第4章 Planner の設定
4.1. 概要
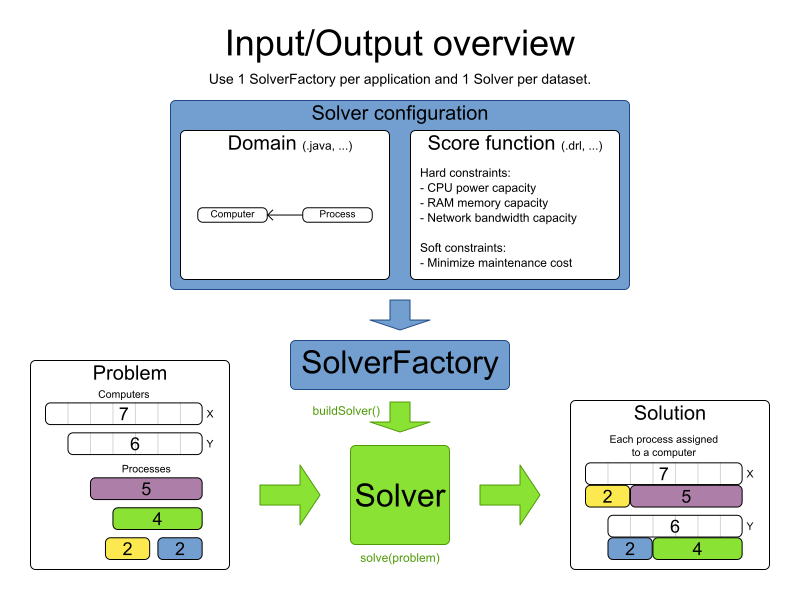
以下の 4 つの手順を行い、Planner で計画問題を解決します。
-
計画問題を、
Solutionインターフェースを実装するクラス (NQueensクラスなど) として モデル化します。 -
Solverを設定します (NQueensインスタンスの FF (First Fit) やタブー探索など)。 - データ層から 問題のデータセットを読み込みます (クィーン 4 個の例など)。これが計画問題です。
-
見つけた最適解を返す
Solver.solve(planningProblem)で、問題を解決します。
4.2. Solver の設定
4.2.1. XML で Solver の設定
SolverFactory で Solver インスタンスを作成します。クラスパスリソースとして提供されている XML の Solver 設定ファイルで SolverFactory を設定します (ClassLoader.getResource() で定義)。
SolverFactory<NQueens> solverFactory = SolverFactory.createFromXmlResource(
"org/optaplanner/examples/nqueens/solver/nqueensSolverConfig.xml");
Solver<NQueens> solver = solverFactory.buildSolver();
通常のプロジェクト (Maven ディレクトリーの構造に準拠) では、XML の solverConfig ファイルは $PROJECT_DIR/src/main/resources/org/optaplanner/examples/nqueens/solver/nqueensSolverConfig.xml にあります。または、SolverFactory.createFromXmlFile() などのメソッドを使用して、File、InputStream、または Reader から SolverFactory を作成することもできます。ただし、移植性の理由から、クラスパスリソースが推奨されます。
一部の環境 (OSGi、JBoss modules など) では、JAR のクラスパス (Solver 設定、スコアの DRL およびドメインクラス) は、optaplanner-core JAR のデフォルトの ClassLoader では利用できない可能性があります。このような場合には、以下のように、クラスの ClassLoader をパラメーターとして指定します。
SolverFactory<NQueens> solverFactory = SolverFactory.createFromXmlResource(
".../nqueensSolverConfig.xml", getClass().getClassLoader());
Workbench または Execution Server を使用する場合に、Drools の KieContainer 機能を活用するには、KieContainer をパラメーターとして指定します。
KieServices kieServices = KieServices.Factory.get();
KieContainer kieContainer = kieServices.newKieContainer(
kieServices.newReleaseId("org.nqueens", "nqueens", "1.0.0"));
SolverFactory<NQueens> solverFactory = SolverFactory.createFromKieContainerXmlResource(
kieContainer, ".../nqueensSolverConfig.xml");Solver 設定の ksessionName を使用します。
Solver および SolverFactory にはいずれも、問題の計画と解 (ソリューション) を表現するクラスである Solution_ という汎用型が含まれています。
XML の Solver 設定ファイルは以下のようになります。
<?xml version="1.0" encoding="UTF-8"?>
<solver>
<!-- Define the model -->
<solutionClass>org.optaplanner.examples.nqueens.domain.NQueens</solutionClass>
<entityClass>org.optaplanner.examples.nqueens.domain.Queen</entityClass>
<!-- Define the score function -->
<scoreDirectorFactory>
<scoreDefinitionType>SIMPLE</scoreDefinitionType>
<scoreDrl>org/optaplanner/examples/nqueens/solver/nQueensScoreRules.drl</scoreDrl>
</scoreDirectorFactory>
<!-- Configure the optimization algorithms (optional) -->
<termination>
...
</termination>
<constructionHeuristic>
...
</constructionHeuristic>
<localSearch>
...
</localSearch>
</solver>これは、以下の 3 つの部分で構成されています。
- モデルの定義
- スコア関数の定義
- 最適化アルゴリズムの定義 (任意)
本書では、この設定について、詳しく説明しています。
Planner では、設定を変更するだけで最適化アルゴリズムを比較的簡単に切り替えることができます。異なる設定を試して、各ユースケースに最適な設定を報告できる ベンチマーカー もあります。
4.2.2. Java API で Solver の設定
Solver は、SolverConfig API を使用して設定することもできます。これは、ランタイム時に動的に値を変更する場合に特に便利です。たとえば、Solver を構築する前に、ユーザーの入力に合わせて実行時間を変更するには、以下のように設定します。
SolverFactory<NQueens> solverFactory = SolverFactory.createFromXmlResource(
"org/optaplanner/examples/nqueens/solver/nqueensSolverConfig.xml");
TerminationConfig terminationConfig = new TerminationConfig();
terminationConfig.setMinutesSpentLimit(userInput);
solverFactory.getSolverConfig().setTerminationConfig(terminationConfig);
Solver<NQueens> solver = solverFactory.buildSolver();
XML の Solver 設定の全要素は、*Config クラス、またはパッケージ名前空間 org.optaplanner.core.config の *Config クラスにあるプロパティーとして利用できます。この *Config クラスは、XML 形式の Java 表現で、(パッケージ名前空間 org.optaplanner.core.impl の) ランタイムコンポーネントを構築して効率的な Solver を組み立てます。
SolverFactory は、設定しないとマルチスレッドセーフにならないため、getSolverConfig() メソッドはスレッドセーフではありません。ユーザー要求に合わせて動的に SolverFactory を設定するには、初期化時にベースとして SolverFactory を構築し、ユーザー要求に対して、cloneSolverFactory() メソッドでクローンを作成します。
private SolverFactory<NQueens> base;
public void init() {
base = SolverFactory.createFromXmlResource(
"org/optaplanner/examples/nqueens/solver/nqueensSolverConfig.xml");
base.getSolverConfig().setTerminationConfig(new TerminationConfig());
}
// Called concurrently from different threads
public void userRequest(..., long userInput)
SolverFactory<NQueens> solverFactory = base.cloneSolverFactory();
solverFactory.getSolverConfig().getTerminationConfig().setMinutesSpentLimit(userInput);
Solver<NQueens> solver = solverFactory.buildSolver();
...
