머신 관리
클러스터 머신 추가 및 유지 보수
초록
1장. 머신 관리 개요
머신 관리를 사용하여 AWS(Amazon Web Services), Azure, Google Cloud Platform(GCP), OpenStack, Red Hat Virtualization(RHV) 및 vSphere와 같은 기본 인프라에서 유연하게 작업할 수 있습니다. 클러스터를 제어하고 특정 워크로드 정책에 따라 클러스터 확장 및 축소와 같은 자동 확장을 수행할 수 있습니다.
OpenShift Container Platform 클러스터는 로드가 증가하거나 감소하면 수평적으로 확장 및 축소할 수 있습니다. 변화하는 워크로드에 맞게 조정하는 클러스터가 있어야 합니다.
머신 관리는 CRD( Custom Resource Definition)로 구현됩니다. CRD 오브젝트는 클러스터에서 새로운 고유한 오브젝트 Kind 를 정의하고 Kubernetes API 서버가 오브젝트의 전체 라이프사이클을 처리할 수 있도록 합니다.
Machine API Operator는 다음 리소스를 프로비저닝합니다.
- MachineSet
- 머신
- 클러스터 Autoscaler
- 머신 Autoscaler
- 머신 상태 점검
1.1. Machine API 개요
Machine API는 업스트림 Cluster API 프로젝트 및 사용자 정의 OpenShift Container Platform 리소스를 기반으로 하는 주요 리소스의 조합입니다.
OpenShift Container Platform 4.11 클러스터의 경우 Machine API는 클러스터 설치가 완료된 후 모든 노드 호스트 프로비저닝 관리 작업을 수행합니다. 이 시스템으로 인해 OpenShift Container Platform 4.11은 퍼블릭 또는 프라이빗 클라우드 인프라에 더하여 탄력적이고 동적인 프로비저닝 방법을 제공합니다.
두 가지 주요 리소스는 다음과 같습니다.
- Machine
-
노드의 호스트를 설명하는 기본 단위입니다. 머신에는
providerSpec사양이 있으며 이는 다른 클라우드 플랫폼에 제공되는 컴퓨팅 노드 유형을 설명합니다. 예를 들어 컴퓨팅 노드의 머신 유형은 특정 시스템 유형과 필수 메타데이터를 정의할 수 있습니다. - 머신 세트
MachineSet리소스는 머신 그룹입니다. 머신 세트는 머신에 연관되어 있고 복제본 세트는 pod에 연관되어 있습니다. 더 많은 머신이 필요하거나 규모를 줄여야 하는 경우 컴퓨터 요구 사항에 맞게 머신 세트의 replicas 필드를 변경합니다.주의컨트롤 플레인 시스템은 머신 세트에서 관리할 수 없습니다.
다음 사용자 지정 리소스는 클러스터에 더 많은 기능을 추가할 수 있습니다.
- 머신 자동 스케일러
MachineAutoscaler리소스는 클라우드에서 컴퓨팅 머신을 자동으로 확장합니다. 지정된 컴퓨팅 머신 세트에서 노드의 최소 및 최대 스케일링 경계를 설정할 수 있으며 머신 자동 스케일러는 해당 노드 범위를 유지합니다.MachineAutoscaler객체는ClusterAutoscaler객체를 설정한 후에 사용할 수 있습니다.ClusterAutoscaler및MachineAutoscaler리소스는 모두ClusterAutoscalerOperator오브젝트에서 사용 가능합니다.- Cluster autoscaler
- 이 리소스는 업스트림 클러스터 자동 스케일러 프로젝트를 기반으로 합니다. OpenShift Container Platform 구현에서는 머신 세트 API를 확장하여 Machine API와 통합됩니다. 코어, 노드, 메모리, GPU 등과 같은 리소스의 클러스터 전체에서 확장 제한을 설정할 수 있습니다. 중요도가 낮은 Pod에 대해 새 노드가 온라인 상태가 되지 않도록 클러스터가 Pod에 우선 순위를 설정할 수 있습니다. 노드를 확장할 수는 있지만 축소할 수 없도록 확장 정책을 설정할 수도 있습니다.
- 머신 상태 점검
-
MachineHealthCheck리소스는 머신의 비정상적인 상태를 감지하여 삭제한 후 지원되는 플랫폼에서 새 머신을 생성합니다.
OpenShift Container Platform 버전 3.11에서는 클러스터가 머신 프로비저닝을 관리하지 않았기 때문에 다중 영역 아키텍처를 쉽게 롤아웃할 수 없었습니다. OpenShift Container Platform 버전 4.1부터 이러한 프로세스가 더 쉬워졌습니다. 각 머신 세트의 범위는 단일 영역에서 지정되므로 설치 프로그램은 사용자를 대신하여 가용성 영역 전체에 머신 세트를 보냅니다. 또한 계산이 동적이고 영역 장애가 발생하여 머신을 재조정해야하는 경우 처리할 수 있는 영역을 확보할 수 있습니다. 여러 가용성 영역이 없는 글로벌 Azure 리전에서는 가용성 세트를 사용하여 고가용성을 보장할 수 있습니다. Autoscaler는 클러스터의 수명 기간 동안 최적의 균형을 유지합니다.
1.2. 컴퓨팅 머신 관리
클러스터 관리자는 다음을 수행할 수 있습니다.
다음에서 머신 세트를 생성합니다.
- 베어 메탈 배포의 머신 세트 생성: 베어 메탈에 컴퓨팅 머신 세트생성
- 머신 세트에서 머신을 추가하거나 제거하여 머신 세트를 수동으로 확장합니다.
-
MachineSetYAML 구성 파일을 통해 머신 세트를 수정합니다. - 머신을 삭제합니다.
- 인프라 머신 세트를 생성합니다.
- 머신 풀에서 손상된 머신을 자동으로 수정하기 위해 머신 상태 점검 을 구성하고 배포합니다.
1.3. OpenShift Container Platform 클러스터에 자동 스케일링 적용
OpenShift Container Platform 클러스터를 자동으로 스케일링하여 워크로드 변경에 대한 유연성을 확보할 수 있습니다. 클러스터를 자동 스케일링 하려면 먼저 클러스터 자동 스케일러를 배포한 다음 각 컴퓨팅 머신 세트에 대한 시스템 자동 스케일러를 배포해야 합니다.
- 클러스터 자동 스케일러 는 배포 요구에 따라 클러스터 크기를 늘리거나 줄입니다.
- 머신 자동 스케일러 는 OpenShift Container Platform 클러스터에 배포하는 컴퓨팅 머신 세트의 머신 수를 조정합니다.
1.4. 사용자 프로비저닝 인프라에 컴퓨팅 머신 추가
사용자 프로비저닝 인프라는 OpenShift Container Platform을 호스팅하는 컴퓨팅, 네트워크 및 스토리지 리소스와 같은 인프라를 배포할 수 있는 환경입니다. 설치 프로세스 중 또는 설치 프로세스 후 사용자 프로비저닝 인프라의 클러스터에 컴퓨팅 머신을 추가할 수 있습니다.
1.5. 클러스터에 RHEL 컴퓨팅 머신 추가
클러스터 관리자는 다음 작업을 수행할 수 있습니다.
2장. Machine API를 사용하여 컴퓨팅 머신 관리
2.1. Alibaba Cloud에 머신 세트 생성
Alibaba Cloud의 OpenShift Container Platform 클러스터에서 특정 목적을 충족하기 위해 다른 머신 세트를 생성할 수 있습니다. 예를 들어, 지원되는 워크로드를 새 머신으로 이동할 수 있도록 인프라 머신 세트 및 관련 머신을 작성할 수 있습니다.
머신 API가 작동하는 클러스터에서만 고급 머신 관리 및 스케일링 기능을 사용할 수 있습니다. 사용자 프로비저닝 인프라가 있는 클러스터에는 Machine API를 사용하려면 추가 검증 및 구성이 필요합니다.
인프라 플랫폼 유형의 클러스터가 Machine API를 사용할 수 없습니다. 이 제한은 클러스터에 연결된 컴퓨팅 시스템이 기능을 지원하는 플랫폼에 설치된 경우에도 적용됩니다. 이 매개변수는 설치 후 변경할 수 없습니다.
클러스터의 플랫폼 유형을 보려면 다음 명령을 실행합니다.
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.1.1. Alibaba Cloud에서 머신 세트 사용자 정의 리소스의 샘플 YAML
이 샘플 YAML은 리전의 지정된 Alibaba Cloud 영역에서 실행되는 머신 세트를 정의하고 node-role.kubernetes.io/<role>: "" 로 레이블이 지정된 노드를 만듭니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <role>은 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
name: <infrastructure_id>-<role>-<zone>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone>
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: machine.openshift.io/v1
credentialsSecret:
name: alibabacloud-credentials
imageId: <image_id>
instanceType: <instance_type>
kind: AlibabaCloudMachineProviderConfig
ramRoleName: <infrastructure_id>-role-worker
regionId: <region>
resourceGroup:
id: <resource_group_id>
type: ID
securityGroups:
- tags:
- Key: Name
Value: <infrastructure_id>-sg-<role>
type: Tags
systemDisk:
category: cloud_essd
size: <disk_size>
tag:
- Key: kubernetes.io/cluster/<infrastructure_id>
Value: owned
userDataSecret:
name: <user_data_secret>
vSwitch:
tags:
- Key: Name
Value: <infrastructure_id>-vswitch-<zone>
type: Tags
vpcId: ""
zoneId: <zone> - 1 5 7
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로하는 인프라 ID를 지정합니다. OpenShift CLI (
oc) 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 8 9
- 추가할 노드 레이블을 지정합니다.
- 4 6 10
- 인프라 ID, 노드 레이블 및 영역을 지정합니다.
- 11
- 사용할 이미지를 지정합니다. 클러스터의 기존 기본 시스템 세트의 이미지를 사용합니다.
- 12
- 머신 세트에 사용할 인스턴스 유형을 지정합니다.
- 13
- 머신 세트에 사용할 RAM 역할의 이름을 지정합니다. 설치 프로그램이 기본 시스템 세트에서 채우는 값을 사용합니다.
- 14
- 머신을 배치할 리전을 지정합니다.
- 15
- 클러스터의 리소스 그룹 및 유형을 지정합니다. 설치 프로그램이 기본 시스템 세트에서 채우는 값을 사용하거나 다른 시스템 집합을 지정할 수 있습니다.
- 16 18 20
- 머신 세트에 사용할 태그를 지정합니다. 최소한 클러스터에 적절한 값을 사용하여 이 예에 표시된 태그를 포함해야 합니다. 설치 프로그램이 생성하는 기본 시스템 세트에 채워지는 태그를 포함하여 필요에 따라 추가 태그를 포함할 수 있습니다.
- 17
- 루트 디스크의 유형 및 크기를 지정합니다. 설치 프로그램이 생성하는 기본 시스템 세트에서 채우는
카테고리값을 사용합니다. 필요한 경우 다른 값을크기(GB)로 지정합니다. - 19
openshift-machine-api네임스페이스에 있는 사용자 데이터 YAML 파일에 시크릿 이름을 지정합니다. 설치 프로그램이 기본 시스템 세트에서 채우는 값을 사용합니다.- 21
- 머신을 배치할 리전 내 영역을 지정합니다. 해당 리전이 지정한 영역을 지원하는지 확인합니다.
2.1.1.1. Alibaba Cloud 사용량 통계에 대한 머신 세트 매개변수
Alibaba Cloud 클러스터에 대해 설치 관리자가 생성하는 기본 머신 세트에는 Alibaba Cloud가 내부적으로 사용하는 nonessential 태그 값이 포함되어 있습니다. 이러한 태그는 spec.template.spec.providerSpec.value 목록의 securityGroups,tag, vSwitch 매개 변수에 채워집니다.
추가 머신을 배포하기 위해 머신 세트를 생성할 때 필요한 Kubernetes 태그를 포함해야 합니다. 생성하는 머신 세트에 지정되지 않은 경우에도 사용량 통계 태그가 기본적으로 적용됩니다. 필요에 따라 추가 태그를 추가할 수도 있습니다.
다음 YAML 스니펫은 기본 머신 세트의 태그가 선택 사항이며 필요한 태그를 나타냅니다.
spec.template.spec.providerSpec.value.securityGroups의 태그
spec:
template:
spec:
providerSpec:
value:
securityGroups:
- tags:
- Key: kubernetes.io/cluster/<infrastructure_id>
Value: owned
- Key: GISV
Value: ocp
- Key: sigs.k8s.io/cloud-provider-alibaba/origin
Value: ocp
- Key: Name
Value: <infrastructure_id>-sg-<role>
type: Tagsspec.template.spec.providerSpec.value.tag의 태그
spec:
template:
spec:
providerSpec:
value:
tag:
- Key: kubernetes.io/cluster/<infrastructure_id>
Value: owned
- Key: GISV
Value: ocp
- Key: sigs.k8s.io/cloud-provider-alibaba/origin
Value: ocpspec.template.spec.providerSpec.value.vSwitch의 태그
spec:
template:
spec:
providerSpec:
value:
vSwitch:
tags:
- Key: kubernetes.io/cluster/<infrastructure_id>
Value: owned
- Key: GISV
Value: ocp
- Key: sigs.k8s.io/cloud-provider-alibaba/origin
Value: ocp
- Key: Name
Value: <infrastructure_id>-vswitch-<zone>
type: Tags2.1.2. 머신 세트 만들기
설치 프로그램에서 생성한 컴퓨팅 머신 세트 외에도 고유한 머신 세트를 생성하여 선택한 특정 워크로드의 머신 컴퓨팅 리소스를 동적으로 관리할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터를 배포합니다.
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다.
절차
머신 세트 CR(사용자 지정 리소스) 샘플이 포함된 이름이
<file_name>.yaml인 새 YAML 파일을 만듭니다.<clusterID>및<role>매개 변수 값을 설정해야 합니다.선택 사항: 특정 필드에 설정할 값이 확실하지 않은 경우 클러스터에서 기존 컴퓨팅 머신 세트를 확인할 수 있습니다.
클러스터의 컴퓨팅 머신 세트를 나열하려면 다음 명령을 실행합니다.
$ oc get machinesets -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m특정 컴퓨팅 머신 세트 CR(사용자 정의 리소스)의 값을 보려면 다음 명령을 실행합니다.
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml출력 예
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
다음 명령을 실행하여
MachineSetCR을 생성합니다.$ oc create -f <file_name>.yaml
검증
다음 명령을 실행하여 컴퓨팅 머신 세트 목록을 확인합니다.
$ oc get machineset -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m새 머신 세트가 사용 가능한 경우
DESIRED및CURRENT값이 일치합니다. 머신 세트를 사용할 수 없는 경우 몇 분 후에 명령을 다시 실행합니다.
2.2. AWS에서 머신 세트 생성
AWS (Amazon Web Services)의 OpenShift Container Platform 클러스터에서 특정 목적을 수행하기 위해 다른 머신 세트를 생성할 수 있습니다. 예를 들어, 지원되는 워크로드를 새 머신으로 이동할 수 있도록 인프라 머신 세트 및 관련 머신을 작성할 수 있습니다.
머신 API가 작동하는 클러스터에서만 고급 머신 관리 및 스케일링 기능을 사용할 수 있습니다. 사용자 프로비저닝 인프라가 있는 클러스터에는 Machine API를 사용하려면 추가 검증 및 구성이 필요합니다.
인프라 플랫폼 유형의 클러스터가 Machine API를 사용할 수 없습니다. 이 제한은 클러스터에 연결된 컴퓨팅 시스템이 기능을 지원하는 플랫폼에 설치된 경우에도 적용됩니다. 이 매개변수는 설치 후 변경할 수 없습니다.
클러스터의 플랫폼 유형을 보려면 다음 명령을 실행합니다.
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.2.1. AWS에서 머신 세트 사용자 지정 리소스의 샘플 YAML
이 샘플 YAML은 us-east-1a AWS (Amazon Web Services) 영역에서 실행되는 머신 세트를 정의하고 node-role.kubernetes.io/<role>: "" 로 레이블이 지정된 노드를 생성합니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <role>은 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
name: <infrastructure_id>-<role>-<zone>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone>
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
ami:
id: ami-046fe691f52a953f9
apiVersion: awsproviderconfig.openshift.io/v1beta1
blockDevices:
- ebs:
iops: 0
volumeSize: 120
volumeType: gp2
credentialsSecret:
name: aws-cloud-credentials
deviceIndex: 0
iamInstanceProfile:
id: <infrastructure_id>-worker-profile
instanceType: m6i.large
kind: AWSMachineProviderConfig
placement:
availabilityZone: <zone>
region: <region>
securityGroups:
- filters:
- name: tag:Name
values:
- <infrastructure_id>-worker-sg
subnet:
filters:
- name: tag:Name
values:
- <infrastructure_id>-private-<zone>
tags:
- name: kubernetes.io/cluster/<infrastructure_id>
value: owned
userDataSecret:
name: worker-user-data- 1 3 5 11 14 16
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID를 지정합니다. OpenShift CLI 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 4 8
- 인프라 ID, 노드 레이블 및 영역을 지정합니다.
- 6 7 9
- 추가할 노드 레이블을 지정합니다.
- 10
- OpenShift Container Platform 노드의 AWS(Amazon Web Services) 영역에 유효한 RHCOS(Red Hat Enterprise Linux CoreOS) AMI를 지정합니다. AWS Marketplace 이미지를 사용하려면 AWS Marketplace에서 OpenShift Container Platform 서브스크립션을 완료해야 리전의 AMI ID를 가져와야 합니다.
- 12
- 영역을 지정합니다(예:
us-east-1a). - 13
- 리전을 지정합니다(예:
us-east-1). - 15
- 인프라 ID 및 영역을 지정합니다.
2.2.2. 머신 세트 만들기
설치 프로그램에서 생성한 컴퓨팅 머신 세트 외에도 고유한 머신 세트를 생성하여 선택한 특정 워크로드의 머신 컴퓨팅 리소스를 동적으로 관리할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터를 배포합니다.
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다.
절차
머신 세트 CR(사용자 지정 리소스) 샘플이 포함된 이름이
<file_name>.yaml인 새 YAML 파일을 만듭니다.<clusterID>및<role>매개 변수 값을 설정해야 합니다.선택 사항: 특정 필드에 설정할 값이 확실하지 않은 경우 클러스터에서 기존 컴퓨팅 머신 세트를 확인할 수 있습니다.
클러스터의 컴퓨팅 머신 세트를 나열하려면 다음 명령을 실행합니다.
$ oc get machinesets -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m특정 컴퓨팅 머신 세트 CR(사용자 정의 리소스)의 값을 보려면 다음 명령을 실행합니다.
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml출력 예
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
다음 명령을 실행하여
MachineSetCR을 생성합니다.$ oc create -f <file_name>.yaml- 다른 가용 영역에 컴퓨팅 머신 세트가 필요한 경우 이 프로세스를 반복하여 추가 컴퓨팅 머신 세트를 생성합니다.
검증
다음 명령을 실행하여 컴퓨팅 머신 세트 목록을 확인합니다.
$ oc get machineset -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m새 머신 세트가 사용 가능한 경우
DESIRED및CURRENT값이 일치합니다. 머신 세트를 사용할 수 없는 경우 몇 분 후에 명령을 다시 실행합니다.
2.2.3. Amazon EC2 인스턴스 메타데이터 서비스에 대한 머신 세트 옵션
머신 세트를 사용하여 특정 버전의 Amazon EC2 Instance Metadata Service(IMDS)를 사용하는 컴퓨팅 머신을 생성할 수 있습니다. 머신 세트는 IMDSv1 및 IMDSv2 또는 IMDSv2 를 사용해야 하는 컴퓨팅 머신을 생성할 수 있습니다.
IMDSv2 사용은 OpenShift Container Platform 버전 4.7 이상으로 생성된 AWS 클러스터에서만 지원됩니다.
기존 컴퓨팅 머신의 IMDS 구성을 변경하려면 해당 머신을 관리하는 머신 세트 YAML 파일을 편집합니다. 선호하는 IMDS 구성을 사용하여 새 컴퓨팅 머신을 배포하려면 적절한 값을 사용하여 머신 세트 YAML 파일을 생성합니다.
컨트롤 플레인 시스템의 IMDS 구성이 클러스터 설치 중에 설정됩니다. 컨트롤 플레인 시스템 IMDS 구성을 변경하려면 AWS CLI를 사용해야 합니다. 자세한 내용은 기존 인스턴스의 인스턴스 메타데이터 옵션 수정 방법에 대한 AWS 설명서를 참조하십시오.
IMDSv2가 필요한 컴퓨팅 머신을 생성하도록 머신 세트를 구성하기 전에 AWS 메타데이터 서비스와 상호 작용하는 모든 워크로드가 IMDSv2를 지원하는지 확인합니다.
2.2.3.1. 머신 세트를 사용하여 IMDS 구성
컴퓨팅 머신의 머신 세트 YAML 파일에서 metadataServiceOptions.authentication 값을 추가하거나 편집하여 IMDSv2를 사용할지 여부를 지정할 수 있습니다.
사전 요구 사항
- IMDSv2를 사용하려면 OpenShift Container Platform 버전 4.7 이상을 사용하여 AWS 클러스터가 생성되어 있어야 합니다.
절차
providerSpec필드 아래에 다음 행을 추가하거나 편집합니다.providerSpec: value: metadataServiceOptions: authentication: Required1 - 1
- IMDSv2를 요구하려면 매개변수 값을
Required로 설정합니다. IMDSv1 및 IMDSv2를 둘 다 사용하도록 허용하려면 매개 변수 값을 선택적으로설정합니다. 값을 지정하지 않으면 IMDSv1 및 IMDSv2가 모두 허용됩니다.
2.2.4. 머신을 Dedicated 인스턴스로 배포하는 머신 세트
AWS에서 실행 중인 머신 세트를 생성하여 머신을 Dedicated 인스턴스로 배포할 수 있습니다. Dedicated 인스턴스는 단일 고객 전용 하드웨어의 VPC(가상 프라이빗 클라우드)에서 실행됩니다. 이러한 Amazon EC2 인스턴스는 호스트 하드웨어 수준에서 물리적으로 분리됩니다. Dedicated 인스턴스의 분리는 인스턴스가 하나의 유료 계정에 연결된 다른 AWS 계정에 속하는 경우에도 발생합니다. 하지만 전용이 아닌 다른 인스턴스는 동일한 AWS 계정에 속하는 경우 Dedicated 인스턴스와 하드웨어를 공유할 수 있습니다.
공용 또는 전용 테넌시가 있는 인스턴스는 Machine API에서 지원됩니다. 공용 테넌시가 있는 인스턴스는 공유 하드웨어에서 실행됩니다. 공용 테넌시는 기본 테넌시입니다. 전용 테넌트가 있는 인스턴스는 단일 테넌트 하드웨어에서 실행됩니다.
2.2.4.1. 머신 세트를 사용하여 Dedicated 인스턴스 생성
Machine API 통합을 사용하여 Dedicated 인스턴스에서 지원하는 머신을 실행할 수 있습니다. 머신 세트 YAML 파일의 tenancy 필드를 설정하여 AWS에서 전용 인스턴스를 시작합니다.
절차
providerSpec필드에서 전용 테넌트를 지정합니다.providerSpec: placement: tenancy: dedicated
2.2.5. 머신을 Spot 인스턴스로 배포하는 머신 세트
AWS에서 실행되는 머신 세트를 생성하여 보장되지 않는 Spot 인스턴스로 머신을 배포하면 비용을 절감할 수 있습니다. Spot 인스턴스는 사용되지 않는 AWS EC2 용량을 사용하며 온 디맨드 인스턴스보다 저렴합니다. 일괄 처리 또는 상태 비저장, 수평적으로 확장 가능한 워크로드와 같이 인터럽트를 허용할 수 있는 워크로드에 Spot 인스턴스를 사용할 수 있습니다.
AWS EC2는 언제든지 Spot 인스턴스를 종료할 수 있습니다. AWS는 중단이 발생하면 사용자에게 2 분 동안 경고 메세지를 보냅니다. OpenShift Container Platform은 AWS가 종료에 대한 경고를 발행할 때 영향을 받는 인스턴스에서 워크로드를 제거하기 시작합니다.
다음과 같은 이유로 Spot 인스턴스를 사용할 때 중단될 수 있습니다.
- 인스턴스 가격이 최대 가격을 초과합니다.
- Spot 인스턴스에 대한 수요가 증가합니다.
- Spot 인스턴스의 공급이 감소합니다.
AWS가 인스턴스를 종료하면 Spot 인스턴스 노드에서 실행중인 종료 프로세스가 머신 리소스를 삭제합니다. 머신 세트 replicas 수량을 충족하기 위해 머신 세트는 Spot 인스턴스를 요청하는 머신을 생성합니다.
2.2.5.1. 머신 세트를 사용하여 Spot 인스턴스 생성
머신 세트 YAML 파일에 spotMarketOptions를 추가하여 AWS에서 Spot 인스턴스를 시작할 수 있습니다.
절차
providerSpec필드 아래에 다음 행을 추가합니다.providerSpec: value: spotMarketOptions: {}선택 옵션으로
spotMarketOptions.maxPrice필드를 설정하여 Spot 인스턴스의 비용을 제한할 수 있습니다. 예를 들어maxPrice: '2.50'을 설정할 수 있습니다.maxPrice가 설정된 경우 이 값은 시간당 최대 Spot 가격으로 사용됩니다. 이 값이 설정되지 않은 경우 기본적으로 최대 가격은 온 디맨드 인스턴스 가격까지 청구됩니다.참고기본적인 온 디맨드 가격을
maxPrice값으로 사용하여 Spot 인스턴스의 최대 가격을 설정하지 않는 것이 좋습니다.
2.3. Azure에서 머신 세트 만들기
Microsoft Azure의 OpenShift Container Platform 클러스터에서 특정 목적을 충족하기 위해 다른 머신 세트를 만들 수 있습니다. 예를 들어, 지원되는 워크로드를 새 머신으로 이동할 수 있도록 인프라 머신 세트 및 관련 머신을 작성할 수 있습니다.
머신 API가 작동하는 클러스터에서만 고급 머신 관리 및 스케일링 기능을 사용할 수 있습니다. 사용자 프로비저닝 인프라가 있는 클러스터에는 Machine API를 사용하려면 추가 검증 및 구성이 필요합니다.
인프라 플랫폼 유형의 클러스터가 Machine API를 사용할 수 없습니다. 이 제한은 클러스터에 연결된 컴퓨팅 시스템이 기능을 지원하는 플랫폼에 설치된 경우에도 적용됩니다. 이 매개변수는 설치 후 변경할 수 없습니다.
클러스터의 플랫폼 유형을 보려면 다음 명령을 실행합니다.
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.3.1. Azure의 머신 세트사용자 지정 리소스에 대한 샘플 YAML
이 샘플 YAML은 리전의 1 Microsoft Azure 영역에서 실행되는 머신 세트를 정의하고 node-role.kubernetes.io/<role>: "" 로 레이블이 지정된 노드를 만듭니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <role>은 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
name: <infrastructure_id>-<role>-<region>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<region>
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<region>
spec:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-machineset: <machineset_name>
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: azureproviderconfig.openshift.io/v1beta1
credentialsSecret:
name: azure-cloud-credentials
namespace: openshift-machine-api
image:
offer: ""
publisher: ""
resourceID: /resourceGroups/<infrastructure_id>-rg/providers/Microsoft.Compute/images/<infrastructure_id>
sku: ""
version: ""
internalLoadBalancer: ""
kind: AzureMachineProviderSpec
location: <region>
managedIdentity: <infrastructure_id>-identity
metadata:
creationTimestamp: null
natRule: null
networkResourceGroup: ""
osDisk:
diskSizeGB: 128
managedDisk:
storageAccountType: Premium_LRS
osType: Linux
publicIP: false
publicLoadBalancer: ""
resourceGroup: <infrastructure_id>-rg
sshPrivateKey: ""
sshPublicKey: ""
tags:
- name: <custom_tag_name>
value: <custom_tag_value>
subnet: <infrastructure_id>-<role>-subnet
userDataSecret:
name: worker-user-data
vmSize: Standard_D4s_v3
vnet: <infrastructure_id>-vnet
zone: "1" - 1 5 7 15 16 19 22
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID를 지정합니다. OpenShift CLI 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster다음 명령을 실행하여 서브넷을 가져올 수 있습니다.
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.subnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1다음 명령을 실행하여 vnet을 가져올 수 있습니다.
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.vnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1 - 2 3 8 9 11 20 21
- 추가할 노드 레이블을 지정합니다.
- 4 6 10
- 인프라 ID, 노드 레이블, 리전을 지정합니다.
- 12
- 머신 세트의 이미지 세부 정보를 지정합니다. Azure Marketplace 이미지를 사용하려면 "Azure Marketplace 이미지 선택"을 참조하십시오.
- 13
- 인스턴스 유형과 호환되는 이미지를 지정합니다. 설치 프로그램에서 만든 Hyper-V 생성 V2 이미지에는
-gen2접미사가 있으며 V1 이미지는 접미사 없이 이름이 동일합니다. - 14
- 머신을 배치할 리전을 지정합니다.
- 23
- 머신을 배치할 리전 내 영역을 지정합니다. 해당 리전이 지정한 영역을 지원하는지 확인합니다.
- 17 18
- 선택 사항: 머신 세트에서 사용자 지정 태그를 지정합니다. 태그 이름을 <
custom_tag_name> 필드에 제공하고 해당 태그 값을 <custom_tag_value> 필드에 입력합니다.
2.3.2. 머신 세트 만들기
설치 프로그램에서 생성한 컴퓨팅 머신 세트 외에도 고유한 머신 세트를 생성하여 선택한 특정 워크로드의 머신 컴퓨팅 리소스를 동적으로 관리할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터를 배포합니다.
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다.
절차
머신 세트 CR(사용자 지정 리소스) 샘플이 포함된 이름이
<file_name>.yaml인 새 YAML 파일을 만듭니다.<clusterID>및<role>매개 변수 값을 설정해야 합니다.선택 사항: 특정 필드에 설정할 값이 확실하지 않은 경우 클러스터에서 기존 컴퓨팅 머신 세트를 확인할 수 있습니다.
클러스터의 컴퓨팅 머신 세트를 나열하려면 다음 명령을 실행합니다.
$ oc get machinesets -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m특정 컴퓨팅 머신 세트 CR(사용자 정의 리소스)의 값을 보려면 다음 명령을 실행합니다.
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml출력 예
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
다음 명령을 실행하여
MachineSetCR을 생성합니다.$ oc create -f <file_name>.yaml
검증
다음 명령을 실행하여 컴퓨팅 머신 세트 목록을 확인합니다.
$ oc get machineset -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m새 머신 세트가 사용 가능한 경우
DESIRED및CURRENT값이 일치합니다. 머신 세트를 사용할 수 없는 경우 몇 분 후에 명령을 다시 실행합니다.
2.3.3. Azure Marketplace 이미지 선택
Azure에서 실행되는 머신 세트를 생성하여 Azure Marketplace 제품을 사용하는 머신을 배포할 수 있습니다. 이 제품을 사용하려면 먼저 Azure Marketplace 이미지를 가져와야 합니다. 이미지를 가져올 때 다음 사항을 고려하십시오.
-
이미지가 동일하지만 Azure Marketplace 게시자는 지역에 따라 다릅니다. 북미에 있는 경우 게시자로
redhat을 지정합니다. EMEA에 있는 경우 게시자로redhat-limited를 지정합니다. -
이 프로모션에는
rh-ocp-workerSKU 및rh-ocp-worker-gen1SKU가 포함되어 있습니다.rh-ocp-workerSKU는 Hyper-V generation 버전 2 VM 이미지를 나타냅니다. OpenShift Container Platform에서 사용되는 기본 인스턴스 유형은 버전 2와 호환됩니다. 버전 1 호환 가능한 인스턴스 유형을 사용하려는 경우rh-ocp-worker-gen1SKU와 연결된 이미지를 사용합니다.rh-ocp-worker-gen1SKU는 Hyper-V 버전 1 VM 이미지를 나타냅니다.
사전 요구 사항
-
Azure CLI 클라이언트
(az)를 설치했습니다. - Azure 계정은 이 제안에 액세스할 수 있으며 Azure CLI 클라이언트를 사용하여 이 계정에 로그인했습니다.
절차
다음 명령 중 하나를 실행하여 사용 가능한 모든 OpenShift Container Platform 이미지를 표시합니다.
북아메리카:
$ az vm image list --all --offer rh-ocp-worker --publisher redhat -o table출력 예
Offer Publisher Sku Urn Version ------------- -------------- ------------------ -------------------------------------------------------------- -------------- rh-ocp-worker RedHat rh-ocp-worker RedHat:rh-ocp-worker:rh-ocpworker:4.8.2021122100 4.8.2021122100 rh-ocp-worker RedHat rh-ocp-worker-gen1 RedHat:rh-ocp-worker:rh-ocp-worker-gen1:4.8.2021122100 4.8.2021122100EMEA:
$ az vm image list --all --offer rh-ocp-worker --publisher redhat-limited -o table출력 예
Offer Publisher Sku Urn Version ------------- -------------- ------------------ -------------------------------------------------------------- -------------- rh-ocp-worker redhat-limited rh-ocp-worker redhat-limited:rh-ocp-worker:rh-ocp-worker:4.8.2021122100 4.8.2021122100 rh-ocp-worker redhat-limited rh-ocp-worker-gen1 redhat-limited:rh-ocp-worker:rh-ocp-worker-gen1:4.8.2021122100 4.8.2021122100
참고설치하는 OpenShift Container Platform 버전에 관계없이 사용할 올바른 버전의 Azure Marketplace 이미지는 4.8.x입니다. 필요한 경우 설치 프로세스의 일부로 VM이 자동으로 업그레이드됩니다.
다음 명령 중 하나를 실행하여 제공 이미지를 검사합니다.
북아메리카:
$ az vm image show --urn redhat:rh-ocp-worker:rh-ocp-worker:<version>EMEA:
$ az vm image show --urn redhat-limited:rh-ocp-worker:rh-ocp-worker:<version>
다음 명령 중 하나를 실행하여 제안 조건을 검토합니다.
북아메리카:
$ az vm image terms show --urn redhat:rh-ocp-worker:rh-ocp-worker:<version>EMEA:
$ az vm image terms show --urn redhat-limited:rh-ocp-worker:rh-ocp-worker:<version>
다음 명령 중 하나를 실행하여 제품 약관에 동의합니다.
북아메리카:
$ az vm image terms accept --urn redhat:rh-ocp-worker:rh-ocp-worker:<version>EMEA:
$ az vm image terms accept --urn redhat-limited:rh-ocp-worker:rh-ocp-worker:<version>
-
제공의 이미지 세부 정보, 특히
게시자의 값,제공,sku및버전을 기록합니다. 제안의 이미지 세부 정보를 사용하여 머신 세트 YAML 파일의
providerSpec섹션에 다음 매개변수를 추가합니다.Azure Marketplace 컴퓨팅 머신의 샘플
providerSpec이미지 값providerSpec: value: image: offer: rh-ocp-worker publisher: redhat resourceID: "" sku: rh-ocp-worker type: MarketplaceWithPlan version: 4.8.2021122100
2.3.4. 머신을 Spot 가상머신으로 배포하는 머신 세트
Azure에서 실행되는 머신 세트를 생성하여 머신을 보장되지 않는 Spot 가상 머신으로 배포하면 비용을 절감할 수 있습니다. Spot 가상 머신은 사용되지 않은 Azure 용량을 사용하며 표준 가상 머신보다 비용이 저렴합니다. 일괄 처리 또는 상태 비저장, 수평적으로 확장 가능한 워크로드와 같이 인터럽트를 허용할 수 있는 워크로드에 Spot 가상 머신을 사용할 수 있습니다.
Azure는 언제든지 Spot 가상 머신을 종료 할 수 있습니다. Azure는 중단이 발생하면 사용자에게 30 초 동안 경고 메세지를 보냅니다. OpenShift Container Platform은 Azure가 종료 경고를 발행할 때 영향을 받는 인스턴스에서 워크로드를 제거하기 시작합니다.
다음과 같은 이유로 Spot 가상 머신을 사용할 때 중단될 수 있습니다.
- 인스턴스 가격이 최대 가격을 초과합니다.
- Spot 가상 머신의 공급이 감소합니다.
- Azure는 용량을 복원해야합니다.
Azure가 인스턴스를 종료하면 Spot 가상 머신 노드에서 실행되는 종료 프로세스가 머신 리소스를 삭제합니다. 머신 세트 replicas 수량을 충족하기 위해 머신 세트는 Spot 가상 머신을 요청하는 머신을 생성합니다.
2.3.4.1. 머신 세트를 사용하여 Spot 가상 머신 생성
머신 세트 YAML 파일에 spotVMOptions를 추가하여 Azure에서 Spot 가상 머신을 시작할 수 있습니다.
절차
providerSpec필드 아래에 다음 행을 추가합니다.providerSpec: value: spotVMOptions: {}선택 옵션으로
spotVMOptions.maxPrice필드를 설정하여 Spot 가상 머신의 비용을 제한할 수 있습니다. 예를 들어maxPrice: '0.98765'를 설정할 수 있습니다.maxPrice가 설정된 경우 이 값은 시간당 최대 Spot 가격으로 사용됩니다. 설정되지 않은 경우 최대 가격은 기본적으로-1로 설정된 표준 가상 머신 가격까지 청구됩니다.Azure는 Spot 가상 머신 가격을 표준 가격으로 제한합니다. 인스턴스가 기본
maxPrice로 설정된 경우 Azure는 가격 설정에 따라 인스턴스를 제거하지 않습니다. 그러나 용량 제한으로 인해 인스턴스를 제거할 수 있습니다.
기본 표준 가상 머신 가격을 maxPrice 값으로 사용하고 Spot 가상 머신의 최대 가격을 설정하지 않는 것이 좋습니다.
2.3.5. Ephemeral OS 디스크에 머신을 배포하는 머신 세트
Azure에서 실행 중인 머신 세트를 생성하여 Ephemeral OS 디스크에 머신을 배포할 수 있습니다. 임시 OS 디스크는 원격 Azure Storage가 아닌 로컬 VM 용량을 사용합니다. 따라서 이 구성에서는 추가 비용이 발생하지 않으며 읽기, 쓰기 및 재imaging에 대한 대기 시간을 줄일 수 있습니다.
2.3.5.1. 머신 세트를 사용하여 임시 OS 디스크에 머신 생성
머신 세트 YAML 파일을 편집하여 Azure의 Ephemeral OS 디스크에서 머신을 시작할 수 있습니다.
사전 요구 사항
- 기존 Microsoft Azure 클러스터가 있어야 합니다.
절차
다음 명령을 실행하여 CR(사용자 정의 리소스)을 편집합니다.
$ oc edit machineset <machine-set-name>여기서
<machine-set-name>은 Ephemeral OS 디스크에 머신을 프로비저닝하려는 머신 세트입니다.providerSpec필드에 다음을 추가합니다.providerSpec: value: ... osDisk: ... diskSettings:1 ephemeralStorageLocation: Local2 cachingType: ReadOnly3 managedDisk: storageAccountType: Standard_LRS4 ...중요OpenShift Container Platform에서 Ephemeral OS 디스크 지원 구현은
CacheDisk배치 유형만 지원합니다.배치구성 설정을 변경하지 마십시오.업데이트된 구성을 사용하여 머신 세트를 생성합니다.
$ oc create -f <machine-set-config>.yaml
검증
-
Microsoft Azure 포털에서 머신 세트에서 배포한 머신의 개요 페이지를 검토하고
Ephemeral OS 디스크 필드가로 설정되어 있는지 확인합니다.OS캐시 배치
2.3.6. 울트라 디스크가 있는 머신을 데이터 디스크로 배포하는 머신 세트
Azure에서 실행되는 머신 세트를 생성하여 대규모 디스크가 있는 머신을 배포할 수 있습니다. Ultra 디스크는 가장 까다로운 데이터 워크로드와 함께 사용하도록 설계된 고성능 스토리지입니다.
또한 Azure에서 지원하는 스토리지 클래스에 동적으로 바인딩하고 Pod에 마운트하는 PVC(영구 볼륨 클레임)를 생성할 수도 있습니다.
데이터 디스크는 디스크 처리량 또는 디스크 IOPS를 지정하는 기능을 지원하지 않습니다. PVC를 사용하여 이러한 속성을 구성할 수 있습니다.
2.3.6.1. 머신 세트를 사용하여 디스크가 있는 머신 생성
머신 세트 YAML 파일을 편집하여 Azure에 보조 디스크가 있는 머신을 배포할 수 있습니다.
사전 요구 사항
- 기존 Microsoft Azure 클러스터가 있어야 합니다.
절차
다음 명령을 실행하여 작업자 데이터 시크릿을 사용하여
openshift-machine-api네임스페이스에 사용자 정의 시크릿을 생성합니다.$ oc -n openshift-machine-api \ get secret worker-user-data \ --template='{{index .data.userData | base64decode}}' | jq > userData.txt여기서
userData.txt는 새 사용자 정의 시크릿의 이름입니다.텍스트 편집기에서
userData.txt파일을 열고 파일에서 최종}문자를 찾습니다.-
즉시 이전 행에서
,을 추가합니다. 다음에 새 행을 생성하고 다음 구성 세부 정보를 추가합니다.
"storage": { "disks": [1 { "device": "/dev/disk/azure/scsi1/lun0",2 "partitions": [3 { "label": "lun0p1",4 "sizeMiB": 1024,5 "startMiB": 0 } ] } ], "filesystems": [6 { "device": "/dev/disk/by-partlabel/lun0p1", "format": "xfs", "path": "/var/lib/lun0p1" } ] }, "systemd": { "units": [7 { "contents": "[Unit]\nBefore=local-fs.target\n[Mount]\nWhere=/var/lib/lun0p1\nWhat=/dev/disk/by-partlabel/lun0p1\nOptions=defaults,pquota\n[Install]\nWantedBy=local-fs.target\n",8 "enabled": true, "name": "var-lib-lun0p1.mount" } ] }- 1
- 노드에 연결하려는 디스크의 구성 세부 정보입니다.
- 2
- 사용 중인 머신 세트의
dataDisks스탠자에 정의된lun값을 지정합니다. 예를 들어 머신 세트에lun: 0이 포함된 경우lun0을 지정합니다. 이 구성 파일에서 여러 "디스크" 항목을 지정하여 여러 데이터 디스크를 초기화할 수 있습니다. 여러 개의"disks"항목을 지정하는 경우 각 항목의lun값이 머신 세트의 값과 일치하는지 확인합니다. - 3
- 디스크의 새 파티션에 대한 구성 세부 정보입니다.
- 4
- 파티션의 레이블을 지정합니다.
lun0의 첫 번째 파티션에lun0p1과 같은 계층적 이름을 사용하는 것이 유용할 수 있습니다. - 5
- 파티션의 총 크기(MiB)를 지정합니다.
- 6
- 파티션을 포맷할 때 사용할 파일 시스템을 지정합니다. 파티션 레이블을 사용하여 파티션을 지정합니다.
- 7
- 부팅 시 파티션을 마운트할
systemd장치를 지정합니다. 파티션 레이블을 사용하여 파티션을 지정합니다. 이 구성 파일에서 여러 개의"파티션"항목을 지정하여 여러 파티션을 생성할 수 있습니다. 여러 개의"파티션"항목을 지정하는 경우 각각에 대해systemd장치를 지정해야 합니다. - 8
Where에서storage.filesystems.path의 값을 지정합니다.What는storage.filesystems.device의 값을 지정합니다.
