安装后配置
OpenShift Container Platform 的第二天操作
摘要
第 1 章 安装后配置概述
安装 OpenShift Container Platform 后,集群管理员可以配置和自定义以下组件:
- 机器
- 裸机
- 集群
- 节点
- Network
- 存储
- 用户
- 警报和通知
1.1. 安装后配置任务
您可以执行安装后配置任务来配置您的环境以满足您的需要。
以下列表详细介绍了这些配置:
-
配置操作系统功能 :Machine Config Operator (MCO) 管理
MachineConfig对象。通过使用 MCO,您可以配置节点和自定义资源。 配置裸机节点 :您可以使用 Bare Metal Operator (BMO) 来管理裸机主机。BMO 可以完成以下操作:
- 检查主机的硬件详情,并将其报告到裸机主机。
- 检查固件并配置 BIOS 设置。
- 使用所需镜像调配主机。
- 在置备主机之前或之后清理主机的磁盘内容。
配置集群功能。您可以修改 OpenShift Container Platform 集群的以下功能:
- 镜像 registry
- 网络配置
- 镜像构建行为
- 用户身份提供程序
- etcd 配置
- 用于处理工作负载的机器集
- 云供应商凭证管理
配置私有集群:默认情况下,安装程序使用公开的 DNS 和端点置备 OpenShift Container Platform。要使集群只能从内部网络进行访问,请配置以下组件使其私有:
- DNS
- Ingress Controller
- API Server
执行节点操作 :默认情况下,OpenShift Container Platform 使用 Red Hat Enterprise Linux CoreOS(RHCOS)计算机器。您可以执行以下操作:
- 添加和删除计算机器。
- 添加和删除污点和容限。
- 配置每个节点的最大 pod 数量。
- 启用设备管理器。
配置用户 :用户可以使用 OAuth 访问令牌向 API 进行身份验证。您可以配置 OAuth 以执行以下任务:
- 指定身份提供程序。
- 使用基于角色的访问控制为用户定义和授予权限。
- 从 OperatorHub 安装 Operator。
- 配置警报通知 :默认情况下,触发的警报显示在 web 控制台的 Alerting UI 中。您还可以配置 OpenShift Container Platform,将警报通知发送到外部系统。
第 2 章 配置私有集群
安装 OpenShift Container Platform 版本 4.16 集群后,您可以将其某些核心组件设置为私有。
2.1. 关于私有集群
默认情况下,OpenShift Container Platform 被置备为使用可公开访问的 DNS 和端点。在部署私有集群后,您可以将 DNS、Ingress Controller 和 API 服务器设置为私有。
如果集群有任何公共子网,管理员创建的负载均衡器服务可能会公开访问。为确保集群安全性,请验证这些服务是否已明确标注为私有。
2.1.1. DNS
如果在安装程序置备的基础架构上安装 OpenShift Container Platform,安装程序会在预先存在的公共区中创建记录,并在可能的情况下为集群自己的 DNS 解析创建一个私有区。在公共区和私有区中,安装程序或集群为 *.apps 和 Ingress 对象创建 DNS 条目,并为 API 服务器创建 api。
公共和私有区中的 *.apps 记录是相同的,因此当您删除公有区时,私有区为集群无缝地提供所有 DNS 解析。
2.1.2. Ingress Controller
由于默认 Ingress 对象是作为公共对象创建的,所以负载均衡器是面向互联网的,因此在公共子网中。
Ingress Operator 为 Ingress Controller 生成默认证书,以充当占位符,直到您配置了自定义默认证书为止。不要在生产环境集群中使用 Operator 生成的默认证书。Ingress Operator 不轮转其自身的签名证书或它生成的默认证书。Operator 生成的默认证书的目的是作为您配置的自定义默认证书的占位者。
2.1.3. API Server
默认情况下,安装程序为 API 服务器创建适当的网络负载均衡器,供内部和外部流量使用。
在 Amazon Web Services(AWS)上,会分别创建独立的公共和私有负载均衡器。负载均衡器是基本相同的,唯一不同是带有一个额外的、用于在集群内部使用的端口。虽然安装程序根据 API 服务器要求自动创建或销毁负载均衡器,但集群并不管理或维护它们。只要保留集群对 API 服务器的访问,您可以手动修改或移动负载均衡器。对于公共负载均衡器,需要打开端口 6443,并根据 /readyz 路径配置 HTTPS 用于健康检查。
在 Google Cloud 上,创建一个负载均衡器来管理内部和外部 API 流量,因此您不需要修改负载均衡器。
在 Microsoft Azure 上,会创建公共和私有负载均衡器。但是,由于当前实施的限制,您刚刚在私有集群中保留两个负载均衡器。
2.2. 配置要在私有区中发布的 DNS 记录
对于所有 OpenShift Container Platform 集群,无论是公共还是私有,DNS 记录都会默认在公共区中发布。
您可以从集群 DNS 配置中删除公共区,以避免向公共公开 DNS 记录。您可能希望避免公开敏感信息,如内部域名、内部 IP 地址或机构中的集群数量,或者您可能不需要公开发布记录。如果所有能够连接到集群内的服务的客户端都使用具有私有区的 DNS 记录的私有 DNS 服务,则不需要集群的公共 DNS 记录。
部署集群后,您可以通过修改 DNS 自定义资源 (CR) 来修改其 DNS 使其只使用私有区。以这种方式修改 DNS CR 意味着,任何随后创建的 DNS 记录都不会发布到公共 DNS 服务器,从而保持对内部用户隔离的 DNS 记录知识。当您将集群配置为私有时,也可以完成此操作,或者如果您不希望 DNS 记录可以公开解析。
或者,即使在私有集群中,您也可以保留 DNS 记录的公共区,因为它允许客户端为该集群中运行的应用程序解析 DNS 名称。例如,机构可以有连接到公共互联网的机器,然后为特定私有 IP 范围建立 VPN 连接,以连接到私有 IP 地址。这些机器的 DNS 查找使用公共 DNS 来确定这些服务的专用地址,然后通过 VPN 连接到私有地址。
流程
运行以下命令并查看输出,查看集群的
DNSCR:oc get dnses.config.openshift.io/cluster -o yaml
$ oc get dnses.config.openshift.io/cluster -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 请注意,
spec部分包含一个私有区和一个公共区。运行以下命令来修补
DNSCR 以删除公共区:oc patch dnses.config.openshift.io/cluster --type=merge --patch='{"spec": {"publicZone": null}}'$ oc patch dnses.config.openshift.io/cluster --type=merge --patch='{"spec": {"publicZone": null}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
dns.config.openshift.io/cluster patched
dns.config.openshift.io/cluster patchedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 当为
IngressController对象创建DNS记录时,Ingress Operator 会参考 DNS CR 定义。如果只指定私有区,则只创建私有记录。重要当您删除公共区时,不会修改现有 DNS 记录。如果您不再希望公开发布它们,则必须手动删除之前发布的公共 DNS 记录。
验证
运行以下命令并查看输出,查看集群的
DNSCR,并确认已删除公共区:oc get dnses.config.openshift.io/cluster -o yaml
$ oc get dnses.config.openshift.io/cluster -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.3. 将 Ingress Controller 设置为私有
部署集群后,您可以修改其 Ingress Controller 使其只使用私有区。
流程
修改默认 Ingress Controller,使其仅使用内部端点:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
ingresscontroller.operator.openshift.io "default" deleted ingresscontroller.operator.openshift.io/default replaced
ingresscontroller.operator.openshift.io "default" deleted ingresscontroller.operator.openshift.io/default replacedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 删除公共 DNS 条目,并更新私有区条目。
2.4. 将 API 服务器限制为私有
将集群部署到 Amazon Web Services(AWS)或 Microsoft Azure 后,可以重新配置 API 服务器,使其只使用私有区。
先决条件
-
安装 OpenShift CLI(
oc)。 -
使用具有
admin权限的用户登陆到 web 控制台。
流程
在云供应商的 web 门户或控制台中,执行以下操作:
找到并删除相关的负载均衡器组件:
- 对于 AWS,删除外部负载均衡器。私有区的 API DNS 条目已指向内部负载均衡器,它使用相同的配置,因此您无需修改内部负载均衡器。
-
对于 Azure,删除公共负载均衡器的
api-internal-v4规则。
-
对于 Azure,将 Ingress Controller 端点发布范围配置为
Internal。如需更多信息,请参阅"将 Ingress Controller 端点发布范围配置为 Internal"。 -
对于 Azure 公共负载均衡器,如果您将 Ingress Controller 端点发布范围配置为
Internal,且公共负载均衡器中没有现有的入站规则,则必须明确创建一个出站规则来为后端地址池提供出站流量。如需更多信息,请参阅 Microsoft Azure 文档中有关添加出站规则的内容。 -
删除 public 区域中的
api.$clustername.$yourdomain或api.$clusternameDNS 条目。
AWS 集群:删除外部负载均衡器:
重要您只能对安装程序置备的基础架构 (IPI) 集群执行以下步骤。对于用户置备的基础架构 (UPI) 集群,您必须手动删除或禁用外部负载均衡器。
如果您的集群使用 control plane 机器集,删除配置公共或外部负载均衡器的 control plane 机器集自定义资源中的行:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果您的集群没有使用 control plane 机器集,您必须从每个 control plane 机器中删除外部负载均衡器。
在终端中,运行以下命令来列出集群机器:
oc get machine -n openshift-machine-api
$ oc get machine -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow control plane 机器在名称中包含
master。从每个 control plane 机器中删除外部负载均衡器:
运行以下命令,将 control plane 机器对象编辑为:
oc edit machines -n openshift-machine-api <control_plane_name>
$ oc edit machines -n openshift-machine-api <control_plane_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 指定要修改的 control plane 机器对象名称。
删除描述外部负载均衡器的行,它们在以下示例中被标记:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 保存更改并退出对象规格。
- 为每个 control plane 机器重复此步骤。
2.5. 在 Azure 上配置私有存储端点
您可以使用 Image Registry Operator 在 Azure 上使用私有端点,它会在 OpenShift Container Platform 部署到私有 Azure 集群上时启用私有存储帐户的无缝配置。这可让您在不公开面向公共的存储端点的情况下部署镜像 registry。
不要在 Microsoft Azure Red Hat OpenShift (ARO) 上配置私有存储端点,因为端点可能会使 Microsoft Azure Red Hat OpenShift 集群置于不可恢复的状态。
您可以通过两种方式之一将 Image Registry Operator 配置为使用 Azure 上的私有存储端点:
- 通过配置 Image Registry Operator 来发现 VNet 和子网名称
- 使用用户提供的 Azure Virtual Network (VNet) 和子网名称
2.5.1. 在 Azure 上配置私有存储端点的限制
在 Azure 上配置私有存储端点时有以下限制:
-
在将 Image Registry Operator 配置为使用私有存储端点时,禁用对存储帐户的公共网络访问。因此,在 registry Operator 配置中设置
disableRedirect: true才能从 OpenShift Container Platform 之外拉取镜像。启用重定向后,registry 会重定向客户端直接从存储帐户拉取镜像,这不再会因为公共网络访问被禁用而工作。如需更多信息,请参阅"在 Azure 上使用私有存储端点时禁用重定向"。 - Image Registry Operator 无法撤销此操作。
以下流程演示了如何通过配置 Image Registry Operator 来发现 VNet 和子网名称在 Azure 上设置私有存储端点。
先决条件
- 您已将镜像 registry 配置为在 Azure 上运行。
使用 Installer Provisioned Infrastructure 安装方法设置了您的网络。
对于具有自定义网络设置的用户,请参阅"使用用户提供的 VNet 和子网名称在 Azure 上配置私有存储端点"。
流程
编辑 Image Registry Operator
config对象,并将networkAccess.type设置为Internal:oc edit configs.imageregistry/cluster
$ oc edit configs.imageregistry/clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow 可选:输入以下命令确认 Operator 已完成置备。这可能需要几分钟时间。
oc get configs.imageregistry/cluster -o=jsonpath="{.spec.storage.azure.privateEndpointName}" -w$ oc get configs.imageregistry/cluster -o=jsonpath="{.spec.storage.azure.privateEndpointName}" -wCopy to Clipboard Copied! Toggle word wrap Toggle overflow 可选:如果 registry 由路由公开,并且要将存储帐户配置为私有,则必须禁用重定向(如果集群外部拉取到集群),则必须禁用重定向才能继续工作。输入以下命令禁用 Image Operator 配置中的重定向:
oc patch configs.imageregistry cluster --type=merge -p '{"spec":{"disableRedirect": true}}'$ oc patch configs.imageregistry cluster --type=merge -p '{"spec":{"disableRedirect": true}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意启用重定向后,从集群外部拉取镜像将无法正常工作。
验证
运行以下命令来获取 registry 服务名称:
oc registry info --internal=true
$ oc registry info --internal=trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
image-registry.openshift-image-registry.svc:5000
image-registry.openshift-image-registry.svc:5000Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令来进入 debug 模式:
oc debug node/<node_name>
$ oc debug node/<node_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行推荐的
chroot命令。例如:chroot /host
$ chroot /hostCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输入以下命令登录到容器 registry:
podman login --tls-verify=false -u unused -p $(oc whoami -t) image-registry.openshift-image-registry.svc:5000
$ podman login --tls-verify=false -u unused -p $(oc whoami -t) image-registry.openshift-image-registry.svc:5000Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Login Succeeded!
Login Succeeded!Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输入以下命令验证您可以从 registry 中拉取镜像:
podman pull --tls-verify=false image-registry.openshift-image-registry.svc:5000/openshift/tools
$ podman pull --tls-verify=false image-registry.openshift-image-registry.svc:5000/openshift/toolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.5.3. 使用用户提供的 VNet 和子网名称在 Azure 上配置私有存储端点
使用以下步骤配置禁用公共网络访问权限的存储帐户,并在 Azure 上的私有存储端点后公开。
先决条件
- 您已将镜像 registry 配置为在 Azure 上运行。
- 您必须知道用于 Azure 环境的 VNet 和子网名称。
- 如果您的网络是在 Azure 中的单独资源组中配置的,还必须知道其名称。
流程
编辑 Image Registry Operator
config对象并使用 VNet 和子网名称配置私有端点:oc edit configs.imageregistry/cluster
$ oc edit configs.imageregistry/clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow 可选:输入以下命令确认 Operator 已完成置备。这可能需要几分钟时间。
oc get configs.imageregistry/cluster -o=jsonpath="{.spec.storage.azure.privateEndpointName}" -w$ oc get configs.imageregistry/cluster -o=jsonpath="{.spec.storage.azure.privateEndpointName}" -wCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意启用重定向后,从集群外部拉取镜像将无法正常工作。
验证
运行以下命令来获取 registry 服务名称:
oc registry info --internal=true
$ oc registry info --internal=trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
image-registry.openshift-image-registry.svc:5000
image-registry.openshift-image-registry.svc:5000Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令来进入 debug 模式:
oc debug node/<node_name>
$ oc debug node/<node_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行推荐的
chroot命令。例如:chroot /host
$ chroot /hostCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输入以下命令登录到容器 registry:
podman login --tls-verify=false -u unused -p $(oc whoami -t) image-registry.openshift-image-registry.svc:5000
$ podman login --tls-verify=false -u unused -p $(oc whoami -t) image-registry.openshift-image-registry.svc:5000Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Login Succeeded!
Login Succeeded!Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输入以下命令验证您可以从 registry 中拉取镜像:
podman pull --tls-verify=false image-registry.openshift-image-registry.svc:5000/openshift/tools
$ podman pull --tls-verify=false image-registry.openshift-image-registry.svc:5000/openshift/toolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.5.4. 可选:在 Azure 上使用私有存储端点时禁用重定向
默认情况下,在使用镜像 registry 时会启用重定向。重定向允许将 registry pod 的流量卸载到对象存储中,从而加快拉取速度。当启用重定向且存储帐户为私有时,来自集群外部的用户无法从 registry 中拉取镜像。
在某些情况下,用户可能希望禁用重定向,以便集群外部的用户可以从 registry 中拉取镜像。
使用以下步骤禁用重定向。
先决条件
- 您已将镜像 registry 配置为在 Azure 上运行。
- 您已配置了路由。
流程
输入以下命令禁用镜像 registry 配置中的重定向:
oc patch configs.imageregistry cluster --type=merge -p '{"spec":{"disableRedirect": true}}'$ oc patch configs.imageregistry cluster --type=merge -p '{"spec":{"disableRedirect": true}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
运行以下命令来获取 registry 服务名称:
oc registry info
$ oc registry infoCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
default-route-openshift-image-registry.<cluster_dns>
default-route-openshift-image-registry.<cluster_dns>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输入以下命令登录到容器 registry:
podman login --tls-verify=false -u unused -p $(oc whoami -t) default-route-openshift-image-registry.<cluster_dns>
$ podman login --tls-verify=false -u unused -p $(oc whoami -t) default-route-openshift-image-registry.<cluster_dns>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Login Succeeded!
Login Succeeded!Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输入以下命令验证您可以从 registry 中拉取镜像:
podman pull --tls-verify=false default-route-openshift-image-registry.<cluster_dns> /openshift/tools
$ podman pull --tls-verify=false default-route-openshift-image-registry.<cluster_dns> /openshift/toolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
第 3 章 裸机配置
在裸机主机上部署 OpenShift Container Platform 时,在置备前或置备后,有时您需要对主机进行更改。这包括检查主机的硬件、固件和固件详情。它还可以包含格式化磁盘或更改可修改的固件设置。
3.1. 用户管理的负载均衡器的服务
您可以将 OpenShift Container Platform 集群配置为使用用户管理的负载均衡器来代替默认负载均衡器。
配置用户管理的负载均衡器取决于您的厂商的负载均衡器。
本节中的信息和示例仅用于指导目的。有关供应商负载均衡器的更多信息,请参阅供应商文档。
红帽支持用户管理的负载均衡器的以下服务:
- Ingress Controller
- OpenShift API
- OpenShift MachineConfig API
您可以选择是否要为用户管理的负载均衡器配置一个或多个所有服务。仅配置 Ingress Controller 服务是一个通用的配置选项。要更好地了解每个服务,请查看以下图表:
图 3.1. 显示 OpenShift Container Platform 环境中运行的 Ingress Controller 的网络工作流示例
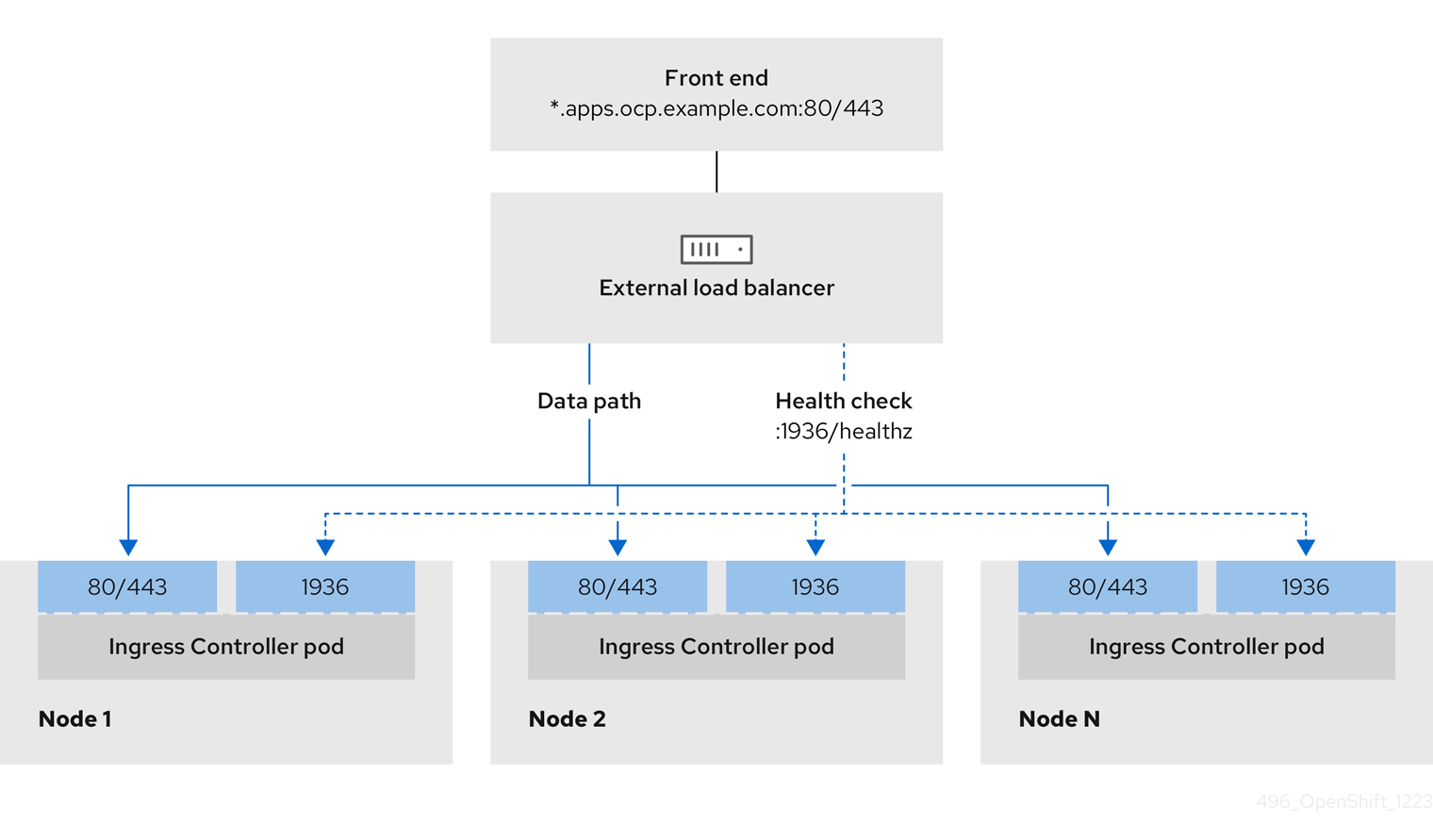
图 3.2. 显示 OpenShift Container Platform 环境中运行的 OpenShift API 的网络工作流示例
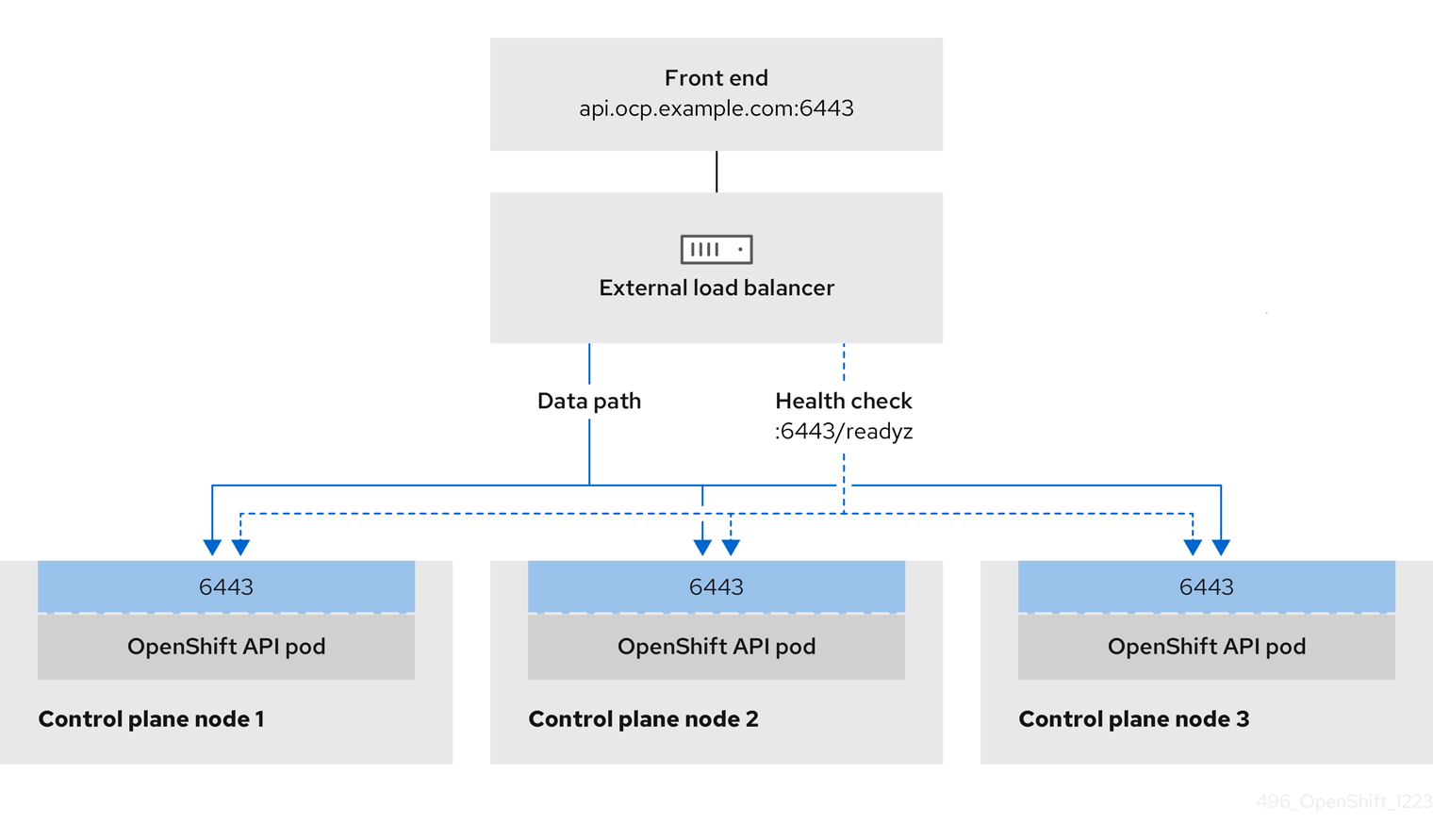
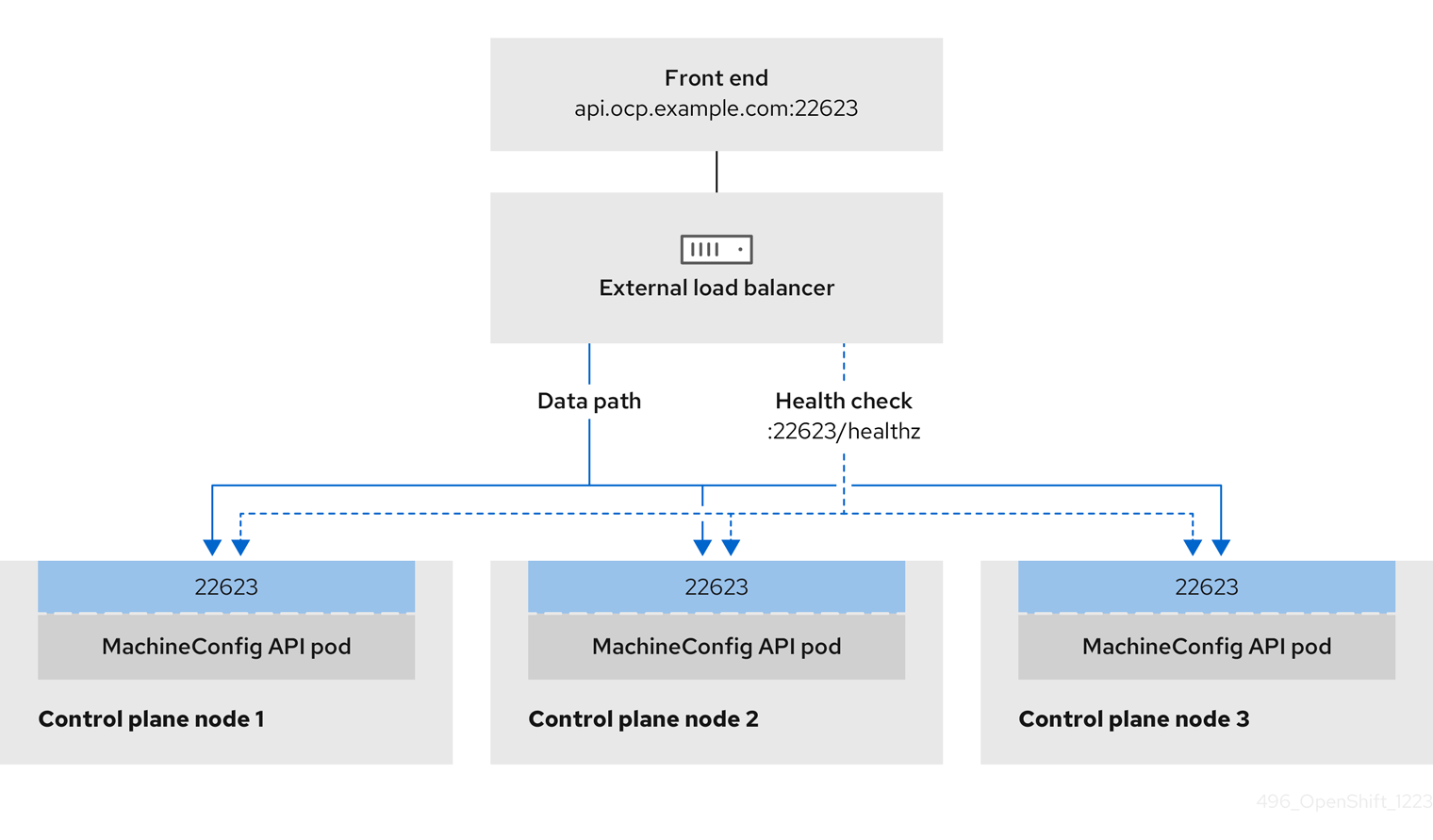
图 3.3. 显示 OpenShift Container Platform 环境中运行的 OpenShift MachineConfig API 的网络工作流示例
用户管理的负载均衡器支持以下配置选项:
- 使用节点选择器将 Ingress Controller 映射到一组特定的节点。您必须为这个集合中的每个节点分配一个静态 IP 地址,或者将每个节点配置为从动态主机配置协议(DHCP)接收相同的 IP 地址。基础架构节点通常接收这种类型的配置。
以子网上的所有 IP 地址为目标。此配置可减少维护开销,因为您可以在这些网络中创建和销毁节点,而无需重新配置负载均衡器目标。如果您使用较小的网络上的机器集来部署入口 pod,如
/27或/28,您可以简化负载均衡器目标。提示您可以通过检查机器配置池的资源来列出网络中存在的所有 IP 地址。
在为 OpenShift Container Platform 集群配置用户管理的负载均衡器前,请考虑以下信息:
- 对于前端 IP 地址,您可以对前端 IP 地址、Ingress Controller 的负载均衡器和 API 负载均衡器使用相同的 IP 地址。查看厂商的文档以获取此功能的相关信息。
对于后端 IP 地址,请确保 OpenShift Container Platform control plane 节点的 IP 地址在用户管理的负载均衡器生命周期内不会改变。您可以通过完成以下操作之一来实现此目的:
- 为每个 control plane 节点分配一个静态 IP 地址。
- 将每个节点配置为在每次节点请求 DHCP 租期时从 DHCP 接收相同的 IP 地址。根据供应商,DHCP 租期可能采用 IP 保留或静态 DHCP 分配的形式。
- 在 Ingress Controller 后端服务的用户管理的负载均衡器中手动定义运行 Ingress Controller 的每个节点。例如,如果 Ingress Controller 移到未定义节点,则可能会出现连接中断。
3.1.1. 配置用户管理的负载均衡器
您可以将 OpenShift Container Platform 集群配置为使用用户管理的负载均衡器来代替默认负载均衡器。
在配置用户管理的负载均衡器前,请确保阅读用户管理的负载均衡器部分。
阅读适用于您要为用户管理的负载均衡器配置的服务的以下先决条件。
MetalLB,在集群中运行,充当用户管理的负载均衡器。
OpenShift API 的先决条件
- 您定义了前端 IP 地址。
TCP 端口 6443 和 22623 在负载均衡器的前端 IP 地址上公开。检查以下项:
- 端口 6443 提供对 OpenShift API 服务的访问。
- 端口 22623 可以为节点提供 ignition 启动配置。
- 前端 IP 地址和端口 6443 可以被您的系统的所有用户访问,其位置为 OpenShift Container Platform 集群外部。
- 前端 IP 地址和端口 22623 只能被 OpenShift Container Platform 节点访问。
- 负载均衡器后端可以在端口 6443 和 22623 上与 OpenShift Container Platform control plane 节点通信。
Ingress Controller 的先决条件
- 您定义了前端 IP 地址。
- TCP 端口 443 和 80 在负载均衡器的前端 IP 地址上公开。
- 前端 IP 地址、端口 80 和端口 443 可以被您的系统所有用户访问,以及 OpenShift Container Platform 集群外部的位置。
- 前端 IP 地址、端口 80 和端口 443 可被 OpenShift Container Platform 集群中运行的所有节点访问。
- 负载均衡器后端可以在端口 80、443 和 1936 上与运行 Ingress Controller 的 OpenShift Container Platform 节点通信。
健康检查 URL 规格的先决条件
您可以通过设置健康检查 URL 来配置大多数负载均衡器,以确定服务是否可用或不可用。OpenShift Container Platform 为 OpenShift API、Machine Configuration API 和 Ingress Controller 后端服务提供这些健康检查。
以下示例显示了之前列出的后端服务的健康检查规格:
Kubernetes API 健康检查规格示例
Path: HTTPS:6443/readyz Healthy threshold: 2 Unhealthy threshold: 2 Timeout: 10 Interval: 10
Path: HTTPS:6443/readyz
Healthy threshold: 2
Unhealthy threshold: 2
Timeout: 10
Interval: 10Machine Config API 健康检查规格示例
Path: HTTPS:22623/healthz Healthy threshold: 2 Unhealthy threshold: 2 Timeout: 10 Interval: 10
Path: HTTPS:22623/healthz
Healthy threshold: 2
Unhealthy threshold: 2
Timeout: 10
Interval: 10Ingress Controller 健康检查规格示例
Path: HTTP:1936/healthz/ready Healthy threshold: 2 Unhealthy threshold: 2 Timeout: 5 Interval: 10
Path: HTTP:1936/healthz/ready
Healthy threshold: 2
Unhealthy threshold: 2
Timeout: 5
Interval: 10流程
配置 HAProxy Ingress Controller,以便您可以在端口 6443、22623、443 和 80 上从负载均衡器访问集群。根据您的需要,您可以在 HAProxy 配置中指定来自多个子网的单个子网或 IP 地址的 IP 地址。
带有列出子网的 HAProxy 配置示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 带有多个列出子网的 HAProxy 配置示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用
curlCLI 命令验证用户管理的负载均衡器及其资源是否正常运行:运行以下命令并查看响应,验证集群机器配置 API 是否可以被 Kubernetes API 服务器资源访问:
curl https://<loadbalancer_ip_address>:6443/version --insecure
$ curl https://<loadbalancer_ip_address>:6443/version --insecureCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果配置正确,您会收到 JSON 对象的响应:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令并观察输出,验证集群机器配置 API 是否可以被 Machine 配置服务器资源访问:
curl -v https://<loadbalancer_ip_address>:22623/healthz --insecure
$ curl -v https://<loadbalancer_ip_address>:22623/healthz --insecureCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果配置正确,命令的输出会显示以下响应:
HTTP/1.1 200 OK Content-Length: 0
HTTP/1.1 200 OK Content-Length: 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令并观察输出,验证控制器是否可以被端口 80 上的 Ingress Controller 资源访问:
curl -I -L -H "Host: console-openshift-console.apps.<cluster_name>.<base_domain>" http://<load_balancer_front_end_IP_address>
$ curl -I -L -H "Host: console-openshift-console.apps.<cluster_name>.<base_domain>" http://<load_balancer_front_end_IP_address>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果配置正确,命令的输出会显示以下响应:
HTTP/1.1 302 Found content-length: 0 location: https://console-openshift-console.apps.ocp4.private.opequon.net/ cache-control: no-cache
HTTP/1.1 302 Found content-length: 0 location: https://console-openshift-console.apps.ocp4.private.opequon.net/ cache-control: no-cacheCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令并观察输出,验证控制器是否可以被端口 443 上的 Ingress Controller 资源访问:
curl -I -L --insecure --resolve console-openshift-console.apps.<cluster_name>.<base_domain>:443:<Load Balancer Front End IP Address> https://console-openshift-console.apps.<cluster_name>.<base_domain>
$ curl -I -L --insecure --resolve console-openshift-console.apps.<cluster_name>.<base_domain>:443:<Load Balancer Front End IP Address> https://console-openshift-console.apps.<cluster_name>.<base_domain>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果配置正确,命令的输出会显示以下响应:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
配置集群的 DNS 记录,使其以用户管理的负载均衡器的前端 IP 地址为目标。您必须在负载均衡器上将记录更新为集群 API 和应用程序的 DNS 服务器。
修改 DNS 记录示例
<load_balancer_ip_address> A api.<cluster_name>.<base_domain> A record pointing to Load Balancer Front End
<load_balancer_ip_address> A api.<cluster_name>.<base_domain> A record pointing to Load Balancer Front EndCopy to Clipboard Copied! Toggle word wrap Toggle overflow <load_balancer_ip_address> A apps.<cluster_name>.<base_domain> A record pointing to Load Balancer Front End
<load_balancer_ip_address> A apps.<cluster_name>.<base_domain> A record pointing to Load Balancer Front EndCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重要DNS 传播可能需要一些时间才能获得每个 DNS 记录。在验证每个记录前,请确保每个 DNS 记录传播。
要使 OpenShift Container Platform 集群使用用户管理的负载均衡器,您必须在集群的
install-config.yaml文件中指定以下配置:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 为
type参数设置UserManaged,为集群指定用户管理的负载均衡器。参数默认为OpenShiftManagedDefault,它表示默认的内部负载均衡器。对于openshift-kni-infra命名空间中定义的服务,用户管理的负载均衡器可将coredns服务部署到集群中的 pod,但忽略keepalived和haproxy服务。 - 2
- 指定用户管理的负载均衡器时所需的参数。指定用户管理的负载均衡器的公共 IP 地址,以便 Kubernetes API 可以与用户管理的负载均衡器通信。
- 3
- 指定用户管理的负载均衡器时所需的参数。指定用户管理的负载均衡器的公共 IP 地址,以便用户管理的负载均衡器可以管理集群的入口流量。
验证
使用
curlCLI 命令验证用户管理的负载均衡器和 DNS 记录配置是否正常工作:运行以下命令并查看输出,验证您可以访问集群 API:
curl https://api.<cluster_name>.<base_domain>:6443/version --insecure
$ curl https://api.<cluster_name>.<base_domain>:6443/version --insecureCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果配置正确,您会收到 JSON 对象的响应:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令并查看输出,验证您可以访问集群机器配置:
curl -v https://api.<cluster_name>.<base_domain>:22623/healthz --insecure
$ curl -v https://api.<cluster_name>.<base_domain>:22623/healthz --insecureCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果配置正确,命令的输出会显示以下响应:
HTTP/1.1 200 OK Content-Length: 0
HTTP/1.1 200 OK Content-Length: 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令并查看输出,验证您可以在端口上访问每个集群应用程序:
curl http://console-openshift-console.apps.<cluster_name>.<base_domain> -I -L --insecure
$ curl http://console-openshift-console.apps.<cluster_name>.<base_domain> -I -L --insecureCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果配置正确,命令的输出会显示以下响应:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令并查看输出,验证您可以在端口 443 上访问每个集群应用程序:
curl https://console-openshift-console.apps.<cluster_name>.<base_domain> -I -L --insecure
$ curl https://console-openshift-console.apps.<cluster_name>.<base_domain> -I -L --insecureCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果配置正确,命令的输出会显示以下响应:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.2. 关于 Bare Metal Operator
使用 Bare Metal Operator (BMO) 来置备、管理和检查集群中的裸机主机。
BMO 使用以下资源来完成这些任务:
-
BareMetalHost -
HostFirmwareSettings -
FirmwareSchema -
HostFirmwareComponents
BMO 通过将每个裸机主机映射到 BareMetalHost 自定义资源定义的实例来维护集群中的物理主机清单。每个 BareMetalHost 资源都有硬件、软件和固件详情。BMO 持续检查集群中的裸机主机,以确保每个 BareMetalHost 资源准确详细说明相应主机的组件。
BMO 还使用 HostFirmwareSettings 资源、FirmwareSchema 资源和 HostFirmwareComponents 资源来详细说明固件规格,以及为裸机主机升级或降级固件。
使用 Ironic API 服务在集群中的裸机主机的 BMO 接口。Ironic 服务使用主机上的 Baseboard Management Controller (BMC) 来与机器进行接口。
使用 BMO 可以完成的一些常见任务包括:
- 使用特定镜像置备裸机主机到集群
- 在置备前或取消置备后格式化主机的磁盘内容
- 打开或关闭主机
- 更改固件设置
- 查看主机的硬件详情
- 将主机的固件升级或降级到一个特定版本
3.2.1. 裸机 Operator 架构
Bare Metal Operator (BMO) 使用以下资源来置备、管理和检查集群中的裸机主机。下图演示了这些资源的架构:
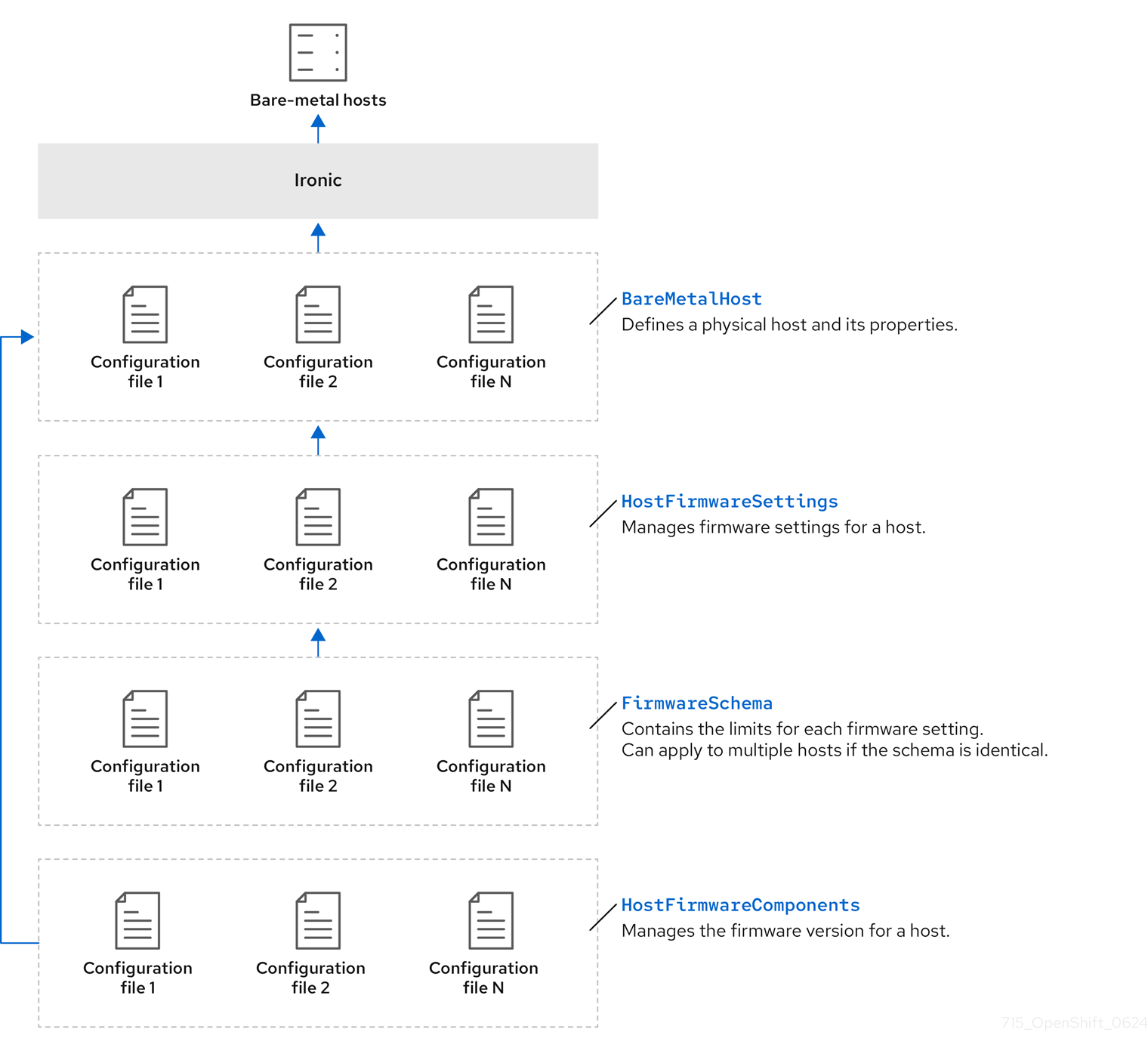
BareMetalHost
BareMetalHost 资源定义物理主机及其属性。将裸机主机置备到集群时,您必须为该主机定义 BareMetalHost 资源。对于主机的持续管理,您可以检查 BareMetalHost 中的信息或更新此信息。
BareMetalHost 资源具有置备信息,如下所示:
- 部署规格,如操作系统引导镜像或自定义 RAM 磁盘
- 置备状态
- 基板管理控制器 (BMC) 地址
- 所需的电源状态
BareMetalHost 资源具有硬件信息,如下所示:
- CPU 数量
- NIC 的 MAC 地址
- 主机的存储设备的大小
- 当前电源状态
HostFirmwareSettings
您可以使用 HostFirmwareSettings 资源来检索和管理主机的固件设置。当主机进入 Available 状态时,Ironic 服务读取主机的固件设置并创建 HostFirmwareSettings 资源。BareMetalHost 资源和 HostFirmwareSettings 资源之间存在一对一映射。
您可以使用 HostFirmwareSettings 资源来检查主机的固件规格,或更新主机的固件规格。
在编辑 HostFirmwareSettings 资源的 spec 字段时,您必须遵循特定于供应商固件的 schema。这个模式在只读 FirmwareSchema 资源中定义。
FirmwareSchema
固件设置因硬件供应商和主机模型而异。FirmwareSchema 资源是一个只读资源,其中包含每个主机模型中每个固件设置的类型和限制。数据通过使用 Ironic 服务直接从 BMC 传递。FirmwareSchema 资源允许您识别 HostFirmwareSettings 资源的 spec 字段中可以指定的有效值。
如果 schema 相同,则 FirmwareSchema 资源可应用到许多 BareMetalHost 资源。
HostFirmwareComponents
Metal3 提供了 HostFirmwareComponents 资源,它描述了 BIOS 和基板管理控制器 (BMC) 固件版本。您可以通过编辑 HostFirmwareComponents 资源的 spec 字段,将主机的固件升级到一个特定版本。这在使用针对特定固件版本测试的验证模式部署时很有用。
3.3. 创建包含一个自定义 br-ex 网桥的清单对象
请考虑以下用例:创建包含自定义 br-ex 网桥的清单对象:
-
您需要对网桥进行安装后更改,如更改 Open vSwitch (OVS) 或 OVN-Kubernetes
br-ex网桥网络。configure-ovs.shshell 脚本不支持对网桥进行安装后更改。 - 您希望将网桥部署到与主机或服务器 IP 地址上可用的接口不同的接口上。
-
您希望通过
configure-ovs.shshell 脚本对网桥进行高级配置。对这些配置使用脚本可能会导致网桥无法连接多个网络接口,并无法正确处理接口之间的数据转发。
先决条件
-
您可以使用
configure-ovs的替代方法来设置一个自定义的br-ex。 - 已安装 Kubernetes NMState Operator。
流程
创建
NodeNetworkConfigurationPolicy(NNCP) CR,并定义自定义的br-ex网桥网络配置。br-exNNCP CR 必须包含 OVN-Kubernetes 伪装 IP 地址和子网。示例 NNCP CR 在ipv4.address.ip和ipv6.address.ip参数中包含默认值。您可以在ipv4.address.ip、ipv6.address.ip或两个参数中设置 masquerade IP 地址。重要作为安装后任务,您无法更改自定义
br-ex网桥的主 IP 地址。如果要将单堆栈集群网络转换为双栈集群网络,您可以在 NNCP CR 中添加或更改辅助 IPv6 地址,但无法更改现有的主 IP 地址。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 其中:
metadata.name- 策略的名称。
interfaces.name- 接口的名称。
interfaces.type- 以太网的类型。
interfaces.state- 创建后接口的请求状态。
ipv4.enabled- 在这个示例中禁用 IPv4 和 IPv6。
port.name- 网桥附加到的节点 NIC。
address.ip- 显示默认 IPv4 和 IPv6 IP 地址。确保设置了网络的 masquerade IPv4 和 IPv6 IP 地址。
auto-route-metric-
将参数设置为
48,以确保br-ex默认路由始终具有最高的优先级(最低指标)。此配置可防止与NetworkManager服务自动配置的任何其他接口冲突。
后续步骤
-
扩展计算节点,以将包含自定义
br-ex网桥的 manifest 对象应用到集群中存在的每个计算节点。如需更多信息,请参阅附加资源部分中的"扩展集群"。
3.4. 关于 BareMetalHost 资源
裸机3 引入了 BareMetalHost 资源的概念,它定义了物理主机及其属性。BareMetalHost 资源包含两个部分:
-
BareMetalHost规格 -
BareMetalHost状态
3.4.1. BareMetalHost 规格
BareMetalHost 资源的 spec 部分定义了主机所需状态。
| 参数 | 描述 |
|---|---|
|
|
在置备和取消置备过程中启用或禁用自动清理的接口。当设置为 |
bmc: address: credentialsName: disableCertificateVerification: |
|
|
| 用于置备主机的 NIC 的 MAC 地址。 |
|
|
主机的引导模式。它默认为 |
|
|
对使用主机的另一个资源的引用。如果另一个资源目前没有使用主机,则它可能为空。例如,当 |
|
| 提供的字符串,用于帮助识别主机。 |
|
| 指明主机置备和取消置备是在外部管理的布尔值。当设置时:
|
|
|
包含有关裸机主机的 BIOS 配置的信息。目前,只有 iRMC、S iDRAC、i iLO4 和 iLO5 BMC 支持
|
image: url: checksum: checksumType: format: |
|
|
| 对包含网络配置数据及其命名空间的 secret 的引用,以便在主机引导以设置网络前将其附加到主机。 |
|
|
指示主机是否应开启的布尔值, |
raid: hardwareRAIDVolumes: softwareRAIDVolumes: | (可选)包含有关裸机主机的 RAID 配置的信息。如果没有指定,它会保留当前的配置。 注意 OpenShift Container Platform 4.16 支持 BMC 的安装驱动器中的硬件 RAID,包括:
OpenShift Container Platform 4.16 不支持安装驱动器中的软件 RAID。 请参见以下配置设置:
您可以将 spec:
raid:
hardwareRAIDVolume: []
如果您收到出错信息表示驱动程序不支持 RAID,则将 |
|
|
|
3.4.2. BareMetalHost 状态
BareMetalHost 状态代表主机的当前状态,包括经过测试的凭证、当前的硬件详情和其他信息。
| 参数 | 描述 |
|---|---|
|
| 对 secret 及其命名空间的引用,其中包含最近一组基板管理控制器(BMC)凭证,以便系统能够验证。 |
|
| 置备后端的最后一个错误的详情(若有)。 |
|
| 表示导致主机进入错误状态的问题类别。错误类型包括:
|
|
|
系统中的 CPU 的
|
hardware: firmware: | 包含 BIOS 固件信息。例如,硬件供应商和版本。 |
|
|
|
hardware: ramMebibytes: | 主机的内存量(兆字节(MiB))。 |
|
|
|
hardware:
systemVendor:
manufacturer:
productName:
serialNumber:
|
包含主机的 |
|
| 主机状态最后一次更新的时间戳。 |
|
| 服务器的状态。状态为以下之一:
|
|
| 指明主机是否开机的布尔值。 |
|
|
|
|
| 对 secret 及其命名空间的引用,其中包含发送到置备后端的最后一个 BMC 凭证集合。 |
3.5. 获取 BareMetalHost 资源
BareMetalHost 资源包含物理主机的属性。您必须获取物理主机的 BareMetalHost 资源才能查看其属性。
流程
获取
BareMetalHost资源列表:oc get bmh -n openshift-machine-api -o yaml
$ oc get bmh -n openshift-machine-api -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意您可以使用
baremetalhost作为oc get命令的bmh长形式。获取主机列表:
oc get bmh -n openshift-machine-api
$ oc get bmh -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 获取特定主机的
BareMetalHost资源:oc get bmh <host_name> -n openshift-machine-api -o yaml
$ oc get bmh <host_name> -n openshift-machine-api -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 其中
<host_name>是主机的名称。输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.6. 编辑 BareMetalHost 资源
在裸机上部署 OpenShift Container Platform 集群后,您可能需要编辑节点的 BareMetalHost 资源。请考虑以下示例:
- 您可以使用 Assisted Installer 部署集群,并需要添加或编辑基板管理控制器 (BMC) 主机名或 IP 地址。
- 您需要在不取消置备的情况下将节点从一个集群移到另一个集群。
先决条件
-
确保节点处于
Provisioned,ExternallyProvisioned, 或Available状态。
流程
获取节点列表:
oc get bmh -n openshift-machine-api
$ oc get bmh -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在编辑节点的
BareMetalHost资源前,运行以下命令从 Ironic 分离节点:oc annotate baremetalhost <node_name> -n openshift-machine-api 'baremetalhost.metal3.io/detached=true'
$ oc annotate baremetalhost <node_name> -n openshift-machine-api 'baremetalhost.metal3.io/detached=true'1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 将
<node_name>替换为节点的名称。
运行以下命令来编辑
BareMetalHost资源:oc edit bmh <node_name> -n openshift-machine-api
$ oc edit bmh <node_name> -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,将节点重新附加到 Ironic:
oc annotate baremetalhost <node_name> -n openshift-machine-api 'baremetalhost.metal3.io/detached'-
$ oc annotate baremetalhost <node_name> -n openshift-machine-api 'baremetalhost.metal3.io/detached'-Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.7. 删除 BareMetalHost 资源时的延迟故障排除
当 Bare Metal Operator (BMO) 删除 BareMetalHost 资源时,Ironic 取消置备裸机主机。例如,在缩减机器集时可能会发生这种情况。取消置备涉及称为 "cleaning" 的进程,它执行以下步骤:
- 关闭裸机主机
- 在裸机主机上引导服务 RAM 磁盘
- 从所有磁盘中删除分区元数据
- 再次关闭裸机主机
如果清理不成功,则删除 BareMetalHost 资源需要很长时间,且可能无法完成。
不要删除终结器来强制删除 BareMetalHost 资源。调配后端具有自己的数据库,后者维护一个主机记录。即使您尝试通过删除终结器来强制删除,运行操作也会继续运行。稍后尝试添加裸机主机时,您可能会遇到意外问题。
流程
- 如果清理过程可以恢复,请等待它完成。
-
如果清理无法恢复,请通过修改
BareMetalHost资源并将automatedCleaningMode字段设置为disabled来禁用清理过程。
如需了解更多详细信息,请参阅"编辑 BareMetalHost 资源"。
3.8. 将不可启动的 ISO 附加到裸机节点
您可以使用 DataImage 资源将通用、不可启动的 ISO 虚拟介质镜像附加到置备的节点上。在应用了资源后,操作系统引导后,ISO 镜像将可以被操作系统访问。这可用于在置备操作系统后配置节点,并在节点第一次引导前配置节点。
先决条件
- 节点必须使用 Redfish 或从中派生的驱动程序来支持此功能。
-
节点必须处于
Provisioned或ExternallyProvisioned状态。 -
名称必须与其在BareMetalHost资源中定义的节点名称相同。 -
有 ISO 镜像的有效
url。
流程
创建一个
DataImage资源:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,将
DataImage资源保存到文件中:vim <node_name>-dataimage.yaml
$ vim <node_name>-dataimage.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令来应用
DataImage资源:oc apply -f <node_name>-dataimage.yaml -n <node_namespace>
$ oc apply -f <node_name>-dataimage.yaml -n <node_namespace>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 替换
<node_namespace>,以便命名空间与BareMetalHost资源的命名空间匹配。例如,openshift-machine-api。
重新引导节点。
注意要重新引导节点,请附加
reboot.metal3.io注解,或重置BareMetalHost资源中的online状态。对裸机节点强制重启会使节点的状态在一段事件内变为NotReady。例如,5 分钟或更长时间。运行以下命令来查看
DataImage资源:oc get dataimage <node_name> -n openshift-machine-api -o yaml
$ oc get dataimage <node_name> -n openshift-machine-api -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.9. 关于 HostFirmwareSettings 资源
您可以使用 HostFirmwareSettings 资源来检索和管理主机的 BIOS 设置。当主机进入 Available 状态时,Ironic 会读取主机的 BIOS 设置并创建 HostFirmwareSettings 资源。资源包含从基板管理控制器(BMC)返回的完整 BIOS 配置。BareMetalHost 资源中的 firmware 字段会返回三个供应商独立的字段,HostFirmwareSettings 资源通常包含每个主机中特定供应商的字段的许多 BIOS 设置。
HostFirmwareSettings 资源包含两个部分:
-
HostFirmwareSettingsspec。 -
HostFirmwareSettings状态。
3.9.1. HostFirmwareSettings spec
HostFirmwareSettings 资源的 spec 部分定义了主机的 BIOS 所需的状态,默认为空。Ironic 使用 spec.settings 部分中的设置,在主机处于 Preparing 状态时更新基板管理控制器(BMC)。使用 FirmwareSchema 资源,确保不向主机发送无效的名称/值对。如需了解更多详细信息,请参阅 "About the FirmwareSchema resource"。
示例
spec:
settings:
ProcTurboMode: Disabled
spec:
settings:
ProcTurboMode: Disabled- 1
- 在foregoing示例中,
spec.settings部分包含一个 name/value 对,它将把ProcTurboModeBIOS 设置为Disabled。
status 部分中列出的整数参数显示为字符串。例如,"1"。当在 spec.settings 部分中设置整数时,这些值应设置为不带引号的整数。例如,1.
