2.2. 分散キャッシュ
Data Grid は、numOwners として設定された、キャッシュ内のエントリーの固定数のコピーを維持しようとします。これにより、分散キャッシュを線形にスケールでき、ノードをクラスターに追加する際により多くのデータを保存できます。
ノードがクラスターに参加およびクラスターから離脱すると、キーのコピー数が numOwners より多い場合と少ない場合があります。特に、numOwners ノードがすぐに連続して離れると、一部のエントリーが失われるため、分散キャッシュは、numOwners - 1 ノードの障害を許容すると言われます。
コピー数は、パフォーマンスとデータの持続性を示すトレードオフを表します。維持するコピーが増えると、パフォーマンスは低くなりますが、サーバーやネットワークの障害によるデータ喪失のリスクも低くなります。
Data Grid は、キーの所有者を 1 つの プライマリー所有者 に分割します。これにより、キーへの書き込みが行われ、ゼロ以上の バックアップ所有者 が調整されます。
以下の図は、クライアントがバックアップ所有者に送信する書き込み操作を示しています。この場合、バックアップノードはプライマリー所有者に書き込みを転送し、書き込みをバックアップに複製します。
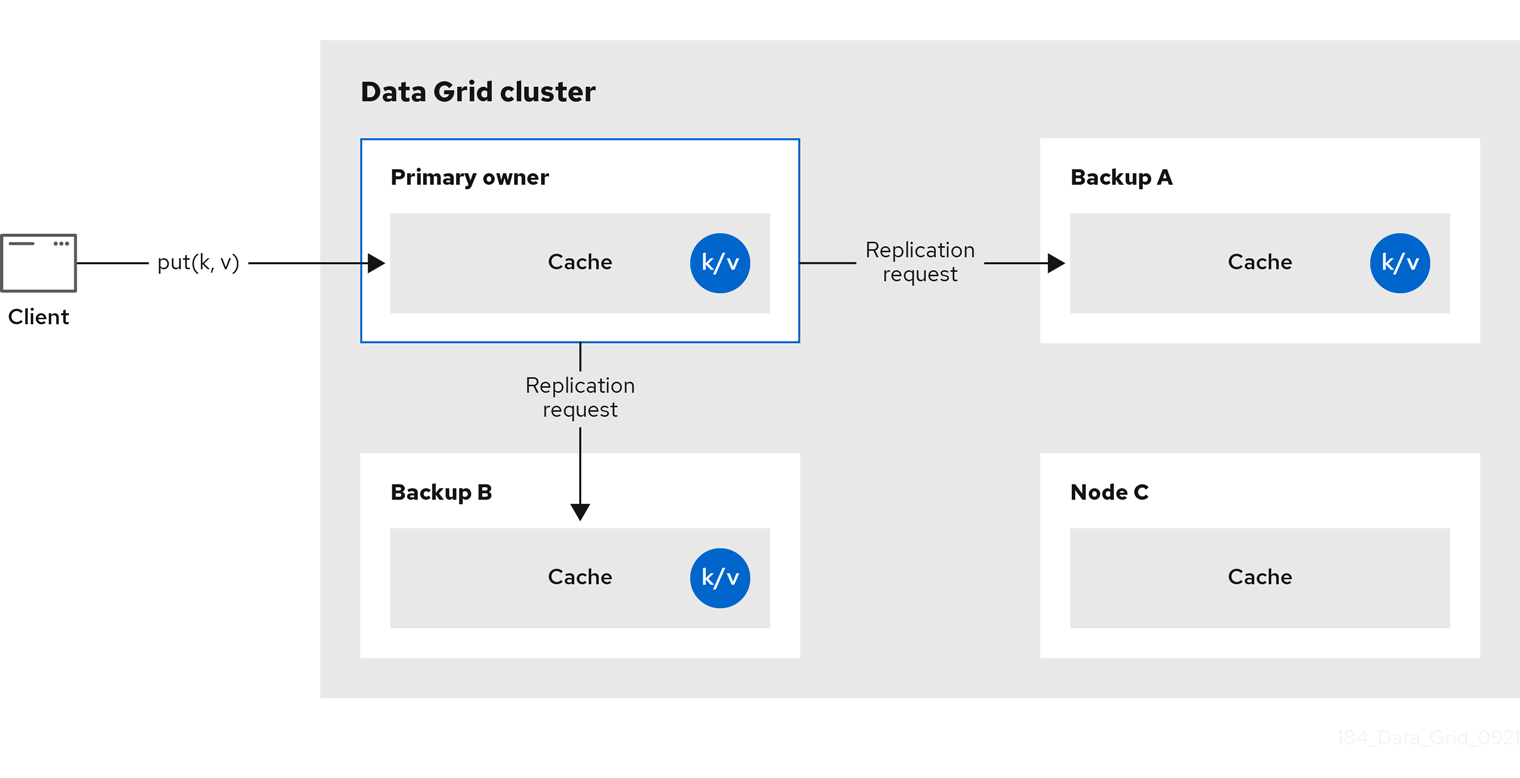
図2.2 クラスターのレプリケーション
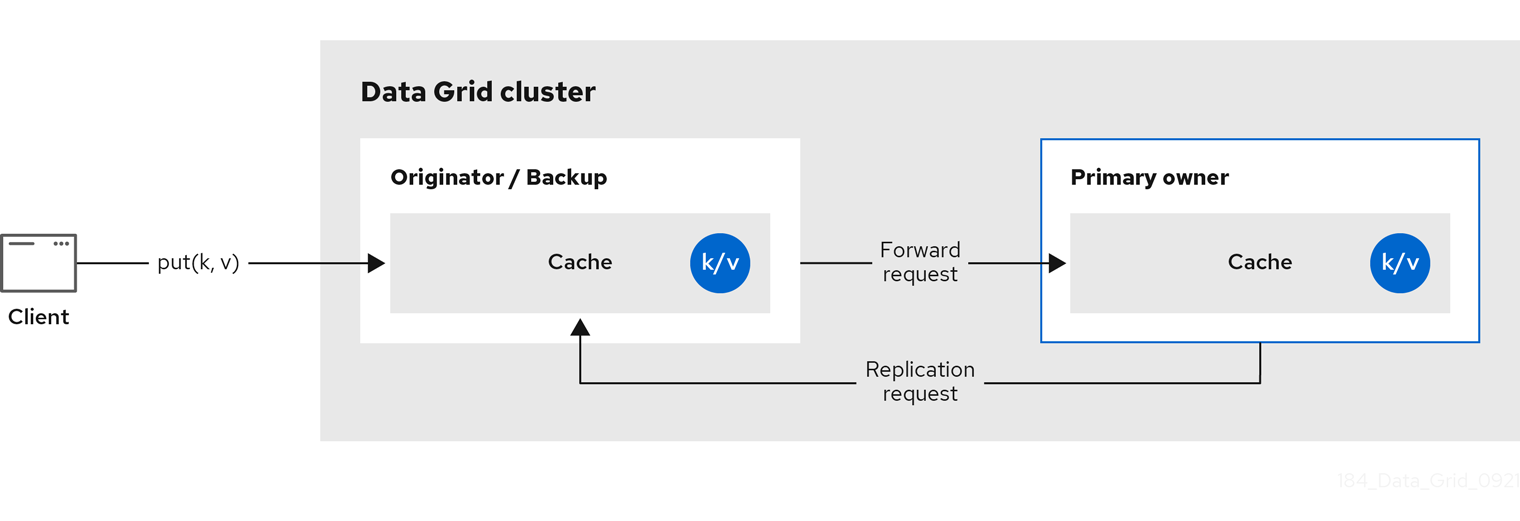
図2.3 分散キャッシュ
読み取り操作
読み取り操作は、プライマリー所有者から値を要求します。プライマリー所有者が妥当な時間内に応答しない場合は、Data Grid はバックアップの所有者から値も要求します。
キーがローカルキャッシュに存在する場合、読み取り操作には 0 メッセージが必要になる場合があり、すべての所有者が遅い場合は最大 2 * numOwners メッセージが必要になる場合があります。
書き込み操作
書き込み操作により、最大 2 * numOwners メッセージが生成されます。発信者からプライマリー所有者への 1 つのメッセージ。プライマリー所有者からバックアップノードへの numOwners - 1 メッセージと、対応する確認応答メッセージ。
キャッシュトポロジーの変更により、読み取り操作と書き込み操作の両方に対して再試行が行われる可能性があります。
同期または非同期のレプリケーション
更新を失う可能性があるため、非同期のレプリケーションは推奨されません。更新の喪失に加えて、非同期の分散キャッシュは、スレッドがキーに書き込むときに古い値を確認し、その後に同じキーをすぐに読み取ることもできます。
トランザクション
トランザクション分散キャッシュは、影響を受けるノードにのみロック/prepare/commit/unlock メッセージを送信します。つまり、トランザクションの影響を受ける 1 つの鍵を所有するすべてのノードを意味します。最適化として、トランザクションが単一のキーに書き込み、送信元がキーの主な所有者である場合、ロックメッセージは複製されません。
2.2.1. 読み取りの一貫性
同期レプリケーションを使用しても、分散キャッシュは線形化できません。トランザクションキャッシュでは、シリアル化/スナップショットの分離はサポートしません。
たとえば、スレッドは 1 つの配置リクエストを行います。
cache.get(k) -> v1
cache.put(k, v2)
cache.get(k) -> v2ただし、別のスレッドでは、異なる順序で値が表示される場合があります。
cache.get(k) -> v2
cache.get(k) -> v1理由は、プライマリー所有者の返信速度が速いかによって、読み取りはどの所有者からでも値を返すことができるからです。書き込みは、すべての所有者全体でアトミックではありません。実際、プライマリーは、バックアップから確認を受け取った後にのみ更新をコミットします。プライマリーがバックアップからの確認メッセージを待機している間、バックアップからの読み取りには新しい値が表示されますが、プライマリーからの読み取りには古い値が表示されます。
