备份和恢复
备份和恢复 OpenShift Container Platform 集群
摘要
第 1 章 备份和恢复
1.1. control plane 备份和恢复操作
作为集群管理员,您可能需要在一段时间内停止 OpenShift Container Platform 集群,并在以后重启集群。重启集群的一些原因是您需要对集群执行维护或希望降低资源成本。在 OpenShift Container Platform 中,您可以对集群执行安全关闭,以便在以后轻松重启集群。
您必须在关闭集群前 备份 etcd 数据 ;etcd 是 OpenShift Container Platform 的键值存储,它会保留所有资源对象的状态。etcd 备份在灾难恢复中扮演着关键角色。在 OpenShift Container Platform 中,您还可以替换不健康的 etcd 成员。
当您希望集群再次运行时,请安全地重启集群。
集群的证书在安装日期后一年后过期。您可以关闭集群,并在证书仍有效时安全地重启集群。虽然集群自动检索过期的 control plane 证书,但您仍需要批准证书签名请求(CSR)。
您可能会遇到 OpenShift Container Platform 无法按预期工作的一些情况,例如:
- 您有一个在重启后无法正常工作的集群,因为意外状况(如节点故障或网络连接问题)无法正常工作。
- 您已错误地删除了集群中的某些关键内容。
- 您丢失了大多数 control plane 主机,从而导致 etcd 仲裁丢失。
通过使用保存的 etcd 快照,始终可以通过将集群恢复到之前的状态来从灾难中恢复。
1.2. 应用程序备份和恢复操作
作为集群管理员,您可以使用 OpenShift API 进行数据保护(OADP)来备份和恢复在 OpenShift Container Platform 上运行的应用程序。
根据下载 Velero CLI 工具中的表,按照命名空间粒度来备份和恢复 Kubernetes 资源和内部镜像。OADP 使用快照或 Restic 来备份和恢复持久性卷(PV)。详情请参阅 OADP 功能。
1.2.1. OADP 要求
OADP 有以下要求:
-
您必须以具有
cluster-admin角色的用户身份登录。 您必须具有用于存储备份的对象存储,比如以下存储类型之一:
- OpenShift Data Foundation
- Amazon Web Services
- Microsoft Azure
- Google Cloud Platform
- S3 兼容对象存储
如果要在 OCP 4.11 及之后的版本中使用 CSI 备份,请安装 OADP 1.1.x。
OADP 1.0.x 不支持 OCP 4.11 及更高版本上的 CSI 备份。OADP 1.0.x 包括 Velero 1.7.x,并需要 API 组 snapshot.storage.k8s.io/v1beta1,这在 OCP 4.11 及更高版本中不存在。
S3 存储的 CloudStorage API 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
要使用快照备份 PV,您必须有具有原生快照 API 的云存储,或者支持 Container Storage Interface(CSI)快照,如以下供应商:
- Amazon Web Services
- Microsoft Azure
- Google Cloud Platform
- 支持 CSI 快照的云存储,如 Ceph RBD 或 Ceph FS
如果您不想使用快照备份 PV,可以使用 Restic,这由 OADP Operator 安装。
1.2.2. 备份和恢复应用程序
您可以通过创建一个 Backup 自定义资源 (CR) 来备份应用程序。请参阅创建备份 CR。您可以配置以下备份选项:
- 创建备份 hook,以便在备份操作之前或之后运行命令
- 调度备份
- Restic backups
-
您可以通过创建一个
Restore(CR) 来恢复应用程序备份。请参阅创建 Restore CR。 - 您可以配置 restore hook,以便在 init 容器或应用程序容器中运行命令。
第 2 章 安全地关闭集群
本文档描述了安全关闭集群的过程。出于维护或者节约资源成本的原因,您可能需要临时关闭集群。
2.1. 先决条件
在关闭集群前进行 etcd 备份。
重要执行此流程前务必要进行 etcd 备份,以便在重启集群遇到任何问题时可以恢复集群。
例如,以下条件可能会导致重启的集群失败:
- 关机过程中的 etcd 数据崩溃
- 因硬件原因造成节点故障
- 网络连接问题
如果集群无法恢复,请按照以下步骤恢复到以前的集群状态。
2.2. 关闭集群
您可以以安全的方式关闭集群,以便稍后重启集群。
您可以在安装日期起的一年内关闭集群,并期望它可以正常重启。安装日期起一年后,集群证书会过期。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。 - 已进行 etcd 备份。
流程
如果您计划长时间关闭集群,请确定集群证书过期的日期。
您需要在证书过期前重启集群。当集群重启时,可能需要您手动批准待处理的证书签名请求 (CSR) 来恢复 kubelet 证书。
检查
kube-apiserver-to-kubelet-signerCA 证书的过期日期:$ oc -n openshift-kube-apiserver-operator get secret kube-apiserver-to-kubelet-signer -o jsonpath='{.metadata.annotations.auth\.openshift\.io/certificate-not-after}{"\n"}'输出示例
2023-08-05T14:37:50Z检查 kubelet 证书的过期日期:
运行以下命令,为控制平面(control plane)节点启动 debug 会话:
$ oc debug node/<node_name>运行以下命令,将根目录改为
/host:sh-4.4# chroot /host运行以下命令,检查 kubelet 客户端证书过期日期:
sh-5.1# openssl x509 -in /var/lib/kubelet/pki/kubelet-client-current.pem -noout -enddate输出示例
notAfter=Jun 6 10:50:07 2023 GMT运行以下命令,检查 kubelet 服务器证书过期日期:
sh-5.1# openssl x509 -in /var/lib/kubelet/pki/kubelet-server-current.pem -noout -enddate输出示例
notAfter=Jun 6 10:50:07 2023 GMT- 退出 debug 会话。
- 重复这些步骤,以检查所有控制平面节点上的证书过期日期。为确保集群可以正常重启,请计划在最早的证书过期前重启它。
关闭集群中的所有节点。您可以从云供应商的 Web 控制台完成此操作,或者运行以下循环:
$ for node in $(oc get nodes -o jsonpath='{.items[*].metadata.name}'); do oc debug node/${node} -- chroot /host shutdown -h 1; done1 - 1
-h 1表示此过程在 control-plane 节点关闭前可以持续的时间(以分钟为单位)。对于具有 10 个或更多节点的大型集群,请它设置为 10 分钟或更长时间,以确保所有计算节点都已关闭。
输出示例
Starting pod/ip-10-0-130-169us-east-2computeinternal-debug ... To use host binaries, run `chroot /host` Shutdown scheduled for Mon 2021-09-13 09:36:17 UTC, use 'shutdown -c' to cancel. Removing debug pod ... Starting pod/ip-10-0-150-116us-east-2computeinternal-debug ... To use host binaries, run `chroot /host` Shutdown scheduled for Mon 2021-09-13 09:36:29 UTC, use 'shutdown -c' to cancel.使用以下方法关闭节点可让 pod 安全终止,从而减少数据崩溃的可能性。
注意为大规模集群调整关闭时间:
$ for node in $(oc get nodes -o jsonpath='{.items[*].metadata.name}'); do oc debug node/${node} -- chroot /host shutdown -h 10; done注意在关闭前,不需要排空 OpenShift Container Platform 中附带的标准 pod 的 control plane 节点。
集群管理员负责确保在集群重启后,彻底重启自己的工作负载。如果因为自定义工作负载的原因已在关闭前排空 control plane 节点,您必须在重启后将 control plane 节点标记为可调度,然后集群才可以重新正常工作。
关闭不再需要的集群依赖项,如外部存储或 LDAP 服务器。在进行操作前请务必查阅您的厂商文档。
重要如果您在云供应商平台上部署了集群,请不要关闭、挂起或删除关联的云资源。如果您删除挂起的虚拟机的云资源,OpenShift Container Platform 可能无法成功恢复。
第 3 章 正常重启集群
本文档论述了在安全关闭后重启集群的过程。
尽管在重启后集群应该可以正常工作,但可能会因为意外状况集群可能无法恢复,例如:
- 关机过程中的 etcd 数据崩溃
- 因硬件原因造成节点故障
- 网络连接问题
如果集群无法恢复,请按照以下步骤恢复到以前的集群状态。
3.1. 先决条件
- 已安全关闭集群。
3.2. 重启集群
您可以在集群被安全关闭后重启它。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。 - 此流程假设您安全关闭集群。
流程
- 启动所有依赖设备,如外部存储或 LDAP 服务器。
启动所有集群机器。
使用适合您的云环境的方法启动机器,例如从云供应商的 Web 控制台启动机器。
等待大约 10 分钟,然后继续检查 control plane 节点的状态。
验证所有 control plane 节点都已就绪。
$ oc get nodes -l node-role.kubernetes.io/master如果状态为
Ready,如以下输出中所示,则代表 control plane 节点已就绪:NAME STATUS ROLES AGE VERSION ip-10-0-168-251.ec2.internal Ready master 75m v1.24.0 ip-10-0-170-223.ec2.internal Ready master 75m v1.24.0 ip-10-0-211-16.ec2.internal Ready master 75m v1.24.0如果 control plane 节点没有就绪,请检查是否有待批准的证书签名请求 (CSR)。
获取当前 CSR 列表:
$ oc get csr查看一个 CSR 的详细信息以验证其是否有效:
$ oc describe csr <csr_name>1 - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
批准每个有效的 CSR:
$ oc adm certificate approve <csr_name>
在 control plane 节点就绪后,验证所有 worker 节点是否已就绪。
$ oc get nodes -l node-role.kubernetes.io/worker如果状态为
Ready,如下所示,则代表 worker 节点已就绪:NAME STATUS ROLES AGE VERSION ip-10-0-179-95.ec2.internal Ready worker 64m v1.24.0 ip-10-0-182-134.ec2.internal Ready worker 64m v1.24.0 ip-10-0-250-100.ec2.internal Ready worker 64m v1.24.0如果 worker 节点 未 就绪,请检查是否有待批准的证书签名请求(CSR)。
获取当前 CSR 列表:
$ oc get csr查看一个 CSR 的详细信息以验证其是否有效:
$ oc describe csr <csr_name>1 - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
批准每个有效的 CSR:
$ oc adm certificate approve <csr_name>
验证集群是否已正确启动。
检查是否有降级的集群 Operator。
$ oc get clusteroperators确定没有
DEGRADED条件为True的集群 Operator。NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE authentication 4.10.0 True False False 59m cloud-credential 4.10.0 True False False 85m cluster-autoscaler 4.10.0 True False False 73m config-operator 4.10.0 True False False 73m console 4.10.0 True False False 62m csi-snapshot-controller 4.10.0 True False False 66m dns 4.10.0 True False False 76m etcd 4.10.0 True False False 76m ...检查所有节点是否处于
Ready状态:$ oc get nodes检查所有节点的状态是否为
Ready。NAME STATUS ROLES AGE VERSION ip-10-0-168-251.ec2.internal Ready master 82m v1.24.0 ip-10-0-170-223.ec2.internal Ready master 82m v1.24.0 ip-10-0-179-95.ec2.internal Ready worker 70m v1.24.0 ip-10-0-182-134.ec2.internal Ready worker 70m v1.24.0 ip-10-0-211-16.ec2.internal Ready master 82m v1.24.0 ip-10-0-250-100.ec2.internal Ready worker 69m v1.24.0
如果集群无法正确启动,您可能需要使用 etcd 备份来恢复集群。
第 4 章 OADP 应用程序备份和恢复
4.1. OpenShift API for Data Protection 简介
OpenShift API for Data Protection (OADP) 产品保护 OpenShift Container Platform 上的客户应用程序。它提供全面的灾难恢复保护,涵盖 OpenShift Container Platform 应用程序、应用程序相关的集群资源、持久性卷和内部镜像。OADP 还能够备份容器化应用程序和虚拟机 (VM)。
但是,OADP 不会充当 etcd 或 OpenShift Operator 的灾难恢复解决方案。
4.1.1. OpenShift API for Data Protection API
OpenShift API for Data Protection (OADP) 提供了 API,它允许多种方法自定义备份,并防止包含不必要的或不当的资源。
OADP 提供以下 API:
4.2. OADP 发行注记
OpenShift API for Data Protection (OADP) 的发行注记介绍了新的功能和增强功能、已弃用的功能、产品建议、已知问题和解决问题。
4.2.1. OADP 1.2.3 发行注记
4.2.1.1. 新功能
OpenShift API for Data Protection (OADP) 1.2.3 版本没有包括新的功能。
4.2.1.2. 已解决的问题
以下主要问题已在 OADP 1.2.3 中解决:
启用的多个 HTTP/2 的 Web 服务器容易受到 DDoS 攻击(Rapid Reset Attack) 的影响
在之前的 OADP 1.2 版本中,HTTP/2 协议易受拒绝服务攻击的影响,因为请求可以快速重置多个流。服务器需要在没有达到每个连接的最大活跃流数量在服务器端的限制的情况下,设置和处理流。这会导致因为服务器的资源被耗尽而出现拒绝服务的问题。有关与此 CVE 关联的所有 OADP 问题列表,请查看以下 JIRA 列表。
如需更多信息,请参阅 CVE-2023-39325 (Rapid Reset Attack)。
有关 OADP 1.2.3 发行版本中解决的所有问题的完整列表,请参阅 JIRA 中的 OADP 1.2.3 解决的问题列表。
4.2.1.3. 已知问题
OADP 1.2.3 发行版本中没有已知的问题。
4.2.2. OADP 1.2.2 发行注记
4.2.2.1. 新功能
OpenShift API for Data Protection (OADP) 1.2.2 版本没有包括新的功能。
4.2.2.2. 已解决的问题
以下主要问题已在 OADP 1.2.2 中解决:
因为 Pod 安全标准,Restic 恢复部分失败
在之前的 OADP 1.2 版本中,OpenShift Container Platform 4.14 强制执行一个 pod 安全准入 (PSA) 策略,在 Restic 恢复过程中会阻止 pod 的就绪度。
这个问题已在 OADP 1.2.2 版本中解决,同时也在 OADP 1.1.6 中解决。因此,建议用户升级到这些版本。
如需更多信息,请参阅因为更改 PSA 策略,在 OCP 4.14 上进行 Restic 恢复部分失败。(OADP-2094)
使用内部镜像备份应用程序部分失败并显示插件 panicked 错误
在以前的 OADP 1.2 版本中,带有内部镜像的应用程序备份部分会失败,并显示插件 panicked 错误。备份部分失败,在 Velero 日志中出现这个错误:
time="2022-11-23T15:40:46Z" level=info msg="1 errors encountered backup up item" backup=openshift-adp/django-persistent-67a5b83d-6b44-11ed-9cba-902e163f806c logSource="/remote-source/velero/app/pkg/backup/backup.go:413" name=django-psql-persistent
time="2022-11-23T15:40:46Z" level=error msg="Error backing up item" backup=openshift-adp/django-persistent-67a5b83d-6b44-11ed-9cba-902e163f8这个问题已在 OADP 1.2.2 中解决。(OADP-1057)。
因为恢复顺序的原因,ACM 集群恢复无法如预期正常工作。
在以前的 OADP 1.2 版本中,因为恢复顺序,ACM 集群恢复无法正常工作。在恢复激活后,ACM 应用程序会在受管集群中被删除并重新创建。(OADP-2505)
由于卷大小不匹配,在备份和恢复时,使用 filesystemOverhead 的虚拟机会失败
在以前的 OADP 1.2 版本中,因为存储供应商实现选择,当应用程序持久性卷声明 (PVC) 存储请求和同一 PVC 的快照大小之间有区别时,使用 filesystemOverhead 的虚拟机在备份和恢复时会失败。 这个问题已在 OADP 1.2.2 的 Data Mover 中解决。(OADP-2144)
OADP 没有包含设置 VolSync 复制源修剪间隔的选项
在之前的 OADP 1.2 版本中,没有设置 VolSync 复制源 pruneInterval 的选项。(OADP-2052)
如果 Velero 在多个命名空间中安装,则可能会出现 pod 卷备份失败
在以前的 OADP 1.2 版本中,如果在多个命名空间中安装 Velero,则可能会出现 pod 卷备份失败。(OADP-2409)
当 VSL 使用自定义 secret 时,备份存储位置会进入不可用阶段
在之前的 OADP 1.2 版本中,当卷快照位置使用自定义 secret 时,备份存储位置将进入不可用阶段。(OADP-1737)
有关 OADP 1.2.2 发行版本中解决的所有问题的完整列表,请参阅 JIRA 中的 OADP 1.2.2 解决的问题列表。
4.2.2.3. 已知问题
在 OADP 1.2.2 发行版本中,以下问题已被明确标识为已知问题:
must-gather 命令无法删除 ClusterRoleBinding 资源
oc adm must-gather 命令无法删除 ClusterRoleBinding 资源,这些资源因为准入 Webhook 留在集群中。因此,删除 ClusterRoleBinding 资源的请求会被拒绝。(OADP-27730)
admission webhook "clusterrolebindings-validation.managed.openshift.io" denied the request: Deleting ClusterRoleBinding must-gather-p7vwj is not allowed有关本发行版本中所有已知问题的完整列表,请参阅 JIRA 中的OADP 1.2.2 已知问题 列表。
4.2.3. OADP 1.2.1 发行注记
4.2.3.1. 新功能
OpenShift API for Data Protection (OADP) 1.2.1 版本没有包括新的功能。
4.2.3.2. 已解决的问题
有关 OADP 1.2.1 发行版本中解决的所有问题的完整列表,请参阅 JIRA 中的 OADP 1.2.1 解决的问题列表。
4.2.3.3. 已知问题
在 OADP 1.2.1 发行版本中,以下问题已被明确标识为已知问题:
DataMover Restic retain 和 prune 策略无法按预期正常工作
VolSync 和 Restic 提供的 retention(保留)和 prune(修剪)功能无法按预期正常工作。因为没有在 VolSync 复制中设置修剪间隔的可用选项,所以您必须在 OADP 之外的 S3 存储上远程管理和修剪存储备份。如需了解更多详细信息,请参阅:
OADP Data Mover 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
有关本发行版本中所有已知问题的完整列表,请参阅 JIRA 中的 OADP 1.2.1 已知问题列表。
4.2.4. OADP 1.2.0 发行注记
OADP 1.2.0 发行注记包括有关新功能、错误修复和已知问题的信息。
4.2.4.1. 新功能
资源超时
新的 resourceTimeout 选项指定等待各种 Velero 资源的超时时间(以分钟为单位)。这个选项适用于资源,如 Velero CRD 可用性、volumeSnapshot 删除和备份存储库可用性。默认持续时间为 10 分钟。
AWS S3 兼容备份存储供应商
您可以在 AWS S3 兼容供应商上备份对象和快照。如需了解更多详细信息,请参阅配置 Amazon Web Services。
4.2.4.1.1. 技术预览功能
data Mover
OADP Data Mover 可让您将 Container Storage Interface (CSI) 卷快照备份到远程对象存储。如果启用了 Data Mover,当出现意外删除、集群故障或数据崩溃的情况时,可以使用从对象存储中拉取的 CSI 卷快照来恢复有状态的应用程序。如需更多信息,请参阅为 CSI 快照使用数据。
OADP Data Mover 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
4.2.4.2. 已解决的问题
有关本发行版本中解决的所有问题的完整列表,请参阅 JIRA 中的 OADP 1.2.0 解决的问题列表。
4.2.4.3. 已知问题
在 OADP 1.2.0 发行版本中,以下问题已被明确标识为已知问题:
启用的多个 HTTP/2 的 Web 服务器容易受到 DDoS 攻击(Rapid Reset Attack) 的影响
HTTP/2 协议易受拒绝服务攻击的影响,因为请求可以快速重置多个流。服务器需要在没有达到每个连接的最大活跃流数量在服务器端的限制的情况下,设置和处理流。这会导致因为服务器的资源被耗尽而出现拒绝服务的问题。有关与此 CVE 关联的所有 OADP 问题列表,请查看以下 JIRA 列表。
建议升级到 OADP 1.2.3,它解决了这个问题。
如需更多信息,请参阅 CVE-2023-39325 (Rapid Reset Attack)。
4.2.5. OADP 1.1.7 发行注记
OADP 1.1.7 发行注记列出了所有已解决的问题和已知问题。
4.2.5.1. 已解决的问题
以下主要问题已在 OADP 1.1.7 中解决:
启用的多个 HTTP/2 的 Web 服务器容易受到 DDoS 攻击(Rapid Reset Attack) 的影响
在之前的 OADP 1.1 版本中,HTTP/2 协议易受拒绝服务攻击的影响,因为请求可以快速重置多个流。服务器需要在没有达到每个连接的最大活跃流数量在服务器端的限制的情况下,设置和处理流。这会导致因为服务器的资源被耗尽而出现拒绝服务的问题。有关与此 CVE 关联的所有 OADP 问题列表,请查看以下 JIRA 列表。
如需更多信息,请参阅 CVE-2023-39325 (Rapid Reset Attack)。
有关 OADP 1.1.7 发行版本中解决的所有问题的完整列表,请参阅 JIRA 中的 OADP 1.1.7 解决的问题列表。
4.2.5.2. 已知问题
OADP 1.1.7 发行版本中没有已知的问题。
4.2.6. OADP 1.1.6 发行注记
OADP 1.1.6 发行注记列出了任何新功能、解决的问题和错误以及已知的问题。
4.2.6.1. 已解决的问题
由于 Pod 安全标准,Restic 恢复部分失败
OCP 4.14 引入了 pod 安全标准,这意味着 privileged 配置集是 enforced。在以前的 OADP 版本中,这个配置集会导致 pod 收到 permission denied 错误。造成这个问题的原因是恢复顺序。pod 在安全性上下文约束 (SCC) 资源之前创建。由于此 pod 违反了 pod 安全标准,因此 pod 被拒绝,然后失败。OADP-2420
恢复作业资源部分失败
在以前的 OADP 版本中,恢复作业资源在 OCP 4.14 中部分失败。旧的 OCP 版本中没有此问题。此问题是由一个额外的标签指向作业资源造成的,这些资源在旧的 OCP 版本中不存在。OADP-2530
有关本发行版本中解决的所有问题的完整列表,请参阅 JIRA 中的 OADP 1.1.6 解决的问题列表。
4.2.6.2. 已知问题
有关本发行版本中所有已知问题的完整列表,请参阅 JIRA 中的 OADP 1.1.6 已知问题列表。
4.2.7. OADP 1.1.5 发行注记
OADP 1.1.5 发行注记列出了任何新功能、解决的问题和错误以及已知的问题。
4.2.7.1. 新功能
这个版本 OADP 是一个服务发行版本。此版本不会添加新功能。
4.2.7.2. 已解决的问题
有关本发行版本中解决的所有问题的完整列表,请参阅 JIRA 中的 OADP 1.1.5 解决的问题列表。
4.2.7.3. 已知问题
有关本发行版本中所有已知问题的完整列表,请参阅 JIRA 中的 OADP 1.1.5 已知问题列表。
4.2.8. OADP 1.1.4 发行注记
OADP 1.1.4 发行注记列出了任何新功能、解决的问题和错误以及已知的问题。
4.2.8.1. 新功能
这个版本 OADP 是一个服务发行版本。此版本不会添加新功能。
4.2.8.2. 已解决的问题
添加对所有 velero 部署服务器参数的支持
在之前的 OADP 版本中,OADP 无法促进所有上游 Velero 服务器参数的支持。这个问题已在 OADP 1.1.4 中解决,所有上游 Velero 服务器参数都支持。OADP-1557
当存在多个 VSR 用于恢复名称和 pvc 名称时,数据 Mover 可以从不正确的快照中恢复
在之前的 OADP 版本中,如果集群中有多个带有相同的 restore 名和 PersistentVolumeClaim (pvc) 名的多个 Volume Snapshot Restore (VSR) 资源,OADP Data Mover 可能会从不正确的快照进行恢复。OADP-1822
Cloud Storage API BSLs 需要 OwnerReference
在之前的 OADP 版本中,ACM 备份调度失败,因为使用 dpa.spec.backupLocations.bucket 创建的 Backup Storage Locations (BSLs) 中缺少 OwnerReference。OADP-1511
有关本发行版本中解决的所有问题的完整列表,请参阅 JIRA 中的 OADP 1.1.4 解决的问题列表。
4.2.8.3. 已知问题
这个版本有以下已知问题:
OADP 备份可能会失败,因为集群中的 UID/GID 范围可能已更改
OADP 备份可能会失败,因为在恢复应用程序的集群上可能会更改 UID/GID 范围,因此 OADP 不会备份和恢复 OpenShift Container Platform UID/GID 范围元数据。要避免这个问题,如果支持的应用程序需要特定的 UUID,请确保恢复时范围可用。一个额外的解决方法是允许 OADP 在恢复操作中创建命名空间。
如果 ArgoCD 使用了 ArgoCD 的标签,则恢复可能会失败
在处理过程中如果使用了 ArgoCD,则恢复可能会失败。这是因为 ArgoCD 使用的一个标签 app.kubernetes.io/instance 造成的。该标签用于标识 ArgoCD 需要管理的资源,它可能会导致与 OADP 在恢复过程中管理资源的过程有冲突。要临时解决这个问题,将 ArgoCD YAML 上的 .spec.resourceTrackingMethod 设置为 annotation+label 或 annotation。如果问题仍然存在,请在开始恢复前禁用 ArgoCD,并在恢复完成后再次启用它。
OADP Velero 插件返回 "received EOF, stop recv loop" 信息
Velero 插件作为单独的进程启动。当 Velero 操作完成后,无论是否成功,它们都会退出。因此,如果您看到 received EOF, stopping recv loop 消息,这并不意味着发生了错误。消息显示插件操作已完成。OADP-2176
有关本发行版本中所有已知问题的完整列表,请参阅 JIRA 中的 OADP 1.1.4 已知问题列表。
4.2.9. OADP 1.1.3 发行注记
OADP 1.1.3 发行注记列出了任何新功能、解决的问题和错误以及已知的问题。
4.2.9.1. 新功能
这个版本 OADP 是一个服务发行版本。此版本不会添加新功能。
4.2.9.2. 已解决的问题
有关本发行版本中解决的所有问题的完整列表,请参阅 JIRA 中的 OADP 1.1.3 解决的问题列表。
4.2.9.3. 已知问题
有关本发行版本中所有已知问题的完整列表,请参阅 JIRA 中的 OADP 1.1.3 已知问题 列表。
4.2.10. OADP 1.1.2 发行注记
OADP 1.1.2 发行注记包括产品建议、修复的错误列表和已知问题的描述。
4.2.10.1. 产品建议
VolSync
要准备从 VolSync 0.5.1 升级到 VolSync stable 频道中的最新版本,您必须运行以下命令在 openshift-adp 命名空间中添加此注解:
$ oc annotate --overwrite namespace/openshift-adp volsync.backube/privileged-movers='true'Velero
在这个发行版本中,Velero 已从 1.9.2 升级到 1.9.5 版本。
Restic
在本发行版本中,Restic 从 0.13.1 升级到 0.14.0 版本。
4.2.10.2. 已解决的问题
本发行版本中解决了以下问题:
4.2.10.3. 已知问题
这个版本有以下已知问题:
4.2.11. OADP 1.1.1 发行注记
OADP 1.1.1 发行注记包括产品建议和已知问题的描述。
4.2.11.1. 产品建议
在安装 OADP 1.1.1 前,建议安装 VolSync 0.5.1 或升级到它。
4.2.11.2. 已知问题
这个版本有以下已知问题:
启用的多个 HTTP/2 的 Web 服务器容易受到 DDoS 攻击(Rapid Reset Attack) 的影响
HTTP/2 协议易受拒绝服务攻击的影响,因为请求可以快速重置多个流。服务器需要在没有达到每个连接的最大活跃流数量在服务器端的限制的情况下,设置和处理流。这会导致因为服务器的资源被耗尽而出现拒绝服务的问题。有关与此 CVE 关联的所有 OADP 问题列表,请查看以下 JIRA 列表。
建议升级到 OADP 1.1.7 或 1.2.3,从而解决了这个问题。
如需更多信息,请参阅 CVE-2023-39325 (Rapid Reset Attack)。
- OADP 目前不支持使用 Velero (OADP-778) 中的 restic 备份和恢复 AWS EFS 卷。
CSI 备份可能会因为每个 PVC 的
VolumeSnapshotContent快照限制而失败。您可以创建同一持久性卷声明(PVC)的许多快照,但无法调度定期创建快照:
4.3. OADP 功能和插件
OpenShift API 用于数据保护(OADP)功能,提供用于备份和恢复应用的选项。
默认插件使 Velero 能够与某些云供应商集成,并备份和恢复 OpenShift Container Platform 资源。
4.3.1. OADP 功能
OpenShift API 用于数据保护(OADP)支持以下功能:
- Backup
您可以使用 OADP 备份 OpenShift Platform 中的所有应用程序,或者您可以根据类型、命名空间或标签过滤资源。
OADP 通过将 Kubernetes 对象和内部镜像保存为对象存储上的存档文件来备份 Kubernetes 对象和内部镜像。OADP 使用原生云快照 API 或通过容器存储接口(CSI)创建快照来备份持久性卷(PV)。对于不支持快照的云供应商,OADP 使用 Restic 备份资源和 PV 数据。
注意您必须从应用程序的备份中排除 Operator,以便成功备份和恢复。
- 恢复
您可以从备份中恢复资源和 PV。您可以恢复备份中的所有对象,或者根据命名空间、PV 或标签过滤对象。
注意您必须从应用程序的备份中排除 Operator,以便成功备份和恢复。
- 调度
- 您可以通过指定的间隔调度备份。
- 钩子
-
您可以使用 hook 在 pod 上的容器中运行命令,如
fsfreeze以冻结文件系统。您可以将 hook 配置为在备份或恢复之前或之后运行。恢复 hook 可以在 init 容器或应用程序容器中运行。
4.3.2. OADP 插件
用于数据保护(OADP)的 OpenShift API 提供了与存储供应商集成的默认 Velero 插件,以支持备份和恢复操作。您可以根据 Velero 插件创建自定义插件。
OADP 还为 OpenShift Container Platform 资源备份、OpenShift Virtualization 资源备份和 Container Storage Interface(CSI)快照提供了插件。
| OADP 插件 | 功能 | 存储位置 |
|---|---|---|
|
| 备份和恢复 Kubernetes 对象。 | AWS S3 |
| 使用快照备份和恢复卷。 | AWS EBS | |
|
| 备份和恢复 Kubernetes 对象。 | Microsoft Azure Blob 存储 |
| 使用快照备份和恢复卷。 | Microsoft Azure 管理的磁盘 | |
|
| 备份和恢复 Kubernetes 对象。 | Google Cloud Storage |
| 使用快照备份和恢复卷。 | Google Compute Engine 磁盘 | |
|
| 备份和恢复 OpenShift Container Platform 资源。[1] | 对象存储 |
|
| 备份和恢复 OpenShift Virtualization 资源。[2] | 对象存储 |
|
| 使用 CSI 快照备份和恢复卷。[3] | 支持 CSI 快照的云存储 |
- 必需。
- 虚拟机磁盘使用 CSI 快照或 Restic 备份。
-
csi插件使用 Velero CSI beta 快照 API。
4.3.3. 关于 OADP Velero 插件
安装 Velero 时,您可以配置两种类型的插件:
- 默认云供应商插件
- 自定义插件
两种类型的插件都是可选的,但大多数用户都会至少配置一个云供应商插件。
4.3.3.1. 默认 Velero 云供应商插件
当您在部署过程中配置 oadp_v1alpha1_dpa.yaml 文件时,您可以安装以下默认 Velero 云供应商插件:
-
aws(Amazon Web Services) -
gcp(Google Cloud Platform) -
azure(Microsoft Azure) -
openshift(OpenShift Velero plugin) -
csi(Container Storage Interface) -
kubevirt(KubeVirt)
在部署过程中,您可以在 oadp_v1alpha1_dpa.yaml 文件中指定所需的默认插件。
示例文件
以下 .yaml 文件会安装 openshift、aws、azure 和 gcp 插件:
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: dpa-sample
spec:
configuration:
velero:
defaultPlugins:
- openshift
- aws
- azure
- gcp4.3.3.2. 自定义 Velero 插件
您可在部署期间配置 oadp_v1alpha1_dpa.yaml 文件时,通过指定插件 镜像和名称来安装自定义 Velero 插件。
在部署过程中,您可以在 oadp_v1alpha1_dpa.yaml 文件中指定所需的自定义插件。
示例文件
以下 .yaml 文件会安装默认的 openshift、azure 和 gcp 插件,以及一个自定义插件,其名称为 custom-plugin-example 和镜像 quay.io/example-repo/custom-velero-plugin :
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: dpa-sample
spec:
configuration:
velero:
defaultPlugins:
- openshift
- azure
- gcp
customPlugins:
- name: custom-plugin-example
image: quay.io/example-repo/custom-velero-plugin4.3.3.3. Velero 插件返回 "received EOF, stop recv loop" 信息
Velero 插件作为单独的进程启动。当 Velero 操作完成后,无论是否成功,它们都会退出。接收到 received EOF, stopping recv loop 消息表示插件操作已完成。这并不意味着发生了错误。
4.3.4. OADP 支持的构架
OpenShift API for Data Protection (OADP) 支持以下构架:
- AMD64
- ARM64
- PPC64le
- s390x
OADP 1.2.0 及更新版本支持 ARM64 架构。
4.3.5. OADP 支持 IBM Power 和 IBM Z
OpenShift API for Data Protection (OADP) 是一个平台中立的平台。以下的信息只与 IBM Power 和 IBM Z 相关。
OADP 1.1.0 对于 IBM Power 和 IBM Z 均针对 OpenShift Container Platform 4.11 进行了成功测试。以下小节介绍了在这些系统的备份位置上为 OADP 1.1.0 的测试和支持信息。
4.3.5.1. OADP 支持使用 IBM Power 的目标备份位置
在 IBM Power 中运行 OpenShift Container Platform 4.11 和 4.12,以及 OpenShift API for Data Protection (OADP) 1.1.2 已针对 AWS S3 备份位置目标成功进行了测试。虽然测试只涉及一个 AWS S3 目标,但红帽也支持针对所有非 AWS S3 备份位置目标在 IBM Power 中运行 OpenShift Container Platform 4.11 和 4.12, 以及 OADP 1.1.2。
4.3.5.2. OADP 测试并支持使用 IBM Z 的目标备份位置
使用 OpenShift Container Platform 4.11 和 4.12 运行 IBM Z,对于数据保护(OADP) 1.1.2 的 OpenShift API 已针对 AWS S3 备份位置目标成功进行了测试。虽然测试只涉及一个 AWS S3 目标,但红帽也支持在 OpenShift Container Platform 4.11 和 4.12 中运行 IBM Z,以及 OADP 1.1.2 针对所有非 AWS S3 备份位置目标。
4.4. 安装和配置 OADP
4.4.1. 关于安装 OADP
作为集群管理员,您可以通过安装 OADP Operator 来为数据保护(OADP)安装 OpenShift API。OADP Operator 安装 Velero 1.11。
从 OADP 1.0.4 开始,所有 OADP 1.0.z 版本都只能用作 MTC Operator 的依赖项,且不适用于独立 Operator。
要备份 Kubernetes 资源和内部镜像,必须将对象存储用作备份位置,如以下存储类型之一:
- Amazon Web Services
- Microsoft Azure
- Google Cloud Platform
- 多云对象网关
- AWS S3 兼容对象存储,如 Multicloud 对象网关或 MinIO
除非另有指定,"NooBaa" 指的是提供轻量级对象存储的开源项目,而 "Multicloud Object Gateway (MCG) " 是指 NooBaa 的红帽发行版本。
如需有关 MCG 的更多信息,请参阅使用应用程序访问多云对象网关。
CloudStorage API(它自动为对象存储创建一个存储桶)只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
您可以使用快照或 Restic 备份持久性卷(PV)。
要使用快照备份 PV,您必须有一个支持原生快照 API 或 Container Storage Interface(CSI)快照的云供应商,如以下云供应商之一:
- Amazon Web Services
- Microsoft Azure
- Google Cloud Platform
- 启用 CSI 快照的云供应商,如 OpenShift Data Foundation
如果要在 OCP 4.11 及之后的版本中使用 CSI 备份,请安装 OADP 1.1.x。
OADP 1.0.x 不支持 OCP 4.11 及更高版本上的 CSI 备份。OADP 1.0.x 包括 Velero 1.7.x,并需要 API 组 snapshot.storage.k8s.io/v1beta1,这在 OCP 4.11 及更高版本中不存在。
如果您的云供应商不支持快照,或者您的存储是 NFS,您可以在对象存储中使用 Restic 备份 来备份应用程序。
您可以创建一个默认 Secret,然后安装数据保护应用程序。
4.4.1.1. AWS S3 兼容备份存储供应商
OADP 与许多对象存储供应商兼容,用于不同的备份和恢复操作。一些对象存储供应商被完全支持,一些不被支持但可以正常工作,另外一些有已知的限制。
4.4.1.1.1. 支持的备份存储供应商
通过 AWS 插件,以下 AWS S3 兼容对象存储供应商被 OADP 完全支持作为备份存储:
- MinIO
- 多云对象网关 (MCG)
- Amazon Web Services (AWS) S3
支持以下兼容对象存储供应商,并有自己的 Velero 对象存储插件:
- Google Cloud Platform (GCP)
- Microsoft Azure
4.4.1.1.2. 不支持的备份存储供应商
通过 AWS 插件,以下 AWS S3 兼容对象存储供应商可以与 Velero 一起正常工作作为备份存储,但它们不被支持,且还没有经过红帽测试:
- IBM Cloud
- Oracle Cloud
- DigitalOcean
- NooBaa,除非使用 Multicloud Object Gateway (MCG) 安装
- Tencent Cloud
- Ceph RADOS v12.2.7
- Quobyte
- Cloudian HyperStore
除非另有指定,"NooBaa" 指的是提供轻量级对象存储的开源项目,而 "Multicloud Object Gateway (MCG) " 是指 NooBaa 的红帽发行版本。
如需有关 MCG 的更多信息,请参阅使用应用程序访问多云对象网关。
4.4.1.1.3. 带有已知限制的备份存储供应商
通过 AWS 插件,以下 AWS S3 兼容对象存储供应商可以与 Velero 搭配使用,但有一些已知的限制:
- Swift - 它可以作为备份存储的备份存储位置,但对于基于文件系统的卷备份和恢复,它与 Restic 不兼容。
如果您在 OpenShift Data Foundation 上为 MCG bucket backupStorageLocation 使用集群存储,请将 MCG 配置为外部对象存储。
将 MCG 配置为外部对象存储可能会导致备份不可用。
除非另有指定,"NooBaa" 指的是提供轻量级对象存储的开源项目,而 "Multicloud Object Gateway (MCG) " 是指 NooBaa 的红帽发行版本。
如需有关 MCG 的更多信息,请参阅使用应用程序访问多云对象网关。
流程
- 将 MCG 配置为外部对象存储,如为混合或多云添加存储资源中所述。
4.4.1.3. 关于 OADP 更新频道
安装 OADP Operator 时,您可以选择更新频道。这个频道决定到您接收到的 OADP Operator 和 Velero 的哪些升级。您可以随时切换频道。
可用的更新频道如下:
-
stable 频道现已弃用。stable 频道包含
oadp.v1.1.z和自oadp.v1.0.z的更老版本的 OADPClusterServiceVersion的补丁 (z-stream 更新)。 -
stable-1.0 频道包含
oadp.v1.0.z,它是最新的 OADP 1.0ClusterServiceVersion。 -
stable-1.1 频道包含
oadp.v1.1.z,它是最新的 OADP 1.1ClusterServiceVersion。 -
stable-1.2 频道包括
oadp.v1.2.z,最新的 OADP 1.2ClusterServiceVersion。 -
stable-1.3 频道包含
oadp.v1.3.z,它是最新的 OADP 1.3ClusterServiceVersion。
哪个更新频道适合您?
