클러스터 업데이트
OpenShift Container Platform 클러스터 업데이트
초록
1장. 클러스터 업데이트 개요
웹 콘솔 또는 OpenShift CLI(oc)를 사용하여 단일 작업으로 OpenShift Container Platform 4 클러스터를 업데이트할 수 있습니다.
1.1. OpenShift Container Platform 업데이트 이해
OpenShift Update Service 정보: 인터넷에 액세스할 수 있는 클러스터의 경우 Red Hat은 공개 API 뒤에 있는 호스팅된 서비스로 OpenShift Container Platform 업데이트 서비스를 사용하여 무선 업데이트를 제공합니다.
1.2. 업데이트 채널 및 릴리스 이해
채널 및 릴리스 업데이트: 업데이트 채널을 사용하면 업데이트 전략을 선택할 수 있습니다. 업데이트 채널은 OpenShift Container Platform의 마이너 버전에 따라 다릅니다. 업데이트 채널은 릴리스 선택만 제어하며 설치하는 클러스터 버전에는 영향을 미치지 않습니다. OpenShift Container Platform의 특정 버전에 대한 openshift-install 바이너리 파일은 항상 해당 마이너 버전을 설치합니다. 자세한 내용은 다음을 참조하십시오.
1.3. 클러스터 Operator 조건 유형 이해
클러스터 Operator의 상태에는 해당 조건 유형이 포함되어 있으며 Operator의 현재 상태를 알립니다. 다음 정의에서는 몇 가지 일반적인 ClusterOperator 조건 유형 목록을 다룹니다. 추가 조건 유형이 있고 Operator별 언어를 사용하는 Operator가 생략되었습니다.
CVO(Cluster Version Operator)는 클러스터 Operator에서 상태 조건을 수집하여 클러스터 관리자가 OpenShift Container Platform 클러스터의 상태를 더 잘 이해할 수 있도록 합니다.
-
Available: 조건 유형
Available은 Operator가 작동하고 클러스터에서 사용할 수 있음을 나타냅니다. 상태가False이면 피연산자 중 하나 이상이 작동하지 않으며 상태를 사용하려면 관리자가 개입해야 합니다. 진행 중: 상태 유형
진행은 Operator가 새 코드를 적극적으로 롤아웃하거나, 구성 변경 사항을 전파하거나, 다른 하나의 정상 상태에서 다른 상태로 이동하고 있음을 나타냅니다.Operator는 이전에 알려진 상태를 조정할 때 조건 유형
Progressing을True로 보고하지 않습니다. 관찰된 클러스터 상태가 변경되어 Operator가 이에 반응하는 경우 상태가 하나의 정상 상태에서 다른 상태로 이동하므로 상태가True로 다시 보고됩니다.degraded:
Degraded조건 유형은 Operator에 일정 기간 동안 필요한 상태와 일치하지 않는 현재 상태가 있음을 나타냅니다. 기간은 구성 요소에 따라 다를 수 있지만성능이 저하된상태는 Operator 상태에 대한 지속적인 관찰을 나타냅니다. 결과적으로 Operator는Degraded상태로 전환되지 않습니다.한 상태에서 다른 상태로의 전환이
Degraded를 보고하기에 충분한 기간 동안 유지되지 않는 경우 다른 조건 유형이 있을 수 있습니다. Operator는 일반 업데이트 중에Degraded를 보고하지 않습니다. Operator는 최종 관리자 개입이 필요한 영구 인프라 장애에 대한 응답으로Degraded를 보고할 수 있습니다.참고이 상태 유형은 조사 및 조정이 필요할 수 있다는 표시일 뿐입니다. Operator를 사용할 수 있는 경우 성능이 저하된 조건으로
인해사용자 워크로드 장애 또는 애플리케이션 다운 타임이 발생하지 않습니다.Upgradeable:
Upgradeable조건 유형은 Operator가 현재 클러스터 상태에 따라 안전하게 업데이트되는지 여부를 나타냅니다. message 필드에는 클러스터가 성공적으로 업데이트하기 위해 관리자가 수행해야 하는 작업에 대해 사람이 읽을 수 있는 설명이 포함되어 있습니다. CVO는 이 조건이True,Unknown또는 missing인 경우 업데이트를 허용합니다.Upgradeable상태가False인 경우 마이너 업데이트만 영향을 받으며 CVO는 강제하지 않는 한 클러스터에서 영향을 받는 업데이트를 수행하지 않습니다.
1.4. 클러스터 버전 조건 유형 이해
CVO(Cluster Version Operator)는 클러스터 Operator 및 기타 구성 요소를 모니터링하고 클러스터 버전과 해당 Operator의 상태를 모두 수집합니다. 이 상태에는 상태 및 OpenShift Container Platform 클러스터의 현재 상태를 알리는 조건 유형이 포함됩니다.
Available,Progressing, Upgradeable 외에도 클러스터 버전 및 Operator에 영향을 미치는 조건 유형이 있습니다.
-
실패: 클러스터 버전 조건 유형
Failing은 클러스터가 원하는 상태에 도달할 수 없음을 나타내며, 비정상적인 상태이며 관리자가 개입해야 함을 나타냅니다. -
invalid: 클러스터 버전 조건 유형
Invalid는 클러스터 버전이 서버가 작업을 수행하지 못하도록 하는 오류가 있음을 나타냅니다. CVO는 이 조건이 설정된 동안 현재 상태만 조정합니다. -
verifydUpdates: 클러스터 버전 조건 유형 ECDHE
dUpdates는 업스트림 업데이트 서버에서 사용 가능한 업데이트가 검색되었는지 여부를 나타냅니다. 이 조건은 검색 전에알 수 없음이며, 최근 업데이트가 실패했거나 검색할 수 없는경우False또는availableUpdates필드가 최근과 정확하면True입니다. -
ReleaseAccepted: Cluster version condition type
ReleaseAcceptedwith aTruestatus는 이미지 확인 및 사전 조건 검사 중에 실패하지 않고 요청된 릴리스 페이로드가 성공적으로 로드되었음을 나타냅니다. -
ImplicitlyEnabledCapabilities: 클러스터 버전 조건 유형
ImplicitlyEnabledCapabilities와 함께True상태의 경우 사용자가spec.capabilities를 통해 현재 요청하지 않는 활성화된 기능이 있음을 나타냅니다. CVO는 이전에 CVO에서 연결된 리소스를 관리하는 경우 기능 비활성화를 지원하지 않습니다.
1.5. EUS-to-EUS 업데이트 수행 준비
EUS-to-EUS 업데이트 수행 준비: 기본 Kubernetes 설계로 인해 마이너 버전 간의 모든 OpenShift Container Platform 업데이트가 직렬화되어야 합니다. OpenShift Container Platform 4.9에서 4.10으로 업데이트한 다음 4.11로 업데이트해야 합니다. OpenShift Container Platform 4.8에서 4.10으로 직접 업데이트할 수 없습니다. 그러나 EUS (Extended Update Support) 두 가지 버전 간에 업데이트하려는 경우 컨트롤 플레인 호스트가 아닌 단일 재부팅만 수행하면 됩니다. 자세한 내용은 다음을 참조하십시오.
1.6. 웹 콘솔을 사용하여 클러스터 업데이트
웹 콘솔 을 사용하여 클러스터 업데이트 : 웹 콘솔 을 사용하여 OpenShift Container Platform 클러스터를 업데이트할 수 있습니다. 다음 단계에서는 마이너 버전의 클러스터를 업데이트합니다. 마이너 버전 간에 클러스터를 업데이트하기 위해 동일한 지침을 사용할 수 있습니다.
1.7. CLI를 사용하여 클러스터 업데이트
CLI를 사용하여 클러스터 업데이트: OpenShift CLI (oc)를 사용하여 마이너 버전에서 OpenShift Container Platform 클러스터를 업데이트할 수 있습니다. 다음 단계에서는 마이너 버전의 클러스터를 업데이트합니다. 마이너 버전 간에 클러스터를 업데이트하기 위해 동일한 지침을 사용할 수 있습니다.
1.8. 카나리아 롤아웃 업데이트 수행
카나리아 롤아웃 업데이트 수행: 작업자 노드에 대한 업데이트 롤아웃을 제어하면 업데이트 프로세스에서 애플리케이션이 실패하는 경우에도 미션 크리티컬 애플리케이션을 전체 업데이트 중에 계속 사용할 수 있는지 확인할 수 있습니다. 조직의 요구에 따라 소수의 작업자 노드를 업데이트하고 일정 기간 동안 클러스터 및 워크로드 상태를 평가한 다음 나머지 노드를 업데이트할 수 있습니다. 이를 카나리아 업데이트라고 합니다. 또는 한 번에 전체 클러스터를 업데이트하는 데 대규모 유지 관리 기간을 사용할 수 없는 경우 호스트 재부팅이 필요한 작업자 노드 업데이트를 작은 유지 관리 기간 내에 배치해야 할 수도 있습니다. 다음 절차를 수행할 수 있습니다.
1.9. RHEL 컴퓨팅 시스템을 포함하는 클러스터 업데이트
RHEL 컴퓨팅 머신이 포함된 클러스터 업데이트: 클러스터에 RHEL (Red Hat Enterprise Linux) 시스템이 포함된 경우 해당 시스템을 업데이트하려면 추가 단계를 수행해야합니다. 다음 절차를 수행할 수 있습니다.
1.10. 연결이 끊긴 환경에서 클러스터 업데이트
연결이 끊긴 환경의 클러스터 업데이트 정보: 미러 호스트가 인터넷과 클러스터에 모두 액세스할 수 없는 경우 이미지를 해당 환경과 연결이 끊긴 파일 시스템에 미러링할 수 있습니다. 그런 다음 해당 호스트 또는 이동식 미디어를 가져올 수 있습니다. 로컬 컨테이너 레지스트리와 클러스터가 레지스트리의 미러 호스트에 연결된 경우 릴리스 이미지를 로컬 레지스트리로 직접 푸시할 수 있습니다.
- 미러 호스트 준비
- 이미지를 미러링할 수 있는 인증 정보 설정
- OpenShift Container Platform 이미지 저장소 미러링
- 연결이 끊긴 클러스터 업데이트
- 이미지 레지스트리 저장소 미러링 설정
- 클러스터 노드 재부팅 빈도를 줄이기 위해 미러 이미지 카탈로그의 범위 확장
- OpenShift Update Service Operator 설치
- OpenShift Update Service 애플리케이션 생성
- OpenShift Update Service 애플리케이션 삭제
- OpenShift Update Service Operator 설치 제거
1.11. vSphere에서 실행되는 노드에서 하드웨어 업데이트
vSphere에서 하드웨어 업데이트 : vSphere 에서 실행 중인 노드가 OpenShift Container Platform에서 지원하는 하드웨어 버전에서 실행 중인지 확인해야 합니다. 현재 클러스터의 vSphere 가상 머신에서 하드웨어 버전 15 이상이 지원됩니다. 자세한 내용은 다음을 참조하십시오.
1.12. 특수 리소스 Operator가 포함된 클러스터 업데이트
SAR( Special Resource Operator )이 포함된 클러스터를 업데이트할 때 새 커널 모듈 버전이 현재 SRO에서 로드된 커널 모듈과 호환되는지 여부를 고려하는 것이 중요합니다. preflight 검사를 실행하여 SRO가 커널 모듈을 업그레이드할 수 있는지 확인할 수 있습니다.
이제 vSphere에서 실행 중인 클러스터 노드에 하드웨어 버전 13을 사용하는 것이 더 이상 사용되지 않습니다. 이 버전은 여전히 완전히 지원되지만 향후 OpenShift Container Platform 버전에서는 지원이 제거됩니다. 이제 OpenShift Container Platform의 vSphere 가상 머신의 하드웨어 버전 15가 기본값이 되었습니다.
2장. OpenShift 업데이트 이해
2.1. OpenShift 업데이트 소개
OpenShift Container Platform 4에서는 웹 콘솔 또는 OpenShift CLI(oc)를 사용하여 단일 작업으로 OpenShift Container Platform 클러스터를 업데이트할 수 있습니다. 플랫폼 관리자는 웹 콘솔에서 관리 → 클러스터 설정으로 이동하거나 oc adm upgrade 명령의 출력을 확인하여 새 업데이트 옵션을 볼 수 있습니다.
Red Hat은 공식 레지스트리의 OpenShift Container Platform 릴리스 이미지를 기반으로 하는 업데이트 가능성 그래프를 제공하는 OSUS(OpenShift Update Service)를 호스팅합니다. 그래프에는 모든 공용 OCP 릴리스에 대한 업데이트 정보가 포함되어 있습니다. OpenShift Container Platform 클러스터는 기본적으로 OSUS에 연결하도록 구성되며 OSUS는 알려진 업데이트 대상에 대한 정보를 사용하여 클러스터에 응답합니다.
클러스터 관리자 또는 자동 업데이트 컨트롤러가 새 버전으로 CVO(Cluster Version Operator)의 CR(사용자 정의 리소스)을 편집할 때 업데이트가 시작됩니다. 새로 지정된 버전으로 클러스터를 조정하기 위해 CVO는 이미지 레지스트리에서 대상 릴리스 이미지를 검색하고 변경 사항을 클러스터에 적용하기 시작합니다.
OLM(Operator Lifecycle Manager)을 통해 이전에 설치한 Operator는 업데이트를 위해 다른 프로세스를 따릅니다. 자세한 내용은 설치된 Operator 업데이트를 참조하십시오.
대상 릴리스 이미지에는 특정 OCP 버전을 구성하는 모든 클러스터 구성 요소에 대한 매니페스트 파일이 포함되어 있습니다. 클러스터를 새 버전으로 업데이트할 때 CVO는 Runlevels라는 별도의 단계에 매니페스트를 적용합니다. 대부분은 아니지만 일부 매니페스트는 클러스터 Operator 중 하나를 지원합니다. CVO는 클러스터 Operator에 매니페스트를 적용하므로 Operator에서 업데이트 작업을 수행하여 새 지정된 버전으로 조정할 수 있습니다.
CVO는 적용되는 각 리소스의 상태 및 모든 클러스터 Operator가 보고한 상태를 모니터링합니다. CVO는 활성 Runlevel의 모든 매니페스트 및 클러스터 Operator가 안정적인 상태에 도달하는 경우에만 업데이트를 진행합니다. CVO는 이 프로세스를 통해 전체 컨트롤 플레인을 업데이트한 후 MCO(Machine Config Operator)는 클러스터의 모든 노드의 운영 체제 및 구성을 업데이트합니다.
2.1.1. 업데이트 가용성에 대한 일반적인 질문
OpenShift Container Platform 클러스터에서 업데이트를 사용할 수 있는 경우 및 경우에 영향을 미치는 몇 가지 요소가 있습니다. 다음 목록은 업데이트 가용성에 대한 일반적인 질문을 제공합니다.
각 업데이트 채널의 차이점은 무엇입니까?
-
처음에 새 릴리스가
candidate채널에 추가됩니다. -
최종 테스트를 완료한 후
candidate채널의 릴리스가fast채널로 승격되고 에라타가 게시되고 릴리스가 완전히 지원됩니다. 지연 후
fast채널의 릴리스는 결국stable채널로 승격됩니다. 이 지연은fast채널과stable채널의 유일한 차이점입니다.참고최신 z-stream 릴리스의 경우 이 지연은 일반적으로 1주 또는 2주가 될 수 있습니다. 그러나 최신 마이너 버전에 대한 초기 업데이트 지연은 일반적으로 45-90일로 더 오래 걸릴 수 있습니다.
-
stable채널로 승격된 릴리스는 동시에eus채널로 확장됩니다.eus채널의 주요 목적은 EUS-to-EUS 업데이트를 수행하는 클러스터의 편의를 제공하는 것입니다.
stable 채널의 릴리스가 fast 채널의 릴리스보다 안전하거나 더 지원됩니까?
-
fast채널의 릴리스에 대해 회귀 문제가 확인되면stable채널의 릴리스에 대해 해당 회귀가 식별된 경우와 동일한 범위로 확인되고 관리됩니다. -
fast및stable채널에서 릴리스의 유일한 차이점은 릴리스가 잠시 동안fast채널에 있는 후에만stable채널에 표시되므로 새로운 업데이트 위험을 더 많이 사용할 수 있다는 것입니다. -
fast채널에서 사용 가능한 릴리스는 이 지연 후stable채널에서 항상 사용할 수 있습니다.
업데이트가 지원되지만 권장되지 않는 경우 무엇을 의미합니까?
- Red Hat은 여러 소스의 데이터를 지속적으로 평가하여 한 버전에서 다른 버전으로의 업데이트가 문제가 발생하는지 확인합니다. 문제가 확인된 경우 업데이트 경로가 더 이상 사용자에게 권장되지 않을 수 있습니다. 그러나 업데이트 경로가 권장되지 않더라도 업데이트를 수행하는 경우에도 고객은 계속 지원됩니다.
Red Hat은 사용자가 특정 버전으로의 업데이트를 차단하지 않습니다. Red Hat은 특정 클러스터에 적용되거나 적용되지 않을 수 있는 조건부 업데이트 위험을 선언할 수 있습니다.
- 선언된 위험은 클러스터 관리자에게 지원되는 업데이트에 대한 자세한 컨텍스트를 제공합니다. 클러스터 관리자는 특정 대상 버전으로의 위험 및 업데이트를 계속 허용할 수 있습니다. 이 업데이트는 조건부 위험 컨텍스트에서 권장되지 않더라도 항상 지원됩니다.
특정 릴리스에 대한 업데이트가 더 이상 권장되지 않는 경우 어떻게 해야 합니까?
- 문제 해결으로 인해 Red Hat이 지원되는 릴리스에서 업데이트 권장 사항을 제거하는 경우 회귀 문제를 수정하는 향후 버전에 후속 업데이트 권장 사항이 제공됩니다. 결함이 수정, 테스트 및 선택한 채널로 승격되는 동안 지연이 발생할 수 있습니다.
다음 z-stream 릴리스를 빠르고 안정적인 채널에서 사용할 수 있는 기간은 얼마나 됩니까?
특정 주기는 여러 요인에 따라 다를 수 있지만 최신 마이너 버전의 새로운 z-stream 릴리스는 일반적으로 매주 사용할 수 있습니다. 시간이 지남에 따라 더 안정적인 이전 마이너 버전은 새로운 z-stream 릴리스를 사용할 수 있도록 하는 데 시간이 오래 걸릴 수 있습니다.
중요이는 z-stream 릴리스에 대한 이전 데이터를 기반으로 하는 추정치일 뿐입니다. Red Hat은 필요에 따라 릴리스 빈도를 변경할 수 있는 권한을 갖습니다. 모든 문제는 이 릴리스 주기에서 불규칙성 및 지연을 유발할 수 있습니다.
-
z-stream 릴리스가 게시되면 해당 마이너 버전의
fast채널에도 표시됩니다. 지연 후 z-stream 릴리스는 해당 마이너 버전의stable채널에 표시될 수 있습니다.
2.1.2. OpenShift 업데이트 서비스 정보
OSUS(OpenShift Update Service)는 RHCOS(Red Hat Enterprise Linux CoreOS)를 포함하여 OpenShift Container Platform에 대한 업데이트 권장 사항을 제공합니다. 구성 요소 Operator의 정점과 이를 연결하는 에지를 포함하는 그래프 또는 다이어그램을 제공합니다. 그래프의 에지에는 안전하게 업데이트할 수 있는 버전이 표시됩니다. 정점은 관리형 클러스터 구성 요소의 상태를 지정하는 업데이트 페이로드입니다.
클러스터의 CVO (Cluster Version Operator)는 OpenShift Update Service를 확인하여 현재 구성 요소 버전 및 그래프의 정보를 기반으로 유효한 업데이트 및 업데이트 경로를 확인합니다. 업데이트를 요청하면 CVO는 해당 릴리스 이미지를 사용하여 클러스터를 업데이트합니다. 릴리스 아티팩트는 Quay에서 컨테이너 이미지로 호스팅됩니다.
OpenShift Update Service가 호환 가능한 업데이트만 제공할 수 있도록 자동화를 지원하는 버전 확인 파이프 라인이 제공됩니다. 각 릴리스 아티팩트는 지원되는 클라우드 플랫폼 및 시스템 아키텍처 및 기타 구성 요소 패키지와의 호환성 여부를 확인합니다. 파이프 라인에서 적용 가능한 버전이 있음을 확인한 후 OpenShift Update Service는 해당 버전 업데이트를 사용할 수 있음을 알려줍니다.
OpenShift Update Service는 현재 클러스터에 권장되는 모든 업데이트를 표시합니다. OpenShift Update Service에서 업데이트 경로를 사용하지 않는 경우 업데이트 또는 대상 릴리스와 관련된 알려진 문제 때문일 수 있습니다.
연속 업데이트 모드에서는 두 개의 컨트롤러가 실행됩니다. 하나의 컨트롤러는 페이로드 매니페스트를 지속적으로 업데이트하여 매니페스트를 클러스터에 적용한 다음 Operator의 제어된 롤아웃 상태를 출력하여 사용 가능한지, 업그레이드했는지 또는 실패했는지의 여부를 나타냅니다. 두 번째 컨트롤러는 OpenShift Update Service를 폴링하여 업데이트를 사용할 수 있는지 확인합니다.
최신 버전으로만 업데이트할 수 있습니다. 클러스터를 이전 버전으로 되돌리거나 롤백을 수행하는 것은 지원되지 않습니다. 업데이트에 실패하면 Red Hat 지원에 문의하십시오.
업데이트 프로세스 중에 MCO (Machine Config Operator)는 새 구성을 클러스터 머신에 적용합니다. MCO는 머신 구성 풀의 maxUnavailable 필드에 지정된 노드 수를 제한하고 사용할 수 없음을 표시합니다. 기본적으로 이 값은 1로 설정됩니다. MCO는 topology.kubernetes.io/zone 레이블을 기반으로 영향을 받는 노드를 영역에 따라 알파벳순으로 업데이트합니다. 영역에 노드가 두 개 이상 있으면 가장 오래된 노드가 먼저 업데이트됩니다. 베어 메탈 배포에서와 같이 영역을 사용하지 않는 노드의 경우 노드가 수명에 따라 업데이트되며 가장 오래된 노드가 먼저 업데이트됩니다. MCO는 한 번에 머신 구성 풀의 maxUnavailable 필드에 지정된 노드 수를 업데이트합니다. MCO는 새 설정을 적용하여 컴퓨터를 다시 시작합니다.
RHEL (Red Hat Enterprise Linux) 머신을 작업자로 사용하는 경우 먼저 시스템에서 OpenShift API를 업데이트해야하기 때문에 MCO는 이 머신에서 kubelet을 업데이트하지 않습니다.
새 버전의 사양이 이전 kubelet에 적용되므로 RHEL 머신을 Ready 상태로 되돌릴 수 없습니다. 컴퓨터를 사용할 수 있을 때까지 업데이트를 완료할 수 없습니다. 그러나 사용 불가능한 최대 노드 수를 설정하면 사용할 수 없는 머신의 수가 이 값을 초과하지 않는 경우에도 정상적인 클러스터 작업을 계속할 수 있습니다.
OpenShift Update Service는 Operator 및 하나 이상의 애플리케이션 인스턴스로 구성됩니다.
2.1.3. 일반 용어
- 컨트롤 플레인
- 컨트롤 플레인 시스템으로 구성된 컨트롤 플레인 은 OpenShift Container Platform 클러스터를 관리합니다. 컨트롤 플레인 머신에서는 작업자 머신이라고도 하는 컴퓨팅 머신의 워크로드를 관리합니다.
- Cluster Version Operator
- CVO( Cluster Version Operator )는 클러스터의 업데이트 프로세스를 시작합니다. 현재 클러스터 버전을 기반으로 OSUS를 확인하고 사용 가능한 업데이트 경로를 포함하는 그래프를 검색합니다.
- Machine Config Operator
- MCO( Machine Config Operator )는 운영 체제 및 머신 구성을 관리하는 클러스터 수준 Operator입니다. MCO를 통해 플랫폼 관리자는 작업자 노드의 systemd, CRI-O 및 Kubelet, 커널, NetworkManager 및 기타 시스템 기능을 구성하고 업데이트할 수 있습니다.
- OpenShift 업데이트 서비스
- OSUS( OpenShift Update Service )는 RHCOS(Red Hat Enterprise Linux CoreOS)를 포함하여 OpenShift Container Platform에 대한 무선 업데이트를 제공합니다. 구성 요소 Operator의 정점과 이를 연결하는 에지를 포함하는 그래프 또는 다이어그램을 제공합니다.
- 채널
- 채널은 OpenShift Container Platform의 마이너 버전과 관련된 업데이트 전략을 선언합니다. OSUS는 이 구성된 전략을 사용하여 해당 전략과 일치하는 에지를 업데이트하는 것이 좋습니다.
- 권장 업데이트 edge
- 권장 업데이트 에지 는 OpenShift Container Platform 릴리스 간에 권장되는 업데이트입니다. 지정된 업데이트가 권장되는지 클러스터의 구성 채널, 현재 버전, 알려진 버그 및 기타 정보에 따라 달라질 수 있습니다. OSUS는 권장 에지를 CVO와 통신하여 모든 클러스터에서 실행됩니다.
- EUS (Extended Update Support)
모든 post-4.7 even-numbered 마이너 릴리스는 EUS ( Extended Update Support ) 릴리스로 레이블이 지정됩니다. 이러한 릴리스에서는 EUS 릴리스 간에 검증된 업데이트 경로를 도입하여 작업자 노드의 업데이트를 간소화하고 EUS에서 EUS에서 OpenShift Container Platform 릴리스의 업데이트 전략을 공식화하여 작업자 노드의 재부팅 횟수를 줄일 수 있습니다.
자세한 내용은 Red Hat OpenShift Extended Update Support (EUS) 개요 를 참조하십시오.
2.2. 클러스터 업데이트 작동 방식
다음 섹션에서는 OCP(OpenShift Container Platform) 업데이트 프로세스의 각 주요 측면을 자세히 설명합니다. 업데이트가 작동하는 방법에 대한 일반적인 개요는 OpenShift 업데이트 소개를 참조하십시오.
2.2.1. Cluster Version Operator
CVO(Cluster Version Operator)는 OpenShift Container Platform 업데이트 프로세스를 오케스트레이션하고 용이하게 하는 주요 구성 요소입니다. 설치 및 표준 클러스터 작업 중에 CVO는 관리 클러스터 Operator의 매니페스트를 클러스터 내부 리소스와 지속적으로 비교하고 불일치를 조정하여 이러한 리소스의 실제 상태가 원하는 상태와 일치하는지 확인합니다.
2.2.1.1. ClusterVersion 오브젝트
CVO(Cluster Version Operator)에서 모니터링하는 리소스 중 하나는 ClusterVersion 리소스입니다.
관리자 및 OpenShift 구성 요소는 ClusterVersion 오브젝트를 통해 CVO와 통신하거나 상호 작용할 수 있습니다. 원하는 CVO 상태는 ClusterVersion 오브젝트를 통해 선언되며 현재 CVO 상태는 오브젝트 상태에 반영됩니다.
ClusterVersion 오브젝트를 직접 수정하지 마십시오. 대신 oc CLI 또는 웹 콘솔과 같은 인터페이스를 사용하여 업데이트 대상을 선언합니다.
CVO는 ClusterVersion 리소스의 spec 속성에 선언된 대상 상태로 클러스터를 지속적으로 조정합니다. 원하는 릴리스가 실제 릴리스와 다른 경우 조정이 클러스터를 업데이트합니다.
가용성 데이터 업데이트
ClusterVersion 리소스에는 클러스터에서 사용할 수 있는 업데이트에 대한 정보도 포함되어 있습니다. 여기에는 클러스터에 적용되는 알려진 위험으로 인해 사용할 수 있지만 권장되지 않는 업데이트가 포함됩니다. 이러한 업데이트를 조건부 업데이트라고 합니다. CVO가 ClusterVersion 리소스의 사용 가능한 업데이트에 대한 이 정보를 유지 관리하는 방법에 대한 자세한 내용은 "업데이트 가용성 평가" 섹션을 참조하십시오.
다음 명령을 사용하여 사용 가능한 모든 업데이트를 검사할 수 있습니다.
$ oc adm upgrade --include-not-recommended참고추가
--include-not-recommended매개변수에는 클러스터에 적용되는 알려진 위험으로 인해 사용할 수 있지만 권장되지 않는 업데이트가 포함되어 있습니다.출력 예
Cluster version is 4.10.22 Upstream is unset, so the cluster will use an appropriate default. Channel: fast-4.11 (available channels: candidate-4.10, candidate-4.11, eus-4.10, fast-4.10, fast-4.11, stable-4.10) Recommended updates: VERSION IMAGE 4.10.26 quay.io/openshift-release-dev/ocp-release@sha256:e1fa1f513068082d97d78be643c369398b0e6820afab708d26acda2262940954 4.10.25 quay.io/openshift-release-dev/ocp-release@sha256:ed84fb3fbe026b3bbb4a2637ddd874452ac49c6ead1e15675f257e28664879cc 4.10.24 quay.io/openshift-release-dev/ocp-release@sha256:aab51636460b5a9757b736a29bc92ada6e6e6282e46b06e6fd483063d590d62a 4.10.23 quay.io/openshift-release-dev/ocp-release@sha256:e40e49d722cb36a95fa1c03002942b967ccbd7d68de10e003f0baa69abad457b Supported but not recommended updates: Version: 4.11.0 Image: quay.io/openshift-release-dev/ocp-release@sha256:300bce8246cf880e792e106607925de0a404484637627edf5f517375517d54a4 Recommended: False Reason: RPMOSTreeTimeout Message: Nodes with substantial numbers of containers and CPU contention may not reconcile machine configuration https://bugzilla.redhat.com/show_bug.cgi?id=2111817#c22oc adm upgrade명령은ClusterVersion리소스에 사용 가능한 업데이트에 대한 정보를 쿼리하고 사용자가 읽을 수 있는 형식으로 제공합니다.CVO에서 생성한 기본 가용성 데이터를 직접 검사하는 한 가지 방법은 다음 명령을 사용하여
ClusterVersion리소스를 쿼리하는 것입니다.$ oc get clusterversion version -o json | jq '.status.availableUpdates'출력 예
[ { "channels": [ "candidate-4.11", "candidate-4.12", "fast-4.11", "fast-4.12" ], "image": "quay.io/openshift-release-dev/ocp-release@sha256:400267c7f4e61c6bfa0a59571467e8bd85c9188e442cbd820cc8263809be3775", "url": "https://access.redhat.com/errata/RHBA-2023:3213", "version": "4.11.41" }, ... ]유사한 명령을 사용하여 조건부 업데이트를 확인할 수 있습니다.
$ oc get clusterversion version -o json | jq '.status.conditionalUpdates'출력 예
[ { "conditions": [ { "lastTransitionTime": "2023-05-30T16:28:59Z", "message": "The 4.11.36 release only resolves an installation issue https://issues.redhat.com//browse/OCPBUGS-11663 , which does not affect already running clusters. 4.11.36 does not include fixes delivered in recent 4.11.z releases and therefore upgrading from these versions would cause fixed bugs to reappear. Red Hat does not recommend upgrading clusters to 4.11.36 version for this reason. https://access.redhat.com/solutions/7007136", "reason": "PatchesOlderRelease", "status": "False", "type": "Recommended" } ], "release": { "channels": [...], "image": "quay.io/openshift-release-dev/ocp-release@sha256:8c04176b771a62abd801fcda3e952633566c8b5ff177b93592e8e8d2d1f8471d", "url": "https://access.redhat.com/errata/RHBA-2023:1733", "version": "4.11.36" }, "risks": [...] }, ... ]
2.2.1.2. 업데이트 가용성 평가
CVO(Cluster Version Operator)는 업데이트 가능성에 대한 최신 데이터에 대해 OSUS(OpenShift Update Service)를 주기적으로 쿼리합니다. 이 데이터는 클러스터의 서브스크립션 채널을 기반으로 합니다. 그런 다음 CVO는 업데이트 권장 사항에 대한 정보를 ClusterVersion 리소스의 availableUpdates 또는 conditionalUpdates 필드에 저장합니다.
CVO는 조건부 업데이트에서 업데이트 위험을 주기적으로 확인합니다. 이러한 위험은 OSUS에서 제공하는 데이터를 통해 전달되며, 여기에는 해당 버전으로 업데이트된 클러스터에 영향을 미칠 수 있는 알려진 문제에 대한 각 버전에 대한 정보가 포함되어 있습니다. 대부분의 위험은 특정 클라우드 플랫폼에 배포된 특정 크기 또는 클러스터가 있는 클러스터와 같이 특정 특성이 있는 클러스터로 제한됩니다.
CVO는 각 조건부 업데이트의 조건부 위험 정보에 대해 클러스터 특성을 지속적으로 평가합니다. CVO가 클러스터가 기준과 일치하도록 발견하면 CVO는 이 정보를 ClusterVersion 리소스의 conditionalUpdates 필드에 저장합니다. CVO가 클러스터가 업데이트 위험과 일치하지 않거나 업데이트와 관련된 위험이 없는 경우 ClusterVersion 리소스의 availableUpdates 필드에 대상 버전을 저장합니다.
사용자 인터페이스(웹 콘솔 또는 OpenShift CLI(oc))는 이 정보를 관리자에게 제목으로 지정합니다. 지원되지만 권장 업데이트 권장 사항은 관리자가 업데이트에 대해 정보에 입각한 결정을 내릴 수 있도록 위험 관련 추가 리소스에 대한 링크가 포함되어 있습니다.
2.2.2. 이미지 릴리스
릴리스 이미지는 특정 OCP(OpenShift Container Platform) 버전에 대한 제공 메커니즘입니다. 릴리스 메타데이터, 릴리스 버전과 일치하는 CVO(Cluster Version Operator) 바이너리, 개별 OpenShift 클러스터 Operator를 배포하는 데 필요한 모든 매니페스트 및 이 OpenShift 버전을 구성하는 모든 컨테이너 이미지에 대한 SHA 다이제스트 버전 참조 목록이 포함되어 있습니다.
다음 명령을 실행하여 특정 릴리스 이미지의 콘텐츠를 검사할 수 있습니다.
$ oc adm release extract <release image>출력 예
$ oc adm release extract quay.io/openshift-release-dev/ocp-release:4.12.6-x86_64
Extracted release payload from digest sha256:800d1e39d145664975a3bb7cbc6e674fbf78e3c45b5dde9ff2c5a11a8690c87b created at 2023-03-01T12:46:29Z
$ ls
0000_03_authorization-openshift_01_rolebindingrestriction.crd.yaml
0000_03_config-operator_01_proxy.crd.yaml
0000_03_marketplace-operator_01_operatorhub.crd.yaml
0000_03_marketplace-operator_02_operatorhub.cr.yaml
0000_03_quota-openshift_01_clusterresourcequota.crd.yaml
...
0000_90_service-ca-operator_02_prometheusrolebinding.yaml
0000_90_service-ca-operator_03_servicemonitor.yaml
0000_99_machine-api-operator_00_tombstones.yaml
image-references
release-metadata2.2.3. 프로세스 워크플로 업데이트
다음 단계는 OCP(OpenShift Container Platform) 업데이트 프로세스의 자세한 워크플로를 나타냅니다.
-
대상 버전은 웹 콘솔 또는 CLI를 통해 관리할 수 있는
ClusterVersion리소스의spec.desiredUpdate.version필드에 저장됩니다. -
CVO(Cluster Version Operator)는
ClusterVersion리소스의desiredUpdate가 현재 클러스터 버전과 다른 것을 감지합니다. OpenShift Update Service의 그래프 데이터를 사용하여 CVO는 원하는 클러스터 버전을 릴리스 이미지의 가져오기 사양으로 확인합니다. - CVO는 릴리스 이미지의 무결성 및 진위 여부를 검증합니다. Red Hat은 이미지 SHA 다이제스트를 고유하고 변경할 수 없는 릴리스 이미지 식별자로 사용하여 사전 정의된 위치에서 게시된 릴리스 이미지에 대해 암호화 방식으로 서명합니다. CVO는 기본 제공 공개 키 목록을 사용하여 선택한 릴리스 이미지와 일치하는 문의 존재 및 서명을 검증합니다.
-
CVO는
openshift-cluster-version네임스페이스에version-$version-$hash라는 작업을 생성합니다. 이 작업은 릴리스 이미지를 실행하는 컨테이너를 사용하므로 클러스터는 컨테이너 런타임을 통해 이미지를 다운로드합니다. 그런 다음 이 작업은 릴리스 이미지의 매니페스트 및 메타데이터를 CVO에 액세스할 수 있는 공유 볼륨으로 추출합니다. - CVO는 추출된 매니페스트 및 메타데이터의 유효성을 검사합니다.
- CVO는 일부 사전 조건을 검사하여 클러스터에서 문제가 있는 상태가 탐지되지 않도록 합니다. 특정 조건은 업데이트가 진행되지 않도록 할 수 있습니다. 이러한 조건은 CVO 자체에 의해 결정되거나, Operator가 업데이트에 문제가 있다고 간주하는 클러스터에 대한 몇 가지 세부 정보를 감지하는 개별 클러스터 Operator에 의해 보고됩니다.
-
CVO는 허용되는 릴리스를
status.desired에 기록하고 새 업데이트에 대한status.history항목을 생성합니다. - CVO는 릴리스 이미지에서 매니페스트를 조정하기 시작합니다. 클러스터 Operator는 Runlevels라는 별도의 단계에서 업데이트되며 CVO는 다음 단계로 진행하기 전에 Runlevel 완료 업데이트의 모든 Operator를 확인합니다.
