3.2. コンピュートリソース
コンピュートリソースは OpenStack クラウドの中核となります。したがって、Red Hat OpenStack Platform のデプロイメントを設計する場合は、物理および仮想リソースの割り当て、分散、フェイルオーバー、および追加のデバイスを考慮することを推奨します。
3.2.1. 一般的な考慮事項
- 各ハイパーバイザーのプロセッサー、メモリー、およびストレージの数
プロセッサーコアおよびスレッドの数は、コンピュートノード上で実行できるワーカースレッドの数に直接影響を与えます。したがって、サービスに基づいて、すべてのサービスのバランスの取れたインフラストラクチャーに基づいて設計を決定する必要があります。
ワークロードプロファイルに応じて、後でクラウドに追加のコンピュートリソースプールを追加できます。場合によっては、特定のインスタンスフレーバーでの需要は、個々のハードウェア設計を正当化しない可能性があり、代わりに商品化されたシステムが優先されます。
いずれの場合も、共通のインスタンス要求に対応することができるハードウェアリソースを割り当てて、設計を開始します。アーキテクチャー全体にハードウェア設計を追加する場合は、後でこれを行うことができます。
- プロセッサータイプ
ハードウェア設計では、特に異なるプロセッサーの機能とパフォーマンス特性を比較する場合に、プロセッサーの選択が重要な考慮事項となります。
プロセッサーには、ハードウェア支援型仮想化やメモリーのページング、EPT シャドウテクノロジーなどの仮想化コンピュートホスト専用の機能を含めることができます。これらの機能は、クラウド仮想マシンのパフォーマンスに大きく影響する可能性があります。
- リソースノード
- クラウド内のハイパーバイザー以外のリソースノードの Compute 要件を考慮する必要があります。リソースノードには、Object Storage、Block Storage、および Networking サービスを実行するコントローラーノードおよびノードが含まれます。
- リソースプール
オンデマンドで提供されるリソースのプールを複数割り当てる Compute 設計を使用します。この設計は、クラウドでのアプリケーションリソース使用量を最大化します。各リソースプールは、インスタンスまたはフレーバーのグループの特定のフレーバーにサービスする必要があります。
複数のリソースプールを設計することで、インスタンスがコンピュートハイパーバイザーにスケジュールされるたびに、ノードリソースの各セットが割り当てられ、利用可能なハードウェアの使用を最大化することができます。通常、これは bin packing と呼ばれます。
リソースプール内のノード間で一貫性のあるハードウェア設計を使用すると、bin パックをサポートするのにも役立ちます。コンピュートリソースプール用に選択したハードウェアノードは、共通のプロセッサー、メモリー、およびストレージレイアウトを共有する必要があります。一般的なハードウェア設計を選択すると、デプロイメント、サポート、およびノードのライフサイクルのメンテナンスが容易になります。
- オーバーコミット率
OpenStack では、ユーザーはコンピュートノードで CPU および RAM をオーバーコミットすることができます。これは、クラウドで実行されるインスタンスの数を増やすのに役立ちます。ただし、オーバーコミットすると、インスタンスのパフォーマンスが低下する可能性があります。
オーバーコミット率は、利用可能な仮想リソースと利用可能な物理リソースの割合です。
