仮想化
OpenShift Virtualization のインストールと使用方法。
概要
第1章 概要
1.1. OpenShift Virtualization について
OpenShift Virtualization の機能およびサポート範囲を確認します。
1.1.1. OpenShift Virtualization の機能
OpenShift Virtualization は、Red Hat OpenShift でスケーラブルなエンタープライズグレードの仮想化機能を提供します。これを使用して、仮想マシン (VM) だけを管理することも、またはコンテナーワークロードと合わせて管理することもできます。
OpenShift Virtualization は、Kubernetes カスタムリソースを使用して仮想化タスクを有効にし、Red Hat OpenShift Service on AWS クラスターに新しいオブジェクトを追加します。これらのタスクには、以下が含まれます。
- Linux および Windows 仮想マシンの作成と管理
- クラスター内で Pod と仮想マシンのワークロードの同時実行
- さまざまなコンソールや CLI ツールを介した仮想マシンへの接続
- 既存の仮想マシンのインポートとクローン作成
- 仮想マシンに接続されたネットワークインターフェイスコントローラーとストレージディスクの管理
- ノード間での仮想マシンのライブマイグレーション
Red Hat OpenShift Service on AWS Web コンソールの Virtualization パースペクティブ、および OpenShift CLI (oc) を使用して、クラスターと仮想化リソースを管理できます。
OpenShift Virtualization は OVN-Kubernetes とともに使用できます。
Compliance Operator をインストールし、ocp4-moderate および ocp4-moderate-node を使用してスキャンを実行することにより、OpenShift Virtualization クラスターのコンプライアンスの問題を確認できます。Compliance Operator は、NIST 認定ツール である OpenSCAP を使用して、セキュリティーポリシーをスキャンし、適用します。
特殊なストレージ、ネットワーク、バックアップ、および追加機能に関して、独立系ソフトウェアベンダー (ISV) およびサービスパートナーと連携する方法は、Red Hat Ecosystem Catalog を参照してください。
1.1.2. OpenShift Virtualization と VMware vSphere の比較
VMware vSphere に精通している場合は、以下の表に記載された、同様のタスクを実行できる OpenShift Virtualization コンポーネントを使用できます。
ただし、OpenShift Virtualization は vSphere とは概念的に異なり、その機能の多くは基盤となる Red Hat OpenShift Service on AWS から提供されるため、OpenShift Virtualization には vSphere のすべての概念やコンポーネントに対する直接的な代替が存在するわけではありません。
| vSphere の概念 | OpenShift Virtualization | 詳細 |
|---|---|---|
| Datastore | 永続ボリューム (PV) 永続ボリューム要求 (PVC) |
仮想マシンディスクを保存します。PV は既存のストレージを表し、PVC 経由で仮想マシンに割り当てられます。 |
| Dynamic Resource Scheduling (DRS) | Pod 退避ポリシー descheduler | アクティブなリソースバランシングを提供します。Pod の退避ポリシーと descheduler の組み合わせにより、仮想マシンはより適切なノードへのライブマイグレーションが可能となり、ノードのリソースの使用状況を管理可能な状態に保つことができます。 |
| NSX | Multus OVN-Kubernetes サードパーティーのコンテナーネットワークインターフェイス (CNI) プラグイン | オーバーレイネットワーク設定を提供します。OpenShift Virtualization の NSX と同等のものはありませんが、OVN-Kubernetes ネットワークプロバイダーを使用するか、認定されたサードパーティー CNI プラグインをインストールすることができます。 |
| Storage Policy Based Management (SPBM) | Storage class | ポリシーベースのストレージの選択を提供します。ストレージクラスは、さまざまなストレージタイプを表し、Quality of Service (QoS)、バックアップポリシー、回収ポリシー、ボリューム拡張が許可されるかどうかなどのストレージ機能を記述します。PVC は、アプリケーションの要件を満たすために特定のストレージクラスを要求できます。 |
| vCenter vRealize Operations | OpenShift メトリクスおよびモニタリング | ホストおよび仮想マシンのメトリクスを提供します。Red Hat OpenShift Service on AWS Web コンソールを使用すると、メトリクスを表示し、クラスターと仮想マシンの全体的な健全性を監視できます。 |
| vMotion | ライブマイグレーション |
実行中の仮想マシンを中断せずに別のノードに移動します。ライブマイグレーションを使用できるようにするには、仮想マシンに割り当てられた PVC に |
| vSwitch DvSwitch | NMState Operator Multus | 物理ネットワーク設定を提供します。NMState Operator を使用して、ステートドリブンのネットワーク設定を適用し、Linux ブリッジやネットワークボンディングなど、さまざまなネットワークインターフェイスタイプを管理できます。Multus を使用すると、複数のネットワークインターフェイスを割り当て、仮想マシンを外部ネットワークに接続できます。 |
1.1.3. OpenShift Virtualization でサポートされるクラスターバージョン
OpenShift Virtualization 4.20 は、Red Hat OpenShift Service on AWS 4 クラスターでの使用がサポートされています。OpenShift Virtualization の最新の z-stream リリースを使用するには、まず、Red Hat OpenShift Service on AWS の最新バージョンにアップグレードする必要があります。
OpenShift Virtualization 4.20 の最新の安定リリースは 4.20.1 です。
OpenShift Virtualization は現在、x86-64 CPU で利用可能です。Arm ベースのノードはまだサポートされていません。
1.1.4. 仮想マシンディスクのボリュームとアクセスモードについて
既知のストレージプロバイダーでストレージ API を使用する場合、ボリュームモードとアクセスモードは自動的に選択されます。ただし、ストレージプロファイルのないストレージクラスを使用する場合は、ボリュームとアクセスモードを設定する必要があります。
OpenShift Virtualization に対応している既知のストレージプロバイダーのリストは、Red Hat Ecosystem Catalog を参照してください。
最良の結果を得るには、ReadWriteMany (RWX) アクセスモードと Block ボリュームモードを使用してください。これは、以下の理由により重要です。
-
ライブマイグレーションには
ReadWriteMany(RWX) アクセスモードが必要です。 -
Blockボリュームモードは、Filesystemボリュームモードよりもパフォーマンスが大幅に優れています。これは、Filesystemボリュームモードでは、ファイルシステムレイヤーやディスクイメージファイルなどを含め、より多くのストレージレイヤーが使用されるためです。仮想マシンのディスクストレージに、これらのレイヤーは必要ありません。
次の設定の仮想マシンをライブマイグレーションすることはできません。
-
ReadWriteOnce(RWO) アクセスモードのストレージボリューム - GPU などのパススルー機能
これらの仮想マシンの evictionStrategy フィールドを None に設定します。None ストラテジーでは、ノードの再起動中に仮想マシンの電源がオフになります。
1.2. セキュリティーポリシー
OpenShift Virtualization のセキュリティーと認可を説明します。
主なポイント
-
OpenShift Virtualization は、Pod セキュリティーの現在のベストプラクティスを強制することを目的とした、
restrictedKubernetes pod security standards プロファイルに準拠しています。 - 仮想マシン (VM) のワークロードは、特権のない Pod として実行されます。
-
Security Context Constraints (SCC) は、
kubevirt-controllerサービスアカウントに対して定義されます。 - OpenShift Virtualization コンポーネントの TLS 証明書は更新され、自動的にローテーションされます。
1.2.1. ワークロードのセキュリティーについて
デフォルトでは、OpenShift Virtualization の仮想マシン (VM) ワークロードは root 権限では実行されず、root 権限を必要とするサポート対象の OpenShift Virtualization 機能はありません。
仮想マシンごとに、virt-launcher Pod が libvirt のインスタンスを セッションモード で実行し、仮想マシンプロセスを管理します。セッションモードでは、libvirt デーモンは root 以外のユーザーアカウントとして実行され、同じユーザー識別子 (UID) で実行されているクライアントからの接続のみを許可します。したがって、仮想マシンは権限のない Pod として実行し、最小権限のセキュリティー原則に従います。
1.2.2. TLS 証明書
OpenShift Virtualization コンポーネントの TLS 証明書は更新され、自動的にローテーションされます。手動で更新する必要はありません。
1.2.2.1. 自動更新スケジュール
TLS 証明書は自動的に削除され、以下のスケジュールに従って置き換えられます。
- KubeVirt 証明書は毎日更新されます。
- Containerized Data Importer controller (CDI) 証明書は、15 日ごとに更新されます。
- MAC プール証明書は毎年更新されます。
TLS 証明書の自動ローテーションはいずれの操作も中断しません。たとえば、以下の操作は中断せずに引き続き機能します。
- 移行
- イメージのアップロード
- VNC およびコンソールの接続
1.2.3. 認可
OpenShift Virtualization は、ロールベースのアクセス制御 (RBAC) を使用して、人間のユーザーとサービスアカウントの権限を定義します。サービスアカウントに定義された権限は、OpenShift Virtualization コンポーネントが実行できるアクションを制御します。
RBAC ロールを使用して、仮想化機能へのユーザーアクセスを管理することもできます。たとえば管理者は、仮想マシンの起動に必要な権限を提供する RBAC ロールを作成できます。管理者は、ロールを特定のユーザーにバインドすることでアクセスを制限できます。
1.2.3.1. OpenShift Virtualization のデフォルトのクラスターロール
クラスターロール集約を使用することで、OpenShift Virtualization はデフォルトの Red Hat OpenShift Service on AWS クラスターロールを拡張して、仮想化オブジェクトにアクセスするための権限を組み込みます。OpenShift Virtualization 固有のロールは、Red Hat OpenShift Service on AWS のロールと集約されません。
| デフォルトのクラスターロール | OpenShift Virtualization のクラスターロール | OpenShift Virtualization クラスターロールの説明 |
|---|---|---|
|
|
| クラスター内の OpenShift Virtualization リソースをすべて表示できるユーザー。ただし、リソースの作成、削除、変更、アクセスはできません。たとえば、ユーザーは仮想マシン (VM) が実行中であることを確認できますが、それをシャットダウンしたり、そのコンソールにアクセスしたりすることはできません。 |
|
|
| クラスター内のすべての OpenShift Virtualization リソースを変更できるユーザー。たとえば、ユーザーは仮想マシンの作成、VM コンソールへのアクセス、仮想マシンの削除を行えます。 |
|
|
|
リソースコレクションの削除を含め、すべての OpenShift Virtualization リソースに対する完全な権限を持つユーザー。このユーザーは、 |
|
|
|
namespace 付きの |
1.2.3.2. OpenShift Virtualization のストレージ機能の RBAC ロール
cdi-operator および cdi-controller サービスアカウントを含む、次のパーミッションがコンテナー化データインポーター (CDI) に付与されます。
1.2.3.2.1. クラスター全体の RBAC のロール
| CDI クラスターのロール | リソース | 動詞 |
|---|---|---|
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
| API グループ | リソース | 動詞 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
許可リスト: |
|
|
|
許可リスト: |
|
|
|
|
|
| API グループ | リソース | 動詞 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1.2.3.2.2. namespace 付きの RBAC ロール
| API グループ | リソース | 動詞 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| API グループ | リソース | 動詞 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1.2.3.3. kubevirt-controller サービスアカウントの追加の SCC とパーミッション
SCC (Security Context Constraints) は Pod のパーミッションを制御します。これらのパーミッションには、コンテナーのコレクションである Pod が実行できるアクションおよびそれがアクセスできるリソース情報が含まれます。SCC を使用して、Pod がシステムに受け入れられるために必要な Pod の実行に関する条件の一覧を定義できます。
virt-controller は、クラスター内の仮想マシンの virt-launcher Pod を作成するクラスターコントローラーです。
デフォルトでは、virt-launcher Pod は namespace 内の default サービスアカウントで実行されます。コンプライアンス制御に一意のサービスアカウントが必要な場合は、仮想マシンに割り当てます。この設定は、VirtualMachineInstance オブジェクトと virt-launcher Pod に適用されます。
kubevirt-controller サービスアカウントには追加の SCC および Linux 機能が付与され、これにより適切なパーミッションを持つ virt-launcher Pod を作成できます。これらの拡張パーミッションにより、仮想マシンは通常の Pod の範囲外の OpenShift Virtualization 機能を利用できます。
kubevirt-controller サービスアカウントには以下の SCC が付与されます。
scc.AllowHostDirVolumePlugin = true- 仮想マシンが hostpath ボリュームプラグインを使用することを許可します。
scc.AllowPrivilegedContainer = false-
virt-launcherPod が特権コンテナーとして実行されないようにします。 scc.AllowedCapabilities = []corev1.Capability{"SYS_NICE", "NET_BIND_SERVICE"}-
SYS_NICEを使用すると、CPU アフィニティーを設定できます。 -
NET_BIND_SERVICEは、DHCP および Slirp 操作を許可します。
-
1.2.3.3.1. kubevirt-controller の SCC および RBAC 定義の表示
oc ツールを使用して kubevirt-controller の SecurityContextConstraints 定義を表示できます。
oc get scc kubevirt-controller -o yaml
$ oc get scc kubevirt-controller -o yaml
oc ツールを使用して kubevirt-controller クラスターロールの RBAC 定義を表示できます。
oc get clusterrole kubevirt-controller -o yaml
$ oc get clusterrole kubevirt-controller -o yaml1.3. OpenShift Virtualization アーキテクチャー
Operator Lifecycle Manager (OLM) は、OpenShift Virtualization の各コンポーネントのオペレーター Pod をデプロイします。
-
コンピューティング:
virt-operator -
ストレージ:
cdi-operator -
ネットワーク:
cluster-network-addons-operator -
スケーリング:
ssp-operator
OLM は、他のコンポーネントのデプロイ、設定、およびライフサイクルを担当する hyperconverged-cluster-operator Pod と、いくつかのヘルパー Pod (hco-webhook および hyperconverged-cluster-cli-download) もデプロイします。
すべての Operator Pod が正常にデプロイされたら、HyperConverged カスタムリソース (CR) を作成する必要があります。HyperConverged CR で設定された設定は、信頼できる唯一の情報源および OpenShift Virtualization のエントリーポイントとして機能し、CR の動作をガイドします。
HyperConverged CR は、リコンシリエーションループに含まれる他の全コンポーネントの Operator に対して対応する CR を作成します。その後、各 Operator は、デーモンセット、config map、および OpenShift Virtualization コントロールプレーン用の追加コンポーネントなどのリソースを作成します。たとえば、HyperConverged Operator (HCO) が KubeVirt CR を作成すると、OpenShift Virtualization Operator がそれを調整し、virt-controller、virt-handler、virt-api などの追加リソースを作成します。
OLM は Hostpath Provisioner (HPP) Operator をデプロイしますが、hostpath-provisioner CR を作成するまで機能しません。
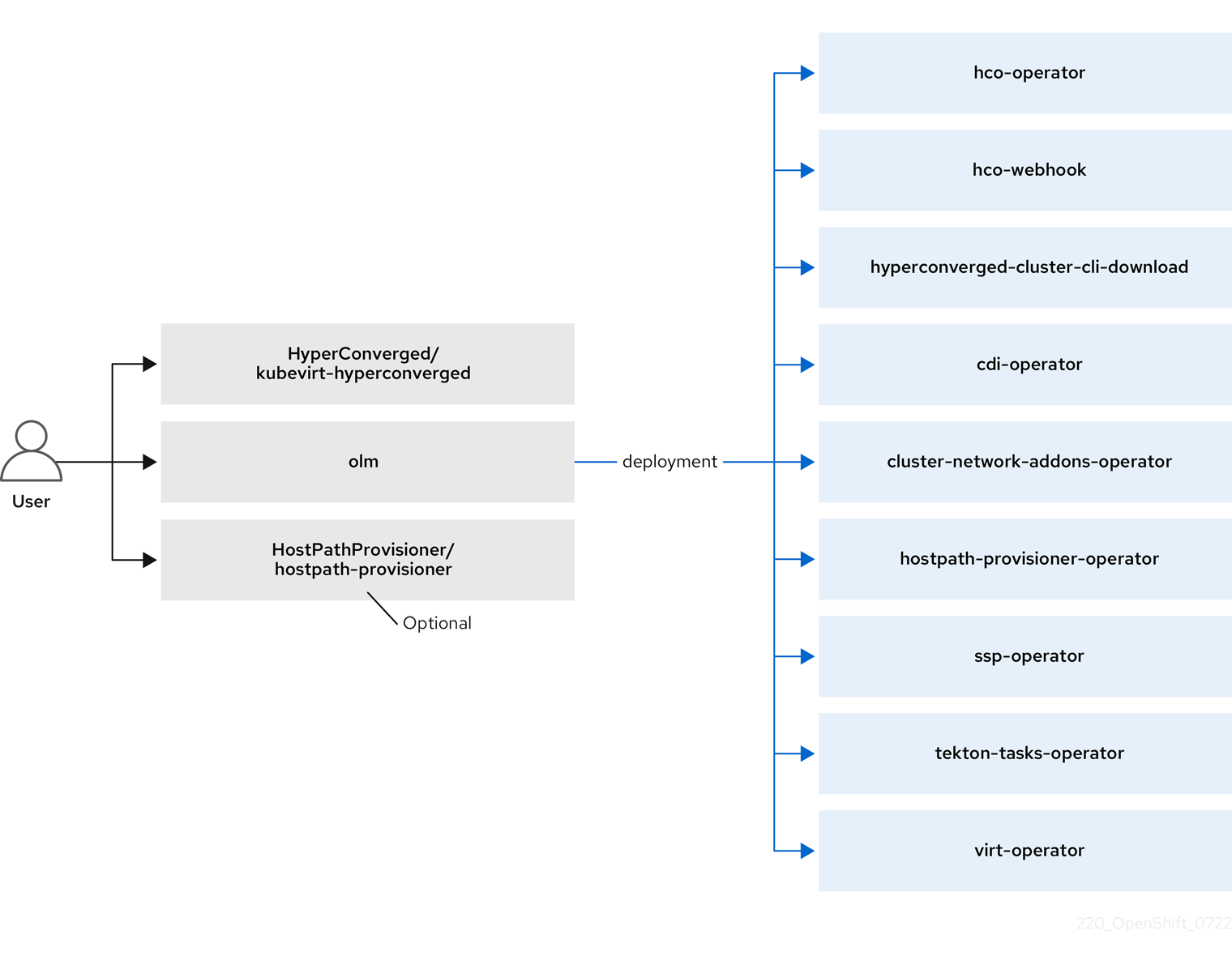
1.3.1. HyperConverged Operator (HCO) について
HCO (hco-operator) は、OpenShift Virtualization と複数のヘルパー Operator を、推奨のデフォルト設定を使用してデプロイおよび管理するための単一のエントリーポイントを提供します。また、これらの Operator のカスタムリソース (CR) も作成します。
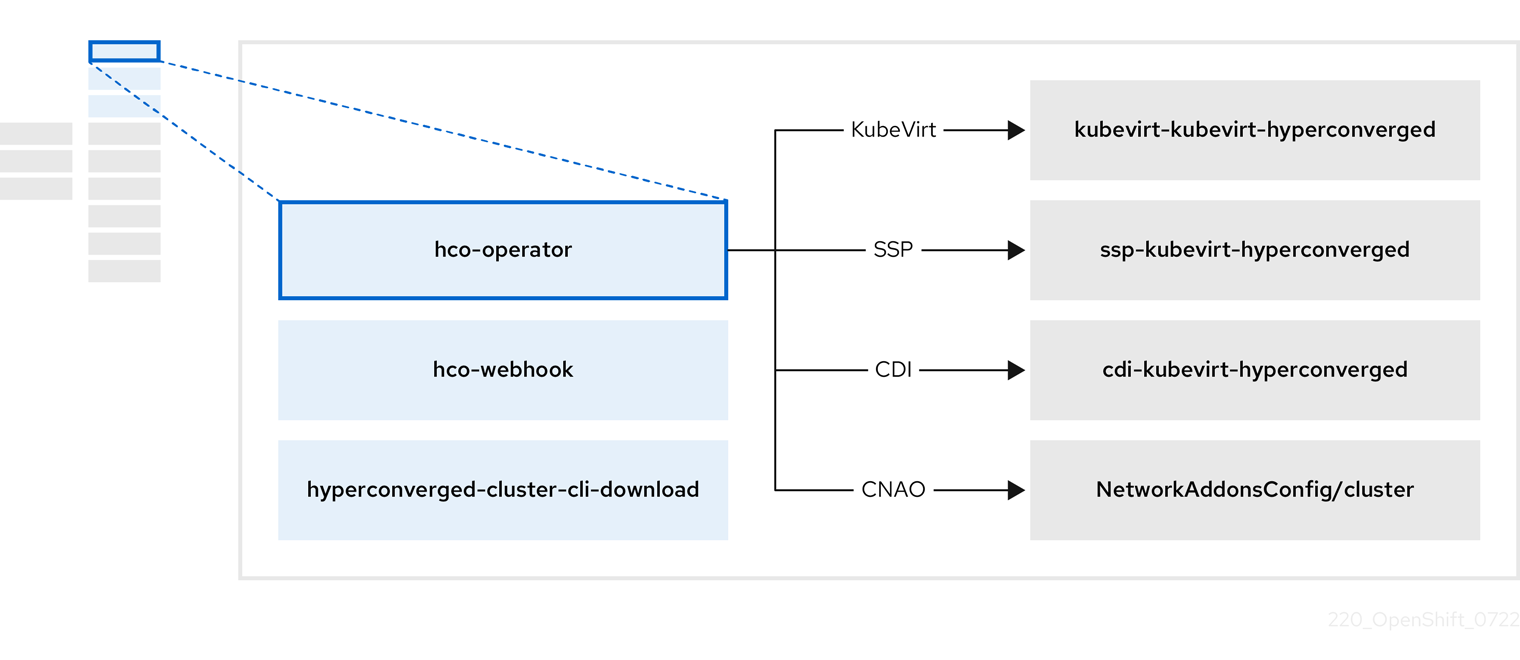
| コンポーネント | 説明 |
|---|---|
|
|
|
|
|
クラスターから直接ダウンロードできるように、 |
|
| OpenShift Virtualization に必要なすべての Operator、CR、およびオブジェクトが含まれています。 |
|
| Scheduling, Scale, and Performance (SSP) CR。これは、HCO によって自動的に作成されます。 |
|
| Containerized Data Importer (CDI) CR。これは、HCO によって自動的に作成されます。 |
|
|
|
1.3.2. Containerized Data Importer (CDI) Operator について
CDI Operator cdi-operator は、CDI とその関連リソースを管理し、データボリュームを使用して仮想マシンイメージを永続ボリューム要求 (PVC) にインポートします。
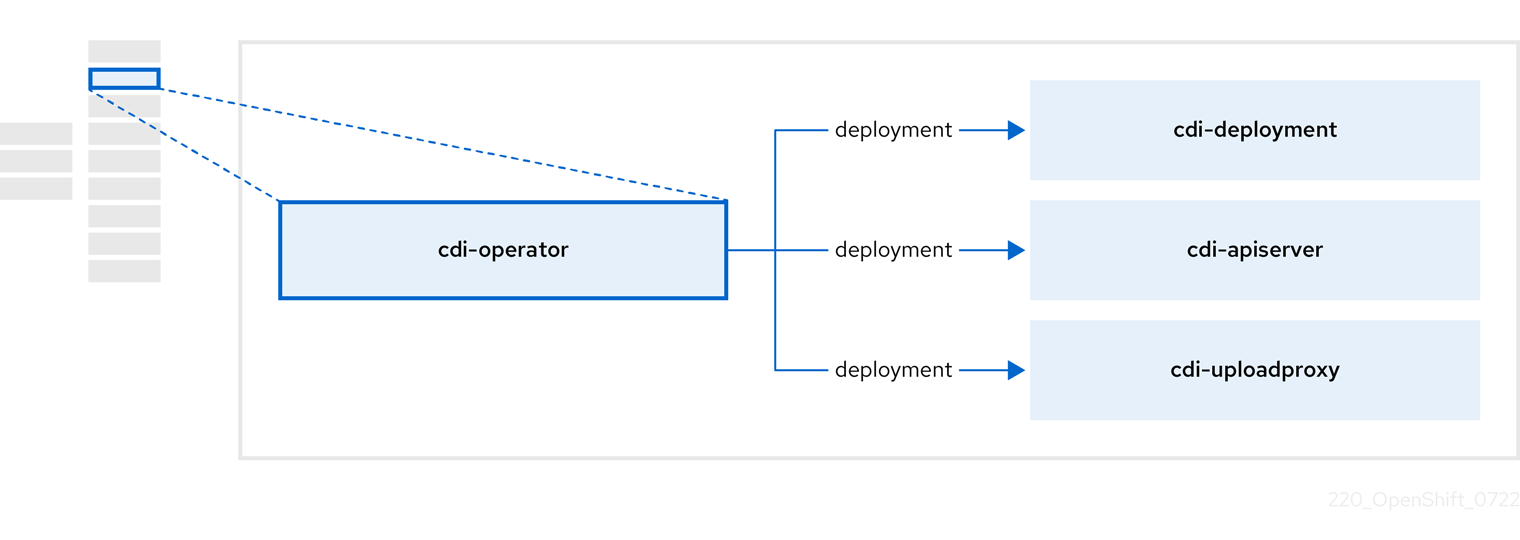
| コンポーネント | 説明 |
|---|---|
|
| セキュアなアップロードトークンを発行して、VM ディスクを PVC にアップロードするための承認を管理します。 |
|
| 外部ディスクのアップロードトラフィックを適切なアップロードサーバー Pod に転送して、正しい PVC に書き込むことができるようにします。有効なアップロードトークンが必要です。 |
|
| データボリュームの作成時に仮想マシンイメージを PVC にインポートするヘルパー Pod。 |
1.3.3. Cluster Network Addons Operator について
Cluster Network Addons Operator (cluster-network-addons-operator) は、クラスターにネットワークコンポーネントをデプロイし、拡張ネットワーク機能の関連リソースを管理します。
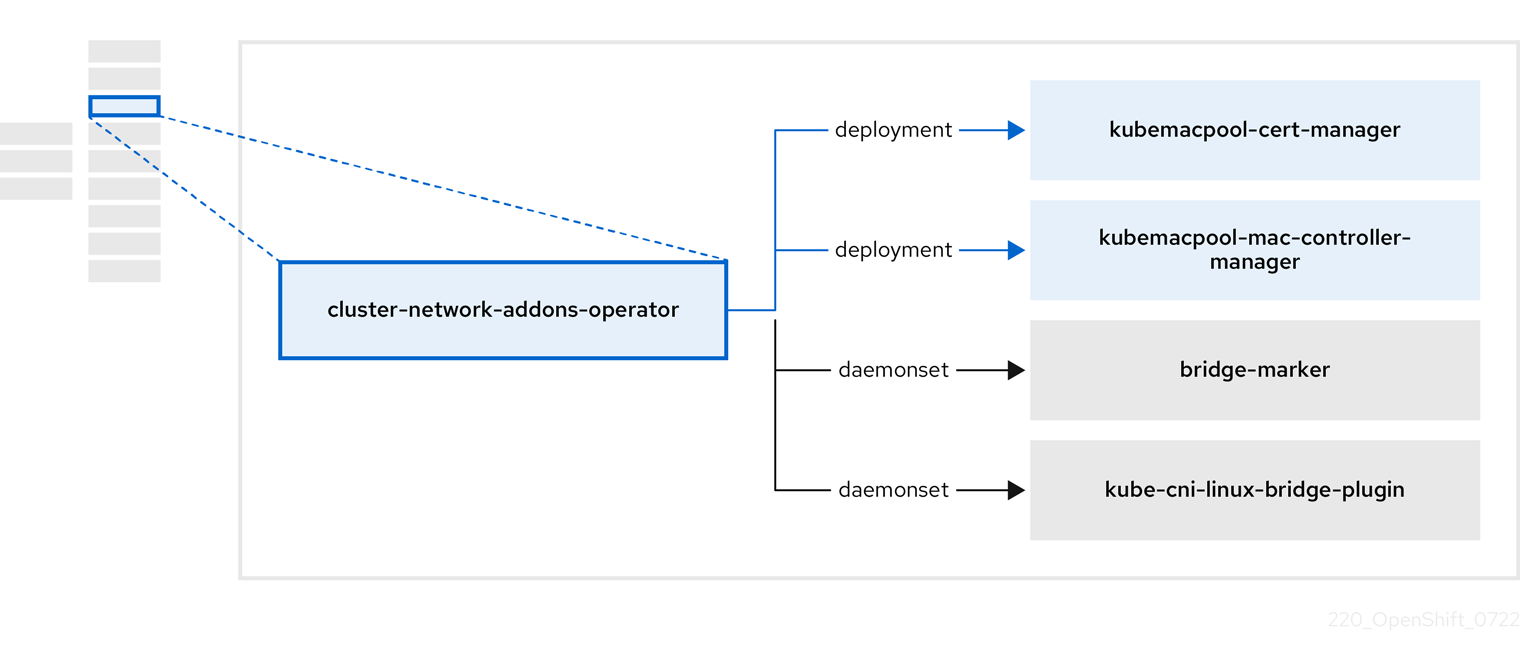
| コンポーネント | 説明 |
|---|---|
|
| Kubemacpool の Webhook の TLS 証明書を管理します。 |
|
| 仮想マシン (VM) ネットワークインターフェイスカード (NIC) の MAC アドレスプールサービスを提供します。 |
|
| ノードで使用可能なネットワークブリッジをノードリソースとしてマークします。 |
|
| クラスターノードに Container Network Interface (CNI) プラグインをインストールし、network attachment definition を介して Linux ブリッジに VM を接続できるようにします。 |
1.3.4. Hostpath Provisioner (HPP) Operator について
HPP オペレーター hostpath-provisioner-operator は、マルチノード HPP および関連リソースをデプロイおよび管理します。
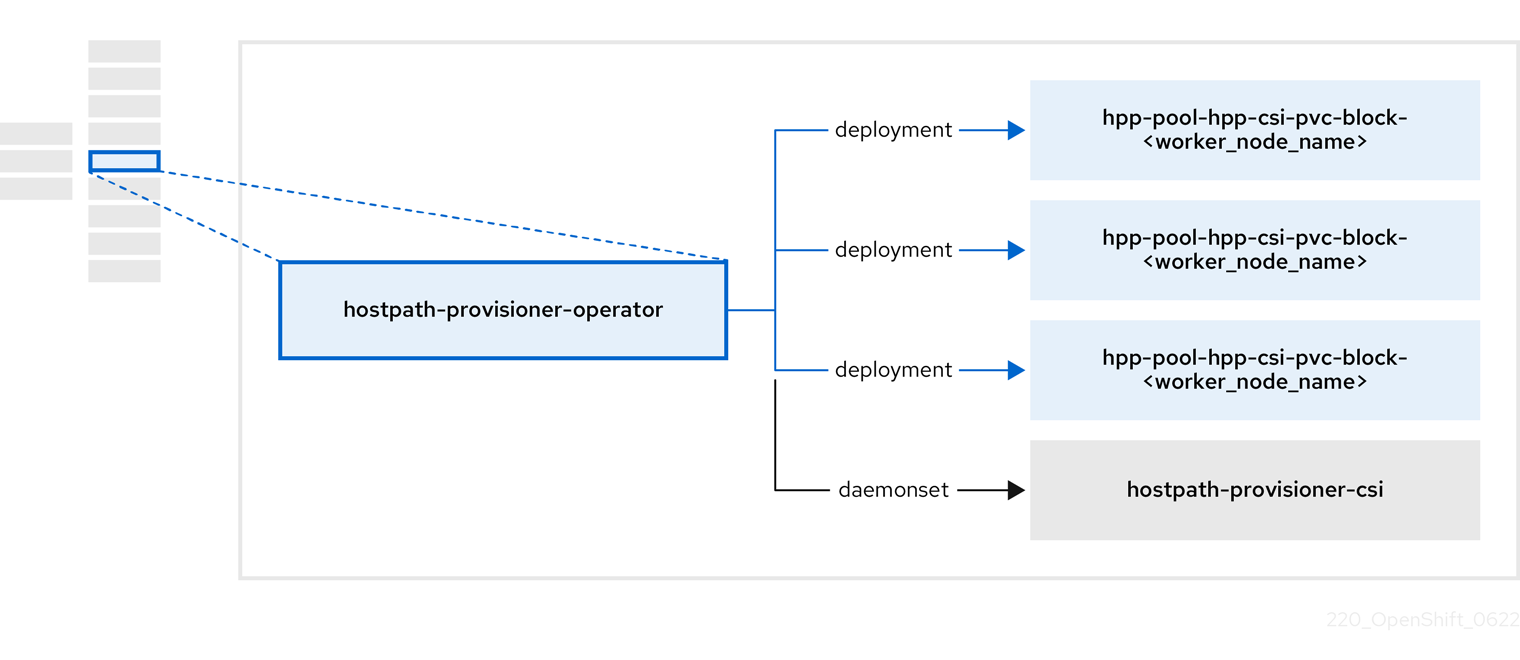
| コンポーネント | 説明 |
|---|---|
|
| HPP の実行が指定されている各ノードにワーカーを提供します。Pod は、指定されたバッキングストレージをノードにマウントします。 |
|
| HPP の Container Storage Interface (CSI) ドライバーインターフェイスを実装します。 |
|
| HPP のレガシードライバーインターフェイスを実装します。 |
1.3.5. Scheduling, Scale, and Performance (SSP) Operator について
SSP オペレーター ssp-operator は、共通テンプレート、関連するデフォルトのブートソース、パイプラインタスク、およびテンプレートバリデーターをデプロイします。
1.3.6. OpenShift Virtualization Operator について
OpenShift Virtualization Operator virt-operator は、現在の仮想マシンワークロードを中断することなく OpenShift Virtualization をデプロイ、アップグレード、管理します。さらに、OpenShift Virtualization Operator は、共通のインスタンスタイプと共通の設定をデプロイします。
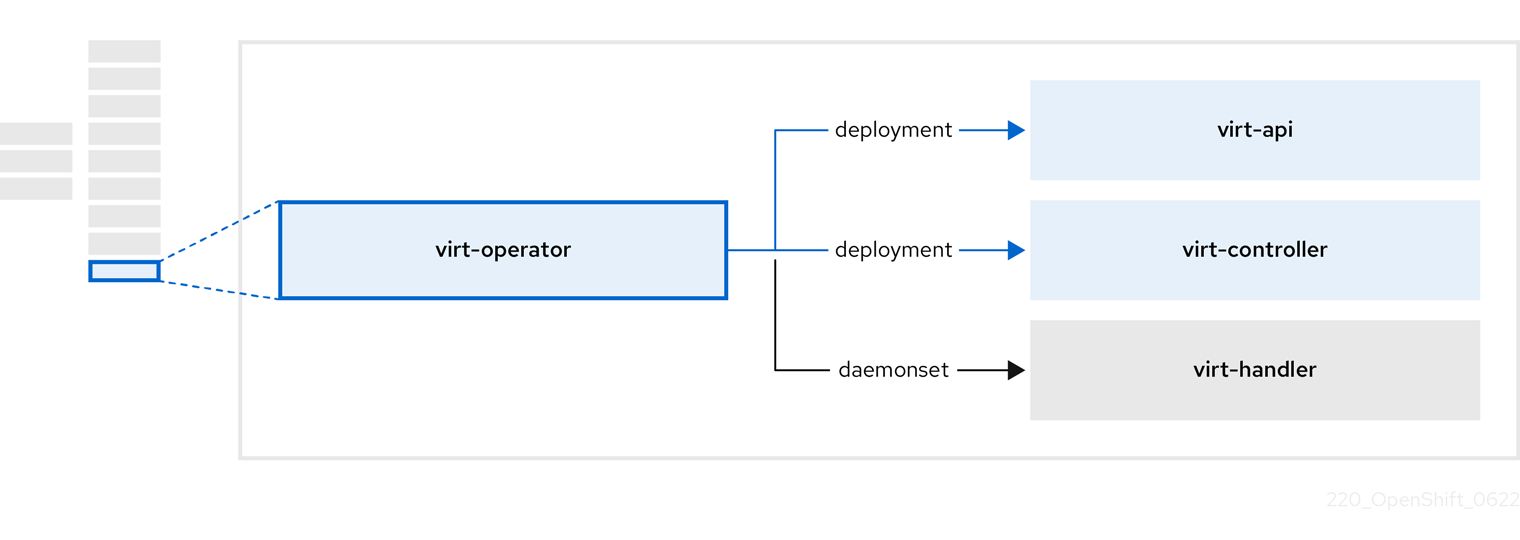
| コンポーネント | 説明 |
|---|---|
|
| すべての仮想化関連フローのエントリーポイントとして機能する HTTP API サーバー。 |
|
|
新しい VM インスタンスオブジェクトの作成を監視し、対応する Pod を作成します。Pod がノードでスケジュールされると、 |
|
|
仮想マシンへの変更を監視し、必要な操作を実行するように |
|
|
|
第2章 スタートガイド
2.1. OpenShift Virtualization の開始
基本的な環境をインストールして設定することにより、OpenShift Virtualization の特徴と機能を調べることができます。
クラスター設定手順には、cluster-admin 権限が必要です。
2.1.1. OpenShift Virtualization の計画とインストール
Red Hat OpenShift Service on AWS クラスターに OpenShift Virtualization を計画してインストールします。
計画およびインストールのリソース
2.1.2. 仮想マシンの作成と管理
仮想マシンを作成します。
Red Hat テンプレートを使用して仮想マシンを作成できます。
- 仮想マシンを作成するには、コンテナーレジストリーまたは Web ページからカスタムイメージをインポートするか、ローカルマシンからイメージをアップロードするか、永続ボリューム要求 (PVC) を複製 することによって実行できます。
仮想マシンをセカンダリーネットワークに接続します。
オープン仮想ネットワーク (OVN)- Kubernetes セカンダリーネットワーク。
注記VM はデフォルトで Pod ネットワークに接続されます。
仮想マシンに接続します。
- 仮想マシンの シリアルコンソール または VNC コンソール に接続します。
- SSH を使用して仮想マシンに接続します。
- Windows 仮想マシンのデスクトップビューアーに接続します。
仮想マシンを管理します。
2.1.3. OpenShift Virtualization への移行
VMware vSphere、Red Hat OpenStack Platform (RHOSP)、Red Hat Virtualization、別の Red Hat OpenShift Service on AWS クラスターなどの外部プロバイダーから仮想マシンを移行するには、Migration Toolkit for Virtualization (MTV) を使用します。VMware vSphere によって作成された Open Virtual Appliance (OVA) ファイルも移行できます。
Migration Toolkit for Virtualization は OpenShift Virtualization に含まれていないため、別途インストールする必要があります。そのため、この手順内のすべてのリンクは OpenShift Virtualization ドキュメントの外部につながります。
前提条件
- Migration Toolkit for Virtualization Operator が インストールされている。
2.1.4. 次のステップ
2.2. CLI ツールの使用
virtctl コマンドラインツールを使用して、OpenShift Virtualization リソースを管理できます。
libguestfs コマンドラインツールを使用すると、仮想マシン (VM) のディスクイメージにアクセスして変更できます。libguestfs をデプロイするには、virtctl libguestfs コマンドを使用します。
2.2.1. virtctl のインストール
Red Hat Enterprise Linux (RHEL) 9、Linux、Windows、および MacOS オペレーティングシステムに virtctl をインストールするには、virtctl バイナリーファイルをダウンロードしてインストールします。
RHEL 8 に virtctl をインストールするには、OpenShift Virtualization リポジトリーを有効にしてから、kubevirt-virtctl パッケージをインストールします。