- CVO 자체에 대한 매니페스트는 프로세스 초기에 적용됩니다. CVO 배포가 적용되면 현재 CVO Pod가 중지되고 새 버전을 사용하는 CVO Pod가 시작됩니다. 새 CVO는 나머지 매니페스트를 조정합니다.
-
업데이트는 전체 컨트롤 플레인이 새 버전으로 업데이트될 때까지 진행됩니다. 개별 클러스터 Operator는 클러스터 도메인에서 업데이트 작업을 수행할 수 있으며 이렇게 하는 동안
Progressing=True조건을 통해 상태를 보고합니다. - MCO(Machine Config Operator) 매니페스트는 프로세스 종료에 적용됩니다. 그런 다음 업데이트된 MCO는 모든 노드의 시스템 구성 및 운영 체제를 업데이트하기 시작합니다. 워크로드를 다시 수락하기 전에 각 노드를 드레이닝, 업데이트 및 재부팅할 수 있습니다.
일반적으로 모든 노드가 업데이트되기 전에 클러스터는 컨트롤 플레인 업데이트가 완료된 후 업데이트된 것으로 보고합니다. 업데이트 후 CVO는 릴리스 이미지에서 전달된 상태와 일치하도록 모든 클러스터 리소스를 유지 관리합니다.
2.2.4. 업데이트 중에 매니페스트가 적용되는 방법 이해
릴리스 이미지에 제공된 일부 매니페스트는 둘 사이의 종속 항목으로 인해 특정 순서로 적용해야 합니다. 예를 들어 일치하는 사용자 지정 리소스보다 먼저 CustomResourceDefinition 리소스를 생성해야 합니다. 또한 클러스터 중단을 최소화하기 위해 개별 클러스터 Operator를 업데이트해야 하는 논리적 순서가 있습니다. CVO(Cluster Version Operator)는 Runlevels라는 개념을 통해 이 논리 순서를 구현합니다.
이러한 종속 항목은 릴리스 이미지에 있는 매니페스트의 파일 이름으로 인코딩됩니다.
0000_<runlevel>_<component>_<manifest-name>.yaml예를 들어 다음과 같습니다.
0000_03_config-operator_01_proxy.crd.yamlCVO는 내부적으로 매니페스트에 대한 종속성 그래프를 빌드하며 CVO는 다음 규칙을 따릅니다.
- 업데이트 중에 더 낮은 Runlevel의 매니페스트가 더 높은 Runlevel의 매니페스트보다 먼저 적용됩니다.
- 하나의 Runlevel 내에서 다른 구성 요소에 대한 매니페스트를 병렬로 적용할 수 있습니다.
- 하나의 Runlevel 내에서 단일 구성 요소에 대한 매니페스트가 사전순으로 적용됩니다.
CVO는 생성된 종속성 그래프 다음에 매니페스트를 적용합니다.
일부 리소스 유형의 경우 CVO는 매니페스트가 적용된 후 리소스를 모니터링하고 리소스가 stable 상태에 도달한 후에만 성공적으로 업데이트되도록 간주합니다. 이 상태를 달성하는 데는 약간의 시간이 걸릴 수 있습니다. 이는 ClusterOperator 리소스에 특히 해당되며 CVO는 클러스터 Operator가 자체적으로 업데이트되고 ClusterOperator 상태를 업데이트할 때까지 대기합니다.
CVO는 Runlevel의 모든 클러스터 Operator가 다음 Runlevel으로 진행하기 전에 다음 조건을 충족할 때까지 기다립니다.
-
클러스터 Operator에는
Available=True조건이 있습니다. -
클러스터 Operator에는
Degraded=False조건이 있습니다.
- 클러스터 Operator는 ClusterOperator 리소스에서 원하는 버전을 달성했다고 선언합니다.
일부 작업은 완료하는 데 상당한 시간이 걸릴 수 있습니다. CVO는 후속 Runlevels가 안전하게 진행할 수 있도록 작업이 완료될 때까지 기다립니다. 처음에는 새 릴리스의 매니페스트를 조정하는 데 총 60~120분이 걸릴 것으로 예상됩니다. 업데이트 기간에 영향을 미치는 요인에 대한 자세한 내용은 OpenShift Container Platform 업데이트 기간 이해 를 참조하십시오.
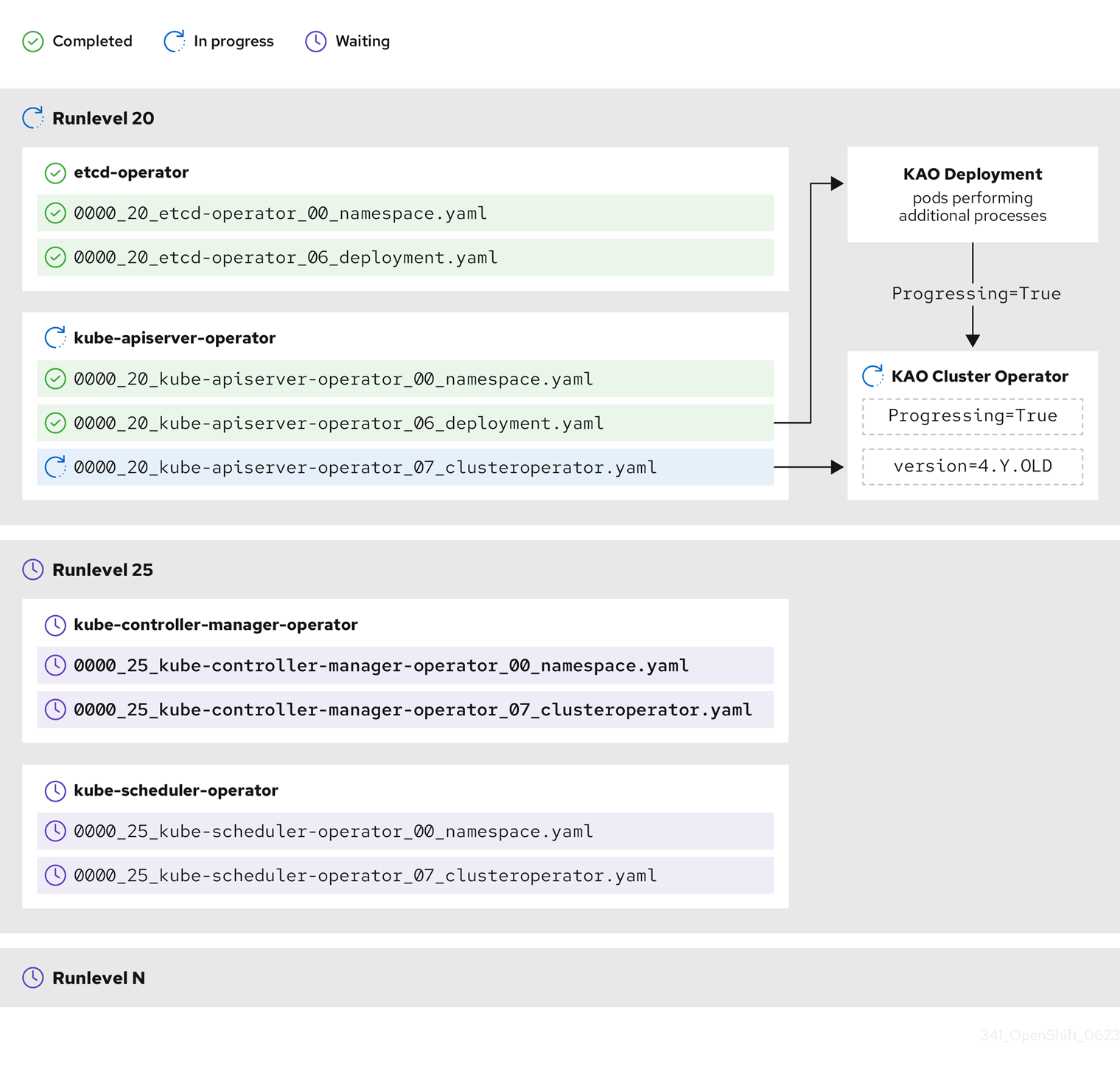
이전 예제 다이어그램에서 CVO는 Runlevel 20에서 모든 작업이 완료될 때까지 대기 중입니다. CVO는 Runlevel의 Operator에 모든 매니페스트를 적용했지만 kube-apiserver-operator ClusterOperator 는 새 버전이 배포된 후 일부 작업을 수행합니다. kube-apiserver-operator ClusterOperator 는 Progressing=True 조건을 통해 이 진행 상황을 선언하고 새 버전을 status.versions 에서 reconciled로 선언하지 않습니다. CVO는 ClusterOperator가 허용 가능한 상태를 보고할 때까지 기다린 다음 Runlevel 25에서 매니페스트를 조정하기 시작합니다.
2.2.5. Machine Config Operator가 노드를 업데이트하는 방법 이해
MCO(Machine Config Operator)는 각 컨트롤 플레인 노드 및 컴퓨팅 노드에 새 머신 구성을 적용합니다. 머신 구성 업데이트 중에 컨트롤 플레인 노드와 컴퓨팅 노드는 머신 풀이 병렬로 업데이트되는 자체 머신 구성 풀로 구성됩니다. 기본 값이 1 인 .spec.maxUnavailable 매개변수는 머신 구성 풀의 노드 수를 동시에 수행할 수 있는 업데이트 프로세스를 결정합니다.
머신 구성 업데이트 프로세스가 시작되면 MCO는 풀에서 현재 사용할 수 없는 노드의 양을 확인합니다. .spec.maxUnavailable 의 값보다 적은 노드가 있는 경우 MCO는 풀에서 사용 가능한 노드에서 다음 작업 시퀀스를 시작합니다.
노드를 차단하고 드레이닝
참고노드가 차단되면 워크로드를 예약할 수 없습니다.
- 노드의 시스템 구성 및 운영 체제(OS) 업데이트
- 노드 재부팅
- 노드 차단 해제
이 프로세스를 수행하는 노드는 차단 해제되고 워크로드를 다시 예약할 수 없을 때까지 사용할 수 없습니다. MCO는 사용할 수 없는 노드 수가 .spec.maxUnavailable 과 동일할 때까지 노드 업데이트를 시작합니다.
노드가 업데이트를 완료하고 사용 가능하게 되면 머신 구성 풀에서 사용할 수 없는 노드 수가 다시 한 번 .spec.maxUnavailable 보다 적습니다. 업데이트해야 하는 노드가 남아 있는 경우 MCO는 .spec.maxUnavailable 제한에 다시 도달할 때까지 노드에서 업데이트 프로세스를 시작합니다. 이 프로세스는 각 컨트롤 플레인 노드와 컴퓨팅 노드가 업데이트될 때까지 반복됩니다.
다음 예제 워크플로우에서는 5개의 노드가 있는 머신 구성 풀에서 이 프로세스가 발생하는 방법을 설명합니다. 여기서 .spec.maxUnavailable 은 3이고 모든 노드를 처음 사용할 수 있습니다.
- MCO는 1, 2, 3 노드를 차단하고 드레이닝하기 시작합니다.
- 노드 2 드레이닝, 재부팅 및 다시 사용할 수 있게 됩니다. MCO는 노드 4를 차단하고 드레이닝을 시작합니다.
- 노드 1이 드레이닝, 재부팅 및 다시 사용할 수 있게 됩니다. MCO 노드 5를 차단하고 드레이닝을 시작합니다.
- 노드 3은 드레이닝을 완료, 재부팅, 다시 사용할 수 있게 됩니다.
- 노드 5 드레이닝, 재부팅 및 다시 사용할 수 있게 됩니다.
- 노드 4 드레이닝, 재부팅 및 다시 사용할 수 있게 됩니다.
각 노드의 업데이트 프로세스는 다른 노드와 독립적이므로 위 예제의 일부 노드는 MCO에 의해 차단된 순서대로 업데이트를 완료합니다.
다음 명령을 실행하여 머신 구성 업데이트의 상태를 확인할 수 있습니다.
$ oc get mcp출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE
master rendered-master-acd1358917e9f98cbdb599aea622d78b True False False 3 3 3 0 22h
worker rendered-worker-1d871ac76e1951d32b2fe92369879826 False True False 2 1 1 0 22h3장. 업데이트 채널 및 릴리스 이해
업데이트 채널은 클러스터를 업데이트하려는 OpenShift Container Platform 마이너 버전을 사용자가 선언하는 메커니즘입니다. 또한 사용자는 빠른,안정적인,후보 및 eus 채널 옵션을 통해 가질 업데이트의 타이밍과 수준을 선택할 수 있습니다. Cluster Version Operator는 다른 조건 정보와 함께 채널 선언을 기반으로 업데이트 그래프를 사용하여 클러스터에 사용 가능한 권장 및 조건부 업데이트 목록을 제공합니다.
업데이트 채널은 OpenShift Container Platform의 마이너 버전에 해당합니다. 채널의 버전 번호는 클러스터의 현재 마이너 버전보다 큰 경우에도 클러스터가 최종적으로 업데이트될 대상 마이너 버전을 나타냅니다.
예를 들어 OpenShift Container Platform 4.10 업데이트 채널은 다음과 같은 권장 사항을 제공합니다.
- 4.10 내에서 업데이트합니다.
- 4.9에서 업데이트
- 4.9에서 4.10으로 업데이트하여 모든 4.9 클러스터에서 최소 z-stream 버전 요구 사항을 즉시 충족하지 않는 경우에도 4.10으로 업데이트할 수 있습니다.
-
EUS-4.10만 해당: 4.8 내의 업데이트입니다. -
EUS-4.10만 해당: 4.8에서 4.9로 업데이트되어 모든 4.8 클러스터를 4.10으로 업데이트할 수 있습니다.
4.10 업데이트 채널은 4.11 이상 릴리스의 업데이트를 권장하지 않습니다. 이 전략을 사용하면 관리자가 OpenShift Container Platform의 다음 마이너 버전으로 업데이트할 것을 명시적으로 결정해야 합니다.
업데이트 채널은 릴리스 선택만 제어하고 설치하는 클러스터의 버전에 영향을 미치지 않습니다. 특정 버전의 OpenShift Container Platform에 대한 openshift-install 바이너리 파일은 항상 해당 버전을 설치합니다.
OpenShift Container Platform 4.11은 다음과 같은 업데이트 채널을 제공합니다.
-
stable-4.11 -
EUS-4.y(EUS 버전에만 제공되며 EUS 버전 간의 업데이트를 용이하게 함) -
fast-4.11 -
candidate-4.11
Cluster Version Operator가 업데이트 권장 서비스에서 사용 가능한 업데이트를 가져오지 않도록 하려면 OpenShift CLI에서 oc adm upgrade channel 명령을 사용하여 빈 채널을 구성할 수 있습니다. 예를 들어 클러스터가 네트워크 액세스를 제한하고 로컬에 연결할 수 있는 업데이트 권장 서비스가 없는 경우 이 구성이 유용할 수 있습니다.
Red Hat은 OpenShift Update Service에서 제안한 버전으로만 업데이트할 것을 권장합니다. 마이너 버전 업데이트의 경우 버전이 연속되어야 합니다. Red Hat은 비지속 버전에 대한 업데이트를 테스트하지 않으며 이전 버전과의 호환성을 보장할 수 없습니다.
3.1. 업데이트 채널
3.1.1. fast-4.11 채널
Red Hat이 버전을 GA(GA) 릴리스로 선언하면 fast-4.11 채널이 새 버전의 OpenShift Container Platform 4.11로 업데이트됩니다. 따라서 이러한 릴리스는 완전히 지원되며 프로덕션 환경에서 사용하도록 설계되었습니다.
3.1.2. stable-4.11 채널
에라타가 출시되면 곧 fast-4.11 채널에 표시되지만 릴리스는 지연 후 stable-4.11 채널에 추가됩니다. 이러한 지연 기간 동안 데이터는 여러 소스에서 수집되어 제품 회귀 표시를 위해 분석됩니다. 상당한 수의 데이터 포인트가 수집되면 이러한 릴리스가 stable 채널에 추가됩니다.
많은 수의 데이터 포인트를 얻는 데 필요한 시간은 여러 요인에 따라 다르기 때문에 빠르고 안정적인 채널 간의 지연 기간 동안 SLO (Service LeveL Objective)가 제공되지 않습니다. 자세한 내용은 "클러스터에 올바른 채널 구성"을 참조하십시오.
새로 설치된 클러스터는 기본적으로 stable 채널을 사용합니다.
3.1.3. EUS-4.y 채널
stable 채널 외에도 OpenShift Container Platform의 모든 짝수의 마이너 버전은 EUS ( Extended Update Support )를 제공합니다. stable 채널로 승격된 릴리스도 EUS 채널로 동시에 승격됩니다. EUS 채널의 주요 목적은 EUS-to-EUS 업데이트를 수행하는 클러스터의 편의를 제공하는 것입니다.
표준 및 비EUS 구독자 모두 모든 EUS 리포지토리 및 필수 RPM(rhel-*-eus-rpms)에 액세스하여 디버깅 및 빌드 드라이버와 같은 중요한 목적을 지원할 수 있습니다.
3.1.4. candidate-4.11 채널
candidate-4.11 채널은 구축된 즉시 릴리스에 대한 조기 액세스 권한을 제공합니다. 후보 채널에만 있는 릴리스에는 최종 GA 릴리스의 전체 기능 세트가 포함되어 있지 않거나 GA 이전에 제거될 수 있습니다. 또한 이러한 릴리스는 Red Hat Quality Assurance의 적용을 받지 않았으며 이후 GA 릴리스에 대한 업데이트 경로를 제공하지 않을 수 있습니다. 이러한 주의 사항을 고려할 때 후보 채널은 클러스터를 삭제하고 다시 생성하는 것이 허용되는 테스트 목적에만 적합합니다.
3.1.5. 채널에서 권장 사항 업데이트
OpenShift Container Platform은 설치된 OpenShift Container Platform 버전과 채널 내에서 가져올 경로를 알고 있는 업데이트 권장 서비스를 유지 관리하여 다음 릴리스로 이동합니다. 업데이트 경로는 현재 선택한 채널 및 승격 특성과 관련된 버전으로 제한됩니다.
채널에서 다음 릴리스를 확인할 수 있습니다.
- 4.11.0
- 4.11.1
- 4.11.3
- 4.11.4
이 서비스는 테스트되어 심각한 회귀 문제가 없는 업데이트만 권장합니다. 예를 들어 클러스터가 4.11.1에 있고 OpenShift Container Platform에서 4.11.4를 권장하는 경우 4.11.1에서 4.11.4로 업데이트하는 것이 좋습니다.
연속적인 패치 번호에 의존하지 않도록하십시오. 이 예에서 4.11.2는 채널에서 사용 불가능합니다. 따라서 4.11.2에 대한 업데이트는 권장되지 않거나 지원되지 않습니다.
3.1.6. 업데이트 권장 사항 및 조건 업데이트
Red Hat은 새로 릴리스된 버전을 모니터링하고 해당 버전과 관련된 경로를 지원되는 채널에 추가하기 전과 이후에 업데이트합니다.
Red Hat이 지원되는 모든 릴리스에서 업데이트 권장 사항을 제거하는 경우 회귀 문제를 수정하는 향후 업데이트 권장 사항이 제공됩니다. 그러나 결함이 수정, 테스트 및 선택한 채널로 승격되는 동안 지연이 발생할 수 있습니다.
OpenShift Container Platform 4.10부터 업데이트 위험이 확인되면 관련 업데이트에 대한 조건부 업데이트 위험으로 선언됩니다. 알려진 각 위험은 모든 클러스터 또는 특정 조건과 일치하는 클러스터에만 적용될 수 있습니다. 몇 가지 예로는 Platform 이 None 으로 설정되거나 CNI 공급자를 OpenShiftSDN 으로 설정하는 것이 있습니다. CVO(Cluster Version Operator)는 현재 클러스터 상태에 대해 알려진 위험을 지속적으로 평가합니다. 위험이 일치하지 않는 경우 업데이트가 권장됩니다. 위험이 일치하면 해당 업데이트가 지원되지만 권장되지 않으며 참조 링크가 제공됩니다. 참조 링크는 클러스터 관리자가 위험을 수락했는지 여부 및 업데이트를 결정하는 데 도움이 됩니다.
Red Hat에서 조건부 업데이트 위험을 선언하도록 선택하면 해당 작업은 모든 관련 채널에서 동시에 수행됩니다. 조건부 업데이트 위험 선언은 업데이트가 지원되는 채널로 승격되기 전이나 후에 발생할 수 있습니다.
3.1.7. 클러스터에 적합한 채널 선택
적절한 채널을 선택하는 것은 두 가지 결정을 포함합니다.
먼저 클러스터 업데이트에 필요한 마이너 버전을 선택합니다. 현재 버전과 일치하는 채널을 선택하면 z-stream 업데이트만 적용하고 기능 업데이트가 제공되지 않습니다. 현재 버전보다 큰 버전이 있는 사용 가능한 채널을 선택하면 하나 이상의 업데이트가 끝나면 클러스터가 해당 버전으로 업데이트됩니다. 클러스터는 현재 버전, 다음 버전 또는 다음 EUS 버전과 일치하는 채널만 제공됩니다.
많은 마이너 버전 간의 업데이트 계획에 관련된 복잡성으로 인해 단일 EUS에서 EUS로의 업데이트 계획을 지원하는 채널은 제공되지 않습니다.
다음으로 원하는 롤아웃 전략을 선택해야 합니다. Red Hat에서 fast 채널을 선택하여 릴리스 GA를 선언하는 즉시 업데이트하거나 Red Hat이 stable 채널로 릴리스를 승격할 때까지 기다려야 할 수 있습니다. fast-4.11 및 stable-4.11 에서 제공되는 업데이트 권장 사항은 완전히 지원되며 지속적인 데이터 분석으로 부터 동일한 이점을 얻을 수 있습니다. stable 채널로 릴리스를 승격하기 전에 승격 지연은 두 채널 간의 유일한 차이점을 나타냅니다. 최신 z-streams에 대한 업데이트는 일반적으로 1주일 또는 2일 내에 stable 채널로 승격되지만, 최신 마이너에 처음 업데이트를 롤아웃할 때 지연 시간은 일반적으로 45-90일입니다. stable 채널로 승격을 기다리는 경우 일정 계획에 영향을 줄 수 있으므로 원하는 채널을 선택할 때 승격 지연을 고려하십시오.
또한 조직이 클러스터를 fast 채널로 이동하게 할 수 있는 몇 가지 요인이 있습니다. 이는 영구적으로 또는 일시적으로 다음을 포함합니다.
- 지연 없이 환경에 영향을 미치는 것으로 알려진 특정 수정 사항을 적용하고자 합니다.
- 지연 없이 CVE 수정 사항 적용. CVE 수정으로 회귀 문제가 발생할 수 있으므로 CVE 수정 사항을 통해 승격 지연이 z-streams에 계속 적용됩니다.
- 내부 테스트 프로세스. 조직에서 릴리스를 확인하는 데 몇 주가 걸리면 대기하지 않고 프로모션 프로세스를 통해 동시에 테스트를 수행하는 것이 가장 좋습니다. 또한 Red Hat에 제공된 모든 Telemetry 신호가 롤아웃에 반영되므로 관련 문제를 보다 신속하게 해결할 수 있습니다.
3.1.8. 네트워크가 제한된 환경의 클러스터
OpenShift Container Platform 클러스터의 컨테이너 이미지를 직접 관리하는 경우 제품 릴리스와 관련된 Red Hat 에라타를 참조하고 업데이트에 영향을 미치는 의견을 기록해야합니다. 업데이트 중에 사용자 인터페이스에서 이러한 버전 간 전환에 대해 경고할 수 있으므로 이러한 경고를 무시하기 전에 적절한 버전을 선택했는지 확인해야 합니다.
3.1.9. 채널 간 전환
채널은 웹 콘솔에서 전환하거나 adm upgrade channel 명령을 통해 전환할 수 있습니다.
$ oc adm upgrade channel <channel>현재 릴리스를 포함하지 않는 채널로 전환하면 웹 콘솔에 경고가 표시됩니다. 웹 콘솔은 현재 릴리스가 없는 채널에서 업데이트를 권장하지 않습니다. 하지만 언제든지 원래 채널로 돌아갈 수 있습니다.
채널을 변경하면 클러스터의 지원 가능성에 영향을 미칠 수 있습니다. 다음과 같은 조건이 적용될 수 있습니다.
-
stable-4.11채널에서fast-4.11채널로 변경해도 클러스터는 계속 지원됩니다. -
언제든지
candidate-4.11채널로 전환할 수 있지만 이 채널의 일부 릴리스는 지원되지 않을 수 있습니다. -
현재 릴리스가 정식 사용 버전 릴리스인 경우
candidate-4.11채널에서fast-4.11채널로 전환할 수 있습니다. -
항상
fast-4.11채널에서stable-4.11채널로 전환할 수 있습니다. 현재 릴리스가 최근에 승격된 경우 릴리스를stable-4.11로 승격시킬 때까지 최대 하루까지 지연될 수 있습니다.
4장. OpenShift Container Platform 업데이트 기간 이해
OpenShift Container Platform 업데이트 기간은 배포 토폴로지에 따라 다릅니다. 이 페이지는 업데이트 기간에 영향을 미치는 요인을 이해하고 환경에서 클러스터 업데이트가 걸리는 시간을 추정하는 데 도움이 됩니다.
4.1. 사전 요구 사항
4.2. 업데이트 기간에 영향을 미치는 요소
다음 요소는 클러스터 업데이트 기간에 영향을 미칠 수 있습니다.
MCO(Machine Config Operator)의 새 머신 구성으로 컴퓨팅 노드를 재부팅
-
머신 구성 풀에서
MaxUnavailable의 값 - PDB(Pod 중단 예산)에 설정된 최소 복제본 수 또는 백분율
-
머신 구성 풀에서
- 클러스터의 노드 수
- 클러스터 노드의 상태
4.3. 클러스터 업데이트 단계
OpenShift Container Platform에서 클러스터 업데이트는 다음 두 단계로 수행됩니다.
- CVO(Cluster Version Operator) 대상 업데이트 페이로드 배포
- MCO(Machine Config Operator) 노드 업데이트
4.3.1. Cluster Version Operator 대상 업데이트 페이로드 배포
CVO(Cluster Version Operator)는 대상 업데이트 릴리스 이미지를 검색하고 클러스터에 적용합니다. 이 단계에서 Pod로 실행되는 모든 구성 요소가 업데이트되는 반면 호스트 구성 요소는 MCO(Machine Config Operator)에서 업데이트합니다. 이 프로세스에는 60~20분이 걸릴 수 있습니다.
업데이트의 CVO 단계는 노드를 재시작하지 않습니다.
4.3.2. Machine Config Operator 노드 업데이트
MCO(Machine Config Operator)는 각 컨트롤 플레인 및 컴퓨팅 노드에 새 머신 구성을 적용합니다. 이 프로세스 중에 MCO는 클러스터의 각 노드에서 다음 작업을 수행합니다.
- 모든 노드를 드레인 (Cordon and drain all the nodes)
- 운영 체제 (OS) 업데이트
- 노드 재부팅
- 모든 노드 설정 해제 및 노드에 워크로드 예약
노드가 차단되면 워크로드를 예약할 수 없습니다.
이 프로세스를 완료하는 시간은 노드 및 인프라 구성을 비롯한 여러 요인에 따라 달라집니다. 이 프로세스는 노드당 완료하는 데 5분 이상 걸릴 수 있습니다.
MCO 외에도 다음 매개변수의 영향을 고려해야 합니다.
- 컨트롤 플레인 노드 업데이트 기간은 예측 가능하며, 컨트롤 플레인 워크로드가 정상 업데이트 및 빠른 드레인을 위해 조정되므로 컴퓨팅 노드보다 더 짧은 경우가 많습니다.
-
MCP(Machine Config Pool)에서
maxUnavailable필드를1이상으로 설정하여 컴퓨팅 노드를 병렬로 업데이트할 수 있습니다. MCO는 maxUnavailable에 지정된 노드 수를제한하고업데이트에 사용할 수 없는 것으로 표시합니다. -
MCP에서
maxUnavailable을 늘리면 풀이 더 빨리 업데이트할 수 있습니다. 그러나maxUnavailable이 너무 높고 여러 노드가 동시에 연결되면 예약 가능한 노드가 복제본을 실행하는 데 사용할 수 없으므로 Pod 중단 예산 (PDB) 보호 워크로드가 드레이닝되지 않을 수 있습니다. MCP에maxUnavailable을 늘리면 PDB 보호 워크로드가 드레인될 수 있도록 스케줄링 가능한 노드가 충분히 있는지 확인하십시오. 업데이트를 시작하기 전에 모든 노드를 사용할 수 있는지 확인해야 합니다. 노드가
maxUnavailable및 Pod 중단 예산에 영향을 미치므로 사용 불가능한 노드가 업데이트 기간에 상당한 영향을 미칠 수 있습니다.터미널에서 노드 상태를 확인하려면 다음 명령을 실행합니다.
$ oc get node출력 예
NAME STATUS ROLES AGE VERSION ip-10-0-137-31.us-east-2.compute.internal Ready,SchedulingDisabled worker 12d v1.23.5+3afdacb ip-10-0-151-208.us-east-2.compute.internal Ready master 12d v1.23.5+3afdacb ip-10-0-176-138.us-east-2.compute.internal Ready master 12d v1.23.5+3afdacb ip-10-0-183-194.us-east-2.compute.internal Ready worker 12d v1.23.5+3afdacb ip-10-0-204-102.us-east-2.compute.internal Ready master 12d v1.23.5+3afdacb ip-10-0-207-224.us-east-2.compute.internal Ready worker 12d v1.23.5+3afdacb노드 상태가
NotReady또는SchedulingDisabled인 경우 노드를 사용할 수 없으며 업데이트 기간에 영향을 미칩니다.컴퓨팅 → 노드를 확장하여 웹 콘솔의 관리자 화면에서 노드의 상태를 확인할 수 있습니다.
4.4. 클러스터 업데이트 시간 추정
유사한 클러스터의 과거 업데이트 기간에서는 향후 클러스터 업데이트에 가장 적합한 추정치를 제공합니다. 그러나 기록 데이터를 사용할 수 없는 경우 다음 규칙을 사용하여 클러스터 업데이트 시간을 추정할 수 있습니다.
Cluster update time = CVO target update payload deployment time + (# node update iterations x MCO node update time)
노드 업데이트 반복은 병렬로 업데이트된 하나 이상의 노드로 구성됩니다. 컨트롤 플레인 노드는 항상 컴퓨팅 노드와 병렬로 업데이트됩니다. 또한 maxUnavailable 값에 따라 하나 이상의 계산 노드를 병렬로 업데이트할 수 있습니다.
예를 들어 업데이트 시간을 추정하려면 세 개의 컨트롤 플레인 노드와 컴퓨팅 노드가 6개인 OpenShift Container Platform 클러스터를 고려하여 각 호스트를 재부팅하는 데 약 5분이 걸립니다.
특정 노드를 재부팅하는 데 걸리는 시간은 크게 다릅니다. 클라우드 인스턴스에서 재부팅에는 약 1~2분이 걸릴 수 있지만, 물리적 베어 메탈 호스트에서는 재부팅에 15분이 걸릴 수 있습니다.
scenario-1
컨트롤 플레인과 컴퓨팅 노드 MCP(Machine Config Pool) 모두에 maxUnavailable 을 1 로 설정하면 6개의 모든 컴퓨팅 노드가 반복될 때마다 서로 업데이트합니다.
Cluster update time = 60 + (6 x 5) = 90 minutesscenario-2
컴퓨팅 노드 MCP 에 maxUnavailable을 2 로 설정하면 각 반복에서 두 개의 컴퓨팅 노드가 병렬로 업데이트됩니다. 따라서 모든 노드를 업데이트하려면 총 세 번의 반복이 필요합니다.
Cluster update time = 60 + (3 x 5) = 75 minutes
maxUnavailable의 기본 설정 은 OpenShift Container Platform의 모든 MCP에 대해 1 입니다. 컨트롤 플레인 MCP에서 maxUnavailable을 변경 하지 않는 것이 좋습니다.
4.5. Red Hat Enterprise Linux (RHEL) 컴퓨팅 노드
Red Hat Enterprise Linux (RHEL) 컴퓨팅 노드는 노드 바이너리 구성 요소를 업데이트하려면 추가 openshift-ansible 을 사용해야 합니다. RHEL 컴퓨팅 노드를 업데이트하는 데 드는 실제 시간은 RHCOS(Red Hat Enterprise Linux CoreOS) 컴퓨팅 노드와 크게 다를 수 없습니다.
5장. EUS-to-EUS 업데이트 수행 준비
기본 Kubernetes 설계로 인해 마이너 버전 간의 모든 OpenShift Container Platform 업데이트는 직렬화되어야 합니다. OpenShift Container Platform <4.y>에서 <4.y+1>으로 업데이트한 다음 <4.y+2>로 업데이트해야 합니다. OpenShift Container Platform <4.y>에서 <4.y+2>로 직접 업데이트할 수 없습니다. 그러나 EUS (Extended Update Support) 버전 두 개를 업데이트하려는 관리자는 컨트롤 플레인 호스트를 한 번만 재부팅할 수 있습니다.
EUS-to-EUS 업데이트는 OpenShift Container Platform의 짝수의 마이너 버전 사이에서만 가능합니다.
EUS-to-EUS 업데이트를 시도할 때 고려해야 할 몇 가지 경고 사항이 있습니다.
-
EUS-to-EUS 업데이트는 관련된 모든 버전 간의 업데이트 후에
stable채널에서만 제공됩니다. - 홀수의 마이너 버전으로 업그레이드하는 동안 또는 이후에 문제가 발생하는 경우, 다음 짝수 번호의 버전으로 업그레이드하기 전에 이러한 문제를 해결하기 전에 이러한 문제를 해결하려면 앞으로 이동하기 전에 비 컨트롤 플레인 호스트가 홀수의 버전으로 업데이트를 완료해야 할 수 있습니다.
- 유지 관리에 걸리는 시간을 수용하도록 작업자 또는 사용자 지정 풀 노드를 업데이트하여 부분 업데이트를 수행할 수 있습니다.
- 중간 단계에서 일시 중지하여 여러 유지 관리 기간 동안 업데이트 프로세스를 완료할 수 있습니다. 그러나 60일 이내에 전체 업데이트를 완료할 계획입니다. 이는 인증서 교체와 관련된 항목을 포함하여 일반 클러스터 자동화 프로세스를 완료하는 데 중요합니다.
- EUS-to-EUS 업데이트 절차를 시작하기 전에 최소한 OpenShift Container Platform 4.8.14를 실행해야 합니다. 이 최소 요구 사항을 충족하지 않는 경우 EUS-to-EUS 업데이트를 시도하기 전에 이후 4.8.z로 업데이트합니다.
- RHEL7 작업자에 대한 지원은 OpenShift Container Platform 4.10에서 제거되었으며 RHEL8 작업자로 교체되어 RHEL7 작업자가 있는 클러스터에서 EUS-to-EUS 업데이트를 사용할 수 없습니다.
- 노드 구성 요소는 OpenShift Container Platform 4.9로 업데이트되지 않습니다. OpenShift Container Platform 4.9에서 수정된 모든 기능 및 버그가 OpenShift Container Platform 4.10으로 업데이트를 완료하고 모든 MachineConfigPools를 업데이트할 수 있을 것으로 예상하지 마십시오.
5.1. EUS-to-EUS 업데이트
다음 절차에서는 마스터 이외의 머신 구성 풀을 일시 정지하고 OpenShift Container Platform 4.8에서 4.9에서 4.10으로 업데이트를 수행한 다음 이전에 일시 중지된 머신 구성 풀의 일시 중지를 해제합니다. 다음 절차에 따라 총 업데이트 기간이 줄어들고 작업자 노드가 재시작되는 횟수가 줄어 듭니다.
사전 요구 사항
- OpenShift Container Platform 4.9 및 4.10의 릴리스 노트를 확인합니다.
- 계층화된 제품 및 OLM(Operator Lifecycle Manager) Operator의 릴리스 노트 및 제품 라이프 사이클을 검토합니다. 일부는 EUS 업데이트 전 또는 EUS 업데이트 중에 업데이트가 필요할 수 있습니다.
5.1.1. 웹 콘솔을 사용한 EUS-to-EUS 업데이트
사전 요구 사항
- 머신 구성 풀이 일시 중지되지 않았는지 확인합니다.
-
admin권한이 있는 사용자로 웹 콘솔에 액세스합니다.
절차
- 웹 콘솔의 관리자 화면을 사용하여 모든 OLM(Operator Lifecycle Manager) Operator를 업데이트된 버전과 호환되는 버전으로 업데이트합니다. "설치된 Operator 업데이트"에서 이 작업을 수행하는 방법에 대한 자세한 내용은 "ECDHE 리소스"를 참조하십시오.
모든 머신 구성 풀의 상태가
Up to date로 표시되고 머신 구성 풀이UPDATING상태를 표시하지 않는지 확인합니다.모든 머신 구성 풀의 상태를 보려면 Compute → MachineConfigPools 를 클릭하고 Update status 열의 내용을 확인합니다.
참고머신 구성 풀의 상태가
Updating인 경우 이 상태가Up to date로 변경될 때까지 기다립니다. 이 프로세스에는 몇 분이 걸릴 수 있습니다.채널을
eus-<4.y+2>로 설정합니다.채널을 설정하려면 Administration → Cluster Settings → Channel 을 클릭합니다. 현재 하이퍼링크된 채널을 클릭하여 채널을 편집할 수 있습니다.
