지원
OpenShift Container Platform 지원 요청
초록
1장. 지원 개요
Red Hat은 클러스터, 모니터링 및 문제 해결을 위한 클러스터 관리자 툴을 제공합니다.
1.1. 지원 받기
지원 받기: Red Hat 고객 포털을 방문하여 지식 베이스 문서를 검토하고, 지원 케이스를 제출하고, 추가 제품 설명서 및 리소스를 검토하십시오.
1.2. HO원격 상태 모니터링 문제
원격 상태 모니터링 문제: OpenShift Container Platform은 클러스터에 대한 Telemetry 및 구성 데이터를 수집하여 Telemeter Client 및 Insights Operator를 사용하여 Red Hat에 보고합니다. Red Hat은 이 데이터를 사용하여 연결된 클러스터 의 문제를 이해하고 해결합니다. 연결된 클러스터와 유사하게 제한된 네트워크에서 원격 상태 모니터링을 사용할 수 있습니다. OpenShift Container Platform은 다음을 사용하여 데이터를 수집하고 상태를 모니터링합니다.
Telemetry: Telemetry 클라이언트는 4분 30초마다 지표 값을 수집하여 Red Hat에 업로드합니다. Red Hat은 이 데이터를 사용하여 다음을 수행합니다.
- 클러스터를 모니터링합니다.
- OpenShift Container Platform 업그레이드를 롤아웃합니다.
- 업그레이드 환경을 개선합니다.
Insights Operator: 기본적으로 OpenShift Container Platform은 2시간마다 구성 및 구성 요소 실패 상태를 보고하는 Insights Operator를 설치하고 활성화합니다. Insights Operator는 다음을 지원합니다.
- 잠재적인 클러스터 문제를 사전에 파악합니다.
- Red Hat OpenShift Cluster Manager에서 솔루션 및 예방 조치를 제공합니다.
Telemetry 정보를 검토 할 수 있습니다.
원격 상태 보고를 활성화한 경우 Insights를 사용하여 클러스터 문제를 식별합니다. 선택적으로 원격 상태 보고를 비활성화할 수 있습니다.
1.3. 클러스터에 대한 데이터 수집
클러스터에 대한 데이터 수집: 지원 케이스를 열 때 디버깅 정보를 수집할 것을 권장합니다. 이를 통해 Red Hat 지원은 근본 원인 분석을 수행할 수 있습니다. 클러스터 관리자는 다음을 사용하여 클러스터에 대한 데이터를 수집할 수 있습니다.
-
must-gather 툴:
must-gather툴을 사용하여 클러스터에 대한 정보를 수집하고 문제를 디버깅합니다. -
sosreport: 디버깅을 위해
sosreport툴을 사용하여 구성 세부 정보, 시스템 정보 및 진단 데이터를 수집합니다. - 클러스터 ID: Red Hat 지원에 정보를 제공할 때 클러스터의 고유 식별자를 가져옵니다.
-
부트스트랩 노드 저널 로그: 부트 스트랩 노드에서
bootkube.servicejournald장치 로그 및 컨테이너 로그를 수집하여 부트스트랩 관련 문제를 해결합니다. -
클러스터 노드 저널 로그: 노드 관련 문제를 해결하기 위해 개별 클러스터 노드의
/var/log내에 있는journald장치 로그 및 로그입니다. - 네트워크 추적: 특정 OpenShift Container Platform 클러스터 노드 또는 컨테이너에서 Red Hat 지원으로 네트워크 패킷 추적을 제공하여 네트워크 관련 문제를 해결합니다.
-
진단 데이터:
redhat-support-tool명령을 사용하여 클러스터에 대한 진단 데이터를 수집합니다.
1.4. 문제 해결
클러스터 관리자는 다음 OpenShift Container Platform 구성 요소 문제를 모니터링하고 해결할 수 있습니다.
설치 문제: OpenShift Container Platform 설치는 다양한 단계로 진행됩니다. 다음을 수행할 수 있습니다.
- 설치 단계를 모니터링합니다.
- 어떤 단계에서 설치 문제가 발생하는지 확인합니다.
- 여러 설치 문제를 조사합니다.
- 실패한 설치에서 로그를 수집합니다.
노드 문제: 클러스터 관리자는 노드의 상태, 리소스 사용량 및 구성을 검토하여 노드 관련 문제를 확인하고 해결할 수 있습니다. 다음을 쿼리할 수 있습니다.
- 노드의 kubelet 상태입니다.
- 클러스터 노드 저널 로그입니다.
crio 문제: 클러스터 관리자는 각 클러스터 노드에서 CRI-O 컨테이너 런타임 엔진 상태를 확인할 수 있습니다. 컨테이너 런타임 문제가 발생하는 경우 다음을 수행합니다.
- CRI-O journald 장치 로그를 수집합니다.
- CRI-O 스토리지 정리.
운영 체제 문제: OpenShift Container Platform은 Red Hat Enterprise Linux CoreOS에서 실행됩니다. 운영 체제 문제가 발생하는 경우 커널 충돌 절차를 조사할 수 있습니다. 다음을 확인하십시오.
- kdump를 활성화합니다.
- kdump 설정을 테스트합니다.
- 코어 덤프를 분석합니다.
네트워크 문제: Open vSwitch 문제를 해결하기 위해 클러스터 관리자는 다음을 수행할 수 있습니다.
- Open vSwitch 로그 수준을 일시적으로 구성합니다.
- Open vSwitch 로그 수준을 영구적으로 구성합니다.
- Open vSwitch 로그를 표시합니다.
Operator 문제: 클러스터 관리자는 다음을 수행하여 Operator 문제를 해결할 수 있습니다.
- Operator 서브스크립션 상태를 확인합니다.
- Operator Pod 상태를 확인합니다.
- Operator 로그를 수집합니다.
Pod 문제: 클러스터 관리자는 Pod 상태를 검토하고 다음을 완료하여 Pod 관련 문제를 해결할 수 있습니다.
- Pod 및 컨테이너 로그를 검토합니다.
- root 액세스 권한으로 디버그 Pod를 시작합니다.
S2I 프로세스에서 오류가 발생한 위치를 확인하기 위해 클러스터 관리자는 S2I 단계를 관찰할 수 있습니다. 다음을 수집하여 S2I(Source-to-Image) 문제를 해결합니다.
- S2I(Source-to-Image) 진단 데이터입니다.
- 애플리케이션 오류를 조사하기 위한 애플리케이션 진단 데이터입니다.
스토리지 문제: 실패한 노드가 연결된 볼륨을 마운트 해제할 수 없기 때문에 새 노드의 마운트 볼륨이 불가능한 경우 다중 연결 스토리지 오류가 발생합니다. 클러스터 관리자는 다음을 수행하여 다중 연결 스토리지 문제를 해결할 수 있습니다.
- RWX 볼륨을 사용하여 여러 연결을 활성화합니다.
- RWO 볼륨을 사용할 때 오류가 발생한 노드를 복구하거나 삭제합니다.
모니터링 문제: 클러스터 관리자는 모니터링을 위해 문제 해결 페이지의 절차를 따를 수 있습니다. 사용자 정의 프로젝트의 지표를 사용할 수 없거나 Prometheus가 많은 디스크 공간을 사용하는 경우 다음을 확인하십시오.
- 사용자 정의 메트릭을 사용할 수 없는 이유를 조사합니다.
- Prometheus가 많은 디스크 공간을 소비하는 이유를 확인합니다.
로깅 문제: 클러스터 관리자는 "지원" 및 "Troubleshooting logging" 섹션의 절차를 따라 로깅 문제를 해결할 수 있습니다.
-
OpenShift CLI(
oc) 문제: 로그 수준을 늘려 OpenShift CLI(oc) 문제 조사
2장. 클러스터 리소스 관리
OpenShift Container Platform에서 글로벌 구성 옵션을 적용할 수 있습니다. Operator는 이러한 구성 설정을 클러스터 전체에 적용합니다.
2.1. 클러스터 리소스와 상호 작용
OpenShift Container Platform에서 OpenShift CLI(oc) 툴을 사용하여 클러스터 리소스와 상호 작용할 수 있습니다. oc api-resources 명령을 실행한 후 표시되는 클러스터 리소스를 편집할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
웹 콘솔에 액세스하거나
ocCLI 툴을 설치했습니다.
프로세스
적용된 구성 Operator를 보려면 다음 명령을 실행합니다.
$ oc api-resources -o name | grep config.openshift.io구성할 수 있는 클러스터 리소스를 보려면 다음 명령을 실행합니다.
$ oc explain <resource_name>.config.openshift.io클러스터에서 CRD(사용자 정의 리소스 정의) 오브젝트의 구성을 보려면 다음 명령을 실행합니다.
$ oc get <resource_name>.config -o yaml클러스터 리소스 구성을 편집하려면 다음 명령을 실행합니다.
$ oc edit <resource_name>.config -o yaml
3장. 지원 요청
3.1. 지원 요청
이 문서에 설명된 절차 또는 일반적으로 OpenShift Container Platform에 문제가 발생하는 경우 Red Hat 고객 포털에 액세스하십시오.
고객 포털에서 다음을 수행할 수 있습니다.
- Red Hat 제품과 관련된 기사 및 솔루션에 대한 Red Hat 지식베이스를 검색하거나 살펴볼 수 있습니다.
- Red Hat 지원에 대한 지원 케이스 제출할 수 있습니다.
- 다른 제품 설명서에 액세스 가능합니다.
클러스터 문제를 식별하기 위해 OpenShift Cluster Manager 에서 Insights를 사용할 수 있습니다. Insights는 문제에 대한 세부 정보 및 문제 해결 방법에 대한 정보를 제공합니다.
이 문서를 개선하기 위한 제안이 있거나 오류를 발견한 경우 가장 관련 문서 구성 요소에 대해 Jira 문제를 제출합니다. 섹션 이름 및 OpenShift Container Platform 버전과 같은 구체적인 정보를 제공합니다.
3.2. Red Hat 지식베이스 정보
Red Hat 지식베이스는 Red Hat의 제품과 기술을 최대한 활용할 수 있도록 풍부한 콘텐츠를 제공합니다. Red Hat 지식베이스는 Red Hat 제품 설치, 설정 및 사용에 대한 기사, 제품 문서 및 동영상으로 구성되어 있습니다. 또한 알려진 문제에 대한 솔루션을 검색할 수 있으며, 간결한 근본 원인 설명 및 해결 단계를 제공합니다.
3.3. Red Hat 지식베이스 검색
OpenShift Container Platform 문제가 발생한 경우 초기 검색을 수행하여 솔루션이 이미 Red Hat Knowledgebase 내에 존재하는지 확인할 수 있습니다.
사전 요구 사항
- Red Hat 고객 포털 계정이 있어야 합니다.
프로세스
- Red Hat 고객 포털에 로그인합니다.
- Search를 클릭합니다
검색 필드에서 다음을 포함하여 문제와 관련된 키워드 및 문자열을 입력합니다.
- OpenShift Container Platform 구성 요소 (etcd 등)
- 관련 절차 (예: installation 등)
- 명시적 실패와 관련된 경고, 오류 메시지 및 기타 출력
- Enter 키를 클릭합니다.
- 선택 사항: OpenShift Container Platform 제품 필터를 선택합니다.
- 선택 사항: 문서 콘텐츠 유형 필터를 선택합니다.
3.4. 지원 케이스 제출
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다. - Red Hat 고객 포털 계정이 있어야 합니다.
- Red Hat Standard 또는 Premium 서브스크립션이 있어야 합니다.
프로세스
- Red Hat 고객 포털의 고객 지원 페이지에 로그인합니다.
- 지원 받기를 클릭합니다.
고객 지원 페이지의 케이스 탭에서 다음을 수행합니다.
- 선택 사항: 필요한 경우 미리 채워진 계정 및 소유자 세부 정보를 변경합니다.
- Bug 또는 Defect 와 같은 문제에 대한 적절한 카테고리를 선택하고 Continue 를 클릭합니다.
다음 정보를 입력합니다.
- 요약 필드에 간결하지만 설명적인 문제 요약을 입력하고 경험되는 증상에 대한 자세한 내용과 기대치를 입력합니다.
- 제품 드롭다운 메뉴에서 OpenShift Container Platform 을 선택합니다.
- 버전 드롭다운에서 4.16 을 선택합니다.
- 보고되는 문제와 관련이 있을 수 있는 권장 Red Hat 지식베이스 솔루션 목록을 확인합니다. 제안된 문서로 문제가 해결되지 않으면 Continue을 클릭합니다.
- 보고되는 문제와 관련있는 제안된 Red Hat 지식베이스 솔루션 목록을 확인하십시오. 케이스 작성 과정에서 더 많은 정보를 제공하면 목록이 구체화됩니다. 제안된 문서로 문제가 해결되지 않으면 Continue을 클릭합니다.
- 제시된 계정 정보가 정확한지 확인하고 필요한 경우 적절하게 수정합니다.
자동 입력된 OpenShift Container Platform 클러스터 ID가 올바른지 확인합니다. 그렇지 않은 경우 클러스터 ID를 수동으로 가져옵니다.
OpenShift Container Platform 웹 콘솔을 사용하여 클러스터 ID를 수동으로 가져오려면 다음을 수행합니다.
- 홈 → 개요 로 이동합니다.
- Details 섹션의 Cluster ID 필드에서 값을 찾습니다.
또는 OpenShift Container Platform 웹 콘솔을 통해 새 지원 케이스를 열고 클러스터 ID를 자동으로 입력할 수 있습니다.
- 툴바에서 (?) Help → Open Support Case로 이동합니다.
- Cluster ID 값이 자동으로 입력됩니다.
OpenShift CLI (
oc)를 사용하여 클러스터 ID를 얻으려면 다음 명령을 실행합니다.$ oc get clusterversion -o jsonpath='{.items[].spec.clusterID}{"\n"}'
프롬프트가 표시되면 다음 질문을 입력한 후 Continue를 클릭합니다.
- 무엇을 경험하고 있습니까? 어떤 일이 발생할 것으로 예상하십니까?
- 귀하 또는 비즈니스에 미치는 영향 또는 가치를 정의합니다.
- 이 동작을 어디에서 경험하고 있습니까? 어떤 시스템 환경을 사용하고 있습니까?
- 이 동작이 언제 발생합니까? 발생 빈도는 어떻게 됩니까? 반복적으로 발생합니까? 특정 시간에만 발생합니까?
-
관련 진단 데이터 파일을 업로드하고 Continue를 클릭합니다.
oc adm must-gather명령을 사용하여 수집된 데이터와 해당 명령으로 수집되지 않은 특정 문제와 관련된 데이터를 제공하는 것이 좋습니다 - 관련 케이스 관리 세부 정보를 입력하고 Continue를 클릭합니다.
- 케이스 세부 정보를 미리보고 Submit을 클릭합니다.
4장. 클러스터에 연결하여 원격 상태 모니터링
4.1. 원격 상태 모니터링 정보
OpenShift Container Platform은 클러스터에 대한 Telemetry 및 구성 데이터를 수집하고 Telemeter Client 및 Insights Operator를 사용하여 Red Hat에 보고합니다. Red Hat에 제공되는 데이터는 이 문서에 설명된 장점을 사용할 수 있습니다.
Telemetry 및 Insights Operator를 통해 Red Hat에 데이터를 보고하는 클러스터는 연결 클러스터(connected cluster)라고 합니다.
Telemetry는 OpenShift Container Platform Telemeter Client에서 Red Hat으로 전송되는 정보를 설명하는 데 사용하는 용어입니다. 경량 속성은 연결된 클러스터에서 Red Hat으로 전송되어 서브스크립션 관리 자동화를 활성화하고, 클러스터의 상태를 모니터링하며, 지원 및 고객 환경을 개선합니다.
Insights Operator는 OpenShift Container Platform 구성 데이터를 수집하여 Red Hat으로 전송합니다. 데이터는 클러스터가 노출될 수 있는 문제에 대한 통찰력을 생성하는 데 사용됩니다. 이러한 통찰력은 OpenShift Cluster Manager 에서 클러스터 관리자에게 전달됩니다.
이 두 프로세스에 대한 자세한 내용은 이 문서에 기재되어 있습니다.
Telemetry 및 Insights Operator의 이점
Telemetry 및 Insights Operator는 최종 사용자에게 다음과 같은 이점을 제공합니다.
- 문제 확인 및 해결 방법을 강화 Red Hat은 최종 사용자에 정상적으로 표시될 수 있는 이벤트를 클러스터 단위로 보다 광범위한 관점에서 확인할 수 있습니다. 일부 문제는 이러한 관점에서 보다 신속하게 확인하고 Jira 문제를 열거나 지원 케이스를 열 필요없이 최종 사용자가 해결 할 수 있습니다.
-
고급 릴리스 관리 OpenShift Container Platform은
candidate,fast,stable릴리스 채널을 제공하므로 이를 통해 업데이트 전략을 선택할 수 있습니다. 릴리스를fast버전에서stable버전으로 업그레이드하는 것은 업데이트의 성공률 및 업그레이드 중에 발생하는 이벤트에 따라 달라집니다. 연결된 클러스터에서 제공하는 정보를 통해 Red Hat은 릴리스 품질을stable채널로 개선하고fast채널에 있는 문제에 신속하게 대응할 수 있습니다. - 새로운 기능 및 기능의 우선 순위를 지정 수집된 데이터는 OpenShift Container Platform의 가장 많이 사용되는 영역에 대한 정보를 제공합니다. 이러한 정보를 통해 Red Hat은 고객에게 가장 큰 영향을 미치는 새로운 기능 및 기능을 개발하는 데 중점을 둘 수 있습니다.
- 간소화된 지원 환경 제공 Red Hat 고객 포털에서 지원 티켓을 생성할 때 연결된 클러스터의 클러스터 ID를 지정할 수 있습니다. 이를 통해 Red Hat은 연결된 정보를 사용하여 클러스터 고유의 간소화된 지원 환경을 제공할 수 있습니다. 이 문서에서는 향상된 지원 환경에 대한 자세한 정보를 제공합니다.
- 예측 분석 OpenShift Cluster Manager 의 클러스터에 대해 표시되는 Insights는 연결된 클러스터에서 수집한 정보로 활성화됩니다. Red Hat은 OpenShift Container Platform 클러스터가 노출되는 문제를 식별하는 데 도움이 되도록 딥 러닝, 머신 러닝, 인공지능 자동화에 중점을 두고 있습니다.
4.1.1. Telemetry 정보
Telemetry는 엄선된 클러스터 모니터링 지표의 일부를 Red Hat으로 보냅니다. Telemeter Client는 4분 30초마다 메트릭 값을 가져와 Red Hat에 데이터를 업로드합니다. 이러한 메트릭에 대한 설명은 이 설명서에서 제공됩니다.
Red Hat은 이러한 데이터 스트림을 사용하여 클러스터를 실시간으로 모니터링하고 필요에 따라 고객에게 영향을 미치는 문제에 대응합니다. 또한 Red Hat은 OpenShift Container Platform 업그레이드를 고객에게 제공하여 서비스 영향을 최소화하고 지속적으로 업그레이드 환경을 개선할 수 있습니다.
이러한 디버깅 정보는 Red Hat 지원 및 엔지니어링 팀에 제공되며, 지원 사례를 통해 보고된 데이터에 액세스하는 것과 동일한 제한 사항이 적용됩니다. Red Hat은 연결된 모든 클러스터 정보를 사용하여 OpenShift Container Platform을 개선하고 사용 편의성을 높입니다.
4.1.1.1. Telemetry에서 수집하는 정보
Telemetry에서 수집되는 정보는 다음과 같습니다.
4.1.1.1.1. 시스템 정보
- OpenShift Container Platform 클러스터 버전 및 업데이트 버전 가용성 확인에 사용되는 업데이트 세부 정보와 같은 버전 정보
- 클러스터당 사용 가능한 업데이트 수, 업데이트 진행 정보, 업데이트 진행 정보에 사용되는 채널 및 이미지 리포지터리, 업데이트에 발생하는 오류 수를 포함한 업데이트 정보
- 설치 중 생성된 임의의 고유 식별자
- Red Hat 지원이 클라우드 인프라 수준, 호스트 이름, IP 주소, Kubernetes Pod 이름, 네임스페이스 및 서비스의 노드 구성을 포함하여 고객에게 유용한 지원을 제공하는 데 도움이 되는 구성 세부 정보
- 클러스터 및 해당 조건 및 상태에 설치된 OpenShift Container Platform 프레임워크 구성 요소
- 성능이 저하된 Operator에 대해 "관련 개체"로 나열된 모든 네임스페이스에 대한 이벤트
- 성능 저하 소프트웨어에 대한 정보
- 인증서의 유효성에 대한 정보
- OpenShift Container Platform이 배포된 공급자 플랫폼의 이름 및 데이터 센터 위치
4.1.1.1.2. 크기 조정 정보
- CPU 코어 수 및 각각에 사용된 RAM 용량을 포함한 클러스터, 시스템 유형 및 머신 크기에 대한 정보
- etcd 멤버 수 및 etcd 클러스터에 저장된 오브젝트 수
- 빌드 전략 유형별 애플리케이션 빌드 수
4.1.1.1.3. 사용 정보
- 구성 요소, 기능 및 확장에 대한 사용 정보
- 기술 프리뷰 및 지원되지 않는 구성에 대한 사용량 세부 정보
Telemetry에서는 사용자 이름 또는 암호와 같은 식별 정보를 수집하지 않습니다. Red Hat은 개인 정보를 수집하지 않습니다. 개인 정보가 의도하지 않게 Red Hat에 수신된 경우 Red Hat은 이러한 정보를 삭제합니다. Telemetry 데이터가 개인 정보를 구성하는 범위까지, Red Hat의 개인정보 보호정책에 대한 자세한 내용은 Red Hat 개인정보처리방침을 참조하십시오.
4.1.2. Insights Operator 정보
Insights Operator는 구성 및 구성 요소 오류 상태를 주기적으로 수집하고 기본적으로 이러한 데이터를 두 시간마다 Red Hat에 보고합니다. 이 정보를 통해 Red Hat은 구성 및 Telemetry를 통해 보고된 것보다 더 깊은 오류 데이터를 평가할 수 있습니다.
OpenShift Container Platform 사용자는 Red Hat Hybrid Cloud Console의 Insights Advisor 서비스에 각 클러스터의 보고서를 표시할 수 있습니다. 문제가 확인된 경우 Insights는 추가 세부 정보와 가능한 경우 문제 해결 방법에 대한 단계를 제공합니다.
Insights Operator는 사용자 이름, 암호 또는 인증서와 같은 식별 정보를 수집하지 않습니다. Red Hat Insights 데이터 수집 및 제어에 대한 정보는 Red Hat Insights Data & Application Security를 참조하십시오.
Red Hat은 연결된 모든 클러스터 정보를 사용하여 다음을 수행합니다.
- 잠재적인 클러스터 문제를 확인하고 Red Hat Hybrid Cloud Console의 Insights Advisor 서비스에서 솔루션 및 예방 조치 제공
- 제품 및 지원팀에 집계되는 중요한 정보를 제공하여 OpenShift Container Platform 개선
- OpenShift Container Platform의 직관성 향상
4.1.2.1. Insights Operator에 의해 수집되는 정보
Insights Operator에서 수집되는 정보는 다음과 같습니다.
- OpenShift Container Platform 버전 및 환경과 관련된 문제를 확인하는 클러스터 및 해당 구성 요소에 대한 일반 정보
- 설정한 매개변수와 관련된 잘못된 설정 및 문제를 확인하는 클러스터 구성 파일(예: 이미지 레지스트리 구성)
- 클러스터 구성 요소에서 발생하는 오류
- 실행 중인 업데이트의 진행 상태 정보 및 구성 요소의 업그레이드 상태
- OpenShift Container Platform이 배포된 플랫폼 및 클러스터가 있는 리전의 세부 정보
- 별도의 TLS(Secure Hash Algorithm) 값으로 변환된 클러스터 워크로드 정보는 Red Hat이 중요한 세부 사항을 분리하지 않고 보안 및 버전 취약점에 대한 워크로드를 평가할 수 있습니다.
-
Operator가 문제를 보고하면
openshift-*및kube-*프로젝트의 코어 OpenShift Container Platform Pod에 대한 정보가 수집됩니다. 여기에는 상태, 리소스, 보안 컨텍스트, 볼륨 정보 등이 포함됩니다.
4.1.3. Telemetry 및 Insights Operator 데이터 흐름 이해
Telemeter Client는 Prometheus API에서 선택한 시계열 데이터를 수집합니다. 시계열 데이터는 처리하기 위해 4분 30초 마다 api.openshift.com에 업로드됩니다.
Insights Operator는 선택한 데이터를 Kubernetes API 및 Prometheus API에서 아카이브로 수집합니다. 아카이브는 처리를 위해 2시간마다 OpenShift Cluster Manager 에 업로드됩니다. Insights Operator는 OpenShift Cluster Manager 에서도 최신 Insights 분석을 다운로드합니다. OpenShift Container Platform 웹 콘솔의 Overview 페이지에 있는 Insights status 팝업을 설정하는 데 사용됩니다.
Red Hat과의 모든 통신은 TLS(Transport Layer Security) 및 상호 인증서 인증을 사용하여 암호화된 채널을 통해 이루어집니다. 모든 데이터는 전송 및 정지 상태에서 암호화됩니다.
고객 데이터를 처리하는 시스템에 대한 액세스는 다단계 인증 및 엄격한 인증 권한에 의해 제어됩니다. 필요에 따라 액세스 권한이 부여되며 필수 작업으로 제한됩니다.
Telemetry 및 Insights Operator 데이터 흐름

4.1.4. 원격 상태 모니터링 데이터 사용 방법에 대한 추가 정보
원격 상태 모니터링을 사용하도록 수집된 정보는 Telemetry에 의해 수집된 정보 및 Insights Operator에 의해 수집된 정보에서 참조하십시오.
이 문서의 이전 섹션에 설명되어 있듯이 Red Hat은 지원 및 업그레이드, 성능 또는 구성 최적화, 서비스에 미치는 영향을 최소화, 위협 식별 및 문제 해결, 문제에 대한 대응 및 청구 등의 목적으로 Red Hat 제품 사용에 대한 데이터를 수집합니다.
수집 보안 조치
Red Hat은 Telemetry 및 구성 데이터를 보호하기 위해 설계된 기술 및 제도 상의 조치를 사용합니다.
공유
Red Hat은 사용자 환경을 개선하기 위해 Telemetry 및 Insights Operator에서 수집한 데이터를 내부적으로 공유할 수 있습니다. Red Hat은 Red Hat 제품 사용 및 고객의 사용을 보다 잘 이해할 수 있도록 돕거나 또는 파트너가 협력하여 제품의 지원을 성공적으로 통합하는 데 도움이 되는 집계 양식에서 Telemetry 및 설정 데이터를 공유할 수 있습니다.
타사
Red Hat은 Telemetry 및 구성 데이터의 수집, 분석 및 저장을 지원하기 위해 특정 타사와 협력할 수 있습니다.
사용자 컨트롤 / Telemetry 및 설정 데이터 수집 활성화 및 비활성화
4.2. 원격 상태 모니터링으로 수집된 데이터 표시
관리자는 Telemetry 및 Insights Operator에서 수집한 메트릭을 검토할 수 있습니다.
4.2.1. Telemetry로 수집한 데이터 표시
Telemetry에서 캡처한 클러스터 및 구성 요소 시계열 데이터를 볼 수 있습니다.
사전 요구 사항
-
OpenShift Container Platform CLI(
oc)를 설치했습니다. -
cluster-admin역할 또는cluster-monitoring-view역할의 사용자로 클러스터에 액세스할 수 있습니다.
프로세스
- 클러스터에 로그인합니다.
- 다음 명령을 실행하여 클러스터의 Prometheus 서비스를 쿼리하고 Telemetry에서 캡처한 전체 시계열 데이터 세트를 반환합니다.
다음 예제에는 AWS의 OpenShift Container Platform과 관련된 몇 가지 값이 포함되어 있습니다.
$ curl -G -k -H "Authorization: Bearer $(oc whoami -t)" \
https://$(oc get route prometheus-k8s-federate -n \
openshift-monitoring -o jsonpath="{.spec.host}")/federate \
--data-urlencode 'match[]={__name__=~"cluster:usage:.*"}' \
--data-urlencode 'match[]={__name__="count:up0"}' \
--data-urlencode 'match[]={__name__="count:up1"}' \
--data-urlencode 'match[]={__name__="cluster_version"}' \
--data-urlencode 'match[]={__name__="cluster_version_available_updates"}' \
--data-urlencode 'match[]={__name__="cluster_version_capability"}' \
--data-urlencode 'match[]={__name__="cluster_operator_up"}' \
--data-urlencode 'match[]={__name__="cluster_operator_conditions"}' \
--data-urlencode 'match[]={__name__="cluster_version_payload"}' \
--data-urlencode 'match[]={__name__="cluster_installer"}' \
--data-urlencode 'match[]={__name__="cluster_infrastructure_provider"}' \
--data-urlencode 'match[]={__name__="cluster_feature_set"}' \
--data-urlencode 'match[]={__name__="instance:etcd_object_counts:sum"}' \
--data-urlencode 'match[]={__name__="ALERTS",alertstate="firing"}' \
--data-urlencode 'match[]={__name__="code:apiserver_request_total:rate:sum"}' \
--data-urlencode 'match[]={__name__="cluster:capacity_cpu_cores:sum"}' \
--data-urlencode 'match[]={__name__="cluster:capacity_memory_bytes:sum"}' \
--data-urlencode 'match[]={__name__="cluster:cpu_usage_cores:sum"}' \
--data-urlencode 'match[]={__name__="cluster:memory_usage_bytes:sum"}' \
--data-urlencode 'match[]={__name__="openshift:cpu_usage_cores:sum"}' \
--data-urlencode 'match[]={__name__="openshift:memory_usage_bytes:sum"}' \
--data-urlencode 'match[]={__name__="workload:cpu_usage_cores:sum"}' \
--data-urlencode 'match[]={__name__="workload:memory_usage_bytes:sum"}' \
--data-urlencode 'match[]={__name__="cluster:virt_platform_nodes:sum"}' \
--data-urlencode 'match[]={__name__="cluster:node_instance_type_count:sum"}' \
--data-urlencode 'match[]={__name__="cnv:vmi_status_running:count"}' \
--data-urlencode 'match[]={__name__="cluster:vmi_request_cpu_cores:sum"}' \
--data-urlencode 'match[]={__name__="node_role_os_version_machine:cpu_capacity_cores:sum"}' \
--data-urlencode 'match[]={__name__="node_role_os_version_machine:cpu_capacity_sockets:sum"}' \
--data-urlencode 'match[]={__name__="subscription_sync_total"}' \
--data-urlencode 'match[]={__name__="olm_resolution_duration_seconds"}' \
--data-urlencode 'match[]={__name__="csv_succeeded"}' \
--data-urlencode 'match[]={__name__="csv_abnormal"}' \
--data-urlencode 'match[]={__name__="cluster:kube_persistentvolumeclaim_resource_requests_storage_bytes:provisioner:sum"}' \
--data-urlencode 'match[]={__name__="cluster:kubelet_volume_stats_used_bytes:provisioner:sum"}' \
--data-urlencode 'match[]={__name__="ceph_cluster_total_bytes"}' \
--data-urlencode 'match[]={__name__="ceph_cluster_total_used_raw_bytes"}' \
--data-urlencode 'match[]={__name__="ceph_health_status"}' \
--data-urlencode 'match[]={__name__="odf_system_raw_capacity_total_bytes"}' \
--data-urlencode 'match[]={__name__="odf_system_raw_capacity_used_bytes"}' \
--data-urlencode 'match[]={__name__="odf_system_health_status"}' \
--data-urlencode 'match[]={__name__="job:ceph_osd_metadata:count"}' \
--data-urlencode 'match[]={__name__="job:kube_pv:count"}' \
--data-urlencode 'match[]={__name__="job:odf_system_pvs:count"}' \
--data-urlencode 'match[]={__name__="job:ceph_pools_iops:total"}' \
--data-urlencode 'match[]={__name__="job:ceph_pools_iops_bytes:total"}' \
--data-urlencode 'match[]={__name__="job:ceph_versions_running:count"}' \
--data-urlencode 'match[]={__name__="job:noobaa_total_unhealthy_buckets:sum"}' \
--data-urlencode 'match[]={__name__="job:noobaa_bucket_count:sum"}' \
--data-urlencode 'match[]={__name__="job:noobaa_total_object_count:sum"}' \
--data-urlencode 'match[]={__name__="odf_system_bucket_count", system_type="OCS", system_vendor="Red Hat"}' \
--data-urlencode 'match[]={__name__="odf_system_objects_total", system_type="OCS", system_vendor="Red Hat"}' \
--data-urlencode 'match[]={__name__="noobaa_accounts_num"}' \
--data-urlencode 'match[]={__name__="noobaa_total_usage"}' \
--data-urlencode 'match[]={__name__="console_url"}' \
--data-urlencode 'match[]={__name__="cluster:ovnkube_master_egress_routing_via_host:max"}' \
--data-urlencode 'match[]={__name__="cluster:network_attachment_definition_instances:max"}' \
--data-urlencode 'match[]={__name__="cluster:network_attachment_definition_enabled_instance_up:max"}' \
--data-urlencode 'match[]={__name__="cluster:ingress_controller_aws_nlb_active:sum"}' \
--data-urlencode 'match[]={__name__="cluster:route_metrics_controller_routes_per_shard:min"}' \
--data-urlencode 'match[]={__name__="cluster:route_metrics_controller_routes_per_shard:max"}' \
--data-urlencode 'match[]={__name__="cluster:route_metrics_controller_routes_per_shard:avg"}' \
--data-urlencode 'match[]={__name__="cluster:route_metrics_controller_routes_per_shard:median"}' \
--data-urlencode 'match[]={__name__="cluster:openshift_route_info:tls_termination:sum"}' \
--data-urlencode 'match[]={__name__="insightsclient_request_send_total"}' \
--data-urlencode 'match[]={__name__="cam_app_workload_migrations"}' \
--data-urlencode 'match[]={__name__="cluster:apiserver_current_inflight_requests:sum:max_over_time:2m"}' \
--data-urlencode 'match[]={__name__="cluster:alertmanager_integrations:max"}' \
--data-urlencode 'match[]={__name__="cluster:telemetry_selected_series:count"}' \
--data-urlencode 'match[]={__name__="openshift:prometheus_tsdb_head_series:sum"}' \
--data-urlencode 'match[]={__name__="openshift:prometheus_tsdb_head_samples_appended_total:sum"}' \
--data-urlencode 'match[]={__name__="monitoring:container_memory_working_set_bytes:sum"}' \
--data-urlencode 'match[]={__name__="namespace_job:scrape_series_added:topk3_sum1h"}' \
--data-urlencode 'match[]={__name__="namespace_job:scrape_samples_post_metric_relabeling:topk3"}' \
--data-urlencode 'match[]={__name__="monitoring:haproxy_server_http_responses_total:sum"}' \
--data-urlencode 'match[]={__name__="rhmi_status"}' \
--data-urlencode 'match[]={__name__="status:upgrading:version:rhoam_state:max"}' \
--data-urlencode 'match[]={__name__="state:rhoam_critical_alerts:max"}' \
--data-urlencode 'match[]={__name__="state:rhoam_warning_alerts:max"}' \
--data-urlencode 'match[]={__name__="rhoam_7d_slo_percentile:max"}' \
--data-urlencode 'match[]={__name__="rhoam_7d_slo_remaining_error_budget:max"}' \
--data-urlencode 'match[]={__name__="cluster_legacy_scheduler_policy"}' \
--data-urlencode 'match[]={__name__="cluster_master_schedulable"}' \
--data-urlencode 'match[]={__name__="che_workspace_status"}' \
--data-urlencode 'match[]={__name__="che_workspace_started_total"}' \
--data-urlencode 'match[]={__name__="che_workspace_failure_total"}' \
--data-urlencode 'match[]={__name__="che_workspace_start_time_seconds_sum"}' \
--data-urlencode 'match[]={__name__="che_workspace_start_time_seconds_count"}' \
--data-urlencode 'match[]={__name__="cco_credentials_mode"}' \
--data-urlencode 'match[]={__name__="cluster:kube_persistentvolume_plugin_type_counts:sum"}' \
--data-urlencode 'match[]={__name__="visual_web_terminal_sessions_total"}' \
--data-urlencode 'match[]={__name__="acm_managed_cluster_info"}' \
--data-urlencode 'match[]={__name__="cluster:vsphere_vcenter_info:sum"}' \
--data-urlencode 'match[]={__name__="cluster:vsphere_esxi_version_total:sum"}' \
--data-urlencode 'match[]={__name__="cluster:vsphere_node_hw_version_total:sum"}' \
--data-urlencode 'match[]={__name__="openshift:build_by_strategy:sum"}' \
--data-urlencode 'match[]={__name__="rhods_aggregate_availability"}' \
--data-urlencode 'match[]={__name__="rhods_total_users"}' \
--data-urlencode 'match[]={__name__="instance:etcd_disk_wal_fsync_duration_seconds:histogram_quantile",quantile="0.99"}' \
--data-urlencode 'match[]={__name__="instance:etcd_mvcc_db_total_size_in_bytes:sum"}' \
--data-urlencode 'match[]={__name__="instance:etcd_network_peer_round_trip_time_seconds:histogram_quantile",quantile="0.99"}' \
--data-urlencode 'match[]={__name__="instance:etcd_mvcc_db_total_size_in_use_in_bytes:sum"}' \
--data-urlencode 'match[]={__name__="instance:etcd_disk_backend_commit_duration_seconds:histogram_quantile",quantile="0.99"}' \
--data-urlencode 'match[]={__name__="appsvcs:cores_by_product:sum"}' \
--data-urlencode 'match[]={__name__="nto_custom_profiles:count"}' \
--data-urlencode 'match[]={__name__="openshift_csi_share_configmap"}' \
--data-urlencode 'match[]={__name__="openshift_csi_share_secret"}' \
--data-urlencode 'match[]={__name__="openshift_csi_share_mount_failures_total"}' \
--data-urlencode 'match[]={__name__="openshift_csi_share_mount_requests_total"}' \
--data-urlencode 'match[]={__name__="cluster:velero_backup_total:max"}' \
--data-urlencode 'match[]={__name__="cluster:velero_restore_total:max"}' \
--data-urlencode 'match[]={__name__="eo_es_storage_info"}' \
--data-urlencode 'match[]={__name__="eo_es_redundancy_policy_info"}' \
--data-urlencode 'match[]={__name__="eo_es_defined_delete_namespaces_total"}' \
--data-urlencode 'match[]={__name__="eo_es_misconfigured_memory_resources_info"}' \
--data-urlencode 'match[]={__name__="cluster:eo_es_data_nodes_total:max"}' \
--data-urlencode 'match[]={__name__="cluster:eo_es_documents_created_total:sum"}' \
--data-urlencode 'match[]={__name__="cluster:eo_es_documents_deleted_total:sum"}' \
--data-urlencode 'match[]={__name__="pod:eo_es_shards_total:max"}' \
--data-urlencode 'match[]={__name__="eo_es_cluster_management_state_info"}' \
--data-urlencode 'match[]={__name__="imageregistry:imagestreamtags_count:sum"}' \
--data-urlencode 'match[]={__name__="imageregistry:operations_count:sum"}' \
--data-urlencode 'match[]={__name__="log_logging_info"}' \
--data-urlencode 'match[]={__name__="log_collector_error_count_total"}' \
--data-urlencode 'match[]={__name__="log_forwarder_pipeline_info"}' \
--data-urlencode 'match[]={__name__="log_forwarder_input_info"}' \
--data-urlencode 'match[]={__name__="log_forwarder_output_info"}' \
--data-urlencode 'match[]={__name__="cluster:log_collected_bytes_total:sum"}' \
--data-urlencode 'match[]={__name__="cluster:log_logged_bytes_total:sum"}' \
--data-urlencode 'match[]={__name__="cluster:kata_monitor_running_shim_count:sum"}' \
--data-urlencode 'match[]={__name__="platform:hypershift_hostedclusters:max"}' \
--data-urlencode 'match[]={__name__="platform:hypershift_nodepools:max"}' \
--data-urlencode 'match[]={__name__="namespace:noobaa_unhealthy_bucket_claims:max"}' \
--data-urlencode 'match[]={__name__="namespace:noobaa_buckets_claims:max"}' \
--data-urlencode 'match[]={__name__="namespace:noobaa_unhealthy_namespace_resources:max"}' \
--data-urlencode 'match[]={__name__="namespace:noobaa_namespace_resources:max"}' \
--data-urlencode 'match[]={__name__="namespace:noobaa_unhealthy_namespace_buckets:max"}' \
--data-urlencode 'match[]={__name__="namespace:noobaa_namespace_buckets:max"}' \
--data-urlencode 'match[]={__name__="namespace:noobaa_accounts:max"}' \
--data-urlencode 'match[]={__name__="namespace:noobaa_usage:max"}' \
--data-urlencode 'match[]={__name__="namespace:noobaa_system_health_status:max"}' \
--data-urlencode 'match[]={__name__="ocs_advanced_feature_usage"}' \
--data-urlencode 'match[]={__name__="os_image_url_override:sum"}' \
--data-urlencode 'match[]={__name__="openshift:openshift_network_operator_ipsec_state:info"}'4.2.2. Insights Operator에 의해 수집된 데이터의 표시
Insights Operator가 수집한 데이터를 검토할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다.
