29.2. 시스템 토폴로지 유형
최신 컴퓨팅에서는 대부분의 최신 시스템에 여러 프로세서가 있으므로 CPU에 대한 아이디어가 오를 수 있습니다. 시스템의 토폴로지는 이러한 프로세서가 서로 연결되고 다른 시스템 리소스에 연결하는 방식입니다. 이는 시스템 및 애플리케이션 성능과 시스템 튜닝 고려 사항에 영향을 미칠 수 있습니다.
다음은 최신 컴퓨팅에 사용되는 두 가지 기본 토폴로지 유형입니다.
대칭 MP(Multi-Processor) 토폴로지- NetNamespace 토폴로지를 사용하면 모든 프로세서가 동일한 시간 내에 메모리에 액세스할 수 있습니다. 그러나 공유 및 동일한 메모리 액세스가 본질적으로 모든 CPU에서 직렬화된 메모리 액세스를 강제 적용하기 때문에 ETL 시스템 확장 제약 조건이 일반적으로 예기치 않은 것으로 표시됩니다. 이러한 이유로 사실상 모든 최신 서버 시스템은 NUMA 시스템입니다.
NUMA(Non-Uniform Memory Access) 토폴로지NUMA 토폴로지는 weekly 토폴로지보다 최근에 개발되었습니다. NUMA 시스템에서는 여러 개의 프로세서가 소켓에 물리적으로 그룹화됩니다. 각 소켓에는 해당 메모리에 대한 로컬 액세스 권한이 있는 전용 메모리 및 프로세서 영역이 있으며 이러한 영역은 노드라고 합니다. 동일한 노드의 프로세서는 해당 노드의 메모리 뱅크에 빠르게 액세스할 수 있으며 노드에 없는 메모리 은행에 대한 액세스 속도가 느려집니다.
따라서 로컬이 아닌 메모리에 액세스할 때 성능이 저하됩니다. 따라서 NUMA 토폴로지가 있는 시스템에서 성능에 민감한 애플리케이션은 애플리케이션을 실행하는 프로세서와 동일한 노드에 있는 메모리에 액세스해야 하며 가능한 경우 원격 메모리에 액세스하지 않아야 합니다.
성능에 민감한 다중 스레드 애플리케이션은 특정 프로세서가 아닌 특정 NUMA 노드에서 실행되도록 구성된 이점을 얻을 수 있습니다. 이것이 적합한지 여부는 시스템 및 애플리케이션의 요구 사항에 따라 달라집니다. 여러 애플리케이션 스레드가 동일한 캐시된 데이터에 액세스하는 경우 동일한 프로세서에서 실행되도록 해당 스레드를 구성하는 것이 적합할 수 있습니다. 그러나 서로 다른 데이터를 액세스 및 캐시하는 여러 스레드가 동일한 프로세서에서 실행되는 경우 각 스레드는 이전 스레드에서 액세스한 캐시된 데이터를 제거할 수 있습니다.However, if multiple threads that access and cache different data execute on the same processor, each thread may remove cached data accessed by a previous thread. 즉, 각 스레드가 캐시를 허용하여 메모리에서 데이터를 가져와 캐시에서 교체하는 실행 시간을 소비합니다.
perf툴을 사용하여 과도한 캐시 누락 수를 확인합니다.
29.2.1. 시스템 토폴로지 표시
시스템의 토폴로지를 이해하는 데 도움이 되는 여러 명령이 있습니다. 다음 절차에서는 시스템 토폴로지를 결정하는 방법을 설명합니다.
절차
시스템 토폴로지 개요를 표시하려면 다음을 수행합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow CPU 아키텍처 정보(예: CPU, 스레드, 코어, 소켓, NUMA 노드 수)를 수집하려면 다음을 수행합니다.
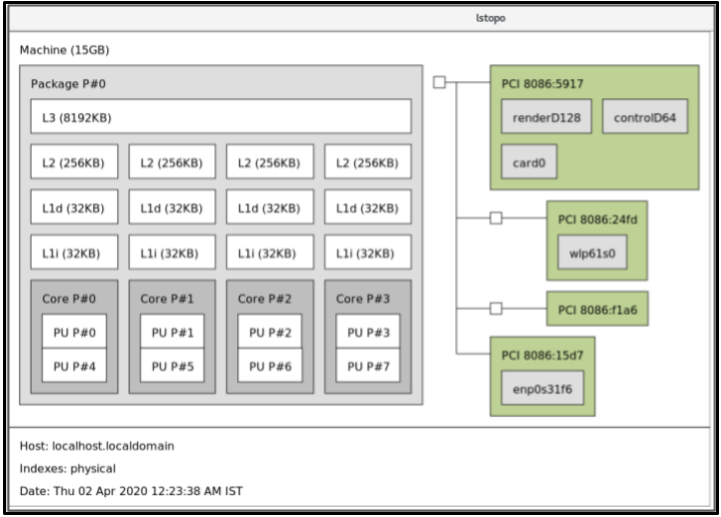
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템의 그래픽 표시를 보려면 다음을 수행합니다.
dnf install hwloc-gui lstopo
# dnf install hwloc-gui # lstopoCopy to Clipboard Copied! Toggle word wrap Toggle overflow 그림 29.1.
lstopo출력자세한 symbols 출력을 보려면 다음을 수행합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow