호스팅된 컨트롤 플레인
OpenShift Container Platform에서 호스팅된 컨트롤 플레인 사용
초록
1장. 호스팅된 컨트롤 플레인 개요
독립 실행형 또는 호스팅된 컨트롤 플레인 구성의 두 가지 다른 컨트롤 플레인 구성을 사용하여 OpenShift Container Platform 클러스터를 배포할 수 있습니다. 독립 실행형 구성은 전용 가상 머신 또는 물리적 시스템을 사용하여 컨트롤 플레인을 호스팅합니다. OpenShift Container Platform의 호스팅된 컨트롤 플레인을 사용하면 각 컨트롤 플레인의 전용 가상 또는 물리적 머신 없이도 호스팅 클러스터에서 컨트롤 플레인을 Pod로 생성합니다.
1.1. 호스팅된 컨트롤 플레인의 일반 개념 및 가상 사용자집
OpenShift Container Platform에 호스팅되는 컨트롤 플레인을 사용하는 경우 주요 개념과 관련 가상 사용자를 이해하는 것이 중요합니다.
1.1.1. 개념
- 호스트된 클러스터
- 관리 클러스터에서 호스팅되는 컨트롤 플레인 및 API 끝점이 있는 OpenShift Container Platform 클러스터입니다. 호스트된 클러스터에는 컨트롤 플레인과 해당 데이터 플레인이 포함됩니다.
- 호스트된 클러스터 인프라
- 테넌트 또는 최종 사용자 클라우드 계정에 존재하는 네트워크, 컴퓨팅 및 스토리지 리소스입니다.
- 호스트된 컨트롤 플레인
- 호스팅된 클러스터의 API 끝점에 의해 노출되는 관리 클러스터에서 실행되는 OpenShift Container Platform 컨트롤 플레인입니다. 컨트롤 플레인의 구성 요소에는 etcd, Kubernetes API 서버, Kubernetes 컨트롤러 관리자 및 VPN이 포함됩니다.
- 호스트 클러스터
- 관리 클러스터를 참조하십시오.
- 관리형 클러스터
- 허브 클러스터가 관리하는 클러스터입니다. 이 용어는 Kubernetes Operator의 다중 클러스터 엔진에서 Red Hat Advanced Cluster Management에서 관리하는 클러스터 라이프사이클에 따라 다릅니다. 관리형 클러스터는 관리 클러스터와 동일하지 않습니다. 자세한 내용은 관리 클러스터를 참조하십시오.
- 관리 클러스터
- HyperShift Operator가 배포되고 호스팅된 클러스터의 컨트롤 플레인이 호스팅되는 OpenShift Container Platform 클러스터입니다. 관리 클러스터는 호스팅 클러스터와 동일합니다.
- 관리 클러스터 인프라
- 관리 클러스터의 네트워크, 컴퓨팅 및 스토리지 리소스입니다.
- 노드 풀
- 컴퓨팅 노드가 포함된 리소스입니다. 컨트롤 플레인에는 노드 풀이 포함되어 있습니다. 컴퓨팅 노드는 애플리케이션 및 워크로드를 실행합니다.
1.1.2. 가상 사용자
- 클러스터 인스턴스 관리자
-
이 역할의 사용자는 독립 실행형 OpenShift Container Platform의 관리자와 동일한 것으로 간주됩니다. 이 사용자에게는 프로비저닝된 클러스터에
cluster-admin역할이 있지만 클러스터 업데이트 또는 구성 시 전원이 켜지지 않을 수 있습니다. 이 사용자는 클러스터에 예상된 일부 구성을 확인하기 위해 읽기 전용 액세스 권한이 있을 수 있습니다. - 클러스터 인스턴스 사용자
- 이 역할의 사용자는 독립 실행형 OpenShift Container Platform의 개발자와 동일한 것으로 간주됩니다. 이 사용자에게는 OperatorHub 또는 머신에 대한 보기가 없습니다.
- 클러스터 서비스 소비자
- 이 역할에서 컨트롤 플레인 및 작업자 노드를 요청하거나, 드라이브 업데이트를 요청하거나, 외부화된 구성을 수정할 수 있다고 가정합니다. 일반적으로 이 사용자는 클라우드 인증 정보 또는 인프라 암호화 키를 관리하거나 액세스하지 않습니다. 클러스터 서비스 소비자 가상 사용자는 호스트된 클러스터를 요청하고 노드 풀과 상호 작용할 수 있습니다. 이 역할에는 논리 경계 내에서 호스팅된 클러스터 및 노드 풀을 생성, 읽기, 업데이트 또는 삭제하는 RBAC가 있다고 가정합니다.
- 클러스터 서비스 공급자
이 역할에는 일반적으로 관리 클러스터에 대한
cluster-admin역할이 있고 HyperShift Operator의 가용성을 모니터링하고 소유할 수 있는 RBAC와 테넌트의 호스트 클러스터에 대한 컨트롤 플레인이 있는 사용자입니다. 클러스터 서비스 공급자 개인은 다음 예제를 포함하여 여러 활동을 담당합니다.- 컨트롤 플레인 가용성, 가동 시간 및 안정성에 대한 서비스 수준 오브젝트 보유
- 컨트롤 플레인을 호스팅할 관리 클러스터의 클라우드 계정 구성
- 사용 가능한 컴퓨팅 리소스에 대한 호스트 인식이 포함된 사용자 프로비저닝 인프라 구성
1.2. 호스트된 컨트롤 플레인 소개
Red Hat OpenShift Container Platform에 호스팅되는 컨트롤 플레인을 사용하여 관리 비용을 줄이고 클러스터 배포 시간을 최적화하며 관리 및 워크로드 문제를 분리하여 애플리케이션에 집중할 수 있습니다.
호스팅되는 컨트롤 플레인은 다음 플랫폼에서 Kubernetes Operator 버전 2.0 이상에 다중 클러스터 엔진 을 사용하여 사용할 수 있습니다.
- 에이전트 공급자를 사용하여 베어 메탈
- OpenShift Virtualization: 연결된 환경에서 일반적으로 사용 가능한 기능으로, 연결이 끊긴 환경의 기술 프리뷰 기능
- AWS(Amazon Web Services) - 기술 프리뷰 기능
- IBM Z, 기술 프리뷰 기능
- IBM Power, 기술 프리뷰 기능
1.2.1. 호스트된 컨트롤 플레인 아키텍처
OpenShift Container Platform은 종종 클러스터가 컨트롤 플레인과 데이터 플레인으로 구성된 결합형 또는 독립 실행형 모델로 배포됩니다. 컨트롤 플레인에는 상태를 확인하는 API 끝점, 스토리지 끝점, 워크로드 스케줄러, 작업자가 포함됩니다. 데이터 플레인에는 워크로드 및 애플리케이션이 실행되는 컴퓨팅, 스토리지 및 네트워킹이 포함됩니다.
독립 실행형 컨트롤 플레인은 쿼럼을 보장하기 위해 최소 수를 사용하여 물리적 또는 가상 노드 전용 그룹에 의해 호스팅됩니다. 네트워크 스택이 공유됩니다. 클러스터에 대한 관리자 액세스는 클러스터의 컨트롤 플레인, 머신 관리 API 및 클러스터 상태에 기여하는 기타 구성 요소를 시각화할 수 있습니다.
독립 실행형 모델이 제대로 작동하지만 일부 상황에서는 컨트롤 플레인 및 데이터 플레인이 분리되는 아키텍처가 필요합니다. 이러한 경우 데이터 플레인은 전용 물리적 호스팅 환경을 사용하는 별도의 네트워크 도메인에 있습니다. 컨트롤 플레인은 Kubernetes의 네이티브 배포 및 상태 저장 세트와 같은 고급 프리미티브를 사용하여 호스팅됩니다. 컨트롤 플레인은 다른 워크로드로 처리됩니다.
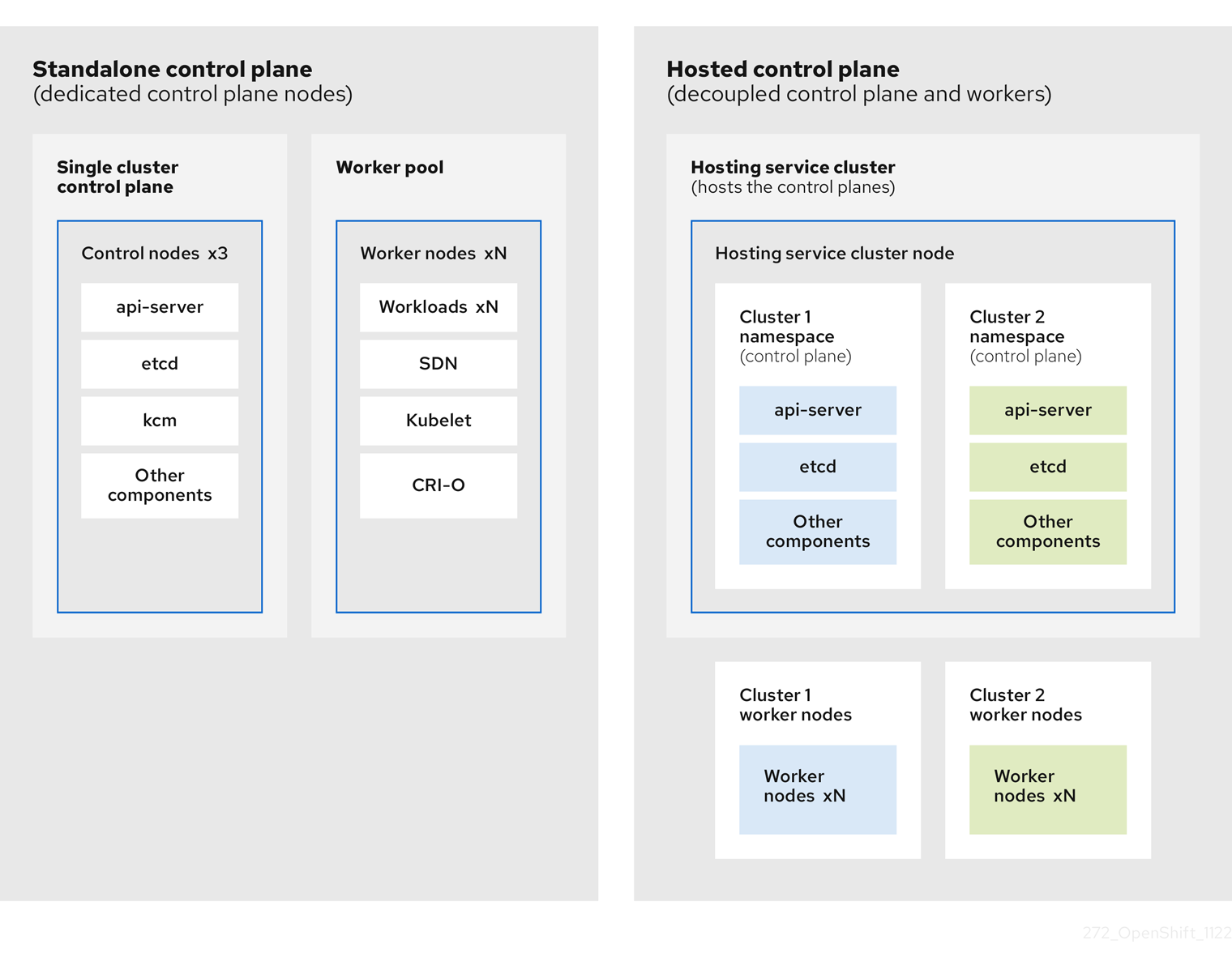
1.2.2. 호스팅된 컨트롤 플레인의 장점
OpenShift Container Platform의 호스팅된 컨트롤 플레인을 사용하면 진정한 하이브리드 클라우드 접근 방식을 구축하고 다른 여러 가지 이점을 누릴 수 있습니다.
- 컨트롤 플레인이 분리되고 전용 호스팅 서비스 클러스터에서 호스팅되므로 관리와 워크로드 간의 보안 경계가 더욱 강화됩니다. 결과적으로 클러스터의 인증 정보를 다른 사용자에게 유출될 가능성이 줄어듭니다. 인프라 시크릿 계정 관리도 분리되므로 클러스터 인프라 관리자는 실수로 컨트롤 플레인 인프라를 삭제할 수 없습니다.
- 호스팅된 컨트롤 플레인을 사용하면 더 적은 수의 노드에서 많은 컨트롤 플레인을 실행할 수 있습니다. 이로 인해 클러스터 비용이 더 경제적이 됩니다.
- 컨트롤 플레인은 OpenShift Container Platform에서 시작되는 Pod로 구성되므로 컨트롤 플레인이 빠르게 시작됩니다. 모니터링, 로깅, 자동 확장과 같은 컨트롤 플레인 및 워크로드에 동일한 원칙이 적용됩니다.
- 인프라 화면에서 레지스트리, HAProxy, 클러스터 모니터링, 스토리지 노드 및 기타 인프라 구성 요소를 테넌트의 클라우드 공급자 계정으로 푸시하여 테넌트에서 사용을 분리할 수 있습니다.
- 운영 화면에서 다중 클러스터 관리는 더 중앙 집중화되어 클러스터 상태 및 일관성에 영향을 미치는 외부 요인이 줄어듭니다. 사이트 안정성 엔지니어는 문제를 디버그하고 클러스터 데이터 플레인으로 이동하여 문제 해결 시간 (TTR: Time to Resolution)이 단축되고 생산성 향상으로 이어질 수 있습니다.
1.3. 호스팅된 컨트롤 플레인과 OpenShift Container Platform의 차이점
호스팅된 컨트롤 플레인은 OpenShift Container Platform의 폼 요소입니다. 호스팅된 클러스터와 독립형 OpenShift Container Platform 클러스터는 다르게 구성 및 관리됩니다. OpenShift Container Platform과 호스팅된 컨트롤 플레인의 차이점을 알아보려면 다음 표를 참조하십시오.
1.3.1. 클러스터 생성 및 라이프사이클
| OpenShift Container Platform | 호스팅된 컨트롤 플레인 |
|---|---|
|
|
기존 OpenShift Container Platform 클러스터에서 |
1.3.2. 클러스터 구성
| OpenShift Container Platform | 호스팅된 컨트롤 플레인 |
|---|---|
|
|
|
1.3.3. etcd 암호화
| OpenShift Container Platform | 호스팅된 컨트롤 플레인 |
|---|---|
|
AES-GCM 또는 AES-CBC와 함께 |
Amazon Web Services의 AES-CBC 또는 KMS와 함께 |
1.3.4. Operator 및 컨트롤 플레인
| OpenShift Container Platform | 호스팅된 컨트롤 플레인 |
|---|---|
| 독립 실행형 OpenShift Container Platform 클러스터에는 각 컨트롤 플레인 구성 요소에 대한 별도의 Operator가 포함되어 있습니다. | 호스팅된 클러스터에는 관리 클러스터의 호스팅된 컨트롤 플레인 네임스페이스에서 실행되는 컨트롤 플레인 Operator라는 단일 Operator가 포함되어 있습니다. |
| etcd는 컨트롤 플레인 노드에 마운트된 스토리지를 사용합니다. etcd 클러스터 Operator는 etcd를 관리합니다. | etcd는 스토리지에 영구 볼륨 클레임을 사용하며 Control Plane Operator에서 관리합니다. |
| Ingress Operator, 네트워크 관련 Operator 및 OLM(Operator Lifecycle Manager)은 클러스터에서 실행됩니다. | Ingress Operator, 네트워크 관련 Operator 및 OLM(Operator Lifecycle Manager)은 관리 클러스터의 호스팅된 컨트롤 플레인 네임스페이스에서 실행됩니다. |
| OAuth 서버는 클러스터 내에서 실행되며 클러스터의 경로를 통해 노출됩니다. | OAuth 서버는 컨트롤 플레인 내부에서 실행되며 관리 클러스터의 경로, 노드 포트 또는 로드 밸런서를 통해 노출됩니다. |
1.3.5. 업데이트
| OpenShift Container Platform | 호스팅된 컨트롤 플레인 |
|---|---|
|
CVO(Cluster Version Operator)는 업데이트 프로세스를 오케스트레이션하고 |
호스팅된 컨트롤 플레인 업데이트로 인해 |
| OpenShift Container Platform 클러스터를 업데이트하면 컨트롤 플레인 및 컴퓨팅 머신이 모두 업데이트됩니다. | 호스팅 클러스터를 업데이트한 후 컨트롤 플레인만 업데이트됩니다. 노드 풀 업데이트를 별도로 수행합니다. |
1.3.6. 머신 구성 및 관리
| OpenShift Container Platform | 호스팅된 컨트롤 플레인 |
|---|---|
|
|
|
| 컨트롤 플레인 시스템 세트를 사용할 수 있습니다. | 컨트롤 플레인 시스템 세트가 없습니다. |
|
|
|
|
|
|
| 머신 및 머신 세트는 클러스터에 노출됩니다. | 업스트림 Cluster CAPI Operator의 머신, 머신 세트 및 머신 배포는 머신을 관리하는 데 사용되지만 사용자에게 노출되지 않습니다. |
| 클러스터를 업데이트할 때 모든 머신 세트가 자동으로 업그레이드됩니다. | 호스트된 클러스터 업데이트와 독립적으로 노드 풀을 업데이트합니다. |
| 클러스터에서 인플레이스 업그레이드만 지원됩니다. | 호스팅된 클러스터에서 교체 및 인플레이스 업그레이드가 모두 지원됩니다. |
| Machine Config Operator는 머신 구성을 관리합니다. | Machine Config Operator는 호스팅된 컨트롤 플레인에 존재하지 않습니다. |
|
|
|
| MCP(Machine Config Daemon)는 각 노드의 구성 변경 및 업데이트를 관리합니다. | 인플레이스 업그레이드의 경우 노드 풀 컨트롤러는 구성에 따라 머신을 업데이트하는 런타임 Pod를 생성합니다. |
| SR-IOV Operator와 같은 머신 구성 리소스를 수정할 수 있습니다. | 머신 구성 리소스를 수정할 수 없습니다. |
1.3.7. 네트워킹
| OpenShift Container Platform | 호스팅된 컨트롤 플레인 |
|---|---|
| Kube API 서버와 노드가 동일한 VPC(Virtual Private Cloud)에 있으므로 Kube API 서버는 노드와 직접 통신합니다. | Kube API 서버는 Konnectivity를 통해 노드와 통신합니다. Kube API 서버 및 노드는 다른 VPC(Virtual Private Cloud)에 있습니다. |
| 노드는 내부 로드 밸런서를 통해 Kube API 서버와 통신합니다. | 노드는 외부 로드 밸런서 또는 노드 포트를 통해 Kube API 서버와 통신합니다. |
1.3.8. 웹 콘솔
| OpenShift Container Platform | 호스팅된 컨트롤 플레인 |
|---|---|
| 웹 콘솔에는 컨트롤 플레인의 상태가 표시됩니다. | 웹 콘솔에 컨트롤 플레인의 상태가 표시되지 않습니다. |
| 웹 콘솔을 사용하여 클러스터를 업데이트할 수 있습니다. | 웹 콘솔을 사용하여 호스팅된 클러스터를 업데이트할 수 없습니다. |
| 웹 콘솔에는 시스템과 같은 인프라 리소스가 표시됩니다. | 웹 콘솔에 인프라 리소스가 표시되지 않습니다. |
|
웹 콘솔을 사용하여 | 웹 콘솔을 사용하여 머신을 구성할 수 없습니다. |
1.4. 호스팅된 컨트롤 플레인, 다중 클러스터 엔진 Operator 및 RHACM 간의 관계
Kubernetes Operator에 다중 클러스터 엔진을 사용하여 호스팅되는 컨트롤 플레인을 구성할 수 있습니다. 다중 클러스터 엔진은 RHACM(Red Hat Advanced Cluster Management)의 통합 부분이며 RHACM을 통해 기본적으로 활성화됩니다. 멀티 클러스터 엔진 Operator 클러스터 라이프사이클은 다양한 인프라 클라우드 공급자, 프라이빗 클라우드 및 온프레미스 데이터 센터에서 Kubernetes 클러스터를 생성, 가져오기, 관리 및 제거하는 프로세스를 정의합니다.