프로세스
Insights Operator에 대해 현재 실행 중인 Pod의 이름을 검색합니다.
$ INSIGHTS_OPERATOR_POD=$(oc get pods --namespace=openshift-insights -o custom-columns=:metadata.name --no-headers --field-selector=status.phase=Running)Insights Operator가 수집한 최근 데이터 아카이브를 복사합니다.
$ oc cp openshift-insights/$INSIGHTS_OPERATOR_POD:/var/lib/insights-operator ./insights-data
최신 Insights Operator 아카이브는 이제 insights-data 디렉토리에서 사용할 수 있습니다.
4.3. 원격 상태 보고
클러스터 의 상태 및 사용량 데이터를 선택, 활성화 또는 비활성화, 보고, 보고할 수 있습니다.
4.3.1. 원격 상태 보고 활성화
사용자 또는 조직에서 원격 상태 보고를 비활성화한 경우 이 기능을 다시 활성화할 수 있습니다. OpenShift Container Platform 웹 콘솔 개요 페이지의 상태 타일에서 Insights를 사용할 수 없는 메시지에서 원격 상태 보고가 비활성화되어 있음을 확인할 수 있습니다.
원격 상태 보고를 활성화하려면 새 권한 부여 토큰을 사용하여 글로벌 클러스터 풀 시크릿을 변경해야 합니다. 원격 상태 보고를 활성화하면 Insights Operator 및 Telemetry를 모두 사용할 수 있습니다.
4.3.2. 원격 상태 보고를 활성화하려면 글로벌 클러스터 풀 시크릿 변경
기존 글로벌 클러스터 풀 시크릿을 변경하여 원격 상태 보고를 활성화할 수 있습니다. 원격 상태 모니터링을 비활성화한 경우 Red Hat OpenShift Cluster Manager에서 console.openshift.com 액세스 토큰을 사용하여 새 풀 시크릿을 다운로드해야 합니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. - OpenShift Cluster Manager에 액세스합니다.
프로세스
- Red Hat Hybrid Cloud Console의 다운로드 페이지로 이동합니다.
토큰 → 가져오기 보안 에서 다운로드 버튼을 클릭합니다.
pull-secret파일에는 JSON 형식의cloud.openshift.com액세스 토큰이 포함되어 있습니다.{ "auths": { "cloud.openshift.com": { "auth": "<your_token>", "email": "<email_address>" } } }로컬 파일 시스템에 글로벌 클러스터 풀 시크릿을 다운로드합니다.
$ oc get secret/pull-secret -n openshift-config --template='{{index .data ".dockerconfigjson" | base64decode}}' > pull-secret풀 시크릿의 백업 사본을 만듭니다.
$ cp pull-secret pull-secret-backup-
텍스트 편집기에서
pull-secret파일을 엽니다. -
이전에 다운로드한
pull-secret파일의cloud.openshift.comJSON 항목을auths파일에 추가합니다. - 파일을 저장합니다.
다음 명령을 실행하여 클러스터의 시크릿을 업데이트합니다.
oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=pull-secret시크릿이 업데이트되고 클러스터가 보고를 시작할 때까지 몇 분 정도 기다려야 할 수 있습니다.
검증
OpenShift Container Platform 웹 콘솔의 확인 확인을 위해 다음 단계를 완료합니다.
- OpenShift Container Platform 웹 콘솔의 개요 페이지로 이동합니다.
- 발견된 문제 수를 보고하는 상태 타일에서 Insights 섹션을 확인합니다.
OpenShift CLI(
oc)의 확인 확인을 위해 다음 명령을 입력하고status매개변수의 값이false로 되어 있는지 확인합니다.$ oc get co insights -o jsonpath='{.status.conditions[?(@.type=="Disabled")]}'
4.3.3. 원격 상태 보고를 비활성화한 경우의 영향
OpenShift Container Platform에서 고객은 사용 정보를 보고하지 않도록 비활성화할 수 있습니다.
원격 상태 보고를 비활성화하기 전에 연결된 클러스터의 다음 이점을 확인하십시오.
- Red Hat은 문제에 보다 신속하게 대응하고 고객에게 더 나은 지원을 제공할 수 있습니다.
- Red Hat은 제품 업그레이드가 클러스터에 미치는 영향을 더 잘 이해할 수 있습니다.
- 연결된 클러스터를 사용하면 서브스크립션 및 인타이틀먼트 프로세스를 단순화할 수 있습니다.
- 연결된 클러스터를 사용하면 OpenShift Cluster Manager 서비스가 클러스터 및 해당 서브스크립션 상태에 대한 개요를 제공할 수 있습니다.
사전 프로덕션, 테스트 및 프로덕션 클러스터에 대해 상태 및 사용량 보고를 활성화한 것이 좋습니다. 즉, Red Hat은 사용자 환경에서 OpenShift Container Platform을 검증하고 제품 문제에 보다 신속하게 대응할 수 있습니다.
다음은 연결된 클러스터에서 원격 상태 보고를 비활성화한 몇 가지 결과를 보여줍니다.
- Red Hat은 오픈 지원 케이스 없이 제품 업그레이드 성공 또는 클러스터 상태를 볼 수 없습니다.
- Red Hat은 구성 데이터를 사용하여 고객 지원 케이스를 보다 효과적으로 분류하고 고객이 중요하게 생각하는 구성을 식별할 수 없습니다.
- OpenShift Cluster Manager는 상태 및 사용 정보가 포함된 클러스터에 대한 데이터를 표시할 수 없습니다.
-
사용 자동 보고 기능 없이
console.redhat.com웹 콘솔에 서브스크립션 정보를 수동으로 입력해야 합니다.
제한된 네트워크에서 Telemetry 및 Insights 데이터는 여전히 프록시의 적절한 구성을 통해 수집됩니다.
4.3.4. 원격 상태 보고 비활성화
기존 글로벌 클러스터 풀 시크릿을 변경하여 원격 상태 보고를 비활성화할 수 있습니다. 이 설정은 Telemetry 및 Insights Operator를 모두 비활성화합니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다.
프로세스
로컬 파일 시스템에 글로벌 클러스터 풀 시크릿을 다운로드합니다.
$ oc extract secret/pull-secret -n openshift-config --to=.텍스트 편집기에서
cloud.openshift.comJSON 항목을 제거하여 다운로드한.dockerconfigjson파일을 편집합니다."cloud.openshift.com":{"auth":"<hash>","email":"<email_address>"}- 파일을 저장합니다.
클러스터에서 시크릿을 업데이트합니다. 자세한 내용은 "글로벌 클러스터 풀 시크릿 업그레이드"를 참조하십시오.
클러스터에서 시크릿이 업데이트될 때까지 몇 분 정도 기다려야 할 수 있습니다.
4.3.5. 연결이 끊긴 클러스터 등록
원격 상태 보고를 비활성화하여 클러스터가 영향을 받지 않도록 Red Hat Hybrid Cloud Console에 연결이 끊긴 OpenShift Container Platform 클러스터를 등록합니다. 자세한 내용은 "원격 상태 보고 비활성화"를 참조하십시오.
연결이 끊긴 클러스터를 등록하면 Red Hat에 서브스크립션 사용량을 계속 보고할 수 있습니다. Red Hat은 서브스크립션과 관련된 정확한 사용량 및 용량 추세를 반환하여 반환된 정보를 사용하여 모든 리소스에서 서브스크립션 할당을 보다 효과적으로 구성할 수 있습니다.
사전 요구 사항
-
OpenShift Container Platform 웹 콘솔에
cluster-admin역할로 로그인했습니다. - Red Hat Hybrid Cloud Console에 로그인할 수 있습니다.
프로세스
- Red Hat Hybrid Cloud Console의 연결이 끊긴 클러스터 웹 페이지로 이동합니다.
- 선택 사항: Red Hat Hybrid Cloud Console의 홈 페이지에서 연결이 끊긴 클러스터 웹 페이지에 액세스하려면 Cluster List 탐색 메뉴 항목으로 이동한 다음 Register cluster 버튼을 선택합니다.
- 등록 연결이 끊긴 클러스터 페이지의 제공된 필드에 클러스터의 세부 정보를 입력합니다.
- 페이지의 서브스크립션 설정 섹션에서 Red Hat 서브스크립션 제품에 적용되는 서브스크립션 설정을 선택합니다.
- 연결이 끊긴 클러스터를 등록하려면 클러스터 동록 버튼을 선택합니다.
- 서브스크립션 서비스에 서브스크립션 데이터가 어떻게 표시됩니까?(서브스크립션 서비스 시작하기)
4.3.6. 글로벌 클러스터 풀 시크릿 업데이트
현재 풀 시크릿을 교체하거나 새 풀 시크릿을 추가하여 클러스터의 글로벌 풀 시크릿을 업데이트할 수 있습니다.
설치 중에 사용된 레지스트리보다 이미지를 저장하기 위해 별도의 레지스트리가 필요한 경우 절차를 사용하십시오.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다.
프로세스
선택 사항: 기존 풀 시크릿에 새 풀 시크릿을 추가하려면 다음 단계를 완료합니다.
다음 명령을 입력하여 풀 시크릿을 다운로드합니다.
$ oc get secret/pull-secret -n openshift-config --template='{{index .data ".dockerconfigjson" | base64decode}}' > <pull_secret_location>1 - 1
<pull_secret_location> : 풀 시크릿 파일의 경로를 포함합니다.
다음 명령을 입력하여 새 풀 시크릿을 추가합니다.
$ oc registry login --registry="<registry>" \1 --auth-basic="<username>:<password>" \2 --to=<pull_secret_location>3 풀 시크릿 파일에 대한 수동 업데이트를 수행할 수도 있습니다.
다음 명령을 입력하여 클러스터의 글로벌 풀 시크릿을 업데이트합니다.
$ oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=<pull_secret_location>1 - 1
<pull_secret_location>: 새 풀 시크릿 파일의 경로를 추가합니다.
이번 업데이트에서는 모든 노드에 롤아웃되며 클러스터 크기에 따라 다소 시간이 걸릴 수 있습니다.
참고OpenShift Container Platform 4.7.4부터 글로벌 풀 시크릿을 변경해도 더 이상 노드 드레이닝 또는 재부팅이 트리거되지 않습니다.
추가 리소스
4.4. Insights를 사용하여 클러스터의 문제 식별
Insights는 Insights Operator가 전송하는 데이터를 반복적으로 분석합니다. 여기에는 Deployment Validation Operator(DVO)의 워크로드 권장 사항이 포함됩니다. OpenShift Container Platform 사용자는 Red Hat Hybrid Cloud Console의 Insights Advisor 서비스에 결과를 표시할 수 있습니다.
4.4.1. OpenShift Container Platform 용 Red Hat Insights Advisor 정보
Insights 권고 서비스를 사용하여 OpenShift Container Platform 클러스터의 상태를 평가하고 모니터링할 수 있습니다. 개별 클러스터에 대한 관심이 있거나 전체 인프라에 관계없이 서비스 가용성, 내결함성, 성능 또는 보안에 영향을 줄 수 있는 문제에 대한 클러스터 인프라 노출을 인식하는 것이 중요합니다.
클러스터에 DVO(Deployment Validation Operator)가 설치된 경우 권장 사항은 구성이 클러스터 상태 문제로 이어질 수 있는 워크로드도 강조 표시합니다.
Insights 분석 결과는 Red Hat Hybrid Cloud Console의 Insights 권고 서비스에서 확인할 수 있습니다. Red Hat Hybrid Cloud Console에서는 다음 작업을 수행할 수 있습니다.
- 특정 권장 사항의 영향을 받는 클러스터 및 워크로드를 확인합니다.
- 강력한 필터링 기능을 사용하여 결과를 해당 권장 사항으로 구체화합니다.
- 개별 권장 사항, 존재하는 위험에 대한 세부 정보, 개별 클러스터에 맞게 조정된 해결 방법에 대해 자세히 알아보십시오.
- 다른 이해 관계자와 결과를 공유하십시오.
4.4.2. Insights Advisor 권장 사항 이해
Insights 서비스는 클러스터 및 워크로드의 서비스 가용성, 내결함성, 성능 또는 보안에 부정적인 영향을 미칠 수 있는 다양한 클러스터 상태 및 구성 요소 구성에 대한 정보를 제공합니다. 이 정보 세트를 Insights 조언 서비스의 권장 사항이라고 합니다. 클러스터의 권장 사항에는 다음 정보가 포함됩니다.
- 이름: 권장 사항에 대한 간결한 설명
- 추가됨: Insights Advisor 서비스 아카이브에 권장 사항이 게시되었을 때
- 카테고리: 문제가 서비스 가용성, 내결함성, 성능 또는 보안에 부정적인 영향을 미칠 수 있는지 여부
- 총 위험: 조건이 클러스터 또는 워크로드에 부정적인 영향을 미칠 가능성 에서 파생된 값 및 이러한 상황이 발생할 경우 운영에 미치는 영향
- 클러스터: 권장 사항이 감지되는 클러스터 목록
- 설명: 클러스터에 미치는 영향을 포함하여 문제에 대한 간략한 개요
4.4.3. 클러스터와 관련된 잠재적인 문제 표시
이 섹션에서는 OpenShift Cluster Manager 의 Insights 권고에 Insights 보고서를 표시하는 방법을 설명합니다.
Insights는 반복적으로 클러스터를 분석하여 최신 결과를 표시합니다. 예를 들어 문제를 해결하거나 새로운 문제가 발견된 경우 이러한 결과가 변경될 수 있습니다.
사전 요구 사항
- 클러스터는 OpenShift Cluster Manager 에 등록되어 있습니다.
- 원격 상태 보고가 활성화되어 있습니다 (기본값).
- OpenShift Cluster Manager 에 로그인되어 있습니다.
프로세스
OpenShift Cluster Manager 에서 Advisor → Recommendations 로 이동합니다.
결과에 따라 Insights 권고 서비스에 다음 중 하나가 표시됩니다.
- Insights에서 문제를 식별하지 않은 경우 일치하는 권장 사항을 찾을 수 없습니다.
- Insights가 감지한 문제 목록으로 위험(낮음, 중간, 중요 및 심각)으로 그룹화되어 있습니다.
- Insights 가 아직 클러스터를 분석하지 않은 경우 아직 클러스터가 없습니다. 클러스터가 설치, 등록 및 인터넷에 연결된 직후 분석이 시작됩니다.
문제가 표시되면 항목 앞의 > 아이콘을 클릭하여 자세한 내용을 확인합니다.
문제에 따라 세부 정보에는 문제에 대한 Red Hat의 자세한 정보 링크가 포함될 수 있습니다.
4.4.4. Insights 조언자 서비스 권장 사항 표시
기본적으로 권장 사항 보기는 클러스터에서 탐지된 권장 사항만 표시합니다. 그러나 advisor 서비스의 아카이브에 있는 모든 권장 사항을 볼 수 있습니다.
사전 요구 사항
- 원격 상태 보고가 활성화되어 있습니다 (기본값).
- 클러스터는 Red Hat Hybrid Cloud Console에 등록되어 있습니다.
- OpenShift Cluster Manager 에 로그인되어 있습니다.
프로세스
- OpenShift Cluster Manager 에서 Advisor → Recommendations 로 이동합니다.
영향을 받는 클러스터 및 상태 필터 옆에 있는 X 아이콘을 클릭합니다.
이제 클러스터에 대한 모든 잠재적인 권장 사항을 확인할 수 있습니다.
4.4.5. Advisor 권장 필터
Insights 권고 서비스는 많은 권장 사항을 반환할 수 있습니다. 가장 중요한 권장 사항에 중점을 두려면 Advisor 권장 사항 목록에 필터를 적용하여 우선순위가 낮은 권장 사항을 제거할 수 있습니다.
기본적으로 필터는 하나 이상의 클러스터에 영향을 미치는 활성화된 권장 사항만 표시하도록 설정됩니다. Insights 라이브러리의 모든 또는 비활성화된 권장 사항을 보려면 필터를 사용자 지정할 수 있습니다.
필터를 적용하려면 필터 유형을 선택한 다음 드롭다운 목록에서 사용할 수 있는 옵션을 기반으로 값을 설정합니다. 권장 사항 목록에 여러 필터를 적용할 수 있습니다.
다음 필터 유형을 설정할 수 있습니다.
- name: 이름으로 권장 사항을 검색합니다.
- 총 위험: 심각,중요,보통 및 낮음에서 하나 이상의 값을 선택하여 클러스터에 미치는 부정적인 영향을 미치는 가능성과 심각도를 나타냅니다.
- 영향: 클러스터 작업의 연속성에 미치는 영향을 나타내는 심각,높음,중간 및 낮음 에서 하나 이상의 값을 선택합니다.
- 가능성: 심각,높음,중간, 낮음 에서 하나 이상의 값을 선택하여 클러스터에 부정적인 영향을 미칠 가능성이 있는지 여부를 나타냅니다.
- 범주: Service Availability,Performance,Fault Tolerance,Security, Best Practice 에서 하나 이상의 카테고리를 선택하여 집중할 수 있습니다.
- 상태: 활성화된 권장 사항(기본값), 비활성화된 권장 사항 또는 모든 권장 사항을 표시하려면 라디오 버튼을 클릭합니다.
- 영향을 받는 클러스터: 현재 하나 이상의 클러스터, 영향을 받지 않는 권장 사항 또는 모든 권장 사항에 영향을 미치는 권장 사항을 표시하도록 필터를 설정합니다.
- 변경 위험: High,Moderate,Low y low 에서 하나 이상의 값을 선택하여 해상도 구현이 클러스터 작업에 미칠 수 있는 위험을 나타냅니다.
4.4.5.1. Insights 권고 서비스 권장 사항 필터링
OpenShift Container Platform 클러스터 관리자는 권장 사항 목록에 표시되는 권장 사항을 필터링할 수 있습니다. 필터를 적용하면 보고된 권장 사항 수를 줄이고 가장 높은 우선 순위 권장 사항에 집중할 수 있습니다.
다음 절차에서는 카테고리 필터를 설정하고 제거하는 방법을 보여줍니다. 그러나 절차는 모든 필터 유형과 각 값에 적용할 수 있습니다.
사전 요구 사항
하이브리드 클라우드 콘솔의 OpenShift Cluster Manager 에 로그인되어 있습니다.
프로세스
- OpenShift > Advisor > Recommendations로 이동합니다.
- 기본 필터 유형 드롭다운 목록에서 카테고리 필터 유형을 선택합니다.
- filter-value 드롭다운 목록을 펼치고 보려는 각 범주의 권장 사항 옆에 있는 확인란을 선택합니다. 불필요한 카테고리에 대해 확인란을 지웁니다.
- 선택 사항: 목록을 추가로 구체화하려면 필터를 추가합니다.
선택한 범주의 권장 사항만 목록에 표시됩니다.
검증
- 필터를 적용한 후 업데이트된 권장 사항 목록을 볼 수 있습니다. 적용된 필터는 기본 필터 옆에 추가됩니다.
4.4.5.2. Insights 조언 서비스 권장 사항에서 필터 제거
권장 사항 목록에 여러 필터를 적용할 수 있습니다. 준비가 되면 개별적으로 제거하거나 완전히 재설정할 수 있습니다.
개별적으로 필터 제거
- 기본 필터를 포함하여 각 필터 옆에 있는 X 아이콘을 클릭하여 개별적으로 제거합니다.
기본이 아닌 모든 필터 제거
- 새로 고침 필터 를 클릭하여 적용한 필터만 제거하고 기본 필터를 그대로 둡니다.
4.4.6. Insights 권고 서비스 권장 사항 비활성화
보고서에 더 이상 표시되지 않도록 클러스터에 영향을 미치는 특정 권장 사항을 비활성화할 수 있습니다. 단일 클러스터 또는 모든 클러스터에 대한 권장 사항을 비활성화할 수 있습니다.
모든 클러스터에 대한 권장 사항을 비활성화하는 것은 향후 클러스터에도 적용됩니다.
사전 요구 사항
- 원격 상태 보고가 활성화되어 있습니다 (기본값).
- 클러스터는 OpenShift Cluster Manager 에 등록되어 있습니다.
- OpenShift Cluster Manager 에 로그인되어 있습니다.
프로세스
- OpenShift Cluster Manager 에서 Advisor → Recommendations 로 이동합니다.
- 선택 사항: 필요에 따라 클러스터에 영향을 미치는 상태 필터를 사용합니다.
다음 방법 중 하나를 사용하여 경고를 비활성화합니다.
경고를 비활성화하려면 다음을 수행합니다.
-
해당 경고에 대한 옵션 메뉴
 를 클릭한 다음 권장 사항 비활성화 를 클릭합니다.
를 클릭한 다음 권장 사항 비활성화 를 클릭합니다.
- 확인 참고 사항을 입력하고 저장을 클릭합니다.
-
해당 경고에 대한 옵션 메뉴
경고를 비활성화하기 전에 이 경고의 영향을 받는 클러스터를 보려면 다음을 수행합니다.
- 비활성화할 권장 사항 이름을 클릭합니다. 단일 권장 사항 페이지로 이동합니다.
- 영향을 받는 클러스터 섹션의 클러스터 목록을 검토합니다.
- 동작 → 권장 사항 비활성화 를 클릭하여 모든 클러스터에 대한 경고를 비활성화합니다.
- 확인 참고 사항을 입력하고 저장을 클릭합니다.
4.4.7. 이전에 비활성화된 Insights 조언 서비스 권장 사항 활성화
모든 클러스터에 대해 권장 사항이 비활성화되면 더 이상 Insights 권고 서비스에 권장 사항이 표시되지 않습니다. 이 동작을 변경할 수 있습니다.
사전 요구 사항
- 원격 상태 보고가 활성화되어 있습니다 (기본값).
- 클러스터는 OpenShift Cluster Manager 에 등록되어 있습니다.
- OpenShift Cluster Manager 에 로그인되어 있습니다.
프로세스
- OpenShift Cluster Manager 에서 Advisor → Recommendations 로 이동합니다.
비활성화된 권장 사항에 표시할 권장 사항을 필터링합니다.
- Status 드롭다운 메뉴에서 Status 를 선택합니다.
- Filter by status 드롭다운 메뉴에서 Disabled 를 선택합니다.
- 선택 사항: 영향을 받는 클러스터 필터를 지웁니다.
- 활성화할 권장 사항을 찾습니다.
-
옵션 메뉴
를 클릭한 다음 권장 사항 사용을 클릭합니다.
4.4.8. 워크로드에 대한 Insights 조언 서비스 권장 사항 정보
OpenShift 어드바이저 서비스에 Red Hat Insights를 사용하여 클러스터뿐만 아니라 워크로드에 영향을 미치는 권장 사항에 대한 정보를 보고 관리할 수 있습니다. 권고 서비스는 배포 검증을 활용하고 OpenShift 클러스터 관리자가 배포 정책의 모든 런타임 위반을 확인할 수 있도록 지원합니다. OpenShift > Advisor > Red Hat Hybrid Cloud Console에서 워크로드에 대한 권장 사항을 확인할 수 있습니다. 자세한 내용은 다음 추가 리소스를 참조하십시오.
4.4.9. 웹 콘솔에 Insights 상태 표시
Insights는 클러스터를 반복적으로 분석하고 OpenShift Container Platform 웹 콘솔에서 확인된 잠재적 클러스터 문제의 상태를 표시할 수 있습니다. 이 상태에는 다양한 카테고리의 문제 수가 표시되고 자세한 내용은 OpenShift Cluster Manager 의 보고서에 대한 링크입니다.
사전 요구 사항
- 클러스터는 OpenShift Cluster Manager 에 등록되어 있습니다.
- 원격 상태 보고가 활성화되어 있습니다 (기본값).
- OpenShift Container Platform 웹 콘솔에 로그인되어 있습니다.
프로세스
- OpenShift Container Platform 웹 콘솔에서 홈 → 개요로 이동합니다.
상태 카드에서 Insights를 클릭합니다.
팝업 창에 잠재적인 문제가 위험으로 그룹화되어 나열됩니다. 개별 카테고리를 클릭하거나 Insights Advisor의 모든 권장 사항 보기를 클릭하여 자세한 내용을 표시합니다.
4.5. Insights Operator 사용
Insights Operator는 구성 및 구성 요소 오류 상태를 주기적으로 수집하고 기본적으로 이러한 데이터를 두 시간마다 Red Hat에 보고합니다. 이 정보를 통해 Red Hat은 구성 및 Telemetry를 통해 보고된 것보다 더 깊은 오류 데이터를 평가할 수 있습니다. OpenShift Container Platform 사용자는 Red Hat Hybrid Cloud Console의 Insights Advisor 서비스에 보고서를 표시할 수 있습니다.
4.5.1. Insights Operator 구성
Insights Operator 구성은 기본 Operator 구성과 openshift-insights 네임스페이스의 insights-config ConfigMap 오브젝트에 저장된 구성 또는 openshift-config 네임스페이스의 support 시크릿에 저장된 구성의 조합입니다.
ConfigMap 오브젝트 또는 지원 시크릿이 있는 경우 포함된 특성 값이 기본 Operator 구성 값을 재정의합니다. ConfigMap 오브젝트 와 지원 시크릿이 둘 다 있는 경우 Operator는 ConfigMap 오브젝트를 읽습니다.
ConfigMap 오브젝트는 기본적으로 존재하지 않으므로 OpenShift Container Platform 클러스터 관리자가 이를 생성해야 합니다.
ConfigMap 오브젝트 구성 구조
insights-config ConfigMap 오브젝트(config.yaml 구성)의 예에서는 표준 YAML 형식을 사용하여 구성 옵션을 보여줍니다.
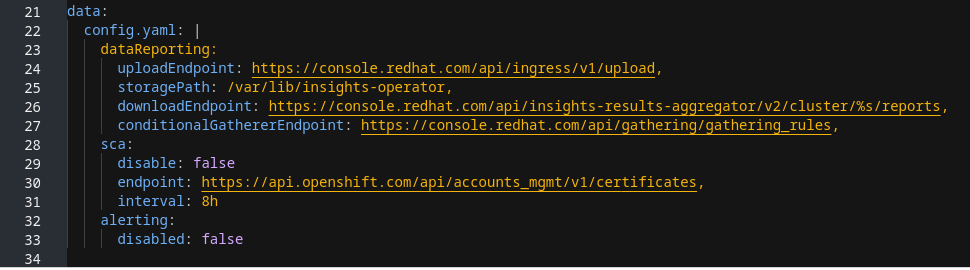
구성 가능한 속성 및 기본값
다음 표에서는 사용 가능한 구성 속성을 설명합니다.
insights-config ConfigMap 오브젝트는 표준 YAML 형식을 따릅니다. 여기서 하위 값은 상위 속성 아래에 있고 두 개의 공백을 들여씁니다. Obfuscation 속성의 경우 부모 속성의 공지된 하위 항목으로 값을 입력합니다.
| 특성 이름 | 설명 | 값 유형 | 기본값 |
|---|---|---|---|
| 클러스터 Prometheus 인스턴스에 대한 Insights Operator 경고를 비활성화합니다. | 부울 |
|
| 클러스터 전송 데이터를 확인하고 다운로드하는 끝점입니다. | URL | https://api.openshift.com/api/accounts_mgmt/v1/cluster_transfers/ |
| 사용 가능한 클러스터 전송을 확인하는 빈도를 설정합니다. | 시간 간격 |
|
| 데이터 수집 및 업로드 빈도를 설정합니다. | 시간 간격 |
|
| 업로드 끝점을 설정합니다. | URL | |
| 보관된 데이터가 저장되는 경로를 구성합니다. | 파일 경로 | /var/lib/insights-operator |
| 최신 Insights 분석을 다운로드하기 위한 끝점을 지정합니다. | URL | |
| 조건부 수집 규칙 정의를 제공하기 위한 끝점을 설정합니다. | URL | |
| IP 주소 및 클러스터 도메인 이름을 전역 난독 처리를 활성화합니다. | 문자열 | 해당 없음 |
| Data Validation Operator 데이터의 난독 처리를 활성화합니다. 리소스 ID가 리소스 이름이 아닌 아카이브 파일에만 표시되는 클러스터 리소스입니다. | 문자열 | 해당 없음 |
| Insights Operator에 대한 사용자 정의 프록시를 설정합니다. | URL | 기본값이 없음 |
| SCA(Simple Content Access) 인타이틀먼트 다운로드 빈도를 지정합니다. | 시간 간격 |
|
| SCA(Simple Content Access) 인타이틀먼트를 다운로드하는 끝점을 지정합니다. | URL | https://api.openshift.com/api/accounts_mgmt/v1/entitlement_certificates |
| 간단한 콘텐츠 액세스 권한 다운로드를 비활성화합니다. | 부울 |
|
4.5.1.1. insights-config ConfigMap 오브젝트 생성
다음 절차에서는 Insights Operator에 대한 insights-config ConfigMap 오브젝트를 생성하여 사용자 정의 구성을 설정하는 방법을 설명합니다.
기본 Insights Operator 구성을 변경하기 전에 Red Hat 지원을 참조하는 것이 좋습니다.
사전 요구 사항
- 원격 상태 보고가 활성화되어 있습니다 (기본값).
-
cluster-admin역할의 사용자로 OpenShift Container Platform 웹 콘솔에 로그인되어 있습니다.
프로세스
- 워크로드 → ConfigMaps 로 이동하여 Project: openshift-insights 를 선택합니다.
- ConfigMap 생성을 클릭합니다.
Configure via: YAML view 를 선택하고 구성 기본 설정을 입력합니다. 예를 들면 다음과 같습니다.
apiVersion: v1 kind: ConfigMap metadata: name: insights-config namespace: openshift-insights data: config.yaml: | dataReporting: obfuscation: - networking - workload_names sca: disabled: false interval: 2h alerting: disabled: false binaryData: {} immutable: false- 선택 사항: 양식 보기를 선택하고 해당 방식으로 필요한 정보를 입력합니다.
- ConfigMap 이름 필드에 insights-config 를 입력합니다.
- 키 필드에 config.yaml 을 입력합니다.
- Value 필드의 경우 필드로 드래그 앤 드롭할 파일을 검색하거나 구성 매개변수를 수동으로 입력합니다.
-
생성 을 클릭하면
ConfigMap오브젝트 및 구성 정보가 표시됩니다.
4.5.2. Insights Operator 경고 이해
Insights Operator는 Prometheus 모니터링 시스템을 통해 Alertmanager에 경고를 선언합니다. 다음 방법 중 하나를 사용하여 OpenShift Container Platform 웹 콘솔의 경고 UI에서 이러한 경고를 볼 수 있습니다.
- 관리자 화면에서 모니터링 → 경고를 클릭합니다.
- 개발자 화면에서 모니터링 → <project_name> → 경고 탭을 클릭합니다.
현재 조건이 충족되면 Insights Operator에서 다음 경고를 보냅니다.
| 경고 | 설명 |
|---|---|
|
| Insights Operator가 비활성화되어 있습니다. |
|
| Red Hat 서브스크립션 관리에서는 간단한 컨텐츠 액세스가 허용되지 않습니다. |
|
| Insights에는 클러스터에 대한 활성 권장 사항이 있습니다. |
4.5.2.1. Insights Operator 경고 비활성화
Insights Operator가 클러스터 Prometheus 인스턴스에 경고를 보내지 못하도록 insights-config ConfigMap 오브젝트를 생성하거나 편집합니다.
이전에는 클러스터 관리자가 openshift-config 네임스페이스의 support 시크릿 을 사용하여 Insights Operator 구성을 생성하거나 편집했습니다. Red Hat Insights는 Operator를 구성하기 위해 ConfigMap 오브젝트 생성을 지원합니다. Operator는 둘 다 있는 경우 지원 시크릿을 통해 구성 맵 구성에 우선 순위를 부여합니다.
insights-config ConfigMap 오브젝트가 없는 경우 사용자 정의 구성을 처음 추가할 때 생성해야 합니다. ConfigMap 오브젝트 내의 구성은 config/pod.yaml 파일에 정의된 기본 설정보다 우선합니다.
사전 요구 사항
- 원격 상태 보고가 활성화되어 있습니다 (기본값).
-
cluster-admin으로 OpenShift Container Platform 웹 콘솔에 로그인되어 있습니다. -
insights-config
ConfigMap오브젝트는openshift-insights네임스페이스에 있습니다.
프로세스
- 워크로드 → ConfigMaps 로 이동하여 Project: openshift-insights 를 선택합니다.
-
insights-config
ConfigMap오브젝트를 클릭하여 엽니다. - 작업을 클릭하고 ConfigMap 편집을 선택합니다.
- YAML 보기 라디오 버튼을 클릭합니다.
파일에서
alerting속성을disabled: true로 설정합니다.apiVersion: v1 kind: ConfigMap # ... data: config.yaml: | alerting: disabled: true # ...- 저장을 클릭합니다. insights-config config-map 세부 정보 페이지가 열립니다.
-
config.yamlalerting속성 값이disabled: true로 설정되어 있는지 확인합니다.
변경 사항을 저장하면 Insights Operator에서 더 이상 클러스터 Prometheus 인스턴스에 경고를 보내지 않습니다.
4.5.2.2. Insights Operator 경고 활성화
경고가 비활성화되면 Insights Operator에서 더 이상 클러스터 Prometheus 인스턴스로 경고를 보내지 않습니다. 다시 활성화할 수 있습니다.
이전에는 클러스터 관리자가 openshift-config 네임스페이스의 support 시크릿 을 사용하여 Insights Operator 구성을 생성하거나 편집했습니다. Red Hat Insights는 Operator를 구성하기 위해 ConfigMap 오브젝트 생성을 지원합니다. Operator는 둘 다 있는 경우 지원 시크릿을 통해 구성 맵 구성에 우선 순위를 부여합니다.
사전 요구 사항
- 원격 상태 보고가 활성화되어 있습니다 (기본값).
-
cluster-admin으로 OpenShift Container Platform 웹 콘솔에 로그인되어 있습니다. -
insights-config
ConfigMap오브젝트는openshift-insights네임스페이스에 있습니다.
프로세스
- 워크로드 → ConfigMaps 로 이동하여 Project: openshift-insights 를 선택합니다.
-
insights-config
ConfigMap오브젝트를 클릭하여 엽니다. - 작업을 클릭하고 ConfigMap 편집을 선택합니다.
- YAML 보기 라디오 버튼을 클릭합니다.
파일에서
alerting속성을disabled: false로 설정합니다.apiVersion: v1 kind: ConfigMap # ... data: config.yaml: | alerting: disabled: false # ...- 저장을 클릭합니다. insights-config config-map 세부 정보 페이지가 열립니다.
-
config.yamlalerting속성 값이disabled: false로 설정되어 있는지 확인합니다.
변경 사항을 저장하면 Insights Operator에서 클러스터 Prometheus 인스턴스에 경고를 다시 보냅니다.
4.5.3. Insights Operator 아카이브 다운로드
Insights Operator는 클러스터의 openshift-insights 네임스페이스에 있는 아카이브에 수집된 데이터를 저장합니다. Insights Operator가 수집한 데이터를 다운로드하여 검토할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다.
프로세스
Insights Operator에 대해 실행 중인 Pod의 이름을 찾습니다.
$ oc get pods --namespace=openshift-insights -o custom-columns=:metadata.name --no-headers --field-selector=status.phase=RunningInsights Operator가 수집한 최근 데이터 아카이브를 복사합니다.
$ oc cp openshift-insights/<insights_operator_pod_name>:/var/lib/insights-operator ./insights-data1 - 1
<insights_operator_pod_name>을 이전 명령의 Pod 이름 출력으로 바꿉니다.
최신 Insights Operator 아카이브는 이제 insights-data 디렉토리에서 사용할 수 있습니다.
4.5.4. Insights Operator 수집 작업 실행
필요에 따라 Insights Operator 데이터 수집 작업을 실행할 수 있습니다. 다음 절차에서는 OpenShift 웹 콘솔 또는 CLI를 사용하여 기본 수집 작업 목록을 실행하는 방법을 설명합니다. on demand gather 함수를 사용자 지정하여 선택한 수집 작업을 제외할 수 있습니다. 기본 목록에서 수집 작업을 비활성화하면 Insights Advisor에서 클러스터에 대한 효과적인 권장 사항을 제공하는 기능이 저하됩니다. 이전에 Insights Operator가 클러스터에서 작업을 수집하지 않은 경우 이 절차에서는 해당 매개변수를 재정의합니다.
DataGather 사용자 정의 리소스는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 다음 링크를 참조하십시오.
클러스터에서 기술 프리뷰를 활성화하면 Insights Operator가 개별 Pod에서 작업을 실행합니다. 이는 Insights Operator에 대한 기술 프리뷰 기능 세트의 일부이며 새로운 데이터 수집 기능을 지원합니다.
4.5.4.1. Insights Operator 수집 기간 보기
Insights Operator에서 아카이브에 포함된 정보를 수집하는 데 걸리는 시간을 볼 수 있습니다. 이를 통해 Insights Operator 리소스 사용량 및 Insights 권고 문제를 이해하는 데 도움이 됩니다.
사전 요구 사항
- Insights Operator 아카이브의 최근 사본.
프로세스
아카이브에서
/insights-operator/gathers.json을 엽니다.파일에는 Insights Operator 수집 작업 목록이 포함되어 있습니다.
{ "name": "clusterconfig/authentication", "duration_in_ms": 730,1 "records_count": 1, "errors": null, "panic": null }- 1
duration_in_ms는 각 수집 작업의 시간(밀리초)입니다.
- 비정상적인 상태에 대한 각 수집 작업을 검사합니다.
4.5.4.2. 웹 콘솔에서 Insights Operator 수집 작업 실행
데이터를 수집하기 위해 OpenShift Container Platform 웹 콘솔을 사용하여 Insights Operator 수집 작업을 실행할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 OpenShift Container Platform 웹 콘솔에 로그인되어 있습니다.
프로세스
- 콘솔에서 Administration → CustomResourceDefinitions 를 선택합니다.
- CustomResourceDefinitions 페이지의 이름으로 검색 필드에서 DataGather 리소스 정의를 찾은 다음 클릭합니다.
- 사용자 정의 리소스 정의 세부 정보 페이지에서 인스턴스 탭을 클릭합니다.
- DataGather 만들기를 클릭합니다.
새
DataGather작업을 생성하려면 다음 구성 파일을 편집하고 변경 사항을 저장합니다.apiVersion: insights.openshift.io/v1alpha1 kind: DataGather metadata: name: <your_data_gather>1 spec: gatherers:2 - name: workloads state: Disabled
이 문자열이 다른 관리 작업을 위해 예약되고 의도된 수집 작업에 영향을 미칠 수 있으므로 gather 작업 이름에 periodic-gathering- 접두사를 추가하지 마십시오.
검증
- 콘솔에서 워크로드 → Pod 로 선택합니다.
- Pod 페이지에서 프로젝트 풀다운 메뉴로 이동한 다음 기본 프로젝트 표시를 선택합니다.
-
프로젝트 풀다운 메뉴에서
openshift-insights프로젝트를 선택합니다. -
openshift-insights프로젝트의 Pod 목록에서 선택한 이름으로 새 수집 작업에 접두어가 있는지 확인합니다. 완료되면 Insights Operator가 처리를 위해 Red Hat에 데이터를 자동으로 업로드합니다.
4.5.4.3. OpenShift CLI에서 Insights Operator 수집 작업 실행
OpenShift Container Platform 명령줄 인터페이스를 사용하여 Insights Operator 수집 작업을 실행할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 OpenShift Container Platform에 로그인되어 있습니다.
프로세스
다음 명령을 입력하여 수집 작업을 실행합니다.
$ oc apply -f <your_datagather_definition>.yaml&
lt;your_datagather_definition>.yaml을 다음 매개변수가 포함된 구성 파일로 바꿉니다.apiVersion: insights.openshift.io/v1alpha1 kind: DataGather metadata: name: <your_data_gather>1 spec: gatherers:2 - name: workloads state: Disabled
이 문자열이 다른 관리 작업을 위해 예약되고 의도된 수집 작업에 영향을 미칠 수 있으므로 gather 작업 이름에 periodic-gathering- 접두사를 추가하지 마십시오.
검증
-
openshift-insights프로젝트의 Pod 목록에서 선택한 이름으로 새 수집 작업에 접두어가 있는지 확인합니다. 완료되면 Insights Operator가 처리를 위해 Red Hat에 데이터를 자동으로 업로드합니다.
4.5.4.4. Insights Operator 수집 작업 비활성화
Insights Operator 수집 작업을 비활성화할 수 있습니다. 수집 작업을 비활성화하면 Insights Operator가 더 이상 Insights 클러스터 보고서를 Red Hat에 전송하지 않으므로 조직의 개인 정보를 향상시킬 수 있습니다. 이렇게 하면 클러스터 전송과 같은 Red Hat과 통신해야 하는 다른 핵심 기능에 영향을 주지 않고 클러스터의 Insights 분석 및 권장 사항이 비활성화됩니다. Insights Operator 아카이브의 /insights-operator/gathers.json 파일에서 시도한 클러스터 수집 작업 목록을 볼 수 있습니다. 일부 수집 작업은 특정 조건이 충족되고 가장 최근 아카이브에 표시되지 않을 때만 발생합니다.
InsightsDataGather 사용자 정의 리소스는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 다음 링크를 참조하십시오.
클러스터에서 기술 프리뷰를 활성화하면 Insights Operator가 개별 Pod에서 작업을 실행합니다. 이는 Insights Operator에 대한 기술 프리뷰 기능 세트의 일부이며 새로운 데이터 수집 기능을 지원합니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 OpenShift Container Platform 웹 콘솔에 로그인되어 있습니다.
프로세스
- 관리 → 클러스터 리소스 정의로 이동합니다.
- 클러스터 리소스 정의 페이지에서 이름으로 검색 필드를 사용하여 InsightsDataGather 리소스 정의를 찾아 클릭합니다.
- 사용자 정의 리소스 정의 세부 정보 페이지에서 인스턴스 탭을 클릭합니다.
- 클러스터를 클릭한 다음 YAML 탭을 클릭합니다.
InsightsDataGather구성 파일에 다음 편집 중 하나를 수행하여 수집 작업을 비활성화합니다.수집 작업을 모두 비활성화하려면
disabledGatherers키 아래에all을 입력합니다.apiVersion: config.openshift.io/v1alpha1 kind: InsightsDataGather metadata: .... spec:1 gatherConfig: disabledGatherers: - all2 개별 수집 작업을 비활성화하려면
disabledGatherers키 아래에 해당 값을 입력합니다.spec: gatherConfig: disabledGatherers: - clusterconfig/container_images1 - clusterconfig/host_subnets - workloads/workload_info- 1
- 개별 수집 작업 예
저장을 클릭합니다.
변경 사항을 저장하면 Insights Operator 수집 구성이 업데이트되고 작업이 더 이상 발생하지 않습니다.
수집 작업을 비활성화하면 Insights 조언 서비스에서 클러스터에 대한 효과적인 권장 사항을 제공할 수 있는 기능이 저하됩니다.
4.5.4.5. Insights Operator 수집 작업 활성화
수집 작업이 비활성화된 경우 Insights Operator 수집 작업을 활성화할 수 있습니다.
InsightsDataGather 사용자 정의 리소스는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 다음 링크를 참조하십시오.
사전 요구 사항
-
cluster-admin역할의 사용자로 OpenShift Container Platform 웹 콘솔에 로그인되어 있습니다.
프로세스
- 관리 → 클러스터 리소스 정의로 이동합니다.
- 클러스터 리소스 정의 페이지에서 이름으로 검색 필드를 사용하여 InsightsDataGather 리소스 정의를 찾아 클릭합니다.
- 사용자 정의 리소스 정의 세부 정보 페이지에서 인스턴스 탭을 클릭합니다.
- 클러스터를 클릭한 다음 YAML 탭을 클릭합니다.
다음 편집 중 하나를 수행하여 수집 작업을 활성화합니다.
비활성화된 모든 gather 작업을 활성화하려면
gatherConfig스탠자를 제거합니다.apiVersion: config.openshift.io/v1alpha1 kind: InsightsDataGather metadata: .... spec: gatherConfig:1 disabledGatherers: all- 1
gatherConfig스탠자를 제거하여 모든 수집 작업을 활성화합니다.
개별 수집 작업을 활성화하려면
disabledGatherers키에서 해당 값을 제거합니다.spec: gatherConfig: disabledGatherers: - clusterconfig/container_images1 - clusterconfig/host_subnets - workloads/workload_info- 1
- 하나 이상의 수집 작업을 제거합니다.
저장을 클릭합니다.
변경 사항을 저장하면 Insights Operator가 구성을 업데이트하고 영향을 받는 수집 작업이 시작됩니다.
수집 작업을 비활성화하면 Insights Advisor의 기능이 클러스터에 대한 효과적인 권장 사항을 제공하는 성능이 저하됩니다.
4.5.5. Deployment Validation Operator 데이터 난독 처리
기본적으로 Deployment Validation Operator(DVO)를 설치할 때 리소스의 이름 및 고유 식별자(UID)는 OpenShift Container Platform용 Insights Operator가 캡처 및 처리하는 데이터에 포함됩니다. 클러스터 관리자인 경우 DVO(Deployment Validation Operator)의 데이터를 난독화하도록 Insights Operator를 구성할 수 있습니다. 예를 들어, Red Hat으로 전송되는 아카이브 파일에서 워크로드 이름을 난독화할 수 있습니다.
리소스 이름을 난독화하려면 다음 절차에 설명된 대로 insights-config ConfigMap 오브젝트 의 난독화 속성을 수동으로 설정해야 합니다.
사전 요구 사항
- 원격 상태 보고가 활성화되어 있습니다 (기본값).
- "cluster-admin" 역할을 사용하여 OpenShift Container Platform 웹 콘솔에 로그인되어 있습니다.
-
insights-config
ConfigMap오브젝트는openshift-insights네임스페이스에 있습니다. - 클러스터가 자체 관리되고 Deployment Validation Operator가 설치됩니다.
프로세스
- 워크로드 → ConfigMaps 로 이동하여 Project: openshift-insights 를 선택합니다.
-
insights-configConfigMap오브젝트를 클릭하여 엽니다. - 작업을 클릭하고 ConfigMap 편집을 선택합니다.
- YAML 보기 라디오 버튼을 클릭합니다.
파일에서
workload_names값을 사용하여난독 처리속성을 설정합니다.apiVersion: v1 kind: ConfigMap # ... data: config.yaml: | dataReporting: obfuscation: - workload_names # ...- 저장을 클릭합니다. insights-config config-map 세부 정보 페이지가 열립니다.
-
config.yaml난독 처리속성 값이- workload_names로 설정되어 있는지 확인합니다.
4.6. 네트워크가 제한된 환경에서 원격 상태 보고 사용
Insights Operator 아카이브를 수동으로 수집 및 업로드하여 제한된 네트워크에서 문제를 진단할 수 있습니다.
제한된 네트워크에서 Insights Operator를 사용하려면 다음을 수행해야 합니다.
- Insights Operator 아카이브 사본을 만듭니다.
- Insights Operator 아카이브를 console.redhat.com에 업로드합니다.
또한 업로드하기 전에 Insights Operator 데이터를 난독화 하도록 선택할 수 있습니다.
4.6.1. Insights Operator 수집 작업 실행
Insights Operator 아카이브를 생성하려면 수집 작업을 실행해야 합니다.
사전 요구 사항
-
cluster-admin으로 OpenShift Container Platform 클러스터에 로그인되어 있습니다.
프로세스
이 템플릿을 사용하여
gather-job.yaml이라는 파일을 생성합니다.apiVersion: batch/v1 kind: Job metadata: name: insights-operator-job annotations: config.openshift.io/inject-proxy: insights-operator spec: backoffLimit: 6 ttlSecondsAfterFinished: 600 template: spec: restartPolicy: OnFailure serviceAccountName: operator nodeSelector: beta.kubernetes.io/os: linux node-role.kubernetes.io/master: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/master operator: Exists - effect: NoExecute key: node.kubernetes.io/unreachable operator: Exists tolerationSeconds: 900 - effect: NoExecute key: node.kubernetes.io/not-ready operator: Exists tolerationSeconds: 900 volumes: - name: snapshots emptyDir: {} - name: service-ca-bundle configMap: name: service-ca-bundle optional: true initContainers: - name: insights-operator image: quay.io/openshift/origin-insights-operator:latest terminationMessagePolicy: FallbackToLogsOnError volumeMounts: - name: snapshots mountPath: /var/lib/insights-operator - name: service-ca-bundle mountPath: /var/run/configmaps/service-ca-bundle readOnly: true ports: - containerPort: 8443 name: https resources: requests: cpu: 10m memory: 70Mi args: - gather - -v=4 - --config=/etc/insights-operator/server.yaml containers: - name: sleepy image: quay.io/openshift/origin-base:latest args: - /bin/sh - -c - sleep 10m volumeMounts: [{name: snapshots, mountPath: /var/lib/insights-operator}]insights-operator이미지 버전을 복사합니다.$ oc get -n openshift-insights deployment insights-operator -o yaml출력 예
apiVersion: apps/v1 kind: Deployment metadata: name: insights-operator namespace: openshift-insights # ... spec: template: # ... spec: containers: - args: # ... image: registry.ci.openshift.org/ocp/4.15-2023-10-12-212500@sha256:a0aa581400805ad0...1 # ...- 1
insights-operator이미지 버전을 지정합니다.
gather-job.yaml에 이미지 버전을 붙여 넣습니다.apiVersion: batch/v1 kind: Job metadata: name: insights-operator-job # ... spec: # ... template: spec: initContainers: - name: insights-operator image: image: registry.ci.openshift.org/ocp/4.15-2023-10-12-212500@sha256:a0aa581400805ad0...1 terminationMessagePolicy: FallbackToLogsOnError volumeMounts:- 1
- 기존 값을
insights-operator이미지 버전으로 교체합니다.
수집 작업을 생성합니다.
$ oc apply -n openshift-insights -f gather-job.yaml작업 Pod의 이름을 찾습니다.
$ oc describe -n openshift-insights job/insights-operator-job출력 예
Name: insights-operator-job Namespace: openshift-insights # ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulCreate 7m18s job-controller Created pod: insights-operator-job-<your_job>- 다음과 같습니다.
-
insights-operator-job-<your_job>은 Pod의 이름입니다.
작업이 완료되었는지 확인합니다.
$ oc logs -n openshift-insights insights-operator-job-<your_job> insights-operator출력 예
I0407 11:55:38.192084 1 diskrecorder.go:34] Wrote 108 records to disk in 33ms생성된 아카이브를 저장합니다.
$ oc cp openshift-insights/insights-operator-job-<your_job>:/var/lib/insights-operator ./insights-data작업을 정리합니다.
$ oc delete -n openshift-insights job insights-operator-job
4.6.2. Insights Operator 아카이브 업로드
Insights Operator 아카이브를 console.redhat.com에 수동으로 업로드하여 잠재적인 문제를 진단할 수 있습니다.
사전 요구 사항
-
cluster-admin으로 OpenShift Container Platform 클러스터에 로그인되어 있습니다. - 무제한 인터넷 액세스가 가능한 워크스테이션이 있습니다.
- Insights Operator 아카이브 사본을 생성했습니다.
프로세스
dockerconfig.json파일을 다운로드합니다.$ oc extract secret/pull-secret -n openshift-config --to=.dockerconfig.json파일에서"cloud.openshift.com""auth"토큰을 복사합니다.{ "auths": { "cloud.openshift.com": { "auth": "<your_token>", "email": "asd@redhat.com" } }console.redhat.com에 아카이브를 업로드합니다.
$ curl -v -H "User-Agent: insights-operator/one10time200gather184a34f6a168926d93c330 cluster/<cluster_id>" -H "Authorization: Bearer <your_token>" -F "upload=@<path_to_archive>; type=application/vnd.redhat.openshift.periodic+tar" https://console.redhat.com/api/ingress/v1/upload여기서
<cluster_id>는 클러스터 ID이며<your_token>은 풀 시크릿의 토큰이며<path_to_archive>는 Insights Operator 아카이브의 경로입니다.작업이 성공하면 명령은
"request_id"및"account_number"를 반환합니다.출력 예
* Connection #0 to host console.redhat.com left intact {"request_id":"393a7cf1093e434ea8dd4ab3eb28884c","upload":{"account_number":"6274079"}}%
검증 단계
- https://console.redhat.com/openshift로 로그인합니다.
- 왼쪽 창에서 Cluster List 메뉴를 클릭합니다.
- 클러스터 이름을 클릭하여 클러스터의 세부 사항을 표시합니다.
클러스터의 Insights 권고 탭을 엽니다.
업로드에 성공하면 탭에 다음 중 하나가 표시됩니다.
- 클러스터에서 모든 권장 사항을 통과: Insights 권고에서 문제가 발견되지 않은 경우 표시됩니다.
- Insights 권고에서 감지한 문제 목록으로 위험 (낮음, 중간, 중요 및 심각)에 따라 우선 순위가 지정됩니다.
4.6.3. Insights Operator 데이터 난독 처리
난독성을 활성화하여 Insights Operator가 console.redhat.com에 전송하는 중요하고 식별 가능한 IPv4 주소 및 클러스터 기본 도메인을 마스킹할 수 있습니다.
이 기능을 사용할 수 있지만 Red Hat은 더욱 효과적인 지원 환경을 위해 난독 처리를 비활성할 것을 권장합니다.
난독 처리는 클러스터 IPv4 주소에 고유하지 않은 값을 할당하고, 메모리에 유지되는 변환 테이블을 사용하여 데이터를 console.redhat.com에 업로드하기 전에 Insights Operator 아카이브 전체의 난독 처리된 버전으로 IP 주소를 변경합니다.
클러스터 기본 도메인의 경우 난독 처리는 기본 도메인을 하드 코딩된 하위 문자열로 변경합니다. 예를 들어 cluster-api.openshift.example.com은 cluster-api.<CLUSTER_BASE_DOMAIN>이 됩니다.
다음 절차에서는 openshift-config 네임스페이스의 support 시크릿을 사용하여 난독화를 활성화합니다.
사전 요구 사항
-
cluster-admin으로 OpenShift Container Platform 웹 콘솔에 로그인되어 있습니다.
프로세스
- 워크로드 → 시크릿으로 이동합니다.
- openshift-config 프로젝트를 선택합니다.
- 이름으로 검색 필드를 사용하여 지원 시크릿을 검색합니다. 존재하지 않는 경우 생성 → 키/값 시크릿을 클릭하여 생성합니다.
-
옵션 메뉴를
클릭한 다음 시크릿 편집을 클릭합니다.
- 키/값 추가 클릭
-
값이
true인enableGlobalObfuscation이라는 키를 생성하고 저장을 클릭합니다. - 워크로드 → Pod로 이동합니다.
-
openshift-insights프로젝트를 선택합니다. -
insights-operatorpod를 찾습니다. -
insights-operatorpod를 다시 시작하려면 옵션 메뉴
를 클릭한 다음 Pod 삭제를 클릭합니다.
검증
- 워크로드 → 시크릿으로 이동합니다.
- openshift-insights 프로젝트를 선택합니다.
- 이름으로 검색 필드를 사용하여 난독화-translation-table 시크릿을 검색합니다.
obfuscation-translation-table 시크릿이 있으면 난독이 활성화되고 작동합니다.
또는 Insights Operator 아카이브의 /insights-operator/gathers.json 값을 "is_global_obfuscation_enabled": true로 검사할 수 있습니다.
4.7. Insights Operator를 사용하여 간단한 콘텐츠 액세스 인타이틀먼트 가져오기
Insights Operator는 OpenShift Cluster Manager 에서 간단한 콘텐츠 액세스 권한을 주기적으로 가져와 openshift-config-managed 네임스페이스의 etc-pki-entitlement 시크릿에 저장합니다. 간단한 컨텐츠 액세스는 인타이틀먼트 도구의 동작을 단순화하는 Red Hat 서브스크립션 도구의 기능입니다. 이 기능을 사용하면 서브스크립션 툴링을 구성하는 복잡성 없이 Red Hat 서브스크립션에서 제공하는 컨텐츠를 더 쉽게 사용할 수 있습니다.
이전에는 클러스터 관리자가 openshift-config 네임스페이스의 support 시크릿 을 사용하여 Insights Operator 구성을 생성하거나 편집했습니다. Red Hat Insights는 Operator를 구성하기 위해 ConfigMap 오브젝트 생성을 지원합니다. Operator는 둘 다 있는 경우 지원 시크릿을 통해 구성 맵 구성에 우선 순위를 부여합니다.
Insights Operator는 8시간마다 간단한 콘텐츠 액세스 인타이틀먼트를 가져오지만 openshift-insights 네임스페이스에서 insights-config ConfigMap 오브젝트를 사용하여 구성하거나 비활성화할 수 있습니다.
가져오기 기능을 사용하려면 Red Hat 서브스크립션 관리에서 간단한 컨텐츠 액세스를 활성화해야 합니다.
4.7.1. 간단한 콘텐츠 액세스 가져오기 간격 구성
openshift-insights 네임스페이스에서 insights-config ConfigMap 오브젝트를 사용하여 Insights Operator에서 간단한 콘텐츠 액세스(sca) 인타이틀먼트를 가져오는 빈도를 구성할 수 있습니다. 인타이틀먼트 가져오기는 일반적으로 8시간마다 발생하지만 insights-config ConfigMap 오브젝트에서 간단한 콘텐츠 액세스 구성을 업데이트하는 경우 이 sca 간격을 단축할 수 있습니다.
이 절차에서는 가져오기 간격을 2시간(2h)으로 업데이트하는 방법을 설명합니다. 시간(h) 또는 시간 및 분을 지정할 수 있습니다(예: 2h30m).
사전 요구 사항
- 원격 상태 보고가 활성화되어 있습니다 (기본값).
-
cluster-admin역할의 사용자로 OpenShift Container Platform 웹 콘솔에 로그인되어 있습니다. -
insights-config
ConfigMap오브젝트는openshift-insights네임스페이스에 있습니다.
프로세스
- 워크로드 → ConfigMaps 로 이동하여 Project: openshift-insights 를 선택합니다.
-
insights-config
ConfigMap오브젝트를 클릭하여 엽니다. - 작업을 클릭하고 ConfigMap 편집을 선택합니다.
- YAML 보기 라디오 버튼을 클릭합니다.
파일의
sca특성을interval: 2h로 설정하여 2시간마다 콘텐츠를 가져옵니다.apiVersion: v1 kind: ConfigMap # ... data: config.yaml: | sca: interval: 2h # ...- 저장을 클릭합니다. insights-config config-map 세부 정보 페이지가 열립니다.
-
config.yamlsca속성 값이interval: 2h로 설정되어 있는지 확인합니다.
4.7.2. 간단한 콘텐츠 액세스 가져오기 비활성화
openshift-insights 네임스페이스에서 insights-config ConfigMap 오브젝트를 사용하여 간단한 콘텐츠 액세스 인타이틀먼트 가져오기를 비활성화할 수 있습니다.
사전 요구 사항
- 원격 상태 보고가 활성화되어 있습니다 (기본값).
-
cluster-admin으로 OpenShift Container Platform 웹 콘솔에 로그인되어 있습니다. -
insights-config
ConfigMap오브젝트는openshift-insights네임스페이스에 있습니다.
프로세스
- 워크로드 → ConfigMaps 로 이동하여 Project: openshift-insights 를 선택합니다.
-
insights-config
ConfigMap오브젝트를 클릭하여 엽니다. - 작업을 클릭하고 ConfigMap 편집을 선택합니다.
- YAML 보기 라디오 버튼을 클릭합니다.
파일에서
sca속성을disabled: true로 설정합니다.apiVersion: v1 kind: ConfigMap # ... data: config.yaml: | sca: disabled: true # ...- 저장을 클릭합니다. insights-config config-map 세부 정보 페이지가 열립니다.
-
config.yamlsca속성 값이disabled: true로 설정되어 있는지 확인합니다.
4.7.3. 이전에 비활성화된 간단한 콘텐츠 액세스 가져오기 활성화
간단한 콘텐츠 액세스 인타이틀먼트를 가져올 수 없는 경우 Insights Operator는 간단한 콘텐츠 액세스 인타이틀먼트를 가져오지 않습니다. 이 동작을 변경할 수 있습니다.
사전 요구 사항
- 원격 상태 보고가 활성화되어 있습니다 (기본값).
-
cluster-admin역할의 사용자로 OpenShift Container Platform 웹 콘솔에 로그인되어 있습니다. -
insights-config
ConfigMap오브젝트는openshift-insights네임스페이스에 있습니다.
프로세스
- 워크로드 → ConfigMaps 로 이동하여 Project: openshift-insights 를 선택합니다.
-
insights-config
ConfigMap오브젝트를 클릭하여 엽니다. - 작업을 클릭하고 ConfigMap 편집을 선택합니다.
- YAML 보기 라디오 버튼을 클릭합니다.
파일에서
sca속성을disabled: false로 설정합니다.apiVersion: v1 kind: ConfigMap # ... data: config.yaml: | sca: disabled: false # ...- 저장을 클릭합니다. insights-config config-map 세부 정보 페이지가 열립니다.
-
config.yamlsca속성 값이disabled: false로 설정되어 있는지 확인합니다.
5장. 클러스터에 대한 데이터 수집
지원 사례를 여는 경우 클러스터에 대한 디버깅 정보를 Red Hat 지원에 제공하면 도움이 됩니다.
다음을 제공하는 것이 좋습니다.
5.1. must-gather 툴 정보
oc adm must-gather CLI 명령은 다음을 포함하여 문제를 디버깅하는 데 필요할 가능성이 높은 클러스터에서 정보를 수집합니다.
- 리소스 정의
- 서비스 로그
기본적으로 oc adm must-gather 명령은 기본 플러그인 이미지를 사용하고 ./must-gather.local 에 씁니다.
또는 다음 섹션에 설명된 대로 적절한 인수로 명령을 실행하여 특정 정보를 수집할 수 있습니다.
하나 이상의 특정 기능과 관련된 데이터를 수집하려면 다음 섹션에 나열된 대로 이미지와 함께
--image인수를 사용합니다.예를 들면 다음과 같습니다.
$ oc adm must-gather \ --image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel9:v4.16.21감사 로그를 수집하려면 다음 섹션에 설명된 대로
-- /usr/bin/gather_audit_logs인수를 사용하십시오.예를 들면 다음과 같습니다.
$ oc adm must-gather -- /usr/bin/gather_audit_logs참고- 감사 로그는 파일 크기를 줄이기 위해 기본 정보 세트의 일부로 수집되지 않습니다.
-
Windows 운영 체제에서
cwRsync클라이언트를 설치하고oc rsync명령과 함께 사용할PATH변수에 추가합니다.
oc adm must-gather 를 실행하면 클러스터의 새 프로젝트에 임의의 이름이 있는 새 Pod가 생성됩니다. 해당 Pod에서 데이터가 수집되어 현재 작업 디렉터리에 must-gather.local 로 시작하는 새 디렉터리에 저장됩니다.
예를 들면 다음과 같습니다.
NAMESPACE NAME READY STATUS RESTARTS AGE
...
openshift-must-gather-5drcj must-gather-bklx4 2/2 Running 0 72s
openshift-must-gather-5drcj must-gather-s8sdh 2/2 Running 0 72s
...
필요한 경우 --run-namespace 옵션을 사용하여 특정 네임스페이스에서 oc adm must-gather 명령을 실행할 수 있습니다.
예를 들면 다음과 같습니다.
$ oc adm must-gather --run-namespace <namespace> \
--image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel9:v4.16.215.1.1. Red Hat 지원을 위한 클러스터에 대한 데이터 수집
oc adm must-gather CLI 명령을 사용하여 클러스터에 대한 디버깅 정보를 수집할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift Container Platform CLI(
oc)가 설치되어 있습니다.
프로세스
must-gather데이터를 저장하려는 디렉터리로 이동합니다.참고클러스터가 연결이 끊긴 환경에 있는 경우 추가 단계를 수행해야 합니다. 미러 레지스트리에 신뢰할 수 있는 CA가 있는 경우 먼저 신뢰할 수 있는 CA를 클러스터에 추가해야 합니다. 연결이 끊긴 환경의 모든 클러스터에 대해 기본
must-gather이미지를 이미지 스트림으로 가져와야 합니다.$ oc import-image is/must-gather -n openshiftoc adm must-gather명령을 실행합니다.$ oc adm must-gather중요연결이 끊긴 환경에 있는 경우
--image플래그를 must-gather의 일부로 사용하여 페이로드 이미지를 가리킵니다.참고이 명령은 기본적으로 임의의 컨트롤 플레인 노드를 선택하므로 Pod가
NotReady및SchedulingDisabled상태인 컨트롤 플레인 노드로 예약할 수 있습니다.예를 들어 클러스터에서 Pod를 예약할 수 없는 경우와 같이 명령이 실패하면
oc adm inspect명령을 사용하여 특정 리소스에 대한 정보를 수집합니다.참고권장되는 리소스를 얻으려면 Red Hat 지원에 문의하십시오.
작업 디렉토리에서 생성된
must-gather디렉토리에서 압축 파일을 만듭니다. 고유한 must-gather 데이터에 대한 날짜 및 클러스터 ID를 제공해야 합니다. 클러스터 ID를 찾는 방법에 대한 자세한 내용은 OpenShift 클러스터에서 클러스터 ID 또는 이름을 찾는 방법을 참조하십시오. 예를 들어 Linux 운영 체제를 사용하는 컴퓨터에서 다음 명령을 실행합니다.$ tar cvaf must-gather-`date +"%m-%d-%Y-%H-%M-%S"`-<cluster_id>.tar.gz <must_gather_local_dir>1 - 1
- &
lt;must_gather_local_dir>을 실제 디렉터리 이름으로 바꿉니다.
- 압축 파일을 Red Hat 고객 포털 의 고객 지원 페이지의 지원 케이스에 첨부합니다.
5.1.2. 특정 기능에 대한 데이터 수집
oc adm must-gather CLI 명령을 --image 또는 --image-stream 인수와 함께 사용하여 특정 기능에 대한 디버깅 정보를 수집할 수 있습니다. must-gather 툴은 여러 이미지를 지원하므로 단일 명령을 실행하여 둘 이상의 기능에 대한 데이터를 수집할 수 있습니다.
| 이미지 | 목적 |
|---|---|
|
| OpenShift Virtualization의 데이터 수집. |
|
| OpenShift Serverless의 데이터 수집. |
|
| Red Hat OpenShift Service Mesh의 데이터 수집 |
|
| 호스팅된 컨트롤 플레인의 데이터 수집 |
|
| Migration Toolkit for Containers의 데이터 수집 |
|
| Red Hat OpenShift Data Foundation의 데이터 수집 |
|
| 로깅을 위한 데이터 수집 |
|
| Network Observability Operator의 데이터 수집 |
|
| OpenShift Shared Resource CSI 드라이버의 데이터 수집 |
|
| Local Storage Operator의 데이터 수집 |
|
| OpenShift 샌드박스 컨테이너의 데이터 수집 |
|
| Self Node Remediation (SNR) Operator, Fence Agents Remediation (FAR) Operator, Machine Deletion Remediation (MDR) Operator, Node Health Check (NHC) Operator 및 Node Health Check Operator (NMO)를 포함하여 Red Hat Workload Availability Operator의 데이터 수집 NHC Operator 버전이 0.9.0 이전 버전인 경우 이 이미지를 사용합니다. 자세한 내용은 수정, 펜싱 및 유지 관리의 특정 Operator에 대한 "Gathering data" 섹션을 참조하십시오(Red Hat OpenShift의 워크로드 가용성 설명서). |
|
| Self Node Remediation (SNR) Operator, Fence Agents Remediation (FAR) Operator, Machine Deletion Remediation (MDR) Operator, Node Health Check (NHC) Operator 및 Node Health Check Operator (NMO)를 포함하여 Red Hat Workload Availability Operator의 데이터 수집 NHC Operator 버전이 0.9.0 이상인 경우 이 이미지를 사용하십시오. 자세한 내용은 수정, 펜싱 및 유지 관리의 특정 Operator에 대한 "Gathering data" 섹션을 참조하십시오(Red Hat OpenShift의 워크로드 가용성 설명서). |
|
| NUMA Resources Operator(NRO)의 데이터 수집 |
|
| PTP Operator의 데이터 수집 |
|
| Red Hat OpenShift GitOps의 데이터 수집 |
|
| Secrets Store CSI Driver Operator의 데이터 수집 |
|
| LVM Operator의 데이터 수집 |
|
| Compliance Operator의 데이터 수집 |
OpenShift Container Platform 구성 요소의 최신 버전을 확인하려면 Red Hat Customer Portal의 OpenShift Operator 라이프 사이클 웹 페이지를 참조하십시오.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift Container Platform CLI(
oc)가 설치되어 있습니다.
프로세스
-
must-gather데이터를 저장하려는 디렉터리로 이동합니다. --image또는--image-stream인수를 하나 이상 사용하여oc adm must-gather명령을 실행합니다.참고-
특정 기능 데이터 외에도 기본
must-gather데이터를 수집하려면--image-stream=openshift/must-gather인수를 추가하십시오. - 사용자 지정 지표 자동 스케일러에 대한 데이터 수집에 대한 자세한 내용은 다음의 추가 리소스 섹션을 참조하십시오.
예를 들어 다음 명령은 기본 클러스터 데이터와 OpenShift Virtualization 관련 정보를 모두 수집합니다.
$ oc adm must-gather \ --image-stream=openshift/must-gather \1 --image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel9:v4.16.212 must-gather툴을 추가 인수와 함께 사용하여 클러스터의 OpenShift 로깅 및 Red Hat OpenShift Logging Operator와 관련된 데이터를 수집할 수 있습니다. OpenShift 로깅의 경우 다음 명령을 실행합니다.$ oc adm must-gather --image=$(oc -n openshift-logging get deployment.apps/cluster-logging-operator \ -o jsonpath='{.spec.template.spec.containers[?(@.name == "cluster-logging-operator")].image}')예 5.1. OpenShift 로깅의
must-gather출력 예├── cluster-logging │ ├── clo │ │ ├── cluster-logging-operator-74dd5994f-6ttgt │ │ ├── clusterlogforwarder_cr │ │ ├── cr │ │ ├── csv │ │ ├── deployment │ │ └── logforwarding_cr │ ├── collector │ │ ├── fluentd-2tr64 │ ├── eo │ │ ├── csv │ │ ├── deployment │ │ └── elasticsearch-operator-7dc7d97b9d-jb4r4 │ ├── es │ │ ├── cluster-elasticsearch │ │ │ ├── aliases │ │ │ ├── health │ │ │ ├── indices │ │ │ ├── latest_documents.json │ │ │ ├── nodes │ │ │ ├── nodes_stats.json │ │ │ └── thread_pool │ │ ├── cr │ │ ├── elasticsearch-cdm-lp8l38m0-1-794d6dd989-4jxms │ │ └── logs │ │ ├── elasticsearch-cdm-lp8l38m0-1-794d6dd989-4jxms │ ├── install │ │ ├── co_logs │ │ ├── install_plan │ │ ├── olmo_logs │ │ └── subscription │ └── kibana │ ├── cr │ ├── kibana-9d69668d4-2rkvz ├── cluster-scoped-resources │ └── core │ ├── nodes │ │ ├── ip-10-0-146-180.eu-west-1.compute.internal.yaml │ └── persistentvolumes │ ├── pvc-0a8d65d9-54aa-4c44-9ecc-33d9381e41c1.yaml ├── event-filter.html ├── gather-debug.log └── namespaces ├── openshift-logging │ ├── apps │ │ ├── daemonsets.yaml │ │ ├── deployments.yaml │ │ ├── replicasets.yaml │ │ └── statefulsets.yaml │ ├── batch │ │ ├── cronjobs.yaml │ │ └── jobs.yaml │ ├── core │ │ ├── configmaps.yaml │ │ ├── endpoints.yaml │ │ ├── events │ │ │ ├── elasticsearch-im-app-1596020400-gm6nl.1626341a296c16a1.yaml │ │ │ ├── elasticsearch-im-audit-1596020400-9l9n4.1626341a2af81bbd.yaml │ │ │ ├── elasticsearch-im-infra-1596020400-v98tk.1626341a2d821069.yaml │ │ │ ├── elasticsearch-im-app-1596020400-cc5vc.1626341a3019b238.yaml │ │ │ ├── elasticsearch-im-audit-1596020400-s8d5s.1626341a31f7b315.yaml │ │ │ ├── elasticsearch-im-infra-1596020400-7mgv8.1626341a35ea59ed.yaml │ │ ├── events.yaml │ │ ├── persistentvolumeclaims.yaml │ │ ├── pods.yaml │ │ ├── replicationcontrollers.yaml │ │ ├── secrets.yaml │ │ └── services.yaml │ ├── openshift-logging.yaml │ ├── pods │ │ ├── cluster-logging-operator-74dd5994f-6ttgt │ │ │ ├── cluster-logging-operator │ │ │ │ └── cluster-logging-operator │ │ │ │ └── logs │ │ │ │ ├── current.log │ │ │ │ ├── previous.insecure.log │ │ │ │ └── previous.log │ │ │ └── cluster-logging-operator-74dd5994f-6ttgt.yaml │ │ ├── cluster-logging-operator-registry-6df49d7d4-mxxff │ │ │ ├── cluster-logging-operator-registry │ │ │ │ └── cluster-logging-operator-registry │ │ │ │ └── logs │ │ │ │ ├── current.log │ │ │ │ ├── previous.insecure.log │ │ │ │ └── previous.log │ │ │ ├── cluster-logging-operator-registry-6df49d7d4-mxxff.yaml │ │ │ └── mutate-csv-and-generate-sqlite-db │ │ │ └── mutate-csv-and-generate-sqlite-db │ │ │ └── logs │ │ │ ├── current.log │ │ │ ├── previous.insecure.log │ │ │ └── previous.log │ │ ├── elasticsearch-cdm-lp8l38m0-1-794d6dd989-4jxms │ │ ├── elasticsearch-im-app-1596030300-bpgcx │ │ │ ├── elasticsearch-im-app-1596030300-bpgcx.yaml │ │ │ └── indexmanagement │ │ │ └── indexmanagement │ │ │ └── logs │ │ │ ├── current.log │ │ │ ├── previous.insecure.log │ │ │ └── previous.log │ │ ├── fluentd-2tr64 │ │ │ ├── fluentd │ │ │ │ └── fluentd │ │ │ │ └── logs │ │ │ │ ├── current.log │ │ │ │ ├── previous.insecure.log │ │ │ │ └── previous.log │ │ │ ├── fluentd-2tr64.yaml │ │ │ └── fluentd-init │ │ │ └── fluentd-init │ │ │ └── logs │ │ │ ├── current.log │ │ │ ├── previous.insecure.log │ │ │ └── previous.log │ │ ├── kibana-9d69668d4-2rkvz │ │ │ ├── kibana │ │ │ │ └── kibana │ │ │ │ └── logs │ │ │ │ ├── current.log │ │ │ │ ├── previous.insecure.log │ │ │ │ └── previous.log │ │ │ ├── kibana-9d69668d4-2rkvz.yaml │ │ │ └── kibana-proxy │ │ │ └── kibana-proxy │ │ │ └── logs │ │ │ ├── current.log │ │ │ ├── previous.insecure.log │ │ │ └── previous.log │ └── route.openshift.io │ └── routes.yaml └── openshift-operators-redhat ├── ...-
특정 기능 데이터 외에도 기본
--image또는--image-stream인수를 하나 이상 사용하여oc adm must-gather명령을 실행합니다. 예를 들어 다음 명령은 기본 클러스터 데이터와 KubeVirt 관련 정보를 모두 수집합니다.$ oc adm must-gather \ --image-stream=openshift/must-gather \1 --image=quay.io/kubevirt/must-gather2 작업 디렉토리에서 생성된
must-gather디렉토리에서 압축 파일을 만듭니다. 고유한 must-gather 데이터에 대한 날짜 및 클러스터 ID를 제공해야 합니다. 클러스터 ID를 찾는 방법에 대한 자세한 내용은 OpenShift 클러스터에서 클러스터 ID 또는 이름을 찾는 방법을 참조하십시오. 예를 들어 Linux 운영 체제를 사용하는 컴퓨터에서 다음 명령을 실행합니다.$ tar cvaf must-gather-`date +"%m-%d-%Y-%H-%M-%S"`-<cluster_id>.tar.gz <must_gather_local_dir>1 - 1
- &
lt;must_gather_local_dir>을 실제 디렉터리 이름으로 바꿉니다.
- 압축 파일을 Red Hat 고객 포털 의 고객 지원 페이지의 지원 케이스에 첨부합니다.
5.2. 추가 리소스
- 사용자 정의 지표 자동 스케일러의 디버깅 데이터 수집입니다.