-
즉시 이전 행에서
다음 명령을 실행하여 비활성화 템플릿 값을
disableTemplating.txt라는 파일에 추출합니다.$ oc -n openshift-machine-api get secret worker-user-data \ --template='{{index .data.disableTemplating | base64decode}}' | jq > disableTemplating.txtuserData.txt파일을 결합하고Templating.txt 파일을 비활성화하여 다음 명령을 실행하여 데이터 시크릿 파일을 생성합니다.$ oc -n openshift-machine-api create secret generic worker-user-data-x5 \ --from-file=userData=userData.txt \ --from-file=disableTemplating=disableTemplating.txt여기서
worker-user-data-x5는 시크릿의 이름입니다.기존 Azure
MachineSetCR(사용자 정의 리소스)을 복사하고 다음 명령을 실행하여 편집합니다.$ oc edit machineset <machine-set-name>여기서
<machine-set-name>은 주요 디스크를 사용하여 머신을 프로비저닝하려는 머신 세트입니다.표시된 위치에 다음 행을 추가합니다.
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet ... spec: ... template: ... spec: metadata: ... labels: ... disk: ultrassd1 ... providerSpec: value: ... ultraSSDCapability: Enabled2 dataDisks:3 - nameSuffix: ultrassd lun: 0 diskSizeGB: 4 deletionPolicy: Delete cachingType: None managedDisk: storageAccountType: UltraSSD_LRS userDataSecret: name: worker-user-data-x54 ...다음 명령을 실행하여 업데이트된 구성을 사용하여 머신 세트를 생성합니다.
$ oc create -f <machine-set-name>.yaml
검증
다음 명령을 실행하여 시스템이 생성되었는지 확인합니다.
$ oc get machines시스템은
Running상태에 있어야 합니다.실행 중이고 노드가 연결되어 있는 시스템의 경우 다음 명령을 실행하여 파티션을 검증합니다.
$ oc debug node/<node-name> -- chroot /host lsblk이 명령에서
oc debug node/<node-name>은 <node-name> 노드에서 디버깅 쉘을 시작하고--를 사용하여 명령을 전달합니다. 전달된 명령chroot /host는 기본 호스트 OS 바이너리에 대한 액세스를 제공하며lsblk는 호스트 OS 시스템에 연결된 블록 장치를 표시합니다.
다음 단계
Pod 내에서 디스크를 사용하려면 마운트 지점을 사용하는 워크로드를 생성합니다. 다음 예와 유사한 YAML 파일을 생성합니다.
apiVersion: v1 kind: Pod metadata: name: ssd-benchmark1 spec: containers: - name: ssd-benchmark1 image: nginx ports: - containerPort: 80 name: "http-server" volumeMounts: - name: lun0p1 mountPath: "/tmp" volumes: - name: lun0p1 hostPath: path: /var/lib/lun0p1 type: DirectoryOrCreate nodeSelector: disktype: ultrassd
2.3.6.2. 자외 디스크를 활성화하는 머신 세트의 리소스 문제 해결
이 섹션의 정보를 사용하여 발생할 수 있는 문제를 이해하고 복구하십시오.
2.3.6.2.1. 잘못된 디스크 구성
자외의 SSDCapability 매개변수의 잘못된 구성이 머신 세트에 지정되면 머신 프로비저닝이 실패합니다.
예를 들어, NetNamespace SSDCapability 매개변수가 Disabled 로 설정되어 있지만 dataDisks 매개변수에 자외 디스크가 지정되면 다음과 같은 오류 메시지가 표시됩니다.
StorageAccountType UltraSSD_LRS can be used only when additionalCapabilities.ultraSSDEnabled is set.- 이 문제를 해결하려면 머신 세트 구성이 올바른지 확인합니다.
2.3.6.2.2. 지원되지 않는 디스크 매개변수
자외 디스크와 호환되지 않는 지역, 가용성 영역 또는 인스턴스 크기가 시스템 세트에 지정되면 시스템 프로비저닝에 실패합니다. 로그에 다음 오류 메시지가 있는지 확인합니다.
failed to create vm <machine_name>: failure sending request for machine <machine_name>: cannot create vm: compute.VirtualMachinesClient#CreateOrUpdate: Failure sending request: StatusCode=400 -- Original Error: Code="BadRequest" Message="Storage Account type 'UltraSSD_LRS' is not supported <more_information_about_why>."- 이 문제를 해결하려면 지원되는 환경에서 이 기능을 사용하고 있으며 머신 세트 구성이 올바른지 확인합니다.
2.3.6.2.3. 디스크를 삭제할 수 없음
데이터 디스크가 예상대로 작동하지 않으면 머신이 삭제되고 데이터 디스크가 분리됩니다. 필요한 경우 고립된 디스크를 수동으로 삭제해야 합니다.
2.3.7. 머신 세트의 고객 관리 암호화 키 활성화
Azure에 암호화 키를 제공하여 관리 대상 디스크의 데이터를 암호화할 수 있습니다. 시스템 API를 사용하여 고객 관리 키로 서버 측 암호화를 활성화할 수 있습니다.
고객 관리 키를 사용하려면 Azure Key Vault, 디스크 암호화 세트 및 암호화 키가 필요합니다. 디스크 암호화 세트는 CCO(Cloud Credential Operator)에 권한이 부여된 리소스 그룹 앞에 있어야 합니다. 그렇지 않은 경우 디스크 암호화 세트에 추가 reader 역할을 부여해야 합니다.
절차
머신 세트 YAML 파일의
providerSpec필드에 설정된 디스크 암호화를 구성합니다. 예를 들어 다음과 같습니다.... providerSpec: value: ... osDisk: diskSizeGB: 128 managedDisk: diskEncryptionSet: id: /subscriptions/<subscription_id>/resourceGroups/<resource_group_name>/providers/Microsoft.Compute/diskEncryptionSets/<disk_encryption_set_name> storageAccountType: Premium_LRS ...
2.3.8. Microsoft Azure VM에 대한 빠른 네트워킹
빠른 네트워킹은 SR-IOV(Single root I/O Virtualization)를 사용하여 Microsoft Azure VM에 스위치에 대한 더 직접적인 경로를 제공합니다. 이를 통해 네트워크 성능이 향상됩니다. 이 기능은 설치 중 또는 설치 후에 활성화할 수 있습니다.
2.3.8.1. 제한 사항
가속 네트워킹 사용 여부를 결정할 때 다음과 같은 제한 사항을 고려하십시오.
- 빠른 네트워킹은 머신 API가 작동하는 클러스터에서만 지원됩니다.
-
Azure 작업자 노드의 최소 요구 사항은 두 개의 vCPU이지만 Accelerated Networking에는 vCPU 4개가 포함된 Azure VM 크기가 필요합니다. 이 요구 사항을 충족하기 위해 머신 세트에서
vmSize값을 변경할 수 있습니다. Azure VM 크기에 대한 자세한 내용은 Microsoft Azure 설명서를 참조하십시오. - 기존 Azure 클러스터에서 이 기능을 활성화하면 새로 프로비저닝된 노드만 영향을 받습니다. 현재 실행 중인 노드는 조정되지 않습니다. 모든 노드에서 기능을 활성화하려면 기존 각 머신을 교체해야 합니다. 이 작업은 각 머신에 대해 개별적으로 수행하거나 복제본을 0으로 축소한 다음 원하는 복제본 수로 다시 스케일링하여 수행할 수 있습니다.
2.3.8.2. 기존 Microsoft Azure 클러스터에서 Accelerated 네트워킹 활성화
머신 세트 YAML 파일에 acceleratedNetworking 을 추가하여 Azure에서 Accelerated Networking을 활성화할 수 있습니다.
사전 요구 사항
- 머신 API가 작동하는 기존 Microsoft Azure 클러스터가 있어야 합니다.
절차
다음 명령을 실행하여 클러스터의 머신 세트를 나열합니다.
$ oc get machinesets -n openshift-machine-api머신 세트는 <
cluster-id>-worker-<region> 형식으로 나열됩니다.출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE jmywbfb-8zqpx-worker-centralus1 1 1 1 1 15m jmywbfb-8zqpx-worker-centralus2 1 1 1 1 15m jmywbfb-8zqpx-worker-centralus3 1 1 1 1 15m각 머신 세트에 대해 다음을 수행합니다.
다음 명령을 실행하여 CR(사용자 정의 리소스)을 편집합니다.
$ oc edit machineset <machine-set-name>providerSpec필드에 다음을 추가합니다.providerSpec: value: ... acceleratedNetworking: true1 ... vmSize: <azure-vm-size>2 ...- 1
- 이 라인은 가속 네트워킹을 활성화합니다.
- 2
- vCPU가 4개 이상인 Azure VM 크기를 지정합니다. VM 크기에 대한 자세한 내용은 Microsoft Azure 설명서를 참조하십시오.
- 현재 실행 중인 노드에서 이 기능을 활성화하려면 기존 각 머신을 교체해야 합니다. 이 작업은 각 머신에 대해 개별적으로 수행하거나 복제본을 0으로 축소한 다음 원하는 복제본 수로 다시 스케일링하여 수행할 수 있습니다.
검증
-
Microsoft Azure 포털에서 머신 세트에서 프로비저닝한 머신의 네트워킹 설정 페이지를 검토하고
Accelerated 네트워킹필드가Enabled로 설정되어 있는지 확인합니다.
2.4. Azure Stack Hub에서 머신 세트 생성
Microsoft Azure Stack Hub의 OpenShift Container Platform 클러스터에서 특정 목적을 충족하기 위해 다른 머신 세트를 생성할 수 있습니다. 예를 들어, 지원되는 워크로드를 새 머신으로 이동할 수 있도록 인프라 머신 세트 및 관련 머신을 작성할 수 있습니다.
머신 API가 작동하는 클러스터에서만 고급 머신 관리 및 스케일링 기능을 사용할 수 있습니다. 사용자 프로비저닝 인프라가 있는 클러스터에는 Machine API를 사용하려면 추가 검증 및 구성이 필요합니다.
인프라 플랫폼 유형의 클러스터가 Machine API를 사용할 수 없습니다. 이 제한은 클러스터에 연결된 컴퓨팅 시스템이 기능을 지원하는 플랫폼에 설치된 경우에도 적용됩니다. 이 매개변수는 설치 후 변경할 수 없습니다.
클러스터의 플랫폼 유형을 보려면 다음 명령을 실행합니다.
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.4.1. Azure Stack Hub에서 머신 세트 사용자 정의 리소스의 샘플 YAML
이 샘플 YAML은 리전의 1 Microsoft Azure 영역에서 실행되는 머신 세트를 정의하고 node-role.kubernetes.io/<role>: "" 로 레이블이 지정된 노드를 만듭니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <role>은 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
name: <infrastructure_id>-<role>-<region>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<region>
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<region>
spec:
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: machine.openshift.io/v1beta1
availabilitySet: <availability_set>
credentialsSecret:
name: azure-cloud-credentials
namespace: openshift-machine-api
image:
offer: ""
publisher: ""
resourceID: /resourceGroups/<infrastructure_id>-rg/providers/Microsoft.Compute/images/<infrastructure_id>
sku: ""
version: ""
internalLoadBalancer: ""
kind: AzureMachineProviderSpec
location: <region>
managedIdentity: <infrastructure_id>-identity
metadata:
creationTimestamp: null
natRule: null
networkResourceGroup: ""
osDisk:
diskSizeGB: 128
managedDisk:
storageAccountType: Premium_LRS
osType: Linux
publicIP: false
publicLoadBalancer: ""
resourceGroup: <infrastructure_id>-rg
sshPrivateKey: ""
sshPublicKey: ""
subnet: <infrastructure_id>-<role>-subnet
userDataSecret:
name: worker-user-data
vmSize: Standard_DS4_v2
vnet: <infrastructure_id>-vnet
zone: "1" - 1 5 7 13 15 16 17 20
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID를 지정합니다. OpenShift CLI 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster다음 명령을 실행하여 서브넷을 가져올 수 있습니다.
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.subnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1다음 명령을 실행하여 vnet을 가져올 수 있습니다.
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.vnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1 - 2 3 8 9 11 18 19
- 추가할 노드 레이블을 지정합니다.
- 4 6 10
- 인프라 ID, 노드 레이블, 리전을 지정합니다.
- 14
- 머신을 배치할 리전을 지정합니다.
- 21
- 머신을 배치할 리전 내 영역을 지정합니다. 해당 리전이 지정한 영역을 지원하는지 확인합니다.
- 12
- 클러스터의 가용성 세트를 지정합니다.
2.4.2. 머신 세트 만들기
설치 프로그램에서 생성한 컴퓨팅 머신 세트 외에도 고유한 머신 세트를 생성하여 선택한 특정 워크로드의 머신 컴퓨팅 리소스를 동적으로 관리할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터를 배포합니다.
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다. - Azure Stack Hub 머신을 배포할 가용성 세트를 만듭니다.
절차
머신 세트 CR(사용자 지정 리소스) 샘플이 포함된 이름이
<file_name>.yaml인 새 YAML 파일을 만듭니다.<
availabilitySet> , <clusterID> , <role> 매개변수 값을 설정해야 합니다.선택 사항: 특정 필드에 설정할 값이 확실하지 않은 경우 클러스터에서 기존 컴퓨팅 머신 세트를 확인할 수 있습니다.
클러스터의 컴퓨팅 머신 세트를 나열하려면 다음 명령을 실행합니다.
$ oc get machinesets -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m특정 컴퓨팅 머신 세트 CR(사용자 정의 리소스)의 값을 보려면 다음 명령을 실행합니다.
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml출력 예
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
다음 명령을 실행하여
MachineSetCR을 생성합니다.$ oc create -f <file_name>.yaml
검증
다음 명령을 실행하여 컴퓨팅 머신 세트 목록을 확인합니다.
$ oc get machineset -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m새 머신 세트가 사용 가능한 경우
DESIRED및CURRENT값이 일치합니다. 머신 세트를 사용할 수 없는 경우 몇 분 후에 명령을 다시 실행합니다.
2.4.3. 머신 세트의 고객 관리 암호화 키 활성화
Azure에 암호화 키를 제공하여 관리 대상 디스크의 데이터를 암호화할 수 있습니다. 시스템 API를 사용하여 고객 관리 키로 서버 측 암호화를 활성화할 수 있습니다.
고객 관리 키를 사용하려면 Azure Key Vault, 디스크 암호화 세트 및 암호화 키가 필요합니다. 디스크 암호화 세트는 CCO(Cloud Credential Operator)에 권한이 부여된 리소스 그룹 앞에 있어야 합니다. 그렇지 않은 경우 디스크 암호화 세트에 추가 reader 역할을 부여해야 합니다.
절차
머신 세트 YAML 파일의
providerSpec필드에 설정된 디스크 암호화를 구성합니다. 예를 들어 다음과 같습니다.... providerSpec: value: ... osDisk: diskSizeGB: 128 managedDisk: diskEncryptionSet: id: /subscriptions/<subscription_id>/resourceGroups/<resource_group_name>/providers/Microsoft.Compute/diskEncryptionSets/<disk_encryption_set_name> storageAccountType: Premium_LRS ...
2.5. GCP에서 머신 세트 생성
Google Cloud Platform (GCP)의 OpenShift Container Platform 클러스터에서 특정 목적을 충족하기 위해 다른 머신 세트를 생성할 수 있습니다. 예를 들어, 지원되는 워크로드를 새 머신으로 이동할 수 있도록 인프라 머신 세트 및 관련 머신을 작성할 수 있습니다.
머신 API가 작동하는 클러스터에서만 고급 머신 관리 및 스케일링 기능을 사용할 수 있습니다. 사용자 프로비저닝 인프라가 있는 클러스터에는 Machine API를 사용하려면 추가 검증 및 구성이 필요합니다.
인프라 플랫폼 유형의 클러스터가 Machine API를 사용할 수 없습니다. 이 제한은 클러스터에 연결된 컴퓨팅 시스템이 기능을 지원하는 플랫폼에 설치된 경우에도 적용됩니다. 이 매개변수는 설치 후 변경할 수 없습니다.
클러스터의 플랫폼 유형을 보려면 다음 명령을 실행합니다.
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.5.1. GCP에서 머신 세트 사용자 정의 리소스의 샘플 YAML
이 샘플 YAML은 Google Cloud Platform (GCP)에서 실행되는 머신 세트를 정의하고 node-role.kubernetes.io/<role>: ""로 레이블이 지정된 노드를 만듭니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <role>은 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
name: <infrastructure_id>-w-a
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-w-a
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-w-a
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: gcpprovider.openshift.io/v1beta1
canIPForward: false
credentialsSecret:
name: gcp-cloud-credentials
deletionProtection: false
disks:
- autoDelete: true
boot: true
image: <path_to_image>
labels: null
sizeGb: 128
type: pd-ssd
gcpMetadata:
- key: <custom_metadata_key>
value: <custom_metadata_value>
kind: GCPMachineProviderSpec
machineType: n1-standard-4
metadata:
creationTimestamp: null
networkInterfaces:
- network: <infrastructure_id>-network
subnetwork: <infrastructure_id>-worker-subnet
projectID: <project_name>
region: us-central1
serviceAccounts:
- email: <infrastructure_id>-w@<project_name>.iam.gserviceaccount.com
scopes:
- https://www.googleapis.com/auth/cloud-platform
tags:
- <infrastructure_id>-worker
userDataSecret:
name: worker-user-data
zone: us-central1-a- 1
- &
lt;infrastructure_id>의 경우 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 인프라 ID를 지정합니다. OpenShift CLI 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2
- &
lt;node> 의 경우 추가할 노드 레이블을 지정합니다. - 3
- 현재 머신 세트에서 사용되는 이미지의 경로를 지정합니다. OpenShift CLI가 설치되어 있으면 다음 명령을 실행하여 이미지에 대한 경로를 얻을 수 있습니다.
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.disks[0].image}{"\n"}' \ get machineset/<infrastructure_id>-worker-aGCP Marketplace 이미지를 사용하려면 사용할 오퍼를 지정합니다.
-
OpenShift Container Platform:
https://www.googleapis.com/compute/v1/projects/redhat-marketplace-public/global/images/redhat-coreos-ocp-48-x86-64-202210040145 -
OpenShift Platform Plus:
https://www.googleapis.com/compute/v1/projects/redhat-marketplace-public/global/images/redhat-coreos-opp-48-x86-64-202206140145 -
OpenShift Kubernetes Engine:
https://www.googleapis.com/compute/v1/projects/redhat-marketplace-public/global/images/redhat-coreos-oke-48-x86-64-202206140145
-
OpenShift Container Platform:
- 4
- 선택 사항:
키:값쌍의 형태로 사용자 지정 메타데이터를 지정합니다. 예를 들어 사용자 정의 메타데이터 설정에 대한 GCP 설명서를 참조하십시오. - 5
- &
lt;project_name>에 대해 클러스터에 사용하는 GCP 프로젝트의 이름을 지정합니다.
2.5.2. 머신 세트 만들기
설치 프로그램에서 생성한 컴퓨팅 머신 세트 외에도 고유한 머신 세트를 생성하여 선택한 특정 워크로드의 머신 컴퓨팅 리소스를 동적으로 관리할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터를 배포합니다.
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다.
절차
머신 세트 CR(사용자 지정 리소스) 샘플이 포함된 이름이
<file_name>.yaml인 새 YAML 파일을 만듭니다.<clusterID>및<role>매개 변수 값을 설정해야 합니다.선택 사항: 특정 필드에 설정할 값이 확실하지 않은 경우 클러스터에서 기존 컴퓨팅 머신 세트를 확인할 수 있습니다.
클러스터의 컴퓨팅 머신 세트를 나열하려면 다음 명령을 실행합니다.
$ oc get machinesets -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m특정 컴퓨팅 머신 세트 CR(사용자 정의 리소스)의 값을 보려면 다음 명령을 실행합니다.
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml출력 예
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
다음 명령을 실행하여
MachineSetCR을 생성합니다.$ oc create -f <file_name>.yaml
검증
다음 명령을 실행하여 컴퓨팅 머신 세트 목록을 확인합니다.
$ oc get machineset -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m새 머신 세트가 사용 가능한 경우
DESIRED및CURRENT값이 일치합니다. 머신 세트를 사용할 수 없는 경우 몇 분 후에 명령을 다시 실행합니다.
2.5.3. 머신 세트를 사용하여 영구 디스크 유형 구성
머신 세트는 머신 세트 YAML 파일을 편집하여 머신을 배포하는 영구 디스크 유형을 구성할 수 있습니다.
영구 디스크 유형, 호환성, 지역 가용성 및 제한 사항에 대한 자세한 내용은 영구 디스크에 대한 GCP Compute Engine 설명서를 참조하십시오.
절차
- 텍스트 편집기에서 기존 시스템 세트의 YAML 파일을 열거나 새 시스템을 생성합니다.
providerSpec필드 아래의 다음 행을 편집합니다.providerSpec: value: disks: type: <pd-disk-type>1 - 1
- 디스크 영구 유형을 지정합니다. 유효한 값은
pd-ssd,pd-standard,pd-balanced입니다. 기본값은pd-standard입니다.
검증
-
Google Cloud 콘솔에서 시스템 세트에서 배포한 시스템의 세부 정보를 검토하고
Type필드가 구성된 디스크 유형과 일치하는지 확인합니다.
2.5.4. 머신을 선점할 수 있는 가상 머신 인스턴스로 배포하는 머신 세트
머신을 보장되지 않는 선점 가능한 가상 머신 인스턴스로 배포하는 GCP에서 실행되는 머신 세트를 만들어 비용을 절감할 수 있습니다. 선점 가능한 가상 머신 인스턴스는 과도한 Compute Engine 용량을 사용하며 일반 인스턴스보다 비용이 저렴합니다. 일괄 처리 또는 상태 비저장, 수평적으로 확장 가능한 워크로드와 같이 인터럽트를 허용할 수있는 워크로드에 선점 가능한 가상 머신 인스턴스를 사용할 수 있습니다.
GCP Compute Engine은 언제든지 선점 가능한 가상 머신 인스턴스를 종료할 수 있습니다. Compute Engine은 인터럽션이 30 초 후에 발생하는 것을 알리는 선점 알림을 사용자에게 보냅니다. OpenShift Container Platform은 Compute Engine이 선점 알림을 발행할 때 영향을 받는 인스턴스에서 워크로드를 제거하기 시작합니다. 인스턴스가 중지되지 않은 경우 ACPI G3 Mechanical Off 신호는 30 초 후에 운영 체제로 전송됩니다. 다음으로 선점 가능한 가상 머신 인스턴스가 Compute Engine에 의해 TERMINATED 상태로 전환됩니다.
다음과 같은 이유로 선점 가능한 가상 머신 인스턴스를 사용할 때 중단될 수 있습니다.
- 시스템 또는 유지 관리 이벤트가 있는 경우
- 선점 가능한 가상 머신 인스턴스의 공급이 감소하는 경우
- 인스턴스가 선점 가능한 가상 머신 인스턴스에 할당된 24 시간 후에 종료되는 경우
GCP가 인스턴스를 종료하면 선점 가능한 가상 머신 인스턴스 노드에서 실행되는 종료 프로세스가 머신 리소스를 삭제합니다. 머신 세트 replicas 수량을 충족하기 위해 머신 세트는 선점 가능한 가상 머신 인스턴스를 요청하는 머신을 생성합니다.
2.5.4.1. 머신 세트를 사용하여 선점 가능한 가상 머신 인스턴스 생성
머신 세트 YAML 파일에 preemptible을 추가하여 GCP에서 선점 가능한 가상 머신 인스턴스를 시작할 수 있습니다.
절차
providerSpec필드 아래에 다음 행을 추가합니다.providerSpec: value: preemptible: truepreemptible이true로 설정된 경우 인스턴스가 시작된 후 머신에interruptable-instance로 레이블이 지정됩니다.
2.5.5. 머신 세트의 고객 관리 암호화 키 활성화
GCP(Google Cloud Platform) Compute Engine을 사용하면 사용자가 암호화 키를 제공하여 디스크의 데이터를 암호화 할 수 있습니다. 키는 고객의 데이터를 암호화하는 것이 아니라 데이터 암호화 키를 암호화하는 데 사용됩니다. 기본적으로 Compute Engine은 Compute Engine 키를 사용하여 이 데이터를 암호화합니다.
Machine API를 사용하여 고객 관리 키로 암호화를 활성화할 수 있습니다. 먼저 KMS 키를 생성하고 서비스 계정에 올바른 권한을 할당해야 합니다. 서비스 계정에서 키를 사용하려면 KMS 키 이름, 키 링 이름 및 위치가 필요합니다.
KMS 암호화에 전용 서비스 계정을 사용하지 않는 경우 Compute Engine 기본 서비스 계정이 대신 사용됩니다. 전용 서비스 계정을 사용하지 않는 경우 키에 액세스할 수 있는 기본 서비스 계정 권한을 부여해야 합니다. Compute Engine 기본 서비스 계정 이름은 service-<project_number>@compute-system.iam.gserviceaccount.com 패턴을 기반으로 합니다.
절차
KMS 키 이름, 키 링 이름 및 위치를 지정하고 다음 명령을 실행하여 특정 서비스 계정에서 KMS 키를 사용하여 서비스 계정에 올바른 IAM 역할을 부여할 수 있습니다.
gcloud kms keys add-iam-policy-binding <key_name> \ --keyring <key_ring_name> \ --location <key_ring_location> \ --member "serviceAccount:service-<project_number>@compute-system.iam.gserviceaccount.com” \ --role roles/cloudkms.cryptoKeyEncrypterDecrypter사용자가 머신 세트 YAML 파일의
providerSpec필드에 암호화 키를 구성할 수 있습니다. 예를 들어 다음과 같습니다.providerSpec: value: # ... disks: - type: # ... encryptionKey: kmsKey: name: machine-encryption-key1 keyRing: openshift-encrpytion-ring2 location: global3 projectID: openshift-gcp-project4 kmsKeyServiceAccount: openshift-service-account@openshift-gcp-project.iam.gserviceaccount.com5 업데이트된
providerSpec개체 구성을 사용하여 새 머신을 생성한 후 디스크 암호화 키는 KMS 키로 암호화됩니다.
2.5.6. 머신 세트의 GPU 지원 활성화
GCP(Google Cloud Platform) Compute Engine을 사용하면 사용자가 VM 인스턴스에 GPU를 추가할 수 있습니다. GPU 리소스에 액세스할 수 있는 워크로드는 이 기능이 활성화된 컴퓨팅 머신에서 더 효과적으로 수행할 수 있습니다. GCP의 OpenShift Container Platform은 A2 및 N1 머신 시리즈에서 NVIDIA GPU 모델을 지원합니다.
| 모델 이름 | GPU 유형 | 기계 유형 [1] |
|---|---|---|
| NVIDIA A100 |
|
|
| NVIDIA K80 |
|
|
| NVIDIA P100 |
| |
| NVIDIA P4 |
| |
| NVIDIA T4 |
| |
| NVIDIA V100 |
|
- 사양, 호환성, 지역 가용성 및 제한 사항을 포함한 머신 유형에 대한 자세한 내용은 N1 머신 시리즈 , A2 머신 시리즈 ,A2 머신 시리즈 , GPU 지역 및 영역 가용성 에 대한 GCP Compute Engine 설명서를 참조하십시오.
Machine API를 사용하여 인스턴스에 사용할 지원되는 GPU를 정의할 수 있습니다.
지원되는 GPU 유형 중 하나로 배포하도록 N1 머신 시리즈에서 머신을 구성할 수 있습니다. A2 머신 시리즈의 머신은 관련 GPU와 함께 제공되며 게스트 가속기를 사용할 수 없습니다.
그래픽 워크로드의 GPU는 지원되지 않습니다.
절차
- 텍스트 편집기에서 기존 시스템 세트의 YAML 파일을 열거나 새 시스템을 생성합니다.
머신 세트 YAML 파일의
providerSpec필드 아래에 GPU 구성을 지정합니다. 유효한 구성의 다음 예제를 참조하십시오.A2 머신 시리즈의 구성 예:
providerSpec: value: machineType: a2-highgpu-1g1 onHostMaintenance: Terminate2 restartPolicy: Always3 N1 시스템 시리즈의 구성 예:
providerSpec: value: gpus: - count: 11 type: nvidia-tesla-p1002 machineType: n1-standard-13 onHostMaintenance: Terminate4 restartPolicy: Always5
2.6. IBM Cloud에서 머신 세트 생성
IBM Cloud의 OpenShift Container Platform 클러스터에서 특정 목적을 충족하기 위해 다른 머신 세트를 생성할 수 있습니다. 예를 들어, 지원되는 워크로드를 새 머신으로 이동할 수 있도록 인프라 머신 세트 및 관련 머신을 작성할 수 있습니다.
머신 API가 작동하는 클러스터에서만 고급 머신 관리 및 스케일링 기능을 사용할 수 있습니다. 사용자 프로비저닝 인프라가 있는 클러스터에는 Machine API를 사용하려면 추가 검증 및 구성이 필요합니다.
인프라 플랫폼 유형의 클러스터가 Machine API를 사용할 수 없습니다. 이 제한은 클러스터에 연결된 컴퓨팅 시스템이 기능을 지원하는 플랫폼에 설치된 경우에도 적용됩니다. 이 매개변수는 설치 후 변경할 수 없습니다.
클러스터의 플랫폼 유형을 보려면 다음 명령을 실행합니다.
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.6.1. IBM Cloud에서 머신 세트 사용자 정의 리소스의 샘플 YAML
이 샘플 YAML은 리전의 지정된 IBM Cloud 영역에서 실행되는 머신 세트를 정의하고 node-role.kubernetes.io/<role>: "" 로 레이블이 지정된 노드를 만듭니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <role>은 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
name: <infrastructure_id>-<role>-<region>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<region>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<region>
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: ibmcloudproviderconfig.openshift.io/v1beta1
credentialsSecret:
name: ibmcloud-credentials
image: <infrastructure_id>-rhcos
kind: IBMCloudMachineProviderSpec
primaryNetworkInterface:
securityGroups:
- <infrastructure_id>-sg-cluster-wide
- <infrastructure_id>-sg-openshift-net
subnet: <infrastructure_id>-subnet-compute-<zone>
profile: <instance_profile>
region: <region>
resourceGroup: <resource_group>
userDataSecret:
name: <role>-user-data
vpc: <vpc_name>
zone: <zone> - 1 5 7
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID입니다. OpenShift CLI 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 8 9 16
- 추가할 노드 레이블입니다.
- 4 6 10
- 인프라 ID, 노드 레이블, 리전입니다.
- 11
- 클러스터 설치에 사용된 사용자 지정 RHCOS(Red Hat Enterprise Linux CoreOS) 이미지입니다.
- 12
- 머신을 배치할 리전 내 인프라 ID 및 영역입니다. 해당 리전이 지정한 영역을 지원하는지 확인합니다.
- 13
- IBM Cloud 인스턴스 프로필을 지정합니다.
- 14
- 머신을 배치할 리전을 지정합니다.
- 15
- 머신 리소스가 배치되는 리소스 그룹입니다. 이는 설치 시 지정된 기존 리소스 그룹 또는 인프라 ID를 기반으로 이름이 지정된 설치 관리자 생성 리소스 그룹입니다.
- 17
- VPC 이름입니다.
- 18
- 머신을 배치할 리전 내 영역을 지정합니다. 해당 리전이 지정한 영역을 지원하는지 확인합니다.
2.6.2. 머신 세트 만들기
설치 프로그램에서 생성한 컴퓨팅 머신 세트 외에도 고유한 머신 세트를 생성하여 선택한 특정 워크로드의 머신 컴퓨팅 리소스를 동적으로 관리할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터를 배포합니다.
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다.
절차
머신 세트 CR(사용자 지정 리소스) 샘플이 포함된 이름이
<file_name>.yaml인 새 YAML 파일을 만듭니다.<clusterID>및<role>매개 변수 값을 설정해야 합니다.선택 사항: 특정 필드에 설정할 값이 확실하지 않은 경우 클러스터에서 기존 컴퓨팅 머신 세트를 확인할 수 있습니다.
클러스터의 컴퓨팅 머신 세트를 나열하려면 다음 명령을 실행합니다.
$ oc get machinesets -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m특정 컴퓨팅 머신 세트 CR(사용자 정의 리소스)의 값을 보려면 다음 명령을 실행합니다.
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml출력 예
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
다음 명령을 실행하여
MachineSetCR을 생성합니다.$ oc create -f <file_name>.yaml
검증
다음 명령을 실행하여 컴퓨팅 머신 세트 목록을 확인합니다.
$ oc get machineset -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m새 머신 세트가 사용 가능한 경우
DESIRED및CURRENT값이 일치합니다. 머신 세트를 사용할 수 없는 경우 몇 분 후에 명령을 다시 실행합니다.
2.7. Nutanix에서 머신 세트 생성
Nutanix의 OpenShift Container Platform 클러스터에서 특정 목적을 수행하기 위해 다른 머신 세트를 만들 수 있습니다. 예를 들어, 지원되는 워크로드를 새 머신으로 이동할 수 있도록 인프라 머신 세트 및 관련 머신을 작성할 수 있습니다.
머신 API가 작동하는 클러스터에서만 고급 머신 관리 및 스케일링 기능을 사용할 수 있습니다. 사용자 프로비저닝 인프라가 있는 클러스터에는 Machine API를 사용하려면 추가 검증 및 구성이 필요합니다.
인프라 플랫폼 유형의 클러스터가 Machine API를 사용할 수 없습니다. 이 제한은 클러스터에 연결된 컴퓨팅 시스템이 기능을 지원하는 플랫폼에 설치된 경우에도 적용됩니다. 이 매개변수는 설치 후 변경할 수 없습니다.
클러스터의 플랫폼 유형을 보려면 다음 명령을 실행합니다.
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.7.1. Nutanix에서 머신 세트 사용자 정의 리소스의 샘플 YAML
이 샘플 YAML은 node-role.kubernetes.io/<role>: "" 로 레이블이 지정된 노드를 생성하는 Nutanix 머신 세트를 정의합니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <role>은 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
name: <infrastructure_id>-<role>-<zone>
namespace: openshift-machine-api
annotations:
machine.openshift.io/memoryMb: "16384"
machine.openshift.io/vCPU: "4"
spec:
replicas: 3
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone>
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: machine.openshift.io/v1
cluster:
type: uuid
uuid: <cluster_uuid>
credentialsSecret:
name: nutanix-credentials
image:
name: <infrastructure_id>-rhcos
type: name
kind: NutanixMachineProviderConfig
memorySize: 16Gi
subnets:
- type: uuid
uuid: <subnet_uuid>
systemDiskSize: 120Gi
userDataSecret:
name: <user_data_secret>
vcpuSockets: 4
vcpusPerSocket: 1 - 1 6 8
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로하는 인프라 ID를 지정합니다. OpenShift CLI (
oc) 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 9 10
- 추가할 노드 레이블을 지정합니다.
- 4 7 11
- 인프라 ID, 노드 레이블 및 영역을 지정합니다.
- 5
- 클러스터 자동 스케일러의 주석입니다.
- 12
- 사용할 이미지를 지정합니다. 클러스터의 기존 기본 시스템 세트의 이미지를 사용합니다.
- 13
- Gi에서 클러스터의 메모리 양을 지정합니다.
- 14
- Gi에서 시스템 디스크의 크기를 지정합니다.
- 15
openshift-machine-api네임스페이스에 있는 사용자 데이터 YAML 파일에 시크릿 이름을 지정합니다. 설치 프로그램이 기본 시스템 세트에서 채우는 값을 사용합니다.- 16
- vCPU 소켓 수를 지정합니다.
- 17
- 소켓당 vCPU 수를 지정합니다.
2.7.2. 머신 세트 만들기
설치 프로그램에서 생성한 컴퓨팅 머신 세트 외에도 고유한 머신 세트를 생성하여 선택한 특정 워크로드의 머신 컴퓨팅 리소스를 동적으로 관리할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터를 배포합니다.
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다.
절차
머신 세트 CR(사용자 지정 리소스) 샘플이 포함된 이름이
<file_name>.yaml인 새 YAML 파일을 만듭니다.<clusterID>및<role>매개 변수 값을 설정해야 합니다.선택 사항: 특정 필드에 설정할 값이 확실하지 않은 경우 클러스터에서 기존 컴퓨팅 머신 세트를 확인할 수 있습니다.
클러스터의 컴퓨팅 머신 세트를 나열하려면 다음 명령을 실행합니다.
$ oc get machinesets -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m특정 컴퓨팅 머신 세트 CR(사용자 정의 리소스)의 값을 보려면 다음 명령을 실행합니다.
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml출력 예
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
다음 명령을 실행하여
MachineSetCR을 생성합니다.$ oc create -f <file_name>.yaml
검증
다음 명령을 실행하여 컴퓨팅 머신 세트 목록을 확인합니다.
$ oc get machineset -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m새 머신 세트가 사용 가능한 경우
DESIRED및CURRENT값이 일치합니다. 머신 세트를 사용할 수 없는 경우 몇 분 후에 명령을 다시 실행합니다.
2.8. OpenStack에서 머신 세트 생성
Red Hat OpenStack Platform (RHOSP)의 OpenShift Container Platform 클러스터에서 특정 목적을 제공하기 위해 다른 머신 세트를 생성할 수 있습니다. 예를 들어, 지원되는 워크로드를 새 머신으로 이동할 수 있도록 인프라 머신 세트 및 관련 머신을 작성할 수 있습니다.
머신 API가 작동하는 클러스터에서만 고급 머신 관리 및 스케일링 기능을 사용할 수 있습니다. 사용자 프로비저닝 인프라가 있는 클러스터에는 Machine API를 사용하려면 추가 검증 및 구성이 필요합니다.
인프라 플랫폼 유형의 클러스터가 Machine API를 사용할 수 없습니다. 이 제한은 클러스터에 연결된 컴퓨팅 시스템이 기능을 지원하는 플랫폼에 설치된 경우에도 적용됩니다. 이 매개변수는 설치 후 변경할 수 없습니다.
클러스터의 플랫폼 유형을 보려면 다음 명령을 실행합니다.
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.8.1. RHOSP에서 머신 세트 사용자 정의 리소스의 샘플 YAML
이 샘플 YAML은 RHOSP(Red Hat OpenStack Platform)에서 실행되는 머신 세트를 정의하고 node-role.kubernetes.io/<role>: "" 로 레이블이 지정된 노드를 생성합니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <role>은 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
name: <infrastructure_id>-<role>
namespace: openshift-machine-api
spec:
replicas: <number_of_replicas>
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
spec:
providerSpec:
value:
apiVersion: openstackproviderconfig.openshift.io/v1alpha1
cloudName: openstack
cloudsSecret:
name: openstack-cloud-credentials
namespace: openshift-machine-api
flavor: <nova_flavor>
image: <glance_image_name_or_location>
serverGroupID: <optional_UUID_of_server_group>
kind: OpenstackProviderSpec
networks:
- filter: {}
subnets:
- filter:
name: <subnet_name>
tags: openshiftClusterID=<infrastructure_id>
primarySubnet: <rhosp_subnet_UUID>
securityGroups:
- filter: {}
name: <infrastructure_id>-worker
serverMetadata:
Name: <infrastructure_id>-worker
openshiftClusterID: <infrastructure_id>
tags:
- openshiftClusterID=<infrastructure_id>
trunk: true
userDataSecret:
name: worker-user-data
availabilityZone: <optional_openstack_availability_zone>- 1 5 7 13 15 16 17 18
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로하는 인프라 ID를 지정합니다. OpenShift CLI 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 8 9 19
- 추가할 노드 레이블을 지정합니다.
- 4 6 10
- 인프라 ID 및 노드 레이블을 지정합니다.
- 11
- MachineSet의 서버 그룹 정책을 설정하려면, 서버 그룹 생성에서 반환된 값을 입력합니다. 대부분의 배포에는
anti-affinity또는soft-anti-affinity정책이 권장됩니다. - 12
- 여러 네트워크에 배포해야 합니다. 여러 네트워크를 지정하려면 네트워크 배열에 다른 항목을 추가합니다. 또한
primarySubnet값으로 사용되는 네트워크를 포함해야 합니다. - 14
- 노드 엔드포인트를 게시할 RHOSP 서브넷을 지정합니다. 일반적으로 이 서브넷은
install-config.yaml파일에서machineSubnet값으로 사용되는 서브넷과 동일합니다.
2.8.2. RHOSP에서 SR-IOV를 사용하는 머신 세트 사용자 정의 리소스의 샘플 YAML
SR-IOV(Single-root I/O Virtualization)에 대해 클러스터를 구성하는 경우 해당 기술을 사용하는 머신 세트를 생성할 수 있습니다.
이 샘플 YAML은 SR-IOV 네트워크를 사용하는 머신 세트를 정의합니다. 생성된 노드에는 node-role.openshift.io/<node_role>: ""로 레이블이 지정됩니다.
이 샘플에서 infrastructure_id는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 node_role은 추가할 노드 레이블입니다.
이 샘플은 "radio" 및 "uplink"라는 두 개의 SR-IOV 네트워크를 가정합니다. 네트워크는 spec.template.spec.providerSpec.value.ports 목록의 포트 정의에 사용됩니다.
SR-IOV 배포와 관련된 매개변수만 이 샘플에 설명되어 있습니다. 더 일반적인 샘플을 검토하려면 "RHOS에서 머신 세트 사용자 정의 리소스의 샘플 YAML"을 참조하십시오.
SR-IOV 네트워크를 사용하는 머신 세트의 예
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <node_role>
machine.openshift.io/cluster-api-machine-type: <node_role>
name: <infrastructure_id>-<node_role>
namespace: openshift-machine-api
spec:
replicas: <number_of_replicas>
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<node_role>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <node_role>
machine.openshift.io/cluster-api-machine-type: <node_role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<node_role>
spec:
metadata:
providerSpec:
value:
apiVersion: openstackproviderconfig.openshift.io/v1alpha1
cloudName: openstack
cloudsSecret:
name: openstack-cloud-credentials
namespace: openshift-machine-api
flavor: <nova_flavor>
image: <glance_image_name_or_location>
serverGroupID: <optional_UUID_of_server_group>
kind: OpenstackProviderSpec
networks:
- subnets:
- UUID: <machines_subnet_UUID>
ports:
- networkID: <radio_network_UUID>
nameSuffix: radio
fixedIPs:
- subnetID: <radio_subnet_UUID>
tags:
- sriov
- radio
vnicType: direct
portSecurity: false
- networkID: <uplink_network_UUID>
nameSuffix: uplink
fixedIPs:
- subnetID: <uplink_subnet_UUID>
tags:
- sriov
- uplink
vnicType: direct
portSecurity: false
primarySubnet: <machines_subnet_UUID>
securityGroups:
- filter: {}
name: <infrastructure_id>-<node_role>
serverMetadata:
Name: <infrastructure_id>-<node_role>
openshiftClusterID: <infrastructure_id>
tags:
- openshiftClusterID=<infrastructure_id>
trunk: true
userDataSecret:
name: <node_role>-user-data
availabilityZone: <optional_openstack_availability_zone>SR-IOV-capable 컴퓨팅 머신을 배포한 후 다음과 같이 레이블을 지정해야 합니다. 예를 들어 명령줄에서 다음을 입력합니다.
$ oc label node <NODE_NAME> feature.node.kubernetes.io/network-sriov.capable="true"
네트워크 및 서브넷 목록의 항목을 통해 생성된 포트에 대해 트렁킹이 활성화됩니다. 이러한 목록에서 생성된 포트의 이름은 <machine_name>-<nameSuffix> 패턴을 따릅니다. nameSuffix 필드는 포트 정의에 필요합니다.
각 포트에 대해 트렁킹을 활성화할 수 있습니다.
선택적으로 태그 목록의 일부로 포트에 tags를 추가할 수 있습니다.
2.8.3. 포트 보안이 비활성화된 SR-IOV 배포를 위한 샘플 YAML
포트 보안이 비활성화된 네트워크에서 SR-IOV(Single-root I/O Virtualization) 포트를 생성하려면 spec.template.spec.providerSpec.value.ports 목록의 항목으로 포트를 포함하는 머신 세트를 정의합니다. 표준 SR-IOV 머신 세트와 이러한 차이점은 네트워크 및 서브넷 인터페이스를 사용하여 생성된 포트에 대해 발생하는 자동 보안 그룹 및 허용되는 주소 쌍 구성 때문입니다.
머신 서브넷에 대해 정의한 포트에는 다음이 필요합니다.