- 마스터 풀을 제외한 모든 작업자 머신 풀을 일시 중지합니다. Compute 페이지의 MachineConfigPools 탭에서 이 작업을 수행할 수 있습니다. 일시 정지하고 업데이트 일시 정지를 클릭합니다.
- 버전 <4.y+1>으로 업데이트하고 저장 단계를 완료합니다. 웹 콘솔을 사용하여 "클러스터 업데이트"에서 이러한 작업을 수행하는 방법에 대한 자세한 내용은 "해결 리소스"를 참조하십시오.
- 마지막 완료된 버전의 클러스터를 확인하여 <4.y+1> 업데이트가 완료되었는지 확인합니다. 이 정보는 세부 정보 탭의 클러스터 설정 페이지에서 확인할 수 있습니다.
- 필요한 경우 웹 콘솔의 관리자 화면을 사용하여 OLM Operator를 업데이트합니다. 이러한 작업을 수행하는 방법에 대한 자세한 내용은 "설치된 Operator 업데이트"를 참조하십시오. "ECDHE 리소스"를 참조하십시오.
- 버전 <4.y+2>로 업데이트하고 저장 단계를 완료합니다. 웹 콘솔을 사용하여 "클러스터 업데이트"에서 이러한 작업을 수행하는 방법에 대한 자세한 내용은 "해결 리소스"를 참조하십시오.
- 클러스터의 마지막 완료된 버전을 확인하여 <4.y+2> 업데이트가 완료되었는지 확인합니다. 이 정보는 세부 정보 탭의 클러스터 설정 페이지에서 확인할 수 있습니다.
이전에 일시 중지된 모든 머신 구성 풀의 일시 정지를 해제합니다. Compute 페이지의 MachineConfigPools 탭에서 이 작업을 수행할 수 있습니다. 일시 정지 해제를 원하는 머신 구성 풀 옆에 있는 수직을 선택하고 업데이트 일시 정지 해제 를 클릭합니다.
중요풀이 일시 중지되지 않는 경우 클러스터는 향후 마이너 버전으로 업그레이드할 수 없으며 인증서 교체와 같은 유지 관리 작업이 금지됩니다. 이로 인해 클러스터가 향후 저하될 위험이 있습니다.
이전에 일시 중지된 풀이 업데이트되고 클러스터가 <4.y+2> 버전으로 업데이트를 완료했는지 확인합니다.
Update status 의 값이 Up to date 인지 확인하여 Compute 페이지의 MachineConfigPools 탭에서 풀이 업데이트되었는지 확인할 수 있습니다.
마지막으로 완료된 클러스터 버전을 확인하여 클러스터가 업데이트를 완료 했는지 확인할 수 있습니다. 이 정보는 세부 정보 탭의 클러스터 설정 페이지에서 확인할 수 있습니다.
5.1.2. CLI를 사용한 EUS-to-EUS 업데이트
사전 요구 사항
- 머신 구성 풀이 일시 중지되지 않았는지 확인합니다.
-
업데이트할 때마다 OpenShift CLI(
oc)를 대상 버전으로 업데이트합니다.
이 사전 요구 사항을 생략하는 것은 매우 권장되지 않습니다. 업데이트 전에 OpenShift CLI(oc)가 대상 버전으로 업데이트되지 않으면 예기치 않은 문제가 발생할 수 있습니다.
절차
- 웹 콘솔의 관리자 화면을 사용하여 모든 OLM(Operator Lifecycle Manager) Operator를 업데이트된 버전과 호환되는 버전으로 업데이트합니다. "설치된 Operator 업데이트"에서 이 작업을 수행하는 방법에 대한 자세한 내용은 "ECDHE 리소스"를 참조하십시오.
모든 머신 구성 풀에
UPDATED상태가 표시되고 머신 구성 풀이UPDATING상태가 표시되는지 확인합니다. 모든 머신 구성 풀의 상태를 보려면 다음 명령을 실행합니다.$ oc get mcp출력 예
NAME CONFIG UPDATED UPDATING master rendered-master-ecbb9582781c1091e1c9f19d50cf836c True False worker rendered-worker-00a3f0c68ae94e747193156b491553d5 True False현재 버전은 <4.y>이며 원하는 버전은 <4.y+2>입니다. 다음 명령을 실행하여
eus-<4.y+2> 채널로 변경합니다.$ oc adm upgrade channel eus-<4.y+2>참고eus-<4.y+2>가 사용 가능한 채널 중 하나가 아님을 나타내는 오류 메시지가 표시되면 Red Hat이 여전히 EUS 버전 업데이트를 롤아웃하고 있음을 나타냅니다. 이 롤아웃 프로세스는 일반적으로 GA 날짜부터 45-90일이 걸립니다.다음 명령을 실행하여 마스터 풀을 제외한 모든 작업자 머신 풀을 일시 중지합니다.
$ oc patch mcp/worker --type merge --patch '{"spec":{"paused":true}}'참고마스터 풀을 일시 정지할 수 없습니다.
다음 명령을 실행하여 최신 버전으로 업데이트합니다.
$ oc adm upgrade --to-latest출력 예
Updating to latest version <4.y+1.z>클러스터 버전을 검토하여 다음 명령을 실행하여 업데이트가 완료되었는지 확인합니다.
$ oc adm upgrade출력 예
Cluster version is <4.y+1.z> ...다음 명령을 실행하여 버전 <4.y+2>로 업데이트합니다.
$ oc adm upgrade --to-latest클러스터 버전을 검색하여 다음 명령을 실행하여 <4.y+2> 업데이트가 완료되었는지 확인합니다.
$ oc adm upgrade출력 예
Cluster version is <4.y+2.z> ...작업자 노드를 <4.y+2>로 업데이트하려면 다음 명령을 실행하여 이전에 일시 중지된 모든 머신 구성 풀의 일시 중지를 해제합니다.
$ oc patch mcp/worker --type merge --patch '{"spec":{"paused":false}}'중요풀이 일시 정지되지 않으면 클러스터는 향후 마이너 버전으로 업데이트할 수 없으며 인증서 교체와 같은 유지 관리 작업이 억제됩니다. 이로 인해 클러스터가 향후 저하될 위험이 있습니다.
다음 명령을 실행하여 이전에 일시 중지된 풀이 업데이트되고 버전 <4.y+2>로 업데이트가 완료되었는지 확인합니다.
$ oc get mcp출력 예
NAME CONFIG UPDATED UPDATING master rendered-master-52da4d2760807cb2b96a3402179a9a4c True False worker rendered-worker-4756f60eccae96fb9dcb4c392c69d497 True False
5.1.3. Operator Lifecycle Manager를 통해 설치된 계층화된 제품 및 Operator에 대한 EUS 업데이트
웹 콘솔 및 CLI에 대해 언급된 EUS-to-EUS 업데이트 단계 외에도 다음을 사용하여 클러스터에 대한 EUS-to-EUS 업데이트를 수행할 때 고려해야 할 추가 단계가 있습니다.
- 계층화된 제품
- OLM(Operator Lifecycle Manager)을 통해 설치된 Operator
계층화된 제품이란 무엇입니까?
계층화된 제품은 함께 사용하려고 하며 개별 서브스크립션으로 나눌 수 없는 여러 기본 제품으로 구성된 제품을 나타냅니다. 계층화된 OpenShift Container Platform 제품의 예는 OpenShift에서 계층화된 오퍼링을 참조하십시오.
계층화된 제품 클러스터 및 OLM을 통해 설치된 Operator에 대해 EUS-to-EUS 업데이트를 수행할 때 다음을 완료해야 합니다.
- OLM을 통해 이전에 설치된 모든 Operator가 최신 채널의 최신 버전으로 업데이트되었는지 확인합니다. Operator를 업데이트하면 클러스터 업데이트 중에 기본 OperatorHub 카탈로그가 현재 마이너 버전에서 다음 버전으로 전환될 때 유효한 업데이트 경로가 제공됩니다. Operator 업데이트 방법에 대한 자세한 내용은 "ECDHE 리소스"에서 "Operator 업데이트 준비"를 참조하십시오.
- 현재 및 의도된 Operator 버전 간의 클러스터 버전 호환성을 확인합니다. Red Hat OpenShift Container Platform Operator Update Information Checker 를 사용하여 OLM Operator가 호환되는 버전을 확인할 수 있습니다.
예를 들어 OpenShift Data Foundation (ODF)의 경우 <4.y>에서 <4.y+2>로 EUS 업데이트를 수행하는 단계는 다음과 같습니다. CLI 또는 웹 콘솔을 통해 이 작업을 수행할 수 있습니다. 원하는 인터페이스를 통해 클러스터를 업데이트하는 방법에 대한 자세한 내용은 웹 콘솔을 사용한 EUS 업데이트 및 "ECDHE 리소스"의 CLI를 사용하여 "EUS-to-EUS 업데이트"를 참조하십시오.
워크플로 예
- 작업자 시스템 풀을 일시 중지합니다.
- 업그레이드 OpenShift <4.y> → OpenShift <4.y+1>.
- 업그레이드 ODF <4.y> → ODF <4.y+1>.
- Upgrade OpenShift <4.y+1> → OpenShift <4.y+2>.
- ODF <4.y+2>로 업그레이드
- 작업자 시스템 풀의 일시 정지를 해제합니다.
ODF <4.y+2>로의 업그레이드는 작업자 머신 풀이 일시 정지되기 전이나 후에 발생할 수 있습니다.
6장. 수동으로 유지 관리되는 인증 정보로 클러스터 업데이트 준비
CCO(Cloud Credential Operator) 수동으로 유지 관리되는 인증 정보가 있는 클러스터의 Upgradable 상태는 기본적으로 False 입니다.
-
마이너 릴리스(예: 4.12에서 4.13로)의 경우 이 상태로 인해 업데이트된 권한을 처리하고
CloudCredential리소스에 주석을 달 때까지 업데이트하여 권한이 다음 버전에 필요에 따라 업데이트됨을 나타낼 수 없습니다. 이 주석은Upgradable상태를True로 변경합니다. - 예를 들어 4.13.0에서 4.13.1로 z-stream 릴리스의 경우 권한이 추가되거나 변경되지 않으므로 업데이트가 차단되지 않습니다.
수동으로 유지 관리되는 인증 정보로 클러스터를 업데이트하기 전에 업데이트 중인 OpenShift Container Platform 버전의 릴리스 이미지에 새 또는 변경된 인증 정보를 수용해야 합니다.
6.1. 수동으로 유지 관리되는 인증 정보를 사용하여 클러스터의 요구 사항 업데이트
CCO(Cloud Credential Operator)에서 수동으로 유지 관리되는 인증 정보를 사용하는 클러스터를 업데이트하기 전에 새 릴리스에 대한 클라우드 공급자 리소스를 업데이트해야 합니다.
CCO 유틸리티(ccoctlccoctl)를 사용하여 클러스터의 클라우드 인증 정보 관리가 구성된 경우 ccoctl 유틸리티를 사용하여 리소스를 업데이트합니다. ccoctl 유틸리티 없이 수동 모드를 사용하도록 구성된 클러스터에는 리소스에 대한 수동 업데이트가 필요합니다.
클라우드 공급자 리소스를 업데이트한 후 업데이트할 준비가 되었음을 나타내기 위해 클러스터에 대한 upgradeable-to 주석을 업데이트해야 합니다.
클라우드 공급자 리소스 및 upgradeable-to 주석을 업데이트하는 프로세스는 명령줄 툴을 사용하여만 완료할 수 있습니다.
6.1.1. 플랫폼 유형별 클라우드 인증 구성 옵션 및 업데이트 요구 사항
일부 플랫폼은 하나의 모드에서 CCO 사용만 지원합니다. 해당 플랫폼에 설치된 클러스터의 경우 플랫폼 유형에 따라 인증 정보 업데이트 요구 사항이 결정됩니다.
여러 모드에서 CCO 사용을 지원하는 플랫폼의 경우 클러스터가 사용하도록 구성된 모드를 결정하고 해당 구성에 필요한 작업을 수행해야 합니다.
그림 6.1. 플랫폼 유형별 인증 정보 업데이트 요구사항
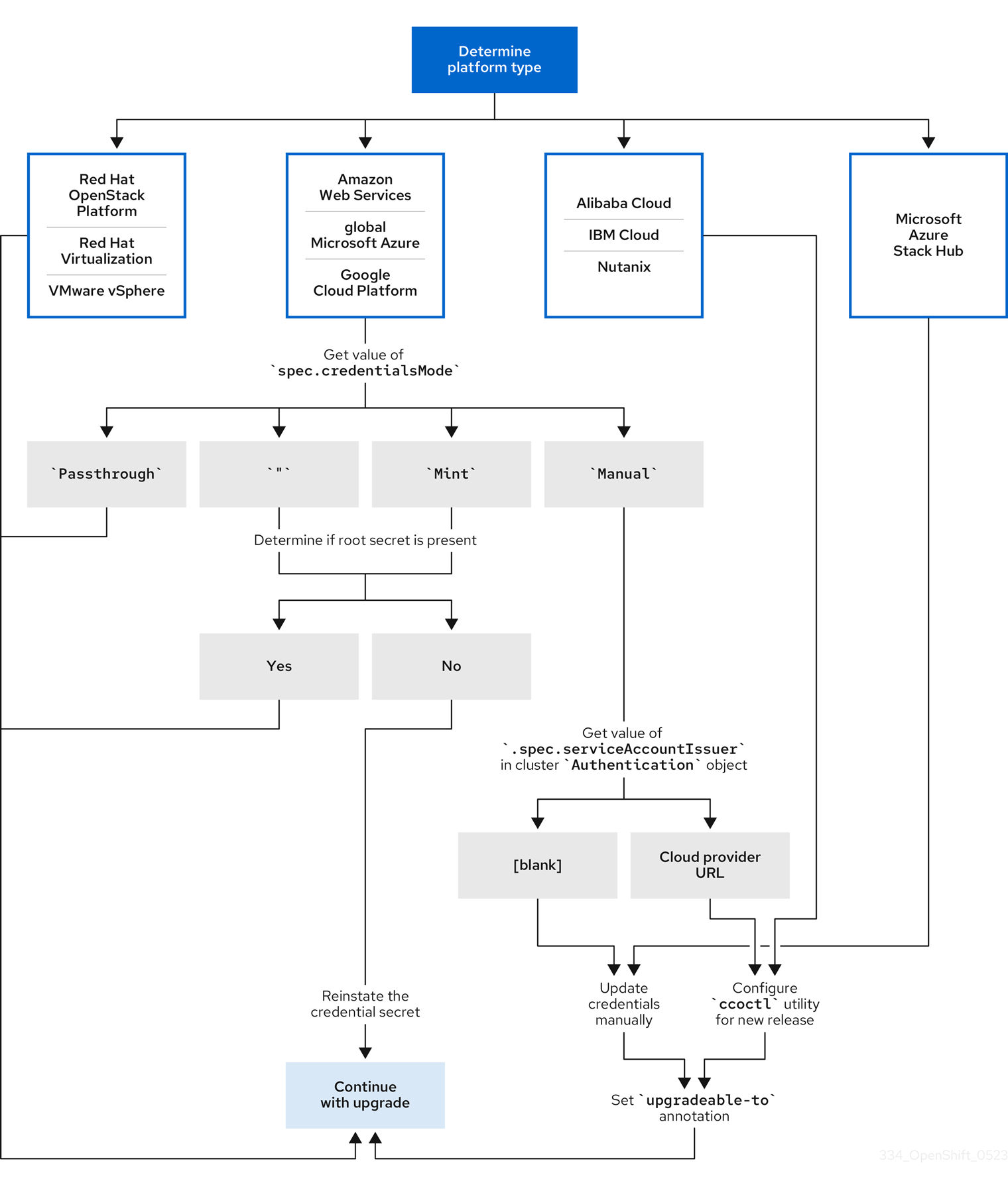
- RHOSP(Red Hat OpenStack Platform), RHV(Red Hat Virtualization) 및 VMware vSphere
이러한 플랫폼은 수동 모드에서 CCO 사용을 지원하지 않습니다. 이러한 플랫폼의 클러스터는 클라우드 공급자 리소스의 변경 사항을 자동으로 처리하고
upgradeable-to주석으로 업데이트할 필요가 없습니다.이러한 플랫폼에 있는 클러스터 관리자는 업데이트 프로세스의 수동으로 유지 관리되는 인증 정보 섹션을 건너뛰어야 합니다.
- CloudEvent Cloud, IBM Cloud, Nutanix
이러한 플랫폼에 설치된 클러스터는
ccoctl유틸리티를 사용하여 구성됩니다.이러한 플랫폼에 있는 클러스터 관리자는 다음 작업을 수행해야 합니다.
-
새 릴리스에 대해
ccoctl유틸리티를 구성합니다. -
ccoctl유틸리티를 사용하여 클라우드 공급자 리소스를 업데이트합니다. -
클러스터가
upgradeable-to주석을 사용하여 업데이트할 준비가 되었음을 나타냅니다.
-
새 릴리스에 대해
- Microsoft Azure Stack Hub
이러한 클러스터는 수명이 긴 인증 정보와 함께 수동 모드를 사용하며
ccoctl유틸리티를 사용하지 않습니다.이러한 플랫폼에 있는 클러스터 관리자는 다음 작업을 수행해야 합니다.
- 새 릴리스의 클라우드 공급자 리소스를 수동으로 업데이트합니다.
-
클러스터가
upgradeable-to주석을 사용하여 업데이트할 준비가 되었음을 나타냅니다.
- AWS(Amazon Web Services), 글로벌 Microsoft Azure 및 GCP(Google Cloud Platform)
이러한 플랫폼에 설치된 클러스터는 여러 CCO 모드를 지원합니다.
필수 업데이트 프로세스는 클러스터가 사용하도록 구성된 모드에 따라 다릅니다. CCO가 클러스터에서 사용하도록 구성된 모드가 확실하지 않은 경우 웹 콘솔 또는 CLI를 사용하여 이 정보를 확인할 수 있습니다.
6.1.2. 웹 콘솔을 사용하여 Cloud Credential Operator 모드 확인
웹 콘솔을 사용하여 CCO(Cloud Credential Operator)가 사용하도록 구성된 모드를 확인할 수 있습니다.
AWS(Amazon Web Services), 글로벌 Microsoft Azure 및 GCP(Google Cloud Platform) 클러스터만 여러 CCO 모드를 지원합니다.
사전 요구 사항
- 클러스터 관리자 권한이 있는 OpenShift Container Platform 계정에 액세스할 수 있습니다.
절차
-
cluster-admin역할의 사용자로 OpenShift Container Platform 웹 콘솔에 로그인합니다. - Administration → Cluster Settings으로 이동합니다.
- 클러스터 설정 페이지에서 구성 탭을 선택합니다.
- Configuration 리소스 에서 CloudCredential 를 선택합니다.
- CloudCredential 세부 정보 페이지에서 YAML 탭을 선택합니다.
YAML 블록에서
spec.credentialsMode의 값을 확인합니다. 다음 값이 모든 플랫폼에서 지원되지는 않지만 모두 지원되는 것은 아닙니다.-
'': CCO가 기본 모드에서 작동합니다. 이 구성에서 CCO는 설치 중에 제공된 인증 정보에 따라 Mint 또는 passthrough 모드에서 작동합니다. -
Mint: CCO가 Mint 모드에서 작동합니다. -
passthrough: CCO가 passthrough 모드에서 작동합니다. -
Manual: CCO가 수동 모드에서 작동합니다.
중요'',Mint또는Manual의spec.credentialsMode가 있는 AWS 또는 GCP 클러스터의 특정 구성을 확인하려면 추가 조사를 수행해야 합니다.AWS 및 GCP 클러스터는 루트 시크릿이 삭제된 상태에서 Mint 모드 사용을 지원합니다. 클러스터가 특별히 Mint 모드를 사용하도록 구성된 경우 또는 기본적으로 Mint 모드를 사용하는 경우 업데이트하기 전에 root 시크릿이 클러스터에 있는지 확인해야 합니다.
수동 모드를 사용하는 AWS 또는 GCP 클러스터는 AWS STS(Security Token Service) 또는 GCP 워크로드 ID를 사용하여 클러스터 외부에서 클라우드 인증 정보를 생성하고 관리하도록 구성할 수 있습니다. cluster
Authentication오브젝트를 검사하여 클러스터에서 이 전략을 사용하는지 확인할 수 있습니다.-
AWS 또는 GCP 클러스터만 Mint 모드를 사용하는: 클러스터가 루트 시크릿없이 작동하는지 확인하려면 워크로드 → 시크릿으로 이동하여 클라우드 공급자의 루트 시크릿을 찾습니다.
참고프로젝트 드롭다운이 All Projects 로 설정되어 있는지 확인합니다.
Expand 플랫폼 시크릿 이름 AWS
aws-credsGCP
gcp-credentials- 이러한 값 중 하나가 표시되면 클러스터에서 root 시크릿이 있는 mint 또는 passthrough 모드를 사용하는 것입니다.
- 이러한 값이 표시되지 않으면 클러스터는 루트 시크릿이 제거된 Mint 모드에서 CCO를 사용하는 것입니다.
AWS 또는 GCP 클러스터만 사용하는: 클러스터 외부에서 클라우드 인증 정보를 생성하고 관리하도록 클러스터가 구성되었는지 확인하려면 클러스터
인증오브젝트 YAML 값을 확인해야 합니다.- Administration → Cluster Settings으로 이동합니다.
- 클러스터 설정 페이지에서 구성 탭을 선택합니다.
- Configuration 리소스 에서 인증을 선택합니다.
- 인증 세부 정보 페이지에서 YAML 탭을 선택합니다.
YAML 블록에서
.spec.serviceAccountIssuer매개변수 값을 확인합니다.-
클라우드 공급자와 연결된 URL이 포함된 값은 CCO가 AWS STS 또는 GCP 워크로드 ID와 함께 수동 모드를 사용하여 클러스터 외부에서 클라우드 인증 정보를 생성하고 관리하는 것을 나타냅니다. 이러한 클러스터는
ccoctl유틸리티를 사용하여 구성됩니다. -
빈 값(
'')은 클러스터가 수동 모드에서 CCO를 사용하고 있지만ccoctl유틸리티를 사용하여 구성되지 않았음을 나타냅니다.
-
클라우드 공급자와 연결된 URL이 포함된 값은 CCO가 AWS STS 또는 GCP 워크로드 ID와 함께 수동 모드를 사용하여 클러스터 외부에서 클라우드 인증 정보를 생성하고 관리하는 것을 나타냅니다. 이러한 클러스터는
다음 단계
- Mint 또는 passthrough 모드에서 CCO가 작동하는 클러스터를 업데이트하고 루트 보안이 있는 경우 클라우드 공급자 리소스를 업데이트할 필요가 없으며 업데이트 프로세스의 다음 부분으로 계속 진행할 수 있습니다.
- 클러스터가 루트 시크릿이 제거된 상태에서 Mint 모드에서 CCO를 사용하는 경우 업데이트 프로세스의 다음 부분을 계속하기 전에 관리자 수준 인증 정보를 사용하여 인증 정보 시크릿을 복원해야 합니다.
CCO 유틸리티(
ccoctlccoctl )를 사용하여 클러스터가 구성된 경우 다음 작업을 수행해야 합니다.-
새 릴리스에 대해
ccoctl유틸리티를 구성하고 이를 사용하여 클라우드 공급자 리소스를 업데이트합니다. -
upgradeable-to주석을 업데이트하여 클러스터를 업데이트할 준비가 되었음을 나타냅니다.
-
새 릴리스에 대해
클러스터가 수동 모드에서 CCO를 사용하지만
ccoctl유틸리티를 사용하여 구성되지 않은 경우 다음 작업을 수행해야 합니다.- 새 릴리스의 클라우드 공급자 리소스를 수동으로 업데이트합니다.
-
upgradeable-to주석을 업데이트하여 클러스터를 업데이트할 준비가 되었음을 나타냅니다.
6.1.3. CLI를 사용하여 Cloud Credential Operator 모드 확인
CLI를 사용하여 CCO(Cloud Credential Operator)가 사용하도록 구성된 모드를 확인할 수 있습니다.
AWS(Amazon Web Services), 글로벌 Microsoft Azure 및 GCP(Google Cloud Platform) 클러스터만 여러 CCO 모드를 지원합니다.
사전 요구 사항
- 클러스터 관리자 권한이 있는 OpenShift Container Platform 계정에 액세스할 수 있습니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
-
cluster-admin역할의 사용자로 클러스터에서oc에 로그인합니다. CCO가 사용하도록 구성된 모드를 결정하려면 다음 명령을 입력합니다.
$ oc get cloudcredentials cluster \ -o=jsonpath={.spec.credentialsMode}다음 출력 값을 사용할 수 있지만 모든 플랫폼에서 모두 지원되는 것은 아닙니다.
-
'': CCO가 기본 모드에서 작동합니다. 이 구성에서 CCO는 설치 중에 제공된 인증 정보에 따라 Mint 또는 passthrough 모드에서 작동합니다. -
Mint: CCO가 Mint 모드에서 작동합니다. -
passthrough: CCO가 passthrough 모드에서 작동합니다. -
Manual: CCO가 수동 모드에서 작동합니다.
중요'',Mint또는Manual의spec.credentialsMode가 있는 AWS 또는 GCP 클러스터의 특정 구성을 확인하려면 추가 조사를 수행해야 합니다.AWS 및 GCP 클러스터는 루트 시크릿이 삭제된 상태에서 Mint 모드 사용을 지원합니다. 클러스터가 특별히 Mint 모드를 사용하도록 구성된 경우 또는 기본적으로 Mint 모드를 사용하는 경우 업데이트하기 전에 root 시크릿이 클러스터에 있는지 확인해야 합니다.
수동 모드를 사용하는 AWS 또는 GCP 클러스터는 AWS STS(Security Token Service) 또는 GCP 워크로드 ID를 사용하여 클러스터 외부에서 클라우드 인증 정보를 생성하고 관리하도록 구성할 수 있습니다. cluster
Authentication오브젝트를 검사하여 클러스터에서 이 전략을 사용하는지 확인할 수 있습니다.-
AWS 또는 GCP 클러스터만 Mint 모드를 사용하는: 클러스터가 루트 시크릿없이 작동하는지 확인하려면 다음 명령을 실행합니다.
$ oc get secret <secret_name> \ -n=kube-system여기서 &
lt;secret_name>은 AWS의aws-creds이거나 GCP의gcp-credentials입니다.루트 시크릿이 있으면 이 명령의 출력에서 보안에 대한 정보를 반환합니다. root 보안이 클러스터에 존재하지 않음을 나타내는 오류가 있습니다.
수동 모드를 사용하는 AWS 또는 GCP 클러스터: 클러스터 외부에서 클라우드 인증 정보를 생성하고 관리하도록 클러스터가 구성되었는지 확인하려면 다음 명령을 실행합니다.
$ oc get authentication cluster \ -o jsonpath \ --template='{ .spec.serviceAccountIssuer }'이 명령은 클러스터
인증오브젝트에서.spec.serviceAccountIssuer매개변수 값을 표시합니다.-
클라우드 공급자와 연결된 URL의 출력은 CCO가 AWS STS 또는 GCP 워크로드 ID와 함께 수동 모드를 사용하여 클러스터 외부에서 클라우드 인증 정보를 생성하고 관리하는 것을 나타냅니다. 이러한 클러스터는
ccoctl유틸리티를 사용하여 구성됩니다. -
빈 출력은 클러스터가 수동 모드에서 CCO를 사용하고 있지만
ccoctl유틸리티를 사용하여 구성되지 않았음을 나타냅니다.
-
클라우드 공급자와 연결된 URL의 출력은 CCO가 AWS STS 또는 GCP 워크로드 ID와 함께 수동 모드를 사용하여 클러스터 외부에서 클라우드 인증 정보를 생성하고 관리하는 것을 나타냅니다. 이러한 클러스터는
다음 단계
- Mint 또는 passthrough 모드에서 CCO가 작동하는 클러스터를 업데이트하고 루트 보안이 있는 경우 클라우드 공급자 리소스를 업데이트할 필요가 없으며 업데이트 프로세스의 다음 부분으로 계속 진행할 수 있습니다.
- 클러스터가 루트 시크릿이 제거된 상태에서 Mint 모드에서 CCO를 사용하는 경우 업데이트 프로세스의 다음 부분을 계속하기 전에 관리자 수준 인증 정보를 사용하여 인증 정보 시크릿을 복원해야 합니다.
CCO 유틸리티(
ccoctlccoctl )를 사용하여 클러스터가 구성된 경우 다음 작업을 수행해야 합니다.-
새 릴리스에 대해
ccoctl유틸리티를 구성하고 이를 사용하여 클라우드 공급자 리소스를 업데이트합니다. -
upgradeable-to주석을 업데이트하여 클러스터를 업데이트할 준비가 되었음을 나타냅니다.
-
새 릴리스에 대해
클러스터가 수동 모드에서 CCO를 사용하지만
ccoctl유틸리티를 사용하여 구성되지 않은 경우 다음 작업을 수행해야 합니다.- 새 릴리스의 클라우드 공급자 리소스를 수동으로 업데이트합니다.
-
upgradeable-to주석을 업데이트하여 클러스터를 업데이트할 준비가 되었음을 나타냅니다.
6.2. 클러스터 업데이트에 대한 Cloud Credential Operator 유틸리티 구성
수동 모드에서 CCO(Cloud Credential Operator)를 사용하여 클러스터 외부에서 클라우드 인증 정보를 생성하고 관리하는 클러스터를 업그레이드하려면 CCO 유틸리티(ccoctl) 바이너리를 추출 및 준비합니다.
ccoctl 유틸리티는 Linux 환경에서 실행해야 하는 Linux 바이너리입니다.
전제 조건
- 클러스터 관리자 액세스 권한이 있는 OpenShift Container Platform 계정에 액세스할 수 있습니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다.
-
클러스터는
ccoctl유틸리티를 사용하여 클러스터 외부에서 클라우드 인증 정보를 생성하고 관리했습니다.
프로세스
다음 명령을 실행하여 OpenShift Container Platform 릴리스 이미지를 가져옵니다.
$ RELEASE_IMAGE=$(./openshift-install version | awk '/release image/ {print $3}')다음 명령을 실행하여 OpenShift Container Platform 릴리스 이미지에서 CCO 컨테이너 이미지를 가져옵니다.
$ CCO_IMAGE=$(oc adm release info --image-for='cloud-credential-operator' $RELEASE_IMAGE -a ~/.pull-secret)참고$RELEASE_IMAGE의 아키텍처가ccoctl툴을 사용할 환경의 아키텍처와 일치하는지 확인합니다.다음 명령을 실행하여 OpenShift Container Platform 릴리스 이미지 내의 CCO 컨테이너 이미지에서
ccoctl바이너리를 추출합니다.$ oc image extract $CCO_IMAGE --file="/usr/bin/ccoctl" -a ~/.pull-secret다음 명령을 실행하여
ccoctl을 실행 가능하게 하려면 권한을 변경합니다.$ chmod 775 ccoctl
검증
ccoctl을 사용할 준비가 되었는지 확인하려면 다음 명령을 실행하여 도움말 파일을 표시합니다.$ ccoctl --helpccoctl --help의 출력OpenShift credentials provisioning tool Usage: ccoctl [command] Available Commands: alibabacloud Manage credentials objects for alibaba cloud aws Manage credentials objects for AWS cloud gcp Manage credentials objects for Google cloud help Help about any command ibmcloud Manage credentials objects for IBM Cloud nutanix Manage credentials objects for Nutanix Flags: -h, --help help for ccoctl Use "ccoctl [command] --help" for more information about a command.
6.3. Cloud Credential Operator 유틸리티를 사용하여 클라우드 공급자 리소스 업데이트
CCO 유틸리티(ccoctl)를 사용하여 구성된 OpenShift Container Platform 클러스터를 업그레이드하는 프로세스는 설치 중에 클라우드 공급자 리소스를 생성하는 것과 유사합니다.
기본적으로 ccoctl은 명령이 실행되는 디렉터리에 오브젝트를 생성합니다. 다른 디렉터리에 오브젝트를 생성하려면 --output-dir 플래그를 사용합니다. 이 절차에서는 & lt;path_to_ccoctl_output_dir >을 사용하여 이 디렉터리를 참조합니다.
AWS 클러스터에서 일부 ccoctl 명령은 AWS API를 호출하여 AWS 리소스를 생성하거나 수정합니다. --dry-run 플래그를 사용하여 API 호출을 방지할 수 있습니다. 이 플래그를 사용하면 로컬 파일 시스템에 JSON 파일이 생성됩니다. JSON 파일을 검토 및 수정한 다음 --cli-input-json 매개변수를 사용하여 AWS CLI 툴로 적용할 수 있습니다.
전제 조건
- 업그레이드할 버전의 OpenShift Container Platform 릴리스 이미지를 가져옵니다.
-
릴리스 이미지에서
ccoctl바이너리를 추출하고 준비합니다.
프로세스
다음 명령을 실행하여 OpenShift Container Platform 릴리스 이미지에서
CredentialsRequestCR(사용자 정의 리소스) 목록을 추출합니다.$ oc adm release extract --credentials-requests \ --cloud=<provider_type> \ --to=<path_to_directory_with_list_of_credentials_requests>/credrequests \ quay.io/<path_to>/ocp-release:<version>다음과 같습니다.
-
<provider_type>은 클라우드 공급자의 값입니다. 유효한 값은alibabacloud,aws,gcp,ibmcloud,nutanix입니다. -
credrequests는CredentialsRequest오브젝트 목록이 저장되는 디렉터리입니다. 이 명령은 디렉터리가 없는 경우 해당 디렉터리를 생성합니다.
-
릴리스 이미지의 각
CredentialsRequestCR에 대해spec.secretRef.namespace필드의 텍스트와 일치하는 네임스페이스가 클러스터에 있는지 확인합니다. 이 필드에는 인증 정보 구성을 보유하는 생성된 시크릿이 저장됩니다.샘플 AWS
CredentialsRequest오브젝트apiVersion: cloudcredential.openshift.io/v1 kind: CredentialsRequest metadata: name: cloud-credential-operator-iam-ro namespace: openshift-cloud-credential-operator spec: providerSpec: apiVersion: cloudcredential.openshift.io/v1 kind: AWSProviderSpec statementEntries: - effect: Allow action: - iam:GetUser - iam:GetUserPolicy - iam:ListAccessKeys resource: "*" secretRef: name: cloud-credential-operator-iam-ro-creds namespace: openshift-cloud-credential-operator1 - 1
- 이 필드는 생성된 시크릿을 보유하기 위해 존재해야 하는 네임스페이스를 나타냅니다.
다른 플랫폼의
CredentialsRequestCR에는 다른 플랫폼별 값이 있는 유사한 형식이 있습니다.클러스터에
spec.secretRef.namespace에 지정된 이름이 있는 네임스페이스가 아직 없는CredentialsRequestCR에 대해 다음 명령을 실행하여 네임스페이스를 생성합니다.$ oc create namespace <component_namespace>ccoctl툴을 사용하여 클라우드 공급자에 대한 명령을 실행하여credrequests디렉터리의 모든CredentialsRequest오브젝트를 처리합니다. 다음 명령은CredentialsRequest오브젝트를 처리합니다.-
CloudEvent Cloud:
ccoctl alibabacloud create-ram-users -
Amazon Web Services (AWS):
ccoctl aws create-iam-roles -
GCP(Google Cloud Platform):
ccoctl gcp create-all -
IBM Cloud:
ccoctl ibmcloud create-service-id -
Nutanix:
ccoctl nutanix create-shared-secrets
중요필요한 인수 및 특수 고려 사항에 대한 중요한 플랫폼별 세부 사항은 클라우드 공급자의 설치 콘텐츠의
ccoctl유틸리티 지침을 참조하십시오.각
CredentialsRequest오브젝트에 대해ccoctl은 OpenShift Container Platform 릴리스 이미지의 각CredentialsRequest오브젝트에 정의된 대로 필요한 공급자 리소스 및 권한 정책을 생성합니다.-
CloudEvent Cloud:
다음 명령을 실행하여 클러스터에 보안을 적용합니다.
$ ls <path_to_ccoctl_output_dir>/manifests/*-credentials.yaml | xargs -I{} oc apply -f {}
검증
클라우드 공급자를 쿼리하여 필요한 공급자 리소스 및 권한 정책이 생성되었는지 확인할 수 있습니다. 자세한 내용은 역할 또는 서비스 계정 나열에 대한 클라우드 공급자 설명서를 참조하십시오.
다음 단계
-
upgradeable-to주석을 업데이트하여 클러스터를 업그레이드할 준비가 되었음을 나타냅니다.
6.4. 수동으로 유지 관리되는 인증 정보로 클라우드 공급자 리소스 업데이트
수동으로 유지 관리되는 인증 정보로 클러스터를 업그레이드하기 전에 업그레이드할 릴리스 이미지에 대한 새 인증 정보를 생성해야 합니다. 기존 인증 정보에 필요한 권한을 검토하고 해당 구성 요소의 새 릴리스에 새 권한 요구 사항을 충족해야 합니다.
절차
새 릴리스에 대한
CredentialsRequest사용자 지정 리소스를 추출하고 검사합니다.클라우드 공급자에 대한 설치 콘텐츠의 "Manually creating IAM" 섹션은 클라우드에 필요한 인증 정보를 얻고 사용하는 방법을 설명합니다.
클러스터에서 수동으로 유지 관리되는 인증 정보를 업데이트합니다.