-
stable 频道现已弃用。如果您已使用 stable 频道,则继续从
oadp.v1.1.z获取更新。 - 选择 stable-1.y 更新频道来安装 OADP 1.y,并继续为其接受补丁。如果您选择此频道,您将收到版本 1.y.z 的所有 z-stream。
何时需要切换更新频道?
- 如果您安装了 OADP 1.y,并且只想接收那个 y-stream 的补丁,则必须从 stable 更新频道切换到 stable-1.y 更新频道。然后,您将收到版本 1.y.z 的所有 z-stream 补丁。
- 如果您安装了 OADP 1.0,希望升级到 OADP 1.1,然后只接收 OADP 1.1 的补丁,则必须从 stable-1.0 更新频道切换到 stable-1.1 更新频道。然后,您将收到版本 1.1.z 的所有 z-stream 补丁。
- 如果您安装了 OADP 1.y,且 y 大于 0,并且希望切换到 OADP 1.0,则必须 卸载 OADP Operator,然后使用 stable-1.0 更新频道重新安装。然后,您将收到 1.0.z 版本的所有 z-stream 补丁。
您无法通过切换更新频道从 OADP 1.y 切换到 OADP 1.0。您必须卸载 Operator,然后重新安装它。
4.4.1.4. 在多个命名空间中安装 OADP
您可以将 OADP 安装到同一集群中的多个命名空间中,以便多个项目所有者可以管理自己的 OADP 实例。这个用例已通过 Restic 和 CSI 验证。
您可以根据本文档中包含的每个平台流程指定安装每个 OADP 实例,并有以下额外的要求:
- 同一集群中的所有 OADP 部署都必须相同版本,如 1.1.4。不支持在同一集群中安装 OADP 的不同版本。
-
每个 OADP 部署都必须具有一组唯一的凭证和唯一的
BackupStorageLocation配置。 - 默认情况下,每个 OADP 部署在不同的命名空间中都有集群级别的访问权限。OpenShift Container Platform 管理员需要仔细检查安全性和 RBAC 设置,并对它们进行任何更改,以确保每个 OADP 实例都有正确的权限。
4.4.1.5. 基于收集到的数据的 Velero CPU 和内存要求
以下建议基于在扩展和性能实验室中观察到的性能。备份和恢复资源可能会受到插件类型、备份或恢复所需的资源数量,以及与这些资源相关的持久性卷 (PV) 中包含的相应数据。
4.4.1.5.1. 配置的 CPU 和内存要求
| 配置类型 | [1] 平均用量 | [2] 大使用 | resourceTimeouts |
|---|---|---|---|
| CSI | Velero: CPU- Request 200m, Limits 1000m 内存 - Request 256Mi, Limits 1024Mi | Velero: CPU- Request 200m, Limits 2000m 内存- Request 256Mi, Limits 2048Mi | N/A |
| Restic | [3] Restic: CPU- Request 1000m, Limits 2000m 内存 - Request 16Gi, Limits 32Gi | [4] Restic: CPU - Request 2000m, Limits 8000m 内存 - Request 16Gi, Limits 40Gi | 900m |
| [5] DataMover | N/A | N/A | 10m - 平均使用 60m - 大型使用 |
- 平均使用 - 将这些设置用于大多数使用情况。
- 大型使用 - 使用这些设置进行大型使用情况,如大型 PV (500GB 使用情况)、多个命名空间(100+)或单个命名空间中的多个 pod (2000 pods+),以及对涉及大型数据集进行备份和恢复的最佳性能。
- Restic 资源使用量与数据的数量和数据类型对应。例如,很多小文件或大量数据都可能会导致 Restic 使用大量资源。在 Velero 文档中 500m 是默认设置,但在我们的大多数测试中,我们认为 200m request 和 1000m limit 是比较适当的设置。如 Velero 文档中所述,除了环境限制外,具体的 CPU 和内存用量还取决于文件和目录的规模。
- 增加 CPU 会对改进备份和恢复时间有重大影响。
- DataMover - DataMover 默认 resourceTimeout 为 10m。我们的测试显示恢复大型 PV (500GB 使用量),需要将 resourceTimeout 增加到 60m。
本指南中列出的资源要求仅用于平均使用。对于大型用途,请按照上表所述调整设置。
4.4.1.5.2. 用于大用量的 NodeAgent CPU
测试显示,在使用 OpenShift API for Data Protection (OADP) 时,增加 NodeAgent CPU 可以显著提高备份和恢复的时间。
因为 Kopia 会以激进的方式消耗资源,因此不建议在没有在运行生产负载的节点上进行限制的环境中使用 Kopia。但是,如果运行 Kopia 时有太低的限制会导致 CPU 的限制,并减慢备份和恢复的速度。测试显示,在具有 20 个内核和 32 Gi 内存的环境中运行 Kopia,支持在跨多个命名空间或在一个命名空间中的 2000 个 pod 中对 100 GB 数据进行备份和恢复操作。
在具有这样配置的环境中的测试中没有出现 CPU 限制或内存饱和的问题。
您可以按照 更改 rook-ceph pod 上的 CPU 和内存资源中的步骤在 Ceph MDS pod 中设置这些限制。
您需要在存储集群自定义资源 (CR) 中添加以下行来设置限制:
resources:
mds:
limits:
cpu: "3"
memory: 128Gi
requests:
cpu: "3"
memory: 8Gi4.4.2. 安装 OADP Operator
您可以使用 Operator Lifecycle Manager(OLM)在 OpenShift Container Platform 4.11 上安装 Data Protection(OADP)Operator 的 OpenShift API。
OADP Operator 安装 Velero 1.11。
先决条件
-
您必须以具有
cluster-admin权限的用户身份登录。
流程
- 在 OpenShift Container Platform Web 控制台中,点击 Operators → OperatorHub。
- 使用 Filter by keyword 字段查找 OADP Operator。
- 选择 OADP Operator 并点 Install。
-
点 Install 在
openshift-adp项目中安装 Operator。 - 点 Operators → Installed Operators 来验证安装。
4.4.2.1. OADP-Velero-OpenShift Container Platform 版本关系
| OADP 版本 | Velero 版本 | OpenShift Container Platform 版本 |
|---|---|---|
| 1.1.0 | 4.9 及更新的版本 | |
| 1.1.1 | 4.9 及更新的版本 | |
| 1.1.2 | 4.9 及更新的版本 | |
| 1.1.3 | 4.9 及更新的版本 | |
| 1.1.4 | 4.9 及更新的版本 | |
| 1.1.5 | 4.9 及更新的版本 | |
| 1.1.6 | 4.11 及更新的版本 | |
| 1.1.7 | 4.11 及更新的版本 | |
| 1.2.0 | 4.11 及更新的版本 | |
| 1.2.1 | 4.11 及更新的版本 | |
| 1.2.2 | 4.11 及更新的版本 | |
| 1.2.3 | 4.11 及更新的版本 |
4.4.3. 为 Amazon Web Services 进行数据保护配置 OpenShift API
您可以通过安装 OADP Operator,使用 Amazon Web Services (AWS) 安装 OpenShift API for Data Protection (OADP)。Operator 会安装 Velero 1.11。
从 OADP 1.0.4 开始,所有 OADP 1.0.z 版本都只能用作 MTC Operator 的依赖项,且不适用于独立 Operator。
您可以为 Velero 配置 AWS,创建一个默认 Secret,然后安装数据保护应用程序。如需了解更多详细信息,请参阅安装 OADP Operator。
要在受限网络环境中安装 OADP Operator,您必须首先禁用默认的 OperatorHub 源并镜像 Operator 目录。详情请参阅在受限网络中使用 Operator Lifecycle Manager。
4.4.3.1. 配置 Amazon Web Services
您可以为 OpenShift API 配置 Amazon Web Services(AWS)以进行数据保护(OADP)。
先决条件
- 已安装 AWS CLI。
流程
设置
BUCKET变量:$ BUCKET=<your_bucket>设置
REGION变量:$ REGION=<your_region>创建 AWS S3 存储桶:
$ aws s3api create-bucket \ --bucket $BUCKET \ --region $REGION \ --create-bucket-configuration LocationConstraint=$REGION1 - 1
us-east-1不支持LocationConstraint。如果您的区域是us-east-1,忽略--create-bucket-configuration LocationConstraint=$REGION。
创建一个 IAM 用户:
$ aws iam create-user --user-name velero1 - 1
- 如果要使用 Velero 备份具有多个 S3 存储桶的集群,请为每个集群创建一个唯一用户名。
创建
velero-policy.json文件:$ cat > velero-policy.json <<EOF { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:DescribeVolumes", "ec2:DescribeSnapshots", "ec2:CreateTags", "ec2:CreateVolume", "ec2:CreateSnapshot", "ec2:DeleteSnapshot" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:DeleteObject", "s3:PutObject", "s3:AbortMultipartUpload", "s3:ListMultipartUploadParts" ], "Resource": [ "arn:aws:s3:::${BUCKET}/*" ] }, { "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetBucketLocation", "s3:ListBucketMultipartUploads" ], "Resource": [ "arn:aws:s3:::${BUCKET}" ] } ] } EOF附加策略,为
velero用户提供所需的最低权限:$ aws iam put-user-policy \ --user-name velero \ --policy-name velero \ --policy-document file://velero-policy.json为
velero用户创建访问密钥:$ aws iam create-access-key --user-name velero输出示例
{ "AccessKey": { "UserName": "velero", "Status": "Active", "CreateDate": "2017-07-31T22:24:41.576Z", "SecretAccessKey": <AWS_SECRET_ACCESS_KEY>, "AccessKeyId": <AWS_ACCESS_KEY_ID> } }创建
credentials-velero文件:$ cat << EOF > ./credentials-velero [default] aws_access_key_id=<AWS_ACCESS_KEY_ID> aws_secret_access_key=<AWS_SECRET_ACCESS_KEY> EOF在安装数据保护应用程序前,您可以使用
credentials-velero文件为 AWS 创建Secret对象。
4.4.3.2. 关于备份和恢复位置及其 secret
您可以在 DataProtectionApplication 自定义资源(CR)中指定备份和快照位置及其 secret。
备份位置
您可以将 S3 兼容对象存储(如 Multicloud Object Gateway 或 MinIO)指定为备份位置。
Velero 将 OpenShift Container Platform 资源、Kubernetes 对象和内部镜像备份为对象存储上的存档文件。
快照位置
如果使用云供应商的原生快照 API 备份持久性卷,您必须将云供应商指定为快照位置。
如果使用 Container Storage Interface(CSI)快照,则不需要指定快照位置,因为您要创建一个 VolumeSnapshotClass CR 来注册 CSI 驱动程序。
如果使用 Restic,则不需要指定快照位置,因为 Restic 备份对象存储中的文件系统。
Secrets
如果备份和快照位置使用相同的凭证,或者不需要快照位置,请创建一个默认 Secret。
如果备份和恢复位置使用不同的凭证,您可以创建两个 secret 对象:
-
您在
DataProtectionApplicationCR 中指定的备份位置的自定义Secret。 -
快照位置的默认
Secret,在DataProtectionApplicationCR 中没有引用。
数据保护应用程序需要一个默认的 Secret。否则,安装将失败。
如果您不想在安装过程中指定备份或快照位置,您可以使用空 credentials-velero 文件创建默认 Secret。
4.4.3.2.1. 创建默认 Secret
如果您的备份和快照位置使用相同的凭证,或者不需要快照位置,则创建一个默认 Secret。
Secret 的默认名称为 cloud-credentials。
DataProtectionApplication 自定义资源(CR)需要一个默认的 Secret。否则,安装将失败。如果没有指定备份位置 Secret 的名称,则会使用默认名称。
如果您不想在安装过程中使用备份位置凭证,您可以使用空 credentials-velero 文件创建带有默认名称的 Secret。
先决条件
- 您的对象存储和云存储(若有)必须使用相同的凭证。
- 您必须为 Velero 配置对象存储。
-
您必须以适当的格式为对象存储创建一个
credentials-velero文件。
流程
使用默认名称创建
Secret:$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero
在安装 Data Protection Application 时,secret 会在 DataProtectionApplication CR 的 spec.backupLocations.credential 块中引用。
4.4.3.2.2. 为不同凭证创建配置集
如果您的备份和快照位置使用不同的凭证,您可以在 credentials-velero 文件中创建单独的配置集。
然后,您可以创建一个 Secret 对象并在 DataProtectionApplication 自定义资源(CR)中指定配置集。
流程
使用备份和快照位置的独立配置集创建一个
credentials-velero文件,如下例所示:[backupStorage] aws_access_key_id=<AWS_ACCESS_KEY_ID> aws_secret_access_key=<AWS_SECRET_ACCESS_KEY> [volumeSnapshot] aws_access_key_id=<AWS_ACCESS_KEY_ID> aws_secret_access_key=<AWS_SECRET_ACCESS_KEY>使用
credentials-velero文件创建Secret对象:$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero1 在
DataProtectionApplicationCR 中添加配置集,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket_name> prefix: <prefix> config: region: us-east-1 profile: "backupStorage" credential: key: cloud name: cloud-credentials snapshotLocations: - name: default velero: provider: aws config: region: us-west-2 profile: "volumeSnapshot"
4.4.3.3. 配置数据保护应用程序
您可以通过设置 Velero 资源分配或启用自签名 CA 证书来配置数据保护应用程序。
4.4.3.3.1. 设置 Velero CPU 和内存分配
您可以通过编辑 DataProtectionApplication 自定义资源(CR)清单来为 Velero pod 设置 CPU 和内存分配。
先决条件
- 您必须安装了 OpenShift API for Data Protection(OADP)Operator。
流程
编辑
DataProtectionApplicationCR 清单的spec.configuration.velero.podConfig.ResourceAllocations块中的值,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node selector>1 resourceAllocations:2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
4.4.3.3.2. 启用自签名 CA 证书
您必须通过编辑 DataProtectionApplication 自定义资源(CR)清单来为对象存储启用自签名 CA 证书,以防止由未知颁发机构签名的证书。
先决条件
- 您必须安装了 OpenShift API for Data Protection(OADP)Operator。
流程
编辑
DataProtectionApplicationCR 清单的spec.backupLocations.velero.objectStorage.caCert参数和spec.backupLocations.velero.config参数:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket> prefix: <prefix> caCert: <base64_encoded_cert_string>1 config: insecureSkipTLSVerify: "false"2 ...
4.4.3.4. 安装数据保护应用程序
您可以通过创建 DataProtectionApplication API 的实例来安装数据保护应用程序(DPA)。
先决条件
- 您必须安装 OADP Operator。
- 您必须将对象存储配置为备份位置。
- 如果使用快照来备份 PV,云供应商必须支持原生快照 API 或 Container Storage Interface(CSI)快照。
-
如果备份和快照位置使用相同的凭证,您必须创建带有默认名称
cloud-credentials的Secret。 如果备份和快照位置使用不同的凭证,则必须使用默认名称
cloud-credentials创建一个Secret,其中包含备份和快照位置凭证的独立配置集。注意如果您不想在安装过程中指定备份或快照位置,您可以使用空
credentials-velero文件创建默认Secret。如果没有默认Secret,安装将失败。注意Velero 在 OADP 命名空间中创建一个名为
velero-repo-credentials的 secret,其中包含默认的备份存储库密码。在运行第一个面向备份存储库的备份之前,您可以使用自己的密码更新 secret,以 base64 编码。要更新的键值是Data[repository-password]。创建 DPA 后,第一次运行指向备份存储库的备份时,Velero 会创建一个备份存储库,其 secret 为
velero-repo-credentials,其中包含默认密码或您替换它。如果在首次备份之后更新 secret 密码,新密码将与velero-repo-credentials中的密码不匹配,因此 Velero 将无法与旧的备份连接。
流程
- 点 Operators → Installed Operators 并选择 OADP Operator。
- 在 Provided APIs 下,点 DataProtectionApplication 框中的 Create 实例。
点 YAML View 并更新
DataProtectionApplication清单的参数:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: configuration: velero: defaultPlugins: - openshift1 - aws resourceTimeout: 10m2 restic: enable: true3 podConfig: nodeSelector: <node_selector>4 backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket_name>5 prefix: <prefix>6 config: region: <region> profile: "default" credential: key: cloud name: cloud-credentials7 snapshotLocations:8 - name: default velero: provider: aws config: region: <region>9 profile: "default"- 1
openshift插件是必需的。- 2
- 指定在超时发生前等待多个 Velero 资源的分钟,如 Velero CRD 可用、volumeSnapshot 删除和备份存储库可用。默认值为 10m。
- 3
- 如果要禁用 Restic 安装,则将此值设置为
false。Restic 部署一个守护进程集,这意味着 Restic pod 在每个工作节点上运行。在 OADP 版本 1.2 及更高版本中,您可以通过在BackupCR 中添加spec.defaultVolumesToFsBackup: true来配置 Restic 进行备份。在 OADP 版本 1.1 中,将spec.defaultVolumesToRestic: true添加到BackupCR 中。 - 4
- 指定 Restic 在哪些节点上可用。默认情况下,Restic 在所有节点上运行。
- 5
- 指定存储桶作为备份存储位置。如果存储桶不是 Velero 备份的专用存储桶,您必须指定一个前缀。
- 6
- 如果存储桶用于多个目的,请为 Velero 备份指定一个前缀,如
velero。 - 7
- 指定您创建的
Secret对象的名称。如果没有指定这个值,则使用默认值cloud-credentials。如果您指定了自定义名称,则使用自定义名称进行备份位置。 - 8
- 指定快照位置,除非您使用 CSI 快照或 Restic 备份 PV。
- 9
- 快照位置必须与 PV 位于同一区域。
- 点 Create。
通过查看 OADP 资源来验证安装:
$ oc get all -n openshift-adp输出示例
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/restic-9cq4q 1/1 Running 0 94s pod/restic-m4lts 1/1 Running 0 94s pod/restic-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/restic 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s
4.4.3.4.1. 在 DataProtectionApplication CR 中启用 CSI
您可以在 DataProtectionApplication 自定义资源(CR)中启用 Container Storage Interface(CSI)来备份持久性卷,以使用 CSI 快照备份持久性卷。
先决条件
- 云供应商必须支持 CSI 快照。
流程
编辑
DataProtectionApplicationCR,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... spec: configuration: velero: defaultPlugins: - openshift - csi1 - 1
- 添加
csi默认插件。
4.4.4. 为 Microsoft Azure 的数据保护配置 OpenShift API
您可以通过安装 OADP Operator,使用 Microsoft Azure 安装 OpenShift API for Data Protection (OADP)。Operator 会安装 Velero 1.11。
从 OADP 1.0.4 开始,所有 OADP 1.0.z 版本都只能用作 MTC Operator 的依赖项,且不适用于独立 Operator。
您可以为 Velero 配置 Azure,创建一个默认 Secret,然后安装数据保护应用程序。如需了解更多详细信息,请参阅安装 OADP Operator。
要在受限网络环境中安装 OADP Operator,您必须首先禁用默认的 OperatorHub 源并镜像 Operator 目录。详情请参阅在受限网络中使用 Operator Lifecycle Manager。
4.4.4.1. 配置 Microsoft Azure
您可以为 OpenShift API 配置 Microsoft Azure 以进行数据保护(OADP)。
先决条件
- 已安装 Azure CLI。
流程
登录到 Azure:
$ az login设置
AZURE_RESOURCE_GROUP变量:$ AZURE_RESOURCE_GROUP=Velero_Backups创建 Azure 资源组:
$ az group create -n $AZURE_RESOURCE_GROUP --location CentralUS1 - 1
- 指定位置。
设置
AZURE_STORAGE_ACCOUNT_ID变量:$ AZURE_STORAGE_ACCOUNT_ID="velero$(uuidgen | cut -d '-' -f5 | tr '[A-Z]' '[a-z]')"创建 Azure 存储帐户:
$ az storage account create \ --name $AZURE_STORAGE_ACCOUNT_ID \ --resource-group $AZURE_RESOURCE_GROUP \ --sku Standard_GRS \ --encryption-services blob \ --https-only true \ --kind BlobStorage \ --access-tier Hot设置
BLOB_CONTAINER变量:$ BLOB_CONTAINER=velero创建 Azure Blob 存储容器:
$ az storage container create \ -n $BLOB_CONTAINER \ --public-access off \ --account-name $AZURE_STORAGE_ACCOUNT_ID获取存储帐户访问密钥:
$ AZURE_STORAGE_ACCOUNT_ACCESS_KEY=`az storage account keys list \ --account-name $AZURE_STORAGE_ACCOUNT_ID \ --query "[?keyName == 'key1'].value" -o tsv`创建具有最低所需权限的自定义角色:
AZURE_ROLE=Velero az role definition create --role-definition '{ "Name": "'$AZURE_ROLE'", "Description": "Velero related permissions to perform backups, restores and deletions", "Actions": [ "Microsoft.Compute/disks/read", "Microsoft.Compute/disks/write", "Microsoft.Compute/disks/endGetAccess/action", "Microsoft.Compute/disks/beginGetAccess/action", "Microsoft.Compute/snapshots/read", "Microsoft.Compute/snapshots/write", "Microsoft.Compute/snapshots/delete", "Microsoft.Storage/storageAccounts/listkeys/action", "Microsoft.Storage/storageAccounts/regeneratekey/action" ], "AssignableScopes": ["/subscriptions/'$AZURE_SUBSCRIPTION_ID'"] }'创建
credentials-velero文件:$ cat << EOF > ./credentials-velero AZURE_SUBSCRIPTION_ID=${AZURE_SUBSCRIPTION_ID} AZURE_TENANT_ID=${AZURE_TENANT_ID} AZURE_CLIENT_ID=${AZURE_CLIENT_ID} AZURE_CLIENT_SECRET=${AZURE_CLIENT_SECRET} AZURE_RESOURCE_GROUP=${AZURE_RESOURCE_GROUP} AZURE_STORAGE_ACCOUNT_ACCESS_KEY=${AZURE_STORAGE_ACCOUNT_ACCESS_KEY}1 AZURE_CLOUD_NAME=AzurePublicCloud EOF- 1
- 必需。如果
credentials-velero文件只包含服务主体凭证,则无法备份内部镜像。
在安装 Data Protection 应用前,您可以使用
credentials-velero文件为 Azure 创建Secret对象。
4.4.4.2. 关于备份和恢复位置及其 secret
您可以在 DataProtectionApplication 自定义资源(CR)中指定备份和快照位置及其 secret。
备份位置
您可以将 S3 兼容对象存储(如 Multicloud Object Gateway 或 MinIO)指定为备份位置。
Velero 将 OpenShift Container Platform 资源、Kubernetes 对象和内部镜像备份为对象存储上的存档文件。
快照位置
如果使用云供应商的原生快照 API 备份持久性卷,您必须将云供应商指定为快照位置。
如果使用 Container Storage Interface(CSI)快照,则不需要指定快照位置,因为您要创建一个 VolumeSnapshotClass CR 来注册 CSI 驱动程序。
如果使用 Restic,则不需要指定快照位置,因为 Restic 备份对象存储中的文件系统。
Secrets
如果备份和快照位置使用相同的凭证,或者不需要快照位置,请创建一个默认 Secret。
如果备份和恢复位置使用不同的凭证,您可以创建两个 secret 对象:
-
您在
DataProtectionApplicationCR 中指定的备份位置的自定义Secret。 -
快照位置的默认
Secret,在DataProtectionApplicationCR 中没有引用。
数据保护应用程序需要一个默认的 Secret。否则,安装将失败。
如果您不想在安装过程中指定备份或快照位置,您可以使用空 credentials-velero 文件创建默认 Secret。
4.4.4.2.1. 创建默认 Secret
如果您的备份和快照位置使用相同的凭证,或者不需要快照位置,则创建一个默认 Secret。
Secret 的默认名称为 cloud-credentials-azure。
DataProtectionApplication 自定义资源(CR)需要一个默认的 Secret。否则,安装将失败。如果没有指定备份位置 Secret 的名称,则会使用默认名称。
如果您不想在安装过程中使用备份位置凭证,您可以使用空 credentials-velero 文件创建带有默认名称的 Secret。
先决条件
- 您的对象存储和云存储(若有)必须使用相同的凭证。
- 您必须为 Velero 配置对象存储。
-
您必须以适当的格式为对象存储创建一个
credentials-velero文件。
流程
使用默认名称创建
Secret:$ oc create secret generic cloud-credentials-azure -n openshift-adp --from-file cloud=credentials-velero
在安装 Data Protection Application 时,secret 会在 DataProtectionApplication CR 的 spec.backupLocations.credential 块中引用。
4.4.4.2.2. 为不同凭证创建 secret
如果您的备份和恢复位置使用不同的凭证,您必须创建两个 Secret 对象:
-
具有自定义名称的备份位置
Secret。自定义名称在DataProtectionApplication自定义资源(CR)的spec.backupLocations块中指定。 -
带有默认名称
cloud-credentials-azure的快照位置Secret。此Secret不在DataProtectionApplicationCR 中指定。
流程
-
为您的云供应商为快照位置创建一个
credentials-velero文件。 使用默认名称为快照位置创建
Secret:$ oc create secret generic cloud-credentials-azure -n openshift-adp --from-file cloud=credentials-velero-
为您的对象存储创建一个用于备份位置的
credentials-velero文件。 使用自定义名称为备份位置创建
Secret:$ oc create secret generic <custom_secret> -n openshift-adp --from-file cloud=credentials-velero将带有自定义名称的
Secret添加到DataProtectionApplicationCR 中,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: ... backupLocations: - velero: config: resourceGroup: <azure_resource_group> storageAccount: <azure_storage_account_id> subscriptionId: <azure_subscription_id> storageAccountKeyEnvVar: AZURE_STORAGE_ACCOUNT_ACCESS_KEY credential: key: cloud name: <custom_secret>1 provider: azure default: true objectStorage: bucket: <bucket_name> prefix: <prefix> snapshotLocations: - velero: config: resourceGroup: <azure_resource_group> subscriptionId: <azure_subscription_id> incremental: "true" name: default provider: azure- 1
- 具有自定义名称的备份位置
Secret。
4.4.4.3. 配置数据保护应用程序
您可以通过设置 Velero 资源分配或启用自签名 CA 证书来配置数据保护应用程序。
4.4.4.3.1. 设置 Velero CPU 和内存分配
您可以通过编辑 DataProtectionApplication 自定义资源(CR)清单来为 Velero pod 设置 CPU 和内存分配。
先决条件
- 您必须安装了 OpenShift API for Data Protection(OADP)Operator。
流程
编辑
DataProtectionApplicationCR 清单的spec.configuration.velero.podConfig.ResourceAllocations块中的值,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node selector>1 resourceAllocations:2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
4.4.4.3.2. 启用自签名 CA 证书
您必须通过编辑 DataProtectionApplication 自定义资源(CR)清单来为对象存储启用自签名 CA 证书,以防止由未知颁发机构签名的证书。
先决条件
- 您必须安装了 OpenShift API for Data Protection(OADP)Operator。
流程
编辑
DataProtectionApplicationCR 清单的spec.backupLocations.velero.objectStorage.caCert参数和spec.backupLocations.velero.config参数:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket> prefix: <prefix> caCert: <base64_encoded_cert_string>1 config: insecureSkipTLSVerify: "false"2 ...