- Red Hat OpenShift Container Platform 라이프 사이클 정책
5.2.1. 네트워크 로그 수집
클러스터의 모든 노드에서 네트워크 로그를 수집할 수 있습니다.
프로세스
-- gather_network_logs를 사용하여oc adm must-gather명령을 실행합니다.$ oc adm must-gather -- gather_network_logs참고기본적으로
must-gather툴은 클러스터의 모든 노드에서 OVNnbdb및sbdb데이터베이스를 수집합니다. OVNnbdb데이터베이스에 대한 OVN-Kubernetes 트랜잭션이 포함된 추가 로그를 포함하도록-- gather_network_logs옵션을 추가합니다.작업 디렉토리에서 생성된
must-gather디렉토리에서 압축 파일을 만듭니다. 고유한 must-gather 데이터에 대한 날짜 및 클러스터 ID를 제공해야 합니다. 클러스터 ID를 찾는 방법에 대한 자세한 내용은 OpenShift 클러스터에서 클러스터 ID 또는 이름을 찾는 방법을 참조하십시오. 예를 들어 Linux 운영 체제를 사용하는 컴퓨터에서 다음 명령을 실행합니다.$ tar cvaf must-gather-`date +"%m-%d-%Y-%H-%M-%S"`-<cluster_id>.tar.gz <must_gather_local_dir>1 - 1
- &
lt;must_gather_local_dir>을 실제 디렉터리 이름으로 바꿉니다.
- 압축 파일을 Red Hat 고객 포털 의 고객 지원 페이지의 지원 케이스에 첨부합니다.
5.2.2. must-gather 스토리지 제한 변경
oc adm must-gather 명령을 사용하여 데이터를 수집할 때 정보의 기본 최대 스토리지는 컨테이너의 스토리지 용량의 30%입니다. 30% 제한에 도달하면 컨테이너가 종료되고 수집 프로세스가 중지됩니다. 이미 수집된 정보는 로컬 스토리지에 다운로드되어 있습니다. must-gather 명령을 다시 실행하려면 스토리지 용량이 더 많은 컨테이너를 사용하거나 최대 볼륨 백분율을 조정해야 합니다.
컨테이너가 스토리지 제한에 도달하면 다음 예와 유사한 오류 메시지가 생성됩니다.
출력 예
Disk usage exceeds the volume percentage of 30% for mounted directory. Exiting...사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있어야 합니다.
프로세스
volume-percentage플래그를 사용하여oc adm must-gather명령을 실행합니다. 새 값은 100을 초과할 수 없습니다.$ oc adm must-gather --volume-percentage <storage_percentage>
5.3. 클러스터 ID 검색
Red Hat 지원에 정보를 제공할 때 클러스터의 고유 식별자를 제공하는 것이 유용합니다. OpenShift Container Platform 웹 콘솔을 사용하여 클러스터 ID를 자동으로 입력할 수 있습니다. 웹 콘솔 또는 OpenShift CLI (oc)를 사용하여 클러스터 ID를 수동으로 검색할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
설치된 웹 콘솔 또는 OpenShift CLI(
oc)에 액세스할 수 있습니다.
프로세스
웹 콘솔을 사용하여 지원 케이스를 열고 클러스터 ID를 자동으로 입력하려면 다음을 수행합니다.
- 툴바에서 (?) Help 를 선택하고 목록에서 피드백 공유를 선택합니다.
- Tell us about your experience 창에서 지원 케이스 열기 를 클릭합니다.
웹 콘솔을 사용하여 클러스터 ID를 수동으로 가져오려면 다음을 수행합니다.
- 홈 → 개요 로 이동합니다.
- 값은 Details 섹션의 Cluster ID 필드에서 사용 가능합니다.
OpenShift CLI (
oc)를 사용하여 클러스터 ID를 얻으려면 다음 명령을 실행합니다.$ oc get clusterversion -o jsonpath='{.items[].spec.clusterID}{"\n"}'
5.4. sosreport 정보
sosreport는 RHEL(Red Hat Enterprise Linux) 및 RHCOS(Red Hat Enterprise Linux CoreOS) 시스템에서 구성 세부 정보, 시스템 정보, 진단 데이터를 수집하는 툴입니다. sosreport는 노드와 관련된 진단 정보를 수집하는 표준화된 방법을 제공합니다. 이러한 정보는 문제 진단을 위해 Red Hat 지원팀에 제공할 수 있습니다.
경우에 따라 Red Hat 지원팀에서 특정 OpenShift Container Platform 노드에 대한 sosreport 아카이브를 수집하도록 요청할 수 있습니다. 예를 들어, oc adm must-gather의 출력에 포함되지 않은 시스템 로그 또는 기타 노드 별 데이터를 확인해야 하는 경우가 있습니다.
5.5. OpenShift Container Platform 클러스터 노드의 sosreport 아카이브 생성
OpenShift Container Platform 4.16 클러스터 노드에 sosreport 를 생성하는 방법으로 디버그 Pod를 사용하는 것이 좋습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. - 호스트에 대한 SSH 액세스 권한이 있어야 합니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다. - Red Hat 표준 또는 프리미엄 서브스크립션이 있습니다.
- Red Hat 고객 포털 계정이 있어야 합니다.
- 기존 Red Hat 지원 케이스 ID가 있습니다.
프로세스
클러스터 노드 목록을 가져옵니다.
$ oc get nodes대상 노드에서 디버그 세션으로 들어갑니다. 이 단계는
<node_name>-debug라는 디버그 Pod를 인스턴스화합니다.$ oc debug node/my-cluster-nodeNoExecute효과로 테인트된 대상 노드에서 디버그 세션에 들어가려면 더미 네임스페이스에 허용 오차를 추가하고 더미 네임스페이스에서 디버그 Pod를 시작합니다.$ oc new-project dummy$ oc patch namespace dummy --type=merge -p '{"metadata": {"annotations": { "scheduler.alpha.kubernetes.io/defaultTolerations": "[{\"operator\": \"Exists\"}]"}}}'$ oc debug node/my-cluster-node디버그 쉘 내에서
/host를 root 디렉터리로 설정합니다. 디버그 Pod는 Pod 내의/host에 호스트의 루트 파일 시스템을 마운트합니다. root 디렉토리를/host로 변경하면 호스트의 실행 경로에 포함된 바이너리를 실행할 수 있습니다.# chroot /host참고RHCOS(Red Hat Enterprise Linux CoreOS)를 실행하는 OpenShift Container Platform 4.16 클러스터 노드는 변경할 수 없으며 Operator를 사용하여 클러스터 변경 사항을 적용합니다. SSH를 사용하여 클러스터 노드에 액세스하는 것은 권장되지 않습니다. 그러나 OpenShift Container Platform API를 사용할 수 없거나 kubelet이 대상 노드에서 제대로 작동하지 않는 경우
oc작업이 영향을 받습니다. 이러한 상황에서 대신ssh core @ <node>.<cluster_name>.<base_domain>을 사용하여 노드에 액세스할 수 있습니다.sosreport를 실행하는 데 필요한 바이너리 및 플러그인이 포함된toolbox컨테이너를 시작합니다.# toolbox참고기존
toolboxPod가 이미 실행 중인 경우toolbox명령은'toolbox-' already exists를 출력합니다. Trying to start…를 출력합니다.podman rm toolbox-에서 실행중인 toolbox 컨테이너를 제거하고 새 toolbox 컨테이너를 생성하여sosreport플러그인 문제를 방지합니다.sosreport아카이브를 수집합니다.sos report명령을 실행하여crio및podman에서 필요한 문제 해결 데이터를 수집합니다.# sos report -k crio.all=on -k crio.logs=on -k podman.all=on -k podman.logs=on1 - 1
-k를 사용하면 기본값 외부에서sosreport플러그인 매개 변수를 정의할 수 있습니다.
선택 사항: 보고서에 있는 노드의 OVN-Kubernetes 네트워킹 구성에 대한 정보를 포함하려면 다음 명령을 실행합니다.
# sos report --all-logs- 프롬프트가 표시되면 Enter를 눌러 계속 진행합니다.
-
Red Hat 지원 사례 ID를 제공합니다.
sosreport는 아카이브의 파일 이름에 ID를 추가합니다. sosreport출력은 아카이브의 위치와 체크섬을 제공합니다. 다음 예에서는 케이스 ID01234567을 참조합니다.Your sosreport has been generated and saved in: /host/var/tmp/sosreport-my-cluster-node-01234567-2020-05-28-eyjknxt.tar.xz1 The checksum is: 382ffc167510fd71b4f12a4f40b97a4e- 1
- toolbox 컨테이너가 호스트의 root 디렉토리를
/host에 마운트하기 때문에sosreport아카이브의 파일 경로는chroot환경 외부에 있습니다.
다음 방법 중 하나를 사용하여 분석을 위해 Red Hat 지원에
sosreport아카이브를 제공합니다.기존 Red Hat 지원 케이스에 파일을 업로드합니다.
oc debug node/<node_name>명령을 실행하여sosreport아카이브를 연결하고 출력을 파일로 리디렉션합니다. 이 명령은 이전oc debug세션을 종료했다고 가정합니다.$ oc debug node/my-cluster-node -- bash -c 'cat /host/var/tmp/sosreport-my-cluster-node-01234567-2020-05-28-eyjknxt.tar.xz' > /tmp/sosreport-my-cluster-node-01234567-2020-05-28-eyjknxt.tar.xz1 - 1
- 디버그 컨테이너는
/host에 호스트의 root 디렉토리를 마운트합니다. 연결할 대상 파일을 지정할 때/host를 포함하여 디버그 컨테이너의 root 디렉토리에서 절대 경로를 참조합니다.
참고RHCOS(Red Hat Enterprise Linux CoreOS)를 실행하는 OpenShift Container Platform 4.16 클러스터 노드는 변경할 수 없으며 Operator를 사용하여 클러스터 변경 사항을 적용합니다.
scp를 사용하여 클러스터 노드에서sosreport아카이브를 전송하는 것은 권장되지 않습니다. 그러나 OpenShift Container Platform API를 사용할 수 없거나 kubelet이 대상 노드에서 제대로 작동하지 않는 경우oc작업이 영향을 받습니다. 이러한 상황에서는scp core@<node>.<cluster_name>.<base_domain>:<file_path> <local_path>를 실행하여 노드에서sosreport아카이브를 복사할 수 있습니다.- Red Hat 고객 포털 의 고객 지원 페이지에서 기존 지원 케이스로 이동합니다.
- Attach files를 선택하고 메시지에 따라 파일을 업로드합니다.
5.6. 부트 스트랩 노드의 저널 로그 쿼리
부트 스트랩 관련 문제가 발생하는 경우 부트 스트랩 노드에서 bootkube.service journald 장치 로그 및 컨테이너 로그를 수집할 수 있습니다.
사전 요구 사항
- 부트 스트랩 노드에 대한 SSH 액세스 권한이 있어야 합니다.
- 부트 스트랩 노드의 정규화된 도메인 이름이 있어야 합니다.
프로세스
OpenShift Container Platform 설치 중에 부트 스트랩 노드에서
bootkube.servicejournald장치 로그를 쿼리합니다.<bootstrap_fqdn>을 부트 스트랩 노드의 정규화된 도메인 이름으로 바꿉니다.$ ssh core@<bootstrap_fqdn> journalctl -b -f -u bootkube.service참고부트스트랩 노드의
bootkube.service로그는 etcdconnectionrejectd 오류를 출력하고 부트스트랩 서버가 컨트롤 플레인 노드의 etcd에 연결할 수 없음을 나타냅니다. 각 컨트롤 플레인 노드에서 etcd를 시작하고 노드가 클러스터에 가입되면 오류가 중지됩니다.부트 스트랩 노드에서
podman을 사용하여 부트 스트랩 노드 컨테이너에서 로그를 수집합니다.<bootstrap_fqdn>을 부트 스트랩 노드의 정규화된 도메인 이름으로 바꿉니다.$ ssh core@<bootstrap_fqdn> 'for pod in $(sudo podman ps -a -q); do sudo podman logs $pod; done'
5.7. 클러스터 노드의 저널 로그 쿼리
개별 클러스터 노드의 /var/log 내에 journald 장치 로그 및 기타 로그를 수집할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다. - API 서비스가 작동하고 있어야 합니다.
- 호스트에 대한 SSH 액세스 권한이 있어야 합니다.
프로세스
OpenShift Container Platform 클러스터 노드에서
kubeletjournald장치 로그를 쿼리합니다. 다음 예제에서는 컨트롤 플레인 노드만 쿼리합니다.$ oc adm node-logs --role=worker -u kubelet-
kubelet: 다른 장치 로그를 쿼리하려면 적절하게 바꿉니다.
-
클러스터 노드의
/var/log/아래에있는 특정 하위 디렉터리에서 로그를 수집합니다./var/log/하위 디렉토리에 포함된 로그 목록을 검색합니다. 다음 예제는 모든 컨트롤 플레인 노드의/var/log/openshift-apiserver/에 있는 파일을 나열합니다.$ oc adm node-logs --role=master --path=openshift-apiserver/var/log/하위 디렉터리 내의 특정 로그를 확인합니다. 다음 예제는 모든 컨트롤 플레인 노드에서/var/log/openshift-apiserver/audit.log내용을 출력합니다.$ oc adm node-logs --role=master --path=openshift-apiserver/audit.logAPI가 작동하지 않는 경우 SSH를 사용하여 각 노드의 로그를 확인합니다. 다음은
/var/log/openshift-apiserver/audit.log예제입니다.$ ssh core@<master-node>.<cluster_name>.<base_domain> sudo tail -f /var/log/openshift-apiserver/audit.log참고RHCOS(Red Hat Enterprise Linux CoreOS)를 실행하는 OpenShift Container Platform 4.16 클러스터 노드는 변경할 수 없으며 Operator를 사용하여 클러스터 변경 사항을 적용합니다. SSH를 사용하여 클러스터 노드에 액세스하는 것은 권장되지 않습니다. SSH를 통해 진단 데이터를 수집하기 전에
oc adm must gather및 기타oc명령을 실행하여 충분한 데이터를 수집할 수 있는지 확인하십시오. 그러나 OpenShift Container Platform API를 사용할 수 없거나 kubelet이 대상 노드에서 제대로 작동하지 않는 경우oc작업이 영향을 받습니다. 이러한 상황에서ssh core@<node>.<cluster_name>.<base_domain>을 사용하여 노드에 액세스할 수 있습니다.
5.8. 네트워크 추적 방법
패킷 캡처 레코드 형태로 네트워크 추적을 수집하면 네트워크 문제 해결과 관련하여 Red Hat 지원을 지원할 수 있습니다.
OpenShift Container Platform은 네트워크 추적을 수행하는 두 가지 방법을 지원합니다. 다음 표를 검토하고 요구 사항에 맞는 방법을 선택합니다.
| 방법 | 이점 및 기능 |
|---|---|
| 호스트 네트워크 추적 수집 | 하나 이상의 노드에 동시에 지정하는 기간에 대해 패킷 캡처를 수행합니다. 지정된 기간이 충족되면 패킷 캡처 파일이 노드에서 클라이언트 시스템으로 전송됩니다. 특정 작업에서 네트워크 통신 문제를 트리거하는 이유를 해결할 수 있습니다. 패킷 캡처를 실행하고 문제를 트리거하는 작업을 수행하고 로그를 사용하여 문제를 진단합니다. |
| OpenShift Container Platform 노드 또는 컨테이너에서 네트워크 추적 수집 |
하나의 노드 또는 하나의 컨테이너에서 패킷 캡처를 수행합니다. 패킷 캡처를 수동으로 시작하고 네트워크 통신 문제를 트리거한 다음 패킷 캡처를 수동으로 중지할 수 있습니다.
이 방법은 |
5.9. 호스트 네트워크 추적 수집
네트워크 통신을 추적하고 동시에 여러 노드에서 패킷을 캡처하여 네트워크 관련 문제를 해결할 수 있습니다.
oc adm must-gather 명령과 registry.redhat.io/openshift4/network-tools-rhel8 컨테이너 이미지 조합을 사용하여 노드에서 패킷 캡처를 수집할 수 있습니다. 패킷 캡처를 분석하면 네트워크 통신 문제를 해결하는 데 도움이 될 수 있습니다.
oc adm must-gather 명령은 특정 노드의 Pod에서 tcpdump 명령을 실행하는 데 사용됩니다. tcpdump 명령은 Pod에 패킷 캡처를 기록합니다. tcpdump 명령이 종료되면 oc adm must-gather 명령은 Pod에서 패킷 캡처가 있는 파일을 클라이언트 머신으로 전송합니다.
다음 절차의 샘플 명령은 tcpdump 명령을 사용하여 패킷 캡처를 수행하는 방법을 보여줍니다. 그러나 --image 인수에 지정된 컨테이너 이미지에서 모든 명령을 실행하여 여러 노드에서 문제 해결 정보를 동시에 수집할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 OpenShift Container Platform에 로그인되어 있습니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
다음 명령을 실행하여 일부 노드에서 호스트 네트워크에서 패킷 캡처를 실행합니다.
$ oc adm must-gather \ --dest-dir /tmp/captures \ <.> --source-dir '/tmp/tcpdump/' \ <.> --image registry.redhat.io/openshift4/network-tools-rhel8:latest \ <.> --node-selector 'node-role.kubernetes.io/worker' \ <.> --host-network=true \ <.> --timeout 30s \ <.> -- \ tcpdump -i any \ <.> -w /tmp/tcpdump/%Y-%m-%dT%H:%M:%S.pcap -W 1 -G 300<.>
--dest-dir인수는oc adm must-gather가 클라이언트 머신의/tmp/captures와 관련된 디렉터리에 패킷 캡처를 저장하도록 지정합니다. 쓰기 가능한 디렉터리를 지정할 수 있습니다. <.>oc adm must-gather가 시작되는 디버그 Pod에서tcpdump가 실행될 때--source-dir인수는 패킷 캡처가 Pod의/tmp/tcpdump디렉터리에 일시적으로 저장되도록 지정합니다. <.>--image인수는tcpdump명령을 포함하는 컨테이너 이미지. <.>--node-selector인수 및 예제 값은 작업자 노드에서 패킷 캡처를 수행하도록 지정합니다. 또는 단일 노드에서 패킷 캡처를 실행하도록--node-name인수를 지정할 수 있습니다.--node-selector및--node-name인수를 모두 생략하면 패킷 캡처가 모든 노드에서 수행됩니다. <.> 패킷 캡처가 노드의 네트워크 인터페이스에서 수행되도록--host-network=true인수가 필요합니다. <.>--timeout인수 및 값은 디버그 Pod를 30 초 동안 실행하기 위해 지정합니다.--timeout인수와 기간을 지정하지 않으면 디버그 Pod가 10분 동안 실행됩니다. <.>tcpdump명령의-i any인수는 모든 네트워크 인터페이스에서 패킷을 캡처하도록 지정합니다. 또는 네트워크 인터페이스 이름을 지정할 수 있습니다.- 네트워크 추적에서 패킷을 캡처하는 동안 네트워크 통신 문제를 트리거하는 웹 애플리케이션 액세스와 같은 작업을 수행합니다.
oc adm must-gather가 Pod에서 클라이언트 머신으로 전송된 패킷 캡처 파일을 확인합니다.tmp/captures ├── event-filter.html ├── ip-10-0-192-217-ec2-internal1 │ └── registry-redhat-io-openshift4-network-tools-rhel8-sha256-bca... │ └── 2022-01-13T19:31:31.pcap ├── ip-10-0-201-178-ec2-internal2 │ └── registry-redhat-io-openshift4-network-tools-rhel8-sha256-bca... │ └── 2022-01-13T19:31:30.pcap ├── ip-... └── timestamp
5.10. OpenShift Container Platform 노드 또는 컨테이너에서 네트워크 추적 수집
잠재적인 네트워크 관련 OpenShift Container Platform 문제를 조사할 때 Red Hat 지원은 특정 OpenShift Container Platform 클러스터 노드 또는 특정 컨테이너에서 네트워크 패킷 추적을 요청할 수 있습니다. OpenShift Container Platform에서 네트워크 추적을 캡처하는 데 권장되는 방법은 디버그 Pod를 사용하는 것입니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다. - 기존 Red Hat 지원 케이스 ID가 있습니다.
- Red Hat 표준 또는 프리미엄 서브스크립션이 있습니다.
- Red Hat 고객 포털 계정이 있어야 합니다.
- 호스트에 대한 SSH 액세스 권한이 있어야 합니다.
프로세스
클러스터 노드 목록을 가져옵니다.
$ oc get nodes대상 노드에서 디버그 세션으로 들어갑니다. 이 단계는
<node_name>-debug라는 디버그 Pod를 인스턴스화합니다.$ oc debug node/my-cluster-node디버그 쉘 내에서
/host를 root 디렉터리로 설정합니다. 디버그 Pod는 Pod 내의/host에 호스트의 루트 파일 시스템을 마운트합니다. root 디렉토리를/host로 변경하면 호스트의 실행 경로에 포함된 바이너리를 실행할 수 있습니다.# chroot /host참고RHCOS(Red Hat Enterprise Linux CoreOS)를 실행하는 OpenShift Container Platform 4.16 클러스터 노드는 변경할 수 없으며 Operator를 사용하여 클러스터 변경 사항을 적용합니다. SSH를 사용하여 클러스터 노드에 액세스하는 것은 권장되지 않습니다. 그러나 OpenShift Container Platform API를 사용할 수 없거나 kubelet이 대상 노드에서 제대로 작동하지 않는 경우
oc작업이 영향을 받습니다. 이러한 상황에서 대신ssh core @ <node>.<cluster_name>.<base_domain>을 사용하여 노드에 액세스할 수 있습니다.chroot환경 콘솔에서 노드의 인터페이스 이름을 가져옵니다.# ip adsosreport를 실행하는 데 필요한 바이너리 및 플러그인이 포함된toolbox컨테이너를 시작합니다.# toolbox참고기존
toolboxPod가 이미 실행 중인 경우toolbox명령은'toolbox-' already exists를 출력합니다. Trying to start…를 출력합니다.tcpdump문제를 방지하려면podman rm toolbox-에서 실행중인 toolbox 컨테이너를 제거하고 새 toolbox 컨테이너를 생성합니다.클러스터 노드에서
tcpdump세션을 시작하고 출력을 캡처 파일로 리디렉션합니다. 이 예에서는ens5를 인터페이스 이름으로 사용합니다.$ tcpdump -nn -s 0 -i ens5 -w /host/var/tmp/my-cluster-node_$(date +%d_%m_%Y-%H_%M_%S-%Z).pcap1 - 1
- toolbox 컨테이너가 호스트의 root 디렉토리를
/host에 마운트하기 때문에tcpdump캡처 파일의 경로는chroot환경 외부에 있습니다.
노드의 특정 컨테이너에
tcpdump캡처가 필요한 경우 다음 단계를 따르십시오.대상 컨테이너 ID를 확인합니다. toolbox 컨테이너가 호스트의 root 디렉토리를
/host에 마운트하기 때문에chroot host명령은 이 단계에서crictl명령 보다 우선합니다.# chroot /host crictl ps컨테이너의 프로세스 ID를 확인합니다. 이 예에서 컨테이너 ID는
a7fe32346b120입니다.# chroot /host crictl inspect --output yaml a7fe32346b120 | grep 'pid' | awk '{print $2}'컨테이너에서
tcpdump세션을 시작하고 출력을 캡처 파일로 리디렉션합니다. 이 예는 컨테이너의 프로세스 ID로49,628을 사용하고 인터페이스 이름으로ens5를 사용합니다.nsenter명령은 대상 프로세스의 네임 스페이스를 입력하고 해당 네임 스페이스를 사용하여 명령을 실행합니다. 이 예에서 대상 프로세스는 컨테이너의 프로세스 ID이므로tcpdump명령은 호스트에서 컨테이너 네임 스페이스를 사용하여 실행됩니다.# nsenter -n -t 49628 -- tcpdump -nn -i ens5 -w /host/var/tmp/my-cluster-node-my-container_$(date +%d_%m_%Y-%H_%M_%S-%Z).pcap1 - 1
- toolbox 컨테이너가 호스트의 root 디렉토리를
/host에 마운트하기 때문에tcpdump캡처 파일의 경로는chroot환경 외부에 있습니다.
분석을 위해 다음 방법 중 하나를 사용하여
tcpdump캡처 파일을 Red Hat 지원팀에 제공합니다.기존 Red Hat 지원 케이스에 파일을 업로드합니다.
oc debug node/<node_name>명령을 실행하여sosreport아카이브를 연결하고 출력을 파일로 리디렉션합니다. 이 명령은 이전oc debug세션을 종료했다고 가정합니다.$ oc debug node/my-cluster-node -- bash -c 'cat /host/var/tmp/my-tcpdump-capture-file.pcap' > /tmp/my-tcpdump-capture-file.pcap1 - 1
- 디버그 컨테이너는
/host에 호스트의 root 디렉토리를 마운트합니다. 연결할 대상 파일을 지정할 때/host를 포함하여 디버그 컨테이너의 root 디렉토리에서 절대 경로를 참조합니다.
참고RHCOS(Red Hat Enterprise Linux CoreOS)를 실행하는 OpenShift Container Platform 4.16 클러스터 노드는 변경할 수 없으며 Operator를 사용하여 클러스터 변경 사항을 적용합니다.
scp를 사용하여 클러스터 노드에서tcpdump캡처 파일을 전송하는 것은 권장되지 않습니다. 그러나 OpenShift Container Platform API를 사용할 수 없거나 kubelet이 대상 노드에서 제대로 작동하지 않는 경우oc작업이 영향을 받습니다. 이러한 상황에서는scp core@<node>.<cluster_name>.<base_domain>:<file_path> <local_path>를 실행하여 노드에서tcpdump캡처 파일을 복사할 수 있습니다.- Red Hat 고객 포털 의 고객 지원 페이지에서 기존 지원 케이스로 이동합니다.
- Attach files를 선택하고 메시지에 따라 파일을 업로드합니다.
5.11. Red Hat 지원에 진단 데이터 제공
OpenShift Container Platform 문제를 조사할 때 Red Hat 지원은 지원 케이스에 진단 데이터를 업로드하도록 요청할 수 있습니다. 파일은 Red Hat 고객 포털을 통해 지원 케이스에 업로드할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다. - 호스트에 대한 SSH 액세스 권한이 있어야 합니다.
- Red Hat 표준 또는 프리미엄 서브스크립션이 있습니다.
- Red Hat 고객 포털 계정이 있어야 합니다.
- 기존 Red Hat 지원 케이스 ID가 있습니다.
프로세스
Red Hat 고객 포털을 통해 기존 Red Hat 지원 케이스에 진단 데이터를 업로드합니다.
oc debug node/<node_name>명령을 사용하여 OpenShift Container Platform 노드에 포함된 진단 파일을 연결하고 출력을 파일로 리디렉션합니다. 다음 예에서는/host/var/tmp/my-diagnostic-data.tar.gz를 디버그 컨테이너에서/var/tmp/my-diagnostic-data.tar.gz로 복사합니다.$ oc debug node/my-cluster-node -- bash -c 'cat /host/var/tmp/my-diagnostic-data.tar.gz' > /var/tmp/my-diagnostic-data.tar.gz1 - 1
- 디버그 컨테이너는
/host에 호스트의 root 디렉토리를 마운트합니다. 연결할 대상 파일을 지정할 때/host를 포함하여 디버그 컨테이너의 root 디렉토리에서 절대 경로를 참조합니다.
참고RHCOS(Red Hat Enterprise Linux CoreOS)를 실행하는 OpenShift Container Platform 4.16 클러스터 노드는 변경할 수 없으며 Operator를 사용하여 클러스터 변경 사항을 적용합니다.
scp를 사용하여 클러스터 노드에서 파일을 전송하는 것은 권장되지 않습니다. 그러나 OpenShift Container Platform API를 사용할 수 없거나 kubelet이 대상 노드에서 제대로 작동하지 않는 경우oc작업이 영향을 받습니다. 이러한 상황에서scp core@<node>.<cluster_name>.<base_domain>:<file_path> <local_path>를 실행하여 노드에서 진단 파일을 복사할 수 있습니다.- Red Hat 고객 포털 의 고객 지원 페이지에서 기존 지원 케이스로 이동합니다.
- Attach files를 선택하고 메시지에 따라 파일을 업로드합니다.
5.12. toolbox정보
toolbox는 RHCOS(Red Hat Enterprise Linux CoreOS) 시스템에서 컨테이너를 시작하는 툴입니다. 이 툴은 주로 sosreport 와 같은 명령을 실행하는 데 필요한 필수 바이너리 및 플러그인이 포함된 컨테이너를 시작하는 데 사용됩니다.
toolbox 컨테이너의 주요 목적은 진단 정보를 수집하여 Red Hat 지원에 제공하는 것입니다. 그러나 추가 진단 도구가 필요한 경우 RPM 패키지를 추가하거나 표준 지원 도구 이미지의 대체 이미지를 실행할 수 있습니다.
5.12.1. toolbox 컨테이너에 패키지 설치
기본적으로 toolbox 명령을 실행하면 registry.redhat.io/rhel9/support-tools:latest 이미지로 컨테이너를 시작합니다. 이 이미지에는 가장 자주 사용되는 지원 도구가 포함되어 있습니다. 이미지에 포함되지 않은 지원 툴이 필요한 노드별 데이터를 수집해야 하는 경우 추가 패키지를 설치할 수 있습니다.
사전 요구 사항
-
oc debug node/<node_name>명령이 있는 노드에 액세스하고 있습니다. - root 권한이 있는 사용자로 시스템에 액세스할 수 있습니다.
프로세스
디버그 쉘 내에서
/host를 root 디렉터리로 설정합니다. 디버그 Pod는 Pod 내의/host에 호스트의 루트 파일 시스템을 마운트합니다. root 디렉토리를/host로 변경하면 호스트의 실행 경로에 포함된 바이너리를 실행할 수 있습니다.# chroot /hosttoolbox 컨테이너를 시작합니다.
# toolboxwget과 같은 추가 패키지를 설치합니다.# dnf install -y <package_name>
5.12.2. toolbox를 사용하여 대체 이미지 시작
기본적으로 toolbox 명령을 실행하면 registry.redhat.io/rhel9/support-tools:latest 이미지로 컨테이너를 시작합니다.
.toolboxrc 파일을 생성하고 실행할 이미지를 지정하여 대체 이미지를 시작할 수 있습니다. 그러나 registry.redhat.io/rhel8/ 와 같은 이전 버전의 support-tools 이미지를 실행하는 것은 OpenShift Container Platform 4.16에서 지원되지 않습니다.
support-tools:latest
사전 요구 사항
-
oc debug node/<node_name>명령이 있는 노드에 액세스하고 있습니다. - root 권한이 있는 사용자로 시스템에 액세스할 수 있습니다.
프로세스
디버그 쉘 내에서
/host를 root 디렉터리로 설정합니다. 디버그 Pod는 Pod 내의/host에 호스트의 루트 파일 시스템을 마운트합니다. root 디렉토리를/host로 변경하면 호스트의 실행 경로에 포함된 바이너리를 실행할 수 있습니다.# chroot /host선택 사항: 기본 이미지 대신 대체 이미지를 사용해야 하는 경우 root 사용자 ID의 홈 디렉터리에
.toolboxrc파일을 생성하고 이미지 메타데이터를 지정합니다.REGISTRY=quay.io1 IMAGE=fedora/fedora:latest2 TOOLBOX_NAME=toolbox-fedora-latest3 다음 명령을 입력하여 toolbox 컨테이너를 시작합니다.
# toolbox참고기존
toolboxPod가 이미 실행 중인 경우toolbox명령은'toolbox-' already exists를 출력합니다. Trying to start…를 출력합니다.sosreport플러그인 문제를 방지하려면podman rm toolbox-에서 실행중인 toolbox 컨테이너를 제거한 다음 새 toolbox 컨테이너를 생성합니다.
6장. 클러스터 사양 요약
6.1. 클러스터 버전 오브젝트를 사용하여 클러스터 사양 요약
clusterversion 리소스를 쿼리하여 OpenShift Container Platform 클러스터 사양 요약을 가져올 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
클러스터 버전, 가용성, 가동 시간 및 일반 상태를 쿼리합니다.
$ oc get clusterversion출력 예
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.13.8 True False 8h Cluster version is 4.13.8클러스터 사양, 업데이트 가용성 및 업데이트 기록에 대한 자세한 요약을 가져옵니다.
$ oc describe clusterversion출력 예
Name: version Namespace: Labels: <none> Annotations: <none> API Version: config.openshift.io/v1 Kind: ClusterVersion # ... Image: quay.io/openshift-release-dev/ocp-release@sha256:a956488d295fe5a59c8663a4d9992b9b5d0950f510a7387dbbfb8d20fc5970ce URL: https://access.redhat.com/errata/RHSA-2023:4456 Version: 4.13.8 History: Completion Time: 2023-08-17T13:20:21Z Image: quay.io/openshift-release-dev/ocp-release@sha256:a956488d295fe5a59c8663a4d9992b9b5d0950f510a7387dbbfb8d20fc5970ce Started Time: 2023-08-17T12:59:45Z State: Completed Verified: false Version: 4.13.8 # ...
7장. 문제 해결
7.1. 설치 문제 해결
7.1.1. 설치 문제가 발생하는 위치 확인
OpenShift Container Platform 설치 문제를 해결할 때 설치 로그를 모니터링하여 문제가 발생하는 단계를 확인할 수 있습니다. 그런 다음 해당 단계와 관련된 진단 데이터를 검색합니다.
OpenShift Container Platform 설치는 다음 단계에 따라 진행됩니다.
- Ignition 구성 파일이 생성됩니다.
- 부트스트랩 머신이 부팅되고 컨트롤 플레인 머신을 부팅하는 데 필요한 원격 리소스 호스팅이 시작됩니다.
- 컨트롤 플레인 머신은 부트스트랩 머신에서 원격 리소스를 가져오고 부팅을 완료합니다.
- 컨트롤 플레인 머신은 부트스트랩 머신을 사용하여 etcd 클러스터를 만듭니다.
- 부트스트랩 머신은 새로운 etcd 클러스터를 사용하여 임시 Kubernetes 컨트롤 플레인을 시작합니다.
- 임시 컨트롤 플레인은 프로덕션 컨트롤러 플레인을 컨트롤 플레인 머신에 예약합니다.
- 임시 컨트롤 플레인이 종료되고 제어를 프로덕션 컨트롤 플레인에 전달합니다.
- 부트스트랩 머신은 OpenShift Container Platform 구성 요소를 프로덕션 컨트롤 플레인에 추가합니다.
- 설치 프로그램이 부트 스트랩 머신을 종료합니다.
- 컨트롤 플레인이 작업자 노드를 설정합니다.
- 컨트롤 플레인은 일련의 Operator 형태로 추가 서비스를 설치합니다.
- 클러스터는 지원되는 환경에서 작업자 머신 생성을 포함하여 일상적인 작업에 필요한 나머지 구성 요소를 다운로드하고 구성합니다.
7.1.2. 사용자 프로비저닝 인프라 설치 고려 사항
기본 설치 방법은 설치 프로그램에서 프로비저닝한 인프라를 사용하는 것입니다. 설치 프로그램에서 프로비저닝한 인프라 클러스터를 통해 OpenShift Container Platform은 운영 체제 자체를 포함하여 클러스터의 모든 측면을 관리합니다. 가능하면 이 기능을 사용하여 클러스터 인프라를 프로비저닝 및 유지 관리의 부담을 덜 수 있습니다.
사용자가 제공하는 인프라에 OpenShift Container Platform 4.16을 설치할 수도 있습니다. 이 설치 방법을 사용하는 경우 사용자가 제공하는 인프라 설치 설명서를 주의 깊게 따르십시오. 또한 설치 전에 다음 고려 사항을 확인하십시오.
- RHEL (Red Hat Enterprise Linux) Ecosystem을 확인하고 선택한 서버 하드웨어 또는 가상화 기술에 대해 제공되는 RHCOS (Red Hat Enterprise Linux CoreOS) 지원 수준을 결정합니다.
- 많은 가상화 및 클라우드 환경에서는 게스트 운영 체제에 에이전트를 설치해야 합니다. 이러한 에이전트가 데몬 세트를 통해 배포되는 컨테이너화된 워크로드로 설치되어 있는지 확인합니다.
동적 스토리지, 온디맨드 서비스 라우팅, 노드 호스트 이름을 Kubernetes 호스트 이름으로 확인, 클러스터 자동 스케일링과 같은 기능을 사용하려면 클라우드 공급자 통합을 설치합니다.
참고서로 다른 클라우드 공급자의 리소스를 결합하거나 여러 물리적 또는 가상 플랫폼에 걸쳐있는 OpenShift Container Platform 환경에서는 클라우드 공급자 통합을 활성화할 수 없습니다. 노드 라이프 사이클 컨트롤러는 기존 공급자 외부에 있는 노드를 클러스터에 추가하는 것을 허용하지 않으며 둘 이상의 클라우드 공급자 통합을 지정할 수 없습니다.
- 머신 세트 또는 자동 스케일링을 사용하여 OpenShift Container Platform 클러스터 노드를 자동으로 프로비저닝하려면 공급자별 Machine API를 구현해야 합니다.
- 선택한 클라우드 공급자가 초기 배포의 일부로 Ignition 구성 파일을 호스트에 삽입하는 방법을 제공하는지 확인합니다. 제공하지 않는 경우 HTTP 서버를 사용하여 Ignition 구성 파일을 호스팅해야합니다. Ignition 구성 파일의 문제 해결 단계는 이 두 가지 방법 중 배포되는 방법에 따라 달라집니다.
- 포함된 컨테이너 레지스트리, Elasticsearch 또는 Prometheus와 같은 선택적 프레임워크 구성 요소를 활용하려면 스토리지를 수동으로 프로비저닝해야 합니다. 이를 명시적으로 구성하지 않는 한 기본 스토리지 클래스는 사용자 프로비저닝 인프라 설치에 정의되지 않습니다.
- 고가용성 OpenShift Container Platform 환경의 모든 컨트롤 플레인 노드에 API 요청을 분산하려면 로드 밸런서가 필요합니다. OpenShift Container Platform DNS 라우팅 및 포트 요구 사항을 충족하는 모든 TCP 기반 부하 분산 솔루션을 사용할 수 있습니다.
7.1.3. OpenShift Container Platform 설치 전에 로드 밸런서 구성 확인
OpenShift Container Platform 설치를 시작하기 전에 로드 밸런서 구성을 확인하십시오.
사전 요구 사항
- OpenShift Container Platform 설치를 준비하기 위해 선택한 외부로드 밸런서를 구성하고 있어야 합니다. 다음 예에서는 HAProxy를 사용하여 클러스터에 로드 밸런싱 서비스를 제공하는 Red Hat Enterprise Linux (RHEL) 호스트를 기반으로합니다.
- OpenShift Container Platform 설치를 준비하기 위해 DNS를 구성하고 있어야 합니다.
- 로드 밸런서에 SSH 액세스 권한이 있어야합니다.