2.2.1.1. RHEL 9、Linux、Windows、macOS への virtctl バイナリーのインストール
Red Hat OpenShift Service on AWS Web コンソールからオペレーティングシステムの virtctl バイナリーをダウンロードしてインストールできます。
手順
- Web コンソールの Virtualization → Overview ページに移動します。
-
Download virtctl リンクをクリックして、オペレーティングシステム用の
virtctlバイナリーをダウンロードします。 virtctlをインストールします。RHEL 9 およびその他の Linux オペレーティングシステムの場合:
アーカイブファイルを解凍します。
tar -xvf <virtctl-version-distribution.arch>.tar.gz
$ tar -xvf <virtctl-version-distribution.arch>.tar.gzCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して、
virtctlバイナリーを実行可能にします。chmod +x <path/virtctl-file-name>
$ chmod +x <path/virtctl-file-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow virtctlバイナリーをPATH環境変数内のディレクトリーに移動します。次のコマンドを実行して、パスを確認できます。
echo $PATH
$ echo $PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow KUBECONFIG環境変数を設定します。export KUBECONFIG=/home/<user>/clusters/current/auth/kubeconfig
$ export KUBECONFIG=/home/<user>/clusters/current/auth/kubeconfigCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Windows の場合:
- アーカイブファイルを展開します。
-
展開したフォルダー階層に移動し、
virtctl実行可能ファイルをダブルクリックしてクライアントをインストールします。 virtctlバイナリーをPATH環境変数内のディレクトリーに移動します。次のコマンドを実行して、パスを確認できます。
path
C:\> pathCopy to Clipboard Copied! Toggle word wrap Toggle overflow
macOS の場合:
- アーカイブファイルを展開します。
virtctlバイナリーをPATH環境変数内のディレクトリーに移動します。次のコマンドを実行して、パスを確認できます。
echo $PATH
echo $PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.1.2. RHEL 8 への virtctl RPM のインストール
OpenShift Virtualization リポジトリーを有効にし、kubevirt-virtctl パッケージをインストールすることで、Red Hat Enterprise Linux (RHEL) 8 に virtctl RPM をインストールできます。
前提条件
- クラスター内の各ホストは Red Hat Subscription Manager (RHSM) に登録され、アクティブな Red Hat OpenShift Service on AWS サブスクリプションがある。
手順
subscription-managerCLI ツールを使用して次のコマンドを実行し、OpenShift Virtualization リポジトリーを有効にします。subscription-manager repos --enable cnv-4.20-for-rhel-8-x86_64-rpms
# subscription-manager repos --enable cnv-4.20-for-rhel-8-x86_64-rpmsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して、
kubevirt-virtctlパッケージをインストールします。yum install kubevirt-virtctl
# yum install kubevirt-virtctlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.2. virtctl コマンド
virtctl クライアントは、OpenShift Virtualization リソースを管理するためのコマンドラインユーティリティーです。
特に指定がない限り、仮想マシンコマンドは仮想マシンインスタンスにも適用されます。
2.2.2.1. virtctl 情報コマンド
次の virtctl 情報コマンドを使用して、virtctl クライアントに関する情報を表示できます。
| コマンド | 説明 |
|---|---|
|
|
|
|
|
|
|
| 特定のコマンドのオプションのリストを表示します。 |
|
|
任意の |
2.2.2.2. 仮想マシン情報コマンド
virtctl を使用すると、仮想マシンおよび仮想マシンインスタンス (VMI) に関する情報を表示できます。
| コマンド | 説明 |
|---|---|
|
| ゲストマシンで使用可能なファイルシステムを表示します。 |
|
| ゲストマシンのオペレーティングシステムに関する情報を表示します。 |
|
| ゲストマシンにログインしているユーザーを表示します。 |
2.2.2.3. 仮想マシンマニフェスト作成コマンド
以下の virtctl create コマンドを使用して、仮想マシン、インスタンスタイプ、および設定のマニフェストを作成できます。
| コマンド | 説明 |
|---|---|
|
|
|
| 仮想マシンの名前を指定して、仮想マシンのマニフェストを作成します。 |
|
| cloud-init 設定を使用して仮想マシンマニフェストの作成、選択したユーザーの作成を行い、指定された文字列から SSH 公開鍵を追加するか、ファイルからパスワードを追加します。 |
|
| 選択したシークレットから注入されたユーザーとパスワードの組み合わせを使用して仮想マシンマニフェストを作成します。 |
|
| 選択したシークレットから注入された SSH 公開鍵を使用して仮想マシンマニフェストを作成します。 |
|
|
sysprep ボリュームとして使用する config map を指定して、仮想マシンマニフェストを作成します。config map には、 |
|
| 既存のクラスター全体のインスタンスタイプを使用する仮想マシンのマニフェストを作成します。 |
|
| 既存の namespaced 付きのインスタンスタイプを使用する仮想マシンのマニフェストを作成します。 |
|
| クラスター全体のインスタンスタイプのマニフェストを作成します。 |
|
| namespace 付きのインスタンスタイプのマニフェストを作成します。 |
|
| 設定の名前を指定して、クラスター全体の仮想マシン設定のマニフェストを作成します。 |
|
| namespace 付きの仮想マシン設定のマニフェストを作成します。 |
2.2.2.4. 仮想マシン管理コマンド
以下の virtctl コマンドを使用して、仮想マシン (VM) および仮想マシンインスタンス (VMI) を管理および移行できます。
| コマンド | 説明 |
|---|---|
|
| 仮想マシンを開始します。 |
|
| 仮想マシンを一時停止状態で起動します。このオプションを使用すると、VNC コンソールからブートプロセスを中断できます。 |
|
| 仮想マシンを停止します。 |
|
| 仮想マシンを強制停止します。このオプションは、データの不整合またはデータ損失を引き起こす可能性があります。 |
|
| 仮想マシンを一時停止します。マシンの状態がメモリーに保持されます。 |
|
| 仮想マシンの一時停止を解除します。 |
|
| 仮想マシンを移行します。 |
|
| 仮想マシンの移行をキャンセルします。 |
|
| 仮想マシンを再起動します。 |
2.2.2.5. 仮想マシン接続コマンド
次の virtctl コマンドを使用してポートを公開し、仮想マシン (VM) および仮想マシンインスタンス (VMI) に接続できます。
| コマンド | 説明 |
|---|---|
|
| 仮想マシンのシリアルコンソールに接続します。 |
|
| 仮想マシンの指定されたポートを転送するサービスを作成し、ノードの指定されたポートでサービスを公開します。
例: |
|
| マシンから仮想マシンにファイルをコピーします。このコマンドは、SSH 鍵ペアの秘密鍵を使用します。仮想マシンは公開鍵を使用して設定する必要があります。 |
|
| 仮想マシンからマシンにファイルをコピーします。このコマンドは、SSH 鍵ペアの秘密鍵を使用します。仮想マシンは公開鍵を使用して設定する必要があります。 |
|
| 仮想マシンとの SSH 接続を開きます。このコマンドは、SSH 鍵ペアの秘密鍵を使用します。仮想マシンは公開鍵を使用して設定する必要があります。 |
|
| 仮想マシンの VNC コンソールに接続します。
|
|
| ポート番号を表示し、VNC 接続を介してビューアーを使用して手動で VM に接続します。 |
|
| ポートが利用可能な場合、その指定されたポートでプロキシーを実行するためにポート番号を指定します。 ポート番号が指定されていない場合、プロキシーはランダムポートで実行されます。 |
2.2.2.6. 仮想マシンエクスポートコマンド
virtctl vmexport コマンドを使用して、仮想マシン、仮想マシンスナップショット、または永続ボリューム要求 (PVC) からエクスポートされたボリュームを作成、ダウンロード、または削除できます。特定のマニフェストには、OpenShift Virtualization が使用できる形式でディスクイメージをインポートするためのエンドポイントへのアクセスを許可するヘッダーシークレットも含まれています。
| コマンド | 説明 |
|---|---|
|
|
仮想マシン、仮想マシンスナップショット、または PVC からボリュームをエクスポートするには、
|
|
|
|
|
|
オプション:
|
|
|
|
|
| 既存のエクスポートのマニフェストを取得します。マニフェストにはヘッダーシークレットが含まれていません。 |
|
| 仮想マシンサンプルの仮想マシンエクスポートを作成し、マニフェストを取得します。マニフェストにはヘッダーシークレットが含まれていません。 |
|
| 仮想マシンスナップショットの例の仮想マシンエクスポートを作成し、マニフェストを取得します。マニフェストにはヘッダーシークレットが含まれていません。 |
|
| 既存のエクスポートのマニフェストを取得します。マニフェストにはヘッダーシークレットが含まれています。 |
|
| 既存のエクスポートのマニフェストを json 形式で取得します。マニフェストにはヘッダーシークレットが含まれていません。 |
|
| 既存のエクスポートのマニフェストを取得します。マニフェストにはヘッダーシークレットが含まれており、指定されたファイルにそれを書き込みます。 |
2.2.2.7. ホットプラグおよびホットアンプラグコマンド
次の virtctl コマンドを使用して、実行中の仮想マシン (VM) および仮想マシンインスタンス (VMI) にリソースを追加または削除できます。
| コマンド | 説明 |
|---|---|
|
| データボリュームまたは永続ボリューム要求 (PVC) をホットプラグします。 オプション:
|
|
| 仮想ディスクをホットアンプラグします。 |
2.2.2.8. イメージアップロードコマンド
次の virtctl image-upload コマンドを使用して、仮想マシンイメージをデータボリュームにアップロードできます。
| コマンド | 説明 |
|---|---|
|
| VM イメージを既存のデータボリュームにアップロードします。 |
|
| 指定された要求されたサイズの新しいデータボリュームに VM イメージをアップロードします。 |
|
|
仮想マシンイメージを新しいデータボリュームにアップロードし、それに関連付けられた |
2.2.3. virtctl を使用した libguestfs のデプロイ
virtctl guestfs コマンドを使用して、libguestfs-tools および永続ボリューム要求 (PVC) がアタッチされた対話型コンテナーをデプロイできます。
手順
libguestfs-toolsでコンテナーをデプロイして PVC をマウントし、シェルを割り当てるには、以下のコマンドを実行します。virtctl guestfs -n <namespace> <pvc_name>
$ virtctl guestfs -n <namespace> <pvc_name>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- PVC 名は必須の引数です。この引数を追加しないと、エラーメッセージが表示されます。
2.2.3.1. Libguestfs および virtctl guestfs コマンド
Libguestfs ツールは、仮想マシン (VM) のディスクイメージにアクセスして変更するのに役立ちます。libguestfs ツールを使用して、ゲスト内のファイルの表示および編集、仮想マシンのクローンおよびビルド、およびディスクのフォーマットおよびサイズ変更を実行できます。
virtctl guestfs コマンドおよびそのサブコマンドを使用して、PVC で仮想マシンディスクを変更して検査し、デバッグすることもできます。使用可能なサブコマンドの完全なリストを表示するには、コマンドラインで virt- と入力して Tab を押します。以下に例を示します。
| コマンド | 説明 |
|---|---|
|
| ターミナルでファイルを対話的に編集します。 |
|
| ゲストに ssh 鍵を注入し、ログインを作成します。 |
|
| 仮想マシンによって使用されるディスク容量を確認します。 |
|
| 完全なリストを含む出力ファイルを作成して、ゲストにインストールされているすべての RPM の全リストを表示します。 |
|
|
ターミナルで |
|
| テンプレートとして使用する仮想マシンディスクイメージをシールします。 |
デフォルトでは、virtctl guestfs は、仮想ディスク管理に必要な項目を含めてセッションを作成します。ただし、動作をカスタマイズできるように、コマンドは複数のフラグオプションもサポートしています。
| フラグオプション | 説明 |
|---|---|
|
|
|
|
| 特定の namespace から PVC を使用します。
|
|
|
|
|
|
デフォルトでは、
クラスターに
設定されていない場合、 |
|
|
|
このコマンドは、PVC が別の Pod によって使用されているかどうかを確認します。使用されている場合には、エラーメッセージが表示されます。ただし、libguestfs-tools プロセスが開始されると、設定では同じ PVC を使用する新規 Pod を回避できません。同じ PVC にアクセスする仮想マシンを起動する前に、アクティブな virtctl guestfs Pod がないことを確認する必要があります。
virtctl guestfs コマンドは、インタラクティブな Pod に割り当てられている PVC 1 つだけを受け入れます。
2.2.4. Ansible の使用
OpenShift Virtualization 用の Ansible コレクションを使用するには、Red Hat Ansible Automation Hub (Red Hat Hybrid Cloud Console) を参照してください。
第3章 インストール
3.1. OpenShift Virtualization のクラスターの準備
OpenShift Virtualization をインストールする前に、このセクションを参照して、クラスターが要件を満たしていることを確認してください。
3.1.1. Red Hat OpenShift Service on AWS での OpenShift Virtualization
OpenShift Virtualization は、Red Hat OpenShift Service on AWS クラスター上で実行できます。
クラスターを設定する前に、サポート対象の機能と制限に関する以下の要約を確認してください。
- インストール
インストーラーでプロビジョニングされるインフラストラクチャーを使用してクラスターをインストールし、ワーカーノードにベアメタルインスタンスタイプを指定する必要があります。たとえば、x86_64 アーキテクチャーをベースとするマシンの
c5n.metalタイプの値を使用できます。詳細は、AWS へのインストールに関する Red Hat OpenShift Service on AWS のドキュメントを参照してください。
- 仮想マシン (VM) へのアクセス
-
virtctlCLI ツールまたは Red Hat OpenShift Service on AWS Web コンソールを使用して仮想マシンにアクセスする方法に変更はありません。 NodePortまたはLoadBalancerサービスを使用して、仮想マシンを公開できます。注記Red Hat OpenShift Service on AWS は AWS にロードバランサーを自動的に作成し、そのライフサイクルを管理するため、ロードバランサーのアプローチが推奨されます。また、セキュリティーグループはロードバランサー用にも作成され、アノテーションを使用して既存のセキュリティーグループをアタッチできます。サービスを削除すると、Red Hat OpenShift Service on AWS はロードバランサーとそれに関連するリソースを削除します。
- ネットワーク
-
アプリケーションで Egress トラフィックを必要としないフラットなレイヤー 2 ネットワークが必要な場合は、
Layer2トポロジーで OVN-Kubernetes セカンダリーオーバーレイネットワークを使用することを検討してください。
- ストレージ
基盤となるプラットフォームとの連携がストレージベンダーによって認定されている任意のストレージソリューションを使用できます。
重要AWS ベアメタル、Red Hat OpenShift Service on AWS、および Red Hat OpenShift Service on AWS クラシックアーキテクチャーの各クラスターで、サポートされるストレージソリューションが異なる場合があります。ストレージベンダーにサポートを確認してください。
OpenShift Virtualization で Amazon Elastic File System (EFS) または Amazon Elastic Block Store (EBS) を使用すると、次の表に示すようにパフォーマンスと機能の制限が発生する可能性があります。
Expand 表3.1 EFS と EBS のパフォーマンスと機能の制限 機能 EBS ボリューム EFS ボリューム 共有ストレージソリューション gp2
gp3
io2
仮想マシンライブマイグレーション
利用不可
利用不可
利用可能
利用可能
利用可能
クローン作成による高速仮想マシン作成
利用可能
利用不可
利用可能
スナップショットを使用した仮想マシンのバックアップと復元
利用可能
利用不可
利用可能
ライブマイグレーション、高速仮想マシンの作成、仮想マシンスナップショット機能の有効化を行うには、ReadWriteMany (RWX)、クローン作成、スナップショットをサポートする CSI ストレージの使用を検討してください。
3.1.2. ARM64 の互換性
ARM64 システムにインストールされた Red Hat OpenShift Service on AWS クラスターで OpenShift Virtualization を使用する機能が一般提供 (GA) されました。
ARM64 ベースのシステムで OpenShift Virtualization を使用する前に、次の制限に留意してください。
- オペレーティングシステム
- Linux ベースのゲストオペレーティングシステムのみがサポートされます。
- RHEL のすべての仮想化制限は、OpenShift Virtualization にも適用されます。詳細は、RHEL ドキュメントの ARM64 の仮想化と AMD64 および Intel 64 の仮想化の違い を参照してください。
- ライブマイグレーション
- ARM64 ベースの Red Hat OpenShift Service on AWS クラスターではライブマイグレーションは サポートされていません。
- ホットプラグはライブマイグレーションに依存するため、ARM64 ベースのクラスターではサポートされていません。
- 仮想マシンの作成
- RHEL 10 は、インスタンスタイプと設定をサポートしますが、テンプレートはサポートしていません。
- RHEL 9 は、テンプレート、インスタンスタイプ、および設定をサポートします。
3.1.3. ハードウェアとオペレーティングシステムの要件
OpenShift Virtualization の次のハードウェアおよびオペレーティングシステム要件を確認してください。
3.1.3.1. CPU の要件
Red Hat Enterprise Linux (RHEL) 9 でサポート。
サポートされている CPU の Red Hat Ecosystem Catalog を参照してください。
注記ワーカーノードの CPU が異なる場合は、CPU ごとに機能が異なるため、ライブマイグレーションが失敗する可能性があります。この問題は、ワーカーノードに適切な容量の CPU が搭載されていることを確認し、仮想マシンのノードアフィニティールールを設定することで軽減できます。
詳細は、ノードアフィニティーの required (必須) ルールの設定 を参照してください。
-
AMD64、Intel 64 ビット (x86-64-v2)、IBM Z® (
s390x)、または ARM64 ベース (arm64またはaarch64) アーキテクチャーとそれぞれの CPU 拡張機能のサポートがある。 -
Intel VT-x、AMD-V、または ARM 仮想化拡張機能が有効になっているか、
s390x仮想化サポートが有効になっている。 - NX (実行なし) フラグが有効になっている。
-
s390xアーキテクチャーを使用する場合、default CPU model がgen15bに設定されている。
3.1.3.2. オペレーティングシステム要件
- ワーカーノードにインストールされた Red Hat Enterprise Linux CoreOS (RHCOS)。
3.1.3.3. ストレージ要件
- Red Hat OpenShift Service on AWS によってサポートされます。
-
ストレージプロビジョナーがスナップショットをサポートしている場合は、
VolumeSnapshotClassオブジェクトをデフォルトのストレージクラスに関連付ける必要があります。
3.1.3.3.1. 仮想マシンディスクのボリュームとアクセスモードについて
既知のストレージプロバイダーでストレージ API を使用する場合、ボリュームモードとアクセスモードは自動的に選択されます。ただし、ストレージプロファイルのないストレージクラスを使用する場合は、ボリュームとアクセスモードを設定する必要があります。
OpenShift Virtualization に対応している既知のストレージプロバイダーのリストは、Red Hat Ecosystem Catalog を参照してください。
最良の結果を得るには、ReadWriteMany (RWX) アクセスモードと Block ボリュームモードを使用してください。これは、以下の理由により重要です。
-
ライブマイグレーションには
ReadWriteMany(RWX) アクセスモードが必要です。 -
Blockボリュームモードは、Filesystemボリュームモードよりもパフォーマンスが大幅に優れています。これは、Filesystemボリュームモードでは、ファイルシステムレイヤーやディスクイメージファイルなどを含め、より多くのストレージレイヤーが使用されるためです。仮想マシンのディスクストレージに、これらのレイヤーは必要ありません。
次の設定の仮想マシンをライブマイグレーションすることはできません。
-
ReadWriteOnce(RWO) アクセスモードのストレージボリューム - GPU などのパススルー機能
これらの仮想マシンの evictionStrategy フィールドを None に設定します。None ストラテジーでは、ノードの再起動中に仮想マシンの電源がオフになります。
3.1.4. ライブマイグレーションの要件
-
ReadWriteMany(RWX) アクセスモードの共有ストレージ 十分な RAM およびネットワーク帯域幅
注記ノードの drain に伴うライブマイグレーションを実行できるように、クラスター内に十分なメモリーリクエスト容量があることを確認する必要があります。以下の計算を使用して、必要な予備のメモリーを把握できます。
Product of (Maximum number of nodes that can drain in parallel) and (Highest total VM memory request allocations across nodes)
Product of (Maximum number of nodes that can drain in parallel) and (Highest total VM memory request allocations across nodes)Copy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターで 並行して実行できるデフォルトの移行数 は 5 です。
- 仮想マシンがホストモデルの CPU を使用する場合、ノードは仮想マシンのホストモデルの CPU をサポートする必要があります。
ライブマイグレーション 専用の Multus ネットワーク を強く推奨します。専用ネットワークは、移行中のテナントワークロードに対するネットワークの飽和状態の影響を最小限に抑えます。
3.1.5. 物理リソースのオーバーヘッド要件
OpenShift Virtualization は、Red Hat OpenShift Service on AWS へのアドオンであり、クラスターの計画時に考慮する必要があるオーバーヘッドが追加されます。
各クラスターマシンは、Red Hat OpenShift Service on AWS 要件に加えて、次のオーバーヘッド要件に対応する必要があります。クラスター内の物理リソースを過剰にサブスクライブすると、パフォーマンスに影響する可能性があります。
このドキュメントに記載されている数は、Red Hat のテスト方法およびセットアップに基づいています。これらの数は、独自のセットアップおよび環境に応じて異なります。
3.1.5.1. メモリーのオーバーヘッド
以下の式を使用して、OpenShift Virtualization のメモリーオーバーヘッドの値を計算します。
- クラスターメモリーのオーバーヘッド
Memory overhead per infrastructure node ≈ 150 MiB
Memory overhead per infrastructure node ≈ 150 MiBCopy to Clipboard Copied! Toggle word wrap Toggle overflow Memory overhead per worker node ≈ 360 MiB
Memory overhead per worker node ≈ 360 MiBCopy to Clipboard Copied! Toggle word wrap Toggle overflow さらに、OpenShift Virtualization 環境リソースには、すべてのインフラストラクチャーノードに分散される合計 2179 MiB の RAM が必要です。
- 仮想マシンのメモリーオーバーヘッド
Memory overhead per virtual machine ≈ (0.002 × requested memory) \ + 218 MiB \ + 8 MiB × (number of vCPUs) \ + 16 MiB × (number of graphics devices) \ + (additional memory overhead)Memory overhead per virtual machine ≈ (0.002 × requested memory) \ + 218 MiB \1 + 8 MiB × (number of vCPUs) \2 + 16 MiB × (number of graphics devices) \3 + (additional memory overhead)4 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
virt-launcherPod で実行されるプロセスに必要です。- 2
- 仮想マシンが要求する仮想 CPU の数。
- 3