4.4.4.4. 安装数据保护应用程序
您可以通过创建 DataProtectionApplication API 的实例来安装数据保护应用程序(DPA)。
先决条件
- 您必须安装 OADP Operator。
- 您必须将对象存储配置为备份位置。
- 如果使用快照来备份 PV,云供应商必须支持原生快照 API 或 Container Storage Interface(CSI)快照。
-
如果备份和快照位置使用相同的凭证,您必须创建带有默认名称
cloud-credentials-azure的Secret。 如果备份和快照位置使用不同的凭证,您必须创建两个
Secret:-
带有备份位置的自定义名称的
secret。您可以将此Secret添加到DataProtectionApplicationCR 中。 带有默认名称
cloud-credentials-azure的secret,用于快照位置。这个Secret不在DataProtectionApplicationCR 中被引用。注意如果您不想在安装过程中指定备份或快照位置,您可以使用空
credentials-velero文件创建默认Secret。如果没有默认Secret,安装将失败。注意Velero 在 OADP 命名空间中创建一个名为
velero-repo-credentials的 secret,其中包含默认的备份存储库密码。在运行第一个面向备份存储库的备份之前,您可以使用自己的密码更新 secret,以 base64 编码。要更新的键值是Data[repository-password]。创建 DPA 后,第一次运行指向备份存储库的备份时,Velero 会创建一个备份存储库,其 secret 为
velero-repo-credentials,其中包含默认密码或您替换它。如果在首次备份之后更新 secret 密码,新密码将与velero-repo-credentials中的密码不匹配,因此 Velero 将无法与旧的备份连接。
-
带有备份位置的自定义名称的
流程
- 点 Operators → Installed Operators 并选择 OADP Operator。
- 在 Provided APIs 下,点 DataProtectionApplication 框中的 Create 实例。
点 YAML View 并更新
DataProtectionApplication清单的参数:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: configuration: velero: defaultPlugins: - azure - openshift1 resourceTimeout: 10m2 restic: enable: true3 podConfig: nodeSelector: <node_selector>4 backupLocations: - velero: config: resourceGroup: <azure_resource_group>5 storageAccount: <azure_storage_account_id>6 subscriptionId: <azure_subscription_id>7 storageAccountKeyEnvVar: AZURE_STORAGE_ACCOUNT_ACCESS_KEY credential: key: cloud name: cloud-credentials-azure8 provider: azure default: true objectStorage: bucket: <bucket_name>9 prefix: <prefix>10 snapshotLocations:11 - velero: config: resourceGroup: <azure_resource_group> subscriptionId: <azure_subscription_id> incremental: "true" name: default provider: azure- 1
openshift插件是必需的。- 2
- 指定在超时发生前等待多个 Velero 资源的分钟,如 Velero CRD 可用、volumeSnapshot 删除和备份存储库可用。默认值为 10m。
- 3
- 如果要禁用 Restic 安装,则将此值设置为
false。Restic 部署一个守护进程集,这意味着 Restic pod 在每个工作节点上运行。在 OADP 版本 1.2 及更高版本中,您可以通过在BackupCR 中添加spec.defaultVolumesToFsBackup: true来配置 Restic 进行备份。在 OADP 版本 1.1 中,将spec.defaultVolumesToRestic: true添加到BackupCR 中。 - 4
- 指定 Restic 在哪些节点上可用。默认情况下,Restic 在所有节点上运行。
- 5
- 指定 Azure 资源组。
- 6
- 指定 Azure 存储帐户 ID。
- 7
- 指定 Azure 订阅 ID。
- 8
- 如果没有指定这个值,则使用默认值
cloud-credentials-azure。如果您指定了自定义名称,则使用自定义名称进行备份位置。 - 9
- 指定存储桶作为备份存储位置。如果存储桶不是 Velero 备份的专用存储桶,您必须指定一个前缀。
- 10
- 如果存储桶用于多个目的,请为 Velero 备份指定一个前缀,如
velero。 - 11
- 如果您使用 CSI 快照或 Restic 备份 PV,则不需要指定快照位置。
- 点 Create。
通过查看 OADP 资源来验证安装:
$ oc get all -n openshift-adp输出示例
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/restic-9cq4q 1/1 Running 0 94s pod/restic-m4lts 1/1 Running 0 94s pod/restic-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/restic 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s
4.4.4.4.1. 在 DataProtectionApplication CR 中启用 CSI
您可以在 DataProtectionApplication 自定义资源(CR)中启用 Container Storage Interface(CSI)来备份持久性卷,以使用 CSI 快照备份持久性卷。
先决条件
- 云供应商必须支持 CSI 快照。
流程
编辑
DataProtectionApplicationCR,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... spec: configuration: velero: defaultPlugins: - openshift - csi1 - 1
- 添加
csi默认插件。
4.4.5. 配置 OpenShift API 以进行 Google Cloud Platform 的数据保护
您可以通过安装 OADP Operator,使用 Google Cloud Platform (GCP) 安装 OpenShift API for Data Protection (OADP)。Operator 会安装 Velero 1.11。
从 OADP 1.0.4 开始,所有 OADP 1.0.z 版本都只能用作 MTC Operator 的依赖项,且不适用于独立 Operator。
您可以为 Velero 配置 GCP,创建一个默认 Secret,然后安装数据保护应用程序。如需了解更多详细信息,请参阅安装 OADP Operator。
要在受限网络环境中安装 OADP Operator,您必须首先禁用默认的 OperatorHub 源并镜像 Operator 目录。详情请参阅在受限网络中使用 Operator Lifecycle Manager。
4.4.5.1. 配置 Google Cloud Platform
对于数据保护(OADP),您可以为 OpenShift API 配置 Google Cloud Platform(GCP)。
先决条件
-
您必须安装了
gcloud和gsutilCLI 工具。详情请查看 Google 云文档。
流程
登录到 GCP:
$ gcloud auth login设置
BUCKET变量:$ BUCKET=<bucket>1 - 1
- 指定存储桶名称。
创建存储桶:
$ gsutil mb gs://$BUCKET/将
PROJECT_ID变量设置为您的活跃项目:$ PROJECT_ID=$(gcloud config get-value project)创建服务帐户:
$ gcloud iam service-accounts create velero \ --display-name "Velero service account"列出服务帐户:
$ gcloud iam service-accounts list设置
SERVICE_ACCOUNT_EMAIL变量,使其与email值匹配:$ SERVICE_ACCOUNT_EMAIL=$(gcloud iam service-accounts list \ --filter="displayName:Velero service account" \ --format 'value(email)')附加策略,为
velero用户提供所需的最低权限:$ ROLE_PERMISSIONS=( compute.disks.get compute.disks.create compute.disks.createSnapshot compute.snapshots.get compute.snapshots.create compute.snapshots.useReadOnly compute.snapshots.delete compute.zones.get storage.objects.create storage.objects.delete storage.objects.get storage.objects.list iam.serviceAccounts.signBlob )创建
velero.server自定义角色:$ gcloud iam roles create velero.server \ --project $PROJECT_ID \ --title "Velero Server" \ --permissions "$(IFS=","; echo "${ROLE_PERMISSIONS[*]}")"为项目添加 IAM 策略绑定:
$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member serviceAccount:$SERVICE_ACCOUNT_EMAIL \ --role projects/$PROJECT_ID/roles/velero.server更新 IAM 服务帐户:
$ gsutil iam ch serviceAccount:$SERVICE_ACCOUNT_EMAIL:objectAdmin gs://${BUCKET}将 IAM 服务帐户的密钥保存到当前目录中的
credentials-velero文件中:$ gcloud iam service-accounts keys create credentials-velero \ --iam-account $SERVICE_ACCOUNT_EMAIL在安装 Data Protection Application 前,您可以使用
credentials-velero文件为 GCP 创建Secret对象。
4.4.5.2. 关于备份和恢复位置及其 secret
您可以在 DataProtectionApplication 自定义资源(CR)中指定备份和快照位置及其 secret。
备份位置
您可以将 S3 兼容对象存储(如 Multicloud Object Gateway 或 MinIO)指定为备份位置。
Velero 将 OpenShift Container Platform 资源、Kubernetes 对象和内部镜像备份为对象存储上的存档文件。
快照位置
如果使用云供应商的原生快照 API 备份持久性卷,您必须将云供应商指定为快照位置。
如果使用 Container Storage Interface(CSI)快照,则不需要指定快照位置,因为您要创建一个 VolumeSnapshotClass CR 来注册 CSI 驱动程序。
如果使用 Restic,则不需要指定快照位置,因为 Restic 备份对象存储中的文件系统。
Secrets
如果备份和快照位置使用相同的凭证,或者不需要快照位置,请创建一个默认 Secret。
如果备份和恢复位置使用不同的凭证,您可以创建两个 secret 对象:
-
您在
DataProtectionApplicationCR 中指定的备份位置的自定义Secret。 -
快照位置的默认
Secret,在DataProtectionApplicationCR 中没有引用。
数据保护应用程序需要一个默认的 Secret。否则,安装将失败。
如果您不想在安装过程中指定备份或快照位置,您可以使用空 credentials-velero 文件创建默认 Secret。
4.4.5.2.1. 创建默认 Secret
如果您的备份和快照位置使用相同的凭证,或者不需要快照位置,则创建一个默认 Secret。
Secret 的默认名称为 cloud-credentials-gcp。
DataProtectionApplication 自定义资源(CR)需要一个默认的 Secret。否则,安装将失败。如果没有指定备份位置 Secret 的名称,则会使用默认名称。
如果您不想在安装过程中使用备份位置凭证,您可以使用空 credentials-velero 文件创建带有默认名称的 Secret。
先决条件
- 您的对象存储和云存储(若有)必须使用相同的凭证。
- 您必须为 Velero 配置对象存储。
-
您必须以适当的格式为对象存储创建一个
credentials-velero文件。
流程
使用默认名称创建
Secret:$ oc create secret generic cloud-credentials-gcp -n openshift-adp --from-file cloud=credentials-velero
在安装 Data Protection Application 时,secret 会在 DataProtectionApplication CR 的 spec.backupLocations.credential 块中引用。
4.4.5.2.2. 为不同凭证创建 secret
如果您的备份和恢复位置使用不同的凭证,您必须创建两个 Secret 对象:
-
具有自定义名称的备份位置
Secret。自定义名称在DataProtectionApplication自定义资源(CR)的spec.backupLocations块中指定。 -
带有默认名称
cloud-credentials-gcp的快照位置Secret。此Secret不在DataProtectionApplicationCR 中指定。
流程
-
为您的云供应商为快照位置创建一个
credentials-velero文件。 使用默认名称为快照位置创建
Secret:$ oc create secret generic cloud-credentials-gcp -n openshift-adp --from-file cloud=credentials-velero-
为您的对象存储创建一个用于备份位置的
credentials-velero文件。 使用自定义名称为备份位置创建
Secret:$ oc create secret generic <custom_secret> -n openshift-adp --from-file cloud=credentials-velero将带有自定义名称的
Secret添加到DataProtectionApplicationCR 中,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: ... backupLocations: - velero: provider: gcp default: true credential: key: cloud name: <custom_secret>1 objectStorage: bucket: <bucket_name> prefix: <prefix> snapshotLocations: - velero: provider: gcp default: true config: project: <project> snapshotLocation: us-west1- 1
- 具有自定义名称的备份位置
Secret。
4.4.5.3. 配置数据保护应用程序
您可以通过设置 Velero 资源分配或启用自签名 CA 证书来配置数据保护应用程序。
4.4.5.3.1. 设置 Velero CPU 和内存分配
您可以通过编辑 DataProtectionApplication 自定义资源(CR)清单来为 Velero pod 设置 CPU 和内存分配。
先决条件
- 您必须安装了 OpenShift API for Data Protection(OADP)Operator。
流程
编辑
DataProtectionApplicationCR 清单的spec.configuration.velero.podConfig.ResourceAllocations块中的值,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node selector>1 resourceAllocations:2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
4.4.5.3.2. 启用自签名 CA 证书
您必须通过编辑 DataProtectionApplication 自定义资源(CR)清单来为对象存储启用自签名 CA 证书,以防止由未知颁发机构签名的证书。
先决条件
- 您必须安装了 OpenShift API for Data Protection(OADP)Operator。
流程
编辑
DataProtectionApplicationCR 清单的spec.backupLocations.velero.objectStorage.caCert参数和spec.backupLocations.velero.config参数:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket> prefix: <prefix> caCert: <base64_encoded_cert_string>1 config: insecureSkipTLSVerify: "false"2 ...
4.4.5.4. 安装数据保护应用程序
您可以通过创建 DataProtectionApplication API 的实例来安装数据保护应用程序(DPA)。
先决条件
- 您必须安装 OADP Operator。
- 您必须将对象存储配置为备份位置。
- 如果使用快照来备份 PV,云供应商必须支持原生快照 API 或 Container Storage Interface(CSI)快照。
-
如果备份和快照位置使用相同的凭证,您必须创建带有默认名称
cloud-credentials-gcp的Secret。 如果备份和快照位置使用不同的凭证,您必须创建两个
Secret:-
带有备份位置的自定义名称的
secret。您可以将此Secret添加到DataProtectionApplicationCR 中。 带有默认名称
cloud-credentials-gcp的secret,用于快照位置。这个Secret不在DataProtectionApplicationCR 中被引用。注意如果您不想在安装过程中指定备份或快照位置,您可以使用空
credentials-velero文件创建默认Secret。如果没有默认Secret,安装将失败。注意Velero 在 OADP 命名空间中创建一个名为
velero-repo-credentials的 secret,其中包含默认的备份存储库密码。在运行第一个面向备份存储库的备份之前,您可以使用自己的密码更新 secret,以 base64 编码。要更新的键值是Data[repository-password]。创建 DPA 后,第一次运行指向备份存储库的备份时,Velero 会创建一个备份存储库,其 secret 为
velero-repo-credentials,其中包含默认密码或您替换它。如果在首次备份之后更新 secret 密码,新密码将与velero-repo-credentials中的密码不匹配,因此 Velero 将无法与旧的备份连接。
-
带有备份位置的自定义名称的
流程
- 点 Operators → Installed Operators 并选择 OADP Operator。
- 在 Provided APIs 下,点 DataProtectionApplication 框中的 Create 实例。
点 YAML View 并更新
DataProtectionApplication清单的参数:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: configuration: velero: defaultPlugins: - gcp - openshift1 resourceTimeout: 10m2 restic: enable: true3 podConfig: nodeSelector: <node_selector>4 backupLocations: - velero: provider: gcp default: true credential: key: cloud name: cloud-credentials-gcp5 objectStorage: bucket: <bucket_name>6 prefix: <prefix>7 snapshotLocations:8 - velero: provider: gcp default: true config: project: <project> snapshotLocation: us-west19 - 1
openshift插件是必需的。- 2
- 指定在超时发生前等待多个 Velero 资源的分钟,如 Velero CRD 可用、volumeSnapshot 删除和备份存储库可用。默认值为 10m。
- 3
- 如果要禁用 Restic 安装,则将此值设置为
false。Restic 部署一个守护进程集,这意味着 Restic pod 在每个工作节点上运行。在 OADP 版本 1.2 及更高版本中,您可以通过在BackupCR 中添加spec.defaultVolumesToFsBackup: true来配置 Restic 进行备份。在 OADP 版本 1.1 中,将spec.defaultVolumesToRestic: true添加到BackupCR 中。 - 4
- 指定 Restic 在哪些节点上可用。默认情况下,Restic 在所有节点上运行。
- 5
- 如果没有指定这个值,则使用默认值
cloud-credentials-gcp。如果您指定了自定义名称,则使用自定义名称进行备份位置。 - 6
- 指定存储桶作为备份存储位置。如果存储桶不是 Velero 备份的专用存储桶,您必须指定一个前缀。
- 7
- 如果存储桶用于多个目的,请为 Velero 备份指定一个前缀,如
velero。 - 8
- 指定快照位置,除非您使用 CSI 快照或 Restic 备份 PV。
- 9
- 快照位置必须与 PV 位于同一区域。
- 点 Create。
通过查看 OADP 资源来验证安装:
$ oc get all -n openshift-adp输出示例
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/restic-9cq4q 1/1 Running 0 94s pod/restic-m4lts 1/1 Running 0 94s pod/restic-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/restic 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s
4.4.5.4.1. 在 DataProtectionApplication CR 中启用 CSI
您可以在 DataProtectionApplication 自定义资源(CR)中启用 Container Storage Interface(CSI)来备份持久性卷,以使用 CSI 快照备份持久性卷。
先决条件
- 云供应商必须支持 CSI 快照。
流程
编辑
DataProtectionApplicationCR,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... spec: configuration: velero: defaultPlugins: - openshift - csi1 - 1
- 添加
csi默认插件。
4.4.6. 为使用多云对象网关的数据保护配置 OpenShift API
您可以通过安装 OADP Operator,使用 Multicloud Object Gateway (MCG) 安装 OpenShift API for Data Protection (OADP)。Operator 会安装 Velero 1.11。
从 OADP 1.0.4 开始,所有 OADP 1.0.z 版本都只能用作 MTC Operator 的依赖项,且不适用于独立 Operator。
您可以将 Multicloud 对象网关 配置为备份位置。MCG 是 OpenShift Data Foundation 的一个组件。您可以将 MCG 配置为 DataProtectionApplication 自定义资源(CR)中的备份位置。
CloudStorage API(它自动为对象存储创建一个存储桶)只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
为备份位置创建一个 Secret,然后安装数据保护应用程序。如需了解更多详细信息,请参阅安装 OADP Operator。
要在受限网络环境中安装 OADP Operator,您必须首先禁用默认的 OperatorHub 源并镜像 Operator 目录。详情请参阅在受限网络中使用 Operator Lifecycle Manager。
4.4.6.1. 检索多云对象网关凭证
您必须检索 Multicloud Object Gateway(MCG)凭证,以便为 OpenShift API 创建用于数据保护(OADP)的 Secret 自定义资源(CR)。
MCG 是 OpenShift Data Foundation 的一个组件。
先决条件
- 请根据相关的 OpenShift Data Foundation 部署指南部署 OpenShift Data Foundation。
流程
-
通过对
NooBaa自定义资源运行describe命令,获取 S3 端点、AWS_ACCESS_KEY_ID和AWS_SECRET_ACCESS_KEY。 创建
credentials-velero文件:$ cat << EOF > ./credentials-velero [default] aws_access_key_id=<AWS_ACCESS_KEY_ID> aws_secret_access_key=<AWS_SECRET_ACCESS_KEY> EOF在安装 Data Protection Application 时,您可以使用
credentials-velero文件创建Secret对象。
4.4.6.2. 关于备份和恢复位置及其 secret
您可以在 DataProtectionApplication 自定义资源(CR)中指定备份和快照位置及其 secret。
备份位置
您可以将 S3 兼容对象存储(如 Multicloud Object Gateway 或 MinIO)指定为备份位置。
Velero 将 OpenShift Container Platform 资源、Kubernetes 对象和内部镜像备份为对象存储上的存档文件。
快照位置
如果使用云供应商的原生快照 API 备份持久性卷,您必须将云供应商指定为快照位置。
如果使用 Container Storage Interface(CSI)快照,则不需要指定快照位置,因为您要创建一个 VolumeSnapshotClass CR 来注册 CSI 驱动程序。
如果使用 Restic,则不需要指定快照位置,因为 Restic 备份对象存储中的文件系统。
Secrets
如果备份和快照位置使用相同的凭证,或者不需要快照位置,请创建一个默认 Secret。
如果备份和恢复位置使用不同的凭证,您可以创建两个 secret 对象:
-
您在
DataProtectionApplicationCR 中指定的备份位置的自定义Secret。 -
快照位置的默认
Secret,在DataProtectionApplicationCR 中没有引用。
数据保护应用程序需要一个默认的 Secret。否则,安装将失败。
如果您不想在安装过程中指定备份或快照位置,您可以使用空 credentials-velero 文件创建默认 Secret。
4.4.6.2.1. 创建默认 Secret
如果您的备份和快照位置使用相同的凭证,或者不需要快照位置,则创建一个默认 Secret。
Secret 的默认名称为 cloud-credentials。
DataProtectionApplication 自定义资源(CR)需要一个默认的 Secret。否则,安装将失败。如果没有指定备份位置 Secret 的名称,则会使用默认名称。
如果您不想在安装过程中使用备份位置凭证,您可以使用空 credentials-velero 文件创建带有默认名称的 Secret。
先决条件
- 您的对象存储和云存储(若有)必须使用相同的凭证。
- 您必须为 Velero 配置对象存储。
-
您必须以适当的格式为对象存储创建一个
credentials-velero文件。
流程
使用默认名称创建
Secret:$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero
在安装 Data Protection Application 时,secret 会在 DataProtectionApplication CR 的 spec.backupLocations.credential 块中引用。
4.4.6.2.2. 为不同凭证创建 secret
如果您的备份和恢复位置使用不同的凭证,您必须创建两个 Secret 对象:
-
具有自定义名称的备份位置
Secret。自定义名称在DataProtectionApplication自定义资源(CR)的spec.backupLocations块中指定。 -
带有默认名称
cloud-credentials的快照位置Secret。此Secret不在DataProtectionApplicationCR 中指定。
流程
-
为您的云供应商为快照位置创建一个
credentials-velero文件。 使用默认名称为快照位置创建
Secret:$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero-
为您的对象存储创建一个用于备份位置的
credentials-velero文件。 使用自定义名称为备份位置创建
Secret:$ oc create secret generic <custom_secret> -n openshift-adp --from-file cloud=credentials-velero将带有自定义名称的
Secret添加到DataProtectionApplicationCR 中,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: ... backupLocations: - velero: config: profile: "default" region: minio s3Url: <url> insecureSkipTLSVerify: "true" s3ForcePathStyle: "true" provider: aws default: true credential: key: cloud name: <custom_secret>1 objectStorage: bucket: <bucket_name> prefix: <prefix>- 1
- 具有自定义名称的备份位置
Secret。
4.4.6.3. 配置数据保护应用程序
您可以通过设置 Velero 资源分配或启用自签名 CA 证书来配置数据保护应用程序。
4.4.6.3.1. 设置 Velero CPU 和内存分配
您可以通过编辑 DataProtectionApplication 自定义资源(CR)清单来为 Velero pod 设置 CPU 和内存分配。
先决条件
- 您必须安装了 OpenShift API for Data Protection(OADP)Operator。
流程
编辑
DataProtectionApplicationCR 清单的spec.configuration.velero.podConfig.ResourceAllocations块中的值,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node selector>1 resourceAllocations:2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
4.4.6.3.2. 启用自签名 CA 证书
您必须通过编辑 DataProtectionApplication 自定义资源(CR)清单来为对象存储启用自签名 CA 证书,以防止由未知颁发机构签名的证书。
先决条件
- 您必须安装了 OpenShift API for Data Protection(OADP)Operator。
流程
编辑
DataProtectionApplicationCR 清单的spec.backupLocations.velero.objectStorage.caCert参数和spec.backupLocations.velero.config参数:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket> prefix: <prefix> caCert: <base64_encoded_cert_string>1 config: insecureSkipTLSVerify: "false"2 ...
4.4.6.4. 安装数据保护应用程序
您可以通过创建 DataProtectionApplication API 的实例来安装数据保护应用程序(DPA)。
先决条件
- 您必须安装 OADP Operator。
- 您必须将对象存储配置为备份位置。
- 如果使用快照来备份 PV,云供应商必须支持原生快照 API 或 Container Storage Interface(CSI)快照。
-
如果备份和快照位置使用相同的凭证,您必须创建带有默认名称
cloud-credentials的Secret。 如果备份和快照位置使用不同的凭证,您必须创建两个
Secret:-
带有备份位置的自定义名称的
secret。您可以将此Secret添加到DataProtectionApplicationCR 中。 带有默认名称
cloud-credentials的secret,用于快照位置。这个Secret没有在DataProtectionApplicationCR 中被引用。注意如果您不想在安装过程中指定备份或快照位置,您可以使用空
credentials-velero文件创建默认Secret。如果没有默认Secret,安装将失败。注意Velero 在 OADP 命名空间中创建一个名为
velero-repo-credentials的 secret,其中包含默认的备份存储库密码。在运行第一个面向备份存储库的备份之前,您可以使用自己的密码更新 secret,以 base64 编码。要更新的键值是Data[repository-password]。创建 DPA 后,第一次运行指向备份存储库的备份时,Velero 会创建一个备份存储库,其 secret 为
velero-repo-credentials,其中包含默认密码或您替换它。如果在首次备份之后更新 secret 密码,新密码将与velero-repo-credentials中的密码不匹配,因此 Velero 将无法与旧的备份连接。
-
带有备份位置的自定义名称的
流程
- 点 Operators → Installed Operators 并选择 OADP Operator。
- 在 Provided APIs 下,点 DataProtectionApplication 框中的 Create 实例。
点 YAML View 并更新
DataProtectionApplication清单的参数:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: configuration: velero: defaultPlugins: - aws - openshift1 resourceTimeout: 10m2 restic: enable: true3 podConfig: nodeSelector: <node_selector>4 backupLocations: - velero: config: profile: "default" region: minio s3Url: <url>5 insecureSkipTLSVerify: "true" s3ForcePathStyle: "true" provider: aws default: true credential: key: cloud name: cloud-credentials6 objectStorage: bucket: <bucket_name>7 prefix: <prefix>8 - 1
openshift插件是必需的。- 2
- 指定在超时发生前等待多个 Velero 资源的分钟,如 Velero CRD 可用、volumeSnapshot 删除和备份存储库可用。默认值为 10m。
- 3
- 如果要禁用 Restic 安装,则将此值设置为
false。Restic 部署一个守护进程集,这意味着 Restic pod 在每个工作节点上运行。在 OADP 版本 1.2 及更高版本中,您可以通过在BackupCR 中添加spec.defaultVolumesToFsBackup: true来配置 Restic 进行备份。在 OADP 版本 1.1 中,将spec.defaultVolumesToRestic: true添加到BackupCR 中。 - 4
- 指定 Restic 在哪些节点上可用。默认情况下,Restic 在所有节点上运行。
- 5
- 指定 S3 端点的 URL。
- 6
- 如果没有指定这个值,则使用默认值
cloud-credentials。如果您指定了自定义名称,则使用自定义名称进行备份位置。 - 7
- 指定存储桶作为备份存储位置。如果存储桶不是 Velero 备份的专用存储桶,您必须指定一个前缀。
- 8
- 如果存储桶用于多个目的,请为 Velero 备份指定一个前缀,如
velero。
- 点 Create。
通过查看 OADP 资源来验证安装:
$ oc get all -n openshift-adp输出示例
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/restic-9cq4q 1/1 Running 0 94s pod/restic-m4lts 1/1 Running 0 94s pod/restic-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/restic 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s
4.4.6.4.1. 在 DataProtectionApplication CR 中启用 CSI
您可以在 DataProtectionApplication 自定义资源(CR)中启用 Container Storage Interface(CSI)来备份持久性卷,以使用 CSI 快照备份持久性卷。
先决条件
- 云供应商必须支持 CSI 快照。
流程
编辑
DataProtectionApplicationCR,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... spec: configuration: velero: defaultPlugins: - openshift - csi1 - 1
- 添加
csi默认插件。
4.4.7. 为 OpenShift Data Foundation 的数据保护配置 OpenShift API
您可以通过安装 OADP Operator 并配置备份位置和快照位置,在 OpenShift Data Foundation 中安装 OpenShift API for Data Protection (OADP)。然后,您要安装数据保护应用程序。
从 OADP 1.0.4 开始,所有 OADP 1.0.z 版本都只能用作 MTC Operator 的依赖项,且不适用于独立 Operator。
您可以将 Multicloud 对象网关 或任何与 S3 兼容对象存储配置为备份位置。
CloudStorage API(它自动为对象存储创建一个存储桶)只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
为备份位置创建一个 Secret,然后安装数据保护应用程序。如需了解更多详细信息,请参阅安装 OADP Operator。
要在受限网络环境中安装 OADP Operator,您必须首先禁用默认的 OperatorHub 源并镜像 Operator 目录。详情请参阅在受限网络中使用 Operator Lifecycle Manager。
4.4.7.1. 关于备份和恢复位置及其 secret
您可以在 DataProtectionApplication 自定义资源(CR)中指定备份和快照位置及其 secret。
备份位置
您可以将 S3 兼容对象存储(如 Multicloud Object Gateway 或 MinIO)指定为备份位置。
Velero 将 OpenShift Container Platform 资源、Kubernetes 对象和内部镜像备份为对象存储上的存档文件。
快照位置
如果使用云供应商的原生快照 API 备份持久性卷,您必须将云供应商指定为快照位置。
如果使用 Container Storage Interface(CSI)快照,则不需要指定快照位置,因为您要创建一个 VolumeSnapshotClass CR 来注册 CSI 驱动程序。
如果使用 Restic,则不需要指定快照位置,因为 Restic 备份对象存储中的文件系统。
Secrets
如果备份和快照位置使用相同的凭证,或者不需要快照位置,请创建一个默认 Secret。
如果备份和恢复位置使用不同的凭证,您可以创建两个 secret 对象:
-
您在
DataProtectionApplicationCR 中指定的备份位置的自定义Secret。 -
快照位置的默认
Secret,在DataProtectionApplicationCR 中没有引用。
数据保护应用程序需要一个默认的 Secret。否则,安装将失败。
如果您不想在安装过程中指定备份或快照位置,您可以使用空 credentials-velero 文件创建默认 Secret。
4.4.7.1.1. 创建默认 Secret
如果您的备份和快照位置使用相同的凭证,或者不需要快照位置,则创建一个默认 Secret。
DataProtectionApplication 自定义资源(CR)需要一个默认的 Secret。否则,安装将失败。如果没有指定备份位置 Secret 的名称,则会使用默认名称。
如果您不想在安装过程中使用备份位置凭证,您可以使用空 credentials-velero 文件创建带有默认名称的 Secret。
先决条件
- 您的对象存储和云存储(若有)必须使用相同的凭证。
- 您必须为 Velero 配置对象存储。
-
您必须以适当的格式为对象存储创建一个
credentials-velero文件。
流程
使用默认名称创建
Secret:$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero
在安装 Data Protection Application 时,secret 会在 DataProtectionApplication CR 的 spec.backupLocations.credential 块中引用。
4.4.7.2. 配置数据保护应用程序
您可以通过设置 Velero 资源分配或启用自签名 CA 证书来配置数据保护应用程序。
4.4.7.2.1. 设置 Velero CPU 和内存分配
您可以通过编辑 DataProtectionApplication 自定义资源(CR)清单来为 Velero pod 设置 CPU 和内存分配。
先决条件
- 您必须安装了 OpenShift API for Data Protection(OADP)Operator。
流程
编辑
DataProtectionApplicationCR 清单的spec.configuration.velero.podConfig.ResourceAllocations块中的值,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node selector>1 resourceAllocations:2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
4.4.7.2.1.1. 根据收集的数据调整 Ceph CPU 和内存要求
以下建议基于在扩展和性能实验室中观察到的性能。更改与 {odf-first} 相关。如果使用 {odf-short},请参阅相关的调优指南来了解官方的建议。
4.4.7.2.1.1.1. 配置的 CPU 和内存要求
备份和恢复操作需要大量 CephFS PersistentVolume (PV)。为了避免 Ceph MDS pod 重启并带有 out-of-memory (OOM) 错误,建议以下配置:
| 配置类型 | Request(请求) | 最大限制 |
|---|---|---|
| CPU | 请求改为 3 | 最大限制为 3 |
| 内存 | 请求改为 8 Gi | 最大限制为 128 Gi |
4.4.7.2.2. 启用自签名 CA 证书
您必须通过编辑 DataProtectionApplication 自定义资源(CR)清单来为对象存储启用自签名 CA 证书,以防止由未知颁发机构签名的证书。
先决条件
- 您必须安装了 OpenShift API for Data Protection(OADP)Operator。
流程
编辑
DataProtectionApplicationCR 清单的spec.backupLocations.velero.objectStorage.caCert参数和spec.backupLocations.velero.config参数:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket> prefix: <prefix> caCert: <base64_encoded_cert_string>1 config: insecureSkipTLSVerify: "false"2 ...
