Chapter 2. Discover
2.1. About OpenShift Serverless
OpenShift Serverless provides Kubernetes native building blocks that enable developers to create and deploy serverless, event-driven applications on OpenShift Container Platform. OpenShift Serverless is based on the open source Knative project, which provides portability and consistency for hybrid and multi-cloud environments by enabling an enterprise-grade serverless platform.
Because OpenShift Serverless releases on a different cadence from OpenShift Container Platform, the OpenShift Serverless documentation does not maintain separate documentation sets for minor versions of the product. The current documentation set applies to all currently supported versions of OpenShift Serverless unless version-specific limitations are called out in a particular topic or for a particular feature.
For additional information about the OpenShift Serverless life cycle and supported platforms, refer to the Platform Life Cycle Policy.
2.1.1. Knative Serving
Knative Serving supports developers who want to create, deploy, and manage cloud-native applications. It provides a set of objects as Kubernetes custom resource definitions (CRDs) that define and control the behavior of serverless workloads on an OpenShift Container Platform cluster.
Developers use these CRDs to create custom resource (CR) instances that can be used as building blocks to address complex use cases. For example:
- Rapidly deploying serverless containers.
- Automatically scaling pods.
2.1.1.1. Knative Serving resources
- Service
-
The
service.serving.knative.devCRD automatically manages the life cycle of your workload to ensure that the application is deployed and reachable through the network. It creates a route, a configuration, and a new revision for each change to a user created service, or custom resource. Most developer interactions in Knative are carried out by modifying services. - Revision
-
The
revision.serving.knative.devCRD is a point-in-time snapshot of the code and configuration for each modification made to the workload. Revisions are immutable objects and can be retained for as long as necessary. - Route
-
The
route.serving.knative.devCRD maps a network endpoint to one or more revisions. You can manage the traffic in several ways, including fractional traffic and named routes. - Configuration
-
The
configuration.serving.knative.devCRD maintains the desired state for your deployment. It provides a clean separation between code and configuration. Modifying a configuration creates a new revision.
2.1.2. Knative Eventing
Knative Eventing on OpenShift Container Platform enables developers to use an event-driven architecture with serverless applications. An event-driven architecture is based on the concept of decoupled relationships between event producers and event consumers.
Event producers create events, and event sinks, or consumers, receive events. Knative Eventing uses standard HTTP POST requests to send and receive events between event producers and sinks. These events conform to the CloudEvents specifications, which enables creating, parsing, sending, and receiving events in any programming language.
Knative Eventing supports the following use cases:
- Publish an event without creating a consumer
- You can send events to a broker as an HTTP POST, and use binding to decouple the destination configuration from your application that produces events.
- Consume an event without creating a publisher
- You can use a trigger to consume events from a broker based on event attributes. The application receives events as an HTTP POST.
To enable delivery to multiple types of sinks, Knative Eventing defines the following generic interfaces that can be implemented by multiple Kubernetes resources:
- Addressable resources
-
Able to receive and acknowledge an event delivered over HTTP to an address defined in the
status.address.urlfield of the event. The KubernetesServiceresource also satisfies the addressable interface. - Callable resources
-
Able to receive an event delivered over HTTP and transform it, returning
0or1new events in the HTTP response payload. These returned events may be further processed in the same way that events from an external event source are processed.
You can propagate an event from an event source to multiple event sinks by using:
- Channels and subscriptions, or
- Brokers and Triggers.
2.1.3. Supported configurations
The set of supported features, configurations, and integrations for OpenShift Serverless, current and past versions, are available at the Supported Configurations page.
2.1.4. Scalability and performance
OpenShift Serverless has been tested with a configuration of 3 main nodes and 3 worker nodes, each of which has 64 CPUs, 457 GB of memory, and 394 GB of storage each.
The maximum number of Knative services that can be created using this configuration is 3,000. This corresponds to the OpenShift Container Platform Kubernetes services limit of 10,000, since 1 Knative service creates 3 Kubernetes services.
The average scale from zero response time was approximately 3.4 seconds, with a maximum response time of 8 seconds, and a 99.9th percentile of 4.5 seconds for a simple Quarkus application. These times might vary depending on the application and the runtime of the application.
2.2. About OpenShift Serverless Functions
OpenShift Serverless Functions enables developers to create and deploy stateless, event-driven functions as a Knative service on OpenShift Container Platform. The kn func CLI is provided as a plugin for the Knative kn CLI. You can use the kn func CLI to create, build, and deploy the container image as a Knative service on the cluster.