- 仮想マシンが要求する仮想グラフィックスカードの数。
- 4
- 追加のメモリーオーバーヘッド:
- お使いの環境に Single Root I/O Virtualization (SR-IOV) ネットワークデバイスまたは Graphics Processing Unit (GPU) が含まれる場合、それぞれのデバイスに 1 GiB の追加のメモリーオーバーヘッドを割り当てます。
- Secure Encrypted Virtualization (SEV) が有効な場合は、256 MiB を追加します。
- Trusted Platform Module (TPM) が有効な場合は、53 MiB を追加します。
3.1.5.2. CPU オーバーヘッド
以下の式を使用して、OpenShift Virtualization のクラスタープロセッサーのオーバーヘッド要件を計算します。仮想マシンごとの CPU オーバーヘッドは、個々の設定によって異なります。
- クラスターの CPU オーバーヘッド
CPU overhead for infrastructure nodes ≈ 4 cores
CPU overhead for infrastructure nodes ≈ 4 coresCopy to Clipboard Copied! Toggle word wrap Toggle overflow OpenShift Virtualization は、ロギング、ルーティング、およびモニタリングなどのクラスターレベルのサービスの全体的な使用率を増加させます。このワークロードに対応するには、インフラストラクチャーコンポーネントをホストするノードに、4 つの追加コア (4000 ミリコア) の容量があり、これがそれらのノード間に分散されていることを確認します。
CPU overhead for worker nodes ≈ 2 cores + CPU overhead per virtual machine
CPU overhead for worker nodes ≈ 2 cores + CPU overhead per virtual machineCopy to Clipboard Copied! Toggle word wrap Toggle overflow 仮想マシンをホストする各ワーカーノードには、仮想マシンのワークロードに必要な CPU に加えて、OpenShift Virtualization 管理ワークロード用に 2 つの追加コア (2000 ミリコア) の容量が必要です。
- 仮想マシンの CPU オーバーヘッド
- 専用の CPU が要求される場合は、仮想マシン 1 台につき CPU 1 つとなり、クラスターの CPU オーバーヘッド要件に影響が出てきます。それ以外の場合は、仮想マシンに必要な CPU の数に関する特別なルールはありません。
3.1.5.3. ストレージのオーバーヘッド
以下のガイドラインを使用して、OpenShift Virtualization 環境のストレージオーバーヘッド要件を見積もります。
- クラスターストレージオーバーヘッド
Aggregated storage overhead per node ≈ 10 GiB
Aggregated storage overhead per node ≈ 10 GiBCopy to Clipboard Copied! Toggle word wrap Toggle overflow 10 GiB は、OpenShift Virtualization のインストール時にクラスター内の各ノードに関するディスク上のストレージの予想される影響に相当します。
- 仮想マシンのストレージオーバーヘッド
- 仮想マシンごとのストレージオーバーヘッドは、仮想マシン内のリソース割り当ての特定の要求により異なります。この要求は、クラスター内の別の場所でホストされるノードまたはストレージリソースの一時ストレージに対するものである可能性があります。OpenShift Virtualization は現在、実行中のコンテナー自体に追加の一時ストレージを割り当てていません。
- 例
- クラスター管理者が、クラスター内の 10 台の (それぞれ 1 GiB の RAM と 2 つの仮想 CPU の) 仮想マシンをホストする予定の場合、クラスター全体で影響を受けるメモリーは 11.68 GiB になります。クラスターの各ノードについて予想されるディスク上のストレージの影響は 10 GiB で示され、仮想マシンのワークロードをホストするワーカーノードに関する CPU の影響は最小 2 コアで示されます。
3.2. OpenShift Virtualization のインストール
OpenShift Virtualization をインストールして、Red Hat OpenShift Service on AWS クラスターに仮想化機能を追加します。
3.2.1. OpenShift Virtualization Operator のインストール
Red Hat OpenShift Service on AWS Web コンソールまたはコマンドラインを使用して、OpenShift Virtualization Operator をインストールします。
3.2.1.1. Web コンソールを使用した OpenShift Virtualization Operator のインストール
Red Hat OpenShift Service on AWS Web コンソールを使用して OpenShift Virtualization Operator をデプロイできます。
前提条件
- Red Hat OpenShift Service on AWS 4 をクラスターにインストールする。
-
cluster-admin権限を持つユーザーとして、Red Hat OpenShift Service on AWS Web コンソールにログインする。 - ベアメタルコンピュートノードインスタンスタイプに基づいてマシンプールを作成する。詳細は、このセクションの関連情報の「マシンプールの作成」を参照してください。
手順
- Administrator パースペクティブから、Ecosystem → Software Catalog をクリックします。
- Filter by keyword に Virtualization と入力します。
- Red Hat ソースラベルが示されている OpenShift Virtualization Operator タイルを選択します。
- Operator の情報を確認してから、Install をクリックします。
Install Operator ページで以下を行います。
- 選択可能な Update Channel オプションの一覧から stable を選択します。これにより、Red Hat OpenShift Service on AWS のバージョンと互換性のある OpenShift Virtualization のバージョンが確実にインストールされます。
インストールされた namespace の場合、Operator recommended namespace オプションが選択されていることを確認します。これにより、Operator が必須の
openshift-cnvnamespace にインストールされます。この namespace は存在しない場合は、自動的に作成されます。警告OpenShift Virtualization Operator を
openshift-cnv以外の namespace にインストールしようとすると、インストールが失敗します。Approval Strategy の場合に、stable 更新チャネルで新しいバージョンが利用可能になったときに OpenShift Virtualization が自動更新されるように、デフォルト値である Automatic を選択することを強く推奨します。
Manual 承認ストラテジーを選択することは、クラスターのサポートと機能に大きなリスクをもたらすため、推奨しません。これらのリスクを完全に理解していて、Automatic を使用できない場合のみ、Manual を選択してください。
警告OpenShift Virtualization は、対応する Red Hat OpenShift Service on AWS バージョンで使用される場合にのみサポートされるため、OpenShift Virtualization の更新が欠落していると、クラスターがサポートされなくなる可能性があります。
-
Install をクリックし、Operator を
openshift-cnvnamespace で利用可能にします。 - Operator が正常にインストールされたら、Create HyperConverged をクリックします。
- オプション: OpenShift Virtualization コンポーネントの Infra および Workloads ノード配置オプションを設定します。
- Create をクリックして OpenShift Virtualization を起動します。
検証
- Workloads → Pods ページに移動して、OpenShift Virtualization Pod がすべて Running 状態になるまでこれらの Pod をモニターします。すべての Pod で Running 状態が表示された後に、OpenShift Virtualization を使用できます。
3.2.1.2. コマンドラインを使用した OpenShift Virtualization Operator のインストール
OpenShift Virtualization カタログをサブスクライブし、クラスターにマニフェストを適用して OpenShift Virtualization Operator をインストールします。
3.2.1.2.1. CLI を使用した OpenShift Virtualization カタログのサブスクライブ
OpenShift Virtualization をインストールする前に、OpenShift Virtualization カタログにサブスクライブする必要があります。サブスクライブにより、openshift-cnv namespace に OpenShift Virtualization Operator へのアクセスが付与されます。
単一マニフェストをクラスターに適用して Namespace、OperatorGroup、および Subscription オブジェクトをサブスクライブし、設定します。
前提条件
- Red Hat OpenShift Service on AWS 4 をクラスターにインストールする。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
以下のマニフェストを含む YAML ファイルを作成します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
stableチャネルを使用することで、Red Hat OpenShift Service on AWS のバージョンと互換性のある OpenShift Virtualization のバージョンが確実にインストールされます。
以下のコマンドを実行して、OpenShift Virtualization に必要な
Namespace、OperatorGroup、およびSubscriptionオブジェクトを作成します。oc apply -f <filename>.yaml
$ oc apply -f <filename>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
OpenShift Virtualization のインストールに進む前に、サブスクリプションの作成が成功したことを確認する必要があります。
ClusterServiceVersion(CSV) オブジェクトが正常に作成されたことを確認します。次のコマンドを実行し、出力を確認します。oc get csv -n openshift-cnv
$ oc get csv -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow CSV が正常に作成された場合、次の出力例に示すように、出力には
NAME値がkubevirt-hyperconverged-operator-*、DISPLAY値がOpenShift Virtualization、PHASE値がSucceededを含むエントリーが表示されます。出力例
NAME DISPLAY VERSION REPLACES PHASE kubevirt-hyperconverged-operator.v4.20.1 OpenShift Virtualization 4.20.1 kubevirt-hyperconverged-operator.v4.19.0 Succeeded
NAME DISPLAY VERSION REPLACES PHASE kubevirt-hyperconverged-operator.v4.20.1 OpenShift Virtualization 4.20.1 kubevirt-hyperconverged-operator.v4.19.0 SucceededCopy to Clipboard Copied! Toggle word wrap Toggle overflow HyperConvergedカスタムリソース (CR) のバージョンが正しいことを確認します。次のコマンドを実行し、出力を確認します。oc get hco -n openshift-cnv kubevirt-hyperconverged -o json | jq .status.versions
$ oc get hco -n openshift-cnv kubevirt-hyperconverged -o json | jq .status.versionsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例
{ "name": "operator", "version": "4.20.1" }{ "name": "operator", "version": "4.20.1" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow HyperConvergedCR の条件を確認します。以下のコマンドを実行して出力を確認します。oc get hco kubevirt-hyperconverged -n openshift-cnv -o json | jq -r '.status.conditions[] | {type,status}'$ oc get hco kubevirt-hyperconverged -n openshift-cnv -o json | jq -r '.status.conditions[] | {type,status}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
YAML ファイルで、証明書のローテーションパラメーターを設定 できます。
3.2.1.2.2. CLI を使用した OpenShift Virtualization Operator のデプロイ
oc CLI を使用して OpenShift Virtualization Operator をデプロイすることができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
openshift-cnvnamespace の OpenShift Virtualization カタログへのサブスクリプション。 -
cluster-admin権限を持つユーザーとしてログインしている。 - ベアメタルコンピュートノードインスタンスタイプに基づいてマシンプールを作成する。
手順
以下のマニフェストを含む YAML ファイルを作成します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下のコマンドを実行して OpenShift Virtualization Operator をデプロイします。
oc apply -f <file_name>.yaml
$ oc apply -f <file_name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
openshift-cnvnamespace の Cluster Service Version (CSV) のPHASEを監視して、OpenShift Virtualization が正常にデプロイされたことを確認します。以下のコマンドを実行します。watch oc get csv -n openshift-cnv
$ watch oc get csv -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下の出力は、デプロイメントに成功したかどうかを表示します。
NAME DISPLAY VERSION REPLACES PHASE kubevirt-hyperconverged-operator.v4.20.1 OpenShift Virtualization 4.20.1 Succeeded
NAME DISPLAY VERSION REPLACES PHASE kubevirt-hyperconverged-operator.v4.20.1 OpenShift Virtualization 4.20.1 SucceededCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.2.2. 次のステップ
- ホストパスプロビジョナー は、OpenShift Virtualization 用に設計されたローカルストレージプロビジョナーです。仮想マシンのローカルストレージを設定する必要がある場合、まずホストパスプロビジョナーを有効にする必要があります。
3.3. OpenShift Virtualization のアンインストール
Web コンソールまたはコマンドラインインターフェイス (CLI) を使用して OpenShift Virtualization をアンインストールし、OpenShift Virtualization のワークロード、Operator、およびそのリソースを削除します。
3.3.1. Web コンソールを使用した OpenShift Virtualization のアンインストール
OpenShift Virtualization をアンインストールするには、Web コンソール を使用して次のタスクを実行します。
まず、すべての 仮想マシン と 仮想マシンインスタンス を削除する必要があります。
ワークロードがクラスターに残っている間は、OpenShift Virtualization をアンインストールできません。
3.3.1.1. HyperConverged カスタムリソースの削除
OpenShift Virtualization をアンインストールするには、最初に HyperConverged カスタムリソース (CR) を削除します。
前提条件
-
cluster-adminパーミッションを持つアカウントを使用して Red Hat OpenShift Service on AWS クラスターにアクセスできる。
手順
- Ecosystem → Installed Operators ページに移動します。
- OpenShift Virtualization Operator を選択します。
- OpenShift Virtualization Deployment タブをクリックします。
-
kubevirt-hyperconvergedの横にある Options メニュー をクリックし、Delete HyperConverged を選択します。
をクリックし、Delete HyperConverged を選択します。
- 確認ウィンドウで Delete をクリックします。
3.3.1.2. Web コンソールの使用によるクラスターからの Operator の削除
クラスター管理者は Web コンソールを使用して、選択した namespace からインストールされた Operators を削除できます。
前提条件
-
dedicated-admin権限を持つアカウントを使用して、Red Hat OpenShift Service on AWS クラスターにアクセスできる。
手順
- Ecosystem → Installed Operators ページに移動します。
- スクロールするか、キーワードを Filter by name フィールドに入力して、削除する Operator を見つけます。次に、それをクリックします。
Operator Details ページの右側で、Actions 一覧から Uninstall Operator を選択します。
Uninstall Operator? ダイアログボックスが表示されます。
Uninstall を選択し、Operator、Operator デプロイメント、および Pod を削除します。このアクションの後には、Operator は実行を停止し、更新を受信しなくなります。
注記このアクションは、カスタムリソース定義 (CRD) およびカスタムリソース (CR) など、Operator が管理するリソースは削除されません。Web コンソールおよび継続して実行されるクラスター外のリソースによって有効にされるダッシュボードおよびナビゲーションアイテムには、手動でのクリーンアップが必要になる場合があります。Operator のアンインストール後にこれらを削除するには、Operator CRD を手動で削除する必要があります。
3.3.1.3. Web コンソールを使用した namespace の削除
Red Hat OpenShift Service on AWS Web コンソールを使用して namespace を削除できます。
前提条件
-
cluster-admin権限を持つアカウントを使用して、Red Hat OpenShift Service on AWS クラスターにアクセスできる。
手順
- Administration → Namespaces に移動します。
- namespace の一覧で削除する必要のある namespace を見つけます。
-
namespace の一覧の右端で、Options メニュー
から Delete Namespace を選択します。
- Delete Namespace ペインが表示されたら、フィールドから削除する namespace の名前を入力します。
- Delete をクリックします。
3.3.1.4. OpenShift Virtualization カスタムリソース定義の削除
Web コンソールを使用して、OpenShift Virtualization カスタムリソース定義 (CRD) を削除できます。
前提条件
-
cluster-admin権限を持つアカウントを使用して、Red Hat OpenShift Service on AWS クラスターにアクセスできる。
手順
- Administration → CustomResourceDefinitions に移動します。
-
Label フィルターを選択し、Search フィールドに
operators.coreos.com/kubevirt-hyperconverged.openshift-cnvと入力して OpenShift Virtualization CRD を表示します。 -
各 CRD の横にある Options メニュー
をクリックし、Delete CustomResourceDefinition の削除を選択します。
3.3.2. CLI を使用した OpenShift Virtualization のアンインストール
OpenShift CLI (oc) を使用して OpenShift Virtualization をアンインストールできます。
前提条件
-
cluster-admin権限を持つアカウントを使用して、Red Hat OpenShift Service on AWS クラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。 - すべての仮想マシンと仮想マシンインスタンスを削除した。ワークロードがクラスターに残っている間は、OpenShift Virtualization をアンインストールできません。
手順
HyperConvergedカスタムリソースを削除します。oc delete HyperConverged kubevirt-hyperconverged -n openshift-cnv
$ oc delete HyperConverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow OpenShift Virtualization Operator サブスクリプションを削除します。
oc delete subscription hco-operatorhub -n openshift-cnv
$ oc delete subscription hco-operatorhub -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow OpenShift Virtualization
ClusterServiceVersionリソースを削除します。oc delete csv -n openshift-cnv -l operators.coreos.com/kubevirt-hyperconverged.openshift-cnv
$ oc delete csv -n openshift-cnv -l operators.coreos.com/kubevirt-hyperconverged.openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow OpenShift Virtualization namespace を削除します。
oc delete namespace openshift-cnv
$ oc delete namespace openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow dry-runオプションを指定してoc delete crdコマンドを実行し、OpenShift Virtualization カスタムリソース定義 (CRD) を一覧表示します。oc delete crd --dry-run=client -l operators.coreos.com/kubevirt-hyperconverged.openshift-cnv
$ oc delete crd --dry-run=client -l operators.coreos.com/kubevirt-hyperconverged.openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow dry-runオプションを指定せずにoc delete crdコマンドを実行して、CRD を削除します。oc delete crd -l operators.coreos.com/kubevirt-hyperconverged.openshift-cnv
$ oc delete crd -l operators.coreos.com/kubevirt-hyperconverged.openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第4章 インストール後の設定
4.1. インストール後の設定
通常、以下の手順は OpenShift Virtualization をインストールした後に実行されます。環境に関連するコンポーネントを設定できます。
- OpenShift Virtualization Operator、ワークロード、およびコントローラーのノード配置ルール
- Red Hat OpenShift Service on AWS Web コンソールを使用したロードバランサーサービスの作成の有効化
- Container Storage Interface (CSI) のデフォルトのストレージクラスの定義
- ホストパスプロビジョナー (HPP) を使用したローカルストレージの設定
4.2. OpenShift Virtualization コンポーネントのノードの指定
ベアメタルノード上の仮想マシン (VM) のデフォルトスケジューリングは、そのままでも機能します。任意で、ノードの配置ルールを設定して、OpenShift Virtualization Operator、ワークロード、およびコントローラーをデプロイするノードを指定できます。
OpenShift Virtualization のインストール後に一部のコンポーネントに対してノード配置ルールを設定できますが、ワークロードに対してノード配置ルールを設定する場合は仮想マシンが存在できません。
4.2.1. OpenShift Virtualization コンポーネントのノード配置ルールについて
ノード配置ルールを使用すると、仮想化ワークロード用のノードにのみ仮想マシンをデプロイしたり、インフラストラクチャーノードにのみ Operator をデプロイしたり、ワークロード間の分離を維持したりすることができます。
オブジェクトに応じて、以下のルールタイプを 1 つ以上使用できます。
nodeSelector- このフィールドで指定したキーと値のペアでラベル付けされたノードで Pod をスケジュールできるようにします。ノードには、リスト表示されたすべてのペアに一致するラベルがなければなりません。
