このコンテンツは選択した言語では利用できません。
24.3. Deploying and Managing Storage Nodes
Raw metric data and aggregated metric data are stored in a dedicated, scalable distributed database. Much like the JBoss ON server, there can be multiple storage nodes in a cluster (installed independently of the server). Nodes can be added and dropped from the cloud easily, allowing the metrics storage to be dynamically expanded according to the needs of the environment.
24.3.1. About High-Speed Metrics Storage
リンクのコピーリンクがクリップボードにコピーされました!
As touched on in Section 16.3, “Potential Impact on Server Performance”, collecting metrics and generating alerts can be resource-intensive. It results in near-constant write operations on the backend database. That creates a natural threshold for the number of metrics that can be collected (30,000 per minute) before encountering performance degradation.
Note
The natural threshold of 30,000 metrics per minute is based on internal performance testing. This threshold varies depending on system resources and overall load.
JBoss ON uses two databases to store its information. One is a central relational database (PostgreSQL or Oracle) which stores all configuration about the JBoss ON servers and agents, all resource inventory data, resource configuration, and other data. The other database is a distributed database (a cluster of storage nodes) which stores all numeric monitoring data — in other words, all collected metrics.
The metrics storage node can be installed on its own dedicated machine, which can significantly improve write performance to the database (and, therefore, improve monitoring performance):
- Dedicated CPU
- More available physical memory
- Faster disks
- More disk space
These are the same performance considerations as installing the relational database on a separate machine from the JBoss ON server. By using two databases, it is also possible to move write-intensive and resource-intensive metrics storage away from resource-intensive configuration data, such as drift snapshots and bundle configuration.
Additionally, the distributed database can be expanded, with multiple nodes in a cluster. This ability to add additional nodes according to load is a crucial management tool for administrators. Rather than encountering that hardware-driven limit of 30,000 metrics collected per minute, additional nodes can be added to improve performance.
The storage node cluster is created and managed by JBoss ON (which also minimizes the metrics storage node management overhead). A storage node is installed on a system, using the
rhqctl install --storage command. The storage node always requires a companion agent.
At least one storage node must be created and managed by JBoss ON (which minimizes the metrics storage node management overhead since no external tools are required).
There are several paths of communication to handle metrics data, all working in parallel.
- The agent sends the storage node configuration to the JBoss ON server. The JBoss ON server then sends that updated storage cluster information to every agent associated with a storage node.Each companion agent then updates its storage cluster configuration, in the
rhq-storage-auth.conf, with the hostname or IP address of the new node. (Likewise, when a node is removed, the server sends the information to each of the companion agents, and the agent removes the hostname or IP address from the list in the local storage node'srhq-storage-auth.conffile.) - The server receives monitoring data from all agents (not just those associated with a storage node), and sends that information to an available storage node to be stored.
- The storage nodes replicate their monitoring data among each other for high availability and integrity.
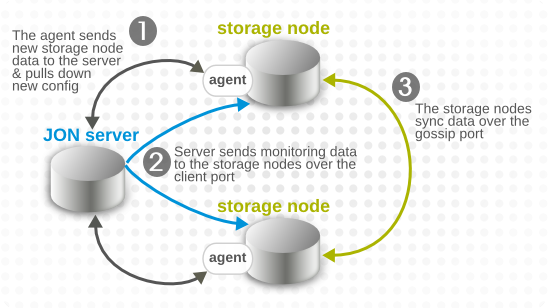
Figure 24.1. Server, Agent, and Metrics Storage Node Communication
Node cluster communication requires three elements:
- The hostname or IP address of every storage node, stored in the
rhq-storage-auth.conf - A common port number for the JBoss ON server to use to communicate with the storage node (the client port)
- A common port number for the other storage nodes in the cluster to use to sync data between each other (the gossip port)
The metrics storage provides data availability and integrity by backing up the data in two ways:
- Replicating data between the storage nodes (over the gossip port)
- Taking local snapshots and backing up the data locally
24.3.2. Deploying and Undeploying Storage Nodes
リンクのコピーリンクがクリップボードにコピーされました!
There can be multiple metrics storage databases in the JBoss ON environment. Much like the JBoss ON servers can operate in a cloud, multiple storage nodes communicate with each other to function in a cluster.
Nodes can be added and removed from the cluster by administrators or dynamically using JBoss ON scripts in response to changes in the environment.
With the default cluster configuration, a node is deployed as soon as it is installed and configured in the JBoss ON server. These are actually two separate steps.
- The bits are installed on a local system and the storage node is registered with the JBoss ON server.
- The new node information is deployed to the cluster.
Whether to deploy nodes automatically or manually can be determined by the provisioning and monitoring requirements of the environment.
24.3.2.1. Storage Node Requirements
リンクのコピーリンクがクリップボードにコピーされました!
There are two critical requirements for deploying nodes:
- The hostnames and IP addresses of all storage nodes and the hostname and bind addresses of the JBoss ON server and agents must all be fully-resolvable in DNS. If the IP addresses and hostnames of the storage nodes, servers, or agents are not properly formatted in DNS, then all communication between the different JBoss ON components will fail.