- API 및 ingress 가상 IP 포트에 허용되는 주소 쌍
- 컴퓨팅 보안 그룹
- 머신 네트워크 및 서브넷에 연결
포트 보안이 비활성화된 SR-IOV 배포와 관련된 매개변수만 이 샘플에 설명되어 있습니다. 일반적인 샘플을 검토하려면 RHOSP에서 SR-IOV를 사용하는 머신 세트 사용자 정의 리소스의 샘플 YAML을 참조하십시오.
SR-IOV 네트워크를 사용하고 포트 보안이 비활성화된 머신 세트의 예
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <node_role>
machine.openshift.io/cluster-api-machine-type: <node_role>
name: <infrastructure_id>-<node_role>
namespace: openshift-machine-api
spec:
replicas: <number_of_replicas>
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<node_role>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <node_role>
machine.openshift.io/cluster-api-machine-type: <node_role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<node_role>
spec:
metadata: {}
providerSpec:
value:
apiVersion: openstackproviderconfig.openshift.io/v1alpha1
cloudName: openstack
cloudsSecret:
name: openstack-cloud-credentials
namespace: openshift-machine-api
flavor: <nova_flavor>
image: <glance_image_name_or_location>
kind: OpenstackProviderSpec
ports:
- allowedAddressPairs:
- ipAddress: <API_VIP_port_IP>
- ipAddress: <ingress_VIP_port_IP>
fixedIPs:
- subnetID: <machines_subnet_UUID>
nameSuffix: nodes
networkID: <machines_network_UUID>
securityGroups:
- <compute_security_group_UUID>
- networkID: <SRIOV_network_UUID>
nameSuffix: sriov
fixedIPs:
- subnetID: <SRIOV_subnet_UUID>
tags:
- sriov
vnicType: direct
portSecurity: False
primarySubnet: <machines_subnet_UUID>
serverMetadata:
Name: <infrastructure_ID>-<node_role>
openshiftClusterID: <infrastructure_id>
tags:
- openshiftClusterID=<infrastructure_id>
trunk: false
userDataSecret:
name: worker-user-data
네트워크 및 서브넷 목록의 항목을 통해 생성된 포트에 대해 트렁킹이 활성화됩니다. 이러한 목록에서 생성된 포트의 이름은 <machine_name>-<nameSuffix> 패턴을 따릅니다. nameSuffix 필드는 포트 정의에 필요합니다.
각 포트에 대해 트렁킹을 활성화할 수 있습니다.
선택적으로 태그 목록의 일부로 포트에 tags를 추가할 수 있습니다.
클러스터가 Kuryr를 사용하고 RHOSP SR-IOV 네트워크에 포트 보안이 비활성화된 경우 컴퓨팅 머신의 기본 포트에는 다음이 있어야 합니다.
-
spec.template.spec.providerSpec.value.networks.portSecurityEnabled매개변수의 값이false로 설정됩니다. -
각 서브넷의
spec.template.spec.providerSpec.value.networks.portSecurityEnabled매개변수 값이false로 설정됩니다. -
spec.template.spec.providerSpec.value.securityGroups값이 empty:[]로 설정됩니다.
SR-IOV를 사용하고 포트 보안이 비활성화된 Kuryr에서 클러스터에 대한 머신 세트 섹션의 예
...
networks:
- subnets:
- uuid: <machines_subnet_UUID>
portSecurityEnabled: false
portSecurityEnabled: false
securityGroups: []
...이 경우 VM이 생성된 후 컴퓨팅 보안 그룹을 기본 VM 인터페이스에 적용할 수 있습니다. 예를 들어 명령줄에서 다음을 수행합니다.
$ openstack port set --enable-port-security --security-group <infrastructure_id>-<node_role> <main_port_ID>SR-IOV-capable 컴퓨팅 머신을 배포한 후 다음과 같이 레이블을 지정해야 합니다. 예를 들어 명령줄에서 다음을 입력합니다.
$ oc label node <NODE_NAME> feature.node.kubernetes.io/network-sriov.capable="true"2.8.4. 머신 세트 만들기
설치 프로그램에서 생성한 컴퓨팅 머신 세트 외에도 고유한 머신 세트를 생성하여 선택한 특정 워크로드의 머신 컴퓨팅 리소스를 동적으로 관리할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터를 배포합니다.
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다.
절차
머신 세트 CR(사용자 지정 리소스) 샘플이 포함된 이름이
<file_name>.yaml인 새 YAML 파일을 만듭니다.<clusterID>및<role>매개 변수 값을 설정해야 합니다.선택 사항: 특정 필드에 설정할 값이 확실하지 않은 경우 클러스터에서 기존 컴퓨팅 머신 세트를 확인할 수 있습니다.
클러스터의 컴퓨팅 머신 세트를 나열하려면 다음 명령을 실행합니다.
$ oc get machinesets -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m특정 컴퓨팅 머신 세트 CR(사용자 정의 리소스)의 값을 보려면 다음 명령을 실행합니다.
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml출력 예
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
다음 명령을 실행하여
MachineSetCR을 생성합니다.$ oc create -f <file_name>.yaml
검증
다음 명령을 실행하여 컴퓨팅 머신 세트 목록을 확인합니다.
$ oc get machineset -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m새 머신 세트가 사용 가능한 경우
DESIRED및CURRENT값이 일치합니다. 머신 세트를 사용할 수 없는 경우 몇 분 후에 명령을 다시 실행합니다.
2.9. RHV에 머신 세트 생성
Red Hat Virtualization (RHV)의 OpenShift Container Platform 클러스터에서 특정 목적을 제공하기 위해 다른 머신 세트를 생성할 수 있습니다. 예를 들어, 지원되는 워크로드를 새 머신으로 이동할 수 있도록 인프라 머신 세트 및 관련 머신을 작성할 수 있습니다.
머신 API가 작동하는 클러스터에서만 고급 머신 관리 및 스케일링 기능을 사용할 수 있습니다. 사용자 프로비저닝 인프라가 있는 클러스터에는 Machine API를 사용하려면 추가 검증 및 구성이 필요합니다.
인프라 플랫폼 유형의 클러스터가 Machine API를 사용할 수 없습니다. 이 제한은 클러스터에 연결된 컴퓨팅 시스템이 기능을 지원하는 플랫폼에 설치된 경우에도 적용됩니다. 이 매개변수는 설치 후 변경할 수 없습니다.
클러스터의 플랫폼 유형을 보려면 다음 명령을 실행합니다.
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.9.1. RHV에서 머신 세트 사용자 정의 리소스의 샘플 YAML
이 샘플 YAML은 RHV에서 실행되는 머신 세트를 정의하고 node-role.kubernetes.io/<role>: ""로 레이블이 지정된 노드를 만듭니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <role>은 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
name: <infrastructure_id>-<role>
namespace: openshift-machine-api
spec:
replicas: <number_of_replicas>
Selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: ovirtproviderconfig.machine.openshift.io/v1beta1
cluster_id: <ovirt_cluster_id>
template_name: <ovirt_template_name>
sparse: <boolean_value>
format: <raw_or_cow>
cpu:
sockets: <number_of_sockets>
cores: <number_of_cores>
threads: <number_of_threads>
memory_mb: <memory_size>
guaranteed_memory_mb: <memory_size>
os_disk:
size_gb: <disk_size>
storage_domain_id: <storage_domain_UUID>
network_interfaces:
vnic_profile_id: <vnic_profile_id>
credentialsSecret:
name: ovirt-credentials
kind: OvirtMachineProviderSpec
type: <workload_type>
auto_pinning_policy: <auto_pinning_policy>
hugepages: <hugepages>
affinityGroupsNames:
- compute
userDataSecret:
name: worker-user-data- 1 7 9
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로하는 인프라 ID를 지정합니다. OpenShift CLI (
oc) 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 10 11 13
- 추가할 노드 레이블을 지정합니다.
- 4 8 12
- 인프라 ID 및 노드 레이블을 지정합니다. 이 두 문자열은 35자를 초과할 수 없습니다.
- 5
- 생성할 머신 수를 지정합니다.
- 6
- 머신의 선택기입니다.
- 14
- 이 VM 인스턴스가 속하는 RHV 클러스터의 UUID를 지정합니다.
- 15
- 머신을 생성하는 데 사용할 RHV VM 템플릿을 지정합니다.
- 16
- 이 옵션을
false로 설정하면 디스크 사전 할당이 가능합니다. 기본값은true입니다.format을raw로 설정하여sparse를true로 설정하는 것은 블록 스토리지 도메인에서 사용할 수 없습니다.원시형식은 전체 가상 디스크를 기본 물리적 디스크에 씁니다. - 17
소또는 초로 설정할 수있습니다. 기본값은 Hus입니다.소형식은 가상 머신에 최적화되어 있습니다.참고파일 스토리지 도메인의 디스크를 사전 할당하면 0이 파일에 씁니다. 실제로 기본 스토리지에 따라 디스크를 사전 할당하지 못할 수 있습니다.
- 18
- 선택 사항: CPU 필드에 소켓, 코어 및 스레드를 포함한 CPU 구성이 포함되어 있습니다.
- 19
- 선택 사항: VM의 소켓 수를 지정합니다.
- 20
- 선택 사항: 소켓당 코어 수를 지정합니다.
- 21
- 선택 사항: 코어당 스레드 수를 지정합니다.
- 22
- 선택 사항: VM의 메모리 크기를 MiB로 지정합니다.
- 23
- 선택 사항: 가상 머신의 보장된 메모리 크기를 MiB 단위로 지정합니다. 이는 풍선 메커니즘에 의해 드레인되지 않도록 하는 메모리 양입니다. 자세한 내용은 Memory Ballooning and Optimization Settings Explained 항목을 참조하십시오.참고
RHV 4.4.8 이전 버전을 사용하는 경우 Red Hat Virtualization 클러스터에서 OpenShift에 대한 보장 메모리 요구 사항을 참조하십시오.
- 24
- 선택사항: 노드의 루트 디스크입니다.
- 25
- 선택사항: 부팅 가능한 디스크 크기를 GiB로 지정합니다.
- 26
- 선택 사항: 컴퓨팅 노드의 디스크에 대한 스토리지 도메인의 UUID를 지정합니다. 제공되지 않는 경우 compute 노드는 제어 노드와 동일한 스토리지 도메인에 생성됩니다. (기본값)
- 27
- 선택사항: VM의 네트워크 인터페이스 목록입니다. 이 매개변수를 포함하는 경우 OpenShift Container Platform은 템플릿에서 모든 네트워크 인터페이스를 삭제하고 새 네트워크 인터페이스를 생성합니다.
- 28
- 선택사항: vNIC 프로필 ID를 지정합니다.
- 29
- RHV 인증 정보를 보유한 보안 오브젝트의 이름을 지정합니다.
- 30
- 선택 사항: 인스턴스가 최적화된 워크로드 유형을 지정합니다. 이 값은
RHV VM매개변수에 영향을 미칩니다. 지원되는 값은desktop,server(기본값),high_performance입니다.high_performance는 VM의 성능을 향상시킵니다. 예를 들어 제한 사항이 있는 경우 그래픽 콘솔을 사용하여 VM에 액세스할 수 없습니다. 자세한 내용은 가상 머신 관리 가이드에서 고성능 가상 머신, 템플릿 및 풀 구성을 참조하십시오. - 31
- 선택 사항: AutoPinningPolicy는 이 인스턴스의 호스트에 고정을 포함하여 CPU 및 NUMA 설정을 자동으로 설정하는 정책을 정의합니다. 지원되는 값:
none,resize_and_pin. 자세한 내용은 가상 머신 관리 가이드에서 NUMA 노드 설정을 참조하십시오. - 32
- 선택 사항: Hugepages는 VM에서 hugepages를 정의하는 KiB 크기입니다. 지원되는 값:
2048또는1048576. 자세한 내용은 가상 머신 관리 가이드에서 Huge Pages 구성을 참조하십시오. - 33
- 선택 사항: VM에 적용할 선호도 그룹 이름 목록입니다. 선호도 그룹은 oVirt에 있어야 합니다.
RHV는 VM을 생성할 때 템플릿을 사용하므로 선택적 매개변수에 대한 값을 지정하지 않으면 RHV는 템플릿에 지정된 해당 매개변수의 값을 사용합니다.
2.9.2. 머신 세트 만들기
설치 프로그램에서 생성한 컴퓨팅 머신 세트 외에도 고유한 머신 세트를 생성하여 선택한 특정 워크로드의 머신 컴퓨팅 리소스를 동적으로 관리할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터를 배포합니다.
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다.
절차
머신 세트 CR(사용자 지정 리소스) 샘플이 포함된 이름이
<file_name>.yaml인 새 YAML 파일을 만듭니다.<clusterID>및<role>매개 변수 값을 설정해야 합니다.선택 사항: 특정 필드에 설정할 값이 확실하지 않은 경우 클러스터에서 기존 컴퓨팅 머신 세트를 확인할 수 있습니다.
클러스터의 컴퓨팅 머신 세트를 나열하려면 다음 명령을 실행합니다.
$ oc get machinesets -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m특정 컴퓨팅 머신 세트 CR(사용자 정의 리소스)의 값을 보려면 다음 명령을 실행합니다.
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml출력 예
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
다음 명령을 실행하여
MachineSetCR을 생성합니다.$ oc create -f <file_name>.yaml
검증
다음 명령을 실행하여 컴퓨팅 머신 세트 목록을 확인합니다.
$ oc get machineset -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m새 머신 세트가 사용 가능한 경우
DESIRED및CURRENT값이 일치합니다. 머신 세트를 사용할 수 없는 경우 몇 분 후에 명령을 다시 실행합니다.
2.10. vSphere에서 머신 세트 생성
VMware vSphere의 OpenShift Container Platform 클러스터에서 특정 목적을 충족하기 위해 다른 머신 세트를 만들 수 있습니다. 예를 들어, 지원되는 워크로드를 새 머신으로 이동할 수 있도록 인프라 머신 세트 및 관련 머신을 작성할 수 있습니다.
머신 API가 작동하는 클러스터에서만 고급 머신 관리 및 스케일링 기능을 사용할 수 있습니다. 사용자 프로비저닝 인프라가 있는 클러스터에는 Machine API를 사용하려면 추가 검증 및 구성이 필요합니다.
인프라 플랫폼 유형의 클러스터가 Machine API를 사용할 수 없습니다. 이 제한은 클러스터에 연결된 컴퓨팅 시스템이 기능을 지원하는 플랫폼에 설치된 경우에도 적용됩니다. 이 매개변수는 설치 후 변경할 수 없습니다.
클러스터의 플랫폼 유형을 보려면 다음 명령을 실행합니다.
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.10.1. vSphere에서 머신 세트 사용자 정의 리소스의 샘플 YAML
이 샘플 YAML은 VMware vSphere에서 실행되는 머신 세트를 정의하고 node-role.kubernetes.io/<role>: ""로 레이블이 지정된 노드를 만듭니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <role>은 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
name: <infrastructure_id>-<role>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
spec:
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: vsphereprovider.openshift.io/v1beta1
credentialsSecret:
name: vsphere-cloud-credentials
diskGiB: 120
kind: VSphereMachineProviderSpec
memoryMiB: 8192
metadata:
creationTimestamp: null
network:
devices:
- networkName: "<vm_network_name>"
numCPUs: 4
numCoresPerSocket: 1
snapshot: ""
template: <vm_template_name>
userDataSecret:
name: worker-user-data
workspace:
datacenter: <vcenter_datacenter_name>
datastore: <vcenter_datastore_name>
folder: <vcenter_vm_folder_path>
resourcepool: <vsphere_resource_pool>
server: <vcenter_server_ip> - 1 3 5
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로하는 인프라 ID를 지정합니다. OpenShift CLI (
oc) 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 4 8
- 인프라 ID 및 노드 레이블을 지정합니다.
- 6 7 9
- 추가할 노드 레이블을 지정합니다.
- 10
- 컴퓨팅 머신 세트를 배포할 vSphere VM 네트워크를 지정합니다. 이 VM 네트워크는 다른 컴퓨팅 시스템이 클러스터에 있는 위치여야 합니다.
- 11
- 사용할 vSphere VM 템플릿 (예:
user-5ddjd-rhcos)을 지정합니다. - 12
- 컴퓨팅 머신 세트를 배포할 vCenter Datacenter를 지정합니다.
- 13
- 컴퓨팅 머신 세트를 배포할 vCenter Datastore를 지정합니다.
- 14
- vCenter의 vSphere VM 폴더에 경로(예:
/dc1/vm/user-inst-5ddjd)를 지정합니다. - 15
- VM의 vSphere 리소스 풀을 지정합니다.
- 16
- vCenter 서버 IP 또는 정규화된 도메인 이름을 지정합니다.
2.10.2. 머신 세트 관리에 필요한 최소 vCenter 권한
vCenter의 OpenShift Container Platform 클러스터에서 머신 세트를 관리하려면 필요한 리소스를 읽고, 생성하고, 삭제하려면 권한이 있는 계정을 사용해야 합니다. 필요한 모든 권한에 액세스할 수 있는 가장 간단한 방법은 글로벌 관리 권한이 있는 계정을 사용하는 것입니다.
글로벌 관리 권한이 있는 계정을 사용할 수 없는 경우 필요한 최소 권한을 부여하려면 역할을 생성해야 합니다. 다음 표에는 머신 세트를 생성, 스케일링 및 삭제하고 OpenShift Container Platform 클러스터에서 머신을 삭제하는 데 필요한 최소 vCenter 역할 및 권한이 나열되어 있습니다.
예 2.1. 머신 세트 관리에 필요한 최소 vCenter 역할 및 권한
| 역할의 vSphere 개체 | 필요한 경우 | 필요한 권한 |
|---|---|---|
| vSphere vCenter | Always |
|
| vSphere vCenter Cluster | Always |
|
| vSphere Datastore | Always |
|
| vSphere Port Group | Always |
|
| 가상 머신 폴더 | Always |
|
| vSphere vCenter Datacenter | 설치 프로그램이 가상 머신 폴더를 생성하는 경우 |
|
|
1 | ||
다음 표에는 머신 세트 관리에 필요한 권한 및 전파 설정이 설명되어 있습니다.
예 2.2. 필수 권한 및 권한 부여 설정
| vSphere 오브젝트 | 폴더 유형 | 하위 항목으로 권한 부여 | 권한 필요 |
|---|---|---|---|
| vSphere vCenter | Always | 필요하지 않음 | 나열된 필수 권한 |
| vSphere vCenter Datacenter | 기존 폴더 | 필요하지 않음 |
|
| 설치 프로그램은 폴더를 생성 | 필수 항목 | 나열된 필수 권한 | |
| vSphere vCenter Cluster | Always | 필수 항목 | 나열된 필수 권한 |
| vSphere vCenter Datastore | Always | 필요하지 않음 | 나열된 필수 권한 |
| vSphere Switch | Always | 필요하지 않음 |
|
| vSphere Port Group | Always | 필요하지 않음 | 나열된 필수 권한 |
| vSphere vCenter Virtual Machine Folder | 기존 폴더 | 필수 항목 | 나열된 필수 권한 |
필요한 권한만으로 계정을 생성하는 방법에 대한 자세한 내용은 vSphere 문서에서 vSphere 권한 및 사용자 관리 작업을 참조하십시오.
2.10.3. 컴퓨팅 머신 세트를 사용하는 사용자 프로비저닝 인프라가 있는 클러스터의 요구사항
사용자 프로비저닝 인프라가 있는 클러스터에서 컴퓨팅 머신 세트를 사용하려면 Machine API를 사용하여 클러스터 구성을 지원해야 합니다.
인프라 ID 가져오기
컴퓨팅 머신 세트를 생성하려면 클러스터의 인프라 ID를 제공할 수 있어야 합니다.
절차
클러스터의 인프라 ID를 가져오려면 다음 명령을 실행합니다.
$ oc get infrastructure cluster -o jsonpath='{.status.infrastructureName}'
vSphere 인증 정보 요구 사항 충족
컴퓨팅 머신 세트를 사용하려면 Machine API가 vCenter와 상호 작용할 수 있어야 합니다. Machine API 구성 요소가 vCenter와 상호 작용하도록 권한을 부여하는 인증 정보는 openshift-machine-api 네임스페이스의 시크릿에 있어야 합니다.
절차
필요한 인증 정보가 있는지 확인하려면 다음 명령을 실행합니다.
$ oc get secret \ -n openshift-machine-api vsphere-cloud-credentials \ -o go-template='{{range $k,$v := .data}}{{printf "%s: " $k}}{{if not $v}}{{$v}}{{else}}{{$v | base64decode}}{{end}}{{"\n"}}{{end}}'샘플 출력
<vcenter-server>.password=<openshift-user-password> <vcenter-server>.username=<openshift-user>여기서 <
vcenter-server>는 vCenter 서버 및 <openshift-user>의 IP 주소 또는 정규화된 도메인 이름(FQDN)이고 <openshift-user-password>는 사용할 OpenShift Container Platform 관리자 자격 증명입니다.시크릿이 없는 경우 다음 명령을 실행하여 시크릿을 생성합니다.
$ oc create secret generic vsphere-cloud-credentials \ -n openshift-machine-api \ --from-literal=<vcenter-server>.username=<openshift-user> --from-literal=<vcenter-server>.password=<openshift-user-password>
Ignition 구성 요구 사항 충족
VM(가상 머신)을 프로비저닝하려면 유효한 Ignition 구성이 필요합니다. Ignition 구성에는 Machine Config Operator에서 추가 Ignition 구성을 가져오기 위한 machine-config-server 주소와 시스템 신뢰 번들이 포함되어 있습니다.
기본적으로 이 구성은 machine-api-operator 네임스페이스의 worker-user-data 시크릿에 저장됩니다. 컴퓨팅 머신 세트는 머신 생성 프로세스 중 시크릿을 참조합니다.
절차
필요한 보안이 존재하는지 확인하려면 다음 명령을 실행합니다.
$ oc get secret \ -n openshift-machine-api worker-user-data \ -o go-template='{{range $k,$v := .data}}{{printf "%s: " $k}}{{if not $v}}{{$v}}{{else}}{{$v | base64decode}}{{end}}{{"\n"}}{{end}}'샘플 출력
disableTemplating: false userData:1 { "ignition": { ... }, ... }- 1
- 전체 출력은 여기에서 생략되지만 이 형식이 있어야 합니다.
시크릿이 없는 경우 다음 명령을 실행하여 시크릿을 생성합니다.
$ oc create secret generic worker-user-data \ -n openshift-machine-api \ --from-file=<installation_directory>/worker.ign여기서
<installation_directory>는 클러스터 설치 중에 설치 자산을 저장하는 데 사용된 디렉터리입니다.
2.10.4. 머신 세트 만들기
설치 프로그램에서 생성한 컴퓨팅 머신 세트 외에도 고유한 머신 세트를 생성하여 선택한 특정 워크로드의 머신 컴퓨팅 리소스를 동적으로 관리할 수 있습니다.
사용자 프로비저닝 인프라로 설치된 클러스터에는 설치 프로그램에서 프로비저닝한 인프라가 있는 클러스터와 다른 네트워킹 스택이 있습니다. 이러한 차이로 인해 사용자가 프로비저닝한 인프라가 있는 클러스터에서 자동 로드 밸런서 관리가 지원되지 않습니다. 이러한 클러스터의 경우 컴퓨팅 머신 세트는 작업자 및 인프라 유형 머신만 생성할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터를 배포합니다.
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다. - vCenter 인스턴스에 가상 머신을 배포하는데 필요한 권한이 있고 지정된 데이터 저장소에 필요한 액세스 권한이 있습니다.
- 클러스터에서 사용자 프로비저닝 인프라를 사용하는 경우 해당 구성에 대한 특정 Machine API 요구 사항을 충족할 수 있습니다.
절차
머신 세트 CR(사용자 지정 리소스) 샘플이 포함된 이름이
<file_name>.yaml인 새 YAML 파일을 만듭니다.<clusterID>및<role>매개 변수 값을 설정해야 합니다.선택 사항: 특정 필드에 설정할 값이 확실하지 않은 경우 클러스터에서 기존 컴퓨팅 머신 세트를 확인할 수 있습니다.
클러스터의 컴퓨팅 머신 세트를 나열하려면 다음 명령을 실행합니다.
$ oc get machinesets -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m특정 컴퓨팅 머신 세트 CR(사용자 정의 리소스)의 값을 보려면 다음 명령을 실행합니다.
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml출력 예
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...사용자 프로비저닝 인프라가 있는 클러스터에 대한 컴퓨팅 머신 세트를 생성하는 경우 다음 중요한 값을 기록해 두십시오.
vSphere
providerSpec값의 예apiVersion: machine.openshift.io/v1beta1 kind: MachineSet ... template: ... spec: providerSpec: value: apiVersion: machine.openshift.io/v1beta1 credentialsSecret: name: vsphere-cloud-credentials1 diskGiB: 120 kind: VSphereMachineProviderSpec memoryMiB: 16384 network: devices: - networkName: "<vm_network_name>" numCPUs: 4 numCoresPerSocket: 4 snapshot: "" template: <vm_template_name>2 userDataSecret: name: worker-user-data3 workspace: datacenter: <vcenter_datacenter_name> datastore: <vcenter_datastore_name> folder: <vcenter_vm_folder_path> resourcepool: <vsphere_resource_pool> server: <vcenter_server_address>4
다음 명령을 실행하여
MachineSetCR을 생성합니다.$ oc create -f <file_name>.yaml
검증
다음 명령을 실행하여 컴퓨팅 머신 세트 목록을 확인합니다.
$ oc get machineset -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m새 머신 세트가 사용 가능한 경우
DESIRED및CURRENT값이 일치합니다. 머신 세트를 사용할 수 없는 경우 몇 분 후에 명령을 다시 실행합니다.
2.11. 베어 메탈에 컴퓨팅 머신 세트 생성
베어 메탈의 OpenShift Container Platform 클러스터에서 특정 목적을 충족하기 위해 다른 컴퓨팅 머신 세트를 생성할 수 있습니다. 예를 들어, 지원되는 워크로드를 새 머신으로 이동할 수 있도록 인프라 머신 세트 및 관련 머신을 작성할 수 있습니다.
머신 API가 작동하는 클러스터에서만 고급 머신 관리 및 스케일링 기능을 사용할 수 있습니다. 사용자 프로비저닝 인프라가 있는 클러스터에는 Machine API를 사용하려면 추가 검증 및 구성이 필요합니다.
인프라 플랫폼 유형의 클러스터가 Machine API를 사용할 수 없습니다. 이 제한은 클러스터에 연결된 컴퓨팅 시스템이 기능을 지원하는 플랫폼에 설치된 경우에도 적용됩니다. 이 매개변수는 설치 후 변경할 수 없습니다.
클러스터의 플랫폼 유형을 보려면 다음 명령을 실행합니다.
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.11.1. 베어 메탈에서 컴퓨팅 머신 세트 사용자 정의 리소스의 샘플 YAML
이 샘플 YAML은 베어 메탈에서 실행되는 컴퓨팅 머신 세트를 정의하고 node-role.kubernetes.io/<role>: "" 로 레이블이 지정된 노드를 생성합니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <role>은 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
name: <infrastructure_id>-<role>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
spec:
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: baremetal.cluster.k8s.io/v1alpha1
hostSelector: {}
image:
checksum: http:/172.22.0.3:6181/images/rhcos-<version>.<architecture>.qcow2.<md5sum>
url: http://172.22.0.3:6181/images/rhcos-<version>.<architecture>.qcow2
kind: BareMetalMachineProviderSpec
metadata:
creationTimestamp: null
userData:
name: worker-user-data- 1 3 5
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로하는 인프라 ID를 지정합니다. OpenShift CLI (
oc) 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 4 8
- 인프라 ID 및 노드 레이블을 지정합니다.
- 6 7 9
- 추가할 노드 레이블을 지정합니다.
- 10
- API VIP 주소를 사용하도록
checksumURL을 편집합니다. - 11
- API VIP 주소를 사용하도록
urlURL을 편집합니다.
2.11.2. 머신 세트 만들기
설치 프로그램에서 생성한 컴퓨팅 머신 세트 외에도 고유한 머신 세트를 생성하여 선택한 특정 워크로드의 머신 컴퓨팅 리소스를 동적으로 관리할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터를 배포합니다.
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다.
절차
머신 세트 CR(사용자 지정 리소스) 샘플이 포함된 이름이
<file_name>.yaml인 새 YAML 파일을 만듭니다.<clusterID>및<role>매개 변수 값을 설정해야 합니다.선택 사항: 특정 필드에 설정할 값이 확실하지 않은 경우 클러스터에서 기존 컴퓨팅 머신 세트를 확인할 수 있습니다.
클러스터의 컴퓨팅 머신 세트를 나열하려면 다음 명령을 실행합니다.
$ oc get machinesets -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m특정 컴퓨팅 머신 세트 CR(사용자 정의 리소스)의 값을 보려면 다음 명령을 실행합니다.
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml출력 예
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
다음 명령을 실행하여
MachineSetCR을 생성합니다.$ oc create -f <file_name>.yaml
검증
다음 명령을 실행하여 컴퓨팅 머신 세트 목록을 확인합니다.
$ oc get machineset -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m새 머신 세트가 사용 가능한 경우
DESIRED및CURRENT값이 일치합니다. 머신 세트를 사용할 수 없는 경우 몇 분 후에 명령을 다시 실행합니다.
3장. 머신 세트 수동 스케일링
머신 세트에서 머신 인스턴스를 추가하거나 삭제할 수 있습니다.
스케일링 이외의 머신 세트 요소를 수정해야하는 경우 머신 세트 수정을 참조하십시오.
3.1. 사전 요구 사항
-
클러스터 전체 프록시를 활성화하고 설치 구성에서
networking.machineNetwork[].cidr에 포함되지 않은 작업자를 확장하는 경우 연결 문제를 방지 하려면 프록시 오브젝트의noProxy필드에 작업자를 추가해야 합니다.
머신 API가 작동하는 클러스터에서만 고급 머신 관리 및 스케일링 기능을 사용할 수 있습니다. 사용자 프로비저닝 인프라가 있는 클러스터에는 Machine API를 사용하려면 추가 검증 및 구성이 필요합니다.
인프라 플랫폼 유형의 클러스터가 Machine API를 사용할 수 없습니다. 이 제한은 클러스터에 연결된 컴퓨팅 시스템이 기능을 지원하는 플랫폼에 설치된 경우에도 적용됩니다. 이 매개변수는 설치 후 변경할 수 없습니다.
클러스터의 플랫폼 유형을 보려면 다음 명령을 실행합니다.
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'3.2. 머신 세트 수동 스케일링
머신 세트에서 머신 인스턴스를 추가하거나 제거하려면 머신 세트를 수동으로 스케일링할 수 있습니다.
이는 완전히 자동화된 설치 프로그램에 의해 프로비저닝된 인프라 설치와 관련이 있습니다. 사용자 지정된 사용자 프로비저닝 인프라 설치에는 머신 세트가 없습니다.
사전 요구 사항
-
OpenShift Container Platform 클러스터 및
oc명령행을 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다.
절차
클러스터에 있는 머신 세트를 확인합니다.
$ oc get machinesets -n openshift-machine-api머신 세트는
<clusterid>-worker-<aws-region-az>형식으로 나열됩니다.클러스터에 있는 머신을 확인합니다.
$ oc get machine -n openshift-machine-api삭제할 머신에서 주석을 설정합니다.
$ oc annotate machine/<machine_name> -n openshift-machine-api machine.openshift.io/cluster-api-delete-machine="true"다음 명령 중 하나를 실행하여 머신 세트를 확장합니다.
$ oc scale --replicas=2 machineset <machineset> -n openshift-machine-api또는 다음을 수행합니다.
$ oc edit machineset <machineset> -n openshift-machine-api작은 정보다음 YAML을 적용하여 머신 세트를 스케일링할 수 있습니다.
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: replicas: 2머신 세트를 확장 또는 축소할 수 있습니다. 새 머신을 사용할 수 있을 때 까지 몇 분 정도 소요됩니다.
중요기본적으로 머신 컨트롤러는 성공할 때까지 머신이 지원하는 노드를 드레이닝하려고 합니다. Pod 중단 예산을 잘못 구성하는 등 일부 상황에서는 드레이닝 작업이 성공하지 못할 수 있습니다. 드레이닝 작업이 실패하면 머신 컨트롤러에서 머신 제거를 진행할 수 없습니다.
특정 머신에서
machine.openshift.io/exclude-node-draining에 주석을 달아 노드 드레이닝을 건너뛸 수 있습니다.
검증
의도한 시스템의 삭제를 확인합니다.
$ oc get machines
3.3. 머신 세트 삭제 정책
Random, Newest 및 Oldest의 세 가지 삭제 옵션이 지원됩니다. 기본값은 Random입니다. 따라서 머신 세트를 축소할 때 임의의 머신이 선택되어 삭제됩니다. 특정 머신 세트를 변경하고 유스 케이스에 따라 삭제 정책을 설정할 수 있습니다.
spec:
deletePolicy: <delete_policy>
replicas: <desired_replica_count>
삭제 정책에 관계없이 관련 머신에 machine.openshift.io/cluster-api-delete-machine=true 주석을 추가하여 특정 머신의 삭제 우선 순위를 지정할 수도 있습니다.
기본적으로 OpenShift Container Platform 라우터 Pod는 작업자에게 배포됩니다. 라우터는 웹 콘솔을 포함한 일부 클러스터 리소스에 액세스해야 하므로 먼저 라우터 Pod를 재배치하지 않는 한 작업자 머신 세트를 0으로 스케일링하지 마십시오.
사용자 정의 머신 세트는 특정 노드에서 서비스가 실행되고 작업자 머신 세트가 축소될 때 컨트롤러에서 해당 서비스를 무시해야 하는 유스 케이스에 사용할 수 있습니다. 이로 인해 서비스 중단을 피할 수 있습니다.
4장. 머신 세트 수정
레이블 추가, 인스턴스 유형 변경 또는 블록 스토리지 변경과 같은 머신 세트를 수정할 수 있습니다.
RHV(Red Hat Virtualization)에서는 머신 세트를 변경하여 다른 스토리지 도메인에서 새 노드를 프로비저닝할 수도 있습니다.
다른 변경없이 머신 세트를 확장해야하는 경우 머신 세트 수동 스케일링을 참조하십시오.
4.1. CLI를 사용하여 머신 세트 수정
머신 세트를 수정하면 업데이트된 MachineSet CR(사용자 정의 리소스)을 저장한 후 생성된 머신에만 변경 사항이 적용됩니다. 변경 사항은 기존 머신에는 영향을 미치지 않습니다. 머신 세트를 스케일링하여 업데이트된 구성을 반영하는 기존 머신을 새 머신으로 교체할 수 있습니다.
다른 변경을 수행하지 않고 머신 세트를 스케일링해야 하는 경우 머신을 삭제할 필요가 없습니다.
기본적으로 OpenShift Container Platform 라우터 Pod는 머신에 배포됩니다. 라우터는 웹 콘솔을 포함한 일부 클러스터 리소스에 액세스해야 하므로 먼저 라우터 Pod를 재배치하지 않는 한 머신 세트를 0 으로 스케일링하지 마십시오.
사전 요구 사항
- OpenShift Container Platform 클러스터는 Machine API를 사용합니다.
-
OpenShift CLI(
oc)를 사용하여 관리자로 클러스터에 로그인했습니다.
절차
머신 세트를 편집합니다.
$ oc edit machineset <machine_set_name> -n openshift-machine-api변경 사항을 적용하기 위해 머신 세트를 스케일링할 때 필요하므로
spec.replicas필드의 값을 확인합니다.apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machine_set_name> namespace: openshift-machine-api spec: replicas: 21 # ...- 1
- 이 절차의 예제에서는
replicas값이2인 머신 세트를 보여줍니다.
- 원하는 구성 옵션으로 머신 세트 CR을 업데이트하고 변경 사항을 저장합니다.
다음 명령을 실행하여 업데이트된 머신 세트에서 관리하는 머신을 나열합니다.
$ oc get -n openshift-machine-api machines -l machine.openshift.io/cluster-api-machineset=<machine_set_name>출력 예
NAME PHASE TYPE REGION ZONE AGE <machine_name_original_1> Running m6i.xlarge us-west-1 us-west-1a 4h <machine_name_original_2> Running m6i.xlarge us-west-1 us-west-1a 4h업데이트된 머신 세트에서 관리하는 각 머신에 대해 다음 명령을 실행하여
삭제주석을 설정합니다.$ oc annotate machine/<machine_name_original_1> \ -n openshift-machine-api \ machine.openshift.io/delete-machine="true"다음 명령을 실행하여 머신 세트를 복제본 수의 두 배로 스케일링합니다.
$ oc scale --replicas=4 \1 machineset <machine_set_name> \ -n openshift-machine-api- 1
- 원래 예제 값
2는4로 두 배가됩니다.
다음 명령을 실행하여 업데이트된 머신 세트에서 관리하는 머신을 나열합니다.
$ oc get -n openshift-machine-api machines -l machine.openshift.io/cluster-api-machineset=<machine_set_name>출력 예
NAME PHASE TYPE REGION ZONE AGE <machine_name_original_1> Running m6i.xlarge us-west-1 us-west-1a 4h <machine_name_original_2> Running m6i.xlarge us-west-1 us-west-1a 4h <machine_name_updated_1> Provisioned m6i.xlarge us-west-1 us-west-1a 55s <machine_name_updated_2> Provisioning m6i.xlarge us-west-1 us-west-1a 55s새 머신이
Running단계에 있는 경우 머신 세트를 원래 복제본 수로 확장할 수 있습니다.다음 명령을 실행하여 머신 세트를 원래 복제본 수로 확장합니다.
$ oc scale --replicas=2 \1 machineset <machine_set_name> \ -n openshift-machine-api- 1
- 원래 예제 값인
2입니다.
검증
업데이트된 구성이 없는 머신이 삭제되었는지 확인하려면 다음 명령을 실행하여 업데이트된 머신 세트에서 관리하는 머신을 나열합니다.
$ oc get -n openshift-machine-api machines -l machine.openshift.io/cluster-api-machineset=<machine_set_name>삭제가 진행되는 동안 출력 예
NAME PHASE TYPE REGION ZONE AGE <machine_name_original_1> Deleting m6i.xlarge us-west-1 us-west-1a 4h <machine_name_original_2> Deleting m6i.xlarge us-west-1 us-west-1a 4h <machine_name_updated_1> Running m6i.xlarge us-west-1 us-west-1a 5m41s <machine_name_updated_2> Running m6i.xlarge us-west-1 us-west-1a 5m41s삭제가 완료되면 출력 예
NAME PHASE TYPE REGION ZONE AGE <machine_name_updated_1> Running m6i.xlarge us-west-1 us-west-1a 6m30s <machine_name_updated_2> Running m6i.xlarge us-west-1 us-west-1a 6m30s업데이트된 머신 세트로 생성된 머신에 올바른 구성이 있는지 확인하려면 다음 명령을 실행하여 새 머신 중 하나에 대해 CR의 관련 필드를 검사합니다.
$ oc describe machine <machine_name_updated_1> -n openshift-machine-api
4.2. RHV의 다른 스토리지 도메인으로 노드 마이그레이션
OpenShift Container Platform 컨트롤 플레인 및 컴퓨팅 노드를 RHV(Red Hat Virtualization) 클러스터의 다른 스토리지 도메인으로 마이그레이션할 수 있습니다.
4.2.1. RHV의 다른 스토리지 도메인으로 컴퓨팅 노드 마이그레이션
사전 요구 사항
- Manager에 로그인되어 있습니다.
- 대상 스토리지 도메인의 이름이 있습니다.
절차
가상 머신 템플릿을 확인합니다.
$ oc get -o jsonpath='{.items[0].spec.template.spec.providerSpec.value.template_name}{"\n"}' machineset -A식별한 템플릿을 기반으로 Manager에서 새 가상 머신을 생성합니다. 다른 모든 설정은 변경하지 않고 그대로 둡니다. 자세한 내용은 Red Hat Virtualization 가상 머신 관리 가이드에서 템플릿 기반의 가상 머신 생성을 참조하십시오.
작은 정보새 가상 머신을 시작할 필요가 없습니다.
- 새 가상 머신에서 새 템플릿을 생성합니다. 대상 스토리지 도메인을 지정합니다. 자세한 내용은 Red Hat Virtualization 가상 머신 관리 가이드에서 템플릿 생성을 참조하십시오.
새 템플릿을 사용하여 OpenShift Container Platform 클러스터에 새 머신 세트를 추가합니다.
현재 머신 세트의 세부 정보를 가져옵니다.
$ oc get machineset -o yaml이러한 세부 정보를 사용하여 머신 세트를 생성합니다. 자세한 내용은 머신 세트 생성을 참조하십시오.
template_name 필드에 새 가상 머신 템플릿 이름을 입력합니다. Manager의 새 템플릿 대화 상자에서 사용한 것과 동일한 템플릿 이름을 사용합니다.
- 이전 머신 세트와 새 머신 세트의 이름을 기록해 둡니다. 후속 단계에서 해당 내용을 참조해야 합니다.
워크로드를 마이그레이션합니다.
새 머신 세트를 확장합니다. 머신 세트 수동 스케일링에 대한 자세한 내용은 머신 세트 스케일링을 참조하십시오.
OpenShift Container Platform은 이전 머신이 제거되면 사용 가능한 작업자로 Pod를 이동합니다.
- 이전 머신 세트를 축소합니다.
이전 머신 세트를 제거합니다.
$ oc delete machineset <machineset-name>
4.2.2. RHV의 다른 스토리지 도메인으로 컨트롤 플레인 노드를 마이그레이션
OpenShift Container Platform은 컨트롤 플레인 노드를 관리하지 않으므로 컴퓨팅 노드보다 쉽게 마이그레이션할 수 있습니다. RHV(Red Hat Virtualization)의 다른 모든 가상 머신과 마찬가지로 마이그레이션할 수 있습니다.
각 노드에 대해 이 절차를 개별적으로 수행합니다.
사전 요구 사항
- Manager에 로그인되어 있습니다.
- 컨트롤 플레인 노드를 확인했습니다. Manager에서 master 로 레이블이 지정됩니다.
절차
- 마스터 레이블이 지정된 가상 머신을 선택합니다.
- 가상 머신을 종료합니다.
- 디스크 탭을 클릭합니다.
- 가상 머신의 디스크를 클릭합니다.
-
더 많은 작업
 을 클릭하고 이동을 선택합니다.
을 클릭하고 이동을 선택합니다.
- 대상 스토리지 도메인을 선택하고 마이그레이션 프로세스가 완료될 때까지 기다립니다.
- 가상 머신을 시작합니다.
OpenShift Container Platform 클러스터가 안정적인지 확인합니다.
$ oc get nodes출력에
Ready상태의 노드가 표시되어야 합니다.- 각 컨트롤 플레인 노드에 이 절차를 반복합니다.
5장. 머신 단계 및 라이프사이클
머신은 정의된 여러 단계가 있는 라이프사이클을 통해 이동합니다. 시스템 라이프사이클 및 해당 단계를 이해하면 프로시저가 완료되었는지 또는 원하지 않는 동작의 문제를 해결하는 데 도움이 될 수 있습니다. OpenShift Container Platform에서는 지원되는 모든 클라우드 공급자에서 머신 라이프사이클이 일관되게 유지됩니다.
5.1. 머신 단계
머신이 라이프사이클을 통과할 때 다양한 단계를 거칩니다. 각 단계는 머신 상태에 대한 기본 표현입니다.
프로비저닝- 새 시스템을 프로비저닝하라는 요청이 있습니다. 시스템은 아직 존재하지 않으며 인스턴스, 공급자 ID 또는 주소가 없습니다.
provisioned-
시스템이 존재하고 공급자 ID 또는 주소가 있습니다. 클라우드 공급자가 시스템에 대한 인스턴스를 생성했습니다. 시스템이 아직 노드가 되지 않았으며 머신 오브젝트의
status.nodeRef섹션이 아직 채워지지 않았습니다. Running-
시스템이 존재하고 공급자 ID 또는 주소가 있습니다. Ignition이 성공적으로 실행되었으며 클러스터 시스템 승인자가 CSR(인증서 서명 요청)을 승인했습니다. 머신이 노드가 되어 머신 오브젝트의
status.nodeRef섹션에 노드 세부 정보가 포함되어 있습니다. 삭제 중-
머신을 삭제하라는 요청이 있습니다. 머신 오브젝트에는 삭제 요청 시간을 나타내는
DeletionTimestamp필드가 있습니다. Failed- 시스템에 복구할 수 없는 문제가 있습니다. 예를 들어 클라우드 공급자가 머신의 인스턴스를 삭제하는 경우 이러한 상황이 발생할 수 있습니다.
