第10章 Local Search (局所探索法)
10.1. 概要
局所探索法は、初期解から始めて、1 つの解をより良い解に進化させます。この探索法は、探索木ではなく、1 つの解の探索パスを使用します。このパスにおける各解は、多くの解の Move を評価し、次の解への最も適した Move を適用し、終了するまで何度も繰り返します (通常は時間が切れるまで続きます)。
局所探索法の振舞いは、人間が計画する際の振る舞いにとても良く似ており、探索パスを 1 つ使用してファクトを移動し、実現の可能性が高い解を見つけます。したがって、これを実装するのがごく一般的です。
局所探索法は通常、初期解から開始する必要があるため、開始する前に構築ヒューリスティックの Solver フェーズを設定する必要があります。
10.2. 局所探索法の概念
10.2.1. 段階的
ステップは勝利 Move です。局所探索法は、現在の解に多くの Move を試し、最適な Move をステップとして選択します。
図10.1 ステップ 0 で次のステップの決定 (クイーン 4 個の例)
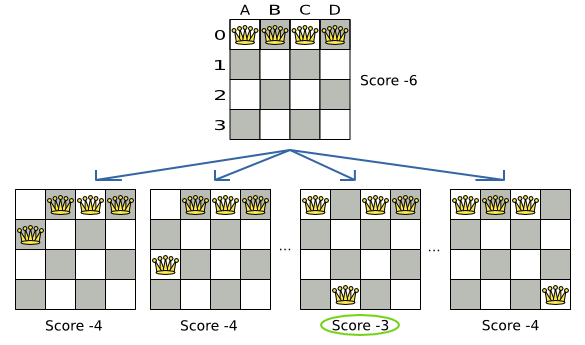
B0 から B3 への Move のスコアが一番高い (-3) ため、これが次のステップとして選択されます。最高スコアの Move が複数ある場合は、そのうちの 1 つがランダムに選択されます (この例では B0 から B3)。(ここには示されていませんが) C0 から C3 への Move もスコアが 3 なので、代わりにこの Move が選択された可能性があります。
このステップが解に適用されたら、次の解に向けて、局所探索法がすべての Move をもう一度繰り返し、次のステップを決定します。これがループして継続していき、以下のような結果となります。
図10.2 全ステップ (クイーン 4 個の例)
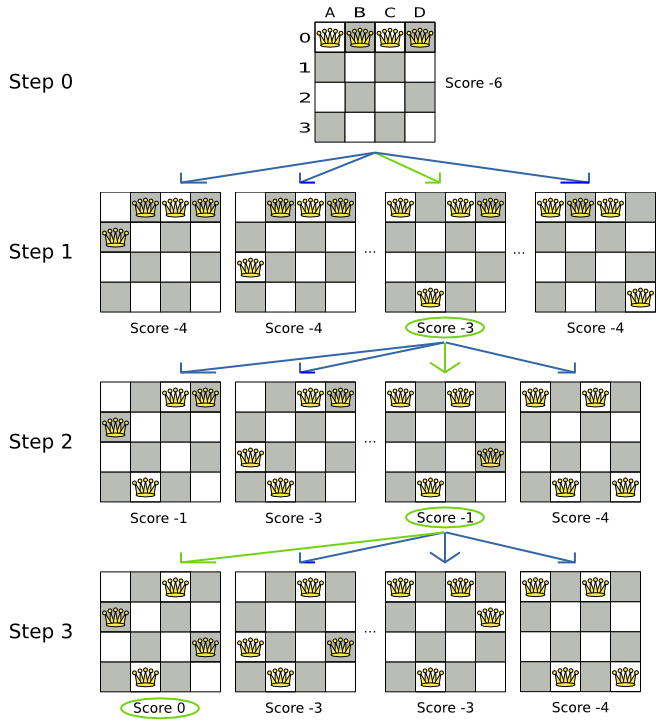
局所探索法は、探索木ではなく、探索パスを使用している点に注意してください。探索パスは緑の矢印で示されます。各ステップで、選択された Move はすべて試されますが、次のステップとして選択されない限り、その解をそれ以上調べることはありません。これが、局所探索法が非常にスケーラブルな理由です。
上記の例が示すように、局所探索法は、クイーン 4 個の問題を、最初の解から始め、以下のステップを順次選択します。
- B0 から B3
- D0 から B2
- A0 から B1
org.optaplanner カテゴリーの デバッグ ログを有効 にすると、ログにこのステップが示されます。
INFO Solving started: time spent (0), best score (-6), random (JDK with seed 0).
DEBUG LS step (0), time spent (20), score (-3), new best score (-3), accepted/selected move count (12/12), picked move (Queen-1 {Row-0 -> Row-3}).
DEBUG LS step (1), time spent (31), score (-1), new best score (-1), accepted/selected move count (12/12), picked move (Queen-3 {Row-0 -> Row-2}).
DEBUG LS step (2), time spent (40), score (0), new best score (0), accepted/selected move count (12/12), picked move (Queen-0 {Row-0 -> Row-1}).
INFO Local Search phase (0) ended: step total (3), time spent (41), best score (0).
INFO Solving ended: time spent (41), best score (0), average calculate count per second (1780).
