インストール後の設定
OpenShift Container Platform の Day 2 オペレーション
概要
第1章 インストール後の設定の概要
OpenShift Container Platform のインストール後に、クラスター管理者は以下のコンポーネントを設定し、カスタマイズできます。
- マシン
- ベアメタル
- クラスター
- ノード
- ネットワーク
- ストレージ
- ユーザー
- アラートおよび通知
1.1. インストール後の設定タスク
インストール後の設定タスクを実行して、ニーズに合わせて環境を設定できます。
次のリストにインストール後の設定の詳細を示します。
-
オペレーティングシステム機能の設定: Machine Config Operator (MCO) は
MachineConfigオブジェクトを管理します。MCO を使用すると、ノードとカスタムリソースを設定できます。 ベアメタルノードの設定: Bare Metal Operator (BMO) を使用してベアメタルホストを管理できます。BMO は次の操作を完了できます。
- ホストのハードウェアの詳細を検査し、ベアメタルホストに報告します。
- ファームウェアを検査し、BIOS を設定します。
- 必要なイメージでホストをプロビジョニングします。
- ホストをプロビジョニングする前または後に、ホストのディスクの内容をクリーンアップします。
クラスター機能の設定: OpenShift Container Platform クラスターの以下の機能を変更できます。
- イメージレジストリー
- ネットワーク設定
- イメージビルドの動作
- アイデンティティープロバイダー
- etcd の設定
- ワークロードを処理するマシンセットの作成
- クラウドプロバイダーの認証情報の管理
プライベートクラスターの設定: デフォルトでは、インストールプログラムはパブリックにアクセス可能な DNS とエンドポイントを使用して、OpenShift Container Platform をプロビジョニングします。内部ネットワーク内からのみクラスターにアクセスできるようにするには、次のコンポーネントを設定してプライベートにします。
- DNS
- Ingress コントローラー
- API サーバー
ノード操作の実施: デフォルトでは、OpenShift Container Platform は Red Hat Enterprise Linux CoreOS (RHCOS) コンピュートマシンを使用します。次のノード操作を実行できます。
- コンピュートマシンの追加および削除
- taint および toleration 追加および削除
- ノードあたりの Pod の最大数の設定
- Device Manager の有効化
ユーザーの設定: ユーザーは、OAuth アクセストークンを使用して API に対して認証を行うことができます。次のタスクを実行するように OAuth を設定できます。
- アイデンティティープロバイダーを指定します。
- ロールベースのアクセス制御を使用して、ユーザーにパーミッションを定義し付与します。
- OperatorHub から Operator をインストールします。
- アラート通知の設定: デフォルトでは、発生中のアラートは Web コンソールのアラート UI に表示されます。外部システムにアラート通知を送信するように OpenShift Container Platform を設定することもできます。
第2章 プライベートクラスターの設定
OpenShift Container Platform バージョン 4.16 クラスターのインストール後に、そのコアコンポーネントの一部を private に設定できます。
2.1. プライベートクラスター
デフォルトで、OpenShift Container Platform は一般にアクセス可能な DNS およびエンドポイントを使用してプロビジョニングされます。プライベートクラスターのデプロイ後に DNS、Ingress コントローラー、および API サーバーを private に設定できます。
クラスターにパブリックサブネットがある場合、管理者により作成されたロードバランサーサービスはパブリックにアクセスできる可能性があります。クラスターのセキュリティーを確保するには、これらのサービスに明示的にプライベートアノテーションが付けられていることを確認してください。
2.1.1. DNS
OpenShift Container Platform を installer-provisioned infrastructure にインストールする場合、インストールプログラムは既存のパブリックゾーンにレコードを作成し、可能な場合はクラスター独自の DNS 解決用のプライベートゾーンを作成します。パブリックゾーンおよびプライベートゾーンの両方で、インストールプログラムまたはクラスターが Ingress オブジェクトの *.apps、および API サーバーの api の DNS エントリーを作成します。
*.apps レコードはパブリックゾーンとプライベートゾーンのどちらでも同じであるため、パブリックゾーンを削除する際に、プライベートゾーンではクラスターのすべての DNS 解決をシームレスに提供します。
2.1.2. Ingress コントローラー
デフォルトの Ingress オブジェクトはパブリックとして作成されるため、ロードバランサーはインターネットに接続され、パブリックサブネットで使用されます。
Ingress Operator は、カスタムのデフォルト証明書を設定するまで、プレースホルダーとして機能する Ingress コントローラーのデフォルト証明書を生成します。実稼働クラスターで Operator が生成するデフォルト証明書は使用しないでください。Ingress Operator は、独自の署名証明書または生成するデフォルト証明書をローテーションしません。Operator が生成するデフォルト証明書は、設定するカスタムデフォルト証明書のプレースホルダーとして使用されます。
2.1.3. API サーバー
デフォルトでは、インストールプログラムは内部トラフィックと外部トラフィックの両方で使用するための API サーバーの適切なネットワークロードバランサーを作成します。
Amazon Web Services (AWS) では、個別のパブリックロードバランサーおよびプライベートロードバランサーが作成されます。ロードバランサーは、クラスター内で使用するために追加ポートが内部で利用可能な場合を除き、常に同一です。インストールプログラムは API サーバー要件に基づいてロードバランサーを自動的に作成または破棄しますが、クラスターはそれらを管理または維持しません。クラスターの API サーバーへのアクセスを保持する限り、ロードバランサーを手動で変更または移動できます。パブリックロードバランサーの場合、ポート 6443 は開放され、ヘルスチェックが HTTPS について /readyz パスに対して設定されます。
Google Cloud では、内部 API トラフィックと外部 API トラフィックの両方を管理するために単一のロードバランサーが作成されるため、ロードバランサーを変更する必要はありません。
Microsoft Azure では、パブリックおよびプライベートロードバランサーの両方が作成されます。ただし、現在の実装には制限があるため、プライベートクラスターで両方のロードバランサーを保持します。
2.2. プライベートゾーンで公開する DNS レコードの設定
すべての OpenShift Container Platform クラスターでは、パブリックかプライベートかにかかわらず、DNS レコードはデフォルトでパブリックゾーンに公開されます。
DNS レコードをパブリックに公開しない場合は、クラスター DNS 設定からパブリックゾーンを削除できます。内部ドメイン名、内部 IP アドレス、組織内のクラスターの数などの機密情報を公開しない場合や、レコードを公開する必要がない場合もあります。クラスター内のサービスに接続できるすべてのクライアントが、プライベートゾーンの DNS レコードを持つプライベート DNS サービスを使用する場合、クラスターのパブリック DNS レコードは必要ありません。
クラスターをデプロイした後、DNS カスタムリソース (CR) を変更して、プライベートゾーンのみを使用するように DNS を変更できます。このように DNS CR を変更すると、その後に作成される DNS レコードはパブリック DNS サーバーに公開されなくなり、DNS レコードに関する情報は内部ユーザーだけに限定されます。これは、クラスターをプライベートに設定する場合、または DNS レコードをパブリックに解決する必要がない場合に適用できます。
または、プライベートクラスターでも DNS レコード用のパブリックゾーンを保持し、クライアントがそのクラスターで実行されているアプリケーションの DNS 名を解決できるようにすることも可能です。たとえば組織は、パブリックインターネットに接続するマシンを所有し、特定のプライベート IP 範囲に対して VPN 接続を確立してプライベート IP アドレスに接続することができます。これらのマシンからの DNS ルックアップでは、パブリック DNS を使用してそれらのサービスのプライベートアドレスを判断し、VPN 経由でプライベートアドレスに接続します。
手順
次のコマンドを実行して出力を確認し、クラスターの
DNSCR を確認します。$ oc get dnses.config.openshift.io/cluster -o yaml出力例
apiVersion: config.openshift.io/v1 kind: DNS metadata: creationTimestamp: "2019-10-25T18:27:09Z" generation: 2 name: cluster resourceVersion: "37966" selfLink: /apis/config.openshift.io/v1/dnses/cluster uid: 0e714746-f755-11f9-9cb1-02ff55d8f976 spec: baseDomain: <base_domain> privateZone: tags: Name: <infrastructure_id>-int kubernetes.io/cluster/<infrastructure_id>: owned publicZone: id: Z2XXXXXXXXXXA4 status: {}specセクションには、プライベートゾーンとパブリックゾーンの両方が含まれることに注意してください。次のコマンドを実行して、
DNSCR にパッチを適用し、パブリックゾーンを削除します。$ oc patch dnses.config.openshift.io/cluster --type=merge --patch='{"spec": {"publicZone": null}}'出力例
dns.config.openshift.io/cluster patchedIngress Operator は、
IngressControllerオブジェクトの DNS レコード作成時にDNSCR 定義を参照します。プライベートゾーンのみ指定されている場合、プライベートレコードのみが作成されます。重要パブリックゾーンを削除しても、既存の DNS レコードは変更されません。以前に公開したパブリック DNS レコードで、パブリックに公開する必要がなくなったものは、手動で削除する必要があります。
検証
次のコマンドを実行し、出力でクラスターの
DNSCR を確認してパブリックゾーンが削除されたことを確認します。$ oc get dnses.config.openshift.io/cluster -o yaml出力例
apiVersion: config.openshift.io/v1 kind: DNS metadata: creationTimestamp: "2019-10-25T18:27:09Z" generation: 2 name: cluster resourceVersion: "37966" selfLink: /apis/config.openshift.io/v1/dnses/cluster uid: 0e714746-f755-11f9-9cb1-02ff55d8f976 spec: baseDomain: <base_domain> privateZone: tags: Name: <infrastructure_id>-int kubernetes.io/cluster/<infrastructure_id>-wfpg4: owned status: {}
2.3. Ingress コントローラーをプライベートに設定する
クラスターのデプロイ後に、その Ingress コントローラーをプライベートゾーンのみを使用するように変更できます。
手順
内部エンドポイントのみを使用するようにデフォルト Ingress コントローラーを変更します。
$ oc replace --force --wait --filename - <<EOF apiVersion: operator.openshift.io/v1 kind: IngressController metadata: namespace: openshift-ingress-operator name: default spec: endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: Internal EOF出力例
ingresscontroller.operator.openshift.io "default" deleted ingresscontroller.operator.openshift.io/default replacedパブリック DNS エントリーが削除され、プライベートゾーンエントリーが更新されます。
2.4. API サーバーをプライベートに制限する
クラスターを Amazon Web Services (AWS) または Microsoft Azure にデプロイした後に、プライベートゾーンのみを使用するように API サーバーを再設定することができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
admin権限を持つユーザーとして Web コンソールにアクセスできること。
手順
クラウドプロバイダーの Web ポータルまたはコンソールで、次の操作を行います。
適切なロードバランサーコンポーネントを見つけて削除します。
- AWS の場合は、外部ロードバランサーを削除します。プライベートゾーンの API DNS エントリーは、同一の設定を使用する内部ロードバランサーをすでに参照するため、内部ロードバランサーを変更する必要はありません。
-
Azure の場合は、パブリックロードバランサーの
api-internal-v4ルールを削除します。
-
Azure の場合、Ingress Controller エンドポイントの公開スコープを
Internalに設定します。詳細は、「Ingress Controller エンドポイント公開スコープを内部に設定」を参照してください。 -
Azure パブリックロードバランサーの場合は、Ingress Controller エンドポイントの公開スコープを
Internalに設定し、パブリックロードバランサーに既存の受信規則がない場合は、バックエンドアドレスプールに送信トラフィックを提供するための送信規則を明示的に作成する必要があります。詳細は、送信ルールの追加に関する Microsoft Azure のドキュメントを参照してください。 -
パブリックゾーンの
api.$clustername.$yourdomainまたはapi.$clusternameDNS エントリーを削除します。
AWS クラスター: 外部ロードバランサーを削除します。
重要以下の手順は、installer-provisioned infrastructure (IPI) のクラスターでのみ実行できます。user-provisioned infrastructure (UPI) のクラスターの場合は、外部ロードバランサーを手動で削除するか、無効にする必要があります。
クラスターがコントロールプレーンマシンセットを使用する場合は、コントロールプレーンマシンセットのカスタムリソースで、パブリックまたは外部ロードバランサーを設定する行を削除します。
# ... providerSpec: value: # ... loadBalancers: - name: lk4pj-ext1 type: network2 - name: lk4pj-int type: network # ...クラスターがコントロールプレーンマシンセットを使用しない場合は、各コントロールプレーンマシンから外部ロードバランサーを削除する必要があります。
ターミナルから、次のコマンドを実行してクラスターマシンを一覧表示します。
$ oc get machine -n openshift-machine-api出力例
NAME STATE TYPE REGION ZONE AGE lk4pj-master-0 running m4.xlarge us-east-1 us-east-1a 17m lk4pj-master-1 running m4.xlarge us-east-1 us-east-1b 17m lk4pj-master-2 running m4.xlarge us-east-1 us-east-1a 17m lk4pj-worker-us-east-1a-5fzfj running m4.xlarge us-east-1 us-east-1a 15m lk4pj-worker-us-east-1a-vbghs running m4.xlarge us-east-1 us-east-1a 15m lk4pj-worker-us-east-1b-zgpzg running m4.xlarge us-east-1 us-east-1b 15mコントロールプレーンマシンの名前には
masterが含まれています。各コントロールプレーンマシンから外部ロードバランサーを削除します。
次のコマンドを実行して、コントロールプレーンマシンオブジェクトを編集します。
$ oc edit machines -n openshift-machine-api <control_plane_name>1 - 1
- 変更するコントロールプレーンマシンオブジェクトの名前を指定します。
次の例でマークされている、外部ロードバランサーを説明する行を削除します。
# ... providerSpec: value: # ... loadBalancers: - name: lk4pj-ext1 type: network2 - name: lk4pj-int type: network # ...- 変更を保存して、オブジェクト仕様を終了します。
- コントロールプレーンマシンごとに、このプロセスを繰り返します。
2.5. Azure 上でプライベートストレージエンドポイントを設定する
Image Registry Operator を利用すると、Azure 上でプライベートエンドポイントを使用できます。これにより、OpenShift Container Platform がプライベート Azure クラスターにデプロイされている場合に、プライベートストレージアカウントのシームレスな設定が可能になります。これにより、パブリック向けのストレージエンドポイントを公開せずにイメージレジストリーをデプロイできます。
Microsoft Azure Red Hat OpenShift (ARO) でプライベートストレージエンドポイントを設定しないでください。エンドポイントによって、Microsoft Azure Red Hat OpenShift クラスターが回復不能な状態になる可能性があります。
次のどちらかの方法で、Azure 上のプライベートストレージエンドポイントを使用するように Image Registry Operator を設定できます。
- Image Registry Operator を設定して VNet 名とサブネット名を検出する
- ユーザーが指定した Azure 仮想ネットワーク (VNet) 名とサブネット名を使用する
2.5.1. Azure 上でプライベートストレージエンドポイントを設定する場合の制限事項
Azure 上でプライベートストレージエンドポイントを設定する場合は、次の制限が適用されます。
-
プライベートストレージエンドポイントを使用するように Image Registry Operator を設定すると、ストレージアカウントへのパブリックネットワークアクセスが無効になります。したがって、OpenShift Container Platform の外部のレジストリーからイメージをプルするには、レジストリーの Operator 設定で
disableRedirect: trueを設定する必要があります。リダイレクトが有効になっていると、ストレージアカウントからイメージを直接プルするように、レジストリーによってクライアントがリダイレクトされますが、これは機能しません。パブリックネットワークアクセスが無効になっているためです。詳細は、「Azure でプライベートストレージエンドポイントを使用する場合にリダイレクトを無効にする」を参照してください。 - この操作は、Image Registry Operator によって元に戻すことはできません。
2.5.2. Image Registry Operator による VNet 名とサブネット名の検出を有効にして Azure 上でプライベートストレージエンドポイントを設定する
次の手順では、VNet 名とサブネット名を検出するように Image Registry Operator を設定して、Azure 上でプライベートストレージエンドポイントを設定する方法を示します。
前提条件
- Azure 上で動作するようにイメージレジストリーを設定している。
ネットワークが、Installer Provisioned Infrastructure インストール方法を使用してセットアップされている。
カスタムネットワーク設定を使用するユーザーの場合は、「ユーザー指定の VNet 名とサブネット名を使用して Azure 上でプライベートストレージエンドポイントを設定する」を参照してください。
手順
Image Registry Operator の
configオブジェクトを編集し、networkAccess.typeをInternalに設定します。$ oc edit configs.imageregistry/cluster# ... spec: # ... storage: azure: # ... networkAccess: type: Internal # ...オプション: 次のコマンドを入力して、Operator がプロビジョニングを完了したことを確認します。これには数分かかる場合があります。
$ oc get configs.imageregistry/cluster -o=jsonpath="{.spec.storage.azure.privateEndpointName}" -wオプション: レジストリーがルートによって公開されており、ストレージアカウントをプライベートに設定する場合、クラスターの外部へのプルを引き続き機能させるには、リダイレクトを無効にする必要があります。次のコマンドを入力して、Image Operator 設定のリダイレクトを無効にします。
$ oc patch configs.imageregistry cluster --type=merge -p '{"spec":{"disableRedirect": true}}'注記リダイレクトが有効になっていると、クラスターの外部からのイメージのプルが機能しなくなります。
検証
次のコマンドを実行して、レジストリーサービス名を取得します。
$ oc registry info --internal=true出力例
image-registry.openshift-image-registry.svc:5000次のコマンドを実行してデバッグモードに入ります。
$ oc debug node/<node_name>推奨される
chrootコマンドを実行します。以下に例を示します。$ chroot /host次のコマンドを入力して、コンテナーレジストリーにログインします。
$ podman login --tls-verify=false -u unused -p $(oc whoami -t) image-registry.openshift-image-registry.svc:5000出力例
Login Succeeded!次のコマンドを入力して、レジストリーからイメージをプルできることを確認します。
$ podman pull --tls-verify=false image-registry.openshift-image-registry.svc:5000/openshift/tools出力例
Trying to pull image-registry.openshift-image-registry.svc:5000/openshift/tools/openshift/tools... Getting image source signatures Copying blob 6b245f040973 done Copying config 22667f5368 done Writing manifest to image destination Storing signatures 22667f53682a2920948d19c7133ab1c9c3f745805c14125859d20cede07f11f9
2.5.3. ユーザー指定の VNet 名とサブネット名を使用して Azure 上でプライベートストレージエンドポイントを設定する
次の手順を使用して、パブリックネットワークアクセスが無効な、Azure 上のプライベートストレージエンドポイントの背後で公開されるストレージアカウントを設定します。
前提条件
- Azure 上で動作するようにイメージレジストリーを設定している。
- Azure 環境で使用する VNet 名とサブネット名を把握している。
- ネットワークが Azure の別のリソースグループに設定されている場合は、そのリソースグループの名前も把握している。
手順
Image Registry Operator の
configオブジェクトを編集し、VNet 名とサブネット名を使用してプライベートエンドポイントを設定します。$ oc edit configs.imageregistry/cluster# ... spec: # ... storage: azure: # ... networkAccess: type: Internal internal: subnetName: <subnet_name> vnetName: <vnet_name> networkResourceGroupName: <network_resource_group_name> # ...オプション: 次のコマンドを入力して、Operator がプロビジョニングを完了したことを確認します。これには数分かかる場合があります。
$ oc get configs.imageregistry/cluster -o=jsonpath="{.spec.storage.azure.privateEndpointName}" -w注記リダイレクトが有効になっていると、クラスターの外部からのイメージのプルが機能しなくなります。
検証
次のコマンドを実行して、レジストリーサービス名を取得します。
$ oc registry info --internal=true出力例
image-registry.openshift-image-registry.svc:5000次のコマンドを実行してデバッグモードに入ります。
$ oc debug node/<node_name>推奨される
chrootコマンドを実行します。以下に例を示します。$ chroot /host次のコマンドを入力して、コンテナーレジストリーにログインします。
$ podman login --tls-verify=false -u unused -p $(oc whoami -t) image-registry.openshift-image-registry.svc:5000出力例
Login Succeeded!次のコマンドを入力して、レジストリーからイメージをプルできることを確認します。
$ podman pull --tls-verify=false image-registry.openshift-image-registry.svc:5000/openshift/tools出力例
Trying to pull image-registry.openshift-image-registry.svc:5000/openshift/tools/openshift/tools... Getting image source signatures Copying blob 6b245f040973 done Copying config 22667f5368 done Writing manifest to image destination Storing signatures 22667f53682a2920948d19c7133ab1c9c3f745805c14125859d20cede07f11f9
2.5.4. オプション: Azure でプライベートストレージエンドポイントを使用する場合にリダイレクトを無効にする
デフォルトでは、イメージレジストリーを使用する場合、リダイレクトが有効になります。リダイレクトにより、レジストリー Pod からオブジェクトストレージへのトラフィックのオフロードが可能になり、プルが高速化されます。リダイレクトが有効で、ストレージアカウントがプライベートである場合、クラスターの外部のユーザーはレジストリーからイメージをプルできません。
場合によっては、クラスターの外部のユーザーがレジストリーからイメージをプルできるように、リダイレクトを無効にする必要があります。
リダイレクトを無効にするには、次の手順を実行します。
前提条件
- Azure 上で動作するようにイメージレジストリーを設定している。
- ルートを設定している。
手順
次のコマンドを入力して、イメージレジストリー設定のリダイレクトを無効にします。
$ oc patch configs.imageregistry cluster --type=merge -p '{"spec":{"disableRedirect": true}}'
検証
次のコマンドを実行して、レジストリーサービス名を取得します。
$ oc registry info出力例
default-route-openshift-image-registry.<cluster_dns>次のコマンドを入力して、コンテナーレジストリーにログインします。
$ podman login --tls-verify=false -u unused -p $(oc whoami -t) default-route-openshift-image-registry.<cluster_dns>出力例
Login Succeeded!次のコマンドを入力して、レジストリーからイメージをプルできることを確認します。
$ podman pull --tls-verify=false default-route-openshift-image-registry.<cluster_dns> /openshift/tools出力例
Trying to pull default-route-openshift-image-registry.<cluster_dns>/openshift/tools... Getting image source signatures Copying blob 6b245f040973 done Copying config 22667f5368 done Writing manifest to image destination Storing signatures 22667f53682a2920948d19c7133ab1c9c3f745805c14125859d20cede07f11f9
第3章 ベアメタルの設定
ベアメタルホストに OpenShift Container Platform をデプロイする場合、プロビジョニングの前後にホストに変更を加える必要がある場合があります。これには、ホストのハードウェア、ファームウェア、ファームウェアの詳細の検証が含まれます。また、ディスクのフォーマットや、変更可能なファームウェア設定の変更も含まれます。
3.1. ユーザー管理ロードバランサーのサービス
デフォルトのロードバランサーの代わりに、ユーザーが管理するロードバランサーを使用するように OpenShift Container Platform クラスターを設定できます。
ユーザー管理ロードバランサーの設定は、ベンダーのロードバランサーによって異なります。
このセクションの情報と例は、ガイドラインのみを目的としています。ベンダーのロードバランサーに関する詳細は、ベンダーのドキュメントを参照してください。
Red Hat は、ユーザー管理ロードバランサーに対して次のサービスをサポートしています。
- Ingress Controller
- OpenShift API
- OpenShift MachineConfig API
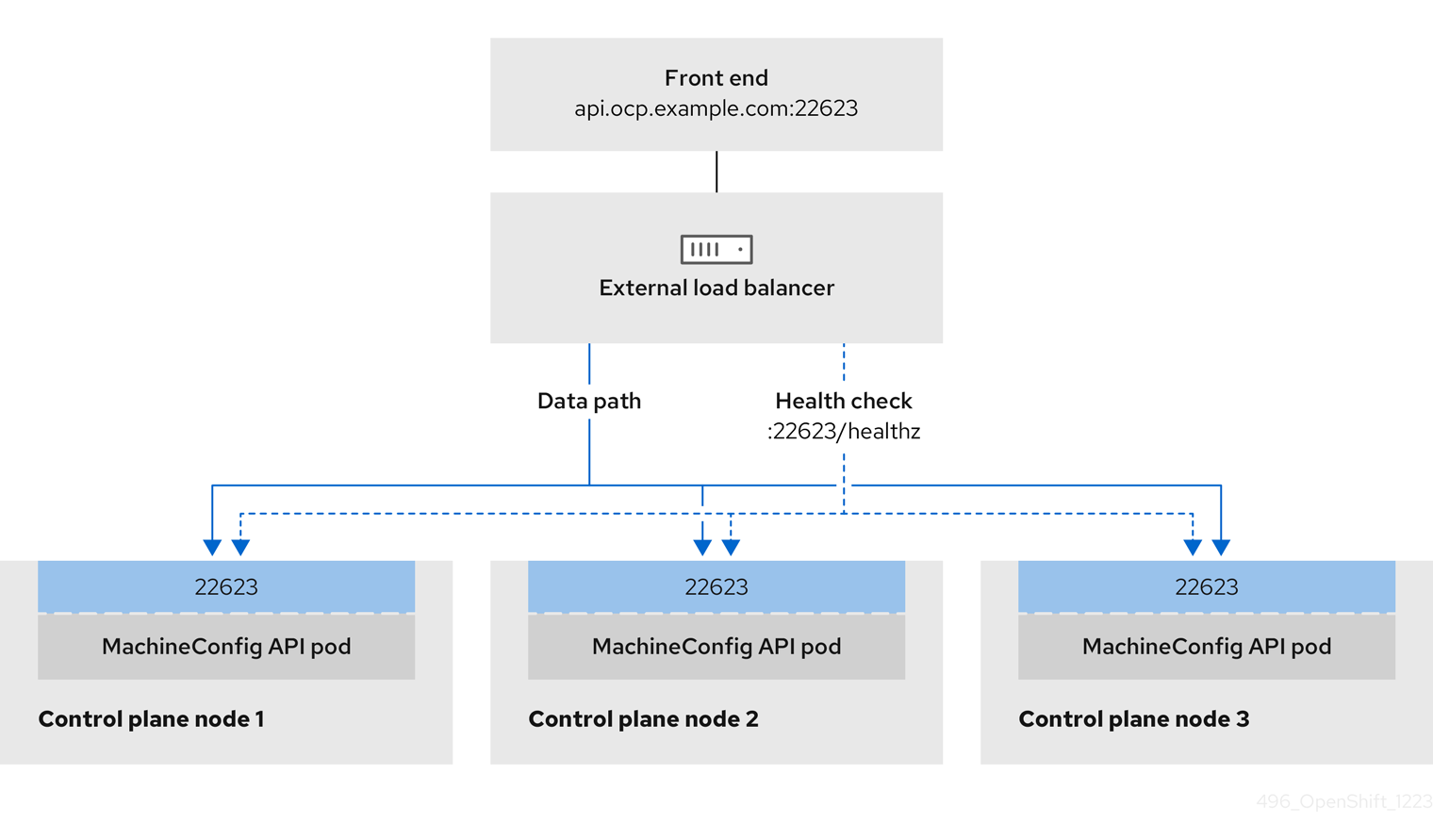
ユーザー管理ロードバランサーに対して、これらのサービスの 1 つを設定するか、すべてを設定するかを選択できます。一般的な設定オプションは、Ingress Controller サービスのみを設定することです。次の図は、各サービスの詳細を示しています。
図3.1 OpenShift Container Platform 環境で動作する Ingress Controller を示すネットワークワークフローの例
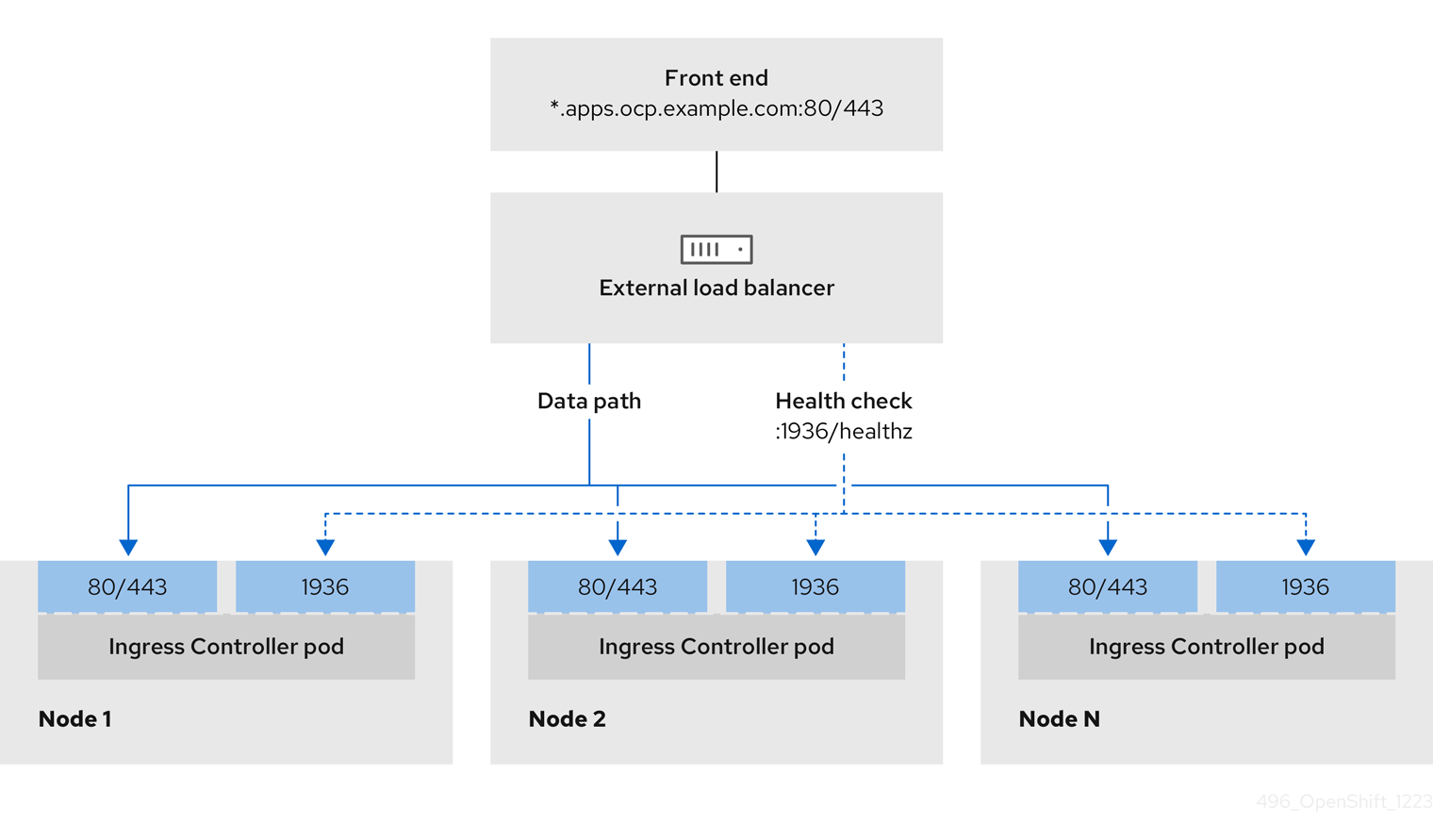
図3.2 OpenShift Container Platform 環境で動作する OpenShift API を示すネットワークワークフローの例
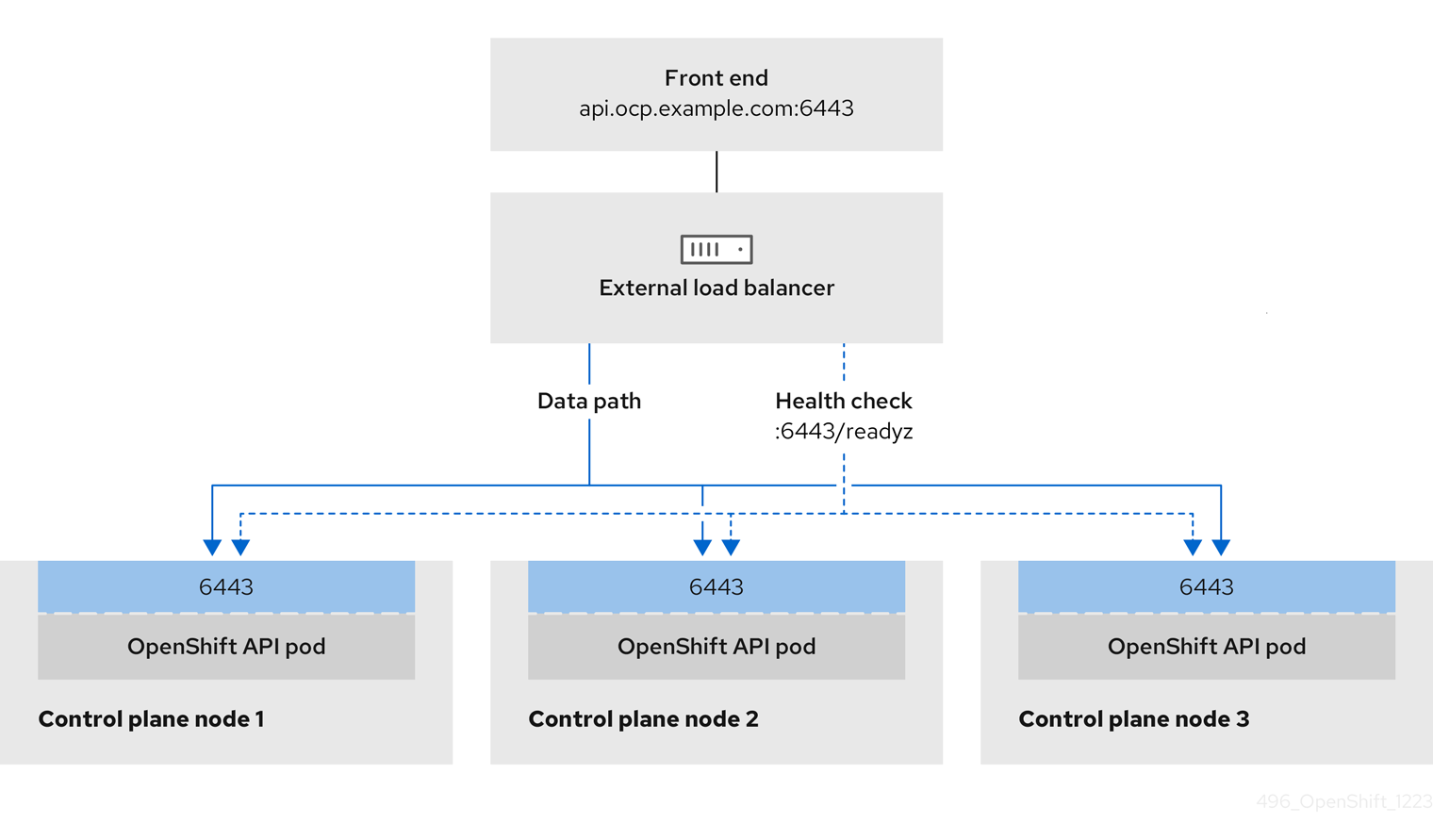
図3.3 OpenShift Container Platform 環境で動作する OpenShift MachineConfig API を示すネットワークワークフローの例
ユーザー管理ロードバランサーでは、次の設定オプションがサポートされています。
- ノードセレクターを使用して、Ingress Controller を特定のノードのセットにマッピングします。このセットの各ノードに静的 IP アドレスを割り当てるか、Dynamic Host Configuration Protocol (DHCP) から同じ IP アドレスを受け取るように各ノードを設定する必要があります。インフラストラクチャーノードは通常、このタイプの設定を受け取ります。
サブネット上のすべての IP アドレスをターゲットにします。この設定では、ロードバランサーターゲットを再設定せずにネットワーク内でノードを作成および破棄できるため、メンテナンスオーバーヘッドを削減できます。
/27や/28などの小規模なネットワーク上に設定されたマシンを使用して Ingress Pod をデプロイする場合、ロードバランサーのターゲットを簡素化できます。ヒントマシン config プールのリソースを確認することで、ネットワーク内に存在するすべての IP アドレスをリスト表示できます。
OpenShift Container Platform クラスターのユーザー管理ロードバランサーを設定する前に、以下の情報を考慮してください。
- フロントエンド IP アドレスの場合、フロントエンド IP アドレス、Ingress Controller のロードバランサー、および API ロードバランサーに同じ IP アドレスを使用できます。この機能は、ベンダーのドキュメントを確認してください。
バックエンド IP アドレスの場合、ユーザー管理ロードバランサーの有効期間中に OpenShift Container Platform コントロールプレーンノードの IP アドレスが変更されないことを確認します。次のいずれかのアクションを実行すると、これを実現できます。
- 各コントロールプレーンノードに静的 IP アドレスを割り当てます。
- ノードが DHCP リースを要求するたびに、DHCP から同じ IP アドレスを受信するように各ノードを設定します。ベンダーによっては、DHCP リースは IP 予約または静的 DHCP 割り当ての形式になる場合があります。
- Ingress Controller バックエンドサービスのユーザー管理ロードバランサーで Ingress Controller を実行する各ノードを手動で定義します。たとえば、Ingress Controller が未定義のノードに移動すると、接続が停止する可能性があります。
3.1.1. ユーザー管理ロードバランサーの設定
デフォルトのロードバランサーの代わりに、ユーザーが管理するロードバランサーを使用するように OpenShift Container Platform クラスターを設定できます。
ユーザー管理ロードバランサーを設定する前に、「ユーザー管理ロードバランサーのサービス」セクションを必ずお読みください。
ユーザー管理ロードバランサー用に設定するサービスに適用される次の前提条件をお読みください。
クラスター上で実行される MetalLB は、ユーザー管理ロードバランサーとして機能します。
OpenShift API の前提条件
- フロントエンド IP アドレスを定義している。
TCP ポート 6443 および 22623 は、ロードバランサーのフロントエンド IP アドレスで公開されている。以下の項目を確認します。
- ポート 6443 が OpenShift API サービスにアクセスできる。
- ポート 22623 が Ignition 起動設定をノードに提供できる。
- フロントエンド IP アドレスとポート 6443 へは、OpenShift Container Platform クラスターの外部の場所にいるシステムのすべてのユーザーがアクセスできる。
- フロントエンド IP アドレスとポート 22623 は、OpenShift Container Platform ノードからのみ到達できる。
- ロードバランサーバックエンドは、ポート 6443 および 22623 の OpenShift Container Platform コントロールプレーンノードと通信できる。
Ingress Controller の前提条件
- フロントエンド IP アドレスを定義している。
- TCP ポート 443 および 80 はロードバランサーのフロントエンド IP アドレスで公開されている。
- フロントエンドの IP アドレス、ポート 80、ポート 443 へは、OpenShift Container Platform クラスターの外部の場所にあるシステムの全ユーザーがアクセスできる。
- フロントエンドの IP アドレス、ポート 80、ポート 443 は、OpenShift Container Platform クラスターで動作するすべてのノードから到達できる。
- ロードバランサーバックエンドは、ポート 80、443、および 1936 で Ingress Controller を実行する OpenShift Container Platform ノードと通信できる。
ヘルスチェック URL 仕様の前提条件
ほとんどのロードバランサーは、サービスが使用可能か使用不可かを判断するヘルスチェック URL を指定して設定できます。OpenShift Container Platform は、OpenShift API、Machine Configuration API、および Ingress Controller バックエンドサービスのこれらのヘルスチェックを提供します。
次の例は、前にリスト表示したバックエンドサービスのヘルスチェック仕様を示しています。
Kubernetes API ヘルスチェック仕様の例
Path: HTTPS:6443/readyz
Healthy threshold: 2
Unhealthy threshold: 2
Timeout: 10
Interval: 10Machine Config API ヘルスチェック仕様の例
Path: HTTPS:22623/healthz
Healthy threshold: 2
Unhealthy threshold: 2
Timeout: 10
Interval: 10Ingress Controller のヘルスチェック仕様の例
Path: HTTP:1936/healthz/ready
Healthy threshold: 2
Unhealthy threshold: 2
Timeout: 5
Interval: 10手順
HAProxy Ingress Controller を設定して、ポート 6443、22623、443、および 80 でロードバランサーからクラスターへのアクセスを有効化できるようにします。必要に応じて、HAProxy 設定で単一のサブネットの IP アドレスまたは複数のサブネットの IP アドレスを指定できます。
1 つのサブネットをリストした HAProxy 設定の例
# ... listen my-cluster-api-6443 bind 192.168.1.100:6443 mode tcp balance roundrobin option httpchk http-check connect http-check send meth GET uri /readyz http-check expect status 200 server my-cluster-master-2 192.168.1.101:6443 check inter 10s rise 2 fall 2 server my-cluster-master-0 192.168.1.102:6443 check inter 10s rise 2 fall 2 server my-cluster-master-1 192.168.1.103:6443 check inter 10s rise 2 fall 2 listen my-cluster-machine-config-api-22623 bind 192.168.1.100:22623 mode tcp balance roundrobin option httpchk http-check connect http-check send meth GET uri /healthz http-check expect status 200 server my-cluster-master-2 192.168.1.101:22623 check inter 10s rise 2 fall 2 server my-cluster-master-0 192.168.1.102:22623 check inter 10s rise 2 fall 2 server my-cluster-master-1 192.168.1.103:22623 check inter 10s rise 2 fall 2 listen my-cluster-apps-443 bind 192.168.1.100:443 mode tcp balance roundrobin option httpchk http-check connect http-check send meth GET uri /healthz/ready http-check expect status 200 server my-cluster-worker-0 192.168.1.111:443 check port 1936 inter 10s rise 2 fall 2 server my-cluster-worker-1 192.168.1.112:443 check port 1936 inter 10s rise 2 fall 2 server my-cluster-worker-2 192.168.1.113:443 check port 1936 inter 10s rise 2 fall 2 listen my-cluster-apps-80 bind 192.168.1.100:80 mode tcp balance roundrobin option httpchk http-check connect http-check send meth GET uri /healthz/ready http-check expect status 200 server my-cluster-worker-0 192.168.1.111:80 check port 1936 inter 10s rise 2 fall 2 server my-cluster-worker-1 192.168.1.112:80 check port 1936 inter 10s rise 2 fall 2 server my-cluster-worker-2 192.168.1.113:80 check port 1936 inter 10s rise 2 fall 2 # ...複数のサブネットをリストした HAProxy 設定の例
# ... listen api-server-6443 bind *:6443 mode tcp server master-00 192.168.83.89:6443 check inter 1s server master-01 192.168.84.90:6443 check inter 1s server master-02 192.168.85.99:6443 check inter 1s server bootstrap 192.168.80.89:6443 check inter 1s listen machine-config-server-22623 bind *:22623 mode tcp server master-00 192.168.83.89:22623 check inter 1s server master-01 192.168.84.90:22623 check inter 1s server master-02 192.168.85.99:22623 check inter 1s server bootstrap 192.168.80.89:22623 check inter 1s listen ingress-router-80 bind *:80 mode tcp balance source server worker-00 192.168.83.100:80 check inter 1s server worker-01 192.168.83.101:80 check inter 1s listen ingress-router-443 bind *:443 mode tcp balance source server worker-00 192.168.83.100:443 check inter 1s server worker-01 192.168.83.101:443 check inter 1s listen ironic-api-6385 bind *:6385 mode tcp balance source server master-00 192.168.83.89:6385 check inter 1s server master-01 192.168.84.90:6385 check inter 1s server master-02 192.168.85.99:6385 check inter 1s server bootstrap 192.168.80.89:6385 check inter 1s listen inspector-api-5050 bind *:5050 mode tcp balance source server master-00 192.168.83.89:5050 check inter 1s server master-01 192.168.84.90:5050 check inter 1s server master-02 192.168.85.99:5050 check inter 1s server bootstrap 192.168.80.89:5050 check inter 1s # ...curlCLI コマンドを使用して、ユーザー管理ロードバランサーとそのリソースが動作していることを確認します。次のコマンドを実行して応答を観察し、クラスターマシン設定 API が Kubernetes API サーバーリソースにアクセスできることを確認します。
$ curl https://<loadbalancer_ip_address>:6443/version --insecure設定が正しい場合は、応答として JSON オブジェクトを受信します。
{ "major": "1", "minor": "11+", "gitVersion": "v1.11.0+ad103ed", "gitCommit": "ad103ed", "gitTreeState": "clean", "buildDate": "2019-01-09T06:44:10Z", "goVersion": "go1.10.3", "compiler": "gc", "platform": "linux/amd64" }次のコマンドを実行して出力を確認し、クラスターマシン設定 API がマシン設定サーバーリソースからアクセスできることを確認します。
$ curl -v https://<loadbalancer_ip_address>:22623/healthz --insecure設定が正しい場合、コマンドの出力には次の応答が表示されます。
HTTP/1.1 200 OK Content-Length: 0次のコマンドを実行して出力を確認し、コントローラーがポート 80 の Ingress Controller リソースにアクセスできることを確認します。
$ curl -I -L -H "Host: console-openshift-console.apps.<cluster_name>.<base_domain>" http://<load_balancer_front_end_IP_address>設定が正しい場合、コマンドの出力には次の応答が表示されます。
HTTP/1.1 302 Found content-length: 0 location: https://console-openshift-console.apps.ocp4.private.opequon.net/ cache-control: no-cache次のコマンドを実行して出力を確認し、コントローラーがポート 443 の Ingress Controller リソースにアクセスできることを確認します。
$ curl -I -L --insecure --resolve console-openshift-console.apps.<cluster_name>.<base_domain>:443:<Load Balancer Front End IP Address> https://console-openshift-console.apps.<cluster_name>.<base_domain>設定が正しい場合、コマンドの出力には次の応答が表示されます。
HTTP/1.1 200 OK referrer-policy: strict-origin-when-cross-origin set-cookie: csrf-token=UlYWOyQ62LWjw2h003xtYSKlh1a0Py2hhctw0WmV2YEdhJjFyQwWcGBsja261dGLgaYO0nxzVErhiXt6QepA7g==; Path=/; Secure; SameSite=Lax x-content-type-options: nosniff x-dns-prefetch-control: off x-frame-options: DENY x-xss-protection: 1; mode=block date: Wed, 04 Oct 2023 16:29:38 GMT content-type: text/html; charset=utf-8 set-cookie: 1e2670d92730b515ce3a1bb65da45062=1bf5e9573c9a2760c964ed1659cc1673; path=/; HttpOnly; Secure; SameSite=None cache-control: private
ユーザー管理ロードバランサーのフロントエンド IP アドレスをターゲットにするようにクラスターの DNS レコードを設定します。ロードバランサー経由で、クラスター API およびアプリケーションの DNS サーバーのレコードを更新する必要があります。
変更された DNS レコードの例
<load_balancer_ip_address> A api.<cluster_name>.<base_domain> A record pointing to Load Balancer Front End<load_balancer_ip_address> A apps.<cluster_name>.<base_domain> A record pointing to Load Balancer Front End重要DNS の伝播では、各 DNS レコードが使用可能になるまでに時間がかかる場合があります。各レコードを検証する前に、各 DNS レコードが伝播されることを確認してください。
OpenShift Container Platform クラスターでユーザー管理ロードバランサーを使用するには、クラスターの
install-config.yamlファイルで次の設定を指定する必要があります。# ... platform: loadBalancer: type: UserManaged1 apiVIPs: - <api_ip>2 ingressVIPs: - <ingress_ip>3 # ...- 1
- クラスターのユーザー管理ロードバランサーを指定するには、
typeパラメーターにUserManagedを設定します。パラメーターのデフォルトはOpenShiftManagedDefaultで、これはデフォルトの内部ロードバランサーを示します。openshift-kni-infranamespace で定義されたサービスの場合、ユーザー管理ロードバランサーはcorednsサービスをクラスター内の Pod にデプロイできますが、keepalivedおよびhaproxyサービスは無視します。 - 2
- ユーザー管理ロードバランサーを指定する場合に必須のパラメーターです。Kubernetes API がユーザー管理ロードバランサーと通信できるように、ユーザー管理ロードバランサーのパブリック IP アドレスを指定します。
- 3
- ユーザー管理ロードバランサーを指定する場合に必須のパラメーターです。ユーザー管理ロードバランサーのパブリック IP アドレスを指定して、ユーザー管理ロードバランサーがクラスターの Ingress トラフィックを管理できるようにします。
検証
curlCLI コマンドを使用して、ユーザー管理ロードバランサーと DNS レコード設定が動作していることを確認します。次のコマンドを実行して出力を確認し、クラスター API にアクセスできることを確認します。
$ curl https://api.<cluster_name>.<base_domain>:6443/version --insecure設定が正しい場合は、応答として JSON オブジェクトを受信します。
{ "major": "1", "minor": "11+", "gitVersion": "v1.11.0+ad103ed", "gitCommit": "ad103ed", "gitTreeState": "clean", "buildDate": "2019-01-09T06:44:10Z", "goVersion": "go1.10.3", "compiler": "gc", "platform": "linux/amd64" }次のコマンドを実行して出力を確認し、クラスターマシン設定にアクセスできることを確認します。
$ curl -v https://api.<cluster_name>.<base_domain>:22623/healthz --insecure設定が正しい場合、コマンドの出力には次の応答が表示されます。
HTTP/1.1 200 OK Content-Length: 0以下のコマンドを実行して出力を確認し、ポートで各クラスターアプリケーションにアクセスできることを確認します。
$ curl http://console-openshift-console.apps.<cluster_name>.<base_domain> -I -L --insecure設定が正しい場合、コマンドの出力には次の応答が表示されます。
HTTP/1.1 302 Found content-length: 0 location: https://console-openshift-console.apps.<cluster-name>.<base domain>/ cache-control: no-cacheHTTP/1.1 200 OK referrer-policy: strict-origin-when-cross-origin set-cookie: csrf-token=39HoZgztDnzjJkq/JuLJMeoKNXlfiVv2YgZc09c3TBOBU4NI6kDXaJH1LdicNhN1UsQWzon4Dor9GWGfopaTEQ==; Path=/; Secure x-content-type-options: nosniff x-dns-prefetch-control: off x-frame-options: DENY x-xss-protection: 1; mode=block date: Tue, 17 Nov 2020 08:42:10 GMT content-type: text/html; charset=utf-8 set-cookie: 1e2670d92730b515ce3a1bb65da45062=9b714eb87e93cf34853e87a92d6894be; path=/; HttpOnly; Secure; SameSite=None cache-control: private次のコマンドを実行して出力を確認し、ポート 443 で各クラスターアプリケーションにアクセスできることを確認します。
$ curl https://console-openshift-console.apps.<cluster_name>.<base_domain> -I -L --insecure設定が正しい場合、コマンドの出力には次の応答が表示されます。
HTTP/1.1 200 OK referrer-policy: strict-origin-when-cross-origin set-cookie: csrf-token=UlYWOyQ62LWjw2h003xtYSKlh1a0Py2hhctw0WmV2YEdhJjFyQwWcGBsja261dGLgaYO0nxzVErhiXt6QepA7g==; Path=/; Secure; SameSite=Lax x-content-type-options: nosniff x-dns-prefetch-control: off x-frame-options: DENY x-xss-protection: 1; mode=block date: Wed, 04 Oct 2023 16:29:38 GMT content-type: text/html; charset=utf-8 set-cookie: 1e2670d92730b515ce3a1bb65da45062=1bf5e9573c9a2760c964ed1659cc1673; path=/; HttpOnly; Secure; SameSite=None cache-control: private
3.2. Bare Metal Operator について
Bare Metal Operator (BMO) を使用して、クラスター内のベアメタルホストをプロビジョニング、管理、検査します。
BMO はこれらのタスクを完了するために次のリソースを使用します。
-
BareMetalHost -
HostFirmwareSettings -
FirmwareSchema -
HostFirmwareComponents
BMO は、各ベアメタルホストを BareMetalHost カスタムリソース定義のインスタンスにマッピングすることにより、クラスター内の物理ホストのインベントリーを維持します。各 BareMetalHost リソースには、ハードウェア、ソフトウェア、およびファームウェアの詳細が含まれています。BMO は、クラスター内のベアメタルホストを継続的に検査して、各 BareMetalHost リソースが対応するホストのコンポーネントを正確に詳述していることを確認します。
BMO は、HostFirmwareSettings リソース、FirmwareSchema リソース、および HostFirmwareComponents リソースを使用して、ファームウェア仕様の詳細を指定し、ベアメタルホストのファームウェアをアップグレードまたはダウングレードします。
BMO は、Ironic API サービスを使用してクラスター内のベアメタルホストと接続します。Ironic サービスは、ホスト上のベースボード管理コントローラー (BMC) を使用して、マシンと接続します。
BMO を使用して実行できる一般的なタスクには、次のようなものがあります。
- 特定のイメージを使用したクラスターへのベアメタルホストのプロビジョニング
- プロビジョニング前またはプロビジョニング解除後におけるホストのディスクコンテンツのフォーマット
- ホストのオン/オフの切り替え
- ファームウェア設定の変更
- ホストのハードウェア詳細の表示
- ホストのファームウェアを特定のバージョンにアップグレードまたはダウングレードする
3.2.1. Bare Metal Operator のアーキテクチャー
Bare Metal Operator (BMO) は、次のリソースを使用して、クラスター内のベアメタルホストをプロビジョニング、管理、検査します。次の図は、これらのリソースのアーキテクチャーを示しています。
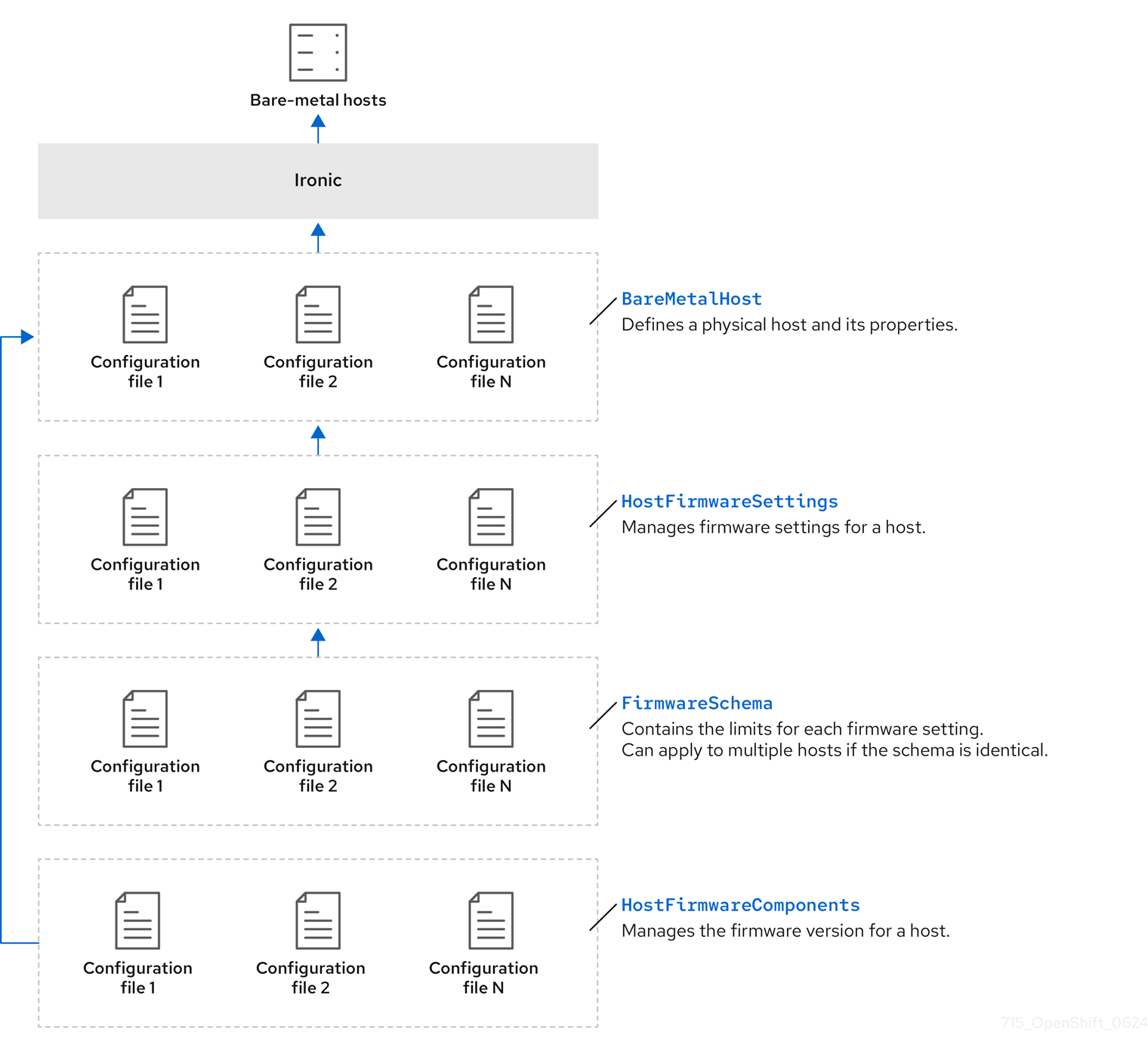
BareMetalHost
BareMetalHost リソースは、物理ホストとそのプロパティーを定義します。ベアメタルホストをクラスターにプロビジョニングするときは、そのホストの BareMetalHost リソースを定義する必要があります。ホストの継続的な管理のために、BareMetalHost の情報を調べたり、この情報を更新したりできます。
BareMetalHost リソースには、次のようなプロビジョニング情報が含まれます。
- オペレーティングシステムのブートイメージやカスタム RAM ディスクなどのデプロイメント仕様
- プロビジョニング状態
- ベースボード管理コントローラー (BMC) アドレス
- 目的の電源状態
BareMetalHost リソースには、次のようなハードウェア情報が含まれます。
- CPU 数
- NIC の MAC アドレス
- ホストのストレージデバイスのサイズ
- 現在の電源状態
HostFirmwareSettings
HostFirmwareSettings リソースを使用して、ホストのファームウェア設定を取得および管理できます。ホストが Available 状態に移行すると、Ironic サービスはホストのファームウェア設定を読み取り、HostFirmwareSettings リソースを作成します。BareMetalHost リソースと HostFirmwareSettings リソースの間には 1 対 1 のマッピングがあります。
HostFirmwareSettings リソースを使用して、ホストのファームウェア仕様を調べたり、ホストのファームウェア仕様を更新したりできます。
HostFirmwareSettings リソースの spec フィールドを編集するときは、ベンダーファームウェアに固有のスキーマに従う必要があります。このスキーマは、読み取り専用の FirmwareSchema リソースで定義されます。
FirmwareSchema
ファームウェア設定は、ハードウェアベンダーやホストモデルによって異なります。FirmwareSchema リソースは、各ホストモデル上の各ファームウェア設定のタイプおよび制限が含まれる読み取り専用リソースです。データは、Ironic サービスを使用して BMC から直接取得されます。FirmwareSchema リソースを使用すると、HostFirmwareSettings リソースの spec フィールドに指定できる有効な値を特定できます。
スキーマが同じであれば、FirmwareSchema リソースは多くの BareMetalHost リソースに適用できます。
HostFirmwareComponents
Metal3 は、BIOS およびベースボード管理コントローラー (BMC) ファームウェアのバージョンを記述する HostFirmwareComponents リソースを提供します。HostFirmwareComponents リソースの spec フィールドを編集することで、ホストのファームウェアを特定のバージョンにアップグレードまたはダウングレードできます。これは、特定のファームウェアバージョンに対してテストされた検証済みパターンを使用してデプロイする場合に便利です。
3.3. カスタマイズした br-ex ブリッジを含むマニフェストオブジェクトの作成
カスタマイズした br-ex ブリッジを含むマニフェストオブジェクトを作成する場合は、次のユースケースを検討してください。
-
Open vSwitch (OVS) または OVN-Kubernetes
br-exブリッジネットワークの変更など、ブリッジにインストール後の変更を加えたい場合。configure-ovs.shシェルスクリプトは、ブリッジへのインストール後の変更をサポートしていません。 - ホストまたはサーバーの IP アドレスで使用可能なインターフェイスとは異なるインターフェイスにブリッジをデプロイします。
-
configure-ovs.shシェルスクリプトでは不可能な、ブリッジの高度な設定を実行したいと考えています。これらの設定にスクリプトを使用すると、ブリッジが複数のネットワークインターフェイスに接続できず、インターフェイス間のデータ転送が促進されない可能性があります。
前提条件
-
configure-ovsの代替方法を使用して、カスタマイズされたbr-exを設定している。 - Kubernetes NMState Operator がインストールされている。
手順
NodeNetworkConfigurationPolicy(NNCP) CR を作成し、カスタマイズされたbr-exブリッジネットワーク設定を定義します。br-exNNCP CR には、ネットワークの OVN-Kubernetes マスカレード IP アドレスとサブネットが含まれている必要があります。サンプルの NNCP CR には、ipv4.address.ipおよびipv6.address.ipパラメーターにデフォルト値が含まれます。ipv4.address.ip、ipv6.address.ip、またはその両方で masquerade IP アドレスを設定できます。重要インストール後のタスクとして、カスタマイズした
br-exブリッジのプライマリー IP アドレスを変更できません。シングルスタッククラスターネットワークをデュアルスタッククラスターネットワークに変換する場合、NNCP CR でセカンダリー IPv6 アドレスは追加または変更できますが、既存のプライマリー IP アドレスは変更できません。apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: name: worker-0-br-ex spec: nodeSelector: kubernetes.io/hostname: worker-0 desiredState: interfaces: - name: enp2s0 type: ethernet state: up ipv4: enabled: false ipv6: enabled: false - name: br-ex type: ovs-bridge state: up ipv4: enabled: false dhcp: false ipv6: enabled: false dhcp: false bridge: options: mcast-snooping-enable: true port: - name: enp2s0 - name: br-ex - name: br-ex type: ovs-interface state: up copy-mac-from: enp2s0 ipv4: enabled: true dhcp: true auto-route-metric: 48 address: - ip: "169.254.0.2" prefix-length: 17 ipv6: enabled: true dhcp: true auto-route-metric: 48 address: - ip: "fd69::2" prefix-length: 112 # ...ここでは、以下のようになります。
metadata.name- ポリシーの名前。
interfaces.name- インターフェイスの名前。
interfaces.type- イーサネットのタイプ。
interfaces.state- 作成後のインターフェイスの要求された状態。
ipv4.enabled- この例では、IPv4 と IPv6 を無効にします。
port.name- ブリッジが接続されているノード NIC。
address.ip- デフォルトの IPv4 および IPv6 の IP アドレスを表示します。ネットワークの masquerade IPv4 および IPv6 の IP アドレスを設定するようにしてください。
auto-route-metric-
br-exデフォルトルートに常に最高の優先度 (最も低いメトリック値) を付与するには、パラメーターを48に設定します。この設定により、NetworkManagerサービスによって自動的に設定される他のインターフェイスとのルーティングの競合が防止されます。
次のステップ
-
コンピュートノードをスケーリングして、クラスター内に存在する各コンピュートノードに、カスタマイズされた
br-exブリッジを含むマニフェストオブジェクトを適用します。詳細は、関連情報 セクションの「クラスターの拡張」を参照してください。
3.4. BareMetalHost リソースについて
Metal3 で、物理ホストとそのプロパティーを定義する BareMetalHost リソースの概念が導入されました。BareMetalHost リソースには、2 つのセクションが含まれます。
-
BareMetalHostspec -
BareMetalHoststatus
3.4.1. BareMetalHost spec
BareMetalHost リソースの spec セクションは、ホストの必要な状態を定義します。
| パラメーター | 説明 |
|---|---|
|
|
プロビジョニングおよびプロビジョニング解除時の自動クリーニングを有効または無効にするインターフェイス。 |
|
|
|
| ホストのプロビジョニングに使用する NIC の MAC アドレス。 |
|
|
ホストのブートモード。デフォルトは |
|
|
ホストを使用している別のリソースへの参照。別のリソースが現在ホストを使用していない場合は、空になることがあります。たとえば、 |
|
| ホストの特定に役立つ、人間が提供した文字列。 |
|
| ホストのプロビジョニングとプロビジョニング解除が外部で管理されるかどうかを示すブール値。設定される場合:
|
|
|
ベアメタルホストの BIOS 設定に関する情報が含まれます。現在、
|
|
|
|
| ネットワーク設定データおよびその namespace が含まれるシークレットへの参照。したがって、ホストが起動してネットワークをセットアップする前にホストに接続することができます。 |
|
|
ホストの電源を入れる ( |
| (オプション) ベアメタルホストの RAID 設定に関する情報が含まれます。指定しない場合は、現在の設定を保持します。 注記 OpenShift Container Platform 4.20 は、BMC のインストールドライブ上で以下のハードウェア RAID をサポートします。
OpenShift Container Platform 4.20 は、インストールドライブ上のソフトウェア RAID をサポートしていません。 次の構成設定を参照してください。
ドライバーが RAID に対応していないことを示すエラーメッセージが表示された場合は、 |
|
|
3.4.2. BareMetalHost status
BareMetalHost status は、ホストの現在の状態を表し、テスト済みの認証情報、現在のハードウェアの詳細などの情報が含まれます。
| パラメーター | 説明 |
|---|---|
|
| シークレットおよびその namespace の参照で、システムが動作中と検証できるベースボード管理コントローラー (BMC) 認証情報のセットが保持されています。 |
|
| プロビジョニングバックエンドが報告する最後のエラーの詳細 (ある場合)。 |
|
| ホストがエラー状態になった原因となった問題のクラスを示します。エラータイプは以下のとおりです。
|
|
|
| BIOS ファームウェア情報が含まれます。たとえば、ハードウェアベンダーおよびバージョンなどです。 |
|
|
| ホストのメモリー容量 (MiB 単位)。 |
|
|
|
ホストの |
|
| ホストのステータスの最終更新時のタイムスタンプ。 |
|
| サーバーのステータス。ステータスは以下のいずれかになります。
|
|
| ホストの電源が入っているかどうかを示すブール値。 |
|
|
|
| プロビジョニングバックエンドに送信された BMC 認証情報の最後のセットを保持するシークレットおよびその namespace への参照。 |
3.5. BareMetalHost リソースの取得
BareMetalHost リソースには、物理ホストのプロパティーが含まれます。物理ホストのプロパティーをチェックするには、その BareMetalHost リソースを取得する必要があります。
手順
BareMetalHostリソースの一覧を取得します。$ oc get bmh -n openshift-machine-api -o yaml注記oc getコマンドで、bmhの長い形式として、baremetalhostを使用できます。ホストのリストを取得します。
$ oc get bmh -n openshift-machine-api特定のホストの
BareMetalHostリソースを取得します。$ oc get bmh <host_name> -n openshift-machine-api -o yamlここで、
<host_name>はホストの名前です。出力例
apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: creationTimestamp: "2022-06-16T10:48:33Z" finalizers: - baremetalhost.metal3.io generation: 2 name: openshift-worker-0 namespace: openshift-machine-api resourceVersion: "30099" uid: 1513ae9b-e092-409d-be1b-ad08edeb1271 spec: automatedCleaningMode: metadata bmc: address: redfish://10.46.61.19:443/redfish/v1/Systems/1 credentialsName: openshift-worker-0-bmc-secret disableCertificateVerification: true bootMACAddress: 48:df:37:c7:f7:b0 bootMode: UEFI consumerRef: apiVersion: machine.openshift.io/v1beta1 kind: Machine name: ocp-edge-958fk-worker-0-nrfcg namespace: openshift-machine-api customDeploy: method: install_coreos online: true rootDeviceHints: deviceName: /dev/disk/by-id/scsi-<serial_number> userData: name: worker-user-data-managed namespace: openshift-machine-api status: errorCount: 0 errorMessage: "" goodCredentials: credentials: name: openshift-worker-0-bmc-secret namespace: openshift-machine-api credentialsVersion: "16120" hardware: cpu: arch: x86_64 clockMegahertz: 2300 count: 64 flags: - 3dnowprefetch - abm - acpi - adx - aes model: Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz firmware: bios: date: 10/26/2020 vendor: HPE version: U30 hostname: openshift-worker-0 nics: - mac: 48:df:37:c7:f7:b3 model: 0x8086 0x1572 name: ens1f3 ramMebibytes: 262144 storage: - hctl: "0:0:0:0" model: VK000960GWTTB name: /dev/disk/by-id/scsi-<serial_number> sizeBytes: 960197124096 type: SSD vendor: ATA systemVendor: manufacturer: HPE productName: ProLiant DL380 Gen10 (868703-B21) serialNumber: CZ200606M3 lastUpdated: "2022-06-16T11:41:42Z" operationalStatus: OK poweredOn: true provisioning: ID: 217baa14-cfcf-4196-b764-744e184a3413 bootMode: UEFI customDeploy: method: install_coreos image: url: "" raid: hardwareRAIDVolumes: null softwareRAIDVolumes: [] rootDeviceHints: deviceName: /dev/disk/by-id/scsi-<serial_number> state: provisioned triedCredentials: credentials: name: openshift-worker-0-bmc-secret namespace: openshift-machine-api credentialsVersion: "16120"
3.6. BareMetalHost リソースの編集
OpenShift Container Platform クラスターをベアメタルにデプロイした後、ノードの BareMetalHost リソースを編集する必要がある場合があります。たとえば、次のような例が考えられます。
- Assisted Installer を使用してクラスターをデプロイし、ベースボード管理コントローラー (BMC) のホスト名または IP アドレスを追加または編集する必要がある。
- ノードをプロビジョニング解除せずに、あるクラスターから別のクラスターに移動する必要がある。
前提条件
-
ノードが
Provisioned、ExternallyProvisioned、またはAvailable状態であることを確認する。
手順
ノードのリストを取得します。
$ oc get bmh -n openshift-machine-apiノードの
BareMetalHostリソースを編集する前に、次のコマンドを実行してノードを Ironic からデタッチします。$ oc annotate baremetalhost <node_name> -n openshift-machine-api 'baremetalhost.metal3.io/detached=true'1 - 1
<node_name>はノード名に置き換えてください。
次のコマンドを実行して、
BareMetalHostリソースを編集します。$ oc edit bmh <node_name> -n openshift-machine-api次のコマンドを実行して、ノードを Ironic に再アタッチします。
$ oc annotate baremetalhost <node_name> -n openshift-machine-api 'baremetalhost.metal3.io/detached'-
3.7. BareMetalHost リソースを削除する際の遅延のトラブルシューティング
Bare Metal Operator (BMO) が BareMetalHost リソースを削除すると、Ironic がベアメタルホストのプロビジョニングを解除します。これは、たとえばマシンセットを縮小するときに発生する可能性があります。プロビジョニング解除には、"クリーニング" と呼ばれるプロセスが含まれます。このプロセスでは、次の手順が実行されます。
- ベアメタルホストの電源をオフにする
- ベアメタルホスト上のサービス RAM ディスクを起動する
- すべてのディスクからパーティションメタデータを削除する
- ベアメタルホストの電源を再度オフにする
クリーニングが成功しない場合は、BareMetalHost リソースの削除に長い時間がかかり、削除が完了しないことがあります。
BareMetalHost リソースを強制的に削除するためにファイナライザーを削除しないでください。プロビジョニングバックエンドには、ホストレコードを保持する独自のデータベースがあります。ファイナライザーを削除して強制的に削除しようとしても、実行中のアクションは引き続き実行されます。後でベアメタルホストを追加しようとしたときに、予期しない問題が発生する可能性があります。
手順
- クリーニングプロセスが回復できる場合は、プロセスが完了するまで待ちます。
-
クリーニングが回復できない場合は、
BareMetalHostリソースを変更し、automaticCleaningModeフィールドをdisabledに設定して、クリーニングプロセスを無効にします。
詳細は、「BareMetalHost リソースの編集」を参照してください。
3.8. ブータブルでない ISO をベアメタルノードにアタッチする
DataImage リソースを使用すると、ブータブルでない汎用の ISO 仮想メディアイメージを、プロビジョニングされたノードにアタッチできます。リソースを適用すると、起動後にオペレーティングシステムから ISO イメージにアクセスできるようになります。これは、オペレーティングシステムをプロビジョニングした後、ノードが初めて起動する前にノードを設定する場合に便利です。
前提条件
- この機能をサポートするために、ノードが Redfish またはそれから派生したドライバーを使用している。
-
ノードが
ProvisionedまたはExternallyProvisioned状態である。 -
nameが、BareMetalHostリソースで定義されているノードの名前と同じである。 -
ISO イメージへの有効な
urlがある。
手順
DataImageリソースを作成します。apiVersion: metal3.io/v1alpha1 kind: DataImage metadata: name: <node_name>1 spec: url: "http://dataimage.example.com/non-bootable.iso"2 次のコマンドを実行して、
DataImageリソースをファイルに保存します。$ vim <node_name>-dataimage.yaml次のコマンドを実行して、
DataImageリソースを適用します。$ oc apply -f <node_name>-dataimage.yaml -n <node_namespace>1 - 1
- namespace が
BareMetalHostリソースの namespace と一致するように<node_namespace>を置き換えます。たとえば、openshift-machine-apiです。
ノードを再起動します。
注記ノードを再起動するには、
reboot.metal3.ioアノテーションを割り当てるか、BareMetalHostリソースでonlineステータスをリセットします。ベアメタルノードを強制的に再起動すると、ノードの状態がしばらくの間NotReadyに変わります。具体的には、5 分以上変わります。次のコマンドを実行して、
DataImageリソースを表示します。$ oc get dataimage <node_name> -n openshift-machine-api -o yaml出力例
apiVersion: v1 items: - apiVersion: metal3.io/v1alpha1 kind: DataImage metadata: annotations: kubectl.kubernetes.io/last-applied-configuration: | {"apiVersion":"metal3.io/v1alpha1","kind":"DataImage","metadata":{"annotations":{},"name":"bmh-node-1","namespace":"openshift-machine-api"},"spec":{"url":"http://dataimage.example.com/non-bootable.iso"}} creationTimestamp: "2024-06-10T12:00:00Z" finalizers: - dataimage.metal3.io generation: 1 name: bmh-node-1 namespace: openshift-machine-api ownerReferences: - apiVersion: metal3.io/v1alpha1 blockOwnerDeletion: true controller: true kind: BareMetalHost name: bmh-node-1 uid: 046cdf8e-0e97-485a-8866-e62d20e0f0b3 resourceVersion: "21695581" uid: c5718f50-44b6-4a22-a6b7-71197e4b7b69 spec: url: http://dataimage.example.com/non-bootable.iso status: attachedImage: url: http://dataimage.example.com/non-bootable.iso error: count: 0 message: "" lastReconciled: "2024-06-10T12:05:00Z"
3.9. HostFirmwareSettings リソースについて
HostFirmwareSettings リソースを使用して、ホストの BIOS 設定を取得および管理できます。ホストが Available 状態に移行すると、Ironic はホストの BIOS 設定を読み取り、HostFirmwareSettings リソースを作成します。リソースには、ベースボード管理コントローラー (BMC) から返される完全な BIOS 設定が含まれます。BareMetalHost リソースの firmware フィールドは、ベンダーに依存しない 3 つのフィールドを返しますが、HostFirmwareSettings リソースは、通常ホストごとにベンダー固有のフィールドの多数の BIOS 設定で構成されます。
HostFirmwareSettings リソースには、以下の 2 つのセクションが含まれます。
-
HostFirmwareSettingsspec -
HostFirmwareSettingsstatus
3.9.1. HostFirmwareSettings spec
HostFirmwareSettings リソースの spec セクションは、ホストの BIOS の必要な状態を定義し、デフォルトでは空です。Ironic は spec.settings セクションの設定を使用して、ホストが Preparing 状態の場合、ベースボード管理コントローラー (BMC) を更新します。FirmwareSchema リソースを使用して、無効な名前と値のペアをホストに送信しないようにします。詳細は、「FirmwareSchema リソースについて」を参照してください。
例
spec:
settings:
ProcTurboMode: Disabled- 1
- 前述の例では、
spec.settingsセクションには、ProcTurboModeBIOS 設定をDisabledに設定する名前/値のペアが含まれます。
status セクションに一覧表示される整数パラメーターは文字列として表示されます。たとえば、"1" と表示されます。spec.settings セクションで整数を設定する場合、値は引用符なしの整数として設定する必要があります。たとえば、1 と設定します。
3.9.2. HostFirmwareSettings status
status は、ホストの BIOS の現在の状態を表します。
| パラメーター | 説明 |
|---|---|
|
|
|
ファームウェア設定の
|
|
|
3.10. HostFirmwareSettings リソースの取得
HostFirmwareSettings リソースには、物理ホストのベンダー固有の BIOS プロパティーが含まれます。物理ホストの BIOS プロパティーをチェックするには、その HostFirmwareSettings リソースを取得する必要があります。
手順
HostFirmwareSettingsリソースの詳細な一覧を取得します。$ oc get hfs -n openshift-machine-api -o yaml注記oc getコマンドで、hfsの長い形式として、hostfirmwaresettingsを使用できます。HostFirmwareSettingsリソースの一覧を取得します。$ oc get hfs -n openshift-machine-api特定のホストの
HostFirmwareSettingsリソースを取得します。$ oc get hfs <host_name> -n openshift-machine-api -o yamlここで、
<host_name>はホストの名前です。
3.11. HostFirmwareSettings リソースの編集
プロビジョニングされたホストの HostFirmwareSettings を編集できます。
読み取り専用の値を除き、ホストが プロビジョニング された状態にある場合にのみ、ホストを編集できます。externally provisioned 状態のホストは編集できません。
手順
HostFirmwareSettingsリソースの一覧を取得します。$ oc get hfs -n openshift-machine-apiホストの
HostFirmwareSettingsリソースを編集します。$ oc edit hfs <host_name> -n openshift-machine-apiここで、
<host_name>はプロビジョニングされたホストの名前です。HostFirmwareSettingsリソースは、ターミナルのデフォルトエディターで開きます。spec.settingsセクションに、名前と値のペアを追加します。例
spec: settings: name: value1 - 1
FirmwareSchemaリソースを使用して、ホストで利用可能な設定を特定します。読み取り専用の値は設定できません。
- 変更を保存し、エディターを終了します。
ホストのマシン名を取得します。
$ oc get bmh <host_name> -n openshift-machine nameここで、
<host_name>はホストの名前です。マシン名はCONSUMERフィールドの下に表示されます。マシンにアノテーションを付け、マシンセットから削除します。
$ oc annotate machine <machine_name> machine.openshift.io/delete-machine=true -n openshift-machine-apiここで、
<machine_name>は削除するマシンの名前です。ノードのリストを取得し、ワーカーノードの数をカウントします。
$ oc get nodesマシンセットを取得します。
$ oc get machinesets -n openshift-machine-apiマシンセットをスケーリングします。
$ oc scale machineset <machineset_name> -n openshift-machine-api --replicas=<n-1>ここで、
<machineset_name>はマシンセットの名前で、<n-1>は減少させたワーカーノードの数です。ホストが
Availableの状態になったら、machineset をスケールアップして、HostFirmwareSettingsリソースの変更を反映させます。$ oc scale machineset <machineset_name> -n openshift-machine-api --replicas=<n>ここで、
<machineset_name>はマシンセットの名前で、<n>はワーカーノードの数です。
3.12. HostFirmware Settings リソースが有効であることの確認
ユーザーが spec.settings セクションを編集して HostFirmwareSetting (HFS) リソースに変更を加えると、Bare Metal Operator (BMO) は読み取り専用リソースである FimwareSchema リソースに対して変更を検証します。この設定が無効な場合、BMO は status.Condition 設定の Type の値を False に設定し、イベントを生成して HFS リソースに保存します。以下の手順を使用して、リソースが有効であることを確認します。
手順
HostFirmwareSettingリソースの一覧を取得します。$ oc get hfs -n openshift-machine-api特定のホストの
HostFirmwareSettingsリソースが有効であることを確認します。$ oc describe hfs <host_name> -n openshift-machine-apiここで、
<host_name>はホストの名前です。出力例
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ValidationFailed 2m49s metal3-hostfirmwaresettings-controller Invalid BIOS setting: Setting ProcTurboMode is invalid, unknown enumeration value - Foo重要応答が
ValidationFailedを返す場合、リソース設定にエラーがあり、FirmwareSchemaリソースに準拠するよう値を更新する必要があります。
3.13. FirmwareSchema リソースについて
BIOS 設定は、ハードウェアベンダーやホストモデルによって異なります。FirmwareSchema リソースは、各ホストモデル上の各 BIOS 設定のタイプおよび制限が含まれる読み取り専用リソースです。データは BMC から Ironic に直接取得されます。FirmwareSchema を使用すると、HostFirmwareSettings リソースの spec フィールドに指定できる有効な値を特定できます。FirmwareSchema リソースには、その設定および制限から派生する一意の識別子があります。同じホストモデルは同じ FirmwareSchema 識別子を使用します。HostFirmwareSettings の複数のインスタンスが同じ FirmwareSchema を使用する可能性が高いです。
| パラメーター | 説明 |
|---|---|
|
|
3.14. FirmwareSchema リソースの取得
各ベンダーの各ホストモデルの BIOS 設定は、それぞれ異なります。HostFirmwareSettings リソースの spec セクションを編集する際に、設定する名前/値のペアはそのホストのファームウェアスキーマに準拠している必要があります。有効な名前と値のペアを設定するには、ホストの FirmwareSchema を取得して確認します。
手順
FirmwareSchemaリソースインスタンスの一覧を取得するには、以下を実行します。$ oc get firmwareschema -n openshift-machine-api特定の