affinity- より表現的な構文を使用して、ノードと Pod に一致するルールを設定できます。アフィニティーを使用すると、ルールの適用方法に追加のニュアンスを持たせることができます。たとえば、ルールが要件ではなく設定であると指定できます。ルールが優先の場合、ルールが満たされていない場合でも Pod はスケジュールされます。
tolerations- 一致する taint を持つノードに Pod をスケジュールすることを許容します。ノードに taint が適用されると、そのノードはその taint を許容する Pod のみを受け入れます。
4.2.2. ノード配置ルールの適用
コマンドラインを使用して Subscription、HyperConverged、または HostPathProvisioner オブジェクトを編集することで、ノード配置ルールを適用できます。
前提条件
-
ocCLI ツールがインストールされている。 - クラスター管理者の権限でログインしています。
手順
次のコマンドを実行して、デフォルトのエディターでオブジェクトを編集します。
oc edit <resource_type> <resource_name> -n openshift-cnv
$ oc edit <resource_type> <resource_name> -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 変更を適用するためにファイルを保存します。
4.2.3. ノード配置ルールの例
Subscription、HyperConverged、または HostPathProvisioner オブジェクトを編集することで、OpenShift Virtualization コンポーネントのノード配置ルールを指定できます。
4.2.3.1. サブスクリプションオブジェクトノード配置ルールの例
OLM が OpenShift Virtualization Operator をデプロイするノードを指定するには、OpenShift Virtualization のインストール時に Subscription オブジェクトを編集します。
現時点では、Web コンソールを使用して Subscription オブジェクトのノードの配置ルールを設定することはできません。
Subscription オブジェクトは、affinity ノードの配置ルールをサポートしていません。
nodeSelector ルールを含む Subscription オブジェクトの例:
- 1
- OLM は、
example.io/example-infra-key = example-infra-valueというラベルのノードに OpenShift Virtualization Operator をデプロイします。
tolerations ルールを含む Subscription オブジェクトの例:
- 1
- OLM は、
key = virtualization:NoScheduletaint のラベルが付けられているノードに OpenShift Virtualization Operator をデプロイします。このノードには、一致する toleration を持つ Pod のみがスケジュールされます。
4.2.3.2. HyperConverged オブジェクトノード配置ルールの例
OpenShift Virtualization がそのコンポーネントをデプロイするノードを指定するには、OpenShift Virtualization のインストール時に作成する HyperConverged カスタムリソース (CR) ファイルに nodePlacement オブジェクトを編集できます。
nodeSelector ルールを含む HyperConverged オブジェクトの例:
affinity ルールを含む HyperConverged オブジェクトの例:
tolerations ルールを含む HyperConverged オブジェクトの例:
- 1
- OpenShift Virtualization コンポーネント用に予約されているノードには、
key = virtualization:NoScheduletaint のラベルが付けられています。予約済みノードには、一致する toleration を持つ Pod のみがスケジュールされます。
4.2.3.3. HostPathProvisioner オブジェクトノード配置ルールの例
HostPathProvisioner オブジェクトは、直接編集することも、Web コンソールを使用して編集することもできます。
ホストパスプロビジョナーと OpenShift Virtualization コンポーネントを同じノード上でスケジュールする必要があります。スケジュールしない場合は、ホストパスプロビジョナーを使用する仮想化 Pod を実行できません。仮想マシンを実行することはできません。
ホストパスプロビジョナー (HPP) ストレージクラスを使用して仮想マシン (VM) をデプロイした後、ノードセレクターを使用して同じノードからホストパスプロビジョナー Pod を削除できます。ただし、少なくともその特定のノードは、まずその変更を元に戻し、仮想マシンを削除しようとする前に Pod が実行されるのを待つ必要があります。
ノード配置ルールを設定するには、ホストパスプロビジョナーのインストール時に作成する HostPathProvisioner オブジェクトの spec.workload フィールドに nodeSelector、affinity、または tolerations を指定します。
nodeSelector ルールを含む HostPathProvisioner オブジェクトの例:
- 1
- ワークロードは、
example.io/example-workloads-key = example-workloads-valueというラベルの付いたノードに配置されます。
4.3. インストール後のネットワーク設定
デフォルトでは、OpenShift Virtualization はインストール後に単一の内部 Pod ネットワークを使用します。
4.3.1. ネットワーキングオペレーターのインストール
4.3.2. Linux ブリッジネットワークの設定
Kubernetes NMState Operator をインストールしたら、ライブマイグレーションまたは仮想マシン (VM) への外部アクセス用に Linux ブリッジネットワークを設定できます。
4.3.2.1. Linux ブリッジ NNCP の作成
Linux ブリッジネットワークの NodeNetworkConfigurationPolicy (NNCP) マニフェストを作成できます。
前提条件
- Kubernetes NMState Operator がインストールされている。
手順
NodeNetworkConfigurationPolicyマニフェストを作成します。この例には、独自の情報で置き換える必要のあるサンプルの値が含まれます。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記IBM Z® で OSA を使用する Linux ブリッジ用の NNCP マニフェストを作成するには、
NodeNetworkConfigurationPolicyマニフェストでrx-vlan-filterをfalseに設定して VLAN フィルタリングを無効にする必要があります。または、ノードへの SSH アクセス権がある場合は、次のコマンドを実行して VLAN フィルタリングを無効にできます。
sudo ethtool -K <osa-interface-name> rx-vlan-filter off
$ sudo ethtool -K <osa-interface-name> rx-vlan-filter offCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.3.2.2. Web コンソールを使用した Linux ブリッジ NAD の作成
Red Hat OpenShift Service on AWS Web コンソールを使用して、ネットワークアタッチメント定義 (NAD) を作成し、Pod と仮想マシンにレイヤー 2 ネットワークを提供できます。
仮想マシンのネットワークアタッチメント定義での IP アドレス管理 (IPAM) の設定はサポートされていません。
手順
- Web コンソールで、Networking → NetworkAttachmentDefinitions をクリックします。
Create Network Attachment Definition をクリックします。
注記network attachment definition は Pod または仮想マシンと同じ namespace にある必要があります。
- 一意の Name およびオプションの Description を入力します。
- Network Type リストから CNV Linux bridge を選択します。
- Bridge Name フィールドにブリッジの名前を入力します。
オプション: リソースに VLAN ID が設定されている場合、VLAN Tag Number フィールドに ID 番号を入力します。
注記IBM Z® 上の OSA インターフェイスは VLAN フィルタリングをサポートしていないため、VLAN タグ付きのトラフィックは破棄されます。OSA インターフェイスでは VLAN タグを使用する NAD を使用しないでください。
- オプション: MAC Spoof Check を選択して、MAC スプーフフィルタリングを有効にします。この機能により、Pod を終了するための MAC アドレスを 1 つだけ許可することで、MAC スプーフィング攻撃に対してセキュリティーを確保します。
- Create をクリックします。
4.3.3. ライブマイグレーション用のネットワークの設定
Linux ブリッジネットワークを設定した後、ライブマイグレーション用の専用ネットワークを設定できます。専用ネットワークは、ライブマイグレーション中のテナントワークロードに対するネットワークの飽和状態の影響を最小限に抑えます。
4.3.3.1. ライブマイグレーション用の専用セカンダリーネットワークの設定
ライブマイグレーション用に専用のセカンダリーネットワークを設定するには、まず CLI を使用してブリッジ network attachment definition (NAD) を作成する必要があります。次に、NetworkAttachmentDefinition オブジェクトの名前を HyperConverged カスタムリソース(CR)に追加できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにログインしている。 - 各ノードには少なくとも 2 つのネットワークインターフェイスカード (NIC) があります。
- ライブマイグレーション用の NIC は同じ VLAN に接続されます。
手順
次の例に従って、
NetworkAttachmentDefinitionマニフェストを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow ここでは、以下のようになります。
metadata.name-
NetworkAttachmentDefinitionオブジェクトの名前を指定します。 config.master- ライブマイグレーションに使用する NIC の名前を指定します。
config.type- NAD にネットワークを提供する CNI プラグインの名前を指定します。
config.range- セカンダリーネットワークの IP アドレス範囲を指定します。この範囲は、メインネットワークの IP アドレスと重複してはなりません。
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow NetworkAttachmentDefinitionオブジェクトの名前をHyperConvergedCR のspec.liveMigrationConfigスタンザに追加します。HyperConvergedマニフェストの例:Copy to Clipboard Copied! Toggle word wrap Toggle overflow ここでは、以下のようになります。
network-
ライブマイグレーションに使用される Multus
NetworkAttachmentDefinitionオブジェクトの名前を指定します。
-
変更を保存し、エディターを終了します。
virt-handlerPod が再起動し、セカンダリーネットワークに接続されます。
検証
仮想マシンが実行されるノードがメンテナンスモードに切り替えられると、仮想マシンは自動的にクラスター内の別のノードに移行します。仮想マシンインスタンス (VMI) メタデータのターゲット IP アドレスを確認して、デフォルトの Pod ネットワークではなく、セカンダリーネットワーク上で移行が発生したことを確認できます。
oc get vmi <vmi_name> -o jsonpath='{.status.migrationState.targetNodeAddress}'$ oc get vmi <vmi_name> -o jsonpath='{.status.migrationState.targetNodeAddress}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
4.3.3.2. Web コンソールを使用して専用ネットワークを選択する
Red Hat OpenShift Service on AWS Web コンソールを使用して、ライブマイグレーション用の専用ネットワークを選択できます。
前提条件
- ライブマイグレーション用に Multus ネットワークが設定されている。
- ネットワークの network attachment definition を作成している。
手順
- Red Hat OpenShift Service on AWS Web コンソールで Virtualization > Overview に移動します。
- Settings タブをクリックし、Live migration をクリックします。
- Live migration network リストからネットワークを選択します。
4.3.4. Web コンソールを使用したロードバランサーサービスの作成の有効化
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想マシン (VM) のロードバランサーサービスの作成を有効にできます。
前提条件
- クラスターのロードバランサーが設定されました。
-
cluster-adminロールを持つユーザーとしてログインしている。 - ネットワークの network attachment definition を作成している。
手順
- Virtualization → Overview に移動します。
- Settings タブで、Cluster をクリックします。
- Expand General settings と SSH configuration を展開します。
- SSH over LoadBalancer service をオンに設定します。
4.3.5. cdi-uploadproxy サービスへの追加ルートの設定
クラスター管理者は、cdi-uploadproxy サービスへの追加ルートを設定し、ユーザーがクラスター外から仮想マシンイメージをアップロードできるようにすることができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにログインしている。
手順
次のコマンドを実行して、外部ホストへのルートを設定します。
oc create route reencrypt <route_name> -n openshift-cnv \ --insecure-policy=Redirect \ --hostname=<host_name_or_address> \ --service=cdi-uploadproxy$ oc create route reencrypt <route_name> -n openshift-cnv \ --insecure-policy=Redirect \ --hostname=<host_name_or_address> \ --service=cdi-uploadproxyCopy to Clipboard Copied! Toggle word wrap Toggle overflow ここでは、以下のようになります。
- <route_name>
- このカスタム ルートに割り当てる名前を指定します。
- <host_name_or_address>
- イメージのアップロードアクセスを提供する外部ホストの完全修飾ドメイン名または IP アドレスを指定します。
以下のコマンドを実行してルートにアノテーションを付けます。これにより、証明書がローテーションされる際に、正しい Containerized Data Importer (CDI) CA 証明書が挿入されます。
oc annotate route <route_name> -n openshift-cnv \ operator.cdi.kubevirt.io/injectUploadProxyCert="true"$ oc annotate route <route_name> -n openshift-cnv \ operator.cdi.kubevirt.io/injectUploadProxyCert="true"Copy to Clipboard Copied! Toggle word wrap Toggle overflow ここでは、以下のようになります。
- <route_name>
- 作成したルートの名前。
4.4. インストール後のストレージ設定
次のストレージ設定タスクは必須です。
- ストレージプロバイダーが Containerized Data Importer (CDI) によって認識されない場合は、ストレージプロファイル を設定する必要があります。ストレージプロファイルは、関連付けられたストレージクラスに基づいて推奨されるストレージ設定を提供します。
オプション: ホストパスプロビジョナー (HPP) を使用して、ローカルストレージを設定できます。
CDI、データボリューム、自動ブートソース更新の設定など、その他のオプションは、ストレージ設定の概要 を参照してください。
4.4.1. HPP を使用したローカルストレージの設定
OpenShift Virtualization Operator のインストール時に、Hostpath Provisioner (HPP) Operator は自動的にインストールされます。HPP Operator は HPP プロビジョナーを作成します。
HPP は、OpenShift Virtualization 用に設計されたローカルストレージプロビジョナーです。HPP を使用するには、HPP カスタムリソース (CR) を作成する必要があります。
HPP ストレージプールは、オペレーティングシステムと同じパーティションにあってはなりません。そうしないと、ストレージプールがオペレーティングシステムパーティションをいっぱいにする可能性があります。オペレーティングシステムのパーティションがいっぱいになると、パフォーマンスに悪影響が生じたり、ノードが不安定になったり使用できなくなったりする可能性があります。
4.4.1.1. storagePools スタンザを使用した CSI ドライバーのストレージクラスの作成
ホストパスプロビジョナー (HPP) を使用するには、コンテナーストレージインターフェイス (CSI) ドライバーに関連するストレージクラスを作成する必要があります。
ストレージクラスの作成時に、ストレージクラスに属する永続ボリューム (PV) の動的プロビジョニングに影響するパラメーターを設定します。StorageClass オブジェクトの作成後には、このオブジェクトのパラメーターを更新できません。
仮想マシンは、ローカル PV に基づくデータボリュームを使用します。ローカル PV は特定のノードにバインドされます。ディスクイメージは仮想マシンで使用するために準備されますが、ローカルストレージ PV がすでに固定されたノードに仮想マシンをスケジュールすることができない可能性があります。
この問題を解決するには、Kubernetes Pod スケジューラーを使用して、永続ボリューム要求 (PVC) を正しいノードの PV にバインドします。volumeBindingMode パラメーターが WaitForFirstConsumer に設定された StorageClass 値を使用することにより、PV のバインディングおよびプロビジョニングは、Pod が PVC を使用して作成されるまで遅延します。
手順
storageclass_csi.yamlファイルを作成して、ストレージクラスを定義します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
reclaimPolicyには、DeleteおよびRetainの 2 つの値があります。値を指定しない場合、デフォルト値はDeleteです。- 2
volumeBindingModeパラメーターは、動的プロビジョニングとボリュームのバインディングが実行されるタイミングを決定します。WaitForFirstConsumerを指定して、永続ボリューム要求 (PVC) を使用する Pod が作成されるまで PV のバインディングおよびプロビジョニングを遅延させます。これにより、PV が Pod のスケジュール要件を満たすようになります。- 3
- HPP CR で定義されているストレージプールの名前を指定します。
- ファイルを保存して終了します。
次のコマンドを実行して、
StorageClassオブジェクトを作成します。oc create -f storageclass_csi.yaml
$ oc create -f storageclass_csi.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.5. 証明書ローテーションの設定
証明書ローテーションパラメーターを設定して、既存の証明書を置き換えます。
4.5.1. 証明書ローテーションの設定
これは、Web コンソールでの OpenShift Virtualization のインストール時に、または HyperConverged カスタムリソース (CR) でインストール後に実行することができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して
HyperConvergedCR を開きます。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下の例のように
spec.certConfigフィールドを編集します。システムのオーバーロードを避けるには、すべての値が 10 分以上であることを確認します。golangParseDuration形式 に準拠する文字列として、すべての値を表現します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
ca.renewBeforeの値はca.durationの値以下である必要があります。 -
server.durationの値はca.durationの値以下である必要があります。 -
server.renewBeforeの値はserver.durationの値以下である必要があります。
-
以下のコマンドを実行して、
HyperConvergedCR に更新を適用します。oc apply -f <filename>.yaml
$ oc apply -f <filename>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc apply -f kubevirt-hyperconverged.yaml
$ oc apply -f kubevirt-hyperconverged.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.5.2. 証明書ローテーションパラメーターのトラブルシューティング
HyperConverged カスタムリソース(CR)で 1 つ以上の certConfig 値を削除すると、certConfig 値はデフォルト値に戻ります。
デフォルト値が以下のいずれかの条件と競合する場合は、代わりにエラーメッセージが表示されます。
-
ca.renewBeforeの値はca.durationの値以下である必要があります。 -
server.durationの値はca.durationの値以下である必要があります。 -
server.renewBeforeの値はserver.durationの値以下である必要があります。
たとえば、server.duration 値を削除すると、デフォルト値の 24h0m0s は ca.duration の値よりも大きく、指定された条件と競合します。
これにより、以下のエラーメッセージが表示されます。
error: hyperconvergeds.hco.kubevirt.io "kubevirt-hyperconverged" could not be patched: admission webhook "validate-hco.kubevirt.io" denied the request: spec.certConfig: ca.duration is smaller than server.duration
error: hyperconvergeds.hco.kubevirt.io "kubevirt-hyperconverged" could not be patched: admission webhook "validate-hco.kubevirt.io" denied the request: spec.certConfig: ca.duration is smaller than server.duration
エラーメッセージには、最初の競合のみが記載されます。続行する前に、すべての certConfig の値を確認します。
第5章 更新
5.1. OpenShift Virtualization の更新
OpenShift Virtualization を最新の状態に保ち、Red Hat OpenShift Service on AWS との互換性を維持する方法について説明します。
5.1.1. OpenShift Virtualization の更新について
OpenShift Virtualization をインストールするときに、更新チャネルと承認ストラテジーを選択します。更新チャネルによって、OpenShift Virtualization が更新されるバージョンが決まります。承認ストラテジー設定により、更新が自動的に行われるか、手動の承認が必要かどうかが決まります。
どちらの設定もサポート性に影響を与える可能性があります。
5.1.1.1. 推奨設定
サポート可能な環境を維持するには、次の設定を使用します。
- 更新チャネル: stable
- 承認ストラテジー: Automatic
これらの設定により、Operator の新しいバージョンが stable チャネルで利用可能になると、更新プロセスが自動的に開始されます。これにより、OpenShift Virtualization と Red Hat OpenShift Service on AWS のバージョンの互換性が確保され、OpenShift Virtualization のバージョンが実稼働環境に適したものになります。
OpenShift Virtualization の各マイナーバージョンは、対応する Red Hat OpenShift Service on AWS バージョンを実行している場合にのみサポートされます。たとえば、Red Hat OpenShift Service on AWS 4.20 で OpenShift Virtualization 4.20 を実行する必要があります。
5.1.1.2. 予想されること
- 更新の完了までにかかる時間は、ネットワーク接続によって異なります。ほとんどの自動更新は 15 分以内に完了します。
- OpenShift Virtualization を更新しても、ネットワーク接続が中断されることはありません。
- データボリュームとそれに関連付けられた永続ボリューム要求は、更新中に保持されます。
AWS Elastic Block Store (EBS) ストレージを使用する仮想マシンを実行している場合、ライブマイグレーションができないため、Red Hat OpenShift Service on AWS クラスター更新がブロックされる可能性があります。
回避策として、仮想マシンを再設定し、クラスターの更新時にそれらの電源を自動的にオフになるようにできます。evictionStrategy フィールドを None に、runStrategy フィールドを Always に設定します。
5.1.1.3. 更新の仕組み
- Operator Lifecycle Manager(OLM) は OpenShift Virtualization Operator のライフサイクルを管理します。Red Hat OpenShift Service on AWS のインストール中にデプロイされる Marketplace Operator により、クラスターで外部 Operators を使用できるようになります。