다중 클러스터 엔진 Operator는 OpenShift Container Platform 및 RHACM 허브 클러스터에 대한 클러스터 관리 기능을 제공하는 클러스터 라이프사이클 Operator입니다. 멀티 클러스터 엔진 Operator는 클러스터 플릿 관리를 개선하고 클라우드 및 데이터 센터 전체에서 OpenShift Container Platform 클러스터 라이프사이클 관리를 지원합니다.
그림 1.1. 클러스터 라이프사이클 및 기반
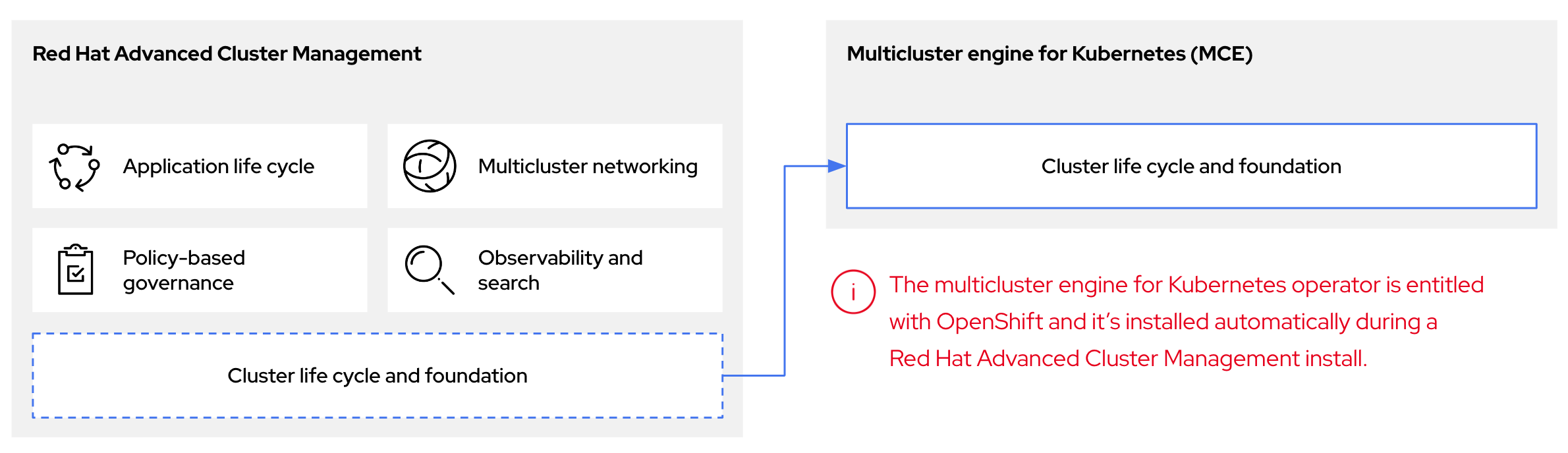
OpenShift Container Platform에서 다중 클러스터 엔진 Operator를 독립 실행형 클러스터 관리자 또는 RHACM 허브 클러스터의 일부로 사용할 수 있습니다.
관리 클러스터를 호스팅 클러스터라고도 합니다.
독립 실행형 또는 호스팅된 컨트롤 플레인 구성의 두 가지 다른 컨트롤 플레인 구성을 사용하여 OpenShift Container Platform 클러스터를 배포할 수 있습니다. 독립 실행형 구성은 전용 가상 머신 또는 물리적 시스템을 사용하여 컨트롤 플레인을 호스팅합니다. OpenShift Container Platform의 호스팅된 컨트롤 플레인을 사용하면 각 컨트롤 플레인의 전용 가상 또는 물리적 머신 없이도 관리 클러스터에서 컨트롤 플레인을 Pod로 생성합니다.
그림 1.2. RHACM 및 다중 클러스터 엔진 Operator 소개 다이어그램
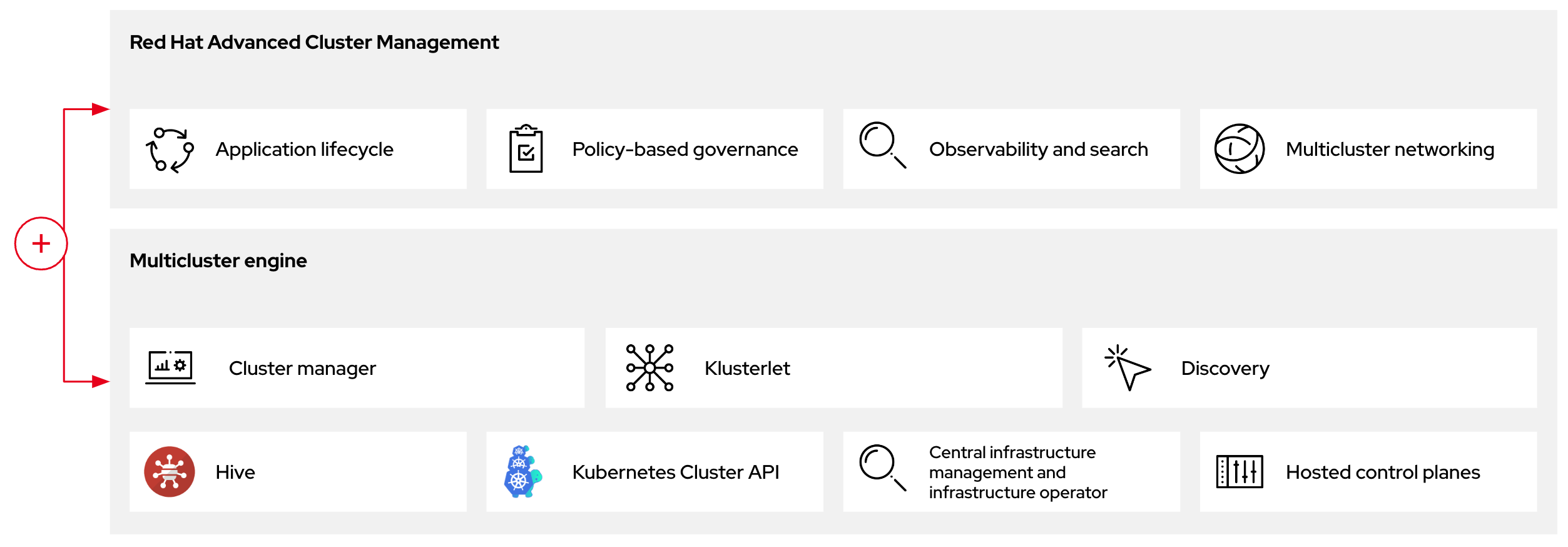
1.5. 호스팅된 컨트롤 플레인 버전 관리
OpenShift Container Platform의 각 메이저, 마이너 또는 패치 버전 릴리스에서 호스팅되는 컨트롤 플레인의 두 가지 구성 요소가 릴리스됩니다.
- HyperShift Operator
-
hcp명령줄 인터페이스(CLI)
HyperShift Operator는 HostedCluster API 리소스로 표시되는 호스팅 클러스터의 라이프사이클을 관리합니다. HyperShift Operator는 각 OpenShift Container Platform 릴리스와 함께 릴리스됩니다. HyperShift Operator는 hypershift 네임스페이스에 supported-versions 구성 맵을 생성합니다. 구성 맵에는 지원되는 호스팅 클러스터 버전이 포함되어 있습니다.
동일한 관리 클러스터에서 다른 버전의 컨트롤 플레인을 호스팅할 수 있습니다.
supported-versions 구성 맵 오브젝트의 예
apiVersion: v1
data:
supported-versions: '{"versions":["4.16"]}'
kind: ConfigMap
metadata:
labels:
hypershift.openshift.io/supported-versions: "true"
name: supported-versions
namespace: hypershift
hcp CLI를 사용하여 호스트된 클러스터를 생성할 수 있습니다.
HostedCluster 및 NodePool 과 같은 hypershift.openshift.io API 리소스를 사용하여 대규모로 OpenShift Container Platform 클러스터를 생성하고 관리할 수 있습니다. HostedCluster 리소스에는 컨트롤 플레인 및 일반 데이터 플레인 구성이 포함되어 있습니다. HostedCluster 리소스를 생성할 때 연결된 노드가 없는 완전히 작동하는 컨트롤 플레인이 있습니다. NodePool 리소스는 HostedCluster 리소스에 연결된 확장 가능한 작업자 노드 집합입니다.
API 버전 정책은 일반적으로 Kubernetes API 버전 관리 정책과 일치합니다.
2장. 호스트된 컨트롤 플레인 시작하기
OpenShift Container Platform의 호스팅된 컨트롤 플레인을 시작하려면 먼저 사용하려는 공급자에서 호스팅된 클러스터를 구성합니다. 그런 다음 몇 가지 관리 작업을 완료합니다.
다음 공급자 중 하나에서 선택하여 절차를 볼 수 있습니다.
2.1. 베어 메탈
- 호스팅된 컨트롤 플레인 크기 조정 지침
- 호스팅된 컨트롤 플레인 명령줄 인터페이스 설치
- 호스트된 클러스터 워크로드 배포
- 베어 메탈 방화벽 및 포트 요구 사항
- 베어 메탈 인프라 요구 사항: 베어 메탈에서 호스팅된 클러스터를 생성하기 위해 인프라 요구 사항을 검토합니다.
- DNS 구성
- 호스트된 클러스터 생성 및 클러스터 생성 확인
-
호스트 클러스터의
NodePool오브젝트를 스케일링 - 호스트 클러스터의 수신 트래픽 처리
- 호스트 클러스터의 노드 자동 확장 활성화
- 연결이 끊긴 환경에서 호스트된 컨트롤 플레인 구성
- 베어 메탈에서 호스트된 클러스터를 삭제하려면 베어 메탈의 호스트 클러스터 삭제 의 지침을 따르십시오.
- 호스팅된 컨트롤 플레인 기능을 비활성화하려면 호스팅된 컨트롤 플레인 기능 비활성화를 참조하십시오.
2.2. OpenShift Virtualization
- 호스팅된 컨트롤 플레인 크기 조정 지침
- 호스팅된 컨트롤 플레인 명령줄 인터페이스 설치
- 호스트된 클러스터 워크로드 배포
- OpenShift Virtualization에서 호스트된 컨트롤 플레인 클러스터 관리: KubeVirt 가상 머신에서 호스팅하는 작업자 노드로 OpenShift Container Platform 클러스터를 생성합니다.
- 연결이 끊긴 환경에서 호스트된 컨트롤 플레인 구성
- 호스트 클러스터를 삭제하려면 OpenShift Virtualization에서 호스트된 클러스터 삭제 의 지침을 따르십시오.
- 호스팅된 컨트롤 플레인 기능을 비활성화하려면 호스팅된 컨트롤 플레인 기능 비활성화를 참조하십시오.
2.3. AWS(Amazon Web Services)
- AWS 인프라 요구 사항: AWS에서 호스팅 클러스터를 생성하기 위해 인프라 요구 사항을 검토합니다.
- AWS 에서 호스팅된 컨트롤 플레인 클러스터 구성: AWS S3 OIDC 시크릿 생성, 라우팅 가능한 퍼블릭 영역 생성, 외부 DNS 활성화, AWS PrivateLink 활성화 및 호스팅된 클러스터 배포가 포함됩니다.
- 호스팅 된 컨트롤 플레인을 위해 SR-IOV Operator 배포: 호스팅 서비스 클러스터를 구성하고 배포한 후 호스팅된 클러스터에서 SR-IOV(Single Root I/O Virtualization) Operator에 대한 서브스크립션을 생성할 수 있습니다. SR-IOV Pod는 컨트롤 플레인이 아닌 작업자 머신에서 실행됩니다.
- AWS에서 호스트된 클러스터를 삭제하려면 AWS의 호스트 클러스터 삭제 의 지침을 따르십시오.
- 호스팅된 컨트롤 플레인 기능을 비활성화하려면 호스팅된 컨트롤 플레인 기능 비활성화를 참조하십시오.
2.4. IBM Z
IBM Z 플랫폼의 호스팅 컨트롤 플레인은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 다음 링크를 참조하십시오.
2.5. IBM Power
IBM Power 플랫폼의 호스팅 컨트롤 플레인은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 다음 링크를 참조하십시오.
2.6. 베어 메탈 에이전트 머신
베어 메탈이 아닌 에이전트 시스템을 사용하는 호스팅된 컨트롤 플레인 클러스터는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 다음 링크를 참조하십시오.
- 호스팅된 컨트롤 플레인 명령줄 인터페이스 설치
- 베어 메탈이 아닌 에이전트를 사용하여 호스팅되는 컨트롤 플레인 클러스터 구성 (기술 프리뷰)
- 베어 메탈이 아닌 에이전트 머신에서 호스팅된 클러스터를 제거하려면 베어 메탈이 아닌 에이전트 머신의 호스트 클러스터 삭제지침을 따르십시오.
- 호스팅된 컨트롤 플레인 기능을 비활성화하려면 호스팅된 컨트롤 플레인 기능 비활성화를 참조하십시오.
3장. 호스팅된 컨트롤 플레인에 대한 인증 및 권한 부여
OpenShift Container Platform 컨트롤 플레인에는 내장 OAuth 서버가 포함되어 있습니다. OpenShift Container Platform API에 인증하기 위해 OAuth 액세스 토큰을 가져올 수 있습니다. 호스팅 클러스터를 생성한 후 ID 공급자를 지정하여 OAuth를 구성할 수 있습니다.
3.1. CLI를 사용하여 호스팅된 클러스터에 대한 OAuth 서버 구성
OpenID Connect ID 공급자(oidc)를 사용하여 호스팅된 클러스터에 대한 내부 OAuth 서버를 구성할 수 있습니다.
지원되는 ID 공급자에 대해 OAuth를 구성할 수 있습니다.
-
oidc -
htpasswd -
Keystone -
ldap -
basic-authentication -
request-header -
github -
gitlab -
google
OAuth 구성에서 ID 공급자를 추가하면 기본 kubeadmin 사용자 공급자가 제거됩니다.
ID 공급자를 구성할 때 먼저 호스팅 클러스터에서 하나 이상의 NodePool 복제본을 구성해야 합니다. DNS 확인을 위한 트래픽은 작업자 노드를 통해 전송됩니다. htpasswd 및 request-header ID 공급자에 대해 NodePool 복제본을 사전에 구성할 필요가 없습니다.
사전 요구 사항
- 호스팅된 클러스터를 생성하셨습니다.
프로세스
다음 명령을 실행하여 호스팅 클러스터에서
HostedClusterCR(사용자 정의 리소스)을 편집합니다.$ oc edit hostedcluster <hosted_cluster_name> -n <hosted_cluster_namespace>다음 예제를 사용하여
HostedClusterCR에 OAuth 구성을 추가합니다.apiVersion: hypershift.openshift.io/v1alpha1 kind: HostedCluster metadata: name: <hosted_cluster_name>1 namespace: <hosted_cluster_namespace>2 spec: configuration: oauth: identityProviders: - openID:3 claims: email:4 - <email_address> name:5 - <display_name> preferredUsername:6 - <preferred_username> clientID: <client_id>7 clientSecret: name: <client_id_secret_name>8 issuer: https://example.com/identity9 mappingMethod: lookup10 name: IAM type: OpenID- 1
- 호스팅된 클러스터 이름을 지정합니다.
- 2
- 호스팅된 클러스터 네임스페이스를 지정합니다.
- 3
- 이 공급자 이름은 ID 클레임 값 앞에 접두어로 지정되어 ID 이름을 형성합니다. 공급자 이름은 리디렉션 URL을 빌드하는 데도 사용됩니다.
- 4
- 이메일 주소로 사용할 속성 목록을 정의합니다.
- 5
- 표시 이름으로 사용할 속성 목록을 정의합니다.
- 6
- 기본 사용자 이름으로 사용할 속성 목록을 정의합니다.
- 7
- OpenID 공급자에 등록된 클라이언트의 ID를 정의합니다. 클라이언트가
https://oauth-openshift.apps.<cluster_name>.<cluster_domain>/oauth2callback/<idp_provider_name> URL로 리디렉션되도록 허용해야 합니다. - 8
- OpenID 공급자에 등록된 클라이언트의 시크릿을 정의합니다.
- 9
- OpenID 사양에 설명된 Issuer Identifier 입니다. 쿼리 또는 조각 구성 요소 없이
https를 사용해야 합니다. - 10
- 이 공급자와
User오브젝트의 ID 간에 매핑이 설정되는 방법을 제어하는 매핑 방법을 정의합니다.
- 파일을 저장하여 변경 사항을 적용합니다.
3.2. 웹 콘솔을 사용하여 호스트 클러스터의 OAuth 서버 구성
OpenShift Container Platform 웹 콘솔을 사용하여 호스팅된 클러스터에 대한 내부 OAuth 서버를 구성할 수 있습니다.
지원되는 ID 공급자에 대해 OAuth를 구성할 수 있습니다.
-
oidc -
htpasswd -
Keystone -
ldap -
basic-authentication -
request-header -
github -
gitlab -
google
OAuth 구성에서 ID 공급자를 추가하면 기본 kubeadmin 사용자 공급자가 제거됩니다.
ID 공급자를 구성할 때 먼저 호스팅 클러스터에서 하나 이상의 NodePool 복제본을 구성해야 합니다. DNS 확인을 위한 트래픽은 작업자 노드를 통해 전송됩니다. htpasswd 및 request-header ID 공급자에 대해 NodePool 복제본을 사전에 구성할 필요가 없습니다.
사전 요구 사항
-
cluster-admin권한이 있는 사용자로 로그인했습니다. - 호스팅된 클러스터를 생성하셨습니다.
프로세스
- 홈 → API Explorer 로 이동합니다.
-
Filter by kind 상자를 사용하여
HostedCluster리소스를 검색합니다. -
편집하려는
HostedCluster리소스를 클릭합니다. - Instances 탭을 클릭합니다.
-
호스팅된 클러스터 이름 항목 옆에 있는 옵션 메뉴
 를 클릭하고 호스트 클러스터 편집을 클릭합니다.
를 클릭하고 호스트 클러스터 편집을 클릭합니다.
YAML 파일에 OAuth 구성을 추가합니다.
spec: configuration: oauth: identityProviders: - openID:1 claims: email:2 - <email_address> name:3 - <display_name> preferredUsername:4 - <preferred_username> clientID: <client_id>5 clientSecret: name: <client_id_secret_name>6 issuer: https://example.com/identity7 mappingMethod: lookup8 name: IAM type: OpenID- 1
- 이 공급자 이름은 ID 클레임 값 앞에 접두어로 지정되어 ID 이름을 형성합니다. 공급자 이름은 리디렉션 URL을 빌드하는 데도 사용됩니다.
- 2
- 이메일 주소로 사용할 속성 목록을 정의합니다.
- 3
- 표시 이름으로 사용할 속성 목록을 정의합니다.
- 4
- 기본 사용자 이름으로 사용할 속성 목록을 정의합니다.
- 5
- OpenID 공급자에 등록된 클라이언트의 ID를 정의합니다. 클라이언트가
https://oauth-openshift.apps.<cluster_name>.<cluster_domain>/oauth2callback/<idp_provider_name> URL로 리디렉션되도록 허용해야 합니다. - 6
- OpenID 공급자에 등록된 클라이언트의 시크릿을 정의합니다.
- 7
- OpenID 사양에 설명된 Issuer Identifier 입니다. 쿼리 또는 조각 구성 요소 없이
https를 사용해야 합니다. - 8
- 이 공급자와
User오브젝트의 ID 간에 매핑이 설정되는 방법을 제어하는 매핑 방법을 정의합니다.
- 저장을 클릭합니다.
3.3. AWS의 호스팅된 클러스터에서 CCO를 사용하여 구성 요소 IAM 역할 할당
AWS(Amazon Web Services)의 호스팅된 클러스터에서 CCO(Cloud Credential Operator)를 사용하여 단기적이고 제한된 권한 보안 인증 정보를 제공하는 IAM 역할을 할당할 수 있습니다. 기본적으로 CCO는 호스팅된 컨트롤 플레인에서 실행됩니다.
