4.3. Compute-Focused アーキテクチャー
セルは、本リリースでは テクノロジープレビュー として提供されているため、Red Hat では全面的にはサポートしていません。これらは、テスト目的にのみご利用いただく機能で、実稼働環境にデプロイすべきではありません。テクノロジープレビュー機能の詳細は、対象範囲の詳細 を参照してください。
コンピュート中心のクラウドは、データ計算または暗号化と復号化などの CPU を集中的に使用するワークロード、インメモリーキャッシュやデータベースサーバーなどの RAM を集中的に使用するワークロード、またはその両方をサポートします。このアーキテクチャータイプは、通常、ストレージを集中的に使用するものではなく、コンピュートリソースの電力を必要とするお客様に対応します。
コンピュートワークロードには、以下のユースケースが含まれます。
- 高性能コンピューティング(HPC)
- Hadoop またはその他の分散データストアを使用したビッグデータ解析
- 継続的インテグレーションまたは継続的デプロイメント(CI/CD)
- Platform-as-a-Service (PaaS)
- ネットワーク機能仮想化(NFV)のシグナル処理
クラウドは通常、永続的なブロックストレージを必要とするアプリケーションをホストしないため、コンピュート中心の OpenStack クラウドは通常は raw ブロックストレージサービスを使用しません。インフラストラクチャーコンポーネントは共有されないため、ワークロードは必要な数の利用可能なリソースを使用できます。インフラストラクチャーコンポーネントも高可用性である必要があります。この設計はロードバランサーを使用します。HAProxy も使用できます。
インストールおよびデプロイメントのドキュメントは、5章デプロイメント情報 を参照してください。
4.3.1. ユースケースの例
組織は、調査プロジェクト用に HPC を提供します。ヨーロッパの 2 つの既存のコンピューティングセンターに 3 番目のコンピュートセンターを追加する必要があります。
以下の表には、追加する各コンピュートセンターの要件をまとめています。
| Data Center | 概算容量 |
|---|---|
| geneva、Switzerland |
|
| Budapest, Hungary |
|
4.3.2. 設計について
このアーキテクチャーでは、セルを使用してコンピュートリソースを分離し、異なるデータセンター間で透過的なスケーリングを行います。この決定は、セキュリティーグループおよびライブマイグレーションのサポートに影響します。さらに、セル全体でフレーバーなどの一部の設定要素を手動でレプリケーションする必要があります。ただし、セルは、ユーザーに単一のパブリック API エンドポイントを公開する間に必要なスケールを提供します。
クラウドは、元の 2 つのデータセンターのそれぞれにコンピュートセルを使用し、新しいデータセンターを追加するたびに新しいコンピュートセルを作成します。各セルには、コンピュートリソースをさらに分離する 3 つのアベイラビリティゾーンと、高可用性のためにミラーリングされたキューを持つクラスタリング用に設定された 3 つ以上の RabbitMQ メッセージブローカーが含まれます。
HAProxy ロードバランサーの背後に存在する API セルは、Switzerland のデータセンターにあります。API セルは、セルスケジューラーのカスタマイズされたバリエーションを使用して、API コールをコンピュートセルに転送します。カスタマイズにより、特定のワークロードを特定のデータセンターまたはセル RAM の可用性に基づいてすべてのデータセンターにルーティングできるようになります。
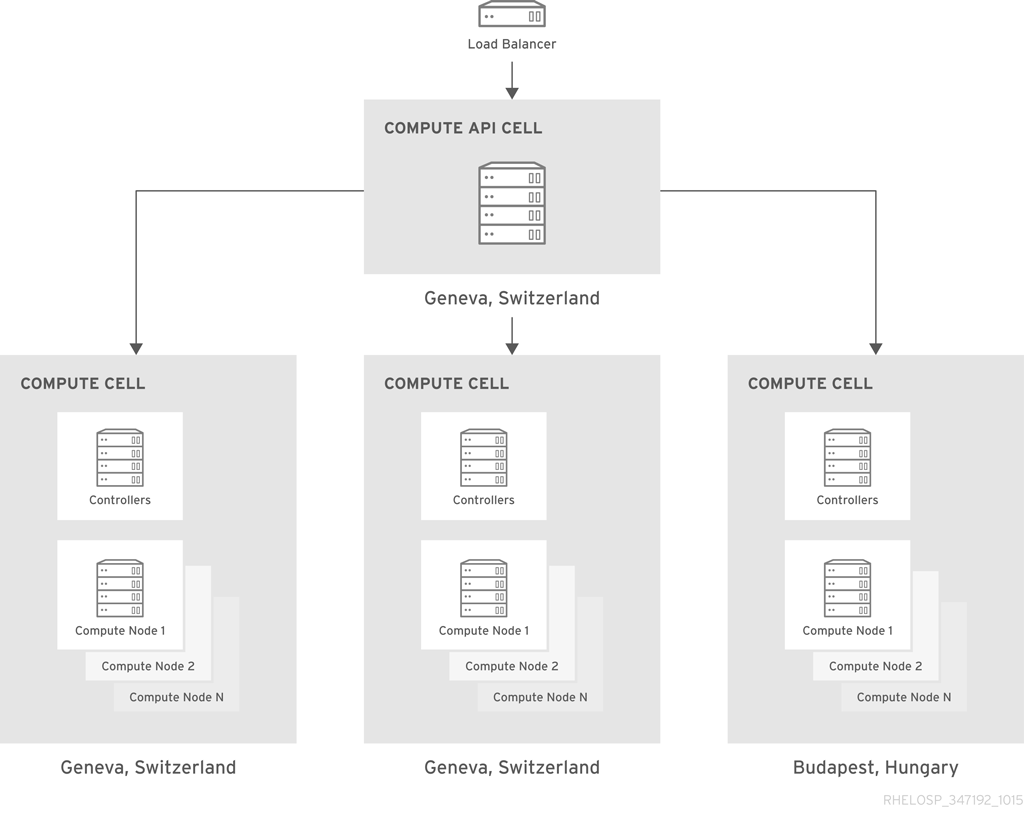
フィルターを使用して、セルでの配置を処理する Compute スケジューラーをカスタマイズすることもできます。たとえば、ImagePropertiesFilter は、ゲストが実行するオペレーティングシステム(Linux、Windows など)に基づいて特別な処理を行います。
