3.5. 安装故障排除
3.5.1. 安装程序工作流故障排除
在对安装环境进行故障排除前,务必要了解裸机上安装程序置备安装的整体流。下图显示了一个故障排除流程,并按步骤划分环境。
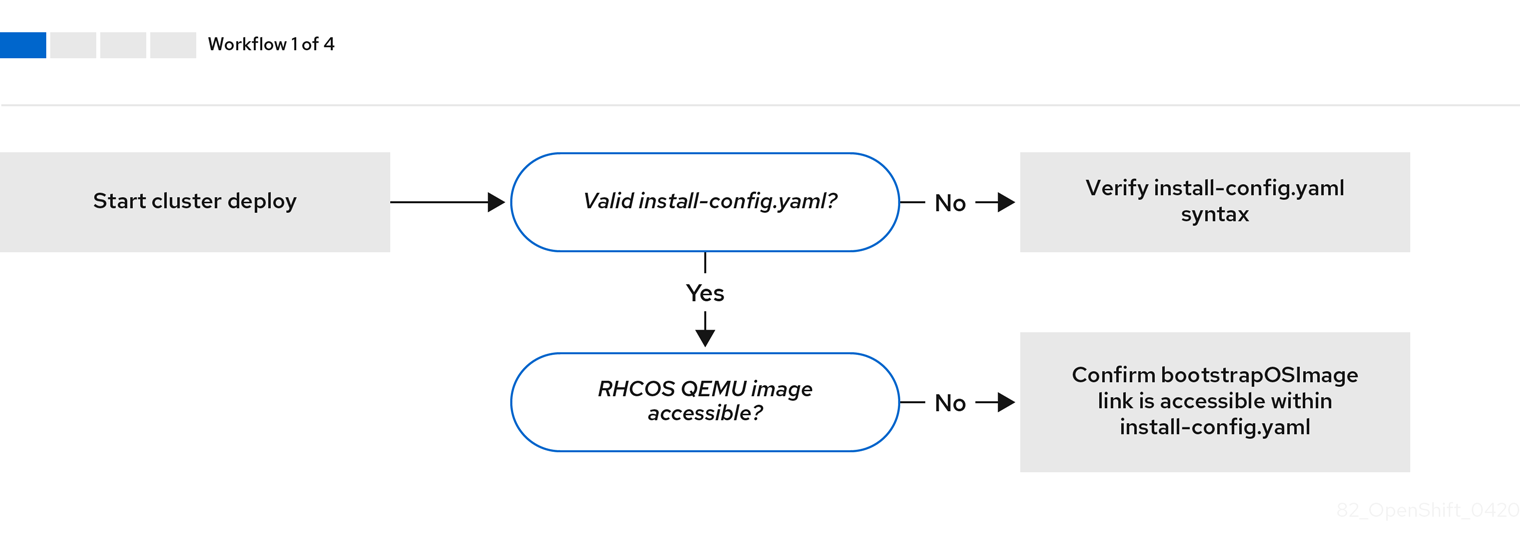
当 install-config.yaml 文件出错或者无法访问 Red Hat Enterprise Linux CoreOS(RHCOS)镜像时,工作流 1(共 4 步) 的工作流演示了故障排除工作流。有关故障排除的建议,请参阅对 install-config.yaml 进行故障排除。
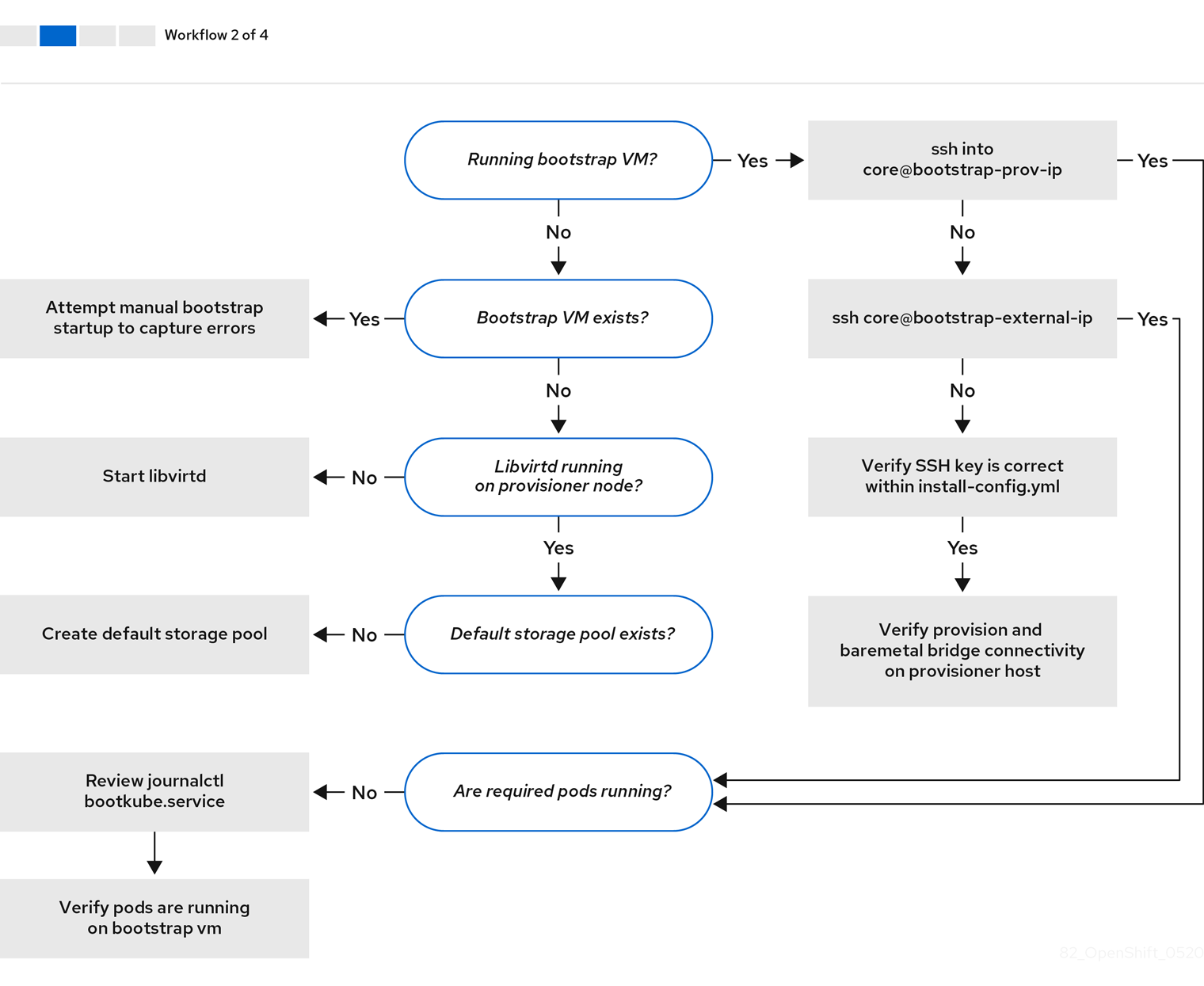
工作流 2(共 4 步)描述了对 bootstrap 虚拟机问题、 无法引导集群节点的 bootstrap 虚拟机 以及 检查日志 的故障排除工作流。当在没有 provisioning 网络的情况下安装 OpenShift Container Platform 集群时,此工作流将不应用。
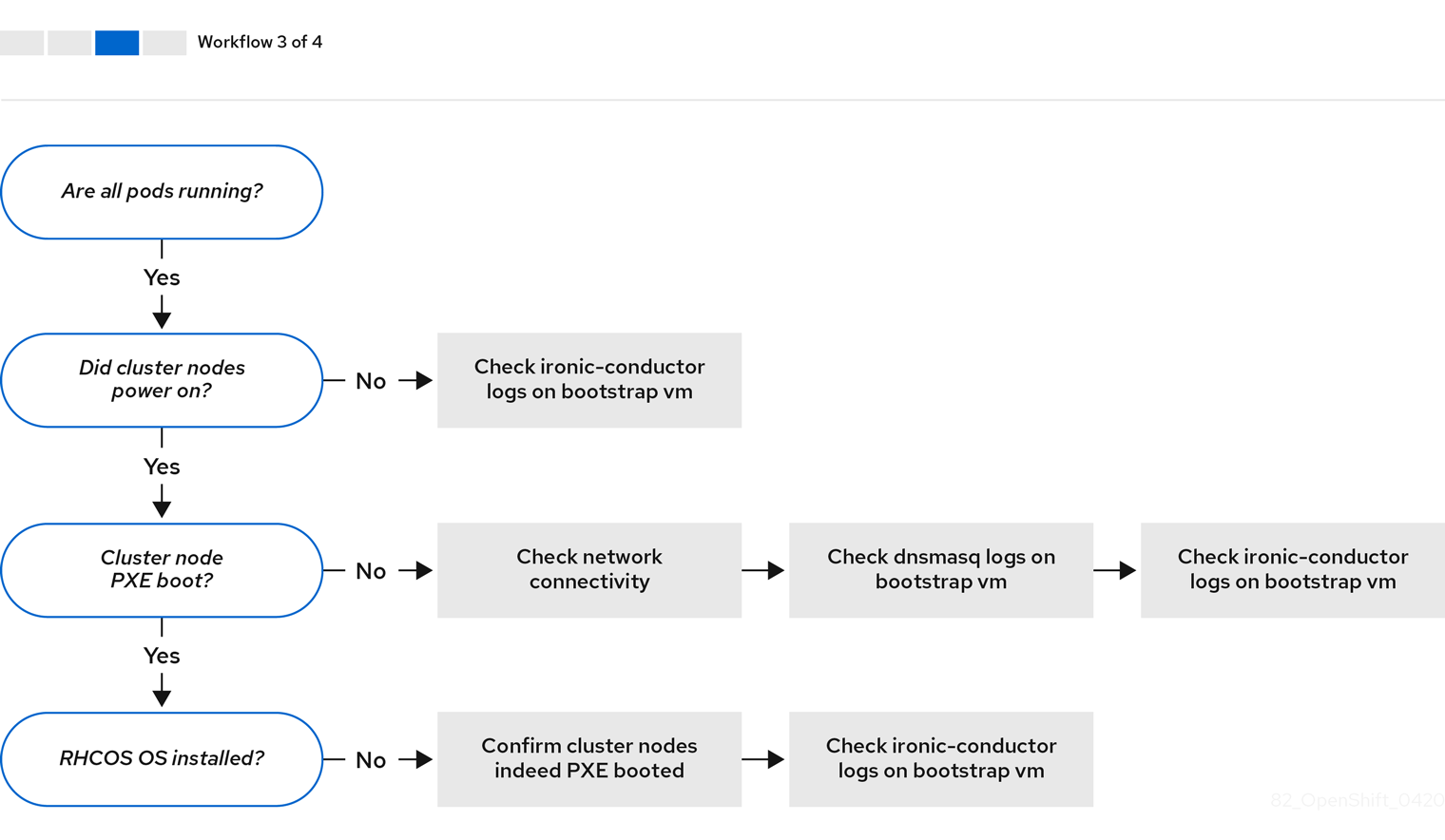
工作流 3(共 4 步)描述了 不能 PXE 引导的集群节点 的故障排除工作流。如果使用 Redfish 虚拟介质进行安装,则每个节点都必须满足安装程序部署该节点的最低固件要求。如需了解更多详细信息,请参阅先决条件部分中的使用虚拟介质安装的固件要求。

3.5.2. install-config.yaml故障排除
install-config.yaml 配置文件代表属于 OpenShift Container Platform 集群的所有节点。该文件包含由 apiVersion、baseDomain、imageContentSources 和虚拟 IP 地址组成的必要选项。如果在 OpenShift Container Platform 集群部署早期发生错误,install-config.yaml 配置文件中可能会出现错误。
流程
- 使用 YAML-tips 中的指南。
- 使用 syntax-check 验证 YAML 语法是否正确。
验证 Red Hat Enterprise Linux CoreOS(RHCOS)QEMU 镜像是否已正确定义,并可通过
install-config.yaml提供的 URL 访问。例如:$ curl -s -o /dev/null -I -w "%{http_code}\n" http://webserver.example.com:8080/rhcos-44.81.202004250133-0-qemu.<architecture>.qcow2.gz?sha256=7d884b46ee54fe87bbc3893bf2aa99af3b2d31f2e19ab5529c60636fbd0f1ce7如果输出为
200,则会从存储 bootstrap 虚拟机镜像的 webserver 获得有效的响应。
3.5.3. bootstrap 虚拟机问题故障排除
OpenShift Container Platform 安装程序生成 bootstrap 节点虚拟机,该虚拟机处理置备 OpenShift Container Platform 集群节点。
流程
触发安装程序后大约 10 到 15 分钟,使用
virsh命令检查 bootstrap 虚拟机是否正常工作:$ sudo virsh listId Name State -------------------------------------------- 12 openshift-xf6fq-bootstrap running注意bootstrap 虚拟机的名称始终是集群名称,后跟一组随机字符,并以"bootstrap"结尾。
如果 bootstrap 虚拟机在 10-15 分钟后没有运行,请执行以下命令来验证
libvirtd是否在系统中运行:$ systemctl status libvirtd● libvirtd.service - Virtualization daemon Loaded: loaded (/usr/lib/systemd/system/libvirtd.service; enabled; vendor preset: enabled) Active: active (running) since Tue 2020-03-03 21:21:07 UTC; 3 weeks 5 days ago Docs: man:libvirtd(8) https://libvirt.org Main PID: 9850 (libvirtd) Tasks: 20 (limit: 32768) Memory: 74.8M CGroup: /system.slice/libvirtd.service ├─ 9850 /usr/sbin/libvirtd如果 bootstrap 虚拟机可以正常工作,请登录它。
使用
virsh console命令查找 bootstrap 虚拟机的 IP 地址:$ sudo virsh console example.comConnected to domain example.com Escape character is ^] Red Hat Enterprise Linux CoreOS 43.81.202001142154.0 (Ootpa) 4.3 SSH host key: SHA256:BRWJktXZgQQRY5zjuAV0IKZ4WM7i4TiUyMVanqu9Pqg (ED25519) SSH host key: SHA256:7+iKGA7VtG5szmk2jB5gl/5EZ+SNcJ3a2g23o0lnIio (ECDSA) SSH host key: SHA256:DH5VWhvhvagOTaLsYiVNse9ca+ZSW/30OOMed8rIGOc (RSA) ens3: fd35:919d:4042:2:c7ed:9a9f:a9ec:7 ens4: 172.22.0.2 fe80::1d05:e52e:be5d:263f localhost login:重要当在没有
provisioning网络的情况下部署 OpenShift Container Platform 集群时,您必须使用公共 IP 地址,而不是专用 IP 地址,如172.22.0.2。获取 IP 地址后,使用
ssh命令登录到 bootstrap 虚拟机:注意在上一步的控制台输出中,您可以使用 ens3 提供的 IPv6 IP 地址或
ens4 提供的 IPv4 IP 地址。$ ssh core@172.22.0.2
如果您无法成功登录 bootstrap 虚拟机,您可能会遇到以下情况之一:
-
您无法访问
172.22.0.0/24网络。验证 provisioner 和provisioning网桥之间的网络连接。如果您使用provisioning网络,则可能会出现此问题。 -
您无法通过公共网络访问 bootstrap 虚拟机。当尝试 SSH via
baremetal 网络时,验证provisioner主机上的连接情况,特别是baremetal网桥的连接。 -
您遇到了
Permission denied(publickey,password,keyboard-interactive)的问题。当尝试访问 bootstrap 虚拟机时,可能会出现Permission denied错误。验证尝试登录到虚拟机的用户的 SSH 密钥是否在install-config.yaml文件中设置。