}4.2.3. Business Central での Solver 設定
Solver の設定には、Business Central の Solver エディターを使用します。Business Central に関する情報は、『Red Hat JBoss BPM Suite User Guide』の 「1.4. 章 Business Central」を参照してください。
Business Central の Business Resource Planner 設定を有効にするには、plannermgmt ロールが必要です。
Business Central に Solver エディターを作成するには、New Item
図4.1 Solver 設定エディター
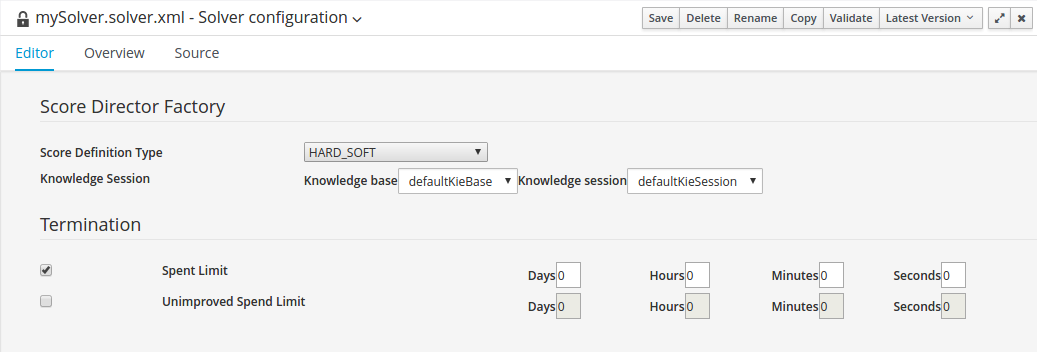
Solver エディターは、基本的な Solver 設定を作成します。KJAR のデプロイ後、Realtime Decision Server またはプレーンな Java コードで、DRL ルール、Planner エンティティー、Planner ソリューションと合わせて実行できます。
エディターで Solver を定義したら、Source をクリックして、XML 形式で表示します。
<solver xStreamId="1">
<scanAnnotatedClasses xStreamId="2"/>
<scoreDirectorFactory xStreamId="3">
<scoreDefinitionType>HARD_SOFT</scoreDefinitionType>
</scoreDirectorFactory>
<termination xStreamId="4">
<secondsSpentLimit>0</secondsSpentLimit>
<minutesSpentLimit>0</minutesSpentLimit>
<hoursSpentLimit>5</hoursSpentLimit>
<daysSpentLimit>0</daysSpentLimit>
</termination>
</solver>Validate ボタンを使用して、Solver 設定を検証します。これにより Solver が作成され、デプロイや実行を行うことなく、プロジェクトの問題が多数提示されます。
デフォルトでは、Solver の設定は、プランニングエンティティーとプランニングソリューションのクラスをすべて自動的にスキャンします。何も見つからない (もしくは結果が多すぎる) と、検証に失敗します。
Data Object タブ
Business Resource Planner で使用するプランニングエンティティーとプランニングソリューションをモデル化するには、データオブジェクトを使用します。データオブジェクトに関する情報は、『Red Hat JBoss BPM Suite User Guide』の「4.14 章 Data models」を参照してください。データオブジェクトを、Planner エンティティーまたはソリューションとして指定する方法は、以下の手順を参照してください。
図4.2 Data Object タブ
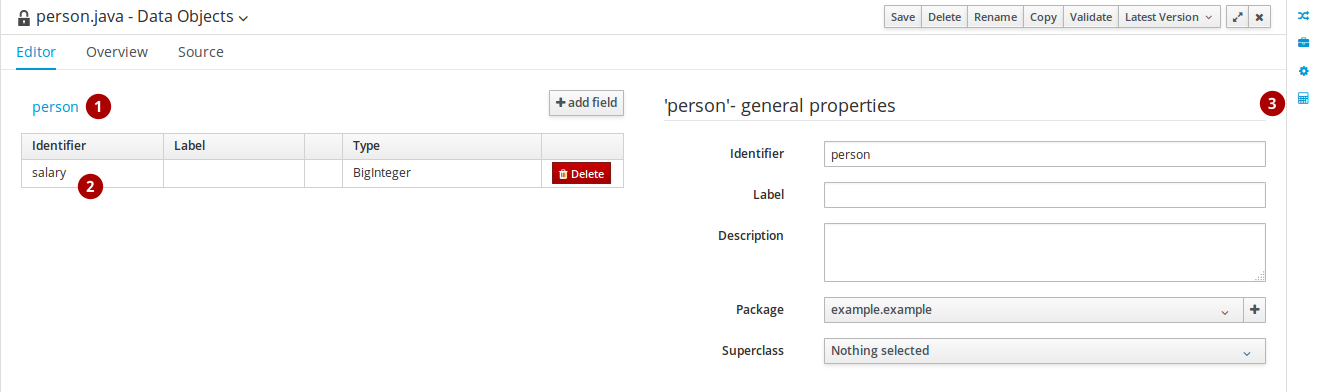
- データオブジェクトのラベルをクリックし、OptaPlanner ツールウィンドウで、オブジェクトを、プランニングエンティティーまたはプランニングソリューションとして設定します。
- 特定のデータオブジェクトフィールドをクリックして、OptaPlanner ツールウィンドウで Business Resource Planner 変数および Solver の関係を設定します。
- OptaPlanner ツールウィンドウでは、コンテキストをもとに Planner 設定を変更できます。つまり、選択した内容によって、このウィンドウの内容が変化します。
4.2.4. アノテーション設定
4.2.4.1. アノテーションの自動スキャン
@PlanningSolution または @PlanningEntity が含まれるクラスを手動で宣言する代わりに以下を行います。
<solver>
<!-- Define the model -->
<solutionClass>org.optaplanner.examples.nqueens.domain.NQueens</solutionClass>
<entityClass>org.optaplanner.examples.nqueens.domain.Queen</entityClass>
...
</solver>Planner では、自動的にクラスパスをスキャンして、検索します。
<solver>
<!-- Define the model -->
<scanAnnotatedClasses/>
...
</solver>クラスパスに複数のモデルがある場合 (またはスキャンのスピードを速める場合) は、以下のようにスキャンするパッケージを指定します。
<solver>
<!-- Define the model -->
<scanAnnotatedClasses>
<packageInclude>org.optaplanner.examples.cloudbalancing</packageInclude>
</scanAnnotatedClasses>
...
</solver>これにより、パッケージまたはサブパッケージのソリューションおよびエンティティークラスがすべて検出されます。
scanAnnotatedClasses を指定していない場合は、org.reflections の Maven 遷移的依存関係を除外することができます。
4.2.4.2. その他のアノテーション方法
Planner は、ドメインモデルのどのクラスが、プランニング変数などをプロパティーとするプランニングエンティティーであるかを指定する必要があります。この情報を渡す方法は複数あります。
- ドメインモデルにクラスアノテーションと JavaBean プロパティーアノテーションを追加します (推奨)。プロパティーアノテーションは、セッターメソッドではなく、ゲッターメソッドに指定する必要があります。このゲッターメソッドを公開する必要はありません。
- ドメインモデルにクラスアノテーションとフィールドアノテーションを追加します。このフィールドは公開する必要がありません。
- アノテーションなし: XML ファイルでのドメイン設定を外部に設置します。これは、未対応 です。
本書は、1 つ目の方法に焦点を当てていますが、明示的に記してない場合でも、すべての機能でこの 3 つの方法に対応しています。
4.3. 計画問題のモデル化
4.3.1. 問題ファクトクラスまたはプランニングエンティティークラス
計画問題のデータセットについて見ていきます。このデータセットに、ドメインクラスがあることが分かるでしょう。これらのドメインクラスは、以下のいずれかに分類できます。
- 関連性のないクラス: どのスコア制約でも使用されません。計画に関して言えば、このデータは使用されません。
-
問題ファクト クラス: スコア制約により使用されますが、(問題が変わらない限り)、計画時に変化しません (例:
Bed、Room、Shift、Employee、Topic、Periodなど)。問題ファクトクラスのプロパティーはすべて、問題プロパティーです。 -
プランニングエンティティー クラス: スコア制約により使用され、計画時に変化します (
BedDesignation、ShiftAssignment、Examなど)。計画時に変化するプロパティーはプランニング変数で、他のプロパティーは問題プロパティーです。
計画時に変化するクラスと、 Solver を使用して変更する変数が含まれるクラス を確認してください。 そのクラスがプランニングエンティティーです。多くのユースケースでは、1 つのプランニングエンティティークラスにプランニング変数が 1 つだけ含まれます。
リアルタイムの計画 では、問題自体が変化しても、計画時に問題ファクトは変化せず、 (Solver は一時的に停止して問題ファクトの変更を適用するため) 次回の計画までに変化します。
適切なモデルを使用すれば、計画の実装が成功する可能性が大幅に高まります。以下のガイドラインに従い、適切なモデルを設計してください。
-
多対一 の関係に当てはめると、通常、プランニングエンティティークラスが 多 になり、他方を参照するプロパティーはプランニング変数ということになります。「従業員の勤務表」サンプルでは、プランニングエンティティークラスは
ShiftAssignmentで、Employeeではありません。プランニング変数はShiftAssignment.getEmployee()です。なぜなら、ShiftAssignmentsは、1 つのEmployeeに対して複数割り当てられますが、1 つのShiftAssignmentにはEmployeeが 1 つしか割り当てられないためです。 プランニングエンティティークラスには、最低でも問題プロパティーが 1 つ必要です。プランニング変数だけを持つプランニングエンティティーは、通常、プランニング変数の 1 つを問題プロパティーに変換して簡素化することができます。これにより、探索空間のサイズ が大幅に縮小されます。たとえば、「従業員の勤務表」では、
ShiftAssignmentのgetShift()が問題プロパティーで、getEmployee()はプランニング変数です。両方をプランニング変数にすると、問題を解決する際の効率がはるかに悪くなります。- 問題プロパティーは最低でも 1 つ必要になりますが、代わりに ID を使用するのは十分ではありません。ビジネスでも理解できる必要があるため、ビジネスキーがあれば十分です。これにより、未割り当てのエンティティーが無名になることを回避できます (ビジネス側で特定できない状態を回避します)。
- こうすることで、プランニングエンティティーを 2 つにするハード制約を追加する必要がなくなります。このプランニングエンティティーは、それぞれの問題プロパティーにより異なっているためです。
-
場合によっては、複数のプランニングエンティティーで問題プロパティーが同じになる可能性があります。このような場合には、追加の問題プロパティーを作成して区別すると便利です。「従業員の勤務表」サンプルの
ShiftAssignmentには、Shiftの問題プロパティーと、indexInShiftの問題プロパティーがあります。
-
計画時には、プランニングエンティティーの数を変更しないことが推奨されます。どのプロパティーがプランニング変数で、どのプロパティーが問題プロパティーにすべきか不明な場合には、エンティティーの数が一定になるように選択してください。たとえば、「従業員の勤務表」サンプルで、プランニングエンティティークラス
EmployeeAssignmentに、問題プロパティーgetEmployee()とプランニング変数getShift()がある場合、各EmployeeにEmployeeAssignmentインスタンスがいくつ作成されるかを正しく推測することは不可能です。
参考として、一般的な設計パターン や、これらのサンプルがドメインをモデル化する方法を確認してください。
配送経路は、連鎖型のプランニング変数 を使用するため特別です。
Planner では、すべての問題ファクトおよびプランニングエンティティーは POJO (Plain Old JavaBean) です。データベース、XML ファイル、データリポジトリー、REST サービス、noSQL cloud などからこれらを読み込むため、問題はありません (「統合」を参照)。
4.3.2. 問題ファクト
問題ファクトとは、計画時に変化しないゲッターを持つ JavaBean (POJO) のことです。インターフェース Serializable の実装が推奨されます (が、必須ではありません)。「 N クィーン」の例では、行と列が問題ファクトです。
public class Column implements Serializable {
private int index;
// ... getters
}public class Row implements Serializable {
private int index;
// ... getters
}問題ファクトも、他の問題ファクトを参照することができます。
public class Course implements Serializable {
private String code;
private Teacher teacher; // Other problem fact
private int lectureSize;
private int minWorkingDaySize;
private List<Curriculum> curriculumList; // Other problem facts
private int studentSize;
// ... getters
}問題ファクトクラスには、Planner 固有のコードは必要ありません。たとえば、JPA アノテーションが付けられているドメインクラスを再利用することができます。
一般的に、ドメインクラスがより適切に設計されていると、スコア制約がより簡単で効率的になります。そのため、整理されていない (正規化されていない) レガシーシステムを扱う場合には、最初に、整理されていないドメインモデルを Planner 固有のモデルに変換することが推奨されます。たとえば、教師が 2 つの学科に所属し、ドメインモデルの Teacher インスタンスが 2 つになる場合は、そのドメインモデルを調整した方が、元のモデルの空き時間に制約を課すスコア制約を記述するよりも簡単になります。
場合によっては、キャッシュされた問題ファクト を導入して、計画のみを対象とするドメインモデルを改良します。
4.3.3. プランニングエンティティー
4.3.3.1. プランニングエンティティーアノテーション
プランニングエンティティーは、問題解決時に変化する JavaBean (POJO) のことで、例としては、別の行に移動する クィーン が挙げられます。また、計画の問題には複数のプランニングエンティティーが含まれます。N クィーンの問題では、各 クィーン がプランニングエンティティーですが、プランニングエンティティークラスは 1 つのみとなっています (例: Queen クラス)。
プランニングエンティティークラスは、@PlanningEntity アノテーションを付ける必要があります。
各プランニングエンティティークラスには、1 つまたは複数の プランニング変数 を追加し、それぞれに 定義 プロパティーを 1 つ以上追加する必要があります。たとえば、N クィーンでは、クィーン は 列 で定義され、行 がプランニング変数になります。これは、問題解決時にクィーンの列を変更せず、行を変更することを示しています。
@PlanningEntity
public class Queen {
private Column column;
// Planning variables: changes during planning, between score calculations.