中央データベースチームは、NetApp ストレージバックエンドを使用したアクティブ/パッシブ設定の各セルの SQL データベースサーバーを管理します。バックアップは 6 時間ごとに実行されます。
4.3.3. アーキテクチャーコンポーネント
| コンポーネント | 説明 |
|---|---|
| コンピュート | コンピュート管理およびスケジューリングサービスは、コントローラーで実行されます。Compute サービスは、各コンピュートノードでも実行されます。 |
| ダッシュボードサービス | OpenStack 管理用の GUI。 |
| Identity サービス | 基本的な認証および承認機能。 |
| Image サービス | API セルで実行され、小さな Linux イメージセットを維持し、オーケストレーションツールがアプリケーションを配置することができます。 |
| ネットワーク | ネットワークサービス。OpenStack Networking の詳細は、2章Networking In-Depthを参照してください。 |
| モニタリング | Telemetry サービスはメータリングを実行し、シャード化され、複製された MongoDB バックエンドでプロジェクトクォータを調整します。API 負荷を分散するには、Telemetry がクエリーできる子セルに openstack-nova-api サービスのインスタンスをデプロイする必要があります。このデプロイメントには、子セル内で Identity や Image などのサポートサービスを設定する必要もあります。キャプチャーする特定の重要なメトリクスには、Compute API への Image ディスクの使用率と応答時間が含まれます。 |
| オーケストレーションサービス | 新しいインスタンスを自動的にデプロイおよびテストします。 |
| Telemetry Service | オーケストレーションの自動スケーリング機能をサポートします。 |
| オブジェクトストレージ | 3 つの PB Ceph クラスターを使用してオブジェクトを保存します。 |
4.3.4. 設計に関する考慮事項
3章設計 で説明されている 「コンピュートリソース」 およびコンピュートノードの設計に関する考慮事項で説明されている基本的な設計に関する考慮事項に加えて、コンピュート集約型アーキテクチャーには以下の項目を考慮する必要があります。
- ワークロード
短期的なワークロードには、継続的インテグレーションと継続的デプロイメント(CI-CD)ジョブが含まれており、同時に多数のコンピューティングインスタンスが作成され、一連のコンピュート集約型タスクが実行されます。次に、環境は、インスタンスを終了する前に、各インスタンスの結果またはアーティファクトを長期ストレージにコピーします。
Hadoop クラスターや HPC クラスターなどの長期的なワークロードは、通常、大規模なデータセットを受け取り、それらのデータセットで計算作業を実行してから、長期ストレージに結果をプッシュします。計算作業が終了すると、インスタンスは別のジョブを受け取るまでアイドル状態になります。有効期間の長いワークロードの環境は、多くの場合、より複雑になりますが、ジョブ間でアクティブに保つことで、これらの環境の構築コストを補正できます。
コンピューティング中心の OpenStack クラウドのワークロードには、通常、Hadoop と HDFS を使用する点を除き、永続的なブロックストレージは必要ありません。共有ファイルシステムまたはオブジェクトストアは、初期データセットを維持し、計算結果を保存するための宛先として機能します。入力出力(IO)のオーバーヘッドを回避することで、ワークロードのパフォーマンスを大幅に強化できます。データセットのサイズによっては、オブジェクトストアまたは共有ファイルシステムをスケーリングする必要がある場合があります。