프로세스
haproxysystemd 서비스가 활성화되어 있는지 확인합니다.$ ssh <user_name>@<load_balancer> systemctl status haproxy로드 밸런서가 필요한 포트에서 수신하고 있는지 확인합니다. 다음 예에서는 포트
80,443,6443,22623을 참조합니다.RHEL (Red Hat Enterprise Linux) 6에서 실행되는 HAProxy 인스턴스의 경우
netstat명령을 사용하여 포트 상태를 확인합니다.$ ssh <user_name>@<load_balancer> netstat -nltupe | grep -E ':80|:443|:6443|:22623'RHEL (Red Hat Enterprise Linux) 7 또는 8에서 실행되는 HAProxy 인스턴스의 경우
ss명령을 사용하여 포트 상태를 확인합니다.$ ssh <user_name>@<load_balancer> ss -nltupe | grep -E ':80|:443|:6443|:22623'참고Red Hat Enterprise Linux(RHEL) 7 이상에서는
netstat대신ss명령을 사용하는 것이 좋습니다.ss는 iproute 패키지에서 제공합니다.ss명령에 대한 자세한 내용은 Red Hat Enterprise Linux (RHEL) 7 성능 조정 가이드를 참조하십시오.
와일드 카드 DNS 레코드가 로드 밸런서로 해결되어 있는지 확인합니다.
$ dig <wildcard_fqdn> @<dns_server>
7.1.4. OpenShift Container Platform 설치 프로그램 로그 수준 지정
기본적으로 OpenShift Container Platform 설치 프로그램 로그 수준은 info로 설정됩니다. 실패한 OpenShift Container Platform 설치를 진단할 때 보다 자세한 로깅이 필요한 경우 다시 설치를 시작할 때 openshift-install 로그 수준을 debug로 높일 수 있습니다.
사전 요구 사항
- 설치 호스트에 대한 액세스 권한이 있어야 합니다.
프로세스
설치를 시작할 때
debug로 설치 로그 수준을 설정합니다.$ ./openshift-install --dir <installation_directory> wait-for bootstrap-complete --log-level debug1 - 1
- 가능한 로그 수준에는
info,warn,error,debug가 있습니다.
7.1.5. openshift-install 명령 문제 해결
openshift-install 명령을 실행하는데 문제가 있는 경우 다음을 확인하십시오.
설치는 Ignition 구성 파일 생성 후 24 시간 이내에 시작되고 있습니다. 다음 명령을 실행하면 Ignition 파일이 생성됩니다.
$ ./openshift-install create ignition-configs --dir=./install_dir-
install-config.yaml파일은 설치 프로그램과 동일한 디렉토리에 있습니다../openshift-install --dir옵션을 사용하여 대체 설치 경로를 선언한 경우 해당 디렉토리에install-config.yaml파일이 있는지 확인합니다.
7.1.6. 설치 진행 상황 모니터링
OpenShift Container Platform 설치가 진행됨에 따라 상위 수준 설치, 부트 스트랩 및 컨트롤 플레인 로그를 모니터링할 수 있습니다. 이렇게 하면 설치 진행 방식에 대한 가시성이 향상되고 설치 실패가 발생하는 단계를 식별할 수 있습니다.
사전 요구 사항
-
cluster-admin클러스터 역할의 사용자로 클러스터에 액세스할 수 있습니다. -
OpenShift CLI(
oc)가 설치되어 있습니다. - 호스트에 대한 SSH 액세스 권한이 있어야 합니다.
부트 스트랩 및 컨트롤 플레인 노드의 완전한 도메인 이름이 있어야 합니다.
참고초기
kubeadmin암호는 설치 호스트의<install_directory>/auth/kubeadmin-password에서 찾을 수 있습니다.
프로세스
설치가 진행되는 동안 설치 로그를 모니터링합니다.
$ tail -f ~/<installation_directory>/.openshift_install.log부트스트랩 노드에서
bootkube.servicejournald 장치 로그를 모니터링합니다. 이를 통해 첫 번째 컨트롤 플레인의 부트 스트랩을 시각화할 수 있습니다.<bootstrap_fqdn>을 부트 스트랩 노드의 정규화된 도메인 이름으로 바꿉니다.$ ssh core@<bootstrap_fqdn> journalctl -b -f -u bootkube.service참고부트스트랩 노드의
bootkube.service로그는 etcdconnectionrejectd 오류를 출력하고 부트스트랩 서버가 컨트롤 플레인 노드의 etcd에 연결할 수 없음을 나타냅니다. 각 컨트롤 플레인 노드에서 etcd를 시작하고 노드가 클러스터에 가입되면 오류가 중지됩니다.컨트롤 플레인 노드가 부팅된 후
kubelet.servicejournald 장치 로그를 모니터링합니다. 이를 통해 컨트롤 플레인 노드 에이전트 활동을 시각화할 수 있습니다.oc를사용하여 로그를 모니터링합니다.$ oc adm node-logs --role=master -u kubeletAPI가 작동하지 않으면 대신 SSH를 사용하여 로그를 확인합니다.
<master-node>.<cluster_name>.<base_domain>을 적절한 값으로 바꿉니다.$ ssh core@<master-node>.<cluster_name>.<base_domain> journalctl -b -f -u kubelet.service
컨트롤 플레인 노드가 부팅된 후
crio.servicejournald 장치 로그를 모니터링합니다. 이를 통해 컨트롤 플레인 노드 CRI-O 컨테이너 런타임 활동을 시각화할 수 있습니다.oc를사용하여 로그를 모니터링합니다.$ oc adm node-logs --role=master -u crioAPI가 작동하지 않으면 대신 SSH를 사용하여 로그를 확인합니다.
<master-node>.<cluster_name>.<base_domain>을 적절한 값으로 바꿉니다.$ ssh core@master-N.cluster_name.sub_domain.domain journalctl -b -f -u crio.service
7.1.7. 부트 스트랩 노드 진단 데이터 수집
부트 스트랩 관련 문제가 발생하면 부트 스트랩 노드에서 bootkube.service journald 장치 로그 및 컨테이너 로그를 수집할 수 있습니다.
사전 요구 사항
- 부트 스트랩 노드에 대한 SSH 액세스 권한이 있어야 합니다.
- 부트 스트랩 노드의 정규화된 도메인 이름이 있어야 합니다.
- HTTP 서버를 사용하여 Ignition 구성 파일을 호스팅하는 경우 HTTP 서버의 정규화된 도메인 이름과 포트 번호가 있어야합니다. 또한 HTTP 호스트에 대한 SSH 액세스 권한이 있어야합니다.
프로세스
- 부트 스트랩 노드의 콘솔에 액세스할 경우 노드가 로그인 프롬프트에 도달할 때까지 콘솔을 모니터링합니다.
Ignition 파일 구성을 확인합니다.
HTTP 서버를 사용하여 Ignition 구성 파일을 호스팅하는 경우:
부트 스트랩 노드 Ignition 파일 URL을 확인합니다.
<http_server_fqdn>을 HTTP 서버의 정규화된 도메인 이름으로 바꿉니다.$ curl -I http://<http_server_fqdn>:<port>/bootstrap.ign1 - 1
-I옵션은 헤더만 반환합니다. 지정된 URL에서 Ignition 파일을 사용할 수있는 경우 명령은200 OK상태를 반환합니다. 사용할 수없는 경우 명령은404 file not found를 반환합니다.
부트 스트랩 노드에서 Ignition 파일을 수신했는지 확인하려면 제공 호스트에서 HTTP 서버 로그를 쿼리합니다. 예를 들어 Apache 웹 서버를 사용하여 Ignition 파일을 제공하는 경우 다음 명령을 입력합니다.
$ grep -is 'bootstrap.ign' /var/log/httpd/access_log부트 스트랩 Ignition 파일이 수신되면 연결된
HTTP GET로그 메시지에 요청이 성공했음을 나타내는200 OK성공 상태가 포함됩니다.- Ignition 파일이 수신되지 않은 경우 Ignition 파일이 존재하고 제공 호스트에 대한 적절한 파일 및 웹 서버 권한이 있는지 직접 확인합니다.
클라우드 공급자 메커니즘을 사용하여 초기 배포의 일부로 호스트에 Ignition 구성 파일을 삽입하는 경우:
- 부트 스트랩 노드의 콘솔을 확인하고 부트 스트랩 노드 Ignition 파일을 삽입하는 메커니즘이 올바르게 작동하고 있는지 확인합니다.
- 부트 스트랩 노드에 할당된 저장 장치의 가용성을 확인합니다.
- 부트 스트랩 노드에 DHCP 서버의 IP 주소가 할당되었는지 확인합니다.
부트 스트랩 노드에서
bootkube.servicejournald 장치 로그를 수집합니다.<bootstrap_fqdn>을 부트 스트랩 노드의 정규화된 도메인 이름으로 바꿉니다.$ ssh core@<bootstrap_fqdn> journalctl -b -f -u bootkube.service참고부트스트랩 노드의
bootkube.service로그는 etcdconnectionrejectd 오류를 출력하고 부트스트랩 서버가 컨트롤 플레인 노드의 etcd에 연결할 수 없음을 나타냅니다. 각 컨트롤 플레인 노드에서 etcd를 시작하고 노드가 클러스터에 가입되면 오류가 중지됩니다.부트 스트랩 노드 컨테이너에서 로그를 수집합니다.
부트 스트랩 노드에서
podman을 사용하여 로그를 수집합니다.<bootstrap_fqdn>을 부트 스트랩 노드의 정규화된 도메인 이름으로 바꿉니다.$ ssh core@<bootstrap_fqdn> 'for pod in $(sudo podman ps -a -q); do sudo podman logs $pod; done'
부트 스트랩 프로세스가 실패한 경우 다음을 확인하십시오.
-
설치 호스트에서
api.<cluster_name>.<base_domain>을 확인할 수 있습니다. - 로드 밸런서는 부트 스트랩 및 컨트롤 플레인 노드에 포트 6443 연결을 프록시합니다. 프록시 구성이 OpenShift Container Platform 설치 요구 사항을 충족하는지 확인합니다.
-
설치 호스트에서
7.1.8. 컨트롤 플레인 노드 설치 문제 조사
컨트롤 플레인 노드 설치에 문제가 발생하면 컨트롤 플레인 노드 OpenShift Container Platform 소프트웨어 정의 네트워크(SDN) 및 네트워크 Operator 상태를 확인합니다. kubelet.service, crio.service journald 장치 로그 및 컨트롤 플레인 노드 컨테이너 로그를 수집하여 컨트롤 플레인 노드 에이전트, CRI-O 컨테이너 런타임, Pod 활동에 대한 가시성을 확보합니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다. - 호스트에 대한 SSH 액세스 권한이 있어야 합니다.
- 부트 스트랩 및 컨트롤 플레인 노드의 완전한 도메인 이름이 있어야 합니다.
HTTP 서버를 사용하여 Ignition 구성 파일을 호스팅하는 경우 HTTP 서버의 정규화된 도메인 이름과 포트 번호가 있어야합니다. 또한 HTTP 호스트에 대한 SSH 액세스 권한이 있어야합니다.
참고초기
kubeadmin암호는 설치 호스트의<install_directory>/auth/kubeadmin-password에서 찾을 수 있습니다.
프로세스
- 컨트롤 플레인 노드의 콘솔에 액세스할 경우 노드가 로그인 프롬프트에 도달할 때 까지 콘솔을 모니터링합니다. 설치 중에 Ignition 로그 메시지가 콘솔에 출력됩니다.
Ignition 파일 설정을 확인합니다.
HTTP 서버를 사용하여 Ignition 구성 파일을 호스팅하는 경우:
컨트롤 플레인 노드의 Ignition 파일 URL을 확인합니다.
<http_server_fqdn>을 HTTP 서버의 정규화된 도메인 이름으로 바꿉니다.$ curl -I http://<http_server_fqdn>:<port>/master.ign1 - 1
-I옵션은 헤더만 반환합니다. 지정된 URL에서 Ignition 파일을 사용할 수있는 경우 명령은200 OK상태를 반환합니다. 사용할 수없는 경우 명령은404 file not found를 반환합니다.
Ignition 파일이 컨트롤 플레인 노드에서 수신되었는지 확인하려면 제공 호스트에서 HTTP 서버 로그를 쿼리합니다. 예를 들어 Apache 웹 서버를 사용하여 Ignition 파일을 제공하는 경우 다음을 확인합니다.
$ grep -is 'master.ign' /var/log/httpd/access_log마스터 Ignition 파일이 수신되면 연결된
HTTP GET로그 메시지에 요청이 성공했음을 나타내는200 OK성공 상태가 포함됩니다.- Ignition 파일이 수신되지 않은 경우 제공 호스트에 존재하는지 확인합니다. 적절한 파일 및 웹 서버 권한이 있는지 확인합니다.
클라우드 공급자 메커니즘을 사용하여 초기 배포의 일부로 호스트에 Ignition 구성 파일을 삽입하는 경우:
- 컨트롤 플레인 노드의 콘솔을 확인하고 컨트롤 플레인 노드의 Ignition 파일을 삽입하는 메커니즘이 올바르게 작동하고 있는지 확인합니다.
- 컨트롤 플레인 노드에 할당된 스토리지 장치의 가용성을 확인합니다.
- 컨트롤 플레인 노드에 DHCP 서버의 IP 주소가 지정되었는지 확인합니다.
컨트롤 플레인 노드 상태를 확인합니다.
컨트롤 플레인 노드 상태를 쿼리합니다.
$ oc get nodes컨트롤 플레인 노드 중 하나가
Ready상태에 도달하지 않으면 자세한 노드 설명을 검색합니다.$ oc describe node <master_node>참고설치 문제로 인해 OpenShift Container Platform API가 실행되지 않거나 kubelet이 각 노드에서 실행되지 않는 경우
oc명령을 실행할 수 없습니다.
OpenShift Container Platform SDN의 상태를 확인합니다.
openshift-sdn네임스페이스에서sdn-controller,sdn,ovs데몬 세트 상태를 검토합니다.$ oc get daemonsets -n openshift-sdn해당 리소스가
Not found로 나열되어 있는 경우openshift-sdn네임스페이스의 Pod를 검토합니다.$ oc get pods -n openshift-sdnopenshift-sdn네임스페이스에서 실패한 OpenShift Container Platform SDN Pod에 대한 로그를 검토합니다.$ oc logs <sdn_pod> -n openshift-sdn
클러스터의 네트워크 구성 상태를 확인합니다.
클러스터의 네트워크 구성이 존재하는지 확인합니다.
$ oc get network.config.openshift.io cluster -o yaml설치 프로그램이 네트워크 구성을 만드는 데 실패한 경우 Kubernetes 매니페스트를 다시 생성하고 메시지 출력을 확인합니다.
$ ./openshift-install create manifestsopenshift-network-operator네임스페이스에서 Pod 상태를 검토하고 CNO(Cluster Network Operator)가 실행 중인지 확인합니다.$ oc get pods -n openshift-network-operatoropenshift-network-operator네임스페이스에서 네트워크 Operator Pod 로그를 수집합니다.$ oc logs pod/<network_operator_pod_name> -n openshift-network-operator
컨트롤 플레인 노드가 부팅된 후
kubelet.servicejournald 장치 로그를 모니터링합니다. 이를 통해 컨트롤 플레인 노드 에이전트 활동을 시각화할 수 있습니다.oc를 사용하여 로그를 검색합니다.$ oc adm node-logs --role=master -u kubeletAPI가 작동하지 않으면 대신 SSH를 사용하여 로그를 확인합니다.
<master-node>.<cluster_name>.<base_domain>을 적절한 값으로 바꿉니다.$ ssh core@<master-node>.<cluster_name>.<base_domain> journalctl -b -f -u kubelet.service참고RHCOS(Red Hat Enterprise Linux CoreOS)를 실행하는 OpenShift Container Platform 4.16 클러스터 노드는 변경할 수 없으며 Operator를 사용하여 클러스터 변경 사항을 적용합니다. SSH를 사용하여 클러스터 노드에 액세스하는 것은 권장되지 않습니다. SSH를 통해 진단 데이터를 수집하기 전에
oc adm must gather및 기타oc명령을 실행하여 충분한 데이터를 수집할 수 있는지 확인하십시오. 그러나 OpenShift Container Platform API를 사용할 수 없거나 kubelet이 대상 노드에서 제대로 작동하지 않는 경우oc작업이 영향을 받습니다. 이러한 상황에서ssh core@<node>.<cluster_name>.<base_domain>을 사용하여 노드에 액세스할 수 있습니다.
컨트롤 플레인 노드가 부팅 된 후
crio.servicejournald 장치 로그를 검색합니다. 이를 통해 컨트롤 플레인 노드 CRI-O 컨테이너 런타임 활동을 시각화할 수 있습니다.oc를 사용하여 로그를 검색합니다.$ oc adm node-logs --role=master -u crioAPI가 작동하지 않으면 대신 SSH를 사용하여 로그를 확인합니다.
$ ssh core@<master-node>.<cluster_name>.<base_domain> journalctl -b -f -u crio.service
컨트롤 플레인 노드의
/var/log/아래에있는 특정 하위 디렉터리에서 로그를 수집합니다./var/log/하위 디렉토리에 포함된 로그 목록을 검색합니다. 다음 예제는 모든 컨트롤 플레인 노드의/var/log/openshift-apiserver/에 있는 파일을 나열합니다.$ oc adm node-logs --role=master --path=openshift-apiserver/var/log/하위 디렉터리 내의 특정 로그를 확인합니다. 다음 예제는 모든 컨트롤 플레인 노드에서/var/log/openshift-apiserver/audit.log내용을 출력합니다.$ oc adm node-logs --role=master --path=openshift-apiserver/audit.logAPI가 작동하지 않는 경우 SSH를 사용하여 각 노드의 로그를 확인합니다. 다음은
/var/log/openshift-apiserver/audit.log예제입니다.$ ssh core@<master-node>.<cluster_name>.<base_domain> sudo tail -f /var/log/openshift-apiserver/audit.log
SSH를 사용하여 컨트롤 플레인 노드 컨테이너 로그를 확인합니다.
컨테이너를 나열합니다.
$ ssh core@<master-node>.<cluster_name>.<base_domain> sudo crictl ps -acrictl를 사용하여 컨테이너의 로그를 검색합니다.$ ssh core@<master-node>.<cluster_name>.<base_domain> sudo crictl logs -f <container_id>
컨트롤 플레인 노드 구성 문제가 발생하는 경우 MCO, MCO 엔드 포인트 및 DNS 레코드가 작동하는지 확인합니다. MCO (Machine Config Operator)는 설치 시 운영 체제 구성을 관리합니다. 또한 시스템 클럭의 정확성과 인증서의 유효성을 확인하합니다.
MCO 엔드 포인트를 사용할 수 있는지 테스트합니다.
<cluster_name>을 적절한 값으로 바꿉니다.$ curl https://api-int.<cluster_name>:22623/config/master- 엔드 포인트가 응답하지 않는 경우 로드 밸런서 구성을 확인합니다. 엔드 포인트가 포트 22623에서 실행되도록 구성되었는지 확인합니다.
MCO 엔드 포인트의 DNS 레코드가 구성되어 로드 밸런서 문제를 해결하고 있는지 확인합니다.
정의된 MCO 엔드 포인트 이름에 대한 DNS 조회를 실행합니다.
$ dig api-int.<cluster_name> @<dns_server>로드 밸런서에서 할당된 MCO IP 주소에 대한 역방향 조회를 실행합니다.
$ dig -x <load_balancer_mco_ip_address> @<dns_server>
MCO가 부트 스트랩 노드에서 직접 작동하는지 확인합니다.
<bootstrap_fqdn>을 부트 스트랩 노드의 정규화된 도메인 이름으로 바꿉니다.$ ssh core@<bootstrap_fqdn> curl https://api-int.<cluster_name>:22623/config/master시스템 클럭은 부트 스트랩, 마스터 및 작업자 노드 간에 동기화되어야 합니다. 각 노드의 시스템 클럭 참조 시간 및 시간 동기화 통계를 확인합니다.
$ ssh core@<node>.<cluster_name>.<base_domain> chronyc tracking인증서의 유효성을 확인합니다.
$ openssl s_client -connect api-int.<cluster_name>:22623 | openssl x509 -noout -text
7.1.9. etcd 설치 문제 조사
설치 중에 etcd 문제가 발생하면 etcd Pod 상태를 확인하고 etcd Pod 로그를 수집할 수 있습니다. etcd DNS 레코드를 확인하고 컨트롤 플레인 노드에서 DNS 가용성을 확인할 수도 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다. - 호스트에 대한 SSH 액세스 권한이 있어야 합니다.
- 컨트롤 플레인 노드의 정규화된 도메인 이름이 있어야 합니다.
프로세스
etcd Pod의 상태를 확인합니다.
openshift-etcd네임스페이스에서 Pod 상태를 검토합니다.$ oc get pods -n openshift-etcdopenshift-etcd-operator네임스페이스에서 Pod 상태를 검토합니다.$ oc get pods -n openshift-etcd-operator
이전 명령으로 나열된 Pod 중
Running또는Completed상태가 표시되지 않는 경우 Pod의 진단 정보를 수집합니다.Pod의 이벤트를 검토합니다.
$ oc describe pod/<pod_name> -n <namespace>Pod의 로그를 검사합니다.
$ oc logs pod/<pod_name> -n <namespace>Pod에 여러 컨테이너가 있는 경우 위의 명령에서 오류가 생성되고 컨테이너 이름이 오류 메시지에 제공됩니다. 각 컨테이너의 로그를 검사합니다.
$ oc logs pod/<pod_name> -c <container_name> -n <namespace>
API가 작동하지 않는 경우 대신 SSH를 사용하여 각 컨트롤 플레인 노드에서 etcd Pod 및 컨테이너 로그를 검토합니다.
<master-node>.<cluster_name>.<base_domain>을 적절한 값으로 바꿉니다.각 컨트롤 플레인 노드에 etcd Pod를 나열합니다.
$ ssh core@<master-node>.<cluster_name>.<base_domain> sudo crictl pods --name=etcd-Ready상태가 표시되지 않는 Pod의 경우 Pod 상태를 자세히 검사합니다.<pod_id>를 이전 명령의 출력에 나열된 Pod ID로 교체합니다.$ ssh core@<master-node>.<cluster_name>.<base_domain> sudo crictl inspectp <pod_id>Pod와 관련된 컨테이너를 나열합니다.
$ ssh core@<master-node>.<cluster_name>.<base_domain> sudo crictl ps | grep '<pod_id>'Ready상태가 표시되지 않는 컨테이너의 경우 컨테이너 상태를 자세히 검사합니다.<container_id>를 이전 명령의 출력에 나열된 컨테이너 ID로 바꿉니다.$ ssh core@<master-node>.<cluster_name>.<base_domain> sudo crictl inspect <container_id>Ready상태가 표시되지 않는 컨테이너의 로그를 확인합니다.<container_id>를 이전 명령의 출력에 나열된 컨테이너 ID로 바꿉니다.$ ssh core@<master-node>.<cluster_name>.<base_domain> sudo crictl logs -f <container_id>참고RHCOS(Red Hat Enterprise Linux CoreOS)를 실행하는 OpenShift Container Platform 4.16 클러스터 노드는 변경할 수 없으며 Operator를 사용하여 클러스터 변경 사항을 적용합니다. SSH를 사용하여 클러스터 노드에 액세스하는 것은 권장되지 않습니다. SSH를 통해 진단 데이터를 수집하기 전에
oc adm must gather및 기타oc명령을 실행하여 충분한 데이터를 수집할 수 있는지 확인하십시오. 그러나 OpenShift Container Platform API를 사용할 수 없거나 kubelet이 대상 노드에서 제대로 작동하지 않는 경우oc작업이 영향을 받습니다. 이러한 상황에서ssh core@<node>.<cluster_name>.<base_domain>을 사용하여 노드에 액세스할 수 있습니다.
- 컨트롤 플레인 노드에서 기본 및 보조 DNS 서버 연결을 확인합니다.
7.1.10. 컨트롤 플레인 노드 kubelet 및 API 서버 문제 조사
설치 중에 컨트롤 플레인 노드 kubelet 및 API 서버 문제를 조사하려면 DNS, DHCP 및 로드 밸런서 기능을 확인합니다. 또한 인증서가 만료되지 않았는지 확인합니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다. - 호스트에 대한 SSH 액세스 권한이 있어야 합니다.
- 컨트롤 플레인 노드의 정규화된 도메인 이름이 있어야 합니다.
프로세스
-
API 서버의 DNS 레코드가 컨트롤 플레인 노드의 kubelet을
https://api-int.<cluster_name>.<base_domain>:6443으로 전송하는지 확인합니다. 레코드가 로드 밸런서를 참조하는지 확인합니다. - 로드 밸런서의 포트 6443 정의가 각 컨트롤 플레인 노드를 참조하는지 확인합니다.
- DHCP에서 고유한 컨트롤 플레인 노드 호스트 이름이 지정되어 있는지 확인합니다.
각 컨트롤 플레인 노드에서
kubelet.servicejournald 장치 로그를 검사합니다.oc를 사용하여 로그를 검색합니다.$ oc adm node-logs --role=master -u kubeletAPI가 작동하지 않으면 대신 SSH를 사용하여 로그를 확인합니다.
<master-node>.<cluster_name>.<base_domain>을 적절한 값으로 바꿉니다.$ ssh core@<master-node>.<cluster_name>.<base_domain> journalctl -b -f -u kubelet.service참고RHCOS(Red Hat Enterprise Linux CoreOS)를 실행하는 OpenShift Container Platform 4.16 클러스터 노드는 변경할 수 없으며 Operator를 사용하여 클러스터 변경 사항을 적용합니다. SSH를 사용하여 클러스터 노드에 액세스하는 것은 권장되지 않습니다. SSH를 통해 진단 데이터를 수집하기 전에
oc adm must gather및 기타oc명령을 실행하여 충분한 데이터를 수집할 수 있는지 확인하십시오. 그러나 OpenShift Container Platform API를 사용할 수 없거나 kubelet이 대상 노드에서 제대로 작동하지 않는 경우oc작업이 영향을 받습니다. 이러한 상황에서ssh core@<node>.<cluster_name>.<base_domain>을 사용하여 노드에 액세스할 수 있습니다.
컨트롤 플레인 노드 kubelet 로그에서 인증서 만료 메시지를 확인합니다.
oc를 사용하여 로그를 검색합니다.$ oc adm node-logs --role=master -u kubelet | grep -is 'x509: certificate has expired'API가 작동하지 않으면 대신 SSH를 사용하여 로그를 확인합니다.
<master-node>.<cluster_name>.<base_domain>을 적절한 값으로 바꿉니다.$ ssh core@<master-node>.<cluster_name>.<base_domain> journalctl -b -f -u kubelet.service | grep -is 'x509: certificate has expired'
7.1.11. 작업자 노드 설치 문제 조사
작업자 노드 설치 문제가 발생하는 경우 작업자 노드 상태를 확인할 수 있습니다. kubelet.service, crio.service journald 장치 로그 및 작업자 노드 컨테이너 로그를 수집하여 작업자 노드 에이전트, CRI-O 컨테이너 런타임, Pod 활동에 대한 가시성을 확보합니다. 또한 Ignition 파일 및 Machine API Operator 기능을 확인할 수 있습니다. 작업자 노드 설치 후 구성에 실패하면 MCO(Machine Config Operator) 및 DNS 기능을 확인합니다. 또한 부트 스트랩, 마스터 및 작업자 노드 간의 시스템 클럭 동기화를 확인하고 인증서의 유효성을 확인할 수도 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다. - 호스트에 대한 SSH 액세스 권한이 있어야 합니다.
- 부트 스트랩 및 작업자 노드의 완전한 도메인 이름이 있어야 합니다.
HTTP 서버를 사용하여 Ignition 구성 파일을 호스팅하는 경우 HTTP 서버의 정규화된 도메인 이름과 포트 번호가 있어야합니다. 또한 HTTP 호스트에 대한 SSH 액세스 권한이 있어야합니다.
참고초기
kubeadmin암호는 설치 호스트의<install_directory>/auth/kubeadmin-password에서 찾을 수 있습니다.
프로세스
- 작업자 노드의 콘솔에 액세스할 경우 노드가 로그인 프롬프트에 도달할 때 까지 콘솔을 모니터링합니다. 설치 중에 Ignition 로그 메시지가 콘솔에 출력됩니다.
Ignition 파일 설정을 확인합니다.
HTTP 서버를 사용하여 Ignition 구성 파일을 호스팅하는 경우:
작업자 노드의 Ignition 파일 URL을 확인합니다.
<http_server_fqdn>을 HTTP 서버의 정규화된 도메인 이름으로 바꿉니다.$ curl -I http://<http_server_fqdn>:<port>/worker.ign1 - 1
-I옵션은 헤더만 반환합니다. 지정된 URL에서 Ignition 파일을 사용할 수있는 경우 명령은200 OK상태를 반환합니다. 사용할 수없는 경우 명령은404 file not found를 반환합니다.
Ignition 파일이 작업자 노드에서 수신 된 것을 확인하려면 HTTP 호스트의 HTTP 서버 로그를 쿼리합니다. 예를 들어 Apache 웹 서버를 사용하여 Ignition 파일을 제공하는 경우 다음을 확인합니다.
$ grep -is 'worker.ign' /var/log/httpd/access_log작업자 Ignition 파일이 수신되면 연결된
HTTP GET로그 메시지에 요청이 성공했음을 나타내는200 OK성공 상태가 포함됩니다.- Ignition 파일이 수신되지 않은 경우 제공 호스트에 존재하는지 확인합니다. 적절한 파일 및 웹 서버 권한이 있는지 확인합니다.
클라우드 공급자 메커니즘을 사용하여 초기 배포의 일부로 호스트에 Ignition 구성 파일을 삽입하는 경우:
- 작업자 노드의 콘솔을 확인하고 작업자 노드의 Ignition 파일을 삽입하는 메커니즘이 올바르게 작동하고 있는지 확인합니다.
- 작업자 노드에 할당된 스토리지 장치의 가용성을 확인합니다.
- 작업자 노드에 DHCP 서버의 IP 주소가 지정되었는지 확인합니다.
작업자 노드 상태를 확인합니다.
노드의 상태를 쿼리합니다.
$ oc get nodesReady상태를 표시하지 않는 작업자 노드에 대한 자세한 노드 설명을 가져옵니다.$ oc describe node <worker_node>참고설치 문제로 인해 OpenShift Container Platform API가 실행되지 않거나 kubelet이 각 노드에서 실행되지 않는 경우
oc명령을 실행할 수 없습니다.
컨트롤 플레인 노드와 달리 작업자 노드는 Machine API Operator를 사용하여 배포 및 조정됩니다. Machine API Operator의 상태를 확인합니다.
Machine API Operator Pod의 상태를 검토합니다.
$ oc get pods -n openshift-machine-apiMachine API Operator Pod의 상태가
Ready가 아닌 경우 Pod의 이벤트를 자세히 설명합니다.$ oc describe pod/<machine_api_operator_pod_name> -n openshift-machine-apimachine-api-operator컨테이너 로그를 검사합니다. 컨테이너는machine-api-operatorPod 내에서 실행됩니다.$ oc logs pod/<machine_api_operator_pod_name> -n openshift-machine-api -c machine-api-operator또한
kube-rbac-proxy컨테이너 로그도 검사합니다. 컨테이너는machine-api-operatorPod 내에서도 실행됩니다.$ oc logs pod/<machine_api_operator_pod_name> -n openshift-machine-api -c kube-rbac-proxy
작업자 노드가 부팅된 후 작업자 노드에서
kubelet.servicejournald 장치 로그를 모니터링합니다. 이를 통해 작업자 노드 에이전트 활동을 시각화할 수 있습니다.oc를 사용하여 로그를 검색합니다.$ oc adm node-logs --role=worker -u kubeletAPI가 작동하지 않으면 대신 SSH를 사용하여 로그를 확인합니다.
<worker-node>.<cluster_name>.<base_domain>을 적절한 값으로 바꿉니다.$ ssh core@<worker-node>.<cluster_name>.<base_domain> journalctl -b -f -u kubelet.service참고RHCOS(Red Hat Enterprise Linux CoreOS)를 실행하는 OpenShift Container Platform 4.16 클러스터 노드는 변경할 수 없으며 Operator를 사용하여 클러스터 변경 사항을 적용합니다. SSH를 사용하여 클러스터 노드에 액세스하는 것은 권장되지 않습니다. SSH를 통해 진단 데이터를 수집하기 전에
oc adm must gather및 기타oc명령을 실행하여 충분한 데이터를 수집할 수 있는지 확인하십시오. 그러나 OpenShift Container Platform API를 사용할 수 없거나 kubelet이 대상 노드에서 제대로 작동하지 않는 경우oc작업이 영향을 받습니다. 이러한 상황에서ssh core@<node>.<cluster_name>.<base_domain>을 사용하여 노드에 액세스할 수 있습니다.
작업자 노드가 부팅 된 후
crio.servicejournald 장치 로그를 검색합니다. 이를 통해 작업자 노드 CRI-O 컨테이너 런타임 활동을 시각화할 수 있습니다.oc를 사용하여 로그를 검색합니다.$ oc adm node-logs --role=worker -u crioAPI가 작동하지 않으면 대신 SSH를 사용하여 로그를 확인합니다.
$ ssh core@<worker-node>.<cluster_name>.<base_domain> journalctl -b -f -u crio.service
작업자 노드의
/var/log/아래에 있는 특정 하위 디렉토리에서 로그를 수집합니다./var/log/하위 디렉토리에 포함된 로그 목록을 검색합니다. 다음 예제는 모든 작업자 노드의/var/log/sssd/에있는 파일을 나열합니다.$ oc adm node-logs --role=worker --path=sssd/var/log/하위 디렉터리 내의 특정 로그를 확인합니다. 다음 예제는 모든 작업자 노드에서/var/log/sssd/sssd.log콘텐츠를 출력합니다.$ oc adm node-logs --role=worker --path=sssd/sssd.logAPI가 작동하지 않는 경우 SSH를 사용하여 각 노드의 로그를 확인합니다. 다음은
/var/log/sssd/sssd.log의 예제입니다.$ ssh core@<worker-node>.<cluster_name>.<base_domain> sudo tail -f /var/log/sssd/sssd.log
SSH를 사용하여 작업자 노드 컨테이너 로그를 확인합니다.
컨테이너를 나열합니다.
$ ssh core@<worker-node>.<cluster_name>.<base_domain> sudo crictl ps -acrictl를 사용하여 컨테이너의 로그를 검색합니다.$ ssh core@<worker-node>.<cluster_name>.<base_domain> sudo crictl logs -f <container_id>
작업자 노드 구성 문제가 발생하는 경우 MCO, MCO 엔드 포인트 및 DNS 레코드가 작동하는지 확인합니다. MCO (Machine Config Operator)는 설치 시 운영 체제 구성을 관리합니다. 또한 시스템 클럭의 정확성과 인증서의 유효성을 확인하합니다.
MCO 엔드 포인트를 사용할 수 있는지 테스트합니다.
<cluster_name>을 적절한 값으로 바꿉니다.$ curl https://api-int.<cluster_name>:22623/config/worker- 엔드 포인트가 응답하지 않는 경우 로드 밸런서 구성을 확인합니다. 엔드 포인트가 포트 22623에서 실행되도록 구성되었는지 확인합니다.
MCO 엔드 포인트의 DNS 레코드가 구성되어 로드 밸런서 문제를 해결하고 있는지 확인합니다.
정의된 MCO 엔드 포인트 이름에 대한 DNS 조회를 실행합니다.
$ dig api-int.<cluster_name> @<dns_server>로드 밸런서에서 할당된 MCO IP 주소에 대한 역방향 조회를 실행합니다.
$ dig -x <load_balancer_mco_ip_address> @<dns_server>
MCO가 부트 스트랩 노드에서 직접 작동하는지 확인합니다.
<bootstrap_fqdn>을 부트 스트랩 노드의 정규화된 도메인 이름으로 바꿉니다.$ ssh core@<bootstrap_fqdn> curl https://api-int.<cluster_name>:22623/config/worker시스템 클럭은 부트 스트랩, 마스터 및 작업자 노드 간에 동기화되어야 합니다. 각 노드의 시스템 클럭 참조 시간 및 시간 동기화 통계를 확인합니다.
$ ssh core@<node>.<cluster_name>.<base_domain> chronyc tracking인증서의 유효성을 확인합니다.
$ openssl s_client -connect api-int.<cluster_name>:22623 | openssl x509 -noout -text
7.1.12. 설치 후 Operator 상태 쿼리
설치가 끝나면 Operator의 상태를 확인할 수 있습니다. 사용할 수 없는 Operator에 대한 진단 데이터를 검색합니다. Pending 중으로 나열되거나 오류 상태인 Operator Pod의 로그를 검토합니다. 문제가 있는 Pod에서 사용하는 기본 이미지의 유효성을 검사합니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
설치가 끝나면 클러스터 Operator가 모두 사용 가능한 상태인지 확인합니다.
$ oc get clusteroperators필요한 모든 CSR(인증서 서명 요청)이 모두 승인되었는지 확인합니다. 일부 노드는
Ready상태로 이동하지 않을 수 있으며 보류 중인 CSR이 있는 경우 일부 클러스터 Operator를 사용하지 못할 수 있습니다.CSR의 상태를 검토하고 클러스터에 추가된 각 시스템에 대해
Pending또는Approved상태의 클라이언트 및 서버 요청이 표시되어 있는지 확인합니다.$ oc get csr출력 예
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending1 csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending2 csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...예에서는 두 시스템이 클러스터에 참여하고 있습니다. 목록에는 승인된 CSR이 더 많이 나타날 수도 있습니다.
CSR이 승인되지 않은 경우, 추가된 시스템에 대한 모든 보류 중인 CSR이
Pending상태로 전환된 후 클러스터 시스템의 CSR을 승인합니다.참고CSR은 교체 주기가 자동으로 만료되므로 클러스터에 시스템을 추가한 후 1시간 이내에 CSR을 승인하십시오. 한 시간 내에 승인하지 않으면 인증서가 교체되고 각 노드에 대해 두 개 이상의 인증서가 표시됩니다. 이러한 인증서를 모두 승인해야 합니다. 첫 번째 CSR을 승인한 후 후속 노드 클라이언트 CSR은 클러스터
kube-controller-manager에 의해 자동으로 승인됩니다.참고베어 메탈 및 기타 사용자 프로비저닝 인프라와 같이 머신 API를 사용하도록 활성화되지 않는 플랫폼에서 실행되는 클러스터의 경우 CSR(Kubelet service Certificate Request)을 자동으로 승인하는 방법을 구현해야 합니다. 요청이 승인되지 않으면 API 서버가 kubelet에 연결될 때 서비스 인증서가 필요하므로
oc exec,oc rsh,oc logs명령을 성공적으로 수행할 수 없습니다. Kubelet 엔드 포인트에 연결하는 모든 작업을 수행하려면 이 인증서 승인이 필요합니다. 이 방법은 새 CSR을 감시하고 CSR이system:node또는system:admin그룹의node-bootstrapper서비스 계정에 의해 제출되었는지 확인하고 노드의 ID를 확인합니다.개별적으로 승인하려면 유효한 CSR 각각에 대해 다음 명령을 실행하십시오.
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
보류 중인 CSR을 모두 승인하려면 다음 명령을 실행하십시오.
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
Operator 이벤트를 표시합니다.
$ oc describe clusteroperator <operator_name>Operator의 네임스페이스 내에서 Operator Pod의 상태를 검토합니다.
$ oc get pods -n <operator_namespace>상태가
Running이 아닌 Pod에 대한 자세한 설명을 가져옵니다.$ oc describe pod/<operator_pod_name> -n <operator_namespace>Pod 로그를 검사합니다.