-
새 릴리스 이미지에서 추가한
CredentialsRequest사용자 정의 리소스에 대한 새 시크릿을 생성합니다. -
시크릿에 저장된 기존 인증 정보에 대한
CredentialsRequest사용자 정의 리소스에 변경된 권한 요구 사항이 있는 경우 필요에 따라 권한을 업데이트합니다.
-
새 릴리스 이미지에서 추가한
다음 단계
-
upgradeable-to주석을 업데이트하여 클러스터를 업그레이드할 준비가 되었음을 나타냅니다.
6.5. 클러스터를 업그레이드할 준비가 되었음을 나타냅니다.
CCO(Cloud Credential Operator) 수동으로 유지 관리되는 인증 정보가 있는 클러스터의 Upgradable 상태는 기본적으로 False 입니다.
사전 요구 사항
-
업그레이드할 릴리스 이미지의 경우 새 인증 정보를 수동으로 처리하거나 Cloud Credential Operator 유틸리티(
ccoctl)를 사용하여 처리했습니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
-
cluster-admin역할의 사용자로 클러스터에서oc에 로그인합니다. CloudCredential리소스를 편집하여 다음 명령을 실행하여metadata필드 내에upgradeable-to주석을 추가합니다.$ oc edit cloudcredential cluster추가할 텍스트
... metadata: annotations: cloudcredential.openshift.io/upgradeable-to: <version_number> ...여기서
<version_number>는x.y.z형식으로 업그레이드할 버전입니다. 예를 들어 OpenShift Container Platform4.12.2에는 4.12.2를 사용합니다.주석을 추가한 후 업그레이드 가능 상태가 변경되는 데 몇 분이 소요될 수 있습니다.
검증
- 웹 콘솔의 관리자 화면에서 관리자 → 클러스터 설정으로 이동합니다.
CCO 상태 세부 정보를 보려면 Cluster Operators 목록에서 cloud-credential을 클릭합니다.
-
Conditions 섹션의 Upgradeable 상태가 False인 경우
upgradeable-to 주석에 오타 오류가 없는지 확인합니다.
-
Conditions 섹션의 Upgradeable 상태가 False인 경우
- Conditions 섹션의 Upgradeable 상태가 True 인 경우 OpenShift Container Platform 업그레이드를 시작합니다.
7장. 웹 콘솔을 사용하여 클러스터 업데이트
웹 콘솔을 사용하여 OpenShift Container Platform 클러스터를 업데이트하거나 업그레이드할 수 있습니다. 다음 단계에서는 마이너 버전의 클러스터를 업데이트합니다. 마이너 버전 간에 클러스터를 업데이트하기 위해 동일한 지침을 사용할 수 있습니다.
웹 콘솔 또는 oc adm upgrade channel <channel> 을 사용하여 업데이트 채널을 변경합니다. 4.11 채널을 변경한 후 업데이트를 완료하기 위해 CLI를 사용하여 클러스터 업데이트 단계를 실행할 수 있습니다.
7.1. 사전 요구 사항
-
admin권한이 있는 사용자로 클러스터에 액세스합니다. RBAC를 사용하여 권한 정의 및 적용을 참조하십시오. - 업데이트가 실패하는 경우 최근 etcd 백업이 있고 클러스터를 이전 상태로 복원해야 합니다.
- RHEL7 작업자에 대한 지원은 OpenShift Container Platform 4.11에서 제거되었습니다. OpenShift Container Platform 4.11로 업그레이드하기 전에 RHEL7 작업자를 RHEL8 또는 RHCOS 작업자로 교체해야 합니다. Red Hat은 RHEL 작업자의 RHEL8 업데이트를 RHEL8에 배치하지 않습니다. 이러한 호스트는 깔끔한 운영 체제 설치로 교체되어야 합니다.
- OLM(Operator Lifecycle Manager)을 통해 이전에 설치된 모든 Operator가 최신 채널의 최신 버전으로 업데이트되었는지 확인합니다. Operator를 업데이트하면 클러스터 업데이트 중에 기본 OperatorHub 카탈로그가 현재 마이너 버전에서 다음 버전으로 전환할 때 유효한 업데이트 경로를 사용할 수 있습니다. 자세한 내용은 설치된 Operator 업데이트를 참조하십시오.
- 모든 MCP(Machine config pool)가 실행 중이고 일시 중지되지 않는지 확인합니다. 업데이트 프로세스 중에 일시 중지된 MCP와 연결된 노드를 건너뜁니다. 카나리아 롤아웃 업데이트 전략을 수행하는 경우 MCP를 일시 중지할 수 있습니다.
- 업데이트하는 데 걸리는 시간을 수용하기 위해 작업자 또는 사용자 지정 풀 노드를 업데이트하여 부분 업데이트를 수행할 수 있습니다. 각 풀의 진행률 표시줄 내에서 일시 중지 및 재개할 수 있습니다.
- 클러스터에서 수동으로 유지 관리되는 인증 정보를 사용하는 경우 새 릴리스의 클라우드 공급자 리소스를 업데이트합니다. 자세한 내용은 수동으로 유지 관리되는 인증 정보를 사용하여 클러스터 업데이트 준비를 참조하십시오.
-
Operator를 실행하거나 Pod 중단 예산을 사용하여 애플리케이션을 구성한 경우 업그레이드 프로세스 중에 중단될 수 있습니다.
PodDisruptionBudget에서minAvailable이 1로 설정된 경우 노드는 제거 프로세스를 차단할 수 있는 보류 중인 머신 구성을 적용하기 위해 드레인됩니다. 여러 노드가 재부팅되면 모든 Pod가 하나의 노드에서만 실행될 수 있으며PodDisruptionBudget필드에서 노드 드레이닝을 방지할 수 있습니다.
- 업데이트가 완료되지 않으면 CVO(Cluster Version Operator)에서 업데이트를 조정하는 동안 차단 구성 요소의 상태를 보고합니다. 클러스터를 이전 버전으로 롤백하는 것은 지원되지 않습니다. 업데이트가 완료되지 않으면 Red Hat 지원에 문의하십시오.
-
unsupportedConfigOverrides섹션을 사용하여 Operator 설정을 변경하는 것은 지원되지 않으며 클러스터 업데이트를 차단할 수 있습니다. 클러스터를 업데이트하려면 먼저 이 설정을 제거해야 합니다.
7.2. 카나리아 롤아웃 업데이트 수행
일부 특정 사용 사례에서는 클러스터의 나머지 부분과 동시에 특정 노드를 업데이트하지 않도록 보다 제어된 업데이트 프로세스를 원할 수 있습니다. 이러한 사용 사례에는 다음이 포함되지만 이에 국한되지는 않습니다.
- 업데이트 중에 사용할 수 없는 미션크리티컬 애플리케이션이 있습니다. 업데이트 후 노드의 애플리케이션을 소규모로 천천히 테스트할 수 있습니다.
- 유지 보수 기간이 짧아서 모든 노드를 업데이트할 수 없거나 유지 보수 기간이 여러 개일 수 있습니다.
롤링 업데이트 프로세스는 일반적인 업데이트 워크플로우가 아닙니다. 대규모 클러스터를 사용하면 여러 명령을 실행해야 하는 시간이 많이 소요될 수 있습니다. 이러한 복잡성으로 인해 전체 클러스터에 영향을 줄 수 있는 오류가 발생할 수 있습니다. 롤링 업데이트를 사용할지 여부를 신중하게 고려하고 시작하기 전에 프로세스 구현을 신중하게 계획하는 것이 좋습니다.
이 주제에서 설명하는 롤링 업데이트 프로세스에는 다음이 포함됩니다.
- 하나 이상의 사용자 지정 MCP(Machine config pool) 생성.
- 해당 노드를 사용자 지정 MCP로 이동하기 위해 즉시 업데이트하지 않으려는 각 노드에 레이블을 지정.
- 해당 노드에 대한 업데이트를 방지하는 사용자 지정 MCP를 일시 중지.
- 클러스터 업데이트 수행.
- 해당 노드에서 업데이트를 트리거하는 하나의 사용자 지정 MCP를 일시 중지 해제.
- 해당 노드에서 애플리케이션을 테스트하여 새로 업데이트된 해당 노드에서 애플리케이션이 예상대로 작동하는지 확인.
- 선택적으로 나머지 노드에서 사용자 지정 레이블을 소규모 배치로 제거하고 해당 노드에서 애플리케이션을 테스트.
MCP를 일시 중지하면 Machine Config Operator에서 연결된 노드에 구성 변경 사항을 적용하지 못합니다. MCP를 일시 중지하면 kube-apiserver-to-kubelet-signer CA 인증서의 자동 CA 순환을 포함하여 자동으로 순환된 인증서가 연결된 노드로 푸시되지 않습니다.
kube-apiserver-to-kubelet-signer CA 인증서가 만료되고 MCO가 인증서를 자동으로 갱신하려고 하면 새 인증서가 생성되지만 해당 머신 구성 풀의 노드에 적용되지 않습니다. 이로 인해 oc debug, ,oc logsoc exec, oc attach 를 포함하여 여러 oc 명령에서 실패합니다. 인증서가 순환될 때 MCP가 일시 중지되면 OpenShift Container Platform 웹 콘솔의 경고 UI에 알림이 표시됩니다.
MCP 일시 중지는 kube-apiserver-to-kubelet-signer CA 인증서 만료에 대해 신중하게 고려하여 단기간 동안만 수행해야 합니다.
카나리아 롤아웃 업데이트 프로세스를 사용하려면 카나리아 롤아웃 업데이트 수행을 참조하십시오.
7.3. 웹 콘솔을 사용하여 MachineHealthCheck 리소스 일시 중지
업그레이드 프로세스 중에 클러스터의 노드를 일시적으로 사용할 수 없게 될 수 있습니다. 작업자 노드의 경우 시스템 상태 점검에서 이러한 노드를 비정상으로 식별하고 재부팅할 수 있습니다. 이러한 노드를 재부팅하지 않으려면 클러스터를 업데이트하기 전에 모든 MachineHealthCheck 리소스를 일시 중지합니다.
사전 요구 사항
-
cluster-admin권한이 있는 클러스터에 액세스할 수 있습니다. - OpenShift Container Platform 웹 콘솔에 액세스할 수 있습니다.
프로세스
- OpenShift Container Platform 웹 콘솔에 로그인합니다.
- Compute → MachineHealthChecks 로 이동합니다.
머신 상태 점검을 일시 중지하려면 각
MachineHealthCheck리소스에cluster.x-k8s.io/paused=""주석을 추가합니다. 예를 들어machine-api-termination-handler리소스에 주석을 추가하려면 다음 단계를 완료합니다.-
machine-api-termination-handler옆에 있는 옵션 메뉴 를 클릭하고 주석 편집을 클릭합니다.
를 클릭하고 주석 편집을 클릭합니다.
- Edit annotations ( 주석 편집) 대화 상자에서 추가 를 클릭합니다.
-
Key 및 Value 필드에서
cluster.x-k8s.io/paused및""값을 각각 추가하고 저장 을 클릭합니다.
-
7.4. 단일 노드 OpenShift Container Platform 업데이트 정보
콘솔 또는 CLI를 사용하여 단일 노드 OpenShift Container Platform 클러스터를 업데이트하거나 업그레이드할 수 있습니다.
그러나 다음과 같은 제한 사항이 있습니다.
-
상태 점검을 수행할 다른 노드가 없으므로
MachineHealthCheck리소스를 일시 중지하기 위한 전제 조건은 필요하지 않습니다. - etcd 백업을 사용하여 단일 노드 OpenShift Container Platform 클러스터를 복원하는 것은 공식적으로 지원되지 않습니다. 그러나 업그레이드가 실패하는 경우 etcd 백업을 수행하는 것이 좋습니다. 컨트롤 플레인이 정상이면 백업을 사용하여 클러스터를 이전 상태로 복원할 수 있습니다.
단일 노드 OpenShift Container Platform 클러스터를 업데이트하려면 다운타임이 필요하며 자동 재부팅을 포함할 수 있습니다. 다운타임의 양은 다음 시나리오에 설명된 대로 업데이트 페이로드에 따라 달라집니다.
- 업데이트 페이로드에 재부팅이 필요한 운영 체제 업데이트가 포함되어 있는 경우 다운타임이 중요하며 클러스터 관리 및 사용자 워크로드에 영향을 미칩니다.
- 업데이트에 재부팅할 필요가 없는 머신 구성 변경이 포함된 경우 다운타임이 줄어들고 클러스터 관리 및 사용자 워크로드에 미치는 영향이 줄어듭니다. 이 경우 노드 드레이닝 단계는 단일 노드 OpenShift Container Platform으로 건너뛰어 워크로드를 다시 예약할 다른 노드가 클러스터에 없기 때문입니다.
- 업데이트 페이로드에 운영 체제 업데이트 또는 머신 구성 변경 사항이 포함되어 있지 않으면 간단한 API 중단이 발생하고 신속하게 해결됩니다.
업데이트된 패키지의 버그와 같은 조건이 있으며 이로 인해 재부팅 후 단일 노드가 다시 시작되지 않을 수 있습니다. 이 경우 업데이트가 자동으로 롤백되지 않습니다.
7.5. 웹 콘솔을 사용하여 클러스터 업데이트
사용 가능한 업데이트가 있으면 웹 콘솔에서 클러스터를 업데이트할 수 있습니다.
사용 가능한 OpenShift Container Platform 권고 및 업데이트는 고객 포털의 에라타 섹션을 참조하십시오.
전제 조건
-
admin권한이 있는 사용자로 웹 콘솔에 액세스합니다. -
모든
MachineHealthCheck리소스를 일시 중지합니다.
프로세스
- 웹 콘솔에서 Administration → Cluster Settings을 클릭하고 Details 탭의 내용을 확인합니다.
프로덕션 클러스터의 경우 Channel 이
stable-4.11과 같이 업데이트하려는 버전에 대해 올바른 채널로 설정되어 있는지 확인합니다.중요프로덕션 클러스터의 경우
stable-*,eus-*또는fast-*채널에 가입해야 합니다.참고다음 마이너 버전으로 이동할 준비가 되면 해당 마이너 버전에 해당하는 채널을 선택합니다. 업데이트 채널을 더 많이 선언할수록 클러스터에서 대상 버전으로 경로를 업데이트하는 것이 좋습니다. 클러스터에서 사용 가능한 모든 업데이트를 평가하고 선택할 수 있는 최상의 업데이트 권장 사항을 제공하는 데 시간이 다소 걸릴 수 있습니다. 업데이트 권장 사항은 현재 사용 가능한 업데이트 옵션을 기반으로 하므로 시간이 지남에 따라 변경될 수 있습니다.
대상 마이너 버전의 업데이트 경로가 표시되지 않는 경우 경로에서 다음 마이너 버전을 사용할 수 있을 때까지 클러스터를 현재 버전의 최신 패치 릴리스로 계속 업데이트하십시오.
- Update status 가 Updates available 이 아닌 경우 클러스터를 업데이트할 수 없습니다.
- Select channel은 클러스터가 실행 중이거나 업데이트 중인 클러스터 버전을 나타냅니다.
업데이트할 버전을 선택하고 저장을 클릭합니다.
입력 채널 Update Status가 Update to <product-version> in progress로 변경되고 Operator 및 노드의 진행률을 확인하여 클러스터 업데이트의 진행 상황을 검토할 수 있습니다.
참고클러스터를 버전 4.y+1과 같이 다음 마이너 버전으로 업그레이드하는 경우 새 기능에 의존하는 워크로드를 배포하기 전에 노드가 업데이트되었는지 확인하는 것이 좋습니다. 아직 업데이트되지 않은 작업자 노드가 있는 풀은 클러스터 설정 페이지에 표시됩니다.
업데이트가 완료되고 Cluster Version Operator가 사용 가능한 업데이트를 새로 고침한 후 현재 채널에서 사용 가능한 추가 업데이트가 있는지 확인합니다.
- 업데이트가 있는 경우 더 이상 업데이트할 수 없을 때까지 현재 채널에서 업데이트를 계속 수행합니다.
-
사용할 수 있는 업데이트가 없는 경우 채널을 다음 마이너 버전의
stable-*,eus-*또는fast-*채널로 변경하고 해당 채널에서 원하는 버전으로 업데이트합니다.
필요한 버전에 도달할 때까지 여러 중간 업데이트를 수행해야 할 수도 있습니다.
7.6. 웹 콘솔을 사용하여 업데이트 서버 변경
업데이트 서버 변경은 선택 사항입니다. 로컬에 설치되어 구성된 OSUS(OpenShift Update Service)가 있는 경우 업데이트 중에 로컬 서버를 사용하도록 서버의 URL을 upstream으로 설정해야 합니다.
프로세스
- 관리 → 클러스터 설정으로 이동하여 버전을 클릭합니다.
YAML 탭을 클릭한 다음
업스트림매개변수 값을 편집합니다.출력 예
... spec: clusterID: db93436d-7b05-42cc-b856-43e11ad2d31a upstream: '<update-server-url>'1 ...- 1
<update-server-url>변수는 업데이트 서버의 URL을 지정합니다.
기본
upstream은https://api.openshift.com/api/upgrades_info/v1/graph입니다.- 저장을 클릭합니다.
8장. CLI를 사용하여 클러스터 업데이트
OpenShift CLI (oc)를 사용하여 마이너 버전에서 OpenShift Container Platform 클러스터를 업데이트하거나 업그레이드할 수 있습니다. 동일한 지침에 따라 마이너 버전 간에 클러스터를 업데이트할 수도 있습니다.
8.1. 전제 조건
-
admin권한이 있는 사용자로 클러스터에 액세스합니다. RBAC를 사용하여 권한 정의 및 적용을 참조하십시오. - 업데이트가 실패하는 경우 최근 etcd 백업이 있고 클러스터를 이전 상태로 복원해야 합니다.
- RHEL7 작업자에 대한 지원은 OpenShift Container Platform 4.11에서 제거되었습니다. OpenShift Container Platform 4.11로 업그레이드하기 전에 RHEL7 작업자를 RHEL8 또는 RHCOS 작업자로 교체해야 합니다. Red Hat은 RHEL 작업자의 RHEL8 업데이트를 RHEL8에 배치하지 않습니다. 이러한 호스트는 깔끔한 운영 체제 설치로 교체되어야 합니다.
- OLM(Operator Lifecycle Manager)을 통해 이전에 설치된 모든 Operator가 최신 채널의 최신 버전으로 업데이트되었는지 확인합니다. Operator를 업데이트하면 클러스터 업데이트 중에 기본 OperatorHub 카탈로그가 현재 마이너 버전에서 다음 버전으로 전환할 때 유효한 업데이트 경로를 사용할 수 있습니다. 자세한 내용은 설치된 Operator 업데이트를 참조하십시오.
- 모든 MCP(Machine config pool)가 실행 중이고 일시 중지되지 않는지 확인합니다. 업데이트 프로세스 중에 일시 중지된 MCP와 연결된 노드를 건너뜁니다. 카나리아 롤아웃 업데이트 전략을 수행하는 경우 MCP를 일시 중지할 수 있습니다.
- 클러스터에서 수동으로 유지 관리되는 인증 정보를 사용하는 경우 새 릴리스의 클라우드 공급자 리소스를 업데이트합니다. 자세한 내용은 수동으로 유지 관리되는 인증 정보를 사용하여 클러스터 업데이트 준비를 참조하십시오.
-
클러스터에서 다음 마이너 버전으로 업데이트할 수 있도록 모든
Upgradeable=False조건을 처리할 수 있는지 확인합니다. 업그레이드할 수 없는 클러스터 Operator가 하나 이상 있는 경우 클러스터 설정 페이지 상단에 경고가 표시됩니다. 현재 사용 중인 마이너 릴리스에 대해 사용 가능한 다음 패치 업데이트로 계속 업데이트할 수 있습니다. -
Operator를 실행하거나 Pod 중단 예산을 사용하여 애플리케이션을 구성한 경우 업그레이드 프로세스 중에 중단될 수 있습니다.
PodDisruptionBudget에서minAvailable이 1로 설정된 경우 노드는 제거 프로세스를 차단할 수 있는 보류 중인 머신 구성을 적용하기 위해 드레인됩니다. 여러 노드가 재부팅되면 모든 Pod가 하나의 노드에서만 실행될 수 있으며PodDisruptionBudget필드에서 노드 드레이닝을 방지할 수 있습니다.
- 업데이트가 완료되지 않으면 CVO(Cluster Version Operator)에서 업데이트를 조정하는 동안 차단 구성 요소의 상태를 보고합니다. 클러스터를 이전 버전으로 롤백하는 것은 지원되지 않습니다. 업데이트가 완료되지 않으면 Red Hat 지원에 문의하십시오.
-
unsupportedConfigOverrides섹션을 사용하여 Operator 설정을 변경하는 것은 지원되지 않으며 클러스터 업데이트를 차단할 수 있습니다. 클러스터를 업데이트하려면 먼저 이 설정을 제거해야 합니다.
8.2. MachineHealthCheck 리소스 일시 중지
업그레이드 프로세스 중에 클러스터의 노드를 일시적으로 사용할 수 없게 될 수 있습니다. 작업자 노드의 경우 시스템 상태 점검에서 이러한 노드를 비정상으로 식별하고 재부팅할 수 있습니다. 이러한 노드를 재부팅하지 않으려면 클러스터를 업데이트하기 전에 모든 MachineHealthCheck 리소스를 일시 중지합니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다.
프로세스
일시 중지하려는 사용 가능한
MachineHealthCheck리소스를 모두 나열하려면 다음 명령을 실행합니다.$ oc get machinehealthcheck -n openshift-machine-api머신 상태 점검을 일시 중지하려면
cluster.x-k8s.io/paused=""주석을MachineHealthCheck리소스에 추가합니다. 다음 명령을 실행합니다.$ oc -n openshift-machine-api annotate mhc <mhc-name> cluster.x-k8s.io/paused=""주석이 지정된
MachineHealthCheck리소스는 다음 YAML 파일과 유사합니다.apiVersion: machine.openshift.io/v1beta1 kind: MachineHealthCheck metadata: name: example namespace: openshift-machine-api annotations: cluster.x-k8s.io/paused: "" spec: selector: matchLabels: role: worker unhealthyConditions: - type: "Ready" status: "Unknown" timeout: "300s" - type: "Ready" status: "False" timeout: "300s" maxUnhealthy: "40%" status: currentHealthy: 5 expectedMachines: 5중요클러스터를 업데이트한 후 머신 상태 점검을 다시 시작합니다. 검사를 다시 시작하려면 다음 명령을 실행하여
MachineHealthCheck리소스에서 일시 중지 주석을 제거합니다.$ oc -n openshift-machine-api annotate mhc <mhc-name> cluster.x-k8s.io/paused-
8.3. 단일 노드 OpenShift Container Platform 업데이트 정보
콘솔 또는 CLI를 사용하여 단일 노드 OpenShift Container Platform 클러스터를 업데이트하거나 업그레이드할 수 있습니다.
그러나 다음과 같은 제한 사항이 있습니다.
-
상태 점검을 수행할 다른 노드가 없으므로
MachineHealthCheck리소스를 일시 중지하기 위한 전제 조건은 필요하지 않습니다. - etcd 백업을 사용하여 단일 노드 OpenShift Container Platform 클러스터를 복원하는 것은 공식적으로 지원되지 않습니다. 그러나 업그레이드가 실패하는 경우 etcd 백업을 수행하는 것이 좋습니다. 컨트롤 플레인이 정상이면 백업을 사용하여 클러스터를 이전 상태로 복원할 수 있습니다.
단일 노드 OpenShift Container Platform 클러스터를 업데이트하려면 다운타임이 필요하며 자동 재부팅을 포함할 수 있습니다. 다운타임의 양은 다음 시나리오에 설명된 대로 업데이트 페이로드에 따라 달라집니다.
- 업데이트 페이로드에 재부팅이 필요한 운영 체제 업데이트가 포함되어 있는 경우 다운타임이 중요하며 클러스터 관리 및 사용자 워크로드에 영향을 미칩니다.
- 업데이트에 재부팅할 필요가 없는 머신 구성 변경이 포함된 경우 다운타임이 줄어들고 클러스터 관리 및 사용자 워크로드에 미치는 영향이 줄어듭니다. 이 경우 노드 드레이닝 단계는 단일 노드 OpenShift Container Platform으로 건너뛰어 워크로드를 다시 예약할 다른 노드가 클러스터에 없기 때문입니다.
- 업데이트 페이로드에 운영 체제 업데이트 또는 머신 구성 변경 사항이 포함되어 있지 않으면 간단한 API 중단이 발생하고 신속하게 해결됩니다.
업데이트된 패키지의 버그와 같은 조건이 있으며 이로 인해 재부팅 후 단일 노드가 다시 시작되지 않을 수 있습니다. 이 경우 업데이트가 자동으로 롤백되지 않습니다.
8.4. CLI를 사용하여 클러스터 업데이트
OpenShift CLI(oc)를 사용하여 클러스터 업데이트를 검토하고 요청할 수 있습니다.
사용 가능한 OpenShift Container Platform 권고 및 업데이트는 고객 포털의 에라타 섹션을 참조하십시오.
전제 조건
-
업데이트된 버전과 일치하는 OpenShift CLI (
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 클러스터에 로그인합니다. -
모든
MachineHealthCheck리소스를 일시 중지합니다.
절차
사용 가능한 업데이트를 확인하고 적용하려는 업데이트의 버전 번호를 기록해 둡니다.
$ oc adm upgrade출력 예
Cluster version is 4.9.23 Upstream is unset, so the cluster will use an appropriate default. Channel: stable-4.9 (available channels: candidate-4.10, candidate-4.9, fast-4.10, fast-4.9, stable-4.10, stable-4.9, eus-4.10) Recommended updates: VERSION IMAGE 4.9.24 quay.io/openshift-release-dev/ocp-release@sha256:6a899c54dda6b844bb12a247e324a0f6cde367e880b73ba110c056df6d018032 4.9.25 quay.io/openshift-release-dev/ocp-release@sha256:2eafde815e543b92f70839972f585cc52aa7c37aa72d5f3c8bc886b0fd45707a 4.9.26 quay.io/openshift-release-dev/ocp-release@sha256:3ccd09dd08c303f27a543351f787d09b83979cd31cf0b4c6ff56cd68814ef6c8 4.9.27 quay.io/openshift-release-dev/ocp-release@sha256:1c7db78eec0cf05df2cead44f69c0e4b2c3234d5635c88a41e1b922c3bedae16 4.9.28 quay.io/openshift-release-dev/ocp-release@sha256:4084d94969b186e20189649b5affba7da59f7d1943e4e5bc7ef78b981eafb7a8 4.9.29 quay.io/openshift-release-dev/ocp-release@sha256:b04ca01d116f0134a102a57f86c67e5b1a3b5da1c4a580af91d521b8fa0aa6ec 4.9.31 quay.io/openshift-release-dev/ocp-release@sha256:2a28b8ebb53d67dd80594421c39e36d9896b1e65cb54af81fbb86ea9ac3bf2d7 4.9.32 quay.io/openshift-release-dev/ocp-release@sha256:ecdb6d0df547b857eaf0edb5574ddd64ca6d9aff1fa61fd1ac6fb641203bedfa참고- 사용 가능한 업데이트가 없는 경우 지원되지만 권장되지 않는 업데이트는 계속 사용할 수 있습니다. 자세한 내용은 조건부 업데이트 경로를 따라 업데이트를 참조하십시오.
-
EUS-to-EUS채널 업데이트를 수행하는 방법에 대한 자세한 내용 및 자세한 내용은 추가 리소스 섹션에 나열된 EUS-to-EUS 업그레이드 준비 페이지를 참조하십시오.
조직 요구 사항에 따라 적절한 업데이트 채널을 설정합니다. 예를 들어 채널을
stable-4.13또는fast-4.13으로 설정할 수 있습니다. 채널에 대한 자세한 내용은 추가 리소스 섹션에 나열된 업데이트 채널 및 릴리스 이해 를 참조하십시오.$ oc adm upgrade channel <channel>예를 들어 채널을
stable-4.11로 설정하려면 다음을 수행합니다.$ oc adm upgrade channel stable-4.11중요프로덕션 클러스터의 경우
stable-*,eus-*또는fast-*채널에 가입해야합니다.참고다음 마이너 버전으로 이동할 준비가 되면 해당 마이너 버전에 해당하는 채널을 선택합니다. 업데이트 채널을 더 많이 선언할수록 클러스터에서 대상 버전으로 경로를 업데이트하는 것이 좋습니다. 클러스터에서 사용 가능한 모든 업데이트를 평가하고 선택할 수 있는 최상의 업데이트 권장 사항을 제공하는 데 시간이 다소 걸릴 수 있습니다. 업데이트 권장 사항은 현재 사용 가능한 업데이트 옵션을 기반으로 하므로 시간이 지남에 따라 변경될 수 있습니다.
대상 마이너 버전의 업데이트 경로가 표시되지 않는 경우 경로에서 다음 마이너 버전을 사용할 수 있을 때까지 클러스터를 현재 버전의 최신 패치 릴리스로 계속 업데이트하십시오.
업데이트를 적용합니다.
클러스터 버전 Operator의 상태를 확인합니다.
$ oc adm upgrade업데이트가 완료되면 클러스터 버전이 새 버전으로 업데이트되었는지 확인합니다.
$ oc get clusterversion출력 예
Cluster version is <version> Upstream is unset, so the cluster will use an appropriate default. Channel: stable-4.10 (available channels: candidate-4.10, candidate-4.11, eus-4.10, fast-4.10, fast-4.11, stable-4.10) No updates available. You may force an upgrade to a specific release image, but doing so might not be supported and might result in downtime or data loss.클러스터를 버전 X.y에서 X.(y+1)로 업데이트하는 경우 새 기능을 사용하는 워크로드를 배포하기 전에 노드가 업데이트되었는지 확인하는 것이 좋습니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ip-10-0-168-251.ec2.internal Ready master 82m v1.24.0 ip-10-0-170-223.ec2.internal Ready master 82m v1.24.0 ip-10-0-179-95.ec2.internal Ready worker 70m v1.24.0 ip-10-0-182-134.ec2.internal Ready worker 70m v1.24.0 ip-10-0-211-16.ec2.internal Ready master 82m v1.24.0 ip-10-0-250-100.ec2.internal Ready worker 69m v1.24.0
8.5. 조건부 업그레이드 경로를 따라 업데이트
웹 콘솔 또는 OpenShift CLI(oc)를 사용하여 권장되는 조건부 업그레이드 경로를 따라 업데이트할 수 있습니다. 조건부 업데이트가 클러스터에 권장되지 않는 경우 OpenShift CLI(oc) 4.10 이상을 사용하여 조건부 업그레이드 경로를 따라 업데이트할 수 있습니다.
프로세스
위험이 적용될 수 있으므로 업데이트에 대한 설명을 보려면 다음 명령을 실행합니다.
$ oc adm upgrade --include-not-recommended클러스터 관리자가 잠재적인 알려진 위험을 평가하고 현재 클러스터에 허용 가능한 것으로 결정하면 관리자는 다음 명령을 실행하여 안전 보호 기능을 포기하고 업데이트를 진행할 수 있습니다.
$ oc adm upgrade --allow-not-recommended --to <version> <.><
.> <version>은 지원되지만 이전 명령의 출력에서 가져온 업데이트 버전은 권장되지 않습니다.
8.6. CLI를 사용하여 업데이트 서버 변경
업데이트 서버 변경은 선택 사항입니다. 로컬에 설치되어 구성된 OSUS(OpenShift Update Service)가 있는 경우 업데이트 중에 로컬 서버를 사용하도록 서버의 URL을 upstream으로 설정해야 합니다. upstream의 기본값은 https://api.openshift.com/api/upgrades_info/v1/graph입니다.
프로세스
클러스터 버전에서
upstream매개변수 값을 변경합니다.$ oc patch clusterversion/version --patch '{"spec":{"upstream":"<update-server-url>"}}' --type=merge<update-server-url>변수는 업데이트 서버의 URL을 지정합니다.출력 예
clusterversion.config.openshift.io/version patched
9장. 카나리아 롤아웃 업데이트 수행
업데이트 프로세스로 인해 애플리케이션이 실패하더라도 전체 업데이트 중에 미션크리티컬 애플리케이션을 계속 사용할 수 있도록 작업자 노드에 대한 업데이트 롤아웃을 보다 제어해야 하는 몇 가지 시나리오가 있을 수 있습니다. 조직의 요구에 따라 작업자 노드의 작은 하위 집합을 업데이트하고 일정 기간 동안 클러스터 및 워크로드 상태를 평가한 다음 나머지 노드를 업데이트할 수 있습니다. 이를 카나리아 업데이트라고 합니다. 또는 호스트 재부팅이 필요한 작업자 노드 업데이트를 한 번에 전체 클러스터를 업데이트할 수 없는 경우 정의된 더 작은 유지 관리 기간으로 전환해야 할 수도 있습니다.
이러한 시나리오에서는 클러스터를 업데이트할 때 특정 작업자 노드가 업데이트되지 않도록 여러 MCP(사용자 정의 머신 구성 풀)를 생성할 수 있습니다. 나머지 클러스터가 업데이트되면 적절한 시간에 배치로 해당 작업자 노드를 업데이트할 수 있습니다.
예를 들어 초과 용량이 10%인 노드가 100개 있는 클러스터가 있는 경우 유지 관리 기간이 4시간을 넘지 않아야 하며 작업자 노드를 드레이닝하고 재부팅하는 데 8분이 걸리기 때문에 MCP를 활용하여 목표를 달성할 수 있습니다. 예를 들어 각각 10, 30개, 30개의 노드가 있는 workerpool-canary, workerpool-A, workerpool-B, workerpool-C라는 4개의 MCP를 정의할 수 있습니다.
첫 번째 유지 관리 기간 동안 workerpool-A, workerpool-B, workerpool-C에 대한 MCP를 일시 중지한 다음 클러스터 업데이트를 시작합니다. 이 경우 해당 풀이 일시 중지되지 않았기 때문에 OpenShift Container Platform에서 실행되는 구성 요소와 workerpool-canary MCP의 멤버인 10개의 노드가 업데이트되었습니다. 나머지 3개의 MCP는 일시 중지되었으므로 업데이트되지 않습니다. 어떠한 이유로 workerpool-canary 업데이트의 클러스터 또는 워크로드 상태가 부정적인 영향을 미치는 경우 문제를 진단할 때까지 충분한 용량을 유지 관리하면서 해당 풀의 모든 노드를 차단하고 드레이닝합니다. 모든 항목이 예상대로 작동하면 일시 중지 해제를 결정하기 전에 클러스터 및 워크로드 상태를 평가하여 각 추가 유지 관리 기간 동안 연속으로 workerpool-A, workerpool-B, workerpool-C를 업데이트합니다.
사용자 지정 MCP를 사용하여 작업자 노드 업데이트를 관리하는 것은 유연성을 제공하지만 여러 명령을 실행해야 하는 시간이 많이 걸리는 프로세스일 수 있습니다. 이러한 복잡성으로 인해 전체 클러스터에 영향을 줄 수 있는 오류가 발생할 수 있습니다. 시작하기 전에 조직의 요구 사항을 신중하게 고려하고 프로세스 구현을 신중하게 계획하는 것이 좋습니다.
MCP를 다른 OpenShift Container Platform 버전으로 업데이트하지 않는 것이 좋습니다. 예를 들어 한 MCP를 4.y.10에서 4.y.11로 다른 MCP를 4.y.12로 업데이트하지 마십시오. 이 시나리오는 테스트되지 않아 정의되지 않은 클러스터 상태가 될 수 있습니다.
머신 구성 풀을 일시 중지하면 Machine Config Operator가 연결된 노드에 구성 변경 사항을 적용할 수 없습니다. MCP를 일시 중지하면 kube-apiserver-to-kubelet-signer CA 인증서의 자동 CA 순환을 포함하여 자동으로 순환된 인증서가 연결된 노드로 푸시되지 않습니다.
kube-apiserver-to-kubelet-signer CA 인증서가 만료되고 MCO가 인증서를 자동으로 업데이트하려고 할 때 MCP가 일시 중지되면 MCO는 새로 순환된 인증서를 해당 노드로 푸시할 수 없습니다. 이로 인해 oc debug, ,oc logsoc exec, oc attach 를 포함하여 여러 oc 명령에서 실패합니다. 인증서가 순환될 때 MCP가 일시 중지되면 OpenShift Container Platform 웹 콘솔의 경고 UI에 알림이 표시됩니다.
MCP 일시 중지는 kube-apiserver-to-kubelet-signer CA 인증서 만료에 대해 신중하게 고려하여 단기간 동안만 수행해야 합니다.
9.1. 카나리아 롤아웃 업데이트 프로세스 및 MCP 정보
OpenShift Container Platform에서 노드는 개별적으로 간주되지 않습니다. 노드는 MCP(Machine config pool)로 그룹화됩니다. 기본 OpenShift Container Platform 클러스터에는 두 개의 MCP가 있습니다. 하나는 컨트롤 플레인 노드용이고 하나는 작업자 노드용입니다. OpenShift Container Platform 업데이트는 모든 MCP에 동시에 영향을 미칩니다.
업데이트 중에 MCO (Machine Config Operator)는 기본적으로 1에서 지정된 maxUnavailable 노드 수(지정된 경우)까지 MCP 내의 모든 노드를 드레이닝하고 차단합니다. 노드를 드레이닝하고 차단하면 노드의 모든 Pod 예약이 취소되고 노드가 예약 불가능으로 표시됩니다. 노드를 드레이닝한 후 Machine Config Daemon은 OS(운영 체제) 업데이트를 포함할 수 있는 새 머신 구성을 적용합니다. OS를 업데이트하려면 호스트가 재부팅해야 합니다.
