーザーが基礎となるインフラストラクチャーの知識がなくてもこれらのリソースを要求できるようにします。GCE Persistent Disk ボリュームは、動的にプロビジョニングできます。永続ボリュームは、単一のプロジェクトまたは namespace にバインドされず、OpenShift Container Platform クラスター全体で共有できます。ただし、Persistent Volume Claim (永続ボリューム要求) は、プロジェクトまたは namespace に固有で、ユーザーが要求できます。
インフラストラクチャーにおけるストレージの高可用性は、基礎となるストレージのプロバイダーに委ねられています。
24.7.2. プロビジョニング
OpenShift Container Platform でストレージをボリュームとしてマウントするには、基礎となるインフラストラクチャーにストレージが存在している必要があります。OpenShift Container Platform が GCE Persistent Disk 用に設定されていることを確認した後、OpenShift Container Platform と GCE に必要となるのは、GCE Persistent Disk ボリューム ID と PersistentVolume API のみです。
24.7.2.1. 永続ボリュームの作成
GCE では、「リサイクル」回収ポリシーはサポートされません。
OpenShift Container Platform に永続ボリュームを作成する前に、永続ボリュームをオブジェクト定義で定義する必要があります。
例24.6 GCE を使用した永続ボリュームオブジェクトの定義
apiVersion: "v1"
kind: "PersistentVolume"
metadata:
name: "pv0001"
spec:
capacity:
storage: "5Gi"
accessModes:
- "ReadWriteOnce"
gcePersistentDisk:
fsType: "ext4"
pdName: "pd-disk-1"
ボリュームをフォーマットしてプロビジョニングした後に fstype パラメーターの値を変更すると、データ損失や Pod にエラーが発生する可能性があります。
定義を gce-pv.yaml などのファイルに保存し、永続ボリュームを作成します。
# oc create -f gce-pv.yaml
persistentvolume "pv0001" created永続ボリュームが作成されたことを確認します。
# oc get pv
NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
pv0001 <none> 5Gi RWO Available 2s次に、ユーザーは永続ボリューム要求 (Persistent Volume Claim) を使用してストレージを要求できるので、この新規の永続ボリュームを活用できます。
Persistent Volume Claim (永続ボリューム要求) は、ユーザーの namespace にのみ存在し、同じ namespace 内の Pod からしか参照できません。別の namespace から永続ボリュームにアクセスしようとすると、Pod にエラーが発生します。
24.7.2.2. ボリュームのフォーマット
OpenShift Container Platform は、ボリュームをマウントしてコンテナーに渡す前に、永続ボリューム定義の fsType パラメーターで指定されたファイルシステムがボリュームにあるかどうか確認します。デバイスが指定されたファイルシステムでフォーマットされていない場合、デバイスのデータはすべて消去され、デバイスはそのファイルシステムで自動的にフォーマットされます。
これにより、OpenShift Container Platform がフォーマットされていない GCE ボリュームを初回の使用前にフォーマットするため、それらを永続ボリュームとして使用することが可能になります。
24.8. iSCSI を使用した永続ストレージ
24.8.1. 概要
iSCSI を使用して、OpenShift Container Platform クラスターに永続ストレージをプロビジョニングできます。これには、Kubernetes と iSCSI についてある程度の理解があることが前提となります。
Kubernetes の 永続ボリュームフレームワークは、管理者がクラスターに永続ストレージをプロビジョニングできるようにします。ユーザーが基礎となるインフラストラクチャーの知識がなくてもこれらのリソースを要求できるようにします。
インフラストラクチャーにおけるストレージの高可用性は、基礎となるストレージのプロバイダーに委ねられています。
24.8.2. プロビジョニング
OpenShift Container Platform でストレージをボリュームとしてマウントする前に、基礎となるインフラストラクチャーにストレージが存在することを確認します。iSCSI に必要になるのは、iSCSI ターゲットポータル、有効な iSCSI 修飾名 (IQN)、有効な LUN 番号、ファイルシステムタイプ、および PersistentVolume API のみです。
オプションで、マルチパススポータルと CHAP (チャレンジハンドシェイク認証プロトコル) 設定を指定できます。
iSCSI では、「リサイクル」回収ポリシーはサポートされません。
例24.7 永続ボリュームオブジェクトの定義
apiVersion: v1
kind: PersistentVolume
metadata:
name: iscsi-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
iscsi:
targetPortal: 10.16.154.81:3260
portals: ['10.16.154.82:3260', '10.16.154.83:3260']
iqn: iqn.2014-12.example.server:storage.target00
lun: 0
fsType: 'ext4'
readOnly: false
chapAuthDiscovery: true
chapAuthSession: true
secretRef:
name: chap-secret24.8.2.1. ディスククォータの実施
LUN パーティションを使用してディスククォータとサイズ制限を実施します。それぞれの LUN には 1 つの永続ボリュームです。Kubernetes では、永続ボリュームに一意の名前を使用する必要があります。
上記の方法でクォータを実施すると、エンドユーザーは永続ストレージを具体的な量 (10Gi など) で要求することができ、これを同等またはそれ以上の容量の対応するボリュームに一致させることができます。
24.8.2.2. iSCSI ボリュームのセキュリティー
ユーザーは PersistentVolumeClaim でストレージを要求します。この要求はユーザーの namespace にのみ存在し、同じ namespace 内の Pod からのみ参照できます。namespace をまたいで永続ボリュームにアクセスしようとすると、Pod にエラーが発生します。
それぞれの iSCSI LUN は、クラスター内のすべてのノードからアクセスできる必要があります。
24.8.2.3. iSCSI のマルチパス化
iSCSI ベースのストレージの場合は、複数のターゲットポータルの IP アドレスに同じ IQN を使用することでマルチパスを設定できます。マルチパス化により、パス内の 1 つ以上のコンポーネントで障害が発生した場合でも、永続ボリュームにアクセスできることができます。
Pod 仕様でマルチパスを指定するには、portals フィールドを使用します。以下は例になります。
apiVersion: v1
kind: PersistentVolume
metadata:
name: iscsi_pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
iscsi:
targetPortal: 10.0.0.1:3260
portals: ['10.0.2.16:3260', '10.0.2.17:3260', '10.0.2.18:3260']
iqn: iqn.2016-04.test.com:storage.target00
lun: 0
fsType: ext4
readOnly: false- 1
portalsフィールドを使用してターゲットポータルを追加します。
24.8.2.4. iSCSI のカスタムイニシエーター IQN
iSCSI ターゲットが特定に IQN に制限されている場合に、カスタムイニシエーターの iSCSI Qualified Name (IQN) を設定します。ただし、iSCSI PV が割り当てられているノードが必ず、これらの IQN を使用する保証はありません。
カスタムのイニシエーター IQN を指定するには、initiatorName フィールドを使用します。
apiVersion: v1
kind: PersistentVolume
metadata:
name: iscsi_pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
iscsi:
targetPortal: 10.0.0.1:3260
portals: ['10.0.2.16:3260', '10.0.2.17:3260', '10.0.2.18:3260']
iqn: iqn.2016-04.test.com:storage.target00
lun: 0
initiatorName: iqn.2016-04.test.com:custom.iqn
fsType: ext4
readOnly: false- 1
- カスタムのイニシエーター IQN を追加するには、
initiatorNameフィールドを使用します。
24.9. ファイバーチャネルを使用した永続ストレージ
24.9.1. 概要
ファイバーチャネルを使用して、OpenShift Container Platform クラスターに永続ストレージをプロビジョニングできます。これには、Kubernetes と Fibre Channel についてある程度の理解があることが前提となります。
Kubernetes の 永続ボリュームフレームワークは、管理者がクラスターに永続ストレージをプロビジョニングできるようにします。ユーザーが基礎となるインフラストラクチャーの知識がなくてもこれらのリソースを要求できるようにします。
インフラストラクチャーにおけるストレージの高可用性は、基礎となるストレージのプロバイダーに委ねられています。
24.9.2. プロビジョニング
OpenShift Container Platform でストレージをボリュームとしてマウントするには、基礎となるインフラストラクチャーにストレージが存在している必要があります。ファイバーチャネルの永続ストレージに必要になるのは、targetWWNs (ファイバーチャネルターゲットのワールドワイド名の配列)、有効な LUN 番号、ファイルシステムタイプ、および PersistentVolume API のみです。 永続ボリュームと LUN は 1 対 1 でマッピングされます。
ファイバーチャネルでは、「リサイクル」回収ポリシーはサポートされません。
永続ボリュームオブジェクトの定義
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0001
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
fc:
targetWWNs: ['500a0981891b8dc5', '500a0981991b8dc5']
lun: 2
fsType: ext4- 1
- ファイバーチャネルl WWN は、
/dev/disk/by-path/pci-<IDENTIFIER>-fc-0x<WWN>-lun-<LUN#>として識別されます。ただし、WWNまでのパス (0xを含む) と WWN の後の文字 (-(ハイフン) を含む) を入力する必要はありません。
ボリュームをフォーマットしてプロビジョニングした後に fstype パラメーターの値を変更すると、データ損失や Pod エラーが発生する可能性があります。
24.9.2.1. ディスククォータの実施
LUN パーティションを使用してディスククォータとサイズ制限を実施します。それぞれの LUN には 1 つの永続ボリュームです。Kubernetes では、永続ボリュームに一意の名前を使用する必要があります。
上記の方法でクォータを実施すると、エンドユーザーは永続ストレージを具体的な量 (10Gi など) で要求することができ、これを同等またはそれ以上の容量の対応するボリュームに一致させることができます。
24.9.2.2. ファイバーチャネルボリュームのセキュリティー
ユーザーは PersistentVolumeClaim でストレージを要求します。この要求はユーザーの namespace にのみ存在し、同じ namespace 内の Pod からのみ参照できます。namespace をまたいで永続ボリュームにアクセスしようとすると、Pod にエラーが発生します。
それぞれのファイバーチャネル LUN は、クラスター内のすべてのノードからアクセスできる必要があります。
24.10. Azure Disk を使用した永続ストレージ
24.10.1. 概要
OpenShift Container Platform では、Microsoft Azure Disk ボリュームがサポートされます。Azure を使用して、OpenShift Container Platform クラスターに永続ストレージをプロビジョニングできます。これには、Kubernetes と Azure についてある程度の理解があることが前提となります。
Kubernetes の 永続ボリュームフレームワークは、管理者がクラスターに永続ストレージをプロビジョニングできるようにします。ユーザーが基礎となるインフラストラクチャーの知識がなくてもこれらのリソースを要求できるようにします。
Azure Disk ボリュームは、動的にプロビジョニングできます。永続ボリュームは、単一のプロジェクトまたは namespace にバインドされず、OpenShift Container Platform クラスター全体で共有できます。ただし、Persistent Volume Claim (永続ボリューム要求) は、プロジェクトまたは namespace に固有で、ユーザーが要求できます。
インフラストラクチャーにおけるストレージの高可用性は、基礎となるストレージのプロバイダーに委ねられています。
24.10.2. 前提条件
Azure を使用して永続ボリュームを作成する前に、OpenShift Container Platform クラスターが以下の要件を満たしていることを確認してください。
- まず、OpenShift Container Platform を Azure Disk 用に設定する必要があります。
- インフラストラクチャー内の各ノードは、Azure 仮想マシン名に一致している必要があります。
- それぞれのノードホストは、同じリソースグループに属している必要があります。
24.10.3. プロビジョニング
OpenShift Container Platform でストレージをボリュームとしてマウントするには、基礎となるインフラストラクチャーにストレージが存在している必要があります。OpenShift Container Platform が Azure Disk 用に設定されていることを確認した後、OpenShift Container Platform と Azure に必要になるのは、Azure Disk Name および Disk URI と PersistentVolume API のみです。
24.10.4. Azure Disk でのリージョンクラウドの設定
Azure には、インスタンスをデプロイする複数のリージョンがあります。必要なリージョンを指定するには、以下を azure.conf ファイルに追加します。
cloud: <region>リージョンは以下のいずれかになります。
-
ドイツクラウド:
AZUREGERMANCLOUD -
中国クラウド:
AZURECHINACLOUD -
パブリッククラウド:
AZUREPUBLICCLOUD -
米国クラウド:
AZUREUSGOVERNMENTCLOUD
24.10.4.1. 永続ボリュームの作成
Azure では、リサイクル回収ポリシーはサポートされません。
OpenShift Container Platform に永続ボリュームを作成する前に、永続ボリュームをオブジェクト定義で定義する必要があります。
例24.8 Azure を使用した永続ボリュームオブジェクトの定義
apiVersion: "v1"
kind: "PersistentVolume"
metadata:
name: "pv0001"
spec:
capacity:
storage: "5Gi"
accessModes:
- "ReadWriteOnce"
azureDisk:
diskName: test2.vhd
diskURI: https://someacount.blob.core.windows.net/vhds/test2.vhd
cachingMode: ReadWrite
fsType: ext4
readOnly: false - 1
- ボリュームの名前です。これは Persistent Volume Claim (永続ボリューム要求)を使用して、または Pod からボリュームを識別するために使用されます。
- 2
- このボリュームに割り当てられるストレージの量。
- 3
- これは使用されるボリュームタイプを定義します (この例では、azureDisk プラグイン)。
- 4
- Blob ストレージのデータディスクの名前。
- 5
- Blob ストレージのデータディスクの URI
- 6
- ホストのキャッシングモード: None、ReadOnly、または ReadWrite。
- 7
- マウントするファイルシステムタイプ (
ext4、xfsなど)。 - 8
- デフォルトは
false(読み取り/書き込み) です。ここでReadOnlyを指定すると、VolumeMountsでReadOnly設定が強制的に実行されます。
ボリュームをフォーマットしてプロビジョニングした後に fsType パラメーターの値を変更すると、データ損失や Pod にエラーが発生する可能性があります。
定義を azure-pv.yaml などのファイルに保存し、永続ボリュームを作成します。
# oc create -f azure-pv.yaml persistentvolume "pv0001" created永続ボリュームが作成されたことを確認します。
# oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE pv0001 <none> 5Gi RWO Available 2s
これで、Persistent Volume Claim (永続ボリューム要求) を使用してストレージを要求し、新規の永続ボリュームを活用できるようになります。
Azure Disk PVC を介してボリュームがマウントされている Pod の場合、新規ノードへの Pod のスケジューリングに数分の時間がかかります。ディスクの割り当て解除操作が完了するまで 2 ~ 3 分待ってから、新規デプロイメントを開始してください。ディスクの割り当て解除操作が完了する前に新規の Pod の作成要求が開始されると、Pod の作成によって開始されたディスクの割り当て操作が失敗し、結果として Pod の作成が失敗します。
Persistent Volume Claim (永続ボリューム要求) は、ユーザーの namespace にのみ存在し、同じ namespace 内の Pod からしか参照できません。別の namespace から永続ボリュームにアクセスしようとすると、Pod にエラーが発生します。
24.10.4.2. ボリュームのフォーマット
OpenShift Container Platform は、ボリュームをマウントしてコンテナーに渡す前に、永続ボリューム定義の fsType パラメーターで指定されたファイルシステムがボリュームにあるかどうか確認します。デバイスが指定されたファイルシステムでフォーマットされていない場合、デバイスのデータはすべて消去され、デバイスはそのファイルシステムで自動的にフォーマットされます。
これにより、OpenShift Container Platform がフォーマットされていない Azure ボリュームを初回の使用前にフォーマットするため、それらを永続ボリュームとして使用することが可能になります。
24.11. Azure File を使用した永続ストレージ
24.11.1. 概要
OpenShift Container Platform では、Microsoft Azure File ボリュームがサポートされます。Azure を使用して、OpenShift Container Platform クラスターに永続ストレージをプロビジョニングできます。これには、Kubernetes と Azure についてのある程度の理解があることが前提となります。