FirmwareSchemaインスタンスを取得するには、以下を実行します。$ oc get firmwareschema <instance_name> -n openshift-machine-api -o yamlここで、
<instance_name>は、HostFirmwareSettingsリソース (表 3 を参照) に記載されているスキーマインスタンスの名前です。
3.15. HostFirmwareComponents リソースについて
Metal3 は、BIOS およびベースボード管理コントローラー (BMC) ファームウェアのバージョンを記述する HostFirmwareComponents リソースを提供します。HostFirmwareComponents リソースには 2 つのセクションが含まれています。
-
HostFirmwareComponentsspec -
HostFirmwareComponentsstatus
3.15.1. HostFirmwareComponents spec
HostFirmwareComponents リソースの spec セクションでは、ホストの BIOS および BMC バージョンの目的の状態を定義します。
| パラメーター | 説明 |
|---|---|
|
|
3.15.2. HostFirmwareComponents status
HostFirmwareComponents リソースの status セクションは、ホストの BIOS および BMC バージョンの現在のステータスを返します。
| パラメーター | 説明 |
|---|---|
|
|
|
|
3.16. HostFirmwareComponents リソースの取得
HostFirmwareComponents リソースには、物理ホストの BIOS およびベースボード管理コントローラー (BMC) の特定のファームウェアバージョンが含まれています。ファームウェアのバージョンとステータスを確認するには、物理ホストの HostFirmwareComponents リソースを取得する必要があります。
手順
HostFirmwareComponentsリソースの詳細なリストを取得します。$ oc get hostfirmwarecomponents -n openshift-machine-api -o yamlHostFirmwareComponentsリソースのリストを取得します。$ oc get hostfirmwarecomponents -n openshift-machine-api特定のホストの
HostFirmwareComponentsリソースを取得します。$ oc get hostfirmwarecomponents <host_name> -n openshift-machine-api -o yamlここで、
<host_name>はホストの名前です。出力例
--- apiVersion: metal3.io/v1alpha1 kind: HostFirmwareComponents metadata: creationTimestamp: 2024-04-25T20:32:06Z" generation: 1 name: ostest-master-2 namespace: openshift-machine-api ownerReferences: - apiVersion: metal3.io/v1alpha1 blockOwnerDeletion: true controller: true kind: BareMetalHost name: ostest-master-2 uid: 16022566-7850-4dc8-9e7d-f216211d4195 resourceVersion: "2437" uid: 2038d63f-afc0-4413-8ffe-2f8e098d1f6c spec: updates: [] status: components: - component: bios currentVersion: 1.0.0 initialVersion: 1.0.0 - component: bmc currentVersion: "1.00" initialVersion: "1.00" conditions: - lastTransitionTime: "2024-04-25T20:32:06Z" message: "" observedGeneration: 1 reason: OK status: "True" type: Valid - lastTransitionTime: "2024-04-25T20:32:06Z" message: "" observedGeneration: 1 reason: OK status: "False" type: ChangeDetected lastUpdated: "2024-04-25T20:32:06Z" updates: []
3.17. HostFirmwareComponents リソースの編集
ノードの HostFirmwareComponents リソースを編集できます。
手順
HostFirmwareComponentsリソースの詳細なリストを取得します。$ oc get hostfirmwarecomponents -n openshift-machine-api -o yamlホストの
HostFirmwareComponentsリソースを編集します。$ oc edit <host_name> hostfirmwarecomponents -n openshift-machine-api1 - 1
- ここで、
<host_name>はホストの名前です。HostFirmwareComponentsリソースが、ターミナルのデフォルトのエディターで開きます。
出力例
--- apiVersion: metal3.io/v1alpha1 kind: HostFirmwareComponents metadata: creationTimestamp: 2024-04-25T20:32:06Z" generation: 1 name: ostest-master-2 namespace: openshift-machine-api ownerReferences: - apiVersion: metal3.io/v1alpha1 blockOwnerDeletion: true controller: true kind: BareMetalHost name: ostest-master-2 uid: 16022566-7850-4dc8-9e7d-f216211d4195 resourceVersion: "2437" uid: 2038d63f-afc0-4413-8ffe-2f8e098d1f6c spec: updates: - name: bios1 url: https://myurl.with.firmware.for.bios2 - name: bmc3 url: https://myurl.with.firmware.for.bmc4 status: components: - component: bios currentVersion: 1.0.0 initialVersion: 1.0.0 - component: bmc currentVersion: "1.00" initialVersion: "1.00" conditions: - lastTransitionTime: "2024-04-25T20:32:06Z" message: "" observedGeneration: 1 reason: OK status: "True" type: Valid - lastTransitionTime: "2024-04-25T20:32:06Z" message: "" observedGeneration: 1 reason: OK status: "False" type: ChangeDetected lastUpdated: "2024-04-25T20:32:06Z"- 変更を保存し、エディターを終了します。
ホストのマシン名を取得します。
$ oc get bmh <host_name> -n openshift-machine name1 - 1
- ここで、
<host_name>はホストの名前です。マシン名はCONSUMERフィールドの下に表示されます。
マシンにアノテーションを付け、マシンセットから削除します。
$ oc annotate machine <machine_name> machine.openshift.io/delete-machine=true -n openshift-machine-api1 - 1
- ここで、
<machine_name>は削除するマシンの名前です。
ノードのリストを取得し、ワーカーノードの数をカウントします。
$ oc get nodesマシンセットを取得します。
$ oc get machinesets -n openshift-machine-apiマシンセットをスケーリングします。
$ oc scale machineset <machineset_name> -n openshift-machine-api --replicas=<n-1>1 - 1
<machineset_name>はマシンセットの名前です。<n-1>は減少させたワーカーノードの数です。
ホストが
Available状態になったら、マシンセットをスケールアップして、HostFirmwareComponentsリソースの変更を有効にします。$ oc scale machineset <machineset_name> -n openshift-machine-api --replicas=<n>1 - 1
<machineset_name>はマシンセットの名前です。<n>はワーカーノードの数です。
第4章 OpenShift クラスターでのマルチアーキテクチャーのコンピュートマシンの設定
4.1. マルチアーキテクチャーのコンピュートマシンを含むクラスターについて
マルチアーキテクチャー計算マシンを使用する OpenShift Container Platform クラスターは、異なるアーキテクチャーのコンピュートマシンをサポートするクラスターです。
マルチアーキテクチャーコンピュートマシンの設定には、さらにいくつかの点を考慮する必要があります。
- クラスター内に複数のアーキテクチャーを持つノードがある場合、ノードにデプロイするコンテナーイメージのアーキテクチャーは、そのノードのアーキテクチャーと一致している必要があります。Pod が適切なアーキテクチャーを持つノードに割り当てられていること、およびそれがコンテナーイメージのアーキテクチャーと一致していることを確認する必要があります。ノードへの Pod の割り当ての詳細は、ノードへの Pod の割り当て を参照してください。
- インストーラーでプロビジョニングされるインストールでは、単一クラウドプロバイダーによって提供されるインフラストラクチャーの使用に制限されます。アーキテクチャーに関係なく、これらのクラスターに外部ノードを追加することはサポートされていません。
プラットフォームタイプ
noneでインストールされたクラスターは、Machine API を使用したコンピュートマシンの管理など、一部の機能を使用できません。この制限は、クラスターに接続されている計算マシンが、通常はこの機能をサポートするプラットフォームにインストールされている場合でも適用されます。このパラメーターは、インストール後に変更することはできません。重要仮想化またはクラウド環境で OpenShift Container Platform クラスターのインストールを試行する前に、guidelines for deploying OpenShift Container Platform on non-tested platforms にある情報を確認してください。
- Cluster Samples Operator は、マルチアーキテクチャーのコンピュートマシンを含むクラスターではサポートされません。この機能がなくてもクラスターを作成できます。詳細は、クラスターの機能 を参照してください。
- 単一アーキテクチャーのクラスターを、マルチアーキテクチャーのコンピュートマシンをサポートするクラスターに移行する方法は、マルチアーキテクチャーのコンピュートマシンを含むクラスターへの移行 を参照してください。
4.1.1. マルチアーキテクチャーのコンピュートマシンを使用したクラスターの設定
各種のインストールオプションとプラットフォームを使用してマルチアーキテクチャーコンピュートマシンを含むクラスターを作成するには、次の表のドキュメントを使用してください。
| ドキュメントのセクション | プラットフォーム | user-provisioned installation | installer-provisioned installation | コントロールプレーン | コンピュートノード |
|---|---|---|---|---|---|
| Microsoft Azure | ✓ | ✓ |
|
| |
| Amazon Web Services (AWS) | ✓ | ✓ |
|
| |
| Google Cloud | ✓ |
|
| ||
| ベアメタル、IBM Power、または IBM Z 上でマルチアーキテクチャーのコンピュートマシンを含むクラスターを作成する | ベアメタル | ✓ |
|
| |
| IBM Power | ✓ |
|
| ||
| IBM Z | ✓ |
|
| ||
| z/VM を使用した IBM Z® および IBM® LinuxONE 上でマルチアーキテクチャーのコンピュートマシンを含むクラスターを作成する | IBM Z® および IBM® LinuxONE | ✓ |
|
| |
| RHEL KVM を使用した IBM Z® および IBM® LinuxONE 上でマルチアーキテクチャーのコンピュートマシンを含むクラスターを作成する | IBM Z® および IBM® LinuxONE | ✓ |
|
| |
| IBM Power® | ✓ |
|
|
現在、Google Cloud ではゼロからの自動スケーリングはサポートされていません。
4.2. Azure 上でマルチアーキテクチャーのコンピュートマシンを含むクラスターを作成する
マルチアーキテクチャーのコンピュートマシンを含む Azure クラスターをデプロイするには、まず、マルチアーキテクチャーインストーラーバイナリーを使用して、Azure インストーラーによってプロビジョニングされたシングルアーキテクチャーのクラスターを作成する必要があります。Azure へのインストールの詳細は、カスタマイズを使用した Azure へのクラスターのインストール を参照してください。
シングルアーキテクチャーのコンピュートマシンを含む現在のクラスターを、マルチアーキテクチャーのコンピュートマシンを含むクラスターに移行することもできます。詳細は、マルチアーキテクチャーのコンピュートマシンを備えたクラスターへの移行 を参照してください。
マルチアーキテクチャークラスターを作成した後、異なるアーキテクチャーのノードをクラスターに追加できます。
4.2.1. クラスターの互換性の確認
異なるアーキテクチャーのコンピュートノードをクラスターに追加する前に、クラスターがマルチアーキテクチャー互換であることを確認する必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
-
OpenShift CLI (
oc) にログインします。 次のコマンドを実行すると、クラスターがアーキテクチャーペイロードを使用していることを確認できます。
$ oc adm release info -o jsonpath="{ .metadata.metadata}"
検証
次の出力が表示された場合、クラスターはマルチアーキテクチャーペイロードを使用しています。
{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }その後、クラスターへのマルチアーキテクチャーコンピュートノードの追加を開始できます。
次の出力が表示された場合、クラスターはマルチアーキテクチャーペイロードを使用していません。
{ "url": "https://access.redhat.com/errata/<errata_version>" }重要クラスターを、マルチアーキテクチャーコンピュートマシンをサポートするクラスターに移行するには、マルチアーキテクチャーコンピュートマシンを含むクラスターへの移行 の手順に従ってください。
4.2.2. Azure イメージギャラリーを使用して 64 ビット ARM ブートイメージを作成する
次の手順では、64 ビット ARM ブートイメージを手動で生成する方法を説明します。
前提条件
-
Azure CLI (
az) をインストールしている。 - マルチアーキテクチャーインストーラーバイナリーを使用して、単一アーキテクチャーの Azure インストーラープロビジョニングクラスターを作成している。
手順
Azure アカウントにログインします。
$ az loginストレージアカウントを作成し、
aarch64仮想ハードディスク (VHD) をストレージアカウントにアップロードします。OpenShift Container Platform インストールプログラムはリソースグループを作成しますが、ブートイメージをカスタムの名前付きリソースグループにアップロードすることもできます。$ az storage account create -n ${STORAGE_ACCOUNT_NAME} -g ${RESOURCE_GROUP} -l westus --sku Standard_LRS1 - 1
westusオブジェクトはリージョンの例です。
生成したストレージアカウントを使用してストレージコンテナーを作成します。
$ az storage container create -n ${CONTAINER_NAME} --account-name ${STORAGE_ACCOUNT_NAME}URL と
aarch64VHD 名を抽出するには、OpenShift Container Platform インストールプログラムの JSON ファイルを使用する必要があります。次のコマンドを実行して、
URLフィールドを抽出し、ファイル名としてRHCOS_VHD_ORIGIN_URLに設定します。$ RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.aarch64."rhel-coreos-extensions"."azure-disk".url')次のコマンドを実行して、
aarch64VHD 名を抽出し、ファイル名としてBLOB_NAMEに設定します。$ BLOB_NAME=rhcos-$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.aarch64."rhel-coreos-extensions"."azure-disk".release')-azure.aarch64.vhd
Shared Access Signature (SAS) トークンを生成します。このトークンを使用して、次のコマンドで RHCOS VHD をストレージコンテナーにアップロードします。
$ end=`date -u -d "30 minutes" '+%Y-%m-%dT%H:%MZ'`$ sas=`az storage container generate-sas -n ${CONTAINER_NAME} --account-name ${STORAGE_ACCOUNT_NAME} --https-only --permissions dlrw --expiry $end -o tsv`RHCOS VHD をストレージコンテナーにコピーします。
$ az storage blob copy start --account-name ${STORAGE_ACCOUNT_NAME} --sas-token "$sas" \ --source-uri "${RHCOS_VHD_ORIGIN_URL}" \ --destination-blob "${BLOB_NAME}" --destination-container ${CONTAINER_NAME}次のコマンドを使用して、コピープロセスのステータスを確認できます。
$ az storage blob show -c ${CONTAINER_NAME} -n ${BLOB_NAME} --account-name ${STORAGE_ACCOUNT_NAME} | jq .properties.copy出力例
{ "completionTime": null, "destinationSnapshot": null, "id": "1fd97630-03ca-489a-8c4e-cfe839c9627d", "incrementalCopy": null, "progress": "17179869696/17179869696", "source": "https://rhcos.blob.core.windows.net/imagebucket/rhcos-411.86.202207130959-0-azure.aarch64.vhd", "status": "success",1 "statusDescription": null }- 1
- status パラメーターに
successオブジェクトが表示されたら、コピープロセスは完了です。
次のコマンドを使用してイメージギャラリーを作成します。
$ az sig create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME}イメージギャラリーを使用してイメージ定義を作成します。次のコマンド例では、
rhcos-arm64がイメージ定義の名前です。$ az sig image-definition create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME} --gallery-image-definition rhcos-arm64 --publisher RedHat --offer arm --sku arm64 --os-type linux --architecture Arm64 --hyper-v-generation V2VHD の URL を取得してファイル名として
RHCOS_VHD_URLに設定するには、次のコマンドを実行します。$ RHCOS_VHD_URL=$(az storage blob url --account-name ${STORAGE_ACCOUNT_NAME} -c ${CONTAINER_NAME} -n "${BLOB_NAME}" -o tsv)RHCOS_VHD_URLファイル、ストレージアカウント、リソースグループ、およびイメージギャラリーを使用して、イメージバージョンを作成します。次の例では、1.0.0がイメージバージョンです。$ az sig image-version create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME} --gallery-image-definition rhcos-arm64 --gallery-image-version 1.0.0 --os-vhd-storage-account ${STORAGE_ACCOUNT_NAME} --os-vhd-uri ${RHCOS_VHD_URL}arm64ブートイメージが生成されました。次のコマンドを使用して、イメージの ID にアクセスできます。$ az sig image-version show -r $GALLERY_NAME -g $RESOURCE_GROUP -i rhcos-arm64 -e 1.0.0次の例のイメージ ID は、コンピュートマシンセットの
recourseIDパラメーターで使用されます。resourceIDの例/resourceGroups/${RESOURCE_GROUP}/providers/Microsoft.Compute/galleries/${GALLERY_NAME}/images/rhcos-arm64/versions/1.0.0
4.2.3. Azure イメージギャラリーを使用して 64 ビット x86 ブートイメージを作成する
次の手順では、64 ビット x86 ブートイメージを手動で生成する方法を説明します。
前提条件
-
Azure CLI (
az) をインストールしている。 - マルチアーキテクチャーインストーラーバイナリーを使用して、単一アーキテクチャーの Azure インストーラープロビジョニングクラスターを作成している。
手順
次のコマンドを実行して、Azure アカウントにログインします。
$ az loginストレージアカウントを作成し、次のコマンドを実行して
x86_64仮想ハードディスク (VHD) をストレージアカウントにアップロードします。OpenShift Container Platform インストールプログラムがリソースグループを作成します。なお、ブートイメージは、カスタム名のリソースグループにアップロードすることもできます。$ az storage account create -n ${STORAGE_ACCOUNT_NAME} -g ${RESOURCE_GROUP} -l westus --sku Standard_LRS1 - 1
westusオブジェクトはリージョンの例です。
次のコマンドを実行して、生成したストレージアカウントを使用してストレージコンテナーを作成します。
$ az storage container create -n ${CONTAINER_NAME} --account-name ${STORAGE_ACCOUNT_NAME}OpenShift Container Platform インストールプログラムの JSON ファイルを使用して、URL と
x86_64VHD 名を抽出します。次のコマンドを実行して、
URLフィールドを抽出し、ファイル名としてRHCOS_VHD_ORIGIN_URLに設定します。$ RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.x86_64."rhel-coreos-extensions"."azure-disk".url')次のコマンドを実行して、
x86_64VHD 名を抽出し、ファイル名としてBLOB_NAMEに設定します。$ BLOB_NAME=rhcos-$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.x86_64."rhel-coreos-extensions"."azure-disk".release')-azure.x86_64.vhd
Shared Access Signature (SAS) トークンを生成します。このトークンを使用して、次のコマンドを実行し、RHCOS VHD をストレージコンテナーにアップロードします。
$ end=`date -u -d "30 minutes" '+%Y-%m-%dT%H:%MZ'`$ sas=`az storage container generate-sas -n ${CONTAINER_NAME} --account-name ${STORAGE_ACCOUNT_NAME} --https-only --permissions dlrw --expiry $end -o tsv`次のコマンドを実行して、RHCOS VHD をストレージコンテナーにコピーします。
$ az storage blob copy start --account-name ${STORAGE_ACCOUNT_NAME} --sas-token "$sas" \ --source-uri "${RHCOS_VHD_ORIGIN_URL}" \ --destination-blob "${BLOB_NAME}" --destination-container ${CONTAINER_NAME}次のコマンドを実行すると、コピープロセスのステータスを確認できます。
$ az storage blob show -c ${CONTAINER_NAME} -n ${BLOB_NAME} --account-name ${STORAGE_ACCOUNT_NAME} | jq .properties.copy出力例
{ "completionTime": null, "destinationSnapshot": null, "id": "1fd97630-03ca-489a-8c4e-cfe839c9627d", "incrementalCopy": null, "progress": "17179869696/17179869696", "source": "https://rhcos.blob.core.windows.net/imagebucket/rhcos-411.86.202207130959-0-azure.aarch64.vhd", "status": "success",1 "statusDescription": null }- 1
statusパラメーターにsuccessオブジェクトが表示されたら、コピープロセスは完了です。
次のコマンドを実行してイメージギャラリーを作成します。
$ az sig create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME}次のコマンドを実行して、イメージギャラリーを使用してイメージ定義を作成します。
$ az sig image-definition create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME} --gallery-image-definition rhcos-x86_64 --publisher RedHat --offer x86_64 --sku x86_64 --os-type linux --architecture x64 --hyper-v-generation V2このコマンド例の
rhcos-x86_64は、イメージ定義の名前です。VHD の URL を取得してファイル名として
RHCOS_VHD_URLに設定するには、次のコマンドを実行します。$ RHCOS_VHD_URL=$(az storage blob url --account-name ${STORAGE_ACCOUNT_NAME} -c ${CONTAINER_NAME} -n "${BLOB_NAME}" -o tsv)次のコマンドを実行して、
RHCOS_VHD_URLファイル、ストレージアカウント、リソースグループ、イメージギャラリーを使用してイメージバージョンを作成します。$ az sig image-version create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME} --gallery-image-definition rhcos-arm64 --gallery-image-version 1.0.0 --os-vhd-storage-account ${STORAGE_ACCOUNT_NAME} --os-vhd-uri ${RHCOS_VHD_URL}この例では、
1.0.0がイメージバージョンです。オプション: 次のコマンドを実行して、生成された
x86_64ブートイメージの ID にアクセスします。$ az sig image-version show -r $GALLERY_NAME -g $RESOURCE_GROUP -i rhcos-x86_64 -e 1.0.0次の例のイメージ ID は、コンピュートマシンセットの
recourseIDパラメーターで使用されます。resourceIDの例/resourceGroups/${RESOURCE_GROUP}/providers/Microsoft.Compute/galleries/${GALLERY_NAME}/images/rhcos-x86_64/versions/1.0.0
4.2.4. Azure クラスターにマルチアーキテクチャーコンピュートマシンセットを追加する
マルチアーキテクチャークラスターを作成した後、異なるアーキテクチャーのノードを追加できます。
マルチアーキテクチャーコンピュートマシンをマルチアーキテクチャークラスターに追加する方法には、次のものがあります。
- 64 ビット ARM コントロールプレーンマシンを使用し、すでに 64 ビット ARM コンピュートマシンが含まれているクラスターに 64 ビット x86 コンピュートマシンを追加します。この場合、64 ビット x86 がセカンダリーアーキテクチャーと見なされます。
- 64 ビット x86 コントロールプレーンマシンを使用し、すでに 64 ビット x86 コンピュートマシンが含まれているクラスターに 64 ビット ARM コンピュートマシンを追加します。この場合、64 ビット ARM がセカンダリーアーキテクチャーと見なされます。
Azure でカスタムコンピュートマシンセットを作成するには、「Azure でのコンピュートマシンセットの作成」を参照してください。
セカンダリーアーキテクチャーノードをクラスターに追加する前に、Multiarch Tuning Operator をインストールし、ClusterPodPlacementConfig カスタムリソースをデプロイすることを推奨します。詳細は、「Multiarch Tuning Operator を使用してマルチアーキテクチャークラスター上のワークロードを管理する」を参照してください。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - 64 ビット ARM または 64 ビット x86 ブートイメージを作成した。
- インストールプログラムを使用し、マルチアーキテクチャーインストーラーバイナリーを使用して、64 ビット ARM または 64 ビット x86 から成るシングルアーキテクチャーの Azure クラスターを作成した。
手順
-
OpenShift CLI (
oc) にログインします。 YAML ファイルを作成し、設定を追加して、クラスター内の 64 ビット ARM または 64 ビット x86 コンピュートノードを制御するコンピュートマシンセットを作成します。
Azure の 64 ビット ARM または 64 ビット x86 コンピュートノードの
MachineSetオブジェクトの例apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker name: <infrastructure_id>-machine-set-0 namespace: openshift-machine-api spec: replicas: 2 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-machine-set-0 template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker machine.openshift.io/cluster-api-machineset: <infrastructure_id>-machine-set-0 spec: lifecycleHooks: {} metadata: {} providerSpec: value: acceleratedNetworking: true apiVersion: machine.openshift.io/v1beta1 credentialsSecret: name: azure-cloud-credentials namespace: openshift-machine-api image: offer: "" publisher: "" resourceID: /resourceGroups/${RESOURCE_GROUP}/providers/Microsoft.Compute/galleries/${GALLERY_NAME}/images/rhcos-arm64/versions/1.0.01 sku: "" version: "" kind: AzureMachineProviderSpec location: <region> managedIdentity: <infrastructure_id>-identity networkResourceGroup: <infrastructure_id>-rg osDisk: diskSettings: {} diskSizeGB: 128 managedDisk: storageAccountType: Premium_LRS osType: Linux publicIP: false publicLoadBalancer: <infrastructure_id> resourceGroup: <infrastructure_id>-rg subnet: <infrastructure_id>-worker-subnet userDataSecret: name: worker-user-data vmSize: Standard_D4ps_v52 vnet: <infrastructure_id>-vnet zone: "<zone>"次のコマンドを実行してコンピュートマシンセットを作成します。
$ oc create -f <file_name>1 - 1
<file_name>は、コンピュートマシン設定を含む YAML ファイルの名前に置き換えます。たとえば、arm64-machine-set-0.yaml、またはamd64-machine-set-0.yamlです。
検証
次のコマンドを実行して、新しいマシンが実行中であることを確認します。
$ oc get machineset -n openshift-machine-api出力に、作成したマシンセットが含まれている必要があります。
出力例
NAME DESIRED CURRENT READY AVAILABLE AGE <infrastructure_id>-machine-set-0 2 2 2 2 10m次のコマンドを実行すると、ノードが準備完了状態でスケジュール可能かどうかを確認できます。
$ oc get nodes
4.3. AWS 上でマルチアーキテクチャーのコンピュートマシンを含むクラスターを作成する
マルチアーキテクチャーのコンピュートマシンを含む AWS クラスターを作成するには、まず、マルチアーキテクチャーインストーラーバイナリーを使用して、AWS インストーラーによってプロビジョニングされたシングルアーキテクチャーのクラスターを作成する必要があります。AWS へのインストールの詳細は、カスタマイズを使用した AWS へのクラスターのインストール を参照してください。
シングルアーキテクチャーのコンピュートマシンを含む現在のクラスターを、マルチアーキテクチャーのコンピュートマシンを含むクラスターに移行することもできます。詳細は、マルチアーキテクチャーのコンピュートマシンを備えたクラスターへの移行 を参照してください。
マルチアーキテクチャークラスターを作成した後、異なるアーキテクチャーのノードをクラスターに追加できます。
4.3.1. クラスターの互換性の確認
異なるアーキテクチャーのコンピュートノードをクラスターに追加する前に、クラスターがマルチアーキテクチャー互換であることを確認する必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
-
OpenShift CLI (
oc) にログインします。 次のコマンドを実行すると、クラスターがアーキテクチャーペイロードを使用していることを確認できます。
$ oc adm release info -o jsonpath="{ .metadata.metadata}"
検証
次の出力が表示された場合、クラスターはマルチアーキテクチャーペイロードを使用しています。
{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }その後、クラスターへのマルチアーキテクチャーコンピュートノードの追加を開始できます。
次の出力が表示された場合、クラスターはマルチアーキテクチャーペイロードを使用していません。
{ "url": "https://access.redhat.com/errata/<errata_version>" }重要クラスターを、マルチアーキテクチャーコンピュートマシンをサポートするクラスターに移行するには、マルチアーキテクチャーコンピュートマシンを含むクラスターへの移行 の手順に従ってください。
4.3.2. AWS クラスターにマルチアーキテクチャーコンピュートマシンセットを追加する
マルチアーキテクチャークラスターを作成した後、異なるアーキテクチャーのノードを追加できます。
マルチアーキテクチャーコンピュートマシンをマルチアーキテクチャークラスターに追加する方法には、次のものがあります。
- 64 ビット ARM コントロールプレーンマシンを使用し、すでに 64 ビット ARM コンピュートマシンが含まれているクラスターに 64 ビット x86 コンピュートマシンを追加します。この場合、64 ビット x86 がセカンダリーアーキテクチャーと見なされます。
- 64 ビット x86 コントロールプレーンマシンを使用し、すでに 64 ビット x86 コンピュートマシンが含まれているクラスターに 64 ビット ARM コンピュートマシンを追加します。この場合、64 ビット ARM がセカンダリーアーキテクチャーと見なされます。
セカンダリーアーキテクチャーノードをクラスターに追加する前に、Multiarch Tuning Operator をインストールし、ClusterPodPlacementConfig カスタムリソースをデプロイすることを推奨します。詳細は、「Multiarch Tuning Operator を使用してマルチアーキテクチャークラスター上のワークロードを管理する」を参照してください。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - インストールプログラムを使用し、マルチアーキテクチャーインストーラーバイナリーを使用して、64 ビット ARM または 64 ビット x86 から成るシングルアーキテクチャーの AWS クラスターを作成した。
手順
-
OpenShift CLI (
oc) にログインします。 YAML ファイルを作成し、設定を追加して、クラスター内の 64 ビット ARM または 64 ビット x86 コンピュートノードを制御するコンピュートマシンセットを作成します。
AWS の 64 ビット ARM または x86 コンピュートノードの
MachineSetオブジェクトの例apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-aws-machine-set-02 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>3 machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone>4 template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role>5 machine.openshift.io/cluster-api-machine-type: <role>6 machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone>7 spec: metadata: labels: node-role.kubernetes.io/<role>: "" providerSpec: value: ami: id: ami-02a574449d4f4d2808 apiVersion: awsproviderconfig.openshift.io/v1beta1 blockDevices: - ebs: iops: 0 volumeSize: 120 volumeType: gp2 credentialsSecret: name: aws-cloud-credentials deviceIndex: 0 iamInstanceProfile: id: <infrastructure_id>-worker-profile9 instanceType: m6g.xlarge10 kind: AWSMachineProviderConfig placement: availabilityZone: us-east-1a11 region: <region>12 securityGroups: - filters: - name: tag:Name values: - <infrastructure_id>-node13 subnet: filters: - name: tag:Name values: - <infrastructure_id>-subnet-private-<zone> tags: - name: kubernetes.io/cluster/<infrastructure_id>14 value: owned - name: <custom_tag_name> value: <custom_tag_value> userDataSecret: name: worker-user-data- 1 2 3 9 13 14
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。OpenShift CLI (
oc) がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。$ oc get -o jsonpath="{.status.infrastructureName}{'\n'}" infrastructure cluster - 4 7
- インフラストラクチャー ID、ロールノードラベル、およびゾーンを指定します。
- 5 6
- 追加するロールノードラベルを指定します。
- 8
- ノードの AWS リージョンに Red Hat Enterprise Linux CoreOS (RHCOS) Amazon Machine Image (AMI) を指定します。RHCOS AMI はマシンのアーキテクチャーと互換性がある必要があります。
$ oc get configmap/coreos-bootimages \ -n openshift-machine-config-operator \ -o jsonpath='{.data.stream}' | jq \ -r '.architectures.<arch>.images.aws.regions."<region>".image' - 10
- 選択した AMI の CPU アーキテクチャーに合ったマシンタイプを指定します。詳細は、「AWS 64 ビット ARM のテスト済みインスタンスタイプ」を参照してください。
- 11
- ゾーンを指定します。たとえば、
us-east-1aです。選択したゾーンに必要なアーキテクチャーを備えたマシンがあることを確認してください。 - 12
- リージョンを指定します。たとえば、
us-east-1などです。選択したゾーンに必要なアーキテクチャーを備えたマシンがあることを確認してください。
次のコマンドを実行してコンピュートマシンセットを作成します。
$ oc create -f <file_name>1 - 1
<file_name>は、コンピュートマシン設定を含む YAML ファイルの名前に置き換えます。たとえば、aws-arm64-machine-set-0.yaml、またはaws-amd64-machine-set-0.yamlです。
検証
次のコマンドを実行して、コンピュートマシンセットのリストを表示します。
$ oc get machineset -n openshift-machine-api出力に、作成したマシンセットが含まれている必要があります。
出力例
NAME DESIRED CURRENT READY AVAILABLE AGE <infrastructure_id>-aws-machine-set-0 2 2 2 2 10m次のコマンドを実行すると、ノードが準備完了状態でスケジュール可能かどうかを確認できます。
$ oc get nodes
4.4. Google Cloud 上でマルチアーキテクチャーのコンピュートマシンを含むクラスターを作成する
マルチアーキテクチャーのコンピュートマシンを含む Google Cloud クラスターを作成するには、まず、マルチアーキテクチャーインストーラーバイナリーを使用して、Google Cloud インストーラーによってプロビジョニングされたシングルアーキテクチャーのクラスターを作成する必要があります。AWS へのインストールの詳細は、カスタマイズを使用した GCP へのクラスターのインストール を参照してください。
シングルアーキテクチャーのコンピュートマシンを含む現在のクラスターを、マルチアーキテクチャーのコンピュートマシンを含むクラスターに移行することもできます。詳細は、マルチアーキテクチャーのコンピュートマシンを備えたクラスターへの移行 を参照してください。
マルチアーキテクチャークラスターを作成した後、異なるアーキテクチャーのノードをクラスターに追加できます。
Google Cloud の 64 ビット ARM マシンでは、セキュアブートは現在サポートされていません。
4.4.1. クラスターの互換性の確認
異なるアーキテクチャーのコンピュートノードをクラスターに追加する前に、クラスターがマルチアーキテクチャー互換であることを確認する必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
-
OpenShift CLI (
oc) にログインします。 次のコマンドを実行すると、クラスターがアーキテクチャーペイロードを使用していることを確認できます。
$ oc adm release info -o jsonpath="{ .metadata.metadata}"
検証
次の出力が表示された場合、クラスターはマルチアーキテクチャーペイロードを使用しています。
{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }その後、クラスターへのマルチアーキテクチャーコンピュートノードの追加を開始できます。
次の出力が表示された場合、クラスターはマルチアーキテクチャーペイロードを使用していません。
{ "url": "https://access.redhat.com/errata/<errata_version>" }重要クラスターを、マルチアーキテクチャーコンピュートマシンをサポートするクラスターに移行するには、マルチアーキテクチャーコンピュートマシンを含むクラスターへの移行 の手順に従ってください。
4.4.2. Google Cloud クラスターにマルチアーキテクチャーコンピュートマシンセットを追加する
マルチアーキテクチャークラスターを作成した後、異なるアーキテクチャーのノードを追加できます。
マルチアーキテクチャーコンピュートマシンをマルチアーキテクチャークラスターに追加する方法には、次のものがあります。
- 64 ビット ARM コントロールプレーンマシンを使用し、すでに 64 ビット ARM コンピュートマシンが含まれているクラスターに 64 ビット x86 コンピュートマシンを追加します。この場合、64 ビット x86 がセカンダリーアーキテクチャーと見なされます。
- 64 ビット x86 コントロールプレーンマシンを使用し、すでに 64 ビット x86 コンピュートマシンが含まれているクラスターに 64 ビット ARM コンピュートマシンを追加します。この場合、64 ビット ARM がセカンダリーアーキテクチャーと見なされます。
セカンダリーアーキテクチャーノードをクラスターに追加する前に、Multiarch Tuning Operator をインストールし、ClusterPodPlacementConfig カスタムリソースをデプロイすることを推奨します。詳細は、「Multiarch Tuning Operator を使用してマルチアーキテクチャークラスター上のワークロードを管理する」を参照してください。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - インストールプログラムを使用し、マルチアーキテクチャーインストーラーバイナリーを使用して、64 ビット x86 または 64 ビット ARM から成るシングルアーキテクチャーの Google Cloud クラスターを作成した。
手順
-
OpenShift CLI (
oc) にログインします。 YAML ファイルを作成し、設定を追加して、クラスター内の 64 ビット ARM または 64 ビット x86 コンピュートノードを制御するコンピュートマシンセットを作成します。
Google Cloud の 64 ビット ARM または 64 ビット x86 コンピュートノードの
MachineSetオブジェクトの例apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-w-a namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-w-a template: metadata: creationTimestamp: null labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role>2 machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-w-a spec: metadata: labels: node-role.kubernetes.io/<role>: "" providerSpec: value: apiVersion: gcpprovider.openshift.io/v1beta1 canIPForward: false credentialsSecret: name: gcp-cloud-credentials deletionProtection: false disks: - autoDelete: true boot: true image: <path_to_image>3 labels: null sizeGb: 128 type: pd-ssd gcpMetadata:4 - key: <custom_metadata_key> value: <custom_metadata_value> kind: GCPMachineProviderSpec machineType: n1-standard-45 metadata: creationTimestamp: null networkInterfaces: - network: <infrastructure_id>-network subnetwork: <infrastructure_id>-worker-subnet projectID: <project_name>6 region: us-central17 serviceAccounts: - email: <infrastructure_id>-w@<project_name>.iam.gserviceaccount.com scopes: - https://www.googleapis.com/auth/cloud-platform tags: - <infrastructure_id>-worker userDataSecret: name: worker-user-data zone: us-central1-a- 1
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。以下のコマンドを実行してインフラストラクチャー ID を取得できます。
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2
- 追加するロールノードラベルを指定します。
- 3
- 現在のコンピュートマシンセットで使用されるイメージへのパスを指定します。イメージへのパスにはプロジェクトとイメージ名が必要です。
プロジェクトとイメージ名にアクセスするには、次のコマンドを実行します。
$ oc get configmap/coreos-bootimages \ -n openshift-machine-config-operator \ -o jsonpath='{.data.stream}' | jq \ -r '.architectures.aarch64.images.gcp'出力例
"gcp": { "release": "415.92.202309142014-0", "project": "rhcos-cloud", "name": "rhcos-415-92-202309142014-0-gcp-aarch64" }出力の
projectパラメーターとnameパラメーターを使用して、マシンセット内のイメージフィールドへのパスを作成します。イメージへのパスは次の形式に従う必要があります。$ projects/<project>/global/images/<image_name> - 4
- オプション:
key:valueのペアの形式でカスタムメタデータを指定します。ユースケースの例は、カスタムメタデータの設定 に関する Google Cloud のドキュメントを参照してください。 - 5
- 選択した OS イメージの CPU アーキテクチャーに合ったマシンタイプを指定します。詳細は、「64 ビット ARM インフラストラクチャー上の Google Cloud のテスト済みのインスタンスタイプ」を参照してください。
- 6
- クラスターに使用する Google Cloud プロジェクトの名前を指定します。
- 7
- リージョンを指定します。たとえば、
us-central1です。選択したゾーンに必要なアーキテクチャーを備えたマシンがあることを確認してください。
次のコマンドを実行してコンピュートマシンセットを作成します。
$ oc create -f <file_name>1 - 1
<file_name>は、コンピュートマシン設定を含む YAML ファイルの名前に置き換えます。たとえば、gcp-arm64-machine-set-0.yaml、またはgcp-amd64-machine-set-0.yamlです。
検証
次のコマンドを実行して、コンピュートマシンセットのリストを表示します。
$ oc get machineset -n openshift-machine-api出力に、作成したマシンセットが含まれている必要があります。
出力例
NAME DESIRED CURRENT READY AVAILABLE AGE <infrastructure_id>-gcp-machine-set-0 2 2 2 2 10m次のコマンドを実行すると、ノードが準備完了状態でスケジュール可能かどうかを確認できます。
$ oc get nodes
4.5. ベアメタル、IBM Power、または IBM Z 上でマルチアーキテクチャーのコンピュートマシンを含むクラスターを作成する
ベアメタル (x86_64 または aarch64)、IBM Power® (ppc64le)、または IBM Z® (s390x) 上にマルチアーキテクチャーコンピュートマシンを含むクラスターを作成するには、そのプラットフォームに既存のシングルアーキテクチャークラスターが必要です。ご使用のプラットフォームのインストール手順に従ってください。
- ユーザーがプロビジョニングするクラスターをベアメタルにインストールします。その後、ベアメタル上の OpenShift Container Platform クラスターに 64 ビット ARM コンピュートマシンを追加できます。
-
IBM Power® にクラスターをインストールします。その後、IBM Power® 上の OpenShift Container Platform クラスターに
x86_64コンピュートマシンを追加できます。 -
IBM Z® および IBM® LinuxONE にクラスターをインストールします。その後、IBM Z® および IBM® LinuxONE 上の OpenShift Container Platform クラスターに
x86_64コンピュートマシンを追加できます。
ベアメタルの installer-provisioned infrastructure および Bare Metal Operator は、クラスターの初期セットアップ中にセカンダリーアーキテクチャーノードを追加することをサポートしていません。セカンダリーアーキテクチャーノードは、初期クラスターのセットアップ後にのみ手動で追加できます。
クラスターに追加のコンピュートノードを追加する前に、クラスターをマルチアーキテクチャーペイロードを使用するクラスターにアップグレードする必要があります。マルチアーキテクチャーペイロードへの移行の詳細は、マルチアーキテクチャーコンピュートマシンを使用したクラスターへの移行 を参照してください。
次の手順では、ISO イメージまたはネットワーク PXE ブートを使用して RHCOS コンピュートマシンを作成する方法を説明します。これにより、クラスターにノードを追加し、マルチアーキテクチャーコンピュートマシンを含むクラスターをデプロイできるようになります。
セカンダリーアーキテクチャーノードをクラスターに追加する前に、Multiarch Tuning Operator をインストールし、ClusterPodPlacementConfig オブジェクトをデプロイすることを推奨します。詳細は、Multiarch Tuning Operator を使用してマルチアーキテクチャークラスター上のワークロードを管理する を参照してください。
4.5.1. クラスターの互換性の確認
異なるアーキテクチャーのコンピュートノードをクラスターに追加する前に、クラスターがマルチアーキテクチャー互換であることを確認する必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
-
OpenShift CLI (
oc) にログインします。 次のコマンドを実行すると、クラスターがアーキテクチャーペイロードを使用していることを確認できます。
$ oc adm release info -o jsonpath="{ .metadata.metadata}"
検証
次の出力が表示された場合、クラスターはマルチアーキテクチャーペイロードを使用しています。
{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }その後、クラスターへのマルチアーキテクチャーコンピュートノードの追加を開始できます。
次の出力が表示された場合、クラスターはマルチアーキテクチャーペイロードを使用していません。
{ "url": "https://access.redhat.com/errata/<errata_version>" }重要クラスターを、マルチアーキテクチャーコンピュートマシンをサポートするクラスターに移行するには、マルチアーキテクチャーコンピュートマシンを含むクラスターへの移行 の手順に従ってください。
4.5.2. ISO イメージを使用した RHCOS マシンの作成
ISO イメージを使用して、ベアメタルクラスターの追加の Red Hat Enterprise Linux CoreOS (RHCOS) コンピュートマシンを作成できます。
前提条件
- クラスターのコンピュートマシンの Ignition 設定ファイルの URL を取得します。このファイルがインストール時に HTTP サーバーにアップロードされている必要があります。
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、クラスターから Ignition 設定ファイルを抽出します。
$ oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ign-
クラスターからエクスポートした
worker.ignIgnition 設定ファイルを HTTP サーバーにアップロードします。これらのファイルの URL をメモします。 Ignition ファイルが URL で利用可能であることを検証できます。次の例では、コンピュートノードの Ignition 設定ファイルを取得します。
$ curl -k http://<HTTP_server>/worker.ign次のコマンドを実行すると、新しいマシンを起動するための ISO イメージにアクセスできます。
RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.<architecture>.artifacts.metal.formats.iso.disk.location')ISO ファイルを使用して、追加のコンピュートマシンに RHCOS をインストールします。クラスターのインストール前にマシンを作成する際に使用したのと同じ方法を使用します。
- ディスクに ISO イメージを書き込み、これを直接起動します。
- LOM インターフェイスで ISO リダイレクトを使用します。
オプションを指定したり、ライブ起動シーケンスを中断したりせずに、RHCOS ISO イメージを起動します。インストーラーが RHCOS ライブ環境でシェルプロンプトを起動するのを待ちます。
注記RHCOS インストールの起動プロセスを中断して、カーネル引数を追加できます。ただし、この ISO 手順では、カーネル引数を追加する代わりに、次の手順で概説するように
coreos-installerコマンドを使用する必要があります。coreos-installerコマンドを実行します。インストール要件に合わせてオプションを指定します。少なくとも、該当するノードタイプ用の Ignition 設定ファイルを指す URL と、インストール先のデバイスを指定する必要があります。$ sudo coreos-installer install --ignition-url=http://<HTTP_server>/<node_type>.ign <device> --ignition-hash=sha512-<digest>1 2 注記TLS を使用する HTTPS サーバーを使用して Ignition 設定ファイルを提供する場合は、
coreos-installerを実行する前に、内部認証局 (CA) をシステムのトラストストアに追加できます。次の例では、
/dev/sdaデバイスへのコンピュートノードのインストールを開始します。コンピュートノードの Ignition 設定ファイルは、IP アドレス 192.168.1.2 の HTTP Web サーバーから取得されます。$ sudo coreos-installer install --ignition-url=http://192.168.1.2:80/installation_directory/worker.ign /dev/sda --ignition-hash=sha512-a5a2d43879223273c9b60af66b44202a1d1248fc01cf156c46d4a79f552b6bad47bc8cc78ddf0116e80c59d2ea9e32ba53bc807afbca581aa059311def2c3e3bマシンのコンソールで RHCOS インストールの進捗を監視します。
重要OpenShift Container Platform のインストールを開始する前に、各ノードでインストールが成功していることを確認します。インストールプロセスを監視すると、発生する可能性のある RHCOS インストールの問題の原因を特定する上でも役立ちます。
- 継続してクラスター用の追加のコンピュートマシンを作成します。
4.5.3. PXE または iPXE ブートによる RHCOS マシンの作成
PXE または iPXE ブートを使用して、ベアメタルクラスターの追加の Red Hat Enterprise Linux CoreOS (RHCOS) コンピュートマシンを作成できます。
前提条件
- クラスターのコンピュートマシンの Ignition 設定ファイルの URL を取得します。このファイルがインストール時に HTTP サーバーにアップロードされている必要があります。
-
クラスターのインストール時に HTTP サーバーにアップロードした RHCOS ISO イメージ、圧縮されたメタル BIOS、
kernel、およびinitramfsファイルの URL を取得します。 - インストール時に OpenShift Container Platform クラスターのマシンを作成するために使用した PXE ブートインフラストラクチャーにアクセスできる必要があります。RHCOS のインストール後にマシンはローカルディスクから起動する必要があります。
-
UEFI を使用する場合、OpenShift Container Platform のインストール時に変更した
grub.confファイルにアクセスできます。
手順
RHCOS イメージの PXE または iPXE インストールが正常に行われていることを確認します。
PXE の場合:
DEFAULT pxeboot TIMEOUT 20 PROMPT 0 LABEL pxeboot KERNEL http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture>1 APPEND initrd=http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img2 - 1
- HTTP サーバーにアップロードしたライブ
kernelファイルの場所を指定します。 - 2
- HTTP サーバーにアップロードした RHCOS ファイルの場所を指定します。
initrdパラメーターはライブinitramfsファイルの場所であり、coreos.inst.ignition_urlパラメーター値はワーカー Ignition 設定ファイルの場所であり、coreos.live.rootfs_urlパラメーター値はライブrootfsファイルの場所になります。coreos.inst.ignition_urlおよびcoreos.live.rootfs_urlパラメーターは HTTP および HTTPS のみをサポートします。
注記この設定では、グラフィカルコンソールを使用するマシンでシリアルコンソールアクセスを有効にしません。別のコンソールを設定するには、
APPEND行に 1 つ以上のconsole=引数を追加します。たとえば、console=tty0 console=ttyS0を追加して、最初の PC シリアルポートをプライマリーコンソールとして、グラフィカルコンソールをセカンダリーコンソールとして設定します。詳細は、How does one set up a serial terminal and/or console in Red Hat Enterprise Linux? を参照してください。iPXE (
x86_64+aarch64) の場合:kernel http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture> initrd=main coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign1 2 initrd --name main http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img3 boot- 1
- HTTP サーバーにアップロードした RHCOS ファイルの場所を指定します。
kernelパラメーター値はkernelファイルの場所であり、initrd=main引数は UEFI システムでの起動に必要であり、coreos.live.rootfs_urlパラメーター値はワーカー Ignition 設定ファイルの場所であり、coreos.inst.ignition_urlパラメーター値はrootfsのライブファイルの場所です。 - 2
- 複数の NIC を使用する場合、
ipオプションに単一インターフェイスを指定します。たとえば、eno1という名前の NIC で DHCP を使用するには、ip=eno1:dhcpを設定します。 - 3
- HTTP サーバーにアップロードした
initramfsファイルの場所を指定します。
注記この設定では、グラフィカルコンソールを備えたマシンでのシリアルコンソールアクセスは有効になりません。別のコンソールを設定するには、
kernel行に 1 つ以上のconsole=引数を追加します。たとえば、console=tty0 console=ttyS0を追加して、最初の PC シリアルポートをプライマリーコンソールとして、グラフィカルコンソールをセカンダリーコンソールとして設定します。詳細は、How does one set up a serial terminal and/or console in Red Hat Enterprise Linux? と、「高度な RHCOS インストール設定」セクションの「PXE および ISO インストール用シリアルコンソールの有効化」を参照してください。注記aarch64アーキテクチャーで CoreOSkernelをネットワークブートするには、IMAGE_GZIPオプションが有効になっているバージョンの iPXE ビルドを使用する必要があります。iPXE のIMAGE_GZIPオプション を参照してください。aarch64上の PXE (第 2 段階として UEFI および GRUB を使用) の場合:menuentry 'Install CoreOS' { linux rhcos-<version>-live-kernel-<architecture> coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign1 2 initrd rhcos-<version>-live-initramfs.<architecture>.img3 }- 1
- HTTP/TFTP サーバーにアップロードした RHCOS ファイルの場所を指定します。
kernelパラメーター値は、TFTP サーバー上のkernelファイルの場所になります。coreos.live.rootfs_urlパラメーター値はrootfsファイルの場所であり、coreos.inst.ignition_urlパラメーター値は HTTP サーバー上のブートストラップ Ignition 設定ファイルの場所になります。 - 2
- 複数の NIC を使用する場合、
ipオプションに単一インターフェイスを指定します。たとえば、eno1という名前の NIC で DHCP を使用するには、ip=eno1:dhcpを設定します。 - 3
- TFTP サーバーにアップロードした
initramfsファイルの場所を指定します。
- PXE または iPXE インフラストラクチャーを使用して、クラスターに必要なコンピュートマシンを作成します。
4.5.4. マシンの証明書署名要求の承認
マシンをクラスターに追加する際に、追加したそれぞれのマシンに対して 2 つの保留状態の証明書署名要求 (CSR) が生成されます。これらの CSR が承認されていることを確認するか、必要な場合はそれらを承認してください。最初にクライアント要求を承認し、次にサーバー要求を承認する必要があります。
前提条件
- マシンがクラスターに追加されています。
手順
クラスターがマシンを認識していることを確認します。
$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.29.4 master-1 Ready master 63m v1.29.4 master-2 Ready master 64m v1.29.4出力には作成したすべてのマシンがリスト表示されます。
注記上記の出力には、一部の CSR が承認されるまで、ワーカーノード (ワーカーノードとも呼ばれる) が含まれない場合があります。
保留中の証明書署名要求 (CSR) を確認し、クラスターに追加したそれぞれのマシンのクライアントおよびサーバー要求に
PendingまたはApprovedステータスが表示されていることを確認します。$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...この例では、2 つのマシンがクラスターに参加しています。このリストにはさらに多くの承認された CSR が表示される可能性があります。
追加したマシンの保留中の CSR すべてが
Pendingステータスになった後に CSR が承認されない場合には、クラスターマシンの CSR を承認します。注記CSR のローテーションは自動的に実行されるため、クラスターにマシンを追加後 1 時間以内に CSR を承認してください。1 時間以内に承認しない場合には、証明書のローテーションが行われ、各ノードに 3 つ以上の証明書が存在するようになります。これらの証明書すべてを承認する必要があります。クライアントの CSR が承認された後に、Kubelet は提供証明書のセカンダリー CSR を作成します。これには、手動の承認が必要になります。次に、後続の提供証明書の更新要求は、Kubelet が同じパラメーターを持つ新規証明書を要求する場合に
machine-approverによって自動的に承認されます。注記ベアメタルおよび他の user-provisioned infrastructure などのマシン API ではないプラットフォームで実行されているクラスターの場合、kubelet 提供証明書要求 (CSR) を自動的に承認する方法を実装する必要があります。要求が承認されない場合、API サーバーが kubelet に接続する際に提供証明書が必須であるため、
oc exec、oc rsh、およびoc logsコマンドは正常に実行できません。Kubelet エンドポイントにアクセスする操作には、この証明書の承認が必要です。この方法は新規 CSR の有無を監視し、CSR がsystem:nodeまたはsystem:adminグループのnode-bootstrapperサービスアカウントによって提出されていることを確認し、ノードの ID を確認します。それらを個別に承認するには、それぞれの有効な CSR に以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve注記一部の Operator は、一部の CSR が承認されるまで利用できない可能性があります。
クライアント要求が承認されたら、クラスターに追加した各マシンのサーバー要求を確認する必要があります。
$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...残りの CSR が承認されず、それらが
Pendingステータスにある場合、クラスターマシンの CSR を承認します。それらを個別に承認するには、それぞれの有効な CSR に以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
すべてのクライアントおよびサーバーの CSR が承認された後に、マシンのステータスが
Readyになります。以下のコマンドを実行して、これを確認します。$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.29.4 master-1 Ready master 73m v1.29.4 master-2 Ready master 74m v1.29.4 worker-0 Ready worker 11m v1.29.4 worker-1 Ready worker 11m v1.29.4注記サーバー CSR の承認後にマシンが
Readyステータスに移行するまでに数分の時間がかかる場合があります。
関連情報
- CSR の詳細は、Certificate Signing Requests を参照してください。
4.6. z/VM を使用した IBM Z および IBM LinuxONE 上でマルチアーキテクチャーのコンピューティングマシンを含むクラスターを作成する
z/VM を使用して IBM Z® および IBM® LinuxONE (s390x) 上にマルチアーキテクチャーのコンピュートマシンを含むクラスターを作成するには、既存の単一アーキテクチャーの x86_64 クラスターが必要です。その後、s390x コンピュートマシンを OpenShift Container Platform クラスターに追加できます。
s390x ノードをクラスターに追加する前に、クラスターをマルチアーキテクチャーペイロードを使用するクラスターにアップグレードする必要があります。マルチアーキテクチャーペイロードへの移行の詳細は、マルチアーキテクチャーコンピュートマシンを使用したクラスターへの移行 を参照してください。
次の手順では、z/VM インスタンスを使用して RHCOS コンピュートマシンを作成する方法を説明します。これにより、s390x ノードをクラスターに追加し、マルチアーキテクチャーのコンピュートマシンを含むクラスターをデプロイメントできるようになります。
x86_64 上でマルチアーキテクチャーコンピュートマシンを含む IBM Z® または IBM® LinuxONE (s390x) クラスターを作成するには、IBM Z® および IBM® LinuxONE へのクラスターのインストール の手順に従ってください。その後、ベアメタル、IBM Power、または IBM Z 上でマルチアーキテクチャーコンピュートマシンを含むクラスターを作成する の説明に従って、x86_64 コンピュートマシンを追加できます。
セカンダリーアーキテクチャーノードをクラスターに追加する前に、Multiarch Tuning Operator をインストールし、ClusterPodPlacementConfig オブジェクトをデプロイすることを推奨します。詳細は、Multiarch Tuning Operator を使用してマルチアーキテクチャークラスター上のワークロードを管理する を参照してください。
4.6.1. クラスターの互換性の確認
異なるアーキテクチャーのコンピュートノードをクラスターに追加する前に、クラスターがマルチアーキテクチャー互換であることを確認する必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
-
OpenShift CLI (
oc) にログインします。 次のコマンドを実行すると、クラスターがアーキテクチャーペイロードを使用していることを確認できます。
$ oc adm release info -o jsonpath="{ .metadata.metadata}"
検証
次の出力が表示された場合、クラスターはマルチアーキテクチャーペイロードを使用しています。
{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }その後、クラスターへのマルチアーキテクチャーコンピュートノードの追加を開始できます。
次の出力が表示された場合、クラスターはマルチアーキテクチャーペイロードを使用していません。
{ "url": "https://access.redhat.com/errata/<errata_version>" }重要クラスターを、マルチアーキテクチャーコンピュートマシンをサポートするクラスターに移行するには、マルチアーキテクチャーコンピュートマシンを含むクラスターへの移行 の手順に従ってください。
4.6.2. z/VM を使用した IBM Z 上での RHCOS マシンの作成
z/VM を使用した IBM Z® 上で実行される Red Hat Enterprise Linux CoreOS (RHCOS) コンピュートマシンをさらに作成し、既存のクラスターに割り当てることができます。
前提条件
- ノードのホスト名および逆引き参照を実行できるドメインネームサーバー (DNS) がある。
- 作成するマシンがアクセスできるプロビジョニングマシンで稼働している HTTP または HTTPS サーバーがある。
手順
次のコマンドを実行して、クラスターから Ignition 設定ファイルを抽出します。
$ oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ign-
クラスターからエクスポートした
worker.ignIgnition 設定ファイルを HTTP サーバーにアップロードします。このファイルの URL をメモします。 Ignition ファイルが URL で利用可能であることを検証できます。次の例では、コンピュートノードの Ignition 設定ファイルを取得します。
$ curl -k http://<http_server>/worker.ign次のコマンドを実行して、RHEL ライブ
kernel、initramfs、およびrootfsファイルをダウンロードします。$ curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.kernel.location')$ curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.initramfs.location')$ curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.rootfs.location')-
ダウンロードした RHEL ライブ
kernel、initramfs、およびrootfsファイルを、追加する RHCOS ゲストからアクセス可能な HTTP または HTTPS サーバーに移動します。 ゲストのパラメーターファイルを作成します。次のパラメーターは仮想マシンに固有です。
オプション: 静的 IP アドレスを指定するには、次のエントリーをコロンで区切って
ip=パラメーターを追加します。- マシンの IP アドレス。
- 空の文字列。
- ゲートウェイ。
- ネットマスク。
-
hostname.domainname形式のマシンホストおよびドメイン名。この値を省略すると、RHCOS が逆引き DNS ルックアップによりホスト名を取得します。 - ネットワークインターフェイス名。この値を省略すると、RHCOS が利用可能なすべてのインターフェイスに IP 設定を適用します。
-
値
none。
-
coreos.inst.ignition_url=には、worker.ignファイルへの URL を指定します。HTTP プロトコルおよび HTTPS プロトコルのみがサポートされます。 -
coreos.live.rootfs_url=の場合、起動しているkernelおよびinitramfsの一致する rootfs アーティファクトを指定します。HTTP プロトコルおよび HTTPS プロトコルのみがサポートされます。 DASD タイプのディスクへのインストールには、以下のタスクを実行します。
-
coreos.inst.install_dev=には、/dev/dasdaを指定します。 -
rd.dasd=を使用して、RHCOS がインストールされる DASD を指定します。 必要に応じてさらにパラメーターを調整できます。
以下はパラメーターファイルの例、
additional-worker-dasd.parmです。cio_ignore=all,!condev rd.neednet=1 \ console=ttysclp0 \ coreos.inst.install_dev=/dev/dasda \ coreos.inst.ignition_url=http://<http_server>/worker.ign \ coreos.live.rootfs_url=http://<http_server>/rhcos-<version>-live-rootfs.<architecture>.img \ ip=<ip>::<gateway>:<netmask>:<hostname>::none nameserver=<dns> \ rd.znet=qeth,0.0.bdf0,0.0.bdf1,0.0.bdf2,layer2=1,portno=0 \ rd.dasd=0.0.3490 \ zfcp.allow_lun_scan=0パラメーターファイルのすべてのオプションを 1 行で記述し、改行文字がないことを確認します。
-
FCP タイプのディスクへのインストールには、以下のタスクを実行します。
rd.zfcp=<adapter>,<wwpn>,<lun>を使用して RHCOS がインストールされる FCP ディスクを指定します。マルチパスの場合、それぞれの追加のステップについてこのステップを繰り返します。注記複数のパスを使用してインストールする場合は、問題が発生する可能性があるため、後でではなくインストールの直後にマルチパスを有効にする必要があります。
インストールデバイスを
coreos.inst.install_dev=/dev/sdaとして設定します。注記追加の LUN が NPIV で設定される場合は、FCP に
zfcp.allow_lun_scan=0が必要です。CSI ドライバーを使用するためにzfcp.allow_lun_scan=1を有効にする必要がある場合などには、各ノードが別のノードのブートパーティションにアクセスできないように NPIV を設定する必要があります。必要に応じてさらにパラメーターを調整できます。
重要マルチパスを完全に有効にするには、インストール後の追加の手順が必要です。詳細は、マシン設定 の「RHCOS のカーネル引数でのマルチパスの有効化」を参照してください。
以下は、マルチパスを使用するワーカーノードのパラメーターファイルの例
additional-worker-fcp.parmです。cio_ignore=all,!condev rd.neednet=1 \ console=ttysclp0 \ coreos.inst.install_dev=/dev/sda \ coreos.live.rootfs_url=http://<http_server>/rhcos-<version>-live-rootfs.<architecture>.img \ coreos.inst.ignition_url=http://<http_server>/worker.ign \ ip=<ip>::<gateway>:<netmask>:<hostname>::none nameserver=<dns> \ rd.znet=qeth,0.0.bdf0,0.0.bdf1,0.0.bdf2,layer2=1,portno=0 \ zfcp.allow_lun_scan=0 \ rd.zfcp=0.0.1987,0x50050763070bc5e3,0x4008400B00000000 \ rd.zfcp=0.0.19C7,0x50050763070bc5e3,0x4008400B00000000 \ rd.zfcp=0.0.1987,0x50050763071bc5e3,0x4008400B00000000 \ rd.zfcp=0.0.19C7,0x50050763071bc5e3,0x4008400B00000000パラメーターファイルのすべてのオプションを 1 行で記述し、改行文字がないことを確認します。
-
FTP などを使用し、
initramfs、kernel、パラメーターファイル、および RHCOS イメージを z/VM に転送します。FTP を使用してファイルを転送し、仮想リーダーから起動する方法の詳細は、IBM Z® でインストールを起動して z/VM に RHEL をインストールする を参照してください。 ファイルを z/VM ゲスト仮想マシンの仮想リーダーに punch します。
IBM® ドキュメントの PUNCH を参照してください。
ヒントCP PUNCH コマンドを使用するか、Linux を使用している場合は、vmur コマンドを使用して 2 つの z/VM ゲスト仮想マシン間でファイルを転送できます。
- ブートストラップマシンで CMS にログインします。
次のコマンドを実行して、リーダーからブートストラップマシンを IPL します。
$ ipl cIBM® ドキュメントの IPL を参照してください。
4.6.3. マシンの証明書署名要求の承認
マシンをクラスターに追加する際に、追加したそれぞれのマシンに対して 2 つの保留状態の証明書署名要求 (CSR) が生成されます。これらの CSR が承認されていることを確認するか、必要な場合はそれらを承認してください。最初にクライアント要求を承認し、次にサーバー要求を承認する必要があります。
前提条件
- マシンがクラスターに追加されています。
手順
クラスターがマシンを認識していることを確認します。
$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.29.4 master-1 Ready master 63m v1.29.4 master-2 Ready master 64m v1.29.4出力には作成したすべてのマシンがリスト表示されます。
注記上記の出力には、一部の CSR が承認されるまで、ワーカーノード (ワーカーノードとも呼ばれる) が含まれない場合があります。
保留中の証明書署名要求 (CSR) を確認し、クラスターに追加したそれぞれのマシンのクライアントおよびサーバー要求に
PendingまたはApprovedステータスが表示されていることを確認します。$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...この例では、2 つのマシンがクラスターに参加しています。このリストにはさらに多くの承認された CSR が表示される可能性があります。
追加したマシンの保留中の CSR すべてが
Pendingステータスになった後に CSR が承認されない場合には、クラスターマシンの CSR を承認します。注記CSR のローテーションは自動的に実行されるため、クラスターにマシンを追加後 1 時間以内に CSR を承認してください。1 時間以内に承認しない場合には、証明書のローテーションが行われ、各ノードに 3 つ以上の証明書が存在するようになります。これらの証明書すべてを承認する必要があります。クライアントの CSR が承認された後に、Kubelet は提供証明書のセカンダリー CSR を作成します。これには、手動の承認が必要になります。次に、後続の提供証明書の更新要求は、Kubelet が同じパラメーターを持つ新規証明書を要求する場合に
machine-approverによって自動的に承認されます。注記ベアメタルおよび他の user-provisioned infrastructure などのマシン API ではないプラットフォームで実行されているクラスターの場合、kubelet 提供証明書要求 (CSR) を自動的に承認する方法を実装する必要があります。要求が承認されない場合、API サーバーが kubelet に接続する際に提供証明書が必須であるため、
oc exec、oc rsh、およびoc logsコマンドは正常に実行できません。Kubelet エンドポイントにアクセスする操作には、この証明書の承認が必要です。この方法は新規 CSR の有無を監視し、CSR がsystem:nodeまたはsystem:adminグループのnode-bootstrapperサービスアカウントによって提出されていることを確認し、ノードの ID を確認します。それらを個別に承認するには、それぞれの有効な CSR に以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve注記一部の Operator は、一部の CSR が承認されるまで利用できない可能性があります。
クライアント要求が承認されたら、クラスターに追加した各マシンのサーバー要求を確認する必要があります。
$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...残りの CSR が承認されず、それらが
Pendingステータスにある場合、クラスターマシンの CSR を承認します。それらを個別に承認するには、それぞれの有効な CSR に以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
すべてのクライアントおよびサーバーの CSR が承認された後に、マシンのステータスが
Readyになります。以下のコマンドを実行して、これを確認します。$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.29.4 master-1 Ready master 73m v1.29.4 master-2 Ready master 74m v1.29.4 worker-0 Ready worker 11m v1.29.4 worker-1 Ready worker 11m v1.29.4注記サーバー CSR の承認後にマシンが
Readyステータスに移行するまでに数分の時間がかかる場合があります。
関連情報
- CSR の詳細は、Certificate Signing Requests を参照してください。
4.7. IBM Z および IBM LinuxONE 上の LPAR にマルチアーキテクチャーコンピュートマシンを含むクラスターを作成する
IBM Z® および IBM® LinuxONE (s390x) 上の LPAR にマルチアーキテクチャーコンピュートマシンを含むクラスターを作成するには、既存のシングルアーキテクチャーの x86_64 クラスターが必要です。その後、s390x コンピュートマシンを OpenShift Container Platform クラスターに追加できます。
s390x ノードをクラスターに追加する前に、クラスターをマルチアーキテクチャーペイロードを使用するクラスターにアップグレードする必要があります。マルチアーキテクチャーペイロードへの移行の詳細は、マルチアーキテクチャーコンピュートマシンを使用したクラスターへの移行 を参照してください。
以下の手順では、LPAR インスタンスを使用して RHCOS コンピュートマシンを作成する方法を説明します。これにより、s390x ノードをクラスターに追加し、マルチアーキテクチャーのコンピュートマシンを含むクラスターをデプロイメントできるようになります。
