第6章 最適化アルゴリズム
6.1. 現実世界における探索空間のサイズ
計画問題に対する可能解の数には圧倒されます。たとえば、以下のようになります。
- クイーンが 4 個の場合、可能解が 256 個 (44)、最適解が 2 個になります。
- クイーンが 5 個の場合、可能解が 3125 個 (55)、最適解が 1 個になります。
- クイーンが 8 個の場合、可能解が 16777216 個 (88)、最適解が 92 個になります。
- クイーンが 64 個になると、可能解は 10115 (6464) を超えます。
- 現実世界の計画問題では、可能解の数は驚異的な数字となりますが、最適解となると、1 個もしくは数個になります。
なお、既知の宇宙に存在する原子の数の最小値は 1080 です。計画問題が大きくなればなるほど、探索空間は急激に大きくなります。したがって、プランニングエンティティーまたは計画値を 1 つ追加すると、アルゴリズムの実行時間が非常に長くなります。

計算する可能解の数は、ドメインモデルの設定によって異なります。

この探索空間のサイズ計算には、以下の原因により (モデルが表示した場合は) 実行不可解も含まれます。
- 最適解が実行できない可能性がある。
- 実際には計算式に組み込めないハード制約が多数ある。たとえば、「クラウドのバランス」の例で、計算式に CPU 容量制約を組み込んでみてください。
「コースの時間割」など、計算式に追加するハード制約が実際には可能だったとしても、その探索空間は膨大になるものもあります。
可能解をすべて確認するアルゴリズム (分枝限定などの枝刈りでさえも) は、現実世界の計画問題を 1 つ実行するのに数億年かかる可能性があります。ここで必要なのは、限られた時間の中で自由に使える最適解を見つけることです。通常は、現実世界の制限を考えると、(International Timetabling Competition などの) 計画コンペティションでは、局所探索の各方法 (タブー探索、焼きなまし、レイトアクセプタンス など) が、能力を最大限に発揮します。
6.2. Planner では最適解が見つけられるのか?
ビジネスでは最適解が必要ですが、必須条件は他にもあります。
- スケールアウト: 本番のデータセットがクラッシュせず、良い結果が得られること。
- 正しい問題を最適化: 実際のビジネスニーズに制約が一致していること。
- 利用可能時間: 実行できなくなる前に解 (ソリューション) を見つけること。
- 信頼性: すべてのデータセットで、少なくとも (人が行う計画以上の) 適切な結果が得られること。
Given these requirements, and despite the promises of some salesmen, it’s usually impossible for anyone or anything to find the optimal solution. Therefore, Planner focuses on finding the best solution in available time. In "realistic, independent competitions", it often comes out as the best reusable software.