ログメッセージには、Move 実装の toString() メソッドが含まれます。これは、たとえば Queen-1 {Row-0 -> Row-3} を返します。
ネイティブの局所探索法の設定は、クイーン 4 個の問題を 3 つのステップで解きますが、可能解として評価するのは 37 個 (3 ステップで、1 ステップあたり 12 個の Move + 最初の解 1 つ) です。この値は、合計で 256 個となる可能解の一部でしかありません。クイーンが 16 個の場合は 31 ステップとなり、解の合計は 18446744073709551616 個になりますが、評価されるのは、そのうち 7441 個です。さらに、構築ヒューリスティック フェーズを最初に使用することで、効率がはるかに良くなります。
10.2.2. 次のステップを決定
局所探索法は、次の設定可能なコンポーネントを 3 つ用いて、次のステップを決めます。
-
現在の解の可能な Move を選択する
MoveSelector。Move と近傍選択 の章を参照してください。 -
認められない Move を除外する
Acceptor。 -
認められた Move を集め、そこから次のステップを選択する
Forager。
Solver フェーズ設定は以下のようになります。
<localSearch>
<unionMoveSelector>
...
</unionMoveSelector>
<acceptor>
...
</acceptor>
<forager>
...
</forager>
</localSearch>
以下の例では、MoveSelector が、青い線で示される Move を集め、Acceptor がそのすべてを認め、Forager が B0 から B3 への Move を選択します。
トレース のログを有効にすると、ログに意思決定が示されます。
INFO Solver started: time spent (0), score (-6), new best score (-6), random (JDK with seed 0).
TRACE Move index (0) not doable, ignoring move (Queen-0 {Row-0 -> Row-0}).
TRACE Move index (1), score (-4), accepted (true), move (Queen-0 {Row-0 -> Row-1}).
TRACE Move index (2), score (-4), accepted (true), move (Queen-0 {Row-0 -> Row-2}).
TRACE Move index (3), score (-4), accepted (true), move (Queen-0 {Row-0 -> Row-3}).
...
TRACE Move index (6), score (-3), accepted (true), move (Queen-1 {Row-0 -> Row-3}).
...
TRACE Move index (9), score (-3), accepted (true), move (Queen-2 {Row-0 -> Row-3}).
...