3.9.2. HostFirmwareSettings 状态
status 代表主机的 BIOS 的当前状态。
| 参数 | 描述 |
|---|---|
|
|
|
status:
schema:
name:
namespace:
lastUpdated:
|
固件设置的
|
status: settings: |
|
3.10. 获取 HostFirmwareSettings 资源
HostFirmwareSettings 资源包含物理主机的特定于供应商的 BIOS 属性。您必须获取物理主机的 HostFirmwareSettings 资源才能查看其 BIOS 属性。
流程
获取
HostFirmwareSettings资源的详细列表:oc get hfs -n openshift-machine-api -o yaml
$ oc get hfs -n openshift-machine-api -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意您可以使用
hostfirmwaresettings作为oc get命令的hfs长形式。获取
HostFirmwareSettings资源列表:oc get hfs -n openshift-machine-api
$ oc get hfs -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 获取特定主机的
HostFirmwareSettings资源oc get hfs <host_name> -n openshift-machine-api -o yaml
$ oc get hfs <host_name> -n openshift-machine-api -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 其中
<host_name>是主机的名称。
3.11. 编辑 HostFirmwareSettings 资源
您可以编辑已置备的主机的 HostFirmwareSettings。
您只能在主机处于 provisioned 状态时编辑主机,不包括只读值。您不能编辑状态为 externally provisioned 的主机。
流程
获取
HostFirmwareSettings资源列表:oc get hfs -n openshift-machine-api
$ oc get hfs -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 编辑主机的
HostFirmwareSettings资源:oc edit hfs <host_name> -n openshift-machine-api
$ oc edit hfs <host_name> -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 其中
<host_name>是置备的主机的名称。HostFirmwareSettings资源将在终端的默认编辑器中打开。将 name/value 对添加到
spec.settings部分:示例
spec: settings: name: valuespec: settings: name: value1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 使用
FirmwareSchema资源来识别主机的可用设置。您不能设置只读值。
- 保存更改并退出编辑器。
获取主机的机器名称:
oc get bmh <host_name> -n openshift-machine name
$ oc get bmh <host_name> -n openshift-machine nameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 其中
<host_name>是主机的名称。机器名称会出现在CONSUMER字段下。注解机器将其从 machineset 中删除:
oc annotate machine <machine_name> machine.openshift.io/delete-machine=true -n openshift-machine-api
$ oc annotate machine <machine_name> machine.openshift.io/delete-machine=true -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 其中
<machine_name>是要删除的机器的名称。获取节点列表并计算 worker 节点数量:
oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 获取 machineset:
oc get machinesets -n openshift-machine-api
$ oc get machinesets -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 缩放 machineset:
oc scale machineset <machineset_name> -n openshift-machine-api --replicas=<n-1>
$ oc scale machineset <machineset_name> -n openshift-machine-api --replicas=<n-1>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 其中
<machineset_name>是 machineset 的名称,<n-1>是 worker 节点数量的减少。当主机进入
Available状态时,扩展 machineset,使HostFirmwareSettings资源更改生效:oc scale machineset <machineset_name> -n openshift-machine-api --replicas=<n>
$ oc scale machineset <machineset_name> -n openshift-machine-api --replicas=<n>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 其中
<machineset_name>是 machineset 的名称,<n>是 worker 节点的数量。
3.12. 验证 HostFirmware Settings 资源是否有效
当用户编辑 spec.settings 部分以更改为 HostFirmwareSetting(HFS)资源时,BMO 会针对 FimwareSchema 资源验证更改,这是只读资源。如果设置无效,BMO 会将 status.Condition 的 Type 值设置为 False,并生成事件并将其存储在 HFS 资源中。使用以下步骤验证资源是否有效。
流程
获取
HostFirmwareSetting资源列表:oc get hfs -n openshift-machine-api
$ oc get hfs -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 验证特定主机的
HostFirmwareSettings资源是否有效:oc describe hfs <host_name> -n openshift-machine-api
$ oc describe hfs <host_name> -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 其中
<host_name>是主机的名称。输出示例
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ValidationFailed 2m49s metal3-hostfirmwaresettings-controller Invalid BIOS setting: Setting ProcTurboMode is invalid, unknown enumeration value - Foo
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ValidationFailed 2m49s metal3-hostfirmwaresettings-controller Invalid BIOS setting: Setting ProcTurboMode is invalid, unknown enumeration value - FooCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重要如果响应返回
ValidationFailed,资源配置中会出现一个错误,您必须更新这些值以符合FirmwareSchema资源。
3.13. 关于 FirmwareSchema 资源
BIOS 设置因硬件供应商和主机模型而异。FirmwareSchema 资源是一个只读资源,其中包含每个主机模型中的每个 BIOS 设置的类型和限值。数据直接通过 Ironic 来自 BMC。FirmwareSchema 允许您识别 HostFirmwareSettings 资源的 spec 字段中可以指定的有效值。FirmwareSchema 资源具有从其设置和限值派生的唯一标识符。相同的主机模型使用相同的 FirmwareSchema 标识符。HostFirmwareSettings 的多个实例可能使用相同的 FirmwareSchema。
| 参数 | 描述 |
|---|---|
|
|
|
3.14. 获取 FirmwareSchema 资源
每个供应商的每个主机模型都有不同的 BIOS 设置。在编辑 HostFirmwareSettings 资源的 spec 部分时,您设置的名称/值对必须符合该主机的固件模式。要确保设置有效的名称/值对,请获取主机的 FirmwareSchema 并查看它。
流程
要获得
FirmwareSchema资源实例列表,请执行以下操作:oc get firmwareschema -n openshift-machine-api
$ oc get firmwareschema -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 要获得特定
FirmwareSchema实例,请执行:oc get firmwareschema <instance_name> -n openshift-machine-api -o yaml
$ oc get firmwareschema <instance_name> -n openshift-machine-api -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 其中
<instance_name>是HostFirmwareSettings资源中所述的 schema 实例的名称(请参阅表 3)。
3.15. 关于 HostFirmwareComponents 资源
Metal3 提供了 HostFirmwareComponents 资源,它描述了 BIOS 和基板管理控制器 (BMC) 固件版本。HostFirmwareComponents 资源包含两个部分:
-
HostFirmwareComponentsspec -
HostFirmwareComponents状态
3.15.1. HostFirmwareComponents spec
HostFirmwareComponents 资源的 spec 部分定义主机的 BIOS 和 BMC 版本的所需状态。
| 参数 | 描述 |
|---|---|
updates: component: url: |
|
3.15.2. HostFirmwareComponents 状态
HostFirmwareComponents 资源的 status 部分返回主机的 BIOS 和 BMC 版本的当前状态。
| 参数 | 描述 |
|---|---|
|
|
|
updates: component: url: |
|
3.16. 获取 HostFirmwareComponents 资源
HostFirmwareComponents 资源包含 BIOS 的特定固件版本,以及物理主机的基板管理控制器 (BMC)。您必须获取物理主机的 HostFirmwareComponents 资源,才能查看固件版本和状态。
流程
获取
HostFirmwareComponents资源的详细列表:oc get hostfirmwarecomponents -n openshift-machine-api -o yaml
$ oc get hostfirmwarecomponents -n openshift-machine-api -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 获取
HostFirmwareComponents资源列表:oc get hostfirmwarecomponents -n openshift-machine-api
$ oc get hostfirmwarecomponents -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 获取特定主机的
HostFirmwareComponents资源:oc get hostfirmwarecomponents <host_name> -n openshift-machine-api -o yaml
$ oc get hostfirmwarecomponents <host_name> -n openshift-machine-api -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 其中
<host_name>是主机的名称。输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.17. 编辑 HostFirmwareComponents 资源
您可以编辑节点的 HostFirmwareComponents 资源。
流程
获取
HostFirmwareComponents资源的详细列表:oc get hostfirmwarecomponents -n openshift-machine-api -o yaml
$ oc get hostfirmwarecomponents -n openshift-machine-api -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 编辑主机的
HostFirmwareComponents资源:oc edit <host_name> hostfirmwarecomponents -n openshift-machine-api
$ oc edit <host_name> hostfirmwarecomponents -n openshift-machine-api1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 其中
<host_name>是主机的名称。HostFirmwareComponents资源将在终端的默认编辑器中打开。
输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 保存更改并退出编辑器。
获取主机的机器名称:
oc get bmh <host_name> -n openshift-machine name
$ oc get bmh <host_name> -n openshift-machine name1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 其中
<host_name>是主机的名称。机器名称会出现在CONSUMER字段下。
注解机器将其从机器集中删除:
oc annotate machine <machine_name> machine.openshift.io/delete-machine=true -n openshift-machine-api
$ oc annotate machine <machine_name> machine.openshift.io/delete-machine=true -n openshift-machine-api1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 其中
<machine_name>是要删除的机器的名称。
获取节点列表并计算 worker 节点数量:
oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 获取机器集:
oc get machinesets -n openshift-machine-api
$ oc get machinesets -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 扩展机器集:
oc scale machineset <machineset_name> -n openshift-machine-api --replicas=<n-1>
$ oc scale machineset <machineset_name> -n openshift-machine-api --replicas=<n-1>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 其中
<machineset_name>是集群集的名称,<n-1>是减少的 worker 节点数量。
当主机进入
Available状态时,扩展 machineset,使HostFirmwareComponents资源更改生效:oc scale machineset <machineset_name> -n openshift-machine-api --replicas=<n>
$ oc scale machineset <machineset_name> -n openshift-machine-api --replicas=<n>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 其中
<machineset_name>是机器集的名称,<n>是 worker 节点的数量。
第 4 章 在 OpenShift 集群中配置多架构计算机器
4.1. 关于带有多架构计算机器的集群
带有多架构计算机器的 OpenShift Container Platform 集群是一个支持具有不同架构的计算机器的集群。
配置多架构计算机器涉及一些额外的注意事项:
- 当集群中有多个架构的节点,部署到节点的容器镜像的架构必须与该节点的架构一致。您需要确保使用适当的架构将 pod 分配给节点,并与容器镜像架构匹配。如需有关将 pod 分配给节点的更多信息,请参阅将 pod 分配给节点。
- 在安装程序置备的安装中,您可以使用单个云供应商提供的基础架构。不支持向这些集群添加外部节点(无论其架构是什么)。
使用平台类型
none安装的集群无法使用一些功能,如使用 Machine API 管理计算机器。即使附加到集群的计算机器安装在通常支持该功能的平台上,也会应用这个限制。在安装后无法更改此参数。重要在尝试在虚拟化或云环境中安装 OpenShift Container Platform 集群前,请参阅有关在未经测试的平台上部署 OpenShift Container Platform 的指南 中的信息。
- 具有多架构计算机器的集群中不支持 Cluster Samples Operator。集群可以在没有此功能的情况下创建。如需更多信息,请参阅集群功能。
- 有关将单架构集群迁移到支持多架构计算机器的集群的详情,请参考使用多架构计算机器迁移到集群。
4.1.1. 使用多架构计算机器配置集群
要使用不同安装选项和平台的多架构计算机器创建集群,您可以使用下表中的文档:
| 文档部分 | 平台 | 用户置备的安装 | 安装程序置备的安装 | Control Plane | Compute 节点 |
|---|---|---|---|---|---|
| Microsoft Azure | ✓ | ✓ |
|
| |
| Amazon Web Services (AWS) | ✓ | ✓ |
|
| |
| Google Cloud | ✓ |
|
| ||
| 裸机 | ✓ |
|
| ||
| IBM Power | ✓ |
|
| ||
| IBM Z | ✓ |
|
| ||
| IBM Z® 和 IBM® LinuxONE | ✓ |
|
| ||
| IBM Z® 和 IBM® LinuxONE | ✓ |
|
| ||
| IBM Power® | ✓ |
|
|
Google Cloud 目前不支持从零自动扩展。
4.2. 在 Azure 上使用多架构计算机器创建集群
要使用多架构计算机器部署 Azure 集群,您必须首先创建一个使用多架构安装程序二进制文件的单架构 Azure 安装程序置备集群。如需有关 Azure 安装的更多信息,请参阅使用自定义在 Azure 上安装集群。
您还可以将带有单架构计算机器的当前集群迁移到使用多架构计算机器的集群。如需更多信息,请参阅使用多架构计算机器迁移到集群。
创建多架构集群后,您可以将具有不同架构的节点添加到集群中。
4.2.1. 验证集群兼容性
在开始在集群中添加不同架构的计算节点前,您必须验证集群是否兼容多架构。
先决条件
-
已安装 OpenShift CLI(
oc)。
流程
-
登录 OpenShift CLI (
oc)。 您可以运行以下命令来检查集群是否使用构架有效负载:
oc adm release info -o jsonpath="{ .metadata.metadata}"$ oc adm release info -o jsonpath="{ .metadata.metadata}"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
如果您看到以下输出,代表集群使用多架构有效负载:
{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 然后,您可以开始在集群中添加多架构计算节点。
如果您看到以下输出,代表集群没有使用多架构有效负载:
{ "url": "https://access.redhat.com/errata/<errata_version>" }{ "url": "https://access.redhat.com/errata/<errata_version>" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要要迁移集群以便集群支持多架构计算机器,请按照使用多架构计算机器迁移到集群的步骤进行操作。
4.2.2. 使用 Azure 镜像 gallery 创建 64 位 ARM 引导镜像
以下流程描述了如何手动生成 64 位 ARM 引导镜像。
先决条件
-
已安装 Azure CLI (
az)。 - 已使用多架构安装程序二进制文件创建了单架构 Azure 安装程序置备集群。
流程
登录到您的 Azure 帐户:
az login
$ az loginCopy to Clipboard Copied! Toggle word wrap Toggle overflow 创建存储帐户并将
aarch64虚拟硬盘 (VHD) 上传到您的存储帐户。OpenShift Container Platform 安装程序会创建一个资源组,但引导镜像也可以上传到名为资源组的自定义中:az storage account create -n ${STORAGE_ACCOUNT_NAME} -g ${RESOURCE_GROUP} -l westus --sku Standard_LRS$ az storage account create -n ${STORAGE_ACCOUNT_NAME} -g ${RESOURCE_GROUP} -l westus --sku Standard_LRS1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
westus对象是一个示例区域。
使用您生成的存储帐户创建存储容器:
az storage container create -n ${CONTAINER_NAME} --account-name ${STORAGE_ACCOUNT_NAME}$ az storage container create -n ${CONTAINER_NAME} --account-name ${STORAGE_ACCOUNT_NAME}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 您必须使用 OpenShift Container Platform 安装程序 JSON 文件提取 URL 和
aarch64VHD 名称:运行以下命令,提取
URL字段并将其设置为RHCOS_VHD_ORIGIN_URL:RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.aarch64."rhel-coreos-extensions"."azure-disk".url')$ RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.aarch64."rhel-coreos-extensions"."azure-disk".url')Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,提取
aarch64VHD 名称并将其设置为BLOB_NAME作为文件名:BLOB_NAME=rhcos-$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.aarch64."rhel-coreos-extensions"."azure-disk".release')-azure.aarch64.vhd$ BLOB_NAME=rhcos-$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.aarch64."rhel-coreos-extensions"."azure-disk".release')-azure.aarch64.vhdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
生成共享访问令牌 (SAS) 令牌。通过以下命令,使用此令牌将 RHCOS VHD 上传到存储容器:
end=`date -u -d "30 minutes" '+%Y-%m-%dT%H:%MZ'`
$ end=`date -u -d "30 minutes" '+%Y-%m-%dT%H:%MZ'`Copy to Clipboard Copied! Toggle word wrap Toggle overflow sas=`az storage container generate-sas -n ${CONTAINER_NAME} --account-name ${STORAGE_ACCOUNT_NAME} --https-only --permissions dlrw --expiry $end -o tsv`$ sas=`az storage container generate-sas -n ${CONTAINER_NAME} --account-name ${STORAGE_ACCOUNT_NAME} --https-only --permissions dlrw --expiry $end -o tsv`Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将 RHCOS VHD 复制到存储容器中:
az storage blob copy start --account-name ${STORAGE_ACCOUNT_NAME} --sas-token "$sas" \ --source-uri "${RHCOS_VHD_ORIGIN_URL}" \ --destination-blob "${BLOB_NAME}" --destination-container ${CONTAINER_NAME}$ az storage blob copy start --account-name ${STORAGE_ACCOUNT_NAME} --sas-token "$sas" \ --source-uri "${RHCOS_VHD_ORIGIN_URL}" \ --destination-blob "${BLOB_NAME}" --destination-container ${CONTAINER_NAME}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 您可以使用以下命令检查复制过程的状态:
az storage blob show -c ${CONTAINER_NAME} -n ${BLOB_NAME} --account-name ${STORAGE_ACCOUNT_NAME} | jq .properties.copy$ az storage blob show -c ${CONTAINER_NAME} -n ${BLOB_NAME} --account-name ${STORAGE_ACCOUNT_NAME} | jq .properties.copyCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 如果 status 参数显示
success对象,则复制过程已完成。
使用以下命令创建镜像 gallery:
az sig create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME}$ az sig create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用镜像 gallery 创建镜像定义。在以下示例中,
rhcos-arm64是镜像定义的名称。az sig image-definition create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME} --gallery-image-definition rhcos-arm64 --publisher RedHat --offer arm --sku arm64 --os-type linux --architecture Arm64 --hyper-v-generation V2$ az sig image-definition create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME} --gallery-image-definition rhcos-arm64 --publisher RedHat --offer arm --sku arm64 --os-type linux --architecture Arm64 --hyper-v-generation V2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 要获取 VHD 的 URL,并将其设置为
RHCOS_VHD_URL作为文件名称,请运行以下命令:RHCOS_VHD_URL=$(az storage blob url --account-name ${STORAGE_ACCOUNT_NAME} -c ${CONTAINER_NAME} -n "${BLOB_NAME}" -o tsv)$ RHCOS_VHD_URL=$(az storage blob url --account-name ${STORAGE_ACCOUNT_NAME} -c ${CONTAINER_NAME} -n "${BLOB_NAME}" -o tsv)Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用
RHCOS_VHD_URL文件、您的存储帐户、资源组和镜像 gallery 创建镜像版本。在以下示例中,1.0.0是镜像版本。az sig image-version create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME} --gallery-image-definition rhcos-arm64 --gallery-image-version 1.0.0 --os-vhd-storage-account ${STORAGE_ACCOUNT_NAME} --os-vhd-uri ${RHCOS_VHD_URL}$ az sig image-version create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME} --gallery-image-definition rhcos-arm64 --gallery-image-version 1.0.0 --os-vhd-storage-account ${STORAGE_ACCOUNT_NAME} --os-vhd-uri ${RHCOS_VHD_URL}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 现在生成您的
arm64引导镜像。您可以使用以下命令访问镜像的 ID:az sig image-version show -r $GALLERY_NAME -g $RESOURCE_GROUP -i rhcos-arm64 -e 1.0.0
$ az sig image-version show -r $GALLERY_NAME -g $RESOURCE_GROUP -i rhcos-arm64 -e 1.0.0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下示例镜像 ID 在计算机器设置的
recourseID参数中使用:resourceID示例/resourceGroups/${RESOURCE_GROUP}/providers/Microsoft.Compute/galleries/${GALLERY_NAME}/images/rhcos-arm64/versions/1.0.0/resourceGroups/${RESOURCE_GROUP}/providers/Microsoft.Compute/galleries/${GALLERY_NAME}/images/rhcos-arm64/versions/1.0.0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
4.2.3. 使用 Azure 镜像 gallery 创建 64 位 x86 引导镜像
以下流程描述了如何手动生成 64 位 x86 引导镜像。
先决条件
-
已安装 Azure CLI (
az)。 - 已使用多架构安装程序二进制文件创建了单架构 Azure 安装程序置备集群。
流程
运行以下命令登录到您的 Azure 帐户:
az login
$ az loginCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,创建一个存储帐户并将
x86_64虚拟硬盘 (VHD) 上传到您的存储帐户。OpenShift Container Platform 安装程序会创建一个资源组。但是,引导镜像也可以上传到名为资源组的自定义中:az storage account create -n ${STORAGE_ACCOUNT_NAME} -g ${RESOURCE_GROUP} -l westus --sku Standard_LRS$ az storage account create -n ${STORAGE_ACCOUNT_NAME} -g ${RESOURCE_GROUP} -l westus --sku Standard_LRS1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
westus对象是一个示例区域。
运行以下命令,使用您生成的存储帐户创建存储容器:
az storage container create -n ${CONTAINER_NAME} --account-name ${STORAGE_ACCOUNT_NAME}$ az storage container create -n ${CONTAINER_NAME} --account-name ${STORAGE_ACCOUNT_NAME}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用 OpenShift Container Platform 安装程序 JSON 文件提取 URL 和
x86_64VHD 名称:运行以下命令,提取
URL字段并将其设置为RHCOS_VHD_ORIGIN_URL:RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.x86_64."rhel-coreos-extensions"."azure-disk".url')$ RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.x86_64."rhel-coreos-extensions"."azure-disk".url')Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,提取
x86_64VHD 名称并将其设置为BLOB_NAME作为文件名:BLOB_NAME=rhcos-$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.x86_64."rhel-coreos-extensions"."azure-disk".release')-azure.x86_64.vhd$ BLOB_NAME=rhcos-$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.x86_64."rhel-coreos-extensions"."azure-disk".release')-azure.x86_64.vhdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
生成共享访问令牌 (SAS) 令牌。运行以下命令,使用此令牌将 RHCOS VHD 上传到存储容器:
end=`date -u -d "30 minutes" '+%Y-%m-%dT%H:%MZ'`
$ end=`date -u -d "30 minutes" '+%Y-%m-%dT%H:%MZ'`Copy to Clipboard Copied! Toggle word wrap Toggle overflow sas=`az storage container generate-sas -n ${CONTAINER_NAME} --account-name ${STORAGE_ACCOUNT_NAME} --https-only --permissions dlrw --expiry $end -o tsv`$ sas=`az storage container generate-sas -n ${CONTAINER_NAME} --account-name ${STORAGE_ACCOUNT_NAME} --https-only --permissions dlrw --expiry $end -o tsv`Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,将 RHCOS VHD 复制到存储容器中:
az storage blob copy start --account-name ${STORAGE_ACCOUNT_NAME} --sas-token "$sas" \ --source-uri "${RHCOS_VHD_ORIGIN_URL}" \ --destination-blob "${BLOB_NAME}" --destination-container ${CONTAINER_NAME}$ az storage blob copy start --account-name ${STORAGE_ACCOUNT_NAME} --sas-token "$sas" \ --source-uri "${RHCOS_VHD_ORIGIN_URL}" \ --destination-blob "${BLOB_NAME}" --destination-container ${CONTAINER_NAME}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 您可以运行以下命令来检查复制过程的状态:
az storage blob show -c ${CONTAINER_NAME} -n ${BLOB_NAME} --account-name ${STORAGE_ACCOUNT_NAME} | jq .properties.copy$ az storage blob show -c ${CONTAINER_NAME} -n ${BLOB_NAME} --account-name ${STORAGE_ACCOUNT_NAME} | jq .properties.copyCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 如果
status参数显示success对象,则代表复制过程已完成。
运行以下命令来创建镜像 gallery:
az sig create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME}$ az sig create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,使用镜像 gallery 创建镜像定义:
az sig image-definition create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME} --gallery-image-definition rhcos-x86_64 --publisher RedHat --offer x86_64 --sku x86_64 --os-type linux --architecture x64 --hyper-v-generation V2$ az sig image-definition create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME} --gallery-image-definition rhcos-x86_64 --publisher RedHat --offer x86_64 --sku x86_64 --os-type linux --architecture x64 --hyper-v-generation V2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在本例中,
rhcos-x86_64是镜像定义的名称。要获取 VHD 的 URL,并将其设置为
RHCOS_VHD_URL作为文件名称,请运行以下命令:RHCOS_VHD_URL=$(az storage blob url --account-name ${STORAGE_ACCOUNT_NAME} -c ${CONTAINER_NAME} -n "${BLOB_NAME}" -o tsv)$ RHCOS_VHD_URL=$(az storage blob url --account-name ${STORAGE_ACCOUNT_NAME} -c ${CONTAINER_NAME} -n "${BLOB_NAME}" -o tsv)Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,使用
RHCOS_VHD_URL文件、存储帐户、资源组和镜像 gallery 创建镜像版本:az sig image-version create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME} --gallery-image-definition rhcos-arm64 --gallery-image-version 1.0.0 --os-vhd-storage-account ${STORAGE_ACCOUNT_NAME} --os-vhd-uri ${RHCOS_VHD_URL}$ az sig image-version create --resource-group ${RESOURCE_GROUP} --gallery-name ${GALLERY_NAME} --gallery-image-definition rhcos-arm64 --gallery-image-version 1.0.0 --os-vhd-storage-account ${STORAGE_ACCOUNT_NAME} --os-vhd-uri ${RHCOS_VHD_URL}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在本例中,
1.0.0是镜像版本。可选:运行以下命令来访问生成的
x86_64引导镜像的 ID:az sig image-version show -r $GALLERY_NAME -g $RESOURCE_GROUP -i rhcos-x86_64 -e 1.0.0
$ az sig image-version show -r $GALLERY_NAME -g $RESOURCE_GROUP -i rhcos-x86_64 -e 1.0.0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下示例镜像 ID 在计算机器设置的
recourseID参数中使用:resourceID示例/resourceGroups/${RESOURCE_GROUP}/providers/Microsoft.Compute/galleries/${GALLERY_NAME}/images/rhcos-x86_64/versions/1.0.0/resourceGroups/${RESOURCE_GROUP}/providers/Microsoft.Compute/galleries/${GALLERY_NAME}/images/rhcos-x86_64/versions/1.0.0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
4.2.4. 在 Azure 集群中添加多架构计算机器集
创建多架构集群后,您可以添加具有不同架构的节点。
您可以使用以下方法将不同架构的计算机器添加到多架构集群中:
- 将 64 位 x86 计算机器添加到使用 64 位 ARM control plane 机器的集群中,且已经包含 64 位 ARM 计算机器。在这种情况下,64 位 x86 被视为辅助架构。
- 将 64 位 ARM 计算机器添加到使用 64 位 x86 control plane 机器的集群,且已经包含 64 位 x86 计算机器。在这种情况下,64 位 ARM 被视为二级架构。
要在 Azure 上创建自定义计算机器集,请参阅"创建 Azure 上的计算机器集"。
在集群中添加二级架构节点前,建议安装 Multiarch Tuning Operator,并部署 ClusterPodPlacementConfig 自定义资源。如需更多信息,请参阅"使用 Multiarch Tuning Operator 在多架构集群上管理工作负载"。
先决条件
-
已安装 OpenShift CLI(
oc)。 - 您创建了 64 位 ARM 或 64 位 x86 引导镜像。
- 您可以使用安装程序创建使用多架构安装程序二进制文件的 64 位 ARM 或 64 位 x86 单架构 Azure 集群。
流程
-
登录 OpenShift CLI (
oc)。 创建 YAML 文件,并添加配置来创建计算机器集来控制集群中的 64 位 ARM 或 64 位 x86 计算节点。
Azure 64 位 ARM 或 64 位 x86 计算节点的
MachineSet对象示例Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令来创建计算机器集:
oc create -f <file_name>
$ oc create -f <file_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 将
<file_name>替换为计算机器设置配置 YAML 文件的名称。例如:arm64-machine-set-0.yaml, 或amd64-machine-set-0.yaml。
验证
运行以下命令验证新机器是否正在运行:
oc get machineset -n openshift-machine-api
$ oc get machineset -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出必须包含您创建的机器集。
输出示例
NAME DESIRED CURRENT READY AVAILABLE AGE <infrastructure_id>-machine-set-0 2 2 2 2 10m
NAME DESIRED CURRENT READY AVAILABLE AGE <infrastructure_id>-machine-set-0 2 2 2 2 10mCopy to Clipboard Copied! Toggle word wrap Toggle overflow 您可以运行以下命令来检查节点是否已就绪并可以调度:
oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.3. 在 AWS 上使用多架构计算机器创建集群
要使用多架构计算机器创建 AWS 集群,您必须首先使用多架构安装程序二进制文件创建一个单架构 AWS 安装程序置备集群。如需有关 AWS 安装的更多信息,请参阅使用自定义在 AWS 上安装集群。
您还可以将带有单架构计算机器的当前集群迁移到使用多架构计算机器的集群。如需更多信息,请参阅使用多架构计算机器迁移到集群。
创建多架构集群后,您可以将具有不同架构的节点添加到集群中。
4.3.1. 验证集群兼容性
在开始在集群中添加不同架构的计算节点前,您必须验证集群是否兼容多架构。
先决条件
-
已安装 OpenShift CLI(
oc)。
流程
-
登录 OpenShift CLI (
oc)。 您可以运行以下命令来检查集群是否使用构架有效负载:
oc adm release info -o jsonpath="{ .metadata.metadata}"$ oc adm release info -o jsonpath="{ .metadata.metadata}"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
如果您看到以下输出,代表集群使用多架构有效负载:
{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 然后,您可以开始在集群中添加多架构计算节点。
如果您看到以下输出,代表集群没有使用多架构有效负载:
{ "url": "https://access.redhat.com/errata/<errata_version>" }{ "url": "https://access.redhat.com/errata/<errata_version>" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要要迁移集群以便集群支持多架构计算机器,请按照使用多架构计算机器迁移到集群的步骤进行操作。
4.3.2. 在 AWS 集群中添加多架构计算机器集
创建多架构集群后,您可以添加具有不同架构的节点。
您可以使用以下方法将不同架构的计算机器添加到多架构集群中:
- 将 64 位 x86 计算机器添加到使用 64 位 ARM control plane 机器的集群中,且已经包含 64 位 ARM 计算机器。在这种情况下,64 位 x86 被视为辅助架构。
- 将 64 位 ARM 计算机器添加到使用 64 位 x86 control plane 机器的集群,且已经包含 64 位 x86 计算机器。在这种情况下,64 位 ARM 被视为二级架构。
在集群中添加二级架构节点前,建议安装 Multiarch Tuning Operator,并部署 ClusterPodPlacementConfig 自定义资源。如需更多信息,请参阅"使用 Multiarch Tuning Operator 在多架构集群上管理工作负载"。
先决条件
-
已安装 OpenShift CLI(
oc)。 - 您可以使用安装程序创建使用多架构安装程序二进制文件的 64 位 ARM 或 64 位 x86 单架构 AWS 集群。
流程
-
登录 OpenShift CLI (
oc)。 创建 YAML 文件,并添加配置来创建计算机器集来控制集群中的 64 位 ARM 或 64 位 x86 计算节点。
AWS 64 位 ARM 或 x86 计算节点的
MachineSet对象示例Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1 2 3 9 13 14
- 指定基于置备集群时所设置的集群 ID 的基础架构 ID。如果已安装 OpenShift CLI(
oc)软件包,您可以通过运行以下命令来获取基础架构 ID:oc get -o jsonpath="{.status.infrastructureName}{'\n'}" infrastructure cluster$ oc get -o jsonpath="{.status.infrastructureName}{'\n'}" infrastructure clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 4 7
- 指定基础架构 ID、角色节点标签和区域。
- 5 6
- 指定要添加的角色节点标签。
- 8
- 为节点的 AWS 区域指定 Red Hat Enterprise Linux CoreOS (RHCOS) Amazon Machine Image (AMI)。RHCOS AMI 必须与机器架构兼容。
oc get configmap/coreos-bootimages \ -n openshift-machine-config-operator \ -o jsonpath='{.data.stream}' | jq \ -r '.architectures.<arch>.images.aws.regions."<region>".image'$ oc get configmap/coreos-bootimages \ -n openshift-machine-config-operator \ -o jsonpath='{.data.stream}' | jq \ -r '.architectures.<arch>.images.aws.regions."<region>".image'Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 10
- 指定与所选 AMI 的 CPU 架构一致的机器类型。如需更多信息,请参阅"为 AWS 64 位 ARM 测试的实例类型"
- 11
- 指定区。例如,
us-east-1a。确保您选择的区有带有所需架构的机器。 - 12
- 指定区域。例如,
us-east-1。确保您选择的区有带有所需架构的机器。
运行以下命令来创建计算机器集:
oc create -f <file_name>
$ oc create -f <file_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 将
<file_name>替换为计算机器设置配置 YAML 文件的名称。例如:aws-arm64-machine-set-0.yaml, 或aws-amd64-machine-set-0.yaml。
验证
运行以下命令,查看计算机器集列表:
oc get machineset -n openshift-machine-api
$ oc get machineset -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出必须包含您创建的机器集。
输出示例
NAME DESIRED CURRENT READY AVAILABLE AGE <infrastructure_id>-aws-machine-set-0 2 2 2 2 10m
NAME DESIRED CURRENT READY AVAILABLE AGE <infrastructure_id>-aws-machine-set-0 2 2 2 2 10mCopy to Clipboard Copied! Toggle word wrap Toggle overflow 您可以运行以下命令来检查节点是否已就绪并可以调度:
oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.4. 在 Google Cloud 上使用多架构计算机器创建集群
要使用多架构计算机器创建 Google Cloud 集群,您必须首先使用多架构安装程序二进制文件创建单架构 Google Cloud installer 置备集群。如需有关 AWS 安装的更多信息,请参阅使用自定义在 Google Cloud 上安装集群。
您还可以将带有单架构计算机器的当前集群迁移到使用多架构计算机器的集群。如需更多信息,请参阅使用多架构计算机器迁移到集群。
创建多架构集群后,您可以将具有不同架构的节点添加到集群中。
目前 Google Cloud 的 64 位 ARM 机器不支持安全引导
4.4.1. 验证集群兼容性
在开始在集群中添加不同架构的计算节点前,您必须验证集群是否兼容多架构。
先决条件
-
已安装 OpenShift CLI(
oc)。
流程
-
登录 OpenShift CLI (
oc)。 您可以运行以下命令来检查集群是否使用构架有效负载:
oc adm release info -o jsonpath="{ .metadata.metadata}"$ oc adm release info -o jsonpath="{ .metadata.metadata}"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
如果您看到以下输出,代表集群使用多架构有效负载:
{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 然后,您可以开始在集群中添加多架构计算节点。
如果您看到以下输出,代表集群没有使用多架构有效负载:
{ "url": "https://access.redhat.com/errata/<errata_version>" }{ "url": "https://access.redhat.com/errata/<errata_version>" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要要迁移集群以便集群支持多架构计算机器,请按照使用多架构计算机器迁移到集群的步骤进行操作。
4.4.2. 在 Google Cloud 集群中添加多架构计算机器集
创建多架构集群后,您可以添加具有不同架构的节点。
您可以使用以下方法将不同架构的计算机器添加到多架构集群中:
- 将 64 位 x86 计算机器添加到使用 64 位 ARM control plane 机器的集群中,且已经包含 64 位 ARM 计算机器。在这种情况下,64 位 x86 被视为辅助架构。
- 将 64 位 ARM 计算机器添加到使用 64 位 x86 control plane 机器的集群,且已经包含 64 位 x86 计算机器。在这种情况下,64 位 ARM 被视为二级架构。
在集群中添加二级架构节点前,建议安装 Multiarch Tuning Operator,并部署 ClusterPodPlacementConfig 自定义资源。如需更多信息,请参阅"使用 Multiarch Tuning Operator 在多架构集群上管理工作负载"。
先决条件
-
已安装 OpenShift CLI(
oc)。 - 您可以使用安装程序创建使用多架构安装程序二进制文件的 64 位 x86 或 64 位 ARM 单架构 Google Cloud 集群。
流程
-
登录 OpenShift CLI (
oc)。 创建 YAML 文件,并添加配置来创建计算机器集来控制集群中的 64 位 ARM 或 64 位 x86 计算节点。
Google Cloud 64 位 ARM 或 64 位 x86 计算节点的
MachineSet对象示例Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 指定基于置备集群时所设置的集群 ID 的基础架构 ID。您可以运行以下命令来获取基础架构 ID:
oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 2
- 指定要添加的角色节点标签。
- 3
- 指定当前计算机器集中使用的镜像的路径。您需要到镜像的路径的项目和镜像名称。
要访问项目和镜像名称,请运行以下命令:
oc get configmap/coreos-bootimages \ -n openshift-machine-config-operator \ -o jsonpath='{.data.stream}' | jq \ -r '.architectures.aarch64.images.gcp'$ oc get configmap/coreos-bootimages \ -n openshift-machine-config-operator \ -o jsonpath='{.data.stream}' | jq \ -r '.architectures.aarch64.images.gcp'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
"gcp": { "release": "415.92.202309142014-0", "project": "rhcos-cloud", "name": "rhcos-415-92-202309142014-0-gcp-aarch64" }"gcp": { "release": "415.92.202309142014-0", "project": "rhcos-cloud", "name": "rhcos-415-92-202309142014-0-gcp-aarch64" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用输出中的
project和name参数,在机器集中创建 image 字段的路径。镜像的路径应该采用以下格式:projects/<project>/global/images/<image_name>
$ projects/<project>/global/images/<image_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 4
- 可选:以
key:value对的形式指定自定义元数据。如需用例,请参阅 Google Cloud 文档 来设置自定义元数据。 - 5
- 指定与所选操作系统镜像的 CPU 架构一致的机器类型。如需更多信息,请参阅"在 64 位 ARM 基础架构上为 Google Cloud 测试的实例类型"。
- 6
- 指定用于集群的 Google Cloud 项目的名称。
- 7
- 指定区域。例如,
us-central1。确保您选择的区有带有所需架构的机器。
运行以下命令来创建计算机器集:
oc create -f <file_name>
$ oc create -f <file_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 将
<file_name>替换为计算机器设置配置 YAML 文件的名称。例如:gcp-arm64-machine-set-0.yaml, 或gcp-amd64-machine-set-0.yaml。
验证
运行以下命令,查看计算机器集列表:
oc get machineset -n openshift-machine-api
$ oc get machineset -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出必须包含您创建的机器集。
输出示例
NAME DESIRED CURRENT READY AVAILABLE AGE <infrastructure_id>-gcp-machine-set-0 2 2 2 2 10m
NAME DESIRED CURRENT READY AVAILABLE AGE <infrastructure_id>-gcp-machine-set-0 2 2 2 2 10mCopy to Clipboard Copied! Toggle word wrap Toggle overflow 您可以运行以下命令来检查节点是否已就绪并可以调度:
oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.5. 在裸机、IBM Power 或 IBM Z 上使用多架构计算机器创建集群
要在裸机 (x86_64 或 aarch64), IBM Power® (ppc64le), or IBM Z® (s390x) 上使用多架构计算机器创建集群,您必须在其中一个平台上有一个现有的单架构集群。按照您的平台安装过程操作:
- 在裸机上安装用户置备的集群。然后,您可以将 64 位 ARM 计算机器添加到裸机上的 OpenShift Container Platform 集群中。
-
在 IBM Power® 上安装集群。然后,您可以将
x86_64计算机器添加到 IBM Power® 上的 OpenShift Container Platform 集群中。 -
在 IBM Z® 和 IBM® LinuxONE 上安装集群。然后,您可以将
x86_64计算机器添加到 IBM Z® 和 IBM® LinuxONE 上的 OpenShift Container Platform 集群中。
裸机安装程序置备的基础架构和 Bare Metal Operator 不支持在初始集群设置过程中添加二级架构节点。您只能在初始集群设置后手动添加二级架构节点。
在为集群添加额外的计算节点前,您必须将集群升级到使用多架构有效负载的节点。有关迁移到多架构有效负载的更多信息,请参阅迁移到具有多架构计算机器的集群。
以下流程解释了如何使用 ISO 镜像或网络 PXE 引导创建 RHCOS 计算机器。这可让您在集群中添加额外的节点,并使用多架构计算机器部署集群。
在集群中添加二级架构节点前,建议安装 Multiarch Tuning Operator,并部署 ClusterPodPlacementConfig 对象。如需更多信息,请参阅使用 Multiarch Tuning Operator 在多架构集群上管理工作负载。
4.5.1. 验证集群兼容性
在开始在集群中添加不同架构的计算节点前,您必须验证集群是否兼容多架构。
先决条件
-
已安装 OpenShift CLI(
oc)。
流程
-
登录 OpenShift CLI (
oc)。 您可以运行以下命令来检查集群是否使用构架有效负载:
oc adm release info -o jsonpath="{ .metadata.metadata}"$ oc adm release info -o jsonpath="{ .metadata.metadata}"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
如果您看到以下输出,代表集群使用多架构有效负载:
{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 然后,您可以开始在集群中添加多架构计算节点。
如果您看到以下输出,代表集群没有使用多架构有效负载:
{ "url": "https://access.redhat.com/errata/<errata_version>" }{ "url": "https://access.redhat.com/errata/<errata_version>" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要要迁移集群以便集群支持多架构计算机器,请按照使用多架构计算机器迁移到集群的步骤进行操作。
4.5.2. 使用 ISO 镜像创建 RHCOS 机器
您可以使用 ISO 镜像为裸机集群创建更多 Red Hat Enterprise Linux CoreOS(RHCOS)计算机器,以创建机器。
先决条件
- 获取集群计算机器的 Ignition 配置文件的 URL。在安装过程中将该文件上传到 HTTP 服务器。
-
已安装 OpenShift CLI (
oc)。
流程
运行以下命令,从集群中删除 Ignition 配置文件:
oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ign
$ oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ignCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
将您从集群导出的
worker.ignIgnition 配置文件上传到 HTTP 服务器。注意这些文件的 URL。 您可以验证 ignition 文件是否在 URL 上可用。以下示例获取计算节点的 Ignition 配置文件:
curl -k http://<HTTP_server>/worker.ign
$ curl -k http://<HTTP_server>/worker.ignCopy to Clipboard Copied! Toggle word wrap Toggle overflow 您可以运行以下命令来访问 ISO 镜像以引导新机器:
RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.<architecture>.artifacts.metal.formats.iso.disk.location')RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.<architecture>.artifacts.metal.formats.iso.disk.location')Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用 ISO 文件在更多计算机器上安装 RHCOS。在安装集群前,使用创建机器时使用的相同方法:
- 将 ISO 镜像刻录到磁盘并直接启动。
- 在 LOM 接口中使用 ISO 重定向。
在不指定任何选项或中断实时引导序列的情况下引导 RHCOS ISO 镜像。等待安装程序在 RHCOS live 环境中引导进入 shell 提示符。
注意您可以中断 RHCOS 安装引导过程来添加内核参数。但是,在这个 ISO 过程中,您应该使用以下步骤中所述的
coreos-installer命令,而不是添加内核参数。运行
coreos-installer命令并指定满足您的安装要求的选项。您至少必须指定指向节点类型的 Ignition 配置文件的 URL,以及您要安装到的设备:sudo coreos-installer install --ignition-url=http://<HTTP_server>/<node_type>.ign <device> --ignition-hash=sha512-<digest>
$ sudo coreos-installer install --ignition-url=http://<HTTP_server>/<node_type>.ign <device> --ignition-hash=sha512-<digest>1 2 Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意如果要通过使用 TLS 的 HTTPS 服务器提供 Ignition 配置文件,您可以在运行
coreos-installer前将内部证书颁发机构(CA)添加到系统信任存储中。以下示例将计算节点安装初始化到
/dev/sda设备。计算节点的 Ignition 配置文件从 IP 地址 192.168.1.2 的 HTTP Web 服务器获取:sudo coreos-installer install --ignition-url=http://192.168.1.2:80/installation_directory/worker.ign /dev/sda --ignition-hash=sha512-a5a2d43879223273c9b60af66b44202a1d1248fc01cf156c46d4a79f552b6bad47bc8cc78ddf0116e80c59d2ea9e32ba53bc807afbca581aa059311def2c3e3b
$ sudo coreos-installer install --ignition-url=http://192.168.1.2:80/installation_directory/worker.ign /dev/sda --ignition-hash=sha512-a5a2d43879223273c9b60af66b44202a1d1248fc01cf156c46d4a79f552b6bad47bc8cc78ddf0116e80c59d2ea9e32ba53bc807afbca581aa059311def2c3e3bCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在机器的控制台上监控 RHCOS 安装的进度。
重要在开始安装 OpenShift Container Platform 之前,确保每个节点中安装成功。观察安装过程可以帮助确定可能会出现 RHCOS 安装问题的原因。
- 继续为集群创建更多计算机器。
4.5.3. 通过 PXE 或 iPXE 启动来创建 RHCOS 机器
您可以使用 PXE 或 iPXE 引导为裸机集群创建更多 Red Hat Enterprise Linux CoreOS(RHCOS)计算机器。
先决条件
- 获取集群计算机器的 Ignition 配置文件的 URL。在安装过程中将该文件上传到 HTTP 服务器。
-
获取您在集群安装过程中上传到 HTTP 服务器的 RHCOS ISO 镜像、压缩的裸机 BIOS、
kernel和initramfs文件的 URL。 - 您可以访问在安装过程中为 OpenShift Container Platform 集群创建机器时使用的 PXE 引导基础架构。机器必须在安装 RHCOS 后从本地磁盘启动。
-
如果使用 UEFI,您可以访问在 OpenShift Container Platform 安装过程中修改的
grub.conf文件。
流程
确认 RHCOS 镜像的 PXE 或 iPXE 安装正确。
对于 PXE:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意此配置不会在图形控制台的机器上启用串行控制台访问。要配置不同的控制台,请在
APPEND行中添加一个或多个console=参数。例如,添加console=tty0 console=ttyS0以将第一个 PC 串口设置为主控制台,并将图形控制台设置为二级控制台。如需更多信息,请参阅 如何在 Red Hat Enterprise Linux 中设置串行终端和/或控制台?对于 iPXE (
x86_64+aarch64):kernel http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture> initrd=main coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign initrd --name main http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img boot
kernel http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture> initrd=main coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign1 2 initrd --name main http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img3 bootCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意此配置不会在使用图形控制台配置不同的控制台的机器上启用串行控制台访问,请在
kernel行中添加一个或多个console=参数。例如,添加console=tty0 console=ttyS0以将第一个 PC 串口设置为主控制台,并将图形控制台设置为二级控制台。如需更多信息,请参阅如何在 Red Hat Enterprise Linux 中设置串行终端和/或控制台? 和"启用 PXE 和 ISO 安装的串行控制台"部分。注意要在
aarch64架构中网络引导 CoreOS内核,您需要使用启用了IMAGE_GZIP选项的 iPXE 构建版本。请参阅 iPXE 中的IMAGE_GZIP选项。对于
aarch64中的 PXE(使用 UEFI 和 GRUB 作为第二阶段):menuentry 'Install CoreOS' { linux rhcos-<version>-live-kernel-<architecture> coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign initrd rhcos-<version>-live-initramfs.<architecture>.img }menuentry 'Install CoreOS' { linux rhcos-<version>-live-kernel-<architecture> coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign1 2 initrd rhcos-<version>-live-initramfs.<architecture>.img3 }Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- 使用 PXE 或 iPXE 基础架构为集群创建所需的计算机器。
4.5.4. 批准机器的证书签名请求
当您将机器添加到集群时,会为您添加的每台机器生成两个待处理证书签名请求(CSR)。您必须确认这些 CSR 已获得批准,或根据需要自行批准。必须首先批准客户端请求,然后批准服务器请求。
先决条件
- 您已将机器添加到集群中。
流程
确认集群可以识别这些机器:
oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.29.4 master-1 Ready master 63m v1.29.4 master-2 Ready master 64m v1.29.4
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.29.4 master-1 Ready master 63m v1.29.4 master-2 Ready master 64m v1.29.4Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出中列出了您创建的所有机器。
注意在有些 CSR 被批准前,前面的输出可能不包括计算节点(也称为 worker 节点)。
检查待处理的 CSR,并确保添加到集群中的每台机器都有
Pending或Approved状态的客户端请求:oc get csr
$ oc get csrCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在本例中,两台机器加入集群。您可能会在列表中看到更多已批准的 CSR。
如果 CSR 没有获得批准,在您添加的机器的所有待处理 CSR 都处于
Pending 状态后,请批准集群机器的 CSR:注意由于 CSR 会自动轮转,因此请在将机器添加到集群后一小时内批准您的 CSR。如果没有在一小时内批准它们,证书将会轮转,每个节点会存在多个证书。您必须批准所有这些证书。批准客户端 CSR 后,Kubelet 为服务证书创建一个二级 CSR,这需要手动批准。然后,如果 Kubelet 请求具有相同参数的新证书,则后续提供证书续订请求由
machine-approver自动批准。注意对于在未启用机器 API 的平台上运行的集群,如裸机和其他用户置备的基础架构,您必须实施一种方法来自动批准 kubelet 提供证书请求(CSR)。如果没有批准请求,则
oc exec、ocrsh和oc logs命令将无法成功,因为 API 服务器连接到 kubelet 时需要服务证书。与 Kubelet 端点联系的任何操作都需要此证书批准。该方法必须监视新的 CSR,确认 CSR 由 system:node或system:admin组中的node-bootstrapper服务帐户提交,并确认节点的身份。要单独批准,请对每个有效的 CSR 运行以下命令:
oc adm certificate approve <csr_name>
$ oc adm certificate approve <csr_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
要批准所有待处理的 CSR,请运行以下命令:
oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approveCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意在有些 CSR 被批准前,一些 Operator 可能无法使用。
现在,您的客户端请求已被批准,您必须查看添加到集群中的每台机器的服务器请求:
oc get csr
$ oc get csrCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果剩余的 CSR 没有被批准,且处于
Pending状态,请批准集群机器的 CSR:要单独批准,请对每个有效的 CSR 运行以下命令:
oc adm certificate approve <csr_name>
$ oc adm certificate approve <csr_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
要批准所有待处理的 CSR,请运行以下命令:
oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approveCopy to Clipboard Copied! Toggle word wrap Toggle overflow
批准所有客户端和服务器 CSR 后,机器将
处于 Ready 状态。运行以下命令验证:oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意批准服务器 CSR 后可能需要几分钟时间让机器过渡到
Ready 状态。
其他信息
- 如需有关 CSR 的更多信息,请参阅 证书签名请求。
4.6. 在带有 z/VM 的 IBM Z 和 IBM LinuxONE 上使用多架构计算机器创建集群
要使用 IBM® Z 和 IBM® LinuxONE (s390x)上的多架构计算机器创建集群,您必须使用现有的单架构 x86_64 集群。然后,您可以在 OpenShift Container Platform 集群中添加 s390x 计算机器。
在为集群添加 s390x 节点前,您必须将集群升级到使用多架构有效负载的节点。有关迁移到多架构有效负载的更多信息,请参阅迁移到具有多架构计算机器的集群。
以下流程描述了如何使用 z/VM 实例创建 RHCOS 计算机器。这将允许您在集群中添加 s390x 节点,并使用多架构计算机器部署集群。
要使用 x86_64 上的多架构计算机器创建 IBM Z® 或 IBM® LinuxONE (s390x) 集群,请按照在 IBM Z® 和 IBM® LinuxONE 上安装集群 的说明进行操作。然后,您可以添加 x86_64 计算机器 ,如在裸机、IBM Power 或 IBM Z 上创建带有多架构计算机器的集群中所述。
在集群中添加二级架构节点前,建议安装 Multiarch Tuning Operator,并部署 ClusterPodPlacementConfig 对象。如需更多信息,请参阅使用 Multiarch Tuning Operator 在多架构集群上管理工作负载。
4.6.1. 验证集群兼容性
在开始在集群中添加不同架构的计算节点前,您必须验证集群是否兼容多架构。
先决条件
-
已安装 OpenShift CLI(
oc)。
流程
-
登录 OpenShift CLI (
oc)。 您可以运行以下命令来检查集群是否使用构架有效负载:
oc adm release info -o jsonpath="{ .metadata.metadata}"$ oc adm release info -o jsonpath="{ .metadata.metadata}"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
如果您看到以下输出,代表集群使用多架构有效负载:
{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 然后,您可以开始在集群中添加多架构计算节点。
如果您看到以下输出,代表集群没有使用多架构有效负载:
{ "url": "https://access.redhat.com/errata/<errata_version>" }{ "url": "https://access.redhat.com/errata/<errata_version>" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要要迁移集群以便集群支持多架构计算机器,请按照使用多架构计算机器迁移到集群的步骤进行操作。
4.6.2. 使用 z/VM 在 IBM Z 上创建 RHCOS 机器
您可以使用 z/VM 创建在 IBM Z® 上运行的更多 Red Hat Enterprise Linux CoreOS (RHCOS)计算机器,并将它们附加到现有集群。
先决条件
- 您有一个域名服务器(DNS),它可以对节点执行主机名和反向查找。
- 您有在置备机器上运行的 HTTP 或 HTTPS 服务器,可供您创建的机器访问。
流程
运行以下命令,从集群中删除 Ignition 配置文件:
oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ign
$ oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ignCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
将您从集群导出的
worker.ignIgnition 配置文件上传到 HTTP 服务器。注意此文件的 URL。 您可以验证 Ignition 文件是否在 URL 上可用。以下示例获取计算节点的 Ignition 配置文件:
curl -k http://<http_server>/worker.ign
$ curl -k http://<http_server>/worker.ignCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令下载 RHEL live
kernel、initramfs和rootfs文件:curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.kernel.location')$ curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.kernel.location')Copy to Clipboard Copied! Toggle word wrap Toggle overflow curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.initramfs.location')$ curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.initramfs.location')Copy to Clipboard Copied! Toggle word wrap Toggle overflow curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.rootfs.location')$ curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.rootfs.location')Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
将下载的 RHEL live
kernel、initramfs和rootfs文件移到可从您要添加的 RHCOS 客户机访问的 HTTP 或 HTTPS 服务器中。 为客户机创建参数文件。以下参数特定于虚拟机:
可选: 要指定一个静态 IP 地址,请添加带有以下条目的
ip=参数,每个条目用冒号隔开:- 计算机的 IP 地址。
- 个空字符串。
- 网关
- 子网掩码.
-
hostname.domainname格式的机器主机和域名。如果没有这个值,RHCOS 通过反向 DNS 查找获取主机名。 - 网络接口名称。如果省略这个值,RHCOS 会将 IP 配置应用到所有可用的接口。
-
值
none。
-
对于
coreos.inst.ignition_url=,请指定worker.ign文件的 URL。仅支持 HTTP 和 HTTPS 协议。 -
对于
coreos.live.rootfs_url=,请为您引导的kernel和initramfs指定匹配的 rootfs 构件。仅支持 HTTP 和 HTTPS 协议。 对于在 DASD 类型磁盘中安装,请完成以下任务:
-
对于
coreos.inst.install_dev=,请指定/dev/dasda。 -
Userd
.dasd=指定安装 RHCOS 的 DASD。 如果需要,您可以对参数进行进一步的调整。
以下是一个示例参数文件
additional-worker-dasd.parm:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将参数文件中的所有选项写为一行,并确保您没有换行字符。
-
对于
对于在 FCP 类型磁盘中安装,请完成以下任务:
User
d.zfcp=<adapter>,<wwpn>,<lun>以指定要安装 RHCOS 的 FCP 磁盘。对于多路径,为每个额外路径重复此步骤。注意当使用多个路径安装时,您必须在安装后直接启用多路径,而不是在以后启用多路径,因为这可能导致问题。
将安装设备设置为:
coreos.inst.install_dev=/dev/sda。注意如果使用 NPIV 配置额外的 LUN,FCP 需要
zfcp.allow_lun_scan=0。如果必须启用zfcp.allow_lun_scan=1,因为您使用 CSI 驱动程序,则必须配置 NPIV,以便每个节点无法访问另一个节点的引导分区。如果需要,您可以对参数进行进一步的调整。
重要需要额外的安装后步骤才能完全启用多路径。如需更多信息,请参阅机器配置中的"使用 RHCOS 上内核参数启用多路径"。
以下是使用多路径的 worker 节点的
additional-worker-fcp.parm示例参数文件:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将参数文件中的所有选项写为一行,并确保您没有换行字符。
-
使用 FTP 将
initramfs、kernel、参数文件和 RHCOS 镜像传送到 z/VM 中。有关如何使用 FTP 传输文件并从虚拟读取器引导的详情,请参考在 IBM Z® 上引导安装,以便在 z/VM 中安装 RHEL。 将文件 punch 到 z/VM 虚拟机的虚拟读取器。
请参阅 IBM® 文档中的 PUNCH。
提示您可以使用 CP PUNCH 命令,或者,如果使用 Linux,则使用 vmur 命令在两个 z/VM 虚拟机之间传输文件。
- 在 bootstrap 机器上登录到 CMS。
运行以下命令,从 reader IPL bootstrap 机器:
ipl c
$ ipl cCopy to Clipboard Copied! Toggle word wrap Toggle overflow 请参阅 IBM® 文档中的 IPL。
4.6.3. 批准机器的证书签名请求
当您将机器添加到集群时,会为您添加的每台机器生成两个待处理证书签名请求(CSR)。您必须确认这些 CSR 已获得批准,或根据需要自行批准。必须首先批准客户端请求,然后批准服务器请求。
先决条件
- 您已将机器添加到集群中。
流程
确认集群可以识别这些机器:
oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.29.4 master-1 Ready master 63m v1.29.4 master-2 Ready master 64m v1.29.4
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.29.4 master-1 Ready master 63m v1.29.4 master-2 Ready master 64m v1.29.4Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出中列出了您创建的所有机器。
注意在有些 CSR 被批准前,前面的输出可能不包括计算节点(也称为 worker 节点)。
检查待处理的 CSR,并确保添加到集群中的每台机器都有
Pending或Approved状态的客户端请求:oc get csr
$ oc get csrCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在本例中,两台机器加入集群。您可能会在列表中看到更多已批准的 CSR。
如果 CSR 没有获得批准,在您添加的机器的所有待处理 CSR 都处于
Pending 状态后,请批准集群机器的 CSR:注意由于 CSR 会自动轮转,因此请在将机器添加到集群后一小时内批准您的 CSR。如果没有在一小时内批准它们,证书将会轮转,每个节点会存在多个证书。您必须批准所有这些证书。批准客户端 CSR 后,Kubelet 为服务证书创建一个二级 CSR,这需要手动批准。然后,如果 Kubelet 请求具有相同参数的新证书,则后续提供证书续订请求由
machine-approver自动批准。注意对于在未启用机器 API 的平台上运行的集群,如裸机和其他用户置备的基础架构,您必须实施一种方法来自动批准 kubelet 提供证书请求(CSR)。如果没有批准请求,则
oc exec、ocrsh和oc logs命令将无法成功,因为 API 服务器连接到 kubelet 时需要服务证书。与 Kubelet 端点联系的任何操作都需要此证书批准。该方法必须监视新的 CSR,确认 CSR 由 system:node或system:admin组中的node-bootstrapper服务帐户提交,并确认节点的身份。要单独批准,请对每个有效的 CSR 运行以下命令:
oc adm certificate approve <csr_name>
$ oc adm certificate approve <csr_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
要批准所有待处理的 CSR,请运行以下命令:
oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approveCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意在有些 CSR 被批准前,一些 Operator 可能无法使用。
现在,您的客户端请求已被批准,您必须查看添加到集群中的每台机器的服务器请求:
oc get csr
$ oc get csrCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果剩余的 CSR 没有被批准,且处于
Pending状态,请批准集群机器的 CSR:要单独批准,请对每个有效的 CSR 运行以下命令:
oc adm certificate approve <csr_name>
$ oc adm certificate approve <csr_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
要批准所有待处理的 CSR,请运行以下命令:
oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approveCopy to Clipboard Copied! Toggle word wrap Toggle overflow
批准所有客户端和服务器 CSR 后,机器将
处于 Ready 状态。运行以下命令验证:oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意批准服务器 CSR 后可能需要几分钟时间让机器过渡到
Ready 状态。
其他信息
- 如需有关 CSR 的更多信息,请参阅 证书签名请求。
4.7. 在 LPAR 中的 IBM Z 和 IBM LinuxONE 上使用多架构计算机器创建集群
要在 LPAR 中创建在 IBM Z® 和 IBM® LinuxONE (s390x) 中使用多架构计算机器的集群,您必须有一个现有的单架构 x86_64 集群。然后,您可以在 OpenShift Container Platform 集群中添加 s390x 计算机器。
在为集群添加 s390x 节点前,您必须将集群升级到使用多架构有效负载的节点。有关迁移到多架构有效负载的更多信息,请参阅迁移到具有多架构计算机器的集群。
以下流程解释了如何使用 LPAR 实例创建 RHCOS 计算机器。这将允许您在集群中添加 s390x 节点,并使用多架构计算机器部署集群。
要使用 x86_64 上的多架构计算机器创建 IBM Z® 或 IBM® LinuxONE (s390x) 集群,请按照在 IBM Z® 和 IBM® LinuxONE 上安装集群 的说明进行操作。然后,您可以添加 x86_64 计算机器 ,如在裸机、IBM Power 或 IBM Z 上创建带有多架构计算机器的集群中所述。
4.7.1. 验证集群兼容性
在开始在集群中添加不同架构的计算节点前,您必须验证集群是否兼容多架构。
先决条件
-
已安装 OpenShift CLI(
oc)。
流程
-
登录 OpenShift CLI (
oc)。 您可以运行以下命令来检查集群是否使用构架有效负载:
oc adm release info -o jsonpath="{ .metadata.metadata}"$ oc adm release info -o jsonpath="{ .metadata.metadata}"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
如果您看到以下输出,代表集群使用多架构有效负载:
{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 然后,您可以开始在集群中添加多架构计算节点。
如果您看到以下输出,代表集群没有使用多架构有效负载:
{ "url": "https://access.redhat.com/errata/<errata_version>" }{ "url": "https://access.redhat.com/errata/<errata_version>" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要要迁移集群以便集群支持多架构计算机器,请按照使用多架构计算机器迁移到集群的步骤进行操作。
4.7.2. 在 LPAR 中的 IBM Z 上创建 RHCOS 机器
您可以在逻辑分区(LPAR)中创建在 IBM Z® 上运行的更多 Red Hat Enterprise Linux CoreOS (RHCOS)计算机器,并将其附加到现有集群中。
先决条件
- 您有一个域名服务器(DNS),它可以对节点执行主机名和反向查找。
- 您有在置备机器上运行的 HTTP 或 HTTPS 服务器,可供您创建的机器访问。
流程
运行以下命令,从集群中删除 Ignition 配置文件:
oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ign
$ oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ignCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
将您从集群导出的
worker.ignIgnition 配置文件上传到 HTTP 服务器。注意此文件的 URL。 您可以验证 Ignition 文件是否在 URL 上可用。以下示例获取计算节点的 Ignition 配置文件:
curl -k http://<http_server>/worker.ign
$ curl -k http://<http_server>/worker.ignCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令下载 RHEL live
kernel、initramfs和rootfs文件:curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.kernel.location')$ curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.kernel.location')Copy to Clipboard Copied! Toggle word wrap Toggle overflow curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.initramfs.location')$ curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.initramfs.location')Copy to Clipboard Copied! Toggle word wrap Toggle overflow curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.rootfs.location')$ curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.rootfs.location')Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
将下载的 RHEL live
kernel、initramfs和rootfs文件移到可从您要添加的 RHCOS 客户机访问的 HTTP 或 HTTPS 服务器中。 为客户机创建参数文件。以下参数特定于虚拟机:
可选: 要指定一个静态 IP 地址,请添加带有以下条目的
ip=参数,每个条目用冒号隔开:- 计算机的 IP 地址。
- 个空字符串。
- 网关
- 子网掩码.
-
hostname.domainname格式的机器主机和域名。如果没有这个值,RHCOS 通过反向 DNS 查找获取主机名。 - 网络接口名称。如果省略这个值,RHCOS 会将 IP 配置应用到所有可用的接口。
-
值
none。
-
对于
coreos.inst.ignition_url=,请指定worker.ign文件的 URL。仅支持 HTTP 和 HTTPS 协议。 -
对于
coreos.live.rootfs_url=,请为您引导的kernel和initramfs指定匹配的 rootfs 构件。仅支持 HTTP 和 HTTPS 协议。 对于在 DASD 类型磁盘中安装,请完成以下任务:
-
对于
coreos.inst.install_dev=,请指定/dev/dasda。 -
Userd
.dasd=指定安装 RHCOS 的 DASD。 如果需要,您可以对参数进行进一步的调整。
以下是一个示例参数文件
additional-worker-dasd.parm:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将参数文件中的所有选项写为一行,并确保您没有换行字符。
-
对于
对于在 FCP 类型磁盘中安装,请完成以下任务:
User
d.zfcp=<adapter>,<wwpn>,<lun>以指定要安装 RHCOS 的 FCP 磁盘。对于多路径,为每个额外路径重复此步骤。注意当使用多个路径安装时,您必须在安装后直接启用多路径,而不是在以后启用多路径,因为这可能导致问题。
将安装设备设置为:
coreos.inst.install_dev=/dev/sda。注意如果使用 NPIV 配置额外的 LUN,FCP 需要
zfcp.allow_lun_scan=0。如果必须启用zfcp.allow_lun_scan=1,因为您使用 CSI 驱动程序,则必须配置 NPIV,以便每个节点无法访问另一个节点的引导分区。如果需要,您可以对参数进行进一步的调整。
重要需要额外的安装后步骤才能完全启用多路径。如需更多信息,请参阅机器配置中的"使用 RHCOS 上内核参数启用多路径"。
以下是使用多路径的 worker 节点的
additional-worker-fcp.parm示例参数文件:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将参数文件中的所有选项写为一行,并确保您没有换行字符。
- 将 initramfs、内核、参数文件和 RHCOS 镜像传送到 LPAR,例如使用 FTP。有关如何使用 FTP 和引导传输文件的详情,请参考 在 IBM Z® 上引导安装,以便在 LPAR 中安装 RHEL。
- 引导机器
4.7.3. 批准机器的证书签名请求
当您将机器添加到集群时,会为您添加的每台机器生成两个待处理证书签名请求(CSR)。您必须确认这些 CSR 已获得批准,或根据需要自行批准。必须首先批准客户端请求,然后批准服务器请求。
先决条件
- 您已将机器添加到集群中。
流程
确认集群可以识别这些机器:
oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.29.4 master-1 Ready master 63m v1.29.4 master-2 Ready master 64m v1.29.4
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.29.4 master-1 Ready master 63m v1.29.4 master-2 Ready master 64m v1.29.4Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出中列出了您创建的所有机器。
注意在有些 CSR 被批准前,前面的输出可能不包括计算节点(也称为 worker 节点)。
检查待处理的 CSR,并确保添加到集群中的每台机器都有
Pending或Approved状态的客户端请求:oc get csr
$ oc get csrCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在本例中,两台机器加入集群。您可能会在列表中看到更多已批准的 CSR。
如果 CSR 没有获得批准,在您添加的机器的所有待处理 CSR 都处于
Pending 状态后,请批准集群机器的 CSR:注意由于 CSR 会自动轮转,因此请在将机器添加到集群后一小时内批准您的 CSR。如果没有在一小时内批准它们,证书将会轮转,每个节点会存在多个证书。您必须批准所有这些证书。批准客户端 CSR 后,Kubelet 为服务证书创建一个二级 CSR,这需要手动批准。然后,如果 Kubelet 请求具有相同参数的新证书,则后续提供证书续订请求由
machine-approver自动批准。注意对于在未启用机器 API 的平台上运行的集群,如裸机和其他用户置备的基础架构,您必须实施一种方法来自动批准 kubelet 提供证书请求(CSR)。如果没有批准请求,则
oc exec、ocrsh和oc logs命令将无法成功,因为 API 服务器连接到 kubelet 时需要服务证书。与 Kubelet 端点联系的任何操作都需要此证书批准。该方法必须监视新的 CSR,确认 CSR 由 system:node或system:admin组中的node-bootstrapper服务帐户提交,并确认节点的身份。要单独批准,请对每个有效的 CSR 运行以下命令:
oc adm certificate approve <csr_name>
$ oc adm certificate approve <csr_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
要批准所有待处理的 CSR,请运行以下命令:
oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approveCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意在有些 CSR 被批准前,一些 Operator 可能无法使用。
现在,您的客户端请求已被批准,您必须查看添加到集群中的每台机器的服务器请求:
oc get csr
$ oc get csrCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果剩余的 CSR 没有被批准,且处于
Pending状态,请批准集群机器的 CSR:要单独批准,请对每个有效的 CSR 运行以下命令:
oc adm certificate approve <csr_name>
$ oc adm certificate approve <csr_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
要批准所有待处理的 CSR,请运行以下命令:
oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approveCopy to Clipboard Copied! Toggle word wrap Toggle overflow
批准所有客户端和服务器 CSR 后,机器将
处于 Ready 状态。运行以下命令验证:oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意批准服务器 CSR 后可能需要几分钟时间让机器过渡到
Ready 状态。
其他信息
- 如需有关 CSR 的更多信息,请参阅 证书签名请求。
4.8. 使用 RHEL KVM 在 IBM Z 和 IBM LinuxONE 上使用多架构计算机器创建集群
要使用 RHEL KVM 在 IBM Z® 和 IBM® LinuxONE (s390x) 上使用多架构计算机器创建集群,您必须有一个现有的单架构 x86_64 集群。然后,您可以在 OpenShift Container Platform 集群中添加 s390x 计算机器。
在为集群添加 s390x 节点前,您必须将集群升级到使用多架构有效负载的节点。有关迁移到多架构有效负载的更多信息,请参阅迁移到具有多架构计算机器的集群。
以下流程描述了如何使用 RHEL KVM 实例创建 RHCOS 计算机器。这将允许您在集群中添加 s390x 节点,并使用多架构计算机器部署集群。
要使用 x86_64 上的多架构计算机器创建 IBM Z® 或 IBM® LinuxONE (s390x) 集群,请按照在 IBM Z® 和 IBM® LinuxONE 上安装集群 的说明进行操作。然后,您可以添加 x86_64 计算机器 ,如在裸机、IBM Power 或 IBM Z 上创建带有多架构计算机器的集群中所述。
在集群中添加二级架构节点前,建议安装 Multiarch Tuning Operator,并部署 ClusterPodPlacementConfig 对象。如需更多信息,请参阅使用 Multiarch Tuning Operator 在多架构集群上管理工作负载。
4.8.1. 验证集群兼容性
在开始在集群中添加不同架构的计算节点前,您必须验证集群是否兼容多架构。
先决条件
-
已安装 OpenShift CLI(
oc)。
流程
-
登录 OpenShift CLI (
oc)。 您可以运行以下命令来检查集群是否使用构架有效负载:
oc adm release info -o jsonpath="{ .metadata.metadata}"$ oc adm release info -o jsonpath="{ .metadata.metadata}"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
如果您看到以下输出,代表集群使用多架构有效负载:
{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 然后,您可以开始在集群中添加多架构计算节点。
如果您看到以下输出,代表集群没有使用多架构有效负载:
{ "url": "https://access.redhat.com/errata/<errata_version>" }{ "url": "https://access.redhat.com/errata/<errata_version>" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要要迁移集群以便集群支持多架构计算机器,请按照使用多架构计算机器迁移到集群的步骤进行操作。
4.8.2. 使用 virt-install 创建 RHCOS 机器
您可以使用 virt-install 为集群创建更多 Red Hat Enterprise Linux CoreOS (RHCOS)计算机器。
先决条件
- 您至少有一个 LPAR 在 KVM 的 RHEL 8.7 或更高版本中运行,在此过程中称为 RHEL KVM 主机。
- KVM/QEMU 管理程序安装在 RHEL KVM 主机上。
- 您有一个域名服务器(DNS),它可以对节点执行主机名和反向查找。
- 设置了 HTTP 或 HTTPS 服务器。
流程
运行以下命令,从集群中删除 Ignition 配置文件:
oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ign
$ oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ignCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
将您从集群导出的
worker.ignIgnition 配置文件上传到 HTTP 服务器。注意此文件的 URL。 您可以验证 Ignition 文件是否在 URL 上可用。以下示例获取计算节点的 Ignition 配置文件:
curl -k http://<HTTP_server>/worker.ign
$ curl -k http://<HTTP_server>/worker.ignCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令下载 RHEL live
kernel、initramfs和rootfs文件:curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.kernel.location')$ curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.kernel.location')Copy to Clipboard Copied! Toggle word wrap Toggle overflow curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.initramfs.location')$ curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.initramfs.location')Copy to Clipboard Copied! Toggle word wrap Toggle overflow curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.rootfs.location')$ curl -LO $(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' \ | jq -r '.architectures.s390x.artifacts.metal.formats.pxe.rootfs.location')Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
在启动
virt-install前,将下载的 RHEL livekernel、initramfs和rootfs文件移到 HTTP 或 HTTPS 服务器中。 使用 RHEL
kernel、initramfs和 Ignition 文件创建新的 KVM 客户机节点;新磁盘镜像,并调整了 parm 行参数。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 对于
os-variant,为 RHCOS 计算机器指定 RHEL 版本。rhel9.4是推荐的版本。要查询支持的操作系统的 RHEL 版本,请运行以下命令:osinfo-query os -f short-id
$ osinfo-query os -f short-idCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意os-variant是区分大小写的。 - 2
- 对于
--location,指定 kernel/initrd 在 HTTP 或 HTTPS 服务器上的位置。 - 3
- 指定
worker.ign配置文件的位置。仅支持 HTTP 和 HTTPS 协议。 - 4
- 指定您要引导的
kernel和initramfs的rootfs工件位置。仅支持 HTTP 和 HTTPS 协议 - 5
- 可选: 对于
hostname,指定客户端机器的完全限定主机名。
注意如果您使用 HAProxy 作为负载均衡器,在
/etc/haproxy/haproxy.cfg配置文件中为ingress-router-443和ingress-router-80更新 HAProxy 规则。- 继续为集群创建更多计算机器。
4.8.3. 批准机器的证书签名请求
当您将机器添加到集群时,会为您添加的每台机器生成两个待处理证书签名请求(CSR)。您必须确认这些 CSR 已获得批准,或根据需要自行批准。必须首先批准客户端请求,然后批准服务器请求。
先决条件
- 您已将机器添加到集群中。
流程
确认集群可以识别这些机器:
oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.29.4 master-1 Ready master 63m v1.29.4 master-2 Ready master 64m v1.29.4
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.29.4 master-1 Ready master 63m v1.29.4 master-2 Ready master 64m v1.29.4Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出中列出了您创建的所有机器。
注意在有些 CSR 被批准前,前面的输出可能不包括计算节点(也称为 worker 节点)。
检查待处理的 CSR,并确保添加到集群中的每台机器都有
Pending或Approved状态的客户端请求:oc get csr
$ oc get csrCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在本例中,两台机器加入集群。您可能会在列表中看到更多已批准的 CSR。
如果 CSR 没有获得批准,在您添加的机器的所有待处理 CSR 都处于
Pending 状态后,请批准集群机器的 CSR:注意由于 CSR 会自动轮转,因此请在将机器添加到集群后一小时内批准您的 CSR。如果没有在一小时内批准它们,证书将会轮转,每个节点会存在多个证书。您必须批准所有这些证书。批准客户端 CSR 后,Kubelet 为服务证书创建一个二级 CSR,这需要手动批准。然后,如果 Kubelet 请求具有相同参数的新证书,则后续提供证书续订请求由
machine-approver自动批准。注意对于在未启用机器 API 的平台上运行的集群,如裸机和其他用户置备的基础架构,您必须实施一种方法来自动批准 kubelet 提供证书请求(CSR)。如果没有批准请求,则
oc exec、ocrsh和oc logs命令将无法成功,因为 API 服务器连接到 kubelet 时需要服务证书。与 Kubelet 端点联系的任何操作都需要此证书批准。该方法必须监视新的 CSR,确认 CSR 由 system:node或system:admin组中的node-bootstrapper服务帐户提交,并确认节点的身份。要单独批准,请对每个有效的 CSR 运行以下命令:
oc adm certificate approve <csr_name>
$ oc adm certificate approve <csr_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
要批准所有待处理的 CSR,请运行以下命令:
oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approveCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意在有些 CSR 被批准前,一些 Operator 可能无法使用。
现在,您的客户端请求已被批准,您必须查看添加到集群中的每台机器的服务器请求:
oc get csr
$ oc get csrCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果剩余的 CSR 没有被批准,且处于
Pending状态,请批准集群机器的 CSR:要单独批准,请对每个有效的 CSR 运行以下命令:
oc adm certificate approve <csr_name>
$ oc adm certificate approve <csr_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
要批准所有待处理的 CSR,请运行以下命令:
oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approveCopy to Clipboard Copied! Toggle word wrap Toggle overflow
批准所有客户端和服务器 CSR 后,机器将
处于 Ready 状态。运行以下命令验证:oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意批准服务器 CSR 后可能需要几分钟时间让机器过渡到
Ready 状态。
其他信息
- 如需有关 CSR 的更多信息,请参阅 证书签名请求。
4.9. 在 IBM Power 上使用多架构计算机器创建集群
要在 IBM Power® (ppc64le) 上使用多架构计算机器创建集群,您必须有一个现有的单架构 (x86_64) 集群。然后,您可以将 ppc64le 计算机器添加到 OpenShift Container Platform 集群中。
在为集群添加 ppc64le 节点前,您必须将集群升级到使用多架构有效负载的节点。有关迁移到多架构有效负载的更多信息,请参阅迁移到具有多架构计算机器的集群。
以下流程解释了如何使用 ISO 镜像或网络 PXE 引导创建 RHCOS 计算机器。这将允许您在集群中添加 ppc64le 节点,并使用多架构计算机器部署集群。
要使用 x86_64 上的多架构计算机器创建 IBM Power® (ppc64le) 集群,请按照在 IBM Power® 上安装集群的说明进行操作。然后,您可以添加 x86_64 计算机器 ,如在裸机、IBM Power 或 IBM Z 上创建带有多架构计算机器的集群中所述。
在集群中添加二级架构节点前,建议安装 Multiarch Tuning Operator,并部署 ClusterPodPlacementConfig 对象。如需更多信息,请参阅使用 Multiarch Tuning Operator 在多架构集群上管理工作负载。
4.9.1. 验证集群兼容性
在开始在集群中添加不同架构的计算节点前,您必须验证集群是否兼容多架构。
先决条件
-
已安装 OpenShift CLI(
oc)。
在使用多个架构时,OpenShift Container Platform 节点的主机必须共享相同的存储层。如果它们没有相同的存储层,请使用 nfs-provisioner 等存储提供程序。
您应该尽可能限制 compute 和 control plane 之间的网络跃点数量。
流程
-
登录 OpenShift CLI (
oc)。 您可以运行以下命令来检查集群是否使用构架有效负载:
oc adm release info -o jsonpath="{ .metadata.metadata}"$ oc adm release info -o jsonpath="{ .metadata.metadata}"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
如果您看到以下输出,代表集群使用多架构有效负载:
{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }{ "release.openshift.io/architecture": "multi", "url": "https://access.redhat.com/errata/<errata_version>" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 然后,您可以开始在集群中添加多架构计算节点。
如果您看到以下输出,代表集群没有使用多架构有效负载:
{ "url": "https://access.redhat.com/errata/<errata_version>" }{ "url": "https://access.redhat.com/errata/<errata_version>" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要要迁移集群以便集群支持多架构计算机器,请按照使用多架构计算机器迁移到集群的步骤进行操作。
4.9.2. 使用 ISO 镜像创建 RHCOS 机器
您可以使用 ISO 镜像为集群创建更多 Red Hat Enterprise Linux CoreOS (RHCOS) 计算机器,以创建机器。
先决条件
- 获取集群计算机器的 Ignition 配置文件的 URL。在安装过程中将该文件上传到 HTTP 服务器。
-
已安装 OpenShift CLI (
oc)。
流程
运行以下命令,从集群中删除 Ignition 配置文件:
oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ign
$ oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ignCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
将您从集群导出的
worker.ignIgnition 配置文件上传到 HTTP 服务器。注意这些文件的 URL。 您可以验证 ignition 文件是否在 URL 上可用。以下示例获取计算节点的 Ignition 配置文件:
curl -k http://<HTTP_server>/worker.ign
$ curl -k http://<HTTP_server>/worker.ignCopy to Clipboard Copied! Toggle word wrap Toggle overflow 您可以运行以下命令来访问 ISO 镜像以引导新机器:
RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.<architecture>.artifacts.metal.formats.iso.disk.location')RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.<architecture>.artifacts.metal.formats.iso.disk.location')Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用 ISO 文件在更多计算机器上安装 RHCOS。在安装集群前,使用创建机器时使用的相同方法:
- 将 ISO 镜像刻录到磁盘并直接启动。
- 在 LOM 接口中使用 ISO 重定向。
在不指定任何选项或中断实时引导序列的情况下引导 RHCOS ISO 镜像。等待安装程序在 RHCOS live 环境中引导进入 shell 提示符。
注意您可以中断 RHCOS 安装引导过程来添加内核参数。但是,在这个 ISO 过程中,您应该使用以下步骤中所述的
coreos-installer命令,而不是添加内核参数。运行
coreos-installer命令并指定满足您的安装要求的选项。您至少必须指定指向节点类型的 Ignition 配置文件的 URL,以及您要安装到的设备:sudo coreos-installer install --ignition-url=http://<HTTP_server>/<node_type>.ign <device> --ignition-hash=sha512-<digest>
$ sudo coreos-installer install --ignition-url=http://<HTTP_server>/<node_type>.ign <device> --ignition-hash=sha512-<digest>1 2 Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意如果要通过使用 TLS 的 HTTPS 服务器提供 Ignition 配置文件,您可以在运行
coreos-installer前将内部证书颁发机构(CA)添加到系统信任存储中。以下示例将计算节点安装初始化到
/dev/sda设备。计算节点的 Ignition 配置文件从 IP 地址 192.168.1.2 的 HTTP Web 服务器获取:sudo coreos-installer install --ignition-url=http://192.168.1.2:80/installation_directory/worker.ign /dev/sda --ignition-hash=sha512-a5a2d43879223273c9b60af66b44202a1d1248fc01cf156c46d4a79f552b6bad47bc8cc78ddf0116e80c59d2ea9e32ba53bc807afbca581aa059311def2c3e3b
$ sudo coreos-installer install --ignition-url=http://192.168.1.2:80/installation_directory/worker.ign /dev/sda --ignition-hash=sha512-a5a2d43879223273c9b60af66b44202a1d1248fc01cf156c46d4a79f552b6bad47bc8cc78ddf0116e80c59d2ea9e32ba53bc807afbca581aa059311def2c3e3bCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在机器的控制台上监控 RHCOS 安装的进度。
重要在开始安装 OpenShift Container Platform 之前,确保每个节点中安装成功。观察安装过程可以帮助确定可能会出现 RHCOS 安装问题的原因。
- 继续为集群创建更多计算机器。
4.9.3. 通过 PXE 或 iPXE 启动来创建 RHCOS 机器
您可以使用 PXE 或 iPXE 引导为裸机集群创建更多 Red Hat Enterprise Linux CoreOS(RHCOS)计算机器。
先决条件
- 获取集群计算机器的 Ignition 配置文件的 URL。在安装过程中将该文件上传到 HTTP 服务器。
-
获取您在集群安装过程中上传到 HTTP 服务器的 RHCOS ISO 镜像、压缩的裸机 BIOS、
kernel和initramfs文件的 URL。 - 您可以访问在安装过程中为 OpenShift Container Platform 集群创建机器时使用的 PXE 引导基础架构。机器必须在安装 RHCOS 后从本地磁盘启动。
-
如果使用 UEFI,您可以访问在 OpenShift Container Platform 安装过程中修改的
grub.conf文件。
流程
确认 RHCOS 镜像的 PXE 或 iPXE 安装正确。
对于 PXE:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意此配置不会在图形控制台的机器上启用串行控制台访问。要配置不同的控制台,请在
APPEND行中添加一个或多个console=参数。例如,添加console=tty0 console=ttyS0以将第一个 PC 串口设置为主控制台,并将图形控制台设置为二级控制台。如需更多信息,请参阅 如何在 Red Hat Enterprise Linux 中设置串行终端和/或控制台?对于 iPXE (
x86_64+ppc64le):kernel http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture> initrd=main coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign initrd --name main http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img boot
kernel http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture> initrd=main coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign1 2 initrd --name main http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img3 bootCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意此配置不会在使用图形控制台配置不同的控制台的机器上启用串行控制台访问,请在
kernel行中添加一个或多个console=参数。例如,添加console=tty0 console=ttyS0以将第一个 PC 串口设置为主控制台,并将图形控制台设置为二级控制台。如需更多信息,请参阅如何在 Red Hat Enterprise Linux 中设置串行终端和/或控制台? 和"启用 PXE 和 ISO 安装的串行控制台"部分。注意要在
ppc64le架构中网络引导 CoreOSkernel,您需要使用启用了IMAGE_GZIP选项的 iPXE 构建版本。请参阅 iPXE 中的IMAGE_GZIP选项。对于
ppc64le上的 PXE (使用 UEFI 和 GRUB 作为第二阶段):menuentry 'Install CoreOS' { linux rhcos-<version>-live-kernel-<architecture> coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign initrd rhcos-<version>-live-initramfs.<architecture>.img }menuentry 'Install CoreOS' { linux rhcos-<version>-live-kernel-<architecture> coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign1 2 initrd rhcos-<version>-live-initramfs.<architecture>.img3 }Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- 使用 PXE 或 iPXE 基础架构为集群创建所需的计算机器。
4.9.4. 批准机器的证书签名请求
当您将机器添加到集群时,会为您添加的每台机器生成两个待处理证书签名请求(CSR)。您必须确认这些 CSR 已获得批准,或根据需要自行批准。必须首先批准客户端请求,然后批准服务器请求。
先决条件
- 您已将机器添加到集群中。
流程
确认集群可以识别这些机器:
oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.29.4 master-1 Ready master 63m v1.29.4 master-2 Ready master 64m v1.29.4
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.29.4 master-1 Ready master 63m v1.29.4 master-2 Ready master 64m v1.29.4Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出中列出了您创建的所有机器。
注意在有些 CSR 被批准前,前面的输出可能不包括计算节点(也称为 worker 节点)。
检查待处理的 CSR,并确保添加到集群中的每台机器都有
Pending或Approved状态的客户端请求:oc get csr
$ oc get csrCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在本例中,两台机器加入集群。您可能会在列表中看到更多已批准的 CSR。
如果 CSR 没有获得批准,在您添加的机器的所有待处理 CSR 都处于
Pending 状态后,请批准集群机器的 CSR:注意由于 CSR 会自动轮转,因此请在将机器添加到集群后一小时内批准您的 CSR。如果没有在一小时内批准它们,证书将会轮转,每个节点会存在多个证书。您必须批准所有这些证书。批准客户端 CSR 后,Kubelet 为服务证书创建一个二级 CSR,这需要手动批准。然后,如果 Kubelet 请求具有相同参数的新证书,则后续提供证书续订请求由
machine-approver自动批准。注意对于在未启用机器 API 的平台上运行的集群,如裸机和其他用户置备的基础架构,您必须实施一种方法来自动批准 kubelet 提供证书请求(CSR)。如果没有批准请求,则
oc exec、ocrsh和oc logs命令将无法成功,因为 API 服务器连接到 kubelet 时需要服务证书。与 Kubelet 端点联系的任何操作都需要此证书批准。该方法必须监视新的 CSR,确认 CSR 由 system:node或system:admin组中的node-bootstrapper服务帐户提交,并确认节点的身份。要单独批准,请对每个有效的 CSR 运行以下命令:
oc adm certificate approve <csr_name>
$ oc adm certificate approve <csr_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
要批准所有待处理的 CSR,请运行以下命令:
oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approveCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意在有些 CSR 被批准前,一些 Operator 可能无法使用。
现在,您的客户端请求已被批准,您必须查看添加到集群中的每台机器的服务器请求:
oc get csr
$ oc get csrCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果剩余的 CSR 没有被批准,且处于
Pending状态,请批准集群机器的 CSR:要单独批准,请对每个有效的 CSR 运行以下命令:
oc adm certificate approve <csr_name>
$ oc adm certificate approve <csr_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
要批准所有待处理的 CSR,请运行以下命令:
oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approveCopy to Clipboard Copied! Toggle word wrap Toggle overflow
批准所有客户端和服务器 CSR 后,机器将
处于 Ready 状态。运行以下命令验证:oc get nodes -o wide
$ oc get nodes -o wideCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意批准服务器 CSR 后可能需要几分钟时间让机器过渡到
Ready 状态。
其他信息
- 如需有关 CSR 的更多信息,请参阅 证书签名请求。
4.10. 使用多架构计算机器管理集群
4.10.1. 使用多架构计算机器在集群中调度工作负载
使用不同架构的计算节点在集群中部署工作负载需要注意和监控集群。您可能需要进行进一步的操作,才能成功将 pod 放置到集群的节点中。
您可以使用 Multiarch Tuning Operator 在带有多架构计算机器的集群中启用对工作负载的架构调度。Multiarch Tuning Operator 根据 pod 在创建时支持的架构在 pod 规格中实施额外的调度程序 predicates。如需更多信息,请参阅使用 Multiarch Tuning Operator 在多架构集群上管理工作负载。
如需有关节点关联性、调度、污点和容限的更多信息,请参阅以下文档:
4.10.1.1. 多架构节点工作负载部署示例
在使用不同架构的计算节点将工作负载调度到具有不同架构的计算节点上之前,请考虑以下用例:
- 使用节点关联性在节点上调度工作负载
您可以只允许将工作负载调度到其镜像支持的一组节点上,您可以在 pod 模板规格中设置
spec.affinity.nodeAffinity字段。将
nodeAffinity设置为特定架构的部署示例Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 指定支持的构架。有效值包括
amd64,arm64, 或这两个值。
- 为特定架构污点每个节点
您可以污点节点,以避免与其架构不兼容的工作负载调度到该节点上。如果集群正在使用
MachineSet对象,您可以在.spec.template.spec.taints字段中添加参数,以避免在带有不支持的架构的节点上调度工作负载。在污点节点前,您必须缩减
MachineSet对象或删除可用的机器。您可以使用以下命令之一缩减机器集:oc scale --replicas=0 machineset <machineset> -n openshift-machine-api
$ oc scale --replicas=0 machineset <machineset> -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 或者:
oc edit machineset <machineset> -n openshift-machine-api
$ oc edit machineset <machineset> -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 有关扩展机器集的更多信息,请参阅"修改计算机器集"。
带有污点集的
MachineSet示例Copy to Clipboard Copied! Toggle word wrap Toggle overflow 您还可以运行以下命令来在特定节点上设置污点:
oc adm taint nodes <node-name> multi-arch.openshift.io/arch=arm64:NoSchedule
$ oc adm taint nodes <node-name> multi-arch.openshift.io/arch=arm64:NoScheduleCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 创建默认容限
您可以运行以下命令来注解命名空间,以便所有工作负载都获得相同的默认容限:
oc annotate namespace my-namespace \ 'scheduler.alpha.kubernetes.io/defaultTolerations'='[{"operator": "Exists", "effect": "NoSchedule", "key": "multi-arch.openshift.io/arch"}]'$ oc annotate namespace my-namespace \ 'scheduler.alpha.kubernetes.io/defaultTolerations'='[{"operator": "Exists", "effect": "NoSchedule", "key": "multi-arch.openshift.io/arch"}]'Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 在工作负载中容忍架构污点
在具有定义污点的节点上,工作负载不会调度到该节点上。但是,您可以通过在 pod 的规格中设置容限来允许调度它们。
具有容限的部署示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 本例部署也可以在指定了
multi-arch.openshift.io/arch=arm64污点的节点上允许。- 使用带有污点和容限的节点关联性
当调度程序计算一组要调度 pod 的节点时,容限可能会扩大集合,而节点关联性会限制集合。如果将污点设置为特定架构的节点,则需要以下示例容限才能调度 pod。
使用节点关联性和容限集的部署示例。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
其他资源
您可以在集群中的 64 位 ARM 计算机器上启用 Red Hat Enterprise Linux CoreOS (RHCOS) 内核中的 64k 内存页。64k 页大小内核规格可用于大型 GPU 或高内存工作负载。这使用 Machine Config Operator (MCO) 完成,它使用机器配置池来更新内核。要启用 64k 页面大小,您必须为 ARM64 指定一个机器配置池,以便在内核中启用。
使用 64k 页专用于 64 位 ARM 架构计算节点或在 64 位 ARM 机器上安装的集群。如果您使用 64 位 x86 机器在机器配置池中配置 64k 页内核,机器配置池和 MCO 将降级。
先决条件
-
已安装 OpenShift CLI(
oc)。 - 您在其中一个支持的平台中使用不同架构的计算节点创建集群。
流程
标记您要运行 64k 页大小内核的节点:
oc label node <node_name> <label>
$ oc label node <node_name> <label>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 示例命令
oc label node worker-arm64-01 node-role.kubernetes.io/worker-64k-pages=
$ oc label node worker-arm64-01 node-role.kubernetes.io/worker-64k-pages=Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建包含使用 ARM64 架构和
worker-64k-pages角色的 worker 角色的机器配置池:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在计算节点上创建机器配置,以使用
64k-pages参数启用64k-pages。oc create -f <filename>.yaml
$ oc create -f <filename>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow MachineConfig 示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意64k-pages类型仅支持基于 64 位 ARM 架构。realtime类型仅支持基于 64 位 x86 架构。
验证
要查看您的新
worker-64k-pages机器配置池,请运行以下命令:oc get mcp
$ oc get mcpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-9d55ac9a91127c36314e1efe7d77fbf8 True False False 3 3 3 0 361d worker rendered-worker-e7b61751c4a5b7ff995d64b967c421ff True False False 7 7 7 0 361d worker-64k-pages rendered-worker-64k-pages-e7b61751c4a5b7ff995d64b967c421ff True False False 2 2 2 0 35m
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-9d55ac9a91127c36314e1efe7d77fbf8 True False False 3 3 3 0 361d worker rendered-worker-e7b61751c4a5b7ff995d64b967c421ff True False False 7 7 7 0 361d worker-64k-pages rendered-worker-64k-pages-e7b61751c4a5b7ff995d64b967c421ff True False False 2 2 2 0 35mCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.10.3. 在多架构计算机器上的镜像流中导入清单列表
在带有多架构计算机器的 OpenShift Container Platform 4.16 集群中,集群中的镜像流不会自动导入清单列表。您必须手动将默认的 importMode 选项改为 PreserveOriginal 选项,才能导入清单列表。
先决条件
-
已安装 OpenShift Container Platform CLI (
oc)。
流程
以下示例命令演示了如何对
ImageStreamcli-artifacts 进行补丁,以便cli-artifacts:latest镜像流标签作为清单列表导入。oc patch is/cli-artifacts -n openshift -p '{"spec":{"tags":[{"name":"latest","importPolicy":{"importMode":"PreserveOriginal"}}]}}'$ oc patch is/cli-artifacts -n openshift -p '{"spec":{"tags":[{"name":"latest","importPolicy":{"importMode":"PreserveOriginal"}}]}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
您可以通过检查镜像流标签来检查是否正确导入的清单列表。以下命令将列出特定标签的各个架构清单。
oc get istag cli-artifacts:latest -n openshift -oyaml
$ oc get istag cli-artifacts:latest -n openshift -oyamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果存在
dockerImageManifests对象,则清单列表导入成功。dockerImageManifests对象的输出示例Copy to Clipboard Copied! Toggle word wrap Toggle overflow
4.11. 使用 Multiarch Tuning Operator 管理多架构集群中的工作负载
Multiarch Tuning Operator 在多架构集群中优化工作负载管理,以及在到多架构环境的单架构集群中进行工作负载管理。
通过架构感知的工作负载调度,调度程序可以将 pod 放置到与 pod 镜像架构匹配的节点上。
默认情况下,调度程序不会在决定新 pod 放置到节点上时考虑 pod 容器镜像的架构。
要启用架构感知工作负载调度,您必须创建 ClusterPodPlacementConfig 对象。在创建 ClusterPodPlacementConfig 对象时,Multiarch Tuning Operator 会部署必要的操作对象来支持架构感知的工作负载调度。您还可以使用 ClusterPodPlacementConfig 对象中的 nodeAffinityScoring 插件来为节点架构设置集群范围的分数。如果启用 nodeAffinityScoring 插件,调度程序首先过滤兼容架构的节点,然后将 pod 放置到分数最高的节点上。
创建 pod 时,操作对象执行以下操作:
-
添加
multiarch.openshift.io/scheduling-gate调度门,以防止调度 pod。 -
计算一个调度 predicate,其中包含
kubernetes.io/arch标签支持的架构值。 -
将调度 predicate 集成为 pod 规格中的
nodeAffinity要求。 - 从 pod 中删除调度授权。
请注意以下操作对象行为:
-
如果
nodeSelector字段已配置了工作负载的kubernetes.io/arch标签,则操作对象不会更新该工作负载的nodeAffinity字段。 -
如果
nodeSelector字段没有使用工作负载的kubernetes.io/arch标签配置,则操作对象会更新该工作负载的nodeAffinity字段。但是,在这个nodeAffinity字段中,操作对象只更新没有使用kubernetes.io/arch标签配置的节点选择器术语。 -
如果已经设置了
nodeName字段,Multiarch Tuning Operator 不会处理 pod。 -
如果 pod 归 DaemonSet 所有,则 operand 不会更新
nodeAffinity字段。 -
如果为
kubernetes.io/arch标签设置了nodeSelector或nodeAffinity和preferredAffinity字段,则 operand 不会更新nodeAffinity字段。 -
如果为
kubernetes.io/arch标签只设置了nodeSelector或nodeAffinity字段,并且禁用了nodeAffinityScoring插件,则 operand 不会更新nodeAffinity字段。 -
如果
nodeAffinity.preferredDuringSchedulingIgnoredDuringExecution字段已包含基于kubernetes.io/arch标签的分数节点的条件,则 operand 会忽略nodeAffinityScoring插件中的配置。
4.11.1. 使用 CLI 安装 Multiarch Tuning Operator
您可以使用 OpenShift CLI (oc)安装 Multiarch Tuning Operator。
先决条件
-
已安装
oc。 -
已以具有
cluster-admin权限的用户身份登录oc。
流程
运行以下命令,创建一个名为
openshift-multiarch-tuning-operator的新项目:oc create ns openshift-multiarch-tuning-operator
$ oc create ns openshift-multiarch-tuning-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow 创建一个
OperatorGroup对象:使用用于创建
OperatorGroup对象的配置创建 YAML 文件。创建
OperatorGroup对象的 YAML 配置示例:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令来创建
OperatorGroup对象:oc create -f <file_name>
$ oc create -f <file_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 将
<file_name>替换为包含OperatorGroup对象配置的 YAML 文件的名称。
创建
Subscription对象:使用用于创建
Subscription对象的配置创建 YAML 文件。创建
Subscription对象的 YAML 配置示例Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令来创建
Subscription对象:oc create -f <file_name>
$ oc create -f <file_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 将
<file_name>替换为包含Subscription对象配置的 YAML 文件的名称。
有关配置 Subscription 对象和 OperatorGroup 对象的详情,请参阅"使用 CLI 安装 OperatorHub"。
验证
要验证是否安装了 Multiarch Tuning Operator,请运行以下命令:
oc get csv -n openshift-multiarch-tuning-operator
$ oc get csv -n openshift-multiarch-tuning-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME DISPLAY VERSION REPLACES PHASE multiarch-tuning-operator.<version> Multiarch Tuning Operator <version> multiarch-tuning-operator.1.0.0 Succeeded
NAME DISPLAY VERSION REPLACES PHASE multiarch-tuning-operator.<version> Multiarch Tuning Operator <version> multiarch-tuning-operator.1.0.0 SucceededCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果 Operator 处于
Succeeded阶段,则安装可以成功。可选:要验证是否创建了
OperatorGroup对象,请运行以下命令:oc get operatorgroup -n openshift-multiarch-tuning-operator
$ oc get operatorgroup -n openshift-multiarch-tuning-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME AGE openshift-multiarch-tuning-operator-q8zbb 133m
NAME AGE openshift-multiarch-tuning-operator-q8zbb 133mCopy to Clipboard Copied! Toggle word wrap Toggle overflow 可选:要验证是否已创建
Subscription对象,请运行以下命令:oc get subscription -n openshift-multiarch-tuning-operator
$ oc get subscription -n openshift-multiarch-tuning-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME PACKAGE SOURCE CHANNEL multiarch-tuning-operator multiarch-tuning-operator redhat-operators stable
NAME PACKAGE SOURCE CHANNEL multiarch-tuning-operator multiarch-tuning-operator redhat-operators stableCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.11.2. 使用 Web 控制台安装 Multiarch Tuning Operator
您可以使用 OpenShift Container Platform Web 控制台安装 Multiarch Tuning Operator。
先决条件
-
您可以使用
cluster-admin权限访问集群。 - 访问 OpenShift Container Platform web 控制台。
流程
- 登陆到 OpenShift Container Platform Web 控制台。
- 进入到 Operators → OperatorHub。
- 在搜索字段中输入 Multiarch Tuning Operator。
- 点 Multiarch Tuning Operator。
- 从 Version 列表中选择 Multiarch Tuning Operator 版本。
- 点 Install
在 Operator 安装页面中设置以下选项 :
- 将 Update Channel 设置为 stable。
- 将 Installation Mode 设置为 All namespaces on the cluster。
将 Installed Namespace 设置为 Operator recommended Namespace 或 Select a Namespace。
推荐的 Operator 命名空间是
openshift-multiarch-tuning-operator。如果openshift-multiarch-tuning-operator命名空间不存在,它会在 Operator 安装过程中创建。如果选择 Select a namespace,则必须从 Select Project 列表中选择 Operator 的命名空间。
将 Update approval 设置为 Automatic 或 Manual。
如果选择 Automatic 更新,Operator Lifecycle Manager (OLM) 将自动更新 Multiarch Tuning Operator 的运行实例,而无需任何干预。
如果选择 手动 更新,OLM 会创建一个更新请求。作为集群管理员,您必须手动批准更新请求,才能将 Multiarch Tuning Operator 更新至更新的版本。
- 可选:选择 Enable Operator recommended cluster monitoring on this Namespace 复选框。
- 点 Install。
验证
- 导航到 Operators → Installed Operators。
-
验证 Multiarch Tuning Operator 是否已列出,Status 字段在
openshift-multiarch-tuning-operator命名空间中为 Succeeded。
4.11.3. Multiarch Tuning Operator pod 标签和构架支持概述
安装 Multiarch Tuning Operator 后,您可以验证集群中工作负载的多架构支持。您可以使用 pod 标签根据其架构兼容性来识别和管理 pod。这些标签会在新创建的 pod 上自动设置,以深入了解其架构支持。
下表描述了创建 pod 时 Multiarch Tuning Operator 添加的标签:
| 标签 | 描述 |
|---|---|
|
| pod 支持多种架构。 |
|
| pod 只支持单架构。 |
|
|
pod 支持 |
|
|
pod 支持 |
|
|
pod 支持 |
|
|
pod 支持 |
|
| Operator 已为架构设置了节点关联性要求。 |
|
| Operator 没有设置节点关联性要求。例如,当 pod 已具有架构的节点关联性时,Multiarch Tuning Operator 会将此标签添加到 pod。 |
|
| pod 被授权。 |
|
| pod 门被删除。 |
|
| 构建节点关联性要求时出错。 |
|
| Operator 在 pod 中设置了架构首选项。 |
|
|
Operator 没有在 pod 中设置架构首选项,因为用户已在 |
4.11.4. 创建 ClusterPodPlacementConfig 对象
安装 Multiarch Tuning Operator 后,您必须创建 ClusterPodPlacementConfig 对象。在创建此对象时,Multiarch Tuning Operator 会部署一个操作对象,以启用架构感知的工作负载调度。
您只能创建 ClusterPodPlacementConfig 对象的一个实例。
ClusterPodPlacementConfig 对象配置示例
- 1
- 您必须将此字段值设置为
cluster。 - 2
- 可选: 您可以将字段值设置为
Normal,Debug,Trace, 或TraceAll。该值默认设置为Normal。 - 3
- 可选: 您可以配置
namespaceSelector来选择 Multiarch Tuning Operator 的 pod 放置操作对象必须处理 pod 的nodeAffinity的命名空间。默认情况下,考虑所有命名空间。 - 4
- 可选:包括架构感知工作负载调度的插件列表。
- 5
- 可选: 您可以使用此插件为 pod 放置设置架构首选项。启用后,调度程序首先过滤掉不满足 pod 要求的节点。然后,它根据
nodeAffinityScoring.platforms字段中定义的架构分数来优先选择剩余的节点。 - 6
- 可选:将此字段设置为
true以启用nodeAffinityScoring插件。默认值为false。 - 7
- 可选:定义架构列表及其对应的分数。
- 8
- 指定节点架构的分数。调度程序会根据您设置的架构分数以及 pod 规格中定义的调度要求来优先选择 pod 放置的节点。接受的值是
arm64,amd64,ppc64le, 或s390x。 - 9
- 为架构分配一个分数。此字段的值需要在
1(最低优先级)到100(最高优先级)范围内。调度程序使用此分数来优先选择 pod 放置的节点,从而优先选择具有更高分数的架构的节点。
在本例中,operator 字段值设置为 DoesNotExist。因此,如果将 key 字段值 (multiarch.openshift.io/exclude-pod-placement) 设置为命名空间中的标签,则操作对象不会处理该命名空间中 pod 的 nodeAffinity。相反,操作对象处理没有包含该标签的命名空间中 pod 的 nodeAffinity。
如果您希望操作对象只处理特定命名空间中的 pod 的 nodeAffinity,您可以配置 namespaceSelector,如下所示:
namespaceSelector:
matchExpressions:
- key: multiarch.openshift.io/include-pod-placement
operator: Exists
namespaceSelector:
matchExpressions:
- key: multiarch.openshift.io/include-pod-placement
operator: Exists
在本例中,operator 字段值设置为 Exists。因此,操作对象仅在包含 multiarch.openshift.io/include-pod-placement 标签的命名空间中处理 pod 的 nodeAffinity。
此 Operator 排除以 kube- 开始的命名空间中的 pod。它还排除要在 control plane 节点上调度的 pod。
4.11.4.1. 使用 CLI 创建 ClusterPodPlacementConfig 对象
要部署启用架构感知工作负载调度的 pod 放置操作对象,您可以使用 OpenShift CLI (oc) 创建 ClusterPodPlacementConfig 对象。
先决条件
-
已安装
oc。 -
已以具有
cluster-admin权限的用户身份登录oc。 - 已安装 Multiarch Tuning Operator。
流程
创建
ClusterPodPlacementConfig对象 YAML 文件:ClusterPodPlacementConfig对象配置示例Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令来创建
ClusterPodPlacementConfig对象:oc create -f <file_name>
$ oc create -f <file_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 将
<file_name>替换为ClusterPodPlacementConfig对象 YAML 文件的名称。
验证
要检查
ClusterPodPlacementConfig对象是否已创建,请运行以下命令:oc get clusterpodplacementconfig
$ oc get clusterpodplacementconfigCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME AGE cluster 29s
NAME AGE cluster 29sCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.11.4.2. 使用 Web 控制台创建 ClusterPodPlacementConfig 对象
要部署启用架构感知工作负载调度的 pod 放置操作对象,您可以使用 OpenShift Container Platform Web 控制台创建 ClusterPodPlacementConfig 对象。
先决条件
-
您可以使用
cluster-admin权限访问集群。 - 访问 OpenShift Container Platform web 控制台。
- 已安装 Multiarch Tuning Operator。
流程
- 登陆到 OpenShift Container Platform Web 控制台。
- 导航到 Operators → Installed Operators。
- 在 Installed Operators 页面中,点 Multiarch Tuning Operator。
- 点 Cluster Pod Placement Config 选项卡。
- 选择 Form view 或 YAML view。
-
配置
ClusterPodPlacementConfig对象参数。 - 点 Create。
可选:如果要编辑
ClusterPodPlacementConfig对象,请执行以下操作:- 点 Cluster Pod Placement Config 选项卡。
- 从选项菜单中选择 Edit ClusterPodPlacementConfig。
-
点 YAML 并编辑
ClusterPodPlacementConfig对象参数。 - 点击 Save。
验证
-
在 Cluster Pod Placement Config 页面中,检查
ClusterPodPlacementConfig对象是否处于Ready状态。
4.11.5. 使用 CLI 删除 ClusterPodPlacementConfig 对象
您只能创建 ClusterPodPlacementConfig 对象的一个实例。如果要重新创建此对象,您必须首先删除现有的实例。
您可以使用 OpenShift CLI (oc)删除此对象。
先决条件
-
已安装
oc。 -
已以具有
cluster-admin权限的用户身份登录oc。
流程
-
登录 OpenShift CLI (
oc)。 运行以下命令来删除
ClusterPodPlacementConfig对象:oc delete clusterpodplacementconfig cluster
$ oc delete clusterpodplacementconfig clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
要检查
ClusterPodPlacementConfig对象是否已删除,请运行以下命令:oc get clusterpodplacementconfig
$ oc get clusterpodplacementconfigCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
No resources found
No resources foundCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.11.6. 使用 Web 控制台删除 ClusterPodPlacementConfig 对象
您只能创建 ClusterPodPlacementConfig 对象的一个实例。如果要重新创建此对象,您必须首先删除现有的实例。
您可以使用 OpenShift Container Platform Web 控制台删除此对象。
先决条件
-
您可以使用
cluster-admin权限访问集群。 - 访问 OpenShift Container Platform web 控制台。
-
您已创建了
ClusterPodPlacementConfig对象。
流程
- 登陆到 OpenShift Container Platform Web 控制台。
- 导航到 Operators → Installed Operators。
- 在 Installed Operators 页面中,点 Multiarch Tuning Operator。
- 点 Cluster Pod Placement Config 选项卡。
- 从选项菜单中选择 Delete ClusterPodPlacementConfig。
- 点击 Delete。
验证
-
在 Cluster Pod Placement Config 页面中,检查
ClusterPodPlacementConfig对象是否已删除。
4.11.7. 使用 CLI 卸载 Multiarch Tuning Operator
您可以使用 OpenShift CLI (oc)卸载 Multiarch Tuning Operator。
先决条件
-
已安装
oc。 -
已以具有
cluster-admin权限的用户身份登录oc。 已删除
ClusterPodPlacementConfig对象。重要在卸载 Multiarch Tuning Operator 前,您必须删除
ClusterPodPlacementConfig对象。在不删除ClusterPodPlacementConfig对象的情况下卸载 Operator 可能会导致意外行为。
流程
运行以下命令,获取 Multiarch Tuning Operator 的
Subscription对象名称:oc get subscription.operators.coreos.com -n <namespace>
$ oc get subscription.operators.coreos.com -n <namespace>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 将
<namespace>替换为您要卸载 Multiarch Tuning Operator 的命名空间的名称。
输出示例
NAME PACKAGE SOURCE CHANNEL openshift-multiarch-tuning-operator multiarch-tuning-operator redhat-operators stable
NAME PACKAGE SOURCE CHANNEL openshift-multiarch-tuning-operator multiarch-tuning-operator redhat-operators stableCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,获取 Multiarch Tuning Operator 的
currentCSV值:oc get subscription.operators.coreos.com <subscription_name> -n <namespace> -o yaml | grep currentCSV
$ oc get subscription.operators.coreos.com <subscription_name> -n <namespace> -o yaml | grep currentCSV1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 将
<subscription_name>替换为Subscription对象名称。例如:openshift-multiarch-tuning-operator。将<namespace>替换为您要卸载 Multiarch Tuning Operator 的命名空间的名称。
输出示例
currentCSV: multiarch-tuning-operator.<version>
currentCSV: multiarch-tuning-operator.<version>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令来删除
Subscription对象:oc delete subscription.operators.coreos.com <subscription_name> -n <namespace>
$ oc delete subscription.operators.coreos.com <subscription_name> -n <namespace>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 将
<subscription_name>替换为Subscription对象名称。将<namespace>替换为您要卸载 Multiarch Tuning Operator 的命名空间的名称。
输出示例
subscription.operators.coreos.com "openshift-multiarch-tuning-operator" deleted
subscription.operators.coreos.com "openshift-multiarch-tuning-operator" deletedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,使用
currentCSV值删除目标命名空间中 Multiarch Tuning Operator 的 CSV:oc delete clusterserviceversion <currentCSV_value> -n <namespace>
$ oc delete clusterserviceversion <currentCSV_value> -n <namespace>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 将
<currentCSV>替换为 Multiarch Tuning Operator 的currentCSV值。例如:multiarch-tuning-operator.<version>。将<namespace>替换为您要卸载 Multiarch Tuning Operator 的命名空间的名称。
输出示例
clusterserviceversion.operators.coreos.com "multiarch-tuning-operator.<version>" deleted
clusterserviceversion.operators.coreos.com "multiarch-tuning-operator.<version>" deletedCopy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
要验证 Multiarch Tuning Operator 是否已卸载,请运行以下命令:
oc get csv -n <namespace>
$ oc get csv -n <namespace>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 将
<namespace>替换为已卸载 Multiarch Tuning Operator 的命名空间的名称。
输出示例
No resources found in openshift-multiarch-tuning-operator namespace.
No resources found in openshift-multiarch-tuning-operator namespace.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
4.11.8. 使用 Web 控制台卸载 Multiarch Tuning Operator
您可以使用 OpenShift Container Platform Web 控制台卸载 Multiarch Tuning Operator。
先决条件
-
您可以使用
cluster-admin权限访问集群。 已删除
ClusterPodPlacementConfig对象。重要在卸载 Multiarch Tuning Operator 前,您必须删除
ClusterPodPlacementConfig对象。在不删除ClusterPodPlacementConfig对象的情况下卸载 Operator 可能会导致意外行为。
流程
- 登陆到 OpenShift Container Platform Web 控制台。
- 进入到 Operators → OperatorHub。
- 在搜索字段中输入 Multiarch Tuning Operator。
- 点 Multiarch Tuning Operator。
- 点 Details 标签页。
- 在 Actions 菜单中,选择 Uninstall Operator。
- 出现提示时,点 Uninstall。
验证
- 导航到 Operators → Installed Operators。
- 在 Installed Operators 页面中,验证 Multiarch Tuning Operator 没有被列出。
4.12. Multiarch Tuning Operator 发行注记
Multiarch Tuning Operator 在多架构集群中优化工作负载管理,以及在到多架构环境的单架构集群中进行工作负载管理。
本发行注记介绍了 Multiarch Tuning Operator 的开发。
如需更多信息,请参阅使用 Multiarch Tuning Operator 在多架构集群上管理工作负载。
4.12.1. Multiarch Tuning Operator 1.1.1 发行注记
发布日期: 2025 年 5 月 27 日
4.12.1.1. 程序错误修复
在以前的版本中,pod 放置操作对象不支持使用 pull secret 主机名中的通配符条目验证 registry。这会导致在拉取镜像时与 Kubelet 不一致的行为,因为在操作对象需要完全匹配时 Kubelet 支持的通配符条目。因此,当 registry 使用通配符主机名时,镜像拉取可能会失败。
在这个版本中,pod 放置操作对象支持包含通配符主机名的 pull secret,确保镜像身份验证和拉取。
在以前的版本中,当镜像检查在所有重试并启用了
nodeAffinityScoring插件后,pod 放置操作对象会应用不正确的nodeAffinityScoring标签。在这个版本中,操作对象可以正确地设置
nodeAffinityScoring标签,即使镜像检查失败。现在,它独立于所需的关联性过程应用这些标签,以确保准确和一致的调度。
4.12.2. Multiarch Tuning Operator 1.1.0 发行注记
发布日期:2025 年 3 月 18 日
4.12.2.1. 新功能及功能增强
- 现在,在受管产品上支持 Multiarch Tuning Operator,包括带有 Hosted Control Planes (HCP) 和其他 HCP 环境的 ROSA。
-
在这个版本中,您可以使用
ClusterPodPlacementConfig对象中的新plugins字段配置架构感知工作负载调度。您可以使用plugins.nodeAffinityScoring字段来为 pod 放置设置架构首选项。如果启用nodeAffinityScoring插件,调度程序首先过滤掉不符合 pod 要求的节点。然后,调度程序会根据nodeAffinityScoring.platforms字段中定义的架构分数来优先选择剩余的节点。
4.12.2.2. 程序错误修复
-
在这个版本中,Multiarch Tuning Operator 不会更新由守护进程集管理的 pod 的
nodeAffinity字段。(OCPBUGS-45885)
4.12.3. Multiarch Tuning Operator 1.0.0 发行注记
发布日期:2024 年 10 月 31 日
4.12.3.1. 新功能及功能增强
- 在这个版本中,Multiarch Tuning Operator 支持自定义网络场景和集群范围的自定义 registry 配置。
- 在这个版本中,您可以使用 Multiarch Tuning Operator 添加到新创建的 pod 的 pod 标签根据架构兼容性来识别 pod。
- 在这个版本中,您可以使用 Cluster Monitoring Operator 中注册的指标和警报来监控 Multiarch Tuning Operator 的行为。
第 5 章 安装后集群任务
安装 OpenShift Container Platform 后,您可以按照自己的要求进一步扩展和自定义集群。
5.1. 可用的集群自定义
大多数集群配置和自定义在 OpenShift Container Platform 集群部署后完成。有若干配置资源可用。
如果在 IBM Z® 上安装集群,则不是所有功能都可用。
您可以修改配置资源来配置集群的主要功能,如镜像 registry、网络配置、镜像构建操作以及用户身份供应商。
如需设置这些资源的当前信息,请使用 oc explain 命令,如 oc explain builds --api-version=config.openshift.io/v1
5.1.1. 集群配置资源
所有集群配置资源都作用于全局范围(而非命名空间),且命名为 cluster。
| 资源名称 | 描述 |
|---|---|
|
| 提供 API 服务器配置,如证书和证书颁发机构。 |
|
| 控制集群的身份提供程序和身份验证配置。 |
|
| 控制集群中所有构建的默认和强制配置。 |
|
| 配置 Web 控制台界面的行为,包括注销行为。 |
|
| 启用 FeatureGates,以便可以使用技术预览功能。 |
|
| 配置应如何对待特定的镜像 registry(允许、禁用、不安全、CA 详情)。 |
|
| 与路由相关的配置详情,如路由的默认域。 |
|
| 配置用户身份供应商,以及与内部 OAuth 服务器流程相关的其他行为。 |
|
| 配置项目的创建方式,包括项目模板。 |
|
| 定义需要外部网络访问的组件要使用的代理。注意:目前不是所有组件都会消耗这个值。 |
|
| 配置 调度程序行为,如配置集和默认节点选择器。 |
5.1.2. Operator 配置资源
这些配置资源是集群范围的实例,即 cluster,控制归特定 Operator 所有的特定组件的行为。
| 资源名称 | 描述 |
|---|---|
|
| 控制控制台外观,如品牌定制 |
|
| 配置 OpenShift 镜像 registry 设置,如公共路由、日志级别、代理设置、资源约束、副本数和存储类型。 |
|
| 配置 Samples Operator,以控制在集群上安装哪些镜像流和模板示例。 |
5.1.3. 其他配置资源
这些配置资源代表一个特定组件的单一实例。在有些情况下,您可以通过创建多个资源实例来请求多个实例。在其他情况下,Operator 只消耗指定命名空间中的特定资源实例名称。如需有关如何和何时创建其他资源实例的详情,请参考具体组件的文档。
| 资源名称 | 实例名称 | 命名空间 | 描述 |
|---|---|---|---|
|
|
|
| 控制 Alertmanager 部署参数。 |
|
|
|
| 配置 Ingress Operator 行为,如域、副本数、证书和控制器放置。 |
5.1.4. 信息资源
可以使用这些资源检索集群信息。有些配置可能需要您直接编辑这些资源。
| 资源名称 | 实例名称 | 描述 |
|---|---|---|
|
|
|
在 OpenShift Container Platform 4.16 中,不得自定义生产集群的 |
|
|
| 无法修改集群的 DNS 设置。您可以检查 DNS Operator 状态。 |
|
|
| 允许集群与其云供应商交互的配置详情。 |
|
|
| 无法在安装后修改集群网络。要自定义您的网络,请遵循相关的流程在安装过程中自定义网络。 |
5.2. 添加 worker 节点
部署 OpenShift Container Platform 集群后,您可以添加 worker 节点来扩展集群资源。您可以根据安装方法和集群的环境,添加 worker 节点的不同方法。
5.2.1. 在安装程序置备的基础架构集群中添加 worker 节点
对于安装程序置备的基础架构集群,您可以手动或自动扩展 MachineSet 对象以匹配可用的裸机主机数量。
要添加裸机主机,您必须配置所有网络先决条件,配置关联的 baremetalhost 对象,然后为集群置备 worker 节点。您可以手动添加裸机主机,或使用 Web 控制台。
5.2.2. 在用户置备的基础架构集群中添加 worker 节点
对于用户置备的基础架构集群,您可以使用 RHEL 或 RHCOS ISO 镜像添加 worker 节点,并使用集群 Ignition 配置文件将其连接到集群。对于 RHEL worker 节点,以下示例使用 Ansible playbook 在集群中添加 worker 节点。对于 RHCOS worker 节点,以下示例使用 ISO 镜像和网络引导来在集群中添加 worker 节点。
5.2.3. 将 worker 节点添加到由 Assisted Installer 管理的集群
对于由 Assisted Installer 管理的集群,您可以使用 Red Hat OpenShift Cluster Manager 控制台(辅助安装程序 REST API)添加 worker 节点,也可以使用 ISO 镜像和集群 Ignition 配置文件手动添加 worker 节点。
5.2.4. 将 worker 节点添加到由 Kubernetes 的多集群引擎管理的集群
对于由 Kubernetes 多集群引擎管理的集群,您可以使用专用多集群引擎控制台添加 worker 节点。
5.3. 调整 worker 节点
如果您在部署过程中错误地定义了 worker 节点的大小,请通过创建一个或多个新计算机器集来调整它们,扩展它们,然后扩展原始的计算机器集,然后再删除它们。
5.3.1. 了解计算机器集和机器配置池之间的区别
MachineSet 对象描述了与云或机器供应商相关的 OpenShift Container Platform 节点。
MachineConfigPool 对象允许 MachineConfigController 组件在升级过程中定义并提供机器的状态。
MachineConfigPool 对象允许用户配置如何将升级应用到机器配置池中的 OpenShift Container Platform 节点。
NodeSelector 对象可以被一个到 MachineSet 对象的引用替换。
5.3.2. 手动扩展计算机器集
要在计算机器集中添加或删除机器实例,您可以手动扩展计算机器集。
这个指南与全自动的、安装程序置备的基础架构安装相关。自定义的、用户置备的基础架构安装没有计算机器集。
先决条件
-
安装 OpenShift Container Platform 集群和
oc命令行。 -
以具有
cluster-admin权限的用户身份登录oc。
流程
运行以下命令,查看集群中的计算机器:
oc get machinesets.machine.openshift.io -n openshift-machine-api
$ oc get machinesets.machine.openshift.io -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 计算机器集以
<clusterid>-worker-<aws-region-az>的形式列出。运行以下命令,查看集群中的计算机器:
oc get machines.machine.openshift.io -n openshift-machine-api
$ oc get machines.machine.openshift.io -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,在要删除的计算机器上设置注解:
oc annotate machines.machine.openshift.io/<machine_name> -n openshift-machine-api machine.openshift.io/delete-machine="true"
$ oc annotate machines.machine.openshift.io/<machine_name> -n openshift-machine-api machine.openshift.io/delete-machine="true"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令来扩展计算机器集:
oc scale --replicas=2 machinesets.machine.openshift.io <machineset> -n openshift-machine-api
$ oc scale --replicas=2 machinesets.machine.openshift.io <machineset> -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 或者:
oc edit machinesets.machine.openshift.io <machineset> -n openshift-machine-api
$ oc edit machinesets.machine.openshift.io <machineset> -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 提示您还可以应用以下 YAML 来扩展计算机器集:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 您可以扩展或缩减计算机器。需要过几分钟以后新机器才可用。
重要默认情况下,机器控制器会尝试排空在机器上运行的节点,直到成功为止。在某些情况下,如错误配置了 pod 中断预算,排空操作可能无法成功。如果排空操作失败,机器控制器无法继续删除机器。
您可以通过在特定机器上注解
machine.openshift.io/exclude-node-draining来跳过排空节点。
验证
运行以下命令,验证删除所需的机器:
oc get machines.machine.openshift.io
$ oc get machines.machine.openshift.ioCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.3.3. 计算机器集删除策略
Random、Newest 和 Oldest 是三个支持的删除选项。默认值为 Random,表示在扩展计算机器时随机选择并删除机器。通过修改特定的计算机器集,可以根据用例设置删除策略:
spec: deletePolicy: <delete_policy> replicas: <desired_replica_count>
spec:
deletePolicy: <delete_policy>
replicas: <desired_replica_count>
无论删除策略是什么,都可通过在相关机器上添加 machine.openshift.io/delete-machine=true 注解来指定机器删除的优先级。
默认情况下,OpenShift Container Platform 路由器 Pod 部署在 worker 上。由于路由器需要访问某些集群资源(包括 Web 控制台),除非先重新放置了路由器 Pod,否则请不要将 worker 计算机器集扩展为 0。
对于需要特定节点运行的用例,可以使用自定义计算机器集,在 worker 计算机器集缩减时,控制器会忽略这些服务。这可防止服务被中断。
5.3.4. 创建默认的集群范围节点选择器
您可以组合使用 pod 上的默认集群范围节点选择器和节点上的标签,将集群中创建的所有 pod 限制到特定节点。
使用集群范围节点选择器时,如果您在集群中创建 pod,OpenShift Container Platform 会将默认节点选择器添加到 pod,并将该 pod 调度到具有匹配标签的节点。
您可以通过编辑调度程序 Operator 自定义资源(CR)来配置集群范围节点选择器。您可向节点、计算机器集或机器配置添加标签。将标签添加到计算机器集可确保节点或机器停机时,新节点具有该标签。如果节点或机器停机,添加到节点或机器配置的标签不会保留。
您可以向 pod 添加额外的键/值对。但是,您无法为一个默认的键添加不同的值。
流程
添加默认的集群范围节点选择器:
编辑调度程序 Operator CR 以添加默认的集群范围节点选择器:
oc edit scheduler cluster
$ oc edit scheduler clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用节点选择器的调度程序 Operator CR 示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 使用适当的
<key>:<value>对添加节点选择器。
完成此更改后,请等待重新部署
openshift-kube-apiserver项目中的 pod。这可能需要几分钟。只有重新部署 pod 后,默认的集群范围节点选择器才会生效。使用计算机器集或直接编辑节点,为节点添加标签:
在创建节点时,使用计算机器集向由计算机器设置管理的节点添加标签:
运行以下命令,将标签添加到
MachineSet对象中:oc patch MachineSet <name> --type='json' -p='[{"op":"add","path":"/spec/template/spec/metadata/labels", "value":{"<key>"="<value>","<key>"="<value>"}}]' -n openshift-machine-api$ oc patch MachineSet <name> --type='json' -p='[{"op":"add","path":"/spec/template/spec/metadata/labels", "value":{"<key>"="<value>","<key>"="<value>"}}]' -n openshift-machine-api1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 为每个标识添加
<key>/<value>对。
例如:
oc patch MachineSet ci-ln-l8nry52-f76d1-hl7m7-worker-c --type='json' -p='[{"op":"add","path":"/spec/template/spec/metadata/labels", "value":{"type":"user-node","region":"east"}}]' -n openshift-machine-api$ oc patch MachineSet ci-ln-l8nry52-f76d1-hl7m7-worker-c --type='json' -p='[{"op":"add","path":"/spec/template/spec/metadata/labels", "value":{"type":"user-node","region":"east"}}]' -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 提示您还可以应用以下 YAML 来向计算机器集中添加标签:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用
oc edit命令验证标签是否已添加到MachineSet对象中:例如:
oc edit MachineSet abc612-msrtw-worker-us-east-1c -n openshift-machine-api
$ oc edit MachineSet abc612-msrtw-worker-us-east-1c -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow MachineSet对象示例Copy to Clipboard Copied! Toggle word wrap Toggle overflow 通过缩减至
0并扩展节点来重新部署与该计算机器集关联的节点:例如:
oc scale --replicas=0 MachineSet ci-ln-l8nry52-f76d1-hl7m7-worker-c -n openshift-machine-api
$ oc scale --replicas=0 MachineSet ci-ln-l8nry52-f76d1-hl7m7-worker-c -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc scale --replicas=1 MachineSet ci-ln-l8nry52-f76d1-hl7m7-worker-c -n openshift-machine-api
$ oc scale --replicas=1 MachineSet ci-ln-l8nry52-f76d1-hl7m7-worker-c -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 当节点就绪并可用时,使用
oc get命令验证该标签是否已添加到节点:oc get nodes -l <key>=<value>
$ oc get nodes -l <key>=<value>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc get nodes -l type=user-node
$ oc get nodes -l type=user-nodeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME STATUS ROLES AGE VERSION ci-ln-l8nry52-f76d1-hl7m7-worker-c-vmqzp Ready worker 61s v1.29.4
NAME STATUS ROLES AGE VERSION ci-ln-l8nry52-f76d1-hl7m7-worker-c-vmqzp Ready worker 61s v1.29.4Copy to Clipboard Copied! Toggle word wrap Toggle overflow
直接向节点添加标签:
为节点编辑
Node对象:oc label nodes <name> <key>=<value>
$ oc label nodes <name> <key>=<value>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如,若要为以下节点添加标签:
oc label nodes ci-ln-l8nry52-f76d1-hl7m7-worker-b-tgq49 type=user-node region=east
$ oc label nodes ci-ln-l8nry52-f76d1-hl7m7-worker-b-tgq49 type=user-node region=eastCopy to Clipboard Copied! Toggle word wrap Toggle overflow 提示您还可以应用以下 YAML 来向节点添加标签:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用
oc get命令验证标签是否已添加到节点:oc get nodes -l <key>=<value>,<key>=<value>
$ oc get nodes -l <key>=<value>,<key>=<value>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc get nodes -l type=user-node,region=east
$ oc get nodes -l type=user-node,region=eastCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME STATUS ROLES AGE VERSION ci-ln-l8nry52-f76d1-hl7m7-worker-b-tgq49 Ready worker 17m v1.29.4
NAME STATUS ROLES AGE VERSION ci-ln-l8nry52-f76d1-hl7m7-worker-b-tgq49 Ready worker 17m v1.29.4Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.4. 使用 worker 延迟配置集提高高延迟环境中的集群稳定性
如果集群管理员为平台验证执行了延迟测试,他们可以发现需要调整集群的操作,以确保高延迟的情况的稳定性。集群管理员只需要更改一个参数,该参数记录在一个文件中,它控制了 Supervisory 进程读取状态并解释集群的运行状况的四个参数。仅更改一个参数可以以方便、可支持的方式提供集群调整。
Kubelet 进程提供监控集群运行状况的起点。Kubelet 为 OpenShift Container Platform 集群中的所有节点设置状态值。Kubernetes Controller Manager (kube controller) 默认每 10 秒读取状态值。如果 kube 控制器无法读取节点状态值,它会在配置的时间后丢失与该节点联系。默认行为是:
-
control plane 上的节点控制器将节点健康状况更新为
Unhealthy,并奖节点Ready的条件标记为 'Unknown'。 - 因此,调度程序会停止将 pod 调度到该节点。
-
Node Lifecycle Controller 添加了一个
node.kubernetes.io/unreachable污点,对节点具有NoExecute效果,默认在五分钟后调度节点上的任何 pod 进行驱除。
如果您的网络容易出现延迟问题,尤其是在网络边缘中有节点时,此行为可能会造成问题。在某些情况下,Kubernetes Controller Manager 可能会因为网络延迟而从健康的节点接收更新。Kubelet 会从节点中驱除 pod,即使节点处于健康状态。
要避免这个问题,您可以使用 worker 延迟配置集调整 kubelet 和 Kubernetes Controller Manager 在执行操作前等待状态更新的频率。如果在控制平面和 worker 节点间存在网络延迟,worker 节点没有处于最近状态,这个调整有助于集群可以正常工作。
这些 worker 延迟配置集包含预定义的三组参数,它们带有经过仔细调优的值,以控制集群对增加的延迟进行适当地响应。不需要手动进行实验以查找最佳值。
您可在安装集群时配置 worker 延迟配置集,或当您发现集群网络中的延迟增加时。
5.4.1. 了解 worker 延迟配置集
worker 延迟配置集带有四个不同的、包括经过仔细调优的参数的类别。实现这些值的四个参数是 node-status-update-frequency、node-monitor-grace-period、default-not-ready-toleration-seconds 和 default-unreachable-toleration-seconds。这些参数可让您使用这些值来控制集群对延迟问题的响应,而无需手动确定最佳值。
不支持手动设置这些参数。参数设置不正确会影响集群的稳定性。
所有 worker 延迟配置集配置以下参数:
- node-status-update-frequency
- 指定 kubelet 将节点状态发布到 API 服务器的频率。
- node-monitor-grace-period
-
指定 Kubernetes Controller Manager 在节点不健康前等待更新的时间(以秒为单位),并将
node.kubernetes.io/not-ready或node.kubernetes.io/unreachable污点添加到节点。 - default-not-ready-toleration-seconds
- 指定在标记节点不健康后,Kube API Server Operator 在从该节点驱除 pod 前等待的时间(以秒为单位)。
- default-unreachable-toleration-seconds
- 指定在节点无法访问后,Kube API Server Operator 在从该节点驱除 pod 前等待的时间(以秒为单位)。
以下 Operator 监控 worker 延迟配置集的更改并相应地响应:
-
Machine Config Operator (MCO) 更新 worker 节点上的
node-status-update-frequency参数。 -
Kubernetes Controller Manager 更新 control plane 节点上的
node-monitor-grace-period参数。 -
Kubernetes API Server Operator 更新 control plane 节点上的
default-not-ready-toleration-seconds和default-unreachable-toleration-seconds参数。
虽然默认配置在大多数情况下可以正常工作,但 OpenShift Container Platform 会为网络遇到比通常更高的延迟的情况提供两个其他 worker 延迟配置集。以下部分描述了三个 worker 延迟配置集:
- 默认 worker 延迟配置集
使用
Default配置集时,每个Kubelet每 10 秒更新其状态(node-status-update-frequency)。Kube Controller Manager每 5 秒检查Kubelet的状态。在认为
Kubelet不健康前,Kubernetes Controller Manager 会等待 40 秒(node-monitor-grace-period)以获取来自Kubelet的状态更新。如果没有可用于 Kubernetes Controller Manager 的使用状态,它会使用node.kubernetes.io/not-ready或node.kubernetes.io/unreachable污点标记节点,并驱除该节点上的 pod。如果 pod 位于具有
NoExecute污点的节点上,则 pod 根据tolerationSeconds运行。如果节点没有污点,它将在 300 秒内被驱除(Kube API Server的default-not-ready-toleration-seconds和default-unreachable-toleration-seconds设置)。Expand profile 组件 参数 值 Default(默认)
kubelet
node-status-update-frequency10s
kubelet Controller Manager
node-monitor-grace-period40s
Kubernetes API Server Operator
default-not-ready-toleration-seconds300s
Kubernetes API Server Operator
default-unreachable-toleration-seconds300s
- 中型 worker 延迟配置集
如果网络延迟比通常稍高,则使用
MediumUpdateAverageReaction配置集。MediumUpdateAverageReaction配置集减少了 kubelet 更新频率为 20 秒,并将 Kubernetes Controller Manager 等待这些更新的时间更改为 2 分钟。该节点上的 pod 驱除周期会减少到 60 秒。如果 pod 具有tolerationSeconds参数,则驱除会等待该参数指定的周期。Kubernetes Controller Manager 会先等待 2 分钟时间,才会认为节点不健康。另一分钟后,驱除过程会启动。
Expand profile 组件 参数 值 MediumUpdateAverageReaction
kubelet
node-status-update-frequency20s
kubelet Controller Manager
node-monitor-grace-period2m
Kubernetes API Server Operator
default-not-ready-toleration-seconds60s
Kubernetes API Server Operator
default-unreachable-toleration-seconds60s
- 低 worker 延迟配置集
如果网络延迟非常高,请使用
LowUpdateSlowReaction配置集。LowUpdateSlowReaction配置集将 kubelet 更新频率减少为 1 分钟,并将 Kubernetes Controller Manager 等待这些更新的时间更改为 5 分钟。该节点上的 pod 驱除周期会减少到 60 秒。如果 pod 具有tolerationSeconds参数,则驱除会等待该参数指定的周期。Kubernetes Controller Manager 在认为节点不健康前会等待 5 分钟。另一分钟后,驱除过程会启动。
Expand profile 组件 参数 值 LowUpdateSlowReaction
kubelet
node-status-update-frequency1m
kubelet Controller Manager
node-monitor-grace-period5m
Kubernetes API Server Operator
default-not-ready-toleration-seconds60s
Kubernetes API Server Operator
default-unreachable-toleration-seconds60s
延迟配置集不支持自定义机器配置池,只有默认的 worker 机器配置池。
5.4.2. 使用和更改 worker 延迟配置集
要更改 worker 延迟配置集以处理网络延迟,请编辑 node.config 对象以添加配置集的名称。当延迟增加或减少时,您可以随时更改配置集。
您必须一次移动一个 worker 延迟配置集。例如,您无法直接从 Default 配置集移到 LowUpdateSlowReaction worker 延迟配置集。您必须首先从 Default worker 延迟配置集移到 MediumUpdateAverageReaction 配置集,然后再移到 LowUpdateSlowReaction。同样,当返回到 Default 配置集时,您必须首先从低配置集移到中配置集,然后移到 Default。
您还可以在安装 OpenShift Container Platform 集群时配置 worker 延迟配置集。
流程
将默认的 worker 延迟配置集改为:
中 worke worker 延迟配置集:
编辑
node.config对象:oc edit nodes.config/cluster
$ oc edit nodes.config/clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 添加
spec.workerLatencyProfile: MediumUpdateAverageReaction:node.config对象示例Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 指定中 worker 延迟策略。
随着更改被应用,每个 worker 节点上的调度都会被禁用。
可选:改为低 worker 延迟配置集:
编辑
node.config对象:oc edit nodes.config/cluster
$ oc edit nodes.config/clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 将
spec.workerLatencyProfile值更改为LowUpdateSlowReaction:node.config对象示例Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 指定使用低 worker 延迟策略。
随着更改被应用,每个 worker 节点上的调度都会被禁用。
验证
当所有节点都返回到
Ready条件时,您可以使用以下命令查看 Kubernetes Controller Manager 以确保应用它:oc get KubeControllerManager -o yaml | grep -i workerlatency -A 5 -B 5
$ oc get KubeControllerManager -o yaml | grep -i workerlatency -A 5 -B 5Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 指定配置集被应用并激活。
要将中配置集改为默认,或将默认改为中,编辑 node.config 对象,并将 spec.workerLatencyProfile 参数设置为适当的值。
5.5. 管理 control plane 机器
control plane 机器集为 control plane 机器提供管理功能,与为计算机器提供的计算机器集类似。集群上的 control plane 机器集的可用性和初始状态取决于您的云供应商和您安装的 OpenShift Container Platform 版本。如需更多信息,请参阅开始使用 control plane 机器集。
5.6. 为生产环境创建基础架构机器集
您可以创建一个计算机器集来创建仅托管基础架构组件的机器,如默认路由器、集成的容器镜像 registry 和组件用于集群指标和监控。这些基础架构机器不会被计算为运行环境所需的订阅总数。
有关基础架构节点以及可在基础架构节点上运行的组件的详情,请参考 创建基础架构机器集。
要创建基础架构节点,您可以使用机器集,为节点分配标签,或使用机器配置池。
有关可用于这些流程的机器集示例,请参阅为不同的云创建机器集。
将特定节点选择器应用到所有基础架构组件会导致 OpenShift Container Platform 使用 该标签将这些工作负载调度到具有该标签的节点。
5.6.1. 创建计算机器集
除了安装程序创建的计算机器集外,您还可以创建自己的来动态管理您选择的特定工作负载的机器计算资源。
先决条件
- 部署一个 OpenShift Container Platform 集群。
-
安装 OpenShift CLI(
oc)。 -
以具有
cluster-admin权限的用户身份登录oc。
流程
创建一个包含计算机器集自定义资源(CR)示例的新 YAML 文件,并将其命名为
<file_name>.yaml。确保设置
<clusterID>和<role>参数值。可选:如果您不确定要为特定字段设置哪个值,您可以从集群中检查现有计算机器集:
要列出集群中的计算机器集,请运行以下命令:
oc get machinesets -n openshift-machine-api
$ oc get machinesets -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 要查看特定计算机器集自定义资源 (CR) 的值,请运行以下命令:
oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
运行以下命令来创建
MachineSetCR:oc create -f <file_name>.yaml
$ oc create -f <file_name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
运行以下命令,查看计算机器集列表:
oc get machineset -n openshift-machine-api
$ oc get machineset -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 当新的计算机器集可用时,
DESIRED和CURRENT的值会匹配。如果 compute 机器集不可用,请等待几分钟,然后再次运行命令。
5.6.2. 创建基础架构节点
请参阅为安装程序置备的基础架构环境创建基础架构机器集,或为其 control plane 节点由机器 API 管理的任何集群创建基础架构机器集。
集群的要求规定基础架构(infra)节点已调配。安装程序只置备 control plane 和 worker 节点。Worker 节点可以通过标记指定为基础架构节点。然后,您可以使用污点和容限将适当的工作负载移到基础架构节点。如需更多信息,请参阅"将资源移到基础架构机器集"。
您可以选择创建默认的集群范围节点选择器。默认节点选择器应用于所有命名空间中创建的 pod,并创建与 pod 上任何现有节点选择器的交集,这额外限制 pod 的选择器。
如果默认节点选择器键与 pod 标签的键冲突,则不会应用默认节点选择器。
但是,不要设置可能会导致 pod 变得不可调度的默认节点选择器。例如,当 pod 的标签被设置为不同的节点角色(如 node-role.kubernetes.io/infra="")时,将默认节点选择器设置为特定的节点角色(如 node-role.kubernetes.io/master="")可能会导致 pod 无法调度。因此,将默认节点选择器设置为特定节点角色时要小心。
您还可以使用项目节点选择器来避免集群范围节点选择器键冲突。
流程
向您要充当基础架构节点的 worker 节点添加标签:
oc label node <node-name> node-role.kubernetes.io/infra=""
$ oc label node <node-name> node-role.kubernetes.io/infra=""Copy to Clipboard Copied! Toggle word wrap Toggle overflow 检查适用节点现在是否具有
infra角色:oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 可选:创建默认的集群范围节点选择器:
编辑
Scheduler对象:oc edit scheduler cluster
$ oc edit scheduler clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用适当的节点选择器添加
defaultNodeSelector字段:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 这个示例节点选择器默认在基础架构节点上部署 pod。
- 保存文件以使改变生效。
现在,您可以将基础架构资源移到新的基础架构节点。另外,在新的基础架构节点上,删除您不想或不属于的任何工作负载。请参阅"OpenShift Container Platform 基础架构组件"中在基础架构节点上支持的工作负载列表。
5.6.3. 为基础架构机器创建机器配置池
如果需要基础架构机器具有专用配置,则必须创建一个 infra 池。
在创建一个默认自定义集群配置池时,如果它们引用同一文件或单元,则创建的自定义机器配置池会覆盖默认的 worker 池配置。
流程
向您要分配为带有特定标签的 infra 节点的节点添加标签:
oc label node <node_name> <label>
$ oc label node <node_name> <label>Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc label node ci-ln-n8mqwr2-f76d1-xscn2-worker-c-6fmtx node-role.kubernetes.io/infra=
$ oc label node ci-ln-n8mqwr2-f76d1-xscn2-worker-c-6fmtx node-role.kubernetes.io/infra=Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建包含 worker 角色和自定义角色作为机器配置选择器的机器配置池:
cat infra.mcp.yaml
$ cat infra.mcp.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意自定义机器配置池从 worker 池中继承机器配置。自定义池使用任何针对 worker 池的机器配置,但增加了部署仅针对自定义池的更改的功能。由于自定义池从 worker 池中继承资源,对 worker 池的任何更改也会影响自定义池。
具有 YAML 文件后,您可以创建机器配置池:
oc create -f infra.mcp.yaml
$ oc create -f infra.mcp.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 检查机器配置,以确保基础架构配置成功:
oc get machineconfig
$ oc get machineconfigCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 您应该会看到一个新的机器配置,带有
rendered-infra-*前缀。可选:要部署对自定义池的更改,请创建一个机器配置,该配置使用自定义池名称作为标签,如本例中的
infra。请注意,这不是必须的,在此包括仅用于指示目的。这样,您可以只应用特定于 infra 节点的任何自定义配置。注意创建新机器配置池后,MCO 会为该池生成一个新的呈现配置,以及该池重启的关联节点以应用新配置。
创建机器配置:
cat infra.mc.yaml
$ cat infra.mc.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 将您添加的标签作为
nodeSelector添加到节点。
将机器配置应用到 infra-labeled 节点:
oc create -f infra.mc.yaml
$ oc create -f infra.mc.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
确认您的新机器配置池可用:
oc get mcp
$ oc get mcpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE infra rendered-infra-60e35c2e99f42d976e084fa94da4d0fc True False False 1 1 1 0 4m20s master rendered-master-9360fdb895d4c131c7c4bebbae099c90 True False False 3 3 3 0 91m worker rendered-worker-60e35c2e99f42d976e084fa94da4d0fc True False False 2 2 2 0 91m
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE infra rendered-infra-60e35c2e99f42d976e084fa94da4d0fc True False False 1 1 1 0 4m20s master rendered-master-9360fdb895d4c131c7c4bebbae099c90 True False False 3 3 3 0 91m worker rendered-worker-60e35c2e99f42d976e084fa94da4d0fc True False False 2 2 2 0 91mCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在本例中,worker 节点被改为一个 infra 节点。
5.7. 为基础架构节点分配机器设置资源
在创建了基础架构机器集后,worker 和 infra 角色将应用到新的 infra 节点。具有 infra 角色的节点不会计入运行环境所需的订阅总数中,即使也应用了 worker 角色。
但是,当为 infra 节点分配 worker 角色时,用户工作负载可能会意外地分配给 infra 节点。要避免这种情况,您可以将污点应用到 infra 节点,并为您要控制的 pod 应用容限。
5.7.1. 使用污点和容限绑定基础架构节点工作负载
如果您有一个分配了 infra 和 worker 角色的基础架构节点,您必须配置该节点,以便不为其分配用户工作负载。
建议您保留为基础架构节点创建的双 infra,worker 标签,并使用污点和容限来管理用户工作负载调度到的节点。如果从节点中删除 worker 标签,您必须创建一个自定义池来管理它。没有自定义池的 MCO 不能识别具有 master 或 worker 以外的标签的节点。如果不存在选择自定义标签的自定义池,维护 worker 标签可允许默认 worker 机器配置池管理节点。infra 标签与集群通信,它不计算订阅总数。
先决条件
-
在 OpenShift Container Platform 集群中配置额外的
MachineSet对象。
流程
为基础架构节点添加污点以防止在其上调度用户工作负载:
确定节点是否具有污点:
oc describe nodes <node_name>
$ oc describe nodes <node_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 本例显示节点具有污点。您可以在下一步中继续向 pod 添加容限。
如果您还没有配置污点以防止在其上调度用户工作负载:
oc adm taint nodes <node_name> <key>=<value>:<effect>
$ oc adm taint nodes <node_name> <key>=<value>:<effect>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc adm taint nodes node1 node-role.kubernetes.io/infra=reserved:NoSchedule
$ oc adm taint nodes node1 node-role.kubernetes.io/infra=reserved:NoScheduleCopy to Clipboard Copied! Toggle word wrap Toggle overflow 提示您还可以编辑 pod 规格来添加污点:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 这些示例在
node1上放置一个具有node-role.kubernetes.io/infra键和NoSchedule污点效果的污点。具有NoSchedule effect的节点仅调度容许该污点的 pod,但允许现有 pod 继续调度到该节点上。如果您在基础架构节点中添加了
NoSchedule污点,则该节点上守护进程集控制的所有 pod 都会被标记为misscheduled。您必须删除 pod,或为 pod 添加容限,如红帽知识库解决方案中所示,在misscheduledDNS pod 上添加容限。请注意,您无法将容限添加到由 Operator 管理的守护进程集对象中。注意如果使用 descheduler,则违反了节点污点的 pod 可能会从集群驱除。
为要在基础架构节点上调度的 pod 添加容限,如路由器、registry 和监控工作负载。引用前面的示例,在
Pod对象规格中添加以下容限:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 此容忍度与
oc adm taint命令创建的污点匹配。具有此容忍度的 pod 可以调度到基础架构节点上。注意并不总是能够将通过 OLM 安装的 Operator 的 Pod 移到基础架构节点。移动 Operator Pod 的能力取决于每个 Operator 的配置。
- 使用调度程序将 pod 调度到基础架构节点。详情请参阅"使用调度程序控制 pod 放置"的文档。
- 在新的基础架构节点上,删除您不想或不属于的任何工作负载。请参阅"OpenShift Container Platform 基础架构组件"中在基础架构节点上支持的工作负载列表。
5.8. 将资源移到基础架构机器集
默认情况下,您的集群中已部署了某些基础架构资源。您可将它们移至您创建的基础架构机器集。
5.8.1. 移动路由器
您可以将路由器 Pod 部署到不同的计算机器集中。默认情况下,pod 部署到 worker 节点。
先决条件
- 在 OpenShift Container Platform 集群中配置额外的计算机器集。
流程
查看路由器 Operator 的
IngressController自定义资源:oc get ingresscontroller default -n openshift-ingress-operator -o yaml
$ oc get ingresscontroller default -n openshift-ingress-operator -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 命令输出类似于以下文本:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 编辑
ingresscontroller资源,并更改nodeSelector以使用infra标签:oc edit ingresscontroller default -n openshift-ingress-operator
$ oc edit ingresscontroller default -n openshift-ingress-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 添加
nodeSelector参数,并设为适用于您想要移动的组件的值。您可以根据为节点指定的值,按所示格式使用nodeSelector参数,或使用<key>: <value>对。如果您在 infrasructure 节点中添加了污点,还要添加匹配的容限。
确认路由器 Pod 在
infra节点上运行。查看路由器 Pod 列表,并记下正在运行的 Pod 的节点名称:
oc get pod -n openshift-ingress -o wide
$ oc get pod -n openshift-ingress -o wideCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES router-default-86798b4b5d-bdlvd 1/1 Running 0 28s 10.130.2.4 ip-10-0-217-226.ec2.internal <none> <none> router-default-955d875f4-255g8 0/1 Terminating 0 19h 10.129.2.4 ip-10-0-148-172.ec2.internal <none> <none>
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES router-default-86798b4b5d-bdlvd 1/1 Running 0 28s 10.130.2.4 ip-10-0-217-226.ec2.internal <none> <none> router-default-955d875f4-255g8 0/1 Terminating 0 19h 10.129.2.4 ip-10-0-148-172.ec2.internal <none> <none>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在本例中,正在运行的 Pod 位于
ip-10-0-217-226.ec2.internal节点上。查看正在运行的 Pod 的节点状态:
oc get node <node_name>
$ oc get node <node_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 指定从 Pod 列表获得的
<node_name>。
输出示例
NAME STATUS ROLES AGE VERSION ip-10-0-217-226.ec2.internal Ready infra,worker 17h v1.29.4
NAME STATUS ROLES AGE VERSION ip-10-0-217-226.ec2.internal Ready infra,worker 17h v1.29.4Copy to Clipboard Copied! Toggle word wrap Toggle overflow 由于角色列表包含
infra,因此 Pod 在正确的节点上运行。
5.8.2. 移动默认 registry
您需要配置 registry Operator,以便将其 Pod 部署到其他节点。
先决条件
- 在 OpenShift Container Platform 集群中配置额外的计算机器集。
流程
查看
config/instance对象:oc get configs.imageregistry.operator.openshift.io/cluster -o yaml
$ oc get configs.imageregistry.operator.openshift.io/cluster -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 编辑
config/instance对象:oc edit configs.imageregistry.operator.openshift.io/cluster
$ oc edit configs.imageregistry.operator.openshift.io/clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 添加
nodeSelector参数,并设为适用于您想要移动的组件的值。您可以根据为节点指定的值,按所示格式使用nodeSelector参数,或使用<key>: <value>对。如果您在 infrasructure 节点中添加了污点,还要添加匹配的容限。
验证 registry pod 已移至基础架构节点。
运行以下命令,以识别 registry pod 所在的节点:
oc get pods -o wide -n openshift-image-registry
$ oc get pods -o wide -n openshift-image-registryCopy to Clipboard Copied! Toggle word wrap Toggle overflow 确认节点具有您指定的标签:
oc describe node <node_name>
$ oc describe node <node_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 查看命令输出,并确认
node-role.kubernetes.io/infra列在LABELS列表中。
5.8.3. 移动监控解决方案
监控堆栈包含多个组件,包括 Prometheus、Thanos Querier 和 Alertmanager。Cluster Monitoring Operator 管理此堆栈。要将监控堆栈重新部署到基础架构节点,您可以创建并应用自定义配置映射。
先决条件
-
您可以使用具有
cluster-admin集群角色的用户身份访问集群。 -
您已创建
cluster-monitoring-configConfigMap对象。 -
已安装 OpenShift CLI(
oc)。
流程
编辑
cluster-monitoring-config配置映射,并更改nodeSelector以使用infra标签:oc edit configmap cluster-monitoring-config -n openshift-monitoring
$ oc edit configmap cluster-monitoring-config -n openshift-monitoringCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 添加
nodeSelector参数,并设为适用于您想要移动的组件的值。您可以根据为节点指定的值,按所示格式使用nodeSelector参数,或使用<key>: <value>对。如果您在 infrasructure 节点中添加了污点,还要添加匹配的容限。
观察监控 pod 移至新机器:
watch 'oc get pod -n openshift-monitoring -o wide'
$ watch 'oc get pod -n openshift-monitoring -o wide'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果组件没有移到
infra节点,请删除带有这个组件的 pod:oc delete pod -n openshift-monitoring <pod>
$ oc delete pod -n openshift-monitoring <pod>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 已删除 pod 的组件在
infra节点上重新创建。
5.8.4. 移动日志记录资源
有关移动日志记录资源的详情,请参考:
5.9. 将自动扩展应用到集群
将自动扩展应用到 OpenShift Container Platform 集群涉及部署集群自动扩展,然后为集群中的每种 Machine 类型部署机器自动扩展。
如需更多信息,请参阅将自动扩展应用到 OpenShift Container Platform 集群。
5.10. 配置 Linux cgroup
自 OpenShift Container Platform 4.14 起,OpenShift Container Platform 在集群中使用 Linux 控制组版本 2 (cgroup v2)。如果您在 OpenShift Container Platform 4.13 或更早版本中使用 cgroup v1,迁移到 OpenShift Container Platform 4.14 或更高版本不会自动将 cgroup 配置更新至版本 2。全新安装 OpenShift Container Platform 4.14 或更高版本默认使用 cgroup v2。但是,您可以在安装时启用 Linux 控制组群版本 1 (cgroup v1)。
cgroup v2 是 Linux cgroup API 的当前版本。cgroup v2 比 cgroup v1 提供多种改进,包括统一层次结构、更安全的子树委派、新功能,如 Pressure Stall Information,以及增强的资源管理和隔离。但是,cgroup v2 与 cgroup v1 具有不同的 CPU、内存和 I/O 管理特征。因此,在运行 cgroup v2 的集群上,一些工作负载可能会遇到内存或 CPU 用量差异。
您可以根据需要在 cgroup v1 和 cgroup v2 之间更改。在 OpenShift Container Platform 中启用 cgroup v1 禁用集群中的所有 cgroup v2 控制器和层次结构。
cgroup v1 是一个已弃用的功能。弃用的功能仍然包含在 OpenShift Container Platform 中,并将继续被支持。但是,这个功能会在以后的发行版本中被删除,且不建议在新的部署中使用。
有关 OpenShift Container Platform 中已弃用或删除的主要功能的最新列表,请参阅 OpenShift Container Platform 发行注记中已弃用和删除的功能部分。
先决条件
- 您有一个正在运行的 OpenShift Container Platform 集群,它使用版本 4.12 或更高版本。
- 以具有管理特权的用户身份登录集群。
流程
在节点上配置所需的 cgroup 版本:
编辑
node.config对象:oc edit nodes.config/cluster
$ oc edit nodes.config/clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 添加
spec.cgroupMode: "v1":node.config对象示例Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 启用 cgroup v1。
验证
检查机器配置以查看是否添加了新的机器配置:
oc get mc
$ oc get mcCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 创建新机器配置,如预期一样。
检查新的
kernelArguments是否已添加到新机器配置中:oc describe mc <name>
$ oc describe mc <name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow cgroup v1 的输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 检查节点以查看是否禁用了在节点上调度。这表示要应用更改:
oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 节点返回
Ready状态后,为该节点启动 debug 会话:oc debug node/<node_name>
$ oc debug node/<node_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将
/host设置为 debug shell 中的根目录:chroot /host
sh-4.4# chroot /hostCopy to Clipboard Copied! Toggle word wrap Toggle overflow 检查您的节点上是否存在
sys/fs/cgroup/cgroup2fs文件。此文件由 cgroup v1 创建:stat -c %T -f /sys/fs/cgroup
$ stat -c %T -f /sys/fs/cgroupCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
cgroup2fs
cgroup2fsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.11. 使用 FeatureGate 启用技术预览功能
您可以通过编辑 FeatureGate 自定义资源(CR)为集群中的所有节点开启当前技术预览功能的子集。
5.11.1. 了解功能门
您可以使用 FeatureGate 自定义资源(CR)在集群中启用特定的功能集。功能集是 OpenShift Container Platform 功能的集合,默认情况下不启用。
您可以使用 FeatureGate CR 激活以下功能集:
TechPreviewNoUpgrade.这个功能集是当前技术预览功能的子集。此功能集允许您在测试集群中启用这些技术预览功能,您可以在测试集群中完全测试它们,同时保留生产集群中禁用的功能。警告在集群中启用
TechPreviewNoUpgrade功能集无法撤消,并会阻止次版本更新。您不应该在生产环境集群中启用此功能。此功能集启用了以下技术预览功能:
-
外部云供应商。为 vSphere、AWS、Azure 和 GCP 上的集群启用外部云供应商的支持。对 OpenStack 的支持是 GA。这是一个内部功能,大多数用户不需要与之交互。(
ExternalCloudProvider) -
OpenShift 构建中的共享资源 CSI 驱动程序。启用 Container Storage Interface (CSI)。(
CSIDriverSharedResource) -
节点上的交换内存。根据每个节点为 OpenShift Container Platform 工作负载启用交换内存使用。(
NodeSwap) -
OpenStack Machine API 提供程序。此最低要求无效,计划在以后的发行版本中从此功能集中删除。(
MachineAPIProviderOpenStack) -
Insights Operator。启用
InsightsDataGatherCRD,允许用户配置一些 Insights 数据收集选项。功能集还启用了DataGatherCRD,允许用户按需运行 Insights 数据收集。(InsightsConfigAPI) -
递归默认存储类.如果 PVC 创建时没有默认存储类(
RetroactiveDefaultStorageClass) 启用 OpenShift Container Platform 会主动地将默认存储类分配给 PVC。 -
动态资源分配 API。启用一个新的 API 在 pod 和容器间请求和共享资源。这是一个内部功能,大多数用户不需要与之交互。(
DynamicResourceAllocation) -
Pod 安全准入强制。为 pod 安全准入启用受限强制模式。如果 pod 违反了 pod 安全标准,它们会被拒绝,而不是仅记录警告信息。(
OpenShiftPodSecurityAdmission) -
StatefulSet pod 可用性升级限制。允许用户定义在更新过程中不可用的 statefulset pod 的最大数量,这可以减少应用程序停机时间。(
MaxUnavailableStatefulSet) -
MatchConditions是一个必须满足的条件列表,只要在满足这些条件时才向此 webhook 发送请求。匹配条件过滤请求,它们已与 rules、namespaceSelector 和 objectSelector 匹配。一个空的matchConditions列表,匹配所有请求。(admissionWebhookMatchConditions) -
gcpLabelsTags -
vSphereStaticIPs -
routeExternalCertificate -
automatedEtcdBackup -
gcpClusterHostedDNS -
vSphereControlPlaneMachineset -
dnsNameResolver -
machineConfigNodes -
metricsServer -
installAlternateInfrastructureAWS -
sdnLiveMigration -
mixedCPUsAllocation -
managedBootImages -
onClusterBuild -
signatureStores -
DisableKubeletCloudCredentialProviders -
BareMetalLoadBalancer -
ClusterAPIInstallAWS -
ClusterAPIInstallNutanix -
ClusterAPIInstallOpenStack -
ClusterAPIInstallVSphere -
HardwareSpeed -
KMSv1 -
NetworkDiagnosticsConfig -
VSphereDriverConfiguration -
ExternalOIDC -
ChunkSizeMiB -
ClusterAPIInstallGCP -
ClusterAPIInstallPowerVS -
EtcdBackendQuota -
Example -
ImagePolicy -
InsightsConfig -
InsightsOnDemandDataGather -
MetricsCollectionProfiles -
NewOLM -
NodeDisruptionPolicy -
PinnedImages -
PlatformOperators -
ServiceAccountTokenNodeBinding -
ServiceAccountTokenNodeBindingValidation -
ServiceAccountTokenPodNodeInfo -
TranslateStreamCloseWebsocketRequests -
UpgradeStatus -
VSphereMultiVCenters -
VolumeGroupSnapshot
-
外部云供应商。为 vSphere、AWS、Azure 和 GCP 上的集群启用外部云供应商的支持。对 OpenStack 的支持是 GA。这是一个内部功能,大多数用户不需要与之交互。(
5.11.2. 使用 Web 控制台启用功能集
您可以通过编辑 FeatureGate 自定义资源(CR)来使用 OpenShift Container Platform Web 控制台为集群中的所有节点启用功能集。
流程
启用功能集:
- 在 OpenShift Container Platform web 控制台中,切换到 Administration → Custom Resource Definitions 页面。
- 在 Custom Resource Definitions 页面中,点击 FeatureGate。
- 在 Custom Resource Definition Details 页面中,点 Instances 选项卡。
- 点 集群 功能门,然后点 YAML 选项卡。
编辑集群实例以添加特定的功能集:
警告在集群中启用
TechPreviewNoUpgrade功能集无法撤消,并会阻止次版本更新。您不应该在生产环境集群中启用此功能。功能门自定义资源示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 保存更改后,会创建新的机器配置,然后更新机器配置池,并在应用更改时在每个节点上调度。
验证
您可以在节点返回就绪状态后查看节点上的 kubelet.conf 文件来验证是否启用了功能门。
- 从 Web 控制台中的 Administrator 视角,进入到 Compute → Nodes。
- 选择一个节点。
- 在 Node 详情页面中,点 Terminal。
在终端窗口中,将根目录改为
/host:chroot /host
sh-4.2# chroot /hostCopy to Clipboard Copied! Toggle word wrap Toggle overflow 查看
kubelet.conf文件:cat /etc/kubernetes/kubelet.conf
sh-4.2# cat /etc/kubernetes/kubelet.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
# ... featureGates: InsightsOperatorPullingSCA: true, LegacyNodeRoleBehavior: false # ...
# ... featureGates: InsightsOperatorPullingSCA: true, LegacyNodeRoleBehavior: false # ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在集群中启用列为
true的功能。注意列出的功能因 OpenShift Container Platform 版本的不同而有所不同。
5.11.3. 使用 CLI 启用功能集
您可以通过编辑 FeatureGate 自定义资源(CR)来使用 OpenShift CLI(oc)为集群中的所有节点启用功能集。
先决条件
-
已安装 OpenShift CLI(
oc)。
流程
启用功能集:
编辑名为
cluster的FeatureGateCR:oc edit featuregate cluster
$ oc edit featuregate clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 警告在集群中启用
TechPreviewNoUpgrade功能集无法撤消,并会阻止次版本更新。您不应该在生产环境集群中启用此功能。FeatureGate 自定义资源示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 保存更改后,会创建新的机器配置,然后更新机器配置池,并在应用更改时在每个节点上调度。
验证
您可以在节点返回就绪状态后查看节点上的 kubelet.conf 文件来验证是否启用了功能门。
- 从 Web 控制台中的 Administrator 视角,进入到 Compute → Nodes。
- 选择一个节点。
- 在 Node 详情页面中,点 Terminal。
在终端窗口中,将根目录改为
/host:chroot /host
sh-4.2# chroot /hostCopy to Clipboard Copied! Toggle word wrap Toggle overflow 查看
kubelet.conf文件:cat /etc/kubernetes/kubelet.conf
sh-4.2# cat /etc/kubernetes/kubelet.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