CCO는 AWS의 호스팅된 클러스터에 대해서만 수동 모드를 지원합니다. 기본적으로 호스팅 클러스터는 수동 모드로 구성됩니다. 관리 클러스터는 수동 이외의 모드를 사용할 수 있습니다.
3.4. AWS의 호스트 클러스터에서 CCO 설치 확인
호스팅된 컨트롤 플레인에서 CCO(Cloud Credential Operator)가 올바르게 실행되고 있는지 확인할 수 있습니다.
사전 요구 사항
- AWS(Amazon Web Services)에서 호스팅된 클러스터를 구성했습니다.
프로세스
다음 명령을 실행하여 CCO가 호스팅 클러스터의 수동 모드로 구성되었는지 확인합니다.
$ oc get cloudcredentials <hosted_cluster_name> -n <hosted_cluster_namespace> -o=jsonpath={.spec.credentialsMode}예상 출력
Manual다음 명령을 실행하여
serviceAccountIssuer리소스의 값이 비어 있지 않은지 확인합니다.$ oc get authentication cluster --kubeconfig <hosted_cluster_name>.kubeconfig -o jsonpath --template '{.spec.serviceAccountIssuer }'출력 예
https://aos-hypershift-ci-oidc-29999.s3.us-east-2.amazonaws.com/hypershift-ci-29999
3.5. Operator가 AWS STS를 사용하여 CCO 기반 워크플로우를 지원하도록 활성화
OLM(Operator Lifecycle Manager)에서 프로젝트를 실행하도록 프로젝트를 설계하는 Operator 작성자는 CCO(Cloud Credential Operator)를 지원하도록 프로젝트를 사용자 정의하여 Operator를 STS 사용 OpenShift Container Platform 클러스터에서 AWS에 대해 인증할 수 있습니다.
이 방법을 사용하면 Operator에서 CredentialsRequest 오브젝트를 생성합니다. 즉 Operator에 이러한 오브젝트를 생성하려면 RBAC 권한이 필요합니다. 그런 다음 Operator에서 결과 Secret 오브젝트를 읽을 수 있어야 합니다.
기본적으로 Operator 배포와 관련된 Pod는 serviceAccountToken 볼륨을 마운트하여 결과 Secret 오브젝트에서 서비스 계정 토큰을 참조할 수 있습니다.
전제 조건
- OpenShift Container Platform 4.14 이상
- STS 모드의 클러스터
- OLM 기반 Operator 프로젝트
프로세스
Operator 프로젝트의 CSV(
ClusterServiceVersion) 오브젝트를 업데이트합니다.Operator에
CredentialsRequests오브젝트를 생성할 수 있는 RBAC 권한이 있는지 확인합니다.예 3.1.
clusterPermissions목록의 예# ... install: spec: clusterPermissions: - rules: - apiGroups: - "cloudcredential.openshift.io" resources: - credentialsrequests verbs: - create - delete - get - list - patch - update - watchAWS STS를 사용하여 이 CCO 기반 워크플로우 방법에 대한 지원을 클레임하려면 다음 주석을 추가합니다.
# ... metadata: annotations: features.operators.openshift.io/token-auth-aws: "true"
Operator 프로젝트 코드를 업데이트합니다.
Subscription오브젝트를 통해 Pod에 설정된 환경 변수에서 ARN 역할을 가져옵니다. 예를 들면 다음과 같습니다.// Get ENV var roleARN := os.Getenv("ROLEARN") setupLog.Info("getting role ARN", "role ARN = ", roleARN) webIdentityTokenPath := "/var/run/secrets/openshift/serviceaccount/token"CredentialsRequest개체를 패치하고 적용할 준비가 되었는지 확인합니다. 예를 들면 다음과 같습니다.예 3.2.
CredentialsRequest오브젝트 생성 예import ( minterv1 "github.com/openshift/cloud-credential-operator/pkg/apis/cloudcredential/v1" corev1 "k8s.io/api/core/v1" metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" ) var in = minterv1.AWSProviderSpec{ StatementEntries: []minterv1.StatementEntry{ { Action: []string{ "s3:*", }, Effect: "Allow", Resource: "arn:aws:s3:*:*:*", }, }, STSIAMRoleARN: "<role_arn>", } var codec = minterv1.Codec var ProviderSpec, _ = codec.EncodeProviderSpec(in.DeepCopyObject()) const ( name = "<credential_request_name>" namespace = "<namespace_name>" ) var CredentialsRequestTemplate = &minterv1.CredentialsRequest{ ObjectMeta: metav1.ObjectMeta{ Name: name, Namespace: "openshift-cloud-credential-operator", }, Spec: minterv1.CredentialsRequestSpec{ ProviderSpec: ProviderSpec, SecretRef: corev1.ObjectReference{ Name: "<secret_name>", Namespace: namespace, }, ServiceAccountNames: []string{ "<service_account_name>", }, CloudTokenPath: "", }, }또는 YAML 형식의
CredentialsRequest오브젝트(예: Operator 프로젝트 코드의 일부)에서 시작하는 경우 다르게 처리할 수 있습니다.예 3.3. YAML 형식의
CredentialsRequest오브젝트 생성 예// CredentialsRequest is a struct that represents a request for credentials type CredentialsRequest struct { APIVersion string `yaml:"apiVersion"` Kind string `yaml:"kind"` Metadata struct { Name string `yaml:"name"` Namespace string `yaml:"namespace"` } `yaml:"metadata"` Spec struct { SecretRef struct { Name string `yaml:"name"` Namespace string `yaml:"namespace"` } `yaml:"secretRef"` ProviderSpec struct { APIVersion string `yaml:"apiVersion"` Kind string `yaml:"kind"` StatementEntries []struct { Effect string `yaml:"effect"` Action []string `yaml:"action"` Resource string `yaml:"resource"` } `yaml:"statementEntries"` STSIAMRoleARN string `yaml:"stsIAMRoleARN"` } `yaml:"providerSpec"` // added new field CloudTokenPath string `yaml:"cloudTokenPath"` } `yaml:"spec"` } // ConsumeCredsRequestAddingTokenInfo is a function that takes a YAML filename and two strings as arguments // It unmarshals the YAML file to a CredentialsRequest object and adds the token information. func ConsumeCredsRequestAddingTokenInfo(fileName, tokenString, tokenPath string) (*CredentialsRequest, error) { // open a file containing YAML form of a CredentialsRequest file, err := os.Open(fileName) if err != nil { return nil, err } defer file.Close() // create a new CredentialsRequest object cr := &CredentialsRequest{} // decode the yaml file to the object decoder := yaml.NewDecoder(file) err = decoder.Decode(cr) if err != nil { return nil, err } // assign the string to the existing field in the object cr.Spec.CloudTokenPath = tokenPath // return the modified object return cr, nil }참고Operator 번들에
CredentialsRequest오브젝트를 추가하는 것은 현재 지원되지 않습니다.인증 정보 요청에 ARN 및 웹 ID 토큰 경로를 추가하고 Operator 초기화 중에 적용합니다.
예 3.4. Operator 초기화 중
CredentialsRequest오브젝트 적용 예// apply credentialsRequest on install credReq := credreq.CredentialsRequestTemplate credReq.Spec.CloudTokenPath = webIdentityTokenPath c := mgr.GetClient() if err := c.Create(context.TODO(), credReq); err != nil { if !errors.IsAlreadyExists(err) { setupLog.Error(err, "unable to create CredRequest") os.Exit(1) } }Operator에서 조정 중인 다른 항목과 함께 호출되는 다음 예와 같이 Operator가 CCO에서
Secret오브젝트가 표시될 때까지 기다릴 수 있습니다.예 3.5.
Secret오브젝트 대기의 예// WaitForSecret is a function that takes a Kubernetes client, a namespace, and a v1 "k8s.io/api/core/v1" name as arguments // It waits until the secret object with the given name exists in the given namespace // It returns the secret object or an error if the timeout is exceeded func WaitForSecret(client kubernetes.Interface, namespace, name string) (*v1.Secret, error) { // set a timeout of 10 minutes timeout := time.After(10 * time.Minute)1 // set a polling interval of 10 seconds ticker := time.NewTicker(10 * time.Second) // loop until the timeout or the secret is found for { select { case <-timeout: // timeout is exceeded, return an error return nil, fmt.Errorf("timed out waiting for secret %s in namespace %s", name, namespace) // add to this error with a pointer to instructions for following a manual path to a Secret that will work on STS case <-ticker.C: // polling interval is reached, try to get the secret secret, err := client.CoreV1().Secrets(namespace).Get(context.Background(), name, metav1.GetOptions{}) if err != nil { if errors.IsNotFound(err) { // secret does not exist yet, continue waiting continue } else { // some other error occurred, return it return nil, err } } else { // secret is found, return it return secret, nil } } } }- 1
시간 초과값은 CCO에서 추가된CredentialsRequest오브젝트를 감지하고Secret오브젝트를 생성하는 속도의 추정치를 기반으로 합니다. Operator가 아직 클라우드 리소스에 액세스하지 않는 이유를 확인할 수 있는 클러스터 관리자에게 시간을 낮추거나 사용자 정의 피드백을 생성하는 것을 고려할 수 있습니다.
인증 정보 요청에서 CCO에서 생성한 보안을 읽고 해당 시크릿의 데이터가 포함된 AWS 구성 파일을 생성하여 AWS 구성을 설정합니다.
예 3.6. AWS 구성 생성 예
func SharedCredentialsFileFromSecret(secret *corev1.Secret) (string, error) { var data []byte switch { case len(secret.Data["credentials"]) > 0: data = secret.Data["credentials"] default: return "", errors.New("invalid secret for aws credentials") } f, err := ioutil.TempFile("", "aws-shared-credentials") if err != nil { return "", errors.Wrap(err, "failed to create file for shared credentials") } defer f.Close() if _, err := f.Write(data); err != nil { return "", errors.Wrapf(err, "failed to write credentials to %s", f.Name()) } return f.Name(), nil }중요시크릿은 존재하는 것으로 가정되지만 Operator 코드는 이 시크릿을 사용할 때 대기하고 재시도하여 CCO에 시간을 할애하여 보안을 생성해야 합니다.
또한 대기 기간은 결국 OpenShift Container Platform 클러스터 버전 및 CCO가 STS 탐지를 사용하여
CredentialsRequest오브젝트 워크플로를 지원하지 않는 이전 버전일 수 있음을 사용자에게 시간 초과하고 경고해야 합니다. 이러한 경우 다른 방법을 사용하여 시크릿을 추가해야 함을 사용자에게 지시합니다.AWS SDK 세션을 구성합니다. 예를 들면 다음과 같습니다.
예 3.7. AWS SDK 세션 구성 예
sharedCredentialsFile, err := SharedCredentialsFileFromSecret(secret) if err != nil { // handle error } options := session.Options{ SharedConfigState: session.SharedConfigEnable, SharedConfigFiles: []string{sharedCredentialsFile}, }
4장. 호스트된 컨트롤 플레인의 머신 구성 처리
독립 실행형 OpenShift Container Platform 클러스터에서 머신 구성 풀은 노드 세트를 관리합니다. MachineConfigPool CR(사용자 정의 리소스)을 사용하여 머신 구성을 처리할 수 있습니다.
NodePool CR의 nodepool.spec.config 필드에서 machineconfiguration.openshift.io 리소스를 참조할 수 있습니다.
호스팅된 컨트롤 플레인에서는 MachineConfigPool CR이 존재하지 않습니다. 노드 풀에는 컴퓨팅 노드 세트가 포함되어 있습니다. 노드 풀을 사용하여 머신 구성을 처리할 수 있습니다.
4.1. 호스팅된 컨트롤 플레인의 노드 풀 구성
호스팅된 컨트롤 플레인에서는 관리 클러스터의 구성 맵 내에 MachineConfig 오브젝트를 생성하여 노드 풀을 구성할 수 있습니다.
절차
관리 클러스터의 구성 맵 내에
MachineConfig오브젝트를 생성하려면 다음 정보를 입력합니다.apiVersion: v1 kind: ConfigMap metadata: name: <configmap_name> namespace: clusters data: config: | apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: <machineconfig_name> spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:... mode: 420 overwrite: true path: ${PATH}1 - 1
MachineConfig오브젝트가 저장된 노드의 경로를 설정합니다.
구성 맵에 오브젝트를 추가한 후 다음과 같이 구성 맵을 노드 풀에 적용할 수 있습니다.
$ oc edit nodepool <nodepool_name> --namespace <hosted_cluster_namespace>apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: config: - name: <configmap_name>1 # ...- 1
- &
lt;configmap_name>을 구성 맵 이름으로 바꿉니다.
4.2. 노드 풀의 kubelet 구성 참조
노드 풀에서 kubelet 구성을 참조하려면 구성 맵에 kubelet 구성을 추가한 다음 NodePool 리소스에 구성 맵을 적용합니다.
프로세스
다음 정보를 입력하여 관리 클러스터의 구성 맵 내부에 kubelet 구성을 추가합니다.
kubelet 구성이 있는
ConfigMap오브젝트의 예apiVersion: v1 kind: ConfigMap metadata: name: <configmap_name>1 namespace: clusters data: config: | apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: <kubeletconfig_name>2 spec: kubeletConfig: registerWithTaints: - key: "example.sh/unregistered" value: "true" effect: "NoExecute"다음 명령을 입력하여 노드 풀에 구성 맵을 적용합니다.
$ oc edit nodepool <nodepool_name> --namespace clusters1 - 1
- &
lt;nodepool_name>을 노드 풀 이름으로 바꿉니다.
NodePool리소스 구성의 예apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: config: - name: <configmap_name>1 # ...- 1
- &
lt;configmap_name>을 구성 맵 이름으로 바꿉니다.
4.3. 호스트 클러스터에서 노드 튜닝 구성
호스팅된 클러스터의 노드에 노드 수준 튜닝을 설정하려면 Node Tuning Operator를 사용할 수 있습니다. 호스팅된 컨트롤 플레인에서는 Tuned 오브젝트가 포함된 구성 맵을 생성하고 노드 풀에 해당 구성 맵을 참조하여 노드 튜닝을 구성할 수 있습니다.
절차
유효한 tuned 매니페스트가 포함된 구성 맵을 생성하고 노드 풀에서 매니페스트를 참조합니다. 다음 예에서
Tuned매니페스트는tuned-1-node-label노드 라벨이 임의의 값이 포함된 노드에서vm.dirty_ratio를 55로 설정하는 프로필을 정의합니다.tuned-1.yaml이라는 파일에 다음ConfigMap매니페스트를 저장합니다.apiVersion: v1 kind: ConfigMap metadata: name: tuned-1 namespace: clusters data: tuning: | apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: tuned-1 namespace: openshift-cluster-node-tuning-operator spec: profile: - data: | [main] summary=Custom OpenShift profile include=openshift-node [sysctl] vm.dirty_ratio="55" name: tuned-1-profile recommend: - priority: 20 profile: tuned-1-profile참고Tuned 사양의
spec.recommend섹션에 있는 항목에 라벨을 추가하지 않으면 node-pool 기반 일치로 간주되므로spec.recommend섹션에서 가장 높은 우선 순위 프로필이 풀의 노드에 적용됩니다. Tuned.spec.recommend.match섹션에서 레이블 값을 설정하여 보다 세분화된 노드 레이블 기반 일치를 수행할 수 있지만 노드 레이블은 노드 풀의.spec.management.upgradeType값을InPlace로 설정하지 않는 한 업그레이드 중에 유지되지 않습니다.관리 클러스터에
ConfigMap오브젝트를 생성합니다.$ oc --kubeconfig="$MGMT_KUBECONFIG" create -f tuned-1.yaml노드 풀을 편집하거나 하나를 생성하여 노드 풀의
spec.tuningConfig필드에서ConfigMap오브젝트를 참조합니다. 이 예에서는 2개의 노드가 포함된nodepool-1이라는NodePool이 하나만 있다고 가정합니다.apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: ... name: nodepool-1 namespace: clusters ... spec: ... tuningConfig: - name: tuned-1 status: ...참고여러 노드 풀에서 동일한 구성 맵을 참조할 수 있습니다. 호스팅된 컨트롤 플레인에서 Node Tuning Operator는 노드 풀 이름과 네임스페이스의 해시를 Tuned CR 이름에 추가하여 구별합니다. 이 경우 동일한 호스트 클러스터에 대해 다른 Tuned CR에 동일한 이름의 여러 TuneD 프로필을 생성하지 마십시오.
검증
이제 Tuned 매니페스트가 포함된 ConfigMap 오브젝트를 생성하여 NodePool 에서 참조하므로 Node Tuning Operator가 Tuned 오브젝트를 호스팅된 클러스터에 동기화합니다. 정의된 Tuned 오브젝트와 각 노드에 적용되는 TuneD 프로필을 확인할 수 있습니다.
호스트 클러스터에서
Tuned오브젝트를 나열합니다.$ oc --kubeconfig="$HC_KUBECONFIG" get tuned.tuned.openshift.io -n openshift-cluster-node-tuning-operator출력 예
NAME AGE default 7m36s rendered 7m36s tuned-1 65s호스팅된 클러스터의
Profile오브젝트를 나열합니다.$ oc --kubeconfig="$HC_KUBECONFIG" get profile.tuned.openshift.io -n openshift-cluster-node-tuning-operator출력 예
NAME TUNED APPLIED DEGRADED AGE nodepool-1-worker-1 tuned-1-profile True False 7m43s nodepool-1-worker-2 tuned-1-profile True False 7m14s참고사용자 지정 프로필이 생성되지 않으면 기본적으로
openshift-node프로필이 적용됩니다.튜닝이 올바르게 적용되었는지 확인하려면 노드에서 디버그 쉘을 시작하고 sysctl 값을 확인합니다.
$ oc --kubeconfig="$HC_KUBECONFIG" debug node/nodepool-1-worker-1 -- chroot /host sysctl vm.dirty_ratio출력 예
vm.dirty_ratio = 55
4.4. 호스트된 컨트롤 플레인을 위한 SR-IOV Operator 배포
AWS 플랫폼의 호스팅 컨트롤 플레인은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 다음 링크를 참조하십시오.
호스팅 서비스 클러스터를 구성하고 배포한 후 호스팅된 클러스터에서 SR-IOV Operator에 대한 서브스크립션을 생성할 수 있습니다. SR-IOV Pod는 컨트롤 플레인이 아닌 작업자 머신에서 실행됩니다.
사전 요구 사항
AWS에 호스팅 클러스터를 구성하고 배포해야 합니다. 자세한 내용은 AWS에서 호스팅 클러스터 구성 (기술 프리뷰) 을 참조하십시오.
절차
네임스페이스 및 Operator 그룹을 생성합니다.
apiVersion: v1 kind: Namespace metadata: name: openshift-sriov-network-operator --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: sriov-network-operators namespace: openshift-sriov-network-operator spec: targetNamespaces: - openshift-sriov-network-operatorSR-IOV Operator에 대한 서브스크립션을 생성합니다.
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: sriov-network-operator-subsription namespace: openshift-sriov-network-operator spec: channel: stable name: sriov-network-operator config: nodeSelector: node-role.kubernetes.io/worker: "" source: redhat-operators sourceNamespace: openshift-marketplace
검증
SR-IOV Operator가 준비되었는지 확인하려면 다음 명령을 실행하고 결과 출력을 확인합니다.
$ oc get csv -n openshift-sriov-network-operator출력 예
NAME DISPLAY VERSION REPLACES PHASE sriov-network-operator.4.16.0-202211021237 SR-IOV Network Operator 4.16.0-202211021237 sriov-network-operator.4.16.0-202210290517 SucceededSR-IOV Pod가 배포되었는지 확인하려면 다음 명령을 실행합니다.
$ oc get pods -n openshift-sriov-network-operator
4.5. 호스팅된 클러스터의 NTP 서버 구성
Butane을 사용하여 호스팅된 클러스터에 대한 NTP(Network Time Protocol) 서버를 구성할 수 있습니다.