インフラストラクチャーにおけるストレージの高可用性は、基礎となるストレージのプロバイダーに委ねられています。
24.11.2. 作業を開始する前の注意事項
すべてのノードに
samba-client、samba-common、およびcifs-utilsをインストールします。$ sudo yum install samba-client samba-common cifs-utilsすべてのノードで SELinux ブール値を有効にします。
$ /usr/sbin/setsebool -P virt_use_samba on $ /usr/sbin/setsebool -P virt_sandbox_use_samba onmountコマンドを実行してdir_modeおよびfile_modeパーミッションなどを確認します。$ mount
dir_mode および file_mode のパーミッションが 0755 に設定されている場合には、デフォルト値 0755 を 0777 または 0775 に変更します。OpenShift Container Platform 3.9 では、デフォルトの dir_mode および file_mode パーミッションが 0777 から 0755 に変更されるので、この手動の手順が必要です。以下の例では、変更された値が含まれる設定ファイルを紹介しています。
Azure File での MySQL および PostgresSQL を使用する場合の留意事項
- Azure File がマウントされるディレクトリーの所有者 UID は、コンテナーの UID とは異なります。
MySQL コンテナーは、マウントされたディレクトリーのファイルの所有者パーミッションを変更します。所有者 UID とコンテナープロセスの UID が一致しないので、この操作に失敗してしまいます。そのため、Azure File で MySQL を実行するには、以下を行うようにしてください。
PV 設定ファイルの
runAsUser変数に、Azure File のマウントされたディレクトリー UID を指定します。spec: containers: ... securityContext: runAsUser: <mounted_dir_uid>PV 設定ファイルの
mountOptionsでコンテナーのプロセス UID を指定します。mountOptions: - dir_mode=0700 - file_mode=0600 - uid=<conatiner_process_uid> - gid=0
- PostgreSQL は Azure File との併用はできません。これは、PostgreSQL に Azure File ディレクトリーのハードリンクが必要であるにもかかわらず、Azure File では ハードリンク をサポートしていないため、Pod の起動に失敗します。
PV 設定ファイル例
# azf-pv.yml
apiVersion: "v1"
kind: "PersistentVolume"
metadata:
name: "azpv"
spec:
capacity:
storage: "1Gi"
accessModes:
- "ReadWriteMany"
azureFile:
secretName: azure-secret
shareName: azftest
readOnly: false
mountOptions:
- dir_mode=0777
- file_mode=0777ストレージクラスの設定ファイル例
$ azure-file-sc.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: azurefile
provisioner: kubernetes.io/azure-file
mountOptions:
- dir_mode=0777
- file_mode=0777
parameters:
storageAccount: ocp39str
location: centralus24.11.3. Azure File でのリージョンクラウドの設定
Azure Disk は複数のリージョンクラウドに対応していますが、Azure File は、エンドポイントがハードコードされているために Azure パブリッククラウドのみをサポートしています。
24.11.4. PV の作成
Azure File では、リサイクル回収ポリシーはサポートされません。
24.11.5. Azure Storage Account シークレットの作成
Azure Storage Account の名前とキーをシークレット設定に定義します。これは後に OpenShift Container Platform で使用できるように base64 に変換されます。
Azure Storage Account の名前とキーを取得し、base64 にエンコードします。
apiVersion: v1 kind: Secret metadata: name: azure-secret type: Opaque data: azurestorageaccountname: azhzdGVzdA== azurestorageaccountkey: eElGMXpKYm5ub2pGTE1Ta0JwNTBteDAyckhzTUsyc2pVN21GdDRMMTNob0I3ZHJBYUo4akQ2K0E0NDNqSm9nVjd5MkZVT2hRQ1dQbU02WWFOSHk3cWc9PQ==シークレット定義を azure-secret.yaml などのファイルに保存し、シークレットを作成します。
$ oc create -f azure-secret.yamlシークレットが作成されたことを確認します。
$ oc get secret azure-secret NAME TYPE DATA AGE azure-secret Opaque 1 23dOpenShift Container Platform に PV を作成する前に、PV をオブジェクト定義に定義します。
Azure File を使用した PV オブジェクト定義の例
apiVersion: "v1" kind: "PersistentVolume" metadata: name: "pv0001"1 spec: capacity: storage: "5Gi"2 accessModes: - "ReadWriteMany" azureFile:3 secretName: azure-secret4 shareName: example5 readOnly: false6 定義を azure-file-pv.yaml などのファイルに保存し、PV を作成します。
$ oc create -f azure-file-pv.yaml persistentvolume "pv0001" createdPV が作成されたことを確認します。
$ oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE pv0001 <none> 5Gi RWM Available 2s
これで、PVC (永続ボリューム要求) を使用してストレージを要求し、新規の永続ボリュームを活用できるようになります。
PVC (永続ボリューム要求) は、ユーザーの namespace にのみ存在し、同じ namespace 内の Pod からしか参照できません。別の namespace から永続ボリュームにアクセスしようとすると、Pod にエラーが発生します。
24.12. FlexVolume プラグインを使用した永続ストレージ
24.12.1. 概要
OpenShift Container Platform には、各種のストレージテクノロジーを使用するためにボリュームプラグインが組み込まれています。組み込みプラグインがないバックエンドのストレージを使用する場合は、FlexVolume ドライバーを使用して OpenShift Container Platform を拡張し、アプリケーションに永続ストレージを提供できます。
24.12.2. FlexVolume ドライバー
FlexVolume ドライバーは、クラスター内のすべてのマシン (マスターとノードの両方) の明確に定義されたディレクトリーに格納されている実行可能ファイルです。OpenShift Container Platform は、flexVolume をソースとする PersistentVolume によって表されるボリュームの割り当て、割り当て解除、マウント、またはアンマウントが必要になるたびに FlexVolume ドライバーを呼び出します。
ドライバーの最初のコマンドライン引数は常に操作名です。その他のパラメーターは操作ごとに異なります。ほとんどの操作は、JSON (JavaScript Object Notation) 文字列をパラメーターとして取ります。このパラメーターは完全な JSON 文字列であり、JSON データを含むファイルの名前ではありません。
FlexVolume ドライバーには以下が含まれます。
-
すべての
flexVolume.options。 -
kubernetes.io/というプレフィックスが付いたflexVolumeのいくつかのオプション。たとえば、fsTypeやreadwriteなどです。 -
kubernetes.io/secret/というプレフィックスが付いた参照先シークレット (指定されている場合) の内容。
FlexVolume ドライバーの JSON 入力例
{
"fooServer": "192.168.0.1:1234",
"fooVolumeName": "bar",
"kubernetes.io/fsType": "ext4",
"kubernetes.io/readwrite": "ro",
"kubernetes.io/secret/<key name>": "<key value>",
"kubernetes.io/secret/<another key name>": "<another key value>",
}OpenShift Container Platform は、ドライバーの標準出力に JSON データが含まれていると想定します。指定されていない場合、出力には操作の結果が示されます。
FlexVolume ドライバーのデフォルトの出力
{
"status": "<Success/Failure/Not supported>",
"message": "<Reason for success/failure>"
}
ドライバーの終了コードは、成功の場合は 0、エラーの場合は 1 です。
操作はべき等です。つまり、すでに割り当てられているボリュームの割り当て操作や、すでにマウントされているボリュームのマウント操作は成功します。
FlexVolume ドライバーは以下の 2 つのモードで動作します。
attach/detach 操作は、OpenShift Container Platform マスターにより、ノードにボリュームを割り当てるため、およびノードからボリュームの割り当てを解除するために使用されます。これは何らかの理由でノードが応答不能になった場合に役立ちます。その後、マスターはノード上のすべての Pod を強制終了し、ノードからすべてのボリュームの割り当てを解除して、ボリュームを他のノードに割り当てることで、元のノードがまだ到達不能な状態であってもアプリケーションを再開できます。
マスター実行の、別のマシンからのボリュームの割り当て解除は、すべてのストレージバックエンドでサポートされる訳ではありません。
24.12.2.1. マスター実行の割り当て/割り当て解除がある FlexVolume ドライバー
マスター制御の割り当て/割り当て解除をサポートする FlexVolume ドライバーは、以下の操作を実装する必要があります。
initドライバーを初期化します。マスターとノードの初期化中に呼び出されます。
- 引数: なし
- 実行場所: マスター、ノード
- 予期される出力: デフォルトの JSON
getvolumenameボリュームの一意の名前を返します。この名前は、後続の
detach呼び出しで<volume-name>として使用されるため、すべてのマスターとノード間で一致している必要があります。<volume-name>の/文字は自動的に~に置き換えられます。-
引数:
<json> - 実行場所: マスター、ノード
予期される出力: デフォルトの JSON +
volumeName:{ "status": "Success", "message": "", "volumeName": "foo-volume-bar"1 }- 1
- ストレージバックエンド
fooのボリュームの一意の名前。
-
引数:
attach指定されたノードに、JSON で表現したボリュームを割り当てます。この操作は、ノード上のデバイスが既知の場合 (つまり、そのデバイスが実行前にストレージバックエンドによって割り当て済みの場合)、そのデバイスの名前を返します。デバイスが既知でない場合は、後続の
waitforattach操作によってノード上のデバイスが検出される必要があります。-
引数:
<json><node-name> - 実行場所: マスター
予期される出力: デフォルトの JSON +
device(既知の場合)。{ "status": "Success", "message": "", "device": "/dev/xvda"1 }- 1
- ノード上のデバイスの名前 (既知の場合)。
-
引数:
waitforattachボリュームがノードに完全に割り当てられ、デバイスが出現するまで待機します。前の
attach操作から<device-name>が返された場合は、それが入力パラメーターとして渡されます。そうでない場合、<device-name>は空であり、この操作によってノード上のデバイスを検出する必要があります。-
引数:
<device-name><json> - 実行場所: ノード
予期される出力: デフォルトの JSON +
device{ "status": "Success", "message": "", "device": "/dev/xvda"1 }- 1
- ノード上のデバイスの名前。
-
引数:
detach指定されたボリュームをノードから割り当て解除します。
<volume-name>は、getvolumename操作から返されるデバイスの名前です。<volume-name>の/文字は、~に自動的に置き換えられます。-
引数:
<volume-name><node-name> - 実行場所: マスター
- 予期される出力: デフォルトの JSON
-
引数:
isattachedボリュームがノードに割り当てられていることを確認します。
-
引数:
<json><node-name> - 実行場所: マスター
予期される出力: デフォルトの JSON +
attached{ "status": "Success", "message": "", "attached": true1 }- 1
- ノードへのボリュームの割り当てのステータス。
-
引数:
mountdeviceボリュームのデバイスをディレクトリーにマウントします。
<device-name>は、前のwaitforattach操作から返されるデバイスの名前です。-
引数:
<mount-dir><device-name><json> - 実行場所: ノード
- 予期される出力: デフォルトの JSON
-
引数:
unmountdeviceボリュームのデバイスをディレクトリーからアンマウントします。
-
引数:
<mount-dir> - 実行場所: ノード
-
引数:
その他のすべての操作は、{"status": "Not supported"} と終了コード 1 を出して JSON を返します。
OpenShift Container Platform 3.6 では、マスター実行の割り当て/割り当て解除操作はデフォルトで有効にされています。これらの操作は古いバージョンでも使用できる場合がありますが、その場合には明示的に有効にする必要があります。「コントローラー管理の割り当ておよび割り当て解除」を参照してください。有効にされていない場合、割り当て/割り当て解除操作は、ボリュームの割り当て/割り当て解除が実行される必要のあるノードで開始されます。FlexVolume ドライバー呼び出しの構文とすべてのパラメーターはどちらの場合も同じになります。
24.12.2.2. マスター実行の割り当て/割り当て解除がない FlexVolume ドライバー
マスター制御の割り当て/割り当て解除をサポートしない FlexVolume ドライバーは、ノードでのみ実行され、以下の操作を実装する必要があります。
initドライバーを初期化します。すべてのノードの初期化中に呼び出されます。
- 引数: なし
- 実行場所: ノード
- 予期される出力: デフォルトの JSON
mountボリュームをディレクトリーにマウントします。これには、ノードへのボリュームの割り当て、ノードのデバイスの検出、その後のデバイスのマウントを含む、ボリュームのマウントに必要なあらゆる操作が含まれます。
-
引数:
<mount-dir><json> - 実行場所: ノード
- 予期される出力: デフォルトの JSON
-
引数:
unmountボリュームをディレクトリーからアンマウントします。これには、ノードからのボリュームの割り当て解除など、アンマウント後のボリュームのクリーンアップに必要なあらゆる操作が含まれます。
-
引数:
<mount-dir> - 実行場所: ノード
- 予期される出力: デフォルトの JSON
-
引数:
その他のすべての操作は、{"status": "Not supported"} と終了コード 1 を出して JSON を返します。
24.12.3. FlexVolume ドライバーのインストール
FlexVolume ドライバーをインストールします。
- この実行可能ファイルがクラスター内のすべてのマスターとノードに存在することを確認します。
- この実行可能ファイルをボリュームプラグインのパス (/usr/libexec/kubernetes/kubelet-plugins/volume/exec/<vendor>~<driver>/<driver>) に配置します。
たとえば、ストレージ foo の FlexVolume ドライバーをインストールするには、実行可能ファイルを /usr/libexec/kubernetes/kubelet-plugins/volume/exec/openshift.com~foo/foo に配置します。
OpenShift Container Platform 3.10 では、controller-manager が静的 Pod として実行されるので、割り当ておよび割り当て解除の操作を行う FlexVolume バイナリーファイルは、外部の依存関係がなく、独立した実行可能ファイルでなければなりません。
Atomic ホストでは、FlexVolume プラグインディレクトリーのデフォルトの場所は /etc/origin/kubelet-plugins/ です。FlexVolume の実行可能ファイルを、クラスター内の全マスターとノードの /etc/origin/kubelet-plugins/volume/exec/<vendor>~<driver>/<driver> ディレクトリーに配置する必要があります。
24.12.4. FlexVolume ドライバーを使用したストレージの使用
インストールされているストレージを参照するには、PersistentVolume オブジェクトを使用します。OpenShift Container Platform の各 PersistentVolume オブジェクトは、ストレージバックエンドの 1 つのストレージアセット (通常はボリューム) を表します。
FlexVolume ドライバーを使用した永続ボリュームオブジェクト定義例
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0001
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
flexVolume:
driver: openshift.com/foo
fsType: "ext4"
secretRef: foo-secret
readOnly: true
options:
fooServer: 192.168.0.1:1234
fooVolumeName: bar- 1
- ボリュームの名前。これはPersistent Volume Claim (永続ボリューム要求) を使用するか、または Pod からボリュームを識別するために使用されます。この名前は、バックエンドストレージのボリューム名とは異なるものにすることができます。
- 2
- このボリュームに割り当てられるストレージの量。
- 3
- ドライバーの名前。このフィールドは必須です。
- 4
- ボリュームに存在するオプションのファイルシステム。このフィールドはオプションです。
- 5
- シークレットへの参照。このシークレットのキーと値は、起動時に FlexVolume ドライバーに渡されます。このフィールドはオプションです。
- 6
- 読み取り専用のフラグ。このフィールドはオプションです。
- 7
- FlexVolume ドライバーの追加オプション。
optionsフィールドでユーザーが指定するフラグに加え、以下のフラグも実行可能ファイルに渡されます。
"fsType":"<FS type>",
"readwrite":"<rw>",
"secret/key1":"<secret1>"
...