# ... featureGates: InsightsOperatorPullingSCA: true, LegacyNodeRoleBehavior: false # ...
# ... featureGates: InsightsOperatorPullingSCA: true, LegacyNodeRoleBehavior: false # ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在集群中启用列为
true的功能。注意列出的功能因 OpenShift Container Platform 版本的不同而有所不同。
5.12. etcd 任务
备份 etcd、启用或禁用 etcd 加密或清除 etcd 数据。
5.12.1. 关于 etcd 加密
默认情况下,OpenShift Container Platform 不加密 etcd 数据。在集群中启用对 etcd 进行加密的功能可为数据的安全性提供额外的保护层。例如,如果 etcd 备份暴露给不应该获得这个数据的人员,它会帮助保护敏感数据。
启用 etcd 加密时,以下 OpenShift API 服务器和 Kubernetes API 服务器资源将被加密:
- Secrets
- 配置映射
- Routes
- OAuth 访问令牌
- OAuth 授权令牌
当您启用 etcd 加密时,会创建加密密钥。您必须具有这些密钥才能从 etcd 备份中恢复。
etcd 加密只加密值,而不加密键。资源类型、命名空间和对象名称是未加密的。
如果在备份过程中启用了 etcd 加密,static_kuberesources_<datetimestamp>.tar.gz 文件包含 etcd 快照的加密密钥。为安全起见,请将此文件与 etcd 快照分开存储。但是,需要这个文件才能从相应的 etcd 快照恢复以前的 etcd 状态。
5.12.2. 支持的加密类型
在 OpenShift Container Platform 中,支持以下加密类型来加密 etcd 数据:
- AES-CBC
- 使用带有 PKCS#7 padding 和 32 字节密钥的 AES-CBC 来执行加密。加密密钥每周轮转。
- AES-GCM
- 使用带有随机 nonce 和 32 字节密钥的 AES-GCM 来执行加密。加密密钥每周轮转。
5.12.3. 启用 etcd 加密
您可以启用 etcd 加密来加密集群中的敏感资源。
在初始加密过程完成前,不要备份 etcd 资源。如果加密过程还没有完成,则备份可能只被部分加密。
启用 etcd 加密后,可能会出现一些更改:
- etcd 加密可能会影响几个资源的内存消耗。
- 您可能会注意到对备份性能具有临时影响,因为领导必须提供备份服务。
- 磁盘 I/O 可能会影响接收备份状态的节点。
您可以在 AES-GCM 或 AES-CBC 加密中加密 etcd 数据库。
要将 etcd 数据库从一个加密类型迁移到另一个加密类型,您可以修改 API 服务器的 spec.encryption.type 字段。将 etcd 数据迁移到新的加密类型会自动进行。
先决条件
-
使用具有
cluster-admin角色的用户访问集群。
流程
修改
APIServer对象:oc edit apiserver
$ oc edit apiserverCopy to Clipboard Copied! Toggle word wrap Toggle overflow 将
spec.encryption.type字段设置为aesgcm或aescbc:spec: encryption: type: aesgcmspec: encryption: type: aesgcm1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 设置为
aesgcm用于 AES-GCM 加密,或设置为aescbc用于 AES-CBC 加密。
保存文件以使改变生效。
加密过程开始。根据 etcd 数据库的大小,这个过程可能需要 20 分钟或更长时间才能完成。
验证 etcd 加密是否成功。
查看 OpenShift API 服务器的
Encrypted状态条件,以验证其资源是否已成功加密:oc get openshiftapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'$ oc get openshiftapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在成功加密后输出显示
EncryptionCompleted:EncryptionCompleted All resources encrypted: routes.route.openshift.io
EncryptionCompleted All resources encrypted: routes.route.openshift.ioCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果输出显示
EncryptionInProgress,加密仍在进行中。等待几分钟后重试。查看 Kubernetes API 服务器的
Encrypted状态条件,以验证其资源是否已成功加密:oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在成功加密后输出显示
EncryptionCompleted:EncryptionCompleted All resources encrypted: secrets, configmaps
EncryptionCompleted All resources encrypted: secrets, configmapsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果输出显示
EncryptionInProgress,加密仍在进行中。等待几分钟后重试。查看 OpenShift OAuth API 服务器的
Encrypted状态条件,以验证其资源是否已成功加密:oc get authentication.operator.openshift.io -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'$ oc get authentication.operator.openshift.io -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在成功加密后输出显示
EncryptionCompleted:EncryptionCompleted All resources encrypted: oauthaccesstokens.oauth.openshift.io, oauthauthorizetokens.oauth.openshift.io
EncryptionCompleted All resources encrypted: oauthaccesstokens.oauth.openshift.io, oauthauthorizetokens.oauth.openshift.ioCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果输出显示
EncryptionInProgress,加密仍在进行中。等待几分钟后重试。
5.12.4. 禁用 etcd 加密
您可以在集群中禁用 etcd 数据的加密。
先决条件
-
使用具有
cluster-admin角色的用户访问集群。
流程
修改
APIServer对象:oc edit apiserver
$ oc edit apiserverCopy to Clipboard Copied! Toggle word wrap Toggle overflow 将
encryption字段类型设置为identity:spec: encryption: type: identityspec: encryption: type: identity1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
identity类型是默认值,意味着没有执行任何加密。
保存文件以使改变生效。
解密过程开始。根据集群的大小,这个过程可能需要 20 分钟或更长的时间才能完成。
验证 etcd 解密是否成功。
查看 OpenShift API 服务器的
Encrypted状态条件,以验证其资源是否已成功解密:oc get openshiftapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'$ oc get openshiftapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在成功解密后输出显示
DecryptionCompleted:DecryptionCompleted Encryption mode set to identity and everything is decrypted
DecryptionCompleted Encryption mode set to identity and everything is decryptedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果输出显示
DecryptionInProgress,解密仍在进行中。等待几分钟后重试。查看 Kubernetes API 服务器的
Encrypted状态条件,以验证其资源是否已成功解密:oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在成功解密后输出显示
DecryptionCompleted:DecryptionCompleted Encryption mode set to identity and everything is decrypted
DecryptionCompleted Encryption mode set to identity and everything is decryptedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果输出显示
DecryptionInProgress,解密仍在进行中。等待几分钟后重试。查看 OpenShift OAuth API 服务器的
Encrypted状态条件,以验证其资源是否已成功解密:oc get authentication.operator.openshift.io -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'$ oc get authentication.operator.openshift.io -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在成功解密后输出显示
DecryptionCompleted:DecryptionCompleted Encryption mode set to identity and everything is decrypted
DecryptionCompleted Encryption mode set to identity and everything is decryptedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果输出显示
DecryptionInProgress,解密仍在进行中。等待几分钟后重试。
5.12.5. 备份 etcd 数据
按照以下步骤,通过创建 etcd 快照并备份静态 pod 的资源来备份 etcd 数据。这个备份可以被保存,并在以后需要时使用它来恢复 etcd 数据。
只保存单一 control plane 主机的备份。不要从集群中的每个 control plane 主机进行备份。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。 您已检查是否启用了集群范围代理。
提示您可以通过查看
oc get proxy cluster -o yaml的输出来检查代理是否已启用。如果httpProxy、httpsProxy和noProxy字段设置了值,则会启用代理。
流程
以 root 用户身份为 control plane 节点启动一个 debug 会话:
oc debug --as-root node/<node_name>
$ oc debug --as-root node/<node_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在 debug shell 中将根目录改为
/host:chroot /host
sh-4.4# chroot /hostCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果启用了集群范围代理,请运行以下命令导出
NO_PROXY、HTTP_PROXY和HTTPS_PROXY环境变量:export HTTP_PROXY=http://<your_proxy.example.com>:8080
$ export HTTP_PROXY=http://<your_proxy.example.com>:8080Copy to Clipboard Copied! Toggle word wrap Toggle overflow export HTTPS_PROXY=https://<your_proxy.example.com>:8080
$ export HTTPS_PROXY=https://<your_proxy.example.com>:8080Copy to Clipboard Copied! Toggle word wrap Toggle overflow export NO_PROXY=<example.com>
$ export NO_PROXY=<example.com>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在 debug shell 中运行
cluster-backup.sh脚本,并传递保存备份的位置。提示cluster-backup.sh脚本作为 etcd Cluster Operator 的一个组件被维护,它是etcdctl snapshot save命令的包装程序(wrapper)。/usr/local/bin/cluster-backup.sh /home/core/assets/backup
sh-4.4# /usr/local/bin/cluster-backup.sh /home/core/assets/backupCopy to Clipboard Copied! Toggle word wrap Toggle overflow 脚本输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在这个示例中,在 control plane 主机上的
/home/core/assets/backup/目录中创建了两个文件:-
snapshot_<datetimestamp>.db:这个文件是 etcd 快照。cluster-backup.sh脚本确认其有效。 static_kuberesources_<datetimestamp>.tar.gz:此文件包含静态 pod 的资源。如果启用了 etcd 加密,它也包含 etcd 快照的加密密钥。注意如果启用了 etcd 加密,建议出于安全考虑,将第二个文件与 etcd 快照分开保存。但是,需要这个文件才能从 etcd 快照中进行恢复。
请记住,etcd 仅对值进行加密,而不对键进行加密。这意味着资源类型、命名空间和对象名称是不加密的。
-
5.12.6. 分离 etcd 数据
对于大型、高密度的集群,如果键空间增长过大并超过空间配额,etcd 的性能将会受到影响。定期维护并处理碎片化的 etcd,以释放数据存储中的空间。监控 Prometheus 以了解 etcd 指标数据,并在需要时对其进行碎片处理;否则,etcd 可能会引发一个集群范围的警报,使集群进入维护模式,仅能接受对键的读和删除操作。
监控这些关键指标:
-
etcd_server_quota_backend_bytes,这是当前配额限制 -
etcd_mvcc_db_total_size_in_use_in_bytes,表示历史压缩后实际数据库使用量 -
etcd_mvcc_db_total_size_in_bytes显示数据库大小,包括等待碎片整理的可用空间
在导致磁盘碎片的事件后(如 etcd 历史记录紧凑)对 etcd 数据进行清理以回收磁盘空间。
历史压缩将自动每五分钟执行一次,并在后端数据库中造成混乱。此碎片空间可供 etcd 使用,但主机文件系统不可用。您必须对碎片 etcd 进行碎片清除,才能使这个空间可供主机文件系统使用。
碎片清理会自动发生,但您也可以手动触发它。
自动清理碎片非常适合大多数情况,因为 etcd operator 使用集群信息来确定用户最有效的操作。
5.12.6.1. 自动清理
etcd Operator 自动清理碎片磁盘。不需要人工干预。
查看以下日志之一来验证碎片整理过程是否成功:
- etcd 日志
- cluster-etcd-operator pod
- Operator 状态错误日志
自动清除可能会导致各种 OpenShift 核心组件中的领导选举失败,如 Kubernetes 控制器管理器,这会触发重启失败的组件。重启会有危害,并会触发对下一个正在运行的实例的故障切换,或者组件在重启后再次恢复工作。
成功进行碎片处理的日志输出示例
etcd member has been defragmented: <member_name>, memberID: <member_id>
etcd member has been defragmented: <member_name>, memberID: <member_id>进行碎片处理失败的日志输出示例
failed defrag on member: <member_name>, memberID: <member_id>: <error_message>
failed defrag on member: <member_name>, memberID: <member_id>: <error_message>5.12.6.2. 手动清理
Prometheus 警报指示您需要手动进行碎片处理。该警报在两个情况下显示:
- 当 etcd 使用超过 50% 的可用空间超过了 10 分钟
- 当 etcd 活跃使用小于其数据库总大小的 50% 超过了 10 分钟
您还可以通过检查 etcd 数据库大小(MB)来决定是否需要进行碎片整理。通过 PromQL 表达 (etcd_mvcc_db_total_size_in_bytes - etcd_mvcc_db_total_size_in_use_in_bytes)/1024/1024 来释放空间。
分离 etcd 是一个阻止性操作。在进行碎片处理完成前,etcd 成员将没有响应。因此,在每个下一个 pod 要进行碎片清理前,至少等待一分钟,以便集群可以恢复正常工作。
按照以下步骤对每个 etcd 成员上的 etcd 数据进行碎片处理。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。
流程
确定哪个 etcd 成员是领导成员,因为领导会进行最后的碎片处理。
获取 etcd pod 列表:
oc -n openshift-etcd get pods -l k8s-app=etcd -o wide
$ oc -n openshift-etcd get pods -l k8s-app=etcd -o wideCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
etcd-ip-10-0-159-225.example.redhat.com 3/3 Running 0 175m 10.0.159.225 ip-10-0-159-225.example.redhat.com <none> <none> etcd-ip-10-0-191-37.example.redhat.com 3/3 Running 0 173m 10.0.191.37 ip-10-0-191-37.example.redhat.com <none> <none> etcd-ip-10-0-199-170.example.redhat.com 3/3 Running 0 176m 10.0.199.170 ip-10-0-199-170.example.redhat.com <none> <none>
etcd-ip-10-0-159-225.example.redhat.com 3/3 Running 0 175m 10.0.159.225 ip-10-0-159-225.example.redhat.com <none> <none> etcd-ip-10-0-191-37.example.redhat.com 3/3 Running 0 173m 10.0.191.37 ip-10-0-191-37.example.redhat.com <none> <none> etcd-ip-10-0-199-170.example.redhat.com 3/3 Running 0 176m 10.0.199.170 ip-10-0-199-170.example.redhat.com <none> <none>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 选择 pod 并运行以下命令来确定哪个 etcd 成员是领导:
oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.com etcdctl endpoint status --cluster -w table
$ oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.com etcdctl endpoint status --cluster -w tableCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 基于此输出的
IS LEADER列,https://10.0.199.170:2379端点是领导。与上一步输出匹配此端点,领导的 pod 名称为etcd-ip-10-0-199-170.example.redhat.com。
清理 etcd 成员。
连接到正在运行的 etcd 容器,传递 不是 领导的 pod 的名称:
oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.com
$ oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow 取消设置
ETCDCTL_ENDPOINTS环境变量:unset ETCDCTL_ENDPOINTS
sh-4.4# unset ETCDCTL_ENDPOINTSCopy to Clipboard Copied! Toggle word wrap Toggle overflow 清理 etcd 成员:
etcdctl --command-timeout=30s --endpoints=https://localhost:2379 defrag
sh-4.4# etcdctl --command-timeout=30s --endpoints=https://localhost:2379 defragCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Finished defragmenting etcd member[https://localhost:2379]
Finished defragmenting etcd member[https://localhost:2379]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果发生超时错误,增加
--command-timeout的值,直到命令成功为止。验证数据库大小是否已缩小:
etcdctl endpoint status -w table --cluster
sh-4.4# etcdctl endpoint status -w table --clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 本例显示这个 etcd 成员的数据库大小现在为 41 MB,而起始大小为 104 MB。
重复这些步骤以连接到其他 etcd 成员并进行碎片处理。最后才对领导进行碎片清除。
至少要在碎片处理操作之间等待一分钟,以便 etcd pod 可以恢复。在 etcd pod 恢复前,etcd 成员不会响应。
如果因为超过空间配额而触发任何
NOSPACE警告,请清除它们。检查是否有
NOSPACE警告:etcdctl alarm list
sh-4.4# etcdctl alarm listCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
memberID:12345678912345678912 alarm:NOSPACE
memberID:12345678912345678912 alarm:NOSPACECopy to Clipboard Copied! Toggle word wrap Toggle overflow 清除警告:
etcdctl alarm disarm
sh-4.4# etcdctl alarm disarmCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.12.7. 恢复到一个以前的集群状态
您可以使用保存的 etcd 备份来恢复以前的集群状态,或恢复丢失了大多数 control plane 主机的集群。
如果您的集群使用 control plane 机器集,请参阅"为 etcd 恢复 control plane 机器集"中的"恢复降级的 etcd Operator"。
恢复集群时,必须使用同一 z-stream 发行版本中获取的 etcd 备份。例如,OpenShift Container Platform 4.7.2 集群必须使用从 4.7.2 开始的 etcd 备份。
先决条件
-
通过一个基于证书的
kubeconfig使用具有cluster-admin角色的用户访问集群,如安装期间的情况。 - 用作恢复主机的健康 control plane 主机。
- SSH 对 control plane 主机的访问。
-
包含从同一备份中获取的 etcd 快照和静态
pod资源的备份目录。该目录中的文件名必须采用以下格式:snapshot_<datetimestamp>.db和static_kuberesources_<datetimestamp>.tar.gz。 - 节点必须能够访问或可引导。
对于非恢复 control plane 节点,不需要建立 SSH 连接或停止静态 pod。您可以逐个删除并重新创建其他非恢复 control plane 机器。
流程
- 选择一个要用作恢复主机的 control plane 主机。这是您要在其中运行恢复操作的主机。
建立到每个 control plane 节点(包括恢复主机)的 SSH 连接。使用一个单独的终端为每个 control plane 节点建立 SSH 连接。
在恢复过程启动后,Kubernetes API 服务器将无法访问,因此您无法通过
oc debug访问 control plane 节点。因此,需要在一个单独的终端中建立到每个control plane 主机的 SSH 连接。重要如果没有完成这个步骤,将无法访问 control plane 主机来完成恢复过程,您将无法从这个状态恢复集群。
将
etcd备份目录复制到恢复 control plane 主机上。此流程假设您将
backup目录(其中包含etcd快照和静态 pod 资源)复制到恢复 control plane 主机的/home/core/目录中。在任何其他 control plane 节点上停止静态 pod。
注意您不需要停止恢复主机上的静态 pod。
- 访问不是恢复主机的 control plane 主机。
运行以下命令,将现有 etcd pod 文件从 kubelet 清单目录中移出:
sudo mv -v /etc/kubernetes/manifests/etcd-pod.yaml /tmp
$ sudo mv -v /etc/kubernetes/manifests/etcd-pod.yaml /tmpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令验证
etcdpod 是否已停止:sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"
$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果这个命令的输出不为空,请等待几分钟,然后再次检查。
运行以下命令,将现有
kube-apiserver文件从 kubelet 清单目录中移出:sudo mv -v /etc/kubernetes/manifests/kube-apiserver-pod.yaml /tmp
$ sudo mv -v /etc/kubernetes/manifests/kube-apiserver-pod.yaml /tmpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令验证
kube-apiserver容器是否已停止:sudo crictl ps | grep kube-apiserver | egrep -v "operator|guard"
$ sudo crictl ps | grep kube-apiserver | egrep -v "operator|guard"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果这个命令的输出不为空,请等待几分钟,然后再次检查。
运行以下命令,将现有
kube-controller-manager文件从 kubelet 清单目录中移出:sudo mv -v /etc/kubernetes/manifests/kube-controller-manager-pod.yaml /tmp
$ sudo mv -v /etc/kubernetes/manifests/kube-controller-manager-pod.yaml /tmpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令验证
kube-controller-manager容器是否已停止:sudo crictl ps | grep kube-controller-manager | egrep -v "operator|guard"
$ sudo crictl ps | grep kube-controller-manager | egrep -v "operator|guard"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果这个命令的输出不为空,请等待几分钟,然后再次检查。
运行以下命令,将现有
kube-scheduler文件从 kubelet 清单目录中移出:sudo mv -v /etc/kubernetes/manifests/kube-scheduler-pod.yaml /tmp
$ sudo mv -v /etc/kubernetes/manifests/kube-scheduler-pod.yaml /tmpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令验证
kube-scheduler容器是否已停止:sudo crictl ps | grep kube-scheduler | egrep -v "operator|guard"
$ sudo crictl ps | grep kube-scheduler | egrep -v "operator|guard"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果这个命令的输出不为空,请等待几分钟,然后再次检查。
使用以下示例将
etcd数据目录移到不同的位置:sudo mv -v /var/lib/etcd/ /tmp
$ sudo mv -v /var/lib/etcd/ /tmpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果存在
/etc/kubernetes/manifests/keepalived.yaml文件,请完成以下步骤。这些步骤是确保 API IP 地址侦听恢复主机所必需的。运行以下命令,将
/etc/kubernetes/manifests/keepalived.yaml文件从 kubelet 清单目录中移出:sudo mv -v /etc/kubernetes/manifests/keepalived.yaml /home/core/
$ sudo mv -v /etc/kubernetes/manifests/keepalived.yaml /home/core/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意在流程完成后,该文件必须恢复到其原始位置。
容器验证由
keepalived守护进程管理的任何容器是否已停止:sudo crictl ps --name keepalived
$ sudo crictl ps --name keepalivedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 命令输出应该为空。如果它不是空的,请等待几分钟后再重新检查。
检查 control plane 是否已分配任何 Virtual IP (VIP):
ip -o address | egrep '<api_vip>|<ingress_vip>'
$ ip -o address | egrep '<api_vip>|<ingress_vip>'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 对于每个报告的 VIP,运行以下命令将其删除:
sudo ip address del <reported_vip> dev <reported_vip_device>
$ sudo ip address del <reported_vip> dev <reported_vip_device>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- 在其他不是恢复主机的 control plane 主机上重复此步骤。
- 访问恢复 control plane 主机。
如果使用
keepalived守护进程,请验证恢复 control plane 节点是否拥有 VIP。否则,重复步骤 4.xi。ip -o address | grep <api_vip>
$ ip -o address | grep <api_vip>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果存在 VIP 的地址(如果存在)。如果 VIP 没有设置或配置不正确,这个命令会返回一个空字符串。
如果启用了集群范围的代理,请确定已导出了
NO_PROXY、HTTP_PROXY和HTTPS_PROXY环境变量。提示您可以通过查看
oc get proxy cluster -o yaml的输出来检查代理是否已启用。如果httpProxy、httpsProxy和noProxy字段设置了值,则会启用代理。在恢复 control plane 主机上运行恢复脚本,并传递到
etcd备份目录的路径:sudo -E /usr/local/bin/cluster-restore.sh /home/core/assets/backup
$ sudo -E /usr/local/bin/cluster-restore.sh /home/core/assets/backupCopy to Clipboard Copied! Toggle word wrap Toggle overflow 脚本输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow cluster-restore.sh 脚本必须显示
etcd、kube-apiserver、kube-controller-manager和kube-schedulerpod 已停止,然后在恢复过程结束时启动。注意如果在上次
etcd备份后更新了节点,则恢复过程可能会导致节点进入NotReady状态。检查节点以确保它们处于
Ready状态。要检查节点,您可以使用堡垒主机或恢复主机。如果使用恢复主机,请运行以下命令:
export KUBECONFIG=/etc/kubernetes/static-pod-resources/kube-apiserver-certs/secrets/node-kubeconfigs/localhost-recovery.kubeconfig
$ export KUBECONFIG=/etc/kubernetes/static-pod-resources/kube-apiserver-certs/secrets/node-kubeconfigs/localhost-recovery.kubeconfigCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc get nodes -w
$ oc get nodes -wCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果使用堡垒主机,请完成以下步骤:
运行以下命令:
oc get nodes -w
$ oc get nodes -wCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 所有节点都可能需要几分钟时间报告其状态。
如果有任何节点处于
NotReady状态,登录到节点,并从每个节点上的/var/lib/kubelet/pki目录中删除所有 PEM 文件。您可以 SSH 到节点,或使用 web 控制台中的终端窗口。ssh -i <ssh-key-path> core@<master-hostname>
$ ssh -i <ssh-key-path> core@<master-hostname>Copy to Clipboard Copied! Toggle word wrap Toggle overflow pki目录示例pwd /var/lib/kubelet/pki ls kubelet-client-2022-04-28-11-24-09.pem kubelet-server-2022-04-28-11-24-15.pem kubelet-client-current.pem kubelet-server-current.pem
sh-4.4# pwd /var/lib/kubelet/pki sh-4.4# ls kubelet-client-2022-04-28-11-24-09.pem kubelet-server-2022-04-28-11-24-15.pem kubelet-client-current.pem kubelet-server-current.pemCopy to Clipboard Copied! Toggle word wrap Toggle overflow
在所有 control plane 主机上重启 kubelet 服务。
在恢复主机中运行以下命令:
sudo systemctl restart kubelet.service
$ sudo systemctl restart kubelet.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 在所有其他 control plane 主机上重复此步骤。
批准待处理的证书签名请求 (CSR):
注意没有 worker 节点的集群(如单节点集群或由三个可调度的 control plane 节点组成的集群)不会批准任何待处理的 CSR。您可以跳过此步骤中列出的所有命令。
运行以下命令,获取当前 CSR 列表:
oc get csr
$ oc get csrCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,查看 CSR 的详情,以验证其是否有效:
oc describe csr <csr_name>
$ oc describe csr <csr_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
运行以下命令来批准每个有效的
node-bootstrapperCSR:oc adm certificate approve <csr_name>
$ oc adm certificate approve <csr_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 对于用户置备的安装,请运行以下命令批准每个有效的 kubelet 服务 CSR:
oc adm certificate approve <csr_name>
$ oc adm certificate approve <csr_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
确认单个成员 control plane 已被成功启动。
在恢复主机上,输入以下命令验证
etcd容器是否正在运行:sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"
$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
3ad41b7908e32 36f86e2eeaaffe662df0d21041eb22b8198e0e58abeeae8c743c3e6e977e8009 About a minute ago Running etcd 0 7c05f8af362f0
3ad41b7908e32 36f86e2eeaaffe662df0d21041eb22b8198e0e58abeeae8c743c3e6e977e8009 About a minute ago Running etcd 0 7c05f8af362f0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在恢复主机上,输入以下命令验证
etcdpod 是否正在运行:oc -n openshift-etcd get pods -l k8s-app=etcd
$ oc -n openshift-etcd get pods -l k8s-app=etcdCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME READY STATUS RESTARTS AGE etcd-ip-10-0-143-125.ec2.internal 1/1 Running 1 2m47s
NAME READY STATUS RESTARTS AGE etcd-ip-10-0-143-125.ec2.internal 1/1 Running 1 2m47sCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果状态是
Pending,或者输出中列出了多个正在运行的etcdpod,请等待几分钟,然后再次检查。
如果使用
OVNKubernetes网络插件,您必须重启ovnkube-controlplanepod。运行以下命令删除所有
ovnkube-controlplanepod:oc -n openshift-ovn-kubernetes delete pod -l app=ovnkube-control-plane
$ oc -n openshift-ovn-kubernetes delete pod -l app=ovnkube-control-planeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,验证所有
ovnkube-controlplanepod 是否已重新部署:oc -n openshift-ovn-kubernetes get pod -l app=ovnkube-control-plane
$ oc -n openshift-ovn-kubernetes get pod -l app=ovnkube-control-planeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
如果使用 OVN-Kubernetes 网络插件,请逐个重启所有节点上的 Open Virtual Network (OVN) Kubernetes pod。使用以下步骤重启每个节点上的 OVN-Kubernetes pod:
重要按照以下顺序重启 OVN-Kubernetes pod
- 恢复控制平面主机
- 其他控制平面主机(如果可用)
- 其他节点
注意验证和变异准入 Webhook 可能会拒绝 pod。如果您添加了额外的 Webhook,其
failurePolicy被设置为Fail的,则它们可能会拒绝 pod,恢复过程可能会失败。您可以通过在恢复集群状态时保存和删除 Webhook 来避免这种情况。成功恢复集群状态后,您可以再次启用 Webhook。另外,您可以在恢复集群状态时临时将
failurePolicy设置为Ignore。成功恢复集群状态后,您可以将failurePolicy设置为Fail。删除北向数据库 (nbdb) 和南向数据库 (sbdb)。使用 Secure Shell (SSH) 访问恢复主机和剩余的 control plane 节点,再运行以下命令:
sudo rm -f /var/lib/ovn-ic/etc/*.db
$ sudo rm -f /var/lib/ovn-ic/etc/*.dbCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重新启动 OpenVSwitch 服务。使用 Secure Shell (SSH) 访问节点,并运行以下命令:
sudo systemctl restart ovs-vswitchd ovsdb-server
$ sudo systemctl restart ovs-vswitchd ovsdb-serverCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令删除节点上的
ovnkube-nodepod,将<node>替换为您要重启的节点的名称:oc -n openshift-ovn-kubernetes delete pod -l app=ovnkube-node --field-selector=spec.nodeName==<node>
$ oc -n openshift-ovn-kubernetes delete pod -l app=ovnkube-node --field-selector=spec.nodeName==<node>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,检查 OVN pod 的状态:
oc get po -n openshift-ovn-kubernetes
$ oc get po -n openshift-ovn-kubernetesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果有任何 OVN pod 处于
Terminating状态,请运行以下命令来删除运行该 OVN pod 的节点。将<node>替换为您要删除的节点的名称:oc delete node <node>
$ oc delete node <node>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,使用 SSH 登录到带有
Terminating状态的 OVN pod 节点:ssh -i <ssh-key-path> core@<node>
$ ssh -i <ssh-key-path> core@<node>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,从
/var/lib/kubelet/pki目录中移动所有 PEM 文件:sudo mv /var/lib/kubelet/pki/* /tmp
$ sudo mv /var/lib/kubelet/pki/* /tmpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令来重启 kubelet 服务:
sudo systemctl restart kubelet.service
$ sudo systemctl restart kubelet.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令返回恢复 etcd 机器:
oc get csr
$ oc get csrCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-<uuid> 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-<uuid> 8m3s kubernetes.io/kubelet-serving system:node:<node_name> PendingCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令来批准所有新的 CSR,将
csr-<uuid>替换为 CSR 的名称:oc adm certificate approve csr-<uuid>
oc adm certificate approve csr-<uuid>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令验证节点是否已返回:
oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
使用以下命令验证
ovnkube-nodepod 已再次运行:oc -n openshift-ovn-kubernetes get pod -l app=ovnkube-node --field-selector=spec.nodeName==<node>
$ oc -n openshift-ovn-kubernetes get pod -l app=ovnkube-node --field-selector=spec.nodeName==<node>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意pod 可能需要几分钟时间来重启。
逐个删除并重新创建其他非恢复 control plane 机器。重新创建机器后,会强制一个新修订版本,
etcd会自动扩展。如果使用用户置备的裸机安装,您可以使用最初创建它时使用的相同方法重新创建 control plane 机器。如需更多信息,请参阅"在裸机上安装用户置备的集群"。
警告不要为恢复主机删除并重新创建机器。
如果您正在运行安装程序置备的基础架构,或者您使用 Machine API 创建机器,请按照以下步骤执行:
警告不要为恢复主机删除并重新创建机器。
对于安装程序置备的基础架构上的裸机安装,不会重新创建 control plane 机器。如需更多信息,请参阅"替换裸机控制平面节点"。
为丢失的 control plane 主机之一获取机器。
在一个终端中使用 cluster-admin 用户连接到集群,运行以下命令:
oc get machines -n openshift-machine-api -o wide
$ oc get machines -n openshift-machine-api -o wideCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 这是用于丢失的 control plane 主机
ip-10-0-131-183.ec2.internal的 control plane 机器。
运行以下命令,删除丢失的 control plane 主机的机器:
oc delete machine -n openshift-machine-api clustername-8qw5l-master-0
$ oc delete machine -n openshift-machine-api clustername-8qw5l-master-01 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 为丢失的 control plane 主机指定 control plane 机器的名称。
删除丢失的 control plane 主机的机器后,会自动置备新机器。
运行以下命令验证新机器是否已创建:
oc get machines -n openshift-machine-api -o wide
$ oc get machines -n openshift-machine-api -o wideCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 新机器
clustername-8qw5l-master-3会被创建,并在阶段从Provisioning变为Running后就绪。
创建新机器可能需要几分钟时间。当机器或节点返回到健康状态时,
etcd集群 Operator 将自动同步。- 对不是恢复主机的每个已丢失的 control plane 主机重复此步骤。
运行以下命令关闭仲裁保护:
oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 此命令可确保您可以成功重新创建机密并推出静态 pod。
如果还没有定义,在恢复主机的一个单独的终端窗口中,运行以下命令来导出恢复
kubeconfig文件:export KUBECONFIG=/etc/kubernetes/static-pod-resources/kube-apiserver-certs/secrets/node-kubeconfigs/localhost-recovery.kubeconfig
$ export KUBECONFIG=/etc/kubernetes/static-pod-resources/kube-apiserver-certs/secrets/node-kubeconfigs/localhost-recovery.kubeconfigCopy to Clipboard Copied! Toggle word wrap Toggle overflow 强制
etcd重新部署。在导出恢复
kubeconfig文件的同一终端窗口中,运行以下命令:oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
forceRedeploymentReason值必须是唯一的,这就是为什么附加时间戳的原因。
etcd重新部署开始。当
etcd集群 Operator 执行重新部署时,现有节点开始使用与初始 bootstrap 扩展类似的新 pod。运行以下命令重新打开仲裁保护:
oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 您可以运行以下命令来验证
unsupportedConfigOverrides部分是否已从对象中删除:oc get etcd/cluster -oyaml
$ oc get etcd/cluster -oyamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 验证所有节点是否已更新至最新的修订版本。
在一个终端中使用
cluster-admin用户连接到集群,运行以下命令:oc get etcd -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'$ oc get etcd -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 查看
etcd的NodeInstallerProgressing状态条件,以验证所有节点是否处于最新的修订版本。在更新成功后,输出会显示AllNodesAtLatestRevision:AllNodesAtLatestRevision 3 nodes are at revision 7
AllNodesAtLatestRevision 3 nodes are at revision 71 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 在本例中,最新的修订版本号是
7。
如果输出包含多个修订号,如
2 个节点为修订版本 6;1 个节点为修订版本 7,这意味着更新仍在进行中。等待几分钟后重试。重新部署
etcd后,为 control plane 强制进行新的推出部署。kube-apiserver将在其他节点上重新安装自己,因为 kubelet 使用内部负载均衡器连接到 API 服务器。在一个终端中使用
cluster-admin用户连接到集群,请完成以下步骤:为
kube-apiserver强制进行新的推出部署:oc patch kubeapiserver cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge$ oc patch kubeapiserver cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 验证所有节点是否已更新至最新的修订版本。
oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 查看
NodeInstallerProgressing状态条件,以验证所有节点是否处于最新版本。在更新成功后,输出会显示AllNodesAtLatestRevision:AllNodesAtLatestRevision 3 nodes are at revision 7
AllNodesAtLatestRevision 3 nodes are at revision 71 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 在本例中,最新的修订版本号是
7。
如果输出包含多个修订号,如
2 个节点为修订版本 6;1 个节点为修订版本 7,这意味着更新仍在进行中。等待几分钟后重试。运行以下命令,为 Kubernetes 控制器管理器强制进行新的推出部署:
oc patch kubecontrollermanager cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge$ oc patch kubecontrollermanager cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,验证所有节点是否已更新至最新的修订版本:
oc get kubecontrollermanager -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'$ oc get kubecontrollermanager -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 查看
NodeInstallerProgressing状态条件,以验证所有节点是否处于最新版本。在更新成功后,输出会显示AllNodesAtLatestRevision:AllNodesAtLatestRevision 3 nodes are at revision 7
AllNodesAtLatestRevision 3 nodes are at revision 71 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 在本例中,最新的修订版本号是
7。
如果输出包含多个修订号,如
2 个节点为修订版本 6;1 个节点为修订版本 7,这意味着更新仍在进行中。等待几分钟后重试。运行以下命令,为
kube-scheduler强制新的推出部署:oc patch kubescheduler cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge$ oc patch kubescheduler cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,验证所有节点是否已更新至最新的修订版本:
oc get kubescheduler -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'$ oc get kubescheduler -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 查看
NodeInstallerProgressing状态条件,以验证所有节点是否处于最新版本。在更新成功后,输出会显示AllNodesAtLatestRevision:AllNodesAtLatestRevision 3 nodes are at revision 7
AllNodesAtLatestRevision 3 nodes are at revision 71 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 在本例中,最新的修订版本号是
7。
如果输出包含多个修订号,如
2 个节点为修订版本 6;1 个节点为修订版本 7,这意味着更新仍在进行中。等待几分钟后重试。
运行以下命令来监控平台 Operator:
oc adm wait-for-stable-cluster
$ oc adm wait-for-stable-clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 这个过程最多可能需要 15 分钟。
为确保所有工作负载在恢复过程后返回到正常操作,请重启所有 control plane 节点。
注意完成前面的流程步骤后,您可能需要等待几分钟,让所有服务返回到恢复的状态。例如,在重启 OAuth 服务器 pod 前,使用
oc login进行身份验证可能无法立即正常工作。考虑使用
system:adminkubeconfig文件立即进行身份验证。这个方法基于 SSL/TLS 客户端证书作为 OAuth 令牌的身份验证。您可以发出以下命令来使用此文件进行身份验证:export KUBECONFIG=<installation_directory>/auth/kubeconfig
$ export KUBECONFIG=<installation_directory>/auth/kubeconfigCopy to Clipboard Copied! Toggle word wrap Toggle overflow 发出以下命令以显示您的验证的用户名:
oc whoami
$ oc whoamiCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 以滚动方式重启所有 worker 节点。
5.12.8. 恢复持久性存储状态的问题和解决方法
如果您的 OpenShift Container Platform 集群使用任何形式的持久性存储,集群的状态通常存储在 etcd 外部。从 etcd 备份中恢复时,还会恢复 OpenShift Container Platform 中工作负载的状态。但是,如果 etcd 快照是旧的,其状态可能无效或过期。
持久性卷(PV)的内容绝不会属于 etcd 快照的一部分。从 etcd 快照恢复 OpenShift Container Platform 集群时,非关键工作负载可能会访问关键数据,反之亦然。
以下是生成过时状态的一些示例情况:
- MySQL 数据库在由 PV 对象支持的 pod 中运行。从 etcd 快照恢复 OpenShift Container Platform 不会使卷恢复到存储供应商上,且不会生成正在运行的 MySQL pod,尽管 pod 会重复尝试启动。您必须通过在存储供应商中恢复卷,然后编辑 PV 以指向新卷来手动恢复这个 pod。
- Pod P1 使用卷 A,它附加到节点 X。如果另一个 pod 在节点 Y 上使用相同的卷,则执行 etcd 恢复时,pod P1 可能无法正确启动,因为卷仍然被附加到节点 Y。OpenShift Container Platform 并不知道附加,且不会自动分离它。发生这种情况时,卷必须从节点 Y 手动分离,以便卷可以在节点 X 上附加,然后 pod P1 才可以启动。
- 在执行 etcd 快照后,云供应商或存储供应商凭证会被更新。这会导致任何依赖于这些凭证的 CSI 驱动程序或 Operator 无法正常工作。您可能需要手动更新这些驱动程序或 Operator 所需的凭证。
在生成 etcd 快照后,会从 OpenShift Container Platform 节点中删除或重命名设备。Local Storage Operator 会为从
/dev/disk/by-id或/dev目录中管理的每个 PV 创建符号链接。这种情况可能会导致本地 PV 引用不再存在的设备。要解决这个问题,管理员必须:
- 手动删除带有无效设备的 PV。
- 从对应节点中删除符号链接。
-
删除
LocalVolume或LocalVolumeSet对象(请参阅 Storage → Configuring persistent storage → Persistent storage → Persistent storage → Deleting the Local Storage Operator Resources)。
5.13. Pod 中断预算
了解并配置 pod 中断预算。
5.13.1. 了解如何使用 pod 中断预算来指定必须在线的 pod 数量
pod 中断预算允许在操作过程中指定 pod 的安全限制,如排空节点以进行维护。
PodDisruptionBudget 是一个 API 对象,用于指定在某一时间必须保持在线的副本的最小数量或百分比。在项目中进行这些设置对节点维护(比如缩减集群或升级集群)有益,而且仅在自愿驱除(而非节点失败)时遵从这些设置。
PodDisruptionBudget 对象的配置由以下关键部分组成:
- 标签选择器,即一组 pod 的标签查询。
可用性级别,用来指定必须同时可用的最少 pod 的数量:
-
minAvailable是必须始终可用的 pod 的数量,即使在中断期间也是如此。 -
maxUnavailable是中断期间可以无法使用的 pod 的数量。
-
Available 指的是具有 Ready=True 的 pod 数量。ready=True 指的是能够服务请求的 pod,并应添加到所有匹配服务的负载平衡池中。
允许 maxUnavailable 为 0% 或 0,minAvailable 为 100% 或等于副本数,但这样设置可能会阻止节点排空操作。
对于 OpenShift Container Platform 中的所有机器配置池,maxUnavailable 的默认设置是 1。建议您不要更改这个值,且一次只更新一个 control plane 节点。对于 control plane 池,请不要将这个值改为 3。
您可以使用以下命令来检查所有项目的 pod 中断预算:
oc get poddisruptionbudget --all-namespaces
$ oc get poddisruptionbudget --all-namespaces以下示例包含特定于 AWS 上的 OpenShift Container Platform 的一些值。
输出示例
如果系统中至少有 minAvailable 个 pod 正在运行,则 PodDisruptionBudget 被视为是健康的。超过这一限制的每个 pod 都可被驱除。
根据您的 pod 优先级与抢占设置,可能会无视 pod 中断预算要求而移除较低优先级 pod。
5.13.2. 使用 pod 中断预算指定必须在线的 pod 数量
您可以使用 PodDisruptionBudget 对象来指定某一时间必须保持在线的副本的最小数量或百分比。
流程
配置 pod 中断预算:
使用类似以下示例的对象定义来创建 YAML 文件:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 或者:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,将对象添加到项目中:
oc create -f </path/to/file> -n <project_name>
$ oc create -f </path/to/file> -n <project_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.13.3. 为不健康的 pod 指定驱除策略
当您使用 pod 中断预算 (PDB) 来指定必须同时有多少 pod 可用时,您还可以定义驱除不健康 pod 的条件。
您可以选择以下策略之一:
- IfHealthyBudget
- 只有在保护的应用程序没有被中断时,运行的还没有处于健康状态的 pod 才能被驱除。
- AlwaysAllow
无论是否满足 pod 中断预算中的条件,运行的还没有处于健康状态的 pod 都可以被驱除。此策略可帮助驱除出现故障的应用程序,如 pod 处于
CrashLoopBackOff状态或无法报告Ready状态的应用程序。注意建议您在
PodDisruptionBudget对象中将unhealthyPodEvictionPolicy字段设置为AlwaysAllow,以便在节点排空期间支持收集错误的应用程序。默认行为是等待应用程序 pod 处于健康状态,然后才能排空操作。
流程
创建定义
PodDisruptionBudget对象的 YAML 文件,并指定不健康的 pod 驱除策略:pod-disruption-budget.yaml文件示例Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 选择
IfHealthyBudget或AlwaysAllow作为不健康 pod 的驱除策略。当unhealthyPodEvictionPolicy字段为空时,默认为IfHealthyBudget。
运行以下命令来创建
PodDisruptionBudget对象:oc create -f pod-disruption-budget.yaml
$ oc create -f pod-disruption-budget.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
现在,设置了 AlwaysAllow 不健康 pod 驱除策略的 PDB,您可以排空节点并驱除受此 PDB 保护的应用程序的 pod。
第 6 章 安装后的节点任务
安装 OpenShift Container Platform 后,您可以通过某些节点任务进一步根据要求扩展和自定义集群。
6.1. 在 OpenShift Container Platform 集群中添加 RHEL 计算机器
理解并使用 RHEL 计算节点。
6.1.1. 关于在集群中添加 RHEL 计算节点
在 OpenShift Container Platform 4.16 中,如果 x86_64 架构中使用用户置备或安装程序置备的基础架构安装,您可以选择将 Red Hat Enterprise Linux (RHEL) 机器用作集群中的计算机器。您必须使用 Red Hat Enterprise Linux CoreOS (RHCOS) 机器作为集群中的控制平面机器。
如果您在集群中使用 RHEL 计算机器,则需要自己负责所有操作系统生命周期的管理和维护任务。您必须执行系统更新、应用补丁并完成所有其他必要的任务。
对于安装程序置备的基础架构集群,您必须手动添加 RHEL 计算机器,因为安装程序置备的基础架构集群中的自动扩展会默认添加 Red Hat Enterprise Linux CoreOS (RHCOS) 计算机器。
- 由于从集群中的机器上删除 OpenShift Container Platform 需要破坏操作系统,因此您必须对添加到集群中的所有 RHEL 机器使用专用的硬件。
- 添加到 OpenShift Container Platform 集群的所有 RHEL 机器上都禁用内存交换功能。您无法在这些机器上启用交换内存。
- 基于软件包的 RHEL 安装已弃用。RHEL 将在以后的发行版本中被删除。RHCOS 镜像分层将替换此功能,并支持在 compute 节点的基本操作系统上安装额外的软件包。
6.1.2. RHEL 计算节点的系统要求
OpenShift Container Platform 环境中的 Red Hat Enterprise Linux(RHEL)计算机器主机必须满足以下最低硬件规格和系统级别要求:
- 您的红帽帐户必须具有有效的 OpenShift Container Platform 订阅。如果没有,请与您的销售代表联系以了解更多信息。
- 生产环境必须提供能支持您的预期工作负载的计算机器。作为集群管理员,您必须计算预期的工作负载,再加上大约 10% 的开销。对于生产环境,请分配足够的资源,以防止节点主机故障影响您的最大容量。
所有系统都必须满足以下硬件要求:
- 物理或虚拟系统,或在公有或私有 IaaS 上运行的实例。
基础操作系统:在 minimal 安装选项中使用 RHEL 8.8 或更高版本。
重要不支持将 RHEL 7 计算机器添加到 OpenShift Container Platform 集群。
如果您有在以前的 OpenShift Container Platform 版本中支持的 RHEL 7 计算机器,则无法将其升级到 RHEL 8。您必须部署新的 RHEL 8 主机,并且应该删除旧的 RHEL 7 主机。如需更多信息,请参阅"删除节点"部分。
有关 OpenShift Container Platform 中已弃用或删除的主要功能的最新列表,请参阅 OpenShift Container Platform 发行注记中已弃用和删除的功能部分。
如果以 FIPS 模式部署 OpenShift Container Platform,则需要在 RHEL 机器上启用 FIPS,然后才能引导它。请参阅 RHEL 8 文档中的启用 FIPS 模式安装 RHEL 8 系统。
重要要为集群启用 FIPS 模式,您必须从配置为以 FIPS 模式操作的 Red Hat Enterprise Linux (RHEL) 计算机运行安装程序。有关在 RHEL 中配置 FIPS 模式的更多信息,请参阅将 RHEL 切换到 FIPS 模式。
当以 FIPS 模式运行 Red Hat Enterprise Linux (RHEL) 或 Red Hat Enterprise Linux CoreOS (RHCOS)时,OpenShift Container Platform 核心组件使用 RHEL 加密库,在 x86_64、ppc64le 和 s390x 架构上提交到 NIST FIPS 140-2/140-3 Validation。
- NetworkManager 1.0 或更高版本。
- 1 个 vCPU。
- 最小 8 GB RAM。
-
最小15 GB 硬盘空间,用于包含
/var/的文件系统。 -
最小1 GB 硬盘空间,用于包含
/usr/local/bin/的文件系统。 - 最小 1 GB 硬盘空间,用于包含其临时目录的文件系统。临时系统目录根据 Python 标准库中 tempfile 模块中定义的规则确定。
-
每个系统都必须满足您的系统提供商的任何其他要求。例如,如果在 VMware vSphere 上安装了集群,必须根据其存储准则配置磁盘,而且必须设置
disk.enableUUID=TRUE属性。 - 每个系统都必须能够使用 DNS 可解析的主机名访问集群的 API 端点。任何现有的网络安全访问控制都必须允许系统访问集群的 API 服务端点。
对于在 Microsoft Azure 上安装的集群:
-
确保系统包含
Standard_D8s_v3虚拟机的硬件要求。 - 启用加速网络。加速网络使用单一根 I/O 虚拟化(SR-IOV)为 Microsoft Azure 虚拟机提供更直接的路径到交换机。
-
确保系统包含
6.1.2.1. 证书签名请求管理
在使用您置备的基础架构时,集群只能有限地访问自动机器管理,因此您必须提供一种在安装后批准集群证书签名请求 (CSR) 的机制。kube-controller-manager 只能批准 kubelet 客户端 CSR。machine-approver 无法保证使用 kubelet 凭证请求的提供证书的有效性,因为它不能确认是正确的机器发出了该请求。您必须决定并实施一种方法,以验证 kubelet 提供证书请求的有效性并进行批准。
6.1.3. 准备机器以运行 Playbook
在将使用 Red Hat Enterprise Linux(RHEL)作为操作系统的计算机器添加到 OpenShift Container Platform 4.16 集群之前,必须准备一个 RHEL 8 机器,以运行向集群添加新节点的 Ansible playbook。这台机器不是集群的一部分,但必须能够访问集群。
先决条件
-
在运行 playbook 的机器上安装 OpenShift CLI(
oc)。 -
以具有
cluster-admin权限的用户身份登录。
流程
-
确保用于安装集群的
kubeconfig文件和用于安装集群的安装程序位于 RHEL 8 机器中。若要实现这一目标,一种方法是使用安装集群时所用的同一台机器。 - 配置机器,以访问您计划用作计算机器的所有 RHEL 主机。您可以使用公司允许的任何方法,包括使用 SSH 代理或 VPN 的堡垒主机。
在运行 playbook 的机器上配置一个用户,该用户对所有 RHEL 主机具有 SSH 访问权限。
重要如果使用基于 SSH 密钥的身份验证,您必须使用 SSH 代理来管理密钥。
如果还没有这样做,请使用 RHSM 注册机器,并为它附加一个带有
OpenShift订阅的池:使用 RHSM 注册机器:
subscription-manager register --username=<user_name> --password=<password>
# subscription-manager register --username=<user_name> --password=<password>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 从 RHSM 获取最新的订阅数据:
subscription-manager refresh
# subscription-manager refreshCopy to Clipboard Copied! Toggle word wrap Toggle overflow 列出可用的订阅:
subscription-manager list --available --matches '*OpenShift*'
# subscription-manager list --available --matches '*OpenShift*'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在上一命令的输出中,找到 OpenShift Container Platform 订阅的池 ID 并附加该池:
subscription-manager attach --pool=<pool_id>
# subscription-manager attach --pool=<pool_id>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
启用 OpenShift Container Platform 4.16 所需的仓库:
subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.16-for-rhel-8-x86_64-rpms"# subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.16-for-rhel-8-x86_64-rpms"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 安装所需的软件包,包括
openshift-ansible:yum install openshift-ansible openshift-clients jq
# yum install openshift-ansible openshift-clients jqCopy to Clipboard Copied! Toggle word wrap Toggle overflow openshift-ansible软件包提供了安装实用程序,并且会拉取将 RHEL 计算节点添加到集群所需要的其他软件包,如 Ansible、playbook 和相关的配置文件。openshift-clients提供ocCLI,jq软件包则可改善命令行中 JSON 输出的显示。
6.1.4. 准备 RHEL 计算节点
在将 Red Hat Enterprise Linux (RHEL) 机器添加到 OpenShift Container Platform 集群之前,您必须将每台主机注册到 Red Hat Subscription Manager (RHSM),为其附加有效的 OpenShift Container Platform 订阅,并且启用所需的存储库。
在每一主机上进行 RHSM 注册:
subscription-manager register --username=<user_name> --password=<password>
# subscription-manager register --username=<user_name> --password=<password>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 从 RHSM 获取最新的订阅数据:
subscription-manager refresh
# subscription-manager refreshCopy to Clipboard Copied! Toggle word wrap Toggle overflow 列出可用的订阅:
subscription-manager list --available --matches '*OpenShift*'
# subscription-manager list --available --matches '*OpenShift*'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在上一命令的输出中,找到 OpenShift Container Platform 订阅的池 ID 并附加该池:
subscription-manager attach --pool=<pool_id>
# subscription-manager attach --pool=<pool_id>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 禁用所有 yum 存储库:
禁用所有已启用的 RHSM 存储库:
subscription-manager repos --disable="*"
# subscription-manager repos --disable="*"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 列出剩余的 yum 存储库,并记录它们在
repo id下的名称(若有):yum repolist
# yum repolistCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用
yum-config-manager禁用剩余的 yum 存储库:yum-config-manager --disable <repo_id>
# yum-config-manager --disable <repo_id>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 或者,禁用所有存储库:
yum-config-manager --disable \*
# yum-config-manager --disable \*Copy to Clipboard Copied! Toggle word wrap Toggle overflow 请注意,有大量可用存储库时可能需要花费几分钟
仅启用 OpenShift Container Platform 4.16 需要的仓库:
subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.16-for-rhel-8-x86_64-rpms" \ --enable="fast-datapath-for-rhel-8-x86_64-rpms"# subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.16-for-rhel-8-x86_64-rpms" \ --enable="fast-datapath-for-rhel-8-x86_64-rpms"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 停止并禁用主机上的防火墙:
systemctl disable --now firewalld.service
# systemctl disable --now firewalld.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意请不要在以后启用防火墙。如果这样做,则无法访问 worker 上的 OpenShift Container Platform 日志。
6.1.5. 在集群中添加 RHEL 计算机器
您可以将使用 Red Hat Enterprise Linux 作为操作系统的计算机器添加到 OpenShift Container Platform 4.16 集群中。
先决条件
- 运行 playbook 的机器上已安装必需的软件包并且执行了必要的配置。
- RHEL 主机已做好安装准备。
流程
在为运行 playbook 而准备的机器上执行以下步骤:
创建一个名为
/<path>/inventory/hosts的 Ansible 清单文件,以定义您的计算机器主机和必要的变量:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 进入到 Ansible playbook 目录:
cd /usr/share/ansible/openshift-ansible
$ cd /usr/share/ansible/openshift-ansibleCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行 playbook:
ansible-playbook -i /<path>/inventory/hosts playbooks/scaleup.yml
$ ansible-playbook -i /<path>/inventory/hosts playbooks/scaleup.yml1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 对于
<path>,指定您创建的Ansible库存文件的路径。
6.1.6. Ansible hosts 文件的必要参数
在将 Red Hat Enterprise Linux (RHEL) 计算机器添加到集群之前,必须在 Ansible hosts 文件中定义以下参数。
| 参数 | 描述 | 值 |
|---|---|---|
|
| 能够以免密码方式进行 SSH 身份验证的 SSH 用户。如果使用基于 SSH 密钥的身份验证,则必须使用 SSH 代理来管理密钥。 |
系统上的用户名。默认值为 |
|
|
如果 |
|
|
|
指定包含集群的 | 配置文件的路径和名称。 |
6.1.7. 可选:从集群中删除 RHCOS 计算机器
将 Red Hat Enterprise Linux(RHEL)计算机器添加到集群后,您可以选择性地删除 Red Hat Enterprise Linux CoreOS(RHCOS)计算机器来释放资源。
先决条件
- 您已将 RHEL 计算机器添加到集群中。
流程
查看机器列表并记录 RHCOS 计算机器的节点名称:
oc get nodes -o wide
$ oc get nodes -o wideCopy to Clipboard Copied! Toggle word wrap Toggle overflow 对于每一台 RHCOS 计算机器,删除其节点:
通过运行
oc adm cordon命令,将节点标记为不可调度:oc adm cordon <node_name>
$ oc adm cordon <node_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 指定其中一台 RHCOS 计算机器的节点名称。
清空节点中的所有 Pod:
oc adm drain <node_name> --force --delete-emptydir-data --ignore-daemonsets
$ oc adm drain <node_name> --force --delete-emptydir-data --ignore-daemonsets1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 指定您隔离的 RHCOS 计算机器的节点名称。
删除节点:
oc delete nodes <node_name>
$ oc delete nodes <node_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 指定您清空的 RHCOS 计算机器的节点名称。
查看计算机器的列表,以确保仅保留 RHEL 节点:
oc get nodes -o wide
$ oc get nodes -o wideCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 从集群的计算机器的负载均衡器中删除 RHCOS 机器。您可以删除虚拟机或重新制作 RHCOS 计算机器物理硬件的镜像。
6.2. 将 RHCOS 计算机器添加到 OpenShift Container Platform 集群
您可以在裸机上的 OpenShift Container Platform 集群中添加更多 Red Hat Enterprise Linux CoreOS(RHCOS)计算机器。
在将更多计算机器添加到在裸机基础架构上安装的集群之前,必须先创建 RHCOS 机器供其使用。您可以使用 ISO 镜像或网络 PXE 引导来创建机器。
6.2.1. 先决条件
- 您在裸机上安装了集群。
- 您有用来创建集群的安装介质和 Red Hat Enterprise Linux CoreOS(RHCOS)镜像。如果没有这些文件,您需要根据安装过程的说明获得这些文件。
6.2.2. 使用 ISO 镜像创建 RHCOS 机器
您可以使用 ISO 镜像为裸机集群创建更多 Red Hat Enterprise Linux CoreOS(RHCOS)计算机器,以创建机器。
先决条件
- 获取集群计算机器的 Ignition 配置文件的 URL。在安装过程中将该文件上传到 HTTP 服务器。
-
已安装 OpenShift CLI (
oc)。
流程
运行以下命令,从集群中删除 Ignition 配置文件:
oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ign
$ oc extract -n openshift-machine-api secret/worker-user-data-managed --keys=userData --to=- > worker.ignCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
将您从集群导出的
worker.ignIgnition 配置文件上传到 HTTP 服务器。注意这些文件的 URL。 您可以验证 ignition 文件是否在 URL 上可用。以下示例获取计算节点的 Ignition 配置文件:
curl -k http://<HTTP_server>/worker.ign
$ curl -k http://<HTTP_server>/worker.ignCopy to Clipboard Copied! Toggle word wrap Toggle overflow 您可以运行以下命令来访问 ISO 镜像以引导新机器:
RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.<architecture>.artifacts.metal.formats.iso.disk.location')RHCOS_VHD_ORIGIN_URL=$(oc -n openshift-machine-config-operator get configmap/coreos-bootimages -o jsonpath='{.data.stream}' | jq -r '.architectures.<architecture>.artifacts.metal.formats.iso.disk.location')Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用 ISO 文件在更多计算机器上安装 RHCOS。在安装集群前,使用创建机器时使用的相同方法:
- 将 ISO 镜像刻录到磁盘并直接启动。
- 在 LOM 接口中使用 ISO 重定向。
在不指定任何选项或中断实时引导序列的情况下引导 RHCOS ISO 镜像。等待安装程序在 RHCOS live 环境中引导进入 shell 提示符。
注意您可以中断 RHCOS 安装引导过程来添加内核参数。但是,在这个 ISO 过程中,您应该使用以下步骤中所述的
coreos-installer命令,而不是添加内核参数。运行
coreos-installer命令并指定满足您的安装要求的选项。您至少必须指定指向节点类型的 Ignition 配置文件的 URL,以及您要安装到的设备:sudo coreos-installer install --ignition-url=http://<HTTP_server>/<node_type>.ign <device> --ignition-hash=sha512-<digest>
$ sudo coreos-installer install --ignition-url=http://<HTTP_server>/<node_type>.ign <device> --ignition-hash=sha512-<digest>1 2 Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意如果要通过使用 TLS 的 HTTPS 服务器提供 Ignition 配置文件,您可以在运行
coreos-installer前将内部证书颁发机构(CA)添加到系统信任存储中。以下示例将计算节点安装初始化到
/dev/sda设备。计算节点的 Ignition 配置文件从 IP 地址 192.168.1.2 的 HTTP Web 服务器获取:sudo coreos-installer install --ignition-url=http://192.168.1.2:80/installation_directory/worker.ign /dev/sda --ignition-hash=sha512-a5a2d43879223273c9b60af66b44202a1d1248fc01cf156c46d4a79f552b6bad47bc8cc78ddf0116e80c59d2ea9e32ba53bc807afbca581aa059311def2c3e3b
$ sudo coreos-installer install --ignition-url=http://192.168.1.2:80/installation_directory/worker.ign /dev/sda --ignition-hash=sha512-a5a2d43879223273c9b60af66b44202a1d1248fc01cf156c46d4a79f552b6bad47bc8cc78ddf0116e80c59d2ea9e32ba53bc807afbca581aa059311def2c3e3bCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在机器的控制台上监控 RHCOS 安装的进度。
重要在开始安装 OpenShift Container Platform 之前,确保每个节点中安装成功。观察安装过程可以帮助确定可能会出现 RHCOS 安装问题的原因。
- 继续为集群创建更多计算机器。
6.2.3. 通过 PXE 或 iPXE 启动来创建 RHCOS 机器
您可以使用 PXE 或 iPXE 引导为裸机集群创建更多 Red Hat Enterprise Linux CoreOS(RHCOS)计算机器。
先决条件
- 获取集群计算机器的 Ignition 配置文件的 URL。在安装过程中将该文件上传到 HTTP 服务器。
-
获取您在集群安装过程中上传到 HTTP 服务器的 RHCOS ISO 镜像、压缩的裸机 BIOS、
kernel和initramfs文件的 URL。 - 您可以访问在安装过程中为 OpenShift Container Platform 集群创建机器时使用的 PXE 引导基础架构。机器必须在安装 RHCOS 后从本地磁盘启动。
-
如果使用 UEFI,您可以访问在 OpenShift Container Platform 安装过程中修改的
grub.conf文件。
流程
确认 RHCOS 镜像的 PXE 或 iPXE 安装正确。
对于 PXE:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意此配置不会在图形控制台的机器上启用串行控制台访问。要配置不同的控制台,请在
APPEND行中添加一个或多个console=参数。例如,添加console=tty0 console=ttyS0以将第一个 PC 串口设置为主控制台,并将图形控制台设置为二级控制台。如需更多信息,请参阅 如何在 Red Hat Enterprise Linux 中设置串行终端和/或控制台?对于 iPXE (
x86_64+aarch64):kernel http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture> initrd=main coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign initrd --name main http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img boot
kernel http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture> initrd=main coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign1 2 initrd --name main http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img3 bootCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意此配置不会在使用图形控制台配置不同的控制台的机器上启用串行控制台访问,请在
kernel行中添加一个或多个console=参数。例如,添加console=tty0 console=ttyS0以将第一个 PC 串口设置为主控制台,并将图形控制台设置为二级控制台。如需更多信息,请参阅如何在 Red Hat Enterprise Linux 中设置串行终端和/或控制台? 和"启用 PXE 和 ISO 安装的串行控制台"部分。注意要在
aarch64架构中网络引导 CoreOS内核,您需要使用启用了IMAGE_GZIP选项的 iPXE 构建版本。请参阅 iPXE 中的IMAGE_GZIP选项。对于
aarch64中的 PXE(使用 UEFI 和 GRUB 作为第二阶段):menuentry 'Install CoreOS' { linux rhcos-<version>-live-kernel-<architecture> coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign initrd rhcos-<version>-live-initramfs.<architecture>.img }menuentry 'Install CoreOS' { linux rhcos-<version>-live-kernel-<architecture> coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign1 2 initrd rhcos-<version>-live-initramfs.<architecture>.img3 }Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- 使用 PXE 或 iPXE 基础架构为集群创建所需的计算机器。
6.2.4. 批准机器的证书签名请求
当您将机器添加到集群时,会为您添加的每台机器生成两个待处理证书签名请求(CSR)。您必须确认这些 CSR 已获得批准,或根据需要自行批准。必须首先批准客户端请求,然后批准服务器请求。
先决条件
- 您已将机器添加到集群中。
流程
确认集群可以识别这些机器:
oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.29.4 master-1 Ready master 63m v1.29.4 master-2 Ready master 64m v1.29.4
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.29.4 master-1 Ready master 63m v1.29.4 master-2 Ready master 64m v1.29.4Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出中列出了您创建的所有机器。
注意在有些 CSR 被批准前,前面的输出可能不包括计算节点(也称为 worker 节点)。
检查待处理的 CSR,并确保添加到集群中的每台机器都有
Pending或Approved状态的客户端请求:oc get csr
$ oc get csrCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在本例中,两台机器加入集群。您可能会在列表中看到更多已批准的 CSR。
如果 CSR 没有获得批准,在您添加的机器的所有待处理 CSR 都处于
Pending 状态后,请批准集群机器的 CSR:注意由于 CSR 会自动轮转,因此请在将机器添加到集群后一小时内批准您的 CSR。如果没有在一小时内批准它们,证书将会轮转,每个节点会存在多个证书。您必须批准所有这些证书。批准客户端 CSR 后,Kubelet 为服务证书创建一个二级 CSR,这需要手动批准。然后,如果 Kubelet 请求具有相同参数的新证书,则后续提供证书续订请求由
machine-approver自动批准。注意对于在未启用机器 API 的平台上运行的集群,如裸机和其他用户置备的基础架构,您必须实施一种方法来自动批准 kubelet 提供证书请求(CSR)。如果没有批准请求,则
oc exec、ocrsh和oc logs命令将无法成功,因为 API 服务器连接到 kubelet 时需要服务证书。与 Kubelet 端点联系的任何操作都需要此证书批准。该方法必须监视新的 CSR,确认 CSR 由 system:node或system:admin组中的node-bootstrapper服务帐户提交,并确认节点的身份。要单独批准,请对每个有效的 CSR 运行以下命令:
oc adm certificate approve <csr_name>
$ oc adm certificate approve <csr_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
要批准所有待处理的 CSR,请运行以下命令:
oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approveCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意在有些 CSR 被批准前,一些 Operator 可能无法使用。
现在,您的客户端请求已被批准,您必须查看添加到集群中的每台机器的服务器请求:
oc get csr
$ oc get csrCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果剩余的 CSR 没有被批准,且处于
Pending状态,请批准集群机器的 CSR:要单独批准,请对每个有效的 CSR 运行以下命令:
oc adm certificate approve <csr_name>
$ oc adm certificate approve <csr_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
<csr_name>是当前 CSR 列表中 CSR 的名称。
要批准所有待处理的 CSR,请运行以下命令:
oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approveCopy to Clipboard Copied! Toggle word wrap Toggle overflow
批准所有客户端和服务器 CSR 后,机器将
处于 Ready 状态。运行以下命令验证:oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意批准服务器 CSR 后可能需要几分钟时间让机器过渡到
Ready 状态。
其他信息
- 如需有关 CSR 的更多信息,请参阅 证书签名请求。
6.2.5. 在 AWS 中使用自定义 /var 分区添加新的 RHCOS worker 节点
OpenShift Container Platform 使用 bootstrap 过程中完成的机器配置支持在安装过程中分区设备。但是,如果您使用 /var 分区,该设备名称必须在安装时确定,且不可更改。如果节点具有不同的设备命名模式,则无法将不同的实例类型添加为节点。例如,如果您将 /var 分区配置为 m4.large 实例的默认 AWS 设备名称,dev/xvdb,则无法直接添加 AWS m5.large 实例,因为 m5.large 实例默认使用 /dev/nvme1n1 设备。由于不同的命名模式,设备可能无法分区。
本节中的步骤演示了如何使用与安装时配置的不同设备名称的实例添加新的 Red Hat Enterprise Linux CoreOS(RHCOS)计算节点。您可以创建自定义用户数据 secret 并配置新的计算机器集。这些步骤特定于 AWS 集群。其原则也适用于其他云部署。但是,针对其他部署的设备命名模式会有所不同,应该根据具体情况进行决定。
流程
在命令行中更改为
openshift-machine-api命名空间:oc project openshift-machine-api
$ oc project openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 从
worker-user-datasecret 创建新 secret:将 secret 的
userData部分导出到文本文件:oc get secret worker-user-data --template='{{index .data.userData | base64decode}}' | jq > userData.txt$ oc get secret worker-user-data --template='{{index .data.userData | base64decode}}' | jq > userData.txtCopy to Clipboard Copied! Toggle word wrap Toggle overflow 编辑文本文件,为要用于新节点的分区添加
storage,filesystems, 和systemd小节。您可以根据需要指定任何 Ignition 配置参数。注意不要更改
ignition小节中的值。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 指定 AWS 块设备的绝对路径。
- 2
- 指定以兆字节为单位的数据分区大小。
- 3
- 指定以兆字节为单位的分区的开头。当在引导磁盘中添加数据分区时,推荐最少使用 25000 MB(Mebibytes)。root 文件系统会自动调整大小以填充所有可用空间(最多到指定的偏移值)。如果没有指定值,或者指定的值小于推荐的最小值,则生成的 root 文件系统会太小,而在以后进行的 RHCOS 重新安装可能会覆盖数据分区的开始部分。
- 4
- 指定到
/var分区的绝对路径。 - 5
- 指定文件系统格式。
- 6
- 指定文件系统的挂载点,而 Ignition 运行时相对于根文件系统挂载的位置。这不一定与应在真实 root 中挂载的位置相同,但鼓励使其相同的位置。
- 7
- 定义将
/dev/disk/by-partlabel/var设备挂载到/var分区的 systemd 挂载单元。
将
disableTemplating部分从work-user-datasecret 提取到文本文件:oc get secret worker-user-data --template='{{index .data.disableTemplating | base64decode}}' | jq > disableTemplating.txt$ oc get secret worker-user-data --template='{{index .data.disableTemplating | base64decode}}' | jq > disableTemplating.txtCopy to Clipboard Copied! Toggle word wrap Toggle overflow 从两个文本文件创建新用户数据机密文件。此用户数据 secret 将
userData.txt文件中的额外节点分区信息传递给新创建的节点。oc create secret generic worker-user-data-x5 --from-file=userData=userData.txt --from-file=disableTemplating=disableTemplating.txt
$ oc create secret generic worker-user-data-x5 --from-file=userData=userData.txt --from-file=disableTemplating=disableTemplating.txtCopy to Clipboard Copied! Toggle word wrap Toggle overflow
为新节点创建新计算机器集:
创建新的计算机器集 YAML 文件,类似于为 AWS 配置的文件。添加所需分区和新创建的用户数据 secret:
提示使用现有计算机器集作为模板,并根据需要更改新节点的参数。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建计算机器集:
$ oc create -f <file-name>.yaml
$ oc create -f <file-name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 机器可能需要一些时间才可用。
验证新分区和节点是否已创建:
验证是否已创建计算机器设置:
oc get machineset
$ oc get machinesetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME DESIRED CURRENT READY AVAILABLE AGE ci-ln-2675bt2-76ef8-bdgsc-worker-us-east-1a 1 1 1 1 124m ci-ln-2675bt2-76ef8-bdgsc-worker-us-east-1b 2 2 2 2 124m worker-us-east-2-nvme1n1 1 1 1 1 2m35s
NAME DESIRED CURRENT READY AVAILABLE AGE ci-ln-2675bt2-76ef8-bdgsc-worker-us-east-1a 1 1 1 1 124m ci-ln-2675bt2-76ef8-bdgsc-worker-us-east-1b 2 2 2 2 124m worker-us-east-2-nvme1n1 1 1 1 1 2m35s1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 这是新的计算机器集。
验证新节点是否已创建:
oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 这是新节点。
验证新节点上是否创建了自定义
/var分区:oc debug node/<node-name> -- chroot /host lsblk
$ oc debug node/<node-name> -- chroot /host lsblkCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc debug node/ip-10-0-217-135.ec2.internal -- chroot /host lsblk
$ oc debug node/ip-10-0-217-135.ec2.internal -- chroot /host lsblkCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
nvme1n1设备被挂载到/var分区。
6.3. 部署机器健康检查
理解并部署机器健康检查。
您只能在 Machine API 操作的集群中使用高级机器管理和扩展功能。具有用户置备的基础架构的集群需要额外的验证和配置才能使用 Machine API。
具有基础架构平台类型 none 的集群无法使用 Machine API。即使附加到集群的计算机器安装在支持该功能的平台上,也会应用这个限制。在安装后无法更改此参数。
要查看集群的平台类型,请运行以下命令:
oc get infrastructure cluster -o jsonpath='{.status.platform}'
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'6.3.1. 关于机器健康检查
您只能对由计算机器集或 control plane 机器集管理的机器应用机器健康检查。
要监控机器的健康状况,创建资源来定义控制器的配置。设置要检查的条件(例如,处于 NotReady 状态达到五分钟或 node-problem-detector 中显示了持久性状况),以及用于要监控的机器集合的标签。
监控 MachineHealthCheck 资源的控制器会检查定义的条件。如果机器无法进行健康检查,则会自动删除机器并创建一个机器来代替它。删除机器之后,您会看到机器被删除事件。
为限制删除机器造成的破坏性影响,控制器一次仅清空并删除一个节点。如果目标机器池中不健康的机器池中不健康的机器数量大于 maxUnhealthy 的值,则补救会停止,需要启用手动干预。
请根据工作负载和要求仔细考虑超时。
- 超时时间较长可能会导致不健康的机器上的工作负载长时间停机。
-
超时时间太短可能会导致补救循环。例如,检查
NotReady状态的超时时间必须足够长,以便机器能够完成启动过程。
要停止检查,请删除资源。
6.3.1.1. 部署机器健康检查时的限制
部署机器健康检查前需要考虑以下限制:
- 只有机器集拥有的机器才可以由机器健康检查修复。
- 如果机器的节点从集群中移除,机器健康检查会认为机器不健康,并立即修复机器。
-
如果机器对应的节点在
nodeStartupTimeout之后没有加入集群,则会修复机器。 -
如果
Machine资源阶段为Failed,则会立即修复机器。
6.3.2. MachineHealthCheck 资源示例
所有基于云的安装类型的 MachineHealthCheck 资源,以及裸机以外的资源,类似以下 YAML 文件:
matchLabels 只是示例; 您必须根据具体需要映射您的机器组。
6.3.2.1. 短路机器健康检查补救
短路可确保仅在集群健康时机器健康检查修复机器。通过 MachineHealthCheck 资源中的 maxUnhealthy 字段配置短路。
如果用户在修复任何机器前为 maxUnhealthy 字段定义了一个值,MachineHealthCheck 会将 maxUnhealthy 的值与它决定不健康的目标池中的机器数量进行比较。如果不健康的机器数量超过 maxUnhealthy 限制,则不会执行补救。
如果没有设置 maxUnhealthy,则默认值为 100%,无论集群状态如何,机器都会被修复。
适当的 maxUnhealthy 值取决于您部署的集群规模以及 MachineHealthCheck 覆盖的机器数量。例如,您可以使用 maxUnhealthy 值覆盖多个可用区间的多个计算机器集,以便在丢失整个区时,maxUnhealthy 设置可以在集群中防止进一步补救。在没有多个可用区的全局 Azure 区域,您可以使用可用性集来确保高可用性。
如果您为 control plane 配置 MachineHealthCheck 资源,请将 maxUnhealthy 的值设置为 1。
此配置可确保当多个 control plane 机器显示为不健康时,机器健康检查不会采取任何操作。多个不健康的 control plane 机器可能会表示 etcd 集群已降级或扩展操作来替换失败的机器。
如果 etcd 集群降级,可能需要手动干预。如果扩展操作正在进行,机器健康检查应该允许它完成。
maxUnhealthy 字段可以设置为整数或百分比。根据 maxUnhealthy 值,有不同的补救实现。
6.3.2.1.1. 使用绝对值设置 maxUnhealthy
如果将 maxUnhealthy 设为 2:
- 如果 2 个或更少节点不健康,则可执行补救
- 如果 3 个或更多节点不健康,则不会执行补救
这些值与机器健康检查要检查的机器数量无关。
6.3.2.1.2. 使用百分比设置 maxUnhealthy
如果 maxUnhealthy 被设置为 40%,有 25 个机器被检查:
- 如果有 10 个或更少节点处于不健康状态,则可执行补救
- 如果 11 个或多个节点不健康,则不会执行补救
如果 maxUnhealthy 被设置为 40%,有 6 个机器被检查:
- 如果 2 个或更少节点不健康,则可执行补救
- 如果 3 个或更多节点不健康,则不会执行补救
当被检查的 maxUnhealthy 机器的百分比不是一个整数时,允许的机器数量会被舍入到一个小的整数。
6.3.3. 创建机器健康检查资源
您可以为集群中的机器集创建 MachineHealthCheck 资源。
您只能对由计算机器集或 control plane 机器集管理的机器应用机器健康检查。
先决条件
-
安装
oc命令行界面。
流程
-
创建一个
healthcheck.yml文件,其中包含您的机器健康检查的定义。 将
healthcheck.yml文件应用到您的集群:oc apply -f healthcheck.yml
$ oc apply -f healthcheck.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.3.4. 手动扩展计算机器集
要在计算机器集中添加或删除机器实例,您可以手动扩展计算机器集。
这个指南与全自动的、安装程序置备的基础架构安装相关。自定义的、用户置备的基础架构安装没有计算机器集。
先决条件
-
安装 OpenShift Container Platform 集群和
oc命令行。 -
以具有
cluster-admin权限的用户身份登录oc。
流程
运行以下命令,查看集群中的计算机器:
oc get machinesets.machine.openshift.io -n openshift-machine-api
$ oc get machinesets.machine.openshift.io -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 计算机器集以
<clusterid>-worker-<aws-region-az>的形式列出。运行以下命令,查看集群中的计算机器:
oc get machines.machine.openshift.io -n openshift-machine-api
$ oc get machines.machine.openshift.io -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,在要删除的计算机器上设置注解:
oc annotate machines.machine.openshift.io/<machine_name> -n openshift-machine-api machine.openshift.io/delete-machine="true"
$ oc annotate machines.machine.openshift.io/<machine_name> -n openshift-machine-api machine.openshift.io/delete-machine="true"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令来扩展计算机器集:
oc scale --replicas=2 machinesets.machine.openshift.io <machineset> -n openshift-machine-api
$ oc scale --replicas=2 machinesets.machine.openshift.io <machineset> -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 或者:
oc edit machinesets.machine.openshift.io <machineset> -n openshift-machine-api
$ oc edit machinesets.machine.openshift.io <machineset> -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 提示您还可以应用以下 YAML 来扩展计算机器集:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 您可以扩展或缩减计算机器。需要过几分钟以后新机器才可用。
重要默认情况下,机器控制器会尝试排空在机器上运行的节点,直到成功为止。在某些情况下,如错误配置了 pod 中断预算,排空操作可能无法成功。如果排空操作失败,机器控制器无法继续删除机器。
您可以通过在特定机器上注解
machine.openshift.io/exclude-node-draining来跳过排空节点。
验证
运行以下命令,验证删除所需的机器:
oc get machines.machine.openshift.io
$ oc get machines.machine.openshift.ioCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.3.5. 了解计算机器集和机器配置池之间的区别
MachineSet 对象描述了与云或机器供应商相关的 OpenShift Container Platform 节点。
MachineConfigPool 对象允许 MachineConfigController 组件在升级过程中定义并提供机器的状态。
MachineConfigPool 对象允许用户配置如何将升级应用到机器配置池中的 OpenShift Container Platform 节点。
NodeSelector 对象可以被一个到 MachineSet 对象的引用替换。
6.4. 推荐的节点主机实践
OpenShift Container Platform 节点配置文件包含重要的选项。例如,控制可以为节点调度的最大 pod 数量的两个参数: podsPerCore 和 maxPods。
当两个参数都被设置时,其中较小的值限制了节点上的 pod 数量。超过这些值可导致:
- CPU 使用率增加。
- 减慢 pod 调度的速度。
- 根据节点中的内存数量,可能出现内存耗尽的问题。
- 耗尽 IP 地址池。
- 资源过量使用,导致用户应用程序性能变差。
在 Kubernetes 中,包含单个容器的 pod 实际使用两个容器。第二个容器用来在实际容器启动前设置联网。因此,运行 10 个 pod 的系统实际上会运行 20 个容器。
云供应商的磁盘 IOPS 节流可能会对 CRI-O 和 kubelet 产生影响。当节点上运行大量 I/O 高负载的 pod 时,可能会出现超载的问题。建议您监控节点上的磁盘 I/O,并使用有足够吞吐量的卷。
podsPerCore 参数根据节点上的处理器内核数来设置节点可运行的 pod 数量。例如:在一个有 4 个处理器内核的节点上将 podsPerCore 设为 10 ,则该节点上允许的最大 pod 数量为 40。
kubeletConfig: podsPerCore: 10
kubeletConfig:
podsPerCore: 10
将 podsPerCore 设置为 0 可禁用这个限制。默认值为 0。podsPerCore 参数的值不能超过 maxPods 参数的值。
maxPods 参数将节点可以运行的 pod 数量设置为固定值,而不考虑节点的属性。
kubeletConfig:
maxPods: 250
kubeletConfig:
maxPods: 2506.4.1. 创建 KubeletConfig CR 以编辑 kubelet 参数
kubelet 配置目前被序列化为 Ignition 配置,因此可以直接编辑。但是,在 Machine Config Controller (MCC) 中同时添加了新的 kubelet-config-controller 。这可让您使用 KubeletConfig 自定义资源 (CR) 来编辑 kubelet 参数。
因为 kubeletConfig 对象中的字段直接从上游 Kubernetes 传递给 kubelet,kubelet 会直接验证这些值。kubeletConfig 对象中的无效值可能会导致集群节点不可用。有关有效值,请参阅 Kubernetes 文档。
请考虑以下指导:
-
编辑现有的
KubeletConfigCR 以修改现有设置或添加新设置,而不是为每个更改创建一个 CR。建议您仅创建一个 CR 来修改不同的机器配置池,或用于临时更改,以便您可以恢复更改。 -
为每个机器配置池创建一个
KubeletConfigCR,带有该池需要更改的所有配置。 -
根据需要,创建多个
KubeletConfigCR,每个集群限制为 10。对于第一个KubeletConfigCR,Machine Config Operator (MCO) 会创建一个机器配置,并附带kubelet。对于每个后续 CR,控制器会创建另一个带有数字后缀的kubelet机器配置。例如,如果您有一个带有-2后缀的kubelet机器配置,则下一个kubelet机器配置会附加-3。
如果要将 kubelet 或容器运行时配置应用到自定义机器配置池,则 machineConfigSelector 中的自定义角色必须与自定义机器配置池的名称匹配。
例如,由于以下自定义机器配置池名为 infra,因此自定义角色也必须是 infra :
如果要删除机器配置,以相反的顺序删除它们,以避免超过限制。例如,在删除 kubelet-2 机器配置前删除 kubelet-3 机器配置。
如果您有一个带有 kubelet-9 后缀的机器配置,并且创建了另一个 KubeletConfig CR,则不会创建新的机器配置,即使少于 10 个 kubelet 机器配置。
KubeletConfig CR 示例
oc get kubeletconfig
$ oc get kubeletconfigNAME AGE set-kubelet-config 15m
NAME AGE
set-kubelet-config 15m显示 KubeletConfig 机器配置示例
oc get mc | grep kubelet
$ oc get mc | grep kubelet... 99-worker-generated-kubelet-1 b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.4.0 26m ...