프로세스
chrony.conf파일의 내용을 포함하는 Butane 구성 파일99-worker-chrony.bu를 만듭니다. Butane에 대한 자세한 내용은 " Butane을 사용하여 머신 구성 생성"을 참조하십시오.99-worker-chrony.bu구성 예# ... variant: openshift version: 4.16.0 metadata: name: 99-worker-chrony labels: machineconfiguration.openshift.io/role: worker storage: files: - path: /etc/chrony.conf mode: 06441 overwrite: true contents: inline: | pool 0.rhel.pool.ntp.org iburst2 driftfile /var/lib/chrony/drift makestep 1.0 3 rtcsync logdir /var/log/chrony # ...참고머신 간 통신의 경우 UDP(User Datagram Protocol) 포트의 NTP는
123입니다. 외부 NTP 시간 서버를 구성한 경우 UDP 포트123을 열어야 합니다.Butane을 사용하여 Butane이 노드에 전송하는 구성이 포함된
MachineConfig파일99-worker-chrony.yaml을 생성합니다. 다음 명령을 실행합니다.$ butane 99-worker-chrony.bu -o 99-worker-chrony.yaml예:
99-worker-chrony.yaml구성# Generated by Butane; do not edit apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: <machineconfig_name> spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:... mode: 420 overwrite: true path: /example/path관리 클러스터의 구성 맵 내에
99-worker-chrony.yaml파일의 내용을 추가합니다.구성 맵 예
apiVersion: v1 kind: ConfigMap metadata: name: <configmap_name> namespace: <namespace>1 data: config: | apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: <machineconfig_name> spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:... mode: 420 overwrite: true path: /example/path # ...- 1
- &
lt;namespace>를클러스터와같이 노드 풀을 생성한 네임스페이스 이름으로 바꿉니다.
다음 명령을 실행하여 노드 풀에 구성 맵을 적용합니다.
$ oc edit nodepool <nodepool_name> --namespace <hosted_cluster_namespace>NodePool구성의 예apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: config: - name: <configmap_name>1 # ...- 1
- &
lt;configmap_name>을 구성 맵 이름으로 바꿉니다.
InfraEnvCR(사용자 정의 리소스)을 정의하는infra-env.yaml파일에 NTP 서버 목록을 추가합니다.infra-env.yaml파일 예apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv # ... spec: additionalNTPSources: - <ntp_server>1 - <ntp_server1> - <ntp_server2> # ...- 1
- &
lt;ntp_server>를 NTP 서버의 이름으로 바꿉니다. 호스트 인벤토리 및InfraEnvCR 생성에 대한 자세한 내용은 "호스트 인벤토리 생성"을 참조하십시오.
다음 명령을 실행하여
InfraEnvCR을 적용합니다.$ oc apply -f infra-env.yaml
검증
다음 필드를 확인하여 호스트 인벤토리의 상태를 확인합니다.
-
conditions: 이미지가 성공적으로 생성되었는지를 나타내는 표준 Kubernetes 상태입니다. -
isoDownloadURL: Discovery Image를 다운로드할 URL입니다. createdTime: 이미지가 마지막으로 생성된 시간입니다.InfraEnvCR을 수정하는 경우 새 이미지를 다운로드하기 전에 타임스탬프를 업데이트했는지 확인합니다.다음 명령을 실행하여 호스트 인벤토리가 생성되었는지 확인합니다.
$ oc describe infraenv <infraenv_resource_name> -n <infraenv_namespace>참고InfraEnvCR을 수정하는 경우InfraEnvCR이createdTime필드를 확인하여 새 검색 이미지를 생성했는지 확인합니다. 이미 호스트를 부팅한 경우 최신 Discovery Image를 사용하여 다시 부팅합니다.
-
5장. 호스트 클러스터에서 기능 게이트 사용
호스트 클러스터에서 기능 게이트를 사용하여 기본 기능 세트의 일부가 아닌 기능을 활성화할 수 있습니다. 호스팅된 클러스터에서 기능 게이트를 사용하여 TechPreviewNoUpgrade 기능을 활성화할 수 있습니다.
5.1. 기능 게이트를 사용하여 기능 세트 활성화
OpenShift CLI로 HostedCluster CR(사용자 정의 리소스)을 편집하여 호스트 클러스터에서 TechPreviewNoUpgrade 기능을 활성화할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다.
프로세스
다음 명령을 실행하여 호스팅 클러스터에서 편집할
HostedClusterCR을 엽니다.$ oc edit hostedcluster <hosted_cluster_name> -n <hosted_cluster_namespace>featureSet필드에 값을 입력하여 기능 세트를 정의합니다. 예를 들면 다음과 같습니다.apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: name: <hosted_cluster_name>1 namespace: <hosted_cluster_namespace>2 spec: configuration: featureGate: featureSet: TechPreviewNoUpgrade3 주의클러스터에서
TechPreviewNoUpgrade기능 세트를 활성화하면 취소할 수 없으며 마이너 버전 업데이트를 방지할 수 없습니다. 이 기능 세트를 사용하면 테스트 클러스터에서 이러한 기술 프리뷰 기능을 완전히 테스트할 수 있습니다. 프로덕션 클러스터에서 이 기능 세트를 활성화하지 마십시오.- 파일을 저장하여 변경 사항을 적용합니다.
검증
다음 명령을 실행하여 호스트 클러스터에서
TechPreviewNoUpgrade기능 게이트가 활성화되어 있는지 확인합니다.$ oc get featuregate cluster -o yaml
6장. 호스팅된 컨트롤 플레인의 인증서 구성
호스팅된 컨트롤 플레인을 사용하면 인증서를 구성하는 단계가 독립 실행형 OpenShift Container Platform과 다릅니다.
6.1. 호스트된 클러스터에서 사용자 정의 API 서버 인증서 구성
API 서버의 사용자 정의 인증서를 구성하려면 HostedCluster 구성의 spec.configuration.apiServer 섹션에 인증서 세부 정보를 지정합니다.
day-1 또는 day-2 작업 중에 사용자 정의 인증서를 구성할 수 있습니다. 그러나 호스트 클러스터 생성 중에 서비스 게시 전략은 변경할 수 없으므로 구성하려는 Kubernetes API 서버의 호스트 이름이 무엇인지 알아야 합니다.
사전 요구 사항
관리 클러스터에 사용자 정의 인증서가 포함된 Kubernetes 시크릿을 생성했습니다. 보안에는 다음 키가 포함되어 있습니다.
-
TLS.crt: 인증서 -
TLS.key: 개인 키
-
-
HostedCluster구성에 로드 밸런서를 사용하는 서비스 게시 전략이 포함된 경우 인증서의 SAN(주체 대체 이름)이 내부 API 끝점(api-int)과 충돌하지 않는지 확인합니다. 내부 API 끝점은 플랫폼에서 자동으로 생성 및 관리합니다. 사용자 정의 인증서와 내부 API 끝점 모두에서 동일한 호스트 이름을 사용하는 경우 라우팅 충돌이 발생할 수 있습니다. 이 규칙의 유일한 예외는Private또는PublicAndPrivate구성이 있는 공급자로 AWS를 사용하는 경우입니다. 이러한 경우 SAN 충돌은 플랫폼에 의해 관리됩니다. - 인증서는 외부 API 끝점에 유효해야 합니다.
- 인증서의 유효 기간은 클러스터의 예상 라이프 사이클과 일치합니다.
프로세스
다음 명령을 입력하여 사용자 정의 인증서로 보안을 생성합니다.
$ oc create secret tls sample-hosted-kas-custom-cert \ --cert=path/to/cert.crt \ --key=path/to/key.key \ -n <hosted_cluster_namespace>다음 예와 같이 사용자 정의 인증서 세부 정보를 사용하여
HostedCluster구성을 업데이트합니다.spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert다음 명령을 입력하여
HostedCluster구성에 변경 사항을 적용합니다.$ oc apply -f <hosted_cluster_config>.yaml
검증
- API 서버 pod를 확인하여 새 인증서가 마운트되었는지 확인합니다.
- 사용자 정의 도메인 이름을 사용하여 API 서버에 대한 연결을 테스트합니다.
-
브라우저에서 인증서 세부 정보를 확인하거나
openssl과 같은 도구를 사용하여 확인합니다.
6.2. 호스트 클러스터의 Kubernetes API 서버 구성
호스팅된 클러스터에 대한 Kubernetes API 서버를 사용자 지정하려면 다음 단계를 완료합니다.
사전 요구 사항
- 실행 중인 호스트 클러스터가 있어야 합니다.
-
HostedCluster리소스를 수정할 수 있습니다. Kubernetes API 서버에 사용할 사용자 정의 DNS 도메인이 있습니다.
- 사용자 정의 DNS 도메인을 올바르게 구성하고 확인할 수 있어야 합니다.
- DNS 도메인에는 유효한 TLS 인증서가 구성되어 있어야 합니다.
- 도메인에 대한 네트워크 액세스는 사용자 환경에 올바르게 구성되어 있어야 합니다.
- 사용자 정의 DNS 도메인은 호스팅된 클러스터 전체에서 고유해야 합니다.
- 사용자 정의 인증서가 구성되어 있습니다. 자세한 내용은 "호스트된 클러스터에서 사용자 정의 API 서버 인증서 구성"을 참조하십시오.
프로세스
공급자 플랫폼에서
kubeAPIServerDNSNameURL이 Kubernetes API 서버가 노출되는 IP 주소를 가리키도록 DNS 레코드를 구성합니다. DNS 레코드를 올바르게 구성하고 클러스터에서 확인할 수 있어야 합니다.DNS 레코드를 구성하는 명령 예
$ dig + short kubeAPIServerDNSNameHostedCluster사양에서 다음 예와 같이kubeAPIServerDNSName필드를 수정합니다.apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: name: <hosted_cluster_name> namespace: <hosted_cluster_namespace> spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert kubeAPIServerDNSName: api-custom-cert-sample-hosted.sample-hosted.example.com3 # ...다음 명령을 입력하여 구성을 적용합니다.
$ oc -f <hosted_cluster_spec>.yaml구성이 적용되면 HyperShift Operator에서 사용자 정의 DNS 도메인을 가리키는 새
kubeconfig시크릿을 생성합니다.CLI 또는 콘솔을 사용하여
kubeconfig시크릿을 검색합니다.CLI를 사용하여 시크릿을 검색하려면 다음 명령을 입력합니다.
$ kubectl get secret <hosted_cluster_name>-custom-admin-kubeconfig \ -n <cluster_namespace> \ -o jsonpath='{.data.kubeconfig}' | base64 -d콘솔을 사용하여 시크릿을 검색하려면 호스팅된 클러스터로 이동하고 Kubeconfig 다운로드를 클릭합니다.
참고콘솔에서 show login 명령 옵션을 사용하여 새
kubeconfig시크릿을 사용할 수 없습니다.
6.3. 사용자 정의 DNS를 사용하여 호스트 클러스터에 액세스 문제 해결
사용자 지정 DNS를 사용하여 호스팅 클러스터에 액세스할 때 문제가 발생하면 다음 단계를 완료합니다.
프로세스
- DNS 레코드가 올바르게 구성되어 해결되었는지 확인합니다.
사용자 정의 도메인의 TLS 인증서가 유효한지 확인하고 다음 명령을 입력하여 도메인에 SAN이 올바른지 확인합니다.
$ oc get secret \ -n clusters <serving_certificate_name> \ -o jsonpath='{.data.tls\.crt}' | base64 \ -d |openssl x509 -text -noout -- 사용자 지정 도메인에 대한 네트워크 연결이 작동하는지 확인합니다.
HostedCluster리소스에서 다음 예와 같이 상태에 올바른 사용자 지정kubeconfig정보가 표시되는지 확인합니다.HostedCluster상태 예status: customKubeconfig: name: sample-hosted-custom-admin-kubeconfig다음 명령을 입력하여
HostedControlPlane네임스페이스에서kube-apiserver로그를 확인합니다.$ oc logs -n <hosted_control_plane_namespace> \ -l app=kube-apiserver -f -c kube-apiserver
7장. 호스트된 컨트롤 플레인 업데이트
호스팅된 컨트롤 플레인을 업데이트하려면 호스팅된 클러스터 및 노드 풀을 업데이트해야 합니다. 업데이트 프로세스 중에 클러스터가 완전히 작동하려면 컨트롤 플레인 및 노드 업데이트를 완료하는 동안 Kubernetes 버전 스큐 정책의 요구 사항을 충족해야 합니다.
7.1. 호스팅된 컨트롤 플레인을 업그레이드하기 위한 요구사항
Kubernetes Operator의 멀티 클러스터 엔진은 하나 이상의 OpenShift Container Platform 클러스터를 관리할 수 있습니다. OpenShift Container Platform에서 호스팅된 클러스터를 생성한 후 multicluster 엔진 Operator에서 호스팅된 클러스터를 관리 클러스터로 가져와야 합니다. 그런 다음 OpenShift Container Platform 클러스터를 관리 클러스터로 사용할 수 있습니다.
호스팅된 컨트롤 플레인 업데이트를 시작하기 전에 다음 요구 사항을 고려하십시오.
- OpenShift Virtualization을 공급자로 사용할 때 OpenShift Container Platform 클러스터에 베어 메탈 플랫폼을 사용해야 합니다.
-
베어 메탈 또는 OpenShift Virtualization을 호스팅된 클러스터의 클라우드 플랫폼으로 사용해야 합니다. 호스팅된 클러스터의 플랫폼 유형은
HostedClusterCR(사용자 정의 리소스)의spec.Platform.type사양에서 찾을 수 있습니다.
다음 작업을 완료하여 OpenShift Container Platform 클러스터, 다중 클러스터 엔진 Operator, 호스트 클러스터 및 노드 풀을 업그레이드해야 합니다.
- OpenShift Container Platform 클러스터를 최신 버전으로 업그레이드합니다. 자세한 내용은 "웹 콘솔을 사용하여 클러스터 업그레이드" 또는 " CLI를 사용하여 클러스터 업그레이드"를 참조하십시오.
- multicluster 엔진 Operator를 최신 버전으로 업그레이드합니다. 자세한 내용은 "설치된 Operator 업그레이드"를 참조하십시오.
- 호스팅된 클러스터 및 노드 풀을 이전 OpenShift Container Platform 버전에서 최신 버전으로 업그레이드합니다. 자세한 내용은 "호스트 클러스터에서 컨트롤 플레인 업그레이드" 및 "호스트된 클러스터에서 노드 풀 업그레이드"를 참조하십시오.
7.2. 호스트 클러스터에서 채널 설정
HostedCluster CR(사용자 정의 리소스)의 HostedCluster.Status 필드에서 사용 가능한 업데이트를 확인할 수 있습니다.
사용 가능한 업데이트는 호스팅된 클러스터의 CVO(Cluster Version Operator)에서 가져오지 않습니다. 사용 가능한 업데이트 목록은 HostedCluster CR(사용자 정의 리소스)의 다음 필드에서 사용 가능한 업데이트와 다를 수 있습니다.
-
status.version.availableUpdates -
status.version.conditionalUpdates
초기 HostedCluster CR에는 status.version.availableUpdates 및 status.version.conditionalUpdates 필드에 정보가 없습니다. spec.channel 필드를 안정적인 OpenShift Container Platform 릴리스 버전으로 설정하면 HyperShift Operator가 HostedCluster CR을 조정하고 사용 가능한 조건부 업데이트로 status.version 필드를 업데이트합니다.
채널 구성이 포함된 HostedCluster CR의 다음 예제를 참조하십시오.
spec:
autoscaling: {}
channel: stable-4.y
clusterID: d6d42268-7dff-4d37-92cf-691bd2d42f41
configuration: {}
controllerAvailabilityPolicy: SingleReplica
dns:
baseDomain: dev11.red-chesterfield.com
privateZoneID: Z0180092I0DQRKL55LN0
publicZoneID: Z00206462VG6ZP0H2QLWK- 1
- &
lt;4.y>를spec.release에서 지정한 OpenShift Container Platform 릴리스 버전으로 바꿉니다. 예를 들어spec.release를ocp-release:4.16.4-multi로 설정하는 경우spec.channel을stable-4.16으로 설정해야 합니다.
HostedCluster CR에서 채널을 구성한 후 status.version. availableUpdates 및 필드의 출력을 보려면 다음 명령을 실행합니다.
status.version.conditionalUpdates
$ oc get -n <hosted_cluster_namespace> hostedcluster <hosted_cluster_name> -o yaml출력 예
version:
availableUpdates:
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:b7517d13514c6308ae16c5fd8108133754eb922cd37403ed27c846c129e67a9a
url: https://access.redhat.com/errata/RHBA-2024:6401
version: 4.16.11
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:d08e7c8374142c239a07d7b27d1170eae2b0d9f00ccf074c3f13228a1761c162
url: https://access.redhat.com/errata/RHSA-2024:6004
version: 4.16.10
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:6a80ac72a60635a313ae511f0959cc267a21a89c7654f1c15ee16657aafa41a0
url: https://access.redhat.com/errata/RHBA-2024:5757
version: 4.16.9
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:ea624ae7d91d3f15094e9e15037244679678bdc89e5a29834b2ddb7e1d9b57e6
url: https://access.redhat.com/errata/RHSA-2024:5422
version: 4.16.8
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:e4102eb226130117a0775a83769fe8edb029f0a17b6cbca98a682e3f1225d6b7
url: https://access.redhat.com/errata/RHSA-2024:4965
version: 4.16.6
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:f828eda3eaac179e9463ec7b1ed6baeba2cd5bd3f1dd56655796c86260db819b
url: https://access.redhat.com/errata/RHBA-2024:4855
version: 4.16.5
conditionalUpdates:
- conditions:
- lastTransitionTime: "2024-09-23T22:33:38Z"
message: |-
Could not evaluate exposure to update risk SRIOVFailedToConfigureVF (creating PromQL round-tripper: unable to load specified CA cert /etc/tls/service-ca/service-ca.crt: open /etc/tls/service-ca/service-ca.crt: no such file or directory)
SRIOVFailedToConfigureVF description: OCP Versions 4.14.34, 4.15.25, 4.16.7 and ALL subsequent versions include kernel datastructure changes which are not compatible with older versions of the SR-IOV operator. Please update SR-IOV operator to versions dated 20240826 or newer before updating OCP.
SRIOVFailedToConfigureVF URL: https://issues.redhat.com/browse/NHE-1171
reason: EvaluationFailed
status: Unknown
type: Recommended
release:
channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:fb321a3f50596b43704dbbed2e51fdefd7a7fd488ee99655d03784d0cd02283f
url: https://access.redhat.com/errata/RHSA-2024:5107
version: 4.16.7
risks:
- matchingRules:
- promql:
promql: |
group(csv_succeeded{_id="d6d42268-7dff-4d37-92cf-691bd2d42f41", name=~"sriov-network-operator[.].*"})
or
0 * group(csv_count{_id="d6d42268-7dff-4d37-92cf-691bd2d42f41"})
type: PromQL
message: OCP Versions 4.14.34, 4.15.25, 4.16.7 and ALL subsequent versions
include kernel datastructure changes which are not compatible with older
versions of the SR-IOV operator. Please update SR-IOV operator to versions
dated 20240826 or newer before updating OCP.
name: SRIOVFailedToConfigureVF
url: https://issues.redhat.com/browse/NHE-11717.3. 호스트된 클러스터에서 OpenShift Container Platform 버전 업데이트
호스팅된 컨트롤 플레인을 사용하면 컨트롤 플레인과 데이터 플레인 간의 업데이트를 분리할 수 있습니다.
클러스터 서비스 공급자 또는 클러스터 관리자는 컨트롤 플레인과 데이터를 별도로 관리할 수 있습니다.
NodePool CR을 수정하여 HostedCluster CR(사용자 정의 리소스) 및 노드를 수정하여 컨트롤 플레인을 업데이트할 수 있습니다. HostedCluster 및 NodePool CR 모두 .release 필드에 OpenShift Container Platform 릴리스 이미지를 지정합니다.
업데이트 프로세스 중에 호스팅 클러스터를 완전히 작동하려면 컨트롤 플레인 및 노드 업데이트가 Kubernetes 버전 스큐 정책을 따라야 합니다.