"secret/keyN":"<secretN>"シークレットは、呼び出しのマウント/マウント解除のためにだけ渡されます。
24.13. 永続ストレージ用の VMware vSphere ボリューム
24.13.1. 概要
OpenShift Container Platform では、VMWare vSphere の仮想マシンディスク (VMDK: Virtual Machine Disk) ボリュームがサポートされます。VMWare vSphere を使用して、OpenShift Container Platform クラスターに永続ストレージをプロビジョニングできます。これには、Kubernetes と VMWare vSphere についてのある程度の理解があることが前提となります。
OpenShift Container Platform の永続ボリューム (PV) フレームワークを使用すると、管理者がクラスターに永続ストレージをプロビジョニングできるようになるだけでなく、ユーザーが、基盤となるインフラストラクチャーに精通していなくてもこれらのリソースを要求できるようになります。VMWare vSphere VMDK ボリュームは、動的にプロビジョニングできます。
永続ボリュームは、単一のプロジェクトまたは namespace にバインドされず、OpenShift Container Platform クラスター全体で共有できます。ただし、PVC (永続ボリューム要求) は、プロジェクトまたは namespace に固有で、ユーザーによる要求が可能です。
インフラストラクチャーにおけるストレージの高可用性は、基礎となるストレージのプロバイダーに委ねられています。
前提条件
vSphere を使用して永続ボリュームを作成する前に、OpenShift Container Platform クラスターが以下の要件を満たしていることを確認してください。
- 最初に OpenShift Container Platform を vSphere 用に設定する必要があります。
- インフラストラクチャー内の各ノードホストは、vSphere 仮想マシン名に一致する必要があります。
- それぞれのノードホストは、同じリソースグループに属している必要があります。
VMDK を使用する前に、以下のいずれかの方法を使用して VMDK を作成します。
vmkfstoolsを使用して作成する。セキュアシェル (SSH) を使用して ESX にアクセスし、以下のコマンドを使用して vmdk ボリュームを作成します。
vmkfstools -c 2G /vmfs/volumes/DatastoreName/volumes/myDisk.vmdkvmware-vdiskmanagerを使用して作成する。shell vmware-vdiskmanager -c -t 0 -s 40GB -a lsilogic myDisk.vmdk
24.13.2. VMware vSphere ボリュームのプロビジョニング
OpenShift Container Platform でストレージをボリュームとしてマウントするには、ストレージが基礎となるインフラストラクチャーに存在している必要があります。OpenShift Container Platform が vSpehere 用に設定されていることを確認した後、OpenShift Container Platform と vSphere に必要になるのは、VM フォルダーパス、ファイルシステムタイプ、および PersistentVolume API のみです。
24.13.2.1. 永続ボリュームの作成
OpenShift Container Platform に PV を作成する前に、PV をオブジェクト定義に定義する必要があります。
VMware vSphere を使用した PV オブジェクト定義の例
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0001
spec:
capacity:
storage: 2Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
vsphereVolume:
volumePath: "[datastore1] volumes/myDisk"
fsType: ext4 - 1
- ボリュームの名前です。これを使用して、PVC (永続ボリューム要求) で、または Pod から、ボリュームを識別する必要があります。
- 2
- このボリュームに割り当てられるストレージの量。
- 3
- これは使用されるボリュームタイプを定義します (この例では、vsphereVolume プラグイン)。
vsphereVolumeラベルは、vSphere VMDK ボリュームを Pod にマウントするために使用されます。ボリュームがアンマウントされてもボリュームのコンテンツは保持されます。このボリュームタイプは、VMFS データストアと VSAN データストアの両方をサポートします。 - 4
- VMDK ボリュームが存在し、ボリューム定義内に括弧 ([]) を含める必要があります。
- 5
- マウントするファイルシステムタイプ (
ext4、xfs、その他のファイルシステムなど)。
ボリュームをフォーマットしてプロビジョニングした後に fsType パラメーターの値を変更すると、データ損失や Pod にエラーが発生する可能性があります。
永続ボリュームを作成します。
定義を vsphere-pv.yaml などのファイルに保存し、PV を作成します。
$ oc create -f vsphere-pv.yaml persistentvolume "pv0001" createdPV が作成されたことを確認します。
$ oc get pv NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE pv0001 <none> 2Gi RWO Available 2s
これで、PVC (永続ボリューム要求) を使用してストレージを要求し、永続ボリュームを活用できるようになります。
PVC (永続ボリューム要求) は、ユーザーの namespace にのみ存在し、同じ namespace 内の Pod からしか参照できません。別の namespace から永続ボリュームにアクセスしようとすると、Pod にエラーが発生します。
24.13.2.2. VMware vSphere ボリュームのフォーマット
OpenShift Container Platform は、ボリュームをマウントしてコンテナーに渡す前に、永続ボリューム定義の fsType パラメーターで指定されたファイルシステムがボリュームにあるかどうか確認します。デバイスが指定されたファイルシステムでフォーマットされていない場合、デバイスのデータはすべて消去され、デバイスはそのファイルシステムで自動的にフォーマットされます。
これにより、OpenShift Container Platform がフォーマットされていない vSphere ボリュームを初回の使用前にフォーマットするため、それらを永続ボリュームとして使用できるようになります。
24.14. ローカルボリュームを使用した永続ストレージ
24.14.1. 概要
OpenShift Container Platform クラスターでは、ローカルボリュームを使用して永続ストレージをプロビジョニングできます。ローカル永続ボリュームを使用すると、標準の PVC インターフェースからディスク、パーティション、ディレクトリーなどのローカルストレージデバイスにアクセスできます。
ローカルボリュームは、Pod をノードに手動でスケジュールせずに使用できます。ボリュームのノード制約がシステムによって認識されるためです。ただし、ローカルボリュームは、依然として基礎となるノードの可用性に依存しており、すべてのアプリケーションに適しているわけではありません。
ローカルボリュームはアルファ機能であり、OpenShift Container Platform の今後のリリースで変更される場合があります。既知の問題と回避策については、「Feature Status(Local Volume)」セクションを参照してください。
ローカルボリュームは、静的に作成された永続ボリュームとしてのみ使用できます。
24.14.2. プロビジョニング
OpenShift Container Platform でストレージをボリュームとしてマウントするには、ストレージが基礎となるインフラストラクチャーに存在している必要があります。PersistentVolume API を使用する前に、OpenShift Container Platform がローカルボリューム用に設定されていることを確認してください。
24.14.3. ローカルの Persistent Volume Claim (永続ボリューム要求) の作成
Persistent Volume Claim (永続ボリューム要求) をオブジェクト定義に定義します。
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: example-local-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: local-storage 24.14.4. 機能のステータス
機能すること:
- ノードアフィニティーがあるディレクトリーを指定して PV を作成する。
- 前述の PV にバインドされている PVC を使用する Pod は常に該当ノードにスケジューリングされる。
- ローカルディレクトリーを検出し、PV の作成、クリーンアップ、および削除を行う外部の静的プロビジョナーデーモンセット。
機能しないこと:
- 単一 Pod に複数のローカル PVC を持たせる。
PVC バインディングでは Pod のスケジューリング要件を考慮しないため、最適でないか、または適切でない決定がなされる可能性がある。
回避策
- ローカルボリュームを必要とする Pod を最初に実行します。
- それらの Pod に高い優先順位を設定します。
- 動作が中断している Pod への PVC のバインドを解除する回避策となるコントローラーを実行します。
外部プロビジョナーの起動後にマウントを追加した場合、外部プロビジョナーはマウントの正確な容量を検出できなくなる。
回避策
- 新規のマウントポイントを追加する前に、デーモンセットを停止し、新規マウントポイントを追加してから deamonset を起動します。
-
同じ PV を使用する複数の Pod で別々の
fsgroupを指定すると、fsgroupの競合が発生する。
24.15. Container Storage Interface (CSI) を使用した永続ストレージ
24.15.1. 概要
Container Storage Interface (CSI) により、OpenShift Container Platform は CSI インターフェースを永続ストレージとして実装するストレージバックエンドからストレージを使用できます。
現時点で CLI ボリュームはテクノロジープレビュー機能で、実稼働のワークロードを対象としていません。CSI ボリュームは、今後の OpenShift Container Platform のリリースで変更される可能性があります。また、テクノロジープレビュー機能は、Red Hat の実稼働環境でのサービスレベルアグリーメント (SLA) ではサポートされていないため、Red Hat では実稼働環境での使用を推奨していません。これらの機能は、近々発表予定の製品機能のリリースに先駆けてご提供することができ、お客様は機能性をテストし、開発プロセス中にフィードバックをお寄せいただくことができます。
詳細は、「テクノロジープレビュー機能のサポート範囲」を参照してください。
OpenShift Container Platform には、CSI ドライバーが含まれていません。コミュニティーまたはストレージベンダー が提供する CSI ドライバーを使用することを推奨します。
OpenShift Container Platform 3.10 は、CSI 仕様 のバージョン 0.2.0 をサポートします。
24.15.2. アーキテクチャー
CSI ドライバーは通常、コンテナーイメージとして提供されます。これらのコンテナーは、実行先の OpenShift Container Platform を認識しません。OpenShift Container Platform でサポートされる CSI 互換のストレージを使用するには、クラスター管理者は、OpenShift Container Platform とストレージドライバーの橋渡しとして機能する、コンポーネントを複数デプロイする必要があります。
以下の図では、OpenShift Container Platform クラスターの Pod で実行されるコンポーネントの俯瞰図を示しています。
異なるストレージバックエンドに対して複数の CSI ドライバーを実行できます。各ドライバーには、独自の外部コントローラーのデプロイメントおよびドライバーと CSI レジストラーを含む DaemonSet が必要です。
24.15.2.1. 外部の CSI コントローラー
外部の CSI コントローラーは、2 つのコンテナーを含む 1 つまたは複数の Pod を配置するデプロイメントです。
-
OpenShift Container Platform からの
attachおよびdetachの呼び出しを適切な CSI ドライバーへのControllerPublishおよびControllerUnpublish呼び出しに変換する外部の CSI アタッチャーコンテナー。 -
OpenShift Container Platform からの
provisionおよびdelete呼び出しを適切な CSI ドライバーへのCreateVolumeおよびDeleteVolume呼び出しに変換する外部の CSI プロビジョナーコンテナー。 - CSI ドライバーコンテナー
CSI アタッチャーおよび CSI プロビジョナーコンテナーは、Unix Domain Socket を使用して、CSI ドライバーコンテナーと対話し、CSI のコミュニケーションが Pod 外に出ないようにします。CSI ドライバーは、Pod 外からはアクセスできません。
attach、detach、provision および delete 操作では通常、CSI ドライバーがストレージバックエンドに対する認証情報を使用する必要があります。CSI コントローラー Pod をインフラストラクチャーノードで実行し、コンピュートノードで致命的なセキュリティー違反が発生した場合でさえも、認証情報がユーザープロセスに漏洩されないようにします。
外部のアタッチャーは、サードパーティーの割り当て/割り当て解除操作をサポートしない CSI ドライバーに対しても実行する必要があります。外部アタッチャーは、CSI ドライバーに対して ControllerPublish または ControllerUnpublish の操作を実行しませんが、依然として、必要とされる OpenShift Container Platform 割り当て API を実装するために実行する必要があります。
24.15.2.2. CSI ドライバーの DaemonSet
最後に CSI ドライバーの DaemonSet は、OpenShift Container Platform が CSI ドライバーで提供されるストレージをノードにマウントして、永続ボリューム (PV) としてユーザーワークロード (Pod) で使用できるように、全ノードで Pod を実行します。CSI ドライバーがインストールされた Pod には、以下のコンテナーが含まれます。
-
ノード上で実行中の
openshift-nodeサービスに、CSI ドライバーを登録する CSI ドライバーレジストラー。このノードで実行中のopenshift-nodeプロセスは、ノードで利用可能な Unix Domain Socket を使用して CSI ドライバーと直接、接続します。 - CSI ドライバー
ノードにデプロイされた CSI ドライバーには、ストレージバックエンドへの認証情報をできる限り少なく指定する必要があります。OpenShift Container Platform は、NodePublish/NodeUnpublish および NodeStage/NodeUnstage (実装されている場合) などの CSI 呼び出しのノードプラグインセットのみを使用します。
24.15.3. デプロイメント例
OpenShift Container Platform は CSI ドライバーがインストールされた状態で提供されないので、この例では、OpenShift Container Platform に OpenStack Cinder 向けのコミュニティードライバーをデプロイする方法が示されています。
CSI コンポーネントの実行先のプロジェクトと、このコンポーネントを実行するサービスアカウントを新たに作成します。明示的なノードセレクターを使用して、マスターノード上でも CSI ドライバーが設定された Daemonset を実行します。
# oc adm new-project csi --node-selector="" Now using project "csi" on server "https://example.com:8443". # oc create serviceaccount cinder-csi serviceaccount "cinder-csi" created # oc adm policy add-scc-to-user privileged system:serviceaccount:csi:cinder-csi scc "privileged" added to: ["system:serviceaccount:csi:cinder-csi"]この YAML ファイルを適用して、外部の CSI アタッチャーとプロビジョナーを含むデプロイメントおよび CSI ドライバーを含む DaemonSet を作成します。
# This YAML file contains all API objects that are necessary to run Cinder CSI # driver. # # In production, this needs to be in separate files, e.g. service account and # role and role binding needs to be created once. # # It server as an example how to use external attacher and external provisioner # images shipped with {product-title} with a community CSI driver. kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: cinder-csi-role rules: - apiGroups: [""] resources: ["persistentvolumes"] verbs: ["create", "delete", "get", "list", "watch", "update", "patch"] - apiGroups: [""] resources: ["events"] verbs: ["create", "get", "list", "watch", "update", "patch"] - apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update", "patch"] - apiGroups: [""] resources: ["nodes"] verbs: ["get", "list", "watch", "update", "patch"] - apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"] - apiGroups: ["storage.k8s.io"] resources: ["volumeattachments"] verbs: ["get", "list", "watch", "update", "patch"] - apiGroups: [""] resources: ["configmaps"] verbs: ["get", "list", "watch", "create", "update", "patch"] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: cinder-csi-role subjects: - kind: ServiceAccount name: cinder-csi namespace: csi roleRef: kind: ClusterRole name: cinder-csi-role apiGroup: rbac.authorization.k8s.io --- apiVersion: v1 data: cloud.conf: W0dsb2JhbF0KYXV0aC11cmwgPSBodHRwczovL2V4YW1wbGUuY29tOjEzMDAwL3YyLjAvCnVzZXJuYW1lID0gYWxhZGRpbgpwYXNzd29yZCA9IG9wZW5zZXNhbWUKdGVuYW50LWlkID0gZTBmYTg1YjZhMDY0NDM5NTlkMmQzYjQ5NzE3NGJlZDYKcmVnaW9uID0gcmVnaW9uT25lCg==1 kind: Secret metadata: creationTimestamp: null name: cloudconfig --- kind: Deployment apiVersion: apps/v1 metadata: name: cinder-csi-controller spec: replicas: 2 selector: matchLabels: app: cinder-csi-controllers template: metadata: labels: app: cinder-csi-controllers spec: serviceAccount: cinder-csi containers: - name: csi-attacher image: registry.access.redhat.com/openshift3/csi-attacher:v3.10 args: - "--v=5" - "--csi-address=$(ADDRESS)" - "--leader-election" - "--leader-election-namespace=$(MY_NAMESPACE)" - "--leader-election-identity=$(MY_NAME)" env: - name: MY_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: MY_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: ADDRESS value: /csi/csi.sock volumeMounts: - name: socket-dir mountPath: /csi - name: csi-provisioner image: registry.access.redhat.com/openshift3/csi-provisioner:v3.10 args: - "--v=5" - "--provisioner=csi-cinderplugin" - "--csi-address=$(ADDRESS)" env: - name: ADDRESS value: /csi/csi.sock volumeMounts: - name: socket-dir mountPath: /csi - name: cinder-driver image: quay.io/jsafrane/cinder-csi-plugin command: [ "/bin/cinder-csi-plugin" ] args: - "--nodeid=$(NODEID)" - "--endpoint=unix://$(ADDRESS)" - "--cloud-config=/etc/cloudconfig/cloud.conf" env: - name: NODEID valueFrom: fieldRef: fieldPath: spec.nodeName - name: ADDRESS value: /csi/csi.sock volumeMounts: - name: socket-dir mountPath: /csi - name: cloudconfig mountPath: /etc/cloudconfig volumes: - name: socket-dir emptyDir: - name: cloudconfig secret: secretName: cloudconfig --- kind: DaemonSet apiVersion: apps/v1 metadata: name: cinder-csi-ds spec: selector: matchLabels: app: cinder-csi-driver template: metadata: labels: app: cinder-csi-driver spec: nodeSelector: role: node serviceAccount: cinder-csi containers: - name: csi-driver-registrar image: registry.access.redhat.com/openshift3/csi-driver-registrar:v3.10 securityContext: privileged: true args: - "--v=5" - "--csi-address=$(ADDRESS)" env: - name: ADDRESS value: /csi/csi.sock - name: KUBE_NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName volumeMounts: - name: socket-dir mountPath: /csi - name: cinder-driver securityContext: privileged: true capabilities: add: ["SYS_ADMIN"] allowPrivilegeEscalation: true image: quay.io/jsafrane/cinder-csi-plugin command: [ "/bin/cinder-csi-plugin" ] args: - "--nodeid=$(NODEID)" - "--endpoint=unix://$(ADDRESS)" - "--cloud-config=/etc/cloudconfig/cloud.conf" env: - name: NODEID valueFrom: fieldRef: fieldPath: spec.nodeName - name: ADDRESS value: /csi/csi.sock volumeMounts: - name: socket-dir mountPath: /csi - name: cloudconfig mountPath: /etc/cloudconfig - name: mountpoint-dir mountPath: /var/lib/origin/openshift.local.volumes/pods/ mountPropagation: "Bidirectional" - name: cloud-metadata mountPath: /var/lib/cloud/data/ - name: dev mountPath: /dev volumes: - name: cloud-metadata hostPath: path: /var/lib/cloud/data/ - name: socket-dir hostPath: path: /var/lib/kubelet/plugins/csi-cinderplugin type: DirectoryOrCreate - name: mountpoint-dir hostPath: path: /var/lib/origin/openshift.local.volumes/pods/ type: Directory - name: cloudconfig secret: secretName: cloudconfig - name: dev hostPath: path: /dev- 1
- 「OpenStack 設定」に記載されているように、OpenStack デプロイメントの
cloud.confに置き換えます。たとえば、シークレットは、oc create secret generic cloudconfig --from-file cloud.conf --dry-run -o yamlを使用して生成できます。
24.15.4. 動的プロビジョニング
永続ストレージの動的プロビジョニングは、CSI ドライバーおよび基盤のストレージバックエンドの機能により異なります。CSI ドライバーのプロバイダーは、OpenShift Container Platform で StorageClass の作成方法および、設定で利用可能なパラメーターについて文書を作成する必要があります。
OpenStack Cinder の例にあるように、この StorageClass をデプロイして、動的プロビジョニングを有効化できます。以下の例では、新規のデフォルトストレージクラスを作成して、特別なストレージクラスを必要としない PVC がすべて、インストールした CSI ドライバーによりプロビジョニングされるようにします。
# oc create -f - << EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: cinder
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: csi-cinderplugin
parameters:
EOF24.15.5. 使用法
CSI ドライバーがデプロイされ、動的プロビジョニング用に StorageClass が作成されたら、OpenShift Container Platform は CSI を使用する準備が整います。以下の例では、変更を加えずに、デフォルトの MySQL テンプレートをインストールします。
# oc new-app mysql-persistent
--> Deploying template "openshift/mysql-persistent" to project default
...
# oc get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql Bound kubernetes-dynamic-pv-3271ffcb4e1811e8 1Gi RWO cinder 3s24.16. OpenStack Manila を使用した永続ストレージ
24.16.1. 概要
OpenStack Manila を使用した永続ボリューム (PV) のプロビジョニングはテクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat の実稼働環境でのサービスレベルアグリーメント (SLA) ではサポートされていないため、Red Hat では実稼働環境での使用を推奨していません。これらの機能は、近々発表予定の製品機能をリリースに先駆けてご提供することにより、お客様は機能性をテストし、開発プロセス中にフィードバックをお寄せいただくことができます。
Red Hat のテクノロジープレビュー機能のサポートについての詳細は、https://access.redhat.com/support/offerings/techpreview/ を参照してください。
OpenShift Container Platform は、OpenStack Manila 共有ファイルシステムサービスを使用して PV をプロビジョニングできます。
OpenStack Manila サービスが正しく設定され、OpenShift Container Platform クラスターからアクセスできることが前提です。プロビジョニングが可能なのは、NFS 共有タイプのみです。
PV、Persistent Volume Claim (永続ボリューム要求、PVC)、動的プロビジョニング および RBAC 認証 について理解しておくことを推奨します。
24.16.2. インストールと設定
この機能は、外部プロビジョナーにより提供され、OpenShift Container Platform クラスターに外部プロビジョナーをインストールし、設定する必要があります。
24.16.2.1. 外部プロビジョナーの起動
外部プロビジョナーサービスは、コンテナーイメージとして配布され、OpenShift Container Platform クラスターで通常通り実行できます。
API オブジェクトを管理しているコンテナーを許可するには、以下のようにして、必要なロールベースアクセス制御 (RBAC) ルールを管理者が設定する必要があります。
ServiceAccountを作成します。apiVersion: v1 kind: ServiceAccount metadata: name: manila-provisioner-runnerClusterRoleを作成します。kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: manila-provisioner-role rules: - apiGroups: [""] resources: ["persistentvolumes"] verbs: ["get", "list", "watch", "create", "delete"] - apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update"] - apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["events"] verbs: ["list", "watch", "create", "update", "patch"]ClusterRoleBindingを使用して、以下のようにルールをバインドします。apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: manila-provisioner roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: manila-provisioner-role subjects: - kind: ServiceAccount name: manila-provisioner-runner namespace: default新しい
StorageClassを作成します。apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: "manila-share" provisioner: "externalstorage.k8s.io/manila" parameters: type: "default"1 zones: "nova"2 - 1
- プロビジョナーがボリューム用に作成する Manila 共有タイプ
- 2
- ボリュームが作成される可能性のある Manila アベイラビリティーゾーンセット
環境変数を使用してプロビジョナーによる Manila サービスへの接続、認証、承認ができるように設定します。以下のリストから、お使いのインストールに合った適切な環境変数の組み合わせを選択します。
OS_USERNAME
OS_PASSWORD
OS_AUTH_URL
OS_DOMAIN_NAME
OS_TENANT_NAMEOS_USERID
OS_PASSWORD
OS_AUTH_URL
OS_TENANT_IDOS_USERNAME
OS_PASSWORD
OS_AUTH_URL
OS_DOMAIN_ID
OS_TENANT_NAMEOS_USERNAME
OS_PASSWORD
OS_AUTH_URL
OS_DOMAIN_ID
OS_TENANT_ID
プロビジョナーに変数を渡すには、Secret を使用します。以下の例は、1 つ目の変数の組み合わせ向けに設定した Secret です。
apiVersion: v1
kind: Secret
metadata:
name: manila-provisioner-env
type: Opaque
data:
os_username: <base64 encoded Manila username>
os_password: <base64 encoded password>
os_auth_url: <base64 encoded OpenStack Keystone URL>
os_domain_name: <base64 encoded Manila service Domain>
os_tenant_name: <base64 encoded Manila service Tenant/Project name>
より新しいバージョンの OpenStack では、「テナント」ではなく「プロジェクト」を使用しますが、プロビジョナーが使用する環境変数は、名前に TENANT を使用する必要があります。
最後の手順では、デプロイメントなどを使用して、プロビジョナー自体を起動します。
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: manila-provisioner
spec:
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: manila-provisioner
spec:
serviceAccountName: manila-provisioner-runner
containers:
- image: "registry.access.redhat.com:8888/openshift3/manila-provisioner:latest"
imagePullPolicy: "IfNotPresent"
name: manila-provisioner
env:
- name: "OS_USERNAME"
valueFrom:
secretKeyRef:
name: manila-provisioner-env
key: os_username
- name: "OS_PASSWORD"
valueFrom:
secretKeyRef:
name: manila-provisioner-env
key: os_password
- name: "OS_AUTH_URL"
valueFrom:
secretKeyRef:
name: manila-provisioner-env
key: os_auth_url
- name: "OS_DOMAIN_NAME"
valueFrom:
secretKeyRef:
name: manila-provisioner-env
key: os_domain_name
- name: "OS_TENANT_NAME"
valueFrom:
secretKeyRef:
name: manila-provisioner-env
key: os_tenant_name24.16.3. 使用法
プロビジョナーの実行後に、PVC と適切な StorageClass を使用して PV をプロビジョニングすることができます。
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: manila-nfs-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2G
storageClassName: manila-share
次に、PersistentVolumeClaim は、新たにプロビジョニングされた Manila 共有でサポートされる PersistentVolume にバインドされます。PersistentVolumeClaim の後に PersistentVolume を削除したら、プロビジョナーは Manila 共有を削除して、エクスポートを中止します。
24.17. 動的プロビジョニングとストレージクラスの作成
24.17.1. 概要
StorageClass リソースオブジェクトは、要求可能なストレージを記述し、分類するほか、動的にプロビジョニングされるストレージのパラメーターを要求に応じて渡すための手段を提供します。StorageClass オブジェクトは、さまざまなレベルのストレージとストレージへのアクセスを制御するための管理メカニズムとしても機能します。クラスター管理者 (cluster-admin) またはストレージ管理者 (storage-admin) は、ユーザーが基礎となるストレージボリュームソースに関する詳しい知識がなくても要求できる StorageClass オブジェクトを定義し、作成します。
OpenShift Container Platform の永続ボリュームフレームワークは、この機能を有効にし、管理者がクラスターに永続ストレージをプロビジョニングできるようにします。このフレームワークにより、ユーザーは基礎となるインフラストラクチャーの知識がなくてもこれらのリソースを要求できるようになります。
OpenShift Container Platform では、数多くのストレージタイプを永続ボリュームとして使用できます。これらはすべて管理者によって静的にプロビジョニングされますが、一部のストレージタイプは組み込みプロバイダーとプラグイン API を使用して動的に作成できます。
動的プロビジョニングを有効にするには、openshift_master_dynamic_provisioning_enabled 変数を Ansible インベントリーファイルの [OSEv3:vars] セクションに追加し、その値を True に設定します。
[OSEv3:vars]
openshift_master_dynamic_provisioning_enabled=True24.17.2. 動的にプロビジョニングされる使用可能なプラグイン
OpenShift Container Platform は、以下のプロビジョナープラグインを提供します。これらには、クラスターの設定済みプロバイダーの API を使用して新規ストレージリソースを作成する動的プロビジョニング用の一般的な実装が含まれます。
| ストレージタイプ | プロビジョナープラグインの名前 | 必要な設定 | 備考 |
|---|---|---|---|
|
OpenStack Cinder |
| ||
|
AWS Elastic Block Store (EBS) |
|
複数クラスターを別々のゾーンで使用する際の動的プロビジョニングの場合、各ノードに | |
|
GCE Persistent Disk (gcePD) |
|
マルチゾーン設定では、PV が現行クラスターのノードが存在しないゾーンで作成されないようにするため、Openshift クラスターを GCE プロジェクトごとに実行することが推奨されます。 | |
|
GlusterFS |
| ||
|
Ceph RBD |
| ||
|
NetApp の Trident |
|
NetApp ONTAP、SolidFire、および E-Series ストレージ向けのストレージオーケストレーター。 | |
|
| |||
|
Azure Disk |
|
選択したプロビジョナープラグインでは、関連するクラウド、ホスト、またはサードパーティープロバイダーを、関連するドキュメントに従って設定する必要もあります。
24.17.3. StorageClass の定義
現時点で、StorageClass オブジェクトはグローバルなスコープ付きオブジェクトであり、cluster-admin または storage-admin ユーザーによって作成される必要があります。
GCE と AWS の場合、デフォルトの StorageClass が OpenShift Container Platform のインストール時に作成されます。デフォルトの StorageClass を変更または削除することができます。
現時点で 6 つのプラグインがサポートされています。以下のセクションでは、StorageClass の基本オブジェクトの定義とサポートされている各プラグインタイプの具体的な例について説明します。
24.17.3.1. 基本 StorageClass オブジェクトの定義
StorageClass 基本オブジェクトの定義
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: foo
annotations:
...
provisioner: kubernetes.io/plug-in-type
parameters:
param1: value
...
