モニタリング
OpenShift Container Platform でのモニタリングスタックの設定および使用
概要
第1章 OpenShift Container Platform モニタリングについて
1.1. OpenShift Container Platform モニタリングについて
OpenShift Container Platform には、コアプラットフォームコンポーネントのモニタリングを提供する事前に設定され、事前にインストールされた自己更新型のモニタリングスタックが含まれます。また、ユーザー定義プロジェクトのモニタリングを有効 にするオプションもあります。
クラスター管理者は、サポートされている設定で モニタリングスタックを設定 できます。OpenShift Container Platform は、追加設定が不要のモニタリングのベストプラクティスを提供します。
クラスターの問題を管理者に即座に通知するアラートのセットがデフォルトで含まれています。OpenShift Container Platform Web コンソールのデフォルトのダッシュボードには、クラスターの状態をすぐに理解できるようにするクラスターのメトリクスの視覚的な表示が含まれます。OpenShift Container Platform Web コンソールを使用すると、メトリクスにアクセス し、アラートを管理 できます。
OpenShift Container Platform のインストール後に、クラスター管理者はオプションでユーザー定義プロジェクトのモニタリングを有効にできます。この機能を使用することで、クラスター管理者、開発者、および他のユーザーは、サービスと Pod を独自のプロジェクトでモニターする方法を指定できます。クラスター管理者は、Troubleshooting monitoring issues で、Prometheus によるユーザーメトリクスの使用不可やディスクスペースの大量消費などの一般的な問題に対する回答を見つけることができます。
1.2. モニタリングスタックアーキテクチャー
OpenShift Container Platform モニタリングスタックは、Prometheus オープンソースプロジェクトおよびその幅広いエコシステムをベースとしています。ここでは、モニタリングスタックアーキテクチャーを説明します。これには、デフォルトのモニタリングコンポーネントおよびユーザー定義プロジェクトのモニタリング用のコンポーネントが含まれます。
1.2.1. モニタリングスタックについて
モニタリングスタックには、以下のコンポーネントが含まれます。
- デフォルトのプラットフォームモニタリングコンポーネント
プラットフォームモニタリングコンポーネントのセットは、OpenShift Container Platform のインストール時にデフォルトで
openshift-monitoringプロジェクトにインストールされます。これにより、Kubernetes サービスを含むコアクラスターコンポーネントのモニタリングが可能になります。デフォルトのモニタリングスタックは、クラスターのリモートのヘルスモニタリングも有効にします。これらのコンポーネントは、以下の図の Installed by default セクションに表示されます。
- ユーザー定義プロジェクトをモニターするためのコンポーネント
ユーザー定義プロジェクトのモニタリングを有効にすると、追加のモニタリングコンポーネントは
openshift-user-workload-monitoringプロジェクトにインストールされます。これにより、ユーザー定義プロジェクトのオプションのモニタリング機能が提供されます。これらのコンポーネントは、以下の図の User セクションに表示されます。
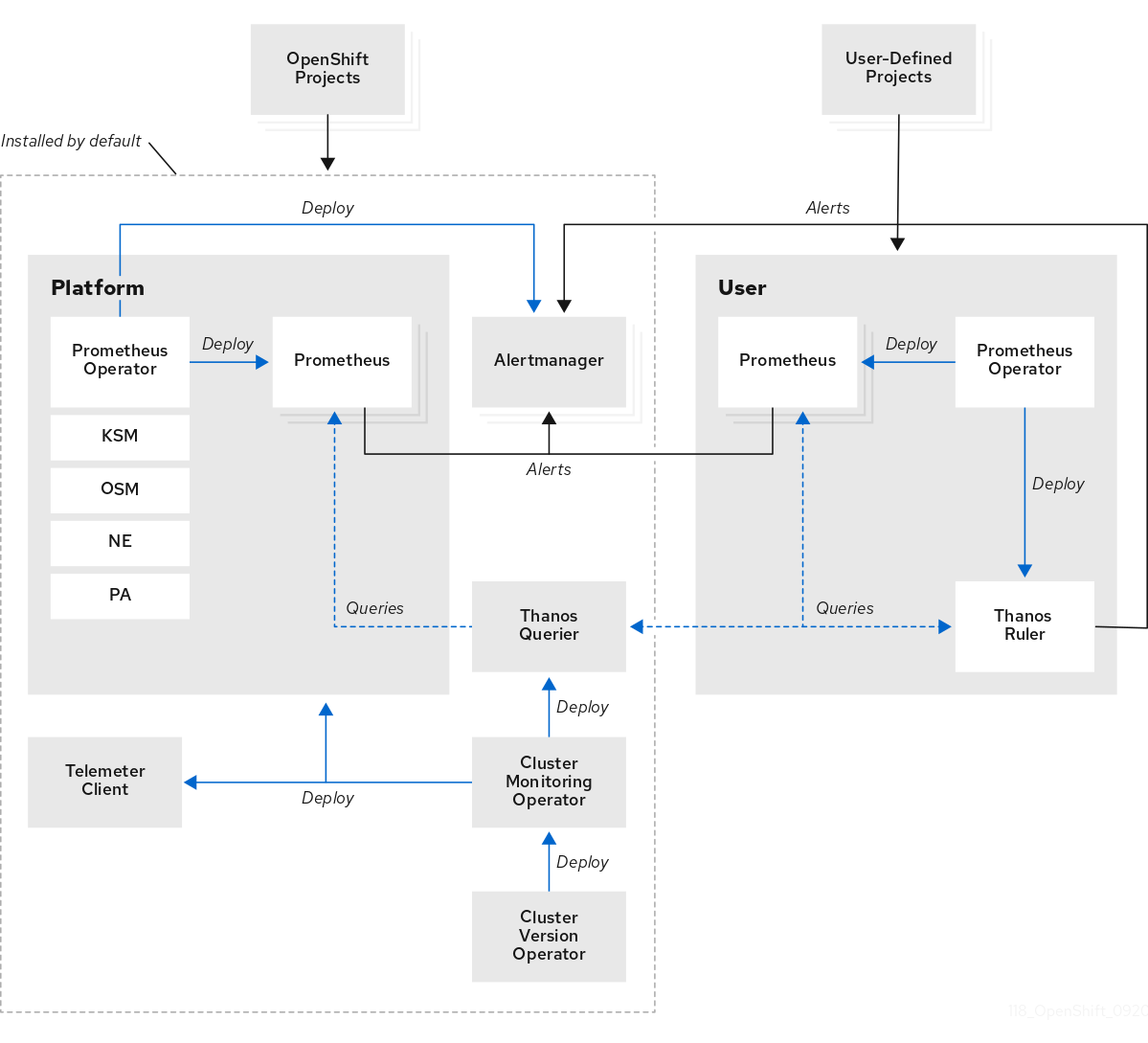
1.2.2. デフォルトのモニタリングコンポーネント
デフォルトで、OpenShift Container Platform 4.19 モニタリングスタックには以下のコンポーネントが含まれます。
| コンポーネント | 説明 |
|---|---|
| Cluster Monitoring Operator | Cluster Monitoring Operator (CMO) は、モニタリングスタックの中心的なコンポーネントです。Prometheus および Alertmanager インスタンス、Thanos Querier、Telemeter Client、およびメトリクスターゲットをデプロイ、管理、および自動更新します。CMO は Cluster Version Operator (CVO) によってデプロイされます。 |
| Prometheus Operator |
|
| Prometheus | OpenShift Container Platform モニタリングスタックは、Prometheus モニタリングシステムをベースにしています。Prometheus は時系列データベースであり、メトリクスのルール評価エンジンです。Prometheus は処理のためにアラートを Alertmanager に送信します。 |
| Prometheus アダプター |
Prometheus アダプター (上記の図の PA) は、Prometheus で使用する Kubernetes ノードおよび Pod クエリーを変換します。変換されるリソースメトリクスには、CPU およびメモリーの使用率メトリクスが含まれます。Prometheus アダプターは、Horizontal Pod Autoscaling のクラスターリソースメトリクス API を公開します。Prometheus アダプターは |
| Metrics Server (テクノロジープレビュー) |
有効にすると、Metrics Server コンポーネントはリソースメトリクスを収集し、他のツールや API で使用できるように
|
| Alertmanager | Alertmanager サービスは、Prometheus から送信されるアラートを処理します。また、Alertmanager は外部の通知システムにアラートを送信します。 |
| kube-state-metrics エージェント | kube-state-metrics エクスポーターエージェント (上記の図の KSM) は、Kubernetes オブジェクトを Prometheus が使用できるメトリクスに変換します。 |
| monitoring-plugin | monitoring-plugin 動的プラグインコンポーネントは、OpenShift Container Platform Web コンソールの Observe セクションにモニタリングページをデプロイします。Cluster Monitoring Operator config map 設定を使用すると、Web コンソールページの monitoring-plugin リソースを管理できます。 |
| openshift-state-metrics エージェント | openshift-state-metrics エクスポーター (上記の図の OSM) は、OpenShift Container Platform 固有のリソースのメトリクスを追加して、kube-state-metrics を拡張します。 |
| node-exporter エージェント | ノードエクスポーターエージェント (上記の図の NE) は、クラスター内のすべてのノードに関するメトリクスを収集します。node-exporter エージェントはすべてのノードにデプロイされます。 |
| Thanos Querier | Thanos Querier は、単一のマルチテナントインターフェイスで、OpenShift Container Platform のコアメトリクスおよびユーザー定義プロジェクトのメトリクスを集約し、オプションでこれらの重複を排除します。 |
| Telemeter クライアント | Telemeter Client は、プラットフォームの Prometheus インスタンスから Red Hat にデータのサブセクションを送信し、クラスターのリモートヘルスモニタリングを有効にします。 |
モニタリングスタックは、スタック内のすべてのコンポーネントを監視します。このコンポーネントは、OpenShift Container Platform の更新時に自動的に更新されます。
1.2.2.1. デフォルトのモニタリングターゲット
スタック自体のコンポーネントに加えて、デフォルトのモニタリングスタックは追加のプラットフォームコンポーネントを監視します。
以下は、モニタリングターゲットの例です。
- CoreDNS
- etcd
- HAProxy
- イメージレジストリー
- Kubelets
- Kubernetes API サーバー
- Kubernetes コントローラーマネージャー
- Kubernetes スケジューラー
- OpenShift API サーバー
- OpenShift Controller Manager
- Operator Lifecycle Manager (OLM)
- ターゲットの正確なリストは、クラスターの機能とインストールされているコンポーネントによって異なる場合があります。
- 各 OpenShift Container Platform コンポーネントはそれぞれのモニタリング設定を行います。OpenShift Container Platform コンポーネントのモニタリングに関する問題は、Jira 問題 で一般的なモニタリングコンポーネントではなく、特定のコンポーネントに対してバグを報告してください。
他の OpenShift Container Platform フレームワークのコンポーネントもメトリクスを公開する場合があります。詳細は、それぞれのドキュメントを参照してください。
1.2.3. ユーザー定義プロジェクトをモニターするためのコンポーネント
OpenShift Container Platform には、ユーザー定義プロジェクトでサービスおよび Pod を監視する際に役立つモニタリングスタックのオプションの機能拡張が含まれています。この機能には、以下のコンポーネントが含まれます。
| コンポーネント | 説明 |
|---|---|
| Prometheus Operator |
|
| Prometheus | Prometheus は、ユーザー定義プロジェクトのモニタリングを提供するモニタリングシステムです。Prometheus は処理のためにアラートを Alertmanager に送信します。 |
| Thanos Ruler | Thanos Ruler は、別のプロセスとしてデプロイされる Prometheus のルール評価エンジンです。OpenShift Container Platform では、Thanos Ruler はユーザー定義プロジェクトをモニタリングするためのルールおよびアラート評価を提供します。 |
| Alertmanager | Alertmanager サービスは、Prometheus および Thanos Ruler から送信されるアラートを処理します。Alertmanager はユーザー定義のアラートを外部通知システムに送信します。このサービスのデプロイは任意です。 |
上記の表のコンポーネントは、ユーザー定義プロジェクトのモニタリングを有効にした後にデプロイされます。
モニタリングスタックは、ユーザー定義プロジェクトのすべてのコンポーネントを監視します。このコンポーネントは、OpenShift Container Platform の更新時に自動的に更新されます。
1.2.3.1. ユーザー定義プロジェクトのターゲットのモニタリング
ユーザー定義プロジェクトのモニタリングを有効にすると、以下を監視できます。
- ユーザー定義プロジェクトのサービスエンドポイント経由で提供されるメトリクス。
- ユーザー定義プロジェクトで実行される Pod。
1.2.4. 高可用性クラスターでのモニタリングスタック
マルチノードクラスターでは、データの損失やサービスの停止を防ぐために、次のコンポーネントがデフォルトで高可用性 (HA) モードで実行されます。
- Prometheus
- Alertmanager
- Thanos Ruler
- Thanos Querier
- Prometheus アダプター
- モニタリングプラグイン
コンポーネントは 2 つの Pod にレプリケートされ、それぞれが別のノードで実行されます。そのため、モニタリングスタックは 1 つの Pod の損失に耐えることができます。
- HA モードの Prometheus
- 両方のレプリカが独立して同じターゲットをスクレイピングし、同じルールを評価します。
- レプリカは相互に通信しません。したがって、Pod 間でデータが異なる場合があります。
- HA モードの Alertmanager
- 2 つのレプリカが通知とサイレンス状態を相互に同期します。これにより、各通知が少なくとも 1 回は送信されます。
- レプリカが通信に失敗した場合、または受信側に問題がある場合、通知は送信されますが、重複する可能性があります。
Prometheus、Alertmanager、Thanos Ruler はステートフルコンポーネントです。高可用性を実現するには、これらのコンポーネントを永続ストレージを使用して設定する必要があります。
1.2.5. モニタリングスタックにおける TLS セキュリティーとローテーション
通信をセキュアに保つために、OpenShift Container Platform モニタリングスタックで TLS プロファイルと証明書のローテーションがどのように機能するか説明します。
- 監視コンポーネントの TLS セキュリティープロファイル
-
モニタリングスタックのすべてのコンポーネントは、クラスター管理者が一元的に設定する TLS セキュリティープロファイル設定を使用します。モニタリングスタックコンポーネントは、グローバル OpenShift Container Platform
apiservers.config.openshift.io/clusterリソースのtlsSecurityProfileフィールドにすでに存在する TLS セキュリティープロファイル設定を使用します。 - TLS 証明書のローテーションと自動再起動
Cluster Monitoring Operator は、モニタリングコンポーネントの内部 TLS 証明書のライフサイクルを管理します。これらの証明書は、モニタリングコンポーネント間の内部通信を保護します。
証明書のローテーション中に、CMO はシークレットと config map を更新し、影響を受ける Pod の自動再起動をトリガーします。これは想定された動作であり、Pod は自動的に回復します。
次の例は、証明書のローテーション中に発生するイベントを示しています。
$ oc get events -n openshift-monitoring LAST SEEN TYPE REASON OBJECT MESSAGE 2h39m Normal SecretUpdated deployment/cluster-monitoring-operator Updated Secret/grpc-tls -n openshift-monitoring because it changed 2h39m Normal SecretCreated deployment/cluster-monitoring-operator Created Secret/prometheus-user-workload-grpc-tls -n openshift-user-workload-monitoring because it was missing 2h39m Normal SecretCreated deployment/cluster-monitoring-operator Created Secret/thanos-querier-grpc-tls -n openshift-monitoring because it was missing 2h39m Normal SecretCreated deployment/cluster-monitoring-operator Created Secret/thanos-ruler-grpc-tls -n openshift-user-workload-monitoring because it was missing 2h39m Normal SecretCreated deployment/cluster-monitoring-operator Created Secret/prometheus-k8s-grpc-tls -n openshift-monitoring because it was missing 2h38m Warning FailedMount pod/prometheus-k8s-0 MountVolume.SetUp failed for volume "secret-grpc-tls" : secret "prometheus-k8s-grpc-tls" not found 2h39m Normal Created pod/prometheus-k8s-0 Created container kube-rbac-proxy-thanos 2h39m Normal Started pod/prometheus-k8s-0 Started container kube-rbac-proxy-thanos 2h39m Normal SuccessfulDelete statefulset/prometheus-k8s delete Pod prometheus-k8s-0 in StatefulSet prometheus-k8s successful 2h39m Normal SuccessfulCreate statefulset/prometheus-k8s create Pod prometheus-k8s-0 in StatefulSet prometheus-k8s successful
1.2.6. OpenShift Container Platform モニタリングの一般用語集
この用語集では、OpenShift Container Platform アーキテクチャーで使用される一般的な用語を定義します。
- Alertmanager
- Alertmanager は、Prometheus から受信したアラートを処理します。また、Alertmanager は外部の通知システムにアラートを送信します。
- アラートルール
- アラートルールには、クラスター内の特定の状態を示す一連の条件が含まれます。アラートは、これらの条件が true の場合にトリガーされます。アラートルールには、アラートのルーティング方法を定義する重大度を割り当てることができます。
- Cluster Monitoring Operator
- Cluster Monitoring Operator (CMO) は、モニタリングスタックの中心的なコンポーネントです。Thanos Querier、Telemeter Client、メトリクスターゲットなどの Prometheus インスタンスをデプロイおよび管理して、それらが最新であることを確認します。CMO は Cluster Version Operator (CVO) によってデプロイされます。
- Cluster Version Operator
- Cluster Version Operator (CVO) は Cluster Operator のライフサイクルを管理し、その多くはデフォルトで OpenShift Container Platform にインストールされます。
- config map
-
config map は、設定データを Pod に注入する方法を提供します。タイプ
ConfigMapのボリューム内の config map に格納されたデータを参照できます。Pod で実行しているアプリケーションは、このデータを使用できます。 - コンテナー
- コンテナーは、ソフトウェアとそのすべての依存関係を含む軽量で実行可能なイメージです。コンテナーは、オペレーティングシステムを仮想化します。そのため、コンテナーはデータセンターからパブリッククラウド、プライベートクラウド、開発者のラップトップなどまで、場所を問わずコンテナーを実行できます。
- カスタムリソース (CR)
- CR は Kubernetes API のエクステンションです。カスタムリソースを作成できます。
- etcd
- etcd は OpenShift Container Platform のキーと値のストアであり、すべてのリソースオブジェクトの状態を保存します。
- Fluentd
Fluentd は、各 OpenShift Container Platform ノードに常駐するログコレクターです。アプリケーション、インフラストラクチャー、および監査ログを収集し、それらをさまざまな出力に転送します。
注記Fluentd は非推奨となっており、今後のリリースで削除される予定です。Red Hat は、現在のリリースのライフサイクル中にこの機能のバグ修正とサポートを提供しますが、この機能は拡張されなくなりました。Fluentd の代わりに、Vector を使用できます。
- Kubelets
- ノード上で実行され、コンテナーマニフェストを読み取ります。定義されたコンテナーが開始され、実行されていることを確認します。
- Kubernetes API サーバー
- Kubernetes API サーバーは、API オブジェクトのデータを検証して設定します。
- Kubernetes コントローラーマネージャー
- Kubernetes コントローラーマネージャーは、クラスターの状態を管理します。
- Kubernetes スケジューラー
- Kubernetes スケジューラーは Pod をノードに割り当てます。
- ラベル
- ラベルは、Pod などのオブジェクトのサブセットを整理および選択するために使用できるキーと値のペアです。
- node
- OpenShift Container Platform クラスター内のコンピュートマシン。ノードは、仮想マシン (VM) または物理マシンのいずれかです。
- Operator
- OpenShift Container Platform クラスターで Kubernetes アプリケーションをパッケージ化、デプロイ、および管理するための推奨される方法。Operator は、人間による操作に関する知識を取り入れて、簡単にパッケージ化してお客様と共有できるソフトウェアにエンコードします。
- Operator Lifecycle Manager (OLM)
- OLM は、Kubernetes ネイティブアプリケーションのライフサイクルをインストール、更新、および管理するのに役立ちます。OLM は、Operator を効果的かつ自動化されたスケーラブルな方法で管理するために設計されたオープンソースのツールキットです。
- 永続ストレージ
- デバイスがシャットダウンされた後でもデータを保存します。Kubernetes は永続ボリュームを使用して、アプリケーションデータを保存します。
- 永続ボリューム要求 (PVC)
- PVC を使用して、PersistentVolume を Pod にマウントできます。クラウド環境の詳細を知らなくてもストレージにアクセスできます。
- Pod
- Pod は、Kubernetes における最小の論理単位です。Pod は、ワーカーノードで実行される 1 つ以上のコンテナーで構成されます。
- Prometheus
- Prometheus は、OpenShift Container Platform モニタリングスタックのベースとなるモニタリングシステムです。Prometheus は時系列データベースであり、メトリクスのルール評価エンジンです。Prometheus は処理のためにアラートを Alertmanager に送信します。
- Prometheus アダプター
- Prometheus アダプターは、Prometheus で使用するために Kubernetes ノードと Pod のクエリーを変換します。変換されるリソースメトリクスには、CPU およびメモリーの使用率が含まれます。Prometheus アダプターは、Horizontal Pod Autoscaling のクラスターリソースメトリクス API を公開します。
- Prometheus Operator
-
openshift-monitoringプロジェクトの Prometheus Operator は、プラットフォーム Prometheus インスタンスおよび Alertmanager インスタンスを作成、設定、および管理します。また、Kubernetes ラベルのクエリーに基づいてモニタリングターゲットの設定を自動生成します。 - サイレンス
- サイレンスをアラートに適用し、アラートの条件が true の場合に通知が送信されることを防ぐことができます。初期通知後はアラートをミュートにして、根本的な問題の解決に取り組むことができます。
- ストレージ
- OpenShift Container Platform は、オンプレミスおよびクラウドプロバイダーの両方で、多くのタイプのストレージをサポートします。OpenShift Container Platform クラスターで、永続データおよび非永続データ用のコンテナーストレージを管理できます。
- Thanos Ruler
- Thanos Ruler は、別のプロセスとしてデプロイされる Prometheus のルール評価エンジンです。OpenShift Container Platform では、Thanos Ruler はユーザー定義プロジェクトをモニタリングするためのルールおよびアラート評価を提供します。
- Vector
- Vector は、各 OpenShift Container Platform ノードにデプロイするログコレクターです。各ノードからログデータを収集し、データを変換して、設定された出力に転送します。
- Web コンソール
- OpenShift Container Platform を管理するためのユーザーインターフェイス (UI)。
1.3. モニタリングスタックについて - 主な概念
OpenShift Container Platform のモニタリングの概念と用語を解説します。クラスターのパフォーマンスとスケールを向上させる方法、データを保存および記録する方法、メトリクスとアラートを管理する方法などを説明します。
1.3.1. パフォーマンスとスケーラビリティーについて
クラスターのパフォーマンスとスケールを最適化できます。次のアクションを実行して、デフォルトのモニタリングスタックを設定できます。
モニタリングコンポーネントの配置と分散を制御します。
- ノードセレクターを使用して、コンポーネントを特定のノードに移動します。
- taint されたノードにコンポーネントを移動できるように toleration を割り当てます。
- Pod トポロジー分散制約を使用します。
- メトリクススクレイピングのボディーサイズ制限を設定します。
- CPU とメモリーのリソースを管理します。
- メトリクス収集プロファイルを使用します。
1.3.1.1. ノードセレクターを使用したモニタリングコンポーネントの移動
ラベル付きノードで nodeSelector 制約を使用すると、任意のモニタリングスタックコンポーネントを特定ノードに移動できます。これにより、クラスター全体のモニタリングコンポーネントの配置と分散を制御できます。
モニタリングコンポーネントの配置と分散を制御して、システムリソースの使用を最適化し、パフォーマンスを高め、特定の要件やポリシーに基づいてワークロードを分離できます。
ノードセレクターと他の制約の連携
ノードセレクターの制約を使用してモニタリングコンポーネントを移動する場合、クラスターに Pod のスケジューリングを制御するための他の制約があることに注意してください。
- Pod の配置を制御するために、トポロジー分散制約が設定されている可能性があります。
- Prometheus、Alertmanager、およびその他のモニタリングコンポーネントでは、コンポーネントの複数の Pod が必ず異なるノードに分散されて高可用性が常に確保されるように、ハードなアンチアフィニティールールが設定されています。
ノード上で Pod をスケジュールする場合、Pod スケジューラーは既存の制約をすべて満たすように Pod の配置を決定します。つまり、Pod スケジューラーがどの Pod をどのノードに配置するかを決定する際に、すべての制約が組み合わされます。
そのため、ノードセレクター制約を設定しても既存の制約をすべて満たすことができない場合、Pod スケジューラーはすべての制約をマッチさせることができず、ノードへの Pod 配置をスケジュールしません。
モニタリングコンポーネントの耐障害性と高可用性を維持するには、コンポーネントを移動するノードセレクター制約を設定する際に、十分な数のノードが利用可能で、すべての制約がマッチすることを確認してください。
1.3.1.2. モニタリングのための Pod トポロジー分散制約について
OpenShift Container Platform Pod が複数のアベイラビリティーゾーンにデプロイされている場合は、Pod トポロジーの分散制約を使用して、モニタリング Pod がネットワークトポロジー全体にどのように分散されるかを制御できます。
Pod トポロジーの分散制約は、ノードがリージョンやリージョン内のゾーンなど、さまざまなインフラストラクチャーレベルに分散している階層トポロジー内で Pod のスケジューリングを制御するのに適しています。さらに、さまざまなゾーンで Pod をスケジュールできるため、特定のシナリオでネットワーク遅延を改善できます。
Cluster Monitoring Operator によってデプロイされたすべての Pod に対して Pod トポロジーの分散制約を設定し、ゾーン全体のノードに Pod レプリカをスケジュールする方法を制御できます。これにより、ワークロードが異なるデータセンターまたは階層型インフラストラクチャーゾーンのノードに分散されるため、Pod の可用性が高まり、より効率的に実行されるようになります。
1.3.1.3. モニタリングコンポーネントの制限と要求の指定について
次のコアプラットフォームモニタリングコンポーネントのリソース制限と要求を設定できます。
- Alertmanager
- kube-state-metrics
- monitoring-plugin
- node-exporter
- openshift-state-metrics
- Prometheus
- Prometheus アダプター
- Prometheus Operator とそのアドミッション Webhook サービス
- Telemeter クライアント
- Thanos Querier
ユーザー定義プロジェクトを監視する以下のコンポーネントのリソース制限および要求を設定できます。
- Alertmanager
- Prometheus
- Thanos Ruler
リソース制限を定義することで、コンテナーのリソース使用量を制限し、コンテナーが CPU およびメモリーリソースの指定された最大値を超えないようにします。
リソース要求を定義することで、要求されたリソースに一致するのに十分な CPU およびメモリーリソースがあるノードでのみコンテナーをスケジュールできることを指定します。
1.3.1.4. メトリクス収集プロファイルについて
メトリクス収集プロファイルはテクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
デフォルトでは、Prometheus は OpenShift Container Platform コンポーネントのすべてのデフォルトのメトリクスターゲットによって公開されたメトリクスを収集します。ただし、特定のシナリオでは、Prometheus がクラスターから収集するメトリクスを少なくしたい場合があります。
- クラスター管理者がアラート、テレメトリー、およびコンソールメトリクスのみを必要とし、他のメトリクスを使用可能にする必要がない場合。
- クラスターのサイズが大きくなり、収集されるデフォルトのメトリクスデータのサイズが大きくなった場合、CPU とメモリーリソースを大幅に増やす必要があります。
メトリクス収集プロファイルを使用して、デフォルトの量のメトリクスデータまたは最小量のメトリクスデータを収集できます。最小限のメトリクスデータを収集すると、アラートなどの基本的なモニタリング機能は引き続き機能します。同時に、Prometheus が必要とする CPU およびメモリーリソースが減少します。
次の 2 つのメトリクス収集プロファイルのいずれかを有効にできます。
- full: Prometheus は、すべてのプラットフォームコンポーネントによって公開されるメトリクスデータを収集します。この設定がデフォルトです。
- minimal: Prometheus は、プラットフォームアラート、記録ルール、テレメトリー、およびコンソールダッシュボードに必要なメトリクスデータのみを収集します。
1.3.2. データの保存と記録について
データを保存および記録することで、データを保護し、トラブルシューティングに役立てることができます。次のアクションを実行して、デフォルトのモニタリングスタックを設定できます。
永続ストレージを設定します。
- メトリクスとアラートデータを永続ボリューム (PV) に保存することで、データ損失から保護します。その結果、Pod が再起動または再作成されても存続できます。
- Alertmanager Pod が再起動したときに、重複した通知を受信したり、アラートのサイレンスが失われたりするのを回避します。
- Prometheus および Thanos Ruler メトリクスデータの保持時間とサイズを変更します。
クラスターの問題のトラブルシューティングに役立つロギングを設定します。
- Metrics Server の監査ログを設定します。
- モニタリングのログレベルを設定します。
- Prometheus および Thanos Querier のクエリーロギングを有効にします。
1.3.2.1. Prometheus メトリクスの保持時間とサイズ
デフォルトで、Prometheus がメトリクスデータを保持する期間のデフォルトは以下のとおりです。
- コアプラットフォームのモニタリング: 15 日間
- ユーザー定義プロジェクトの監視: 24 時間
Prometheus インスタンスの保持時間を変更して、データが削除されるまでの時間を変更できます。保持されるメトリクスデータが使用するディスク容量の最大量を設定することもできます。データがこのサイズ制限に達すると、使用するディスク領域が上限を下回るまで、Prometheus は最も古いデータを削除します。
これらのデータ保持設定は、以下の挙動に注意してください。
-
サイズベースのリテンションポリシーは、
/prometheusディレクトリー内のすべてのデータブロックディレクトリーに適用され、永続ブロック、ライトアヘッドログ (WAL) データ、および m-mapped チャンクも含まれます。 -
/walおよび/head_chunksディレクトリー内のデータは保持サイズ制限にカウントされますが、Prometheus がサイズまたは時間ベースの保持ポリシーに基づいてこれらのディレクトリーからデータをパージすることはありません。したがって、/walディレクトリーおよび/head_chunksディレクトリーに設定された最大サイズよりも低い保持サイズ制限を設定すると、/prometheusデータディレクトリーにデータブロックを保持しないようにシステムを設定している。 - サイズベースの保持ポリシーは、Prometheus が新規データブロックをカットする場合にのみ適用されます。これは、WAL に少なくとも 3 時間のデータが含まれてから 2 時間ごとに実行されます。
-
retentionまたはretentionSizeの値を明示的に定義しない場合、保持期間のデフォルトは、コアプラットフォームの監視は 15 日間、ユーザー定義プロジェクトの監視は 24 時間です。保持サイズは設定されていません。 -
retentionおよびretentionSizeの両方に値を定義すると、両方の値が適用されます。データブロックが定義された保持時間または定義されたサイズ制限を超える場合、Prometheus はこれらのデータブロックをパージします。 -
retentionSizeの値を定義してretentionを定義しない場合、retentionSize値のみが適用されます。 -
retentionSizeの値を定義しておらず、pretentionの値のみを定義する場合、retention値のみが適用されます。 -
retentionSizeまたはretentionの値を0に設定すると、デフォルト設定が適用されます。保持期間のデフォルト設定は、コアプラットフォームの監視の場合は 15 日間、ユーザー定義プロジェクトの監視の場合は 24 時間です。デフォルトでは、保持サイズは設定されていません。
データコンパクションは 2 時間ごとに実行されます。そのため、コンパクションが実行される前に永続ボリューム (PV) がいっぱいになり、retentionSize 制限を超える可能性があります。その場合、PV 上のスペースが retentionSize 制限を下回るまで、KubePersistentVolumeFillingUp アラートが発生します。
1.3.3. メトリクスについて
OpenShift Container Platform 4.15 では、クラスターコンポーネントはサービスエンドポイントで公開されるメトリクスを収集することによりモニターされます。ユーザー定義プロジェクトのメトリクスのコレクションを設定することもできます。メトリクスを使用すると、クラスターコンポーネントおよび独自のワークロードの実行方法をモニターできます。
Prometheus クライアントライブラリーをアプリケーションレベルで使用することで、独自のワークロードに指定するメトリクスを定義できます。
OpenShift Container Platform では、メトリクスは /metrics の正規名の下に HTTP サービスエンドポイント経由で公開されます。curl クエリーを http://<endpoint>/metrics に対して実行して、サービスの利用可能なすべてのメトリクスをリスト表示できます。たとえば、prometheus-example-app サンプルアプリケーションへのルートを公開し、以下のコマンドを実行して利用可能なすべてのメトリクスを表示できます。
$ curl http://<example_app_endpoint>/metrics出力例
# HELP http_requests_total Count of all HTTP requests
# TYPE http_requests_total counter
http_requests_total{code="200",method="get"} 4
http_requests_total{code="404",method="get"} 2
# HELP version Version information about this binary
# TYPE version gauge
version{version="v0.1.0"} 11.3.3.1. ユーザー定義プロジェクトでバインドされていないメトリクス属性の影響の制御
開発者は、キーと値のペアの形式でメトリクスの属性を定義するためにラベルを作成できます。使用できる可能性のあるキーと値のペアの数は、属性に使用できる可能性のある値の数に対応します。数が無制限の値を持つ属性は、バインドされていない属性と呼ばれます。たとえば、customer_id 属性は、使用できる値が無限にあるため、バインドされていない属性になります。
割り当てられるキーと値のペアにはすべて、一意の時系列があります。ラベルに多数のバインドされていない値を使用すると、作成される時系列の数が指数関数的に増加する可能性があります。これは Prometheus のパフォーマンスに影響する可能性があり、多くのディスク領域を消費する可能性があります。
クラスター管理者は、以下の手段を使用して、ユーザー定義プロジェクトでのバインドされていないメトリクス属性の影響を制御できます。
- ユーザー定義プロジェクトでターゲットスクレイピングごとの許容可能なサンプル数を制限する
- 収集されたラベルの数、ラベル名の長さ、およびラベル値の長さを制限します。
- 収集サンプルのしきい値に達するか、ターゲットを収集できない場合に実行されるアラートを作成します。
スクレイピングサンプル数を制限すると、ラベルにバインドされない属性を多数追加することによって発生する問題を防ぐことができます。さらに開発者は、メトリクスに定義するバインドされていない属性の数を制限することにより、根本的な原因を防ぐことができます。使用可能な値の制限されたセットにバインドされる属性を使用すると、可能なキーと値のペアの組み合わせの数が減ります。
1.3.3.2. クラスター ID ラベルのメトリクスへの追加
複数の OpenShift Container Platform クラスターを管理し、リモート書き込み機能を使用してメトリクスデータをこれらのクラスターから外部ストレージの場所に送信する場合、クラスター ID ラベルを追加して、異なるクラスターから送られるメトリクスデータを特定できます。次に、これらのラベルをクエリーし、メトリクスのソースクラスターを特定し、そのデータを他のクラスターによって送信される同様のメトリクスデータと区別することができます。
これにより、複数の顧客に対して多数のクラスターを管理し、メトリクスデータを単一の集中ストレージシステムに送信する場合、クラスター ID ラベルを使用して特定のクラスターまたはお客様のメトリクスをクエリーできます。
クラスター ID ラベルの作成および使用には、以下の 3 つの一般的な手順が必要です。
- リモート書き込みストレージの書き込みラベルの設定。
- クラスター ID ラベルをメトリクスに追加します。
- これらのラベルを取得し、メトリクスのソースクラスターまたはカスタマーを特定します。
1.3.4. モニタリングダッシュボードについて
OpenShift Container Platform は、クラスターコンポーネントとユーザー定義のワークロードの状態を理解するのに役立つ一連のモニタリングダッシュボードを提供します。
1.3.4.1. Administrator パースペクティブでのダッシュボードの監視
Administrator パースペクティブを使用して、以下を含む OpenShift Container Platform のコアコンポーネントのダッシュボードにアクセスします。
- API パフォーマンス
- etcd
- Kubernetes コンピュートリソース
- Kubernetes ネットワークリソース
- Prometheus
- クラスターおよびノードのパフォーマンスに関連する USE メソッドダッシュボード
- ノードのパフォーマンスメトリクス
図1.1 Administrator パースペクティブのダッシュボードの例

1.3.4.2. Developer パースペクティブでのダッシュボードの監視
Developer パースペクティブを使用して、選択されたプロジェクトの以下のアプリケーションメトリクスを提供する Kubernetes コンピュートリソースダッシュボードにアクセスします。
- CPU usage (CPU の使用率)
- メモリー使用量
- 帯域幅に関する情報
- パケットレート情報
図1.2 Developer パースペクティブのダッシュボードの例

1.3.5. アラートの管理
OpenShift Container Platform では、アラート UI を使用してアラート、サイレンス、およびアラートルールを管理できます。
- アラートルール。アラートルールには、クラスター内の特定の状態を示す一連の条件が含まれます。アラートは、これらの条件が true の場合にトリガーされます。アラートルールには、アラートのルーティング方法を定義する重大度を割り当てることができます。
- アラート。アラートは、アラートルールで定義された条件が true の場合に発生します。アラートは、一連の状況が OpenShift Container Platform クラスター内で明確であることを示す通知を提供します。
- サイレンス。サイレンスをアラートに適用し、アラートの条件が true の場合に通知が送信されることを防ぐことができます。最初の通知の後、問題の解決に取り組んでいる間は、アラートをミュートすることができます。
アラート UI で利用可能なアラート、サイレンス、およびアラートルールは、アクセス可能なプロジェクトに関連付けられます。たとえば、cluster-admin ロールを持つユーザーとしてログインしている場合は、すべてのアラート、サイレント、およびアラートルールにアクセスできます。
1.3.5.1. サイレンスの管理
OpenShift Container Platform Web コンソールの Administrator パースペクティブと Developer パースペクティブの両方で、アラートのサイレンスを作成できます。サイレンスを作成すると、アラートが発生したときにアラートに関する通知を受信しなくなります。
サイレントの作成は、最初のアラート通知を受信し、アラートの発生の原因となっている根本的な問題を解決するまでの間、さらなる通知を受け取りたくないシナリオで役立ちます。
サイレンスの作成時に、サイレンスをすぐにアクティブにするか、後にアクティブにするかを指定する必要があります。また、サイレンスの有効期限を設定する必要もあります。
サイレンスを作成した後、それらを表示、編集、および期限切れにすることができます。
サイレンスを作成すると、それらは Alertmanager Pod 全体に複製されます。ただし、Alertmanager の永続ストレージを設定しないと、サイレンスが失われる可能性があります。これは、たとえば、すべての Alertmanager Pod が同時に再起動した場合に発生する可能性があります。
1.3.5.2. コアプラットフォームモニタリングのアラートルールの管理
OpenShift Container Platform のモニタリングには、プラットフォームメトリクス用のデフォルトのアラートルールが多数用意されています。クラスター管理者は、このルールセットを 2 つの方法でカスタマイズできます。
-
しきい値を調整するか、ラベルを追加および変更して、既存のプラットフォームのアラートルールの設定を変更します。たとえば、アラートの
severityラベルをwarningからcriticalに変更すると、アラートのフラグが付いた問題のルーティングおよびトリアージに役立ちます。 -
openshift-monitoringnamespace のコアプラットフォームメトリクスに基づいてクエリー式を作成することにより、新しいカスタムアラートルールを定義して追加します。
コアプラットフォームのアラートルールの考慮事項
- 新規のアラートルールはデフォルトの OpenShift Container Platform モニタリングメトリクスをベースとする必要があります。
-
openshift-monitoringnamespace にAlertingRuleオブジェクトとAlertRelabelConfigオブジェクトを作成する必要があります。 - アラートルールのみを追加および変更できます。新しい記録ルールを作成したり、既存の記録ルールを変更したりすることはできません。
-
AlertRelabelConfigオブジェクトを使用して既存のプラットフォームのアラートルールを変更する場合、変更は Prometheus アラート API に反映されません。そのため、削除されたアラートは Alertmanager に転送されていなくても OpenShift Container Platform Web コンソールに表示されます。さらに、severityラベルの変更など、アラートへの変更は Web コンソールには表示されません。
1.3.5.3. コアプラットフォームモニタリングのアラートルールを最適化するためのヒント
組織の特定のニーズに合わせてコアプラットフォームのアラートルールをカスタマイズする場合は、次のガイドラインに従って、カスタマイズされたルールが効率的かつ効果的であることを確認してください。
- 新しいルールの数を最小限に抑えます。特定の要件に不可欠なルールのみを作成します。ルールの数を最小限に抑えることで、より管理しやすく、焦点を絞ったアラートシステムをモニタリング環境に作成できます。
- 原因ではなく症状に焦点を当てます。根本的な原因ではなく症状をユーザーに通知するルールを作成します。このアプローチにより、関連する症状がユーザーに即座に通知され、アラートがトリガーされた後に根本原因を調査できるようになります。この戦略により、作成する必要があるルールの総数も大幅に削減されます。
- 変更を実装する前に、ニーズを計画し、評価します。まず、どの症状が重要であり、これらの症状が発生した場合にユーザーにどのようなアクションをとってもらいたいかを決定します。次に、既存のルールを評価し、症状ごとにまったく新しいルールを作成するのではなく、ニーズを満たすためにルールを変更できるかどうかを判断します。既存のルールを変更し、新しいルールを慎重に作成することで、アラートシステムを合理化できます。
- クリアなアラートメッセージングを提供します。アラートメッセージを作成するときは、症状、考えられる原因、推奨されるアクションを説明します。明確で簡潔な説明と、トラブルシューティング手順または詳細情報へのリンクを含めます。そうすることで、ユーザーは状況を迅速に評価し、適切に対応することができます。
