第16章 統合
16.1. 概要
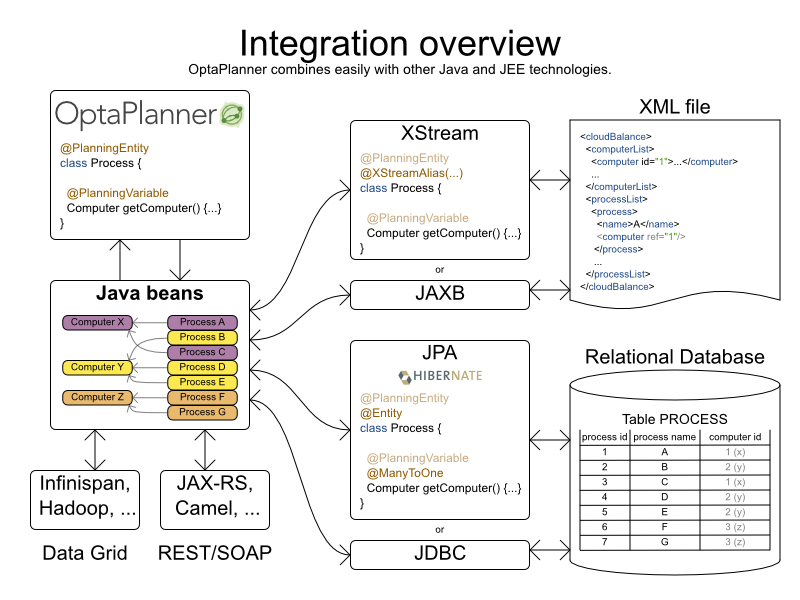
Planner が入力および出力したデータ (計画問題と最適解) は POJO (plain old JavaBeans) であるため、その他の Java テクノロジーとの統合は単純です。たとえば以下のようになります。
- 計画問題をデータベースから読み込み、そこに最適解を保存するには、JPA アノテーションを持つドメイン POJO をアノテートします。
- XML ファイルから計画問題を読み込み、そこに最適解を保存するには、XStream アノテーションまたは JAXB アノテーションを持つドメインの POJO をアノテートします。
-
Solver を、計画問題を読み込み、最適解で応答する REST サービスとして公開するには、XStream アノテーションまたは JAXB アノテーションを持つドメイン POJO をアノテートし、Camel または RESTEasy で
Solverをフックします。
16.2. 永続ストレージ
16.2.1. データベース: JPA および Hibernate
データベースに保存するために、ドメイン POJO (ソリューション、エンティティー、問題ファクト) を JPA アノテーションで改良します。
JPA の @Entity アノテーションと、Planner の @PlanningEntity アノテーションを混在しないでください。両方とも、同じクラスで使用できます。
@PlanningEntity // OptaPlanner annotation
@Entity // JPA annotation
public class Talk {...}
追加の統合機能を利用するために、optaplanner-persistence-jpa JAR に依存関係を追加します。
16.2.1.1. JPA および Hibernate: スコアの永続化
スコア がリレーショナルデータベースに永続化される場合は、JPA および Hibernate がデフォルトで BLOB カラムにシリアル化します。これには、いくつかのデメリットがあります。
-
Scoreクラスの Java のシリアル化形式は現在、後方互換性がありません。新しい Planner バージョンにアップグレードすると、既存のデータベースを読み込む際に破損する可能性があります。 - データベースのコンソールで実行されたクエリーでは、スコアを簡単に読み取ることができません。これでは、開発時に不便です。
- SQL または JPA-QL クエリーでスコアを使用して、その結果にフィルターを設定することはできません。たとえば、実行できないスケジュールをすべてクエリーするには、以下のようにします。
この問題を回避するには、使用している スコア タイプ (HardSoftScore など) に適切な *ScoreHibernateType を使用して、2 つの INTEGER 列を使用するように設定します。
@PlanningSolution
@Entity
@TypeDef(defaultForType = HardSoftScore.class, typeClass = HardSoftScoreHibernateType.class)
public class CloudBalance implements Solution<HardSoftScore> {
@Columns(columns = {@Column(name = "hardScore"), @Column(name = "softScore")})
protected HardSoftScore score;
...
}
スコアに、スコアレベルの数と同じだけ @Column アノテーション数を設定します。設定しないと、プロパティーマッピングで列数が正しくなくなるため、Hibernate でフェイルファーストが発生します。
この場合、DDL は以下のようになります。
CREATE TABLE CloudBalance(
...
hardScore INTEGER,
softScore INTEGER
);
BigDecimal ベースの Score を使用する場合は、列の精度とスケールを指定して、通知なく丸めが行われることを回避します。
@PlanningSolution
@Entity
@TypeDef(defaultForType = HardSoftBigDecimalScore.class, typeClass = HardSoftBigDecimalScoreHibernateType.class)
public class CloudBalance implements Solution<HardSoftBigDecimalScore> {
@Columns(columns = {
@Column(name = "hardScore", precision = 10, scale = 5),
@Column(name = "softScore", precision = 10, scale = 5)})
protected HardSoftBigDecimalScore score;
...
}
丸められる スコア のタイプを使用して、ハードおよびソフトのレベルサイズをパラメーターとして指定します。
@PlanningSolution
@Entity
@TypeDef(defaultForType = BendableScore.class, typeClass = BendableScoreHibernateType.class, parameters = {
@Parameter(name = "hardLevelsSize", value = "3"),
@Parameter(name = "softLevelsSize", value = "2")})
public class Schedule implements Solution<BendableScore> {
@Columns(columns = {
@Column(name = "hard0Score"),
@Column(name = "hard1Score"),
@Column(name = "hard2Score"),
@Column(name = "soft0Score"),
@Column(name = "soft1Score")})
protected BendableScore score;
...
}このサポートは Hibernate に固有のものです。複数列に変換するのをサポートしていないため、現時点では、JPA 2.1 のコンバーターではサポートしていません。
16.2.1.2. JPA および Hibernate: 計画のクローン作成
JPA および Hibernate では、多くの問題ファクトクラスからプランニングソリューションクラスへの、@ManyToOne の関係があります。したがって、問題ファクトクラスは、プランニングソリューションクラスを参照します。したがって、そのソリューションが クローンが作成された計画 の場合は、問題ファクトクラスのクローンも作成する必要があります。そのような各問題ファクトクラスで @DeepPlanningClone を使用して、それを強化します。
@PlanningSolution // OptaPlanner annotation
@Entity // JPA annotation
public class Conference {
@OneToMany(mappedBy = "conference")
private List<Room> roomList;
...
}@DeepPlanningClone // OptaPlanner annotation: Force the default planning cloner to planning clone this class too
@Entity // JPA annotation
public class Room {
@ManyToOne
private Conference conference; // Because of this reference, this problem fact needs to be planning cloned too
}これを行わないと、ソリューションが重複したり、JPA 例外が発生したりなどの問題が発生する可能性があります。
16.2.2. XML または JSON: XStream
ドメイン POJO (ソリューション、エンティティー、および問題ファクト) を XStream アノテーションで改良して、XML または JSON とのやりとりでシリアル化します。
追加の統合機能を利用するために、依存関係を optaplanner-persistence-xstream JAR に追加します。
16.2.2.1. XStream: スコアのマーシャリング
デフォルトの XStream 設定で、スコア が XML または JSON にマーシャリングされると、非常に長くなり扱いにくくなります。これを修正するには、XStreamScoreConverter で、 ScoreDefinition をパラメーターとして設定します。
@PlanningSolution
@XStreamAlias("CloudBalance")
public class CloudBalance implements Solution<HardSoftScore> {
@XStreamConverter(value = XStreamScoreConverter.class, types = {HardSoftScoreDefinition.class})
private HardSoftScore score;
...
}たとえば、以下のように設定すると、良質の XML が生成されます。
<CloudBalance>
...
<score>0hard/-200soft</score>
</CloudBalance>
丸められるスコアのタイプにこれを使用するには、hardLevelsSize および softLevelsSize を定義する 2 つの int パラメーターを提供します。
@PlanningSolution
@XStreamAlias("Schedule")
public class Schedule implements Solution<BendableScore> {
@XStreamConverter(value = XStreamScoreConverter.class, types = {BendableScoreDefinition.class}, ints = {2, 3})
private BendableScore score;
...
}たとえば、以下を生成します。
<Schedule>
...