- デフォルトの CPU 割り当て比率は、16:1 では、スケジューラーはすべての物理コアに最大 16 個の仮想コアを割り当てます。たとえば、物理ノードに 12 コアがある場合、スケジューラーは最大 192 個の仮想コアを割り当てることができます。インスタンスごとに 4 つの仮想コアの通常のフレーバー定義により、この比率では物理ノード上で 48 つのインスタンスを提供することができます。
- デフォルトの RAM 割り当て比率の 1.5:1 は、インスタンスに関連付けられた RAM の合計量が物理ノード上では 1.5 倍未満の場合に、スケジューラーはインスタンスを物理ノードに割り当てることを意味します。
設計フェーズで CPU とメモリーのオーバーコミット率を調整することは、コンピュートノードのハードウェアレイアウトに直接影響を与えるので、重要です。ハードウェアノードを、インスタンスに対するコンピュートリソースプールとして設計する場合には、ノードで利用可能なプロセッサーコアの数だけでなく、十分な容量で実行されるサービスインスタンスに必要なディスクおよびメモリーも検討してください。
たとえば、m1.small インスタンスは 1 つの vCPU、20 GB の一時ストレージ、および 2,048 MB のメモリーを使用します。それぞれ 10 コアで 2 つの CPU を搭載したサーバーの場合、ハイパースレッディングをオンにします。
- デフォルトの CPU オーバーコミット比率が 16:1 の場合、合計 m1.small インスタンスに対して 640 (2 × 10 × 16)が許可されます。
- デフォルトのメモリーが 1.5:1 の場合は、サーバーに 853 GB (640 × 2,048 MB / 1.5)以上の RAM が必要です。
メモリー用のノードのサイジング時には、オペレーティングシステムおよびサービスのニーズに必要とされる追加のメモリーも考慮することが重要です。
3.2.2. Flavors
作成する各インスタンスには、インスタンスのサイズや容量を決定するフレーバーまたはリソースのテンプレートが提供されます。フレーバーは、セカンダリー一時ストレージ、スワップディスク、使用量を制限するメタデータ、または特別なプロジェクトアクセスを指定することもできます。デフォルトのフレーバーには、これらの追加属性が定義されていません。インスタンスのフレーバーにより、容量予測が可能です。これは、一般的なユースケースは予測されるサイズで、アドホックにはサイズ設定ではないためです。
仮想マシンを物理ホストにパックしやすくするために、フレーバーのデフォルト選択で、すべてのディメンションにおいて、最大のフレーバーのサイズを半分(合計)します。フレーバーには、vCPU の半分、vRAM の半分、エフェメラルディスク領域の半分があります。後続の最大のフレーバーはそれぞれ、前のフレーバーの半分になります。
次の図は、汎用的なコンピューティング設計と、CPU 最適化のパックされたサーバーでのフレーバー割り当てを視覚的に示しています。
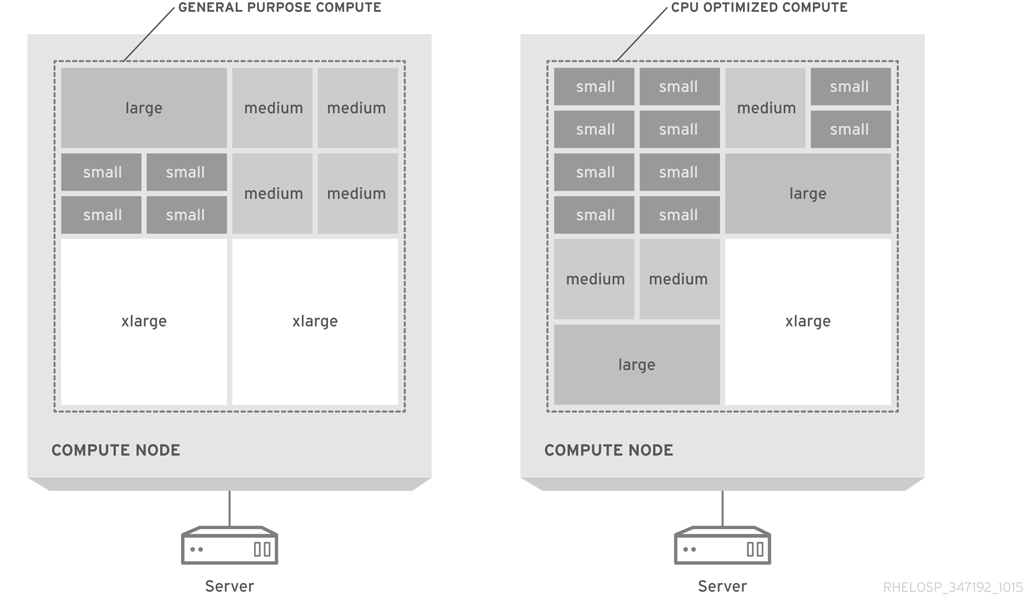
デフォルトのフレーバーは、コモディティーサーバーハードウェアの典型的な設定に適しています。使用率を最大化するには、フレーバーをカスタマイズしたり、新規フレーバーを作成してインスタンスサイズを利用可能なハードウェアに合わせたりする必要がある場合があります。
可能であれば、フレーバーを各フレーバーの 1 つの仮想 CPU に制限します。タイプ 1 ハイパーバイザーは、1 つの vCPU で設定された仮想マシンにとって、CPU 時間をより簡単にスケジュールできることに注意してください。たとえば、4 vCPU で設定されている仮想マシンに CPU 時間をスケジュールするハイパーバイザーは、タスクが 1 つの vCPU のみを実行する必要がある場合でも、4 つの物理コアが使用可能になるまで待機する必要があります。