x86_64 上でマルチアーキテクチャーコンピュートマシンを含む IBM Z® または IBM® LinuxONE (s390x) クラスターを作成するには、IBM Z® および IBM® LinuxONE へのクラスターのインストール の手順に従ってください。その後、ベアメタル、IBM Power、または IBM Z 上でマルチアーキテクチャーコンピュートマシンを含むクラスターを作成する の説明に従って、x86_64 コンピュートマシンを追加できます。
4.7.1. クラスターの互換性の確認
異なるアーキテクチャーのコンピュートノードをクラスターに追加する前に、クラスターがマルチアーキテクチャー互換であることを確認する必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
-
OpenShift CLI (
oc) にログインします。 次のコマンドを実行すると、クラスターがアーキテクチャーペイロードを使用していることを確認できます。
$ oc adm release info -o jsonpath="{ .metadata.metadata}"
検証
次の出力が表示された場合、クラスターはマルチアーキテクチャーペイロードを使用しています。
{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }その後、クラスターへのマルチアーキテクチャーコンピュートノードの追加を開始できます。
次の出力が表示された場合、クラスターはマルチアーキテクチャーペイロードを使用していません。
{ "url": "https://access.redhat.com/errata/<errata_version>" }重要クラスターを、マルチアーキテクチャーコンピュートマシンをサポートするクラスターに移行するには、マルチアーキテクチャーコンピュートマシンを含むクラスターへの移行 の手順に従ってください。
4.7.2. LPAR 内の IBM Z 上に RHCOS マシンを作成する
論理パーティション (LPAR) 内の IBM Z® 上で実行される Red Hat Enterprise Linux CoreOS (RHCOS) コンピュートマシンをさらに作成し、既存のクラスターに割り当てることができます。
前提条件
- ノードのホスト名および逆引き参照を実行できるドメインネームサーバー (DNS) がある。
- 作成するマシンがアクセスできるプロビジョニングマシンで稼働している HTTP または HTTPS サーバーがある。
手順
次のコマンドを実行して、クラスターから Ignition 設定ファイルを抽出します。
$ oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ign-
クラスターからエクスポートした
worker.ignIgnition 設定ファイルを HTTP サーバーにアップロードします。このファイルの URL をメモします。 Ignition ファイルが URL で利用可能であることを検証できます。次の例では、コンピュートノードの Ignition 設定ファイルを取得します。
$ curl -k http://<http_server>/worker.ign次のコマンドを実行して、RHEL ライブ
kernel、initramfs、およびrootfsファイルをダウンロードします。$ curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.kernel.location')$ curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.initramfs.location')$ curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.rootfs.location')-
ダウンロードした RHEL ライブ
kernel、initramfs、およびrootfsファイルを、追加する RHCOS ゲストからアクセス可能な HTTP または HTTPS サーバーに移動します。 ゲストのパラメーターファイルを作成します。次のパラメーターは仮想マシンに固有です。
オプション: 静的 IP アドレスを指定するには、次のエントリーをコロンで区切って
ip=パラメーターを追加します。- マシンの IP アドレス。
- 空の文字列。
- ゲートウェイ。
- ネットマスク。
-
hostname.domainname形式のマシンホストおよびドメイン名。この値を省略すると、RHCOS が逆引き DNS ルックアップによりホスト名を取得します。 - ネットワークインターフェイス名。この値を省略すると、RHCOS が利用可能なすべてのインターフェイスに IP 設定を適用します。
-
値
none。
-
coreos.inst.ignition_url=には、worker.ignファイルへの URL を指定します。HTTP プロトコルおよび HTTPS プロトコルのみがサポートされます。 -
coreos.live.rootfs_url=の場合、起動しているkernelおよびinitramfsの一致する rootfs アーティファクトを指定します。HTTP プロトコルおよび HTTPS プロトコルのみがサポートされます。 DASD タイプのディスクへのインストールには、以下のタスクを実行します。
-
coreos.inst.install_dev=には、/dev/dasdaを指定します。 -
rd.dasd=を使用して、RHCOS がインストールされる DASD を指定します。 必要に応じてさらにパラメーターを調整できます。
以下はパラメーターファイルの例、
additional-worker-dasd.parmです。cio_ignore=all,!condev rd.neednet=1 \ console=ttysclp0 \ coreos.inst.install_dev=/dev/dasda \ coreos.inst.ignition_url=http://<http_server>/worker.ign \ coreos.live.rootfs_url=http://<http_server>/rhcos-<version>-live-rootfs.<architecture>.img \ ip=<ip>::<gateway>:<netmask>:<hostname>::none nameserver=<dns> \ rd.znet=qeth,0.0.bdf0,0.0.bdf1,0.0.bdf2,layer2=1,portno=0 \ rd.dasd=0.0.3490 \ zfcp.allow_lun_scan=0パラメーターファイルのすべてのオプションを 1 行で記述し、改行文字がないことを確認します。
-
FCP タイプのディスクへのインストールには、以下のタスクを実行します。
rd.zfcp=<adapter>,<wwpn>,<lun>を使用して RHCOS がインストールされる FCP ディスクを指定します。マルチパスの場合、それぞれの追加のステップについてこのステップを繰り返します。注記複数のパスを使用してインストールする場合は、問題が発生する可能性があるため、後でではなくインストールの直後にマルチパスを有効にする必要があります。
インストールデバイスを
coreos.inst.install_dev=/dev/sdaとして設定します。注記追加の LUN が NPIV で設定される場合は、FCP に
zfcp.allow_lun_scan=0が必要です。CSI ドライバーを使用するためにzfcp.allow_lun_scan=1を有効にする必要がある場合などには、各ノードが別のノードのブートパーティションにアクセスできないように NPIV を設定する必要があります。必要に応じてさらにパラメーターを調整できます。
重要マルチパスを完全に有効にするには、インストール後の追加の手順が必要です。詳細は、マシン設定 の「RHCOS のカーネル引数でのマルチパスの有効化」を参照してください。
以下は、マルチパスを使用するワーカーノードのパラメーターファイルの例
additional-worker-fcp.parmです。cio_ignore=all,!condev rd.neednet=1 \ console=ttysclp0 \ coreos.inst.install_dev=/dev/sda \ coreos.live.rootfs_url=http://<http_server>/rhcos-<version>-live-rootfs.<architecture>.img \ coreos.inst.ignition_url=http://<http_server>/worker.ign \ ip=<ip>::<gateway>:<netmask>:<hostname>::none nameserver=<dns> \ rd.znet=qeth,0.0.bdf0,0.0.bdf1,0.0.bdf2,layer2=1,portno=0 \ zfcp.allow_lun_scan=0 \ rd.zfcp=0.0.1987,0x50050763070bc5e3,0x4008400B00000000 \ rd.zfcp=0.0.19C7,0x50050763070bc5e3,0x4008400B00000000 \ rd.zfcp=0.0.1987,0x50050763071bc5e3,0x4008400B00000000 \ rd.zfcp=0.0.19C7,0x50050763071bc5e3,0x4008400B00000000パラメーターファイルのすべてのオプションを 1 行で記述し、改行文字がないことを確認します。
- FTP などを使用し、initramfs、kernel、パラメーターファイル、および RHCOS イメージを LPAR に転送します。FTP を使用してファイルを転送し、起動する方法の詳細は、IBM Z® でインストールを起動して LPAR に RHEL をインストールする を参照してください。
- マシンを起動します。
4.7.3. マシンの証明書署名要求の承認
マシンをクラスターに追加する際に、追加したそれぞれのマシンに対して 2 つの保留状態の証明書署名要求 (CSR) が生成されます。これらの CSR が承認されていることを確認するか、必要な場合はそれらを承認してください。最初にクライアント要求を承認し、次にサーバー要求を承認する必要があります。
前提条件
- マシンがクラスターに追加されています。
手順
クラスターがマシンを認識していることを確認します。
$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.29.4 master-1 Ready master 63m v1.29.4 master-2 Ready master 64m v1.29.4出力には作成したすべてのマシンがリスト表示されます。
注記上記の出力には、一部の CSR が承認されるまで、ワーカーノード (ワーカーノードとも呼ばれる) が含まれない場合があります。
保留中の証明書署名要求 (CSR) を確認し、クラスターに追加したそれぞれのマシンのクライアントおよびサーバー要求に
PendingまたはApprovedステータスが表示されていることを確認します。$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...この例では、2 つのマシンがクラスターに参加しています。このリストにはさらに多くの承認された CSR が表示される可能性があります。
追加したマシンの保留中の CSR すべてが
Pendingステータスになった後に CSR が承認されない場合には、クラスターマシンの CSR を承認します。注記CSR のローテーションは自動的に実行されるため、クラスターにマシンを追加後 1 時間以内に CSR を承認してください。1 時間以内に承認しない場合には、証明書のローテーションが行われ、各ノードに 3 つ以上の証明書が存在するようになります。これらの証明書すべてを承認する必要があります。クライアントの CSR が承認された後に、Kubelet は提供証明書のセカンダリー CSR を作成します。これには、手動の承認が必要になります。次に、後続の提供証明書の更新要求は、Kubelet が同じパラメーターを持つ新規証明書を要求する場合に
machine-approverによって自動的に承認されます。注記ベアメタルおよび他の user-provisioned infrastructure などのマシン API ではないプラットフォームで実行されているクラスターの場合、kubelet 提供証明書要求 (CSR) を自動的に承認する方法を実装する必要があります。要求が承認されない場合、API サーバーが kubelet に接続する際に提供証明書が必須であるため、
oc exec、oc rsh、およびoc logsコマンドは正常に実行できません。Kubelet エンドポイントにアクセスする操作には、この証明書の承認が必要です。この方法は新規 CSR の有無を監視し、CSR がsystem:nodeまたはsystem:adminグループのnode-bootstrapperサービスアカウントによって提出されていることを確認し、ノードの ID を確認します。それらを個別に承認するには、それぞれの有効な CSR に以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve注記一部の Operator は、一部の CSR が承認されるまで利用できない可能性があります。
クライアント要求が承認されたら、クラスターに追加した各マシンのサーバー要求を確認する必要があります。
$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...残りの CSR が承認されず、それらが
Pendingステータスにある場合、クラスターマシンの CSR を承認します。それらを個別に承認するには、それぞれの有効な CSR に以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
すべてのクライアントおよびサーバーの CSR が承認された後に、マシンのステータスが
Readyになります。以下のコマンドを実行して、これを確認します。$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.29.4 master-1 Ready master 73m v1.29.4 master-2 Ready master 74m v1.29.4 worker-0 Ready worker 11m v1.29.4 worker-1 Ready worker 11m v1.29.4注記サーバー CSR の承認後にマシンが
Readyステータスに移行するまでに数分の時間がかかる場合があります。
関連情報
- CSR の詳細は、Certificate Signing Requests を参照してください。
4.8. RHEL KVM を使用した IBM Z および IBM LinuxONE 上でマルチアーキテクチャーのコンピュートマシンを含むクラスターを作成する
RHEL KVM を使用して IBM Z® および IBM® LinuxONE (s390x) 上のマルチアーキテクチャーコンピュートマシンでクラスターを作成するには、既存の単一アーキテクチャー x86_64 クラスターが必要です。その後、s390x コンピュートマシンを OpenShift Container Platform クラスターに追加できます。
s390x ノードをクラスターに追加する前に、クラスターをマルチアーキテクチャーペイロードを使用するクラスターにアップグレードする必要があります。マルチアーキテクチャーペイロードへの移行の詳細は、マルチアーキテクチャーコンピュートマシンを使用したクラスターへの移行 を参照してください。
次の手順では、RHEL KVM インスタンスを使用して RHCOS コンピュートマシンを作成する方法を説明します。これにより、s390x ノードをクラスターに追加し、マルチアーキテクチャーのコンピュートマシンを含むクラスターをデプロイメントできるようになります。
x86_64 上でマルチアーキテクチャーコンピュートマシンを含む IBM Z® または IBM® LinuxONE (s390x) クラスターを作成するには、IBM Z® および IBM® LinuxONE へのクラスターのインストール の手順に従ってください。その後、ベアメタル、IBM Power、または IBM Z 上でマルチアーキテクチャーコンピュートマシンを含むクラスターを作成する の説明に従って、x86_64 コンピュートマシンを追加できます。
セカンダリーアーキテクチャーノードをクラスターに追加する前に、Multiarch Tuning Operator をインストールし、ClusterPodPlacementConfig オブジェクトをデプロイすることを推奨します。詳細は、Multiarch Tuning Operator を使用してマルチアーキテクチャークラスター上のワークロードを管理する を参照してください。
4.8.1. クラスターの互換性の確認
異なるアーキテクチャーのコンピュートノードをクラスターに追加する前に、クラスターがマルチアーキテクチャー互換であることを確認する必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
-
OpenShift CLI (
oc) にログインします。 次のコマンドを実行すると、クラスターがアーキテクチャーペイロードを使用していることを確認できます。
$ oc adm release info -o jsonpath="{ .metadata.metadata}"
検証
次の出力が表示された場合、クラスターはマルチアーキテクチャーペイロードを使用しています。
{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }その後、クラスターへのマルチアーキテクチャーコンピュートノードの追加を開始できます。
次の出力が表示された場合、クラスターはマルチアーキテクチャーペイロードを使用していません。
{ "url": "https://access.redhat.com/errata/<errata_version>" }重要クラスターを、マルチアーキテクチャーコンピュートマシンをサポートするクラスターに移行するには、マルチアーキテクチャーコンピュートマシンを含むクラスターへの移行 の手順に従ってください。
4.8.2. virt-install を使用した RHCOS マシンの作成
virt-install を使用すると、クラスター用にさらに Red Hat Enterprise Linux CoreOS (RHCOS) コンピュートマシンを作成できます。
前提条件
- この手順では RHEL KVM ホストと呼ばれる、KVM を使用する RHEL 8.7 以降で実行されている少なくとも 1 つの LPAR がある。
- KVM/QEMU ハイパーバイザーが RHEL KVM ホストにインストーされている
- ノードのホスト名および逆引き参照を実行できるドメインネームサーバー (DNS) がある。
- HTTP または HTTPS サーバーが設定されている。
手順
次のコマンドを実行して、クラスターから Ignition 設定ファイルを抽出します。
$ oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ign-
クラスターからエクスポートした
worker.ignIgnition 設定ファイルを HTTP サーバーにアップロードします。このファイルの URL をメモします。 Ignition ファイルが URL で利用可能であることを検証できます。次の例では、コンピュートノードの Ignition 設定ファイルを取得します。
$ curl -k http://<HTTP_server>/worker.ign次のコマンドを実行して、RHEL ライブ
kernel、initramfs、およびrootfsファイルをダウンロードします。$ curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.kernel.location')$ curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.initramfs.location')$ curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.rootfs.location')-
virt-installを起動する前に、ダウンロードした RHEL ライブkernel、initramfs、およびrootfsファイルを HTTP または HTTPS サーバーに移動します。 RHEL
kernel、initramfs、および Ignition ファイル、新規ディスクイメージ、および調整された parm 引数を使用して、新規 KVM ゲストノードを作成します。$ virt-install \ --connect qemu:///system \ --name <vm_name> \ --autostart \ --os-variant rhel9.4 \1 --cpu host \ --vcpus <vcpus> \ --memory <memory_mb> \ --disk <vm_name>.qcow2,size=<image_size> \ --network network=<virt_network_parm> \ --location <media_location>,kernel=<rhcos_kernel>,initrd=<rhcos_initrd> \2 --extra-args "rd.neednet=1" \ --extra-args "coreos.inst.install_dev=/dev/vda" \ --extra-args "coreos.inst.ignition_url=http://<http_server>/worker.ign " \3 --extra-args "coreos.live.rootfs_url=http://<http_server>/rhcos-<version>-live-rootfs.<architecture>.img" \4 --extra-args "ip=<ip>::<gateway>:<netmask>:<hostname>::none" \5 --extra-args "nameserver=<dns>" \ --extra-args "console=ttysclp0" \ --noautoconsole \ --wait- 1
os-variantには、RHCOS コンピュートマシンの RHEL バージョンを指定します。rhel9.4が推奨バージョンです。オペレーティングシステムのサポートされている RHEL バージョンを照会するには、次のコマンドを実行します。$ osinfo-query os -f short-id注記os-variantでは大文字と小文字が区別されます。- 2
--locationには、HTTP サーバーまたは HTTPS サーバーのカーネル/initrd の場所を指定します。- 3
worker.ign設定ファイルの場所を指定します。HTTP プロトコルおよび HTTPS プロトコルのみがサポートされます。- 4
- 起動する
kernelとinitramfsのrootfsアーティファクトの場所を指定します。HTTP および HTTPS プロトコルのみがサポートされています。 - 5
- オプション:
hostnameには、クライアントマシンの完全修飾ホスト名を指定します。
注記HAProxy をロードバランサーとして使用している場合は、
/etc/haproxy/haproxy.cfg設定ファイル内のingress-router-443およびingress-router-80の HAProxy ルールを更新します。- 継続してクラスター用の追加のコンピュートマシンを作成します。
4.8.3. マシンの証明書署名要求の承認
マシンをクラスターに追加する際に、追加したそれぞれのマシンに対して 2 つの保留状態の証明書署名要求 (CSR) が生成されます。これらの CSR が承認されていることを確認するか、必要な場合はそれらを承認してください。最初にクライアント要求を承認し、次にサーバー要求を承認する必要があります。
前提条件
- マシンがクラスターに追加されています。
手順
クラスターがマシンを認識していることを確認します。
$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.29.4 master-1 Ready master 63m v1.29.4 master-2 Ready master 64m v1.29.4出力には作成したすべてのマシンがリスト表示されます。
注記上記の出力には、一部の CSR が承認されるまで、ワーカーノード (ワーカーノードとも呼ばれる) が含まれない場合があります。
保留中の証明書署名要求 (CSR) を確認し、クラスターに追加したそれぞれのマシンのクライアントおよびサーバー要求に
PendingまたはApprovedステータスが表示されていることを確認します。$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...この例では、2 つのマシンがクラスターに参加しています。このリストにはさらに多くの承認された CSR が表示される可能性があります。
追加したマシンの保留中の CSR すべてが
Pendingステータスになった後に CSR が承認されない場合には、クラスターマシンの CSR を承認します。注記CSR のローテーションは自動的に実行されるため、クラスターにマシンを追加後 1 時間以内に CSR を承認してください。1 時間以内に承認しない場合には、証明書のローテーションが行われ、各ノードに 3 つ以上の証明書が存在するようになります。これらの証明書すべてを承認する必要があります。クライアントの CSR が承認された後に、Kubelet は提供証明書のセカンダリー CSR を作成します。これには、手動の承認が必要になります。次に、後続の提供証明書の更新要求は、Kubelet が同じパラメーターを持つ新規証明書を要求する場合に
machine-approverによって自動的に承認されます。注記ベアメタルおよび他の user-provisioned infrastructure などのマシン API ではないプラットフォームで実行されているクラスターの場合、kubelet 提供証明書要求 (CSR) を自動的に承認する方法を実装する必要があります。要求が承認されない場合、API サーバーが kubelet に接続する際に提供証明書が必須であるため、
oc exec、oc rsh、およびoc logsコマンドは正常に実行できません。Kubelet エンドポイントにアクセスする操作には、この証明書の承認が必要です。この方法は新規 CSR の有無を監視し、CSR がsystem:nodeまたはsystem:adminグループのnode-bootstrapperサービスアカウントによって提出されていることを確認し、ノードの ID を確認します。それらを個別に承認するには、それぞれの有効な CSR に以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve注記一部の Operator は、一部の CSR が承認されるまで利用できない可能性があります。
クライアント要求が承認されたら、クラスターに追加した各マシンのサーバー要求を確認する必要があります。
$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...残りの CSR が承認されず、それらが
Pendingステータスにある場合、クラスターマシンの CSR を承認します。それらを個別に承認するには、それぞれの有効な CSR に以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
すべてのクライアントおよびサーバーの CSR が承認された後に、マシンのステータスが
Readyになります。以下のコマンドを実行して、これを確認します。$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.29.4 master-1 Ready master 73m v1.29.4 master-2 Ready master 74m v1.29.4 worker-0 Ready worker 11m v1.29.4 worker-1 Ready worker 11m v1.29.4注記サーバー CSR の承認後にマシンが
Readyステータスに移行するまでに数分の時間がかかる場合があります。
関連情報
- CSR の詳細は、Certificate Signing Requests を参照してください。
4.9. IBM Power 上でマルチアーキテクチャーのコンピュートマシンを含むクラスターを作成する
IBM Power® (ppc64le) 上でマルチアーキテクチャーのコンピュートマシンを含むクラスターを作成するには、既存の単一アーキテクチャー (x86_64) クラスターが必要です。その後、ppc64le コンピュートマシンを OpenShift Container Platform クラスターに追加できます。
ppc64le ノードをクラスターに追加する前に、クラスターをマルチアーキテクチャーペイロードを使用するクラスターにアップグレードする必要があります。マルチアーキテクチャーペイロードへの移行の詳細は、マルチアーキテクチャーコンピュートマシンを使用したクラスターへの移行 を参照してください。
次の手順では、ISO イメージまたはネットワーク PXE ブートを使用して RHCOS コンピュートマシンを作成する方法を説明します。これにより、ppc64le ノードをクラスターに追加し、マルチアーキテクチャーのコンピュートマシンを含むクラスターをデプロイできるようになります。
x86_64 上でマルチアーキテクチャーのコンピュートマシンを含む IBM Power® (ppc64le) クラスターを作成するには、IBM Power® へのクラスターのインストール の手順に従ってください。その後、ベアメタル、IBM Power、または IBM Z 上でマルチアーキテクチャーコンピュートマシンを含むクラスターを作成する の説明に従って、x86_64 コンピュートマシンを追加できます。
セカンダリーアーキテクチャーノードをクラスターに追加する前に、Multiarch Tuning Operator をインストールし、ClusterPodPlacementConfig オブジェクトをデプロイすることを推奨します。詳細は、Multiarch Tuning Operator を使用してマルチアーキテクチャークラスター上のワークロードを管理する を参照してください。
4.9.1. クラスターの互換性の確認
異なるアーキテクチャーのコンピュートノードをクラスターに追加する前に、クラスターがマルチアーキテクチャー互換であることを確認する必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
複数のアーキテクチャーを使用する場合、OpenShift Container Platform ノードのホストは同じストレージレイヤーを共有する必要があります。同じストレージレイヤーがない場合は、nfs-provisioner などのストレージプロバイダーを使用します。
コンピュートプレーンとコントロールプレーン間のネットワークホップ数をできる限り制限する必要があります。
手順
-
OpenShift CLI (
oc) にログインします。 次のコマンドを実行すると、クラスターがアーキテクチャーペイロードを使用していることを確認できます。
$ oc adm release info -o jsonpath="{ .metadata.metadata}"
検証
次の出力が表示された場合、クラスターはマルチアーキテクチャーペイロードを使用しています。
{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }その後、クラスターへのマルチアーキテクチャーコンピュートノードの追加を開始できます。
次の出力が表示された場合、クラスターはマルチアーキテクチャーペイロードを使用していません。
{ "url": "https://access.redhat.com/errata/<errata_version>" }重要クラスターを、マルチアーキテクチャーコンピュートマシンをサポートするクラスターに移行するには、マルチアーキテクチャーコンピュートマシンを含むクラスターへの移行 の手順に従ってください。
4.9.2. ISO イメージを使用した RHCOS マシンの作成
ISO イメージを使用して、クラスターの追加の Red Hat Enterprise Linux CoreOS (RHCOS) コンピュートマシンを作成できます。
前提条件
- クラスターのコンピュートマシンの Ignition 設定ファイルの URL を取得します。このファイルがインストール時に HTTP サーバーにアップロードされている必要があります。
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、クラスターから Ignition 設定ファイルを抽出します。
$ oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ign-
クラスターからエクスポートした
worker.ignIgnition 設定ファイルを HTTP サーバーにアップロードします。これらのファイルの URL をメモします。 Ignition ファイルが URL で利用可能であることを検証できます。次の例では、コンピュートノードの Ignition 設定ファイルを取得します。
$ curl -k http://<HTTP_server>/worker.ign次のコマンドを実行すると、新しいマシンを起動するための ISO イメージにアクセスできます。
RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.<architecture>.artifacts.metal.formats.iso.disk.location')ISO ファイルを使用して、追加のコンピュートマシンに RHCOS をインストールします。クラスターのインストール前にマシンを作成する際に使用したのと同じ方法を使用します。
- ディスクに ISO イメージを書き込み、これを直接起動します。
- LOM インターフェイスで ISO リダイレクトを使用します。
オプションを指定したり、ライブ起動シーケンスを中断したりせずに、RHCOS ISO イメージを起動します。インストーラーが RHCOS ライブ環境でシェルプロンプトを起動するのを待ちます。
注記RHCOS インストールの起動プロセスを中断して、カーネル引数を追加できます。ただし、この ISO 手順では、カーネル引数を追加する代わりに、次の手順で概説するように
coreos-installerコマンドを使用する必要があります。coreos-installerコマンドを実行します。インストール要件に合わせてオプションを指定します。少なくとも、該当するノードタイプ用の Ignition 設定ファイルを指す URL と、インストール先のデバイスを指定する必要があります。$ sudo coreos-installer install --ignition-url=http://<HTTP_server>/<node_type>.ign <device> --ignition-hash=sha512-<digest>1 2 注記TLS を使用する HTTPS サーバーを使用して Ignition 設定ファイルを提供する場合は、
coreos-installerを実行する前に、内部認証局 (CA) をシステムのトラストストアに追加できます。次の例では、
/dev/sdaデバイスへのコンピュートノードのインストールを開始します。コンピュートノードの Ignition 設定ファイルは、IP アドレス 192.168.1.2 の HTTP Web サーバーから取得されます。$ sudo coreos-installer install --ignition-url=http://192.168.1.2:80/installation_directory/worker.ign /dev/sda --ignition-hash=sha512-a5a2d43879223273c9b60af66b44202a1d1248fc01cf156c46d4a79f552b6bad47bc8cc78ddf0116e80c59d2ea9e32ba53bc807afbca581aa059311def2c3e3bマシンのコンソールで RHCOS インストールの進捗を監視します。
重要OpenShift Container Platform のインストールを開始する前に、各ノードでインストールが成功していることを確認します。インストールプロセスを監視すると、発生する可能性のある RHCOS インストールの問題の原因を特定する上でも役立ちます。
- 継続してクラスター用の追加のコンピュートマシンを作成します。
4.9.3. PXE または iPXE ブートによる RHCOS マシンの作成
PXE または iPXE ブートを使用して、ベアメタルクラスターの追加の Red Hat Enterprise Linux CoreOS (RHCOS) コンピュートマシンを作成できます。
前提条件
- クラスターのコンピュートマシンの Ignition 設定ファイルの URL を取得します。このファイルがインストール時に HTTP サーバーにアップロードされている必要があります。
-
クラスターのインストール時に HTTP サーバーにアップロードした RHCOS ISO イメージ、圧縮されたメタル BIOS、
kernel、およびinitramfsファイルの URL を取得します。 - インストール時に OpenShift Container Platform クラスターのマシンを作成するために使用した PXE ブートインフラストラクチャーにアクセスできる必要があります。RHCOS のインストール後にマシンはローカルディスクから起動する必要があります。
-
UEFI を使用する場合、OpenShift Container Platform のインストール時に変更した
grub.confファイルにアクセスできます。
手順
RHCOS イメージの PXE または iPXE インストールが正常に行われていることを確認します。
PXE の場合:
DEFAULT pxeboot TIMEOUT 20 PROMPT 0 LABEL pxeboot KERNEL http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture>1 APPEND initrd=http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img2 - 1
- HTTP サーバーにアップロードしたライブ
kernelファイルの場所を指定します。 - 2
- HTTP サーバーにアップロードした RHCOS ファイルの場所を指定します。
initrdパラメーターはライブinitramfsファイルの場所であり、coreos.inst.ignition_urlパラメーター値はワーカー Ignition 設定ファイルの場所であり、coreos.live.rootfs_urlパラメーター値はライブrootfsファイルの場所になります。coreos.inst.ignition_urlおよびcoreos.live.rootfs_urlパラメーターは HTTP および HTTPS のみをサポートします。
注記この設定では、グラフィカルコンソールを使用するマシンでシリアルコンソールアクセスを有効にしません。別のコンソールを設定するには、
APPEND行に 1 つ以上のconsole=引数を追加します。たとえば、console=tty0 console=ttyS0を追加して、最初の PC シリアルポートをプライマリーコンソールとして、グラフィカルコンソールをセカンダリーコンソールとして設定します。詳細は、How does one set up a serial terminal and/or console in Red Hat Enterprise Linux? を参照してください。iPXE (
x86_64+ppc64le) の場合:kernel http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture> initrd=main coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign1 2 initrd --name main http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img3 boot- 1
- HTTP サーバーにアップロードした RHCOS ファイルの場所を指定します。
kernelパラメーター値はkernelファイルの場所であり、initrd=main引数は UEFI システムでの起動に必要であり、coreos.live.rootfs_urlパラメーター値はワーカー Ignition 設定ファイルの場所であり、coreos.inst.ignition_urlパラメーター値はrootfsのライブファイルの場所です。 - 2
- 複数の NIC を使用する場合、
ipオプションに単一インターフェイスを指定します。たとえば、eno1という名前の NIC で DHCP を使用するには、ip=eno1:dhcpを設定します。 - 3
- HTTP サーバーにアップロードした
initramfsファイルの場所を指定します。
注記この設定では、グラフィカルコンソールを備えたマシンでのシリアルコンソールアクセスは有効になりません。別のコンソールを設定するには、
kernel行に 1 つ以上のconsole=引数を追加します。たとえば、console=tty0 console=ttyS0を追加して、最初の PC シリアルポートをプライマリーコンソールとして、グラフィカルコンソールをセカンダリーコンソールとして設定します。詳細は、How does one set up a serial terminal and/or console in Red Hat Enterprise Linux? と、「高度な RHCOS インストール設定」セクションの「PXE および ISO インストール用シリアルコンソールの有効化」を参照してください。注記ppc64leアーキテクチャーで CoreOSkernelをネットワークブートするには、IMAGE_GZIPオプションが有効になっているバージョンの iPXE ビルドを使用する必要があります。iPXE のIMAGE_GZIPオプション を参照してください。ppc64le上の PXE (第 2 段階として UEFI と GRUB を使用) の場合:menuentry 'Install CoreOS' { linux rhcos-<version>-live-kernel-<architecture> coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign1 2 initrd rhcos-<version>-live-initramfs.<architecture>.img3 }- 1
- HTTP/TFTP サーバーにアップロードした RHCOS ファイルの場所を指定します。
kernelパラメーター値は、TFTP サーバー上のkernelファイルの場所になります。coreos.live.rootfs_urlパラメーター値はrootfsファイルの場所であり、coreos.inst.ignition_urlパラメーター値は HTTP サーバー上のブートストラップ Ignition 設定ファイルの場所になります。 - 2
- 複数の NIC を使用する場合、
ipオプションに単一インターフェイスを指定します。たとえば、eno1という名前の NIC で DHCP を使用するには、ip=eno1:dhcpを設定します。 - 3
- TFTP サーバーにアップロードした
initramfsファイルの場所を指定します。
- PXE または iPXE インフラストラクチャーを使用して、クラスターに必要なコンピュートマシンを作成します。
4.9.4. マシンの証明書署名要求の承認
マシンをクラスターに追加する際に、追加したそれぞれのマシンに対して 2 つの保留状態の証明書署名要求 (CSR) が生成されます。これらの CSR が承認されていることを確認するか、必要な場合はそれらを承認してください。最初にクライアント要求を承認し、次にサーバー要求を承認する必要があります。
前提条件
- マシンがクラスターに追加されています。
手順
クラスターがマシンを認識していることを確認します。
$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.29.4 master-1 Ready master 63m v1.29.4 master-2 Ready master 64m v1.29.4出力には作成したすべてのマシンがリスト表示されます。
注記上記の出力には、一部の CSR が承認されるまで、ワーカーノード (ワーカーノードとも呼ばれる) が含まれない場合があります。
保留中の証明書署名要求 (CSR) を確認し、クラスターに追加したそれぞれのマシンのクライアントおよびサーバー要求に
PendingまたはApprovedステータスが表示されていることを確認します。$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...この例では、2 つのマシンがクラスターに参加しています。このリストにはさらに多くの承認された CSR が表示される可能性があります。
追加したマシンの保留中の CSR すべてが
Pendingステータスになった後に CSR が承認されない場合には、クラスターマシンの CSR を承認します。注記CSR のローテーションは自動的に実行されるため、クラスターにマシンを追加後 1 時間以内に CSR を承認してください。1 時間以内に承認しない場合には、証明書のローテーションが行われ、各ノードに 3 つ以上の証明書が存在するようになります。これらの証明書すべてを承認する必要があります。クライアントの CSR が承認された後に、Kubelet は提供証明書のセカンダリー CSR を作成します。これには、手動の承認が必要になります。次に、後続の提供証明書の更新要求は、Kubelet が同じパラメーターを持つ新規証明書を要求する場合に
machine-approverによって自動的に承認されます。注記ベアメタルおよび他の user-provisioned infrastructure などのマシン API ではないプラットフォームで実行されているクラスターの場合、kubelet 提供証明書要求 (CSR) を自動的に承認する方法を実装する必要があります。要求が承認されない場合、API サーバーが kubelet に接続する際に提供証明書が必須であるため、
oc exec、oc rsh、およびoc logsコマンドは正常に実行できません。Kubelet エンドポイントにアクセスする操作には、この証明書の承認が必要です。この方法は新規 CSR の有無を監視し、CSR がsystem:nodeまたはsystem:adminグループのnode-bootstrapperサービスアカウントによって提出されていることを確認し、ノードの ID を確認します。それらを個別に承認するには、それぞれの有効な CSR に以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve注記一部の Operator は、一部の CSR が承認されるまで利用できない可能性があります。
クライアント要求が承認されたら、クラスターに追加した各マシンのサーバー要求を確認する必要があります。
$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...残りの CSR が承認されず、それらが
Pendingステータスにある場合、クラスターマシンの CSR を承認します。それらを個別に承認するには、それぞれの有効な CSR に以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
すべてのクライアントおよびサーバーの CSR が承認された後に、マシンのステータスが
Readyになります。以下のコマンドを実行して、これを確認します。$ oc get nodes -o wide出力例
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME worker-0-ppc64le Ready worker 42d v1.29.5 192.168.200.21 <none> Red Hat Enterprise Linux CoreOS 415.92.202309261919-0 (Plow) 5.14.0-284.34.1.el9_2.ppc64le cri-o://1.29.5-3.rhaos4.15.gitb36169e.el9 worker-1-ppc64le Ready worker 42d v1.29.5 192.168.200.20 <none> Red Hat Enterprise Linux CoreOS 415.92.202309261919-0 (Plow) 5.14.0-284.34.1.el9_2.ppc64le cri-o://1.29.5-3.rhaos4.15.gitb36169e.el9 master-0-x86 Ready control-plane,master 75d v1.29.5 10.248.0.38 10.248.0.38 Red Hat Enterprise Linux CoreOS 415.92.202309261919-0 (Plow) 5.14.0-284.34.1.el9_2.x86_64 cri-o://1.29.5-3.rhaos4.15.gitb36169e.el9 master-1-x86 Ready control-plane,master 75d v1.29.5 10.248.0.39 10.248.0.39 Red Hat Enterprise Linux CoreOS 415.92.202309261919-0 (Plow) 5.14.0-284.34.1.el9_2.x86_64 cri-o://1.29.5-3.rhaos4.15.gitb36169e.el9 master-2-x86 Ready control-plane,master 75d v1.29.5 10.248.0.40 10.248.0.40 Red Hat Enterprise Linux CoreOS 415.92.202309261919-0 (Plow) 5.14.0-284.34.1.el9_2.x86_64 cri-o://1.29.5-3.rhaos4.15.gitb36169e.el9 worker-0-x86 Ready worker 75d v1.29.5 10.248.0.43 10.248.0.43 Red Hat Enterprise Linux CoreOS 415.92.202309261919-0 (Plow) 5.14.0-284.34.1.el9_2.x86_64 cri-o://1.29.5-3.rhaos4.15.gitb36169e.el9 worker-1-x86 Ready worker 75d v1.29.5 10.248.0.44 10.248.0.44 Red Hat Enterprise Linux CoreOS 415.92.202309261919-0 (Plow) 5.14.0-284.34.1.el9_2.x86_64 cri-o://1.29.5-3.rhaos4.15.gitb36169e.el9注記サーバー CSR の承認後にマシンが
Readyステータスに移行するまでに数分の時間がかかる場合があります。
関連情報
- CSR の詳細は、Certificate Signing Requests を参照してください。
4.10. マルチアーキテクチャーコンピュートマシンを含むクラスターの管理
4.10.1. マルチアーキテクチャーのコンピュートマシンを含むクラスターでワークロードをスケジュールする
さまざまなアーキテクチャーのコンピュートノードを含むクラスターにワークロードをデプロイするには、クラスターの注意と監視が必要です。クラスターのノードに Pod を正常に配置するには、さらにアクションが必要な場合があります。
Multiarch Tuning Operator を使用すると、マルチアーキテクチャーコンピュートマシンを含むクラスターで、アーキテクチャーを考慮したワークロードのスケジューリングを有効にできます。Multiarch Tuning Operator は、Pod が作成時にサポートできるアーキテクチャーに基づいて、Pod 仕様に追加のスケジューラー述語を実装します。詳細は、Multiarch Tuning Operator を使用してマルチアーキテクチャークラスター上のワークロードを管理する を参照してください。
ノードアフィニティー、スケジューリング、taint、toleration の詳細は、次のドキュメントを参照してください。
4.10.1.1. マルチアーキテクチャーノードのワークロードデプロイメントのサンプル
異なるアーキテクチャーのコンピュートノードを含むクラスター上でワークロードをスケジュールする前に、次の使用例を考慮してください。
- ノードアフィニティーを使用してノード上のワークロードをスケジュールする
イメージによってサポートされるアーキテクチャーを持つ一連のノード上でのみワークロードをスケジュールできるようにすることができ、Pod のテンプレート仕様で
spec.affinity.nodeAffinityフィールドを設定できます。特定のアーキテクチャーに設定された
nodeAffinityを使用したデプロイメントの例apiVersion: apps/v1 kind: Deployment metadata: # ... spec: # ... template: # ... spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/arch operator: In values:1 - amd64 - arm64- 1
- サポートされるアーキテクチャーを指定します。有効な値には、
amd64、arm64、または両方の値が含まれます。
- 特定のアーキテクチャー向けにすべてのノードを taint する
ノードを taint して、そのノード上でそのアーキテクチャーと互換性のないワークロードがスケジュールされるのを回避できます。クラスターが
MachineSetオブジェクトを使用している場合は、サポートされていないアーキテクチャーのノードでワークロードがスケジュールされるのを回避するために、パラメーターを.spec.template.spec.taintsフィールドに追加できます。ノードを taint する前に、
MachineSetオブジェクトをスケールダウンするか、使用可能なマシンを削除する必要があります。次のコマンドのいずれかを使用して、マシンセットをスケールダウンできます。$ oc scale --replicas=0 machineset <machineset> -n openshift-machine-apiまたは、以下を実行します。
$ oc edit machineset <machineset> -n openshift-machine-apiマシンセットのスケーリングの詳細は、「コンピュートマシンセットの変更」を参照してください。
taint セットを含む
MachineSetの例apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: # ... spec: # ... template: # ... spec: # ... taints: - effect: NoSchedule key: multi-arch.openshift.io/arch value: arm64次のコマンドを実行して、特定のノードに taint を設定することもできます。
$ oc adm taint nodes <node-name> multi-arch.openshift.io/arch=arm64:NoSchedule- デフォルト許容範囲の作成
次のコマンドを実行して、namespace にアノテーションを付けて、すべてのワークロードが同じデフォルトの許容範囲を取得できるようにすることができます。
$ oc annotate namespace my-namespace \ 'scheduler.alpha.kubernetes.io/defaultTolerations'='[{"operator": "Exists", "effect": "NoSchedule", "key": "multi-arch.openshift.io/arch"}]'- ワークロードにおけるアーキテクチャーの taint を許容する
taint が定義されたノードでは、そのノード上でワークロードはスケジュールされません。ただし、Pod の仕様で toleration を設定することで、スケジュールを許可できます。
許容を備えた導入例
apiVersion: apps/v1 kind: Deployment metadata: # ... spec: # ... template: # ... spec: tolerations: - key: "multi-arch.openshift.io/arch" value: "arm64" operator: "Equal" effect: "NoSchedule"このデプロイメント例は、
multi-arch.openshift.io/arch=arm64taint が指定されたノードでも許可できます。- taint および許容でのノードアフィニティーの使用
スケジューラーが Pod をスケジュールするためにノードのセットを計算する場合は、ノードアフィニティーによってセットが制限される一方で、許容によってセットが拡大する可能性があります。特定のアーキテクチャーのノードに taint を設定する場合、Pod のスケジュールには次の例の許容が必要です。
ノードアフィニティーと許容セットを使用したデプロイメントの例。
apiVersion: apps/v1 kind: Deployment metadata: # ... spec: # ... template: # ... spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/arch operator: In values: - amd64 - arm64 tolerations: - key: "multi-arch.openshift.io/arch" value: "arm64" operator: "Equal" effect: "NoSchedule"
関連情報
4.10.2. Red Hat Enterprise Linux CoreOS (RHCOS) カーネルでの 64k ページの有効化
クラスター内の 64 ビット ARM コンピュートマシン上の Red Hat Enterprise Linux CoreOS (RHCOS) カーネルで 64k メモリーページを有効にすることができます。64k ページサイズのカーネル仕様は、大規模な GPU または高メモリーのワークロードに使用できます。これは、マシン設定プールを使用してカーネルを更新する Machine Config Operator (MCO) を使用して行われます。64k ページサイズを有効にするには、ARM64 専用のマシン設定プールをカーネルで有効にする必要があります。
64k ページの使用は、64 ビット ARM マシンにインストールされた 64 ビット ARM アーキテクチャーのコンピュートノードまたはクラスターに限定されます。64 ビット x86 マシンを使用してマシン設定プールに 64k ページのカーネルを設定すると、マシン設定プールと MCO がデグレード状態になります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - サポート対象のいずれかのプラットフォームで、異なるアーキテクチャーのコンピュートノードを含むクラスターを作成している。
手順
64k ページサイズのカーネルを実行するノードにラベルを付けます。
$ oc label node <node_name> <label>コマンドの例
$ oc label node worker-arm64-01 node-role.kubernetes.io/worker-64k-pages=ARM64 アーキテクチャーを使用するワーカーロールと
worker-64k-pagesロールを含むマシン設定プールを作成します。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: worker-64k-pages spec: machineConfigSelector: matchExpressions: - key: machineconfiguration.openshift.io/role operator: In values: - worker - worker-64k-pages nodeSelector: matchLabels: node-role.kubernetes.io/worker-64k-pages: "" kubernetes.io/arch: arm64コンピュートノード上にマシン設定を作成し、
64k-pagesパラメーターを使用して64k-pagesを有効にします。$ oc create -f <filename>.yamlMachineConfig の例
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: "worker-64k-pages"1 name: 99-worker-64kpages spec: kernelType: 64k-pages2 注記64k-pagesタイプは、64 ビット ARM アーキテクチャーベースのコンピュートノードでのみサポートされます。realtimeタイプは、64 ビット x86 アーキテクチャーベースのコンピュートノードでのみサポートされます。
検証
新しい
worker-64k-pagesマシン設定プールを表示するには、次のコマンドを実行します。$ oc get mcp出力例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-9d55ac9a91127c36314e1efe7d77fbf8 True False False 3 3 3 0 361d worker rendered-worker-e7b61751c4a5b7ff995d64b967c421ff True False False 7 7 7 0 361d worker-64k-pages rendered-worker-64k-pages-e7b61751c4a5b7ff995d64b967c421ff True False False 2 2 2 0 35m
4.10.3. マルチアーキテクチャーコンピュートマシンのイメージストリームにマニフェストリストをインポートする
マルチアーキテクチャーコンピュートマシンを持つ OpenShift Container Platform 4.16 クラスターでは、クラスター内のイメージストリームはマニフェストリストを自動的にインポートしません。マニフェストリストをインポートするには、デフォルトの importMode オプションを PreserveOriginal オプションに手動で変更する必要があります。
前提条件
-
OpenShift Container Platform CLI (
oc) をインストールしている。
手順
次のコマンド例は、
ImageStreamcli-artifacts にパッチを適用して、cli-artifacts:latestイメージストリームタグがマニフェストリストとしてインポートされるようにする方法を示しています。$ oc patch is/cli-artifacts -n openshift -p '{"spec":{"tags":[{"name":"latest","importPolicy":{"importMode":"PreserveOriginal"}}]}}'
検証
イメージストリームタグを調べて、マニフェストリストが正しくインポートされたことを確認できます。次のコマンドは、特定のタグの個々のアーキテクチャーマニフェストを一覧表示します。
$ oc get istag cli-artifacts:latest -n openshift -oyamldockerImageManifestsオブジェクトが存在する場合、マニフェストリストのインポートは成功しています。dockerImageManifestsオブジェクトの出力例dockerImageManifests: - architecture: amd64 digest: sha256:16d4c96c52923a9968fbfa69425ec703aff711f1db822e4e9788bf5d2bee5d77 manifestSize: 1252 mediaType: application/vnd.docker.distribution.manifest.v2+json os: linux - architecture: arm64 digest: sha256:6ec8ad0d897bcdf727531f7d0b716931728999492709d19d8b09f0d90d57f626 manifestSize: 1252 mediaType: application/vnd.docker.distribution.manifest.v2+json os: linux - architecture: ppc64le digest: sha256:65949e3a80349cdc42acd8c5b34cde6ebc3241eae8daaeea458498fedb359a6a manifestSize: 1252 mediaType: application/vnd.docker.distribution.manifest.v2+json os: linux - architecture: s390x digest: sha256:75f4fa21224b5d5d511bea8f92dfa8e1c00231e5c81ab95e83c3013d245d1719 manifestSize: 1252 mediaType: application/vnd.docker.distribution.manifest.v2+json os: linux
4.11. Multiarch Tuning Operator を使用してマルチアーキテクチャークラスター上のワークロードを管理する
Multiarch Tuning Operator は、マルチアーキテクチャークラスター内およびマルチアーキテクチャー環境に移行するシングルアーキテクチャークラスター内のワークロード管理を最適化します。
アーキテクチャーを考慮したワークロードスケジューリングにより、スケジューラーは Pod イメージのアーキテクチャーに一致するノードに Pod を配置できます。
スケジューラーは、新しい Pod のノードへの配置を決定する際に、デフォルトでは Pod のコンテナーイメージのアーキテクチャーを考慮しません。
アーキテクチャーを考慮したワークロードのスケジューリングを有効にするには、ClusterPodPlacementConfig オブジェクトを作成する必要があります。ClusterPodPlacementConfig オブジェクトを作成すると、Multiarch Tuning Operator は、アーキテクチャーを考慮したワークロードスケジューリングをサポートするために必要なオペランドをデプロイします。ClusterPodPlacementConfig オブジェクトの nodeAffinityScoring プラグインを使用して、ノードアーキテクチャーのクラスター全体のスコアを設定することもできます。nodeAffinityScoring プラグインを有効にすると、スケジューラーによって、互換性のあるアーキテクチャーを持つノードがフィルタリングされてから、スコアが最も高いノードに Pod が配置されます。
Pod が作成されると、オペランドは次のアクションを実行します。
-
Pod のスケジュールを防止するスケジューリングゲート
multiarch.openshift.io/scheduling-gateを追加します。 -
kubernetes.io/archラベルでサポートされているアーキテクチャー値を含むスケジューリング述語を計算します。 -
スケジューリング述語を Pod 仕様の
nodeAffinity要件として統合します。 - Pod からスケジューリングゲートを削除します。
オペランドの次の動作に注意してください。
-
nodeSelectorフィールドがすでにワークロードのkubernetes.io/archラベルで設定されている場合、オペランドはそのワークロードのnodeAffinityフィールドを更新しません。 -
nodeSelectorフィールドがワークロードのkubernetes.io/archラベルで設定されていない場合、オペランドはそのワークロードのnodeAffinityフィールドを更新します。ただしnodeAffinityフィールドでは、オペランドはkubernetes.io/archラベルで設定されていないノードセレクター条件のみ更新します。 -
nodeNameフィールドがすでに設定されている場合、Multiarch Tuning Operator は Pod を処理しません。 -
Pod が DaemonSet によって所有されている場合、オペランドは
nodeAffinityフィールドを更新しません。 -
kubernetes.io/archラベルにnodeSelectorまたはnodeAffinityとpreferredAffinityの両方のフィールドが設定されている場合、オペランドはnodeAffinityフィールドを更新しません。 -
kubernetes.io/archラベルにnodeSelectorまたはnodeAffinityフィールドのみが設定され、nodeAffinityScoringプラグインが無効になっている場合、オペランドはnodeAffinityフィールドを更新しません。 -
nodeAffinity.preferredDuringSchedulingIgnoredDuringExecutionフィールドに、kubernetes.io/archラベルに基づいてノードにスコアを割り当てる条件がすでに含まれている場合、オペランドはnodeAffinityScoringプラグイン内の設定を無視します。
4.11.1. CLI を使用した Multiarch Tuning Operator のインストール
OpenShift CLI (oc) を使用して、Multiarch Tuning Operator をインストールできます。
前提条件
-
ocがインストールされている。 -
cluster-admin権限を持つユーザーとしてocにログインしている。
手順
次のコマンドを実行して、
openshift-multiarch-tuning-operatorという名前の新しいプロジェクトを作成します。$ oc create ns openshift-multiarch-tuning-operatorOperatorGroupオブジェクトを作成します。OperatorGroupオブジェクトを作成するための設定を含む YAML ファイルを作成します。OperatorGroupオブジェクトを作成するための YAML 設定の例apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: openshift-multiarch-tuning-operator namespace: openshift-multiarch-tuning-operator spec: {}以下のコマンドを実行して
OperatorGroupオブジェクトを作成します。$ oc create -f <file_name>1 - 1
<file_name>は、OperatorGroupオブジェクトの設定を含む YAML ファイルの名前に置き換えます。
Subscriptionオブジェクトを作成します。Subscriptionオブジェクトを作成するための設定を含む YAML ファイルを作成します。Subscriptionオブジェクトを作成するための YAML 設定の例apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: openshift-multiarch-tuning-operator namespace: openshift-multiarch-tuning-operator spec: channel: stable name: multiarch-tuning-operator source: redhat-operators sourceNamespace: openshift-marketplace installPlanApproval: Automatic startingCSV: multiarch-tuning-operator.<version>以下のコマンドを実行して
Subscriptionオブジェクトを作成します。$ oc create -f <file_name>1 - 1
<file_name>は、Subscriptionオブジェクトの設定を含む YAML ファイルの名前に置き換えます。
Subscription オブジェクトと OperatorGroup オブジェクトの設定の詳細は、「CLI を使用した OperatorHub からのインストール」を参照してください。
検証
Multiarch Tuning Operator がインストールされていることを確認するには、次のコマンドを実行します。
$ oc get csv -n openshift-multiarch-tuning-operator出力例
NAME DISPLAY VERSION REPLACES PHASE multiarch-tuning-operator.<version> Multiarch Tuning Operator <version> multiarch-tuning-operator.1.0.0 SucceededOperator が
Succeededフェーズにある場合、インストールは成功しています。オプション:
OperatorGroupオブジェクトが作成されたことを確認するには、次のコマンドを実行します。$ oc get operatorgroup -n openshift-multiarch-tuning-operator出力例
NAME AGE openshift-multiarch-tuning-operator-q8zbb 133mオプション:
Subscriptionオブジェクトが作成されたことを確認するには、次のコマンドを実行します。$ oc get subscription -n openshift-multiarch-tuning-operator出力例
NAME PACKAGE SOURCE CHANNEL multiarch-tuning-operator multiarch-tuning-operator redhat-operators stable
4.11.2. Web コンソールを使用した Multiarch Tuning Operator のインストール
OpenShift Container Platform Web コンソールを使用して、Multiarch Tuning Operator をインストールできます。
前提条件
-
cluster-admin権限でクラスターにアクセスできる。 - OpenShift Container Platform Web コンソールにアクセスできる。
手順
- OpenShift Container Platform Web コンソールにログインします。
- Operators → OperatorHub に移動します。
- 検索フィールドに Multiarch Tuning Operator と入力します。
- Multiarch Tuning Operator をクリックします。
- Version リストから Multiarch Tuning Operator のバージョンを選択します。
- Install をクリックします。
Operator Installation ページで次のオプションを設定します。
- Update Channel を stable に設定します。
- Installation Mode を All namespaces on the cluster に設定します。
Installed Namespace を、Operator recommended Namespace か Select a Namespace に設定します。
推奨される Operator namespace は
openshift-multiarch-tuning-operatorです。openshift-multiarch-tuning-operatornamespace が存在しない場合は、Operator のインストール中に作成されます。Select a namespace を選択した場合は、Select Project リストから Operator の namespace を選択する必要があります。
Update approval で Automatic または Manual を選択します。
Automatic 更新を選択すると、Operator Lifecycle Manager (OLM) が管理者の介入なしで Multiarch Tuning Operator の実行中のインスタンスを自動的に更新します。
Manual 更新を選択すると、OLM は更新要求を作成します。クラスター管理者は、Multiarch Tuning Operator を新しいバージョンに更新するために、更新要求を手動で承認する必要があります。
- オプション: Enable Operator recommended cluster monitoring on this Namespace チェックボックスを選択します。
- Install をクリックします。
検証
- Operators → Installed Operators に移動します。
-
Multiarch Tuning Operator が、
openshift-multiarch-tuning-operatornamespace の Status フィールドに Succeeded としてリストされていることを確認します。
4.11.3. Multiarch Tuning Operator Pod ラベルとアーキテクチャーサポートの概要
Multiarch Tuning Operator をインストールした後、クラスター内のワークロードに対するマルチアーキテクチャーのサポートを確認できます。Pod ラベルを使用して、アーキテクチャーの互換性に基づき Pod を識別および管理できます。これらのラベルは、アーキテクチャーサポートに関する情報を提供するために、新しく作成された Pod に自動的に設定されます。
次の表は、Pod の作成時に Multiarch Tuning Operator が追加するラベルを説明しています。
| ラベル | 説明 |
|---|---|
|
| Pod は複数のアーキテクチャーをサポートします。 |
|
| Pod は単一のアーキテクチャーのみサポートします。 |
|
|
Pod は |
|
|
Pod は |
|
|
Pod は |
|
|
Pod は |
|
| Operator は、アーキテクチャーのノードアフィニティー要件を設定しました。 |
|
| Operator はノードアフィニティー要件を設定しませんでした。たとえば、Pod にすでにアーキテクチャーのノードアフィニティーがある場合、Multiarch Tuning Operator はこのラベルを Pod に追加します。 |
|
| Pod にはゲートがあります。 |
|
| Pod ゲートが削除されました。 |
|
| ノードアフィニティー要件のビルド時にエラーが発生しました。 |
|
| Operator が Pod のアーキテクチャー優先設定を指定しました。 |
|
|
ユーザーがすでに |
4.11.4. ClusterPodPlacementConfig オブジェクトの作成
Multiarch Tuning Operator をインストールしたら、ClusterPodPlacementConfig オブジェクトを作成する必要があります。このオブジェクトを作成すると、Multiarch Tuning Operator が、アーキテクチャーを考慮したワークロードスケジューリングを可能にするオペランドをデプロイします。
ClusterPodPlacementConfig オブジェクトのインスタンスは 1 つだけ作成できます。
ClusterPodPlacementConfig オブジェクトの設定例
apiVersion: multiarch.openshift.io/v1beta1
kind: ClusterPodPlacementConfig
metadata:
name: cluster
spec:
logVerbosityLevel: Normal
namespaceSelector:
matchExpressions:
- key: multiarch.openshift.io/exclude-pod-placement
operator: DoesNotExist
plugins:
nodeAffinityScoring:
enabled: true
platforms:
- architecture: amd64
weight: 100
- architecture: arm64
weight: 50- 1
- このフィールドの値を
clusterに設定する必要があります。 - 2
- オプション: フィールドの値を
Normal、Debug、Trace、またはTraceAllに設定できます。デフォルトでは、値はNormalに設定されています。 - 3
- オプション:
namespaceSelectorを設定すると、Multiarch Tuning Operator の Pod 配置オペランドによって Pod のnodeAffinityを処理する必要がある namespace を選択できます。デフォルトではすべての namespace が考慮されます。 - 4
- オプション: アーキテクチャーを考慮したワークロードスケジューリング用のプラグインのリストを含めます。
- 5
- オプション: このプラグインを使用すると、Pod 配置用のアーキテクチャー優先設定を指定できます。有効にすると、スケジューラーによって、まず Pod の要件を満たさないノードが除外されます。次に、
nodeAffinityScoring.platformsフィールドで定義されたアーキテクチャースコアに基づいて、残りのノードに優先順位が付けられます。 - 6
- オプション:
nodeAffinityScoringプラグインを有効にするには、このフィールドをtrueに設定します。デフォルト値はfalseです。 - 7
- オプション: アーキテクチャーとそれに対応するスコアのリストを定義します。
- 8
- スコアを割り当てるノードアーキテクチャーを指定します。スケジューラーは、設定したアーキテクチャースコアと Pod 仕様で定義されたスケジューリング要件に基づいて、Pod を配置するノードを優先順位付けします。許可される値は、
arm64、amd64、ppc64le、またはs390xです。 - 9
- アーキテクチャーにスコアを割り当てます。このフィールドの値は、
1(最低優先度) から100(最高優先度) の範囲で設定する必要があります。スケジューラーは、このスコアを使用して Pod を配置するノードを優先順位付けし、スコアが高いアーキテクチャーのノードを優先します。
この例では、operator フィールドの値が DoesNotExist に設定されています。したがって、key フィールドの値 (multiarch.openshift.io/exclude-pod-placement) が namespace のラベルとして設定されている場合、オペランドはその namespace 内の Pod の nodeAffinity を処理しません。代わりに、オペランドはこのラベルを含まない namespace 内の Pod の nodeAffinity を処理します。
オペランドで特定の namespace 内の Pod の nodeAffinity のみを処理する場合は、次のように namespaceSelector を設定できます。
namespaceSelector:
matchExpressions:
- key: multiarch.openshift.io/include-pod-placement
operator: Exists
この例では、operator フィールドの値が Exists に設定されています。したがって、オペランドは、multiarch.openshift.io/include-pod-placement ラベルを含む namespace 内の Pod の nodeAffinity のみを処理します。
この Operator は、kube- で始まる namespace 内の Pod を除外します。また、コントロールプレーンノードでスケジュールされることが予想される Pod も除外されます。
4.11.4.1. CLI を使用した ClusterPodPlacementConfig オブジェクトの作成
アーキテクチャーを考慮したワークロードのスケジューリングを可能にする Pod 配置オペランドをデプロイするには、OpenShift CLI (oc) を使用して ClusterPodPlacementConfig オブジェクトを作成します。
前提条件
-
ocがインストールされている。 -
cluster-admin権限を持つユーザーとしてocにログインしている。 - Multiarch Tuning Operator がインストールされている。
手順
ClusterPodPlacementConfigオブジェクトの YAML ファイルを作成します。ClusterPodPlacementConfigオブジェクトの設定例apiVersion: multiarch.openshift.io/v1beta1 kind: ClusterPodPlacementConfig metadata: name: cluster spec: logVerbosityLevel: Normal namespaceSelector: matchExpressions: - key: multiarch.openshift.io/exclude-pod-placement operator: DoesNotExist plugins: nodeAffinityScoring: enabled: true platforms: - architecture: amd64 weight: 100 - architecture: arm64 weight: 50次のコマンドを実行して
ClusterPodPlacementConfigオブジェクトを作成します。$ oc create -f <file_name>1 - 1
<file_name>は、ClusterPodPlacementConfigオブジェクトの YAML ファイルの名前に置き換えます。
検証
ClusterPodPlacementConfigオブジェクトが作成されたことを確認するには、次のコマンドを実行します。$ oc get clusterpodplacementconfig出力例
NAME AGE cluster 29s
4.11.4.2. Web コンソールを使用した ClusterPodPlacementConfig オブジェクトの作成
アーキテクチャーを考慮したワークロードのスケジューリングを可能にする Pod 配置オペランドをデプロイするには、OpenShift Container Platform Web コンソールを使用して ClusterPodPlacementConfig オブジェクトを作成します。
前提条件
-
cluster-admin権限でクラスターにアクセスできる。 - OpenShift Container Platform Web コンソールにアクセスできる。
- Multiarch Tuning Operator がインストールされている。
手順
- OpenShift Container Platform Web コンソールにログインします。
- Operators → Installed Operators に移動します。
- Installed Operators ページで、Multiarch Tuning Operator をクリックします。
- Cluster Pod Placement Config タブをクリックします。
- Form view または YAML view のいずれかを選択します。
-
ClusterPodPlacementConfigオブジェクトのパラメーターを設定します。 - Create をクリックします。
オプション:
ClusterPodPlacementConfigオブジェクトを編集する場合は、次の操作を実行します。- Cluster Pod Placement Config タブをクリックします。
- オプションメニューから Edit ClusterPodPlacementConfig を選択します。
-
YAML をクリックし、
ClusterPodPlacementConfigオブジェクトのパラメーターを編集します。 - Save をクリックします。
検証
-
Cluster Pod Placement Config ページで、
ClusterPodPlacementConfigオブジェクトがReady状態であることを確認します。
4.11.5. CLI を使用した ClusterPodPlacementConfig オブジェクトの削除
ClusterPodPlacementConfig オブジェクトのインスタンスは 1 つだけ作成できます。このオブジェクトを再作成する場合は、まず既存のインスタンスを削除する必要があります。
OpenShift CLI (oc) を使用してこのオブジェクトを削除できます。
前提条件
-
ocがインストールされている。 -
cluster-admin権限を持つユーザーとしてocにログインしている。
手順
-
OpenShift CLI (
oc) にログインします。 次のコマンドを実行して
ClusterPodPlacementConfigオブジェクトを削除します。$ oc delete clusterpodplacementconfig cluster
検証
ClusterPodPlacementConfigオブジェクトが削除されたことを確認するには、次のコマンドを実行します。$ oc get clusterpodplacementconfig出力例
No resources found
4.11.6. Web コンソールを使用した ClusterPodPlacementConfig オブジェクトの削除
ClusterPodPlacementConfig オブジェクトのインスタンスは 1 つだけ作成できます。このオブジェクトを再作成する場合は、まず既存のインスタンスを削除する必要があります。
OpenShift Container Platform Web コンソールを使用してこのオブジェクトを削除できます。
前提条件
-
cluster-admin権限でクラスターにアクセスできる。 - OpenShift Container Platform Web コンソールにアクセスできる。
-
ClusterPodPlacementConfigオブジェクトを作成した。
手順
- OpenShift Container Platform Web コンソールにログインします。
- Operators → Installed Operators に移動します。
- Installed Operators ページで、Multiarch Tuning Operator をクリックします。
- Cluster Pod Placement Config タブをクリックします。
- オプションメニューから Delete ClusterPodPlacementConfig を選択します。
- Delete をクリックします。
検証
-
Cluster Pod Placement Config ページで、
ClusterPodPlacementConfigオブジェクトが削除されていることを確認します。
4.11.7. CLI を使用した Multiarch Tuning Operator のアンインストール
OpenShift CLI (oc) を使用して、Multiarch Tuning Operator をアンインストールできます。
前提条件
-
ocがインストールされている。 -
cluster-admin権限を持つユーザーとしてocにログインしている。 ClusterPodPlacementConfigオブジェクトを削除した。重要Multiarch Tuning Operator をアンインストールする前に、
ClusterPodPlacementConfigオブジェクトを削除する必要があります。ClusterPodPlacementConfigオブジェクトを削除せずに Operator をアンインストールすると、予期しない動作が発生する可能性があります。
手順
次のコマンドを実行して、Multiarch Tuning Operator の
Subscriptionオブジェクト名を取得します。$ oc get subscription.operators.coreos.com -n <namespace>1 - 1
<namespace>は、Multiarch Tuning Operator をアンインストールする namespace の名前に置き換えます。
出力例
NAME PACKAGE SOURCE CHANNEL openshift-multiarch-tuning-operator multiarch-tuning-operator redhat-operators stable次のコマンドを実行して、Multiarch Tuning Operator の
currentCSV値を取得します。$ oc get subscription.operators.coreos.com <subscription_name> -n <namespace> -o yaml | grep currentCSV1 - 1
<subscription_name>をSubscriptionオブジェクト名に置き換えます。たとえば、openshift-multiarch-tuning-operatorです。<namespace>は、Multiarch Tuning Operator をアンインストールする namespace の名前に置き換えます。
出力例
currentCSV: multiarch-tuning-operator.<version>次のコマンドを実行して、
Subscriptionオブジェクトを削除します。$ oc delete subscription.operators.coreos.com <subscription_name> -n <namespace>1 - 1
<subscription_name>をSubscriptionオブジェクト名に置き換えます。<namespace>は、Multiarch Tuning Operator をアンインストールする namespace の名前に置き換えます。
出力例
subscription.operators.coreos.com "openshift-multiarch-tuning-operator" deleted次のコマンドを実行して、
currentCSV値を使用してターゲット namespace 内の Multiarch Tuning Operator の CSV を削除します。$ oc delete clusterserviceversion <currentCSV_value> -n <namespace>1 - 1
<currentCSV>は、Multiarch Tuning Operator のcurrentCSV値に置き換えます。たとえば、multiarch-tuning-operator.<version>です。<namespace>は、Multiarch Tuning Operator をアンインストールする namespace の名前に置き換えます。
出力例
clusterserviceversion.operators.coreos.com "multiarch-tuning-operator.<version>" deleted
検証
Multiarch Tuning Operator がアンインストールされたことを確認するには、次のコマンドを実行します。
$ oc get csv -n <namespace>1 - 1
<namespace>は、Multiarch Tuning Operator をアンインストールした namespace の名前に置き換えます。
出力例
No resources found in openshift-multiarch-tuning-operator namespace.