2.2.2. キーの所有権
分散キャッシュは、エントリーを固定数のセグメントに分割し、各セグメントを所有者ノードのリストに割り当てます。レプリケートされたキャッシュは同じで、すべてのノードが所有者である場合を除きます。
所有者リストの最初のノードはプライマリー所有者です。リストのその他のノードはバックアップの所有者です。キャッシュトポロジーが変更するると、ノードがクラスターに参加またはクラスターから離脱するため、セグメント所有権テーブルがすべてのノードにブロードキャストされます。これにより、ノードはマルチキャスト要求を行ったり、各キーのメタデータを維持したりすることなく、キーを見つけることができます。
numSegments プロパティーでは、利用可能なセグメントの数を設定します。ただし、クラスターが再起動しない限り、セグメントの数は変更できません。
同様に、キーからセグメントのマッピングは変更できません。鍵は、クラスタートポロジーの変更に関係なく、常に同じセグメントにマップする必要があります。キーからセグメントのマッピングは、クラスタートポロジーの変更時に移動する必要のあるセグメント数を最小限に抑える一方で、各ノードに割り当てられたセグメント数を均等に分散することが重要になります。
| 一貫性のあるハッシュファクトリーの実装 | 説明 |
|---|---|
|
| 一貫性のあるハッシュ に基づくアルゴリズムを使用します。サーバーヒントを無効にした場合は、デフォルトで選択されています。 この実装では、クラスターが対称である限り、すべてのキャッシュの同じノードに常にキーが割り当てられます。つまり、すべてのキャッシュがすべてのノードで実行します。この実装には、負荷の分散が若干不均等であるため、負のポイントが若干異なります。また、参加または脱退時に厳密に必要な数よりも多くのセグメントを移動します。 |
|
|
|
|
|
|
|
|
|
|
| レプリケートされたキャッシュの実装に内部で使用されます。このアルゴリズムは分散キャッシュで明示的に選択しないでください。 |
ハッシュ設定
組み込みキャッシュのみを使用して、カスタムを含む ConsistentHashFactory 実装を設定できます。
XML
<distributed-cache name="distributedCache"
owners="2"
segments="100"
capacity-factor="2" />ConfigurationBuilder
Configuration c = new ConfigurationBuilder()
.clustering()
.cacheMode(CacheMode.DIST_SYNC)
.hash()
.numOwners(2)
.numSegments(100)
.capacityFactor(2)
.build();2.2.3. 容量要素
容量係数は、クラスター内の各ノードで利用可能なリソースに基づいてセグメント数を割り当てます。
ノードの容量係数は、ノードがプライマリー所有者とバックアップ所有者の両方であるセグメントに適用されます。つまり、容量係数は、ノードがクラスター内の他のノードと比較した合計容量です。
デフォルト値は 1 です。つまり、クラスターのすべてのノードに同じ容量があり、Data Grid はクラスターのすべてのノードに同じ数のセグメントを割り当てます。
ただし、ノードにさまざまなメモリー量がある場合は、Data Grid ハッシュアルゴリズムが各ノードの容量で重み付けする多数のセグメントを割り当てるように、キャパシティー係数を設定することができます。
