1.2. ストレージ
「OpenStack Block Storage (cinder)」
「OpenStack Object Storage (swift)」
「OpenStack Database-as-a-Service (trove)」
1.2.1. OpenStack Block Storage (cinder)
OpenStack Block Storage サービスは、仮想ハードドライブの永続的なブロックストレージ管理機能を提供します。Block Storage により、ユーザーはブロックデバイスの作成/削除やサーバーへの Block Device の接続を管理することができます。
実際のデバイスの割り当て/割り当て解除は、Compute サービスとの統合により処理されます。リージョンおよびゾーンを使用して、分散ブロックストレージホストを処理できます。
Block Storage は、データベースのストレージや拡張可能なファイルシステムなど、パフォーマンスの影響を受けやすいシナリオで使用できます。また、raw のブロックレベルのストレージにアクセスできるサーバーとして使用することもできます。また、ボリュームスナップショットを作成してデータを復元したり、新しいブロックストレージボリュームを作成したりできます。スナップショットはドライバーのサポートに依存します。
OpenStack Block Storage の利点は以下のとおりです。
- ボリュームおよびスナップショットの作成、一覧表示、および削除。
- 実行中の仮想マシンへのボリュームのアタッチおよび割り当て解除。
ボリューム、スケジューラー、API などのメインの Block Storage サービスは実稼働環境で同じ場所に配置できますが、ボリュームサービスのインスタンスを複数デプロイして API およびスケジューラーサービスのインスタンスを管理する方が一般的です。
| コンポーネント | 説明 |
|---|---|
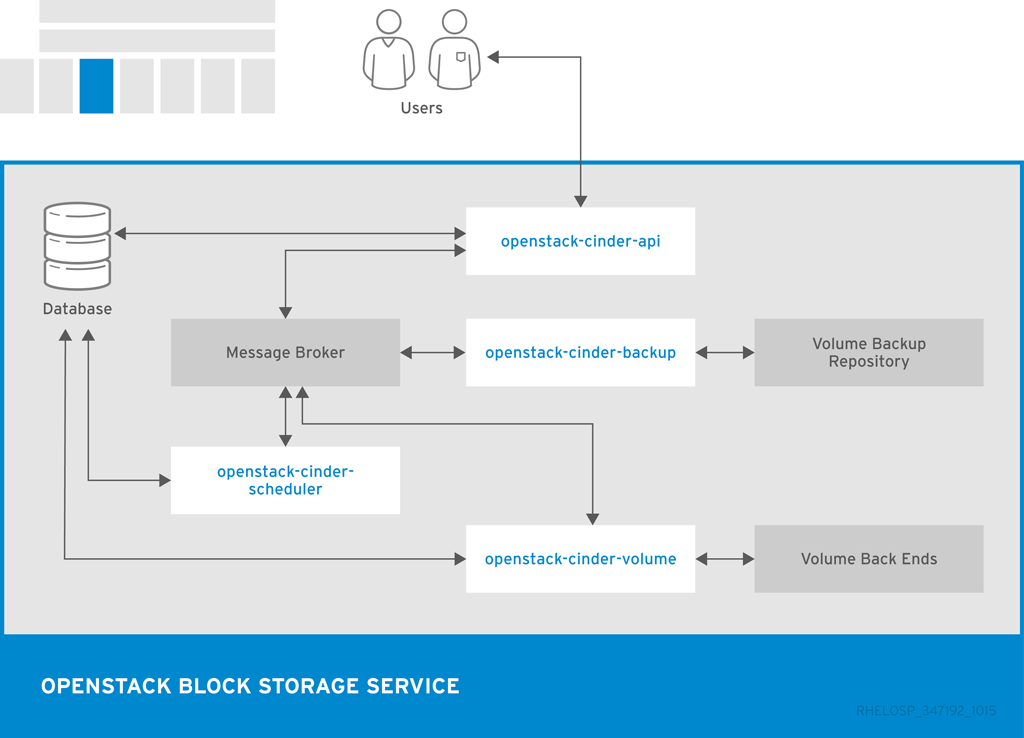
| openstack-cinder-api | 要求に応答し、メッセージキューに配置します。リクエストを受け取ると、API サービスはアイデンティティー要件を満たしていることを確認し、要求を必要なブロックストレージアクションを含むメッセージに変換します。その後、メッセージはメッセージブローカーに送信され、他の Block Storage サービスによって処理されます。 |
| openstack-cinder-backup | Block Storage ボリュームを外部ストレージリポジトリーにバックアップします。デフォルトでは、OpenStack は Object Storage サービスを使用してバックアップを保存します。Ceph または NFS バックエンドをバックアップのストレージリポジトリーとして使用することもできます。 |
| openstack-cinder-scheduler | キューにタスクを割り当て、プロビジョニングボリュームサーバーを決定します。スケジューラーサービスはメッセージキューから要求を読み取り、どのブロックストレージホストが要求されたアクションを実行するかを決定します。その後、スケジューラーは選択したホストの openstack-cinder-volume サービスと通信し、要求を処理する。 |
| openstack-cinder-volume | 仮想マシンのストレージを指定します。ボリュームサービスは、ブロックストレージデバイスとの対話を管理します。スケジューラーから要求が到達すると、ボリュームサービスはボリュームを作成、変更、または削除できます。ボリュームサービスには、NFS、Red Hat Storage、Dell EqualLogic などのブロックストレージデバイスと対話するための複数のドライバーが含まれています。 |
| cinder | Block Storage API にアクセスするためのコマンドラインクライアント。 |