4.11.8. Web コンソールを使用した Multiarch Tuning Operator のアンインストール
OpenShift Container Platform Web コンソールを使用して、Multiarch Tuning Operator をアンインストールできます。
前提条件
-
cluster-admin権限でクラスターにアクセスできます。 ClusterPodPlacementConfigオブジェクトを削除した。重要Multiarch Tuning Operator をアンインストールする前に、
ClusterPodPlacementConfigオブジェクトを削除する必要があります。ClusterPodPlacementConfigオブジェクトを削除せずに Operator をアンインストールすると、予期しない動作が発生する可能性があります。
手順
- OpenShift Container Platform Web コンソールにログインします。
- Operators → OperatorHub に移動します。
- 検索フィールドに Multiarch Tuning Operator と入力します。
- Multiarch Tuning Operator をクリックします。
- Details タブをクリックします。
- Actions メニューから、Uninstall Operator を選択します。
- プロンプトが表示されたら、Uninstall をクリックします。
検証
- Operators → Installed Operators に移動します。
- Installed Operator ページで、Multiarch Tuning Operator がリストされていないことを確認します。
4.12. Multiarch Tuning Operator のリリースノート
Multiarch Tuning Operator は、マルチアーキテクチャークラスター内およびマルチアーキテクチャー環境に移行するシングルアーキテクチャークラスター内のワークロード管理を最適化します。
これらのリリースノートでは、Multiarch Tuning Operator の開発を追跡します。
詳細は、Multiarch Tuning Operator を使用してマルチアーキテクチャークラスター上のワークロードを管理する を参照してください。
4.12.1. Multiarch Tuning Operator 1.1.1 のリリースノート
発行日: 2025 年 5 月 27 日
4.12.1.1. バグ修正
以前は、Pod 配置オペランドが、プルシークレットのホスト名にワイルドカードエントリーを使用してレジストリーを認証することをサポートしていませんでした。そのため、イメージをプルするときの Kubelet の動作に一貫性がありませんでした。Kubelet はワイルドカードエントリーをサポートしていましたが、オペランドにはホスト名の正確なマッチが必要であったためです。その結果、レジストリーがワイルドカードホスト名を使用する場合にイメージのプルが予期せず失敗する可能性がありました。
このリリースでは、Pod 配置オペランドはワイルドカードホスト名を含むプルシークレットをサポートしています。これにより、イメージ認証とプルの一貫性と信頼性が確保されます。
以前は、すべての再試行の実行後にイメージ検査が失敗し、
nodeAffinityScoringプラグインが有効である場合、Pod 配置オペランドによって誤ったnodeAffinityScoringラベルが適用されていました。このリリースでは、イメージ検査が失敗した場合でも、オペランドは
nodeAffinityScoringラベルを正しく設定します。このラベルは、スケジュールの正確性と一貫性を確保するために、必要なアフィニティープロセスとは別に適用されます。
4.12.2. Multiarch Tuning Operator 1.1.0 のリリースノート
発行日: 2025 年 3 月 18 日
4.12.2.1. 新機能および機能拡張
- Multiarch Tuning Operator は、ROSA with Hosted Control Plane (HCP) やその他の HCP 環境など、マネージドサービスでサポートされるようになりました。
-
このリリースでは、
ClusterPodPlacementConfigオブジェクトの新しいpluginsフィールドを使用して、アーキテクチャーを考慮したワークロードスケジューリングを設定できます。plugins.nodeAffinityScoringフィールドを使用して、Pod 配置用のアーキテクチャー優先設定を指定できます。nodeAffinityScoringプラグインを有効にすると、スケジューラーによって、まず Pod の要件を満たさないノードが除外されます。次に、nodeAffinityScoring.platformsフィールドで定義されたアーキテクチャースコアに基づいて、残りのノードに優先順位が付けられます。
4.12.2.2. バグ修正
-
このリリースでは、Multiarch Tuning Operator は、デーモンセットによって管理される Pod の
nodeAffinityフィールドを更新しません。(OCPBUGS-45885)
4.12.3. Multiarch Tuning Operator 1.0.0 のリリースノート
発行日: 2024 年 10 月 31 日
4.12.3.1. 新機能および機能拡張
- このリリースでは、Multiarch Tuning Operator はカスタムネットワークシナリオとクラスター全体のカスタムレジストリー設定をサポートします。
- このリリースでは、Multiarch Tuning Operator が新しく作成された Pod に追加する Pod ラベルを使用して、アーキテクチャーの互換性に基づき Pod を識別できます。
- このリリースでは、Cluster Monitoring Operator に登録されているメトリクスとアラートを使用して、Multiarch Tuning Operator の動作を監視できます。
第5章 インストール後のクラスタータスク
OpenShift Container Platform のインストール後に、クラスターをさらに拡張し、要件に合わせてカスタマイズできます。
5.1. 利用可能なクラスターのカスタマイズ
OpenShift Container Platform クラスターのデプロイ後は、大半のクラスター設定およびカスタマイズが終了していることになります。数多くの 設定リソース が利用可能です。
クラスターを IBM Z® にインストールする場合は、すべての特長および機能が利用可能である訳ではありません。
イメージレジストリー、ネットワーク設定、イメージビルドの動作およびアイデンティティープロバイダーなどのクラスターの主要な機能を設定するために設定リソースを変更します。
これらのリソースを使用して制御する設定の現在の記述は、oc explain コマンドを使用します (例: oc explain builds --api-version=config.openshift.io/v1)。
5.1.1. クラスター設定リソース
すべてのクラスター設定リソースは、グローバルスコープであり (namespace に属さない)、cluster という名前が付けられます。
| リソース名 | 説明 |
|---|---|
|
| 証明書および認証局 などの API サーバー設定を提供します。 |
|
| クラスターの アイデンティティープロバイダー および認証設定を制御します。 |
|
| クラスター上のすべてのビルドの、デフォルトおよび強制された 設定 を制御します。 |
|
| ログアウト動作 を含む Web コンソールインターフェイスの動作を設定します。 |
|
| FeatureGates を有効にして、テクノロジープレビュー機能を使用できるようにします。 |
|
| 特定の イメージレジストリー が処理される方法を設定します (allowed、disallowed、insecure、CA の詳細)。 |
|
| ルートのデフォルトドメインなどの ルーティング に関連する設定の詳細。 |
|
| 内部 OAuth サーバー フローに関連するアイデンティティープロバイダーと他の動作を設定します。 |
|
| プロジェクトテンプレートを含む プロジェクトの作成方法 を設定します。 |
|
| 外部ネットワークアクセスを必要とするコンポーネントで使用されるプロキシーを定義します。注: すべてのコンポーネントがこの値を使用する訳ではありません。 |
|
| プロファイルやデフォルトのノードセレクターなどの スケジューラー の動作を設定します。 |
5.1.2. Operator 設定リソース
これらの設定リソースは、cluster という名前のクラスタースコープのインスタンスです。これは、特定の Operator によって所有される特定コンポーネントの動作を制御します。
| リソース名 | 説明 |
|---|---|
|
| ブランドのカスタマイズなどのコンソールの外観の制御 |
|
| パブリックルーティング、ログレベル、プロキシー設定、リソース制約、レプリカ数、ストレージタイプなどの OpenShift イメージレジストリー設定 を設定します。 |
|
| Samples Operator を設定して、クラスターにインストールされるイメージストリームとテンプレートのサンプルを制御します。 |
5.1.3. 追加の設定リソース
これらの設定リソースは、特定コンポーネントの単一インスタンスを表します。場合によっては、リソースの複数のインスタンスを作成して、複数のインスタンスを要求できます。他の場合には、Operator は特定の namespace の特定のリソースインスタンス名のみを使用できます。追加のリソースインスタンスの作成方法や作成するタイミングの詳細は、コンポーネント固有のドキュメントを参照してください。
| リソース名 | インスタンス名 | Namespace | 説明 |
|---|---|---|---|
|
|
|
| Alertmanager のデプロイメントパラメーターを制御します。 |
|
|
|
| ドメイン、レプリカ数、証明書、およびコントローラーの配置など、Ingress Operator の動作を設定します。 |
5.1.4. 情報リソース
これらのリソースを使用して、クラスターに関する情報を取得します。設定によっては、これらのリソースの直接編集が必要になる場合があります。
| リソース名 | インスタンス名 | 説明 |
|---|---|---|
|
|
|
OpenShift Container Platform 4.16 では、実稼働クラスターの |
|
|
| クラスターの DNS 設定を変更することはできません。DNS Operator のステータスを確認 できます。 |
|
|
| クラスターはそのクラウドプロバイダーとの対話を可能にする設定の詳細。 |
|
|
| インストール後にクラスターのネットワークを変更することはできません。ネットワークをカスタマイズするには、インストール時にネットワークをカスタマイズする プロセスを実行します。 |
5.2. ワーカーノードの追加
OpenShift Container Platform クラスターをデプロイしたら、ワーカーノードを追加してクラスターリソースをスケーリングできます。インストール方法とクラスターの環境に応じて、ワーカーノードを追加するさまざまな方法があります。
5.2.1. installer-provisioned infrastructure へのワーカーノードの追加
installer-provisioned infrastructure クラスターの場合、MachineSet オブジェクトを手動または自動でスケーリングして、利用可能なベアメタルホストの数に一致させることができます。
ベアメタルホストを追加するには、すべてのネットワーク前提条件を設定し、関連する baremetalhost オブジェクトを設定してから、クラスターにワーカーノードをプロビジョニングする必要があります。手動で、または Web コンソールを使用して、ベアメタルホストを追加できます。
5.2.2. user-provisioned infrastructure クラスターへのワーカーノードの追加
user-provisioned infrastructure クラスターの場合、RHEL または RHCOS ISO イメージを使用し、クラスター Ignition 設定ファイルを使用してこれをクラスターに接続することで、ワーカーノードを追加できます。RHEL ワーカーノードの場合、次の例では、Ansible Playbook を使用してクラスターにワーカーノードを追加します。RHCOS ワーカーノードの場合、次の例では、ISO イメージとネットワークブートを使用してワーカーノードをクラスターに追加します。
5.2.3. Assisted Installer によって管理されるクラスターへのワーカーノードの追加
Assisted Installer によって管理されるクラスターの場合、Red Hat OpenShift Cluster Manager コンソール、Assisted Installer REST API を使用してワーカーノードを追加するか、ISO イメージとクラスター Ignition 設定ファイルを使用してワーカーノードを手動で追加することができます。
5.2.4. Kubernetes のマルチクラスターエンジンによって管理されるクラスターへのワーカーノードの追加
Kubernetes のマルチクラスターエンジンによって管理されるクラスターの場合、専用のマルチクラスターエンジンコンソールを使用してワーカーノードを追加することができます。
5.3. ワーカーノードの調整
デプロイメント時にワーカーノードのサイズを誤って設定した場合には、1 つ以上の新規コンピュートマシンセットを作成してそれらをスケールアップしてから、元のコンピュートマシンセットを削除する前にスケールダウンしてこれらのワーカーノードを調整します。
5.3.1. コンピュートマシンセットとマシン設定プールの相違点について
MachineSet オブジェクトは、クラウドまたはマシンプロバイダーに関する OpenShift Container Platform ノードを記述します。
MachineConfigPool オブジェクトにより、MachineConfigController コンポーネントがアップグレードのコンテキストでマシンのステータスを定義し、提供できるようになります。
MachineConfigPool オブジェクトにより、ユーザーはマシン設定プールの OpenShift Container Platform ノードにアップグレードをデプロイメントする方法を設定できます。
NodeSelector オブジェクトは MachineSet オブジェクトへの参照に置き換えることができます。
5.3.2. コンピュートマシンセットの手動スケーリング
コンピュートマシンセットのマシンのインスタンスを追加したり、削除したりする必要がある場合、コンピュートマシンセットを手動でスケーリングできます。
このガイダンスは、完全に自動化された installer-provisioned infrastructure のインストールに関連します。user-provisioned infrastructure のカスタマイズされたインストールにはコンピュートマシンセットがありません。
前提条件
-
OpenShift Container Platform クラスターおよび
ocコマンドラインをインストールすること。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。
手順
次のコマンドを実行して、クラスター内のコンピュートマシンセットを表示します。
$ oc get machinesets.machine.openshift.io -n openshift-machine-apiコンピュートマシンセットは
<clusterid>-worker-<aws-region-az>の形式で一覧表示されます。次のコマンドを実行して、クラスター内のコンピュートマシンを表示します。
$ oc get machines.machine.openshift.io -n openshift-machine-api次のコマンドを実行して、削除するコンピュートマシンに注釈を設定します。
$ oc annotate machines.machine.openshift.io/<machine_name> -n openshift-machine-api machine.openshift.io/delete-machine="true"次のいずれかのコマンドを実行して、コンピュートマシンセットをスケーリングします。
$ oc scale --replicas=2 machinesets.machine.openshift.io <machineset> -n openshift-machine-apiまたは、以下を実行します。
$ oc edit machinesets.machine.openshift.io <machineset> -n openshift-machine-apiヒントまたは、以下の YAML を適用してコンピュートマシンセットをスケーリングすることもできます。
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: replicas: 2コンピュートマシンセットをスケールアップまたはスケールダウンできます。新規マシンが利用可能になるまで数分の時間がかかります。
重要デフォルトでは、マシンコントローラーは、成功するまでマシンによってサポートされるノードを drain しようとします。場合によっては、drain 操作が成功しない可能性があります。たとえば、Pod Disruption Budget が間違っている場合などです。drain 操作が失敗した場合、マシンコントローラーはマシンの削除を続行できません。
特定のマシンの
machine.openshift.io/exclude-node-drainingにアノテーションを付けると、ノードの drain を省略できます。
検証
次のコマンドを実行して、目的のマシンが削除されたことを確認します。
$ oc get machines.machine.openshift.io
5.3.3. コンピュートマシンセットの削除ポリシー
Random、Newest、および Oldest は 3 つのサポートされる削除オプションです。デフォルトは Random です。これは、コンピュートマシンセットのスケールダウン時にランダムなマシンが選択され、削除されることを意味します。削除ポリシーは、特定のコンピュートマシンセットを変更し、ユースケースに基づいて設定できます。
spec:
deletePolicy: <delete_policy>
replicas: <desired_replica_count>
削除に関する特定のマシンの優先順位は、削除ポリシーに関係なく、関連するマシンにアノテーション machine.openshift.io/delete-machine=true を追加して設定できます。
デフォルトで、OpenShift Container Platform ルーター Pod はワーカーにデプロイされます。ルーターは Web コンソールなどの一部のクラスターリソースにアクセスすることが必要であるため、ルーター Pod をまず再配置しない限り、ワーカーのコンピュートマシンセットを 0 にスケーリングできません。
カスタムのコンピュートマシンセットは、サービスを特定のノードサービスで実行し、それらのサービスがワーカーのコンピュートマシンセットのスケールダウン時にコントローラーによって無視されるようにする必要があるユースケースで使用できます。これにより、サービスの中断が回避されます。
5.3.4. クラスタースコープのデフォルトノードセレクターの作成
クラスター内の作成されたすべての Pod を特定のノードに制限するために、デフォルトのクラスタースコープのノードセレクターをノード上のラベルと共に Pod で使用することができます。
クラスタースコープのノードセレクターを使用する場合、クラスターで Pod を作成すると、OpenShift Container Platform はデフォルトのノードセレクターを Pod に追加し、一致するラベルのあるノードで Pod をスケジュールします。
スケジューラー Operator カスタムリソース (CR) を編集して、クラスタースコープのノードセレクターを設定します。ラベルをノード、コンピュートマシンセット、またはマシン設定に追加します。コンピュートマシンセットにラベルを追加すると、ノードまたはマシンが停止した場合に、新規ノードにそのラベルが追加されます。ノードまたはマシン設定に追加されるラベルは、ノードまたはマシンが停止すると維持されません。
Pod にキーと値のペアを追加できます。ただし、デフォルトキーの異なる値を追加することはできません。
手順
デフォルトのクラスタースコープのセレクターを追加するには、以下を実行します。
スケジューラー Operator CR を編集して、デフォルトのクラスタースコープのノードクラスターを追加します。
$ oc edit scheduler clusterノードセレクターを含むスケジューラー Operator CR のサンプル
apiVersion: config.openshift.io/v1 kind: Scheduler metadata: name: cluster ... spec: defaultNodeSelector: type=user-node,region=east1 mastersSchedulable: false- 1
- 適切な
<key>:<value>ペアが設定されたノードセレクターを追加します。
この変更を加えた後に、
openshift-kube-apiserverプロジェクトの Pod の再デプロイを待機します。これには数分の時間がかかる場合があります。デフォルトのクラスター全体のノードセレクターは、Pod の再起動まで有効になりません。コンピュートマシンセットを使用するか、ノードを直接編集してラベルをノードに追加します。
コンピュートマシンセットを使用して、ノードの作成時にコンピュートマシンセットによって管理されるノードにラベルを追加します。
以下のコマンドを実行してラベルを
MachineSetオブジェクトに追加します。$ oc patch MachineSet <name> --type='json' -p='[{"op":"add","path":"/spec/template/spec/metadata/labels", "value":{"<key>"="<value>","<key>"="<value>"}}]' -n openshift-machine-api1 - 1
- それぞれのラベルに
<key>/<value>ペアを追加します。
以下に例を示します。
$ oc patch MachineSet ci-ln-l8nry52-f76d1-hl7m7-worker-c --type='json' -p='[{"op":"add","path":"/spec/template/spec/metadata/labels", "value":{"type":"user-node","region":"east"}}]' -n openshift-machine-apiヒントあるいは、以下の YAML を適用してコンピュートマシンセットにラベルを追加することもできます。
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: template: spec: metadata: labels: region: "east" type: "user-node"oc editコマンドを使用して、ラベルがMachineSetオブジェクトに追加されていることを確認します。以下に例を示します。
$ oc edit MachineSet abc612-msrtw-worker-us-east-1c -n openshift-machine-apiMachineSetオブジェクトの例apiVersion: machine.openshift.io/v1beta1 kind: MachineSet ... spec: ... template: metadata: ... spec: metadata: labels: region: east type: user-node ...0にスケールダウンし、ノードをスケールアップして、そのコンピュートマシンセットに関連付けられたノードを再デプロイします。以下に例を示します。
$ oc scale --replicas=0 MachineSet ci-ln-l8nry52-f76d1-hl7m7-worker-c -n openshift-machine-api$ oc scale --replicas=1 MachineSet ci-ln-l8nry52-f76d1-hl7m7-worker-c -n openshift-machine-apiノードの準備ができ、利用可能な状態になったら、
oc getコマンドを使用してラベルがノードに追加されていることを確認します。$ oc get nodes -l <key>=<value>以下に例を示します。
$ oc get nodes -l type=user-node出力例
NAME STATUS ROLES AGE VERSION ci-ln-l8nry52-f76d1-hl7m7-worker-c-vmqzp Ready worker 61s v1.29.4
ラベルをノードに直接追加します。
ノードの
Nodeオブジェクトを編集します。$ oc label nodes <name> <key>=<value>たとえば、ノードにラベルを付けるには、以下を実行します。
$ oc label nodes ci-ln-l8nry52-f76d1-hl7m7-worker-b-tgq49 type=user-node region=eastヒントあるいは、以下の YAML を適用してノードにラベルを追加することもできます。
kind: Node apiVersion: v1 metadata: name: <node_name> labels: type: "user-node" region: "east"oc getコマンドを使用して、ラベルがノードに追加されていることを確認します。$ oc get nodes -l <key>=<value>,<key>=<value>以下に例を示します。
$ oc get nodes -l type=user-node,region=east出力例
NAME STATUS ROLES AGE VERSION ci-ln-l8nry52-f76d1-hl7m7-worker-b-tgq49 Ready worker 17m v1.29.4
5.4. ワーカーレイテンシープロファイルを使用したレイテンシーの高い環境でのクラスターの安定性の向上
クラスター管理者が遅延テストを実行してプラットフォームを検証した際に、遅延が大きい場合でも安定性を確保するために、クラスターの動作を調整する必要性が判明することがあります。クラスター管理者が変更する必要があるのは、ファイルに記録されている 1 つのパラメーターだけです。このパラメーターは、監視プロセスがステータスを読み取り、クラスターの健全性を解釈する方法に影響を与える 4 つのパラメーターを制御するものです。1 つのパラメーターのみを変更し、サポートしやすく簡単な方法でクラスターをチューニングできます。
Kubelet プロセスは、クラスターの健全性を監視する上での出発点です。Kubelet は、OpenShift Container Platform クラスター内のすべてのノードのステータス値を設定します。Kubernetes コントローラーマネージャー (kube controller) は、デフォルトで 10 秒ごとにステータス値を読み取ります。ノードのステータス値を読み取ることができない場合、設定期間が経過すると、kube controller とそのノードとの接続が失われます。デフォルトの動作は次のとおりです。
-
コントロールプレーン上のノードコントローラーが、ノードの健全性を
Unhealthyに更新し、ノードのReady状態を `Unknown` とマークします。 - この操作に応じて、スケジューラーはそのノードへの Pod のスケジューリングを停止します。
-
ノードライフサイクルコントローラーが、
NoExecuteeffect を持つnode.kubernetes.io/unreachabletaint をノードに追加し、デフォルトでノード上のすべての Pod を 5 分後に退避するようにスケジュールします。
この動作は、ネットワークが遅延の問題を起こしやすい場合、特にネットワークエッジにノードがある場合に問題が発生する可能性があります。場合によっては、ネットワークの遅延が原因で、Kubernetes コントローラーマネージャーが正常なノードから更新を受信できないことがあります。Kubelet は、ノードが正常であっても、ノードから Pod を削除します。
この問題を回避するには、ワーカーレイテンシープロファイル を使用して、Kubelet と Kubernetes コントローラーマネージャーがアクションを実行する前にステータスの更新を待機する頻度を調整できます。これらの調整により、コントロールプレーンとワーカーノード間のネットワーク遅延が最適でない場合に、クラスターが適切に動作するようになります。
これらのワーカーレイテンシープロファイルには、3 つのパラメーターセットが含まれています。パラメーターは、遅延の増加に対するクラスターの反応を制御するように、慎重に調整された値で事前定義されています。試験により手作業で最良の値を見つける必要はありません。
クラスターのインストール時、またはクラスターネットワークのレイテンシーの増加に気付いたときはいつでも、ワーカーレイテンシープロファイルを設定できます。
5.4.1. ワーカーレイテンシープロファイルについて
ワーカーレイテンシープロファイルは、4 つの異なるカテゴリーからなる慎重に調整されたパラメーターです。これらの値を実装する 4 つのパラメーターは、node-status-update-frequency、node-monitor-grace-period、default-not-ready-toleration-seconds、および default-unreachable-toleration-seconds です。これらのパラメーターにより、遅延の問題に対するクラスターの反応を制御できる値を使用できます。手作業で最適な値を決定する必要はありません。
これらのパラメーターの手動設定はサポートされていません。パラメーター設定が正しくないと、クラスターの安定性に悪影響が及びます。
すべてのワーカーレイテンシープロファイルは、次のパラメーターを設定します。
- node-status-update-frequency
- kubelet がノードのステータスを API サーバーにポストする頻度を指定します。
- node-monitor-grace-period
-
Kubernetes コントローラーマネージャーが、ノードを異常とマークし、
node.kubernetes.io/not-readyまたはnode.kubernetes.io/unreachabletaint をノードに追加する前に、kubelet からの更新を待機する時間を秒単位で指定します。 - default-not-ready-toleration-seconds
- ノードを異常とマークした後、Kube API Server Operator がそのノードから Pod を削除するまでに待機する時間を秒単位で指定します。
- default-unreachable-toleration-seconds
- ノードを到達不能とマークした後、Kube API Server Operator がそのノードから Pod を削除するまでに待機する時間を秒単位で指定します。
次の Operator は、ワーカーレイテンシープロファイルの変更を監視し、それに応じて対応します。
-
Machine Config Operator (MCO) は、ワーカーノードの
node-status-update-frequencyパラメーターを更新します。 -
Kubernetes コントローラーマネージャーは、コントロールプレーンノードの
node-monitor-grace-periodパラメーターを更新します。 -
Kubernetes API Server Operator は、コントロールプレーンノードの
default-not-ready-toleration-secondsおよびdefault-unreachable-toleration-secondsパラメーターを更新します。
ほとんどの場合はデフォルト設定が機能しますが、OpenShift Container Platform は、ネットワークで通常よりも高いレイテンシーが発生している状況に対して、他に 2 つのワーカーレイテンシープロファイルを提供します。次のセクションでは、3 つのワーカーレイテンシープロファイルを説明します。
- デフォルトのワーカーレイテンシープロファイル
Defaultプロファイルを使用すると、各Kubeletが 10 秒ごとにステータスを更新します (node-status-update-frequency)。Kube Controller Managerは、5 秒ごとにKubeletのステータスをチェックします。Kubernetes Controller Manager は、
Kubeletからのステータス更新を 40 秒 (node-monitor-grace-period) 待機した後、Kubeletが正常ではないと判断します。ステータスが提供されない場合、Kubernetes コントローラーマネージャーは、ノードにnode.kubernetes.io/not-readyまたはnode.kubernetes.io/unreachabletaint のマークを付け、そのノードの Pod を削除します。Pod が
NoExecutetaint を持つノード上にある場合、Pod はtolerationSecondsに従って実行されます。ノードに taint がない場合、そのノードは 300 秒以内に削除されます (Kube API Serverのdefault-not-ready-toleration-secondsおよびdefault-unreachable-toleration-seconds設定)。Expand プロファイル コンポーネント パラメーター 値 デフォルト
kubelet
node-status-update-frequency10s
Kubelet コントローラーマネージャー
node-monitor-grace-period40s
Kubernetes API Server Operator
default-not-ready-toleration-seconds300s
Kubernetes API Server Operator
default-unreachable-toleration-seconds300s
- 中規模のワーカーレイテンシープロファイル
ネットワークレイテンシーが通常よりもわずかに高い場合は、
MediumUpdateAverageReactionプロファイルを使用します。MediumUpdateAverageReactionプロファイルは、kubelet の更新の頻度を 20 秒に減らし、Kubernetes コントローラーマネージャーがそれらの更新を待機する期間を 2 分に変更します。そのノード上の Pod の Pod 排除期間は 60 秒に短縮されます。Pod にtolerationSecondsパラメーターがある場合、エビクションはそのパラメーターで指定された期間待機します。Kubernetes コントローラーマネージャーは、ノードが異常であると判断するまでに 2 分間待機します。別の 1 分間でエビクションプロセスが開始されます。
Expand プロファイル コンポーネント パラメーター 値 MediumUpdateAverageReaction
kubelet
node-status-update-frequency20s
Kubelet コントローラーマネージャー
node-monitor-grace-period2m
Kubernetes API Server Operator
default-not-ready-toleration-seconds60s
Kubernetes API Server Operator
default-unreachable-toleration-seconds60s
- ワーカーの低レイテンシープロファイル
ネットワーク遅延が非常に高い場合は、
LowUpdateSlowReactionプロファイルを使用します。LowUpdateSlowReactionプロファイルは、kubelet の更新頻度を 1 分に減らし、Kubernetes コントローラーマネージャーがそれらの更新を待機する時間を 5 分に変更します。そのノード上の Pod の Pod 排除期間は 60 秒に短縮されます。Pod にtolerationSecondsパラメーターがある場合、エビクションはそのパラメーターで指定された期間待機します。Kubernetes コントローラーマネージャーは、ノードが異常であると判断するまでに 5 分間待機します。別の 1 分間でエビクションプロセスが開始されます。
Expand プロファイル コンポーネント パラメーター 値 LowUpdateSlowReaction
kubelet
node-status-update-frequency1m
Kubelet コントローラーマネージャー
node-monitor-grace-period5m
Kubernetes API Server Operator
default-not-ready-toleration-seconds60s
Kubernetes API Server Operator
default-unreachable-toleration-seconds60s
レイテンシープロファイルは、カスタムのマシン設定プールをサポートしていません。デフォルトのワーカーマシン設定プールのみをサポートしていします。
5.4.2. ワーカーレイテンシープロファイルの使用と変更
ネットワークの遅延に対処するためにワーカー遅延プロファイルを変更するには、node.config オブジェクトを編集してプロファイルの名前を追加します。遅延が増加または減少したときに、いつでもプロファイルを変更できます。
ワーカーレイテンシープロファイルは、一度に 1 つずつ移行する必要があります。たとえば、Default プロファイルから LowUpdateSlowReaction ワーカーレイテンシープロファイルに直接移行することはできません。まず Default ワーカーレイテンシープロファイルから MediumUpdateAverageReaction プロファイルに移行し、次に LowUpdateSlowReaction プロファイルに移行する必要があります。同様に、Default プロファイルに戻る場合は、まずロープロファイルからミディアムプロファイルに移行し、次に Default に移行する必要があります。
OpenShift Container Platform クラスターのインストール時にワーカーレイテンシープロファイルを設定することもできます。
手順
デフォルトのワーカーレイテンシープロファイルから移動するには、以下を実行します。
中規模のワーカーのレイテンシープロファイルに移動します。
node.configオブジェクトを編集します。$ oc edit nodes.config/clusterspec.workerLatencyProfile: MediumUpdateAverageReactionを追加します。node.configオブジェクトの例apiVersion: config.openshift.io/v1 kind: Node metadata: annotations: include.release.openshift.io/ibm-cloud-managed: "true" include.release.openshift.io/self-managed-high-availability: "true" include.release.openshift.io/single-node-developer: "true" release.openshift.io/create-only: "true" creationTimestamp: "2022-07-08T16:02:51Z" generation: 1 name: cluster ownerReferences: - apiVersion: config.openshift.io/v1 kind: ClusterVersion name: version uid: 36282574-bf9f-409e-a6cd-3032939293eb resourceVersion: "1865" uid: 0c0f7a4c-4307-4187-b591-6155695ac85b spec: workerLatencyProfile: MediumUpdateAverageReaction1 # ...- 1
- 中規模のワーカーレイテンシーポリシーを指定します。
変更が適用されると、各ワーカーノードでのスケジューリングは無効になります。
必要に応じて、ワーカーのレイテンシーが低いプロファイルに移動します。
node.configオブジェクトを編集します。$ oc edit nodes.config/clusterspec.workerLatencyProfileの値をLowUpdateSlowReactionに変更します。node.configオブジェクトの例apiVersion: config.openshift.io/v1 kind: Node metadata: annotations: include.release.openshift.io/ibm-cloud-managed: "true" include.release.openshift.io/self-managed-high-availability: "true" include.release.openshift.io/single-node-developer: "true" release.openshift.io/create-only: "true" creationTimestamp: "2022-07-08T16:02:51Z" generation: 1 name: cluster ownerReferences: - apiVersion: config.openshift.io/v1 kind: ClusterVersion name: version uid: 36282574-bf9f-409e-a6cd-3032939293eb resourceVersion: "1865" uid: 0c0f7a4c-4307-4187-b591-6155695ac85b spec: workerLatencyProfile: LowUpdateSlowReaction1 # ...- 1
- 低ワーカーレイテンシーポリシーの使用を指定します。
変更が適用されると、各ワーカーノードでのスケジューリングは無効になります。
検証
全ノードが
Ready状態に戻ると、以下のコマンドを使用して Kubernetes Controller Manager を確認し、これが適用されていることを確認できます。$ oc get KubeControllerManager -o yaml | grep -i workerlatency -A 5 -B 5出力例
# ... - lastTransitionTime: "2022-07-11T19:47:10Z" reason: ProfileUpdated status: "False" type: WorkerLatencyProfileProgressing - lastTransitionTime: "2022-07-11T19:47:10Z"1 message: all static pod revision(s) have updated latency profile reason: ProfileUpdated status: "True" type: WorkerLatencyProfileComplete - lastTransitionTime: "2022-07-11T19:20:11Z" reason: AsExpected status: "False" type: WorkerLatencyProfileDegraded - lastTransitionTime: "2022-07-11T19:20:36Z" status: "False" # ...- 1
- プロファイルが適用され、アクティブであることを指定します。
ミディアムプロファイルからデフォルト、またはデフォルトからミディアムに変更する場合、node.config オブジェクトを編集し、spec.workerLatencyProfile パラメーターを適切な値に設定します。
5.5. コントロールプレーンマシンの管理
コントロールプレーンマシンセット は、コンピュートマシンセットがコンピュートマシンに提供するものと同様の管理機能をコントロールプレーンマシンに提供します。クラスター上のコントロールプレーンマシンセットの可用性と初期ステータスは、クラウドプロバイダーと、インストールした OpenShift Container Platform のバージョンによって異なります。詳細は、コントロールプレーンマシンセットの概要 を参照してください。
5.6. 実稼働環境用のインフラストラクチャーマシンセットの作成
コンピュートマシンセットを作成して、デフォルトのルーター、統合コンテナーイメージレジストリー、およびクラスターメトリクスおよびモニタリングのコンポーネントなどのインフラストラクチャーコンポーネントのみをホストするマシンを作成できます。これらのインフラストラクチャーマシンは、環境の実行に必要なサブスクリプションの合計数にカウントされません。
インフラストラクチャーノードおよびインフラストラクチャーノードで実行できるコンポーネントの情報は、Creating infrastructure machine setsを参照してください。
インフラストラクチャーノードを作成するには、マシンセットを使用する か ノードにラベルを割り当てる か、マシン設定プールを使用します。
これらの手順で使用できるサンプルマシンセットについては、さまざまなクラウド用のマシンセットの作成 を参照してください。
特定のノードセレクターをすべてのインフラストラクチャーコンポーネントに適用すると、OpenShift Container Platform は そのラベルを持つノードでそれらのワークロードをスケジュール します。
5.6.1. コンピュートマシンセットの作成
インストールプログラムによって作成されるコンピュートセットセットに加えて、独自のマシンセットを作成して、選択した特定のワークロードのマシンコンピューティングリソースを動的に管理できます。
前提条件
- OpenShift Container Platform クラスターをデプロイしている。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。
手順
コンピュートマシンセットのカスタムリソース (CR) サンプルを含む新しい YAML ファイルを作成し、
<file_name>.yamlという名前を付けます。<clusterID>および<role>パラメーターの値を設定していることを確認します。オプション: 特定のフィールドに設定する値がわからない場合は、クラスターから既存のコンピュートマシンセットを確認できます。
クラスター内のコンピュートマシンセットをリスト表示するには、次のコマンドを実行します。
$ oc get machinesets -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m特定のコンピュートマシンセットカスタムリソース (CR) 値を表示するには、以下のコマンドを実行します。
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml出力例
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
次のコマンドを実行して
MachineSetCR を作成します。$ oc create -f <file_name>.yaml
検証
次のコマンドを実行して、コンピュートマシンセットのリストを表示します。
$ oc get machineset -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m新しいコンピュートマシンセットが利用可能になると、
DESIREDとCURRENTの値が一致します。コンピュートマシンセットが使用できない場合は、数分待ってからコマンドを再実行してください。
5.6.2. インフラストラクチャーノードの作成
installer-provisioned infrastructure 環境またはコントロールプレーンノードが Machine API によって管理されるクラスターの場合は、「インフラストラクチャーマシンセットの作成」を参照してください。
クラスターの要件によっては、インフラストラクチャー (infra) ノードをプロビジョニングする必要があります。インストールプログラムによってプロビジョニングされるのは、コントロールプレーンとワーカーノードだけです。ワーカーノードは、ラベル付けによってインフラストラクチャーノードとして指定できます。その後、taint と toleration を使用して、適切なワークロードをインフラストラクチャーノードに移動できます。詳細は、「インフラストラクチャーマシンセットへのリソースの移動」を参照してください。
必要に応じて、クラスター全体のデフォルトのノードセレクターを作成できます。デフォルトのノードセレクターは、すべての namespace で作成された Pod に適用され、Pod の既存のノードセレクターと重なります。これにより、Pod のセレクターがさらに制約されます。
デフォルトのノードセレクターのキーが Pod のラベルのキーと競合する場合、デフォルトのノードセレクターは適用されません。
ただし、Pod がスケジュール対象外になる可能性のあるデフォルトノードセレクターを設定しないでください。たとえば、Pod のラベルが node-role.kubernetes.io/master="" などの別のノードロールに設定されている場合、デフォルトのノードセレクターを node-role.kubernetes.io/infra="" などの特定のノードロールに設定すると、Pod がスケジュール不能になる可能性があります。このため、デフォルトのノードセレクターを特定のノードロールに設定する際には注意が必要です。
または、プロジェクトノードセレクターを使用して、クラスター全体でのノードセレクターの競合を避けることができます。
手順
インフラストラクチャーノードとして機能する必要のあるワーカーノードにラベルを追加します。
$ oc label node <node-name> node-role.kubernetes.io/infra=""該当するノードに
infraロールがあるかどうかを確認します。$ oc get nodesオプション: クラスター全体のデフォルトのノードセレクターを作成します。
Schedulerオブジェクトを編集します。$ oc edit scheduler cluster適切なノードセレクターと共に
defaultNodeSelectorフィールドを追加します。apiVersion: config.openshift.io/v1 kind: Scheduler metadata: name: cluster spec: defaultNodeSelector: node-role.kubernetes.io/infra=""1 # ...- 1
- この例のノードセレクターは、デフォルトでインフラストラクチャーノードに Pod をデプロイします。
- 変更を適用するためにファイルを保存します。
これで、インフラストラクチャーリソースを新しいインフラストラクチャーノードに移動できるようになりました。また、新しいインフラストラクチャーノード上の不要なワークロードやノードに属さないワークロードを削除してください。「OpenShift Container Platform インフラストラクチャーコンポーネント」で、インフラストラクチャーノードでの使用がサポートされているワークロードのリストを参照してください。
5.6.3. インフラストラクチャーマシンのマシン設定プール作成
インフラストラクチャーマシンに専用の設定が必要な場合は、infra プールを作成する必要があります。
カスタムマシン設定プールを作成すると、デフォルトのワーカープール設定がオーバーライドされます (デフォルトのワーカープール設定が同じファイルまたはユニットを参照する場合)。
手順
特定のラベルを持つ infra ノードとして割り当てるノードに、ラベルを追加します。
$ oc label node <node_name> <label>$ oc label node ci-ln-n8mqwr2-f76d1-xscn2-worker-c-6fmtx node-role.kubernetes.io/infra=ワーカーロールとカスタムロールの両方をマシン設定セレクターとして含まれるマシン設定プールを作成します。
$ cat infra.mcp.yaml出力例
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: infra spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,infra]}1 nodeSelector: matchLabels: node-role.kubernetes.io/infra: ""2 注記カスタムマシン設定プールは、ワーカープールからマシン設定を継承します。カスタムプールは、ワーカープールのターゲット設定を使用しますが、カスタムプールのみをターゲットに設定する変更をデプロイする機能を追加します。カスタムプールはワーカープールから設定を継承するため、ワーカープールへの変更もカスタムプールに適用されます。
YAML ファイルを用意した後に、マシン設定プールを作成できます。
$ oc create -f infra.mcp.yamlマシン設定をチェックして、インフラストラクチャー設定が正常にレンダリングされていることを確認します。
$ oc get machineconfig出力例
NAME GENERATEDBYCONTROLLER IGNITIONVERSION CREATED 00-master 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 00-worker 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-master-container-runtime 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-master-kubelet 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-worker-container-runtime 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-worker-kubelet 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 99-master-1ae2a1e0-a115-11e9-8f14-005056899d54-registries 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 99-master-ssh 3.2.0 31d 99-worker-1ae64748-a115-11e9-8f14-005056899d54-registries 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 99-worker-ssh 3.2.0 31d rendered-infra-4e48906dca84ee702959c71a53ee80e7 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 23m rendered-master-072d4b2da7f88162636902b074e9e28e 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-master-3e88ec72aed3886dec061df60d16d1af 02c07496ba0417b3e12b78fb32baf6293d314f79 3.2.0 31d rendered-master-419bee7de96134963a15fdf9dd473b25 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 17d rendered-master-53f5c91c7661708adce18739cc0f40fb 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 13d rendered-master-a6a357ec18e5bce7f5ac426fc7c5ffcd 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 7d3h rendered-master-dc7f874ec77fc4b969674204332da037 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-worker-1a75960c52ad18ff5dfa6674eb7e533d 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-worker-2640531be11ba43c61d72e82dc634ce6 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-worker-4e48906dca84ee702959c71a53ee80e7 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 7d3h rendered-worker-4f110718fe88e5f349987854a1147755 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 17d rendered-worker-afc758e194d6188677eb837842d3b379 02c07496ba0417b3e12b78fb32baf6293d314f79 3.2.0 31d rendered-worker-daa08cc1e8f5fcdeba24de60cd955cc3 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 13d新規のマシン設定には、接頭辞
rendered-infra-*が表示されるはずです。オプション: カスタムプールへの変更をデプロイするには、
infraなどのラベルとしてカスタムプール名を使用するマシン設定を作成します。これは必須ではありませんが、説明の目的でのみ表示されていることに注意してください。これにより、インフラストラクチャーノードのみに固有のカスタム設定を適用できます。注記新規マシン設定プールの作成後に、MCO はそのプールに新たにレンダリングされた設定を生成し、そのプールに関連付けられたノードは再起動して、新規設定を適用します。
マシン設定を作成します。
$ cat infra.mc.yaml出力例
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: name: 51-infra labels: machineconfiguration.openshift.io/role: infra1 spec: config: ignition: version: 3.2.0 storage: files: - path: /etc/infratest mode: 0644 contents: source: data:,infra- 1
- ノードに追加したラベルを
nodeSelectorとして追加します。
マシン設定を infra のラベルが付いたノードに適用します。
$ oc create -f infra.mc.yaml
新規のマシン設定プールが利用可能であることを確認します。
$ oc get mcp出力例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE infra rendered-infra-60e35c2e99f42d976e084fa94da4d0fc True False False 1 1 1 0 4m20s master rendered-master-9360fdb895d4c131c7c4bebbae099c90 True False False 3 3 3 0 91m worker rendered-worker-60e35c2e99f42d976e084fa94da4d0fc True False False 2 2 2 0 91mこの例では、ワーカーノードが infra ノードに変更されました。
5.7. マシンセットリソースのインフラストラクチャーノードへの割り当て
インフラストラクチャーマシンセットの作成後、worker および infra ロールが新規の infra ノードに適用されます。infra ロールが割り当てられたノードは、worker ロールも適用されている場合でも、環境を実行するために必要なサブスクリプションの合計数にはカウントされません。
ただし、infra ノードに worker ロールが割り当てられている場合は、ユーザーのワークロードが誤って infra ノードに割り当てられる可能性があります。これを回避するには、taint を、制御する必要のある Pod の infra ノードおよび toleration に適用できます。
5.7.1. taint および toleration を使用したインフラストラクチャーノードのワークロードのバインディング
infra および worker ロールが割り当てられているインフラストラクチャーノードがある場合、ユーザーのワークロードがそのノードに割り当てられないようにノードを設定する必要があります。
インフラストラクチャーノード用に作成した infra,worker ラベルを両方とも保持し、ユーザーのワークロードがスケジュールされるノードを taint および toleration を使用して管理することを推奨します。ノードから worker ラベルを削除する場合には、カスタムプールを作成して管理する必要があります。master または worker 以外のラベルが割り当てられたノードは、カスタムプールなしには MCO で認識されません。worker ラベルを維持すると、カスタムラベルを選択するカスタムプールが存在しない場合に、ノードをデフォルトのワーカーマシン設定プールで管理できます。infra ラベルは、サブスクリプションの合計数にカウントされないクラスターと通信します。
前提条件
-
追加の
MachineSetを OpenShift Container Platform クラスターに設定します。
手順
インフラストラクチャーノードに taint を追加して、そのノードにユーザーのワークロードがスケジュールされないようにします。
ノードに taint があるかどうかを判別します。
$ oc describe nodes <node_name>出力例
oc describe node ci-ln-iyhx092-f76d1-nvdfm-worker-b-wln2l Name: ci-ln-iyhx092-f76d1-nvdfm-worker-b-wln2l Roles: worker ... Taints: node-role.kubernetes.io/infra=reserved:NoSchedule ...この例では、ノードに taint があることを示しています。次の手順に進み、toleration を Pod に追加してください。
ユーザーワークロードをスケジューリングできないように、taint を設定していない場合は、以下を実行します。
$ oc adm taint nodes <node_name> <key>=<value>:<effect>以下に例を示します。
$ oc adm taint nodes node1 node-role.kubernetes.io/infra=reserved:NoScheduleヒントまたは、Pod 仕様を編集して taint を追加することもできます。
apiVersion: v1 kind: Node metadata: name: node1 # ... spec: taints: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule # ...これらの例では、
node-role.kubernetes.io/infraキーとNoScheduletaint effect を持つnode1に taint を適用します。effect がNoScheduleのノードは、taint を容認する Pod のみをスケジュールしますが、既存の Pod はノードにスケジュールされたままになります。インフラストラクチャーノードに
NoScheduletaint を追加した場合、そのノードに設定されたデーモンによって制御されるすべての Pod は、misscheduledとマークされます。Red Hat ナレッジベースソリューション add toleration onmisscheduledDNS pods に示されているように、Pod を削除するか、Pod に toleration を追加する必要があります。Operator によって管理されるデーモンセットオブジェクトには toleration を追加できないことに注意してください。注記Descheduler が使用されると、ノードの taint に違反する Pod はクラスターからエビクトされる可能性があります。
インフラストラクチャーノードにスケジュールする Pod (ルーター、レジストリー、モニタリングワークロードなど) に toleration を追加します。前の例を参考にして、
Podオブジェクト仕様に次の toleration を追加します。apiVersion: v1 kind: Pod metadata: annotations: # ... spec: # ... tolerations: - key: node-role.kubernetes.io/infra1 value: reserved2 effect: NoSchedule3 operator: Equal4 この toleration は、
oc adm taintコマンドで作成された taint と一致します。この toleration を持つ Pod は、インフラストラクチャーノードにスケジュールできます。注記OLM によってインストールされた Operator の Pod は、必ずしもインフラストラクチャーノードに移動できません。Operator Pod を移動する機能は、各 Operator の設定によって異なります。
- スケジューラーを使用して、Pod をインフラストラクチャーノードにスケジュールします。詳細は、「スケジューラーによる Pod 配置の制御」のドキュメントを参照してください。
- 新しいインフラストラクチャーノード上の不要なワークロードやノードに属さないワークロードを削除します。「OpenShift Container Platform インフラストラクチャーコンポーネント」で、インフラストラクチャーノードでの使用がサポートされているワークロードのリストを参照してください。
5.8. リソースのインフラストラクチャーマシンセットへの移行
インフラストラクチャーリソースの一部はデフォルトでクラスターにデプロイされます。それらは、作成したインフラストラクチャーマシンセットに移行できます。
5.8.1. ルーターの移動
ルーター Pod を異なるコンピュートマシンセットにデプロイできます。デフォルトで、この Pod はワーカーノードにデプロイされます。
前提条件
- 追加のコンピュートマシンセットを OpenShift Container Platform クラスターに設定します。
手順
ルーター Operator の
IngressControllerカスタムリソースを表示します。$ oc get ingresscontroller default -n openshift-ingress-operator -o yamlコマンド出力は以下のテキストのようになります。
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: creationTimestamp: 2019-04-18T12:35:39Z finalizers: - ingresscontroller.operator.openshift.io/finalizer-ingresscontroller generation: 1 name: default namespace: openshift-ingress-operator resourceVersion: "11341" selfLink: /apis/operator.openshift.io/v1/namespaces/openshift-ingress-operator/ingresscontrollers/default uid: 79509e05-61d6-11e9-bc55-02ce4781844a spec: {} status: availableReplicas: 2 conditions: - lastTransitionTime: 2019-04-18T12:36:15Z status: "True" type: Available domain: apps.<cluster>.example.com endpointPublishingStrategy: type: LoadBalancerService selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller=defaultingresscontrollerリソースを編集し、nodeSelectorをinfraラベルを使用するように変更します。$ oc edit ingresscontroller default -n openshift-ingress-operatorapiVersion: operator.openshift.io/v1 kind: IngressController metadata: creationTimestamp: "2025-03-26T21:15:43Z" finalizers: - ingresscontroller.operator.openshift.io/finalizer-ingresscontroller generation: 1 name: default # ... spec: nodePlacement: nodeSelector:1 matchLabels: node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved # ...- 1
- 適切な値が設定された
nodeSelectorパラメーターを、移動する必要のあるコンポーネントに追加します。上記の形式でnodeSelectorパラメーターを使用することも、ノードに指定された値に基づいて<key>: <value>ペアを使用することもできます。インフラストラクチャーノードに taint を追加した場合は、一致する toleration も追加します。
ルーター Pod が
infraノードで実行されていることを確認します。ルーター Pod のリストを表示し、実行中の Pod のノード名をメモします。
$ oc get pod -n openshift-ingress -o wide出力例
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES router-default-86798b4b5d-bdlvd 1/1 Running 0 28s 10.130.2.4 ip-10-0-217-226.ec2.internal <none> <none> router-default-955d875f4-255g8 0/1 Terminating 0 19h 10.129.2.4 ip-10-0-148-172.ec2.internal <none> <none>この例では、実行中の Pod は
ip-10-0-217-226.ec2.internalノードにあります。実行中の Pod のノードのステータスを表示します。
$ oc get node <node_name>1 - 1
- Pod のリストより取得した
<node_name>を指定します。
出力例
NAME STATUS ROLES AGE VERSION ip-10-0-217-226.ec2.internal Ready infra,worker 17h v1.29.4ロールのリストに
infraが含まれているため、Pod は正しいノードで実行されます。
5.8.2. デフォルトレジストリーの移行
レジストリー Operator を、その Pod を複数の異なるノードにデプロイするように設定します。
前提条件
- 追加のコンピュートマシンセットを OpenShift Container Platform クラスターに設定します。
手順
config/instanceオブジェクトを表示します。$ oc get configs.imageregistry.operator.openshift.io/cluster -o yaml出力例
apiVersion: imageregistry.operator.openshift.io/v1 kind: Config metadata: creationTimestamp: 2019-02-05T13:52:05Z finalizers: - imageregistry.operator.openshift.io/finalizer generation: 1 name: cluster resourceVersion: "56174" selfLink: /apis/imageregistry.operator.openshift.io/v1/configs/cluster uid: 36fd3724-294d-11e9-a524-12ffeee2931b spec: httpSecret: d9a012ccd117b1e6616ceccb2c3bb66a5fed1b5e481623 logging: 2 managementState: Managed proxy: {} replicas: 1 requests: read: {} write: {} storage: s3: bucket: image-registry-us-east-1-c92e88cad85b48ec8b312344dff03c82-392c region: us-east-1 status: ...config/instanceオブジェクトを編集します。$ oc edit configs.imageregistry.operator.openshift.io/clusterapiVersion: imageregistry.operator.openshift.io/v1 kind: Config metadata: name: cluster # ... spec: logLevel: Normal managementState: Managed nodeSelector:1 node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved- 1
- 適切な値が設定された
nodeSelectorパラメーターを、移動する必要のあるコンポーネントに追加します。上記の形式でnodeSelectorパラメーターを使用することも、ノードに指定された値に基づいて<key>: <value>ペアを使用することもできます。インフラストラクチャーノードに taint を追加した場合は、一致する toleration も追加します。
レジストリー Pod がインフラストラクチャーノードに移動していることを確認します。
以下のコマンドを実行して、レジストリー Pod が置かれているノードを特定します。
$ oc get pods -o wide -n openshift-image-registryノードに指定したラベルがあることを確認します。
$ oc describe node <node_name>コマンド出力を確認し、
node-role.kubernetes.io/infraがLABELSリストにあることを確認します。
5.8.3. モニタリングソリューションの移動
監視スタックには、Prometheus、Thanos Querier、Alertmanager などの複数のコンポーネントが含まれています。Cluster Monitoring Operator は、このスタックを管理します。モニタリングスタックをインフラストラクチャーノードに再デプロイするために、カスタム config map を作成して適用できます。
前提条件
-
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。 -
OpenShift CLI (
oc) がインストールされている。
手順
cluster-monitoring-configconfig map を編集し、nodeSelectorを変更してinfraラベルを使用します。$ oc edit configmap cluster-monitoring-config -n openshift-monitoringapiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: |+ alertmanagerMain: nodeSelector:1 node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule prometheusK8s: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule prometheusOperator: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule metricsServer: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule kubeStateMetrics: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule telemeterClient: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule openshiftStateMetrics: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule thanosQuerier: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule monitoringPlugin: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule- 1
- 適切な値が設定された
nodeSelectorパラメーターを、移動する必要のあるコンポーネントに追加します。上記の形式でnodeSelectorパラメーターを使用することも、ノードに指定された値に基づいて<key>: <value>ペアを使用することもできます。インフラストラクチャーノードに taint を追加した場合は、一致する toleration も追加します。
モニタリング Pod が新規マシンに移行することを確認します。
$ watch 'oc get pod -n openshift-monitoring -o wide'コンポーネントが
infraノードに移動していない場合は、このコンポーネントを持つ Pod を削除します。$ oc delete pod -n openshift-monitoring <pod>削除された Pod からのコンポーネントが
infraノードに再作成されます。
5.8.4. ロギングリソースの移動
ロギングリソースの移動の詳細は、以下を参照してください。
5.9. クラスターへの自動スケーリングの適用
自動スケーリングの OpenShift Container Platform クラスターへの適用には、クラスターへの Cluster Autoscaler のデプロイと各マシンタイプの Machine Autoscaler のデプロイが必要です。
詳細は、OpenShift Container Platform クラスターへの自動スケーリングの適用 を参照してください。
5.10. Linux cgroup の設定
OpenShift Container Platform 4.14 以降、OpenShift Container Platform はクラスター内で Linux コントロールグループバージョン 2 (cgroup v2) を使用します。OpenShift Container Platform 4.13 以前で cgroup v1 を使用している場合、OpenShift Container Platform 4.14 以降に移行しても、cgroup 設定はバージョン 2 に自動的に更新されません。OpenShift Container Platform 4.14 以降の新規インストールでは、デフォルトで cgroup v2 が使用されます。ただし、インストール時に Linux コントロールグループバージョン 1 (cgroup v1) を有効にできます。
cgroup v2 は、Linux cgroup API の現行バージョンです。cgroup v2 では、統一された階層、安全なサブツリー委譲、Pressure Stall Information 等の新機能、および強化されたリソース管理および分離など、cgroup v1 に対していくつかの改善が行われています。ただし、cgroup v2 には、cgroup v1 とは異なる CPU、メモリー、および I/O 管理特性があります。したがって、一部のワークロードでは、cgroup v2 を実行するクラスター上のメモリーまたは CPU 使用率にわずかな違いが発生する可能性があります。
必要に応じて、cgroup v1 と cgroup v2 の間で変更できます。OpenShift Container Platform で cgroup v1 を有効にすると、クラスター内のすべての cgroup v2 コントローラーと階層が無効になります。
cgroup v1 は非推奨の機能です。非推奨の機能は依然として OpenShift Container Platform に含まれており、引き続きサポートされますが、この製品の今後のリリースで削除されるため、新規デプロイメントでの使用は推奨されません。
OpenShift Container Platform で非推奨となったか、削除された主な機能の最新の一覧は、OpenShift Container Platform リリースノートの 非推奨および削除された機能 セクションを参照してください。
前提条件
- OpenShift Container Platform クラスター (バージョン 4.12 以降) が実行中。
- 管理者権限を持つユーザーとしてクラスターにログインしている。
手順
ノードに、必要な cgroup バージョンを設定します。
node.configオブジェクトを編集します。$ oc edit nodes.config/clusterAdd
spec.cgroupMode: "v1":node.configオブジェクトの例apiVersion: config.openshift.io/v1 kind: Node metadata: annotations: include.release.openshift.io/ibm-cloud-managed: "true" include.release.openshift.io/self-managed-high-availability: "true" include.release.openshift.io/single-node-developer: "true" release.openshift.io/create-only: "true" creationTimestamp: "2022-07-08T16:02:51Z" generation: 1 name: cluster ownerReferences: - apiVersion: config.openshift.io/v1 kind: ClusterVersion name: version uid: 36282574-bf9f-409e-a6cd-3032939293eb resourceVersion: "1865" uid: 0c0f7a4c-4307-4187-b591-6155695ac85b spec: cgroupMode: "v1"1 ...- 1
- cgroup v1 を有効にします。
検証
マシン設定をチェックして、新しいマシン設定が追加されたことを確認します。
$ oc get mc出力例
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 00-master 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 00-worker 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-master-container-runtime 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-master-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-worker-container-runtime 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 01-worker-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 97-master-generated-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-worker-generated-kubelet 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-master-generated-registries 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-master-ssh 3.2.0 40m 99-worker-generated-registries 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m 99-worker-ssh 3.2.0 40m rendered-master-23d4317815a5f854bd3553d689cfe2e9 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 10s1 rendered-master-23e785de7587df95a4b517e0647e5ab7 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m rendered-worker-5d596d9293ca3ea80c896a1191735bb1 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 33m rendered-worker-dcc7f1b92892d34db74d6832bcc9ccd4 52dd3ba6a9a527fc3ab42afac8d12b693534c8c9 3.2.0 10s- 1
- 予想どおり、新しいマシン設定が作成されます。
新しい
kernelArgumentsが新しいマシン設定に追加されたことを確認します。$ oc describe mc <name>cgroup v1 の出力例
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 05-worker-kernelarg-selinuxpermissive spec: kernelArguments: systemd.unified_cgroup_hierarchy=01 systemd.legacy_systemd_cgroup_controller=12 psi=0ノードをチェックして、ノードのスケジューリングが無効になっていることを確認します。これは、変更が適用されていることを示しています。
$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION ci-ln-fm1qnwt-72292-99kt6-master-0 Ready,SchedulingDisabled master 58m v1.29.4 ci-ln-fm1qnwt-72292-99kt6-master-1 Ready master 58m v1.29.4 ci-ln-fm1qnwt-72292-99kt6-master-2 Ready master 58m v1.29.4 ci-ln-fm1qnwt-72292-99kt6-worker-a-h5gt4 Ready,SchedulingDisabled worker 48m v1.29.4 ci-ln-fm1qnwt-72292-99kt6-worker-b-7vtmd Ready worker 48m v1.29.4 ci-ln-fm1qnwt-72292-99kt6-worker-c-rhzkv Ready worker 48m v1.29.4ノードが
Ready状態に戻ったら、そのノードのデバッグセッションを開始します。$ oc debug node/<node_name>/hostをデバッグシェル内のルートディレクトリーとして設定します。sh-4.4# chroot /hostsys/fs/cgroup/cgroup2fsファイルがノードに存在することを確認します。このファイルは cgroup v1 によって作成されます。$ stat -c %T -f /sys/fs/cgroup出力例
cgroup2fs
5.11. FeatureGate の使用によるテクノロジープレビュー機能の有効化
FeatureGate カスタムリソース (CR) を編集して、クラスターのすべてのノードに対して現在のテクノロジープレビュー機能のサブセットをオンにすることができます。
5.11.1. フィーチャーゲートについて
FeatureGate カスタムリソース (CR) を使用して、クラスター内の特定の機能セットを有効にすることができます。機能セットは、デフォルトで有効にされない OpenShift Container Platform 機能のコレクションです。
FeatureGate CR を使用して、以下の機能セットをアクティブにすることができます。
TechPreviewNoUpgrade: この機能セットは、現在のテクノロジープレビュー機能のサブセットです。この機能セットを使用すると、テストクラスターでこれらのテクノロジープレビュー機能を有効にすることができます。そこでは、これらの機能を完全にテストできますが、運用クラスターでは機能を無効にしたままにできます。警告クラスターで
TechPreviewNoUpgrade機能セットを有効にすると、元に戻すことができず、マイナーバージョンの更新が妨げられます。本番クラスターでは、この機能セットを有効にしないでください。この機能セットにより、以下のテクノロジープレビュー機能が有効になります。
-
外部クラウドプロバイダー。vSphere、AWS、Azure、GCP 上にあるクラスターの外部クラウドプロバイダーのサポートを有効にします。OpenStack のサポートは GA です。これは内部機能であり、ほとんどのユーザーは操作する必要はありません。(
ExternalCloudProvider) -
OpenShift Builds の共有リソース CSI ドライバー。Container Storage Interface (CSI) を有効にします。(
CSIDriverSharedResource) -
ノード上のスワップメモリー。ノードごとに OpenShift Container Platform ワークロードのスワップメモリーの使用を有効にします。(
NodeSwap) -
OpenStack Machine API プロバイダー。このゲートは効果がなく、今後のリリースでこの機能セットから削除される予定です。(
MachineAPIProviderOpenStack) -
Insights Operator。
InsightsDataGatherCRD を有効にし、ユーザーがいくつかの Insights データ収集オプションを設定できるようにします。この機能セットにより、DataGatherCRD も有効になり、ユーザーがオンデマンドで Insights データ収集を実行できるようになります。(InsightsConfigAPI) -
Retroactive デフォルトストレージクラス。PVC 作成時にデフォルトのストレージクラスがない場合に、OpenShift Container Platform は PVC に対してデフォルトのストレージクラスを遡及的に割り当てることができます。(
RetroactiveDefaultStorageClass) -
動的リソース割り当て API。Pod とコンテナー間でリソースを要求および共有するための新しい API が有効になります。これは内部機能であり、ほとんどのユーザーは操作する必要はありません。(
DynamicResourceAllocation) -
Pod セキュリティーアドミッションの適用。Pod セキュリティーアドミッションの制限付き強制モードを有効にします。警告をログに記録するだけでなく、Pod のセキュリティー基準に違反している場合、Pod は拒否されます。(
OpenShiftPodSecurityAdmission) -
StatefulSet Pod の可用性アップグレードの制限。ユーザーは、更新中に使用できないステートフルセット Pod の最大数を定義できるため、アプリケーションのダウンタイムが削減されます。(
MaxUnavailableStatefulSet) -
MatchConditionsは、この Webhook にリクエストを送信するために満たす必要がある条件のリストです。Match Conditions は、ルール、namespaceSelector、および objectSelector ですでに一致しているリクエストをフィルター処理します。matchConditionsの空のリストは、すべてのリクエストに一致します。(admissionWebhookMatchConditions) -
gcpLabelsTags -
vSphereStaticIPs -
routeExternalCertificate -
automatedEtcdBackup -
gcpClusterHostedDNS -
vSphereControlPlaneMachineset -
dnsNameResolver -
machineConfigNodes -
metricsServer -
installAlternateInfrastructureAWS -
sdnLiveMigration -
mixedCPUsAllocation -
managedBootImages -
onClusterBuild -
signatureStores -
DisableKubeletCloudCredentialProviders -
BareMetalLoadBalancer -
ClusterAPIInstallAWS -
ClusterAPIInstallNutanix -
ClusterAPIInstallOpenStack -
ClusterAPIInstallVSphere -
HardwareSpeed -
KMSv1 -
NetworkDiagnosticsConfig -
VSphereDriverConfiguration -
ExternalOIDC -
ChunkSizeMiB -
ClusterAPIInstallGCP -
ClusterAPIInstallPowerVS -
EtcdBackendQuota -
例 -
ImagePolicy -
InsightsConfig -
InsightsOnDemandDataGather -
MetricsCollectionProfiles -
NewOLM -
NodeDisruptionPolicy -
PinnedImages -
PlatformOperators -
ServiceAccountTokenNodeBinding -
ServiceAccountTokenNodeBindingValidation -
ServiceAccountTokenPodNodeInfo -
TranslateStreamCloseWebsocketRequests -
UpgradeStatus -
VSphereMultiVCenters -
VolumeGroupSnapshot
-
外部クラウドプロバイダー。vSphere、AWS、Azure、GCP 上にあるクラスターの外部クラウドプロバイダーのサポートを有効にします。OpenStack のサポートは GA です。これは内部機能であり、ほとんどのユーザーは操作する必要はありません。(
5.11.2. Web コンソールを使用した機能セットの有効化
FeatureGate カスタムリソース (CR) を編集して、OpenShift Container Platform Web コンソールを使用してクラスター内のすべてのノードの機能セットを有効にすることができます。
手順
機能セットを有効にするには、以下を実行します。
- OpenShift Container Platform Web コンソールで、Administration → Custom Resource Definitions ページに切り替えます。
- Custom Resource Definitions ページで、FeatureGate をクリックします。
- Custom Resource Definition Details ページで、Instances タブをクリックします。
- cluster フィーチャーゲートをクリックし、YAML タブをクリックします。
cluster インスタンスを編集して特定の機能セットを追加します。
警告クラスターで
TechPreviewNoUpgrade機能セットを有効にすると、元に戻すことができず、マイナーバージョンの更新が妨げられます。本番クラスターでは、この機能セットを有効にしないでください。フィーチャーゲートカスタムリソースのサンプル
apiVersion: config.openshift.io/v1 kind: FeatureGate metadata: name: cluster1 # ... spec: featureSet: TechPreviewNoUpgrade2 変更を保存すると、新規マシン設定が作成され、マシン設定プールが更新され、変更が適用されている間に各ノードのスケジューリングが無効になります。
検証
ノードが準備完了状態に戻った後、ノード上の kubelet.conf ファイルを確認することで、フィーチャーゲートが有効になっていることを確認できます。
- Web コンソールの Administrator パースペクティブで、Compute → Nodes に移動します。
- ノードを選択します。
- Node details ページで Terminal をクリックします。
ターミナルウィンドウで、root ディレクトリーを
/hostに切り替えます。sh-4.2# chroot /hostkubelet.confファイルを表示します。sh-4.2# cat /etc/kubernetes/kubelet.conf出力例
# ... featureGates: InsightsOperatorPullingSCA: true, LegacyNodeRoleBehavior: false # ...trueとして一覧表示されている機能は、クラスターで有効になっています。注記一覧表示される機能は、OpenShift Container Platform のバージョンによって異なります。
5.11.3. CLI を使用した機能セットの有効化
FeatureGate カスタムリソース (CR) を編集し、OpenShift CLI (oc) を使用してクラスター内のすべてのノードの機能セットを有効にすることができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
機能セットを有効にするには、以下を実行します。
clusterという名前のFeatureGateCR を編集します。$ oc edit featuregate cluster警告クラスターで
TechPreviewNoUpgrade機能セットを有効にすると、元に戻すことができず、マイナーバージョンの更新が妨げられます。本番クラスターでは、この機能セットを有効にしないでください。FeatureGate カスタムリソースのサンプル
apiVersion: config.openshift.io/v1 kind: FeatureGate metadata: name: cluster1 # ... spec: featureSet: TechPreviewNoUpgrade2 変更を保存すると、新規マシン設定が作成され、マシン設定プールが更新され、変更が適用されている間に各ノードのスケジューリングが無効になります。
検証
ノードが準備完了状態に戻った後、ノード上の kubelet.conf ファイルを確認することで、フィーチャーゲートが有効になっていることを確認できます。
- Web コンソールの Administrator パースペクティブで、Compute → Nodes に移動します。
- ノードを選択します。
- Node details ページで Terminal をクリックします。
ターミナルウィンドウで、root ディレクトリーを
/hostに切り替えます。sh-4.2# chroot /hostkubelet.confファイルを表示します。sh-4.2# cat /etc/kubernetes/kubelet.conf出力例
# ... featureGates: InsightsOperatorPullingSCA: true, LegacyNodeRoleBehavior: false # ...trueとして一覧表示されている機能は、クラスターで有効になっています。注記一覧表示される機能は、OpenShift Container Platform のバージョンによって異なります。
5.12. etcd タスク
etcd のバックアップ、etcd 暗号化の有効化または無効化、または etcd データのデフラグを行います。
5.12.1. etcd 暗号化について
デフォルトで、etcd データは OpenShift Container Platform で暗号化されません。クラスターの etcd 暗号化を有効にして、データセキュリティーのレイヤーを追加で提供することができます。たとえば、etcd バックアップが正しくない公開先に公開される場合に機密データが失われないように保護することができます。
etcd の暗号化を有効にすると、以下の OpenShift API サーバーおよび Kubernetes API サーバーリソースが暗号化されます。
- シークレット
- config map
- ルート
- OAuth アクセストークン
- OAuth 認証トークン
etcd 暗号を有効にすると、暗号化キーが作成されます。etcd バックアップから復元するには、これらのキーが必要です。
etcd 暗号化は、キーではなく、値のみを暗号化します。リソースの種類、namespace、およびオブジェクト名は暗号化されません。
バックアップ中に etcd 暗号化が有効になっている場合は、static_kuberesources_<datetimestamp>.tar.gz ファイルに etcd スナップショットの暗号化キーが含まれています。セキュリティー上の理由から、このファイルは etcd スナップショットとは別に保存してください。ただし、このファイルは、それぞれの etcd スナップショットから etcd の以前の状態を復元するために必要です。
5.12.2. サポートされている暗号化の種類
以下の暗号化タイプは、OpenShift Container Platform で etcd データを暗号化するためにサポートされています。
- AES-CBC
- 暗号化を実行するために、PKCS#7 パディングと 32 バイトの鍵を含む AES-CBC を使用します。暗号化キーは毎週ローテーションされます。
- AES-GCM
- AES-GCM とランダムナンスおよび 32 バイトキーを使用して暗号化を実行します。暗号化キーは毎週ローテーションされます。
5.12.3. etcd 暗号化の有効化
etcd 暗号化を有効にして、クラスターで機密性の高いリソースを暗号化できます。
初期暗号化プロセスが完了するまで、etcd リソースをバックアップしないでください。暗号化プロセスが完了しない場合、バックアップは一部のみ暗号化される可能性があります。
etcd 暗号化を有効にすると、いくつかの変更が発生する可能性があります。
- etcd 暗号化は、いくつかのリソースのメモリー消費に影響を与える可能性があります。
- リーダーがバックアップを提供する必要があるため、バックアップのパフォーマンスに一時的な影響が生じる場合があります。
- ディスク I/O は、バックアップ状態を受け取るノードに影響を与える可能性があります。
etcd データベースは、AES-GCM または AES-CBC 暗号化で暗号化できます。
etcd データベースをある暗号化タイプから別の暗号化タイプに移行するには、API サーバーの spec.encryption.type フィールドを変更します。etcd データの新しい暗号化タイプへの移行は自動的に行われます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
APIServerオブジェクトを変更します。$ oc edit apiserverspec.encryption.typeフィールドをaesgcmまたはaescbcに設定します。spec: encryption: type: aesgcm1 - 1
- AES-CBC 暗号化の場合は
aescbcに、AES-GCM 暗号化の場合はaesgcmに設定します。
変更を適用するためにファイルを保存します。
暗号化プロセスが開始されます。etcd データベースのサイズによっては、このプロセスが完了するまでに 20 分以上かかる場合があります。
etcd 暗号化が正常に行われたことを確認します。
OpenShift API サーバーの
Encryptedステータスを確認し、そのリソースが正常に暗号化されたことを確認します。$ oc get openshiftapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'この出力には、暗号化が正常に実行されると
EncryptionCompletedが表示されます。EncryptionCompleted All resources encrypted: routes.route.openshift.io出力に
EncryptionInProgressが表示される場合、これは暗号化が進行中であることを意味します。数分待機した後に再試行します。Kubernetes API サーバーの
Encryptedステータス状態を確認し、そのリソースが正常に暗号化されたことを確認します。$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'この出力には、暗号化が正常に実行されると
EncryptionCompletedが表示されます。EncryptionCompleted All resources encrypted: secrets, configmaps出力に
EncryptionInProgressが表示される場合、これは暗号化が進行中であることを意味します。数分待機した後に再試行します。OpenShift OAuth API サーバーの
Encryptedステータスを確認し、そのリソースが正常に暗号化されたことを確認します。$ oc get authentication.operator.openshift.io -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'この出力には、暗号化が正常に実行されると
EncryptionCompletedが表示されます。EncryptionCompleted All resources encrypted: oauthaccesstokens.oauth.openshift.io, oauthauthorizetokens.oauth.openshift.io出力に
EncryptionInProgressが表示される場合、これは暗号化が進行中であることを意味します。数分待機した後に再試行します。
5.12.4. etcd 暗号化の無効化
クラスターで etcd データの暗号化を無効にできます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
APIServerオブジェクトを変更します。$ oc edit apiserverencryptionフィールドタイプをidentityに設定します。spec: encryption: type: identity1 - 1
identityタイプはデフォルト値であり、暗号化は実行されないことを意味します。
変更を適用するためにファイルを保存します。
復号化プロセスが開始されます。クラスターのサイズによっては、このプロセスが完了するまで 20 分以上かかる場合があります。
etcd の復号化が正常に行われたことを確認します。
OpenShift API サーバーの
Encryptedステータス条件を確認し、そのリソースが正常に暗号化されたことを確認します。$ oc get openshiftapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'この出力には、復号化が正常に実行されると
DecryptionCompletedが表示されます。DecryptionCompleted Encryption mode set to identity and everything is decrypted出力に
DecryptionInProgressが表示される場合、これは復号化が進行中であることを意味します。数分待機した後に再試行します。Kubernetes API サーバーの
Encryptedステータス状態を確認し、そのリソースが正常に復号化されたことを確認します。$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'この出力には、復号化が正常に実行されると
DecryptionCompletedが表示されます。DecryptionCompleted Encryption mode set to identity and everything is decrypted出力に
DecryptionInProgressが表示される場合、これは復号化が進行中であることを意味します。数分待機した後に再試行します。OpenShift API サーバーの
Encryptedステータス条件を確認し、そのリソースが正常に復号化されたことを確認します。$ oc get authentication.operator.openshift.io -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'この出力には、復号化が正常に実行されると
DecryptionCompletedが表示されます。DecryptionCompleted Encryption mode set to identity and everything is decrypted出力に
DecryptionInProgressが表示される場合、これは復号化が進行中であることを意味します。数分待機した後に再試行します。
5.12.5. etcd データのバックアップ
以下の手順に従って、etcd スナップショットを作成し、静的 Pod のリソースをバックアップして etcd データをバックアップします。このバックアップは保存でき、etcd を復元する必要がある場合に後で使用することができます。
単一のコントロールプレーンホストからのバックアップのみを保存します。クラスター内の各コントロールプレーンホストからのバックアップは取得しないでください。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 クラスター全体のプロキシーが有効になっているかどうかを確認している。
ヒントoc get proxy cluster -o yamlの出力を確認して、プロキシーが有効にされているかどうかを確認できます。プロキシーは、httpProxy、httpsProxy、およびnoProxyフィールドに値が設定されている場合に有効にされます。
手順
コントロールプレーンノードの root としてデバッグセッションを開始します。
$ oc debug --as-root node/<node_name>デバッグシェルで root ディレクトリーを
/hostに変更します。sh-4.4# chroot /hostクラスター全体のプロキシーが有効になっている場合は、次のコマンドを実行して、
NO_PROXY、HTTP_PROXY、およびHTTPS_PROXY環境変数をエクスポートします。$ export HTTP_PROXY=http://<your_proxy.example.com>:8080$ export HTTPS_PROXY=https://<your_proxy.example.com>:8080$ export NO_PROXY=<example.com>デバッグシェルで
cluster-backup.shスクリプトを実行し、バックアップの保存先となる場所を渡します。ヒントcluster-backup.shスクリプトは etcd Cluster Operator のコンポーネントとして維持され、etcdctl snapshot saveコマンドに関連するラッパーです。sh-4.4# /usr/local/bin/cluster-backup.sh /home/core/assets/backupスクリプトの出力例
found latest kube-apiserver: /etc/kubernetes/static-pod-resources/kube-apiserver-pod-6 found latest kube-controller-manager: /etc/kubernetes/static-pod-resources/kube-controller-manager-pod-7 found latest kube-scheduler: /etc/kubernetes/static-pod-resources/kube-scheduler-pod-6 found latest etcd: /etc/kubernetes/static-pod-resources/etcd-pod-3 ede95fe6b88b87ba86a03c15e669fb4aa5bf0991c180d3c6895ce72eaade54a1 etcdctl version: 3.4.14 API version: 3.4 {"level":"info","ts":1624647639.0188997,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"/home/core/assets/backup/snapshot_2021-06-25_190035.db.part"} {"level":"info","ts":"2021-06-25T19:00:39.030Z","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"} {"level":"info","ts":1624647639.0301006,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"https://10.0.0.5:2379"} {"level":"info","ts":"2021-06-25T19:00:40.215Z","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"} {"level":"info","ts":1624647640.6032252,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"https://10.0.0.5:2379","size":"114 MB","took":1.584090459} {"level":"info","ts":1624647640.6047094,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"/home/core/assets/backup/snapshot_2021-06-25_190035.db"} Snapshot saved at /home/core/assets/backup/snapshot_2021-06-25_190035.db {"hash":3866667823,"revision":31407,"totalKey":12828,"totalSize":114446336} snapshot db and kube resources are successfully saved to /home/core/assets/backupこの例では、コントロールプレーンホストの
/home/core/assets/backup/ディレクトリーにファイルが 2 つ作成されます。-
snapshot_<datetimestamp>.db: このファイルは etcd スナップショットです。cluster-backup.shスクリプトで、その有効性を確認します。 static_kuberesources_<datetimestamp>.tar.gz: このファイルには、静的 Pod のリソースが含まれます。etcd 暗号化が有効にされている場合、etcd スナップショットの暗号化キーも含まれます。注記etcd 暗号化が有効にされている場合、セキュリティー上の理由から、この 2 つ目のファイルを etcd スナップショットとは別に保存することが推奨されます。ただし、このファイルは etcd スナップショットから復元するために必要になります。
etcd 暗号化はキーではなく値のみを暗号化することに注意してください。つまり、リソースタイプ、namespace、およびオブジェクト名は暗号化されません。
-
5.12.6. etcd データのデフラグ
大規模で密度の高いクラスターの場合、キースペースが大きくなりすぎてスペースのクォータを超えると、etcd のパフォーマンスが低下する可能性があります。定期的に etcd をメンテナンスしてデフラグし、データストアの領域を解放してください。Prometheus で etcd メトリクスを監視し、必要に応じてデフラグしてください。そうしないと、etcd がクラスター全体のアラームを発し、クラスターがキーの読み取りと削除しか受け付けないメンテナンスモードになる可能性があります。
以下の主要なメトリクスを監視してください。
-
etcd_server_quota_backend_bytes。これは現在のクォータ制限です。 -
etcd_mvcc_db_total_size_in_use_in_bytes。履歴圧縮後の実際のデータベース使用量を示します。 -
etcd_mvcc_db_total_size_in_bytes。デフラグ待ちの空き領域を含むデータベースのサイズを示します。
etcd データをデフラグし、etcd 履歴の圧縮などのディスクの断片化を引き起こすイベント後にディスク領域を回収します。
履歴の圧縮は 5 分ごとに自動的に行われ、これによりバックエンドデータベースにギャップが生じます。この断片化された領域は etcd が使用できますが、ホストファイルシステムでは利用できません。ホストファイルシステムでこの領域を使用できるようにするには、etcd をデフラグする必要があります。
デフラグは自動的に行われますが、手動でトリガーすることもできます。
etcd Operator はクラスター情報を使用してユーザーの最も効率的な操作を決定するため、ほとんどの場合、自動デフラグが適しています。
5.12.6.1. 自動デフラグ
etcd Operator はディスクを自動的にデフラグします。手動による介入は必要ありません。
以下のログのいずれかを表示して、デフラグプロセスが成功したことを確認します。
- etcd ログ
- cluster-etcd-operator Pod
- Operator ステータスのエラーログ
自動デフラグにより、Kubernetes コントローラーマネージャーなどのさまざまな OpenShift コアコンポーネントでリーダー選出の失敗が発生し、失敗したコンポーネントの再起動がトリガーされる可能性があります。再起動は無害であり、次に実行中のインスタンスへのフェイルオーバーをトリガーするか、再起動後にコンポーネントが再び作業を再開します。
デフラグ成功時のログ出力例
etcd member has been defragmented: <member_name>, memberID: <member_id>デフラグ失敗時のログ出力例
failed defrag on member: <member_name>, memberID: <member_id>: <error_message>5.12.6.2. 手動デフラグ
Prometheus アラートは、手動でのデフラグを使用する必要がある場合を示します。アラートは次の 2 つの場合に表示されます。
- etcd が使用可能なスペースの 50% 以上を 10 分を超過して使用する場合
- etcd が合計データベースサイズの 50% 未満を 10 分を超過してアクティブに使用している場合