ワークロードの特徴は、特に CPU、RAM、または HDD 要件の異なる比率をタスクの場合に、ハードウェアの選択とフレーバーの設定にも影響を与える可能性があります。フレーバーに関する情報は、インスタンスおよびイメージの管理 を 参照してください。
3.2.3. vCPU から物理への CPU コア比率
Red Hat OpenStack Platform のデフォルトの割り当て率は、物理(ハイパースレッディング)またはハイパースレッドごとに 16 vCPU です。
次の表に、システム用に予約されている 4GB など、使用可能な合計メモリーに基づいて物理ホストで適切に実行できる仮想マシンの最大数を示します。
| 合計 RAM | 仮想マシン | 合計仮想 CPU |
|---|---|---|
| 64 GB | 14 | 56 |
| 96 GB | 20 | 80 |
| 128 GB | 29 | 116 |
たとえば、60 インスタンスの最初の greenfields 表現を計画するには、3+1 コンピュートノードが必要です。通常、メモリーのボトルネックは CPU のボトルネックよりも一般的です。ただし、必要に応じて割り当て比率を物理コアごとに 8 vCPU に下げることができます。
3.2.4. メモリーのオーバーヘッド
KVM ハイパーバイザーには、共有不可能なメモリーなど、少量の仮想マシンメモリーのオーバーヘッドが必要です。QEMU/KVM システムの共有可能なメモリーは、各ハイパーバイザーで 200 MB に丸めることができます。
| vRAM | 物理メモリー使用量(平均) |
|---|---|
| 256 | 310 |
| 512 | 610 |
| 1024 | 1080 |
| 2048 | 2120 |
| 4096 | 4180 |
通常、仮想マシンごとに 100MB のハイパーバイザーのオーバーヘッドを予測できます。
3.2.5. オーバーサブスクリプション
メモリーは、ハイパーバイザーのデプロイメントの制限要素です。各物理ホストで実行できる仮想マシンの数は、ホストがアクセスできるメモリーの量によって制限されます。たとえば、256 GB の RAM、200 1 GB を超えるインスタンスを持つクアッドコア CPU をデプロイすると、パフォーマンスが低下します。したがって、インスタンス全体に分散するには、CPU コアとメモリーの最適な比率を慎重に決定する必要があります。
3.2.6. 密度
- インスタンスの密度
- コンピュート重視アーキテクチャーでは、インスタンスの密度は低くなります。つまり、CPU と RAM の過剰比も低くなります。特に設計でデュアルソケットハードウェア設計が使用されている場合は、インスタンスの密度が低い場合に、予想されるスケールをサポートするために、より多くのホストが必要になる場合があります。
- ホストの密度
- クアッドソケットプラットフォームを使用して、デュアルソケット設計のより高いホスト数に対応できます。このプラットフォームによりホストの密度が低下し、ラック数が増えます。この構成は、ネットワーク要件や電源接続の数に影響し、コロケーションの要件にも影響を及ぼす可能性があります。
- パワーと協調密度
- パワーと協調の密度の削減は、古いインフラストラクチャーを持つデータセンターにとって重要な考慮事項です。たとえば、2U、3U、または 4U サーバー設計の電源および協調密度の要件は、ホストの密度が低いため、ブレード、sled、または 1U サーバー設計よりも低い場合があります。
