8.5. 聚合器
概述
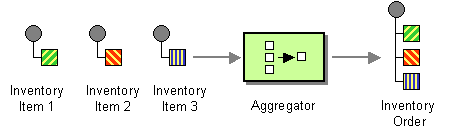
借助在 图 8.5 “聚合器模式” 中显示的 聚合器 模式,您可以将相关消息批处理合并到单个消息中。
图 8.5. 聚合器模式
要控制聚合器的行为,Apache Camel 允许您指定 Enterprise Integration Patterns 中描述的属性,如下所示:
- correlation 表达式 libselinux-eviction 确定应聚合哪些消息。在每条传入消息上评估关联表达式,以生成 关联键。然后,具有相同关联密钥的传入消息被分组到同一个批处理中。例如,如果要将 所有传入 的信息聚合到一个消息中,您可以使用一个恒定表达式。
- 完整的信息完成时,完整性条件 10.10.10.2-eviction 确定了。您可以将此设置指定为一个简单的大小限制,或者更一般,您可以指定在批处理完成后标记的 predicate 条件。
- 聚合算法 InventoryService-jaxb Com 组合了单一关联密钥的消息交换功能到单个消息交换中。
例如,考虑一个可每秒接收 30,000 条消息的库存市场数据系统。如果您的 GUI 工具无法与如此大规模的更新率合作,则您可能希望减慢消息流。只需选择最新的报价并丢弃旧的价格,即可聚合传入的库存报价。(如果您愿意捕获历史信息,可以应用 delta 处理算法。)
现在,聚合器现在使用包含更多信息的 ManagedAggregateProcessorMBean 形式列出 JMX。它允许您使用聚合控制器来控制它。
聚合器的工作方式
图 8.6 “聚合器实施” 展示了聚合器如何工作的概览,假设它通过带有关联键的交换流(如 A、B、C 或 D)进行交换流。
图 8.6. 聚合器实施
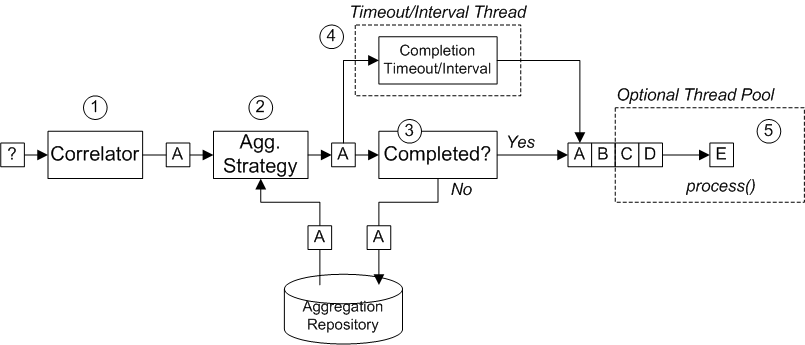
图 8.6 “聚合器实施” 中显示的传入的交换流如下:
- 关联器负责 根据关联密钥对交换进行排序。对于每个传入的交换,评估了关联表达式,从而生成关联密钥。例如,对于 图 8.6 “聚合器实施” 中显示的交换,关联键将评估为 A。
聚合策略 负责与相同关联密钥进行合并交换。当新的交换 A 处于 A 时,聚合器会在聚合存储库中查找对应的 聚合交换、A',并将其与新交换合并。
在完成特定的聚合周期前,传入的交换将继续与对应的聚合交换一起聚合。聚合周期持续到其中一个完成机制终止为止。
注意从 Camel 2.16,新的 XSLT 聚合策略允许您将两个消息与 XSLT 文件合并。您可以从 toolbox 访问
AggregationStrategies.xslt()文件。如果在聚合器上指定了完成 predicate,则会测试聚合交换,以确定是否准备好发送到路由中的下一个处理器。处理继续,如下所示:
- 如果完成,聚合交换由路由中的后方处理。这里有两种替代模型: 同步 (默认),这会导致调用线程块或 异步 (如果启用并行处理),其中将聚合交换提交至 executor 线程池(如 图 8.6 “聚合器实施”)。
- 如果没有完成,聚合交换将返回到聚合存储库。
-
与同步完成测试并行,可以通过启用
completionTimeout选项或completionInterval选项来启用异步完成测试。这些完成测试在单独的线程中运行,每当完成测试满意时,对应的交换都会标记为完成,并开始由路由后面的部分处理(同步或异步,具体取决于是否启用并行处理)。 - 如果启用了并行处理,一个线程池负责在路由后面的部分处理交换。默认情况下,这个线程池包含十个线程,但您可以选择自定义池(“线程选项”一节)。
Java DSL 示例
以下示例使用 UseLatestAggregationStrategy 聚合策略来聚合具有相同 VDDK Symbol 标头值的交换。对于给定的 prepare Symbol 值,如果收到了与该关联密钥的最后三秒钟以上,则聚合的交换被视为完成状态并发送到 模拟 端点。
from("direct:start")
.aggregate(header("id"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");XML DSL 示例
以下示例演示了如何在 XML 中配置相同的路由:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
completionTimeout="3000">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.aggregate.UseLatestAggregationStrategy"/>指定关联表达式
在 Java DSL 中,关联表达式始终作为第一个参数传递给 aggregate() DSL 命令。这里没有限制使用 Simple 表达式语言。您可以使用任何表达式语言或脚本语言(如 XPath、XQuery、SQL 等)指定关联表达式。
对于考试,若要使用 XPath 表达式关联交换,您可以使用以下 Java DSL 路由:
from("direct:start")
.aggregate(xpath("/stockQuote/@symbol"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");