また、デフラグによって解放される etcd データベースのサイズ (MB 単位) を確認することで、デフラグが必要かどうかを判断することもできます。これは (etcd_mvcc_db_total_size_in_bytes - etcd_mvcc_db_total_size_in_use_in_bytes)/1024/1024 という PromQL 式を使用して確認できます。
etcd のデフラグはプロセスを阻止するアクションです。etcd メンバーはデフラグが完了するまで応答しません。このため、各 Pod のデフラグアクションごとに少なくとも 1 分間待機し、クラスターが回復できるようにします。
以下の手順に従って、各 etcd メンバーで etcd データをデフラグします。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
リーダーを最後にデフラグする必要があるため、どの etcd メンバーがリーダーであるかを判別します。
etcd Pod のリストを取得します。
$ oc -n openshift-etcd get pods -l k8s-app=etcd -o wide出力例
etcd-ip-10-0-159-225.example.redhat.com 3/3 Running 0 175m 10.0.159.225 ip-10-0-159-225.example.redhat.com <none> <none> etcd-ip-10-0-191-37.example.redhat.com 3/3 Running 0 173m 10.0.191.37 ip-10-0-191-37.example.redhat.com <none> <none> etcd-ip-10-0-199-170.example.redhat.com 3/3 Running 0 176m 10.0.199.170 ip-10-0-199-170.example.redhat.com <none> <none>Pod を選択し、以下のコマンドを実行して、どの etcd メンバーがリーダーであるかを判別します。
$ oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.com etcdctl endpoint status --cluster -w table出力例
Defaulting container name to etcdctl. Use 'oc describe pod/etcd-ip-10-0-159-225.example.redhat.com -n openshift-etcd' to see all of the containers in this pod. +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://10.0.191.37:2379 | 251cd44483d811c3 | 3.5.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.159.225:2379 | 264c7c58ecbdabee | 3.5.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.199.170:2379 | 9ac311f93915cc79 | 3.5.9 | 104 MB | true | false | 7 | 91624 | 91624 | | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+この出力の
IS LEADER列に基づいて、https://10.0.199.170:2379エンドポイントがリーダーになります。このエンドポイントを直前の手順の出力に一致させると、リーダーの Pod 名はetcd-ip-10-0-199-170.example.redhat.comになります。
etcd メンバーのデフラグ。
実行中の etcd コンテナーに接続し、リーダーでは ない Pod の名前を渡します。
$ oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.comETCDCTL_ENDPOINTS環境変数の設定を解除します。sh-4.4# unset ETCDCTL_ENDPOINTSetcd メンバーのデフラグを実行します。
sh-4.4# etcdctl --command-timeout=30s --endpoints=https://localhost:2379 defrag出力例
Finished defragmenting etcd member[https://localhost:2379]タイムアウトエラーが発生した場合は、コマンドが正常に実行されるまで
--command-timeoutの値を増やします。データベースサイズが縮小されていることを確認します。
sh-4.4# etcdctl endpoint status -w table --cluster出力例
+---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://10.0.191.37:2379 | 251cd44483d811c3 | 3.5.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.159.225:2379 | 264c7c58ecbdabee | 3.5.9 | 41 MB | false | false | 7 | 91624 | 91624 | |1 | https://10.0.199.170:2379 | 9ac311f93915cc79 | 3.5.9 | 104 MB | true | false | 7 | 91624 | 91624 | | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+この例では、この etcd メンバーのデータベースサイズは、開始時のサイズの 104 MB ではなく 41 MB です。
これらの手順を繰り返して他の etcd メンバーのそれぞれに接続し、デフラグします。常に最後にリーダーをデフラグします。
etcd Pod が回復するように、デフラグアクションごとに 1 分以上待機します。etcd Pod が回復するまで、etcd メンバーは応答しません。
領域のクォータの超過により
NOSPACEアラームがトリガーされる場合、それらをクリアします。NOSPACEアラームがあるかどうかを確認します。sh-4.4# etcdctl alarm list出力例
memberID:12345678912345678912 alarm:NOSPACEアラームをクリアします。
sh-4.4# etcdctl alarm disarm
5.12.7. クラスターの直前の状態への復元
保存された etcd のバックアップを使用して、クラスターの以前の状態を復元したり、大多数のコントロールプレーンホストが失われたクラスターを復元したりできます。
クラスターがコントロールプレーンマシンセットを使用している場合は、「コントロールプレーンマシンセットのトラブルシューティング」の「劣化した etcd Operator のリカバリー」で etcd のリカバリー手順を参照してください。
クラスターを復元する際に、同じ z-stream リリースから取得した etcd バックアップを使用する必要があります。たとえば、OpenShift Container Platform 4.7.2 クラスターは、4.7.2 から取得した etcd バックアップを使用する必要があります。
前提条件
-
インストール時に使用したものと同様、証明書ベースの
kubeconfigファイルを介して、cluster-adminロールを持つユーザーとしてクラスターにアクセスします。 - リカバリーホストとして使用する正常なコントロールプレーンホストがあること。
- コントロールプレーンホストへの SSH アクセス。
-
etcdスナップショットと静的 Pod のリソースの両方を含むバックアップディレクトリー (同じバックアップから取られるもの)。ディレクトリー内のファイル名は、snapshot_<datetimestamp>.dbおよびstatic_kuberesources_<datetimestamp>.tar.gzの形式にする必要があります。 - ノードはアクセス可能またはブート可能である。
非リカバリーコントロールプレーンノードの場合は、SSH 接続を確立したり、静的 Pod を停止したりする必要はありません。他のリカバリー以外のコントロールプレーンマシンを 1 つずつ削除し、再作成します。
手順
- リカバリーホストとして使用するコントロールプレーンホストを選択します。これは、復元操作を実行するホストです。
リカバリーホストを含む、各コントロールプレーンノードへの SSH 接続を確立します。別のターミナルを使用して、各コントロールプレーンノードの SSH 接続を確立します。
Kubernetes API サーバーは復元プロセスの開始後にアクセスできなくなるため、
oc debugメソッドを使用してコントロールプレーンノードにアクセスすることはできません。このため、別のターミナルで各コントロールプレーンホストへの SSH 接続を確立します。重要この手順を完了しないと、復元手順を完了するためにコントロールプレーンホストにアクセスすることができなくなり、この状態からクラスターを回復できなくなります。
etcdバックアップディレクトリーをリカバリーコントロールプレーンホストにコピーします。この手順では、
etcdスナップショットおよび静的 Pod のリソースを含むbackupディレクトリーを、リカバリーコントロールプレーンホストの/home/core/ディレクトリーにコピーしていることを前提としています。他のすべてのコントロールプレーンノードで静的 Pod を停止します。
注記リカバリーホストで静的 Pod を停止する必要はありません。
- リカバリーホストではないコントロールプレーンホストにアクセスします。
次のコマンドを実行して、既存の etcd Pod ファイルを kubelet マニフェストディレクトリーから移動します。
$ sudo mv -v /etc/kubernetes/manifests/etcd-pod.yaml /tmp次のコマンドを実行して、
etcdPod が停止していることを確認します。$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"このコマンドの出力が空でない場合は、数分待ってからもう一度確認してください。
以下のコマンドを実行して、既存の
kube-apiserverファイルを kubelet マニフェストディレクトリーから移動します。$ sudo mv -v /etc/kubernetes/manifests/kube-apiserver-pod.yaml /tmp以下のコマンドを実行して、
kube-apiserverコンテナーが停止していることを確認します。$ sudo crictl ps | grep kube-apiserver | egrep -v "operator|guard"このコマンドの出力が空でない場合は、数分待ってからもう一度確認してください。
次のコマンドを実行して、既存の
kube-controller-managerファイルを kubelet マニフェストディレクトリーから移動します。$ sudo mv -v /etc/kubernetes/manifests/kube-controller-manager-pod.yaml /tmp以下のコマンドを実行して、
kube-controller-managerコンテナーが停止していることを確認します。$ sudo crictl ps | grep kube-controller-manager | egrep -v "operator|guard"このコマンドの出力が空でない場合は、数分待ってからもう一度確認してください。
次のコマンドを実行して、既存の
kube-schedulerファイルを kubelet マニフェストディレクトリーから移動します。$ sudo mv -v /etc/kubernetes/manifests/kube-scheduler-pod.yaml /tmp以下のコマンドを実行して、
kube-schedulerコンテナーが停止していることを確認します。$ sudo crictl ps | grep kube-scheduler | egrep -v "operator|guard"このコマンドの出力が空でない場合は、数分待ってからもう一度確認してください。
次の例を使用して、
etcdデータディレクトリーを別の場所に移動します。$ sudo mv -v /var/lib/etcd/ /tmp/etc/kubernetes/manifests/keepalived.yamlファイルが存在する場合は、以下の手順を実行します。これらの手順は、API IP アドレスがリカバリーホストでリッスンしていることを確認するために必要です。次のコマンドを実行して、
/etc/kubernetes/manifests/keepalived.yamlファイルを kubelet マニフェストディレクトリーから移動します。$ sudo mv -v /etc/kubernetes/manifests/keepalived.yaml /home/core/注記このファイルは、手順の完了後に元の場所に復元する必要があります。
keepalivedデーモンによって管理されているコンテナーが停止していることを確認します。$ sudo crictl ps --name keepalivedコマンドの出力は空であるはずです。空でない場合は、数分待機してから再度確認します。
コントロールプレーンに仮想 IP (VIP) が割り当てられているかどうかを確認します。
$ ip -o address | egrep '<api_vip>|<ingress_vip>'報告された仮想 IP ごとに、次のコマンドを実行して仮想 IP を削除します。
$ sudo ip address del <reported_vip> dev <reported_vip_device>
- リカバリーホストではない他のコントロールプレーンホストでこの手順を繰り返します。
- リカバリーコントロールプレーンホストにアクセスします。
keepalivedデーモンが使用されている場合は、リカバリーコントロールプレーンノードが仮想 IP を所有していることを確認します。それ以外の場合は、手順 4.xi を繰り返します。$ ip -o address | grep <api_vip>仮想 IP のアドレスが存在する場合、出力内で強調表示されます。仮想 IP が設定されていないか、正しく設定されていない場合、このコマンドは空の文字列を返します。
クラスター全体のプロキシーが有効になっている場合は、
NO_PROXY、HTTP_PROXY、およびHTTPS_PROXY環境変数をエクスポートしていることを確認します。ヒントoc get proxy cluster -o yamlの出力を確認して、プロキシーが有効にされているかどうかを確認できます。プロキシーは、httpProxy、httpsProxy、およびnoProxyフィールドに値が設定されている場合に有効にされます。リカバリーコントロールプレーンホストで復元スクリプトを実行し、パスを
etcdバックアップディレクトリーに渡します。$ sudo -E /usr/local/bin/cluster-restore.sh /home/core/assets/backupスクリプトの出力例
...stopping kube-scheduler-pod.yaml ...stopping kube-controller-manager-pod.yaml ...stopping etcd-pod.yaml ...stopping kube-apiserver-pod.yaml Waiting for container etcd to stop .complete Waiting for container etcdctl to stop .............................complete Waiting for container etcd-metrics to stop complete Waiting for container kube-controller-manager to stop complete Waiting for container kube-apiserver to stop ..........................................................................................complete Waiting for container kube-scheduler to stop complete Moving etcd data-dir /var/lib/etcd/member to /var/lib/etcd-backup starting restore-etcd static pod starting kube-apiserver-pod.yaml static-pod-resources/kube-apiserver-pod-7/kube-apiserver-pod.yaml starting kube-controller-manager-pod.yaml static-pod-resources/kube-controller-manager-pod-7/kube-controller-manager-pod.yaml starting kube-scheduler-pod.yaml static-pod-resources/kube-scheduler-pod-8/kube-scheduler-pod.yamlcluster-restore.sh スクリプトは、
etcd、kube-apiserver、kube-controller-manager、およびkube-schedulerPod が停止され、復元プロセスの最後に開始されたことを示す必要があります。注記最後の
etcdバックアップの後にノード証明書が更新された場合、復元プロセスによってノードがNotReady状態になる可能性があります。ノードをチェックして、
Ready状態であることを確認します。ノードを確認するには、bastion ホストまたはリカバリーホストのいずれかを使用できます。リカバリーホストを使用する場合は、次のコマンドを実行します。
$ export KUBECONFIG=/etc/kubernetes/static-pod-resources/kube-apiserver-certs/secrets/node-kubeconfigs/localhost-recovery.kubeconfig$ oc get nodes -wbastion ホストを使用する場合は、以下の手順を実行します。
以下のコマンドを実行します。
$ oc get nodes -w出力例
NAME STATUS ROLES AGE VERSION host-172-25-75-28 Ready master 3d20h v1.29.4 host-172-25-75-38 Ready infra,worker 3d20h v1.29.4 host-172-25-75-40 Ready master 3d20h v1.29.4 host-172-25-75-65 Ready master 3d20h v1.29.4 host-172-25-75-74 Ready infra,worker 3d20h v1.29.4 host-172-25-75-79 Ready worker 3d20h v1.29.4 host-172-25-75-86 Ready worker 3d20h v1.29.4 host-172-25-75-98 Ready infra,worker 3d20h v1.29.4すべてのノードが状態を報告するのに数分かかる場合があります。
NotReady状態のノードがある場合は、ノードにログインし、各ノードの/var/lib/kubelet/pkiディレクトリーからすべての PEM ファイルを削除します。ノードに SSH 接続するか、Web コンソールのターミナルウィンドウを使用できます。$ ssh -i <ssh-key-path> core@<master-hostname>サンプル
pkiディレクトリーsh-4.4# pwd /var/lib/kubelet/pki sh-4.4# ls kubelet-client-2022-04-28-11-24-09.pem kubelet-server-2022-04-28-11-24-15.pem kubelet-client-current.pem kubelet-server-current.pem
すべてのコントロールプレーンホストで kubelet サービスを再起動します。
リカバリーホストから以下のコマンドを実行します。
$ sudo systemctl restart kubelet.service- 他のすべてのコントロールプレーンホストでこの手順を繰り返します。
保留中の証明書署名要求 (CSR) を承認します。
注記単一ノードクラスターや 3 つのスケジュール可能なコントロールプレーンノードで構成されるクラスターなど、ワーカーノードを持たないクラスターには、承認する保留中の CSR はありません。この手順にリストされているすべてのコマンドをスキップできます。
次のコマンドを実行して、現在の CSR のリストを取得します。
$ oc get csr出力例
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-2s94x 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending1 csr-4bd6t 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending2 csr-4hl85 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending3 csr-zhhhp 3m8s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending4 ...以下のコマンドを実行して CSR の詳細をレビューし、これが有効であることを確認します。
$ oc describe csr <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
次のコマンドを実行して、それぞれの有効な
node-bootstrapperCSR を承認します。$ oc adm certificate approve <csr_name>ユーザーによってプロビジョニングされるインストールの場合は、以下のコマンドを実行してそれぞれの有効な kubelet サービス CSR を承認します。
$ oc adm certificate approve <csr_name>
単一メンバーのコントロールプレーンが正常に起動していることを確認します。
リカバリーホストから、次のコマンドを入力して、
etcdコンテナーが実行されていることを確認します。$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"出力例
3ad41b7908e32 36f86e2eeaaffe662df0d21041eb22b8198e0e58abeeae8c743c3e6e977e8009 About a minute ago Running etcd 0 7c05f8af362f0リカバリーホストから、次のコマンドを入力して、
etcdPod が実行されていることを確認します。$ oc -n openshift-etcd get pods -l k8s-app=etcd出力例
NAME READY STATUS RESTARTS AGE etcd-ip-10-0-143-125.ec2.internal 1/1 Running 1 2m47sステータスが
Pendingの場合や出力に複数の実行中のetcdPod が一覧表示される場合、数分待機してから再度チェックを行います。
OVNKubernetesネットワークプラグインを使用している場合は、ovnkube-controlplanePod を再起動する必要があります。次のコマンドを実行して、すべての
ovnkube-controlplanePod を削除します。$ oc -n openshift-ovn-kubernetes delete pod -l app=ovnkube-control-plane次のコマンドを実行して、すべての
ovnkube-controlplanePod が再デプロイされたことを確認します。$ oc -n openshift-ovn-kubernetes get pod -l app=ovnkube-control-plane
OVN-Kubernetes ネットワークプラグインを使用している場合は、すべてのノードで Open Virtual Network (OVN) Kubernetes Pod を 1 つずつ再起動します。次の手順を使用して、各ノードで OVN-Kubernetes Pod を再起動します。
重要OVN-Kubernetes Pod は次の順序で再起動してください。
- リカバリーコントロールプレーンホスト
- 他のコントロールプレーンホスト (利用可能な場合)
- 他のノード
注記検証および変更用の受付 Webhook は Pod を拒否することができます。
failurePolicyをFailに設定して追加の Webhook を追加すると、Pod が拒否され、復元プロセスが失敗する可能性があります。これは、クラスターの状態の復元中に Webhook を保存および削除することで回避できます。クラスターの状態が正常に復元された後に、Webhook を再度有効にできます。または、クラスターの状態の復元中に
failurePolicyを一時的にIgnoreに設定できます。クラスターの状態が正常に復元された後に、failurePolicyをFailにすることができます。ノースバウンドデータベース (nbdb) とサウスバウンドデータベース (sbdb) を削除します。Secure Shell (SSH) を使用してリカバリーホストと残りのコントロールプレーンノードにアクセスし、次のコマンドを実行します。
$ sudo rm -f /var/lib/ovn-ic/etc/*.dbOpenVSwitch サービスを再起動します。Secure Shell (SSH) を使用してノードにアクセスし、次のコマンドを実行します。
$ sudo systemctl restart ovs-vswitchd ovsdb-server次のコマンドを実行して、ノード上の
ovnkube-nodePod を削除します。<node>は、再起動するノードの名前に置き換えます。$ oc -n openshift-ovn-kubernetes delete pod -l app=ovnkube-node --field-selector=spec.nodeName==<node>次のコマンドを実行して、Pod のステータスを確認します。
$ oc get po -n openshift-ovn-kubernetesOVN Pod のステータスが
Terminatingである場合は、次のコマンドを実行して、OVN Pod を実行しているノードを削除します。<node> を、削除するノードの名前に置き換えます。$ oc delete node <node>次のコマンドを実行して、SSH を使用して
Terminatingステータスの OVN Pod ノードにログインします。$ ssh -i <ssh-key-path> core@<node>次のコマンドを実行して、すべての PEM ファイルを
/var/lib/kubelet/pkiディレクトリーから移動します。$ sudo mv /var/lib/kubelet/pki/* /tmp次のコマンドを実行して、kubelet サービスを無効にします。
$ sudo systemctl restart kubelet.service次のコマンドを実行して、リカバリー etcd マシンに戻ります。
$ oc get csr出力例
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-<uuid> 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending以下のコマンドを実行して、すべての新規 CSR を承認します。ここで、
csr-<uuid> は CSR の名前に置き換えてください。oc adm certificate approve csr-<uuid>次のコマンドを実行して、ノードが復旧していることを確認します。
$ oc get nodes
以下を使用して、
ovnkube-nodePod が再度実行されていることを確認します。$ oc -n openshift-ovn-kubernetes get pod -l app=ovnkube-node --field-selector=spec.nodeName==<node>注記Pod が再起動するまでに数分かかる場合があります。
他の非復旧のコントロールプレーンマシンを 1 つずつ削除して再作成します。マシンが再作成された後、新しいリビジョンが強制され、
etcdが自動的にスケールアップします。ユーザーがプロビジョニングしたベアメタルインストールを使用する場合は、最初に作成したときと同じ方法を使用して、コントロールプレーンマシンを再作成できます。詳細は、「ユーザーによってプロビジョニングされるクラスターのベアメタルへのインストール」を参照してください。
警告リカバリーホストのマシンを削除し、再作成しないでください。
installer-provisioned infrastructure を実行している場合、またはマシン API を使用してマシンを作成している場合は、以下の手順を実行します。
警告リカバリーホストのマシンを削除し、再作成しないでください。
installer-provisioned infrastructure でのベアメタルインストールの場合、コントロールプレーンマシンは再作成されません。詳細は、「ベアメタルコントロールプレーンノードの交換」を参照してください。
失われたコントロールプレーンホストのいずれかのマシンを取得します。
クラスターにアクセスできるターミナルで、cluster-admin ユーザーとして以下のコマンドを実行します。
$ oc get machines -n openshift-machine-api -o wide出力例
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-0 Running m4.xlarge us-east-1 us-east-1a 3h37m ip-10-0-131-183.ec2.internal aws:///us-east-1a/i-0ec2782f8287dfb7e stopped1 clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- これは、失われたコントロールプレーンホストのコントロールプレーンマシンです (
ip-10-0-131-183.ec2.internal)。
以下を実行して、失われたコントロールプレーンホストのマシンを削除します。
$ oc delete machine -n openshift-machine-api clustername-8qw5l-master-01 - 1
- 失われたコントロールプレーンホストのコントロールプレーンマシンの名前を指定します。
失われたコントロールプレーンホストのマシンを削除すると、新しいマシンが自動的にプロビジョニングされます。
以下を実行して、新しいマシンが作成されたことを確認します。
$ oc get machines -n openshift-machine-api -o wide出力例
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-master-3 Provisioning m4.xlarge us-east-1 us-east-1a 85s ip-10-0-173-171.ec2.internal aws:///us-east-1a/i-015b0888fe17bc2c8 running1 clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- 新規マシン
clustername-8qw5l-master-3が作成され、ProvisioningからRunningにフェーズが変更されると準備状態になります。
新規マシンが作成されるまでに数分の時間がかかる場合があります。
etcdクラスター Operator は、マシンまたはノードが正常な状態に戻ると自動的に同期します。- リカバリーホストではない喪失したコントロールプレーンホストで、これらのステップを繰り返します。
次のコマンドを実行して、クォーラムガードをオフにします。
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'このコマンドにより、シークレットを正常に再作成し、静的 Pod をロールアウトできるようになります。
リカバリーホスト内の別のターミナルウィンドウで、次のコマンドを実行してリカバリー
kubeconfigファイルをエクスポートします。$ export KUBECONFIG=/etc/kubernetes/static-pod-resources/kube-apiserver-certs/secrets/node-kubeconfigs/localhost-recovery.kubeconfigetcdの再デプロイメントを強制的に実行します。リカバリー
kubeconfigファイルをエクスポートしたのと同じターミナルウィンドウで、次のコマンドを実行します。$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge1 - 1
forceRedeploymentReason値は一意である必要があります。そのため、タイムスタンプが付加されます。
etcdの再デプロイメントが開始します。etcdクラスター Operator が再デプロイメントを実行すると、初期ブートストラップのスケールアップと同様に、既存のノードが新規 Pod と共に起動します。次のコマンドを実行して、クォーラムガードをオンに戻します。
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'以下のコマンドを実行して、
unsupportedConfigOverridesセクションがオブジェクトから削除されたことを確認できます。$ oc get etcd/cluster -oyamlすべてのノードが最新のリビジョンに更新されていることを確認します。
クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc get etcd -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'etcdのNodeInstallerProgressingステータス条件を確認し、すべてのノードが最新のリビジョンであることを確認します。更新が正常に実行されると、この出力にはAllNodesAtLatestRevisionが表示されます。AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- この例では、最新のリビジョン番号は
7です。
出力に
2 nodes are at revision 6; 1 nodes are at revision 7などの複数のリビジョン番号が含まれる場合、これは更新が依然として進行中であることを意味します。数分待機した後に再試行します。etcdの再デプロイ後に、コントロールプレーンの新規ロールアウトを強制的に実行します。kubelet は内部ロードバランサーを使用して API サーバーに接続されているため、kube-apiserverは他のノードに再インストールされます。クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下の手順を実行します。kube-apiserverの新規ロールアウトを強制します。$ oc patch kubeapiserver cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeすべてのノードが最新のリビジョンに更新されていることを確認します。
$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'NodeInstallerProgressing状況条件を確認し、すべてのノードが最新のリビジョンであることを確認します。更新が正常に実行されると、この出力にはAllNodesAtLatestRevisionが表示されます。AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- この例では、最新のリビジョン番号は
7です。
出力に
2 nodes are at revision 6; 1 nodes are at revision 7などの複数のリビジョン番号が含まれる場合、これは更新が依然として進行中であることを意味します。数分待機した後に再試行します。次のコマンドを実行して、Kubernetes コントローラーマネージャーの新規ロールアウトを強制します。
$ oc patch kubecontrollermanager cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge以下のコマンドを実行して、すべてのノードが最新のリビジョンに更新されていることを確認します。
$ oc get kubecontrollermanager -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'NodeInstallerProgressing状況条件を確認し、すべてのノードが最新のリビジョンであることを確認します。更新が正常に実行されると、この出力にはAllNodesAtLatestRevisionが表示されます。AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- この例では、最新のリビジョン番号は
7です。
出力に
2 nodes are at revision 6; 1 nodes are at revision 7などの複数のリビジョン番号が含まれる場合、これは更新が依然として進行中であることを意味します。数分待機した後に再試行します。以下のコマンドを実行して
kube-schedulerの新規ロールアウトを強制的に実行します。$ oc patch kubescheduler cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge以下のコマンドを実行して、すべてのノードが最新のリビジョンに更新されていることを確認します。
$ oc get kubescheduler -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'NodeInstallerProgressing状況条件を確認し、すべてのノードが最新のリビジョンであることを確認します。更新が正常に実行されると、この出力にはAllNodesAtLatestRevisionが表示されます。AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- この例では、最新のリビジョン番号は
7です。
出力に
2 nodes are at revision 6; 1 nodes are at revision 7などの複数のリビジョン番号が含まれる場合、これは更新が依然として進行中であることを意味します。数分待機した後に再試行します。
次のコマンドを実行して、プラットフォーム Operator をモニターします。
$ oc adm wait-for-stable-clusterこのプロセスには最大 15 分かかる場合があります。
リカバリー手順の後にすべてのワークロードが通常の操作に戻るようにするには、すべてのコントロールプレーンノードを再起動します。
注記前の手順が完了したら、すべてのサービスが復元された状態に戻るまで数分間待つ必要がある場合があります。たとえば、
oc loginを使用した認証は、OAuth サーバー Pod が再起動するまですぐに機能しない可能性があります。即時認証に
system:adminkubeconfigファイルを使用することを検討してください。この方法は、OAuth トークンではなく SSL/TLS クライアント証明書に基づいて認証を行います。以下のコマンドを実行し、このファイルを使用して認証できます。$ export KUBECONFIG=<installation_directory>/auth/kubeconfig以下のコマンドを実行て、認証済みユーザー名を表示します。
$ oc whoami- ローリング方式ですべてのワーカーノードを再起動します。
5.12.8. 永続ストレージの状態復元に関する問題および回避策
OpenShift Container Platform クラスターがいずれかの形式の永続ストレージを使用する場合に、クラスターの状態は通常 etcd 外に保存されます。etcd バックアップから復元する場合には、OpenShift Container Platform のワークロードのステータスも復元されます。ただし、etcd スナップショットが古い場合には、ステータスは無効または期限切れの可能性があります。
永続ボリューム (PV) の内容は etcd スナップショットには含まれません。etcd スナップショットから OpenShift Container Platform クラスターを復元する時に、重要ではないワークロードから重要なデータにアクセスしたり、その逆ができたりする場合があります。
以下は、古いステータスを生成するシナリオ例です。
- MySQL データベースが PV オブジェクトでバックアップされる Pod で実行されている。etcd スナップショットから OpenShift Container Platform を復元すると、Pod の起動を繰り返し試行しても、ボリュームをストレージプロバイダーに戻したり、実行中の MySQL Pod が生成したりされるわけではありません。この Pod は、ストレージプロバイダーでボリュームを復元し、次に PV を編集して新規ボリュームを参照するように手動で復元する必要があります。
- Pod P1 は、ノード X に割り当てられているボリューム A を使用している。別の Pod がノード Y にある同じボリュームを使用している場合に etcd スナップショットが作成された場合に、etcd の復元が実行されると、ボリュームがノード Y に割り当てられていることが原因で Pod P1 が正常に起動できなくなる可能性があります。OpenShift Container Platform はこの割り当てを認識せず、ボリュームが自動的に切り離されるわけではありません。これが生じる場合には、ボリュームをノード Y から手動で切り離し、ノード X に割り当ててることで Pod P1 を起動できるようにします。
- クラウドプロバイダーまたはストレージプロバイダーの認証情報が etcd スナップショットの作成後に更新された。これが原因で、プロバイダーの認証情報に依存する CSI ドライバーまたは Operator が機能しなくなります。これらのドライバーまたは Operator で必要な認証情報を手動で更新する必要がある場合があります。
デバイスが etcd スナップショットの作成後に OpenShift Container Platform ノードから削除されたか、名前が変更された。ローカルストレージ Operator で、
/dev/disk/by-idまたは/devディレクトリーから管理する各 PV のシンボリックリンクが作成されます。この状況では、ローカル PV が存在しないデバイスを参照してしまう可能性があります。この問題を修正するには、管理者は以下を行う必要があります。
- デバイスが無効な PV を手動で削除します。
- 各ノードからシンボリックリンクを削除します。
-
LocalVolumeまたはLocalVolumeSetオブジェクトを削除します (ストレージ → 永続ストレージの設定 → ローカルボリュームを使用した永続ストレージ → ローカルストレージ Operator のリソースの削除 を参照)。
5.13. Pod Disruption Budget
Pod Disruption Budget を理解して設定します。
5.13.1. 起動している必要がある Pod の数を Pod Disruption Budget を使用して指定する方法について
Pod Disruption Budget を使用すると、メンテナンスのためにノードの drain (Pod の退避) を実行するなど、運用中の Pod に対して安全上の制約を指定できます。
PodDisruptionBudget は、同時に起動している必要のあるレプリカの最小数またはパーセンテージを指定する API オブジェクトです。これらをプロジェクトに設定することは、ノードのメンテナンス (クラスターのスケールダウンまたはクラスターのアップグレードなどの実行) 時に役立ち、この設定は (ノードの障害時ではなく) 自発的な退避の場合にのみ許可されます。
PodDisruptionBudget オブジェクトの設定は、次の主要な部分で構成されます。
- 一連の Pod に対するラベルのクエリー機能であるラベルセレクター。
同時に利用可能にする必要のある Pod の最小数を指定する可用性レベル。
-
minAvailableは、中断時にも常に利用可能である必要のある Pod 数です。 -
maxUnavailableは、中断時に利用不可にできる Pod 数です。
-
Available は、Ready=True の状態にある Pod 数を指します。Ready=True は、要求に対応でき、一致するすべてのサービスの負荷分散プールに追加する必要がある Pod を指します。
maxUnavailable の 0% または 0 あるいは minAvailable の 100%、ないしはレプリカ数に等しい値は許可されますが、これによりノードがドレイン (解放) されないようにブロックされる可能性があります。
OpenShift Container Platform のすべてのマシン設定プールにおける maxUnavailable のデフォルト設定は 1 です。この値を変更せず、一度に 1 つのコントロールプレーンノードを更新することを推奨します。コントロールプレーンプールのこの値を 3 に変更しないでください。
次のコマンドで、すべてのプロジェクトの Pod Disruption Budget を確認できます。
$ oc get poddisruptionbudget --all-namespaces次の例には、OpenShift Container Platform on AWS に固有の値がいくつか含まれています。
出力例
NAMESPACE NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
openshift-apiserver openshift-apiserver-pdb N/A 1 1 121m
openshift-cloud-controller-manager aws-cloud-controller-manager 1 N/A 1 125m
openshift-cloud-credential-operator pod-identity-webhook 1 N/A 1 117m
openshift-cluster-csi-drivers aws-ebs-csi-driver-controller-pdb N/A 1 1 121m
openshift-cluster-storage-operator csi-snapshot-controller-pdb N/A 1 1 122m
openshift-cluster-storage-operator csi-snapshot-webhook-pdb N/A 1 1 122m
openshift-console console N/A 1 1 116m
#...
PodDisruptionBudget は、最低でも minAvailable Pod がシステムで実行されている場合は正常であるとみなされます。この制限を超えるすべての Pod は退避の対象となります。
Pod の優先度とプリエンプションの設定によっては、Pod Disruption Budget の要件にもかかわらず、優先度の低い Pod が削除される可能性があります。
5.13.2. 起動している必要がある Pod の数を Pod Disruption Budget を使用して指定する
同時に起動している必要のあるレプリカの最小数またはパーセンテージは、PodDisruptionBudget オブジェクトを使用して指定します。
手順
Pod Disruption Budget を設定するには、次の手順を実行します。
YAML ファイルを以下のようなオブジェクト定義で作成します。
apiVersion: policy/v11 kind: PodDisruptionBudget metadata: name: my-pdb spec: minAvailable: 22 selector:3 matchLabels: name: my-podまたは、以下を実行します。
apiVersion: policy/v11 kind: PodDisruptionBudget metadata: name: my-pdb spec: maxUnavailable: 25%2 selector:3 matchLabels: name: my-pod以下のコマンドを実行してオブジェクトをプロジェクトに追加します。
$ oc create -f </path/to/file> -n <project_name>
5.13.3. 正常でない Pod のエビクションポリシーの指定
Pod Disruption Budget (PDB) を使用して、同時に使用可能にする必要がある Pod の数を指定する場合、異常な Pod をエビクション対象として考慮する基準も定義できます。
以下のポリシーから選択できます。
- IfHealthyBudget
- 正常ではない実行中の Pod は、保護されたアプリケーションが停止されない場合に限り退避できます。
- AlwaysAllow
まだ正常ではない実行中の Pod は、Pod Disruption Budget の基準が満たされているかどうかに関係なく削除される可能性があります。このポリシーは、Pod が
CrashLoopBackOff状態でスタックしているアプリケーションやReadyステータスの報告に失敗しているアプリケーションなど、正常に動作しないアプリケーションを退避するために使用できます。注記ノードドレイン中に誤動作するアプリケーションのエビクションをサポートするには、
PodDisruptionBudgetオブジェクトのunhealthyPodEvictionPolicyフィールドをAlwaysAllowに設定することを推奨します。デフォルトの動作では、ドレインを続行する前に、アプリケーション Pod が正常になるまで待機します。
手順
PodDisruptionBudgetオブジェクトを定義する YAML ファイルを作成し、正常でない Pod のエビクションポリシーを指定します。pod-disruption-budget.yamlファイルの例apiVersion: policy/v1 kind: PodDisruptionBudget metadata: name: my-pdb spec: minAvailable: 2 selector: matchLabels: name: my-pod unhealthyPodEvictionPolicy: AlwaysAllow1 - 1
- 正常でない Pod エビクションポリシーとして
IfHealthyBudgetまたはAlwaysAllowのいずれかを選択します。unhealthyPodEvictionPolicyフィールドが空の場合、デフォルトはIfHealthyBudgetです。
以下のコマンドを実行して
PodDisruptionBudgetオブジェクトを作成します。$ oc create -f pod-disruption-budget.yaml
PDB で正常でない Pod のエビクションポリシーが AlwaysAllow に設定されている場合、ノードをドレイン (解放)、この PDB が保護する正常に動作しないアプリケーションの Pod を退避できます。
第6章 インストール後のノードタスク
OpenShift Container Platform のインストール後に、特定のノードタスクでクラスターをさらに拡張し、要件に合わせてカスタマイズできます。
6.1. RHEL コンピュートマシンの OpenShift Container Platform クラスターへの追加
RHEL コンピュートノードについて理解し、これを使用します。
6.1.1. RHEL コンピュートノードのクラスターへの追加について
OpenShift Container Platform 4.16 では、x86_64 アーキテクチャー上で user-provisioned infrastructure インストールまたは installer-provisioned infrastructure インストールを使用する場合、クラスター内のコンピュートマシンとして Red Hat Enterprise Linux (RHEL) マシンを使用するオプションがあります。クラスター内のコントロールプレーンマシンには Red Hat Enterprise Linux CoreOS (RHCOS) マシンを使用する必要があります。
クラスターで RHEL コンピュートマシンを使用することを選択した場合は、すべてのオペレーティングシステムのライフサイクル管理とメンテナンスを担当します。システムの更新を実行し、パッチを適用し、その他すべての必要なタスクを完了する必要があります。
installer-provisioned infrastructure クラスターの場合、installer-provisioned infrastructure クラスターの自動スケーリングにより Red Hat Enterprise Linux CoreOS (RHCOS) コンピューティングマシンがデフォルトで追加されるため、RHEL コンピューティングマシンを手動で追加する必要があります。
- OpenShift Container Platform をクラスター内のマシンから削除するには、オペレーティングシステムを破棄する必要があるため、クラスターに追加する RHEL マシンには専用のハードウェアを使用する必要があります。
- swap メモリーは、OpenShift Container Platform クラスターに追加されるすべての RHEL マシンで無効にされます。これらのマシンで swap メモリーを有効にすることはできません。
- パッケージベースの RHEL のインストールが非推奨になりました。これは今後のリリースで削除されます。RHCOS イメージの階層化により、この機能が置き換えられ、ワーカーノードのベースオペレーティングシステムへの追加パッケージのインストールがサポートされます。
6.1.2. RHEL コンピュートノードのシステム要件
OpenShift Container Platform 環境の Red Hat Enterprise Linux (RHEL) コンピュートマシンは以下の最低のハードウェア仕様およびシステムレベルの要件を満たしている必要があります。
- まず、お使いの Red Hat アカウントに有効な OpenShift Container Platform サブスクリプションがなければなりません。これがない場合は、営業担当者にお問い合わせください。
- 実稼働環境では、予想されるワークロードに対応するコンピュートマシンを提供する必要があります。クラスター管理者は、予想されるワークロードを計算し、オーバーヘッドの約 10 % を追加する必要があります。実稼働環境の場合、ノードホストの障害が最大容量に影響を与えることがないよう、十分なリソースを割り当てるようにします。
各システムは、以下のハードウェア要件を満たしている必要があります。
- 物理または仮想システム、またはパブリックまたはプライベート IaaS で実行されるインスタンス。
基本オペレーティングシステム: RHEL 8.8 以降のバージョン と最小インストールオプションを使用している。
重要OpenShift Container Platform クラスターへの RHEL 7 コンピュートマシンの追加はサポートされません。
以前の OpenShift Container Platform のバージョンで以前にサポートされていた RHEL 7 コンピュートマシンがある場合、RHEL 8 にアップグレードすることはできません。新しい RHEL 8 ホストをデプロイする必要があり、古い RHEL 7 ホストを削除する必要があります。詳細は、「ノードの削除」セクションを参照してください。
OpenShift Container Platform で非推奨となったか、削除された主な機能の最新の一覧は、OpenShift Container Platform リリースノートの 非推奨および削除された機能 セクションを参照してください。
FIPS モードで OpenShift Container Platform をデプロイしている場合、起動する前に FIPS を RHEL マシン上で有効にする必要があります。RHEL 8 ドキュメントの Installing a RHEL 8 system with FIPS mode enabled を参照してください。
重要クラスターで FIPS モードを有効にするには、FIPS モードで動作するように設定された Red Hat Enterprise Linux (RHEL) コンピューターからインストールプログラムを実行する必要があります。RHEL で FIPS モードを設定する方法の詳細は、RHEL から FIPS モードへの切り替え を参照してください。
FIPS モードでブートされた Red Hat Enterprise Linux (RHEL) または Red Hat Enterprise Linux CoreOS (RHCOS) を実行する場合、OpenShift Container Platform コアコンポーネントは、x86_64、ppc64le、および s390x アーキテクチャーのみで、FIPS 140-2/140-3 検証のために NIST に提出された RHEL 暗号化ライブラリーを使用します。
- NetworkManager 1.0 以降。
- 1 vCPU。
- 最小 8 GB の RAM。
-
/var/を含むファイルシステムの最小 15 GB のハードディスク領域。 -
/usr/local/bin/を含むファイルシステムの最小 1 GB のハードディスク領域。 - 一時ディレクトリーを含むファイルシステムの最小 1 GB のハードディスク領域。システムの一時ディレクトリーは、Python の標準ライブラリーの tempfile モジュールで定義されるルールに基づいて決定されます。
-
各システムは、システムプロバイダーの追加の要件を満たす必要があります。たとえば、クラスターを VMware vSphere にインストールした場合、その ストレージガイドライン に従ってディスクを設定し、
disk.enableUUID=TRUE属性を設定する必要があります。 - 各システムは、DNS で解決可能なホスト名を使用してクラスターの API エンドポイントにアクセスできる必要があります。配置されているネットワークセキュリティーアクセス制御は、クラスターの API サービスエンドポイントへのシステムアクセスを許可する必要があります。
Microsoft Azure にインストールされたクラスターの場合:
-
システムに
Standard_D8s_v3仮想マシンのハードウェア要件が含まれていることを確認します。 - 高速ネットワークを有効にします。アクセラレートネットワークは、Single Root I/O Virtualization (SR-IOV) を使用して、スイッチへのより直接的なパスを持つ Microsoft Azure 仮想マシンを提供します。
-
システムに
6.1.2.1. 証明書署名要求の管理
ユーザーがプロビジョニングするインフラストラクチャーを使用する場合、クラスターの自動マシン管理へのアクセスは制限されるため、インストール後にクラスターの証明書署名要求 (CSR) のメカニズムを提供する必要があります。kube-controller-manager は kubelet クライアント CSR のみを承認します。machine-approver は、kubelet 認証情報を使用して要求されるサービング証明書の有効性を保証できません。適切なマシンがこの要求を発行したかどうかを確認できないためです。kubelet 提供証明書の要求の有効性を検証し、それらを承認する方法を判別し、実装する必要があります。
6.1.3. Playbook 実行のためのマシンの準備
Red Hat Enterprise Linux (RHEL) をオペレーティングシステムとして使用するコンピュートマシンを OpenShift Container Platform 4.16 クラスターに追加する前に、新たなノードをクラスターに追加する Ansible Playbook を実行する RHEL 8 マシンを準備する必要があります。このマシンはクラスターの一部にはなりませんが、クラスターにアクセスできる必要があります。
前提条件
-
Playbook を実行するマシンに OpenShift CLI (
oc) をインストールします。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
-
クラスターの
kubeconfigファイルおよびクラスターのインストールに使用したインストールプログラムが RHEL 8 マシン上にあることを確認します。これを実行する 1 つの方法として、クラスターのインストールに使用したマシンと同じマシンを使用することができます。 - マシンを、コンピュートマシンとして使用する予定のすべての RHEL ホストにアクセスできるように設定します。Bastion と SSH プロキシーまたは VPN の使用など、所属する会社で許可されるすべての方法を利用できます。
すべての RHEL ホストへの SSH アクセスを持つユーザーを Playbook を実行するマシンで設定します。
重要SSH キーベースの認証を使用する場合、キーを SSH エージェントで管理する必要があります。
これを実行していない場合には、マシンを RHSM に登録し、
OpenShiftサブスクリプションのプールをこれにアタッチします。マシンを RHSM に登録します。
# subscription-manager register --username=<user_name> --password=<password>RHSM から最新のサブスクリプションデータをプルします。
# subscription-manager refresh利用可能なサブスクリプションをリスト表示します。
# subscription-manager list --available --matches '*OpenShift*'直前のコマンドの出力で、OpenShift Container Platform サブスクリプションのプール ID を見つけ、これをアタッチします。
# subscription-manager attach --pool=<pool_id>
OpenShift Container Platform 4.16 で必要なリポジトリーを有効にします。
# subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.16-for-rhel-8-x86_64-rpms"openshift-ansibleを含む必要なパッケージをインストールします。# yum install openshift-ansible openshift-clients jqopenshift-ansibleパッケージはインストールプログラムユーティリティーを提供し、Ansible Playbook などのクラスターに RHEL コンピュートノードを追加するために必要な他のパッケージおよび関連する設定ファイルをプルします。openshift-clientsはocCLI を提供し、jqパッケージはコマンドライン上での JSON 出力の表示方法を向上させます。
6.1.4. RHEL コンピュートノードの準備
Red Hat Enterprise Linux (RHEL) マシンを OpenShift Container Platform クラスターに追加する前に、各ホストを Red Hat Subscription Manager (RHSM) に登録し、有効な OpenShift Container Platform サブスクリプションをアタッチし、必要なリポジトリーを有効にする必要があります。
各ホストで RHSM に登録します。
# subscription-manager register --username=<user_name> --password=<password>RHSM から最新のサブスクリプションデータをプルします。
# subscription-manager refresh利用可能なサブスクリプションをリスト表示します。
# subscription-manager list --available --matches '*OpenShift*'直前のコマンドの出力で、OpenShift Container Platform サブスクリプションのプール ID を見つけ、これをアタッチします。
# subscription-manager attach --pool=<pool_id>yum リポジトリーをすべて無効にします。
有効にされている RHSM リポジトリーをすべて無効にします。
# subscription-manager repos --disable="*"残りの yum リポジトリーをリスト表示し、
repo idの下にその名前が表示されたら、メモします。# yum repolistyum-config-managerを使用して、残りの yum リポジトリーを無効にします。# yum-config-manager --disable <repo_id>または、すべてのリポジトリーを無効にします。
# yum-config-manager --disable \*利用可能なリポジトリーが多い場合には、数分の時間がかかることがあります。
OpenShift Container Platform 4.16 で必要なリポジトリーのみを有効にします。
# subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.16-for-rhel-8-x86_64-rpms" \ --enable="fast-datapath-for-rhel-8-x86_64-rpms"ホストで firewalld を停止し、無効にします。
# systemctl disable --now firewalld.service注記firewalld は、後で有効にすることはできません。これを実行する場合、ワーカー上の OpenShift Container Platform ログにはアクセスできません。
6.1.5. RHEL コンピュートマシンのクラスターへの追加
Red Hat Enterprise Linux をオペレーティングシステムとして使用するコンピュートマシンを、OpenShift Container Platform 4.16 クラスターに追加できます。
前提条件
- Playbook を実行するマシンに必要なパッケージをインストールし、必要な設定が行われています。
- インストール用の RHEL ホストを準備しています。
手順
Playbook を実行するために準備しているマシンで以下の手順を実行します。
コンピュートマシンホストおよび必要な変数を定義する
/<path>/inventory/hostsという名前の Ansible インベントリーファイルを作成します。[all:vars] ansible_user=root1 #ansible_become=True2 openshift_kubeconfig_path="~/.kube/config"3 [new_workers]4 mycluster-rhel8-0.example.com mycluster-rhel8-1.example.com- 1
- Ansible タスクをリモートコンピュートマシンで実行するユーザー名を指定します。
- 2
ansible_userのrootを指定しない場合、ansible_becomeをTrueに設定し、ユーザーに sudo パーミッションを割り当てる必要があります。- 3
- クラスターの
kubeconfigファイルへのパスを指定します。 - 4
- クラスターに追加する各 RHEL マシンをリスト表示します。各ホストについて完全修飾ドメイン名を指定する必要があります。この名前は、クラスターがマシンにアクセスするために使用するホスト名であるため、マシンにアクセスできるように正しいパブリックまたはプライベートの名前を設定します。
Ansible Playbook ディレクトリーに移動します。
$ cd /usr/share/ansible/openshift-ansiblePlaybook を実行します。
$ ansible-playbook -i /<path>/inventory/hosts playbooks/scaleup.yml1 - 1
<path>には、作成した Ansible インベントリーファイルへのパスを指定します。
6.1.6. Ansible ホストファイルの必須パラメーター
Red Hat Enterprise Linux (RHEL) コンピュートマシンをクラスターに追加する前に、以下のパラメーターを Ansible ホストファイルに定義する必要があります。
| パラメーター | 説明 | 値 |
|---|---|---|
|
| パスワードなしの SSH ベースの認証を許可する SSH ユーザー。SSH キーベースの認証を使用する場合、キーを SSH エージェントで管理する必要があります。 |
システム上のユーザー名。デフォルト値は |
|
|
|
|
|
|
クラスターの | 設定ファイルのパスと名前。 |
6.1.7. オプション: RHCOS コンピュートマシンのクラスターからの削除
Red Hat Enterprise Linux (RHEL) コンピュートマシンをクラスターに追加した後に、オプションで Red Hat Enterprise Linux CoreOS (RHCOS) コンピュートマシンを削除し、リソースを解放できます。
前提条件
- RHEL コンピュートマシンをクラスターに追加済みです。
手順
マシンのリストを表示し、RHCOS コンピューマシンのノード名を記録します。
$ oc get nodes -o wideそれぞれの RHCOS コンピュートマシンについて、ノードを削除します。
oc adm cordonコマンドを実行して、ノードにスケジュール対象外 (unschedulable) のマークを付けます。$ oc adm cordon <node_name>1 - 1
- RHCOS コンピュートマシンのノード名を指定します。
ノードからすべての Pod をドレイン (解放) します。
$ oc adm drain <node_name> --force --delete-emptydir-data --ignore-daemonsets1 - 1
- 分離した RHCOS コンピュートマシンのノード名を指定します。
ノードを削除します。
$ oc delete nodes <node_name>1 - 1
- ドレイン (解放) した RHCOS コンピュートマシンのノード名を指定します。
コンピュートマシンのリストを確認し、RHEL ノードのみが残っていることを確認します。
$ oc get nodes -o wide- RHCOS マシンをクラスターのコンピュートマシンのロードバランサーから削除します。仮想マシンを削除したり、RHCOS コンピュートマシンの物理ハードウェアを再イメージ化したりできます。
6.2. RHCOS コンピュートマシンの OpenShift Container Platform クラスターへの追加
ベアメタルの OpenShift Container Platform クラスターに Red Hat Enterprise Linux CoreOS (RHCOS) コンピュートマシンを追加することができます。
ベアメタルインフラストラクチャーにインストールされているクラスターにコンピュートマシンを追加する前に、それが使用する RHCOS マシンを作成する必要があります。ISO イメージまたはネットワーク PXE ブートを使用してマシンを作成できます。
6.2.1. 前提条件
- クラスターをベアメタルにインストールしている。
- クラスターの作成に使用したインストールメディアおよび Red Hat Enterprise Linux CoreOS (RHCOS) イメージがある。これらのファイルがない場合は、インストール手順 の説明に従って取得する必要があります。
6.2.2. ISO イメージを使用した RHCOS マシンの作成
ISO イメージを使用して、ベアメタルクラスターの追加の Red Hat Enterprise Linux CoreOS (RHCOS) コンピュートマシンを作成できます。
前提条件
- クラスターのコンピュートマシンの Ignition 設定ファイルの URL を取得します。このファイルがインストール時に HTTP サーバーにアップロードされている必要があります。
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、クラスターから Ignition 設定ファイルを抽出します。
$ oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ign-
クラスターからエクスポートした
worker.ignIgnition 設定ファイルを HTTP サーバーにアップロードします。これらのファイルの URL をメモします。 Ignition ファイルが URL で利用可能であることを検証できます。次の例では、コンピュートノードの Ignition 設定ファイルを取得します。
$ curl -k http://<HTTP_server>/worker.ign次のコマンドを実行すると、新しいマシンを起動するための ISO イメージにアクセスできます。
RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.<architecture>.artifacts.metal.formats.iso.disk.location')ISO ファイルを使用して、追加のコンピュートマシンに RHCOS をインストールします。クラスターのインストール前にマシンを作成する際に使用したのと同じ方法を使用します。
- ディスクに ISO イメージを書き込み、これを直接起動します。
- LOM インターフェイスで ISO リダイレクトを使用します。
オプションを指定したり、ライブ起動シーケンスを中断したりせずに、RHCOS ISO イメージを起動します。インストーラーが RHCOS ライブ環境でシェルプロンプトを起動するのを待ちます。
注記RHCOS インストールの起動プロセスを中断して、カーネル引数を追加できます。ただし、この ISO 手順では、カーネル引数を追加する代わりに、次の手順で概説するように
coreos-installerコマンドを使用する必要があります。coreos-installerコマンドを実行します。インストール要件に合わせてオプションを指定します。少なくとも、該当するノードタイプ用の Ignition 設定ファイルを指す URL と、インストール先のデバイスを指定する必要があります。$ sudo coreos-installer install --ignition-url=http://<HTTP_server>/<node_type>.ign <device> --ignition-hash=sha512-<digest>1 2 注記TLS を使用する HTTPS サーバーを使用して Ignition 設定ファイルを提供する場合は、
coreos-installerを実行する前に、内部認証局 (CA) をシステムのトラストストアに追加できます。次の例では、
/dev/sdaデバイスへのコンピュートノードのインストールを開始します。コンピュートノードの Ignition 設定ファイルは、IP アドレス 192.168.1.2 の HTTP Web サーバーから取得されます。$ sudo coreos-installer install --ignition-url=http://192.168.1.2:80/installation_directory/worker.ign /dev/sda --ignition-hash=sha512-a5a2d43879223273c9b60af66b44202a1d1248fc01cf156c46d4a79f552b6bad47bc8cc78ddf0116e80c59d2ea9e32ba53bc807afbca581aa059311def2c3e3bマシンのコンソールで RHCOS インストールの進捗を監視します。
重要OpenShift Container Platform のインストールを開始する前に、各ノードでインストールが成功していることを確認します。インストールプロセスを監視すると、発生する可能性のある RHCOS インストールの問題の原因を特定する上でも役立ちます。
- 継続してクラスター用の追加のコンピュートマシンを作成します。
6.2.3. PXE または iPXE ブートによる RHCOS マシンの作成
PXE または iPXE ブートを使用して、ベアメタルクラスターの追加の Red Hat Enterprise Linux CoreOS (RHCOS) コンピュートマシンを作成できます。
前提条件
- クラスターのコンピュートマシンの Ignition 設定ファイルの URL を取得します。このファイルがインストール時に HTTP サーバーにアップロードされている必要があります。
-
クラスターのインストール時に HTTP サーバーにアップロードした RHCOS ISO イメージ、圧縮されたメタル BIOS、
kernel、およびinitramfsファイルの URL を取得します。 - インストール時に OpenShift Container Platform クラスターのマシンを作成するために使用した PXE ブートインフラストラクチャーにアクセスできる必要があります。RHCOS のインストール後にマシンはローカルディスクから起動する必要があります。
-
UEFI を使用する場合、OpenShift Container Platform のインストール時に変更した
grub.confファイルにアクセスできます。
手順
RHCOS イメージの PXE または iPXE インストールが正常に行われていることを確認します。
PXE の場合:
DEFAULT pxeboot TIMEOUT 20 PROMPT 0 LABEL pxeboot KERNEL http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture>1 APPEND initrd=http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img2 - 1
- HTTP サーバーにアップロードしたライブ
kernelファイルの場所を指定します。 - 2
- HTTP サーバーにアップロードした RHCOS ファイルの場所を指定します。
initrdパラメーターはライブinitramfsファイルの場所であり、coreos.inst.ignition_urlパラメーター値はワーカー Ignition 設定ファイルの場所であり、coreos.live.rootfs_urlパラメーター値はライブrootfsファイルの場所になります。coreos.inst.ignition_urlおよびcoreos.live.rootfs_urlパラメーターは HTTP および HTTPS のみをサポートします。
注記この設定では、グラフィカルコンソールを使用するマシンでシリアルコンソールアクセスを有効にしません。別のコンソールを設定するには、
APPEND行に 1 つ以上のconsole=引数を追加します。たとえば、console=tty0 console=ttyS0を追加して、最初の PC シリアルポートをプライマリーコンソールとして、グラフィカルコンソールをセカンダリーコンソールとして設定します。詳細は、How does one set up a serial terminal and/or console in Red Hat Enterprise Linux? を参照してください。iPXE (
x86_64+aarch64) の場合:kernel http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture> initrd=main coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign1 2 initrd --name main http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img3 boot- 1
- HTTP サーバーにアップロードした RHCOS ファイルの場所を指定します。
kernelパラメーター値はkernelファイルの場所であり、initrd=main引数は UEFI システムでの起動に必要であり、coreos.live.rootfs_urlパラメーター値はワーカー Ignition 設定ファイルの場所であり、coreos.inst.ignition_urlパラメーター値はrootfsのライブファイルの場所です。 - 2
- 複数の NIC を使用する場合、
ipオプションに単一インターフェイスを指定します。たとえば、eno1という名前の NIC で DHCP を使用するには、ip=eno1:dhcpを設定します。 - 3
- HTTP サーバーにアップロードした
initramfsファイルの場所を指定します。
注記この設定では、グラフィカルコンソールを備えたマシンでのシリアルコンソールアクセスは有効になりません。別のコンソールを設定するには、
kernel行に 1 つ以上のconsole=引数を追加します。たとえば、console=tty0 console=ttyS0を追加して、最初の PC シリアルポートをプライマリーコンソールとして、グラフィカルコンソールをセカンダリーコンソールとして設定します。詳細は、How does one set up a serial terminal and/or console in Red Hat Enterprise Linux? と、「高度な RHCOS インストール設定」セクションの「PXE および ISO インストール用シリアルコンソールの有効化」を参照してください。注記aarch64アーキテクチャーで CoreOSkernelをネットワークブートするには、IMAGE_GZIPオプションが有効になっているバージョンの iPXE ビルドを使用する必要があります。iPXE のIMAGE_GZIPオプション を参照してください。aarch64上の PXE (第 2 段階として UEFI および GRUB を使用) の場合:menuentry 'Install CoreOS' { linux rhcos-<version>-live-kernel-<architecture> coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign1 2 initrd rhcos-<version>-live-initramfs.<architecture>.img3 }- 1
- HTTP/TFTP サーバーにアップロードした RHCOS ファイルの場所を指定します。
kernelパラメーター値は、TFTP サーバー上のkernelファイルの場所になります。coreos.live.rootfs_urlパラメーター値はrootfsファイルの場所であり、coreos.inst.ignition_urlパラメーター値は HTTP サーバー上のブートストラップ Ignition 設定ファイルの場所になります。 - 2
- 複数の NIC を使用する場合、
ipオプションに単一インターフェイスを指定します。たとえば、eno1という名前の NIC で DHCP を使用するには、ip=eno1:dhcpを設定します。 - 3
- TFTP サーバーにアップロードした
initramfsファイルの場所を指定します。
- PXE または iPXE インフラストラクチャーを使用して、クラスターに必要なコンピュートマシンを作成します。
6.2.4. マシンの証明書署名要求の承認
マシンをクラスターに追加する際に、追加したそれぞれのマシンに対して 2 つの保留状態の証明書署名要求 (CSR) が生成されます。これらの CSR が承認されていることを確認するか、必要な場合はそれらを承認してください。最初にクライアント要求を承認し、次にサーバー要求を承認する必要があります。
前提条件
- マシンがクラスターに追加されています。
手順
クラスターがマシンを認識していることを確認します。
$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.29.4 master-1 Ready master 63m v1.29.4 master-2 Ready master 64m v1.29.4出力には作成したすべてのマシンがリスト表示されます。
注記上記の出力には、一部の CSR が承認されるまで、ワーカーノード (ワーカーノードとも呼ばれる) が含まれない場合があります。
保留中の証明書署名要求 (CSR) を確認し、クラスターに追加したそれぞれのマシンのクライアントおよびサーバー要求に
PendingまたはApprovedステータスが表示されていることを確認します。$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...この例では、2 つのマシンがクラスターに参加しています。このリストにはさらに多くの承認された CSR が表示される可能性があります。
追加したマシンの保留中の CSR すべてが
Pendingステータスになった後に CSR が承認されない場合には、クラスターマシンの CSR を承認します。注記CSR のローテーションは自動的に実行されるため、クラスターにマシンを追加後 1 時間以内に CSR を承認してください。1 時間以内に承認しない場合には、証明書のローテーションが行われ、各ノードに 3 つ以上の証明書が存在するようになります。これらの証明書すべてを承認する必要があります。クライアントの CSR が承認された後に、Kubelet は提供証明書のセカンダリー CSR を作成します。これには、手動の承認が必要になります。次に、後続の提供証明書の更新要求は、Kubelet が同じパラメーターを持つ新規証明書を要求する場合に
machine-approverによって自動的に承認されます。注記ベアメタルおよび他の user-provisioned infrastructure などのマシン API ではないプラットフォームで実行されているクラスターの場合、kubelet 提供証明書要求 (CSR) を自動的に承認する方法を実装する必要があります。要求が承認されない場合、API サーバーが kubelet に接続する際に提供証明書が必須であるため、
oc exec、oc rsh、およびoc logsコマンドは正常に実行できません。Kubelet エンドポイントにアクセスする操作には、この証明書の承認が必要です。この方法は新規 CSR の有無を監視し、CSR がsystem:nodeまたはsystem:adminグループのnode-bootstrapperサービスアカウントによって提出されていることを確認し、ノードの ID を確認します。それらを個別に承認するには、それぞれの有効な CSR に以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve注記一部の Operator は、一部の CSR が承認されるまで利用できない可能性があります。
クライアント要求が承認されたら、クラスターに追加した各マシンのサーバー要求を確認する必要があります。
$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...残りの CSR が承認されず、それらが
Pendingステータスにある場合、クラスターマシンの CSR を承認します。それらを個別に承認するには、それぞれの有効な CSR に以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
すべてのクライアントおよびサーバーの CSR が承認された後に、マシンのステータスが
Readyになります。以下のコマンドを実行して、これを確認します。$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.29.4 master-1 Ready master 73m v1.29.4 master-2 Ready master 74m v1.29.4 worker-0 Ready worker 11m v1.29.4 worker-1 Ready worker 11m v1.29.4注記サーバー CSR の承認後にマシンが
Readyステータスに移行するまでに数分の時間がかかる場合があります。
関連情報
- CSR の詳細は、Certificate Signing Requests を参照してください。
6.2.5. AWS でのカスタム /var パーティションを持つ新規 RHCOS ワーカーノードの追加
OpenShift Container Platform は、ブートストラップ時に処理されるマシン設定を使用したインストール時のデバイスのパーティション設定をサポートします。ただし、/var パーティション設定を使用する場合は、デバイス名はインストール時に決定する必要があり、変更することはできません。デバイス命名スキーマが異なる場合は、異なるインスタンスタイプをノードとして追加することはできません。たとえば、/var パーティションを m4.large インスタンスのデフォルトの AWS デバイス名 dev/xvdb で設定した場合、m5.large インスタンスはデフォルトで /dev/nvme1n1 デバイスを使用するため、AWS m5.large インスタンスを直接追加することはできません。異なる命名スキーマにより、デバイスはパーティション設定に失敗する可能性があります。
本セクションの手順では、インストール時に設定したものとは異なるデバイス名を使用するインスタンスと共に、新規の Red Hat Enterprise Linux CoreOS (RHCOS) コンピュートノードを追加する方法を説明します。カスタムユーザーデータシークレットを作成し、新規コンピュートマシンセットを設定します。これらの手順は AWS クラスターに固有のものです。この原則は、他のクラウドデプロイメントにも適用されます。ただし、デバイスの命名スキーマは他のデプロイメントでは異なり、ケースごとに決定する必要があります。
手順
コマンドラインで、
openshift-machine-apinamespace に移動します。$ oc project openshift-machine-apiworker-user-dataシークレットから新規シークレットを作成します。シークレットの
userDataセクションをテキストファイルにエクスポートします。$ oc get secret worker-user-data --template='{{index .data.userData | base64decode}}' | jq > userData.txtテキストファイルを編集して、新規ノードに使用するパーティションの
storage、filesystems、およびsystemdスタンザを追加します。必要に応じて Ignition 設定パラメーター を指定できます。注記ignitionスタンザの値は変更しないでください。{ "ignition": { "config": { "merge": [ { "source": "https:...." } ] }, "security": { "tls": { "certificateAuthorities": [ { "source": "data:text/plain;charset=utf-8;base64,.....==" } ] } }, "version": "3.2.0" }, "storage": { "disks": [ { "device": "/dev/nvme1n1",1 "partitions": [ { "label": "var", "sizeMiB": 50000,2 "startMiB": 03 } ] } ], "filesystems": [ { "device": "/dev/disk/by-partlabel/var",4 "format": "xfs",5 "path": "/var"6 } ] }, "systemd": { "units": [7 { "contents": "[Unit]\nBefore=local-fs.target\n[Mount]\nWhere=/var\nWhat=/dev/disk/by-partlabel/var\nOptions=defaults,pquota\n[Install]\nWantedBy=local-fs.target\n", "enabled": true, "name": "var.mount" } ] } }- 1
- AWS ブロックデバイスへの絶対パスを指定します。
- 2
- データパーティションのサイズをメビバイト単位で指定します。
- 3
- メビバイト単位でパーティションの開始点を指定します。データパーティションをブートディスクに追加する場合は、最小値の 25000 MB (メビバイト) が推奨されます。ルートファイルシステムは、指定したオフセットまでの利用可能な領域をすべて埋めるためにサイズを自動的に変更します。値の指定がない場合や、指定した値が推奨される最小値よりも小さい場合、生成されるルートファイルシステムのサイズは小さ過ぎるため、RHCOS の再インストールでデータパーティションの最初の部分が上書きされる可能性があります。
- 4
/varパーティションへの絶対パスを指定します。- 5
- ファイルシステムのフォーマットを指定します。
- 6
- Ignition がルートファイルシステムがマウントされる場所に対して相対的な場所で実行される、ファイルシステムのマウントポイントを指定します。これは実際のルートにマウントする場所と同じである必要はありませんが、同じにすることが推奨されます。
- 7
/dev/disk/by-partlabel/varデバイスを/varパーティションにマウントする systemd マウントユニットを定義します。
disableTemplatingセクションをwork-user-dataシークレットからテキストファイルに展開します。$ oc get secret worker-user-data --template='{{index .data.disableTemplating | base64decode}}' | jq > disableTemplating.txt2 つのテキストファイルから新しいユーザーデータのシークレットファイルを作成します。このユーザーデータのシークレットは、
userData.txtファイルの追加のノードパーティション情報を新規作成されたノードに渡します。$ oc create secret generic worker-user-data-x5 --from-file=userData=userData.txt --from-file=disableTemplating=disableTemplating.txt
新規ノードの新規コンピュートマシンセットを作成します。
AWS 向けに設定される新規のコンピュートマシンセット YAML ファイルを、以下のように作成します。必要なパーティションおよび新規に作成されたユーザーデータシークレットを追加します。
ヒント既存のコンピュートマシンセットをテンプレートとして使用し、新規ノード用に必要に応じてパラメーターを変更します。
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: auto-52-92tf4 name: worker-us-east-2-nvme1n11 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: auto-52-92tf4 machine.openshift.io/cluster-api-machineset: auto-52-92tf4-worker-us-east-2b template: metadata: labels: machine.openshift.io/cluster-api-cluster: auto-52-92tf4 machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker machine.openshift.io/cluster-api-machineset: auto-52-92tf4-worker-us-east-2b spec: metadata: {} providerSpec: value: ami: id: ami-0c2dbd95931a apiVersion: awsproviderconfig.openshift.io/v1beta1 blockDevices: - DeviceName: /dev/nvme1n12 ebs: encrypted: true iops: 0 volumeSize: 120 volumeType: gp2 - DeviceName: /dev/nvme1n23 ebs: encrypted: true iops: 0 volumeSize: 50 volumeType: gp2 credentialsSecret: name: aws-cloud-credentials deviceIndex: 0 iamInstanceProfile: id: auto-52-92tf4-worker-profile instanceType: m6i.large kind: AWSMachineProviderConfig metadata: creationTimestamp: null placement: availabilityZone: us-east-2b region: us-east-2 securityGroups: - filters: - name: tag:Name values: - auto-52-92tf4-worker-sg subnet: id: subnet-07a90e5db1 tags: - name: kubernetes.io/cluster/auto-52-92tf4 value: owned userDataSecret: name: worker-user-data-x54 コンピュートマシンセットを作成します。
$ oc create -f <file-name>.yamlマシンが利用可能になるまでに少し時間がかかる場合があります。
新しいパーティションとノードが作成されたことを確認します。
コンピュートマシンセットが作成されていることを確認します。
$ oc get machineset出力例
NAME DESIRED CURRENT READY AVAILABLE AGE ci-ln-2675bt2-76ef8-bdgsc-worker-us-east-1a 1 1 1 1 124m ci-ln-2675bt2-76ef8-bdgsc-worker-us-east-1b 2 2 2 2 124m worker-us-east-2-nvme1n1 1 1 1 1 2m35s1 - 1
- これが新しいコンピュートマシンセットです。
新規ノードが作成されていることを確認します。
$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION ip-10-0-128-78.ec2.internal Ready worker 117m v1.29.4 ip-10-0-146-113.ec2.internal Ready master 127m v1.29.4 ip-10-0-153-35.ec2.internal Ready worker 118m v1.29.4 ip-10-0-176-58.ec2.internal Ready master 126m v1.29.4 ip-10-0-217-135.ec2.internal Ready worker 2m57s v1.29.41 ip-10-0-225-248.ec2.internal Ready master 127m v1.29.4 ip-10-0-245-59.ec2.internal Ready worker 116m v1.29.4- 1
- これは新しいノードです。
カスタム
/varパーティションが新しいノードに作成されていることを確認します。$ oc debug node/<node-name> -- chroot /host lsblk以下に例を示します。
$ oc debug node/ip-10-0-217-135.ec2.internal -- chroot /host lsblk出力例
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT nvme0n1 202:0 0 120G 0 disk |-nvme0n1p1 202:1 0 1M 0 part |-nvme0n1p2 202:2 0 127M 0 part |-nvme0n1p3 202:3 0 384M 0 part /boot `-nvme0n1p4 202:4 0 119.5G 0 part /sysroot nvme1n1 202:16 0 50G 0 disk `-nvme1n1p1 202:17 0 48.8G 0 part /var1 - 1
nvme1n1デバイスが/varパーティションにマウントされます。
6.3. マシンヘルスチェックのデプロイ
マシンヘルスチェックについて確認し、これをデプロイします。
高度なマシン管理およびスケーリング機能は、Machine API が動作しているクラスターでのみ使用できます。user-provisioned infrastructure を持つクラスターでは、Machine API を使用するために追加の検証と設定が必要です。
インフラストラクチャープラットフォームタイプが none のクラスターでは、Machine API を使用できません。この制限は、クラスターに接続されている計算マシンが、この機能をサポートするプラットフォームにインストールされている場合でも適用されます。このパラメーターは、インストール後に変更することはできません。
クラスターのプラットフォームタイプを表示するには、以下のコマンドを実行します。
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'6.3.1. マシンのヘルスチェック
マシンのヘルスチェックは、コンピュートマシンセットまたはコントロールプレーンマシンセットにより管理されるマシンにのみ適用できます。
マシンの正常性を監視するには、リソースを作成し、コントローラーの設定を定義します。5 分間 NotReady ステータスにすることや、node-problem-detector に永続的な条件を表示すること、および監視する一連のマシンのラベルなど、チェックする条件を設定します。
MachineHealthCheck リソースを監視するコントローラーは定義済みのステータスをチェックします。マシンがヘルスチェックに失敗した場合、このマシンは自動的に検出され、その代わりとなるマシンが作成されます。マシンが削除されると、machine deleted イベントが表示されます。
マシンの削除による破壊的な影響を制限するために、コントローラーは 1 度に 1 つのノードのみを drain し、これを削除します。マシンのターゲットプールで許可される maxUnhealthy しきい値を上回る数の正常でないマシンがある場合、修復が停止するため、手動による介入が可能になります。
タイムアウトについて注意深い検討が必要であり、ワークロードと要件を考慮してください。
- タイムアウトの時間が長くなると、正常でないマシンのワークロードのダウンタイムが長くなる可能性があります。
-
タイムアウトが短すぎると、修復ループが生じる可能性があります。たとえば、
NotReadyステータスを確認するためのタイムアウトは、マシンが起動プロセスを完了できるように十分な時間を設定する必要があります。
チェックを停止するには、リソースを削除します。
6.3.1.1. マシンヘルスチェックのデプロイ時の制限
マシンヘルスチェックをデプロイする前に考慮すべき制限事項があります。
- マシンセットが所有するマシンのみがマシンヘルスチェックによって修復されます。
- マシンのノードがクラスターから削除される場合、マシンヘルスチェックはマシンが正常ではないとみなし、すぐにこれを修復します。
-
nodeStartupTimeoutの後にマシンの対応するノードがクラスターに加わらない場合、マシンは修復されます。 -
MachineリソースフェーズがFailedの場合、マシンはすぐに修復されます。
6.3.2. サンプル MachineHealthCheck リソース
ベアメタルを除くすべてのクラウドベースのインストールタイプの MachineHealthCheck リソースは、以下の YAML ファイルのようになります。
apiVersion: machine.openshift.io/v1beta1
kind: MachineHealthCheck
metadata:
name: example
namespace: openshift-machine-api
spec:
selector:
matchLabels:
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <cluster_name>-<label>-<zone>
unhealthyConditions:
- type: "Ready"
timeout: "300s"
status: "False"
- type: "Ready"
timeout: "300s"
status: "Unknown"
maxUnhealthy: "40%"
nodeStartupTimeout: "10m" - 1
- デプロイするマシンヘルスチェックの名前を指定します。
- 2 3
- チェックする必要のあるマシンプールのラベルを指定します。
- 4
- 追跡するマシンセットを
<cluster_name>-<label>-<zone>形式で指定します。たとえば、prod-node-us-east-1aとします。 - 5 6
- ノードの状態のタイムアウト期間を指定します。タイムアウト期間の条件が満たされると、マシンは修正されます。タイムアウトの時間が長くなると、正常でないマシンのワークロードのダウンタイムが長くなる可能性があります。
- 7
- ターゲットプールで同時に修復できるマシンの数を指定します。これはパーセンテージまたは整数として設定できます。正常でないマシンの数が
maxUnhealthyで設定された制限を超える場合、修復は実行されません。 - 8
- マシンが正常でないと判別される前に、ノードがクラスターに参加するまでマシンヘルスチェックが待機する必要のあるタイムアウト期間を指定します。
matchLabels はあくまでもサンプルであるため、特定のニーズに応じてマシングループをマッピングする必要があります。
6.3.2.1. マシンヘルスチェックによる修復の一時停止 (short-circuiting)
一時停止 (short-circuiting) が実行されることにより、マシンのヘルスチェックはクラスターが正常な場合にのみマシンを修復するようになります。一時停止 (short-circuiting) は、MachineHealthCheck リソースの maxUnhealthy フィールドで設定されます。
ユーザーがマシンの修復前に maxUnhealthy フィールドの値を定義する場合、MachineHealthCheck は maxUnhealthy の値を、正常でないと判別するターゲットプール内のマシン数と比較します。正常でないマシンの数が maxUnhealthy の制限を超える場合、修復は実行されません。
maxUnhealthy が設定されていない場合、値は 100% にデフォルト設定され、マシンはクラスターの状態に関係なく修復されます。
適切な maxUnhealthy 値は、デプロイするクラスターの規模や、MachineHealthCheck が対応するマシンの数によって異なります。たとえば、maxUnhealthy 値を使用して複数のアベイラビリティーゾーン間で複数のマシンセットに対応でき、ゾーン全体が失われると、maxUnhealthy の設定によりクラスター内で追加の修復を防ぐことができます。複数のアベイラビリティーゾーンを持たないグローバル Azure リージョンでは、アベイラビリティーセットを使用して高可用性を確保できます。
コントロールプレーンの MachineHealthCheck リソースを設定する場合は、maxUnhealthy の値を 1 に設定します。
この設定により、複数のコントロールプレーンマシンが異常であると思われる場合に、マシンのヘルスチェックがアクションを実行しないことが保証されます。複数の異常なコントロールプレーンマシンは、etcd クラスターが劣化していること、または障害が発生したマシンを置き換えるためのスケーリング操作が進行中であることを示している可能性があります。
etcd クラスターが劣化している場合は、手動での介入が必要になる場合があります。スケーリング操作が進行中の場合は、マシンのヘルスチェックで完了できるようにする必要があります。
maxUnhealthy フィールドは整数またはパーセンテージのいずれかに設定できます。maxUnhealthy の値によって、修復の実装が異なります。
6.3.2.1.1. 絶対値を使用した maxUnhealthy の設定
maxUnhealthy が 2 に設定される場合:
- 2 つ以下のノードが正常でない場合に、修復が実行されます。
- 3 つ以上のノードが正常でない場合は、修復は実行されません。
これらの値は、マシンヘルスチェックによってチェックされるマシン数と別個の値です。
6.3.2.1.2. パーセンテージを使用した maxUnhealthy の設定
maxUnhealthy が 40% に設定され、25 のマシンがチェックされる場合:
- 10 以下のノードが正常でない場合に、修復が実行されます。
- 11 以上のノードが正常でない場合は、修復は実行されません。
maxUnhealthy が 40% に設定され、6 マシンがチェックされる場合:
- 2 つ以下のノードが正常でない場合に、修復が実行されます。
- 3 つ以上のノードが正常でない場合は、修復は実行されません。
チェックされる maxUnhealthy マシンの割合が整数ではない場合、マシンの許可される数は切り捨てられます。
6.3.3. マシンヘルスチェックリソースの作成
クラスター内のマシンセットの MachineHealthCheck リソースを作成できます。
マシンのヘルスチェックは、コンピュートマシンセットまたはコントロールプレーンマシンセットにより管理されるマシンにのみ適用できます。
前提条件
-
ocコマンドラインインターフェイスをインストールします。
手順
-
マシンヘルスチェックの定義を含む
healthcheck.ymlファイルを作成します。 healthcheck.ymlファイルをクラスターに適用します。$ oc apply -f healthcheck.yml
6.3.4. コンピュートマシンセットの手動スケーリング
コンピュートマシンセットのマシンのインスタンスを追加したり、削除したりする必要がある場合、コンピュートマシンセットを手動でスケーリングできます。
このガイダンスは、完全に自動化された installer-provisioned infrastructure のインストールに関連します。user-provisioned infrastructure のカスタマイズされたインストールにはコンピュートマシンセットがありません。
前提条件
-
OpenShift Container Platform クラスターおよび
ocコマンドラインをインストールすること。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。
手順
次のコマンドを実行して、クラスター内のコンピュートマシンセットを表示します。
$ oc get machinesets.machine.openshift.io -n openshift-machine-apiコンピュートマシンセットは
<clusterid>-worker-<aws-region-az>の形式で一覧表示されます。次のコマンドを実行して、クラスター内のコンピュートマシンを表示します。
$ oc get machines.machine.openshift.io -n openshift-machine-api次のコマンドを実行して、削除するコンピュートマシンに注釈を設定します。
$ oc annotate machines.machine.openshift.io/<machine_name> -n openshift-machine-api machine.openshift.io/delete-machine="true"次のいずれかのコマンドを実行して、コンピュートマシンセットをスケーリングします。
$ oc scale --replicas=2 machinesets.machine.openshift.io <machineset> -n openshift-machine-apiまたは、以下を実行します。
$ oc edit machinesets.machine.openshift.io <machineset> -n openshift-machine-apiヒントまたは、以下の YAML を適用してコンピュートマシンセットをスケーリングすることもできます。
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: replicas: 2コンピュートマシンセットをスケールアップまたはスケールダウンできます。新規マシンが利用可能になるまで数分の時間がかかります。
重要デフォルトでは、マシンコントローラーは、成功するまでマシンによってサポートされるノードを drain しようとします。場合によっては、drain 操作が成功しない可能性があります。たとえば、Pod Disruption Budget が間違っている場合などです。drain 操作が失敗した場合、マシンコントローラーはマシンの削除を続行できません。
特定のマシンの
machine.openshift.io/exclude-node-drainingにアノテーションを付けると、ノードの drain を省略できます。
検証
次のコマンドを実行して、目的のマシンが削除されたことを確認します。
$ oc get machines.machine.openshift.io
6.3.5. コンピュートマシンセットとマシン設定プールの相違点について
MachineSet オブジェクトは、クラウドまたはマシンプロバイダーに関する OpenShift Container Platform ノードを記述します。
MachineConfigPool オブジェクトにより、MachineConfigController コンポーネントがアップグレードのコンテキストでマシンのステータスを定義し、提供できるようになります。
MachineConfigPool オブジェクトにより、ユーザーはマシン設定プールの OpenShift Container Platform ノードにアップグレードをデプロイメントする方法を設定できます。
NodeSelector オブジェクトは MachineSet オブジェクトへの参照に置き換えることができます。
6.4. ノードホストに関する推奨プラクティス
OpenShift Container Platform ノードの設定ファイルには、重要なオプションが含まれています。たとえば、podsPerCore および maxPods の 2 つのパラメーターはノードにスケジュールできる Pod の最大数を制御します。
両方のオプションが使用されている場合、2 つの値の低い方の値により、ノード上の Pod 数が制限されます。これらの値を超えると、以下の状態が生じる可能性があります。
- CPU 使用率の増大。
- Pod のスケジューリングの速度が遅くなる。
- (ノードのメモリー量によって) メモリー不足のシナリオが生じる可能性。
- IP アドレスのプールを消費する。
- リソースのオーバーコミット、およびこれによるアプリケーションのパフォーマンスの低下。
Kubernetes では、単一コンテナーを保持する Pod は実際には 2 つのコンテナーを使用します。2 つ目のコンテナーは実際のコンテナーの起動前にネットワークを設定するために使用されます。そのため、10 の Pod を使用するシステムでは、実際には 20 のコンテナーが実行されていることになります。
クラウドプロバイダーからのディスク IOPS スロットリングは CRI-O および kubelet に影響を与える可能性があります。ノード上に多数の I/O 集約型 Pod が実行されている場合、それらはオーバーロードする可能性があります。ノード上のディスク I/O を監視し、ワークロード用に十分なスループットを持つボリュームを使用することが推奨されます。
podsPerCore パラメーターは、ノードのプロセッサーコアの数に基づいて、ノードが実行できる Pod の数を設定します。たとえば、4 プロセッサーコアを搭載したノードで podsPerCore が 10 に設定される場合、このノードで許可される Pod の最大数は 40 になります。
kubeletConfig:
podsPerCore: 10
podsPerCore を 0 に設定すると、この制限が無効になります。デフォルトは 0 です。podsPerCore パラメーターの値は、maxPods パラメーターの値を超えることはできません。
maxPods パラメーターは、ノードのプロパティーに関係なく、ノードが実行できる Pod の数を固定値に設定します。
kubeletConfig:
maxPods: 2506.4.1. Kubelet パラメーターを編集するための KubeletConfig CR の作成
kubelet 設定は、現時点で Ignition 設定としてシリアル化されているため、直接編集することができます。ただし、新規の kubelet-config-controller も Machine Config Controller (MCC) に追加されます。これにより、KubeletConfig カスタムリソース (CR) を使用して kubelet パラメーターを編集できます。
kubeletConfig オブジェクトのフィールドはアップストリーム Kubernetes から kubelet に直接渡されるため、kubelet はそれらの値を直接検証します。kubeletConfig オブジェクトに無効な値があると、クラスターノードを利用できなくなる可能性があります。有効な値は、Kubernetes ドキュメント を参照してください。
以下のガイダンスを参照してください。
-
既存の
KubeletConfigCR を編集して既存の設定を編集するか、変更ごとに新規 CR を作成する代わりに新規の設定を追加する必要があります。CR を作成するのは、別のマシン設定プールを変更する場合、または一時的な変更を目的とした変更の場合のみにして、変更を元に戻すことができるようにすることを推奨します。 -
マシン設定プールごとに、そのプールに加える設定変更をすべて含めて、
KubeletConfigCR を 1 つ作成します。 -
必要に応じて、クラスターごとに 10 個を上限として、複数の
KubeletConfigCR を作成します。最初のKubeletConfigCR について、Machine Config Operator (MCO) はkubeletで追加されたマシン設定を作成します。それぞれの後続の CR で、コントローラーは数字の接尾辞が付いた別のkubeletマシン設定を作成します。たとえば、kubeletマシン設定があり、その接尾辞が-2の場合に、次のkubeletマシン設定には-3が付けられます。
kubelet またはコンテナーのランタイム設定をカスタムマシン設定プールに適用する場合、machineConfigSelector のカスタムロールは、カスタムマシン設定プールの名前と一致する必要があります。
たとえば、次のカスタムマシン設定プールの名前は infra であるため、カスタムロールも infra にする必要があります。
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfigPool
metadata:
name: infra
spec:
machineConfigSelector:
matchExpressions:
- {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,infra]}
# ...
マシン設定を削除する場合は、制限を超えないようにそれらを逆の順序で削除する必要があります。たとえば、kubelet-3 マシン設定を、kubelet-2 マシン設定を削除する前に削除する必要があります。
接尾辞が kubelet-9 のマシン設定があり、別の KubeletConfig CR を作成する場合には、kubelet マシン設定が 10 未満の場合でも新規マシン設定は作成されません。
KubeletConfig CR の例
$ oc get kubeletconfigNAME AGE
set-kubelet-config 15mKubeletConfig マシン設定を示す例
$ oc get mc | grep kubelet...