$ oc logs pod/<operator_pod_name> -n <operator_namespace>Pod 기본 이미지 관련 문제가 발생하면 기본 이미지 상태를 검토합니다.
문제가 있는 Pod에서 사용되는 기본 이미지의 세부 정보를 가져옵니다.
$ oc get pod -o "jsonpath={range .status.containerStatuses[*]}{.name}{'\t'}{.state}{'\t'}{.image}{'\n'}{end}" <operator_pod_name> -n <operator_namespace>기본 이미지 릴리스 정보를 나열합니다.
$ oc adm release info <image_path>:<tag> --commits
7.1.13. 실패한 설치에서 로그 수집
설치 프로그램에 SSH 키를 지정한 경우 실패한 설치에 대한 데이터를 수집할 수 있습니다.
실패한 설치에 대한 로그를 수집하는데 사용되는 명령은 실행중인 클러스터에서 로그를 수집할 때 사용되는 명령과 다릅니다. 실행중인 클러스터에서 로그를 수집해야하는 경우 oc adm must-gather 명령을 사용하십시오.
사전 요구 사항
- 부트스트랩 프로세스가 완료되기 전에 OpenShift Container Platform 설치에 실패합니다. 부트스트랩 노드가 실행 중이며 SSH를 통해 액세스할 수 있습니다.
-
ssh-agent프로세스는 컴퓨터에서 활성화되어 있으며ssh-agent프로세스 및 설치 프로그램에 동일한 SSH 키를 제공하고 있습니다. - 프로비저닝하는 인프라에 클러스터를 설치하려는 경우 부트스트랩 및 컨트롤 플레인 노드의 정규화된 도메인 이름이 있어야 합니다.
프로세스
부트스트랩 및 컨트롤 플레인 시스템에서 설치 로그를 가져오는데 필요한 명령을 생성합니다.
설치 관리자 프로비저닝 인프라를 사용한 경우 설치 프로그램이 포함된 디렉터리로 변경하고 다음 명령을 실행합니다.
$ ./openshift-install gather bootstrap --dir <installation_directory>1 - 1
installation_directory는./openshift-install create cluster를 실행할 때 지정한 디렉터리입니다. 이 디렉터리에는 설치 프로그램이 생성한 OpenShift Container Platform 정의 파일이 포함되어 있습니다.
설치 프로그램이 프로비저닝한 인프라의 경우 설치 프로그램은 클러스터에 대한 정보를 저장하므로 호스트 이름 또는 IP 주소를 지정할 필요가 없습니다.
자체적으로 프로비저닝한 인프라를 사용한 경우 설치 프로그램이 포함된 디렉터리로 변경하고 다음 명령을 실행합니다.
$ ./openshift-install gather bootstrap --dir <installation_directory> \1 --bootstrap <bootstrap_address> \2 --master <master_1_address> \3 --master <master_2_address> \4 --master <master_3_address>5 - 1
installation_directory의 경우./openshift-install create cluster를 실행할 때 지정한 것과 동일한 디렉터리를 지정합니다. 이 디렉터리에는 설치 프로그램이 생성한 OpenShift Container Platform 정의 파일이 포함되어 있습니다.- 2
<bootstrap_address>는 클러스터 부트스트랩 시스템의 정규화된 도메인 이름 또는 IP 주소입니다.- 3 4 5
- 클러스터의 각 컨트롤 플레인 또는 마스터 시스템에 대해
<master_*_address>를 정규화된 도메인 이름 또는 IP 주소로 변경합니다.
참고기본 클러스터에는 세 개의 컨트롤 플레인 시스템이 있습니다. 클러스터가 사용하는 수에 관계없이 표시된대로 모든 컨트롤 플레인 시스템을 나열합니다.
출력 예
INFO Pulling debug logs from the bootstrap machine INFO Bootstrap gather logs captured here "<installation_directory>/log-bundle-<timestamp>.tar.gz"설치 실패에 대한 Red Hat 지원 케이스를 만들 경우 압축된 로그를 케이스에 포함해야 합니다.
7.2. 노드 상태 확인
7.2.1. 노드 상태, 리소스 사용량 및 구성 확인
클러스터 노드 상태, 리소스 사용량 통계 및 노드 로그를 확인합니다. 또한 개별 노드에서 kubelet 상태를 쿼리합니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
클러스터의 모든 노드 이름, 상태 및 역할을 나열합니다.
$ oc get nodes클러스터 내의 각 노드에 대한 CPU 및 메모리 사용량을 요약합니다.
$ oc adm top nodes특정 노드의 CPU 및 메모리 사용량을 요약합니다.
$ oc adm top node my-node
7.2.2. 노드에서 kubelet의 상태 쿼리
클러스터 노드 상태, 리소스 사용량 통계 및 노드 로그를 확인할 수 있습니다. 또한 개별 노드에서 kubelet 상태를 쿼리할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. - API 서비스가 작동하고 있어야 합니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
kubelet은 각 노드에서 systemd 서비스를 사용하여 관리됩니다. 디버그 Pod 내에서
kubeletsystemd 서비스를 쿼리하여 kubelet의 상태를 검토합니다.노드의 디버그 Pod를 시작합니다.
$ oc debug node/my-node참고컨트롤 플레인 노드에서
oc debug를 실행하는 경우/etc/kubernetes/static-pod-resources/kube-apiserver-certs/secrets/node-kubeconfigs디렉터리에서 관리kubeconfig파일을 찾을 수 있습니다.디버그 쉘 내에서
/host를 root 디렉터리로 설정합니다. 디버그 Pod는 Pod 내의/host에 호스트의 루트 파일 시스템을 마운트합니다. root 디렉토리를/host로 변경하면 호스트의 실행 경로에 포함된 바이너리를 실행할 수 있습니다.# chroot /host참고RHCOS(Red Hat Enterprise Linux CoreOS)를 실행하는 OpenShift Container Platform 4.16 클러스터 노드는 변경할 수 없으며 Operator를 사용하여 클러스터 변경 사항을 적용합니다. SSH를 사용하여 클러스터 노드에 액세스하는 것은 권장되지 않습니다. 그러나 OpenShift Container Platform API를 사용할 수 없거나
kubelet이 대상 노드에서 제대로 작동하지 않는 경우oc작업이 영향을 받습니다. 이러한 상황에서 대신ssh core @ <node>.<cluster_name>.<base_domain>을 사용하여 노드에 액세스할 수 있습니다.kubeletsystemd 서비스가 노드에서 활성화되어 있는지 여부를 확인합니다.# systemctl is-active kubelet더 자세한
kubelet.service상태 요약을 출력합니다.# systemctl status kubelet
7.2.3. 클러스터 노드의 저널 로그 쿼리
개별 클러스터 노드의 /var/log 내에 journald 장치 로그 및 기타 로그를 수집할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다. - API 서비스가 작동하고 있어야 합니다.
- 호스트에 대한 SSH 액세스 권한이 있어야 합니다.
프로세스
OpenShift Container Platform 클러스터 노드에서
kubeletjournald장치 로그를 쿼리합니다. 다음 예제에서는 컨트롤 플레인 노드만 쿼리합니다.$ oc adm node-logs --role=worker -u kubelet-
kubelet: 다른 장치 로그를 쿼리하려면 적절하게 바꿉니다.
-
클러스터 노드의
/var/log/아래에있는 특정 하위 디렉터리에서 로그를 수집합니다./var/log/하위 디렉토리에 포함된 로그 목록을 검색합니다. 다음 예제는 모든 컨트롤 플레인 노드의/var/log/openshift-apiserver/에 있는 파일을 나열합니다.$ oc adm node-logs --role=master --path=openshift-apiserver/var/log/하위 디렉터리 내의 특정 로그를 확인합니다. 다음 예제는 모든 컨트롤 플레인 노드에서/var/log/openshift-apiserver/audit.log내용을 출력합니다.$ oc adm node-logs --role=master --path=openshift-apiserver/audit.logAPI가 작동하지 않는 경우 SSH를 사용하여 각 노드의 로그를 확인합니다. 다음은
/var/log/openshift-apiserver/audit.log예제입니다.$ ssh core@<master-node>.<cluster_name>.<base_domain> sudo tail -f /var/log/openshift-apiserver/audit.log참고RHCOS(Red Hat Enterprise Linux CoreOS)를 실행하는 OpenShift Container Platform 4.16 클러스터 노드는 변경할 수 없으며 Operator를 사용하여 클러스터 변경 사항을 적용합니다. SSH를 사용하여 클러스터 노드에 액세스하는 것은 권장되지 않습니다. SSH를 통해 진단 데이터를 수집하기 전에
oc adm must gather및 기타oc명령을 실행하여 충분한 데이터를 수집할 수 있는지 확인하십시오. 그러나 OpenShift Container Platform API를 사용할 수 없거나 kubelet이 대상 노드에서 제대로 작동하지 않는 경우oc작업이 영향을 받습니다. 이러한 상황에서ssh core@<node>.<cluster_name>.<base_domain>을 사용하여 노드에 액세스할 수 있습니다.
7.3. CRI-O 컨테이너 런타임 문제 해결
7.3.1. CRI-O 컨테이너 런타임 엔진 정보
CRI-O는 Kubernetes 네이티브 컨테이너 엔진 구현으로 운영 체제와 긴밀하게 통합되어 효율적이고 최적화된 Kubernetes 환경을 제공합니다. CRI-O 컨테이너 엔진은 각 OpenShift Container Platform 클러스터 노드에서 systemd 서비스로 실행됩니다.
컨테이너 런타임 문제가 발생하면 각 노드에서 crio systemd 서비스의 상태를 확인합니다. 컨테이너 런타임 문제가 있는 노드에서 CRI-O journald 장치 로그를 수집합니다.
7.3.2. CRI-O 런타임 엔진 상태 확인
각 클러스터 노드에서 CRI-O 컨테이너 런타임 엔진 상태를 확인할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
디버그 Pod 내에서 노드의
criosystemd 서비스를 쿼리하여 CRI-O 상태를 검토합니다.노드의 디버그 Pod를 시작합니다.
$ oc debug node/my-node디버그 쉘 내에서
/host를 root 디렉터리로 설정합니다. 디버그 Pod는 Pod 내의/host에 호스트의 루트 파일 시스템을 마운트합니다. root 디렉토리를/host로 변경하면 호스트의 실행 경로에 포함된 바이너리를 실행할 수 있습니다.# chroot /host참고RHCOS(Red Hat Enterprise Linux CoreOS)를 실행하는 OpenShift Container Platform 4.16 클러스터 노드는 변경할 수 없으며 Operator를 사용하여 클러스터 변경 사항을 적용합니다. SSH를 사용하여 클러스터 노드에 액세스하는 것은 권장되지 않습니다. 그러나 OpenShift Container Platform API를 사용할 수 없거나 kubelet이 대상 노드에서 제대로 작동하지 않는 경우
oc작업이 영향을 받습니다. 이러한 상황에서 대신ssh core @ <node>.<cluster_name>.<base_domain>을 사용하여 노드에 액세스할 수 있습니다.criosystemd 서비스가 노드에서 활성 상태인지 확인합니다.# systemctl is-active crio보다 자세한
crio.service상태 요약을 출력합니다.# systemctl status crio.service
7.3.3. CRI-O journald 장치 로그 수집
CRI-O 문제가 발생하는 경우 노드에서 CRI-O journald 장치 로그를 얻을 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. - API 서비스가 작동하고 있어야 합니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다. - 컨트롤 플레인 또는 컨트롤 플레인 시스템의 정규화된 도메인 이름이 있어야 합니다.
프로세스
CRI-O journald 장치 로그를 수집합니다. 다음 예제는 클러스터 내의 모든 컨트롤 플레인 노드에서 로그를 수집합니다.
$ oc adm node-logs --role=master -u crio특정 노드에서 CRI-O journald 장치 로그를 수집합니다.
$ oc adm node-logs <node_name> -u crioAPI가 작동하지 않으면 대신 SSH를 사용하여 로그를 확인합니다.
<node>.<cluster_name>.<base_domain>을 적절한 값으로 바꿉니다.$ ssh core@<node>.<cluster_name>.<base_domain> journalctl -b -f -u crio.service참고RHCOS(Red Hat Enterprise Linux CoreOS)를 실행하는 OpenShift Container Platform 4.16 클러스터 노드는 변경할 수 없으며 Operator를 사용하여 클러스터 변경 사항을 적용합니다. SSH를 사용하여 클러스터 노드에 액세스하는 것은 권장되지 않습니다. SSH를 통해 진단 데이터를 수집하기 전에
oc adm must gather및 기타oc명령을 실행하여 충분한 데이터를 수집할 수 있는지 확인하십시오. 그러나 OpenShift Container Platform API를 사용할 수 없거나 kubelet이 대상 노드에서 제대로 작동하지 않는 경우oc작업이 영향을 받습니다. 이러한 상황에서ssh core@<node>.<cluster_name>.<base_domain>을 사용하여 노드에 액세스할 수 있습니다.
7.3.4. CRI-O 스토리지 정리
다음 문제가 발생하는 경우 CRI-O 임시 스토리지를 수동으로 삭제할 수 있습니다.
노드는 Pod를 실행할 수 없으며 이 오류가 표시됩니다.
Failed to create pod sandbox: rpc error: code = Unknown desc = failed to mount container XXX: error recreating the missing symlinks: error reading name of symlink for XXX: open /var/lib/containers/storage/overlay/XXX/link: no such file or directory작업 노드에 새 컨테이너를 생성할 수 없으며 "can't stat lower layer" 오류가 나타납니다.
can't stat lower layer ... because it does not exist. Going through storage to recreate the missing symlinks.-
클러스터 업그레이드 후 또는 재부팅을 시도하는 경우 노드는
NotReady상태입니다. -
crio(컨테이너 런타임 구현)가 제대로 작동하지 않습니다. -
컨테이너 런타임 인스턴스(
crio)가 작동하지 않기 때문에oc debug node/<node_name>을 사용하여 노드에서 디버그 쉘을 시작할 수 없습니다.
CRI-O 스토리지를 완전히 지우고 오류를 해결하려면 다음 프로세스를 따르십시오.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
노드에서
cordon을 사용합니다. 이는 노드가Ready상태가 되면 워크로드가 예약되지 않도록 하기 위한 것입니다.SchedulingDisabled가 상태 섹션에 있으면 예약이 비활성화되어 있음을 알 수 있습니다.$ oc adm cordon <node_name>노드를 cluster-admin으로 드레이닝합니다.
$ oc adm drain <node_name> --ignore-daemonsets --delete-emptydir-data참고Pod 또는 Pod 템플릿의
terminationGracePeriodSeconds속성은 정상 종료 기간을 제어합니다. 이 속성은 30초에 기본값으로 설정되지만 필요에 따라 각 애플리케이션에 맞게 사용자 지정할 수 있습니다. 90초 이상으로 설정하면 Pod가SIGKILLed로 표시되고 성공적으로 종료되지 않을 수 있습니다.노드가 반환되면 SSH 또는 콘솔을 통해 노드에 다시 연결합니다. 그런 다음 root 사용자에 연결합니다.
$ ssh core@node1.example.com $ sudo -ikubelet을 수동으로 중지합니다.
# systemctl stop kubelet컨테이너 및 pod를 중지합니다.
다음 명령을 사용하여
HostNetwork에 없는 Pod를 중지합니다. 제거를 통해HostNetwork에 있는 네트워킹 플러그인 pod를 사용하므로 먼저 제거해야 합니다... for pod in $(crictl pods -q); do if [[ "$(crictl inspectp $pod | jq -r .status.linux.namespaces.options.network)" != "NODE" ]]; then crictl rmp -f $pod; fi; done다른 모든 Pod를 중지합니다.
# crictl rmp -fa
crio 서비스를 수동으로 중지합니다.
# systemctl stop crio이러한 명령을 실행한 후 임시 스토리지를 완전히 초기화할 수 있습니다.
# crio wipe -fcrio 및 kubelet 서비스를 시작합니다.
# systemctl start crio # systemctl start kubeletcrio 및 kubelet 서비스가 시작되고 노드가
Ready상태에 있으면 정리가 작동했는지 알 수 있습니다.$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ci-ln-tkbxyft-f76d1-nvwhr-master-1 Ready, SchedulingDisabled master 133m v1.29.4노드를 예약 가능으로 표시합니다.
SchedulingDisabled상태가 더 이상 아닐 때 예약이 활성화되어 있음을 알 수 있습니다.$ oc adm uncordon <node_name>출력 예
NAME STATUS ROLES AGE VERSION ci-ln-tkbxyft-f76d1-nvwhr-master-1 Ready master 133m v1.29.4
7.4. 운영 체제 문제 해결
OpenShift Container Platform은 RHCOS에서 실행됩니다. 다음 절차에 따라 운영 체제와 관련된 문제를 해결할 수 있습니다.
7.4.1. 커널 크래시 조사
kexec-tools 패키지에 포함된 kdump 서비스는 크래시 덤프 메커니즘을 제공합니다. 이 서비스를 사용하여 이후 분석을 위해 시스템 메모리의 내용을 저장할 수 있습니다.
x86_64 아키텍처는 GA(General Availability) 상태에서 kdump를 지원하는 반면 다른 아키텍처는 TP(기술 프리뷰) 상태의 kdump를 지원합니다.
다음 표에서는 다양한 아키텍처의 kdump 지원 수준에 대해 자세히 설명합니다.
| 아키텍처 | 지원 수준 |
|---|---|
|
|
GA |
|
|
TP |
|
|
TP |
|
|
TP |
표의 이전 세 아키텍처의 kdump 지원은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 다음 링크를 참조하십시오.
7.4.1.1. kdump 활성화
RHCOS는 kexec-tools 패키지와 함께 제공되지만 kdump 서비스를 활성화하려면 수동 구성이 필요합니다.
프로세스
다음 단계를 수행하여 RHCOS에서 kdump를 활성화합니다.
첫 번째 커널 부팅 중에 크래시 커널의 메모리를 예약하려면 다음 명령을 입력하여 커널 인수를 제공합니다.
# rpm-ostree kargs --append='crashkernel=256M'참고ppc64le플랫폼의 경우crashkernel의 권장되는 값은crashkernel=2G-4G:384M,4G-16G:512M,16G-64G:1G,64G-128G:2G,128G-:4G입니다.선택 사항: 기본 로컬
/var/crash위치 대신 크래시 덤프를 네트워크 또는 다른 위치에 작성하려면/etc/kdump.conf구성 파일을 편집합니다.참고노드에서 LUKS 암호화 장치를 사용하는 경우 kdump에서 LUKS 암호화 장치에 대한 크래시 덤프 저장 기능을 지원하지 않으므로 네트워크 덤프를 사용해야 합니다.
kdump서비스 구성에 대한 자세한 내용은n/etc/sysconfig/kdump,/etc/kdump.conf,kdump.conf메뉴얼 페이지의 주석을 참조하십시오. 덤프 대상 구성에 대한 자세한 내용은 RHEL kdump 문서를 참조하십시오.중요기본 디스크에 멀티패스가 활성화된 경우 덤프 대상은 NFS 또는 SSH 서버여야 하며
/etc/kdump.conf구성 파일에서 multipath 모듈을 제외해야 합니다.kdumpsystemd 서비스를 활성화합니다.# systemctl enable kdump.service시스템을 재부팅합니다.
# systemctl reboot-
kdump.servicesystemd 서비스가 시작 및 종료되었는지 확인하고 kdump가 크래시 커널을 로드했는지 확인하고cat /sys/kernel/kexec_crash_loaded이라는 명령이 값1을 출력하는지 확인합니다.
7.4.1.2. Day-1에 kdump 활성화
kdump 서비스는 노드별로 커널 문제를 디버그하도록 사용하도록 설정되어 있습니다. kdump를 활성화하는 데 드는 비용이 있고 추가 kdump 지원 노드마다 비용이 누적되므로 필요에 따라 kdump 서비스를 각 노드에서만 활성화하는 것이 좋습니다. 각 노드에서 kdump 서비스를 활성화할 수 있는 비용은 다음과 같습니다.
- 크래시 커널에 대해 예약된 메모리로 인해 사용 가능한 RAM이 줄어듭니다.
- 커널이 코어를 덤프하는 동안 노드를 사용할 수 없습니다.
- 크래시 덤프를 저장하는 데 추가 스토리지 공간이 사용됩니다.
kdump 서비스 활성화의 단점 및 장단점을 알고 있는 경우 클러스터 전체에서 kdump를 활성화할 수 있습니다. 시스템별 머신 구성은 아직 지원되지 않지만 MachineConfig 오브젝트의 systemd 단위를 Day-1 사용자 지정으로 사용하고 클러스터의 모든 노드에서 kdump를 사용하도록 설정할 수 있습니다. MachineConfig 개체를 생성하고 해당 개체를 클러스터 설정 중에 Ignition에서 사용하는 매니페스트 파일 세트에 삽입할 수 있습니다.
Ignition 구성 사용 방법에 대한 자세한 내용은 설치 → 설치 구성 섹션의 " 노드 정의"를 참조하십시오.
프로세스
클러스터 전체 구성을 위한 MachineConfig 오브젝트를 생성합니다.
kdump를 구성하고 활성화하는 Butane 구성 파일
99-worker-kdump.bu를 생성합니다.참고구성 파일에 지정하는 Butane 버전이 OpenShift Container Platform 버전과 일치해야 하며 항상
0으로 끝나야 합니다. 예를 들면4.16.0입니다. Butane에 대한 자세한 내용은 “Butane 을 사용하여 머신 구성 생성”을 참조하십시오.variant: openshift version: 4.16.0 metadata: name: 99-worker-kdump1 labels: machineconfiguration.openshift.io/role: worker2 openshift: kernel_arguments:3 - crashkernel=256M storage: files: - path: /etc/kdump.conf4 mode: 0644 overwrite: true contents: inline: | path /var/crash core_collector makedumpfile -l --message-level 7 -d 31 - path: /etc/sysconfig/kdump5 mode: 0644 overwrite: true contents: inline: | KDUMP_COMMANDLINE_REMOVE="hugepages hugepagesz slub_debug quiet log_buf_len swiotlb" KDUMP_COMMANDLINE_APPEND="irqpoll nr_cpus=1 reset_devices cgroup_disable=memory mce=off numa=off udev.children-max=2 panic=10 rootflags=nofail acpi_no_memhotplug transparent_hugepage=never nokaslr novmcoredd hest_disable"6 KEXEC_ARGS="-s" KDUMP_IMG="vmlinuz" systemd: units: - name: kdump.service enabled: true- 1 2
- 컨트롤 플레인 노드에
MachineConfig개체를 생성할 때 두 위치 모두에서worker를master로 바꿉니다. - 3
- 크래시 커널용 메모리를 예약하기 위해 커널 인수를 제공합니다. 필요한 경우 다른 커널 인수를 추가할 수 있습니다.
ppc64le플랫폼의 경우crashkernel의 권장되는 값은crashkernel=2G-4G:384M,4G-16G:512M,16G-64G:1G,64G-128G:2G,128G-:4G입니다. - 4
/etc/kdump.conf의 내용을 기본값에서 변경하려면 이 섹션을 포함하고 그에 따라inline하위 섹션을 수정합니다.- 5
/etc/sysconfig/kdump의 내용을 기본값에서 변경하려면 이 섹션을 포함하고 이에 따라inline하위 섹션을 수정합니다.- 6
ppc64le플랫폼의 경우nr_cpus=1을 이 플랫폼에서 지원되지 않는maxcpus=1로 바꿉니다.
덤프를 NFS 대상으로 내보내려면 일부 커널 모듈을 구성 파일에 명시적으로 추가해야 합니다.
/etc/kdump.conf 파일의 예
nfs server.example.com:/export/cores
core_collector makedumpfile -l --message-level 7 -d 31
extra_bins /sbin/mount.nfs
extra_modules nfs nfsv3 nfs_layout_nfsv41_files blocklayoutdriver nfs_layout_flexfiles nfs_layout_nfsv41_filesButane을 사용하여 노드에 전달할 구성이 포함된 시스템 구성 YAML 파일
99-worker-kdump.yaml을 생성합니다.$ butane 99-worker-kdump.bu -o 99-worker-kdump.yaml클러스터 설정 중에 YAML 파일을
<installation_directory>/manifests/디렉터리에 배치합니다. YAML 파일을 사용하여 클러스터 설정 후 이MachineConfig오브젝트를 생성할 수도 있습니다.$ oc create -f 99-worker-kdump.yaml
7.4.1.3. kdump 설정 테스트
kdump에 대한 내용은 RHEL 문서의 kdump 설정 테스트 섹션을 참조하십시오.
7.4.1.4. 코어 덤프 분석
kdump에 대한 내용은 RHEL 문서의 코어 덤프 분석 섹션을 참조하십시오.
별도의 RHEL 시스템에서 vmcore 분석을 수행하는 것이 좋습니다.
7.4.2. Ignition 실패 디버깅
머신을 프로비저닝할 수 없는 경우 Ignition이 실패하고 RHCOS가 긴급 쉘로 부팅됩니다. 디버깅 정보를 얻으려면 다음 절차를 사용하십시오.
프로세스
다음 명령을 실행하여 어떤 서비스 단위가 실패했는지 표시합니다.
$ systemctl --failed선택 사항: 개별 서비스 장치에서 다음 명령을 실행하여 자세한 정보를 확인합니다.
$ journalctl -u <unit>.service
7.5. 네트워크 문제 해결
7.5.1. 네트워크 인터페이스 선택 방법
베어 메탈 또는 둘 이상의 NIC(네트워크 인터페이스 컨트롤러)가 있는 가상 머신에 설치할 경우 OpenShift Container Platform이 Kubernetes API 서버와의 통신에 사용하는 NIC는 노드가 부팅될 때 systemd에서 실행하는 nodeip-configuration.service 서비스 유닛에 의해 결정됩니다. nodeip-configuration.service 는 기본 경로와 연결된 인터페이스에서 IP를 선택합니다.
nodeip-configuration.service 서비스에서 올바른 NIC를 확인한 후 서비스는 /etc/systemd/system/kubelet.service.d/20-nodenet.conf 파일을 만듭니다. 20-nodenet.conf 파일은 KUBELET_NODE_IP 환경 변수를 서비스가 선택한 IP 주소로 설정합니다.
kubelet 서비스가 시작되면 20-nodenet.conf 파일에서 환경 변수 값을 읽고 IP 주소를 --node-ip kubelet 명령줄 인수 값으로 설정합니다. 결과적으로 kubelet 서비스는 선택한 IP 주소를 노드 IP 주소로 사용합니다.
설치 후 하드웨어 또는 네트워킹을 재구성하거나 노드 IP가 기본 라우팅 인터페이스에서 제공되지 않는 네트워킹 레이아웃이 있는 경우 재부팅 후 nodeip-configuration.service 서비스에서 다른 NIC를 선택할 수 있습니다. 경우에 따라 oc get nodes -o wide 명령의 출력에서 INTERNAL-IP 열을 검토하여 다른 NIC가 선택되었는지 감지할 수 있습니다.
다른 NIC가 선택되어 네트워크 통신이 중단되거나 잘못 구성된 경우 EtcdCertSignerControllerDegraded 오류가 표시될 수 있습니다. NODEIP_HINT 변수를 포함하는 힌트 파일을 생성하여 기본 IP 선택 논리를 덮어쓸 수 있습니다. 자세한 내용은 선택 사항: 기본 노드 IP 선택 논리를 참조하십시오.
7.5.1.1. 선택 사항: 기본 노드 IP 선택 논리를 덮어 쓰기
기본 IP 선택 논리를 재정의하려면 NODEIP_HINT 변수를 포함하는 힌트 파일을 생성하여 기본 IP 선택 논리를 재정의할 수 있습니다. 힌트 파일을 만들면 NODEIP_HINT 변수에 지정된 IP 주소 서브넷의 인터페이스에서 특정 노드 IP 주소를 선택할 수 있습니다.
예를 들어 노드에 주소가 10.0.0.10/24 인 eth0 과 주소가 192.0.2.5/24 인 eth1 이 있고 기본 경로는 eth0 (10.0.0.10)을 가리킵니다. 노드 IP 주소는 일반적으로 10.0.0.10 IP 주소를 사용합니다.
사용자는 서브넷의 알려진 IP를 가리키도록 NODEIP_HINT 변수를 구성할 수 있습니다(예: 192.0.2.1 과 같은 서브넷 게이트웨이) 다른 서브넷 192.0.2.0/24 가 선택되도록 합니다. 따라서 eth1 의 192.0.2.5 IP 주소가 노드에 사용됩니다.
다음 절차에서는 기본 노드 IP 선택 논리를 재정의하는 방법을 보여줍니다.
프로세스
힌트 파일을
/etc/default/nodeip-configuration파일에 추가합니다. 예를 들면 다음과 같습니다.NODEIP_HINT=192.0.2.1중요-
노드의 정확한 IP 주소를 힌트로 사용하지 마십시오(예:
192.0.2.5). 노드의 정확한 IP 주소를 사용하면 노드가 힌트 IP 주소를 사용하는 경우 올바르게 구성되지 않습니다. - 힌트 파일의 IP 주소는 올바른 서브넷을 결정하는 데만 사용됩니다. 힌트 파일에 나타나는 결과로 트래픽을 수신하지 않습니다.
-
노드의 정확한 IP 주소를 힌트로 사용하지 마십시오(예:
다음 명령을 실행하여
base-64로 인코딩된 콘텐츠를 생성합니다.$ echo -n 'NODEIP_HINT=192.0.2.1' | base64 -w0출력 예
Tk9ERUlQX0hJTlQ9MTkyLjAuMCxxxx==클러스터를 배포하기 전에
master및worker역할에 대한 머신 구성 매니페스트를 생성하여 힌트를 활성화합니다.99-nodeip-hint-master.yaml
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 99-nodeip-hint-master spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;charset=utf-8;base64,<encoded_content>1 mode: 0644 overwrite: true path: /etc/default/nodeip-configuration- 1
<encoded_contents>를/etc/default/nodeip-configuration파일의 base64 인코딩 콘텐츠(예:Tk9ERUlQX0hJTlQ9MTkyLjAuMC=== )로 바꿉니다. 쉼표 이후와 인코딩된 콘텐츠 전에는 공백을 사용할 수 없습니다.
99-nodeip-hint-worker.yaml
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 99-nodeip-hint-worker spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;charset=utf-8;base64,<encoded_content>1 mode: 0644 overwrite: true path: /etc/default/nodeip-configuration- 1
<encoded_contents>를/etc/default/nodeip-configuration파일의 base64 인코딩 콘텐츠(예:Tk9ERUlQX0hJTlQ9MTkyLjAuMC=== )로 바꿉니다. 쉼표 이후와 인코딩된 콘텐츠 전에는 공백을 사용할 수 없습니다.
-
클러스터 구성을 저장하는 디렉터리에 매니페스트를 저장합니다(예:
~/clusterconfigs). - 클러스터를 배포합니다.
7.5.1.2. 보조 OVS 브리지를 사용하도록 OVN-Kubernetes 구성
OVN-Kubernetes는 OpenShift Container Platform 노드의 외부 게이트웨이를 정의하는 데 사용하는 추가 또는 보조 Open vSwitch(OVS) 브리지 br-ex1 을 생성하고 여러 외부 게이트웨이(MEG) 구현을 생성할 수 있습니다. AdminPolicyBasedExternalRoute CR(사용자 정의 리소스)에서 MEG를 정의할 수 있습니다. MEG 구현에서는 Pod에 여러 게이트웨이, ECMP( equal-cost multipath) 경로 및 BFD( Bidirectional Forwarding Detection) 구현에 액세스할 수 있습니다.
여러 외부 게이트웨이(MEG) 기능의 영향을 받는 Pod의 사용 사례를 고려하고 노드에서 다른 인터페이스(예: br-ex1 )로 트래픽을 송신하려는 경우를 고려하십시오. MEG의 영향을 받지 않는 Pod의 송신 트래픽은 기본 OVS br-ex 브리지로 라우팅됩니다.
현재 MEG는 송신 IP, 송신 방화벽 또는 송신 라우터와 같은 다른 송신 기능과 함께 사용할 수 없습니다. 송신 IP와 같은 송신 기능과 함께 MEG를 사용하면 라우팅 및 트래픽 흐름 충돌이 발생할 수 있습니다. 이는 OVN-Kubernetes가 라우팅 및 소스 네트워크 주소 변환(SNAT)을 처리하는 방식 때문에 발생합니다. 이로 인해 라우팅이 일관되지 않으며 반환 경로가 들어오는 경로를 패치해야 하는 일부 환경에서 연결이 중단될 수 있습니다.
머신 구성 매니페스트 파일의 인터페이스 정의에 추가 브릿지를 정의해야 합니다. Machine Config Operator는 매니페스트를 사용하여 호스트의 /etc/ovnk/extra_bridge 에 새 파일을 생성합니다. 새 파일에는 추가 OVS 브리지가 노드에 대해 구성하는 네트워크 인터페이스의 이름이 포함되어 있습니다.
매니페스트 파일을 생성하고 편집한 후 Machine Config Operator가 다음 순서로 작업을 완료합니다.
- 선택한 머신 구성 풀에 따라 노드를 단일 순서로 드레이닝합니다.
-
각 노드가 추가
br-ex1브리지 네트워크 구성을 수신하도록 Ignition 구성 파일을 각 노드에 삽입합니다. -
br-exMAC 주소가br-ex가 네트워크 연결에 사용하는 인터페이스의 MAC 주소와 일치하는지 확인합니다. -
새 인터페이스 정의를 참조하는
configure-ovs.sh쉘 스크립트를 실행합니다. -
br-ex및br-ex1을 호스트 노드에 추가합니다. - 노드를 분리합니다.
모든 노드가 Ready 상태로 돌아가고 OVN-Kubernetes Operator가 br-ex 및 을 감지하고 구성한 후 Operator는 br-ex 1k8s.ovn.org/l3-gateway-config 주석을 각 노드에 적용합니다.
추가 br-ex1 브리지 및 항상 기본 br-ex 브리지가 필요한 상황에 대한 자세한 내용은 "Localnet 토폴로지에 대한 구성"을 참조하십시오.
프로세스
선택 사항: 추가 브릿지
br-ex1에서 다음 단계를 완료하여 사용할 수 있는 인터페이스 연결을 생성합니다. 예제 단계에서는 모두 머신 구성 매니페스트 파일에 정의된 새 본딩 및 해당 종속 인터페이스를 생성하는 방법을 보여줍니다. 추가 브릿지는MachineConfig오브젝트를 사용하여 추가 본딩 인터페이스를 형성합니다.중요추가 인터페이스를 정의하기 위해 Kubernetes NMState Operator를 사용하거나
NodeNetworkConfigurationPolicy(NNCP) 매니페스트 파일을 정의하지 마십시오.또한
본딩인터페이스를 정의할 때 기존br-exOVN Kubernetes 네트워크 배포에서 추가 인터페이스 또는 하위 인터페이스를 사용하지 않는지 확인합니다.다음 인터페이스 정의 파일을 생성합니다. 호스트 노드가 정의 파일에 액세스할 수 있도록 이러한 파일이 머신 구성 매니페스트 파일에 추가됩니다.
eno1.config라는 첫 번째 인터페이스 정의 파일의 예[connection] id=eno1 type=ethernet interface-name=eno1 master=bond1 slave-type=bond autoconnect=true autoconnect-priority=20eno2.config라는 두 번째 인터페이스 정의 파일의 예[connection] id=eno2 type=ethernet interface-name=eno2 master=bond1 slave-type=bond autoconnect=true autoconnect-priority=20bond1.config라는 두 번째 본딩 인터페이스 정의 파일의 예[connection] id=bond1 type=bond interface-name=bond1 autoconnect=true connection.autoconnect-slaves=1 autoconnect-priority=20 [bond] mode=802.3ad miimon=100 xmit_hash_policy="layer3+4" [ipv4] method=auto다음 명령을 실행하여 정의 파일을 Base64 인코딩 문자열로 변환합니다.
$ base64 <directory_path>/en01.config$ base64 <directory_path>/eno2.config$ base64 <directory_path>/bond1.config
환경 변수를 준비합니다. <
machine_role>을worker와 같은 노드 역할로 바꾸고 <interface_name>을 추가br-ex브리지 이름의 이름으로 바꿉니다.$ export ROLE=<machine_role>머신 구성 매니페스트 파일에 각 인터페이스 정의를 정의합니다.
bond1,eno1및en02에 대한 정의가 추가된 머신 구성 파일의 예apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: ${worker} name: 12-${ROLE}-sec-bridge-cni spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:;base64,<base-64-encoded-contents-for-bond1.conf> path: /etc/NetworkManager/system-connections/bond1.nmconnection filesystem: root mode: 0600 - contents: source: data:;base64,<base-64-encoded-contents-for-eno1.conf> path: /etc/NetworkManager/system-connections/eno1.nmconnection filesystem: root mode: 0600 - contents: source: data:;base64,<base-64-encoded-contents-for-eno2.conf> path: /etc/NetworkManager/system-connections/eno2.nmconnection filesystem: root mode: 0600 # ...터미널에 다음 명령을 입력하여 네트워크 플러그인을 구성하기 위한 머신 구성 매니페스트 파일을 생성합니다.
$ oc create -f <machine_config_file_name>OVN-Kubernetes 네트워크 플러그인을 사용하여
extra_bridge파일 을 생성하여 노드에 OVS(Open vSwitch) 브리지br-ex1을 만듭니다. 파일을 호스트의/etc/ovnk/extra_bridge경로에 저장해야 합니다. 파일에는 노드의 기본 IP 주소가 있는br-ex를 지원하는 기본 인터페이스가 아닌 추가 브릿지를 지원하는 인터페이스 이름을 지정해야 합니다.추가 인터페이스를 참조하는
extra_bridge파일/etc/ovnk/extra_bridge에 대한 설정 예bond1클러스터에서 재시작한 모든 노드에서
br-ex1을 호스팅하는 기존 정적 인터페이스를 정의하는 머신 구성 매니페스트 파일을 생성합니다.br-ex1호스팅 인터페이스로bond1을 정의하는 머신 구성 파일의 예apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: ${worker} name: 12-worker-extra-bridge spec: config: ignition: version: 3.2.0 storage: files: - path: /etc/ovnk/extra_bridge mode: 0420 overwrite: true contents: source: data:text/plain;charset=utf-8,bond1 filesystem: root선택한 노드에 머신 구성을 적용합니다.
$ oc create -f <machine_config_file_name>선택 사항:
/var/lib/ovnk/iface_default_hint리소스를 생성하는 머신 구성 파일을 생성하여 노드의br-ex선택 논리를 덮어쓸 수 있습니다.참고리소스에는
br-ex가 클러스터에 대해 선택하는 인터페이스의 이름이 나열됩니다. 기본적으로br-ex는 시스템 네트워크의 부팅 순서 및 IP 주소 서브넷을 기반으로 노드의 기본 인터페이스를 선택합니다. 특정 머신 네트워크 구성을 사용하려면br-ex가 호스트 노드의 기본 인터페이스 또는 본딩을 계속 선택해야 할 수 있습니다.호스트 노드에 머신 구성 파일을 생성하여 기본 인터페이스를 재정의합니다.