7.3.1. 다중 클러스터 엔진 Operator 허브 관리 클러스터
Kubernetes Operator용 멀티 클러스터 엔진에는 관리 클러스터가 지원되는 상태로 유지되려면 특정 OpenShift Container Platform 버전이 필요합니다. OpenShift Container Platform 웹 콘솔의 OperatorHub에서 다중 클러스터 엔진 Operator를 설치할 수 있습니다.
다중 클러스터 엔진 Operator 버전은 다음과 같은 지원을 참조하십시오.
멀티 클러스터 엔진 Operator는 다음 OpenShift Container Platform 버전을 지원합니다.
- 릴리스되지 않은 최신 버전
- 최신 릴리스 버전
- 최신 릴리스 버전 이전 두 버전
또한 RHACM(Red Hat Advanced Cluster Management)의 일부로 다중 클러스터 엔진 Operator 버전을 가져올 수도 있습니다.
7.3.2. 호스트 클러스터에서 지원되는 OpenShift Container Platform 버전
호스트 클러스터를 배포할 때 관리 클러스터의 OpenShift Container Platform 버전은 호스팅된 클러스터의 OpenShift Container Platform 버전에 영향을 미치지 않습니다.
HyperShift Operator는 hypershift 네임스페이스에 supported-versions ConfigMap을 생성합니다. supported-versions ConfigMap은 배포할 수 있는 지원되는 OpenShift Container Platform 버전 범위를 설명합니다.
supported-versions ConfigMap의 다음 예제를 참조하십시오.
apiVersion: v1
data:
server-version: 2f6cfe21a0861dea3130f3bed0d3ae5553b8c28b
supported-versions: '{"versions":["4.17","4.16","4.15","4.14"]}'
kind: ConfigMap
metadata:
creationTimestamp: "2024-06-20T07:12:31Z"
labels:
hypershift.openshift.io/supported-versions: "true"
name: supported-versions
namespace: hypershift
resourceVersion: "927029"
uid: f6336f91-33d3-472d-b747-94abae725f70
호스트된 클러스터를 생성하려면 지원 버전 범위에서 OpenShift Container Platform 버전을 사용해야 합니다. 그러나 다중 클러스터 엔진 Operator는 n+1 과 n-2 OpenShift Container Platform 버전 간에만 관리할 수 있습니다. 여기서 n 은 현재 마이너 버전을 정의합니다. 다중 클러스터 엔진 Operator 지원 매트릭스를 확인하여 다중 클러스터 엔진 Operator에서 관리하는 호스트 클러스터가 지원되는 OpenShift Container Platform 범위 내에 있는지 확인할 수 있습니다.
OpenShift Container Platform에 호스트된 클러스터의 상위 버전을 배포하려면 새 버전의 Hypershift Operator를 배포하려면 multicluster 엔진 Operator를 새 마이너 버전 릴리스로 업데이트해야 합니다. 다중 클러스터 엔진 Operator를 새 패치 또는 z-stream으로 업그레이드해도 HyperShift Operator가 다음 버전으로 업데이트되지 않습니다.
관리 클러스터에서 OpenShift Container Platform 4.16에 지원되는 OpenShift Container Platform 버전을 보여주는 hcp version 명령의 다음 예제 출력을 참조하십시오.
Client Version: openshift/hypershift: fe67b47fb60e483fe60e4755a02b3be393256343. Latest supported OCP: 4.17.0
Server Version: 05864f61f24a8517731664f8091cedcfc5f9b60d
Server Supports OCP Versions: 4.17, 4.16, 4.15, 4.147.4. 호스팅된 클러스터 업데이트
spec.release.image 값은 컨트롤 플레인의 버전을 지정합니다. HostedCluster 오브젝트는 의도한 spec.release.image 값을 HostedControlPlane.spec.releaseImage 값으로 전송하고 적절한 Control Plane Operator 버전을 실행합니다.
호스팅된 컨트롤 플레인은 새로운 버전의 CVO(Cluster Version Operator)를 통해 OpenShift Container Platform 구성 요소와 함께 새 버전의 컨트롤 플레인 구성 요소의 롤아웃을 관리합니다.
호스팅된 컨트롤 플레인에서 NodeHealthCheck 리소스는 CVO의 상태를 감지할 수 없습니다. 클러스터 관리자는 새 수정 작업이 클러스터 업데이트를 방해하지 않도록 클러스터 업데이트와 같은 중요한 작업을 수행하기 전에 NodeHealthCheck 에서 트리거한 수정을 수동으로 일시 중지해야 합니다.
수정을 일시 중지하려면 NodeHealthCheck 리소스의 pauseRequests 필드 값으로 pause-test-cluster 와 같은 문자열 배열을 입력합니다. 자세한 내용은 Node Health Check Operator 정보를 참조하십시오.
클러스터 업데이트가 완료되면 수정을 편집하거나 삭제할 수 있습니다. Compute → NodeHealthCheck 페이지로 이동하여 노드 상태 점검을 클릭한 다음 드롭다운 목록이 표시되는 작업을 클릭합니다.
7.5. 노드 풀 업데이트
노드 풀을 사용하면 spec.release 및 spec.config 값을 노출하여 노드에서 실행 중인 소프트웨어를 구성할 수 있습니다. 다음과 같은 방법으로 롤링 노드 풀 업데이트를 시작할 수 있습니다.
-
spec.release또는spec.config값을 변경합니다. - AWS 인스턴스 유형과 같은 플랫폼별 필드를 변경합니다. 결과는 새 유형의 새 인스턴스 집합입니다.
- 클러스터 구성을 변경하면 변경 사항이 노드로 전파됩니다.
노드 풀은 업데이트 및 인플레이스 업데이트를 교체할 수 있습니다. nodepool.spec.release 값은 특정 노드 풀의 버전을 지정합니다. NodePool 오브젝트는 .spec.management.upgradeType 값에 따라 교체 또는 인플레이스 롤링 업데이트를 완료합니다.
노드 풀을 생성한 후에는 업데이트 유형을 변경할 수 없습니다. 업데이트 유형을 변경하려면 노드 풀을 생성하고 다른 노드를 삭제해야 합니다.
7.5.1. 노드 풀 교체 업데이트
교체 업데이트는 이전 버전에서 이전 인스턴스를 제거하는 동안 새 버전에 인스턴스를 생성합니다. 이 업데이트 유형은 이러한 수준의 불변성을 비용 효율적으로 사용하는 클라우드 환경에서 효과가 있습니다.
교체 업데이트에서는 노드가 완전히 다시 프로비저닝되므로수동 변경 사항이 유지되지 않습니다.
7.5.2. 노드 풀의 인플레이스 업데이트
인플레이스 업데이트는 인스턴스의 운영 체제를 직접 업데이트합니다. 이 유형은 베어 메탈과 같이 인프라 제약 조건이 높은 환경에 적합합니다.
인플레이스 업데이트는 수동 변경 사항을 유지할 수 있지만 kubelet 인증서와 같이 클러스터가 직접 관리하는 파일 시스템 또는 운영 체제 구성을 수동으로 변경하면 오류를 보고합니다.
7.6. 호스트 클러스터에서 노드 풀 업데이트
호스팅된 클러스터의 노드 풀을 업데이트하여 OpenShift Container Platform 버전을 업데이트할 수 있습니다. 노드 풀 버전은 호스팅된 컨트롤 플레인 버전을 초과해서는 안 됩니다.
NodePool CR(사용자 정의 리소스)의 .spec.release 필드에는 노드 풀 버전이 표시됩니다.
프로세스
다음 명령을 입력하여 노드 풀에서
spec.release.image값을 변경합니다.$ oc patch nodepool <node_pool_name> -n <hosted_cluster_namespace> --type=merge -p '{"spec":{"nodeDrainTimeout":"60s","release":{"image":"<openshift_release_image>"}}}'1 2
검증
새 버전이 롤아웃되었는지 확인하려면 다음 명령을 실행하여 노드 풀에서
.status.conditions값을 확인합니다.$ oc get -n <hosted_cluster_namespace> nodepool <node_pool_name> -o yaml출력 예
status: conditions: - lastTransitionTime: "2024-05-20T15:00:40Z" message: 'Using release image: quay.io/openshift-release-dev/ocp-release:4.y.z-x86_64'1 reason: AsExpected status: "True" type: ValidReleaseImage- 1
- &
lt;4.y.z>를 지원되는 OpenShift Container Platform 버전으로 교체합니다.
7.7. 호스트 클러스터에서 컨트롤 플레인 업데이트
호스팅된 컨트롤 플레인에서는 호스팅된 클러스터를 업데이트하여 OpenShift Container Platform 버전을 업그레이드할 수 있습니다. HostedCluster CR(사용자 정의 리소스)의 .spec.release 에는 컨트롤 플레인의 버전이 표시됩니다. HostedCluster 는 .spec.release 필드를 HostedControlPlane.spec.release 로 업데이트하고 적절한 Control Plane Operator 버전을 실행합니다.
HostedControlPlane 리소스는 새 버전의 CVO(Cluster Version Operator)를 통해 데이터 플레인의 OpenShift Container Platform 구성 요소와 함께 새 버전의 컨트롤 플레인 구성 요소의 롤아웃을 오케스트레이션합니다. HostedControlPlane 에는 다음과 같은 아티팩트가 포함되어 있습니다.
- CVO
- CNO(Cluster Network Operator)
- Cluster Ingress Operator
- Kube API 서버, 스케줄러 및 관리자에 대한 매니페스트
- 머신 승인자
- 자동 스케일러
- Kube API 서버, ignition 및 konnectivity와 같은 컨트롤 플레인 끝점에 대한 수신을 활성화하는 인프라 리소스
status.version.availableUpdates 및 status.version.conditionalUpdates 필드의 정보를 사용하여 컨트롤 플레인을 업데이트하도록 HostedCluster CR에서 .spec.release 필드를 설정할 수 있습니다.
프로세스
다음 명령을 입력하여
하이퍼shift.openshift.io/force-upgrade-to=<openshift_release_image> 주석을 호스트된 클러스터에 추가합니다.$ oc annotate hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> "hypershift.openshift.io/force-upgrade-to=<openshift_release_image>" --overwrite1 2 - 1
- <
hosted_cluster_name> 및 <hosted_cluster_namespace>를 호스팅된 클러스터 이름 및 호스팅 클러스터 네임스페이스로 각각 바꿉니다. - 2
- <
openshift_release_image> 변수는 업그레이드할 새 OpenShift Container Platform 릴리스 이미지를 지정합니다(예:quay.io/openshift-release-dev/ocp-release:4.y.z-x86_64). <4.y.z>를 지원되는 OpenShift Container Platform 버전으로 교체합니다.
다음 명령을 입력하여 호스팅된 클러스터에서
spec.release.image값을 변경합니다.$ oc patch hostedcluster <hosted_cluster_name> -n <hosted_cluster_namespace> --type=merge -p '{"spec":{"release":{"image":"<openshift_release_image>"}}}'
검증
새 버전이 롤아웃되었는지 확인하려면 다음 명령을 실행하여 호스팅된 클러스터에서
.status.conditions및.status.version값을 확인합니다.$ oc get -n <hosted_cluster_namespace> hostedcluster <hosted_cluster_name> -o yaml출력 예
status: conditions: - lastTransitionTime: "2024-05-20T15:01:01Z" message: Payload loaded version="4.y.z" image="quay.io/openshift-release-dev/ocp-release:4.y.z-x86_64"1 status: "True" type: ClusterVersionReleaseAccepted #... version: availableUpdates: null desired: image: quay.io/openshift-release-dev/ocp-release:4.y.z-x86_642 version: 4.y.z
7.8. 다중 클러스터 엔진 Operator 콘솔을 사용하여 호스트 클러스터 클러스터 업데이트
다중 클러스터 엔진 Operator 콘솔을 사용하여 호스팅 클러스터를 업데이트할 수 있습니다.
호스팅 클러스터를 업데이트하기 전에 호스팅 클러스터의 사용 가능한 조건부 업데이트를 참조해야 합니다. 잘못된 릴리스 버전을 선택하면 호스팅된 클러스터가 중단될 수 있습니다.
프로세스
- 모든 클러스터를 선택합니다.
- 인프라 → 클러스터로 이동하여 관리되는 호스팅 클러스터를 확인합니다.
- 사용 가능한 업그레이드 링크를 클릭하여 컨트롤 플레인 및 노드 풀을 업데이트합니다.
7.9. 가져온 호스팅 클러스터를 관리하는 데 대한 제한 사항
호스팅된 클러스터는 독립 실행형 OpenShift Container Platform 또는 타사 클러스터와 달리 Kubernetes Operator의 로컬 멀티 클러스터 엔진으로 자동으로 가져옵니다. 호스팅된 클러스터는 에이전트에서 클러스터의 리소스를 사용하지 않도록 호스팅 모드에서 일부 에이전트를 실행합니다.
호스팅된 클러스터를 자동으로 가져오는 경우 관리 클러스터에서 HostedCluster 리소스를 사용하여 호스팅된 클러스터에서 노드 풀과 컨트롤 플레인을 업데이트할 수 있습니다. 노드 풀과 컨트롤 플레인을 업데이트하려면 "호스트 클러스터에서 노드 풀 업그레이드" 및 "호스팅 클러스터에서 컨트롤 플레인 업그레이드"를 참조하십시오.
RHACM(Red Hat Advanced Cluster Management)을 사용하여 호스팅된 클러스터를 로컬 다중 클러스터 엔진 Operator 이외의 위치로 가져올 수 있습니다. 자세한 내용은 "Red Hat Advanced Cluster Management에서 Kubernetes Operator 호스팅 클러스터용 다중 클러스터 엔진 검색"을 참조하십시오.
이 토폴로지에서는 클러스터가 호스팅되는 Kubernetes Operator에 대한 명령줄 인터페이스 또는 로컬 다중 클러스터 엔진의 콘솔을 사용하여 호스팅되는 클러스터를 업데이트해야 합니다. RHACM 허브 클러스터를 통해 호스팅된 클러스터를 업데이트할 수 없습니다.
8장. 호스트된 컨트롤 플레인 Observability
메트릭 세트를 구성하여 호스팅되는 컨트롤 플레인의 메트릭을 수집할 수 있습니다. HyperShift Operator는 관리하는 각 호스팅 클러스터의 관리 클러스터에서 모니터링 대시보드를 생성하거나 삭제할 수 있습니다.
8.1. 호스팅된 컨트롤 플레인에 대한 메트릭 세트 구성
Red Hat OpenShift Container Platform의 호스트된 컨트롤 플레인은 각 컨트롤 플레인 네임스페이스에서 ServiceMonitor 리소스를 생성하여 Prometheus 스택이 컨트롤 플레인에서 지표를 수집할 수 있습니다. ServiceMonitor 리소스는 메트릭 재레이블을 사용하여 etcd 또는 Kubernetes API 서버와 같은 특정 구성 요소에서 포함되거나 제외되는 메트릭을 정의합니다. 컨트롤 플레인에서 생성하는 메트릭 수는 이를 수집하는 모니터링 스택의 리소스 요구 사항에 직접적인 영향을 미칩니다.
모든 상황에 적용되는 고정된 수의 메트릭을 생성하는 대신 각 컨트롤 플레인에 생성할 메트릭 세트를 식별하는 메트릭 세트를 구성할 수 있습니다. 다음 메트릭 세트가 지원됩니다.
-
Telemetry: 이러한 메트릭은 Telemetry에 필요합니다. 이 세트는 기본 세트이며 가장 작은 메트릭 세트입니다. -
SRE:이 세트에는 경고를 생성하고 컨트롤 플레인 구성 요소의 문제 해결을 허용하는 데 필요한 메트릭이 포함되어 있습니다. -
All: 이 세트에는 독립 실행형 OpenShift Container Platform 컨트롤 플레인 구성 요소에서 생성하는 모든 메트릭이 포함됩니다.
메트릭 세트를 구성하려면 다음 명령을 입력하여 HyperShift Operator 배포에서 METRICS_SET 환경 변수를 설정합니다.
$ oc set env -n hypershift deployment/operator METRICS_SET=All8.1.1. SRE 메트릭 세트 구성
SRE 메트릭 세트를 지정하면 HyperShift Operator는 단일 key: config 를 사용하여 sre-metric-set 이라는 구성 맵을 찾습니다. config 키 값에는 컨트롤 플레인 구성 요소로 구성된 RelabelConfigs 세트가 포함되어야 합니다.
다음 구성 요소를 지정할 수 있습니다.
-
etcd -
kubeAPIServer -
kubeControllerManager -
openshiftAPIServer -
openshiftControllerManager -
openshiftRouteControllerManager -
cvo -
olm -
catalogOperator -
registryOperator -
nodeTuningOperator -
controlPlaneOperator -
hostedClusterConfigOperator
다음 예에는 SRE 메트릭 세트 구성이 설명되어 있습니다.
kubeAPIServer:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_controller_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_step_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "scheduler_(e2e_scheduling_latency_microseconds|scheduling_algorithm_predicate_evaluation|scheduling_algorithm_priority_evaluation|scheduling_algorithm_preemption_evaluation|scheduling_algorithm_latency_microseconds|binding_latency_microseconds|scheduling_latency_seconds)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_(request_count|request_latencies|request_latencies_summary|dropped_requests|storage_data_key_generation_latencies_microseconds|storage_transformation_failures_total|storage_transformation_latencies_microseconds|proxy_tunnel_sync_latency_secs)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "docker_(operations|operations_latency_microseconds|operations_errors|operations_timeout)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "reflector_(items_per_list|items_per_watch|list_duration_seconds|lists_total|short_watches_total|watch_duration_seconds|watches_total)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "etcd_(helper_cache_hit_count|helper_cache_miss_count|helper_cache_entry_count|request_cache_get_latencies_summary|request_cache_add_latencies_summary|request_latencies_summary)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "transformation_(transformation_latencies_microseconds|failures_total)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "network_plugin_operations_latency_microseconds|sync_proxy_rules_latency_microseconds|rest_client_request_latency_seconds"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_request_duration_seconds_bucket;(0.15|0.25|0.3|0.35|0.4|0.45|0.6|0.7|0.8|0.9|1.25|1.5|1.75|2.5|3|3.5|4.5|6|7|8|9|15|25|30|50)"
sourceLabels: ["__name__", "le"]
kubeControllerManager:
- action: "drop"
regex: "etcd_(debugging|disk|request|server).*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "rest_client_request_latency_seconds_(bucket|count|sum)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "root_ca_cert_publisher_sync_duration_seconds_(bucket|count|sum)"
sourceLabels: ["__name__"]
openshiftAPIServer:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_controller_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_step_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_request_duration_seconds_bucket;(0.15|0.25|0.3|0.35|0.4|0.45|0.6|0.7|0.8|0.9|1.25|1.5|1.75|2.5|3|3.5|4.5|6|7|8|9|15|25|30|50)"
sourceLabels: ["__name__", "le"]
openshiftControllerManager:
- action: "drop"
regex: "etcd_(debugging|disk|request|server).*"
sourceLabels: ["__name__"]
openshiftRouteControllerManager:
- action: "drop"
regex: "etcd_(debugging|disk|request|server).*"
sourceLabels: ["__name__"]
olm:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
catalogOperator:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
cvo:
- action: drop
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]8.2. 호스트 클러스터에서 모니터링 대시보드 활성화
구성 맵을 생성하여 호스트 클러스터에서 모니터링 대시보드를 활성화할 수 있습니다.
프로세스
local-cluster네임스페이스에hypershift-operator-install-flags구성 맵을 생성합니다. 다음 예제 구성을 참조하십시오.kind: ConfigMap apiVersion: v1 metadata: name: hypershift-operator-install-flags namespace: local-cluster data: installFlagsToAdd: "--monitoring-dashboards --metrics-set=All"1 installFlagsToRemove: ""- 1
--monitoring-dashboards --metrics-set=All플래그는 모든 메트릭에 대한 모니터링 대시보드를 추가합니다.