如果无法在特定的交换中评估关联表达式,聚合器默认会抛出 CamelExchangeException。您可以通过设置 ignoreCorrelationKeys 选项来限制这个异常。例如,在 Java DSL 中:
from(...).aggregate(...).ignoreInvalidCorrelationKeys()
在 XML DSL 中,您可以设置 ignoreInvalidCorrelationKeys 选项作为属性,如下所示:
<aggregate strategyRef="aggregatorStrategy"
ignoreInvalidCorrelationKeys="true"
...>
...
</aggregate>指定聚合策略
在 Java DSL 中,您可以将聚合策略作为第二参数传递给 aggregate() DSL 命令,或使用 aggregationStrategy() 子句指定。例如,您可以使用 aggregationStrategy() 子句,如下所示:
from("direct:start")
.aggregate(header("id"))
.aggregationStrategy(new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");
Apache Camel 提供以下基本的聚合策略(即类属于 org.apache.camel.processor.aggregate Java 软件包):
UseLatestAggregationStrategy- 返回给定关联密钥的最后交换,用该密钥丢弃之前的所有交换。例如,此策略对于对来自股票交易所馈送的换算者来说非常有用,其中您只想了解特定库存符号的最新价格。
UseOriginalAggregationStrategy-
返回给定关联密钥的第一个交换,用此密钥丢弃所有之后的交换。您必须在可以使用此策略前调用
UseOriginalAggregationStrategy.setOriginal()来设置第一个交换。 GroupedExchangeAggregationStrategy-
将给定关联键 的所有 交换串联为列表,该列表存储在
Exchange.GROUPED_EXCHANGE交换属性中。请参阅 “分组交换”一节。
实施自定义聚合策略
如果要应用不同的聚合策略,可以实施以下聚合策略基础接口之一:
org.apache.camel.processor.aggregate.AggregationStrategy- 基本聚合策略接口。
org.apache.camel.processor.aggregate.TimeoutAwareAggregationStrategy实施这个接口,如果您希望实施在聚合周期超时时收到通知。
超时通知方法有以下签名:void timeout(Exchange oldExchange, int index, int total, long timeout)org.apache.camel.processor.aggregate.CompletionAwareAggregationStrategy实施这个接口,如果您要在聚合周期正常完成时收到通知,则实施此接口。通知方法有以下签名:
void onCompletion(Exchange exchange)
例如,以下代码显示了两个不同的自定义聚合策略,StringAggregationStrategy 和 ArrayListAggregationStrategy::
//simply combines Exchange String body values using '' as a delimiter
class StringAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
if (oldExchange == null) {
return newExchange;
}
String oldBody = oldExchange.getIn().getBody(String.class);
String newBody = newExchange.getIn().getBody(String.class);
oldExchange.getIn().setBody(oldBody + "" + newBody);
return oldExchange;
}
}
//simply combines Exchange body values into an ArrayList<Object>
class ArrayListAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
Object newBody = newExchange.getIn().getBody();
ArrayList<Object> list = null;
if (oldExchange == null) {
list = new ArrayList<Object>();
list.add(newBody);
newExchange.getIn().setBody(list);
return newExchange;
} else {
list = oldExchange.getIn().getBody(ArrayList.class);
list.add(newBody);
return oldExchange;
}
}
}