중요br-ex선택 논리를 변경하기 위해 이 머신 구성 파일만 생성합니다. 이 파일을 사용하여 클러스터에 있는 기존 노드의 IP 주소를 변경하는 것은 지원되지 않습니다.기본 인터페이스를 재정의하는 머신 구성 파일의 예
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: ${worker} name: 12-worker-br-ex-override spec: config: ignition: version: 3.2.0 storage: files: - path: /var/lib/ovnk/iface_default_hint mode: 0420 overwrite: true contents: source: data:text/plain;charset=utf-8,bond01 filesystem: root- 1
- 머신 구성 파일을 노드에 적용하기 전에
bond0이 노드에 있는지 확인합니다.
-
클러스터의 모든 새 노드에 구성을 적용하기 전에 호스트 노드를 재부팅하여
br-ex가 의도한 인터페이스를 선택하고br-ex1에 정의된 새 인터페이스와 충돌하지 않는지 확인합니다. 클러스터의 모든 새 노드에 머신 구성 파일을 적용합니다.
$ oc create -f <machine_config_file_name>
검증
클러스터에서
exgw-ip-addresses라벨을 사용하여 노드의 IP 주소를 확인하여 노드가 기본 브리지 대신 추가 브릿지를 사용하는지 확인합니다.$ oc get nodes -o json | grep --color exgw-ip-addresses출력 예
"k8s.ovn.org/l3-gateway-config": \"exgw-ip-address\":\"172.xx.xx.yy/24\",\"next-hops\":[\"xx.xx.xx.xx\"],호스트 노드에서 네트워크 인터페이스 이름을 검토하여 대상 노드에 추가 브릿지가 있는지 확인합니다.
$ oc debug node/<node_name> -- chroot /host sh -c "ip a | grep mtu | grep br-ex"출력 예
Starting pod/worker-1-debug ... To use host binaries, run `chroot /host` # ... 5: br-ex: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000 6: br-ex1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000선택 사항:
/var/lib/ovnk/iface_default_hint를 사용하는 경우br-ex의 MAC 주소가 선택한 기본 인터페이스의 MAC 주소와 일치하는지 확인합니다.$ oc debug node/<node_name> -- chroot /host sh -c "ip a | grep -A1 -E 'br-ex|bond0'br-ex의 기본 인터페이스를bond0으로 표시하는 출력 예Starting pod/worker-1-debug ... To use host binaries, run `chroot /host` # ... sh-5.1# ip a | grep -A1 -E 'br-ex|bond0' 2: bond0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master ovs-system state UP group default qlen 1000 link/ether fa:16:3e:47:99:98 brd ff:ff:ff:ff:ff:ff -- 5: br-ex: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000 link/ether fa:16:3e:47:99:98 brd ff:ff:ff:ff:ff:ff inet 10.xx.xx.xx/21 brd 10.xx.xx.255 scope global dynamic noprefixroute br-ex
7.5.2. Open vSwitch 문제 해결
일부 OVS(Open vSwitch) 문제를 해결하려면 자세한 정보를 포함하도록 로그 수준을 구성해야 할 수 있습니다.
노드에서 로그 수준을 일시적으로 수정하는 경우 다음 예와 같이 노드의 머신 구성 데몬에서 로그 메시지를 받을 수 있습니다.
E0514 12:47:17.998892 2281 daemon.go:1350] content mismatch for file /etc/systemd/system/ovs-vswitchd.service: [Unit]불일치와 관련된 로그 메시지를 방지하려면 문제 해결을 완료한 후 로그 수준 변경 사항을 되돌립니다.
7.5.2.1. 일시적으로 Open vSwitch 로그 수준 구성
단기 문제 해결을 위해 OVS(Open vSwitch) 로그 수준을 일시적으로 구성할 수 있습니다. 다음 절차에 따라 노드를 재부팅할 필요가 없습니다. 또한 노드를 재부팅할 때 마다 구성 변경 사항이 유지되지 않습니다.
이 절차를 수행하여 로그 수준을 변경하면 ovs-vswitchd.service에 대한 콘텐츠 불일치가 있음을 나타내는 머신 구성 데몬에서 로그 메시지를 수신할 수 있습니다. 로그 메시지를 방지하려면 이 절차를 반복하고 로그 수준을 원래 값으로 설정합니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
노드의 디버그 Pod를 시작합니다.
$ oc debug node/<node_name>디버그 쉘 내에서
/host를 root 디렉터리로 설정합니다. 디버그 Pod는 Pod 내의/host에 호스트의 root 파일 시스템을 마운트합니다. root 디렉토리를/host로 변경하면 호스트 파일 시스템에서 바이너리를 실행할 수 있습니다.# chroot /hostOVS 모듈의 현재 syslog 수준을 확인합니다.
# ovs-appctl vlog/list다음 예제 출력은
info로 설정된 syslog의 로그 수준을 보여줍니다.출력 예
console syslog file ------- ------ ------ backtrace OFF INFO INFO bfd OFF INFO INFO bond OFF INFO INFO bridge OFF INFO INFO bundle OFF INFO INFO bundles OFF INFO INFO cfm OFF INFO INFO collectors OFF INFO INFO command_line OFF INFO INFO connmgr OFF INFO INFO conntrack OFF INFO INFO conntrack_tp OFF INFO INFO coverage OFF INFO INFO ct_dpif OFF INFO INFO daemon OFF INFO INFO daemon_unix OFF INFO INFO dns_resolve OFF INFO INFO dpdk OFF INFO INFO .../etc/systemd/system/ovs-vswitchd.service.d/10-ovs-vswitchd-restart.conf파일에서 로그 수준을 지정합니다.Restart=always ExecStartPre=-/bin/sh -c '/usr/bin/chown -R :$${OVS_USER_ID##*:} /var/lib/openvswitch' ExecStartPre=-/bin/sh -c '/usr/bin/chown -R :$${OVS_USER_ID##*:} /etc/openvswitch' ExecStartPre=-/bin/sh -c '/usr/bin/chown -R :$${OVS_USER_ID##*:} /run/openvswitch' ExecStartPost=-/usr/bin/ovs-appctl vlog/set syslog:dbg ExecReload=-/usr/bin/ovs-appctl vlog/set syslog:dbg이전 예에서 로그 수준은
dbg로 설정됩니다.syslog:<log_level>을off,emer,err,warn,info또는dbg로 설정하여 마지막 두 행을 변경합니다.off로그 수준은 모든 로그 메시지를 필터링합니다.서비스를 다시 시작하십시오.
# systemctl daemon-reload# systemctl restart ovs-vswitchd
7.5.2.2. 영구적으로 Open vSwitch 로그 수준 구성
OVS(Open vSwitch) 로그 수준을 장기적으로 변경할 경우 로그 수준을 영구적으로 변경할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
다음 예제와 같은
MachineConfig오브젝트를 사용하여99-change-ovs-loglevel.yaml과 같은 파일을 생성합니다.apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master1 name: 99-change-ovs-loglevel spec: config: ignition: version: 3.2.0 systemd: units: - dropins: - contents: | [Service] ExecStartPost=-/usr/bin/ovs-appctl vlog/set syslog:dbg2 ExecReload=-/usr/bin/ovs-appctl vlog/set syslog:dbg name: 20-ovs-vswitchd-restart.conf name: ovs-vswitchd.service머신 구성을 적용합니다.
$ oc apply -f 99-change-ovs-loglevel.yaml
7.5.2.3. Open vSwitch 로그 표시
다음 절차에 따라 OVS(Open vSwitch) 로그를 표시합니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
다음 명령 중 하나를 실행합니다.
클러스터 외부에서
oc명령을 사용하여 로그를 표시합니다.$ oc adm node-logs <node_name> -u ovs-vswitchd클러스터의 노드에 로그인한 후 로그를 표시합니다.
# journalctl -b -f -u ovs-vswitchd.service노드에 로그인하는 한 가지 방법은
oc debug node/<node_name>명령을 사용하는 것입니다.
7.6. Operator 문제 해결
Operator는 OpenShift Container Platform 애플리케이션을 패키징, 배포 및 관리하는 방법입니다. Operator는 소프트웨어 공급 업체의 엔지니어링 팀의 확장 기능으로 OpenShift Container Platform 환경을 모니터링하고 현재 상태를 사용하여 실시간으로 의사 결정을 내립니다. Operator는 업그레이드를 원활하게 처리하고 오류 발생에 자동으로 대응하며 시간을 절약하기 위해 소프트웨어 백업 프로세스를 생략하는 것과 같은 바로가기를 실행하지 않습니다.
OpenShift Container Platform 4.16에는 클러스터가 제대로 작동하는 데 필요한 기본 Operator 세트가 포함되어 있습니다. 이러한 기본 운영자는 CVO (Cluster Version Operator)에 의해 관리됩니다.
클러스터 관리자는 OpenShift Container Platform 웹 콘솔 또는 CLI를 사용하여 OperatorHub에서 애플리케이션 Operator를 설치할 수 있습니다. 그런 다음 Operator를 하나 이상의 네임 스페이스에 가입시켜 클러스터의 개발자가 사용할 수 있도록합니다. 애플리케이션 Operator는 OLM (Operator Lifecycle Manager)에서 관리합니다.
Operator 문제가 발생하면 Operator 서브스크립션 상태를 확인하십시오. 클러스터 전체에서 Operator Pod 상태를 확인하고 진단을 위해 Operator 로그를 수집합니다.
7.6.1. Operator 서브스크립션 상태 유형
서브스크립션은 다음 상태 유형을 보고할 수 있습니다.
| 상태 | 설명 |
|---|---|
|
| 해결에 사용되는 일부 또는 모든 카탈로그 소스가 정상 상태가 아닙니다. |
|
| 서브스크립션 설치 계획이 없습니다. |
|
| 서브스크립션 설치 계획이 설치 대기 중입니다. |
|
| 서브스크립션 설치 계획이 실패했습니다. |
|
| 서브스크립션의 종속성 확인에 실패했습니다. |
기본 OpenShift Container Platform 클러스터 Operator는 CVO(Cluster Version Operator)에서 관리하며 Subscription 오브젝트가 없습니다. 애플리케이션 Operator는 OLM(Operator Lifecycle Manager)에서 관리하며 Subscription 오브젝트가 있습니다.
7.6.2. CLI를 사용하여 Operator 서브스크립션 상태 보기
CLI를 사용하여 Operator 서브스크립션 상태를 볼 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
Operator 서브스크립션을 나열합니다.
$ oc get subs -n <operator_namespace>oc describe명령을 사용하여Subscription리소스를 검사합니다.$ oc describe sub <subscription_name> -n <operator_namespace>명령 출력에서 Operator 서브스크립션 조건 유형의 상태에 대한
Conditions섹션을 확인합니다. 다음 예에서 사용 가능한 모든 카탈로그 소스가 정상이므로CatalogSourcesUnhealthy조건 유형의 상태가false입니다.출력 예
Name: cluster-logging Namespace: openshift-logging Labels: operators.coreos.com/cluster-logging.openshift-logging= Annotations: <none> API Version: operators.coreos.com/v1alpha1 Kind: Subscription # ... Conditions: Last Transition Time: 2019-07-29T13:42:57Z Message: all available catalogsources are healthy Reason: AllCatalogSourcesHealthy Status: False Type: CatalogSourcesUnhealthy # ...
기본 OpenShift Container Platform 클러스터 Operator는 CVO(Cluster Version Operator)에서 관리하며 Subscription 오브젝트가 없습니다. 애플리케이션 Operator는 OLM(Operator Lifecycle Manager)에서 관리하며 Subscription 오브젝트가 있습니다.
7.6.3. CLI를 사용하여 Operator 카탈로그 소스 상태 보기
CLI를 사용하여 Operator 카탈로그 소스의 상태를 볼 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
네임스페이스의 카탈로그 소스를 나열합니다. 예를 들어 클러스터 전체 카탈로그 소스에 사용되는
openshift-marketplace네임스페이스를 확인할 수 있습니다.$ oc get catalogsources -n openshift-marketplace출력 예
NAME DISPLAY TYPE PUBLISHER AGE certified-operators Certified Operators grpc Red Hat 55m community-operators Community Operators grpc Red Hat 55m example-catalog Example Catalog grpc Example Org 2m25s redhat-marketplace Red Hat Marketplace grpc Red Hat 55m redhat-operators Red Hat Operators grpc Red Hat 55moc describe명령을 사용하여 카탈로그 소스에 대한 자세한 내용 및 상태를 가져옵니다.$ oc describe catalogsource example-catalog -n openshift-marketplace출력 예
Name: example-catalog Namespace: openshift-marketplace Labels: <none> Annotations: operatorframework.io/managed-by: marketplace-operator target.workload.openshift.io/management: {"effect": "PreferredDuringScheduling"} API Version: operators.coreos.com/v1alpha1 Kind: CatalogSource # ... Status: Connection State: Address: example-catalog.openshift-marketplace.svc:50051 Last Connect: 2021-09-09T17:07:35Z Last Observed State: TRANSIENT_FAILURE Registry Service: Created At: 2021-09-09T17:05:45Z Port: 50051 Protocol: grpc Service Name: example-catalog Service Namespace: openshift-marketplace # ...앞의 예제 출력에서 마지막으로 관찰된 상태는
TRANSIENT_FAILURE입니다. 이 상태는 카탈로그 소스에 대한 연결을 설정하는 데 문제가 있음을 나타냅니다.카탈로그 소스가 생성된 네임스페이스의 Pod를 나열합니다.
$ oc get pods -n openshift-marketplace출력 예
NAME READY STATUS RESTARTS AGE certified-operators-cv9nn 1/1 Running 0 36m community-operators-6v8lp 1/1 Running 0 36m marketplace-operator-86bfc75f9b-jkgbc 1/1 Running 0 42m example-catalog-bwt8z 0/1 ImagePullBackOff 0 3m55s redhat-marketplace-57p8c 1/1 Running 0 36m redhat-operators-smxx8 1/1 Running 0 36m카탈로그 소스가 네임스페이스에 생성되면 해당 네임스페이스에 카탈로그 소스의 Pod가 생성됩니다. 위 예제 출력에서
example-catalog-bwt8zpod의 상태는ImagePullBackOff입니다. 이 상태는 카탈로그 소스의 인덱스 이미지를 가져오는 데 문제가 있음을 나타냅니다.자세한 정보는
oc describe명령을 사용하여 Pod를 검사합니다.$ oc describe pod example-catalog-bwt8z -n openshift-marketplace출력 예
Name: example-catalog-bwt8z Namespace: openshift-marketplace Priority: 0 Node: ci-ln-jyryyg2-f76d1-ggdbq-worker-b-vsxjd/10.0.128.2 ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 48s default-scheduler Successfully assigned openshift-marketplace/example-catalog-bwt8z to ci-ln-jyryyf2-f76d1-fgdbq-worker-b-vsxjd Normal AddedInterface 47s multus Add eth0 [10.131.0.40/23] from openshift-sdn Normal BackOff 20s (x2 over 46s) kubelet Back-off pulling image "quay.io/example-org/example-catalog:v1" Warning Failed 20s (x2 over 46s) kubelet Error: ImagePullBackOff Normal Pulling 8s (x3 over 47s) kubelet Pulling image "quay.io/example-org/example-catalog:v1" Warning Failed 8s (x3 over 47s) kubelet Failed to pull image "quay.io/example-org/example-catalog:v1": rpc error: code = Unknown desc = reading manifest v1 in quay.io/example-org/example-catalog: unauthorized: access to the requested resource is not authorized Warning Failed 8s (x3 over 47s) kubelet Error: ErrImagePull앞의 예제 출력에서 오류 메시지는 권한 부여 문제로 인해 카탈로그 소스의 인덱스 이미지를 성공적으로 가져오지 못한 것으로 표시됩니다. 예를 들어 인덱스 이미지는 로그인 인증 정보가 필요한 레지스트리에 저장할 수 있습니다.
7.6.4. Operator Pod 상태 쿼리
클러스터 내의 Operator Pod 및 해당 상태를 나열할 수 있습니다. 자세한 Operator Pod 요약을 수집할 수도 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. - API 서비스가 작동하고 있어야 합니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
클러스터에서 실행중인 Operator를 나열합니다. 출력에는 Operator 버전, 가용성 및 가동 시간 정보가 포함됩니다.
$ oc get clusteroperatorsOperator의 네임스페이스에서 실행 중인 Operator Pod와 Pod 상태, 재시작, 경과 시간을 표시합니다.
$ oc get pod -n <operator_namespace>자세한 Operator Pod 요약을 출력합니다.
$ oc describe pod <operator_pod_name> -n <operator_namespace>Operator 문제가 노드와 관련된 경우 해당 노드에서 Operator 컨테이너 상태를 쿼리합니다.
노드의 디버그 Pod를 시작합니다.
$ oc debug node/my-node디버그 쉘 내에서
/host를 root 디렉터리로 설정합니다. 디버그 Pod는 Pod 내의/host에 호스트의 루트 파일 시스템을 마운트합니다. root 디렉토리를/host로 변경하면 호스트의 실행 경로에 포함된 바이너리를 실행할 수 있습니다.# chroot /host참고RHCOS(Red Hat Enterprise Linux CoreOS)를 실행하는 OpenShift Container Platform 4.16 클러스터 노드는 변경할 수 없으며 Operator를 사용하여 클러스터 변경 사항을 적용합니다. SSH를 사용하여 클러스터 노드에 액세스하는 것은 권장되지 않습니다. 그러나 OpenShift Container Platform API를 사용할 수 없거나 kubelet이 대상 노드에서 제대로 작동하지 않는 경우
oc작업이 영향을 받습니다. 이러한 상황에서 대신ssh core @ <node>.<cluster_name>.<base_domain>을 사용하여 노드에 액세스할 수 있습니다.상태 및 관련 Pod ID를 포함하여 노드의 컨테이너에 대한 세부 정보를 나열합니다.
# crictl ps노드의 특정 Operator 컨테이너에 대한 정보를 나열합니다. 다음 예는
network-operator컨테이너에 대한 정보를 나열합니다.# crictl ps --name network-operator- 디버그 쉘을 종료합니다.
7.6.5. Operator 로그 수집
Operator 문제가 발생하면 Operator Pod 로그에서 자세한 진단 정보를 수집할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. - API 서비스가 작동하고 있어야 합니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다. - 컨트롤 플레인 또는 컨트롤 플레인 시스템의 정규화된 도메인 이름이 있어야 합니다.
프로세스
Operator의 네임스페이스에서 실행 중인 Operator Pod와 Pod 상태, 재시작, 경과 시간을 표시합니다.
$ oc get pods -n <operator_namespace>Operator Pod의 로그를 검토합니다.
$ oc logs pod/<pod_name> -n <operator_namespace>Operator Pod에 컨테이너가 여러 개 있는 경우 위 명령에 의해 각 컨테이너의 이름이 포함된 오류가 생성됩니다. 개별 컨테이너의 로그를 쿼리합니다.
$ oc logs pod/<operator_pod_name> -c <container_name> -n <operator_namespace>API가 작동하지 않는 경우 대신 SSH를 사용하여 각 컨트롤 플레인 노드에서 Operator Pod 및 컨테이너 로그를 검토합니다.
<master-node>.<cluster_name>.<base_domain>을 적절한 값으로 바꿉니다.각 컨트롤 플레인 노드에 Pod를 나열합니다.
$ ssh core@<master-node>.<cluster_name>.<base_domain> sudo crictl podsReady상태가 표시되지 않는 Operator Pod의 경우 Pod 상태를 자세히 검사합니다.<operator_pod_id>를 이전 명령의 출력에 나열된 Operator Pod의 ID로 교체합니다.$ ssh core@<master-node>.<cluster_name>.<base_domain> sudo crictl inspectp <operator_pod_id>Operator Pod와 관련된 컨테이너를 나열합니다.
$ ssh core@<master-node>.<cluster_name>.<base_domain> sudo crictl ps --pod=<operator_pod_id>Ready상태가 표시되지 않는 Operator 컨테이너의 경우 컨테이너 상태를 자세히 검사합니다.<container_id>를 이전 명령의 출력에 나열된 컨테이너 ID로 바꿉니다.$ ssh core@<master-node>.<cluster_name>.<base_domain> sudo crictl inspect <container_id>Ready상태가 표시되지 않는 Operator 컨테이너의 로그를 확인합니다.<container_id>를 이전 명령의 출력에 나열된 컨테이너 ID로 바꿉니다.$ ssh core@<master-node>.<cluster_name>.<base_domain> sudo crictl logs -f <container_id>참고RHCOS(Red Hat Enterprise Linux CoreOS)를 실행하는 OpenShift Container Platform 4.16 클러스터 노드는 변경할 수 없으며 Operator를 사용하여 클러스터 변경 사항을 적용합니다. SSH를 사용하여 클러스터 노드에 액세스하는 것은 권장되지 않습니다. SSH를 통해 진단 데이터를 수집하기 전에
oc adm must gather및 기타oc명령을 실행하여 충분한 데이터를 수집할 수 있는지 확인하십시오. 그러나 OpenShift Container Platform API를 사용할 수 없거나 kubelet이 대상 노드에서 제대로 작동하지 않는 경우oc작업이 영향을 받습니다. 이러한 상황에서ssh core@<node>.<cluster_name>.<base_domain>을 사용하여 노드에 액세스할 수 있습니다.
7.6.6. Machine Config Operator가 자동으로 재부팅되지 않도록 비활성화
Machine Config Operator(MCO)에서 구성을 변경한 경우 변경 사항을 적용하려면 RHCOS(Red Hat Enterprise Linux CoreOS)를 재부팅해야 합니다. 구성 변경이 자동이든 수동이든 RHCOS 노드는 일시 중지되지 않는 한 자동으로 재부팅됩니다.
MCO가 다음 변경 사항을 감지하면 노드를 드레이닝하거나 재부팅하지 않고 업데이트를 적용합니다.
-
머신 구성의
spec.config.passwd.users.sshAuthorizedKeys매개변수에서 SSH 키 변경 -
openshift-config네임 스페이스에서 글로벌 풀 시크릿 또는 풀 시크릿 관련 변경 사항 -
Kubernetes API Server Operator의
/etc/kubernetes/kubelet-ca.crt인증 기관(CA) 자동 교체
-
머신 구성의
MCO가
ImageDigestMirrorSet,ImageTagMirrorSet또는ImageContentSourcePolicy개체 편집과 같은/etc/containers/registries.conf파일의 변경을 감지하면 해당 노드를 비우고 변경 사항을 적용한 다음 노드를 분리합니다. 다음 변경에는 노드 드레이닝이 발생하지 않습니다.-
각 미러에 대해 설정된
pull-from-mirror = "digest-only"매개변수를 사용하여 레지스트리를 추가합니다. -
레지스트리에 설정된
pull-from-mirror = "digest-only"매개변수를 사용하여 미러를 추가합니다. -
unqualified-search-registries목록에 항목이 추가되었습니다.
-
각 미러에 대해 설정된
원치 않는 중단을 방지하기 위해 Operator에서 머신 구성을 변경한 후 자동 재부팅되지 않도록 머신 구성 풀(MCP)을 수정할 수 있습니다.
7.6.6.1. 콘솔을 사용하여 Machine Config Operator가 자동으로 재부팅되지 않도록 비활성화
MCO(Machine Config Operator)에서 원하지 않는 변경을 방지하기 위해 OpenShift Container Platform 웹 콘솔을 사용하여 MCO가 해당 풀의 노드를 변경하지 않도록 MCP(머신 구성 풀)를 수정할 수 있습니다. 이렇게 하면 일반적으로 MCO 업데이트 프로세스의 일부인 재부팅을 방지할 수 있습니다.
Machine Config Operator가 자동으로 재부팅되지 않도록 설정할 때 두 번째 참고 사항을 참조하십시오.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다.
프로세스
자동 MCO 업데이트 재부팅을 일시 중지하거나 일시 중지 해제하려면 다음을 수행합니다.
자동 재부팅 프로세스를 일시 중지합니다.
-
cluster-admin역할의 사용자로 OpenShift Container Platform 웹 콘솔에 로그인합니다. - 컴퓨팅 → MachineConfigPools 를 클릭합니다.
- MachineConfigPools 페이지에서 재부팅을 일시 정지하려는 노드에 따라 마스터 또는 작업자 를 클릭합니다.
- 마스터 또는 작업자 페이지에서 YAML을 클릭합니다.
YAML에서
spec.paused필드를true로 업데이트합니다.샘플 MachineConfigPool 오브젝트
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool # ... spec: # ... paused: true1 # ...- 1
spec.paused필드를true로 업데이트하여 재부팅을 일시 중지합니다.
MCP가 일시 중지되었는지 확인하려면 MachineConfigPools 페이지로 돌아갑니다.
MachineConfigPools 페이지에서 일시 중지된 열에 수정한 MCP에 대해 True 가 보고됩니다.
일시 중지된 동안 MCP에 보류 중인 변경 사항이 있는 경우 Updated 열은 False이고 Updating 열은 False입니다. Updated이 True이고 Updating이 False인 경우 보류 중인 변경 사항이 없습니다.
중요Updated 및 Updating 열이 모두 False인 보류 중인 변경 사항이 있는 경우 최대한 빨리 재부팅할 수 있도록 유지 관리 기간을 예약하는 것이 좋습니다. 자동 재부팅 프로세스를 일시 중지 해제하려면 다음 단계를 사용하여 마지막 재부팅 이후 대기열에 있는 변경 사항을 적용합니다.
-
자동 재부팅 프로세스의 일시 중지를 해제합니다.
-
cluster-admin역할의 사용자로 OpenShift Container Platform 웹 콘솔에 로그인합니다. - 컴퓨팅 → MachineConfigPools 를 클릭합니다.
- MachineConfigPools 페이지에서 재부팅을 일시 정지하려는 노드에 따라 마스터 또는 작업자 를 클릭합니다.
- 마스터 또는 작업자 페이지에서 YAML을 클릭합니다.
YAML에서
spec.paused필드를false로 업데이트합니다.샘플 MachineConfigPool 오브젝트
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool # ... spec: # ... paused: false1 # ...- 1
- 재부팅을 허용하도록
spec.paused필드를false로 업데이트합니다.
참고MCP의 일시 정지를 해제하면 MCO는 모든 일시 중지된 변경 사항이 필요에 따라 RHCOS(Red Hat Enterprise Linux CoreOS) 재부팅을 적용합니다.
MCP가 일시 중지되었는지 확인하려면 MachineConfigPools 페이지로 돌아갑니다.
MachineConfigPools 페이지에서 일시 중지된 열에 수정한 MCP에 대해 False 를 보고합니다.
MCP가 보류 중인 변경 사항을 적용하는 경우 Updated 열은 False이고 Updating인 열은 True입니다. 업데이트됨이 True이고 업데이트 중이 False인 경우 추가 변경 사항이 적용되지 않습니다.
-
7.6.6.2. CLI를 사용하여 Machine Config Operator가 자동으로 재부팅되지 않도록 비활성화
MCO(Machine Config Operator)의 변경으로 인한 원치 않는 중단을 방지하려면 OpenShift CLI(oc)를 사용하여 MCP(Machine Config Pool)를 수정하여 MCO가 해당 풀의 노드를 변경하지 못하도록 할 수 있습니다. 이렇게 하면 일반적으로 MCO 업데이트 프로세스의 일부인 재부팅을 방지할 수 있습니다.
Machine Config Operator가 자동으로 재부팅되지 않도록 설정할 때 두 번째 참고 사항을 참조하십시오.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
자동 MCO 업데이트 재부팅을 일시 중지하거나 일시 중지 해제하려면 다음을 수행합니다.
자동 재부팅 프로세스를 일시 중지합니다.
MachineConfigPool사용자 정의 리소스를 업데이트하여spec.paused필드를true로 설정합니다.컨트롤 플레인 (마스터) 노드
$ oc patch --type=merge --patch='{"spec":{"paused":true}}' machineconfigpool/master작업자 노드
$ oc patch --type=merge --patch='{"spec":{"paused":true}}' machineconfigpool/workerMCP가 일시 중지되었는지 확인합니다.
컨트롤 플레인 (마스터) 노드
$ oc get machineconfigpool/master --template='{{.spec.paused}}'작업자 노드
$ oc get machineconfigpool/worker --template='{{.spec.paused}}'출력 예
truespec.paused필드가true이고 MCP가 일시 중지되었습니다.MCP에 보류 중인 변경 사항이 있는지 확인합니다.
# oc get machineconfigpool출력 예
NAME CONFIG UPDATED UPDATING master rendered-master-33cf0a1254318755d7b48002c597bf91 True False worker rendered-worker-e405a5bdb0db1295acea08bcca33fa60 False FalseUPDATED 열이 False이고 UPDATING이 False이면 보류 중인 변경 사항이 있습니다. UPDATED가 True이고 UPDATING이 False인 경우 보류 중인 변경 사항이 없습니다. 이전 예에서 작업자 노드에 보류 중인 변경 사항이 있습니다. 컨트롤 플레인 노드에는 보류 중인 변경 사항이 없습니다.
중요Updated 및 Updating 열이 모두 False인 보류 중인 변경 사항이 있는 경우 최대한 빨리 재부팅할 수 있도록 유지 관리 기간을 예약하는 것이 좋습니다. 자동 재부팅 프로세스를 일시 중지 해제하려면 다음 단계를 사용하여 마지막 재부팅 이후 대기열에 있는 변경 사항을 적용합니다.
자동 재부팅 프로세스의 일시 중지를 해제합니다.
MachineConfigPool사용자 정의 리소스에서spec.paused필드를false로 업데이트합니다.컨트롤 플레인 (마스터) 노드
$ oc patch --type=merge --patch='{"spec":{"paused":false}}' machineconfigpool/master작업자 노드
$ oc patch --type=merge --patch='{"spec":{"paused":false}}' machineconfigpool/worker참고MCP의 일시 정지를 해제하면 MCO는 일시 중지된 모든 변경 사항을 적용하고 필요에 따라 RHCOS(Red Hat Enterprise Linux CoreOS)를 재부팅합니다.
MCP가 일시 중지되지 않았는지 확인합니다.
컨트롤 플레인 (마스터) 노드
$ oc get machineconfigpool/master --template='{{.spec.paused}}'작업자 노드
$ oc get machineconfigpool/worker --template='{{.spec.paused}}'출력 예
falsespec.paused필드가false이고 MCP가 일시 중지되지 않습니다.MCP에 보류 중인 변경 사항이 있는지 확인합니다.
$ oc get machineconfigpool출력 예
NAME CONFIG UPDATED UPDATING master rendered-master-546383f80705bd5aeaba93 True False worker rendered-worker-b4c51bb33ccaae6fc4a6a5 False TrueMCP에서 보류 중인 변경 사항을 적용하는 경우 UPDATED 열은 False이고 UPDATING 열은 True입니다. UPDATED가 True이고 UPDATING이 False이면 추가 변경 사항이 없습니다. 이전 예에서 MCO는 작업자 노드를 업데이트하고 있습니다.
7.6.7. 실패한 서브스크립션 새로 고침
OLM(Operator Lifecycle Manager)에서는 네트워크상에서 액세스할 수 없는 이미지를 참조하는 Operator를 구독하는 경우 openshift-marketplace 네임스페이스에 다음 오류로 인해 실패하는 작업을 확인할 수 있습니다.
출력 예
ImagePullBackOff for
Back-off pulling image "example.com/openshift4/ose-elasticsearch-operator-bundle@sha256:6d2587129c846ec28d384540322b40b05833e7e00b25cca584e004af9a1d292e"출력 예
rpc error: code = Unknown desc = error pinging docker registry example.com: Get "https://example.com/v2/": dial tcp: lookup example.com on 10.0.0.1:53: no such host결과적으로 서브스크립션이 이러한 장애 상태에 고착되어 Operator를 설치하거나 업그레이드할 수 없습니다.
서브스크립션, CSV(클러스터 서비스 버전) 및 기타 관련 오브젝트를 삭제하여 실패한 서브스크립션을 새로 고칠 수 있습니다. 서브스크립션을 다시 생성하면 OLM에서 올바른 버전의 Operator를 다시 설치합니다.
사전 요구 사항
- 액세스할 수 없는 번들 이미지를 가져올 수 없는 실패한 서브스크립션이 있습니다.
- 올바른 번들 이미지에 액세스할 수 있는지 확인했습니다.
프로세스
Operator가 설치된 네임스페이스에서
Subscription및ClusterServiceVersion오브젝트의 이름을 가져옵니다.$ oc get sub,csv -n <namespace>출력 예
NAME PACKAGE SOURCE CHANNEL subscription.operators.coreos.com/elasticsearch-operator elasticsearch-operator redhat-operators 5.0 NAME DISPLAY VERSION REPLACES PHASE clusterserviceversion.operators.coreos.com/elasticsearch-operator.5.0.0-65 OpenShift Elasticsearch Operator 5.0.0-65 Succeeded서브스크립션을 삭제합니다.
$ oc delete subscription <subscription_name> -n <namespace>클러스터 서비스 버전을 삭제합니다.
$ oc delete csv <csv_name> -n <namespace>openshift-marketplace네임스페이스에서 실패한 모든 작업 및 관련 구성 맵의 이름을 가져옵니다.$ oc get job,configmap -n openshift-marketplace출력 예
NAME COMPLETIONS DURATION AGE job.batch/1de9443b6324e629ddf31fed0a853a121275806170e34c926d69e53a7fcbccb 1/1 26s 9m30s NAME DATA AGE configmap/1de9443b6324e629ddf31fed0a853a121275806170e34c926d69e53a7fcbccb 3 9m30s작업을 삭제합니다.
$ oc delete job <job_name> -n openshift-marketplace이렇게 하면 액세스할 수 없는 이미지를 가져오려는 Pod가 다시 생성되지 않습니다.
구성 맵을 삭제합니다.
$ oc delete configmap <configmap_name> -n openshift-marketplace- 웹 콘솔에서 OperatorHub를 사용하여 Operator를 다시 설치합니다.
검증
Operator가 제대로 다시 설치되었는지 확인합니다.
$ oc get sub,csv,installplan -n <namespace>
7.6.8. 실패한 제거 후 Operator 다시 설치
동일한 Operator를 다시 설치하기 전에 Operator를 성공적으로 제거하고 완전히 제거해야 합니다. Operator를 완전히 제거하지 못하면 프로젝트 또는 네임스페이스와 같은 리소스가 "종료 중" 상태에 고정되어 "리소스 해결 오류" 메시지가 나타날 수 있습니다. 예를 들면 다음과 같습니다.
Project 리소스 설명의 예
...
message: 'Failed to delete all resource types, 1 remaining: Internal error occurred:
error resolving resource'
...이러한 유형의 문제로 인해 Operator가 다시 설치되지 않을 수 있습니다.
네임스페이스를 강제로 삭제해도 "종료 중" 상태 문제가 해결되지 않고 불안정하거나 예측할 수 없는 클러스터 동작이 발생할 수 있으므로 네임스페이스 삭제를 방해할 수 있는 관련 리소스를 찾는 것이 좋습니다. 자세한 내용은 Red Hat Knowledgebase Solution #4165791 을 참조하십시오.
다음 절차에서는 이전 Operator 설치의 기존 CRD(사용자 정의 리소스 정의)에서 관련 네임스페이스가 삭제되지 않기 때문에 Operator를 다시 설치할 수 없는 경우 문제를 해결하는 방법을 보여줍니다.
프로세스
"종료 중" 상태로 중단된 Operator와 관련된 네임스페이스가 있는지 확인합니다.
$ oc get namespaces출력 예
operator-ns-1 Terminating실패한 제거 후에도 여전히 존재하는 Operator와 관련된 CRD가 있는지 확인합니다.
$ oc get crds참고CRD는 글로벌 클러스터 정의입니다. CRD와 관련된 실제 CR(사용자 정의 리소스) 인스턴스는 다른 네임스페이스에 있거나 글로벌 클러스터 인스턴스일 수 있습니다.
Operator에서 제공하거나 관리하는 CRD가 있고 제거 후 삭제해야 하는 CRD가 있는 경우 CRD를 삭제합니다.
$ oc delete crd <crd_name>제거 후에도 여전히 존재하는 Operator와 관련된 나머지 CR 인스턴스가 있는지 확인하고 CR을 삭제합니다.
검색할 CR 유형은 제거 후 결정하기 어려울 수 있으며 Operator에서 관리하는 CRD를 알아야 할 수 있습니다. 예를 들어
EtcdClusterCRD를 제공하는 etcd Operator의 설치 제거 문제를 해결하는 경우 네임스페이스에서 나머지EtcdClusterCR을 검색할 수 있습니다.$ oc get EtcdCluster -n <namespace_name>또는 모든 네임스페이스에서 검색할 수 있습니다.
$ oc get EtcdCluster --all-namespaces제거해야 하는 나머지 CR이 있는 경우 인스턴스를 삭제합니다.
$ oc delete <cr_name> <cr_instance_name> -n <namespace_name>
네임스페이스 삭제가 성공적으로 해결되었는지 확인합니다.
$ oc get namespace <namespace_name>중요네임스페이스 또는 기타 Operator 리소스가 여전히 제거되지 않은 경우 Red Hat 지원팀에 문의하십시오.
- 웹 콘솔에서 OperatorHub를 사용하여 Operator를 다시 설치합니다.
검증
Operator가 제대로 다시 설치되었는지 확인합니다.
$ oc get sub,csv,installplan -n <namespace>
7.7. Pod 문제 조사
OpenShift Container Platform은 호스트에 함께 배포되는 하나 이상의 컨테이너인 Pod의 Kubernetes 개념을 활용합니다. Pod는 OpenShift Container Platform 4.16에서 정의, 배포 및 관리할 수 있는 최소 컴퓨팅 단위입니다.
Pod가 정의되면 컨테이너가 종료될 때까지 또는 제거될 때까지 노드에서 실행되도록 할당됩니다. 정책 및 종료 코드에 따라 Pod는 종료 후 제거되거나 해당 로그에 액세스할 수 있도록 유지됩니다.
Pod 문제 발생 시 가장 먼저 Pod의 상태를 확인합니다. Pod의 명시적인 오류가 발생한 경우에는 Pod의 오류 상태를 확인하여 특정 이미지, 컨테이너 또는 Pod 네트워크 문제를 파악합니다. 오류 상태에 따라 진단 데이터를 수집합니다. Pod 이벤트 메시지와 Pod 및 컨테이너 로그 정보를 확인합니다. 명령줄에서 실행 중인 Pod에 액세스하여 문제를 동적으로 진단하거나 문제가 있는 Pod의 배포 구성을 기반으로 루트 액세스 권한으로 디버그 Pod를 시작합니다.
7.7.1. Pod 오류 상태 이해
Pod에서 오류가 발생하면 명시적 오류 상태를 반환하며 oc get Pods 출력의 status 필드에서 확인할 수 있습니다. Pod 오류 상태에는 이미지, 컨테이너 및 컨테이너 네트워크 관련 오류가 포함됩니다.
다음 표에는 Pod 오류 상태 및 설명이 기재되어 있습니다.
| Pod 오류 상태 | 설명 |
|---|---|
|
| 일반 이미지 검색 오류입니다. |
|
| 이미지 검색에 실패하여 백 오프되었습니다. |
|
| 지정된 이미지 이름이 잘못되었습니다. |
|
| 이미지 검사에 실패했습니다. |
|
|
|
|
| 레지스트리에서 이미지 검색을 시도할 때 HTTP 오류가 발생했습니다. |
|
| 지정된 컨테이너가 선언된 Pod에 존재하지 않거나 kubelet에 의해 관리되지 않습니다. |
|
| 컨테이너 초기화에 실패했습니다. |
|
| Pod의 컨테이너가 정상적으로 시작되지 않았습니다. |
|
| Pod의 컨테이너가 정상적으로 종료되지 않았습니다. |
|
| 컨테이너가 종료되었습니다. kubelet은 재시작을 시도하지 않습니다. |
|
| 컨테이너 또는 이미지가 root 권한으로 실행하려고 했습니다. |
|
| Pod 샌드 박스 생성에 실패했습니다. |
|
| Pod 샌드 박스 구성을 가져오지 못했습니다. |
|
| Pod의 샌드박스가 정상적으로 중지되지 않았습니다. |
|
| 네트워크 초기화에 실패했습니다. |
|
| 네트워크 종료에 실패했습니다. |
7.7.2. Pod 상태 검토
Pod 상태 및 오류 상태를 쿼리할 수 있습니다. Pod의 관련 배포 구성을 쿼리하고 기본 이미지 가용성을 검토할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다. -
skopeo가 설치되어 있어야 합니다.