paramN: value24.17.3.2. StorageClass のアノテーション
StorageClass をクラスター全体のデフォルトとして設定するには、以下を実行します。
storageclass.kubernetes.io/is-default-class: "true"これにより、特定のボリュームを指定しない Persistent Volume Claim (永続ボリューム要求、PVC) が デフォルト StorageClass によって自動的にプロビジョニングされるようになります。
ベータアノテーションの storageclass.beta.kubernetes.io/is-default-class は以前として使用可能ですが、今後のリリースで削除される予定です。
StorageClass の記述を設定するには、以下のように指定します。
kubernetes.io/description: My StorageClass Description24.17.3.3. OpenStack Cinder オブジェクトの定義
cinder-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: gold
provisioner: kubernetes.io/cinder
parameters:
type: fast
availability: nova
fsType: ext4 24.17.3.4. AWS ElasticBlockStore (EBS) オブジェクトの定義
aws-ebs-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: slow
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
zone: us-east-1d
iopsPerGB: "10"
encrypted: "true"
kmsKeyId: keyvalue
fsType: ext4 - 1
- 2
- AWS ゾーン。ゾーンを指定しない場合、ボリュームは通常、OpenShift Container Platform クラスターのノードがあるすべてのアクティブゾーンでラウンドロビンされます。zone パラメーターと zones パラメーターを同時に使用することはできません。
- 3
- io1 ボリュームのみ。1 GiB あたり 1 秒あたりの I/O 処理数。AWS ボリュームプラグインは、この値と要求されたボリュームのサイズを乗算してボリュームの IOPS を算出します。値の上限は、AWS でサポートされる最大値である 20,000 IOPS です。詳細については、AWS のドキュメントを参照してください。
- 4
- EBS ボリュームを暗号化するかどうかを示します。有効な値は
trueまたはfalseです。 - 5
- オプション。ボリュームを暗号化する際に使用するキーの完全な ARN。値を指定しない場合でも
encyptedがtrueに設定されている場合は、AWS によってキーが生成されます。有効な ARN 値については、AWS のドキュメントを参照してください。 - 6
- 動的にプロビジョニングされたボリュームで作成されるファイルシステム。この値は、動的にプロビジョニングされる永続ボリュームの
fsTypeフィールドにコピーされ、ボリュームの初回マウント時にファイルシステムが作成されます。デフォルト値はext4です。
24.17.3.5. GCE PersistentDisk (gcePD) オブジェクトの定義
gce-pd-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: slow
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
zone: us-central1-a
zones: us-central1-a, us-central1-b, us-east1-b
fsType: ext4 - 1
pd-standardまたはpd-ssdのいずれかを選択します。デフォルトはpd-ssdです。- 2
- GCE ゾーン。ゾーンを指定しない場合、ボリュームは通常、OpenShift Container Platform クラスターのノードがあるすべてのアクティブゾーンでラウンドロビンされます。zone パラメーターと zones パラメーターを同時に使用することはできません。
- 3
- GCE ゾーンのコンマ区切りの一覧。ゾーンを指定しない場合、ボリュームは通常、OpenShift Container Platform クラスターのノードがあるすべてのアクティブゾーンでラウンドロビンされます。zone パラメーターと zones パラメーターを同時に使用することはできません。
- 4
- 動的にプロビジョニングされたボリュームで作成されるファイルシステム。この値は、動的にプロビジョニングされる永続ボリュームの
fsTypeフィールドにコピーされ、ボリュームの初回マウント時にファイルシステムが作成されます。デフォルト値はext4です。
24.17.3.6. GlusterFS オブジェクトの定義
glusterfs-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: slow
provisioner: kubernetes.io/glusterfs
parameters:
resturl: http://127.0.0.1:8081
restuser: admin
secretName: heketi-secret
secretNamespace: default
gidMin: "40000"
gidMax: "50000"
volumeoptions: group metadata-cache, nl-cache on
volumetype: replicate:3 - 1
- 一覧表示されているのは、必須パラメーターおよびいくつかのオプションのパラメーターです。追加のパラメーターについては、「Registering a Storage Class」を参照してください。
- 2
- GlusterFS ボリュームをオンデマンドでプロビジョニングする heketi (Gluster 用のボリューム管理 REST サービス) URL。一般的な形式は
{http/https}://{IPaddress}:{Port}です。GlusterFS 動的プロビジョナーの場合、これは必須パラメーターです。heketi サービスが OpenShift Container Platform で ルーティング可能なサービスとして公開されている場合には、解決可能な完全修飾ドメイン名 (FQDN) と heketi サービス URL が割り当てられます。 - 3
- ボリュームを作成するためのアクセスを持つ heketi ユーザー。通常は「admin」です。
- 4
- heketi との通信に使用するユーザーパスワードを含むシークレットの ID。オプションです。
secretNamespaceとsecretNameの両方を省略した場合、空のパスワードが使用されます。指定するシークレットは"kubernetes.io/glusterfs"タイプである必要があります。 - 5
- 前述の
secretNameの namespace。オプションです。secretNamespaceとsecretNameの両方を省略した場合、空のパスワードが使用されます。指定するシークレットは"kubernetes.io/glusterfs"タイプである必要があります。 - 6
- オプション。この StorageClass のボリュームの GID 範囲の最小値です。
- 7
- オプション。この StorageClass のボリュームの GID 範囲の最大値です。
- 8
- オプション。新規に作成されたボリュームのオプションです。これにより、パフォーマンスチューニングが可能になります。GlusterFS ボリュームの他のオプションについては、「Tuning Volume Options」を参照してください。
- 9
- オプション。使用するボリュームのタイプです。
gidMin 値と gidMax 値を指定しない場合、デフォルトはそれぞれ 2000 と 2147483647 になります。動的にプロビジョニングされる各ボリュームには、この範囲 (gidMin-gidMax) の GID が割り当てられます。GID は、対応するボリュームが削除されるとプールから解放されます。GID プールは StorageClass ごとに設定されます。複数のストレージクラス間で GID 範囲が重複している場合、プロビジョナーによって、重複する GID が割り当てられる可能性があります。
heketi 認証を使用する場合は、管理キーを含むシークレットも存在している必要があります。
heketi-secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: heketi-secret
namespace: default
data:
key: bXlwYXNzd29yZA==
type: kubernetes.io/glusterfs- 1
- base64 でエンコードされたパスワード。例:
echo -n "mypassword" | base64
PV が動的にプロビジョニングされると、GlusterFS プラグインによってエンドポイントと gluster-dynamic-<claimname> という名前のヘッドレスサービスが自動的に作成されます。PVC が削除されると、これらの動的リソースは自動的に削除されます。
24.17.3.7. Ceph RBD オブジェクトの定義
ceph-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast
provisioner: kubernetes.io/rbd
parameters:
monitors: 10.16.153.105:6789
adminId: admin
adminSecretName: ceph-secret
adminSecretNamespace: kube-system
pool: kube
userId: kube
userSecretName: ceph-secret-user
fsType: ext4 - 1
- Ceph モニター (コンマ区切り)。必須です。
- 2
- Ceph クライアント ID。これにより、プール内にイメージを作成できます。デフォルトは「admin」です。
- 3
adminIdのシークレット名。必須です。設定するシークレットのタイプは「kubernetes.io/rbd」である必要があります。- 4
adminSecretの namespace。デフォルトは「default」です。- 5
- Ceph RBD プール。デフォルトは「rbd」です。
- 6
- Ceph RBD イメージのマッピングに使用される Ceph クライアント ID。デフォルトは
adminIdと同じです。 - 7
- Ceph RBD イメージをマッピングするために使用する
userId用の Ceph シークレットの名前。PVC と同じ namespace に存在する必要があります。必須です。 - 8
- 動的にプロビジョニングされたボリュームで作成されるファイルシステム。この値は、動的にプロビジョニングされる永続ボリュームの
fsTypeフィールドにコピーされ、ボリュームの初回マウント時にファイルシステムが作成されます。デフォルト値はext4です。
24.17.3.8. Trident オブジェクトの定義
trident.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: gold
provisioner: netapp.io/trident
parameters:
media: "ssd"
provisioningType: "thin"
snapshots: "true"Trident は、これらのパラメーターを Trident に登録されているさまざまなストレージプールの選択条件として使用します。Trident 自体は個別に設定されます。
- 1
- Trident を OpenShift Container Platform にインストールする方法の詳細については、Trident のドキュメントを参照してください。
- 2
- サポートされているパラメーターの詳細については、Trident のドキュメントのストレージ属性に関するセクションを参照してください。
24.17.3.9. VMWare vSphere オブジェクトの定義
vsphere-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1beta1
metadata:
name: slow
provisioner: kubernetes.io/vsphere-volume
parameters:
diskformat: thin - 1
- VMWare vSphere を OpenShift Container Platform で使用する方法の詳細については、VMWare vSphere のドキュメントを参照してください。
- 2
diskformat:thin、zeroedthick、およびeagerzeroedthick。詳細については、vSphere のドキュメントを参照してください。デフォルト:thin
24.17.3.10. Azure File のオブジェクト定義
Azure file の動的プロビジョニングを設定するには、以下を実行します。
ユーザーのプロジェクトにロールを作成します。
$ cat azf-role.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: system:controller:persistent-volume-binder namespace: <user's project name> rules: - apiGroups: [""] resources: ["secrets"] verbs: ["create", "get", "delete"]persistent-volume-binderサービスにバインドされるロールをkube-systemプロジェクトに作成します。$ cat azf-rolebind.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: system:controller:persistent-volume-binder namespace: <user's project> roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: system:controller:persistent-volume-binder subjects: - kind: ServiceAccount name: persistent-volume-binder namespace: kube-systemadminとして、ユーザーのプロジェクトにサービスアカウントを追加します。$ oc policy add-role-to-user admin system:serviceaccount:kube-system:persistent-volume-binder -n <user's project>Azure File 向けにストレージクラスを作成します。
$ cat azfsc.yaml | oc create -f - kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: azfsc provisioner: kubernetes.io/azure-file mountOptions: - dir_mode=0777 - file_mode=0777
ユーザーは、このストレージクラスを使用する PVC を作成できるようになりました。
24.17.3.11. Azure Disk オブジェクト定義
azure-advanced-disk-storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: slow
provisioner: kubernetes.io/azure-disk
parameters:
storageAccount: azure_storage_account_name
storageaccounttype: Standard_LRS
kind: Dedicated - 1
- Azure ストレージアカウントの名前。これはクラスターと同じリソースグループに存在している必要があります。ストレージアカウントを指定した場合、
locationは無視されます。ストレージアカウントを指定しない場合、新しいストレージアカウントがクラスターと同じリソースグループに作成されます。storageAccountを指定する場合は、kindの値はDedicatedでなければなりません。 - 2
- Azure ストレージアカウントの SKU の層。デフォルトは空です。注: プレミアム VM は Standard_LRS ディスクと Premium_LRS ディスクの両方を割り当て、標準 VM は Standard_LRS ディスクのみを、マネージド VM はマネージドディスクのみを、アンマネージド VM はアンマネージドディスクのみを割り当てることができます。
- 3
- 許容値は、
Shared(デフォルト)、DedicatedおよびManagedです。-
kindがSharedに設定されている場合は、Azure は、クラスターと同じリソースグループにあるいくつかの共有ストレージアカウントに、アンマネージドディスクをすべて作成します。 -
kindがManagedに設定されている場合は、Azure は新しいマネージドディスクを作成します。 kindがDedicatedに設定されており、storageAccountが指定されている場合には、Azure は、クラスターと同じリソースグループ内にある新規のアンマネージドディスク用に、指定のストレージアカウントを使用します。これを機能させるには、以下が前提となっています。- 指定のストレージアカウントが、同じリージョン内にあること。
- Azure Cloud Provider にストレージアカウントへの書き込み権限があること。
-
kindがDedicatedに設定されており、storageAccountが指定されていない場合には、Azure はクラスターと同じリソースグループ内の新規のアンマネージドディスク用に、新しい専用のストレージアカウントを作成します。
-
Azure StorageClass は OpenShift Container Platform バージョン 3.7 で改訂され、以前のバージョンからアップグレードした場合には、以下のいずれかを行ってください。
-
kind: dedicatedのプロパティーを指定して、アップグレード前に作成した Azure StorageClass を使用し続ける。または、 -
azure.conf ファイルにロケーションのパラメーター (例:
"location": "southcentralus",) を追加して、デフォルトのプロパティーkind: sharedを使用します。こうすることで、新しいストレージアカウントを作成し、今後使用できるようになります。
24.17.4. デフォルト StorageClass の変更
GCE と AWS を使用している場合にデフォルトの StorageClass を変更するには、以下のプロセスを使用します。
StorageClass の一覧を表示します。
$ oc get storageclass NAME TYPE gp2 (default) kubernetes.io/aws-ebs1 standard kubernetes.io/gce-pd- 1
(default)はデフォルトの StorageClass を示します。
デフォルトの StorageClass のアノテーション
storageclass.kubernetes.io/is-default-classの値をfalseに変更します。$ oc patch storageclass gp2 -p '{"metadata": {"annotations": \ {"storageclass.kubernetes.io/is-default-class": "false"}}}'アノテーション
storageclass.kubernetes.io/is-default-class=trueを追加するか、このアノテーションに変更して別の StorageClass をデフォルトにします。$ oc patch storageclass standard -p '{"metadata": {"annotations": \ {"storageclass.kubernetes.io/is-default-class": "true"}}}'変更内容を確認します。
$ oc get storageclass NAME TYPE gp2 kubernetes.io/aws-ebs standard (default) kubernetes.io/gce-pd
24.17.5. 追加情報とサンプル
24.18. ボリュームのセキュリティー
24.18.1. 概要
このトピックでは、ボリュームのセキュリティーに関連する Pod のセキュリティーについての一般的なガイドを提供します。Pod レベルのセキュリティーに関する全般的な情報については、SCC (Security Context Constraints) の管理と SCC (Security Context Constraints) の概念に関するトピックを参照してください。OpenShift Container Platform の永続ボリューム (PV) フレームワークに関する全般的な情報については、永続ストレージの概念に関するトピックを参照してください。
永続ストレージにアクセスするには、クラスター管理者/ストレージ管理者とエンド開発者間の調整が必要です。クラスター管理者は、基礎となる物理ストレージを抽象化する PV を作成します。開発者は、容量などの一致条件に基づいて Pod と (必要に応じて) PV にバインドされる PVC を作成します。
同じプロジェクト内の複数の Persistent Volume Claim (永続ボリューム要求、PVC) を同じ PV にバインドできます。ただし、PVC を PV にバインドすると、最初の要求のプロジェクトの外部にある要求をその PV にバインドできなくなります。基礎となるストレージに複数のプロジェクトからアクセスする必要がある場合は、プロジェクトごとに独自の PV が必要です。これらの PV は同じ物理ストレージを参照できます。これに関連して、バインドされる PV はプロジェクトに結び付けられます。PV と PVC の詳細な例については、「WordPress and MySQL using NFS」を参照してください。
クラスター管理者が PV への Pod アクセスを許可するには、以下を行う必要があります。
- 実際のストレージに割り当てられるグループ ID またはユーザー ID を把握しておく
- SELinux に関する考慮事項を理解しておく
- これらの ID が Pod の要件に一致するプロジェクトまたは SCC に対して定義される正式な ID の範囲で許可されることを確認する
グループ ID、ユーザー ID および SELinux の値は、Pod 定義の SecurityContext セクションで定義します。グループ ID は、Pod に対してグローバルであり、Pod で定義されるすべてのコンテナーに適用されます。ユーザー ID は同様にグローバルにすることも、コンテナーごとに固有にすることもできます。ボリュームへのアクセスは以下の 4 つのセクションで制御します。
24.18.2. SCC、デフォルト値および許可される範囲
SCC により、Pod にデフォルトのユーザー ID、fsGroup ID、補助グループ ID、および SELinux ラベルが割り当てられるかが左右されます。また、SCC で、許容可能な ID の範囲に対して、Pod 定義 (またはイメージ) で指定される ID を検証するかも決まります。検証が必要な場合で検証が失敗すると、Pod も失敗します。
SCC は、runAsUser、supplementalGroups、fsGroup などのストラテジーを定義します。これらのストラテジーは Pod に権限があるかどうかを判断するのに役立ちます。RunAsAny に設定されるストラテジーの値は、Pod が対象のストラテジーの内容を何でも実行できると実質的に宣言します。このストラテジーに対する承認は省略され、このストラテジーをもとに生成される OpenShift Container Platform のデフォルト値はありません。したがって、生成されるコンテナーの ID と SELinux ラベルは、OpenShift Container Platform ポリシーではなく、コンテナーのデフォルトに基づいて割り当てられます。
以下に RunAsAny の簡単な概要を示します。
- Pod 定義 (またはイメージ) に定義されるすべての ID が許可されます。
- Pod 定義 (およびイメージ) に ID がない場合は、コンテナーによって ID が割り当てられます。Docker の場合、この ID は root (0) です。
- SELinux ラベルは定義されないため、Docker によって一意のラベルが割り当てられます。
このような理由により、ID 関連のストラテジーについて RunAsAny が設定された SCC は、通常の開発者がアクセスできないように保護する必要があります。一方、MustRunAs または MustRunAsRange に設定された SCC ストラテジーは、(ID 関連のストラテジーについての) ID 検証をトリガーします。その結果、Pod 定義またはイメージに値が直接指定されていない場合は、OpenShift Container Platform によってデフォルト値がコンテナーに割り当てられます。
RunAsAny FSGroup ストラテジーが設定された SCC へのアクセスを許可すると、ユーザーがブロックデバイスにアクセスするのを防止することもできます。Pod では、ユーザーのブロックデバイスを引き継ぐために fsGroup を指定する必要があります。通常、これを行うには、SCC FSGroup ストラテジーを MustRunAs に設定します。ユーザーの Pod に RunAsAny FSGroup ストラテジーが設定された SCC が割り当てられている場合、ユーザーが fsGroup ストラテジーを各自で指定する必要があることに気づくまで、permission denied エラーが出される可能性があります。
SCC では、許可される ID (ユーザーまたはグループ) の範囲を定義できます。範囲チェックが必要な場合 (MustRunAs を使用する場合など) で、許容可能な範囲が SCC で定義されていない場合は、プロジェクトによって ID 範囲が決定されます。したがって、プロジェクトでは、許容可能な ID の範囲がサポートされます。ただし、SCC とは異なり、プロジェクトは runAsUser などのストラテジーを定義しません。
許容可能な範囲を設定すると、コンテナー ID の境界を定義するだけでなく、範囲の最小値を対象の ID のデフォルト値にできるので役に立ちます。たとえば、SCC ID ストラテジーの値が MustRunAs で、ID 範囲の最小値が 100で、ID が Pod 定義に存在しない場合、100 がこの ID のデフォルト値になります。
Pod の受付プロセスの一環として、Pod で使用可能な SCC が (ほとんどの場合は優先順位の高い SCC から最も制限の厳しい SCC の順序で) 検査され、Pod の要求に最も一致する SCC が選択されます。SCC のストラテジータイプを RunAsAny に設定すると、制限が緩和されます。一方、MustRunAs タイプに設定すると、制限がより厳しくなります。これらすべてのストラテジーが評価されます。Pod に割り当てられた SCC を確認するには、oc get pod コマンドを使用します。
# oc get pod <pod_name> -o yaml
...
metadata:
annotations:
openshift.io/scc: nfs-scc
name: nfs-pod1
namespace: default
...- 1
- Pod が使用した SCC (この場合は、カスタム SCC) の名前。
- 2
- Pod の名前。
- 3
- プロジェクトの名前。OpenShift Container Platform では、「namespace」と「プロジェクト」は置き換え可能な用語として使用されています。詳細については、「Projects and Users」を参照してください。
Pod で一致した SCC をすぐに確認できない場合があります。そのため、上記のコマンドは、ライブコンテナーの UID、補助グループ、および SELinux のラベル変更を理解するのに非常に役立ちます。
ストラテジーが RunAsAny に設定された SCC では、そのストラテジーの特定の値を Pod 定義 (またはイメージ) に定義できます。これがユーザー ID (runAsUser) に適用される場合、コンテナーが root として実行されないように SCC へのアクセスを制限することが推奨されます。
Pod が 制限付き SCC に一致することが多くあるため、これに伴うセキュリティーについて理解しておくことが重要です。制限付き SCC には以下の特性があります。
-
runAsUserストラテジーが MustRunAsRange に設定されているため、ユーザー ID が制限されます。これにより、ユーザー ID の検証が強制的に実行されます。 -
許可できるユーザー ID の範囲が SCC で定義されないため (詳細については、oc get -o yaml --export scc restricted を参照してください)、プロジェクトの
openshift.io/sa.scc.uid-range範囲が範囲のチェックとデフォルト ID に使用されます (必要な場合)。 -
デフォルトのユーザー ID は、ユーザー ID が Pod 定義で指定されておらず、一致する SCC の
runAsUserが MustRunAsRange に設定されている場合に生成されます。 -
SELinux ラベルが必要です (
seLinuxContextが MustRunAs に設定されているため)。プロジェクトのデフォルトの MCS ラベルが使用されます。 -
FSGroupストラテジーが MustRunAs に設定され、指定される最初の範囲の最小値を値に使用するように指示されているため、fsGroupID が単一の値に制限されます。 -
許容可能な
fsGroupID の範囲が SCC で定義されないため、プロジェクトのopenshift.io/sa.scc.supplemental-groupsの範囲 (またはユーザー ID に使用されるものと同じ範囲) の最小値が検証とデフォルト ID に使用されます (必要な場合)。 -
デフォルトの
fsGroupID は、fsGroupID が Pod で指定されておらず、一致する SCC のFSGroupが MustRunAs に設定されている場合に生成されます。 -
範囲チェックが必要でないため、任意の補助グループ ID が許可されます。これは
supplementalGroupsストラテジーが RunAsAny に設定されているためです。 - 実行中の Pod に対してデフォルトの補助グループは生成されません。上記の 2 つのストラテジーについて RunAsAny が設定されているためです。したがって、グループが Pod 定義 (またはイメージ) に定義されていない場合は、コンテナーには補助グループが事前に定義されません。
以下に、SCC とプロジェクトの相互関係をまとめた default プロジェクトとカスタム SCC (my-custom-scc) の例を示します。
$ oc get project default -o yaml
...
metadata:
annotations:
openshift.io/sa.scc.mcs: s0:c1,c0
openshift.io/sa.scc.supplemental-groups: 1000000000/10000
openshift.io/sa.scc.uid-range: 1000000000/10000
$ oc get scc my-custom-scc -o yaml
...
fsGroup:
type: MustRunAs
ranges:
- min: 5000
max: 6000
runAsUser:
type: MustRunAsRange
uidRangeMin: 1000100000
uidRangeMax: 1000100999
seLinuxContext:
type: MustRunAs
SELinuxOptions:
user: <selinux-user-name>
role: ...
type: ...
level: ...
supplementalGroups:
type: MustRunAs
ranges:
- min: 5000
max: 6000- 1
- default はプロジェクトの名前です。
- 2
- デフォルト値は、対応する SCC 戦略が RunAsAny でない場合にのみ生成されます。
- 3
- Pod 定義または SCC で定義されていない場合の SELinux のデフォルト値です。
- 4
- 許容可能なグループ ID の範囲です。ID の検証は、SCC ストラテジーが RunAsAny の場合にのみ実行されます。複数の範囲をコンマで区切って指定できます。サポートされている形式についてはこちらを参照してください。
- 5
- <4> と同じですが、ユーザー ID に使用されます。また、ユーザー ID の単一の範囲のみがサポートされます。
- 6 10
- MustRunAs は、グループ ID の範囲チェックを実施して、コンテナーのグループのデフォルトを指定します。この SCC の定義に基づく場合、デフォルトは 5000 になります (最小の ID 値)。範囲が SCC から省略される場合、デフォルトは 1000000000 になります (プロジェクトから派生します)。サポートされている別のタイプ RunAsAny では、範囲チェックを実行しないため、いずれのグループ ID も許可され、デフォルトグループは生成されません。
- 7
- MustRunAsRange は、ユーザー ID の範囲チェックを実施して、UID のデフォルトを指定します。この SCC の定義に基づく場合、デフォルトの UID は 1000100000 になります (最小値)。最小範囲と最大範囲が SCC から省略される場合、デフォルトのユーザー ID は 1000000000 になります (プロジェクトから派生します)。これ以外には MustRunAsNonRoot と RunAsAny のタイプがサポートされます。許可される ID の範囲は、ターゲットのストレージに必要ないずれのユーザー ID も含めるように定義することができます。
- 8
- MustRunAs に設定した場合は、コンテナーは SCC の SELinux オプション、またはプロジェクトに定義される MCS のデフォルトを使用して作成されます。RunAsAny というタイプは、SELinux コンテキストが不要であることや、Pod に定義されていない場合はコンテナーに設定されないことを示します。
- 9
- SELinux のユーザー名、ロール名、タイプ、およびラベルは、ここで定義できます。
2 つの形式が許可される範囲にサポートされています。
-
M/N。Mは開始 ID でNはカウントです。したがって、範囲はMからM+N-1(これ自体を含む) までになります。 -
M-N。Mは同じく開始 ID でNは終了 ID です。デフォルトのグループ ID が最初の範囲の開始 ID になります (このプロジェクトでは1000000000desu )。SCC で最小のグループ ID が定義されていない場合は、プロジェクトのデフォルトの ID が適用されます。
24.18.3. 補助グループ
補助グループの操作にあたっては、事前に「SCC、デフォルト、許可される範囲」の説明をお読みください。
補助グループは Linux の正規グループです。Linux で実行されるプロセスには、UID、GID、および 1 つ以上の補助グループがあります。これらの属性はコンテナーのメインプロセスで設定されます。supplementalGroups ID は、通常は NFS や GlusterFS などの共有ストレージへのアクセスを制御する場合に使用されます。一方、fsGroup は Ceph RBD や iSCSI などのブロックストレージへのアクセスを制御する場合に使用されます。
OpenShift Container Platform の共有ストレージプラグインは、マウントの POSIX パーミッションとターゲットストレージのパーミッションが一致するようにボリュームをマウントします。たとえば、ターゲットストレージの所有者 ID が 1234 で、そのグループ ID が 5678 の場合、ホストノードのマウントとコンテナーのマウントはそれらの同じ ID を持ちます。したがって、ボリュームにアクセスするためにはコンテナーのメインプロセスがこれらの ID の一方または両方と一致する必要があります。
たとえば、以下の NFS エクスポートについて見てみましょう。
OpenShift Container Platform ノード側:
showmount では、NFS サーバーの rpcbind および rpc.mount が使用するポートへのアクセスが必要です。
# showmount -e <nfs-server-ip-or-hostname>
Export list for f21-nfs.vm:
/opt/nfs *NFS サーバー側:
# cat /etc/exports
/opt/nfs *(rw,sync,root_squash)
...
# ls -lZ /opt/nfs -d
drwx------. 1000100001 5555 unconfined_u:object_r:usr_t:s0 /opt/nfs/opt/nfs/ エクスポートには UID 1000100001 とグループ 5555 でアクセスすることができます。通常、コンテナーは root として実行しないようにする必要があります。そのため、この NFS の例では、UID 1000100001 として実行されないコンテナーやグループ 5555 のメンバーでないコンテナーは、NFS エクスポートにアクセスできません。
多くの場合、Pod と一致する SCC では特定のユーザー ID の指定は許可されません。そのため、Pod へのストレージアクセスを許可する場合には、補助グループを使用する方法はより柔軟な方法として使用できます。たとえば、前述のエクスポートへの NFS アクセスを許可する場合は、グループ 5555 を Pod 定義に定義できます。
apiVersion: v1
kind: Pod
...
spec:
containers:
- name: ...
volumeMounts:
- name: nfs
mountPath: /usr/share/...
securityContext:
supplementalGroups: [5555]
volumes:
- name: nfs
nfs:
server: <nfs_server_ip_or_host>
path: /opt/nfs - 1
- ボリュームマウントの名前。
volumesセクションの名前と一致する必要があります。 - 2
- コンテナーで表示される NFS エクスポートのパス。
- 3
- Pod のグローバルセキュリティーコンテキスト。Pod 内部のすべてのコンテナーに適用されます。コンテナーではそれぞれ独自の
securityContextを定義することもできますが、グループ ID は Pod に対してグローバルであり、個々のコンテナーに対して定義することはできません。 - 4
- 補助グループ (ID の配列) は 5555 に設定しています。これで、エクスポートへのグループアクセスが許可されます。
- 5
- ボリュームの名前。
volumeMountsセクションの名前と一致する必要があります。 - 6
- NFS サーバー上の実際の NFS エクスポートのパス。
前述の Pod にあるすべてのコンテナー (一致する SCC またはプロジェクトでグループ 5555 を許可することを前提とします) は、グループ 5555 のメンバーとなり、コンテナーのユーザー ID に関係なくボリュームにアクセスできます。ただし、ここでの前提条件に留意してください。場合によっては、SCC が許可されるグループ ID の範囲を定義されておらず、代わりにグループ ID の検証が必要になることがあります (supplementalGroups を MustRunAs に設定した結果など)。ただし、制限付き SCC の場合はこれと異なります。プロジェクトがこの NFS エクスポートにアクセスするようにカスタマイズされていない限り、通常プロジェクトが 5555 というグループ ID を許可することはありません。したがって、このシナリオでは、前述の Pod の 5555 というグループ ID は SCC またはプロジェクトの許可されたグループ ID の範囲内にないために Pod は失敗します。
補助グループとカスタム SCC
前述の例にあるような状況に対応するため、以下のようカスタム SCC を作成することができます。
- 最小と最大のグループ ID を定義する。
- ID の範囲チェックを実施する。
- グループ ID 5555 を許可する。
多くの場合、定義済みの SCC を修正したり、定義済みプロジェクトで許可される ID の範囲を変更したりするよりも、新規の SCC を作成する方が適切です。
新規 SCC を作成するには、既存の SCC をエクスポートし、新規の SCC の要件を満たすように YAML ファイルをカスタマイズするのが最も簡単な方法です。たとえば、以下を実行します。
制限付き SCC を新規 SCC のテンプレートとして使用します。
$ oc get -o yaml --export scc restricted > new-scc.yaml- 必要な仕様に合うように new-scc.yaml ファイルを編集します。
新規 SCC を作成します。
$ oc create -f new-scc.yaml
oc edit scc コマンドを使用して、インスタンス化された SCC を修正することができます。
以下の例は nfs-scc という名前の新規 SCC の一部です。
$ oc get -o yaml --export scc nfs-scc
allowHostDirVolumePlugin: false
...