从 Apache Camel 2.0 开始,在第一个交换中也调用 AggregationStrategy.aggregate() 回调方法。在 aggregate 方法的第一个调用中,oldExchange 参数为 null,newExchange 参数包含第一个传入的交换。
要使用自定义策略类 ArrayListAggregationStrategy 来聚合消息,请按如下所示定义一个路由:
from("direct:start")
.aggregate(header("StockSymbol"), new ArrayListAggregationStrategy())
.completionTimeout(3000)
.to("mock:result");您还可以使用 XML 中的自定义聚合策略配置路由,如下所示:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
completionTimeout="3000">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy" class="com.my_package_name.ArrayListAggregationStrategy"/>控制自定义聚合策略的生命周期
您可以实施自定义聚合策略,以便其生命周期与控制它的企业集成模式的生命周期一致。这可用于确保聚合策略可以安全地关闭。
要实现具有生命周期支持的聚合策略,您必须实现 org.apache.camel.Service 接口(除 AggregationStrategy 接口外),并提供 start() 和 stop() 生命周期方法的实现。例如,以下代码示例演示了具有生命周期支持的聚合策略:
// Java
import org.apache.camel.processor.aggregate.AggregationStrategy;
import org.apache.camel.Service;
import java.lang.Exception;
...
class MyAggStrategyWithLifecycleControl
implements AggregationStrategy, Service {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
// Implementation not shown...
...
}
public void start() throws Exception {
// Actions to perform when the enclosing EIP starts up
...
}
public void stop() throws Exception {
// Actions to perform when the enclosing EIP is stopping
...
}
}Exchange 属性
每个聚合交换中会设置以下属性:
| 标头 | 类型 | 描述聚合交换属性 |
|---|---|---|
|
|
| 整合到此交换的交换总数。 |
|
|
|
表示负责完成聚合交换的机制。可能的值有: |
以下属性在由 SQL 组件聚合存储库进行交换上设置(请参阅 “持久性聚合存储库”一节):
| 标头 | 类型 | 描述 Red Hatlivered Exchange Properties |
|---|---|---|
|
|
|
当前重新传送尝试的序列号(从 |
指定完成条件
至少需要指定一个 完成条件,它决定聚合交换离开聚合器并继续路由上的下一个节点。可以指定以下完成条件:
completionPredicate-
聚合每个交换后评估 predicate,以确定完整性。
true表示聚合交换已完成。另外,您可以定义一个自定义AggregationStrategy来实施Predicate接口,在这种情况下,AggregationStrategy将用作 completion predicate。 completionSize- 聚合指定数量的传入的交换后,完成聚合的交换。
completionTimeout(与
completionInterval兼容) 在指定的超时时间内没有聚合交换时完成聚合交换。换句话说,超时机制会跟踪 每个 关联键值的超时。在收到带有特定密钥值的最新交换后,时钟开始选择。如果指定超时内 未收到 具有相同键值的另一个交换,则对应的聚合交换标记为完成并发送到路由上的下一个节点。
completionInterval(与
completionTimeout兼容 ) 将 完成所有 未完成的聚合交换,经过每个时间间隔(指定长度)过后。间隔 不会 为每个聚合交换量身定制。这种机制会强制同步完成所有未完成的聚合交换。因此,在某些情况下,这种机制可在聚合后立即完成聚合交换。
completionFromBatchConsumer- 与支持 批处理消费者 机制的消费者端点结合使用时,此完成选项会根据从消费者端点接收的信息,在当前批量交换完成后自动找出出。请参阅 “批量消费者”一节。
forceCompletionOnStop- 启用此选项后,它会强制在当前路由上下文停止后完成所有未完成的聚合交换。
除了 completionTimeout 和 completionInterval 条件(无法同时启用)外,前面的完成条件可以任意组合使用。当条件组合使用时,触发的第一个完成条件是有效的完成条件。
指定完成 predicate
您可以指定一个任意 predicate 表达式,决定聚合交换完成后决定。评估 predicate 表达式的方法有两种:
- 在最新的聚合交换 中,the default behavior是默认行为。
-
当您启用
eagerCheckCompletion选项时,会选择最新传入的 Exchange 您要将这个行为被选择。
例如,如果您想要在每次收到 ALERT 消息时终止库存引号流(如最新传入的交换中 MsgType 标头的值所示),您可以定义一个类似如下的路由:
from("direct:start")
.aggregate(
header("id"),
new UseLatestAggregationStrategy()
)
.completionPredicate(
header("MsgType").isEqualTo("ALERT")
)
.eagerCheckCompletion()
.to("mock:result");以下示例演示了如何使用 XML 配置同一路由:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
eagerCheckCompletion="true">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionPredicate>
<simple>$MsgType = 'ALERT'</simple>
</completionPredicate>
<to uri="mock:result"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.aggregate.UseLatestAggregationStrategy"/>指定动态完成超时
可以指定 动态完成超时,其中为每个传入的交换重新计算超时值。例如,若要从每个传入交换中的 超时标头设置超时值,您可以按照如下所示定义路由:
from("direct:start")
.aggregate(header("StockSymbol"), new UseLatestAggregationStrategy())
.completionTimeout(header("timeout"))
.to("mock:aggregated");您可以在 XML DSL 中配置相同的路由,如下所示:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionTimeout>
<header>timeout</header>
</completionTimeout>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.UseLatestAggregationStrategy"/>
您还可以添加固定超时值,如果动态值是 null 或 0, 则 Apache Camel 会返回使用这个值。
指定动态完成大小
可以指定 动态完成大小,在其中为每个传入的交换重新计算完成大小。例如,要在每个传入交换中从 mySize 标头设置完成大小,您可以按照如下所示定义路由:
from("direct:start")
.aggregate(header("StockSymbol"), new UseLatestAggregationStrategy())
.completionSize(header("mySize"))
.to("mock:aggregated");以及使用 Spring XML 相同的示例:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionSize>
<header>mySize</header>
</completionSize>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.UseLatestAggregationStrategy"/>
您还可以添加固定大小值,如果动态值是 null 或 0, 则 Apache Camel 会返回使用这个值。
从 AggregationStrategy 内强制完成单个组
如果实施自定义 AggregationStrategy 类,可以通过一种机制来强制完成当前消息组,方法是将 Exchange.AGGREGATION_COMPLETE_CURRENT_GROUP Exchange 属性设为 true。这种机制 仅影响 当前组:其他消息组(具有不同关联 ID) 不会被 强制完成。这种机制会覆盖任何其他完成机制,如 predicate、大小、超时等。
例如,如果消息正文大小大于 5,以下示例 AggregationStrategy 类将完成当前的组:
// Java
public final class MyCompletionStrategy implements AggregationStrategy {
@Override
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
if (oldExchange == null) {
return newExchange;
}
String body = oldExchange.getIn().getBody(String.class) + "+"