- 重大度レベルを含めます。ルールに重大度レベルを割り当てて、症状が発生してアラートがトリガーされたときにユーザーがどのように反応する必要があるかを示します。たとえば、アラートを Critical として分類すると、個人または重要な対応チームが直ちに対応する必要があることを示します。重大度レベルを定義することで、ユーザーがアラートへの対応方法を理解し、最も緊急性の高い問題に迅速な対応を確実に受けられるようになります。
1.3.5.4. ユーザー定義プロジェクトのアラートルールの作成
ユーザー定義プロジェクトのアラートルールを作成する場合は、新しいルールを定義する際に次の主要な動作と重要な制限事項を考慮してください。
ユーザー定義のアラートルールには、コアプラットフォームのモニタリングからのデフォルトメトリクスに加えて、独自のプロジェクトが公開したメトリクスを含めることができます。別のユーザー定義プロジェクトのメトリクスを含めることはできません。
たとえば、
ns1ユーザー定義プロジェクトのアラートルールでは、CPU やメモリーメトリクスなどのコアプラットフォームメトリクスに加えて、ns1プロジェクトが公開したメトリクスも使用できます。ただし、ルールには、別のns2ユーザー定義プロジェクトからのメトリクスを含めることはできません。レイテンシーを短縮し、コアプラットフォームモニタリングコンポーネントの負荷を最小限に抑えるために、ルールに
openshift.io/prometheus-rule-evaluation-scope: leaf-prometheusラベルを追加できます。このラベルは、openshift-user-workload-monitoringプロジェクトにデプロイされた Prometheus インスタンスのみにアラートルールの評価を強制し、Thanos Ruler インスタンスによる評価を防ぎます。重要アラートルールにこのラベルが付いている場合、そのアラートルールはユーザー定義プロジェクトが公開するメトリクスのみを使用できます。デフォルトのプラットフォームメトリクスに基づいて作成したアラートルールでは、アラートがトリガーされない場合があります。
1.3.5.5. ユーザー定義プロジェクトのアラートルールの管理
OpenShift Container Platform では、ユーザー定義プロジェクト内のアラートルールを表示、編集、削除できます。
アラートルールに関する考慮事項
- デフォルトのアラートルールは OpenShift Container Platform クラスター用に使用され、それ以外の目的では使用されません。
- 一部のアラートルールには、複数の意図的に同じ名前が含まれます。それらは同じイベントに関するアラートを送信しますが、それぞれ異なるしきい値、重大度およびそれらの両方が設定されます。
- 抑制 (inhibition) ルールは、高い重大度のアラートが実行される際に実行される低い重大度のアラートの通知を防ぎます。
1.3.5.6. ユーザー定義プロジェクトのアラートの最適化
アラートルールの作成時に以下の推奨事項を考慮して、独自のプロジェクトのアラートを最適化できます。
- プロジェクト用に作成するアラートルールの数を最小限にします。影響を与える状況を通知するアラートルールを作成します。影響を与えない条件に対して多数のアラートを生成すると、関連するアラートに気づくのがさらに困難になります。
- 原因ではなく現象に関するアラートルールを作成します。根本的な原因に関係なく、状態を通知するアラートルールを作成します。次に、原因を調査できます。アラートルールのそれぞれが特定の原因にのみ関連する場合に、さらに多くのアラートルールが必要になります。そのため、いくつかの原因は見落される可能性があります。
- アラートルールを作成する前にプランニングを行います。重要な現象と、その発生時に実行するアクションを決定します。次に、現象別にアラートルールをビルドします。
- クリアなアラートメッセージングを提供します。アラートメッセージに現象および推奨されるアクションを記載します。
- アラートルールに重大度レベルを含めます。アラートの重大度は、報告される現象が生じた場合に取るべき対応によって異なります。たとえば、現象に個人または緊急対策チーム (Critical Response Team) による早急な対応が必要な場合は、重大アラートをトリガーする必要があります。
1.3.5.7. アラート、サイレンスおよびアラートルールの検索およびフィルター
アラート UI に表示されるアラート、サイレンス、およびアラートルールをフィルターできます。このセクションでは、利用可能な各フィルターオプションを説明します。
1.3.5.7.1. アラートフィルターについて
Administrator パースペクティブでは、アラート UI の Alerts ページに、デフォルトの OpenShift Container Platform プロジェクトおよびユーザー定義プロジェクトに関連するアラートの詳細が提供されます。このページには、各アラートの重大度、状態、およびソースの概要が含まれます。アラートが現在の状態に切り替わった時間も表示されます。
アラートの状態、重大度、およびソースでフィルターできます。デフォルトでは、Firing の Platform アラートのみが表示されます。以下では、それぞれのアラートフィルターオプションを説明します。
State フィルター:
-
Firing。アラート条件が true で、オプションの
forの期間を経過しているためにアラートが実行されます。条件が true である間、アラートの発生が続きます。 - Pending。アラートはアクティブですが、アラート実行前のアラートルールに指定される期間待機します。
- Silenced。指定の期間、アラートがサイレントになります。定義するラベルセレクターのセットに基づいてアラートを一時的にミュートします。リストされたすべての値または正規表現に一致するアラートの土は送信されません。
-
Firing。アラート条件が true で、オプションの
Severity フィルター:
- Critical。アラートをトリガーした状態は重大な影響を与える可能性があります。このアラートには、実行時に早急な対応が必要となり、通常は個人または緊急対策チーム (Critical Response Team) に送信先が設定されます。
- Warning。アラートは、問題の発生を防ぐために注意が必要になる可能性のある問題に関する警告通知を提供します。通常、警告は早急な対応を要さないレビュー用にチケットシステムにルート指定されます。
- Info。アラートは情報提供のみを目的として提供されます。
- None。アラートには重大度が定義されていません。
- また、ユーザー定義プロジェクトに関連するアラートの重大度の定義を作成することもできます。
Source フィルター:
- Platform。プラットフォームレベルのアラートは、デフォルトの OpenShift Container Platform プロジェクトにのみ関連します。これらのプロジェクトは OpenShift Container Platform のコア機能を提供します。
- User。ユーザーアラートはユーザー定義のプロジェクトに関連します。これらのアラートはユーザーによって作成され、カスタマイズ可能です。ユーザー定義のワークロードモニタリングはインストール後に有効にでき、独自のワークロードへの可観測性を提供します。
1.3.5.7.2. サイレンスフィルターについて
Administrator パースペクティブでは、アラート UI の Silences ページには、デフォルトの OpenShift Container Platform およびユーザー定義プロジェクトのアラートに適用されるサイレンスに関する詳細が示されます。このページには、それぞれのサイレンスの状態の概要とサイレンスが終了する時間の概要が含まれます。
サイレンス状態でフィルターを実行できます。デフォルトでは、Active および Pending のサイレンスのみが表示されます。以下は、それぞれのサイレンス状態のフィルターオプションを説明しています。
State フィルター:
- Active。サイレンスはアクティブで、アラートはサイレンスが期限切れになるまでミュートされます。
- Pending。サイレンスがスケジュールされており、アクティブな状態ではありません。
- Expiredアラートの条件が true の場合は、サイレンスが期限切れになり、通知が送信されます。
1.3.5.7.3. アラートルールフィルターについて
Administrator パースペクティブでは、アラート UI の Alerting rules ページに、デフォルトの OpenShift Container Platform およびユーザー定義プロジェクトに関連するアラートルールの詳細が示されます。このページには、各アラートルールの状態、重大度およびソースの概要が含まれます。
アラート状態、重大度、およびソースを使用してアラートルールをフィルターできます。デフォルトでは、プラットフォーム のアラートルールのみが表示されます。以下では、それぞれのアラートルールのフィルターオプションを説明します。
Alert state フィルター:
-
Firing。アラート条件が true で、オプションの
forの期間を経過しているためにアラートが実行されます。条件が true である間、アラートの発生が続きます。 - Pending。アラートはアクティブですが、アラート実行前のアラートルールに指定される期間待機します。
- Silenced。指定の期間、アラートがサイレントになります。定義するラベルセレクターのセットに基づいてアラートを一時的にミュートします。リストされたすべての値または正規表現に一致するアラートの土は送信されません。
- Not Firingアラートは実行されません。
-
Firing。アラート条件が true で、オプションの
Severity フィルター:
- Critical。アラートルールで定義される状態は重大な影響を与える可能性があります。true の場合は、この状態に早急な対応が必要です。通常、ルールに関連するアラートは個別または緊急対策チーム (Critical Response Team) に送信先が設定されます。
- Warning。アラートルールで定義される状態は、問題の発生を防ぐために注意を要する場合があります。通常、ルールに関連するアラートは早急な対応を要さないレビュー用にチケットシステムにルート指定されます。
- Info。アラートルールは情報アラートのみを提供します。
- None。アラートルールには重大度が定義されていません。
- ユーザー定義プロジェクトに関連するアラートルールのカスタム重大度定義を作成することもできます。
Source フィルター:
- Platform。プラットフォームレベルのアラートルールは、デフォルトの OpenShift Container Platform プロジェクトにのみ関連します。これらのプロジェクトは OpenShift Container Platform のコア機能を提供します。
- User。ユーザー定義のワークロードアラートルールは、ユーザー定義プロジェクトに関連します。これらのアラートルールはユーザーによって作成され、カスタマイズ可能です。ユーザー定義のワークロードモニタリングはインストール後に有効にでき、独自のワークロードへの可観測性を提供します。
1.3.5.7.4. Developer パースペクティブでのアラート、サイレンスおよびアラートルールの検索およびフィルター
Developer パースペクティブでは、アラート UI の Alerts ページに、選択したプロジェクトに関連するアラートとサイレンスを組み合わせたビューが提供されています。規定するアラートルールへのリンクが表示されるアラートごとに提供されます。
このビューでは、アラートの状態と重大度でフィルターを実行できます。デフォルトで、プロジェクトへのアクセス権限がある場合は、選択されたプロジェクトのすべてのアラートが表示されます。これらのフィルターは Administrator パースペクティブについて記載されているフィルターと同じです。
1.3.6. ユーザー定義プロジェクトのアラートルーティングについて
クラスター管理者は、ユーザー定義プロジェクトのアラートルーティングを有効にできます。この機能を使用すると、alert-routing-edit クラスターロールを持つユーザーが、ユーザー定義プロジェクトのアラート通知ルーティングとレシーバーを設定できるようになります。これらの通知は、デフォルトの Alertmanager インスタンスで指定されるか、有効にされている場合にユーザー定義のモニタリング専用のオプションの Alertmanager インスタンスによってルーティングされます。
次に、ユーザーはユーザー定義プロジェクトの AlertmanagerConfig オブジェクトを作成または編集して、ユーザー定義のアラートルーティングを作成し、設定できます。
ユーザーがユーザー定義のプロジェクトのアラートルーティングを定義した後に、ユーザー定義のアラート通知は以下のようにルーティングされます。
-
デフォルトのプラットフォーム Alertmanager インスタンスを使用する場合、
openshift-monitoringnamespace のalertmanager-mainPod に対してこれを実行します。 -
ユーザー定義プロジェクトの Alertmanager の別のインスタンスを有効にしている場合に、
openshift-user-workload-monitoringnamespace でalertmanager-user-workloadPod を行うには、以下を実行します。
ユーザー定義プロジェクトのアラートルーティングに関する次の制限事項を確認してください。
-
ユーザー定義のアラートルールの場合、ユーザー定義のルーティングはリソースが定義される namespace に対してスコープ指定されます。たとえば、namespace
ns1のルーティング設定は、同じ namespace のPrometheusRulesリソースにのみ適用されます。 -
namespace がユーザー定義のモニタリングから除外される場合、namespace の
AlertmanagerConfigリソースは、Alertmanager 設定の一部ではなくなります。
1.3.7. 外部システムへの通知の送信
OpenShift Container Platform 4.15 では、実行するアラートをアラート UI に表示できます。アラートは、デフォルトでは通知システムに送信されるように設定されません。以下のレシーバータイプにアラートを送信するように OpenShift Container Platform を設定できます。
- PagerDuty
- Webhook
- Slack
- Microsoft Teams
レシーバーへのアラートのルートを指定することにより、障害が発生する際に適切なチームに通知をタイムリーに送信できます。たとえば、重大なアラートには早急な対応が必要となり、通常は個人または緊急対策チーム (Critical Response Team) に送信先が設定されます。重大ではない警告通知を提供するアラートは、早急な対応を要さないレビュー用にチケットシステムにルート指定される可能性があります。
Watchdog アラートの使用によるアラートが機能することの確認
OpenShift Container Platform モニタリングには、継続的に実行される Watchdog アラートが含まれます。Alertmanager は、Watchdog のアラート通知を設定された通知プロバイダーに繰り返し送信します。通常、プロバイダーは watchdog アラートの受信を停止する際に管理者に通知するように設定されます。このメカニズムは、Alertmanager と通知プロバイダー間の通信に関連する問題を迅速に特定するのに役立ちます。
第2章 スタートガイド
2.1. モニタリングのメンテナンスおよびサポート
モニタリングスタックのすべての設定オプションが公開されているわけではありません。唯一サポートされている OpenShift Container Platform モニタリング設定方法は、Cluster Monitoring Operator (CMO) の Config map リファレンス で説明されているオプションを使用して Cluster Monitoring Operator を設定する方法です。サポートされていない他の設定は使用しないでください。
設定のパラダイムが Prometheus リリース間で変更される可能性があり、このような変更には、設定のすべての可能性が制御されている場合のみ適切に対応できます。Cluster Monitoring Operator の Config map リファレンス で説明されている設定以外の設定を使用すると、デフォルトおよび設計により、CMO が自動的に差異を調整し、サポートされていない変更を元の定義済みの状態にリセットするため、変更は消えてしまいます。
2.1.1. モニタリングのサポートに関する考慮事項
メトリクス、記録ルールまたはアラートルールの後方互換性を保証されません。
以下の変更は明示的にサポートされていません。
-
追加の
ServiceMonitor、PodMonitor、およびPrometheusRuleオブジェクトをopenshift-*およびkube-*プロジェクトに作成します。 openshift-monitoringまたはopenshift-user-workload-monitoringプロジェクトにデプロイされるリソースまたはオブジェクト変更OpenShift Container Platform モニタリングスタックによって作成されるリソースは、後方互換性の保証がないために他のリソースで使用されることは意図されていません。注記Alertmanager 設定は、
openshift-monitoringnamespace のalertmanager-mainシークレットリソースとしてデプロイされます。ユーザー定義のアラートルーティング用に別の Alertmanager インスタンスを有効にしている場合、Alertmanager 設定もopenshift-user-workload-monitoringnamespace のalertmanager-user-workloadシークレットリソースとしてデプロイされます。Alertmanager のインスタンスの追加ルートを設定するには、そのシークレットをデコードし、変更し、エンコードする必要があります。この手順は、前述のステートメントに対してサポートされる例外です。- スタックのリソースの変更。OpenShift Container Platform モニタリングスタックは、そのリソースが常に期待される状態にあることを確認します。これらが変更される場合、スタックはこれらをリセットします。
-
ユーザー定義ワークロードの
openshift-*、およびkube-*プロジェクトへのデプロイ。これらのプロジェクトは Red Hat が提供するコンポーネント用に予約され、ユーザー定義のワークロードに使用することはできません。 -
Prometheus Operator での
Probeカスタムリソース定義 (CRD) による現象ベースのモニタリングの有効化。 -
openshift.io/cluster-monitoring: "true"ラベルを持つ namespace にモニタリングリソースを手動でデプロイ。 -
namespace に
openshift.io/cluster-monitoring: "true"ラベルを追加。このラベルは、コア OpenShift Container Platform コンポーネントと Red Hat 認定コンポーネントを含む namespace 用に予約されています。 - カスタム Prometheus インスタンスの OpenShift Container Platform へのインストール。カスタムインスタンスは、Prometheus Operator によって管理される Prometheus カスタムリソース (CR) です。
2.1.2. Operator のモニタリングに関するサポートポリシー
モニタリング Operator により、OpenShift Container Platform モニタリングリソースの設定およびテスト通りに機能することを確認できます。Operator の Cluster Version Operator (CVO) コントロールがオーバーライドされる場合、Operator は設定の変更に対応せず、クラスターオブジェクトの意図される状態を調整したり、更新を受信したりしません。
Operator の CVO コントロールのオーバーライドはデバッグ時に役立ちますが、これはサポートされず、クラスター管理者は個々のコンポーネントの設定およびアップグレードを完全に制御することを前提としています。
Cluster Version Operator のオーバーライド
spec.overrides パラメーターを CVO の設定に追加すると、管理者はコンポーネントに関する CVO の動作にオーバーライドのリストを追加できます。コンポーネントの spec.overrides[].unmanaged パラメーターを true に設定すると、クラスターのアップグレードがブロックされ、CVO のオーバーライドが設定された後に管理者にアラートが送信されます。
Disabling ownership via cluster version overrides prevents upgrades. Please remove overrides before continuing.CVO のオーバーライドを設定すると、クラスター全体がサポートされていない状態になり、モニタリングスタックをその意図された状態に調整されなくなります。これは Operator に組み込まれた信頼性の機能に影響を与え、更新が受信されなくなります。サポートを継続するには、オーバーライドを削除した後に、報告された問題を再現する必要があります。
2.1.3. モニタリングコンポーネントのサポートバージョンマトリックス
以下のマトリックスには、OpenShift Container Platform 4.12 以降のリリースのモニタリングコンポーネントのバージョンに関する情報が含まれています。
| OpenShift Container Platform | Prometheus Operator | Prometheus | Prometheus アダプター | Metrics Server (テクノロジープレビュー) | Alertmanager | kube-state-metrics エージェント | monitoring-plugin | node-exporter エージェント | Thanos |
|---|---|---|---|---|---|---|---|---|---|
| 4.15 | 0.70.0 | 2.48.0 | 0.11.2 | 0.6.4 | 0.26.0 | 2.10.1 | 1.0.0 | 1.7.0 | 0.32.5 |
| 4.14 | 0.67.1 | 2.46.0 | 0.10.0 | 該当なし | 0.25.0 | 2.9.2 | 1.0.0 | 1.6.1 | 0.30.2 |
| 4.13 | 0.63.0 | 2.42.0 | 0.10.0 | 該当なし | 0.25.0 | 2.8.1 | 該当なし | 1.5.0 | 0.30.2 |
| 4.12 | 0.60.1 | 2.39.1 | 0.10.0 | 該当なし | 0.24.0 | 2.6.0 | 該当なし | 1.4.0 | 0.28.1 |
openshift-state-metrics エージェントと Telemeter Client は、OpenShift 固有のコンポーネントです。したがって、それらのバージョンは OpenShift Container Platform のバージョンに対応します。
2.2. コアプラットフォームモニタリングの最初のステップ
OpenShift Container Platform がインストールされると、コアプラットフォームモニタリングコンポーネントは、照会と表示が可能なメトリクスの収集をすぐに開始します。デフォルトのクラスター内モニタリングスタックには、クラスターからメトリクスを収集するコアプラットフォーム Prometheus インスタンスや、アラートをルーティングするコア Alertmanager インスタンスなどのコンポーネントが含まれます。モニタリングスタックを誰がどのような目的で使用するかに応じて、クラスター管理者は、さまざまな状況で各ユーザーのニーズに合わせてこれらのモニタリングコンポーネントをさらに設定できます。
2.2.1. コアプラットフォームモニタリングの設定: インストール後の手順
OpenShift Container Platform がインストールされた後、クラスター管理者は通常、ニーズに合わせてコアプラットフォームのモニタリングを設定します。これらのアクティビティーには、ストレージのセットアップや、Prometheus、Alertmanager、その他のモニタリングコンポーネントのオプションの設定が含まれます。
デフォルトでは、新しくインストールされた OpenShift Container Platform システムで、ユーザーは収集されたメトリクスを照会および表示できます。ユーザーにアラート通知を受信させる場合にのみ、アラートレシーバーを設定する必要があります。ここにリストされているその他の設定オプションはすべて任意です。
-
cluster-monitoring-configConfigMapオブジェクト が存在しない場合は作成します。 - Alertmanager がメール、Slack、PagerDuty などの外部通知システムにアラートを送信できるように、デフォルトのプラットフォームアラートの通知を設定 します。
より短期間のデータ保持の場合は、Prometheus と Alertmanager の 永続ストレージを設定 して、メトリクスとアラートデータを保存してください。Prometheus および Thanos Ruler のメトリクスデータ保持パラメーターを指定します。
重要- マルチノードクラスターでは、高可用性を実現するために、Prometheus、Alertmanager、および Thanos Ruler の永続ストレージを設定する必要があります。
-
デフォルトでは、新しくインストールされた OpenShift Container Platform システムでは、モニタリングの
ClusterOperatorリソースがPrometheusDataPersistenceNotConfiguredステータスメッセージを報告し、ストレージが設定されていないことを通知します。
データをより長期間保持するには、リモート書き込み機能を設定 して、取り込んだメトリクスを Prometheus がリモートシステムに送信して保存できるようにします。
重要リモート書き込みストレージ設定で使用するために、メトリクスにクラスター ID ラベルを必ず追加 してください。
- 特定のモニタリング機能にアクセスする必要がある管理者以外のユーザーに モニタリングクラスターロールを付与 します。
- 管理者が taint されたノードに移動できるように、モニタリングスタックコンポーネントに toleration を割り当て ます。
- メトリクス収集の ボディーサイズ制限を設定 すると、スクレイピングされたターゲットが大量のデータを含む応答を返すときに Prometheus が過剰にメモリーを消費する状況を回避できます。
- クラスターの アラートルールを変更または作成 します。これらのルールは、CPU またはメモリーの使用率が高い、ネットワークの遅延など、アラートをトリガーする条件を指定します。
- モニタリングコンポーネントを実行するコンテナーに十分な CPU およびメモリーリソースを確保するために、モニタリングコンポーネントのリソース制限および要求を指定 します。
モニタリングスタックがニーズに合わせて設定されると、Prometheus は指定されたサービスからメトリクスを収集し、設定に従ってこれらのメトリクスを保存します。OpenShift Container Platform Web コンソールの Observe ページに移動して、収集されたメトリクスの表示とクエリー、アラートの管理、パフォーマンスのボトルネックの特定、必要に応じてリソースのスケーリングを行うことができます。
- ダッシュボードを表示 して、収集されたメトリクスを視覚化し、アラートをトラブルシューティングし、クラスターに関するその他の情報を監視します。
- PromQL クエリーを作成するか、定義済みクエリーを使用して、収集されたメトリクスを照会 します。
2.3. ユーザーワークロードモニタリングの最初のステップ
クラスター管理者は、コアプラットフォームのモニタリングに加えて、オプションでユーザー定義プロジェクトの監視を有効にできます。開発者などの管理者以外のユーザーは、コアプラットフォームモニタリングの外部で独自のプロジェクトを監視できます。
クラスター管理者は通常、ユーザーが収集されたメトリクスを表示し、これらのメトリクスを照会し、自分のプロジェクトに関するアラートを受信できるように、ユーザー定義プロジェクトを設定するために次のアクティビティーを実行します。
- ユーザーワークロードモニタリングを有効にします。
-
管理者以外のユーザーに、
monitoring-rules-view、monitoring-rules-edit、またはmonitoring-editクラスターロールを割り当てることで、ユーザー定義プロジェクトを監視する権限を付与 します。 -
管理者以外のユーザーに、
user-workload-monitoring-config-editロールを割り当て、ユーザー定義プロジェクトを設定する権限を付与します。 - ユーザー定義のプロジェクトのアラートルーティングを有効にして、開発者やその他のユーザーがプロジェクトのカスタムアラートとアラートルーティングを設定できるようにします。
- 必要に応じて、ユーザー定義プロジェクト専用のオプションの Alertmanager インスタンスを使用 するように、ユーザー定義プロジェクトのアラートルーティングを設定します。
- ユーザー定義のアラートの通知を設定 します。
- ユーザー定義のアラートルーティングにプラットフォーム Alertmanager インスタンスを使用する場合は、デフォルトのプラットフォームアラートとユーザー定義のアラートに 異なるアラートレシーバーを設定 します。
2.4. 開発者および非管理者の手順
ユーザー定義プロジェクトのモニタリングを有効にして設定したら、開発者やその他の管理者以外のユーザーは、次のアクティビティーを実行して、独自のプロジェクトのモニタリングを設定および使用できるようになります。
- サービスをデプロイおよび監視 します。
- アラートルールを作成および管理 します。
- プロジェクトの アラートを受信して管理 します。
-
alert-routing-editクラスターロールが付与されている場合は、アラートルーティングを設定 します。 - OpenShift Container Platform Web コンソールを使用して ダッシュボードを表示 します。
- PromQL クエリーを作成するか、定義済みクエリーを使用して、収集されたメトリクスを照会 します。
第3章 コアプラットフォームモニタリングの設定
3.1. コアプラットフォームモニタリングスタックを設定する準備
OpenShift Container Platform インストールプログラムは、インストール前の少数の設定オプションのみを提供します。ほとんどの OpenShift Container Platform フレームワークコンポーネント (クラスターモニタリングスタックを含む) の設定はインストール後に行われます。
このセクションでは、設定できるモニタリングコンポーネントと、モニタリングスタックを設定するための準備方法を説明します。
- モニタリングスタックのすべての設定パラメーターが公開されるわけではありません。設定では、Cluster Monitoring Operator の config map 参照 にリストされているパラメーターとフィールドのみがサポートされます。
- モニタリングスタックには、追加のリソース要件があります。Cluster Monitoring Operator のスケーリング でコンピューティングリソースに関する推奨事項を参照し、十分なリソースがあることを確認してください。
3.1.1. 設定可能なモニタリングコンポーネント
次の表に、設定できるモニタリングコンポーネントと、cluster-monitoring-config config map でコンポーネントを指定するために使用するキーを示します。
| Component | cluster-monitoring-config config map キー |
|---|---|
| Prometheus Operator |
|
| Prometheus |
|
| Alertmanager |
|
| Thanos Querier |
|
| kube-state-metrics |
|
| monitoring-plugin |
|
| openshift-state-metrics |
|
| Telemeter クライアント |
|
| Prometheus アダプター |
|
ConfigMap オブジェクトの設定変更によって、結果も異なります。
- Pod は再デプロイされません。したがって、サービスの停止はありません。
変更された Pod が再デプロイされます。
- 単一ノードクラスターの場合、一時的なサービスが停止します。
- マルチノードクラスターの場合、高可用性であるため、影響を受ける Pod は徐々にロールアウトされ、モニタリングスタックは引き続き利用可能です。
- 永続ボリュームの設定およびサイズ変更を行うと、高可用性であるかどうかに関係なく、常にサービスが停止します。
config map の変更を必要とする手順にはそれぞれ、想定される結果が含まれます。
3.1.2. クラスターモニタリング config map の作成
openshift-monitoring プロジェクトで cluster-monitoring-config config map を作成および更新することで、OpenShift Container Platform のコアモニタリングコンポーネントを設定できます。その後、Cluster Monitoring Operator (CMO) がモニタリングスタックのコアコンポーネントを設定します。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
cluster-monitoring-configConfigMapオブジェクトが存在するかどうかを確認します。$ oc -n openshift-monitoring get configmap cluster-monitoring-configConfigMapオブジェクトが存在しない場合:以下の YAML マニフェストを作成します。以下の例では、このファイルは
cluster-monitoring-config.yamlという名前です。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: |設定を適用して
ConfigMapを作成します。$ oc apply -f cluster-monitoring-config.yaml
3.1.3. ユーザーへのコアプラットフォームモニタリング権限の付与
クラスター管理者は、すべての OpenShift Container Platform のコアプロジェクトおよびユーザー定義プロジェクトを監視できます。
開発者や他のユーザーに、コアプラットフォームモニタリングに関するさまざまな権限を付与することもできます。次のいずれかのモニタリングロールまたはクラスターロールを割り当てることで、権限を付与できます。
| 名前 | 説明 | プロジェクト |
|---|---|---|
|
| このロールを持つユーザーは、Thanos Querier API エンドポイントにアクセスできます。さらに、コアプラットフォームの Prometheus API とユーザー定義の Thanos Ruler API エンドポイントへのアクセスが許可されます。 |
|
|
|
このロールを持つユーザーは、コアプラットフォームモニタリング用の |
|
|
| このロールを持つユーザーは、コアプラットフォームモニタリング用の Alertmanager API を管理できます。また、OpenShift Container Platform Web コンソールの Administrator パースペクティブでアラートサイレンスを管理することもできます。 |
|
|
| このロールを持つユーザーは、コアプラットフォームモニタリング用の Alertmanager API を監視できます。OpenShift Container Platform Web コンソールの Administrator パースペクティブでアラートサイレンスを表示することもできます。 |
|
|
|
このクラスターロールを持つユーザーには、 |
ユーザー定義の Prometheus の |
3.1.3.1. Web コンソールを使用したユーザー権限の付与
OpenShift Container Platform Web コンソールを使用して、openshift-monitoring プロジェクトまたはユーザー自身のプロジェクトに対する権限をユーザーに付与できます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 - ロールを割り当てるユーザーアカウントがすでに存在している。
手順
- OpenShift Container Platform Web コンソールの Administrator パースペクティブで、User Management → RoleBindings → Create binding に移動します。
- Binding Type セクションで、Namespace Role Binding タイプを選択します。
- Name フィールドに、ロールバインディングの名前を入力します。
Namespace フィールドで、アクセスを許可するプロジェクトを選択します。
重要この手順を使用してユーザーに付与するモニタリングロールまたはクラスターロールの権限は、Namespace フィールドで選択したプロジェクトにのみ適用されます。
- Role Name リストからモニタリングロールまたはクラスターロールを選択します。
- Subject セクションで、User を選択します。
- Subject Name フィールドにユーザーの名前を入力します。
- Create を選択して、ロールバインディングを適用します。
3.1.3.2. CLI を使用したユーザー権限の付与
OpenShift CLI (oc) を使用して、openshift-monitoring プロジェクトまたはユーザー自身のプロジェクトに対する権限をユーザーに付与できます。
どちらのロールまたはクラスターロールを選択する場合でも、クラスター管理者が特定のプロジェクトにバインドする必要があります。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 - ロールを割り当てるユーザーアカウントがすでに存在している。
-
OpenShift CLI (
oc) がインストールされている。
手順
プロジェクトのユーザーにモニタリングロールを割り当てるには、次のコマンドを入力します。
$ oc adm policy add-role-to-user <role> <user> -n <namespace> --role-namespace <namespace>1 - 1
<role>は必要なモニタリングロールに、<user>はロールを割り当てるユーザーに、<namespace>はアクセスを許可するプロジェクトに置き換えます。
プロジェクトのユーザーにモニタリングクラスターロールを割り当てるには、次のコマンドを入力します。
$ oc adm policy add-cluster-role-to-user <cluster-role> <user> -n <namespace>1 - 1
<cluster-role>は必要なモニタリングクラスターロールに、<user>はクラスターロールを割り当てるユーザーに、<namespace>はアクセスを許可するプロジェクトに置き換えます。
3.2. コアプラットフォームモニタリングのパフォーマンスとスケーラビリティーの設定
モニタリングスタックを設定して、クラスターのパフォーマンスとスケールを最適化できます。次のドキュメントでは、モニタリングコンポーネントを分散する方法と、モニタリングスタックが CPU およびメモリーリソースに与える影響を制御する方法を説明します。
3.2.1. モニタリングコンポーネントの配置と分散の制御
次の方法で、モニタリングスタックコンポーネントを特定のノードに移動できます。
-
ラベル付きノードで
nodeSelector制約を使用して、任意のモニタリングスタックコンポーネントを特定のノードに移動します。 - taint されたノードにコンポーネントを移動できるように toleration を割り当てます。
これにより、クラスター全体のモニタリングコンポーネントの配置と分散を制御できます。
モニタリングコンポーネントの配置と分散を制御して、システムリソースの使用を最適化し、パフォーマンスを高め、特定の要件やポリシーに基づいてワークロードを分離できます。
3.2.1.1. モニタリングコンポーネントの異なるノードへの移動
モニタリングスタックコンポーネントを実行するクラスター内のノードを指定するには、ノードに割り当てられたラベルと一致するように、cluster-monitoring-config config map 内のコンポーネントの nodeSelector 制約を設定します。
ノードセレクター制約を既存のスケジュール済み Pod に直接追加することはできません。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。 -
OpenShift CLI (
oc) がインストールされている。
手順
まだの場合は、モニタリングコンポーネントを実行するノードにラベルを追加します。
$ oc label nodes <node_name> <node_label>1 - 1
<node_name>は、ラベルを追加するノードの名前に置き換えます。<node_label>は、必要なラベルの名前に置き換えます。
openshift-monitoringプロジェクトでcluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configdata/config.yamlでコンポーネントのnodeSelector制約のノードラベルを指定します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | # ... <component>:1 nodeSelector: <node_label_1>2 <node_label_2>3 # ...注記nodeSelectorの制約を設定した後もモニタリングコンポーネントがPending状態のままになっている場合は、Pod イベントで taint および toleration に関連するエラーの有無を確認します。- 変更を適用するためにファイルを保存します。新しい設定で指定されたコンポーネントは自動的に新しいノードに移動され、新しい設定の影響を受ける Pod は再デプロイされます。
3.2.1.2. モニタリングコンポーネントへの toleration の割り当て
toleration をモニタリングスタックのコンポーネントに割り当て、それらを taint されたノードに移動することができます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。 -
OpenShift CLI (
oc) がインストールされている。
手順
openshift-monitoringプロジェクトでcluster-monitoring-configconfig map を編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configコンポーネントの
tolerationsを指定します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | <component>: tolerations: <toleration_specification><component>および<toleration_specification>を随時置き換えます。たとえば、
oc adm taint nodes node1 key1=value1:NoScheduleは、キーがkey1で、値がvalue1のnode1に taint を追加します。これにより、モニタリングコンポーネントがnode1に Pod をデプロイするのを防ぎます。ただし、その taint に対して toleration が設定されている場合を除きます。以下の例は、サンプルの taint を容認するようにalertmanagerMainコンポーネントを設定します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | alertmanagerMain: tolerations: - key: "key1" operator: "Equal" value: "value1" effect: "NoSchedule"- 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
3.2.2. メトリクススクレイピング (収集) のボディーサイズ制限の設定
デフォルトでは、スクレイピングされたメトリクスターゲットから返されるデータの非圧縮のボディーサイズに制限はありません。スクレイピングされたターゲットが大量のデータを含む応答を返すときに Prometheus が過剰にメモリーを消費する状況を回避するために、ボディーサイズの制限を設定できます。さらに、ボディーサイズ制限を設定することで、悪意のあるターゲットが Prometheus およびクラスター全体に与える影響を軽減できます。
enforcedBodySizeLimit の値を設定した後、少なくとも 1 つの Prometheus スクレイプターゲットが、設定された値より大きいレスポンスボディーで応答すると、アラート PrometheusScrapeBodySizeLimitHit が発生します。
ターゲットからスクレイピングされたメトリクスデータの非圧縮ボディーサイズが、設定されたサイズ制限を超えていると、スクレイピングは失敗します。次に、Prometheus はこのターゲットがダウンしていると見なし、その up メトリクス値を 0 に設定します。これにより、TargetDown アラートをトリガーできます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
openshift-monitoringnamespace でcluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configenforcedBodySizeLimitの値をdata/config.yaml/prometheusK8sに追加して、ターゲットスクレイプごとに受け入れ可能なボディーサイズを制限します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: |- prometheusK8s: enforcedBodySizeLimit: 40MB1 - 1
- スクレイピングされたメトリクスターゲットの最大ボディーサイズを指定します。この
enforcedBodySizeLimitの例では、ターゲットスクレイプごとの非圧縮サイズを 40 メガバイトに制限しています。有効な数値は、B (バイト)、KB (キロバイト)、MB (メガバイト)、GB (ギガバイト)、TB (テラバイト)、PB (ペタバイト)、および EB (エクサバイト) の Prometheus データサイズ形式を使用します。デフォルト値は0で、制限は指定されません。値をautomaticに設定して、クラスターの容量に基づいて制限を自動的に計算することもできます。
- 変更を適用するためにファイルを保存します。新しい設定は自動的に適用されます。
3.2.3. モニタリングコンポーネントの CPU およびメモリーリソースの管理
モニタリングコンポーネントを実行するコンテナーに十分な CPU リソースとメモリーリソースを確保するには、これらのコンポーネントのリソース制限および要求の値を指定します。
openshift-monitoring namespace で、コアプラットフォームモニタリングコンポーネントのリソース制限および要求を設定できます。
3.2.3.1. 制限および要求の指定
CPU およびメモリーリソースを設定するには、openshift-monitoring namespace の cluster-monitoring-config ConfigMap オブジェクトでリソース制限および要求の値を指定します。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configという名前のConfigMapオブジェクトを作成した。 -
OpenShift CLI (
oc) がインストールされている。
手順