3.2.7. Compute ハードウェア
- ブレードサーバー
- ほとんどのブレードサーバーは、デュアルソケット、マルチコア CPU に対応します。CPU の制限を超えないようにするには、フル幅 または 全 負荷のブレードを選択します。これらのブレードタイプはサーバー密度を低下させることもできます。たとえば、HP BladeSystem や Dell PowerEdge M1000e などの高密度ブレードサーバーは、10 個のラックユニットでのみ最大 16 個のサーバーをサポートします。半次ブレードは、高密度のブレードとして 2 倍になり、第 10 のラックユニットごとに 8 台のサーバーしかありません。
- 1U サーバー
1U のラックマウント済みサーバー(ラックユニットを 1 つだけ使用する)は、ブレードサーバーソリューションよりも高いサーバー密度を提供する場合があります。1 つのラックに 40 台のユニットを 1U サーバーで使用すると、ラック(ToR)スイッチの上の領域を確保できます。比較すると、32 個のフル幅ブレードサーバーしか使用できません。1 つのラックでのみ使用できます。
ただし、主要なベンダーの 1U サーバーには、デュアルソケット、マルチコア CPU 設定のみがあります。1U のラックマウントフォーム要素でより高い CPU 設定をサポートするには、システムを元の設計メーカー(ODM)または第 2 層の製造元から購入します。
- 2U サーバー
- 2U ラックマウントサーバーでは、クアッドソケット、マルチコア CPU のサポートが提供されますが、サーバー密度は対応する減少です。2U のラックマウント済みサーバーは、1U のラックマウント済みサーバーが提供する密度の半分を提供します。
- 大規模なサーバー
- 4U サーバーなど、ラックマウントが大きいサーバーでは、多くの場合、高い CPU 容量が提供され、通常は 4 つ以上の CPU ソケットに対応します。これらのサーバーは拡張性が高くなっていますが、サーバーの密度が大幅に低く、多くの場合、より高価です。
- sled servers
あるサーバーは、単一の 2U または 3U ロボットで、複数の独立したサーバーをサポートするラックマウントサーバーです。これらのサーバーは、一般的な 1U または 2U のラックマウントされたサーバーよりも高い密度を提供します。
たとえば、多くのサーバーでは、合計 8 つの CPU ソケットに対して 2U に 4 つの独立したデュアルソケットノードを提供します。ただし、個々のノードでのデュアルソケットの制限については、追加のコストと設定の複雑さを補正するには十分ではない場合があります。
3.2.8. 追加デバイス
コンピュートノード用に、以下のような追加デバイスを検討する場合があります。
- 高性能コンピューティングジョブのグラフィックス処理ユニット(GPU)。
-
暗号化ルーチンのエントロピー不足を避ける、ハードウェアベースの乱数ジェネレーター。インスタンスイメージの属性と共に、乱数ジェネレーターデバイスをインスタンスに追加することができます。
/dev/randomはデフォルトのエントロピーソースです。 - データベース管理システムの読み取り/書き込み時間を最大化する一時ストレージ用の SSD。
- ホストアグリゲートは、ハードウェア類似点など、同様の特性を共有するホストをまとめてグループ化することで機能します。クラウドデプロイメントに固有のハードウェアを追加すると、各ノードのコストが追加される可能性があるため、すべてのコンピュートノードに追加のカスタマイズが必要であるか、またはサブセットのみが必要であるかを検討してください。