...
99-worker-generated-kubelet-1 b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.4.0 26m
...以下流程演示了如何配置每个节点的最大 pod 数量、每个节点的最大 PID 以及 worker 节点上的最大容器日志大小。
先决条件
为您要配置的节点类型获取与静态
MachineConfigPoolCR 关联的标签。执行以下步骤之一:查看机器配置池:
oc describe machineconfigpool <name>
$ oc describe machineconfigpool <name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc describe machineconfigpool worker
$ oc describe machineconfigpool workerCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 如果添加了标签,它会出现在
labels下。
如果标签不存在,则添加一个键/值对:
oc label machineconfigpool worker custom-kubelet=set-kubelet-config
$ oc label machineconfigpool worker custom-kubelet=set-kubelet-configCopy to Clipboard Copied! Toggle word wrap Toggle overflow
流程
查看您可以选择的可用机器配置对象:
oc get machineconfig
$ oc get machineconfigCopy to Clipboard Copied! Toggle word wrap Toggle overflow 默认情况下,与 kubelet 相关的配置为
01-master-kubelet和01-worker-kubelet。检查每个节点的最大 pod 的当前值:
oc describe node <node_name>
$ oc describe node <node_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc describe node ci-ln-5grqprb-f76d1-ncnqq-worker-a-mdv94
$ oc describe node ci-ln-5grqprb-f76d1-ncnqq-worker-a-mdv94Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在
Allocatable小节中找到value: pods: <value>:输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 根据需要配置 worker 节点:
创建一个类似如下的 YAML 文件,其中包含 kubelet 配置:
重要以特定机器配置池为目标的 kubelet 配置也会影响任何依赖的池。例如,为包含 worker 节点的池创建 kubelet 配置也适用于任何子集池,包括包含基础架构节点的池。要避免这种情况,您必须使用仅包含 worker 节点的选择表达式创建新的机器配置池,并让 kubelet 配置以这个新池为目标。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
使用
podPidsLimit在任何 pod 中设置最大 PID 数量。 -
使用
containerLogMaxSize在轮转容器日志文件前设置容器日志文件的最大大小。 使用
maxPods设置每个节点的最大 pod。注意kubelet 与 API 服务器进行交互的频率取决于每秒的查询数量 (QPS) 和 burst 值。如果每个节点上运行的 pod 数量有限,使用默认值(
kubeAPIQPS为50,kubeAPIBurst为100)就可以。如果节点上有足够 CPU 和内存资源,则建议更新 kubelet QPS 和 burst 速率。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
使用
为带有标签的 worker 更新机器配置池:
oc label machineconfigpool worker custom-kubelet=set-kubelet-config
$ oc label machineconfigpool worker custom-kubelet=set-kubelet-configCopy to Clipboard Copied! Toggle word wrap Toggle overflow 创建
KubeletConfig对象:oc create -f change-maxPods-cr.yaml
$ oc create -f change-maxPods-cr.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
验证
KubeletConfig对象是否已创建:oc get kubeletconfig
$ oc get kubeletconfigCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME AGE set-kubelet-config 15m
NAME AGE set-kubelet-config 15mCopy to Clipboard Copied! Toggle word wrap Toggle overflow 根据集群中的 worker 节点数量,等待每个 worker 节点被逐个重启。对于有 3 个 worker 节点的集群,这个过程可能需要大约 10 到 15 分钟。
验证更改是否已应用到节点:
在 worker 节点上检查
maxPods值已更改:oc describe node <node_name>
$ oc describe node <node_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 找到
Allocatable小节:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 在本例中,
pods参数应报告您在KubeletConfig对象中设置的值。
验证
KubeletConfig对象中的更改:oc get kubeletconfigs set-kubelet-config -o yaml
$ oc get kubeletconfigs set-kubelet-config -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 这应该显示
True状态和type:Success,如下例所示:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.4.3. Control plane 节点大小
控制平面节点资源要求取决于集群中的节点和对象的数量和类型。以下控制平面节点大小是基于控制平面密度测试的结果,或 Clusterdensity。此测试会在给定很多命名空间中创建以下对象:
- 1 个镜像流
- 1 个构建
-
5 个部署,其中 2 个 pod 副本处于
睡眠状态,每个状态都挂载 4 个 secret、4 个配置映射和 1 Downward API 卷 - 5 个服务,每个服务都指向前一个部署的 TCP/8080 和 TCP/8443 端口
- 1 个路由指向上一个服务的第一个路由
- 包含 2048 个随机字符串字符的 10 个 secret
- 10 个配置映射包含 2048 个随机字符串字符
| worker 节点数量 | 集群密度(命名空间) | CPU 内核 | 内存 (GB) |
|---|---|---|---|
| 24 | 500 | 4 | 16 |
| 120 | 1000 | 8 | 32 |
| 252 | 4000 | 16,但如果使用 OVN-Kubernetes 网络插件,则为 24 | 64,但在使用 OVN-Kubernetes 网络插件时为 128 |
| 501,但使用 OVN-Kubernetes 网络插件时未测试 | 4000 | 16 | 96 |
上表中的数据基于在 AWS 上运行的 OpenShift Container Platform,使用 r5.4xlarge 实例作为 control-plane 节点,m5.2xlarge 实例作为 worker 节点。
在具有三个 control plane 节点的大型高密度集群中,当其中一个节点停止、重启或失败时,CPU 和内存用量将会激增。故障可能是因为电源、网络、底层基础架构或意外情况造成意外问题,因为集群在关闭后重启,以节约成本。其余两个 control plane 节点必须处理负载才能高度可用,从而增加资源使用量。另外,在升级过程中还会有这个预期,因为 control plane 节点被封锁、排空并按顺序重新引导,以应用操作系统更新以及 control plane Operator 更新。为了避免级联失败,请将 control plane 节点上的总体 CPU 和内存资源使用量保留为最多 60% 的所有可用容量,以处理资源使用量激增。相应地增加 control plane 节点上的 CPU 和内存,以避免因为缺少资源而造成潜在的停机。
节点大小取决于集群中的节点和对象数量。它还取决于集群上是否正在主动创建这些对象。在创建对象时,control plane 在资源使用量方面与对象处于运行(running)阶段的时间相比更活跃。
Operator Lifecycle Manager(OLM)在 control plane 节点上运行,其内存占用量取决于 OLM 在集群中管理的命名空间和用户安装的 operator 的数量。Control plane 节点需要相应地调整大小,以避免 OOM 终止。以下数据基于集群最大测试的结果。
| 命名空间数量 | 处于空闲状态的 OLM 内存(GB) | 安装了 5 个用户 operator 的 OLM 内存(GB) |
|---|---|---|
| 500 | 0.823 | 1.7 |
| 1000 | 1.2 | 2.5 |
| 1500 | 1.7 | 3.2 |
| 2000 | 2 | 4.4 |
| 3000 | 2.7 | 5.6 |
| 4000 | 3.8 | 7.6 |
| 5000 | 4.2 | 9.02 |
| 6000 | 5.8 | 11.3 |
| 7000 | 6.6 | 12.9 |
| 8000 | 6.9 | 14.8 |
| 9000 | 8 | 17.7 |
| 10,000 | 9.9 | 21.6 |
您只能为以下配置修改正在运行的 OpenShift Container Platform 4.16 集群中的 control plane 节点大小:
- 使用用户置备的安装方法安装的集群。
- 使用安装程序置备的基础架构安装方法安装的 AWS 集群。
- 使用 control plane 机器集管理 control plane 机器的集群。
对于所有其他配置,您必须估计节点总数并在安装过程中使用推荐的 control plane 节点大小。
建议基于在带有 OpenShiftSDN 作为网络插件的 OpenShift Container Platform 集群上捕获的数据点。
在 OpenShift Container Platform 4.16 中,与 OpenShift Container Platform 3.11 及之前的版本相比,系统现在默认保留半个 CPU 内核(500 millicore)。确定大小时应该考虑这一点。
6.4.4. 设置 CPU Manager
要配置 CPU Manager,请创建一个 KubeletConfig 自定义资源 (CR) 并将其应用到所需的一组节点。
流程
运行以下命令来标记节点:
oc label node perf-node.example.com cpumanager=true
# oc label node perf-node.example.com cpumanager=trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow 要为所有计算节点启用 CPU Manager,请运行以下命令来编辑 CR:
oc edit machineconfigpool worker
# oc edit machineconfigpool workerCopy to Clipboard Copied! Toggle word wrap Toggle overflow 将
custom-kubelet: cpumanager-enabled标签添加到metadata.labels部分。metadata: creationTimestamp: 2020-xx-xxx generation: 3 labels: custom-kubelet: cpumanager-enabledmetadata: creationTimestamp: 2020-xx-xxx generation: 3 labels: custom-kubelet: cpumanager-enabledCopy to Clipboard Copied! Toggle word wrap Toggle overflow 创建
KubeletConfig,cpumanager-kubeletconfig.yaml,自定义资源 (CR) 。请参阅上一步中创建的标签,以便使用新的 kubelet 配置更新正确的节点。请参见MachineConfigPoolSelector部分:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令来创建动态 kubelet 配置:
oc create -f cpumanager-kubeletconfig.yaml
# oc create -f cpumanager-kubeletconfig.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 这会在 kubelet 配置中添加 CPU Manager 功能,如果需要,Machine Config Operator(MCO)将重启节点。要启用 CPU Manager,则不需要重启。
运行以下命令,检查合并的 kubelet 配置:
oc get machineconfig 99-worker-XXXXXX-XXXXX-XXXX-XXXXX-kubelet -o json | grep ownerReference -A7
# oc get machineconfig 99-worker-XXXXXX-XXXXX-XXXX-XXXXX-kubelet -o json | grep ownerReference -A7Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,检查更新的
kubelet.conf文件的计算节点:oc debug node/perf-node.example.com sh-4.2# cat /host/etc/kubernetes/kubelet.conf | grep cpuManager
# oc debug node/perf-node.example.com sh-4.2# cat /host/etc/kubernetes/kubelet.conf | grep cpuManagerCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
cpuManagerPolicy: static cpuManagerReconcilePeriod: 5s
cpuManagerPolicy: static1 cpuManagerReconcilePeriod: 5s2 Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令来创建项目:
oc new-project <project_name>
$ oc new-project <project_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建请求一个或多个内核的 pod。限制和请求都必须将其 CPU 值设置为一个整数。这是专用于此 pod 的内核数:
cat cpumanager-pod.yaml
# cat cpumanager-pod.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建 pod:
oc create -f cpumanager-pod.yaml
# oc create -f cpumanager-pod.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
运行以下命令,验证 pod 是否已调度到您标记的节点:
oc describe pod cpumanager
# oc describe pod cpumanagerCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,验证 CPU 是否已完全分配给 pod:
oc describe node --selector='cpumanager=true' | grep -i cpumanager- -B2
# oc describe node --selector='cpumanager=true' | grep -i cpumanager- -B2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAMESPACE NAME CPU Requests CPU Limits Memory Requests Memory Limits Age cpuman cpumanager-mlrrz 1 (28%) 1 (28%) 1G (13%) 1G (13%) 27m
NAMESPACE NAME CPU Requests CPU Limits Memory Requests Memory Limits Age cpuman cpumanager-mlrrz 1 (28%) 1 (28%) 1G (13%) 1G (13%) 27mCopy to Clipboard Copied! Toggle word wrap Toggle overflow 确认正确配置了
cgroups。运行以下命令,获取cluster进程的进程 ID (PID):oc debug node/perf-node.example.com
# oc debug node/perf-node.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow systemctl status | grep -B5 pause
sh-4.2# systemctl status | grep -B5 pauseCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意如果输出返回多个暂停进程条目,您必须识别正确的暂停进程。
输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,验证 pod 服务质量(QoS)等级
Guaranteed是否在kubepods.slice子目录中:cd /sys/fs/cgroup/kubepods.slice/kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice/crio-b5437308f1ad1a7db0574c542bdf08563b865c0345c86e9585f8c0b0a655612c.scope
# cd /sys/fs/cgroup/kubepods.slice/kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice/crio-b5437308f1ad1a7db0574c542bdf08563b865c0345c86e9585f8c0b0a655612c.scopeCopy to Clipboard Copied! Toggle word wrap Toggle overflow for i in `ls cpuset.cpus cgroup.procs` ; do echo -n "$i "; cat $i ; done
# for i in `ls cpuset.cpus cgroup.procs` ; do echo -n "$i "; cat $i ; doneCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意其他 QoS 等级的 Pod 会位于父
kubepods的子cgroups中。输出示例
cpuset.cpus 1 tasks 32706
cpuset.cpus 1 tasks 32706Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,检查任务允许的 CPU 列表:
grep ^Cpus_allowed_list /proc/32706/status
# grep ^Cpus_allowed_list /proc/32706/statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Cpus_allowed_list: 1
Cpus_allowed_list: 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 验证系统中的另一个 pod 无法在为
Guaranteedpod 分配的内核中运行。例如,要验证besteffortQoS 层中的 pod,请运行以下命令:cat /sys/fs/cgroup/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-podc494a073_6b77_11e9_98c0_06bba5c387ea.slice/crio-c56982f57b75a2420947f0afc6cafe7534c5734efc34157525fa9abbf99e3849.scope/cpuset.cpus
# cat /sys/fs/cgroup/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-podc494a073_6b77_11e9_98c0_06bba5c387ea.slice/crio-c56982f57b75a2420947f0afc6cafe7534c5734efc34157525fa9abbf99e3849.scope/cpuset.cpusCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc describe node perf-node.example.com
# oc describe node perf-node.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 这个 VM 有两个 CPU 内核。
system-reserved设置保留 500 millicores,这代表一个内核中的一半被从节点的总容量中减小,以达到Node Allocatable的数量。您可以看到Allocatable CPU是 1500 毫秒。这意味着您可以运行一个 CPU Manager pod,因为每个 pod 需要一个完整的内核。一个完整的内核等于 1000 毫秒。如果您尝试调度第二个 pod,系统将接受该 pod,但不会调度它:NAME READY STATUS RESTARTS AGE cpumanager-6cqz7 1/1 Running 0 33m cpumanager-7qc2t 0/1 Pending 0 11s
NAME READY STATUS RESTARTS AGE cpumanager-6cqz7 1/1 Running 0 33m cpumanager-7qc2t 0/1 Pending 0 11sCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.5. 巨页
了解并配置巨页。
6.5.1. 巨页的作用
内存在块(称为页)中进行管理。在大多数系统中,页的大小为 4Ki。1Mi 内存相当于 256 个页,1Gi 内存相当于 256,000 个页。CPU 有内置的内存管理单元,可在硬件中管理这些页的列表。Translation Lookaside Buffer (TLB) 是虚拟页到物理页映射的小型硬件缓存。如果在硬件指令中包括的虚拟地址可以在 TLB 中找到,则其映射信息可以被快速获得。如果没有包括在 TLN 中,则称为 TLB miss。系统将会使用基于软件的,速度较慢的地址转换机制,从而出现性能降低的问题。因为 TLB 的大小是固定的,因此降低 TLB miss 的唯一方法是增加页的大小。
巨页指一个大于 4Ki 的内存页。在 x86_64 构架中,有两个常见的巨页大小: 2Mi 和 1Gi。在其它构架上的大小会有所不同。要使用巨页,必须写相应的代码以便应用程序了解它们。Transparent Huge Pages(THP)试图在应用程序不需要了解的情况下自动管理巨页,但这个技术有一定的限制。特别是,它的页大小会被限为 2Mi。当有较高的内存使用率时,THP 可能会导致节点性能下降,或出现大量内存碎片(因为 THP 的碎片处理)导致内存页被锁定。因此,有些应用程序可能更适用于(或推荐)使用预先分配的巨页,而不是 THP。
6.5.2. 应用程序如何使用巨页
节点必须预先分配巨页以便节点报告其巨页容量。一个节点只能预先分配一个固定大小的巨页。
巨页可以使用名为 hugepages-<size> 的容器一级的资源需求被消耗。其中 size 是特定节点上支持的整数值的最精简的二进制标记。例如:如果某个节点支持 2048KiB 页大小,它将会有一个可调度的资源 hugepages-2Mi。与 CPU 或者内存不同,巨页不支持过量分配。
- 1
- 为
巨页指定要分配的准确内存数量。不要将这个值指定为巨页内存大小乘以页的大小。例如,巨页的大小为 2MB,如果应用程序需要使用由巨页组成的 100MB 的内存,则需要分配 50 个巨页。OpenShift Container Platform 会进行相应的计算。如上例所示,您可以直接指定100MB。
分配特定大小的巨页
有些平台支持多个巨页大小。要分配指定大小的巨页,在巨页引导命令参数前使用巨页大小选择参数hugepagesz=<size>。<size> 的值必须以字节为单位,并可以使用一个可选的后缀 [kKmMgG]。默认的巨页大小可使用 default_hugepagesz=<size> 引导参数定义。
巨页要求
- 巨页面请求必须等于限制。如果指定了限制,则它是默认的,但请求不是。
- 巨页在 pod 范围内被隔离。容器隔离功能计划在以后的版本中推出。
-
后端为巨页的
EmptyDir卷不能消耗大于 pod 请求的巨页内存。 -
通过带有
SHM_HUGETLB的shmget()来使用巨页的应用程序,需要运行一个匹配 proc/sys/vm/hugetlb_shm_group 的 supplemental 组。
6.5.3. 在引导时配置巨页
节点必须预先分配在 OpenShift Container Platform 集群中使用的巨页。保留巨页的方法有两种: 在引导时和在运行时。在引导时进行保留会增加成功的可能性,因为内存还没有很大的碎片。Node Tuning Operator 目前支持在特定节点上分配巨页。
流程
要减少节点重启的情况,请按照以下步骤顺序进行操作:
通过标签标记所有需要相同巨页设置的节点。
oc label node <node_using_hugepages> node-role.kubernetes.io/worker-hp=
$ oc label node <node_using_hugepages> node-role.kubernetes.io/worker-hp=Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建一个包含以下内容的文件,并把它命名为
hugepages_tuning.yaml:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建 Tuned
hugepages对象oc create -f hugepages-tuned-boottime.yaml
$ oc create -f hugepages-tuned-boottime.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 创建一个带有以下内容的文件,并把它命名为
hugepages-mcp.yaml:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建机器配置池:
oc create -f hugepages-mcp.yaml
$ oc create -f hugepages-mcp.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
因为有足够的非碎片内存,worker-hp 机器配置池中的所有节点现在都应分配 50 个 2Mi 巨页。
oc get node <node_using_hugepages> -o jsonpath="{.status.allocatable.hugepages-2Mi}"
100Mi
$ oc get node <node_using_hugepages> -o jsonpath="{.status.allocatable.hugepages-2Mi}"
100MiTuneD bootloader 插件只支持 Red Hat Enterprise Linux CoreOS (RHCOS) worker 节点。
6.6. 了解设备插件
设备插件提供一致并可移植的解决方案,以便跨集群消耗硬件设备。设备插件通过一种扩展机制为这些设备提供支持,从而使这些设备可供容器使用,提供这些设备的健康检查,并安全地共享它们。
OpenShift Container Platform 支持设备插件 API,但设备插件容器由各个供应商提供支持。
设备插件是在节点(kubelet 的外部)上运行的 gRPC 服务,负责管理特定的硬件资源。任何设备插件都必须支持以下远程过程调用 (RPC):
6.6.1. 设备插件示例
对于简单设备插件参考实现,设备管理器代码中有一个 stub 设备插件: vendor/k8s.io/kubernetes/pkg/kubelet/cm/deviceplugin/device_plugin_stub.go。
6.6.2. 设备插件部署方法
- 守护进程集是设备插件部署的推荐方法。
- 在启动时,设备插件会尝试在节点上 /var/lib/kubelet/device-plugin/ 创建一个 UNIX 域套接字,以便服务来自于设备管理器的 RPC。
- 由于设备插件必须管理硬件资源、主机文件系统的访问权以及套接字创建,它们必须在一个特权安全上下文中运行。
- 各种设备插件实现中提供了有关部署步骤的更多细节。
6.6.3. 了解设备管理器
设备管理器提供了一种机制,可借助称为“设备插件”的插件公告专用节点硬件资源。
您可以公告专用的硬件,而不必修改任何上游代码。
OpenShift Container Platform 支持设备插件 API,但设备插件容器由各个供应商提供支持。
设备管理器将设备公告为外部资源。用户 pod 可以利用相同的限制/请求机制来使用设备管理器公告的设备,这一机制也用于请求任何其他扩展资源。
在启动时,设备插件会在 /var/lib/kubelet/device-plugins/kubelet.sock 上调用 Register 将自身注册到设备管理器,并启动位于 / var/lib/kubelet/device-plugins/<plugin>.sock 的 gRPC 服务,以服务设备管理器请求。
在处理新的注册请求时,设备管理器会在设备插件服务中调用 ListAndWatch 远程过程调用 (RPC)。作为响应,设备管理器通过 gRPC 流从插件中获取设备对象的列表。设备管理器对流进行持续监控,以确认插件有没有新的更新。在插件一端,插件也会使流保持开放;只要任何设备的状态有所改变,就会通过相同的流传输连接将新设备列表发送到设备管理器。
在处理新的 pod 准入请求时,Kubelet 将请求的扩展资源传递给设备管理器以进行设备分配。设备管理器在其数据库中检查,以验证是否存在对应的插件。如果插件存在并且有可分配的设备及本地缓存,则在该特定设备插件上调用 Allocate RPC。
此外,设备插件也可以执行其他几个特定于设备的操作,如驱动程序安装、设备初始化和设备重置。这些功能视具体实现而异。
6.6.4. 启用设备管理器
启用设备管理器来实现设备插件,在不更改上游代码的前提下公告专用硬件。
设备管理器提供了一种机制,可借助称为“设备插件”的插件公告专用节点硬件资源。
输入以下命令为您要配置的节点类型获取与静态
MachineConfigPoolCRD 关联的标签。执行以下步骤之一:查看机器配置:
oc describe machineconfig <name>
# oc describe machineconfig <name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc describe machineconfig 00-worker
# oc describe machineconfig 00-workerCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Name: 00-worker Namespace: Labels: machineconfiguration.openshift.io/role=worker
Name: 00-worker Namespace: Labels: machineconfiguration.openshift.io/role=worker1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 设备管理器所需标签。
流程
为配置更改创建自定义资源 (CR)。
设备管理器 CR 配置示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建设备管理器:
oc create -f devicemgr.yaml
$ oc create -f devicemgr.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
kubeletconfig.machineconfiguration.openshift.io/devicemgr created
kubeletconfig.machineconfiguration.openshift.io/devicemgr createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 通过确认节点上已创建了 /var/lib/kubelet/device-plugins/kubelet.sock,确保已启用了设备管理器。这是设备管理器 gRPC 服务器在其上侦听新插件注册的 UNIX 域套接字。只有启用了设备管理器,才会在 Kubelet 启动时创建此 sock 文件。
6.7. 污点和容限
理解并使用污点和容限。
6.7.1. 了解污点和容限
通过使用污点(taint),节点可以拒绝调度 pod,除非 pod 具有匹配的容限(toleration)。
您可以通过节点规格(NodeSpec)将污点应用到节点,并通过 Pod 规格(PodSpec)将容限应用到 pod。当您应用污点时,调度程序无法将 pod 放置到该节点上,除非 pod 可以容限该污点。
节点规格中的污点示例
Pod 规格中的容限示例
污点与容限由 key、value 和 effect 组成。
| 参数 | 描述 | ||||||
|---|---|---|---|---|---|---|---|
|
|
| ||||||
|
|
| ||||||
|
| effect 的值包括:
| ||||||
|
|
|
如果向 control plane 节点添加了一个
NoSchedule污点,节点必须具有node-role.kubernetes.io/master=:NoSchedule污点,这默认会添加。例如:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
容限与污点匹配:
如果
operator参数设为Equal:-
key参数相同; -
value参数相同; -
effect参数相同。
-
如果
operator参数设为Exists:-
key参数相同; -
effect参数相同。
-
OpenShift Container Platform 中内置了以下污点:
-
node.kubernetes.io/not-ready:节点未就绪。这与节点状况Ready=False对应。 -
node.kubernetes.io/unreachable:节点无法从节点控制器访问。这与节点状况Ready=Unknown对应。 -
node.kubernetes.io/memory-pressure:节点存在内存压力问题。这与节点状况MemoryPressure=True对应。 -
node.kubernetes.io/disk-pressure:节点存在磁盘压力问题。这与节点状况DiskPressure=True对应。 -
node.kubernetes.io/network-unavailable:节点网络不可用。 -
node.kubernetes.io/unschedulable:节点不可调度。 -
node.cloudprovider.kubernetes.io/uninitialized:当节点控制器通过外部云提供商启动时,在节点上设置这个污点来将其标记为不可用。在云控制器管理器中的某个控制器初始化这个节点后,kubelet 会移除此污点。 node.kubernetes.io/pid-pressure:节点具有 pid 压力。这与节点状况PIDPressure=True对应。重要OpenShift Container Platform 不设置默认的 pid.available
evictionHard。
6.7.2. 添加污点和容限
您可以为 pod 和污点添加容限,以便节点能够控制哪些 pod 应该或不应该调度到节点上。对于现有的 pod 和节点,您应首先将容限添加到 pod,然后将污点添加到节点,以避免在添加容限前从节点上移除 pod。
流程
通过编辑
Podspec 使其包含tolerations小节来向 pod 添加容限:使用 Equal 运算符的 pod 配置文件示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
使用 Exists 运算符的 pod 配置文件示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
Exists运算符不会接受一个value。
本例在
node1上放置一个键为key1且值为value1的污点,污点效果是NoExecute。通过以下命令,使用 Taint 和 toleration 组件表中描述的参数为节点添加污点:
oc adm taint nodes <node_name> <key>=<value>:<effect>
$ oc adm taint nodes <node_name> <key>=<value>:<effect>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc adm taint nodes node1 key1=value1:NoExecute
$ oc adm taint nodes node1 key1=value1:NoExecuteCopy to Clipboard Copied! Toggle word wrap Toggle overflow 此命令在
node1上放置一个键为key1,值为value1的污点,其效果是NoExecute。注意如果向 control plane 节点添加了一个
NoSchedule污点,节点必须具有node-role.kubernetes.io/master=:NoSchedule污点,这默认会添加。例如:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow pod 上的容限与节点上的污点匹配。具有任一容限的 pod 可以调度到
node1上。
6.7.3. 使用计算机器集添加污点和容限
您可以使用计算机器集为节点添加污点。与 MachineSet 对象关联的所有节点都会使用污点更新。容限响应由计算机器设置添加的污点,其方式与直接添加到节点的污点相同。
流程
通过编辑
Podspec 使其包含tolerations小节来向 pod 添加容限:使用
Equal运算符的 pod 配置文件示例Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
使用
Exists运算符的 pod 配置文件示例Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将污点添加到
MachineSet对象:为您想要污点的节点编辑
MachineSetYAML,也可以创建新MachineSet对象:oc edit machineset <machineset>
$ oc edit machineset <machineset>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将污点添加到
spec.template.spec部分:计算机器设置规格中的污点示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 本例在节点上放置一个键为
key1,值为value1的污点,污点效果是NoExecute。将计算机器设置为 0:
oc scale --replicas=0 machineset <machineset> -n openshift-machine-api
$ oc scale --replicas=0 machineset <machineset> -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 提示您还可以应用以下 YAML 来扩展计算机器集:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 等待机器被删除。
根据需要扩展计算机器:
oc scale --replicas=2 machineset <machineset> -n openshift-machine-api
$ oc scale --replicas=2 machineset <machineset> -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 或者:
oc edit machineset <machineset> -n openshift-machine-api
$ oc edit machineset <machineset> -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 等待机器启动。污点添加到与
MachineSet对象关联的节点上。
6.7.4. 使用污点和容限将用户绑定到节点
如果要指定一组节点供特定用户独占使用,为 pod 添加容限。然后,在这些节点中添加对应的污点。具有容限的 pod 被允许使用污点节点,或集群中的任何其他节点。
如果您希望确保 pod 只调度到那些污点节点,还要将标签添加到同一组节点,并为 pod 添加节点关联性,以便 pod 只能调度到具有该标签的节点。
流程
配置节点以使用户只能使用该节点:
为这些节点添加对应的污点:
例如:
oc adm taint nodes node1 dedicated=groupName:NoSchedule
$ oc adm taint nodes node1 dedicated=groupName:NoScheduleCopy to Clipboard Copied! Toggle word wrap Toggle overflow 提示您还可以应用以下 YAML 来添加污点:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 通过编写自定义准入控制器,为 pod 添加容限。
6.7.5. 使用污点和容限控制具有特殊硬件的节点
如果集群中有少量节点具有特殊的硬件,您可以使用污点和容限让不需要特殊硬件的 pod 与这些节点保持距离,从而将这些节点保留给那些确实需要特殊硬件的 pod。您还可以要求需要特殊硬件的 pod 使用特定的节点。
您可以将容限添加到需要特殊硬件并污点具有特殊硬件的节点的 pod 中。
流程
确保为特定 pod 保留具有特殊硬件的节点:
为需要特殊硬件的 pod 添加容限。
例如:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用以下命令之一,给拥有特殊硬件的节点添加污点:
oc adm taint nodes <node-name> disktype=ssd:NoSchedule
$ oc adm taint nodes <node-name> disktype=ssd:NoScheduleCopy to Clipboard Copied! Toggle word wrap Toggle overflow 或者:
oc adm taint nodes <node-name> disktype=ssd:PreferNoSchedule
$ oc adm taint nodes <node-name> disktype=ssd:PreferNoScheduleCopy to Clipboard Copied! Toggle word wrap Toggle overflow 提示您还可以应用以下 YAML 来添加污点:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.7.6. 删除污点和容限
您可以根据需要,从节点移除污点并从 pod 移除容限。您应首先将容限添加到 pod,然后将污点添加到节点,以避免在添加容限前从节点上移除 pod。
流程
移除污点和容限:
从节点移除污点:
oc adm taint nodes <node-name> <key>-
$ oc adm taint nodes <node-name> <key>-Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc adm taint nodes ip-10-0-132-248.ec2.internal key1-
$ oc adm taint nodes ip-10-0-132-248.ec2.internal key1-Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
node/ip-10-0-132-248.ec2.internal untainted
node/ip-10-0-132-248.ec2.internal untaintedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 要从 pod 移除某一容限,请编辑
Pod规格来移除该容限:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.8. 拓扑管理器
理解并使用拓扑管理器。
6.8.1. 拓扑管理器策略
拓扑管理器通过从 Hint 提供者(如 CPU Manager 和设备管理器)收集拓扑提示来调整所有级别服务质量(QoS)的 Pod 资源,并使用收集的提示来匹配 Pod 资源。
拓扑管理器支持四个分配策略,这些策略在名为 cpumanager-enabled 的 KubeletConfig 自定义资源 (CR) 中分配:
none策略- 这是默认策略,不执行任何拓扑对齐调整。
best-effort策略-
对于带有
best-effort拓扑管理策略的 pod 中的每个容器,kubelet 会尝试根据该容器的首选 NUMA 节点关联性来匹配 NUMA 节点上的所有所需资源。即使因为资源不足而无法分配,Topology Manager 仍然接受 pod,但分配会与其他 NUMA 节点共享。 restricted策略-
对于带有
restricted拓扑管理策略的 pod 中的每个容器,kubelet 决定理论上可以满足请求的 NUMA 节点数量。如果实际分配需要超过该数量的 NUMA 节点,则拓扑管理器会拒绝准入,将 pod 置于Terminated状态。如果 NUMA 节点数量可以满足请求,则拓扑管理器会接受 pod 和 pod 开始运行。 single-numa-node策略-
对于带有
single-numa-node拓扑管理策略的 pod 中的每个容器,如果 pod 所需的所有资源可以在同一 NUMA 节点上分配,kubelet 会接受 pod。如果无法使用单一 NUMA 节点关联性,则拓扑管理器会拒绝来自节点的 pod。这会导致 pod 处于Terminated状态,且 pod 准入失败。
6.8.2. 设置拓扑管理器
要使用拓扑管理器,您必须在名为 cpumanager-enabled 的 KubeletConfig 自定义资源 (CR) 中配置分配策略。如果您设置了 CPU Manager,则该文件可能会存在。如果这个文件不存在,您可以创建该文件。
先决条件
-
将 CPU Manager 策略配置为
static。
流程
激活拓扑管理器:
在自定义资源中配置拓扑管理器分配策略。
oc edit KubeletConfig cpumanager-enabled
$ oc edit KubeletConfig cpumanager-enabledCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.8.3. Pod 与拓扑管理器策略的交互
以下的 Pod specs 示例演示了 Pod 与 Topology Manager 的交互。
因为没有指定资源请求或限制,以下 pod 以 BestEffort QoS 类运行。
spec:
containers:
- name: nginx
image: nginx
spec:
containers:
- name: nginx
image: nginx
因为请求小于限制,下一个 pod 以 Burstable QoS 类运行。
如果所选策略不是 none,则拓扑管理器将处理所有 pod,并且仅针对 Guaranteed Qos Pod 规格强制实施资源校准。当拓扑管理器策略设置为 none 时,相关的容器会被固定到任何可用的 CPU 中,而不考虑 NUMA 关联性。这是默认行为,不会针对性能敏感的工作负载进行优化。其他值支持使用来自设备插件核心资源(如 CPU 和内存)的拓扑感知信息。当策略设置为不是 none 的其他值时,拓扑管理器会尝试根据节点的拓扑匹配 CPU、内存和设备分配。有关可用值的更多信息,请参阅拓扑管理器策略。
以下示例 pod 以 Guaranteed QoS 类运行,因为请求等于限制。
拓扑管理器将考虑这个 pod。拓扑管理器会参考 Hint 提供者,即 CPU Manager、设备管理器和 Memory Manager,以获取 pod 的拓扑提示。
拓扑管理器将使用此信息存储该容器的最佳拓扑。在本 pod 中,CPU Manager 和设备管理器将在资源分配阶段使用此存储的信息。
6.9. 资源请求和过量使用
对于每个计算资源,容器可以指定一个资源请求和限制。根据确保节点有足够可用容量以满足请求值的请求来做出调度决策。如果容器指定了限制,但忽略了请求,则请求会默认采用这些限制。容器无法超过节点上指定的限制。
限制的强制实施取决于计算资源类型。如果容器没有请求或限制,容器会调度到没有资源保障的节点。在实践中,容器可以在最低本地优先级适用的范围内消耗指定的资源。在资源较少的情况下,不指定资源请求的容器将获得最低的服务质量。
调度基于请求的资源,而配额和硬限制指的是资源限制,它们可以设置为高于请求的资源。请求和限制的差值决定了过量使用程度;例如,如果为容器赋予 1Gi 内存请求和 2Gi 内存限制,则根据 1Gi 请求将容器调度到节点上,但最多可使用 2Gi;因此过量使用为 100%。
6.10. 使用 Cluster Resource Override Operator 的集群级别的过量使用
Cluster Resource Override Operator 是一个准入 Webhook,可让您控制过量使用的程度,并在集群中的所有节点上管理容器密度。Operator 控制特定项目中节点可以如何超过定义的内存和 CPU 限值。
Operator 修改开发人员容器上设置的请求和限值之间的比率。与指定限制和默认值的每个项目限制范围结合使用,您可以达到所需的过量使用程度。
您必须使用 OpenShift Container Platform 控制台或 CLI 安装 Cluster Resource override Operator,如下所示。部署 Cluster Resource Override Operator 后,Operator 会修改特定命名空间中的所有新 pod。在部署 Operator 前,Operator 不会编辑存在的 pod。
在安装过程中,您会创建一个 ClusterResourceOverride 自定义资源 (CR),其中设置过量使用级别,如下例所示:
如果容器上没有设置限值,则 Cluster Resourceoverride Operator 覆盖无效。创建一个针对单独项目的带有默认限制的 LimitRange 对象,或在 Pod specs 中配置要应用的覆盖的限制。
配置后,您可以通过将以下标签应用到要应用覆盖的每个项目的 Namespace 对象来在每个项目上启用覆盖。例如,您可以配置覆盖,以便基础架构组件不会受到覆盖的影响。
Operator 监视 ClusterResourceOverride CR, 并确保 ClusterResourceOverride 准入 Webhook 被安装到与 Operator 相同的命名空间。
例如,pod 有以下资源限值:
Cluster Resource Override Operator 截获原始 pod 请求,然后根据 ClusterResourceOverride 对象中设置的配置覆盖资源。
6.10.1. 使用 Web 控制台安装 Cluster Resource Override Operator
您可以使用 OpenShift Container Platform Web 控制台来安装 Cluster Resource Override Operator,以帮助控制集群中的过量使用。
先决条件
-
如果容器上未设置限值,Cluster Resourceoverride Operator 将没有作用。您必须使用一个
LimitRange对象为项目指定默认限值,或在Podspec 中配置要应用的覆盖的限制。
流程
使用 OpenShift Container Platform web 控制台安装 Cluster Resource Override Operator:
在 OpenShift Container Platform web 控制台中进入 Home → Projects
- 点击 Create Project。
-
指定
clusterresourceoverride-operator作为项目的名称。 - 点击 Create。
进入 Operators → OperatorHub。
- 从可用 Operator 列表中选择 ClusterResourceOverride Operator,再点击 Install。
- 在 Install Operator 页面中,确保为 Installation Mode 选择了 A specific Namespace on the cluster。
- 确保为 Installed Namespace 选择了 clusterresourceoverride-operator。
- 指定更新频道和批准策略。
- 点击 Install。
在 Installed Operators 页面中,点 ClusterResourceOverride。
- 在 ClusterResourceOverride Operator 详情页面中,点 Create ClusterResourceOverride。
在 Create ClusterResourceOverride 页面中,点 YAML 视图并编辑 YAML 模板,以根据需要设置过量使用值:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 点击 Create。
通过检查集群自定义资源的状态来检查准入 Webhook 的当前状态:
- 在 ClusterResourceOverride Operator 页面中,点击 cluster。
在 ClusterResourceOverride Details 页中,点 YAML。当 webhook 被调用时,
mutatingWebhookConfigurationRef项会出现。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 引用
ClusterResourceOverride准入Webhook。
6.10.2. 使用 CLI 安装 Cluster Resource Override Operator
您可以使用 OpenShift Container Platform CLI 来安装 Cluster Resource Override Operator,以帮助控制集群中的过量使用。
先决条件
-
如果容器上未设置限值,Cluster Resourceoverride Operator 将没有作用。您必须使用一个
LimitRange对象为项目指定默认限值,或在Podspec 中配置要应用的覆盖的限制。
流程
使用 CLI 安装 Cluster Resource Override Operator:
为 Cluster Resource Override Operator 创建命名空间:
为 Cluster Resource Override Operator 创建一个
Namespace空间对象 YAML 文件(如cro-namespace.yaml):apiVersion: v1 kind: Namespace metadata: name: clusterresourceoverride-operator
apiVersion: v1 kind: Namespace metadata: name: clusterresourceoverride-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow 创建命名空间:
oc create -f <file-name>.yaml
$ oc create -f <file-name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc create -f cro-namespace.yaml
$ oc create -f cro-namespace.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
创建一个 Operator 组:
为 Cluster Resource Override Operator 创建一个
OperatorGroup对象 YAML 文件(如 cro-og.yaml):Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建 Operator 组:
oc create -f <file-name>.yaml
$ oc create -f <file-name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc create -f cro-og.yaml
$ oc create -f cro-og.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
创建一个订阅:
为 Cluster Resourceoverride Operator 创建一个
Subscription对象 YAML 文件(如 cro-sub.yaml):Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建订阅:
oc create -f <file-name>.yaml
$ oc create -f <file-name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc create -f cro-sub.yaml
$ oc create -f cro-sub.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
在
clusterresourceoverride-operator命名空间中创建ClusterResourceOverride自定义资源(CR)对象:进入
clusterresourceoverride-operator命名空间。oc project clusterresourceoverride-operator
$ oc project clusterresourceoverride-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow 为 Cluster Resourceoverride Operator 创建
ClusterResourceOverride对象 YAML 文件(如 cro-cr.yaml):Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建
ClusterResourceOverride对象:oc create -f <file-name>.yaml
$ oc create -f <file-name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc create -f cro-cr.yaml
$ oc create -f cro-cr.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
通过检查集群自定义资源的状态来验证准入 Webhook 的当前状态。
oc get clusterresourceoverride cluster -n clusterresourceoverride-operator -o yaml
$ oc get clusterresourceoverride cluster -n clusterresourceoverride-operator -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 当 webhook 被调用时,
mutatingWebhookConfigurationRef项会出现。输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 引用
ClusterResourceOverride准入Webhook。
6.10.3. 配置集群级别的过量使用
Cluster Resource Override Operator 需要一个 ClusterResourceOverride 自定义资源 (CR),以及您希望 Operator 来控制过量使用的每个项目的标识。
先决条件
-
如果容器上未设置限值,Cluster Resourceoverride Operator 将没有作用。您必须使用一个
LimitRange对象为项目指定默认限值,或在Podspec 中配置要应用的覆盖的限制。
流程
修改集群级别的过量使用:
编辑
ClusterResourceOverrideCR:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 确保在每个您希望 Cluster Resourceoverride Operator 来控制过量使用的项目中都添加了以下标识:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 把这个标识添加到每个项目。
6.11. 节点级别的过量使用
您可以使用各种方法来控制特定节点上的过量使用,如服务质量 (QOS) 保障、CPU 限值或保留资源。您还可以为特定节点和特定项目禁用过量使用功能。
6.11.1. 了解计算资源和容器
计算资源的节点强制行为特定于资源类型。
6.11.1.1. 了解容器 CPU 请求
容器可以保证获得其请求的 CPU 量,还可额外消耗节点上提供的超额 CPU,但不会超过容器指定的限制。如果多个容器试图使用超额 CPU,则会根据每个容器请求的 CPU 数量来分配 CPU 时间。
例如,如果一个容器请求了 500m CPU 时间,另一个容器请求了 250m CPU 时间,那么该节点上提供的额外 CPU 时间以 2:1 比例在这两个容器之间分配。如果容器指定了一个限制,它将被限速,无法使用超过指定限制的 CPU。使用 Linux 内核中的 CFS 共享支持强制实施 CPU 请求。默认情况下,使用 Linux 内核中的 CFS 配额支持以 100ms 测量间隔强制实施 CPU 限制,但这可以禁用。
6.11.1.2. 了解容器内存请求
容器可以保证获得其请求的内存量。容器可以使用高于请求量的内存,但一旦超过请求量,就有可能在节点上遇到内存不足情形时被终止。如果容器使用的内存少于请求量,它不会被终止,除非系统任务或守护进程需要的内存量超过了节点资源保留考虑在内的内存量。如果容器指定了内存限制,则超过限制数量时会立即被终止。
6.11.2. 了解过量分配和服务质量类
当节点上调度了没有发出请求的 pod,或者节点上所有 pod 的限制总和超过了机器可用容量时,该节点处于过量使用状态。
在过量使用环境中,节点上的 pod 可能会在任意给定时间点尝试使用超过可用量的计算资源。发生这种情况时,节点必须为 pod 赋予不同的优先级。有助于做出此决策的工具称为服务质量 (QoS) 类。
pod 被指定为三个 QoS 类中的一个,带有降序排列:
| 优先级 | 类名称 | 描述 |
|---|---|---|
| 1(最高) | Guaranteed | 如果为所有资源设置了限制和可选请求(不等于 0)并且它们相等,则 pod 被归类为 Guaranteed。 |
| 2 | Burstable | 如果为所有资源设置了请求和可选限制(不等于 0)并且它们不相等,则 pod 被归类为 Burstable。 |
| 3(最低) | BestEffort | 如果没有为任何资源设置请求和限制,则 pod 被归类为 BestEffort。 |
内存是一种不可压缩的资源,因此在内存量较低的情况下,优先级最低的容器首先被终止:
- Guaranteed 容器优先级最高,并且保证只有在它们超过限制或者系统遇到内存压力且没有优先级更低的容器可被驱除时,才会被终止。
- 在遇到系统内存压力时,Burstable 容器如果超过其请求量并且不存在其他 BestEffort 容器,则有较大的可能会被终止。
- BestEffort 容器被视为优先级最低。系统内存不足时,这些容器中的进程最先被终止。
6.11.2.1. 了解如何为不同的服务质量层级保留内存
您可以使用 qos-reserved 参数指定在特定 QoS 级别上 pod 要保留的内存百分比。此功能尝试保留请求的资源,阻止较低 QoS 类中的 pod 使用较高 QoS 类中 pod 所请求的资源。
OpenShift Container Platform 按照如下所示使用 qos-reserved 参数:
-
值为
qos-reserved=memory=100%时,阻止Burstable和BestEffortQoS 类消耗较高 QoS 类所请求的内存。这会增加BestEffort和Burstable工作负载上为了提高Guaranteed和Burstable工作负载的内存资源保障而遭遇 OOM 的风险。 -
值为
qos-reserved=memory=50%时,允许Burstable和BestEffortQoS 类消耗较高 QoS 类所请求的内存的一半。 -
值为
qos-reserved=memory=0%时,允许Burstable和BestEffortQoS 类最多消耗节点的所有可分配数量(若可用),但会增加Guaranteed工作负载不能访问所请求内存的风险。此条件等同于禁用这项功能。
6.11.3. 了解交换内存和 QoS
您可以在节点上默认禁用交换,以便保持服务质量 (QoS) 保障。否则,节点上的物理资源会超额订阅,从而影响 Kubernetes 调度程序在 pod 放置过程中所做的资源保障。
例如,如果两个有保障 pod 达到其内存限制,各个容器可以开始使用交换内存。最终,如果没有足够的交换空间,pod 中的进程可能会因为系统被超额订阅而被终止。
如果不禁用交换,会导致节点无法意识到它们正在经历 MemoryPressure,从而造成 pod 无法获得它们在调度请求中索取的内存。这样节点上就会放置更多 pod,进一步增大内存压力,最终增加遭遇系统内存不足 (OOM) 事件的风险。
如果启用了交换,则对于可用内存的资源不足处理驱除阈值将无法正常发挥作用。利用资源不足处理,允许在遇到内存压力时从节点中驱除 pod,并且重新调度到没有此类压力的备选节点上。
6.11.4. 了解节点过量使用
在过量使用的环境中,务必要正确配置节点,以提供最佳的系统行为。
当节点启动时,它会确保为内存管理正确设置内核可微调标识。除非物理内存不足,否则内核应该永不会在内存分配时失败。
为确保这一行为,OpenShift Container Platform 通过将 vm.overcommit_memory 参数设置为 1 来覆盖默认操作系统设置,从而将内核配置为始终过量使用内存。
OpenShift Container Platform 还通过将 vm.panic_on_oom 参数设置为 0,将内核配置为不会在内存不足时崩溃。设置为 0 可告知内核在内存不足 (OOM) 情况下调用 oom_killer,以根据优先级终止进程
您可以通过对节点运行以下命令来查看当前的设置:
sysctl -a |grep commit
$ sysctl -a |grep commit输出示例
#... vm.overcommit_memory = 0 #...
#...
vm.overcommit_memory = 0
#...sysctl -a |grep panic
$ sysctl -a |grep panic输出示例
#... vm.panic_on_oom = 0 #...