프로세스
프로젝트로 전환합니다.
$ oc project <project_name>네임스페이스 내에서 실행 중인 Pod와 Pod 상태, 오류 상태, 재시작, 경과 시간을 표시합니다.
$ oc get pods네임 스페이스가 배포 구성에 의해 관리되는지 확인합니다.
$ oc status네임 스페이스가 배포 구성으로 관리되는 경우 출력에 배포 구성 이름과 기본 이미지 참조가 포함됩니다.
이전 명령의 출력에서 참조되는 기본 이미지를 검사합니다.
$ skopeo inspect docker://<image_reference>기본 이미지 참조가 올바르지 않으면 배치 구성에서 참조를 업데이트합니다.
$ oc edit deployment/my-deployment배포 구성이 완료된 후 변경되면 구성이 자동으로 다시 배포됩니다. 배포가 진행되는 동안 Pod 상태를 확인하여 문제가 해결되었는지 확인합니다.
$ oc get pods -wPod 실패와 관련된 진단 정보를 보려면 네임스페이스 내의 이벤트를 검토합니다.
$ oc get events
7.7.3. Pod 및 컨테이너 로그 검사
Pod 및 컨테이너 로그에서 명시적 Pod 실패와 관련된 경고 및 오류 메시지를 검사할 수 있습니다. 정책 및 종료 코드에 따라 Pod가 종료된 후에도 Pod 및 컨테이너 로그를 계속 사용할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. - API 서비스가 작동하고 있어야 합니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
특정 Pod의 로그를 쿼리합니다.
$ oc logs <pod_name>Pod에서 특정 컨테이너의 로그를 쿼리합니다.
$ oc logs <pod_name> -c <container_name>이전
oc logs명령을 사용하여 검색된 로그는 Pod 또는 컨테이너 내에서 stdout으로 전송된 메시지로 구성됩니다.Pod에서
/var/log/에 포함된 로그를 검사합니다.Pod에서
/var/log에 포함된 로그 파일 및 하위 디렉터리를 나열합니다.$ oc exec <pod_name> -- ls -alh /var/log출력 예
total 124K drwxr-xr-x. 1 root root 33 Aug 11 11:23 . drwxr-xr-x. 1 root root 28 Sep 6 2022 .. -rw-rw----. 1 root utmp 0 Jul 10 10:31 btmp -rw-r--r--. 1 root root 33K Jul 17 10:07 dnf.librepo.log -rw-r--r--. 1 root root 69K Jul 17 10:07 dnf.log -rw-r--r--. 1 root root 8.8K Jul 17 10:07 dnf.rpm.log -rw-r--r--. 1 root root 480 Jul 17 10:07 hawkey.log -rw-rw-r--. 1 root utmp 0 Jul 10 10:31 lastlog drwx------. 2 root root 23 Aug 11 11:14 openshift-apiserver drwx------. 2 root root 6 Jul 10 10:31 private drwxr-xr-x. 1 root root 22 Mar 9 08:05 rhsm -rw-rw-r--. 1 root utmp 0 Jul 10 10:31 wtmpPod에서
/var/log에 포함된 특정 로그 파일을 쿼리합니다.$ oc exec <pod_name> cat /var/log/<path_to_log>출력 예
2023-07-10T10:29:38+0000 INFO --- logging initialized --- 2023-07-10T10:29:38+0000 DDEBUG timer: config: 13 ms 2023-07-10T10:29:38+0000 DEBUG Loaded plugins: builddep, changelog, config-manager, copr, debug, debuginfo-install, download, generate_completion_cache, groups-manager, needs-restarting, playground, product-id, repoclosure, repodiff, repograph, repomanage, reposync, subscription-manager, uploadprofile 2023-07-10T10:29:38+0000 INFO Updating Subscription Management repositories. 2023-07-10T10:29:38+0000 INFO Unable to read consumer identity 2023-07-10T10:29:38+0000 INFO Subscription Manager is operating in container mode. 2023-07-10T10:29:38+0000 INFO특정 컨테이너의
/var/log에 포함된 로그 파일 및 하위 디렉토리를 나열합니다.$ oc exec <pod_name> -c <container_name> ls /var/log특정 컨테이너의
/var/log에 포함된 특정 로그 파일을 쿼리합니다.$ oc exec <pod_name> -c <container_name> cat /var/log/<path_to_log>
7.7.4. 실행 중인 Pod에 액세스
Pod 내에서 쉘을 열거나 포트 전달을 통해 네트워크 액세스 권한을 취득하여 실행 중인 Pod를 동적으로 확인할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. - API 서비스가 작동하고 있어야 합니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
액세스하려는 Pod가 포함된 프로젝트로 전환합니다. 이는
oc rsh명령이-nnamespace 옵션을 허용하지 않기 때문에 필요합니다.$ oc project <namespace>Pod에서 원격 쉘을 시작합니다.
$ oc rsh <pod_name>1 - 1
- Pod에 컨테이너가 여러 개 있는 경우
-c <container_name>을 지정하지 않으면oc rsh는 첫 번째 컨테이너로 기본 설정됩니다.
Pod에서 특정 컨테이너로 원격 쉘을 시작합니다.
$ oc rsh -c <container_name> pod/<pod_name>Pod에서 포트로의 포트 전달 세션을 만듭니다.
$ oc port-forward <pod_name> <host_port>:<pod_port>1 - 1
Ctrl+C를 입력하여 포트 전달 세션을 취소합니다.
7.7.5. 루트 액세스 권한으로 디버그 Pod 시작
문제가 있는 Pod 배포 또는 배포 구성에 따라 루트 액세스 권한으로 디버그 Pod를 시작할 수 있습니다. 일반적으로 Pod 사용자는 루트가 아닌 권한으로 실행되지만 임시 루트 권한으로 문제 해결 Pod를 실행하면 문제 해결에 유용할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. - API 서비스가 작동하고 있어야 합니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
배포에 따라 루트 액세스 권한으로 디버그 Pod를 시작합니다.
프로젝트의 배포 이름을 가져옵니다.
$ oc get deployment -n <project_name>배포에 따라 루트 권한으로 디버그 Pod를 시작합니다.
$ oc debug deployment/my-deployment --as-root -n <project_name>
배포 구성에 따라 루트 액세스 권한으로 디버그 Pod를 시작합니다.
프로젝트의 배포 구성 이름을 가져옵니다.
$ oc get deploymentconfigs -n <project_name>배포 구성에 따라 루트 권한으로 디버그 Pod를 시작합니다.
$ oc debug deploymentconfig/my-deployment-configuration --as-root -n <project_name>
대화형 쉘을 실행하는 대신 -<command>를 이전 oc debug 명령에 추가하여 디버그 Pod 내에서 개별 명령을 실행할 수 있습니다.
7.7.6. Pod 및 컨테이너 간 파일 복사
Pod 간에 파일을 복사하여 구성 변경을 테스트하거나 진단 정보를 수집할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. - API 서비스가 작동하고 있어야 합니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다.
7.8. Source-to-Image 프로세스 문제 해결
7.8.1. Source-to-Image 문제 해결을 위한 전략
Source-to-Image (S2I)를 사용하여 재현 가능한 Docker 형식의 컨테이너 이미지를 빌드합니다. 컨테이너 이미지에 애플리케이션 소스 코드를 삽입하고 새 이미지를 어셈블하여 바로 실행할 수있는 이미지를 만들 수 있습니다. 새 이미지는 기본 이미지 (빌더)와 빌드된 소스를 결합합니다.
프로세스
S2I 프로세스에서 오류가 발생한 위치를 확인하기 위해 다음 S2I 단계 관련 Pod의 상태를 확인할 수 있습니다.
- 빌드 구성 단계에서 빌드 Pod는 기본 이미지 및 애플리케이션 소스 코드에서 애플리케이션 컨테이너 이미지를 만드는 데 사용됩니다.
- 배포 구성 단계에서 배포 Pod는 빌드 구성 단계에서 빌드된 애플리케이션 컨테이너 이미지에서 애플리케이션 Pod를 배포하는 데 사용됩니다. 배포 Pod는 서비스 및 경로와 같은 다른 리소스도 배포합니다. 배포 구성은 빌드 구성이 성공한 후에 시작됩니다.
-
배포 Pod에서 애플리케이션 Pod를 시작한 후 실행 중인 애플리케이션 Pod 내에서 애플리케이션 오류가 발생할 수 있습니다. 예를 들어 애플리케이션 Pod가
Running상태인 경우에도 애플리케이션이 예상대로 작동하지 않을 수 있습니다. 이 시나리오에서는 실행 중인 애플리케이션 Pod에 액세스하여 Pod 내의 애플리케이션 오류를 조사할 수 있습니다.
S2I 문제를 해결할 때 다음 전략을 따르십시오.
- 빌드, 배포 및 애플리케이션 Pod 상태를 모니터링합니다.
- 문제가 발생한 S2I 프로세스의 단계를 확인합니다.
- 실패한 단계에 해당하는 로그를 검토합니다.
7.8.2. Source-to-Image 진단 데이터 수집
S2I 툴은 빌드 Pod와 배포 Pod를 순서대로 실행합니다. 배포 Pod는 빌드 단계에서 생성된 애플리케이션 컨테이너 이미지를 기반으로 애플리케이션 Pod를 배포합니다. 빌드, 배포 및 애플리케이션 Pod 상태를 모니터링하여 S2I 프로세스에서 오류가 발생하는 위치를 확인합니다. 다음은 이에 따라 진단 데이터를 수집합니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. - API 서비스가 작동하고 있어야 합니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
S2I 프로세스 전체에서 Pod의 상태를 확인하고 오류가 발생하는 단계를 확인합니다.
$ oc get pods -w1 - 1
Ctrl+C를 사용하여 명령을 종료할 때까지-w를 사용하여 Pod의 변경 사항을 모니터링합니다.
실패한 Pod 로그에서 오류가 있는지 확인합니다.
빌드 Pod가 실패하면 빌드 Pod의 로그를 검토합니다.
$ oc logs -f pod/<application_name>-<build_number>-build참고또는
oc logs -f bc/<application_name>을 사용하여 빌드 구성의 로그를 확인할 수 있습니다. 빌드 구성의 로그에는 빌드 Pod의 로그가 포함됩니다.배포 Pod가 실패하면 배포 Pod의 로그를 검토합니다.
$ oc logs -f pod/<application_name>-<build_number>-deploy참고또는
oc logs -f dc/<application_name>을 사용하여 배포 구성의 로그를 확인할 수 있습니다. 이렇게 하면 배포 Pod가 성공적으로 완료될 때까지 배포 Pod의 로그가 출력됩니다. 이 명령을 배포 Pod가 완료된 후 실행하면 애플리케이션 Pod에서 로그를 출력합니다. 배포 Pod가 완료된 후에도oc logs -f pod/<application_name>-<build_number>-deploy를 실행하여 로그에 계속 액세스할 수 있습니다.애플리케이션 Pod가 실패하거나 애플리케이션이 실행 중인 애플리케이션 Pod 내에서 예상대로 작동하지 않으면 애플리케이션 Pod의 로그를 확인합니다.
$ oc logs -f pod/<application_name>-<build_number>-<random_string>
7.8.3. 애플리케이션 오류 조사를 위한 애플리케이션 진단 데이터 수집
실행 중인 애플리케이션 Pod 내에서 애플리케이션 오류가 발생할 수 있습니다. 이러한 상태에서 다음 전략을 사용하여 진단 정보를 검색할 수 있습니다.
- 애플리케이션 Pod와 관련된 이벤트를 검토합니다.
- OpenShift Logging 프레임워크에서 수집하지 않는 애플리케이션별 로그 파일을 포함하여 애플리케이션 Pod의 로그를 검토합니다.
- 애플리케이션 기능을 대화 형으로 테스트하고 애플리케이션 컨테이너에서 진단 도구를 실행합니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
특정 애플리케이션 Pod와 관련된 이벤트를 나열합니다. 다음 예에서는
my-app-1-akdlg라는 애플리케이션 Pod의 이벤트를 검색합니다.$ oc describe pod/my-app-1-akdlg애플리케이션 Pod에서 로그를 검토합니다.
$ oc logs -f pod/my-app-1-akdlg실행 중인 애플리케이션 Pod 내에서 특정 로그를 쿼리합니다. stdout으로 전송되는 로그는 OpenShift Logging 프레임 워크에서 수집되며 위의 명령의 출력에 포함됩니다. 다음 쿼리는 stdout으로 전송되지 않은 로그에만 필요합니다.
Pod 내에서 루트 권한 없이 애플리케이션 로그에 액세스할 수 있는 경우 다음과 같이 로그 파일을 연결합니다.
$ oc exec my-app-1-akdlg -- cat /var/log/my-application.log애플리케이션 로그를 보기 위해 root 액세스가 필요한 경우 root 권한으로 디버그 컨테이너를 시작한 다음 컨테이너 내에서 로그 파일을 볼 수 있습니다. 프로젝트의
DeploymentConfig개체에서 디버그 컨테이너를 시작합니다. 일반적으로 Pod 사용자는 루트 이외의 권한으로 실행되지만 임시 루트 권한으로 문제 해결 Pod를 실행하면 문제 해결에 유용할 수 있습니다.$ oc debug dc/my-deployment-configuration --as-root -- cat /var/log/my-application.log참고-- <command>를 추가하지 않고oc debug dc/<deployment_configuration> --as-root를 실행하면 디버그 Pod에서 루트 액세스 권한으로 대화형 쉘에 액세스할 수 있습니다.
대화형 쉘이 있는 애플리케이션 컨테이너에서 대화형으로 애플리케이션 기능을 테스트하고 진단 도구를 실행합니다.
애플리케이션 컨테이너에서 대화형 쉘을 시작합니다.
$ oc exec -it my-app-1-akdlg /bin/bash- 쉘에서 대화형으로 애플리케이션 기능을 테스트합니다. 예를 들어 컨테이너의 엔트리 포인트 명령을 실행하고 결과를 확인할 수 있습니다. 그런 다음 S2I 프로세스를 통해 소스 코드를 업데이트하고 애플리케이션 컨테이너를 다시 빌드하기 전에 명령 줄에서 직접 변경 사항을 테스트합니다.
컨테이너에서 사용 가능한 진단 바이너리를 실행합니다.
참고일부 진단 바이너리를 실행하려면 root 권한이 필요합니다. 이러한 상황에서는
oc debug dc/<deployment_configuration> --as-root를 실행하여 문제가 있는 Pod의DeploymentConfig개체에 따라 루트 액세스 권한으로 디버그 Pod를 시작할 수 있습니다. 그런 다음 디버그 Pod 내에서 루트로 진단 바이너리를 실행할 수 있습니다.
컨테이너 내에서 진단 바이너리를 사용할 수 없는 경우
nsenter를 사용하여 컨테이너의 네임 스페이스에서 호스트의 진단 바이너리를 실행할 수 있습니다. 다음 예제는 호스트의IP바이너리를 사용하여 컨테이너의 네임 스페이스에서ip ad를 실행합니다.대상 노드에서 디버그 세션으로 들어갑니다. 이 단계는
<node_name>-debug라는 디버그 Pod를 인스턴스화합니다.$ oc debug node/my-cluster-node디버그 쉘 내에서
/host를 root 디렉터리로 설정합니다. 디버그 Pod는 Pod 내의/host에 호스트의 루트 파일 시스템을 마운트합니다. root 디렉토리를/host로 변경하면 호스트의 실행 경로에 포함된 바이너리를 실행할 수 있습니다.# chroot /host참고RHCOS(Red Hat Enterprise Linux CoreOS)를 실행하는 OpenShift Container Platform 4.16 클러스터 노드는 변경할 수 없으며 Operator를 사용하여 클러스터 변경 사항을 적용합니다. SSH를 사용하여 클러스터 노드에 액세스하는 것은 권장되지 않습니다. 그러나 OpenShift Container Platform API를 사용할 수 없거나 kubelet이 대상 노드에서 제대로 작동하지 않는 경우
oc작업이 영향을 받습니다. 이러한 상황에서 대신ssh core @ <node>.<cluster_name>.<base_domain>을 사용하여 노드에 액세스할 수 있습니다.대상 컨테이너 ID를 확인합니다.
# crictl ps컨테이너의 프로세스 ID를 확인합니다. 이 예에서 대상 컨테이너 ID는
a7fe32346b120입니다.# crictl inspect a7fe32346b120 --output yaml | grep 'pid:' | awk '{print $2}'호스트의
ip바이너리를 사용하여 컨테이너의 네임 스페이스에서ip ad를 실행합니다. 이 예에서는 컨테이너의 프로세스 ID로31150을 사용합니다.nsenter명령은 대상 프로세스의 네임 스페이스를 입력하고 네임 스페이스에서 명령을 실행합니다. 이 경우 대상 프로세스는 컨테이너의 프로세스 ID이므로ip ad명령은 호스트의 컨테이너 네임 스페이스에서 실행됩니다.# nsenter -n -t 31150 -- ip ad참고컨테이너의 네임 스페이스 에서 호스트의 진단 바이너리를 실행하는 것은 디버그 노드와 같은 권한 있는 컨테이너를 사용하는 경우에만 가능합니다.
7.9. 스토리지 문제 해결
7.9.1. 다중 연결 오류 해결
노드가 예기치 않게 중단되거나 종료되면 연결된 RWO(ReadWriteOnce) 볼륨이 노드에서 마운트 해제되어 다른 노드에서 예약된 Pod에서 사용할 수 있습니다.
그러나 오류가 발생한 노드가 연결된 볼륨을 마운트 해제할 수 없기 때문에 새 노드에 마운트할 수 없습니다.
다중 연결 오류가 보고됩니다.
출력 예
Unable to attach or mount volumes: unmounted volumes=[sso-mysql-pvol], unattached volumes=[sso-mysql-pvol default-token-x4rzc]: timed out waiting for the condition
Multi-Attach error for volume "pvc-8837384d-69d7-40b2-b2e6-5df86943eef9" Volume is already used by pod(s) sso-mysql-1-ns6b4프로세스
다중 연결 문제를 해결하려면 다음 해결 방법 중 하나를 사용합니다.
RWX 볼륨을 사용하여 여러 연결을 활성화합니다.
대부분의 스토리지 솔루션의 경우 RWX (ReadWriteMany) 볼륨을 사용하여 다중 연결 오류를 방지할 수 있습니다.
RWO 볼륨을 사용할 때 오류가 발생한 노드를 복구하거나 삭제합니다.
VMware vSphere와 같이 RWX를 지원하지 않는 스토리지의 경우 RWO 볼륨을 대신 사용해야합니다. 그러나 RWO 볼륨은 여러 노드에 마운트할 수 없습니다.
RWO 볼륨에 다중 연결 오류 메시지가 표시되면 종료되거나 충돌한 노드에서 pod를 강제로 삭제하여 동적 영구 볼륨이 연결된 경우와 같이 중요한 워크로드의 데이터 손실을 방지합니다.
$ oc delete pod <old_pod> --force=true --grace-period=0이 명령은 종료되거나 중단된 노드에서 멈춘 볼륨을 6분 후 삭제합니다.
7.10. Windows 컨테이너 워크로드 문제 해결
7.10.1. Windows Machine Config Operator가 설치되지 않음
WMCO(Windows Machine Config Operator) 설치 프로세스를 완료했지만 Operator가 InstallWaiting 단계에서 멈춘 경우 네트워킹 문제로 인해 문제가 발생한 것일 수 있습니다.
WMCO를 사용하려면 OVN-Kubernetes를 사용하는 하이브리드 네트워킹으로 OpenShift Container Platform 클러스터를 구성해야 합니다. WMCO는 사용 가능한 하이브리드 네트워킹이 없으면 설치 프로세스를 완료할 수 없습니다. 이는 다중 운영 체제(OS) 및 OS 변형에서 노드를 관리하는 데 필요합니다. 클러스터를 설치하는 동안 완료해야 합니다.
자세한 내용은 하이브리드 네트워킹 구성을 참조하십시오.
7.10.2. Windows 머신이 컴퓨팅 노드가 되지 않는 이유 조사
Windows 머신이 컴퓨팅 노드가 되지 않는 데에는 다양한 이유가 있습니다. 이 문제를 조사하는 가장 좋은 방법은 WMCO(Windows Machine Config Operator) 로그를 수집하는 것입니다.
사전 요구 사항
- OLM(Operator Lifecycle Manager)을 사용하여 WMCO(Windows Machine Config Operator)를 설치했습니다.
- Windows 컴퓨팅 머신 세트를 생성했습니다.
프로세스
다음 명령을 실행하여 WMCO 로그를 수집합니다.
$ oc logs -f deployment/windows-machine-config-operator -n openshift-windows-machine-config-operator
7.10.3. Windows 노드에 액세스
oc debug node 명령을 사용하여 Windows 노드에 액세스할 수 없습니다. 이 명령을 사용하려면 노드에서 권한 있는 Pod를 실행해야 하는데, 이 기능은 아직 Windows에서 지원되지 않습니다. 대신 SSH(Secure Shell) 또는 RDP(Remote Desktop Protocol)를 사용하여 Windows 노드에 액세스할 수 있습니다. 두 방법 모두 SSH bastion이 필요합니다.
7.10.3.1. SSH를 사용하여 Windows 노드에 액세스
SSH(Secure Shell)를 사용하여 Windows 노드에 액세스할 수 있습니다.
사전 요구 사항
- OLM(Operator Lifecycle Manager)을 사용하여 WMCO(Windows Machine Config Operator)를 설치했습니다.
- Windows 컴퓨팅 머신 세트를 생성했습니다.
-
cloud-private-key보안에 사용한 키와 클러스터를 만들 때 사용한 키를 ssh-agent에 추가했습니다. 보안상의 이유로 사용 후에는 ssh-agent에서 키를 제거해야 합니다. -
ssh-bastionPod를 사용하여 Windows 노드에 연결했습니다.
프로세스
다음 명령을 실행하여 Windows 노드에 액세스합니다.
$ ssh -t -o StrictHostKeyChecking=no -o ProxyCommand='ssh -A -o StrictHostKeyChecking=no \ -o ServerAliveInterval=30 -W %h:%p core@$(oc get service --all-namespaces -l run=ssh-bastion \ -o go-template="{{ with (index (index .items 0).status.loadBalancer.ingress 0) }}{{ or .hostname .ip }}{{end}}")' <username>@<windows_node_internal_ip>1 2 $ oc get nodes <node_name> -o jsonpath={.status.addresses[?\(@.type==\"InternalIP\"\)].address}
7.10.3.2. RDP를 사용하여 Windows 노드에 액세스
RDP(Remote Desktop Protocol)를 사용하여 Windows 노드에 액세스할 수 있습니다.
사전 요구 사항
- OLM(Operator Lifecycle Manager)을 사용하여 WMCO(Windows Machine Config Operator)를 설치했습니다.
- Windows 컴퓨팅 머신 세트를 생성했습니다.
-
cloud-private-key보안에 사용한 키와 클러스터를 만들 때 사용한 키를 ssh-agent에 추가했습니다. 보안상의 이유로 사용 후에는 ssh-agent에서 키를 제거해야 합니다. -
ssh-bastionPod를 사용하여 Windows 노드에 연결했습니다.
프로세스
다음 명령을 실행하여 SSH 터널을 설정합니다.
$ ssh -L 2020:<windows_node_internal_ip>:3389 \1 core@$(oc get service --all-namespaces -l run=ssh-bastion -o go-template="{{ with (index (index .items 0).status.loadBalancer.ingress 0) }}{{ or .hostname .ip }}{{end}}")- 1
- 노드의 내부 IP 주소를 지정합니다. 이 IP 주소는 다음 명령을 실행하여 검색할 수 있습니다.
$ oc get nodes <node_name> -o jsonpath={.status.addresses[?\(@.type==\"InternalIP\"\)].address}결과 쉘 내에서 SSH를 통해 Windows 노드에 연결하고 다음 명령을 실행하여 사용자 암호를 만듭니다.
C:\> net user <username> *1 - 1
- 클라우드 공급자 사용자 이름을 지정합니다(예: AWS의
Administrator, Azure의capi).
이제 RDP 클라이언트를 사용하여 localhost:2020에서 Windows 노드에 원격으로 액세스할 수 있습니다.
7.10.4. Windows 컨테이너에 대한 Kubernetes 노드 로그 수집
Windows 컨테이너 로깅은 Linux 컨테이너 로깅과 다르게 작동합니다. Windows 워크로드에 대한 Kubernetes 노드 로그는 기본적으로 C:\var\logs 디렉터리로 스트리밍됩니다. 따라서 해당 디렉터리에서 Windows 노드 로그를 수집해야 합니다.
사전 요구 사항
- OLM(Operator Lifecycle Manager)을 사용하여 WMCO(Windows Machine Config Operator)를 설치했습니다.
- Windows 컴퓨팅 머신 세트를 생성했습니다.
프로세스
C:\var\logs의 모든 디렉터리에 있는 로그를 보려면 다음 명령을 실행합니다.$ oc adm node-logs -l kubernetes.io/os=windows --path= \ /ip-10-0-138-252.us-east-2.compute.internal containers \ /ip-10-0-138-252.us-east-2.compute.internal hybrid-overlay \ /ip-10-0-138-252.us-east-2.compute.internal kube-proxy \ /ip-10-0-138-252.us-east-2.compute.internal kubelet \ /ip-10-0-138-252.us-east-2.compute.internal pods동일한 명령을 사용하여 디렉터리의 파일을 나열하고 개별 로그 파일을 볼 수 있습니다. 예를 들어 kubelet 로그를 보려면 다음 명령을 실행합니다.
$ oc adm node-logs -l kubernetes.io/os=windows --path=/kubelet/kubelet.log
7.10.5. Windows 애플리케이션 이벤트 로그 수집
kubelet logs 끝점의 Get-WinEvent shim을 사용하여 Windows 머신에서 애플리케이션 이벤트 로그를 수집할 수 있습니다.
사전 요구 사항
- OLM(Operator Lifecycle Manager)을 사용하여 WMCO(Windows Machine Config Operator)를 설치했습니다.
- Windows 컴퓨팅 머신 세트를 생성했습니다.
프로세스
Windows 머신의 이벤트 로그에 로깅하는 모든 애플리케이션의 로그를 보려면 다음을 실행합니다.
$ oc adm node-logs -l kubernetes.io/os=windows --path=journaloc adm must-gather로 로그를 수집할 때와 같은 명령이 실행됩니다.-u플래그를 사용하여 각 서비스를 지정하면 이벤트 로그의 다른 Windows 애플리케이션 로그도 수집할 수 있습니다. 예를 들어 다음 명령을 실행하여 컨테이너 컨테이너 런타임 서비스에 대한 로그를 수집할 수 있습니다.$ oc adm node-logs -l kubernetes.io/os=windows --path=journal -u containerd
7.10.6. Windows 컨테이너에 대한 컨테이너 로그 수집
Windows 컨테이너 서비스는 로그 데이터를 stdout로 스트리밍하지 않고 대신 로그 데이터를 Windows 이벤트 로그로 스트리밍합니다. 컨테이너된 이벤트 로그를 보고 Windows 컨테이너 서비스로 인해 발생할 수 있는 문제를 조사할 수 있습니다.
사전 요구 사항
- OLM(Operator Lifecycle Manager)을 사용하여 WMCO(Windows Machine Config Operator)를 설치했습니다.
- Windows 컴퓨팅 머신 세트를 생성했습니다.
프로세스
다음 명령을 실행하여 컨테이너된 로그를 확인합니다.
$ oc adm node-logs -l kubernetes.io/os=windows --path=containerd
7.11. 모니터링 문제 조사
OpenShift Container Platform에는 핵심 플랫폼 구성 요소에 대한 모니터링을 제공하는 사전 구성된 사전 설치된 자체 업데이트 모니터링 스택이 포함되어 있습니다. OpenShift Container Platform 4.16에서 클러스터 관리자는 선택 옵션으로 사용자 정의 프로젝트에 대한 모니터링을 활성화할 수 있습니다.
다음 문제가 발생하는 경우 다음 절차를 사용하십시오.
- 자체 메트릭을 사용할 수 없습니다.
- Prometheus는 많은 디스크 공간을 사용하고 있습니다.
-
Prometheus에서
KubePersistentVolumeFillingUp경고가 실행됩니다.
7.11.2. Prometheus가 많은 디스크 공간을 소비하는 이유 확인
개발자는 라벨을 생성하여 키-값 쌍의 형식으로 메트릭의 속성을 정의할 수 있습니다. 잠재적인 키-값 쌍의 수는 속성에 사용 가능한 값의 수에 해당합니다. 무제한의 잠재적인 값이 있는 속성을 바인딩되지 않은 속성이라고 합니다. 예를 들어, customer_id 속성은 무제한 가능한 값이 있기 때문에 바인딩되지 않은 속성입니다.
할당된 모든 키-값 쌍에는 고유한 시계열이 있습니다. 라벨에 있는 바인딩되지 않은 많은 속성을 사용하면 생성되는 시계열 수가 기하급수적으로 증가할 수 있습니다. 이는 Prometheus 성능에 영향을 미칠 수 있으며 많은 디스크 공간을 소비할 수 있습니다.
Prometheus가 많은 디스크를 사용하는 경우 다음 조치를 사용할 수 있습니다.
- 가장 많은 시계열 데이터를 생성하는 라벨에 대한 자세한 내용은 Prometheus HTTP API를 사용하여 시계열 데이터베이스(TSDB) 상태를 확인합니다. 이렇게 하려면 클러스터 관리자 권한이 필요합니다.
- 수집 중인 스크랩 샘플 수를 확인합니다.
사용자 정의 메트릭에 할당되는 바인딩되지 않은 속성의 수를 줄임으로써 생성되는 고유의 시계열 수를 감소합니다.
참고사용 가능한 값의 제한된 집합에 바인딩되는 속성을 사용하면 가능한 키 - 값 쌍 조합의 수가 줄어듭니다.
- 사용자 정의 프로젝트에서 스크랩할 수 있는 샘플 수를 제한합니다. 여기에는 클러스터 관리자 권한이 필요합니다.
사전 요구 사항
-
cluster-admin클러스터 역할의 사용자로 클러스터에 액세스할 수 있습니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
- 관리자 화면에서 모니터링 → 메트릭으로 이동합니다.
Expression 필드에 PromQL(Prometheus Query Language) 쿼리를 입력합니다. 다음 예제 쿼리는 디스크 공간 소비가 증가할 수 있는 높은 카디널리티 메트릭을 식별하는 데 도움이 됩니다.
다음 쿼리를 실행하면 스크랩 샘플 수가 가장 많은 10개의 작업을 확인할 수 있습니다.
topk(10, max by(namespace, job) (topk by(namespace, job) (1, scrape_samples_post_metric_relabeling)))다음 쿼리를 실행하면 지난 시간에 가장 많은 시계열 데이터를 생성한 10개의 작업을 식별하여 시계열 churn을 정확하게 지정할 수 있습니다.
topk(10, sum by(namespace, job) (sum_over_time(scrape_series_added[1h])))
예상 스크랩 샘플 수보다 많은 메트릭에 할당된 바인딩되지 않은 라벨 값의 수를 조사합니다.
- 메트릭이 사용자 정의 프로젝트와 관련된 경우 워크로드에 할당된 메트릭의 키-값 쌍을 확인합니다. 이는 애플리케이션 수준에서 Prometheus 클라이언트 라이브러리를 통해 구현됩니다. 라벨에서 참조되는 바인딩되지 않은 속성의 수를 제한하십시오.
- 메트릭이 OpenShift Container Platform의 주요 프로젝트와 관련된 경우 Red Hat Customer Portal에서 Red Hat 지원 케이스를 생성하십시오.
클러스터 관리자로 로그인할 때 다음 단계에 따라 Prometheus HTTP API를 사용하여 TSDB 상태를 확인합니다.
다음 명령을 실행하여 Prometheus API 경로 URL을 가져옵니다.
$ HOST=$(oc -n openshift-monitoring get route prometheus-k8s -ojsonpath='{.status.ingress[].host}')다음 명령을 실행하여 인증 토큰을 추출합니다.
$ TOKEN=$(oc whoami -t)다음 명령을 실행하여 Prometheus의 TSDB 상태를 쿼리합니다.
$ curl -H "Authorization: Bearer $TOKEN" -k "https://$HOST/api/v1/status/tsdb"출력 예
"status": "success","data":{"headStats":{"numSeries":507473, "numLabelPairs":19832,"chunkCount":946298,"minTime":1712253600010, "maxTime":1712257935346},"seriesCountByMetricName": [{"name":"etcd_request_duration_seconds_bucket","value":51840}, {"name":"apiserver_request_sli_duration_seconds_bucket","value":47718}, ...
7.11.3. Prometheus에 대해 KubePersistentVolumeFillingUp 경고가 실행됨
클러스터 관리자는 Prometheus에 대해 KubePersistentVolumeFillingUp 경고가 트리거되는 문제를 해결할 수 있습니다.
openshift-monitoring 프로젝트의 prometheus-k8s-* Pod에서 클레임한 PV(영구 볼륨)가 남아 있는 총 공간이 3% 미만인 경우 발생합니다. 이로 인해 Prometheus가 비정상적으로 작동할 수 있습니다.
KubePersistentVolumeFillingUp 경고 두 가지가 있습니다.
-
critical alert: mounted PV의 총 공간이 3% 미만이면
severity="critical"라벨이 있는 경고가 트리거됩니다. -
경고 알림: 마운트된 PV의 총 공간이 15 % 미만이고 4 일 이내에 채울 것으로 예상되는 경우
severity="warning"라벨이 있는 경고가 트리거됩니다.
이 문제를 해결하려면 Prometheus TSDB(time-series database) 블록을 제거하여 PV에 더 많은 공간을 생성할 수 있습니다.
사전 요구 사항
-
cluster-admin클러스터 역할의 사용자로 클러스터에 액세스할 수 있습니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
다음 명령을 실행하여 가장 오래된 것에서 최신으로 정렬된 모든 TSDB 블록의 크기를 나열합니다.
$ oc debug <prometheus_k8s_pod_name> -n openshift-monitoring \1 -c prometheus --image=$(oc get po -n openshift-monitoring <prometheus_k8s_pod_name> \2 -o jsonpath='{.spec.containers[?(@.name=="prometheus")].image}') \ -- sh -c 'cd /prometheus/;du -hs $(ls -dtr */ | grep -Eo "[0-9|A-Z]{26}")'출력 예
308M 01HVKMPKQWZYWS8WVDAYQHNMW6 52M 01HVK64DTDA81799TBR9QDECEZ 102M 01HVK64DS7TRZRWF2756KHST5X 140M 01HVJS59K11FBVAPVY57K88Z11 90M 01HVH2A5Z58SKT810EM6B9AT50 152M 01HV8ZDVQMX41MKCN84S32RRZ1 354M 01HV6Q2N26BK63G4RYTST71FBF 156M 01HV664H9J9Z1FTZD73RD1563E 216M 01HTHXB60A7F239HN7S2TENPNS 104M 01HTHMGRXGS0WXA3WATRXHR36B제거할 수 있는 블록 수와 블록을 확인한 다음 블록을 제거합니다. 다음 예제 명령은
prometheus-k8s-0Pod에서 가장 오래된 세 가지 Prometheus TSDB 블록을 제거합니다.$ oc debug prometheus-k8s-0 -n openshift-monitoring \ -c prometheus --image=$(oc get po -n openshift-monitoring prometheus-k8s-0 \ -o jsonpath='{.spec.containers[?(@.name=="prometheus")].image}') \ -- sh -c 'ls -latr /prometheus/ | egrep -o "[0-9|A-Z]{26}" | head -3 | \ while read BLOCK; do rm -r /prometheus/$BLOCK; done'마운트된 PV의 사용량을 확인하고 다음 명령을 실행하여 사용 가능한 공간이 충분한지 확인합니다.
$ oc debug <prometheus_k8s_pod_name> -n openshift-monitoring \1 --image=$(oc get po -n openshift-monitoring <prometheus_k8s_pod_name> \2 -o jsonpath='{.spec.containers[?(@.name=="prometheus")].image}') -- df -h /prometheus/다음 예제 출력에서는
prometheus-k8s-0Pod에서 클레임한 마운트된 PV가 남아 있는 공간의 63%를 보여줍니다.출력 예
Starting pod/prometheus-k8s-0-debug-j82w4 ... Filesystem Size Used Avail Use% Mounted on /dev/nvme0n1p4 40G 15G 40G 37% /prometheus Removing debug pod ...
7.12. OpenShift CLI (oc) 문제 진단
7.12.1. OpenShift CLI (oc) 로그 수준 이해
OpenShift CLI (oc)를 사용하면 터미널에서 애플리케이션을 생성하고 OpenShift Container Platform 프로젝트를 관리할 수 있습니다.
oc 명령 관련 문제가 발생하면 oc 로그 수준을 높여서 명령으로 생성된 API 요청, API 응답 및 curl 요청 세부 정보를 출력합니다. 이를 통해 특정 oc 명령의 기본 작업에 대한 세부적인 보기를 통해 오류 특성에 대한 통찰력을 제공할 수 있습니다.
oc 로그 수준은 1에서 10까지 있습니다. 다음 표에서는 oc 로그 수준을 설명합니다.
| 로그 수준 | 설명 |
|---|---|
| 1~5 | stderr에 대한 추가 로깅이 없습니다. |
| 6 | stderr에 API 요청을 기록합니다. |
| 7 | stderr에 API 요청 및 헤더를 기록합니다. |
| 8 | stderr에 API 요청, 헤더 및 본문과 API 응답 헤더 및 본문을 기록합니다. |
| 9 |
stderr에 API 요청, 헤더 및 본문, API 응답 헤더 및 본문, |
| 10 |
stderr에 API 요청, 헤더 및 본문, API 응답 헤더 및 본문, |
7.12.2. OpenShift CLI (oc) 로그 수준 지정
명령의 로그 수준을 높여 OpenShift CLI (oc) 문제를 조사할 수 있습니다.
일반적으로 OpenShift Container Platform 사용자의 현재 세션 토큰은 필요한 경우 로깅된 curl 요청에 포함됩니다. oc 명령의 기본 프로세스 측면을 단계별로 테스트할 때 사용할 현재 사용자의 세션 토큰을 수동으로 가져올 수도 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다.
프로세스
oc명령을 실행할 때oc로그 레벨을 지정합니다.$ oc <command> --loglevel <log_level>다음과 같습니다.
- <command>
- 실행 중인 명령을 지정합니다.
- <log_level>
- 명령에 적용할 로그 수준을 지정합니다.
현재 사용자의 세션 토큰을 얻으려면 다음 명령을 실행합니다.
$ oc whoami -t출력 예
sha256~RCV3Qcn7H-OEfqCGVI0CvnZ6...
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.