NP 完全問題の性質は、最大の関心事をスケールします。データセットが小さいときの結果の品質が、データセットが大きくなったときの結果の品質を保証するものではありません。スケーリング問題は、のちにハードウェアを購入しても軽減されるものではありません。本番サイズのデータセットをできるだけ早めにテストするようにしてください。品質は、データセットが小さい時に評価しないでください (本番でも同規模のデータセットを使用する場合は除きます)。代わりに、本番サイズのデータセットを解決し、アルゴリズムを変えて長時間実行したときの結果と比較します (可能な場合は手動での計画の結果も比較します)。
6.3. アーキテクチャーの概要
Planner は、最適化アルゴリズム (メタヒューリスティクなど) と、ルールエンジン (Drools Expert など) によるスコア計算を比較する、初めてのフレームワークです。この組み合わせは、以下の理由により、非常に効率的です。
- Drools Expert などのルールエンジンは、計画問題のソリューションのスコアを計算するのに優れています。「教師は、1 日 7 時間以上指導はしてはいけない」などのソフトまたはハードの制約を追加して簡単にスケールすることができます。また、差分ベースのスコア計算が、コードを追加しなくても可能です。ただし、これは、実際に新しいソリューションを見つけるのには適していません。
- 最適化アルゴリズムは、計画問題において、すべてのソリューションをしらみつぶしに評価しなくても、新たに改善したソリューションを見つけるのに適しています。ただし、それにはソリューションのスコアが必要で、そのスコアを効率的に計算することには対応していません。
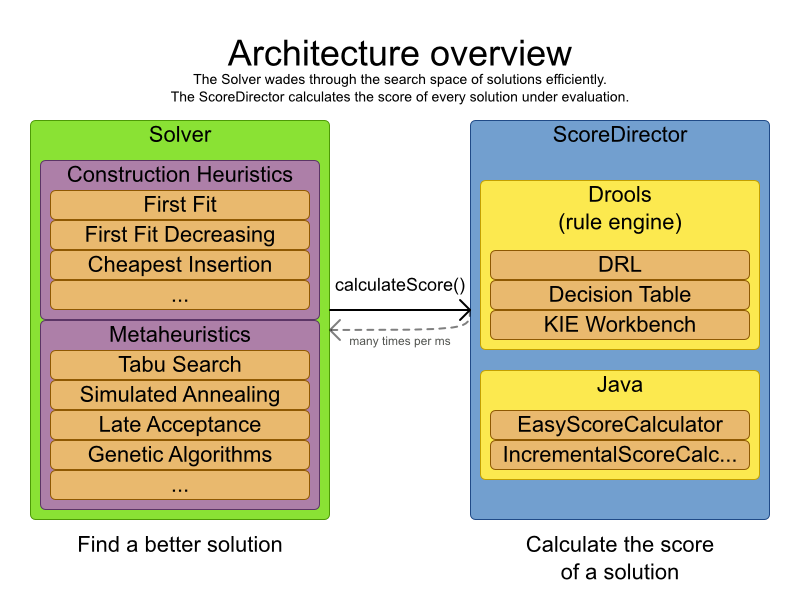
6.4. 最適化アルゴリズムの概要
Planner は、最適化アルゴリズムの 3 つのファミリー (しらみつぶし探索、構築ヒューリスティック、およびメタヒューリスティク) に対応しています。選択肢としては、(構築ヒューリスティックと組み合わせて初期化する) メタヒューリスティックが推奨されます。
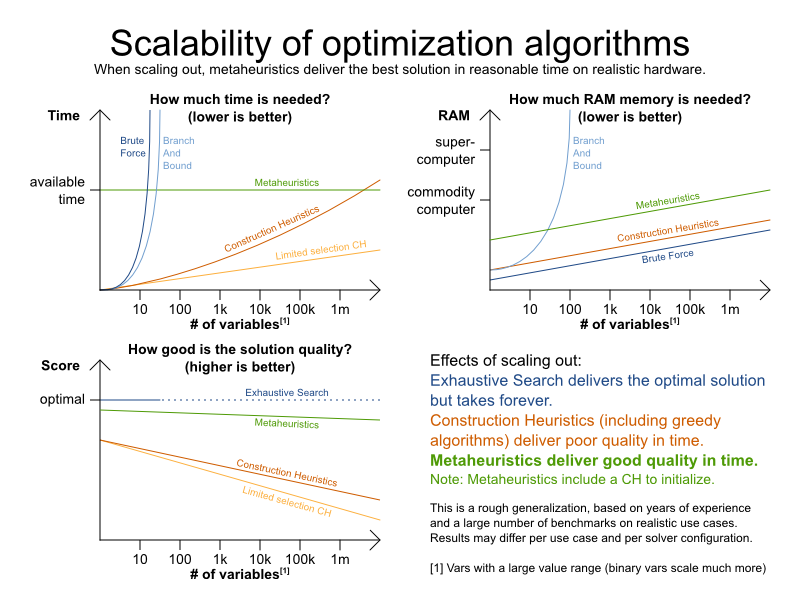
各ファミリーのアルゴリズムには、複数の最適化アルゴリズムがあります。
| アルゴリズム | 拡張可能か? | 最適か? | 使いやすいか? | 調整可能か? | CH が必要か? |
|---|---|---|---|---|---|
|
Exhaustive Search (しらみつぶし探索) (ES) | |||||
|
☆☆☆☆☆ |
★★★★★ |
★★★★★ |
☆☆☆☆☆ |
なし | |
|
☆☆☆☆☆ |
★★★★★ |
★★★★☆ |
★★☆☆☆ |
なし | |
|
Construction heuristics (構築ヒューリスティック) (CH) | |||||
|
★★★★★ |
★☆☆☆☆ |
★★★★★ |
★☆☆☆☆ |
なし | |
|
★★★★★ |
★★☆☆☆ |
★★★★☆ |
★★☆☆☆ |
なし | |
|
★★★★★ |
★★☆☆☆ |
★★★★☆ |
★★☆☆☆ |
なし | |
|
★★★★★ |
★★☆☆☆ |
★★★★☆ |
★★☆☆☆ |
なし | |
|
★★★★★ |
★★☆☆☆ |
★★★★☆ |
★★☆☆☆ |
なし | |
|
★★★★★ |
★★☆☆☆ |
★★★★☆ |
★★☆☆☆ |
なし | |
|
★★★☆☆ |
★★☆☆☆ |
★★★★★ |
★★☆☆☆ |