5.2. 머신 라이프사이클
라이프사이클은 시스템 프로비저닝 요청으로 시작하여 시스템이 더 이상 존재하지 않을 때까지 계속됩니다.
머신 라이프사이클은 다음 순서로 진행됩니다. 오류 또는 라이프사이클 후크로 인한 중단은 이 개요에 포함되어 있지 않습니다.
다음 이유 중 하나를 위해 새 시스템을 프로비저닝하라는 요청이 있습니다.
- 클러스터 관리자는 추가 시스템이 필요하므로 머신 세트를 확장합니다.
- 자동 스케일링 정책은 추가 머신이 필요하므로 머신 세트를 스케일링합니다.
- 머신 세트에서 관리하는 머신이 실패하거나 삭제되고 머신 세트는 필요한 수를 유지하기 위해 교체를 생성합니다.
-
시스템이
프로비저닝단계에 들어갑니다. - 인프라 공급자는 시스템에 대한 인스턴스를 생성합니다.
-
시스템에는 공급자 ID 또는 주소가 있으며
프로비저닝된단계를 입력합니다. - Ignition 구성 파일이 처리됩니다.
- kubelet은 CSR(인증서 서명 요청)을 발행합니다.
- 클러스터 시스템 승인자가 CSR을 승인합니다.
-
시스템이 노드가 되어
Running단계로 들어갑니다. 다음과 같은 이유 중 하나로 기존 머신이 삭제될 예정입니다.
-
cluster-admin권한이 있는 사용자는oc delete machine명령을 사용합니다. -
머신은
machine.openshift.io/delete-machine주석을 가져옵니다. - 머신을 관리하는 머신 세트는 복제 수를 조정의 일부로 줄이기 위해 삭제를 위해 표시합니다.
- 클러스터 자동 스케일러는 클러스터의 배포 요구 사항을 충족하는 데 불필요한 노드를 식별합니다.
- 비정상 머신을 교체하도록 머신 상태 점검이 구성되어 있습니다.
-
-
머신은
삭제로 표시되지만 API에는 여전히 존재합니다. - 머신 컨트롤러는 인프라 공급자에서 인스턴스를 제거합니다.
-
머신 컨트롤러는
Node오브젝트를 삭제합니다.
5.3. 머신의 단계 확인
OpenShift CLI(oc)를 사용하거나 웹 콘솔을 사용하여 머신의 단계를 찾을 수 있습니다. 이 정보를 사용하여 프로시저가 완료되었는지 또는 원하지 않는 동작의 문제를 해결할 수 있습니다.
5.3.1. CLI를 사용하여 머신의 단계 확인
OpenShift CLI(oc)를 사용하여 머신의 단계를 찾을 수 있습니다.
사전 요구 사항
-
cluster-admin권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다. -
ocCLI를 설치했습니다.
절차
다음 명령을 실행하여 클러스터의 머신을 나열합니다.
$ oc get machine -n openshift-machine-api출력 예
NAME PHASE TYPE REGION ZONE AGE mycluster-5kbsp-master-0 Running m6i.xlarge us-west-1 us-west-1a 4h55m mycluster-5kbsp-master-1 Running m6i.xlarge us-west-1 us-west-1b 4h55m mycluster-5kbsp-master-2 Running m6i.xlarge us-west-1 us-west-1a 4h55m mycluster-5kbsp-worker-us-west-1a-fmx8t Running m6i.xlarge us-west-1 us-west-1a 4h51m mycluster-5kbsp-worker-us-west-1a-m889l Running m6i.xlarge us-west-1 us-west-1a 4h51m mycluster-5kbsp-worker-us-west-1b-c8qzm Running m6i.xlarge us-west-1 us-west-1b 4h51m출력의
PHASE열에는 각 시스템의 단계가 포함됩니다.
5.3.2. 웹 콘솔을 사용하여 머신의 단계 확인
OpenShift Container Platform 웹 콘솔을 사용하여 머신의 단계를 찾을 수 있습니다.
사전 요구 사항
-
cluster-admin권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다.
절차
-
cluster-admin역할의 사용자로 웹 콘솔에 로그인합니다. - 컴퓨팅 → 머신으로 이동합니다.
- 머신 페이지에서 단계를 찾을 머신의 이름을 선택합니다.
- 머신 세부 정보 페이지에서 YAML 탭을 선택합니다.
YAML 블록에서
status.phase필드의 값을 찾습니다.YAML 스니펫의 예
apiVersion: machine.openshift.io/v1beta1 kind: Machine metadata: name: mycluster-5kbsp-worker-us-west-1a-fmx8t # ... status: phase: Running1 - 1
- 이 예제에서 단계는
실행중입니다.
6장. 머신 삭제
특정 머신을 삭제할 수 있습니다.
6.1. 특정 머신 삭제
특정 머신을 삭제할 수 있습니다.
컨트롤 플레인 머신을 삭제할 수 없습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터를 설치합니다.
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다.
절차
다음 명령을 실행하여 클러스터에 있는 머신을 확인합니다.
$ oc get machine -n openshift-machine-api명령 출력에는 <
clusterid>-<role>-<cloud_region> 형식의 머신 목록이 포함되어 있습니다.- 삭제할 머신을 확인합니다.
다음 명령을 실행하여 시스템을 삭제합니다.
$ oc delete machine <machine> -n openshift-machine-api중요기본적으로 머신 컨트롤러는 성공할 때까지 머신이 지원하는 노드를 드레이닝하려고 합니다. Pod 중단 예산을 잘못 구성하는 등 일부 상황에서는 드레이닝 작업이 성공하지 못할 수 있습니다. 드레이닝 작업이 실패하면 머신 컨트롤러에서 머신 제거를 진행할 수 없습니다.
특정 머신에서
machine.openshift.io/exclude-node-draining에 주석을 달아 노드 드레이닝을 건너뛸 수 있습니다.삭제한 머신이 머신 세트에 속하는 경우 지정된 복제본 수를 충족하기 위해 새 머신이 즉시 생성됩니다.
6.2. 머신 삭제 단계의 라이프사이클 후크
머신 라이프사이클 후크는 일반 라이프사이클 프로세스가 중단될 수 있는 시스템의 조정 라이프사이클에 있는 지점입니다. 머신 삭제 단계에서 이러한 중단은 구성 요소가 머신 삭제 프로세스를 수정할 수 있는 기회를 제공합니다.
6.2.1. 용어 및 정의
시스템 삭제 단계에 대한 라이프사이클 후크의 동작을 이해하려면 다음 개념을 이해해야 합니다.
- 조정
- 조정은 컨트롤러가 클러스터의 실제 상태 및 오브젝트 사양의 요구 사항과 일치하는 오브젝트를 만드는 프로세스입니다.
- 머신 컨트롤러
머신 컨트롤러는 머신의 조정 라이프사이클을 관리합니다. 클라우드 플랫폼의 머신의 경우 머신 컨트롤러는 OpenShift Container Platform 컨트롤러와 클라우드 공급자의 플랫폼별 작동기 조합입니다.
머신 삭제 컨텍스트에서 머신 컨트롤러는 다음 작업을 수행합니다.
- 머신에서 지원하는 노드를 드레이닝합니다.
- 클라우드 공급자에서 머신 인스턴스를 삭제합니다.
-
Node오브젝트를 삭제합니다.
- 라이프사이클 후크
라이프사이클 후크는 일반 라이프사이클 프로세스가 중단될 수 있는 오브젝트의 조정 라이프사이클에서 정의된 지점입니다. 구성 요소에서는 라이프사이클 후크를 사용하여 원하는 결과를 얻기 위해 변경 사항을 프로세스에 삽입할 수 있습니다.
머신
삭제단계에는 다음 두 개의 라이프사이클 후크가 있습니다.
-
사전Drain라이프사이클 후크는 시스템에서 지원하는 노드를 드레인하기 전에 확인해야 합니다. -
인프라 공급자에서 인스턴스를 제거하려면
사전종료 라이프사이클 후크를 해결해야 합니다.
- hook-iECDHE 컨트롤러
후크는 라이프사이클 후크와 상호 작용할 수 있는 머신 컨트롤러가 아닌 컨트롤러입니다. 후크-i>-< 컨트롤러는 다음 작업 중 하나 이상을 수행할 수 있습니다.
- 라이프사이클 후크를 추가합니다.
- 라이프사이클 후크에 응답합니다.
- 라이프사이클 후크를 제거합니다.
각 라이프사이클 후크에는 단일 후크-iECDHE 컨트롤러가 있지만 hook-iECDHE 컨트롤러는 하나 이상의 후크를 관리할 수 있습니다.
6.2.2. 머신 삭제 처리 순서
OpenShift Container Platform 4.11에는 머신 삭제 단계에는 preDrain 및 preTerminate 의 두 가지 라이프사이클 후크가 있습니다. 지정된 라이프사이클 포인트의 모든 후크가 제거되면 정상적으로 조정이 계속됩니다.
그림 6.1. 머신 삭제 흐름
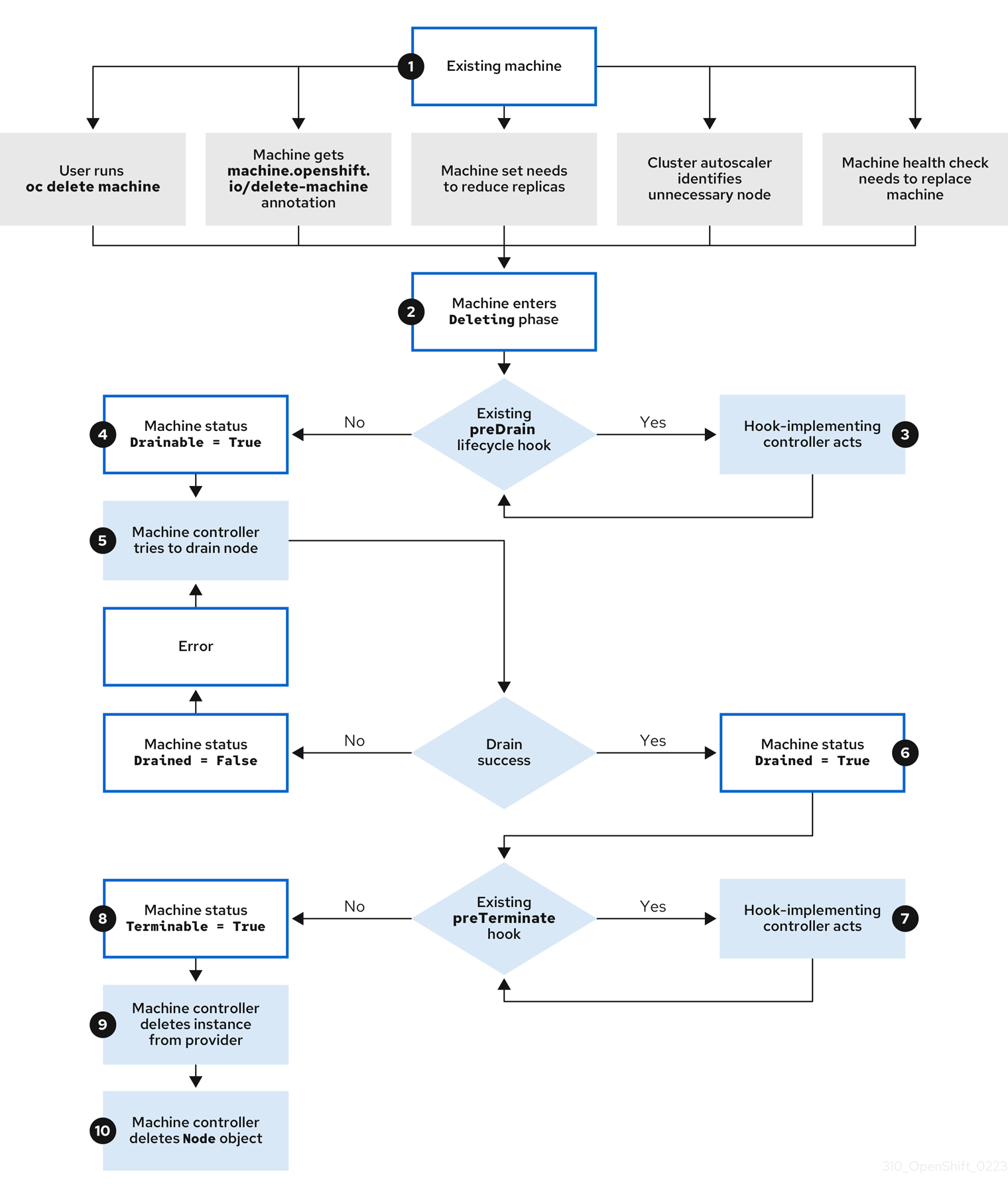
머신 삭제 단계는 다음 순서로 진행됩니다.
다음과 같은 이유 중 하나로 기존 머신이 삭제될 예정입니다.
-
cluster-admin권한이 있는 사용자는oc delete machine명령을 사용합니다. -
머신은
machine.openshift.io/delete-machine주석을 가져옵니다. - 머신을 관리하는 머신 세트는 복제 수를 조정의 일부로 줄이기 위해 삭제를 위해 표시합니다.
- 클러스터 자동 스케일러는 클러스터의 배포 요구 사항을 충족하는 데 불필요한 노드를 식별합니다.
- 비정상 머신을 교체하도록 머신 상태 점검이 구성되어 있습니다.
-
-
머신은
삭제로 표시되지만 API에는 여전히 존재합니다. preDrain라이프사이클 후크가 있는 경우 해당 후크를 관리하는 컨트롤러에서 지정된 작업을 수행합니다.모든
사전 라이프사이클 후크가 충족될 때까지 시스템 상태 조건Drainable은False로 설정됩니다.-
해결되지 않은 라이프사이클 후크가 없으며 시스템 상태 조건
Drainable은True로 설정됩니다. 머신 컨트롤러에서 머신에서 지원하는 노드를 드레이닝하려고 합니다.
-
드레인링에 실패하면
Drained가False로 설정되고 머신 컨트롤러에서 노드를 다시 드레이닝하려고 합니다. -
드레인링에 성공하면
Drained가True로 설정됩니다.
-
드레인링에 실패하면
-
Drained머신 상태 조건은True로 설정됩니다. preTerminate라이프사이클 후크가 있는 경우 해당 후크를 관리하는 컨트롤러에서 지정된 작업을 수행합니다.preTerminate라이프사이클 후크가 모두 충족될 때까지 시스템 상태 조건Terminable이False로 설정됩니다.-
확인되지 않은 라이프사이클 후크가 없으며 시스템 상태 조건
Terminable은True로 설정됩니다. - 머신 컨트롤러는 인프라 공급자에서 인스턴스를 제거합니다.
-
머신 컨트롤러는
Node오브젝트를 삭제합니다.
6.2.3. 라이프사이클 후크 구성 삭제
다음 YAML 스니펫에서는 머신 세트 내의 라이프사이클 후크 구성의 형식 및 배치를 보여줍니다.
preDrain 라이프사이클 후크를 보여주는 YAML 스니펫
apiVersion: machine.openshift.io/v1beta1
kind: Machine
metadata:
...
spec:
lifecycleHooks:
preDrain:
- name: <hook_name>
owner: <hook_owner>
...사전 종료 라이프사이클 후크를 보여주는 YAML 스니펫
apiVersion: machine.openshift.io/v1beta1
kind: Machine
metadata:
...
spec:
lifecycleHooks:
preTerminate:
- name: <hook_name>
owner: <hook_owner>
...라이프사이클 후크 구성 예
다음 예제에서는 시스템 삭제 프로세스를 중단하는 여러 가지 주요 라이프사이클 후크를 구현하는 방법을 보여줍니다.
라이프사이클 후크 구성 예
apiVersion: machine.openshift.io/v1beta1
kind: Machine
metadata:
...
spec:
lifecycleHooks:
preDrain:
- name: MigrateImportantApp
owner: my-app-migration-controller
preTerminate:
- name: BackupFileSystem
owner: my-backup-controller
- name: CloudProviderSpecialCase
owner: my-custom-storage-detach-controller
- name: WaitForStorageDetach
owner: my-custom-storage-detach-controller
...6.2.4. Operator 개발자의 머신 삭제 라이프사이클 후크 예
Operator는 시스템 삭제 단계에 라이프사이클 후크를 사용하여 시스템 삭제 프로세스를 수정할 수 있습니다. 다음 예제에서는 Operator에서 이 기능을 사용할 수 있는 방법을 보여줍니다.
preDrain 라이프사이클 후크의 사용 사례 예
- 능동적으로 교체 머신
-
Operator는
preDrain라이프사이클 후크를 사용하여 삭제된 머신의 인스턴스를 제거하기 전에 교체 머신이 성공적으로 생성되고 클러스터에 조인되도록 할 수 있습니다. 이를 통해 머신 교체 또는 즉시 초기화하지 않는 교체 인스턴스의 중단의 영향을 완화할 수 있습니다. - 사용자 정의 드레이닝 논리 구현
Operator는
preDrain라이프사이클 후크를 사용하여 머신 컨트롤러를 드레이닝 논리를 다른 드레이닝 컨트롤러로 교체할 수 있습니다. 드레이닝 논리를 교체하면 Operator는 각 노드에서 워크로드의 라이프사이클을 보다 유연하게 제어할 수 있었습니다.예를 들어 머신 컨트롤러 드레이닝 라이브러리는 순서를 지원하지 않지만 사용자 정의 드레이닝 공급자가 이 기능을 제공할 수 있습니다. Operator는 사용자 정의 드레인 공급자를 사용하여 클러스터 용량이 제한된 경우 서비스 중단을 최소화하도록 노드를 드레이닝하기 전에 미션 크리티컬 애플리케이션을 이동하는 우선 순위를 지정할 수 있습니다.
사전Terminate 라이프사이클 후크의 사용 사례 예
- 스토리지 분리 확인
-
Operator는
사전 종료 라이프사이클 후크를 사용하여 머신이 인프라 공급자에서 제거되기 전에 머신에 연결된 스토리지를 분리할 수 있습니다. - 로그 안정성 개선
노드를 드레이닝한 후 로그 내보내기 데몬에서 로그를 중앙 집중식 로깅 시스템에 동기화하는 데 시간이 걸립니다.
로깅 Operator는
preTerminate라이프사이클 후크를 사용하여 노드 드레이닝 시기와 인프라 공급자에서 머신이 제거된 시점 사이에 지연을 추가할 수 있습니다. 이 지연으로 인해 Operator에서 기본 워크로드가 제거되고 더 이상 로그 백로그에 추가되지 않도록 하는 시간이 제공됩니다. 로그 백로그에 새 데이터가 추가되지 않으면 로그 내보내기에서 동기화 프로세스를 따라 이동하여 모든 애플리케이션 로그를 캡처할 수 있습니다.
6.2.5. 머신 라이프사이클 후크를 통한 쿼럼 보호
Machine API Operator를 사용하는 OpenShift Container Platform 클러스터의 경우 etcd Operator는 머신 삭제 단계에 라이프사이클 후크를 사용하여 쿼럼 보호 메커니즘을 구현합니다.
preDrain 라이프사이클 후크를 사용하면 etcd Operator에서 컨트롤 플레인 시스템의 pod가 드레이닝 및 제거되는 시기를 제어할 수 있습니다. etcd 쿼럼을 보호하기 위해 etcd Operator는 해당 멤버를 클러스터 내의 새 노드로 마이그레이션할 때까지 etcd 멤버를 제거할 수 있습니다.
이 메커니즘을 통해 etcd Operator는 etcd 쿼럼의 멤버를 정확하게 제어할 수 있으며 Machine API Operator는 etcd 클러스터에 대한 특정 운영 지식 없이도 컨트롤 플레인 머신을 안전하게 생성 및 제거할 수 있습니다.
6.2.5.1. 쿼럼 보호 처리 순서를 사용한 컨트롤 플레인 삭제
OpenShift Container Platform 4.11 이상으로 클러스터에서 컨트롤 플레인 머신이 교체되면 클러스터에 4개의 컨트롤 플레인 머신이 일시적으로 부여됩니다. 네 번째 컨트롤 플레인 노드가 클러스터에 참여하면 etcd Operator는 교체 노드에서 새 etcd 멤버를 시작합니다. etcd Operator는 이전 컨트롤 플레인 머신이 삭제로 표시된 것을 관찰하면 이전 노드에서 etcd 멤버를 중지하고 대체 etcd 멤버를 승격하여 클러스터의 쿼럼에 참여하도록 합니다.
컨트롤 플레인 머신 삭제 단계는 다음 순서로 진행됩니다.
- 컨트롤 플레인 시스템이 삭제될 예정입니다.
-
컨트롤 플레인 시스템이
삭제단계에 들어갑니다. preDrain라이프사이클 후크를 충족하기 위해 etcd Operator는 다음 작업을 수행합니다.-
etcd Operator는 중단된 컨트롤 플레인 시스템이 etcd 멤버로 클러스터에 추가될 때까지 기다립니다. 이 새 etcd 멤버는
Running이지만 etcd 리더에서 전체 데이터베이스 업데이트를 수신할 때까지 준비되지않았습니다. - 새 etcd 멤버가 전체 데이터베이스 업데이트를 수신하면 etcd Operator는 새 etcd 멤버를 투표 멤버로 승격하고 클러스터에서 이전 etcd 멤버를 제거합니다.
이 전환이 완료되면 이전 etcd pod 및 해당 데이터를 제거할 수 있으므로
preDrain라이프사이클 후크가 제거됩니다.-
etcd Operator는 중단된 컨트롤 플레인 시스템이 etcd 멤버로 클러스터에 추가될 때까지 기다립니다. 이 새 etcd 멤버는
-
컨트롤 플레인 머신 상태 조건
Drainable은True로 설정됩니다. 머신 컨트롤러는 컨트롤 플레인 머신에서 지원하는 노드를 드레이닝하려고 합니다.
-
드레인링에 실패하면
Drained가False로 설정되고 머신 컨트롤러에서 노드를 다시 드레이닝하려고 합니다. -
드레인링에 성공하면
Drained가True로 설정됩니다.
-
드레인링에 실패하면
-
컨트롤 플레인 시스템 상태
조건이True로 설정됩니다. -
다른 Operator에
preTerminate라이프사이클 후크를 추가하지 않은 경우 컨트롤 플레인 머신 상태 조건Terminable이True로 설정됩니다. - 머신 컨트롤러는 인프라 공급자에서 인스턴스를 제거합니다.
-
머신 컨트롤러는
Node오브젝트를 삭제합니다.
etcd 쿼럼 보호 preDrain 라이프사이클 후크를 보여주는 YAML 스니펫
apiVersion: machine.openshift.io/v1beta1
kind: Machine
metadata:
...
spec:
lifecycleHooks:
preDrain:
- name: EtcdQuorumOperator
owner: clusteroperator/etcd
...7장. OpenShift Container Platform 클러스터에 자동 스케일링 적용
OpenShift Container Platform 클러스터에 자동 스케일링을 적용하려면클러스터 자동 스케일러를 배포한 다음 클러스터의 각 머신 유형에 대해 머신 자동 스케일러를 배포해야 합니다.
Machine API Operator가 작동하는 클러스터에서만 클러스터 자동 스케일러를 구성할 수 있습니다.
7.1. 클러스터 자동 스케일러 정보
클러스터 자동 스케일러는 현재 배포 요구 사항에 따라 OpenShift Container Platform 클러스터의 크기를 조정합니다. 이는 Kubernetes 형식의 선언적 인수를 사용하여 특정 클라우드 공급자의 개체에 의존하지 않는 인프라 관리를 제공합니다. 클러스터 자동 스케일러에는 클러스터 범위가 있으며 특정 네임 스페이스와 연결되어 있지 않습니다.
리소스가 부족하여 현재 작업자 노드에서 Pod를 예약할 수 없거나 배포 요구를 충족시키기 위해 다른 노드가 필요한 경우 클러스터 자동 스케일러는 클러스터 크기를 늘립니다. 클러스터 자동 스케일러는 사용자가 지정한 제한을 초과하여 클러스터 리소스를 늘리지 않습니다.
클러스터 자동 스케일러는 컨트롤 플레인 노드를 관리하지 않는 경우에도 클러스터의 모든 노드의 총 메모리, CPU 및 GPU를 계산합니다. 이러한 값은 단일 시스템 지향이 아닙니다. 이는 전체 클러스터에 있는 모든 리소스의 집계입니다. 예를 들어 최대 메모리 리소스 제한을 설정하면 현재 메모리 사용량을 계산할 때 클러스터 자동 스케일러에 클러스터의 모든 노드가 포함됩니다. 그런 다음 이러한 계산을 사용하여 클러스터 자동 스케일러에 더 많은 작업자 리소스를 추가할 수 있는 용량이 있는지 확인합니다.
작성한 ClusterAutoscaler 리솟스 정의의 maxNodesTotal 값이 클러스터에서 예상되는 총 머신 수를 대응하기에 충분한 크기의 값인지 확인합니다. 이 값에는 컨트롤 플레인 머신 수 및 확장 가능한 컴퓨팅 머신 수가 포함되어야 합니다.
클러스터 자동 스케일러는 10초마다 클러스터에서 불필요한 노드를 확인하고 제거합니다. 다음 조건이 적용되는 경우 클러스터 자동 스케일러는 노드를 제거하도록 간주합니다.
-
노드 사용률이 클러스터의 노드 사용률 수준 임계값보다 적습니다. 노드 사용률 수준은 요청된 리소스의 합계가 노드에 할당된 리소스로 나눈 값입니다.
ClusterAutoscaler사용자 정의 리소스에 값을 지정하지 않으면 클러스터 자동 스케일러는 기본값0.5를 사용하며 이는 50% 사용률에 해당합니다. - 클러스터 자동 스케일러는 노드에서 실행 중인 모든 Pod를 다른 노드로 이동할 수 있습니다. Kubernetes 스케줄러는 노드에서 Pod를 예약하는 역할을 합니다.
- 클러스터 자동 스케일러에는 축소 비활성화 주석이 없습니다.
노드에 다음 유형의 pod가 있는 경우 클러스터 자동 스케일러는 해당 노드를 제거하지 않습니다.
- 제한적인 PDB (Pod Disruption Budgets)가 있는 pod
- 기본적으로 노드에서 실행되지 않는 Kube 시스템 pod
- PDB가 없거나 제한적인 PDB가있는 Kube 시스템 pod
- deployment, replica set 또는 stateful set와 같은 컨트롤러 객체가 지원하지 않는 pod
- 로컬 스토리지가 있는 pod
- 리소스 부족, 호환되지 않는 노드 선택기 또는 어피니티(affinity), 안티-어피니티(anti-affinity) 일치 등으로 인해 다른 위치로 이동할 수 없는 pod
-
"cluster-autoscaler.kubernetes.io/safe-to-evict": "true"주석이없는 경우"cluster-autoscaler.kubernetes.io/safe-to-evict": "false"주석이 있는 pod
예를 들어 최대 CPU 제한을 64개의 코어로 설정하고 각각 8개의 코어가 있는 머신만 생성하도록 클러스터 자동 스케일러를 구성합니다. 클러스터가 30개의 코어로 시작하는 경우 클러스터 자동 스케일러는 총 62개의 코어에 대해 최대 4개의 노드를 32개의 코어로 추가할 수 있습니다.
클러스터 자동 스케일러를 구성하면 추가 사용 제한이 적용됩니다.
- 자동 스케일링된 노드 그룹에 있는 노드를 직접 변경하지 마십시오. 동일한 노드 그룹 내의 모든 노드는 동일한 용량 및 레이블을 가지며 동일한 시스템 pod를 실행합니다.
- pod 요청을 지정합니다.
- pod가 너무 빨리 삭제되지 않도록 해야 하는 경우 적절한 PDB를 구성합니다.
- 클라우드 제공자 할당량이 구성하는 최대 노드 풀을 지원할 수 있는 충분한 크기인지를 확인합니다.
- 추가 노드 그룹 Autoscaler, 특히 클라우드 제공자가 제공하는 Autoscaler를 실행하지 마십시오.
HPA (Horizond Pod Autoscaler) 및 클러스터 자동 스케일러는 다른 방식으로 클러스터 리소스를 변경합니다. HPA는 현재 CPU 로드를 기준으로 배포 또는 복제 세트의 복제 수를 변경합니다. 로드가 증가하면 HPA는 클러스터에 사용 가능한 리소스 양에 관계없이 새 복제본을 만듭니다. 리소스가 충분하지 않은 경우 클러스터 자동 스케일러는 리소스를 추가하고 HPA가 생성한 pod를 실행할 수 있도록 합니다. 로드가 감소하면 HPA는 일부 복제를 중지합니다. 이 동작으로 일부 노드가 충분히 활용되지 않거나 완전히 비어 있을 경우 클러스터 자동 스케일러가 불필요한 노드를 삭제합니다.
클러스터 자동 스케일러는 pod 우선 순위를 고려합니다. Pod 우선 순위 및 선점 기능을 사용하면 클러스터에 충분한 리소스가 없는 경우 우선 순위에 따라 pod를 예약할 수 있지만 클러스터 자동 스케일러는 클러스터에 모든 pod를 실행하는 데 필요한 리소스가 있는지 확인합니다. 두 기능을 충족하기 위해 클러스터 자동 스케일러에는 우선 순위 컷오프 기능이 포함되어 있습니다. 이 컷오프 기능을 사용하여 "best-effort" pod를 예약하면 클러스터 자동 스케일러가 리소스를 늘리지 않고 사용 가능한 예비 리소스가 있을 때만 실행됩니다.
컷오프 값보다 우선 순위가 낮은 pod는 클러스터가 확장되지 않거나 클러스터가 축소되지 않도록합니다. pod를 실행하기 위해 추가된 새 노드가 없으며 이러한 pod를 실행하는 노드는 리소스를 확보하기 위해 삭제될 수 있습니다.
머신 API를 사용할 수 있는 플랫폼에서 클러스터 자동 스케일링이 지원됩니다.
7.2. 클러스터 자동 스케일러 구성
먼저 클러스터 자동 스케일러를 배포하여 OpenShift Container Platform 클러스터에서 리소스의 자동 스케일링을 관리합니다.
클러스터 자동 스케일러의 범위는 전체 클러스터에 설정되므로 클러스터에 대해 하나의 클러스터 자동 스케일러만 만들 수 있습니다.
7.2.1. 클러스터 자동 스케일러 리소스 정의
이 ClusterAutoscaler 리소스 정의는 클러스터 자동 스케일러의 매개 변수 및 샘플 값을 표시합니다.
apiVersion: "autoscaling.openshift.io/v1"
kind: "ClusterAutoscaler"
metadata:
name: "default"
spec:
podPriorityThreshold: -10
resourceLimits:
maxNodesTotal: 24
cores:
min: 8
max: 128
memory:
min: 4
max: 256
gpus:
- type: nvidia.com/gpu
min: 0
max: 16
- type: amd.com/gpu
min: 0
max: 4
scaleDown:
enabled: true
delayAfterAdd: 10m
delayAfterDelete: 5m
delayAfterFailure: 30s
unneededTime: 5m
utilizationThreshold: "0.4" - 1
- 클러스터 자동 스케일러가 추가 노드를 배포하도록 하려면 pod가 초과해야하는 우선 순위를 지정합니다. 32 비트 정수 값을 입력합니다.
podPriorityThreshold값은 각 pod에 할당한PriorityClass의 값과 비교됩니다. - 2
- 배포할 최대 노드 수를 지정합니다. 이 값은 Autoscaler가 제어하는 머신뿐 만 아니라 클러스터에 배치 된 총 머신 수입니다. 이 값이 모든 컨트롤 플레인 및 컴퓨팅 머신과
MachineAutoscaler리소스에 지정한 총 복제본 수에 대응할 수 있을 만큼 충분한 크기의 값인지 확인합니다. - 3
- 클러스터에 배포할 최소 코어 수를 지정합니다.
- 4
- 클러스터에 배포할 최대 코어 수를 지정합니다.
- 5
- 클러스터에서 최소 메모리 크기를 GiB 단위로 지정합니다.
- 6
- 클러스터에서 최대 메모리 크기를 GiB단위로 지정합니다.
- 7
- 선택 사항: 배포할 GPU 노드 유형을 지정합니다.
nvidia.com/gpu및amd.com/gpu만 유효한 유형입니다. - 8
- 클러스터에 배포할 최소 GPU 수를 지정합니다.
- 9
- 클러스터에 배포할 최대 GPU 수를 지정합니다.
- 10
- 11
- 클러스터 자동 스케일러가 불필요한 노드를 제거할 수 있는지 여부를 지정합니다.
- 12
- 선택 사항: 노드가 최근에 추가된 후 노드를 삭제하기 전에 대기할 기간을 지정합니다. 값을 지정하지 않으면 기본값으로
10m이 사용됩니다. - 13
- 선택 사항: 노드가 최근에 삭제된 후 노드를 삭제하기 전에 대기할 기간을 지정합니다. 값을 지정하지 않으면 기본값
0s가 사용됩니다. - 14
- 선택 사항: 축소 실패 후 노드를 삭제하기 전에 대기할 기간을 지정합니다. 값을 지정하지 않으면 기본값으로
3m가 사용됩니다. - 15
- 선택 사항: 불필요한 노드가 삭제되기 전에 기간을 지정합니다. 값을 지정하지 않으면 기본값으로
10m이 사용됩니다. - 16
- 선택 사항: 불필요한 노드가 삭제할 수 있는 노드 사용률 수준을 지정합니다. 노드 사용률 수준은 노드에 할당된 리소스로 나누어진 요청된 리소스의 합계이며
"0"보다 크고"1"미만의 값이어야 합니다. 값을 지정하지 않으면 클러스터 자동 스케일러는 기본값"0.5"를 사용합니다. 이 값은 50% 사용률에 해당합니다. 이 값은 문자열로 표현되어야 합니다.
스케일링 작업을 수행할 때 클러스터 자동 스케일러는 클러스터에서 배포할 최소 및 최대 코어 수 또는 메모리 양과 같은 ClusterAutoscaler 리소스 정의에 설정된 범위 내에 유지됩니다. 그러나 클러스터 자동 스케일러는 해당 범위 내에 있는 클러스터의 현재 값을 수정하지 않습니다.
최소 및 최대 CPU, 메모리 및 GPU 값은 클러스터 자동 스케일러가 노드를 관리하지 않는 경우에도 클러스터의 모든 노드에서 해당 리소스를 계산하여 결정됩니다. 예를 들어 클러스터 자동 스케일러가 컨트롤 플레인 노드를 관리하지 않는 경우에도 컨트롤 플레인 노드는 클러스터의 총 메모리에서 고려됩니다.
7.2.2. 클러스터 자동 스케일러 배포
클러스터 자동 스케일러를 배포하려면 ClusterAutoscaler 리소스의 인스턴스를 만듭니다.
절차
-
사용자 지정 리소스 정의가 포함된
ClusterAutoscaler리소스에 대한 YAML 파일을 만듭니다. 다음 명령을 실행하여 클러스터에 사용자 지정 리소스를 생성합니다.
$ oc create -f <filename>.yaml1 - 1
<filename>은 사용자 정의 리소스 파일의 이름입니다.
다음 단계
- 클러스터 자동 스케일러를 구성한 후 하나 이상의 머신 자동 스케일러를 구성해야 합니다.
7.3. 머신 자동 스케일러 정보
머신 자동 스케일러는 OpenShift Container Platform 클러스터에 배포하는 머신 세트의 Machine 수를 조정합니다. 기본 worker 머신 세트와 사용자가 만든 다른 머신 세트를 모두 확장할 수 있습니다. 머신 자동 스케일러는 클러스터에 더 많은 배포를 지원하기에 충분한 리소스가 없으면 Machine을 추가합니다. 최소 또는 최대 인스턴스 수와 같은 MachineAutoscaler 리소스의 값에 대한 모든 변경 사항은 대상이 되는 머신 세트에 즉시 적용됩니다.
머신을 확장하려면 클러스터 자동 스케일러의 머신 자동 스케일러를 배포해야합니다. 클러스터 자동 스케일러는 머신 자동 스케일러가 설정한 머신 세트의 주석을 사용하여 확장할 수있는 리소스를 결정합니다. 머신 자동 스케일러도 정의하지 않고 클러스터 자동 스케일러를 정의하면 클러스터 자동 스케일러는 클러스터를 확장하지 않습니다.
7.4. 머신 자동 스케일러 구성
ClusterAutoscaler를 배포한 후 클러스터를 확장하는 데 사용되는 머신 세트를 참조하는 MachineAutoscaler 리소스를 배포합니다.
ClusterAutoscaler 리소스를 배포 한 후 하나 이상의 MachineAutoscaler 리소스를 배포해야합니다.
각 머신 세트에 대해 별도의 리소스를 구성해야합니다. 머신 세트는 리전마다 다르므로 여러 지역에서 머신 스케일링을 활성화할지 여부를 고려합니다. 스케일링하는 머신 세트에는 하나 이상의 머신이 있어야합니다.
7.4.1. 머신 자동 스케일러 리소스 정의
이 MachineAutoscaler 리소스 정의는 머신 자동 스케일러의 매개 변수 및 샘플 값을 표시합니다.
apiVersion: "autoscaling.openshift.io/v1beta1"
kind: "MachineAutoscaler"
metadata:
name: "worker-us-east-1a"
namespace: "openshift-machine-api"
spec:
minReplicas: 1
maxReplicas: 12
scaleTargetRef:
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
name: worker-us-east-1a - 1
- 머신 자동 스케일러 이름을 지정합니다. 이 머신 자동 스케일러가 스케일링하는 머신 세트 보다 쉽게 식별할 수 있도록 스케일링할 머신 세트의 이름을 지정하거나 포함합니다. 머신 세트 이름의 형식은 <
clusterid>-<machineset>-<region>입니다. - 2
- 클러스터 자동 스케일러가 클러스터 스케일링을 시작한 후 지정된 영역에 남아 있어야하는 지정된 유형의 최소 머신 수를 지정하십시오. AWS, GCP, Azure, RHOSP, vSphere에서 실행중인 경우 이 값을
0으로 설정할 수 있습니다. 다른 공급 업체의 경우 이 값을0으로 설정하지 마십시오.특수 워크로드에 사용되는 비용이 많이 드는 하드웨어 또는 대규모 머신으로 머신 세트를 확장하는 등의 사용 사례에 이 값을
0으로 설정하여 비용을 절감할 수 있습니다. 머신을 사용하지 않는 경우 클러스터 자동 스케일러가 머신 세트를 0으로 축소합니다.중요설치 관리자 프로비저닝 인프라의 OpenShift Container Platform 설치 프로세스 중에 생성된 세 개의 컴퓨팅 머신 세트의
spec.minReplicas값을0으로 설정하지 마십시오. - 3
- 클러스터 자동 스케일러가 클러스터 스케일링을 초기화한 후 지정된 영역에 배포할 수 있는 지정된 유형의 최대 머신 수를 지정합니다.
ClusterAutoscaler리소스 정의에서maxNodesTotal값이 머신 자동 스케일러가 머신 수를 배포할 수 있는 충분한 크기의 값임을 확인합니다. - 4
- 이 섹션에서는 스케일링할 기존 머신 세트를 설명하는 값을 지정합니다.
- 5
kind매개 변수 값은 항상MachineSet입니다.- 6
metadata.name매개 변수 값에 표시된 것처럼name값은 기존 머신 세트의 이름과 일치해야합니다.
7.4.2. 머신 자동 스케일러 배포
머신 자동 스케일러를 배포하려면 MachineAutoscaler 리소스의 인스턴스를 만듭니다.
절차
-
사용자 지정 리소스 정의가 포함된
MachineAutoscaler리소스에 대한 YAML 파일을 생성합니다. 다음 명령을 실행하여 클러스터에 사용자 지정 리소스를 생성합니다.
$ oc create -f <filename>.yaml1 - 1
<filename>은 사용자 정의 리소스 파일의 이름입니다.
7.5. 자동 스케일링 비활성화
클러스터에서 개별 머신 자동 스케일러를 비활성화하거나 클러스터에서 자동 스케일링을 완전히 비활성화할 수 있습니다.
7.5.1. 머신 자동 스케일러 비활성화
머신 자동 스케일러를 비활성화하려면 해당 MachineAutoscaler CR(사용자 정의 리소스)을 삭제합니다.
머신 자동 스케일러를 비활성화해도 클러스터 자동 스케일러가 비활성화되지 않습니다. 클러스터 자동 스케일러를 비활성화하려면 "클러스터 자동 스케일러 비활성화"의 지침을 따르십시오.
절차
다음 명령을 실행하여 클러스터의
MachineAutoscalerCR을 나열합니다.$ oc get MachineAutoscaler -n openshift-machine-api출력 예
NAME REF KIND REF NAME MIN MAX AGE compute-us-east-1a MachineSet compute-us-east-1a 1 12 39m compute-us-west-1a MachineSet compute-us-west-1a 2 4 37m선택 사항: 다음 명령을 실행하여
MachineAutoscalerCR의 YAML 파일 백업을 생성합니다.$ oc get MachineAutoscaler/<machine_autoscaler_name> \1 -n openshift-machine-api \ -o yaml> <machine_autoscaler_name_backup>.yaml2 다음 명령을 실행하여
MachineAutoscalerCR을 삭제합니다.$ oc delete MachineAutoscaler/<machine_autoscaler_name> -n openshift-machine-api출력 예
machineautoscaler.autoscaling.openshift.io "compute-us-east-1a" deleted
검증
머신 자동 스케일러가 비활성화되어 있는지 확인하려면 다음 명령을 실행합니다.
$ oc get MachineAutoscaler -n openshift-machine-api비활성화된 머신 자동 스케일러가 머신 자동 스케일러 목록에 표시되지 않습니다.
다음 단계
-
머신 자동 스케일러를 다시 활성화해야 하는 경우 <
machine_autoscaler_name_backup>.yaml백업 파일을 사용하고 "머신 자동 스케일러 배포"의 지침을 따르십시오.
7.5.2. 클러스터 자동 스케일러 비활성화
클러스터 자동 스케일러를 비활성화하려면 해당 ClusterAutoscaler 리소스를 삭제합니다.
클러스터 자동 스케일러를 비활성화하면 클러스터에 기존 머신 자동 스케일러가 있더라도 클러스터에서 자동 스케일링을 비활성화합니다.
절차
다음 명령을 실행하여 클러스터의
ClusterAutoscaler리소스를 나열합니다.$ oc get ClusterAutoscaler출력 예
NAME AGE default 42m선택 사항: 다음 명령을 실행하여
ClusterAutoscalerCR의 YAML 파일 백업을 만듭니다.$ oc get ClusterAutoscaler/default \1 -o yaml> <cluster_autoscaler_backup_name>.yaml2 다음 명령을 실행하여
ClusterAutoscalerCR을 삭제합니다.$ oc delete ClusterAutoscaler/default출력 예
clusterautoscaler.autoscaling.openshift.io "default" deleted
검증
클러스터 자동 스케일러가 비활성화되어 있는지 확인하려면 다음 명령을 실행합니다.
$ oc get ClusterAutoscaler예상 출력
No resources found
다음 단계
-
ClusterAutoscalerCR을 삭제하여 클러스터 자동 스케일러를 비활성화하면 클러스터가 자동 스케일링되지 않지만 클러스터의 기존 머신 자동 스케일러는 삭제되지 않습니다. 불필요한 머신 자동 스케일러를 정리하려면 "시스템 자동 스케일러 비활성화"를 참조하십시오. -
클러스터 자동 스케일러를 다시 활성화해야 하는 경우 <
cluster_autoscaler_name_backup>.yaml백업 파일을 사용하고 "클러스터 자동 스케일러 배포"의 지침을 따르십시오.