openshift-monitoringプロジェクトでcluster-monitoring-configconfig map を編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-config値を追加して、設定する各コンポーネントのリソース制限および要求を定義します。
重要制限に設定した値が常に要求に設定された値よりも大きくなることを確認してください。そうでない場合、エラーが発生し、コンテナーは実行されません。
リソース制限とリクエストの設定例
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | alertmanagerMain: resources: limits: cpu: 500m memory: 1Gi requests: cpu: 200m memory: 500Mi prometheusK8s: resources: limits: cpu: 500m memory: 3Gi requests: cpu: 200m memory: 500Mi thanosQuerier: resources: limits: cpu: 500m memory: 1Gi requests: cpu: 200m memory: 500Mi prometheusOperator: resources: limits: cpu: 500m memory: 1Gi requests: cpu: 200m memory: 500Mi k8sPrometheusAdapter: resources: limits: cpu: 500m memory: 1Gi requests: cpu: 200m memory: 500Mi kubeStateMetrics: resources: limits: cpu: 500m memory: 1Gi requests: cpu: 200m memory: 500Mi telemeterClient: resources: limits: cpu: 500m memory: 1Gi requests: cpu: 200m memory: 500Mi openshiftStateMetrics: resources: limits: cpu: 500m memory: 1Gi requests: cpu: 200m memory: 500Mi nodeExporter: resources: limits: cpu: 50m memory: 150Mi requests: cpu: 20m memory: 50Mi monitoringPlugin: resources: limits: cpu: 500m memory: 1Gi requests: cpu: 200m memory: 500Mi prometheusOperatorAdmissionWebhook: resources: limits: cpu: 50m memory: 100Mi requests: cpu: 20m memory: 50Mi- 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
3.2.4. メトリクス収集プロファイルの選択
メトリクス収集プロファイルはテクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
コア OpenShift Container Platform モニタリングコンポーネントのメトリクス収集プロファイルを選択するには、cluster-monitoring-config ConfigMap オブジェクトを編集します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
FeatureGateカスタムリソース (CR) を使用して、テクノロジープレビュー機能を有効にしました。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。 -
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。
手順
openshift-monitoringプロジェクトでcluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configdata/config.yaml/prometheusK8sの下にメトリクス収集プロファイル設定を追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: collectionProfile: <metrics_collection_profile_name>1 - 1
- メトリクス収集プロファイルの名前。使用可能な値は
fullまたはminimalです。値を指定しない場合、またはcollectionProfileキー名が config map に存在しない場合は、デフォルト設定のfullが使用されます。
次の例では、Prometheus のコアプラットフォームインスタンスのメトリクスコレクションプロファイルを
minimalに設定します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: collectionProfile: minimal- 変更を適用するためにファイルを保存します。新しい設定は自動的に適用されます。
3.2.5. Pod トポロジー分散制約の設定
Cluster Monitoring Operator によってデプロイされたすべての Pod に対して Pod トポロジーの分散制約を設定し、ゾーン全体のノードに Pod レプリカをスケジュールする方法を制御できます。これにより、ワークロードが異なるデータセンターまたは階層型インフラストラクチャーゾーンのノードに分散されるため、Pod の可用性が高まり、より効率的に実行されるようになります。
cluster-monitoring-config config map を使用して、Pod を監視するための Pod トポロジーの分散制約を設定できます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。 -
OpenShift CLI (
oc) がインストールされている。
手順
openshift-monitoringプロジェクトでcluster-monitoring-configconfig map を編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configPod トポロジーの分散制約を設定するには、
data/config.yamlフィールドの下に次の設定を追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | <component>:1 topologySpreadConstraints: - maxSkew: <n>2 topologyKey: <key>3 whenUnsatisfiable: <value>4 labelSelector:5 <match_option>- 1
- Pod トポロジーの分散制約を設定するコンポーネントの名前を指定します。
- 2
maxSkewの数値を指定します。これは、どの程度まで Pod が不均等に分散されることを許可するか定義します。- 3
topologyKeyにノードラベルのキーを指定します。このキーと同じ値のラベルを持つノードは、同じトポロジーにあると見なされます。スケジューラーは、各ドメインにバランスの取れた数の Pod を配置しようとします。- 4
whenUnsatisfiableの値を指定します。利用可能なオプションはDoNotScheduleとScheduleAnywayです。maxSkew値で、ターゲットトポロジー内の一致する Pod の数とグローバル最小値との間で許容される最大差を定義する場合は、DoNotScheduleを指定します。スケジューラーが引き続き Pod をスケジュールするが、スキューを減らす可能性のあるノードにより高い優先度を与える場合は、ScheduleAnywayを指定します。- 5
- 一致する Pod を見つけるには、
labelSelectorを指定します。このラベルセレクターに一致する Pod は、対応するトポロジードメイン内の Pod の数を決定するためにカウントされます。
Prometheus の設定例
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: topologySpreadConstraints: - maxSkew: 1 topologyKey: monitoring whenUnsatisfiable: DoNotSchedule labelSelector: matchLabels: app.kubernetes.io/name: prometheus- 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
3.3. コアプラットフォームモニタリングのデータの保存と記録
メトリクスとアラートデータの保存および記録、ログの設定と記録するアクティビティーの指定、Prometheus が保存されたデータを保持する期間の制御、データの最大ディスク領域の設定を行います。これらのアクションは、データを保護し、データをトラブルシューティングに使用するのに役立ちます。
3.3.1. 永続ストレージの設定
永続ストレージを使用してクラスターモニタリングを実行すると、次の利点が得られます。
- メトリクスとアラートデータを永続ボリューム (PV) に保存することで、データ損失から保護します。その結果、Pod が再起動または再作成されても存続できます。
- Alertmanager Pod が再起動したときに、重複した通知を受信したり、アラートのサイレンスが失われたりするのを回避します。
マルチノードクラスターでは、高可用性を確保するために Prometheus および Alertmanager の永続ストレージを設定する必要があります。
実稼働環境では、永続ストレージを設定することを強く推奨します。
3.3.1.1. 永続ストレージの前提条件
- ディスクが一杯にならないように十分な永続ストレージを確保します。
永続ボリュームを設定する際に、
volumeModeパラメーターのストレージタイプ値としてFilesystemを使用します。重要-
PersistentVolumeリソースでvolumeMode: Blockで記述されている生のブロックボリュームを使用しないでください。Prometheus は raw ブロックボリュームを使用できません。 - Prometheus は、POSIX に準拠していないファイルシステムをサポートしません。たとえば、一部の NFS ファイルシステム実装は POSIX に準拠していません。ストレージに NFS ファイルシステムを使用する場合は、NFS 実装が完全に POSIX に準拠していることをベンダーに確認してください。
-
3.3.1.2. 永続ボリューム要求の設定
コンポーネントの監視に永続ボリューム (PV) を使用するには、永続ボリューム要求 (PVC) を設定する必要があります。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。 -
OpenShift CLI (
oc) がインストールされている。
手順
openshift-monitoringプロジェクトでcluster-monitoring-configconfig map を編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configコンポーネントの PVC 設定を
data/config.yamlの下に追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | <component>:1 volumeClaimTemplate: spec: storageClassName: <storage_class>2 resources: requests: storage: <amount_of_storage>3 次の例では、Prometheus の永続ストレージを要求する PVC を設定します。
PVC 設定の例
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: volumeClaimTemplate: spec: storageClassName: my-storage-class resources: requests: storage: 40Gi変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされ、新しいストレージ設定が適用されます。
警告PVC 設定で config map を更新すると、影響を受ける
StatefulSetオブジェクトが再作成され、一時的なサービス停止が発生します。
3.3.1.3. 永続ボリュームのサイズ変更
モニタリングコンポーネント (Prometheus や Alertmanager など) の永続ボリューム (PV) のサイズを変更できます。永続ボリューム要求 (PVC) を手動で拡張し、コンポーネントが設定されている config map を更新する必要があります。
PVC のサイズのみ拡張可能です。ストレージサイズを縮小することはできません。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。 - コア OpenShift Container Platform モニタリングコンポーネント用に少なくとも 1 つの PVC を設定しました。
-
OpenShift CLI (
oc) がインストールされている。
手順
- 更新されたストレージ要求を使用して PVC を手動で拡張します。詳細は、永続ボリュームの拡張 の「ファイルシステムを使用した永続ボリューム要求 (PVC) の拡張」を参照してください。
openshift-monitoringプロジェクトでcluster-monitoring-configconfig map を編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configdata/config.yamlの下に、コンポーネントの PVC 設定用の新しいストレージサイズを追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | <component>:1 volumeClaimTemplate: spec: resources: requests: storage: <amount_of_storage>2 次の例では、Prometheus インスタンスの新しい PVC 要求を 100 ギガバイトに設定します。
prometheusK8sのストレージ設定例apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: volumeClaimTemplate: spec: resources: requests: storage: 100Gi変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
警告新しいストレージサイズで config map を更新すると、影響を受ける
StatefulSetオブジェクトが再作成され、サービスが一時的に停止します。
3.3.2. Prometheus メトリクスデータの保持期間およびサイズの変更
デフォルトでは、Prometheus はコアプラットフォームモニタリングのメトリクスデータを 15 日間保持します。データの削除時に Prometheus インスタンスが変更する保持時間を変更できます。保持されるメトリクスデータが使用するディスク容量の最大量を設定することもできます。
データコンパクションは 2 時間ごとに実行されます。そのため、コンパクションが実行される前に永続ボリューム (PV) がいっぱいになり、retentionSize 制限を超える可能性があります。その場合、PV 上のスペースが retentionSize 制限を下回るまで、KubePersistentVolumeFillingUp アラートが発生します。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。 -
OpenShift CLI (
oc) がインストールされている。
手順
openshift-monitoringプロジェクトでcluster-monitoring-configconfig map を編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-config保持期間およびサイズ設定を
data/config.yamlに追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: retention: <time_specification>1 retentionSize: <size_specification>2 次の例では、Prometheus インスタンスの保持時間を 24 時間、保持サイズを 10 ギガバイトに設定します。
Prometheus の保持期間を設定する例
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: retention: 24h retentionSize: 10GB- 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
3.3.3. Prometheus アダプターの監査ログレベルの設定
デフォルトのプラットフォームモニタリングでは、Prometheus アダプターの監査ログレベルを設定できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。
手順
デフォルトの openshift-monitoring プロジェクトで Prometheus アダプターの監査ログレベルを設定できます。
openshift-monitoringプロジェクトでcluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configk8sPrometheusAdapter/auditセクションにprofile:をdata/config.yamlの下に追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | k8sPrometheusAdapter: audit: profile: <audit_log_level>1 - 1
- Prometheus アダプターに適用する監査ログレベル。
profile:パラメーターに以下のいずれかの値を使用して、監査ログレベルを設定します。-
None: イベントをログに記録しません。 -
Metadata: ユーザー、タイムスタンプなど、リクエストのメタデータのみをログに記録します。リクエストテキストと応答テキストはログに記録しないでください。metadataはデフォルトの監査ログレベルです。 -
Request: メタデータと要求テキストのみをログに記録しますが、応答テキストはログに記録しません。このオプションは、リソース以外の要求には適用されません。 -
RequestResponse: イベントのメタデータ、要求テキスト、および応答テキストをログに記録します。このオプションは、リソース以外の要求には適用されません。
-
- 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
検証
-
config map の
k8sPrometheusAdapter/audit/profileで、ログレベルをRequestに設定し、ファイルを保存します。 Prometheus アダプターの Pod が実行されていることを確認します。以下の例は、
openshift-monitoringプロジェクトの Pod のステータスを一覧表示します。$ oc -n openshift-monitoring get pods監査ログレベルと監査ログファイルのパスが正しく設定されていることを確認します。
$ oc -n openshift-monitoring get deploy prometheus-adapter -o yaml出力例
... - --audit-policy-file=/etc/audit/request-profile.yaml - --audit-log-path=/var/log/adapter/audit.log正しいログレベルが
openshift-monitoringプロジェクトのprometheus-adapterデプロイメントに適用されていることを確認します。$ oc -n openshift-monitoring exec deploy/prometheus-adapter -c prometheus-adapter -- cat /etc/audit/request-profile.yaml出力例
"apiVersion": "audit.k8s.io/v1" "kind": "Policy" "metadata": "name": "Request" "omitStages": - "RequestReceived" "rules": - "level": "Request"注記ConfigMapオブジェクトで Prometheus アダプターに認識されないprofile値を入力すると、Prometheus アダプターには変更が加えられず、Cluster Monitoring Operator によってエラーがログに記録されます。Prometheus アダプターの監査ログを確認します。
$ oc -n openshift-monitoring exec -c <prometheus_adapter_pod_name> -- cat /var/log/adapter/audit.log
3.3.4. モニタリングコンポーネントのログレベルの設定
Alertmanager、Prometheus Operator、Prometheus、および Thanos Querier のログレベルを設定できます。
cluster-monitoring-config ConfigMap オブジェクト内の関連コンポーネントには、次のログレベルを適用できます。
-
debug:デバッグ、情報、警告、およびエラーメッセージをログに記録します。 -
info:情報、警告およびエラーメッセージをログに記録します。 -
warn:警告およびエラーメッセージのみをログに記録します。 -
error:エラーメッセージのみをログに記録します。
デフォルトのログレベルは info です。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。 -
OpenShift CLI (
oc) がインストールされている。
手順
openshift-monitoringプロジェクトでcluster-monitoring-configconfig map を編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configコンポーネントの
logLevel: <log_level>をdata/config.yamlの下に追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | <component>:1 logLevel: <log_level>2 - 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
関連するプロジェクトでデプロイメントまたは Pod 設定を確認し、ログレベルが適用されていることを確認します。以下の例では、
prometheus-operatorデプロイメントのログレベルを確認します。$ oc -n openshift-monitoring get deploy prometheus-operator -o yaml | grep "log-level"出力例
- --log-level=debugコンポーネントの Pod が実行中であることを確認します。次の例では、Pod のステータスをリスト表示します。
$ oc -n openshift-monitoring get pods注記認識されない
logLevel値がConfigMapオブジェクトに含まれる場合は、コンポーネントの Pod が正常に再起動しない可能性があります。
3.3.5. Prometheus のクエリーログファイルの有効化
エンジンによって実行されたすべてのクエリーをログファイルに書き込むように Prometheus を設定できます。
ログローテーションはサポートされていないため、問題のトラブルシューティングが必要な場合にのみ、この機能を一時的に有効にします。トラブルシューティングが終了したら、ConfigMap オブジェクトに加えた変更を元に戻してクエリーログを無効にし、機能を有効にします。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。 -
OpenShift CLI (
oc) がインストールされている。
手順
openshift-monitoringプロジェクトでcluster-monitoring-configconfig map を編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configPrometheus の
queryLogFileパラメーターをdata/config.yamlの下に追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: queryLogFile: <path>1 - 1
- クエリーが記録されるファイルへの完全なパスを追加します。
- 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
コンポーネントの Pod が実行中であることを確認します。次のコマンド例は、Pod のステータスを表示します。
$ oc -n openshift-monitoring get pods出力例
... prometheus-operator-567c9bc75c-96wkj 2/2 Running 0 62m prometheus-k8s-0 6/6 Running 1 57m prometheus-k8s-1 6/6 Running 1 57m thanos-querier-56c76d7df4-2xkpc 6/6 Running 0 57m thanos-querier-56c76d7df4-j5p29 6/6 Running 0 57m ...クエリーログを読みます。
$ oc -n openshift-monitoring exec prometheus-k8s-0 -- cat <path>重要ログに記録されたクエリー情報を確認した後、config map の設定を元に戻します。
3.3.6. Thanos Querier のクエリーロギングの有効化
openshift-monitoring プロジェクトのデフォルトのプラットフォームモニタリングの場合、Cluster Monitoring Operator (CMO) を有効にして Thanos Querier によって実行されるすべてのクエリーをログに記録できます。
ログローテーションはサポートされていないため、問題のトラブルシューティングが必要な場合にのみ、この機能を一時的に有効にします。トラブルシューティングが終了したら、ConfigMap オブジェクトに加えた変更を元に戻してクエリーログを無効にし、機能を有効にします。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。
手順
openshift-monitoring プロジェクトで Thanos Querier のクエリーロギングを有効にすることができます。
openshift-monitoringプロジェクトでcluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-config以下の例のように
thanosQuerierセクションをdata/config.yamlに追加し、値を追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | thanosQuerier: enableRequestLogging: <value>1 logLevel: <value>2 - 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
検証
Thanos Querier Pod が実行されていることを確認します。次のコマンドの例は、
openshift-monitoringプロジェクトの Pod のステータスを一覧表示します。$ oc -n openshift-monitoring get pods以下のサンプルコマンドをモデルとして使用して、テストクエリーを実行します。
$ token=`oc create token prometheus-k8s -n openshift-monitoring`$ oc -n openshift-monitoring exec -c prometheus prometheus-k8s-0 -- curl -k -H "Authorization: Bearer $token" 'https://thanos-querier.openshift-monitoring.svc:9091/api/v1/query?query=cluster_version'以下のコマンドを実行してクエリーログを読み取ります。
$ oc -n openshift-monitoring logs <thanos_querier_pod_name> -c thanos-query注記thanos-querierPod は高可用性 (HA) Pod であるため、1 つの Pod でのみログを表示できる可能性があります。-
ログに記録されたクエリー情報を確認したら、config map で
enableRequestLoggingの値をfalseに変更してクエリーロギングを無効にします。
3.4. コアプラットフォームモニタリングのメトリクスの設定
クラスターコンポーネントと独自のワークロードのパフォーマンスを監視するためのメトリクスのコレクションを設定します。
取り込んだメトリクスをリモートシステムに送信して長期保存したり、別のクラスターからのデータを識別するためにメトリクスにクラスター ID ラベルを追加したりできます。
3.4.1. リモート書き込みストレージの設定
リモート書き込みストレージを設定して、Prometheus が取り込んだメトリクスをリモートシステムに送信して長期保存できるようにします。これを行っても、Prometheus がメトリクスを保存する方法や期間には影響はありません。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。 -
OpenShift CLI (
oc) がインストールされている。 リモート書き込み互換性のあるエンドポイント (Thanos) を設定し、エンドポイント URL を把握している。リモート書き込み機能と互換性のないエンドポイントの情報ては、Prometheus リモートエンドポイントおよびストレージに関するドキュメント を参照してください。
重要Red Hat は、リモート書き込み送信側の設定に関する情報のみを提供し、受信側エンドポイントの設定に関するガイダンスは提供しません。お客様は、リモート書き込みと互換性のある独自のエンドポイントを設定する責任があります。エンドポイントレシーバー設定に関する問題は、Red Hat 製品サポートには含まれません。
リモート書き込みエンドポイントの
Secretオブジェクトに認証クレデンシャルを設定している。openshift-monitoringnamespace にシークレットを作成する必要があります。警告セキュリティーリスクを軽減するには、HTTPS および認証を使用してメトリクスをエンドポイントに送信します。
手順
openshift-monitoringプロジェクトでcluster-monitoring-configconfig map を編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-config以下の例のように、
data/config.yaml/prometheusK8sの下にremoteWrite:セクションを追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: remoteWrite: - url: "https://remote-write-endpoint.example.com"1 <endpoint_authentication_credentials>2 認証クレデンシャルの後に、書き込みの再ラベル設定値を追加します。
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: remoteWrite: - url: "https://remote-write-endpoint.example.com" <endpoint_authentication_credentials> writeRelabelConfigs: - <your_write_relabel_configs>1 - 1
- リモートエンドポイントに送信するメトリクスの設定を追加します。
my_metricという単一メトリクスを転送する例apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: remoteWrite: - url: "https://remote-write-endpoint.example.com" writeRelabelConfigs: - sourceLabels: [__name__] regex: 'my_metric' action: keepmy_namespacenamespace にmy_metric_1およびmy_metric_2というメトリクスを転送する例apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: remoteWrite: - url: "https://remote-write-endpoint.example.com" writeRelabelConfigs: - sourceLabels: [__name__,namespace] regex: '(my_metric_1|my_metric_2);my_namespace' action: keep- 変更を適用するためにファイルを保存します。新しい設定は自動的に適用されます。
3.4.1.1. サポート対象のリモート書き込み認証設定
異なる方法を使用して、リモート書き込みエンドポイントとの認証を行うことができます。現時点でサポートされている認証方法は AWS 署名バージョン 4、Basic 認証、認可、OAuth 2.0、および TLS クライアントです。以下の表は、リモート書き込みで使用するサポート対象の認証方法の詳細を示しています。
| 認証方法 | config map フィールド | 説明 |
|---|---|---|
| AWS 署名バージョン 4 |
| この方法では、AWS Signature Version 4 認証を使用して要求を署名します。この方法は、認可、OAuth 2.0、または Basic 認証と同時に使用することはできません。 |
| Basic 認証 |
| Basic 認証は、設定されたユーザー名とパスワードを使用してすべてのリモート書き込み要求に承認ヘッダーを設定します。 |
| 認可 |
|
Authorization は、設定されたトークンを使用して、すべてのリモート書き込みリクエストに |
| OAuth 2.0 |
|
OAuth 2.0 設定は、クライアントクレデンシャル付与タイプを使用します。Prometheus は、リモート書き込みエンドポイントにアクセスするために、指定されたクライアント ID およびクライアントシークレットを使用して |
| TLS クライアント |
| TLS クライアント設定は、TLS を使用してリモート書き込みエンドポイントサーバーで認証するために使用される CA 証明書、クライアント証明書、およびクライアントキーファイル情報を指定します。設定例は、CA 証明書ファイル、クライアント証明書ファイル、およびクライアントキーファイルがすでに作成されていることを前提としています。 |
3.4.1.2. リモート書き込み認証の設定例
次のサンプルは、リモート書き込みエンドポイントに接続するために使用できるさまざまな認証設定を示しています。各サンプルでは、認証情報やその他の関連設定を含む対応する Secret オブジェクトを設定する方法も示しています。それぞれのサンプルは、openshift-monitoring namespace でデフォルトのプラットフォームモニタリングで使用する認証を設定します。
3.4.1.2.1. AWS 署名バージョン 4 認証のサンプル YAML
以下は、openshift-monitoring namespace の sigv4-credentials という名前の sigv4 シークレットの設定を示しています。
apiVersion: v1
kind: Secret
metadata:
name: sigv4-credentials
namespace: openshift-monitoring
stringData:
accessKey: <AWS_access_key>
secretKey: <AWS_secret_key>
type: Opaque
以下は、openshift-monitoring namespace の sigv4-credentials という名前の Secret オブジェクトを使用する AWS Signature Version 4 リモート書き込み認証のサンプルを示しています。
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
prometheusK8s:
remoteWrite:
- url: "https://authorization.example.com/api/write"
sigv4:
region: <AWS_region>
accessKey:
name: sigv4-credentials
key: accessKey
secretKey:
name: sigv4-credentials
key: secretKey
profile: <AWS_profile_name>
roleArn: <AWS_role_arn> 3.4.1.2.2. Basic 認証用のサンプル YAML
以下に、openshift-monitoring namespace 内の rw-basic-auth という名前の Secret オブジェクトの基本認証設定のサンプルを示します。
apiVersion: v1
kind: Secret
metadata:
name: rw-basic-auth
namespace: openshift-monitoring
stringData:
user: <basic_username>
password: <basic_password>
type: Opaque
以下の例は、openshift-monitoring namespace の rw-basic-auth という名前の Secret オブジェクトを使用する basicAuth リモート書き込み設定を示しています。これは、エンドポイントの認証認証情報がすでに設定されていることを前提としています。
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
prometheusK8s:
remoteWrite:
- url: "https://basicauth.example.com/api/write"
basicAuth:
username:
name: rw-basic-auth
key: user
password:
name: rw-basic-auth
key: password 3.4.1.2.3. Secret オブジェクトを使用したベアラートークンによる認証のサンプル YAML
以下は、openshift-monitoring namespace の rw-bearer-auth という名前の Secret オブジェクトのベアラートークン設定を示しています。
apiVersion: v1
kind: Secret
metadata:
name: rw-bearer-auth
namespace: openshift-monitoring
stringData:
token: <authentication_token>
type: Opaque- 1
- 認証トークン。
以下は、openshift-monitoring namespace の rw-bearer-auth という名前の Secret オブジェクトを使用するベアラートークン config map の設定例を示しています。
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
prometheusK8s:
remoteWrite:
- url: "https://authorization.example.com/api/write"
authorization:
type: Bearer
credentials:
name: rw-bearer-auth
key: token 3.4.1.2.4. OAuth 2.0 認証のサンプル YAML
以下は、openshift-monitoring namespace の oauth2-credentials という名前の Secret オブジェクトの OAuth 2.0 設定のサンプルを示しています。
apiVersion: v1
kind: Secret
metadata:
name: oauth2-credentials
namespace: openshift-monitoring
stringData:
id: <oauth2_id>
secret: <oauth2_secret>
type: Opaque
以下は、openshift-monitoring namespace の oauth2-credentials という Secret オブジェクトを使用した oauth2 リモート書き込み認証のサンプル設定です。
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
prometheusK8s:
remoteWrite:
- url: "https://test.example.com/api/write"
oauth2:
clientId:
secret:
name: oauth2-credentials
key: id
clientSecret:
name: oauth2-credentials
key: secret
tokenUrl: https://example.com/oauth2/token
scopes:
- <scope_1>
- <scope_2>
endpointParams:
param1: <parameter_1>
param2: <parameter_2>- 1 3
- 対応する
Secretオブジェクトの名前。ClientIdはConfigMapオブジェクトを参照することもできますが、clientSecretはSecretオブジェクトを参照する必要があることに注意してください。 - 2 4
- 指定された
Secretオブジェクトの OAuth 2.0 認証情報が含まれるキー。 - 5
- 指定された
clientIdおよびclientSecretでトークンを取得するために使用される URL。 - 6
- 認可要求の OAuth 2.0 スコープ。これらのスコープは、トークンがアクセスできるデータを制限します。
- 7
- 認可サーバーに必要な OAuth 2.0 認可要求パラメーター。
3.4.1.2.5. TLS クライアント認証のサンプル YAML
以下は、openshift-monitoring namespace 内の mtls-bundle という名前の tls Secret オブジェクトに対する TLS クライアント設定のサンプルです。
apiVersion: v1
kind: Secret
metadata:
name: mtls-bundle
namespace: openshift-monitoring
data:
ca.crt: <ca_cert>
client.crt: <client_cert>
client.key: <client_key>
type: tls
以下の例は、mtls-bundle という名前の TLS Secret オブジェクトを使用する tlsConfig リモート書き込み認証設定を示しています。
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
prometheusK8s:
remoteWrite:
- url: "https://remote-write-endpoint.example.com"
tlsConfig:
ca:
secret:
name: mtls-bundle
key: ca.crt
cert:
secret:
name: mtls-bundle
key: client.crt
keySecret:
name: mtls-bundle
key: client.key 3.4.1.3. リモート書き込みキューの設定例
リモート書き込み用の queueConfig オブジェクトを使用して、リモート書き込みキューパラメーターを調整できます。次の例は、openshift-monitoring namespace のデフォルトプラットフォームモニタリングのキューパラメーターとそのデフォルト値を示しています。
デフォルト値を使用したリモート書き込みパラメーターの設定例
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
prometheusK8s:
remoteWrite:
- url: "https://remote-write-endpoint.example.com"
<endpoint_authentication_credentials>
queueConfig:
capacity: 10000
minShards: 1
maxShards: 50
maxSamplesPerSend: 2000
batchSendDeadline: 5s
minBackoff: 30ms
maxBackoff: 5s
retryOnRateLimit: false 3.4.1.4. リモート書き込みメトリクスの表
次の表に、リモート書き込みおよびリモート書き込み関連のメトリクスと、リモート書き込みの設定時に発生する問題を解決するのに役立つ詳細な説明を記載します。
| メトリクス | 説明 |
|---|---|
|
| 任意のサンプルについて、Prometheus が先行書き込みログ (WAL) に保存した最新のタイムスタンプを表示します。 |
|
| リモート書き込みキューが正常に送信した最新のタイムスタンプを表示します。 |
|
| リモート書き込みが送信に失敗し、リモートストレージに再送信する必要があったサンプルの数。このメトリクスの値が一定して高い場合は、ネットワークまたはリモートストレージエンドポイントに問題があります。 |
|
| 各リモートエンドポイントで現在実行されているシャードの数を示します。 |
|
| 現在の書き込みスループットと、受信サンプルと送信サンプルの比率に基づいて計算された必要なシャードの数を示します。 |
|
| 現在の設定に基づくシャードの最大数を示します。 |
|
| 現在の設定に基づくシャードの最小数を示します。 |
|
| Prometheus が現在新しいデータを書き込んでいる WAL セグメントファイル。 |
|
| 各リモート書き込みインスタンスが現在読み取っている WAL セグメントファイル。 |
3.4.2. メトリクスのクラスター ID ラベルの作成
openshift-monitoring namespace の cluster-monitoring-config config map にリモート書き込みストレージ用の write_relabel 設定を追加することで、メトリクスのクラスター ID ラベルを作成できます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。 -
OpenShift CLI (
oc) がインストールされている。 - リモート書き込みストレージを設定している。
手順
openshift-monitoringプロジェクトでcluster-monitoring-configconfig map を編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configdata/config.yaml/prometheusK8s/remoteWriteの下にあるwriteRelabelConfigs:セクションで、クラスター ID の再ラベル付け設定値を追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: remoteWrite: - url: "https://remote-write-endpoint.example.com" <endpoint_authentication_credentials> writeRelabelConfigs:1 - <relabel_config>2 次のサンプルは、クラスター ID ラベル