private Row row;
// ... getters and setters
}
プランニングエンティティークラスには、複数のプランニング変数を指定することができます。たとえば、授業 は、コース やコースのインデックス (1 つのコースには複数の授業が含まれるため) で定義されます。各 授業 は、時間帯 と 講義室 のスケジュールを組む必要があるので、プランニング変数 (時間帯と講義室) は 2 つになります。たとえば、数学のコースでは、1 週間に授業が 8 個あり、最初の授業は月曜の午前 8 時に 212 号室で開催されます。
@PlanningEntity
public class Lecture {
private Course course;
private int lectureIndexInCourse;
// Planning variables: changes during planning, between score calculations.
private Period period;
private Room room;
// ...
}また、自動スキャン がない場合には、Solver 設定で以下のように各プランニングエンティティーを宣言する必要があります。
<solver>
...
<entityClass>org.optaplanner.examples.nqueens.domain.Queen</entityClass>
...
</solver>ユースケースによっては、複数のプランニングエンティティークラスが含まれます。たとえば、鉄道路線図に、貨物および車両を追加します。このとき、1 つの貨物を輸送するのに車両を複数使用したり、1 つの車両で貨物を複数輸送したりできます。このように、プランニングエンティティークラスが複数になると、ユースケース実装の複雑性が増します。
不要なプランニングエンティティークラスは作成しないようにしてください。不要なクラスがあると Move 実装が複雑になり、スコアの計算に時間がかかります。
たとえば、授業 プランニングエンティティーが変化するのに合わせて、最新の状態に保つ必要があるので、教師の空き時間合計を格納するプランニングエンティティークラスは作成しないでください。代わりに、(シャドウ変数 として) スコア制約で空き時間を計算し、教師ごとに割り出した結果を、論理的に挿入するスコアオブジェクトに配置します。
履歴データも考慮する必要がある場合には、計画枠に収まり、 この枠を含めない 過去の割り当て合計を保持する問題ファクトを作成し (これによりプランニングエンティティーが変化しても変更されない)、スコア制約が考慮されるようにします。
4.3.3.2. プランニングエンティティーの難易度
計画がより困難なプランニングエンティティーが予測できる場合には、最適化アルゴリズムはより効率的に機能します。たとえば、ビンパッキング問題ではアイテムが大きくなればなるほど詰めるのは難しく、コースの時間割では授業に出席する学生が多くなればなるほど時間割を作成するのは困難になります。また、N クィーンでは、真ん中のクィーンの配置場所を決めるのがより困難です。
そのため、以下のように、@PlanningEntity アノテーションに difficultyComparatorClass を設定できます。
@PlanningEntity(difficultyComparatorClass = CloudProcessDifficultyComparator.class)
public class CloudProcess {
// ...
}public class CloudProcessDifficultyComparator implements Comparator<CloudProcess> {
public int compare(CloudProcess a, CloudProcess b) {
return new CompareToBuilder()
.append(a.getRequiredMultiplicand(), b.getRequiredMultiplicand())
.append(a.getId(), b.getId())
.toComparison();
}
}
または、以下のように、Solution からも残りの問題ファクトにアクセスできるように、@PlanningEntity アノテーションに difficultyWeightFactoryClass を設定することも可能です。
@PlanningEntity(difficultyWeightFactoryClass = QueenDifficultyWeightFactory.class)
public class Queen {
// ...
}詳しい情報は「ソートした選択」を参照してください。
難易度は、昇順に実装する必要があります。つまり、簡単なエンティティーから困難なエンティティーの順に実装します。したがって、ビンパッキング問題の場合は、「小さいアイテム < 中サイズのアイテム < 大きいアイテム」の順になります。
多くのアルゴリズムは、より困難なエンティティーから開始しますが、これは順番が逆になっているだけです。
プランニングエンティティーの難易度を比較するのに、現在のプランニング変数の状態を使用するべきではありません。構築ヒューリスティックの間、これらの変数は null の可能性が高くなります。たとえば、クィーン の row 変数は使用するべきではありません。
4.3.4. プランニング変数
4.3.4.1. プランニング変数アノテーション
プランニング変数とは、プランニングエンティティーにある JavaBean プロパティー (つまり、ゲッターとセッター) のことです。この変数は、計画時に変化する計画値を参照します。たとえば、クィーン の row プロパティーはプランニング変数となります。計画時に、クィーン の row プロパティーが Row に変化した場合でも、Row インスタンス自体は変化しません。
プランニング変数のゲッターには、@PlanningVariable のアノテーションを付ける必要があります。このアノテーションは、空以外の valueRangeProviderRefs プロパティーを必要とします。
@PlanningEntity
public class Queen {
...
private Row row;
@PlanningVariable(valueRangeProviderRefs = {"rowRange"})
public Row getRow() {
return row;
}
public void setRow(Row row) {
this.row = row;
}
}
valueRangeProviderRefs プロパティーは、対象のプランニング変数で許容可能な計画値は何かを定義します。このプロパティーは、1 つまたは複数の @ValueRangeProvider ID を参照します。
@PlanningVariable アノテーションは、@PlanningEntity アノテーションが付いたクラスに所属する必要があります。このアノテーションがないと、親クラスまたはサブクラスで無視されてしまいます。
プロパティーではなく、フィールドにアノテーション を付けることも可能です。
@PlanningEntity
public class Queen {
...
@PlanningVariable(valueRangeProviderRefs = {"rowRange"})
private Row row;
}4.3.4.2. null 許容型のプランニング変数
デフォルトでは、初期化されたプランニング変数は null にすることができないので、初期化されたソリューションが、プランニング変数に null を使用することはありません。過制約のユースケースではこれは逆効果です。たとえば、従業員にタスクが過剰に割り当てられてしまう場合には、優先順位の低いタスクを、負担の多いスタッフに割り当てるのではなく、未割り当ての状態にしておきます。
初期化されたプランニング変数を null に設定できるようにするには、nullable を true に設定します。
@PlanningVariable(..., nullable = true)
public Worker getWorker() {
return worker;
}
Planner は、自動的に値の範囲に null 値を追加します。ValueRangeProvider で使用するコレクションに null を追加する必要はありません。
null 許容型のプランニング変数を使用すると、スコア計算で null 値を使用して変数を減点 (または加点) することになります。
反復計画 (特に リアルタイム計画) は、null 許容型変数と適切に連携しません。Solver が開始したり、問題ファクトが変更したりするたびに、構築ヒューリスティック は null 変数すべてを再初期化しようとして、長時間無駄にしてしまう可能性があります。これに対応するには、reinitializeVariableEntityFilter で、プランニングエンティティーを再初期化するタイミングを変更します。
@PlanningVariable(..., nullable = true, reinitializeVariableEntityFilter = ReinitializeTaskFilter.class)
public Worker getWorker() {
return worker;
}4.3.4.3. プランニング変数が初期化したと見なされるタイミング
プランニング変数は、値が null でない場合、または変数が nullable の場合に初期化されると見なされるため、カスタムの reinitializeVariableEntityFilter が構築ヒューリスティック時に再初期化をトリガーする場合でも、null 許容型変数は常に初期化すると見なされます。
プランニング変数すべてが初期化されると、プランニングエンティティーは初期化されます。
また、プランニングエンティティーがすべて初期化されると、ソリューション が初期化されます。
4.3.5. 計画値と計画値の範囲
4.3.5.1. 計画値
計画値は、プランニング変数の許容値です。通常、計画値は問題ファクトですが、double などのオブジェクトの場合もあります。また、別のプランニングエンティティーや、プランニングエンティティーと問題ファクトの両方が実装したインターフェースの可能性もあります。
プランニング変数の範囲は、プランニング変数が許容できる一連の値のことです。この一連の値として、可算値 (例: 1、2、3、または 4) または、非可算値 (例: 0.0 から 1.0 の間の double) などを指定できます。
4.3.5.2. 計画値の範囲プロバイダー
4.3.5.2.1. 概要
プランニング変数の値の範囲は @ValueRangeProvider アノテーションで定義します。@ValueRangeProvider アノテーションには、@PlanningVariable プロパティーの valueRangeProviderRefs が参照する ID プロパティーが常に含まれます。
このアノテーションは、2 種類のメソッドに配置される可能性があります。
- ソリューションメソッド: 全プランニングエンティティーは同じ値の範囲を共有します。
- プランニングエンティティーメソッド: 値の範囲はプランニングエンティティーごとに異なり、一般的ではありません。
@ValueRangeProvider アノテーションは、@PlanningSolution または @PlanningEntity アノテーションが付いたクラスに所属する必要があります。このアノテーションがないと、親クラスまたはサブクラスで無視されてしまいます。
対象のメソッドの戻り値型には 2 種類あります。
-
Collection: 値の範囲は、許容値のCollection(通常List) で定義されます。 -
ValueRange: 値の範囲は、限界で定義されますが、これは一般的ではありません。
4.3.5.2.2. ソリューションの ValueRangeProvider
同じプランニングエンティティークラスの全インスタンスは、対象のプランニング変数で許容できる計画値の同じ範囲を共有します。これは、値の範囲を設定する最も一般的な方法です。
ソリューション の実装には、Collection (または ValueRange) を返すメソッドがあります。その Collection からの値は、対象のプランニング変数で許容できる計画値です。
@PlanningVariable(valueRangeProviderRefs = {"rowRange"})
public Row getRow() {
return row;
}@PlanningSolution
public class NQueens implements Solution<SimpleScore> {
// ...