특정 노드가 업데이트되지 않도록 하려면 드레이닝, 차단 및 업데이트되지 않도록 사용자 지정 MCP를 생성할 수 있습니다. 그런 다음 해당 MCP를 일시 중지하여 해당 MCP와 연결된 노드가 업데이트되지 않았는지 확인합니다. MCO는 일시 중지된 MCP를 업데이트하지 않습니다. 하나 이상의 사용자 지정 MCP를 생성하여 해당 노드를 업데이트하는 순서에 대해 더 많은 제어 권한을 부여할 수 있습니다. 첫 번째 MCP에서 노드를 업데이트한 후 애플리케이션 호환성을 확인한 다음 나머지 노드를 새 버전으로 점진적으로 업데이트할 수 있습니다.
컨트롤 플레인의 안정성을 보장하기 위해 컨트롤 플레인 노드에서 사용자 정의 MCP를 생성하는 것은 지원되지 않습니다. MCO(Machine Config Operator)는 컨트롤 플레인 노드에 대해 생성된 사용자 정의 MCP를 무시합니다.
워크로드 배포 토폴로지에 따라 생성하는 MCP 수와 각 MCP의 노드 수를 신중하게 고려해야 합니다. 예를 들어 특정 유지 관리 창에 업데이트를 조정해야 하는 경우 창 내에서 OpenShift Container Platform을 업데이트할 수 있는 노드 수를 알아야 합니다. 이 숫자는 고유한 클러스터 및 워크로드 특성에 따라 달라집니다.
또한 클러스터에서 사용할 수 있는 추가 용량을 고려해야 합니다. 예를 들어 업데이트된 노드에서 애플리케이션이 예상대로 작동하지 않는 경우 풀의 해당 노드를 차단하고 드레이닝하여 애플리케이션 pod를 다른 노드로 이동할 수 있습니다. 필요한 사용자 지정 MCP 수와 각 MCP에 있는 노드 수를 확인하기 위해 사용 가능한 추가 용량을 고려해야 합니다. 예를 들어 두 개의 사용자 지정 MCP를 사용하고 노드의 50%가 각 풀에 있는 경우 노드의 50%를 실행하면 애플리케이션에 충분한 QoS(Quality-of-service)를 제공하는지 확인해야 합니다.
이 업데이트 프로세스를 문서화된 모든 OpenShift Container Platform 업데이트 프로세스와 함께 사용할 수 있습니다. 그러나 이 프로세스는 Ansible 플레이북을 사용하여 업데이트되는 RHEL(Red Hat Enterprise Linux) 시스템에서는 작동하지 않습니다.
9.2. 카나리아 롤아웃 업데이트 수행 정보
다음에서는 카나리아 롤아웃 업데이트 프로세스의 일반적인 워크플로에 대해 설명합니다. 워크플로의 각 작업을 수행하는 단계는 다음 섹션에 설명되어 있습니다.
작업자 풀을 기반으로 MCP를 생성합니다. 각 MCP의 노드 수는 각 MCP의 유지 관리 기간 및 클러스터에서 사용할 수 있는 추가 작업자 노드를 의미하는 예약 용량과 같은 몇 가지 요소에 따라 다릅니다.
참고MCP에서
maxUnavailable설정을 변경하여 언제든지 업데이트할 수 있는 머신 수를 지정할 수 있습니다. 기본값은 1입니다.사용자 지정 MCP에 노드 선택기를 추가합니다. 나머지 클러스터와 동시에 업데이트하지 않으려는 각 노드에 대해 일치하는 레이블을 노드에 추가합니다. 이 레이블은 노드를 MCP에 연결합니다.
참고노드에서 기본 작업자 레이블을 제거하지 마십시오. 노드에는 클러스터에서 제대로 작동하려면 역할 레이블이 있어야 합니다.
업데이트 프로세스의 일부로 업데이트하지 않으려는 MCP를 일시 중지합니다.
참고MCP를 일시 중지하면
kube-apiserver-to-kubelet-signer자동 CA 인증서 순환이 일시 중지됩니다. 새 CA 인증서는 설치 날짜로부터 292일로 생성되며 이전 인증서는 설치 날짜로부터 365일에 제거됩니다. 다음 자동 CA 인증서 교체까지 남은 시간을 알아보려면 Red Hat OpenShift 4의 CA 인증서 자동 갱신 이해을 참조하십시오.CA 인증서 교체가 발생할 때 풀이 일시 중지되지 않았는지 확인합니다. MCP가 일시 중지되면 MCO는 새로 순환된 인증서를 해당 노드로 푸시할 수 없습니다. 이로 인해 클러스터의 성능이 저하되고
oc debug,oclogsoc exec,oc attach를 포함하여 여러 oc 명령에서 오류가 발생합니다. 인증서가 순환될 때 MCP가 일시 중지되면 OpenShift Container Platform 웹 콘솔의 경고 UI에 알림이 표시됩니다.- 클러스터 업데이트를 수행합니다. 업데이트 프로세스는 컨트롤 플레인 노드를 포함하여 일시 중지되지 않은 MCP를 업데이트합니다.
- 업데이트된 노드에서 애플리케이션을 테스트하여 애플리케이션이 예상대로 작동하는지 확인합니다.
-
나머지 MCP를 하나씩 일시 중지 해제하고 모든 작업자 노드가 업데이트될 때까지 해당 노드에서 애플리케이션을 테스트합니다. MCP의 일시 중지를 해제하면 해당 MCP와 연결된 노드의 업데이트 프로세스가 시작됩니다. 관리 → 클러스터 설정을 클릭하여 웹 콘솔에서 업데이트 진행 상황을 확인할 수 있습니다. 또는
oc get machineconfigpoolsCLI 명령을 사용합니다. - 선택적으로 업데이트된 노드에서 사용자 지정 레이블을 제거하고 사용자 지정 MCP를 삭제합니다.
9.3. 카나리아 롤아웃 업데이트를 수행할 머신 구성 풀 생성
카나리아 롤아웃 업데이트를 수행하는 첫 번째 작업은 MCP(Machine config pool)를 하나 이상 생성하는 것입니다.
작업자 노드에서 MCP를 생성합니다.
클러스터의 작업자 노드를 나열합니다.
$ oc get -l 'node-role.kubernetes.io/master!=' -o 'jsonpath={range .items[*]}{.metadata.name}{"\n"}{end}' nodes출력 예
ci-ln-pwnll6b-f76d1-s8t9n-worker-a-s75z4 ci-ln-pwnll6b-f76d1-s8t9n-worker-b-dglj2 ci-ln-pwnll6b-f76d1-s8t9n-worker-c-lldbm지연할 노드의 경우 사용자 지정 라벨을 노드에 추가합니다.
$ oc label node <node name> node-role.kubernetes.io/<custom-label>=예를 들어 다음과 같습니다.
$ oc label node ci-ln-0qv1yp2-f76d1-kl2tq-worker-a-j2ssz node-role.kubernetes.io/workerpool-canary=출력 예
node/ci-ln-gtrwm8t-f76d1-spbl7-worker-a-xk76k labeled새 MCP를 생성합니다.
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: workerpool-canary1 spec: machineConfigSelector: matchExpressions:2 - { key: machineconfiguration.openshift.io/role, operator: In, values: [worker,workerpool-canary] } nodeSelector: matchLabels: node-role.kubernetes.io/workerpool-canary: ""3 $ oc create -f <file_name>출력 예
machineconfigpool.machineconfiguration.openshift.io/workerpool-canary created클러스터의 MCP 목록과 현재 상태를 확인합니다.
$ oc get machineconfigpool출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-b0bb90c4921860f2a5d8a2f8137c1867 True False False 3 3 3 0 97m workerpool-canary rendered-workerpool-canary-87ba3dec1ad78cb6aecebf7fbb476a36 True False False 1 1 1 0 2m42s worker rendered-worker-87ba3dec1ad78cb6aecebf7fbb476a36 True False False 2 2 2 0 97m새 머신 구성 풀
workerpool-canary가 생성되고 사용자 정의 레이블을 추가한 노드 수가 머신 수에 표시됩니다. 작업자 MCP 머신 수는 동일한 수만큼 줄어듭니다. 시스템 수를 업데이트하는 데 몇 분이 걸릴 수 있습니다. 이 예에서는 하나의 노드가workerMCP에서workerpool-canaryMCP로 이동되었습니다.
9.4. 머신 구성 풀 일시 중지
이 카나리아 롤아웃 업데이트 프로세스에서 나머지 OpenShift Container Platform 클러스터로 업데이트하지 않을 노드에 레이블을 지정한 후 MCP(Machine config pool)를 생성하고 해당 MCP를 일시 중지합니다. MCP를 일시 중지하면 MCO(Machine Config Operator)가 해당 MCP와 연결된 노드를 업데이트할 수 없습니다.
MCP를 일시 중지하면 kube-apiserver-to-kubelet-signer 자동 CA 인증서 순환이 일시 중지됩니다. 새 CA 인증서는 설치 날짜로부터 292일로 생성되며 이전 인증서는 설치 날짜로부터 365일에 제거됩니다. 다음 자동 CA 인증서 교체까지 남은 시간을 알아보려면 Red Hat OpenShift 4의 CA 인증서 자동 갱신 이해을 참조하십시오.
CA 인증서 교체가 발생할 때 풀이 일시 중지되지 않았는지 확인합니다. MCP가 일시 중지되면 MCO는 새로 순환된 인증서를 해당 노드로 푸시할 수 없습니다. 이로 인해 클러스터의 성능이 저하되고 oc debug, ,oc logsoc exec, oc attach 를 포함하여 여러 oc 명령에서 오류가 발생합니다. 인증서가 순환될 때 MCP가 일시 중지되면 OpenShift Container Platform 웹 콘솔의 경고 UI에 알림이 표시됩니다.
MCP를 일시 중지하려면 다음을 수행합니다.
일시 중지하려는 MCP를 패치합니다.
$ oc patch mcp/<mcp_name> --patch '{"spec":{"paused":true}}' --type=merge예를 들어 다음과 같습니다.
$ oc patch mcp/workerpool-canary --patch '{"spec":{"paused":true}}' --type=merge출력 예
machineconfigpool.machineconfiguration.openshift.io/workerpool-canary patched
9.5. 클러스터 업데이트 수행
MCP가 준비 상태가 되면 클러스터 업데이트를 포맷할 수 있습니다. 클러스터에 적합한 다음 업데이트 방법 중 하나를 참조하십시오.
업데이트가 완료되면 MCP의 일시 중지를 하나씩 해제할 수 있습니다.
9.6. 머신 구성 풀 일시 중지 해제
이 카나리아 롤아웃 업데이트 프로세스에서 OpenShift Container Platform 업데이트가 완료된 후 사용자 정의 MCP를 하나씩 일시 중지 해제합니다. MCP의 일시 중지를 해제하면 MCO(Machine Config Operator)가 해당 MCP와 연결된 노드를 업데이트할 수 있습니다.
MCP 일시 중지를 해제하려면 다음을 수행합니다.
일시 중지 해제할 MCP를 패치합니다.
$ oc patch mcp/<mcp_name> --patch '{"spec":{"paused":false}}' --type=merge예를 들어 다음과 같습니다.
$ oc patch mcp/workerpool-canary --patch '{"spec":{"paused":false}}' --type=merge출력 예
machineconfigpool.machineconfiguration.openshift.io/workerpool-canary patchedoc get machineconfigpools명령을 사용하여 업데이트 진행 상황을 확인할 수 있습니다.- 업데이트된 노드에서 애플리케이션을 테스트하여 애플리케이션이 예상대로 작동하는지 확인합니다.
- 일시 중지된 다른 MCP를 하나씩 일시 중지 해제하고 애플리케이션이 작동하는지 확인합니다.
9.6.1. 애플리케이션 장애 발생 시
업데이트된 노드에서 작동하지 않는 애플리케이션 등의 오류가 발생하는 경우 풀의 노드를 차단하고 드레이닝하여 애플리케이션 pod를 다른 노드로 이동하여 애플리케이션의 서비스 품질을 유지 관리할 수 있습니다. 첫 번째 MCP는 초과 용량보다 크지 않아야 합니다.
9.7. 노드를 원래 머신 구성 풀로 이동
이 카나리아 롤아웃 업데이트 프로세스에서 사용자 정의 MCP(MCP)를 일시 중지 해제하고 해당 MCP와 연결된 노드의 애플리케이션이 예상대로 작동하는지 확인한 후 노드에 추가한 사용자 정의 레이블을 제거하여 노드를 원래 MCP로 다시 이동해야 합니다.
노드에는 클러스터에서 제대로 작동하는 역할이 있어야 합니다.
노드를 원래 MCP로 이동하려면 다음을 수행합니다.
노드에서 사용자 지정 레이블을 제거합니다.
$ oc label node <node_name> node-role.kubernetes.io/<custom-label>-예를 들어 다음과 같습니다.
$ oc label node ci-ln-0qv1yp2-f76d1-kl2tq-worker-a-j2ssz node-role.kubernetes.io/workerpool-canary-출력 예
node/ci-ln-0qv1yp2-f76d1-kl2tq-worker-a-j2ssz labeledMCO는 노드를 원래 MCP로 다시 이동하고 노드를 MCP 구성으로 조정합니다.
클러스터의 MCP 목록과 현재 상태를 확인합니다.
$oc get mcpNAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-1203f157d053fd987c7cbd91e3fbc0ed True False False 3 3 3 0 61m workerpool-canary rendered-mcp-noupdate-5ad4791166c468f3a35cd16e734c9028 True False False 0 0 0 0 21m worker rendered-worker-5ad4791166c468f3a35cd16e734c9028 True False False 3 3 3 0 61m노드는 사용자 지정 MCP에서 제거되고 원래 MCP로 다시 이동합니다. 시스템 수를 업데이트하는 데 몇 분이 걸릴 수 있습니다. 이 예에서는 하나의 노드가 제거된
workerpool-canaryMCP에서 'worker'MCP로 이동되었습니다.선택 사항: 사용자 정의 MCP를 삭제합니다.
$ oc delete mcp <mcp_name>
10장. RHEL 컴퓨팅 시스템을 포함하는 클러스터 업데이트
OpenShift Container Platform 클러스터를 업데이트하거나 업그레이드할 수 있습니다. 클러스터에 RHEL (Red Hat Enterprise Linux) 시스템이 포함된 경우 해당 시스템을 업데이트하기 위해 추가 단계를 수행해야합니다.
10.1. 전제 조건
-
admin권한이 있는 사용자로 클러스터에 액세스합니다. RBAC를 사용하여 권한 정의 및 적용을 참조하십시오. - 업데이트가 실패하는 경우 최근 etcd 백업이 있고 클러스터를 이전 상태로 복원해야 합니다.
- RHEL7 작업자에 대한 지원은 OpenShift Container Platform 4.11에서 제거되었습니다. OpenShift Container Platform 4.11로 업그레이드하기 전에 RHEL7 작업자를 RHEL8 또는 RHCOS 작업자로 교체해야 합니다. Red Hat은 RHEL 작업자의 RHEL8 업데이트를 RHEL8에 배치하지 않습니다. 이러한 호스트는 깔끔한 운영 체제 설치로 교체되어야 합니다.
- 클러스터에서 수동으로 유지 관리되는 인증 정보를 사용하는 경우 새 릴리스의 클라우드 공급자 리소스를 업데이트합니다. 자세한 내용은 수동으로 유지 관리되는 인증 정보를 사용하여 클러스터 업데이트 준비를 참조하십시오.
-
Operator를 실행하거나 Pod 중단 예산을 사용하여 애플리케이션을 구성한 경우 업그레이드 프로세스 중에 중단될 수 있습니다.
PodDisruptionBudget에서minAvailable이 1로 설정된 경우 노드는 제거 프로세스를 차단할 수 있는 보류 중인 머신 구성을 적용하기 위해 드레인됩니다. 여러 노드가 재부팅되면 모든 Pod가 하나의 노드에서만 실행될 수 있으며PodDisruptionBudget필드에서 노드 드레이닝을 방지할 수 있습니다.
10.2. 웹 콘솔을 사용하여 클러스터 업데이트
사용 가능한 업데이트가 있으면 웹 콘솔에서 클러스터를 업데이트할 수 있습니다.
사용 가능한 OpenShift Container Platform 권고 및 업데이트는 고객 포털의 에라타 섹션을 참조하십시오.
전제 조건
-
admin권한이 있는 사용자로 웹 콘솔에 액세스합니다. -
모든
MachineHealthCheck리소스를 일시 중지합니다.
프로세스
- 웹 콘솔에서 Administration → Cluster Settings을 클릭하고 Details 탭의 내용을 확인합니다.
프로덕션 클러스터의 경우 Channel 이
stable-4.11과 같이 업데이트하려는 버전에 대해 올바른 채널로 설정되어 있는지 확인합니다.중요프로덕션 클러스터의 경우
stable-*,eus-*또는fast-*채널에 가입해야 합니다.참고다음 마이너 버전으로 이동할 준비가 되면 해당 마이너 버전에 해당하는 채널을 선택합니다. 업데이트 채널을 더 많이 선언할수록 클러스터에서 대상 버전으로 경로를 업데이트하는 것이 좋습니다. 클러스터에서 사용 가능한 모든 업데이트를 평가하고 선택할 수 있는 최상의 업데이트 권장 사항을 제공하는 데 시간이 다소 걸릴 수 있습니다. 업데이트 권장 사항은 현재 사용 가능한 업데이트 옵션을 기반으로 하므로 시간이 지남에 따라 변경될 수 있습니다.
대상 마이너 버전의 업데이트 경로가 표시되지 않는 경우 경로에서 다음 마이너 버전을 사용할 수 있을 때까지 클러스터를 현재 버전의 최신 패치 릴리스로 계속 업데이트하십시오.
- Update status 가 Updates available 이 아닌 경우 클러스터를 업데이트할 수 없습니다.
- Select channel은 클러스터가 실행 중이거나 업데이트 중인 클러스터 버전을 나타냅니다.
업데이트할 버전을 선택하고 저장을 클릭합니다.
입력 채널 Update Status가 Update to <product-version> in progress로 변경되고 Operator 및 노드의 진행률을 확인하여 클러스터 업데이트의 진행 상황을 검토할 수 있습니다.
참고클러스터를 버전 4.y+1과 같이 다음 마이너 버전으로 업그레이드하는 경우 새 기능에 의존하는 워크로드를 배포하기 전에 노드가 업데이트되었는지 확인하는 것이 좋습니다. 아직 업데이트되지 않은 작업자 노드가 있는 풀은 클러스터 설정 페이지에 표시됩니다.
업데이트가 완료되고 Cluster Version Operator가 사용 가능한 업데이트를 새로 고침한 후 현재 채널에서 사용 가능한 추가 업데이트가 있는지 확인합니다.
- 업데이트가 있는 경우 더 이상 업데이트할 수 없을 때까지 현재 채널에서 업데이트를 계속 수행합니다.
-
사용할 수 있는 업데이트가 없는 경우 채널을 다음 마이너 버전의
stable-*,eus-*또는fast-*채널로 변경하고 해당 채널에서 원하는 버전으로 업데이트합니다.
필요한 버전에 도달할 때까지 여러 중간 업데이트를 수행해야 할 수도 있습니다.
참고RHEL (Red Hat Enterprise Linux) 작업자 시스템이 포함된 클러스터를 업데이트하면 업데이트 프로세스 중에 해당 작업자를 일시적으로 사용할 수 없게 됩니다. 클러스터가
NotReady상태가 되면 각 RHEL 시스템에 대해 업그레이드 플레이 북을 실행하여 업데이트를 완료해야 합니다.
10.3. 선택 사항: RHEL 시스템에서 Ansible 작업을 실행하기 위한 후크 추가
OpenShift Container Platform을 업데이트할 때 후크를 사용하여 RHEL 컴퓨팅 시스템에서 Ansible 작업을 실행할 수 있습니다.
10.3.1. 업그레이드를 위한 Ansible Hook 사용 정보
OpenShift Container Platform을 업데이트할 때 후크를 사용하여 특정 작업 중에 RHEL (Red Hat Enterprise Linux) 노드에서 사용자 정의 작업을 실행할 수 있습니다. 후크를 사용하면 특정 업데이트 작업 전후에 실행할 작업을 정의하는 파일을 지정할 수 있습니다. OpenShift Container Platform 클러스터에서 RHEL 컴퓨팅 노드를 업데이트할 때 후크를 사용하여 사용자 정의 인프라의 유효성을 검사하거나 변경할 수 있습니다.
후크가 실패하면 작업도 실패하므로 후크를 여러 번 실행하고 동일한 결과를 얻도록 설계해야합니다.
후크에는 다음과 같은 제한이 있습니다.-후크에는 정의되거나 버전이 지정된 인터페이스가 없습니다. 후크는 내부 openshift-ansible 변수를 사용할 수 있지만 이러한 변수는 향후 OpenShift Container Platform 릴리스에서 수정되거나 제거될 수 있습니다. -후크에는 오류 처리 기능이 없으므로 후크에 오류가 발생하면 업데이트 프로세스가 중단됩니다. 오류가 발생하면 문제를 해결한 다음 업그레이드를 다시 시작해야합니다.
10.3.2. 후크를 사용하도록 Ansible 인벤토리 파일 설정
all : vars 섹션 아래의 hosts 인벤토리 파일에서 작업자 시스템이라고도 하는 RHEL (Red Hat Enterprise Linux) 컴퓨팅 시스템을 업데이트할 때 사용할 후크를 정의합니다.
사전 요구 사항
-
RHEL 컴퓨팅 시스템 클러스터를 추가하는 데 사용되는 컴퓨터에 액세스할 수 있어여 합니다. RHEL 시스템을 정의하는
hostsAnsible 인벤토리 파일에 액세스할 수 있어야 합니다.
프로세스
후크를 설계한 후 Ansible 작업을 정의하는 YAML 파일을 만듭니다. 이 파일은 다음 예와 같이 Playbook이 아닌 일련의 작업으로 구성되어 있어야 합니다.
--- # Trivial example forcing an operator to acknowledge the start of an upgrade # file=/home/user/openshift-ansible/hooks/pre_compute.yml - name: note the start of a compute machine update debug: msg: "Compute machine upgrade of {{ inventory_hostname }} is about to start" - name: require the user agree to start an upgrade pause: prompt: "Press Enter to start the compute machine update"hostsAnsible 인벤토리 파일을 수정하여 후크 파일을 지정합니다. 후크 파일은 다음과 같이[all : vars]섹션에서 매개 변수 값으로 지정됩니다.인벤토리 파일에서 후크 정의의 예
[all:vars] openshift_node_pre_upgrade_hook=/home/user/openshift-ansible/hooks/pre_node.yml openshift_node_post_upgrade_hook=/home/user/openshift-ansible/hooks/post_node.yml후크 경로의 모호성을 피하려면 정의에서 상대 경로 대신 절대 경로를 사용합니다.
10.3.3. RHEL 컴퓨팅 시스템에서 사용 가능한 후크
OpenShift Container Platform 클러스터에서 RHEL (Red Hat Enterprise Linux) 컴퓨팅 시스템을 업데이트 할 때 다음 후크를 사용할 수 있습니다.
| 후크 이름 | 설명 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
10.4. 클러스터에서 RHEL 컴퓨팅 시스템 업데이트
클러스터를 업데이트한 후 클러스터의 RHEL (Red Hat Enterprise Linux) 컴퓨팅 시스템을 업데이트해야합니다.
RHEL (Red Hat Enterprise Linux) 버전 8.6 이상은 RHEL 컴퓨팅 머신에서 지원됩니다.
RHEL을 운영 체제로 사용하는 경우 컴퓨팅 머신을 다른 OpenShift Container Platform 마이너 버전으로 업데이트할 수도 있습니다. 마이너 버전 업데이트를 수행할 때 RHEL에서 RPM 패키지를 제외할 필요가 없습니다.
RHEL 7 컴퓨팅 머신을 RHEL 8로 업그레이드할 수 없습니다. 새 RHEL 8 호스트를 배포해야 하며 이전 RHEL 7 호스트를 제거해야 합니다.
사전 요구 사항
클러스터가 업데이트되었습니다.
중요RHEL 시스템에 업데이트 프로세스를 완료하기 위해 클러스터에서 생성한 자산이 필요하므로 RHEL 작업자 시스템을 업데이트하기 전에 클러스터를 업데이트해야 합니다.
-
RHEL 컴퓨팅 머신을 클러스터에 추가하는 데 사용한 로컬 시스템에 액세스할 수 있습니다. RHEL 시스템 및
upgradePlaybook을 정의하는hostsAnsible 인벤토리 파일에 액세스할 수 있어야 합니다. - 마이너 버전을 업데이트하기 위해 RPM 리포지토리는 클러스터에서 실행 중인 동일한 버전의 OpenShift Container Platform을 사용하고 있습니다.
프로세스
호스트에서 firewalld를 중지하고 비활성화합니다.
# systemctl disable --now firewalld.service참고기본적으로 "최소"설치 옵션을 사용하는 기본 OS RHEL은 firewalld 서비스를 활성화합니다. 호스트에서 firewalld 서비스를 활성화하면 작업자의 OpenShift Container Platform 로그에 액세스할 수 없습니다. 작업자의 OpenShift Container Platform 로그에 계속 액세스하려면 나중에 firewalld를 활성화하지 마십시오.
OpenShift Container Platform 4.11에 필요한 리포지토리를 활성화합니다.
Ansible Playbook을 실행하는 컴퓨터에서 필요한 리포지토리를 업데이트합니다.
# subscription-manager repos --disable=rhocp-4.10-for-rhel-8-x86_64-rpms \ --disable=ansible-2.9-for-rhel-8-x86_64-rpms \ --enable=rhocp-4.11-for-rhel-8-x86_64-rpms중요OpenShift Container Platform 4.11부터 Ansible 플레이북은 RHEL 8에서만 제공됩니다. RHEL 7 시스템이 OpenShift Container Platform 4.10 Ansible 플레이북의 호스트로 사용된 경우 Ansible 호스트를 RHEL 8로 업그레이드하거나 RHEL 8 시스템에서 새 Ansible 호스트를 생성하고 이전 Ansible 호스트의 인벤토리를 복사해야 합니다.
Ansible Playbook을 실행하는 시스템에서 Ansible 패키지를 업데이트합니다.
# yum swap ansible ansible-coreAnsible Playbook을 실행하는 시스템에서
openshift-ansible을 포함하여 필요한 패키지를 업데이트합니다.# yum update openshift-ansible openshift-clients각 RHEL 컴퓨팅 노드에 필요한 리포지토리를 업데이트합니다.
# subscription-manager repos --disable=rhocp-4.10-for-rhel-8-x86_64-rpms \ --enable=rhocp-4.11-for-rhel-8-x86_64-rpms
RHEL 작업자 시스템을 업데이트합니다.
다음 예와 같이
/<path>/inventory/hosts에서 Ansible 인벤토리 파일을 검토하고 RHEL 8 머신이[workers]섹션에 나열되도록 내용을 업데이트합니다.[all:vars] ansible_user=root #ansible_become=True openshift_kubeconfig_path="~/.kube/config" [workers] mycluster-rhel8-0.example.com mycluster-rhel8-1.example.com mycluster-rhel8-2.example.com mycluster-rhel8-3.example.comopenshift-ansible디렉토리로 변경합니다.$ cd /usr/share/ansible/openshift-ansibleupgradePlaybook을 실행합니다.$ ansible-playbook -i /<path>/inventory/hosts playbooks/upgrade.yml1 - 1
<path>에 대해 생성한 Ansible 인벤토리 파일의 경로를 지정합니다.
참고upgrade플레이북은 OpenShift Container Platform 패키지만 업그레이드합니다. 운영 체제 패키지를 업데이트하지 않습니다.
모든 작업자를 업데이트한 후 모든 클러스터 노드가 새 버전으로 업데이트되었는지 확인합니다.
# oc get node출력 예
NAME STATUS ROLES AGE VERSION mycluster-control-plane-0 Ready master 145m v1.24.0 mycluster-control-plane-1 Ready master 145m v1.24.0 mycluster-control-plane-2 Ready master 145m v1.24.0 mycluster-rhel8-0 Ready worker 98m v1.24.0 mycluster-rhel8-1 Ready worker 98m v1.24.0 mycluster-rhel8-2 Ready worker 98m v1.24.0 mycluster-rhel8-3 Ready worker 98m v1.24.0선택 사항:
upgrade플레이북에서 업데이트하지 않은 운영 체제 패키지를 업데이트합니다. 4.11이 아닌 패키지를 업데이트하려면 다음 명령을 사용하십시오.# yum update참고4.11을 설치할 때 사용한 것과 동일한 RPM 리포지토리를 사용하는 경우 RPM 패키지를 제외할 필요가 없습니다.
11장. 연결이 끊긴 환경에서 클러스터 업데이트
11.1. 연결이 끊긴 환경의 클러스터 업데이트 정보
연결이 끊긴 환경은 클러스터 노드가 인터넷에 액세스할 수 없는 환경입니다. 따라서 레지스트리에 설치 이미지를 입력해야합니다. 레지스트리 호스트가 인터넷과 클러스터에 모두 액세스할 수 없는 경우 이미지를 해당 환경과 연결이 끊긴 파일 시스템으로 미러링한 다음 호스트 또는 이동식 미디어를 가져올 수 있습니다. 로컬 컨테이너 레지스트리와 클러스터가 미러 레지스트리의 호스트에 연결된 경우 릴리스 이미지를 로컬 레지스트리로 직접 푸시할 수 있습니다.
단일 컨테이너 이미지 레지스트리는 연결이 끊긴 네트워크의 여러 클러스터에 대해 미러링된 이미지를 호스팅하기에 충분합니다.
11.1.1. OpenShift Container Platform 이미지 저장소 미러링
연결이 끊긴 환경에서 클러스터를 업데이트하려면 클러스터 환경에서 대상 업데이트에 필요한 이미지 및 리소스가 있는 미러 레지스트리에 액세스할 수 있어야 합니다. 다음 페이지에는 연결이 끊긴 클러스터의 저장소에 이미지를 미러링하는 방법에 대한 지침이 있습니다.
11.1.2. 연결이 끊긴 환경에서 클러스터 업데이트 수행
다음 절차 중 하나를 사용하여 연결이 끊긴 OpenShift Container Platform 클러스터를 업데이트할 수 있습니다.
11.1.3. 클러스터에서 OpenShift Update Service 설치 제거
다음 절차에 따라 클러스터에서 OSUS(OpenShift Update Service)의 로컬 사본을 제거할 수 있습니다.
11.2. OpenShift Container Platform 이미지 저장소 미러링
연결이 끊긴 환경에서 클러스터를 업데이트하려면 먼저 컨테이너 이미지를 미러 레지스트리에 미러링해야 합니다. 연결된 환경에서 이 프로세스를 사용하여 클러스터가 외부 콘텐츠에 대해 조직의 제어 조건을 충족하는 승인된 컨테이너 이미지만 실행하도록 할 수 있습니다.
클러스터가 실행되는 동안 미러 레지스트리가 항상 실행되고 있어야 합니다.
다음 단계에서는 이미지를 미러 레지스트리에 미러링하는 방법에 대한 고급 워크플로를 간략하게 설명합니다.
-
릴리스 이미지를 검색하고 내보내는 데 사용되는 모든 장치에 OpenShift CLI(
oc)를 설치합니다. - 레지스트리 풀 시크릿을 다운로드하여 클러스터에 추가합니다.
oc-mirror OpenShift CLI(
oc) 플러그인 을 사용하는 경우 :- 릴리스 이미지를 검색하고 내보내는 데 사용되는 모든 장치에 oc-mirror 플러그인을 설치합니다.
- 미러링할 릴리스 이미지를 결정할 때 사용할 플러그인의 이미지 세트 구성 파일을 생성합니다. 나중에 이 구성 파일을 편집하여 플러그인이 미러링하는 릴리스 이미지를 변경할 수 있습니다.
- 대상 릴리스 이미지를 미러 레지스트리 또는 이동식 미디어에 직접 미러링한 다음 미러 레지스트리에 미러링합니다.
- oc-mirror 플러그인에서 생성한 리소스를 사용하도록 클러스터를 구성합니다.
- 필요에 따라 이 단계를 반복하여 미러 레지스트리를 업데이트합니다.
oc adm release mirror명령을 사용하는 경우 다음을 수행합니다.- 사용자 환경과 미러링할 릴리스 이미지에 해당하는 환경 변수를 설정합니다.
- 대상 릴리스 이미지를 미러 레지스트리 또는 이동식 미디어에 직접 미러링한 다음 미러 레지스트리에 미러링합니다.
- 필요에 따라 이 단계를 반복하여 미러 레지스트리를 업데이트합니다.
oc adm release mirror 명령 사용과 비교하여 oc-mirror 플러그인은 다음과 같은 이점이 있습니다.
- 컨테이너 이미지 이외의 콘텐츠를 미러링할 수 있습니다.
- 처음으로 이미지를 미러링한 후 레지스트리에서 이미지를 더 쉽게 업데이트할 수 있습니다.
- oc-mirror 플러그인은 Quay에서 릴리스 페이로드를 미러링하고 연결이 끊긴 환경에서 실행되는 OpenShift Update Service의 최신 그래프 데이터 이미지도 빌드하는 자동화된 방법을 제공합니다.
11.2.1. 사전 요구 사항
Red Hat Quay와 같이 OpenShift Container Platform 클러스터를 호스팅할 위치에 Docker v2-2 를 지원하는 컨테이너 이미지 레지스트리가 있어야 합니다.
참고Red Hat Quay를 사용하는 경우 oc-mirror 플러그인에서 버전 3.6 이상을 사용해야 합니다. Red Hat Quay에 대한 인타이틀먼트가 있는 경우 개념 증명 목적으로 또는 Quay Operator를 사용하여 Red Hat Quay 배포에 대한 설명서를 참조하십시오. 레지스트리를 선택 및 설치하는 데 추가 지원이 필요한 경우 영업 담당자 또는 Red Hat 지원팀에 문의하십시오.
컨테이너 이미지 레지스트리의 기존 솔루션이 없는 경우 Red Hat OpenShift의 미러 레지스트리가 OpenShift Container Platform 서브스크립션에 포함되어 있습니다. Red Hat OpenShift의 미러 레지스트리 는 연결이 끊긴 설치 및 업데이트에서 OpenShift Container Platform 컨테이너 이미지를 미러링하는 데 사용할 수 있는 소규모 컨테이너 레지스트리입니다.
11.2.2. 미러 호스트 준비
미러 단계를 수행하기 전에 호스트는 콘텐츠를 검색하고 원격 위치로 푸시할 준비가 되어 있어야 합니다.
11.2.2.1. 바이너리를 다운로드하여 OpenShift CLI 설치
명령줄 인터페이스를 사용하여 OpenShift Container Platform과 상호 작용하기 위해 OpenShift CLI(oc)를 설치할 수 있습니다. Linux, Windows 또는 macOS에 oc를 설치할 수 있습니다.
이전 버전의 oc 를 설치한 경우 OpenShift Container Platform 4.11의 모든 명령을 완료하는 데 해당 버전을 사용할 수 없습니다. 새 버전의 oc를 다운로드하여 설치합니다. 연결이 끊긴 환경에서 클러스터를 업그레이드하는 경우 업그레이드하려는 oc 버전을 설치합니다.
Linux에서 OpenShift CLI 설치
다음 절차를 사용하여 Linux에서 OpenShift CLI(oc) 바이너리를 설치할 수 있습니다.
절차
- Red Hat 고객 포털에서 OpenShift Container Platform 다운로드 페이지로 이동합니다.
- Product Variant 드롭다운 메뉴에서 아키텍처를 선택합니다.
- 버전 드롭다운 메뉴에서 적절한 버전을 선택합니다.
- OpenShift v4.11 Linux Client 항목 옆에 있는 지금 다운로드를 클릭하고 파일을 저장합니다.
아카이브의 압축을 풉니다.
$ tar xvf <file>oc바이너리를PATH에 있는 디렉터리에 배치합니다.PATH를 확인하려면 다음 명령을 실행합니다.$ echo $PATH
검증
OpenShift CLI를 설치한 후
oc명령을 사용할 수 있습니다.$ oc <command>
Windows에서 OpenSfhit CLI 설치
다음 절차에 따라 Windows에 OpenShift CLI(oc) 바이너리를 설치할 수 있습니다.
절차
- Red Hat 고객 포털에서 OpenShift Container Platform 다운로드 페이지로 이동합니다.
- 버전 드롭다운 메뉴에서 적절한 버전을 선택합니다.
- OpenShift v4.11 Windows Client 항목 옆에 있는 지금 다운로드를 클릭하고 파일을 저장합니다.
- ZIP 프로그램으로 아카이브의 압축을 풉니다.
oc바이너리를PATH에 있는 디렉터리로 이동합니다.PATH를 확인하려면 명령 프롬프트를 열고 다음 명령을 실행합니다.C:\> path
검증
OpenShift CLI를 설치한 후
oc명령을 사용할 수 있습니다.C:\> oc <command>
macOS에 OpenShift CLI 설치
다음 절차에 따라 macOS에서 OpenShift CLI(oc) 바이너리를 설치할 수 있습니다.
절차
- Red Hat 고객 포털에서 OpenShift Container Platform 다운로드 페이지로 이동합니다.
- 버전 드롭다운 메뉴에서 적절한 버전을 선택합니다.