- 拡張計画
クラウドユーザーは、必要に応じて新規リソースへの即時アクセスを想定しています。したがって、通常の使用量と、リソース需要の突然的なスパイクを計画する必要があります。安定せずに計画すると、クラウドのオーバーサブスクリプションが予期せず発生する可能性があります。積極的に計画を立てることで、クラウドの不要な運用やメンテナンスコストの不正使用が予測できない状況が生じる可能性があります。
拡張計画における重要な要素は、時間経過に伴うクラウド使用量の傾向の分析です。クラウドの平均速度や容量ではなく、サービスを提供する一貫性を測定します。この情報は、容量パフォーマンスのモデル化や、クラウドの現在および将来の容量を決定するのに役立ちます。
ソフトウェアの監視については、「追加ソフトウェア」 を参照してください。
- CPU および RAM
現在、一般的なサーバーには、最大 12 個のコアを持つ CPU が含まれています。さらに、一部の Intel CPU はハイパースレッディングテクノロジー(HTT)をサポートしているため、コア容量が 2 倍になります。したがって、HTT を使用する複数の CPU をサポートするサーバーは、利用可能なコア数を掛けます。HTT は、Intel CPU での並列化を向上するために使用される Intel プロプライエタリー同時マルチスレッド実装です。マルチスレッドアプリケーションのパフォーマンスを向上させるために、HTT を有効にすることを検討してください。
CPU で HTT を有効にする方法は、ユースケースによって異なります。たとえば、HTT を無効にすると、集中的なコンピューティング環境に役立ちます。HTT の有無にかかわらず、ローカルワークロードのパフォーマンステストを実行すると、どのオプションが特定のケースに適しているかを判断するのに役立ちます。
- 容量のプランニング
以下のストラテジーの 1 つまたは複数を使用して、コンピューティング環境に容量を追加できます。
クラウドに容量を追加して水平スケーリングします。ライブマイグレーション機能が中断される可能性を減らすために、追加のノードで同じ CPU または同様の CPU を使用する必要があります。ハイパーバイザーホストのスケールアウトは、ネットワークおよびその他のデータセンターリソースにも影響します。ラック容量に達した場合や、ネットワークスイッチを追加する必要がある場合は、この点を考慮してください。
注記ノードを適切なアベイラビリティーゾーンおよびホストアグリゲートに配置するために必要な追加の作業に注意してください。
- 使用量の増加をサポートするために内部コンピュートホストコンポーネントの容量を増やすことで垂直スケーリングします。たとえば、CPU をより多くのコアに置き換えるか、サーバーの RAM を増やすことができます。
平均ワークロードを評価し、必要な場合は、オーバーコミットの比率を調整して、コンピュート環境で実行可能なインスタンスの数を増やします。
重要計算対象の OpenStack 設計アーキテクチャーの CPU のオーバーコミット率を増やしないでください。CPU のオーバーコミット比率を変更すると、CPU リソースを必要とする他のノードとの競合が発生する可能性があります。
- Compute ハードウェア
計算した OpenStack クラウドは、プロセッサーとメモリーリソースに関して非常に需要です。したがって、より多くの CPU ソケット、より多くの CPU コア、より多くの RAM を優先できるサーバーハードウェアを優先する必要があります。
このアーキテクチャーでは、ネットワーク接続とストレージ容量が重要ではありません。ハードウェアは、最低限のユーザー要件を満たすのに十分なネットワーク接続とストレージ容量を提供する必要がありますが、ストレージおよびネットワークコンポーネントは主に計算クラスターにデータセットを読み込み、一貫したパフォーマンスを必要としません。
- ストレージハードウェア