cluster_idを使用してメトリクスを転送する方法を示しています。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: remoteWrite: - url: "https://remote-write-endpoint.example.com" writeRelabelConfigs: - sourceLabels: - __tmp_openshift_cluster_id__1 targetLabel: cluster_id2 action: replace3 - 1
- システムは最初に
__tmp_openshift_cluster_id__という名前の一時的なクラスター ID ソースラベルを適用します。この一時的なラベルは、指定するクラスター ID ラベル名に置き換えられます。 - 2
- リモート書き込みストレージに送信されるメトリクスのクラスター ID ラベルの名前を指定します。メトリクスにすでに存在するラベル名を使用する場合、その値はこのクラスター ID ラベルの名前でオーバーライドされます。ラベル名には
__tmp_openshift_cluster_id__は使用しないでください。最後の再ラベル手順では、この名前を使用するラベルを削除します。 - 3
replace置き換えラベルの再設定アクションは、一時ラベルを送信メトリクスのターゲットラベルに置き換えます。このアクションはデフォルトであり、アクションが指定されていない場合に適用されます。
- 変更を適用するためにファイルを保存します。新しい設定は自動的に適用されます。
3.5. コアプラットフォームモニタリングのアラートと通知の設定
ローカルまたは外部の Alertmanager インスタンスを設定して、Prometheus からエンドポイントレシーバーにアラートをルーティングできます。すべての時系列とアラートにカスタムラベルを割り当てて、便利なメタデータ情報を追加することもできます。
3.5.1. 外部 Alertmanager インスタンスの設定
OpenShift Container Platform モニタリングスタックには、Prometheus からのアラートのルートなど、ローカルの Alertmanager インスタンスが含まれます。
外部の Alertmanager インスタンスを追加すると、OpenShift Container Platform コアプロジェクトのアラートをルーティングできます。
複数のクラスターに同じ外部 Alertmanager 設定を追加し、クラスターごとにローカルインスタンスを無効にする場合には、単一の外部 Alertmanager インスタンスを使用して複数のクラスターのアラートルーティングを管理できます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。 -
OpenShift CLI (
oc) がインストールされている。
手順
openshift-monitoringプロジェクトでcluster-monitoring-configconfig map を編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configdata/config.yaml/prometheusK8sの下に、設定の詳細を含むadditionalAlertmanagerConfigsセクションを追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: additionalAlertmanagerConfigs: - <alertmanager_specification>1 - 1
<alertmanager_specification>は、追加の Alertmanager インスタンスの認証やその他の設定の詳細に置き換えます。現時点で、サポートされている認証方法はベアラートークン (bearerToken) およびクライアント TLS(tlsConfig) です。
次のサンプル config map は、クライアント TLS 認証でベアラートークンを使用して、Prometheus 用の追加の Alertmanager を設定します。
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: additionalAlertmanagerConfigs: - scheme: https pathPrefix: / timeout: "30s" apiVersion: v1 bearerToken: name: alertmanager-bearer-token key: token tlsConfig: key: name: alertmanager-tls key: tls.key cert: name: alertmanager-tls key: tls.crt ca: name: alertmanager-tls key: tls.ca staticConfigs: - external-alertmanager1-remote.com - external-alertmanager1-remote2.com- 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
3.5.1.1. ローカル Alertmanager の無効化
Prometheus インスタンスからのアラートをルーティングするローカル Alertmanager は、OpenShift Container Platform モニタリングスタックの openshift-monitoring プロジェクトではデフォルトで有効になっています。
ローカル Alertmanager を必要としない場合、openshift-monitoring プロジェクトで cluster-monitoring-config config map を指定して無効にできます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configconfig map を作成している。 -
OpenShift CLI (
oc) がインストールされている。
手順
openshift-monitoringプロジェクトでcluster-monitoring-configconfig map を編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configdata/config.yamlの下に、alertmanagerMainコンポーネントのenabled: falseを追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | alertmanagerMain: enabled: false- 変更を適用するためにファイルを保存します。Alertmanager インスタンスは、この変更を適用すると自動的に無効にされます。
3.5.2. Alertmanager のシークレットの設定
OpenShift Container Platform モニタリングスタックには、アラートを Prometheus からエンドポイントレシーバーにルーティングする Alertmanager が含まれています。Alertmanager がアラートを送信できるようにレシーバーで認証する必要がある場合は、レシーバーの認証認証情報を含むシークレットを使用するように Alertmanager を設定できます。
たとえば、シークレットを使用して、プライベート認証局 (CA) によって発行された証明書を必要とするエンドポイント受信者を認証するように Alertmanager を設定できます。また、基本 HTTP 認証用のパスワードファイルを必要とする受信者で認証するためにシークレットを使用するように Alertmanager を設定することもできます。いずれの場合も、認証の詳細は、ConfigMap オブジェクトではなく Secret オブジェクトに含まれています。
3.5.2.1. Alertmanager 設定へのシークレットの追加
openshift-monitoring プロジェクトの cluster-monitoring-config config map を編集することで、Alertmanager 設定にシークレットを追加できます。
config map にシークレットを追加すると、シークレットは、Alertmanager Pod の alertmanager コンテナー内の /etc/alertmanager/secrets/<secret_name> にボリュームとしてマウントされます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configconfig map を作成している。 -
openshift-monitoringプロジェクトの Alertmanager で設定するシークレットを作成しました。 -
OpenShift CLI (
oc) がインストールされている。
手順
openshift-monitoringプロジェクトでcluster-monitoring-configconfig map を編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configdata/config.yaml/alertmanagerMainの下にsecrets:セクションを次の設定で追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | alertmanagerMain: secrets:1 - <secret_name_1>2 - <secret_name_2>次の config map 設定の例では、
test-secret-basic-authおよびtest-secret-api-tokenという名前の 2 つのSecretオブジェクトを使用するように Alertmanager を設定します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | alertmanagerMain: secrets: - test-secret-basic-auth - test-secret-api-token- 変更を適用するためにファイルを保存します。新しい設定は自動的に適用されます。
3.5.3. 追加ラベルの時系列 (time series) およびアラートへの割り当て
Prometheus の外部ラベル機能を使用して、Prometheus から送信されるすべての時系列とアラートにカスタムラベルを付けることができます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。 -
OpenShift CLI (
oc) がインストールされている。
手順
openshift-monitoringプロジェクトでcluster-monitoring-configconfig map を編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configdata/config.yamlの下の各メトリクスに追加するラベルを定義します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: externalLabels: <key>: <value>1 - 1
<key>: <value>をキーと値のペアに置き換えます。<key>は新しいラベルの一意の名前、<value>はその値です。
警告-
prometheusまたはprometheus_replicaは予約され、オーバーライドされるため、これらをキー名として使用しないでください。 -
キー名に
clusterを使用しないでください。これを使用すると、開発者ダッシュボードでデータが表示されない問題が発生する可能性があります。
たとえば、リージョンと環境に関するメタデータをすべての時系列とアラートに追加するには、次の例を使用します。
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: externalLabels: region: eu environment: prod- 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
3.5.4. アラート通知の設定
OpenShift Container Platform 4.20 では、アラート UI でアラートの発生を確認できます。アラートレシーバーを設定することで、デフォルトのプラットフォームアラートに関する通知を送信するように Alertmanager を設定できます。
Alertmanager はデフォルトでは通知を送信しません。Web コンソールまたは alertmanager-main シークレットを通じてアラートレシーバーを設定して、通知を受信するように Alertmanager を設定することを強く推奨します。
3.5.4.1. デフォルトのプラットフォームアラートのアラートルーティングを設定する
クラスターからの重要なアラートを受信するために通知を送信するように Alertmanager を設定できます。Alertmanager からデフォルトのプラットフォームアラートに関する通知を送信する場所と方法をカスタマイズするには、openshift-monitoring namespace の alertmanager-main シークレットのデフォルト設定を編集します。
サポート対象のアップストリームバージョンの Alertmanager 機能はすべて、OpenShift Container Platform の Alertmanager 設定でもサポートされます。サポート対象のアップストリーム Alertmanager バージョンのあらゆる設定オプションを確認するには、Alertmanager configuration (Prometheus ドキュメント) を参照してください。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
現在アクティブな Alertmanager 設定を
alertmanager-mainシークレットから展開し、ローカルのalertmanager.yamlファイルとして保存します。$ oc -n openshift-monitoring get secret alertmanager-main --template='{{ index .data "alertmanager.yaml" }}' | base64 --decode > alertmanager.yaml-
alertmanager.yamlファイルを開きます。 Alertmanager の設定を編集します。
オプション: デフォルトの Alertmanager 設定を変更します。
デフォルトの Alertmanager シークレット YAML の例
global: resolve_timeout: 5m route: group_wait: 30s1 group_interval: 5m2 repeat_interval: 12h3 receiver: default routes: - matchers: - "alertname=Watchdog" repeat_interval: 2m receiver: watchdog receivers: - name: default - name: watchdog- 1
- Alertmanager が通知を送信する前に、アラートグループの初期アラートを収集するまで待機する時間を指定します。
- 2
- 最初の通知がすでに送信されているアラートグループに追加された新しいアラートに関する通知を Alertmanager が送信するまでの時間を指定します。
- 3
- アラート通知を繰り返すまでの最小時間を指定します。各グループの間隔で通知を繰り返す場合は、
repeat_intervalの値をgroup_intervalの値よりも小さく設定します。ただし、特定の Alertmanager Pod が再起動または再スケジュールされた場合などには、通知の繰り返しが遅れる可能性があります。
アラートレシーバーの設定を追加します。
# ... receivers: - name: default - name: watchdog - name: <receiver>1 <receiver_configuration>2 # ...PagerDuty をアラートレシーバーとして設定する例
# ... receivers: - name: default - name: watchdog - name: team-frontend-page pagerduty_configs: - routing_key: xxxxxxxxxx1 # ...- 1
- PagerDuty 統合キーを定義します。
メールアドレスをアラートレシーバーとして設定する例
# ... receivers: - name: default - name: watchdog - name: team-frontend-page email_configs: - to: myemail@example.com1 from: alertmanager@example.com2 smarthost: 'smtp.example.com:587'3 auth_username: alertmanager@example.com4 auth_password: password hello: alertmanager5 # ...重要Alertmanager には、メールアラートを送信するために外部 SMTP サーバーが必要です。メールアラートのレシーバーを設定する際には、外部 SMTP サーバーの必要な接続の詳細情報があることを確認してください。
ルーティング設定を追加します。
# ... route: group_wait: 30s group_interval: 5m repeat_interval: 12h receiver: default routes: - matchers: - "alertname=Watchdog" repeat_interval: 2m receiver: watchdog - matchers:1 - "<your_matching_rules>"2 receiver: <receiver>3 # ...警告match、match_re、target_match、target_match_re、source_match、source_match_reのキー名は使用しないでください。これらは非推奨であり、今後のリリースで削除される予定です。アラートルーティングの例
# ... route: group_wait: 30s group_interval: 5m repeat_interval: 12h receiver: default routes: - matchers: - "alertname=Watchdog" repeat_interval: 2m receiver: watchdog - matchers:1 - "service=example-app" routes:2 - matchers: - "severity=critical" receiver: team-frontend-page # ...前の例では、
example-appサービスによって発生した重大度がcriticalのアラートが、team-frontend-pageレシーバーにルーティングされます。通常、このタイプのアラートは、個人または緊急対応チームに通知します。
新規設定をファイルで適用します。
$ oc -n openshift-monitoring create secret generic alertmanager-main --from-file=alertmanager.yaml --dry-run=client -o=yaml | oc -n openshift-monitoring replace secret --filename=-ルーティングツリーを可視化してルーティング設定を確認します。
$ oc exec alertmanager-main-0 -n openshift-monitoring -- amtool config routes show --alertmanager.url http://localhost:9093出力例
Routing tree: . └── default-route receiver: default ├── {alertname="Watchdog"} receiver: Watchdog └── {service="example-app"} receiver: default └── {severity="critical"} receiver: team-frontend-page
3.5.4.2. OpenShift Container Platform Web コンソールを使用したアラートルーティングの設定
OpenShift Container Platform Web コンソールを使用してアラートルーティングを設定すると、クラスターの重要な問題を確実に把握できます。
OpenShift Container Platform Web コンソールでは、alertmanager-main シークレットよりもアラートルーティングを設定するための設定が少なくなっています。より多くの設定にアクセスしてアラートルーティングを設定するには、「デフォルトのプラットフォームアラートのアラートルーティングを設定する」を参照してください。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。
手順
Administrator パースペクティブで、Administration → Cluster Settings → Configuration → Alertmanager に移動します。
注記または、通知ドロワーから同じページに移動することもできます。OpenShift Container Platform Web コンソールの右上にあるベルのアイコンを選択し、AlertmanagerReceiverNotConfigured アラートで Configure を選択します。
- ページの Receivers セクションで、Create Receiver をクリックします。
- Create Receiver フォームで、Receiver name を追加し、リストから Receiver type を選択します。
レシーバー設定を編集します。
PagerDuty receiver の場合:
- 統合のタイプを選択し、PagerDuty 統合キーを追加します。
- PagerDuty インストールの URL を追加します。
- クライアントおよびインシデントの詳細または重大度の指定を編集する場合は、Show advanced configuration をクリックします。
Webhook receiver の場合:
- HTTP POST リクエストを送信するエンドポイントを追加します。
- デフォルトオプションを編集して解決したアラートを receiver に送信する場合は、Show advanced configuration をクリックします。
メール receiver の場合:
- 通知を送信するメールアドレスを追加します。
SMTP 設定の詳細を追加します。これには、通知の送信先のアドレス、メールの送信に使用する smarthost およびポート番号、SMTP サーバーのホスト名、および認証情報を含む詳細情報が含まれます。
重要Alertmanager には、メールアラートを送信するために外部 SMTP サーバーが必要です。メールアラートのレシーバーを設定する際には、外部 SMTP サーバーの必要な接続の詳細情報があることを確認してください。
- TLS が必要かどうかを選択します。
- 解決済みのアラートが receiver に送信されないようにデフォルトオプションを編集する、またはメール通知設定のボディーを編集する必要がある場合は、Show advanced configuration をクリックします。
Slack receiver の場合:
- Slack Webhook の URL を追加します。
- 通知を送信する Slack チャネルまたはユーザー名を追加します。
- デフォルトオプションを編集して解決済みのアラートが receiver に送信されないようにしたり、アイコンおよびユーザー設定を編集する必要がある場合は、Show advanced configuration を選択します。チャネル名とユーザー名を検索し、これらをリンクするかどうかを選択することもできます。
デフォルトでは、すべてのセレクターに一致するラベルを持つ Firing アラートが receiver に送信されます。receiver に送信する前に、Firing アラートのラベル値を完全に一致させる場合は、次の手順を実行します。
- フォームの Routing Labels セクションに、ルーティングラベルの名前と値を追加します。
- Add label を選択して、さらにルーティングラベルを追加します。
- Create をクリックしてレシーバーを作成します。
3.5.4.3. デフォルトのプラットフォームアラートとユーザー定義アラートに異なるアラートレシーバーを設定する
デフォルトのプラットフォームアラートとユーザー定義アラートに異なるアラートレシーバーを設定して、次の結果を確実に得ることができます。
- すべてのデフォルトのプラットフォームアラートは、これらのアラートを担当するチームが所有する受信機に送信されます。
- すべてのユーザー定義アラートは別の受信者に送信されるため、チームはプラットフォームアラートにのみ集中できます。
これを実現するには、Cluster Monitoring Operator によってすべてのプラットフォームアラートに追加される openshift_io_alert_source="platform" ラベルを使用します。
-
デフォルトのプラットフォームアラートを一致させるには、
openshift_io_alert_source="platform"マッチャーを使用します。 -
ユーザー定義のアラートを一致させるには、
openshift_io_alert_source!="platform"または'openshift_io_alert_source=""'マッチャーを使用します。
ユーザー定義アラート専用の Alertmanager の別のインスタンスを有効にしている場合、この設定は適用されません。
第4章 ユーザーワークロードモニタリングの設定
4.1. ユーザーワークロードモニタリングスタックを設定する準備
このセクションでは、設定できるユーザー定義のモニタリングコンポーネント、ユーザーワークロードモニタリングを有効にする方法、およびユーザーワークロードモニタリングスタックを設定するための準備方法について説明します。
- モニタリングスタックのすべての設定パラメーターが公開されるわけではありません。設定では、Cluster Monitoring Operator の config map 参照 にリストされているパラメーターとフィールドのみがサポートされます。
- モニタリングスタックには、追加のリソース要件があります。Cluster Monitoring Operator のスケーリング でコンピューティングリソースに関する推奨事項を参照し、十分なリソースがあることを確認してください。
4.1.1. 設定可能なモニタリングコンポーネント
この表には、設定できるモニタリングコンポーネントと、user-workload-monitoring-config config map でコンポーネントを指定するために使用されるキーが表示されます。
| コンポーネント | user-workload-monitoring-config 設定マップキー |
|---|---|
| Prometheus Operator |
|
| Prometheus |
|
| Alertmanager |
|
| Thanos Ruler |
|
ConfigMap オブジェクトの設定変更によって、結果も異なります。
- Pod は再デプロイされません。したがって、サービスの停止はありません。
変更された Pod が再デプロイされます。
- 単一ノードクラスターの場合、一時的なサービスが停止します。
- マルチノードクラスターの場合、高可用性であるため、影響を受ける Pod は徐々にロールアウトされ、モニタリングスタックは引き続き利用可能です。
- 永続ボリュームの設定およびサイズ変更を行うと、高可用性であるかどうかに関係なく、常にサービスが停止します。
config map の変更を必要とする手順にはそれぞれ、想定される結果が含まれます。
4.1.2. ユーザー定義プロジェクトのモニタリングの有効化
OpenShift Container Platform では、デフォルトのプラットフォームのモニタリングに加えて、ユーザー定義プロジェクトのモニタリングを有効にできます。追加のモニタリングソリューションを必要とせずに、OpenShift Container Platform で独自のプロジェクトをモニタリングできます。この機能を使用することで、コアプラットフォームコンポーネントおよびユーザー定義プロジェクトのモニタリングが一元化されます。
Operator Lifecycle Manager (OLM) を使用してインストールされた Prometheus Operator のバージョンは、ユーザー定義のモニタリングと互換性がありません。そのため、OLM Prometheus Operator によって管理される Prometheus カスタムリソース (CR) としてインストールされるカスタム Prometheus インスタンスは OpenShift Container Platform ではサポートされていません。
4.1.2.1. ユーザー定義プロジェクトのモニタリングの有効化
クラスター管理者は、クラスターモニタリング ConfigMap オブジェクトに enableUserWorkload: true フィールドを設定し、ユーザー定義プロジェクトのモニタリングを有効にできます。
ユーザー定義プロジェクトのモニタリングを有効にする前に、カスタム Prometheus インスタンスを削除する必要があります。
OpenShift Container Platform のユーザー定義プロジェクトのモニタリングを有効にするには、cluster-admin クラスターロールを持つユーザーとしてクラスターにアクセスできる必要があります。これにより、クラスター管理者は任意で、ユーザー定義のプロジェクトをモニターするコンポーネントを設定する権限をユーザーに付与できます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。 オプションで
user-workload-monitoring-configConfigMapをopenshift-user-workload-monitoringプロジェクトに作成している。ユーザー定義プロジェクトをモニターするコンポーネントのConfigMapに設定オプションを追加できます。注記設定の変更を
user-workload-monitoring-configConfigMapに保存するたびに、openshift-user-workload-monitoringプロジェクトの Pod が再デプロイされます。これらのコンポーネントが再デプロイするまで時間がかかる場合があります。
手順
cluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configenableUserWorkload: trueをdata/config.yamlの下に追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | enableUserWorkload: true1 - 1
trueに設定すると、enableUserWorkloadパラメーターはクラスター内のユーザー定義プロジェクトのモニタリングを有効にします。
変更を適用するためにファイルを保存します。ユーザー定義プロジェクトのモニタリングは自動的に有効になります。
注記ユーザー定義プロジェクトの監視を有効にすると、デフォルトで
user-workload-monitoring-configConfigMapオブジェクトが作成されます。prometheus-operator、prometheus-user-workloadおよびthanos-ruler-user-workloadPod がopenshift-user-workload-monitoringプロジェクトで実行中であることを確認します。Pod が起動するまでに少し時間がかかる場合があります。$ oc -n openshift-user-workload-monitoring get pod出力例
NAME READY STATUS RESTARTS AGE prometheus-operator-6f7b748d5b-t7nbg 2/2 Running 0 3h prometheus-user-workload-0 4/4 Running 1 3h prometheus-user-workload-1 4/4 Running 1 3h thanos-ruler-user-workload-0 3/3 Running 0 3h thanos-ruler-user-workload-1 3/3 Running 0 3h
4.1.2.2. ユーザーに対するユーザー定義プロジェクトのモニタリングを設定するための権限の付与
クラスター管理者は、user-workload-monitoring-config-edit ロールをユーザーに割り当てることができます。これにより、OpenShift Container Platform のコアモニタリングコンポーネントの設定および管理権限を付与せずに、ユーザー定義プロジェクトのモニタリングを設定および管理する権限が付与されます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 - ロールを割り当てるユーザーアカウントがすでに存在している。
-
OpenShift CLI (
oc) がインストールされている。
手順
user-workload-monitoring-config-editロールをopenshift-user-workload-monitoringプロジェクトのユーザーに割り当てます。$ oc -n openshift-user-workload-monitoring adm policy add-role-to-user \ user-workload-monitoring-config-edit <user> \ --role-namespace openshift-user-workload-monitoring関連するロールバインディングを表示して、ユーザーが
user-workload-monitoring-config-editロールに正しく割り当てられていることを確認します。$ oc describe rolebinding <role_binding_name> -n openshift-user-workload-monitoringコマンドの例
$ oc describe rolebinding user-workload-monitoring-config-edit -n openshift-user-workload-monitoring出力例
Name: user-workload-monitoring-config-edit Labels: <none> Annotations: <none> Role: Kind: Role Name: user-workload-monitoring-config-edit Subjects: Kind Name Namespace ---- ---- --------- User user11 - 1
- この例では、
user1がuser-workload-monitoring-config-editロールに割り当てられています。
4.1.3. ユーザー定義プロジェクトのアラートルーティングの有効化
OpenShift Container Platform では、管理者はユーザー定義プロジェクトのアラートルーティングを有効にできます。このプロセスには、以下の手順が含まれます。
ユーザー定義プロジェクトのアラートルーティングを有効にします。
- デフォルトのプラットフォーム Alertmanager インスタンスを使用します。
- ユーザー定義プロジェクトにのみ、別の Alertmanager インスタンスを使用します。
- ユーザー定義プロジェクトのアラートルーティングを設定するための権限をユーザーに付与します。
これらの手順を完了すると、開発者およびその他のユーザーはユーザー定義のプロジェクトのカスタムアラートおよびアラートルーティングを設定できます。
4.1.3.1. ユーザー定義のアラートルーティングのプラットフォーム Alertmanager インスタンスの有効化
ユーザーは、Alertmanager のメインプラットフォームインスタンスを使用するユーザー定義のアラートルーティング設定を作成できます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 - クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
OpenShift CLI (
oc) がインストールされている。
手順
cluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configalertmanagerMainセクションにenableUserAlertmanagerConfig: trueをdata/config.yamlの下に追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | # ... alertmanagerMain: enableUserAlertmanagerConfig: true1 # ...- 1
enableUserAlertmanagerConfig値をtrueに設定して、ユーザーが Alertmanager のメインプラットフォームインスタンスを使用するユーザー定義のアラートルーティング設定を作成できるようにします。
- 変更を適用するためにファイルを保存します。新しい設定は自動的に適用されます。
4.1.3.2. ユーザー定義のアラートルーティング用の個別の Alertmanager インスタンスの有効化
クラスターによっては、ユーザー定義のプロジェクト用に専用の Alertmanager インスタンスをデプロイする必要がある場合があります。これは、デフォルトのプラットフォーム Alertmanager インスタンスの負荷を軽減するのに役立ちます。また、デフォルトのプラットフォームアラートとユーザー定義のアラートを分離することができます。このような場合、必要に応じて、Alertmanager の別のインスタンスを有効にして、ユーザー定義のプロジェクトのみにアラートを送信できます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 - ユーザー定義プロジェクトのモニタリングが有効化されている。
-
OpenShift CLI (
oc) がインストールされている。
手順
user-workload-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configdata/config.yamlの下にあるalertmanagerセクションにenabled: trueおよびenableAlertmanagerConfig: trueを追加します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | alertmanager: enabled: true1 enableAlertmanagerConfig: true2 - 1
enabledの値をtrueに設定して、クラスター内のユーザー定義プロジェクトの Alertmanager の専用インスタンスを有効にします。値をfalseに設定するか、キーを完全に省略してユーザー定義プロジェクトの Alertmanager を無効にします。この値をfalseに設定した場合や、キーを省略すると、ユーザー定義のアラートはデフォルトのプラットフォーム Alertmanager インスタンスにルーティングされます。- 2
enableAlertmanagerConfig値をtrueに設定して、ユーザーがAlertmanagerConfigオブジェクトで独自のアラートルーティング設定を定義できるようにします。
- 変更を適用するためにファイルを保存します。ユーザー定義プロジェクトの Alertmanager の専用インスタンスが自動的に起動します。
検証
user-workloadAlertmanager インスタンスが起動していることを確認します。$ oc -n openshift-user-workload-monitoring get alertmanager出力例
NAME VERSION REPLICAS AGE user-workload 0.24.0 2 100s
4.1.3.3. ユーザー定義プロジェクトのアラートルーティングを設定するためのユーザーへの権限の付与
ユーザー定義プロジェクトのアラートルーティングを設定する権限をユーザーに付与できます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 - ユーザー定義プロジェクトのモニタリングが有効化されている。
- ロールを割り当てるユーザーアカウントがすでに存在している。
-
OpenShift CLI (
oc) がインストールされている。
手順
ユーザー定義プロジェクトのユーザーに
alert-routing-editクラスターロールを割り当てます。$ oc -n <namespace> adm policy add-role-to-user alert-routing-edit <user>1 - 1
<namespace>は、ns1などのユーザー定義プロジェクトの namespace に置き換えます。<user>は、ロールを割り当てるアカウントのユーザー名に置き換えます。
4.1.4. ユーザー定義プロジェクトの監視権限をユーザーに付与する
クラスター管理者は、すべての OpenShift Container Platform のコアプロジェクトおよびユーザー定義プロジェクトを監視できます。
以下の場合に、開発者と他のユーザーに異なる権限を付与することもできます。
- ユーザー定義プロジェクトの監視
- ユーザー定義プロジェクトを監視するコンポーネントの設定
- ユーザー定義プロジェクトのアラートルーティングの設定
- ユーザー定義プロジェクトのアラートとサイレンスの管理
次のいずれかのモニタリングロールまたはクラスターロールを割り当てることで、権限を付与できます。
| ロール名 | 説明 | プロジェクト |
|---|---|---|
|
|
このロールを持つユーザーは、 |
|
|
| このロールを持つユーザーには、ユーザー定義の Alertmanager が有効な場合、全プロジェクトのユーザー定義の Alertmanager API に対する読み取りアクセス権が付与されます。 |
|
|
| このロールを持つユーザーには、ユーザー定義の Alertmanager が有効な場合、全プロジェクトのユーザー定義の Alertmanager API に対する読み取りおよび書き込みアクセス権が付与されます。 |
|
| クラスターロール名 | 説明 | プロジェクト |
|---|---|---|
|
|
このクラスターロールを持つユーザーには、ユーザー定義プロジェクトの |
|
|
|
このクラスターロールを持つユーザーは、ユーザー定義プロジェクトの |
|
|
|
このクラスターロールを持つユーザーには、 |
|
|
|
このクラスターロールを持つユーザーは、ユーザー定義プロジェクトの |
|
4.1.4.1. Web コンソールを使用したユーザー権限の付与
OpenShift Container Platform Web コンソールを使用して、openshift-monitoring プロジェクトまたはユーザー自身のプロジェクトに対する権限をユーザーに付与できます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 - ロールを割り当てるユーザーアカウントがすでに存在している。
手順
- OpenShift Container Platform Web コンソールの Administrator パースペクティブで、User Management → RoleBindings → Create binding に移動します。
- Binding Type セクションで、Namespace Role Binding タイプを選択します。
- Name フィールドに、ロールバインディングの名前を入力します。
Namespace フィールドで、アクセスを許可するプロジェクトを選択します。
重要この手順を使用してユーザーに付与するモニタリングロールまたはクラスターロールの権限は、Namespace フィールドで選択したプロジェクトにのみ適用されます。
- Role Name リストからモニタリングロールまたはクラスターロールを選択します。
- Subject セクションで、User を選択します。
- Subject Name フィールドにユーザーの名前を入力します。
- Create を選択して、ロールバインディングを適用します。
4.1.4.2. CLI を使用したユーザー権限の付与
OpenShift CLI (oc) を使用して、独自のプロジェクトをモニターする権限をユーザーに付与できます。
どちらのロールまたはクラスターロールを選択する場合でも、クラスター管理者が特定のプロジェクトにバインドする必要があります。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 - ロールを割り当てるユーザーアカウントがすでに存在している。
-
OpenShift CLI (
oc) がインストールされている。
手順
プロジェクトのユーザーにモニタリングロールを割り当てるには、次のコマンドを入力します。
$ oc adm policy add-role-to-user <role> <user> -n <namespace> --role-namespace <namespace>1 - 1
<role>は必要なモニタリングロールに、<user>はロールを割り当てるユーザーに、<namespace>はアクセスを許可するプロジェクトに置き換えます。
プロジェクトのユーザーにモニタリングクラスターロールを割り当てるには、次のコマンドを入力します。
$ oc adm policy add-cluster-role-to-user <cluster-role> <user> -n <namespace>1 - 1
<cluster-role>は必要なモニタリングクラスターロールに、<user>はクラスターロールを割り当てるユーザーに、<namespace>はアクセスを許可するプロジェクトに置き換えます。
4.1.5. モニタリングからのユーザー定義のプロジェクトを除く
ユーザー定義のプロジェクトは、ユーザーワークロードモニタリングから除外できます。これを実行するには、openshift.io/user-monitoring ラベルに false を指定して、プロジェクトの namespace に追加します。
手順
ラベルをプロジェクト namespace に追加します。
$ oc label namespace my-project 'openshift.io/user-monitoring=false'モニタリングを再度有効にするには、namespace からラベルを削除します。
$ oc label namespace my-project 'openshift.io/user-monitoring-'注記プロジェクトにアクティブなモニタリングターゲットがあった場合、ラベルを追加した後、Prometheus がそれらのスクレイピングを停止するまでに数分かかる場合があります。
4.1.6. ユーザー定義プロジェクトのモニタリングの無効化
ユーザー定義プロジェクトのモニタリングを有効にした後に、クラスターモニタリング ConfigMap オブジェクトに enableUserWorkload: false を設定してこれを再度無効にできます。
または、enableUserWorkload: true を削除して、ユーザー定義プロジェクトのモニタリングを無効にできます。
手順
cluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configdata/config.yamlでenableUserWorkload:をfalseに設定します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | enableUserWorkload: false
- 変更を適用するためにファイルを保存します。ユーザー定義プロジェクトのモニタリングは自動的に無効になります。
prometheus-operator、prometheus-user-workloadおよびthanos-ruler-user-workloadPod がopenshift-user-workload-monitoringプロジェクトで終了していることを確認します。これには少し時間がかかる場合があります。$ oc -n openshift-user-workload-monitoring get pod出力例
No resources found in openshift-user-workload-monitoring project.