- OLM は、OpenShift Virtualization の z-stream およびマイナーバージョンの更新を提供します。Red Hat OpenShift Service on AWS を次のマイナーバージョンに更新すると、マイナーバージョンの更新が利用可能になります。最初に Red Hat OpenShift Service on AWS を更新しない限り、OpenShift Virtualization を次のマイナーバージョンに更新できません。
5.1.1.4. RHEL 9 の互換性
OpenShift Virtualization 4.20 は、Red Hat Enterprise Linux (RHEL) 9 をベースにしています。標準の OpenShift Virtualization 更新手順に従って、RHEL 8 をベースとするバージョンから OpenShift Virtualization 4.20 に更新できます。追加の手順は必要ありません。
以前のバージョンと同様に、実行中のワークロードを中断することなく更新を実行できます。OpenShift Virtualization 4.20 では、RHEL 8 ノードから RHEL 9 ノードへのライブマイグレーションがサポートされています。
5.1.1.4.1. RHEL 9 マシンタイプ
OpenShift Virtualization に含まれるすべての仮想マシンテンプレートは、デフォルトで RHEL 9 マシンタイプ machineType: pc-q35-rhel9.<y>.0 を使用するようになりました。この場合の <y> は RHEL 9 の最新のマイナーバージョンに対応する 1 桁の数字です。たとえば、RHEL 9.2 の場合は pc-q35-rhel9.2.0 の値が使用されます。
OpenShift Virtualization を更新しても、既存仮想マシンの machineType 値は変更されません。これらの仮想マシンは、引き続き更新前と同様に機能します。RHEL 9 での改良を反映するために、オプションで仮想マシンのマシンタイプを変更できます。
仮想マシンの machineType 値を変更する前に、仮想マシンをシャットダウンする必要があります。
5.1.2. 更新ステータスの監視
OpenShift Virtualization Operator の更新のステータスをモニターするには、クラスターサービスバージョン (CSV) PHASE を監視します。Web コンソールを使用するか、ここに提供されているコマンドを実行して CSV の状態をモニターすることもできます。
PHASE および状態の値は利用可能な情報に基づく近似値になります。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにログインしている。 -
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行します。
oc get csv -n openshift-cnv
$ oc get csv -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力を確認し、
PHASEフィールドをチェックします。以下に例を示します。VERSION REPLACES PHASE 4.9.0 kubevirt-hyperconverged-operator.v4.8.2 Installing 4.9.0 kubevirt-hyperconverged-operator.v4.9.0 Replacing
VERSION REPLACES PHASE 4.9.0 kubevirt-hyperconverged-operator.v4.8.2 Installing 4.9.0 kubevirt-hyperconverged-operator.v4.9.0 ReplacingCopy to Clipboard Copied! Toggle word wrap Toggle overflow オプション: 以下のコマンドを実行して、すべての OpenShift Virtualization コンポーネントの状態の集約されたステータスをモニターします。
oc get hyperconverged kubevirt-hyperconverged -n openshift-cnv \ -o=jsonpath='{range .status.conditions[*]}{.type}{"\t"}{.status}{"\t"}{.message}{"\n"}{end}'$ oc get hyperconverged kubevirt-hyperconverged -n openshift-cnv \ -o=jsonpath='{range .status.conditions[*]}{.type}{"\t"}{.status}{"\t"}{.message}{"\n"}{end}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow アップグレードが成功すると、以下の出力が得られます。
ReconcileComplete True Reconcile completed successfully Available True Reconcile completed successfully Progressing False Reconcile completed successfully Degraded False Reconcile completed successfully Upgradeable True Reconcile completed successfully
ReconcileComplete True Reconcile completed successfully Available True Reconcile completed successfully Progressing False Reconcile completed successfully Degraded False Reconcile completed successfully Upgradeable True Reconcile completed successfullyCopy to Clipboard Copied! Toggle word wrap Toggle overflow
5.1.3. 仮想マシンワークロードの更新
OpenShift Virtualization を更新すると、ライブマイグレーションをサポートしている場合には libvirt、virt-launcher、および qemu などの仮想マシンのワークロードが自動的に更新されます。
各仮想マシンには、仮想マシンインスタンス (VMI) を実行する virt-launcher Pod があります。virt-launcher Pod は、仮想マシン (VM) のプロセスを管理するために使用される libvirt のインスタンスを実行します。
HyperConverged カスタムリソース (CR) の spec.workloadUpdateStrategy スタンザを編集して、ワークロードの更新方法を設定できます。ワークロードの更新方法として、LiveMigrate と Evict の 2 つが利用可能です。
Evict メソッドは VMI Pod をシャットダウンするため、デフォルトでは LiveMigrate 更新ストラテジーのみが有効になっています。
LiveMigrate が有効な唯一の更新ストラテジーである場合:
- ライブマイグレーションをサポートする VMI は更新プロセス時に移行されます。VM ゲストは、更新されたコンポーネントが有効になっている新しい Pod に移動します。
ライブマイグレーションをサポートしない VMI は中断または更新されません。
-
VMI に
LiveMigrate退避ストラテジーがあるが、ライブマイグレーションをサポートしていない場合、VMI は更新されません。
-
VMI に
LiveMigrate と Evict の両方を有効にした場合:
-
ライブマイグレーションをサポートする VMI は、
LiveMigrate更新ストラテジーを使用します。 -
ライブマイグレーションをサポートしない VMI は、
Evict更新ストラテジーを使用します。VMI がrunStrategy: Alwaysに設定されたVirtualMachineオブジェクトによって制御される場合、新規の VMI は、更新されたコンポーネントを使用して新規 Pod に作成されます。
5.1.3.1. 移行の試行とタイムアウト
ワークロードを更新するときに、Pod が次の期間 Pending 状態の場合、ライブマイグレーションは失敗します。
- 5 分間
-
Pod が
Unschedulableであるために保留中の場合。 - 15 分
- 何らかの理由で Pod が保留状態のままになっている場合。
VMI が移行に失敗すると、virt-controller は VMI の移行を再試行します。すべての移行可能な VMI が新しい virt-launcher Pod で実行されるまで、このプロセスが繰り返されます。ただし、VMI が不適切に設定されている場合、これらの試行は無限に繰り返される可能性があります。
各試行は、移行オブジェクトに対応します。直近の 5 回の試行のみがバッファーに保持されます。これにより、デバッグ用の情報を保持しながら、移行オブジェクトがシステムに蓄積されるのを防ぎます。
5.1.3.2. ワークロードの更新方法の設定
HyperConverged カスタムリソース (CR) を編集することにより、ワークロードの更新方法を設定できます。
前提条件
ライブマイグレーションを更新方法として使用するには、まずクラスターでライブマイグレーションを有効にする必要があります。
注記VirtualMachineInstanceCR にevictionStrategy: LiveMigrateが含まれており、仮想マシンインスタンス (VMI) がライブマイグレーションをサポートしない場合には、VMI は更新されません。-
OpenShift CLI (
oc) がインストールされている。
手順
デフォルトエディターで
HyperConvergedCR を作成するには、以下のコマンドを実行します。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow HyperConvergedCR のworkloadUpdateStrategyスタンザを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- ワークロードの自動更新を実行するのに使用できるメソッド。設定可能な値は
LiveMigrateおよびEvictです。上記の例のように両方のオプションを有効にした場合に、ライブマイグレーションをサポートする VMI にはLiveMigrateを、ライブマイグレーションをサポートしない VMI にはEvictを、更新に使用します。ワークロードの自動更新を無効にするには、workloadUpdateStrategyスタンザを削除するか、workloadUpdateMethods: []を設定して配列を空のままにします。 - 2
- 中断を最小限に抑えた更新メソッド。ライブマイグレーションをサポートする VMI は、仮想マシン (VM) ゲストを更新されたコンポーネントが有効なっている新規 Pod に移行することで更新されます。
LiveMigrateがリストされている唯一のワークロード更新メソッドである場合には、ライブマイグレーションをサポートしない VMI は中断または更新されません。 - 3
- アップグレード時に VMI Pod をシャットダウンする破壊的な方法。
Evictは、ライブマイグレーションがクラスターで有効でない場合に利用可能な唯一の更新方法です。VMI がrunStrategy: Alwaysに設定されたVirtualMachineオブジェクトによって制御される場合には、新規の VMI は、更新されたコンポーネントを使用して新規 Pod に作成されます。 - 4
Evictメソッドを使用して一度に強制的に更新できる VMI の数。これは、LiveMigrateメソッドには適用されません。- 5
- 次のワークロードバッチを退避するまで待機する間隔。これは、
LiveMigrateメソッドには適用されません。
注記HyperConvergedCR のspec.liveMigrationConfigスタンザを編集することにより、ライブマイグレーションの制限とタイムアウトを設定できます。- 変更を適用するには、エディターを保存し、終了します。
5.1.3.3. 古くなった仮想マシンワークロードの表示
CLI を使用して、古くなった仮想マシン (VM) ワークロードのリストを表示できます。
クラスターに以前の仮想化 Pod がある場合には、OutdatedVirtualMachineInstanceWorkloads アラートが実行されます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以前の仮想マシンインスタンス (VMI) の一覧を表示するには、以下のコマンドを実行します。
oc get vmi -l kubevirt.io/outdatedLauncherImage --all-namespaces
$ oc get vmi -l kubevirt.io/outdatedLauncherImage --all-namespacesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
VMI が自動的に更新されるようにするには、ワークロードの更新を設定します。
5.1.4. 高度なオプション
ほとんどの OpenShift Virtualization インストールでは、stable リリースチャネルと Automatic 承認ストラテジーが推奨されます。リスクを理解している場合にのみ、他の設定を使用してください。
5.1.4.1. 更新設定の変更
Web コンソールを使用して、OpenShift Virtualization Operator サブスクリプションの更新チャネルと承認ストラテジーを変更できます。
前提条件
- OpenShift Virtualization Operator がインストールされている。
- 管理者権限がある。
手順
- Ecosystem → Installed Operators をクリックします。
- リストから OpenShift Virtualization を選択します。
- Subscription タブをクリックします。
- Subscription details セクションで、変更する設定をクリックします。たとえば、承認ストラテジーを Manual から Automatic に変更するには、Manual をクリックします。
- 開いたウィンドウで、新しい更新チャネルまたは承認ストラテジーを選択します。
- Save をクリックします。
5.1.4.2. 手動承認ストラテジー
Manual 承認ストラテジーを使用する場合は、すべての保留中の更新を手動で承認する必要があります。Red Hat OpenShift Service on AWS と OpenShift Virtualization の更新が同期していない場合、クラスターはサポートされなくなります。
クラスターのサポート性と機能性を危険にさらさないようにするには、Automatic 承認ストラテジーを使用します。Manual 承認ストラテジーを使用する必要がある場合は、保留中の Operator 更新が利用可能になり次第承認し、サポート可能なクラスターを維持します。
5.1.4.3. 保留中の Operator 更新の手動による承認
インストールされた Operator のサブスクリプションの承認ストラテジーが Manual に設定されている場合、新規の更新が現在の更新チャネルにリリースされると、インストールを開始する前に更新を手動で承認する必要があります。
前提条件
- Operator Lifecycle Manager (OLM) を使用して以前にインストールされている Operator。
手順
- Red Hat OpenShift Service on AWS Web コンソールで、Ecosystem → Installed Operators に移動します。
- 更新が保留中の Operators は Upgrade available のステータスを表示します。更新する Operator の名前をクリックします。
- Subscription タブをクリックします。承認が必要な更新は、Upgrade status の横に表示されます。たとえば、1 requires approval が表示される可能性があります。
- 1 requires approval をクリックしてから、Preview Install Plan をクリックします。
- 更新に利用可能なリソースとして一覧表示されているリソースを確認します。問題がなければ、Approve をクリックします。
- Ecosystem → Installed Operators ページに戻って、更新の進行状況を監視します。完了時に、ステータスは Succeeded および Up to date に変更されます。
5.1.5. 早期アクセスリリース
ご使用の OpenShift Virtualization バージョンの candidate 更新チャネルをサブスクライブすると、開発中のビルドにアクセスできます。
早期アクセスリリースは、Red Hat によって完全にテストされておらず、サポート対象でもありませんが、そのバージョン用に開発している機能やバグ修正をテストするために、非実稼働クラスターで使用することができます。
stable チャネルは実稼働システムに適しています。このチャネルは基盤となる Red Hat OpenShift Service on AWS のバージョンと一致し、完全にテストされています。Operator Hub で stable チャネルと candidate チャネルを切り替えることができます。ただし、candidate チャネルリリースから stable チャネルリリースへの更新は Red Hat によってテストされていません。
一部の candidate リリースは stable チャネルに昇格されます。ただし、candidate チャネルにのみ存在するリリースには、一般提供 (GA) されるすべての機能が含まれていない可能性があります。また、candidate ビルドの一部の機能は GA の前に削除される可能性があります。さらに、candidate リリースには、後の GA リリースへの更新パスがない場合があります。
candidate チャネルは、クラスターの破棄と再作成が許容されるテスト目的にのみ適しています。
第6章 仮想マシンの作成
6.1. インスタンスタイプからの仮想マシンの作成
Red Hat OpenShift Service on AWS Web コンソールまたは CLI を使用して仮想マシンを作成する場合でも、インスタンスタイプを使用することで仮想マシン (仮想マシン) の作成を簡素化できます。
Red Hat OpenShift Service on AWS クラスターでは、OpenShift Virtualization 4.15 のインスタンスタイプから仮想マシンを作成することがサポートされています。OpenShift Virtualization 4.14 では、インスタンスタイプからの仮想マシンの作成はテクノロジープレビュー機能であり、Red Hat OpenShift Service on AWS クラスターでの使用はサポートされていません。
6.1.1. インスタンスタイプについて
インスタンスタイプは、新しい仮想マシンに適用するリソースと特性を定義できる再利用可能なオブジェクトです。カスタムインスタンスタイプを定義したり、OpenShift Virtualization のインストール時に含まれるさまざまなインスタンスタイプを使用したりできます。
新しいインスタンスタイプを作成するには、まず手動で、または virtctl CLI ツールを使用してマニフェストを作成する必要があります。次に、マニフェストをクラスターに適用してインスタンスタイプオブジェクトを作成します。
OpenShift Virtualization は、インスタンスタイプを設定するための 2 つの CRD を提供します。
-
namespace 付きのオブジェクト:
VirtualMachineInstancetype -
クラスター全体のオブジェクト:
VirtualMachineClusterInstancetype
これらのオブジェクトは同じ VirtualMachineInstancetypeSpec を使用します。
6.1.1.1. 必須の属性
インスタンスタイプを設定するときは、cpu および memory 属性を定義する必要があります。その他の属性はオプションです。
インスタンスタイプから仮想マシンを作成する場合は、インスタンスタイプで定義されているパラメーターをオーバーライドすることはできません。
インスタンスタイプには定義された CPU およびメモリー属性が必要であるため、OpenShift Virtualization は、インスタンスタイプから仮想マシンを作成するときに、これらのリソースに対する追加の要求を常に拒否します。
インスタンスタイプマニフェストを手動で作成できます。以下に例を示します。
virtctl CLI ユーティリティーを使用してインスタンスタイプマニフェストを作成できます。以下に例を示します。
virtctl create instancetype --cpu 2 --memory 256Mi
$ virtctl create instancetype --cpu 2 --memory 256Miここでは、以下のようになります。
--cpu <value>- ゲストに割り当てる仮想 CPU の数を指定します。必須。
--memory <value>- ゲストに割り当てるメモリーの量を指定します。必須。
次のコマンドを実行すると、新しいマニフェストからオブジェクトをすぐに作成できます。
virtctl create instancetype --cpu 2 --memory 256Mi | oc apply -f -
$ virtctl create instancetype --cpu 2 --memory 256Mi | oc apply -f -6.1.1.2. オプション属性
必須の cpu および memory 属性に加えて、VirtualMachineInstancetypeSpec に次のオプション属性を含めることができます。
annotations- 仮想マシンに適用するアノテーションをリスト表示します。
gpus- パススルー用の仮想 GPU をリスト表示します。
hostDevices- パススルー用のホストデバイスをリスト表示します。
ioThreadsPolicy- 専用ディスクアクセスを管理するための IO スレッドポリシーを定義します。
launchSecurity- セキュア暗号化仮想化 (SEV) を設定します。
nodeSelector- この仮想マシンがスケジュールされているノードを制御するためのノードセレクターを指定します。
schedulerName- デフォルトのスケジューラーの代わりに、この仮想マシンに使用するカスタムスケジューラーを定義します。
6.1.1.3. コントローラーリビジョン
インスタンスタイプを使用して仮想マシンを作成すると、ControllerRevision オブジェクトにインスタンスタイプオブジェクトのイミュータブルなスナップショットが保持されます。このスナップショットにより、必要なゲスト CPU やメモリーなど、インスタンスタイプオブジェクトで定義されているリソース関連の特性が固定されます。また、仮想マシンのステータスに、ControllerRevision オブジェクトへの参照が含まれます。
このスナップショットはバージョン管理に不可欠です。このスナップショットにより、仮想マシンの実行中にその元になったインスタンスタイプオブジェクトが更新されても、仮想マシンの起動時に作成される仮想マシンインスタンスが変更されないことが保証されます。
6.1.2. 定義済みのインスタンスタイプ
OpenShift Virtualization には、common-instancetypes と呼ばれる事前定義されたインスタンスタイプのセットが含まれています。特定のワークロードに特化したものもあれば、ワークロードに依存しないものもあります。
これらのインスタンスタイプリソースは、シリーズ、バージョン、サイズに応じて名前が付けられます。サイズの値は . 区切り文字に続き、範囲は nano から 8xlarge です。
| ユースケース | シリーズ | 特徴 | 仮想 CPU とメモリーの比率 | リソースの例 |
|---|---|---|---|---|
| ネットワーク | N |
| 1:2 |
|
| 過剰コミットメント | O |
| 1:4 |
|
| コンピュート専用 | CX |
| 1:2 |
|
| 一般的用途 | U |
| 1:4 |
|
| メモリー集約型 | M |
| 1:8 |
|
6.1.3. インスタンスタイプまたは設定の指定
インスタンスタイプまたは優先度、またはその両方を指定して、複数の仮想マシンで再利用するためのワークロードサイジングとランタイム特性を定義できます。
6.1.3.1. フラグを使用したインスタンスタイプと設定の指定
フラグを使用してインスタンスタイプと設定を指定できます。
前提条件
- クラスターにインスタンスタイプ、プリファレンス、またはその両方がある。
手順
仮想マシンを作成するときにインスタンスタイプを指定するには、
--instancetypeフラグを使用します。設定を指定するには、--preferenceフラグを使用します。次の例には両方のフラグが含まれています。virtctl create vm --instancetype <my_instancetype> --preference <my_preference>
$ virtctl create vm --instancetype <my_instancetype> --preference <my_preference>Copy to Clipboard Copied! Toggle word wrap Toggle overflow オプション: namespace 付きのインスタンスタイプまたは設定を指定するには、
--instancetypeまたは--preferenceフラグコマンドに渡される値にkindを含めます。namespace 付きのインスタンスタイプまたは設定は、仮想マシンを作成するのと同じ namespace に存在する必要があります。次の例には、namespace 付きインスタンスタイプと namespace 付き設定のフラグが含まれています。virtctl create vm --instancetype virtualmachineinstancetype/<my_instancetype> --preference virtualmachinepreference/<my_preference>
$ virtctl create vm --instancetype virtualmachineinstancetype/<my_instancetype> --preference virtualmachinepreference/<my_preference>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.1.3.2. インスタンスタイプまたは設定の推測
インスタンスタイプの推論、設定、またはその両方がデフォルトで有効になっており、inferFromVolume 属性の inferFromVolumeFailure ポリシーは Ignore に設定されています。ブートボリュームから推測する場合、エラーは無視され、インスタンスタイプと設定が未設定のままで仮想マシンが作成されます。
ただし、フラグが適用されると、inferFromVolumeFailure ポリシーはデフォルトで Reject に設定されます。ブートボリュームから推測する場合、エラーが発生すると、その仮想マシンの作成が拒否されます。
--infer-instancetype フラグと --infer-preference フラグを使用すると、仮想マシンのワークロードのサイズ設定と実行時特性を定義するために使用するインスタンスタイプ、設定、またはその両方を推測できます。
前提条件
-
virtctlツールがインストールされている。
手順
仮想マシンの起動に使用されるボリュームから明示的にインスタンスタイプを推測するには、
--infer-instancetypeフラグを使用します。設定を明示的に推測するには、--infer-preferenceフラグを使用します。次のコマンドには両方のフラグが含まれます。virtctl create vm --volume-import type:pvc,src:my-ns/my-pvc --infer-instancetype --infer-preference
$ virtctl create vm --volume-import type:pvc,src:my-ns/my-pvc --infer-instancetype --infer-preferenceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 仮想マシンのブートに使用されるボリューム以外のボリュームからインスタンスタイプまたは設定を推測するには、
