1.8. Linux Virtual Server
Il Linux Virtual Server (LVS) è un insieme di componenti software integrati per il bilanciamento del carico IP attraverso un set di real server. LVS viene eseguito su di una coppia di computer configurati in modo simile: un router LVS attivo ed un router LVS di backup. Il router LVS attivo viene utilizzato per:
- Bilanciare il carico attraverso i real server.
- Controllare l'integrità dei servizi su ogni real server.
Il router LVS di backup monitorizza il router LVS attivo, sostituendolo nel caso in cui il router LVS attivo fallisce.
Figura 1.19, «Components of a Running LVS Cluster» provides an overview of the LVS components and their interrelationship.
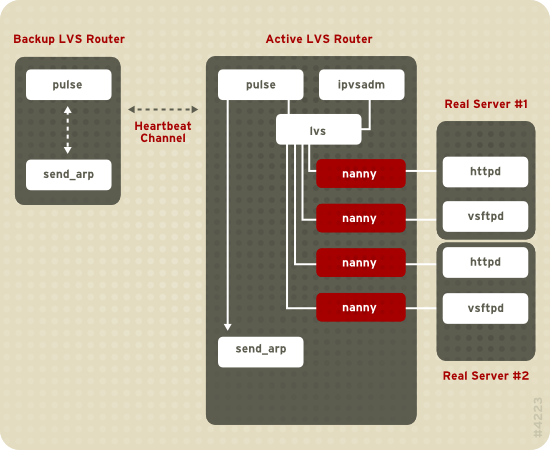
Figura 1.19. Components of a Running LVS Cluster
Il demone
pulse viene eseguito sia sul router LVS attivo che su quello passivo. Sul router LVS di backup, pulse invia un heartbeat all'interfaccia pubblica del router attivo, in modo da assicurarsi che il router LVS attivo funzioni correttamente. Sul router LVS attivo, pulse avvia il demone lvs, e risponde alle interrogazioni heartbeat provenienti dal router LVS di backup.
Una volta avviato, il demone
lvs chiama l'utilità ipvsadm per configurare e gestire la tabella d'instradamento IPVS (IP Virtual Server) nel kernel, e successivamente avvia un processo nanny per ogni server virtuale configurato su ogni real server. Ogni processo nanny controlla lo stato di un servizio configurato su di un real server, ed indica al demone lvs se è presente un malfunzionamento del servizio su quel real server. Se tale malfunzionamento viene rilevato, il demone lvs indica a ipvsadm di rimuovere il real server in questione dalla tabella d'instradamento di IPVS.
Se il router LVS di backup non riceve alcuna risposta dal router LVS attivo, esso inizia un processo di failover attraverso la chiamata
send_arp, riassegnando tutti gli indirizzi IP virtuali agli indirizzi hardware NIC (indirizzo MAC) del router LVS di backup, ed inviando un comando al router LVS attivo tramite l'interfaccia di rete privata e quella pubblica in modo da interrompere il demone lvs sul router LVS attivo. A questo punto verrà avviato il demone lvs sul router LVS di backup ed accettate tutte le richieste per i server virtuali configurati.
Per un utente esterno che accede ad un servizio hosted (come ad esempio le applicazioni databese o website), LVS può apparire come un unico server. Tuttavia l'utente accede ai real server situati oltre i router LVS.
Poichè non è presente alcun componente interno a LVS per condividere i dati tra i server reali, sono disponibili due opzioni di base:
- La sincronizzazione dei dati attraverso i real server.
- L'aggiunta di un terzo livello alla topologia per l'accesso dei dati condivisi.
Verrà utilizzata la prima opzione per i server che non permettono un numero di utenti molto grande per caricare o modificare i dati sui real server. Se i real server permettono un numero esteso di utenti per la modifica dei dati, come ad esempio un sito web e-commerce, allora sarà preferita l'aggiunta di un terzo livello.