openshift-user-workload-monitoring プロジェクトの user-workload-monitoring-config ConfigMap オブジェクトは、ユーザー定義プロジェクトのモニタリングが無効にされている場合は自動的に削除されません。これにより、ConfigMap で作成した可能性のあるカスタム設定を保持されます。
4.2. ユーザーワークロードモニタリングのパフォーマンスとスケーラビリティーの設定
モニタリングスタックを設定して、クラスターのパフォーマンスとスケールを最適化できます。次のドキュメントでは、モニタリングコンポーネントを分散する方法と、モニタリングスタックが CPU およびメモリーリソースに与える影響を制御する方法を説明します。
4.2.1. モニタリングコンポーネントの配置と分散の制御
次の方法で、モニタリングスタックコンポーネントを特定のノードに移動できます。
-
ラベル付きノードで
nodeSelector制約を使用して、任意のモニタリングスタックコンポーネントを特定のノードに移動します。 - taint されたノードにコンポーネントを移動できるように toleration を割り当てます。
これにより、クラスター全体のモニタリングコンポーネントの配置と分散を制御できます。
モニタリングコンポーネントの配置と分散を制御して、システムリソースの使用を最適化し、パフォーマンスを高め、特定の要件やポリシーに基づいてワークロードを分離できます。
4.2.1.1. モニタリングコンポーネントの異なるノードへの移動
ユーザー定義プロジェクトのワークロードをモニターする任意のコンポーネントを特定のワーカーノードに移動できます。
コンポーネントをコントロールプレーンまたはインフラストラクチャーノードに移動することは許可されていません。
前提条件
-
cluster-adminクラスターロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 - クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
OpenShift CLI (
oc) がインストールされている。
手順
まだの場合は、モニタリングコンポーネントを実行するノードにラベルを追加します。
$ oc label nodes <node_name> <node_label>1 - 1
<node_name>は、ラベルを追加するノードの名前に置き換えます。<node_label>は、必要なラベルの名前に置き換えます。
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configdata/config.yamlでコンポーネントのnodeSelector制約のノードラベルを指定します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | # ... <component>:1 nodeSelector: <node_label_1>2 <node_label_2>3 # ...注記nodeSelectorの制約を設定した後もモニタリングコンポーネントがPending状態のままになっている場合は、Pod イベントで taint および toleration に関連するエラーの有無を確認します。- 変更を適用するためにファイルを保存します。新しい設定で指定されたコンポーネントは自動的に新しいノードに移動され、新しい設定の影響を受ける Pod は再デプロイされます。
4.2.1.2. モニタリングコンポーネントへの toleration の割り当て
ユーザー定義プロジェクトをモニターするコンポーネントに許容値を割り当てて、テイントされたワーカーノードにプロジェクトを移動できるようにすることができます。コントロールプレーンまたはインフラストラクチャーノードでのスケジューリングは許可されていません。
前提条件
-
cluster-adminクラスターロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 - クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
OpenShift CLI (
oc) がインストールされている。
手順
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configconfig map を編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configコンポーネントの
tolerationsを指定します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>: tolerations: <toleration_specification><component>および<toleration_specification>を随時置き換えます。たとえば、
oc adm taint nodes node1 key1=value1:NoScheduleは、キーがkey1で、値がvalue1のnode1に taint を追加します。これにより、モニタリングコンポーネントがnode1に Pod をデプロイするのを防ぎます。ただし、その taint に対して toleration が設定されている場合を除きます。以下の例では、サンプルの taint を容認するようにthanosRulerコンポーネントを設定します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | thanosRuler: tolerations: - key: "key1" operator: "Equal" value: "value1" effect: "NoSchedule"- 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
4.2.2. モニタリングコンポーネントの CPU およびメモリーリソースの管理
モニタリングコンポーネントを実行するコンテナーに十分な CPU リソースとメモリーリソースを確保するには、これらのコンポーネントのリソース制限および要求の値を指定します。
openshift-user-workload-monitoring namespace で、ユーザー定義プロジェクトを監視するモニタリングコンポーネントのリソース制限および要求を設定できます。
4.2.2.1. 制限および要求の指定
CPU およびメモリーリソースを設定するには、openshift-user-workload-monitoring namespace の user-workload-monitoring-config ConfigMap オブジェクトでリソース制限と要求の値を指定します。
前提条件
-
cluster-adminクラスターロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configconfig map を編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-config値を追加して、設定する各コンポーネントのリソース制限および要求を定義します。
重要制限に設定した値が常に要求に設定された値よりも大きくなることを確認してください。そうでない場合、エラーが発生し、コンテナーは実行されません。
リソース制限とリクエストの設定例
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | alertmanager: resources: limits: cpu: 500m memory: 1Gi requests: cpu: 200m memory: 500Mi prometheus: resources: limits: cpu: 500m memory: 3Gi requests: cpu: 200m memory: 500Mi thanosRuler: resources: limits: cpu: 500m memory: 1Gi requests: cpu: 200m memory: 500Mi- 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
4.2.3. ユーザー定義プロジェクトでバインドされていないメトリクス属性の影響の制御
クラスター管理者は、以下の手段を使用して、ユーザー定義プロジェクトでのバインドされていないメトリクス属性の影響を制御できます。
- ユーザー定義プロジェクトでターゲットスクレイピングごとの許容可能なサンプル数を制限する
- 収集されたラベルの数、ラベル名の長さ、およびラベル値の長さを制限します。
- 収集サンプルのしきい値に達するか、ターゲットを収集できない場合に実行されるアラートを作成します。
スクレイピングサンプル数を制限すると、ラベルにバインドされない属性を多数追加することによって発生する問題を防ぐことができます。さらに開発者は、メトリクスに定義するバインドされていない属性の数を制限することにより、根本的な原因を防ぐことができます。使用可能な値の制限されたセットにバインドされる属性を使用すると、可能なキーと値のペアの組み合わせの数が減ります。
4.2.3.1. ユーザー定義プロジェクトの収集サンプルおよびラベル制限の設定
ユーザー定義プロジェクトで、ターゲット収集ごとに受け入れ可能なサンプル数を制限できます。収集されたラベルの数、ラベル名の長さ、およびラベル値の長さを制限することもできます。
サンプルまたはラベルの制限を設定している場合、制限に達した後にそのターゲット収集に関する追加のサンプルデータは取得されません。
前提条件
-
cluster-adminクラスターロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 - クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
OpenShift CLI (
oc) がインストールされている。
手順
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configenforcedSampleLimit設定をdata/config.yamlに追加し、ユーザー定義プロジェクトのターゲットの収集ごとに受け入れ可能なサンプルの数を制限できます。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: enforcedSampleLimit: 500001 - 1
- このパラメーターが指定されている場合は、値が必要です。この
enforcedSampleLimitの例では、ユーザー定義プロジェクトのターゲット収集ごとに受け入れ可能なサンプル数を 50,000 に制限します。
enforcedLabelLimit、enforcedLabelNameLengthLimit、およびenforcedLabelValueLengthLimit設定をdata/config.yamlに追加し、収集されるラベルの数、ラベル名の長さ、およびユーザー定義プロジェクトでのラベル値の長さを制限します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: enforcedLabelLimit: 5001 enforcedLabelNameLengthLimit: 502 enforcedLabelValueLengthLimit: 6003 - 変更を適用するためにファイルを保存します。制限は自動的に適用されます。
4.2.3.2. 収集サンプルアラートの作成
以下の場合に通知するアラートを作成できます。
-
ターゲットを収集できず、指定された
forの期間利用できない -
指定された
forの期間、収集サンプルのしきい値に達するか、この値を上回る
前提条件
-
cluster-adminクラスターロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 - クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
enforcedSampleLimitを使用して、ユーザー定義プロジェクトのターゲット収集ごとに受け入れ可能なサンプル数を制限している。 -
OpenShift CLI (
oc) がインストールされている。
手順
ターゲットがダウンし、実行されたサンプル制限に近づく際に通知するアラートを指定して YAML ファイルを作成します。この例のファイルは
monitoring-stack-alerts.yamlという名前です。apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: labels: prometheus: k8s role: alert-rules name: monitoring-stack-alerts1 namespace: ns12 spec: groups: - name: general.rules rules: - alert: TargetDown3 annotations: message: '{{ printf "%.4g" $value }}% of the {{ $labels.job }}/{{ $labels.service }} targets in {{ $labels.namespace }} namespace are down.'4 expr: 100 * (count(up == 0) BY (job, namespace, service) / count(up) BY (job, namespace, service)) > 10 for: 10m5 labels: severity: warning6 - alert: ApproachingEnforcedSamplesLimit7 annotations: message: '{{ $labels.container }} container of the {{ $labels.pod }} pod in the {{ $labels.namespace }} namespace consumes {{ $value | humanizePercentage }} of the samples limit budget.'8 expr: scrape_samples_scraped/50000 > 0.89 for: 10m10 labels: severity: warning11 - 1
- アラートルールの名前を定義します。
- 2
- アラートルールをデプロイするユーザー定義のプロジェクトを指定します。
- 3
TargetDownアラートは、forの期間にターゲットを収集できないか、利用できない場合に実行されます。- 4
TargetDownアラートが実行される場合に出力されるメッセージ。- 5
- アラートが実行される前に、
TargetDownアラートの条件がこの期間中 true である必要があります。 - 6
TargetDownアラートの重大度を定義します。- 7
ApproachingEnforcedSamplesLimitアラートは、指定されたforの期間に定義された収集サンプルのしきい値に達するか、この値を上回る場合に実行されます。- 8
ApproachingEnforcedSamplesLimitアラートの実行時に出力されるメッセージ。- 9
ApproachingEnforcedSamplesLimitアラートのしきい値。この例では、ターゲット収集ごとのサンプル数が実行されたサンプル制限50000の 80% を超えるとアラートが実行されます。アラートが実行される前に、forの期間も経過している必要があります。式scrape_samples_scraped/<number> > <threshold>の<number>はuser-workload-monitoring-configConfigMapオブジェクトで定義されるenforcedSampleLimit値に一致する必要があります。- 10
- アラートが実行される前に、
ApproachingEnforcedSamplesLimitアラートの条件がこの期間中 true である必要があります。 - 11
ApproachingEnforcedSamplesLimitアラートの重大度を定義します。
設定をユーザー定義プロジェクトに適用します。
$ oc apply -f monitoring-stack-alerts.yaml
4.2.4. Pod トポロジー分散制約の設定
ユーザー定義のモニタリング用にすべての Pod に対して Pod トポロジーの拡散制約を設定し、ゾーン全体のノードに Pod レプリカをスケジュールする方法を制御できます。これにより、ワークロードが異なるデータセンターまたは階層型インフラストラクチャーゾーンのノードに分散されるため、Pod の可用性が高まり、より効率的に実行されるようになります。
user-workload-monitoring-config config map を使用して、Pod を監視するための Pod トポロジーの分散制約を設定できます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 - クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
OpenShift CLI (
oc) がインストールされている。
手順
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configconfig map を編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configPod トポロジーの分散制約を設定するには、
data/config.yamlフィールドの下に次の設定を追加します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>:1 topologySpreadConstraints: - maxSkew: <n>2 topologyKey: <key>3 whenUnsatisfiable: <value>4 labelSelector:5 <match_option>- 1
- Pod トポロジーの分散制約を設定するコンポーネントの名前を指定します。
- 2
maxSkewの数値を指定します。これは、どの程度まで Pod が不均等に分散されることを許可するか定義します。- 3
topologyKeyにノードラベルのキーを指定します。このキーと同じ値のラベルを持つノードは、同じトポロジーにあると見なされます。スケジューラーは、各ドメインにバランスの取れた数の Pod を配置しようとします。- 4
whenUnsatisfiableの値を指定します。利用可能なオプションはDoNotScheduleとScheduleAnywayです。maxSkew値で、ターゲットトポロジー内の一致する Pod の数とグローバル最小値との間で許容される最大差を定義する場合は、DoNotScheduleを指定します。スケジューラーが引き続き Pod をスケジュールするが、スキューを減らす可能性のあるノードにより高い優先度を与える場合は、ScheduleAnywayを指定します。- 5
- 一致する Pod を見つけるには、
labelSelectorを指定します。このラベルセレクターに一致する Pod は、対応するトポロジードメイン内の Pod の数を決定するためにカウントされます。
Thanos Ruler の設定例
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | thanosRuler: topologySpreadConstraints: - maxSkew: 1 topologyKey: monitoring whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app.kubernetes.io/name: thanos-ruler- 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
4.3. ユーザーワークロードモニタリングのデータの保存と記録
メトリクスとアラートデータの保存および記録、ログの設定と記録するアクティビティーの指定、Prometheus が保存されたデータを保持する期間の制御、データの最大ディスク領域の設定を行います。これらのアクションは、データを保護し、データをトラブルシューティングに使用するのに役立ちます。
4.3.1. 永続ストレージの設定
永続ストレージを使用してクラスターモニタリングを実行すると、次の利点が得られます。
- メトリクスとアラートデータを永続ボリューム (PV) に保存することで、データ損失から保護します。その結果、Pod が再起動または再作成されても存続できます。
- Alertmanager Pod が再起動したときに、重複した通知を受信したり、アラートのサイレンスが失われたりするのを回避します。
マルチノードクラスターでは、高可用性を実現するために、Prometheus、Alertmanager、および Thanos Ruler の永続ストレージを設定する必要があります。
実稼働環境では、永続ストレージを設定することを強く推奨します。
4.3.1.1. 永続ストレージの前提条件
- ディスクが一杯にならないように十分な永続ストレージを確保します。
永続ボリュームを設定する際に、
volumeModeパラメーターのストレージタイプ値としてFilesystemを使用します。重要-
PersistentVolumeリソースでvolumeMode: Blockで記述されている生のブロックボリュームを使用しないでください。Prometheus は raw ブロックボリュームを使用できません。 - Prometheus は、POSIX に準拠していないファイルシステムをサポートしません。たとえば、一部の NFS ファイルシステム実装は POSIX に準拠していません。ストレージに NFS ファイルシステムを使用する場合は、NFS 実装が完全に POSIX に準拠していることをベンダーに確認してください。
-
4.3.1.2. 永続ボリューム要求の設定
コンポーネントの監視に永続ボリューム (PV) を使用するには、永続ボリューム要求 (PVC) を設定する必要があります。
前提条件
-
cluster-adminクラスターロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 - クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
OpenShift CLI (
oc) がインストールされている。
手順
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configconfig map を編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configコンポーネントの PVC 設定を
data/config.yamlの下に追加します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>:1 volumeClaimTemplate: spec: storageClassName: <storage_class>2 resources: requests: storage: <amount_of_storage>3 以下の例では、Thanos Ruler の永続ストレージを要求する PVC を設定します。
PVC 設定の例
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | thanosRuler: volumeClaimTemplate: spec: storageClassName: my-storage-class resources: requests: storage: 10Gi注記thanosRulerコンポーネントのストレージ要件は、評価されルールの数や、各ルールが生成するサンプル数により異なります。変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされ、新しいストレージ設定が適用されます。
警告PVC 設定で config map を更新すると、影響を受ける
StatefulSetオブジェクトが再作成され、一時的なサービス停止が発生します。
4.3.1.3. 永続ボリュームのサイズ変更
Prometheus、Thanos Ruler、および Alertmanager インスタンスの永続ボリューム (PV) のサイズを変更できます。永続ボリューム要求 (PVC) を手動で拡張し、コンポーネントが設定されている config map を更新する必要があります。
PVC のサイズのみ拡張可能です。ストレージサイズを縮小することはできません。
前提条件
-
cluster-adminクラスターロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 - クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にしている。
- ユーザー定義プロジェクトを監視するコンポーネント用に少なくとも 1 つの PVC を設定しました。
-
OpenShift CLI (
oc) がインストールされている。
手順
- 更新されたストレージ要求を使用して PVC を手動で拡張します。詳細は、永続ボリュームの拡張 の「ファイルシステムを使用した永続ボリューム要求 (PVC) の拡張」を参照してください。
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configconfig map を編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configdata/config.yamlの下に、コンポーネントの PVC 設定用の新しいストレージサイズを追加します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>:1 volumeClaimTemplate: spec: resources: requests: storage: <amount_of_storage>2 次の例では、Thanos Ruler の新しい PVC 要求を 20 ギガバイトに設定します。
thanosRulerのストレージ設定例apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | thanosRuler: volumeClaimTemplate: spec: resources: requests: storage: 20Gi注記thanosRulerコンポーネントのストレージ要件は、評価されルールの数や、各ルールが生成するサンプル数により異なります。変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
警告新しいストレージサイズで config map を更新すると、影響を受ける
StatefulSetオブジェクトが再作成され、サービスが一時的に停止します。
4.3.2. Prometheus メトリクスデータの保持期間およびサイズの変更
デフォルトでは、Prometheus はユーザー定義のプロジェクトを監視するためにメトリクスデータを 24 時間保持します。データの削除時に Prometheus インスタンスが変更する保持時間を変更できます。保持されるメトリクスデータが使用するディスク容量の最大量を設定することもできます。
データコンパクションは 2 時間ごとに実行されます。そのため、コンパクションが実行される前に永続ボリューム (PV) がいっぱいになり、retentionSize 制限を超える可能性があります。その場合、PV 上のスペースが retentionSize 制限を下回るまで、KubePersistentVolumeFillingUp アラートが発生します。
前提条件
-
cluster-adminクラスターロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 - クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
OpenShift CLI (
oc) がインストールされている。
手順
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configconfig map を編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-config保持期間およびサイズ設定を
data/config.yamlに追加します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: retention: <time_specification>1 retentionSize: <size_specification>2 次の例では、Prometheus インスタンスの保持時間を 24 時間、保持サイズを 10 ギガバイトに設定します。
Prometheus の保持期間を設定する例
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: retention: 24h retentionSize: 10GB- 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
4.3.2.1. Thanos Ruler メトリクスデータの保持期間の変更
デフォルトでは、ユーザー定義のプロジェクトでは、Thanos Ruler は 24 時間にわたりメトリクスデータを自動的に保持します。openshift-user-workload-monitoring namespace の user-workload-monitoring-config の config map に時間の値を指定して、このデータの保持期間を変更できます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 - クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
OpenShift CLI (
oc) がインストールされている。
手順
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-config保持期間の設定を
data/config.yamlに追加します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | thanosRuler: retention: <time_specification>1 - 1
- 保持時間は、
ms(ミリ秒)、s(秒)、m(分)、h(時)、d(日)、w(週)、y(年) が直後に続く数字で指定します。1h30m15sなどの特定の時間に時間値を組み合わせることもできます。デフォルトは24hです。
以下の例では、Thanos Ruler データの保持期間を 10 日間に設定します。
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | thanosRuler: retention: 10d- 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
4.3.3. モニタリングコンポーネントのログレベルの設定
Alertmanager、Prometheus Operator、Prometheus および Thanos Ruler のログレベルを設定できます。
以下のログレベルは、user-workload-monitoring-config ConfigMap オブジェクトの関連コンポーネントに適用できます。
-
debug:デバッグ、情報、警告、およびエラーメッセージをログに記録します。 -
info:情報、警告およびエラーメッセージをログに記録します。 -
warn:警告およびエラーメッセージのみをログに記録します。 -
error:エラーメッセージのみをログに記録します。
デフォルトのログレベルは info です。
前提条件
-
cluster-adminクラスターロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 - クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
OpenShift CLI (
oc) がインストールされている。
手順
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configconfig map を編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configコンポーネントの
logLevel: <log_level>をdata/config.yamlの下に追加します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>:1 logLevel: <log_level>2 - 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
関連するプロジェクトでデプロイメントまたは Pod 設定を確認し、ログレベルが適用されていることを確認します。以下の例では、
prometheus-operatorデプロイメントのログレベルを確認します。$ oc -n openshift-user-workload-monitoring get deploy prometheus-operator -o yaml | grep "log-level"出力例
- --log-level=debugコンポーネントの Pod が実行中であることを確認します。次の例では、Pod のステータスをリスト表示します。
$ oc -n openshift-user-workload-monitoring get pods注記認識されない
logLevel値がConfigMapオブジェクトに含まれる場合は、コンポーネントの Pod が正常に再起動しない可能性があります。
4.3.4. Prometheus のクエリーログファイルの有効化
エンジンによって実行されたすべてのクエリーをログファイルに書き込むように Prometheus を設定できます。
ログローテーションはサポートされていないため、問題のトラブルシューティングが必要な場合にのみ、この機能を一時的に有効にします。トラブルシューティングが終了したら、ConfigMap オブジェクトに加えた変更を元に戻してクエリーログを無効にし、機能を有効にします。
前提条件
-
cluster-adminクラスターロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 - クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
OpenShift CLI (
oc) がインストールされている。
手順
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configconfig map を編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configPrometheus の
queryLogFileパラメーターをdata/config.yamlの下に追加します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: queryLogFile: <path>1 - 1
- クエリーが記録されるファイルへの完全なパスを追加します。
- 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
コンポーネントの Pod が実行中であることを確認します。次のコマンド例は、Pod のステータスを表示します。
$ oc -n openshift-user-workload-monitoring get pods出力例
... prometheus-operator-776fcbbd56-2nbfm 2/2 Running 0 132m prometheus-user-workload-0 5/5 Running 1 132m prometheus-user-workload-1 5/5 Running 1 132m thanos-ruler-user-workload-0 3/3 Running 0 132m thanos-ruler-user-workload-1 3/3 Running 0 132m ...クエリーログを読みます。
$ oc -n openshift-user-workload-monitoring exec prometheus-user-workload-0 -- cat <path>重要ログに記録されたクエリー情報を確認した後、config map の設定を元に戻します。
4.4. ユーザーワークロードモニタリングのメトリクスの設定
クラスターコンポーネントと独自のワークロードのパフォーマンスを監視するためのメトリクスのコレクションを設定します。
取り込んだメトリクスをリモートシステムに送信して長期保存したり、別のクラスターからのデータを識別するためにメトリクスにクラスター ID ラベルを追加したりできます。
4.4.1. リモート書き込みストレージの設定
リモート書き込みストレージを設定して、Prometheus が取り込んだメトリクスをリモートシステムに送信して長期保存できるようにします。これを行っても、Prometheus がメトリクスを保存する方法や期間には影響はありません。
前提条件
-
cluster-adminクラスターロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 - クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
OpenShift CLI (
oc) がインストールされている。 リモート書き込み互換性のあるエンドポイント (Thanos) を設定し、エンドポイント URL を把握している。リモート書き込み機能と互換性のないエンドポイントの情報ては、Prometheus リモートエンドポイントおよびストレージに関するドキュメント を参照してください。
重要Red Hat は、リモート書き込み送信側の設定に関する情報のみを提供し、受信側エンドポイントの設定に関するガイダンスは提供しません。お客様は、リモート書き込みと互換性のある独自のエンドポイントを設定する責任があります。エンドポイントレシーバー設定に関する問題は、Red Hat 製品サポートには含まれません。
リモート書き込みエンドポイントの
Secretオブジェクトに認証クレデンシャルを設定している。シークレットはopenshift-user-workload-monitoringnamespace に作成する必要があります。警告セキュリティーリスクを軽減するには、HTTPS および認証を使用してメトリクスをエンドポイントに送信します。
手順
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configconfig map を編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-config以下の例のように、
data/config.yaml/prometheusの下にremoteWrite:セクションを追加します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: remoteWrite: - url: "https://remote-write-endpoint.example.com"1 <endpoint_authentication_credentials>2 認証クレデンシャルの後に、書き込みの再ラベル設定値を追加します。
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: remoteWrite: - url: "https://remote-write-endpoint.example.com" <endpoint_authentication_credentials> writeRelabelConfigs: - <your_write_relabel_configs>1 - 1
- リモートエンドポイントに送信するメトリクスの設定を追加します。
my_metricという単一メトリクスを転送する例apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: remoteWrite: - url: "https://remote-write-endpoint.example.com" writeRelabelConfigs: - sourceLabels: [__name__] regex: 'my_metric' action: keepmy_namespacenamespace にmy_metric_1およびmy_metric_2というメトリクスを転送する例apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: remoteWrite: - url: "https://remote-write-endpoint.example.com" writeRelabelConfigs: - sourceLabels: [__name__,namespace] regex: '(my_metric_1|my_metric_2);my_namespace' action: keep- 変更を適用するためにファイルを保存します。新しい設定は自動的に適用されます。
4.4.1.1. サポート対象のリモート書き込み認証設定
異なる方法を使用して、リモート書き込みエンドポイントとの認証を行うことができます。現時点でサポートされている認証方法は AWS 署名バージョン 4、Basic 認証、認可、OAuth 2.0、および TLS クライアントです。以下の表は、リモート書き込みで使用するサポート対象の認証方法の詳細を示しています。
| 認証方法 | config map フィールド | 説明 |
|---|---|---|
| AWS 署名バージョン 4 |
| この方法では、AWS Signature Version 4 認証を使用して要求を署名します。この方法は、認可、OAuth 2.0、または Basic 認証と同時に使用することはできません。 |
| Basic 認証 |
| Basic 認証は、設定されたユーザー名とパスワードを使用してすべてのリモート書き込み要求に承認ヘッダーを設定します。 |
| 認可 |
|
Authorization は、設定されたトークンを使用して、すべてのリモート書き込みリクエストに |
| OAuth 2.0 |
|
OAuth 2.0 設定は、クライアントクレデンシャル付与タイプを使用します。Prometheus は、リモート書き込みエンドポイントにアクセスするために、指定されたクライアント ID およびクライアントシークレットを使用して |
| TLS クライアント |
| TLS クライアント設定は、TLS を使用してリモート書き込みエンドポイントサーバーで認証するために使用される CA 証明書、クライアント証明書、およびクライアントキーファイル情報を指定します。設定例は、CA 証明書ファイル、クライアント証明書ファイル、およびクライアントキーファイルがすでに作成されていることを前提としています。 |
4.4.1.2. リモート書き込み認証の設定例
次のサンプルは、リモート書き込みエンドポイントに接続するために使用できるさまざまな認証設定を示しています。各サンプルでは、認証情報やその他の関連設定を含む対応する Secret オブジェクトを設定する方法も示しています。各サンプルは openshift-user-workload-monitoring namespace 内のユーザー定義プロジェクトのモニタリングで使用する認証を設定します。
4.4.1.2.1. AWS 署名バージョン 4 認証のサンプル YAML
以下は、openshift-user-workload-monitoring namespace の sigv4-credentials という名前の sigv4 シークレットの設定を示しています。
apiVersion: v1
kind: Secret
metadata:
name: sigv4-credentials
namespace: openshift-user-workload-monitoring
stringData:
accessKey: <AWS_access_key>
secretKey: <AWS_secret_key>
type: Opaque
以下は、openshift-user-workload-monitoring namespace の sigv4-credentials という名前の Secret オブジェクトを使用する AWS Signature Version 4 リモート書き込み認証のサンプルを示しています。
apiVersion: v1
kind: ConfigMap
metadata:
name: user-workload-monitoring-config
namespace: openshift-user-workload-monitoring
data:
config.yaml: |
prometheus:
remoteWrite:
- url: "https://authorization.example.com/api/write"
sigv4:
region: <AWS_region>
accessKey:
name: sigv4-credentials
key: accessKey
secretKey:
name: sigv4-credentials
key: secretKey
profile: <AWS_profile_name>
roleArn: <AWS_role_arn> 4.4.1.2.2. Basic 認証用のサンプル YAML
以下は、openshift-user-workload-monitoring namespace の rw-basic-auth という名前の Secret オブジェクトの Basic 認証設定の例を示しています。
apiVersion: v1
kind: Secret
metadata:
name: rw-basic-auth
namespace: openshift-user-workload-monitoring
stringData:
user: <basic_username>
password: <basic_password>
type: Opaque
以下の例は、openshift-user-workload-monitoring namespace の rw-basic-auth という名前の Secret オブジェクトを使用する basicAuth リモート書き込み設定を示しています。これは、エンドポイントの認証認証情報がすでに設定されていることを前提としています。
apiVersion: v1
kind: ConfigMap
metadata:
name: user-workload-monitoring-config
namespace: openshift-user-workload-monitoring
data:
config.yaml: |
prometheus:
remoteWrite:
- url: "https://basicauth.example.com/api/write"
basicAuth:
username:
name: rw-basic-auth
key: user
password:
name: rw-basic-auth
key: password 4.4.1.2.3. Secret オブジェクトを使用したベアラートークンによる認証のサンプル YAML
以下は、openshift-user-workload-monitoring namespace の rw-bearer-auth という名前の Secret オブジェクトのベアラートークン設定を示しています。
apiVersion: v1
kind: Secret
metadata:
name: rw-bearer-auth
namespace: openshift-user-workload-monitoring
stringData:
token: <authentication_token>
type: Opaque- 1
- 認証トークン。
以下は、openshift-user-workload-monitoring namespace の rw-bearer-auth という名前の Secret オブジェクトを使用するベアラートークン設定マップの設定例を示しています。
apiVersion: v1
kind: ConfigMap
metadata:
name: user-workload-monitoring-config
namespace: openshift-user-workload-monitoring
data:
config.yaml: |
prometheus:
remoteWrite:
- url: "https://authorization.example.com/api/write"
authorization:
type: Bearer
credentials:
name: rw-bearer-auth
key: token 4.4.1.2.4. OAuth 2.0 認証のサンプル YAML
以下は、openshift-user-workload-monitoring namespace の oauth2-credentials という名前の Secret オブジェクトの OAuth 2.0 設定のサンプルを示しています。
apiVersion: v1
kind: Secret
metadata:
name: oauth2-credentials
namespace: openshift-user-workload-monitoring
stringData:
id: <oauth2_id>
secret: <oauth2_secret>
type: Opaque
以下は、openshift-user-workload-monitoring namespace の oauth2-credentials という Secret オブジェクトを使用した oauth2 リモート書き込み認証のサンプル設定です。
apiVersion: v1
kind: ConfigMap
metadata:
name: user-workload-monitoring-config
namespace: openshift-user-workload-monitoring
data:
config.yaml: |
prometheus:
remoteWrite:
- url: "https://test.example.com/api/write"
oauth2:
clientId:
secret:
name: oauth2-credentials
key: id
clientSecret:
name: oauth2-credentials
key: secret
tokenUrl: https://example.com/oauth2/token
scopes:
- <scope_1>
- <scope_2>
endpointParams:
param1: <parameter_1>
param2: <parameter_2>- 1 3
- 対応する
Secretオブジェクトの名前。ClientIdはConfigMapオブジェクトを参照することもできますが、clientSecretはSecretオブジェクトを参照する必要があることに注意してください。 - 2 4
- 指定された
Secretオブジェクトの OAuth 2.0 認証情報が含まれるキー。 - 5
- 指定された
clientIdおよびclientSecretでトークンを取得するために使用される URL。 - 6
- 認可要求の OAuth 2.0 スコープ。これらのスコープは、トークンがアクセスできるデータを制限します。
- 7
- 認可サーバーに必要な OAuth 2.0 認可要求パラメーター。
4.4.1.2.5. TLS クライアント認証のサンプル YAML
以下は、openshift-user-workload-monitoring namespace 内の mtls-bundle という名前の tls Secret オブジェクトに対する TLS クライアント設定のサンプルです。
apiVersion: v1
kind: Secret
metadata:
name: mtls-bundle
namespace: openshift-user-workload-monitoring
data:
ca.crt: <ca_cert>
client.crt: <client_cert>
client.key: <client_key>
type: tls
以下の例は、mtls-bundle という名前の TLS Secret オブジェクトを使用する tlsConfig リモート書き込み認証設定を示しています。
apiVersion: v1
kind: ConfigMap
metadata:
name: user-workload-monitoring-config
namespace: openshift-user-workload-monitoring
data:
config.yaml: |
prometheus:
remoteWrite:
- url: "https://remote-write-endpoint.example.com"
tlsConfig:
ca:
secret:
name: mtls-bundle
key: ca.crt
cert:
secret:
name: mtls-bundle
key: client.crt
keySecret:
name: mtls-bundle
key: client.key 4.4.1.3. リモート書き込みキューの設定例
リモート書き込み用の queueConfig オブジェクトを使用して、リモート書き込みキューパラメーターを調整できます。以下の例は、キューパラメーターと、openshift-user-workload-monitoring namespace のユーザー定義プロジェクトのモニタリング用のデフォルト値を示しています。
デフォルト値を使用したリモート書き込みパラメーターの設定例
apiVersion: v1
kind: ConfigMap
metadata:
name: user-workload-monitoring-config
namespace: openshift-user-workload-monitoring
data:
config.yaml: |
prometheus:
remoteWrite:
- url: "https://remote-write-endpoint.example.com"
<endpoint_authentication_credentials>
queueConfig:
capacity: 10000
minShards: 1
maxShards: 50
maxSamplesPerSend: 2000
batchSendDeadline: 5s
minBackoff: 30ms
maxBackoff: 5s
retryOnRateLimit: false 4.4.1.4. リモート書き込みメトリクスの表
次の表に、リモート書き込みおよびリモート書き込み関連のメトリクスと、リモート書き込みの設定時に発生する問題を解決するのに役立つ詳細な説明を記載します。
| メトリクス | 説明 |
|---|---|
|
| 任意のサンプルについて、Prometheus が先行書き込みログ (WAL) に保存した最新のタイムスタンプを表示します。 |
|
| リモート書き込みキューが正常に送信した最新のタイムスタンプを表示します。 |
|
| リモート書き込みが送信に失敗し、リモートストレージに再送信する必要があったサンプルの数。このメトリクスの値が一定して高い場合は、ネットワークまたはリモートストレージエンドポイントに問題があります。 |
|
| 各リモートエンドポイントで現在実行されているシャードの数を示します。 |
|
| 現在の書き込みスループットと、受信サンプルと送信サンプルの比率に基づいて計算された必要なシャードの数を示します。 |
|
| 現在の設定に基づくシャードの最大数を示します。 |
|
| 現在の設定に基づくシャードの最小数を示します。 |
|
| Prometheus が現在新しいデータを書き込んでいる WAL セグメントファイル。 |
|
| 各リモート書き込みインスタンスが現在読み取っている WAL セグメントファイル。 |
4.4.2. メトリクスのクラスター ID ラベルの作成
openshift-user-workload-monitoring namespace の user-workload-monitoring-config config map にリモート書き込みストレージの write_relabel 設定を追加することで、メトリクスのクラスター ID ラベルを作成できます。
Prometheus が namespace ラベルを公開するユーザーワークロードターゲットをスクレイプすると、システムはこのラベルを exported_namespace として保存します。この動作により、最終的な namespace ラベル値がターゲット Pod の namespace と等しくなります。このデフォルトは、PodMonitor または ServiceMonitor オブジェクトの honorLabels フィールドの値を true に設定してオーバーライドすることはできません。
前提条件
-
cluster-adminクラスターロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 - クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
OpenShift CLI (
oc) がインストールされている。 - リモート書き込みストレージを設定している。
手順