8장. 인프라 머신 세트 생성
머신 API가 작동하는 클러스터에서만 고급 머신 관리 및 스케일링 기능을 사용할 수 있습니다. 사용자 프로비저닝 인프라가 있는 클러스터에는 Machine API를 사용하려면 추가 검증 및 구성이 필요합니다.
인프라 플랫폼 유형의 클러스터가 Machine API를 사용할 수 없습니다. 이 제한은 클러스터에 연결된 컴퓨팅 시스템이 기능을 지원하는 플랫폼에 설치된 경우에도 적용됩니다. 이 매개변수는 설치 후 변경할 수 없습니다.
클러스터의 플랫폼 유형을 보려면 다음 명령을 실행합니다.
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'인프라 머신 세트를 사용하여 기본 라우터, 통합 컨테이너 이미지 레지스트리, 클러스터 지표 및 모니터링 구성 요소와 같은 인프라 구성 요소만 호스팅하는 머신을 생성할 수 있습니다. 이러한 인프라 시스템은 환경을 실행하는 데 필요한 총 서브스크립션 수에 포함되지 않습니다.
프로덕션 배포에서는 인프라 구성 요소를 유지하기 위해 3개 이상의 머신 세트를 배포하는 것이 좋습니다. OpenShift Logging 및 Red Hat OpenShift Service Mesh는 모두 Elasticsearch를 배포합니다. 이 경우 서로 다른 노드에 3개의 인스턴스를 설치해야 합니다. 이러한 각 노드는 고가용성을 위해 서로 다른 가용성 영역에 배포할 수 있습니다. 이 구성에는 가용성 영역마다 하나씩 3개의 서로 다른 머신 세트가 필요합니다. 여러 가용성 영역이 없는 글로벌 Azure 리전에서는 가용성 세트를 사용하여 고가용성을 보장할 수 있습니다.
8.1. OpenShift Container Platform 인프라 구성 요소
다음 인프라 워크로드에서는 OpenShift Container Platform 작업자 서브스크립션이 발생하지 않습니다.
- 마스터에서 실행되는 Kubernetes 및 OpenShift Container Platform 컨트롤 플레인 서비스
- 기본 라우터
- 통합된 컨테이너 이미지 레지스트리
- HAProxy 기반 Ingress 컨트롤러
- 사용자 정의 프로젝트를 모니터링하기위한 구성 요소를 포함한 클러스터 메트릭 수집 또는 모니터링 서비스
- 클러스터 집계 로깅
- 서비스 브로커
- Red Hat Quay
- Red Hat OpenShift Data Foundation
- Red Hat Advanced Cluster Manager
- Red Hat Advanced Cluster Security for Kubernetes
- Red Hat OpenShift GitOps
- Red Hat OpenShift Pipelines
다른 컨테이너, Pod 또는 구성 요소를 실행하는 모든 노드는 서브스크립션을 적용해야 하는 작업자 노드입니다.
인프라 노드 및 인프라 노드에서 실행할 수 있는 구성 요소에 대한 자세한 내용은 엔터프라이즈 Kubernetes 문서의 OpenShift 크기 조정 및 서브스크립션 가이드의 "Red Hat OpenShift 컨트롤 플레인 및 인프라 노드" 섹션을 참조하십시오.
인프라 노드를 생성하려면 머신 세트를 사용하거나노드에 레이블을 지정하거나 머신 구성 풀을 사용할 수 있습니다.
8.2. 프로덕션 환경의 인프라 머신 세트 생성
프로덕션 배포에서는 인프라 구성 요소를 유지하기 위해 3개 이상의 머신 세트를 배포하는 것이 좋습니다. OpenShift Logging 및 Red Hat OpenShift Service Mesh는 모두 Elasticsearch를 배포합니다. 이 경우 서로 다른 노드에 3개의 인스턴스를 설치해야 합니다. 이러한 각 노드는 고가용성을 위해 서로 다른 가용성 영역에 배포할 수 있습니다. 이와 같은 구성에는 각 가용성 영역에 하나씩 3개의 서로 다른 머신 세트가 필요합니다. 여러 가용성 영역이 없는 글로벌 Azure 리전에서는 가용성 세트를 사용하여 고가용성을 보장할 수 있습니다.
8.2.1. 다른 클라우드의 머신 세트 생성
클라우드에 샘플 머신 세트를 사용합니다.
8.2.1.1. Alibaba Cloud에서 머신 세트 사용자 정의 리소스의 샘플 YAML
이 샘플 YAML은 리전의 지정된 Alibaba Cloud 영역에서 실행되는 머신 세트를 정의하고 node-role.kubernetes.io/infra: "" 로 레이블이 지정된 노드를 생성합니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <infra>는 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
name: <infrastructure_id>-<infra>-<zone>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<infra>-<zone>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<infra>-<zone>
spec:
metadata:
labels:
node-role.kubernetes.io/infra: ""
providerSpec:
value:
apiVersion: machine.openshift.io/v1
credentialsSecret:
name: alibabacloud-credentials
imageId: <image_id>
instanceType: <instance_type>
kind: AlibabaCloudMachineProviderConfig
ramRoleName: <infrastructure_id>-role-worker
regionId: <region>
resourceGroup:
id: <resource_group_id>
type: ID
securityGroups:
- tags:
- Key: Name
Value: <infrastructure_id>-sg-<role>
type: Tags
systemDisk:
category: cloud_essd
size: <disk_size>
tag:
- Key: kubernetes.io/cluster/<infrastructure_id>
Value: owned
userDataSecret:
name: <user_data_secret>
vSwitch:
tags:
- Key: Name
Value: <infrastructure_id>-vswitch-<zone>
type: Tags
vpcId: ""
zoneId: <zone>
taints:
- key: node-role.kubernetes.io/infra
effect: NoSchedule- 1 5 7
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID를 지정합니다. OpenShift CLI (
oc) 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 8 9
<infra>노드 레이블을 지정합니다.- 4 6 10
- 인프라 ID,
<infra>노드 레이블 및 영역을 지정합니다. - 11
- 사용할 이미지를 지정합니다. 클러스터의 기존 기본 시스템 세트의 이미지를 사용합니다.
- 12
- 머신 세트에 사용할 인스턴스 유형을 지정합니다.
- 13
- 머신 세트에 사용할 RAM 역할의 이름을 지정합니다. 설치 프로그램이 기본 시스템 세트에서 채우는 값을 사용합니다.
- 14
- 머신을 배치할 리전을 지정합니다.
- 15
- 클러스터의 리소스 그룹 및 유형을 지정합니다. 설치 프로그램이 기본 시스템 세트에서 채우는 값을 사용하거나 다른 시스템 집합을 지정할 수 있습니다.
- 16 18 20
- 머신 세트에 사용할 태그를 지정합니다. 최소한 클러스터에 적절한 값을 사용하여 이 예에 표시된 태그를 포함해야 합니다. 설치 프로그램이 생성하는 기본 시스템 세트에 채워지는 태그를 포함하여 필요에 따라 추가 태그를 포함할 수 있습니다.
- 17
- 루트 디스크의 유형 및 크기를 지정합니다. 설치 프로그램이 생성하는 기본 시스템 세트에서 채우는
카테고리값을 사용합니다. 필요한 경우 다른 값을크기(GB)로 지정합니다. - 19
openshift-machine-api네임스페이스에 있는 사용자 데이터 YAML 파일에 시크릿 이름을 지정합니다. 설치 프로그램이 기본 시스템 세트에서 채우는 값을 사용합니다.- 21
- 머신을 배치할 리전 내 영역을 지정합니다. 해당 리전이 지정한 영역을 지원하는지 확인합니다.
- 22
- 사용자 워크로드가 인프라 노드에서 예약되지 않도록 테인트를 지정합니다.참고
인프라 노드에
NoSchedule테인트를 추가하면 해당 노드에서 실행 중인 기존 DNS Pod가잘못된 일정으로 표시됩니다.잘못된 예약DNS Pod에서 허용 오차를 삭제하거나 추가해야 합니다.
Alibaba Cloud 사용량 통계에 대한 머신 세트 매개변수
Alibaba Cloud 클러스터에 대해 설치 관리자가 생성하는 기본 머신 세트에는 Alibaba Cloud가 내부적으로 사용하는 nonessential 태그 값이 포함되어 있습니다. 이러한 태그는 spec.template.spec.providerSpec.value 목록의 securityGroups,tag, vSwitch 매개 변수에 채워집니다.
추가 머신을 배포하기 위해 머신 세트를 생성할 때 필요한 Kubernetes 태그를 포함해야 합니다. 생성하는 머신 세트에 지정되지 않은 경우에도 사용량 통계 태그가 기본적으로 적용됩니다. 필요에 따라 추가 태그를 추가할 수도 있습니다.
다음 YAML 스니펫은 기본 머신 세트의 태그가 선택 사항이며 필요한 태그를 나타냅니다.
spec.template.spec.providerSpec.value.securityGroups의 태그
spec:
template:
spec:
providerSpec:
value:
securityGroups:
- tags:
- Key: kubernetes.io/cluster/<infrastructure_id>
Value: owned
- Key: GISV
Value: ocp
- Key: sigs.k8s.io/cloud-provider-alibaba/origin
Value: ocp
- Key: Name
Value: <infrastructure_id>-sg-<role>
type: Tagsspec.template.spec.providerSpec.value.tag의 태그
spec:
template:
spec:
providerSpec:
value:
tag:
- Key: kubernetes.io/cluster/<infrastructure_id>
Value: owned
- Key: GISV
Value: ocp
- Key: sigs.k8s.io/cloud-provider-alibaba/origin
Value: ocpspec.template.spec.providerSpec.value.vSwitch의 태그
spec:
template:
spec:
providerSpec:
value:
vSwitch:
tags:
- Key: kubernetes.io/cluster/<infrastructure_id>
Value: owned
- Key: GISV
Value: ocp
- Key: sigs.k8s.io/cloud-provider-alibaba/origin
Value: ocp
- Key: Name
Value: <infrastructure_id>-vswitch-<zone>
type: Tags8.2.1.2. AWS에서 머신 세트 사용자 지정 리소스의 샘플 YAML
이 샘플 YAML은 us-east-1a AWS(Amazon Web Services) 영역에서 실행되는 머신 세트를 정의하고 node-role.kubernetes.io/infra: "" 로 레이블이 지정된 노드를 생성합니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <infra>는 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
name: <infrastructure_id>-infra-<zone>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra-<zone>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra-<zone>
spec:
metadata:
labels:
node-role.kubernetes.io/infra: ""
taints:
- key: node-role.kubernetes.io/infra
effect: NoSchedule
providerSpec:
value:
ami:
id: ami-046fe691f52a953f9
apiVersion: awsproviderconfig.openshift.io/v1beta1
blockDevices:
- ebs:
iops: 0
volumeSize: 120
volumeType: gp2
credentialsSecret:
name: aws-cloud-credentials
deviceIndex: 0
iamInstanceProfile:
id: <infrastructure_id>-worker-profile
instanceType: m6i.large
kind: AWSMachineProviderConfig
placement:
availabilityZone: <zone>
region: <region>
securityGroups:
- filters:
- name: tag:Name
values:
- <infrastructure_id>-worker-sg
subnet:
filters:
- name: tag:Name
values:
- <infrastructure_id>-private-<zone>
tags:
- name: kubernetes.io/cluster/<infrastructure_id>
value: owned
userDataSecret:
name: worker-user-data- 1 3 5 12 15 17
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID를 지정합니다. OpenShift CLI 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 4 8
- 인프라 ID,
<infra>노드 레이블 및 영역을 지정합니다. - 6 7 9
<infra>노드 레이블을 지정합니다.- 10
- 사용자 워크로드가 인프라 노드에서 예약되지 않도록 테인트를 지정합니다.참고
인프라 노드에
NoSchedule테인트를 추가하면 해당 노드에서 실행 중인 기존 DNS Pod가잘못된 일정으로 표시됩니다.잘못된 예약DNS Pod에서 허용 오차를 삭제하거나 추가해야 합니다. - 11
- OpenShift Container Platform 노드의 AWS(Amazon Web Services) 영역에 유효한 RHCOS(Red Hat Enterprise Linux CoreOS) AMI를 지정합니다. AWS Marketplace 이미지를 사용하려면 AWS Marketplace에서 OpenShift Container Platform 서브스크립션을 완료해야 리전의 AMI ID를 가져와야 합니다.
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.ami.id}{"\n"}' \ get machineset/<infrastructure_id>-worker-<zone> - 13
- 영역을 지정합니다(예:
us-east-1a). - 14
- 리전을 지정합니다(예:
us-east-1). - 16
- 인프라 ID 및 영역을 지정합니다.
AWS에서 실행되는 머신 세트는 보장되지 않는 Spot 인스턴스 를 지원합니다. AWS의 온 디맨드 인스턴스에 비해 저렴한 가격으로 Spot 인스턴스를 사용하여 비용을 절약할 수 있습니다. spotMarketOptions 를 MachineSet YAML 파일에 추가하여 Spot 인스턴스를 구성합니다.
8.2.1.3. Azure의 머신 세트사용자 지정 리소스에 대한 샘플 YAML
이 샘플 YAML은 리전의 1 Microsoft Azure 영역에서 실행되는 머신 세트를 정의하고 node-role.kubernetes.io/infra: "" 로 레이블이 지정된 노드를 만듭니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <infra>는 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
name: <infrastructure_id>-infra-<region>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra-<region>
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra-<region>
spec:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-machineset: <machineset_name>
node-role.kubernetes.io/infra: ""
providerSpec:
value:
apiVersion: azureproviderconfig.openshift.io/v1beta1
credentialsSecret:
name: azure-cloud-credentials
namespace: openshift-machine-api
image:
offer: ""
publisher: ""
resourceID: /resourceGroups/<infrastructure_id>-rg/providers/Microsoft.Compute/images/<infrastructure_id>
sku: ""
version: ""
internalLoadBalancer: ""
kind: AzureMachineProviderSpec
location: <region>
managedIdentity: <infrastructure_id>-identity
metadata:
creationTimestamp: null
natRule: null
networkResourceGroup: ""
osDisk:
diskSizeGB: 128
managedDisk:
storageAccountType: Premium_LRS
osType: Linux
publicIP: false
publicLoadBalancer: ""
resourceGroup: <infrastructure_id>-rg
sshPrivateKey: ""
sshPublicKey: ""
tags:
- name: <custom_tag_name>
value: <custom_tag_value>
subnet: <infrastructure_id>-<role>-subnet
userDataSecret:
name: worker-user-data
vmSize: Standard_D4s_v3
vnet: <infrastructure_id>-vnet
zone: "1"
taints:
- key: node-role.kubernetes.io/infra
effect: NoSchedule- 1 5 7 15 16 19 22
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID를 지정합니다. OpenShift CLI 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster다음 명령을 실행하여 서브넷을 가져올 수 있습니다.
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.subnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1다음 명령을 실행하여 vnet을 가져올 수 있습니다.
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.vnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1 - 2 3 8 9 11 20 21
<infra>노드 레이블을 지정합니다.- 4 6 10
- 인프라 ID,
<infra>노드 레이블 및 리전을 지정합니다. - 12
- 머신 세트의 이미지 세부 정보를 지정합니다. Azure Marketplace 이미지를 사용하려면 "Azure Marketplace 이미지 선택"을 참조하십시오.
- 13
- 인스턴스 유형과 호환되는 이미지를 지정합니다. 설치 프로그램에서 만든 Hyper-V 생성 V2 이미지에는
-gen2접미사가 있으며 V1 이미지는 접미사 없이 이름이 동일합니다. - 14
- 머신을 배치할 리전을 지정합니다.
- 23
- 머신을 배치할 리전 내 영역을 지정합니다. 해당 리전이 지정한 영역을 지원하는지 확인합니다.
- 17 18
- 선택 사항: 머신 세트에서 사용자 지정 태그를 지정합니다. 태그 이름을 <
custom_tag_name> 필드에 제공하고 해당 태그 값을 <custom_tag_value> 필드에 입력합니다. - 24
- 사용자 워크로드가 인프라 노드에서 예약되지 않도록 테인트를 지정합니다.참고
인프라 노드에
NoSchedule테인트를 추가하면 해당 노드에서 실행 중인 기존 DNS Pod가잘못된 일정으로 표시됩니다.잘못된 예약DNS Pod에서 허용 오차를 삭제하거나 추가해야 합니다.
Azure에서 실행되는 머신 세트는 보장되지 않는 Spot 가상 머신을 지원합니다. Azure의 표준 가상 머신에 비해 더 낮은 가격으로 Spot 가상 머신을 사용하여 비용을 절감할 수 있습니다. spot VMOptions 을 할 수 있습니다.
MachineSet YAML 파일에 추가하여 Spot 가상 머신을 구성
8.2.1.4. Azure Stack Hub에서 머신 세트 사용자 정의 리소스의 샘플 YAML
이 샘플 YAML은 리전의 1 Microsoft Azure 영역에서 실행되는 머신 세트를 정의하고 node-role.kubernetes.io/infra: "" 로 레이블이 지정된 노드를 만듭니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <infra>는 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
name: <infrastructure_id>-infra-<region>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra-<region>
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra-<region>
spec:
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/infra: ""
taints:
- key: node-role.kubernetes.io/infra
effect: NoSchedule
providerSpec:
value:
apiVersion: machine.openshift.io/v1beta1
availabilitySet: <availability_set>
credentialsSecret:
name: azure-cloud-credentials
namespace: openshift-machine-api
image:
offer: ""
publisher: ""
resourceID: /resourceGroups/<infrastructure_id>-rg/providers/Microsoft.Compute/images/<infrastructure_id>
sku: ""
version: ""
internalLoadBalancer: ""
kind: AzureMachineProviderSpec
location: <region>
managedIdentity: <infrastructure_id>-identity
metadata:
creationTimestamp: null
natRule: null
networkResourceGroup: ""
osDisk:
diskSizeGB: 128
managedDisk:
storageAccountType: Premium_LRS
osType: Linux
publicIP: false
publicLoadBalancer: ""
resourceGroup: <infrastructure_id>-rg
sshPrivateKey: ""
sshPublicKey: ""
subnet: <infrastructure_id>-<role>-subnet
userDataSecret:
name: worker-user-data
vmSize: Standard_DS4_v2
vnet: <infrastructure_id>-vnet
zone: "1" - 1 5 7 14 16 17 18 21
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID를 지정합니다. OpenShift CLI 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster다음 명령을 실행하여 서브넷을 가져올 수 있습니다.
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.subnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1다음 명령을 실행하여 vnet을 가져올 수 있습니다.
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.vnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1 - 2 3 8 9 11 19 20
<infra>노드 레이블을 지정합니다.- 4 6 10
- 인프라 ID,
<infra>노드 레이블 및 리전을 지정합니다. - 12
- 사용자 워크로드가 인프라 노드에서 예약되지 않도록 테인트를 지정합니다.참고
인프라 노드에
NoSchedule테인트를 추가하면 해당 노드에서 실행 중인 기존 DNS Pod가잘못된 일정으로 표시됩니다.잘못된 예약DNS Pod에서 허용 오차를 삭제하거나 추가해야 합니다. - 15
- 머신을 배치할 리전을 지정합니다.
- 13
- 클러스터의 가용성 세트를 지정합니다.
- 22
- 머신을 배치할 리전 내 영역을 지정합니다. 해당 리전이 지정한 영역을 지원하는지 확인합니다.
Azure Stack Hub에서 실행되는 머신 세트는 보장되지 않는 Spot 가상 머신을 지원하지 않습니다.
8.2.1.5. IBM Cloud에서 머신 세트 사용자 정의 리소스의 샘플 YAML
이 샘플 YAML은 리전의 지정된 IBM Cloud 영역에서 실행되는 머신 세트를 정의하고 node-role.kubernetes.io/infra: "" 로 레이블이 지정된 노드를 만듭니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <infra>는 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
name: <infrastructure_id>-<infra>-<region>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<infra>-<region>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<infra>-<region>
spec:
metadata:
labels:
node-role.kubernetes.io/infra: ""
providerSpec:
value:
apiVersion: ibmcloudproviderconfig.openshift.io/v1beta1
credentialsSecret:
name: ibmcloud-credentials
image: <infrastructure_id>-rhcos
kind: IBMCloudMachineProviderSpec
primaryNetworkInterface:
securityGroups:
- <infrastructure_id>-sg-cluster-wide
- <infrastructure_id>-sg-openshift-net
subnet: <infrastructure_id>-subnet-compute-<zone>
profile: <instance_profile>
region: <region>
resourceGroup: <resource_group>
userDataSecret:
name: <role>-user-data
vpc: <vpc_name>
zone: <zone>
taints:
- key: node-role.kubernetes.io/infra
effect: NoSchedule- 1 5 7
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID입니다. OpenShift CLI 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 8 9 16
- <
;infra> 노드 레이블입니다. - 4 6 10
- 인프라 ID, <
;infra> 노드 레이블 및 리전입니다. - 11
- 클러스터 설치에 사용된 사용자 지정 RHCOS(Red Hat Enterprise Linux CoreOS) 이미지입니다.
- 12
- 머신을 배치할 리전 내 인프라 ID 및 영역입니다. 해당 리전이 지정한 영역을 지원하는지 확인합니다.
- 13
- IBM Cloud 인스턴스 프로필을 지정합니다.
- 14
- 머신을 배치할 리전을 지정합니다.
- 15
- 머신 리소스가 배치되는 리소스 그룹입니다. 이는 설치 시 지정된 기존 리소스 그룹 또는 인프라 ID를 기반으로 이름이 지정된 설치 관리자 생성 리소스 그룹입니다.
- 17
- VPC 이름입니다.
- 18
- 머신을 배치할 리전 내 영역을 지정합니다. 해당 리전이 지정한 영역을 지원하는지 확인합니다.
- 19
- 사용자 워크로드가 인프라 노드에 예약되지 않도록 하는 테인트입니다.참고
인프라 노드에
NoSchedule테인트를 추가하면 해당 노드에서 실행 중인 기존 DNS Pod가잘못된 일정으로 표시됩니다.잘못된 예약DNS Pod에서 허용 오차를 삭제하거나 추가해야 합니다.
8.2.1.6. GCP에서 머신 세트 사용자 정의 리소스의 샘플 YAML
이 샘플 YAML은 GCP(Google Cloud Platform)에서 실행되는 머신 세트를 정의하고 node-role.kubernetes.io/infra: ""로 레이블이 지정된 노드를 생성합니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <infra>는 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
name: <infrastructure_id>-w-a
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-w-a
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-w-a
spec:
metadata:
labels:
node-role.kubernetes.io/infra: ""
providerSpec:
value:
apiVersion: gcpprovider.openshift.io/v1beta1
canIPForward: false
credentialsSecret:
name: gcp-cloud-credentials
deletionProtection: false
disks:
- autoDelete: true
boot: true
image: <path_to_image>
labels: null
sizeGb: 128
type: pd-ssd
gcpMetadata:
- key: <custom_metadata_key>
value: <custom_metadata_value>
kind: GCPMachineProviderSpec
machineType: n1-standard-4
metadata:
creationTimestamp: null
networkInterfaces:
- network: <infrastructure_id>-network
subnetwork: <infrastructure_id>-worker-subnet
projectID: <project_name>
region: us-central1
serviceAccounts:
- email: <infrastructure_id>-w@<project_name>.iam.gserviceaccount.com
scopes:
- https://www.googleapis.com/auth/cloud-platform
tags:
- <infrastructure_id>-worker
userDataSecret:
name: worker-user-data
zone: us-central1-a
taints:
- key: node-role.kubernetes.io/infra
effect: NoSchedule- 1
- &
lt;infrastructure_id>의 경우 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 인프라 ID를 지정합니다. OpenShift CLI 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2
- <
;infra> 의 경우 <infra>노드 레이블을 지정합니다. - 3
- 현재 머신 세트에서 사용되는 이미지의 경로를 지정합니다. OpenShift CLI가 설치되어 있으면 다음 명령을 실행하여 이미지에 대한 경로를 얻을 수 있습니다.
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.disks[0].image}{"\n"}' \ get machineset/<infrastructure_id>-worker-aGCP Marketplace 이미지를 사용하려면 사용할 오퍼를 지정합니다.
-
OpenShift Container Platform:
https://www.googleapis.com/compute/v1/projects/redhat-marketplace-public/global/images/redhat-coreos-ocp-48-x86-64-202210040145 -
OpenShift Platform Plus:
https://www.googleapis.com/compute/v1/projects/redhat-marketplace-public/global/images/redhat-coreos-opp-48-x86-64-202206140145 -
OpenShift Kubernetes Engine:
https://www.googleapis.com/compute/v1/projects/redhat-marketplace-public/global/images/redhat-coreos-oke-48-x86-64-202206140145
-
OpenShift Container Platform:
- 4
- 선택 사항:
키:값쌍의 형태로 사용자 지정 메타데이터를 지정합니다. 예를 들어 사용자 정의 메타데이터 설정에 대한 GCP 설명서를 참조하십시오. - 5
- &
lt;project_name>에 대해 클러스터에 사용하는 GCP 프로젝트의 이름을 지정합니다. - 6
- 사용자 워크로드가 인프라 노드에서 예약되지 않도록 테인트를 지정합니다.참고
인프라 노드에
NoSchedule테인트를 추가하면 해당 노드에서 실행 중인 기존 DNS Pod가잘못된 일정으로 표시됩니다.잘못된 예약DNS Pod에서 허용 오차를 삭제하거나 추가해야 합니다.
GCP에서 실행되는 머신 세트는 보장되지 않은 선점 가능한 가상 머신 인스턴스를 지원합니다. GCP의 일반 인스턴스에 비해 더 낮은 가격으로 선점 가능한 가상 머신 인스턴스를 사용하여 비용을 절감할 수 있습니다. MachineSet YAML 파일에 preemptible 을 추가하여 선점 가능한 가상 머신 인스턴스를 구성 할 수 있습니다.
8.2.1.7. Nutanix에서 머신 세트 사용자 정의 리소스의 샘플 YAML
이 샘플 YAML은 node-role.kubernetes.io/infra: "" 로 레이블이 지정된 노드를 생성하는 Nutanix 머신 세트를 정의합니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <infra>는 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
name: <infrastructure_id>-<infra>-<zone>
namespace: openshift-machine-api
annotations:
machine.openshift.io/memoryMb: "16384"
machine.openshift.io/vCPU: "4"
spec:
replicas: 3
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<infra>-<zone>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<infra>-<zone>
spec:
metadata:
labels:
node-role.kubernetes.io/infra: ""
providerSpec:
value:
apiVersion: machine.openshift.io/v1
cluster:
type: uuid
uuid: <cluster_uuid>
credentialsSecret:
name: nutanix-credentials
image:
name: <infrastructure_id>-rhcos
type: name
kind: NutanixMachineProviderConfig
memorySize: 16Gi
subnets:
- type: uuid
uuid: <subnet_uuid>
systemDiskSize: 120Gi
userDataSecret:
name: <user_data_secret>
vcpuSockets: 4
vcpusPerSocket: 1
taints:
- key: node-role.kubernetes.io/infra
effect: NoSchedule- 1 6 8
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID를 지정합니다. OpenShift CLI (
oc) 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 9 10
<infra>노드 레이블을 지정합니다.- 4 7 11
- 인프라 ID,
<infra>노드 레이블 및 영역을 지정합니다. - 5
- 클러스터 자동 스케일러의 주석입니다.
- 12
- 사용할 이미지를 지정합니다. 클러스터의 기존 기본 시스템 세트의 이미지를 사용합니다.
- 13
- Gi에서 클러스터의 메모리 양을 지정합니다.
- 14
- Gi에서 시스템 디스크의 크기를 지정합니다.
- 15
openshift-machine-api네임스페이스에 있는 사용자 데이터 YAML 파일에 시크릿 이름을 지정합니다. 설치 프로그램이 기본 시스템 세트에서 채우는 값을 사용합니다.- 16
- vCPU 소켓 수를 지정합니다.
- 17
- 소켓당 vCPU 수를 지정합니다.
- 18
- 사용자 워크로드가 인프라 노드에서 예약되지 않도록 테인트를 지정합니다.참고
인프라 노드에
NoSchedule테인트를 추가하면 해당 노드에서 실행 중인 기존 DNS Pod가잘못된 일정으로 표시됩니다.잘못된 예약DNS Pod에서 허용 오차를 삭제하거나 추가해야 합니다.
8.2.1.8. RHOSP에서 머신 세트 사용자 정의 리소스의 샘플 YAML
이 샘플 YAML은 RHOSP(Red Hat OpenStack Platform)에서 실행되는 머신 세트를 정의하고 node-role.kubernetes.io/infra: "" 로 레이블이 지정된 노드를 생성합니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <infra>는 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
name: <infrastructure_id>-infra
namespace: openshift-machine-api
spec:
replicas: <number_of_replicas>
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra
spec:
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/infra: ""
taints:
- key: node-role.kubernetes.io/infra
effect: NoSchedule
providerSpec:
value:
apiVersion: openstackproviderconfig.openshift.io/v1alpha1
cloudName: openstack
cloudsSecret:
name: openstack-cloud-credentials
namespace: openshift-machine-api
flavor: <nova_flavor>
image: <glance_image_name_or_location>
serverGroupID: <optional_UUID_of_server_group>
kind: OpenstackProviderSpec
networks:
- filter: {}
subnets:
- filter:
name: <subnet_name>
tags: openshiftClusterID=<infrastructure_id>
primarySubnet: <rhosp_subnet_UUID>
securityGroups:
- filter: {}
name: <infrastructure_id>-worker
serverMetadata:
Name: <infrastructure_id>-worker
openshiftClusterID: <infrastructure_id>
tags:
- openshiftClusterID=<infrastructure_id>
trunk: true
userDataSecret:
name: worker-user-data
availabilityZone: <optional_openstack_availability_zone>- 1 5 7 14 16 17 18 19
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID를 지정합니다. OpenShift CLI 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 8 9 20
<infra>노드 레이블을 지정합니다.- 4 6 10
- 인프라 ID 및
<infra>노드 레이블을 지정합니다. - 11
- 사용자 워크로드가 인프라 노드에서 예약되지 않도록 테인트를 지정합니다.참고
인프라 노드에
NoSchedule테인트를 추가하면 해당 노드에서 실행 중인 기존 DNS Pod가잘못된 일정으로 표시됩니다.잘못된 예약DNS Pod에서 허용 오차를 삭제하거나 추가해야 합니다. - 12
- MachineSet의 서버 그룹 정책을 설정하려면, 서버 그룹 생성에서 반환된 값을 입력합니다. 대부분의 배포에는
anti-affinity또는soft-anti-affinity정책이 권장됩니다. - 13
- 여러 네트워크에 배포해야 합니다. 여러 네트워크에 배포하는 경우 이 목록에는
primarySubnet값으로 사용되는 네트워크를 포함해야 합니다. - 15
- 노드 엔드포인트를 게시할 RHOSP 서브넷을 지정합니다. 일반적으로 이 서브넷은
install-config.yaml파일에서machineSubnet값으로 사용되는 서브넷과 동일합니다.
8.2.1.9. RHV에서 머신 세트 사용자 정의 리소스의 샘플 YAML
이 샘플 YAML은 RHV에서 실행되는 머신 세트를 정의하고 node-role.kubernetes.io/<role>: ""로 레이블이 지정된 노드를 만듭니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <role>은 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
name: <infrastructure_id>-<role>
namespace: openshift-machine-api
spec:
replicas: <number_of_replicas>
Selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: ovirtproviderconfig.machine.openshift.io/v1beta1
cluster_id: <ovirt_cluster_id>
template_name: <ovirt_template_name>
sparse: <boolean_value>
format: <raw_or_cow>
cpu:
sockets: <number_of_sockets>
cores: <number_of_cores>
threads: <number_of_threads>
memory_mb: <memory_size>
guaranteed_memory_mb: <memory_size>
os_disk:
size_gb: <disk_size>
storage_domain_id: <storage_domain_UUID>
network_interfaces:
vnic_profile_id: <vnic_profile_id>
credentialsSecret:
name: ovirt-credentials
kind: OvirtMachineProviderSpec
type: <workload_type>
auto_pinning_policy: <auto_pinning_policy>
hugepages: <hugepages>
affinityGroupsNames:
- compute
userDataSecret:
name: worker-user-data- 1 7 9
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID를 지정합니다. OpenShift CLI (
oc) 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 10 11 13
- 추가할 노드 레이블을 지정합니다.
- 4 8 12
- 인프라 ID 및 노드 레이블을 지정합니다. 이 두 문자열은 35자를 초과할 수 없습니다.
- 5
- 생성할 머신 수를 지정합니다.
- 6
- 머신의 선택기입니다.
- 14
- 이 VM 인스턴스가 속하는 RHV 클러스터의 UUID를 지정합니다.
- 15
- 머신을 생성하는 데 사용할 RHV VM 템플릿을 지정합니다.
- 16
- 이 옵션을
false로 설정하면 디스크 사전 할당이 가능합니다. 기본값은true입니다.format을raw로 설정하여sparse를true로 설정하는 것은 블록 스토리지 도메인에서 사용할 수 없습니다.원시형식은 전체 가상 디스크를 기본 물리적 디스크에 씁니다. - 17
소또는 초로 설정할 수있습니다. 기본값은 Hus입니다.소형식은 가상 머신에 최적화되어 있습니다.참고파일 스토리지 도메인의 디스크를 사전 할당하면 0이 파일에 씁니다. 실제로 기본 스토리지에 따라 디스크를 사전 할당하지 못할 수 있습니다.
- 18
- 선택 사항: CPU 필드에 소켓, 코어 및 스레드를 포함한 CPU 구성이 포함되어 있습니다.
- 19
- 선택 사항: VM의 소켓 수를 지정합니다.
- 20
- 선택 사항: 소켓당 코어 수를 지정합니다.
- 21
- 선택 사항: 코어당 스레드 수를 지정합니다.
- 22
- 선택 사항: VM의 메모리 크기를 MiB로 지정합니다.
- 23
- 선택 사항: 가상 머신의 보장된 메모리 크기를 MiB 단위로 지정합니다. 이는 풍선 메커니즘에 의해 드레인되지 않도록 하는 메모리 양입니다. 자세한 내용은 Memory Ballooning and Optimization Settings Explained 항목을 참조하십시오.참고
RHV 4.4.8 이전 버전을 사용하는 경우 Red Hat Virtualization 클러스터에서 OpenShift에 대한 보장 메모리 요구 사항을 참조하십시오.
- 24
- 선택사항: 노드의 루트 디스크입니다.
- 25
- 선택사항: 부팅 가능한 디스크 크기를 GiB로 지정합니다.
- 26
- 선택 사항: 컴퓨팅 노드의 디스크에 대한 스토리지 도메인의 UUID를 지정합니다. 제공되지 않는 경우 compute 노드는 제어 노드와 동일한 스토리지 도메인에 생성됩니다. (기본값)
- 27
- 선택사항: VM의 네트워크 인터페이스 목록입니다. 이 매개변수를 포함하는 경우 OpenShift Container Platform은 템플릿에서 모든 네트워크 인터페이스를 삭제하고 새 네트워크 인터페이스를 생성합니다.
- 28
- 선택사항: vNIC 프로필 ID를 지정합니다.
- 29
- RHV 인증 정보를 보유한 보안 오브젝트의 이름을 지정합니다.
- 30
- 선택 사항: 인스턴스가 최적화된 워크로드 유형을 지정합니다. 이 값은
RHV VM매개변수에 영향을 미칩니다. 지원되는 값은desktop,server(기본값),high_performance입니다.high_performance는 VM의 성능을 향상시킵니다. 예를 들어 제한 사항이 있는 경우 그래픽 콘솔을 사용하여 VM에 액세스할 수 없습니다. 자세한 내용은 가상 머신 관리 가이드에서 고성능 가상 머신, 템플릿 및 풀 구성을 참조하십시오. - 31
- 선택 사항: AutoPinningPolicy는 이 인스턴스의 호스트에 고정을 포함하여 CPU 및 NUMA 설정을 자동으로 설정하는 정책을 정의합니다. 지원되는 값:
none,resize_and_pin. 자세한 내용은 가상 머신 관리 가이드에서 NUMA 노드 설정을 참조하십시오. - 32
- 선택 사항: Hugepages는 VM에서 hugepages를 정의하는 KiB 크기입니다. 지원되는 값:
2048또는1048576. 자세한 내용은 가상 머신 관리 가이드에서 Huge Pages 구성을 참조하십시오. - 33
- 선택 사항: VM에 적용할 선호도 그룹 이름 목록입니다. 선호도 그룹은 oVirt에 있어야 합니다.
RHV는 VM을 생성할 때 템플릿을 사용하므로 선택적 매개변수에 대한 값을 지정하지 않으면 RHV는 템플릿에 지정된 해당 매개변수의 값을 사용합니다.
8.2.1.10. vSphere에서 머신 세트 사용자 정의 리소스의 샘플 YAML
이 샘플 YAML은 VMware vSphere에서 실행되는 머신 세트를 정의하고 node-role.kubernetes.io/infra: "" 로 레이블이 지정된 노드를 만듭니다.
이 샘플에서 <infrastructure_id>는 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID 레이블이며 <infra>는 추가할 노드 레이블입니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
name: <infrastructure_id>-infra
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra
spec:
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/infra: ""
taints:
- key: node-role.kubernetes.io/infra
effect: NoSchedule
providerSpec:
value:
apiVersion: vsphereprovider.openshift.io/v1beta1
credentialsSecret:
name: vsphere-cloud-credentials
diskGiB: 120
kind: VSphereMachineProviderSpec
memoryMiB: 8192
metadata:
creationTimestamp: null
network:
devices:
- networkName: "<vm_network_name>"
numCPUs: 4
numCoresPerSocket: 1
snapshot: ""
template: <vm_template_name>
userDataSecret:
name: worker-user-data
workspace:
datacenter: <vcenter_datacenter_name>
datastore: <vcenter_datastore_name>
folder: <vcenter_vm_folder_path>
resourcepool: <vsphere_resource_pool>
server: <vcenter_server_ip> - 1 3 5
- 클러스터를 프로비저닝할 때 설정한 클러스터 ID를 기반으로 하는 인프라 ID를 지정합니다. OpenShift CLI (
oc) 패키지가 설치되어 있으면 다음 명령을 실행하여 인프라 ID를 얻을 수 있습니다.$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 4 8
- 인프라 ID 및
<infra>노드 레이블을 지정합니다. - 6 7 9
<infra>노드 레이블을 지정합니다.- 10
- 사용자 워크로드가 인프라 노드에서 예약되지 않도록 테인트를 지정합니다.참고
인프라 노드에
NoSchedule테인트를 추가하면 해당 노드에서 실행 중인 기존 DNS Pod가잘못된 일정으로 표시됩니다.잘못된 예약DNS Pod에서 허용 오차를 삭제하거나 추가해야 합니다. - 11
- 머신 세트를 배포할 vSphere VM 네트워크를 지정합니다. 이 VM 네트워크는 다른 컴퓨팅 시스템이 클러스터에 있는 위치여야 합니다.
- 12
- 사용할 vSphere VM 템플릿 (예:
user-5ddjd-rhcos)을 지정합니다. - 13
- 머신 세트를 배포할 vCenter Datacenter를 지정합니다.
- 14
- 머신 세트를 배포할 vCenter Datastore를 지정합니다.
- 15
- vCenter의 vSphere VM 폴더에 경로(예:
/dc1/vm/user-inst-5ddjd)를 지정합니다. - 16
- VM의 vSphere 리소스 풀을 지정합니다.
- 17
- vCenter 서버 IP 또는 정규화된 도메인 이름을 지정합니다.
8.2.2. 머신 세트 만들기
설치 프로그램에서 생성한 컴퓨팅 머신 세트 외에도 고유한 머신 세트를 생성하여 선택한 특정 워크로드의 머신 컴퓨팅 리소스를 동적으로 관리할 수 있습니다.
전제 조건
- OpenShift Container Platform 클러스터를 배포합니다.
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다.
프로세스
머신 세트 CR(사용자 지정 리소스) 샘플이 포함된 이름이
<file_name>.yaml인 새 YAML 파일을 만듭니다.<clusterID>및<role>매개 변수 값을 설정해야 합니다.선택 사항: 특정 필드에 설정할 값이 확실하지 않은 경우 클러스터에서 기존 컴퓨팅 머신 세트를 확인할 수 있습니다.
클러스터의 컴퓨팅 머신 세트를 나열하려면 다음 명령을 실행합니다.
$ oc get machinesets -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m특정 컴퓨팅 머신 세트 CR(사용자 정의 리소스)의 값을 보려면 다음 명령을 실행합니다.
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml출력 예
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
다음 명령을 실행하여
MachineSetCR을 생성합니다.$ oc create -f <file_name>.yaml
검증
다음 명령을 실행하여 컴퓨팅 머신 세트 목록을 확인합니다.
$ oc get machineset -n openshift-machine-api출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m새 머신 세트가 사용 가능한 경우
DESIRED및CURRENT값이 일치합니다. 머신 세트를 사용할 수 없는 경우 몇 분 후에 명령을 다시 실행합니다.
8.2.3. 인프라 노드 생성
설치 관리자 프로비저닝 인프라 환경 또는 머신 API에서 컨트롤 플레인 노드를 관리하는 클러스터의 인프라 머신 세트 생성을 참조하십시오.
클러스터의 요구 사항은 infra 노드라고도 불리는 인프라를 프로비저닝해야 합니다. 설치 프로그램은 컨트롤 플레인 및 작업자 노드에 대한 프로비저닝만 제공합니다. 작업자 노드는 레이블을 통해 인프라 노드 또는 애플리케이션 ( app, app 이라고도 함)으로 지정할 수 있습니다.
프로세스
애플리케이션 노드 역할을 수행할 작업자 노드에 레이블을 추가합니다.
$ oc label node <node-name> node-role.kubernetes.io/app=""인프라 노드 역할을 수행할 작업자 노드에 레이블을 추가합니다.
$ oc label node <node-name> node-role.kubernetes.io/infra=""해당 노드에
infra역할 및app역할이 있는지 확인합니다.$ oc get nodes기본 클러스터 수준 노드 선택기를 생성합니다. 기본 노드 선택기는 모든 네임스페이스에서 생성된 Pod에 적용됩니다. 이렇게 하면 Pod의 기존 노드 선택기와 교차점이 생성되어 Pod의 선택기가 추가로 제한됩니다.
중요기본 노드 선택기 키가 Pod 라벨 키와 충돌하는 경우 기본 노드 선택기가 적용되지 않습니다.
그러나 Pod를 예약할 수 없게 만들 수 있는 기본 노드 선택기를 설정하지 마십시오. 예를 들어 Pod의 라벨이
node-role.kubernetes.io/master=""와 같은 다른 노드 역할로 설정된 경우 기본 노드 선택기를node-role.kubernetes.io/infra=""와 같은 특정 노드 역할로 설정하면 Pod를 예약할 수 없게 될 수 있습니다. 따라서 기본 노드 선택기를 특정 노드 역할로 설정할 때 주의해야 합니다.또는 프로젝트 노드 선택기를 사용하여 클러스터 수준 노드 선택기 키 충돌을 방지할 수 있습니다.
Scheduler오브젝트를 편집합니다.$ oc edit scheduler cluster적절한 노드 선택기를 사용하여
defaultNodeSelector필드를 추가합니다.apiVersion: config.openshift.io/v1 kind: Scheduler metadata: name: cluster spec: defaultNodeSelector: topology.kubernetes.io/region=us-east-11 # ...- 1
- 이 예제 노드 선택기는 기본적으로
us-east-1리전의 노드에 Pod를 배포합니다.
- 파일을 저장하여 변경 사항을 적용합니다.
인프라 리소스를 새로 레이블이 지정된 인프라 노드로 이동할 수 있습니다.
