18장. 인스턴스 및 컨테이너 그룹
자동화 컨트롤러를 사용하면 필요한 서비스 계정이 프로비저닝된 상태에서 클러스터 또는 OpenShift 클러스터의 네임스페이스에서 직접 Ansible 플레이북을 통해 작업을 실행할 수 있습니다. 이를 컨테이너 그룹이라고 합니다.
컨테이너 그룹에서 플레이북당 필요한 만큼만 작업을 실행할 수 있습니다. 자세한 내용은 컨테이너 그룹을 참조하십시오.
실행 환경의 경우 실행 환경을 참조하십시오.
18.1. 인스턴스 그룹
인스턴스를 하나 이상의 인스턴스 그룹으로 그룹화할 수 있습니다. 다음 나열된 리소스 중 하나에 인스턴스 그룹을 할당할 수 있습니다.
- 조직
- 인벤토리
- 작업 템플릿
리소스 중 하나와 연결된 작업이 실행되면 해당 리소스와 연결된 인스턴스 그룹에 할당됩니다. 실행 프로세스 중에 작업 템플릿과 연결된 인스턴스 그룹이 인벤토리와 연결된 인스턴스 그룹보다 먼저 확인됩니다. 인벤토리와 연결된 인스턴스 그룹은 조직과 연결된 인스턴스 그룹보다 먼저 확인됩니다. 따라서 세 가지 리소스에 대한 인스턴스 그룹 할당은 계층 구조를 형성합니다.
작업 템플릿 > 인벤토리 > 조직
인스턴스 그룹으로 작업할 때는 다음을 고려하십시오.
-
해당 그룹에서 다른 그룹 및 그룹 인스턴스를 정의할 수 있습니다. 이러한 그룹의 접두사는
instance_group_이어야 합니다. 다른instance_group_그룹과 함께 Automationcontroller또는execution_nodes그룹에 인스턴스가 있어야 합니다. 클러스터형 설정에서는 API 인스턴스 그룹에컨트롤 플레인으로 표시되는 Automationcontroller그룹에 하나 이상의 인스턴스가 있어야 합니다. 자세한 내용 및 예제 시나리오는자동화 컨트롤러에대한 그룹 정책을 참조하십시오. controlplane인스턴스 그룹을 수정할 수 없으며 이 작업을 시도하면 모든 사용자에 대한 permission denied 오류가 발생합니다.따라서 Disassociate 옵션은
컨트롤 플레인의 Instances 탭에서 사용할 수 없습니다.-
기본API 인스턴스 그룹은 작업을 실행할 수 있는 모든 노드를 사용하여 자동으로 생성됩니다. 다른 인스턴스 그룹과 유사하지만 특정 인스턴스 그룹이 특정 리소스와 연결되지 않은 경우 작업 실행은 항상 기본 인스턴스 그룹으로 대체됩니다. 기본 인스턴스 그룹이 항상 존재하며, 삭제하거나 이름을 변경할 수 없습니다. -
instance_group_default라는 그룹을 생성하지 마십시오. - 그룹 이름과 동일한 인스턴스 이름을 지정하지 마십시오.
18.1.1. 자동화 컨트롤러에대한 그룹 정책
노드를 정의할 때는 다음 기준을 사용합니다.
-
Automation
controller 그룹의 노드는node_typehostvar을하이브리드(기본값) 또는제어로 정의할 수 있습니다. -
execution_nodes 그룹의 노드는node_typehostvar을실행(기본값) 또는홉으로 정의할 수 있습니다.
instance_group_* 로 그룹 이름을 지정하여 인벤토리 파일에서 사용자 지정 그룹을 정의할 수 있습니다. 여기서 * 는 API에서 그룹 이름이 됩니다. 설치가 완료된 후 API에 사용자 지정 인스턴스 그룹을 생성할 수도 있습니다.
현재 동작에서는 instance_group_* 의 멤버가 Automation controller 또는 execution_nodes 그룹의 일부가 될 것으로 예상합니다.
예 18.1. 인스턴스 그룹 정의
[automationcontroller]
126-addr.tatu.home ansible_host=192.168.111.126 node_type=control
[automationcontroller:vars]
peers=execution_nodes
[execution_nodes]
[instance_group_test]
110-addr.tatu.home ansible_host=192.168.111.110 receptor_listener_port=8928설치 프로그램을 실행하면 다음 오류가 표시됩니다.