3.5.3.1. Bootstrap 虚拟机无法引导集群节点
在部署过程中,bootstrap 虚拟机可能无法引导集群节点,这会阻止虚拟机使用 RHCOS 镜像置备节点。这可能是因为以下原因:
-
install-config.yaml文件存在问题。 - 使用 baremetal 网络时出现带外网络访问的问题。
要验证这个问题,有三个与 ironic 相关的容器:
-
ironic -
ironic-inspector
流程
登录到 bootstrap 虚拟机:
$ ssh core@172.22.0.2要检查容器日志,请执行以下操作:
[core@localhost ~]$ sudo podman logs -f <container_name>将
<container_name>替换为ironic或ironic-inspector之一。如果您遇到 control plane 节点没有从 PXE 引导的问题,请检查ironicpod。ironicpod 包含有关尝试引导集群节点的信息,因为它尝试通过 IPMI 登录节点。
潜在原因
集群节点在部署启动时可能处于 ON 状态。
解决方案
在通过 IPMI 开始安装前关闭 OpenShift Container Platform 集群节点:
$ ipmitool -I lanplus -U root -P <password> -H <out_of_band_ip> power off3.5.3.2. 检查日志
在下载或访问 RHCOS 镜像时,首先验证 install-config.yaml 配置文件中的 URL 是否正确。
内部 webserver 托管 RHCOS 镜像的示例
bootstrapOSImage: http://<ip:port>/rhcos-43.81.202001142154.0-qemu.<architecture>.qcow2.gz?sha256=9d999f55ff1d44f7ed7c106508e5deecd04dc3c06095d34d36bf1cd127837e0c
clusterOSImage: http://<ip:port>/rhcos-43.81.202001142154.0-openstack.<architecture>.qcow2.gz?sha256=a1bda656fa0892f7b936fdc6b6a6086bddaed5dafacedcd7a1e811abb78fe3b0
coreos-downloader 容器从 webserver 或外部 quay.io registry 下载资源(由 install-config.yaml 配置文件指定)。验证 coreos-downloader 容器是否正在运行,并根据需要检查其日志。
流程
登录到 bootstrap 虚拟机:
$ ssh core@172.22.0.2运行以下命令,检查 bootstrap 虚拟机中的
coreos-downloader容器的状态:[core@localhost ~]$ sudo podman logs -f coreos-downloader如果 bootstrap 虚拟机无法访问镜像的 URL,请使用
curl命令验证虚拟机是否可以访问镜像。要检查
bootkube日志,以指示部署阶段是否启动了所有容器,请执行以下操作:[core@localhost ~]$ journalctl -xe[core@localhost ~]$ journalctl -b -f -u bootkube.service验证包括
dnsmasq、mariadb、httpd和ironic等所有 pod 都在运行:[core@localhost ~]$ sudo podman ps如果 pod 存在问题,请检查有问题的容器日志。要检查
ironic服务的日志,请运行以下命令:[core@localhost ~]$ sudo podman logs ironic
3.5.5. 对初始化集群失败进行故障排除
安装程序使用 Cluster Version Operator 创建 OpenShift Container Platform 集群的所有组件。当安装程序无法初始化集群时,您可以从 ClusterVersion 和 ClusterOperator 对象检索最重要的信息。
流程
运行以下命令检查
ClusterVersion对象:$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusterversion -o yaml输出示例
apiVersion: config.openshift.io/v1 kind: ClusterVersion metadata: creationTimestamp: 2019-02-27T22:24:21Z generation: 1 name: version resourceVersion: "19927" selfLink: /apis/config.openshift.io/v1/clusterversions/version uid: 6e0f4cf8-3ade-11e9-9034-0a923b47ded4 spec: channel: stable-4.1 clusterID: 5ec312f9-f729-429d-a454-61d4906896ca status: availableUpdates: null conditions: - lastTransitionTime: 2019-02-27T22:50:30Z message: Done applying 4.1.1 status: "True" type: Available - lastTransitionTime: 2019-02-27T22:50:30Z status: "False" type: Failing - lastTransitionTime: 2019-02-27T22:50:30Z message: Cluster version is 4.1.1 status: "False" type: Progressing - lastTransitionTime: 2019-02-27T22:24:31Z message: 'Unable to retrieve available updates: unknown version 4.1.1 reason: RemoteFailed status: "False" type: RetrievedUpdates desired: image: registry.svc.ci.openshift.org/openshift/origin-release@sha256:91e6f754975963e7db1a9958075eb609ad226968623939d262d1cf45e9dbc39a version: 4.1.1 history: - completionTime: 2019-02-27T22:50:30Z image: registry.svc.ci.openshift.org/openshift/origin-release@sha256:91e6f754975963e7db1a9958075eb609ad226968623939d262d1cf45e9dbc39a startedTime: 2019-02-27T22:24:31Z state: Completed version: 4.1.1 observedGeneration: 1 versionHash: Wa7as_ik1qE=运行以下命令来查看条件:
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusterversion version \ -o=jsonpath='{range .status.conditions[*]}{.type}{" "}{.status}{" "}{.message}{"\n"}{end}'某些最重要的条件包括
Failing、Available和Progressing。输出示例
Available True Done applying 4.1.1 Failing False Progressing False Cluster version is 4.0.0-0.alpha-2019-02-26-194020 RetrievedUpdates False Unable to retrieve available updates: unknown version 4.1.1运行以下命令检查
ClusterOperator对象:$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperator该命令返回集群 Operator 的状态。
输出示例
NAME VERSION AVAILABLE PROGRESSING FAILING SINCE cluster-baremetal-operator True False False 17m cluster-autoscaler True False False 17m cluster-storage-operator True False False 10m console True False False 7m21s dns True False False 31m image-registry True False False 9m58s ingress True False False 10m kube-apiserver True False False 28m kube-controller-manager True False False 21m kube-scheduler True False False 25m machine-api True False False 17m machine-config True False False 17m marketplace-operator True False False 10m monitoring True False False 8m23s network True False False 13m node-tuning True False False 11m openshift-apiserver True False False 15m openshift-authentication True False False 20m openshift-cloud-credential-operator True False False 18m openshift-controller-manager True False False 10m openshift-samples True False False 8m42s operator-lifecycle-manager True False False 17m service-ca True False False 30m运行以下命令检查单个集群 Operator:
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperator <operator> -oyaml1 - 1
- 将
<operator>替换为集群 Operator 的名称。此命令可用于识别集群 Operator 没有达到Available状态的原因或处于Failed状态。
输出示例
apiVersion: config.openshift.io/v1 kind: ClusterOperator metadata: creationTimestamp: 2019-02-27T22:47:04Z generation: 1 name: monitoring resourceVersion: "24677" selfLink: /apis/config.openshift.io/v1/clusteroperators/monitoring uid: 9a6a5ef9-3ae1-11e9-bad4-0a97b6ba9358 spec: {} status: conditions: - lastTransitionTime: 2019-02-27T22:49:10Z message: Successfully rolled out the stack. status: "True" type: Available - lastTransitionTime: 2019-02-27T22:49:10Z status: "False" type: Progressing - lastTransitionTime: 2019-02-27T22:49:10Z status: "False" type: Failing extension: null relatedObjects: null version: ""要获取集群 Operator 的状态条件,请运行以下命令:
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperator <operator> \ -o=jsonpath='{range .status.conditions[*]}{.type}{" "}{.status}{" "}{.message}{"\n"}{end}'将
<operator>替换为以上其中一个 Operator 的名称。输出示例
Available True Successfully rolled out the stack Progressing False Failing False要检索集群 Operator 拥有的对象列表,请执行以下命令:
oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperator kube-apiserver \ -o=jsonpath='{.status.relatedObjects}'输出示例
[map[resource:kubeapiservers group:operator.openshift.io name:cluster] map[group: name:openshift-config resource:namespaces] map[group: name:openshift-config-managed resource:namespaces] map[group: name:openshift-kube-apiserver-operator resource:namespaces] map[group: name:openshift-kube-apiserver resource:namespaces]]