以下の図は、Block Storage API、スケジューラー、ボリュームサービス、およびその他の OpenStack コンポーネントの関係を示しています。
1.2.2. OpenStack Object Storage (swift)
Object Storage サービスは、HTTP 経由でアクセス可能な、大量データ用のストレージシステムを提供します。ビデオ、イメージ、メールのメッセージ、ファイル、仮想マシンイメージなどの静的エンティティーをすべて保管することができます。オブジェクトは、各ファイルの拡張属性に保管されているメタデータとともに、下層のファイルシステムにバイナリーとして保管されます。
Object Storage 分散アーキテクチャーは、ソフトウェアベースのデータのレプリケーションによる水平スケーリングおよびフェイルオーバーの冗長性をサポートします。このサービスは非同期および最終的な一貫性のレプリケーションをサポートするため、複数のデータセンターデプロイメントで使用できます。
OpenStack Object Storage の利点は以下のとおりです。
- ストレージレプリカは、停止時にオブジェクトの状態を維持します。少なくとも 3 つのレプリカが推奨されます。
- ストレージゾーンホストレプリカ。ゾーンにより、特定のオブジェクトの各レプリカを個別に保存できます。ゾーンは、個々のディスクドライブ、アレイ、サーバー、サーバーのラック、またはデータセンター全体を表す場合があります。
- ストレージ領域は、ロケーション別にゾーンをグループ化できます。リージョンには、通常同じ地理的領域にあるサーバーまたはサーバーファームを含めることができます。リージョンには、Object Storage サービスのインストールごとに個別の API エンドポイントがあり、個別のサービスを分離することができます。
オブジェクトストレージは、データベースおよび設定ファイルとして機能するリング .gz ファイルを使用します。これらのファイルには、すべてのストレージデバイスの詳細と、保存されたエンティティーから各ファイルの物理的な場所へのマッピングが含まれます。したがって、リングファイルを使用して、特定のデータの場所を判断できます。各オブジェクト、アカウント、およびコンテナーサーバーには、一意のリングファイルがあります。
Object Storage サービスは、他の OpenStack サービスとコンポーネントに依存してアクションを実行します。たとえば、Identity サービス(keystone)、rsync デーモン、およびロードバランサーがすべて必要です。
| コンポーネント | 説明 |
|---|---|
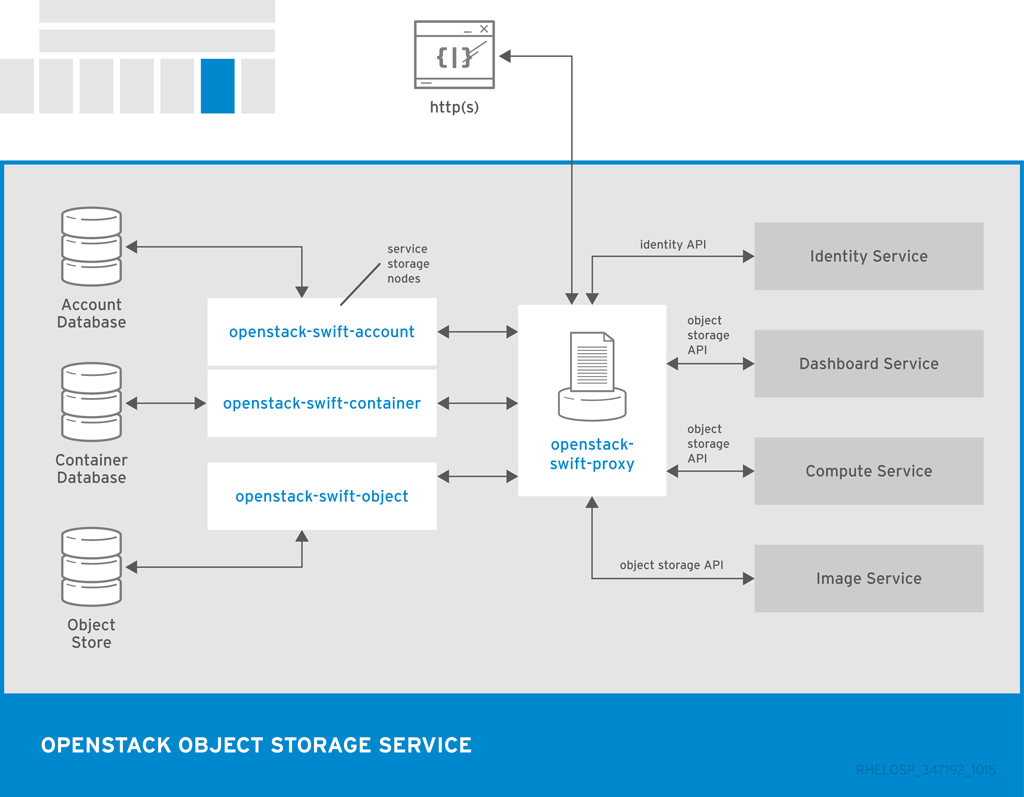
| openstack-swift-account | アカウントデータベースでコンテナーの一覧を処理します。 |
| openstack-swift-container | コンテナーデータベースを含む特定のコンテナーに含まれるオブジェクトの一覧を処理します。 |
| openstack-swift-object | オブジェクトを格納、取得、および削除します。 |
| openstack-swift-proxy | パブリック API を公開し、認証およびルーティング要求を行います。オブジェクトは、スプールせずにプロキシーサーバーを介してユーザーにストリーミングされます。 |
| swift | Object Storage API にアクセスするためのコマンドラインクライアント。 |
| Housekeeping | コンポーネント | 説明 |
|---|---|---|
| 監査 |
| Object Storage アカウント、コンテナー、およびオブジェクトの整合性を検証し、データの破損から保護するのに役立ちます。 |
| レプリケーション |