なし | |
|
★★★☆☆ |
★★☆☆☆ |
★★★★★ |
★★☆☆☆ |
なし | |
|
Metaheuristics (メタヒューリスティク) (MH) | |||||
|
Local Search (局所探索法) | |||||
|
★★★★★ |
★★☆☆☆ |
★★★★☆ |
★★★☆☆ |
あり | |
|
★★★★★ |
★★★★☆ |
★★★☆☆ |
★★★★★ |
あり | |
|
★★★★★ |
★★★★☆ |
★★☆☆☆ |
★★★★★ |
あり | |
|
★★★★★ |
★★★★☆ |
★★★☆☆ |
★★★★★ |
あり | |
|
★★★★★ |
★★★★☆ |
★★★☆☆ |
★★★★★ |
あり | |
|
Evolutionary Algorithms (進化アルゴリズム) | |||||
|
★★★★☆ |
★★★☆☆ |
★★☆☆☆ |
★★★★★ |
あり | |
|
★★★★☆ |
★★★☆☆ |
★★☆☆☆ |
★★★★★ |
あり | |
メタヒューリスティクの詳細は、無料の書籍『Essentials of Metaheuristics』または『Clever Algorithms』を参照してください。
6.5. どの最適化アルゴリズムを使用すべきか?
ユースケースによって、一番適した 最適化アルゴリズム設定は異なります。ただし、以下の一般的な方法に比べると非常に優れており、おそらくこれまで使用していたものよりもはるかに優れています。
設定と最適化コードには全く、もしくはほとんど関与しない簡単な設定から始めます。
次に、計画エンティティの難易度の比較を実装し、以下のように変更します。
次に、レイトアクセプタンスを追加します。
- First Fit Decreasing (FFD)
- Late Acceptance (レイトアクセプタンス)。通常、レイトアクセプタンスを 400 にすると適切に機能します。
ここまでは簡単です。これ以上時間をかけても、時間に対して得られる結果は少なくなります。また、この時点で得られた結果は、十分優れています。
ただし、かかった時間に対して得られるものは少なくなりますが、さらに優れた結果を得ることはできます。ベンチマーカー を使用して、異なる設定 (タブー探索、焼きなまし法、レイトアクセプタンス など) をいくつか試します。
- First Fit Decreasing (FFD)
- Tabu Search (タブー探索)。エンティティーのタブーの大きさを 7 にすると、通常は適切に機能します。
ベンチマーカー を使用して、このサイズパラメーターの値を改善します。
時間をかける価値がある場合は、さらに検証を行います。複数のアルゴリズムを組み合わせてみてください。
- First Fit Decreasing (FFD)
- Late Acceptance (レイトアクセプタンス) (時間は比較的長くなります)
- Tabu Search (タブー探索) (時間は比較的短くなります)
6.6. 調整またはパラメーターのデフォルト値
多くの最適化アルゴリズムには、結果とスケーラビリティーに影響するパラメーターがあります。Planner は、例外による設定を提供するため、すべての最適化アルゴリズムにはデフォルトのパラメーター値があります。これは、JVM のガベージコレクションパラメーターに非常に良く似ているため、多くの場合はこれを調整する必要はありませんが、上級者は調整してください。