Sono disponibili diverse modalità per la sincronizzazione dei dati tra i real server. Per esempio è possibile utilizzare gli script della shell per postare simultaneamente le pagine web aggiornate sui real server. Altresì è possibile utilizzare programmi come
rsync, per replicare i dati modificati attraverso tutti i nodi in un intervallo di tempo determinato. Tuttavia in ambienti dove gli utenti caricano spesso file o emettono transazioni del database, l'utilizzo di script o del comando rsync per la sincronizzazione dei dati, non funzionerà in maniera ottimale. Per questo motivo per real server con un numero di upload molto elevato, e per transazioni del database o di traffico simile, una topologia three-tiered risulta essere più appropriata se desiderate sincronizzare i dati.
1.8.1. Two-Tier LVS Topology
Copia collegamentoCollegamento copiato negli appunti!
Figura 1.20, «Two-Tier LVS Topology» shows a simple LVS configuration consisting of two tiers: LVS routers and real servers. The LVS-router tier consists of one active LVS router and one backup LVS router. The real-server tier consists of real servers connected to the private network. Each LVS router has two network interfaces: one connected to a public network (Internet) and one connected to a private network. A network interface connected to each network allows the LVS routers to regulate traffic between clients on the public network and the real servers on the private network. In Figura 1.20, «Two-Tier LVS Topology», the active LVS router uses Network Address Translation (NAT) to direct traffic from the public network to real servers on the private network, which in turn provide services as requested. The real servers pass all public traffic through the active LVS router. From the perspective of clients on the public network, the LVS router appears as one entity.
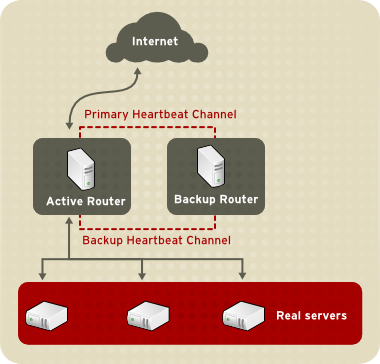
Figura 1.20. Two-Tier LVS Topology
Le richieste del servizio che arrivano ad un router LVS vengono indirizzate ad un indirizzo IP virtuale o VIP. Esso rappresenta un indirizzo instradabile pubblicamente che l'amministratore del sito associa con un fully-qualified domain name, come ad esempio www.example.com, e assegnato ad uno o più server virtuali[1]. Nota bene che un indirizzo IP migra da un router LVS ad un altro durante un failover, mantenendo così una presenza in quel indirizzo IP, conosciuto anche come Indirizzi IP floating.
È possibile eseguire l'alias degli indirizzi VIP, sullo stesso dispositivo che esegue il collegamento del router LVS con la rete pubblica. Per esempio, se eth0 è collegato ad internet, allora sarà possibile eseguire l'alias dei server virtuali multipli su
eth0:1. Alternativamente ogni server virtuale può essere associato con un dispositivo separato per servizio. Per esempio, il traffico HTTP può essere gestito su eth0:1, ed il traffico FTP gestito su eth0:2.
Solo un router LVS alla volta può essere attivo. Il ruolo del router LVS attivo è quello di ridirezionare le richieste di servizio dagli indirizzi IP virtuali ai real server. Questo processo si basa su uno degli otto algoritmi per il bilanciamento del carico:
- Round-Robin Scheduling — Distribuisce ogni richiesta in successione all'interno di un gruppo di real server. Utilizzando questo algoritmo, tutti i real server vengono trattati allo stesso modo, senza considerare la loro capacità o il loro carico.
- Weighted Round-Robin Scheduling — Distribuisce ogni richiesta in successione all'interno di un gruppo di real server, dando un carico di lavoro maggiore ai server con maggiore capacità. La capacità viene indicata da un fattore di peso assegnato dall'utente, e viene modificata in base alle informazioni sul carico dinamico. Essa rappresenta la scelta preferita se sono presenti differenze sostanziali di capacità dei real server all'interno di un gruppo di server. Tuttavia se la richiesta di carico varia sensibilmente, un server con un carico di lavoro molto elevato potrebbe operare oltre ai propri limiti.
- Least-Connection — Distribuisce un numero maggiore di richieste ai real server con un numero minore di collegamenti attivi. Questo è un tipo di algoritmo di programmazione dinamico, il quale rappresenta la scelta migliore se siete in presenza di una elevata variazione nelle richieste di carico. Offre il meglio di se per un gruppo di real server dove ogni nodo del server presenta una capacità simile. Se i real server in questione hanno una gamma varia di capacità, allora il weighted least-connection scheduling rappresenta la scelta migliore.
- Weighted Least-Connections (default) — Distribuisce un numero maggiore di richieste ai server con un numero minore di collegamenti attivi, in base alle proprie capacità. La capacità viene indicata da un peso assegnato dall'utente, e viene modificata in base alle informazioni relative al carico dinamico. L'aggiunta di peso rende questo algoritmo ideale quando il gruppo del real server contiene un hardware di varia capacità.
- Locality-Based Least-Connection Scheduling — Distribuisce un numero maggiore di richieste ai server con un numero minore di collegamenti attivi, in base ai propri IP di destinazione. Questo algoritmo viene utilizzato in un cluster di server proxy-cache. Esso indirizza i pacchetti per un indirizzo IP al server per quel indirizzo, a meno che il server in questione non abbia superato la sua capacità e sia presente al tempo stesso un server che utilizzi metà della propria capacità. In questo caso l'indirizzo IP verrà assegnato al real server con un carico minore.
- Locality-Based Least-Connection Scheduling con Replication Scheduling — Distribuisce un numero maggiore di richieste ai server con un numero minore di collegamenti attivi, in base ai propri IP di destinazione. Questo algoritmo viene usato anche in un cluster di server proxy-cache. Esso differisce da Locality-Based Least-Connection Scheduling a causa della mappatura dell'indirizzo IP target su di un sottoinsieme di nodi del real server. Le richieste vengono indirizzate ad un server presente in questo sottoinsieme con il numero più basso di collegamenti. Se tutti i nodi per l'IP di destinazione sono al di sopra della propria capacità, esso sarà in grado di replicare un nuovo server per quel indirizzo IP di destinazione, aggiungendo il real server con un numero minore di collegamenti del gruppo di real server, al sottoinsieme di real server per quel IP di destinazione. Il nodo maggiormente carico verrà rilasciato dal sottoinsieme di real server in modo da evitare un processo di riproduzione non corretto.
- Source Hash Scheduling — Distribuisce le richieste al gruppo di real server, cercando l'IP sorgente in una tabella hash statica. Questo algoritmo viene usato per i router LVS con firewall multipli.
Altresì, il router LVS attivo monitorizza dinamicamente lo stato generale dei servizi specifici sui real server, attraverso semplici script send/expect. Per assistervi nella rilevazione dello stato dei servizi che richiedono dati dinamici, come ad esempio HTTPS o SSL, è possibile richiamare gli eseguibili esterni. Se un servizio non funziona correttamente su di un real server, il router LVS attivo interrompe l'invio di lavori al server interessato, fino a quando non vengono ripristinate le normali funzioni.
Il router LVS di backup esegue il ruolo di un sistema in standby 'attesa'. I router LVS scambiano periodicamente messaggi heartbeat attraverso l'interfaccia pubblica esterna primaria e, in una situazione di failover, attraverso l'interfaccia privata. Se il router LVS di backup non riceve un messaggio heartbeat entro un intervallo di tempo determinato, esso inizierà un processo di failover assumendo così il ruolo di router LVS attivo. Durante il processo di failover, il router LVS di backup prende a carico gli indirizzi VIP serviti dal router fallito utilizzando una tecnica conosciuta come ARP spoofing — con questa tecnica il router LVS di backup si presenta come destinazione per i pacchetti IP indirizzati al nodo fallito. Quando il nodo in questione ritorna in uno stato di servizio attivo, il router LVS di backup assume il proprio ruolo di backup.
The simple, two-tier configuration in Figura 1.20, «Two-Tier LVS Topology» is suited best for clusters serving data that does not change very frequently — such as static web pages — because the individual real servers do not automatically synchronize data among themselves.