@ValueRangeProvider(id = "rowRange")
public List<Row> getRowList() {
return rowList;
}
}
対象の Collection (または ValueRange) には、null 許容型プランニング変数 であっても、null 値を含めることはできません。
プロパティーではなく、フィールドにアノテーション を付けることも可能です。
@PlanningSolution
public class NQueens implements Solution<SimpleScore> {
...
@ValueRangeProvider(id = "rowRange")
private List<Row> rowList;
}4.3.5.2.3. プランニングエンティティーの ValueRangeProvider
プランニングエンティティーにはそれぞれ、プランニング変数に対して独自の値の範囲 (許容値のセット) があります。たとえば、教師が所属部門以外の講義室で 教鞭を取ること ができない場合に、この教師が授業を行う講義室の値の範囲が、その所属する部門の講義室に制限されてしまう可能性があります。
@PlanningVariable(valueRangeProviderRefs = {"departmentRoomRange"})
public Room getRoom() {
return room;
}
@ValueRangeProvider(id = "departmentRoomRange")
public List<Room> getPossibleRoomList() {
return getCourse().getTeacher().getDepartment().getRoomList();
}これを使用して、ソフト制約 (または問題に実行可能解がない場合にはハード制約) を強制しないようにしてください。たとえば、所属部門以外の講義室を使う以外に、教師が授業を行うことができない場合があります。このように、所属部門以外の講義室を使う以外に手段がない可能性があるため、教師に対して講義室の値の範囲を制限すべきではありません。
特定のプランニングエンティティーの値の範囲を制限することで、組み込み型のハード制約 が効率的に作成されます。これにより、可能解の数を大幅に減らす利点がありますが、最適化アルゴリズムが、一時的に制約に違反して、局所最適を回避することができなくなる可能性があります。
プランニングエンティティーは、他のプランニングエンティティーを使用して値の範囲を決定するべきではありません。他のプランニングエンティティーを使用して値の範囲を決定すると、プランニングエンティティーが問題そのものを解決しようとし、最適化アルゴリズムを妨害する結果となります。
複数のエンティティーに同じ値の範囲が割り当てられていない限り、エンティティーには独自の List インスタンスがあります。たとえば、教師 A および B が同じ部門に所属する場合には、同じ List<Room> インスタンスを使用します。さらに、各 List には同じ計画値のインスタンスのサブセットが含まれます。たとえば、部門 A と B の両方が講義室 X を使用できる場合に、List<Room> インスタンスには同じ Room インスタンスが含まれます。
プランニングエンティティーの ValueRangeProvider は、ソリューションの ValueRangeProvider よりもメモリーを多く消費し、特定の自動パフォーマンス最適化を無効にします。
プランニングエンティティーの ValueRangeProvider は現在、連鎖 変数には対応していません。
4.3.5.2.4. ValueRangeFactory
Collection の代わりに、ValueRangeFactory で構築される ValueRange または CountableValueRange を返すことも可能です。
@ValueRangeProvider(id = "delayRange")
public CountableValueRange<Integer> getDelayRange() {
return ValueRangeFactory.createIntValueRange(0, 5000);
}
ValueRange は、限界のみを保持するため、使用するメモリーははるかに少なくなります。上記の例では、Collection には、2 つの限界だけではなく、5000 の int をすべて保持する必要があります。
さらに、たとえば、200 個単位で在庫を購入する必要がある場合には、incrementUnit を指定することができます。
@ValueRangeProvider(id = "stockAmountRange")
public CountableValueRange<Integer> getStockAmountRange() {
// Range: 0, 200, 400, 600, ..., 9999600, 9999800, 10000000
return ValueRangeFactory.createIntValueRange(0, 10000000, 200);
}
(Planner が可算値であることが理解できるように) できる限り、ValueRange ではなく、CountableValueRange を返します
ValueRangeFactory には、複数の値クラス型に対する作成メソッドがあります。
-
int: 32 ビットの整数の範囲 -
long: 64 ビットの整数の範囲 -
double: 64 ビットの浮動小数点の範囲。(CountableValueRangeを実装しないため) 任意抽出のみをサポートします。 -
BigInteger: 任意精度の整数の範囲 -
BigDecimal: 小数点の範囲。デフォルトでは、インクリメントの単位は、限度の範囲内で最小となるゼロ以外の値となっています。
4.3.5.2.5. ValueRangeProviders の組み合わせ
以下のように、ValueRangeProvider は組み合わせることができます。
@PlanningVariable(valueRangeProviderRefs = {"companyCarRange", "personalCarRange"})
public Car getCar() {
return car;
} @ValueRangeProvider(id = "companyCarRange")
public List<CompanyCar> getCompanyCarList() {
return companyCarList;
}
@ValueRangeProvider(id = "personalCarRange")
public List<PersonalCar> getPersonalCarList() {
return personalCarList;
}4.3.5.3. 計画値の強度
最適化アルゴリズムは、より強度の高い計画値を予測できる場合に、より効率的に機能します。つまり、プランニングエンティティーを満たす可能性が高くなります。たとえば、ビンパッキング問題では、大きい容器のほうがアイテムが入りやすく、またコースの時間割では、大きい講義室のほうが学生の収容人数の制約に違反する可能性が低くなります。
そのため、@PlanningVariable アノテーションに strengthComparatorClass を設定できます。
@PlanningVariable(..., strengthComparatorClass = CloudComputerStrengthComparator.class)
public CloudComputer getComputer() {
// ...
}public class CloudComputerStrengthComparator implements Comparator<CloudComputer> {
public int compare(CloudComputer a, CloudComputer b) {
return new CompareToBuilder()
.append(a.getMultiplicand(), b.getMultiplicand())
.append(b.getCost(), a.getCost()) // Descending (but this is debatable)
.append(a.getId(), b.getId())
.toComparison();
}
}
同じ値の範囲に複数の計画値クラスがある場合、strengthComparatorClass は一般的なスーパークラスの Comparator を実装して (例: Comparator<Object>)、これらの異なるクラスのインスタンスを比較できるようにする必要があります。
または、ソリューションから残りの問題ファクトにアクセスできるように、@PlanningVariable アノテーションに strengthWeightFactoryClass を設定することも可能です。
@PlanningVariable(..., strengthWeightFactoryClass = RowStrengthWeightFactory.class)
public Row getRow() {
// ...
}詳しい情報は「ソートした選択」を参照してください。
強度は昇順に実装する必要があります。つまり、順番は、弱いものから強いものになります。ビンパッキング問題の場合は、「小さい容器 < 中程度の容器 < 大きい容器」の順になります。
プランニングエンティティーの現在のプランニング変数を使用して、計画値を比較しないでください。構築ヒューリスティックの間、これらの変数は null の可能性が高くなります。たとえば、クィーン の row 変数を使用して、Row の強度を判断することはできません。
4.3.5.4. 連鎖型プランニング変数 (TSP、VRP など)
TSP や配送経路のユースケースには、連鎖が必要です。つまり、プランニングエンティティー同士で相互参照し、連鎖を形成します。(ツリー/ループのセットではなく) 連鎖セットとして問題をモデル化すると、探索空間を大幅に縮小することができます。
連鎖するプランニング変数は、以下のいずれかです。
- アンカー と呼ばれる問題ファクト (またはプランニングエンティティー) を直接参照する
- 同じプランニング変数を使用する別のプランニングエンティティーを参照して、再帰的にアンカーを参照する
以下に有効な連鎖と無効な連鎖の例を示します。
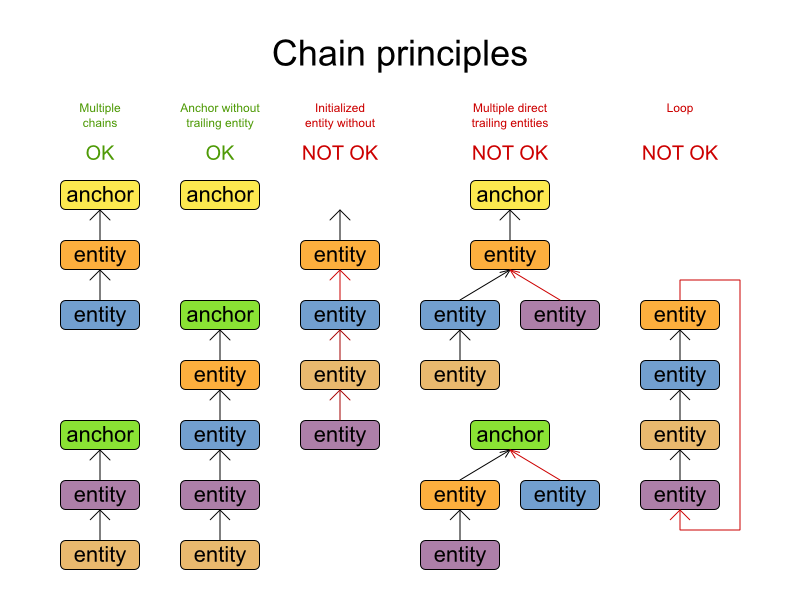
初期化されるプランニングエンティティーはすべて、アンカーから始まる、一端が開放型の連鎖に含まれます。有効なモデルとは以下のとおりです。
- 連鎖はループにはなりません。一端が必ず開いています。
- 連鎖にはすべてアンカーが 1 つだけ含まれます。このアンカーが問題ファクトで、プランニングエンティティーにはなりません。
- 連鎖はツリーにはならず、必ず 1 本の線となります。アンカーまたはプランニングエンティティーに続くプランニングエンティティーは、多くても 1 つだけです。
- 初期化されるプランニングエンティティーはすべて、連鎖に含まれます。
- プランニングエンティティーに参照されていないアンカーも連鎖とみなされます。
Solver に渡される計画問題のインスタンスは、有効でなければなりません。
制約が閉鎖型の連鎖を示す場合には、一端が開放された連鎖 (データベースで永続しやすい) としてモデル化し、最後のエンティティーをアンカーにつなげるスコア制約を実装します。
最適化アルゴリズムと組み込みの Move は、連鎖的に修正して、モデルが有効な状態を保てるようにします。

カスタムの Move 実装は、モデルを有効な状態にする必要があります。
たとえば、TSP では、アンカーは Domicile です (配送経路ではアンカーは Vehicle です)。
public class Domicile ... implements Standstill {
...