デフォルトのパラメーターは、多くの場合 (特にプロトタイプに対して) 十分優れていますが、開発時間に余裕がある場合は、さらに良い結果を得るために、ベンチマーカー を使用して調整する価値は十分あります。それぞれの最適化アルゴリズムに関するドキュメントでは、調整を行う高度な設定も示します。
マイナーバージョン間におけるパラメーターのデフォルト値は、多くのユーザーを対象にした機能改善を目的に、変更されます (すべての場合に改善するとは限りません)。良くも悪くも、この変更の影響を受けないようにするには、常に高度な設定を使用するようにしてください。ただし、これは推奨はされません。
6.7. Solver のフェーズ
Solver は、複数の最適化アルゴリズムを順番に使用できます。最適化アルゴリズムは、それぞれ Solver の フェーズ として示されます。複数の フェーズ のソリューションを同時に導出することはありません。
一部の フェーズ実装では、複数の最適化アルゴリズムのテクニックを組み合わせることができますが、フェーズ の数としては 1 つとなります。たとえば、局所探索のフェーズ では、エンティティーのタブーを使用した焼きなまし法を行うことができます。
以下の設定では、3 つのフェーズが順番に実行します。
<solver>
...
<constructionHeuristic>
... <!-- First phase: First Fit Decreasing -->
</constructionHeuristic>
<localSearch>
... <!-- Second phase: Late Acceptance -->
</localSearch>
<localSearch>
... <!-- Third phase: Tabu Search -->
</localSearch>
</solver>
Solver のフェーズは、Solver の設定で指定した順番で実行します。最初の フェーズ が終了すると次の フェーズ が開始し、それが終了すると次が開始します。最後の フェーズ が終了すると、Solver が終了します。通常、Solver は最初に構築ヒューリスティックを実行してから、メタヒューリスティックスを 1 つまたは複数実行します。
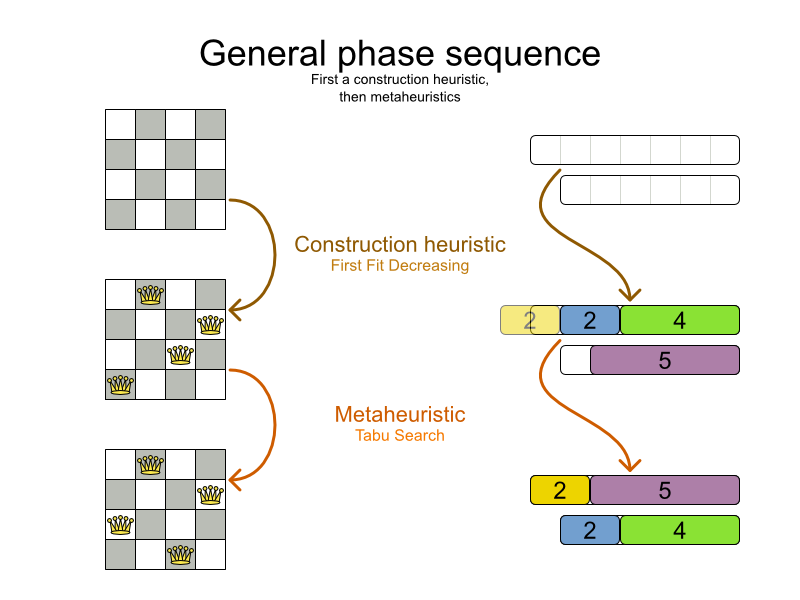
フェーズが設定されていない場合、Planner は、デフォルトで、構築ヒューリスティックフェーズ、局所探索法フェーズの順に行います。
一部のフェーズ (特に構築ヒューリスティック) は自動的に終了します。自動的に終了しないフェーズ (特にメタヒューリスティック) は、フェーズが終了するように設定している場合に限り終了します。
<solver>
...
<termination><!-- Solver termination -->
<secondsSpentLimit>90</secondsSpentLimit>
</termination>
<localSearch>
<termination><!-- Phase termination -->
<secondsSpentLimit>60</secondsSpentLimit><!-- Give the next phase a chance to run too, before the Solver terminates -->
</termination>
...
</localSearch>
<localSearch>
...
</localSearch>
</solver>
(最後の フェーズ が完了する前に) Solver が終了すると、現在のフェーズが終了し、後続のフェーズは実行されません。
6.8. スコープの概要
Solver は、フェーズを繰り返し実行します。各フェーズは、通常、Move を振り返し実行します。したがって、4 つのスコープ (Solver、フェーズ、ステップ、Move) がネスト状態となります。
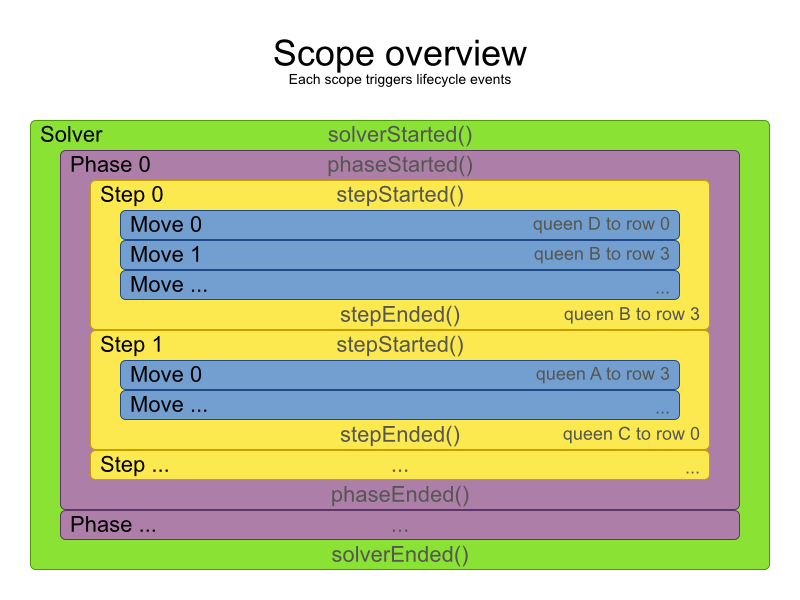
ログを設定して、各スコープのログメッセージを表示します。
6.9. 終了
すべてのフェーズが自動的に終了するとは限らず、また終了するまで待たずに終わらせる場合もあります。Solver は、事前設定により同期的に、または別のスレッドから非同期に終了できます。
特にメタヒューリスティックフェーズでは、問題解決を終了するタイミングを設定する必要があります。たとえば、時間が終了した時、完全スコアに到達した時、もしくはそのソリューションが使用される直前などです。使用できない唯一の設定は、最適解を見つけることです (ただし、最適解が分かっている場合は可能です)。なぜなら、通常、メタヒューリスティックアルゴリズムが、いつ最適解を見つけるか分からないからです。現実世界では、これは大きな問題にはなりません。なぜなら、最適解を見つけるのに何年もかかることがあり、それよりも早く終了したくなるためです。これが問題となるのは、利用可能な期間に最適解を見つけられる場合です。
終了が設定されておらず、メタヒューリスティックアルゴリズムが使用されている場合は、別のスレッドから terminateEarly() が呼び出されるまで、Solver は永久に継続します。これは、特に リアルタイム計画 で一般的です。
同期終了については、Solver または フェーズ の 終了 で、停止するタイミングを設定します。自分で作成した 終了 を実装することもできますが、組み込みの実装でも大概のニーズを満たします。すべての 終了 で、(一部の最適化アルゴリズムに必要な) 時間勾配 を計算できます。これは、Solver または フェーズ で問題解決にかかると見積もられている時間に対する、実際にこれまでかかった時間の割合です。
6.9.1. TimeMillisSpentTermination
指定した時間が経過したら終了します。
<termination>
<millisecondsSpentLimit>500</millisecondsSpentLimit>
</termination> <termination>
<secondsSpentLimit>10</secondsSpentLimit>
</termination> <termination>
<minutesSpentLimit>5</minutesSpentLimit>
</termination> <termination>
<hoursSpentLimit>1</hoursSpentLimit>
</termination> <termination>
<daysSpentLimit>2</daysSpentLimit>
</termination>時間の種類は組み合わせて使用できます。たとえば、設定した時間が 150 分の場合は、以下のようにその値を直接設定します。
<termination>
<minutesSpentLimit>150</minutesSpentLimit>
</termination>もしくは、合計で 150 分になるように組み合わせて指定できます。
<termination>
<hoursSpentLimit>2</hoursSpentLimit>
<minutesSpentLimit>30</minutesSpentLimit>
</termination>
この 終了 を使用すると、実行ごとに利用可能な CPU 時間が異なることが多いので、(environmentMode REPRODUCIBLE を使用していても) 完全再現性が犠牲になる可能性が非常に高くなります。
- 利用可能な CPU 時間は、実行するステップの数に影響し、少し増減する可能性があります。
-
終了では、時間勾配の値がわずかに異なる可能性があります。これにより、まったく異なるパスに時間勾配アルゴリズム (焼きなまし法) が送られます。
6.9.2. UnimprovedTimeMillisSpentTermination
指定した時間内に最高スコアが変更しないと終了します。
<localSearch>
<termination>
<unimprovedMillisecondsSpentLimit>500</unimprovedMillisecondsSpentLimit>
</termination>
</localSearch> <localSearch>
<termination>