4.4.7.3. 安装数据保护应用程序
您可以通过创建 DataProtectionApplication API 的实例来安装数据保护应用程序(DPA)。
先决条件
- 您必须安装 OADP Operator。
- 您必须将对象存储配置为备份位置。
- 如果使用快照来备份 PV,云供应商必须支持原生快照 API 或 Container Storage Interface(CSI)快照。
如果备份和快照位置使用相同的凭证,您必须创建带有默认名称
cloud-credentials的Secret。注意如果您不想在安装过程中指定备份或快照位置,您可以使用空
credentials-velero文件创建默认Secret。如果没有默认Secret,安装将失败。注意Velero 在 OADP 命名空间中创建一个名为
velero-repo-credentials的 secret,其中包含默认的备份存储库密码。在运行第一个面向备份存储库的备份之前,您可以使用自己的密码更新 secret,以 base64 编码。要更新的键值是Data[repository-password]。创建 DPA 后,第一次运行指向备份存储库的备份时,Velero 会创建一个备份存储库,其 secret 为
velero-repo-credentials,其中包含默认密码或您替换它。如果在首次备份之后更新 secret 密码,新密码将与velero-repo-credentials中的密码不匹配,因此 Velero 将无法与旧的备份连接。
流程
- 点 Operators → Installed Operators 并选择 OADP Operator。
- 在 Provided APIs 下,点 DataProtectionApplication 框中的 Create 实例。
-
点 YAML View 并更新
DataProtectionApplication清单的参数: - 点 Create。
通过查看 OADP 资源来验证安装:
$ oc get all -n openshift-adp输出示例
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/restic-9cq4q 1/1 Running 0 94s pod/restic-m4lts 1/1 Running 0 94s pod/restic-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/restic 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s
如果您在 OpenShift Data Foundation 上将集群存储用于 Multicloud 对象网关 (MCG) 存储桶 backupStorageLocation,请使用 OpenShift Web 控制台创建一个对象 Bucket 声明 (OBC)。
未能配置对象 Bucket 声明 (OBC) 可能会导致备份不可用。
除非另有指定,"NooBaa" 指的是提供轻量级对象存储的开源项目,而 "Multicloud Object Gateway (MCG) " 是指 NooBaa 的红帽发行版本。
如需有关 MCG 的更多信息,请参阅使用应用程序访问多云对象网关。
流程
- 使用 OpenShift Web 控制台创建对象 Bucket 声明 (OBC),如使用 OpenShift Web 控制台创建对象 Bucket 声明中所述。
4.4.7.3.2. 在 DataProtectionApplication CR 中启用 CSI
您可以在 DataProtectionApplication 自定义资源(CR)中启用 Container Storage Interface(CSI)来备份持久性卷,以使用 CSI 快照备份持久性卷。
先决条件
- 云供应商必须支持 CSI 快照。
流程
编辑
DataProtectionApplicationCR,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... spec: configuration: velero: defaultPlugins: - openshift - csi1 - 1
- 添加
csi默认插件。
4.5. 卸载 OADP
4.5.1. 为数据保护卸载 OpenShift API
您可以通过删除 OADP Operator 来卸载 OpenShift API for Data Protection(OADP)。详情请参阅从集群中删除 Operator。
4.6. OADP 备份
4.6.1. 备份应用程序
您可以通过创建一个 Backup 自定义资源 (CR) 来备份应用程序。请参阅创建备份 CR。
Backup CR 为 Kubernetes 资源和内部镜像(S3 对象存储)和持久性卷(PV)创建备份文件,如果云供应商使用原生快照 API 或 Container Storage Interface (CSI) 来创建快照,如 OpenShift Data Foundation 4。
有关 CSI 卷快照的更多信息,请参阅 CSI 卷快照。
S3 存储的 CloudStorage API 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
-
如果您的云供应商有原生快照 API 或支持 CSI 快照,则
BackupCR 通过创建快照来备份持久性卷 (PV)。有关使用 CSI 快照的更多信息,请参阅使用 CSI 快照备份持久性卷。 - 如果您的云供应商不支持快照,或者应用程序位于 NFS 数据卷中,您可以使用 Restic 创建备份。请参阅使用 Restic 备份应用程序。
OpenShift API for Data Protection (OADP) 不支持对由其他软件创建的卷快照进行备份。
您可以创建备份 hook,以便在备份操作之前或之后运行命令。请参阅创建备份 hook。
您可以通过创建一个 Schedule CR 而不是 Backup CR 来调度备份。请参阅调度备份。
4.6.1.1. 已知问题
OpenShift Container Platform 4.14 强制执行一个 pod 安全准入 (PSA) 策略,该策略可能会在 Restic 恢复过程中阻止 pod 的就绪度。
这个问题已在 OADP 1.1.6 和 OADP 1.2.2 版本中解决,因此建议用户升级到这些版本。
4.6.2. 创建备份 CR
您可以通过创建 Backup 备份自定义资源(CR)来备份 Kubernetes 镜像、内部镜像和持久性卷(PV)。
先决条件
- 您必须安装用于数据保护(OADP)Operator 的 OpenShift API。
-
DataProtectionApplicationCR 必须处于Ready状态。 备份位置先决条件:
- 您必须为 Velero 配置 S3 对象存储。
-
您必须在
DataProtectionApplicationCR 中配置了一个备份位置。
快照位置先决条件:
- 您的云供应商必须具有原生快照 API 或支持 Container Storage Interface(CSI)快照。
-
对于 CSI 快照,您必须创建一个
VolumeSnapshotClassCR 来注册 CSI 驱动程序。 -
您必须在
DataProtectionApplicationCR 中配置了一个卷位置。
流程
输入以下命令来检索
backupStorageLocationsCR:$ oc get backupStorageLocations -n openshift-adp输出示例
NAMESPACE NAME PHASE LAST VALIDATED AGE DEFAULT openshift-adp velero-sample-1 Available 11s 31m创建一个
BackupCR,如下例所示:apiVersion: velero.io/v1 kind: Backup metadata: name: <backup> labels: velero.io/storage-location: default namespace: openshift-adp spec: hooks: {} includedNamespaces: - <namespace>1 includedResources: []2 excludedResources: []3 storageLocation: <velero-sample-1>4 ttl: 720h0m0s labelSelector:5 matchLabels: app=<label_1> app=<label_2> app=<label_3> orLabelSelectors:6 - matchLabels: app=<label_1> app=<label_2> app=<label_3>验证
BackupCR 的状态是否为Completed:$ oc get backup -n openshift-adp <backup> -o jsonpath='{.status.phase}'
4.6.3. 使用 CSI 快照备份持久性卷
在创建 Backup CR 前,您可以编辑云存储的 VolumeSnapshotClass 自定义资源(CR)来使用 Container Storage Interface (CSI) 快照备份持久性卷,请参阅 CSI 卷快照。
如需更多信息,请参阅 创建备份 CR。
先决条件
- 云供应商必须支持 CSI 快照。
-
您必须在
DataProtectionApplicationCR 中启用 CSI。
流程
将
metadata.labels.velero.io/csi-volumesnapshot-class: "true"键值对添加到VolumeSnapshotClassCR:apiVersion: snapshot.storage.k8s.io/v1 kind: VolumeSnapshotClass metadata: name: <volume_snapshot_class_name> labels: velero.io/csi-volumesnapshot-class: "true" driver: <csi_driver> deletionPolicy: Retain
现在,您可以创建一个 Backup CR。
4.6.4. 使用 Restic 备份应用程序
如果您的云供应商不支持快照,或者应用程序位于 NFS 数据卷中,您可以使用 Restic 创建备份。
默认情况下,Restic 由 OADP Operator 安装。
Restic 与 OADP 集成提供了一种解决方案,用于备份和恢复几乎任何类型的 Kubernetes 卷。这个集成是 OADP 功能的补充,而不是替换现有功能。
您可以通过编辑备份自定义资源(CR)来使用 Restic Backup 资源、内部镜像和持久性卷备份 Kubernetes 资源。
您不需要在 DataProtectionApplication CR 中指定快照位置。
Restic 不支持备份 hostPath 卷。如需更多信息,请参阅额外的 Restic 限制。
先决条件
- 您必须安装用于数据保护(OADP)Operator 的 OpenShift API。
-
您不能将
DataProtectionApplicationCR 中的spec.configuration.restic.enable设置为false来禁用默认的 Restic 安装。 -
DataProtectionApplicationCR 必须处于Ready状态。
流程
创建
BackupCR,如下例所示:apiVersion: velero.io/v1 kind: Backup metadata: name: <backup> labels: velero.io/storage-location: default namespace: openshift-adp spec: defaultVolumesToRestic: true1 ...- 1
- 将
defaultVolumesToRestic: true添加到spec块中。
4.6.5. 创建备份 hook
在执行备份时,可以根据正在备份的 pod,指定在 pod 内要执行的一个或多个命令。
可将命令配置为在任何自定义操作处理(Pre hook)或所有自定义操作完成后执行,且由自定义操作指定的任何其他项目都已备份。
在备份后运行 Post hook。
您可以通过编辑备份自定义资源(CR)来创建 Backup hook 以在 pod 中运行的容器中运行命令。
流程
在
BackupCR 的spec.hooks块中添加 hook,如下例所示:apiVersion: velero.io/v1 kind: Backup metadata: name: <backup> namespace: openshift-adp spec: hooks: resources: - name: <hook_name> includedNamespaces: - <namespace>1 excludedNamespaces:2 - <namespace> includedResources: [] - pods3 excludedResources: []4 labelSelector:5 matchLabels: app: velero component: server pre:6 - exec: container: <container>7 command: - /bin/uname8 - -a onError: Fail9 timeout: 30s10 post:11 ...- 1
- 可选:您可以指定 hook 应用的命名空间。如果没有指定这个值,则 hook 适用于所有命名空间。
- 2
- 可选:您可以指定 hook 不应用到的命名空间。
- 3
- 目前,pod 是唯一可以应用 hook 的支持的资源。
- 4
- 可选:您可以指定 hook 不应用到的资源。
- 5
- 可选:此 hook 仅适用于与标签匹配的对象。如果没有指定这个值,则 hook 适用于所有命名空间。
- 6
- 备份前要运行的 hook 数组。
- 7
- 可选:如果没有指定容器,该命令将在 pod 的第一个容器中运行。
- 8
- 这是添加
init容器的入口点。 - 9
- 错误处理允许的值是
Fail和Continue。默认值为Fail。 - 10
- 可选:等待命令运行的时间。默认值为
30s。 - 11
- 此块定义了在备份后运行的一组 hook,其参数与 pre-backup hook 相同。
4.6.6. 使用 Schedule CR 调度备份
调度操作允许您在指定时间创建由 Cron 表达式定义的数据的备份。
您可以通过创建 Schedule 自定义资源(CR)而不是 Backup CR 来调度备份。
在您的备份调度中留有足够的时间,以便在创建另一个备份前完成了当前的备份。
例如,如果对一个命名空间进行备份通常需要 10 分钟才能完成,则调度的备份频率不应该超过每 15 分钟一次。
先决条件
- 您必须安装用于数据保护(OADP)Operator 的 OpenShift API。
-
DataProtectionApplicationCR 必须处于Ready状态。
流程
检索
backupStorageLocationsCR:$ oc get backupStorageLocations -n openshift-adp输出示例
NAMESPACE NAME PHASE LAST VALIDATED AGE DEFAULT openshift-adp velero-sample-1 Available 11s 31m创建一个
ScheduleCR,如下例所示:$ cat << EOF | oc apply -f - apiVersion: velero.io/v1 kind: Schedule metadata: name: <schedule> namespace: openshift-adp spec: schedule: 0 7 * * *1 template: hooks: {} includedNamespaces: - <namespace>2 storageLocation: <velero-sample-1>3 defaultVolumesToRestic: true4 ttl: 720h0m0s EOF在调度的备份运行后验证
ScheduleCR 的状态是否为Completed:$ oc get schedule -n openshift-adp <schedule> -o jsonpath='{.status.phase}'
4.6.7. 删除备份
您可以通过删除 Backup 自定义资源 (CR) 来删除备份文件。
删除 Backup CR 和关联的对象存储数据后,您无法恢复删除的数据。
先决条件
-
您创建了
BackupCR。 -
您知道
BackupCR 的名称以及包含它的命名空间。 - 下载 Velero CLI 工具。
- 您可以访问集群中的 Velero 二进制文件。
流程
选择以下操作之一来删除
BackupCR:要删除
BackupCR 并保留关联的对象存储数据,请运行以下命令:$ oc delete backup <backup_CR_name> -n <velero_namespace>要删除
BackupCR 并删除关联的对象存储数据,请运行以下命令:$ velero backup delete <backup_CR_name> -n <velero_namespace>其中:
- <backup_CR_name>
-
指定
Backup自定义资源的名称。 - <velero_namespace>
-
指定包含
Backup自定义资源的命名空间。
4.6.8. 关于 Kopia
Kopia 是一个快速安全的开源备份和恢复工具,可让您创建数据的加密快照,并将快照保存到您选择的远程或云存储中。
Kopia 支持网络和本地存储位置,以及许多云或远程存储位置,包括:
- Amazon S3 以及与 S3 兼容的任何云存储
- Azure Blob Storage
- Google Cloud Storage Platform
Kopia 对快照使用可内容访问的存储:
- 每个快照始终都是增量的形式。这意味着,根据文件的内容,所有数据都只上传到存储库一次。仅当文件被修改时,文件才会再次上传到存储库。
- 同一文件的多个副本会被存储一次,这意味着没有重复数据。在移动或重命名大型文件时,Kopia 可以识别出它们是否具有相同的内容,如果是相同的,则不会重新上传它们。
4.6.8.1. OADP 与 Kopia 集成
除了 Restic 外,OADP 1.3 还支持 Kopia 作为 pod 卷备份的备份机制。您需要在安装时通过在 DataProtectionApplication 自定义资源(CR) 中设置 uploaderType 字段来选择其中一个。可能的值为 restic 或 kopia。如果没有指定 uploaderType,OADP 1.3 默认为使用 Kopia 作为备份机制。数据会从一个统一的存储库中读取或写入。
Kopia 的 DataProtectionApplication 配置
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: dpa-sample
spec:
configuration:
nodeAgent:
enable: true
uploaderType: kopia
# ...4.7. OADP 恢复
4.7.1. 恢复应用程序
您可以通过创建一个 Restore 自定义资源 (CR) 来恢复应用程序备份。请参阅创建 Restore CR。
您可以创建恢复 hook,以便在 pod 中的容器中运行命令,同时通过编辑 Restore (CR) 恢复应用程序。请参阅创建恢复 hook
4.7.1.1. 创建恢复 CR
您可以通过创建一个 Restore CR 来恢复 Backup 自定义资源(CR)。
先决条件
- 您必须安装用于数据保护(OADP)Operator 的 OpenShift API。
-
DataProtectionApplicationCR 必须处于Ready状态。 -
您必须具有 Velero
BackupCR。 - 调整请求的大小,以便持久性卷 (PV) 容量与备份时请求的大小匹配。
流程
创建一个
RestoreCR,如下例所示:apiVersion: velero.io/v1 kind: Restore metadata: name: <restore> namespace: openshift-adp spec: backupName: <backup>1 includedResources: []2 excludedResources: - nodes - events - events.events.k8s.io - backups.velero.io - restores.velero.io - resticrepositories.velero.io restorePVs: true3 输入以下命令验证
RestoreCR 的状态是否为Completed:$ oc get restore -n openshift-adp <restore> -o jsonpath='{.status.phase}'输入以下命令验证备份资源是否已恢复:
$ oc get all -n <namespace>1 - 1
- 备份的命名空间。
如果您使用 Restic 恢复
DeploymentConfig对象,或使用 post-restore hook,请输入以下命令运行dc-restic-post-restore.shcleanup 脚本:$ bash dc-restic-post-restore.sh <restore-name>注意在恢复过程中,OADP Velero 插件会缩减
DeploymentConfig对象,并将 pod 恢复为独立 pod,以防止集群在恢复时立即删除恢复的DeploymentConfigpod,并允许 Restic 和 post-restore hook 在恢复的 pod 上完成其操作。清理脚本会删除这些断开连接的 pod,并将任何DeploymentConfig对象扩展至适当的副本数。例 4.1.
dc-restic-post-restore.shcleanup 脚本#!/bin/bash set -e # if sha256sum exists, use it to check the integrity of the file if command -v sha256sum >/dev/null 2>&1; then CHECKSUM_CMD="sha256sum" else CHECKSUM_CMD="shasum -a 256" fi label_name () { if [ "${#1}" -le "63" ]; then echo $1 return fi sha=$(echo -n $1|$CHECKSUM_CMD) echo "${1:0:57}${sha:0:6}" } OADP_NAMESPACE=${OADP_NAMESPACE:=openshift-adp} if [[ $# -ne 1 ]]; then echo "usage: ${BASH_SOURCE} restore-name" exit 1 fi echo using OADP Namespace $OADP_NAMESPACE echo restore: $1 label=$(label_name $1) echo label: $label echo Deleting disconnected restore pods oc delete pods -l oadp.openshift.io/disconnected-from-dc=$label for dc in $(oc get dc --all-namespaces -l oadp.openshift.io/replicas-modified=$label -o jsonpath='{range .items[*]}{.metadata.namespace}{","}{.metadata.name}{","}{.metadata.annotations.oadp\.openshift\.io/original-replicas}{","}{.metadata.annotations.oadp\.openshift\.io/original-paused}{"\n"}') do IFS=',' read -ra dc_arr <<< "$dc" if [ ${#dc_arr[0]} -gt 0 ]; then echo Found deployment ${dc_arr[0]}/${dc_arr[1]}, setting replicas: ${dc_arr[2]}, paused: ${dc_arr[3]} cat <<EOF | oc patch dc -n ${dc_arr[0]} ${dc_arr[1]} --patch-file /dev/stdin spec: replicas: ${dc_arr[2]} paused: ${dc_arr[3]} EOF fi done
4.7.1.2. 创建恢复 hook
您可以创建恢复 hook,以便在 pod 中运行的容器运行命令,同时通过编辑 Restore 自定义资源(CR)恢复应用程序。
您可以创建两种类型的恢复 hook:
inithook 将 init 容器添加到 pod,以便在应用程序容器启动前执行设置任务。如果您恢复 Restic 备份,则会在恢复 hook init 容器前添加
restic-waitinit 容器。-
exechook 在恢复的 pod 的容器中运行命令或脚本。
流程
在
RestoreCR 的spec.hooks块中添加 hook,如下例所示:apiVersion: velero.io/v1 kind: Restore metadata: name: <restore> namespace: openshift-adp spec: hooks: resources: - name: <hook_name> includedNamespaces: - <namespace>1 excludedNamespaces: - <namespace> includedResources: - pods2 excludedResources: [] labelSelector:3 matchLabels: app: velero component: server postHooks: - init: initContainers: - name: restore-hook-init image: alpine:latest volumeMounts: - mountPath: /restores/pvc1-vm name: pvc1-vm command: - /bin/ash - -c timeout:4 - exec: container: <container>5 command: - /bin/bash6 - -c - "psql < /backup/backup.sql" waitTimeout: 5m7 execTimeout: 1m8 onError: Continue9 - 1
- 可选: hook 应用的命名空间数组。如果没有指定这个值,则 hook 适用于所有命名空间。
- 2
- 目前,pod 是唯一可以应用 hook 的支持的资源。
- 3
- 可选:此 hook 仅适用于与标签选择器匹配的对象。
- 4
- 可选:超时指定了 Velero 等待
initContainers完成的最大时间长度。 - 5
- 可选:如果没有指定容器,该命令将在 pod 的第一个容器中运行。
- 6
- 这是正在添加的 init 容器的入口点。
- 7
- 可选:等待容器就绪的时间。这应该足够长,以便容器可以启动,在相同容器中的任何以前的 hook 可以完成。如果没有设置,恢复过程会无限期等待。
- 8
- 可选:等待命令运行的时间。默认值为
30s。 - 9
- 错误处理的允许值为
Fail和Continue:-
Continue: 只记录命令失败。 -
Fail: 任何 pod 中的任何容器中没有更多恢复 hook 运行。RestoreCR 的状态将是PartiallyFailed。
-
4.8. OADP Data Mover
4.8.1. OADP Data Mover 介绍
OADP Data Mover 允许您在故障、意外删除或集群崩溃时从存储中恢复有状态的应用程序。
OADP 1.1 Data Mover 是一个技术预览功能。
OADP 1.2 Data Mover 显著提高了特性和性能,但它现在还仅是一个技术预览功能。
OADP Data Mover 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
- 您可以使用 OADP Data Mover 将 Container Storage Interface (CSI) 卷快照备份到远程对象存储。对于 CSI 快照,请参阅使用数据 Mover。
- 您可以使用 OADP 1.2 Data Mover,为使用 CephFS、CephRBD 或这两者的集群备份和恢复应用程序数据。请参阅使用 OADP 1.2 数据与 Ceph 存储。
- 如果您使用 OADP 1.1 Data Mover,则必须在执行备份后执行数据清理。请参阅使用 OADP 1.1 数据 Mover 备份后清除。
迁移后 hook 可能无法与 OADP 1.3 Data Mover 正常工作。
OADP 1.1 和 OADP 1.2 Data Movers 使用同步进程来备份和恢复应用程序数据。由于进程是同步的,因此用户只能在相关 pod 的持久性卷(PV)由 Data Mover 的持久性卷声明(PVC)发布后执行。
但是,OADP 1.3 Data Movers 使用异步过程。因此,在 Data Mover 的 PVC 发布相关的 PV 前,可能会调用后一个 post-restore hook。如果发生这种情况,pod 会一直处于 Pending 状态,且无法运行 hook。hook 尝试可能会在 pod 发布前超时,从而导致 PartiallyFailed 恢复操作。
4.8.1.1. OADP Data Mover 先决条件
- 您有一个有状态应用程序在单独的命名空间中运行。
- 已使用 Operator Lifecycle Manager (OLM) 安装 OADP Operator。
-
您已创建了适当的
VolumeSnapshotClass和StorageClass。 - 已使用 OLM 安装 VolSync operator。
4.8.2. 对 CSI 快照使用 Data Mover
OADP Data Mover 可让客户将 Container Storage Interface (CSI) 卷快照备份到远程对象存储。启用 Data Mover 时,如果出现故障、意外删除或集群崩溃,您可以使用从对象存储中提取的 CSI 卷快照来恢复有状态的应用程序。
Data Mover 解决方案使用 VolSync 的 Restic 选项。
数据 Mover 支持 CSI 卷快照的备份和恢复。
在 OADP 1.2 Data Mover 中,VolumeSnapshotBackups (VSBs) 和 VolumeSnapshotRestores (VSR) 使用 VolumeSnapshotMover (VSM) 排队。通过指定 VSB 和 VSR 同时处于 InProgress 的并发数量,可以提高 VSM 的性能。在所有异步插件操作都完成后,备份将标记为完成。
OADP 1.1 Data Mover 是一个技术预览功能。
OADP 1.2 Data Mover 显著提高了特性和性能,但它现在还仅是一个技术预览功能。
OADP Data Mover 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
红帽建议使用 OADP 1.2 Data Mover 来备份和恢复 ODF CephFS 卷,升级或安装 OpenShift Container Platform 版本 4.12 或更高版本以提高性能。OADP Data Mover 可以利用 OpenShift Container Platform 版本 4.12 或更高版本中的 CephFS shouldow 卷,基于我们的测试,这可以提高备份时间的性能。
先决条件
-
已确认
StorageClass和VolumeSnapshotClass自定义资源 (CR) 支持 CSI。 您已确认只有一个
VolumeSnapshotClassCR 具有注解snapshot.storage.kubernetes.io/is-default-class: "true"。注意在 OpenShift Container Platform 版本 4.12 或更高版本中,验证这是唯一的默认
VolumeSnapshotClass。-
您已确认
VolumeSnapshotClassCR 的deletionPolicy被设置为Retain。 -
您已确认只有一个
StorageClassCR 具有注解storageclass.kubernetes.io/is-default-class: "true"。 -
您已在
VolumeSnapshotClassCR 中包含标签velero.io/csi-volumesnapshot-class: "true"。 您已确认
OADP 命名空间具有注解oc annotate --overwrite namespace/openshift-adp volsync.backube/privileged-movers="true"。注意在 OADP 1.1 中,上述设置是必须的。
在 OADP 1.2 中,多数情况下不需要
privileged-movers设置。恢复容器权限应该足以满足 Volsync 副本。在某些用户场景中,可能会有权限错误,privileged-mover=true设置应被解析。已使用 Operator Lifecycle Manager (OLM) 安装 VolSync Operator。
注意使用 OADP Data Mover 需要 VolSync Operator。
- 已使用 OLM 安装 OADP operator。
流程
通过创建一个
.yaml文件来配置 Restic secret,如下所示:apiVersion: v1 kind: Secret metadata: name: <secret_name> namespace: openshift-adp type: Opaque stringData: RESTIC_PASSWORD: <secure_restic_password>注意默认情况下,Operator 会查找名为
dm-credential的 secret。如果您使用其他名称,您需要使用dpa.spec.features.dataMover.credentialName通过 Data Protection Application (DPA) CR 指定名称。创建类似以下示例的 DPA CR。默认插件包括 CSI。
数据保护应用程序 (DPA) CR 示例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: velero-sample namespace: openshift-adp spec: backupLocations: - velero: config: profile: default region: us-east-1 credential: key: cloud name: cloud-credentials default: true objectStorage: bucket: <bucket_name> prefix: <bucket-prefix> provider: aws configuration: restic: enable: <true_or_false> velero: itemOperationSyncFrequency: "10s" defaultPlugins: - openshift - aws - csi - vsm1 features: dataMover: credentialName: restic-secret enable: true maxConcurrentBackupVolumes: "3"2 maxConcurrentRestoreVolumes: "3"3 pruneInterval: "14"4 volumeOptions:5 sourceVolumeOptions: accessMode: ReadOnlyMany cacheAccessMode: ReadWriteOnce cacheCapacity: 2Gi destinationVolumeOptions: storageClass: other-storageclass-name cacheAccessMode: ReadWriteMany snapshotLocations: - velero: config: profile: default region: us-west-2 provider: awsOADP Operator 安装两个自定义资源定义 (CRD)、
VolumeSnapshotBackup和VolumeSnapshotRestore。VolumeSnapshotBackupCRD 示例apiVersion: datamover.oadp.openshift.io/v1alpha1 kind: VolumeSnapshotBackup metadata: name: <vsb_name> namespace: <namespace_name>1 spec: volumeSnapshotContent: name: <snapcontent_name> protectedNamespace: <adp_namespace>2 resticSecretRef: name: <restic_secret_name>VolumeSnapshotRestoreCRD 示例apiVersion: datamover.oadp.openshift.io/v1alpha1 kind: VolumeSnapshotRestore metadata: name: <vsr_name> namespace: <namespace_name>1 spec: protectedNamespace: <protected_ns>2 resticSecretRef: name: <restic_secret_name> volumeSnapshotMoverBackupRef: sourcePVCData: name: <source_pvc_name> size: <source_pvc_size> resticrepository: <your_restic_repo> volumeSnapshotClassName: <vsclass_name>您可以执行以下步骤备份卷快照:
创建备份 CR:
apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_name> namespace: <protected_ns>1 spec: includedNamespaces: - <app_ns>2 storageLocation: velero-sample-1等待 10 分钟,并输入以下命令来检查
VolumeSnapshotBackupCR 状态是否为Completed:$ oc get vsb -n <app_ns>$ oc get vsb <vsb_name> -n <app_ns> -o jsonpath="{.status.phase}"在对象存储中创建快照是在 DPA 中配置。
注意如果
VolumeSnapshotBackupCR 的状态变为Failed,请参阅 Velero 日志进行故障排除。
您可以执行以下步骤来恢复卷快照:
-
删除由 Velero CSI 插件创建的 application 命名空间和
VolumeSnapshotContent。 创建
RestoreCR,并将restorePV设置为true。RestoreCR 示例apiVersion: velero.io/v1 kind: Restore metadata: name: <restore_name> namespace: <protected_ns> spec: backupName: <previous_backup_name> restorePVs: true等待 10 分钟,并通过输入以下命令来检查
VolumeSnapshotRestoreCR 状态是否为Completed:$ oc get vsr -n <app_ns>$ oc get vsr <vsr_name> -n <app_ns> -o jsonpath="{.status.phase}"检查您的应用程序数据和资源是否已恢复。
注意如果
VolumeSnapshotRestoreCR 的状态变成 'Failed',请参阅 Velero 日志进行故障排除。
-
删除由 Velero CSI 插件创建的 application 命名空间和
4.8.3. 使用带有 Ceph 存储的 OADP 1.2 Data Mover
您可以使用 OADP 1.2 Data Mover,为使用 CephFS、CephRBD 或这两者的集群备份和恢复应用程序数据。
OADP 1.2 Data Mover 会利用支持大规模环境的 Ceph 功能。其中之一是 shallow copy 方法,可用于 OpenShift Container Platform 4.12 及更新的版本。此功能支持备份和恢复源持久性卷声明 (PVC) 上找到的 StorageClass 和 AccessMode 资源。
CephFS shallow copy 是一个备份功能。它不是恢复操作的一部分。
4.8.3.1. 在 Ceph 存储中使用 OADP 1.2 Data Mover 的先决条件
以下先决条件适用于在使用 Ceph 存储的集群中通过 OpenShift API for Data Protection (OADP) 1.2 Data Mover 进行数据备份和恢复的操作:
- 已安装 OpenShift Container Platform 4.12 或更高版本。
- 已安装 OADP Operator。
-
您已在命名空间
openshift-adp中创建了 secretcloud-credentials。 - 已安装 Red Hat OpenShift Data Foundation。
- 已使用 Operator Lifecycle Manager 安装最新的 VolSync Operator。
4.8.3.2. 定义用于 OADP 1.2 Data Mover 的自定义资源
安装 Red Hat OpenShift Data Foundation 时,它会自动创建默认的 CephFS 和 CephRBD StorageClass 和 VolumeSnapshotClass 自定义资源 (CR)。您必须定义这些 CR 以用于 OpenShift API for Data Protection (OADP) 1.2 Data Mover。
定义 CR 后,您必须对环境进行一些其他更改,然后才能执行备份和恢复操作。
4.8.3.2.1. 定义 CephFS 自定义资源以用于 OADP 1.2 Data Mover
安装 Red Hat OpenShift Data Foundation 时,它会自动创建默认的 CephFS StorageClass 自定义资源 (CR) 和默认的 CephFS VolumeSnapshotClass CR。您可以定义这些 CR 以用于 OpenShift API for Data Protection (OADP) 1.2 Data Mover。
流程
定义
VolumeSnapshotClassCR,如下例所示:VolumeSnapshotClassCR 示例apiVersion: snapshot.storage.k8s.io/v1 deletionPolicy: Retain1 driver: openshift-storage.cephfs.csi.ceph.com kind: VolumeSnapshotClass metadata: annotations: snapshot.storage.kubernetes.io/is-default-class: true2 labels: velero.io/csi-volumesnapshot-class: true3 name: ocs-storagecluster-cephfsplugin-snapclass parameters: clusterID: openshift-storage csi.storage.k8s.io/snapshotter-secret-name: rook-csi-cephfs-provisioner csi.storage.k8s.io/snapshotter-secret-namespace: openshift-storage定义
StorageClassCR,如下例所示:StorageClassCR 示例kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: ocs-storagecluster-cephfs annotations: description: Provides RWO and RWX Filesystem volumes storageclass.kubernetes.io/is-default-class: true1 provisioner: openshift-storage.cephfs.csi.ceph.com parameters: clusterID: openshift-storage csi.storage.k8s.io/controller-expand-secret-name: rook-csi-cephfs-provisioner csi.storage.k8s.io/controller-expand-secret-namespace: openshift-storage csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node csi.storage.k8s.io/node-stage-secret-namespace: openshift-storage csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner csi.storage.k8s.io/provisioner-secret-namespace: openshift-storage fsName: ocs-storagecluster-cephfilesystem reclaimPolicy: Delete allowVolumeExpansion: true volumeBindingMode: Immediate- 1
- 必须设置为
true。
4.8.3.2.2. 定义 CephRBD 自定义资源以用于 OADP 1.2 Data Mover
安装 Red Hat OpenShift Data Foundation 时,它会自动创建默认的 CephRBD StorageClass 自定义资源 (CR) 和默认的 CephRBD VolumeSnapshotClass CR。您可以定义这些 CR 以用于 OpenShift API for Data Protection (OADP) 1.2 Data Mover。
流程
定义
VolumeSnapshotClassCR,如下例所示:VolumeSnapshotClassCR 示例apiVersion: snapshot.storage.k8s.io/v1 deletionPolicy: Retain1 driver: openshift-storage.rbd.csi.ceph.com kind: VolumeSnapshotClass metadata: labels: velero.io/csi-volumesnapshot-class: true2 name: ocs-storagecluster-rbdplugin-snapclass parameters: clusterID: openshift-storage csi.storage.k8s.io/snapshotter-secret-name: rook-csi-rbd-provisioner csi.storage.k8s.io/snapshotter-secret-namespace: openshift-storage定义
StorageClassCR,如下例所示:StorageClassCR 示例kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: ocs-storagecluster-ceph-rbd annotations: description: 'Provides RWO Filesystem volumes, and RWO and RWX Block volumes' provisioner: openshift-storage.rbd.csi.ceph.com parameters: csi.storage.k8s.io/fstype: ext4 csi.storage.k8s.io/provisioner-secret-namespace: openshift-storage csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node csi.storage.k8s.io/controller-expand-secret-name: rook-csi-rbd-provisioner imageFormat: '2' clusterID: openshift-storage imageFeatures: layering csi.storage.k8s.io/controller-expand-secret-namespace: openshift-storage pool: ocs-storagecluster-cephblockpool csi.storage.k8s.io/node-stage-secret-namespace: openshift-storage reclaimPolicy: Delete allowVolumeExpansion: true volumeBindingMode: Immediate
4.8.3.2.3. 定义用于 OADP 1.2 Data Mover 的额外自定义资源
在重新定义默认 StorageClass 和 CephRBD VolumeSnapshotClass 自定义资源 (CR) 后,您必须创建以下 CR:
-
定义为使用 shallow 复制功能的 CephFS
StorageClassCR -
Restic
SecretCR
流程
创建 CephFS
StorageClassCR,并将backingSnapshot参数设置为true,如下例所示:将
backingSnapshot设置为true的 CephFSStorageClassCR 示例kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: ocs-storagecluster-cephfs-shallow annotations: description: Provides RWO and RWX Filesystem volumes storageclass.kubernetes.io/is-default-class: false provisioner: openshift-storage.cephfs.csi.ceph.com parameters: csi.storage.k8s.io/provisioner-secret-namespace: openshift-storage csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node csi.storage.k8s.io/controller-expand-secret-name: rook-csi-cephfs-provisioner clusterID: openshift-storage fsName: ocs-storagecluster-cephfilesystem csi.storage.k8s.io/controller-expand-secret-namespace: openshift-storage backingSnapshot: true1 csi.storage.k8s.io/node-stage-secret-namespace: openshift-storage reclaimPolicy: Delete allowVolumeExpansion: true volumeBindingMode: Immediate- 1
- 必须设置为
true。
重要确保 CephFS
VolumeSnapshotClass和StorageClassCR 对provisioner有相同的值。配置 Restic
SecretCR,如下例所示:Restic
SecretCR 示例apiVersion: v1 kind: Secret metadata: name: <secret_name> namespace: <namespace> type: Opaque stringData: RESTIC_PASSWORD: <restic_password>
4.8.3.3. 使用 OADP 1.2 Data Mover 和 CephFS 存储备份和恢复数据
您可以通过启用 CephFS 的 shallow copy 功能,使用 OpenShift API for Data Protection (OADP) 1.2 Data Mover 来备份和恢复使用 CephFS 存储的数据。
先决条件