kind: SecurityContextConstraints
metadata:
...
name: nfs-scc
priority: 9
...
supplementalGroups:
type: MustRunAs
ranges:
- min: 5000
max: 6000
...- 1
allowブール値は制限付き SCC の場合と同じです。- 2
- 新規 SCC の名前。
- 3
- 数値が大きいほど優先順位が高くなります。Nil の場合や省略した場合は優先順位が最も低くなります。優先順位が高い SCC は優先順位が低い SCC より前に並べ替えられるため、新規 Pod と一致する確率が高くなります。
- 4
supplementalGroupsはストラテジーであり、MustRunAs に設定されています。つまり、グループ ID のチェックが必要になります。- 5
- 複数の範囲を使用することができます。ここで許可されるグループ ID の範囲は 5000 ~ 5999 で、デフォルトの補助グループは 5000 です。
前述の Pod をこの新規 SCC に対して実行すると (当然ですが Pod が新規 SCC に一致することを前提とします)、Pod が開始されます。これは、Pod 定義で指定したグループ 5555 がカスタム SCC によって許可されるようになったためです。
24.18.4. fsGroup
補助グループの操作にあたっては、事前に「SCC、デフォルト、許可される範囲」の説明をお読みください。
fsGroup は Pod の「ファイルシステムグループ」の ID を定義するもので、コンテナーの補助グループに追加されます。supplementalGroups の ID は共有ストレージに適用されますが、fsGroup の ID はブロックストレージに使用されます。
ブロックストレージ (Ceph RBD、iSCSI、各種クラウドストレージなど) は通常、ブロックストレージボリュームを直接に、または PVC を使用して要求した単一 Pod に専用のものとして設定されます。共有ストレージとは異なり、ブロックストレージは Pod によって引き継がれます。つまり、Pod 定義 (またはイメージ) で指定されたユーザー ID とグループ ID が実際の物理ブロックデバイスに適用されます。通常、ブロックストレージは共有されません。
以下の fsGroup の定義は Pod 定義の一部分です。
kind: Pod
...
spec:
containers:
- name: ...
securityContext:
fsGroup: 5555
...
supplementalGroups と同様に、前述の Pod にあるすべてのコンテナー (一致する SCC またはプロジェクトでグループ 5555 を許可することを前提とします) は、グループ 5555 のメンバーとなり、コンテナーのユーザー ID に関係なくブロックボリュームにアクセスできます。Pod が制限付き SCC に一致し、その fsGroup ストラテジーが MustRunAs である場合、Pod の実行は失敗します。しかし、SCC の fsGroup ストラテジーを RunAsAny に設定した場合は、任意の fsGroup ID (5555 を含む) が許可されます。SCC の fsGroup ストラテジーを RunAsAny に設定して、fsGroup ID を指定しない場合は、ブロックストレージの「引き継ぎ」は行われず、Pod へのパーミッションが拒否される可能性があります。
fsGroups とカスタム SCC
前述の例にあるような状況に対応するため、以下のようにカスタム SCC を作成することができます。
- 最小と最大のグループ ID を定義する。
- ID の範囲チェックを実施する。
- グループ ID 5555 を許可する。
定義済みの SCC を修正したり、定義済みプロジェクトで許可される ID の範囲を変更したりするよりも、新規の SCC を作成する方が適切です。
以下の新規 SCC の定義の一部について見てみましょう。
# oc get -o yaml --export scc new-scc
...
kind: SecurityContextConstraints
...
fsGroup:
type: MustRunAs
ranges:
- max: 6000
min: 5000
...- 1
- MustRunAs ではグループ ID の範囲チェックをトリガーします。一方、RunAsAny では範囲チェックは必要ありません。
- 2
- 許可されるグループ ID の範囲は 5000 ~ 5999 (これら自体を含む) です。複数の範囲がサポートされていますが、1 つしか使用していません。ここで許可されるグループ ID の範囲は 5000 ~ 5999 で、デフォルトの
fsGroupは 5000 です。 - 3
- 最小値 (または範囲全体) を SCC から省略することができます。その場合、範囲のチェックとデフォルト値の生成はプロジェクトの
openshift.io/sa.scc.supplemental-groupsの範囲に従います。fsGroupとsupplementalGroupsではプロジェクト内の同じグループフィールドが使用されます。fsGroupに別の範囲が存在する訳ではありません。
前述の Pod をこの新規 SCC に対して実行すると (当然ですが Pod が新しい SCC に一致することを前提とします)、Pod が開始されます。これは、Pod 定義で指定したグループ 5555 がカスタム SCC によって許可されているためです。また、Pod でブロックデバイスの「引き継ぎ」が行われます。そのため、ブロックストレージを Pod の外部のプロセスから表示する場合、そのグループ ID は実際には 5555 になります。
以下は、ブロックの所有権をサポートしているボリュームの例です。
- AWS Elastic Block Store
- OpenStack Cinder
- Ceph RBD
- GCE Persistent Disk
- iSCSI
- emptyDir
- gitRepo
この一覧にはすべてが網羅されている訳ではありません。
24.18.5. ユーザー ID
補助グループの操作にあたっては、事前に「SCC、デフォルト、許可される範囲」の説明をお読みください。
ユーザー ID はコンテナーイメージまたは Pod 定義で定義できます。Pod 定義では、1 つのユーザー ID をすべてのコンテナーに対してグローバルに定義するか、個々のコンテナーに固有のものとして定義するか、またはその両方として定義できます。以下の Pod 定義の一部ではユーザー ID を指定しています。
spec:
containers:
- name: ...
securityContext:
runAsUser: 1000100001
1000100001 はコンテナー固有の ID であり、エクスポートの所有者 ID と一致します。NFS エクスポートの所有者 ID が 54321 である場合は、その番号が Pod 定義で使用されます。コンテナー定義の外部で securityContext を指定すると、ID は Pod 内のすべてのコンテナーに対してグローバルになります。
グループ ID と同じように、SCC やプロジェクトで設定されているポリシーに従ってユーザー ID を検証することもできます。SCC の runAsUser ストラテジーを RunAsAny に設定した場合は、Pod 定義またはイメージで定義されているすべてのユーザー ID が許可されます。
これは、0 (root) の UID も許可されることを意味します。
代わりに runAsUser ストラテジーを MustRunAsRange に設定した場合は、指定したユーザー ID について、許可される ID の範囲にあるかどうかが検証されます。Pod でユーザー ID を指定しない場合は、デフォルト ID が許可されるユーザー ID の範囲の最小値に設定されます。
先の「NFS の例」に戻って、コンテナーでその UID を 1000100001 に設定する必要があります (上記の Pod の例を参照してください)。デフォルトプロジェクトと制限付き SCC を想定した場合、Pod で要求した 1000100001 というユーザー ID は許可されず、したがって Pod は失敗します。Pod が失敗するのは以下の理由によります。
- Pod が独自のユーザー ID として 1000100001 を要求している。
-
使用可能なすべての SCC が独自の
runAsUserストラテジーとして MustRunAsRange を使用しており、そのため UID の範囲チェックが要求される。 - 1000100001 が SCC にもプロジェクトのユーザー ID 範囲にも含まれていない。
この状況に対応するには、適切なユーザー ID 範囲を指定して新規 SCC を作成します。また、新規プロジェクトを適切なユーザー ID 範囲を定義して作成することもできます。さらに、以下のような推奨されない他のオプションがあります。
- 最小および最大のユーザー ID 範囲に 1000100001 を組み込むように 制限付き SCC を変更できます。ただし、これは定義済みの SCC の変更をできる限り避ける必要があるため推奨されません。
-
RunAsAny を
runAsUserの値に使用できるように 制限付き SCC を変更できます。これにより、ID 範囲のチェックを省略できます。この方法ではコンテナーが root として実行される可能性があるため、この方法を使用しないことを「強く」推奨します。 - ユーザー ID 1000100001 を許可するように デフォルトプロジェクトの UID 範囲を変更できます。通常、この方法も推奨できません。ユーザー ID に単一範囲しか指定できず、範囲が変更された場合に他の Pod が実行されなくなる可能性があるためです。
ユーザー ID とカスタム SCC
定義済みの SCC を変更することは可能な限り避ける必要があります。組織のセキュリティー上のニーズに合ったカスタム SCC を作成するか、または必要なユーザー ID をサポートする新規プロジェクトを作成することを推奨します。
前述の例にあるような状況に対応するため、以下のようにカスタム SCC を作成することができます。
- 最小と最大のユーザー ID を定義する。
- UID の範囲チェックを引き続き実施する。
- 1000100001 という UID を許可する。
以下は例を示しています。
$ oc get -o yaml --export scc nfs-scc
allowHostDirVolumePlugin: false
...
kind: SecurityContextConstraints
metadata:
...
name: nfs-scc
priority: 9
requiredDropCapabilities: null
runAsUser:
type: MustRunAsRange
uidRangeMax: 1000100001
uidRangeMin: 1000100001
...
これで、先の例の Pod 定義に runAsUser: 1000100001 が表示され、Pod が新規の nfs-scc と一致し、UID 1000100001 で実行できるようになります。
24.18.6. SELinux オプション
特権付き SCC を除くすべての定義済み SCC では、seLinuxContext を MustRunAs に設定します。そのため、Pod の要件と一致する可能性が高い SCC の場合、Pod での SELinux ポリシーの使用を強制的に実行します。Pod で使用される SELinux ポリシーは、その Pod 自体やイメージ、SCC、またはプロジェクト (デフォルトを指定する) で定義できます。
SELinux のラベルは Pod の securityContext.seLinuxOptions セクションで定義でき、user、role、type、および level を使用できます。
このトピックでは、レベルと MCS ラベルを置き換え可能な用語として使用します。
...
securityContext:
seLinuxOptions:
level: "s0:c123,c456"
...以下の例は SCC とデフォルトプロジェクトからの抜粋です。
$ oc get -o yaml --export scc scc-name
...
seLinuxContext:
type: MustRunAs
# oc get -o yaml --export namespace default
...
metadata:
annotations:
openshift.io/sa.scc.mcs: s0:c1,c0
...