3.5.6. 对获取控制台 URL 失败进行故障排除
安装程序通过在 openshift-console 命名空间中使用 [route][route-object] 检索 OpenShift Container Platform 控制台的 URL。如果安装程序失败,请检索控制台的 URL,请使用以下步骤。
流程
运行以下命令,检查控制台路由器是否处于
Available或Failing状态:$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperator console -oyamlapiVersion: config.openshift.io/v1 kind: ClusterOperator metadata: creationTimestamp: 2019-02-27T22:46:57Z generation: 1 name: console resourceVersion: "19682" selfLink: /apis/config.openshift.io/v1/clusteroperators/console uid: 960364aa-3ae1-11e9-bad4-0a97b6ba9358 spec: {} status: conditions: - lastTransitionTime: 2019-02-27T22:46:58Z status: "False" type: Failing - lastTransitionTime: 2019-02-27T22:50:12Z status: "False" type: Progressing - lastTransitionTime: 2019-02-27T22:50:12Z status: "True" type: Available - lastTransitionTime: 2019-02-27T22:46:57Z status: "True" type: Upgradeable extension: null relatedObjects: - group: operator.openshift.io name: cluster resource: consoles - group: config.openshift.io name: cluster resource: consoles - group: oauth.openshift.io name: console resource: oauthclients - group: "" name: openshift-console-operator resource: namespaces - group: "" name: openshift-console resource: namespaces versions: null执行以下命令手动检索控制台 URL:
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get route console -n openshift-console \ -o=jsonpath='{.spec.host}' console-openshift-console.apps.adahiya-1.devcluster.openshift.com
3.5.7. 对将入口证书添加到 kubeconfig 失败的问题
安装程序将默认入口证书添加到 ${INSTALL_DIR}/auth/kubeconfig 中的可信客户端证书颁发机构列表中。如果安装程序无法将入口证书添加到 kubeconfig 文件中,您可以从集群中检索证书并添加它。
流程
使用以下命令从集群中删除证书:
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get configmaps default-ingress-cert \ -n openshift-config-managed -o=jsonpath='{.data.ca-bundle\.crt}'-----BEGIN CERTIFICATE----- MIIC/TCCAeWgAwIBAgIBATANBgkqhkiG9w0BAQsFADAuMSwwKgYDVQQDDCNjbHVz dGVyLWluZ3Jlc3Mtb3BlcmF0b3JAMTU1MTMwNzU4OTAeFw0xOTAyMjcyMjQ2Mjha Fw0yMTAyMjYyMjQ2MjlaMC4xLDAqBgNVBAMMI2NsdXN0ZXItaW5ncmVzcy1vcGVy YXRvckAxNTUxMzA3NTg5MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA uCA4fQ+2YXoXSUL4h/mcvJfrgpBfKBW5hfB8NcgXeCYiQPnCKblH1sEQnI3VC5Pk 2OfNCF3PUlfm4i8CHC95a7nCkRjmJNg1gVrWCvS/ohLgnO0BvszSiRLxIpuo3C4S EVqqvxValHcbdAXWgZLQoYZXV7RMz8yZjl5CfhDaaItyBFj3GtIJkXgUwp/5sUfI LDXW8MM6AXfuG+kweLdLCMm3g8WLLfLBLvVBKB+4IhIH7ll0buOz04RKhnYN+Ebw tcvFi55vwuUCWMnGhWHGEQ8sWm/wLnNlOwsUz7S1/sW8nj87GFHzgkaVM9EOnoNI gKhMBK9ItNzjrP6dgiKBCQIDAQABoyYwJDAOBgNVHQ8BAf8EBAMCAqQwEgYDVR0T AQH/BAgwBgEB/wIBADANBgkqhkiG9w0BAQsFAAOCAQEAq+vi0sFKudaZ9aUQMMha CeWx9CZvZBblnAWT/61UdpZKpFi4eJ2d33lGcfKwHOi2NP/iSKQBebfG0iNLVVPz vwLbSG1i9R9GLdAbnHpPT9UG6fLaDIoKpnKiBfGENfxeiq5vTln2bAgivxrVlyiq +MdDXFAWb6V4u2xh6RChI7akNsS3oU9PZ9YOs5e8vJp2YAEphht05X0swA+X8V8T C278FFifpo0h3Q0Dbv8Rfn4UpBEtN4KkLeS+JeT+0o2XOsFZp7Uhr9yFIodRsnNo H/Uwmab28ocNrGNiEVaVH6eTTQeeZuOdoQzUbClElpVmkrNGY0M42K0PvOQ/e7+y AQ== -----END CERTIFICATE------
将证书添加到
${INSTALL_DIR}/auth/kubeconfig文件中的client-certificate-authority-data字段中。
3.5.8. 对集群节点的 SSH 访问故障排除
为提高安全性,您无法默认从集群外部通过 SSH 连接到集群。但是,您可以从 provisioner 节点访问 control plane 和 worker 节点。如果无法从 provisioner 节点通过 SSH 连接到集群节点,则节点可能会在 bootstrap 虚拟机上等待。control plane 节点从 bootstrap 虚拟机检索其引导配置,如果它们没有检索引导配置,则无法成功引导。