99-worker-generated-kubelet-1 b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.4.0 26m
...次の手順は、ノードあたりの Pod の最大数、ノードあたりの PID の最大数、およびワーカーノード上のコンテナーログの最大サイズを設定する方法を示した例です。
前提条件
設定するノードタイプの静的な
MachineConfigPoolCR に関連付けられたラベルを取得します。以下のいずれかの手順を実行します。マシン設定プールを表示します。
$ oc describe machineconfigpool <name>以下に例を示します。
$ oc describe machineconfigpool worker出力例
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: creationTimestamp: 2019-02-08T14:52:39Z generation: 1 labels: custom-kubelet: set-kubelet-config1 - 1
- ラベルが追加されると、
labelsの下に表示されます。
ラベルが存在しない場合は、キー/値のペアを追加します。
$ oc label machineconfigpool worker custom-kubelet=set-kubelet-config
手順
選択可能なマシン設定オブジェクトを表示します。
$ oc get machineconfigデフォルトで、2 つの kubelet 関連の設定である
01-master-kubeletおよび01-worker-kubeletを選択できます。ノードあたりの最大 Pod の現在の値を確認します。
$ oc describe node <node_name>以下に例を示します。
$ oc describe node ci-ln-5grqprb-f76d1-ncnqq-worker-a-mdv94Allocatableスタンザでvalue: pods: <value>を検索します。出力例
Allocatable: attachable-volumes-aws-ebs: 25 cpu: 3500m hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 15341844Ki pods: 250必要に応じてワーカーノードを設定します。
kubelet 設定を含む次のような YAML ファイルを作成します。
重要特定のマシン設定プールをターゲットとする kubelet 設定は、依存するプールにも影響します。たとえば、ワーカーノードを含むプール用の kubelet 設定を作成すると、インフラストラクチャーノードを含むプールを含むすべてのサブセットプールにも設定が適用されます。これを回避するには、ワーカーノードのみを含む選択式を使用して新しいマシン設定プールを作成し、kubelet 設定でこの新しいプールをターゲットにする必要があります。
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-kubelet-config spec: machineConfigPoolSelector: matchLabels: custom-kubelet: set-kubelet-config1 kubeletConfig:2 podPidsLimit: 8192 containerLogMaxSize: 50Mi maxPods: 500-
podPidsLimitを使用して、任意の Pod 内の PID の最大数を設定します。 -
containerLogMaxSizeを使用して、コンテナーログファイルがローテーションされる前の最大サイズを設定します。 maxPodsを使用して、ノードあたりの Pod の最大数を設定します。注記kubelet が API サーバーと通信する速度は、1 秒あたりのクエリー (QPS) およびバースト値により異なります。デフォルト値の
50(kubeAPIQPSの場合) および100(kubeAPIBurstの場合) は、各ノードで制限された Pod が実行されている場合には十分な値です。ノード上に CPU およびメモリーリソースが十分にある場合には、kubelet QPS およびバーストレートを更新することが推奨されます。apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-kubelet-config spec: machineConfigPoolSelector: matchLabels: custom-kubelet: set-kubelet-config kubeletConfig: maxPods: <pod_count> kubeAPIBurst: <burst_rate> kubeAPIQPS: <QPS>
-
ラベルを使用してワーカーのマシン設定プールを更新します。
$ oc label machineconfigpool worker custom-kubelet=set-kubelet-configKubeletConfigオブジェクトを作成します。$ oc create -f change-maxPods-cr.yaml
検証
KubeletConfigオブジェクトが作成されていることを確認します。$ oc get kubeletconfig出力例
NAME AGE set-kubelet-config 15mクラスター内のワーカーノードの数によっては、ワーカーノードが 1 つずつ再起動されるのを待機します。3 つのワーカーノードを持つクラスターの場合は、10 分から 15 分程度かかる可能性があります。
変更がノードに適用されていることを確認します。
maxPods値が変更されたワーカーノードで確認します。$ oc describe node <node_name>Allocatableスタンザを見つけます。... Allocatable: attachable-volumes-gce-pd: 127 cpu: 3500m ephemeral-storage: 123201474766 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 14225400Ki pods: 5001 ...- 1
- この例では、
podsパラメーターはKubeletConfigオブジェクトに設定した値を報告するはずです。
KubeletConfigオブジェクトの変更を確認します。$ oc get kubeletconfigs set-kubelet-config -o yamlこれは、以下の例のように
Trueおよびtype:Successのステータスを表示します。spec: kubeletConfig: containerLogMaxSize: 50Mi maxPods: 500 podPidsLimit: 8192 machineConfigPoolSelector: matchLabels: custom-kubelet: set-kubelet-config status: conditions: - lastTransitionTime: "2021-06-30T17:04:07Z" message: Success status: "True" type: Success
6.4.3. コントロールプレーンノードのサイジング
コントロールプレーンノードのリソース要件は、クラスター内のノードとオブジェクトの数とタイプによって異なります。次のコントロールプレーンノードサイズの推奨事項は、コントロールプレーン密度に焦点を当てたテストまたは クラスター密度 の結果に基づいています。このテストでは、指定された数の namespace にわたって次のオブジェクトを作成します。
- 1 イメージストリーム
- 1 ビルド
-
5 つのデプロイメント、
sleep状態の 2 つの Pod レプリカ、4 つのシークレット、4 つの config map、およびそれぞれ 1 つの下位 API ボリュームのマウント - 5 つのサービス。それぞれが以前のデプロイメントの 1 つの TCP/8080 および TCP/8443 ポートを指します。
- 以前のサービスの最初を指す 1 つのルート
- 2048 個のランダムな文字列文字を含む 10 個のシークレット
- 2048 個のランダムな文字列文字を含む 10 個の config map
| ワーカーノードの数 | クラスター密度 (namespace) | CPU コア数 | メモリー (GB) |
|---|---|---|---|
| 24 | 500 | 4 | 16 |
| 120 | 1000 | 8 | 32 |
| 252 | 4000 | 16、ただし OVN-Kubernetes ネットワークプラグインを使用する場合は 24 | 64、ただし OVN-Kubernetes ネットワークプラグインを使用する場合は 128 |
| 501、ただし OVN-Kubernetes ネットワークプラグインではテストされていません | 4000 | 16 | 96 |
上の表のデータは、r5.4xlarge インスタンスをコントロールプレーンノードとして使用し、m5.2xlarge インスタンスをワーカーノードとして使用する、AWS 上で実行される OpenShift Container Platform をベースとしています。
3 つのコントロールプレーンノードを持つ大規模で高密度なクラスターでは、いずれかのノードが停止、再起動、または障害が発生すると、CPU とメモリーの使用量が急増します。障害は、電源、ネットワーク、または基礎となるインフラストラクチャーの予期しない問題、またはコストを節約するためにシャットダウンした後にクラスターが再起動する意図的なケースが原因である可能性があります。残りの 2 つのコントロールプレーンノードは、高可用性を維持するために負荷を処理する必要があります。これにより、リソースの使用量が増えます。この動作はアップグレード時にも予想されます。オペレーティングシステムの更新とコントロールプレーン Operator の更新を適用するために、コントロールプレーンノードに cordon (スケジューリング対象からの除外) と drain (Pod の退避) が実行され、ノードが順次再起動されるためです。障害が繰り返し発生しないようにするには、コントロールプレーンノードでの全体的な CPU およびメモリーリソース使用状況を、利用可能な容量の最大 60% に維持し、使用量の急増に対応できるようにします。リソース不足による潜在的なダウンタイムを回避するために、コントロールプレーンノードの CPU およびメモリーを適宜増やします。
ノードのサイジングは、クラスター内のノードおよびオブジェクトの数によって異なります。また、オブジェクトがそのクラスター上でアクティブに作成されるかどうかによっても異なります。オブジェクトの作成時に、コントロールプレーンは、オブジェクトが running フェーズにある場合と比較し、リソースの使用状況においてよりアクティブな状態になります。
Operator Lifecycle Manager (OLM) はコントロールプレーンノードで実行され、OLM のメモリーフットプリントは OLM がクラスター上で管理する必要のある namespace およびユーザーによってインストールされる Operator の数によって異なります。OOM による強制終了を防ぐには、コントロールプレーンノードのサイズを適切に設定する必要があります。以下のデータポイントは、クラスター最大のテストの結果に基づいています。
| namespace 数 | アイドル状態の OLM メモリー (GB) | ユーザー Operator が 5 つインストールされている OLM メモリー (GB) |
|---|---|---|
| 500 | 0.823 | 1.7 |
| 1000 | 1.2 | 2.5 |
| 1500 | 1.7 | 3.2 |
| 2000 | 2 | 4.4 |
| 3000 | 2.7 | 5.6 |
| 4000 | 3.8 | 7.6 |
| 5000 | 4.2 | 9.02 |
| 6000 | 5.8 | 11.3 |
| 7000 | 6.6 | 12.9 |
| 8000 | 6.9 | 14.8 |
| 9000 | 8 | 17.7 |
| 10,000 | 9.9 | 21.6 |
以下の設定でのみ、実行中の OpenShift Container Platform 4.16 クラスターでコントロールプレーンのノードサイズを変更できます。
- ユーザーがプロビジョニングしたインストール方法でインストールされたクラスター。
- installer-provisioned infrastructure インストール方法でインストールされた AWS クラスター。
- コントロールプレーンマシンセットを使用してコントロールプレーンマシンを管理するクラスター。
他のすべての設定では、合計ノード数を見積もり、インストール時に推奨されるコントロールプレーンノードサイズを使用する必要があります。
この推奨事項は、ネットワークプラグインとして OpenShift SDN を使用して OpenShift Container Platform クラスターでキャプチャーされたデータポイントに基づいています。
OpenShift Container Platform 3.11 以前のバージョンと比較すると、OpenShift Container Platform 4.16 ではデフォルトで CPU コア (500 ミリコア) の半分がシステムによって予約されるようになりました。サイズはこれを考慮に入れて決定されます。
6.4.4. CPU マネージャーの設定
CPU マネージャーを設定するには、KubeletConfig カスタムリソース (CR) を作成し、それを目的のノードセットに適用します。
手順
次のコマンドを実行してノードにラベルを付けます。
# oc label node perf-node.example.com cpumanager=trueすべてのコンピュートノードに対して CPU マネージャーを有効にするには、次のコマンドを実行して CR を編集します。
# oc edit machineconfigpool workercustom-kubelet: cpumanager-enabledラベルをmetadata.labelsセクションに追加します。metadata: creationTimestamp: 2020-xx-xxx generation: 3 labels: custom-kubelet: cpumanager-enabledKubeletConfig、cpumanager-kubeletconfig.yaml、カスタムリソース (CR) を作成します。直前の手順で作成したラベルを参照し、適切なノードを新規の kubelet 設定で更新します。machineConfigPoolSelectorセクションを参照してください。apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cpumanager-enabled spec: machineConfigPoolSelector: matchLabels: custom-kubelet: cpumanager-enabled kubeletConfig: cpuManagerPolicy: static1 cpuManagerReconcilePeriod: 5s2 次のコマンドを実行して、動的 kubelet 設定を作成します。
# oc create -f cpumanager-kubeletconfig.yamlこれにより、CPU マネージャー機能が kubelet 設定に追加され、必要な場合には Machine Config Operator (MCO) がノードを再起動します。CPU マネージャーを有効にするために再起動する必要はありません。
次のコマンドを実行して、マージされた kubelet 設定を確認します。
# oc get machineconfig 99-worker-XXXXXX-XXXXX-XXXX-XXXXX-kubelet -o json | grep ownerReference -A7出力例
"ownerReferences": [ { "apiVersion": "machineconfiguration.openshift.io/v1", "kind": "KubeletConfig", "name": "cpumanager-enabled", "uid": "7ed5616d-6b72-11e9-aae1-021e1ce18878" } ]次のコマンドを実行して、更新された
kubelet.confファイルをコンピュートノードで確認します。# oc debug node/perf-node.example.com sh-4.2# cat /host/etc/kubernetes/kubelet.conf | grep cpuManager出力例
cpuManagerPolicy: static1 cpuManagerReconcilePeriod: 5s2 次のコマンドを実行してプロジェクトを作成します。
$ oc new-project <project_name>コア 1 つまたは複数を要求する Pod を作成します。制限および要求の CPU の値は整数にする必要があります。これは、対象の Pod 専用のコア数です。
# cat cpumanager-pod.yaml出力例
apiVersion: v1 kind: Pod metadata: generateName: cpumanager- spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: cpumanager image: gcr.io/google_containers/pause:3.2 resources: requests: cpu: 1 memory: "1G" limits: cpu: 1 memory: "1G" securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] nodeSelector: cpumanager: "true"Pod を作成します。
# oc create -f cpumanager-pod.yaml
検証
次のコマンドを実行して、ラベルを付けたノードに Pod がスケジュールされていることを確認します。
# oc describe pod cpumanager出力例
Name: cpumanager-6cqz7 Namespace: default Priority: 0 PriorityClassName: <none> Node: perf-node.example.com/xxx.xx.xx.xxx ... Limits: cpu: 1 memory: 1G Requests: cpu: 1 memory: 1G ... QoS Class: Guaranteed Node-Selectors: cpumanager=true次のコマンドを実行して、CPU が Pod 専用として割り当てられていることを確認します。
# oc describe node --selector='cpumanager=true' | grep -i cpumanager- -B2出力例
NAMESPACE NAME CPU Requests CPU Limits Memory Requests Memory Limits Age cpuman cpumanager-mlrrz 1 (28%) 1 (28%) 1G (13%) 1G (13%) 27mcgroupsが正しく設定されていることを確認します。次のコマンドを実行して、pauseプロセスのプロセス ID (PID) を取得します。# oc debug node/perf-node.example.comsh-4.2# systemctl status | grep -B5 pause注記出力で複数の pause プロセスエントリーが返される場合は、正しい一時停止プロセスを特定する必要があります。
出力例
# ├─init.scope │ └─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 17 └─kubepods.slice ├─kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice │ ├─crio-b5437308f1a574c542bdf08563b865c0345c8f8c0b0a655612c.scope │ └─32706 /pause次のコマンドを実行して、サービス品質 (QoS) 層 (
Guaranteed) の Pod がkubepods.sliceサブディレクトリー内に配置されていることを確認します。# cd /sys/fs/cgroup/kubepods.slice/kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice/crio-b5437308f1ad1a7db0574c542bdf08563b865c0345c86e9585f8c0b0a655612c.scope# for i in `ls cpuset.cpus cgroup.procs` ; do echo -n "$i "; cat $i ; done注記他の QoS 階層の Pod は、親
kubepodsの子であるcgroupsに配置されます。出力例
cpuset.cpus 1 tasks 32706次のコマンドを実行して、タスクに許可されている CPU リストを確認します。
# grep ^Cpus_allowed_list /proc/32706/status出力例
Cpus_allowed_list: 1システム上の別の Pod が、
GuaranteedPod に割り当てられたコアで実行できないことを確認します。たとえば、besteffortQoS 階層の Pod を検証するには、次のコマンドを実行します。# cat /sys/fs/cgroup/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-podc494a073_6b77_11e9_98c0_06bba5c387ea.slice/crio-c56982f57b75a2420947f0afc6cafe7534c5734efc34157525fa9abbf99e3849.scope/cpuset.cpus# oc describe node perf-node.example.com出力例
... Capacity: attachable-volumes-aws-ebs: 39 cpu: 2 ephemeral-storage: 124768236Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 8162900Ki pods: 250 Allocatable: attachable-volumes-aws-ebs: 39 cpu: 1500m ephemeral-storage: 124768236Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 7548500Ki pods: 250 ------- ---- ------------ ---------- --------------- ------------- --- default cpumanager-6cqz7 1 (66%) 1 (66%) 1G (12%) 1G (12%) 29m Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 1440m (96%) 1 (66%)この仮想マシンには、2 つの CPU コアがあります。
system-reserved設定は 500 ミリコアを予約し、Node Allocatableの量になるようにノードの全容量からコアの半分を引きます。ここでAllocatable CPUは 1500 ミリコアであることを確認できます。これは、それぞれがコアを 1 つ受け入れるので、CPU マネージャー Pod の 1 つを実行できることを意味します。1 つのコア全体は 1000 ミリコアに相当します。2 つ目の Pod をスケジュールしようとする場合、システムは Pod を受け入れますが、これがスケジュールされることはありません。NAME READY STATUS RESTARTS AGE cpumanager-6cqz7 1/1 Running 0 33m cpumanager-7qc2t 0/1 Pending 0 11s
6.5. Huge Page
Huge Page を理解し、これを設定します。
6.5.1. Huge Page の機能
メモリーは Page と呼ばれるブロックで管理されます。多くのシステムでは、1 ページは 4Ki です。メモリー 1Mi は 256 ページに、メモリー 1Gi は 256,000 ページに相当します。CPU には、内蔵のメモリー管理ユニットがあり、ハードウェアでこのようなページリストを管理します。トランスレーションルックアサイドバッファー (TLB: Translation Lookaside Buffer) は、仮想から物理へのページマッピングの小規模なハードウェアキャッシュのことです。ハードウェアの指示で渡された仮想アドレスが TLB にあれば、マッピングをすばやく決定できます。そうでない場合には、TLB ミスが発生し、システムは速度が遅く、ソフトウェアベースのアドレス変換にフォールバックされ、パフォーマンスの問題が発生します。TLB のサイズは固定されているので、TLB ミスの発生率を減らすには Page サイズを大きくする必要があります。
Huge Page とは、4Ki より大きいメモリーページのことです。x86_64 アーキテクチャーでは、2Mi と 1Gi の 2 つが一般的な Huge Page サイズです。別のアーキテクチャーではサイズは異なります。Huge Page を使用するには、アプリケーションが認識できるようにコードを書き込む必要があります。Transparent Huge Page (THP) は、アプリケーションによる認識なしに、Huge Page の管理を自動化しようとしますが、制約があります。特に、ページサイズは 2Mi に制限されます。THP では、THP のデフラグが原因で、メモリー使用率が高くなり、断片化が起こり、パフォーマンスの低下につながり、メモリーページがロックされてしまう可能性があります。このような理由から、アプリケーションは THP ではなく、事前割り当て済みの Huge Page を使用するように設計 (また推奨) される場合があります。
6.5.2. Huge Page がアプリケーションによって消費される仕組み
ノードは、Huge Page の容量をレポートできるように Huge Page を事前に割り当てる必要があります。ノードは、単一サイズの Huge Page のみを事前に割り当てることができます。
Huge Page は、リソース名の hugepages-<size> を使用してコンテナーレベルのリソース要件で消費可能です。この場合、サイズは特定のノードでサポートされる整数値を使用した最もコンパクトなバイナリー表記です。たとえば、ノードが 2048KiB ページサイズをサポートする場合、これはスケジュール可能なリソース hugepages-2Mi を公開します。CPU やメモリーとは異なり、Huge Page はオーバーコミットをサポートしません。
apiVersion: v1
kind: Pod
metadata:
generateName: hugepages-volume-
spec:
containers:
- securityContext:
privileged: true
image: rhel7:latest
command:
- sleep
- inf
name: example
volumeMounts:
- mountPath: /dev/hugepages
name: hugepage
resources:
limits:
hugepages-2Mi: 100Mi
memory: "1Gi"
cpu: "1"
volumes:
- name: hugepage
emptyDir:
medium: HugePages- 1
hugepagesのメモリー量は、実際に割り当てる量に指定します。この値は、ページサイズで乗算したhugepagesのメモリー量に指定しないでください。たとえば、Huge Page サイズが 2MB と仮定し、アプリケーションに Huge Page でバックアップする RAM 100 MB を使用する場合には、Huge Page は 50 に指定します。OpenShift Container Platform により、計算処理が実行されます。上記の例にあるように、100MBを直接指定できます。
指定されたサイズの Huge Page の割り当て
プラットフォームによっては、複数の Huge Page サイズをサポートするものもあります。特定のサイズの Huge Page を割り当てるには、Huge Page の起動コマンドパラメーターの前に、Huge Page サイズの選択パラメーター hugepagesz=<size> を指定してください。<size> の値は、バイトで指定する必要があります。その際、オプションでスケール接尾辞 [kKmMgG] を指定できます。デフォルトの Huge Page サイズは、default_hugepagesz=<size> の起動パラメーターで定義できます。
Huge page の要件
- Huge Page 要求は制限と同じでなければなりません。制限が指定されているにもかかわらず、要求が指定されていない場合には、これがデフォルトになります。
- Huge Page は、Pod のスコープで分割されます。コンテナーの分割は、今後のバージョンで予定されています。
-
Huge Page がサポートする
EmptyDirボリュームは、Pod 要求よりも多くの Huge Page メモリーを消費することはできません。 -
shmget()でSHM_HUGETLBを使用して Huge Page を消費するアプリケーションは、proc/sys/vm/hugetlb_shm_group に一致する補助グループで実行する必要があります。
6.5.3. 起動時の Huge Page 設定
ノードは、OpenShift Container Platform クラスターで使用される Huge Page を事前に割り当てる必要があります。Huge Page を予約する方法は、ブート時とランタイム時に実行する 2 つの方法があります。ブート時の予約は、メモリーが大幅に断片化されていないために成功する可能性が高くなります。Node Tuning Operator は、現時点で特定のノードでの Huge Page のブート時の割り当てをサポートします。
手順
ノードの再起動を最小限にするには、以下の手順の順序に従う必要があります。
ラベルを使用して同じ Huge Page 設定を必要とするすべてのノードにラベルを付けます。
$ oc label node <node_using_hugepages> node-role.kubernetes.io/worker-hp=以下の内容でファイルを作成し、これに
hugepages-tuned-boottime.yamlという名前を付けます。apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: hugepages1 namespace: openshift-cluster-node-tuning-operator spec: profile:2 - data: | [main] summary=Boot time configuration for hugepages include=openshift-node [bootloader] cmdline_openshift_node_hugepages=hugepagesz=2M hugepages=503 name: openshift-node-hugepages recommend: - machineConfigLabels:4 machineconfiguration.openshift.io/role: "worker-hp" priority: 30 profile: openshift-node-hugepagesチューニングされた
hugepagesオブジェクトの作成$ oc create -f hugepages-tuned-boottime.yaml以下の内容でファイルを作成し、これに
hugepages-mcp.yamlという名前を付けます。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: worker-hp labels: worker-hp: "" spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,worker-hp]} nodeSelector: matchLabels: node-role.kubernetes.io/worker-hp: ""マシン設定プールを作成します。
$ oc create -f hugepages-mcp.yaml
断片化されていないメモリーが十分にある場合、worker-hp マシン設定プールのすべてのノードには 50 2Mi の Huge Page が割り当てられているはずです。
$ oc get node <node_using_hugepages> -o jsonpath="{.status.allocatable.hugepages-2Mi}"
100MiTuneD ブートローダープラグインは、Red Hat Enterprise Linux CoreOS (RHCOS) ワーカーノードのみサポートします。
6.6. デバイスプラグインについて
デバイスプラグインは、クラスター間でハードウェアデバイスを使用する際の一貫した移植可能なソリューションを提供します。デバイスプラグインは、拡張メカニズムを通じてこれらのデバイスをサポートし (これにより、コンテナーがこれらのデバイスを利用できるようになります)、デバイスのヘルスチェックを実施し、それらを安全に共有します。
OpenShift Container Platform はデバイスのプラグイン API をサポートしますが、デバイスプラグインコンテナーは個別のベンダーによりサポートされます。
デバイスプラグインは、特定のハードウェアリソースの管理を行う、ノード上で実行される gRPC サービスです (kubelet の外部にあります)。デバイスプラグインは以下のリモートプロシージャーコール (RPC) をサポートしている必要があります。
service DevicePlugin {
// GetDevicePluginOptions returns options to be communicated with Device
// Manager
rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {}
// ListAndWatch returns a stream of List of Devices
// Whenever a Device state change or a Device disappears, ListAndWatch
// returns the new list
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// Allocate is called during container creation so that the Device
// Plug-in can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
// PreStartcontainer is called, if indicated by Device Plug-in during
// registration phase, before each container start. Device plug-in
// can run device specific operations such as resetting the device
// before making devices available to the container
rpc PreStartcontainer(PreStartcontainerRequest) returns (PreStartcontainerResponse) {}
}6.6.1. デバイスプラグインの例
デバイスプラグイン参照の実装を容易にするために、vendor/k8s.io/kubernetes/pkg/kubelet/cm/deviceplugin/device_plugin_stub.go という Device Manager コードのスタブデバイスプラグインを使用できます。
6.6.2. デバイスプラグインのデプロイ方法
- デーモンセットは、デバイスプラグインのデプロイメントに推奨される方法です。
- 起動時にデバイスプラグインは、Device Manager から RPC を送信するためにノードの /var/lib/kubelet/device-plugin/ での UNIX ドメインソケットの作成を試行します。
- デバイスプラグインは、ソケットの作成のほかにもハードウェアリソース、ホストファイルシステムへのアクセスを管理する必要があるため、特権付きセキュリティーコンテキストで実行される必要があります。
- デプロイメント手順の詳細は、それぞれのデバイスプラグインの実装で確認できます。
6.6.3. Device Manager について
Device Manager は、特殊なノードのハードウェアリソースを、デバイスプラグインとして知られるプラグインを使用して公開するメカニズムを提供します。
特殊なハードウェアは、アップストリームのコード変更なしに公開できます。
OpenShift Container Platform はデバイスのプラグイン API をサポートしますが、デバイスプラグインコンテナーは個別のベンダーによりサポートされます。
Device Manager はデバイスを 拡張リソース として公開します。ユーザー Pod は、他の 拡張リソース を要求するために使用されるのと同じ 制限/要求 メカニズムを使用して Device Manager で公開されるデバイスを消費できます。
使用開始時に、デバイスプラグインは /var/lib/kubelet/device-plugins/kubelet.sock の Register を起動して Device Manager に自己登録し、Device Manager の要求を提供するために /var/lib/kubelet/device-plugins/<plugin>.sock で gRPC サービスを起動します。
Device Manager は、新規登録要求の処理時にデバイスプラグインサービスで ListAndWatch リモートプロシージャーコール (RPC) を起動します。応答として Device Manager は gRPC ストリームでプラグインから デバイス オブジェクトの一覧を取得します。Device Manager はプラグインからの新規の更新の有無についてストリームを監視します。プラグイン側では、プラグインはストリームを開いた状態にし、デバイスの状態に変更があった場合には常に新規デバイスの一覧が同じストリーム接続で Device Manager に送信されます。
新しい Pod の受付リクエストの処理中に、Kubelet が要求された Extended Resources をデバイス割り当てのためにデバイスマネージャーに渡します。Device Manager はそのデータベースにチェックインして対応するプラグインが存在するかどうかを確認します。プラグインが存在し、ローカルキャッシュと共に割り当て可能な空きデバイスがある場合、Allocate RPC がその特定デバイスのプラグインで起動します。
さらにデバイスプラグインは、ドライバーのインストール、デバイスの初期化、およびデバイスのリセットなどの他のいくつかのデバイス固有の操作も実行できます。これらの機能は実装ごとに異なります。
6.6.4. Device Manager の有効化
Device Manager を有効にし、デバイスプラグインを実装してアップストリームのコード変更なしに特殊なハードウェアを公開できるようにします。
Device Manager は、特殊なノードのハードウェアリソースを、デバイスプラグインとして知られるプラグインを使用して公開するメカニズムを提供します。
次のコマンドを入力して、設定するノードタイプの静的な
MachineConfigPoolCRD に関連付けられたラベルを取得します。以下のいずれかの手順を実行します。マシン設定を表示します。
# oc describe machineconfig <name>以下に例を示します。
# oc describe machineconfig 00-worker出力例
Name: 00-worker Namespace: Labels: machineconfiguration.openshift.io/role=worker1 - 1
- Device Manager に必要なラベル。
手順
設定変更のためのカスタムリソース (CR) を作成します。
Device Manager CR の設定例
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: devicemgr1 spec: machineConfigPoolSelector: matchLabels: machineconfiguration.openshift.io: devicemgr2 kubeletConfig: feature-gates: - DevicePlugins=true3 Device Manager を作成します。
$ oc create -f devicemgr.yaml出力例
kubeletconfig.machineconfiguration.openshift.io/devicemgr created- Device Manager が実際に有効にされるように、/var/lib/kubelet/device-plugins/kubelet.sock がノードで作成されていることを確認します。これは、Device Manager の gRPC サーバーが新規プラグインの登録がないかどうかリッスンする UNIX ドメインソケットです。このソケットファイルは、Device Manager が有効にされている場合にのみ Kubelet の起動時に作成されます。
6.7. taint および toleration
taint および toleration を理解し、これらを使用します。
6.7.1. taint および toleration について
taint により、ノードは Pod に一致する toleration がない場合に Pod のスケジュールを拒否することができます。
taint は Node 仕様 (NodeSpec) でノードに適用され、toleration は Pod 仕様 (PodSpec) で Pod に適用されます。taint をノードに適用する場合、スケジューラーは Pod が taint を容認しない限り、Pod をそのノードに配置することができません。
ノード仕様の taint の例
apiVersion: v1
kind: Node
metadata:
name: my-node
#...
spec:
taints:
- effect: NoExecute
key: key1
value: value1
#...Pod 仕様での toleration の例
apiVersion: v1
kind: Pod
metadata:
name: my-pod
#...
spec:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600
#...taint および toleration は、key、value、および effect で構成されます。
| パラメーター | 説明 | ||||||
|---|---|---|---|---|---|---|---|
|
|
| ||||||
|
|
| ||||||
|
| effect は以下のいずれかにすることができます。
| ||||||
|
|
|
NoScheduletaint をコントロールプレーンノードに追加すると、ノードには、デフォルトで追加されるnode-role.kubernetes.io/master=:NoScheduletaint が必要です。以下に例を示します。
apiVersion: v1 kind: Node metadata: annotations: machine.openshift.io/machine: openshift-machine-api/ci-ln-62s7gtb-f76d1-v8jxv-master-0 machineconfiguration.openshift.io/currentConfig: rendered-master-cdc1ab7da414629332cc4c3926e6e59c name: my-node #... spec: taints: - effect: NoSchedule key: node-role.kubernetes.io/master #...
toleration は taint と一致します。
operatorパラメーターがEqualに設定されている場合:-
keyパラメーターが同じである。 -
valueパラメーターが同じである。 -
effectパラメーターが同じである。
-
operatorパラメーターがExistsに設定されている場合:-
keyパラメーターが同じである。 -
effectパラメーターが同じである。
-
以下の taint は OpenShift Container Platform に組み込まれています。
-
node.kubernetes.io/not-ready: ノードは準備状態にありません。これはノード条件Ready=Falseに対応します。 -
node.kubernetes.io/unreachable: ノードはノードコントローラーから到達不能です。これはノード条件Ready=Unknownに対応します。 -
node.kubernetes.io/memory-pressure: ノードにはメモリー不足の問題が発生しています。これはノード条件MemoryPressure=Trueに対応します。 -
node.kubernetes.io/disk-pressure: ノードにはディスク不足の問題が発生しています。これはノード条件DiskPressure=Trueに対応します。 -
node.kubernetes.io/network-unavailable: ノードのネットワークは使用できません。 -
node.kubernetes.io/unschedulable: ノードはスケジュールが行えません。 -
node.cloudprovider.kubernetes.io/uninitialized: ノードコントローラーが外部のクラウドプロバイダーを使用して起動すると、この taint はノード上に設定され、使用不可能とマークされます。cloud-controller-manager のコントローラーがこのノードを初期化した後に、kubelet がこの taint を削除します。 node.kubernetes.io/pid-pressure: ノードが pid 不足の状態です。これはノード条件PIDPressure=Trueに対応します。重要OpenShift Container Platform では、デフォルトの pid.available
evictionHardは設定されません。
6.7.2. taint および toleration の追加
toleration を Pod に、taint をノードに追加することで、ノードはノード上でスケジュールする必要のある (またはスケジュールすべきでない) Pod を制御できます。既存の Pod およびノードの場合、最初に toleration を Pod に追加してから taint をノードに追加して、toleration を追加する前に Pod がノードから削除されないようにする必要があります。
手順
Pod仕様をtolerationsスタンザを含めるように編集して、toleration を Pod に追加します。Equal 演算子を含む Pod 設定ファイルのサンプル
apiVersion: v1 kind: Pod metadata: name: my-pod #... spec: tolerations: - key: "key1"1 value: "value1" operator: "Equal" effect: "NoExecute" tolerationSeconds: 36002 #...以下に例を示します。
Exists 演算子を含む Pod 設定ファイルのサンプル
apiVersion: v1 kind: Pod metadata: name: my-pod #... spec: tolerations: - key: "key1" operator: "Exists"1 effect: "NoExecute" tolerationSeconds: 3600 #...- 1
ExistsOperator はvalueを取りません。
この例では、taint を、キー
key1、値value1、および taint effectNoExecuteを持つnode1に taint を配置します。taint および toleration コンポーネント の表で説明されているパラメーターと共に以下のコマンドを使用して taint をノードに追加します。
$ oc adm taint nodes <node_name> <key>=<value>:<effect>以下に例を示します。
$ oc adm taint nodes node1 key1=value1:NoExecuteこのコマンドは、キー
key1、値value1、および effectNoExecuteを持つ taint をnode1に配置します。注記NoScheduletaint をコントロールプレーンノードに追加すると、ノードには、デフォルトで追加されるnode-role.kubernetes.io/master=:NoScheduletaint が必要です。以下に例を示します。
apiVersion: v1 kind: Node metadata: annotations: machine.openshift.io/machine: openshift-machine-api/ci-ln-62s7gtb-f76d1-v8jxv-master-0 machineconfiguration.openshift.io/currentConfig: rendered-master-cdc1ab7da414629332cc4c3926e6e59c name: my-node #... spec: taints: - effect: NoSchedule key: node-role.kubernetes.io/master #...Pod の toleration はノードの taint に一致します。いずれかの toleration のある Pod は
node1にスケジュールできます。
6.7.3. コンピュートマシンセットを使用した taint および toleration の追加
コンピュートマシンセットを使用して taint をノードに追加できます。MachineSet オブジェクトに関連付けられるすべてのノードが taint で更新されます。toleration は、ノードに直接追加された taint と同様に、コンピュートマシンセットによって追加される taint に応答します。
手順
Pod仕様をtolerationsスタンザを含めるように編集して、toleration を Pod に追加します。Equal演算子を含む Pod 設定ファイルのサンプルapiVersion: v1 kind: Pod metadata: name: my-pod #... spec: tolerations: - key: "key1"1 value: "value1" operator: "Equal" effect: "NoExecute" tolerationSeconds: 36002 #...以下に例を示します。
Exists演算子を含む Pod 設定ファイルのサンプルapiVersion: v1 kind: Pod metadata: name: my-pod #... spec: tolerations: - key: "key1" operator: "Exists" effect: "NoExecute" tolerationSeconds: 3600 #...taint を
MachineSetオブジェクトに追加します。taint を付けるノードの
MachineSetYAML を編集するか、新規MachineSetオブジェクトを作成できます。$ oc edit machineset <machineset>taint を
spec.template.specセクションに追加します。コンピュートマシンセット仕様の taint の例
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: my-machineset #... spec: #... template: #... spec: taints: - effect: NoExecute key: key1 value: value1 #...この例では、キー
key1、値value1、および taint effectNoExecuteを持つ taint をノードに配置します。コンピュートマシンセットを 0 にスケールダウンします。
$ oc scale --replicas=0 machineset <machineset> -n openshift-machine-apiヒントまたは、以下の YAML を適用してコンピュートマシンセットをスケーリングすることもできます。
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: replicas: 0マシンが削除されるまで待機します。
コンピュートマシンセットを随時スケールアップします。
$ oc scale --replicas=2 machineset <machineset> -n openshift-machine-apiまたは、以下を実行します。
$ oc edit machineset <machineset> -n openshift-machine-apiマシンが起動するまで待ちます。taint は
MachineSetオブジェクトに関連付けられたノードに追加されます。
6.7.4. taint および toleration 使用してユーザーをノードにバインドする
ノードのセットを特定のユーザーセットによる排他的な使用のために割り当てる必要がある場合、toleration をそれらの Pod に追加します。次に、対応する taint をそれらのノードに追加します。toleration が設定された Pod は、taint が付けられたノードまたはクラスター内の他のノードを使用できます。
Pod が taint が付けられたノードのみにスケジュールされるようにするには、ラベルを同じノードセットに追加し、ノードのアフィニティーを Pod に追加し、Pod がそのラベルの付いたノードのみにスケジュールできるようにします。
手順
ノードをユーザーの使用可能な唯一のノードとして設定するには、以下を実行します。
対応する taint をそれらのノードに追加します。
以下に例を示します。
$ oc adm taint nodes node1 dedicated=groupName:NoScheduleヒントまたは、以下の YAML を適用して taint を追加できます。
kind: Node apiVersion: v1 metadata: name: my-node #... spec: taints: - key: dedicated value: groupName effect: NoSchedule #...- カスタム受付コントローラーを作成して toleration を Pod に追加します。
6.7.5. taint および toleration を使用して特殊ハードウェアを持つノードを制御する
ノードの小規模なサブセットが特殊ハードウェアを持つクラスターでは、taint および toleration を使用して、特殊ハードウェアを必要としない Pod をそれらのノードから切り離し、特殊ハードウェアを必要とする Pod をそのままにすることができます。また、特殊ハードウェアを必要とする Pod に対して特定のノードを使用することを要求することもできます。
これは、特殊ハードウェアを必要とする Pod に toleration を追加し、特殊ハードウェアを持つノードに taint を付けることで実行できます。
手順
特殊ハードウェアを持つノードが特定の Pod 用に予約されるようにするには、以下を実行します。
toleration を特別なハードウェアを必要とする Pod に追加します。
以下に例を示します。
apiVersion: v1 kind: Pod metadata: name: my-pod #... spec: tolerations: - key: "disktype" value: "ssd" operator: "Equal" effect: "NoSchedule" tolerationSeconds: 3600 #...以下のコマンドのいずれかを使用して、特殊ハードウェアを持つノードに taint を設定します。
$ oc adm taint nodes <node-name> disktype=ssd:NoScheduleまたは、以下を実行します。
$ oc adm taint nodes <node-name> disktype=ssd:PreferNoScheduleヒントまたは、以下の YAML を適用して taint を追加できます。
kind: Node apiVersion: v1 metadata: name: my_node #... spec: taints: - key: disktype value: ssd effect: PreferNoSchedule #...
6.7.6. taint および toleration の削除
必要に応じてノードから taint を、Pod から toleration をそれぞれ削除できます。最初に toleration を Pod に追加してから taint をノードに追加して、toleration を追加する前に Pod がノードから削除されないようにする必要があります。
手順
taint および toleration を削除するには、以下を実行します。
ノードから taint を削除するには、以下を実行します。
$ oc adm taint nodes <node-name> <key>-以下に例を示します。
$ oc adm taint nodes ip-10-0-132-248.ec2.internal key1-出力例
node/ip-10-0-132-248.ec2.internal untaintedPod から toleration を削除するには、toleration を削除するための
Pod仕様を編集します。apiVersion: v1 kind: Pod metadata: name: my-pod #... spec: tolerations: - key: "key2" operator: "Exists" effect: "NoExecute" tolerationSeconds: 3600 #...
6.8. Topology Manager
Topology Manager を理解し、これを使用します。
6.8.1. Topology Manager ポリシー
Topology Manager は、CPU マネージャーや Device Manager などの Hint Provider からトポロジーのヒントを収集し、収集したヒントを使用して Pod リソースを調整することで、すべての Quality of Service (QoS) クラスの Pod リソースを調整します。
Topology Manager は 4 つの割り当てポリシーをサポートしています。これらのポリシーは、cpumanager-enabled という名前の KubeletConfig カスタムリソース (CR) で指定します。
noneポリシー- これはデフォルトのポリシーで、トポロジーの配置は実行しません。
best-effortポリシー-
best-effortトポロジー管理ポリシーが設定された Pod 内の各コンテナーに対して、kubelet が、そのコンテナーの優先される NUMA ノードアフィニティーに従って、必要なすべてのリソースを NUMA ノードに配置しようと試みます。リソース不足のために割り当てが不可能な場合でも、Topology Manager は Pod を許可しますが、その割り当ては他の NUMA ノードと共有されます。 restrictedポリシー-
restrictedトポロジー管理ポリシーが設定された Pod 内の各コンテナーに対して、kubelet が、要求を満たすことができる NUMA ノードの理論上の最小数を決定します。その数を超える NUMA ノード数が実際の割り当てに必要な場合、Topology Manager は許可を拒否し、Pod をTerminated状態にします。NUMA ノード数が要求を満たすことができる場合、Topology Manager は Pod を許可し、Pod は実行を開始します。 single-numa-nodeポリシー-
single-numa-nodeトポロジー管理ポリシーが設定された Pod 内の各コンテナーに対して、kubelet が、Pod に必要なすべてのリソースを同じ NUMA ノードに割り当てることができる場合に Pod を許可します。リソースを単一の NUMA ノードに割り当てることが不可能な場合、Topology Manager はノードから Pod を拒否します。その結果、Pod は受付の失敗によりTerminated状態になります。
6.8.2. Topology Manager のセットアップ
Topology Manager を使用するには、cpumanager-enabled という名前の KubeletConfig カスタムリソース (CR) で割り当てポリシーを設定する必要があります。CPU マネージャーをセットアップしている場合は、このファイルが存在している可能性があります。ファイルが存在しない場合は、作成できます。
前提条件
-
CPU マネージャーのポリシーを
staticに設定します。
手順
Topology Manager をアクティブにするには、以下を実行します。
カスタムリソースで Topology Manager 割り当てポリシーを設定します。
$ oc edit KubeletConfig cpumanager-enabledapiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cpumanager-enabled spec: machineConfigPoolSelector: matchLabels: custom-kubelet: cpumanager-enabled kubeletConfig: cpuManagerPolicy: static1 cpuManagerReconcilePeriod: 5s topologyManagerPolicy: single-numa-node2
6.8.3. Pod と Topology Manager ポリシーのやり取り
次の Pod 仕様の例は、Topology Manager と Pod のやり取りを示しています。
以下の Pod は、リソース要求や制限が指定されていないために BestEffort QoS クラスで実行されます。
spec:
containers:
- name: nginx
image: nginx
以下の Pod は、要求が制限よりも小さいために Burstable QoS クラスで実行されます。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
選択したポリシーが none 以外の場合、Topology Manager はすべての Pod を処理し、Guaranteed Qos Pod 仕様に対してのみリソースの配置を適用します。Topology Manager ポリシーが none に設定されている場合、該当するコンテナーが NUMA アフィニティーを考慮せずに使用可能な CPU にピニングされます。これはデフォルトの動作であり、パフォーマンスが重要なワークロードに最適なものではありません。それ以外の値を設定すると、デバイスプラグインのコアリソース (CPU やメモリーなど) からのトポロジー認識情報が使用可能になります。ポリシーが none 以外の値に設定されている場合、Topology Manager はノードのトポロジーに従って、CPU、メモリー、およびデバイスの割り当ての調整を試みます。使用可能な値の詳細は、Topology Manager ポリシー を参照してください。
次の Pod の例は、要求が制限と等しいため、Guaranteed QoS クラスで実行されます。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"Topology Manager はこの Pod を考慮します。Topology Manager は、CPU Manager、Device Manager、Memory Manager などの Hint Provider を参照して、Pod のトポロジーヒントを取得します。
Topology Manager はこの情報を使用して、このコンテナーに最適なトポロジーを保管します。この Pod の場合、CPU マネージャーおよび Device Manager は、リソース割り当ての段階でこの保存された情報を使用します。
6.9. リソース要求とオーバーコミット
各コンピュートリソースについて、コンテナーはリソース要求および制限を指定できます。スケジューリングの決定は要求に基づいて行われ、ノードに要求される値を満たす十分な容量があることが確認されます。コンテナーが制限を指定するものの、要求を省略する場合、要求はデフォルトで制限値に設定されます。コンテナーは、ノードの指定される制限を超えることはできません。
制限の実施方法は、コンピュートリソースのタイプによって異なります。コンテナーが要求または制限を指定しない場合、コンテナーはリソース保証のない状態でノードにスケジュールされます。実際に、コンテナーはローカルの最も低い優先順位で利用できる指定リソースを消費できます。リソースが不足する状態では、リソース要求を指定しないコンテナーに最低レベルの quality of service が設定されます。
スケジューリングは要求されるリソースに基づいて行われる一方で、クォータおよびハード制限はリソース制限のことを指しており、これは要求されるリソースよりも高い値に設定できます。要求と制限の差によってオーバーコミットのレベルが決まります。たとえば、コンテナーに 1 Gi のメモリー要求と 2 Gi のメモリー制限が指定されている場合、そのコンテナーは、ノードで利用可能な 1 Gi の要求に基づいてスケジュールされますが、最大 2 Gi まで使用できます。そのため、この場合は 100% オーバーコミットされます。
6.10. Cluster Resource Override Operator を使用したクラスターレベルのオーバーコミット
Cluster Resource Override Operator は、クラスター内のすべてのノードでオーバーコミットのレベルを制御し、コンテナーの密度を管理できる受付 Webhook です。Operator は、特定のプロジェクトのノードが定義されたメモリーおよび CPU 制限を超える場合に制御します。
Operator は、開発者コンテナーに設定されている要求と制限の比率を変更します。制限とデフォルトを指定するプロジェクトごとの制限範囲と組み合わせることで、必要なレベルのオーバーコミットを実現できます。
次のセクションに示すように、OpenShift Container Platform コンソールまたは CLI を使用して、Cluster Resource Override Operator をインストールする必要があります。Cluster Resource Override Operator をデプロイすると、この Operator が特定の namespace 内のすべての新しい Pod を変更します。この Operator は、Operator をデプロイする前に存在していた Pod は編集しません。
インストール時に、以下の例のように、オーバーコミットのレベルを設定する ClusterResourceOverride カスタムリソース (CR) を作成します。
apiVersion: operator.autoscaling.openshift.io/v1
kind: ClusterResourceOverride
metadata:
name: cluster
spec:
podResourceOverride:
spec:
memoryRequestToLimitPercent: 50
cpuRequestToLimitPercent: 25
limitCPUToMemoryPercent: 200
# ...- 1
- 名前は
clusterでなければなりません。 - 2
- オプション: コンテナーのメモリー制限が指定されているか、デフォルトに設定されている場合、メモリー要求は制限のパーセンテージ (1-100) に対して上書きされます。デフォルトは 50 です。
- 3
- オプション: コンテナーの CPU 制限が指定されているか、デフォルトに設定されている場合、CPU 要求は、1-100 までの制限のパーセンテージに対応して上書きされます。デフォルトは 25 です。
- 4
- オプション: コンテナーのメモリー制限が指定されているか、デフォルトに設定されている場合、CPU 制限は、指定されている場合にメモリーのパーセンテージに対して上書きされます。1Gi の RAM の 100 パーセントでのスケーリングは、1 CPU コアに等しくなります。これは、CPU 要求を上書きする前に処理されます (設定されている場合)。デフォルトは 200 です。
コンテナーに制限が設定されていない場合、Cluster Resource Override Operator のオーバーライドは効果がありません。個別プロジェクトごとのデフォルト制限を使用して LimitRange オブジェクトを作成するか、Pod 仕様で制限を設定し、上書きが適用されるようにします。
設定したら、オーバーライドを適用する各プロジェクトの Namespace オブジェクトに次のラベルを適用することで、プロジェクトごとにオーバーライドを有効にできます。たとえば、インフラストラクチャーコンポーネントがオーバーライドの対象にならないようにオーバーライドを設定できます。
apiVersion: v1
kind: Namespace
metadata:
# ...
labels:
clusterresourceoverrides.admission.autoscaling.openshift.io/enabled: "true"
# ...
Operator は ClusterResourceOverride CR の有無を監視し、ClusterResourceOverride 受付 Webhook が Operator と同じ namespace にインストールされるようにします。
たとえば、Pod に次のリソース制限があるとします。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
namespace: my-namespace
# ...
spec:
containers:
- name: hello-openshift
image: openshift/hello-openshift
resources:
limits:
memory: "512Mi"
cpu: "2000m"
# ...
Cluster Resource Override Operator は、元の Pod 要求をインターセプトし、ClusterResourceOverride オブジェクトに設定された設定に従ってリソースをオーバーライドします。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
namespace: my-namespace
# ...
spec:
containers:
- image: openshift/hello-openshift
name: hello-openshift
resources:
limits:
cpu: "1"
memory: 512Mi
requests:
cpu: 250m
memory: 256Mi
# ...6.10.1. Web コンソールを使用した Cluster Resource Override Operator のインストール
クラスターでオーバーコミットを制御できるように、OpenShift Container Platform Web コンソールを使用して Cluster Resource Override Operator をインストールできます。
前提条件
-
制限がコンテナーに設定されていない場合、Cluster Resource Override Operator は影響を与えません。
LimitRangeオブジェクトを使用してプロジェクトのデフォルト制限を指定するか、Pod仕様で制限を設定して上書きが適用されるようにする必要があります。
手順
OpenShift Container Platform Web コンソールを使用して Cluster Resource Override Operator をインストールするには、以下を実行します。
OpenShift Container Platform Web コンソールで、Home → Projects に移動します。
- Create Project をクリックします。
-
clusterresourceoverride-operatorをプロジェクトの名前として指定します。 - Create をクリックします。
Operators → OperatorHub に移動します。
- 利用可能な Operator のリストから ClusterResourceOverride Operator を選択し、Install をクリックします。
- Install Operator ページで、A specific Namespace on the cluster が Installation Mode に選択されていることを確認します。
- clusterresourceoverride-operator が Installed Namespace に選択されていることを確認します。
- Update Channel および Approval Strategy を選択します。
- Install をクリックします。
Installed Operators ページで、ClusterResourceOverride をクリックします。
- ClusterResourceOverride Operator 詳細ページで、Create ClusterResourceOverride をクリックします。
Create ClusterResourceOverride ページで、YAML view をクリックして、YAML テンプレートを編集し、必要に応じてオーバーコミット値を設定します。
apiVersion: operator.autoscaling.openshift.io/v1 kind: ClusterResourceOverride metadata: name: cluster1 spec: podResourceOverride: spec: memoryRequestToLimitPercent: 502 cpuRequestToLimitPercent: 253 limitCPUToMemoryPercent: 2004 # ...- 1
- 名前は
clusterでなければなりません。 - 2
- オプション: コンテナーメモリーの制限を上書きするためのパーセンテージが使用される場合は、これを 1-100 までの値で指定します。デフォルトは 50 です。
- 3
- オプション: コンテナー CPU の制限を上書きするためのパーセンテージが使用される場合は、これを 1-100 までの値で指定します。デフォルトは 25 です。
- 4
- オプション: コンテナーメモリーの制限を上書きするためのパーセンテージが使用される場合は、これを指定します。1Gi の RAM の 100 パーセントでのスケーリングは、1 CPU コアに等しくなります。これは、CPU 要求を上書きする前に処理されます (設定されている場合)。デフォルトは 200 です。
- Create をクリックします。
クラスターカスタムリソースのステータスをチェックして、受付 Webhook の現在の状態を確認します。
- ClusterResourceOverride Operator ページで、cluster をクリックします。
ClusterResourceOverride Details ページで、YAML をクリックします。Webhook の呼び出し時に、
mutatingWebhookConfigurationRefセクションが表示されます。apiVersion: operator.autoscaling.openshift.io/v1 kind: ClusterResourceOverride metadata: annotations: kubectl.kubernetes.io/last-applied-configuration: | {"apiVersion":"operator.autoscaling.openshift.io/v1","kind":"ClusterResourceOverride","metadata":{"annotations":{},"name":"cluster"},"spec":{"podResourceOverride":{"spec":{"cpuRequestToLimitPercent":25,"limitCPUToMemoryPercent":200,"memoryRequestToLimitPercent":50}}}} creationTimestamp: "2019-12-18T22:35:02Z" generation: 1 name: cluster resourceVersion: "127622" selfLink: /apis/operator.autoscaling.openshift.io/v1/clusterresourceoverrides/cluster uid: 978fc959-1717-4bd1-97d0-ae00ee111e8d spec: podResourceOverride: spec: cpuRequestToLimitPercent: 25 limitCPUToMemoryPercent: 200 memoryRequestToLimitPercent: 50 status: # ... mutatingWebhookConfigurationRef:1 apiVersion: admissionregistration.k8s.io/v1 kind: MutatingWebhookConfiguration name: clusterresourceoverrides.admission.autoscaling.openshift.io resourceVersion: "127621" uid: 98b3b8ae-d5ce-462b-8ab5-a729ea8f38f3 # ...- 1
ClusterResourceOverride受付 Webhook への参照。
6.10.2. CLI を使用した Cluster Resource Override Operator のインストール
OpenShift Container Platform CLI を使用して Cluster Resource Override Operator をインストールし、クラスターでのオーバーコミットを制御できます。
前提条件
-
制限がコンテナーに設定されていない場合、Cluster Resource Override Operator は影響を与えません。
LimitRangeオブジェクトを使用してプロジェクトのデフォルト制限を指定するか、Pod仕様で制限を設定して上書きが適用されるようにする必要があります。
手順
CLI を使用して Cluster Resource Override Operator をインストールするには、以下を実行します。
Cluster Resource Override の namespace を作成します。
Cluster Resource Override Operator の
Namespaceオブジェクト YAML ファイル (cro-namespace.yamlなど) を作成します。apiVersion: v1 kind: Namespace metadata: name: clusterresourceoverride-operatornamespace を作成します。
$ oc create -f <file-name>.yaml以下に例を示します。
$ oc create -f cro-namespace.yaml
Operator グループを作成します。
Cluster Resource Override Operator の
OperatorGroupオブジェクトの YAML ファイル (cro-og.yaml など) を作成します。apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: clusterresourceoverride-operator namespace: clusterresourceoverride-operator spec: targetNamespaces: - clusterresourceoverride-operatorOperator グループを作成します。
$ oc create -f <file-name>.yaml以下に例を示します。
$ oc create -f cro-og.yaml
サブスクリプションを作成します。
Cluster Resource Override Operator の
Subscriptionオブジェクト YAML ファイル (cro-sub.yaml など) を作成します。apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: clusterresourceoverride namespace: clusterresourceoverride-operator spec: channel: "stable" name: clusterresourceoverride source: redhat-operators sourceNamespace: openshift-marketplaceサブスクリプションを作成します。
$ oc create -f <file-name>.yaml以下に例を示します。
$ oc create -f cro-sub.yaml
ClusterResourceOverrideカスタムリソース (CR) オブジェクトをclusterresourceoverride-operatornamespace に作成します。clusterresourceoverride-operatornamespace に切り替えます。$ oc project clusterresourceoverride-operatorCluster Resource Override Operator の
ClusterResourceOverrideオブジェクト YAML ファイル (cro-cr.yaml など) を作成します。apiVersion: operator.autoscaling.openshift.io/v1 kind: ClusterResourceOverride metadata: name: cluster1 spec: podResourceOverride: spec: memoryRequestToLimitPercent: 502 cpuRequestToLimitPercent: 253 limitCPUToMemoryPercent: 2004 - 1
- 名前は
clusterでなければなりません。 - 2
- オプション: コンテナーメモリーの制限を上書きするためのパーセンテージが使用される場合は、これを 1-100 までの値で指定します。デフォルトは 50 です。
- 3
- オプション: コンテナー CPU の制限を上書きするためのパーセンテージが使用される場合は、これを 1-100 までの値で指定します。デフォルトは 25 です。
- 4
- オプション: コンテナーメモリーの制限を上書きするためのパーセンテージが使用される場合は、これを指定します。1Gi の RAM の 100 パーセントでのスケーリングは、1 CPU コアに等しくなります。これは、CPU 要求を上書きする前に処理されます (設定されている場合)。デフォルトは 200 です。
ClusterResourceOverrideオブジェクトを作成します。$ oc create -f <file-name>.yaml以下に例を示します。
$ oc create -f cro-cr.yaml
クラスターカスタムリソースのステータスをチェックして、受付 Webhook の現在の状態を確認します。
$ oc get clusterresourceoverride cluster -n clusterresourceoverride-operator -o yamlWebhook の呼び出し時に、
mutatingWebhookConfigurationRefセクションが表示されます。出力例
apiVersion: operator.autoscaling.openshift.io/v1 kind: ClusterResourceOverride metadata: annotations: kubectl.kubernetes.io/last-applied-configuration: | {"apiVersion":"operator.autoscaling.openshift.io/v1","kind":"ClusterResourceOverride","metadata":{"annotations":{},"name":"cluster"},"spec":{"podResourceOverride":{"spec":{"cpuRequestToLimitPercent":25,"limitCPUToMemoryPercent":200,"memoryRequestToLimitPercent":50}}}} creationTimestamp: "2019-12-18T22:35:02Z" generation: 1 name: cluster resourceVersion: "127622" selfLink: /apis/operator.autoscaling.openshift.io/v1/clusterresourceoverrides/cluster uid: 978fc959-1717-4bd1-97d0-ae00ee111e8d spec: podResourceOverride: spec: cpuRequestToLimitPercent: 25 limitCPUToMemoryPercent: 200 memoryRequestToLimitPercent: 50 status: # ... mutatingWebhookConfigurationRef:1 apiVersion: admissionregistration.k8s.io/v1 kind: MutatingWebhookConfiguration name: clusterresourceoverrides.admission.autoscaling.openshift.io resourceVersion: "127621" uid: 98b3b8ae-d5ce-462b-8ab5-a729ea8f38f3 # ...- 1
ClusterResourceOverride受付 Webhook への参照。
6.10.3. クラスターレベルのオーバーコミットの設定
Cluster Resource Override Operator には、Operator がオーバーコミットを制御する必要のある各プロジェクトの ClusterResourceOverride カスタムリソース (CR) およびラベルが必要です。
前提条件
-
制限がコンテナーに設定されていない場合、Cluster Resource Override Operator は影響を与えません。
LimitRangeオブジェクトを使用してプロジェクトのデフォルト制限を指定するか、Pod仕様で制限を設定して上書きが適用されるようにする必要があります。
手順
クラスターレベルのオーバーコミットを変更するには、以下を実行します。
ClusterResourceOverrideCR を編集します。apiVersion: operator.autoscaling.openshift.io/v1 kind: ClusterResourceOverride metadata: name: cluster spec: podResourceOverride: spec: memoryRequestToLimitPercent: 501 cpuRequestToLimitPercent: 252 limitCPUToMemoryPercent: 2003 # ...- 1
- オプション: コンテナーメモリーの制限を上書きするためのパーセンテージが使用される場合は、これを 1-100 までの値で指定します。デフォルトは 50 です。
- 2
- オプション: コンテナー CPU の制限を上書きするためのパーセンテージが使用される場合は、これを 1-100 までの値で指定します。デフォルトは 25 です。
- 3
- オプション: コンテナーメモリーの制限を上書きするためのパーセンテージが使用される場合は、これを指定します。1Gi の RAM の 100 パーセントでのスケーリングは、1 CPU コアに等しくなります。これは、CPU 要求を上書きする前に処理されます (設定されている場合)。デフォルトは 200 です。
以下のラベルが Cluster Resource Override Operator がオーバーコミットを制御する必要のある各プロジェクトの namespace オブジェクトに追加されていることを確認します。
apiVersion: v1 kind: Namespace metadata: # ... labels: clusterresourceoverrides.admission.autoscaling.openshift.io/enabled: "true"1 # ...- 1
- このラベルを各プロジェクトに追加します。
6.11. ノードレベルのオーバーコミット
quality of service (QOS) 保証、CPU 制限、またはリソースの予約など、特定ノードでオーバーコミットを制御するさまざまな方法を使用できます。特定のノードおよび特定のプロジェクトのオーバーコミットを無効にすることもできます。
6.11.1. コンピュートリソースとコンテナーについて
コンピュートリソースに関するノードで実施される動作は、リソースタイプによって異なります。
6.11.1.1. コンテナーの CPU 要求について
コンテナーには要求する CPU の量が保証され、さらにコンテナーで指定される任意の制限までノードで利用可能な CPU を消費できます。複数のコンテナーが追加の CPU の使用を試行する場合、CPU 時間が各コンテナーで要求される CPU の量に基づいて分配されます。
たとえば、あるコンテナーが 500m の CPU 時間を要求し、別のコンテナーが 250m の CPU 時間を要求した場合、ノードで利用可能な追加の CPU 時間は 2:1 の比率でコンテナー間で分配されます。コンテナーが制限を指定している場合、指定した制限を超えて CPU を使用しないようにスロットリングされます。CPU 要求は、Linux カーネルの CFS 共有サポートを使用して適用されます。デフォルトで、CPU 制限は、Linux カーネルの CFS クォータサポートを使用して 100ms の測定間隔で適用されます。ただし、これは無効にすることができます。
6.11.1.2. コンテナーのメモリー要求について
コンテナーには要求するメモリー量が保証されます。コンテナーは要求したよりも多くのメモリーを使用できますが、いったん要求した量を超えた場合には、ノードのメモリーが不足している状態では強制終了される可能性があります。コンテナーが要求した量よりも少ないメモリーを使用する場合、システムタスクやデーモンがノードのリソース予約で確保されている分よりも多くのメモリーを必要としない限りそれが強制終了されることはありません。コンテナーがメモリーの制限を指定する場合、その制限量を超えると即時に強制終了されます。
6.11.2. オーバーコミットメントと quality of service クラスについて
ノードは、要求を指定しない Pod がスケジュールされている場合やノードのすべての Pod での制限の合計が利用可能なマシンの容量を超える場合に オーバーコミット されます。
オーバーコミットされる環境では、ノード上の Pod がいずれかの時点で利用可能なコンピュートリソースよりも多くの量の使用を試行することができます。これが生じると、ノードはそれぞれの Pod に優先順位を指定する必要があります。この決定を行うために使用される機能は、Quality of Service (QoS) クラスと呼ばれます。
Pod は、優先度の高い順に 3 つの QoS クラスの 1 つとして指定されます。
| 優先順位 | クラス名 | 説明 |
|---|---|---|
| 1 (最高) | Guaranteed | 制限およびオプションの要求がすべてのリソースに設定されている場合 (0 と等しくない) でそれらの値が等しい場合、Pod は Guaranteed として分類されます。 |
| 2 | Burstable | 制限およびオプションの要求がすべてのリソースに設定されている場合 (0 と等しくない) でそれらの値が等しくない場合、Pod は Burstable として分類されます。 |
| 3 (最低) | BestEffort | 要求および制限がリソースのいずれにも設定されない場合、Pod は BestEffort として分類されます。 |
メモリーは圧縮できないリソースであるため、メモリー不足の状態では、最も優先順位の低いコンテナーが最初に強制終了されます。
- Guaranteed コンテナーは優先順位が最も高いコンテナーとして見なされ、保証されます。強制終了されるのは、これらのコンテナーで制限を超えるか、システムがメモリー不足の状態にあるものの、退避できる優先順位の低いコンテナーが他にない場合のみです。
- システム不足の状態にある Burstable コンテナーは、制限を超過し、BestEffort コンテナーが他に存在しない場合に強制終了される可能性があります。
- BestEffort コンテナーは優先順位の最も低いコンテナーとして処理されます。これらのコンテナーのプロセスは、システムがメモリー不足になると最初に強制終了されます。
6.11.2.1. Quality of Service (QoS) 層でのメモリーの予約方法について
qos-reserved パラメーターを使用して、特定の QoS レベルの Pod で予約されるメモリーのパーセンテージを指定することができます。この機能は、最も低い OoS クラスの Pod が高い QoS クラスの Pod で要求されるリソースを使用できないようにするために要求されたリソースの予約を試行します。
OpenShift Container Platform は、以下のように qos-reserved パラメーターを使用します。
-
qos-reserved=memory=100%の値は、BurstableおよびBestEffortQoS クラスが、これらより高い QoS クラスで要求されたメモリーを消費するのを防ぎます。これにより、GuaranteedおよびBurstableワークロードのメモリーリソースの保証レベルを上げることが優先され、BestEffortおよびBurstableワークロードでの OOM が発生するリスクが高まります。 -
qos-reserved=memory=50%の値は、BurstableおよびBestEffortQoS クラスがこれらより高い QoS クラスによって要求されるメモリーの半分を消費することを許可します。 -
qos-reserved=memory=0%の値は、BurstableおよびBestEffortQoS クラスがノードの割り当て可能分を完全に消費することを許可しますが (利用可能な場合)、これにより、Guaranteedワークロードが要求したメモリーにアクセスできなくなるリスクが高まります。この状況により、この機能は無効にされています。
6.11.3. swap メモリーと QOS について
Quality of Service (QOS) 保証を維持するため、swap はノード上でデフォルトで無効にすることができます。そうしない場合、ノードの物理リソースがオーバーサブスクライブし、Pod の配置時の Kubernetes スケジューラーによるリソース保証が影響を受ける可能性があります。
たとえば、2 つの Guaranteed Pod がメモリー制限に達した場合、それぞれのコンテナーが swap メモリーを使用し始める可能性があります。十分な swap 領域がない場合には、pod のプロセスはシステムのオーバーサブスクライブのために終了する可能性があります。
swap を無効にしないと、ノードが MemoryPressure にあることを認識しなくなり、Pod がスケジューリング要求に対応するメモリーを受け取れなくなります。結果として、追加の Pod がノードに配置され、メモリー不足の状態が加速し、最終的にはシステムの Out Of Memory (OOM) イベントが発生するリスクが高まります。
swap が有効にされている場合、利用可能なメモリーに関するリソース不足の処理 (out-of-resource handling) のエビクションしきい値は予期どおりに機能しなくなります。メモリー不足の状態の場合に Pod をノードから退避し、Pod を不足状態にない別のノードで再スケジューリングできるようにリソース不足の処理 (out-of-resource handling) を利用できるようにします。
6.11.4. ノードのオーバーコミットについて
オーバーコミット環境では、最適なシステム動作を提供できるようにノードを適切に設定する必要があります。
ノードが起動すると、メモリー管理用のカーネルの調整可能なフラグが適切に設定されます。カーネルは、物理メモリーが不足しない限り、メモリーの割り当てに失敗するこはありません。
この動作を確認するため、OpenShift Container Platform は、vm.overcommit_memory パラメーターを 1 に設定し、デフォルトのオペレーティングシステムの設定を上書きすることで、常にメモリーをオーバーコミットするようにカーネルを設定します。
また、OpenShift Container Platform は vm.panic_on_oom パラメーターを 0 に設定することで、メモリーが不足したときでもカーネルがパニックにならないようにします。0 の設定は、Out of Memory (OOM) 状態のときに oom_killer を呼び出すようカーネルに指示します。これにより、優先順位に基づいてプロセスを強制終了します。
現在の設定は、ノードに以下のコマンドを実行して表示できます。
$ sysctl -a |grep commit出力例
#...
vm.overcommit_memory = 0
#...$ sysctl -a |grep panic出力例
#...