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configconfig map を編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configdata/config.yaml/prometheus/remoteWriteの下にあるwriteRelabelConfigs:セクションで、クラスター ID の再ラベル付け設定値を追加します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: remoteWrite: - url: "https://remote-write-endpoint.example.com" <endpoint_authentication_credentials> writeRelabelConfigs:1 - <relabel_config>2 次のサンプルは、クラスター ID ラベル
cluster_idを使用してメトリクスを転送する方法を示しています。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: remoteWrite: - url: "https://remote-write-endpoint.example.com" writeRelabelConfigs: - sourceLabels: - __tmp_openshift_cluster_id__1 targetLabel: cluster_id2 action: replace3 - 1
- システムは最初に
__tmp_openshift_cluster_id__という名前の一時的なクラスター ID ソースラベルを適用します。この一時的なラベルは、指定するクラスター ID ラベル名に置き換えられます。 - 2
- リモート書き込みストレージに送信されるメトリクスのクラスター ID ラベルの名前を指定します。メトリクスにすでに存在するラベル名を使用する場合、その値はこのクラスター ID ラベルの名前でオーバーライドされます。ラベル名には
__tmp_openshift_cluster_id__は使用しないでください。最後の再ラベル手順では、この名前を使用するラベルを削除します。 - 3
replace置き換えラベルの再設定アクションは、一時ラベルを送信メトリクスのターゲットラベルに置き換えます。このアクションはデフォルトであり、アクションが指定されていない場合に適用されます。
- 変更を適用するためにファイルを保存します。新しい設定は自動的に適用されます。
4.4.3. ユーザー定義プロジェクトのメトリクス収集の設定
ServiceMonitor リソースを作成して、ユーザー定義プロジェクトのサービスエンドポイントからメトリクスを収集できます。これは、アプリケーションが Prometheus クライアントライブラリーを使用してメトリクスを /metrics の正規の名前に公開していることを前提としています。
このセクションでは、ユーザー定義のプロジェクトでサンプルサービスをデプロイし、次にサービスのモニター方法を定義する ServiceMonitor リソースを作成する方法を説明します。
4.4.3.1. サンプルサービスのデプロイ
ユーザー定義のプロジェクトでサービスのモニタリングをテストするには、サンプルサービスをデプロイできます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとして、または namespace の管理権限を持つユーザーとして、クラスターにアクセスできる。
手順
-
サービス設定の YAML ファイルを作成します。この例では、
prometheus-example-app.yamlという名前です。 以下のデプロイメントおよびサービス設定の詳細をファイルに追加します。
apiVersion: v1 kind: Namespace metadata: name: ns1 --- apiVersion: apps/v1 kind: Deployment metadata: labels: app: prometheus-example-app name: prometheus-example-app namespace: ns1 spec: replicas: 1 selector: matchLabels: app: prometheus-example-app template: metadata: labels: app: prometheus-example-app spec: containers: - image: ghcr.io/rhobs/prometheus-example-app:0.4.2 imagePullPolicy: IfNotPresent name: prometheus-example-app --- apiVersion: v1 kind: Service metadata: labels: app: prometheus-example-app name: prometheus-example-app namespace: ns1 spec: ports: - port: 8080 protocol: TCP targetPort: 8080 name: web selector: app: prometheus-example-app type: ClusterIPこの設定は、
prometheus-example-appという名前のサービスをユーザー定義のns1プロジェクトにデプロイします。このサービスは、カスタムversionメトリクスを公開します。設定をクラスターに適用します。
$ oc apply -f prometheus-example-app.yamlサービスをデプロイするには多少時間がかかります。
Pod が実行中であることを確認できます。
$ oc -n ns1 get pod出力例
NAME READY STATUS RESTARTS AGE prometheus-example-app-7857545cb7-sbgwq 1/1 Running 0 81m
4.4.3.2. サービスのモニター方法の指定
サービスが公開するメトリクスを使用するには、OpenShift Container モニタリングを、/metrics エンドポイントからメトリクスを収集できるように設定する必要があります。これは、サービスのモニタリング方法を指定する ServiceMonitor カスタムリソース定義、または Pod のモニタリング方法を指定する PodMonitor CRD を使用して実行できます。前者の場合は Service オブジェクトが必要ですが、後者の場合は不要です。これにより、Prometheus は Pod によって公開されるメトリクスエンドポイントからメトリクスを直接収集することができます。
この手順では、ユーザー定義プロジェクトでサービスの ServiceMonitor リソースを作成する方法を説明します。
前提条件
-
cluster-adminクラスターロールまたはmonitoring-editクラスターロールのあるユーザーとしてクラスターにアクセスできる。 - ユーザー定義プロジェクトのモニタリングが有効化されている。
この例では、
prometheus-example-appサンプルサービスをns1プロジェクトにデプロイしている。注記prometheus-example-appサンプルサービスは TLS 認証をサポートしません。
手順
-
example-app-service-monitor.yamlという名前の新しい YAML 設定ファイルを作成します。 ServiceMonitorリソースを YAML ファイルに追加します。以下の例では、prometheus-example-monitorという名前のサービスモニターを作成し、ns1namespace のprometheus-example-appサービスによって公開されるメトリクスを収集します。apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: prometheus-example-monitor namespace: ns11 spec: endpoints: - interval: 30s port: web2 scheme: http selector:3 matchLabels: app: prometheus-example-app注記ユーザー定義の namespace の
ServiceMonitorリソースは、同じ namespace のサービスのみを検出できます。つまり、ServiceMonitorリソースのnamespaceSelectorフィールドは常に無視されます。設定をクラスターに適用します。
$ oc apply -f example-app-service-monitor.yamlServiceMonitorをデプロイするのに多少時間がかかります。ServiceMonitorリソースが実行されていることを確認します。$ oc -n <namespace> get servicemonitor出力例
NAME AGE prometheus-example-monitor 81m
4.4.3.3. サービスエンドポイント認証設定の例
ServiceMonitor および PodMonitor カスタムリソース定義 (CRD) を使用して、ユーザー定義のプロジェクト監視用のサービスエンドポイントの認証を設定できます。
次のサンプルは、ServiceMonitor リソースのさまざまな認証設定を示しています。各サンプルでは、認証認証情報やその他の関連設定を含む対応する Secret オブジェクトを設定する方法を示します。
4.4.3.3.1. ベアラートークンを使用した YAML 認証の例
以下の例は、ns1 namespace の example-bearer-auth という名前の Secret オブジェクトのベアラートークン設定を示しています。
ベアラートークンシークレットの例
apiVersion: v1
kind: Secret
metadata:
name: example-bearer-auth
namespace: ns1
stringData:
token: <authentication_token> - 1
- 認証トークンを指定します。
以下の例は、ServiceMonitor CRD のベアラートークン認証設定を示しています。この例では、example-bearer-auth という名前の Secret オブジェクトを使用しています。
ベアラートークンの認証設定の例
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: prometheus-example-monitor
namespace: ns1
spec:
endpoints:
- authorization:
credentials:
key: token
name: example-bearer-auth
port: web
selector:
matchLabels:
app: prometheus-example-app
bearerTokenFile を使用してベアラートークンを設定しないでください。bearerTokenFile 設定を使用する場合、ServiceMonitor リソースは拒否されます。
4.4.3.3.2. Basic 認証用のサンプル YAML
次のサンプルは、ns1 の example-basic-auth という名前の Secret オブジェクトの Basic 認証設定を示しています。
Basic 認証シークレットの例
apiVersion: v1
kind: Secret
metadata:
name: example-basic-auth
namespace: ns1
stringData:
user: <basic_username>
password: <basic_password>
以下の例は、ServiceMonitor CRD の Basic 認証設定を示しています。この例では、example-basic-auth という名前の Secret オブジェクトを使用しています。
Basic 認証の設定例
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: prometheus-example-monitor
namespace: ns1
spec:
endpoints:
- basicAuth:
username:
key: user
name: example-basic-auth
password:
key: password
name: example-basic-auth
port: web
selector:
matchLabels:
app: prometheus-example-app4.4.3.3.3. OAuth 2.0 を使用した YAML 認証のサンプル
以下の例は、ns1 namespace の example-oauth2 という名前の Secret オブジェクトの OAuth 2.0 設定を示しています。
OAuth 2.0 シークレットの例
apiVersion: v1
kind: Secret
metadata:
name: example-oauth2
namespace: ns1
stringData:
id: <oauth2_id>
secret: <oauth2_secret>
以下の例は、ServiceMonitor CRD の OAuth 2.0 認証設定を示しています。この例では、example-oauth2 という名前の Secret オブジェクトを使用します。
OAuth 2.0 認証の設定例
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: prometheus-example-monitor
namespace: ns1
spec:
endpoints:
- oauth2:
clientId:
secret:
key: id
name: example-oauth2
clientSecret:
key: secret
name: example-oauth2
tokenUrl: https://example.com/oauth2/token
port: web
selector:
matchLabels:
app: prometheus-example-app4.5. ユーザーワークロードモニタリングのアラートと通知の設定
ローカルまたは外部の Alertmanager インスタンスを設定して、Prometheus からエンドポイントレシーバーにアラートをルーティングできます。すべての時系列とアラートにカスタムラベルを割り当てて、便利なメタデータ情報を追加することもできます。
4.5.1. 外部 Alertmanager インスタンスの設定
OpenShift Container Platform モニタリングスタックには、Prometheus からのアラートのルートなど、ローカルの Alertmanager インスタンスが含まれます。
外部 Alertmanager インスタンスを追加して、ユーザー定義プロジェクトのアラートをルーティングできます。
複数のクラスターに同じ外部 Alertmanager 設定を追加し、クラスターごとにローカルインスタンスを無効にする場合には、単一の外部 Alertmanager インスタンスを使用して複数のクラスターのアラートルーティングを管理できます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 - クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
OpenShift CLI (
oc) がインストールされている。
手順
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configconfig map を編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configdata/config.yaml/<component>下に、設定の詳細を含むadditionalAlertmanagerConfigsセクションを追加します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>:1 additionalAlertmanagerConfigs: - <alertmanager_specification>2 次のサンプル config map は、クライアント TLS 認証でベアラートークンを使用して、Thanos Ruler 用の追加の Alertmanager を設定します。
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | thanosRuler: additionalAlertmanagerConfigs: - scheme: https pathPrefix: / timeout: "30s" apiVersion: v1 bearerToken: name: alertmanager-bearer-token key: token tlsConfig: key: name: alertmanager-tls key: tls.key cert: name: alertmanager-tls key: tls.crt ca: name: alertmanager-tls key: tls.ca staticConfigs: - external-alertmanager1-remote.com - external-alertmanager1-remote2.com- 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
4.5.2. Alertmanager のシークレットの設定
OpenShift Container Platform モニタリングスタックには、アラートを Prometheus からエンドポイントレシーバーにルーティングする Alertmanager が含まれています。Alertmanager がアラートを送信できるようにレシーバーで認証する必要がある場合は、レシーバーの認証認証情報を含むシークレットを使用するように Alertmanager を設定できます。
たとえば、シークレットを使用して、プライベート認証局 (CA) によって発行された証明書を必要とするエンドポイント受信者を認証するように Alertmanager を設定できます。また、基本 HTTP 認証用のパスワードファイルを必要とする受信者で認証するためにシークレットを使用するように Alertmanager を設定することもできます。いずれの場合も、認証の詳細は、ConfigMap オブジェクトではなく Secret オブジェクトに含まれています。
4.5.2.1. Alertmanager 設定へのシークレットの追加
openshift-user-workload-monitoring プロジェクトの user-workload-monitoring-config config map を編集することで、Alertmanager 設定にシークレットを追加できます。
config map にシークレットを追加すると、シークレットは、Alertmanager Pod の alertmanager コンテナー内の /etc/alertmanager/secrets/<secret_name> にボリュームとしてマウントされます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 - クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
openshift-user-workload-monitoringプロジェクトの Alertmanager で設定するシークレットを作成しました。 -
OpenShift CLI (
oc) がインストールされている。
手順
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configconfig map を編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-config次の設定で、
data/config.yaml/alertmanagerの下にsecrets:セクションを追加します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | alertmanager: secrets:1 - <secret_name_1>2 - <secret_name_2>次の config map 設定の例では、
test-secret-basic-authおよびtest-secret-api-tokenという名前の 2 つのSecretオブジェクトを使用するように Alertmanager を設定します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | alertmanager: secrets: - test-secret-basic-auth - test-secret-api-token- 変更を適用するためにファイルを保存します。新しい設定は自動的に適用されます。
4.5.3. 追加ラベルの時系列 (time series) およびアラートへの割り当て
Prometheus の外部ラベル機能を使用して、Prometheus から送信されるすべての時系列とアラートにカスタムラベルを付けることができます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 - クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
OpenShift CLI (
oc) がインストールされている。
手順
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configconfig map を編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configdata/config.yamlの下の各メトリクスに追加するラベルを定義します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: externalLabels: <key>: <value>1 - 1
<key>: <value>をキーと値のペアに置き換えます。<key>は新しいラベルの一意の名前、<value>はその値です。
警告-
prometheusまたはprometheus_replicaは予約され、オーバーライドされるため、これらをキー名として使用しないでください。 -
キー名に
clusterを使用しないでください。これを使用すると、開発者ダッシュボードでデータが表示されない問題が発生する可能性があります。
注記openshift-user-workload-monitoringプロジェクトでは、Prometheus はメトリクスを処理し、Thanos Ruler はアラートおよび記録ルールを処理します。user-workload-monitoring-configConfigMapオブジェクトでprometheusのexternalLabelsを設定すると、すべてのルールではなく、メトリクスの外部ラベルのみが設定されます。たとえば、リージョンと環境に関するメタデータをすべての時系列とアラートに追加するには、次の例を使用します。
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: externalLabels: region: eu environment: prod- 変更を適用するためにファイルを保存します。新しい設定の影響を受ける Pod は自動的に再デプロイされます。
4.5.4. アラート通知の設定
OpenShift Container Platform では、管理者は次のいずれかの方法でユーザー定義プロジェクトのアラートルーティングを有効にできます。
- デフォルトのプラットフォーム Alertmanager インスタンスを使用します。
- ユーザー定義プロジェクトにのみ、別の Alertmanager インスタンスを使用します。
alert-routing-edit クラスターロールを持つ開発者およびその他のユーザーは、アラートレシーバーを設定することによって、ユーザー定義プロジェクトのカスタムアラート通知を設定できます。
ユーザー定義プロジェクトのアラートルーティングに関する次の制限事項を確認してください。
-
ユーザー定義のアラートルーティングのスコープは、リソースが定義されている namespace に指定されます。たとえば、namespace
ns1のルーティング設定は、同じ namespace のPrometheusRulesリソースにのみ適用されます。 -
namespace がユーザー定義のモニタリングから除外される場合、namespace の
AlertmanagerConfigリソースは、Alertmanager 設定の一部ではなくなります。
4.5.4.1. ユーザー定義プロジェクトのアラートルーティングの設定
alert-routing-edit クラスターロールが付与されている管理者以外のユーザーの場合は、ユーザー定義プロジェクトのアラートルーティングを作成または編集できます。
前提条件
- クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にしている。
- クラスター管理者が、ユーザー定義プロジェクトのアラートルーティングを有効にしている。
-
アラートルーティングを作成する必要のあるプロジェクトの
alert-routing-editクラスターロールを持つユーザーとしてログインしている。 -
OpenShift CLI (
oc) がインストールされている。
手順
-
アラートルーティングの YAML ファイルを作成します。この手順の例では、
example-app-alert-routing.yamlという名前のファイルを使用します。 AlertmanagerConfigYAML 定義をファイルに追加します。以下に例を示します。apiVersion: monitoring.coreos.com/v1beta1 kind: AlertmanagerConfig metadata: name: example-routing namespace: ns1 spec: route: receiver: default groupBy: [job] receivers: - name: default webhookConfigs: - url: https://example.org/post- ファイルを保存します。
リソースをクラスターに適用します。
$ oc apply -f example-app-alert-routing.yamlこの設定は Alertmanager Pod に自動的に適用されます。
4.5.4.2. Alertmanager シークレットを使用したユーザー定義プロジェクトのアラートルーティングの設定
ユーザー定義のアラートルーティング専用の Alertmanager の別のインスタンスを有効にしている場合は、openshift-user-workload-monitoring namespace の alertmanager-user-workload シークレットを編集して、インスタンスが通知を送信する場所と方法をカスタマイズできます。
サポート対象のアップストリームバージョンの Alertmanager 機能はすべて、OpenShift Container Platform の Alertmanager 設定でもサポートされます。サポート対象のアップストリーム Alertmanager バージョンのあらゆる設定オプションを確認するには、Alertmanager configuration (Prometheus ドキュメント) を参照してください。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 - ユーザー定義のアラートルーティング用に、Alertmanager の別のインスタンスを有効にした。
-
OpenShift CLI (
oc) がインストールされている。
手順
現在アクティブな Alertmanager 設定をファイル
alertmanager.yamlに出力します。$ oc -n openshift-user-workload-monitoring get secret alertmanager-user-workload --template='{{ index .data "alertmanager.yaml" }}' | base64 --decode > alertmanager.yamlalertmanager.yamlで設定を編集します。route: receiver: Default group_by: - name: Default routes: - matchers: - "service = prometheus-example-monitor"1 receiver: <receiver>2 receivers: - name: Default - name: <receiver> <receiver_configuration>3 新規設定をファイルで適用します。
$ oc -n openshift-user-workload-monitoring create secret generic alertmanager-user-workload --from-file=alertmanager.yaml --dry-run=client -o=yaml | oc -n openshift-user-workload-monitoring replace secret --filename=-
4.5.4.3. デフォルトのプラットフォームアラートとユーザー定義アラートに異なるアラートレシーバーを設定する
デフォルトのプラットフォームアラートとユーザー定義アラートに異なるアラートレシーバーを設定して、次の結果を確実に得ることができます。
- すべてのデフォルトのプラットフォームアラートは、これらのアラートを担当するチームが所有する受信機に送信されます。
- すべてのユーザー定義アラートは別の受信者に送信されるため、チームはプラットフォームアラートにのみ集中できます。
これを実現するには、Cluster Monitoring Operator によってすべてのプラットフォームアラートに追加される openshift_io_alert_source="platform" ラベルを使用します。
-
デフォルトのプラットフォームアラートを一致させるには、
openshift_io_alert_source="platform"マッチャーを使用します。 -
ユーザー定義のアラートを一致させるには、
openshift_io_alert_source!="platform"または'openshift_io_alert_source=""'マッチャーを使用します。
ユーザー定義アラート専用の Alertmanager の別のインスタンスを有効にしている場合、この設定は適用されません。
第5章 メトリクスへのアクセス
5.1. 管理者としてメトリクスにアクセスする
メトリクスにアクセスして、クラスターコンポーネントとワークロードのパフォーマンスを監視できます。
5.1.1. 利用可能なメトリクスのリストを表示する
クラスター管理者またはすべてのプロジェクトの表示権限を持つユーザーとして、クラスターで使用可能なメトリクスのリストを表示し、リストを JSON 形式で出力できます。
前提条件
-
クラスター管理者であるか、
cluster-monitoring-viewクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift Container Platform CLI (
oc) がインストールされている。 - Thanos Querier の OpenShift Container Platform API ルートを取得しました。
oc whoami -tコマンドを使用してベアラートークンを取得できます。重要Thanos Querier API ルートにアクセスするには、ベアラートークン認証のみを使用できます。
手順
Thanos Querier の OpenShift Container Platform API ルートを取得していない場合は、以下のコマンドを実行します。
$ oc get routes -n openshift-monitoring thanos-querier -o jsonpath='{.status.ingress[0].host}'次のコマンドを実行して、Thanos Querier API ルートから JSON 形式のメトリクスのリストを取得します。このコマンドは、
ocを使用してベアラートークンで認証します。$ curl -k -H "Authorization: Bearer $(oc whoami -t)" https://<thanos_querier_route>/api/v1/metadata1 - 1
<thanos_querier_route>を Thanos Querier の OpenShift Container Platform API ルートに置き換えます。
5.1.2. OpenShift Container Platform Web コンソールを使用してすべてのプロジェクトのメトリクスをクエリーする
OpenShift Container Platform メトリクスクエリーブラウザーを使用して Prometheus Query Language (PromQL) クエリーを実行し、プロットに可視化されるメトリクスを検査できます。この機能により、クラスターの状態と、モニターしているユーザー定義のワークロードに関する情報が提供されます。
クラスター管理者またはすべてのプロジェクトの表示権限を持つユーザーとして、メトリクス UI ですべてのデフォルト OpenShift Container Platform およびユーザー定義プロジェクトのメトリクスにアクセスできます。
前提条件
-
cluster-adminクラスターロールまたはすべてのプロジェクトの表示権限を持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
- OpenShift Container Platform Web コンソールの Administrator パースペクティブから、Observe → Metrics を選択します。
1 つ以上のクエリーを追加するには、次のいずれかを実行します。
Expand オプション 説明 カスタムクエリーを作成します。
Prometheus Query Language (PromQL) クエリーを Expression フィールドに追加します。
PromQL 式を入力すると、オートコンプリートの提案がドロップダウンリストに表示されます。これらの提案には、関数、メトリクス、ラベル、および時間トークンが含まれます。キーボードの矢印を使用して提案された項目のいずれかを選択し、Enter を押して項目を式に追加できます。また、マウスポインターを推奨項目の上に移動して、その項目の簡単な説明を表示することもできます。
複数のクエリーを追加します。
クエリーの追加 を選択します。
既存のクエリーを複製します。
オプションメニューを選択します
 クエリーの横にある Duplicate query を選択します。
クエリーの横にある Duplicate query を選択します。
クエリーの実行を無効にします。
オプションメニューを選択します
クエリーの横にある Disable query を選択します。
作成したクエリーを実行するには、Run queries を選択します。クエリーからのメトリクスはプロットで可視化されます。クエリーが無効な場合は、UI にエラーメッセージが表示されます。
注記大量のデータで動作するクエリーは、時系列グラフの描画時にタイムアウトするか、ブラウザーをオーバーロードする可能性があります。これを回避するには、Hide graph を選択し、メトリクステーブルのみを使用してクエリーを調整します。次に、使用できるクエリーを確認した後に、グラフを描画できるようにプロットを有効にします。
注記デフォルトでは、クエリーテーブルに、すべてのメトリクスとその現在の値をリスト表示する拡張ビューが表示されます。˅ を選択すると、クエリーの拡張ビューを最小にすることができます。
- オプション: このクエリーのセットを今後再度使用するには、ページの URL を保存します。
視覚化されたメトリクスを調べます。最初に、有効な全クエリーの全メトリクスがプロットに表示されます。次のいずれかを実行して、表示するメトリクスを選択できます。
Expand オプション 説明 クエリーからすべてのメトリクスを非表示にします。
オプションメニューをクリックします
クエリーを選択し、Hide all series をクリックします。
特定のメトリクスを非表示にします。
クエリーテーブルに移動し、メトリクス名の近くにある色付きの四角形をクリックします。
プロットを拡大し、時間範囲を変更します。
次のいずれかになります。
- プロットを水平にクリックし、ドラッグして、時間範囲を視覚的に選択します。
- 左上隅のメニューを使用して、時間範囲を選択します。
時間範囲をリセットします。
Reset zoom を選択します。
特定の時点でのすべてのクエリーの出力を表示します。
その時点でプロット上にマウスカーソルを置きます。クエリーの出力はポップアップに表示されます。
プロットを非表示にします。
Hide graph を選択します。
5.1.3. メトリクスターゲットに関する詳細情報の取得を参照してください。
OpenShift Container Platform Web コンソールを使用すると、現在スクレイピングの対象となっているエンドポイントを表示、検索、フィルタリングできます。これは問題の特定とトラブルシューティングに役立ちます。たとえば、ターゲットエンドポイントの現在のステータスを表示して、OpenShift Container Platform モニタリングでターゲットコンポーネントからメトリクスをスクレイピングできないのはいつなのかを確認できます。
Metrics targets ページには、デフォルトの OpenShift Container Platform プロジェクトのターゲットとユーザー定義プロジェクトのターゲットが表示されます。
前提条件
- メトリクスターゲットを表示するプロジェクトの管理者としてクラスターにアクセスできる。
手順
OpenShift Container Platform Web コンソールの Administrator パースペクティブで、Observe → Targets に移動します。Metrics targets ページが開き、メトリクス用にスクレイピングされているすべてのサービスエンドポイントターゲットのリストが表示されます。
このページには、デフォルトの OpenShift Container Platform のターゲットとユーザー定義プロジェクトの詳細が表示されます。このページには、ターゲットごとに以下の情報がリスト表示されます。
- スクレイピングされるサービスエンドポイント URL
-
モニター対象の
ServiceMonitorリソース - ターゲットの アップ または ダウン ステータス
- Namespace
- 最後のスクレイプ時間
- 最後のスクレイピングの継続期間
オプション: 特定のターゲットを検索するには、次のいずれかのアクションを実行します。
Expand オプション 説明 ステータスとソースによってターゲットをフィルタリングします。
Filter リストでフィルターを選択します。
以下のフィルタリングオプションが利用できます。
ステータス フィルター:
- Up.ターゲットは現在 up で、メトリクスに対してアクティブにスクレイピングされています。
- Down.ターゲットは現在 down しており、メトリクス用にスクレイピングされていません。
Source フィルター:
- Platform。プラットフォームレベルのターゲットは、デフォルトの Red Hat OpenShift Service on AWS プロジェクトにのみ該当します。これらのプロジェクトは、Red Hat OpenShift Service on AWS のコア機能を提供します。
- User。ユーザーターゲットは、ユーザー定義プロジェクトに関連します。これらのプロジェクトはユーザーが作成したもので、カスタマイズすることができます。
名前またはラベルでターゲットを検索します。
検索ボックスの横にある Text または Label フィールドに検索語を入力します。
ターゲットを並べ替えます。
Endpoint Status、Namespace、Last Scrape、および Scrape Duration 列ヘッダーの 1 つ以上をクリックします。
ターゲットの Endpoint 列の URL をクリックすると、その Target details ページに移動します。このページには、ターゲットに関する以下の情報が表示されます。
- メトリクスのためにスクレイピングされているエンドポイント URL
- 現在のターゲットのステータス (Up または Down)
- namespace へのリンク
-
ServiceMonitorリソースの詳細へのリンク - ターゲットに割り当てられたラベル
- ターゲットがメトリクス用にスクレイピングされた直近の時間
5.1.4. クラスター管理者としてのモニタリングダッシュボードの確認
Administrator パースペクティブでは、OpenShift Container Platform クラスターのコアコンポーネントに関連するダッシュボードを表示できます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。
手順
- OpenShift Container Platform Web コンソールの Administrator パースペクティブで、Observe → Dashboards に移動します。
- Dashboard 一覧でダッシュボードを選択します。etcd や Prometheus ダッシュボードなどの一部のダッシュボードは、選択時に追加のサブメニューを生成します。
必要に応じて、Time Range 一覧でグラフの時間範囲を選択します。
- 事前定義された期間を選択します。
Time Range リストで Custom time range をクリックして、カスタムの時間範囲を設定します。
- From および To の日付と時間を入力または選択します。
- Save をクリックして、カスタムの時間範囲を保存します。
- オプション: Refresh Interval を選択します。
- ダッシュボードの各グラフにカーソルを合わせて、特定の項目に関する詳細情報を表示します。
5.2. 開発者としてメトリクスにアクセスする
メトリクスにアクセスして、クラスターワークロードのパフォーマンスを監視できます。
5.2.1. 利用可能なメトリクスのリストを表示する
クラスター管理者またはすべてのプロジェクトの表示権限を持つユーザーとして、クラスターで使用可能なメトリクスのリストを表示し、リストを JSON 形式で出力できます。
前提条件
-
クラスター管理者であるか、
cluster-monitoring-viewクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift Container Platform CLI (
oc) がインストールされている。 - Thanos Querier の OpenShift Container Platform API ルートを取得しました。
oc whoami -tコマンドを使用してベアラートークンを取得できます。重要Thanos Querier API ルートにアクセスするには、ベアラートークン認証のみを使用できます。
手順
Thanos Querier の OpenShift Container Platform API ルートを取得していない場合は、以下のコマンドを実行します。
$ oc get routes -n openshift-monitoring thanos-querier -o jsonpath='{.status.ingress[0].host}'次のコマンドを実行して、Thanos Querier API ルートから JSON 形式のメトリクスのリストを取得します。このコマンドは、
ocを使用してベアラートークンで認証します。$ curl -k -H "Authorization: Bearer $(oc whoami -t)" https://<thanos_querier_route>/api/v1/metadata1 - 1
<thanos_querier_route>を Thanos Querier の OpenShift Container Platform API ルートに置き換えます。
5.2.2. OpenShift Container Platform Web コンソールを使用してユーザー定義プロジェクトのメトリクスをクエリーする
OpenShift Container Platform メトリクスクエリーブラウザーを使用して Prometheus Query Language (PromQL) クエリーを実行し、プロットに可視化されるメトリクスを検査できます。この機能により、モニタリングしているユーザー定義ワークロードに関する情報が提供されます。
開発者として、メトリクスのクエリー時にプロジェクト名を指定する必要があります。選択したプロジェクトのメトリクスを表示するには、必要な権限が必要です。
Developer パースペクティブには、選択したプロジェクトの事前に定義された CPU、メモリー、帯域幅、およびネットワークパケットのクエリーが含まれます。また、プロジェクトの CPU、メモリー、帯域幅、ネットワークパケット、およびアプリケーションメトリクスについてカスタム Prometheus Query Language (PromQL) クエリーを実行することもできます。
開発者は Developer パースペクティブのみを使用でき、Administrator パースペクティブは使用できません。開発者は、1 度に 1 つのプロジェクトのメトリクスのみをクエリーできます。
前提条件
- 開発者として、またはメトリクスで表示しているプロジェクトの表示権限を持つユーザーとしてクラスターへのアクセスがある。
- ユーザー定義プロジェクトのモニタリングが有効化されている。
- ユーザー定義プロジェクトにサービスをデプロイしている。
-
サービスのモニター方法を定義するために、サービスの
ServiceMonitorカスタムリソース定義 (CRD) を作成している。
手順
- OpenShift Container Platform Web コンソールの Developer パースペクティブから、Observe → Metrics を選択します。
- Project: リストから、メトリクスを表示するプロジェクトを選択します。
Select query 一覧からクエリーを選択するか、Show PromQL を選択して、選択したクエリーに基づいてカスタム PromQL クエリーを作成します。クエリーからのメトリクスはプロットで可視化されます。
注記Developer パースペクティブでは、1 度に 1 つのクエリーのみを実行できます。
次のいずれかを実行して、視覚化されたメトリクスを調べます。
Expand オプション 説明 プロットを拡大し、時間範囲を変更します。
次のいずれかになります。
- プロットを水平にクリックし、ドラッグして、時間範囲を視覚的に選択します。
- 左上隅のメニューを使用して、時間範囲を選択します。
時間範囲をリセットします。
Reset zoom を選択します。
特定の時点でのすべてのクエリーの出力を表示します。
その時点でプロット上にマウスカーソルを置きます。クエリーの出力はポップアップに表示されます。
5.2.3. 開発者が行うモニタリングダッシュボードの確認
Developer パースペクティブでは、選択されたプロジェクトに関連するダッシュボードを表示できます。
開発者 パースペクティブでは、一度に 1 つのプロジェクトのダッシュボードのみを表示できます。
前提条件
- 開発者またはユーザーとしてクラスターにアクセスできる。
- ダッシュボードを表示するプロジェクトの表示権限がある。
手順
- OpenShift Container Platform Web コンソールの Developer パースペクティブで、Observe → Dashboard に移動します。
- Project: ドロップダウンリストからプロジェクトを選択します。
Dashboard ドロップダウンリストからダッシュボードを選択し、フィルターされたメトリクスを表示します。
注記すべてのダッシュボードは、Kubernetes / Compute Resources / Namespace(Pod) を除く、選択時に追加のサブメニューを生成します。
必要に応じて、Time Range 一覧でグラフの時間範囲を選択します。
- 事前定義された期間を選択します。
Time Range リストで Custom time range をクリックして、カスタムの時間範囲を設定します。
- From および To の日付と時間を入力または選択します。
- Save をクリックして、カスタムの時間範囲を保存します。
- オプション: Refresh Interval を選択します。
- ダッシュボードの各グラフにカーソルを合わせて、特定の項目に関する詳細情報を表示します。
5.3. CLI を使用した API のモニタリング
OpenShift Container Platform では、コマンドラインインターフェイス (CLI) から一部のモニタリングコンポーネントの Web サービス API にアクセスできます。
特定の状況では、特にエンドポイントを使用して大量のメトリクスデータを取得、送信、またはクエリーする場合、API エンドポイントにアクセスするとクラスターのパフォーマンスとスケーラビリティーが低下する可能性があります。
この問題を回避するには、次の推奨事項を考慮してください。
- エンドポイントに頻繁にクエリーを実行しないようにします。クエリーを 30 秒ごとに最大 1 つに制限します。
-
Prometheus の
/federateエンドポイントを介してすべてのメトリクスデータを取得しないでください。このエンドポイントにクエリーを実行するのは、集約された限られたデータセットを取得する場合だけにしてください。たとえば、各要求で 1,000 未満のサンプルを取得すると、パフォーマンスが低下するリスクを最小限に抑えることができます。
5.3.1. モニタリング Web サービス API へのアクセスについて
次の監視スタックコンポーネントのコマンドラインから Web サービス API エンドポイントに直接アクセスできます。
- Prometheus
- Alertmanager
- Thanos Ruler
- Thanos Querier
Thanos Ruler および Thanos Querier サービス API にアクセスするには、要求元のアカウントが namespace リソースに対するアクセス許可を get している必要があります。これは、アカウントに cluster-monitoring-view クラスターロールをバインドして付与することで実行できます。
モニタリングコンポーネントの Web サービス API エンドポイントにアクセスする場合は、以下の制限事項に注意してください。
- Bearer Token 認証のみを使用して API エンドポイントにアクセスできます。
-
ルートの
/apiパスのエンドポイントにのみアクセスできます。Web ブラウザーで API エンドポイントにアクセスしようとすると、Application is not availableエラーが発生します。Web ブラウザーでモニタリング機能にアクセスするには、OpenShift Container Platform Web コンソールを使用して、モニタリングダッシュボードを確認します。
5.3.2. 監視 Web サービス API へのアクセス
次の例は、コアプラットフォームの監視で使用される Alertmanager サービスのサービス API レシーバーをクエリーする方法を示しています。同様の方法を使用して、コアプラットフォーム Prometheus の prometheus-k8s サービスと Thanos Ruler の thanos-ruler サービスにアクセスできます。
前提条件
-
openshift-monitoringnamespace のmonitoring-alertmanager-editロールにバインドされているアカウントにログインしている。 Alertmanager API ルートを取得する権限を持つアカウントにログインしている。
注記アカウントに Alertmanager API ルートの取得権限がない場合、クラスター管理者はルートの URL を提供できます。
手順
次のコマンドを実行して認証トークンを抽出します。
$ TOKEN=$(oc whoami -t)次のコマンドを実行して、
alertmanager-mainAPI ルート URL を抽出します。$ HOST=$(oc -n openshift-monitoring get route alertmanager-main -ojsonpath='{.status.ingress[].host}')次のコマンドを実行して、サービス API レシーバーに Alertmanager をクエリーを実行します。
$ curl -H "Authorization: Bearer $TOKEN" -k "https://$HOST/api/v2/receivers"
5.3.3. Prometheus のフェデレーションエンドポイントを使用したメトリクスのクエリー
Prometheus のフェデレーションエンドポイントを使用して、クラスターの外部のネットワークの場所からプラットフォームとユーザー定義のメトリクスを収集できます。これを実行するには、OpenShift Container Platform ルートを使用してクラスターの Prometheus /federate エンドポイントにアクセスします。
メトリクスデータの取得の遅延は、フェデレーションを使用すると発生します。この遅延は、収集されたメトリクスの精度とタイムラインに影響を与えます。
フェデレーションエンドポイントを使用すると、特にフェデレーションエンドポイントを使用して大量のメトリクスデータを取得する場合に、クラスターのパフォーマンスおよびスケーラビリティーを低下させることもできます。これらの問題を回避するには、以下の推奨事項に従ってください。
- Prometheus のフェデレーションエンドポイントを介してすべてのメトリクスデータを取得しようとしないでください。制限された集約されたデータセットを取得する場合のみ、クエリーを実行します。たとえば、各要求で 1,000 未満のサンプルを取得すると、パフォーマンスが低下するリスクを最小限に抑えることができます。
- Prometheus のフェデレーションエンドポイントに対して頻繁にクエリーすることは避けてください。クエリーを 30 秒ごとに最大 1 つに制限します。
クラスター外に大量のデータを転送する必要がある場合は、代わりにリモート書き込みを使用します。詳細は、リモート書き込みストレージの設定 セクションを参照してください。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 cluster-monitoring-viewクラスターロールを持つユーザーとしてクラスターにアクセスできるか、namespacesリソースのget権限を持つベアラートークンを取得している。注記Prometheus フェデレーションエンドポイントへのアクセスには、ベアラートークン認証のみを使用できます。
Prometheus フェデレーションルートを取得する権限を持つアカウントにログインしている。
注記アカウントに Prometheus フェデレーションルートを取得する権限がない場合、クラスター管理者はルートの URL を提供できます。
手順
次のコマンドを実行してベアラートークンを取得します。
$ TOKEN=$(oc whoami -t)次のコマンドを実行して、Prometheus フェデレーションルート URL を取得します。
$ HOST=$(oc -n openshift-monitoring get route prometheus-k8s-federate -ojsonpath='{.status.ingress[].host}')/federateルートからメトリクスをクエリーを実行します。次のコマンド例は、upメトリクスをクエリーを実行します。$ curl -G -k -H "Authorization: Bearer $TOKEN" https://$HOST/federate --data-urlencode 'match[]=up'出力例
# TYPE up untyped up{apiserver="kube-apiserver",endpoint="https",instance="10.0.143.148:6443",job="apiserver",namespace="default",service="kubernetes",prometheus="openshift-monitoring/k8s",prometheus_replica="prometheus-k8s-0"} 1 1657035322214 up{apiserver="kube-apiserver",endpoint="https",instance="10.0.148.166:6443",job="apiserver",namespace="default",service="kubernetes",prometheus="openshift-monitoring/k8s",prometheus_replica="prometheus-k8s-0"} 1 1657035338597 up{apiserver="kube-apiserver",endpoint="https",instance="10.0.173.16:6443",job="apiserver",namespace="default",service="kubernetes",prometheus="openshift-monitoring/k8s",prometheus_replica="prometheus-k8s-0"} 1 1657035343834 ...