<unimprovedSecondsSpentLimit>10</unimprovedSecondsSpentLimit>
</termination>
</localSearch> <localSearch>
<termination>
<unimprovedMinutesSpentLimit>5</unimprovedMinutesSpentLimit>
</termination>
</localSearch> <localSearch>
<termination>
<unimprovedHoursSpentLimit>1</unimprovedHoursSpentLimit>
</termination>
</localSearch> <localSearch>
<termination>
<unimprovedDaysSpentLimit>1</unimprovedDaysSpentLimit>
</termination>
</localSearch>
構築ヒューリスティックでは、最適解が更新されるのは最後だけなので、この終了は構築ヒューリスティックには適用されません。したがって、Solver そのものではなく、(<localSearch> などの) 特定の フェーズに設定することが推奨されます。
この 終了 を使用すると、実行ごとに利用可能な CPU 時間が異なることが多いので、(environmentMode REPRODUCIBLE を使用していても) 完全再現性が犠牲になる可能性が非常に高くなります。
- 利用可能な CPU 時間は、実行するステップの数に影響し、少し増減する可能性があります。
-
終了では、時間勾配の値がわずかに異なる可能性があります。これにより、まったく異なるパスに時間勾配アルゴリズム (焼きなまし法) が送られます。
6.9.3. BestScoreTermination
特定のスコアに到達すると終了します。この 終了 は、(たとえばクイーンが 4 個の場合に) 完全スコアが分かっている場合に限り使用します (これには SimpleScore が使用されます)。
<termination>
<bestScoreLimit>0</bestScoreLimit>
</termination>計画問題に HardSoftScore が指定されている場合は、以下のようになります。
<termination>
<bestScoreLimit>0hard/-5000soft</bestScoreLimit>
</termination>計画問題に、BendableScore が指定されており、ハードレベルが 3 で、ソフトレベルが 1 の場合は、以下のようになります。
<termination>
<bestScoreLimit>0/0/0/-5000</bestScoreLimit>
</termination>
この終了には bestScoreLimit (0hard/-2147483648soft など) が必要になるため、実行可能解に到達したら終了するように設定する場合は、この 終了 は実用的ではありません。代わりに、次の終了を使用します。
6.9.4. BestScoreFeasibleTermination
特定のスコアが実行可能な場合は終了します。スコア 実装に FeasibilityScore が実装されている必要があります。
<termination>
<bestScoreFeasible>true</bestScoreFeasible>
</termination>
この 終了 は、通常は、別の終了と組み合わせます。
6.9.5. StepCountTermination
ステップの数に到達したら終了します。これは、ハードウェアパフォーマンスに依存せずに実行している場合に役に立ちます。
<localSearch>
<termination>
<stepCountLimit>100</stepCountLimit>
</termination>
</localSearch>
この 終了 は、フェーズ (<localSearch> など) にのみ使用でき、Solver 自身には使用できません。
6.9.6. UnimprovedStepCountTermination
多数のステップを行っても最高スコアが変わらない場合に終了します。これは、ハードウェアパフォーマンスに依存せずに実行している場合に便利です。
<localSearch>
<termination>
<unimprovedStepCountLimit>100</unimprovedStepCountLimit>
</termination>
</localSearch>スコアがしばらく変わらず、おそらく今後もしばらく変わることがない場合は、継続しても有効ではありません。新たに最適解が見つかったら、(しばらく最適解が変わっていない場合でも) 次の数ステップで最適解が変わる傾向にあることが分かりました。