vm.panic_on_oom = 0
#...上記のフラグはノード上にすでに設定されているはずであるため、追加のアクションは不要です。
各ノードに対して以下の設定を実行することもできます。
- CPU CFS クォータを使用した CPU 制限の無効化または実行
- システムプロセスのリソース予約
- Quality of Service (QoS) 層でのメモリー予約
6.11.5. CPU CFS クォータの使用による CPU 制限の無効化または実行
デフォルトで、ノードは Linux カーネルの Completely Fair Scheduler (CFS) クォータのサポートを使用して、指定された CPU 制限を実行します。
CPU 制限の適用を無効にする場合、それがノードに与える影響を理解しておくことが重要になります。
- コンテナーに CPU 要求がある場合、これは Linux カーネルの CFS 共有によって引き続き適用されます。
- コンテナーに CPU 要求がなく、CPU 制限がある場合は、CPU 要求はデフォルトで指定される CPU 制限に設定され、Linux カーネルの CFS 共有によって適用されます。
- コンテナーに CPU 要求と制限の両方がある場合、CPU 要求は Linux カーネルの CFS 共有によって適用され、CPU 制限はノードに影響を与えません。
前提条件
次のコマンドを入力して、設定するノードタイプの静的な
MachineConfigPoolCRD に関連付けられたラベルを取得します。$ oc edit machineconfigpool <name>以下に例を示します。
$ oc edit machineconfigpool worker出力例
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: creationTimestamp: "2022-11-16T15:34:25Z" generation: 4 labels: pools.operator.machineconfiguration.openshift.io/worker: ""1 name: worker- 1
- Labels の下にラベルが表示されます。
ヒントラベルが存在しない場合は、次のようなキー/値のペアを追加します。
$ oc label machineconfigpool worker custom-kubelet=small-pods
手順
設定変更のためのカスタムリソース (CR) を作成します。
CPU 制限を無効化する設定例
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: disable-cpu-units1 spec: machineConfigPoolSelector: matchLabels: pools.operator.machineconfiguration.openshift.io/worker: ""2 kubeletConfig: cpuCfsQuota: false3 以下のコマンドを実行して CR を作成します。
$ oc create -f <file_name>.yaml
6.11.6. システムリソースのリソース予約
より信頼できるスケジューリングを実現し、ノードリソースのオーバーコミットメントを最小化するために、各ノードでは、クラスターが機能できるようノードで実行する必要のあるシステムデーモン用にそのリソースの一部を予約することができます。
メモリーなどの圧縮できないリソース用にリソースを予約することを推奨します。
手順
Pod 以外のプロセスのリソースを明示的に予約するには、スケジューリングで利用可能なリソースを指定することにより、ノードリソースを割り当てます。詳細は、ノードのリソースの割り当てを参照してください。
6.11.7. ノードのオーバーコミットの無効化
有効にされているオーバーコミットを、各ノードで無効にできます。
手順
ノード内のオーバーコミットを無効にするには、そのノード上で以下のコマンドを実行します。
$ sysctl -w vm.overcommit_memory=06.12. プロジェクトレベルの制限
オーバーコミットを制御するには、プロジェクトごとのリソース制限の範囲を設定し、オーバーコミットが超過できないプロジェクトのメモリーおよび CPU 制限およびデフォルト値を指定できます。
プロジェクトレベルのリソース制限の詳細は、関連情報を参照してください。
または、特定のプロジェクトのオーバーコミットを無効にすることもできます。
6.12.1. プロジェクトでのオーバーコミットメントの無効化
有効にされているオーバーコミットメントをプロジェクトごとに無効にすることができます。たとえば、インフラストラクチャーコンポーネントはオーバーコミットメントから独立して設定できます。
手順
- namespace オブジェクトファイルを作成または編集します。
以下のアノテーションを追加します。
apiVersion: v1 kind: Namespace metadata: annotations: quota.openshift.io/cluster-resource-override-enabled: "false" <.> # ...<.> このアノテーションを
falseに設定すると、この namespace のオーバーコミットが無効になります。
6.13. ガベージコレクションを使用しているノードリソースの解放
ガベージコレクションについて理解し、これを使用します。
6.13.1. 終了したコンテナーがガベージコレクションによって削除される仕組みについて
コンテナーのガベージコレクションは、エビクションしきい値を使用して、終了したコンテナーを削除します。
エビクションしきい値がガーベージコレクションに設定されていると、ノードは Pod のコンテナーが API から常にアクセス可能な状態になるよう試みます。Pod が削除された場合、コンテナーも削除されます。コンテナーは Pod が削除されず、エビクションしきい値に達していない限り保持されます。ノードがディスク不足 (disk pressure) の状態になっていると、コンテナーが削除され、それらのログは oc logs を使用してアクセスできなくなります。
- eviction-soft - ソフトエビクションのしきい値は、エビクションしきい値と要求される管理者指定の猶予期間を組み合わせます。
- eviction-hard - ハードエビクションのしきい値には猶予期間がなく、検知されると、OpenShift Container Platform はすぐにアクションを実行します。
以下の表は、エビクションしきい値のリストです。
| ノードの状態 | エビクションシグナル | 説明 |
|---|---|---|
| MemoryPressure |
| ノードで利用可能なメモリー。 |
| DiskPressure |
|
ノードのルートファイルシステム ( |
evictionHard の場合、これらのパラメーターをすべて指定する必要があります。すべてのパラメーターを指定しないと、指定したパラメーターのみが適用され、ガベージコレクションが正しく機能しません。
ノードがソフトエビクションしきい値の上限と下限の間で変動し、その関連する猶予期間を超えていない場合、対応するノードは、true と false の間で常に変動します。したがって、スケジューラーは適切なスケジュールを決定できない可能性があります。
この変動を防ぐには、evictionpressure-transition-period フラグを使用して、OpenShift Container Platform が不足状態から移行するまでにかかる時間を制御します。OpenShift Container Platform は、false 状態に切り替わる前の指定された期間に、エビクションしきい値を指定された不足状態に一致するように設定しません。
evictionPressureTransitionPeriod パラメーターを 0 に設定すると、デフォルト値の 5 分が設定されます。エビクション不足移行期間を 0 秒に設定することはできません。
6.13.2. イメージがガベージコレクションによって削除される仕組みについて
イメージガベージコレクションは、実行中の Pod によって参照されていないイメージを削除します。
OpenShift Container Platform は、cAdvisor によって報告されたディスク使用量に基づいて、ノードから削除するイメージを決定します。
イメージのガベージコレクションのポリシーは、以下の 2 つの条件に基づいています。
- イメージのガべージコレクションをトリガーするディスク使用量のパーセンテージ (整数で表される) です。デフォルトは 85 です。
- イメージのガべージコレクションが解放しようとするディスク使用量のパーセンテージ (整数で表される) です。デフォルトは 80 です。
イメージのガベージコレクションのために、カスタムリソースを使用して、次の変数のいずれかを変更することができます。
| 設定 | 説明 |
|---|---|
|
| ガベージコレクションによって削除されるまでの未使用のイメージの有効期間。デフォルトは、2m です。 |
|
|
イメージのガべージコレクションをトリガーするディスク使用量のパーセンテージ (整数で表される) です。デフォルトは 85 です。この値は |
|
|
イメージのガべージコレクションが解放しようとするディスク使用量のパーセンテージ (整数で表される) です。デフォルトは 80 です。この値は、 |
以下の 2 つのイメージリストがそれぞれのガベージコレクターの実行で取得されます。
- 1 つ以上の Pod で現在実行されているイメージのリスト
- ホストで利用可能なイメージのリスト
新規コンテナーの実行時に新規のイメージが表示されます。すべてのイメージにはタイムスタンプのマークが付けられます。イメージが実行中 (上記の最初の一覧) か、新規に検出されている (上記の 2 番目の一覧) 場合、これには現在の時間のマークが付けられます。残りのイメージには以前のタイムスタンプのマークがすでに付けられています。すべてのイメージはタイムスタンプで並び替えられます。
コレクションが開始されると、停止条件を満たすまでイメージが最も古いものから順番に削除されます。
6.13.3. コンテナーおよびイメージのガベージコレクションの設定
管理者は、kubeletConfig オブジェクトを各マシン設定プール用に作成し、OpenShift Container Platform によるガベージコレクションの実行方法を設定できます。
OpenShift Container Platform は、各マシン設定プールの kubeletConfig オブジェクトを 1 つのみサポートします。
次のいずれかの組み合わせを設定できます。
- コンテナーのソフトエビクション
- コンテナーのハードエビクション
- イメージのエビクション
コンテナーのガベージコレクションは終了したコンテナーを削除します。イメージガベージコレクションは、実行中の Pod によって参照されていないイメージを削除します。
前提条件
次のコマンドを入力して、設定するノードタイプの静的な
MachineConfigPoolCRD に関連付けられたラベルを取得します。$ oc edit machineconfigpool <name>以下に例を示します。
$ oc edit machineconfigpool worker出力例
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: creationTimestamp: "2022-11-16T15:34:25Z" generation: 4 labels: pools.operator.machineconfiguration.openshift.io/worker: ""1 name: worker #...- 1
- Labels の下にラベルが表示されます。
ヒントラベルが存在しない場合は、次のようなキー/値のペアを追加します。
$ oc label machineconfigpool worker custom-kubelet=small-pods
手順
設定変更のためのカスタムリソース (CR) を作成します。
重要ファイルシステムが 1 つの場合、または
/var/lib/kubeletと/var/lib/containers/が同じファイルシステムにある場合、最も大きな値の設定が満たされるとエビクションがトリガーされます。ファイルシステムはエビクションをトリガーします。コンテナーのガベージコレクション CR のサンプル設定
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: worker-kubeconfig1 spec: machineConfigPoolSelector: matchLabels: pools.operator.machineconfiguration.openshift.io/worker: ""2 kubeletConfig: evictionSoft:3 memory.available: "500Mi"4 nodefs.available: "10%" nodefs.inodesFree: "5%" imagefs.available: "15%" imagefs.inodesFree: "10%" evictionSoftGracePeriod:5 memory.available: "1m30s" nodefs.available: "1m30s" nodefs.inodesFree: "1m30s" imagefs.available: "1m30s" imagefs.inodesFree: "1m30s" evictionHard:6 memory.available: "200Mi" nodefs.available: "5%" nodefs.inodesFree: "4%" imagefs.available: "10%" imagefs.inodesFree: "5%" evictionPressureTransitionPeriod: 3m7 imageMinimumGCAge: 5m8 imageGCHighThresholdPercent: 809 imageGCLowThresholdPercent: 7510 #...- 1
- オブジェクトの名前。
- 2
- マシン設定プールからラベルを指定します。
- 3
- コンテナーのガベージコレクションの場合: エビクションのタイプ:
evictionSoftまたはevictionHard。 - 4
- コンテナーのガベージコレクションの場合: 特定のエビクショントリガー信号に基づくエビクションしきい値。
- 5
- コンテナーのガベージコレクションの場合: ソフトエビクションの猶予期間。このパラメーターは、
eviction-hardには適用されません。 - 6
- コンテナーのガベージコレクションの場合: 特定のエビクショントリガー信号に基づくエビクションしきい値。
evictionHardの場合、これらのパラメーターをすべて指定する必要があります。すべてのパラメーターを指定しないと、指定したパラメーターのみが適用され、ガベージコレクションが正しく機能しません。 - 7
- コンテナーのガベージコレクションの場合: エビクションプレッシャー状態から移行するまでの待機時間。
evictionPressureTransitionPeriodパラメーターを0に設定すると、デフォルト値の 5 分が設定されます。 - 8
- イメージのガベージコレクションの場合: イメージがガベージコレクションによって削除されるまでの、未使用のイメージの最小保存期間。
- 9
- イメージガベージコレクションの場合: イメージガベージコレクションは、(整数で表される) 指定されたディスク使用率でトリガーされます。この値は
imageGCLowThresholdPercent値より大きくする必要があります。 - 10
- イメージガベージコレクションの場合: イメージガベージコレクションは、(整数で表される) 指定されたディスク使用率までリソースの解放を試みます。この値は、
imageGCHighThresholdPercent値より小さくする必要があります。
以下のコマンドを実行して CR を作成します。
$ oc create -f <file_name>.yaml以下に例を示します。
$ oc create -f gc-container.yaml出力例
kubeletconfig.machineconfiguration.openshift.io/gc-container created
検証
次のコマンドを入力して、ガベージコレクションがアクティブであることを確認します。カスタムリソースで指定した Machine Config Pool では、変更が完全に実行されるまで
UPDATINGが 'true` と表示されます。$ oc get machineconfigpool出力例
NAME CONFIG UPDATED UPDATING master rendered-master-546383f80705bd5aeaba93 True False worker rendered-worker-b4c51bb33ccaae6fc4a6a5 False True
6.14. Node Tuning Operator の使用
Node Tuning Operator について理解し、これを使用します。
Node Tuning Operator は、TuneD デーモンを調整することでノードレベルのチューニングを管理し、Performance Profile コントローラーを使用して低レイテンシーのパフォーマンスを実現するのに役立ちます。ほとんどの高パフォーマンスアプリケーションでは、一定レベルのカーネルのチューニングが必要です。Node Tuning Operator は、ノードレベルの sysctl の統一された管理インターフェイスをユーザーに提供し、ユーザーが指定するカスタムチューニングを追加できるよう柔軟性を提供します。
Operator は、コンテナー化された OpenShift Container Platform の TuneD デーモンを Kubernetes デーモンセットとして管理します。これにより、カスタムチューニング仕様が、デーモンが認識する形式でクラスターで実行されるすべてのコンテナー化された TuneD デーモンに渡されます。デーモンは、ノードごとに 1 つずつ、クラスターのすべてのノードで実行されます。
コンテナー化された TuneD デーモンによって適用されるノードレベルの設定は、プロファイルの変更をトリガーするイベントで、または終了シグナルの受信および処理によってコンテナー化された TuneD デーモンが正常に終了する際にロールバックされます。
Node Tuning Operator は、パフォーマンスプロファイルコントローラーを使用して自動チューニングを実装し、OpenShift Container Platform アプリケーションの低レイテンシーパフォーマンスを実現します。
クラスター管理者は、以下のようなノードレベルの設定を定義するパフォーマンスプロファイルを設定します。
- カーネルを kernel-rt に更新します。
- ハウスキーピング用の CPU を選択します。
- 実行中のワークロード用の CPU を選択します。
Node Tuning Operator は、バージョン 4.1 以降における標準的な OpenShift Container Platform インストールの一部となっています。
OpenShift Container Platform の以前のバージョンでは、Performance Addon Operator を使用して自動チューニングを実装し、OpenShift アプリケーションの低レイテンシーパフォーマンスを実現していました。OpenShift Container Platform 4.11 以降では、この機能は Node Tuning Operator の一部です。
6.14.1. Node Tuning Operator 仕様サンプルへのアクセス
このプロセスを使用して Node Tuning Operator 仕様サンプルにアクセスします。
手順
次のコマンドを実行して、Node Tuning Operator 仕様の例にアクセスします。
oc get tuned.tuned.openshift.io/default -o yaml -n openshift-cluster-node-tuning-operator
デフォルトの CR は、OpenShift Container Platform プラットフォームの標準的なノードレベルのチューニングを提供することを目的としており、Operator 管理の状態を設定するためにのみ変更できます。デフォルト CR へのその他のカスタム変更は、Operator によって上書きされます。カスタムチューニングの場合は、独自のチューニングされた CR を作成します。新規に作成された CR は、ノード/Pod ラベルおよびプロファイルの優先順位に基づいて OpenShift Container Platform ノードに適用されるデフォルトの CR およびカスタムチューニングと組み合わされます。
特定の状況で Pod ラベルのサポートは必要なチューニングを自動的に配信する便利な方法ですが、この方法は推奨されず、とくに大規模なクラスターにおいて注意が必要です。デフォルトの調整された CR は Pod ラベル一致のない状態で提供されます。カスタムプロファイルが Pod ラベル一致のある状態で作成される場合、この機能はその時点で有効になります。Pod ラベル機能は、Node Tuning Operator の将来のバージョンで非推奨になる予定です。
6.14.2. カスタムチューニング仕様
Operator のカスタムリソース (CR) には 2 つの重要なセクションがあります。1 つ目のセクションの profile: は TuneD プロファイルおよびそれらの名前のリストです。2 つ目の recommend: は、プロファイル選択ロジックを定義します。
複数のカスタムチューニング仕様は、Operator の namespace に複数の CR として共存できます。新規 CR の存在または古い CR の削除は Operator によって検出されます。既存のカスタムチューニング仕様はすべてマージされ、コンテナー化された TuneD デーモンの適切なオブジェクトは更新されます。
管理状態
Operator 管理の状態は、デフォルトの Tuned CR を調整して設定されます。デフォルトで、Operator は Managed 状態であり、spec.managementState フィールドはデフォルトの Tuned CR に表示されません。Operator Management 状態の有効な値は以下のとおりです。
- Managed: Operator は設定リソースが更新されるとそのオペランドを更新します。
- Unmanaged: Operator は設定リソースへの変更を無視します。
- Removed: Operator は Operator がプロビジョニングしたオペランドおよびリソースを削除します。
プロファイルデータ
profile: セクションは、TuneD プロファイルおよびそれらの名前をリスト表示します。
profile:
- name: tuned_profile_1
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_1 profile
[sysctl]
net.ipv4.ip_forward=1
# ... other sysctl's or other TuneD daemon plugins supported by the containerized TuneD
# ...
- name: tuned_profile_n
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_n profile
# tuned_profile_n profile settings推奨プロファイル
profile: 選択ロジックは、CR の recommend: セクションによって定義されます。recommend: セクションは、選択基準に基づくプロファイルの推奨項目のリストです。
recommend:
<recommend-item-1>
# ...
<recommend-item-n>リストの個別項目:
- machineConfigLabels:
<mcLabels>
match:
<match>
priority: <priority>
profile: <tuned_profile_name>
operand:
debug: <bool>
tunedConfig:
reapply_sysctl: <bool> - 1
- オプション。
- 2
- キー/値の
MachineConfigラベルのディクショナリー。キーは一意である必要があります。 - 3
- 省略する場合は、優先度の高いプロファイルが最初に一致するか、
machineConfigLabelsが設定されていない限り、プロファイルの一致が想定されます。 - 4
- オプションのリスト。
- 5
- プロファイルの順序付けの優先度。数値が小さいほど優先度が高くなります (
0が最も高い優先度になります)。 - 6
- 一致に適用する TuneD プロファイル。例:
tuned_profile_1 - 7
- オプションのオペランド設定。
- 8
- TuneD デーモンのデバッグオンまたはオフを有効にします。オプションは、オンの場合は
true、オフの場合はfalseです。デフォルトはfalseです。 - 9
- TuneD デーモンの
reapply_sysctl機能をオンまたはオフにします。オプションは on でtrue、オフの場合はfalseです。
<match> は、以下のように再帰的に定義されるオプションの一覧です。
- label: <label_name>
value: <label_value>
type: <label_type>
<match>
<match> が省略されない場合、ネストされたすべての <match> セクションが true に評価される必要もあります。そうでない場合には false が想定され、それぞれの <match> セクションのあるプロファイルは適用されず、推奨されません。そのため、ネスト化 (子の <match> セクション) は論理 AND 演算子として機能します。これとは逆に、<match> 一覧のいずれかの項目が一致する場合は、<match> の一覧全体が true に評価されます。そのため、リストは論理 OR 演算子として機能します。
machineConfigLabels が定義されている場合は、マシン設定プールベースのマッチングが指定の recommend: 一覧の項目に対してオンになります。<mcLabels> はマシン設定のラベルを指定します。マシン設定は、プロファイル <tuned_profile_name> にカーネル起動パラメーターなどのホスト設定を適用するために自動的に作成されます。この場合は、マシン設定セレクターが <mcLabels> に一致するすべてのマシン設定プールを検索し、プロファイル <tuned_profile_name> を確認されるマシン設定プールが割り当てられるすべてのノードに設定する必要があります。マスターロールとワーカーのロールの両方を持つノードをターゲットにするには、マスターロールを使用する必要があります。
リスト項目の match および machineConfigLabels は論理 OR 演算子によって接続されます。match 項目は、最初にショートサーキット方式で評価されます。そのため、true と評価される場合、machineConfigLabels 項目は考慮されません。
マシン設定プールベースのマッチングを使用する場合は、同じハードウェア設定を持つノードを同じマシン設定プールにグループ化することが推奨されます。この方法に従わない場合は、TuneD オペランドが同じマシン設定プールを共有する 2 つ以上のノードの競合するカーネルパラメーターを計算する可能性があります。
例: ノードまたは Pod のラベルベースのマッチング
- match:
- label: tuned.openshift.io/elasticsearch
match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
type: pod
priority: 10
profile: openshift-control-plane-es
- match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
priority: 20
profile: openshift-control-plane
- priority: 30
profile: openshift-node
上記のコンテナー化された TuneD デーモンの CR は、プロファイルの優先順位に基づいてその recommend.conf ファイルに変換されます。最も高い優先順位 (10) を持つプロファイルは openshift-control-plane-es であるため、これが最初に考慮されます。指定されたノードで実行されるコンテナー化された TuneD デーモンは、同じノードに tuned.openshift.io/elasticsearch ラベルが設定された Pod が実行されているかどうかを確認します。これがない場合は、<match> セクション全体が false として評価されます。このラベルを持つこのような Pod がある場合に、<match> セクションが true に評価されるようにするには、ノードラベルを node-role.kubernetes.io/master または node-role.kubernetes.io/infra にする必要もあります。
優先順位が 10 のプロファイルのラベルが一致した場合は、openshift-control-plane-es プロファイルが適用され、その他のプロファイルは考慮されません。ノード/Pod ラベルの組み合わせが一致しない場合は、2 番目に高い優先順位プロファイル (openshift-control-plane) が考慮されます。このプロファイルは、コンテナー化された TuneD Pod が node-role.kubernetes.io/master または node-role.kubernetes.io/infra ラベルを持つノードで実行される場合に適用されます。
最後に、プロファイル openshift-node には最低の優先順位である 30 が設定されます。これには <match> セクションがないため、常に一致します。これは、より高い優先順位の他のプロファイルが指定されたノードで一致しない場合に openshift-node プロファイルを設定するために、最低の優先順位のノードが適用される汎用的な (catch-all) プロファイルとして機能します。

例: マシン設定プールベースのマッチング
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: openshift-node-custom
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Custom OpenShift node profile with an additional kernel parameter
include=openshift-node
[bootloader]
cmdline_openshift_node_custom=+skew_tick=1
name: openshift-node-custom
recommend:
- machineConfigLabels:
machineconfiguration.openshift.io/role: "worker-custom"
priority: 20
profile: openshift-node-customノードの再起動を最小限にするには、ターゲットノードにマシン設定プールのノードセレクターが一致するラベルを使用してラベルを付け、上記の Tuned CR を作成してから、最後にカスタムのマシン設定プール自体を作成します。
クラウドプロバイダー固有の TuneD プロファイル
この機能により、すべてのクラウドプロバイダー固有のノードに、OpenShift Container Platform クラスター上の特定のクラウドプロバイダーに合わせて特別に調整された TuneD プロファイルを簡単に割り当てることができます。これは、追加のノードラベルを追加したり、ノードをマシン設定プールにグループ化したりせずに実行できます。
この機能は、<cloud-provider>://<cloud-provider-specific-id> という形式の spec.providerID ノードオブジェクト値を利用し、NTO オペランドコンテナーに値 <cloud-provider> を持つファイル /var/lib/ocp-tuned/provider を書き込みます。その後、このファイルのコンテンツは TuneD により、プロバイダー provider-<cloud-provider> プロファイル (存在する場合) を読み込むために使用されます。
openshift-control-plane および openshift-node プロファイルの両方の設定を継承する openshift プロファイルは、条件付きプロファイルの読み込みを使用してこの機能を使用するよう更新されるようになりました。現時点で、NTO や TuneD にクラウドプロバイダー固有のプロファイルは含まれていません。ただし、すべてのクラウドプロバイダー固有のクラスターノードに適用されるカスタムプロファイル provider-<cloud-provider> を作成できます。
GCE クラウドプロバイダープロファイルの例
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: provider-gce
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=GCE Cloud provider-specific profile
# Your tuning for GCE Cloud provider goes here.
name: provider-gce
プロファイルの継承により、provider-<cloud-provider> プロファイルで指定された設定は、openshift プロファイルとその子プロファイルによってオーバーライドされます。
6.14.3. クラスターに設定されるデフォルトのプロファイル
以下は、クラスターに設定されるデフォルトのプロファイルです。
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: default
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Optimize systems running OpenShift (provider specific parent profile)
include=-provider-${f:exec:cat:/var/lib/ocp-tuned/provider},openshift
name: openshift
recommend:
- profile: openshift-control-plane
priority: 30
match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
- profile: openshift-node
priority: 40
OpenShift Container Platform 4.9 以降では、すべての OpenShift TuneD プロファイルが TuneD パッケージに含まれています。oc exec コマンドを使用して、これらのプロファイルの内容を表示できます。
$ oc exec $tuned_pod -n openshift-cluster-node-tuning-operator -- find /usr/lib/tuned/openshift{,-control-plane,-node} -name tuned.conf -exec grep -H ^ {} \;6.14.4. サポートされている TuneD デーモンプラグイン
[main] セクションを除き、以下の TuneD プラグインは、Tuned CR の profile: セクションで定義されたカスタムプロファイルを使用する場合にサポートされます。
- audio
- cpu
- disk
- eeepc_she
- modules
- mounts
- net
- scheduler
- scsi_host
- selinux
- sysctl
- sysfs
- usb
- video
- vm
- bootloader
これらのプラグインの一部によって提供される動的チューニング機能の中に、サポートされていない機能があります。以下の TuneD プラグインは現時点でサポートされていません。
- script
- systemd
TuneD ブートローダープラグインは、Red Hat Enterprise Linux CoreOS (RHCOS) ワーカーノードのみサポートします。
6.15. ノードあたりの Pod の最大数の設定
podsPerCore および maxPods の 2 つのパラメーターはノードに対してスケジュールできる Pod の最大数を制御します。両方のオプションを使用した場合、より低い値の方がノード上の Pod の数を制限します。
たとえば、podsPerCore が 4 つのプロセッサーコアを持つノード上で、10 に設定されていると、ノード上で許容される Pod の最大数は 40 になります。
前提条件
次のコマンドを入力して、設定するノードタイプの静的な
MachineConfigPoolCRD に関連付けられたラベルを取得します。$ oc edit machineconfigpool <name>以下に例を示します。
$ oc edit machineconfigpool worker出力例
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: creationTimestamp: "2022-11-16T15:34:25Z" generation: 4 labels: pools.operator.machineconfiguration.openshift.io/worker: ""1 name: worker #...- 1
- Labels の下にラベルが表示されます。
ヒントラベルが存在しない場合は、次のようなキー/値のペアを追加します。
$ oc label machineconfigpool worker custom-kubelet=small-pods
手順
設定変更のためのカスタムリソース (CR) を作成します。
max-podsCR の設定例apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-max-pods1 spec: machineConfigPoolSelector: matchLabels: pools.operator.machineconfiguration.openshift.io/worker: ""2 kubeletConfig: podsPerCore: 103 maxPods: 2504 #...注記podsPerCoreを0に設定すると、この制限が無効になります。上記の例では、
podsPerCoreのデフォルト値は10であり、maxPodsのデフォルト値は250です。つまり、ノードのコア数が 25 以上でない限り、デフォルトによりpodsPerCoreが制限要素になります。以下のコマンドを実行して CR を作成します。
$ oc create -f <file_name>.yaml
検証
変更が適用されるかどうかを確認するために、
MachineConfigPoolCRD を一覧表示します。変更が Machine Config Controller によって取得されると、UPDATING列でTrueと報告されます。$ oc get machineconfigpools出力例
NAME CONFIG UPDATED UPDATING DEGRADED master master-9cc2c72f205e103bb534 False False False worker worker-8cecd1236b33ee3f8a5e False True False変更が完了すると、
UPDATED列でTrueと報告されます。$ oc get machineconfigpools出力例
NAME CONFIG UPDATED UPDATING DEGRADED master master-9cc2c72f205e103bb534 False True False worker worker-8cecd1236b33ee3f8a5e True False False
6.16. 静的 IP アドレスを使用したマシンのスケーリング
静的 IP アドレスを持つノードを実行するようにクラスターをデプロイした後、これらの静的 IP アドレスのいずれかを使用するようにマシンまたはマシンセットのインスタンスをスケーリングできます。
6.16.1. 静的 IP アドレスを使用するようにマシンをスケーリングする
追加のマシンセットを拡張して、クラスター上で事前定義された静的 IP アドレスを使用できます。この設定では、マシンリソース YAML ファイルを作成し、このファイルに静的 IP アドレスを定義する必要があります。
前提条件
- 設定された静的 IP アドレスを持つ少なくとも 1 つのノードを実行するクラスターをデプロイしました。
手順
マシンリソースの YAML ファイルを作成し、
networkパラメーターに静的 IP アドレスのネットワーク情報を定義します。networkパラメーターで定義された静的 IP アドレス情報を含むマシンリソース YAML ファイルの例。apiVersion: machine.openshift.io/v1beta1 kind: Machine metadata: creationTimestamp: null labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> name: <infrastructure_id>-<role> namespace: openshift-machine-api spec: lifecycleHooks: {} metadata: {} providerSpec: value: apiVersion: machine.openshift.io/v1beta1 credentialsSecret: name: vsphere-cloud-credentials diskGiB: 120 kind: VSphereMachineProviderSpec memoryMiB: 8192 metadata: creationTimestamp: null network: devices: - gateway: 192.168.204.11 ipAddrs: - 192.168.204.8/242 nameservers:3 - 192.168.204.1 networkName: qe-segment-204 numCPUs: 4 numCoresPerSocket: 2 snapshot: "" template: <vm_template_name> userDataSecret: name: worker-user-data workspace: datacenter: <vcenter_data_center_name> datastore: <vcenter_datastore_name> folder: <vcenter_vm_folder_path> resourcepool: <vsphere_resource_pool> server: <vcenter_server_ip> status: {}- 1
- ネットワークインターフェイスのデフォルトゲートウェイの IP アドレス。
- 2
- インストールプログラムがネットワークインターフェイスに渡す IPv4、IPv6、またはその両方の IP アドレスをリストします。どちらの IP ファミリーも、デフォルトネットワークに同じネットワークインターフェイスを使用する必要があります。
- 3
- DNS ネームサーバーをリストします。最大 3 つの DNS ネームサーバーを定義できます。1 つの DNS ネームサーバーが到達不能になった場合に、DNS 解決を利用できるように、複数の DNS ネームサーバーを定義することを検討してください。
ターミナルに次のコマンドを入力して、
machineのカスタムリソース (CR) を作成します。$ oc create -f <file_name>.yaml
6.16.2. 静的 IP アドレスが設定されたマシンのマシンセットスケーリング
マシンセットを使用して、設定された静的 IP アドレスを持つマシンをスケールすることができます。
マシンの静的 IP アドレスを要求するようにマシンセットを設定した後、マシンコントローラーは openshift-machine-api namespace に IPAddressClaim リソースを作成します。次に、外部コントローラーは IPAddress リソースを作成し、静的 IP アドレスを IPAddressClaim リソースにバインドします。
組織では、さまざまな種類の IP アドレス管理 (IPAM) サービスを使用している場合があります。OpenShift Container Platform で特定の IPAM サービスを有効にする場合は、YAML 定義で IPAddressClaim リソースを手動で作成し、oc CLI で次のコマンドを入力してこのリソースに静的 IP アドレスをバインドしないといけない場合があります。
$ oc create -f <ipaddressclaim_filename>
次に、IPAddressClaim リソースの例を示します。
kind: IPAddressClaim
metadata:
finalizers:
- machine.openshift.io/ip-claim-protection
name: cluster-dev-9n5wg-worker-0-m7529-claim-0-0
namespace: openshift-machine-api
spec:
poolRef:
apiGroup: ipamcontroller.example.io
kind: IPPool
name: static-ci-pool
status: {}
マシンコントローラーはマシンを IPAddressClaimed のステータスで更新し、静的 IP アドレスが IPAddressClaim リソースに正常にバインドされたことを示します。マシンコントローラーは、バインドされた静的 IP アドレスをそれぞれに含む複数の IPAddressClaim リソースを持つマシンに同じステータスを適用します。その後、マシンコントローラーは仮想マシンを作成し、マシンの設定の providerSpec にリストされているすべてのノードに静的 IP アドレスを適用します。
6.16.3. マシンセットを使用して設定された静的 IP アドレスを持つマシンをスケールする
マシンセットを使用して、設定された静的 IP アドレスを持つマシンをスケールすることができます。
この手順の例では、マシンセット内のマシンをスケーリングするためのコントローラーの使用方法を示します。
前提条件
- 設定された静的 IP アドレスを持つ少なくとも 1 つのノードを実行するクラスターをデプロイしました。
手順
マシンセットの YAML ファイルの
network.devices.addressesFromPoolsスキーマに IP プール情報を指定して、マシンセットを設定します。apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: annotations: machine.openshift.io/memoryMb: "8192" machine.openshift.io/vCPU: "4" labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> name: <infrastructure_id>-<role> namespace: openshift-machine-api spec: replicas: 0 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: ipam: "true" machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: lifecycleHooks: {} metadata: {} providerSpec: value: apiVersion: machine.openshift.io/v1beta1 credentialsSecret: name: vsphere-cloud-credentials diskGiB: 120 kind: VSphereMachineProviderSpec memoryMiB: 8192 metadata: {} network: devices: - addressesFromPools:1 - group: ipamcontroller.example.io name: static-ci-pool resource: IPPool nameservers: - "192.168.204.1"2 networkName: qe-segment-204 numCPUs: 4 numCoresPerSocket: 2 snapshot: "" template: rvanderp4-dev-9n5wg-rhcos-generated-region-generated-zone userDataSecret: name: worker-user-data workspace: datacenter: IBMCdatacenter datastore: /IBMCdatacenter/datastore/vsanDatastore folder: /IBMCdatacenter/vm/rvanderp4-dev-9n5wg resourcePool: /IBMCdatacenter/host/IBMCcluster//Resources server: vcenter.ibmc.devcluster.openshift.com- 1
- 静的 IP アドレスまたは静的 IP アドレスの範囲をリストする IP プールを指定します。IP プールは、カスタムリソース定義 (CRD) への参照、または
IPAddressClaimsリソースハンドラーによってサポートされるリソースのいずれかになります。マシンコントローラーは、マシンセットの設定にリストされている静的 IP アドレスにアクセスし、各アドレスを各マシンに割り当てます。 - 2
- ネームサーバーをリストします。Dynamic Host Configuration Protocol (DHCP) ネットワーク設定は静的 IP アドレスをサポートしていないため、静的 IP アドレスを受け取るノードにはネームサーバーを指定する必要があります。
ocCLI で次のコマンドを入力して、マシンセットをスケールします。$ oc scale --replicas=2 machineset <machineset> -n openshift-machine-apiまたは、以下を実行します。
$ oc edit machineset <machineset> -n openshift-machine-api各マシンがスケールアップされた後、マシンコントローラーが
IPAddressClaimリソースを作成します。オプション: 次のコマンドを入力して、
IPAddressClaimリソースがopenshift-machine-apinamespace に存在することを確認します。$ oc get ipaddressclaims.ipam.cluster.x-k8s.io -n openshift-machine-apiopenshift-machine-apinamespace にリストされている 2 つの IP プールをリストするocCLI 出力の例NAME POOL NAME POOL KIND cluster-dev-9n5wg-worker-0-m7529-claim-0-0 static-ci-pool IPPool cluster-dev-9n5wg-worker-0-wdqkt-claim-0-0 static-ci-pool IPPool次のコマンドを入力して、
IPAddressリソースを作成します。$ oc create -f ipaddress.yaml次の例は、定義されたネットワーク設定情報と 1 つの静的 IP アドレスが定義された
IPAddressリソースを示しています。apiVersion: ipam.cluster.x-k8s.io/v1alpha1 kind: IPAddress metadata: name: cluster-dev-9n5wg-worker-0-m7529-ipaddress-0-0 namespace: openshift-machine-api spec: address: 192.168.204.129 claimRef:1 name: cluster-dev-9n5wg-worker-0-m7529-claim-0-0 gateway: 192.168.204.1 poolRef:2 apiGroup: ipamcontroller.example.io kind: IPPool name: static-ci-pool prefix: 23注記デフォルトでは、外部コントローラーはマシンセット内のリソースを自動的にスキャンして、認識可能なアドレスプールタイプを探します。外部コントローラーが
IPAddressリソースで定義されたkind: IPPoolを見つけると、コントローラーは静的 IP アドレスをIPAddressClaimリソースにバインドします。IPAddressリソースへの参照を使用してIPAddressClaimステータスを更新します。$ oc --type=merge patch IPAddressClaim cluster-dev-9n5wg-worker-0-m7529-claim-0-0 -p='{"status":{"addressRef": {"name": "cluster-dev-9n5wg-worker-0-m7529-ipaddress-0-0"}}}' -n openshift-machine-api --subresource=status
第7章 インストール後のネットワーク設定
OpenShift Container Platform のインストール後に、ネットワークをさらに拡張し、要件に合わせてカスタマイズできます。
7.1. Cluster Network Operator の使用
Cluster Network Operator (CNO) を使用すると、インストール時にクラスター用に選択された Container Network Interface (CNI) ネットワークプラグインを含む、OpenShift Container Platform クラスター上のクラスターネットワークコンポーネントをデプロイおよび管理できます。
詳細は、OpenShift Container Platform における Cluster Network Operator を参照してください。
7.2. ネットワーク設定タスク
7.2.1. 新規プロジェクトのデフォルトネットワークポリシーの作成
クラスター管理者は、新規プロジェクトの作成時に NetworkPolicy オブジェクトを自動的に含めるように新規プロジェクトテンプレートを変更できます。
7.2.1.1. 新規プロジェクトのテンプレートの変更
クラスター管理者は、デフォルトのプロジェクトテンプレートを変更し、新規プロジェクトをカスタム要件に基づいて作成できます。
独自のカスタムプロジェクトテンプレートを作成するには、以下を実行します。
前提条件
-
cluster-adminパーミッションを持つアカウントを使用して OpenShift Container Platform クラスターにアクセスできる。
手順
-
cluster-admin権限を持つユーザーとしてログインします。 デフォルトのプロジェクトテンプレートを生成します。
$ oc adm create-bootstrap-project-template -o yaml > template.yaml-
オブジェクトを追加するか、既存オブジェクトを変更することにより、テキストエディターで生成される
template.yamlファイルを変更します。 プロジェクトテンプレートは、
openshift-confignamespace に作成する必要があります。変更したテンプレートを読み込みます。$ oc create -f template.yaml -n openshift-configWeb コンソールまたは CLI を使用し、プロジェクト設定リソースを編集します。
Web コンソールの使用
- Administration → Cluster Settings ページに移動します。
- Configuration をクリックし、すべての設定リソースを表示します。
- Project のエントリーを見つけ、Edit YAML をクリックします。
CLI の使用
project.config.openshift.io/clusterリソースを編集します。$ oc edit project.config.openshift.io/cluster
specセクションを、projectRequestTemplateおよびnameパラメーターを組み込むように更新し、アップロードされたプロジェクトテンプレートの名前を設定します。デフォルト名はproject-requestです。カスタムプロジェクトテンプレートを含むプロジェクト設定リソース
apiVersion: config.openshift.io/v1 kind: Project metadata: # ... spec: projectRequestTemplate: name: <template_name> # ...- 変更を保存した後、変更が正常に適用されたことを確認するために、新しいプロジェクトを作成します。
7.2.1.2. 新規プロジェクトへのネットワークポリシーの追加
クラスター管理者は、ネットワークポリシーを新規プロジェクトのデフォルトテンプレートに追加できます。OpenShift Container Platform は、プロジェクトのテンプレートに指定されたすべての NetworkPolicy オブジェクトを自動的に作成します。
前提条件
-
クラスターは、
mode: NetworkPolicyが設定された OpenShift SDN ネットワークプラグインなど、NetworkPolicyオブジェクトをサポートするデフォルトの CNI ネットワークプラグインを使用します。このモードは OpenShift SDN のデフォルトです。 -
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインする。 - 新規プロジェクトのカスタムデフォルトプロジェクトテンプレートを作成している。
手順
以下のコマンドを実行して、新規プロジェクトのデフォルトテンプレートを編集します。
$ oc edit template <project_template> -n openshift-config<project_template>を、クラスターに設定したデフォルトテンプレートの名前に置き換えます。デフォルトのテンプレート名はproject-requestです。テンプレートでは、各
NetworkPolicyオブジェクトを要素としてobjectsパラメーターに追加します。objectsパラメーターは、1 つ以上のオブジェクトのコレクションを受け入れます。以下の例では、
objectsパラメーターのコレクションにいくつかのNetworkPolicyオブジェクトが含まれます。objects: - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-same-namespace spec: podSelector: {} ingress: - from: - podSelector: {} - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-ingress spec: ingress: - from: - namespaceSelector: matchLabels: policy-group.network.openshift.io/ingress: podSelector: {} policyTypes: - Ingress - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-kube-apiserver-operator spec: ingress: - from: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: openshift-kube-apiserver-operator podSelector: matchLabels: app: kube-apiserver-operator policyTypes: - Ingress ...オプション: 新しいプロジェクトを作成し、ネットワークポリシーオブジェクトが正常に作成されたことを確認します。
プロジェクトを新規作成します。
$ oc new-project <project>1 - 1
<project>を、作成しているプロジェクトの名前に置き換えます。
新規プロジェクトテンプレートのネットワークポリシーオブジェクトが新規プロジェクトに存在することを確認します。
$ oc get networkpolicy想定される出力:
NAME POD-SELECTOR AGE allow-from-openshift-ingress <none> 7s allow-from-same-namespace <none> 7s
第8章 イメージストリームとイメージレジストリーの設定
現在のプルシークレットを置き換えるか、新しいプルシークレットを追加することで、クラスターのグローバルプルシークレットを更新できます。ユーザーがインストール中に使用したレジストリーとは別のレジストリーを使用してイメージを保存する場合は、この手順が必要です。詳細は、イメージプルシークレットの使用 を参照してください。
イメージと、イメージストリームまたはイメージレジストリーの設定の詳細は、次のドキュメントを参照してください。
8.1. 非接続クラスターのイメージストリームの設定
OpenShift Container Platform を非接続環境でインストールした後に、Cluster Samples Operator のイメージストリームおよび must-gather イメージストリームを設定します。
8.1.1. ミラーリングの Cluster Samples Operator のサポート
インストール中に、OpenShift Container Platform は、openshift-cluster-samples-operator namespace に imagestreamtag-to-image という名前の config map を作成します。
imagestreamtag-to-image config map には、各イメージストリームタグのエントリー (入力されるイメージ) が含まれています。
この config map に含まれるデータフィールドの各エントリーのキーは、<image_stream_name>_<image_stream_tag_name> という形式です。
OpenShift Container Platform の非接続インストール時に、Cluster Samples Operator のステータスは Removed に設定されます。これを Managed に変更することを選択した場合、サンプルがインストールされます。
ネットワークが制限されている環境や非接続環境でサンプルを使用するには、ネットワーク外部のサービスにアクセスする必要がある場合があります。サービスの例には、Github、Maven Central、npm、RubyGems、PyPi などがあります。場合によっては、Cluster Samples Operator オブジェクトが必要なサービスに到達できるようにするために、追加の手順を実行する必要があります。
イメージストリームによるインポート用に、どのイメージをミラーリングする必要があるかを判断する際には、次の原則を使用してください。
-
Cluster Samples Operator が
Removedに設定される場合、ミラーリングされたレジストリーを作成するか、使用する必要のある既存のミラーリングされたレジストリーを判別できます。 - 新しい config map をガイドとして使用し、ミラーリングされたレジストリーに必要なサンプルをミラーリングします。
-
Cluster Samples Operator 設定オブジェクトの
skippedImagestreamsリストに、ミラーリングされていないイメージストリームを追加します。 -
Cluster Samples Operator 設定オブジェクトの
samplesRegistryをミラーリングされたレジストリーに設定します。 -
次に、Cluster Samples Operator を
Managedに設定し、ミラーリングしたイメージストリームをインストールします。
8.1.2. 代替のレジストリーまたはミラーリングされたレジストリーでの Cluster Samples Operator イメージストリームの使用
Red Hat レジストリーを使用する代わりに、代替またはミラーレジストリーを使用してイメージストリームをホストすることができます。
Cluster Samples Operator によって管理される openshift namespace のほとんどのイメージストリームは、Red Hat レジストリーの registry.redhat.io にあるイメージを参照します。
cli、installer、must-gather、および tests イメージストリームはインストールペイロードの一部ですが、Cluster Samples Operator によって管理されません。これは、この手順で扱いません。
Cluster Samples Operator は、非接続環境では Managed に設定する必要があります。イメージストリームをインストールするには、ミラーリングされたレジストリーが必要です。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - ミラーレジストリーのプルシークレットの作成。
手順
ミラーリングする特定のイメージストリームのイメージにアクセスします。
$ oc get is <imagestream> -n openshift -o json | jq .spec.tags[].from.name | grep registry.redhat.io必要なイメージストリームに関連付けられた registry.redhat.io のイメージをミラーリングします。
$ oc image mirror registry.redhat.io/rhscl/ruby-25-rhel7:latest ${MIRROR_ADDR}/rhscl/ruby-25-rhel7:latest次のコマンドを実行して、クラスターのイメージ設定オブジェクトを作成します。
$ oc create configmap registry-config --from-file=${MIRROR_ADDR_HOSTNAME}..5000=$path/ca.crt -n openshift-configイメージ設定オブジェクトに、ミラーに必要な信頼される CA を追加します。
$ oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"registry-config"}}}' --type=mergeCluster Samples Operator 設定オブジェクトの
samplesRegistryフィールドを、ミラー設定で定義されたミラーの場所のhostnameの部分を含むように更新します。$ oc edit configs.samples.operator.openshift.io -n openshift-cluster-samples-operator重要現時点では、イメージストリームのインポートプロセスでミラーまたは検索メカニズムが使用されないので、この手順が必要です。
Cluster Samples Operator 設定オブジェクトの
skippedImagestreamsフィールドにミラーリングされないイメージストリームを追加します。または、サンプルイメージストリームのいずれもサポートする必要がない場合は、Cluster Samples Operator を Cluster Samples Operator 設定オブジェクトのRemovedに設定します。注記Cluster Samples Operator は、イメージストリームのインポートに失敗した場合にアラートを発行しますが、Cluster Samples Operator は定期的に再試行する場合もあれば、それらを再試行していないように見える場合もあります。
openshiftnamespace のテンプレートの多くはイメージストリームを参照します。Removedを使用してイメージストリームとテンプレートの両方をパージできます。これにより、イメージストリームが欠落しているためにテンプレートが機能しない場合にテンプレートの使用を試行する可能性がなくなります。
8.1.3. サポートデータを収集するためのクラスターの準備
ネットワークが制限された環境を使用するクラスターは、Red Hat サポート用のデバッグデータを収集するために、デフォルトの must-gather イメージをインポートする必要があります。must-gather イメージはデフォルトでインポートされず、ネットワークが制限された環境のクラスターは、リモートリポジトリーから最新のイメージをプルするためにインターネットにアクセスできません。
手順
ミラーレジストリーの信頼される CA を Cluster Samples Operator 設定の一部としてクラスターのイメージ設定オブジェクトに追加していない場合は、以下の手順を実行します。
クラスターのイメージ設定オブジェクトを作成します。
$ oc create configmap registry-config --from-file=${MIRROR_ADDR_HOSTNAME}..5000=$path/ca.crt -n openshift-configクラスターのイメージ設定オブジェクトに、ミラーに必要な信頼される CA を追加します。
$ oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"registry-config"}}}' --type=merge
インストールペイロードからデフォルトの must-gather イメージをインポートします。
$ oc import-image is/must-gather -n openshift
oc adm must-gather コマンドの実行時に、以下の例のように --image フラグを使用し、ペイロードイメージを参照します。
$ oc adm must-gather --image=$(oc adm release info --image-for must-gather)8.2. Cluster Sample Operator イメージストリームタグの定期的なインポートの設定
新しいバージョンが利用可能になったときにイメージストリームタグを定期的にインポートすることで、Cluster Sample Operator イメージの最新バージョンに常にアクセスできるようになります。
手順
次のコマンドを実行して、
openshiftnamespace のすべてのイメージストリームを取得します。oc get imagestreams -n openshift次のコマンドを実行して、
openshiftnamespace のすべてのイメージストリームのタグを取得します。$ oc get is <image-stream-name> -o jsonpath="{range .spec.tags[*]}{.name}{'\t'}{.from.name}{'\n'}{end}" -n openshift以下に例を示します。
$ oc get is ubi8-openjdk-17 -o jsonpath="{range .spec.tags[*]}{.name}{'\t'}{.from.name}{'\n'}{end}" -n openshift出力例
1.11 registry.access.redhat.com/ubi8/openjdk-17:1.11 1.12 registry.access.redhat.com/ubi8/openjdk-17:1.12次のコマンドを実行して、イメージストリームに存在する各タグのイメージの定期的なインポートをスケジュールします。
$ oc tag <repository/image> <image-stream-name:tag> --scheduled -n openshift以下に例を示します。
$ oc tag registry.access.redhat.com/ubi8/openjdk-17:1.11 ubi8-openjdk-17:1.11 --scheduled -n openshift$ oc tag registry.access.redhat.com/ubi8/openjdk-17:1.12 ubi8-openjdk-17:1.12 --scheduled -n openshift注記外部のコンテナーイメージレジストリーを使用している場合、イメージを定期的に再インポートするには、
--scheduledフラグを使用することを推奨します。--scheduledフラグを使用すると、最新バージョンとセキュリティー更新を確実に受け取ることができます。さらに、この設定により、一時的なエラーによって最初にイメージをインポートできなかった場合でも、インポートプロセスが自動的に再試行されるようになります。デフォルトでは、定期的なイメージのインポートは、クラスター全体で 15 分ごとに実行されます。
次のコマンドを実行して、定期的なインポートのスケジュールステータスを確認します。
oc get imagestream <image-stream-name> -o jsonpath="{range .spec.tags[*]}Tag: {.name}{'\t'}Scheduled: {.importPolicy.scheduled}{'\n'}{end}" -n openshift以下に例を示します。
oc get imagestream ubi8-openjdk-17 -o jsonpath="{range .spec.tags[*]}Tag: {.name}{'\t'}Scheduled: {.importPolicy.scheduled}{'\n'}{end}" -n openshift出力例
Tag: 1.11 Scheduled: true Tag: 1.12 Scheduled: true
第9章 インストール後のストレージ設定
OpenShift Container Platform のインストール後に、ストレージの設定を含め、クラスターをさらに拡張し、要件に合わせてカスタマイズできます。
デフォルトでは、コンテナーは一時ストレージまたは一時的なローカルストレージを使用して動作します。一時ストレージには有効期間の制限があります。データを長期間保存するには、永続ストレージを設定する必要があります。以下の方法のいずれかを使用してストレージを設定できます。
- 動的プロビジョニング
- ストレージアクセスを含む異なるレベルのストレージを制御するストレージクラスを定義して作成することで、オンデマンドでストレージを動的にプロビジョニングできます。
- 静的プロビジョニング
- Kubernetes 永続ボリュームを使用して、既存のストレージをクラスターで利用できるようにすることができます。静的プロビジョニングは、さまざまなデバイス設定とマウントオプションをサポートできます。
9.1. 動的プロビジョニング
動的プロビジョニングにより、ストレージボリュームをオンデマンドで作成し、クラスター管理者がストレージを事前にプロビジョニングする必要をなくすことができます。動的プロビジョニング を参照してください。
9.2. 設定可能な推奨のストレージ技術
以下の表では、特定の OpenShift Container Platform クラスターアプリケーション向けに設定可能な推奨のストレージ技術をまとめています。
| ストレージタイプ | ブロック | ファイル | オブジェクト |
|---|---|---|---|
|
1
2 3 Prometheus はメトリックに使用される基礎となるテクノロジーです。 4 これは、物理ディスク、VM 物理ディスク、VMDK、NFS 経由のループバック、AWS EBS、および Azure Disk には該当しません。
5 メトリックの場合、 6 ログは、ログストアの永続ストレージの設定セクションで推奨されるストレージソリューションを確認してください。NFS ストレージを永続ボリュームとして使用するか、Gluster などの NAS を介して使用すると、データが破損する可能性があります。したがって、NFS は、OpenShift Container Platform Logging の Elasticsearch ストレージおよび LokiStack ログストアではサポートされていません。ログストアごとに 1 つの永続的なボリュームタイプを使用する必要があります。 7 オブジェクトストレージは、OpenShift Container Platform の PV/PVC で消費されません。アプリは、オブジェクトストレージの REST API と統合する必要があります。 | |||
| ROX1 | はい4 | はい4 | はい |
| RWX2 | いいえ | はい | はい |
| レジストリー | 設定可能 | 設定可能 | 推奨 |
| スケーリングされたレジストリー | 設定不可 | 設定可能 | 推奨 |
| メトリクス3 | 推奨 | 設定可能5 | 設定不可 |
| Elasticsearch ロギング | 推奨 | 設定可能6 | サポート対象外6 |
| Loki ロギング | 設定不可 | 設定不可 | 推奨 |
| アプリ | 推奨 | 推奨 | 設定不可7 |
スケーリングされたレジストリーは、2 つ以上の Pod レプリカが実行されている OpenShift イメージレジストリーです。
9.2.1. 特定アプリケーションのストレージの推奨事項
テストにより、NFS サーバーを Red Hat Enterprise Linux (RHEL) でコアサービスのストレージバックエンドとして使用することに関する問題が検出されています。これには、OpenShift Container レジストリーおよび Quay、メトリックストレージの Prometheus、およびロギングストレージの Elasticsearch が含まれます。そのため、コアサービスで使用される PV をサポートするために RHEL NFS を使用することは推奨されていません。
他の NFS の実装ではこれらの問題が検出されない可能性があります。OpenShift Container Platform コアコンポーネントに対して実施された可能性のあるテストに関する詳細情報は、個別の NFS 実装ベンダーにお問い合わせください。
9.2.1.1. レジストリー
スケーリングされていない/高可用性 (HA) OpenShift イメージレジストリークラスターのデプロイメントでは、次のようになります。
- ストレージ技術は、RWX アクセスモードをサポートする必要はありません。
- ストレージ技術は、リードアフターライト (Read-After-Write) の一貫性を確保する必要があります。
- 推奨されるストレージ技術はオブジェクトストレージであり、次はブロックストレージです。
- ファイルストレージは、実稼働ワークロードを使用した OpenShift イメージレジストリークラスターのデプロイメントには推奨されません。
9.2.1.2. スケーリングされたレジストリー
スケーリングされた/HA OpenShift イメージレジストリークラスターのデプロイメントでは、次のようになります。
- ストレージ技術は、RWX アクセスモードをサポートする必要があります。
- ストレージ技術は、リードアフターライト (Read-After-Write) の一貫性を確保する必要があります。
- 推奨されるストレージ技術はオブジェクトストレージです。
- Red Hat OpenShift Data Foundation、Amazon Simple Storage Service (Amazon S3)、Google Cloud Storage (GCS)、Microsoft Azure Blob Storage、OpenStack Swift がサポートされています。
- オブジェクトストレージは S3 または Swift に準拠する必要があります。
- vSphere やベアメタルインストールなどのクラウド以外のプラットフォームの場合、設定可能な技術はファイルストレージのみです。
- ブロックストレージは設定できません。
- OpenShift Container Platform での Network File System (NFS) ストレージの使用がサポートされています。ただし、スケーリングされたレジストリーで NFS ストレージを使用すると、既知の問題が発生する可能性があります。詳細は、Red Hat ナレッジベースソリューション Is NFS supported for OpenShift cluster internal components in Production? を参照してください。
9.2.1.3. メトリクス
OpenShift Container Platform がホストするメトリックのクラスターデプロイメント:
- 推奨されるストレージ技術はブロックストレージです。
- オブジェクトストレージは設定できません。
実稼働ワークロードがあるホスト型のメトリッククラスターデプロイメントにファイルストレージを使用することは推奨されません。
9.2.1.4. ロギング
OpenShift Container Platform がホストするロギングのクラスターデプロイメント:
Loki Operator:
- 推奨されるストレージテクノロジーは、S3 互換のオブジェクトストレージです。
- ブロックストレージは設定できません。
OpenShift Elasticsearch Operator:
- 推奨されるストレージ技術はブロックストレージです。
- オブジェクトストレージはサポートされていません。
Logging バージョン 5.4.3 の時点で、OpenShift Elasticsearch Operator は非推奨であり、今後のリリースで削除される予定です。Red Hat は、この機能に対して現在のリリースライフサイクル中にバグ修正とサポートを提供しますが、拡張機能の提供はなく、この機能は今後削除される予定です。OpenShift Elasticsearch Operator を使用してデフォルトのログストレージを管理する代わりに、Loki Operator を使用できます。
9.2.1.5. アプリケーション
以下の例で説明されているように、アプリケーションのユースケースはアプリケーションごとに異なります。
- 動的な PV プロビジョニングをサポートするストレージ技術は、マウント時のレイテンシーが低く、ノードに関連付けられておらず、正常なクラスターをサポートします。
- アプリケーション開発者はアプリケーションのストレージ要件や、それがどのように提供されているストレージと共に機能するかを理解し、アプリケーションのスケーリング時やストレージレイヤーと対話する際に問題が発生しないようにしておく必要があります。
9.2.2. 特定のアプリケーションおよびストレージの他の推奨事項
etcd などの Write 集中型ワークロードで RAID 設定を使用することは推奨しません。RAID 設定で etcd を実行している場合、ワークロードでパフォーマンスの問題が発生するリスクがある可能性があります。
- Red Hat OpenStack Platform (RHOSP) Cinder: RHOSP Cinder は ROX アクセスモードのユースケースで適切に機能する傾向があります。
- データベース: データベース (RDBMS、NoSQL DB など) は、専用のブロックストレージで最適に機能することが予想されます。
- etcd データベースには、大規模なクラスターを有効にするのに十分なストレージと十分なパフォーマンス容量が必要です。十分なストレージと高性能環境を確立するための監視およびベンチマークツールに関する情報は、推奨される etcd プラクティス に記載されています。
9.3. Red Hat OpenShift Data Foundation のデプロイ
Red Hat OpenShift Data Foundation は、インハウスまたはハイブリッドクラウドのいずれの場合でもファイル、ブロックおよびオブジェクトストレージをサポートし、OpenShift Container Platform のすべてに対応する永続ストレージのプロバイダーです。Red Hat のストレージソリューションとして、Red Hat OpenShift Data Foundation は、デプロイメント、管理およびモニタリングを行うために OpenShift Container Platform に完全に統合されています。詳細は、Red Hat OpenShift Data Foundation のドキュメント を参照してください。
OpenShift Container Platform でインストールされた仮想マシンをホストするハイパーコンバージドノードを使用する Red Hat Hyperconverged Infrastructure (RHHI) for Virtualization の上部にある OpenShift Data Foundation は、サポート対象の設定ではありません。サポートされるプラットフォームの詳細は、Red Hat OpenShift Data Foundation Supportability and Interoperability Guide を参照してください。
| Red Hat OpenShift Data Foundation に関する情報 | Red Hat OpenShift Data Foundation のドキュメントの参照先 |
|---|---|
| 新機能、既知の問題、主なバグ修正およびテクノロジープレビュー | |
| サポートされるワークロード、レイアウト、ハードウェアおよびソフトウェア要件、サイジング、スケーリングに関する推奨事項 | |
| 外部の Red Hat Ceph Storage クラスターを使用するように OpenShift Data Foundation をデプロイする手順 | |
| ベアメタルインフラストラクチャーでローカルストレージを使用した OpenShift Data Foundation のデプロイ手順 | |
| Red Hat OpenShift Container Platform VMware vSphere クラスターへの OpenShift Data Foundation のデプロイ手順 | |
| ローカルまたはクラウドストレージの Amazon Web Services を使用した OpenShift Data Foundation のデプロイ手順 | Amazon Web Services を使用した OpenShift Data Foundation 4.12 のデプロイ |
| 既存の Red Hat OpenShift Container Platform Google Cloud クラスターへの OpenShift Data Foundation のデプロイおよび管理手順 | Google Cloud を使用した OpenShift Data Foundation 4.12 のデプロイおよび管理 |
| 既存の Red Hat OpenShift Container Platform Azure クラスターへの OpenShift Data Foundation のデプロイおよび管理手順 | Microsoft Azure を使用した OpenShift Data Foundation 4.12 のデプロイおよび管理 |
| IBM Power® インフラストラクチャーでローカルストレージを使用するように OpenShift Data Foundation をデプロイする手順 | |
| IBM Z® インフラストラクチャーでローカルストレージを使用するように OpenShift Data Foundation をデプロイする手順 | |
| スナップショットおよびクローンを含む、Red Hat OpenShift Data Foundation のコアサービスおよびホスト型アプリケーションへのストレージの割り当て | |
| Multicloud Object Gateway (NooBaa) を使用したハイブリッドクラウドまたはマルチクラウド環境でのストレージリソースの管理 | |
| Red Hat OpenShift Data Foundation のストレージデバイスの安全な置き換え | |
| Red Hat OpenShift Data Foundation クラスター内のノードの安全な置き換え | |
| Red Hat OpenShift Data Foundation でのスケーリング操作 | |
| Red Hat OpenShift Data Foundation 4.12 クラスターのモニタリング | |
| 操作中に発生する問題の解決 | |
| OpenShift Container Platform クラスターのバージョン 3 からバージョン 4 への移行 |
第10章 ユーザー向けの準備
OpenShift Container Platform のインストール後に、ユーザー向けに準備するための手順を含め、クラスターをさらに拡張し、要件に合わせてカスタマイズできます。
10.1. アイデンティティープロバイダー設定について
OpenShift Container Platform コントロールプレーンには、組み込まれた OAuth サーバーが含まれます。開発者および管理者は OAuth アクセストークンを取得して、API に対して認証します。
管理者は、クラスターのインストール後に、OAuth をアイデンティティープロバイダーを指定するように設定できます。
10.1.1. OpenShift Container Platform のアイデンティティープロバイダーについて
デフォルトでは、kubeadmin ユーザーのみがクラスターに存在します。アイデンティティープロバイダーを指定するには、アイデンティティープロバイダーを記述し、これをクラスターに追加するカスタムリソースを作成する必要があります。
/、:、および % を含む OpenShift Container Platform ユーザー名はサポートされません。
10.1.2. サポートされるアイデンティティープロバイダー
以下の種類のアイデンティティープロバイダーを設定できます。
| アイデンティティープロバイダー | 説明 |
|---|---|
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
|
アイデンティティープロバイダーを定義した後、RBAC を使用してパーミッションを定義および適用 できます。
10.1.3. アイデンティティープロバイダーパラメーター
以下のパラメーターは、すべてのアイデンティティープロバイダーに共通するパラメーターです。
| パラメーター | 説明 |
|---|---|
|
| プロバイダー名は、プロバイダーのユーザー名に接頭辞として付加され、アイデンティティー名が作成されます。 |
|
| 新規アイデンティティーがログイン時にユーザーにマップされる方法を定義します。以下の値のいずれかを入力します。
|
mappingMethod パラメーターを add に設定すると、アイデンティティープロバイダーの追加または変更時に新規プロバイダーのアイデンティティーを既存ユーザーにマッピングできます。
10.1.4. アイデンティティープロバイダー CR のサンプル
以下のカスタムリソース (CR) は、アイデンティティープロバイダーを設定するために使用するパラメーターおよびデフォルト値を示します。この例では、htpasswd アイデンティティープロバイダーを使用しています。
アイデンティティープロバイダー CR のサンプル
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- name: my_identity_provider
mappingMethod: claim
type: HTPasswd
htpasswd:
fileData:
name: htpass-secret 10.2. RBAC の使用によるパーミッションの定義および適用
ロールベースのアクセス制御を理解し、これを適用します。
10.2.1. RBAC の概要
ロールベースアクセス制御 (RBAC) オブジェクトは、ユーザーがプロジェクト内で所定のアクションを実行することが許可されるかどうかを決定します。
これにより、プラットフォーム管理者はクラスターロールおよびバインディングを使用して、OpenShift Container Platform プラットフォーム自体およびすべてのプロジェクトへの各種のアクセスレベルを持つユーザーを制御できます。
開発者はローカルロールとバインディングを使用して、プロジェクトにアクセスできるユーザーを制御できます。認可は認証とは異なる手順であることに注意してください。認証はアクションを実行するユーザーのアイデンティティーの判別により密接に関連しています。
認可は以下を使用して管理されます。
| 認可オブジェクト | 説明 |
|---|---|
| ルール |
オブジェクトのセットで許可されている動詞のセット(例: ユーザーまたはサービスアカウントが Pod の |
| ロール | ルールのコレクション。ユーザーおよびグループを複数のロールに関連付けたり、バインドしたりできます。 |
| バインディング | ロールを使用したユーザー/グループ間の関連付けです。 |
2 つのレベルの RBAC ロールおよびバインディングが認可を制御します。
| RBAC レベル | 説明 |
|---|---|
| クラスター RBAC | すべてのプロジェクトで適用可能なロールおよびバインディングです。クラスターロール はクラスター全体で存在し、クラスターロールのバインディング はクラスターロールのみを参照できます。 |
| ローカル RBAC | 所定のプロジェクトにスコープ設定されているロールおよびバインディングです。ローカルロール は単一プロジェクトのみに存在し、ローカルロールのバインディングはクラスターロールおよびローカルロールの 両方 を参照できます。 |
クラスターのロールバインディングは、クラスターレベルで存在するバインディングですが、ロールバインディングはプロジェクトレベルで存在します。ロールバインディングは、プロジェクトレベルで存在します。クラスターの view (表示) ロールは、ユーザーがプロジェクトを表示できるようローカルのロールバインディングを使用してユーザーにバインドする必要があります。ローカルロールは、クラスターのロールが特定の状況に必要なパーミッションのセットを提供しない場合にのみ作成する必要があります。
この 2 つのレベルからなる階層により、ローカルロールで個別プロジェクト内のカスタマイズが可能になる一方で、クラスターロールによる複数プロジェクト間での再利用が可能になります。
評価時に、クラスターロールのバインディングおよびローカルロールのバインディングが使用されます。以下に例を示します。
- クラスター全体の "allow" ルールがチェックされます。
- ローカルにバインドされた "allow" ルールがチェックされます。
- デフォルトで拒否します。
10.2.1.1. デフォルトのクラスターロール
OpenShift Container Platform には、クラスター全体で、またはローカルにユーザーおよびグループにバインドできるデフォルトのクラスターロールのセットが含まれます。
デフォルトのクラスターロールを手動で変更することは推奨されません。このようなシステムロールへの変更は、クラスターが正常に機能しなくなることがあります。
| デフォルトのクラスターロール | 説明 |
|---|---|
|
|
プロジェクトマネージャー。ローカルバインディングで使用される場合、 |
|
| プロジェクトおよびユーザーに関する基本的な情報を取得できるユーザーです。 |
|
| すべてのプロジェクトですべてのアクションを実行できるスーパーユーザーです。ローカルバインディングでユーザーにバインドされる場合は、クォータに対する完全な制御およびプロジェクト内のすべてのリソースに対するすべてのアクションを実行できます。 |
|
| 基本的なクラスターのステータス情報を取得できるユーザーです。 |
|
| ほとんどのオブジェクトを取得または表示できるが、変更できないユーザー。 |
|
| プロジェクトのほとんどのプロジェクトを変更できるが、ロールまたはバインディングを表示したり、変更したりする機能を持たないユーザーです。 |
|
| 独自のプロジェクトを作成できるユーザーです。 |
|
| 変更できないものの、プロジェクトでほとんどのオブジェクトを確認できるユーザーです。それらはロールまたはバインディングを表示したり、変更したりできません。 |
ローカルバインディングとクラスターバインディングに関する違いに留意してください。ローカルのロールバインディングを使用して cluster-admin ロールをユーザーにバインドする場合、このユーザーがクラスター管理者の特権を持っているように表示されます。しかし、実際はそうではありません。一方、cluster-admin をプロジェクトのユーザーにバインドすると、そのプロジェクトにのみ有効なスーパー管理者の権限がそのユーザーに付与されます。そのユーザーはクラスターロール admin のパーミッションを有するほか、レート制限を編集する機能などの、そのプロジェクトに関するいくつかの追加パーミッションを持ちます。このバインディングは、クラスター管理者にバインドされるクラスターのロールバインディングをリスト表示しない Web コンソール UI を使うと分かりにくくなります。ただし、これは、cluster-admin をローカルにバインドするために使用するローカルのロールバインディングをリスト表示します。
クラスターロール、クラスターロールのバインディング、ローカルロールのバインディング、ユーザー、グループおよびサービスアカウントの関係は以下に説明されています。
get pods/exec、get pods/*、および get * ルールは、ロールに適用されると実行権限を付与します。最小権限の原則を適用し、ユーザーおよびエージェントに必要な最小限の RBAC 権限のみを割り当てます。詳細は、RBAC ルールによる実行権限の許可 を参照してください。
10.2.1.2. 認可の評価
OpenShift Container Platform は以下を使用して認可を評価します。
- アイデンティティー
- ユーザーが属するユーザー名とグループのリスト。
- アクション
実行する動作。ほとんどの場合、これは以下で構成されます。
- プロジェクト: アクセスするプロジェクト。プロジェクトは追加のアノテーションを含む Kubernetes namespace であり、これにより、ユーザーのコミュニティーは、他のコミュニティーと分離された状態で独自のコンテンツを編成し、管理できます。
-
動詞:
get、list、create、update、delete、deletecollection、またはwatchなどのアクション自体。 - リソース名: アクセスする API エンドポイント。
- バインディング
- バインディングの詳細なリスト、ロールを持つユーザーまたはグループ間の関連付け。
OpenShift Container Platform は以下の手順を使用して認可を評価します。
- アイデンティティーおよびプロジェクトでスコープ設定されたアクションは、ユーザーおよびそれらのグループに適用されるすべてのバインディングを検索します。
- バインディングは、適用されるすべてのロールを見つけるために使用されます。
- ロールは、適用されるすべてのルールを見つけるために使用されます。
- 一致を見つけるために、アクションが各ルールに対してチェックされます。
- 一致するルールが見つからない場合、アクションはデフォルトで拒否されます。
ユーザーおよびグループは一度に複数のロールに関連付けたり、バインドしたりできることに留意してください。
プロジェクト管理者は CLI を使用してローカルロールとローカルバインディングを表示できます。これには、それぞれのロールが関連付けられる動詞およびリソースのマトリクスが含まれます。
プロジェクト管理者にバインドされるクラスターロールは、ローカルバインディングによってプロジェクト内で制限されます。これは、cluster-admin または system:admin に付与されるクラスターロールのようにクラスター全体でバインドされる訳ではありません。
クラスターロールは、クラスターレベルで定義されるロールですが、クラスターレベルまたはプロジェクトレベルのいずれかでバインドできます。
10.2.1.2.1. クラスターロールの集計
デフォルトの admin、edit、view、cluster-reader クラスターロールでは、クラスターロールの集約 がサポートされており、各ロールは新規ルール作成時に動的に更新されます。この機能は、カスタムリソースを作成して Kubernetes API を拡張する場合にのみ適用できます。
10.2.2. プロジェクトおよび namespace
Kubernetes namespace は、クラスターでスコープ設定するメカニズムを提供します。namespace の詳細は、Kubernetes ドキュメント を参照してください。
namespace は、次の一意のスコープを提供します。
- 基本的な命名の衝突を避けるための名前付きリソース。
- 信頼されるユーザーに委任された管理権限。
- コミュニティーリソースの消費を制限する機能。
システム内の大半のオブジェクトのスコープは namespace で設定されますが、一部はノードやユーザーを含め、除外され、namespace が設定されません。
プロジェクト は追加のアノテーションを持つ Kubernetes namespace であり、通常ユーザーのリソースへのアクセスが管理される中心的な手段です。プロジェクトはユーザーのコミュニティーが他のコミュニティーとは切り離してコンテンツを編成し、管理することを許可します。ユーザーには、管理者によってプロジェクトへのアクセスが付与される必要があり、許可される場合はプロジェクトを作成でき、それらの独自のプロジェクトへのアクセスが自動的に付与されます。
プロジェクトには、別個の name、displayName、および description を設定できます。
-
必須の
nameはプロジェクトの一意の識別子であり、CLI ツールまたは API を使用する場合に最も表示されます。名前の最大長さは 63 文字です。 -
オプションの
displayNameは、Web コンソールでのプロジェクトの表示方法を示します (デフォルトはnameに設定される)。 -
オプションの
descriptionには、プロジェクトのさらに詳細な記述を使用でき、これも Web コンソールで表示できます。
各プロジェクトは、以下の独自のセットのスコープを設定します。
| オブジェクト | 説明 |
|---|---|
|
| Pod、サービス、レプリケーションコントローラーなど。 |
|
| ユーザーがオブジェクトに対してアクションを実行できるかどうかに関するルール。 |
|
| 制限を設定できるそれぞれの種類のオブジェクトのクォータ。 |
|
| サービスアカウントは、プロジェクトのオブジェクトへの指定されたアクセスで自動的に機能します。 |
クラスター管理者はプロジェクトを作成でき、プロジェクトの管理者権限をユーザーコミュニティーの任意のメンバーに委任できます。クラスター管理者は、開発者が独自のプロジェクトを作成することも許可できます。
開発者および管理者は、CLI または Web コンソールを使用してプロジェクトとの対話を実行できます。
10.2.3. デフォルトプロジェクト
OpenShift Container Platform にはデフォルトのプロジェクトが多数含まれ、openshift- で始まるプロジェクトはユーザーにとって最も重要になります。これらのプロジェクトは、Pod として実行されるマスターコンポーネントおよび他のインフラストラクチャーコンポーネントをホストします。Critical Pod アノテーション を持つこれらの namespace で作成される Pod は Critical (重要) とみなされ、kubelet によるアドミッションが保証されます。これらの namespace のマスターコンポーネント用に作成された Pod には、すでに Critical のマークが付けられています。
デフォルトプロジェクトでワークロードを実行したり、デフォルトプロジェクトへのアクセスを共有したりしないでください。デフォルトのプロジェクトは、コアクラスターコンポーネントを実行するために予約されています。
デフォルトプロジェクトである default、kube-public、kube-system、openshift、openshift-infra、openshift-node、および openshift.io/run-level ラベルが 0 または 1 に設定されているその他のシステム作成プロジェクトは、高い特権があるとみなされます。Pod セキュリティーアドミッション、Security Context Constraints、クラスターリソースクォータ、イメージ参照解決などのアドミッションプラグインに依存する機能は、高い特権を持つプロジェクトでは機能しません。
10.2.4. クラスターロールおよびバインディングの表示
oc CLI で oc describe コマンドを使用して、クラスターロールおよびバインディングを表示できます。
前提条件
-
ocCLI がインストールされている。 - クラスターロールおよびバインディングを表示するパーミッションを取得します。
クラスター全体でバインドされた cluster-admin のデフォルトのクラスターロールを持つユーザーは、クラスターロールおよびバインディングの表示を含む、すべてのリソースでのすべてのアクションを実行できます。
手順
クラスターロールおよびそれらの関連付けられたルールセットを表示するには、以下を実行します。
$ oc describe clusterrole.rbac出力例
Name: admin Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate: true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- .packages.apps.redhat.com [] [] [* create update patch delete get list watch] imagestreams [] [] [create delete deletecollection get list patch update watch create get list watch] imagestreams.image.openshift.io [] [] [create delete deletecollection get list patch update watch create get list watch] secrets [] [] [create delete deletecollection get list patch update watch get list watch create delete deletecollection patch update] buildconfigs/webhooks [] [] [create delete deletecollection get list patch update watch get list watch] buildconfigs [] [] [create delete deletecollection get list patch update watch get list watch] buildlogs [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs/scale [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamimages [] [] [create delete deletecollection get list patch update watch get list watch] imagestreammappings [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamtags [] [] [create delete deletecollection get list patch update watch get list watch] processedtemplates [] [] [create delete deletecollection get list patch update watch get list watch] routes [] [] [create delete deletecollection get list patch update watch get list watch] templateconfigs [] [] [create delete deletecollection get list patch update watch get list watch] templateinstances [] [] [create delete deletecollection get list patch update watch get list watch] templates [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs.apps.openshift.io/scale [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs.apps.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] buildconfigs.build.openshift.io/webhooks [] [] [create delete deletecollection get list patch update watch get list watch] buildconfigs.build.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] buildlogs.build.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamimages.image.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] imagestreammappings.image.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamtags.image.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] routes.route.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] processedtemplates.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] templateconfigs.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] templateinstances.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] templates.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] serviceaccounts [] [] [create delete deletecollection get list patch update watch impersonate create delete deletecollection patch update get list watch] imagestreams/secrets [] [] [create delete deletecollection get list patch update watch] rolebindings [] [] [create delete deletecollection get list patch update watch] roles [] [] [create delete deletecollection get list patch update watch] rolebindings.authorization.openshift.io [] [] [create delete deletecollection get list patch update watch] roles.authorization.openshift.io [] [] [create delete deletecollection get list patch update watch] imagestreams.image.openshift.io/secrets [] [] [create delete deletecollection get list patch update watch] rolebindings.rbac.authorization.k8s.io [] [] [create delete deletecollection get list patch update watch] roles.rbac.authorization.k8s.io [] [] [create delete deletecollection get list patch update watch] networkpolicies.extensions [] [] [create delete deletecollection patch update create delete deletecollection get list patch update watch get list watch] networkpolicies.networking.k8s.io [] [] [create delete deletecollection patch update create delete deletecollection get list patch update watch get list watch] configmaps [] [] [create delete deletecollection patch update get list watch] endpoints [] [] [create delete deletecollection patch update get list watch] persistentvolumeclaims [] [] [create delete deletecollection patch update get list watch] pods [] [] [create delete deletecollection patch update get list watch] replicationcontrollers/scale [] [] [create delete deletecollection patch update get list watch] replicationcontrollers [] [] [create delete deletecollection patch update get list watch] services [] [] [create delete deletecollection patch update get list watch] daemonsets.apps [] [] [create delete deletecollection patch update get list watch] deployments.apps/scale [] [] [create delete deletecollection patch update get list watch] deployments.apps [] [] [create delete deletecollection patch update get list watch] replicasets.apps/scale [] [] [create delete deletecollection patch update get list watch] replicasets.apps [] [] [create delete deletecollection patch update get list watch] statefulsets.apps/scale [] [] [create delete deletecollection patch update get list watch] statefulsets.apps [] [] [create delete deletecollection patch update get list watch] horizontalpodautoscalers.autoscaling [] [] [create delete deletecollection patch update get list watch] cronjobs.batch [] [] [create delete deletecollection patch update get list watch] jobs.batch [] [] [create delete deletecollection patch update get list watch] daemonsets.extensions [] [] [create delete deletecollection patch update get list watch] deployments.extensions/scale [] [] [create delete deletecollection patch update get list watch] deployments.extensions [] [] [create delete deletecollection patch update get list watch] ingresses.extensions [] [] [create delete deletecollection patch update get list watch] replicasets.extensions/scale [] [] [create delete deletecollection patch update get list watch] replicasets.extensions [] [] [create delete deletecollection patch update get list watch] replicationcontrollers.extensions/scale [] [] [create delete deletecollection patch update get list watch] poddisruptionbudgets.policy [] [] [create delete deletecollection patch update get list watch] deployments.apps/rollback [] [] [create delete deletecollection patch update] deployments.extensions/rollback [] [] [create delete deletecollection patch update] catalogsources.operators.coreos.com [] [] [create update patch delete get list watch] clusterserviceversions.operators.coreos.com [] [] [create update patch delete get list watch] installplans.operators.coreos.com [] [] [create update patch delete get list watch] packagemanifests.operators.coreos.com [] [] [create update patch delete get list watch] subscriptions.operators.coreos.com [] [] [create update patch delete get list watch] buildconfigs/instantiate [] [] [create] buildconfigs/instantiatebinary [] [] [create] builds/clone [] [] [create] deploymentconfigrollbacks [] [] [create] deploymentconfigs/instantiate [] [] [create] deploymentconfigs/rollback [] [] [create] imagestreamimports [] [] [create] localresourceaccessreviews [] [] [create] localsubjectaccessreviews [] [] [create] podsecuritypolicyreviews [] [] [create] podsecuritypolicyselfsubjectreviews [] [] [create] podsecuritypolicysubjectreviews [] [] [create] resourceaccessreviews [] [] [create] routes/custom-host [] [] [create] subjectaccessreviews [] [] [create] subjectrulesreviews [] [] [create] deploymentconfigrollbacks.apps.openshift.io [] [] [create] deploymentconfigs.apps.openshift.io/instantiate [] [] [create] deploymentconfigs.apps.openshift.io/rollback [] [] [create] localsubjectaccessreviews.authorization.k8s.io [] [] [create] localresourceaccessreviews.authorization.openshift.io [] [] [create] localsubjectaccessreviews.authorization.openshift.io [] [] [create] resourceaccessreviews.authorization.openshift.io [] [] [create] subjectaccessreviews.authorization.openshift.io [] [] [create] subjectrulesreviews.authorization.openshift.io [] [] [create] buildconfigs.build.openshift.io/instantiate [] [] [create] buildconfigs.build.openshift.io/instantiatebinary [] [] [create] builds.build.openshift.io/clone [] [] [create] imagestreamimports.image.openshift.io [] [] [create] routes.route.openshift.io/custom-host [] [] [create] podsecuritypolicyreviews.security.openshift.io [] [] [create] podsecuritypolicyselfsubjectreviews.security.openshift.io [] [] [create] podsecuritypolicysubjectreviews.security.openshift.io [] [] [create] jenkins.build.openshift.io [] [] [edit view view admin edit view] builds [] [] [get create delete deletecollection get list patch update watch get list watch] builds.build.openshift.io [] [] [get create delete deletecollection get list patch update watch get list watch] projects [] [] [get delete get delete get patch update] projects.project.openshift.io [] [] [get delete get delete get patch update] namespaces [] [] [get get list watch] pods/attach [] [] [get list watch create delete deletecollection patch update] pods/exec [] [] [get list watch create delete deletecollection patch update] pods/portforward [] [] [get list watch create delete deletecollection patch update] pods/proxy [] [] [get list watch create delete deletecollection patch update] services/proxy [] [] [get list watch create delete deletecollection patch update] routes/status [] [] [get list watch update] routes.route.openshift.io/status [] [] [get list watch update] appliedclusterresourcequotas [] [] [get list watch] bindings [] [] [get list watch] builds/log [] [] [get list watch] deploymentconfigs/log [] [] [get list watch] deploymentconfigs/status [] [] [get list watch] events [] [] [get list watch] imagestreams/status [] [] [get list watch] limitranges [] [] [get list watch] namespaces/status [] [] [get list watch] pods/log [] [] [get list watch] pods/status [] [] [get list watch] replicationcontrollers/status [] [] [get list watch] resourcequotas/status [] [] [get list watch] resourcequotas [] [] [get list watch] resourcequotausages [] [] [get list watch] rolebindingrestrictions [] [] [get list watch] deploymentconfigs.apps.openshift.io/log [] [] [get list watch] deploymentconfigs.apps.openshift.io/status [] [] [get list watch] controllerrevisions.apps [] [] [get list watch] rolebindingrestrictions.authorization.openshift.io [] [] [get list watch] builds.build.openshift.io/log [] [] [get list watch] imagestreams.image.openshift.io/status [] [] [get list watch] appliedclusterresourcequotas.quota.openshift.io [] [] [get list watch] imagestreams/layers [] [] [get update get] imagestreams.image.openshift.io/layers [] [] [get update get] builds/details [] [] [update] builds.build.openshift.io/details [] [] [update] Name: basic-user Labels: <none> Annotations: openshift.io/description: A user that can get basic information about projects. rbac.authorization.kubernetes.io/autoupdate: true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- selfsubjectrulesreviews [] [] [create] selfsubjectaccessreviews.authorization.k8s.io [] [] [create] selfsubjectrulesreviews.authorization.openshift.io [] [] [create] clusterroles.rbac.authorization.k8s.io [] [] [get list watch] clusterroles [] [] [get list] clusterroles.authorization.openshift.io [] [] [get list] storageclasses.storage.k8s.io [] [] [get list] users [] [~] [get] users.user.openshift.io [] [~] [get] projects [] [] [list watch] projects.project.openshift.io [] [] [list watch] projectrequests [] [] [list] projectrequests.project.openshift.io [] [] [list] Name: cluster-admin Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate: true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- *.* [] [] [*] [*] [] [*] ...各種のロールにバインドされたユーザーおよびグループを示す、クラスターのロールバインディングの現在のセットを表示するには、以下を実行します。
$ oc describe clusterrolebinding.rbac出力例
Name: alertmanager-main Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: alertmanager-main Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount alertmanager-main openshift-monitoring Name: basic-users Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate: true Role: Kind: ClusterRole Name: basic-user Subjects: Kind Name Namespace ---- ---- --------- Group system:authenticated Name: cloud-credential-operator-rolebinding Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: cloud-credential-operator-role Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount default openshift-cloud-credential-operator Name: cluster-admin Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate: true Role: Kind: ClusterRole Name: cluster-admin Subjects: Kind Name Namespace ---- ---- --------- Group system:masters Name: cluster-admins Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate: true Role: Kind: ClusterRole Name: cluster-admin Subjects: Kind Name Namespace ---- ---- --------- Group system:cluster-admins User system:admin Name: cluster-api-manager-rolebinding Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: cluster-api-manager-role Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount default openshift-machine-api ...