TASK [ansible.automation_platform_installer.check_config_static : Validate mesh topology] ***
fatal: [126-addr.tatu.home -> localhost]: FAILED! => {"msg": "The host '110-addr.tatu.home' is not present in either [automationcontroller] or [execution_nodes]"}
이 문제를 해결하려면 다음과 같이 110-addr.tatu.home 상자를 execution_node 그룹으로 이동합니다.
[automationcontroller]
126-addr.tatu.home ansible_host=192.168.111.126 node_type=control
[automationcontroller:vars]
peers=execution_nodes
[execution_nodes]
110-addr.tatu.home ansible_host=192.168.111.110 receptor_listener_port=8928
[instance_group_test]
110-addr.tatu.home결과는 다음과 같습니다.
TASK [ansible.automation_platform_installer.check_config_static : Validate mesh topology] ***
ok: [126-addr.tatu.home -> localhost] => {"changed": false, "mesh": {"110-addr.tatu.home": {"node_type": "execution", "peers": [], "receptor_control_filename": "receptor.sock", "receptor_control_service_name": "control", "receptor_listener": true, "receptor_listener_port": 8928, "receptor_listener_protocol": "tcp", "receptor_log_level": "info"}, "126-addr.tatu.home": {"node_type": "control", "peers": ["110-addr.tatu.home"], "receptor_control_filename": "receptor.sock", "receptor_control_service_name": "control", "receptor_listener": false, "receptor_listener_port": 27199, "receptor_listener_protocol": "tcp", "receptor_log_level": "info"}}}
자동화 컨트롤러 4.0 또는 이전 버전에서 업그레이드한 후 레거시 instance_group_ 멤버에 awx 코드가 설치되어 있을 가능성이 큽니다. 그러면 해당 노드가 Automation controller 그룹에 배치됩니다.
18.1.2. API에서 인스턴스 그룹 구성
시스템 관리자로 /api/v2/instance_groups 에 POST를 수행하여 인스턴스 그룹을 생성할 수 있습니다.
생성되면 다음을 사용하여 인스턴스를 인스턴스 그룹과 연결할 수 있습니다.
HTTP POST /api/v2/instance_groups/x/instances/ {'id': y}`인스턴스 그룹에 추가된 인스턴스는 그룹의 작업 큐에서 수신 대기하도록 자동으로 재구성됩니다. 자세한 내용은 인스턴스 그룹 정책을 참조하십시오.
18.1.3. 인스턴스 그룹 정책
정책을 정의하여 온라인 상태가 되면 인스턴스 그룹에 자동으로 참여하도록 자동화 컨트롤러 인스턴스를 구성할 수 있습니다. 이러한 정책은 온라인 상태의 모든 새 인스턴스를 대상으로 평가됩니다.
인스턴스 그룹 정책은 인스턴스 그룹의 다음 세 개의 선택적 필드에 의해 제어됩니다.
-
policy_instance_percentage: 0에서 100 사이의 숫자입니다. 이 백분율의 활성 자동화 컨트롤러 인스턴스가 이 인스턴스 그룹에 추가됩니다. 새 인스턴스가 온라인 상태가 되면 총 인스턴스 수에 비해 이 그룹의 인스턴스 수가 지정된 백분율보다 작으면 백분율 조건이 충족될 때까지 새 인스턴스가 추가됩니다. -
policy_instance_minimum: 이 정책은 인스턴스 그룹에서 이 많은 인스턴스를 유지하려고 합니다. 사용 가능한 인스턴스 수가 이 최소값보다 작으면 모든 인스턴스가 이 인스턴스 그룹에 배치됩니다. -
policy_instance_list: 이 인스턴스 그룹에 항상 포함할 인스턴스 이름의 고정 목록입니다.
자동화 컨트롤러 UI(사용자 인터페이스)의 인스턴스 그룹 목록 보기는 인스턴스 그룹 정책에 따라 각 인스턴스 그룹의 용량 수준을 요약합니다.

추가 리소스
자세한 내용은 인스턴스 그룹 관리 섹션을 참조하십시오.