다음 환경 변수를 포함하도록
hypershift네임스페이스에서 HyperShift Operator 배포를 업데이트할 때까지 몇 분 정도 기다립니다.- name: MONITORING_DASHBOARDS value: "1"모니터링 대시보드가 활성화된 경우 HyperShift Operator가 관리하는 각 호스팅 클러스터에 대해 Operator는
openshift-config-managed네임스페이스에cp-<hosted_cluster_namespace>-<hosted_cluster_name>이라는 구성 맵을 생성합니다. 여기서 <hosted_cluster_namespace>는 호스팅된 클러스터의 네임스페이스이고 <hosted_cluster_name>은 호스트된 클러스터의 이름입니다. 결과적으로 관리 클러스터의 관리 콘솔에 새 대시보드가 추가됩니다.- 대시보드를 보려면 관리 클러스터 콘솔에 로그인하고 모니터링 → 대시보드를 클릭하여 호스트 클러스터의 대시보드로 이동합니다.
-
선택 사항: 호스트 클러스터에서 모니터링 대시보드를 비활성화하려면
hypershift-operator-install-flags구성 맵에서--monitoring-dashboards --metrics-set=All플래그를 제거합니다. 호스트 클러스터를 삭제하면 해당 대시보드도 삭제됩니다.
8.2.1. 대시보드 사용자 정의
HyperShift Operator는 호스트된 각 클러스터에 대한 대시보드를 생성하기 위해 Operator 네임스페이스(hypershift)의 monitoring-dashboard-template 구성 맵에 저장된 템플릿을 사용합니다. 이 템플릿에는 대시보드에 대한 메트릭이 포함된 Grafana 패널 세트가 포함되어 있습니다. 구성 맵의 콘텐츠를 편집하여 대시보드를 사용자 지정할 수 있습니다.
대시보드가 생성되면 다음 문자열이 특정 호스팅 클러스터에 해당하는 값으로 교체됩니다.
| 이름 | 설명 |
|---|---|
|
| 호스트된 클러스터의 이름 |
|
| 호스팅된 클러스터의 네임스페이스 |
|
| 호스팅된 클러스터의 컨트롤 플레인 Pod가 배치되는 네임스페이스 |
|
|
호스팅된 클러스터 메트릭의 |
9장. 호스트된 컨트롤 플레인의 고가용성
9.1. 호스트된 컨트롤 플레인의 고가용성 정보
다음 작업을 구현하여 호스트된 컨트롤 플레인의 HA(고가용성)를 유지 관리할 수 있습니다.
- 호스트 클러스터의 etcd 멤버를 복구합니다.
- 호스트 클러스터의 etcd를 백업하고 복원합니다.
- 호스트된 클러스터에 대한 재해 복구 프로세스를 수행합니다.
9.1.1. 실패한 관리 클러스터 구성 요소의 영향
관리 클러스터 구성 요소가 실패하면 워크로드에 영향을 미치지 않습니다. OpenShift Container Platform 관리 클러스터에서 컨트롤 플레인은 데이터 플레인과 분리되어 복원력을 제공합니다.
다음 표에서는 컨트롤 플레인 및 데이터 플레인에 실패한 관리 클러스터 구성 요소의 영향을 설명합니다. 그러나 표에는 관리 클러스터 구성 요소 실패의 모든 시나리오가 포함되어 있지 않습니다.
| 실패한 구성 요소의 이름 | 호스팅된 컨트롤 플레인 API 상태 | 호스트된 클러스터 데이터 플레인 상태 |
|---|---|---|
| 작업자 노드 | Available | Available |
| 가용성 영역 | Available | Available |
| 관리 클러스터 컨트롤 플레인 | Available | Available |
| 관리 클러스터 컨트롤 플레인 및 작업자 노드 | 사용할 수 없음 | Available |
9.2. 비정상적인 etcd 클러스터 복구
고가용성 컨트롤 플레인에서 세 개의 etcd pod는 etcd 클러스터에서 상태 저장 세트의 일부로 실행됩니다. etcd 클러스터를 복구하려면 etcd 클러스터 상태를 확인하여 비정상 etcd pod를 확인합니다.
9.2.1. etcd 클러스터 상태 확인
etcd pod에 로그인하여 etcd 클러스터 상태의 상태를 확인할 수 있습니다.
프로세스
다음 명령을 입력하여 etcd pod에 로그인합니다.
$ oc rsh -n openshift-etcd -c etcd <etcd_pod_name>다음 명령을 입력하여 etcd 클러스터의 상태를 출력합니다.
sh-4.4# etcdctl endpoint status -w table출력 예
+------------------------------+-----------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +------------------------------+-----------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://192.168.1xxx.20:2379 | 8fxxxxxxxxxx | 3.5.12 | 123 MB | false | false | 10 | 180156 | 180156 | | | https://192.168.1xxx.21:2379 | a5xxxxxxxxxx | 3.5.12 | 122 MB | false | false | 10 | 180156 | 180156 | | | https://192.168.1xxx.22:2379 | 7cxxxxxxxxxx | 3.5.12 | 124 MB | true | false | 10 | 180156 | 180156 | | +-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
9.2.2. 실패한 etcd pod 복구
3-노드 클러스터의 각 etcd pod에는 데이터를 저장할 자체 PVC(영구 볼륨 클레임)가 있습니다. 데이터가 손상되거나 누락되어 etcd pod가 실패할 수 있습니다. 실패한 etcd pod 및 해당 PVC를 복구할 수 있습니다.
프로세스
etcd pod가 실패했는지 확인하려면 다음 명령을 입력합니다.
$ oc get pods -l app=etcd -n openshift-etcd출력 예
NAME READY STATUS RESTARTS AGE etcd-0 2/2 Running 0 64m etcd-1 2/2 Running 0 45m etcd-2 1/2 CrashLoopBackOff 1 (5s ago) 64m실패한 etcd pod는
CrashLoopBackOff또는Error상태가 될 수 있습니다.다음 명령을 입력하여 실패한 Pod 및 해당 PVC를 삭제합니다.
$ oc delete pods etcd-2 -n openshift-etcd
검증
다음 명령을 입력하여 새 etcd pod가 실행 중인지 확인합니다.
$ oc get pods -l app=etcd -n openshift-etcd출력 예
NAME READY STATUS RESTARTS AGE etcd-0 2/2 Running 0 67m etcd-1 2/2 Running 0 48m etcd-2 2/2 Running 0 2m2s
9.3. 온프레미스 환경에서 etcd 백업 및 복원
온프레미스 환경의 호스팅 클러스터에서 etcd를 백업하고 복원하여 오류를 수정할 수 있습니다.
9.3.1. 온프레미스 환경의 호스팅 클러스터에서 etcd 백업 및 복원
호스트 클러스터에서 etcd를 백업하고 복원하면 3개의 노드 클러스터의 etcd 멤버의 손상된 데이터 또는 누락된 데이터와 같은 오류를 해결할 수 있습니다. etcd 클러스터의 여러 멤버가 데이터 손실이 발생하거나 CrashLoopBackOff 상태인 경우 이 접근 방식은 etcd 쿼럼 손실을 방지하는 데 도움이 됩니다.
이 절차에는 API 다운타임이 필요합니다.
사전 요구 사항
-
oc및jq바이너리가 설치되어 있습니다.
절차
먼저 환경 변수를 설정하고 API 서버를 축소합니다.
다음 명령을 입력하여 호스팅된 클러스터에 대한 환경 변수를 설정하여 필요에 따라 값을 바꿉니다.
$ CLUSTER_NAME=my-cluster$ HOSTED_CLUSTER_NAMESPACE=clusters$ CONTROL_PLANE_NAMESPACE="${HOSTED_CLUSTER_NAMESPACE}-${CLUSTER_NAME}"다음 명령을 입력하여 호스팅 클러스터의 조정을 일시 중지하여 필요에 따라 값을 교체합니다.
$ oc patch -n ${HOSTED_CLUSTER_NAMESPACE} hostedclusters/${CLUSTER_NAME} -p '{"spec":{"pausedUntil":"true"}}' --type=merge다음 명령을 입력하여 API 서버를 축소합니다.
kube-apiserver를 축소합니다.$ oc scale -n ${CONTROL_PLANE_NAMESPACE} deployment/kube-apiserver --replicas=0openshift-apiserver를 축소합니다.$ oc scale -n ${CONTROL_PLANE_NAMESPACE} deployment/openshift-apiserver --replicas=0openshift-oauth-apiserver를 축소 :$ oc scale -n ${CONTROL_PLANE_NAMESPACE} deployment/openshift-oauth-apiserver --replicas=0
다음으로 다음 방법 중 하나를 사용하여 etcd의 스냅샷을 만듭니다.
- 이전에 백업한 etcd 스냅샷을 사용합니다.
사용 가능한 etcd pod가 있는 경우 다음 단계를 완료하여 활성 etcd pod에서 스냅샷을 만듭니다.
다음 명령을 입력하여 etcd pod를 나열합니다.
$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcdPod 데이터베이스의 스냅샷을 가져와서 다음 명령을 입력하여 시스템에 로컬로 저장합니다.
$ ETCD_POD=etcd-0$ oc exec -n ${CONTROL_PLANE_NAMESPACE} -c etcd -t ${ETCD_POD} -- env ETCDCTL_API=3 /usr/bin/etcdctl \ --cacert /etc/etcd/tls/etcd-ca/ca.crt \ --cert /etc/etcd/tls/client/etcd-client.crt \ --key /etc/etcd/tls/client/etcd-client.key \ --endpoints=https://localhost:2379 \ snapshot save /var/lib/snapshot.db다음 명령을 입력하여 스냅샷이 성공했는지 확인합니다.
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} -c etcd -t ${ETCD_POD} -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/snapshot.db
다음 명령을 입력하여 스냅샷의 로컬 사본을 만듭니다.
$ oc cp -c etcd ${CONTROL_PLANE_NAMESPACE}/${ETCD_POD}:/var/lib/snapshot.db /tmp/etcd.snapshot.dbetcd 영구 스토리지에서 스냅샷 데이터베이스의 사본을 만듭니다.
다음 명령을 입력하여 etcd pod를 나열합니다.
$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd실행 중인 Pod를 찾아
ETCD_POD: ETCD_POD=etcd-0의 값으로 설정한 다음 다음 명령을 입력하여 스냅샷 데이터베이스를 복사합니다.$ oc cp -c etcd ${CONTROL_PLANE_NAMESPACE}/${ETCD_POD}:/var/lib/data/member/snap/db /tmp/etcd.snapshot.db
다음으로 다음 명령을 입력하여 etcd 상태 저장 세트를 축소합니다.
$ oc scale -n ${CONTROL_PLANE_NAMESPACE} statefulset/etcd --replicas=0다음 명령을 입력하여 두 번째 및 세 번째 멤버의 볼륨을 삭제합니다.
$ oc delete -n ${CONTROL_PLANE_NAMESPACE} pvc/data-etcd-1 pvc/data-etcd-2pod를 생성하여 첫 번째 etcd 멤버의 데이터에 액세스합니다.
다음 명령을 입력하여 etcd 이미지를 가져옵니다.
$ ETCD_IMAGE=$(oc get -n ${CONTROL_PLANE_NAMESPACE} statefulset/etcd -o jsonpath='{ .spec.template.spec.containers[0].image }')etcd 데이터에 액세스할 수 있는 pod를 만듭니다.
$ cat << EOF | oc apply -n ${CONTROL_PLANE_NAMESPACE} -f - apiVersion: apps/v1 kind: Deployment metadata: name: etcd-data spec: replicas: 1 selector: matchLabels: app: etcd-data template: metadata: labels: app: etcd-data spec: containers: - name: access image: $ETCD_IMAGE volumeMounts: - name: data mountPath: /var/lib command: - /usr/bin/bash args: - -c - |- while true; do sleep 1000 done volumes: - name: data persistentVolumeClaim: claimName: data-etcd-0 EOFetcd-datapod의 상태를 확인하고 다음 명령을 입력하여 실행할 때까지 기다립니다.$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd-data다음 명령을 입력하여
etcd-datapod의 이름을 가져옵니다.$ DATA_POD=$(oc get -n ${CONTROL_PLANE_NAMESPACE} pods --no-headers -l app=etcd-data -o name | cut -d/ -f2)
다음 명령을 입력하여 etcd 스냅샷을 포드에 복사합니다.
$ oc cp /tmp/etcd.snapshot.db ${CONTROL_PLANE_NAMESPACE}/${DATA_POD}:/var/lib/restored.snap.db다음 명령을 입력하여
etcd-data포드에서 이전 데이터를 제거합니다.$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- rm -rf /var/lib/data$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- mkdir -p /var/lib/data다음 명령을 입력하여 etcd 스냅샷을 복원합니다.
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- etcdutl snapshot restore /var/lib/restored.snap.db \ --data-dir=/var/lib/data --skip-hash-check \ --name etcd-0 \ --initial-cluster-token=etcd-cluster \ --initial-cluster etcd-0=https://etcd-0.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380,etcd-1=https://etcd-1.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380,etcd-2=https://etcd-2.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380 \ --initial-advertise-peer-urls https://etcd-0.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380다음 명령을 입력하여 포드에서 임시 etcd 스냅샷을 제거하십시오.
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- rm /var/lib/restored.snap.db다음 명령을 입력하여 데이터 액세스 배포를 삭제합니다.
$ oc delete -n ${CONTROL_PLANE_NAMESPACE} deployment/etcd-data다음 명령을 입력하여 etcd 클러스터를 확장합니다.
$ oc scale -n ${CONTROL_PLANE_NAMESPACE} statefulset/etcd --replicas=3etcd 멤버 pod가 반환되고 다음 명령을 입력하여 사용 가능한 것으로 보고할 때까지 기다립니다.
$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd -w다음 명령을 입력하여 모든 etcd-writer 배포를 확장합니다.
$ oc scale deployment -n ${CONTROL_PLANE_NAMESPACE} --replicas=3 kube-apiserver openshift-apiserver openshift-oauth-apiserver
다음 명령을 입력하여 호스팅 클러스터의 조정을 복원합니다.
$ oc patch -n ${HOSTED_CLUSTER_NAMESPACE} hostedclusters/${CLUSTER_NAME} -p '{"spec":{"pausedUntil":""}}' --type=merge
9.4. AWS에서 etcd 백업 및 복원
AWS(Amazon Web Services)의 호스팅 클러스터에서 etcd를 백업하고 복원하여 오류를 수정할 수 있습니다.
AWS 플랫폼의 호스팅 컨트롤 플레인은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 다음 링크를 참조하십시오.
9.4.1. 호스트 클러스터의 etcd 스냅샷 생성
호스트 클러스터의 etcd를 백업하려면 etcd의 스냅샷을 작성해야 합니다. 나중에 스냅샷을 사용하여 etcd를 복원할 수 있습니다.
이 절차에는 API 다운타임이 필요합니다.
프로세스
다음 명령을 입력하여 호스트 클러스터의 조정을 일시 중지합니다.
$ oc patch -n clusters hostedclusters/<hosted_cluster_name> -p '{"spec":{"pausedUntil":"true"}}' --type=merge다음 명령을 입력하여 모든 etcd-writer 배포를 중지합니다.
$ oc scale deployment -n <hosted_cluster_namespace> --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserveretcd 스냅샷을 만들려면 다음 명령을 입력하여 각 etcd 컨테이너에서
exec명령을 사용하십시오.$ oc exec -it <etcd_pod_name> -n <hosted_cluster_namespace> -- env ETCDCTL_API=3 /usr/bin/etcdctl --cacert /etc/etcd/tls/etcd-ca/ca.crt --cert /etc/etcd/tls/client/etcd-client.crt --key /etc/etcd/tls/client/etcd-client.key --endpoints=localhost:2379 snapshot save /var/lib/data/snapshot.db스냅샷 상태를 확인하려면 다음 명령을 실행하여 각 etcd 컨테이너에서
exec명령을 사용하십시오.$ oc exec -it <etcd_pod_name> -n <hosted_cluster_namespace> -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/data/snapshot.db스냅샷 데이터를 S3 버킷과 같이 나중에 검색할 수 있는 위치에 복사합니다. 다음 예제를 참조하십시오.
참고다음 예제에서는 서명 버전 2를 사용합니다. 서명 버전 4를 지원하는 리전에 있는 경우
us-east-2리전과 같이 서명 버전 4를 사용합니다. 그렇지 않으면 스냅샷을 S3 버킷에 복사할 때 업로드가 실패합니다.예
BUCKET_NAME=somebucket FILEPATH="/${BUCKET_NAME}/${CLUSTER_NAME}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" ACCESS_KEY=accesskey SECRET_KEY=secret SIGNATURE_HASH=`echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac ${SECRET_KEY} -binary | base64` oc exec -it etcd-0 -n ${HOSTED_CLUSTER_NAMESPACE} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${CLUSTER_NAME}-snapshot.db나중에 새 클러스터에서 스냅샷을 복원하려면 호스팅된 클러스터가 참조하는 암호화 시크릿을 저장합니다.
다음 명령을 입력하여 보안 암호화 키를 가져옵니다.
$ oc get hostedcluster <hosted_cluster_name> -o=jsonpath='{.spec.secretEncryption.aescbc}' {"activeKey":{"name":"<hosted_cluster_name>-etcd-encryption-key"}}다음 명령을 입력하여 보안 암호화 키를 저장합니다.
$ oc get secret <hosted_cluster_name>-etcd-encryption-key -o=jsonpath='{.data.key}'새 클러스터에서 스냅샷을 복원할 때 이 키의 암호를 해독할 수 있습니다.
다음 단계
etcd 스냅샷을 복원하십시오.
9.4.2. 호스트 클러스터에서 etcd 스냅샷 복원
호스팅된 클러스터에서 etcd 스냅샷이 있는 경우 복원할 수 있습니다. 현재 클러스터 생성 중에만 etcd 스냅샷을 복원할 수 있습니다.
etcd 스냅샷을 복원하려면 create cluster --render 명령에서 출력을 수정하고 HostedCluster 사양의 etcd 섹션에 restoreSnapshotURL 값을 정의합니다.
hcp create 명령의 --render 플래그는 시크릿을 렌더링하지 않습니다. 보안을 렌더링하려면 hcp create 명령에서 --render 및 --render-sensitive 플래그를 모두 사용해야 합니다.
사전 요구 사항
호스팅된 클러스터에서 etcd 스냅샷을 작성했습니다.
절차
awsCLI(명령줄 인터페이스)에서 인증 정보를 etcd 배포에 전달하지 않고 S3에서 etcd 스냅샷을 다운로드할 수 있도록 사전 서명된 URL을 생성합니다.ETCD_SNAPSHOT=${ETCD_SNAPSHOT:-"s3://${BUCKET_NAME}/${CLUSTER_NAME}-snapshot.db"} ETCD_SNAPSHOT_URL=$(aws s3 presign ${ETCD_SNAPSHOT})URL을 참조하도록
HostedCluster사양을 수정합니다.spec: etcd: managed: storage: persistentVolume: size: 4Gi type: PersistentVolume restoreSnapshotURL: - "${ETCD_SNAPSHOT_URL}" managementType: Managed-
spec.secretEncryption.aescbc값에서 참조한 보안에 이전 단계에서 저장한 것과 동일한 AES 키가 포함되어 있는지 확인합니다.
9.5. AWS에서 호스트된 클러스터에 대한 재해 복구
호스트 클러스터를 AWS(Amazon Web Services) 내의 동일한 리전으로 복구할 수 있습니다. 예를 들어 관리 클러스터 업그레이드에 실패하고 호스트 클러스터가 읽기 전용 상태인 경우 재해 복구가 필요합니다.
호스팅된 컨트롤 플레인은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 다음 링크를 참조하십시오.
재해 복구 프로세스에는 다음 단계가 포함됩니다.
- 소스 관리 클러스터에서 호스트된 클러스터 백업
- 대상 관리 클러스터에서 호스팅 클러스터 복원
- 소스 관리 클러스터에서 호스팅 클러스터 삭제
프로세스 중에 워크로드가 계속 실행됩니다. 기간 동안 클러스터 API를 사용할 수 없지만, 이는 작업자 노드에서 실행 중인 서비스에는 영향을 미치지 않습니다.
API 서버 URL을 유지하려면 소스 관리 클러스터와 대상 관리 클러스터에 모두 --external-dns 플래그가 있어야 합니다. 이렇게 하면 서버 URL이 https://api-sample-hosted.sample-hosted.aws.openshift.com 로 끝납니다. 다음 예제를 참조하십시오.