OpenShift v4.11 macOS Client 항목 옆에 있는 지금 다운로드를 클릭하고 파일을 저장합니다.
참고macOS ARM64의 경우 OpenShift v4.11 macOS ARM64 Client 항목을 선택합니다.
- 아카이브의 압축을 해제하고 압축을 풉니다.
oc바이너리 PATH의 디렉터리로 이동합니다.PATH를 확인하려면 터미널을 열고 다음 명령을 실행합니다.$ echo $PATH
검증
OpenShift CLI를 설치한 후
oc명령을 사용할 수 있습니다.$ oc <command>
11.2.2.2. 이미지를 미러링할 수 있는 인증 정보 설정
Red Hat에서 미러로 이미지를 미러링할 수 있는 컨테이너 이미지 레지스트리 인증 정보 파일을 생성합니다.
클러스터를 설치할 때 이 이미지 레지스트리 인증 정보 파일을 풀 시크릿(pull secret)으로 사용하지 마십시오. 클러스터를 설치할 때 이 파일을 지정하면 클러스터의 모든 시스템에 미러 레지스트리에 대한 쓰기 권한이 부여됩니다.
이 프로세스에서는 미러 레지스트리의 컨테이너 이미지 레지스트리에 대한 쓰기 권한이 있어야 하며 인증 정보를 레지스트리 풀 시크릿에 추가해야 합니다.
사전 요구 사항
- 연결이 끊긴 환경에서 사용할 미러 레지스트리를 구성했습니다.
- 미러 레지스트리에서 이미지를 미러링할 이미지 저장소 위치를 확인했습니다.
- 이미지를 해당 이미지 저장소에 업로드할 수 있는 미러 레지스트리 계정을 제공하고 있습니다.
절차
설치 호스트에서 다음 단계를 수행합니다.
-
Red Hat OpenShift Cluster Manager에서
registry.redhat.io풀 시크릿을 다운로드합니다. 풀 시크릿을 JSON 형식으로 복사합니다.
$ cat ./pull-secret | jq . > <path>/<pull_secret_file_in_json>1 - 1
- 풀 시크릿을 저장할 폴더의 경로와 생성한 JSON 파일의 이름을 지정합니다.
파일의 내용은 다음 예와 유사합니다.
{ "auths": { "cloud.openshift.com": { "auth": "b3BlbnNo...", "email": "you@example.com" }, "quay.io": { "auth": "b3BlbnNo...", "email": "you@example.com" }, "registry.connect.redhat.com": { "auth": "NTE3Njg5Nj...", "email": "you@example.com" }, "registry.redhat.io": { "auth": "NTE3Njg5Nj...", "email": "you@example.com" } } }-
선택 사항: oc-mirror 플러그인을 사용하는 경우 파일을
~/.docker/config.json또는$XDG_RUNTIME_DIR/containers/auth.json로 저장합니다. 미러 레지스트리에 대한 base64로 인코딩된 사용자 이름 및 암호 또는 토큰을 생성합니다.
$ echo -n '<user_name>:<password>' | base64 -w01 BGVtbYk3ZHAtqXs=- 1
<user_name>및<password>의 경우 레지스트리에 설정한 사용자 이름 및 암호를 지정합니다.
JSON 파일을 편집하고 레지스트리를 설명하는 섹션을 추가합니다.
"auths": { "<mirror_registry>": {1 "auth": "<credentials>",2 "email": "you@example.com" } },파일은 다음 예제와 유사합니다.
{ "auths": { "registry.example.com": { "auth": "BGVtbYk3ZHAtqXs=", "email": "you@example.com" }, "cloud.openshift.com": { "auth": "b3BlbnNo...", "email": "you@example.com" }, "quay.io": { "auth": "b3BlbnNo...", "email": "you@example.com" }, "registry.connect.redhat.com": { "auth": "NTE3Njg5Nj...", "email": "you@example.com" }, "registry.redhat.io": { "auth": "NTE3Njg5Nj...", "email": "you@example.com" } } }
11.2.3. oc-mirror 플러그인을 사용하여 리소스 미러링
oc-mirror OpenShift CLI (oc) 플러그인을 사용하여 완전히 또는 부분적으로 연결이 끊긴 환경의 미러 레지스트리에 이미지를 미러링할 수 있습니다. 인터넷에 연결되어 있는 시스템에서 oc-mirror를 실행하여 공식 Red Hat 레지스트리에서 필요한 이미지를 다운로드해야 합니다.
11.2.3.1. oc-mirror 플러그인 정보
oc-mirror OpenShift CLI(oc) 플러그인을 사용하여 단일 툴을 사용하여 필요한 모든 OpenShift Container Platform 콘텐츠 및 기타 이미지를 미러 레지스트리에 미러링할 수 있습니다. 다음과 같은 기능을 제공합니다.
- OpenShift Container Platform 릴리스, Operator, helm 차트 및 기타 이미지를 미러링하는 중앙 집중식 방법을 제공합니다.
- OpenShift Container Platform 및 Operator의 업데이트 경로를 유지 관리합니다.
- 선언적 이미지 세트 구성 파일을 사용하여 클러스터에 필요한 OpenShift Container Platform 릴리스, Operator 및 이미지만 포함합니다.
- 증분 미러링을 수행하여 향후 이미지 세트의 크기를 줄입니다.
- 이전 실행 이후 이미지 세트 구성에서 제외된 대상 미러 레지스트리에서 이미지를 정리합니다.
- 선택적으로 OpenShift Update Service (OSUS) 사용에 대한 지원 아티팩트를 생성합니다.
oc-mirror 플러그인을 사용하는 경우 이미지 세트 구성 파일에서 미러링할 콘텐츠를 지정합니다. 이 YAML 파일에서는 클러스터에 필요한 OpenShift Container Platform 릴리스와 Operator만 포함하도록 구성을 미세 조정할 수 있습니다. 이렇게 하면 다운로드 및 전송에 필요한 데이터 양이 줄어듭니다. oc-mirror 플러그인은 임의의 helm 차트 및 추가 컨테이너 이미지를 미러링하여 사용자가 워크로드를 미러 레지스트리에 원활하게 동기화할 수 있도록 지원합니다.
oc-mirror 플러그인을 처음 실행하는 경우 연결이 끊긴 클러스터 설치 또는 업데이트를 수행하는 데 필요한 콘텐츠로 미러 레지스트리를 채웁니다. 연결이 끊긴 클러스터가 업데이트를 계속 받으려면 미러 레지스트리를 계속 업데이트해야 합니다. 미러 레지스트리를 업데이트하려면 처음 실행할 때와 동일한 구성을 사용하여 oc-mirror 플러그인을 실행합니다. oc-mirror 플러그인은 스토리지 백엔드의 메타데이터를 참조하고 도구를 마지막으로 실행한 후 릴리스된 항목만 다운로드합니다. 이는 OpenShift Container Platform 및 Operator의 업데이트 경로를 제공하고 필요에 따라 종속성 확인을 수행합니다.
oc-mirror CLI 플러그인을 사용하여 미러 레지스트리를 채우는 경우 oc-mirror 툴을 사용하여 미러 레지스트리에 대한 추가 업데이트를 수행해야 합니다.
11.2.3.2. oc-mirror 호환성 및 지원
oc-mirror 플러그인은 OpenShift Container Platform 버전 4.9 이상용 OpenShift Container Platform 페이로드 이미지 및 Operator 카탈로그를 미러링하는 기능을 지원합니다.
미러링해야 하는 OpenShift Container Platform 버전에 관계없이 사용 가능한 최신 버전의 oc-mirror 플러그인을 사용합니다.
OpenShift Container Platform 4.10에 대해 oc-mirror 플러그인의 기술 프리뷰 버전을 사용한 경우 미러 레지스트리를 OpenShift Container Platform 4.11로 마이그레이션할 수 없습니다. 새 oc-mirror 플러그인을 다운로드하고, 새 스토리지 백엔드를 사용하고, 대상 미러 레지스트리에서 새로운 최상위 네임스페이스를 사용해야 합니다.
11.2.3.3. 미러 레지스트리 정보
OpenShift Container Platform 설치 및 후속 제품 업데이트에 필요한 이미지를 Red Hat Quay와 같은 Docker v2-2 를 지원하는 컨테이너 미러 레지스트리에 미러링할 수 있습니다. 대규모 컨테이너 레지스트리에 액세스할 수 없는 경우 OpenShift Container Platform 서브스크립션에 포함된 소규모 컨테이너 레지스트리인 Red Hat OpenShift에 미러 레지스트리를 사용할 수 있습니다.
선택한 레지스트리에 관계없이 인터넷상의 Red Hat 호스팅 사이트의 콘텐츠를 격리된 이미지 레지스트리로 미러링하는 절차는 동일합니다. 콘텐츠를 미러링한 후 미러 레지스트리에서 이 콘텐츠를 검색하도록 각 클러스터를 설정합니다.
OpenShift 이미지 레지스트리는 미러링 프로세스 중에 필요한 태그 없이 푸시를 지원하지 않으므로 대상 레지스트리로 사용할 수 없습니다.
Red Hat OpenShift의 미러 레지스트리가 아닌 컨테이너 레지스트리를 선택하는 경우 프로비저닝하는 클러스터의 모든 시스템에서 액세스할 수 있어야 합니다. 레지스트리에 연결할 수 없는 경우 설치, 업데이트 또는 워크로드 재배치와 같은 일반 작업이 실패할 수 있습니다. 따라서 고가용성 방식으로 미러 레지스트리를 실행해야하며 미러 레지스트리는 최소한 OpenShift Container Platform 클러스터의 프로덕션 환경의 가용성조건에 일치해야 합니다.
미러 레지스트리를 OpenShift Container Platform 이미지로 채우면 다음 두 가지 시나리오를 수행할 수 있습니다. 호스트가 인터넷과 미러 레지스트리에 모두 액세스할 수 있지만 클러스터 노드에 액세스 할 수 없는 경우 해당 머신의 콘텐츠를 직접 미러링할 수 있습니다. 이 프로세스를 connected mirroring(미러링 연결)이라고 합니다. 그러한 호스트가 없는 경우 이미지를 파일 시스템에 미러링한 다음 해당 호스트 또는 이동식 미디어를 제한된 환경에 배치해야 합니다. 이 프로세스를 미러링 연결 해제라고 합니다.
미러링된 레지스트리의 경우 가져온 이미지의 소스를 보려면 CRI-O 로그의 Trying to access 로그 항목을 검토해야 합니다. 노드에서 crictl images 명령을 사용하는 등의 이미지 가져오기 소스를 보는 다른 방법은 미러링되지 않은 이미지 이름을 표시합니다.
Red Hat은 OpenShift Container Platform에서 타사 레지스트리를 테스트하지 않습니다.
11.2.3.4. oc-mirror OpenShift CLI 플러그인 설치
oc-mirror OpenShift CLI 플러그인을 사용하여 레지스트리 이미지를 미러링하려면 플러그인을 설치해야 합니다. 완전히 연결이 끊긴 환경에서 이미지 세트를 미러링하는 경우 인터넷 액세스 권한이 있고 미러 레지스트리에 액세스할 수 있는 연결이 끊긴 환경의 호스트에 oc-mirror 플러그인을 설치해야 합니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
oc-mirror CLI 플러그인을 다운로드합니다.
- OpenShift Cluster Manager 하이브리드 클라우드 콘솔 의 다운로드 페이지로 이동합니다.
- OpenShift 연결 설치 툴 섹션에서 OpenShift Client(oc) 미러 플러그인 다운로드를 클릭하고 파일을 저장합니다.
아카이브를 추출합니다.
$ tar xvzf oc-mirror.tar.gz필요한 경우 플러그인 파일을 실행 가능하게 업데이트합니다.
$ chmod +x oc-mirror참고oc-mirror파일의 이름을 바꾸지 마십시오.파일을
PATH에 배치하여 oc-mirror CLI 플러그인을 설치합니다(예:/usr/local/bin).$ sudo mv oc-mirror /usr/local/bin/.
검증
oc mirror help를 실행하여 플러그인이 성공적으로 설치되었는지 확인합니다.$ oc mirror help
11.2.3.5. 이미지 세트 구성 생성
oc-mirror 플러그인을 사용하여 이미지 세트를 미러링하려면 먼저 이미지 세트 구성 파일을 생성해야 합니다. 이 이미지 세트 구성 파일은 oc-mirror 플러그인의 다른 구성 설정과 함께 미러링할 OpenShift Container Platform 릴리스, Operator 및 기타 이미지를 정의합니다.
이미지 세트 구성 파일에 스토리지 백엔드를 지정해야 합니다. 이 스토리지 백엔드는 로컬 디렉터리 또는 Docker v2-2 를 지원하는 레지스트리일 수 있습니다. oc-mirror 플러그인은 이미지 세트 생성 중에 이 스토리지 백엔드에 메타데이터를 저장합니다.
oc-mirror 플러그인에 의해 생성된 메타데이터를 삭제하거나 수정하지 마십시오. oc-mirror 플러그인을 동일한 미러 레지스트리에 대해 실행할 때마다 동일한 스토리지 백엔드를 사용해야 합니다.
사전 요구 사항
- 컨테이너 이미지 레지스트리 인증 정보 파일이 생성되어 있습니다. 자세한 내용은 이미지를 미러링할 수 있는 인증 정보 구성을 참조하십시오.
프로세스
oc mirror init명령을 사용하여 이미지 세트 구성에 대한 템플릿을 생성하고imageset-config.yaml이라는 파일에 저장합니다.$ oc mirror init --registry example.com/mirror/oc-mirror-metadata > imageset-config.yaml1 - 1
example.com/mirror/oc-mirror-metadata를 스토리지 백엔드의 레지스트리 위치로 바꿉니다.
파일을 편집하고 필요에 따라 설정을 조정합니다.
kind: ImageSetConfiguration apiVersion: mirror.openshift.io/v1alpha2 archiveSize: 41 storageConfig:2 registry: imageURL: example.com/mirror/oc-mirror-metadata3 skipTLS: false mirror: platform: channels: - name: stable-4.114 type: ocp graph: true5 operators: - catalog: registry.redhat.io/redhat/redhat-operator-index:v4.116 packages: - name: serverless-operator7 channels: - name: stable8 additionalImages: - name: registry.redhat.io/ubi8/ubi:latest9 helm: {}- 1
archiveSize를 추가하여 이미지 세트 내에서 각 파일의 최대 크기를 GiB 단위로 설정합니다.- 2
- 이미지 세트 메타데이터를 저장할 백엔드 위치를 설정합니다. 이 위치는 레지스트리 또는 로컬 디렉터리일 수 있습니다.
storageConfig값을 지정해야 합니다. - 3
- 스토리지 백엔드의 레지스트리 URL을 설정합니다.
- 4
- 채널을 설정하여 OpenShift Container Platform 이미지를 검색합니다.
- 5
graph: true를 추가하여 graph-data 이미지를 미러 레지스트리로 빌드하고 내보냅니다. graph-data 이미지는 OSUS(OpenShift Update Service)를 생성하는 데 필요합니다.graph: true필드도UpdateService사용자 정의 리소스 매니페스트를 생성합니다.ocCLI(명령줄 인터페이스)는UpdateService사용자 정의 리소스 매니페스트를 사용하여 OSUS를 생성할 수 있습니다. 자세한 내용은 OpenShift 업데이트 서비스 정보를 참조하십시오.- 6
- Operator 카탈로그를 설정하여 OpenShift Container Platform 이미지를 검색합니다.
- 7
- 이미지 세트에 포함할 특정 Operator 패키지만 지정합니다. 이 필드를 제거하여 카탈로그의 모든 패키지를 검색합니다.
- 8
- 이미지 세트에 포함할 Operator 패키지의 특정 채널만 지정합니다. 해당 채널에서 번들을 사용하지 않는 경우에도 Operator 패키지의 기본 채널을 포함해야 합니다.
oc mirror list operators --catalog=<catalog_name> --package=<package_name> 명령을 실행하여 기본 채널을 찾을 수 있습니다. - 9
- 이미지 세트에 포함할 추가 이미지를 지정합니다.
다양한 미러링 사용 사례에 대한 전체 매개변수 및 이미지 세트 구성 예제는 이미지 세트 구성 매개변수를 참조하십시오.
업데이트된 파일을 저장합니다.
이 이미지 세트 구성 파일은 컨텐츠를 미러링할 때
oc mirror명령에 필요합니다.
11.2.3.6. 미러 레지스트리로 이미지 세트 미러링
oc-mirror CLI 플러그인을 사용하여 부분적으로 연결이 끊긴 환경 또는 완전히 연결이 끊긴 환경에서 미러 레지스트리에 이미지를 미러링할 수 있습니다.
다음 절차에서는 미러 레지스트리가 이미 설정되어 있다고 가정합니다.
11.2.3.6.1. 부분적으로 연결이 끊긴 환경에서 이미지 세트 미러링
부분적으로 연결이 끊긴 환경에서는 대상 미러 레지스트리에 직접 설정된 이미지를 미러링할 수 있습니다.
11.2.3.6.1.1. 미러에서 미러로 미러링
oc-mirror 플러그인을 사용하여 이미지 세트 생성 중에 액세스할 수 있는 대상 미러 레지스트리로 직접 이미지 세트를 미러링할 수 있습니다.
이미지 세트 구성 파일에서 스토리지 백엔드를 지정해야 합니다. 이 스토리지 백엔드는 로컬 디렉터리 또는 Docker v2 레지스트리일 수 있습니다. oc-mirror 플러그인은 이미지 세트 생성 중에 이 스토리지 백엔드에 메타데이터를 저장합니다.
oc-mirror 플러그인에 의해 생성된 메타데이터를 삭제하거나 수정하지 마십시오. oc-mirror 플러그인을 동일한 미러 레지스트리에 대해 실행할 때마다 동일한 스토리지 백엔드를 사용해야 합니다.
사전 요구 사항
- 필요한 컨테이너 이미지를 얻으려면 인터넷에 액세스할 수 있습니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
oc-mirrorCLI 플러그인을 설치했습니다. - 이미지 세트 구성 파일을 생성했습니다.
프로세스
oc mirror명령을 실행하여 지정된 이미지 세트 구성의 이미지를 지정된 레지스트리로 미러링합니다.$ oc mirror --config=./imageset-config.yaml \1 docker://registry.example:50002
검증
-
생성된
oc-mirror-workspace/디렉터리로 이동합니다. -
결과 디렉터리로 이동합니다 (예:
results-1639608409/). -
ImageContentSourcePolicy및CatalogSource리소스에 YAML 파일이 있는지 확인합니다.
다음 단계
- oc-mirror에서 생성한 리소스를 사용하도록 클러스터를 구성합니다.
문제 해결
11.2.3.6.2. 완전히 연결이 끊긴 환경에서 이미지 세트 미러링
완전히 연결이 끊긴 환경에서 이미지 세트를 미러링하려면 먼저 이미지 세트를 디스크로 미러링 한 다음 디스크의 이미지 세트 파일을 미러에 미러링해야 합니다.
11.2.3.6.2.1. 미러에서 디스크로 미러링
oc-mirror 플러그인을 사용하여 이미지 세트를 생성하고 콘텐츠를 디스크에 저장할 수 있습니다. 그런 다음 생성된 이미지 세트를 연결이 끊긴 환경으로 전송하고 대상 레지스트리에 미러링할 수 있습니다.
이미지 세트 구성 파일에 지정된 구성에 따라 oc-mirror를 사용하여 이미지를 미러링하는 경우 수백 기가바이트의 데이터를 디스크에 다운로드할 수 있습니다.
미러 레지스트리를 채울 때 초기 이미지 세트 다운로드는 종종 가장 큰 것입니다. 명령을 마지막으로 실행한 후 변경된 이미지만 다운로드하므로 oc-mirror 플러그인을 다시 실행할 때 생성된 이미지 세트가 작은 경우가 많습니다.
이미지 세트 구성 파일에서 스토리지 백엔드를 지정해야 합니다. 이 스토리지 백엔드는 로컬 디렉터리 또는 docker v2 레지스트리일 수 있습니다. oc-mirror 플러그인은 이미지 세트 생성 중에 이 스토리지 백엔드에 메타데이터를 저장합니다.
oc-mirror 플러그인에 의해 생성된 메타데이터를 삭제하거나 수정하지 마십시오. oc-mirror 플러그인을 동일한 미러 레지스트리에 대해 실행할 때마다 동일한 스토리지 백엔드를 사용해야 합니다.
사전 요구 사항
- 필요한 컨테이너 이미지를 얻으려면 인터넷에 액세스할 수 있습니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
oc-mirrorCLI 플러그인을 설치했습니다. - 이미지 세트 구성 파일을 생성했습니다.
절차
oc mirror명령을 실행하여 지정된 이미지 세트 구성의 이미지를 디스크로 미러링합니다.$ oc mirror --config=./imageset-config.yaml \1 file://<path_to_output_directory>2
검증
출력 디렉터리로 이동합니다.
$ cd <path_to_output_directory>이미지 세트
.tar파일이 생성되었는지 확인합니다.$ ls출력 예
mirror_seq1_000000.tar
다음 단계
- 이미지 세트 .tar 파일을 연결이 끊긴 환경으로 전송합니다.
문제 해결
11.2.3.6.2.2. 디스크에서 미러로 미러링
oc-mirror 플러그인을 사용하여 생성된 이미지 세트의 콘텐츠를 대상 미러 레지스트리로 미러링할 수 있습니다.
사전 요구 사항
-
연결이 끊긴 환경에 OpenShift CLI (
oc)를 설치했습니다. -
연결이 끊긴 환경에
oc-mirrorCLI 플러그인을 설치했습니다. -
oc mirror명령을 사용하여 이미지 세트 파일을 생성했습니다. - 이미지 세트 파일을 연결이 끊긴 환경으로 전송했습니다.
프로세스
oc mirror명령을 실행하여 디스크에서 이미지 세트 파일을 처리하고 콘텐츠를 대상 미러 레지스트리에 미러링합니다.$ oc mirror --from=./mirror_seq1_000000.tar \1 docker://registry.example:50002 이 명령은 이미지 세트로 미러 레지스트리를 업데이트하고
ImageContentSourcePolicy및CatalogSource리소스를 생성합니다.
검증
-
생성된
oc-mirror-workspace/디렉터리로 이동합니다. -
결과 디렉터리로 이동합니다 (예:
results-1639608409/). -
ImageContentSourcePolicy및CatalogSource리소스에 YAML 파일이 있는지 확인합니다.
다음 단계
- oc-mirror에서 생성한 리소스를 사용하도록 클러스터를 구성합니다.
문제 해결
11.2.3.7. oc-mirror에서 생성한 리소스를 사용하도록 클러스터 구성
이미지를 미러 레지스트리로 미러링한 후 생성된 ImageContentSourcePolicy,CatalogSource, 이미지 서명 리소스를 클러스터에 적용해야 합니다.
ImageContentSourcePolicy 리소스는 미러 레지스트리를 소스 레지스트리와 연결하고 온라인 레지스트리에서 미러 레지스트리로 이미지 가져오기 요청을 리디렉션합니다. CatalogSource 리소스는 OLM(Operator Lifecycle Manager)에서 미러 레지스트리에서 사용 가능한 Operator에 대한 정보를 검색하는 데 사용됩니다. 릴리스 이미지 서명은 미러링된 릴리스 이미지를 확인하는 데 사용됩니다.
사전 요구 사항
- 연결이 끊긴 환경에서 레지스트리 미러로 이미지를 미러링했습니다.
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다.
프로세스
-
cluster-admin역할의 사용자로 OpenShift CLI에 로그인합니다. 다음 명령을 실행하여 결과 디렉터리의 YAML 파일을 클러스터에 적용합니다.
$ oc apply -f ./oc-mirror-workspace/results-1639608409/미러링된 릴리스 이미지가 있는 경우 다음 명령을 실행하여 릴리스 이미지 서명을 클러스터에 적용합니다.
$ oc apply -f ./oc-mirror-workspace/results-1639608409/release-signatures/참고클러스터 대신 Operator를 미러링하는 경우
$ oc apply -f ./oc-mirror-workspace/results-1639608409/release-signatures/를 실행할 필요가 없습니다. 적용할 릴리스 이미지 서명이 없으므로 해당 명령을 실행하면 오류가 반환됩니다.
검증
다음 명령을 실행하여
ImageContentSourcePolicy리소스가 설치되었는지 확인합니다.$ oc get imagecontentsourcepolicy --all-namespaces다음 명령을 실행하여
CatalogSource리소스가 설치되었는지 확인합니다.$ oc get catalogsource --all-namespaces
11.2.3.8. 미러 레지스트리 콘텐츠 업데이트
대상 미러 레지스트리를 초기 이미지 세트로 채우면 최신 콘텐츠가 표시되도록 정기적으로 업데이트해야 합니다. 가능한 경우 정기적으로 미러 레지스트리를 업데이트하도록 cron 작업을 설정할 수 있습니다.
필요에 따라 OpenShift Container Platform 및 Operator 릴리스를 추가하거나 제거하도록 이미지 세트 구성을 업데이트합니다. 제거된 이미지는 미러 레지스트리에서 정리됩니다.
11.2.3.8.1. 미러 레지스트리 콘텐츠 업데이트 정보
oc-mirror 플러그인을 다시 실행하면 이전 실행 이후 새 이미지 및 업데이트된 이미지만 포함하는 이미지 세트가 생성됩니다. 이전 이미지 세트가 생성된 이후 차이점만 가져오기 때문에 생성된 이미지 세트가 초기 이미지 세트보다 더 작고 빠르게 처리할 수 있습니다.
생성된 이미지 세트는 순차적이며 대상 미러 레지스트리로 순서대로 푸시해야 합니다. 생성된 이미지 세트 아카이브 파일의 파일 이름에서 시퀀스 번호를 가져올 수 있습니다.
새로운 이미지 및 업데이트된 이미지 추가
이미지 세트 구성의 설정에 따라 oc-mirror가 이후에 새로운 이미지와 업데이트된 이미지를 미러링할 수 있습니다. 이미지 세트 구성의 설정을 검토하여 필요에 따라 새 버전을 검색하고 있는지 확인합니다. 예를 들어 특정 버전으로 제한하려는 경우 미러링할 최소 및 최대 Operator 버전을 설정할 수 있습니다. 또는 최소 버전을 미러 시작점으로 설정할 수 있지만 나중에 oc-mirror를 실행할 때 새 Operator 버전을 계속 수신하도록 버전 범위를 열린 상태로 유지할 수 있습니다. 최소 또는 최대 버전을 생략하면 채널에서 Operator의 전체 버전 기록이 제공됩니다. 명시적으로 이름이 지정된 채널을 생략하면 지정된 Operator의 모든 채널에서 모든 릴리스가 제공됩니다. Operator를 생략하면 모든 Operator의 전체 카탈로그와 모든 버전이 릴리스됩니다.
이러한 모든 제약 조건 및 조건은 모든 oc-mirror 호출 시 Red Hat에서 공개한 콘텐츠에 대해 평가됩니다. 이렇게 하면 새 릴리스와 완전히 새로운 Operator가 자동으로 선택됩니다. 제한 조건은 원하는 Operator 세트를 나열하여 지정할 수 있으며 새로 릴리스된 다른 Operator는 미러 세트에 자동으로 추가되지 않습니다. 또한 새로 추가된 채널뿐만 아니라 이 채널로 미러링을 제한하는 특정 릴리스 채널을 지정할 수도 있습니다. 이는 마이너 릴리스에 다른 릴리스 채널을 사용하는 Red Hat Quay와 같은 Operator 제품에 중요합니다. 마지막으로, 특정 Operator의 최대 버전을 지정할 수 있으므로 도구가 지정된 버전 범위만 미러링하여 최신 릴리스를 자동으로 미러링하지 않도록 할 수 있습니다. 이러한 모든 경우 대상 레지스트리에서 다른 Operator, 새 채널 및 최신 버전의 Operator를 사용하도록 Operator 미러링의 범위를 넓히도록 이미지 세트 구성 파일을 업데이트해야 합니다.
채널 사양 또는 버전 범위와 같은 제약 조건을 특정 Operator에서 선택한 릴리스 전략에 정렬하는 것이 좋습니다. 예를 들어 Operator에서 stable 채널을 사용하는 경우 해당 채널로 미러링을 제한하고 다운로드 볼륨 간의 적절한 균형을 찾고 안정적인 업데이트를 정기적으로 확인하려면 해당 채널에 대한 미러링을 제한해야 합니다. Operator가 릴리스 버전 채널 스키마(예: stable-3.7 )를 선택하는 경우 해당 채널의 모든 릴리스를 미러링해야 합니다. 이를 통해 Operator의 패치 버전(예: 3.7.1 )을 계속 수신할 수 있습니다. 새 제품 릴리스 채널(예: stable-3.8 )을 추가하도록 이미지 세트 구성을 정기적으로 조정할 수도 있습니다.
이미지 정리
이미지가 생성되고 미러링된 최신 이미지 세트에 더 이상 포함되지 않는 경우 대상 미러 레지스트리에서 자동으로 정리됩니다. 이를 통해 불필요한 콘텐츠를 쉽게 관리하고 정리하고 스토리지 리소스를 회수할 수 있습니다.
더 이상 필요하지 않은 OpenShift Container Platform 릴리스 또는 Operator 버전이 있는 경우 이미지 세트 구성을 수정하여 제외하도록 수정할 수 있으며 미러링 시 미러 레지스트리에서 정리됩니다. 이 작업은 이미지 세트 구성 파일에서 Operator당 최소 또는 최대 버전 범위 설정을 조정하거나 카탈로그에서 미러링할 Operator 목록에서 Operator를 삭제하여 수행할 수 있습니다. 구성 파일에서 전체 Operator 카탈로그 또는 전체 OpenShift Container Platform 릴리스를 제거할 수도 있습니다.
미러링할 새 이미지 또는 업데이트된 이미지가 없으면 대상 미러 레지스트리에서 제외된 이미지가 정리되지 않습니다. 또한 Operator 게시자가 채널에서 Operator 버전을 제거하는 경우 제거된 버전이 대상 미러 레지스트리에서 정리됩니다.
11.2.3.8.2. 미러 레지스트리 콘텐츠 업데이트
초기 이미지 세트를 미러 레지스트리에 게시한 후 oc-mirror 플러그인을 사용하여 연결이 끊긴 클러스터를 업데이트할 수 있습니다.
이미지 세트 구성에 따라 oc-mirror는 최신 릴리스의 OpenShift Container Platform 및 선택한 Operator를 inital 미러를 완료한 후 자동으로 감지합니다. 제품 및 보안 업데이트를 적시에 수신하려면 야간 cron 작업과 같이 정기적으로 oc-mirror를 실행하는 것이 좋습니다.
사전 요구 사항
- oc-mirror 플러그인을 사용하여 초기 이미지 세트를 미러 레지스트리로 미러링했습니다.
oc-mirror 플러그인의 초기 실행에 사용된 스토리지 백엔드에 액세스할 수 있습니다.
참고동일한 미러 레지스트리에 대해 oc-mirror의 초기 실행과 동일한 스토리지 백엔드를 사용해야 합니다. oc-mirror 플러그인에서 생성된 메타데이터 이미지를 삭제하거나 수정하지 마십시오.
프로세스
- 필요한 경우 새로운 OpenShift Container Platform 및 Operator 버전을 가져오도록 이미지 세트 구성 파일을 업데이트합니다. 미러링 사용 사례 예는 이미지 세트 구성 예제 를 참조하십시오.
초기 이미지를 미러 레지스트리로 미러링하는 데 사용한 것과 동일한 단계를 따릅니다. 자세한 내용은 부분적으로 연결이 끊긴 환경에서 이미지 세트 미러링 또는 완전히 연결이 끊긴 환경에서 이미지 세트 미러링을 참조하십시오.
중요- 비차적 이미지 세트만 생성 및 미러링되도록 동일한 스토리지 백엔드를 제공해야 합니다.
- 초기 이미지 세트 생성 중에 미러 레지스트리의 최상위 네임스페이스를 지정한 경우 동일한 미러 레지스트리에 oc-mirror 플러그인을 실행할 때마다 이 동일한 네임스페이스를 사용해야 합니다.
- oc-mirror에서 생성한 리소스를 사용하도록 클러스터를 구성합니다.
11.2.3.9. 시험 실행 수행
oc-mirror를 사용하여 실제로 이미지를 미러링하지 않고도 시험 실행을 수행할 수 있습니다. 이를 통해 미러링되는 이미지 목록과 미러 레지스트리에서 정리할 이미지를 검토할 수 있습니다. 또한 이미지 세트 구성으로 오류를 조기에 포착하거나 생성된 이미지 목록을 다른 도구와 함께 사용하여 미러링 작업을 수행할 수 있습니다.
사전 요구 사항
- 필요한 컨테이너 이미지를 얻으려면 인터넷에 액세스할 수 있습니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
oc-mirrorCLI 플러그인을 설치했습니다. - 이미지 세트 구성 파일을 생성했습니다.
프로세스
--dry-run플래그와 함께oc mirror명령을 실행하여 예행 실행을 수행합니다.$ oc mirror --config=./imageset-config.yaml \1 docker://registry.example:5000 \2 --dry-run3 출력 예
Checking push permissions for registry.example:5000 Creating directory: oc-mirror-workspace/src/publish Creating directory: oc-mirror-workspace/src/v2 Creating directory: oc-mirror-workspace/src/charts Creating directory: oc-mirror-workspace/src/release-signatures No metadata detected, creating new workspace wrote mirroring manifests to oc-mirror-workspace/operators.1658342351/manifests-redhat-operator-index ... info: Planning completed in 31.48s info: Dry run complete Writing image mapping to oc-mirror-workspace/mapping.txt생성된 작업 공간 디렉터리로 이동합니다.
$ cd oc-mirror-workspace/생성된
mapping.txt파일을 검토합니다.이 파일에는 미러링될 모든 이미지 목록이 포함되어 있습니다.
생성된
prune-plan.json파일을 검토합니다.이 파일에는 이미지 세트가 게시될 때 미러 레지스트리에서 정리할 모든 이미지 목록이 포함되어 있습니다.
참고prune
-plan.json 파일은 oc-mirror 명령이 미러 레지스트리를 가리키며 정리할이미지가 있는 경우에만 생성됩니다.
11.2.3.10. 이미지 세트 구성 매개변수
oc-mirror 플러그인에는 미러링할 이미지를 정의하는 이미지 세트 구성 파일이 필요합니다. 다음 표에는 ImageSetConfiguration 리소스에 사용 가능한 매개변수가 나열되어 있습니다.
| 매개변수 | 설명 | 값 |
|---|---|---|
|
|
|
문자열. 예: |
|
| 이미지 세트 내의 각 아카이브 파일의 최대 크기(GiB)입니다. |
정수. 예: |
|
| 이미지 세트의 구성입니다. | 개체 |
|
| 이미지 세트의 추가 이미지 구성입니다. | 개체의 배열입니다. 예를 들어 다음과 같습니다. |
|
| 미러링할 이미지의 태그 또는 다이제스트입니다. |
문자열. 예: |
|
| 미러링에서 차단할 이미지의 전체 태그, 다이제스트 또는 패턴입니다. |
문자열 배열입니다. 예: |
|
| 이미지 세트의 helm 구성입니다. oc-mirror 플러그인은 렌더링 시 사용자 입력이 필요하지 않은 helm 차트만 지원합니다. | 개체 |
|
| 미러링할 로컬 helm 차트입니다. | 개체의 배열입니다. 예를 들어 다음과 같습니다. |
|
| 미러링할 로컬 helm 차트의 이름입니다. |
문자열. 예: |
|
| 미러링할 로컬 helm 차트의 경로입니다. |
문자열. 예: |
|
| 미러링할 원격 helm 리포지토리입니다. | 개체의 배열입니다. 예를 들어 다음과 같습니다. |
|
| 미러링할 helm 저장소 이름입니다. |
문자열. 예: |
|
| 미러링할 helm 리포지토리의 URL입니다. |
문자열. 예: |
|
| 미러링할 원격 helm 차트입니다. | 개체의 배열입니다. |
|
| 미러링할 helm 차트의 이름입니다. |
문자열. 예: |
|
| 미러링할 이름이 helm 차트의 버전입니다. |
문자열. 예: |
|
| 이미지 세트의 Operator 구성 | 개체의 배열입니다. 예를 들어 다음과 같습니다. |
|
| 이미지 세트에 포함할 Operator 카탈로그입니다. |
문자열. 예: |
|
|
|
부울. 기본값은 |
|
| Operator 패키지 구성입니다. | 개체의 배열입니다. 예를 들어 다음과 같습니다. |
|
| 이미지 세트에 포함할 Operator 패키지 이름 |
문자열. 예: |
|
| Operator 패키지 채널 구성입니다. | 개체 |
|
| 이미지 세트에 포함할 Operator 채널 이름은 패키지 내에서 고유합니다. |
문자열. 예: |
|
| 존재하는 모든 채널에서 Operator 미러의 최고 버전입니다. |
문자열. 예: |
|
| 포함할 최소 번들의 이름 및 채널 헤드로의 업그레이드 그래프의 모든 번들입니다. 이름이 지정된 번들에 의미 있는 버전 메타데이터가 없는 경우에만 이 필드를 설정합니다. |
문자열. 예: |
|
| Operator가 존재하는 모든 채널에서 미러링할 Operator의 가장 낮은 버전입니다. |
문자열. 예: |
|
| Operator가 존재하는 모든 채널에서 미러링할 Operator의 최고 버전입니다. |
문자열. 예: |
|
| Operator가 존재하는 모든 채널에서 미러링할 Operator의 가장 낮은 버전입니다. |
문자열. 예: |
|
|
|
부울. 기본값은 |
|
| 참조된 카탈로그를 미러링할 선택적 대체 이름입니다. |
문자열. 예: |
|
|
|
문자열. 예: |
|
| 이미지 세트의 플랫폼 구성입니다. | 개체 |
|
| 미러링할 플랫폼 릴리스 페이로드의 아키텍처입니다. | 문자열 배열입니다. 예를 들어 다음과 같습니다. |
|
| 이미지 세트의 플랫폼 채널 구성입니다. | 개체의 배열입니다. 예를 들어 다음과 같습니다. |
|
|
|
부울. 기본값은 |
|
| 릴리스 채널의 이름입니다. |
문자열. 예: |
|
| 참조되는 플랫폼의 최소 버전이 미러링될 수 있습니다. |
문자열. 예: |
|
| 미러링할 참조 플랫폼의 가장 높은 버전입니다. |
문자열. 예: |
|
| 잘못된 경로 미러링 또는 전체 범위 미러링을 전환합니다. |
부울. 기본값은 |
|
| 미러링할 플랫폼의 유형입니다. |
문자열. 예: |
|
| OSUS 그래프가 이미지 세트에 추가되어 나중에 미러에 게시되는지 여부를 나타냅니다. |
부울. 기본값은 |
|
| 이미지 세트의 백엔드 구성입니다. | 개체 |
|
| 이미지 세트의 로컬 백엔드 구성입니다. | 개체 |
|
| 이미지 세트 메타데이터를 포함할 디렉터리의 경로입니다. |
문자열. 예: |
|
| 이미지 세트의 레지스트리 백엔드 구성입니다. | 개체 |
|
| 백엔드 레지스트리 URI입니다. URI에 네임스페이스 참조를 선택적으로 포함할 수 있습니다. |
문자열. 예: |
|
| 필요한 경우 참조된 백엔드 레지스트리의 TLS 확인을 건너뜁니다. |
부울. 기본값은 |
11.2.3.11. 이미지 세트 구성 예
다음 ImageSetConfiguration 파일 예제에서는 다양한 미러링 사용 사례에 대한 구성을 보여줍니다.
사용 사례: 임의의 이미지 및 helm 차트 포함
다음 ImageSetConfiguration 파일은 레지스트리 스토리지 백엔드를 사용하며 helm 차트 및 추가 Red Hat UBI(Universal Base Image)를 포함합니다.
ImageSetConfiguration 파일 예
apiVersion: mirror.openshift.io/v1alpha2
kind: ImageSetConfiguration
archiveSize: 4
storageConfig:
registry:
imageURL: example.com/mirror/oc-mirror-metadata
skipTLS: false
mirror:
platform:
architectures:
- "s390x"
channels:
- name: stable-4.11
operators:
- catalog: registry.redhat.io/redhat/redhat-operator-index:v4.11
helm:
repositories:
- name: redhat-helm-charts
url: https://raw.githubusercontent.com/redhat-developer/redhat-helm-charts/master
charts:
- name: ibm-mongodb-enterprise-helm
version: 0.2.0
additionalImages:
- name: registry.redhat.io/ubi8/ubi:latest사용 사례: Operator 버전을 최소에서 최신 버전으로 포함
다음 ImageSetConfiguration 파일은 로컬 스토리지 백엔드를 사용하며 최신 채널의 3.68.0 이상 버전에서 시작되는 Kubernetes Operator용 Red Hat Advanced Cluster Security만 포함합니다.
ImageSetConfiguration 파일 예
apiVersion: mirror.openshift.io/v1alpha2
kind: ImageSetConfiguration
storageConfig:
local:
path: /home/user/metadata
mirror:
operators:
- catalog: registry.redhat.io/redhat/redhat-operator-index:v4.11
packages:
- name: rhacs-operator
channels:
- name: latest
minVersion: 3.68.0사용 사례: 가장 짧은 OpenShift Container Platform 업그레이드 경로 포함
다음 ImageSetConfiguration 파일은 로컬 스토리지 백엔드를 사용하며 최소 4.9.37 버전에서 최대 4.10.22 까지의 가장 짧은 업그레이드 경로를 따라 모든 OpenShift Container Platform 버전을 포함합니다.
ImageSetConfiguration 파일 예
apiVersion: mirror.openshift.io/v1alpha2
kind: ImageSetConfiguration
storageConfig:
local:
path: /home/user/metadata
mirror:
platform:
channels:
- name: stable-4.10
minVersion: 4.9.37
maxVersion: 4.10.22
shortestPath: true사용 사례: 모든 OpenShift Container Platform 버전을 최소에서 최신 버전까지 포함
다음 ImageSetConfiguration 파일은 레지스트리 스토리지 백엔드를 사용하며 최소 4.10.10 부터 채널의 최신 버전으로 시작하는 모든 OpenShift Container Platform 버전을 포함합니다.
이 이미지 세트 구성으로 oc-mirror를 호출하면 stable-4.10 채널의 최신 릴리스가 평가되므로 정기적으로 oc-mirror를 실행하면 OpenShift Container Platform 이미지의 최신 릴리스가 자동으로 수신됩니다.
ImageSetConfiguration 파일 예
apiVersion: mirror.openshift.io/v1alpha2
kind: ImageSetConfiguration
storageConfig:
registry:
imageURL: example.com/mirror/oc-mirror-metadata
skipTLS: false
mirror:
platform:
channels:
- name: stable-4.10
minVersion: 4.10.10사용 사례: Operator 버전을 최소에서 최대로 포함
다음 ImageSetConfiguration 파일은 로컬 스토리지 백엔드를 사용하며 stable 채널의 1.0.0 에서 2.0.0 까지 시작하는 버전인 예제 Operator만 포함합니다.
이를 통해 특정 Operator의 특정 버전 범위만 미러링할 수 있습니다. 시간이 지남에 따라 이러한 설정을 사용하여 최신 릴리스로 버전을 조정할 수 있습니다(예: 더 이상 1.0.0을 실행 중인 버전 1.0.0 이 더 이상 실행 중인 경우). 이 시나리오에서는 minVersion 을 최신 버전 (예: 1.5.0 )으로 늘릴 수 있습니다. oc-mirror가 업데이트된 버전 범위에서 다시 실행되는 경우 1.5.0 이전 릴리스가 더 이상 필요하지 않으며 레지스트리에서 해당 릴리스를 삭제하여 스토리지 공간을 절약할 수 있음을 자동으로 탐지합니다.
ImageSetConfiguration 파일 예
apiVersion: mirror.openshift.io/v1alpha2
kind: ImageSetConfiguration
storageConfig:
local:
path: /home/user/metadata
mirror:
operators:
- catalog: registry.redhat.io/redhat/redhat-operator-index:v4.11
packages:
- name: example-operator
channels:
- name: stable
minVersion: '1.0.0'
maxVersion: '2.0.0'11.2.3.12. oc-mirror의 명령 참조
다음 표에서는 oc mirror 하위 명령 및 플래그를 설명합니다.
| 하위 명령 | 설명 |
|---|---|
|
| 지정된 쉘에 대한 자동 완성 스크립트를 생성합니다. |
|
| 이미지 세트의 내용을 출력합니다. |
|
| 하위 명령에 대한 도움말을 표시합니다. |
|
| 초기 이미지 세트 구성 템플릿을 출력합니다. |
|
| 사용 가능한 플랫폼 및 Operator 콘텐츠 및 해당 버전을 나열합니다. |
|
| oc-mirror 버전을 출력합니다. |
| 플래그 | 설명 |
|---|---|
|
| 이미지 세트 구성 파일의 경로를 지정합니다. |
|
| 이미지 가져오기 관련 오류가 발생하면 계속 진행하여 미러링을 최대한 시도합니다. |
|
| 대상 레지스트리에 대한 TLS 검증을 비활성화합니다. |
|
| 대상 레지스트리에 일반 HTTP를 사용합니다. |
|
|
이미지를 미러링하지 않고 작업을 인쇄합니다. |
|
| 대상 레지스트리로 로드할 oc-mirror 실행으로 생성된 이미지 세트 아카이브의 경로를 지정합니다. |
|
| 도움말을 표시합니다. |
|
| 이미지 및 패키징 계층을 다운로드할 때 이전 미러를 무시합니다. 증분 미러링을 비활성화하고 더 많은 데이터를 다운로드할 수 있습니다. |
|
|
미러 레지스트리를 사용하도록 클러스터를 구성하기 위해 |
|
|
레지스트리당 허용된 동시 요청 수를 지정합니다. 기본값은 |
|
| 아티팩트 디렉터리 제거를 건너뜁니다. |
|
| Operator 카탈로그의 이미지 태그를 다이제스트 핀으로 대체하지 마십시오. |
|
|
이미지 세트를 게시할 때 메타데이터를 건너뜁니다. 이미지 세트가 |
|
| 이미지를 찾을 수 없는 경우 오류를 보고하고 실행을 중단하는 대신 이미지를 건너뜁니다. 이미지 세트 구성에 명시적으로 지정된 사용자 지정 이미지에는 적용되지 않습니다. |
|
| 다이제스트 확인을 건너뜁니다. |
|
| 소스 레지스트리에 대한 TLS 검증을 비활성화합니다. |
|
| 소스 레지스트리에 일반 HTTP를 사용합니다. |
|
|
로그 수준 상세 정보 표시 수를 지정합니다. 유효한 값은 |
11.2.4. oc adm release mirror 명령을 사용하여 이미지 미러링
OpenShift Update Service 애플리케이션에서 과도한 메모리 사용을 방지하려면 다음 절차에 설명된 대로 릴리스 이미지를 별도의 저장소에 미러링해야 합니다.
사전 요구 사항
- 연결이 끊긴 환경에서 사용할 미러 레지스트리를 설정하고 구성한 인증서 및 인증 정보에 액세스할 수 있습니다.
- Red Hat OpenShift Cluster Manager에서 풀 시크릿을 다운로드하여 미러 저장소에 대한 인증을 포함하도록 수정했습니다.
- 자체 서명된 인증서를 사용하는 경우 인증서에 주체 대체 이름을 지정했습니다.
프로세스
- Red Hat OpenShift Container Platform Upgrade Graph 시각화 프로그램 및 업데이트 플래너 를 사용하여 한 버전에서 다른 버전으로의 업데이트를 계획합니다. OpenShift Upgrade Graph는 채널 그래프와 현재 클러스터 버전과 예약된 클러스터 버전 간의 업데이트 경로가 있는지 확인하는 방법을 제공합니다.
필요한 환경 변수를 설정합니다.
릴리스 버전을 내보냅니다.
$ export OCP_RELEASE=<release_version>&
lt;release_version>에 대해 업데이트할 OpenShift Container Platform 버전에 해당하는 태그를 지정합니다 (예:4.5.4) .로컬 레지스트리 이름 및 호스트 포트를 내보냅니다.
$ LOCAL_REGISTRY='<local_registry_host_name>:<local_registry_host_port>'<local_registry_host_name>의 경우 미러 저장소의 레지스트리 도메인 이름을 지정하고<local_registry_host_port>의 경우 콘텐츠를 제공하는데 사용되는 포트를 지정합니다.로컬 저장소 이름을 내보냅니다.
$ LOCAL_REPOSITORY='<local_repository_name>'<local_repository_name>의 경우 레지스트리에 작성할 저장소 이름 (예:ocp4/openshift4)을 지정합니다.OpenShift Update Service를 사용하는 경우 릴리스 이미지를 포함하도록 추가 로컬 리포지토리 이름을 내보냅니다.
$ LOCAL_RELEASE_IMAGES_REPOSITORY='<local_release_images_repository_name>'<local_release_images_repository_name>의 경우 레지스트리에 작성할 저장소 이름 (예:ocp4/openshift4-release-images)을 지정합니다.미러링할 저장소 이름을 내보냅니다.
$ PRODUCT_REPO='openshift-release-dev'프로덕션 환경의 릴리스의 경우
openshift-release-dev를 지정해야 합니다.레지스트리 풀 시크릿의 경로를 내보냅니다.
$ LOCAL_SECRET_JSON='<path_to_pull_secret>'생성한 미러 레지스트리에 대한 풀 시크릿의 절대 경로 및 파일 이름을
<path_to_pull_secret>에 지정합니다.참고클러스터에서
ImageContentSourcePolicy오브젝트를 사용하여 저장소 미러링을 구성하는 경우 미러링된 레지스트리에 대한 글로벌 풀 시크릿만 사용할 수 있습니다. 프로젝트에 풀 시크릿을 추가할 수 없습니다.릴리스 미러를 내보냅니다.
$ RELEASE_NAME="ocp-release"프로덕션 환경의 릴리스의 경우
ocp-release를 지정해야 합니다.서버의 아키텍처 유형 (예:
x86_64)을 내보냅니다.$ ARCHITECTURE=<server_architecture>미러링된 이미지를 호스트할 디렉터리의 경로를 내보냅니다.
$ REMOVABLE_MEDIA_PATH=<path>1 - 1
- 초기 슬래시 (/) 문자를 포함하여 전체 경로를 지정합니다.
미러링할 이미지 및 설정 매니페스트를 확인합니다.
$ oc adm release mirror -a ${LOCAL_SECRET_JSON} --to-dir=${REMOVABLE_MEDIA_PATH}/mirror quay.io/${PRODUCT_REPO}/${RELEASE_NAME}:${OCP_RELEASE}-${ARCHITECTURE} --dry-run버전 이미지를 미러 레지스트리에 미러링합니다.
미러 호스트가 인터넷에 액세스할 수 없는 경우 다음 작업을 수행합니다.
- 이동식 미디어를 인터넷에 연결된 시스템에 연결합니다.
이미지 및 설정 매니페스트를 이동식 미디어의 디렉토리에 미러링합니다.
$ oc adm release mirror -a ${LOCAL_SECRET_JSON} --to-dir=${REMOVABLE_MEDIA_PATH}/mirror quay.io/${PRODUCT_REPO}/${RELEASE_NAME}:${OCP_RELEASE}-${ARCHITECTURE}참고또한 이 명령은 미러링된 릴리스 이미지 서명 구성 맵을 이동식 미디어에 생성하고 저장합니다.
미디어를 연결이 끊긴 환경으로 가져와서 이미지를 로컬 컨테이너 레지스트리에 업로드합니다.
$ oc image mirror -a ${LOCAL_SECRET_JSON} --from-dir=${REMOVABLE_MEDIA_PATH}/mirror "file://openshift/release:${OCP_RELEASE}*" ${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}1 - 1
REMOVABLE_MEDIA_PATH의 경우 이미지를 미러링 할 때 지정한 것과 동일한 경로를 사용해야 합니다.
-
ocCLI(명령줄 인터페이스)를 사용하여 업그레이드 중인 클러스터에 로그인합니다. 미러링된 릴리스 이미지 서명 config map을 연결된 클러스터에 적용합니다.
$ oc apply -f ${REMOVABLE_MEDIA_PATH}/mirror/config/<image_signature_file>1 - 1
- <
image_signature_file>의 경우 파일의 경로와 이름을 지정합니다(예:signature-sha256-81154f5c03294534.yaml).
OpenShift Update Service를 사용하는 경우 릴리스 이미지를 별도의 저장소에 미러링합니다.
$ oc image mirror -a ${LOCAL_SECRET_JSON} ${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE} ${LOCAL_REGISTRY}/${LOCAL_RELEASE_IMAGES_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE}
로컬 컨테이너 레지스트리와 클러스터가 미러 호스트에 연결된 경우 다음 작업을 수행합니다.
릴리스 이미지를 로컬 레지스트리로 직접 푸시하고 다음 명령을 사용하여 구성 맵을 클러스터에 적용합니다.
$ oc adm release mirror -a ${LOCAL_SECRET_JSON} --from=quay.io/${PRODUCT_REPO}/${RELEASE_NAME}:${OCP_RELEASE}-${ARCHITECTURE} \ --to=${LOCAL_REGISTRY}/${LOCAL_REPOSITORY} --apply-release-image-signature참고--apply-release-image-signature옵션이 포함된 경우 이미지 서명 확인을 위해 config map을 작성하지 않습니다.OpenShift Update Service를 사용하는 경우 릴리스 이미지를 별도의 저장소에 미러링합니다.
$ oc image mirror -a ${LOCAL_SECRET_JSON} ${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE} ${LOCAL_REGISTRY}/${LOCAL_RELEASE_IMAGES_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE}
11.3. OpenShift Update Service를 사용하여 연결이 끊긴 환경에서 클러스터 업데이트
연결된 클러스터와 유사한 업데이트 환경을 얻으려면 다음 절차를 사용하여 연결이 끊긴 환경에서 OSUS(OpenShift Update Service)를 설치 및 구성할 수 있습니다.
다음 단계에서는 OSUS를 사용하여 연결이 끊긴 환경에서 클러스터를 업데이트하는 방법에 대한 고급 워크플로를 간략하게 설명합니다.
- 보안 레지스트리에 대한 액세스를 구성합니다.
- 미러 레지스트리에 액세스하려면 글로벌 클러스터 풀 시크릿을 업데이트합니다.
- OSUS Operator를 설치합니다.
- OpenShift Update Service의 그래프 데이터 컨테이너 이미지를 생성합니다.
- OSUS 애플리케이션을 설치하고 로컬 OpenShift Update Service를 사용하도록 클러스터를 구성합니다.
- 연결된 클러스터와 마찬가지로 문서에서 지원되는 업데이트 프로세스를 수행합니다.
11.3.1. 연결이 끊긴 환경에서 OpenShift Update Service 사용
OSUS(OpenShift Update Service)는 OpenShift Container Platform 클러스터에 대한 업데이트 권장 사항을 제공합니다. Red Hat은 OpenShift Update Service를 공개적으로 호스팅하고 연결된 환경의 클러스터는 공용 API를 통해 서비스에 연결하여 업데이트 권장 사항을 검색할 수 있습니다.
그러나 연결이 끊긴 환경의 클러스터는 업데이트 정보를 검색하기 위해 이러한 공용 API에 액세스할 수 없습니다. 연결이 끊긴 환경에서 유사한 업데이트 환경을 제공하기 위해 로컬에서 OpenShift 업데이트 서비스를 설치하고 구성하여 연결이 끊긴 환경에서 사용할 수 있도록 할 수 있습니다.
단일 OSUS 인스턴스는 수천 개의 클러스터에 권장 사항을 제공할 수 있습니다. OSUS는 복제본 값을 변경하여 더 많은 클러스터를 수용하도록 수평으로 확장할 수 있습니다. 따라서 대부분의 연결이 끊긴 사용 사례의 경우 하나의 OSUS 인스턴스만으로도 충분합니다. 예를 들어, Red Hat은 연결된 클러스터의 전체 플릿에 대해 하나의 OSUS 인스턴스를 호스팅합니다.
다른 환경에서 업데이트 권장 사항을 별도로 유지하려면 각 환경에 대해 하나의 OSUS 인스턴스를 실행할 수 있습니다. 예를 들어 별도의 테스트 및 스테이징 환경이 있는 경우 스테이지 환경의 클러스터가 테스트 환경에서 테스트 환경에서 테스트되지 않은 경우 버전 A에 대한 업데이트 권장 사항을 수신하지 않도록 할 수 있습니다.
다음 섹션에서는 로컬 OSUS 인스턴스를 설치하고 클러스터에 업데이트 권장 사항을 제공하도록 구성하는 방법을 설명합니다.
11.3.2. 사전 요구 사항
-
oc명령 줄 인터페이스 (CLI) 툴이 설치되어 있어야합니다. - OpenShift Container Platform 이미지 저장소 미러링에 설명된 대로 업데이트를 위한 컨테이너 이미지로 로컬 컨테이너 이미지 레지스트리를 프로비저닝해야 합니다.
11.3.3. OpenShift Update Service의 보안 레지스트리에 대한 액세스 구성
릴리스 이미지가 사용자 정의 인증 기관에서 HTTPS X.509 인증서가 서명한 레지스트리에 포함된 경우 업데이트 서비스에 대한 다음 변경과 함께 이미지 레지스트리 액세스를 위한 추가 신뢰 저장소 구성 단계를 완료합니다.
OpenShift Update Service Operator는 레지스트리 CA 인증서에 구성 맵 키 이름 updateservice-registry가 필요합니다.
업데이트 서비스에 대한 이미지 레지스트리 CA 구성 맵의 예
apiVersion: v1
kind: ConfigMap
metadata:
name: my-registry-ca
data:
updateservice-registry: |
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
registry-with-port.example.com..5000: |
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----11.3.4. 글로벌 클러스터 풀 시크릿 업데이트
현재 풀 시크릿을 교체하거나 새 풀 시크릿을 추가하여 클러스터의 글로벌 풀 시크릿을 업데이트할 수 있습니다.
사용자가 별도의 레지스트리를 사용하여 설치 중에 사용된 레지스트리보다 이미지를 저장하는 경우 절차가 필요합니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다.
프로세스
선택 사항: 기존 풀 시크릿에 새 풀 시크릿을 추가하려면 다음 단계를 완료합니다.
다음 명령을 입력하여 풀 시크릿을 다운로드합니다.
$ oc get secret/pull-secret -n openshift-config --template='{{index .data ".dockerconfigjson" | base64decode}}' ><pull_secret_location>1 - 1
- 풀 시크릿 파일에 경로를 제공합니다.
다음 명령을 입력하여 새 풀 시크릿을 추가합니다.
$ oc registry login --registry="<registry>" \1 --auth-basic="<username>:<password>" \2 --to=<pull_secret_location>3 또는 가져오기 시크릿 파일에 대한 수동 업데이트를 수행할 수 있습니다.
다음 명령을 입력하여 클러스터의 글로벌 풀 시크릿을 업데이트합니다.
$ oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=<pull_secret_location>1 - 1
- 새 풀 시크릿 파일의 경로를 제공합니다.
이 업데이트는 모든 노드로 롤아웃되며 클러스터 크기에 따라 작업에 약간의 시간이 걸릴 수 있습니다.
참고OpenShift Container Platform 4.7.4부터 글로벌 풀 시크릿을 변경해도 더 이상 노드 드레이닝 또는 재부팅이 트리거되지 않습니다.
11.3.5. OpenShift Update Service Operator 설치
OpenShift Update Service를 설치하려면 먼저 OpenShift Container Platform 웹 콘솔 또는 CLI를 사용하여 OpenShift Update Service Operator를 설치해야 합니다.
연결이 끊긴 환경에 설치된 클러스터의 경우 Operator Lifecycle Manager는 기본적으로 원격 레지스트리에서 호스팅되는 Red Hat 제공 OperatorHub 소스에 액세스할 수 없습니다. 이러한 원격 소스에는 완전한 인터넷 연결이 필요하기 때문입니다. 자세한 내용은 제한된 네트워크에서 Operator Lifecycle Manager 사용을 참조하십시오.
11.3.5.1. 웹 콘솔을 사용하여 OpenShift Update Service Operator 설치
웹 콘솔을 사용하여 OpenShift Update Service Operator를 설치할 수 있습니다.
프로세스
웹 콘솔에서 Operator → OperatorHub를 클릭합니다.
참고Update Service를 키워드로 필터링… 필드에 입력하여 Operator를 더 빠르게 찾습니다.사용 가능한 Operator 목록에서 OpenShift Update Service를 선택한 다음 설치를 클릭합니다.
-
채널
v1은 이 릴리스에서 사용할 수 있는 유일한 채널이므로 업데이트 채널로 선택됩니다. - 설치 모드에서 클러스터의 특정 네임스페이스를 선택합니다.
-
설치된 네임스페이스의 네임스페이스를 선택하거나 권장 네임스페이스
openshift-update-service를 수락합니다. 승인 전략을 선택합니다.
- 자동 전략을 사용하면 Operator 새 버전이 준비될 때 OLM(Operator Lifecycle Manager)이 자동으로 Operator를 업데이트할 수 있습니다.
- 수동 전략을 사용하려면 클러스터 관리자가 Operator 업데이트를 승인해야 합니다.
- 설치를 클릭합니다.
-
채널
- Operator → Installed Operator 페이지로 전환하여 OpenShift Update Service Operator가 설치되었는지 확인합니다.
- OpenShift Update Service가 선택한 네임스페이스에 성공 상태로 나열되어 있는지 확인합니다.
11.3.5.2. CLI를 사용하여 OpenShift Update Service Operator 설치
OpenShift CLI(oc)를 사용하여 OpenShift Update Service Operator를 설치할 수 있습니다.
프로세스
OpenShift OpenShift Update Service Operator의 네임스페이스를 생성합니다.
OpenShift Update Service Operator에 대해
Namespace오브젝트 YAML 파일 (예:update-service-namespace.yaml)을 만듭니다.apiVersion: v1 kind: Namespace metadata: name: openshift-update-service annotations: openshift.io/node-selector: "" labels: openshift.io/cluster-monitoring: "true"1 - 1
- 이 네임스페이스에서 Operator가 권장하는 클러스터 모니터링을 사용하도록 하려면
openshift.io/cluster-monitoring레이블을 설정합니다.
네임스페이스를 생성합니다.
$ oc create -f <filename>.yaml예를 들어 다음과 같습니다.
$ oc create -f update-service-namespace.yaml
다음 오브젝트를 생성하여 OpenShift Update Service Operator를 설치합니다.
OperatorGroup오브젝트 YAML 파일을 만듭니다 (예:update-service-operator-group.yaml).apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: update-service-operator-group spec: targetNamespaces: - openshift-update-serviceOperatorGroup오브젝트를 생성합니다.$ oc -n openshift-update-service create -f <filename>.yaml예를 들어 다음과 같습니다.
$ oc -n openshift-update-service create -f update-service-operator-group.yamlSubscription오브젝트 YAML 파일(예:update-service-subscription.yaml)을 생성합니다.서브스크립션의 예
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: update-service-subscription spec: channel: v1 installPlanApproval: "Automatic" source: "redhat-operators"1 sourceNamespace: "openshift-marketplace" name: "cincinnati-operator"- 1
- Operator를 제공하는 카탈로그 소스의 이름을 지정합니다. 사용자 정의 OLM(Operator Lifecycle Manager)을 사용하지 않는 클러스터의 경우
redhat-operators를 지정합니다. OpenShift Container Platform 클러스터가 연결이 끊긴 환경에 설치된 경우 OLM(Operator Lifecycle Manager)을 구성할 때 생성된CatalogSource오브젝트의 이름을 지정합니다.
Subscription오브젝트를 생성합니다.$ oc create -f <filename>.yaml예를 들어 다음과 같습니다.
$ oc -n openshift-update-service create -f update-service-subscription.yamlOpenShift Update Service Operator는
openshift-update-service네임스페이스에 설치되고openshift-update-service네임스페이스를 대상으로 합니다.
Operator 설치를 확인합니다.
$ oc -n openshift-update-service get clusterserviceversions출력 예
NAME DISPLAY VERSION REPLACES PHASE update-service-operator.v4.6.0 OpenShift Update Service 4.6.0 Succeeded ...OpenShift Update Service Operator가 나열된 경우 설치에 성공한 것입니다. 버전 번호가 표시된 것과 다를 수 있습니다.
11.3.6. OpenShift Update Service 그래프 데이터 컨테이너 이미지 생성
OpenShift Update Service에는 그래프 데이터 컨테이너 이미지가 필요합니다. 이 이미지를 통해 OpenShift Update Service에서 채널 멤버십 및 차단된 업데이트 에지에 대한 정보를 검색합니다. 일반적으로 그래프 데이터는 업그레이드 그래프 데이터 리포지토리에서 직접 가져옵니다. 인터넷 연결이 불가능한 환경에서 init 컨테이너에서 이 정보를 로드하는 것도 OpenShift 업데이트 서비스에서 그래프 데이터를 사용할 수 있도록 하는 또 다른 방법입니다. init 컨테이너의 역할은 그래프 데이터의 로컬 사본을 제공하는 것이며 pod 초기화 중에 init 컨테이너가 서비스에서 액세스할 수 있는 볼륨에 데이터를 복사하는 것입니다.
oc-mirror OpenShift CLI(oc) 플러그인은 릴리스 이미지 미러링 외에도 이 그래프 데이터 컨테이너 이미지를 생성합니다. oc-mirror 플러그인을 사용하여 릴리스 이미지를 미러링한 경우 이 프로세스를 건너뛸 수 있습니다.
프로세스
다음을 포함하는 Dockerfile(예:
./Dockerfile)을 생성합니다.FROM registry.access.redhat.com/ubi8/ubi:8.1 RUN curl -L -o cincinnati-graph-data.tar.gz https://api.openshift.com/api/upgrades_info/graph-data RUN mkdir -p /var/lib/cincinnati-graph-data && tar xvzf cincinnati-graph-data.tar.gz -C /var/lib/cincinnati-graph-data/ --no-overwrite-dir --no-same-owner CMD ["/bin/bash", "-c" ,"exec cp -rp /var/lib/cincinnati-graph-data/* /var/lib/cincinnati/graph-data"]위 단계에서 생성된 Docker 파일을 사용하여 그래프 데이터 컨테이너 이미지(예:
registry.example.com/openshift/graph-data:latest)를 빌드합니다.$ podman build -f ./Dockerfile -t registry.example.com/openshift/graph-data:latest이전 단계에서 생성된 그래프 데이터 컨테이너 이미지를 OpenShift 업데이트 서비스(예:
registry.example.com/openshift/graph-data:latest)에 액세스할 수 있는 리포지토리로 내보냅니다.$ podman push registry.example.com/openshift/graph-data:latest참고그래프 데이터 이미지를 연결이 끊긴 환경의 로컬 레지스트리로 푸시하려면 이전 단계에서 생성한 그래프 데이터 컨테이너 이미지를 OpenShift Update Service에서 액세스할 수 있는 리포지토리로 복사합니다. 사용 가능한 옵션에 대해
oc image mirror --help를 실행합니다.
11.3.7. OpenShift Update Service 애플리케이션 생성
OpenShift Container Platform 웹 콘솔 또는 CLI를 사용하여 OpenShift Update Service 애플리케이션을 생성할 수 있습니다.
11.3.7.1. 웹 콘솔을 사용하여 OpenShift Update Service 애플리케이션 생성
OpenShift Container Platform 웹 콘솔을 사용하여 OpenShift Update Service Operator를 사용하여 OpenShift Update Service 애플리케이션을 생성할 수 있습니다.
사전 요구 사항
- OpenShift Update Service Operator가 설치되었습니다.
- OpenShift Update Service 그래프 데이터 컨테이너 이미지가 생성되어 OpenShift Update Service에서 액세스할 수 있는 리포지토리로 푸시되었습니다.
- 현재 릴리스 및 업데이트 대상 릴리스는 로컬에 액세스 가능한 레지스트리로 미러링되었습니다.
프로세스
- 웹 콘솔에서 Operator → Installed Operator를 클릭합니다.
- 설치된 Operator 목록에서 OpenShift Update Service를 선택합니다.
- Update Service 탭을 클릭합니다.
- Create UpdateService를 클릭합니다.
-
Name 필드에 이름을 입력합니다. (예:
service) -
Graph Data Image 필드에 "OpenShift Update Service 그래프 데이터 컨테이너 이미지 생성"에서 생성된 그래프 데이터 컨테이너 이미지에 로컬 pullspec을 입력합니다(예:
registry.example.com/openshift/graph-data:latest). -
Releases 필드에서 "OpenShift Container Platform 이미지 리포지토리 미러링"의 릴리스 이미지를 포함하도록 생성된 로컬 레지스트리 및 리포지토리를 입력합니다(예:
registry.example.com/ocp4/openshift4-release-images). -
Replicas 필드에
2를 입력합니다. - Create를 클릭하여 OpenShift Update Service 애플리케이션을 생성합니다.
OpenShift Update Service 애플리케이션 확인
- Update Service 탭의 UpdateServices 목록에서 방금 만든 업데이트 서비스 애플리케이션을 클릭합니다.
- Resources 탭을 클릭합니다.
- 각 애플리케이션 리소스의 상태가 Created인지 확인합니다.
11.3.7.2. CLI를 사용하여 OpenShift Update Service 애플리케이션 생성
OpenShift CLI(oc)를 사용하여 OpenShift Update Service 애플리케이션을 생성할 수 있습니다.
사전 요구 사항
- OpenShift Update Service Operator가 설치되었습니다.
- OpenShift Update Service 그래프 데이터 컨테이너 이미지가 생성되어 OpenShift Update Service에서 액세스할 수 있는 리포지토리로 푸시되었습니다.
- 현재 릴리스 및 업데이트 대상 릴리스는 로컬에 액세스 가능한 레지스트리로 미러링되었습니다.
프로세스
OpenShift Update Service 대상 네임스페이스를 구성합니다(예:
openshift-update-service).$ NAMESPACE=openshift-update-service네임스페이스는 Operator 그룹의
targetNamespaces값과 일치해야 합니다.OpenShift Update Service 애플리케이션의 이름을 구성합니다(예:
service).$ NAME=service"OpenShift Container Platform 이미지 리포지토리 미러링"에 구성된 릴리스 이미지의 로컬 레지스트리 및 리포지토리를 구성합니다(예:
registry.example.com/ocp4/openshift4-release-images).$ RELEASE_IMAGES=registry.example.com/ocp4/openshift4-release-images그래프 데이터 이미지의 로컬 pullspec을 "OpenShift Update Service 그래프 데이터 컨테이너 이미지 생성"에서 생성된 그래프 데이터 컨테이너 이미지로 설정합니다(예:
registry.example.com/openshift/graph-data:latest).$ GRAPH_DATA_IMAGE=registry.example.com/openshift/graph-data:latestOpenShift Update Service 애플리케이션 오브젝트를 생성합니다.
$ oc -n "${NAMESPACE}" create -f - <<EOF apiVersion: updateservice.operator.openshift.io/v1 kind: UpdateService metadata: name: ${NAME} spec: replicas: 2 releases: ${RELEASE_IMAGES} graphDataImage: ${GRAPH_DATA_IMAGE} EOFOpenShift Update Service 애플리케이션 확인
다음 명령을 사용하여 정책 엔진 경로를 가져옵니다.
$ while sleep 1; do POLICY_ENGINE_GRAPH_URI="$(oc -n "${NAMESPACE}" get -o jsonpath='{.status.policyEngineURI}/api/upgrades_info/v1/graph{"\n"}' updateservice "${NAME}")"; SCHEME="${POLICY_ENGINE_GRAPH_URI%%:*}"; if test "${SCHEME}" = http -o "${SCHEME}" = https; then break; fi; done명령이 성공할 때까지 폴링해야 할 수도 있습니다.
정책 엔진에서 그래프를 검색합니다.
channel에 유효한 버전을 지정해야 합니다. 예를 들어 OpenShift Container Platform 4.11에서 실행중인 경우stable-4.11을 사용합니다.$ while sleep 10; do HTTP_CODE="$(curl --header Accept:application/json --output /dev/stderr --write-out "%{http_code}" "${POLICY_ENGINE_GRAPH_URI}?channel=stable-4.6")"; if test "${HTTP_CODE}" -eq 200; then break; fi; echo "${HTTP_CODE}"; done이 경우 그래프 요청이 성공할 때까지 폴링되지만 미러링된 릴리스 이미지에 따라 결과 그래프가 비어 있을 수 있습니다.
정책 엔진 경로 이름은 RFC-1123을 기반으로 63자 이하여야 합니다. host must conform to DNS 1123 naming convention and must be no more than 63 characters로 인해 CreateRouteFailed 이유와 함께 ReconcileCompleted 상태가 false인 경우 더 짧은 이름으로 업데이트 서비스를 생성하십시오.
11.3.7.2.1. Cluster Version Operator (CVO) 구성
OpenShift Update Service Operator가 설치되고 OpenShift Update Service 애플리케이션이 생성된 후 로컬에 설치된 OpenShift Update Service에서 그래프 데이터를 가져오도록 CVO(Cluster Version Operator)를 업데이트할 수 있습니다.
사전 요구 사항
- OpenShift Update Service Operator가 설치되었습니다.
- OpenShift Update Service 그래프 데이터 컨테이너 이미지가 생성되어 OpenShift Update Service에서 액세스할 수 있는 리포지토리로 푸시되었습니다.
- 현재 릴리스 및 업데이트 대상 릴리스는 로컬에 액세스 가능한 레지스트리로 미러링되었습니다.
- OpenShift Update Service 애플리케이션이 생성되었습니다.
프로세스
OpenShift Update Service 대상 네임스페이스를 설정합니다(예:
openshift-update-service).$ NAMESPACE=openshift-update-serviceOpenShift Update Service 애플리케이션의 이름을 설정합니다(예:
service).$ NAME=service정책 엔진 경로를 가져옵니다.
$ POLICY_ENGINE_GRAPH_URI="$(oc -n "${NAMESPACE}" get -o jsonpath='{.status.policyEngineURI}/api/upgrades_info/v1/graph{"\n"}' updateservice "${NAME}")"풀 그래프 데이터의 패치를 설정합니다.
$ PATCH="{\"spec\":{\"upstream\":\"${POLICY_ENGINE_GRAPH_URI}\"}}"CVO를 패치하여 로컬 OpenShift Update Service를 사용합니다.
$ oc patch clusterversion version -p $PATCH --type merge
업데이트 서버를 신뢰하도록 CA를 구성하려면 클러스터 전체 프록시 활성화를 참조하십시오.
11.3.8. 다음 단계
클러스터를 업데이트하기 전에 다음 조건이 충족되었는지 확인합니다.
- CVO(Cluster Version Operator)는 로컬에서 설치된 OpenShift Update Service 애플리케이션을 사용하도록 구성되어 있습니다.