8.2.4. 인프라 머신의 머신 구성 풀 생성
전용 구성을 위한 인프라 머신이 필요한 경우 인프라 풀을 생성해야 합니다.
프로세스
특정 레이블이 있는 인프라 노드로 할당하려는 노드에 레이블을 추가합니다.
$ oc label node <node_name> <label>$ oc label node ci-ln-n8mqwr2-f76d1-xscn2-worker-c-6fmtx node-role.kubernetes.io/infra=작업자 역할과 사용자 지정 역할을 모두 포함하는 머신 구성 풀을 머신 구성 선택기로 생성합니다.
$ cat infra.mcp.yaml출력 예
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: infra spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,infra]}1 nodeSelector: matchLabels: node-role.kubernetes.io/infra: ""2 참고사용자 지정 머신 구성 풀은 작업자 풀의 머신 구성을 상속합니다. 사용자 지정 풀은 작업자 풀을 대상으로 하는 머신 구성을 사용하지만 사용자 지정 풀을 대상으로 하는 변경 사항만 배포할 수 있는 기능을 추가합니다. 사용자 지정 풀은 작업자 풀에서 리소스를 상속하므로 작업자 풀을 변경하면 사용자 지정 풀에도 영향을 줍니다.
YAML 파일이 있으면 머신 구성 풀을 생성할 수 있습니다.
$ oc create -f infra.mcp.yaml머신 구성을 확인하고 인프라 구성이 성공적으로 렌더링되었는지 확인합니다.
$ oc get machineconfig출력 예
NAME GENERATEDBYCONTROLLER IGNITIONVERSION CREATED 00-master 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 00-worker 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-master-container-runtime 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-master-kubelet 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-worker-container-runtime 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-worker-kubelet 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 99-master-1ae2a1e0-a115-11e9-8f14-005056899d54-registries 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 99-master-ssh 3.2.0 31d 99-worker-1ae64748-a115-11e9-8f14-005056899d54-registries 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 99-worker-ssh 3.2.0 31d rendered-infra-4e48906dca84ee702959c71a53ee80e7 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 23m rendered-master-072d4b2da7f88162636902b074e9e28e 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-master-3e88ec72aed3886dec061df60d16d1af 02c07496ba0417b3e12b78fb32baf6293d314f79 3.2.0 31d rendered-master-419bee7de96134963a15fdf9dd473b25 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 17d rendered-master-53f5c91c7661708adce18739cc0f40fb 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 13d rendered-master-a6a357ec18e5bce7f5ac426fc7c5ffcd 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 7d3h rendered-master-dc7f874ec77fc4b969674204332da037 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-worker-1a75960c52ad18ff5dfa6674eb7e533d 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-worker-2640531be11ba43c61d72e82dc634ce6 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-worker-4e48906dca84ee702959c71a53ee80e7 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 7d3h rendered-worker-4f110718fe88e5f349987854a1147755 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 17d rendered-worker-afc758e194d6188677eb837842d3b379 02c07496ba0417b3e12b78fb32baf6293d314f79 3.2.0 31d rendered-worker-daa08cc1e8f5fcdeba24de60cd955cc3 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 13drendered-infra-*접두사가 있는 새 머신 구성이 표시되어야 합니다.선택 사항: 사용자 지정 풀에 변경 사항을 배포하려면
infra와 같은 사용자 지정 풀 이름을 레이블로 사용하는 머신 구성을 생성합니다. 필수 사항은 아니며 지침 용도로만 표시됩니다. 이렇게 하면 인프라 노드에 고유한 사용자 지정 구성을 적용할 수 있습니다.참고새 머신 구성 풀을 생성한 후 MCO는 해당 풀에 대해 새로 렌더링된 구성과 해당 풀의 관련 노드를 다시 부팅하여 새 구성을 적용합니다.
머신 구성을 생성합니다.
$ cat infra.mc.yaml출력 예
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: name: 51-infra labels: machineconfiguration.openshift.io/role: infra1 spec: config: ignition: version: 3.2.0 storage: files: - path: /etc/infratest mode: 0644 contents: source: data:,infra- 1
- 노드에 추가한 레이블을
nodeSelector로 추가합니다.
머신 구성을 인프라 레이블 노드에 적용합니다.
$ oc create -f infra.mc.yaml
새 머신 구성 풀을 사용할 수 있는지 확인합니다.
$ oc get mcp출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE infra rendered-infra-60e35c2e99f42d976e084fa94da4d0fc True False False 1 1 1 0 4m20s master rendered-master-9360fdb895d4c131c7c4bebbae099c90 True False False 3 3 3 0 91m worker rendered-worker-60e35c2e99f42d976e084fa94da4d0fc True False False 2 2 2 0 91m이 예에서는 작업자 노드가 인프라 노드로 변경되었습니다.
8.3. 인프라 노드에 머신 세트 리소스 할당
인프라 머신 세트를 생성 한 후 worker 및 infra 역할이 새 인프라 노드에 적용됩니다. infra 역할이 적용된 노드는 worker 역할이 적용된 경우에도 환경을 실행하는 데 필요한 총 서브스크립션 수에 포함되지 않습니다.
그러나 인프라 노드가 작업자로 할당되면 사용자 워크로드가 실수로 인프라 노드에 할당될 수 있습니다. 이를 방지하려면 제어하려는 pod에 대한 허용 오차를 적용하고 인프라 노드에 테인트를 적용할 수 있습니다.
8.3.1. 테인트 및 허용 오차를 사용하여 인프라 노드 워크로드 바인딩
infra 및 worker 역할이 할당된 인프라 노드가 있는 경우 사용자 워크로드가 할당되지 않도록 노드를 구성해야 합니다.
인프라 노드에 대해 생성된 이중 infra,worker 레이블을 유지하고 테인트 및 허용 오차를 사용하여 사용자 워크로드가 예약된 노드를 관리하는 것이 좋습니다. 노드에서 worker 레이블을 제거하는 경우 이를 관리할 사용자 지정 풀을 생성해야 합니다. master 또는 worker 이외의 레이블이 있는 노드는 사용자 지정 풀없이 MCO에서 인식되지 않습니다. worker 레이블을 유지 관리하면 사용자 정의 레이블을 선택하는 사용자 정의 풀이 없는 경우 기본 작업자 머신 구성 풀에서 노드를 관리할 수 있습니다. infra 레이블은 총 서브스크립션 수에 포함되지 않는 클러스터와 통신합니다.
사전 요구 사항
-
OpenShift Container Platform 클러스터에서 추가
MachineSet개체를 구성합니다.
절차
인프라 노드에 테인트를 추가하여 사용자 워크로드를 예약하지 않도록합니다.
노드에 테인트가 있는지 확인합니다.
$ oc describe nodes <node_name>샘플 출력
oc describe node ci-ln-iyhx092-f76d1-nvdfm-worker-b-wln2l Name: ci-ln-iyhx092-f76d1-nvdfm-worker-b-wln2l Roles: worker ... Taints: node-role.kubernetes.io/infra:NoSchedule ...이 예에서는 노드에 테인트가 있음을 보여줍니다. 다음 단계에서 Pod에 허용 오차를 추가할 수 있습니다.
사용자 워크로드를 예약하지 않도록 테인트를 구성하지 않은 경우 다음을 수행합니다.
$ oc adm taint nodes <node_name> <key>=<value>:<effect>예를 들면 다음과 같습니다.
$ oc adm taint nodes node1 node-role.kubernetes.io/infra=reserved:NoExecute작은 정보다음 YAML을 적용하여 테인트를 추가할 수도 있습니다.
kind: Node apiVersion: v1 metadata: name: <node_name> labels: ... spec: taints: - key: node-role.kubernetes.io/infra effect: NoExecute value: reserved ...이 예에서는 키
node-role.kubernetes.io/infra및 taint 효과NoSchedule이 있는node1에 taint를 배치합니다.NoSchedule효과가 있는 노드는 taint를 허용하는 pod만 예약하지만 기존 pod는 노드에서 예약된 상태를 유지할 수 있습니다.참고descheduler를 사용하면 노드 taint를 위반하는 pod가 클러스터에서 제거될 수 있습니다.
라우터, 레지스트리 및 모니터링 워크로드와 같이 인프라 노드에서 예약하려는 pod 구성에 대한 허용 오차를 추가합니다. 다음 코드를
Pod개체 사양에 추가합니다.tolerations: - effect: NoExecute1 key: node-role.kubernetes.io/infra2 operator: Exists3 value: reserved4 이 허용 오차는
oc adm taint명령으로 생성된 taint와 일치합니다. 이 허용 오차가 있는 pod를 인프라 노드에 예약할 수 있습니다.참고OLM을 통해 설치된 Operator의 pod를 인프라 노드로 이동할 수는 없습니다. Operator pod를 이동하는 기능은 각 Operator의 구성에 따라 다릅니다.
- 스케줄러를 사용하여 pod를 인프라 노드에 예약합니다. 자세한 내용은 노드에서 pod 배치 제어에 대한 설명서를 참조하십시오.
8.4. 인프라 머신 세트로 리소스 이동
일부 인프라 리소스는 기본적으로 클러스터에 배포됩니다. 다음과 같이 인프라 노드 선택기를 추가하여 생성한 인프라 머신 세트로 이동할 수 있습니다.
spec:
nodePlacement:
nodeSelector:
matchLabels:
node-role.kubernetes.io/infra: ""
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/infra
value: reserved
- effect: NoExecute
key: node-role.kubernetes.io/infra
value: reserved- 1
- 적절한 값이 설정된
nodeSelector매개변수를 이동하려는 구성 요소에 추가합니다. 표시된 형식으로nodeSelector를 사용하거나 노드에 지정된 값에 따라<key>: <value>쌍을 사용할 수 있습니다. 인프라 노드에 테인트를 추가한 경우 일치하는 톨러레이션도 추가합니다.
모든 인프라 구성 요소에 특정 노드 선택기를 적용하면 OpenShift Container Platform에서 해당 라벨을 사용하여 노드에서 해당 워크로드를 예약 합니다.
8.4.1. 라우터 이동
라우터 Pod를 다른 머신 세트에 배포할 수 있습니다. 기본적으로 Pod는 작업자 노드에 배포됩니다.
사전 요구 사항
- OpenShift Container Platform 클러스터에서 추가 머신 세트를 구성합니다.
절차
라우터 Operator의
IngressController사용자 정의 리소스를 표시합니다.$ oc get ingresscontroller default -n openshift-ingress-operator -o yaml명령 출력은 다음 예제와 유사합니다.
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: creationTimestamp: 2019-04-18T12:35:39Z finalizers: - ingresscontroller.operator.openshift.io/finalizer-ingresscontroller generation: 1 name: default namespace: openshift-ingress-operator resourceVersion: "11341" selfLink: /apis/operator.openshift.io/v1/namespaces/openshift-ingress-operator/ingresscontrollers/default uid: 79509e05-61d6-11e9-bc55-02ce4781844a spec: {} status: availableReplicas: 2 conditions: - lastTransitionTime: 2019-04-18T12:36:15Z status: "True" type: Available domain: apps.<cluster>.example.com endpointPublishingStrategy: type: LoadBalancerService selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller=defaultingresscontroller리소스를 편집하고infra레이블을 사용하도록nodeSelector를 변경합니다.$ oc edit ingresscontroller default -n openshift-ingress-operatorspec: nodePlacement: nodeSelector:1 matchLabels: node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved- 1
- 적절한 값이 설정된
nodeSelector매개변수를 이동하려는 구성 요소에 추가합니다. 표시된 형식으로nodeSelector를 사용하거나 노드에 지정된 값에 따라<key>: <value>쌍을 사용할 수 있습니다. 인프라 노드에 테인트를 추가한 경우 일치하는 허용 오차도 추가합니다.
라우터 pod가
infra노드에서 실행되고 있는지 확인합니다.라우터 pod 목록을 표시하고 실행중인 pod의 노드 이름을 기록해 둡니다.
$ oc get pod -n openshift-ingress -o wide출력 예
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES router-default-86798b4b5d-bdlvd 1/1 Running 0 28s 10.130.2.4 ip-10-0-217-226.ec2.internal <none> <none> router-default-955d875f4-255g8 0/1 Terminating 0 19h 10.129.2.4 ip-10-0-148-172.ec2.internal <none> <none>이 예에서 실행중인 pod는
ip-10-0-217-226.ec2.internal노드에 있습니다.실행중인 pod의 노드 상태를 표시합니다.
$ oc get node <node_name>1 - 1
- pod 목록에서 얻은
<node_name>을 지정합니다.
출력 예
NAME STATUS ROLES AGE VERSION ip-10-0-217-226.ec2.internal Ready infra,worker 17h v1.24.0역할 목록에
infra가 포함되어 있으므로 pod가 올바른 노드에서 실행됩니다.
8.4.2. 기본 레지스트리 이동
Pod를 다른 노드에 배포하도록 레지스트리 Operator를 구성합니다.
전제 조건
- OpenShift Container Platform 클러스터에서 추가 머신 세트를 구성합니다.
절차
config/instance개체를 표시합니다.$ oc get configs.imageregistry.operator.openshift.io/cluster -o yaml출력 예
apiVersion: imageregistry.operator.openshift.io/v1 kind: Config metadata: creationTimestamp: 2019-02-05T13:52:05Z finalizers: - imageregistry.operator.openshift.io/finalizer generation: 1 name: cluster resourceVersion: "56174" selfLink: /apis/imageregistry.operator.openshift.io/v1/configs/cluster uid: 36fd3724-294d-11e9-a524-12ffeee2931b spec: httpSecret: d9a012ccd117b1e6616ceccb2c3bb66a5fed1b5e481623 logging: 2 managementState: Managed proxy: {} replicas: 1 requests: read: {} write: {} storage: s3: bucket: image-registry-us-east-1-c92e88cad85b48ec8b312344dff03c82-392c region: us-east-1 status: ...config/instance개체를 편집합니다.$ oc edit configs.imageregistry.operator.openshift.io/clusterspec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - podAffinityTerm: namespaces: - openshift-image-registry topologyKey: kubernetes.io/hostname weight: 100 logLevel: Normal managementState: Managed nodeSelector:1 node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved- 1
- 적절한 값이 설정된
nodeSelector매개변수를 이동하려는 구성 요소에 추가합니다. 표시된 형식으로nodeSelector를 사용하거나 노드에 지정된 값에 따라<key>: <value>쌍을 사용할 수 있습니다. 인프라 노드에 테인트를 추가한 경우 일치하는 톨러레이션도 추가합니다.
레지스트리 pod가 인프라 노드로 이동되었는지 검증합니다.
다음 명령을 실행하여 레지스트리 pod가 있는 노드를 식별합니다.
$ oc get pods -o wide -n openshift-image-registry노드에 지정된 레이블이 있는지 확인합니다.
$ oc describe node <node_name>명령 출력을 확인하고
node-role.kubernetes.io/infra가LABELS목록에 있는지 확인합니다.
8.4.3. 모니터링 솔루션 이동
모니터링 스택에는 Prometheus, Thanos Querier 및 Alertmanager를 비롯한 여러 구성 요소가 포함되어 있습니다. Cluster Monitoring Operator는 이 스택을 관리합니다. 모니터링 스택을 인프라 노드에 재배포하기 위해 사용자 정의 구성 맵을 생성하고 적용할 수 있습니다.
절차
cluster-monitoring-config구성 맵을 편집하고infra레이블을 사용하도록nodeSelector를 변경합니다.$ oc edit configmap cluster-monitoring-config -n openshift-monitoringapiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: |+ alertmanagerMain: nodeSelector:1 node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute prometheusK8s: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute prometheusOperator: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute k8sPrometheusAdapter: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute kubeStateMetrics: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute telemeterClient: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute openshiftStateMetrics: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute thanosQuerier: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute- 1
- 적절한 값이 설정된
nodeSelector매개변수를 이동하려는 구성 요소에 추가합니다. 표시된 형식으로nodeSelector를 사용하거나 노드에 지정된 값에 따라<key>: <value>쌍을 사용할 수 있습니다. 인프라 노드에 테인트를 추가한 경우 일치하는 톨러레이션도 추가합니다.
모니터링 pod가 새 머신으로 이동하는 것을 확인합니다.
$ watch 'oc get pod -n openshift-monitoring -o wide'구성 요소가
infra노드로 이동하지 않은 경우 이 구성 요소가 있는 pod를 제거합니다.$ oc delete pod -n openshift-monitoring <pod>삭제된 pod의 구성 요소가
infra노드에 다시 생성됩니다.
8.4.4. 로깅 리소스 이동
Elasticsearch 및 Kibana와 같은 로깅 구성 요소용 Pod를 다른 노드에 배포하도록 Red Hat OpenShift Logging Operator를 구성할 수 있습니다. 설치된 위치에서 Red Hat OpenShift Logging Operator Pod를 이동할 수 없습니다.
예를 들어 높은 CPU, 메모리 및 디스크 요구 사항으로 인해 Elasticsearch Pod를 다른 노드로 옮길 수 있습니다.
사전 요구 사항
- Red Hat OpenShift Logging Operator 및 OpenShift Elasticsearch Operator를 설치했습니다.
절차
openshift-logging프로젝트에서ClusterLogging사용자 정의 리소스(CR)를 편집합니다.$ oc edit ClusterLogging instanceClusterLoggingCR의 예apiVersion: logging.openshift.io/v1 kind: ClusterLogging # ... spec: logStore: elasticsearch: nodeCount: 3 nodeSelector:1 node-role.kubernetes.io/infra: '' tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved redundancyPolicy: SingleRedundancy resources: limits: cpu: 500m memory: 16Gi requests: cpu: 500m memory: 16Gi storage: {} type: elasticsearch managementState: Managed visualization: kibana: nodeSelector:2 node-role.kubernetes.io/infra: '' tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved proxy: resources: null replicas: 1 resources: null type: kibana # ...
검증
oc get pod -o wide 명령을 사용하여 구성 요소가 이동했는지 확인할 수 있습니다.
예를 들면 다음과 같습니다.
ip-10-0-147-79.us-east-2.compute.internal노드에서 Kibana pod를 이동하려고 경우 다음을 실행합니다.$ oc get pod kibana-5b8bdf44f9-ccpq9 -o wide출력 예
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kibana-5b8bdf44f9-ccpq9 2/2 Running 0 27s 10.129.2.18 ip-10-0-147-79.us-east-2.compute.internal <none> <none>Kibana Pod를 전용 인프라 노드인
ip-10-0-139-48.us-east-2.compute.internal노드로 이동하려는 경우 다음을 실행합니다.$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ip-10-0-133-216.us-east-2.compute.internal Ready master 60m v1.24.0 ip-10-0-139-146.us-east-2.compute.internal Ready master 60m v1.24.0 ip-10-0-139-192.us-east-2.compute.internal Ready worker 51m v1.24.0 ip-10-0-139-241.us-east-2.compute.internal Ready worker 51m v1.24.0 ip-10-0-147-79.us-east-2.compute.internal Ready worker 51m v1.24.0 ip-10-0-152-241.us-east-2.compute.internal Ready master 60m v1.24.0 ip-10-0-139-48.us-east-2.compute.internal Ready infra 51m v1.24.0노드에는
node-role.kubernetes.io/infra : ''레이블이 있음에 유의합니다.$ oc get node ip-10-0-139-48.us-east-2.compute.internal -o yaml출력 예
kind: Node apiVersion: v1 metadata: name: ip-10-0-139-48.us-east-2.compute.internal selfLink: /api/v1/nodes/ip-10-0-139-48.us-east-2.compute.internal uid: 62038aa9-661f-41d7-ba93-b5f1b6ef8751 resourceVersion: '39083' creationTimestamp: '2020-04-13T19:07:55Z' labels: node-role.kubernetes.io/infra: '' ...Kibana pod를 이동하려면
ClusterLoggingCR을 편집하여 노드 선택기를 추가합니다.apiVersion: logging.openshift.io/v1 kind: ClusterLogging # ... spec: # ... visualization: kibana: nodeSelector:1 node-role.kubernetes.io/infra: '' proxy: resources: null replicas: 1 resources: null type: kibana- 1
- 노드 사양의 레이블과 일치하는 노드 선택기를 추가합니다.
CR을 저장하면 현재 Kibana pod가 종료되고 새 pod가 배포됩니다.
$ oc get pods출력 예
NAME READY STATUS RESTARTS AGE cluster-logging-operator-84d98649c4-zb9g7 1/1 Running 0 29m elasticsearch-cdm-hwv01pf7-1-56588f554f-kpmlg 2/2 Running 0 28m elasticsearch-cdm-hwv01pf7-2-84c877d75d-75wqj 2/2 Running 0 28m elasticsearch-cdm-hwv01pf7-3-f5d95b87b-4nx78 2/2 Running 0 28m collector-42dzz 1/1 Running 0 28m collector-d74rq 1/1 Running 0 28m collector-m5vr9 1/1 Running 0 28m collector-nkxl7 1/1 Running 0 28m collector-pdvqb 1/1 Running 0 28m collector-tflh6 1/1 Running 0 28m kibana-5b8bdf44f9-ccpq9 2/2 Terminating 0 4m11s kibana-7d85dcffc8-bfpfp 2/2 Running 0 33s새 pod는
ip-10-0-139-48.us-east-2.compute.internal노드에 있습니다.$ oc get pod kibana-7d85dcffc8-bfpfp -o wide출력 예
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kibana-7d85dcffc8-bfpfp 2/2 Running 0 43s 10.131.0.22 ip-10-0-139-48.us-east-2.compute.internal <none> <none>잠시 후 원래 Kibana pod가 제거됩니다.
$ oc get pods출력 예
NAME READY STATUS RESTARTS AGE cluster-logging-operator-84d98649c4-zb9g7 1/1 Running 0 30m elasticsearch-cdm-hwv01pf7-1-56588f554f-kpmlg 2/2 Running 0 29m elasticsearch-cdm-hwv01pf7-2-84c877d75d-75wqj 2/2 Running 0 29m elasticsearch-cdm-hwv01pf7-3-f5d95b87b-4nx78 2/2 Running 0 29m collector-42dzz 1/1 Running 0 29m collector-d74rq 1/1 Running 0 29m collector-m5vr9 1/1 Running 0 29m collector-nkxl7 1/1 Running 0 29m collector-pdvqb 1/1 Running 0 29m collector-tflh6 1/1 Running 0 29m kibana-7d85dcffc8-bfpfp 2/2 Running 0 62s
9장. OpenShift Container Platform 클러스터에 RHEL 컴퓨팅 머신 추가
OpenShift Container Platform에서는 RHEL(Red Hat Enterprise Linux) 컴퓨팅 머신을 사용자 프로비저닝 인프라 클러스터 또는 x86_64 아키텍처의 설치 프로비저닝 인프라 클러스터에 추가할 수 있습니다. 컴퓨팅 머신에서만 RHEL을 운영 체제로 사용할 수 있습니다.
9.1. 클러스터에 RHEL 컴퓨팅 노드 추가 정보
OpenShift Container Platform 4.11에서는 x86_64 아키텍처에 사용자 프로비저닝 또는 설치 관리자 프로비저닝 인프라 설치를 사용하는 경우 RHEL (Red Hat Enterprise Linux) 머신을 클러스터의 컴퓨팅 머신으로 사용하는 옵션이 있습니다. 클러스터의 컨트롤 플레인 머신에 RHCOS(Red Hat Enterprise Linux CoreOS) 시스템을 사용해야 합니다.
클러스터에서 RHEL 컴퓨팅 머신을 사용하도록 선택하는 경우 모든 운영 체제의 라이프 사이클 관리 및 유지보수를 수행해야 합니다. 시스템 업데이트를 수행하고 패치를 적용하고 기타 필요한 모든 작업을 완료해야 합니다.
설치 관리자 프로비저닝 인프라 클러스터의 경우 설치 관리자 프로비저닝 인프라 클러스터에서 자동으로 확장되어 RHCOS(Red Hat Enterprise Linux CoreOS) 컴퓨팅 머신을 기본적으로 추가하므로 RHEL 컴퓨팅 머신을 수동으로 추가해야 합니다.
- 클러스터의 시스템에서 OpenShift Container Platform을 제거하려면 운영 체제를 제거해야하므로 클러스터에 추가한 모든 RHEL 머신에 전용 하드웨어를 사용해야합니다.
- OpenShift Container Platform 클러스터에 추가한 모든 RHEL 머신에서 스왑 메모리가 비활성화됩니다. 이 머신에서 스왑 메모리를 활성화할 수 없습니다.
컨트롤 플레인을 초기화한 후 RHEL 컴퓨팅 머신을 클러스터에 추가해야합니다.
9.2. RHEL 컴퓨팅 노드의 시스템 요구 사항
OpenShift Container Platform 환경의 RHEL (Red Hat Enterprise Linux) 컴퓨팅 머신 호스트는 다음과 같은 최소 하드웨어 사양 및 시스템 수준 요구 사항을 충족해야합니다.
- Red Hat 계정에 유효한 OpenShift Container Platform 서브스크립션이 있어야합니다. 서브스크립션이 없는 경우 영업 담당자에게 자세한 내용을 문의하십시오.
- 프로덕션 환경에서 예상 워크로드를 지원할 수 있는 컴퓨팅 머신을 제공해야합니다. 클러스터 관리자는 예상 워크로드를 계산하고 오버 헤드에 약 10%를 추가해야합니다. 프로덕션 환경의 경우 노드 호스트 장애가 최대 용량에 영향을 미치지 않도록 충분한 리소스를 할당해야 합니다.
각 시스템은 다음 하드웨어 요구 사항을 충족해야합니다.
- 물리적 또는 가상 시스템 또는 퍼블릭 또는 프라이빗 IaaS에서 실행되는 인스턴스.
기본 OS: RHEL 8.6 이상, "최소" 설치 옵션이 있습니다.
중요OpenShift Container Platform 클러스터에 RHEL 7 컴퓨팅 머신을 추가하는 것은 지원되지 않습니다.
이전 OpenShift Container Platform 버전에서 이전에 지원되는 RHEL 7 컴퓨팅 머신이 있는 경우 RHEL 8로 업그레이드할 수 없습니다. 새 RHEL 8 호스트를 배포해야 하며 이전 RHEL 7 호스트를 제거해야 합니다. 자세한 내용은 "노드 삭제" 섹션을 참조하십시오.
OpenShift Container Platform에서 더 이상 사용되지 않거나 삭제된 주요 기능의 최신 목록은 OpenShift Container Platform 릴리스 노트에서 더 이상 사용되지 않고 삭제된 기능 섹션을 참조하십시오.
- FIPS 모드에서 OpenShift Container Platform을 배포하는 경우 부팅하기 전에 RHEL 시스템에서 FIPS를 활성화해야합니다. RHEL 8 설명서에서 FIPS 모드가 활성화된 RHEL 8 시스템 설치를 참조하십시오.
클러스터의 FIPS 모드를 활성화하려면 FIPS 모드에서 작동하도록 구성된 RHEL(Red Hat Enterprise Linux) 컴퓨터에서 설치 프로그램을 실행해야 합니다. RHEL에서 FIPS 모드 구성에 대한 자세한 내용은 FIPS 모드에서 시스템 설치를 참조하십시오. FIPS 검증 또는 모듈 In Process 암호화 라이브러리 사용은 x86_64 아키텍처의 OpenShift Container Platform 배포에서만 지원됩니다.
- NetworkManager 1.0 이상
- vCPU 1개
- 최소 8GB RAM
-
/var/를 포함하는 파일 시스템의 최소 15GB 하드 디스크 공간 -
/usr/local/bin/을 포함하는 파일 시스템의 최소 1GB 하드 디스크 공간 임시 디렉토리를 포함하는 파일 시스템의 최소 1GB의 하드 디스크 공간 임시 시스템 디렉토리는 Python 표준 라이브러리의 tempfile 모듈에 정의된 규칙에 따라 결정됩니다.
-
각 시스템은 시스템 제공 업체의 추가 요구 사항을 충족해야합니다. 예를 들어 VMware vSphere에 클러스터를 설치하는 경우 스토리지 지침에 따라 디스크를 구성하고
disk.enableUUID=true속성을 설정해야합니다. - 각 시스템은 DNS 확인 가능한 호스트 이름을 사용하여 클러스터의 API 끝점에 액세스할 수 있어야 합니다. 모든 네트워크 보안 액세스 제어는 클러스터의 API 서비스 엔드 포인트에 대한 시스템 액세스를 허용해야합니다.
-
각 시스템은 시스템 제공 업체의 추가 요구 사항을 충족해야합니다. 예를 들어 VMware vSphere에 클러스터를 설치하는 경우 스토리지 지침에 따라 디스크를 구성하고
9.2.1. 인증서 서명 요청 관리
사용자가 프로비저닝하는 인프라를 사용하는 경우 자동 시스템 관리 기능으로 인해 클러스터의 액세스가 제한되므로 설치한 후 클러스터 인증서 서명 요청(CSR)을 승인하는 메커니즘을 제공해야 합니다. kube-controller-manager는 kubelet 클라이언트 CSR만 승인합니다. machine-approver는 올바른 시스템에서 발행한 요청인지 확인할 수 없기 때문에 kubelet 자격 증명을 사용하여 요청하는 서비스 인증서의 유효성을 보장할 수 없습니다. kubelet 서빙 인증서 요청의 유효성을 확인하고 요청을 승인하는 방법을 결정하여 구현해야 합니다.
9.3. 클라우드 이미지 준비
AWS에서 다양한 이미지 형식을 직접 사용할 수 없기 때문에 Amazon 머신 이미지(AMI)가 필요합니다. Red Hat에서 제공하는 AMI를 사용하거나 자체 이미지를 수동으로 가져올 수 있습니다. EC2 인스턴스를 프로비저닝하기 전에 AMI가 있어야 합니다. 컴퓨팅 시스템에 필요한 올바른 RHEL 버전이 선택하려면유효한 AMI ID가 필요합니다.
9.3.1. AWS에서 사용 가능한 최신 RHEL 이미지 나열
AMI ID는 AWS의 기본 부팅 이미지에 해당합니다. AMI는 EC2 인스턴스를 프로비저닝하기 전에 존재해야 하므로 구성 전에 AMI ID를 알아야 합니다. AWS CLI(Command Line Interface)는 사용 가능한 RHEL(Red Hat Enterprise Linux) 이미지 ID를 나열하는 데 사용됩니다.
전제 조건
- AWS CLI를 설치했습니다.
프로세스
이 명령을 사용하여 RHEL 8.4 AMI(Amazon Machine Images)를 나열합니다.
$ aws ec2 describe-images --owners 309956199498 \1 --query 'sort_by(Images, &CreationDate)[*].[CreationDate,Name,ImageId]' \2 --filters "Name=name,Values=RHEL-8.4*" \3 --region us-east-1 \4 --output table5 - 1
--owners명령 옵션은 계정 ID309956199498에 기반한 Red Hat 이미지를 보여줍니다.중요Red Hat에서 제공하는 이미지의 AMI ID를 표시하려면 이 계정 ID가 필요합니다.
- 2
--query명령 옵션은'sort_by(Images, &CreationDate)[*].[CreationDate,Name,ImageId]매개변수로 이미지가 정렬되는 방법을 설정합니다. 이 경우 이미지는 생성 날짜에 따라 정렬되며 테이블은 생성 날짜, 이미지 이름 및 AMI ID를 표시하도록 구성됩니다.- 3
--filter명령 옵션은 표시되는 RHEL 버전을 설정합니다. 이 예에서는 필터가"Name=name,Values=RHEL-8.4*"로 설정되므로 RHEL 8.4 AMI가 표시됩니다.- 4
--region명령 옵션은 AMI가 저장된 리전을 설정합니다.- 5
--output명령 옵션은 결과가 표시되는 방법을 설정합니다.
AWS용 RHEL 컴퓨팅 머신을 생성할 때 AMI가 RHEL 8.4 또는 8.5인지 확인합니다.
출력 예
------------------------------------------------------------------------------------------------------------
| DescribeImages |
+---------------------------+-----------------------------------------------------+------------------------+
| 2021-03-18T14:23:11.000Z | RHEL-8.4.0_HVM_BETA-20210309-x86_64-1-Hourly2-GP2 | ami-07eeb4db5f7e5a8fb |
| 2021-03-18T14:38:28.000Z | RHEL-8.4.0_HVM_BETA-20210309-arm64-1-Hourly2-GP2 | ami-069d22ec49577d4bf |
| 2021-05-18T19:06:34.000Z | RHEL-8.4.0_HVM-20210504-arm64-2-Hourly2-GP2 | ami-01fc429821bf1f4b4 |
| 2021-05-18T20:09:47.000Z | RHEL-8.4.0_HVM-20210504-x86_64-2-Hourly2-GP2 | ami-0b0af3577fe5e3532 |
+---------------------------+-----------------------------------------------------+------------------------+9.4. Playbook 실행을 위한 머신 준비
RHEL(Red Hat Enterprise Linux)을 운영 체제로 사용하는 컴퓨팅 머신을 OpenShift Container Platform 4.11 클러스터에 추가하려면 먼저 새 노드를 클러스터에 추가하는 Ansible 플레이북을 실행하도록 RHEL 8 시스템을 준비해야 합니다. 이 머신은 클러스터의 일부가 아니지만 클러스터에 액세스할 수 있어야합니다.
전제 조건
-
Playbook을 실행하는 머신에 OpenShift CLI (
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
프로세스
-
클러스터의
kubeconfig파일 및 클러스터 설치에 사용된 설치 프로그램이 RHEL 8 머신에 있는지 확인합니다. 이를 수행하는 한 가지 방법으로 클러스터 설치에 사용된 머신과 동일한 머신을 사용하는 것입니다. - 컴퓨팅 머신으로 사용하려는 모든 RHEL 호스트에 액세스하도록 머신을 구성합니다. SSH 프록시 또는 VPN을 사용하는 Bastion를 포함하여 회사에서 허용하는 모든 방법을 사용할 수 있습니다.
Playbook을 실행하는 머신에서 모든 RHEL 호스트에 대한 SSH 액세스 권한이있는 사용자를 구성하십시오.
중요SSH 키 기반 인증을 사용하는 경우 SSH 에이전트를 사용하여 키를 관리해야합니다.
아직 등록하지 않은 경우 RHSM으로 머신을 등록하고
OpenShift서브스크립션이 있는 풀을 머신에 연결합니다.RHSM으로 머신를 등록합니다.
# subscription-manager register --username=<user_name> --password=<password>RHSM에서 최신 서브스크립션 데이터를 가져옵니다.
# subscription-manager refresh사용 가능한 서브스크립션을 나열하십시오.
# subscription-manager list --available --matches '*OpenShift*'이전 명령의 출력에서 OpenShift Container Platform 서브스크립션의 풀 ID를 찾아서 이를 연결합니다.
# subscription-manager attach --pool=<pool_id>
OpenShift Container Platform 4.11에 필요한 리포지토리를 활성화합니다.
# subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.11-for-rhel-8-x86_64-rpms"openshift-ansible을 포함한 필수 패키지를 설치합니다.# yum install openshift-ansible openshift-clients jqopenshift-ansible패키지는 설치 프로그램 유틸리티를 제공하고 Ansible, Playbook 및 관련 구성 파일과 같이 RHEL 컴퓨팅 노드를 클러스터에 추가하는데 필요한 다른 패키지를 가져옵니다.openshift-clients는ocCLI를 제공하고jq패키지는 명령 행에서 JSON 출력 표시 방법을 개선할 수 있습니다.
9.5. RHEL 컴퓨팅 노드 준비
RHEL (Red Hat Enterprise Linux) 시스템을 OpenShift Container Platform 클러스터에 추가하기 전에 각 호스트를 RHSM (Red Hat Subscription Manager)에 등록하고 활성 OpenShift Container Platform 서브스크립션을 연결하고 필요한 저장소를 활성화해야합니다. NetworkManager 가 호스트의 모든 인터페이스를 제어하도록 활성화 및 구성되었는지 확인합니다.
각 호스트에서 RHSM으로 동륵합니다.
# subscription-manager register --username=<user_name> --password=<password>RHSM에서 최신 서브스크립션 데이터를 가져옵니다.
# subscription-manager refresh사용 가능한 서브스크립션을 나열하십시오.
# subscription-manager list --available --matches '*OpenShift*'이전 명령의 출력에서 OpenShift Container Platform 서브스크립션의 풀 ID를 찾아서 이를 연결합니다.
# subscription-manager attach --pool=<pool_id>모든 yum 저장소를 비활성화합니다.
활성화된 모든 RHSM 저장소를 비활성화합니다.
# subscription-manager repos --disable="*"나머지 yum 저장소를 나열하고
repo id아래에 해당 이름을 적어 둡니다.# yum repolistyum-config-manager를 사용하여 나머지 yum 리포지토리를 비활성화합니다.# yum-config-manager --disable <repo_id>또는 모든 리포지토리를 비활성화합니다.
# yum-config-manager --disable \*사용 가능한 리포지토리가 많으면 몇 분의 시간이 소요될 수 있습니다.
OpenShift Container Platform 4.11에 필요한 리포지토리를 활성화합니다.
# subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.11-for-rhel-8-x86_64-rpms" \ --enable="fast-datapath-for-rhel-8-x86_64-rpms"호스트에서 firewalld를 중지하고 비활성화합니다.
# systemctl disable --now firewalld.service참고나중에 firewalld를 활성화할 수 없습니다. 활성화하면 작업자의 OpenShift Container Platform 로그에 액세스할 수 없습니다.
9.6. AWS의 RHEL 인스턴스에 역할 권한 연결
브라우저에서 Amazon IAM 콘솔을 사용하여 필요한 역할을 선택하고 작업자 노드에 할당할 수 있습니다.
절차
- AWS IAM 콘솔에서 원하는 IAM 역할을 생성합니다.
- 원하는 작업자 노드에 IAM 역할을 연결합니다.
9.7. RHEL 작업자 노드를 owned 또는 shared로 태그 지정
클러스터는 kubernetes.io/cluster/<clusterid>,Value=(owned|shared) 태그 값을 사용하여 AWS 클러스터와 관련된 리소스의 수명을 결정합니다.
-
클러스터 제거의 일부로 리소스를 제거해야 하는 경우
owned태그 값을 추가해야 합니다. -
클러스터가 제거된 후에도 리소스가 계속 존재하는 경우
shared태그 값을 추가해야 합니다. 이 태그는 클러스터가 이 리소스를 사용하지만 리소스에 대해 별도의 소유자가 있음을 나타냅니다.
절차
-
RHEL 컴퓨팅 머신의 경우 RHEL 작업자 인스턴스는
kubernetes.io/cluster/<clusterid>=owned또는kubernetes.io/cluster/<cluster-id>=shared로 태그 지정해야 합니다.
kubernetes.io/cluster/<name>,Value=<clusterid> 태그로 기존 보안 그룹을 태그하지 마십시오. 그렇지 않으면 ELB(Elastic Load Balancing)에서 로드 밸런서를 생성할 수 없습니다.
9.8. 클러스터에 RHEL 컴퓨팅 머신 추가
Red Hat Enterprise Linux를 운영 체제로 사용하는 컴퓨팅 머신을 OpenShift Container Platform 4.11 클러스터에 추가할 수 있습니다.
사전 요구 사항
- Playbook을 실행하는 머신에 필요한 패키지를 설치하고 필요한 구성이 수행되어 있습니다.
- RHEL 호스트 설치가 준비되어 있습니다.
절차
Playbook을 실행할 준비가 되어 있는 머신에서 다음 단계를 수행합니다.
컴퓨팅 머신 호스트 및 필수 변수를 정의하는
/<path>/inventory/hosts라는 Ansible 인벤토리 파일을 만듭니다.[all:vars] ansible_user=root1 #ansible_become=True2 openshift_kubeconfig_path="~/.kube/config"3 [new_workers]4 mycluster-rhel8-0.example.com mycluster-rhel8-1.example.com- 1
- 원격 컴퓨팅 머신에서 Ansible 태스크를 실행하는 사용자 이름을 지정합니다.
- 2
ansible_user의root를 지정하지 않으면ansible_become을True로 설정하고 사용자 sudo 권한을 지정해야합니다.- 3
- 클러스터
kubeconfig파일의 경로와 파일 이름을 지정합니다. - 4
- 클러스터에 추가할 각 RHEL 머신을 나열합니다. 각 호스트에 대해 정규화된 도메인 이름을 지정해야합니다. 이 이름은 클러스터가 시스템에 액세스하는 데 사용하는 호스트 이름이므로 올바른 공용 또는 개인 이름을 설정하여 시스템에 액세스합니다.
Ansible Playbook 디렉토리로 이동합니다.
$ cd /usr/share/ansible/openshift-ansiblePlaybook을 실행합니다.
$ ansible-playbook -i /<path>/inventory/hosts playbooks/scaleup.yml1 - 1
<path>에 대해 생성한 Ansible 인벤토리 파일의 경로를 지정합니다.
9.9. 시스템의 인증서 서명 요청 승인
클러스터에 시스템을 추가하면 추가한 시스템별로 보류 중인 인증서 서명 요청(CSR)이 두 개씩 생성됩니다. 이러한 CSR이 승인되었는지 확인해야 하며, 필요한 경우 이를 직접 승인해야 합니다. 클라이언트 요청을 먼저 승인한 다음 서버 요청을 승인해야 합니다.
사전 요구 사항
- 클러스터에 시스템을 추가했습니다.
절차
클러스터가 시스템을 인식하는지 확인합니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.24.0 master-1 Ready master 63m v1.24.0 master-2 Ready master 64m v1.24.0출력에 생성된 모든 시스템이 나열됩니다.
참고이전 출력에는 일부 CSR이 승인될 때까지 컴퓨팅 노드(작업자 노드라고도 함)가 포함되지 않을 수 있습니다.
보류 중인 CSR을 검토하고 클러스터에 추가한 각 시스템에 대해
Pending또는Approved상태의 클라이언트 및 서버 요청이 표시되는지 확인합니다.$ oc get csr출력 예
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...예에서는 두 시스템이 클러스터에 참여하고 있습니다. 목록에는 승인된 CSR이 더 많이 나타날 수도 있습니다.
CSR이 승인되지 않은 경우, 추가된 시스템에 대한 모든 보류 중인 CSR이
Pending상태로 전환된 후 클러스터 시스템의 CSR을 승인합니다.참고CSR은 교체 주기가 자동으로 만료되므로 클러스터에 시스템을 추가한 후 1시간 이내에 CSR을 승인하십시오. 한 시간 내에 승인하지 않으면 인증서가 교체되고 각 노드에 대해 두 개 이상의 인증서가 표시됩니다. 이러한 인증서를 모두 승인해야 합니다. 클라이언트 CSR이 승인되면 Kubelet은 인증서에 대한 보조 CSR을 생성하므로 수동 승인이 필요합니다. 그러면 Kubelet에서 동일한 매개변수를 사용하여 새 인증서를 요청하는 경우 인증서 갱신 요청은
machine-approver에 의해 자동으로 승인됩니다.참고베어 메탈 및 기타 사용자 프로비저닝 인프라와 같이 머신 API를 사용하도록 활성화되지 않는 플랫폼에서 실행되는 클러스터의 경우 CSR(Kubelet service Certificate Request)을 자동으로 승인하는 방법을 구현해야 합니다. 요청이 승인되지 않으면 API 서버가 kubelet에 연결될 때 서비스 인증서가 필요하므로
oc exec,oc rsh,oc logs명령을 성공적으로 수행할 수 없습니다. Kubelet 엔드 포인트에 연결하는 모든 작업을 수행하려면 이 인증서 승인이 필요합니다. 이 방법은 새 CSR을 감시하고 CSR이system:node또는system:admin그룹의node-bootstrapper서비스 계정에 의해 제출되었는지 확인하고 노드의 ID를 확인합니다.개별적으로 승인하려면 유효한 CSR 각각에 대해 다음 명령을 실행하십시오.
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
보류 중인 CSR을 모두 승인하려면 다음 명령을 실행하십시오.
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve참고일부 Operator는 일부 CSR이 승인될 때까지 사용할 수 없습니다.
이제 클라이언트 요청이 승인되었으므로 클러스터에 추가한 각 머신의 서버 요청을 검토해야 합니다.