+ newExchange.getIn().getBody(String.class);
oldExchange.getIn().setBody(body);
if (body.length() >= 5) {
oldExchange.setProperty(Exchange.AGGREGATION_COMPLETE_CURRENT_GROUP, true);
}
return oldExchange;
}
}强制使用特殊消息完成所有组
通过向路由发送带有特殊标头的消息,可以强制完成所有未完成的聚合消息。您可以使用两种替代标头设置来强制完成:
Exchange.AGGREGATION_COMPLETE_ALL_GROUPS-
设置为
true,以强制完成当前的聚合周期。此消息仅以信号形式运作,不包含在 任何聚合周期内。处理此信号消息后,会丢弃消息的内容。 Exchange.AGGREGATION_COMPLETE_ALL_GROUPS_INCLUSIVE-
设置为
true,以强制完成当前的聚合周期。此消息 包含在 当前聚合周期中。
使用 AggregateController
org.apache.camel.processor.aggregate.AggregateController 可让您使用 Java 或 JMX API 控制运行时的聚合。这可用于强制完成交换组,或者查询当前运行时统计信息。
如果没有配置自定义,聚合器提供了一个默认的实现,您可以使用 getAggregateController() 方法访问它。但是,使用 aggregateController 轻松地在路由中配置控制器。
private AggregateController controller = new DefaultAggregateController();
from("direct:start")
.aggregate(header("id"), new MyAggregationStrategy()).completionSize(10).id("myAggregator")
.aggregateController(controller)
.to("mock:aggregated");
另外,您可以使用 AggregateController上的 API 来强制完成。例如,使用键 foo 完成组
int groups = controller.forceCompletionOfGroup("foo");数值返回将是已完成的组数。以下是完成所有组的 API:
int groups = controller.forceCompletionOfAllGroups();强制唯一关联密钥
在一些聚合场景中,您可能希望强制关联密钥对每批交换是唯一的条件。换而言之,当特定关联键的聚合交换完成时,您希望确保不进一步的聚合交换,不能与这个关联键进行进一步的交换。例如,如果路由中的后者部分与唯一关联键值进行交换,您可能希望强制执行此条件。
根据配置完成条件的方式,可能会遇到使用特定关联密钥生成多个聚合交换的风险。例如,虽然您可以定义一个完成 predicate,以便等到接收具有特定关联密钥 的所有 交换前,您也可以定义完成超时,这可以在与该密钥到达的所有交换之前触发。在这种情况下,较晚的交换可能会给 第二个 聚合交换带来的增加,具有相同关联键的值。
对于这样的场景,您可以通过设置 closeCorrelationKeyOnCompletion 选项,将聚合器配置为绕过重复之前关联键值的聚合交换。为绕过重复的关联键值,聚合器需要在缓存中记录之前的关联键值。此缓存的大小(缓存的关联键的数量)被指定为 closeCorrelationKeyOnCompletion() DSL 命令的参数。要指定无限大小的缓存,您可以传递一个零个或一个负整数。例如,指定 10000 个键值的缓存大小:
from("direct:start")
.aggregate(header("UniqueBatchID"), new MyConcatenateStrategy())
.completionSize(header("mySize"))
.closeCorrelationKeyOnCompletion(10000)
.to("mock:aggregated");
如果聚合交换以重复的关联键值完成,聚合器会抛出 ClosedCorrelationKeyException 异常。
使用简单表达式的基于流的处理
您可以将 Simple 语言表达式用作使用流模式的 tokenizeXML 子命令的令牌。使用简单语言表达式将支持动态令牌。
例如,要使用 Java 将一系列名称分割成标签用户角色,您可以使用 令牌izeXML bean 和简单语言令牌将 文件分成 名称 元素。
public void testTokenizeXMLPairSimple() throws Exception {
Expression exp = TokenizeLanguage.tokenizeXML("${header.foo}", null);
获取由 < person > 划分的名称输入字符串,并将 < ;person& gt; 设置为令牌。
exchange.getIn().setHeader("foo", "<person>");