特権付き SCC を除くすべての定義済み SCC では、seLinuxContext を MustRunAs に設定します。これにより、Pod での MCS ラベルの使用が強制的に実行されます。MCS ラベルは、Pod 定義やイメージで定義するか、またはデフォルトとして指定されます。
SCC によって、SELinux ラベルを必要とするかどうかが決まります。また、SCC でデフォルトラベルを指定できます。seLinuxContext ストラテジーを MustRunAs に設定していて、Pod (またはイメージ) がラベルを定義していない場合は、OpenShift Container Platform は SCC 自体またはプロジェクトから選択されるラベルにデフォルト設定されます。
seLinuxContext を RunAsAnyに設定した場合は、デフォルトラベルは提供されず、コンテナーによって最終的なラベルが決められます。Docker の場合、コンテナーでは一意の MCS ラベルが使用されますが、これが既存のストレージマウントのラベル付けに一致する可能性はほとんどありません。SELinux 管理をサポートしているボリュームについては、指定されるラベルからアクセスできるようにラベルの再設定がなされ、ラベルの排他性によってはそのラベルのみがアクセスできるようになります。
この場合、特権なしコンテナーについては以下の 2 つが関係します。
-
ボリュームには、特権なしのコンテナーからのアクセス可能なタイプが指定されます。このタイプは、通常は Red Hat Enterprise Linux (RHEL) バージョン 7.5 以降の
container_file_tになります。このタイプはボリュームをコンテナーコンテキストとして処理します。以前の RHEL バージョンの RHEL 7.4、7.3 などでは、ボリュームにsvirt_sandbox_file_tタイプが指定されます。 -
levelを指定した場合は、指定される MCS ラベルを使用してボュームのラベルが設定されます。
Pod からボリュームにアクセスできるようにするためには、Pod で両方のボリュームカテゴリーを持つ必要があります。たとえば、s0:c1,c2 を持つ Pod は、s0:c1,c2 のボリュームにアクセスでき、s0 のボリュームにはすべての Pod からアクセスできるようにします。
Pod で承認が失敗する場合、またはパーミッションエラーが原因でストレージのマウントが失敗している場合は、SELinux の実施による干渉が生じている可能性があります。これについては、たとえば以下を実行してチェックできます。
# ausearch -m avc --start recentこれは、ログファイルに AVC (Access Vector Cache) のエラーがないかどうかを検査します。
24.19. セレクターとラベルによるボリュームのバインディング
24.19.1. 概要
ここでは、selector 属性と label 属性を使用して Persistent Volume Claim (永続ボリューム要求、PVC) を永続ボリューム (PV) にバインドするための必要な手順について説明します。セレクターとラベルを実装することで、通常のユーザーは、クラスター管理者が定義する識別子を使用して、プロビジョニングされたストレージをターゲットに設定することができます。
24.19.2. 必要になる状況
静的にプロビジョニングされるストレージの場合、永続ストレージを必要とする開発者は、PVC をデプロイしてバインドするためにいくつかの PV の識別属性を把握しておく必要がありますが、その際、問題となる状況がいくつか生じます。通常のユーザーは、PVC のデプロイでも PV の値の指定においても、クラスター管理者に問い合わせをする必要が生じる場合があります。PV 属性だけでは、ストレージボリュームの用途も、ボリュームをグループ化する方法も確認できないためです。
selector 属性と label 属性を使用すると、ユーザーが意識せずに済むように PV の詳細を抽象化できると同時に、分かりやすくカスタマイズ可能なタグを使用してボリュームを識別する手段をクラスター管理者に提供できます。セレクターとラベルによるバインディングの方法を使用することで、ユーザーは管理者によって定義されているラベルのみを確認することが必要になります。
セレクターとラベルの機能は、現時点では静的にプロビジョニングされるストレージの場合にのみ使用できます。現時点では、動的にプロビジョニングされるストレージ用には実装されていません。
24.19.3. デプロイメント
このセクションでは、PVC の定義方法とデプロイ方法を説明します。
24.19.3.1. 前提条件
- 実行中の OpenShift Container Platform 3.3 以降のクラスター
- サポート対象のストレージプロバイダーによって提供されているボリューム
- cluster-admin ロールのバインディングを持つユーザー
24.19.3.2. 永続ボリュームと要求の定義
cluser-admin ユーザーとして、PV を定義します。この例では GlusterFS ボリュームを使用します。プロバイダーの設定については、該当する「ストレージプロバイダー」を参照してください。
例24.9 ラベルのある永続ボリューム
apiVersion: v1 kind: PersistentVolume metadata: name: gluster-volume labels:1 volume-type: ssd aws-availability-zone: us-east-1 spec: capacity: storage: 2Gi accessModes: - ReadWriteMany glusterfs: endpoints: glusterfs-cluster path: myVol1 readOnly: false persistentVolumeReclaimPolicy: Recycle- 1
- セレクターが すべての PV のラベルと一致する PVC がバインドされます (PV が使用可能であることを前提とします)。
PVC を定義します。
例24.10 セレクターのある Persistent Volume Claim (永続ボリューム要求)
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: gluster-claim spec: accessModes: - ReadWriteMany resources: requests: storage: 1Gi selector:1 matchLabels:2 volume-type: ssd aws-availability-zone: us-east-1
24.19.3.3. 永続ボリュームと要求のデプロイ
cluster-admin ユーザーとして、永続ボリュームを作成します。
例24.11 永続ボリュームの作成
# oc create -f gluster-pv.yaml
persistentVolume "gluster-volume" created
# oc get pv
NAME LABELS CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
gluster-volume map[] 2147483648 RWX Available 2sPV が作成されると、セレクターがその「すべての」ラベルと一致するユーザーであれば PVC を作成できます。
例24.12 Persistent Volume Claim (永続ボリューム要求) の作成
# oc create -f gluster-pvc.yaml
persistentVolumeClaim "gluster-claim" created
# oc get pvc
NAME LABELS STATUS VOLUME
gluster-claim Bound gluster-volume24.20. コントローラー管理の割り当ておよび割り当て解除
24.20.1. 概要
OpenShift Container Platform 3.4 の時点では、ノードセット自体による各自のボリュームの割り当て/割り当て解除操作の管理のままにするのではなく、管理者がクラスターのマスターで実行されるコントローラーを有効にして、ノードセットに代わってボリュームの割り当て/割り当て解除操作を管理することができます。
コントローラー管理の割り当ておよび割り当て解除を有効にすることには、以下のメリットがあります。
- ノードが失われた場合でも、そのノードに割り当てられていたボリュームの割り当て解除をコントローラーによって実行でき、これを別の場所で再び割り当てることができます。
- 割り当て/割り当て解除に必要な認証情報をすべてのノードで用意する必要がないため、セキュリティーが強化されます。
OpenShift Container Platform 3.6 の時点では、コントローラーで管理される割り当て/割り当て解除はデフォルトの設定になっています。
24.20.2. 割り当て/割り当て解除の管理元の判別
ノード自体にアノテーション volumes.kubernetes.io/controller-managed-attach-detach が設定されている場合、そのノードの割り当て/割り当て解除操作はコントローラーによって管理されます。コントローラーは、すべてのノードでこのアノテーションの有無を自動的に検査し、その有無に応じて動作します。したがって、ユーザーがノードでこのアノテーションの有無を調べることで、コントローラーが管理する割り当て/割り当て解除がそのノードで有効にされているかどうかを判別することができます。
さらに、ノードでコントローラー管理の割り当て/割り当て解除が選択されていることを確認するには、ノードのログで以下の行を検索します。
Setting node annotation to enable volume controller attach/detachこの行が見つからない場合は、以下の行が代わりにログに含まれているはずです。
Controller attach/detach is disabled for this node; Kubelet will attach and detach volumes
コントローラーの端末から、コントローラーが特定ノードの割り当て/割り当て解除操作を管理しているかどうかを確認するには、まずロギングレベルを少なくとも 4 に設定する必要があります。次に、以下の行を見つけます。
processVolumesInUse for node <node_hostname>ログの表示方法とロギングレベルの設定方法については、「ロギングレベルの設定」を参照してください。
24.20.3. コントローラー管理の割り当て/割り当て解除を有効にするノードの設定
コントローラー管理の割り当て/割り当て解除を有効にするには、個々のノードで独自の割り当て/割り当て解除をオプトインし、無効にするように設定します。編集対象のノード設定ファイルについての詳細は、「ノード設定ファイル」を参照してください。このファイルには、以下の行を追加します。
kubeletArguments:
enable-controller-attach-detach:
- "true"ノードを設定したら、設定を有効にするためにノードを再起動する必要があります。
24.21. 永続ボリュームスナップショット
24.21.1. 概要
永続ボリュームスナップショットはテクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat の実稼働環境でのサービスレベルアグリーメント (SLA) ではサポートされていないため、Red Hat では実稼働環境での使用を推奨していません。これらの機能は、近々発表予定の製品機能をリリースに先駆けてご提供することにより、お客様は機能性をテストし、開発プロセス中にフィードバックをお寄せいただくことができます。
Red Hat のテクノロジープレビュー機能のサポートについての詳細は、https://access.redhat.com/support/offerings/techpreview/ を参照してください。
ストレージシステムの多くは、データを損失から保護するために永続ボリューム (PV) の「スナップショット」を作成する機能を備えています。外部のスナップショットコントローラーおよびプロビジョナーは、この機能を OpenShift Container Platform クラスターで使用して OpenShift Container Platform API を使用してボリュームスナップショットを扱う方法を提供しています。
本書では、OpenShift Container Platform におけるボリュームスナップショットのサポートの現状について説明しています。PV、Persistent Volume Claim (永続ボリューム要求、PVC)、および動的プロビジョニングについて理解しておくことを推奨されます。
24.21.2. 機能
-
PersistentVolumeClaimにバインドされるPersistentVolumeのスナップショットの作成 -
既存の
VolumeSnapshotsの一覧表示 -
既存の
VolumeSnapshotの削除 -
既存の
VolumeSnapshotからのPersistentVolumeの新規作成 サポートされている
PersistentVolumeのタイプ:- AWS Elastic Block Store (EBS)
- Google Compute Engine (GCE) Persistent Disk (PD)
24.21.3. インストールと設定
外部のスナップショットコントローラーおよびプロビジョナーは、ボリュームスナップショットの機能を提供する外部コンポーネントです。これらの外部コンポーネントはクラスターで実行されます。コントローラーは、ボリュームスナップショットの作成、削除、および関連イベントのレポートを行います。プロビジョナーは、ボリュームスナップショットから新規の PersistentVolumes を作成します。詳細は、「スナップショットの作成」および「スナップショットの復元」を参照してください。
24.21.3.1. 外部のコントローラーおよびプロビジョナーの起動
外部のコントローラーおよびプロビジョナーサービスはコンテナーイメージとして配布され、OpenShift Container Platform クラスターで通常どおり実行できます。また、コントローラーおよびプロビジョナーの RPM バージョンもあります。
API オブジェクトを管理しているコンテナーを許可するには、以下のようにして、必要なロールベースアクセス制御 (RBAC) ルールを管理者が設定する必要があります。
ServiceAccountとClusterRoleを以下のように作成します。apiVersion: v1 kind: ServiceAccount metadata: name: snapshot-controller-runner kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: snapshot-controller-role rules: - apiGroups: [""] resources: ["persistentvolumes"] verbs: ["get", "list", "watch", "create", "delete"] - apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update"] - apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["events"] verbs: ["list", "watch", "create", "update", "patch"] - apiGroups: ["apiextensions.k8s.io"] resources: ["customresourcedefinitions"] verbs: ["create", "list", "watch", "delete"] - apiGroups: ["volumesnapshot.external-storage.k8s.io"] resources: ["volumesnapshots"] verbs: ["get", "list", "watch", "create", "update", "patch", "delete"] - apiGroups: ["volumesnapshot.external-storage.k8s.io"] resources: ["volumesnapshotdatas"] verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]ClusterRoleBindingを使用して、以下のようにルールをバインドします。apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: snapshot-controller roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: snapshot-controller-role subjects: - kind: ServiceAccount name: snapshot-controller-runner namespace: default
外部のコントローラーおよびプロビジョナーを Amazon Web Services (AWS) にデプロイしている場合、それらはアクセスキーを使用して認証できる必要があります。認証情報を Pod に提供するために、管理者が以下のように新規のシークレットを作成します。
apiVersion: v1
kind: Secret
metadata:
name: awskeys
type: Opaque
data:
access-key-id: <base64 encoded AWS_ACCESS_KEY_ID>
secret-access-key: <base64 encoded AWS_SECRET_ACCESS_KEY>AWS における外部のコントローラーおよびプロビジョナーコンテナーのデプロイメント (どちらの Pod コンテナーもシークレットを使用して AWS のクラウドプロバイダー API にアクセスします):
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: snapshot-controller
spec:
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: snapshot-controller
spec:
serviceAccountName: snapshot-controller-runner
containers:
- name: snapshot-controller
image: "registry.access.redhat.com/openshift3/snapshot-controller:latest"
imagePullPolicy: "IfNotPresent"
args: ["-cloudprovider", "aws"]
env:
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: awskeys
key: access-key-id
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: awskeys
key: secret-access-key
- name: snapshot-provisioner
image: "registry.access.redhat.com/openshift3/snapshot-provisioner:latest"
imagePullPolicy: "IfNotPresent"
args: ["-cloudprovider", "aws"]
env:
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: awskeys
key: access-key-id
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: awskeys
key: secret-access-keyGCE の場合、GCE のクラウドプロバイダー API にアクセスするためにシークレットを使用する必要はありません。管理者は以下のようにデプロイメントに進むことができます。
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: snapshot-controller
spec:
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: snapshot-controller
spec:
serviceAccountName: snapshot-controller-runner
containers:
- name: snapshot-controller
image: "registry.access.redhat.com/openshift3/snapshot-controller:latest"
imagePullPolicy: "IfNotPresent"
args: ["-cloudprovider", "gce"]
- name: snapshot-provisioner
image: "registry.access.redhat.com/openshift3/snapshot-provisioner:latest"
imagePullPolicy: "IfNotPresent"
args: ["-cloudprovider", "gce"]24.21.3.2. スナップショットユーザーの管理
クラスターの設定によっては、管理者以外のユーザーが API サーバーで VolumeSnapshot オブジェクトを操作できるようにする必要があります。これは、特定のユーザーまたはグループにバインドされる ClusterRole を作成することで実行できます。
たとえば、ユーザー「alice」がクラスター内のスナップショットを操作する必要があるとします。クラスター管理者は以下の手順を実行します。
新規の
ClusterRoleを定義します。apiVersion: v1 kind: ClusterRole metadata: name: volumesnapshot-admin rules: - apiGroups: - "volumesnapshot.external-storage.k8s.io" attributeRestrictions: null resources: - volumesnapshots verbs: - create - delete - deletecollection - get - list - patch - update - watchClusterRoleバインドオブジェクトを作成してクラスターロールをユーザー「alice」にバインドします。apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: volumesnapshot-admin roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: volumesnapshot-admin subjects: - kind: User name: alice
これは API アクセス設定の一例にすぎません。VolumeSnapshot オブジェクトの動作は他の OpenShift Container Platform API オブジェクトと同様です。API RBAC の管理についての詳細は、API アクセス制御のドキュメントを参照してください。
24.21.4. ボリュームスナップショットとボリュームスナップショットデータのライフサイクル
24.21.4.1. Persistent Volume Claim (永続ボリューム要求) と永続ボリューム
PersistentVolumeClaim は PersistentVolume にバインドされます。PersistentVolume のタイプは、スナップショットがサポートするいずれかの永続ボリュームタイプである必要があります。
24.21.4.1.1. スナップショットプロモーター
StorageClass を作成するには、以下を実行します。
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: snapshot-promoter
provisioner: volumesnapshot.external-storage.k8s.io/snapshot-promoter
この StorageClass は、先に作成した VolumeSnapshot から PersistentVolume を復元する場合に必要です。
24.21.4.2. スナップショットの作成
PV のスナップショットを作成するには、新しい VolumeSnapshot オブジェクトを以下のように作成します。
apiVersion: volumesnapshot.external-storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: snapshot-demo
spec:
persistentVolumeClaimName: ebs-pvc
persistentVolumeClaimName は、PersistentVolume にバインドされる PersistentVolumeClaim の名前です。この特定 PV のスナップショットが作成されます。
次に、VolumeSnapshot に基づく VolumeSnapshotData オブジェクトが自動的に作成されます。VolumeSnapshot と VolumeSnapshotData の関係は PersistentVolumeClaim と PersistentVolume の関係に似ています。
PV のタイプによっては、反映される VolumeSnapshot の状態に応じ、操作が複数の段階にわたる場合があります。
-
新規
VolumeSnapshotオブジェクトが作成されます。 -
コントローラーによってスナップショット操作が開始されます。スナップショット対象の
PersistentVolumeをフリーズし、アプリケーションを一時停止する必要が生じる場合があります。 -
ストレージシステムによるスナップショットの作成が完了し (スナップショットが「切り取られ」)、スナップショット対象の
PersistentVolumeが通常の操作に戻ります。スナップショット自体の準備はまだできていません。ここでの状態はPendingタイプで状態の値はTrueです。実際のスナップショットを表すVolumeSnapshotDataオブジェクトが新たに作成されます。 -
新規スナップショットの作成が完成し、使用できる状態になります。ここでの状態は
Readyタイプで、状態の値はTrueです。
データの整合性の確保 (Pod/アプリケーションの停止、キャッシュのフラッシュ、ファイルシステムのフリーズなど) はユーザーの責任で行う必要があります。
エラーの場合は、VolumeSnapshot の状態が Error 状態に追加されます。
VolumeSnapshot の状態を表示するには、以下を実行します。
$ oc get volumesnapshot -o yaml状態が以下のように表示されます。
apiVersion: volumesnapshot.external-storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
clusterName: ""
creationTimestamp: 2017-09-19T13:58:28Z
generation: 0
labels:
Timestamp: "1505829508178510973"
name: snapshot-demo
namespace: default
resourceVersion: "780"
selfLink: /apis/volumesnapshot.external-storage.k8s.io/v1/namespaces/default/volumesnapshots/snapshot-demo
uid: 9cc5da57-9d42-11e7-9b25-90b11c132b3f
spec:
persistentVolumeClaimName: ebs-pvc
snapshotDataName: k8s-volume-snapshot-9cc8813e-9d42-11e7-8bed-90b11c132b3f
status:
conditions:
- lastTransitionTime: null
message: Snapshot created successfully
reason: ""
status: "True"
type: Ready
creationTimestamp: null24.21.4.3. スナップショットの復元
VolumeSnapshot から PV を復元するには、以下のように PVC を作成します。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: snapshot-pv-provisioning-demo
annotations:
snapshot.alpha.kubernetes.io/snapshot: snapshot-demo
spec:
storageClassName: snapshot-promoter
annotations: snapshot.alpha.kubernetes.io/snapshot は、復元する VolumeSnapshot の名前です。 storageClassName: StorageClass はVolumeSnapshot を復元するために管理者によって作成されます。
新規の PersistentVolume が作成されて PersistentVolumeClaim にバインドされます。PV のタイプによっては処理に数分の時間がかかることがあります。
24.21.4.4. スナップショットの削除
snapshot-demo を削除するには、以下を実行します。
$ oc delete volumesnapshot/snapshot-demo
VolumeSnapshot にバインドされている VolumeSnapshotData が自動的に削除されます。