public City getCity() {...}
}
アンカー (つまり、問題ファクト) とプランニングエンティティーは、たとえば TSP の Standstill のように共通のインターフェースを実装します。
public interface Standstill {
City getCity();
}
このインターフェースがプランニング変数の戻り値型で、さらにプランニング変数は連鎖されています (例: TSP の Visit、配送経路の Customer)。
@PlanningEntity
public class Visit ... implements Standstill {
...
public City getCity() {...}
@PlanningVariable(graphType = PlanningVariableGraphType.CHAINED,
valueRangeProviderRefs = {"domicileRange", "visitRange"})
public Standstill getPreviousStandstill() {
return previousStandstill;
}
public void setPreviousStandstill(Standstill previousStandstill) {
this.previousStandstill = previousStandstill;
}
}この 2 つの ValueRangeProvider が、通常、統合されている点に注目してください。
-
domicileListなど、アンカーを保持する ValueRangeProivder。 -
visitListなど、初期化されるプランニングエンティティーを保持する ValueRangeProvider。
4.3.6. シャドウ変数
4.3.6.1. 概要
シャドウ変数とは、正しい値を正規のプランニング変数の状態から推測できる変数のことです。この変数が定義上、正規化の原則に違反するにもかかわらず、ユースケースによっては、特により自然に制約を表現する場合など、シャドウ変数を使用すると非常に実用的です。たとえば、時間枠がある配送経路の場合には、車両が顧客先に到着する時間は、その車両がその前に顧客先に訪問したタイミング (および、2 箇所の既知の移動時間) をベースに計算することができます。

車両が対応する顧客が変化すると、各顧客先への到着時間は自動的に調節されます。詳しい情報は、「配送経路ドメインモデル」を参照してください。
スコア計算の観点からすると、シャドウ変数は他のプランニング変数とよく似ています。最適化の観点からすると、Planner は正規の変数を効果的に最適化するだけです (シャドウ変数はほぼ無視されます)。正規の変数が変化すると、従属のシャドウ変数もそれに合わせて変化するようにするだけです。
以下のように、組み込みのシャドウ変数は複数あります。
4.3.6.2. 双方向変数 (逆関係のシャドウ変数)
2 つの変数は、各変数のインスタンスが常に相互参照する場合には、双方向となります (一方が null を参照し、他方が存在しない場合を除きます)。そのため、A が B を参照している場合には、B は A を参照することになります。
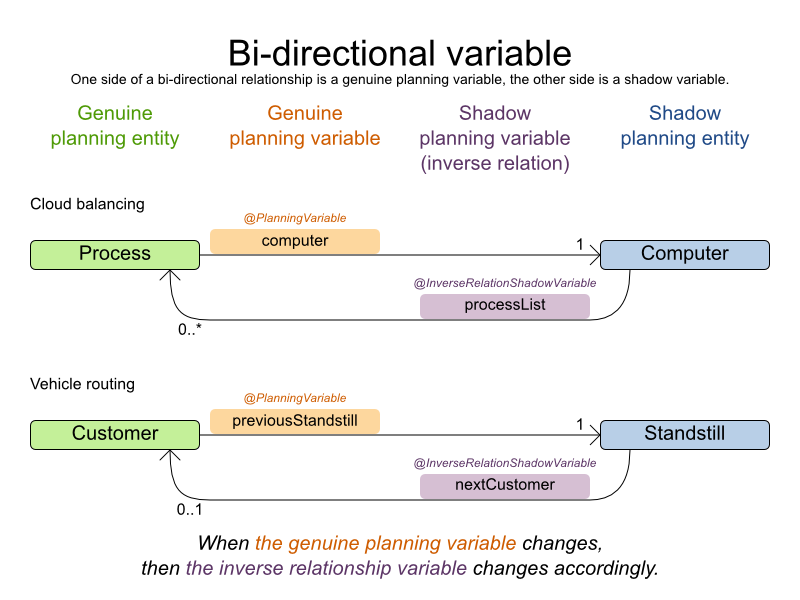
非連鎖型のプランニング変数の場合には、双方向の関係は、多対一の関係である必要があります。2 つのプランニング変数間で双方向の関係をマッピングするには、マスターの方 (正規の変数) を通常のプランニング変数としてアノテーションを付けます。
@PlanningEntity
public class CloudProcess {
@PlanningVariable(...)
public CloudComputer getComputer() {
return computer;
}
public void setComputer(CloudComputer computer) {...}
}
次に、もう一方 (シャドウ変数) には、Collection (通常は Set または List) プロパティーで @InverseRelationShadowVariable アノテーションを付けます。
@PlanningEntity
public class CloudComputer {
@InverseRelationShadowVariable(sourceVariableName = "computer")
public List<CloudProcess> getProcessList() {
return processList;
}
}
sourceVariableName プロパティーは、ゲッターの戻り値型の正規プランニング変数の名前です (つまり、他方 の正規プランニング変数の名前)。
シャドウプロパティー (Collection) は、null にすることはできません。そのシャドウエンティティーを参照する正規変数がない場合には、Collection は空になります。さらに、Solver が正規プランニング変数を初期化または変更しはじめると、それに合わせてそのシャドウ変数の Collections に対して追加/削除が行われるため、Collection は可変にする必要があります。
連鎖型のプランニング変数の場合には、双方向の関係は一対一にする必要があります。この場合、正規変数の側の設定は以下のようになります。
@PlanningEntity
public class Customer ... {
@PlanningVariable(graphType = PlanningVariableGraphType.CHAINED, ...)
public Standstill getPreviousStandstill() {
return previousStandstill;
}
public void setPreviousStandstill(Standstill previousStandstill) {...}
}また、シャドウ変数側の設定は以下のとおりです。
@PlanningEntity
public class Standstill {
@InverseRelationShadowVariable(sourceVariableName = "previousStandstill")
public Customer getNextCustomer() {
return nextCustomer;
}
public void setNextCustomer(Customer nextCustomer) {...}
}
Solver の入力計画問題は、双方向の関係を無視できません。A が B を参照する場合は、B が A を参照する必要があります。Planner は、計画時にこの原理に違反しませんが、入力もこの原理に違反することはできません。
4.3.6.3. アンカーシャドウ変数
アンカーシャドウ変数は、連鎖型変数 のアンカーのことです。
アンカーのプロパティーは、@AnchorShadowVariable でアノテーションを付けます。
@PlanningEntity
public class Customer {
@AnchorShadowVariable(sourceVariableName = "previousStandstill")
public Vehicle getVehicle() {...}
public void setVehicle(Vehicle vehicle) {...}
}
sourceVariableName プロパティーは、同じエンティティークラスの連鎖型変数の名前を指定します。
4.3.6.4. カスタムの VariableListener
Planner は、シャドウ変数を更新するのに VariableListener を使用します。また、カスタムのシャドウ変数を定義するには、カスタムの VariableListener を記述します。インターフェースを実装して、変更が必要なシャドウ変数にアノテーションを付けます。
@PlanningVariable(...)
public Standstill getPreviousStandstill() {
return previousStandstill;
}
@CustomShadowVariable(variableListenerClass = VehicleUpdatingVariableListener.class,
sources = {@CustomShadowVariable.Source(variableName = "previousStandstill")})
public Vehicle getVehicle() {
return vehicle;
}
variableName は、シャドウ変数で変更をトリガーする変数を指定します。
トリガー変数のクラスがシャドウ変数と異なる場合には、@CustomShadowVariable.Source で entityClass を指定します。この場合には、対象の entityClass が Solver 設定でプランニングエンティティークラスとして正しく設定されていることも確認します。正しく設定されていないと VariableListener はトリガーされません。
正規プランニング変数が含まれていなくても、シャドウ変数が最低 1 つ含まれるクラスは、プランニングエンティティークラスとなります。
たとえば VehicleUpdatingVariableListener は連鎖のアンカーの役割を果たし、連鎖内のすべての Customer に同じ Vehicle が指定されるようにします。
public class VehicleUpdatingVariableListener implements VariableListener<Customer> {
public void afterEntityAdded(ScoreDirector scoreDirector, Customer customer) {
updateVehicle(scoreDirector, customer);
}
public void afterVariableChanged(ScoreDirector scoreDirector, Customer customer) {
updateVehicle(scoreDirector, customer);
}
...
protected void updateVehicle(ScoreDirector scoreDirector, Customer sourceCustomer) {
Standstill previousStandstill = sourceCustomer.getPreviousStandstill();
Vehicle vehicle = previousStandstill == null ? null : previousStandstill.getVehicle();
Customer shadowCustomer = sourceCustomer;
while (shadowCustomer != null && shadowCustomer.getVehicle() != vehicle) {
scoreDirector.beforeVariableChanged(shadowCustomer, "vehicle");
shadowCustomer.setVehicle(vehicle);
scoreDirector.afterVariableChanged(shadowCustomer, "vehicle");
shadowCustomer = shadowCustomer.getNextCustomer();
}
}
}
VariableListener は、シャドウ変数のみを変更できます。正規プランニング変数や問題ファクトを変更することはできません。
シャドウ変数を変更した場合は、ScoreDirector に通知する必要があります。
( VariableListeners を 2 つ設定するのは効率的でないため) 1 つの VariableListener が 2 つのシャドウ変数を変更する場合に、variableListenerClass でアノテーションを付けるのを 1 番目のシャドウ変数に限定し、他のシャドウ変数が 1 番目のシャドウ変数を参照するように設定します。
@PlanningVariable(...)