18.1.4. 주요 정책 고려 사항
다음 정책 고려 사항을 고려하십시오.
policy_instance_percentage및policy_instance_minimum모두 최소 할당을 설정합니다. 그룹에 더 많은 인스턴스가 할당되도록 하는 규칙이 적용됩니다.예를 들어
policy_instance_percentage가 50%이고policy_instance_minimum이 2인 경우 6개의 인스턴스를 시작하면 인스턴스 그룹 3개가 할당됩니다.클러스터의 총 인스턴스 수를 2로 줄이면
policy_instance_minimum을 충족하기 위해 두 인스턴스 모두 인스턴스 그룹에 할당됩니다. 이를 통해 사용 가능한 리소스 양에 더 낮은 제한을 설정할 수 있습니다.정책을 적용해도 인스턴스가 여러 인스턴스 그룹과 연결되는 것을 적극적으로 차단하지는 않지만 백분율을 100으로 추가하면 됩니다.
4개의 인스턴스 그룹이 있는 경우 각각 백분율 값 25를 할당하고 인스턴스가 겹치지 않고 해당 그룹 간에 배포됩니다.
18.1.5. 인스턴스를 특정 그룹에 수동으로 고정
특정 인스턴스 그룹에만 할당되어야 하는 특수 인스턴스가 있지만 "percentage" 또는 "최소" 정책으로 다른 그룹에 자동으로 참여하지 않도록 하려면 다음을 수행합니다.
프로세스
-
하나 이상의 인스턴스 그룹의
policy_instance_list에 인스턴스를 추가합니다. -
인스턴스의
managed_by_policy속성을False로 업데이트합니다.
이렇게 하면 백분율 및 최소 정책에 따라 인스턴스가 다른 그룹에 자동으로 추가되지 않습니다. 이는 수동으로 할당한 그룹에만 속합니다.
HTTP PATCH /api/v2/instance_groups/N/
{
"policy_instance_list": ["special-instance"]
}
HTTP PATCH /api/v2/instances/X/
{
"managed_by_policy": False
}18.1.6. 작업 런타임 동작
인스턴스 그룹과 연결된 작업을 실행하는 경우 다음 동작을 기록해 둡니다.
- 클러스터를 별도의 인스턴스 그룹으로 나누면 클러스터 전체와 비슷하게 작동합니다.
- 그룹에 두 개의 인스턴스를 할당하면 동일한 그룹의 다른 인스턴스처럼 작업이 수신될 가능성이 높습니다.
- 자동화 컨트롤러 인스턴스가 온라인 상태가 되면 시스템의 작업 용량이 효과적으로 확장됩니다.
- 해당 인스턴스를 인스턴스 그룹에 배치하면 해당 그룹의 용량도 확장됩니다.
- 인스턴스가 작업을 수행하고 여러 그룹의 멤버인 경우 해당 용량이 멤버인 모든 그룹에서 용량이 줄어듭니다.
- 인스턴스를 프로비저닝 해제하면 인스턴스가 할당될 때마다 클러스터에서 용량을 제거합니다. 자세한 내용은 인스턴스 그룹 프로비저닝 섹션을 참조하십시오.
모든 인스턴스를 동일한 용량으로 프로비저닝해야 하는 것은 아닙니다.
18.1.7. 작업이 실행되는 위치 제어
인스턴스 그룹을 작업 템플릿, 인벤토리 또는 조직과 연결하는 경우 해당 작업 템플릿에서 실행되는 작업은 기본 동작을 수행할 수 없습니다. 즉, 이 세 개의 리소스와 연결된 인스턴스 그룹 내의 모든 인스턴스가 용량이 부족하면 용량을 사용할 수 있을 때까지 작업이 보류 중 상태로 유지됩니다.
작업을 제출할 인스턴스 그룹을 결정하는 기본 설정 순서는 다음과 같습니다.
- 작업 템플릿
- 인벤토리
- 조직(프로젝트를 통해)
인스턴스 그룹을 작업 템플릿과 연결하고 모든 작업이 용량에 있는 경우 인벤토리에 지정된 인스턴스 그룹 및 조직에 제출됩니다. 해당 그룹에서는 리소스를 사용할 수 있으므로 작업이 우선 순위순으로 실행되어야 합니다.