流程
- 如果您有对节点的物理访问权限,请检查其控制台输出以确定它们是否已成功引导。如果节点仍然检索其引导配置,则 bootstrap 虚拟机可能会出现问题。
-
确保您在
install-config.yaml文件中配置了sshKey: '<ssh_pub_key>'设置,其中<ssh_pub_key>是 provisioner 节点上的kni用户的公钥。
3.5.9. 集群节点不能 PXE 引导
当 OpenShift Container Platform 集群节点无法 PXE 引导时,请在不能 PXE 引导的集群节点上执行以下检查。在没有 provisioning 网络安装 OpenShift Container Platform 集群时,此流程不适用。
流程
-
检查与
provisioning网络的网络连接。 -
确保
provisioning网络的 NIC 上启用了 PXE,并为所有其他 NIC 禁用 PXE。 验证
install-config.yaml配置文件是否包含rootDeviceHints参数,以及连接到provisioning网络的 NIC 的引导 MAC 地址。例如:control plane 节点设置
bootMACAddress: 24:6E:96:1B:96:90 # MAC of bootable provisioning NICWorker 节点设置
bootMACAddress: 24:6E:96:1B:96:90 # MAC of bootable provisioning NIC
3.5.10. 安装不会创建 worker 节点
安装程序不会直接置备 worker 节点。相反,Machine API Operator 会在受支持的平台上扩展节点。如果 worker 节点在 15 到 20 分钟后没有创建,具体取决于集群互联网连接的速度,请调查 Machine API Operator。
流程
运行以下命令检查 Machine API Operator:
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig \ --namespace=openshift-machine-api get deployments如果环境中没有设置
${INSTALL_DIR},请将该值替换为安装目录的名称。输出示例
NAME READY UP-TO-DATE AVAILABLE AGE cluster-autoscaler-operator 1/1 1 1 86m cluster-baremetal-operator 1/1 1 1 86m machine-api-controllers 1/1 1 1 85m machine-api-operator 1/1 1 1 86m运行以下命令检查机器控制器日志:
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig \ --namespace=openshift-machine-api logs deployments/machine-api-controllers \ --container=machine-controller
3.5.11. Cluster Network Operator 故障排除
Cluster Network Operator 负责部署网络组件。它在安装过程中的早期运行,在 control plane 节点启动后,但安装程序删除 bootstrap control plane 前。此 Operator 的问题可能表示安装程序问题。
流程
运行以下命令确保网络配置存在:
$ oc get network -o yaml cluster如果不存在,安装程序不会创建它。要找出原因,请运行以下命令:
$ openshift-install create manifests查看清单,以确定安装程序没有创建网络配置的原因。
输入以下命令来确保网络正在运行:
$ oc get po -n openshift-network-operator
3.5.12. 无法使用 BMC 发现新的裸机主机
在某些情况下,安装程序将无法发现新的裸机主机并发出错误,因为它无法挂载远程虚拟介质共享。
例如:
ProvisioningError 51s metal3-baremetal-controller Image provisioning failed: Deploy step deploy.deploy failed with BadRequestError: HTTP POST
https://<bmc_address>/redfish/v1/Managers/iDRAC.Embedded.1/VirtualMedia/CD/Actions/VirtualMedia.InsertMedia
returned code 400.
Base.1.8.GeneralError: A general error has occurred. See ExtendedInfo for more information
Extended information: [
{
"Message": "Unable to mount remote share https://<ironic_address>/redfish/boot-<uuid>.iso.",
"MessageArgs": [
"https://<ironic_address>/redfish/boot-<uuid>.iso"
],
"MessageArgs@odata.count": 1,
"MessageId": "IDRAC.2.5.RAC0720",
"RelatedProperties": [
"#/Image"
],
"RelatedProperties@odata.count": 1,
"Resolution": "Retry the operation.",
"Severity": "Informational"
}
].在这种情况下,如果您使用带有未知证书颁发机构的虚拟介质,您可以配置基板管理控制器 (BMC) 远程文件共享设置,以信任未知证书颁发机构以避免这个错误。
这个解析已在带有 Dell iDRAC 9 的 OpenShift Container Platform 4.11 上测试,固件版本 5.10.50。
3.5.13. 无法加入集群的 worker 节点故障排除
安装程序置备的集群使用 DNS 服务器部署,其中包含 api-int.<cluster_name>.<base_domain> URL 的 DNS 条目。如果集群中的节点使用外部或上游 DNS 服务器解析 api-int.<cluster_name>.<base_domain> URL,且没有这样的条目,则 worker 节点可能无法加入集群。确保集群中的所有节点都可以解析域名。
流程
添加 DNS A/AAAA 或 CNAME 记录,以内部标识 API 负载均衡器。例如,在使用 dnsmasq 时,修改