public Standstill getPreviousStandstill() {
return previousStandstill;
}
@CustomShadowVariable(variableListenerClass = TransportTimeAndCapacityUpdatingVariableListener.class,
sources = {@CustomShadowVariable.Source(variableName = "previousStandstill")})
public Integer getTransportTime() {
return transportTime;
}
@CustomShadowVariable(variableListenerRef = @PlanningVariableReference(variableName = "transportTime"))
public Integer getCapacity() {
return capacity;
}4.3.6.5. VariableListener による順番のトリガー
すべてのシャドウ変数は、組み込みまたはカスタムにかかわらず、VariableListener によりトリガーされます。正規の変数およびシャドウ変数でグラフが形成され、afterEntityAdded() メソッド、afterVariableChanged() メソッド、afterEntityRemoved() メソッドが呼び出される順番を決定します。
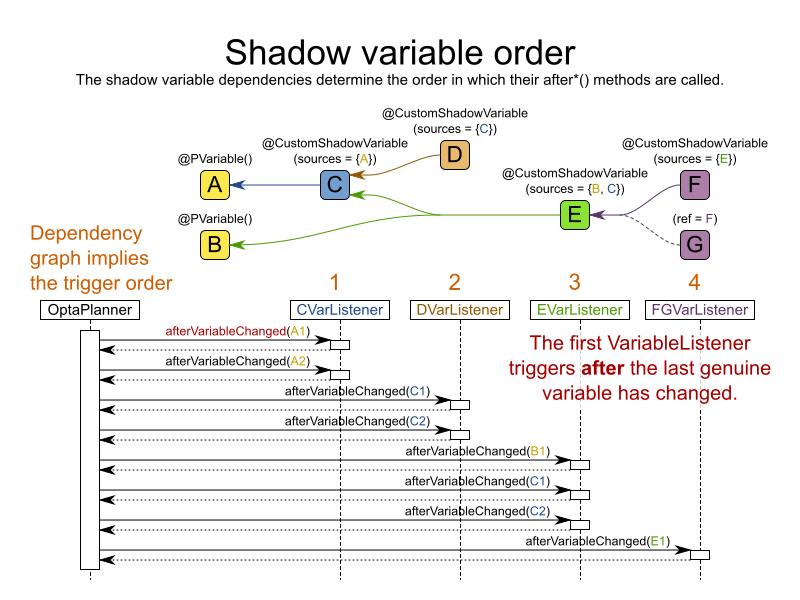
上記の例では、D は E (または F) との間に直接的/間接的な依存関係がないので、E (または F) の後に指定することも可能です。
Planner は以下を保証します。
-
最初の
VariableListenerafter*()メソッドは、最後の正規変数が変化した後にトリガーされます。正規変数 (上記の例では A と B) は、すべてのMoveが適用されているため、全インスタンス (上記の例では A1、A2、B1) で確実に整合性が取れた状態となっています。 -
2 番目の
VariableListenerafter*()メソッドは、最初のシャドウ変数が変化した後にトリガーされます。最初のシャドウ変数 (上記の例では C) と正規変数も、全インスタンス (上記の例では値 C1、C2) で確実に整合性が取れた状態になっています。 - その他
影響を受けた順番になる可能性は高くなりますが、Planner は、異なるパラメーター (上記の例では A1 と A2) が指定した 同じ VariableListener に対して after*() メソッドが呼び出される順番を保証しません。
4.3.7. 計画問題およびその解
4.3.7.1. 計画問題インスタンス
計画問題のデータセットは、Solver が解 (ソリューション) を出せるように、クラス内でラッピングする必要があります。このクラスは必ず実装してください。たとえば N クィーン問題では、Column リスト、Row リスト、Queen リストが含まれる NQueens クラスです。
計画問題とは、未解決のプランニングソリューション、または 未初期化の ソリューション のことです。そのため、ラッピングクラスは Solution インターフェースを実装する必要があります。たとえば、N クィーン問題で、NQueens クラスは Solution を実装しますが、新しい NQueens に含まれる全 Queen は Row に割り当てられていません (クィーンの row プロパティーは null です)。これは実行可能解でも、可能解ではなく、未初期化解となります。
4.3.7.2. ソリューションインターフェース
Solver に対する Solution インスタンスとして問題を提示する必要があるため、クラスは Solution インターフェースを実装する必要があります。
public interface Solution<S extends Score> {
S getScore();
void setScore(S score);
Collection<? extends Object> getProblemFacts();
}
たとえば、NQueens インスタンスは、全行、全列、全 Queen インスタンスの一覧を保持します。
@PlanningSolution
public class NQueens implements Solution<SimpleScore> {
private int n;
// Problem facts
private List<Column> columnList;
private List<Row> rowList;
// Planning entities
private List<Queen> queenList;
// ...
}
また、プランニングソリューションクラスは、@PlanningSolution アノテーションを付ける必要があります。自動スキャン がない場合には、Solver 設定はプランニングソリューションクラスも宣言する必要があります。
<solver>
...
<solutionClass>org.optaplanner.examples.nqueens.domain.NQueens</solutionClass>
...
</solver>4.3.7.3. ソリューションからのエントリーの抽出
Planner は、Solution インスタンスからエンティティーインスタンスを抽出する必要があります。これは、@PlanningEntityCollectionProperty アノテーションが付いた全ゲッター (フィールド) を呼び出してこれらのコレクションを取得します。
@PlanningSolution
public class NQueens implements Solution<SimpleScore> {
...
private List<Queen> queenList;
@PlanningEntityCollectionProperty
public List<Queen> getQueenList() {
return queenList;
}
}
@PlanningEntityCollectionProperty のアノテーションがついたメンバーが複数存在する可能性があります。このようなメンバーは、同じエンティティークラスタイプの Collection を返すことも可能です。
@PlanningEntityCollectionProperty アノテーションは、@PlanningSolution アノテーションの付いたクラスに所属する必要があります。このアノテーションがないと、親クラスまたはサブクラスで無視されます。
あまり一般的ではありませんが、ゲッター (またはフィールド) の @PlanningEntityProperty を使用するなど、プランニングエンティティーがシングルトンの可能性があります。
4.3.7.4. getScore() および setScore() メソッド
Solution には、スコアプロパティーが必要です。スコアプロパティーは、Solution が初期化されていない場合や、スコアが (再) 計算されていない場合には null になります。score プロパティーは通常、使用する固有の Score 実装に型指定されます。たとえば、NQueens は SimpleScore を使用します。
@PlanningSolution
public class NQueens implements Solution<SimpleScore> {
private SimpleScore score;
public SimpleScore getScore() {
return score;
}
public void setScore(SimpleScore score) {
this.score = score;
}
// ...
}
代わりに、多くのユースケースでは、HardSoftScore を使用します。
@PlanningSolution
public class CourseSchedule implements Solution<HardSoftScore> {
private HardSoftScore score;
public HardSoftScore getScore() {
return score;
}
public void setScore(HardSoftScore score) {
this.score = score;
}
// ...
}
Score 実装に関する詳しい情報は、スコア計算のセクションを参照してください。
4.3.7.5. getProblemFacts() メソッド
このメソッドは、スコア計算に Drools を使用する場合にのみ使用します。他のスコアディレクターは、このメソッドを使用しません。
getProblemFacts() メソッドが返すオブジェクトはすべて、Drools のワーキングメモリーにアサートされるので、スコアルールがそのオブジェクトにアクセスできます。たとえば、NQueens は Column インスタンスと Row インスタンスだけを返します。
public Collection<? extends Object> getProblemFacts() {
List<Object> facts = new ArrayList<Object>();
facts.addAll(columnList);
facts.addAll(rowList);
// Do not add the planning entities (queenList) because that will be done automatically
return facts;
}
プランニングエンティティーはすべて自動的に Drools のワーキングメモリーに挿入されます。getProblemFacts() メソッドには追加しないでください。
よくある間違いとして、Collection に対して fact.addAll(…) ではなく、facts.add(…) を使用し、Collection の要素が Drools のワーキングメモリーに含まれていないため、スコアルールと照合できなくなってしまいます。
getProblemFacts() メソッドは、Solver スレッドの各 Solver フェーズで呼び出されるのは 1 度だけで、頻繁には呼び出されません。
4.3.7.5.1. キャッシュされた問題ファクト
キャッシュされた問題ファクトとは、実際のドメインモデルには存在せずに、Solver が実際に問題を解決し始める前に計算される問題ファクトのことです。getProblemFacts() メソッドは、キャッシュされた問題ファクトを使用してドメインモデルを改良できるため、スコア制約の簡素化、迅速化につながる可能性があります。
たとえば、キャッシュされた問題ファクト TopicConflict は、Student を少なくても 1 つ共有する 2 つの Topics に対して作成されます。
public Collection<? extends Object> getProblemFacts() {
List<Object> facts = new ArrayList<Object>();
// ...
facts.addAll(calculateTopicConflictList());
// ...