TRACE Move index (12), score (-4), accepted (true), move (Queen-3 {Row-0 -> Row-3}).
DEBUG LS step (0), time spent (6), score (-3), new best score (-3), accepted/selected move count (12/12), picked move (Queen-1 {Row-0 -> Row-3}).
...
(たとえばタブー探索で) 最終解のスコアを下げることができるため、 Solver は、探索パス全体で見つけた最適解を記憶します。毎回、その時の解は、前の回の最適解を上回るため、その時点の解の クローンが作成され、新しい最適解として参照されます。

10.2.3. Acceptor
タブー探索、焼きなまし法、レイトアクセプタンスを有効にするために、(Forager とともに) Acceptor が使用されます。Acceptor は、各 Move に対し、それが認められるかどうかを確認します。
設定行をいくつか変更するだけで、タブー探索から、焼きなまし法またはレイトアクセプタンスに簡単に切り替え、元に戻すこともできます。
独自の Acceptor を実装することはできますが、組み込まれているもので大概のニーズに沿うはずです。複数の Acceptor を組み合わせることもできます。
10.2.4. Forager
Forager は、認められた Move をすべて集め、次のステップとなる Move を選択します。通常は、認められた Move の中で一番スコアが高いものが選択されます。スコアが一番高いものが複数ある場合は、その中からランダムに選択します。ランダムに選択することがより良い結果につながります。
10.2.4.1. 認められる数の制約
可能な Move が多数ある場合は、各ステップですべての Move を評価するのは非効率です。すべての Move でランダムなサブセットだけを評価するには、以下を使用します。
整数値
acceptedCountLimit。各ステップで認められた Move の中からいくつ評価するかを指定します。デフォルトでは、各ステップで、認められたすべての Move が評価されます。<forager> <acceptedCountLimit>1000</acceptedCountLimit> </forager>
N クィーンの問題とは異なり、現実世界の問題では acceptedCountLimit を使用する必要があります。acceptedCountLimit を 2 秒以内に 1 ステップ行うことからはじめます。デバッグ ログを有効 にし、ステップの回数を確認します。
DEBUG LS step (0), time spent (20), score (-3), new best score (-3), ...ベンチマーカー を使用して、値を調整します。
acceptedCountLimit を低く (つまり、ステップ移動のアルゴリズムを速く) した場合、selectionOrder SHUFFLED は使用しないようにしてください。シャッフルを行うことで、セレクターの全要素にランダムな値を生成するため時間がかかりますが、実際に選択される要素はほんのわずかになるからです。
10.2.4.2. 早期発見のタイプ
forager はステップの早い段階で Move を選択し、その後に選択される Move を無視することができます。局所探索法には、3 つの早期発見のタイプがあります。
NEVER: Move が早期に選択されることはありません。その選択が許可する Move がすべて評価されます。これがデフォルトです。<forager> <pickEarlyType>NEVER</pickEarlyType> </forager>FIRST_BEST_SCORE_IMPROVING: 最高スコアを上回る、最初に許可された Move を選択します。最高スコアを上回るものがなければ、pickEarlyTypeNEVERと同じ振舞いになります。<forager> <pickEarlyType>FIRST_BEST_SCORE_IMPROVING</pickEarlyType> </forager>FIRST_LAST_STEP_SCORE_IMPROVING: 最後のステップスコアを上回る、最初に許可された Move を選択します。最後のステップスコアを上回るものがなければ、pickEarlyTypeNEVERと同じ振舞いになります。<forager> <pickEarlyType>FIRST_LAST_STEP_SCORE_IMPROVING</pickEarlyType> </forager>
10.3. Hill Climbing (山登り法) (Simple Local Search: 簡易局所探索法)
10.3.1. アルゴリズムの説明
山登り法は、選択したすべての Move を試し、スコアが一番高い解を生む最適な Move を選択します。最適な Move は、ステップ Move と呼ばれます。その新しい解から、再度選択したすべての Move を試し、最適な Move を選択し、それを繰り返します。最適な Move が複数ある場合は、そのうちの 1 つがランダムに選択されます。
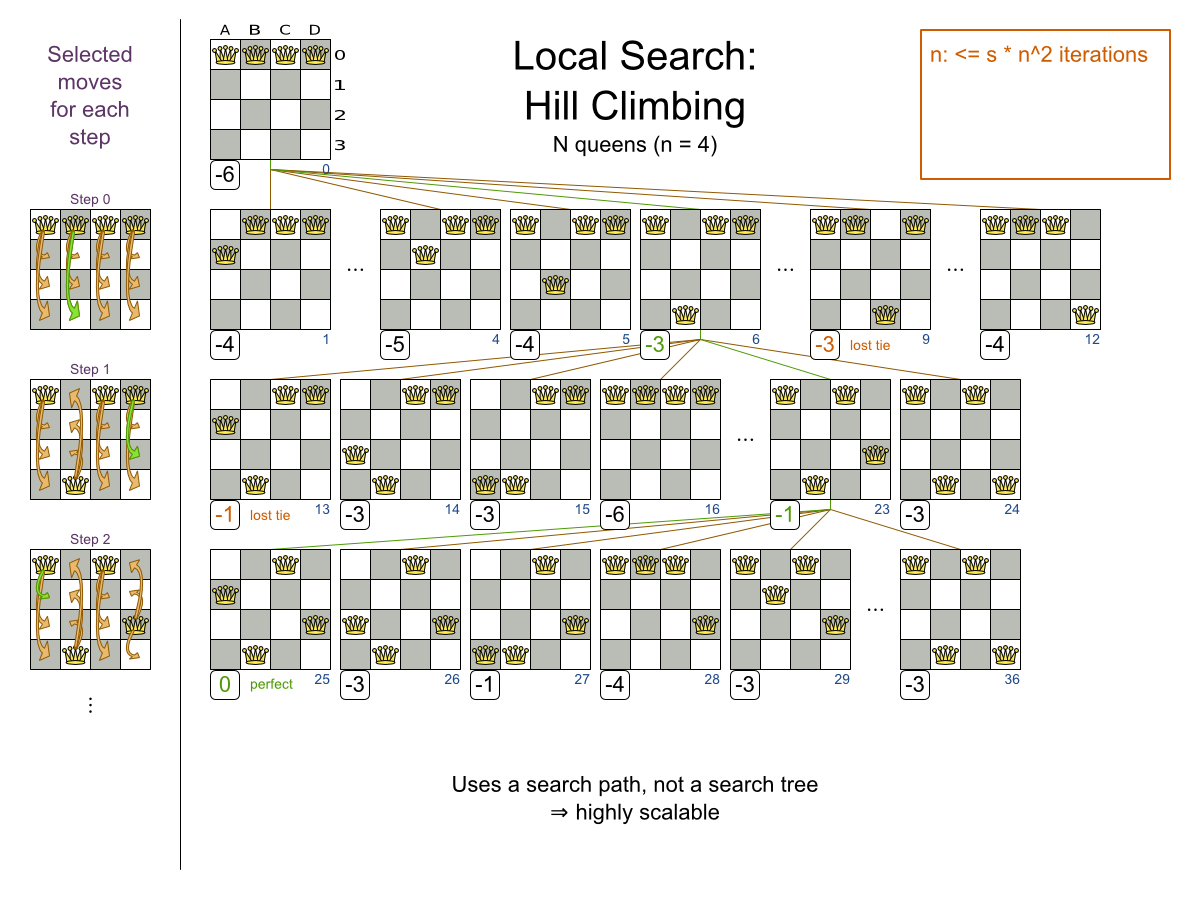
クイーンが動いたら、再度動かせます。NP 完全問題では、プランニング変数に最適な最終値を予測することは不可能なので、これは利点となります。
10.3.2. 局所最適条件での行き詰まり
山登り法は改善する Move を常に取得します。これは利点であるように思われますが、実際は利点ではありません。山登り法は局所最適条件で簡単に行き詰まる可能性があります。これは、すべての Move がスコアを下げる解にたどり着くと発生します。いずれの Move を選択しても、次のステップで元の解に戻り、無限ループとなります。
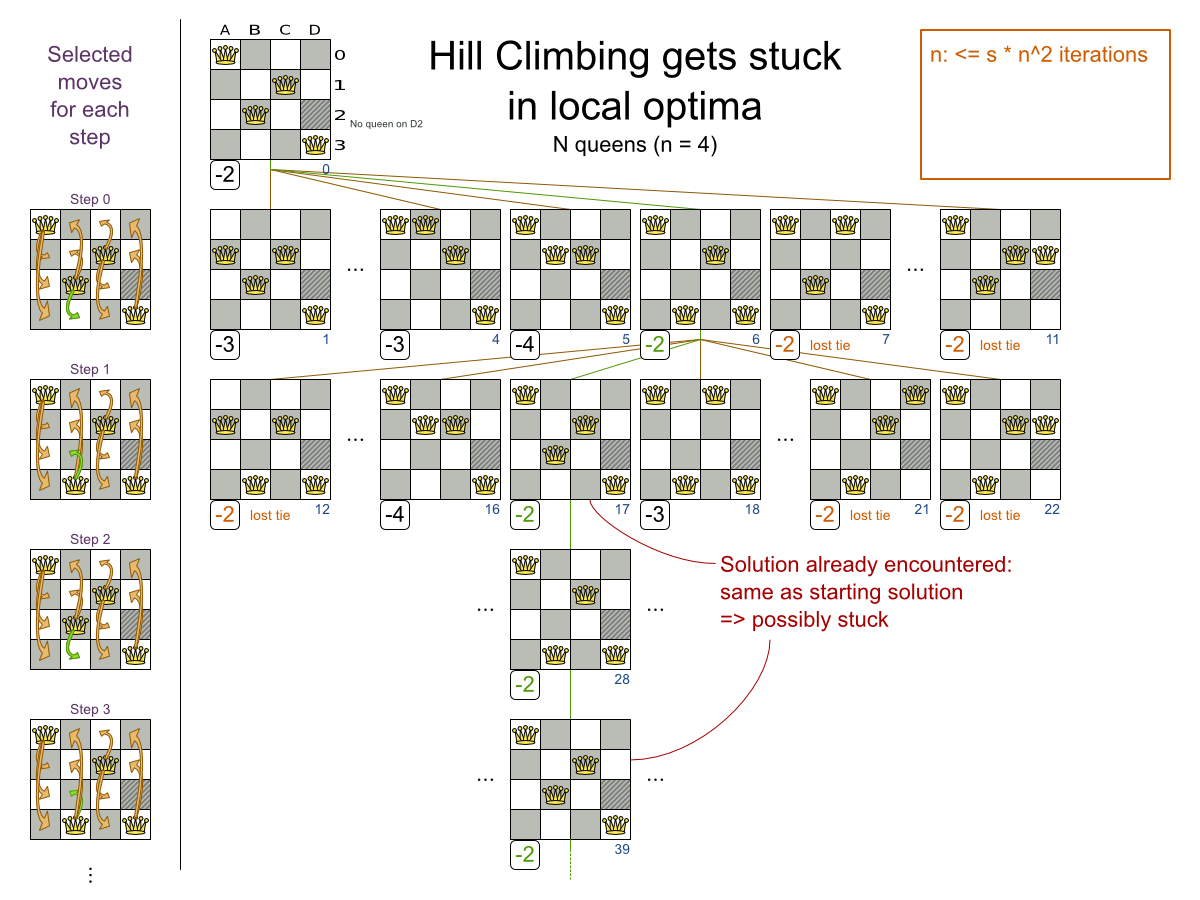
山登り法における改善 (タブー探索、焼きなまし法、レイトアクセプタンスなど) は、局所最適条件で行き詰まる問題に対応します。したがって、計画問題に局所最適条件がないことが明らかな場合を除いて、山登り法を使用することは推奨されません。
10.3.3. 設定
最も簡単な設定方法:
<localSearch>
<localSearchType>HILL_CLIMBING</localSearchType>
</localSearch>高度な設定方法:
<localSearch>
...
<acceptor>
<acceptorType>HILL_CLIMBING</acceptorType>
</acceptor>
<forager>
<acceptedCountLimit>1</acceptedCountLimit>
</forager>
</localSearch>10.4. Tabu Search (タブー探索)
10.4.1. アルゴリズムの説明
タブー探索は、山登り法と同じように機能しますが、局所最適条件で行き詰まらないようにタブーリストを維持します。タブーリストには、直近で使用され、今は使用が禁止されるオブジェクトが保持されています。タブーリストのオブジェクトに関連する Move は容認されません。タブーリストのオブジェクトは、Move に関するもの (プランニングエンティティー、計画値、Move、解など) になります。以下は、クイーン 4 個でエンティティータブーを持つ例で、このクイーンはタブーリストに入っています。
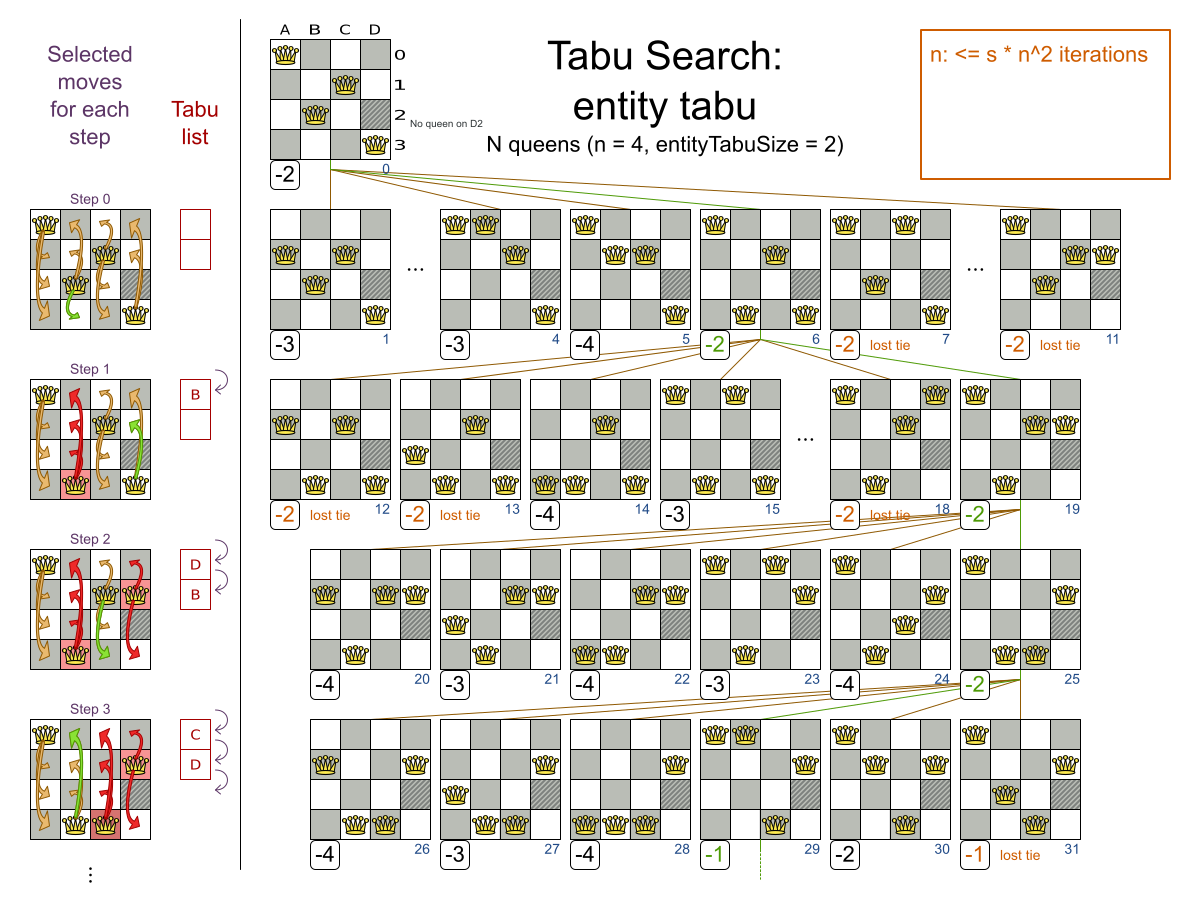
タブー検索の英語のスペルは、Taboo Search ではなく Tabu Search です。
学術論文: Tabu Search - Part 1 and Part 2 by Fred Glover (1989 - 1990)
10.4.2. 設定
最も簡単な設定方法:
<localSearch>
<localSearchType>TABU_SEARCH</localSearchType>
</localSearch>タブー検索がステップを選択していくと、1 つまたは複数のタブーが作成されます。多くのステップでは、その Move がタブーに違反する場合は Move が許可されません。ステップ数がタブーのサイズになります。高度は設定方法は以下のようになります。
<localSearch>
...
<acceptor>
<entityTabuSize>7</entityTabuSize>
</acceptor>
<forager>
<acceptedCountLimit>1000</acceptedCountLimit>
</forager>
</localSearch>
タブー探索アクセプターでは、acceptedCountLimit を高く (1000 など) 設定する必要があります。
Planner には、タブーのタイプが複数あります。
プランニングエンティティーのタブー (推奨) は、直近のステップタブーのプランニングエンティティーを作成します。たとえば、N クィーンの場合は、直近に移動したクィーンのタブーが作成されます。まずはこのタブータイプを使用することが推奨されます。
<acceptor> <entityTabuSize>7</entityTabuSize> </acceptor>タブーサイズをハードコードしないようにするには、エンティティー数に対するタブーの割合 (2% など) を設定します。
<acceptor> <entityTabuRatio>0.02</entityTabuRatio> </acceptor>計画値のタブー は、直近のステップのタブーのプランニングエンティティーを作成します。たとえば、N クィーンの場合は、直近に行を移動したクィーンをタブーにします。
<acceptor> <valueTabuSize>7</valueTabuSize> </acceptor>タブーサイズをハードコードしないようにするには、値に対するタブーの割合 (2% など) を設定します。
<acceptor> <valueTabuRatio>0.02</valueTabuRatio> </acceptor>Move のタブー は、直近のステップのタブーを選択します。そのステップの 1 に等しい Move は許可されません。
<acceptor> <moveTabuSize>7</moveTabuSize> </acceptor>Move の取り消しタブー は、直近に移動した Move の取り消しがタブーになります。
<acceptor> <undoMoveTabuSize>7</undoMoveTabuSize> </acceptor>解のタブーは、直近にたどり着いた解をタブーにします。そのいずれかの解に向かう Move は許可されません。解 (
ソリューション) にequals()とhashCode()が適切に実装されている必要があります。メモリーに余裕がある場合は、このタブーのサイズを大きくします。<acceptor> <solutionTabuSize>1000</solutionTabuSize> </acceptor>重要なケースでは、解のタブーは通常役に立ちません。探索領域サイズ により、同じ解に 2 回到達するには統計的にまずありえません。したがって、データセットが小さい場合を除き、これを使用することは推奨されません。
タブーの種類を複数組み合わせると便利な場合があります。
<acceptor>
<entityTabuSize>7</entityTabuSize>
<valueTabuSize>3</valueTabuSize>
</acceptor>タブーのサイズが小さすぎると、Solver は局所最適条件で行き詰まる可能性があります。逆に、タブーのサイズが大きすぎると、壁で跳ね返って役に立たない可能性があります。ベンチマーカー を使用して、設定を適切に調整します。
10.5. Simulated Annealing (焼きなまし法)
10.5.1. アルゴリズムの説明
焼きなまし法は、ステップごとに数 Move だけを評価するため、すぐに次に進みます。標準的な実装では、最初に許可された Move が勝利ステップになります。Move は、スコアを減らさない場合は許可されます。スコアを減らした場合は、ランダムチェックを通過します。スコアを減らす Move がランダムチェックを通る可能性は、スコアのデクリメントの大きさと、フェーズが実行している時期 (度合い (temperature) として表現されます) に応じて減ります。
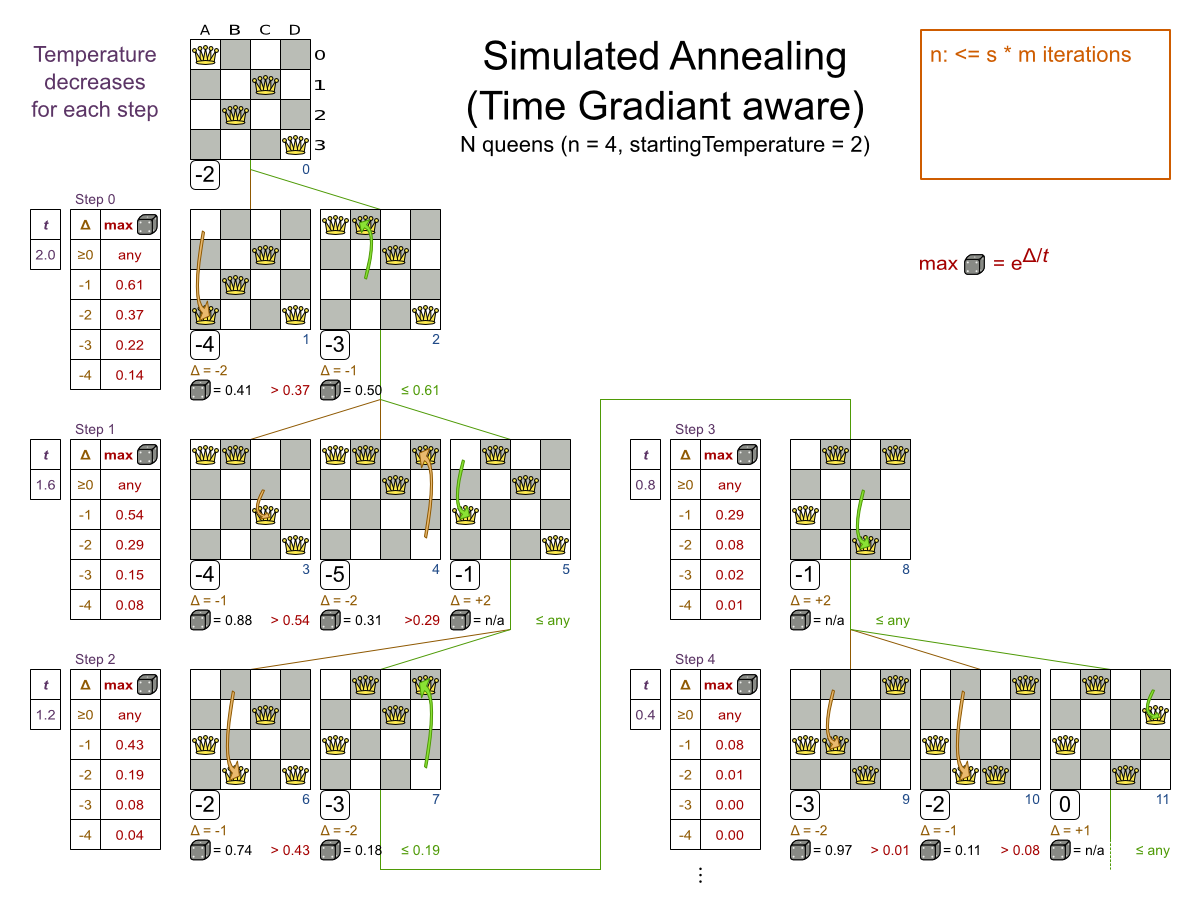
焼きなまし法は、スコアが一番高い Move を常に選択するわけではありません。また、1 ステップに対して Move を多数評価するわけでもありません。少なくても最初はそのように振舞います。改善しない Move が選択される可能性もありますが、これは、その Move のスコアと、終了 の時間勾配によります。最終的には、次第に山登り法になっていき、改善する Move だけを許可します。
10.5.2. 設定
まずは、simulatedAnnealingStartingTemperature を、1 つの Move が原因となる最大スコアデルタに設定します。ベンチマーカー で値を調整します。以下は、高度な設定になります。
<localSearch>
...
<acceptor>
<simulatedAnnealingStartingTemperature>2hard/100soft</simulatedAnnealingStartingTemperature>
</acceptor>
<forager>
<acceptedCountLimit>1</acceptedCountLimit>
</forager>
</localSearch>
焼きなまし法では、acceptedCountLimit は低くする必要があります。標準的なアルゴリズムでは、acceptedCountLimit を 1 にしますが、4 にした方がパフォーマンスが高いこともしばしばあります。
焼きなまし法は、タブーアクセプターと一緒に使用することができます。これにより、焼きなまし法が少し良くなります。タブー探索だけを使用する場合と比べて、タブーのサイズを小さくします。
<localSearch>
...
<acceptor>
<simulatedAnnealingStartingTemperature>2hard/100soft</simulatedAnnealingStartingTemperature>
<entityTabuSize>5</entityTabuSize>
</acceptor>
<forager>
<acceptedCountLimit>1</acceptedCountLimit>
</forager>
</localSearch>10.6. Late Acceptance (レイトアクセプタンス)
10.6.1. アルゴリズムの説明
レイトアクセプタンス (LAHC (Late Acceptance Hill Climbing) とも呼ばれています) は、ステップごとに数 Move だけを評価します。スコアが減らない場合、もしくは最後のスコアと同じスコアになった (一定の前ステップでは勝利スコアだったもの) 場合は、Move が許可されます。
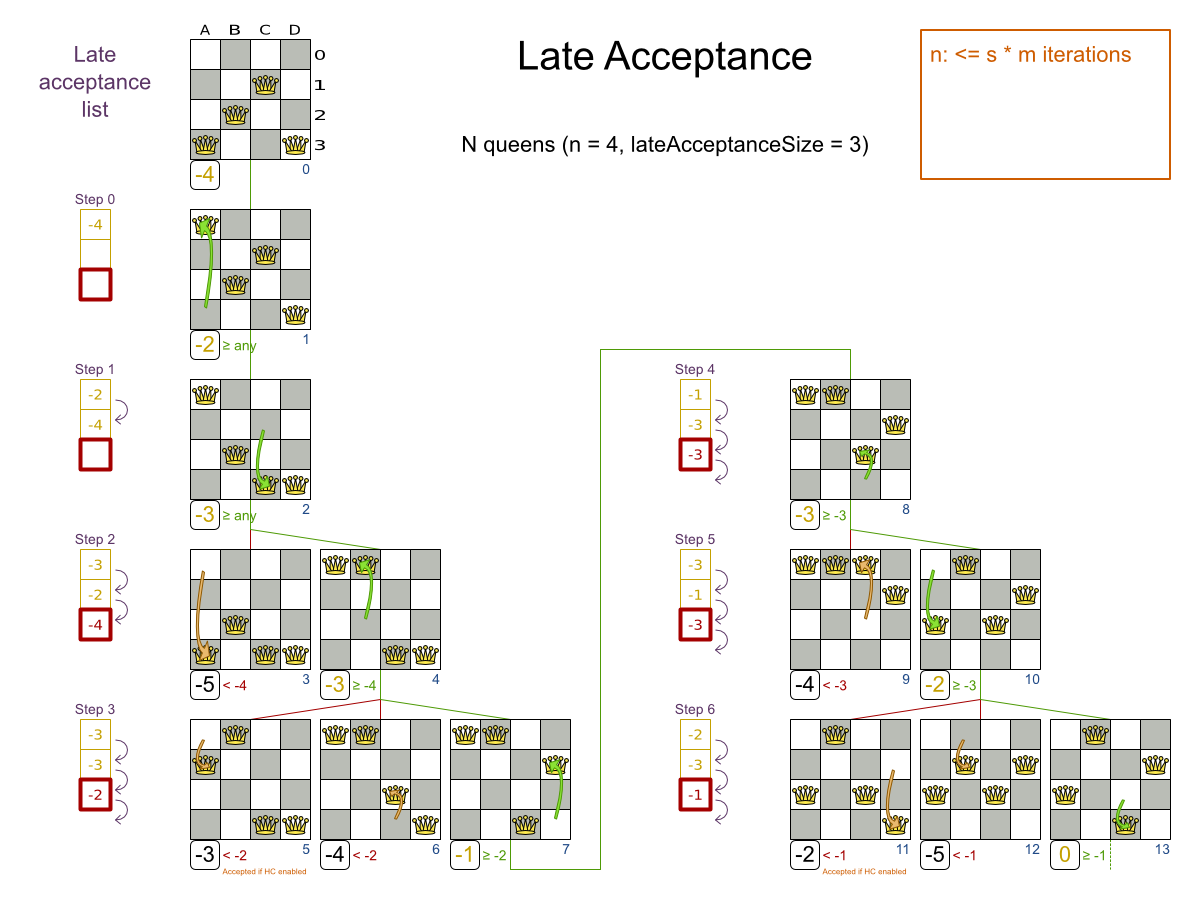
学術論文: The Late Acceptance Hill-Climbing Heuristic by Edmund K. Burke, Yuri Bykov (2012)
10.6.2. 設定
最も簡単な設定方法:
<localSearch>
<localSearchType>LATE_ACCEPTANCE</localSearchType>
</localSearch>
レイトアクセプタンスは、何ステップも前に最適スコアだったものよりも高いスコアを持つ Move を許可します。このステップの数は lateAcceptanceSize です。以下は高度な設定になります。
<localSearch>
...
<acceptor>
<lateAcceptanceSize>400</lateAcceptanceSize>
</acceptor>
<forager>
<acceptedCountLimit>1</acceptedCountLimit>
</forager>
</localSearch>
レイトアクセプタンスでは、acceptedCountLimit を低くする必要があります。
レイトアクセプタンスは、タブアクセプターと一緒に使用することができます。これにより、レイトアクセプタンスが少し良くなります。タブー探索を使用する場合と比べて、タブーのサイズを小さくします。
<localSearch>
...
<acceptor>
<lateAcceptanceSize>400</lateAcceptanceSize>
<entityTabuSize>5</entityTabuSize>
</acceptor>
<forager>
<acceptedCountLimit>1</acceptedCountLimit>
</forager>
</localSearch>10.7. Step Counting Hill Climbing (SCHC)
10.7.1. アルゴリズムの説明
SCHC (Step Counting Hill Climbing) も、ステップごとに数 Move だけ評価します。ステップのスコアをしきい値として保持します。スコアが減らない場合、またはスコアがそのしきい値以上になる場合は、Move が許可されます。
10.7.2. 設定
SCHC (Step Counting Hill Climbing) は、しきい値スコアよりも高いスコアを持つ Move だけを許可します。(stepCountingHillClimbingSize で指定した) すべてのステップで、しきい値はステップのスコアに設定されます。
<localSearch>
...
<acceptor>
<stepCountingHillClimbingSize>400</stepCountingHillClimbingSize>
</acceptor>
<forager>
<acceptedCountLimit>1</acceptedCountLimit>
</forager>
</localSearch>
SCHC (Step Counting Hill Climbing) では、acceptedCountLimit を低くする必要があります。
SCHC (Step Counting Hill Climbing) は、レイトアクセプタンスセクション で説明しているように、タブーアクセプターと同時に使用することができます。
10.8. Strategic Oscillation (SO)
10.8.1. アルゴリズムの説明
SO (Strategic Oscillation) は、特に タブー探索 と使用すると効果があるアドオンです。スコアが一番高い、許可された Move を選択するのではなく、別のメカニズムを使用します。改善される Move がある場合は、それを選択しますが、ない場合は、よりハードなスコアを壊すのが少ない Move よりは、よりソフトなスコアレベルを改善する Move を選択します。
10.8.2. 設定
以下の例では、タブー探索設定で finalistPodiumType を設定します。
<localSearch>
...
<acceptor>
<entityTabuSize>7</entityTabuSize>
</acceptor>
<forager>
<acceptedCountLimit>1000</acceptedCountLimit>
<finalistPodiumType>STRATEGIC_OSCILLATION</finalistPodiumType>
</forager>
</localSearch>
以下の finalistPodiumTypes がサポートされます。
-
HIGHEST_SCORE(デフォルト): 許可された Move の中でスコアが一番高いものを選択します。 -
STRATEGIC_OSCILLATION: デフォルトの SO (Strategic Oscillation) バリアントに対するエイリアスです。 -
STRATEGIC_OSCILLATION_BY_LEVEL: 許可されている、改善する Move がある場合はそれを選択します。そのような Move がない場合は、許可された Move の中から、よりソフトなスコアレベルを改善するものを選択します (ハードなスコアレベルは考慮されません)。最後に完了したステップスコアよりも良くなると、Move は改善しています。 -
STRATEGIC_OSCILLATION_BY_LEVEL_ON_BEST_SCORE:STRATEGIC_OSCILLATION_BY_LEVELと同じですが、(最後に完了したステップのスコアではなく) 最高スコアよりも良くなるように定義します。
10.9. カスタムの終了、MoveSelector、EntitySelector、ValueSelector、またはアクセプターの使用
抽象型クラスと、それに関連する *Config クラスを拡張して、カスタムの 終了、MoveSelector、EntitySelector、ValueSelector、または アクセプター を組み込むことができます。
たとえば、カスタムの MoveSelector を使用するには、AbstractMoveSelector クラスを拡張し、MoveSelectorConfig クラスを拡張してSolver 設定で設定します。
以下の理由により、(Config クラスも拡張するのを避けるために) 終了 などのインスタンスを直接追加することはできません。
-
SolverFactoryは、複数のSolverインスタンスを構築しますが、これにはそれぞれ、Terminationなどのインスタンスが必要です。 -
Solver 設定では、XML とのやり取りをシリアル化する必要があります。これにより、XML で複数の
Solverバリアントを設定できるため、PlannerBenchmarkを使用したベンチマーク作成が特に簡単になります。 -
Configクラスは、設定がより簡単で明確になることが多々あります。たとえば、TerminationConfigは、minutesSpentLimitとsecondsSpentLimitをtimeMillisSpentLimitに変換します。
ドメイン固有ではなく、より良い実装を構築する場合は、それを GitHub での pulll リクエストとして還元することを検討してください。それを最適化し、今後のリファクタリングに採用します。