dnsmasq.conf配置文件:$ sudo nano /etc/dnsmasq.confaddress=/api-int.<cluster_name>.<base_domain>/<IP_address> address=/api-int.mycluster.example.com/192.168.1.10 address=/api-int.mycluster.example.com/2001:0db8:85a3:0000:0000:8a2e:0370:7334添加 DNS PTR 记录以内部标识 API 负载均衡器。例如,在使用 dnsmasq 时,修改
dnsmasq.conf配置文件:$ sudo nano /etc/dnsmasq.confptr-record=<IP_address>.in-addr.arpa,api-int.<cluster_name>.<base_domain> ptr-record=10.1.168.192.in-addr.arpa,api-int.mycluster.example.com重启 DNS 服务器。例如,在使用 dnsmasq 时执行以下命令:
$ sudo systemctl restart dnsmasq
这些记录必须可以从集群中的所有节点解析。
3.5.14. 清理以前的安装
如果以前部署失败,请在尝试再次部署 OpenShift Container Platform 前从失败的尝试中删除工件。
流程
使用以下命令安装 OpenShift Container Platform 集群前关闭所有裸机节点:
$ ipmitool -I lanplus -U <user> -P <password> -H <management_server_ip> power off使用以下脚本,删除所有旧的 bootstrap 资源:
for i in $(sudo virsh list | tail -n +3 | grep bootstrap | awk {'print $2'}); do sudo virsh destroy $i; sudo virsh undefine $i; sudo virsh vol-delete $i --pool $i; sudo virsh vol-delete $i.ign --pool $i; sudo virsh pool-destroy $i; sudo virsh pool-undefine $i; done使用以下命令删除早期安装生成的工件:
$ cd ; /bin/rm -rf auth/ bootstrap.ign master.ign worker.ign metadata.json \ .openshift_install.log .openshift_install_state.json使用以下命令重新创建 OpenShift Container Platform 清单:
$ ./openshift-baremetal-install --dir ~/clusterconfigs create manifests
3.5.15. 创建 registry 的问题
在创建断开连接的 registry 时,在尝试镜像 registry 时,可能会遇到 "User Not Authorized" 错误。如果您没有将新身份验证附加到现有的 pull-secret.txt 文件中,可能会发生这个错误。
流程
检查以确保身份验证成功:
$ /usr/local/bin/oc adm release mirror \ -a pull-secret-update.json --from=$UPSTREAM_REPO \ --to-release-image=$LOCAL_REG/$LOCAL_REPO:${VERSION} \ --to=$LOCAL_REG/$LOCAL_REPO注意用于镜像安装镜像的变量输出示例:
UPSTREAM_REPO=${RELEASE_IMAGE} LOCAL_REG=<registry_FQDN>:<registry_port> LOCAL_REPO='ocp4/openshift4'在为 OpenShift 安装设置环境 部分的 获取 OpenShift 安装程序 步骤中,设置了
RELEASE_IMAGE和VERSION的值。镜像 registry 后,确认您可以在断开连接的环境中访问它:
$ curl -k -u <user>:<password> https://registry.example.com:<registry_port>/v2/_catalog {"repositories":["<Repo_Name>"]}
3.5.16. 其它问题
3.5.16.1. 解决 运行时网络未就绪 错误
部署集群后,您可能会收到以下错误:
`runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: Missing CNI default network`
Cluster Network Operator 负责部署网络组件以响应安装程序创建的特殊对象。它会在安装过程的早期阶段运行(在 control plane(master)节点启动后,bootstrap control plane 被停止前运行。它可能会显示更细微的安装程序问题,比如启动 control plane (master)节点时延迟时间过长,或者 apiserver 通讯的问题。
流程
检查
openshift-network-operator命名空间中的 pod:$ oc get all -n openshift-network-operatorNAME READY STATUS RESTARTS AGE pod/network-operator-69dfd7b577-bg89v 0/1 ContainerCreating 0 149m在
provisioner节点上,确定存在网络配置:$ kubectl get network.config.openshift.io cluster -oyamlapiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: serviceNetwork: - 172.30.0.0/16 clusterNetwork: - cidr: 10.128.0.0/14 hostPrefix: 23 networkType: OVNKubernetes如果不存在,安装程序不会创建它。要确定安装程序没有创建它的原因,请执行以下操作:
$ openshift-install create manifests检查
network-operator是否正在运行:$ kubectl -n openshift-network-operator get pods检索日志:
$ kubectl -n openshift-network-operator logs -l "name=network-operator"在具有三个或更多 control plane 节点的高可用性集群中,Operator 将执行领导选举机制,所有其他 Operator 将会休眠。如需了解更多详细信息,请参阅 故障排除。
部署集群后,您可能会收到以下出错信息:
No disk found with matching rootDeviceHints
要解决 No disk found with matching rootDeviceHints 错误,一个临时解决方法是将 rootDeviceHints 更改为 minSizeGigabytes: 300。
更改 rootDeviceHints 设置后,使用以下命令引导 CoreOS,然后使用以下命令验证磁盘信息:
$ udevadm info /dev/sda
如果您使用 DL360 Gen 10 服务器,请注意它们有一个 SD-card 插槽,它可能会被分配 /dev/sda 设备名称。如果服务器中没有 SD 卡,可能会导致冲突。确定在服务器的 BIOS 设置中禁用 SD 卡插槽。
如果 minSizeGigabytes 临时解决方案没有满足要求,您可能需要将 rootDeviceHints 恢复为 /dev/sda。此更改允许 ironic 镜像成功引导。
修复此问题的另一种方法是使用磁盘的串行 ID。但是,请注意,发现串行 ID 可能具有挑战性,并且可能会导致配置文件无法读取。如果选择此路径,请确保使用之前记录的命令收集串行 ID,并将其合并到您的配置中。
3.5.16.3. 集群节点没有通过 DHCP 获得正确的 IPv6 地址
如果集群节点没有通过 DHCP 获得正确的 IPv6 地址,请检查以下内容:
- 确保保留的 IPv6 地址不在 DHCP 范围内。
在 DHCP 服务器上的 IP 地址保留中,确保保留指定了正确的 DHCP 唯一标识符(DUID)。例如:
# This is a dnsmasq dhcp reservation, 'id:00:03:00:01' is the client id and '18:db:f2:8c:d5:9f' is the MAC Address for the NIC id:00:03:00:01:18:db:f2:8c:d5:9f,openshift-master-1,[2620:52:0:1302::6]- 确保路由声明正常工作。
- 确保 DHCP 服务器正在侦听提供 IP 地址范围所需的接口。
3.5.16.4. 集群节点没有通过 DHCP 获得正确的主机名
在 IPv6 部署过程中,集群节点必须通过 DHCP 获得其主机名。有时 NetworkManager 不会立即分配主机名。control plane(master)节点可能会报告错误,例如:
Failed Units: 2
NetworkManager-wait-online.service
nodeip-configuration.service
这个错误表示集群节点可能在没有从 DHCP 服务器接收主机名的情况下引导,这会导致 kubelet 使用 localhost.localdomain 主机名引导。要解决错误,请强制节点更新主机名。
流程
检索
主机名:[core@master-X ~]$ hostname如果主机名是
localhost,请执行以下步骤。注意其中
X是 control plane 节点号。强制集群节点续订 DHCP 租期:
[core@master-X ~]$ sudo nmcli con up "<bare_metal_nic>"将
<bare_metal_nic>替换为与baremetal网络对应的有线连接。再次检查
主机名:[core@master-X ~]$ hostname如果主机名仍然是
localhost.localdomain,重启NetworkManager:[core@master-X ~]$ sudo systemctl restart NetworkManager-
如果主机名仍然是
localhost.localdomain,请等待几分钟并再次检查。如果主机名仍为localhost.localdomain,请重复前面的步骤。 重启
nodeip-configuration服务:[core@master-X ~]$ sudo systemctl restart nodeip-configuration.service此服务将使用正确的主机名引用来重新配置
kubelet服务。因为 kubelet 在上一步中更改,所以重新载入单元文件定义:
[core@master-X ~]$ sudo systemctl daemon-reload重启
kubelet服务:[core@master-X ~]$ sudo systemctl restart kubelet.service确保
kubelet使用正确的主机名引导:[core@master-X ~]$ sudo journalctl -fu kubelet.service
如果集群节点在集群启动并运行后没有通过 DHCP 获得正确的主机名,比如在重启过程中,集群会有一个待处理的 csr。不要 批准 csr,否则可能会出现其他问题。
处理 csr
在集群上获取 CSR:
$ oc get csr验证待处理的
csr是否包含Subject Name: localhost.localdomain:$ oc get csr <pending_csr> -o jsonpath='{.spec.request}' | base64 --decode | openssl req -noout -text删除包含
Subject Name: localhost.localdomain的任何csr:$ oc delete csr <wrong_csr>
3.5.16.5. 路由无法访问端点
在安装过程中,可能会出现虚拟路由器冗余协议(VRRP)冲突。如果之前使用特定集群名称部署的 OpenShift Container Platform 节点仍在运行,但不是使用相同集群名称部署的当前 OpenShift Container Platform 集群的一部分,则可能会出现冲突。例如,一个集群使用集群名称 openshift 部署,它 部署了三个 control plane(master)节点和三个 worker 节点。之后,一个单独的安装使用相同的集群名称 openshift,但这个重新部署只安装了三个 control plane(master)节点,使以前部署的三个 worker 节点处于 ON 状态。这可能导致 Virtual Router Identifier(VRID)冲突和 VRRP 冲突。
获取路由:
$ oc get route oauth-openshift检查服务端点:
$ oc get svc oauth-openshiftNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE oauth-openshift ClusterIP 172.30.19.162 <none> 443/TCP 59m尝试从 control plane(master)节点访问该服务:
[core@master0 ~]$ curl -k https://172.30.19.162{ "kind": "Status", "apiVersion": "v1", "metadata": { }, "status": "Failure", "message": "forbidden: User \"system:anonymous\" cannot get path \"/\"", "reason": "Forbidden", "details": { }, "code": 403识别