5.3.4. カスタムアプリケーションに関するクラスター外からのメトリクスへのアクセス
ユーザー定義プロジェクトを使用して独自のサービスを監視する場合は、クラスターの外部から Prometheus メトリクスをクエリーできます。このデータには、thanos-querier ルートを使用してクラスターの外部からアクセスします。
このアクセスは、認証に Bearer Token を使用することのみをサポートします。
前提条件
- 「ユーザー定義プロジェクトのモニタリングの有効化」の手順に従い、独自のサービスをデプロイしている。
-
Thanos Querier API へのアクセス権限を持つ
cluster-monitoring-viewクラスターロールでアカウントにログインしている。 Thanos Querier API ルートの取得権限を持つアカウントにログインしています。
注記アカウントに Thanos Querier API ルートの取得権限がない場合、クラスター管理者はルートの URL を提供できます。
手順
次のコマンドを実行して、Prometheus に接続するための認証トークンを展開します。
$ TOKEN=$(oc whoami -t)次のコマンドを実行して、
thanos-querierAPI ルート URL を展開します。$ HOST=$(oc -n openshift-monitoring get route thanos-querier -ojsonpath='{.status.ingress[].host}')次のコマンドを使用して、サービスが実行されている namespace に namespace を設定します。
$ NAMESPACE=ns1次のコマンドを実行して、コマンドラインで独自のサービスのメトリクスに対してクエリーを実行します。
$ curl -H "Authorization: Bearer $TOKEN" -k "https://$HOST/api/v1/query?" --data-urlencode "query=up{namespace='$NAMESPACE'}"出力には、Prometheus がスクレイピングしている各アプリケーション Pod のステータスが表示されます。
フォーマット済み出力例
{ "status": "success", "data": { "resultType": "vector", "result": [ { "metric": { "__name__": "up", "endpoint": "web", "instance": "10.129.0.46:8080", "job": "prometheus-example-app", "namespace": "ns1", "pod": "prometheus-example-app-68d47c4fb6-jztp2", "service": "prometheus-example-app" }, "value": [ 1591881154.748, "1" ] } ], } }注記-
フォーマット済み出力例では、
jqなどのフィルタリングツールを使用して、フォーマット済みのインデントされた JSON を出力しています。jqの使用に関する詳細は、jq Manual (jq ドキュメント) を参照してください。 - このコマンドは、ある時点でセレクターを評価する Thanos Querier サービスのインスタントクエリーエンドポイントを要求します。
-
フォーマット済み出力例では、
第6章 アラートの管理
6.1. 管理者としてアラートを管理する
OpenShift Container Platform では、アラート UI を使用してアラート、サイレンス、およびアラートルールを管理できます。
アラート UI で利用可能なアラート、サイレンス、およびアラートルールは、アクセス可能なプロジェクトに関連付けられます。たとえば、cluster-admin ロールを持つユーザーとしてログインしている場合は、すべてのアラート、サイレント、およびアラートルールにアクセスできます。
6.1.1. Administrator パースペクティブからのアラート UI へのアクセス
アラート UI には、OpenShift Container Platform Web コンソールの Administrator パースペクティブからアクセスできます。
- Administrator パースペクティブから、Observe → Alerting に移動します。このパースペクティブのアラート UI には主要なページが 3 つあり、それが Alerts ページ、Silences ページ、Alerting rules ページです。
6.1.2. Administrator パースペクティブからアラート、サイレンス、アラートルールに関する情報を取得する
アラート UI は、アラートおよびそれらを規定するアラートルールおよびサイレンスの詳細情報を提供します。
前提条件
- アラートを表示しているプロジェクトの表示権限を持つユーザーとしてクラスターにアクセスできる。
手順
アラートに関する情報を取得するには、以下を実行します。
- OpenShift Container Platform Web コンソールの Administrator パースペクティブから、Observe → Alerting → Alerts ページに移動します。
- オプション: 検索リストで Name フィールドを使用し、アラートを名前で検索します。
- オプション: Filter リストでフィルターを選択し、アラートを状態、重大度およびソースでフィルターします。
- オプション: 1 つ以上の Name、Severity、State、および Source 列ヘッダーをクリックし、アラートを並べ替えます。
アラートの名前をクリックして、Alert details ページを表示します。このページには、アラートの時系列データを示すグラフが含まれます。アラートに関する次の情報も提供されます。
- アラートの説明
- アラートに関連付けられたメッセージ
- アラートの GitHub 上の Runbook ページへのリンク (ページが存在する場合)
- アラートに割り当てられるラベル
- アラートを規定するアラートルールへのリンク
- アラートが存在する場合のアラートのサイレンス
サイレンスの情報を取得するには、以下を実行します。
- OpenShift Container Platform Web コンソールの Administrator パースペクティブから、Observe → Alerting → Silences ページに移動します。
- オプション: Search by name フィールドを使用し、サイレンスを名前でフィルターします。
- オプション: Filter リストでフィルターを選択し、サイレンスをフィルターします。デフォルトでは、Active および Pending フィルターが適用されます。
- オプション: Name、Firing alerts、State、Creator 列のヘッダーを 1 つ以上クリックして、サイレンスを並べ替えます。
サイレンスの名前を選択すると、その Silence details ページが表示されます。このページには、以下の詳細が含まれます。
- アラート仕様
- 開始時間
- 終了時間
- サイレンス状態
- 発生するアラートの数およびリスト
アラートルールの情報を取得するには、以下を実行します。
- OpenShift Container Platform Web コンソールの Administrator パースペクティブから、Observe → Alerting → Alerting rules ページに移動します。
- オプション: Filter 一覧でフィルターを選択し、アラートルールを状態、重大度およびソースでフィルターします。
- オプション: Name、Severity、Alert State、Source 列のヘッダーを 1 つ以上クリックし、アラートルールを並べ替えます。
アラートルールの名前を選択して、その Alerting rule details ページを表示します。このページには、アラートルールに関する以下の情報が含まれます。
- アラートルール名、重大度、説明
- アラートを発動する条件を定義する式
- 条件が true で持続してアラートが発生するまでの期間
- アラートルールで管理される各アラートのグラフ。アラートが発動される値が表示されます。
- アラートルールで管理されるすべてのアラートを示す表。
6.1.3. サイレンスの管理
OpenShift Container Platform Web コンソールの Administrator パースペクティブでアラートのサイレンスを作成できます。サイレンスを作成した後、それらを表示、編集、および期限切れにすることができます。また、アラートが発生しても、サイレンスが適用されたアラートに関する通知は届きません。
サイレンスを作成すると、それらは Alertmanager Pod 全体に複製されます。ただし、Alertmanager の永続ストレージを設定しないと、サイレンスが失われる可能性があります。これは、たとえば、すべての Alertmanager Pod が同時に再起動した場合に発生する可能性があります。
6.1.3.1. Administrator パースペクティブからアラートをサイレントにする
特定のアラート、または定義する仕様に一致するアラートのいずれかをサイレントにすることができます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
特定のアラートをサイレントにするには、以下を実行します。
- OpenShift Container Platform Web コンソールの Administrator パースペクティブから、Observe → Alerting → Alerts に移動します。
-
サイレントにするアラートに対して、
をクリックし、Silence alert を選択すると、選択したアラートのデフォルト設定を含む Silence alert ページが開きます。
オプション: サイレンスのデフォルト設定の詳細を変更します。
注記サイレンスを保存する前にコメントを追加する必要があります。
- サイレンスを保存するには、Silence をクリックします。
一連のアラートをサイレントにします。
- OpenShift Container Platform Web コンソールの Administrator パースペクティブから、Observe → Alerting → Silences に移動します。
- Create silence をクリックします。
Create silence フォームで、アラートのスケジュール、期間、およびラベルの詳細を設定します。
注記サイレンスを保存する前にコメントを追加する必要があります。
- 入力したラベルと一致するアラートのサイレンスを作成するには、Silence をクリックします。
6.1.3.2. Administrator パースペクティブからサイレンス設定を編集する
サイレンスを編集すると、既存のサイレンスが期限切れになり、変更された設定で新しいサイレンスが作成されます。
前提条件
-
クラスター管理者の場合は、
cluster-adminロールを持つユーザーとしてクラスターにアクセスできます。 管理者以外のユーザーの場合は、次のユーザーロールを持つユーザーとしてクラスターにアクセスできる。
-
Alertmanager へのアクセスを許可する
cluster-monitoring-viewクラスターロール。 -
monitoring-alertmanager-editロール。これにより、Web コンソールの Administrator パースペクティブでアラートを作成して無効にできます。
-
Alertmanager へのアクセスを許可する
手順
- OpenShift Container Platform Web コンソールの Administrator パースペクティブから、Observe → Alerting → Silences に移動します。
変更するサイレンスの
をクリックして Edit silence を選択します。
または、Actions をクリックし、サイレンスの Silence details ページで Edit silence を選択することもできます。
- Edit silence ページで変更を加え、Silence をクリックします。これにより、既存のサイレンスが期限切れになり、更新された設定でサイレンスが作成されます。
6.1.3.3. Administrator パースペクティブからサイレンスの有効期限を設定する
単一のサイレンスまたは複数のサイレンスを期限切れにすることができます。サイレンスを期限切れにすると、そのサイレンスは永久に非アクティブ化されます。
サイレンスが適用された期限切れのアラートは削除できません。120 時間を超えて期限切れになったサイレンスはガベージコレクションされます。
前提条件
-
クラスター管理者の場合は、
cluster-adminロールを持つユーザーとしてクラスターにアクセスできます。 管理者以外のユーザーの場合は、次のユーザーロールを持つユーザーとしてクラスターにアクセスできる。
-
Alertmanager へのアクセスを許可する
cluster-monitoring-viewクラスターロール。 -
monitoring-alertmanager-editロール。これにより、Web コンソールの Administrator パースペクティブでアラートを作成して無効にできます。
-
Alertmanager へのアクセスを許可する
手順
- Observe → Alerting → Silences に移動します。
- 期限切れにするサイレンスは、対応する行のチェックボックスを選択します。
Expire 1 silence をクリックして選択した 1 つのサイレンスを期限切れにするか、Expire <n> silences をクリックして複数の沈黙を期限切れにします (<n> は選択した沈黙の数になります)。
または、単一の沈黙を期限切れにするには、Actions をクリックし、サイレンスの Silence details ページで Expire silence を選択します。
6.1.4. コアプラットフォームモニタリングのアラートルールの管理
OpenShift Container Platform のモニタリングには、プラットフォームメトリクス用のデフォルトのアラートルールが多数用意されています。クラスター管理者は、このルールセットを 2 つの方法でカスタマイズできます。
-
しきい値を調整するか、ラベルを追加および変更して、既存のプラットフォームのアラートルールの設定を変更します。たとえば、アラートの
severityラベルをwarningからcriticalに変更すると、アラートのフラグが付いた問題のルーティングおよびトリアージに役立ちます。 -
openshift-monitoringプロジェクトのコアプラットフォームメトリクスに基づいてクエリー式を作成することにより、新しいカスタムアラートルールを定義して追加します。
6.1.4.1. 新規アラートルールの作成
クラスター管理者は、プラットフォームメトリクスに基づいて新規のアラートルールを作成できます。これらのアラートルールは、選択したメトリクスの値に基づいてアラートをトリガーします。
-
既存のプラットフォームアラートルールに基づいてカスタマイズされた
AlertingRuleリソースを作成する場合は、元のアラートをサイレントに設定して、競合するアラートを受信しないようにします。 - ユーザーがアラートの影響と原因を理解できるように、アラートルールにアラートメッセージと重大度値が含まれていることを確認します。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
-
example-alerting-rule.yamlという名前の新しい YAML 設定ファイルを作成します。 AlertingRuleリソースを YAML ファイルに追加します。以下の例では、デフォルトのWatchdogアラートと同様にexampleという名前の新規アラートルールを作成します。apiVersion: monitoring.openshift.io/v1 kind: AlertingRule metadata: name: example namespace: openshift-monitoring1 spec: groups: - name: example-rules rules: - alert: ExampleAlert2 for: 1m3 expr: vector(1)4 labels: severity: warning5 annotations: message: This is an example alert.6 重要openshift-monitoringnamespace にAlertingRuleオブジェクトを作成する必要があります。それ以外の場合は、アラートルールが受け入れられません。設定ファイルをクラスターに適用します。
$ oc apply -f example-alerting-rule.yaml
6.1.4.2. コアプラットフォームのアラートルールの変更
クラスター管理者は、Alertmanager がコアプラットフォームアラートをレシーバーにルーティングする前に変更できます。たとえば、アラートの重大度のラベルを変更したり、カスタムラベルを追加したり、アラートの送信から Alertmanager に送信されないようにしたりできます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
-
example-modified-alerting-rule.yamlという名前の新しい YAML 設定ファイルを作成します。 AlertRelabelConfigリソースを YAML ファイルに追加します。以下の例では、デフォルトのプラットフォームwatchdogアラートルールのseverity設定をcriticalに変更します。apiVersion: monitoring.openshift.io/v1 kind: AlertRelabelConfig metadata: name: watchdog namespace: openshift-monitoring1 spec: configs: - sourceLabels: [alertname,severity]2 regex: "Watchdog;none"3 targetLabel: severity4 replacement: critical5 action: Replace6 重要openshift-monitoringnamespace にAlertRelabelConfigオブジェクトを作成する必要があります。それ以外の場合は、アラートラベルが変更しません。設定ファイルをクラスターに適用します。
$ oc apply -f example-modified-alerting-rule.yaml
6.1.5. ユーザー定義プロジェクトのアラートルールの管理
OpenShift Container Platform では、ユーザー定義プロジェクトのアラートルールを作成、表示、編集、削除できます。これらのアラートルールは、選択したメトリクスの値に基づいてアラートをトリガーします。
6.1.5.1. ユーザー定義プロジェクトのアラートルールの作成
ユーザー定義のプロジェクトに対してアラートルールを作成できます。これらのアラートルールは、選択したメトリクスの値に基づいてアラートをトリガーします。
- アラートルールを作成すると、別のプロジェクトに同じ名前のルールが存在する場合でも、そのルールにプロジェクトラベルが適用されます。
- ユーザーがアラートの影響と原因を理解できるように、アラートルールにアラートメッセージと重大度値が含まれていることを確認します。
前提条件
- ユーザー定義プロジェクトのモニタリングが有効化されている。
-
アラートルールを作成するプロジェクトのクラスター管理者または
monitoring-rules-editクラスターロールを持つユーザーとしてログインする。 -
OpenShift CLI (
oc) がインストールされている。
手順
-
アラートルールの YAML ファイルを作成します。この例では、
example-app-alerting-rule.yamlという名前です。 アラートルール設定を YAML ファイルに追加します。以下の例では、
example-alertという名前の新規アラートルールを作成します。アラートルールは、サンプルサービスによって公開されるversionメトリクスが0になるとアラートを実行します。apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: name: example-alert namespace: ns1 spec: groups: - name: example rules: - alert: VersionAlert1 for: 1m2 expr: version{job="prometheus-example-app"} == 03 labels: severity: warning4 annotations: message: This is an example alert.5 設定ファイルをクラスターに適用します。
$ oc apply -f example-app-alerting-rule.yaml
6.1.5.2. 単一ビューでのすべてのプロジェクトのアラートルールのリスト表示
クラスター管理者は、OpenShift Container Platform のコアプロジェクトおよびユーザー定義プロジェクトのアラートルールを単一ビューでリスト表示できます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
- OpenShift Container Platform Web コンソールの Administrator パースペクティブから、Observe → Alerting → Alerting rules に移動します。
Filter ドロップダウンメニューで、Platform および User ソースを選択します。
注記Platform ソースはデフォルトで選択されます。
6.1.5.3. ユーザー定義プロジェクトのアラートルールの削除
ユーザー定義プロジェクトのアラートルールを削除できます。
前提条件
- ユーザー定義プロジェクトのモニタリングが有効化されている。
-
アラートルールを作成するプロジェクトのクラスター管理者または
monitoring-rules-editクラスターロールを持つユーザーとしてログインする。 -
OpenShift CLI (
oc) がインストールされている。
手順
<namespace>内のルール<alerting_rule>を削除するには、次のコマンドを実行します。$ oc -n <namespace> delete prometheusrule <alerting_rule>
6.2. 開発者としてアラートを管理する
OpenShift Container Platform では、アラート UI を使用してアラート、サイレンス、およびアラートルールを管理できます。
アラート UI で利用可能なアラート、サイレンス、およびアラートルールは、アクセス可能なプロジェクトに関連付けられます。
6.2.1. Developer パースペクティブからのアラート UI へのアクセス
アラート UI には、OpenShift Container Platform Web コンソールの Developer パースペクティブからアクセスできます。
- Developer パースペクティブから、Observe、Alerts タブの順に移動します。
- Project: リストからアラートを管理するプロジェクトを選択します。
このパースペクティブのアラートでは、サイレンスおよびアラートルールはすべて Alerts タブで管理されます。Alerts タブに表示される結果は、選択したプロジェクトに固有のものです。
Developer パースペクティブでは、コア OpenShift Container Platform と、Project: <project_name> リスト内のアクセス可能なユーザー定義プロジェクトから選択できます。ただし、クラスター管理者としてログインしていない場合、コア OpenShift Container Platform プロジェクトに関連するアラート、サイレンス、およびアラートルールは表示されません。
6.2.2. Developer パースペクティブからアラート、サイレンス、アラートルールに関する情報を取得する
アラート UI は、アラートおよびそれらを規定するアラートルールおよびサイレンスの詳細情報を提供します。
前提条件
- アラートを表示しているプロジェクトの表示権限を持つユーザーとしてクラスターにアクセスできる。
手順
アラート、サイレンス、アラートルールに関する情報を取得します。
- OpenShift Container Platform Web コンソールの Developer パースペクティブから、Observe → <project_name> → Alerts ページに移動します。
アラート、サイレンス、またはアラートルールの詳細を表示します。
- Alert details を表示するには、アラート名の横にある大なり記号 (>) をクリックし、リストからアラートを選択します。
Silence details を表示するには、Alert details ページの Silenced by セクションでサイレンスを選択します。Silence details ページには、以下の情報が含まれます。
- アラート仕様
- 開始時間
- 終了時間
- サイレンス状態
- 発生するアラートの数およびリスト
-
Alerting rule details を表示するには、Alerts ページのアラートの横にある
メニューをクリックし、View Alerting Rule をクリックします。
選択したプロジェクトに関連するアラート、サイレンスおよびアラートルールのみが Developer パースペクティブに表示されます。
6.2.3. サイレンスの管理
OpenShift Container Platform Web コンソールの Developer パースペクティブでアラートのサイレンスを作成できます。サイレンスを作成した後、それらを表示、編集、および期限切れにすることができます。また、アラートが発生しても、サイレンスが適用されたアラートに関する通知は届きません。
サイレンスを作成すると、それらは Alertmanager Pod 全体に複製されます。ただし、Alertmanager の永続ストレージを設定しないと、サイレンスが失われる可能性があります。これは、たとえば、すべての Alertmanager Pod が同時に再起動した場合に発生する可能性があります。
6.2.3.1. Developer パースペクティブからアラートをサイレントにする
特定のアラート、または定義する仕様に一致するアラートのいずれかをサイレントにすることができます。
前提条件
-
クラスター管理者の場合は、
cluster-adminロールを持つユーザーとしてクラスターにアクセスできます。 管理者以外のユーザーの場合は、次のユーザーロールを持つユーザーとしてクラスターにアクセスできる。
-
Alertmanager へのアクセスを許可する
cluster-monitoring-viewクラスターロール。 -
monitoring-alertmanager-editロール。これにより、Web コンソールの Administrator パースペクティブでアラートを作成して無効にできます。 -
monitoring-rules-editクラスターロール。これにより、Web コンソールの Developer パースペクティブでアラートを作成して無効にできます。
-
Alertmanager へのアクセスを許可する
手順
特定のアラートをサイレントにするには、以下を実行します。
- OpenShift Container Platform Web コンソールの Developer パースペクティブから、Observe に移動し、Alerts タブに移動します。
- Project: リストからアラートをサイレントにするプロジェクトを選択します。
- 必要に応じて、アラート名の横にある大なり記号 (>) をクリックし、アラートの詳細を展開します。
- 展開されたビューでアラートメッセージをクリックすると、そのアラートの Alert details ページが開きます。
- Silence alert をクリックして、アラートのデフォルト設定を含む Silence alert ページを開きます。
オプション: サイレンスのデフォルト設定の詳細を変更します。
注記サイレンスを保存する前にコメントを追加する必要があります。
- サイレンスを保存するには、Silence をクリックします。
一連のアラートをサイレントにします。
- OpenShift Container Platform Web コンソールの Developer パースペクティブから、Observe に移動し、Silences タブに移動します。
- Project: リストから、アラートをサイレントにするプロジェクトを選択します。
- Create silence をクリックします。
Create silence ページで、アラートの期間とラベルの詳細を設定します。
注記サイレンスを保存する前にコメントを追加する必要があります。
- 入力したラベルと一致するアラートのサイレンスを作成するには、Silence をクリックします。
6.2.3.2. Developer パースペクティブからサイレンス設定を編集する
サイレンスを編集すると、既存のサイレンスが期限切れになり、変更された設定で新しいサイレンスが作成されます。
前提条件
-
クラスター管理者の場合は、
cluster-adminロールを持つユーザーとしてクラスターにアクセスできます。 管理者以外のユーザーの場合は、次のユーザーロールを持つユーザーとしてクラスターにアクセスできる。
-
Alertmanager へのアクセスを許可する
cluster-monitoring-viewクラスターロール。 -
monitoring-rules-editクラスターロール。これにより、Web コンソールの Developer パースペクティブでアラートを作成して無効にできます。
-
Alertmanager へのアクセスを許可する
手順
- OpenShift Container Platform Web コンソールの Developer パースペクティブから、Observe に移動し、Silences タブに移動します。
- Project: リストからサイレンス設定を編集するプロジェクトを選択します。
変更するサイレンスの
をクリックして Edit silence を選択します。
または、Actions をクリックし、サイレンスの Silence details ページで Edit silence を選択することもできます。
- Edit silence ページで変更を加え、Silence をクリックします。これにより、既存のサイレンスが期限切れになり、更新された設定でサイレンスが作成されます。
6.2.3.3. Developer パースペクティブからサイレンスの有効期限を設定する
単一のサイレンスまたは複数のサイレンスを期限切れにすることができます。サイレンスを期限切れにすると、そのサイレンスは永久に非アクティブ化されます。
サイレンスが適用された期限切れのアラートは削除できません。120 時間を超えて期限切れになったサイレンスはガベージコレクションされます。
前提条件
-
クラスター管理者の場合は、
cluster-adminロールを持つユーザーとしてクラスターにアクセスできます。 管理者以外のユーザーの場合は、次のユーザーロールを持つユーザーとしてクラスターにアクセスできる。
-
Alertmanager へのアクセスを許可する
cluster-monitoring-viewクラスターロール。 -
monitoring-rules-editクラスターロール。これにより、Web コンソールの Developer パースペクティブでアラートを作成して無効にできます。
-
Alertmanager へのアクセスを許可する
手順
- OpenShift Container Platform Web コンソールの Developer パースペクティブから、Observe に移動し、Silences タブに移動します。
- Project: リストから、サイレンスを期限切れにするプロジェクトを選択します。
- 期限切れにするサイレンスについては、対応する行のチェックボックスを選択します。
Expire 1 silence をクリックして選択した 1 つのサイレンスを期限切れにするか、Expire <n> silences をクリックして複数の沈黙を期限切れにします (<n> は選択した沈黙の数になります)。
または、単一の沈黙を期限切れにするには、Actions をクリックし、サイレンスの Silence details ページで Expire silence を選択します。
6.2.4. ユーザー定義プロジェクトのアラートルールの管理
OpenShift Container Platform では、ユーザー定義プロジェクトのアラートルールを作成、表示、編集、削除できます。これらのアラートルールは、選択したメトリクスの値に基づいてアラートをトリガーします。
6.2.4.1. ユーザー定義プロジェクトのアラートルールの作成
ユーザー定義のプロジェクトに対してアラートルールを作成できます。これらのアラートルールは、選択したメトリクスの値に基づいてアラートをトリガーします。
- アラートルールを作成すると、別のプロジェクトに同じ名前のルールが存在する場合でも、そのルールにプロジェクトラベルが適用されます。
- ユーザーがアラートの影響と原因を理解できるように、アラートルールにアラートメッセージと重大度値が含まれていることを確認します。
前提条件
- ユーザー定義プロジェクトのモニタリングが有効化されている。
-
アラートルールを作成するプロジェクトのクラスター管理者または
monitoring-rules-editクラスターロールを持つユーザーとしてログインする。 -
OpenShift CLI (
oc) がインストールされている。
手順
-
アラートルールの YAML ファイルを作成します。この例では、
example-app-alerting-rule.yamlという名前です。 アラートルール設定を YAML ファイルに追加します。以下の例では、
example-alertという名前の新規アラートルールを作成します。アラートルールは、サンプルサービスによって公開されるversionメトリクスが0になるとアラートを実行します。apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: name: example-alert namespace: ns1 spec: groups: - name: example rules: - alert: VersionAlert1 for: 1m2 expr: version{job="prometheus-example-app"} == 03 labels: severity: warning4 annotations: message: This is an example alert.5 設定ファイルをクラスターに適用します。
$ oc apply -f example-app-alerting-rule.yaml
6.2.4.2. ユーザー定義プロジェクトのアラートルールへのアクセス
ユーザー定義プロジェクトのアラートルールを一覧表示するには、プロジェクトの monitoring-rules-view クラスターロールが割り当てられている必要があります。
前提条件
- ユーザー定義プロジェクトのモニタリングが有効化されている。
-
プロジェクトの
monitoring-rules-viewクラスターロールを持つユーザーとしてログインしている。 -
OpenShift CLI (
oc) がインストールされている。
手順
<project>でアラートルールを一覧表示するには、以下を実行します。$ oc -n <project> get prometheusruleアラートルールの設定をリスト表示するには、以下を実行します。
$ oc -n <project> get prometheusrule <rule> -o yaml
6.2.4.3. ユーザー定義プロジェクトのアラートルールの削除
ユーザー定義プロジェクトのアラートルールを削除できます。
前提条件
- ユーザー定義プロジェクトのモニタリングが有効化されている。
-
アラートルールを作成するプロジェクトのクラスター管理者または
monitoring-rules-editクラスターロールを持つユーザーとしてログインする。 -
OpenShift CLI (
oc) がインストールされている。
手順
<namespace>内のルール<alerting_rule>を削除するには、次のコマンドを実行します。$ oc -n <namespace> delete prometheusrule <alerting_rule>
第7章 モニタリングの問題のトラブルシューティング
コアプラットフォームおよびユーザー定義プロジェクトのモニタリングに関する一般的な問題のトラブルシューティング手順を参照してください。
7.2. Prometheus が大量のディスク領域を消費している理由の特定
開発者は、キーと値のペアの形式でメトリクスの属性を定義するためにラベルを作成できます。使用できる可能性のあるキーと値のペアの数は、属性に使用できる可能性のある値の数に対応します。数が無制限の値を持つ属性は、バインドされていない属性と呼ばれます。たとえば、customer_id 属性は、使用できる値が無限にあるため、バインドされていない属性になります。
割り当てられるキーと値のペアにはすべて、一意の時系列があります。ラベルに多数のバインドされていない値を使用すると、作成される時系列の数が指数関数的に増加する可能性があります。これは Prometheus のパフォーマンスに影響する可能性があり、多くのディスク領域を消費する可能性があります。
Prometheus が多くのディスクを消費する場合、以下の手段を使用できます。
- どのラベルが最も多くの時系列データを作成しているか詳しく知るには、Prometheus HTTP API を使用して時系列データベース (TSDB) のステータスを確認 します。これを実行するには、クラスター管理者権限が必要です。
- 収集されている スクレイプサンプルの数を確認 します。
ユーザー定義メトリクスに割り当てられるバインドされていない属性の数を減らすことで、作成される一意の時系列の数を減らします。
注記使用可能な値の制限されたセットにバインドされる属性を使用すると、可能なキーと値のペアの組み合わせの数が減ります。
- ユーザー定義のプロジェクト全体で スクレイピングできるサンプルの数に制限を適用 します。これには、クラスター管理者の権限が必要です。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
- Administrator パースペクティブで、Observe → Metrics に移動します。
Expression フィールドに、Prometheus Query Language (PromQL) クエリーを入力します。次のクエリー例は、ディスク領域の消費量の増加につながる可能性のある高カーディナリティメトリクスを識別するのに役立ちます。
次のクエリーを実行すると、スクレイプサンプルの数が最も多いジョブを 10 個特定できます。
topk(10, max by(namespace, job) (topk by(namespace, job) (1, scrape_samples_post_metric_relabeling)))次のクエリーを実行すると、過去 1 時間に最も多くの時系列データを作成したジョブを 10 個特定して、時系列のチャーンを正確に特定できます。
topk(10, sum by(namespace, job) (sum_over_time(scrape_series_added[1h])))
想定よりもサンプルのスクレイプ数が多いメトリクスに割り当てられたラベルで、値が割り当てられていないものの数を確認します。
- メトリクスがユーザー定義のプロジェクトに関連する場合、ワークロードに割り当てられたメトリクスのキーと値のペアを確認します。これらのライブラリーは、アプリケーションレベルで Prometheus クライアントライブラリーを使用して実装されます。ラベルで参照されるバインドされていない属性の数の制限を試行します。
- メトリクスが OpenShift Container Platform のコアプロジェクトに関連する場合、Red Hat サポートケースを Red Hat カスタマーポータル で作成してください。
クラスター管理者としてログインしてから、次の手順に従い Prometheus HTTP API を使用して TSDB ステータスを確認します。
次のコマンドを実行して、Prometheus API ルート URL を取得します。
$ HOST=$(oc -n openshift-monitoring get route prometheus-k8s -ojsonpath='{.status.ingress[].host}')次のコマンドを実行して認証トークンを抽出します。
$ TOKEN=$(oc whoami -t)次のコマンドを実行して、Prometheus の TSDB ステータスのクエリーを実行します。
$ curl -H "Authorization: Bearer $TOKEN" -k "https://$HOST/api/v1/status/tsdb"出力例
"status": "success","data":{"headStats":{"numSeries":507473, "numLabelPairs":19832,"chunkCount":946298,"minTime":1712253600010, "maxTime":1712257935346},"seriesCountByMetricName": [{"name":"etcd_request_duration_seconds_bucket","value":51840}, {"name":"apiserver_request_sli_duration_seconds_bucket","value":47718}, ...