2.2.1. Included runtimes
OpenShift Serverless Functions provides templates that can be used to create basic functions for the following runtimes:
2.2.2. Next steps
2.3. Event sources
A Knative event source can be any Kubernetes object that generates or imports cloud events, and relays those events to another endpoint, known as a sink. Sourcing events is critical to developing a distributed system that reacts to events.
You can create and manage Knative event sources by using the Developer perspective in the OpenShift Container Platform web console, the Knative (kn) CLI, or by applying YAML files.
Currently, OpenShift Serverless supports the following event source types:
- API server source
- Brings Kubernetes API server events into Knative. The API server source sends a new event each time a Kubernetes resource is created, updated or deleted.
- Ping source
- Produces events with a fixed payload on a specified cron schedule.
- Kafka event source
- Connects a Kafka cluster to a sink as an event source.
You can also create a custom event source.
2.4. Brokers
Brokers can be used in combination with triggers to deliver events from an event source to an event sink. Events are sent from an event source to a broker as an HTTP POST request. After events have entered the broker, they can be filtered by CloudEvent attributes using triggers, and sent as an HTTP POST request to an event sink.
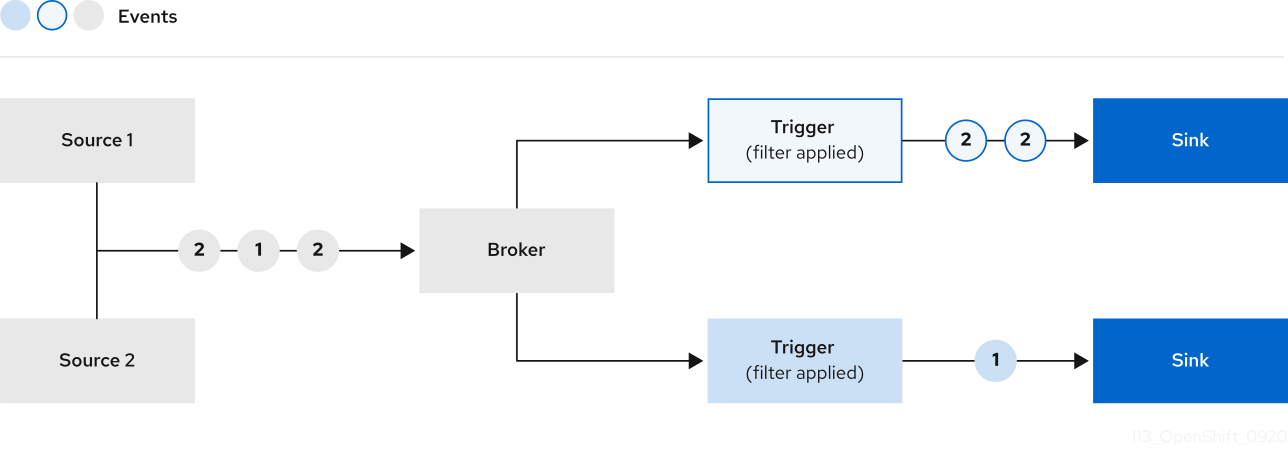
2.4.1. Broker types
Cluster administrators can set the default broker implementation for a cluster. When you create a broker, the default broker implementation is used, unless you provide set configurations in the Broker object.
2.4.1.1. Default broker implementation for development purposes
Knative provides a default, channel-based broker implementation. This channel-based broker can be used for development and testing purposes, but does not provide adequate event delivery guarantees for production environments. The default broker is backed by the InMemoryChannel channel implementation by default.
If you want to use Kafka to reduce network hops, use the Kafka broker implementation. Do not configure the channel-based broker to be backed by the KafkaChannel channel implementation.
2.4.1.2. Production-ready Kafka broker implementation
For production-ready Knative Eventing deployments, Red Hat recommends using the Knative Kafka broker implementation. The Kafka broker is an Apache Kafka native implementation of the Knative broker, which sends CloudEvents directly to the Kafka instance.
The Federal Information Processing Standards (FIPS) mode is disabled for Kafka broker.
