このコンテンツは選択した言語では利用できません。
18.3. Detailed Discussion: Availability Duration and Performance
Availability as a monitoring mechanism has two important facets: the immediate effect of when it changes and then the historic perspective on how changes in availability reflect resource performance.
An historic perspective introduces the idea of availability duration. How long was a resource in a particular state? How often does it change?
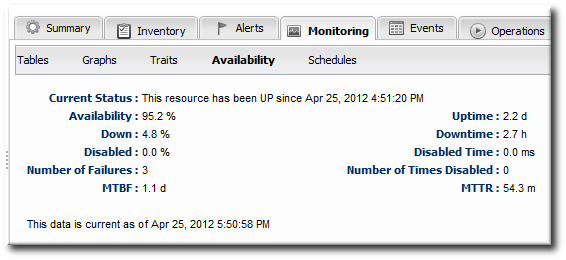
Figure 18.4. Availability Counts
The idea of availability duration is important to get an accurate picture of how a resource is performing. There are several ways that JBoss ON breaks out that information:
- Total time in up, down, and disabled states
- Percentage of time time in up, down, and disabled states
- The number of times the resource has been in a down or disabled state
- The mean time between failures (MTBF) and mean time to recovery (MTTR)
Note
Unknown states are not included in calculating the resource's overall availability history.
The last element is particularly important in assessing the resource's performance in light of its availability. The mean time between failures is the time between when a resource comes up and when it next goes down — it is the mean[4] of all of its up periods. This gives an idea of how stable a system is. The mean time to recovery gives an idea of how long the resource stays down, which indicates its resilience or fault tolerance. A low MTBF and high MTTR indicate some potential maintenance problems or application instability on a resource.
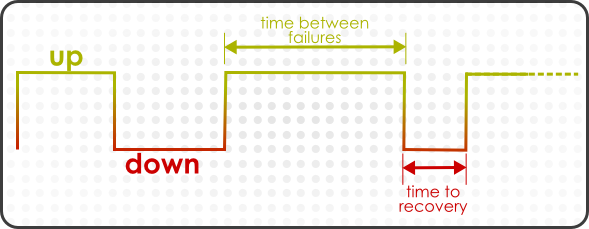
Figure 18.5. Up and Down Monitoring
From a monitoring perspective, the historic perspective is critical, particularly when planning equipment replacements and upgrades.
From an alerting perspective — from an immediate response perspective — only availability changes matter.
The first and most obvious alert condition issues an alert based solely on a state change.
However, resources can cycle or can have a few seconds or minutes where they are inaccessible but that doesn't affect the overall performance of the resource or of whatever function it performs. A resource hits a certain state and has to stay there for a certain amount of time before the state becomes important.
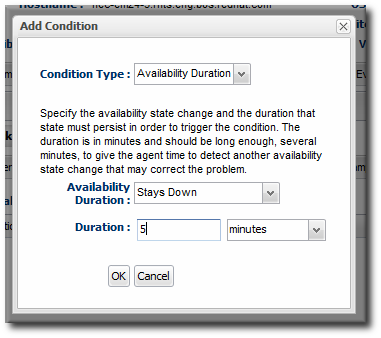
Figure 18.6. Availability Duration Alert
Note
An availability alert does not lend itself to dampening, because the state changes and then stays, such as an availability alert that fires when the resource changes to a down state. If a resource is cycling, it may go down and up several times, each time triggering a new alert, but it may all be related to the same performance issue on the resource.
Instead of dampening, a disable setting on the alert will fire the alert once, then disable that alert definition until it is acknowledged by an administrator, as described in Section 25.2.5, “Detailed Discussion: Automatically Disabling and Recovering Alerts”. (In this case, do not set a corresponding recover setting; otherwise, if the resource is cycling, every UP reading would reset the alert and then the next DOWN report would fire another notification — essentially undoing the dampening effect of disabling the alert until acknowledgment.)
[4]
This is mean in the statistical sense. It is the middle data point of all collected uptime lengths.