$ oc get csr출력 예
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...나머지 CSR이 승인되지 않고
Pending상태인 경우 클러스터 머신의 CSR을 승인합니다.개별적으로 승인하려면 유효한 CSR 각각에 대해 다음 명령을 실행하십시오.
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
보류 중인 CSR을 모두 승인하려면 다음 명령을 실행하십시오.
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
모든 클라이언트 및 서버 CSR이 승인된 후 머신은
Ready상태가 됩니다. 다음 명령을 실행하여 확인합니다.$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.24.0 master-1 Ready master 73m v1.24.0 master-2 Ready master 74m v1.24.0 worker-0 Ready worker 11m v1.24.0 worker-1 Ready worker 11m v1.24.0참고머신이
Ready상태로 전환하는 데 서버 CSR의 승인 후 몇 분이 걸릴 수 있습니다.
추가 정보
- CSR에 대한 자세한 내용은 인증서 서명 요청을 참조하십시오.
9.10. Ansible 호스트 파일의 필수 매개 변수
RHEL (Red Hat Enterprise Linux) 컴퓨팅 머신을 클러스터에 추가하기 전에 Ansible 호스트 파일에서 다음 매개 변수를 정의해야합니다.
| 매개변수 | 설명 | 값 |
|---|---|---|
|
| 암호없이 SSH 기반 인증을 허용하는 SSH 사용자입니다. SSH 키 기반 인증을 사용하는 경우 SSH 에이전트를 사용하여 키를 관리해야합니다. |
시스템의 사용자 이름입니다. 기본값은 |
|
|
|
|
|
|
클러스터의 | 구성 파일의 경로 및 이름 |
9.10.1. 선택 사항: 클러스터에서 RHCOS 컴퓨팅 머신 제거
RHEL (Red Hat Enterprise Linux) 컴퓨팅 머신을 클러스터에 추가 한 후 선택 옵션으로 RHCOS (Red Hat Enterprise Linux CoreOS) 컴퓨팅 머신을 제거하여 리소스를 확보할 수 있습니다.
사전 요구 사항
- RHEL 컴퓨팅 머신이 클러스터에 추가되어 있습니다.
프로세스
머신 목록을 표시하고 RHCOS 컴퓨팅 머신의 노드 이름을 기록합니다.
$ oc get nodes -o wide각 RHCOS 컴퓨팅 머신의 노드를 제거합니다.
oc adm cordon명령을 실행하여 노드를 스케줄 예약 해제로 표시합니다.$ oc adm cordon <node_name>1 - 1
- RHCOS 컴퓨팅 머신의 노드 이름을 지정합니다.
노드에서 모든 pod를 드레인합니다.
$ oc adm drain <node_name> --force --delete-emptydir-data --ignore-daemonsets1 - 1
- 분리 한 RHCOS 컴퓨팅 머신의 노드 이름을 지정합니다.
노드를 제거합니다.
$ oc delete nodes <node_name>1 - 1
- 드레인한 RHCOS 컴퓨팅 머신의 노드 이름을 지정합니다.
컴퓨팅 머신 목록을 확인하고 RHEL 노드만 남아 있는지 확인합니다.
$ oc get nodes -o wide- 클러스터 컴퓨팅 머신의 로드 밸런서에서 RHCOS 머신을 제거합니다. 가상 머신을 삭제하거나 RHCOS 컴퓨팅 머신의 실제 하드웨어를 다시 이미지화 할 수 있습니다.
10장. OpenShift Container Platform 클러스터에 RHEL 컴퓨팅 머신 추가
OpenShift Container Platform 클러스터에 작업자 시스템이라고도하는 RHEL (Red Hat Enterprise Linux) 컴퓨팅 시스템이 이미 포함되어있는 경우 RHEL 컴퓨팅 시스템을 더 추가할 수 있습니다.
10.1. 클러스터에 RHEL 컴퓨팅 노드 추가 정보
OpenShift Container Platform 4.11에서는 x86_64 아키텍처에 사용자 프로비저닝 또는 설치 관리자 프로비저닝 인프라 설치를 사용하는 경우 RHEL (Red Hat Enterprise Linux) 머신을 클러스터의 컴퓨팅 머신으로 사용하는 옵션이 있습니다. 클러스터의 컨트롤 플레인 머신에 RHCOS(Red Hat Enterprise Linux CoreOS) 시스템을 사용해야 합니다.
클러스터에서 RHEL 컴퓨팅 머신을 사용하도록 선택하는 경우 모든 운영 체제의 라이프 사이클 관리 및 유지보수를 수행해야 합니다. 시스템 업데이트를 수행하고 패치를 적용하고 기타 필요한 모든 작업을 완료해야 합니다.
설치 관리자 프로비저닝 인프라 클러스터의 경우 설치 관리자 프로비저닝 인프라 클러스터에서 자동으로 확장되어 RHCOS(Red Hat Enterprise Linux CoreOS) 컴퓨팅 머신을 기본적으로 추가하므로 RHEL 컴퓨팅 머신을 수동으로 추가해야 합니다.
- 클러스터의 시스템에서 OpenShift Container Platform을 제거하려면 운영 체제를 제거해야하므로 클러스터에 추가한 모든 RHEL 머신에 전용 하드웨어를 사용해야합니다.
- OpenShift Container Platform 클러스터에 추가한 모든 RHEL 머신에서 스왑 메모리가 비활성화됩니다. 이 머신에서 스왑 메모리를 활성화할 수 없습니다.
컨트롤 플레인을 초기화한 후 RHEL 컴퓨팅 머신을 클러스터에 추가해야합니다.
10.2. RHEL 컴퓨팅 노드의 시스템 요구 사항
OpenShift Container Platform 환경의 RHEL (Red Hat Enterprise Linux) 컴퓨팅 머신 호스트는 다음과 같은 최소 하드웨어 사양 및 시스템 수준 요구 사항을 충족해야합니다.
- Red Hat 계정에 유효한 OpenShift Container Platform 서브스크립션이 있어야합니다. 서브스크립션이 없는 경우 영업 담당자에게 자세한 내용을 문의하십시오.
- 프로덕션 환경에서 예상 워크로드를 지원할 수 있는 컴퓨팅 머신을 제공해야합니다. 클러스터 관리자는 예상 워크로드를 계산하고 오버 헤드에 약 10%를 추가해야합니다. 프로덕션 환경의 경우 노드 호스트 장애가 최대 용량에 영향을 미치지 않도록 충분한 리소스를 할당해야 합니다.
각 시스템은 다음 하드웨어 요구 사항을 충족해야합니다.
- 물리적 또는 가상 시스템 또는 퍼블릭 또는 프라이빗 IaaS에서 실행되는 인스턴스.
기본 OS: RHEL 8.6 이상, "최소" 설치 옵션이 있습니다.
중요OpenShift Container Platform 클러스터에 RHEL 7 컴퓨팅 머신을 추가하는 것은 지원되지 않습니다.
이전 OpenShift Container Platform 버전에서 이전에 지원되는 RHEL 7 컴퓨팅 머신이 있는 경우 RHEL 8로 업그레이드할 수 없습니다. 새 RHEL 8 호스트를 배포해야 하며 이전 RHEL 7 호스트를 제거해야 합니다. 자세한 내용은 "노드 삭제" 섹션을 참조하십시오.
OpenShift Container Platform에서 더 이상 사용되지 않거나 삭제된 주요 기능의 최신 목록은 OpenShift Container Platform 릴리스 노트에서 더 이상 사용되지 않고 삭제된 기능 섹션을 참조하십시오.
- FIPS 모드에서 OpenShift Container Platform을 배포하는 경우 부팅하기 전에 RHEL 시스템에서 FIPS를 활성화해야합니다. RHEL 8 설명서에서 FIPS 모드가 활성화된 RHEL 8 시스템 설치를 참조하십시오.
클러스터의 FIPS 모드를 활성화하려면 FIPS 모드에서 작동하도록 구성된 RHEL(Red Hat Enterprise Linux) 컴퓨터에서 설치 프로그램을 실행해야 합니다. RHEL에서 FIPS 모드 구성에 대한 자세한 내용은 FIPS 모드에서 시스템 설치를 참조하십시오. FIPS 검증 또는 모듈 In Process 암호화 라이브러리 사용은 x86_64 아키텍처의 OpenShift Container Platform 배포에서만 지원됩니다.
- NetworkManager 1.0 이상
- vCPU 1개
- 최소 8GB RAM
-
/var/를 포함하는 파일 시스템의 최소 15GB 하드 디스크 공간 -
/usr/local/bin/을 포함하는 파일 시스템의 최소 1GB 하드 디스크 공간 임시 디렉토리를 포함하는 파일 시스템의 최소 1GB의 하드 디스크 공간 임시 시스템 디렉토리는 Python 표준 라이브러리의 tempfile 모듈에 정의된 규칙에 따라 결정됩니다.
-
각 시스템은 시스템 제공 업체의 추가 요구 사항을 충족해야합니다. 예를 들어 VMware vSphere에 클러스터를 설치하는 경우 스토리지 지침에 따라 디스크를 구성하고
disk.enableUUID=true속성을 설정해야합니다. - 각 시스템은 DNS 확인 가능한 호스트 이름을 사용하여 클러스터의 API 끝점에 액세스할 수 있어야 합니다. 모든 네트워크 보안 액세스 제어는 클러스터의 API 서비스 엔드 포인트에 대한 시스템 액세스를 허용해야합니다.
-
각 시스템은 시스템 제공 업체의 추가 요구 사항을 충족해야합니다. 예를 들어 VMware vSphere에 클러스터를 설치하는 경우 스토리지 지침에 따라 디스크를 구성하고
10.2.1. 인증서 서명 요청 관리
사용자가 프로비저닝하는 인프라를 사용하는 경우 자동 시스템 관리 기능으로 인해 클러스터의 액세스가 제한되므로 설치한 후 클러스터 인증서 서명 요청(CSR)을 승인하는 메커니즘을 제공해야 합니다. kube-controller-manager는 kubelet 클라이언트 CSR만 승인합니다. machine-approver는 올바른 시스템에서 발행한 요청인지 확인할 수 없기 때문에 kubelet 자격 증명을 사용하여 요청하는 서비스 인증서의 유효성을 보장할 수 없습니다. kubelet 서빙 인증서 요청의 유효성을 확인하고 요청을 승인하는 방법을 결정하여 구현해야 합니다.
10.3. 클라우드 이미지 준비
AWS에서 다양한 이미지 형식을 직접 사용할 수 없기 때문에 Amazon 머신 이미지(AMI)가 필요합니다. Red Hat에서 제공하는 AMI를 사용하거나 자체 이미지를 수동으로 가져올 수 있습니다. EC2 인스턴스를 프로비저닝하기 전에 AMI가 있어야 합니다. 컴퓨팅 시스템에 필요한 올바른 RHEL 버전이 선택되도록 AMI ID를 나열해야 합니다.
10.3.1. AWS에서 사용 가능한 최신 RHEL 이미지 나열
AMI ID는 AWS의 기본 부팅 이미지에 해당합니다. AMI는 EC2 인스턴스를 프로비저닝하기 전에 존재해야 하므로 구성 전에 AMI ID를 알아야 합니다. AWS CLI(Command Line Interface)는 사용 가능한 RHEL(Red Hat Enterprise Linux) 이미지 ID를 나열하는 데 사용됩니다.
사전 요구 사항
- AWS CLI를 설치했습니다.
절차
이 명령을 사용하여 RHEL 8.4 AMI(Amazon Machine Images)를 나열합니다.
$ aws ec2 describe-images --owners 309956199498 \1 --query 'sort_by(Images, &CreationDate)[*].[CreationDate,Name,ImageId]' \2 --filters "Name=name,Values=RHEL-8.4*" \3 --region us-east-1 \4 --output table5 - 1
--owners명령 옵션은 계정 ID309956199498에 기반한 Red Hat 이미지를 보여줍니다.중요Red Hat에서 제공하는 이미지의 AMI ID를 표시하려면 이 계정 ID가 필요합니다.
- 2
--query명령 옵션은'sort_by(Images, &CreationDate)[*].[CreationDate,Name,ImageId]매개변수로 이미지가 정렬되는 방법을 설정합니다. 이 경우 이미지는 생성 날짜에 따라 정렬되며 테이블은 생성 날짜, 이미지 이름 및 AMI ID를 표시하도록 구성됩니다.- 3
--filter명령 옵션은 표시되는 RHEL 버전을 설정합니다. 이 예에서는 필터가"Name=name,Values=RHEL-8.4*"로 설정되므로 RHEL 8.4 AMI가 표시됩니다.- 4
--region명령 옵션은 AMI가 저장된 리전을 설정합니다.- 5
--output명령 옵션은 결과가 표시되는 방법을 설정합니다.
AWS용 RHEL 컴퓨팅 머신을 생성할 때 AMI가 RHEL 8.4 또는 8.5인지 확인합니다.
출력 예
------------------------------------------------------------------------------------------------------------
| DescribeImages |
+---------------------------+-----------------------------------------------------+------------------------+
| 2021-03-18T14:23:11.000Z | RHEL-8.4.0_HVM_BETA-20210309-x86_64-1-Hourly2-GP2 | ami-07eeb4db5f7e5a8fb |
| 2021-03-18T14:38:28.000Z | RHEL-8.4.0_HVM_BETA-20210309-arm64-1-Hourly2-GP2 | ami-069d22ec49577d4bf |
| 2021-05-18T19:06:34.000Z | RHEL-8.4.0_HVM-20210504-arm64-2-Hourly2-GP2 | ami-01fc429821bf1f4b4 |
| 2021-05-18T20:09:47.000Z | RHEL-8.4.0_HVM-20210504-x86_64-2-Hourly2-GP2 | ami-0b0af3577fe5e3532 |
+---------------------------+-----------------------------------------------------+------------------------+10.4. RHEL 컴퓨팅 노드 준비
RHEL (Red Hat Enterprise Linux) 시스템을 OpenShift Container Platform 클러스터에 추가하기 전에 각 호스트를 RHSM (Red Hat Subscription Manager)에 등록하고 활성 OpenShift Container Platform 서브스크립션을 연결하고 필요한 저장소를 활성화해야합니다. NetworkManager 가 호스트의 모든 인터페이스를 제어하도록 활성화 및 구성되었는지 확인합니다.
각 호스트에서 RHSM으로 동륵합니다.
# subscription-manager register --username=<user_name> --password=<password>RHSM에서 최신 서브스크립션 데이터를 가져옵니다.
# subscription-manager refresh사용 가능한 서브스크립션을 나열하십시오.
# subscription-manager list --available --matches '*OpenShift*'이전 명령의 출력에서 OpenShift Container Platform 서브스크립션의 풀 ID를 찾아서 이를 연결합니다.
# subscription-manager attach --pool=<pool_id>모든 yum 저장소를 비활성화합니다.
활성화된 모든 RHSM 저장소를 비활성화합니다.
# subscription-manager repos --disable="*"나머지 yum 저장소를 나열하고
repo id아래에 해당 이름을 적어 둡니다.# yum repolistyum-config-manager를 사용하여 나머지 yum 리포지토리를 비활성화합니다.# yum-config-manager --disable <repo_id>또는 모든 리포지토리를 비활성화합니다.
# yum-config-manager --disable \*사용 가능한 리포지토리가 많으면 몇 분의 시간이 소요될 수 있습니다.
OpenShift Container Platform 4.11에 필요한 리포지토리를 활성화합니다.
# subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.11-for-rhel-8-x86_64-rpms" \ --enable="fast-datapath-for-rhel-8-x86_64-rpms"호스트에서 firewalld를 중지하고 비활성화합니다.
# systemctl disable --now firewalld.service참고나중에 firewalld를 활성화할 수 없습니다. 활성화하면 작업자의 OpenShift Container Platform 로그에 액세스할 수 없습니다.
10.5. AWS의 RHEL 인스턴스에 역할 권한 연결
브라우저에서 Amazon IAM 콘솔을 사용하여 필요한 역할을 선택하고 작업자 노드에 할당할 수 있습니다.
프로세스
- AWS IAM 콘솔에서 원하는 IAM 역할을 생성합니다.
- 원하는 작업자 노드에 IAM 역할을 연결합니다.
10.6. RHEL 작업자 노드를 owned 또는 shared로 태그 지정
클러스터는 kubernetes.io/cluster/<clusterid>,Value=(owned|shared) 태그 값을 사용하여 AWS 클러스터와 관련된 리소스의 수명을 결정합니다.
-
클러스터 제거의 일부로 리소스를 제거해야 하는 경우
owned태그 값을 추가해야 합니다. -
클러스터가 제거된 후에도 리소스가 계속 존재하는 경우
shared태그 값을 추가해야 합니다. 이 태그는 클러스터가 이 리소스를 사용하지만 리소스에 대해 별도의 소유자가 있음을 나타냅니다.
프로세스
-
RHEL 컴퓨팅 머신의 경우 RHEL 작업자 인스턴스는
kubernetes.io/cluster/<clusterid>=owned또는kubernetes.io/cluster/<cluster-id>=shared로 태그 지정해야 합니다.
kubernetes.io/cluster/<name>,Value=<clusterid> 태그로 기존 보안 그룹을 태그하지 마십시오. 그렇지 않으면 ELB(Elastic Load Balancing)에서 로드 밸런서를 생성할 수 없습니다.
10.7. 클러스터에 더 많은 RHEL 컴퓨팅 시스템 업데이트 추가
RHEL(Red Hat Enterprise Linux)을 운영 체제로 사용하는 컴퓨팅 머신을 OpenShift Container Platform 4.11 클러스터에 더 추가할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터에는 이미 RHEL 컴퓨팅 노드가 포함되어 있습니다.
-
첫 번째 RHEL 컴퓨팅 머신을 클러스터에 추가하는 데 사용한
hosts파일은 Playbook을 실행하는 머신에 있습니다. - Playbook을 실행하는 컴퓨터는 모든 RHEL 호스트에 액세스할 수 있어야합니다. SSH 프록시 또는 VPN을 사용하는 Bastion를 포함하여 회사에서 허용하는 모든 방법을 사용할 수 있습니다.
-
클러스터의
kubeconfig파일 및 클러스터를 설치에 사용된 설치 프로그램은 Playbook을 실행하는 머신에 있습니다. - 설치를 위해 RHEL 호스트를 준비해야합니다.
- Playbook을 실행하는 머신에서 모든 RHEL 호스트에 대한 SSH 액세스 권한이있는 사용자를 구성하십시오.
- SSH 키 기반 인증을 사용하는 경우 SSH 에이전트를 사용하여 키를 관리해야합니다.
-
Playbook을 실행하는 머신에 OpenShift CLI (
oc)를 설치합니다.
프로세스
-
컴퓨팅 시스템 호스트 및 필수 변수를 정의하는
/<path>/inventory/hosts에서 Ansible 인벤토리 파일을 엽니 다. -
파일의
[new_workers]섹션 이름을[workers]로 변경합니다. [new_workers]섹션을 파일에 추가하고 각각의 새 호스트의 정규화된 도메인 이름을 정의합니다. 파일은 다음 예제와 유사합니다.[all:vars] ansible_user=root #ansible_become=True openshift_kubeconfig_path="~/.kube/config" [workers] mycluster-rhel8-0.example.com mycluster-rhel8-1.example.com [new_workers] mycluster-rhel8-2.example.com mycluster-rhel8-3.example.com이 예에서
mycluster-rhel8-0.example.com및mycluster-rhel8-1.example.com시스템은 클러스터에 있으며mycluster-rhel8-2.example.com및mycluster-rhel8-3.example.com시스템을 추가합니다.Ansible Playbook 디렉토리로 이동합니다.
$ cd /usr/share/ansible/openshift-ansible스케일 업 Playbook을 실행합니다.
$ ansible-playbook -i /<path>/inventory/hosts playbooks/scaleup.yml1 - 1
<path>에 대해 생성한 Ansible 인벤토리 파일의 경로를 지정합니다.
10.8. 시스템의 인증서 서명 요청 승인
클러스터에 시스템을 추가하면 추가한 시스템별로 보류 중인 인증서 서명 요청(CSR)이 두 개씩 생성됩니다. 이러한 CSR이 승인되었는지 확인해야 하며, 필요한 경우 이를 직접 승인해야 합니다. 클라이언트 요청을 먼저 승인한 다음 서버 요청을 승인해야 합니다.
전제 조건
- 클러스터에 시스템을 추가했습니다.
프로세스
클러스터가 시스템을 인식하는지 확인합니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.24.0 master-1 Ready master 63m v1.24.0 master-2 Ready master 64m v1.24.0출력에 생성된 모든 시스템이 나열됩니다.
참고이전 출력에는 일부 CSR이 승인될 때까지 컴퓨팅 노드(작업자 노드라고도 함)가 포함되지 않을 수 있습니다.
보류 중인 CSR을 검토하고 클러스터에 추가한 각 시스템에 대해
Pending또는Approved상태의 클라이언트 및 서버 요청이 표시되는지 확인합니다.$ oc get csr출력 예
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...예에서는 두 시스템이 클러스터에 참여하고 있습니다. 목록에는 승인된 CSR이 더 많이 나타날 수도 있습니다.
CSR이 승인되지 않은 경우, 추가된 시스템에 대한 모든 보류 중인 CSR이
Pending상태로 전환된 후 클러스터 시스템의 CSR을 승인합니다.참고CSR은 교체 주기가 자동으로 만료되므로 클러스터에 시스템을 추가한 후 1시간 이내에 CSR을 승인하십시오. 한 시간 내에 승인하지 않으면 인증서가 교체되고 각 노드에 대해 두 개 이상의 인증서가 표시됩니다. 이러한 인증서를 모두 승인해야 합니다. 클라이언트 CSR이 승인되면 Kubelet은 인증서에 대한 보조 CSR을 생성하므로 수동 승인이 필요합니다. 그러면 Kubelet에서 동일한 매개변수를 사용하여 새 인증서를 요청하는 경우 인증서 갱신 요청은
machine-approver에 의해 자동으로 승인됩니다.참고베어 메탈 및 기타 사용자 프로비저닝 인프라와 같이 머신 API를 사용하도록 활성화되지 않는 플랫폼에서 실행되는 클러스터의 경우 CSR(Kubelet service Certificate Request)을 자동으로 승인하는 방법을 구현해야 합니다. 요청이 승인되지 않으면 API 서버가 kubelet에 연결될 때 서비스 인증서가 필요하므로
oc exec,oc rsh,oc logs명령을 성공적으로 수행할 수 없습니다. Kubelet 엔드 포인트에 연결하는 모든 작업을 수행하려면 이 인증서 승인이 필요합니다. 이 방법은 새 CSR을 감시하고 CSR이system:node또는system:admin그룹의node-bootstrapper서비스 계정에 의해 제출되었는지 확인하고 노드의 ID를 확인합니다.개별적으로 승인하려면 유효한 CSR 각각에 대해 다음 명령을 실행하십시오.
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
보류 중인 CSR을 모두 승인하려면 다음 명령을 실행하십시오.
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve참고일부 Operator는 일부 CSR이 승인될 때까지 사용할 수 없습니다.
이제 클라이언트 요청이 승인되었으므로 클러스터에 추가한 각 머신의 서버 요청을 검토해야 합니다.
$ oc get csr출력 예
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...나머지 CSR이 승인되지 않고
Pending상태인 경우 클러스터 머신의 CSR을 승인합니다.개별적으로 승인하려면 유효한 CSR 각각에 대해 다음 명령을 실행하십시오.
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
보류 중인 CSR을 모두 승인하려면 다음 명령을 실행하십시오.
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
모든 클라이언트 및 서버 CSR이 승인된 후 머신은
Ready상태가 됩니다. 다음 명령을 실행하여 확인합니다.$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.24.0 master-1 Ready master 73m v1.24.0 master-2 Ready master 74m v1.24.0 worker-0 Ready worker 11m v1.24.0 worker-1 Ready worker 11m v1.24.0참고머신이
Ready상태로 전환하는 데 서버 CSR의 승인 후 몇 분이 걸릴 수 있습니다.
추가 정보
- CSR에 대한 자세한 내용은 인증서 서명 요청을 참조하십시오.
10.9. Ansible 호스트 파일의 필수 매개 변수
RHEL (Red Hat Enterprise Linux) 컴퓨팅 머신을 클러스터에 추가하기 전에 Ansible 호스트 파일에서 다음 매개 변수를 정의해야합니다.
| 매개변수 | 설명 | 값 |
|---|---|---|
|
| 암호없이 SSH 기반 인증을 허용하는 SSH 사용자입니다. SSH 키 기반 인증을 사용하는 경우 SSH 에이전트를 사용하여 키를 관리해야합니다. |
시스템의 사용자 이름입니다. 기본값은 |
|
|
|
|
|
|
클러스터의 | 구성 파일의 경로 및 이름 |
11장. 수동으로 사용자 프로비저닝 인프라 관리
11.1. 사용자 프로비저닝 인프라가 있는 클러스터에 수동으로 컴퓨팅 머신 추가
설치 프로세스의 일부 또는 설치 후 사용자 프로비저닝 인프라의 클러스터에 컴퓨팅 머신을 추가할 수 있습니다. 설치 후 프로세스에는 설치 중에 사용된 것과 동일한 구성 파일과 매개 변수 중 일부가 필요합니다.
11.1.1. Amazon Web Services에 컴퓨팅 머신 추가
AWS(Amazon Web Services)의 OpenShift Container Platform 클러스터에 컴퓨팅 머신을 추가하려면 CloudFormation 템플릿을 사용하여 AWS에 컴퓨팅 머신 추가 를 참조하십시오.
11.1.2. Microsoft Azure에 컴퓨팅 머신 추가
Microsoft Azure의 OpenShift Container Platform 클러스터에 컴퓨팅 머신을 추가하려면 Azure에서 추가 작업자 머신 생성을 참조하십시오.
11.1.3. Azure Stack Hub에 컴퓨팅 머신 추가
Azure Stack Hub의 OpenShift Container Platform 클러스터에 컴퓨팅 머신을 추가하려면 Azure Stack Hub 에서 추가 작업자 머신 생성을 참조하십시오.
11.1.4. Google Cloud Platform에 컴퓨팅 머신 추가
GCP(Google Cloud Platform)의 OpenShift Container Platform 클러스터에 컴퓨팅 머신을 추가하려면 GCP에 추가 작업자 머신 생성을 참조하십시오.
11.1.5. vSphere에 컴퓨팅 머신 추가
컴퓨팅 머신 세트를 사용하여 vSphere에서 OpenShift Container Platform 클러스터에 대한 추가 컴퓨팅 머신 생성을 자동화할 수 있습니다.
클러스터에 컴퓨팅 머신을 수동으로 추가하려면 vSphere에 컴퓨팅 머신 추가를 수동으로 참조하십시오.
11.1.6. RHV에 컴퓨팅 시스템 추가
RHV의 OpenShift Container Platform 클러스터에 더 많은 컴퓨팅 머신을 추가하려면 RHV에 컴퓨팅 시스템 추가를 참조하십시오.
11.1.7. 베어 메탈에 컴퓨팅 머신 추가
베어 메탈의 OpenShift Container Platform 클러스터에 컴퓨팅 머신을 추가하려면 베어 메탈에 컴퓨팅 머신 추가를 참조하십시오.
11.2. CloudFormation 템플릿을 사용하여 AWS에 컴퓨팅 머신 추가
샘플 CloudFormation 템플릿을 사용하여 생성한 AWS(Amazon Web Services)의 OpenShift Container Platform 클러스터에 더 많은 컴퓨팅 머신을 추가할 수 있습니다.
11.2.1. 사전 요구 사항
- 제공된 AWS CloudFormation 템플릿을 사용하여 AWS 에 클러스터를 설치했습니다.
- 클러스터 설치 중에 컴퓨팅 시스템을 생성하는 데 사용한 JSON 파일 및 CloudFormation 템플릿이 있습니다. 이러한 파일이 없는 경우 설치 절차에 따라 파일을 다시 생성해야 합니다.
11.2.2. CloudFormation 템플릿을 사용하여 AWS 클러스터에 추가
샘플 CloudFormation 템플릿을 사용하여 생성한 AWS(Amazon Web Services)의 OpenShift Container Platform 클러스터에 더 많은 컴퓨팅 머신을 추가할 수 있습니다.
CloudFormation 템플릿은 하나의 컴퓨팅 시스템을 나타내는 스택을 생성합니다. 각 컴퓨팅 시스템의 스택을 생성해야 합니다.
컴퓨팅 노드를 생성하는 데 제공된 CloudFormation 템플릿을 사용하지 않는 경우, 제공된 정보를 검토하고 수동으로 인프라를 생성해야 합니다.. 클러스터가 올바르게 초기화되지 않은 경우, Red Hat 지원팀에 설치 로그를 제시하여 문의해야 할 수도 있습니다.
사전 요구 사항
- CloudFormation 템플릿을 사용하여 OpenShift Container Platform 클러스터를 설치하고 클러스터 설치 중에 컴퓨팅 시스템을 생성하는 데 사용한 JSON 파일 및 CloudFormation 템플릿에 액세스할 수 있습니다.
- AWS CLI를 설치했습니다.
절차
다른 컴퓨팅 스택을 생성합니다.
템플릿을 시작합니다.
$ aws cloudformation create-stack --stack-name <name> \1 --template-body file://<template>.yaml \2 --parameters file://<parameters>.json3 템플릿 구성 요소가 있는지 확인합니다.
$ aws cloudformation describe-stacks --stack-name <name>
- 클러스터에 충분한 컴퓨팅 시스템을 생성할 때까지 계속해서 컴퓨팅 스택을 생성합니다.
11.2.3. 시스템의 인증서 서명 요청 승인
클러스터에 시스템을 추가하면 추가한 시스템별로 보류 중인 인증서 서명 요청(CSR)이 두 개씩 생성됩니다. 이러한 CSR이 승인되었는지 확인해야 하며, 필요한 경우 이를 직접 승인해야 합니다. 클라이언트 요청을 먼저 승인한 다음 서버 요청을 승인해야 합니다.
사전 요구 사항
- 클러스터에 시스템을 추가했습니다.
절차
클러스터가 시스템을 인식하는지 확인합니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.24.0 master-1 Ready master 63m v1.24.0 master-2 Ready master 64m v1.24.0출력에 생성된 모든 시스템이 나열됩니다.
참고이전 출력에는 일부 CSR이 승인될 때까지 컴퓨팅 노드(작업자 노드라고도 함)가 포함되지 않을 수 있습니다.
보류 중인 CSR을 검토하고 클러스터에 추가한 각 시스템에 대해
Pending또는Approved상태의 클라이언트 및 서버 요청이 표시되는지 확인합니다.$ oc get csr출력 예
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...예에서는 두 시스템이 클러스터에 참여하고 있습니다. 목록에는 승인된 CSR이 더 많이 나타날 수도 있습니다.
CSR이 승인되지 않은 경우, 추가된 시스템에 대한 모든 보류 중인 CSR이
Pending상태로 전환된 후 클러스터 시스템의 CSR을 승인합니다.참고CSR은 교체 주기가 자동으로 만료되므로 클러스터에 시스템을 추가한 후 1시간 이내에 CSR을 승인하십시오. 한 시간 내에 승인하지 않으면 인증서가 교체되고 각 노드에 대해 두 개 이상의 인증서가 표시됩니다. 이러한 인증서를 모두 승인해야 합니다. 클라이언트 CSR이 승인되면 Kubelet은 인증서에 대한 보조 CSR을 생성하므로 수동 승인이 필요합니다. 그러면 Kubelet에서 동일한 매개변수를 사용하여 새 인증서를 요청하는 경우 인증서 갱신 요청은
machine-approver에 의해 자동으로 승인됩니다.참고베어 메탈 및 기타 사용자 프로비저닝 인프라와 같이 머신 API를 사용하도록 활성화되지 않는 플랫폼에서 실행되는 클러스터의 경우 CSR(Kubelet service Certificate Request)을 자동으로 승인하는 방법을 구현해야 합니다. 요청이 승인되지 않으면 API 서버가 kubelet에 연결될 때 서비스 인증서가 필요하므로
oc exec,oc rsh,oc logs명령을 성공적으로 수행할 수 없습니다. Kubelet 엔드 포인트에 연결하는 모든 작업을 수행하려면 이 인증서 승인이 필요합니다. 이 방법은 새 CSR을 감시하고 CSR이system:node또는system:admin그룹의node-bootstrapper서비스 계정에 의해 제출되었는지 확인하고 노드의 ID를 확인합니다.개별적으로 승인하려면 유효한 CSR 각각에 대해 다음 명령을 실행하십시오.
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
보류 중인 CSR을 모두 승인하려면 다음 명령을 실행하십시오.
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve참고일부 Operator는 일부 CSR이 승인될 때까지 사용할 수 없습니다.
이제 클라이언트 요청이 승인되었으므로 클러스터에 추가한 각 머신의 서버 요청을 검토해야 합니다.
$ oc get csr출력 예
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...나머지 CSR이 승인되지 않고
Pending상태인 경우 클러스터 머신의 CSR을 승인합니다.개별적으로 승인하려면 유효한 CSR 각각에 대해 다음 명령을 실행하십시오.
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
보류 중인 CSR을 모두 승인하려면 다음 명령을 실행하십시오.
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
모든 클라이언트 및 서버 CSR이 승인된 후 머신은
Ready상태가 됩니다. 다음 명령을 실행하여 확인합니다.$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.24.0 master-1 Ready master 73m v1.24.0 master-2 Ready master 74m v1.24.0 worker-0 Ready worker 11m v1.24.0 worker-1 Ready worker 11m v1.24.0참고머신이
Ready상태로 전환하는 데 서버 CSR의 승인 후 몇 분이 걸릴 수 있습니다.
추가 정보
- CSR에 대한 자세한 내용은 인증서 서명 요청을 참조하십시오.
11.3. vSphere에 수동으로 컴퓨팅 머신 추가
VMware vSphere의 OpenShift Container Platform 클러스터에 더 많은 컴퓨팅 머신을 수동으로 추가할 수 있습니다.
컴퓨팅 머신 세트를 사용하여 클러스터에 대한 추가 VMware vSphere 컴퓨팅 머신 생성을 자동화할 수도 있습니다.
11.3.1. 사전 요구 사항
- vSphere에 클러스터가 설치되어 있어야 합니다.
- 클러스터를 만드는 데 사용한 설치 미디어 및 Red Hat Enterprise Linux CoreOS (RHCOS) 이미지가 있습니다. 이러한 파일이 없는 경우 설치 절차에 따라 파일을 가져와야 합니다.
클러스터를 생성하는 데 사용되는 RHCOS(Red Hat Enterprise Linux CoreOS) 이미지에 액세스할 수 없는 경우 최신 버전의 RHCOS(Red Hat Enterprise Linux CoreOS) 이미지를 사용하여 OpenShift Container Platform 클러스터에 더 많은 컴퓨팅 머신을 추가할 수 있습니다. 자세한 내용은 OpenShift 4.6+로 업그레이드한 후 UPI 클러스터에 새 노드 추가 실패를 참조하십시오.
11.3.2. vSphere의 클러스터에 더 많은 컴퓨팅 머신 추가
VMware vSphere에서 사용자가 프로비저닝한 OpenShift Container Platform 클러스터에 더 많은 컴퓨팅 머신을 추가할 수 있습니다.
사전 요구 사항
- 컴퓨팅 머신의 base64로 인코딩된 Ignition 파일을 가져옵니다.
- 클러스터에 생성한 vSphere 템플릿에 액세스할 수 있습니다.
절차
템플릿이 배포된 후 클러스터에서 시스템의 가상 머신을 배포합니다.
- 템플릿 이름을 마우스 오른쪽 버튼으로 클릭하고 Clone → Clone to Virtual Machine을 클릭합니다.
Select a name and folder 탭에서 가상 머신의 이름을 지정합니다.
compute-1과 같은 머신 유형을 이름에 포함할 수 있습니다.참고vSphere 설치의 모든 가상 머신 이름이 고유한지 확인합니다.
- Select a name and folder 탭에서 클러스터에 대해 생성한 폴더의 이름을 선택합니다.
- Select a compute resource 탭에서 데이터 센터의 호스트 이름을 선택합니다.
- Select clone options에서 Customize this virtual machine’s hardware를 선택합니다.
Customize hardware 탭에서 VM Options → Advanced를 클릭합니다.
Edit Configuration을 클릭하고 Configuration Parameters 창에서 Add Configuration Params를 클릭합니다. 다음 매개변수 이름 및 값을 정의합니다.
-
guestinfo.ignition.config.data: 이 머신 유형에 대해 base64로 인코딩된 컴퓨팅 Ignition 구성 파일의 내용을 붙여넣습니다. -
guestinfo.ignition.config.data.encoding:base64를 지정합니다. -
disk.EnableUUID:TRUE를 지정합니다.
-
- Customize hardware 탭의 Virtual Hardware 패널에서 지정된 값을 필요에 따라 수정합니다. RAM, CPU 및 디스크 스토리지의 양이 시스템 유형에 대한 최소 요구사항을 충족하는지 확인합니다. 또한 사용 가능한 네트워크가 여러 개인 경우 Add network adapter에서 올바른 네트워크를 선택해야 합니다.
- 구성을 완료하고 VM의 전원을 켭니다.
- 계속해서 클러스터에 추가 컴퓨팅 머신을 만듭니다.
11.3.3. 시스템의 인증서 서명 요청 승인
클러스터에 시스템을 추가하면 추가한 시스템별로 보류 중인 인증서 서명 요청(CSR)이 두 개씩 생성됩니다. 이러한 CSR이 승인되었는지 확인해야 하며, 필요한 경우 이를 직접 승인해야 합니다. 클라이언트 요청을 먼저 승인한 다음 서버 요청을 승인해야 합니다.
사전 요구 사항
- 클러스터에 시스템을 추가했습니다.
프로세스
클러스터가 시스템을 인식하는지 확인합니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.24.0 master-1 Ready master 63m v1.24.0 master-2 Ready master 64m v1.24.0출력에 생성된 모든 시스템이 나열됩니다.
참고이전 출력에는 일부 CSR이 승인될 때까지 컴퓨팅 노드(작업자 노드라고도 함)가 포함되지 않을 수 있습니다.
보류 중인 CSR을 검토하고 클러스터에 추가한 각 시스템에 대해
Pending또는Approved상태의 클라이언트 및 서버 요청이 표시되는지 확인합니다.$ oc get csr출력 예
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...예에서는 두 시스템이 클러스터에 참여하고 있습니다. 목록에는 승인된 CSR이 더 많이 나타날 수도 있습니다.
CSR이 승인되지 않은 경우, 추가된 시스템에 대한 모든 보류 중인 CSR이
Pending상태로 전환된 후 클러스터 시스템의 CSR을 승인합니다.참고CSR은 교체 주기가 자동으로 만료되므로 클러스터에 시스템을 추가한 후 1시간 이내에 CSR을 승인하십시오. 한 시간 내에 승인하지 않으면 인증서가 교체되고 각 노드에 대해 두 개 이상의 인증서가 표시됩니다. 이러한 인증서를 모두 승인해야 합니다. 클라이언트 CSR이 승인되면 Kubelet은 인증서에 대한 보조 CSR을 생성하므로 수동 승인이 필요합니다. 그러면 Kubelet에서 동일한 매개변수를 사용하여 새 인증서를 요청하는 경우 인증서 갱신 요청은
machine-approver에 의해 자동으로 승인됩니다.참고베어 메탈 및 기타 사용자 프로비저닝 인프라와 같이 머신 API를 사용하도록 활성화되지 않는 플랫폼에서 실행되는 클러스터의 경우 CSR(Kubelet service Certificate Request)을 자동으로 승인하는 방법을 구현해야 합니다. 요청이 승인되지 않으면 API 서버가 kubelet에 연결될 때 서비스 인증서가 필요하므로
oc exec,oc rsh,oc logs명령을 성공적으로 수행할 수 없습니다. Kubelet 엔드 포인트에 연결하는 모든 작업을 수행하려면 이 인증서 승인이 필요합니다. 이 방법은 새 CSR을 감시하고 CSR이system:node또는system:admin그룹의node-bootstrapper서비스 계정에 의해 제출되었는지 확인하고 노드의 ID를 확인합니다.개별적으로 승인하려면 유효한 CSR 각각에 대해 다음 명령을 실행하십시오.
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
보류 중인 CSR을 모두 승인하려면 다음 명령을 실행하십시오.
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve참고일부 Operator는 일부 CSR이 승인될 때까지 사용할 수 없습니다.
이제 클라이언트 요청이 승인되었으므로 클러스터에 추가한 각 머신의 서버 요청을 검토해야 합니다.
$ oc get csr출력 예
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...나머지 CSR이 승인되지 않고
Pending상태인 경우 클러스터 머신의 CSR을 승인합니다.개별적으로 승인하려면 유효한 CSR 각각에 대해 다음 명령을 실행하십시오.
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
보류 중인 CSR을 모두 승인하려면 다음 명령을 실행하십시오.
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
모든 클라이언트 및 서버 CSR이 승인된 후 머신은
Ready상태가 됩니다. 다음 명령을 실행하여 확인합니다.$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.24.0 master-1 Ready master 73m v1.24.0 master-2 Ready master 74m v1.24.0 worker-0 Ready worker 11m v1.24.0 worker-1 Ready worker 11m v1.24.0참고머신이
Ready상태로 전환하는 데 서버 CSR의 승인 후 몇 분이 걸릴 수 있습니다.
추가 정보
- CSR에 대한 자세한 내용은 인증서 서명 요청을 참조하십시오.
11.4. RHV의 클러스터에 컴퓨팅 시스템 추가
OpenShift Container Platform 버전 4.11에서는 RHV의 사용자 프로비저닝 OpenShift Container Platform 클러스터에 더 많은 컴퓨팅 머신을 추가할 수 있습니다.
사전 요구 사항
- 사용자 프로비저닝 인프라를 사용하여 RHV에 클러스터를 설치했습니다.
11.4.1. RHV의 클러스터에 더 많은 컴퓨팅 시스템 추가
프로세스
-
새 작업자를 포함하도록
inventory.yml파일을 수정합니다. create-templates-and-vmsAnsible 플레이북을 실행하여 디스크 및 가상 머신을 생성합니다.$ ansible-playbook -i inventory.yml create-templates-and-vms.ymlworkers.ymlAnsible 플레이북을 실행하여 가상 머신을 시작합니다.$ ansible-playbook -i inventory.yml workers.yml클러스터에 가입하는 새 작업자의 CSR은 관리자가 승인해야 합니다. 다음 명령은 보류 중인 모든 요청을 승인하는 데 도움이 됩니다.
$ oc get csr -ojson | jq -r '.items[] | select(.status == {} ) | .metadata.name' | xargs oc adm certificate approve
11.5. 베어 메탈에 컴퓨팅 머신 추가
베어 메탈의 OpenShift Container Platform 클러스터에 더 많은 컴퓨팅 머신을 추가할 수 있습니다.
11.5.1. 사전 요구 사항
- 베어 메탈에 클러스터가 설치되어 있어야 합니다.
- 클러스터를 만드는 데 사용한 설치 미디어 및 Red Hat Enterprise Linux CoreOS (RHCOS) 이미지가 있습니다. 이러한 파일이 없는 경우 설치 절차에 따라 파일을 가져와야 합니다.
- 사용자 프로비저닝 인프라에 DHCP 서버를 사용할 수 있는 경우 추가 컴퓨팅 머신의 세부 정보를 DHCP 서버 구성에 추가했습니다. 여기에는 영구 IP 주소, DNS 서버 정보 및 각 시스템의 호스트 이름이 포함됩니다.
- 추가하려는 각 컴퓨팅 시스템의 레코드 이름 및 IP 주소를 포함하도록 DNS 구성을 업데이트했습니다. DNS 조회 및 역방향 DNS 조회가 올바르게 확인되었는지 확인했습니다.