#...
vm.panic_on_oom = 0
#...节点上应该已设置了上述标记,不需要进一步操作。
您还可以为每个节点执行以下配置:
- 使用 CPU CFS 配额禁用或强制实施 CPU 限制
- 为系统进程保留资源
- 为不同的服务质量等级保留内存
6.11.5. 使用 CPU CFS 配额禁用或强制实施 CPU 限制
默认情况下,节点使用 Linux 内核中的完全公平调度程序 (CFS) 配额支持来强制实施指定的 CPU 限制。
如果禁用了 CPU 限制强制实施,了解其对节点的影响非常重要:
- 如果容器有 CPU 请求,则请求仍由 Linux 内核中的 CFS 共享来实施。
- 如果容器没有 CPU 请求,但没有 CPU 限制,则 CPU 请求默认为指定的 CPU 限值,并由 Linux 内核中的 CFS 共享强制。
- 如果容器同时具有 CPU 请求和限制,则 CPU 请求由 Linux 内核中的 CFS 共享强制实施,且 CPU 限制不会对节点产生影响。
先决条件
输入以下命令为您要配置的节点类型获取与静态
MachineConfigPoolCRD 关联的标签:oc edit machineconfigpool <name>
$ oc edit machineconfigpool <name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc edit machineconfigpool worker
$ oc edit machineconfigpool workerCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 标签会出现在 Labels 下。
提示如果标签不存在,请添加键/值对,例如:
oc label machineconfigpool worker custom-kubelet=small-pods
$ oc label machineconfigpool worker custom-kubelet=small-podsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.11.6. 为系统进程保留资源
为提供更可靠的调度并且最大程度减少节点资源过量使用,每个节点都可以保留一部分资源供系统守护进程使用(节点上必须运行这些守护进程才能使集群正常工作)。
建议您为内存等不可压缩的资源保留资源。
流程
要明确为非 pod 进程保留资源,请通过指定可用于调度的资源来分配节点资源。如需了解更多详细信息,请参阅“为节点分配资源”。
6.11.7. 禁用节点过量使用
启用之后,可以在每个节点上禁用过量使用。
流程
要在节点中禁用过量使用,请在该节点上运行以下命令:
sysctl -w vm.overcommit_memory=0
$ sysctl -w vm.overcommit_memory=06.12. 项目级别限值
为帮助控制过量使用,您可以设置每个项目的资源限值范围,为过量使用无法超过的项目指定内存和 CPU 限值,以及默认值。
如需有关项目级别资源限值的信息,请参阅附加资源。
另外,您可以为特定项目禁用过量使用。
6.12.1. 禁用项目过量使用
启用之后,可以按项目禁用过量使用。例如,您可以允许独立于过量使用配置基础架构组件。
流程
- 创建或编辑命名空间对象文件。
添加以下注解:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow <.> 将此注解设置为
false可禁用这个命名空间的过量使用。
6.13. 使用垃圾回收释放节点资源
理解并使用垃圾回收。
6.13.1. 了解如何通过垃圾回收移除已终止的容器
容器垃圾回收使用驱除阈值移除已终止的容器。
为垃圾回收设定了驱除阈值时,节点会尝试为任何可从 API 访问的 pod 保留容器。如果 pod 已被删除,则容器也会被删除。只要 pod 没有被删除且没有达到驱除阈值,容器就会保留。如果节点遭遇磁盘压力,它会移除容器,并且无法再通过 oc logs 访问其日志。
- eviction-soft - 软驱除阈值将驱除阈值与一个由管理员指定的必要宽限期配对。
- removal-hard - 硬驱除阈值没有宽限期,如果观察到,OpenShift Container Platform 就会立即采取行动。
下表列出了驱除阈值:
| 节点状况 | 驱除信号 | 描述 |
|---|---|---|
| MemoryPressure |
| 节点上的可用内存。 |
| DiskPressure |
|
节点根文件系统、 |
对于 evictionHard,您必须指定所有这些参数。如果没有指定所有参数,则只应用指定的参数,垃圾回收将无法正常工作。
如果节点在软驱除阈值上下浮动,但没有超过其关联的宽限期,则对应的节点将持续在 true 和 false 之间振荡。因此,调度程序可能会做出不当的调度决策。
要防止这种情况的出现,请使用 remove-pressure-transition-period 标记来控制 OpenShift Container Platform 在摆脱压力状况前必须等待的时间。OpenShift Container Platform 不会设置在状况切换回 false 前,在指定期限内针对指定压力状况满足的驱除阈值。
将 evictionPressureTransitionPeriod 参数设置为 0 会将默认值配置为 5 分钟。您不能将驱除压力转换周期设置为零秒。
6.13.2. 了解如何通过垃圾回收移除镜像
镜像垃圾回收会删除未被任何正在运行的 pod 引用的镜像。
OpenShift Container Platform 根据 cAdvisor 报告的磁盘用量决定要从节点中删除哪些镜像。
镜像垃圾收集策略基于两个条件:
- 触发镜像垃圾回收的磁盘用量百分比(以整数表示)。默认值为 85。
- 镜像垃圾回收试尝试释放的磁盘用量百分比(以整数表示)。默认值为 80。
对于镜像垃圾回收,您可以使用自定义资源修改以下任意变量。
| 设置 | 描述 |
|---|---|
|
| 在通过垃圾收集移除镜像前,未用镜像的最小年龄。默认值为 2m。 |
|
|
触发镜像垃圾回收的磁盘用量百分比,以整数表示。默认值为 85。这个值必须大于 |
|
|
镜像垃圾回收试尝试释放的磁盘用量百分比,以整数表示。默认值为 80。这个值必须小于 |
每次运行垃圾收集器都会检索两个镜像列表:
- 目前在至少一个 pod 中运行的镜像的列表。
- 主机上可用镜像的列表。
随着新容器运行,新镜像即会出现。所有镜像都标有时间戳。如果镜像正在运行(上方第一个列表)或者刚被检测到(上方第二个列表),它将标上当前的时间。其余镜像的标记来自于以前的运行。然后,所有镜像都根据时间戳进行排序。
一旦开始回收,首先删除最旧的镜像,直到满足停止条件。
6.13.3. 为容器和镜像配置垃圾回收
作为管理员,您可以通过为各个机器配置池创建 kubeletConfig 对象来配置 OpenShift Container Platform 执行垃圾回收的方式。
OpenShift Container Platform 只支持每个机器配置池的一个 kubeletConfig 对象。
您可以配置以下几项的任意组合:
- 容器软驱除
- 容器硬驱除
- 镜像驱除
容器垃圾回收会移除已终止的容器。镜像垃圾回收会删除未被任何正在运行的 pod 引用的镜像。
先决条件
输入以下命令为您要配置的节点类型获取与静态
MachineConfigPoolCRD 关联的标签:oc edit machineconfigpool <name>
$ oc edit machineconfigpool <name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc edit machineconfigpool worker
$ oc edit machineconfigpool workerCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 标签会出现在 Labels 下。
提示如果标签不存在,请添加键/值对,例如:
oc label machineconfigpool worker custom-kubelet=small-pods
$ oc label machineconfigpool worker custom-kubelet=small-podsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
流程
为配置更改创建自定义资源 (CR)。
重要如果只有一个文件系统,或者
/var/lib/kubelet和/var/lib/containers/位于同一文件系统中,则具有最高值的设置会触发驱除操作,因为它们被首先满足。文件系统会触发驱除。容器垃圾回收 CR 的配置示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 对象的名称。
- 2
- 指定机器配置池中的标签。
- 3
- 对于容器垃圾回收:
eviction Soft或evictionHard的驱除类型。 - 4
- 对于容器垃圾回收:根据特定驱除触发器信号驱除阈值。
- 5
- 对于容器垃圾回收:软驱除周期。此参数不适用于
eviction-hard。 - 6
- 对于容器垃圾回收:根据特定驱除触发器信号驱除阈值。对于
evictionHard,您必须指定所有这些参数。如果没有指定所有参数,则只应用指定的参数,垃圾回收将无法正常工作。 - 7
- 对于容器垃圾回收: 摆脱驱除压力状况前等待的持续时间。将
evictionPressureTransitionPeriod参数设置为0会将默认值配置为 5 分钟。 - 8
- 对于镜像垃圾回收:在镜像被垃圾回收移除前,未使用的镜像的最小期限。
- 9
- 对于镜像垃圾回收:镜像垃圾回收会在使用了指定的磁盘用量百分比(以整数表示)时触发。这个值必须大于
imageGCLowThresholdPercent值。 - 10
- 对于镜像垃圾回收:镜像垃圾回收会尝试将资源释放到指定的磁盘用量百分比(以整数表示)。这个值必须小于
imageGCHighThresholdPercent值。
运行以下命令来创建 CR:
oc create -f <file_name>.yaml
$ oc create -f <file_name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc create -f gc-container.yaml
$ oc create -f gc-container.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
kubeletconfig.machineconfiguration.openshift.io/gc-container created
kubeletconfig.machineconfiguration.openshift.io/gc-container createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
输入以下命令验证垃圾回收是否活跃。您在自定义资源中指定的 Machine Config Pool 会将
UPDATING显示为“true”,直到更改完全实施为止:oc get machineconfigpool
$ oc get machineconfigpoolCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME CONFIG UPDATED UPDATING master rendered-master-546383f80705bd5aeaba93 True False worker rendered-worker-b4c51bb33ccaae6fc4a6a5 False True
NAME CONFIG UPDATED UPDATING master rendered-master-546383f80705bd5aeaba93 True False worker rendered-worker-b4c51bb33ccaae6fc4a6a5 False TrueCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.14. 使用 Node Tuning Operator
理解并使用 Node Tuning Operator。
Node Tuning Operator 可以帮助您通过编排 TuneD 守护进程来管理节点级别的性能优化,并使用 Performance Profile 控制器获得低延迟性能。大多数高性能应用程序都需要一定程度的内核级性能优化。Node Tuning Operator 为用户提供了一个统一的、节点一级的 sysctl 管理接口,并可以根据具体用户的需要灵活地添加自定义性能优化设置。
Operator 将为 OpenShift Container Platform 容器化 TuneD 守护进程作为一个 Kubernetes 守护进程集进行管理。它保证了自定义性能优化设置以可被守护进程支持的格式传递到在集群中运行的所有容器化的 TuneD 守护进程中。相应的守护进程会在集群的所有节点上运行,每个节点上运行一个。
在发生触发配置集更改的事件时,或通过接收和处理终止信号安全终止容器化 TuneD 守护进程时,容器化 TuneD 守护进程所应用的节点级设置将被回滚。
Node Tuning Operator 使用 Performance Profile 控制器来实现自动性能优化,从而实现 OpenShift Container Platform 应用程序的低延迟性能。
集群管理员配置了性能配置集以定义节点级别的设置,例如:
- 将内核更新至 kernel-rt。
- 为内务选择 CPU。
- 为运行工作负载选择 CPU。
在版本 4.1 及更高版本中,OpenShift Container Platform 标准安装中包含了 Node Tuning Operator。
在早期版本的 OpenShift Container Platform 中,Performance Addon Operator 用来实现自动性能优化,以便为 OpenShift 应用程序实现低延迟性能。在 OpenShift Container Platform 4.11 及更新的版本中,这个功能是 Node Tuning Operator 的一部分。
6.14.1. 访问 Node Tuning Operator 示例规格
使用此流程来访问 Node Tuning Operator 的示例规格。
流程
运行以下命令以访问 Node Tuning Operator 示例规格:
oc get tuned.tuned.openshift.io/default -o yaml -n openshift-cluster-node-tuning-operator
oc get tuned.tuned.openshift.io/default -o yaml -n openshift-cluster-node-tuning-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow
默认 CR 旨在为 OpenShift Container Platform 平台提供标准的节点级性能优化,它只能被修改来设置 Operator Management 状态。Operator 将覆盖对默认 CR 的任何其他自定义更改。若进行自定义性能优化,请创建自己的 Tuned CR。新创建的 CR 将与默认的 CR 合并,并基于节点或 pod 标识和配置文件优先级对节点应用自定义调整。
虽然在某些情况下,对 pod 标识的支持可以作为自动交付所需调整的一个便捷方式,但我们不鼓励使用这种方法,特别是在大型集群中。默认 Tuned CR 并不带有 pod 标识匹配。如果创建了带有 pod 标识匹配的自定义配置集,则该功能将在此时启用。在以后的 Node Tuning Operator 版本中将弃用 pod 标识功能。
6.14.2. 自定义调整规格
Operator 的自定义资源 (CR) 包含两个主要部分。第一部分是 profile:,这是 TuneD 配置集及其名称的列表。第二部分是 recommend:,用来定义配置集选择逻辑。
多个自定义调优规格可以共存,作为 Operator 命名空间中的多个 CR。Operator 会检测到是否存在新 CR 或删除了旧 CR。所有现有的自定义性能优化设置都会合并,同时更新容器化 TuneD 守护进程的适当对象。
管理状态
通过调整默认的 Tuned CR 来设置 Operator Management 状态。默认情况下,Operator 处于 Managed 状态,默认的 Tuned CR 中没有 spec.managementState 字段。Operator Management 状态的有效值如下:
- Managed: Operator 会在配置资源更新时更新其操作对象
- Unmanaged: Operator 将忽略配置资源的更改
- Removed: Operator 将移除 Operator 置备的操作对象和资源
配置集数据
profile: 部分列出了 TuneD 配置集及其名称。
建议的配置集
profile: 选择逻辑通过 CR 的 recommend: 部分来定义。recommend: 部分是根据选择标准推荐配置集的项目列表。
recommend: <recommend-item-1> # ... <recommend-item-n>
recommend:
<recommend-item-1>
# ...
<recommend-item-n>列表中的独立项:
- 1
- 可选。
- 2
MachineConfig标签的键/值字典。键必须是唯一的。- 3
- 如果省略,则会假设配置集匹配,除非设置了优先级更高的配置集,或设置了
machineConfigLabels。 - 4
- 可选列表。
- 5
- 配置集排序优先级。较低数字表示优先级更高(
0是最高优先级)。 - 6
- 在匹配项中应用的 TuneD 配置集。例如
tuned_profile_1。 - 7
- 可选操作对象配置。
- 8
- 为 TuneD 守护进程打开或关闭调试。
true为打开,false为关闭。默认值为false。 - 9
- 为 TuneD 守护进程打开或关闭
reapply_sysctl功能。选择true代表开启,false代表关闭。
<match> 是一个递归定义的可选数组,如下所示:
- label: <label_name>
value: <label_value>
type: <label_type>
<match>
- label: <label_name>
value: <label_value>
type: <label_type>
<match>
如果不省略 <match>,则所有嵌套的 <match> 部分也必须评估为 true。否则会假定 false,并且不会应用或建议具有对应 <match> 部分的配置集。因此,嵌套(子级 <match> 部分)会以逻辑 AND 运算来运作。反之,如果匹配 <match> 列表中任何一项,整个 <match> 列表评估为 true。因此,该列表以逻辑 OR 运算来运作。
如果定义 了 machineConfigLabels,基于机器配置池的匹配会对给定的 recommend: 列表项打开。<mcLabels> 指定机器配置标签。机器配置会自动创建,以在配置集 <tuned_profile_name> 中应用主机设置,如内核引导参数。这包括使用与 <mcLabels> 匹配的机器配置选择器查找所有机器配置池,并在分配了找到的机器配置池的所有节点上设置配置集 <tuned_profile_name>。要针对同时具有 master 和 worker 角色的节点,您必须使用 master 角色。
列表项 match 和 machineConfigLabels 由逻辑 OR 操作符连接。match 项首先以短电路方式评估。因此,如果它被评估为 true,则不考虑 MachineConfigLabels 项。
当使用基于机器配置池的匹配时,建议将具有相同硬件配置的节点分组到同一机器配置池中。不遵循这个原则可能会导致在共享同一机器配置池的两个或者多个节点中 TuneD 操作对象导致内核参数冲突。
示例:基于节点或 pod 标签的匹配
根据配置集优先级,以上 CR 针对容器化 TuneD 守护进程转换为 recommend.conf 文件。优先级最高 (10) 的配置集是 openshift-control-plane-es,因此会首先考虑它。在给定节点上运行的容器化 TuneD 守护进程会查看同一节点上是否在运行设有 tuned.openshift.io/elasticsearch 标签的 pod。如果没有,则整个 <match> 部分评估为 false。如果存在具有该标签的 pod,为了让 <match> 部分评估为 true,节点标签也需要是 node-role.kubernetes.io/master 或 node-role.kubernetes.io/infra。
如果这些标签对优先级为 10 的配置集而言匹配,则应用 openshift-control-plane-es 配置集,并且不考虑其他配置集。如果节点/pod 标签组合不匹配,则考虑优先级第二高的配置集 (openshift-control-plane)。如果容器化 TuneD Pod 在具有标签 node-role.kubernetes.io/master 或 node-role.kubernetes.io/infra 的节点上运行,则应用此配置集。
最后,配置集 openshift-node 的优先级最低 (30)。它没有 <match> 部分,因此始终匹配。如果给定节点上不匹配任何优先级更高的配置集,它会作为一个适用于所有节点的配置集来设置 openshift-node 配置集。
示例:基于机器配置池的匹配
为尽量减少节点的重新引导情况,为目标节点添加机器配置池将匹配的节点选择器标签,然后创建上述 Tuned CR,最后创建自定义机器配置池。
特定于云供应商的 TuneD 配置集
使用此功能,所有针对于 OpenShift Container Platform 集群上的云供应商都可以方便地分配 TuneD 配置集。这可实现,而无需添加额外的节点标签或将节点分组到机器配置池中。
这个功能会利用 spec.providerID 节点对象值(格式为 <cloud-provider>://<cloud-provider-specific-id>),并在 NTO operand 容器中写带有 <cloud-provider> 值的文件 /var/lib/ocp-tuned/provider。然后,TuneD 会使用这个文件的内容来加载 provider-<cloud-provider> 配置集(如果这个配置集存在)。
openshift 配置集(openshift-control-plane 和 openshift-node 配置集都从其中继承设置)现在被更新来使用这个功能(通过使用条件配置集加载)。NTO 或 TuneD 目前不包含任何特定于云供应商的配置集。但是,您可以创建一个自定义配置集 provider-<cloud-provider>,它将适用于所有针对于所有云供应商的集群节点。
GCE 云供应商配置集示例
由于配置集的继承,provider-<cloud-provider> 配置集中指定的任何设置都会被 openshift 配置集及其子配置集覆盖。
6.14.3. 在集群中设置默认配置集
以下是在集群中设置的默认配置集。
从 OpenShift Container Platform 4.9 开始,所有 OpenShift TuneD 配置集都随 TuneD 软件包一起提供。您可以使用 oc exec 命令查看这些配置集的内容:
oc exec $tuned_pod -n openshift-cluster-node-tuning-operator -- find /usr/lib/tuned/openshift{,-control-plane,-node} -name tuned.conf -exec grep -H ^ {} \;
$ oc exec $tuned_pod -n openshift-cluster-node-tuning-operator -- find /usr/lib/tuned/openshift{,-control-plane,-node} -name tuned.conf -exec grep -H ^ {} \;6.14.4. 支持的 TuneD 守护进程插件
在使用 Tuned CR 的 profile: 部分中定义的自定义配置集时,以下 TuneD 插件都受到支持,但 [main] 部分除外:
- audio
- cpu
- disk
- eeepc_she
- modules
- mounts
- net
- scheduler
- scsi_host
- selinux
- sysctl
- sysfs
- usb
- video
- vm
- bootloader
其中一些插件提供了不受支持的动态性能优化功能。目前不支持以下 TuneD 插件:
- script
- systemd
TuneD bootloader 插件只支持 Red Hat Enterprise Linux CoreOS (RHCOS) worker 节点。
其他资源
6.15. 配置每个节点的最大 pod 数量
有两个参数控制可调度到节点的 pod 数量上限,分别为 podsPerCore 和 maxPods。如果您同时使用这两个选项,则取两者中较小的限制来限制节点上的 pod 数。
例如,如果将一个有 4 个处理器内核的节点上的 podsPerCore 设置为 10,则该节点上允许的 pod 数量上限为 40。
先决条件
输入以下命令为您要配置的节点类型获取与静态
MachineConfigPoolCRD 关联的标签:oc edit machineconfigpool <name>
$ oc edit machineconfigpool <name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc edit machineconfigpool worker
$ oc edit machineconfigpool workerCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 标签会出现在 Labels 下。
提示如果标签不存在,请添加键/值对,例如:
oc label machineconfigpool worker custom-kubelet=small-pods
$ oc label machineconfigpool worker custom-kubelet=small-podsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
流程
为配置更改创建自定义资源 (CR)。
max-podsCR 配置示例Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意将
podsPerCore设置为0可禁用这个限制。在上例中,
podsPerCore的默认值为10,maxPods的默认值则为250。这意味着,除非节点有 25 个以上的内核,否则podsPerCore就是默认的限制因素。运行以下命令来创建 CR:
oc create -f <file_name>.yaml
$ oc create -f <file_name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
列出
MachineConfigPoolCRD 以查看是否应用了更改。如果 Machine Config Controller 抓取到更改,则UPDATING列会报告True:oc get machineconfigpools
$ oc get machineconfigpoolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME CONFIG UPDATED UPDATING DEGRADED master master-9cc2c72f205e103bb534 False False False worker worker-8cecd1236b33ee3f8a5e False True False
NAME CONFIG UPDATED UPDATING DEGRADED master master-9cc2c72f205e103bb534 False False False worker worker-8cecd1236b33ee3f8a5e False True FalseCopy to Clipboard Copied! Toggle word wrap Toggle overflow 更改完成后,
UPDATED列会报告True。oc get machineconfigpools
$ oc get machineconfigpoolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME CONFIG UPDATED UPDATING DEGRADED master master-9cc2c72f205e103bb534 False True False worker worker-8cecd1236b33ee3f8a5e True False False
NAME CONFIG UPDATED UPDATING DEGRADED master master-9cc2c72f205e103bb534 False True False worker worker-8cecd1236b33ee3f8a5e True False FalseCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.16. 使用静态 IP 地址进行机器扩展
在将集群部署到使用静态 IP 地址运行节点后,您可以扩展机器实例或机器集以使用这些静态 IP 地址之一。
6.16.1. 扩展机器以使用静态 IP 地址
您可以扩展额外的机器集,以使用集群中的预定义静态 IP 地址。对于此配置,您需要创建机器资源 YAML 文件,然后在此文件中定义静态 IP 地址。
先决条件
- 您已部署了至少一个具有配置静态 IP 地址的节点运行的集群。
流程
创建机器资源 YAML 文件,并在
network参数中定义静态 IP 地址网络信息。使用
network参数中定义的静态 IP 地址信息的机器资源 YAML 文件示例。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 网络接口默认网关的 IP 地址。
- 2
- 列出安装程序传递给网络接口的 IPv4、IPv6 或两个 IP 地址。两个 IP 系列都必须为默认网络使用相同的网络接口。
- 3
- 列出 DNS 名称服务器。您可以定义最多 3 个 DNS 名称服务器。如果一个 DNS 名称服务器变得不可访问,请考虑定义多个 DNS 名称服务器以利用 DNS 解析。
在终端中输入以下命令来创建
machine自定义资源(CR):oc create -f <file_name>.yaml
$ oc create -f <file_name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.16.2. 使用配置的静态 IP 地址的机器设置扩展
您可以使用机器集来扩展带有配置的静态 IP 地址的机器。
在将机器集配置为为机器请求静态 IP 地址后,机器控制器会在 openshift-machine-api 命名空间中创建 IPAddressClaim 资源。然后,外部控制器会创建一个 IPAddress 资源,并将任何静态 IP 地址绑定到 IPAddressClaim 资源。
您的组织可能会使用许多类型的 IP 地址管理(IPAM)服务。如果要在 OpenShift Container Platform 上启用特定的 IPAM 服务,您可能需要在 YAML 定义中手动创建 IPAddressClaim 资源,然后在 oc CLI 中输入以下命令来将静态 IP 地址绑定到这个资源:
oc create -f <ipaddressclaim_filename>
$ oc create -f <ipaddressclaim_filename>
以下示例演示了 IPAddressClaim 资源的示例:
机器控制器更新状态为 IPAddressClaimed 的机器,以指示静态 IP 地址被成功绑定到 IPAddressClaim 资源。机器控制器将相同的状态应用到具有多个 IPAddressClaim 资源的机器,每个都包含一个绑定静态 IP 地址。机器控制器会创建一个虚拟机,并将静态 IP 地址应用到机器配置的 providerSpec 中列出的任何节点。
6.16.3. 使用机器集扩展带有配置的静态 IP 地址的机器
您可以使用机器集来扩展带有配置的静态 IP 地址的机器。
该流程中的示例演示了使用控制器在机器集中扩展机器。
先决条件
- 您已部署了至少一个具有配置静态 IP 地址的节点运行的集群。
流程
通过在机器集的 YAML 文件的
network.devices.addressesFromPoolsschema 中指定 IP 池信息来配置机器集:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在
ocCLI 中输入以下命令来扩展机器集:oc scale --replicas=2 machineset <machineset> -n openshift-machine-api
$ oc scale --replicas=2 machineset <machineset> -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 或者:
oc edit machineset <machineset> -n openshift-machine-api
$ oc edit machineset <machineset> -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 扩展每台机器后,机器控制器会创建一个
IPAddressClaim资源。可选:输入以下命令检查
openshift-machine-api命名空间中是否存在IPAddressClaim资源:oc get ipaddressclaims.ipam.cluster.x-k8s.io -n openshift-machine-api
$ oc get ipaddressclaims.ipam.cluster.x-k8s.io -n openshift-machine-apiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 列出
openshift-machine-api命名空间中列出两个 IP 池的ocCLI 输出示例NAME POOL NAME POOL KIND cluster-dev-9n5wg-worker-0-m7529-claim-0-0 static-ci-pool IPPool cluster-dev-9n5wg-worker-0-wdqkt-claim-0-0 static-ci-pool IPPool
NAME POOL NAME POOL KIND cluster-dev-9n5wg-worker-0-m7529-claim-0-0 static-ci-pool IPPool cluster-dev-9n5wg-worker-0-wdqkt-claim-0-0 static-ci-pool IPPoolCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输入以下命令来创建
IPAddress资源:oc create -f ipaddress.yaml
$ oc create -f ipaddress.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下示例显示了带有定义网络配置信息的
IPAddress资源,以及一个定义的静态 IP 地址:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意默认情况下,外部控制器会自动扫描机器集中的任何资源,以了解可识别的地址池类型。当外部控制器找到
IPAddress资源中定义的kind: IPPool时,控制器会将任何静态 IP 地址绑定到IPAddressClaim资源。使用对
IPAddress资源的引用更新IPAddressClaim状态:oc --type=merge patch IPAddressClaim cluster-dev-9n5wg-worker-0-m7529-claim-0-0 -p='{"status":{"addressRef": {"name": "cluster-dev-9n5wg-worker-0-m7529-ipaddress-0-0"}}}' -n openshift-machine-api --subresource=status$ oc --type=merge patch IPAddressClaim cluster-dev-9n5wg-worker-0-m7529-claim-0-0 -p='{"status":{"addressRef": {"name": "cluster-dev-9n5wg-worker-0-m7529-ipaddress-0-0"}}}' -n openshift-machine-api --subresource=statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第 7 章 安装后的网络配置
安装 OpenShift Container Platform 后,您可以按照您的要求进一步扩展和自定义网络。
7.1. 使用 Cluster Network Operator
Cluster Network Operator (CNO)在 OpenShift Container Platform 集群上部署和管理集群网络组件,包括在安装过程中为集群选择的 Container Network Interface (CNI) 网络插件。
如需更多信息,请参阅 OpenShift Container Platform 中的 Cluster Network Operator。
7.2. 网络配置任务
7.2.1. 为新项目创建默认网络策略
作为集群管理员,您可以在创建新项目时修改新项目模板,使其自动包含 NetworkPolicy 对象。
7.2.1.1. 为新项目修改模板
作为集群管理员,您可以修改默认项目模板,以便使用自定义要求创建新项目。
创建自己的自定义项目模板:
先决条件
-
可以使用具有
cluster-admin权限的账户访问 OpenShift Container Platform 集群。
流程
-
以具有
cluster-admin特权的用户身份登录。 生成默认项目模板:
oc adm create-bootstrap-project-template -o yaml > template.yaml
$ oc adm create-bootstrap-project-template -o yaml > template.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
使用文本编辑器,通过添加对象或修改现有对象来修改生成的
template.yaml文件。 项目模板必须创建在
openshift-config命名空间中。加载修改后的模板:oc create -f template.yaml -n openshift-config
$ oc create -f template.yaml -n openshift-configCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用 Web 控制台或 CLI 编辑项目配置资源。
使用 Web 控制台:
- 导航至 Administration → Cluster Settings 页面。
- 单击 Configuration 以查看所有配置资源。
- 找到 Project 的条目,并点击 Edit YAML。
使用 CLI:
编辑
project.config.openshift.io/cluster资源:oc edit project.config.openshift.io/cluster
$ oc edit project.config.openshift.io/clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow
更新
spec部分,使其包含projectRequestTemplate和name参数,再设置您上传的项目模板的名称。默认名称为project-request。带有自定义项目模板的项目配置资源
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 保存更改后,创建一个新项目来验证是否成功应用了您的更改。
7.2.1.2. 在新项目模板中添加网络策略
作为集群管理员,您可以在新项目的默认模板中添加网络策略。OpenShift Container Platform 将自动创建项目中模板中指定的所有 NetworkPolicy 对象。
先决条件
-
集群使用支持
NetworkPolicy对象的默认 CNI 网络插件,如设置了mode: NetworkPolicy的 OpenShift SDN 网络插件。此模式是 OpenShift SDN 的默认模式。 -
已安装 OpenShift CLI(
oc)。 -
您需要使用具有
cluster-admin权限的用户登陆到集群。 - 您必须已为新项目创建了自定义的默认项目模板。
流程
运行以下命令来编辑新项目的默认模板:
oc edit template <project_template> -n openshift-config
$ oc edit template <project_template> -n openshift-configCopy to Clipboard Copied! Toggle word wrap Toggle overflow 将
<project_template>替换为您为集群配置的缺省模板的名称。默认模板名称为project-request。在模板中,将每个
NetworkPolicy对象作为一个元素添加到objects参数中。objects参数可以是一个或多个对象的集合。在以下示例中,
objects参数集合包括几个NetworkPolicy对象。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 可选:创建一个新项目,并确认您的网络策略对象成功创建。
创建一个新项目
oc new-project <project>
$ oc new-project <project>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 将
<project>替换为您要创建的项目的名称。
确认新项目模板中的网络策略对象存在于新项目中:
oc get networkpolicy
$ oc get networkpolicyCopy to Clipboard Copied! Toggle word wrap Toggle overflow 预期输出:
NAME POD-SELECTOR AGE allow-from-openshift-ingress <none> 7s allow-from-same-namespace <none> 7s
NAME POD-SELECTOR AGE allow-from-openshift-ingress <none> 7s allow-from-same-namespace <none> 7sCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第 8 章 配置镜像流和镜像 registry
您可以通过替换当前的 pull secret 或附加新的 pull secret 来更新集群的全局 pull secret。当用户使用单独的 registry 存储镜像而不使用安装过程中的 registry时,需要这个过程。如需更多信息,请参阅使用镜像 pull secret。
有关镜像和配置镜像流或镜像 registry 的详情,请查看以下文档:
8.1. 为断开连接的集群配置镜像流
在断开连接的环境中安装 OpenShift Container Platform 后,为 Cluster Samples Operator 和 must-gather 镜像流配置镜像流。
8.1.1. 协助镜像的 Cluster Samples Operator
在安装过程中,OpenShift Container Platform 在 openshift-cluster-samples-operator 命名空间中创建一个名为 imagestreamtag-to-image 的配置映射。
imagestreamtag-to-image 配置映射包含每个镜像流标签的条目(填充镜像)。
配置映射中 data 字段中每个条目的键格式为 <image_stream_name>_<image_stream_tag_name>。
在断开连接的 OpenShift Container Platform 安装过程中,Cluster Samples Operator 的状态被设置为 Removed。如果您将其改为 Managed,它会安装示例。
在网络限制或断开连接的环境中使用示例可能需要访问网络外部的服务。某些示例服务包括:Github、Maven Central、npm、RubyGems、PyPi 等。可能需要执行额外的步骤来允许 Cluster Samples Operator 对象访问它们所需的服务。
使用以下原则来决定导入镜像流所需的镜像:
-
在 Cluster Samples Operator 被设置为
Removed时,您可以创建镜像的 registry,或决定您要使用哪些现有镜像 registry。 - 使用新的配置映射作为指南来镜像您要镜像的 registry 的示例。
-
将没有镜像的任何镜像流添加到 Cluster Samples Operator 配置对象的
skippedImagestreams列表中。 -
将 Cluster Samples Operator 配置对象的
samplesRegistry设置为已镜像的 registry。 -
然后,将 Cluster Samples Operator 设置为
Managed来安装您已镜像的镜像流。
8.1.2. 使用带有备用或镜像 registry 的 Cluster Samples Operator 镜像流
您可以使用备用或镜像 registry 托管镜像流,而不是使用 Red Hat registry。
openshift 命名空间中大多数由 Cluster Samples Operator 管理的镜像流指向位于 registry.redhat.io 上红帽 registry 中的镜像。
cli、installer、must-gather 和 test 镜像流虽然属于安装有效负载的一部分,但不由 Cluster Samples Operator 管理。此流程中不涉及这些镜像流。
Cluster Samples Operator 必须在断开连接的环境中设置为 Managed。要安装镜像流,您必须有一个镜像的 registry。
先决条件
-
使用具有
cluster-admin角色的用户访问集群。 - 为您的镜像 registry 创建 pull secret。
流程
访问被镜像(mirror)的特定镜像流的镜像,例如:
oc get is <imagestream> -n openshift -o json | jq .spec.tags[].from.name | grep registry.redhat.io
$ oc get is <imagestream> -n openshift -o json | jq .spec.tags[].from.name | grep registry.redhat.ioCopy to Clipboard Copied! Toggle word wrap Toggle overflow 镜像 registry.redhat.io 中与您需要的任何镜像流关联的镜像
oc image mirror registry.redhat.io/rhscl/ruby-25-rhel7:latest ${MIRROR_ADDR}/rhscl/ruby-25-rhel7:latest$ oc image mirror registry.redhat.io/rhscl/ruby-25-rhel7:latest ${MIRROR_ADDR}/rhscl/ruby-25-rhel7:latestCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令为集群创建镜像配置对象:
oc create configmap registry-config --from-file=${MIRROR_ADDR_HOSTNAME}..5000=$path/ca.crt -n openshift-config$ oc create configmap registry-config --from-file=${MIRROR_ADDR_HOSTNAME}..5000=$path/ca.crt -n openshift-configCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在镜像配置对象中为镜像添加所需的可信 CA:
oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"registry-config"}}}' --type=merge$ oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"registry-config"}}}' --type=mergeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 更新 Cluster Samples Operator 配置对象中的
samplesRegistry字段,使其包含镜像配置中定义的镜像位置的hostname部分:oc edit configs.samples.operator.openshift.io -n openshift-cluster-samples-operator
$ oc edit configs.samples.operator.openshift.io -n openshift-cluster-samples-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重要此步骤是必需的,因为镜像流导入过程在此刻不使用镜像或搜索机制。
将所有未镜像的镜像流添加到 Cluster Samples Operator 配置对象的
skippedImagestreams字段。或者,如果您不想支持任何示例镜像流,在 Cluster Samples Operator 配置对象中将 Cluster Samples Operator 设置为Removed。注意如果镜像流导入失败,Cluster Samples Operator 会发出警告,但 Cluster Samples Operator 会定期重试,或看起来并没有重试它们。
openshift命名空间中的许多模板都引用镜像流。您可以使用Removed清除镜像流和模板。这消除了因任何缺失的镜像流而导致试图使用模板的可能性。
8.1.3. 准备集群以收集支持数据
使用受限网络的集群必须导入默认的 must-gather 镜像,以便为红帽支持收集调试数据。在默认情况下,must-gather 镜像不会被导入,受限网络中的集群无法访问互联网来从远程存储库拉取最新的镜像。
流程
如果您还没有将镜像 registry 的可信 CA 添加到集群的镜像配置对象中,作为 Cluster Samples Operator 配置的一部分,请执行以下步骤:
创建集群的镜像配置对象:
oc create configmap registry-config --from-file=${MIRROR_ADDR_HOSTNAME}..5000=$path/ca.crt -n openshift-config$ oc create configmap registry-config --from-file=${MIRROR_ADDR_HOSTNAME}..5000=$path/ca.crt -n openshift-configCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在集群的镜像配置对象中,为镜像添加所需的可信 CA:
oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"registry-config"}}}' --type=merge$ oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"registry-config"}}}' --type=mergeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
从您的安装有效负载中导入默认 must-gather 镜像:
oc import-image is/must-gather -n openshift
$ oc import-image is/must-gather -n openshiftCopy to Clipboard Copied! Toggle word wrap Toggle overflow
在运行 oc adm must-gather 命令时,请使用 --image 标志并指向有效负载镜像,如下例所示:
oc adm must-gather --image=$(oc adm release info --image-for must-gather)
$ oc adm must-gather --image=$(oc adm release info --image-for must-gather)8.2. 配置定期导入 Cluster Sample Operator 镜像流标签
您可以在新版本可用时定期导入镜像流标签,以确保始终可以访问 Cluster Sample Operator 镜像的最新版本。
流程
运行以下命令,获取
openshift命名空间中的所有镜像流:oc get imagestreams -n openshift
oc get imagestreams -n openshiftCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,获取
openshift命名空间中的每个镜像流的标签:oc get is <image-stream-name> -o jsonpath="{range .spec.tags[*]}{.name}{'\t'}{.from.name}{'\n'}{end}" -n openshift$ oc get is <image-stream-name> -o jsonpath="{range .spec.tags[*]}{.name}{'\t'}{.from.name}{'\n'}{end}" -n openshiftCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc get is ubi8-openjdk-17 -o jsonpath="{range .spec.tags[*]}{.name}{'\t'}{.from.name}{'\n'}{end}" -n openshift$ oc get is ubi8-openjdk-17 -o jsonpath="{range .spec.tags[*]}{.name}{'\t'}{.from.name}{'\n'}{end}" -n openshiftCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
1.11 registry.access.redhat.com/ubi8/openjdk-17:1.11 1.12 registry.access.redhat.com/ubi8/openjdk-17:1.12
1.11 registry.access.redhat.com/ubi8/openjdk-17:1.11 1.12 registry.access.redhat.com/ubi8/openjdk-17:1.12Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,调度镜像流中存在的每个标签的镜像定期导入:
oc tag <repository/image> <image-stream-name:tag> --scheduled -n openshift
$ oc tag <repository/image> <image-stream-name:tag> --scheduled -n openshiftCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc tag registry.access.redhat.com/ubi8/openjdk-17:1.11 ubi8-openjdk-17:1.11 --scheduled -n openshift
$ oc tag registry.access.redhat.com/ubi8/openjdk-17:1.11 ubi8-openjdk-17:1.11 --scheduled -n openshiftCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc tag registry.access.redhat.com/ubi8/openjdk-17:1.12 ubi8-openjdk-17:1.12 --scheduled -n openshift
$ oc tag registry.access.redhat.com/ubi8/openjdk-17:1.12 ubi8-openjdk-17:1.12 --scheduled -n openshiftCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意使用-
scheduled标志时,建议在使用外部容器镜像 registry 时定期重新导入镜像。-scheduled标志可帮助您收到最新版本的安全更新。另外,如果临时错误最初阻止导入镜像导入,则此设置允许导入过程自动重试。默认情况下,调度的镜像导入每 15 分钟进行一次。
运行以下命令,验证定期导入的调度状态:
oc get imagestream <image-stream-name> -o jsonpath="{range .spec.tags[*]}Tag: {.name}{'\t'}Scheduled: {.importPolicy.scheduled}{'\n'}{end}" -n openshiftoc get imagestream <image-stream-name> -o jsonpath="{range .spec.tags[*]}Tag: {.name}{'\t'}Scheduled: {.importPolicy.scheduled}{'\n'}{end}" -n openshiftCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc get imagestream ubi8-openjdk-17 -o jsonpath="{range .spec.tags[*]}Tag: {.name}{'\t'}Scheduled: {.importPolicy.scheduled}{'\n'}{end}" -n openshiftoc get imagestream ubi8-openjdk-17 -o jsonpath="{range .spec.tags[*]}Tag: {.name}{'\t'}Scheduled: {.importPolicy.scheduled}{'\n'}{end}" -n openshiftCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Tag: 1.11 Scheduled: true Tag: 1.12 Scheduled: true
Tag: 1.11 Scheduled: true Tag: 1.12 Scheduled: trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第 9 章 安装后存储配置
安装 OpenShift Container Platform 后,您可以按照自己的要求进一步扩展和自定义集群,包括存储配置。
默认情况下,容器使用临时存储或临时存储进行操作。临时存储具有生命周期限制。要长期存储数据,您必须配置持久性存储。您可以使用以下方法之一配置存储:
- 动态置备
- 您可以通过定义并创建控制不同级别的存储类(包括存储访问)来按需动态置备存储。
- 静态置备
- 您可以使用 Kubernetes 持久性卷使现有存储可供集群使用。静态置备支持各种设备配置和挂载选项。
9.1. 动态置备
通过动态置备,您可以按需创建存储卷,使集群管理员无需预置备存储。请参阅动态置备。
9.2. 推荐的可配置存储技术
下表总结了为给定的 OpenShift Container Platform 集群应用程序推荐的可配置存储技术。
| 存储类型 | Block | File | 对象 |
|---|---|---|---|
|
1
2 3 Prometheus 是用于指标数据的底层技术。 4 这不适用于物理磁盘、虚拟机物理磁盘、VMDK 、NFS 回送、AWS EBS 和 Azure 磁盘。
5 对于指标数据,使用 6 用于日志记录,请参阅为日志存储配置持久性存储中的推荐存储解决方案。使用 NFS 存储作为持久性卷或通过 NAS (如 Gluster)可能会破坏数据。因此,OpenShift Container Platform Logging 中的 Elasticsearch 存储和 LokiStack 日志存储不支持 NFS。您必须为每个日志存储使用一个持久性卷类型。 7 对象存储不会通过 OpenShift Container Platform 的 PV 或 PVC 使用。应用程序必须与对象存储 REST API 集成。 | |||
| ROX1 | Yes4 | Yes4 | 是 |
| RWX2 | 否 | 是 | 是 |
| Registry | 可配置 | 可配置 | 推荐的 |
| 扩展的 registry | 无法配置 | 可配置 | 推荐的 |
| Metrics3 | 推荐的 | Configurable5 | 无法配置 |
| Elasticsearch Logging | 推荐的 | Configurable6 | 不支持6 |
| Loki Logging | 无法配置 | 无法配置 | 推荐的 |
| Apps | 推荐的 | 推荐的 | Not configurable7 |
扩展的容器镜像仓库(registry)是一个 OpenShift 镜像 registry,它有两个或更多个 pod 运行副本。
9.2.1. 特定应用程序存储建议
测试显示在 Red Hat Enterprise Linux(RHEL) 中使用 NFS 服务器作为核心服务的存储后端的问题。这包括 OpenShift Container Registry 和 Quay,Prometheus 用于监控存储,以及 Elasticsearch 用于日志存储。因此,不建议使用 RHEL NFS 作为 PV 后端用于核心服务。
市场上的其他 NFS 实现可能没有这些问题。如需了解更多与此问题相关的信息,请联络相关的 NFS 厂商。
9.2.1.1. Registry
在非扩展的/高可用性 (HA) OpenShift 镜像 registry 集群部署中:
- 存储技术不需要支持 RWX 访问模式。
- 存储技术必须保证读写一致性。
- 首选存储技术是对象存储,然后是块存储。
- 对于应用于生产环境工作负载的 OpenShift 镜像 Registry 集群部署,我们不推荐使用文件存储。
9.2.1.2. 扩展的 registry
在扩展的/HA OpenShift 镜像 registry 集群部署中:
- 存储技术必须支持 RWX 访问模式。
- 存储技术必须保证读写一致性。
- 首选存储技术是对象存储。
- 支持 Red Hat OpenShift Data Foundation, Amazon Simple Storage Service (Amazon S3), Google Cloud Storage (GCS), Microsoft Azure Blob Storage, 和 OpenStack Swift。
- 对象存储应该兼容 S3 或 Swift。
- 对于非云平台,如 vSphere 和裸机安装,唯一可配置的技术是文件存储。
- 块存储是不可配置的。
- 支持将网络文件系统(NFS)存储与 OpenShift Container Platform 搭配使用。但是,将 NFS 存储与扩展 registry 搭配使用可能会导致已知问题。如需更多信息,请参阅红帽知识库解决方案,是否在生产阶段中对 OpenShift 集群内部组件支持 NFS?
9.2.1.3. 指标
在 OpenShift Container Platform 托管的 metrics 集群部署中:
- 首选存储技术是块存储。
- 对象存储是不可配置的。
在带有生产环境负载的托管 metrics 集群部署中不推荐使用文件存储。
9.2.1.4. 日志记录
在 OpenShift Container Platform 托管的日志集群部署中:
Loki Operator:
- 首选存储技术是 S3 兼容对象存储。
- 块存储是不可配置的。
OpenShift Elasticsearch Operator:
- 首选存储技术是块存储。
- 不支持对象存储。
自日志记录版本 5.4.3 起,OpenShift Elasticsearch Operator 已被弃用,计划在以后的发行版本中删除。红帽将在当前发行生命周期中提供对这个功能的程序漏洞修复和支持,但这个功能将不再获得改进,并将被删除。您可以使用 Loki Operator 作为 OpenShift Elasticsearch Operator 的替代方案来管理默认日志存储。
9.2.1.5. 应用程序
应用程序的用例会根据不同应用程序而不同,如下例所示:
- 支持动态 PV 部署的存储技术的挂载时间延迟较低,且不与节点绑定来支持一个健康的集群。
- 应用程序开发人员需要了解应用程序对存储的要求,以及如何与所需的存储一起工作以确保应用程序扩展或者与存储层交互时不会出现问题。
9.2.2. 其他特定的应用程序存储建议
不建议在 Write 密集型工作负载(如 etcd )中使用 RAID 配置。如果您使用 RAID 配置运行 etcd,您可能会遇到工作负载性能问题的风险。
- Red Hat OpenStack Platform(RHOSP)Cinder: RHOSP Cinder 倾向于在 ROX 访问模式用例中使用。
- 数据库:数据库(RDBMS 、nosql DBs 等等)倾向于使用专用块存储来获得最好的性能。
- etcd 数据库必须具有足够的存储和适当的性能容量才能启用大型集群。有关监控和基准测试工具的信息,以建立基本存储和高性能环境,请参阅 推荐 etcd 实践。
9.3. 部署 Red Hat OpenShift Data Foundation
Red Hat OpenShift Data Foundation 是 OpenShift Container Platform 支持的文件、块和对象存储的持久性存储供应商,可以在内部或混合云环境中使用。作为红帽存储解决方案,Red Hat OpenShift Data Foundation 与 OpenShift Container Platform 完全集成,用于部署、管理和监控。如需更多信息,请参阅 Red Hat OpenShift Data Foundation 文档。
虚拟化的 Red Hat Hyperconverged Infrastructure(RHHI)上的 OpenShift Data Foundation 不被支持。它使用超融合节点来托管 OpenShift Container Platform 安装的虚拟机。有关支持的平台的更多信息,请参阅 Red Hat OpenShift Data Foundation 支持性和互操作性指南。
| 如果您要寻找 Red Hat OpenShift Data Foundation 的相关信息 | 请参阅以下 Red Hat OpenShift Data Foundation 文档: |
|---|---|
| 新的、已知的问题、显著的程序错误修复以及技术预览 | |
| 支持的工作负载、布局、硬件和软件要求、调整和扩展建议 | |
| 部署 OpenShift Data Foundation 以使用外部 Red Hat Ceph Storage 集群的说明 | |
| 有关使用裸机基础架构上的本地存储部署 OpenShift Data Foundation 的说明 | |
| 有关在 Red Hat OpenShift Container Platform VMware vSphere 集群上部署 OpenShift Data Foundation 的说明 | |
| 有关使用 Amazon Web Services 进行本地或云存储部署 OpenShift Data Foundation 的说明 | |
| 在现有 Red Hat OpenShift Container Platform Google Cloud 集群上部署和管理 OpenShift Data Foundation 的说明 | |
| 在现有 Red Hat OpenShift Container Platform Azure 集群上部署和管理 OpenShift Data Foundation 的说明 | |
| 有关部署 OpenShift Data Foundation 在 IBM Power® 基础架构上使用本地存储的说明 | |
| 有关部署 OpenShift Data Foundation 在 IBM Z® 基础架构上使用本地存储的说明 | |
| 将存储分配给 Red Hat OpenShift Data Foundation 中的核心服务和托管应用程序,包括快照和克隆 | |
| 使用多云对象网关(NooBaa)在混合云或多云环境中管理存储资源 | |
| 为 Red Hat OpenShift Data Foundation 安全替换存储设备 | |
| 安全替换 Red Hat OpenShift Data Foundation 集群中的节点 | |
| 在 Red Hat OpenShift Data Foundation 中扩展操作 | |
| 监控 Red Hat OpenShift Data Foundation 4.12 集群 | |
| 解决操作过程中遇到的问题 | |
| 将 OpenShift Container Platform 集群从版本 3 迁移到版本 4 |
第 10 章 准备供用户使用
安装 OpenShift Container Platform 后,您可以按照您的要求进一步扩展和自定义集群,包括为用户准备步骤。
10.1. 了解身份提供程序配置
OpenShift Container Platform control plane 包含内置的 OAuth 服务器。开发人员和管理员获取 OAuth 访问令牌,以完成自身的 API 身份验证。
作为管理员,您可以在安装集群后通过配置 OAuth 来指定身份提供程序。
10.1.1. 关于 OpenShift Container Platform 中的身份提供程序
默认情况下,集群中只有 kubeadmin 用户。要指定身份提供程序,您必须创建一个自定义资源(CR) 来描述该身份提供程序并把它添加到集群中。
OpenShift Container Platform 用户名不能包括 /、: 和 %。
10.1.2. 支持的身份提供程序
您可以配置以下类型的身份提供程序:
| 用户身份提供程序 | 描述 |
|---|---|
|
配置 | |
|
配置 | |
|
配置 | |
|
配置 | |
|
配置 | |
|
配置 | |
|
配置 | |
|
配置 | |
|
配置 |
定义了身份提供程序后,您可以使用 RBAC 定义并应用权限。
10.1.3. 身份提供程序参数
以下是所有身份提供程序通用的参数:
| 参数 | 描述 |
|---|---|
|
| 此提供程序名称作为前缀放在提供程序用户名前,以此组成身份名称。 |
|
| 定义在用户登录时如何将新身份映射到用户。输入以下值之一:
|
在添加或更改身份提供程序时,您可以通过把 mappingMethod 参数设置为 add,将新提供程序中的身份映射到现有的用户。
10.1.4. 身份提供程序 CR 示例
以下自定义资源 (CR) 显示用来配置身份提供程序的参数和默认值。本例使用 htpasswd 身份提供程序。
身份提供程序 CR 示例
10.2. 使用 RBAC 定义和应用权限
理解并应用基于角色的访问控制。
10.2.1. RBAC 概述
基于角色的访问控制 (RBAC) 对象决定是否允许用户在项目内执行给定的操作。
集群管理员可以使用集群角色和绑定来控制谁对 OpenShift Container Platform 平台本身和所有项目具有各种访问权限等级。
开发人员可以使用本地角色和绑定来控制谁有权访问他们的项目。请注意,授权是与身份验证分开的一个步骤,身份验证更在于确定执行操作的人的身份。
授权通过使用以下几项来管理:
| 授权对象 | 描述 |
|---|---|
| 规则 |
一组对象上允许的操作集合。例如,用户或服务帐户能否 |
| 角色 | 规则的集合。可以将用户和组关联或绑定到多个角色。 |
| 绑定 | 用户和/组与角色之间的关联。 |
控制授权的 RBAC 角色和绑定有两个级别:
| RBAC 级别 | 描述 |
|---|---|
| 集群 RBAC | 对所有项目均适用的角色和绑定。集群角色存在于集群范围,集群角色绑定只能引用集群角色。 |
| 本地 RBAC | 作用于特定项目的角色和绑定。虽然本地角色只存在于单个项目中,但本地角色绑定可以同时引用集群和本地角色。 |
集群角色绑定是存在于集群级别的绑定。角色绑定存在于项目级别。集群角色 view 必须使用本地角色绑定来绑定到用户,以便该用户能够查看项目。只有集群角色不提供特定情形所需的权限集合时才应创建本地角色。
这种双级分级结构允许通过集群角色在多个项目间重复使用,同时允许通过本地角色在个别项目中自定义。
在评估过程中,同时使用集群角色绑定和本地角色绑定。例如:
- 选中集群范围的“allow”规则。
- 选中本地绑定的“allow”规则。
- 默认为拒绝。
10.2.1.1. 默认集群角色
OpenShift Container Platform 包括了一组默认的集群角色,您可以在集群范围或本地将它们绑定到用户和组。
不建议手动修改默认集群角色。对这些系统角色的修改可能会阻止集群正常工作。
| 默认集群角色 | 描述 |
|---|---|
|
|
项目管理者。如果在本地绑定中使用,则 |
|
| 此用户可以获取有关项目和用户的基本信息。 |
|
| 此超级用户可以在任意项目中执行任何操作。当使用本地绑定来绑定一个用户时,这些用户可以完全控制项目中每一资源的配额和所有操作。 |
|
| 此用户可以获取基本的集群状态信息。 |
|
| 用户可以获取或查看大多数对象,但不能修改它们。 |
|
| 此用户可以修改项目中大多数对象,但无权查看或修改角色或绑定。 |
|
| 此用户可以创建自己的项目。 |
|
| 此用户无法进行任何修改,但可以查看项目中的大多数对象。不能查看或修改角色或绑定。 |
请注意本地和集群绑定之间的区别。例如,如果使用本地角色绑定将 cluster-admin 角色绑定到一个用户,这可能看似该用户具有了集群管理员的特权。事实并非如此。将 cluster-admin 绑定到项目里的某一用户,仅会将该项目的超级管理员特权授予这一用户。该用户具有集群角色 admin 的权限,以及该项目的一些额外权限,例如能够编辑项目的速率限制。通过 web 控制台 UI 操作时此绑定可能会令人混淆,因为它不会列出绑定到真正集群管理员的集群角色绑定。然而,它会列出可用来本地绑定 cluster-admin 的本地角色绑定。
下方展示了集群角色、本地角色、集群角色绑定、本地角色绑定、用户、组和服务帐户之间的关系。

当它们被应用到一个角色时,get pods/exec, get pods/*, 和 get * 规则会授予执行权限。应用最小特权的原则,仅分配用户和代理所需的最小 RBAC 权限。如需更多信息,请参阅 RBAC 规则允许执行权限。
10.2.1.2. 评估授权
OpenShift Container Platform 使用以下几项来评估授权:
- 身份
- 用户名以及用户所属组的列表。
- 操作
您执行的操作。在大多数情况下,这由以下几项组成:
- 项目:您访问的项目。项目是一种附带额外注解的 Kubernetes 命名空间,使一个社区的用户可以在与其他社区隔离的前提下组织和管理其内容。
-
操作动词:操作本身:
get、list、create、update、delete、deletecollection或watch。 - 资源名称:您访问的 API 端点。
- 绑定
- 绑定的完整列表,用户或组与角色之间的关联。
OpenShift Container Platform 通过以下几个步骤评估授权:
- 使用身份和项目范围操作来查找应用到用户或所属组的所有绑定。
- 使用绑定来查找应用的所有角色。
- 使用角色来查找应用的所有规则。
- 针对每一规则检查操作,以查找匹配项。
- 如果未找到匹配的规则,则默认拒绝该操作。
请记住,用户和组可以同时关联或绑定到多个角色。
项目管理员可以使用 CLI 查看本地角色和绑定信息,包括与每个角色关联的操作动词和资源的一览表。
通过本地绑定来绑定到项目管理员的集群角色会限制在一个项目内。不会像授权给 cluster-admin 或 system:admin 的集群角色那样在集群范围绑定。
集群角色是在集群级别定义的角色,但可在集群级别或项目级别进行绑定。
10.2.1.2.1. 集群角色聚合
默认的 admin、edit、view 和 cluster-reader 集群角色支持集群角色聚合,其中每个角色的集群规则可在创建了新规则时动态更新。只有通过创建自定义资源扩展 Kubernetes API 时,此功能才有意义。
10.2.2. 项目和命名空间
Kubernetes 命名空间提供设定集群中资源范围的机制。Kubernetes 文档中提供有关命名空间的更多信息。
命名空间为以下对象提供唯一范围:
- 指定名称的资源,以避免基本命名冲突。
- 委派给可信用户的管理授权。
- 限制社区资源消耗的能力。
系统中的大多数对象都通过命名空间来设定范围,但一些对象不在此列且没有命名空间,如节点和用户。
项目是附带额外注解的 Kubernetes 命名空间,是管理常规用户资源访问权限的集中载体。通过项目,一个社区的用户可以在与其他社区隔离的前提下组织和管理其内容。用户必须由管理员授予对项目的访问权限;或者,如果用户有权创建项目,则自动具有自己创建项目的访问权限。
项目可以有单独的 name、displayName 和 description。
-
其中必备的
name是项目的唯一标识符,在使用 CLI 工具或 API 时最常见。名称长度最多为 63 个字符。 -
可选的
displayName是项目在 web 控制台中的显示形式(默认为name)。 -
可选的
description可以为项目提供更加详细的描述,也可显示在 web 控制台中。
每个项目限制了自己的一组:
| 对象 | 描述 |
|---|---|
|
| Pod、服务和复制控制器等。 |
|
| 用户能否对对象执行操作的规则。 |
|
| 对各种对象进行限制的配额。 |
|
| 服务帐户自动使用项目中对象的指定访问权限进行操作。 |
集群管理员可以创建项目,并可将项目的管理权限委派给用户社区的任何成员。集群管理员也可以允许开发人员创建自己的项目。
开发人员和管理员可以使用 CLI 或 Web 控制台与项目交互。
10.2.3. 默认项目
OpenShift Container Platform 附带若干默认项目,名称以 openshift-- 开头的项目对用户而言最为重要。这些项目托管作为 Pod 运行的主要组件和其他基础架构组件。在这些命名空间中创建的带有关键 (critical) Pod 注解的 Pod 是很重要的,它们可以保证被 kubelet 准入。在这些命名空间中为主要组件创建的 Pod 已标记为“critical”。
不要在默认项目中运行工作负载或共享对默认项目的访问权限。为运行核心集群组件保留默认项目。
以下默认项目被视为具有高度特权:default, kube-public, kube-system, openshift, openshift-infra, openshift-node,其他系统创建的项目的标签 openshift.io/run-level 被设置为 0 或 1。依赖于准入插件(如 pod 安全准入、安全性上下文约束、集群资源配额和镜像引用解析)的功能无法在高特权项目中工作。
10.2.4. 查看集群角色和绑定
通过 oc describe 命令,可以使用 oc CLI 来查看集群角色和绑定。
先决条件
-
安装
ocCLI。 - 获取查看集群角色和绑定的权限。
在集群范围内绑定了 cluster-admin 默认集群角色的用户可以对任何资源执行任何操作,包括查看集群角色和绑定。
流程
查看集群角色及其关联的规则集:
oc describe clusterrole.rbac
$ oc describe clusterrole.rbacCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 查看当前的集群角色绑定集合,这显示绑定到不同角色的用户和组:
oc describe clusterrolebinding.rbac
$ oc describe clusterrolebinding.rbacCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
10.2.5. 查看本地角色和绑定
使用 oc describe 命令通过 oc CLI 来查看本地角色和绑定。
先决条件
-
安装
ocCLI。 获取查看本地角色和绑定的权限:
-
在集群范围内绑定了
cluster-admin默认集群角色的用户可以对任何资源执行任何操作,包括查看本地角色和绑定。 -
本地绑定了
admin默认集群角色的用户可以查看并管理项目中的角色和绑定。
-
在集群范围内绑定了
流程
查看当前本地角色绑定集合,这显示绑定到当前项目的不同角色的用户和组:
oc describe rolebinding.rbac
$ oc describe rolebinding.rbacCopy to Clipboard Copied! Toggle word wrap Toggle overflow 要查其他项目的本地角色绑定,请向命令中添加
-n标志:oc describe rolebinding.rbac -n joe-project
$ oc describe rolebinding.rbac -n joe-projectCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
10.2.6. 向用户添加角色
可以使用 oc adm 管理员 CLI 管理角色和绑定。
将角色绑定或添加到用户或组可让用户或组具有该角色授予的访问权限。您可以使用 oc adm policy 命令向用户和组添加和移除角色。
您可以将任何默认集群角色绑定到项目中的本地用户或组。
流程
向指定项目中的用户添加角色:
oc adm policy add-role-to-user <role> <user> -n <project>
$ oc adm policy add-role-to-user <role> <user> -n <project>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如,您可以运行以下命令,将
admin角色添加到joe项目中的alice用户:oc adm policy add-role-to-user admin alice -n joe
$ oc adm policy add-role-to-user admin alice -n joeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 提示您还可以应用以下 YAML 向用户添加角色:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 查看本地角色绑定,并在输出中验证添加情况:
oc describe rolebinding.rbac -n <project>
$ oc describe rolebinding.rbac -n <project>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如,查看
joe项目的本地角色绑定:oc describe rolebinding.rbac -n joe
$ oc describe rolebinding.rbac -n joeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
alice用户已添加到adminsRoleBinding。
10.2.7. 创建本地角色
您可以为项目创建本地角色,然后将其绑定到用户。
流程
要为项目创建本地角色,请运行以下命令:
oc create role <name> --verb=<verb> --resource=<resource> -n <project>
$ oc create role <name> --verb=<verb> --resource=<resource> -n <project>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在此命令中,指定:
-
<name>,本地角色的名称 -
<verb>,以逗号分隔的、应用到角色的操作动词列表 -
<resource>,角色应用到的资源 -
<project>,项目名称
例如,要创建一个本地角色来允许用户查看
blue项目中的 Pod,请运行以下命令:oc create role podview --verb=get --resource=pod -n blue
$ oc create role podview --verb=get --resource=pod -n blueCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
要将新角色绑定到用户,运行以下命令:
oc adm policy add-role-to-user podview user2 --role-namespace=blue -n blue
$ oc adm policy add-role-to-user podview user2 --role-namespace=blue -n blueCopy to Clipboard Copied! Toggle word wrap Toggle overflow
10.2.8. 创建集群角色
您可以创建集群角色。
流程
要创建集群角色,请运行以下命令:
oc create clusterrole <name> --verb=<verb> --resource=<resource>
$ oc create clusterrole <name> --verb=<verb> --resource=<resource>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在此命令中,指定:
-
<name>,本地角色的名称 -
<verb>,以逗号分隔的、应用到角色的操作动词列表 -
<resource>,角色应用到的资源
例如,要创建一个集群角色来允许用户查看 Pod,请运行以下命令:
oc create clusterrole podviewonly --verb=get --resource=pod
$ oc create clusterrole podviewonly --verb=get --resource=podCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
10.2.9. 本地角色绑定命令
在使用以下操作为本地角色绑定管理用户或组的关联角色时,可以使用 -n 标志来指定项目。如果未指定,则使用当前项目。
您可以使用以下命令进行本地 RBAC 管理。
| 命令 | 描述 |
|---|---|
|
| 指出哪些用户可以对某一资源执行某种操作。 |
|
| 将指定角色绑定到当前项目中的指定用户。 |
|
| 从当前项目中的指定用户移除指定角色。 |
|
| 移除当前项目中的指定用户及其所有角色。 |
|
| 将给定角色绑定到当前项目中的指定组。 |
|
| 从当前项目中的指定组移除给定角色。 |
|
| 移除当前项目中的指定组及其所有角色。 |
10.2.10. 集群角色绑定命令
您也可以使用以下操作管理集群角色绑定。因为集群角色绑定使用没有命名空间的资源,所以这些操作不使用 -n 标志。
| 命令 | 描述 |
|---|---|
|
| 将给定角色绑定到集群中所有项目的指定用户。 |
|
| 从集群中所有项目的指定用户移除给定角色。 |
|
| 将给定角色绑定到集群中所有项目的指定组。 |
|
| 从集群中所有项目的指定组移除给定角色。 |
10.2.11. 创建集群管理员
需要具备 cluster-admin 角色才能在 OpenShift Container Platform 集群上执行管理员级别的任务,例如修改集群资源。
先决条件
- 您必须已创建了要定义为集群管理员的用户。
流程
将用户定义为集群管理员:
oc adm policy add-cluster-role-to-user cluster-admin <user>
$ oc adm policy add-cluster-role-to-user cluster-admin <user>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
10.2.12. 未经身份验证的组的集群角色绑定
在 OpenShift Container Platform 4.16 之前,未经身份验证的组可以访问一些集群角色。在 OpenShift Container Platform 4.16 之前,从版本更新的集群会保留这个未经身份验证的组的访问权限。
为了安全起见,OpenShift Container Platform 4.16 不允许未经身份验证的组具有集群角色的默认访问权限。
在有些用例中,可能需要将 system:unauthenticated 添加到集群角色中。
集群管理员可以将未经身份验证的用户添加到以下集群角色中:
-
system:scope-impersonation -
system:webhook -
system:oauth-token-deleter -
self-access-reviewer
在修改未经身份验证的访问时,始终验证符合您机构的安全标准。
10.2.13. 将未经身份验证的组添加到集群角色中
作为集群管理员,您可以通过创建集群角色绑定将未经身份验证的用户添加到 OpenShift Container Platform 中的以下集群角色中。未经身份验证的用户无法访问非公共集群角色。这只应在需要时在特定用例中完成。
您可以将未经身份验证的用户添加到以下集群角色中:
-
system:scope-impersonation -
system:webhook -
system:oauth-token-deleter -
self-access-reviewer
在修改未经身份验证的访问时,始终验证符合您机构的安全标准。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。 -
已安装 OpenShift CLI(
oc)。
流程
创建名为
add-<cluster_role>-unauth.yaml的 YAML 文件,并添加以下内容:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令来应用配置:
oc apply -f add-<cluster_role>.yaml
$ oc apply -f add-<cluster_role>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
10.3. kubeadmin 用户
OpenShift Container Platform 在安装过程完成后会创建一个集群管理员 kubeadmin。
此用户自动具有 cluster-admin 角色,并视为集群的 root 用户。其密码是动态生成的,对 OpenShift Container Platform 环境中是唯一的。安装完成后,安装程序的输出中会包括这个密码。例如:
INFO Install complete! INFO Run 'export KUBECONFIG=<your working directory>/auth/kubeconfig' to manage the cluster with 'oc', the OpenShift CLI. INFO The cluster is ready when 'oc login -u kubeadmin -p <provided>' succeeds (wait a few minutes). INFO Access the OpenShift web-console here: https://console-openshift-console.apps.demo1.openshift4-beta-abcorp.com INFO Login to the console with user: kubeadmin, password: <provided>
INFO Install complete!