- 有状态应用在单独的命名空间中运行,并将 CephFS 用作置备程序的持久性卷声明 (PVC)。
-
为 CephFS 和 OADP 1.2 Data Mover 定义
StorageClass和VolumeSnapshotClass自定义资源 (CR)。 -
openshift-adp命名空间中有一个 secretcloud-credentials。
4.8.3.3.1. 创建用于 CephFS 存储的 DPA
在通过 OpenShift API for Data Protection (OADP) 1.2 Data Mover 来备份和存储使用 CephFS 存储的数据时,需要先创建一个 Data Protection Application (DPA) CR。
流程
运行以下命令,验证
VolumeSnapshotClassCR 的deletionPolicy字段是否已设置为Retain:$ oc get volumesnapshotclass -A -o jsonpath='{range .items[*]}{"Name: "}{.metadata.name}{" "}{"Retention Policy: "}{.deletionPolicy}{"\n"}{end}'运行以下命令,验证
VolumeSnapshotClassCR 的标签是否已设置为true:$ oc get volumesnapshotclass -A -o jsonpath='{range .items[*]}{"Name: "}{.metadata.name}{" "}{"labels: "}{.metadata.labels}{"\n"}{end}'运行以下命令,验证
StorageClassCR 的storageclass.kubernetes.io/is-default-class注解是否已设置为true:$ oc get storageClass -A -o jsonpath='{range .items[*]}{"Name: "}{.metadata.name}{" "}{"annotations: "}{.metadata.annotations}{"\n"}{end}'创建一个类似以下示例的 Data Protection Application (DPA) CR:
DPA CR 示例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: velero-sample namespace: openshift-adp spec: backupLocations: - velero: config: profile: default region: us-east-1 credential: key: cloud name: cloud-credentials default: true objectStorage: bucket: <my_bucket> prefix: velero provider: aws configuration: restic: enable: false1 velero: defaultPlugins: - openshift - aws - csi - vsm features: dataMover: credentialName: <restic_secret_name>2 enable: true3 volumeOptionsForStorageClasses: ocs-storagecluster-cephfs: sourceVolumeOptions: accessMode: ReadOnlyMany cacheAccessMode: ReadWriteMany cacheStorageClassName: ocs-storagecluster-cephfs storageClassName: ocs-storagecluster-cephfs-shallow
4.8.3.3.2. 使用 OADP 1.2 Data Mover 和 CephFS 存储备份数据
您可以通过启用 CephFS 存储的 shallow copy 功能,使用 OpenShift API for Data Protection (OADP) 1.2 Data Mover 来备份使用 CephFS 存储的数据。
流程
如以下示例所示,创建一个
BackupCR:BackupCR 示例apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_name> namespace: <protected_ns> spec: includedNamespaces: - <app_ns> storageLocation: velero-sample-1通过完成以下步骤来监控
VolumeSnapshotBackupCR 的进度:要检查所有
VolumeSnapshotBackupCR 的进度,请运行以下命令:$ oc get vsb -n <app_ns>要检查特定
VolumeSnapshotBackupCR 的进度,请运行以下命令:$ oc get vsb <vsb_name> -n <app_ns> -ojsonpath="{.status.phase}`
-
等待几分钟,直到
VolumeSnapshotBackupCR 的状态为Completed。 -
验证 Restic
Secret中至少有一个快照在对象存储中提供。您可以在带有前缀/<OADP_namespace>的目标BackupStorageLocation存储供应商中检查这个快照。
4.8.3.3.3. 使用 OADP 1.2 Data Mover 和 CephFS 存储恢复数据
如果备份过程启用了 CephFS 存储的 shallow copy 功能,您可以使用 OpenShift API for Data Protection (OADP) 1.2 Data Mover 来恢复使用 CephFS 存储的数据。修剪复制功能没有在恢复过程中使用。
流程
运行以下命令来删除应用程序命名空间:
$ oc delete vsb -n <app_namespace> --all运行以下命令,删除在备份过程中创建的
VolumeSnapshotContentCR:$ oc delete volumesnapshotcontent --all创建一个
RestoreCR,如下例所示:RestoreCR 示例apiVersion: velero.io/v1 kind: Restore metadata: name: <restore_name> namespace: <protected_ns> spec: backupName: <previous_backup_name>通过执行以下操作来监控
VolumeSnapshotRestoreCR 的进度:要检查所有
VolumeSnapshotRestoreCR 的进度,请运行以下命令:$ oc get vsr -n <app_ns>要检查特定
VolumeSnapshotRestoreCR 的进度,请运行以下命令:$ oc get vsr <vsr_name> -n <app_ns> -ojsonpath="{.status.phase}
运行以下命令验证您的应用程序数据是否已恢复:
$ oc get route <route_name> -n <app_ns> -ojsonpath="{.spec.host}"
您可以使用 OpenShift API for Data Protection (OADP) 1.2 Data Mover 在具有 分割卷 的环境中备份和恢复数据,即使用 CephFS 和 CephRBD 的环境。
先决条件
- 有状态应用在单独的命名空间中运行,并将 CephFS 用作置备程序的持久性卷声明 (PVC)。
-
为 CephFS 和 OADP 1.2 Data Mover 定义
StorageClass和VolumeSnapshotClass自定义资源 (CR)。 -
openshift-adp命名空间中有一个 secretcloud-credentials。
4.8.3.4.1. 创建用于分割卷的 DPA
在使用 OpenShift API for Data Protection (OADP) 1.2 Data Mover 来使用分割卷来备份和恢复数据前,您必须创建一个数据保护应用程序 (DPA) CR。
流程
创建一个数据保护应用程序 (DPA) CR,如下例所示:
带有分割卷的环境的 DPA CR 示例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: velero-sample namespace: openshift-adp spec: backupLocations: - velero: config: profile: default region: us-east-1 credential: key: cloud name: cloud-credentials default: true objectStorage: bucket: <my-bucket> prefix: velero provider: aws configuration: restic: enable: false velero: defaultPlugins: - openshift - aws - csi - vsm features: dataMover: credentialName: <restic_secret_name>1 enable: true volumeOptionsForStorageClasses:2 ocs-storagecluster-cephfs: sourceVolumeOptions: accessMode: ReadOnlyMany cacheAccessMode: ReadWriteMany cacheStorageClassName: ocs-storagecluster-cephfs storageClassName: ocs-storagecluster-cephfs-shallow ocs-storagecluster-ceph-rbd: sourceVolumeOptions: storageClassName: ocs-storagecluster-ceph-rbd cacheStorageClassName: ocs-storagecluster-ceph-rbd destinationVolumeOptions: storageClassName: ocs-storagecluster-ceph-rbd cacheStorageClassName: ocs-storagecluster-ceph-rbd
4.8.3.4.2. 使用 OADP 1.2 Data Mover 和 split 卷备份数据
您可以使用 OpenShift API 进行数据保护 (OADP) 1.2 Data Mover 在有分割卷的环境中备份数据。
流程
如以下示例所示,创建一个
BackupCR:BackupCR 示例apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_name> namespace: <protected_ns> spec: includedNamespaces: - <app_ns> storageLocation: velero-sample-1通过完成以下步骤来监控
VolumeSnapshotBackupCR 的进度:要检查所有
VolumeSnapshotBackupCR 的进度,请运行以下命令:$ oc get vsb -n <app_ns>要检查特定
VolumeSnapshotBackupCR 的进度,请运行以下命令:$ oc get vsb <vsb_name> -n <app_ns> -ojsonpath="{.status.phase}`
-
等待几分钟,直到
VolumeSnapshotBackupCR 的状态为Completed。 -
验证 Restic
Secret中至少有一个快照在对象存储中提供。您可以在带有前缀/<OADP_namespace>的目标BackupStorageLocation存储供应商中检查这个快照。
4.8.3.4.3. 使用 OADP 1.2 Data Mover 和 split 卷恢复数据
如果备份过程启用了 CephFS 存储的 shallow copy 功能,您可以使用 OpenShift API 进行数据保护 (OADP) 1.2 Data Mover 在带有分割卷的环境中恢复数据。修剪复制功能没有在恢复过程中使用。
流程
运行以下命令来删除应用程序命名空间:
$ oc delete vsb -n <app_namespace> --all运行以下命令,删除在备份过程中创建的
VolumeSnapshotContentCR:$ oc delete volumesnapshotcontent --all创建一个
RestoreCR,如下例所示:RestoreCR 示例apiVersion: velero.io/v1 kind: Restore metadata: name: <restore_name> namespace: <protected_ns> spec: backupName: <previous_backup_name>通过执行以下操作来监控
VolumeSnapshotRestoreCR 的进度:要检查所有
VolumeSnapshotRestoreCR 的进度,请运行以下命令:$ oc get vsr -n <app_ns>要检查特定
VolumeSnapshotRestoreCR 的进度,请运行以下命令:$ oc get vsr <vsr_name> -n <app_ns> -ojsonpath="{.status.phase}
运行以下命令验证您的应用程序数据是否已恢复:
$ oc get route <route_name> -n <app_ns> -ojsonpath="{.spec.host}"
4.8.4. 使用 OADP 1.1 Data Mover 进行备份后的清除处理
对于 OADP 1.1 Data Mover,在执行备份后必须执行数据清理。
清理过程会删除以下资源:
- 存储桶中的快照
- 集群资源
- 在由一个调度运行或重复运行的备份过程后的卷快照备份 (VSB)
4.8.4.1. 删除存储桶中的快照
在备份后,数据 Mover 可能会在存储桶中保留一个或多个快照。您可以删除所有快照或删除单个快照。
流程
-
要删除存储桶中的所有快照,请删除在数据保护应用程序(DPA)
.spec.backupLocation.objectStorage.bucket资源中指定的/<protected_namespace>文件夹。 删除单个快照:
-
浏览到在 DPA
.spec.backupLocation.objectStorage.bucket资源中指定的/<protected_namespace>。 -
删除前缀为
/<volumeSnapshotContent name>-pvc的适当文件夹,其中<VolumeSnapshotContent_name>是根据每个 PVC 创建的VolumeSnapshotContent。
-
浏览到在 DPA
4.8.4.2. 删除集群资源
无论是成功将容器存储接口 (CSI) 卷快照备份到远程对象存储,OADP 1.1 Data Mover 都可能会保留集群资源。
4.8.4.2.1. 在使用 Data Mover 成功备份和恢复后,删除集群资源
您使用 Data Mover 成功备份和恢复后,可以删除保留在您的应用程序命名空间中的 VolumeSnapshotBackup 或 VolumeSnapshotRestore CR。
流程
在使用 Data Mover 备份后,删除位于应用程序命名空间中、带有应用程序 PVC 的命名空间来备份和恢复的集群资源:
$ oc delete vsb -n <app_namespace> --all删除在使用 Data Mover 恢复后保留的集群资源:
$ oc delete vsr -n <app_namespace> --all如果需要,删除使用 Data Mover 备份和恢复后保留的任何
VolumeSnapshotContent资源:$ oc delete volumesnapshotcontent --all
4.8.4.2.2. 在使用 Data Mover 备份部分成功或失败后删除集群资源
如果使用 Data Mover 进行的备份和恢复操作部分成功或完全失败,您需要清理应用程序命名空间中存在的任何 VolumeSnapshotBackup (VSB) 或 VolumeSnapshotRestore 自定义资源定义(CRD),并清理这些控制器中创建的任何额外资源。
流程
输入以下命令清理使用 Data Mover 的备份操作后保留的集群资源:
删除应用程序命名空间中的 VSB CRD,带有应用程序 PVC 的命名空间用于备份和恢复:
$ oc delete vsb -n <app_namespace> --all删除
VolumeSnapshotCR:$ oc delete volumesnapshot -A --all删除
VolumeSnapshotContentCR:$ oc delete volumesnapshotcontent --all删除受保护的命名空间中的任何 PVC,在其中安装 Operator 的命名空间。
$ oc delete pvc -n <protected_namespace> --all删除命名空间中的所有
ReplicationSource资源。$ oc delete replicationsource -n <protected_namespace> --all
输入以下命令,清理使用 Data Mover 进行的恢复操作后保留的集群资源:
删除 VSR CRD:
$ oc delete vsr -n <app-ns> --all删除
VolumeSnapshotCR:$ oc delete volumesnapshot -A --all删除
VolumeSnapshotContentCR:$ oc delete volumesnapshotcontent --all删除命名空间中的所有
ReplicationDestination资源。$ oc delete replicationdestination -n <protected_namespace> --all
4.9. OADP 1.3 Data Mover
4.9.1. 关于 OADP 1.3 Data Mover
OADP 1.3 包含一个内置的 Data Mover,您可以使用它将 Container Storage Interface (CSI) 卷快照移到远程对象存储。如果发生故障、意外删除或损坏,内置的 Data Mover 可让您从远程对象存储中恢复有状态的应用程序。它使用 Kopia 作为上传程序机制来读取快照数据并写入统一存储库。
OADP 支持以下 CSI 快照:
- Red Hat OpenShift Data Foundation
- 使用支持 Kubernetes 卷快照 API 的 Container Storage Interface(CSI)驱动程序的任何其他云存储供应商
OADP 的内置 Data Mover 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
4.9.1.1. 启用内置 Data Mover
要启用内置 Data Mover,您必须在 DataProtectionApplication 自定义资源 (CR) 中包含 CSI 插件并启用节点代理。节点代理是一个 Kubernetes daemonset,用于托管数据移动模块。这包括 Data Mover 控制器、上传程序和存储库。
DataProtectionApplication 清单示例
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: dpa-sample
spec:
configuration:
nodeAgent:
enable: true
uploaderType: kopia
velero:
defaultPlugins:
- openshift
- aws
- csi
# ...4.9.1.2. 内置数据管理控制器和自定义资源定义 (CRD)
内置的 Data Mover 功能引入了三个新的 API 对象,被定义为 CRD,用于管理备份和恢复:
-
DataDownload: 代表卷快照的数据下载。CSI 插件为每个要恢复的卷创建一个DataDownload对象。DataDownloadCR 包含有关目标卷的信息、指定的 Data Mover、当前数据下载的进度、指定的备份存储库以及进程完成后当前数据下载的结果。 -
DataUpload:代表卷快照的数据上传。CSI 插件为每个 CSI 快照创建一个DataUpload对象。DataUploadCR 包含有关指定快照的信息、指定的 Data Mover、指定的备份存储库、当前数据上传的进度,以及进程完成后当前数据上传的结果。 -
BackupRepository: 代表和管理备份存储库的生命周期。当请求第一个 CSI 快照备份或恢复命名空间时,OADP 会为每个命名空间创建一个备份存储库。
4.9.2. 备份和恢复 CSI 快照
您可以使用 OADP 1.3 Data Mover 备份和恢复持久性卷。
4.9.2.1. 使用 CSI 快照备份持久性卷
您可以使用 OADP Data Mover 将 Container Storage Interface (CSI) 卷快照备份到远程对象存储。
先决条件
-
您可以使用
cluster-admin角色访问集群。 - 已安装 OADP Operator。
-
您已在
DataProtectionApplication自定义资源(CR) 中包含了 CSI 插件并启用了节点代理。 - 您有一个应用程序,其持久性卷在单独的命名空间中运行。
-
您已将
metadata.labels.velero.io/csi-volumesnapshot-class: "true"键值对添加到VolumeSnapshotClassCR。
流程
为
Backup对象创建一个 YAML 文件,如下例所示:BackupCR 示例kind: Backup apiVersion: velero.io/v1 metadata: name: backup namespace: openshift-adp spec: csiSnapshotTimeout: 10m0s defaultVolumesToFsBackup: false includedNamespaces: - mysql-persistent itemOperationTimeout: 4h0m0s snapshotMoveData: true1 storageLocation: default ttl: 720h0m0s volumeSnapshotLocations: - dpa-sample-1 # ...- 1
- 设置为
true以启用将 CSI 快照移到远程对象存储。
应用清单:
$ oc create -f backup.yaml在快照创建完成后会创建一个
DataUploadCR。
验证
通过监控
DataUploadCR 的status.phase字段来验证快照数据是否已成功传送到远程对象存储。可能的值为In Progress、Completed、Failed或Canceled。对象存储在DataProtectionApplicationCR 的backupLocations小节中配置。运行以下命令获取所有
DataUpload对象的列表:$ oc get datauploads -A输出示例
NAMESPACE NAME STATUS STARTED BYTES DONE TOTAL BYTES STORAGE LOCATION AGE NODE openshift-adp backup-test-1-sw76b Completed 9m47s 108104082 108104082 dpa-sample-1 9m47s ip-10-0-150-57.us-west-2.compute.internal openshift-adp mongo-block-7dtpf Completed 14m 1073741824 1073741824 dpa-sample-1 14m ip-10-0-150-57.us-west-2.compute.internal运行以下命令,检查特定
DataUpload对象的status.phase字段的值:$ oc get datauploads <dataupload_name> -o yaml输出示例
apiVersion: velero.io/v2alpha1 kind: DataUpload metadata: name: backup-test-1-sw76b namespace: openshift-adp spec: backupStorageLocation: dpa-sample-1 csiSnapshot: snapshotClass: "" storageClass: gp3-csi volumeSnapshot: velero-mysql-fq8sl operationTimeout: 10m0s snapshotType: CSI sourceNamespace: mysql-persistent sourcePVC: mysql status: completionTimestamp: "2023-11-02T16:57:02Z" node: ip-10-0-150-57.us-west-2.compute.internal path: /host_pods/15116bac-cc01-4d9b-8ee7-609c3bef6bde/volumes/kubernetes.io~csi/pvc-eead8167-556b-461a-b3ec-441749e291c4/mount phase: Completed1 progress: bytesDone: 108104082 totalBytes: 108104082 snapshotID: 8da1c5febf25225f4577ada2aeb9f899 startTimestamp: "2023-11-02T16:56:22Z"- 1
- 代表快照数据成功传输到远程对象存储。
4.9.2.2. 恢复 CSI 卷快照
您可以通过创建一个 Restore CR 来恢复卷快照。
您不能使用 OAPD 1.3 内置数据 Mover 从 OADP 1.2 恢复 Volsync 备份。在升级到 OADP 1.3 之前,建议使用 Restic 对所有工作负载进行文件系统备份。
先决条件
-
您可以使用
cluster-admin角色访问集群。 -
您有一个 OADP
BackupCR,可从中恢复数据。
流程
为
RestoreCR 创建 YAML 文件,如下例所示:RestoreCR 示例apiVersion: velero.io/v1 kind: Restore metadata: name: restore namespace: openshift-adp spec: backupName: <backup> # ...应用清单:
$ oc create -f restore.yaml恢复启动时会创建一个
DataDownloadCR。
验证
您可以通过检查
DataDownloadCR 的status.phase字段来监控恢复过程的状态。可能的值为In Progress、Completed、Failed或Canceled。要获取所有
DataDownload对象的列表,请运行以下命令:$ oc get datadownloads -A输出示例
NAMESPACE NAME STATUS STARTED BYTES DONE TOTAL BYTES STORAGE LOCATION AGE NODE openshift-adp restore-test-1-sk7lg Completed 7m11s 108104082 108104082 dpa-sample-1 7m11s ip-10-0-150-57.us-west-2.compute.internal输入以下命令检查特定
DataDownload对象的status.phase字段的值:$ oc get datadownloads <datadownload_name> -o yaml输出示例
apiVersion: velero.io/v2alpha1 kind: DataDownload metadata: name: restore-test-1-sk7lg namespace: openshift-adp spec: backupStorageLocation: dpa-sample-1 operationTimeout: 10m0s snapshotID: 8da1c5febf25225f4577ada2aeb9f899 sourceNamespace: mysql-persistent targetVolume: namespace: mysql-persistent pv: "" pvc: mysql status: completionTimestamp: "2023-11-02T17:01:24Z" node: ip-10-0-150-57.us-west-2.compute.internal phase: Completed1 progress: bytesDone: 108104082 totalBytes: 108104082 startTimestamp: "2023-11-02T17:00:52Z"- 1
- 表示 CSI 快照数据已被成功恢复。
4.10. 故障排除
您可以使用 OpenShift CLI 工具或 Velero CLI 工具调试 Velero 自定义资源(CR)。Velero CLI 工具提供更详细的日志和信息。
您可以检查 安装问题、备份和恢复 CR 问题,以及 Restic 问题。
您可以使用 must-gather 工具收集日志和 CR 信息。
您可以通过以下方法获取 Velero CLI 工具:
- 下载 Velero CLI 工具
- 访问集群中的 Velero 部署中的 Velero 二进制文件
4.10.1. 下载 Velero CLI 工具
您可以按照 Velero 文档页面中的说明下载并安装 Velero CLI 工具。
该页面包括:
- 使用 Homebrew 的 macOS
- GitHub
- 使用 Chocolatey 的 Windows
先决条件
- 您可以访问启用了 DNS 和容器网络的 Kubernetes 集群 v1.16 或更高版本。
-
您已在本地安装了
kubectl。
流程
- 打开浏览器,进入到在 Velero 网站上的"安装 CLI"。
- 按照 macOS、GitHub 或 Windows 的适当流程。
- 下载适用于 OADP 和 OpenShift Container Platform 版本的 Velero 版本。
4.10.1.1. OADP-Velero-OpenShift Container Platform 版本关系
| OADP 版本 | Velero 版本 | OpenShift Container Platform 版本 |
|---|---|---|
| 1.1.0 | 4.9 及更新的版本 | |
| 1.1.1 | 4.9 及更新的版本 | |
| 1.1.2 | 4.9 及更新的版本 | |
| 1.1.3 | 4.9 及更新的版本 | |
| 1.1.4 | 4.9 及更新的版本 | |
| 1.1.5 | 4.9 及更新的版本 | |
| 1.1.6 | 4.11 及更新的版本 | |
| 1.1.7 | 4.11 及更新的版本 | |
| 1.2.0 | 4.11 及更新的版本 | |
| 1.2.1 | 4.11 及更新的版本 | |
| 1.2.2 | 4.11 及更新的版本 | |
| 1.2.3 | 4.11 及更新的版本 |
4.10.2. 访问集群中的 Velero 部署中的 Velero 二进制文件
您可以使用 shell 命令访问集群中的 Velero 部署中的 Velero 二进制文件。
先决条件
-
您的
DataProtectionApplication自定义资源的状态为Reconcile complete。
流程
输入以下命令设定所需的别名:
$ alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'
4.10.3. 使用 OpenShift CLI 工具调试 Velero 资源
您可以使用 OpenShift CLI 工具检查 Velero 自定义资源(CR)和 Velero pod 日志来调试失败的备份或恢复。
Velero CR
使用 oc describe 命令检索与 Backup 或 Restore CR 关联的警告和错误概述:
$ oc describe <velero_cr> <cr_name>Velero pod 日志
使用 oc logs 命令检索 Velero pod 日志:
$ oc logs pod/<velero>Velero pod 调试日志
您可以在 DataProtectionApplication 资源中指定 Velero 日志级别,如下例所示。
这个选项可从 OADP 1.0.3 开始。
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: velero-sample
spec:
configuration:
velero:
logLevel: warning
可用的 logLevel 值如下:
-
trace -
debug -
info -
warning -
错误 -
fatal -
panic
对于多数日志,建议使用 debug。
4.10.4. 使用 Velero CLI 工具调试 Velero 资源
您可以调试 Backup 和 Restore 自定义资源(CR)并使用 Velero CLI 工具检索日志。
Velero CLI 工具比 OpenShift CLI 工具提供更详细的信息。
语法
使用 oc exec 命令运行 Velero CLI 命令:
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
<backup_restore_cr> <command> <cr_name>Example
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
backup describe 0e44ae00-5dc3-11eb-9ca8-df7e5254778b-2d8ql帮助选项
使用 velero --help 列出所有 Velero CLI 命令:
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
--helpdescribe 命令
使用 velero describe 命令检索与 Backup 或 Restore CR 关联的警告和错误概述:
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
<backup_restore_cr> describe <cr_name>Example
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
backup describe 0e44ae00-5dc3-11eb-9ca8-df7e5254778b-2d8qllogs 命令
使用 velero logs 命令检索 Backup 或 Restore CR 的日志:
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
<backup_restore_cr> logs <cr_name>Example
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
restore logs ccc7c2d0-6017-11eb-afab-85d0007f5a19-x4lbf4.10.5. 因内存不足或 CPU 造成 pod 崩溃或重启
如果 Velero 或 Restic pod 因为缺少内存或 CPU 而导致崩溃,您可以为其中任何一个资源设置特定的资源请求。
4.10.5.1. 为 Velero pod 设置资源请求
您可以使用 oadp_v1alpha1_dpa.yaml 文件中的 configuration.velero.podConfig.resourceAllocations 规格字段为 Velero pod 设置特定的资源请求。
流程
在 YAML 文件中设置
cpu和memory资源请求:Velero 文件示例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... configuration: velero: podConfig: resourceAllocations:1 requests: cpu: 200m memory: 256Mi- 1
- 列出的
resourceAllocations用于平均使用。
4.10.5.2. 为 Restic pod 设置资源请求
您可以使用 configuration.restic.podConfig.resourceAllocations specification 字段为 Restic pod 设置特定的资源请求。
流程
在 YAML 文件中设置
cpu和memory资源请求:Restic 文件示例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... configuration: restic: podConfig: resourceAllocations:1 requests: cpu: 1000m memory: 16Gi- 1
- 列出的
resourceAllocations用于平均使用。
资源请求字段的值必须遵循与 Kubernetes 资源要求相同的格式。另外,如果您没有指定 configuration.velero.podConfig.resourceAllocations 或 configuration.restic.podConfig.resourceAllocations,则 Velero pod 或 Restic pod 的默认 resources 规格如下:
requests:
cpu: 500m
memory: 128Mi4.10.6. Velero 和准入 Webhook 的问题
Velero 在恢复过程中解决准入 Webhook 问题的能力有限。如果您的工作负载带有准入 webhook,您可能需要使用额外的 Velero 插件或更改如何恢复工作负载。
通常,带有准入 Webhook 的工作负载需要您首先创建特定类型的资源。如果您的工作负载具有子资源,因为准入 webhook 通常阻止子资源,则会出现这种情况。
例如,创建或恢复顶层对象,如 service.serving.knative.dev 通常会自动创建子资源。如果您首先这样做,则不需要使用 Velero 创建和恢复这些资源。这可避免由 Velero 可使用的准入 Webhook 阻断子资源的问题。
4.10.6.1. 为使用准入 webhook 的 Velero 备份恢复临时解决方案
本节介绍了使用准入 webhook 的一些类型的 Velero 备份恢复资源所需的额外步骤。
4.10.6.1.1. 恢复 Knative 资源
您可能会遇到使用 Velero 备份使用准入 webhook 的 Knative 资源的问题。
在备份和恢复使用准入 webhook 的 Knative 资源时,您可以通过首先恢复顶层 Service 资源来避免这个问题。
流程
恢复顶层
service.serving.knavtive.dev Service资源:$ velero restore <restore_name> \ --from-backup=<backup_name> --include-resources \ service.serving.knavtive.dev
4.10.6.1.2. 恢复 IBM AppConnect 资源
如果您使用 Velero 恢复具有准入 webhook 的 IBM AppConnect 资源时遇到问题,您可以在此过程中运行检查。
流程
检查集群中是否有
kind: MutatingWebhookConfiguration的变异准入插件:$ oc get mutatingwebhookconfigurations-
检查每个
kind: MutatingWebhookConfiguration的 YAML 文件,以确保其没有规则块创建存在问题的对象。如需更多信息,请参阅官方 Kubernetes 文档。 -
检查在备份时使用的
type: Configuration.appconnect.ibm.com/v1beta1中的spec.version被已安装的 Operator 支持。
4.10.6.2. Velero 插件返回 "received EOF, stop recv loop" 信息
Velero 插件作为单独的进程启动。当 Velero 操作完成后,无论是否成功,它们都会退出。接收到 received EOF, stopping recv loop 消息表示插件操作已完成。这并不意味着发生了错误。
4.10.7. 安装问题
在安装数据保护应用程序时,您可能会遇到使用无效目录或不正确的凭证导致的问题。
4.10.7.1. 备份存储包含无效目录
Velero pod 日志显示错误消息,备份存储包含无效的顶级目录。
原因
对象存储包含不是 Velero 目录的顶级目录。
解决方案
如果对象存储不适用于 Velero,则必须通过设置 DataProtectionApplication 清单中的 spec.backupLocations.velero.objectStorage.prefix 参数为存储桶指定一个前缀。
4.10.7.2. AWS 凭证不正确
oadp-aws-registry pod 日志会显示错误消息 InvalidAccessKeyId: The AWS Access Key Id you provided does not exist in our records.
Velero pod 日志显示错误消息 NoCredentialProviders: no valid provider in chain。
原因
用于创建 Secret 对象的 credentials-velero 文件会错误地格式化。
解决方案
确保 credentials-velero 文件已正确格式化,如下例所示:
credentials-velero 文件示例
[default]
aws_access_key_id=AKIAIOSFODNN7EXAMPLE
aws_secret_access_key=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY4.10.8. OADP Operator 问题
OpenShift API for Data Protection (OADP) Operator 可能会遇到它无法解决的问题。
4.10.8.1. OADP Operator 静默失败
OADP Operator 的 S3 存储桶可能为空,但在运行 oc get po -n <OADP_Operator_namespace> 命令时,您会看到 Operator 的状态变为 Running。在这种情况下,Operator 被认为有静默地失败,因为它错误地报告它正在运行。
原因
这个问题是因为云凭证提供的权限不足。
解决方案
检索备份存储位置列表(BSL),并检查每个 BSL 的清单是否有凭证问题。
流程
运行以下命令之一以检索 BSL 列表:
使用 OpenShift CLI:
$ oc get backupstoragelocation -A使用 Velero CLI:
$ velero backup-location get -n <OADP_Operator_namespace>
使用 BSL 列表,运行以下命令来显示每个 BSL 的清单,并检查每个清单是否有错误。
$ oc get backupstoragelocation -n <namespace> -o yaml
结果示例
apiVersion: v1
items:
- apiVersion: velero.io/v1
kind: BackupStorageLocation
metadata:
creationTimestamp: "2023-11-03T19:49:04Z"
generation: 9703
name: example-dpa-1
namespace: openshift-adp-operator
ownerReferences:
- apiVersion: oadp.openshift.io/v1alpha1
blockOwnerDeletion: true
controller: true
kind: DataProtectionApplication
name: example-dpa
uid: 0beeeaff-0287-4f32-bcb1-2e3c921b6e82
resourceVersion: "24273698"
uid: ba37cd15-cf17-4f7d-bf03-8af8655cea83
spec:
config:
enableSharedConfig: "true"
region: us-west-2
credential:
key: credentials
name: cloud-credentials
default: true
objectStorage:
bucket: example-oadp-operator
prefix: example
provider: aws
status:
lastValidationTime: "2023-11-10T22:06:46Z"
message: "BackupStorageLocation \"example-dpa-1\" is unavailable: rpc
error: code = Unknown desc = WebIdentityErr: failed to retrieve credentials\ncaused
by: AccessDenied: Not authorized to perform sts:AssumeRoleWithWebIdentity\n\tstatus
code: 403, request id: d3f2e099-70a0-467b-997e-ff62345e3b54"
phase: Unavailable
kind: List
metadata:
resourceVersion: ""4.10.9. OADP 超时
通过扩展超时,可以允许复杂的或资源密集型的进程在没有预先终止的情况下成功完成。此配置可减少错误、重试或失败的可能性。
确保您在扩展超时设置时符合正常的逻辑,,以便不会因为设置的超时时间太长导致隐藏了底层存在的问题。仔细考虑并监控超时设置,以符合相关进程的需求和整体系统性能要求。
以下是不同的 OADP 超时设置的信息:
4.10.9.1. Restic 超时
timeout 定义 Restic 超时。默认值为 1h。
在以下情况下使用 Restic timeout :
- 对总 PV 数据使用量大于 500GB 的 Restic 备份。
如果备份超时并显示以下错误:
level=error msg="Error backing up item" backup=velero/monitoring error="timed out waiting for all PodVolumeBackups to complete"
流程
编辑
DataProtectionApplicationCR 清单中的spec.configuration.restic.timeout块的值,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: configuration: restic: timeout: 1h # ...
4.10.9.2. Velero 资源超时
resourceTimeout 定义在超时发生前等待 Velero 资源的时间,如等待 Velero 自定义资源定义 (CRD)可用、volumeSnapshot 删除和存储库可用。默认值为 10m。
在以下情况下使用 resourceTimeout :
对总 PV 数据使用量大于 1TB 的备份。当在将备份标记为完成前,Velero 尝试清理或删除 Container Storage Interface (CSI)快照时使用此参数作为超时值。
- 这个清理过程的一个子任务会尝试修补 VSC,此超时可用于该任务。
- 要创建或确保一个备份存储库已准备好用于 Restic 或 Kopia 的基于文件系统的备份。
- 在从备份中恢复自定义资源 (CR) 或资源前,检查集群中的 Velero CRD 是否可用。
流程
编辑
DataProtectionApplicationCR 清单的spec.configuration.velero.resourceTimeout块中的值,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: configuration: velero: resourceTimeout: 10m # ...
4.10.9.3. Data Mover timeout
timeout 是一个用户提供的、完成 VolumeSnapshotBackup 和 VolumeSnapshotRestore 的超时值。默认值为 10m。
在以下情况下使用 Data Mover timeout :
-
如果创建
VolumeSnapshotBackups(VSBs) 和VolumeSnapshotRestores(VSR),则会在 10 分钟后超时。 -
对于总 PV 数据使用量超过 500GB 的大型环境。设置
1h的超时时间。 -
使用
VolumeSnapshotMover(VSM) 插件。 - 只适用于 OADP 1.1.x。
流程
编辑
DataProtectionApplicationCR 清单的spec.features.dataMover.timeout块中的值,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: features: dataMover: timeout: 10m # ...
4.10.9.4. CSI 快照超时
CSISnapshotTimeout 指定,在创建过程返回超时错误前,需要等待 CSI VolumeSnapshot 状态变为 ReadyToUse 的时间。默认值为 10m。
在以下情况下使用 CSISnapshotTimeout :
- 使用 CSI 插件。
- 对于非常大型的存储卷,进行快照的时间可能会超过 10 分钟。如果在日志中出现超时信息,请调整此超时设置。
通常,不需要调整 CSISnapshotTimeout,因为默认设置已考虑到大型存储卷的情况。
流程
编辑
BackupCR 清单的spec.csiSnapshotTimeout块中的值,如下例所示:apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_name> spec: csiSnapshotTimeout: 10m # ...
4.10.9.5. Velero 默认项目操作超时
defaultItemOperationTimeout 定义在超时前等待异步 BackupItemActions 和 RestoreItemActions 所需的时间。默认值为 1h。
在以下情况下使用 defaultItemOperationTimeout :
- 只有 Data Mover 1.2.x。
- 要指定一个特定备份或恢复应等待异步操作完成的时间长度。在 OADP 功能上下文中,这个值用于涉及 Container Storage Interface (CSI) Data Mover 功能的异步操作。
-
当使用
defaultItemOperationTimeout在 Data Protection Application (DPA) 中定义defaultItemOperationTimeout时,它适用于备份和恢复操作。您可以使用itemOperationTimeout来只定义这些 CR 的备份过程或恢复过程,如以下 "Item operation timeout - restore" 和 "Item operation timeout - backup" 部分所述。
流程
编辑
DataProtectionApplicationCR 清单的spec.configuration.velero.defaultItemOperationTimeout块中的值,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: configuration: velero: defaultItemOperationTimeout: 1h # ...
4.10.9.6. 项目操作超时 - 恢复
ItemOperationTimeout 指定用于等待 RestoreItemAction 操作的时间。默认值为 1h。
在以下情况下,使用 restore ItemOperationTimeout :
- 只有 Data Mover 1.2.x。
-
对于 Data Mover,上传到
BackupStorageLocation或从其中下载。如果在达到超时时没有完成恢复操作,它将标记为失败。如果因为存储卷太大出现超时并导致数据 Data Mover 操作失败,则可能需要增加这个超时设置。
流程
编辑
RestoreCR 清单的Restore.spec.itemOperationTimeout块中的值,如下例所示:apiVersion: velero.io/v1 kind: Restore metadata: name: <restore_name> spec: itemOperationTimeout: 1h # ...