return facts;
}
private List<TopicConflict> calculateTopicConflictList() {
List<TopicConflict> topicConflictList = new ArrayList<TopicConflict>();
for (Topic leftTopic : topicList) {
for (Topic rightTopic : topicList) {
if (leftTopic.getId() < rightTopic.getId()) {
int studentSize = 0;
for (Student student : leftTopic.getStudentList()) {
if (rightTopic.getStudentList().contains(student)) {
studentSize++;
}
}
if (studentSize > 0) {
topicConflictList.add(new TopicConflict(leftTopic, rightTopic, studentSize));
}
}
}
}
return topicConflictList;
}
スコア制約を使用して、学生を共有するトピックの試験が、近い時間帯でスケジュールされないように確認する必要がある場合には (同時、続けて、または同じ日など制約によって異なります)、2 つの Student インスタンスに統合するのではなく、TopicConflict インスタンスを問題ファクトとして使用できます。
4.3.7.6. ソリューションのクローン作成
(すべてではないとしても) 多くの最適化アルゴリズムは、新しい最適解を見つけた場合 (後で呼び出すため)、または複数の解を並行して使用できるように、その解 (ソリューション) のクローンを作成します。
シャロークローン、ディープクローンなど、クローンには多数の方法があります。このコンテキストでは、計画クローン にフォーカスします。
ソリューション の計画クローンは、以下の要件を満たす必要があります。
- クローンは同じ計画問題を表現する必要があります。通常、元のものと同じ問題ファクトおよび問題ファクトコレクションのインスタンスを再利用します。
-
クローンは、エンティティーおよびエンティティーコレクションをクローンした異なるインスタンスを使用する必要があります。元の
ソリューションエンティティーの変数に変更を加えても、クローンに影響があってはいけません。
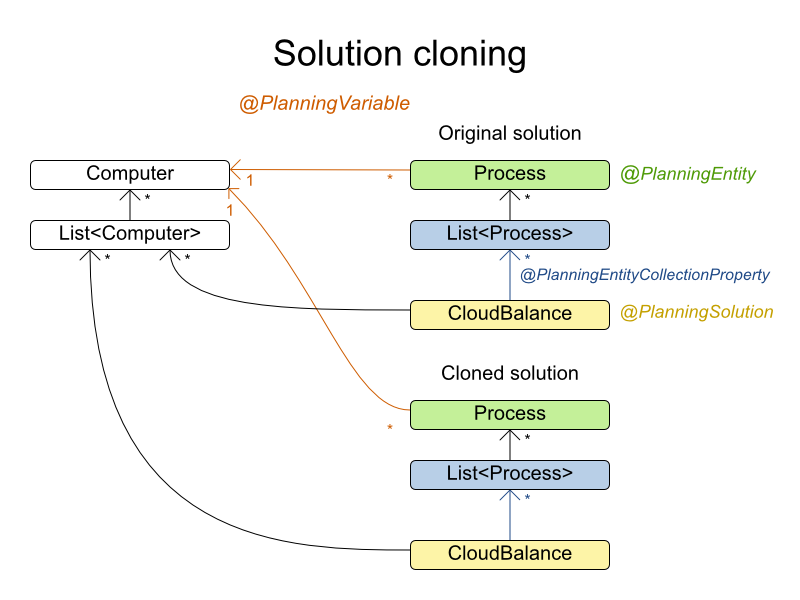
計画クローンメソッドを実装するのは困難なので、実装する必要はありません。
4.3.7.6.1. FieldAccessingSolutionCloner
この SolutionCloner はデフォルトで使用されます。多くのユースケースと適切に機能します。
FieldAccessingSolutionCloner がエンティティーコレクションのクローンを作成する場合には、実装が認識されずに ArrayList、LinkedHashSet または TreeSet (より適切なもの) に置き換えられる可能性があります。ただし、一般的な JDK Collection 実装の大半は認識されます。
FieldAccessingSolutionCloner は、デフォルトでは問題ファクトのクローンを作成しません。問題ファクトにプランニングエンティティーまたはプランニングソリューションを参照させるなど、問題ファクトをデープクローンして計画クローンにする必要がある場合には、以下のように @DeepPlanningClone アノテーションを付けます。
@DeepPlanningClone
public class SeatDesignationDependency {
private SeatDesignation leftSeatDesignation; // planning entity
private SeatDesignation rightSeatDesignation; // planning entity
...
}
上記の例のように、SeatDesignation はプランニングエンティティー (つまり、自動的にディープ計画クローンされる) ので、SeatDesignationDependency もディープ計画クローンする必要があります。
または @DeepPlanningClone アノテーションをゲッターメソッドで使用することも可能です。
4.3.7.6.2. カスタムクローン: ソリューションでの PlanningCloneable の実装
Solution が PlanningCloneable を実装する場合に、planningClone() メソッドを呼び出すと自動的に Planner がクローンします。
public interface PlanningCloneable<T> {
T planningClone();
}
例: NQueens が PlanningCloneable を実装する場合には、すべての Queen インスタンスをディープクローンするだけです。計画中に クィーン を変更して元のソリューションが変更された場合には、このクローンは変化しません。
public class NQueens implements Solution<...>, PlanningCloneable<NQueens> {
...
/**
* Clone will only deep copy the {@link #queenList}.
*/
public NQueens planningClone() {
NQueens clone = new NQueens();
clone.id = id;
clone.n = n;
clone.columnList = columnList;
clone.rowList = rowList;
List<Queen> clonedQueenList = new ArrayList<Queen>(queenList.size());
for (Queen queen : queenList) {
clonedQueenList.add(queen.planningClone());
}
clone.queenList = clonedQueenList;
clone.score = score;
return clone;
}
}
planningClone() メソッドは、プランニングエンティティーだけをディープクローンする必要があります。Column および Row などの問題ファクトは通常クローンされない点に注意してください。さらに、これらの List インスタンスもクローンされません。問題ファクトもクローンする場合には、新しいプランニングエンティティークローンが、ソリューションにより使用される新しい問題ファクトのクローンを参照しているようにする必要があります。たとえば、すべての Row インスタンスのクローンを作成する場合には、各 Queen および NQueens のクローン自体は、これらの新しい Row クローンを参照する必要があります。
連鎖型 変数でエンティティーをクローンする方法は正しくありません。エンティティー A の変数は別のエンティティー B に参照します。A がクローンされる場合には、A の変数は、元の B ではなく、B のクローンを参照する必要があります。
4.3.7.7. 初期化されていないソリューションの作成
Solution インスタンスを作成して、計画問題のデータセットを表現するため、解決する計画問題として、Solver に設定することができます。たとえば N クィーンでは、NQueens インスタンスが、必須の Column インスタンスおよび Row インスタンスで作成され、全 Queen は異なる column に、全 row は null に設定されます。
private NQueens createNQueens(int n) {
NQueens nQueens = new NQueens();
nQueens.setId(0L);
nQueens.setN(n);
nQueens.setColumnList(createColumnList(nQueens));
nQueens.setRowList(createRowList(nQueens));
nQueens.setQueenList(createQueenList(nQueens));
return nQueens;
}
private List<Queen> createQueenList(NQueens nQueens) {
int n = nQueens.getN();
List<Queen> queenList = new ArrayList<Queen>(n);
long id = 0L;
for (Column column : nQueens.getColumnList()) {
Queen queen = new Queen();
queen.setId(id);
id++;
queen.setColumn(column);
// Notice that we leave the PlanningVariable properties on null
queenList.add(queen);
}
return queenList;
}図4.3 クィーン 4 個のパズルの初期化前の解
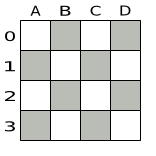
通常、データ層から来るこのデータや Solution 実装の多くは、対象のデータを累積して、計画する未初期化プランニングエンティティーインスタンスを作成します。
private void createLectureList(CourseSchedule schedule) {
List<Course> courseList = schedule.getCourseList();
List<Lecture> lectureList = new ArrayList<Lecture>(courseList.size());
long id = 0L;
for (Course course : courseList) {
for (int i = 0; i < course.getLectureSize(); i++) {
Lecture lecture = new Lecture();
lecture.setId(id);
id++;
lecture.setCourse(course);
lecture.setLectureIndexInCourse(i);
// Notice that we leave the PlanningVariable properties (period and room) on null
lectureList.add(lecture);
}
}
schedule.setLectureList(lectureList);
}4.4. Solver の使用
4.4.1. Solver インターフェース
Solver を実装し、計画問題を解決します。
public interface Solver<S extends Solution> {
S solve(S planningProblem);
...
}
Solver が一度に解決できるのは、1 つの計画問題インスタンスだけです。Solver は、1 つのスレッドからのみアクセスするようにしてください。ただし、特にスレッドセーフとして Javadoc に記述されているメソッドは除きます。SolverFactory で構築しているため、自分で実装する必要はありません。
4.4.2. 問題の解決
以下があれば、問題の解決は非常に簡単です。
-
Solver 設定からビルドした
Solver -
計画問題インスタンスを示す
ソリューション
計画問題を、solve() メソッドへの引数として指定すると、見つかった最適解が返されます。
NQueens bestSolution = solver.solve(planningProblem);
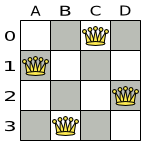
たとえば N クィーンでは、solve() メソッドは、Row に割り当てられたすべての クィーン を含む NQueens インスタンスを返します。
図4.4 8ms でクィーン 4 個のパズルに対する最善解 (および最適解 )
solve(Solution) メソッドは、(問題のサイズや Solver 設定によって) 時間がかかる場合があります。Solver は、可能解の 探索空間 からインテリジェントに情報を取得し、問題解決時に見つけた最善解を記憶します。さまざまな要因によっては (問題サイズ、Solver の所有時間 (許容範囲)、Solver 設定など)、最善解が、最適解となる場合と、ならない場合があります。
solve(Solution) メソッドに渡される Solution インスタンスは、Solver によって変更しますが、最善解ではないので間違わないようにしてください。
solve(Solution) または getBestSolution() が返す Solution インスタンスは、solve(Solution) メソッドに渡すインスタンスの 計画クローン である可能性が最も高くなります。つまり、これは別のソリューションということになります。
solve(Solution) メソッドに渡す Solution インスタンスは、初期化する必要はありません。一部または完全に初期化することは可能で、反復計画 の場合に頻繁に該当します。
4.4.3. 環境モード: コードにおける問題の有無
環境モードでは、実装内の共通のバグを検出できます。このモードによるロギングレベルに影響はありません。
以下のように、Solver 設定の XML ファイルで環境モードを設定します。
<solver>
<environmentMode>FAST_ASSERT</environmentMode>
...