--infer-instancetype-fromおよび--infer-preference-fromフラグを使用して、仮想マシンのボリュームのいずれかを指定します。以下の例では、仮想マシンはvolume-aから起動しますが、volume-bからインスタンスタイプと設定を推測しています。virtctl create vm \ --volume-import=type:pvc,src:my-ns/my-pvc-a,name:volume-a \ --volume-import=type:pvc,src:my-ns/my-pvc-b,name:volume-b \ --infer-instancetype-from volume-b \ --infer-preference-from volume-b
$ virtctl create vm \ --volume-import=type:pvc,src:my-ns/my-pvc-a,name:volume-a \ --volume-import=type:pvc,src:my-ns/my-pvc-b,name:volume-b \ --infer-instancetype-from volume-b \ --infer-preference-from volume-bCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.1.3.3. inferFromVolume ラベルの設定
PVC、データソース、またはデータボリュームで次のラベルを使用して、ボリュームから起動するときに使用するインスタンスタイプ、設定、またはその両方を推論メカニズムに指示します。
-
クラスター全体のインスタンスのタイプ:
instancetype.kubevirt.io/default-instancetypeラベル。 -
namespace 付きのインスタンスタイプ:
instancetype.kubevirt.io/default-instancetype-kindラベル。空のままにすると、デフォルトでVirtualMachineClusterInstancetypeラベルになります。 -
クラスター全体の設定:
instancetype.kubevirt.io/default-preferenceラベル。 -
namespace 付きの設定:
instancetype.kubevirt.io/default-preference-kindラベル。空のままにすると、デフォルトでVirtualMachineClusterPreferenceラベルになります。
前提条件
- クラスターにインスタンスタイプ、プリファレンス、またはその両方がある。
-
OpenShift CLI (
oc) がインストールされている。
手順
データソースにラベルを適用するには、
oc labelを使用します。次のコマンドは、クラスター全体のインスタンスタイプを指すラベルを適用します。oc label DataSource foo instancetype.kubevirt.io/default-instancetype=<my_instancetype>
$ oc label DataSource foo instancetype.kubevirt.io/default-instancetype=<my_instancetype>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.1.4. Web コンソールを使用したインスタンスタイプからの仮想マシンの作成
Red Hat OpenShift Service on AWS Web コンソールを使用して、インスタンスタイプから仮想マシン (VM) を作成できます。Web コンソールを使用して、既存のスナップショットをコピーするか仮想マシンを複製して、仮想マシンを作成することもできます。
使用可能な起動可能なボリュームのリストから仮想マシンを作成できます。Linux ベースまたは Windows ベースのボリュームをリストに追加できます。
手順
Web コンソールで、Virtualization → Catalog に移動します。
InstanceTypes タブがデフォルトで開きます。
注記仮想マシン設定を使用する IBM Z® システムで downward-metrics デバイスを設定する場合は、
spec.preference.name値をrhel.9.s390xに設定するか、*.s390xという形式の使用可能な別の設定を指定する必要があります。- 異種クラスターのみ: 提供されているオプションを使用して起動可能なボリュームをフィルタリングするには、Architecture をクリックします。
次のオプションのいずれかを選択します。
リストから適切な起動可能なボリュームを選択します。リストが切り捨てられている場合は、Show all ボタンをクリックしてリスト全体を表示します。
注記ブート可能ボリュームテーブルには、
openshift-virtualization-os-imagesnamespace 内のinstancetype.kubevirt.io/default-preferenceラベルを持つボリュームのみリストされます。- オプション: 星アイコンをクリックして、ブート可能ボリュームをお気に入りとして指定します。星付きのブート可能ボリュームは、ボリュームリストの最初に表示されます。
新しいボリュームをアップロードするか、既存の永続ボリューム要求 (PVC)、ボリュームスナップショット、または
containerDiskボリュームを使用するには Add volume をクリックします。Save をクリックします。クラスターで使用できないオペレーティングシステムのロゴは、リストの下部に表示されます。Add volume リンクをクリックすると、必要なオペレーティングシステムのボリュームを追加できます。
さらに、Windows の起動可能なボリュームを作成する クイックスタートへのリンクもあります。Select volume to boot from の横にある疑問符アイコンの上にポインターを置くと、ポップオーバーに同じリンクが表示されます。
環境をインストールした直後、または環境が切断された直後は、起動元のボリュームのリストは空になります。その場合、Windows、RHEL、Linux の 3 つのオペレーティングシステムのロゴが表示されます。Add volume ボタンをクリックすると、要件を満たす新しいボリュームを追加できます。
- インスタンスタイプのタイルをクリックし、ワークロードに適したリソースサイズを選択します。Red Hat が提供する M および CX シリーズのインスタンスタイプでは、huge page を選択できます。huge page オプションは、1gi で終わる名前で識別されます。
オプション: 起動元のボリュームに適用される仮想マシンの詳細 (仮想マシンの名前を含む) を選択します。
Linux ベースのボリュームの場合は、次の手順に従って SSH を設定します。
- プロジェクトに SSH 公開鍵をまだ追加していない場合は、VirtualMachine details セクションの Authorized SSH key の横にある編集アイコンをクリックします。
以下のオプションのいずれかを選択します。
- Use existing: シークレットリストからシークレットを選択します。
Add new: 以下の手順に従ってください。
- SSH 公開鍵ファイルを参照するか、ファイルを鍵のフィールドに貼り付けます。
- シークレット名を入力します。
- オプション: Automatically apply this key to any new VirtualMachine you create in this project を選択します。
- Save をクリックします。
Windows ボリュームの場合は、次のいずれかの手順に従って sysprep オプションを設定します。
Windows ボリュームに sysprep オプションをまだ追加していない場合は、次の手順に従います。
- VirtualMachine details セクションの Sysprep の横にある編集アイコンをクリックします。
- Autoattend.xml アンサーファイルを追加します。
- Unattend.xml アンサーファイルを追加します。
- Save をクリックします。
Windows ボリュームに既存の sysprep オプションを使用する場合は、次の手順に従います。
- 既存の sysprep を添付 をクリックします。
- 既存の sysprep Unattend.xml アンサーファイルの名前を入力します。
- Save をクリックします。
オプション: Windows 仮想マシンを作成する場合は、Windows ドライバーディスクをマウントできます。
- Customize VirtualMachine ボタンをクリックします。
- VirtualMachine details ページで、Storage をクリックします。
- Mount Windows drivers disk チェックボックスを選択します。
- オプション: View YAML & CLI をクリックして YAML ファイルを表示します。CLI をクリックして CLI コマンドを表示します。YAML ファイルの内容または CLI コマンドをダウンロードまたはコピーすることもできます。
- Create VirtualMachine をクリックします。
結果
仮想マシンの作成後、VirtualMachine details ページでステータスを監視できます。
6.1.5. 仮想マシンのインスタンスタイプの変更
クラスター管理者または仮想マシン所有者は、次の理由により、既存の仮想マシンのインスタンスタイプを変更する必要がある場合があります。
- 仮想マシンのワークロードが増加した場合、パフォーマンスのボトルネックを防ぐために、インスタンスタイプを、より多くの CPU、より多くのメモリー、または特定のハードウェアリソースを備えたインスタンスタイプに変更することがあります。
- 特殊なワークロードを使用している場合、パフォーマンス向上のために、別のインスタンスタイプに切り替えることがあります。一部のインスタンスタイプは、特定のユースケース向けに最適化されているためです。
既存の仮想マシンのインスタンスタイプは、Red Hat OpenShift Service on AWS Web コンソールまたは OpenShift CLI (oc) を使用して変更できます。
6.1.5.1. Web コンソールを使用して仮想マシンのインスタンスタイプを変更する
Web コンソールを使用して、実行中の仮想マシン (VM) に関連付けられているインスタンスタイプを変更できます。変更は即座に有効になります。
前提条件
- インスタンスタイプを使用して仮想マシンを作成している。
手順
- Red Hat OpenShift Service on AWS Web コンソールで、Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Configuration タブをクリックします。
- Details タブで、インスタンスタイプテキストをクリックして Edit Instancetype ダイアログを開きます。たとえば、1 CPU | 2 GiB Memory をクリックします。
Series および Size リストを使用して、インスタンスタイプを編集します。
- Series リストからアイテムを選択して、そのシリーズに関連するサイズを表示します。たとえば、General Purpose を選択します。
- Size リストから仮想マシンの新しいインスタンスタイプを選択します。たとえば、medium: 1 CPUs, 4Gi Memory を選択します。これは、General Purpose シリーズで利用できます。
- Save をクリックします。
検証
- YAML タブをクリックします。
- Reload をクリックします。
- 仮想マシン YAML を確認し、インスタンスタイプが変更されたことを確認します。
6.1.5.2. CLI を使用して仮想マシンのインスタンスタイプを変更する
仮想マシンのインスタンスタイプを変更するには、仮想マシン仕様の name フィールドを変更します。これにより、更新ロジックがトリガーされ、新しいリソース設定の新しいイミュータブルなコントローラーリビジョンのスナップショットが確実に作成されます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - インスタンスタイプを使用して仮想マシンを作成したか、変更する仮想マシンに対する管理者特権を持っている。
手順
- 仮想マシンを停止します。
次のコマンドを実行します。
<vm_name>は、仮想マシンの名前に置き換えます。<new_instancetype>は、変更後のインスタンスタイプの名前に置き換えます。oc patch vm/<vm_name> --type merge -p '{"spec":{"instancetype":{"name": "<new_instancetype>"}}}'$ oc patch vm/<vm_name> --type merge -p '{"spec":{"instancetype":{"name": "<new_instancetype>"}}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
更新された仮想マシンの
statusフィールドでコントローラーリビジョンの参照を確認します。次のコマンドを実行し、出力でリビジョン名が更新されていることを確認します。oc get vms/<vm_name> -o json | jq .status.instancetypeRef
$ oc get vms/<vm_name> -o json | jq .status.instancetypeRefCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow オプション: 仮想マシンインスタンスが最新のコントローラーリビジョンで定義された新しい設定を実行していることを確認します。たとえば、インスタンスタイプを 1 個ではなく 2 個の仮想 CPU を使用するように更新した場合は、次のコマンドを実行して出力を確認します。
oc get vmi/<vm_name> -o json | jq .spec.domain.cpu
$ oc get vmi/<vm_name> -o json | jq .spec.domain.cpuCopy to Clipboard Copied! Toggle word wrap Toggle overflow リビジョンが 2 つの仮想 CPU を使用していることを示す出力の例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.2. テンプレートからの仮想マシンの作成
Red Hat OpenShift Service on AWS Web コンソールを使用して、Red Hat テンプレートから仮想マシン (VM) を作成できます。
6.2.1. 仮想マシンテンプレートについて
仮想マシンテンプレートを使用すると、仮想マシンを簡単に作成できます。
- ブートソースを使用して作成を迅速化する
使用可能なブートソースが設定されているテンプレートを使用すると、仮想マシンの作成を効率化できます。ブートソースのあるテンプレートには、カスタムラベルがない場合、Available boot source ラベルが付けられます。
ブートソースのないテンプレートには、Boot source required というラベルが付けられます。詳細は、ブートソースの自動更新の管理 を参照してください。
- 仮想マシンを起動する前にカスタマイズする
仮想マシンを起動する前に、ディスクソースと仮想マシンパラメーターをカスタマイズできます。
注記すべてのラベルとアノテーションとともに仮想マシンテンプレートをコピーすると、新しいバージョンの Scheduling、Scale、and Performance (SSP) Operator がデプロイされたときに、そのバージョンのテンプレートが非推奨に指定されます。この指定は削除できます。Web コンソールを使用してカスタマイズされた仮想マシンテンプレートから非推奨の指定を削除する を参照してください。
- シングルノード OpenShift
-
ストレージの動作の違いにより、一部のテンプレートはシングルノード OpenShift と互換性がありません。互換性を確保するには、データボリュームまたはストレージプロファイルを使用するテンプレートまたは仮想マシンに
evictionStrategyフィールドを設定しないでください。
6.2.2. テンプレートから仮想マシンを作成する
Red Hat OpenShift Service on AWS Web コンソールを使用すると、利用可能なブートソースを持つテンプレートから仮想マシン (VM) を作成できます。仮想マシンを起動する前に、データソース、Cloud-init、SSH 鍵などのテンプレートまたは仮想マシンパラメーターをカスタマイズできます。
仮想マシンを作成するには、Web コンソールで 2 つのビューから選択できます。
- 仮想化に重点を置いたビュー。ビューの上部に仮想化関連のオプションを簡潔にまとめたリストが表示されます。
- 仮想化 を含むさまざまな Web コンソールオプションにアクセスできる一般ビュー。
手順
Red Hat OpenShift Service on AWS Web コンソールから、ビューを選択します。
- 仮想化に重点を置いたビューの場合は、Administrator → Virtualization → Catalog を選択します。
- 一般的なビューは、Virtualization → Catalog に移動します。
- Template catalog タブをクリックします。
- ブートソースのあるテンプレートをフィルタリングするには、Boot source available チェックボックスをクリックします。カタログにはデフォルトのテンプレートが表示されます。
- 異種クラスターのみ: 検索結果をフィルタリングして、特定のアーキテクチャーに関連付けられたテンプレートを表示するには、Architecture Type をクリックします。
フィルターに使用可能なテンプレートを表示するには、All templates をクリックします。
-
特定のテンプレートに焦点を合わせるには、
Filter by keywordフィールドにキーワードを入力します。 - All projects ドロップダウンメニューからテンプレートプロジェクトを選択するか、すべてのプロジェクトを表示します。
-
特定のテンプレートに焦点を合わせるには、
テンプレートタイルをクリックして詳細を表示します。
- オプション: Windows テンプレートを使用している場合は、Mount Windows drivers disk チェックボックスを選択することで、Windows ドライバーディスクをマウントできます。
- テンプレートまたは仮想マシンパラメーターをカスタマイズする必要がない場合は、Quick create VirtualMachine をクリックして、テンプレートから仮想マシンを作成します。
テンプレートまたは仮想マシンパラメーターをカスタマイズする必要がある場合は、次の手順を実行します。
- Customize VirtualMachine をクリックします。Customize and create VirtualMachine ペインには、Overview、YAML、Scheduling、Environment、Network interfaces、Disks、Scripts、および Metadata タブが表示されます。
-
Scripts タブをクリックして、
Cloud-init、SSH key、Sysprep(Windows 仮想マシンのみ) など、仮想マシンの起動前に設定する必要があるパラメーターを編集します。 - オプション: Start this virtualmachine after creation (Always) チェックボックスをクリックします。
Create VirtualMachine をクリックします。
VirtualMachine details ページには、プロビジョニングステータスが表示されます。
6.2.3. Web コンソールを使用してカスタマイズされた仮想マシンテンプレートから非推奨の指定を削除する
仮想マシンを起動する前に、データソース、cloud-init、SSH 鍵など、仮想マシンまたはテンプレートのパラメーターを変更することで、既存の仮想マシン (VM) テンプレートをカスタマイズできます。テンプレートをコピーし、すべてのラベルとアノテーションを含めてテンプレートをカスタマイズすると、新しいバージョンの Scheduling、Scale、and Performance (SSP) Operator がデプロイされたときに、カスタマイズしたテンプレートが非推奨に指定されます。
この非推奨の指定は、カスタマイズしたテンプレートから削除できます。
手順
- Web コンソールで Virtualization → Templates に移動します。
- 仮想マシンテンプレートのリストから、非推奨とマークされているテンプレートをクリックします。
- Labels の近くにある鉛筆アイコンの横にある Edit をクリックします。
次の 2 つのラベルを削除します。
-
template.kubevirt.io/type: "base" -
template.kubevirt.io/version: "version"
-
- Save をクリックします。
- 既存の Annotations の数の横にある鉛筆アイコンをクリックします。
次のアノテーションを削除します。
-
template.kubevirt.io/deprecated
-
- Save をクリックします。
6.2.4. Web コンソールでのカスタム仮想マシンテンプレートの作成
Red Hat OpenShift Service on AWS Web コンソールで YAML ファイルの例を編集して、仮想マシンテンプレートを作成できます。
手順
- Web コンソールのサイドメニューで、Virtualization → Templates をクリックします。
-
オプション: Project ドロップダウンメニューを使用して、新しいテンプレートに関連付けられたプロジェクトを変更します。すべてのテンプレートは、デフォルトで
openshiftプロジェクトに保存されます。 - Create Template をクリックします。
- YAML ファイルを編集して、テンプレートパラメーターを指定します。
Create をクリックします。
テンプレートが Templates ページに表示されます。
- オプション: Download をクリックして、YAML ファイルをダウンロードして保存します。
6.2.5. カスタム namespace へのテンプレートの追加
Scheduling, Scale, and Performance (SSP) Operator は、デフォルトで仮想マシンテンプレートを openshift namespace にデプロイします。これらのテンプレートをカスタム namespace でも公開するには、HyperConverged カスタムリソース (CR) の commonTemplatesNamespace フィールドを設定します。テンプレートがカスタム namespace に同期されたら、そこでテンプレートを変更または削除できます。
openshift namespace 内のテンプレートは編集しないでください。この namespace は SSP Operator によってリコンサイルされ、変更が上書きされます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - cluster-admin 権限を持つユーザーとしてログインしている。
手順
オプション: カスタム namespace がまだ存在しない場合は作成します。
oc create namespace <custom_namespace>
$ oc create namespace <custom_namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow オプション:
openshiftnamespace 内のテンプレートのリストを表示します。oc get templates -n openshift
$ oc get templates -n openshiftCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。oc edit hco -n openshift-cnv kubevirt-hyperconverged
$ oc edit hco -n openshift-cnv kubevirt-hyperconvergedCopy to Clipboard Copied! Toggle word wrap Toggle overflow commonTemplatesNamespaceフィールドを追加し、ターゲット namespace を設定します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 保存して終了します。SSP Operator により、カスタム namespace 内でテンプレートが作成または更新されます。
カスタム namespace 内のテンプレートを検証します。
oc get templates -n <custom_namespace>
$ oc get templates -n <custom_namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.2.6. カスタム namespace からのテンプレートの削除
カスタム namespace から仮想マシンテンプレートを削除するには、HyperConverged カスタムリソース (CR) から commonTemplateNamespace 属性を削除し、そのカスタム namespace から各テンプレートを削除します。
手順
以下のコマンドを実行して、デフォルトエディターで
HyperConvergedCR を編集します。oc edit hco -n openshift-cnv kubevirt-hyperconverged
$ oc edit hco -n openshift-cnv kubevirt-hyperconvergedCopy to Clipboard Copied! Toggle word wrap Toggle overflow commonTemplateNamespace属性を削除します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow HyperConvergedCR から削除したカスタム namespace から、特定のテンプレートを削除します。oc delete templates -n <custom_namespace> <template_name>
$ oc delete templates -n <custom_namespace> <template_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
テンプレートがカスタム namespace から削除されたことを確認します。
oc get templates -n <custom_namespace>
$ oc get templates -n <custom_namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
第7章 高度な仮想マシンの作成
7.1. Red Hat イメージからの仮想マシンの作成
7.1.1. Red Hat イメージから仮想マシンを作成する
Red Hat イメージは ゴールデンイメージ です。これらは、セキュアなレジストリー内のコンテナーディスクとして公開されます。Containerized Data Importer (CDI) は、コンテナーディスクをポーリングしてクラスターにインポートし、スナップショットまたは永続ボリュームクレーム (PVC) として openshift-virtualization-os-images プロジェクトに保存します。オプションで、ゴールデンイメージにカスタム namespace を使用できます。カスタム名前空間の使用の詳細は、次を参照してください。
Red Hat イメージは自動的に更新されます。これらのイメージの自動更新を無効にして再度有効にすることができます。Red Hat ブートソースの更新の管理 を参照してください。
クラスター管理者は、OpenShift Virtualization Web コンソール で Red Hat Enterprise Linux (RHEL) 仮想マシンの自動サブスクリプションを有効にできるようになりました。
次のいずれかの方法を使用して、Red Hat が提供するオペレーティングシステムイメージから仮想マシンを作成できます。
デフォルトの openshift-* namespace に仮想マシンを作成しないでください。代わりに、openshift 接頭辞なしの新規 namespace を作成するか、既存 namespace を使用します。
7.1.1.1. ゴールデンイメージについて
ゴールデンイメージは、新しい仮想マシンをデプロイメントするためのリソースとして使用できる、仮想マシンの事前設定されたスナップショットです。たとえば、ゴールデンイメージを使用すると、同じシステム環境を一貫してプロビジョニングし、システムをより迅速かつ効率的にデプロイメントできます。
7.1.1.1.1. ゴールデンイメージはどのように機能しますか?