10.2.5. ローカルのロールバインディングの表示
oc CLI で oc describe コマンドを使用して、ローカルロールおよびバインディングを表示できます。
前提条件
-
ocCLI がインストールされている。 ローカルロールおよびバインディングを表示するパーミッションを取得します。
-
クラスター全体でバインドされた
cluster-adminのデフォルトのクラスターロールを持つユーザーは、ローカルロールおよびバインディングの表示を含む、すべてのリソースでのすべてのアクションを実行できます。 -
ローカルにバインドされた
adminのデフォルトのクラスターロールを持つユーザーは、そのプロジェクトのロールおよびバインディングを表示し、管理できます。
-
クラスター全体でバインドされた
手順
現在のプロジェクトの各種のロールにバインドされたユーザーおよびグループを示す、ローカルのロールバインディングの現在のセットを表示するには、以下を実行します。
$ oc describe rolebinding.rbac別のプロジェクトのローカルロールバインディングを表示するには、
-nフラグをコマンドに追加します。$ oc describe rolebinding.rbac -n joe-project出力例
Name: admin Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- User kube:admin Name: system:deployers Labels: <none> Annotations: openshift.io/description: Allows deploymentconfigs in this namespace to rollout pods in this namespace. It is auto-managed by a controller; remove subjects to disa... Role: Kind: ClusterRole Name: system:deployer Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount deployer joe-project Name: system:image-builders Labels: <none> Annotations: openshift.io/description: Allows builds in this namespace to push images to this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-builder Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount builder joe-project Name: system:image-pullers Labels: <none> Annotations: openshift.io/description: Allows all pods in this namespace to pull images from this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-puller Subjects: Kind Name Namespace ---- ---- --------- Group system:serviceaccounts:joe-project
10.2.6. ロールのユーザーへの追加
oc adm 管理者 CLI を使用してロールおよびバインディングを管理できます。
ロールをユーザーまたはグループにバインドするか、追加することにより、そのロールによって付与されるアクセスがそのユーザーまたはグループに付与されます。oc adm policy コマンドを使用して、ロールのユーザーおよびグループへの追加、またはユーザーおよびグループからの削除を行うことができます。
デフォルトのクラスターロールのすべてを、プロジェクト内のローカルユーザーまたはグループにバインドできます。
手順
ロールを特定プロジェクトのユーザーに追加します。
$ oc adm policy add-role-to-user <role> <user> -n <project>たとえば、以下を実行して
adminロールをjoeプロジェクトのaliceユーザーに追加できます。$ oc adm policy add-role-to-user admin alice -n joeヒントまたは、以下の YAML を適用してユーザーにロールを追加できます。
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: admin-0 namespace: joe roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: admin subjects: - apiGroup: rbac.authorization.k8s.io kind: User name: alice出力でローカルロールバインディングを確認し、追加の内容を確認します。
$ oc describe rolebinding.rbac -n <project>たとえば、
joeプロジェクトのローカルロールバインディングを表示するには、以下を実行します。$ oc describe rolebinding.rbac -n joe出力例
Name: admin Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- User kube:admin Name: admin-0 Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- User alice1 Name: system:deployers Labels: <none> Annotations: openshift.io/description: Allows deploymentconfigs in this namespace to rollout pods in this namespace. It is auto-managed by a controller; remove subjects to disa... Role: Kind: ClusterRole Name: system:deployer Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount deployer joe Name: system:image-builders Labels: <none> Annotations: openshift.io/description: Allows builds in this namespace to push images to this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-builder Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount builder joe Name: system:image-pullers Labels: <none> Annotations: openshift.io/description: Allows all pods in this namespace to pull images from this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-puller Subjects: Kind Name Namespace ---- ---- --------- Group system:serviceaccounts:joe- 1
aliceユーザーがadminsRoleBindingに追加されています。
10.2.7. ローカルロールの作成
プロジェクトのローカルロールを作成し、これをユーザーにバインドできます。
手順
プロジェクトのローカルロールを作成するには、以下のコマンドを実行します。
$ oc create role <name> --verb=<verb> --resource=<resource> -n <project>このコマンドで以下を指定します。
-
<name>: ローカルのロール名です。 -
<verb>: ロールに適用する動詞のコンマ区切りのリストです。 -
<resource>: ロールが適用されるリソースです。 -
<project>(プロジェクト名)
たとえば、ユーザーが
blueプロジェクトで Pod を閲覧できるようにするローカルロールを作成するには、以下のコマンドを実行します。$ oc create role podview --verb=get --resource=pod -n blue-
新規ロールをユーザーにバインドするには、以下のコマンドを実行します。
$ oc adm policy add-role-to-user podview user2 --role-namespace=blue -n blue
10.2.8. クラスターロールの作成
クラスターロールを作成できます。
手順
クラスターロールを作成するには、以下のコマンドを実行します。
$ oc create clusterrole <name> --verb=<verb> --resource=<resource>このコマンドで以下を指定します。
-
<name>: ローカルのロール名です。 -
<verb>: ロールに適用する動詞のコンマ区切りのリストです。 -
<resource>: ロールが適用されるリソースです。
たとえば、ユーザーが Pod を閲覧できるようにするクラスターロールを作成するには、以下のコマンドを実行します。
$ oc create clusterrole podviewonly --verb=get --resource=pod-
10.2.9. ローカルロールバインディングのコマンド
以下の操作を使用し、ローカルのロールバインディングでのユーザーまたはグループの関連付けられたロールを管理する際に、プロジェクトは -n フラグで指定できます。これが指定されていない場合には、現在のプロジェクトが使用されます。
ローカル RBAC 管理に以下のコマンドを使用できます。
| コマンド | 説明 |
|---|---|
|
| リソースに対してアクションを実行できるユーザーを示します。 |
|
| 指定されたロールを現在のプロジェクトの指定ユーザーにバインドします。 |
|
| 現在のプロジェクトの指定ユーザーから指定されたロールを削除します。 |
|
| 現在のプロジェクトの指定ユーザーと、そのすべてのロールを削除します。 |
|
| 指定されたロールを現在のプロジェクトの指定グループにバインドします。 |
|
| 現在のプロジェクトの指定グループから指定されたロールを削除します。 |
|
| 現在のプロジェクトの指定グループと、そのすべてのロールを削除します。 |
10.2.10. クラスターのロールバインディングコマンド
以下の操作を使用して、クラスターのロールバインディングも管理できます。クラスターのロールバインディングは namespace を使用していないリソースを使用するため、-n フラグはこれらの操作に使用されません。
| コマンド | 説明 |
|---|---|
|
| 指定されたロールをクラスターのすべてのプロジェクトの指定ユーザーにバインドします。 |
|
| 指定されたロールをクラスターのすべてのプロジェクトの指定ユーザーから削除します。 |
|
| 指定されたロールをクラスターのすべてのプロジェクトの指定グループにバインドします。 |
|
| 指定されたロールをクラスターのすべてのプロジェクトの指定グループから削除します。 |
10.2.11. クラスター管理者の作成
cluster-admin ロールは、クラスターリソースの変更など、OpenShift Container Platform クラスターでの管理者レベルのタスクを実行するために必要です。
前提条件
- クラスター管理者として定義するユーザーを作成している。
手順
ユーザーをクラスター管理者として定義します。
$ oc adm policy add-cluster-role-to-user cluster-admin <user>
10.2.12. 認証されていないグループのクラスターロールバインディング
OpenShift Container Platform 4.16 より前では、認証されていないグループでも一部のクラスターロールへのアクセスが許可されていました。OpenShift Container Platform 4.16 より前のバージョンから更新されたクラスターは、認証されていないグループに対してこのアクセスを保持します。
セキュリティー上の理由から、OpenShift Container Platform 4.16 では、デフォルトで、認証されていないグループはクラスターロールにアクセスできません。
ユースケースによっては、クラスターロールに system:unauthenticated を追加する必要があります。
クラスター管理者は、認証されていないユーザーを次のクラスターロールに追加できます。
-
system:scope-impersonation -
system:webhook -
system:oauth-token-deleter -
self-access-reviewer
認証されていないアクセスを変更するときは、常に組織のセキュリティー標準に準拠していることを確認してください。
10.2.13. 認証されていないグループのクラスターロールへの追加
クラスター管理者は、クラスターロールバインディングを作成することにより、OpenShift Container Platform の次のクラスターロールに認証されていないユーザーを追加できます。認証されていないユーザーには、パブリックではないクラスターロールへのアクセス権はありません。これは、特定のユースケースで必要な場合にのみ行うようにしてください。
認証されていないユーザーを以下のクラスターロールに追加できます。
-
system:scope-impersonation -
system:webhook -
system:oauth-token-deleter -
self-access-reviewer
認証されていないアクセスを変更するときは、常に組織のセキュリティー標準に準拠していることを確認してください。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
add-<cluster_role>-unauth.yamlという名前の YAML ファイルを作成し、次のコンテンツを追加します。apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "true" name: <cluster_role>access-unauthenticated roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: <cluster_role> subjects: - apiGroup: rbac.authorization.k8s.io kind: Group name: system:unauthenticated以下のコマンドを実行して設定を適用します。
$ oc apply -f add-<cluster_role>.yaml
10.3. kubeadmin ユーザー
OpenShift Container Platform は、インストールプロセスの完了後にクラスター管理者 kubeadmin を作成します。
このユーザーには、cluster-admin ロールが自動的に適用され、このユーザーはクラスターの root ユーザーとしてみなされます。パスワードは動的に生成され、OpenShift Container Platform 環境に対して一意です。インストールの完了後に、パスワードはインストールプログラムの出力で提供されます。以下に例を示します。
INFO Install complete!
INFO Run 'export KUBECONFIG=<your working directory>/auth/kubeconfig' to manage the cluster with 'oc', the OpenShift CLI.
INFO The cluster is ready when 'oc login -u kubeadmin -p <provided>' succeeds (wait a few minutes).
INFO Access the OpenShift web-console here: https://console-openshift-console.apps.demo1.openshift4-beta-abcorp.com
INFO Login to the console with user: kubeadmin, password: <provided>10.3.1. kubeadmin ユーザーの削除
アイデンティティープロバイダーを定義し、新規 cluster-admin ユーザーを作成した後に、クラスターのセキュリティーを強化するために kubeadmin を削除できます。
別のユーザーが cluster-admin になる前にこの手順を実行する場合、OpenShift Container Platform は再インストールされる必要があります。このコマンドをやり直すことはできません。
前提条件
- 1 つ以上のアイデンティティープロバイダーを設定しておく必要があります。
-
cluster-adminロールをユーザーに追加しておく必要があります。 - 管理者としてログインしている必要があります。
手順
kubeadminシークレットを削除します。$ oc delete secrets kubeadmin -n kube-system
10.4. ミラーリングされた Operator カタログからの OperatorHub の入力
非接続クラスターで使用するように Operator カタログをミラーリングする場合は、OperatorHub をミラーリングされたカタログの Operator で設定できます。ミラーリングプロセスから生成されたマニフェストを使用して、必要な ImageContentSourcePolicy および CatalogSource オブジェクトを作成できます。
10.4.1. 前提条件
10.4.1.1. ImageContentSourcePolicy オブジェクトの作成
Operator カタログコンテンツをミラーレジストリーにミラーリングした後に、必要な ImageContentSourcePolicy (ICSP) オブジェクトを作成します。ICSP オブジェクトは、Operator マニフェストおよびミラーリングされたレジストリーに保存されるイメージ参照間で変換するようにノードを設定します。
手順
非接続クラスターへのアクセスのあるホストで、以下のコマンドを実行して manifests ディレクトリーで
imageContentSourcePolicy.yamlファイルを指定して ICSP を作成します。$ oc create -f <path/to/manifests/dir>/imageContentSourcePolicy.yamlここで、
<path/to/manifests/dir>は、ミラーリングされたコンテンツに関する manifests ディレクトリーへのパスです。ミラーリングされたインデックスイメージおよび Operator コンテンツを参照する
CatalogSourceを作成できるようになりました。
10.4.1.2. クラスターへのカタログソースの追加
OpenShift Container Platform クラスターにカタログソースを追加すると、ユーザーが Operator を検索してインストールできるようになります。クラスター管理者は、インデックスイメージを参照する CatalogSource オブジェクトを作成できます。OperatorHub はカタログソースを使用してユーザーインターフェイスを設定します。
または、Web コンソールを使用してカタログソースを管理できます。Administration → Cluster Settings → Configuration → OperatorHub ページから、Sources タブをクリックして、個別のソースを作成、更新、削除、無効化、有効化できます。
前提条件
- インデックスイメージをビルドしてレジストリーにプッシュしている。
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
インデックスイメージを参照する
CatalogSourceオブジェクトを作成します。oc adm catalog mirrorコマンドを使用してカタログをターゲットレジストリーにミラーリングする場合、manifests ディレクトリーに生成されるcatalogSource.yamlファイルを開始点としてそのまま使用することができます。仕様を以下のように変更し、これを
catalogSource.yamlファイルとして保存します。apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: my-operator-catalog1 namespace: openshift-marketplace2 spec: sourceType: grpc grpcPodConfig: securityContextConfig: <security_mode>3 image: <registry>/<namespace>/redhat-operator-index:v4.164 displayName: My Operator Catalog publisher: <publisher_name>5 updateStrategy: registryPoll:6 interval: 30m- 1
- レジストリーにアップロードする前にローカルファイルにコンテンツをミラーリングする場合は、
metadata.nameフィールドからバックスラッシュ (/) 文字を削除し、オブジェクトの作成時に "invalid resource name" エラーを回避します。 - 2
- カタログソースを全 namespace のユーザーがグローバルに利用できるようにする場合は、
openshift-marketplacenamespace を指定します。それ以外の場合は、そのカタログの別の namespace を対象とし、その namespace のみが利用できるように指定できます。 - 3
legacyまたはrestrictedの値を指定します。フィールドが設定されていない場合、デフォルト値はlegacyです。今後の OpenShift Container Platform リリースでは、デフォルト値がrestrictedになる予定です。注記restricted権限でカタログを実行できない場合は、このフィールドを手動でlegacyに設定することを推奨します。- 4
- インデックスイメージを指定します。イメージ名の後にタグを指定した場合 (
:v4.16など)、カタログソース Pod はAlwaysのイメージプルポリシーを使用します。これは、Pod が常にコンテナーを開始する前にイメージをプルすることを意味します。@sha256:<id>などのダイジェストを指定した場合、イメージプルポリシーはIfNotPresentになります。これは、イメージがノード上にまだ存在しない場合にのみ、Pod がイメージをプルすることを意味します。 - 5
- カタログを公開する名前または組織名を指定します。
- 6
- カタログソースは新規バージョンの有無を自動的にチェックし、最新の状態を維持します。
このファイルを使用して
CatalogSourceオブジェクトを作成します。$ oc apply -f catalogSource.yaml
以下のリソースが正常に作成されていることを確認します。
Pod を確認します。
$ oc get pods -n openshift-marketplace出力例
NAME READY STATUS RESTARTS AGE my-operator-catalog-6njx6 1/1 Running 0 28s marketplace-operator-d9f549946-96sgr 1/1 Running 0 26hカタログソースを確認します。
$ oc get catalogsource -n openshift-marketplace出力例
NAME DISPLAY TYPE PUBLISHER AGE my-operator-catalog My Operator Catalog grpc 5sパッケージマニフェストを確認します。
$ oc get packagemanifest -n openshift-marketplace出力例
NAME CATALOG AGE jaeger-product My Operator Catalog 93s
OpenShift Container Platform Web コンソールで、OperatorHub ページから Operator をインストールできるようになりました。
10.5. OperatorHub を使用した Operator のインストールについて
OperatorHub は Operator を検出するためのユーザーインターフェイスです。これは Operator Lifecycle Manager (OLM) と連携し、クラスター上で Operator をインストールし、管理します。
クラスター管理者は、OpenShift Container Platform Web コンソールまたは CLI を使用して OperatorHub から Operator をインストールできます。Operator を 1 つまたは複数の namespace にサブスクライブし、Operator をクラスター上で開発者が使用できるようにできます。
インストール時に、Operator の以下の初期設定を判別する必要があります。
- インストールモード
- All namespaces on the cluster (default) を選択して Operator をすべての namespace にインストールするか、(利用可能な場合は) 個別の namespace を選択し、選択された namespace のみに Operator をインストールします。この例では、All namespaces… を選択し、Operator をすべてのユーザーおよびプロジェクトで利用可能にします。
- 更新チャネル
- Operator が複数のチャネルで利用可能な場合、サブスクライブするチャネルを選択できます。たとえば、(利用可能な場合に) stable チャネルからデプロイするには、これをリストから選択します。
- 承認ストラテジー
自動 (Automatic) または手動 (Manual) のいずれかの更新を選択します。
インストールされた Operator に自動更新を選択する場合、Operator の新規バージョンが選択されたチャネルで利用可能になると、Operator Lifecycle Manager (OLM) は人の介入なしに、Operator の実行中のインスタンスを自動的にアップグレードします。
手動更新を選択する場合、Operator の新規バージョンが利用可能になると、OLM は更新要求を作成します。クラスター管理者は、Operator が新規バージョンに更新されるように更新要求を手動で承認する必要があります。
10.5.1. Web コンソールを使用して OperatorHub からインストールする
OpenShift Container Platform Web コンソールを使用して OperatorHub から Operator をインストールし、これをサブスクライブできます。
前提条件
-
cluster-admin権限を持つアカウントを使用して OpenShift Container Platform クラスターにアクセスできる。
手順
- Web コンソールで、Operators → OperatorHub ページに移動します。
スクロールするか、キーワードを Filter by keyword ボックスに入力し、必要な Operator を見つけます。たとえば、
jaegerと入力し、Jaeger Operator を検索します。また、インフラストラクチャー機能 でオプションをフィルターすることもできます。たとえば、非接続環境 (ネットワークが制限された環境ともしても知られる) で機能する Operators を表示するには、Disconnected を選択します。
Operator を選択して、追加情報を表示します。
注記コミュニティー Operator を選択すると、Red Hat がコミュニティー Operator を認定していないことを警告します。続行する前に警告を確認する必要があります。
- Operator の情報を確認してから、Install をクリックします。
Install Operator ページで、Operator のインストールを設定します。
特定のバージョンの Operator をインストールする場合は、リストから Update channel と Version を選択します。Operator のすべてのチャネルから Operator のさまざまなバージョンを参照し、そのチャネルとバージョンのメタデータを表示して、インストールする正確なバージョンを選択できます。
注記バージョン選択のデフォルトは、選択したチャネルの最新バージョンです。チャネルの最新バージョンが選択されている場合は、自動 承認戦略がデフォルトで有効になります。それ以外の場合、選択したチャネルの最新バージョンをインストールしない場合は、手動 による承認が必要です。
手動 承認を使用して Operator をインストールすると、namespace 内にインストールされたすべての Operators が 手動 承認戦略で機能し、すべての Operators が一緒に更新されます。Operators を個別に更新する場合は、Operators を別の namespace にインストールします。
Operator のインストールモードを確認します。
-
All namespaces on the cluster (default) は、デフォルトの
openshift-operatorsnamespace で Operator をインストールし、クラスターのすべての namespace を監視し、Operator をこれらの namespace に対して利用可能にします。このオプションは常に選択可能です。 - A specific namespace on the cluster では、Operator をインストールする特定の単一 namespace を選択できます。Operator は監視のみを実行し、この単一 namespace で使用されるように利用可能になります。
-
All namespaces on the cluster (default) は、デフォルトの
トークン認証が有効になっているクラウドプロバイダー上のクラスターの場合:
- クラスターが AWS STS (Web コンソールの STS モード) を使用する場合は、ロール ARN フィールドにサービスアカウントの AWS IAM ロールの Amazon Resource Name (ARN) を入力します。ロールの ARN を作成するには、AWS アカウントの準備 で説明されている手順に従います。
- クラスターが Microsoft Entra Workload ID (Web コンソールの Workload アイデンティティー/フェデレーションされたアイデンティティーモード) を使用する場合は、適切なフィールドにクライアント ID、テナント ID、サブスクリプション ID を追加します。
Update approval で、承認ストラテジー Automatic または Manual を選択します。
重要Web コンソールに、クラスターが AWS STS または Microsoft Entra Workload ID を使用していることが示されている場合は、Update approval を Manual に設定する必要があります。
更新前に権限の変更が必要になる可能性があるため、自動更新承認のあるサブスクリプションは推奨できません。手動更新承認付きのサブスクリプションにより、管理者は新しいバージョンの権限を確認し、更新前に必要な手順を実行する機会が確保されます。
Install をクリックし、Operator をこの OpenShift Container Platform クラスターの選択した namespace で利用可能にします。
手動 の承認ストラテジーを選択している場合、サブスクリプションのアップグレードステータスは、そのインストール計画を確認し、承認するまで Upgrading のままになります。
Install Plan ページでの承認後に、サブスクリプションのアップグレードステータスは Up to date に移行します。
- 自動 の承認ストラテジーを選択している場合、アップグレードステータスは、介入なしに Up to date に解決するはずです。
検証
サブスクリプションのアップグレードステータスが Up to date になった後に、Operators → Installed Operators を選択し、インストールされた Operator のクラスターサービスバージョン (CSV) が表示されることを確認します。Status は、関連する namespace で最終的に Succeeded に解決されるはずです。
注記All namespaces… インストールモードの場合、ステータスは
openshift-operatorsnamespace で Succeeded になりますが、他の namespace でチェックする場合、ステータスは Copied になります。上記通りにならない場合、以下を実行します。
-
さらにトラブルシューティングを行うために問題を報告している Workloads → Pods ページで、
openshift-operatorsプロジェクト (または A specific namespace… インストールモードが選択されている場合は他の関連の namespace) の Pod のログを確認します。
-
さらにトラブルシューティングを行うために問題を報告している Workloads → Pods ページで、
Operator をインストールすると、メタデータに、インストールされているチャネルとバージョンが示されます。
注記ドロップダウンメニュー Channel および Version は、このカタログコンテキストで他のバージョンのメタデータを表示するために引き続き使用できます。
10.5.2. CLI を使用して OperatorHub からインストールする
OpenShift Container Platform Web コンソールを使用する代わりに、CLI を使用して OperatorHub から Operator をインストールできます。oc コマンドを使用して、Subscription オブジェクトを作成または更新します。
SingleNamespace インストールモードの場合は、関連する namespace に適切な Operator グループが存在することも確認する必要があります。OperatorGroup で定義される Operator グループは、Operator グループと同じ namespace 内のすべての Operators に必要な RBAC アクセスを生成するターゲット namespace を選択します。
ほとんどの場合は、この手順の Web コンソール方式が推奨されます。これは、SingleNamespace モードを選択したときに OperatorGroup オブジェクトおよび Subscription オブジェクトの作成を自動的に処理するなど、バックグラウンドでタスクが自動化されるためです。
前提条件
-
cluster-admin権限を持つアカウントを使用して OpenShift Container Platform クラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
OperatorHub からクラスターで利用できる Operators のリストを表示します。
$ oc get packagemanifests -n openshift-marketplace例10.1 出力例
NAME CATALOG AGE 3scale-operator Red Hat Operators 91m advanced-cluster-management Red Hat Operators 91m amq7-cert-manager Red Hat Operators 91m # ... couchbase-enterprise-certified Certified Operators 91m crunchy-postgres-operator Certified Operators 91m mongodb-enterprise Certified Operators 91m # ... etcd Community Operators 91m jaeger Community Operators 91m kubefed Community Operators 91m # ...必要な Operator のカタログをメモします。
必要な Operator を検査して、サポートされるインストールモードおよび利用可能なチャネルを確認します。
$ oc describe packagemanifests <operator_name> -n openshift-marketplace例10.2 出力例
# ... Kind: PackageManifest # ... Install Modes:1 Supported: true Type: OwnNamespace Supported: true Type: SingleNamespace Supported: false Type: MultiNamespace Supported: true Type: AllNamespaces # ... Entries: Name: example-operator.v3.7.11 Version: 3.7.11 Name: example-operator.v3.7.10 Version: 3.7.10 Name: stable-3.72 # ... Entries: Name: example-operator.v3.8.5 Version: 3.8.5 Name: example-operator.v3.8.4 Version: 3.8.4 Name: stable-3.83 Default Channel: stable-3.84 ヒント次のコマンドを実行すると、Operator のバージョンとチャネル情報を YAML 形式で出力できます。
$ oc get packagemanifests <operator_name> -n <catalog_namespace> -o yamlnamespace に複数のカタログがインストールされている場合は、次のコマンドを実行して、特定のカタログから Operator の使用可能なバージョンとチャネルを検索します。
$ oc get packagemanifest \ --selector=catalog=<catalogsource_name> \ --field-selector metadata.name=<operator_name> \ -n <catalog_namespace> -o yaml重要Operator のカタログを指定しない場合、
oc get packagemanifestおよびoc describe packagemanifestコマンドを実行すると、次の条件が満たされると予期しないカタログからパッケージが返される可能性があります。- 複数のカタログが同じ namespace にインストールされます。
- カタログには、同じ Operators、または同じ名前の Operators が含まれています。
インストールする Operator が
AllNamespacesインストールモードをサポートしており、このモードを使用することを選択した場合は、openshift-operatorsnamespace にglobal-operatorsと呼ばれる適切な Operator グループがデフォルトですでに配置されているため、この手順をスキップしてください。インストールする Operator が
SingleNamespaceインストールモードをサポートしており、このモードを使用することを選択した場合は、関連する namespace に適切な Operator グループが存在することを確認する必要があります。存在しない場合は、次の手順に従って作成できます。重要namespace ごとに Operator グループを 1 つだけ持つことができます。詳細は、「Operator グループ」を参照してください。
SingleNamespaceインストールモード用に、OperatorGroupオブジェクト YAML ファイル (例:operatorgroup.yaml) を作成します。SingleNamespaceインストールモードのOperatorGroupオブジェクトの例apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: <operatorgroup_name> namespace: <namespace>1 spec: targetNamespaces: - <namespace>2 OperatorGroupオブジェクトを作成します。$ oc apply -f operatorgroup.yaml
namespace を Operator にサブスクライブするための
Subscriptionオブジェクトを作成します。Subscriptionオブジェクトの YAML ファイル (例:subscription.yaml) を作成します。注記特定のバージョンの Operator をサブスクライブする場合は、
startingCSVフィールドを目的のバージョンに設定し、installPlanApprovalフィールドをManualに設定して、カタログに新しいバージョンが存在する場合に Operator が自動的にアップグレードされないようにします。詳細は、次の「特定の開始 Operator バージョンを持つSubscriptionオブジェクトの例」を参照してください。例10.3
Subscriptionオブジェクトの例apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: <subscription_name> namespace: <namespace_per_install_mode>1 spec: channel: <channel_name>2 name: <operator_name>3 source: <catalog_name>4 sourceNamespace: <catalog_source_namespace>5 config: env:6 - name: ARGS value: "-v=10" envFrom:7 - secretRef: name: license-secret volumes:8 - name: <volume_name> configMap: name: <configmap_name> volumeMounts:9 - mountPath: <directory_name> name: <volume_name> tolerations:10 - operator: "Exists" resources:11 requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m" nodeSelector:12 foo: bar- 1
- デフォルトの
AllNamespacesインストールモードの使用は、openshift-operatorsnamespace を指定します。カスタムグローバル namespace を作成している場合はこれを指定できます。SingleNamespaceインストールモードを使用する場合は、関連する単一の namespace を指定します。 - 2
- サブスクライブするチャネルの名前。
- 3
- サブスクライブする Operator の名前。
- 4
- Operator を提供するカタログソースの名前。
- 5
- カタログソースの namespace。デフォルトの OperatorHub カタログソースには
openshift-marketplaceを使用します。 - 6
envパラメーターは、OLM によって作成される Pod のすべてのコンテナーに存在する必要がある環境変数の一覧を定義します。- 7
envFromパラメーターは、コンテナーの環境変数に反映するためのソースの一覧を定義します。- 8
volumesパラメーターは、OLM によって作成される Pod に存在する必要があるボリュームの一覧を定義します。- 9
volumeMountsパラメーターは、OLM によって作成される Pod のすべてのコンテナーに存在する必要があるボリュームマウントの一覧を定義します。存在しないvolumeをvolumeMountが参照すると、OLM が Operator のデプロイに失敗します。- 10
tolerationsパラメーターは、OLM によって作成される Pod の toleration の一覧を定義します。- 11
resourcesパラメーターは、OLM によって作成される Pod のすべてのコンテナーのリソース制約を定義します。- 12
nodeSelectorパラメーターは、OLM によって作成される Pod のNodeSelectorを定義します。
例10.4 特定の開始 Operator バージョンを持つ
Subscriptionオブジェクトの例apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: example-operator namespace: example-operator spec: channel: stable-3.7 installPlanApproval: Manual1 name: example-operator source: custom-operators sourceNamespace: openshift-marketplace startingCSV: example-operator.v3.7.102 トークン認証が有効になっているクラウドプロバイダー上のクラスターの場合は、次の手順に従って
Subscriptionオブジェクトを設定します。Subscriptionオブジェクトが手動更新承認に設定されていることを確認します。kind: Subscription # ... spec: installPlanApproval: Manual1 - 1
- 更新前に権限の変更が必要になる可能性があるため、自動更新承認のあるサブスクリプションは推奨できません。手動更新承認付きのサブスクリプションにより、管理者は新しいバージョンの権限を確認し、更新前に必要な手順を実行する機会が確保されます。
関連するクラウドプロバイダー固有のフィールドを
Subscriptionオブジェクトのconfigセクションに含めます。クラスターが AWS STS モードの場合は、次のフィールドを含めます。
kind: Subscription # ... spec: config: env: - name: ROLEARN value: "<role_arn>"1 - 1
- ロール ARN の詳細を含めます。
クラスターが Microsoft Entra Workload ID モードの場合は、次のフィールドを含めます。
kind: Subscription # ... spec: config: env: - name: CLIENTID value: "<client_id>"1 - name: TENANTID value: "<tenant_id>"2 - name: SUBSCRIPTIONID value: "<subscription_id>"3 ここでは、以下のようになります。
<client_id>- クライアント ID です。
<tenant_id>- テナント ID です。
<subscription_id>- サブスクリプション ID です。
以下のコマンドを実行して
Subscriptionオブジェクトを作成します。$ oc apply -f subscription.yaml
-
installPlanApprovalフィールドをManualに設定する場合は、保留中のインストールプランを手動で承認して Operator のインストールを完了します。詳細は、「保留中の Operator 更新の手動による承認」を参照してください。
この時点で、OLM は選択した Operator を認識します。Operator のクラスターサービスバージョン (CSV) はターゲット namespace に表示され、Operator で指定される API は作成用に利用可能になります。
検証
次のコマンドを実行して、インストールされている Operator の
Subscriptionオブジェクトのステータスを確認します。$ oc describe subscription <subscription_name> -n <namespace>SingleNamespaceインストールモードの Operator グループを作成した場合は、次のコマンドを実行してOperatorGroupオブジェクトのステータスを確認します。$ oc describe operatorgroup <operatorgroup_name> -n <namespace>
第11章 クラウドプロバイダーの認証情報の設定変更
サポートされる構成では、OpenShift Container Platform がクラウドプロバイダーに対して認証する方法を変更できます。
クラスターが使用するクラウド認証情報ストラテジーを決定するには、Cloud Credential Operator モードの決定 を参照してください。
11.1. クラウドプロバイダーの認証情報のローテーションまたは削除
OpenShift Container Platform のインストール後に、一部の組織では、初回インストール時に使用されたクラウドプロバイダーの認証情報のローテーションまたは削除が必要になります。
クラスターが新規の認証情報を使用できるようにするには、Cloud Credential Operator (CCO) が使用するシークレットを更新して、クラウドプロバイダーの認証情報を管理できるようにする必要があります。
11.1.1. Cloud Credential Operator ユーティリティーを使用したクラウドプロバイダー認証情報のローテーション
Cloud Credential Operator (CCO) ユーティリティー ccoctl は、IBM Cloud® にインストールされたクラスターのシークレットの更新をサポートしています。
11.1.1.1. API キーのローテーション
既存のサービス ID の API キーをローテーションし、対応するシークレットを更新できます。
前提条件
-
ccoctlバイナリーを設定している。 - インストールされているライブ OpenShift Container Platform クラスターに既存のサービス ID がある。
手順
ccoctlユーティリティーを使用して、サービス ID の API キーをローテーションし、シークレットを更新します。$ ccoctl <provider_name> refresh-keys \1 --kubeconfig <openshift_kubeconfig_file> \2 --credentials-requests-dir <path_to_credential_requests_directory> \3 --name <name>4 注記クラスターで
TechPreviewNoUpgrade機能セットによって有効化されたテクノロジープレビュー機能を使用している場合は、--enable-tech-previewパラメーターを含める必要があります。
11.1.2. クラウドプロバイダーの認証情報の手動によるローテーション
クラウドプロバイダーの認証情報が何らかの理由で変更される場合、クラウドプロバイダーの認証情報の管理に Cloud Credential Operator (CCO) が使用するシークレットを手動で更新する必要があります。
クラウド認証情報をローテーションするプロセスは、CCO を使用するように設定されているモードによって変わります。mint モードを使用しているクラスターの認証情報をローテーションした後に、削除された認証情報で作成されたコンポーネントの認証情報は手動で削除する必要があります。
前提条件
クラスターは、使用している CCO モードでのクラウド認証情報の手動ローテーションをサポートするプラットフォームにインストールされている。
- ミントモードでは、Amazon Web Services (AWS) と Google Cloud がサポートされています。
- パススルーモードでは、Amazon Web Services (AWS)、Microsoft Azure、Google Cloud、Red Hat OpenStack Platform (RHOSP)、および VMware vSphere がサポートされています。
- クラウドプロバイダーとのインターフェイスに使用される認証情報を変更している。
- 新規認証情報には、モードの CCO がクラスターで使用されるように設定するのに十分なパーミッションがある。
手順
- Web コンソールの Administrator パースペクティブで、Workloads → Secrets に移動します。
Secrets ページの表で、クラウドプロバイダーのルートシークレットを見つけます。
Expand プラットフォーム シークレット名 AWS
aws-credsAzure
azure-credentialsGoogle Cloud
gcp-credentialsRHOSP
openstack-credentialsVMware vSphere
vsphere-creds-
シークレットと同じ行にある Options メニュー
 をクリックし、Edit Secret を選択します。
をクリックし、Edit Secret を選択します。
- Value フィールドの内容を記録します。この情報を使用して、認証情報の更新後に値が異なることを確認できます。
- Value フィールドのテキストをクラウドプロバイダーの新規の認証情報で更新し、Save をクリックします。
vSphere CSI Driver Operator が有効になっていない vSphere クラスターの認証情報を更新する場合は、Kubernetes コントローラーマネージャーを強制的にロールアウトして更新された認証情報を適用する必要があります。
注記vSphere CSI Driver Operator が有効になっている場合、この手順は不要です。
更新された vSphere 認証情報を適用するには、
cluster-adminロールを持つユーザーとして OpenShift Container Platform CLI にログインし、以下のコマンドを実行します。$ oc patch kubecontrollermanager cluster \ -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date )"'"}}' \ --type=merge認証情報がロールアウトされている間、Kubernetes Controller Manager Operator のステータスは
Progressing=trueを報告します。ステータスを表示するには、次のコマンドを実行します。$ oc get co kube-controller-managerクラスターの CCO が mint モードを使用するように設定されている場合、個別の
CredentialsRequestオブジェクトによって参照される各コンポーネントシークレットを削除します。-
cluster-adminロールを持つユーザーとして OpenShift Container Platform CLI にログインします。 参照されたすべてのコンポーネントシークレットの名前および namespace を取得します。
$ oc -n openshift-cloud-credential-operator get CredentialsRequest \ -o json | jq -r '.items[] | select (.spec.providerSpec.kind=="<provider_spec>") | .spec.secretRef'ここで、
<provider_spec>はクラウドプロバイダーの対応する値になります。-
AWS:
AWSProviderSpec -
Google Cloud:
GCPProviderSpec
AWS の部分的なサンプル出力
{ "name": "ebs-cloud-credentials", "namespace": "openshift-cluster-csi-drivers" } { "name": "cloud-credential-operator-iam-ro-creds", "namespace": "openshift-cloud-credential-operator" }-
AWS:
参照されるコンポーネントの各シークレットを削除します。
$ oc delete secret <secret_name> \1 -n <secret_namespace>2 AWS シークレットの削除例
$ oc delete secret ebs-cloud-credentials -n openshift-cluster-csi-driversプロバイダーコンソールから認証情報を手動で削除する必要はありません。参照されるコンポーネントのシークレットを削除すると、CCO はプラットフォームから既存の認証情報を削除し、新規の認証情報を作成します。
-
検証
認証情報が変更されたことを確認するには、以下を実行します。
- Web コンソールの Administrator パースペクティブで、Workloads → Secrets に移動します。
- Value フィールドの内容が変更されていることを確認します。
11.1.3. クラウドプロバイダーの認証情報の削除
mint モードの Cloud Credential Operator (CCO) を使用するクラスターの場合、管理者レベルの認証情報が kube-system namespace に保存されます。CCO は、admin 認証情報を使用してクラスター内の CredentialsRequest オブジェクトを処理し、制限された権限を持つコンポーネントのユーザーを作成します。
mint モードの CCO を使用して OpenShift Container Platform クラスターをインストールした後、クラスターの kube-system namespace から管理者レベルの認証情報シークレットを削除できます。CCO が管理者レベルの認証情報を必要とするのは、マイナークラスターバージョンの更新など、新しいまたは変更された CredentialsRequest カスタムリソースの調整が必要な変更を行うときだけです。
マイナーバージョンのクラスター更新 (たとえば、OpenShift Container Platform 4.16 から 4.17 への更新) を実行する前に、管理者レベルの認証情報を使用して認証情報シークレットを復元する必要があります。認証情報が存在しない場合は、更新がブロックされる可能性があります。
前提条件
- クラスターが、CCO からのクラウド認証情報の削除をサポートするプラットフォームにインストールされている。サポートされているプラットフォームは AWS と Google Cloud です。
手順
- Web コンソールの Administrator パースペクティブで、Workloads → Secrets に移動します。
Secrets ページの表で、クラウドプロバイダーのルートシークレットを見つけます。
Expand プラットフォーム シークレット名 AWS
aws-credsGoogle Cloud
gcp-credentials-
シークレットと同じ行にある Options メニュー
をクリックし、Delete Secret を選択します。
11.2. トークンベースの認証の有効化
Microsoft Azure OpenShift Container Platform クラスターをインストールした後、Microsoft Entra Workload ID を有効にして短期認証情報を使用できます。
11.2.1. Cloud Credential Operator ユーティリティーの設定
クラスターの外部からクラウド認証情報を作成および管理するように既存のクラスターを設定するには、Cloud Credential Operator ユーティリティー (ccoctl) バイナリーを抽出して準備します。
ccoctl ユーティリティーは、Linux 環境で実行する必要がある Linux バイナリーです。
前提条件
- クラスター管理者のアクセスを持つ OpenShift Container Platform アカウントを使用できる。
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、OpenShift Container Platform リリースイメージの変数を設定します。
$ RELEASE_IMAGE=$(oc get clusterversion -o jsonpath={..desired.image})以下のコマンドを実行して、OpenShift Container Platform リリースイメージから CCO コンテナーイメージを取得します。
$ CCO_IMAGE=$(oc adm release info --image-for='cloud-credential-operator' $RELEASE_IMAGE -a ~/.pull-secret)注記$RELEASE_IMAGEのアーキテクチャーが、ccoctlツールを使用する環境のアーキテクチャーと一致していることを確認してください。以下のコマンドを実行して、OpenShift Container Platform リリースイメージ内の CCO コンテナーイメージから
ccoctlバイナリーを抽出します。$ oc image extract $CCO_IMAGE \ --file="/usr/bin/ccoctl.<rhel_version>" \1 -a ~/.pull-secret- 1
<rhel_version>には、ホストが使用する Red Hat Enterprise Linux (RHEL) のバージョンに対応する値を指定します。値が指定されていない場合は、デフォルトでccoctl.rhel8が使用されます。次の値が有効です。-
rhel8: RHEL 8 を使用するホストの場合はこの値を指定します。 -
rhel9: RHEL 9 を使用するホストの場合はこの値を指定します。
-
注記ccoctlバイナリーは、/usr/bin/ではなく、コマンドを実行したディレクトリーに作成されます。ディレクトリーの名前を変更するか、ccoctl.<rhel_version>バイナリーをccoctlに移動する必要があります。次のコマンドを実行して、権限を変更して
ccoctlを実行可能にします。$ chmod 775 ccoctl
検証
ccoctlが使用できることを確認するには、help ファイルを表示します。コマンドを実行するときは、相対ファイル名を使用します。以下に例を示します。$ ./ccoctl出力例
OpenShift credentials provisioning tool Usage: ccoctl [command] Available Commands: aws Manage credentials objects for AWS cloud azure Manage credentials objects for Azure gcp Manage credentials objects for Google cloud help Help about any command ibmcloud Manage credentials objects for IBM Cloud nutanix Manage credentials objects for Nutanix Flags: -h, --help help for ccoctl Use "ccoctl [command] --help" for more information about a command.
11.2.2. 既存クラスターでの Microsoft Entra Workload ID の有効化
インストール時に Microsoft Azure OpenShift Container Platform クラスターを Microsoft Entra Workload ID を使用するように設定しなかった場合は、既存のクラスターでこの認証方法を有効にできます。
既存のクラスターで Workload ID を有効にするプロセスは、サービスの停止を伴い、かなりの時間がかかります。続行する前に、次の考慮事項を確認してください。
- 次の手順を読み、必ず時間の要件を理解してご承知おきください。正確な所要時間は個々のクラスターによって異なりますが、少なくとも 1 時間かかる可能性があります。
- このプロセス中に、すべてのサービスアカウントを更新し、クラスター上のすべての Pod を再起動する必要があります。これらのアクションはワークロードの中断を伴います。この影響を軽減するには、これらのサービスを一時的に停止し、クラスターの準備ができたときに再デプロイすることができます。
- このプロセスを開始した後は、完了するまでクラスターの更新を試みないでください。更新がトリガーされると、既存のクラスターで Workload ID を有効にするプロセスが失敗します。
前提条件
- Microsoft Azure に OpenShift Container Platform クラスターをインストールした。
-
cluster-admin権限を持つアカウントを使用してクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。 -
Cloud Credential Operator ユーティリティー (
ccoctl) バイナリーを展開して準備した。 -
Azure CLI (
az) を使用して Azure アカウントにアクセスできる。
手順
-
ccoctlユーティリティーが生成するマニフェストの出力ディレクトリーを作成します。この手順では、./output_dirを例として使用します。 次のコマンドを実行して、クラスターのサービスアカウントの公開署名鍵を出力ディレクトリーに抽出します。
$ oc get configmap \ --namespace openshift-kube-apiserver bound-sa-token-signing-certs \ --output 'go-template={{index .data "service-account-001.pub"}}' > ./output_dir/serviceaccount-signer.public1 - 1
- この手順では、例として
serviceaccount-signer.publicという名前のファイルを使用します。
抽出したサービスアカウント公開署名鍵を使用して、次のコマンドを実行し、OpenID Connect (OIDC) 発行者と、OIDC 設定ファイルを含む Azure Blob ストレージコンテナーを作成します。
$ ./ccoctl azure create-oidc-issuer \ --name <azure_infra_name> \1 --output-dir ./output_dir \ --region <azure_region> \2 --subscription-id <azure_subscription_id> \3 --tenant-id <azure_tenant_id> \ --public-key-file ./output_dir/serviceaccount-signer.public4 次のコマンドを実行して、Azure pod identity webhook の設定ファイルが作成されたことを確認します。
$ ll ./output_dir/manifests出力例
total 8 -rw-------. 1 cloud-user cloud-user 193 May 22 02:29 azure-ad-pod-identity-webhook-config.yaml1 -rw-------. 1 cloud-user cloud-user 165 May 22 02:29 cluster-authentication-02-config.yaml- 1
- ファイル
azure-ad-pod-identity-webhook-config.yamlには、Azure pod identity webhook 設定が含まれています。
次のコマンドを実行して、出力ディレクトリーに生成されたマニフェストの OIDC 発行者 URL を使用して
OIDC_ISSUER_URL変数を設定します。$ OIDC_ISSUER_URL=`awk '/serviceAccountIssuer/ { print $2 }' ./output_dir/manifests/cluster-authentication-02-config.yaml`次のコマンドを実行して、クラスターの
authentication設定のspec.serviceAccountIssuerパラメーターを更新します。$ oc patch authentication cluster \ --type=merge \ -p "{\"spec\":{\"serviceAccountIssuer\":\"${OIDC_ISSUER_URL}\"}}"次のコマンドを実行して、設定の更新の進行状況を監視します。
$ oc adm wait-for-stable-clusterこのプロセスには 15 分以上かかる場合があります。次の出力は、プロセスが完了したことを示します。
All clusteroperators are stable次のコマンドを実行して、クラスター内のすべての Pod を再起動します。
$ oc adm reboot-machine-config-pool mcp/worker mcp/masterPod を再起動すると、
serviceAccountIssuerフィールドが更新され、サービスアカウントの公開署名鍵が更新されます。次のコマンドを実行して、再起動と更新のプロセスを監視します。
$ oc adm wait-for-node-reboot nodes --allこのプロセスには 15 分以上かかる場合があります。次の出力は、プロセスが完了したことを示します。
All nodes rebooted次のコマンドを実行して、Cloud Credential Operator の
spec.credentialsModeパラメーターをManualに更新します。$ oc patch cloudcredential cluster \ --type=merge \ --patch '{"spec":{"credentialsMode":"Manual"}}'以下のコマンドを実行して、OpenShift Container Platform リリースイメージから
CredentialsRequestオブジェクトのリストを抽出します。$ oc adm release extract \ --credentials-requests \ --included \ --to <path_to_directory_for_credentials_requests> \ --registry-config ~/.pull-secret注記このコマンドの実行には少し時間がかかる場合があります。
次のコマンドを実行して、Azure リソースグループ名を使用して
AZURE_INSTALL_RG変数を設定します。$ AZURE_INSTALL_RG=`oc get infrastructure cluster -o jsonpath --template '{ .status.platformStatus.azure.resourceGroupName }'`次のコマンドを実行して、
ccoctlユーティリティーを使用してすべてのCredentialsRequestオブジェクトのマネージド ID を作成します。注記次のコマンドでは、使用可能なすべてのオプションは表示されません。特定のユースケースで必要となる可能性のあるものを含め、すべてのオプションのリストを表示するには、
$ ccoctl azure create-managed-identities --helpを実行してください。$ ccoctl azure create-managed-identities \ --name <azure_infra_name> \ --output-dir ./output_dir \ --region <azure_region> \ --subscription-id <azure_subscription_id> \ --credentials-requests-dir <path_to_directory_for_credentials_requests> \ --issuer-url "${OIDC_ISSUER_URL}" \ --dnszone-resource-group-name <azure_dns_zone_resourcegroup_name> \1 --installation-resource-group-name "${AZURE_INSTALL_RG}" \ --network-resource-group-name <azure_resource_group>2 次のコマンドを実行して、Workload ID の Azure pod identity webhook 設定を適用します。
$ oc apply -f ./output_dir/manifests/azure-ad-pod-identity-webhook-config.yaml次のコマンドを実行して、
ccoctlユーティリティーによって生成されたシークレットを適用します。$ find ./output_dir/manifests -iname "openshift*yaml" -print0 | xargs -I {} -0 -t oc replace -f {}このプロセスには数分の時間がかかる可能性があります。
次のコマンドを実行して、クラスター内のすべての Pod を再起動します。
$ oc adm reboot-machine-config-pool mcp/worker mcp/masterPod を再起動すると、
serviceAccountIssuerフィールドが更新され、サービスアカウントの公開署名鍵が更新されます。次のコマンドを実行して、再起動と更新のプロセスを監視します。
$ oc adm wait-for-node-reboot nodes --allこのプロセスには 15 分以上かかる場合があります。次の出力は、プロセスが完了したことを示します。
All nodes rebooted次のコマンドを実行して、設定の更新の進行状況を監視します。
$ oc adm wait-for-stable-clusterこのプロセスには 15 分以上かかる場合があります。次の出力は、プロセスが完了したことを示します。
All clusteroperators are stableオプション: 次のコマンドを実行して、Azure の root 認証情報シークレットを削除します。
$ oc delete secret -n kube-system azure-credentials
11.2.3. クラスターが短期認証情報を使用していることを確認する
クラスター内の Cloud Credential Operator (CCO) 設定やその他の値で、クラスターが個々のコンポーネントに対して短期的なセキュリティー認証情報を使用していることを確認できます。
前提条件
-
Cloud Credential Operator ユーティリティー (
ccoctl) を使用して OpenShift Container Platform クラスターをデプロイし、短期認証情報を実装した。 -
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
次のコマンドを実行して、CCO が手動モードで動作するように設定されていることを確認します。
$ oc get cloudcredentials cluster \ -o=jsonpath={.spec.credentialsMode}次の出力は、CCO が手動モードで動作していることを示しています。
出力例
Manual次のコマンドを実行して、クラスターに
root認証情報がないことを確認します。$ oc get secrets \ -n kube-system <secret_name><secret_name>は、クラウドプロバイダーのルートシークレットの名前です。Expand プラットフォーム シークレット名 Amazon Web Services (AWS)
aws-credsMicrosoft Azure
azure-credentialsGoogle Cloud
gcp-credentialsエラーは、ルートシークレットがクラスター上に存在しないことを確認します。
AWS クラスターの出力例
Error from server (NotFound): secrets "aws-creds" not found次のコマンドを実行して、コンポーネントが個々のコンポーネントに対して短期セキュリティー認証情報を使用していることを確認します。
$ oc get authentication cluster \ -o jsonpath \ --template='{ .spec.serviceAccountIssuer }'このコマンドは、クラスター
Authenticationオブジェクトの.spec.serviceAccountIssuerパラメーターの値を表示します。クラウドプロバイダーに関連付けられた URL の出力は、クラスターがクラスターの外部から作成および管理される短期認証情報を使用して手動モードを使用していることを示します。Azure クラスター: 次のコマンドを実行して、コンポーネントがシークレットマニフェストで指定された Azure クライアント ID を想定していることを確認します。
$ oc get secrets \ -n openshift-image-registry installer-cloud-credentials \ -o jsonpath='{.data}'出力に
azure_client_idフィールドとazure_federated_token_fileフィールドが含まれている場合は、コンポーネントが Azure クライアント ID を想定しています。Azure クラスター: 次のコマンドを実行して、pod identity webhook を実行していることを確認します。
$ oc get pods \ -n openshift-cloud-credential-operator出力例
NAME READY STATUS RESTARTS AGE cloud-credential-operator-59cf744f78-r8pbq 2/2 Running 2 71m pod-identity-webhook-548f977b4c-859lz 1/1 Running 1 70m
第12章 アラート通知の設定
OpenShift Container Platform では、アラートは、アラートルールで定義された条件が true の場合に発生します。アラートは、クラスター内で一連の状況が発生していることを通知するものです。発生中のアラートは、デフォルトでは OpenShift Container Platform Web コンソールのアラート UI で確認できます。インストール後に、OpenShift Container Platform を外部システムにアラート通知を送信するように設定できます。
12.1. 外部システムへの通知の送信
OpenShift Container Platform 4.16 では、実行するアラートをアラート UI に表示できます。アラートは、デフォルトでは通知システムに送信されるように設定されません。以下のレシーバータイプにアラートを送信するように OpenShift Container Platform を設定できます。
- PagerDuty
- Webhook
- Slack
- Microsoft Teams
レシーバーへのアラートのルートを指定することにより、障害が発生する際に適切なチームに通知をタイムリーに送信できます。たとえば、重大なアラートには早急な対応が必要となり、通常は個人または緊急対策チーム (Critical Response Team) に送信先が設定されます。重大ではない警告通知を提供するアラートは、早急な対応を要さないレビュー用にチケットシステムにルート指定される可能性があります。
Watchdog アラートの使用によるアラートが機能することの確認
OpenShift Container Platform モニタリングには、継続的に実行される Watchdog アラートが含まれます。Alertmanager は、Watchdog のアラート通知を設定された通知プロバイダーに繰り返し送信します。通常、プロバイダーは watchdog アラートの受信を停止する際に管理者に通知するように設定されます。このメカニズムは、Alertmanager と通知プロバイダー間の通信に関連する問題を迅速に特定するのに役立ちます。
第13章 接続クラスターの非接続クラスターへの変換
OpenShift Container Platform クラスターを接続クラスターから非接続クラスターに変換する必要のあるシナリオがある場合があります。
制限されたクラスターとも呼ばれる非接続クラスターには、インターネットへのアクティブな接続がありません。そのため、レジストリーおよびインストールメディアのコンテンツをミラーリングする必要があります。インターネットと閉じられたネットワークの両方にアクセスできるホスト上にこのミラーレジストリーを作成したり、ネットワークの境界を越えて移動できるデバイスにイメージをコピーしたりすることができます。
このトピックでは、既存の接続クラスターを非接続クラスターに変換する一般的なプロセスを説明します。
13.1. ミラーレジストリーについて
必要なコンテナーイメージを取得するには、インターネットへのアクセスが必要です。代替レジストリーを使用すると、お使いのネットワークとインターネットの両方にアクセスできるミラーホストにミラーレジストリーを配置することになります。
OpenShift Container Platform のインストールとその後の製品更新に必要なイメージは、Red Hat Quay、JFrog Artifactory、Sonatype Nexus Repository、Harbor などのコンテナーミラーレジストリーにミラーリングできます。大規模なコンテナーレジストリーにアクセスできない場合は、OpenShift Container Platform サブスクリプションに含まれる小規模なコンテナーレジストリーである mirror registry for Red Hat OpenShift を使用できます。
Red Hat Quay、mirror registry for Red Hat OpenShift、Artifactory、Sonatype Nexus リポジトリー、Harbor など、Dockerv2-2 をサポートする任意のコンテナーレジストリーを使用できます。選択したレジストリーに関係なく、インターネット上の Red Hat がホストするサイトから分離されたイメージレジストリーにコンテンツをミラーリングする手順は同じです。コンテンツをミラーリングした後に、各クラスターをミラーレジストリーからこのコンテンツを取得するように設定します。
OpenShift イメージレジストリーはターゲットレジストリーとして使用できません。これは、ミラーリングプロセスで必要となるタグを使わないプッシュをサポートしないためです。
mirror registry for Red Hat OpenShift 以外のコンテナーレジストリーを選択する場合は、プロビジョニングするクラスター内のすべてのマシンからそのレジストリーにアクセスできる必要があります。レジストリーに到達できない場合、インストール、更新、またはワークロードの再配置などの通常の操作が失敗する可能性があります。そのため、ミラーレジストリーは可用性の高い方法で実行し、ミラーレジストリーは少なくとも OpenShift Container Platform クラスターの実稼働環境の可用性の条件に一致している必要があります。
ミラーレジストリーを OpenShift Container Platform イメージで設定する場合、2 つのシナリオを実行することができます。インターネットとミラーレジストリーの両方にアクセスできるホストがあり、クラスターノードにアクセスできない場合は、そのマシンからコンテンツを直接ミラーリングできます。このプロセスは、connected mirroring (接続ミラーリング) と呼ばれます。このようなホストがない場合は、イメージをファイルシステムにミラーリングしてから、そのホストまたはリムーバブルメディアを制限された環境に配置する必要があります。このプロセスは、disconnected mirroring (非接続ミラーリング) と呼ばれます。
ミラーリングされたレジストリーの場合は、プルされたイメージのソースを表示するには、CRI-O ログで Trying to access のログエントリーを確認する必要があります。ノードで crictl images コマンドを使用するなど、イメージのプルソースを表示する他の方法では、イメージがミラーリングされた場所からプルされている場合でも、ミラーリングされていないイメージ名を表示します。
Red Hat は、OpenShift Container Platform を使用してサードパーティーのレジストリーをテストしません。
13.2. 前提条件
-
ocクライアントがインストールされている。 - 実行中のクラスター。
OpenShift Container Platform クラスターをホストする場所で Docker v2-2 をサポートするコンテナーイメージレジストリーであるミラーレジストリーがインストールされている (例: 以下のレジストリーのいずれか)。
Red Hat Quay のサブスクリプションをお持ちの場合は、Red Hat Quay のデプロイに関するドキュメントの 概念実証の目的、または Quay Operator の使用 を参照してください。
- ミラーリポジトリーは、イメージを共有するように設定される必要があります。たとえば、Red Hat Quay リポジトリーでは、イメージを共有するために Organizations が必要です。
- 必要なコンテナーイメージを取得するためのインターネットへのアクセス。
13.3. ミラーリングのためのクラスターの準備
クラスターの接続を切断する前に、非接続クラスター内のすべてのノードから到達可能なミラーレジストリーにイメージをミラーリングまたはコピーする必要があります。イメージをミラーリングするには、以下を実行してクラスターを準備する必要があります。
- ミラーレジストリー証明書をホストの信頼される CA のリストに追加する。
-
cloud.openshift.comトークンからのイメージプルシークレットが含まれる.dockerconfigjsonファイルを作成する。
手順
イメージのミラーリングを可能にする認証情報を設定します。
単純な PEM または DER ファイル形式で、ミラーレジストリーの CA 証明書を信頼される CA のリストに追加します。以下に例を示します。
$ cp </path/to/cert.crt> /usr/share/pki/ca-trust-source/anchors/- ここでは、以下のようになります。,
</path/to/cert.crt> - ローカルファイルシステムの証明書へのパスを指定します。
- ここでは、以下のようになります。,
CA 信頼を更新します。たとえば、Linux の場合は以下のようになります。
$ update-ca-trustグローバルプルシークレットから
.dockerconfigjsonファイルを展開します。$ oc extract secret/pull-secret -n openshift-config --confirm --to=.出力例
.dockerconfigjson.dockerconfigjsonファイルを編集し、ミラーレジストリーおよび認証情報を追加し、これを新規ファイルとして保存します。{"auths":{"<local_registry>": {"auth": "<credentials>","email": "you@example.com"}}},"<registry>:<port>/<namespace>/":{"auth":"<token>"}}}ここでは、以下のようになります。
<local_registry>- ミラーレジストリーがコンテンツを提供するために使用するレジストリーのドメイン名およびポート (オプション) を指定します。
auth- ミラーレジストリーの base64 でエンコードされたユーザー名およびパスワードを指定します。
<registry>:<port>/<namespace>- ミラーレジストリーの詳細を指定します。
<token>ミラーレジストリーの base64 でエンコードされた
username:passwordを指定します。以下に例を示します。
$ {"auths":{"cloud.openshift.com":{"auth":"b3BlbnNoaWZ0Y3UjhGOVZPT0lOMEFaUjdPUzRGTA==","email":"user@example.com"}, "quay.io":{"auth":"b3BlbnNoaWZ0LXJlbGVhc2UtZGOVZPT0lOMEFaUGSTd4VGVGVUjdPUzRGTA==","email":"user@example.com"}, "registry.connect.redhat.com"{"auth":"NTE3MTMwNDB8dWhjLTFEZlN3VHkxOSTd4VGVGVU1MdTpleUpoYkdjaUailA==","email":"user@example.com"}, "registry.redhat.io":{"auth":"NTE3MTMwNDB8dWhjLTFEZlN3VH3BGSTd4VGVGVU1MdTpleUpoYkdjaU9fZw==","email":"user@example.com"}, "registry.svc.ci.openshift.org":{"auth":"dXNlcjpyWjAwWVFjSEJiT2RKVW1pSmg4dW92dGp1SXRxQ3RGN1pwajJhN1ZXeTRV"},"my-registry:5000/my-namespace/":{"auth":"dXNlcm5hbWU6cGFzc3dvcmQ="}}}
13.4. イメージのミラーリング
クラスターを適切に設定した後に、外部リポジトリーからミラーリポジトリーにイメージをミラーリングできます。
手順
Operator Lifecycle Manager (OLM) イメージをミラーリングします。
$ oc adm catalog mirror registry.redhat.io/redhat/redhat-operator-index:v{product-version} <mirror_registry>:<port>/olm -a <reg_creds>ここでは、以下のようになります。
product-version-
インストールする OpenShift Container Platform のバージョンに対応するタグを指定します (例:
4.8)。 mirror_registry-
Operator コンテンツをミラーリングするターゲットレジストリーおよび namespace の完全修飾ドメイン名 (FQDN) を指定します。ここで、
<namespace>はレジストリーの既存の namespace です。 reg_creds-
変更した
.dockerconfigjsonファイルの場所を指定します。
以下に例を示します。
$ oc adm catalog mirror registry.redhat.io/redhat/redhat-operator-index:v4.8 mirror.registry.com:443/olm -a ./.dockerconfigjson --index-filter-by-os='.*'他の Red Hat が提供する Operator の内容をミラーリングします。
$ oc adm catalog mirror <index_image> <mirror_registry>:<port>/<namespace> -a <reg_creds>ここでは、以下のようになります。
index_image- ミラーリングするカタログのインデックスイメージを指定します。
mirror_registry-
Operator コンテンツをミラーリングするターゲットレジストリーの FQDN および namespace を指定します。ここで、
<namespace>はレジストリーの既存の namespace です。 reg_creds- オプション: 必要な場合は、レジストリー認証情報ファイルの場所を指定します。
以下に例を示します。
$ oc adm catalog mirror registry.redhat.io/redhat/community-operator-index:v4.8 mirror.registry.com:443/olm -a ./.dockerconfigjson --index-filter-by-os='.*'OpenShift Container Platform イメージリポジトリーをミラーリングします。
$ oc adm release mirror -a .dockerconfigjson --from=quay.io/openshift-release-dev/ocp-release:v<product-version>-<architecture> --to=<local_registry>/<local_repository> --to-release-image=<local_registry>/<local_repository>:v<product-version>-<architecture>ここでは、以下のようになります。
product-version-
インストールする OpenShift Container Platform のバージョンに対応するタグを指定します (例:
4.8.15-x86_64)。 architecture-
サーバーのアーキテクチャーのタイプを指定します (例:
x86_64)。 local_registry- ミラーリポジトリーのレジストリードメイン名を指定します。
local_repository-
レジストリーに作成するリポジトリーの名前を指定します (例:
ocp4/openshift4)。
以下に例を示します。
$ oc adm release mirror -a .dockerconfigjson --from=quay.io/openshift-release-dev/ocp-release:4.8.15-x86_64 --to=mirror.registry.com:443/ocp/release --to-release-image=mirror.registry.com:443/ocp/release:4.8.15-x86_64出力例
info: Mirroring 109 images to mirror.registry.com/ocp/release ... mirror.registry.com:443/ ocp/release manifests: sha256:086224cadce475029065a0efc5244923f43fb9bb3bb47637e0aaf1f32b9cad47 -> 4.8.15-x86_64-thanos sha256:0a214f12737cb1cfbec473cc301aa2c289d4837224c9603e99d1e90fc00328db -> 4.8.15-x86_64-kuryr-controller sha256:0cf5fd36ac4b95f9de506623b902118a90ff17a07b663aad5d57c425ca44038c -> 4.8.15-x86_64-pod sha256:0d1c356c26d6e5945a488ab2b050b75a8b838fc948a75c0fa13a9084974680cb -> 4.8.15-x86_64-kube-client-agent ….. sha256:66e37d2532607e6c91eedf23b9600b4db904ce68e92b43c43d5b417ca6c8e63c mirror.registry.com:443/ocp/release:4.5.41-multus-admission-controller sha256:d36efdbf8d5b2cbc4dcdbd64297107d88a31ef6b0ec4a39695915c10db4973f1 mirror.registry.com:443/ocp/release:4.5.41-cluster-kube-scheduler-operator sha256:bd1baa5c8239b23ecdf76819ddb63cd1cd6091119fecdbf1a0db1fb3760321a2 mirror.registry.com:443/ocp/release:4.5.41-aws-machine-controllers info: Mirroring completed in 2.02s (0B/s) Success Update image: mirror.registry.com:443/ocp/release:4.5.41-x86_64 Mirror prefix: mirror.registry.com:443/ocp/release必要に応じて他のレジストリーをミラーリングします。
$ oc image mirror <online_registry>/my/image:latest <mirror_registry>
関連情報
- Operator カタログのミラーリングの詳細は、Mirroring an Operator catalogを参照してください。
-
oc adm catalog mirrorコマンドの詳細は、OpenShift CLI administrator command referenceを参照してください。
13.5. ミラーレジストリー用のクラスターの設定
イメージを作成し、ミラーレジストリーにミラーリングした後に、Pod がミラーレジストリーからイメージをプルできるようにクラスターを変更する必要があります。
以下を行う必要があります。
- ミラーレジストリー認証情報をグローバルプルシークレットに追加します。
- ミラーレジストリーサーバー証明書をクラスターに追加します。
ミラーレジストリーをソースレジストリーに関連付ける
ImageContentSourcePolicyカスタムリソース (ICSP) を作成します。ミラーレジストリー認証情報をクラスターのグローバル pull-secret に追加します。
$ oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=<pull_secret_location>1 - 1
- 新規プルシークレットファイルへのパスを指定します。
以下に例を示します。
$ oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=.mirrorsecretconfigjsonCA 署名のミラーレジストリーサーバー証明書をクラスター内のノードに追加します。
ミラーレジストリーのサーバー証明書が含まれる設定マップを作成します。
$ oc create configmap <config_map_name> --from-file=<mirror_address_host>..<port>=$path/ca.crt -n openshift-config以下に例を示します。
S oc create configmap registry-config --from-file=mirror.registry.com..443=/root/certs/ca-chain.cert.pem -n openshift-config設定マップを使用して
image.config.openshift.io/clusterカスタムリソース (CR) を更新します。OpenShift Container Platform は、この CR への変更をクラスター内のすべてのノードに適用します。$ oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"<config_map_name>"}}}' --type=merge以下に例を示します。
$ oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"registry-config"}}}' --type=merge
ICSP を作成し、オンラインレジストリーからミラーレジストリーにコンテナープルリクエストをリダイレクトします。
ImageContentSourcePolicyカスタムリソースを作成します。apiVersion: operator.openshift.io/v1alpha1 kind: ImageContentSourcePolicy metadata: name: mirror-ocp spec: repositoryDigestMirrors: - mirrors: - mirror.registry.com:443/ocp/release1 source: quay.io/openshift-release-dev/ocp-release2 - mirrors: - mirror.registry.com:443/ocp/release source: quay.io/openshift-release-dev/ocp-v4.0-art-devICSP オブジェクトを作成します。
$ oc create -f registryrepomirror.yaml出力例
imagecontentsourcepolicy.operator.openshift.io/mirror-ocp createdOpenShift Container Platform は、この CR への変更をクラスター内のすべてのノードに適用します。
ミラーレジストリーの認証情報、CA、および ICSP が追加されていることを確認します。
ノードにログインします。
$ oc debug node/<node_name>/hostをデバッグシェル内のルートディレクトリーとして設定します。sh-4.4# chroot /hostconfig.jsonファイルで認証情報の有無を確認します。sh-4.4# cat /var/lib/kubelet/config.json出力例
{"auths":{"brew.registry.redhat.io":{"xx=="},"brewregistry.stage.redhat.io":{"auth":"xxx=="},"mirror.registry.com:443":{"auth":"xx="}}}1 - 1
- ミラーレジストリーおよび認証情報が存在することを確認します。
certs.dディレクトリーに移動します。sh-4.4# cd /etc/docker/certs.d/certs.dディレクトリーの証明書を一覧表示します。sh-4.4# ls出力例
image-registry.openshift-image-registry.svc.cluster.local:5000 image-registry.openshift-image-registry.svc:5000 mirror.registry.com:4431 - 1
- ミラーレジストリーがリストにあることを確認します。
ICSP がミラーレジストリーを
registries.confファイルに追加していることを確認します。sh-4.4# cat /etc/containers/registries.conf出力例
unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] [[registry]] prefix = "" location = "quay.io/openshift-release-dev/ocp-release" mirror-by-digest-only = true [[registry.mirror]] location = "mirror.registry.com:443/ocp/release" [[registry]] prefix = "" location = "quay.io/openshift-release-dev/ocp-v4.0-art-dev" mirror-by-digest-only = true [[registry.mirror]] location = "mirror.registry.com:443/ocp/release"registry.mirrorパラメーターは、ミラーレジストリーが元のレジストリーの前に検索されることを示します。ノードを終了します。
sh-4.4# exit
13.6. アプリケーションが引き続き動作することの確認
ネットワークからクラスターを切断する前に、クラスターが想定どおりに機能しており、すべてのアプリケーションが想定どおりに機能していることを確認します。
手順
以下のコマンドを使用して、クラスターのステータスを確認します。
Pod が実行されていることを確認します。
$ oc get pods --all-namespaces出力例
NAMESPACE NAME READY STATUS RESTARTS AGE kube-system apiserver-watcher-ci-ln-47ltxtb-f76d1-mrffg-master-0 1/1 Running 0 39m kube-system apiserver-watcher-ci-ln-47ltxtb-f76d1-mrffg-master-1 1/1 Running 0 39m kube-system apiserver-watcher-ci-ln-47ltxtb-f76d1-mrffg-master-2 1/1 Running 0 39m openshift-apiserver-operator openshift-apiserver-operator-79c7c646fd-5rvr5 1/1 Running 3 45m openshift-apiserver apiserver-b944c4645-q694g 2/2 Running 0 29m openshift-apiserver apiserver-b944c4645-shdxb 2/2 Running 0 31m openshift-apiserver apiserver-b944c4645-x7rf2 2/2 Running 0 33m ...ノードが READY のステータスにあることを確認します。
$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION ci-ln-47ltxtb-f76d1-mrffg-master-0 Ready master 42m v1.29.4 ci-ln-47ltxtb-f76d1-mrffg-master-1 Ready master 42m v1.29.4 ci-ln-47ltxtb-f76d1-mrffg-master-2 Ready master 42m v1.29.4 ci-ln-47ltxtb-f76d1-mrffg-worker-a-gsxbz Ready worker 35m v1.29.4 ci-ln-47ltxtb-f76d1-mrffg-worker-b-5qqdx Ready worker 35m v1.29.4 ci-ln-47ltxtb-f76d1-mrffg-worker-c-rjkpq Ready worker 34m v1.29.4
13.7. ネットワークからクラスターを切断します。
すべての必要なリポジトリーをミラーリングし、非接続クラスターとして機能するようにクラスターを設定した後に、ネットワークからクラスターを切断できます。
クラスターがインターネット接続を失うと、Insights Operator のパフォーマンスが低下します。復元できるまで、一時的に Insights Operator を無効にする ことで、この問題を回避できます。
13.8. パフォーマンスが低下した Insights Operator の復元
ネットワークからクラスターを切断すると、クラスターのインターネット接続が失われます。Insights Operator は Red Hat Insights へのアクセスが必要であるため、そのパフォーマンスが低下します。
このトピックでは、Insights Operator をパフォーマンスが低下した状態から復元する方法を説明します。
手順
.dockerconfigjsonファイルを編集し、cloud.openshift.comエントリーを削除します。以下に例を示します。"cloud.openshift.com":{"auth":"<hash>","email":"user@example.com"}- ファイルを保存します。
編集した
.dockerconfigjsonファイルでクラスターシークレットを更新します。$ oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=./.dockerconfigjsonInsights Operator のパフォーマンスが低下しなくなったことを確認します。
$ oc get co insights出力例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE insights 4.5.41 True False False 3d
13.9. ネットワークの復元
非接続クラスターを再接続し、オンラインレジストリーからイメージをプルする場合は、クラスターの ImageContentSourcePolicy (ICSP) オブジェクトを削除します。ICSP がない場合、外部レジストリーへのプルリクエストはミラーレジストリーにリダイレクトされなくなります。
手順
クラスターの ICSP オブジェクトを表示します。
$ oc get imagecontentsourcepolicy出力例
NAME AGE mirror-ocp 6d20h ocp4-index-0 6d18h qe45-index-0 6d15hクラスターの切断時に作成した ICSP オブジェクトをすべて削除します。
$ oc delete imagecontentsourcepolicy <icsp_name> <icsp_name> <icsp_name>以下に例を示します。
$ oc delete imagecontentsourcepolicy mirror-ocp ocp4-index-0 qe45-index-0出力例
imagecontentsourcepolicy.operator.openshift.io "mirror-ocp" deleted imagecontentsourcepolicy.operator.openshift.io "ocp4-index-0" deleted imagecontentsourcepolicy.operator.openshift.io "qe45-index-0" deletedすべてのノードが再起動して READY ステータスに戻るまで待ち、
registries.confファイルがミラーレジストリーではなく、元のレジストリーを参照していることを確認します。ノードにログインします。
$ oc debug node/<node_name>/hostをデバッグシェル内のルートディレクトリーとして設定します。sh-4.4# chroot /hostregistries.confファイルを確認します。sh-4.4# cat /etc/containers/registries.conf出力例
unqualified-search-registries = ["registry.access.redhat.com", "docker.io"]1 - 1
- 削除した ICSP によって作成された
registryおよびregistry.mirrorエントリーが削除されています。
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.