</solver>
Solver には Random インスタンスが 1 つ含まれます。Solver の設定によっては、他よりもはるかに多い Random インスタンスを使用するものもあります。たとえば、焼きなまし法は、乱数に大きく依存していますが、タブー探索はスコアとの紐付けを処理する場合にのみ依存します。環境モードは、Random インスタンスのシードに影響を与えます。
以下は環境モードです。
4.4.3.1. FULL_ASSERT
FULL_ASSERT モードは (インクリメンタルスコアの計算を Move ごとに低下させないようにするアサーションなど) すべてのアサーションをオンにして、Move 実装、スコアルール、ルールエンジン自体などでバグがあった場合にフェイルファストさせます。
このモードは、再現可能です (再現可能モードを参照)。また、アサーション以外のモードと比べ、calculateScore() メソッドは頻繁に呼び出されるため、割り込みも可能です。
FULL_ASSERT モードは、(インクリメンタルスコアの計算には依存しないので) 極めて遅いです。
4.4.3.2. NON_INTRUSIVE_FULL_ASSERT
NON_INTRUSIVE_FULL_ASSERT は、複数のアサーションをオンにして、Move 実装、スコアルール、ルールエンジン自体などにバグがあった場合にフェイルファストさせます。
このモードは、再現可能です (再現可能モードを参照)。また、アサーション以外のモードと比べ、calculateScore() メソッドはより頻繁に呼び出されないので、割り込みはしません。
NON_INTRUSIVE_FULL_ASSERT モードは、(インクリメンタルスコアの計算には依存しないので) 極めて遅いです。
4.4.3.3. FAST_ASSERT
FAST_ASSERT モードは、(undoMove のスコアが Move の前と同じであるとのアサーションなど) 大半のアサーションをオンにして、Move 実装、スコアルール、ルールエンジン自体などでバグがあった場合にフェイルファストさせます。
このモードは、再現可能です (再現可能モードを参照)。また、アサーション以外のモードと比べ、calculateScore() メソッドがより頻繁に呼び出されるので、割り込みが可能です。
FAST_ASSERT モードは遅いです。
FAST_ASSERT モードがオンの状態で計画問題を簡略的に実行するテストケースを記述することを推奨します。
4.4.3.4. REPRODUCIBLE (デフォルト)
再現可能モードは、開発中に推奨されるモードであるため、デフォルトのモードとなっています。このモードでは、Planner バージョンを実行した場合に実行されるコードの順番は常に同じです。そして、以下の注意点が適用されている場合を除き、どのステップでも同じ結果となります。こうすることで、一貫性を持ってバグを再現することができます。したがって、実行を繰り返しながら、特定のリファクタリング (例: スコア制約のパフォーマンスの最適化) をベンチマーク化することができます。
再現可能モードでも、以下の理由から、アプリケーションを完全に再現できない可能性があります。
-
特に
ソリューションの実装で、プランニングエンティティーまたは計画値 (ただし一般的な問題ファクトでないもの) のコレクションにHashSet(または、JVM 実行間の順番に一貫性のない別のコレクション) を使用しているため。これは、LinkedHashSetに置き換えます。 - 時間の勾配に依存するアルゴリズム (特に焼きなまし法) が Time Spent Termination (所要時間による終了) と組み合わせられているため。割り当てられた CPU 時間に大きな相違があると、時間勾配の値にも影響があります。焼きなまし法をレイトアクセプタンスに置き換えるか、Time Spent Termination (所要時間による終了) を Step Count Termination (ステップ数による終了) に置き換えます。
再現可能モードは、実稼働モードより若干遅くなります。実稼働環境で再現性が必要な場合には、このモードを実稼働環境でも使用してください。
シードを指定しない場合は、このモードではデフォルトで固定の 乱数シード が使用され、特定の同時最適化 (例: ワークスティーリング) も無効にします。
4.4.3.5. PRODUCTION
実稼働モードは、最速ですが再現性はありません。このモードは、再現性の必要がない、実稼働環境に推奨されます。
シードを指定しない場合は、このモードでは固定の 乱数シード は使用されません。
4.4.4. ログレベル: Solver の機能
Solver の理解を容易にする最適な方法として、ロギングレベルを使用することが挙げられます。
error:
RuntimeExceptionとして呼び出しコードに送出されるエラー以外のエラーをログに記録します。注記エラーが発生した場合には、Planner は通常、呼び出しコードに対する詳細メッセージを含む
RuntimeExceptionのサブクラスを送出し、フェイルファスト (処理が中断) されます。ログメッセージが重複しないように、これはエラーとしてログに記録されません。呼び出しコードがこのRuntimeExceptionを明示的に受けて処理した場合を除き、ThreadのデフォルトのExceptionHandlerは、エラーとしてログに記録されます。一方で、被害が大きくなったり、エラーが複雑になり分かりにくくならないように、コードが中断されます。- warn: 不審な状況をログに記録します。
- info: すべてのフェーズおよび Solver 自体をログに記録します。「スコープの概要」を参照してください。
- debug: 全フェーズの全ステップをログに記録します。「スコープの概要」を参照してください。
trace: 全フェーズの全ステップに含まれる全 Move をログに記録します。「スコープの概要」を参照してください。
注記traceログをオンにすると、パフォーマンスが大幅に低下します。通常は、4 倍ほど遅くなります。ただし、開発中にボトルネックを発見するのに非常に有効です。デバッグログでさえも、(レイトアクセプタンスや焼きなまし法などの) ステップの動きが速いアルゴリズムでは、パフォーマンスが大幅に低下する可能性がありますが、(タブー探索などの) ステップの動きが遅いアルゴリズムはパフォーマンスでは低下しません。
たとえば、debug ログに設定して、フェーズが終了するタイミングや、ステップの速度を確認してみます。
INFO Solving started: time spent (3), best score (uninitialized/0), random (JDK with seed 0).
DEBUG CH step (0), time spent (5), score (0), selected move count (1), picked move (Queen-2 {null -> Row-0}).
DEBUG CH step (1), time spent (7), score (0), selected move count (3), picked move (Queen-1 {null -> Row-2}).
DEBUG CH step (2), time spent (10), score (0), selected move count (4), picked move (Queen-3 {null -> Row-3}).
DEBUG CH step (3), time spent (12), score (-1), selected move count (4), picked move (Queen-0 {null -> Row-1}).
INFO Construction Heuristic phase (0) ended: step total (4), time spent (12), best score (-1).
DEBUG LS step (0), time spent (19), score (-1), best score (-1), accepted/selected move count (12/12), picked move (Queen-1 {Row-2 -> Row-3}).
DEBUG LS step (1), time spent (24), score (0), new best score (0), accepted/selected move count (9/12), picked move (Queen-3 {Row-3 -> Row-2}).
INFO Local Search phase (1) ended: step total (2), time spent (24), best score (0).
INFO Solving ended: time spent (24), best score (0), average calculate count per second (1625).かかった時間はすべてミリ秒単位で表示されています。
すべてのログが SLF4J に記録されます。SLF4J とは、シンプルなログファサードで、Logback、Apache Commons Logging、Log4j、または java.util.logging にすべてのログメッセージを委ねます。任意のログフレームワークのログアダプターに依存関係を追加します。
まだどのログフレームワークも使用していない場合には、以下の Maven の依存関係を追加して Logback を使用してください (別のブリッジ依存関係を追加する必要はありません)。
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.x</version>
</dependency>
logback.xml ファイルで org.optaplanner パッケージのログレベルを設定します。
<configuration>
<logger name="org.optaplanner" level="debug"/>
...
<configuration>Logback ではなく Log4J 1.x を使用している場合 (かつ、高速な後継バージョンである Logback に切り替えない場合) には、ブリッジ依存関係を追加します。
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.x</version>
</dependency>
さらに、log4j.xml ファイルで org.optaplanner パッケージにログレベルを設定します。
<log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/">
<category name="org.optaplanner">
<priority value="debug" />
</category>
...
</log4j:configuration>
マルチテナント型のアプリケーションでは、複数の Solver インスタンスが同時に実行する可能性があります。ログを別のファイルに分けるには、MDC で solve() 呼び出しを囲んでください。
MDC.put("tenant.name", tenantName);
Solution bestSolution = solver.solve(planningProblem);
MDC.remove("tenant.name");
次に ${tenant.name} ごとに異なるファイルを使用するロガーを設定します。たとえば、Logback の場合は、logback.xml で SiftingAppender を使用します。
<appender name="fileAppender" class="ch.qos.logback.classic.sift.SiftingAppender">
<discriminator>
<key>tenant.name</key>
<defaultValue>unknown</defaultValue>
</discriminator>
<sift>
<appender name="fileAppender.${tenant.name}" class="...FileAppender">
<file>local/log/optaplanner-${tenant.name}.log</file>
...
</appender>
</sift>
</appender>4.4.5. 乱数生成器
多くのヒューリスティックやメタヒューリスティックは、Move の選択に擬似乱数生成器を使用し、スコアの連携、確立ベースの Move アクセプタンスなどを解決します。問題解決時、同じ Random インスタンスが再利用され、再現性、パフォーマンス、乱数値の均等分布を向上させます。
Random インスタンスの乱数シードを変更するには、以下のように randomSeed を指定します。
<solver>
<randomSeed>0</randomSeed>
...
</solver>
疑似乱数生成器の実装を変更するには、以下のように randomType を指定します。
<solver>
<randomType>MERSENNE_TWISTER</randomType>
...
</solver>以下のタイプがサポートされます。
-
JDK(デフォルト): 標準実装 (java.util.Random). -
MERSENNE_TWISTER: Commons Math による実装 -
WELL512A、WELL1024A、WELL19937A、WELL19937C、WELL44497A、およびWELL44497B: Commons Math による実装
多くのユースケースでは、複数のデータセットにおける最善解の平均的な品質に対して、randomType からの影響は全くありません。実際のユースケースでこの点を確認する場合は、ベンチマーカー をご利用ください。