새 릴리스의 릴리스 이미지 서명 구성 맵이 클러스터에 적용됩니다.
참고릴리스 이미지 서명 구성 맵을 사용하면 CVO(Cluster Version Operator)에서 실제 이미지 서명이 예상 서명과 일치하는지 확인하여 릴리스 이미지의 무결성을 확인할 수 있습니다.
- 현재 릴리스 및 업데이트 대상 릴리스 이미지는 로컬에 액세스할 수 있는 레지스트리로 미러링됩니다.
- 최근 그래프 데이터 컨테이너 이미지가 로컬 레지스트리에 미러링되었습니다.
최신 버전의 OpenShift Update Service Operator가 설치되어 있습니다.
참고OpenShift Update Service Operator를 최근에 설치하거나 업데이트하지 않은 경우 더 최신 버전이 있을 수 있습니다. 연결이 끊긴 환경에서 OLM 카탈로그를 업데이트하는 방법에 대한 자세한 내용은 제한된 네트워크에서 Operator Lifecycle Manager 사용을 참조하십시오.
로컬에서 설치한 OpenShift Update Service 및 로컬 미러 레지스트리를 사용하도록 클러스터를 구성한 후 다음 업데이트 방법을 사용할 수 있습니다.
11.4. OpenShift Update Service 없이 연결이 끊긴 환경에서 클러스터 업데이트
다음 절차에 따라 OpenShift Update Service에 액세스하지 않고 연결이 끊긴 환경에서 클러스터를 업데이트합니다.
11.4.1. 사전 요구 사항
-
oc명령 줄 인터페이스 (CLI) 툴이 설치되어 있어야합니다. - OpenShift Container Platform 이미지 저장소 미러링에 설명된 대로 업데이트를 위한 컨테이너 이미지로 로컬 컨테이너 이미지 레지스트리를 프로비저닝해야 합니다.
-
admin권한이 있는 사용자로 클러스터에 액세스할 수 있어야 합니다. RBAC를 사용하여 권한 정의 및 적용을 참조하십시오. - 업데이트가 실패하는 경우 etcd 백업이 있어야 하며 클러스터를 이전 상태로 복원 해야 합니다.
- 모든 MCP(Machine config pool)가 실행 중이고 일시 중지되지 않았는지 확인해야 합니다. 업데이트 프로세스 중에 일시 중지된 MCP와 연결된 노드를 건너뜁니다. 카나리아 롤아웃 업데이트 전략을 수행하는 경우 MCP를 일시 중지할 수 있습니다.
- 클러스터에서 수동으로 유지 관리되는 인증 정보를 사용하는 경우 새 릴리스의 클라우드 공급자 리소스를 업데이트합니다. 자세한 내용은 수동으로 유지 관리되는 인증 정보를 사용하여 클러스터 업데이트 준비를 참조하십시오.
-
Operator를 실행하거나 Pod 중단 예산을 사용하여 애플리케이션을 구성한 경우 업그레이드 프로세스 중에 중단될 수 있습니다.
PodDisruptionBudget에서minAvailable이 1로 설정된 경우 노드는 제거 프로세스를 차단할 수 있는 보류 중인 머신 구성을 적용하기 위해 드레인됩니다. 여러 노드가 재부팅되면 모든 Pod가 하나의 노드에서만 실행될 수 있으며PodDisruptionBudget필드에서 노드 드레이닝을 방지할 수 있습니다.
Operator를 실행하거나 Pod 중단 예산을 사용하여 애플리케이션을 구성한 경우 업그레이드 프로세스 중에 중단될 수 있습니다. PodDisruptionBudget 에서 minAvailable 이 1로 설정된 경우 노드는 제거 프로세스를 차단할 수 있는 보류 중인 머신 구성을 적용하기 위해 드레인됩니다. 여러 노드가 재부팅되면 모든 Pod가 하나의 노드에서만 실행될 수 있으며 PodDisruptionBudget 필드에서 노드 드레이닝을 방지할 수 있습니다.
11.4.2. MachineHealthCheck 리소스 일시 중지
업그레이드 프로세스 중에 클러스터의 노드를 일시적으로 사용할 수 없게 될 수 있습니다. 작업자 노드의 경우 시스템 상태 점검에서 이러한 노드를 비정상으로 식별하고 재부팅할 수 있습니다. 이러한 노드를 재부팅하지 않으려면 클러스터를 업데이트하기 전에 모든 MachineHealthCheck 리소스를 일시 중지합니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다.
프로세스
일시 중지하려는 사용 가능한
MachineHealthCheck리소스를 모두 나열하려면 다음 명령을 실행합니다.$ oc get machinehealthcheck -n openshift-machine-api머신 상태 점검을 일시 중지하려면
cluster.x-k8s.io/paused=""주석을MachineHealthCheck리소스에 추가합니다. 다음 명령을 실행합니다.$ oc -n openshift-machine-api annotate mhc <mhc-name> cluster.x-k8s.io/paused=""주석이 지정된
MachineHealthCheck리소스는 다음 YAML 파일과 유사합니다.apiVersion: machine.openshift.io/v1beta1 kind: MachineHealthCheck metadata: name: example namespace: openshift-machine-api annotations: cluster.x-k8s.io/paused: "" spec: selector: matchLabels: role: worker unhealthyConditions: - type: "Ready" status: "Unknown" timeout: "300s" - type: "Ready" status: "False" timeout: "300s" maxUnhealthy: "40%" status: currentHealthy: 5 expectedMachines: 5중요클러스터를 업데이트한 후 머신 상태 점검을 다시 시작합니다. 검사를 다시 시작하려면 다음 명령을 실행하여
MachineHealthCheck리소스에서 일시 중지 주석을 제거합니다.$ oc -n openshift-machine-api annotate mhc <mhc-name> cluster.x-k8s.io/paused-
11.4.3. 릴리스 이미지 다이제스트 검색
oc adm upgrade 명령을 --to-image 옵션과 함께 사용하여 연결이 끊긴 환경에서 클러스터를 업데이트하려면 대상 릴리스 이미지에 해당하는 sha256 다이제스트를 참조해야 합니다.
프로세스
인터넷에 연결된 장치에서 다음 명령을 실행합니다.
$ oc adm release info -o 'jsonpath={.digest}{"\n"}' quay.io/openshift-release-dev/ocp-release:${OCP_RELEASE_VERSION}-${ARCHITECTURE}{OCP_RELEASE_VERSION}의 경우4.10.16과 같이 업데이트할 OpenShift Container Platform 버전을 지정합니다.{ARCHITECTURE}의 경우x86_64,aarch64,s390x,ppc64le과 같은 클러스터의 아키텍처를 지정합니다.출력 예
sha256:a8bfba3b6dddd1a2fbbead7dac65fe4fb8335089e4e7cae327f3bad334add31d- 클러스터를 업데이트할 때 사용할 sha256 다이제스트를 복사합니다.
11.4.4. 연결이 끊긴 클러스터 업데이트
연결이 끊긴 클러스터를 다운로드한 릴리스 이미지의 OpenShift Container Platform 버전으로 업데이트합니다.
로컬 OpenShift Update Service가 있는 경우 이 절차 대신 연결된 웹 콘솔 또는 CLI 지침을 사용하여 업데이트할 수 있습니다.
사전 요구 사항
- 새 릴리스의 이미지를 레지스트리에 미러링하고 있습니다.
새 릴리스의 릴리스 이미지 서명 ConfigMap을 클러스터에 적용하고 있습니다.
참고릴리스 이미지 서명 구성 맵을 사용하면 CVO(Cluster Version Operator)에서 실제 이미지 서명이 예상 서명과 일치하는지 확인하여 릴리스 이미지의 무결성을 확인할 수 있습니다.
- 대상 릴리스 이미지에 대한 sha256 다이제스트를 가져옵니다.
-
OpenShift CLI(
oc)를 설치합니다. -
모든
MachineHealthCheck리소스를 일시 중지했습니다.
프로세스
클러스터를 업데이트합니다.
$ oc adm upgrade --allow-explicit-upgrade --to-image ${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}@<digest>1 - 1
- <
digest> 값은 대상 릴리스 이미지의 sha256 다이제스트입니다(예:sha256:81154f5c03294534e1eaf0319bef7a601134f891689ccede5d705ef659aa8c92).
미러 레지스트리에
ImageContentSourcePolicy를 사용하는 경우LOCAL_REGISTRY대신 표준 레지스트리 이름을 사용할 수 있습니다.참고ImageContentSourcePolicy개체가 있는 클러스터에 대한 글로벌 풀 시크릿만 구성할 수 있습니다. 프로젝트에 풀 시크릿을 추가할 수 없습니다.
11.4.5. 이미지 레지스트리 저장소 미러링 설정
컨테이너 레지스트리 저장소 미러링을 설정하면 다음을 수행할 수 있습니다.
- 소스 이미지 레지스트리의 저장소에서 이미지를 가져오기 위해 요청을 리디렉션하고 미러링된 이미지 레지스트리의 저장소에서 이를 해석하도록 OpenShift Container Platform 클러스터를 설정합니다.
- 하나의 미러가 다운된 경우 다른 미러를 사용할 수 있도록 각 대상 저장소에 대해 여러 미러링된 저장소를 확인합니다.
다음은 OpenShift Container Platform의 저장소 미러링의 몇 가지 속성입니다.
- 이미지 풀은 레지스트리 다운타임에 탄력적으로 대처할 수 있습니다.
- 연결이 끊긴 환경의 클러스터는 중요한 위치(예: quay.io)에서 이미지를 가져오고 회사 방화벽 뒤의 레지스트리에서 요청된 이미지를 제공하도록 할 수 있습니다.
- 이미지 가져오기 요청이 있으면 특정한 레지스트리 순서로 가져오기를 시도하며 일반적으로 영구 레지스트리는 마지막으로 시도합니다.
-
입력한 미러링 정보는 OpenShift Container Platform 클러스터의 모든 노드에서
/etc/containers/registries.conf파일에 추가됩니다. - 노드가 소스 저장소에서 이미지를 요청하면 요청된 컨텐츠를 찾을 때 까지 미러링된 각 저장소를 차례로 시도합니다. 모든 미러가 실패하면 클러스터는 소스 저장소를 시도합니다. 성공하면 이미지를 노드로 가져올 수 있습니다.
저장소 미러링은 다음과 같은 방법으로 설정할 수 있습니다.
OpenShift Container Platform 설치 시
OpenShift Container Platform에 필요한 컨테이너 이미지를 가져온 다음 해당 이미지를 회사 방화벽 뒤에 배치하면 연결이 끊긴 환경에 있는 데이터 센터에 OpenShift Container Platform을 설치할 수 있습니다.
OpenShift Container Platform 설치 후
OpenShift Container Platform 설치 시 미러링을 설정하지 않고
ImageContentSourcePolicy개체를 사용하여 나중에 설정할 수 있습니다.
다음 절차에서는 설치 후 미러 구성을 제공합니다. 이때 다음을 식별하는 ImageContentSourcePolicy 오브젝트를 생성할 수 있습니다.
- 미러링하려는 컨테이너 이미지 저장소의 소스
- 소스 저장소에서 요청된 컨텐츠를 제공하는 각 미러 저장소에 대한 개별 항목
ImageContentSourcePolicy 개체가 있는 클러스터에 대한 글로벌 풀 시크릿만 구성할 수 있습니다. 프로젝트에 풀 시크릿을 추가할 수 없습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다.
프로세스
미러링된 저장소를 설정합니다.
- Red Hat Quay Repository Mirroring에 설명된대로 Red Hat Quay를 사용하여 미러링된 저장소를 설정합니다. Red Hat Quay를 사용하면 한 저장소에서 다른 저장소로 이미지를 복사하고 시간이 지남에 따라 해당 저장소를 반복해서 자동으로 동기화할 수 있습니다.
skopeo와 같은 툴을 사용하여 소스 디렉토리에서 미러링된 저장소로 이미지를 수동으로 복사합니다.예를 들어, Red Hat Enterprise Linux(RHEL) 7 또는 RHEL 8 시스템에 skopeo RPM 패키지를 설치한 후 다음 예와 같이
skopeo명령을 사용합니다.$ skopeo copy \ docker://registry.access.redhat.com/ubi8/ubi-minimal@sha256:5cfbaf45ca96806917830c183e9f37df2e913b187adb32e89fd83fa455ebaa6 \ docker://example.io/example/ubi-minimal이 예제에는
example.io라는 컨테이너 이미지 레지스트리가 있으며,registry.access.redhat.com에서ubi8/ubi-minimal이미지를 복사할example이라는 이미지 저장소가 있습니다. 레지스트리를 생성한 후 OpenShift Container Platform 클러스터를 설정하여 소스 저장소의 요청을 미러링된 저장소로 리디렉션할 수 있습니다.
- OpenShift Container Platform 클러스터에 로그인합니다.
ImageContentSourcePolicy파일(예:registryrepomirror.yaml)을 생성하고 소스 및 미러를 특정 레지스트리 및 저장소 쌍과 이미지로 교체합니다.apiVersion: operator.openshift.io/v1alpha1 kind: ImageContentSourcePolicy metadata: name: ubi8repo spec: repositoryDigestMirrors: - mirrors: - example.io/example/ubi-minimal1 - example.com/example/ubi-minimal2 source: registry.access.redhat.com/ubi8/ubi-minimal3 - mirrors: - mirror.example.com/redhat source: registry.redhat.io/openshift44 - mirrors: - mirror.example.com source: registry.redhat.io5 - mirrors: - mirror.example.net/image source: registry.example.com/example/myimage6 - mirrors: - mirror.example.net source: registry.example.com/example7 - mirrors: - mirror.example.net/registry-example-com source: registry.example.com8 - 1
- 이미지 레지스트리 및 저장소의 이름을 가리킵니다.
- 2
- 각 대상 저장소에 대해 여러 미러 리포지토리를 나타냅니다. 하나의 미러가 다운된 경우 대상 저장소에서 다른 미러를 사용할 수 있습니다.
- 3
- 미러링된 컨텐츠를 포함하는 레지스트리 및 저장소를 가리킵니다.
- 4
- 해당 네임스페이스의 이미지를 사용하도록 레지스트리 내에서 네임스페이스를 구성할 수 있습니다. 레지스트리 도메인을 소스로 사용하는 경우
ImageContentSourcePolicy리소스가 레지스트리의 모든 리포지토리에 적용됩니다. - 5
- 레지스트리 이름을 구성하면
ImageContentSourcePolicy리소스가 소스 레지스트리에서 미러 레지스트리로 모든 리포지토리에 적용됩니다. - 6
mirror.example.net/image@sha256:…이미지를 가져옵니다.- 7
- 미러
mirror.example.net/에서 소스 레지스트리 네임스페이스의 myimage 이미지를 가져옵니다.myimage@sha256:… - 8
- 미러 레지스트리
mirror.example.net/registry-example-com/example/myimage@sha256:…에서 이미지registry.example.com/example/myimage/myimage/myimage/myimage@sha256을 가져옵니다.ImageContentSourcePolicy리소스는 소스 레지스트리에서 미러 레지스트리mirror.example.net/registry-example-com으로 모든 리포지토리에 적용됩니다.
새
ImageContentSourcePolicy개체를 생성합니다.$ oc create -f registryrepomirror.yamlImageContentSourcePolicy개체가 생성된 후 새 설정이 각 노드에 배포된 클러스터는 소스 저장소에 대한 요청에 미러링된 저장소를 사용하기 시작합니다.미러링된 설정이 적용되었는지 확인하려면 노드 중 하나에서 다음을 수행하십시오.
노드를 나열합니다.
$ oc get node출력 예
NAME STATUS ROLES AGE VERSION ip-10-0-137-44.ec2.internal Ready worker 7m v1.24.0 ip-10-0-138-148.ec2.internal Ready master 11m v1.24.0 ip-10-0-139-122.ec2.internal Ready master 11m v1.24.0 ip-10-0-147-35.ec2.internal Ready worker 7m v1.24.0 ip-10-0-153-12.ec2.internal Ready worker 7m v1.24.0 ip-10-0-154-10.ec2.internal Ready master 11m v1.24.0Imagecontentsourcepolicy리소스는 노드를 재시작하지 않습니다.디버깅 프로세스를 시작하고 노드에 액세스합니다.
$ oc debug node/ip-10-0-147-35.ec2.internal출력 예
Starting pod/ip-10-0-147-35ec2internal-debug ... To use host binaries, run `chroot /host`루트 디렉토리를
/host로 변경합니다.sh-4.2# chroot /host/etc/containers/registries.conf파일을 체크하여 변경 사항이 적용되었는지 확인합니다.sh-4.2# cat /etc/containers/registries.conf출력 예
unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] short-name-mode = "" [[registry]] prefix = "" location = "registry.access.redhat.com/ubi8/ubi-minimal" mirror-by-digest-only = true [[registry.mirror]] location = "example.io/example/ubi-minimal" [[registry.mirror]] location = "example.com/example/ubi-minimal" [[registry]] prefix = "" location = "registry.example.com" mirror-by-digest-only = true [[registry.mirror]] location = "mirror.example.net/registry-example-com" [[registry]] prefix = "" location = "registry.example.com/example" mirror-by-digest-only = true [[registry.mirror]] location = "mirror.example.net" [[registry]] prefix = "" location = "registry.example.com/example/myimage" mirror-by-digest-only = true [[registry.mirror]] location = "mirror.example.net/image" [[registry]] prefix = "" location = "registry.redhat.io" mirror-by-digest-only = true [[registry.mirror]] location = "mirror.example.com" [[registry]] prefix = "" location = "registry.redhat.io/openshift4" mirror-by-digest-only = true [[registry.mirror]] location = "mirror.example.com/redhat"소스의 이미지 다이제스트를 노드로 가져와 실제로 미러링에 의해 해결되는지 확인합니다.
ImageContentSourcePolicy개체는 이미지 태그가 아닌 이미지 다이제스트만 지원합니다.sh-4.2# podman pull --log-level=debug registry.access.redhat.com/ubi8/ubi-minimal@sha256:5cfbaf45ca96806917830c183e9f37df2e913b187adb32e89fd83fa455ebaa6
저장소 미러링 문제 해결
저장소 미러링 절차가 설명대로 작동하지 않는 경우 저장소 미러링 작동 방법에 대한 다음 정보를 사용하여 문제를 해결하십시오.
- 가져온 이미지는 첫 번째 작동 미러를 사용하여 공급합니다.
- 주요 레지스트리는 다른 미러가 작동하지 않는 경우에만 사용됩니다.
-
시스템 컨텍스트에서
Insecure플래그가 폴백으로 사용됩니다. -
/etc/containers/registries.conf파일 형식이 최근에 변경되었습니다. 현재 버전은 TOML 형식의 버전 2입니다.
11.4.6. 클러스터 노드 재부팅 빈도를 줄이기 위해 미러 이미지 카탈로그의 범위 확장
미러링된 이미지 카탈로그의 범위를 저장소 수준 또는 더 넓은 레지스트리 수준에서 지정할 수 있습니다. 광범위한 ImageContentSourcePolicy 리소스는 리소스 변경에 따라 노드를 재부팅해야 하는 횟수를 줄입니다.
ImageContentSourcePolicy 리소스에서 미러 이미지 카탈로그의 범위를 확장하려면 다음 절차를 수행합니다.
사전 요구 사항
-
OpenShift Container Platform CLI
oc를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다. - 연결이 끊긴 클러스터에서 사용할 미러링된 이미지 카탈로그를 구성합니다.
프로세스
<local_registry>,<pull_spec>, 및<pull_secret_file>에 대한 값을 지정하여 다음 명령을 실행합니다.$ oc adm catalog mirror <local_registry>/<pull_spec> <local_registry> -a <pull_secret_file> --icsp-scope=registry다음과 같습니다.
- <local_registry>
-
연결이 끊긴 클러스터에 대해 구성한 로컬 레지스트리입니다 (예:
local.registry:5000). - <pull_spec>
-
연결이 끊긴 레지스트리에 구성된 가져오기 사양입니다(예:
redhat/redhat-operator-index:v4.11) - <pull_secret_file>
-
.json파일 형식의registry.redhat.io풀 시크릿입니다. Red Hat OpenShift Cluster Manager에서 풀 시크릿을 다운로드할 수 있습니다.
oc adm catalog mirror명령은/redhat-operator-index-manifests디렉터리를 생성하고imageContentSourcePolicy.yaml,catalogSource.yaml및mapping.txt파일을 생성합니다.새
ImageContentSourcePolicy리소스를 클러스터에 적용합니다.$ oc apply -f imageContentSourcePolicy.yaml
검증
oc apply가ImageContentSourcePolicy에 변경 사항을 성공적으로 적용했는지 확인합니다.$ oc get ImageContentSourcePolicy -o yaml출력 예
apiVersion: v1 items: - apiVersion: operator.openshift.io/v1alpha1 kind: ImageContentSourcePolicy metadata: annotations: kubectl.kubernetes.io/last-applied-configuration: | {"apiVersion":"operator.openshift.io/v1alpha1","kind":"ImageContentSourcePolicy","metadata":{"annotations":{},"name":"redhat-operator-index"},"spec":{"repositoryDigestMirrors":[{"mirrors":["local.registry:5000"],"source":"registry.redhat.io"}]}} ...
ImageContentSourcePolicy 리소스를 업데이트한 후 OpenShift Container Platform은 새 설정을 각 노드에 배포하고 클러스터는 소스 저장소에 대한 요청에 미러링된 저장소를 사용하기 시작합니다.
11.5. 클러스터에서 OpenShift Update Service 설치 제거
클러스터에서 OSUS(OpenShift Update Service)의 로컬 사본을 제거하려면 먼저 OSUS 애플리케이션을 삭제한 다음 OSUS Operator를 제거해야 합니다.
11.5.1. OpenShift Update Service 애플리케이션 삭제
OpenShift Container Platform 웹 콘솔 또는 CLI를 사용하여 OpenShift Update Service 애플리케이션을 삭제할 수 있습니다.
11.5.1.1. 웹 콘솔을 사용하여 OpenShift Update Service 애플리케이션 삭제
OpenShift Container Platform 웹 콘솔을 사용하여 OpenShift Update Service Operator로 OpenShift Update Service 애플리케이션을 삭제할 수 있습니다.
사전 요구 사항
- OpenShift Update Service Operator가 설치되었습니다.
프로세스
- 웹 콘솔에서 Operator → Installed Operator를 클릭합니다.
- 설치된 Operator 목록에서 OpenShift Update Service를 선택합니다.
- Update Service 탭을 클릭합니다.
- 설치된 OpenShift Update Service 애플리케이션 목록에서 삭제할 애플리케이션을 선택한 다음Delete UpdateService를 클릭합니다.
- Delete UpdateService? 확인 프롬프트에서 Delete를 클릭하여 삭제를 확인합니다.
11.5.1.2. CLI를 사용하여 OpenShift Update Service 애플리케이션 삭제
OpenShift CLI(oc)를 사용하여 OpenShift Update Service 애플리케이션을 삭제할 수 있습니다.
프로세스
OpenShift Update Service 애플리케이션이 생성된 네임스페이스(예:
openshift-update-service)를 사용하여 OpenShift Update Service 애플리케이션 이름을 가져옵니다.$ oc get updateservice -n openshift-update-service출력 예
NAME AGE service 6s이전 단계의
NAME값과 OpenShift Update Service 애플리케이션이 생성된 네임스페이스(예:openshift-update-service)를 사용하여 OpenShift Update Service 애플리케이션을 삭제합니다.$ oc delete updateservice service -n openshift-update-service출력 예
updateservice.updateservice.operator.openshift.io "service" deleted
11.5.2. OpenShift Update Service Operator 설치 제거
OpenShift Container Platform 웹 콘솔 또는 CLI를 사용하여 OpenShift Update Service Operator를 설치 제거할 수 있습니다.
11.5.2.1. 웹 콘솔을 사용하여 OpenShift Update Service Operator 설치 제거
OpenShift Container Platform 웹 콘솔을 사용하여 OpenShift Update Service Operator를 설치 제거할 수 있습니다.
사전 요구 사항
- 모든 OpenShift Update Service 애플리케이션이 삭제되어 있어야 합니다.
프로세스
- 웹 콘솔에서 Operator → Installed Operator를 클릭합니다.
- 설치된 Operator 목록에서 OpenShift Update Service을 선택하고 Uninstall Operator를 클릭합니다.
- Uninstall Operator? 확인 대화 상자에서 Uninstall를 클릭하고 제거를 확인합니다.
11.5.2.2. CLI를 사용하여 OpenShift Update Service Operator 설치 제거
OpenShift CLI(oc)를 사용하여 OpenShift Update Service Operator를 제거할 수 있습니다.
사전 요구 사항
- 모든 OpenShift Update Service 애플리케이션이 삭제되어 있어야 합니다.
프로세스
OpenShift Update Service Operator가 포함된 프로젝트로 변경합니다(예:
openshift-update-service).$ oc project openshift-update-service출력 예
Now using project "openshift-update-service" on server "https://example.com:6443".OpenShift Update Service Operator Operator 그룹의 이름을 가져옵니다.
$ oc get operatorgroup출력 예
NAME AGE openshift-update-service-fprx2 4m41soperator 그룹을 삭제합니다(예:
openshift-update-service-fprx2).$ oc delete operatorgroup openshift-update-service-fprx2출력 예
operatorgroup.operators.coreos.com "openshift-update-service-fprx2" deletedOpenShift Update Service Operator 서브스크립션의 이름을 가져옵니다.
$ oc get subscription출력 예
NAME PACKAGE SOURCE CHANNEL update-service-operator update-service-operator updateservice-index-catalog v1이전 단계의
Name값을 사용하여currentCSV필드에서 구독한 OpenShift Update Service Operator의 현재 버전을 확인합니다.$ oc get subscription update-service-operator -o yaml | grep " currentCSV"출력 예
currentCSV: update-service-operator.v0.0.1서브스크립션을 삭제합니다(예:
update-service-operator).$ oc delete subscription update-service-operator출력 예
subscription.operators.coreos.com "update-service-operator" deleted이전 단계의
currentCSV값을 사용하여 OpenShift Update Service Operator의 CSV를 삭제합니다.$ oc delete clusterserviceversion update-service-operator.v0.0.1출력 예
clusterserviceversion.operators.coreos.com "update-service-operator.v0.0.1" deleted
12장. vSphere에서 실행 중인 노드에서 하드웨어 업데이트
vSphere에서 실행 중인 노드가 OpenShift Container Platform에서 지원하는 하드웨어 버전에서 실행되고 있는지 확인해야 합니다. 현재 클러스터의 vSphere 가상 머신에서 하드웨어 버전 15 이상이 지원됩니다.
가상 하드웨어를 즉시 업데이트하거나 vCenter에 업데이트를 예약할 수 있습니다.
OpenShift Container Platform 버전 4.11에는 VMware 가상 하드웨어 버전 15 이상이 필요합니다.
12.1. vSphere에서 가상 하드웨어 업데이트
VMware vSphere에서 VM(가상 머신)의 하드웨어를 업데이트하려면 가상 머신을 별도로 업데이트하여 클러스터의 다운타임 위험을 줄입니다.
12.1.1. vSphere에서 컨트롤 플레인 노드의 가상 하드웨어 업데이트
다운 타임 위험을 줄이려면 컨트롤 플레인 노드를 직렬로 업데이트하는 것이 좋습니다. 이렇게 하면 Kubernetes API를 계속 사용할 수 있으며 etcd는 쿼럼을 유지합니다.
사전 요구 사항
- OpenShift Container Platform 클러스터를 호스팅하는 vCenter 인스턴스에서 필요한 권한을 실행할 수 있는 클러스터 관리자 권한이 있습니다.
- vSphere ESXi 호스트는 7.0U2 이상 버전입니다.
프로세스
클러스터의 컨트롤 플레인 노드를 나열합니다.
$ oc get nodes -l node-role.kubernetes.io/master출력 예
NAME STATUS ROLES AGE VERSION control-plane-node-0 Ready master 75m v1.24.0 control-plane-node-1 Ready master 75m v1.24.0 control-plane-node-2 Ready master 75m v1.24.0컨트롤 플레인 노드의 이름을 확인합니다.
컨트롤 플레인 노드를 예약할 수 없음으로 표시합니다.
$ oc adm cordon <control_plane_node>- 컨트롤 플레인 노드와 연결된 VM(가상 머신)을 종료합니다. VM을 마우스 오른쪽 버튼으로 클릭하고 Power → Shut Down Guest OS를 선택하여 vSphere 클라이언트에서 이 작업을 수행합니다. 안전하게 종료되지 않을 수 있으므로 Power Off (전원 끄기)를 사용하여 VM을 종료하지 마십시오.
- vSphere 클라이언트에서 VM을 업데이트합니다. 자세한 내용은 VMware 문서에서 수동으로 가상 머신의 호환성 업그레이드 를 따르십시오.
- 컨트롤 플레인 노드와 연결된 VM의 전원을 켭니다. VM을 마우스 오른쪽 버튼으로 클릭하고 Power On을 선택하여 vSphere 클라이언트에서 이 작업을 수행합니다.
노드가
Ready로 보고될 때까지 기다립니다.$ oc wait --for=condition=Ready node/<control_plane_node>컨트롤 플레인 노드를 다시 예약 가능으로 표시합니다.
$ oc adm uncordon <control_plane_node>- 클러스터의 각 컨트롤 플레인 노드에 대해 이 절차를 반복합니다.
12.1.2. vSphere에서 컴퓨팅 노드의 가상 하드웨어 업데이트
다운타임의 위험을 줄이려면 컴퓨팅 노드를 직렬로 업데이트하는 것이 좋습니다.
지정된 워크로드를 병렬로 여러 계산 노드를 업데이트할 수 있으며 NotReady 상태에 있는 노드가 있어야 합니다. 관리자가 필요한 컴퓨팅 노드를 사용할 수 있는지 확인해야 합니다.
사전 요구 사항
- OpenShift Container Platform 클러스터를 호스팅하는 vCenter 인스턴스에서 필요한 권한을 실행할 수 있는 클러스터 관리자 권한이 있습니다.
- vSphere ESXi 호스트는 7.0U2 이상 버전입니다.
프로세스
클러스터의 컴퓨팅 노드를 나열합니다.
$ oc get nodes -l node-role.kubernetes.io/worker출력 예
NAME STATUS ROLES AGE VERSION compute-node-0 Ready worker 30m v1.24.0 compute-node-1 Ready worker 30m v1.24.0 compute-node-2 Ready worker 30m v1.24.0컴퓨팅 노드의 이름을 확인합니다.
컴퓨팅 노드를 예약 불가로 표시합니다.
$ oc adm cordon <compute_node>컴퓨팅 노드에서 pod를 비웁니다. 이 작업을 수행하는 방법에는 여러 가지가 있습니다. 예를 들어 노드의 모든 Pod 또는 선택한 Pod를 비울 수 있습니다.
$ oc adm drain <compute_node> [--pod-selector=<pod_selector>]노드에서 pod를 비우기 위한 다른 옵션은 "노드에서 pod를 비우는 방법 이해" 섹션을 참조하십시오.
- 컴퓨팅 노드와 연결된 VM(가상 머신)을 종료합니다. VM을 마우스 오른쪽 버튼으로 클릭하고 Power → Shut Down Guest OS를 선택하여 vSphere 클라이언트에서 이 작업을 수행합니다. 안전하게 종료되지 않을 수 있으므로 Power Off (전원 끄기)를 사용하여 VM을 종료하지 마십시오.
- vSphere 클라이언트에서 VM을 업데이트합니다. 자세한 내용은 VMware 문서에서 수동으로 가상 머신의 호환성 업그레이드 를 따르십시오.
- 컴퓨팅 노드와 연결된 VM의 전원을 켭니다. VM을 마우스 오른쪽 버튼으로 클릭하고 Power On을 선택하여 vSphere 클라이언트에서 이 작업을 수행합니다.
노드가
Ready로 보고될 때까지 기다립니다.$ oc wait --for=condition=Ready node/<compute_node>컴퓨팅 노드를 다시 예약 가능으로 표시합니다.
$ oc adm uncordon <compute_node>- 클러스터의 각 컴퓨팅 노드에 대해 이 절차를 반복합니다.
12.1.3. vSphere에서 템플릿의 가상 하드웨어 업데이트
사전 요구 사항
- OpenShift Container Platform 클러스터를 호스팅하는 vCenter 인스턴스에서 필요한 권한을 실행할 수 있는 클러스터 관리자 권한이 있습니다.
- vSphere ESXi 호스트는 7.0U2 이상 버전입니다.
프로세스
RHCOS 템플릿이 vSphere 템플릿으로 구성된 경우 다음 단계 를 수행하기 전에 템플릿을 VMware 설명서의 가상 머신으로 변환 합니다.
참고템플릿에서 변환한 후에는 가상 머신의 전원을 켜지 마십시오.
- vSphere 클라이언트에서 VM을 업데이트합니다. 자세한 내용은 VMware 문서에서 수동으로 가상 머신의 호환성 업그레이드 를 따르십시오.
- vSphere 클라이언트의 VM을 VM에서 템플릿으로 변환합니다. 자세한 내용은 VMware 문서의 vSphere Client의 템플릿으로 가상 머신 변환 을 따르십시오.
12.2. vSphere에서 가상 하드웨어 업데이트 예약
가상 시스템의 전원을 켜거나 재부팅할 때 가상 하드웨어 업데이트를 수행할 수 있습니다. VMware 설명서의 가상 머신에 대한 호환성 업그레이드 예약에 따라 vCenter에서만 가상 하드웨어 업데이트를 예약할 수 있습니다.
OpenShift Container Platform 업그레이드를 수행하기 전에 업그레이드를 예약하면 OpenShift Container Platform 업그레이드 과정에서 노드가 재부팅될 때 가상 하드웨어 업데이트가 발생합니다.
13장. 특수 리소스 Operator가 포함된 클러스터 업데이트
SAR(Special Resource Operator)이 포함된 클러스터를 업데이트할 때 새 커널 모듈 버전이 현재 SRO에서 로드된 커널 모듈과 호환되는지 여부를 고려해야 합니다. preflight 검사를 실행하여 SRO가 커널 모듈을 업그레이드할 수 있는지 확인할 수 있습니다.
13.1. 사용자 정의 리소스 및 확인 상태 정보
preflight 검사는 사용자 정의 리소스(CR) 상태 및 확인 상태에 대한 정보를 제공합니다.
가능한 CR 상태
가능한 CR 상태는 다음과 같습니다.
True- SAR(Special Resource Operator) CR은 커널 호환성 문제 없이 업그레이드됩니다.
False-
CR의 커널 호환성에 문제가 있습니다.
Status Reason필드는 이에 대한 추가 정보를 제공합니다. 오류-
내부 오류로 인해 상태 확인이 완료되지 않았습니다.
Status Reason필드는 이 디버깅에 대한 추가 정보를 제공합니다. 알 수 없음- 검사에서 CR 상태를 아직 확인하지 않았습니다. 프로세스가 특정 CR에 도달하지 않았거나 검사를 완료하는 데 시간이 경과하지 않았기 때문일 수 있습니다.
가능한 확인 상태
가능한 확인 상태는 다음과 같습니다.
True-
이미지가 존재하며 호환되거나 이미지가 존재하지 않지만
BuildConfig리소스가 있습니다. False이미지가 존재하지 않고
BuildConfig리소스가 없거나 이미지가 존재하지만 새 커널 버전과 호환되지 않습니다.확인 상태가
False인 경우 다음 단계 중 하나를 수행할 수 있습니다.- 올바른 이름으로 사전 빌드된 이미지를 생성하고 status 필드를 다시 확인합니다.
-
BuildConfigReosurce를 포함하도록 CR을 변경합니다.
13.2. 특수 리소스 Operator에 대한 preflight 검사 실행
다음 예제 프로세스를 사용하여 SAR(Special Resource Operator)이 포함된 클러스터를 업데이트하기 전에 커널 모듈 버전의 호환성을 확인할 수 있습니다.
사전 요구 사항
- 실행 중인 OpenShift Container Platform 클러스터가 있어야 합니다.
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 OpenShift CLI에 로그인되어 있습니다. - SRO를 설치했습니다.
프로세스
다음 preflight 검증 CRD(사용자 정의 리소스 정의)를 생성하고 YAML을
prevalidation.yaml로 저장합니다.apiVersion: sro.openshift.io/v1beta1 kind: PreflightValidation metadata: name: preflight namespace: preflight spec: updateImage: quay.io/openshift-release-dev/ocp-release@sha256:f7f252c39b64601c8ac3de737a584ba4f6016b1f4b17801d726ca2fd154928781 - 1
- 여기에서 업데이트 이미지의 이름을 지정합니다.
다음 명령을 실행하여 검증 검사를 시작합니다.
$ oc apply -f prevalidation.yaml
검증
다음 명령을 실행하여 CR(사용자 정의 리소스)의 상태를 확인합니다.
$ oc describe preflightvalidations.sro.openshift.io/v1beta1 preflight출력 예
다음은 클러스터에 배포된
SpecialResourceCR인simple-oot의 출력 예입니다.Status: Cr Statuses: Last Transition Time: 2022-08-02T08:48:45Z Name: simple-oot Status Reason: Verification successful, all driver-containers for the next kernel version are present Verification Stage: Image Verification Status: True Events: <none>preflight 검사는 모든 CR이 검증될 때까지 계속 실행됩니다. 이전 명령을 반복하여 상태를 확인할 수 있습니다. 모든 CR을 확인한 후 preflight CR을 삭제해야 합니다.
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.