- The firewall must allow communication over the two ports used by the storage nodes. By default, the ports are 9142 and 7100 for the server/client and gossip ports, respectively.
24.3.2.2. Installing Additional Nodes
リンクのコピーリンクがクリップボードにコピーされました!
When creating a new storage node, two components are always installed: the storage node and a companion agent. The only required information to set up the node is the IP address of the JBoss ON server. The agent registers with the server and then sends the storage node hostname or IP address. The server then distributes that information among the other agents and it gets propagated into the cluster.
If the cluster is using custom client and gossip ports, then edit the
rhq-storage.properties file with the correct ports before running the installation script.
Run the installation script with the
--agent-preference option to supply the server bind address. For example:
serverRoot/jon-server-3.2.GA1/bin/rhqctl install --storage --agent-preference="rhq.agent.server.bind-address=0.0.0.0"
[root@server ~]# serverRoot/jon-server-3.2.GA1/bin/rhqctl install --storage --agent-preference="rhq.agent.server.bind-address=0.0.0.0"Note
When installing on Linux, the
rhqctl command must be run as root. On Windows, the command prompt must be opened with the option Run as Administrator.
The deployment operation can take several minutes to complete, as the new node information is propagated among the existing nodes. Until the deploy operation is complete, the node shows a status of Joining.
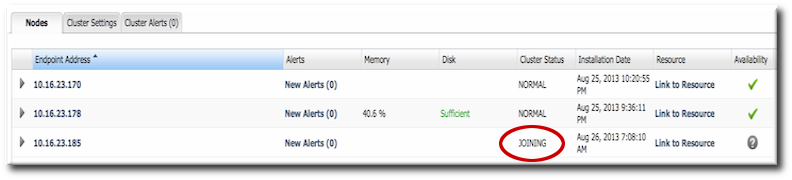
Figure 24.2. Joining the Cluster
Warning
Deploying a node lists that node's host in the cluster configuration and any allowed host can gain access to the data in the storage cluster.
Restrict access to the
rhq-storage-auth.conf file so that the allowed hosts list cannot be altered to allow an attacker to gain access to the cluster and the stored data.
24.3.2.3. Deploying Nodes Manually
リンクのコピーリンクがクリップボードにコピーされました!
By default, when a new storage node is installed, it is automatically deployed to the cluster. However, there is a cluster setting that disables automatic deployments. This can be useful if machines are being provisioned and taken offline repeatedly (such as in virtual environments) or if nodes should only be online during certain periods.
Warning
Deploying a node lists that node's host in the cluster configuration and any allowed host can gain access to the data in the storage cluster.
Restrict access to the
rhq-storage-auth.conf file so that the allowed hosts list cannot be altered to allow an attacker to gain access to the cluster and the stored data.
To deploy a node manually:
- Install a node using the
rhqctl installcommand. - Click the Administration tab in the top navigation bar.
- In the Topology area on the left, select the Storage Nodes item.
- In the Nodes tab, select the row of the node to deploy.
- Click the button.


A node can also be deployed by running a
Deploy operation on the storage node resource.
Note
Storage nodes can be deployed using the JBoss ON CLI and scripts, as well. This can be useful when provisioning new systems in the infrastructure.
For example:
// deploy a storage node nodes = StorageNodeManager.findStorageNodesByCriteria(StorageNodeCriteria()); node = nodes.get(0); StorageNodeManager.deployStorageNode(node);
// deploy a storage node
nodes = StorageNodeManager.findStorageNodesByCriteria(StorageNodeCriteria());
node = nodes.get(0); StorageNodeManager.deployStorageNode(node);
This can be key in dynamically adding storage nodes as demands on the infrastructure increase. Nodes can be installed in advance and then hot-deployed and removed as necessary.
24.3.2.4. Removing Nodes
リンクのコピーリンクがクリップボードにコピーされました!
Undeploying a storage node removes it from the cluster and then removes the resource from the inventory and uninstalls the storage node bits from the machine.
- Click the Administration tab in the top navigation bar.
- In the Topology area on the left, select the Storage Nodes item.
- In the Nodes tab, select the row of the node to remove. To select multiple rows, hold the Ctrl key and click the desired rows.
- Click the button, and confirm the operation.
A node can also be removed by running an
Undeploy operation on the storage node resource.
Note
Storage nodes can be removed using the JBoss ON CLI and scripts, as well. This can be useful when provisioning and removing systems from the infrastructure.
For example:
// undeploy a storage node nodes = StorageNodeManager.findStorageNodesByCriteria(StorageNodeCriteria()); node = nodes.get(0); StorageNodeManager.undeployStorageNode(node);
// undeploy a storage node
nodes = StorageNodeManager.findStorageNodesByCriteria(StorageNodeCriteria());
node = nodes.get(0); StorageNodeManager.undeployStorageNode(node);