INFO Run 'export KUBECONFIG=<your working directory>/auth/kubeconfig' to manage the cluster with 'oc', the OpenShift CLI.
INFO The cluster is ready when 'oc login -u kubeadmin -p <provided>' succeeds (wait a few minutes).
INFO Access the OpenShift web-console here: https://console-openshift-console.apps.demo1.openshift4-beta-abcorp.com
INFO Login to the console with user: kubeadmin, password: <provided>10.3.1. 移除 kubeadmin 用户
在定义了身份提供程序并创建新的 cluster-admin 用户后,您可以移除 kubeadmin 来提高集群安全性。
如果在另一用户成为 cluster-admin 前按照这个步骤操作,则必须重新安装 OpenShift Container Platform。此命令无法撤销。
先决条件
- 必须至少配置了一个身份提供程序。
-
必须向用户添加了
cluster-admin角色。 - 必须已经以管理员身份登录。
流程
移除
kubeadminSecret:oc delete secrets kubeadmin -n kube-system
$ oc delete secrets kubeadmin -n kube-systemCopy to Clipboard Copied! Toggle word wrap Toggle overflow
10.4. 从镜像的 Operator 目录填充 OperatorHub
如果用于断开连接的集群的 Operator 目录的镜像 (mirror),您可以在镜像目录中为 OperatorHub 填充 Operator。您可以使用镜像过程中生成的清单来创建所需的 ImageContentSourcePolicy 和 CatalogSource 对象。
10.4.1. 先决条件
10.4.1.1. 创建 ImageContentSourcePolicy 对象
将 Operator 目录内容镜像到镜像 registry 后,创建所需的 ImageContentSourcePolicy (ICSP)对象。ICSP 对象配置节点,以在 Operator 清单中存储的镜像引用和镜像的 registry 间进行转换。
流程
在可以访问断开连接的集群的主机上,运行以下命令指定 manifests 目录中的
imageContentSourcePolicy.yaml文件来创建 ICSP:oc create -f <path/to/manifests/dir>/imageContentSourcePolicy.yaml
$ oc create -f <path/to/manifests/dir>/imageContentSourcePolicy.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 其中
<path/to/manifests/dir>是镜像内容的 manifests 目录的路径。现在,您可以创建一个
CatalogSource来引用您的镜像索引镜像和 Operator 内容。
10.4.1.2. 在集群中添加目录源
将目录源添加到 OpenShift Container Platform 集群可为用户发现和安装 Operator。集群管理员可以创建一个 CatalogSource 对象来引用索引镜像。OperatorHub 使用目录源来填充用户界面。
或者,您可以使用 Web 控制台管理目录源。在 Administration → Cluster Settings → Configuration → OperatorHub 页面中,点 Sources 选项卡,您可以在其中创建、更新、删除、禁用和启用单独的源。
先决条件
- 构建并推送索引镜像到 registry。
-
您可以使用具有
cluster-admin角色的用户访问集群。
流程
创建一个
CatalogSource对象来引用索引镜像。如果使用oc adm catalog mirror命令将目录镜像到目标 registry,您可以使用 manifests 目录中生成的catalogSource.yaml文件作为起点。根据您的规格修改以下内容,并将它保存为
catalogSource.yaml文件:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 如果您在上传到 registry 前将内容镜像到本地文件,请从
metadata.name字段中删除任何反斜杠(/)字符,以避免在创建对象时出现 "invalid resource name" 错误。 - 2
- 如果您希望目录源对所有命名空间中的用户全局可用,请指定
openshift-marketplace命名空间。否则,您可以指定一个不同的命名空间来对目录进行作用域并只对该命名空间可用。 - 3
- 指定
legacy或restricted的值。如果没有设置该字段,则默认值为legacy。在以后的 OpenShift Container Platform 发行版本中,计划默认值为restricted。注意如果您的目录无法使用
restricted权限运行,建议您手动将此字段设置为legacy。 - 4
- 指定索引镜像。如果您在镜像名称后指定了标签,如
:v4.16,则目录源 Pod 会使用镜像 pull 策略Always,这意味着 pod 始终在启动容器前拉取镜像。如果您指定了摘要,如@sha256:<id>,则镜像拉取策略为IfNotPresent,这意味着仅在节点上不存在的镜像时才拉取镜像。 - 5
- 指定发布目录的名称或机构名称。
- 6
- 目录源可以自动检查新版本以保持最新。
使用该文件创建
CatalogSource对象:oc apply -f catalogSource.yaml
$ oc apply -f catalogSource.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
确定成功创建以下资源。
检查 pod:
oc get pods -n openshift-marketplace
$ oc get pods -n openshift-marketplaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME READY STATUS RESTARTS AGE my-operator-catalog-6njx6 1/1 Running 0 28s marketplace-operator-d9f549946-96sgr 1/1 Running 0 26h
NAME READY STATUS RESTARTS AGE my-operator-catalog-6njx6 1/1 Running 0 28s marketplace-operator-d9f549946-96sgr 1/1 Running 0 26hCopy to Clipboard Copied! Toggle word wrap Toggle overflow 检查目录源:
oc get catalogsource -n openshift-marketplace
$ oc get catalogsource -n openshift-marketplaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME DISPLAY TYPE PUBLISHER AGE my-operator-catalog My Operator Catalog grpc 5s
NAME DISPLAY TYPE PUBLISHER AGE my-operator-catalog My Operator Catalog grpc 5sCopy to Clipboard Copied! Toggle word wrap Toggle overflow 检查软件包清单:
oc get packagemanifest -n openshift-marketplace
$ oc get packagemanifest -n openshift-marketplaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME CATALOG AGE jaeger-product My Operator Catalog 93s
NAME CATALOG AGE jaeger-product My Operator Catalog 93sCopy to Clipboard Copied! Toggle word wrap Toggle overflow
现在,您可以在 OpenShift Container Platform Web 控制台中通过 OperatorHub 安装 Operator。
10.5. 关于使用 OperatorHub 安装 Operator
OperatorHub 是一个发现 Operator 的用户界面,它与 Operator Lifecycle Manager(OLM)一起工作,后者在集群中安装和管理 Operator。
作为集群管理员,您可以使用 OpenShift Container Platform Web 控制台或 CLI 安装来自 OperatorHub 的 Operator。将 Operator 订阅到一个或多个命名空间,供集群上的开发人员使用。
安装过程中,您必须为 Operator 确定以下初始设置:
- 安装模式
- 选择 All namespaces on the cluster (default) 将 Operator 安装至所有命名空间;或选择单个命名空间(如果可用),仅在选定命名空间中安装 Operator。本例选择 All namespaces… 使 Operator 可供所有用户和项目使用。
- 更新频道
- 如果某个 Operator 可通过多个频道获得,则可任选您想要订阅的频道。例如,要通过 stable 频道部署(如果可用),则从列表中选择这个选项。
- 批准策略
您可以选择自动或者手动更新。
如果选择自动更新某个已安装的 Operator,则当所选频道中有该 Operator 的新版本时,Operator Lifecycle Manager(OLM)将自动升级 Operator 的运行实例,而无需人为干预。
如果选择手动更新,则当有新版 Operator 可用时,OLM 会创建更新请求。作为集群管理员,您必须手动批准该更新请求,才可将 Operator 更新至新版本。
10.5.1. 使用 Web 控制台,从 OperatorHub 安装
您可以使用 OpenShift Container Platform Web 控制台从 OperatorHub 安装并订阅 Operator。
先决条件
-
使用具有
cluster-admin权限的账户访问 OpenShift Container Platform 集群。
流程
- 在 Web 控制台中导航至 Operators → OperatorHub 页面。
找到您需要的 Operator(滚动页面会在 Filter by keyword 框中输入查找关键字)。例如,键入
jaeger来查找 Jaeger Operator。您还可以根据基础架构功能过滤选项。例如,如果您希望 Operator 在断开连接的环境中工作,请选择 Disconnected。
选择要显示更多信息的 Operator。
注意选择 Community Operator 会警告红帽没有认证社区 Operator ; 您必须确认该警告方可继续。
- 阅读 Operator 信息并点 Install。
在 Install Operator 页面中,配置 Operator 安装:
如果要安装 Operator 的特定版本,请从列表中选择 Update channel 和 Version。您可以在可能具有的任何频道中浏览 Operator 的不同版本,查看该频道和版本的元数据,然后选择您要安装的确切版本。
注意版本选择默认为所选频道的最新版本。如果选择了频道的最新版本,则默认启用 Automatic 批准策略。如果没有为所选频道安装最新版本,则需要手动批准。
使用手动批准安装 Operator 会导致命名空间中安装的所有 Operator 并使用 Manual 批准策略和所有 Operator 一起更新。如果要独立更新 Operator,将 Operator 安装到单独的命名空间中。
确认 Operator 的安装模式:
-
All namespaces on the cluster (default),选择该项会将 Operator 安装至默认
openshift-operators命名空间,以便供集群中的所有命名空间监视和使用。该选项并非始终可用。 - A specific namespace on the cluster,该项支持您选择单一特定命名空间来安装 Operator。该 Operator 仅限在该单一命名空间中监视和使用。
-
All namespaces on the cluster (default),选择该项会将 Operator 安装至默认
对于启用了令牌身份验证的云供应商上的集群:
- 如果集群使用 AWS STS (Web 控制台中的STS 模式 ),在 role ARN 字段中输入服务帐户的 AWS IAM 角色的 Amazon Resource Name (ARN)。要创建角色的 ARN,请按照 准备 AWS 帐户 中所述的步骤进行操作。
- 如果集群使用 Microsoft Entra Workload ID (Web 控制台中的Workload Identity / Federated Identity Mode ),请在适当的项中添加客户端 ID、租户 ID 和订阅 ID。
对于 更新批准,请选择 Automatic 或 Manual 批准策略。
重要如果 web 控制台显示集群使用 AWS STS 或 Microsoft Entra Workload ID,您必须将 Update approval 设置为 Manual。
不建议使用具有自动更新批准的订阅,因为更新前可能会有权限更改。使用手动批准的订阅可确保管理员有机会验证更新版本的权限,并在更新前采取必要的操作。
点 Install 使 Operator 可供 OpenShift Container Platform 集群上的所选命名空间使用:
如果选择了手动批准策略,订阅的升级状态将保持在 Upgrading 状态,直至您审核并批准安装计划。
在 Install Plan 页面批准后,订阅的升级状态将变为 Up to date。
- 如果选择了 Automatic 批准策略,升级状态会在不用人工参与的情况下变为 Up to date。
验证
在订阅的升级状态变为 Up to date 后,选择 Operators → Installed Operators 来验证已安装 Operator 的集群服务版本(CSV)是否最终出现了。状态 最终会在相关命名空间中变为 Succeeded。
注意对于 All namespaces… 安装模式,状态会在
openshift-operators命名空间中解析为 Succeeded,但如果检查其他命名空间,则状态为 Copied。如果没有:
-
检查
openshift-operators项目(如果选择了 A specific namespace… 安装模式)中的 openshift-operators 项目中的 pod 的日志,这会在 Workloads → Pods 页面中报告问题以便进一步排除故障。
-
检查
安装 Operator 时,元数据会指示安装了哪个频道和版本。
注意此目录上下文中仍可使用 Channel 和 Version 下拉菜单查看其他版本元数据。
10.5.2. 使用 CLI 从 OperatorHub 安装
您可以使用 CLI 从 OperatorHub 安装 Operator,而不必使用 OpenShift Container Platform Web 控制台。使用 oc 命令来创建或更新一个订阅对象。
对于 SingleNamespace 安装模式,还必须确保相关命名空间中存在适当的 Operator 组。一个 Operator 组(由 OperatorGroup 对象定义),在其中选择目标命名空间,在其中为与 Operator 组相同的命名空间中的所有 Operator 生成所需的 RBAC 访问权限。
在大多数情况下,使用 Web 控制台是首选的方法,因为它会在后台自动执行任务,比如在选择 SingleNamespace 模式时自动处理 OperatorGroup 和 Subscription 对象的创建。
先决条件
-
使用具有
cluster-admin权限的账户访问 OpenShift Container Platform 集群。 -
已安装 OpenShift CLI(
oc)。
流程
查看 OperatorHub 中集群可用的 Operator 列表:
oc get packagemanifests -n openshift-marketplace
$ oc get packagemanifests -n openshift-marketplaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例 10.1. 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 记录下所需 Operator 的目录。
检查所需 Operator,以验证其支持的安装模式和可用频道:
oc describe packagemanifests <operator_name> -n openshift-marketplace
$ oc describe packagemanifests <operator_name> -n openshift-marketplaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例 10.2. 输出示例
提示您可以运行以下命令来以 YAML 格式打印 Operator 的版本和频道信息:
oc get packagemanifests <operator_name> -n <catalog_namespace> -o yaml
$ oc get packagemanifests <operator_name> -n <catalog_namespace> -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果在命名空间中安装多个目录,请运行以下命令从特定目录中查找 Operator 的可用版本和频道:
oc get packagemanifest \ --selector=catalog=<catalogsource_name> \ --field-selector metadata.name=<operator_name> \ -n <catalog_namespace> -o yaml
$ oc get packagemanifest \ --selector=catalog=<catalogsource_name> \ --field-selector metadata.name=<operator_name> \ -n <catalog_namespace> -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重要如果没有指定 Operator 的目录,运行
oc get packagemanifest和oc describe packagemanifest命令可能会在满足以下条件时从一个意料外的目录中返回一个软件包:- 在同一命名空间中安装多个目录。
- 目录包含具有相同名称的相同 Operator 或 Operator。
如果要安装的 Operator 支持
AllNamespaces安装模式,而您选择使用这个模式,请跳过这一步,因为openshift-operators命名空间默认有一个适当的 Operator 组,称为global-operators。如果要安装的 Operator 支持
SingleNamespace安装模式,而选择使用此模式,您必须确保相关命名空间中存在适当的 Operator 组。如果不存在,您可以按照以下步骤创建一个:重要每个命名空间只能有一个 Operator 组。如需更多信息,请参阅 "Operator 组"。
为
SingleNamespace安装模式创建一个OperatorGroup对象 YAML 文件,如operatorgroup.yaml:SingleNamespace安装模式的OperatorGroup对象示例Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建
OperatorGroup对象:oc apply -f operatorgroup.yaml
$ oc apply -f operatorgroup.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
创建一个
Subscription对象来订阅一个命名空间到 Operator:为
Subscription对象创建一个 YAML 文件,如subscription.yaml:注意如果要订阅 Operator 的特定版本,请将
startCSV字段设置为所需的版本,并将installPlanApproval字段设置为Manual,以防止 Operator 在目录中有更新的版本时自动升级。详情请参阅以下 "ExampleSubscriptionobject with a specific starting Operator version"。例 10.3.
Subscription对象示例Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 对于默认的
AllNamespaces安装模式用法,请指定openshift-operators命名空间。另外,如果创建了自定义全局命名空间,您可以指定一个自定义全局命名空间。对于SingleNamespace安装模式的使用,请指定相关的单一命名空间。 - 2
- 要订阅的频道的名称。
- 3
- 要订阅的 Operator 的名称。
- 4
- 提供 Operator 的目录源的名称。
- 5
- 目录源的命名空间。将
openshift-marketplace用于默认的 OperatorHub 目录源。 - 6
env参数定义必须存在于由 OLM 创建的 pod 中所有容器中的环境变量列表。- 7
envFrom参数定义要在容器中填充环境变量的源列表。- 8
volumes参数定义了由 OLM 创建的、在 pod 上必须存在的卷列表。- 9
volumeMounts参数定义由 OLM 创建的 pod 中必须存在的卷挂载列表。如果volumeMount引用不存在的卷,OLM 无法部署 Operator。- 10
tolerations参数为 OLM 创建的 pod 定义容限列表。- 11
resources参数为 OLM 创建的 pod 中所有容器定义资源限制。- 12
nodeSelector参数为 OLM 创建的 pod 定义NodeSelector。
对于启用了令牌身份验证的云供应商上的集群,按照以下步骤配置您的
Subscription对象:确保
Subscription对象被设置为手动更新批准:kind: Subscription # ... spec: installPlanApproval: Manual
kind: Subscription # ... spec: installPlanApproval: Manual1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 不建议使用具有自动更新批准的订阅,因为更新前可能会有权限更改。使用手动批准的订阅可确保管理员有机会验证更新版本的权限,并在更新前采取必要的操作。
在
Subscription对象的config部分包括相关的云供应商相关字段:如果集群处于 AWS STS 模式,请包含以下字段:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 包含角色 ARN 详情。
如果集群处于 Microsoft Entra Workload ID 模式,请包括以下字段:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 其中:
<client_id>- 是客户端 ID。
<tenant_id>- 是租户 ID。
<subscription_id>- 是订阅 ID。
运行以下命令来创建
Subscription对象:oc apply -f subscription.yaml
$ oc apply -f subscription.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
-
如果将
installPlanApproval字段设置为Manual,请手动批准待处理的安装计划以完成 Operator 安装。如需更多信息,请参阅"手动批准待处理的 Operator 更新"。
此时,OLM 已了解所选的 Operator。Operator 的集群服务版本(CSV)应出现在目标命名空间中,由 Operator 提供的 API 应可用于创建。
验证
运行以下命令,检查已安装的 Operator 的
Subscription对象状态:oc describe subscription <subscription_name> -n <namespace>
$ oc describe subscription <subscription_name> -n <namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果您为
SingleNamespace安装模式创建了 Operator 组,请运行以下命令检查OperatorGroup对象的状态:oc describe operatorgroup <operatorgroup_name> -n <namespace>
$ oc describe operatorgroup <operatorgroup_name> -n <namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
第 11 章 更改云供应商凭证配置
对于支持的配置,您可以更改 OpenShift Container Platform 与云供应商进行身份验证的方式。
要确定集群使用哪个云凭证策略,请参阅 确定 Cloud Credential Operator 模式。
11.1. 轮转或删除云供应商凭证
安装 OpenShift Container Platform 后,一些机构需要轮转或删除初始安装过程中使用的云供应商凭证。
要允许集群使用新凭证,您必须更新 Cloud Credential Operator(CCO)用来管理云供应商凭证的 secret。
11.1.1. 使用 Cloud Credential Operator 实用程序轮转云供应商凭证
Cloud Credential Operator (CCO) 实用程序 ccoctl 支持为 IBM Cloud® 上安装的集群更新 secret。
11.1.1.1. 轮转 API 密钥
您可以为现有服务 ID 轮转 API 密钥,并更新对应的 secret。
先决条件
-
您已配置了
ccoctl二进制文件。 - 已安装 live OpenShift Container Platform 集群中现有的服务 ID。
流程
使用
ccoctl实用程序轮转服务 ID 的 API 密钥并更新 secret:ccoctl <provider_name> refresh-keys \ --kubeconfig <openshift_kubeconfig_file> \ --credentials-requests-dir <path_to_credential_requests_directory> \ --name <name>$ ccoctl <provider_name> refresh-keys \1 --kubeconfig <openshift_kubeconfig_file> \2 --credentials-requests-dir <path_to_credential_requests_directory> \3 --name <name>4 Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意如果您的集群使用
TechPreviewNoUpgrade功能集启用的技术预览功能,则必须包含--enable-tech-preview参数。
11.1.2. 手动轮转云供应商凭证
如果因为某种原因更改了云供应商凭证,您必须手动更新 Cloud Credential Operator(CCO)用来管理云供应商凭证的 secret。
轮转云凭证的过程取决于 CCO 配置使用的模式。在为使用 mint 模式的集群轮转凭证后,您必须手动删除由删除凭证创建的组件凭证。
先决条件
您的集群会在支持使用您要使用的 CCO 模式手动轮转云凭证的平台上安装:
- 对于 mint 模式,支持 Amazon Web Services (AWS)和 Google Cloud。
- 对于 passthrough 模式,支持 Amazon Web Services (AWS)、Microsoft Azure、Google Cloud、Red Hat OpenStack Platform (RHOSP)和 VMware vSphere。
- 您已更改了用于与云供应商接口的凭证。
- 新凭证有足够的权限来在集群中使用 CCO 模式。
流程
- 在 web 控制台的 Administrator 视角中,导航到 Workloads → Secrets。
在 Secrets 页面的表中,找到您的云供应商的 root secret。
Expand 平台 Secret 名称 AWS
aws-credsAzure
azure-credentialsGoogle Cloud
gcp-credentialsRHOSP
openstack-credentialsVMware vSphere
vsphere-creds-
点击与 secret 相同的行
 中的 Options 菜单,然后选择 Edit Secret。
中的 Options 菜单,然后选择 Edit Secret。
- 记录 Value 字段的内容。您可以使用这些信息验证在更新凭证后该值是否不同。
- 使用云供应商的新身份验证信息更新 Value 字段的文本,然后点 Save。
如果您要为没有启用 vSphere CSI Driver Operator 的 vSphere 集群更新凭证,您必须强制推出 Kubernetes 控制器管理器以应用更新的凭证。
注意如果启用了 vSphere CSI Driver Operator,则不需要这一步。
要应用更新的 vSphere 凭证,请以具有
cluster-admin角色的用户身份登录到 OpenShift Container Platform CLI,并运行以下命令:oc patch kubecontrollermanager cluster \ -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date )"'"}}' \ --type=merge$ oc patch kubecontrollermanager cluster \ -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date )"'"}}' \ --type=mergeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 当凭证被推出时,Kubernetes Controller Manager Operator 的状态会报告
Progressing=true。要查看状态,请运行以下命令:oc get co kube-controller-manager
$ oc get co kube-controller-managerCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果集群的 CCO 配置为使用 mint 模式,请删除各个
CredentialsRequest对象引用的每个组件 secret。-
以具有
cluster-admin角色的用户身份登录 OpenShift Container Platform CLI。 获取所有引用的组件 secret 的名称和命名空间:
oc -n openshift-cloud-credential-operator get CredentialsRequest \ -o json | jq -r '.items[] | select (.spec.providerSpec.kind=="<provider_spec>") | .spec.secretRef'
$ oc -n openshift-cloud-credential-operator get CredentialsRequest \ -o json | jq -r '.items[] | select (.spec.providerSpec.kind=="<provider_spec>") | .spec.secretRef'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 其中
<provider_spec>是您的云供应商的对应值:-
AWS:
AWSProviderSpec -
Google Cloud:
GCPProviderSpec
AWS 输出的部分示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
AWS:
删除每个引用的组件 secret:
oc delete secret <secret_name> \ -n <secret_namespace>
$ oc delete secret <secret_name> \1 -n <secret_namespace>2 Copy to Clipboard Copied! Toggle word wrap Toggle overflow 删除 AWS secret 示例
oc delete secret ebs-cloud-credentials -n openshift-cluster-csi-drivers
$ oc delete secret ebs-cloud-credentials -n openshift-cluster-csi-driversCopy to Clipboard Copied! Toggle word wrap Toggle overflow 您不需要从供应商控制台手动删除凭证。删除引用的组件 secret 将导致 CCO 从平台中删除现有凭证并创建新凭证。
-
以具有
验证
验证凭证是否已更改:
- 在 web 控制台的 Administrator 视角中,导航到 Workloads → Secrets。
- 验证 Value 字段的内容已改变。
11.1.3. 删除云供应商凭证
对于以 mint 模式使用 Cloud Credential Operator (CCO)的集群,管理员级别的凭证存储在 kube-system 命名空间中。CCO 使用 admin 凭证来处理集群中的 CredentialsRequest 对象,并为具有有限权限的组件创建用户。
在以 mint 模式使用 CCO 安装 OpenShift Container Platform 集群后,您可以从集群中的 kube-system 命名空间中删除管理员级别的凭证 secret。CCO 在需要协调新的或修改的 CredentialsRequest 自定义资源(如次版本更新)更改时只需要管理员级别的凭证。
在执行次版本集群更新前(例如,从 OpenShift Container Platform 4.16 更新至 4.17),您必须使用管理员级别的凭证重新恢复凭证 secret。如果没有凭证,则可能会阻止更新。
先决条件
- 集群安装在支持从 CCO 中删除云凭证的平台上。支持的平台是 AWS 和 Google Cloud。
流程
- 在 web 控制台的 Administrator 视角中,导航到 Workloads → Secrets。
在 Secrets 页面的表中,找到您的云供应商的 root secret。
Expand 平台 Secret 名称 AWS
aws-credsGoogle Cloud
gcp-credentials-
点击与 secret 相同的行
中的 Options 菜单,然后选择 Delete Secret。
11.2. 启用基于令牌的身份验证
安装 Microsoft Azure OpenShift Container Platform 集群后,您可以启用 Microsoft Entra Workload ID 来使用简短凭证。
11.2.1. 配置 Cloud Credential Operator 工具
要将现有集群配置为从集群外部创建和管理云凭证,请提取并准备 Cloud Credential Operator 实用程序(ccoctl)二进制文件。
ccoctl 工具是在 Linux 环境中运行的 Linux 二进制文件。
先决条件
- 您可以访问具有集群管理员权限的 OpenShift Container Platform 帐户。
-
已安装 OpenShift CLI(
oc)。
流程
运行以下命令,为 OpenShift Container Platform 发行镜像设置变量:
RELEASE_IMAGE=$(oc get clusterversion -o jsonpath={..desired.image})$ RELEASE_IMAGE=$(oc get clusterversion -o jsonpath={..desired.image})Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,从 OpenShift Container Platform 发行镜像获取 CCO 容器镜像:
CCO_IMAGE=$(oc adm release info --image-for='cloud-credential-operator' $RELEASE_IMAGE -a ~/.pull-secret)
$ CCO_IMAGE=$(oc adm release info --image-for='cloud-credential-operator' $RELEASE_IMAGE -a ~/.pull-secret)Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意确保
$RELEASE_IMAGE的架构与将使用ccoctl工具的环境架构相匹配。运行以下命令,将 CCO 容器镜像中的
ccoctl二进制文件提取到 OpenShift Container Platform 发行镜像中:oc image extract $CCO_IMAGE \ --file="/usr/bin/ccoctl.<rhel_version>" \ -a ~/.pull-secret
$ oc image extract $CCO_IMAGE \ --file="/usr/bin/ccoctl.<rhel_version>" \1 -a ~/.pull-secretCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 对于
<rhel_version>,请指定与主机使用的 Red Hat Enterprise Linux (RHEL) 版本对应的值。如果没有指定值,则默认使用ccoctl.rhel8。以下值有效:-
rhel8: 为使用 RHEL 8 的主机指定这个值。 -
rhel9:为使用 RHEL 9 的主机指定这个值。
-
注意ccoctl二进制文件在您执行此命令的目录中创建,而不是在/usr/bin/中创建。您必须重命名目录或将ccoctl.<rhel_version> 二进制文件移到ccoctl。运行以下命令更改权限以使
ccoctl可执行:chmod 775 ccoctl
$ chmod 775 ccoctlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
要验证
ccoctl是否准备就绪,可以尝试显示帮助文件。运行命令时使用相对文件名,例如:./ccoctl
$ ./ccoctlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
11.2.2. 在现有集群中启用 Microsoft Entra Workload ID
如果您没有将 Microsoft Azure OpenShift Container Platform 集群配置为在安装过程中使用 Microsoft Entra Workload ID,您可以在现有集群上启用此验证方法。
在现有集群中启用工作负载 ID 的过程具有破坏性,需要花费大量时间。在继续操作前,请观察以下注意事项:
- 阅读以下步骤,并确保您了解并接受时间要求。具体的时间要求因单个集群而异,但可能需要至少一个小时。
- 在此过程中,您必须刷新所有服务帐户并重启集群中的所有 pod。这些操作对工作负载具有破坏性。要缓解这种影响,您可以临时停止这些服务,然后在集群就绪时重新部署它们。
- 启动此过程后,在完成前不要尝试更新集群。如果触发更新,在现有集群中启用 Workload ID 的过程会失败。
先决条件
- 您已在 Microsoft Azure 上安装了 OpenShift Container Platform 集群。
-
您可以使用具有
cluster-admin权限的账户访问集群。 -
已安装 OpenShift CLI(
oc)。 -
您已提取并准备 Cloud Credential Operator 实用程序 (
ccoctl) 二进制文件。 -
您可以使用 Azure CLI (
az) 访问 Azure 帐户。
流程
-
为
ccoctl工具生成的清单创建一个输出目录。此流程使用./output_dir作为示例。 运行以下命令,将集群的服务帐户公钥密钥提取到输出目录中:
oc get configmap \ --namespace openshift-kube-apiserver bound-sa-token-signing-certs \ --output 'go-template={{index .data "service-account-001.pub"}}' > ./output_dir/serviceaccount-signer.public$ oc get configmap \ --namespace openshift-kube-apiserver bound-sa-token-signing-certs \ --output 'go-template={{index .data "service-account-001.pub"}}' > ./output_dir/serviceaccount-signer.public1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 此流程使用名为
serviceaccount-signer.public的文件作为示例。
运行以下命令,使用提取的服务帐户公钥创建 OpenID Connect (OIDC) 签发者和 Azure blob 存储容器:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,验证 Azure pod 身份 Webhook 的配置文件是否已创建:
ll ./output_dir/manifests
$ ll ./output_dir/manifestsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
total 8 -rw-------. 1 cloud-user cloud-user 193 May 22 02:29 azure-ad-pod-identity-webhook-config.yaml -rw-------. 1 cloud-user cloud-user 165 May 22 02:29 cluster-authentication-02-config.yaml
total 8 -rw-------. 1 cloud-user cloud-user 193 May 22 02:29 azure-ad-pod-identity-webhook-config.yaml1 -rw-------. 1 cloud-user cloud-user 165 May 22 02:29 cluster-authentication-02-config.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 文件
azure-ad-pod-identity-webhook-config.yaml包含 Azure pod 身份 Webhook 配置。
运行以下命令,使用输出目录中生成的清单中的
OIDC_ISSUER_URL变量设置 OIDC_ISSUER_URL 变量:OIDC_ISSUER_URL=`awk '/serviceAccountIssuer/ { print $2 }' ./output_dir/manifests/cluster-authentication-02-config.yaml`$ OIDC_ISSUER_URL=`awk '/serviceAccountIssuer/ { print $2 }' ./output_dir/manifests/cluster-authentication-02-config.yaml`Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,更新集群
身份验证配置的spec.serviceAccountIssuer参数:oc patch authentication cluster \ --type=merge \ -p "{\"spec\":{\"serviceAccountIssuer\":\"${OIDC_ISSUER_URL}\"}}"$ oc patch authentication cluster \ --type=merge \ -p "{\"spec\":{\"serviceAccountIssuer\":\"${OIDC_ISSUER_URL}\"}}"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令监控配置更新进度:
oc adm wait-for-stable-cluster
$ oc adm wait-for-stable-clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 这个过程可能需要 15 分钟或更长时间。以下输出表示进程已完成:
All clusteroperators are stable
All clusteroperators are stableCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令重启集群中的所有 pod:
oc adm reboot-machine-config-pool mcp/worker mcp/master
$ oc adm reboot-machine-config-pool mcp/worker mcp/masterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启 pod 会更新
serviceAccountIssuer字段,并刷新服务帐户公钥。运行以下命令监控重启和更新进程:
oc adm wait-for-node-reboot nodes --all
$ oc adm wait-for-node-reboot nodes --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow 这个过程可能需要 15 分钟或更长时间。以下输出表示进程已完成:
All nodes rebooted
All nodes rebootedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,将 Cloud Credential Operator
spec.credentialsMode参数更新为Manual:oc patch cloudcredential cluster \ --type=merge \ --patch '{"spec":{"credentialsMode":"Manual"}}'$ oc patch cloudcredential cluster \ --type=merge \ --patch '{"spec":{"credentialsMode":"Manual"}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,从 OpenShift Container Platform 发行镜像中提取
CredentialsRequest对象列表:oc adm release extract \ --credentials-requests \ --included \ --to <path_to_directory_for_credentials_requests> \ --registry-config ~/.pull-secret
$ oc adm release extract \ --credentials-requests \ --included \ --to <path_to_directory_for_credentials_requests> \ --registry-config ~/.pull-secretCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意此命令可能需要一些时间才能运行。
运行以下命令,使用 Azure 资源组名称设置
AZURE_INSTALL_RG变量:AZURE_INSTALL_RG=`oc get infrastructure cluster -o jsonpath --template '{ .status.platformStatus.azure.resourceGroupName }'`$ AZURE_INSTALL_RG=`oc get infrastructure cluster -o jsonpath --template '{ .status.platformStatus.azure.resourceGroupName }'`Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,使用
ccoctl工具为所有CredentialsRequest对象创建受管身份:注意以下命令没有显示所有可用的选项。如需完整的选项列表,包括可能需要特定用例的选项列表,请运行
$ ccoctl azure create-managed-identities --help。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,为 Workload ID 应用 Azure pod 身份 Webhook 配置:
oc apply -f ./output_dir/manifests/azure-ad-pod-identity-webhook-config.yaml
$ oc apply -f ./output_dir/manifests/azure-ad-pod-identity-webhook-config.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令应用
ccoctl工具生成的 secret:find ./output_dir/manifests -iname "openshift*yaml" -print0 | xargs -I {} -0 -t oc replace -f {}$ find ./output_dir/manifests -iname "openshift*yaml" -print0 | xargs -I {} -0 -t oc replace -f {}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 这可能需要几分钟。
运行以下命令重启集群中的所有 pod:
oc adm reboot-machine-config-pool mcp/worker mcp/master
$ oc adm reboot-machine-config-pool mcp/worker mcp/masterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启 pod 会更新
serviceAccountIssuer字段,并刷新服务帐户公钥。运行以下命令监控重启和更新进程:
oc adm wait-for-node-reboot nodes --all
$ oc adm wait-for-node-reboot nodes --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow 这个过程可能需要 15 分钟或更长时间。以下输出表示进程已完成:
All nodes rebooted
All nodes rebootedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令监控配置更新进度:
oc adm wait-for-stable-cluster
$ oc adm wait-for-stable-clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 这个过程可能需要 15 分钟或更长时间。以下输出表示进程已完成:
All clusteroperators are stable
All clusteroperators are stableCopy to Clipboard Copied! Toggle word wrap Toggle overflow 可选:运行以下命令来删除 Azure root 凭证 secret:
oc delete secret -n kube-system azure-credentials
$ oc delete secret -n kube-system azure-credentialsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
11.2.3. 验证集群是否使用短期凭证
您可以通过检查集群中的 Cloud Credential Operator (CCO) 配置和其他值来验证集群是否对各个组件使用简短安全凭证。
先决条件
-
已使用 Cloud Credential Operator 实用程序(
ccoctl)部署了 OpenShift Container Platform 集群来实现短期凭证。 -
已安装 OpenShift CLI(
oc)。 -
您以具有
cluster-admin权限的用户身份登录。
流程
运行以下命令,验证 CCO 是否配置为以手动模式运行:
oc get cloudcredentials cluster \ -o=jsonpath={.spec.credentialsMode}$ oc get cloudcredentials cluster \ -o=jsonpath={.spec.credentialsMode}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下输出确认 CCO 以手动模式运行:
输出示例
Manual
ManualCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,验证集群没有
root凭证:oc get secrets \ -n kube-system <secret_name>
$ oc get secrets \ -n kube-system <secret_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 其中
<secret_name>是云供应商的 root secret 的名称。Expand 平台 Secret 名称 Amazon Web Services (AWS)
aws-credsMicrosoft Azure
azure-credentialsGoogle Cloud
gcp-credentials一个错误确认集群中不存在 root secret。
AWS 集群的输出示例
Error from server (NotFound): secrets "aws-creds" not found
Error from server (NotFound): secrets "aws-creds" not foundCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行以下命令,验证组件是否在单个组件中使用短期安全凭证:
oc get authentication cluster \ -o jsonpath \ --template='{ .spec.serviceAccountIssuer }'$ oc get authentication cluster \ -o jsonpath \ --template='{ .spec.serviceAccountIssuer }'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 此命令显示集群
Authentication对象中.spec.serviceAccountIssuer参数的值。与云供应商关联的 URL 的输出表示集群使用从集群外部创建和管理的简短凭证的手动模式。Azure 集群:通过运行以下命令,验证组件假定 secret 清单中指定的 Azure 客户端 ID:
oc get secrets \ -n openshift-image-registry installer-cloud-credentials \ -o jsonpath='{.data}'$ oc get secrets \ -n openshift-image-registry installer-cloud-credentials \ -o jsonpath='{.data}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出中包含了
azure_client_id和azure_federated_token_file字段代表组件假定 Azure 客户端 ID。Azure 集群 :运行以下命令来验证 pod 身份 Webhook 是否正在运行:
oc get pods \ -n openshift-cloud-credential-operator
$ oc get pods \ -n openshift-cloud-credential-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME READY STATUS RESTARTS AGE cloud-credential-operator-59cf744f78-r8pbq 2/2 Running 2 71m pod-identity-webhook-548f977b4c-859lz 1/1 Running 1 70m
NAME READY STATUS RESTARTS AGE cloud-credential-operator-59cf744f78-r8pbq 2/2 Running 2 71m pod-identity-webhook-548f977b4c-859lz 1/1 Running 1 70mCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第 12 章 配置警报通知
在 OpenShift Container Platform 中,当警报规则中定义的条件满足时会触发警报。警报提供一条通知,表示集群中存在一组情况。默认情况下,触发的警报可在 OpenShift Container Platform Web 控制台中的 Alerting UI 中查看。安装后,您可以配置 OpenShift Container Platform,将警报通知发送到外部系统。
12.1. 将通知发送到外部系统
在 OpenShift Container Platform 4.16 中,可在 Alerting UI 中查看触发警报。默认不会将警报配置为发送到任何通知系统。您可以将 OpenShift Container Platform 配置为将警报发送到以下类型的接收器:
- PagerDuty
- Webhook
- 电子邮件
- Slack
- Microsoft Teams
通过将警报路由到接收器,您可在出现故障时及时向适当的团队发送通知。例如,关键警报需要立即关注,通常会传给个人或关键响应团队。相反,提供非关键警告通知的警报可能会被路由到一个问题单系统进行非即时的审阅。
使用 watchdog 警报检查警报是否工作正常
OpenShift Container Platform 监控功能包含持续触发的 watchdog 警报。Alertmanager 重复向已配置的通知提供程序发送 watchdog 警报通知。此提供程序通常会配置为在其停止收到 watchdog 警报时通知管理员。这种机制可帮助您快速识别 Alertmanager 和通知提供程序之间的任何通信问题。
第 13 章 将连接的集群转换为断开连接的集群
在某些情况下,您可能需要将 OpenShift Container Platform 集群从连接的集群转换为断开连接的集群。
断开连接的集群(也称为受限集群)没有与互联网的活跃连接。因此,您必须镜像 registry 和安装介质的内容。您可以在可以访问互联网和您的封闭网络的主机上创建此镜像 registry,或者将镜像复制到可跨网络界限的设备中。
本主题描述了将现有连接的集群转换为断开连接的集群的一般过程。
13.1. 关于镜像 registry
您必须可以访问互联网来获取所需的容器镜像。使用替代 registry 意味着将镜像 registry 放在可访问您的网络以及互联网的镜像(mirror)主机上。
您可以镜像 OpenShift Container Platform 安装所需的镜像,以及容器镜像 registry 的后续产品更新,如 Red Hat Quay、JFrog Artifactory、Sonatype Nexus Repository 或 Harbor。如果您无法访问大型容器 registry,可以使用 mirror registry for Red Hat OpenShift,它是包括在 OpenShift Container Platform 订阅中的一个小型容器 registry。
您可以使用支持 Docker v2-2 的任何容器 registry,如 Red Hat Quay, mirror registry for Red Hat OpenShift, Artifactory, Sonatype Nexus Repository, 或 Harbor。无论您所选 registry 是什么,都会将互联网上红帽托管站点的内容镜像到隔离的镜像 registry 相同。镜像内容后,您要将每个集群配置为从镜像 registry 中检索此内容。
OpenShift 镜像 registry 不能用作目标 registry,因为它不支持没有标签的推送,在镜像过程中需要这个推送。
如果选择的容器 registry 不是 mirror registry for Red Hat OpenShift,则需要集群中置备的每台机器都可以访问它。如果 registry 无法访问,安装、更新或常规操作(如工作负载重新定位)可能会失败。因此,您必须以高度可用的方式运行镜像 registry,镜像 registry 至少必须与 OpenShift Container Platform 集群的生产环境可用性相匹配。
使用 OpenShift Container Platform 镜像填充镜像 registry 时,可以遵循以下两种情况。如果您的主机可以同时访问互联网和您的镜像 registry,而不能访问您的集群节点,您可以直接从该机器中镜像该内容。这个过程被称为 连接的镜像(mirror)。如果没有这样的主机,则必须将该镜像文件镜像到文件系统中,然后将该主机或者可移动介质放入受限环境中。这个过程被称为 断开连接的镜像。
对于已镜像的 registry,若要查看拉取镜像的来源,您必须查看 Trying 以访问 CRI-O 日志中的日志条目。查看镜像拉取源的其他方法(如在节点上使用 crictl images 命令)显示非镜像镜像名称,即使镜像是从镜像位置拉取的。
红帽不会在 OpenShift Container Platform 中测试第三方 registry。
13.2. 先决条件
-
已安装
oc客户端。 - 一个正在运行的集群。
安装的镜像 registry,这是支持托管 OpenShift Container Platform 集群的位置的 Docker v2-2 的容器镜像 registry,如以下 registry 之一:
如果您有 Red Hat Quay 订阅,请参阅有关部署 Red Hat Quay for 概念验证 的文档,或使用 Quay Operator。
- 必须将镜像存储库配置为共享镜像。例如,Red Hat Quay 仓库需要 机构 才能共享镜像。
- 访问互联网来获取所需的容器镜像。
13.3. 为镜像准备集群
在断开集群的连接前,您必须镜像(mirror)或复制(mirror)或复制(mirror)或复制镜像(mirror) registry。要镜像镜像,您必须通过以下方法准备集群:
- 将镜像 registry 证书添加到主机上的可信 CA 列表中。
-
创建包含您的镜像 pull secret 的
.dockerconfigjson文件,该文件来自cloud.openshift.com令牌。
流程
配置允许镜像镜像的凭证:
将镜像 registry 的 CA 证书(采用简单 PEM 或 DER 文件格式)添加到可信 CA 列表中。例如:
cp </path/to/cert.crt> /usr/share/pki/ca-trust-source/anchors/
$ cp </path/to/cert.crt> /usr/share/pki/ca-trust-source/anchors/Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 其中,
</path/to/cert.crt> - 指定本地文件系统中的证书路径。
- 其中,
更新 CA 信任。例如,在 Linux 中:
update-ca-trust
$ update-ca-trustCopy to Clipboard Copied! Toggle word wrap Toggle overflow 从全局 pull secret 中提取
.dockerconfigjson文件:oc extract secret/pull-secret -n openshift-config --confirm --to=.
$ oc extract secret/pull-secret -n openshift-config --confirm --to=.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
.dockerconfigjson
.dockerconfigjsonCopy to Clipboard Copied! Toggle word wrap Toggle overflow 编辑
.dockerconfigjson文件以添加您的镜像 registry 和身份验证凭证,并将它保存为新文件:{"auths":{"<local_registry>": {"auth": "<credentials>","email": "you@example.com"}}},"<registry>:<port>/<namespace>/":{"auth":"<token>"}}}{"auths":{"<local_registry>": {"auth": "<credentials>","email": "you@example.com"}}},"<registry>:<port>/<namespace>/":{"auth":"<token>"}}}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 其中:
<local_registry>- 指定 registry 域名,以及您的镜像 registry 用来提供内容的可选端口。
auth- 为您的镜像 registry 指定 base64 编码的用户名和密码。
<registry>:<port>/<namespace>- 指定镜像 registry 详情。
<token>为您的镜像 registry 指定 base64 编码的
username:password。例如:
{"auths":{"cloud.openshift.com":{"auth":"b3BlbnNoaWZ0Y3UjhGOVZPT0lOMEFaUjdPUzRGTA==","email":"user@example.com"}, "quay.io":{"auth":"b3BlbnNoaWZ0LXJlbGVhc2UtZGOVZPT0lOMEFaUGSTd4VGVGVUjdPUzRGTA==","email":"user@example.com"}, "registry.connect.redhat.com"{"auth":"NTE3MTMwNDB8dWhjLTFEZlN3VHkxOSTd4VGVGVU1MdTpleUpoYkdjaUailA==","email":"user@example.com"}, "registry.redhat.io":{"auth":"NTE3MTMwNDB8dWhjLTFEZlN3VH3BGSTd4VGVGVU1MdTpleUpoYkdjaU9fZw==","email":"user@example.com"}, "registry.svc.ci.openshift.org":{"auth":"dXNlcjpyWjAwWVFjSEJiT2RKVW1pSmg4dW92dGp1SXRxQ3RGN1pwajJhN1ZXeTRV"},"my-registry:5000/my-namespace/":{"auth":"dXNlcm5hbWU6cGFzc3dvcmQ="}}}$ {"auths":{"cloud.openshift.com":{"auth":"b3BlbnNoaWZ0Y3UjhGOVZPT0lOMEFaUjdPUzRGTA==","email":"user@example.com"}, "quay.io":{"auth":"b3BlbnNoaWZ0LXJlbGVhc2UtZGOVZPT0lOMEFaUGSTd4VGVGVUjdPUzRGTA==","email":"user@example.com"}, "registry.connect.redhat.com"{"auth":"NTE3MTMwNDB8dWhjLTFEZlN3VHkxOSTd4VGVGVU1MdTpleUpoYkdjaUailA==","email":"user@example.com"}, "registry.redhat.io":{"auth":"NTE3MTMwNDB8dWhjLTFEZlN3VH3BGSTd4VGVGVU1MdTpleUpoYkdjaU9fZw==","email":"user@example.com"}, "registry.svc.ci.openshift.org":{"auth":"dXNlcjpyWjAwWVFjSEJiT2RKVW1pSmg4dW92dGp1SXRxQ3RGN1pwajJhN1ZXeTRV"},"my-registry:5000/my-namespace/":{"auth":"dXNlcm5hbWU6cGFzc3dvcmQ="}}}Copy to Clipboard Copied! Toggle word wrap Toggle overflow
13.4. 对容器镜像进行镜像处理(mirror)
正确配置集群后,您可以将外部存储库中的镜像镜像到镜像存储库。
流程
镜像 Operator Lifecycle Manager(OLM)镜像:
oc adm catalog mirror registry.redhat.io/redhat/redhat-operator-index:v{product-version} <mirror_registry>:<port>/olm -a <reg_creds>$ oc adm catalog mirror registry.redhat.io/redhat/redhat-operator-index:v{product-version} <mirror_registry>:<port>/olm -a <reg_creds>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 其中:
product-version-
指定要与 OpenShift Container Platform 版本对应的标签,如
4.8。 mirror_registry-
指定用于镜像 Operator 内容的目标 registry 和命名空间的完全限定域名(FQDN),其中
<namespace>是 registry 上的任何现有命名空间。 reg_creds-
指定您修改的
.dockerconfigjson文件的位置。
例如:
oc adm catalog mirror registry.redhat.io/redhat/redhat-operator-index:v4.8 mirror.registry.com:443/olm -a ./.dockerconfigjson --index-filter-by-os='.*'
$ oc adm catalog mirror registry.redhat.io/redhat/redhat-operator-index:v4.8 mirror.registry.com:443/olm -a ./.dockerconfigjson --index-filter-by-os='.*'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 为任何其他红帽提供的 Operator 镜像内容:
oc adm catalog mirror <index_image> <mirror_registry>:<port>/<namespace> -a <reg_creds>
$ oc adm catalog mirror <index_image> <mirror_registry>:<port>/<namespace> -a <reg_creds>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 其中:
index_image- 指定您要镜像的目录的索引镜像。
mirror_registry-
指定要将 Operator 内容镜像到的目标 registry 和命名空间的 FQDN,其中
<namespace>是 registry 上的任何现有命名空间。 reg_creds- 可选:如果需要,指定 registry 凭证文件的位置。
例如:
oc adm catalog mirror registry.redhat.io/redhat/community-operator-index:v4.8 mirror.registry.com:443/olm -a ./.dockerconfigjson --index-filter-by-os='.*'
$ oc adm catalog mirror registry.redhat.io/redhat/community-operator-index:v4.8 mirror.registry.com:443/olm -a ./.dockerconfigjson --index-filter-by-os='.*'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 镜像 OpenShift Container Platform 镜像存储库:
oc adm release mirror -a .dockerconfigjson --from=quay.io/openshift-release-dev/ocp-release:v<product-version>-<architecture> --to=<local_registry>/<local_repository> --to-release-image=<local_registry>/<local_repository>:v<product-version>-<architecture>
$ oc adm release mirror -a .dockerconfigjson --from=quay.io/openshift-release-dev/ocp-release:v<product-version>-<architecture> --to=<local_registry>/<local_repository> --to-release-image=<local_registry>/<local_repository>:v<product-version>-<architecture>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 其中:
product-version-
指定与要安装的 OpenShift Container Platform 版本对应的标签,如
4.8.15-x86_64。 架构-
为您的服务器指定构架类型,如
x86_64。 local_registry- 指定镜像存储库的 registry 域名。
local_repository-
指定要在 registry 中创建的存储库名称,如
ocp4/openshift4。
例如:
oc adm release mirror -a .dockerconfigjson --from=quay.io/openshift-release-dev/ocp-release:4.8.15-x86_64 --to=mirror.registry.com:443/ocp/release --to-release-image=mirror.registry.com:443/ocp/release:4.8.15-x86_64
$ oc adm release mirror -a .dockerconfigjson --from=quay.io/openshift-release-dev/ocp-release:4.8.15-x86_64 --to=mirror.registry.com:443/ocp/release --to-release-image=mirror.registry.com:443/ocp/release:4.8.15-x86_64Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 根据需要镜像任何其他 registry:
oc image mirror <online_registry>/my/image:latest <mirror_registry>
$ oc image mirror <online_registry>/my/image:latest <mirror_registry>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
附加信息
- 如需有关镜像 Operator 目录的更多信息,请参阅 镜像 Operator 目录。
-
如需有关
oc adm catalog mirror命令的更多信息,请参阅 OpenShift CLI 管理员命令参考。
13.5. 为镜像 registry 配置集群
在将镜像创建并镜像(mirror)到镜像 registry 后,您必须修改集群,以便 pod 可以从镜像 registry 中拉取镜像。
您必须:
- 将镜像 registry 凭证添加到全局 pull secret 中。
- 在集群中添加镜像 registry 服务器证书。
创建
ImageContentSourcePolicy自定义资源(ICSP),它将镜像 registry 与源 registry 关联。将镜像 registry 凭证添加到集群全局 pull-secret 中:
oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=<pull_secret_location>
$ oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=<pull_secret_location>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 提供新 pull secret 文件的路径。
例如:
oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=.mirrorsecretconfigjson
$ oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=.mirrorsecretconfigjsonCopy to Clipboard Copied! Toggle word wrap Toggle overflow 将 CA 签名的镜像 registry 服务器证书添加到集群中的节点:
创建包含镜像 registry 的服务器证书的配置映射
oc create configmap <config_map_name> --from-file=<mirror_address_host>..<port>=$path/ca.crt -n openshift-config
$ oc create configmap <config_map_name> --from-file=<mirror_address_host>..<port>=$path/ca.crt -n openshift-configCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
S oc create configmap registry-config --from-file=mirror.registry.com..443=/root/certs/ca-chain.cert.pem -n openshift-config
S oc create configmap registry-config --from-file=mirror.registry.com..443=/root/certs/ca-chain.cert.pem -n openshift-configCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用配置映射更新
image.config.openshift.io/cluster自定义资源(CR)。OpenShift Container Platform 将对此 CR 的更改应用到集群中的所有节点:oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"<config_map_name>"}}}' --type=merge$ oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"<config_map_name>"}}}' --type=mergeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"registry-config"}}}' --type=merge$ oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"registry-config"}}}' --type=mergeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
创建一个 ICSP,将在线 registry 中的容器拉取请求重定向到镜像 registry:
创建
ImageContentSourcePolicy自定义资源:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建 ICSP 对象:
oc create -f registryrepomirror.yaml
$ oc create -f registryrepomirror.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
imagecontentsourcepolicy.operator.openshift.io/mirror-ocp created
imagecontentsourcepolicy.operator.openshift.io/mirror-ocp createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow OpenShift Container Platform 会将对此 CR 的更改应用到集群中的所有节点。
验证已添加了镜像 registry 的凭证、CA 和 ICSP:
登录到节点:
oc debug node/<node_name>
$ oc debug node/<node_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将
/host设置为 debug shell 中的根目录:chroot /host
sh-4.4# chroot /hostCopy to Clipboard Copied! Toggle word wrap Toggle overflow 检查凭证的
config.json文件:cat /var/lib/kubelet/config.json
sh-4.4# cat /var/lib/kubelet/config.jsonCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
{"auths":{"brew.registry.redhat.io":{"xx=="},"brewregistry.stage.redhat.io":{"auth":"xxx=="},"mirror.registry.com:443":{"auth":"xx="}}}{"auths":{"brew.registry.redhat.io":{"xx=="},"brewregistry.stage.redhat.io":{"auth":"xxx=="},"mirror.registry.com:443":{"auth":"xx="}}}1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 确保存在镜像 registry 和凭证。
进入
certs.d目录cd /etc/docker/certs.d/
sh-4.4# cd /etc/docker/certs.d/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 列出
certs.d目录中的证书:ls
sh-4.4# lsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
image-registry.openshift-image-registry.svc.cluster.local:5000 image-registry.openshift-image-registry.svc:5000 mirror.registry.com:443
image-registry.openshift-image-registry.svc.cluster.local:5000 image-registry.openshift-image-registry.svc:5000 mirror.registry.com:4431 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 确保镜像 registry 位于列表中。
检查 ICSP 是否将镜像 registry 添加到
registry.conf文件中:cat /etc/containers/registries.conf
sh-4.4# cat /etc/containers/registries.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow registry.mirror参数表示在原始 registry 前搜索镜像 registry。退出节点。
exit
sh-4.4# exitCopy to Clipboard Copied! Toggle word wrap Toggle overflow
13.6. 确保应用程序继续工作
在断开集群与网络的连接前,请确保集群按预期运行,并且所有应用程序都按预期工作。
流程
使用以下命令检查集群的状态:
确定您的 pod 正在运行:
oc get pods --all-namespaces
$ oc get pods --all-namespacesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 确定您的节点处于 READY 状态:
oc get nodes
$ oc get nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
13.7. 断开集群与网络的连接
镜像所有所需的软件仓库并配置集群以作为断开连接的集群后,您可以断开集群与网络的连接。
当集群丢失了互联网连接时,Insights Operator 会降级。您可以通过临时禁用 Insights Operator 来避免这个问题,直到您可以恢复它。
13.8. 恢复降级的 Insights Operator
从网络断开集群的连接会导致集群丢失互联网连接。Insights Operator 会降级,因为它需要访问 Red Hat Insights。
本节描述了如何从降级的 Insights Operator 恢复。
流程
编辑
.dockerconfigjson文件以删除cloud.openshift.com条目,例如:"cloud.openshift.com":{"auth":"<hash>","email":"user@example.com"}"cloud.openshift.com":{"auth":"<hash>","email":"user@example.com"}Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 保存该文件。
使用编辑的
.dockerconfigjson文件更新集群 secret:oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=./.dockerconfigjson
$ oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=./.dockerconfigjsonCopy to Clipboard Copied! Toggle word wrap Toggle overflow 验证 Insights Operator 不再降级:
oc get co insights
$ oc get co insightsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE insights 4.5.41 True False False 3d
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE insights 4.5.41 True False False 3dCopy to Clipboard Copied! Toggle word wrap Toggle overflow
13.9. 恢复网络
如果要重新连接断开连接的集群并从在线 registry 中拉取镜像,请删除集群的 ImageContentSourcePolicy(ICSP)对象。如果没有 ICSP,对外部 registry 的拉取请求不再重定向到镜像 registry。
流程
查看集群中的 ICSP 对象:
oc get imagecontentsourcepolicy
$ oc get imagecontentsourcepolicyCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
NAME AGE mirror-ocp 6d20h ocp4-index-0 6d18h qe45-index-0 6d15h
NAME AGE mirror-ocp 6d20h ocp4-index-0 6d18h qe45-index-0 6d15hCopy to Clipboard Copied! Toggle word wrap Toggle overflow 删除断开集群时创建的所有 ICSP 对象:
oc delete imagecontentsourcepolicy <icsp_name> <icsp_name> <icsp_name>
$ oc delete imagecontentsourcepolicy <icsp_name> <icsp_name> <icsp_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
oc delete imagecontentsourcepolicy mirror-ocp ocp4-index-0 qe45-index-0
$ oc delete imagecontentsourcepolicy mirror-ocp ocp4-index-0 qe45-index-0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
imagecontentsourcepolicy.operator.openshift.io "mirror-ocp" deleted imagecontentsourcepolicy.operator.openshift.io "ocp4-index-0" deleted imagecontentsourcepolicy.operator.openshift.io "qe45-index-0" deleted
imagecontentsourcepolicy.operator.openshift.io "mirror-ocp" deleted imagecontentsourcepolicy.operator.openshift.io "ocp4-index-0" deleted imagecontentsourcepolicy.operator.openshift.io "qe45-index-0" deletedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 等待所有节点重启并返回到 READY 状态,并验证
registry.conf文件是否指向原始 registry,而不是镜像 registry:登录到节点:
oc debug node/<node_name>
$ oc debug node/<node_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将
/host设置为 debug shell 中的根目录:chroot /host
sh-4.4# chroot /hostCopy to Clipboard Copied! Toggle word wrap Toggle overflow 检查
registry.conf文件:cat /etc/containers/registries.conf
sh-4.4# cat /etc/containers/registries.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
unqualified-search-registries = ["registry.access.redhat.com", "docker.io"]
unqualified-search-registries = ["registry.access.redhat.com", "docker.io"]1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 您删除的、由 ICSP 创建的
registry和registry.mirror条目已被删除。
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.