플레이북에 정의된 사용자 지정 인스턴스 그룹과 같은 글로벌 기본 그룹을 리소스와 연결할 수 있습니다. 이 인스턴스를 사용하여 작업 템플릿 또는 인벤토리에서 기본 인스턴스 그룹을 지정할 수 있지만, 용량이 부족한 경우에도 작업을 모든 인스턴스에 제출할 수 있습니다.
-
group_adefault그룹을 해당 인벤토리와 연결하는 경우 group_a가 용량 부족인 경우default그룹을 폴백으로 사용할 수 있습니다. - 또한 인스턴스 그룹을 하나의 리소스와 연결하지 않고 다른 리소스를 폴백으로 선택할 수 있습니다. 예를 들어 인스턴스 그룹을 작업 템플릿과 연결하지 않고 인벤토리 또는 조직의 인스턴스 그룹으로 대체됩니다.
이는 다음과 같은 사항을 제공합니다.
- 인스턴스 그룹을 인벤토리와 연결하여(인스턴스 그룹에 작업 템플릿을 할당하지 않음) 특정 인벤토리에 대해 실행되는 모든 플레이북이 연결된 그룹에서만 실행되도록 합니다. 이 기능은 해당 인스턴스에만 관리 노드에 대한 직접 링크가 있는 경우에 유용합니다.
관리자는 조직에 인스턴스 그룹을 할당할 수 있습니다.
이를 통해 관리자는 전체 인프라를 분할하고 각 조직이 작업을 실행할 수 있는 다른 조직의 기능을 방해하지 않고 작업을 실행할 수 있는 용량을 확보할 수 있습니다.
관리자는 다음 시나리오와 유사하게 각 조직에 여러 그룹을 할당할 수 있습니다.
- 세 개의 인스턴스 그룹이 있습니다. A, B 및 C. 조직의 조직: Org1 및 Org2
- 관리자는 Org1 에 그룹 A 를, Org2 에 B 를 그룹화한 다음, 필요한 추가 용량에 대한 오버플로로 Org1 및 Org2 모두에 그룹 C 를 할당합니다.
- 그러면 조직 관리자가 원하는 그룹에 인벤토리 또는 작업 템플릿을 자유롭게 할당하거나 조직에서 기본 순서를 상속하도록 할 수 있습니다.
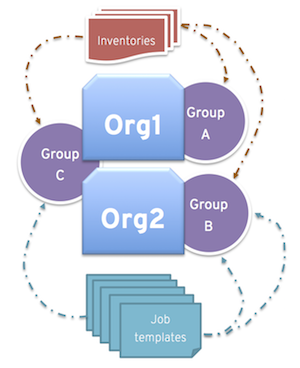
이러한 방식으로 리소스를 배치하면 유연성을 제공합니다. 하나의 인스턴스만으로 인스턴스 그룹을 생성하여 자동화 컨트롤러 클러스터에서 매우 구체적인 호스트로 작업을 보낼 수도 있습니다.
18.1.8. 인스턴스 그룹 용량 제한
인스턴스 그룹으로 전송되는 작업의 동시성 또는 사용할 최대 포크 수를 제한해야 하는 외부 비즈니스 논리가 있습니다.
기존 인스턴스 및 인스턴스 그룹의 경우 두 조직이 동일한 기본 인스턴스에서 작업을 실행할 수 있지만 각 조직의 총 동시 작업 수를 제한할 수 있습니다. 이를 위해 각 조직의 인스턴스 그룹을 생성하고 max_concurrent_jobs 의 값을 할당할 수 있습니다.
자동화 컨트롤러 그룹의 경우 자동화 컨트롤러는 일반적으로 OpenShift 클러스터의 리소스 제한을 인식하지 못합니다. 네임스페이스의 Pod 수에 제한을 설정하거나 자동 스케일링이 없는 경우 한 번에 특정 수의 Pod를 예약하는 데 사용할 수 있는 리소스만 설정할 수 있습니다. 이 경우 max_concurrent_jobs 의 값을 조정할 수 있습니다.