provisioner节点的 authentication-operator错误:$ oc logs deployment/authentication-operator -n openshift-authentication-operatorEvent(v1.ObjectReference{Kind:"Deployment", Namespace:"openshift-authentication-operator", Name:"authentication-operator", UID:"225c5bd5-b368-439b-9155-5fd3c0459d98", APIVersion:"apps/v1", ResourceVersion:"", FieldPath:""}): type: 'Normal' reason: 'OperatorStatusChanged' Status for clusteroperator/authentication changed: Degraded message changed from "IngressStateEndpointsDegraded: All 2 endpoints for oauth-server are reporting"
解决方案
- 确保每个部署的集群名称都是唯一的,确保没有冲突。
- 关闭所有不是使用相同集群名称的集群部署的一部分的节点。否则,OpenShift Container Platform 集群的身份验证 pod 可能无法成功启动。
3.5.16.6. 在 Firstboot 过程中 Ignition 失败
在 Firstboot 过程中,Ignition 配置可能会失败。
流程
连接到 Ignition 配置失败的节点:
Failed Units: 1 machine-config-daemon-firstboot.service重启
machine-config-daemon-firstboot服务:[core@worker-X ~]$ sudo systemctl restart machine-config-daemon-firstboot.service
3.5.16.7. NTP 不同步
OpenShift Container Platform 集群的部署需要集群节点间的 NTP 同步时钟。如果没有同步时钟,如果时间差大于 2 秒,则部署可能会因为时钟偏移而失败。
流程
检查集群节点的
AGE的不同。例如:$ oc get nodesNAME STATUS ROLES AGE VERSION master-0.cloud.example.com Ready master 145m v1.32.3 master-1.cloud.example.com Ready master 135m v1.32.3 master-2.cloud.example.com Ready master 145m v1.32.3 worker-2.cloud.example.com Ready worker 100m v1.32.3检查时钟偏移导致的时间延迟。例如:
$ oc get bmh -n openshift-machine-apimaster-1 error registering master-1 ipmi://<out_of_band_ip>$ sudo timedatectlLocal time: Tue 2020-03-10 18:20:02 UTC Universal time: Tue 2020-03-10 18:20:02 UTC RTC time: Tue 2020-03-10 18:36:53 Time zone: UTC (UTC, +0000) System clock synchronized: no NTP service: active RTC in local TZ: no
处理现有集群中的时钟偏移
创建一个 Butane 配置文件,其中包含要发送到节点的
chrony.conf文件的内容。在以下示例中,创建99-master-chrony.bu将文件添加到 control plane 节点。您可以修改 worker 节点的 文件,或者对 worker 角色重复此步骤。注意有关 Butane 的信息,请参阅"使用 Butane 创建机器配置"。
variant: openshift version: 4.19.0 metadata: name: 99-master-chrony labels: machineconfiguration.openshift.io/role: master storage: files: - path: /etc/chrony.conf mode: 0644 overwrite: true contents: inline: | server <NTP_server> iburst1 stratumweight 0 driftfile /var/lib/chrony/drift rtcsync makestep 10 3 bindcmdaddress 127.0.0.1 bindcmdaddress ::1 keyfile /etc/chrony.keys commandkey 1 generatecommandkey noclientlog logchange 0.5 logdir /var/log/chrony- 1
- 将
<NTP_server>替换为 NTP 服务器的 IP 地址。
使用 Butane 生成
MachineConfig对象文件99-master-chrony.yaml,其中包含要交付至节点的配置:$ butane 99-master-chrony.bu -o 99-master-chrony.yaml应用
MachineConfig对象文件:$ oc apply -f 99-master-chrony.yaml确保
系统时钟同步值为 yes :$ sudo timedatectlLocal time: Tue 2020-03-10 19:10:02 UTC Universal time: Tue 2020-03-10 19:10:02 UTC RTC time: Tue 2020-03-10 19:36:53 Time zone: UTC (UTC, +0000) System clock synchronized: yes NTP service: active RTC in local TZ: no要在部署前设置时钟同步,请生成清单文件并将此文件添加到
openshift目录中。例如:$ cp chrony-masters.yaml ~/clusterconfigs/openshift/99_masters-chrony-configuration.yaml然后,继续创建集群。
3.5.17. 检查安装
安装后,请确保安装程序成功部署节点和 pod。
流程
当正确安装 OpenShift Container Platform 集群节点时,在
STATUS列中会显示以下Ready 状态:$ oc get nodesNAME STATUS ROLES AGE VERSION master-0.example.com Ready master,worker 4h v1.32.3 master-1.example.com Ready master,worker 4h v1.32.3 master-2.example.com Ready master,worker 4h v1.32.3确认安装程序成功部署了所有 pod。以下命令将移除仍在运行或已完成的 pod 作为输出的一部分。
$ oc get pods --all-namespaces | grep -iv running | grep -iv complete