4.10.9.7. 项目操作超时 - 备份
ItemOperationTimeout 指定用于等待异步 BackupItemAction 操作的时间。默认值为 1h。
在以下情况下,使用 backup ItemOperationTimeout :
- 只有 Data Mover 1.2.x。
-
对于 Data Mover,上传到
BackupStorageLocation或从其中下载。如果在达到超时时没有完成备份操作,它将标记为失败。如果因为存储卷太大出现超时并导致数据 Data Mover 操作失败,则可能需要增加这个超时设置。
流程
编辑
BackupCR 清单的Backup.spec.itemOperationTimeout块中的值,如下例所示:apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_name> spec: itemOperationTimeout: 1h # ...
4.10.10. 备份和恢复 CR 问题
您可能会遇到 Backup 和 Restore 自定义资源(CR)的常见问题。
4.10.10.1. 备份 CR 无法检索卷
Backup CR 显示错误消息 InvalidVolume.NotFound: The volume ‘vol-xxxx’ does not exist。
原因
持久性卷(PV)和快照位置位于不同的区域。
解决方案
-
编辑
DataProtectionApplication清单中的spec.snapshotLocations.velero.config.region键的值,使快照位置位于与 PV 相同的区域。 -
创建新的
BackupCR。
4.10.10.2. 备份 CR 状态在进行中
Backup CR 的状态保留在 InProgress 阶段,且未完成。
原因
如果备份中断,则无法恢复。
解决方案
检索
BackupCR 的详细信息:$ oc -n {namespace} exec deployment/velero -c velero -- ./velero \ backup describe <backup>删除
BackupCR:$ oc delete backup <backup> -n openshift-adp您不需要清理备份位置,因为正在进行中的
BackupCR 没有上传文件到对象存储。-
创建新的
BackupCR。
4.10.10.3. 备份 CR 状态处于 PartiallyFailed
在没有 Restic 使用时一个 Backup CR 的状态保留在 PartiallyFailed 阶段,且没有完成。从属 PVC 的快照没有创建。
原因
如果备份是基于 CSI 快照类创建的,但缺少标签,CSI 快照插件将无法创建快照。因此,Velero pod 会记录类似如下的错误:
+
time="2023-02-17T16:33:13Z" level=error msg="Error backing up item" backup=openshift-adp/user1-backup-check5 error="error executing custom action (groupResource=persistentvolumeclaims, namespace=busy1, name=pvc1-user1): rpc error: code = Unknown desc = failed to get volumesnapshotclass for storageclass ocs-storagecluster-ceph-rbd: failed to get volumesnapshotclass for provisioner openshift-storage.rbd.csi.ceph.com, ensure that the desired volumesnapshot class has the velero.io/csi-volumesnapshot-class label" logSource="/remote-source/velero/app/pkg/backup/backup.go:417" name=busybox-79799557b5-vprq解决方案
删除
BackupCR:$ oc delete backup <backup> -n openshift-adp-
如果需要,清理
BackupStorageLocation上存储的数据以释放空间。 将标签
velero.io/csi-volumesnapshot-class=true应用到VolumeSnapshotClass对象:$ oc label volumesnapshotclass/<snapclass_name> velero.io/csi-volumesnapshot-class=true-
创建新的
BackupCR。
4.10.11. Restic 问题
在使用 Restic 备份应用程序时,您可能会遇到这些问题。
4.10.11.1. 启用了 root_squash 的 NFS 数据卷的 Restic 权限错误
Restic pod 日志显示错误消息, controller=pod-volume-backup error="fork/exec/usr/bin/restic: permission denied"。
原因
如果您的 NFS 数据卷启用了 root_squash,Restic 映射到 nfsnobody,且没有创建备份的权限。
解决方案
您可以通过为 Restic 创建补充组并将组 ID 添加到 DataProtectionApplication 清单中来解决这个问题:
-
在 NFS 数据卷中为
Restic创建补充组。 -
在 NFS 目录上设置
setgid位,以便继承组所有权。 将
spec.configuration.restic.supplementalGroups参数和组 ID 添加到DataProtectionApplication清单中,如下例所示:spec: configuration: restic: enable: true supplementalGroups: - <group_id>1 - 1
- 指定补充组 ID。
-
等待
Resticpod 重启,以便应用更改。
4.10.11.2. 在存储桶被强制后重新创建 Restic Backup CR
如果您为命名空间创建 Restic Backup CR,请清空对象存储的存储桶,然后为同一命名空间重新创建 Backup CR,重新创建的 Backup CR 会失败。
velero pod 日志显示以下错误消息:stderr=Fatal: unable to open config file: Stat: The specified key does not exist.\nIs there a repository at the following location?。
原因
如果 Restic 目录从对象存储中删除,Velero 不会从 ResticRepository 清单重新创建或更新 Restic 存储库。如需更多信息,请参阅 Velero 问题 4421。
解决方案
运行以下命令,从命名空间中删除相关的 Restic 存储库:
$ oc delete resticrepository openshift-adp <name_of_the_restic_repository>在以下错误日志中,
mysql-persistent是有问题的 Restic 存储库。存储库的名称会出现在其说明中。time="2021-12-29T18:29:14Z" level=info msg="1 errors encountered backup up item" backup=velero/backup65 logSource="pkg/backup/backup.go:431" name=mysql-7d99fc949-qbkds time="2021-12-29T18:29:14Z" level=error msg="Error backing up item" backup=velero/backup65 error="pod volume backup failed: error running restic backup, stderr=Fatal: unable to open config file: Stat: The specified key does not exist.\nIs there a repository at the following location?\ns3:http://minio-minio.apps.mayap-oadp- veleo-1234.qe.devcluster.openshift.com/mayapvelerooadp2/velero1/ restic/mysql-persistent\n: exit status 1" error.file="/remote-source/ src/github.com/vmware-tanzu/velero/pkg/restic/backupper.go:184" error.function="github.com/vmware-tanzu/velero/ pkg/restic.(*backupper).BackupPodVolumes" logSource="pkg/backup/backup.go:435" name=mysql-7d99fc949-qbkds
4.10.12. 使用 must-gather 工具
您可以使用 must-gather 工具收集有关 OADP 自定义资源的日志、指标和信息。
must-gather 数据必须附加到所有客户案例。
先决条件
-
您必须使用具有
cluster-admin角色的用户登录到 OpenShift Container Platform 集群。 -
已安装 OpenShift CLI (
oc)。
流程
-
进入存储
must-gather数据的目录。 为以下数据收集选项之一运行
oc adm must-gather命令:$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel8:v1.1数据保存为
must-gather/must-gather.tar.gz。您可以将此文件上传到红帽客户门户网站中的支持问题单中。$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel8:v1.1 \ -- /usr/bin/gather_metrics_dump此操作可能需要很长时间。数据保存为
must-gather/metrics/prom_data.tar.gz。
4.10.12.1. 使用 must-gather 工具合并选项
目前,无法组合 must-gather 脚本,例如指定超时阈值,同时允许不安全的 TLS 连接。在某些情况下,您可以通过在 must-gather 命令行中设置内部变量来解决这个限制,如下例所示:
$ oc adm must-gather --image=brew.registry.redhat.io/rh-osbs/oadp-oadp-mustgather-rhel8:1.1.1-8 -- skip_tls=true /usr/bin/gather_with_timeout <timeout_value_in_seconds>
在本例中,在运行 gather_with_timeout 脚本前设置 skip_tls 变量。结果是 gather_with_timeout 和 gather_without_tls 的组合。
您可以以这种方式指定的其他变量是如下:
-
logs_since,默认值为72h -
request_timeout,默认值为0s
4.10.13. OADP Monitoring
OpenShift Container Platform 提供了一个监控堆栈,允许用户和管理员有效地监控和管理其集群,并监控和分析集群中运行的用户应用程序和服务的工作负载性能,包括在事件发生时收到警报。
4.10.13.1. OADP 监控设置
OADP Operator 利用 OpenShift Monitoring Stack 提供的 OpenShift User Workload Monitoring 从 Velero 服务端点检索指标。监控堆栈允许使用 OpenShift Metrics 查询前端创建用户定义的 Alerting Rules 或查询指标。
启用 User Workload Monitoring 后,可以配置和使用任何与 Prometheus 兼容的第三方 UI (如 Grafana)来视觉化 Velero 指标。
监控指标需要为用户定义的项目启用监控,并创建一个 ServiceMonitor 资源,以便从位于 openshift-adp 命名空间中的已启用的 OADP 服务端点中提取这些指标。
先决条件
-
可以使用具有
cluster-admin权限的账户访问 OpenShift Container Platform 集群。 - 您已创建了集群监控配置映射。
流程
编辑
openshift-monitoring命名空间中的cluster-monitoring-configConfigMap对象:$ oc edit configmap cluster-monitoring-config -n openshift-monitoring在
data部分的config.yaml字段中添加或启用enableUserWorkload选项:apiVersion: v1 data: config.yaml: | enableUserWorkload: true1 kind: ConfigMap metadata: # ...- 1
- 添加这个选项或设置为
true
通过检查以下组件是否在
openshift-user-workload-monitoring命名空间中运行,等待较短的时间段来验证 User Workload Monitoring Setup:$ oc get pods -n openshift-user-workload-monitoring输出示例
NAME READY STATUS RESTARTS AGE prometheus-operator-6844b4b99c-b57j9 2/2 Running 0 43s prometheus-user-workload-0 5/5 Running 0 32s prometheus-user-workload-1 5/5 Running 0 32s thanos-ruler-user-workload-0 3/3 Running 0 32s thanos-ruler-user-workload-1 3/3 Running 0 32s验证
openshift-user-workload-monitoring中是否存在user-workload-monitoring-configConfigMap。如果存在,请跳过这个过程中的剩余步骤。$ oc get configmap user-workload-monitoring-config -n openshift-user-workload-monitoring输出示例
Error from server (NotFound): configmaps "user-workload-monitoring-config" not found为 User Workload Monitoring 创建一个
user-workload-monitoring-configConfigMap对象,并将它保存为2_configure_user_workload_monitoring.yaml文件:输出示例
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: |应用
2_configure_user_workload_monitoring.yaml文件:$ oc apply -f 2_configure_user_workload_monitoring.yaml configmap/user-workload-monitoring-config created
4.10.13.2. 创建 OADP 服务监控器
OADP 提供了一个 openshift-adp-velero-metrics-svc 服务,它会在配置 DPA 时创建。用户工作负载监控使用的服务监控器必须指向定义的服务。
运行以下命令来获取该服务的详情:
流程
确保
openshift-adp-velero-metrics-svc服务存在。它应当包含app.kubernetes.io/name=velero标签,这些标签将用作ServiceMonitor对象的选择器。$ oc get svc -n openshift-adp -l app.kubernetes.io/name=velero输出示例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE openshift-adp-velero-metrics-svc ClusterIP 172.30.38.244 <none> 8085/TCP 1h创建一个与现有 service 标签匹配的
ServiceMonitorYAML 文件,并将文件保存为3_create_oadp_service_monitor.yaml。服务监控器在openshift-adp命名空间中创建,其中openshift-adp-velero-metrics-svc服务所在的位置。ServiceMonitor对象示例apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: app: oadp-service-monitor name: oadp-service-monitor namespace: openshift-adp spec: endpoints: - interval: 30s path: /metrics targetPort: 8085 scheme: http selector: matchLabels: app.kubernetes.io/name: "velero"应用
3_create_oadp_service_monitor.yaml文件:$ oc apply -f 3_create_oadp_service_monitor.yaml输出示例
servicemonitor.monitoring.coreos.com/oadp-service-monitor created
验证
使用 OpenShift Container Platform Web 控制台的 Administrator 视角确认新服务监控器处于 Up 状态:
- 进入到 Observe → Targets 页面。
-
确保没有选择 Filter,或选择了 User source,并在
Text搜索字段中输入openshift-adp。 验证服务监控器的 Status 的状态是否为 Up。
图 4.1. OADP 指标目标
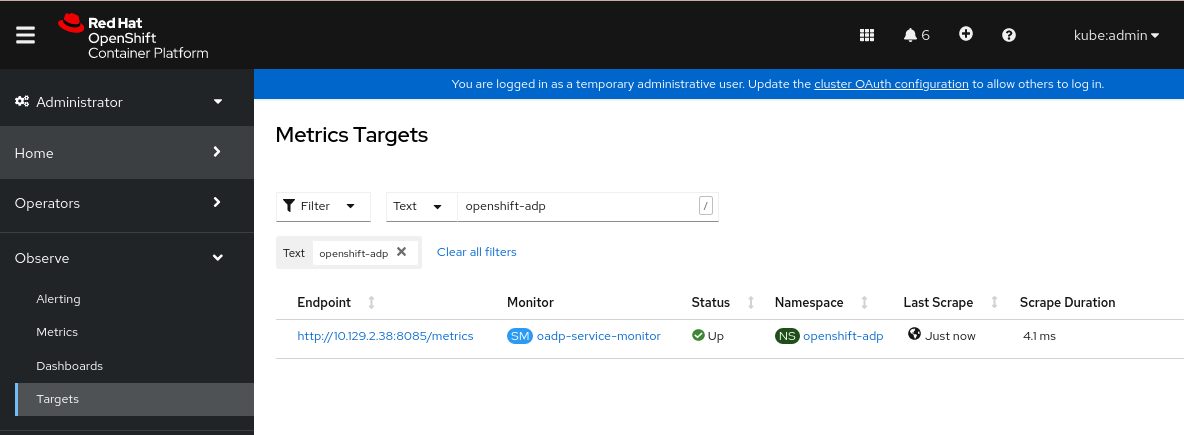
4.10.13.3. 创建警报规则
OpenShift Container Platform 监控堆栈允许接收使用 Alerting Rules 配置的 Alerts。要为 OADP 项目创建 Alerting 规则,请使用用户工作负载监控提取的其中一个指标。
流程
使用示例
OADPBackupFailing警报创建一个PrometheusRuleYAML 文件,并将其保存为4_create_oadp_alert_rule.yaml。OADPBackupFailing警报示例apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: name: sample-oadp-alert namespace: openshift-adp spec: groups: - name: sample-oadp-backup-alert rules: - alert: OADPBackupFailing annotations: description: 'OADP had {{$value | humanize}} backup failures over the last 2 hours.' summary: OADP has issues creating backups expr: | increase(velero_backup_failure_total{job="openshift-adp-velero-metrics-svc"}[2h]) > 0 for: 5m labels: severity: warning在本例中,Alert 在以下情况下显示:
- 在最后 2 个小时内增加了新的故障备份(大于 0),且状态至少维持了 5 分钟。
-
如果第一次增加的时间小于 5 分钟,则 Alert 将处于
Pending状态,之后它将进入Firing状态。
应用
4_create_oadp_alert_rule.yaml文件,该文件在openshift-adp命名空间中创建PrometheusRule对象:$ oc apply -f 4_create_oadp_alert_rule.yaml输出示例
prometheusrule.monitoring.coreos.com/sample-oadp-alert created
验证
在触发 Alert 后,您可以使用以下方法查看它:
- 在 Developer 视角中,选择 Observe 菜单。
在 Observe → Alerting 菜单下的 Administrator 视角中,在 Filter 框中选择 User。否则,默认只会显示 Platform Alerts。
图 4.2. OADP 备份失败警报
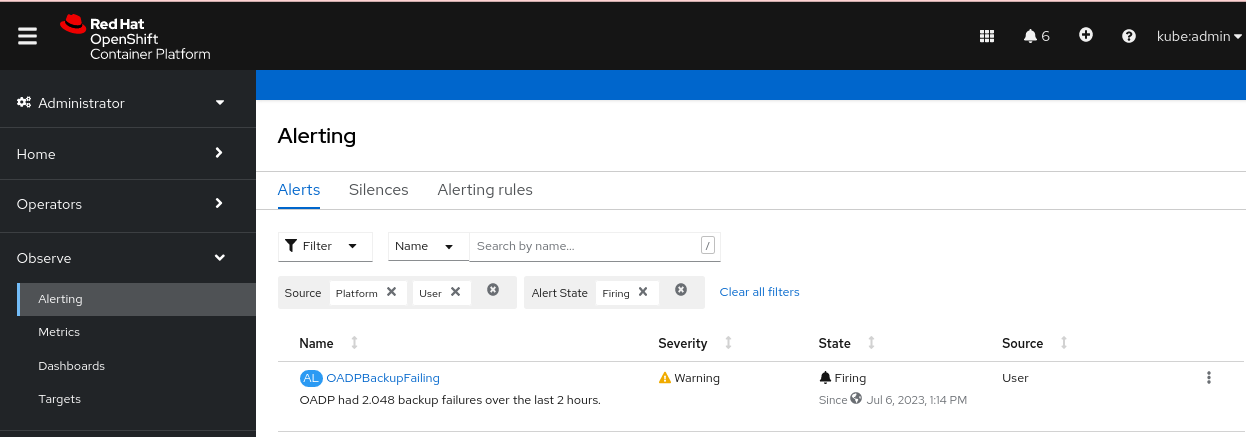
4.10.13.4. 可用指标列表
这些是 OADP 提供的指标列表,以及它们的 类型。
| 指标名称 | 描述 | 类型 |
|---|---|---|
|
| 从缓存检索的字节数 | 计数 |
|
| 从缓存检索内容的次数 | 计数 |
|
| 从缓存中读取不正确的内容的次数 | 计数 |
|
| 没有在缓存中找到内容并获取它的次数 | 计数 |
|
| 从底层存储检索的字节数 | 计数 |
|
| 在底层存储中无法找到内容的次数 | 计数 |
|
| 无法保存到缓存中的次数 | 计数 |
|
|
使用 | 计数 |
|
|
| 计数 |
|
|
调用 | 计数 |
|
|
调用 | 计数 |
|
|
传递给 | 计数 |
|
|
| 计数 |
|
| 试图备份的总数 | 计数 |
|
| 试图备份删除的总数 | 计数 |
|
| 删除失败的备份总数 | 计数 |
|
| 成功删除备份的总数 | 计数 |
|
| 完成备份所需的时间,以秒为单位 | Histogram |
|
| 失败备份的总数 | 计数 |
|
| 备份过程中遇到的错误总数 | 量表 |
|
| 备份的项目总数 | 量表 |
|
| 备份的最后状态。值 1 代表成功,0。 | 量表 |
|
| 备份最后一次运行成功的时间,Unix 时间戳(以秒为单位) | 量表 |
|
| 部分失败的备份总数 | 计数 |
|
| 成功备份的总数 | 计数 |
|
| 备份的大小,以字节为单位 | 量表 |
|
| 当前存在的备份数量 | 量表 |
|
| 验证失败的备份总数 | 计数 |
|
| 警告备份的总数 | 计数 |
|
| CSI 试图卷快照的总数 | 计数 |
|
| CSI 失败卷快照的总数 | 计数 |
|
| CSI 成功卷快照总数 | 计数 |
|
| 尝试恢复的总数 | 计数 |
|
| 恢复的失败总数 | 计数 |
|
| 恢复部分失败的总数 | 计数 |
|
| 成功恢复的总数 | 计数 |
|
| 当前存在的恢复数量 | 量表 |
|
| 恢复失败验证的总数 | 计数 |
|
| 尝试的卷快照总数 | 计数 |
|
| 失败的卷快照总数 | 计数 |
|
| 成功卷快照的总数 | 计数 |
4.10.13.5. 使用 Observe UI 查看指标
您可以从 Administrator 或 Developer 视角查看 OpenShift Container Platform Web 控制台中的指标,该视角必须有权访问 openshift-adp 项目。
流程
进入到 Observe → Metrics 页面:
如果使用 Developer 视角,请按照以下步骤执行:
- 选择 Custom query,或者点 Show PromQL 链接。
- 输入查询并点 Enter。
如果使用 Administrator 视角,请在文本字段中输入表达式,然后选择 Run Queries。
图 4.3. OADP 指标查询
4.11. 与 OADP 一起使用的 API
本文档提供有关您可以在 OADP 一起使用的以下 API 的信息:
- Velero API
- OADP API
4.11.1. Velero API
Velero API 文档由 Velero 维护,而不是由红帽维护。它可在 Velero API 类型中找到。
4.11.2. OADP API
下表提供了 OADP API 的结构:
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
定义用于 | |
|
|
定义 | |
|
| map [ UnsupportedImageKey ] string |
可用于覆盖为开发而部署的依赖镜像。选项为 |
|
| 用于将注解添加到 Operator 部署的 pod。 | |
|
| 定义 Pod 的 DNS 的配置。 | |
|
|
定义除了由 | |
|
| *bool | 用于指定是否要部署 registry 以启用镜像的备份和恢复。 |
|
| 用于定义数据保护应用服务器配置。 | |
|
|
* | 定义 DPA 的配置以启用技术预览功能。 |
| 属性 | 类型 | 描述 |
|---|---|---|
|
| 存储卷快照的位置,如备份存储位置所述。 | |
|
| [技术预览] 在某些云存储供应商处自动创建存储桶,用作备份存储位置。 |
bucket 参数只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
类型 BackupLocation 的完整 schema 定义。
| 属性 | 类型 | 描述 |
|---|---|---|
|
| 用于存储卷快照的位置,如卷快照位置。 |
类型 SnapshotLocation 的完整 schema 定义。
| 属性 | 类型 | 描述 |
|---|---|---|
|
| 定义 Velero 服务器配置。 | |
|
| 定义 Restic 服务器配置。 |
类型 ApplicationConfig 的完整 schema 定义。
| 属性 | 类型 | 描述 |
|---|---|---|
|
| [] string | 定义为 Velero 实例启用的功能列表。 |
|
| [] string |
可以安装以下类型的默认 Velero 插件: |
|
| 用于安装自定义 Velero 插件。 默认的以及自定义的插件信息包括在OADP plug-ins 中 | |
|
|
代表一个配置映射,它在定义与 | |
|
|
要在没有默认备份存储位置的情况下安装 Velero,您必须设置 | |
|
|
定义 | |
|
|
Velero 服务器日志级别(在最精细的日志中使用 |
类型为 VeleroConfig 的完整 schema 定义。
类型 CustomPlugin 的完整 schema 定义。
| 属性 | 类型 | 描述 |
|---|---|---|
|
| *bool |
如果设置为 |
|
| []int64 |
定义要应用到 |
|
|
定义 Restic 超时的用户提供的持续时间字符串。默认值为 | |
|
|
定义 |
类型为 ResticConfig 的完整 schema 定义。
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
定义要提供给 | |
|
|
定义要应用到 Velero 部署或 Restic | |
|
|
为一个 | |
|
| 要添加到 pod 的标签。 |
| 属性 | 类型 | 描述 |
|---|---|---|
|
| 定义 Data Mover 的配置。 |
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
如果设置为 | |
|
|
Data Mover 用户提供的 Restic | |
|
|
要完成 |
OADP API 在 OADP Operator 中更为详细。
4.12. 高级 OADP 特性和功能
本文档提供有关 OpenShift API for Data Protection (OADP) 的高级功能。
4.12.1. 在同一集群中使用不同的 Kubernetes API 版本
4.12.1.1. 列出集群中的 Kubernetes API 组版本
源集群可能会提供多个 API 版本,其中的一个版本是首选的 API 版本。例如,带有名为 Example 的 API 的源集群可能包括在 example.com/v1 和 example.com/v1beta2 API 组中。
如果您使用 Velero 备份和恢复这样的源集群,Velero 仅备份了使用 Kubernetes API 首选版本的该资源的版本。
要返回上例,如果 example.com/v1 是首选的 API,则 Velero 只备份使用 example.com/v1 的资源的版本。另外,目标集群需要 example.com/v1 在它的一组可用 API 资源中注册,以便 Velero 恢复目标集群上的资源。
因此,您需要在目标集群上生成 Kubernetes API 组版本列表,以确保在一组可用的 API 资源中注册了首选的 API 版本。
流程
- 输入以下命令:
$ oc api-resources4.12.1.2. 关于启用 API 组版本
默认情况下,Velero 只备份使用 Kubernetes API 的首选版本的资源。但是,Velero 还包括一个启用 API 组版本功能,它解决了这个限制。当在源集群中启用时,这个功能会使 Velero 备份集群中支持的所有 Kubernetes API 组版本,而不只是首选集群。当版本存储在备份 .tar 文件中被保存后,可以在目标集群上恢复它们。
例如,带有名为 Example 的 API 的源集群可能包括在 example.com/v1 和 example.com/v1beta2 API 组中,example.com/v1 是首选 API。
如果没有启用 Enable API Group Versions 功能,Velero 仅备份 Example 的首选 API 组版本,即 example.com/v1。启用该功能后,Velero 还会备份 example.com/v1beta2。
当目标集群上启用了“启用 API 组版本”功能时,Velero 根据 API 组版本优先级顺序选择恢复的版本。
启用 API 组版本仍处于测试阶段。
Velero 使用以下算法为 API 版本分配优先级,并将 1 作为最高优先级:
- destination 集群的首选版本
- source_ cluster 的首选版本
- 带有最高 Kubernetes 版本优先级的通用非首选支持版本
4.12.1.3. 使用启用 API 组版本
您可以使用 Velero 的启用 API 组版本功能来备份集群中支持的所有 Kubernetes API 组版本,而不只是首选版本。
启用 API 组版本仍处于测试阶段。
流程
-
配置
EnableAPIGroupVersions功能标记:
apiVersion: oadp.openshift.io/vialpha1
kind: DataProtectionApplication
...