容量係数の設定の値は正の値で、1.5 などの分数になります。容量係数 0 を設定することもできますが、クラスターを一時的に参加するノードのみに推奨されます。代わりに、容量設定を使用することが推奨されます。
2.2.3.1. ゼロ容量ノード
すべてのキャッシュ、ユーザー定義のキャッシュ、および内部キャッシュに対して容量係数が 0 であるノードを設定できます。ゼロ容量ノードを定義する場合、ノードにはデータを保持しません。
ゼロ容量ノードの設定
XML
<infinispan>
<cache-container zero-capacity-node="true" />
</infinispan>JSON
{
"infinispan" : {
"cache-container" : {
"zero-capacity-node" : "true"
}
}
}YAML
infinispan:
cacheContainer:
zeroCapacityNode: "true"ConfigurationBuilder
new GlobalConfigurationBuilder().zeroCapacityNode(true);2.2.4. レベル 1(L1) キャッシュ
Data Grid ノードは、clsuter の別のノードからエントリーを取得すると、ローカルレプリカを作成します。L1 キャッシュは、プライマリー所有者ノードでエントリーを繰り返し検索せずに、パフォーマンスを追加します。
以下の図は、L1 キャッシュの動作を示しています。
図2.4 L1 cache
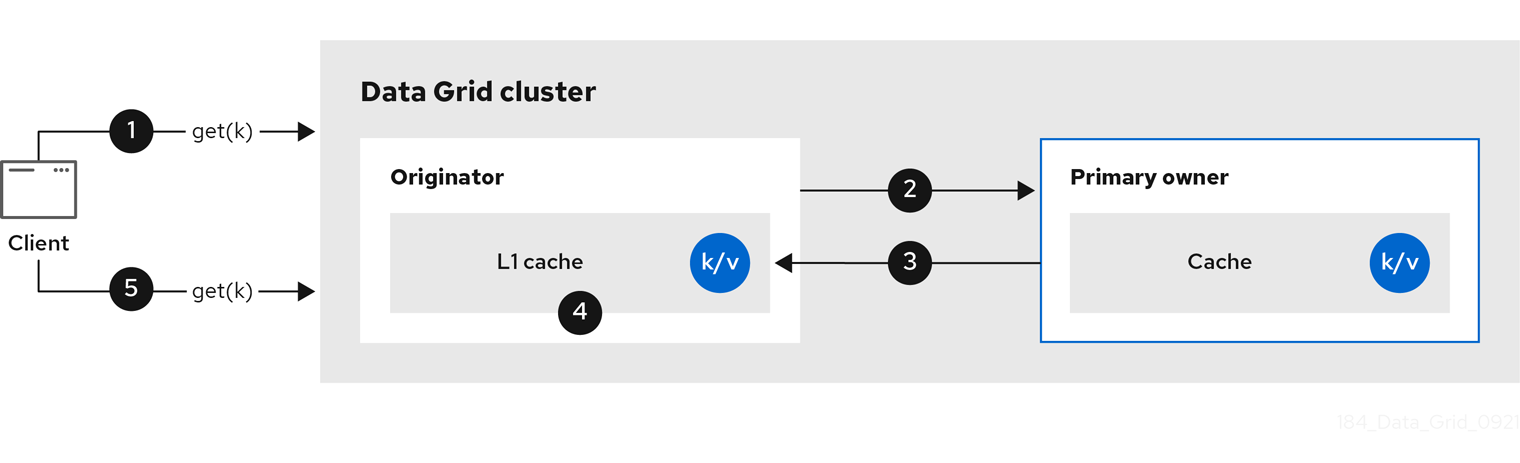
L1 cache の図では、以下のようになります。
-
クライアントは
cache.get()を呼び出して、クラスター内の別のノードがプライマリー所有者であるエントリーを読み取ります。 - 元のノードは読み取り操作をプライマリー所有者に転送します。
- プライマリー所有者はキー/値エントリーを返します。
- 元のノードはローカルコピーを作成します。
-
後続の
cache.get()呼び出しは、プライマリー所有者に転送するのではなく、ローカルエントリーを返します。
L1 キャッシュパフォーマンス
L1 を有効にすると読み取り操作のパフォーマンスが改善されますが、エントリーが変更されたときにプライマリー所有者ノードがメッセージをブロードキャストする必要があります。これにより、Data Grid はクラスター全体で古くなったレプリカをすべて削除します。ただし、これにより書き込み操作のパフォーマンスが低下し、メモリー使用量が増大し、キャッシュの全体的な容量が削減されます。
Data Grid は、他のキャッシュエントリーと同様に、ローカルレプリカまたは L1 エントリーをエビクトして期限切れにします。
L1 キャッシュ設定
XML
<distributed-cache l1-lifespan="5000"
l1-cleanup-interval="60000">
</distributed-cache>JSON
{
"distributed-cache": {
"l1-lifespan": "5000",
"l1-cleanup-interval": "60000"
}
}YAML
distributedCache:
l1Lifespan: "5000"
l1-cleanup-interval: "60000"ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC)
.l1()
.lifespan(5000, TimeUnit.MILLISECONDS)
.cleanupTaskFrequency(60000, TimeUnit.MILLISECONDS);2.2.5. サーバーヒント
サーバーヒントは、できるだけ多くのサーバー、ラック、およびデータセンター間でエントリーをレプリケートすることで、分散キャッシュのデータ可用性を高めます。
サーバーのヒントは、分散キャッシュにのみ適用されます。