exchange.getIn().setBody("<persons><person>James</person><person>Claus</person><person>Jonathan</person><person>Hadrian</person></persons>");列出从输入中分割的名称。
List<?> names = exp.evaluate(exchange, List.class);
assertEquals(4, names.size());
assertEquals("<person>James</person>", names.get(0));
assertEquals("<person>Claus</person>", names.get(1));
assertEquals("<person>Jonathan</person>", names.get(2));
assertEquals("<person>Hadrian</person>", names.get(3));
}分组交换
您可以将传出批处理中的所有聚合交换组合为一个 org.apache.camel.impl.GroupedExchange holder 类。要启用分组的交换,请指定 groupExchanges() 选项,如以下 Java DSL 路由中所示:
from("direct:start")
.aggregate(header("StockSymbol"))
.completionTimeout(3000)
.groupExchanges()
.to("mock:result");
发送至 模拟:result 的分组交换列表包含消息正文中的聚合交换列表。以下行显示后续的处理器如何以列表的形式访问分组交换的内容:
// Java
List<Exchange> grouped = ex.getIn().getBody(List.class);当您启用分组的交换功能时,不得 配置聚合策略(分组交换功能本身就是一个聚合策略)。
从传出交换的属性访问分组交换的旧方法是已弃用,并将在以后的发行版本中删除。
批量消费者
聚合器可以和 批处理消费者 模式一起工作,以汇总批处理消费者报告的消息总数(批处理端点设置 CamelBatchSize、CamelBatchIndex 和 CamelBatchComplete 属性)。例如,若要聚合由文件消费者端点找到的所有文件,您可以按照以下方式使用路由:
from("file://inbox")
.aggregate(xpath("//order/@customerId"), new AggregateCustomerOrderStrategy())
.completionFromBatchConsumer()
.to("bean:processOrder");目前,以下端点支持批处理消费者机制:文件、FTP、邮件、iBatis 和 JPA。
持久性聚合存储库
默认聚合器只使用内存的 AggregationRepository。如果要永久存储待处理聚合交换,您可以使用 SQL 组件 作为持久聚合存储库。SQL 组件包含一个 JdbcAggregationRepository,可持续保留聚合的消息,并确保您不会丢失任何消息。
当成功处理交换后,当存储库上调用 确认方法时,它将标记为 complete。这意味着,如果同样的交换再次失败,它将重试,直到成功为止。
添加对 camel-sql 的依赖
要使用 SQL 组件,您必须在项目中包含对 camel-sql 的依赖。例如,如果您使用 Maven pom.xml 文件:
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-sql</artifactId>
<version>x.x.x</version>
<!-- use the same version as your Camel core version -->
</dependency>创建聚合数据库表
您必须创建一个单独的聚合和已完成的数据库表以实现持久性。例如,以下查询会为名为 my_aggregation_repo 的数据库创建表:
CREATE TABLE my_aggregation_repo (
id varchar(255) NOT NULL,
exchange blob NOT NULL,
constraint aggregation_pk PRIMARY KEY (id)
);
CREATE TABLE my_aggregation_repo_completed (
id varchar(255) NOT NULL,
exchange blob NOT NULL,
constraint aggregation_completed_pk PRIMARY KEY (id)
);
}配置聚合存储库
您还必须在框架 XML 文件中配置聚合存储库(如 Spring 或 Blueprint):
<bean id="my_repo"
class="org.apache.camel.processor.aggregate.jdbc.JdbcAggregationRepository">
<property name="repositoryName" value="my_aggregation_repo"/>
<property name="transactionManager" ref="my_tx_manager"/>
<property name="dataSource" ref="my_data_source"/>
...