| ガベージコレクションを含む、オブジェクトストレージクラスター全体で一貫したレプリケーションと利用可能なレプリケーションを確保します。 |
| 更新 |
| 失敗した更新を特定して再試行する。 |
以下の図は、Object Storage が他の OpenStack サービス、データベース、ブローカーとの対話に使用する主なインターフェイスを示しています。
1.2.3. OpenStack Database-as-a-Service (trove)
DEPRECATION NOTICE: Red Hat OpenStack Platform 10 以降、OpenStack Trove サービスは Red Hat OpenStack Platform ディストリビューションに含まれなくなります。お客様に実稼働に対応した DBaaS サービスを提供するために、信頼できるパートナーと協力しています。このオプションの詳細については、営業アカウントマネージャーにお問い合わせください。
この機能は、本リリースでは テクノロジープレビュー として提供しているため、Red Hat では全面的にはサポートしていません。これは、テスト用途にのみご利用いただく機能です。実稼働環境にはデプロイしないでください。テクノロジープレビュー機能の詳細は、対象範囲の詳細 を参照してください。
OpenStack Database-as-a-Service では、ユーザーはさまざまなリレーショナルデータベースおよび非リレーショナルデータベースを選択、プロビジョニング、および操作することができ、より複雑なデータベース管理タスクを標準で処理できます。
OpenStack Database-as-a-Service には、以下のような利点があります。
- ユーザーおよびデータベース管理者は、クラウドで複数のデータベースインスタンスをプロビジョニングおよび管理できます。
- デプロイメント、設定、パッチ適用、バックアップ、復元、監視などの複雑な管理タスクを自動化しつつ、高性能のリソース分離。
| コンポーネント | 説明 |
|---|---|
| openstack-trove-api | Database-as-a-Service インスタンスをプロビジョニングおよび管理するための JSON および XML をサポートする RESTful API。 |
| openstack-trove-conductor | ホストで実行され、ホストに関する情報を更新する要求でゲストインスタンスからメッセージを受信します。要求には、インスタンスのステータスまたはバックアップの現在のステータスを含めることができます。 openstack-trove-conductor を使用すると、ゲストインスタンスはホストデータベースに直接接続する必要はありません。このサービスは、メッセージバスを介して RPC メッセージをリッスンし、要求された操作を実行します。 |
| openstack-trove-guestagent | ゲストインスタンスで実行され、ホストデータベースで直接操作を管理および実行します。openstack-trove-guestagent は、メッセージバスを介して RPC メッセージをリッスンし、要求された操作を実行します。 |
| openstack-trove-taskmanager | インスタンスの作成、インスタンスのライフサイクルの管理、データベースインスタンスでの操作などのタスクを行います。 |
| trove | Database-as-a-Service API にアクセスするためのコマンドラインクライアント。 |
以下の図は、Database-as-a-Service と他の OpenStack サービスの関係を示しています。

- OpenStack Database-as-a-Service はデフォルトの OpenStack チャネルから利用できますが、コンポーネントを手動でインストールして設定する必要があります。