ゴールデンイメージは、リファレンスマシンまたは仮想マシンにオペレーティングシステムとソフトウェアアプリケーションをインストールして設定することによって作成されます。これには、システムのセットアップ、必要なドライバーのインストール、パッチと更新の適用、特定のオプションと設定の指定が含まれます。
ゴールデンイメージは、作成後、複数のクラスターに複製してデプロイできるテンプレートまたはイメージファイルとして保存されます。ゴールデンイメージは、メンテナーによって定期的に更新されて、必要なソフトウェア更新とパッチが組み込まれるため、イメージが最新かつセキュアな状態に保たれ、新しく作成された仮想マシンはこの更新されたイメージに基づいています。
7.1.1.1.2. Red Hat のゴールデンイメージの実装
Red Hat は、Red Hat Enterprise Linux (RHEL) のバージョンのレジストリー内のコンテナーディスクとしてゴールデンイメージを公開します。コンテナーディスクは、コンテナーイメージレジストリーにコンテナーイメージとして保存される仮想マシンイメージです。公開されたイメージは、OpenShift Virtualization のインストール後に、接続されたクラスターで自動的に使用できるようになります。イメージがクラスター内で使用可能になると、仮想マシンの作成に使用できるようになります。
7.1.1.2. 仮想マシンブートソースについて
仮想マシンは、仮想マシン定義と、データボリュームによってバックアップされる 1 つ以上のディスクで構成されます。仮想マシンテンプレートを使用すると、事前定義された仕様を使用して仮想マシンを作成できます。
すべてのテンプレートにはブートソースが必要です。ブートソースは、設定されたドライバーを含む完全に設定されたディスクイメージです。各テンプレートには、ブートソースへのポインターを含む仮想マシン定義が含まれています。各ブートソースには、事前に定義された名前および namespace があります。オペレーティングシステムによっては、ブートソースは自動的に提供されます。これが提供されない場合、管理者はカスタムブートソースを準備する必要があります。
提供されたブートソースは、オペレーティングシステムの最新バージョンに自動的に更新されます。自動更新されるブートソースの場合、永続ボリュームクレーム (PVC) とボリュームスナップショットはクラスターのデフォルトストレージクラスで作成されます。設定後に別のデフォルトストレージクラスを選択した場合は、以前のデフォルトストレージクラスで設定されたクラスター namespace 内の既存のブートソースを削除する必要があります。
7.1.1.3. Web コンソールを使用したゴールデンイメージのカスタム namespace の設定
Red Hat OpenShift Service on AWS Web コンソールを使用して、クラスター内のゴールデンイメージのカスタム namespace を設定できます。
手順
- Web コンソールで、Virtualization → Overview を選択します。
- Settings タブを選択します。
- Cluster タブで、General settings → Bootable volumes project を選択します。
ゴールデンイメージに使用する namespace を選択します。
- すでに namespace を作成している場合は、Project リストから選択します。
namespace を作成していない場合は、リストの一番下までスクロールして Create project をクリックします。
- Create project ダイアログの Name フィールドに新しい namespace の名前を入力します。
- Create をクリックします。
7.1.1.4. CLI を使用したゴールデンイメージのカスタム namespace の設定
HyperConverged カスタムリソース (CR) の spec.commonBootImageNamespace フィールドを設定することで、クラスター内のゴールデンイメージのカスタム namespace を設定できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - ゴールデンイメージに使用する namespace を作成した。
手順
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow spec.commonBootImageNamespaceフィールドの値を更新して、カスタム namespace を設定します。設定ファイルの例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- ゴールデンイメージに使用する namespace。
- 変更を保存し、エディターを終了します。
7.1.2. 異種クラスターのサポート
異種クラスターのゴールデンイメージのサポートは、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、以下のリンクを参照してください。
異種クラスターとは、ノードが異なるアーキテクチャーを持つクラスターのことです。異種クラスターは、1 つのクラスター内に異なるタイプのハードウェアを混在させることにより、コンピュートリソースの最適な使用を促進します。これにより、汎用コンピュートプラットフォームではなく、ワークロードタスク用のハードウェアにワークロードをより適切に適合させることができます。たとえば、異種クラスターでは、GPU と汎用コンピュートリソースを組み合わせて、ワークロードを適切なハードウェアに割り当てることができます。
ゴールデンイメージのサポートが異種クラスターで無効になっていると、ノードとイメージアーキテクチャー間で不整合が生じる可能性があります。これは、ノードアーキテクチャーと一致しないイメージが仮想マシンの作成に使用された場合に発生します。これにより、仮想マシンの起動が失敗したり、仮想マシンが期待どおりに実行されなくなったりする可能性があります。異種クラスターでこの機能が有効になっていない場合、警告レベルのアラート HCOMultiArchGoldenImagesDisabled が生成されます。
異種クラスターを使用していても、複数アーキテクチャーのサポートを有効にする必要がない場合は、異種クラスター内のワークロードノードの配置を変更する で、ノードの配置を特定のアーキテクチャーに制限する手順を参照してください。
異種クラスターのゴールデンイメージサポートは、次のエリアでゴールデンイメージサポートを拡張します。
- 仮想マシン作成者が、特定のアーキテクチャーで永続的な仮想マシンをデプロイできるようにします。
- 仮想マシン作成者が、異種クラスターをサポートするカスタムのゴールデンイメージを定義できるようにします。
ブートイメージが必要なアーキテクチャーをサポートしている場合は、同じゴールデンイメージを異なるアーキテクチャーのノードで使用できます。たとえば、ARM アーキテクチャーと AMD アーキテクチャーの両方をサポートするゴールデンイメージは、両方のタイプのノードで使用できます。
異種クラスターのゴールデンイメージサポートは、デフォルトでは有効になっていません。この機能を有効にする手順は、異種クラスターサポートの有効化 を参照してください。
7.1.2.1. 異種クラスターサポートの有効化
HyperConverged カスタムリソース (CR) で enableMultiArchBootImageImport フィーチャーゲートを true に設定することで、異種クラスターのゴールデンイメージサポートを有効にできます。
異種クラスターのゴールデンイメージのサポートは、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、以下のリンクを参照してください。
前提条件
-
cluster-admin権限を持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、
enableMultiArchBootImageImportフィーチャーゲートを有効にします。oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv \ --type json -p '[{"op":"replace","path":"/spec/featureGates/enableMultiArchBootImageImport", "value": true}]'$ oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv \ --type json -p '[{"op":"replace","path":"/spec/featureGates/enableMultiArchBootImageImport", "value": true}]'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
7.1.2.2. 異種クラスター内の共通のゴールデンイメージソースを変更する
HyperConverged カスタムリソース (CR) の ssp.kubevirt.io/dict.architectures アノテーションでサポートされているアーキテクチャーを指定することにより、異種クラスター内の共通ゴールデンイメージのイメージソースを変更できます。
異種クラスターのゴールデンイメージのサポートは、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、以下のリンクを参照してください。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow HyperConvergedCR を編集し、dataImportCronTemplatesセクションのssp.kubevirt.io/dict.architecturesアノテーションに適切な値を追加します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- このイメージでサポートされているアーキテクチャーのコンマ区切りリスト。たとえば、イメージが
amd64およびarm64アーキテクチャーをサポートしている場合、値は"amd64,arm64"になります。
-
エディターを保存して終了し、
HyperConvergedCR を更新します。
7.1.2.3. 異種クラスターにカスタムゴールデンイメージを追加する
異種クラスターのゴールデンイメージのサポートは、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、以下のリンクを参照してください。
HyperConverged カスタムリソース (CR) の spec.dataImportCronTemplates.metadata.annotations スタンザに ssp.kubevirt.io/dict.architectures アノテーションを設定して、異種クラスターにカスタムゴールデンイメージを追加します。このアノテーションには、イメージでサポートされているアーキテクチャーがリストされます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow HyperConvergedCR を編集して、カスタムゴールデンイメージを追加します。dataImportCronTemplatesセクションにssp.kubevirt.io/dict.architecturesアノテーションに適切な値を追加する必要があります。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- このイメージでサポートされているアーキテクチャーのコンマ区切りリスト。たとえば、イメージが
amd64およびarm64アーキテクチャーをサポートしている場合、値は"amd64,arm64"になります。
注記イメージは、クラスターで使用するよりも多くのアーキテクチャーをサポートしている場合があります。イメージがサポートするすべてのアーキテクチャーをリストする必要はなく、ブートソースを作成するアーキテクチャーのみをリストします。
-
エディターを保存して終了し、
HyperConvergedCR を更新します。
7.1.2.4. 異種クラスター内のワークロードノードの配置を変更する
異種クラスターのゴールデンイメージのサポートは、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、以下のリンクを参照してください。
異機種混合クラスターがあり、複数のアーキテクチャーのサポートを有効にしたくない場合は、HyperConverged カスタムリソース (CR) 内のワークロードノードの配置を変更して、特定のアーキテクチャーのノードのみを含めることができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow HyperConvergedCR を編集してワークロードのノードの配置を変更し、特定のアーキテクチャーを持つノードのみを含めます。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
<node_architecture>は、ターゲットアーキテクチャーに置き換えます。たとえば、配置を AMD ノードに制限するには、amd64を使用します。
-
エディターを保存して終了し、
HyperConvergedCR を更新します。
7.2. Web コンソールでの仮想マシンの作成
7.2.1. Web ページからイメージをインポートして仮想マシンを作成する
Web ページからオペレーティングシステムイメージをインポートすることで、仮想マシンを作成できます。
Red Hat が提供していないオペレーティングシステムイメージから作成された仮想マシンには、QEMU ゲストエージェント をインストールする必要があります。
7.2.1.1. Web コンソールを使用して Web ページ上のイメージから仮想マシンを作成する
Red Hat OpenShift Service on AWS Web コンソールを使用して Web ページからイメージをインポートすることで、仮想マシン (VM) を作成できます。
前提条件
- イメージを含む Web ページにアクセスできる。
手順
- Web コンソールで Virtualization → Catalog に移動します。
- 使用可能なブートソースのないテンプレートタイルをクリックします。
- Customize VirtualMachine をクリックします。
- Customize template parameters ページで、Storage を展開し、Disk source リストから URL (creates PVC) を選択します。
-
イメージの URL を入力します。例:
https://access.redhat.com/downloads/content/69/ver=/rhel---7/7.9/x86_64/product-software - ディスクサイズを設定します。
- Next をクリックします。
- Create VirtualMachine をクリックします。
7.2.1.2. CLI を使用して Web ページ上のイメージから仮想マシンを作成する
コマンドラインを使用して、Web ページ上のイメージから仮想マシンを作成できます。
仮想マシンが作成されると、イメージを含むデータボリュームが永続ストレージにインポートされます。
前提条件
- イメージが含まれている Web ページへのアクセス認証情報を持っている。
-
virtctlCLI がインストールされている。 -
OpenShift CLI (
oc) がインストールされている。
手順
仮想マシンの
VirtualMachineマニフェストを作成し、YAML ファイルとして保存します。たとえば、Web ページ上のイメージから最小限の Red Hat Enterprise Linux (RHEL) 仮想マシンを作成するには、次のコマンドを実行します。virtctl create vm --name vm-rhel-9 --instancetype u1.small --preference rhel.9 --volume-import type:http,url:https://example.com/rhel9.qcow2,size:10Gi
$ virtctl create vm --name vm-rhel-9 --instancetype u1.small --preference rhel.9 --volume-import type:http,url:https://example.com/rhel9.qcow2,size:10GiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 仮想マシンの
VirtualMachineマニフェストを確認します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して VM を作成します。
oc create -f <vm_manifest_file>.yaml
$ oc create -f <vm_manifest_file>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc createコマンドは、データボリュームと仮想マシンを作成します。CDI コントローラーは適切なアノテーションを使用して基礎となる PVC を作成し、インポートプロセスが開始されます。インポートが完了すると、データボリュームのステータスがSucceededに変わります。仮想マシンを起動できます。データボリュームのプロビジョニングはバックグランドで実行されるため、これをプロセスをモニターする必要はありません。
検証
インポーター Pod は、指定された URL からイメージをダウンロードし、プロビジョニングされた永続ボリュームに保存します。インポーター Pod のステータスを表示します。
oc get pods
$ oc get podsCopy to Clipboard Copied! Toggle word wrap Toggle overflow データボリュームの状態を監視します。
oc get dv <data_volume_name>
$ oc get dv <data_volume_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow プロビジョニングが成功すると、データボリュームのフェーズが
Succeededになります。出力例:
NAME PHASE PROGRESS RESTARTS AGE imported-volume-6dcpf Succeeded 100.0% 18s
NAME PHASE PROGRESS RESTARTS AGE imported-volume-6dcpf Succeeded 100.0% 18sCopy to Clipboard Copied! Toggle word wrap Toggle overflow プロビジョニングが完了し、シリアルコンソールにアクセスして仮想マシンが起動したことを確認します。
virtctl console <vm_name>
$ virtctl console <vm_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 仮想マシンが実行中でシリアルコンソールにアクセスできる場合、出力は次のようになります。
Successfully connected to vm-rhel-9 console. The escape sequence is ^]
Successfully connected to vm-rhel-9 console. The escape sequence is ^]Copy to Clipboard Copied! Toggle word wrap Toggle overflow
7.2.2. イメージをアップロードして仮想マシンを作成する
ローカルマシンからオペレーティングシステムイメージをアップロードすることで、仮想マシンを作成できます。
Windows イメージを PVC にアップロードすることで、Windows 仮想マシンを作成できます。次に、仮想マシンの作成時に PVC のクローンを作成します。
Red Hat が提供していないオペレーティングシステムイメージから作成された仮想マシンには、QEMU ゲストエージェント をインストールする必要があります。
Windows 仮想マシンにも VirtIO ドライバー をインストールする必要があります。
7.2.2.1. Web コンソールを使用して、アップロードされたイメージから仮想マシンを作成する
Red Hat OpenShift Service on AWS Web コンソールを使用して、アップロードされたオペレーティングシステムイメージから仮想マシン (VM) を作成できます。
前提条件
-
IMG、ISO、またはQCOW2イメージファイルが必要です。
手順
- Web コンソールで Virtualization → Catalog に移動します。
- 使用可能なブートソースのないテンプレートタイルをクリックします。
- Customize VirtualMachine をクリックします。
- Customize template parameters ページで、Storage を展開し、Disk source リストから Upload (Upload a new file to a PVC) を選択します。
- ローカルマシン上のイメージを参照し、ディスクサイズを設定します。
- Customize VirtualMachine をクリックします。
- Create VirtualMachine をクリックします。
7.2.2.1.1. 仮想マシンイメージの一般化
システム固有の設定データをすべて削除して Red Hat Enterprise Linux (RHEL) イメージを一般化してから、そのイメージを使用してゴールデンイメージ (仮想マシンの事前設定済みスナップショット) を作成できます。ゴールデンイメージを使用して新しい仮想マシンをデプロイできます。
virtctl、guestfs、virt-sysprep ツールを使用して、RHEL 仮想マシンを一般化できます。
前提条件
- ベースの仮想マシンとして使用する RHEL 仮想マシンがある。
-
OpenShift CLI (
oc) がインストールされている。 -
virtctlツールがインストールされている。
手順
実行中の RHEL 仮想マシンを停止するには、次のコマンドを入力します。
virtctl stop <my_vm_name>
$ virtctl stop <my_vm_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - オプション: 元の仮想マシンのデータが失われないように、仮想マシンのクローンを作成します。その後、クローンの仮想マシンを一般化できます。
次のコマンドを実行して、仮想マシンのルートファイルシステムを格納する
dataVolumeを取得します。oc get vm <my_vm_name> -o jsonpath="{.spec.template.spec.volumes}{'\n'}"$ oc get vm <my_vm_name> -o jsonpath="{.spec.template.spec.volumes}{'\n'}"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
[{"dataVolume":{"name":"<my_vm_volume>"},"name":"rootdisk"},{"cloudInitNoCloud":{...}][{"dataVolume":{"name":"<my_vm_volume>"},"name":"rootdisk"},{"cloudInitNoCloud":{...}]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して、リストされた
dataVolumeに一致する永続ボリューム要求 (PVC) を取得します。oc get pvc
$ oc get pvcCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE <my_vm_volume> Bound …
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE <my_vm_volume> Bound …Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記クラスター設定により仮想マシンを複製できない場合は、元の仮想マシンのデータが失われないように、代わりに仮想マシン PVC をデータボリュームに複製できます。その後、複製した PVC を使用してゴールデンイメージを作成できます。
PVC を複製してゴールデンイメージを作成する場合は、複製された PVC を使用して次の手順に進みます。
libguestfs-toolsを使用して新しいインタラクティブコンテナーをデプロイし、次のコマンドを実行して PVC をそれにアタッチします。virtctl guestfs <my-vm-volume> --uid 107
$ virtctl guestfs <my-vm-volume> --uid 107Copy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、次のコマンドを実行するためのシェルを開きます。
次のコマンドを実行して、システム固有のすべての設定を削除します。
virt-sysprep -a disk.img
$ virt-sysprep -a disk.imgCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Red Hat OpenShift Service on AWS コンソールで、Virtualization → Catalog をクリックします。
- Add volume をクリックします。
Add volume ウィンドウで、以下を実行します。
- Source type リストから、Use existing Volume を選択します。
- Volume project リストからプロジェクトを選択します。
- Volume name リストから正しい PVC を選択します。
- Volume name フィールドに、新しいゴールデンイメージの名前を入力します。
- Preference リストから、使用している RHEL バージョンを選択します。
- Default Instance Type リストから、以前に選択した RHEL バージョンに適した CPU とメモリーの要件を持つインスタンスタイプを選択します。
- 異種クラスターのみ: Architecture リストから、選択したボリュームに対応するアーキテクチャーを選択します。
- Save をクリックします。
結果
新しいボリュームが Select volume to boot from リストに表示されます。これが新しいゴールデンイメージです。このボリュームを使用して新しい仮想マシンを作成できます。
7.2.2.2. Windows 仮想マシンの作成
Windows 仮想マシン (VM) を作成するには、Windows イメージを永続ボリューム要求 (PVC) にアップロードし、Red Hat OpenShift Service on AWS Web コンソールを使用した仮想マシンの作成時に PVC のクローンを作成します。
前提条件
- Windows Media Creation Tool を使用して Windows インストール DVD または USB が作成されている。Microsoft ドキュメントの Create Windows 10 installation media を参照してください。
-
autounattend.xmlアンサーファイルを作成しました。Microsoft ドキュメントの Answer files (unattend.xml) を参照してください。
手順
Windows イメージを新しい PVC としてアップロードします。
- Web コンソールで Storage → PersistentVolumeClaims に移動します。
- Create PersistentVolumeClaim → With Data upload form をクリックします。
- Windows イメージを参照して選択します。
PVC 名を入力し、ストレージクラスとサイズを選択して、Upload をクリックします。
Windows イメージは PVC にアップロードされます。
アップロードされた PVC のクローンを作成して、新しい仮想マシンを設定します。
- Virtualization → Catalog に移動します。
- Windows テンプレートタイルを選択し、Customize VirtualMachine をクリックします。
- Disk source リストから Clone (clone PVC) を選択します。
- PVC プロジェクト、Windows イメージ PVC、およびディスクサイズを選択します。
アンサーファイルを仮想マシンに適用します。
- VirtualMachine パラメーターのカスタマイズ をクリックします。
- Scripts タブの Sysprep セクションで、Edit をクリックします。
-
autounattend.xml応答ファイルを参照し、Save をクリックします。
仮想マシンの実行ストラテジーを設定します。
- 仮想マシンがすぐに起動しないように、Start this VirtualMachine after creation をオフにします。
- Create VirtualMachine をクリックします。
-
YAML タブで、
running:falseをrunStrategy: RerunOnFailureに置き換え、Save をクリックします。
Options メニュー
をクリックして Start を選択します。
仮想マシンは、
autounattend.xmlアンサーファイルを含むsysprepディスクから起動します。
7.2.2.2.1. Windows 仮想マシンイメージの一般化
Windows オペレーティングシステムイメージを一般化して、イメージを使用して新しい仮想マシンを作成する前に、システム固有の設定データをすべて削除できます。
仮想マシンを一般化する前に、Windows の無人インストール後に sysprep ツールが応答ファイルを検出できないことを確認する必要があります。
前提条件
- QEMU ゲストエージェントがインストールされた実行中の Windows 仮想マシン。
手順
- Red Hat OpenShift Service on AWS コンソールで、Virtualization → VirtualMachines をクリックします。
- Windows 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Configuration → Disks をクリックします。
-
sysprepディスクの横にある Options メニュー
をクリックし、Detach を選択します。
- Detach をクリックします。
-
sysprepツールによる検出を回避するために、C:\Windows\Panther\unattend.xmlの名前を変更します。 次のコマンドを実行して、