Data Grid がデータのコピーを配布する場合は、サイト、ラック、マシン、およびノードの優先順位に従います。すべての設定属性はオプションです。たとえば、ラック ID のみを指定する場合、Data Grid はコピーを別のラックおよびノードに分散します。
サーバーのヒントは、キャッシュのセグメント数が少なすぎる場合に必要以上のセグメントを移動し、クラスターのリバランス操作に影響を与える可能性があります。
複数のデータセンターにおけるクラスターの代替は、クロスサイトレプリケーションです。
サーバーヒントの設定
XML
<cache-container>
<transport cluster="MyCluster"
machine="LinuxServer01"
rack="Rack01"
site="US-WestCoast"/>
</cache-container>JSON
{
"infinispan" : {
"cache-container" : {
"transport" : {
"cluster" : "MyCluster",
"machine" : "LinuxServer01",
"rack" : "Rack01",
"site" : "US-WestCoast"
}
}
}
}YAML
cacheContainer:
transport:
cluster: "MyCluster"
machine: "LinuxServer01"
rack: "Rack01"
site: "US-WestCoast"GlobalConfigurationBuilder
GlobalConfigurationBuilder global = GlobalConfigurationBuilder.defaultClusteredBuilder()
.transport()
.clusterName("MyCluster")
.machineId("LinuxServer01")
.rackId("Rack01")
.siteId("US-WestCoast");2.2.6. キーアフィニティーサービス
分散キャッシュでは、不透明なアルゴリズムを使用してノードのリストにキーが割り当てられます。計算を逆にし、特定のノードにマップする鍵を生成する簡単な方法はありません。ただし、Data Grid は一連の (疑似) ランダムキーを生成し、それらのプライマリー所有者が何であるかを確認し、特定のノードへのキーマッピングが必要なときにアプリケーションに渡すことができます。
以下のコードスニペットは、このサービスへの参照を取得し、使用する方法を示しています。
// 1. Obtain a reference to a cache
Cache cache = ...
Address address = cache.getCacheManager().getAddress();
// 2. Create the affinity service
KeyAffinityService keyAffinityService = KeyAffinityServiceFactory.newLocalKeyAffinityService(
cache,
new RndKeyGenerator(),
Executors.newSingleThreadExecutor(),
100);
// 3. Obtain a key for which the local node is the primary owner
Object localKey = keyAffinityService.getKeyForAddress(address);
// 4. Insert the key in the cache
cache.put(localKey, "yourValue");サービスはステップ 2 で開始します。この時点以降、サービスは提供されたエグゼキューターを使用してキーを生成してキューに入れます。ステップ 3 では、サービスから鍵を取得し、手順 4 ではそれを使用します。