예: 외부 DNS 플래그
--external-dns-provider=aws \
--external-dns-credentials=<path_to_aws_credentials_file> \
--external-dns-domain-filter=<basedomain>
API 서버 URL을 유지하기 위해 --external-dns 플래그를 포함하지 않으면 호스팅된 클러스터를 마이그레이션할 수 없습니다.
9.5.1. 백업 및 복원 프로세스 개요
백업 및 복원 프로세스는 다음과 같이 작동합니다.
관리 클러스터 1에서 소스 관리 클러스터로 간주할 수 있는 컨트롤 플레인 및 작업자는 외부 DNS API를 사용하여 상호 작용합니다. 외부 DNS API에 액세스할 수 있으며 로드 밸런서는 관리 클러스터 간에 위치합니다.

etcd, 컨트롤 플레인 및 작업자 노드가 포함된 호스팅 클러스터의 스냅샷을 생성합니다. 이 프로세스 중에 작업자 노드는 액세스할 수 없는 경우에도 외부 DNS API에 계속 액세스하려고 합니다. 워크로드가 실행 중이고 컨트롤 플레인은 로컬 매니페스트 파일에 저장되고 etcd는 S3 버킷으로 백업됩니다. 데이터 플레인이 활성 상태이고 컨트롤 플레인이 일시 중지되었습니다.

대상 관리 클러스터 2로 간주할 수 있는 관리 클러스터 2에서는 S3 버킷에서 etcd를 복원하고 로컬 매니페스트 파일에서 컨트롤 플레인을 복원합니다. 이 프로세스 중에 외부 DNS API가 중지되고 호스팅된 클러스터 API에 액세스할 수 없게 되고 API를 사용하는 모든 작업자는 매니페스트 파일을 업데이트할 수 없지만 워크로드는 여전히 실행 중입니다.

외부 DNS API에 다시 액세스할 수 있으며 작업자 노드는 이를 사용하여 관리 클러스터 2로 이동합니다. 외부 DNS API는 컨트롤 플레인을 가리키는 로드 밸런서에 액세스할 수 있습니다.

관리 클러스터 2에서 컨트롤 플레인 및 작업자 노드는 외부 DNS API를 사용하여 상호 작용합니다. etcd의 S3 백업을 제외하고 관리 클러스터 1에서 리소스가 삭제됩니다. 관리 클러스터 1에서 호스트 클러스터를 다시 설정하려고 하면 작동하지 않습니다.

9.5.2. 호스팅된 클러스터 백업
대상 관리 클러스터에서 호스팅된 클러스터를 복구하려면 먼저 모든 관련 데이터를 백업해야 합니다.
절차
다음 명령을 입력하여 소스 관리 클러스터를 선언할 configmap 파일을 생성합니다.
$ oc create configmap mgmt-parent-cluster -n default --from-literal=from=${MGMT_CLUSTER_NAME}다음 명령을 입력하여 호스팅된 클러스터 및 노드 풀에서 조정을 종료합니다.
$ PAUSED_UNTIL="true" $ oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge $ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator$ PAUSED_UNTIL="true" $ oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge $ oc patch -n ${HC_CLUSTER_NS} nodepools/${NODEPOOLS} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge $ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator이 bash 스크립트를 실행하여 etcd를 백업하고 S3 버킷에 데이터를 업로드합니다.
작은 정보이 스크립트를 함수로 래핑하고 기본 함수에서 호출합니다.
# ETCD Backup ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi for POD in ${ETCD_PODS}; do # Create an etcd snapshot oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl --cacert /etc/etcd/tls/client/etcd-client-ca.crt --cert /etc/etcd/tls/client/etcd-client.crt --key /etc/etcd/tls/client/etcd-client.key --endpoints=localhost:2379 snapshot save /var/lib/data/snapshot.db oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/data/snapshot.db FILEPATH="/${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" set +x ACCESS_KEY=$(grep aws_access_key_id ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SECRET_KEY=$(grep aws_secret_access_key ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SIGNATURE_HASH=$(echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac "${SECRET_KEY}" -binary | base64) set -x # FIXME: this is pushing to the OIDC bucket oc exec -it etcd-0 -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${HC_CLUSTER_NAME}-${POD}-snapshot.db doneetcd 백업에 대한 자세한 내용은 "호스트 클러스터에서 etcd 백업 및 복원"을 참조하십시오.
다음 명령을 입력하여 Kubernetes 및 OpenShift Container Platform 오브젝트를 백업합니다. 다음 오브젝트를 백업해야 합니다.
-
HostedCluster 네임스페이스의
HostedCluster및NodePool오브젝트 -
HostedCluster 네임스페이스의
HostedCluster시크릿 -
HostedControl Plane 네임 스페이스의
HostedControlPlane -
호스팅 컨트롤 플레인 네임스페이스의
Cluster -
호스팅된 컨트롤 플레인 네임스페이스에서
AWSCluster,AWSMachineTemplate,AWSMachine -
Hosted Control Plane 네임스페이스에서
MachineDeployments,MachineSets,Machines 호스팅된 컨트롤 플레인 네임스페이스의
ControlPlane시크릿$ mkdir -p ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS} ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $ chmod 700 ${BACKUP_DIR}/namespaces/ # HostedCluster $ echo "Backing Up HostedCluster Objects:" $ oc get hc ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml $ echo "--> HostedCluster" $ sed -i '' -e '/^status:$/,$d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml # NodePool $ oc get np ${NODEPOOLS} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml $ echo "--> NodePool" $ sed -i '' -e '/^status:$/,$ d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml # Secrets in the HC Namespace $ echo "--> HostedCluster Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS} | grep "^${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-${s}.yaml done # Secrets in the HC Control Plane Namespace $ echo "--> HostedCluster ControlPlane Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} | egrep -v "docker|service-account-token|oauth-openshift|NAME|token-${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-${s}.yaml done # Hosted Control Plane $ echo "--> HostedControlPlane:" $ oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-${HC_CLUSTER_NAME}.yaml # Cluster $ echo "--> Cluster:" $ CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) $ oc get cluster ${CL_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-${HC_CLUSTER_NAME}.yaml # AWS Cluster $ echo "--> AWS Cluster:" $ oc get awscluster ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-${HC_CLUSTER_NAME}.yaml # AWS MachineTemplate $ echo "--> AWS Machine Template:" $ oc get awsmachinetemplate ${NODEPOOLS} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-${HC_CLUSTER_NAME}.yaml # AWS Machines $ echo "--> AWS Machine:" $ CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) for s in $(oc get awsmachines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --no-headers | grep ${CL_NAME} | cut -f1 -d\ ); do oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} awsmachines $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-${s}.yaml done # MachineDeployments $ echo "--> HostedCluster MachineDeployments:" for s in $(oc get machinedeployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do mdp_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-${mdp_name}.yaml done # MachineSets $ echo "--> HostedCluster MachineSets:" for s in $(oc get machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do ms_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-${ms_name}.yaml done # Machines $ echo "--> HostedCluster Machine:" for s in $(oc get machine -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do m_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-${m_name}.yaml done
-
HostedCluster 네임스페이스의
다음 명령을 입력하여
ControlPlane경로를 정리합니다.$ oc delete routes -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all해당 명령을 입력하면 ExternalDNS Operator가 Route53 항목을 삭제할 수 있습니다.
이 스크립트를 실행하여 Route53 항목이 정리되었는지 확인합니다.
function clean_routes() { if [[ -z "${1}" ]];then echo "Give me the NS where to clean the routes" exit 1 fi # Constants if [[ -z "${2}" ]];then echo "Give me the Route53 zone ID" exit 1 fi ZONE_ID=${2} ROUTES=10 timeout=40 count=0 # This allows us to remove the ownership in the AWS for the API route oc delete route -n ${1} --all while [ ${ROUTES} -gt 2 ] do echo "Waiting for ExternalDNS Operator to clean the DNS Records in AWS Route53 where the zone id is: ${ZONE_ID}..." echo "Try: (${count}/${timeout})" sleep 10 if [[ $count -eq timeout ]];then echo "Timeout waiting for cleaning the Route53 DNS records" exit 1 fi count=$((count+1)) ROUTES=$(aws route53 list-resource-record-sets --hosted-zone-id ${ZONE_ID} --max-items 10000 --output json | grep -c ${EXTERNAL_DNS_DOMAIN}) done } # SAMPLE: clean_routes "<HC ControlPlane Namespace>" "<AWS_ZONE_ID>" clean_routes "${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" "${AWS_ZONE_ID}"
검증
모든 OpenShift Container Platform 오브젝트 및 S3 버킷을 확인하여 모든 것이 예상대로 표시되는지 확인합니다.
다음 단계
호스팅된 클러스터를 복원합니다.
9.5.3. 호스팅된 클러스터 복원
백업한 모든 오브젝트를 수집하고 대상 관리 클러스터에 복원합니다.
사전 요구 사항
소스 관리 클러스터에서 데이터를 백업합니다.
대상 관리 클러스터의 kubeconfig 파일이 KUBECONFIG 변수에 설정되거나 스크립트를 사용하는 경우 MGMT2_KUBECONFIG 변수에 배치되었는지 확인합니다. export KUBECONFIG=<Kubeconfig FilePath>를 사용하거나 스크립트를 사용하는 경우 export KUBECONFIG=$MGMT2_KUBECONFIG} 를 사용합니다.
절차
다음 명령을 입력하여 복원 중인 클러스터의 네임스페이스가 새 관리 클러스터에 포함되어 있지 않은지 확인합니다.
$ export KUBECONFIG=${MGMT2_KUBECONFIG}$ BACKUP_DIR=${HC_CLUSTER_DIR}/backup대상 관리 클러스터의 네임스페이스 삭제
$ oc delete ns ${HC_CLUSTER_NS} || true$ oc delete ns ${HC_CLUSTER_NS}-{HC_CLUSTER_NAME} || true다음 명령을 입력하여 삭제된 네임스페이스를 다시 생성합니다.
네임스페이스 생성 명령
$ oc new-project ${HC_CLUSTER_NS}$ oc new-project ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}다음 명령을 입력하여 HC 네임스페이스에 보안을 복원합니다.
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-*다음 명령을 입력하여
HostedCluster컨트롤 플레인 네임스페이스에서 오브젝트를 복원합니다.시크릿 명령 복원
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-*클러스터 복원 명령
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-*노드와 노드 풀을 복구하여 AWS 인스턴스를 재사용하는 경우 다음 명령을 입력하여 HC 컨트롤 플레인 네임스페이스에서 오브젝트를 복원합니다.
AWS 명령
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-*머신 명령
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-*이 bash 스크립트를 실행하여 etcd 데이터 및 호스팅 클러스터를 복원합니다.
ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi HC_RESTORE_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-restore.yaml HC_BACKUP_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml HC_NEW_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-new.yaml cat ${HC_BACKUP_FILE} > ${HC_NEW_FILE} cat > ${HC_RESTORE_FILE} <<EOF restoreSnapshotURL: EOF for POD in ${ETCD_PODS}; do # Create a pre-signed URL for the etcd snapshot ETCD_SNAPSHOT="s3://${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" ETCD_SNAPSHOT_URL=$(AWS_DEFAULT_REGION=${MGMT2_REGION} aws s3 presign ${ETCD_SNAPSHOT}) # FIXME no CLI support for restoreSnapshotURL yet cat >> ${HC_RESTORE_FILE} <<EOF - "${ETCD_SNAPSHOT_URL}" EOF done cat ${HC_RESTORE_FILE} if ! grep ${HC_CLUSTER_NAME}-snapshot.db ${HC_NEW_FILE}; then sed -i '' -e "/type: PersistentVolume/r ${HC_RESTORE_FILE}" ${HC_NEW_FILE} sed -i '' -e '/pausedUntil:/d' ${HC_NEW_FILE} fi HC=$(oc get hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} -o name || true) if [[ ${HC} == "" ]];then echo "Deploying HC Cluster: ${HC_CLUSTER_NAME} in ${HC_CLUSTER_NS} namespace" oc apply -f ${HC_NEW_FILE} else echo "HC Cluster ${HC_CLUSTER_NAME} already exists, avoiding step" fi노드와 노드 풀을 복구하여 AWS 인스턴스를 재사용하는 경우 다음 명령을 입력하여 노드 풀을 복원합니다.
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-*
검증
노드가 완전히 복원되었는지 확인하려면 다음 기능을 사용합니다.
timeout=40 count=0 NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 while [ ${NODE_POOL_REPLICAS} != ${NODE_STATUS} ] do echo "Waiting for Nodes to be Ready in the destination MGMT Cluster: ${MGMT2_CLUSTER_NAME}" echo "Try: (${count}/${timeout})" sleep 30 if [[ $count -eq timeout ]];then echo "Timeout waiting for Nodes in the destination MGMT Cluster" exit 1 fi count=$((count+1)) NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 done
다음 단계
클러스터를 종료하고 삭제합니다.
9.5.4. 소스 관리 클러스터에서 호스트된 클러스터 삭제
호스팅된 클러스터를 백업하고 대상 관리 클러스터로 복원한 후 소스 관리 클러스터에서 호스팅된 클러스터를 종료하고 삭제합니다.
사전 요구 사항
데이터를 백업하고 소스 관리 클러스터에 복원했습니다.
대상 관리 클러스터의 kubeconfig 파일이 KUBECONFIG 변수에 설정되거나 스크립트를 사용하는 경우 MGMT_KUBECONFIG 변수에 배치되었는지 확인합니다. export KUBECONFIG=<Kubeconfig FilePath>를 사용하거나 스크립트를 사용하는 경우 export KUBECONFIG=$MGMT_KUBECONFIG} 를 사용합니다.
절차
다음 명령을 입력하여
deployment및statefulset오브젝트를 확장합니다.중요spec.persistentVolumeClaimRetentionPolicy.whenScaled필드의 값이Delete로 설정된 경우 데이터 손실이 발생할 수 있으므로 상태 저장 세트를 스케일링하지 마십시오.이 문제를 해결하려면
spec.persistentVolumeClaimRetentionPolicy.whenScaled필드의 값을Retain으로 업데이트합니다. 상태 저장 세트를 조정하는 컨트롤러가 없는지 확인하고 값을Delete로 다시 반환하여 데이터가 손실될 수 있습니다.$ export KUBECONFIG=${MGMT_KUBECONFIG}배포 명령 축소
$ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all$ oc scale statefulset.apps -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all$ sleep 15다음 명령을 입력하여
NodePool오브젝트를 삭제합니다.NODEPOOLS=$(oc get nodepools -n ${HC_CLUSTER_NS} -o=jsonpath='{.items[?(@.spec.clusterName=="'${HC_CLUSTER_NAME}'")].metadata.name}') if [[ ! -z "${NODEPOOLS}" ]];then oc patch -n "${HC_CLUSTER_NS}" nodepool ${NODEPOOLS} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' oc delete np -n ${HC_CLUSTER_NS} ${NODEPOOLS} fi다음 명령을 입력하여
machine및machineset오브젝트를 삭제합니다.# Machines for m in $(oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done$ oc delete machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all || true다음 명령을 입력하여 클러스터 오브젝트를 삭제합니다.
$ C_NAME=$(oc get cluster -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name)$ oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${C_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'$ oc delete cluster.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all이러한 명령을 입력하여 AWS 머신(Kubernetes 오브젝트)을 삭제합니다. 실제 AWS 머신 삭제에 대해 우려하지 마십시오. 클라우드 인스턴스는 영향을 받지 않습니다.
for m in $(oc get awsmachine.infrastructure.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name) do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done다음 명령을 입력하여
HostedControlPlane및ControlPlaneHC 네임스페이스 오브젝트를 삭제합니다.HCP 및 ControlPlane HC NS 명령 삭제
$ oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} hostedcontrolplane.hypershift.openshift.io ${HC_CLUSTER_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'$ oc delete hostedcontrolplane.hypershift.openshift.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all$ oc delete ns ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} || true다음 명령을 입력하여
HostedCluster및 HC 네임스페이스 오브젝트를 삭제합니다.HC 및 HC 네임스페이스 명령 삭제
$ oc -n ${HC_CLUSTER_NS} patch hostedclusters ${HC_CLUSTER_NAME} -p '{"metadata":{"finalizers":null}}' --type merge || true$ oc delete hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} || true$ oc delete ns ${HC_CLUSTER_NS} || true
검증
모든 것이 작동하는지 확인하려면 다음 명령을 입력합니다.
검증 명령
$ export KUBECONFIG=${MGMT2_KUBECONFIG}$ oc get hc -n ${HC_CLUSTER_NS}$ oc get np -n ${HC_CLUSTER_NS}$ oc get pod -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}$ oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}HostedCluster 내부 명령
$ export KUBECONFIG=${HC_KUBECONFIG}$ oc get clusterversion$ oc get nodes
다음 단계
새 관리 클러스터에서 실행되는 새 OVN 컨트롤 플레인에 연결할 수 있도록 호스팅 클러스터에서 OVN Pod를 삭제합니다.
-
호스팅 클러스터의 kubeconfig 경로를 사용하여
KUBECONFIG환경 변수를 로드합니다. 다음 명령을 입력합니다.
$ oc delete pod -n openshift-ovn-kubernetes --all
9.6. OADP를 사용하여 호스트된 클러스터에 대한 재해 복구
OADP(OpenShift API for Data Protection) Operator를 사용하여 AWS(Amazon Web Services) 및 베어 메탈에서 재해 복구를 수행할 수 있습니다.
OADP(OpenShift API for Data Protection)의 재해 복구 프로세스에는 다음 단계가 포함됩니다.
- OADP를 사용하도록 Amazon Web Services 또는 베어 메탈과 같은 플랫폼 준비
- 데이터 플레인 워크로드 백업
- 컨트롤 플레인 워크로드 백업
- OADP를 사용하여 호스트 클러스터 복원
9.6.1. 사전 요구 사항
관리 클러스터에서 다음 사전 요구 사항을 충족해야 합니다.
- OADP Operator가 설치되어 있어야 합니다.
- 스토리지 클래스를 생성하셨습니다.
-
cluster-admin권한이 있는 클러스터에 액세스할 수 있습니다. - 카탈로그 소스를 통해 OADP 서브스크립션에 액세스할 수 있습니다.
- S3, Microsoft Azure, Google Cloud 또는 MinIO와 같은 OADP와 호환되는 클라우드 스토리지 공급자에 액세스할 수 있습니다.
- 연결이 끊긴 환경에서는 OADP와 호환되는 자체 호스팅 스토리지 공급자(예: Red Hat OpenShift Data Foundation 또는 MinIO )에 액세스할 수 있습니다.
- 호스팅된 컨트롤 플레인 pod가 실행 중입니다.
9.6.2. OADP를 사용하도록 AWS 준비
호스트된 클러스터에 대한 재해 복구를 수행하려면 AWS(Amazon Web Services) S3 호환 스토리지에서 OADP(OpenShift API for Data Protection)를 사용할 수 있습니다. DataProtectionApplication 오브젝트를 생성하면 openshift-adp 네임스페이스에 새 velero 배포 및 node-agent Pod가 생성됩니다.
OADP를 사용하도록 AWS를 준비하려면 "Multicloud Object Gateway로 데이터 보호를 위한 OpenShift API 구성"을 참조하십시오.
다음 단계
- 데이터 플레인 워크로드 백업
- 컨트롤 플레인 워크로드 백업
9.6.3. OADP를 사용하도록 베어 메탈 준비
호스트된 클러스터에 대한 재해 복구를 수행하려면 베어 메탈에서 OADP(OpenShift API for Data Protection)를 사용할 수 있습니다. DataProtectionApplication 오브젝트를 생성하면 openshift-adp 네임스페이스에 새 velero 배포 및 node-agent Pod가 생성됩니다.
OADP를 사용하도록 베어 메탈을 준비하려면 "AWS S3 호환 스토리지로 데이터 보호를 위한 OpenShift API 구성"을 참조하십시오.
다음 단계
- 데이터 플레인 워크로드 백업
- 컨트롤 플레인 워크로드 백업
9.6.4. 데이터 플레인 워크로드 백업
데이터 플레인 워크로드가 중요하지 않은 경우 이 절차를 건너뛸 수 있습니다. OADP Operator를 사용하여 데이터 플레인 워크로드를 백업하려면 "애플리케이션 백업"을 참조하십시오.