<score>0/0/-100/-20/-3</score>
</Schedule>16.2.3. XML または JSON: JAXB
JAXB アノテーションを使用して、ドメイン POJO (ソリューション、エンティティー、問題ファクト) を改良して、XML または JSON とシリアル化します。
16.3. SOA および ESB
16.3.1. Camel および Karaf
Camel (Camel 2.13 以降) は、Planner のサポートが含まれるエンタープライズインテグレーションフレームワークです。これは、ユースケースを REST サービス、SOAP サービス、JMS サービスなどとして公開します。
camel-optaplanner コンポーネントのドキュメントを参照してください。Karaf でもそのコンポーネントは機能します。
16.4. その他の環境
16.4.1. JBoss モジュール、WildFly、および JBoss EAP
WildFly に Planner web アプリケーションをデプロイする場合は、optaplanner-webexamples-*.war に記載しているように、(その他の依存関係と同じように) WAR ファイルの WEB-INF/lib ディレクトリーに optaplanner 依存関係 JAR を追加します。ただし、この方法では、WAR ファイルのサイズが簡単に数 MB にまで増えます。1 回のデプロイメントではこのサイズでも問題はありませんが、(特にネットワーク接続が遅い場合は) が重量すぎるためデプロイメントを何度もやりなおすことはできません。
この問題を解決するには、optaplanner JAR を JBoss module として WildFly に配置し、軽量な WAR を作成します。org.optaplanner という名前のモジュールを作成します。
${WILDFLY_HOME}/modules/system/layers/base/ディレクトリーに移動します。このディレクトリーには、WildFly の JBoss モジュールが含まれます。新しいモジュール用にorg/optaplanner/mainディレクトリー構造を作成します。-
optaplanner-core-${version}.jarと、その直接および推移的な依存関係の JAR を、新しいディレクトリーにコピーします。各 optaplanner アーティファクトでmvn dependency:treeコマンドを使用して、すべての依存関係を検出します。 新しいディレクトリーに
module.xmlを作成し、そのファイルに以下を記載します。<?xml version="1.0" encoding="UTF-8"?> <module xmlns="urn:jboss:module:1.3" name="org.optaplanner"> <resources> ... <resource-root path="kie-api-${version}.jar"/> ... <resource-root path="optaplanner-core-${version}.jar"/> ... <resource-root path="."/> </resources> <dependencies> <module name="javaee.api"/> </dependencies> </module>
-
デプロイした WAR ファイルに移動します。
-
optaplanner-core-${version}.jarと、その直接および推移的な依存関係の JAR を、WAR ファイルのWEB-INF/libディレクトリーから削除します。 WEB-INF/libディレクトリーにjboss-deployment-structure.xmlファイルを作成します。そのファイルに以下を記載します。<?xml version="1.0" encoding="UTF-8" ?> <jboss-deployment-structure> <deployment> <dependencies> <module name="org.optaplanner" export="true"/> </dependencies> </deployment> </jboss-deployment-structure>
-
JBoss モジュールの ClassLoader magic があるため、SolverFactory 作成時 に、お使いのクラスの ClassLoader を提供することがおそらく必要になります。これにより、(Solver 設定、スコア DRL とドメインのクラスなど) JAR の classpath リソースを見つけることができます。
16.4.2. OSGi
OSGi 環境でも適切に機能するように、optaplanner-core JAR は、その MANIFEST.MF に OSGi メタデータを追加します。さらに、Maven アーティファクト drools-karaf-features (名前が kie-karaf-features に変更になります) には、OSGi 機能 optaplanner-engine をサポートする features.xml ファイルが含まれます。
OSGi の ClassLoader magic があるため、SolverFactory 作成時 に、お使いのクラスの ClassLoader を提供することがおそらく必要になります。これにより、(Solver 設定、スコア DRL とドメインのクラスなど) JAR の classpath リソースを見つけることができます。
Planner には OSGi が必要ありません。これは、通常の Java 環境でも問題なく動作します。
16.4.3. Android
(一部の JDK ライブラリーが不足しているため) Android は完全な JVM ではありませんが、Planner は Android でも、easy Java または Java インクリメント演算子 によるスコア計算を使用すれば機能します。Android では Drools ルールエンジンに対応しておらず、 Drools スコア計算は Android では機能しないため、その依存関係は削除する必要があります。
Android で Planner を使用するための回避策:
依存関係を、使用する Android プロジェクトの
build.gradleファイルに追加して、org.droolsとxmlpullの依存関係を除外します。dependencies { ... compile('org.optaplanner:optaplanner-core:...') { exclude group: 'xmlpull' exclude group: 'org.drools' } ... }
16.5. Planner と手動での計画の統合 (駆け引き)
Planner の実装が適切に行われていて、単純ではないデータセットを使用した場合は、手動での計画よりも Planner の方が良い結果が得られます。専門家の多くがこれを認めませんが、それは、自動化システムを脅威だと思っているからです。
実際には、専門家が Planner の監督者となると、両方に対する利益になります。
手動で、スコア関数を定義および検証します。
-
簡単なスコア制約に対する重みを定義する
Parametrizationオブジェクトが公開されている例もあります。実行時に手動でこの重みを調整できます。 - ビジネスが変更したら、多くの場合、スコア関数も変更する必要があります。担当者は、スコア制約を追加、変更、または削除するのを開発者に知らせることができます。
-
簡単なスコア制約に対する重みを定義する
人間が、常に Planner を管理します。
- 「コースの時間割」の例で示しているように、手動で、1 つ以上のプランニング変数を、特定の計画値にロックして動かせないようにすることができます。この変数は 動かせない ため、Planner は変更できません。手動で強制的に行われた設定により、計画が最適化されます。手動ですべてのプランニングエンティティーをロックしたら、Planner を使用する必要はなくなります。
- プロトタイプの実装では、この方法が使用されることもありますが、実装が十分に成長したら、この方法は選択されなくなります。ただ、手動で導いた結果を再確認するために、この機能は動かしたままにします。または、スコア制約が調整される前にビジネスが大幅に変更するかもしれません。
したがって、実際のプロジェクトでは、多くの場合、Planner と人間を共存することが推奨されます。