</bean>
repositories Name、transactionManager 和 dataSource 属性是必需的。有关持久性聚合存储库的更多信息,请参阅 Apache Camel 组件参考指南 中的 SQL 组件。
线程选项
如 图 8.6 “聚合器实施” 所示,聚合器与路由中的后方分离,后者将发送到路由后面的部分,后者由专用线程池处理。默认情况下,这个池仅包含单个线程。如果要指定多个线程的池,启用 parallelProcessing 选项,如下所示:
from("direct:start")
.aggregate(header("id"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.parallelProcessing()
.to("mock:aggregated");默认情况下,这会创建一个有 10 个 worker 线程的池。
如果要对创建的线程池进行更多控制,请使用 executorService 选项指定自定义 java.util.concurrent.ExecutorService 实例(在这种情况下,不需要启用 parallelProcessing 选项)。
聚合到列表中
常见的聚合场景涉及将一系列传入的消息正文聚合到一个 List 对象中。为便于这种情况,Apache Camel 提供了 AbstractListAggregationStrategy 抽象类,您可以快速扩展来为本例创建聚合策略。传入类型为 T 的消息正文,聚合到一个完成的交换中,以及类型为 List<T> 的消息正文。
例如,若要将一系列 Integer 消息正文聚合到一个 List<Integer > 对象中,您可以使用以下定义的聚合策略:
import org.apache.camel.processor.aggregate.AbstractListAggregationStrategy;
...
/**
* Strategy to aggregate integers into a List<Integer>.
*/
public final class MyListOfNumbersStrategy extends AbstractListAggregationStrategy<Integer> {
@Override
public Integer getValue(Exchange exchange) {
// the message body contains a number, so just return that as-is
return exchange.getIn().getBody(Integer.class);
}
}aggregator 选项
聚合器支持以下选项:
| 选项 | 默认值 | 描述 |
|---|---|---|
|
|
强制表达式,用于评估用于聚合的关联密钥。具有相同关联密钥的 Exchange 会聚合在一起。如果无法评估关联密钥,则引发 Exception。您可以使用 | |
|
|
mandatory | |
|
|
在 registry 中查询 | |
|
|
聚合完成前聚合的消息数量。这个选项可以被设置为固定值或使用表达式(允许您动态评估大小)将使用 | |
|
|
聚合交换的时间在完成前应不活跃。这个选项可以设置为固定值或使用允许您动态评估超时的表达式 - 将因此使用 | |
|
| 在聚合器中重复一个期间,聚合器将完成所有当前的聚合交换。Camel 有一个后台任务,每个任务都会触发。您不能将此选项与 completionTimeout 一起使用,只能同时使用其中之一。 | |
|
|
指定 predicate( | |
|
|
|
这个选项是,如果交换来自一个 Batch Consumer。然后,当启用 第 8.5 节 “聚合器” 时,将使用在消息标头 |
|
|
|
在收到新传入的 Exchange 时,是否检查是否完成。这个选项会影响 |
|
|
|
如果为 |
|
|
|
如果启用,Camel 将所有聚合的 Exchanges 分组到一个整合的 |
|
|
| 是否忽略无法被评估到值的关联键。默认情况下,Camel 将抛出 Exception,但您可以启用这个选项并忽略这种情况。 |
|
|
是否应该接受 后期 的 Exchanges。您可以启用此项来指示是否已完成关联密钥,然后与相同关联密钥的任何新交换都将被拒绝。然后,CamelationKeyException 异常会引发 | |
|
|
| Camel 2.5: 由于超时而完成的交换应该被丢弃。如果启用,则当超时发生时,聚合的消息 不会 发出出去但丢弃(无意图)。 |
|
|
允许您自行插入 | |
|
|
引用在 registry | |
|
|
| 当聚合完成后,它们将从聚合器中发送。此选项指明 Camel 是否应使用带有多个线程的线程池来实现并发性。如果没有指定自定义线程池,Camel 会创建一个带有 10 个并发线程的默认池。 |
|
|
如果使用 | |
|
|
在 Registry 中查询 | |
|
|
如果使用一个 | |
|
|
在 registry 中查找 | |
|
| 当您停止聚合器时,这个选项允许它完成来自聚合存储库的所有待处理交换。 | |
|
|
| 打开开放式锁定,它可以与聚合存储库结合使用。 |
|
| 为选择锁定配置重试策略。 |