spec:
configuration:
velero:
featureFlags:
- EnableAPIGroupVersions4.12.2. 从一个集群中备份数据,并将其恢复到另一个集群
4.12.2.1. 关于从一个集群中备份数据,并在另一个集群中恢复数据
OpenShift API for Data Protection (OADP) 旨在在同一 OpenShift Container Platform 集群中备份和恢复应用程序数据。MTC (Migration Toolkit for Containers) 旨在将容器(包括应用程序数据)从一个 OpenShift Container Platform 集群迁移到另一个集群。
您可以使用 OADP 从一个 OpenShift Container Platform 集群中备份应用程序数据,并在另一个集群中恢复它。但是,这样做比使用 MTC 或使用 OADP 在同一集群中备份和恢复更为复杂。
要成功使用 OADP 从一个集群备份数据并将其恢复到另一个集群,除了使用 OADP 备份和恢复数据需要的先决条件和步骤外,还需要考虑以下因素:
- Operator
- 使用 Velero
- UID 和 GID 范围
4.12.2.1.1. Operator
您必须从应用程序的备份中排除 Operator,以便成功备份和恢复。
4.12.2.1.2. 使用 Velero
Velero (基于 OADP 构建)不支持在云供应商间原生迁移持久性卷快照。要在云平台之间迁移卷快照数据,您需要启用 Velero Restic 文件系统备份选项,该选项会在文件系统级别备份卷内容,或使用 OADP Data Mover 进行 CSI 快照。
在 OADP 1.1 及更早版本中,Velero Restic 文件系统备份选项被称为 restic。在 OADP 1.2 及更高版本中,Velero Restic 文件系统备份选项称为 file-system-backup。
- 您还必须使用 Velero 的 文件系统备份 在 AWS 区域或 Microsoft Azure 区域之间迁移数据。
- Velero 不支持将数据恢复到比源集群 更早的 Kubernetes 版本的集群。
- 在理论上,可以将工作负载迁移到比源更新的 Kubernetes 版本,但您必须考虑每个自定义资源的集群间 API 组的兼容性。如果 Kubernetes 版本升级会破坏内核或原生 API 组的兼容性,您必须首先更新受影响的自定义资源。
4.12.2.2. 关于确定要备份的 pod 卷
在使用文件系统备份(FSB)启动备份操作前,您必须指定包含要备份的卷的 pod。Velero 将此过程称为"发现"适当的 pod 卷。
Velero 支持两种方法确定 pod 卷:
- opt-in 方法 : opt-in 方法要求您主动表示您要包含 - opt-in - 一个卷在备份中。您可以通过标记包含要备份的卷的每个 pod 来达到此目的。当 Velero 找到持久性卷 (PV) 时,它会检查挂载卷的 pod。如果 pod 使用卷名称标记,Velero 会备份 pod。
- opt-out 方法 :使用 opt-out 方法,您必须主动指定您要从备份中排除卷。为此,您可以标记包含您不想备份的卷的每个 pod。当 Velero 找到 PV 时,它会检查挂载卷的 pod。如果 pod 使用卷的名称标记,Velero 不会备份 pod。
4.12.2.2.1. 限制
-
FSB 不支持备份和恢复
hostpath卷。但是 FSB 支持备份和恢复本地卷。 - Velero 对它创建的所有备份存储库使用静态通用加密密钥。这个静态密钥意味着可以访问备份存储的任何人也可以解密您的备份数据。务必要限制对备份存储的访问。
对于 PVC,每个增量备份链都会在 pod 重新调度之间维护。
对于不是 PVC 的 pod 卷,如
emptyDir卷,如果一个 pod 被删除或重新创建(例如,通过ReplicaSet或一个部署),则这些卷的下一次备份将是完整备份,而不是增量备份。假设 pod 卷的生命周期由其 pod 定义。- 虽然备份数据可能会以递增方式保存,备份大型文件(如数据库)可能需要很长时间。这是因为 FSB 使用 deduplication 来查找需要备份的区别。
- FSB 通过访问运行该 pod 的节点的文件系统来读取和写入卷中的数据。因此,FSB 只能备份从 pod 挂载的卷,而不直接从 PVC 进行挂载。有些 Velero 用户通过运行一个 staging pod (如 BusyBox 或 Alpine 容器)来解决这个限制,以便在执行 Velero 备份前挂载这些 PVC 和 PV 对。
-
FSB 要求将卷挂载到
<hostPath>/<pod UID>下,<hostPath>可以被配置。有些 Kubernetes 系统(如 vCluster)不会在<pod UID>子目录下挂载卷,VFB 无法按预期工作。
4.12.2.2.2. 使用 opt-in 方法备份 pod 卷
您可以使用 opt-in 方法来指定需要由文件系统备份(FSB)备份哪些卷。您可以使用 backup.velero.io/backup-volumes 命令进行此操作。
流程
在每个包含您要备份的一个或多个卷的 pod 中,输入以下命令:
$ oc -n <your_pod_namespace> annotate pod/<your_pod_name> \ backup.velero.io/backup-volumes=<your_volume_name_1>, \ <your_volume_name_2>>,...,<your_volume_name_n>其中:
<your_volume_name_x>- 指定 pod 规格中 xth 卷的名称。
4.12.2.2.3. 使用 opt-out 方法备份 pod 卷
使用 opt-out 方法时,所有 pod 卷都使用文件系统备份(FSB)备份,但有一些例外:
- 挂载默认服务帐户令牌、secret 和配置映射的卷。
-
hostPath卷
您可以使用 opt-out 方法指定不要备份的卷。您可以使用 backup.velero.io/backup-volumes-excludes 命令进行此操作。
流程
在包含您不想备份的一个或多个卷的 pod 中,运行以下命令:
$ oc -n <your_pod_namespace> annotate pod/<your_pod_name> \ backup.velero.io/backup-volumes-excludes=<your_volume_name_1>, \ <your_volume_name_2>>,...,<your_volume_name_n>其中:
<your_volume_name_x>- 指定 pod 规格中 xth 卷的名称。
您可以使用 --default-volumes-to-fs-backup 标志运行 velero install 命令,为所有 Velero 备份启用此行为。
4.12.2.3. UID 和 GID 范围
如果您从一个集群备份数据并将其恢复到另一个集群,则可能会出现 UID (用户 ID)和 GID (组 ID)范围的问题。下面的部分解释了这些潜在问题和缓解措施:
- 问题概述
- 命名空间 UID 和 GID 范围可能会因目标集群而异。OADP 不会备份和恢复 OpenShift UID 范围元数据。如果备份的应用程序需要特定的 UID,请确保范围是可用的。如需有关 OpenShift 的 UID 和 GID 范围的更多信息,请参阅 OpenShift 和 UID 的指南。
- 问题详细描述
当您使用
oc create namespace在 OpenShift Container Platform 中创建命名空间时,OpenShift Container Platform 会为命名空间分配一个唯一用户 ID (UID) 范围,即 Supplemental Group (GID)范围和唯一的 SELinux MCS 标签。此信息存储在集群的metadata.annotations字段中。此信息是安全性上下文约束(SCC)注解的一部分,它由以下组件组成:-
openshift.io/sa.scc.mcs -
openshift.io/sa.scc.supplemental-groups -
openshift.io/sa.scc.uid-range
-
当使用 OADP 恢复命名空间时,它会自动使用 metadata.annotations 中的信息,而无需为目标集群重置它。因此,如果满足以下条件,工作负载可能无法访问备份的数据:
- 存在一个带有其他 SCC 注解的现有命名空间,例如在另一个集群中。在这种情况下,OADP 在备份过程中使用现有命名空间,而不是您要恢复的命名空间。
备份过程中使用了标签选择器,但执行工作负载的命名空间没有标签。在这种情况下,OADP 不会备份命名空间,而是在恢复过程中创建一个新的命名空间,该命名空间不包含备份命名空间的注解。这会导致为命名空间分配一个新的 UID 范围。
如果 OpenShift Container Platform 根据从持久性卷数据备份时更改的命名空间注解为 pod 为
securityContextUID,则可能会出现问题。- 容器 UID 不再与文件所有者的 UID 匹配。
发生错误,因为 OpenShift Container Platform 没有修改目标集群的 UID 范围,以匹配备份集群的数据。因此,备份集群与目标集群的 UID 不同,这意味着应用程序无法向目标集群读取或写入数据。
- 缓解方案
- 您可以使用以下一个或多个缓解方案来解决 UID 和 GID 范围问题:
简单的缓解方案:
-
如果您在
BackupCR 中使用标签选择器过滤要包含在备份中的对象,请确保将此标签选择器添加到包含工作区的命名空间中。 - 在尝试恢复具有相同名称的命名空间前,请删除目标集群上任何已存在的命名空间版本。
-
如果您在
高级缓解方案:
- 迁移后,通过在 OpenShift 命名空间中解决重叠的 UID 范围来修复 UID 范围。第 1 步是可选的。
有关 OpenShift Container Platform 中 UID 和 GID 范围的详细讨论,重点放在一个集群中备份数据并在另一个集群中恢复数据时出现问题,请参阅 OpenShift 和 UID 的指南。
4.12.2.4. 从一个集群中备份数据,并将其恢复到另一个集群
通常,您可以从一个 OpenShift Container Platform 集群备份数据,并以与将数据备份并恢复到同一集群的方式在另一个 OpenShift Container Platform 集群上恢复数据。但是,从一个 OpenShift Container Platform 集群备份数据时,会有一些额外的前提条件和不同之处,并在另一个集群中恢复它。
先决条件
- 所有在平台上备份和恢复的相关先决条件(如 AWS、Microsoft Azure、GCP 等),特别是数据保护应用程序(DPA) 的先决条件。
流程
在为您的平台提供的流程中添加以下内容:
- 确保备份存储位置 (BSL) 和卷快照位置具有相同的名称和路径,以将资源恢复到另一个集群。
- 在集群间共享相同的对象存储位置凭证。
- 为获得最佳结果,请使用 OADP 在目标集群中创建命名空间。
如果您使用 Velero
file-system-backup选项,请运行以下命令启用--default-volumes-to-fs-backup标志以便在备份过程中使用:$ velero backup create <backup_name> --default-volumes-to-fs-backup <any_other_options>
在 OADP 1.2 及更高版本中,Velero Restic 选项名为 file-system-backup。
第 5 章 control plane 备份和恢复
5.1. 备份 etcd
etcd 是 OpenShift Container Platform 的以”键-值”形式进行的存储,它会保留所有资源对象的状态。
定期备份集群的 etcd 数据,并在 OpenShift Container Platform 环境以外的安全位置保存备份数据。不要在第一个证书轮转完成前(安装后的 24 小时内)进行 etcd 备份,否则备份将包含过期的证书。另外,建议您在非高峰期使用 etcd 备份,因为 etcd 快照有较高的 I/O 成本。
确保升级集群后执行 etcd 备份。这很重要,因为当恢复集群时,必须使用从同一 z-stream 发行版本中获取的 etcd 备份。例如,OpenShift Container Platform 4.y.z 集群必须使用从 4.y.z 中获得的 etcd 备份。
通过在 control plane 主机上执行一次备份脚本来备份集群的 etcd 数据。不要为每个 control plane 主机进行备份。
在进行了 etcd 备份后,就可以恢复到一个以前的集群状态。
5.1.1. 备份 etcd 数据
按照以下步骤,通过创建 etcd 快照并备份静态 pod 的资源来备份 etcd 数据。这个备份可以被保存,并在以后需要时使用它来恢复 etcd 数据。
只保存单一 control plane 主机的备份。不要从集群中的每个 control plane 主机进行备份。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。 您已检查是否启用了集群范围代理。
提示您可以通过查看
oc get proxy cluster -o yaml的输出来检查代理是否已启用。如果httpProxy、httpsProxy和noProxy字段设置了值,则会启用代理。
流程
为 control plane 节点启动一个 debug 会话:
$ oc debug node/<node_name>将您的根目录改为
/host:sh-4.2# chroot /host-
如果启用了集群范围的代理,请确定已导出了
NO_PROXY、HTTP_PROXY和HTTPS_PROXY环境变量。 运行
cluster-backup.sh脚本,输入保存备份的位置。提示cluster-backup.sh脚本作为 etcd Cluster Operator 的一个组件被维护,它是etcdctl snapshot save命令的包装程序(wrapper)。sh-4.4# /usr/local/bin/cluster-backup.sh /home/core/assets/backup脚本输出示例
found latest kube-apiserver: /etc/kubernetes/static-pod-resources/kube-apiserver-pod-6 found latest kube-controller-manager: /etc/kubernetes/static-pod-resources/kube-controller-manager-pod-7 found latest kube-scheduler: /etc/kubernetes/static-pod-resources/kube-scheduler-pod-6 found latest etcd: /etc/kubernetes/static-pod-resources/etcd-pod-3 ede95fe6b88b87ba86a03c15e669fb4aa5bf0991c180d3c6895ce72eaade54a1 etcdctl version: 3.4.14 API version: 3.4 {"level":"info","ts":1624647639.0188997,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"/home/core/assets/backup/snapshot_2021-06-25_190035.db.part"} {"level":"info","ts":"2021-06-25T19:00:39.030Z","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"} {"level":"info","ts":1624647639.0301006,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"https://10.0.0.5:2379"} {"level":"info","ts":"2021-06-25T19:00:40.215Z","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"} {"level":"info","ts":1624647640.6032252,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"https://10.0.0.5:2379","size":"114 MB","took":1.584090459} {"level":"info","ts":1624647640.6047094,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"/home/core/assets/backup/snapshot_2021-06-25_190035.db"} Snapshot saved at /home/core/assets/backup/snapshot_2021-06-25_190035.db {"hash":3866667823,"revision":31407,"totalKey":12828,"totalSize":114446336} snapshot db and kube resources are successfully saved to /home/core/assets/backup在这个示例中,在 control plane 主机上的
/home/core/assets/backup/目录中创建了两个文件:-
snapshot_<datetimestamp>.db:这个文件是 etcd 快照。cluster-backup.sh脚本确认其有效。 static_kuberesources_<datetimestamp>.tar.gz:此文件包含静态 pod 的资源。如果启用了 etcd 加密,它也包含 etcd 快照的加密密钥。注意如果启用了 etcd 加密,建议出于安全考虑,将第二个文件与 etcd 快照分开保存。但是,需要这个文件才能从 etcd 快照中进行恢复。
请记住,etcd 仅对值进行加密,而不对键进行加密。这意味着资源类型、命名空间和对象名称是不加密的。
-
5.2. 替换不健康的 etcd 成员
本文档描述了替换一个不健康 etcd 成员的过程。
此过程取决于 etcd 成员不健康的原因,如机器没有运行,或节点未就绪,或 etcd pod 处于 crashlooping 状态。
如果您丢失了大多数 control plane 主机,请按照灾难恢复流程恢复到以前的一个集群状态,而不是这个过程。
如果 control plane 证书在被替换的成员中无效,则必须遵循从已过期 control plane 证书中恢复的步骤,而不是此过程。
如果 control plane 节点丢失并且创建了一个新节点,etcd 集群 Operator 将处理生成新 TLS 证书并将节点添加为 etcd 成员。
5.2.1. 先决条件
- 在替换不健康的 etcd 成员,需要进行 etcd 备份。
5.2.2. 找出一个不健康的 etcd 成员
您可以识别集群是否有不健康的 etcd 成员。
先决条件
-
使用具有
cluster-admin角色的用户访问集群。
流程
使用以下命令检查
EtcdMembersAvailable状态条件的状态:$ oc get etcd -o=jsonpath='{range .items[0].status.conditions[?(@.type=="EtcdMembersAvailable")]}{.message}{"\n"}'查看输出:
2 of 3 members are available, ip-10-0-131-183.ec2.internal is unhealthy这个示例输出显示
ip-10-0-131-183.ec2.internaletcd 成员不健康。
5.2.3. 确定不健康的 etcd 成员的状态
替换不健康 etcd 成员的步骤取决于 etcd 的以下状态:
- 机器没有运行或者该节点未就绪
- etcd pod 处于 crashlooping 状态
此流程决定了 etcd 成员处于哪个状态。这可让您了解替换不健康的 etcd 成员要遵循的步骤。
如果您知道机器没有运行或节点未就绪,但它们应该很快返回健康状态,那么您就不需要执行替换 etcd 成员的流程。当机器或节点返回一个健康状态时,etcd cluster Operator 将自动同步。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。 - 您已找到不健康的 etcd 成员。
流程
检查 机器是否没有运行:
$ oc get machines -A -ojsonpath='{range .items[*]}{@.status.nodeRef.name}{"\t"}{@.status.providerStatus.instanceState}{"\n"}' | grep -v running输出示例
ip-10-0-131-183.ec2.internal stopped1 - 1
- 此输出列出了节点以及节点机器的状态。如果状态不是
running,则代表机器没有运行。
如果机器没有运行,按照替换机器没有运行或节点没有就绪的非健康 etcd 成员过程进行操作。
确定 节点是否未就绪。
如果以下任何一种情况是正确的,则代表节点没有就绪。
如果机器正在运行,检查节点是否不可访问:
$ oc get nodes -o jsonpath='{range .items[*]}{"\n"}{.metadata.name}{"\t"}{range .spec.taints[*]}{.key}{" "}' | grep unreachable输出示例
ip-10-0-131-183.ec2.internal node-role.kubernetes.io/master node.kubernetes.io/unreachable node.kubernetes.io/unreachable1 - 1
- 如果节点带有
unreachable污点,则节点没有就绪。
如果该节点仍然可访问,则检查该节点是否列为
NotReady:$ oc get nodes -l node-role.kubernetes.io/master | grep "NotReady"输出示例
ip-10-0-131-183.ec2.internal NotReady master 122m v1.24.01 - 1
- 如果节点列表为
NotReady,则 该节点没有就绪。
如果节点没有就绪,按照替换机器没有运行或节点没有就绪的 etcd 成员的步骤进行操作。
确定 etcd Pod 是否处于 crashlooping 状态。
如果机器正在运行并且节点已就绪,请检查 etcd pod 是否处于 crashlooping 状态。
验证所有 control plane 节点都列为
Ready:$ oc get nodes -l node-role.kubernetes.io/master输出示例
NAME STATUS ROLES AGE VERSION ip-10-0-131-183.ec2.internal Ready master 6h13m v1.24.0 ip-10-0-164-97.ec2.internal Ready master 6h13m v1.24.0 ip-10-0-154-204.ec2.internal Ready master 6h13m v1.24.0检查 etcd pod 的状态是否为
Error或CrashLoopBackOff:$ oc -n openshift-etcd get pods -l k8s-app=etcd输出示例
etcd-ip-10-0-131-183.ec2.internal 2/3 Error 7 6h9m1 etcd-ip-10-0-164-97.ec2.internal 3/3 Running 0 6h6m etcd-ip-10-0-154-204.ec2.internal 3/3 Running 0 6h6m- 1
- 由于此 pod 的状态是
Error,因此 etcd pod 为 crashlooping 状态。
如果 etcd pod 为 crashlooping 状态,请按照替换 etcd pod 处于 crashlooping 状态的不健康的 etcd 成员的步骤进行操作。
5.2.4. 替换不健康的 etcd 成员
根据不健康的 etcd 成员的状态,使用以下一个流程:
5.2.4.1. 替换机器没有运行或节点未就绪的不健康 etcd 成员
此流程详细介绍了替换因机器没有运行或节点未就绪造成不健康的 etcd 成员的步骤。
先决条件
- 您已找出不健康的 etcd 成员。
您已确认机器没有运行,或者该节点未就绪。
重要您必须等待其他 control plane 节点关闭。control plane 节点必须保持关闭状态,直到替换完不健康的 etcd 成员为止。
-
您可以使用具有
cluster-admin角色的用户访问集群。 已进行 etcd 备份。
重要执行此流程前务必要进行 etcd 备份,以便在遇到任何问题时可以恢复集群。
流程
删除不健康的成员。
选择一个不在受影响节点上的 pod:
在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc -n openshift-etcd get pods -l k8s-app=etcd输出示例
etcd-ip-10-0-131-183.ec2.internal 3/3 Running 0 123m etcd-ip-10-0-164-97.ec2.internal 3/3 Running 0 123m etcd-ip-10-0-154-204.ec2.internal 3/3 Running 0 124m连接到正在运行的 etcd 容器,传递没有在受影响节点上的 pod 的名称:
在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc rsh -n openshift-etcd etcd-ip-10-0-154-204.ec2.internal查看成员列表:
sh-4.2# etcdctl member list -w table输出示例
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | 6fc1e7c9db35841d | started | ip-10-0-131-183.ec2.internal | https://10.0.131.183:2380 | https://10.0.131.183:2379 | | 757b6793e2408b6c | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | ca8c2990a0aa29d1 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+记录不健康的 etcd 成员的 ID 和名称,因为稍后需要这些值。
$ etcdctl endpoint health命令将列出已删除的成员,直到完成替换过程并添加了新成员。通过向
etcdctl member remove命令提供 ID 来删除不健康的 etcd 成员 :sh-4.2# etcdctl member remove 6fc1e7c9db35841d输出示例
Member 6fc1e7c9db35841d removed from cluster ead669ce1fbfb346再次查看成员列表,并确认成员已被删除:
sh-4.2# etcdctl member list -w table输出示例
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | 757b6793e2408b6c | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | ca8c2990a0aa29d1 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+现在您可以退出节点 shell。
输入以下命令关闭仲裁保护:
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'此命令可确保您可以成功重新创建机密并推出静态 pod。
重要关闭仲裁保护后,在剩余的 etcd 实例进行重启以使配置改变生效期间,集群可能无法访问。
注意在只使用两个成员运行时,etcd 将无法容忍任何成员失败。重启剩余的成员会破坏仲裁,并导致集群出现停机问题。由于可能导致停机的配置更改,仲裁保护可以防止 etcd 重启,因此必须禁用它才能完成这个过程。
删除已删除的不健康 etcd 成员的旧 secret。
列出已删除的不健康 etcd 成员的 secret。
$ oc get secrets -n openshift-etcd | grep ip-10-0-131-183.ec2.internal1 - 1
- 传递您之前在这个过程中记录的不健康 etcd 成员的名称。
有一个对等的、服务和指标的 secret,如以下输出所示:
输出示例
etcd-peer-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m etcd-serving-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m etcd-serving-metrics-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m删除已删除的不健康 etcd 成员的 secret。
删除 peer(对等)secret:
$ oc delete secret -n openshift-etcd etcd-peer-ip-10-0-131-183.ec2.internal删除 serving secret:
$ oc delete secret -n openshift-etcd etcd-serving-ip-10-0-131-183.ec2.internal删除 metrics secret:
$ oc delete secret -n openshift-etcd etcd-serving-metrics-ip-10-0-131-183.ec2.internal
删除并重新创建 control plane 机器。重新创建此机器后,会强制一个新修订版本并自动扩展 etcd。
如果您正在运行安装程序置备的基础架构,或者您使用 Machine API 创建机器,请按照以下步骤执行。否则,您必须使用最初创建 master 时使用的相同方法创建新的 master。
获取不健康成员的机器。
在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc get machines -n openshift-machine-api -o wide输出示例
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-0 Running m4.xlarge us-east-1 us-east-1a 3h37m ip-10-0-131-183.ec2.internal aws:///us-east-1a/i-0ec2782f8287dfb7e stopped1 clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-154-204.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-164-97.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- 这是不健康节点的 control plane 机器
ip-10-0-131-183.ec2.internal。
将机器配置保存到文件系统中的一个文件中:
$ oc get machine clustername-8qw5l-master-0 \1 -n openshift-machine-api \ -o yaml \ > new-master-machine.yaml- 1
- 为不健康的节点指定 control plane 机器的名称。
编辑上一步中创建的
new-master-machine.yaml文件,以分配新名称并删除不必要的字段。删除整个
status部分:status: addresses: - address: 10.0.131.183 type: InternalIP - address: ip-10-0-131-183.ec2.internal type: InternalDNS - address: ip-10-0-131-183.ec2.internal type: Hostname lastUpdated: "2020-04-20T17:44:29Z" nodeRef: kind: Node name: ip-10-0-131-183.ec2.internal uid: acca4411-af0d-4387-b73e-52b2484295ad phase: Running providerStatus: apiVersion: awsproviderconfig.openshift.io/v1beta1 conditions: - lastProbeTime: "2020-04-20T16:53:50Z" lastTransitionTime: "2020-04-20T16:53:50Z" message: machine successfully created reason: MachineCreationSucceeded status: "True" type: MachineCreation instanceId: i-0fdb85790d76d0c3f instanceState: stopped kind: AWSMachineProviderStatus将
metadata.name字段更改为新名称。建议您保留与旧机器相同的基础名称,并将结束号码改为下一个可用数字。在本例中,
clustername-8qw5l-master-0改为clustername-8qw5l-master-3。例如:
apiVersion: machine.openshift.io/v1beta1 kind: Machine metadata: ... name: clustername-8qw5l-master-3 ...删除
spec.providerID字段:providerID: aws:///us-east-1a/i-0fdb85790d76d0c3f
删除不健康成员的机器:
$ oc delete machine -n openshift-machine-api clustername-8qw5l-master-01 - 1
- 为不健康的节点指定 control plane 机器的名称。
验证机器是否已删除:
$ oc get machines -n openshift-machine-api -o wide输出示例
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-154-204.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-164-97.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running使用
new-master-machine.yaml文件创建新机器:$ oc apply -f new-master-machine.yaml验证新机器是否已创建:
$ oc get machines -n openshift-machine-api -o wide输出示例
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-154-204.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-164-97.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-master-3 Provisioning m4.xlarge us-east-1 us-east-1a 85s ip-10-0-133-53.ec2.internal aws:///us-east-1a/i-015b0888fe17bc2c8 running1 clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- 新机器
clustername-8qw5l-master-3将被创建,并当阶段从Provisioning变为Running后就可以使用。
创建新机器可能需要几分钟时间。当机器或节点返回一个健康状态时,etcd cluster Operator 将自动同步。
输入以下命令重新打开仲裁保护:
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'您可以输入以下命令验证
unsupportedConfigOverrides部分是否已从对象中删除:$ oc get etcd/cluster -oyaml如果使用单节点 OpenShift,请重启该节点。否则,您可能会在 etcd 集群 Operator 中遇到以下错误:
输出示例
EtcdCertSignerControllerDegraded: [Operation cannot be fulfilled on secrets "etcd-peer-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-metrics-sno-0": the object has been modified; please apply your changes to the latest version and try again]
验证
验证所有 etcd pod 是否都正常运行。
在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc -n openshift-etcd get pods -l k8s-app=etcd输出示例
etcd-ip-10-0-133-53.ec2.internal 3/3 Running 0 7m49s etcd-ip-10-0-164-97.ec2.internal 3/3 Running 0 123m etcd-ip-10-0-154-204.ec2.internal 3/3 Running 0 124m如果上一命令的输出只列出两个 pod,您可以手动强制重新部署 etcd。在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge1 - 1
forceRedeploymentReason值必须是唯一的,这就是为什么附加时间戳的原因。
验证只有三个 etcd 成员。
连接到正在运行的 etcd 容器,传递没有在受影响节点上的 pod 的名称:
在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc rsh -n openshift-etcd etcd-ip-10-0-154-204.ec2.internal查看成员列表:
sh-4.2# etcdctl member list -w table输出示例
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | 5eb0d6b8ca24730c | started | ip-10-0-133-53.ec2.internal | https://10.0.133.53:2380 | https://10.0.133.53:2379 | | 757b6793e2408b6c | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | ca8c2990a0aa29d1 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+如果上一命令的输出列出了超过三个 etcd 成员,您必须删除不需要的成员。
警告确保删除正确的 etcd 成员;如果删除了正常的 etcd 成员则有可能会导致仲裁丢失。
5.2.4.2. 替换其 etcd Pod 处于 crashlooping 状态的不健康 etcd 成员
此流程详细介绍了替换因 etcd pod 处于 crashlooping 状态造成不健康的 etcd 成员的步骤。
先决条件
- 您已找出不健康的 etcd 成员。
- 已确认 etcd pod 处于 crashlooping 状态。
-
您可以使用具有
cluster-admin角色的用户访问集群。 已进行 etcd 备份。
重要执行此流程前务必要进行 etcd 备份,以便在遇到任何问题时可以恢复集群。
流程
停止处于 crashlooping 状态的 etcd pod。
对处于 crashlooping 状态的节点进行调试。
在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc debug node/ip-10-0-131-183.ec2.internal1 - 1
- 使用不健康节点的名称来替换它。
将您的根目录改为
/host:sh-4.2# chroot /host将现有 etcd pod 文件从 Kubelet 清单目录中移出:
sh-4.2# mkdir /var/lib/etcd-backupsh-4.2# mv /etc/kubernetes/manifests/etcd-pod.yaml /var/lib/etcd-backup/将 etcd 数据目录移到不同的位置:
sh-4.2# mv /var/lib/etcd/ /tmp现在您可以退出节点 shell。
删除不健康的成员。
选择一个不在受影响节点上的 pod。
在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc -n openshift-etcd get pods -l k8s-app=etcd输出示例
etcd-ip-10-0-131-183.ec2.internal 2/3 Error 7 6h9m etcd-ip-10-0-164-97.ec2.internal 3/3 Running 0 6h6m etcd-ip-10-0-154-204.ec2.internal 3/3 Running 0 6h6m连接到正在运行的 etcd 容器,传递没有在受影响节点上的 pod 的名称。
在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc rsh -n openshift-etcd etcd-ip-10-0-154-204.ec2.internal查看成员列表:
sh-4.2# etcdctl member list -w table输出示例
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | 62bcf33650a7170a | started | ip-10-0-131-183.ec2.internal | https://10.0.131.183:2380 | https://10.0.131.183:2379 | | b78e2856655bc2eb | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | d022e10b498760d5 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+记录不健康的 etcd 成员的 ID 和名称,因为稍后需要这些值。
通过向
etcdctl member remove命令提供 ID 来删除不健康的 etcd 成员 :sh-4.2# etcdctl member remove 62bcf33650a7170a输出示例
Member 62bcf33650a7170a removed from cluster ead669ce1fbfb346再次查看成员列表,并确认成员已被删除:
sh-4.2# etcdctl member list -w table输出示例
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | b78e2856655bc2eb | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | d022e10b498760d5 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+现在您可以退出节点 shell。
输入以下命令关闭仲裁保护:
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'此命令可确保您可以成功重新创建机密并推出静态 pod。
删除已删除的不健康 etcd 成员的旧 secret。
列出已删除的不健康 etcd 成员的 secret。
$ oc get secrets -n openshift-etcd | grep ip-10-0-131-183.ec2.internal1 - 1
- 传递您之前在这个过程中记录的不健康 etcd 成员的名称。
有一个对等的、服务和指标的 secret,如以下输出所示:
输出示例
etcd-peer-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m etcd-serving-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m etcd-serving-metrics-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m删除已删除的不健康 etcd 成员的 secret。
删除 peer(对等)secret:
$ oc delete secret -n openshift-etcd etcd-peer-ip-10-0-131-183.ec2.internal删除 serving secret:
$ oc delete secret -n openshift-etcd etcd-serving-ip-10-0-131-183.ec2.internal删除 metrics secret:
$ oc delete secret -n openshift-etcd etcd-serving-metrics-ip-10-0-131-183.ec2.internal
强制 etcd 重新部署。
在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "single-master-recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge1 - 1
forceRedeploymentReason值必须是唯一的,这就是为什么附加时间戳的原因。
当 etcd 集群 Operator 执行重新部署时,它会确保所有 control plane 节点都有可正常工作的 etcd pod。
输入以下命令重新打开仲裁保护:
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'您可以输入以下命令验证
unsupportedConfigOverrides部分是否已从对象中删除:$ oc get etcd/cluster -oyaml如果使用单节点 OpenShift,请重启该节点。否则,您可能会在 etcd 集群 Operator 中遇到以下错误:
输出示例
EtcdCertSignerControllerDegraded: [Operation cannot be fulfilled on secrets "etcd-peer-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-metrics-sno-0": the object has been modified; please apply your changes to the latest version and try again]
验证
确认新成员可用且健康。
连接到正在运行的 etcd 容器。
在一个终端中使用 cluster-admin 用户连接到集群,运行以下命令:
$ oc rsh -n openshift-etcd etcd-ip-10-0-154-204.ec2.internal验证所有成员是否健康:
sh-4.2# etcdctl endpoint health输出示例
https://10.0.131.183:2379 is healthy: successfully committed proposal: took = 16.671434ms https://10.0.154.204:2379 is healthy: successfully committed proposal: took = 16.698331ms https://10.0.164.97:2379 is healthy: successfully committed proposal: took = 16.621645ms
5.2.4.3. 替换机器没有运行或节点未就绪的不健康裸机 etcd 成员
此流程详细介绍了替换因机器没有运行或节点未就绪造成不健康的裸机 etcd 成员的步骤。
如果您正在运行安装程序置备的基础架构,或者您使用 Machine API 创建机器,请按照以下步骤执行。否则,您必须使用最初创建控制平面节点时使用的相同方法创建新的控制平面。
先决条件
- 您已找出不健康的裸机 etcd 成员。
- 您已确认机器没有运行,或者该节点未就绪。
-
您可以使用具有
cluster-admin角色的用户访问集群。 已进行 etcd 备份。
重要执行此流程前务必要进行 etcd 备份,以便在遇到任何问题时可以恢复集群。
流程
验证并删除不健康的成员。
选择一个不在受影响节点上的 pod:
在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc -n openshift-etcd get pods -l k8s-app=etcd -o wide输出示例
etcd-openshift-control-plane-0 5/5 Running 11 3h56m 192.168.10.9 openshift-control-plane-0 <none> <none> etcd-openshift-control-plane-1 5/5 Running 0 3h54m 192.168.10.10 openshift-control-plane-1 <none> <none> etcd-openshift-control-plane-2 5/5 Running 0 3h58m 192.168.10.11 openshift-control-plane-2 <none> <none>连接到正在运行的 etcd 容器,传递没有在受影响节点上的 pod 的名称:
在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc rsh -n openshift-etcd etcd-openshift-control-plane-0查看成员列表:
sh-4.2# etcdctl member list -w table输出示例
+------------------+---------+--------------------+---------------------------+---------------------------+---------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+--------------------+---------------------------+---------------------------+---------------------+ | 7a8197040a5126c8 | started | openshift-control-plane-2 | https://192.168.10.11:2380/ | https://192.168.10.11:2379/ | false | | 8d5abe9669a39192 | started | openshift-control-plane-1 | https://192.168.10.10:2380/ | https://192.168.10.10:2379/ | false | | cc3830a72fc357f9 | started | openshift-control-plane-0 | https://192.168.10.9:2380/ | https://192.168.10.9:2379/ | false | +------------------+---------+--------------------+---------------------------+---------------------------+---------------------+记录不健康的 etcd 成员的 ID 和名称,因为稍后需要这些值。
etcdctl endpoint health命令将列出已删除的成员,直到完成替换过程并添加了新成员。通过向
etcdctl member remove命令提供 ID 来删除不健康的 etcd 成员 :警告确保删除正确的 etcd 成员;如果删除了正常的 etcd 成员则有可能会导致仲裁丢失。
sh-4.2# etcdctl member remove 7a8197040a5126c8输出示例
Member 7a8197040a5126c8 removed from cluster b23536c33f2cdd1b再次查看成员列表,并确认成员已被删除:
sh-4.2# etcdctl member list -w table输出示例
+------------------+---------+--------------------+---------------------------+---------------------------+-------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+--------------------+---------------------------+---------------------------+-------------------------+ | 7a8197040a5126c8 | started | openshift-control-plane-2 | https://192.168.10.11:2380/ | https://192.168.10.11:2379/ | false | | 8d5abe9669a39192 | started | openshift-control-plane-1 | https://192.168.10.10:2380/ | https://192.168.10.10:2379/ | false | +------------------+---------+--------------------+---------------------------+---------------------------+-------------------------+现在您可以退出节点 shell。
重要删除成员后,在剩余的 etcd 实例重启时,集群可能无法访问。
输入以下命令关闭仲裁保护:
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'此命令可确保您可以成功重新创建机密并推出静态 pod。
运行以下命令,删除已删除的不健康 etcd 成员的旧 secret。
列出已删除的不健康 etcd 成员的 secret。
$ oc get secrets -n openshift-etcd | grep openshift-control-plane-2传递您之前在这个过程中记录的不健康 etcd 成员的名称。
有一个对等的、服务和指标的 secret,如以下输出所示:
etcd-peer-openshift-control-plane-2 kubernetes.io/tls 2 134m etcd-serving-metrics-openshift-control-plane-2 kubernetes.io/tls 2 134m etcd-serving-openshift-control-plane-2 kubernetes.io/tls 2 134m删除已删除的不健康 etcd 成员的 secret。
删除 peer(对等)secret:
$ oc delete secret etcd-peer-openshift-control-plane-2 -n openshift-etcd secret "etcd-peer-openshift-control-plane-2" deleted删除 serving secret:
$ oc delete secret etcd-serving-metrics-openshift-control-plane-2 -n openshift-etcd secret "etcd-serving-metrics-openshift-control-plane-2" deleted删除 metrics secret:
$ oc delete secret etcd-serving-openshift-control-plane-2 -n openshift-etcd secret "etcd-serving-openshift-control-plane-2" deleted
删除 control plane 机器。
如果您正在运行安装程序置备的基础架构,或者您使用 Machine API 创建机器,请按照以下步骤执行。否则,您必须使用最初创建控制平面节点时使用的相同方法创建新的控制平面。
获取不健康成员的机器。
在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc get machines -n openshift-machine-api -o wide输出示例
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE examplecluster-control-plane-0 Running 3h11m openshift-control-plane-0 baremetalhost:///openshift-machine-api/openshift-control-plane-0/da1ebe11-3ff2-41c5-b099-0aa41222964e externally provisioned1 examplecluster-control-plane-1 Running 3h11m openshift-control-plane-1 baremetalhost:///openshift-machine-api/openshift-control-plane-1/d9f9acbc-329c-475e-8d81-03b20280a3e1 externally provisioned examplecluster-control-plane-2 Running 3h11m openshift-control-plane-2 baremetalhost:///openshift-machine-api/openshift-control-plane-2/3354bdac-61d8-410f-be5b-6a395b056135 externally provisioned examplecluster-compute-0 Running 165m openshift-compute-0 baremetalhost:///openshift-machine-api/openshift-compute-0/3d685b81-7410-4bb3-80ec-13a31858241f provisioned examplecluster-compute-1 Running 165m openshift-compute-1 baremetalhost:///openshift-machine-api/openshift-compute-1/0fdae6eb-2066-4241-91dc-e7ea72ab13b9 provisioned- 1
- 这是不健康节点的 control plane 机器,
examplecluster-control-plane-2。
将机器配置保存到文件系统中的一个文件中:
$ oc get machine examplecluster-control-plane-2 \1 -n openshift-machine-api \ -o yaml \ > new-master-machine.yaml- 1
- 为不健康的节点指定 control plane 机器的名称。
编辑上一步中创建的
new-master-machine.yaml文件,以分配新名称并删除不必要的字段。删除整个