The Kafka broker has a native integration with Kafka for storing and routing events. This allows better integration with Kafka for the broker and trigger model over other broker types, and reduces network hops. Other benefits of the Kafka broker implementation include:
- At-least-once delivery guarantees
- Ordered delivery of events, based on the CloudEvents partitioning extension
- Control plane high availability
- A horizontally scalable data plane
The Knative Kafka broker stores incoming CloudEvents as Kafka records, using the binary content mode. This means that all CloudEvent attributes and extensions are mapped as headers on the Kafka record, while the data spec of the CloudEvent corresponds to the value of the Kafka record.
2.4.2. Next steps
2.5. Channels and subscriptions
Channels are custom resources that define a single event-forwarding and persistence layer. After events have been sent to a channel from an event source or producer, these events can be sent to multiple Knative services or other sinks by using a subscription.
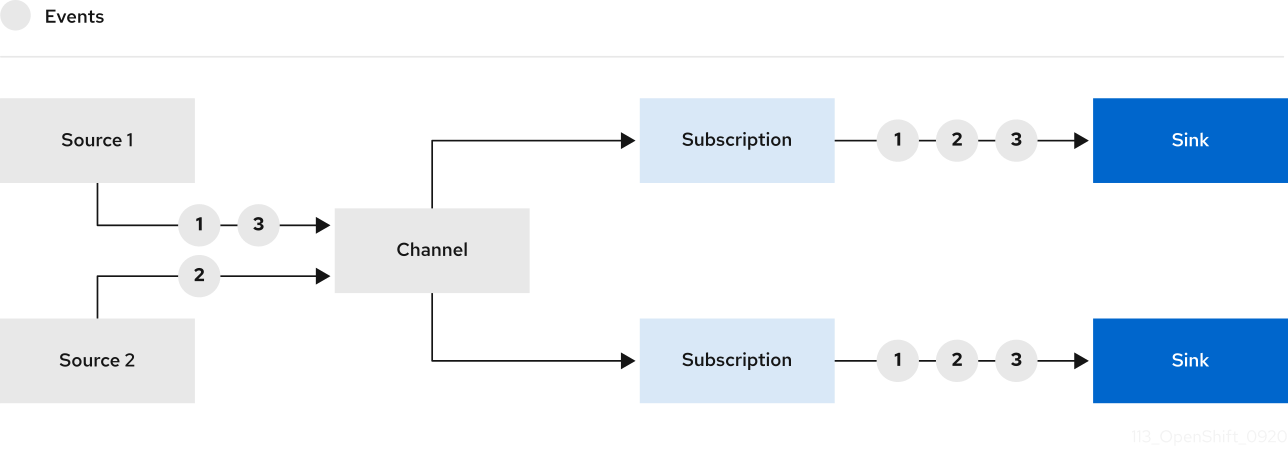
You can create channels by instantiating a supported Channel object, and configure re-delivery attempts by modifying the delivery spec in a Subscription object.
After you create a Channel object, a mutating admission webhook adds a set of spec.channelTemplate properties for the Channel object based on the default channel implementation. For example, for an InMemoryChannel default implementation, the Channel object looks as follows:
apiVersion: messaging.knative.dev/v1
kind: Channel
metadata:
name: example-channel
namespace: default
spec:
channelTemplate:
apiVersion: messaging.knative.dev/v1
kind: InMemoryChannel
The channel controller then creates the backing channel instance based on the spec.channelTemplate configuration.
The spec.channelTemplate properties cannot be changed after creation, because they are set by the default channel mechanism rather than by the user.
When this mechanism is used with the preceding example, two objects are created: a generic backing channel and an InMemoryChannel channel. If you are using a different default channel implementation, the InMemoryChannel is replaced with one that is specific to your implementation. For example, with Knative Kafka, the KafkaChannel channel is created.
The backing channel acts as a proxy that copies its subscriptions to the user-created channel object, and sets the user-created channel object status to reflect the status of the backing channel.
2.5.1. Channel implementation types
InMemoryChannel and KafkaChannel channel implementations can be used with OpenShift Serverless for development use.
The following are limitations of InMemoryChannel type channels:
- No event persistence is available. If a pod goes down, events on that pod are lost.
-
InMemoryChannelchannels do not implement event ordering, so two events that are received in the channel at the same time can be delivered to a subscriber in any order. -
If a subscriber rejects an event, there are no re-delivery attempts by default. You can configure re-delivery attempts by modifying the
deliveryspec in theSubscriptionobject.
For more information about Kafka channels, see the Knative Kafka documentation.
2.5.2. Next steps
- Create a channel.
- If you are a cluster administrator, you can configure default settings for channels. See Configuring channel defaults.