ライフサイクル
KeyAffinityService は ライフサイクル を拡張し、停止と (再) 起動を可能にします。
public interface Lifecycle {
void start();
void stop();
}
サービスは KeyAffinityServiceFactory でインスタンス化されます。ファクトリーメソッドはすべて Executor パラメーターを持ち、これは非同期キー生成に使用されます (呼び出し元のスレッドでは処理されません)。ユーザーは、この Executor のシャットダウンを処理します。
KeyAffinityService が起動したら、明示的に停止する必要があります。これにより、バックグラウンドキーの生成が停止し、保持されている他のリソースが解放されます。
KeyAffinityService がそれ自体で停止する唯一の状況は、登録済みの Cache Manager がシャットダウンした時です。
トポロジーの変更
キャッシュトポロジーが変更すると、KeyAffinityService によって生成されたキーの所有権が変更される可能性があります。主なアフィニティーサービスはこれらのトポロジーの変更を追跡し、現在別のノードにマップされるキーを返しませんが、先に生成したキーに関しては何も実行しません。
そのため、アプリケーションは KeyAffinityService を純粋に最適化として処理し、正確性のために生成されたキーの場所に依存しないようにしてください。
特に、アプリケーションは、同じアドレスが常に一緒に配置されるように、KeyAffinityService によって生成されたキーに依存するべきではありません。キーのコロケーションは、Grouping API によってのみ提供されます。
2.2.7. グループ化 API
キーアフィニティーサービスを補完する Grouping API を使用すると、実際のノードを選択することなく、同じノードにエントリーのグループを同じ場所にコロケートできます。
デフォルトでは、キーのセグメントはキーの hashCode() を使用して計算されます。Grouping API を使用する場合、Data Grid はグループのセグメントを計算し、それをキーのセグメントとして使用します。
Grouping API が使用されている場合、すべてのノードが他のノードと通信せずにすべてのキーの所有者を計算できることが重要です。このため、グループは手動で指定できません。グループは、エントリーに固有 (キークラスによって生成される) または外部 (外部関数によって生成される) のいずれかです。
Grouping API を使用するには、グループを有効にする必要があります。
Configuration c = new ConfigurationBuilder()
.clustering().hash().groups().enabled()
.build();<distributed-cache>
<groups enabled="true"/>
</distributed-cache>
キークラスを制御できる場合 (クラス定義を変更できるが、変更不可能なライブラリーの一部ではない)、組み込みグループを使用することを推奨します。侵入グループは、@Group アノテーションをメソッドに追加して指定します。以下に例を示します。
class User {
...
String office;
...
public int hashCode() {
// Defines the hash for the key, normally used to determine location
...
}
// Override the location by specifying a group
// All keys in the same group end up with the same owners