status部分:status: addresses: - address: "" type: InternalIP - address: fe80::4adf:37ff:feb0:8aa1%ens1f1.373 type: InternalDNS - address: fe80::4adf:37ff:feb0:8aa1%ens1f1.371 type: Hostname lastUpdated: "2020-04-20T17:44:29Z" nodeRef: kind: Machine name: fe80::4adf:37ff:feb0:8aa1%ens1f1.372 uid: acca4411-af0d-4387-b73e-52b2484295ad phase: Running providerStatus: apiVersion: machine.openshift.io/v1beta1 conditions: - lastProbeTime: "2020-04-20T16:53:50Z" lastTransitionTime: "2020-04-20T16:53:50Z" message: machine successfully created reason: MachineCreationSucceeded status: "True" type: MachineCreation instanceId: i-0fdb85790d76d0c3f instanceState: stopped kind: Machine
将
metadata.name字段更改为新名称。建议您保留与旧机器相同的基础名称,并将结束号码改为下一个可用数字。在本例中,
examplecluster-control-plane-2改为examplecluster-control-plane-3。例如:
apiVersion: machine.openshift.io/v1beta1 kind: Machine metadata: ... name: examplecluster-control-plane-3 ...删除
spec.providerID字段:providerID: baremetalhost:///openshift-machine-api/openshift-control-plane-2/3354bdac-61d8-410f-be5b-6a395b056135删除
metadata.annotations和metadata.generation字段:annotations: machine.openshift.io/instance-state: externally provisioned ... generation: 2删除
spec.conditions、spec.lastUpdated、spec.nodeRef和spec.phase字段:lastTransitionTime: "2022-08-03T08:40:36Z" message: 'Drain operation currently blocked by: [{Name:EtcdQuorumOperator Owner:clusteroperator/etcd}]' reason: HookPresent severity: Warning status: "False" type: Drainable lastTransitionTime: "2022-08-03T08:39:55Z" status: "True" type: InstanceExists lastTransitionTime: "2022-08-03T08:36:37Z" status: "True" type: Terminable lastUpdated: "2022-08-03T08:40:36Z" nodeRef: kind: Node name: openshift-control-plane-2 uid: 788df282-6507-4ea2-9a43-24f237ccbc3c phase: Running
运行以下命令,确保 Bare Metal Operator 可用:
$ oc get clusteroperator baremetal输出示例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE baremetal 4.11.3 True False False 3d15h运行以下命令来删除旧的
BareMetalHost对象:$ oc delete bmh openshift-control-plane-2 -n openshift-machine-api输出示例
baremetalhost.metal3.io "openshift-control-plane-2" deleted运行以下命令来删除不健康成员的机器:
$ oc delete machine -n openshift-machine-api examplecluster-control-plane-2删除
BareMetalHost和Machine对象后,MachineController 会自动删除Node对象。如果删除机器因任何原因或者命令被移动而延迟而延迟而延迟,您可以通过删除机器对象终结器字段来强制删除。
重要不要通过按
Ctrl+c中断机器删除。您必须允许命令继续完成。打开一个新的终端窗口来编辑并删除 finalizer 字段。运行以下命令来编辑机器配置:
$ oc edit machine -n openshift-machine-api examplecluster-control-plane-2删除
Machine自定义资源中的以下字段,然后保存更新的文件:finalizers: - machine.machine.openshift.io输出示例
machine.machine.openshift.io/examplecluster-control-plane-2 edited
运行以下命令验证机器是否已删除:
$ oc get machines -n openshift-machine-api -o wide输出示例
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE examplecluster-control-plane-0 Running 3h11m openshift-control-plane-0 baremetalhost:///openshift-machine-api/openshift-control-plane-0/da1ebe11-3ff2-41c5-b099-0aa41222964e externally provisioned examplecluster-control-plane-1 Running 3h11m openshift-control-plane-1 baremetalhost:///openshift-machine-api/openshift-control-plane-1/d9f9acbc-329c-475e-8d81-03b20280a3e1 externally provisioned examplecluster-compute-0 Running 165m openshift-compute-0 baremetalhost:///openshift-machine-api/openshift-compute-0/3d685b81-7410-4bb3-80ec-13a31858241f provisioned examplecluster-compute-1 Running 165m openshift-compute-1 baremetalhost:///openshift-machine-api/openshift-compute-1/0fdae6eb-2066-4241-91dc-e7ea72ab13b9 provisioned运行以下命令验证节点是否已删除:
$ oc get nodes NAME STATUS ROLES AGE VERSION openshift-control-plane-0 Ready master 3h24m v1.24.0+9546431 openshift-control-plane-1 Ready master 3h24m v1.24.0+9546431 openshift-compute-0 Ready worker 176m v1.24.0+9546431 openshift-compute-1 Ready worker 176m v1.24.0+9546431创建新的
BareMetalHost对象和 secret,以存储 BMC 凭证:$ cat <<EOF | oc apply -f - apiVersion: v1 kind: Secret metadata: name: openshift-control-plane-2-bmc-secret namespace: openshift-machine-api data: password: <password> username: <username> type: Opaque --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: openshift-control-plane-2 namespace: openshift-machine-api spec: automatedCleaningMode: disabled bmc: address: redfish://10.46.61.18:443/redfish/v1/Systems/1 credentialsName: openshift-control-plane-2-bmc-secret disableCertificateVerification: true bootMACAddress: 48:df:37:b0:8a:a0 bootMode: UEFI externallyProvisioned: false online: true rootDeviceHints: deviceName: /dev/sda userData: name: master-user-data-managed namespace: openshift-machine-api EOF注意用户名和密码可从其他裸机主机的 secret 中找到。
bmc:address中使用的协议可以从其他 bmh 对象获取。重要如果您从现有 control plane 主机重复使用
BareMetalHost对象定义,请不要将 externalProvisioned字段保留为true。如果 OpenShift Container Platform 安装程序置备,现有 control plane
BareMetalHost对象可能会将externallyProvisioned标记设为true。检查完成后,
BareMetalHost对象会被创建并可用置备。使用可用的
BareMetalHost对象验证创建过程:$ oc get bmh -n openshift-machine-api NAME STATE CONSUMER ONLINE ERROR AGE openshift-control-plane-0 externally provisioned examplecluster-control-plane-0 true 4h48m openshift-control-plane-1 externally provisioned examplecluster-control-plane-1 true 4h48m openshift-control-plane-2 available examplecluster-control-plane-3 true 47m openshift-compute-0 provisioned examplecluster-compute-0 true 4h48m openshift-compute-1 provisioned examplecluster-compute-1 true 4h48m使用
new-master-machine.yaml文件创建新 control plane 机器:$ oc apply -f new-master-machine.yaml验证新机器是否已创建:
$ oc get machines -n openshift-machine-api -o wide输出示例
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE examplecluster-control-plane-0 Running 3h11m openshift-control-plane-0 baremetalhost:///openshift-machine-api/openshift-control-plane-0/da1ebe11-3ff2-41c5-b099-0aa41222964e externally provisioned1 examplecluster-control-plane-1 Running 3h11m openshift-control-plane-1 baremetalhost:///openshift-machine-api/openshift-control-plane-1/d9f9acbc-329c-475e-8d81-03b20280a3e1 externally provisioned examplecluster-control-plane-2 Running 3h11m openshift-control-plane-2 baremetalhost:///openshift-machine-api/openshift-control-plane-2/3354bdac-61d8-410f-be5b-6a395b056135 externally provisioned examplecluster-compute-0 Running 165m openshift-compute-0 baremetalhost:///openshift-machine-api/openshift-compute-0/3d685b81-7410-4bb3-80ec-13a31858241f provisioned examplecluster-compute-1 Running 165m openshift-compute-1 baremetalhost:///openshift-machine-api/openshift-compute-1/0fdae6eb-2066-4241-91dc-e7ea72ab13b9 provisioned- 1
- 新机器
clustername-8qw5l-master-3会被创建,并在阶段从Provisioning变为Running后就绪。
创建新机器需要几分钟时间。当机器或节点返回一个健康状态时,etcd cluster Operator 将自动同步。
运行以下命令验证裸机主机是否被置备,且没有报告的错误:
$ oc get bmh -n openshift-machine-api输出示例
$ oc get bmh -n openshift-machine-api NAME STATE CONSUMER ONLINE ERROR AGE openshift-control-plane-0 externally provisioned examplecluster-control-plane-0 true 4h48m openshift-control-plane-1 externally provisioned examplecluster-control-plane-1 true 4h48m openshift-control-plane-2 provisioned examplecluster-control-plane-3 true 47m openshift-compute-0 provisioned examplecluster-compute-0 true 4h48m openshift-compute-1 provisioned examplecluster-compute-1 true 4h48m运行以下命令验证新节点是否已添加并处于就绪状态:
$ oc get nodes输出示例
$ oc get nodes NAME STATUS ROLES AGE VERSION openshift-control-plane-0 Ready master 4h26m v1.24.0+9546431 openshift-control-plane-1 Ready master 4h26m v1.24.0+9546431 openshift-control-plane-2 Ready master 12m v1.24.0+9546431 openshift-compute-0 Ready worker 3h58m v1.24.0+9546431 openshift-compute-1 Ready worker 3h58m v1.24.0+9546431
输入以下命令重新打开仲裁保护:
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'您可以输入以下命令验证
unsupportedConfigOverrides部分是否已从对象中删除:$ oc get etcd/cluster -oyaml如果使用单节点 OpenShift,请重启该节点。否则,您可能会在 etcd 集群 Operator 中遇到以下错误:
输出示例
EtcdCertSignerControllerDegraded: [Operation cannot be fulfilled on secrets "etcd-peer-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-metrics-sno-0": the object has been modified; please apply your changes to the latest version and try again]
验证
验证所有 etcd pod 是否都正常运行。
在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc -n openshift-etcd get pods -l k8s-app=etcd输出示例
etcd-openshift-control-plane-0 5/5 Running 0 105m etcd-openshift-control-plane-1 5/5 Running 0 107m etcd-openshift-control-plane-2 5/5 Running 0 103m如果上一命令的输出只列出两个 pod,您可以手动强制重新部署 etcd。在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge1 - 1
forceRedeploymentReason值必须是唯一的,这就是为什么附加时间戳的原因。
要验证是否有完全有三个 etcd 成员,连接到正在运行的 etcd 容器,传递没有在受影响节点上的 pod 的名称。在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc rsh -n openshift-etcd etcd-openshift-control-plane-0查看成员列表:
sh-4.2# etcdctl member list -w table输出示例
+------------------+---------+--------------------+---------------------------+---------------------------+-----------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+--------------------+---------------------------+---------------------------+-----------------+ | 7a8197040a5126c8 | started | openshift-control-plane-2 | https://192.168.10.11:2380 | https://192.168.10.11:2379 | false | | 8d5abe9669a39192 | started | openshift-control-plane-1 | https://192.168.10.10:2380 | https://192.168.10.10:2379 | false | | cc3830a72fc357f9 | started | openshift-control-plane-0 | https://192.168.10.9:2380 | https://192.168.10.9:2379 | false | +------------------+---------+--------------------+---------------------------+---------------------------+-----------------+注意如果上一命令的输出列出了超过三个 etcd 成员,您必须删除不需要的成员。
运行以下命令,验证所有 etcd 成员是否健康:
# etcdctl endpoint health --cluster输出示例
https://192.168.10.10:2379 is healthy: successfully committed proposal: took = 8.973065ms https://192.168.10.9:2379 is healthy: successfully committed proposal: took = 11.559829ms https://192.168.10.11:2379 is healthy: successfully committed proposal: took = 11.665203ms运行以下命令,验证所有节点是否处于最新的修订版本:
$ oc get etcd -o=jsonpath='{range.items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'AllNodesAtLatestRevision
5.3. 灾难恢复
5.3.1. 关于灾难恢复
灾难恢复文档为管理员提供了如何从 OpenShift Container Platform 集群可能出现的几个灾难情形中恢复的信息。作为管理员,您可能需要遵循以下一个或多个步骤将集群恢复为工作状态。
灾难恢复要求您至少有一个健康的 control plane 主机。
- 恢复到一个以前的集群状态
如果您希望将集群恢复到一个以前的状态时(例如,管理员错误地删除了一些关键信息),则可以使用这个解决方案。这包括您丢失了大多数 control plane 主机并导致 etcd 仲裁丢失,且集群离线的情况。只要您执行了 etcd 备份,就可以按照这个步骤将集群恢复到之前的状态。
如果适用,您可能还需要从过期的 control plane 证书中恢复。
警告在一个正在运行的集群中恢复到以前的集群状态是破坏性的,而不稳定的操作。这仅应作为最后的手段使用。
在执行恢复前,请参阅关于恢复集群状态以了解有关对集群的影响的更多信息。
注意如果大多数 master 仍可用,且仍有 etcd 仲裁,请按照以下步骤替换一个不健康的 etcd 成员。
- 从 control plane 证书已过期的情况下恢复
- 如果 control plane 证书已经过期,则可以使用这个解决方案。例如:在第一次证书轮转前(在安装后 24 小时内)关闭了集群,您的证书将不会被轮转,且会过期。可以按照以下步骤从已过期的 control plane 证书中恢复。
5.3.2. 恢复到一个以前的集群状态
为了将集群还原到以前的状态,您必须已通过创建快照备份了 etcd 数据 。您将需要使用此快照来还原集群状态。
5.3.2.1. 关于恢复集群状态
您可以使用 etcd 备份将集群恢复到以前的状态。在以下情况中可以使用这个方法进行恢复:
- 集群丢失了大多数 control plane 主机(仲裁丢失)。
- 管理员删除了一些关键内容,必须恢复才能恢复集群。
在一个正在运行的集群中恢复到以前的集群状态是破坏性的,而不稳定的操作。这仅应作为最后的手段使用。
如果您可以使用 Kubernetes API 服务器检索数据,则代表 etcd 可用,且您不应该使用 etcd 备份来恢复。
恢复 etcd 实际相当于把集群返回到以前的一个状态,所有客户端都会遇到一个有冲突的、并行历史记录。这会影响 kubelet、Kubernetes 控制器、SDN 控制器和持久性卷控制器等监视组件的行为。
当 etcd 中的内容与磁盘上的实际内容不匹配时,可能会导致 Operator churn,从而导致 Kubernetes API 服务器、Kubernetes 控制器管理器、Kubernetes 调度程序和 etcd 的 Operator 在磁盘上的文件与 etcd 中的内容冲突时卡住。这可能需要手动操作来解决问题。
在极端情况下,集群可能会丢失持久性卷跟踪,删除已不存在的关键工作负载,重新镜像机器,以及重写带有过期证书的 CA 捆绑包。
5.3.2.2. 恢复到一个以前的集群状态
您可以使用保存的 etcd 备份来恢复以前的集群状态,或恢复丢失了大多数 control plane 主机的集群。
如果您的集群使用 control plane 机器集,请参阅 "Troubleshooting control plane 机器集"来了解有关 etcd 恢复的过程。
恢复集群时,必须使用同一 z-stream 发行版本中获取的 etcd 备份。例如,OpenShift Container Platform 4.7.2 集群必须使用从 4.7.2 开始的 etcd 备份。
先决条件
-
通过一个基于证书的
kubeconfig使用具有cluster-admin角色的用户访问集群,如安装期间的情况。 - 用作恢复主机的健康 control plane 主机。
- SSH 对 control plane 主机的访问。
-
包含从同一备份中获取的 etcd 快照和静态
pod资源的备份目录。该目录中的文件名必须采用以下格式:snapshot_<datetimestamp>.db和static_kuberesources_<datetimestamp>.tar.gz。
对于非恢复 control plane 节点,不需要建立 SSH 连接或停止静态 pod。您可以逐个删除并重新创建其他非恢复 control plane 机器。
流程
- 选择一个要用作恢复主机的 control plane 主机。这是您要在其中运行恢复操作的主机。
建立到每个 control plane 节点(包括恢复主机)的 SSH 连接。
恢复过程启动后,
kube-apiserver将无法访问,因此您无法访问 control plane 节点。因此,建议在一个单独的终端中建立到每个control plane 主机的 SSH 连接。重要如果没有完成这个步骤,将无法访问 control plane 主机来完成恢复过程,您将无法从这个状态恢复集群。
将
etcd备份目录复制到恢复 control plane 主机上。此流程假设您将
backup目录(其中包含etcd快照和静态 pod 资源)复制到恢复 control plane 主机的/home/core/目录中。在任何其他 control plane 节点上停止静态 pod。
注意您不需要停止恢复主机上的静态 pod。
- 访问不是恢复主机的 control plane 主机。
运行以下命令,将现有 etcd pod 文件从 kubelet 清单目录中移出:
$ sudo mv /etc/kubernetes/manifests/etcd-pod.yaml /tmp使用以下命令验证
etcdpod 是否已停止:$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"如果这个命令的输出不为空,请等待几分钟,然后再次检查。
运行以下命令,将现有
kube-apiserver文件从 kubelet 清单目录中移出:$ sudo mv /etc/kubernetes/manifests/kube-apiserver-pod.yaml /tmp运行以下命令验证
kube-apiserver容器是否已停止:$ sudo crictl ps | grep kube-apiserver | egrep -v "operator|guard"如果这个命令的输出不为空,请等待几分钟,然后再次检查。
使用以下方法将现有
kube-controller-manager文件从 kubelet 清单目录中移出:$ sudo mv /etc/kubernetes/manifests/kube-controller-manager-pod.yaml /tmp运行以下命令验证
kube-controller-manager容器是否已停止:$ sudo crictl ps | grep kube-controller-manager | egrep -v "operator|guard"如果这个命令的输出不为空,请等待几分钟,然后再次检查。
使用以下方法将现有
kube-scheduler文件从 kubelet 清单目录中移出:$ sudo mv /etc/kubernetes/manifests/kube-scheduler-pod.yaml /tmp使用以下命令验证
kube-scheduler容器是否已停止:$ sudo crictl ps | grep kube-scheduler | egrep -v "operator|guard"如果这个命令的输出不为空,请等待几分钟,然后再次检查。
使用以下示例将
etcd数据目录移到不同的位置:$ sudo mv /var/lib/etcd/ /tmp如果存在
/etc/kubernetes/manifests/keepalived.yaml文件,请按照以下步骤执行:将
/etc/kubernetes/manifests/keepalived.yaml文件从 kubelet 清单目录中移出:$ sudo mv /etc/kubernetes/manifests/keepalived.yaml /tmp容器验证由
keepalived守护进程管理的任何容器是否已停止:$ sudo crictl ps --name keepalived命令输出应该为空。如果它不是空的,请等待几分钟后再重新检查。
检查 control plane 是否已分配任何 Virtual IP (VIP):
$ ip -o address | egrep '<api_vip>|<ingress_vip>'对于每个报告的 VIP,运行以下命令将其删除:
$ sudo ip address del <reported_vip> dev <reported_vip_device>
- 在其他不是恢复主机的 control plane 主机上重复此步骤。
- 访问恢复 control plane 主机。
如果使用
keepalived守护进程,请验证恢复 control plane 节点是否拥有 VIP:$ ip -o address | grep <api_vip>如果存在 VIP 的地址(如果存在)。如果 VIP 没有设置或配置不正确,这个命令会返回一个空字符串。
如果启用了集群范围的代理,请确定已导出了
NO_PROXY、HTTP_PROXY和HTTPS_PROXY环境变量。提示您可以通过查看
oc get proxy cluster -o yaml的输出来检查代理是否已启用。如果httpProxy、httpsProxy和noProxy字段设置了值,则会启用代理。在恢复 control plane 主机上运行恢复脚本,并传递到
etcd备份目录的路径:$ sudo -E /usr/local/bin/cluster-restore.sh /home/core/backup脚本输出示例
...stopping kube-scheduler-pod.yaml ...stopping kube-controller-manager-pod.yaml ...stopping etcd-pod.yaml ...stopping kube-apiserver-pod.yaml Waiting for container etcd to stop .complete Waiting for container etcdctl to stop .............................complete Waiting for container etcd-metrics to stop complete Waiting for container kube-controller-manager to stop complete Waiting for container kube-apiserver to stop ..........................................................................................complete Waiting for container kube-scheduler to stop complete Moving etcd data-dir /var/lib/etcd/member to /var/lib/etcd-backup starting restore-etcd static pod starting kube-apiserver-pod.yaml static-pod-resources/kube-apiserver-pod-7/kube-apiserver-pod.yaml starting kube-controller-manager-pod.yaml static-pod-resources/kube-controller-manager-pod-7/kube-controller-manager-pod.yaml starting kube-scheduler-pod.yaml static-pod-resources/kube-scheduler-pod-8/kube-scheduler-pod.yamlcluster-restore.sh 脚本必须显示
etcd、kube-apiserver、kube-controller-manager和kube-schedulerpod 已停止,然后在恢复过程结束时启动。注意如果在上次
etcd备份后更新了节点,则恢复过程可能会导致节点进入NotReady状态。检查节点以确保它们处于
Ready状态。运行以下命令:
$ oc get nodes -w输出示例
NAME STATUS ROLES AGE VERSION host-172-25-75-28 Ready master 3d20h v1.24.0 host-172-25-75-38 Ready infra,worker 3d20h v1.24.0 host-172-25-75-40 Ready master 3d20h v1.24.0 host-172-25-75-65 Ready master 3d20h v1.24.0 host-172-25-75-74 Ready infra,worker 3d20h v1.24.0 host-172-25-75-79 Ready worker 3d20h v1.24.0 host-172-25-75-86 Ready worker 3d20h v1.24.0 host-172-25-75-98 Ready infra,worker 3d20h v1.24.0所有节点都可能需要几分钟时间报告其状态。
如果有任何节点处于
NotReady状态,登录到节点,并从每个节点上的/var/lib/kubelet/pki目录中删除所有 PEM 文件。您可以 SSH 到节点,或使用 web 控制台中的终端窗口。$ ssh -i <ssh-key-path> core@<master-hostname>pki目录示例sh-4.4# pwd /var/lib/kubelet/pki sh-4.4# ls kubelet-client-2022-04-28-11-24-09.pem kubelet-server-2022-04-28-11-24-15.pem kubelet-client-current.pem kubelet-server-current.pem
在所有 control plane 主机上重启 kubelet 服务。
在恢复主机中运行:
$ sudo systemctl restart kubelet.service- 在所有其他 control plane 主机上重复此步骤。
批准待处理的证书签名请求 (CSR):
注意没有 worker 节点的集群(如单节点集群或由三个可调度的 control plane 节点组成的集群)不会批准任何待处理的 CSR。您可以跳过此步骤中列出的所有命令。
运行以下命令获取当前 CSR 列表:
$ oc get csr输出示例
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-2s94x 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending1 csr-4bd6t 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending2 csr-4hl85 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending3 csr-zhhhp 3m8s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending4 ...
CSR (用于用户置备的安装)。<2>待处理的 node-bootstrapper CSR。
运行以下命令,查看 CSR 的详情以验证其是否有效:
$ oc describe csr <csr_name>1 - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
运行以下命令来批准每个有效的
node-bootstrapperCSR:$ oc adm certificate approve <csr_name>对于用户置备的安装,运行以下命令批准每个有效的 kubelet 服务 CSR:
$ oc adm certificate approve <csr_name>- 确认单个成员 control plane 已被成功启动。
在恢复主机上,使用以下命令验证
etcd容器是否正在运行:$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"输出示例
3ad41b7908e32 36f86e2eeaaffe662df0d21041eb22b8198e0e58abeeae8c743c3e6e977e8009 About a minute ago Running etcd 0 7c05f8af362f0在恢复主机上,使用以下命令验证
etcdpod 是否正在运行:$ oc -n openshift-etcd get pods -l k8s-app=etcd输出示例
NAME READY STATUS RESTARTS AGE etcd-ip-10-0-143-125.ec2.internal 1/1 Running 1 2m47s如果状态是
Pending,或者输出中列出了多个正在运行的etcdpod,请等待几分钟,然后再次检查。-
如果使用
OVNKubernetes网络插件,您必须重启ovnkube-controlplanepod。
-
如果使用
运行以下命令删除所有
ovnkube-controlplanepod:$ oc -n openshift-ovn-kubernetes delete pod -l app=ovnkube-control-plane使用以下命令验证所有
ovnkube-controlplanepod 是否已重新部署:$ oc -n openshift-ovn-kubernetes get pod -l app=ovnkube-control-plane验证 Cluster Network Operator (CNO) 是否已重新部署 OVN-Kubernetes control plane,并且不再引用非恢复控制器 IP 地址。要验证此结果,请定期检查以下命令的输出。等待返回空结果,然后继续下一步的所有主机上重启 Open Virtual Network (OVN) Kubernetes pod。
$ oc -n openshift-ovn-kubernetes get ds/ovnkube-master -o yaml | grep -E '<non-recovery_controller_ip_1>|<non-recovery_controller_ip_2>'注意重新部署 OVN-Kubernetes control plane 并至少需要 5 到 10 分钟,并且上一命令返回空输出。
在所有主机上重启 Open Virtual Network (OVN) Kubernetes pod。
注意验证和变异准入 Webhook 可能会拒绝 pod。如果您添加了额外的 Webhook,其
failurePolicy被设置为Fail的,则它们可能会拒绝 pod,恢复过程可能会失败。您可以通过在恢复集群状态时保存和删除 Webhook 来避免这种情况。成功恢复集群状态后,您可以再次启用 Webhook。另外,您可以在恢复集群状态时临时将
failurePolicy设置为Ignore。成功恢复集群状态后,您可以将failurePolicy设置为Fail。
删除北向数据库 (nbdb) 和南向数据库 (sbdb)。使用 Secure Shell (SSH) 访问恢复主机和剩余的 control plane 节点,并运行:
$ sudo rm -f /var/lib/ovn/etc/*.db运行以下命令删除所有 OVN-Kubernetes control plane pod:
$ oc delete pods -l app=ovnkube-master -n openshift-ovn-kubernetes运行以下命令,确保任何 OVN-Kubernetes control plane pod 已再次部署,并处于
Running状态:$ oc get pods -l app=ovnkube-master -n openshift-ovn-kubernetes输出示例
NAME READY STATUS RESTARTS AGE ovnkube-master-nb24h 4/4 Running 0 48s使用以下命令验证
ovnkube-nodepod 已再次运行:$ oc get pods -n openshift-ovn-kubernetes -o name | grep ovnkube-node | while read p ; do oc delete $p -n openshift-ovn-kubernetes ; done运行以下命令,确保所有
ovnkube-nodepod 已再次部署,并处于Running状态:$ oc get pods -n openshift-ovn-kubernetes | grep ovnkube-node逐个删除并重新创建其他非恢复 control plane 机器。重新创建机器后,会强制一个新修订版本,
etcd会自动扩展。如果使用用户置备的裸机安装,您可以使用最初创建它时使用的相同方法重新创建 control plane 机器。如需更多信息,请参阅"在裸机上安装用户置备的集群"。
警告不要为恢复主机删除并重新创建机器。
如果您正在运行安装程序置备的基础架构,或者您使用 Machine API 创建机器,请按照以下步骤执行:
警告不要为恢复主机删除并重新创建机器。
对于安装程序置备的基础架构上的裸机安装,不会重新创建 control plane 机器。如需更多信息,请参阅"替换裸机控制平面节点"。
为丢失的 control plane 主机之一获取机器。
在一个终端中使用 cluster-admin 用户连接到集群,运行以下命令:
$ oc get machines -n openshift-machine-api -o wide输出示例:
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-0 Running m4.xlarge us-east-1 us-east-1a 3h37m ip-10-0-131-183.ec2.internal aws:///us-east-1a/i-0ec2782f8287dfb7e stopped1 clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- 这是用于丢失的 control plane 主机
ip-10-0-131-183.ec2.internal的 control plane 机器。
运行以下命令,将机器配置保存到文件系统中的一个文件中:
$ oc get machine clustername-8qw5l-master-0 \1 -n openshift-machine-api \ -o yaml \ > new-master-machine.yaml- 1
- 为丢失的 control plane 主机指定 control plane 机器的名称。
编辑上一步中创建的
new-master-machine.yaml文件,以分配新名称并删除不必要的字段。运行以下命令删除整个
status部分:status: addresses: - address: 10.0.131.183 type: InternalIP - address: ip-10-0-131-183.ec2.internal type: InternalDNS - address: ip-10-0-131-183.ec2.internal type: Hostname lastUpdated: "2020-04-20T17:44:29Z" nodeRef: kind: Node name: ip-10-0-131-183.ec2.internal uid: acca4411-af0d-4387-b73e-52b2484295ad phase: Running providerStatus: apiVersion: awsproviderconfig.openshift.io/v1beta1 conditions: - lastProbeTime: "2020-04-20T16:53:50Z" lastTransitionTime: "2020-04-20T16:53:50Z" message: machine successfully created reason: MachineCreationSucceeded status: "True" type: MachineCreation instanceId: i-0fdb85790d76d0c3f instanceState: stopped kind: AWSMachineProviderStatus运行以下命令,将
metadata.name字段改为新名称:建议您保留与旧机器相同的基础名称,并将结束号码改为下一个可用数字。在本例中,
clustername-8qw5l-master-0被改为clustername-8qw5l-master-3:apiVersion: machine.openshift.io/v1beta1 kind: Machine metadata: ... name: clustername-8qw5l-master-3 ...运行以下命令来删除
spec.providerID字段:providerID: aws:///us-east-1a/i-0fdb85790d76d0c3f运行以下命令,删除
metadata.annotations和metadata.generation字段:annotations: machine.openshift.io/instance-state: running ... generation: 2运行以下命令,删除
metadata.resourceVersion和metadata.uid字段:resourceVersion: "13291" uid: a282eb70-40a2-4e89-8009-d05dd420d31a
运行以下命令,删除丢失的 control plane 主机的机器:
$ oc delete machine -n openshift-machine-api clustername-8qw5l-master-01 - 1
- 为丢失的 control plane 主机指定 control plane 机器的名称。
运行以下命令验证机器是否已删除:
$ oc get machines -n openshift-machine-api -o wide输出示例:
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running运行以下命令,使用
new-master-machine.yaml文件创建机器:$ oc apply -f new-master-machine.yaml运行以下命令验证新机器是否已创建:
$ oc get machines -n openshift-machine-api -o wide输出示例:
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-master-3 Provisioning m4.xlarge us-east-1 us-east-1a 85s ip-10-0-173-171.ec2.internal aws:///us-east-1a/i-015b0888fe17bc2c8 running1 clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- 新机器
clustername-8qw5l-master-3会被创建,并在阶段从Provisioning变为Running后就绪。
创建新机器可能需要几分钟时间。当机器或节点返回到健康状态时,
etcd集群 Operator 将自动同步。对不是恢复主机的每个已丢失的 control plane 主机重复此步骤。
输入以下内容关闭仲裁保护:
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'此命令可确保您可以成功重新创建机密并推出静态 pod。
在恢复主机中的一个单独的终端窗口中,运行以下命令导出恢复
kubeconfig文件:$ export KUBECONFIG=/etc/kubernetes/static-pod-resources/kube-apiserver-certs/secrets/node-kubeconfigs/localhost-recovery.kubeconfig强制
etcd重新部署。在导出恢复
kubeconfig文件的同一终端窗口中,运行:$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge1 - 1
forceRedeploymentReason值必须是唯一的,这就是为什么附加时间戳的原因。
当
etcd集群 Operator 执行重新部署时,现有节点开始使用与初始 bootstrap 扩展类似的新 pod。输入以下内容重新打开仲裁保护:
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'您可以运行以下命令来验证
unsupportedConfigOverrides部分是否已从对象中删除:$ oc get etcd/cluster -oyaml验证所有节点是否已更新至最新的修订版本。
在一个终端中使用
cluster-admin用户连接到集群,请运行:$ oc get etcd -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'查看
etcd的NodeInstallerProgressing状态条件,以验证所有节点是否处于最新的修订版本。在更新成功后,输出会显示AllNodesAtLatestRevision:AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- 在本例中,最新的修订版本号是
7。
如果输出包含多个修订号,如
2 个节点为修订版本 6;1 个节点为修订版本 7,这意味着更新仍在进行中。等待几分钟后重试。重新部署
etcd后,为 control plane 强制进行新的推出部署。kube-apiserver将在其他节点上重新安装自己,因为 kubelet 使用内部负载均衡器连接到 API 服务器。在一个终端中使用
cluster-admin用户连接到集群,请运行:
为
kube-apiserver强制进行新的推出部署:$ oc patch kubeapiserver cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge验证所有节点是否已更新至最新的修订版本。
$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'查看
NodeInstallerProgressing状态条件,以验证所有节点是否处于最新版本。在更新成功后,输出会显示AllNodesAtLatestRevision:AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- 在本例中,最新的修订版本号是
7。
如果输出包含多个修订号,如
2 个节点为修订版本 6;1 个节点为修订版本 7,这意味着更新仍在进行中。等待几分钟后重试。运行以下命令,为 Kubernetes 控制器管理器强制进行新的推出部署:
$ oc patch kubecontrollermanager cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge运行以下命令,验证所有节点是否已更新至最新的修订版本:
$ oc get kubecontrollermanager -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'查看
NodeInstallerProgressing状态条件,以验证所有节点是否处于最新版本。在更新成功后,输出会显示AllNodesAtLatestRevision:AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- 在本例中,最新的修订版本号是
7。
如果输出包含多个修订号,如
2 个节点为修订版本 6;1 个节点为修订版本 7,这意味着更新仍在进行中。等待几分钟后重试。运行以下命令,为
kube-scheduler强制进行新的推出部署:$ oc patch kubescheduler cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge使用以下命令验证所有节点是否已更新至最新的修订版本:
$ oc get kubescheduler -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'查看
NodeInstallerProgressing状态条件,以验证所有节点是否处于最新版本。在更新成功后,输出会显示AllNodesAtLatestRevision:AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- 在本例中,最新的修订版本号是
7。
如果输出包含多个修订号,如
2 个节点为修订版本 6;1 个节点为修订版本 7,这意味着更新仍在进行中。等待几分钟后重试。验证所有 control plane 主机是否已启动并加入集群。
在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:$ oc -n openshift-etcd get pods -l k8s-app=etcd输出示例
etcd-ip-10-0-143-125.ec2.internal 2/2 Running 0 9h etcd-ip-10-0-154-194.ec2.internal 2/2 Running 0 9h etcd-ip-10-0-173-171.ec2.internal 2/2 Running 0 9h
为确保所有工作负载在恢复过程后返回到正常操作,请重启存储 kube-apiserver 信息的每个 pod。这包括 OpenShift Container Platform 组件,如路由器、Operator 和第三方组件。
完成前面的流程步骤后,您可能需要等待几分钟,让所有服务返回到恢复的状态。例如,在重启 OAuth 服务器 pod 前,使用 oc login 进行身份验证可能无法立即正常工作。
考虑使用 system:admin kubeconfig 文件立即进行身份验证。这个方法基于 SSL/TLS 客户端证书作为 OAuth 令牌的身份验证。您可以发出以下命令来使用此文件进行身份验证:
$ export KUBECONFIG=<installation_directory>/auth/kubeconfig发出以下命令以显示您的验证的用户名:
$ oc whoami5.3.2.4. 恢复持久性存储状态的问题和解决方法
如果您的 OpenShift Container Platform 集群使用任何形式的持久性存储,集群的状态通常存储在 etcd 外部。它可能是在 pod 中运行的 Elasticsearch 集群,或者在 StatefulSet 对象中运行的数据库。从 etcd 备份中恢复时,还会恢复 OpenShift Container Platform 中工作负载的状态。但是,如果 etcd 快照是旧的,其状态可能无效或过期。
持久性卷(PV)的内容绝不会属于 etcd 快照的一部分。从 etcd 快照恢复 OpenShift Container Platform 集群时,非关键工作负载可能会访问关键数据,反之亦然。
以下是生成过时状态的一些示例情况:
- MySQL 数据库在由 PV 对象支持的 pod 中运行。从 etcd 快照恢复 OpenShift Container Platform 不会使卷恢复到存储供应商上,且不会生成正在运行的 MySQL pod,尽管 pod 会重复尝试启动。您必须通过在存储供应商中恢复卷,然后编辑 PV 以指向新卷来手动恢复这个 pod。
- Pod P1 使用卷 A,它附加到节点 X。如果另一个 pod 在节点 Y 上使用相同的卷,则执行 etcd 恢复时,pod P1 可能无法正确启动,因为卷仍然被附加到节点 Y。OpenShift Container Platform 并不知道附加,且不会自动分离它。发生这种情况时,卷必须从节点 Y 手动分离,以便卷可以在节点 X 上附加,然后 pod P1 才可以启动。
- 在执行 etcd 快照后,云供应商或存储供应商凭证会被更新。这会导致任何依赖于这些凭证的 CSI 驱动程序或 Operator 无法正常工作。您可能需要手动更新这些驱动程序或 Operator 所需的凭证。
在生成 etcd 快照后,会从 OpenShift Container Platform 节点中删除或重命名设备。Local Storage Operator 会为从
/dev/disk/by-id或/dev目录中管理的每个 PV 创建符号链接。这种情况可能会导致本地 PV 引用不再存在的设备。要解决这个问题,管理员必须:
- 手动删除带有无效设备的 PV。
- 从对应节点中删除符号链接。
-
删除
LocalVolume或LocalVolumeSet对象(请参阅 Storage → Configuring persistent storage → Persistent storage → Persistent storage → Deleting the Local Storage Operator Resources)。
5.3.3. 从 control plane 证书已过期的情况下恢复
5.3.3.1. 从 control plane 证书已过期的情况下恢复
集群可以从过期的 control plane 证书中自动恢复。
但是,您需要手动批准待处理的 node-bootstrapper 证书签名请求(CSR)来恢复 kubelet 证书。对于用户置备的安装,您可能需要批准待处理的 kubelet 服务 CSR。
使用以下步骤批准待处理的 CSR:
流程
获取当前 CSR 列表:
$ oc get csr输出示例
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-2s94x 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending1 csr-4bd6t 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending csr-4hl85 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending2 csr-zhhhp 3m8s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...查看一个 CSR 的详细信息以验证其是否有效:
$ oc describe csr <csr_name>1 - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
批准每个有效的
node-bootstrapperCSR:$ oc adm certificate approve <csr_name>对于用户置备的安装,请批准每个有效的 kubelet 服务 CSR:
$ oc adm certificate approve <csr_name>
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.