사용 가능한 또 다른 매개변수는 max_forks 입니다. 이는 인스턴스 그룹 또는 컨테이너 그룹에서 사용되는 용량을 제한하기 위한 추가 유연성을 제공합니다. 다양한 인벤토리 크기 및 "포크" 값이 실행되는 경우 이 작업을 사용할 수 있습니다. 조직에서 동시에 최대 10개의 작업을 실행하도록 제한할 수 있지만 한 번에 최대 50개의 포크를 사용할 수 없습니다.
max_concurrent_jobs: 10
max_forks: 50포크 5개를 사용하는 10개의 작업이 각각 실행되면 11번째 작업은 해당 그룹 중 하나가 완료될 때까지 기다립니다(또는 용량이 있는 다른 그룹에서 예약됨).
각각 20개의 포크로 2개의 작업이 실행 중인 경우 task_impact 가 11개 이상인 세 번째 작업은 해당 그룹 중 하나가 완료될 때까지 기다립니다(또는 용량이 있는 다른 그룹에서 예약됨).
컨테이너 그룹의 경우 작업의 "포크" 값에 관계없이 동일한 리소스 요청이 있는 동일한 pod_spec 을 사용하여 모든 작업이 제출되는 경우 max_forks 값을 사용하는 것이 유용합니다. 기본 pod_spec 은 제한이 아닌 요청을 설정하므로 Pod는 제한되거나 다시 실행되지 않고 요청된 값 이상으로 "브스트링"할 수 있습니다. max_forks 값을 설정하면 포크 값이 너무 많은 작업이 동시에 예약되고 요청된 값보다 많은 리소스를 사용하여 여러 Pod로 OpenShift 노드가 오버서브스크립션되는 시나리오를 방지할 수 있습니다.
인스턴스 그룹에서 동시 작업 및 포크의 최대 값을 설정하려면 인스턴스 그룹 생성을 참조하십시오.
18.1.9. 인스턴스 그룹 프로비저닝 해제
현재 클러스터는 의도적으로 또는 오류로 인해 오프라인 상태로 전환된 인스턴스를 구분하지 않으므로 설정 플레이북을 다시 실행하면 인스턴스가 프로비저닝 해제되지 않습니다. 대신 자동화 컨트롤러 인스턴스에서 모든 서비스를 종료한 다음 다른 인스턴스에서 프로비저닝 해제 툴을 실행합니다.
프로세스
다음 명령을 사용하여 인스턴스를 종료하거나 서비스를 중지합니다.
automation-controller-service stop다른 인스턴스에서 다음 프로비저닝 해제 명령을 실행하여 컨트롤러 클러스터 레지스트리에서 제거합니다.
awx-manage deprovision_instance --hostname=<name used in inventory file>예를 들면 다음과 같습니다
awx-manage deprovision_instance --hostname=hostB자동화 컨트롤러에서 인스턴스 그룹을 프로비저닝 해제해도 인스턴스 그룹을 자동으로 프로비저닝 해제하거나 제거하지는 종종 다시 프로비저닝되지 않는 경우가 많습니다. API 끝점 및 통계 모니터링에 계속 표시될 수 있습니다. 다음 명령을 사용하여 이러한 그룹을 제거할 수 있습니다.
awx-manage unregister_queue --queuename=<name>인벤토리 파일의 인스턴스 그룹에서 인스턴스 멤버십을 제거하고 설정 플레이북을 다시 실행하면 인스턴스가 그룹에 다시 추가되지 않습니다. 인스턴스가 그룹에 다시 추가되지 않도록 하려면 API를 통해 해당 인스턴스를 제거하고 인벤토리 파일에서도 제거합니다. 인벤토리 파일에서 인스턴스 그룹 정의를 중지할 수도 있습니다. 자동화 컨트롤러 UI를 통해 인스턴스 그룹 토폴로지를 관리할 수 있습니다. UI에서 인스턴스 그룹을 관리하는 방법에 대한 자세한 내용은 인스턴스 그룹 관리를 참조하십시오.
이전 버전의 자동화 컨트롤러(3.8.x 및 이전 버전)에서 생성된 격리된 인스턴스 그룹이 있고 이를 실행 노드로 마이그레이션하여 자동화 메시 아키텍처와 함께 사용할 수 있도록 하려면 Ansible Automation Platform 업그레이드 및 마이그레이션 가이드의 실행 노드로 격리된 인스턴스 마이그레이션을 참조하십시오.