@Group
public String getOffice() {
return office;
}
}
}
group メソッドは String を返す必要があります。
キークラスを制御できない場合、またはグループの決定がキークラスと直交する懸念事項である場合は、外部グループを使用することを推奨します。外部グループは、Grouper インターフェイスを実装することによって指定されます。
public interface Grouper<T> {
String computeGroup(T key, String group);
Class<T> getKeyType();
}
同じキータイプに対して複数の Grouper クラスが設定されている場合は、それらすべてが呼び出され、前のクラスで計算された値を受け取ります。キークラスにも @Group アノテーションがある場合、最初の Grouper はアノテーション付きのメソッドによって計算されたグループを受信します。これにより、組み込みグループを使用するときに、グループをさらに細かく制御できます。
Grouper 実装の例
public class KXGrouper implements Grouper<String> {
// The pattern requires a String key, of length 2, where the first character is
// "k" and the second character is a digit. We take that digit, and perform
// modular arithmetic on it to assign it to group "0" or group "1".
private static Pattern kPattern = Pattern.compile("(^k)(<a>\\d</a>)$");
public String computeGroup(String key, String group) {
Matcher matcher = kPattern.matcher(key);
if (matcher.matches()) {
String g = Integer.parseInt(matcher.group(2)) % 2 + "";
return g;
} else {
return null;
}
}
public Class<String> getKeyType() {
return String.class;
}
}
Grouper 実装は、キャッシュ設定で明示的に登録する必要があります。プログラムを用いて Data Grid を設定している場合は、以下を行います。
Configuration c = new ConfigurationBuilder()
.clustering().hash().groups().enabled().addGrouper(new KXGrouper())
.build();または、XML を使用している場合は、以下を行います。
<distributed-cache>
<groups enabled="true">
<grouper class="com.example.KXGrouper" />
</groups>
</distributed-cache>高度な API
AdvancedCache には、グループ固有のメソッドが 2 つあります。
-
getGroup(groupName)は、グループに属するキャッシュ内のすべてのキーを取得します。 -
removeGroup(groupName)は、グループに属するキャッシュにあるすべてのキーを削除します。
どちらのメソッドもデータコンテナー全体とストア (存在する場合) を繰り返し処理するため、キャッシュに多くの小規模なグループが含まれる場合に処理が遅くなる可能性があります。