7.3. Prometheus に対する KubePersistentVolumeFillingUp アラートの解決
クラスター管理者は、Prometheus に対してトリガーされている KubePersistentVolumeFillingUp アラートを解決できます。
openshift-monitoring プロジェクトの prometheus-k8s-* Pod によって要求された永続ボリューム (PV) の合計残り容量が 3% 未満になると、重大アラートが発生します。これにより、Prometheus の動作異常が発生する可能性があります。
KubePersistentVolumeFillingUp アラートは 2 つあります。
-
重大アラート: マウントされた PV の合計残り容量が 3% 未満になると、
severity="critical"ラベルの付いたアラートがトリガーされます。 -
警告アラート: マウントされた PV の合計空き容量が 15% 未満になり、4 日以内にいっぱいになると予想される場合、
severity="warning"ラベルの付いたアラートがトリガーされます。
この問題に対処するには、Prometheus 時系列データベース (TSDB) のブロックを削除して、PV 用のスペースを増やすことができます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、すべての TSDB ブロックのサイズを古いものから新しいものの順にリスト表示します。
$ oc debug <prometheus_k8s_pod_name> -n openshift-monitoring \1 -c prometheus --image=$(oc get po -n openshift-monitoring <prometheus_k8s_pod_name> \2 -o jsonpath='{.spec.containers[?(@.name=="prometheus")].image}') \ -- sh -c 'cd /prometheus/;du -hs $(ls -dtr */ | grep -Eo "[0-9|A-Z]{26}")'出力例
308M 01HVKMPKQWZYWS8WVDAYQHNMW6 52M 01HVK64DTDA81799TBR9QDECEZ 102M 01HVK64DS7TRZRWF2756KHST5X 140M 01HVJS59K11FBVAPVY57K88Z11 90M 01HVH2A5Z58SKT810EM6B9AT50 152M 01HV8ZDVQMX41MKCN84S32RRZ1 354M 01HV6Q2N26BK63G4RYTST71FBF 156M 01HV664H9J9Z1FTZD73RD1563E 216M 01HTHXB60A7F239HN7S2TENPNS 104M 01HTHMGRXGS0WXA3WATRXHR36B削除できるブロックとその数を特定し、ブロックを削除します。次のコマンド例は、
prometheus-k8s-0Pod から最も古い 3 つの Prometheus TSDB ブロックを削除します。$ oc debug prometheus-k8s-0 -n openshift-monitoring \ -c prometheus --image=$(oc get po -n openshift-monitoring prometheus-k8s-0 \ -o jsonpath='{.spec.containers[?(@.name=="prometheus")].image}') \ -- sh -c 'ls -latr /prometheus/ | egrep -o "[0-9|A-Z]{26}" | head -3 | \ while read BLOCK; do rm -r /prometheus/$BLOCK; done'次のコマンドを実行して、マウントされた PV の使用状況を確認し、十分な空き容量があることを確認します。
$ oc debug <prometheus_k8s_pod_name> -n openshift-monitoring \1 --image=$(oc get po -n openshift-monitoring <prometheus_k8s_pod_name> \2 -o jsonpath='{.spec.containers[?(@.name=="prometheus")].image}') -- df -h /prometheus/次の出力例は、
prometheus-k8s-0Pod によって要求されるマウントされた PV に、63% の空き容量が残っていることを示しています。出力例
Starting pod/prometheus-k8s-0-debug-j82w4 ... Filesystem Size Used Avail Use% Mounted on /dev/nvme0n1p4 40G 15G 40G 37% /prometheus Removing debug pod ...
7.4. AlertmanagerReceiversNotConfigured アラートの解決
デフォルトで、デプロイされるすべてのクラスターで AlertmanagerReceiversNotConfigured アラートが発生します。この問題を解決するには、アラートレシーバーを設定する必要があります。
- デフォルトのプラットフォーム監視は、コアプラットフォーム監視の設定 の「アラート通知の設定」の手順に従います。
- ユーザーワークロードの監視は、ユーザーワークロードの監視の設定 の「アラート通知の設定」の手順に従います。
第8章 Cluster Monitoring Operator の config map リファレンス
8.1. Cluster Monitoring Operator 設定リファレンス
OpenShift Container Platform クラスターモニタリングの一部は設定可能です。API には、さまざまな config map で定義されるパラメーターを設定してアクセスできます。
-
モニタリングコンポーネントを設定するには、
openshift-monitoringnamespace でcluster-monitoring-configという名前のConfigMapオブジェクトを編集します。このような設定は ClusterMonitoringConfiguration によって定義されます。 -
ユーザー定義プロジェクトを監視するモニタリングコンポーネントを設定するには、
openshift-user-workload-monitoringnamespace でuser-workload-monitoring-configという名前のConfigMapオブジェクトを編集します。これらの設定は UserWorkloadConfiguration で定義されます。
設定ファイルは、常に config map データの config.yaml キーで定義されます。
- モニタリングスタックのすべての設定パラメーターが公開されるわけではありません。このリファレンスにリストされているパラメーターとフィールドのみが設定でサポートされます。サポートされている設定の詳細は、以下を参照してください。
- モニタリングのメンテナンスおよびサポート
- クラスターモニタリングの設定はオプションです。
- 設定が存在しないか、空の場合には、デフォルト値が使用されます。
-
設定が無効な場合、Cluster Monitoring Operator はリソースの調整を停止し、Operator のステータス条件で
Degraded=Trueを報告します。
8.2. AdditionalAlertmanagerConfig
8.2.1. 説明
AdditionalAlertmanagerConfig リソースは、コンポーネントが追加の Alertmanager インスタンスと通信する方法の設定を定義します。
8.2.2. 必須
-
apiVersion
出現場所: PrometheusK8sConfig、PrometheusRestrictedConfig、ThanosRulerConfig
| プロパティー | 型 | 説明 |
|---|---|---|
| apiVersion | string |
Alertmanager の API バージョンを定義します。使用できる値は |
| bearerToken | *v1.SecretKeySelector | Alertmanager への認証時に使用するベアラートークンを含むシークレットキー参照を定義します。 |
| pathPrefix | string | プッシュエンドポイントパスの前に追加するパス接頭辞を定義します。 |
| scheme | string |
Alertmanager インスタンスとの通信時に使用する URL スキームを定義します。使用できる値は |
| staticConfigs | []string |
|
| timeout | *文字列 | アラートの送信時に使用されるタイムアウト値を定義します。 |
| tlsConfig | Alertmanager 接続に使用する TLS 設定を定義します。 |
8.3. AlertmanagerMainConfig
8.3.1. 説明
AlertmanagerMainConfig リソースは、openshift-monitoring namespace で Alertmanager コンポーネントの設定を定義します。
表示場所: ClusterMonitoringConfiguration
| プロパティー | 型 | 説明 |
|---|---|---|
| enabled | *bool |
|
| enableUserAlertmanagerConfig | bool |
|
| logLevel | string |
Alertmanager のログレベル設定を定義します。使用できる値は、 |
| nodeSelector | map[string]string | Pod がスケジュールされるノードを定義します。 |
| resources | *v1.ResourceRequirements | Alertmanager コンテナーのリソース要求および制限を定義します。 |
| secrets | []string |
Alertmanager にマウントされるシークレットの一覧を定義します。シークレットは、Alertmanager オブジェクトと同じ namespace 内になければなりません。これらは |
| tolerations | []v1.Toleration | Pod の toleration を定義します。 |
| topologySpreadConstraints | []v1.TopologySpreadConstraint | Pod のトポロジー分散制約を定義します。 |
| volumeClaimTemplate | *monv1.EmbeddedPersistentVolumeClaim | Alertmanager の永続ストレージを定義します。この設定を使用して、ストレージクラス、ボリュームサイズ、名前などの永続ボリューム要求を設定します。 |
8.4. AlertmanagerUserWorkloadConfig
8.4.1. 説明
AlertmanagerUserWorkloadConfig リソースは、ユーザー定義プロジェクトに使用される Alertmanager インスタンスの設定を定義します。
表示場所: UserWorkloadConfiguration
| プロパティー | 型 | 説明 |
|---|---|---|
| enabled | bool |
|
| enableAlertmanagerConfig | bool |
|
| logLevel | string |
ユーザーワークロードモニタリング用の Alertmanager のログレベル設定を定義します。使用できる値は、 |
| resources | *v1.ResourceRequirements | Alertmanager コンテナーのリソース要求および制限を定義します。 |
| secrets | []string |
Alertmanager にマウントされるシークレットの一覧を定義します。シークレットは、Alertmanager オブジェクトと同じ namespace 内に配置する必要があります。これらは |
| nodeSelector | map[string]string | Pod がスケジュールされるノードを定義します。 |
| tolerations | []v1.Toleration | Pod の toleration を定義します。 |
| topologySpreadConstraints | []v1.TopologySpreadConstraint | Pod のトポロジー分散制約を定義します。 |
| volumeClaimTemplate | *monv1.EmbeddedPersistentVolumeClaim | Alertmanager の永続ストレージを定義します。この設定を使用して、ストレージクラス、ボリュームサイズ、名前などの永続ボリューム要求を設定します。 |
8.5. ClusterMonitoringConfiguration
8.5.1. 説明
ClusterMonitoringConfiguration リソースは、openshift-monitoring namespace の cluster-monitoring-config config map を使用してデフォルトのプラットフォームモニタリングスタックをカスタマイズする設定を定義します。
| プロパティー | 型 | 説明 |
|---|---|---|
| alertmanagerMain |
| |
| enableUserWorkload | *bool |
|
| k8sPrometheusAdapter |
| |
| kubeStateMetrics |
| |
| metricsServer |
| |
| prometheusK8s |
| |
| prometheusOperator |
| |
| prometheusOperatorAdmissionWebhook |
| |
| openshiftStateMetrics |
| |
| telemeterClient |
| |
| thanosQuerier |
| |
| nodeExporter |
| |
| monitoringPlugin |
|
8.6. DedicatedServiceMonitors
8.6.1. 説明
この設定は非推奨であり、今後の OpenShift Container Platform バージョンで削除される予定です。この設定は、現在のバージョンにまだ存在しますが、効果はありません。
DedicatedServiceMonitors リソースを使用して、Prometheus アダプターの専用のサービスモニターを設定できます。
表示場所: K8sPrometheusAdapter
| プロパティー | 型 | 説明 |
|---|---|---|
| enabled | bool |
|
8.7. K8sPrometheusAdapter
8.7.1. 説明
K8sPrometheusAdapter リソースは、Prometheus Adapter コンポーネントの設定を定義します。
表示場所: ClusterMonitoringConfiguration
| プロパティー | 型 | 説明 |
|---|---|---|
| audit | *Audit |
Prometheus アダプターインスタンスによって使用される監査設定を定義します。使用できる値は |
| nodeSelector | map[string]string | Pod がスケジュールされるノードを定義します。 |
| resources | *v1.ResourceRequirements |
|
| tolerations | []v1.Toleration | Pod の toleration を定義します。 |
| topologySpreadConstraints | []v1.TopologySpreadConstraint | Pod のトポロジー分散制約を定義します。 |
| dedicatedServiceMonitors | 専用のサービスモニターを定義します。 |
8.8. KubeStateMetricsConfig
8.8.1. 説明
KubeStateMetricsConfig リソースは、kube-state-metrics エージェントの設定を定義します。
表示場所: ClusterMonitoringConfiguration
| プロパティー | 型 | 説明 |
|---|---|---|
| nodeSelector | map[string]string | Pod がスケジュールされるノードを定義します。 |
| resources | *v1.ResourceRequirements |
|
| tolerations | []v1.Toleration | Pod の toleration を定義します。 |
| topologySpreadConstraints | []v1.TopologySpreadConstraint | Pod のトポロジー分散制約を定義します。 |
8.9. MetricsServerConfig
8.9.1. 説明
Metrics Server はテクノロジープレビューのみの機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
MetricsServerConfig リソースは、Metrics Server コンポーネントの設定を定義します。この設定は、TechPreviewNoUpgrade フィーチャーゲートが有効な場合にのみ適用されることに注意してください。
表示場所: ClusterMonitoringConfiguration
| プロパティー | 型 | 説明 |
|---|---|---|
| nodeSelector | map[string]string | Pod がスケジュールされるノードを定義します。 |
| tolerations | []v1.Toleration | Pod の toleration を定義します。 |
| resources | *v1.ResourceRequirements | Metrics Server コンテナーのリソース要求および制限を定義します。 |
| topologySpreadConstraints | []v1.TopologySpreadConstraint | Pod のトポロジー分散制約を定義します。 |
8.10. PrometheusOperatorAdmissionWebhookConfig
8.10.1. 説明
PrometheusOperatorAdmissionWebhookConfig リソースは、Prometheus Operator のアドミッション Webhook ワークロードの設定を定義します。
表示場所: ClusterMonitoringConfiguration
| プロパティー | 型 | 説明 |
|---|---|---|
| resources | *v1.ResourceRequirements |
|
| topologySpreadConstraints | []v1.TopologySpreadConstraint | Pod のトポロジー分散制約を定義します。 |
8.11. MonitoringPluginConfig
8.11.1. 説明
MonitoringPluginConfig リソースは、openshift-monitoring namespace の Web コンソールプラグインコンポーネントの設定を定義します。
表示場所: ClusterMonitoringConfiguration
| プロパティー | 型 | 説明 |
|---|---|---|
| nodeSelector | map[string]string | Pod がスケジュールされるノードを定義します。 |
| resources | *v1.ResourceRequirements |
|
| tolerations | []v1.Toleration | Pod の toleration を定義します。 |
| topologySpreadConstraints | []v1.TopologySpreadConstraint | Pod のトポロジー分散制約を定義します。 |
8.12. NodeExporterCollectorBuddyInfoConfig
8.12.1. 説明
NodeExporterCollectorBuddyInfoConfig リソースは、node-exporter エージェントの buddyinfo コレクターのオン/オフスイッチとして機能します。デフォルトでは、buddyinfo コレクターは無効になっています。
表示場所: NodeExporterCollectorConfig
| プロパティー | 型 | 説明 |
|---|---|---|
| enabled | bool |
|
8.13. NodeExporterCollectorConfig
8.13.1. 説明
NodeExporterCollectorConfig リソースは、node-exporter エージェントの個別コレクターの設定を定義します。
表示場所: NodeExporterConfig
| プロパティー | 型 | 説明 |
|---|---|---|
| cpufreq |
CPU 周波数の統計情報を収集する | |
| tcpstat |
TCP 接続の統計情報を収集する | |
| netdev |
ネットワークデバイスの統計情報を収集する | |
| netclass |
ネットワークデバイスに関する情報を収集する | |
| buddyinfo |
| |
| mountstats |
NFS ボリューム I/O アクティビティーに関する統計を収集する | |
| ksmd |
カーネルの同一ページ結合デーモンから統計を収集する | |
| processes |
システム内で実行しているプロセスとスレッドから統計を収集する | |
| systemd |
systemd デーモンとそのマネージドサービスに関する統計を収集する |
8.14. NodeExporterCollectorCpufreqConfig
8.14.1. 説明
NodeExporterCollectorCpufreqConfig リソースを使用して、node-exporter エージェントの cpufreq コレクターを有効または無効にします。デフォルトでは、cpufreq コレクターは無効になっています。特定の状況下で cpufreq コレクターを有効にすると、多数のコアを持つマシンの CPU 使用率が増加します。マシンに多数のコアがある場合にこのコレクターを有効にする際は、CPU の過剰使用がないかシステムを監視してください。
表示場所: NodeExporterCollectorConfig
| プロパティー | 型 | 説明 |
|---|---|---|
| enabled | bool |
|
8.15. NodeExporterCollectorKSMDConfig
8.15.1. 説明
NodeExporterCollectorKSMDConfig リソースを使用して、node-exporter エージェントの ksmd コレクターを有効または無効にします。デフォルトでは、ksmd コレクターは無効になっています。
表示場所: NodeExporterCollectorConfig
| プロパティー | 型 | 説明 |
|---|---|---|
| enabled | bool |
|
8.16. NodeExporterCollectorMountStatsConfig
8.16.1. 説明
NodeExporterCollectorMountStatsConfig リソースを使用して、node-exporter エージェントの mountstats コレクターを有効または無効にします。デフォルトでは、mountstats コレクターは無効になっています。コレクターを有効にすると、node_mountstats_nfs_read_bytes_total、node_mountstats_nfs_write_bytes_total、node_mountstats_nfs_operations_requests_total のメトリクスが使用可能になります。これらのメトリクスはカーディナリティが高くなる可能性があることに注意してください。このコレクターを有効にした場合は、prometheus-k8s Pod のメモリー使用量の増加を注意深く監視してください。
表示場所: NodeExporterCollectorConfig
| プロパティー | 型 | 説明 |
|---|---|---|
| enabled | bool |
|
8.17. NodeExporterCollectorNetClassConfig
8.17.1. 説明
NodeExporterCollectorNetClassConfig リソースを使用して、node-exporter エージェントの netclass コレクターを有効または無効にします。デフォルトでは、netclass コレクターが有効になっています。無効にすると、次のメトリクスが利用できなくなります (node_network_info、node_network_address_assign_type、node_network_carrier、node_network_carrier_changes_total、node_network_carrier_up_changes_total、node_network_carrier_down_changes_total、node_network_device_id、node_network_dormant、node_network_flags、node_network_iface_id、node_network_iface_link、node_network_iface_link_mode、node_network_mtu_bytes、node_network_name_assign_type、node_network_net_dev_group、node_network_speed_bytes、node_network_transmit_queue_length、および node_network_protocol_type)。
表示場所: NodeExporterCollectorConfig
| プロパティー | 型 | 説明 |
|---|---|---|
| enabled | bool |
|
| useNetlink | bool |
|
8.18. NodeExporterCollectorNetDevConfig
8.18.1. 説明
NodeExporterCollectorNetDevConfig リソースを使用して、node-exporter エージェントの netdev コレクターを有効または無効にします。デフォルトでは、netdev コレクターが有効になっています。無効にすると、次のメトリクスが利用できなくなります (node_network_receive_bytes_total、node_network_receive_compressed_total、node_network_receive_drop_total、node_network_receive_errs_total、node_network_receive_fifo_total、node_network_receive_frame_total、node_network_receive_multicast_total、node_network_receive_nohandler_total、node_network_receive_packets_total、node_network_transmit_bytes_total、node_network_transmit_carrier_total、node_network_transmit_colls_total、node_network_transmit_compressed_total、node_network_transmit_drop_total、node_network_transmit_errs_total、node_network_transmit_fifo_total、および node_network_transmit_packets_total)。
表示場所: NodeExporterCollectorConfig
| プロパティー | 型 | 説明 |
|---|---|---|
| enabled | bool |
|
8.19. NodeExporterCollectorProcessesConfig
8.19.1. 説明
NodeExporterCollectorProcessesConfig リソースを使用して、node-exporter エージェントの processes コレクターを有効または無効にします。コレクターが有効な場合は、次のメトリクスが使用可能になります (node_processes_max_processes、node_processes_pids、node_processes_state、node_processes_threads、node_processes_threads_state)。メトリクス node_processes_state と node_processes_threads_state には、プロセスとスレッドの状態に応じて、それぞれ最大 5 つのシリーズを含めることができます。プロセスまたはスレッドの可能な状態は、D (UNINTERRUPTABLE_SLEEP)、R (RUNNING & RUNNABLE)、S (INTERRUPTABLE_SLEEP)、T (STOPPED)、または Z (ZOMBIE) です。デフォルトでは、processes コレクターは無効になっています。
表示場所: NodeExporterCollectorConfig
| プロパティー | 型 | 説明 |
|---|---|---|
| enabled | bool |
|
8.20. NodeExporterCollectorSystemdConfig
8.20.1. 説明
NodeExporterCollectorSystemdConfig リソースを使用して、node-exporter エージェントの systemd コレクターを有効または無効にします。デフォルトでは、systemd コレクターは無効になっています。有効にすると、次のメトリクスが使用可能になります (node_systemd_system_running、node_systemd_units、node_systemd_version)。ユニットがソケットを使用する場合、次のメトリクスも生成します (node_systemd_socket_accepted_connections_total、node_systemd_socket_current_connections、node_systemd_socket_refused_connections_total)。units パラメーターを使用して、systemd コレクターに含める systemd ユニットを選択できます。選択したユニットは、各 systemd ユニットの状態を示す node_systemd_unit_state メトリクスを生成するために使用されます。ただし、このメトリクスのカーディナリティーは高くなる可能性があります (ノードごとのユニットごとに少なくとも 5 シリーズ)。選択したユニットの長いリストを使用してこのコレクターを有効にする場合は、過剰なメモリー使用量がないか prometheus-k8s デプロイメントを注意深く監視してください。node_systemd_timer_last_trigger_seconds メトリクスは、units パラメーターの値を logrotate.timer として設定した場合にのみ表示されることに注意してください。
表示場所: NodeExporterCollectorConfig
| プロパティー | 型 | 説明 |
|---|---|---|
| enabled | bool |
|
| units | []string |
|
8.21. NodeExporterCollectorTcpStatConfig
8.21.1. 説明
NodeExporterCollectorTcpStatConfig リソースは、node-exporter エージェントの tcpstat コレクターのオン/オフスイッチとして機能します。デフォルトでは、tcpstat コレクターは無効になっています。
表示場所: NodeExporterCollectorConfig
| プロパティー | 型 | 説明 |
|---|---|---|
| enabled | bool |
|
8.22. NodeExporterConfig
8.22.1. 説明
NodeExporterConfig リソースは、node-exporter エージェントの設定を定義します。
表示場所: ClusterMonitoringConfiguration
| プロパティー | 型 | 説明 |
|---|---|---|
| コレクター | 有効にするコレクターと、それらの追加の設定パラメーターを定義します。 | |
| maxProcs | uint32 |
node-exporter のプロセスが実行する CPU のターゲット数。デフォルト値は |
| ignoredNetworkDevices | *[]string |
|
| resources | *v1.ResourceRequirements |
|
8.23. OpenShiftStateMetricsConfig
8.23.1. 説明
OpenShiftStateMetricsConfig リソースは、openshift-state-metrics エージェントの設定を定義します。
表示場所: ClusterMonitoringConfiguration
| プロパティー | 型 | 説明 |
|---|---|---|
| nodeSelector | map[string]string | Pod がスケジュールされるノードを定義します。 |
| resources | *v1.ResourceRequirements |
|
| tolerations | []v1.Toleration | Pod の toleration を定義します。 |
| topologySpreadConstraints | []v1.TopologySpreadConstraint | Pod のトポロジー分散制約を定義します。 |
8.24. PrometheusK8sConfig
8.24.1. 説明
PrometheusK8sConfig リソースは、Prometheus コンポーネントの設定を定義します。
表示場所: ClusterMonitoringConfiguration
| プロパティー | 型 | 説明 |
|---|---|---|
| additionalAlertmanagerConfigs | Prometheus コンポーネントからアラートを受信する追加の Alertmanager インスタンスを設定します。デフォルトでは、追加の Alertmanager インスタンスは設定されません。 | |
| enforcedBodySizeLimit | string |
Prometheus がスクレイピングしたメトリクスにボディーサイズの制限を適用します。収集された対象のボディーの応答が制限値よりも大きい場合には、スクレイピングは失敗します。制限なしを指定する空の値、Prometheus サイズ形式の数値 ( |
| externalLabels | map[string]string | フェデレーション、リモートストレージ、Alertmanager などの外部システムと通信する際に、任意の時系列またはアラートに追加されるラベルを定義します。デフォルトでは、ラベルは追加されません。 |
| logLevel | string |
Prometheus のログレベル設定を定義します。使用できる値は、 |
| nodeSelector | map[string]string | Pod がスケジュールされるノードを定義します。 |
| queryLogFile | string |
PromQL クエリーがログに記録されるファイルを指定します。この設定は、ファイル名 (クエリーが |
| remoteWrite | URL、認証、再ラベル付け設定など、リモート書き込み設定を定義します。 | |
| resources | *v1.ResourceRequirements |
|
| retention | string |
Prometheus がデータを保持する期間を定義します。この定義は、次の正規表現パターンを使用して指定する必要があります ( |
| retentionSize | string |
データブロックと先行書き込みログ (WAL) によって使用されるディスク領域の最大量を定義します。サポートされる値は、 |
| tolerations | []v1.Toleration | Pod の toleration を定義します。 |
| topologySpreadConstraints | []v1.TopologySpreadConstraint | Pod のトポロジー分散制約を定義します。 |
| collectionProfile | CollectionProfile |
Prometheus がプラットフォームコンポーネントからメトリクスを収集するために使用するメトリクスコレクションプロファイルを定義します。使用可能な値は、 |
| volumeClaimTemplate | *monv1.EmbeddedPersistentVolumeClaim | Prometheus の永続ストレージを定義します。この設定を使用して、ストレージクラス、ボリュームサイズ、名前などの永続ボリューム要求を設定します。 |
8.25. PrometheusOperatorConfig
8.25.1. 説明
PrometheusOperatorConfig リソースは、Prometheus Operator コンポーネントの設定を定義します。
表示場所: ClusterMonitoringConfiguration、UserWorkloadConfiguration
| プロパティー | 型 | 説明 |
|---|---|---|
| logLevel | string |
Prometheus Operator のログレベル設定を定義します。使用できる値は、 |
| nodeSelector | map[string]string | Pod がスケジュールされるノードを定義します。 |
| resources | *v1.ResourceRequirements |
|
| tolerations | []v1.Toleration | Pod の toleration を定義します。 |
| topologySpreadConstraints | []v1.TopologySpreadConstraint | Pod のトポロジー分散制約を定義します。 |
8.26. PrometheusRestrictedConfig
8.26.1. 説明
PrometheusRestrictedConfig リソースは、ユーザー定義プロジェクトをモニターする Prometheus コンポーネントの設定を定義します。
表示場所: UserWorkloadConfiguration
| プロパティー | 型 | 説明 |
|---|---|---|
| additionalAlertmanagerConfigs | Prometheus コンポーネントからアラートを受信する追加の Alertmanager インスタンスを設定します。デフォルトでは、追加の Alertmanager インスタンスは設定されません。 | |
| enforcedLabelLimit | *uint64 |
サンプルで受け入れられるラベルの数に、収集ごとの制限を指定します。メトリクスの再ラベル後にラベルの数がこの制限を超えると、スクレイプ全体が失敗として扱われます。デフォルト値は |
| enforcedLabelNameLengthLimit | *uint64 |
サンプルのラベル名の長さにスクレイプごとの制限を指定します。ラベル名の長さがメトリクスの再ラベル付け後にこの制限を超える場合には、スクレイプ全体が失敗として扱われます。デフォルト値は |
| enforcedLabelValueLengthLimit | *uint64 |
サンプルのラベル値の長さにスクレイプごとの制限を指定します。ラベル値の長さがメトリクスの再ラベル付け後にこの制限を超える場合、スクレイプ全体が失敗として扱われます。デフォルト値は |
| enforcedSampleLimit | *uint64 |
受け入れられるスクレイプされたサンプル数のグローバル制限を指定します。この設定は、値が |
| enforcedTargetLimit | *uint64 |
収集された対象数に対してグローバル制限を指定します。この設定は、値が |
| externalLabels | map[string]string | フェデレーション、リモートストレージ、Alertmanager などの外部システムと通信する際に、任意の時系列またはアラートに追加されるラベルを定義します。デフォルトでは、ラベルは追加されません。 |
| logLevel | string |
Prometheus のログレベル設定を定義します。使用できる値は、 |
| nodeSelector | map[string]string | Pod がスケジュールされるノードを定義します。 |
| queryLogFile | string |
PromQL クエリーがログに記録されるファイルを指定します。この設定は、ファイル名 (クエリーが |
| remoteWrite | URL、認証、再ラベル付け設定など、リモート書き込み設定を定義します。 | |
| resources | *v1.ResourceRequirements | Prometheus コンテナーのリソース要求および制限を定義します。 |
| retention | string |
Prometheus がデータを保持する期間を定義します。この定義は、次の正規表現パターンを使用して指定する必要があります ( |
| retentionSize | string |
データブロックと先行書き込みログ (WAL) によって使用されるディスク領域の最大量を定義します。サポートされる値は、 |
| tolerations | []v1.Toleration | Pod の toleration を定義します。 |
| topologySpreadConstraints | []v1.TopologySpreadConstraint | Pod のトポロジー分散制約を定義します。 |
| volumeClaimTemplate | *monv1.EmbeddedPersistentVolumeClaim | Prometheus の永続ストレージを定義します。この設定を使用して、ボリュームのストレージクラスおよびサイズを設定します。 |
8.27. RemoteWriteSpec
8.27.1. 説明
RemoteWriteSpec リソースは、リモート書き込みストレージの設定を定義します。
8.27.2. 必須
-
url
出現場所: PrometheusK8sConfig、PrometheusRestrictedConfig
| プロパティー | 型 | 説明 |
|---|---|---|
| 認可 | *monv1.SafeAuthorization | リモート書き込みストレージの認証設定を定義します。 |
| basicAuth | *monv1.BasicAuth | リモート書き込みエンドポイント URL の Basic 認証設定を定義します。 |
| bearerTokenFile | string | リモート書き込みエンドポイントのベアラートークンが含まれるファイルを定義します。ただし、シークレットを Pod にマウントできないため、実際にはサービスアカウントのトークンのみを参照できます。 |
| headers | map[string]string | 各リモート書き込み要求とともに送信されるカスタム HTTP ヘッダーを指定します。Prometheus によって設定されるヘッダーはオーバーライドできません。 |
| metadataConfig | *monv1.MetadataConfig | シリーズのメタデータをリモート書き込みストレージに送信するための設定を定義します。 |
| name | string | リモート書き込みキューの名前を定義します。この名前は、メトリクスとロギングでキューを区別するために使用されます。指定する場合、この名前は一意である必要があります。 |
| oauth2 | *monv1.OAuth2 | リモート書き込みエンドポイントの OAuth2 認証設定を定義します。 |
| proxyUrl | string | オプションのプロキシー URL を定義します。有効になっている場合は、クラスター全体のプロキシーによって置き換えられます。 |
| queueConfig | *monv1.QueueConfig | リモート書き込みキューパラメーターの調整を許可します。 |
| remoteTimeout | string | リモート書き込みエンドポイントへの要求のタイムアウト値を定義します。 |
| sendExemplars | *bool | リモート書き込みによるエグザンプラーの送信を有効にします。この設定を有効にすると、最大 100,000 個のエグザンプラーをメモリーに保存するように Prometheus が設定されます。この設定はユーザー定義のモニタリングにのみ適用され、コアプラットフォームのモニタリンには適用されません。 |
| sigv4 | *monv1.Sigv4 | AWS 署名バージョン 4 の認証設定を定義します。 |
| tlsConfig | *monv1.SafeTLSConfig | リモート書き込みエンドポイントの TLS 認証設定を定義します。 |
| url | string | サンプルの送信先となるリモート書き込みエンドポイントの URL を定義します。 |
| writeRelabelConfigs | []monv1.RelabelConfig | リモート書き込みの再ラベル設定のリストを定義します。 |
8.28. TLSConfig
8.28.1. 説明
TLSConfig リソースは、TLS 接続の設定を設定します。
8.28.2. 必須
-
insecureSkipVerify
表示場所: AdditionalAlertmanagerConfig
| プロパティー | 型 | 説明 |
|---|---|---|
| ca | *v1.SecretKeySelector | リモートホストに使用する認証局 (CA) を含む秘密鍵の参照を定義します。 |
| cert | *v1.SecretKeySelector | リモートホストに使用する公開証明書を含む秘密鍵の参照を定義します。 |
| key | *v1.SecretKeySelector | リモートホストに使用する秘密鍵を含む秘密鍵の参照を定義します。 |
| serverName | string | 返された証明書のホスト名を確認するために使用されます。 |
| insecureSkipVerify | bool |
|
8.29. TelemeterClientConfig
8.29.1. 説明
TelemeterClientConfig は、Telemeter Client コンポーネントの設定を定義します。
8.29.2. 必須
-
nodeSelector -
tolerations
表示場所: ClusterMonitoringConfiguration
| プロパティー | 型 | 説明 |
|---|---|---|
| nodeSelector | map[string]string | Pod がスケジュールされるノードを定義します。 |
| resources | *v1.ResourceRequirements |
|
| tolerations | []v1.Toleration | Pod の toleration を定義します。 |
| topologySpreadConstraints | []v1.TopologySpreadConstraint | Pod のトポロジー分散制約を定義します。 |
8.30. ThanosQuerierConfig
8.30.1. 説明
ThanosQuerierConfig リソースは、Thanos Querier コンポーネントの設定を定義します。
表示場所: ClusterMonitoringConfiguration
| プロパティー | 型 | 説明 |
|---|---|---|
| enableRequestLogging | bool |
要求ロギングを有効または無効にするブール値フラグ。デフォルト値は |
| logLevel | string |
Thanos Querier のログレベル設定を定義します。使用できる値は、 |
| enableCORS | bool |
CORS ヘッダーの設定を可能にするブール型フラグ。ヘッダーにより、あらゆる発信元からのアクセスが許可されます。デフォルト値は |
| nodeSelector | map[string]string | Pod がスケジュールされるノードを定義します。 |
| resources | *v1.ResourceRequirements | Thanos Querier コンテナーのリソース要求および制限を定義します。 |
| tolerations | []v1.Toleration | Pod の toleration を定義します。 |
| topologySpreadConstraints | []v1.TopologySpreadConstraint | Pod のトポロジー分散制約を定義します。 |
8.31. ThanosRulerConfig
8.31.1. 説明
ThanosRulerConfig リソースは、ユーザー定義プロジェクトの Thanos Ruler インスタンスの設定を定義します。
表示場所: UserWorkloadConfiguration
| プロパティー | 型 | 説明 |
|---|---|---|
| additionalAlertmanagerConfigs |
Thanos Ruler コンポーネントが追加の Alertmanager インスタンスと通信する方法を設定します。デフォルト値は | |
| logLevel | string |
Thanos Ruler のログレベル設定を定義します。使用できる値は、 |
| nodeSelector | map[string]string | Pod がスケジュールされるノードを定義します。 |
| resources | *v1.ResourceRequirements | Alertmanager コンテナーのリソース要求および制限を定義します。 |
| retention | string |
Prometheus がデータを保持する期間を定義します。この定義は、次の正規表現パターンを使用して指定する必要があります ( |
| toleration | []v1.Toleration | Pod の toleration を定義します。 |
| topologySpreadConstraints | []v1.TopologySpreadConstraint | Pod のトポロジー分散制約を定義します。 |
| volumeClaimTemplate | *monv1.EmbeddedPersistentVolumeClaim | Thanos Ruler の永続ストレージを定義します。この設定を使用して、ボリュームのストレージクラスおよびサイズを設定します。 |
8.32. UserWorkloadConfiguration
8.32.1. 説明
UserWorkloadConfiguration リソースは、openshift-user-workload-monitoring namespace の user-workload-monitoring-config config map でユーザー定義プロジェクトに対応する設定を定義します。UserWorkloadConfiguration は、openshift-monitoring namespace の下にある cluster-monitoring-config config map で enableUserWorkload を true に設定した後にのみ有効にできます。
| プロパティー | 型 | 説明 |
|---|---|---|
| alertmanager | ユーザーワークロードモニタリングで Alertmanager コンポーネントの設定を定義します。 | |
| prometheus | ユーザーワークロードモニタリングで Prometheus コンポーネントの設定を定義します。 | |
| prometheusOperator | ユーザーワークロードモニタリングでの Prometheus Operator コンポーネントの設定を定義します。 | |
| thanosRuler | ユーザーワークロードモニタリングで Thanos Ruler コンポーネントの設定を定義します。 |
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.