オープンソースソフトウェアでコモディティハードウェアを使用してストレージアレイを構築することはできますが、それをデプロイするために専門的な専門知識が必要になる可能性があります。サーバーで直接接続されたストレージと共にスケールアウトストレージソリューションを使用することもできますが、サーバーハードウェアがストレージソリューションをサポートしていることを確認する必要があります。
ストレージハードウェアを設計するときは、次の要素を考慮してください。
- 可用性。インスタンスの可用性が高く、またはホスト間での移行が可能である必要がある場合は、一時インスタンスデータに共有ストレージファイルシステムを使用して、ノードに障害が発生した場合にコンピュートサービスが中断しないようにします。
- レイテンシーソリッドステートドライブ(SSD)ディスクを使用して、インスタンスのストレージレイテンシーを最小限に抑え、CPU の遅延を減らし、パフォーマンスを向上させます。ベースとなるディスクサブシステムのパフォーマンスを向上させるには、コンピュートホストで RAID コントローラーカードを使用することを検討してください。
- Performance通常、コンピュート中心のクラウドにはストレージに対する主要なデータ I/O は必要ありませんが、ストレージのパフォーマンスは考慮すべき重要な要素となります。ストレージ I/O 要求のレイテンシーを監視することで、ストレージハードウェアのパフォーマンスを測定できます。コンピューティング集約型のワークロードによっては、ストレージからデータをフェッチしながら、CPU の経験を最小限に抑えると、アプリケーションの全体的なパフォーマンスが大幅に向上します。
- 拡張性。ストレージソリューションの最大容量を決定します。たとえば、50 PB に拡大するソリューションは、10PB にのみ拡張されるソリューションよりも拡張できます。このメトリクスは、スケーラビリティーに関連しますが、スケーラビリティーは拡張する際のソリューションパフォーマンスの計測値です。
- 接続性。接続はストレージソリューションの要件を満たしている必要があります。集中型ストレージアレイを選択した場合は、ハイパーバイザーをストレージアレイに接続する方法を決定します。接続性は、レイテンシーとパフォーマンスに影響を及ぼす可能性があります。したがって、ネットワークの特性を使用することで、環境の全体的なパフォーマンスを向上させるレイテンシーが最小限に抑えられます。
- ネットワークハードウェア
2章Networking In-Depth で説明されている基本的なネットワークに関する考慮事項に加えて、次の要素を考慮してください。
- 必要なポート数は、ネットワーク設計に必要な物理領域に影響します。たとえば、1U サーバーの各ポートに 10 GbE 容量のポートを提供するスイッチは、2U サーバーのポートごとに 10 GbE 容量の 24 ポートを提供するスイッチよりも、ポート密度が高くなります。ポートの密度が高いため、コンピュートまたはストレージコンポーネントのラック領域が多くなります。障害ドメインと電源密度も考慮する必要があります。より高価な場合ですが、機能要件を超えてネットワークを設計すべきではないため、高密度のスイッチも検討することができます。
- リーフ対応モデルなど、容量や帯域幅の追加に役立つスケーラブルなネットワークモデルでネットワークアーキテクチャーを設計する必要があります。このタイプのネットワーク設計では、帯域幅を追加したり、ギアの追加ラックにスケールアウトしたりできます。
- 必要なポート数、ポート速度、ポート密度をサポートするネットワークハードウェアを選択することが重要になります。また、ワークロードの需要が増えると将来の増加も許容します。また、ネットワークアーキテクチャーのどこで冗長性を提供することが重要であるかを評価することも重要です。ネットワークの可用性と冗長性が向上します。そのため、追加のコストと、冗長なネットワークスイッチとホストレベルでのボンディングインターフェイスの利点を比較する必要があります。