클러스터를 생성하는 데 사용되는 RHCOS(Red Hat Enterprise Linux CoreOS) 이미지에 액세스할 수 없는 경우 최신 버전의 RHCOS(Red Hat Enterprise Linux CoreOS) 이미지를 사용하여 OpenShift Container Platform 클러스터에 더 많은 컴퓨팅 머신을 추가할 수 있습니다. 자세한 내용은 OpenShift 4.6+로 업그레이드한 후 UPI 클러스터에 새 노드 추가 실패를 참조하십시오.
11.5.2. RHCOS(Red Hat Enterprise Linux CoreOS) 시스템 생성
베어메탈 인프라에 설치된 클러스터에 컴퓨팅 머신을 추가하기 전에 사용할 RHCOS 머신을 생성해야 합니다. ISO 이미지 또는 네트워크 PXE 부팅을 사용하여 시스템을 생성합니다.
클러스터에 새 노드를 모두 배포하기 위해 클러스터를 설치하는 데 사용한 것과 동일한 ISO 이미지를 사용해야 합니다. 동일한 Ignition 구성 파일을 사용하는 것이 좋습니다. 노드는 워크로드를 실행하기 전에 첫 번째 부팅 시 자동으로 업그레이드됩니다. 업그레이드 전이나 후에 노드를 추가할 수 있습니다.
11.5.2.1. ISO 이미지를 사용하여 추가 RHCOS 머신 생성
ISO 이미지를 사용하여 머신을 생성함으로써 베어 메탈 클러스터에 대해 더 많은 Red Hat Enterprise Linux CoreOS (RHCOS) 컴퓨팅 머신을 생성할 수 있습니다.
사전 요구 사항
- 클러스터의 컴퓨팅 머신에 대한 Ignition 구성 파일의 URL을 가져옵니다. 설치 중에 이 파일은 HTTP 서버에 업로드되어 있어야 합니다.
프로세스
ISO 파일을 사용하여 추가 컴퓨팅 머신에 RHCOS를 설치합니다. 클러스터를 설치하기 전에 머신을 만들 때 사용한 것과 동일한 방법을 사용합니다.
- ISO 이미지를 디스크에 굽고 직접 부팅합니다.
- LOM 인터페이스에서 ISO 리디렉션을 사용합니다.
옵션을 지정하거나 라이브 부팅 시퀀스를 중단하지 않고 RHCOS ISO 이미지를 부팅합니다. 설치 프로그램이 RHCOS 라이브 환경에서 쉘 프롬프트로 부팅될 때까지 기다립니다.
참고커널 인수를 추가하기 위해 RHCOS 설치 부팅 프로세스를 중단할 수 있습니다. 그러나 이 ISO 프로세스에서는 커널 인수를 추가하는 대신 다음 단계에 설명된 대로
coreos-installer명령을 사용해야 합니다.coreos-installer명령을 실행하고 설치 요구 사항을 충족하는 옵션을 지정합니다. 최소한 노드 유형에 대한 Ignition 구성 파일과 설치할 장치를 가리키는 URL을 지정해야 합니다.$ sudo coreos-installer install --ignition-url=http://<HTTP_server>/<node_type>.ign <device> --ignition-hash=sha512-<digest>1 2 참고TLS를 사용하는 HTTPS 서버를 통해 Ignition 구성 파일을 제공하려는 경우
coreos-installer를 실행하기 전에 내부 인증 기관(CA)을 시스템 신뢰 저장소에 추가할 수 있습니다.다음 예제에서는
/dev/sda장치에 부트스트랩 노드 설치를 초기화합니다. 부트스트랩 노드의 Ignition 구성 파일은 IP 주소 192.168.1.2가 있는 HTTP 웹 서버에서 가져옵니다.$ sudo coreos-installer install --ignition-url=http://192.168.1.2:80/installation_directory/bootstrap.ign /dev/sda --ignition-hash=sha512-a5a2d43879223273c9b60af66b44202a1d1248fc01cf156c46d4a79f552b6bad47bc8cc78ddf0116e80c59d2ea9e32ba53bc807afbca581aa059311def2c3e3b머신 콘솔에서 RHCOS 설치 진행률을 모니터링합니다.
중요OpenShift Container Platform 설치를 시작하기 전에 각 노드에서 성공적으로 설치되었는지 확인합니다. 설치 프로세스를 관찰하면 발생할 수 있는 RHCOS 설치 문제의 원인을 파악하는 데 도움이 될 수 있습니다.
- 계속해서 클러스터에 추가 컴퓨팅 머신을 만듭니다.
11.5.2.2. PXE 또는 iPXE 부팅을 통해 RHCOS 머신 생성
PXE 또는 iPXE 부팅을 사용하여 베어 메탈 클러스터에 대해 추가 Red Hat Enterprise Linux CoreOS (RHCOS) 컴퓨팅 머신을 생성할 수 있습니다.
사전 요구 사항
- 클러스터의 컴퓨팅 머신에 대한 Ignition 구성 파일의 URL을 가져옵니다. 설치 중에 이 파일은 HTTP 서버에 업로드되어 있어야 합니다.
-
클러스터 설치 중에 HTTP 서버에 업로드 한 RHCOS ISO 이미지, 압축된 메탈 BIOS,
kernel및initramfs파일의 URL을 가져옵니다. - 설치 중에 OpenShift Container Platform 클러스터에 대한 머신을 생성하는 데 사용한 PXE 부팅 인프라에 액세스할 수 있습니다. RHCOS가 설치된 후 로컬 디스크에서 머신을 부팅해야합니다.
-
UEFI를 사용하는 경우 OpenShift Container Platform 설치 중에 수정 한
grub.conf파일에 액세스할 수 있습니다.
절차
RHCOS 이미지의 PXE 또는 iPXE가 올바르게 설치되었는지 확인합니다.
PXE의 경우:
DEFAULT pxeboot TIMEOUT 20 PROMPT 0 LABEL pxeboot KERNEL http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture>1 APPEND initrd=http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img2 - 1
- HTTP 서버에 업로드한 라이브
kernel파일의 위치를 지정합니다. - 2
- HTTP 서버에 업로드한 RHCOS 파일의 위치를 지정합니다.
initrd매개변수 값은initramfs파일의 위치이고coreos.inst.ignition_url매개변수 값은 작업자 Ignition 설정 파일의 위치이며coreos.live.rootfs_url매개 변수 값은 라이브rootfs파일의 위치입니다.coreos.inst.ignition_url및coreos.live.rootfs_url매개변수는 HTTP 및 HTTPS만 지원합니다.
이 구성은 그래픽 콘솔이 있는 시스템에서 직렬 콘솔 액세스를 활성화하지 않습니다. 다른 콘솔을 구성하려면 APPEND 행에 하나 이상의 console= 인수를 추가합니다. 예를 들어 console=tty0 console=ttyS0을 추가하여 첫 번째 PC 직렬 포트를 기본 콘솔로 설정하고 그래픽 콘솔을 보조 콘솔로 설정합니다. 자세한 내용은 Red Hat Enterprise Linux에서 직렬 터미널 및/또는 콘솔 설정 방법을 참조하십시오.
iPXE의 경우 :
kernel http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture> initrd=main coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img1 initrd --name main http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img2 - 1
- HTTP 서버에 업로드한 RHCOS 파일의 위치를 지정합니다.
kernel매개변수 값은kernel파일의 위치이고initrd=main매개변수는 UEFI 시스템에서 부팅하는 데 필요하며coreos.inst.ignition_url매개 변수 값은 작업자 Ignition 설정 파일의 위치이며,coreos.live.rootfs_url매개 변수 값은 라이브rootfs파일의 위치입니다.coreos.inst.ignition_url및coreos.live.rootfs_url매개변수는 HTTP 및 HTTPS만 지원합니다. - 2
- HTTP 서버에 업로드한
initramfs파일의 위치를 지정합니다.
이 구성은 그래픽 콘솔이 있는 시스템에서 직렬 콘솔 액세스를 활성화하지 않습니다. 다른 콘솔을 구성하려면 kernel 행에 하나 이상의 console= 인수를 추가합니다. 예를 들어 console=tty0 console=ttyS0을 추가하여 첫 번째 PC 직렬 포트를 기본 콘솔로 설정하고 그래픽 콘솔을 보조 콘솔로 설정합니다. 자세한 내용은 Red Hat Enterprise Linux에서 직렬 터미널 및/또는 콘솔 설정 방법을 참조하십시오.
- PXE 또는 iPXE 인프라를 사용하여 클러스터에 필요한 컴퓨팅 머신을 만듭니다.
11.5.3. 시스템의 인증서 서명 요청 승인
클러스터에 시스템을 추가하면 추가한 시스템별로 보류 중인 인증서 서명 요청(CSR)이 두 개씩 생성됩니다. 이러한 CSR이 승인되었는지 확인해야 하며, 필요한 경우 이를 직접 승인해야 합니다. 클라이언트 요청을 먼저 승인한 다음 서버 요청을 승인해야 합니다.
사전 요구 사항
- 클러스터에 시스템을 추가했습니다.
절차
클러스터가 시스템을 인식하는지 확인합니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.24.0 master-1 Ready master 63m v1.24.0 master-2 Ready master 64m v1.24.0출력에 생성된 모든 시스템이 나열됩니다.
참고이전 출력에는 일부 CSR이 승인될 때까지 컴퓨팅 노드(작업자 노드라고도 함)가 포함되지 않을 수 있습니다.
보류 중인 CSR을 검토하고 클러스터에 추가한 각 시스템에 대해
Pending또는Approved상태의 클라이언트 및 서버 요청이 표시되는지 확인합니다.$ oc get csr출력 예
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...예에서는 두 시스템이 클러스터에 참여하고 있습니다. 목록에는 승인된 CSR이 더 많이 나타날 수도 있습니다.
CSR이 승인되지 않은 경우, 추가된 시스템에 대한 모든 보류 중인 CSR이
Pending상태로 전환된 후 클러스터 시스템의 CSR을 승인합니다.참고CSR은 교체 주기가 자동으로 만료되므로 클러스터에 시스템을 추가한 후 1시간 이내에 CSR을 승인하십시오. 한 시간 내에 승인하지 않으면 인증서가 교체되고 각 노드에 대해 두 개 이상의 인증서가 표시됩니다. 이러한 인증서를 모두 승인해야 합니다. 클라이언트 CSR이 승인되면 Kubelet은 인증서에 대한 보조 CSR을 생성하므로 수동 승인이 필요합니다. 그러면 Kubelet에서 동일한 매개변수를 사용하여 새 인증서를 요청하는 경우 인증서 갱신 요청은
machine-approver에 의해 자동으로 승인됩니다.참고베어 메탈 및 기타 사용자 프로비저닝 인프라와 같이 머신 API를 사용하도록 활성화되지 않는 플랫폼에서 실행되는 클러스터의 경우 CSR(Kubelet service Certificate Request)을 자동으로 승인하는 방법을 구현해야 합니다. 요청이 승인되지 않으면 API 서버가 kubelet에 연결될 때 서비스 인증서가 필요하므로
oc exec,oc rsh,oc logs명령을 성공적으로 수행할 수 없습니다. Kubelet 엔드 포인트에 연결하는 모든 작업을 수행하려면 이 인증서 승인이 필요합니다. 이 방법은 새 CSR을 감시하고 CSR이system:node또는system:admin그룹의node-bootstrapper서비스 계정에 의해 제출되었는지 확인하고 노드의 ID를 확인합니다.개별적으로 승인하려면 유효한 CSR 각각에 대해 다음 명령을 실행하십시오.
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
보류 중인 CSR을 모두 승인하려면 다음 명령을 실행하십시오.
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve참고일부 Operator는 일부 CSR이 승인될 때까지 사용할 수 없습니다.
이제 클라이언트 요청이 승인되었으므로 클러스터에 추가한 각 머신의 서버 요청을 검토해야 합니다.
$ oc get csr출력 예
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...나머지 CSR이 승인되지 않고
Pending상태인 경우 클러스터 머신의 CSR을 승인합니다.개별적으로 승인하려면 유효한 CSR 각각에 대해 다음 명령을 실행하십시오.
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
보류 중인 CSR을 모두 승인하려면 다음 명령을 실행하십시오.
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
모든 클라이언트 및 서버 CSR이 승인된 후 머신은
Ready상태가 됩니다. 다음 명령을 실행하여 확인합니다.$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.24.0 master-1 Ready master 73m v1.24.0 master-2 Ready master 74m v1.24.0 worker-0 Ready worker 11m v1.24.0 worker-1 Ready worker 11m v1.24.0참고머신이
Ready상태로 전환하는 데 서버 CSR의 승인 후 몇 분이 걸릴 수 있습니다.
추가 정보
- CSR에 대한 자세한 내용은 인증서 서명 요청을 참조하십시오.
12장. 클러스터 API를 사용하여 머신 관리
클러스터 API를 사용하여 머신을 관리하는 것은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
Cluster API 는 AWS(Amazon Web Services) 및 GCP(Google Cloud Platform) 클러스터의 기술 프리뷰로 OpenShift Container Platform에 통합된 업스트림 프로젝트입니다. Cluster API를 사용하여 OpenShift Container Platform 클러스터에서 머신 세트 및 머신을 생성하고 관리할 수 있습니다. 이 기능은 Machine API를 사용하여 머신 관리하는 것에 대한 대안이나 추가 기능입니다.
OpenShift Container Platform 4.11 클러스터의 경우 Cluster API를 사용하여 클러스터 설치가 완료된 후 노드 호스트 프로비저닝 관리 작업을 수행할 수 있습니다. 이 시스템을 사용하면 퍼블릭 또는 프라이빗 클라우드 인프라에 더하여 탄력적이고 동적인 프로비저닝 방법을 사용할 수 있습니다.
Cluster API Technology Preview를 사용하면 지원되는 공급자를 위해 OpenShift Container Platform 클러스터에 컴퓨팅 머신 및 머신 세트를 생성할 수 있습니다. 이 구현에서 활성화되는 기능은 Machine API에서 사용할 수 없는 기능도 탐색할 수 있습니다.
혜택
OpenShift Container Platform 사용자 및 개발자는 클러스터 API를 사용하여 다음과 같은 이점을 실현할 수 있습니다.
- 시스템 API에서 지원하지 않을 수 있는 업스트림 커뮤니티 클러스터 API 인프라 공급자를 사용하는 옵션입니다.
- 인프라 공급업체에서 머신 컨트롤러를 유지보수하는 타사와 협업할 수 있는 기회를 제공합니다.
- OpenShift Container Platform에서 인프라 관리에 동일한 Kubernetes 툴 세트를 사용하는 기능
- Machine API에서 사용할 수 없는 기능을 지원하는 클러스터 API를 사용하여 머신 세트를 생성하는 기능입니다.
제한 사항
클러스터 API를 사용하여 시스템 관리 기능은 기술 프리뷰 기능이며 다음과 같은 제한 사항이 있습니다.
- AWS 및 GCP 클러스터만 지원됩니다.
-
이 기능을 사용하려면
TechPreviewNoUpgrade기능 세트를 활성화해야 합니다. 이 기능 세트를 활성화하면 실행 취소할 수 없으며 마이너 버전 업데이트를 방지할 수 있습니다. - 클러스터 API에 필요한 기본 리소스를 수동으로 생성해야 합니다.
- 컨트롤 플레인 시스템은 클러스터 API에서 관리할 수 없습니다.
- Machine API에서 Cluster API 머신 세트로 생성한 기존 머신 세트의 마이그레이션은 지원되지 않습니다.
- Machine API와의 전체 기능 패리티를 사용할 수 없습니다.
12.1. 클러스터 API 아키텍처
업스트림 Cluster API의 OpenShift Container Platform 통합은 Cluster CAPI Operator에 의해 구현 및 관리됩니다. Cluster CAPI Operator 및 해당 피연산자는 openshift-machine-api 네임스페이스를 사용하는 Machine API와 달리 openshift-cluster-api 네임스페이스에서 프로비저닝됩니다.
12.1.1. Cluster CAPI Operator
Cluster CAPI Operator는 Cluster API 리소스의 라이프사이클을 유지보수하는 OpenShift Container Platform Operator입니다. 이 Operator는 OpenShift Container Platform 클러스터 내에서 클러스터 API 프로젝트 배포와 관련된 모든 관리 작업을 담당합니다.
클러스터 API를 사용할 수 있도록 클러스터가 올바르게 구성된 경우 Cluster CAPI Operator는 클러스터에 Cluster API Operator를 설치합니다.
Cluster CAPI Operator는 업스트림 Cluster API Operator와 다릅니다.
자세한 내용은 Cluster Operators 참조 콘텐츠의 Cluster CAPI Operator 항목을 참조하십시오.
12.1.2. 기본 리소스
클러스터 API는 다음과 같은 기본 리소스로 구성됩니다. 이 기능의 기술 프리뷰의 경우 openshift-cluster-api 네임스페이스에서 이러한 리소스를 수동으로 생성해야 합니다.
- Cluster
- 클러스터 API에서 관리하는 클러스터를 나타내는 기본 단위입니다.
- 인프라
- 클러스터의 모든 머신 세트에서 공유하는 속성(예: 지역 및 서브넷)을 정의하는 공급자별 리소스입니다.
- 머신 템플릿
- 머신 세트에서 생성하는 머신의 속성을 정의하는 공급자별 템플릿입니다.
- 머신 세트
시스템 그룹입니다.
머신 세트는 머신에 연관되어 있고 복제본 세트는 pod에 연관되어 있습니다. 더 많은 머신이 필요하거나 규모를 줄여야하는 경우 컴퓨팅 요구 사항에 맞게 머신 세트의
replicas필드를 변경합니다.클러스터 API를 사용하면 머신 세트는
Cluster오브젝트 및 공급자별 머신 템플릿을 참조합니다.- 머신
노드의 호스트를 설명하는 기본 단위입니다.
클러스터 API는 머신 템플릿의 구성을 기반으로 머신을 생성합니다.
12.2. 샘플 YAML 파일
Cluster API Technology Preview의 경우 Cluster API에 필요한 기본 리소스를 수동으로 생성해야 합니다. 이 섹션의 YAML 파일 예제에서는 이러한 리소스가 함께 작동하도록 하고 사용자 환경에 적합한 머신의 설정을 구성하는 방법을 보여줍니다.
12.2.1. 클러스터 API 클러스터 리소스의 샘플 YAML
클러스터 리소스는 클러스터의 이름 및 인프라 공급자를 정의하고 Cluster API에서 관리합니다. 이 리소스는 모든 공급자에 대해 동일한 구조를 갖습니다.
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: <cluster_name>
namespace: openshift-cluster-api
spec:
infrastructureRef:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: <infrastructure_kind>
name: <cluster_name>
namespace: openshift-cluster-api나머지 클러스터 API 리소스는 공급자별로 다릅니다. 클러스터의 YAML 파일 예를 참조하십시오.
12.2.2. Amazon Web Services 클러스터 구성을 위한 샘플 YAML 파일
일부 클러스터 API 리소스는 공급자별로 다릅니다. 이 섹션의 YAML 파일의 예제에서는 AWS(Amazon Web Services) 클러스터의 구성을 보여줍니다.
12.2.2.1. Amazon Web Services에서 클러스터 API 인프라 리소스의 샘플 YAML
인프라 리소스는 공급자별이며, 지역 및 서브넷과 같이 클러스터의 모든 머신 세트에서 공유하는 속성을 정의합니다. 머신 세트는 머신을 생성할 때 이 리소스를 참조합니다.
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: AWSCluster
metadata:
name: <cluster_name>
namespace: openshift-cluster-api
spec:
region: <region> 12.2.2.2. Amazon Web Services에서 클러스터 API 머신 템플릿 리소스의 샘플 YAML
머신 템플릿 리소스는 공급자별이며 머신 세트가 생성하는 머신의 기본 속성을 정의합니다. 머신 세트는 머신을 생성할 때 이 템플릿을 참조합니다.
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha4
kind: AWSMachineTemplate
metadata:
name: <template_name>
namespace: openshift-cluster-api
spec:
template:
spec:
uncompressedUserData: true
iamInstanceProfile: ....
instanceType: m5.large
cloudInit:
insecureSkipSecretsManager: true
ami:
id: ....
subnet:
filters:
- name: tag:Name
values:
- ...
additionalSecurityGroups:
- filters:
- name: tag:Name
values:
- ...12.2.2.3. Amazon Web Services에서 클러스터 API 머신 세트 리소스의 샘플 YAML
머신 세트 리소스는 생성하는 시스템의 추가 속성을 정의합니다. 머신 세트는 머신을 생성할 때 인프라 리소스 및 머신 템플릿도 참조합니다.
apiVersion: cluster.x-k8s.io/v1alpha4
kind: MachineSet
metadata:
name: <machine_set_name>
namespace: openshift-cluster-api
spec:
clusterName: <cluster_name>
replicas: 1
selector:
matchLabels:
test: example
template:
metadata:
labels:
test: example
spec:
bootstrap:
dataSecretName: worker-user-data
clusterName: <cluster_name>
infrastructureRef:
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha4
kind: AWSMachineTemplate
name: <cluster_name> 12.2.3. Google Cloud Platform 클러스터 구성을 위한 샘플 YAML 파일
일부 클러스터 API 리소스는 공급자별로 다릅니다. 이 섹션의 YAML 파일의 예제에서는 GCP(Google Cloud Platform) 클러스터의 구성을 보여줍니다.
12.2.3.1. Google Cloud Platform에서 클러스터 API 인프라 리소스의 샘플 YAML
인프라 리소스는 공급자별이며, 지역 및 서브넷과 같이 클러스터의 모든 머신 세트에서 공유하는 속성을 정의합니다. 머신 세트는 머신을 생성할 때 이 리소스를 참조합니다.
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: GCPCluster
metadata:
name: <cluster_name>
spec:
network:
name: <cluster_name>-network
project: <project>
region: <region> 12.2.3.2. Google Cloud Platform에서 클러스터 API 머신 템플릿 리소스의 샘플 YAML
머신 템플릿 리소스는 공급자별이며 머신 세트가 생성하는 머신의 기본 속성을 정의합니다. 머신 세트는 머신을 생성할 때 이 템플릿을 참조합니다.
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: GCPMachineTemplate
metadata:
name: <template_name>
namespace: openshift-cluster-api
spec:
template:
spec:
rootDeviceType: pd-ssd
rootDeviceSize: 128
instanceType: n1-standard-4
image: projects/rhcos-cloud/global/images/rhcos-411-85-202203181601-0-gcp-x86-64
subnet: <cluster_name>-worker-subnet
serviceAccounts:
email: <service_account_email_address>
scopes:
- https://www.googleapis.com/auth/cloud-platform
additionalLabels:
kubernetes-io-cluster-<cluster_name>: owned
additionalNetworkTags:
- <cluster_name>-worker
ipForwarding: Disabled12.2.3.3. Google Cloud Platform에서 클러스터 API 머신 세트 리소스의 샘플 YAML
머신 세트 리소스는 생성하는 시스템의 추가 속성을 정의합니다. 머신 세트는 머신을 생성할 때 인프라 리소스 및 머신 템플릿도 참조합니다.
apiVersion: cluster.x-k8s.io/v1beta1
kind: MachineSet
metadata:
name: <machine_set_name>
namespace: openshift-cluster-api
spec:
clusterName: <cluster_name>
replicas: 1
selector:
matchLabels:
test: test
template:
metadata:
labels:
test: test
spec:
bootstrap:
dataSecretName: worker-user-data
clusterName: <cluster_name>
infrastructureRef:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: GCPMachineTemplate
name: <machine_set_name>
failureDomain: <failure_domain> 12.3. 클러스터 API 머신 세트 생성
클러스터 API를 사용하여 선택한 특정 워크로드에 대한 머신 컴퓨팅 리소스를 동적으로 관리하는 머신 세트를 생성할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터를 배포합니다.
- 클러스터 API 사용을 활성화합니다.
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다.
프로세스
클러스터 CR(사용자 정의 리소스)이 포함된 YAML 파일을 생성하고 이름이 <
cluster_resource_file>.yaml입니다.<
cluster_name> 매개변수에 설정할 값이 확실하지 않은 경우 클러스터에서 기존 Machine API 머신 세트의 값을 확인할 수 있습니다.Machine API 머신 세트를 나열하려면 다음 명령을 실행합니다.
$ oc get machinesets -n openshift-machine-api1 - 1
openshift-machine-api네임스페이스를 지정합니다.
출력 예
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m특정 머신 세트 CR의 내용을 표시하려면 다음 명령을 실행합니다.
$ oc get machineset <machineset_name> \ -n openshift-machine-api \ -o yaml출력 예
... template: metadata: labels: machine.openshift.io/cluster-api-cluster: agl030519-vplxk1 machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker machine.openshift.io/cluster-api-machineset: agl030519-vplxk-worker-us-east-1a ...- 1
- <cluster
_name> 매개변수에 사용하는 클러스터ID입니다.
다음 명령을 실행하여 클러스터 CR을 생성합니다.
$ oc create -f <cluster_resource_file>.yaml검증
클러스터 CR이 생성되었는지 확인하려면 다음 명령을 실행합니다.
$ oc get cluster출력 예
NAME PHASE AGE VERSION <cluster_name> Provisioning 4h6m-
인프라 CR이 포함된 YAML 파일을 생성하고 이름이 <
infrastructure_resource_file>.yaml입니다. 다음 명령을 실행하여 인프라 CR을 생성합니다.
$ oc create -f <infrastructure_resource_file>.yaml검증
인프라 CR이 생성되었는지 확인하려면 다음 명령을 실행합니다.
$ oc get <infrastructure_kind>여기서
<infrastructure_kind>는 해당 플랫폼에 해당하는 값입니다.출력 예
NAME CLUSTER READY VPC BASTION IP <cluster_name> <cluster_name> true-
머신 템플릿 CR이 포함된 YAML 파일을 생성하고 이름이 <
machine_template_resource_file>.yaml입니다. 다음 명령을 실행하여 머신 템플릿 CR을 생성합니다.
$ oc create -f <machine_template_resource_file>.yaml검증
머신 템플릿 CR이 생성되었는지 확인하려면 다음 명령을 실행합니다.
$ oc get <machine_template_kind>여기서
<machine_template_kind>는 해당 플랫폼에 해당하는 값입니다.출력 예
NAME AGE <template_name> 77m-
머신 세트 CR이 포함된 YAML 파일을 생성하고 이름이 <
machine_set_resource_file>.yaml입니다. 다음 명령을 실행하여 머신 세트 CR을 생성합니다.
$ oc create -f <machine_set_resource_file>.yaml검증
머신 세트 CR이 생성되었는지 확인하려면 다음 명령을 실행합니다.
$ oc get machineset -n openshift-cluster-api1 - 1
openshift-cluster-api네임스페이스를 지정합니다.
출력 예
NAME CLUSTER REPLICAS READY AVAILABLE AGE VERSION <machine_set_name> <cluster_name> 1 1 1 17m새 머신 세트가 사용 가능한 경우
REPLICAS및AVAILABLE값이 일치합니다. 머신 세트를 사용할 수 없는 경우 몇 분 후에 명령을 다시 실행합니다.
검증
머신 세트가 원하는 구성에 따라 머신을 생성하는지 확인하려면 클러스터의 시스템 및 노드 목록을 검토할 수 있습니다.
클러스터 API 시스템 목록을 보려면 다음 명령을 실행합니다.
$ oc get machine -n openshift-cluster-api1 - 1
openshift-cluster-api네임스페이스를 지정합니다.
출력 예
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION <machine_set_name>-<string_id> <cluster_name> <ip_address>.<region>.compute.internal <provider_id> Running 8m23s노드 목록을 보려면 다음 명령을 실행합니다.
$ oc get node출력 예
NAME STATUS ROLES AGE VERSION <ip_address_1>.<region>.compute.internal Ready worker 5h14m v1.24.0+284d62a <ip_address_2>.<region>.compute.internal Ready master 5h19m v1.24.0+284d62a <ip_address_3>.<region>.compute.internal Ready worker 7m v1.24.0+284d62a
12.4. Cluster API를 사용하는 클러스터 문제 해결
이 섹션의 정보를 사용하여 발생할 수 있는 문제를 이해하고 복구하십시오. 일반적으로 클러스터 API 문제 해결 단계는 시스템 API 문제 해결을 위한 해당 단계와 유사합니다.
클러스터 CAPI Operator 및 해당 피연산자는 openshift-cluster-api 네임스페이스에서 프로비저닝되지만 Machine API는 openshift-machine-api 네임스페이스를 사용합니다. 네임스페이스를 참조하는 oc 명령을 사용하는 경우 올바른 네임스페이스를 참조해야 합니다.
12.4.1. CLI 명령에서 클러스터 API 머신 반환
Cluster API를 사용하는 클러스터의 경우 Cluster API 시스템의 명령이 있습니다. 문자 oc get machine return results와 같은 occ 가 알파벳순으로 문자 앞에 있기 때문에 클러스터 API 머신이 Machine API 머신보다 먼저 반환에 표시됩니다.
Machine API 머신만 나열하려면
oc get machine명령을 실행할 때 정규화된 이름machines.machine.openshift.io를 사용합니다.$ oc get machines.machine.openshift.io클러스터 API 시스템만 나열하려면
oc get machine명령을 실행할 때 정규화된 이름machines.cluster.x-k8s.io를 사용합니다.$ oc get machines.cluster.x-k8s.io
13장. 머신 상태 점검 배포
머신 풀에서 손상된 머신을 자동으로 복구하도록 머신 상태 점검을 구성하고 배포할 수 있습니다.
머신 API가 작동하는 클러스터에서만 고급 머신 관리 및 스케일링 기능을 사용할 수 있습니다. 사용자 프로비저닝 인프라가 있는 클러스터에는 Machine API를 사용하려면 추가 검증 및 구성이 필요합니다.
인프라 플랫폼 유형의 클러스터가 Machine API를 사용할 수 없습니다. 이 제한은 클러스터에 연결된 컴퓨팅 시스템이 기능을 지원하는 플랫폼에 설치된 경우에도 적용됩니다. 이 매개변수는 설치 후 변경할 수 없습니다.
클러스터의 플랫폼 유형을 보려면 다음 명령을 실행합니다.
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'13.1. 머신 상태 점검 정보
머신 상태 점검에서는 특정 머신 풀의 비정상적인 머신을 자동으로 복구합니다.
머신 상태를 모니터링하기 위해 컨트롤러 구성을 정의할 리소스를 만듭니다. NotReady 상태를 5 분 동안 유지하거나 노드 문제 탐지기(node-problem-detector)에 영구적인 조건을 표시하는 등 검사할 조건과 모니터링할 머신 세트의 레이블을 설정합니다.
마스터 역할이 있는 머신에는 머신 상태 점검을 적용할 수 없습니다.
MachineHealthCheck 리소스를 관찰하는 컨트롤러에서 정의된 상태를 확인합니다. 머신이 상태 확인에 실패하면 머신이 자동으로 삭제되고 대체할 머신이 만들어집니다. 머신이 삭제되면 machine deleted 이벤트가 표시됩니다.
머신 삭제로 인한 영향을 제한하기 위해 컨트롤러는 한 번에 하나의 노드 만 드레인하고 삭제합니다. 대상 머신 풀에서 허용된 maxUnhealthy 임계값 보다 많은 비정상적인 머신이 있는 경우 수동 개입이 수행될 수 있도록 복구가 중지됩니다.
워크로드 및 요구 사항을 살펴보고 신중하게 시간 초과를 고려하십시오.
- 시간 제한이 길어지면 비정상 머신의 워크로드에 대한 다운타임이 길어질 수 있습니다.
-
시간 초과가 너무 짧으면 수정 루프가 발생할 수 있습니다. 예를 들어
NotReady상태를 확인하는 시간은 머신이 시작 프로세스를 완료할 수 있을 만큼 충분히 길어야 합니다.
검사를 중지하려면 리소스를 제거합니다.
13.1.1. 머신 상태 검사 배포 시 제한 사항
머신 상태 점검을 배포하기 전에 고려해야 할 제한 사항은 다음과 같습니다.
- 머신 세트가 소유한 머신만 머신 상태 검사를 통해 업데이트를 적용합니다.
- 컨트롤 플레인 시스템은 현재 지원되지 않으며 비정상적인 경우 업데이트 적용되지 않습니다.
- 머신의 노드가 클러스터에서 제거되면 머신 상태 점검에서 이 머신을 비정상적으로 간주하고 즉시 업데이트를 적용합니다.
-
nodeStartupTimeout후 시스템의 해당 노드가 클러스터에 참여하지 않으면 업데이트가 적용됩니다. -
Machine리소스 단계가Failed하면 즉시 머신에 업데이트를 적용합니다.
13.2. MachineHealthCheck 리소스 샘플
베어 메탈 이외의 모든 클라우드 기반 설치 유형에 대한 MachineHealthCheck 리소스는 다음 YAML 파일과 유사합니다.
apiVersion: machine.openshift.io/v1beta1
kind: MachineHealthCheck
metadata:
name: example
namespace: openshift-machine-api
spec:
selector:
matchLabels:
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <cluster_name>-<label>-<zone>
unhealthyConditions:
- type: "Ready"
timeout: "300s"
status: "False"
- type: "Ready"
timeout: "300s"
status: "Unknown"
maxUnhealthy: "40%"
nodeStartupTimeout: "10m" - 1
- 배포할 머신 상태 점검의 이름을 지정합니다.
- 2 3
- 확인할 머신 풀의 레이블을 지정합니다.
- 4
- 추적할 머신 세트를
<cluster_name>-<label>-<zone>형식으로 지정합니다. 예를 들어prod-node-us-east-1a입니다. - 5 6
- 노드 상태에 대한 시간 제한을 지정합니다. 시간 제한 기간 중 상태가 일치되면 머신이 수정됩니다. 시간 제한이 길어지면 비정상 머신의 워크로드에 대한 다운타임이 길어질 수 있습니다.
- 7
- 대상 풀에서 동시에 복구할 수 있는 시스템 수를 지정합니다. 이는 백분율 또는 정수로 설정할 수 있습니다. 비정상 머신의 수가
maxUnhealthy에서의 설정 제한을 초과하면 복구가 수행되지 않습니다. - 8
- 머신 상태가 비정상으로 확인되기 전에 노드가 클러스터에 참여할 때까지 기다려야 하는 시간 초과 기간을 지정합니다.
matchLabels는 예제일 뿐입니다. 특정 요구에 따라 머신 그룹을 매핑해야 합니다.
13.2.1. 쇼트 서킷 (Short Circuit) 머신 상태 점검 및 수정
쇼트 서킷 (Short Circuit)은 클러스터가 정상일 경우에만 머신 상태 점검을 통해 머신을 조정합니다. 쇼트 서킷은 MachineHealthCheck 리소스의 maxUnhealthy 필드를 통해 구성됩니다.
사용자가 시스템을 조정하기 전에 maxUnhealthy 필드 값을 정의하는 경우 MachineHealthCheck는 비정상적으로 결정된 대상 풀 내의 maxUnhealthy 값과 비교합니다. 비정상 머신의 수가 maxUnhealthy 제한을 초과하면 수정을 위한 업데이트가 수행되지 않습니다.
maxUnhealthy가 설정되지 않은 경우 기본값은 100%로 설정되고 클러스터 상태와 관계없이 머신이 수정됩니다.
적절한 maxUnhealthy 값은 배포하는 클러스터의 규모와 MachineHealthCheck에서 다루는 시스템 수에 따라 달라집니다. 예를 들어 maxUnhealthy 값을 사용하여 여러 가용 영역에서 여러 머신 세트를 처리할 수 있으므로 전체 영역을 손실하면 maxUnhealthy 설정이 클러스터 내에서 추가 수정을 방지 할 수 있습니다. 여러 가용성 영역이 없는 글로벌 Azure 리전에서는 가용성 세트를 사용하여 고가용성을 보장할 수 있습니다.
maxUnhealthy 필드는 정수 또는 백분율로 설정할 수 있습니다. maxUnhealthy 값에 따라 다양한 수정을 적용할 수 있습니다.
13.2.1.1. 절대 값을 사용하여 maxUnhealthy 설정
maxUnhealthy가 2로 설정된 경우
- 2개 이상의 노드가 비정상인 경우 수정을 위한 업데이트가 수행됩니다.
- 3개 이상의 노드가 비정상이면 수정을 위한 업데이트가 수행되지 않습니다
이러한 값은 머신 상태 점검에서 확인할 수 있는 머신 수와 관련이 없습니다.
13.2.1.2. 백분율을 사용하여 maxUnhealthy 설정
maxUnhealthy가 40%로 설정되어 있고 25 대의 시스템이 확인되고 있는 경우 다음을 수행하십시오.
- 10개 이상의 노드가 비정상인 경우 수정을 위한 업데이트가 수행됩니다.
- 11개 이상의 노드가 비정상인 경우 수정을 위한 업데이트가 수행되지 않습니다.
maxUnhealthy가 40%로 설정되어 있고 6 대의 시스템이 확인되고 있는 경우 다음을 수행하십시오.
- 2개 이상의 노드가 비정상인 경우 수정을 위한 업데이트가 수행됩니다.
- 3개 이상의 노드가 비정상이면 수정을 위한 업데이트가 수행되지 않습니다
maxUnhealthy 머신의 백분율이 정수가 아닌 경우 허용되는 머신 수가 반올림됩니다.
13.3. MachineHealthCheck 리소스 만들기
클러스터의 모든 MachineSets에 대해 MachineHealthCheck 리소스를 생성할 수 있습니다. 컨트롤 플레인 시스템을 대상으로 하는 MachineHealthCheck 리소스를 생성해서는 안 됩니다.
사전 요구 사항
-
oc명령행 인터페이스를 설치합니다.
절차
-
머신 상태 점검 정의가 포함된
healthcheck.yml파일을 생성합니다. healthcheck.yml파일을 클러스터에 적용합니다.$ oc apply -f healthcheck.yml
머신 상태 점검을 구성하고 배포하여 비정상적인 베어 메탈 노드를 감지하고 복구할 수 있습니다.
13.4. 베어 메탈의 전원 기반 업데이트 적용 정보
베어 메탈 클러스터에서 노드의 업데이트 적용은 클러스터의 전반적인 상태를 보장하는 데 중요합니다. 물리적으로 클러스터에 업데이트를 적용하는 것은 어려움이 있을 수 있으며 머신을 안전하거나 운영 체제로 전환하기 위한 지연으로 인해 클러스터가 성능 저하된 상태로 유지되는 시간이 길어지고 이후의 장애 발생으로 인해 클러스터가 클러스터를 오프라인 상태가 될 수 있습니다. 전원 기반 문제 해결은 이러한 문제에 대응하는 데 도움이 됩니다.
전원 기반 업데이트 적용에서는 노드를 재프로비저닝하는 대신 전원 컨트롤러를 사용하여 작동하지 않는 노드의 전원을 끕니다. 이러한 유형의 수정을 전원 펜싱이라고 합니다.
OpenShift Container Platform은 MachineHealthCheck 컨트롤러를 사용하여 문제가 있는 베어 메탈 노드를 감지합니다. 전원 기반 업데이트 적용은 신속하게 수행되며 클러스터에서 문제가 있는 노드를 제거하는 대신 재부팅합니다.
전원 기반 업데이트 적용은 다음과 같은 기능을 제공합니다.
- 컨트롤 플레인 노드를 복구 가능
- 하이퍼 컨버지드 환경에서 데이터 손실 위험 감소
- 물리적 머신 복구와 관련된 다운타임 감소
13.4.1. 베어 메탈에서 MachineHealthCheck
베어 메탈 클러스터에서 머신 삭제를 사용하면 베어 메탈 호스트의 재프로비저닝이 트리거됩니다. 일반적으로 베어 메탈 재프로비저닝은 시간이 오래 걸리는 프로세스로, 이 과정에서 클러스터에 컴퓨팅 리소스가 누락되고 애플리케이션이 중단될 수 있습니다. 기본 수정 프로세스를 머신 삭제에서 호스트 전원 사이클로 변경하려면 machine.openshift.io/remediation-strategy: external-baremetal 주석을 MachineHealthCheck 리소스에 추가합니다.
주석을 설정하면 BMC 인증 정보를 사용하여 비정상 머신이 전원을 껐다가 켭니다.
13.4.2. 수정 프로세스 이해
수정 프로세스는 다음과 같이 작동합니다.
- MHC(MachineHealthCheck) 컨트롤러는 노드가 비정상임을 감지합니다.
- MHC는 비정상 노드의 전원을 끄도록 요청하는 베어 메탈 머신 컨트롤러에 통지합니다.
- 전원이 꺼지면 노드가 삭제되어 클러스터가 다른 노드에서 영향을 받는 워크로드를 다시 예약할 수 있습니다.
- 베어 메탈 머신 컨트롤러에서 노드의 전원을 켜도록 요청합니다.
- 노드가 가동되면 노드가 클러스터와 함께 다시 등록되어 새 노드가 생성됩니다.
- 노드가 다시 생성되면 베어 메탈 머신 컨트롤러는 삭제하기 전에 비정상 노드에 존재하는 주석 및 레이블을 복원합니다.
전원 작업이 완료되지 않은 경우 베어 메탈 머신 컨트롤러는 컨트롤 플레인 노드 또는 외부 프로비저닝 노드가 아닌 한 비정상 노드의 재프로비저닝을 트리거합니다.
13.4.3. 베어 메탈의 MachineHealthCheck 리소스 생성
사전 요구 사항
- OpenShift Container Platform은 설치 관리자 프로비저닝 인프라(IPI)를 사용하여 설치됩니다.
- BMC(Baseboard Management Controller) 인증 정보 (또는 각 노드에 대한 BMC 액세스)에 액세스합니다.
- 비정상 노드의 BMC 인터페이스에 대한 네트워크 액세스가 있어야 합니다.
절차
-
머신 상태 점검 정의가 포함된
healthcheck.yaml파일을 생성합니다. -
다음 명령을 사용하여
healthcheck.yaml파일을 클러스터에 적용합니다.
$ oc apply -f healthcheck.yaml베어 메탈의 MachineHealthCheck 리소스 샘플
apiVersion: machine.openshift.io/v1beta1
kind: MachineHealthCheck
metadata:
name: example
namespace: openshift-machine-api
annotations:
machine.openshift.io/remediation-strategy: external-baremetal
spec:
selector:
matchLabels:
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <cluster_name>-<label>-<zone>
unhealthyConditions:
- type: "Ready"
timeout: "300s"
status: "False"
- type: "Ready"
timeout: "300s"
status: "Unknown"
maxUnhealthy: "40%"
nodeStartupTimeout: "10m" - 1
- 배포할 머신 상태 점검의 이름을 지정합니다.
- 2
- 베어 메탈 클러스터의 경우 전원 사이클 수정을 활성화하려면
annotations섹션에machine.openshift.io/remediation-strategy: external-baremetal주석을 포함해야 합니다. 이 업데이트 적용 전략으로 비정상 호스트가 클러스터에서 제거되지 않고 재부팅됩니다. - 3 4
- 확인할 머신 풀의 레이블을 지정합니다.
- 5
- 추적할 머신 세트를
<cluster_name>-<label>-<zone>형식으로 지정합니다. 예를 들어prod-node-us-east-1a입니다. - 6 7
- 노드 상태에 대한 시간 제한을 지정합니다. 시간 제한 기간 중 상태가 일치되면 머신이 수정됩니다. 시간 제한이 길어지면 비정상 머신의 워크로드에 대한 다운타임이 길어질 수 있습니다.
- 8
- 대상 풀에서 동시에 복구할 수 있는 시스템 수를 지정합니다. 이는 백분율 또는 정수로 설정할 수 있습니다. 비정상 머신의 수가
maxUnhealthy에서의 설정 제한을 초과하면 복구가 수행되지 않습니다. - 9
- 머신 상태가 비정상으로 확인되기 전에 노드가 클러스터에 참여할 때까지 기다려야 하는 시간 초과 기간을 지정합니다.
matchLabels는 예제일 뿐입니다. 특정 요구에 따라 머신 그룹을 매핑해야 합니다.
전원 기반 수정 문제를 해결하려면 다음을 확인합니다.
- BMC에 액세스할 수 있습니다.
- BMC는 수정 작업을 실행하는 컨트롤 플레인 노드에 연결됩니다.
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.