다음 단계
- OADP를 사용하여 호스트 클러스터 복원
9.6.5. 컨트롤 플레인 워크로드 백업
Backup CR(사용자 정의 리소스)을 생성하여 컨트롤 플레인 워크로드를 백업할 수 있습니다.
백업 프로세스를 모니터링하고 관찰하려면 "백업 및 복원 프로세스 예약"을 참조하십시오.
프로세스
다음 명령을 실행하여
HostedCluster리소스의 조정을 일시 중지합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ --type json -p '[{"op": "add", "path": "/spec/pausedUntil", "value": "true"}]'다음 명령을 실행하여
NodePool리소스의 조정을 일시 중지합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch nodepool -n <hosted_cluster_namespace> <node_pool_name> \ --type json -p '[{"op": "add", "path": "/spec/pausedUntil", "value": "true"}]'다음 명령을 실행하여
AgentCluster리소스의 조정을 일시 중지합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate agentcluster -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused=true --all'다음 명령을 실행하여
AgentMachine리소스의 조정을 일시 중지합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate agentmachine -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused=true --all'다음 명령을 실행하여 호스팅된 컨트롤 플레인 네임스페이스를 삭제하지 않도록
HostedCluster리소스에 주석을 답니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ hypershift.openshift.io/skip-delete-hosted-controlplane-namespace=trueBackupCR을 정의하는 YAML 파일을 생성합니다.예 9.1.
backup-control-plane.yaml파일 예apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_resource_name>1 namespace: openshift-adp labels: velero.io/storage-location: default spec: hooks: {} includedNamespaces:2 - <hosted_cluster_namespace>3 - <hosted_control_plane_namespace>4 includedResources: - sa - role - rolebinding - pod - pvc - pv - bmh - configmap - infraenv5 - priorityclasses - pdb - agents - hostedcluster - nodepool - secrets - services - deployments - hostedcontrolplane - cluster - agentcluster - agentmachinetemplate - agentmachine - machinedeployment - machineset - machine excludedResources: [] storageLocation: default ttl: 2h0m0s snapshotMoveData: true6 datamover: "velero"7 defaultVolumesToFsBackup: true8 - 1
backup_resource_name을Backup리소스의 이름으로 교체합니다.- 2
- 특정 네임스페이스를 선택하여 오브젝트를 백업합니다. 호스팅 클러스터 네임스페이스와 호스팅된 컨트롤 플레인 네임스페이스를 포함해야 합니다.
- 3
<hosted_cluster_namespace>를 호스트된 클러스터 네임스페이스의 이름으로 바꿉니다(예:클러스터).- 4
<hosted_control_plane_namespace>를 호스트된 컨트롤 플레인 네임스페이스의 이름으로 바꿉니다(예:클러스터 호스팅).- 5
- 별도의 네임스페이스에
infraenv리소스를 생성해야 합니다. 백업 프로세스 중에infraenv리소스를 삭제하지 마십시오. - 6 7
- CSI 볼륨 스냅샷을 활성화하고 컨트롤 플레인 워크로드를 클라우드 스토리지에 자동으로 업로드합니다.
- 8
- PV(영구 볼륨)의
fs-backup방법을 기본값으로 설정합니다. 이 설정은 CSI(Container Storage Interface) 볼륨 스냅샷과fs-backup방법을 조합할 때 유용합니다.
참고CSI 볼륨 스냅샷을 사용하려면
backup.velero.io/backup-volumes-excludes=<pv_name>주석을 PV에 추가해야 합니다.다음 명령을 실행하여
BackupCR을 적용합니다.$ oc apply -f backup-control-plane.yaml
검증
다음 명령을 실행하여
status.phase의 값이완료되었는지 확인합니다.$ oc get backups.velero.io <backup_resource_name> -n openshift-adp -o jsonpath='{.status.phase}'
다음 단계
- OADP를 사용하여 호스트 클러스터 복원
9.6.6. OADP를 사용하여 호스트 클러스터 복원
Restore CR(사용자 정의 리소스)을 생성하여 호스팅된 클러스터를 복원할 수 있습니다.
- 인플레이스 업데이트를 사용하는 경우 InfraEnv에는 예비 노드가 필요하지 않습니다. 새 관리 클러스터에서 작업자 노드를 다시 프로비저닝해야 합니다.
- 교체 업데이트를 사용하는 경우 작업자 노드를 배포하려면 InfraEnv에 대한 예비 노드가 필요합니다.
호스트 클러스터를 백업한 후 이를 삭제하여 복원 프로세스를 시작해야 합니다. 노드 프로비저닝을 시작하려면 호스팅 클러스터를 삭제하기 전에 데이터 플레인의 워크로드를 백업해야 합니다.
사전 요구 사항
- 콘솔을 사용하여 호스팅된 클러스터를 삭제하여 클러스터 제거 단계를 완료했습니다.
- 클러스터를 제거한 후 나머지 리소스 제거 단계를 완료했습니다.
백업 프로세스를 모니터링하고 관찰하려면 "백업 및 복원 프로세스 예약"을 참조하십시오.
프로세스
다음 명령을 실행하여 호스팅된 컨트롤 플레인 네임스페이스에 Pod 및 PVC(영구 볼륨 클레임)가 없는지 확인합니다.
$ oc get pod pvc -n <hosted_control_plane_namespace>예상 출력
No resources foundRestoreCR을 정의하는 YAML 파일을 생성합니다.restore-hosted-cluster.yaml파일의 예apiVersion: velero.io/v1 kind: Restore metadata: name: <restore_resource_name>1 namespace: openshift-adp spec: backupName: <backup_resource_name>2 restorePVs: true3 existingResourcePolicy: update4 excludedResources: - nodes - events - events.events.k8s.io - backups.velero.io - restores.velero.io - resticrepositories.velero.io중요별도의 네임스페이스에
infraenv리소스를 생성해야 합니다. 복원 프로세스 중에infraenv리소스를 삭제하지 마십시오. 새 노드를 다시 프로비저닝하려면infraenv리소스가 필요합니다.다음 명령을 실행하여
RestoreCR을 적용합니다.$ oc apply -f restore-hosted-cluster.yaml다음 명령을 실행하여
status.phase의 값이완료되었는지 확인합니다.$ oc get hostedcluster <hosted_cluster_name> -n <hosted_cluster_namespace> -o jsonpath='{.status.phase}'복원 프로세스가 완료되면 컨트롤 플레인 워크로드를 백업하는 동안 일시 중지된
HostedCluster및NodePool리소스의 조정을 시작합니다.다음 명령을 실행하여
HostedCluster리소스의 조정을 시작합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ --type json -p '[{"op": "add", "path": "/spec/pausedUntil", "value": "false"}]'다음 명령을 실행하여
NodePool리소스의 조정을 시작합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch nodepool -n <hosted_cluster_namespace> <node_pool_name> \ --type json -p '[{"op": "add", "path": "/spec/pausedUntil", "value": "false"}]'
컨트롤 플레인 워크로드를 백업하는 동안 일시 중지된 에이전트 공급자 리소스의 조정을 시작합니다.
다음 명령을 실행하여
AgentCluster리소스의 조정을 시작합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate agentcluster -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused- --overwrite=true --all다음 명령을 실행하여
AgentMachine리소스의 조정을 시작합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate agentmachine -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused- --overwrite=true --all
다음 명령을 실행하여 호스팅된 컨트롤 플레인 네임스페이스를 수동으로 삭제하지 않도록
HostedCluster리소스에서hypershift.openshift.io/skip-delete-hosted-controlplane-namespace-annotations을 제거합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ hypershift.openshift.io/skip-delete-hosted-controlplane-namespace- \ --overwrite=true --all다음 명령을 실행하여
NodePool리소스를 원하는 복제본 수로 조정합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ scale nodepool -n <hosted_cluster_namespace> <node_pool_name> \ --replicas <replica_count>1 - 1
<replica_count>를 정수 값으로 바꿉니다(예:3).
9.6.7. 백업 및 복원 프로세스 관찰
OADP(OpenShift API for Data Protection)를 사용하여 호스팅된 클러스터를 백업하고 복원할 때 프로세스를 모니터링하고 관찰할 수 있습니다.
프로세스
다음 명령을 실행하여 백업 프로세스를 관찰합니다.
$ watch "oc get backups.velero.io -n openshift-adp <backup_resource_name> -o jsonpath='{.status}'"다음 명령을 실행하여 복원 프로세스를 관찰합니다.
$ watch "oc get restores.velero.io -n openshift-adp <backup_resource_name> -o jsonpath='{.status}'"다음 명령을 실행하여 Velero 로그를 관찰합니다.
$ oc logs -n openshift-adp -ldeploy=velero -f다음 명령을 실행하여 모든 OADP 오브젝트의 진행 상황을 확인합니다.
$ watch "echo BackupRepositories:;echo;oc get backuprepositories.velero.io -A;echo; echo BackupStorageLocations: ;echo; oc get backupstoragelocations.velero.io -A;echo;echo DataUploads: ;echo;oc get datauploads.velero.io -A;echo;echo DataDownloads: ;echo;oc get datadownloads.velero.io -n openshift-adp; echo;echo VolumeSnapshotLocations: ;echo;oc get volumesnapshotlocations.velero.io -A;echo;echo Backups:;echo;oc get backup -A; echo;echo Restores:;echo;oc get restore -A"
9.6.8. velero CLI를 사용하여 백업 및 복원 리소스 설명
데이터 보호를 위한 OpenShift API를 사용하는 경우 velero CLI(명령줄 인터페이스)를 사용하여 Backup 및 Restore 리소스에 대한 자세한 정보를 얻을 수 있습니다.
프로세스
다음 명령을 실행하여 컨테이너에서
veleroCLI를 사용하도록 별칭을 생성합니다.$ alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'다음 명령을 실행하여
RestoreCR(사용자 정의 리소스)에 대한 세부 정보를 가져옵니다.$ velero restore describe <restore_resource_name> --details1 - 1
<restore_resource_name>을Restore리소스의 이름으로 바꿉니다.
다음 명령을 실행하여
BackupCR에 대한 세부 정보를 가져옵니다.$ velero restore describe <backup_resource_name> --details1 - 1
<backup_resource_name>을Backup리소스의 이름으로 바꿉니다.
10장. 호스트된 컨트롤 플레인 문제 해결
호스트된 컨트롤 플레인에 문제가 있는 경우 다음 정보를 참조하여 문제 해결을 안내하십시오.
10.1. 호스트된 컨트롤 플레인 문제를 해결하기 위한 정보 수집
호스팅된 컨트롤 플레인 클러스터 문제를 해결해야 하는 경우 must-gather 명령을 실행하여 정보를 수집할 수 있습니다. 명령은 관리 클러스터 및 호스팅 클러스터에 대한 출력을 생성합니다.
관리 클러스터의 출력에는 다음 내용이 포함됩니다.
- 클러스터 범위 리소스: 이러한 리소스는 관리 클러스터의 노드 정의입니다.
-
hypershift-dump압축 파일: 이 파일은 다른 사용자와 콘텐츠를 공유해야 하는 경우에 유용합니다. - 네임스페이스 리소스: 이러한 리소스에는 구성 맵, 서비스, 이벤트 및 로그와 같은 관련 네임스페이스의 모든 오브젝트가 포함됩니다.
- 네트워크 로그: 이 로그에는 OVN northbound 및 southbound 데이터베이스와 각각에 대한 상태가 포함됩니다.
- 호스트 클러스터: 이 수준의 출력에는 호스팅된 클러스터 내부의 모든 리소스가 포함됩니다.
호스팅 클러스터의 출력에는 다음 내용이 포함됩니다.
- 클러스터 범위 리소스: 이러한 리소스에는 노드 및 CRD와 같은 모든 클러스터 전체 오브젝트가 포함됩니다.
- 네임스페이스 리소스: 이러한 리소스에는 구성 맵, 서비스, 이벤트 및 로그와 같은 관련 네임스페이스의 모든 오브젝트가 포함됩니다.
출력에 클러스터의 보안 오브젝트가 포함되어 있지 않지만 보안 이름에 대한 참조를 포함할 수 있습니다.
사전 요구 사항
-
관리 클러스터에 대한
cluster-admin액세스 권한이 있어야 합니다. -
HostedCluster리소스의name값과 CR이 배포된 네임스페이스가 필요합니다. -
hcp명령줄 인터페이스가 설치되어 있어야 합니다. 자세한 내용은 호스팅된 컨트롤 플레인 명령줄 인터페이스 설치를 참조하십시오. -
OpenShift CLI(
oc)가 설치되어 있어야 합니다. -
kubeconfig파일이 로드되고 관리 클러스터를 가리키는지 확인해야 합니다.
프로세스
문제 해결을 위해 출력을 수집하려면 다음 명령을 입력합니다.
$ oc adm must-gather --image=registry.redhat.io/multicluster-engine/must-gather-rhel9:v<mce_version> \ /usr/bin/gather hosted-cluster-namespace=HOSTEDCLUSTERNAMESPACE hosted-cluster-name=HOSTEDCLUSTERNAME \ --dest-dir=NAME ; tar -cvzf NAME.tgz NAME다음과 같습니다.
-
<
;mce_version>을 사용 중인 다중 클러스터 엔진 Operator 버전(예:2.6)으로 바꿉니다. -
hosted-cluster-namespace=HOSTEDCLUSTERNAMESPACE매개변수는 선택 사항입니다. 이를 포함하지 않으면 호스트 클러스터가 기본 네임스페이스인 클러스터인 것처럼 명령이실행됩니다. -
--dest-dir=NAME매개변수는 선택 사항입니다. 명령 결과를 압축 파일에 저장하려면NAME을 결과를 저장하려는 디렉터리의 이름으로 교체합니다.
-
<
10.2. 호스팅된 컨트롤 플레인 구성 요소 다시 시작
호스트된 컨트롤 플레인의 관리자인 경우 hypershift.openshift.io/restart-date 주석을 사용하여 특정 HostedCluster 리소스에 대한 모든 컨트롤 플레인 구성 요소를 다시 시작할 수 있습니다. 예를 들어 인증서 교체를 위해 컨트롤 플레인 구성 요소를 다시 시작해야 할 수 있습니다.
프로세스
컨트롤 플레인을 다시 시작하려면 다음 명령을 입력하여
HostedCluster리소스에 주석을 답니다.$ oc annotate hostedcluster \ -n <hosted_cluster_namespace> \ <hosted_cluster_name> \ hypershift.openshift.io/restart-date=$(date --iso-8601=seconds)1 - 1
- 주석 값이 변경될 때마다 컨트롤 플레인이 다시 시작됩니다.
date명령은 고유한 문자열의 소스로 사용됩니다. 주석은 타임스탬프가 아닌 문자열로 처리됩니다.
검증
컨트롤 플레인을 다시 시작한 후 다음 호스팅 컨트롤 플레인 구성 요소가 일반적으로 재시작됩니다.
다른 구성 요소에서 구현한 변경 사항의 측면 효과로 일부 추가 구성 요소가 다시 시작될 수 있습니다.
- catalog-operator
- certified-operators-catalog
- cluster-api
- cluster-autoscaler
- cluster-policy-controller
- cluster-version-operator
- community-operators-catalog
- control-plane-operator
- hosted-cluster-config-operator
- ignition-server
- ingress-operator
- konnectivity-agent
- konnectivity-server
- kube-apiserver
- kube-controller-manager
- kube-scheduler
- machine-approver
- oauth-openshift
- olm-operator
- openshift-apiserver
- openshift-controller-manager
- openshift-oauth-apiserver
- packageserver
- redhat-marketplace-catalog
- redhat-operators-catalog
10.3. 호스트 클러스터 및 호스팅된 컨트롤 플레인의 조정 일시 중지
클러스터 인스턴스 관리자인 경우 호스트 클러스터 및 호스팅된 컨트롤 플레인의 조정을 일시 중지할 수 있습니다. etcd 데이터베이스를 백업 및 복원하거나 호스팅된 클러스터 또는 호스팅된 컨트롤 플레인 문제를 디버깅해야 하는 경우 조정을 일시 중지해야 할 수 있습니다.
프로세스
호스트 클러스터 및 호스팅된 컨트롤 플레인에 대한 조정을 일시 중지하려면
HostedCluster리소스의pausedUntil필드를 채웁니다.특정 시간까지 조정을 일시 중지하려면 다음 명령을 입력합니다.
$ oc patch -n <hosted_cluster_namespace> hostedclusters/<hosted_cluster_name> -p '{"spec":{"pausedUntil":"<timestamp>"}}' --type=merge1 - 1
- RFC339 형식으로 타임스탬프를 지정합니다(예:
2024-03-03T03:28:48Z). 지정된 시간이 전달될 때까지 조정이 일시 중지됩니다.
조정을 무기한 일시 중지하려면 다음 명령을 입력합니다.
$ oc patch -n <hosted_cluster_namespace> hostedclusters/<hosted_cluster_name> -p '{"spec":{"pausedUntil":"true"}}' --type=mergeHostedCluster리소스에서 필드를 제거할 때까지 조정이 일시 중지됩니다.HostedCluster리소스에 대한 일시 중지 조정 필드가 채워지면 관련HostedControlPlane리소스에 필드가 자동으로 추가됩니다.
pausedUntil필드를 제거하려면 다음 패치 명령을 입력합니다.$ oc patch -n <hosted_cluster_namespace> hostedclusters/<hosted_cluster_name> -p '{"spec":{"pausedUntil":null}}' --type=merge
10.4. 데이터 플레인을 0으로 축소
호스팅된 컨트롤 플레인을 사용하지 않는 경우 리소스 및 비용을 절약하기 위해 데이터 플레인을 0으로 축소할 수 있습니다.
데이터 플레인을 0으로 축소할 준비가 되었는지 확인합니다. 작업자 노드의 워크로드는 축소 후 사라집니다.
프로세스
다음 명령을 실행하여 호스팅 클러스터에 액세스하도록
kubeconfig파일을 설정합니다.$ export KUBECONFIG=<install_directory>/auth/kubeconfig다음 명령을 실행하여 호스팅된 클러스터에 연결된
NodePool리소스의 이름을 가져옵니다.$ oc get nodepool --namespace <HOSTED_CLUSTER_NAMESPACE>선택 사항: Pod가 드레이닝되지 않도록 다음 명령을 실행하여
NodePool리소스에nodeDrainTimeout필드를 추가합니다.$ oc edit nodepool <nodepool_name> --namespace <hosted_cluster_namespace>출력 예
apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: arch: amd64 clusterName: clustername1 management: autoRepair: false replace: rollingUpdate: maxSurge: 1 maxUnavailable: 0 strategy: RollingUpdate upgradeType: Replace nodeDrainTimeout: 0s2 # ...참고노드 드레이닝 프로세스가 일정 기간 동안 계속될 수 있도록
nodeDrainTimeout필드의 값을 적절하게 설정할 수 있습니다(예:nodeDrainTimeout: 1m).다음 명령을 실행하여 호스팅된 클러스터에 연결된
NodePool리소스를 축소합니다.$ oc scale nodepool/<NODEPOOL_NAME> --namespace <HOSTED_CLUSTER_NAMESPACE> --replicas=0참고데이터 계획을 0으로 축소한 후 컨트롤 플레인의 일부 Pod는
Pending상태를 유지하고 호스팅된 컨트롤 플레인은 계속 실행 중입니다. 필요한 경우NodePool리소스를 확장할 수 있습니다.선택 사항: 다음 명령을 실행하여 호스팅된 클러스터에 연결된
NodePool리소스를 확장합니다.$ oc scale nodepool/<NODEPOOL_NAME> --namespace <HOSTED_CLUSTER_NAMESPACE> --replicas=1NodePool리소스를 다시 확장한 후NodePool리소스가Ready상태에서 사용 가능하게 될 때까지 몇 분 정도 기다립니다.
검증
다음 명령을 실행하여
nodeDrainTimeout필드의 값이0s보다 큰지 확인합니다.$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -ojsonpath='{.spec.nodeDrainTimeout}'
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.