この 終了 は、フェーズ (<localSearch> など) にのみ使用でき、Solver 自身には使用できません。
6.9.7. CalculateCountTermination
スコア計算の数 (通常は Move の数とステップの数の合計) に到達したら終了します。これはベンチマークに使用すると役に立ちます。
<termination>
<calculateCountLimit>100000</calculateCountLimit>
</termination>EnvironmentMode に切り替えると、この終了が終わるタイミングに大きな影響を及ぼす可能性があります。
6.9.8. 複数の終了の組み合わせ
終了は組み合わせて使用できます。たとえば、以下の例では、ステップ数が 100 になるか、スコアが 0 がなったら終了します。
<termination>
<terminationCompositionStyle>OR</terminationCompositionStyle>
<stepCountLimit>100</stepCountLimit>
<bestScoreLimit>0</bestScoreLimit>
</termination>
また、AND も使用できます。以下の例では、実行可能解の数が -100 になり、5 ステップ中に値が改善しない場合は終了します。
<termination>
<terminationCompositionStyle>AND</terminationCompositionStyle>
<unimprovedStepCountLimit>5</unimprovedStepCountLimit>
<bestScoreLimit>-100</bestScoreLimit>
</termination>この例では、実行可能解を見つけただけでは終了せず、その解における明確な変化が完了した場合に終了します。
6.9.9. 別のスレッドからの非同期終了
ユーザー操作、またはサーバーの再起動で、別のスレッドから Solver を早期終了させる場合もあります。終了の有無やタイミングを予測することができないため、終了 を使って設定することはできません。したがって、Solver インターフェースには、このようなスレッドセーフメソッドが 2 つあります。
public interface Solver<S extends Solution> {
// ...
boolean terminateEarly();
boolean isTerminateEarly();
}
terminateEarly() メソッドを別のスレッドから呼び出すと、Solver は、終了が可能になり次第終了し、(元の Solver スレッドで) solve(Solution) メソッドが返ります。
Solver スレッド (Solver.solve(Solution) を呼び出すスレッド) を中断することは、terminateEarly() を呼び出すのと同じ影響がありますが、スレッドが中断状態のままになる点だけが異なります。これにより、ExecutorService (スレッドプールなど) がシャットダウンするときに正常なシャットダウンが行われます。なぜなら、これにより、プール内でアクティブなスレッドだけをすべて中断するためです。
6.10. SolverEventListener
最適解が新たに見つかるたびに、Solver は 、Solver のスレッドで BestSolutionChangedEvent を発生させます。
このようなイベントをリッスンするには、SolverEventListener を Solver に追加します。
public interface Solver<S extends Solution> {
// ...
void addEventListener(SolverEventListener<S> eventListener);
void removeEventListener(SolverEventListener<S> eventListener);
}
BestSolutionChangedEvent の newBestSolution は初期化されていないか実行可能ではない場合があります。このような状況を検出するには、BestSolutionChangedEvent でこのメソッドを使用します。
solver.addEventListener(new SolverEventListener<CloudBalance>() {
public void bestSolutionChanged(BestSolutionChangedEvent<CloudBalance> event) {
// Ignore invalid solutions
if (event.isNewBestSolutionInitialized()
&& event.getNewBestSolution().getScore().isFeasible()) {
...
}
}
});
bestSolutionChanged() メソッドは、問題解決が遅くならないように速やかに解 (ソリューション) を返し、Solver.solve() の一部として、Solver のスレッドで呼び出されます。
6.11. カスタムの Solver フェーズ
フェーズ全体を実装せずにカスタムの構築ヒューリスティックを実装する場合など、フェーズ間、または最初のフェーズの前に、カスタムの最適化アルゴリズムを実行して、ソリューション を初期化したり、簡単に達成できる目標を定めてより良いスコアをすぐに得たりするだけでなく、スコア計算を再利用する場合があります。
大抵の場合、Solver フェーズをカスタマイズする価値はありません。対応している 構築ヒューリスティック は設定で変えられ (調整には ベンチマーカー を使用)、終了 は、一部初期化されたソリューションも認識、対応します。
CustomPhaseCommand インターフェースは以下のようになります。
public interface CustomPhaseCommand {
void applyCustomProperties(Map<String, String> customPropertyMap);
void changeWorkingSolution(ScoreDirector scoreDirector);
}
たとえば、AbstractCustomPhaseCommand を拡張し、changeWorkingSolution() メソッドを実装します。
public class ToOriginalMachineSolutionInitializer extends AbstractCustomPhaseCommand {
public void changeWorkingSolution(ScoreDirector scoreDirector) {
MachineReassignment machineReassignment = (MachineReassignment) scoreDirector.getWorkingSolution();
for (MrProcessAssignment processAssignment : machineReassignment.getProcessAssignmentList()) {
scoreDirector.beforeVariableChanged(processAssignment, "machine");
processAssignment.setMachine(processAssignment.getOriginalMachine());
scoreDirector.afterVariableChanged(processAssignment, "machine");
scoreDirector.triggerVariableListeners();
}
}
}
CustomPhaseCommand でプランニングエンティティーを変更した場合は、ScoreDirector に通知する必要があります。
CustomPhaseCommand における問題ファクトを変更しないでください。変更すると、以前のスコアやソリューションが別の問題のものになり、Solver が壊れます。これを行うには、代わりに、反復計画 に記載されている ProblemFactChange を使用してください。
CustomPhaseCommand を以下のように設定します。
<solver>
...
<customPhase>
<customPhaseCommandClass>org.optaplanner.examples.machinereassignment.solver.solution.initializer.ToOriginalMachineSolutionInitializer</customPhaseCommandClass>
</customPhase>
... <!-- Other phases -->
</solver>
複数の customPhaseCommandClass インスタンスが順番に実行するように設定します。
CustomPhaseCommand を変更してもスコアが良くならない場合は、最適解が変更しません (したがって、実際には、次の フェーズ または CustomPhaseCommand で何も変更しません)。このような変更を強制するには、forceUpdateBestSolution を使用します。
<customPhase>
<customPhaseCommandClass>...MyUninitializer</customPhaseCommandClass>
<forceUpdateBestSolution>true</forceUpdateBestSolution>
</customPhase>
CustomPhaseCommand が実行中の場合でも、Solver または フェーズ を終了する場合は、CustomPhaseCommand が終わるまで待ちます。ただし、これには時間がかかります。組み込み Solver フェーズでは、この問題の影響を受けません。
Solver 設定で CustomPhaseCommand の値を動的に設定するには (ベンチマーカー でこのパラメーターを調整可能)、customProperties 要素を使用します。
<customPhase>
<customProperties>
<mySelectionSize>5</mySelectionSize>
</customProperties>
</customPhase>
次に、applyCustomProperties() メソッドを上書きして、Solver を構築する時に解析して適用します。
public class MySolutionInitializer extends AbstractCustomPhaseCommand {
private int mySelectionSize;
public void applyCustomProperties(Map<String, String> customPropertyMap) {
String mySelectionSizeString = customPropertyMap.get("mySelectionSize");
if (mySelectionSizeString == null) {
throw new IllegalArgumentException("A customProperty (mySelectionSize) is missing from the solver configuration.");
}
solverFactory = SolverFactory.createFromXmlResource(partitionSolverConfigResource);
if (customPropertyMap.size() != 1) {
throw new IllegalArgumentException("The customPropertyMap's size (" + customPropertyMap.size() + ") is not 1.");
}
mySelectionSize = Integer.parseInt(mySelectionSizeString);
}
...
}