sysprepプログラムを開始します。%WINDIR%\System32\Sysprep\sysprep.exe /generalize /shutdown /oobe /mode:vm
%WINDIR%\System32\Sysprep\sysprep.exe /generalize /shutdown /oobe /mode:vmCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
sysprepツールが完了すると、Windows 仮想マシンがシャットダウンします。これで、仮想マシンのディスクイメージを Windows 仮想マシンのインストールイメージとして使用できるようになりました。
結果
これで、仮想マシンを特殊化できます。
7.2.2.2.2. Windows 仮想マシンイメージの特殊化
Windows 仮想マシンを特殊化すると、一般化された Windows イメージから VM にコンピューター固有の情報が設定されます。
前提条件
- 一般化された Windows ディスクイメージが必要です。
-
unattend.xml応答ファイルを作成する必要があります。詳細は、Microsoft のドキュメント を参照してください。
手順
- Red Hat OpenShift Service on AWS コンソールで、Virtualization → Catalog をクリックします。
- Windows テンプレートを選択し、Customize VirtualMachine をクリックします。
- Disk source リストから PVC (clone PVC) を選択します。
- 一般化された Windows イメージの PVC プロジェクトと PVC 名を選択します。
- VirtualMachine パラメーターのカスタマイズ をクリックします。
- Scripts タブをクリックします。
-
Sysprep セクションで、Edit をクリックし、
unattend.xml応答ファイルを参照して、Save をクリックします。 - Create VirtualMachine をクリックします。
結果
Windows は初回起動時に、unattend.xml 応答ファイルを使用して VM を特殊化します。これで、仮想マシンを使用する準備が整いました。
7.2.2.3. CLI を使用してアップロードしたイメージから仮想マシンを作成する
virtctl コマンドラインツールを使用して、オペレーティングシステムイメージをアップロードできます。既存のデータボリュームを使用することも、イメージ用に新しいデータボリュームを作成することもできます。
前提条件
-
ISO、IMG、またはQCOW2オペレーティングシステムイメージファイルがある。 -
最高のパフォーマンスを得るには、virt-sparsify ツールまたは
xzユーティリティーまたはgzipユーティリティーを使用してイメージファイルを圧縮しておく。 - クライアントマシンは、Red Hat OpenShift Service on AWS ルーターの証明書を信頼するように設定する必要があります。
-
virtctlCLI がインストールされている。 -
OpenShift CLI (
oc) がインストールされている。
手順
virtctl image-uploadコマンドを実行してイメージをアップロードします。virtctl image-upload dv <datavolume_name> \ --size=<datavolume_size> \ --image-path=</path/to/image> \
$ virtctl image-upload dv <datavolume_name> \1 --size=<datavolume_size> \2 --image-path=</path/to/image> \3 Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記-
新規データボリュームを作成する必要がない場合は、
--sizeパラメーターを省略し、--no-createフラグを含めます。 - ディスクイメージを PVC にアップロードする場合、PVC サイズは圧縮されていない仮想ディスクのサイズよりも大きくなければなりません。
-
HTTPS を使用したセキュアでないサーバー接続を許可するには、
--insecureパラメーターを使用します。--insecureフラグを使用する際に、アップロードエンドポイントの信頼性は検証 されない 点に注意してください。
-
新規データボリュームを作成する必要がない場合は、
オプション: データボリュームが作成されたことを確認するには、以下のコマンドを実行してすべてのデータボリュームを表示します。
oc get dvs
$ oc get dvsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
7.2.3. 仮想マシンのクローン作成
仮想マシンのクローンを作成するか、スナップショットから新しい仮想マシンを作成できます。
vTPM デバイスがアタッチされた仮想マシンのクローン作成や、そのスナップショットからの新しい仮想マシンの作成は、サポートされていません。
7.2.3.1. Web コンソールを使用して仮想マシンを複製する
Web コンソールを使用して、既存の仮想マシンを複製できます。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
Actions をクリックします。
または、仮想マシンを右クリックして、ツリービューで同じメニューにアクセスします。
- Clone を選択します。
- Clone VirtualMachine ページで、新しい仮想マシンの名前を入力します。
- (オプション) Start cloned VM チェックボックスを選択して、複製された仮想マシンを開始します。
- Clone をクリックします。
7.2.3.2. Web コンソールを使用して既存のスナップショットから仮想マシンを作成する
既存のスナップショットをコピーすることで、新しい仮想マシンを作成できます。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Snapshots タブをクリックします。
-
コピーするスナップショットの Options メニュー
をクリックします。
- Create VirtualMachine を選択します。
- 仮想マシンの名前を入力します。
- (オプション) Start this VirtualMachine after creation チェックボックスを選択して、新しい仮想マシンを起動します。
- Create をクリックします。
7.3. CLI を使用した仮想マシンの作成
7.3.1. CLI からの仮想マシンの作成
VirtualMachine マニフェストを編集または作成することで、コマンドラインから仮想マシン (VM) を作成できます。仮想マシンマニフェストで インスタンスタイプ を使用すると、仮想マシン設定を簡素化できます。
Web コンソールを使用してインスタンスタイプから仮想マシンを作成 することもできます。
7.3.1.1. VirtualMachine マニフェストからの仮想マシンの作成
VirtualMachine マニフェストから仮想マシンを作成できます。これらのマニフェストの作成を簡素化するには、virtctl コマンドラインツールを使用できます。
前提条件
-
virtctlCLI がインストールされている。 -
OpenShift CLI (
oc) がインストールされている。
手順
仮想マシンの
VirtualMachineマニフェストを作成し、YAML ファイルとして保存します。たとえば、最小限の Red Hat Enterprise Linux (RHEL) 仮想マシンを作成するには、次のコマンドを実行します。virtctl create vm --name rhel-9-minimal --volume-import type:ds,src:openshift-virtualization-os-images/rhel9
$ virtctl create vm --name rhel-9-minimal --volume-import type:ds,src:openshift-virtualization-os-images/rhel9Copy to Clipboard Copied! Toggle word wrap Toggle overflow 仮想マシンの
VirtualMachineマニフェストを確認します。注記このサンプルマニフェストでは、仮想マシン認証は設定されません。
RHEL 仮想マシンのマニフェストの例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow マニフェストファイルを使用して仮想マシンを作成します。
oc create -f <vm_manifest_file>.yaml
$ oc create -f <vm_manifest_file>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow オプション: 仮想マシンを起動します。
virtctl start <vm_name>
$ virtctl start <vm_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
次のステップ
7.3.2. コンテナーディスクを使用した仮想マシンの作成
オペレーティングシステムイメージから構築されたコンテナーディスクを使用して、仮想マシンを作成できます。
コンテナーディスクの自動更新を有効にすることができます。詳細は、ブートソースの自動更新の管理 を参照してください。
コンテナーディスクが大きい場合は、I/O トラフィックが増加し、ワーカーノードが使用できなくなる可能性があります。この問題を解決するには、DeploymentConfig オブジェクトを削除します。
次の手順を実行して、コンテナーディスクから仮想マシンを作成します。
- オペレーティングシステムイメージをコンテナーディスクに構築し、それをコンテナーレジストリーにアップロードします。
- コンテナーレジストリーに TLS がない場合は、レジストリーの TLS を無効にするように環境を設定します。
- Web コンソール または コマンドライン を使用して、コンテナーディスクをディスクソースとして使用する仮想マシンを作成します。
Red Hat が提供していないオペレーティングシステムイメージから作成された仮想マシンには、QEMU ゲストエージェント をインストールする必要があります。
7.3.2.1. コンテナーディスクの構築とアップロード
仮想マシンイメージをコンテナーディスクに構築し、レジストリーにアップロードできます。
コンテナーディスクのサイズは、コンテナーディスクがホストされているレジストリーの最大レイヤーサイズによって制限されます。
Red Hat Quay の場合、Red Hat Quay の初回デプロイ時に作成される YAML 設定ファイルを編集して、最大レイヤーサイズを変更できます。
前提条件
-
podmanがインストールされている必要があります。 - QCOW2 または RAW イメージファイルが必要です。
手順
Dockerfile を作成して、仮想マシンイメージをコンテナーイメージにビルドします。仮想マシンイメージは、UID
107を持つ QEMU によって所有され、コンテナー内の/disk/ディレクトリーに配置される必要があります。次に、/disk/ディレクトリーのパーミッションは0440に設定する必要があります。以下の例では、Red Hat Universal Base Image (UBI) を使用して最初の段階でこれらの設定変更を処理し、2 番目の段階で最小の
scratchイメージを使用して結果を保存します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
<vm_image>は、QCOW2 または RAW 形式のイメージです。リモートイメージを使用する場合は、<vm_image>.qcow2を完全な URL に置き換えます。
コンテナーをビルドし、これにタグ付けします。
podman build -t <registry>/<container_disk_name>:latest .
$ podman build -t <registry>/<container_disk_name>:latest .Copy to Clipboard Copied! Toggle word wrap Toggle overflow コンテナーイメージをレジストリーにプッシュします。
podman push <registry>/<container_disk_name>:latest
$ podman push <registry>/<container_disk_name>:latestCopy to Clipboard Copied! Toggle word wrap Toggle overflow
7.3.2.2. コンテナーレジストリーの TLS を無効にする
HyperConverged カスタムリソースの insecureRegistries フィールドを編集して、1 つ以上のコンテナーレジストリーの TLS(トランスポート層セキュリティー) を無効にできます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow セキュアでないレジストリーのリストを
spec.storageImport.insecureRegistriesフィールドに追加します。HyperConvergedカスタムリソースの例:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- このリストのサンプルを、有効なレジストリーホスト名に置き換えます。
7.3.2.3. Web コンソールを使用してコンテナーディスクから仮想マシンを作成する
Red Hat OpenShift Service on AWS Web コンソールを使用して、コンテナーレジストリーからコンテナーディスクをインポートすることで、仮想マシン (VM) を作成できます。
手順
- Web コンソールで Virtualization → Catalog に移動します。
- 使用可能なブートソースのないテンプレートタイルをクリックします。
- Customize VirtualMachine をクリックします。
- Customize template parameters ページで、Storage を展開し、Disk source リストから Registry (creates PVC) を選択します。
-
コンテナーイメージの URL を入力します。例:
https://mirror.arizona.edu/fedora/linux/releases/38/Cloud/x86_64/images/Fedora-Cloud-Base-38-1.6.x86_64.qcow2 - ディスクサイズを設定します。
- Next をクリックします。
- Create VirtualMachine をクリックします。
7.3.2.4. CLI を使用してコンテナーディスクから仮想マシンを作成する
コマンドラインを使用して、コンテナーディスクから仮想マシンを作成できます。
前提条件
- コンテナーディスクを含むコンテナーレジストリーへのアクセス認証情報が必要です。
-
virtctlCLI がインストールされている。 -
OpenShift CLI (
oc) がインストールされている。
手順
仮想マシンの
VirtualMachineマニフェストを作成し、YAML ファイルとして保存します。たとえば、コンテナーディスクから最小限の Red Hat Enterprise Linux (RHEL) 仮想マシンを作成するには、次のコマンドを実行します。virtctl create vm --name vm-rhel-9 --instancetype u1.small --preference rhel.9 --volume-containerdisk src:registry.redhat.io/rhel9/rhel-guest-image:9.5
$ virtctl create vm --name vm-rhel-9 --instancetype u1.small --preference rhel.9 --volume-containerdisk src:registry.redhat.io/rhel9/rhel-guest-image:9.5Copy to Clipboard Copied! Toggle word wrap Toggle overflow 仮想マシンの
VirtualMachineマニフェストを確認します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して VM を作成します。
oc create -f <vm_manifest_file>.yaml
$ oc create -f <vm_manifest_file>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
仮想マシンのステータスを監視します。
oc get vm <vm_name>
$ oc get vm <vm_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow プロビジョニングが成功すると、仮想マシンのステータスが
Runningになります。出力例:NAME AGE STATUS READY vm-rhel-9 18s Running True
NAME AGE STATUS READY vm-rhel-9 18s Running TrueCopy to Clipboard Copied! Toggle word wrap Toggle overflow プロビジョニングが完了し、シリアルコンソールにアクセスして仮想マシンが起動したことを確認します。
virtctl console <vm_name>
$ virtctl console <vm_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 仮想マシンが実行中でシリアルコンソールにアクセスできる場合、出力は次のようになります。
Successfully connected to vm-rhel-9 console. The escape sequence is ^]
Successfully connected to vm-rhel-9 console. The escape sequence is ^]Copy to Clipboard Copied! Toggle word wrap Toggle overflow
7.3.3. PVC のクローン作成による仮想マシンの作成
カスタムイメージを使用して既存の永続ボリューム要求 (PVC) のクローンを作成することで、仮想マシンを作成できます。
Red Hat が提供していないオペレーティングシステムイメージから作成された仮想マシンには、QEMU ゲストエージェント をインストールする必要があります。
PVC のクローンを作成するには、ソース PVC を参照するデータボリュームを作成します。
7.3.3.1. クローン作成について
データボリュームのクローンを作成する際、Containerized Data Importer (CDI) は、Container Storage Interface (CSI) クローン方式のうちの 1 つ、つまり CSI ボリュームクローニングとスマートクローニングのどちらかを選択します。どちらの方法も効率的ですが、特定の要件があります。要件が満たされていない場合、CDI はホスト支援型クローン作成を使用します。
ホスト支援型クローン作成は、最も時間がかかり、最も効率の悪いクローン作成方法ですが、他の 2 つのクローン作成方法よりも要件の数が少ないです。
7.3.3.1.1. CSI ボリュームのクローン作成
Container Storage Interface (CSI) のクローン作成では、CSI ドライバー機能を使用して、ソースデータボリュームのクローンをより効率的に作成します。
CSI ボリュームのクローン作成には次の要件があります。
- 永続ボリューム要求 (PVC) のストレージクラスをサポートする CSI ドライバーは、ボリュームのクローン作成をサポートする必要があります。
-
CDI によって認識されないプロビジョナーの場合、対応するストレージプロファイルの
cloneStrategyが CSI Volume Cloning に設定されている必要があります。 - ソース PVC とターゲット PVC は、同じストレージクラスとボリュームモードを持つ必要があります。
-
データボリュームを作成する場合は、ソース namespace に
datavolumes/sourceリソースを作成するパーミッションが必要です。 - ソースボリュームは使用されていない状態である必要があります。
7.3.3.1.2. スマートクローン作成
スナップショット機能を備えた Container Storage Interface (CSI) プラグインが使用可能な場合、Containerized Data Importer (CDI) はスナップショットから永続ボリューム要求 (PVC) を作成し、これにより、追加の PVC の効率的なクローン作成を可能にします。
スマートクローン作成には次の要件があります。
- ストレージクラスに関連付けられたスナップショットクラスが存在する必要があります。
- ソース PVC とターゲット PVC は、同じストレージクラスとボリュームモードを持つ必要があります。
-
データボリュームを作成する場合は、ソース namespace に
datavolumes/sourceリソースを作成するパーミッションが必要です。 - ソースボリュームは使用されていない状態である必要があります。
7.3.3.1.3. ホスト支援型クローン作成
Container Storage Interface (CSI) ボリュームのクローン作成もスマートクローン作成の要件も満たされていない場合、ホスト支援型クローン作成がフォールバック方法として使用されます。ホスト支援型クローン作成は、他の 2 つのクローン作成方法と比べると効率が悪いです。
ホスト支援型クローン作成では、ソース Pod とターゲット Pod を使用して、ソースボリュームからターゲットボリュームにデータをコピーします。ターゲットの永続ボリューム要求 (PVC) には、ホスト支援型クローン作成が使用された理由を説明するフォールバック理由のアノテーションが付けられ、イベントが作成されます。
PVC ターゲットアノテーションの例:
イベントの例:
NAMESPACE LAST SEEN TYPE REASON OBJECT MESSAGE test-ns 0s Warning IncompatibleVolumeModes persistentvolumeclaim/test-target The volume modes of source and target are incompatible
NAMESPACE LAST SEEN TYPE REASON OBJECT MESSAGE
test-ns 0s Warning IncompatibleVolumeModes persistentvolumeclaim/test-target The volume modes of source and target are incompatible7.3.3.2. Web コンソールを使用した PVC からの仮想マシンの作成
Red Hat OpenShift Service on AWS Web コンソールを使用して永続ボリューム要求 (PVC) のクローンを作成し、仮想マシン (VM) を作成できます。
前提条件
- ソース PVC を含む namespace にアクセスできる。
手順
- Web コンソールで Virtualization → Catalog に移動します。
- 使用可能なブートソースのないテンプレートタイルをクリックします。
- Customize VirtualMachine をクリックします。
- テンプレートパラメーターのカスタマイズ ページで、Storage を展開し、Disk source リストから PVC (clone PVC) を選択します。
- PVC プロジェクトと PVC 名を選択します。
- ディスクサイズを設定します。
- Next をクリックします。
- Create VirtualMachine をクリックします。
7.3.3.3. CLI を使用して PVC から仮想マシンを作成する
コマンドラインを使用して既存の仮想マシンの永続ボリューム要求 (PVC) のクローンを作成することで、仮想マシンを作成できます。
次のオプションのいずれかを使用して、PVC のクローンを作成できます。
PVC を新しいデータボリュームに複製します。
この方法では、ライフサイクルが元の仮想マシンから独立したデータボリュームが作成されます。元の仮想マシンを削除しても、新しいデータボリュームやそれに関連付けられた PVC には影響しません。
dataVolumeTemplatesスタンザを含むVirtualMachineマニフェストを作成して、PVC を複製します。この方法では、ライフサイクルが元の仮想マシンに依存するデータボリュームが作成されます。元の仮想マシンを削除すると、クローン作成されたデータボリュームとそれに関連付けられた PVC も削除されます。
7.3.3.3.1. OpenShift Data Foundation における大規模なクローンパフォーマンスの最適化
OpenShift Data Foundation を使用する場合、ストレージプロファイルはデフォルトのクローン作成ストラテジーを csi-clone として設定します。ただし、次のリンクに示すように、この方法には制限があります。
永続ボリューム要求 (PVC) から一定数のクローンが作成されると、バックグラウンドでフラット化プロセスが開始され、大規模なクローン作成のパフォーマンスが大幅に低下する可能性があります。
単一のソース PVC から数百のクローンを作成する際のパフォーマンスを高めるためには、デフォルトの csi-clone ストラテジーの代わりに VolumeSnapshot クローン作成メソッドを使用します。
手順
次のコンテンツを使用して、ソースイメージの
VolumeSnapshotカスタムリソース (CR) を作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow VolumeSnapshotをDataVolume cloneのソースとして参照するためのspec.source.snapshotスタンザを追加します。spec: source: snapshot: namespace: golden-ns name: golden-volumesnapshotspec: source: snapshot: namespace: golden-ns name: golden-volumesnapshotCopy to Clipboard Copied! Toggle word wrap Toggle overflow
7.3.3.3.2. データボリュームへの PVC のクローン作成
コマンドラインを使用して、既存の仮想マシンディスクの永続ボリューム要求 (PVC) のクローンをデータボリュームに作成できます。
元のソース PVC を参照するデータボリュームを作成します。新しいデータボリュームのライフサイクルは、元の仮想マシンから独立しています。元の仮想マシンを削除しても、新しいデータボリュームやそれに関連付けられた PVC には影響しません。
異なるボリュームモード間のクローン作成は、ソース PV とターゲット PV が kubevirt コンテンツタイプに属している限り、ブロック永続ボリューム (PV) からファイルシステム PV へのクローン作成など、ホスト支援型クローン作成でサポートされます。
スマートクローン作成は、スナップショットを使用して PVC のクローンを作成するため、ホスト支援型クローン作成よりも高速かつ効率的です。スマートクローン作成は、Red Hat OpenShift Data Foundation など、スナップショットをサポートするストレージプロバイダーによってサポートされています。
異なるボリュームモード間のクローン作成は、スマートクローン作成ではサポートされていません。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - ソース PVC を含む仮想マシンの電源をオフにする必要があります。
- PVC を別の namespace に複製する場合は、ターゲットの namespace にリソースを作成するパーミッションが必要です。
スマートクローン作成の追加の前提条件:
- ストレージプロバイダーはスナップショットをサポートする必要がある。
- ソース PVC とターゲット PVC には、同じストレージプロバイダーとボリュームモードがある必要があります。
次の例に示すように、
VolumeSnapshotClassオブジェクトのdriverキーの値は、StorageClassオブジェクトのprovisionerキーの値と一致する必要があります。VolumeSnapshotClassオブジェクトの例:kind: VolumeSnapshotClass apiVersion: snapshot.storage.k8s.io/v1 driver: openshift-storage.rbd.csi.ceph.com # ...
kind: VolumeSnapshotClass apiVersion: snapshot.storage.k8s.io/v1 driver: openshift-storage.rbd.csi.ceph.com # ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow StorageClassオブジェクトの例:kind: StorageClass apiVersion: storage.k8s.io/v1 # ... provisioner: openshift-storage.rbd.csi.ceph.com
kind: StorageClass apiVersion: storage.k8s.io/v1 # ... provisioner: openshift-storage.rbd.csi.ceph.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow
手順
次の例に示すように、
DataVolumeマニフェストを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下のコマンドを実行してデータボリュームを作成します。
oc create -f <datavolume>.yaml
$ oc create -f <datavolume>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注記データ量により、PVC が準備される前に仮想マシンが起動できなくなります。PVC のクローン作成中に、新しいデータボリュームを参照する仮想マシンを作成できます。
7.3.3.3.3. データボリュームテンプレートを使用したクローン PVC からの仮想マシンの作成
データボリュームテンプレートを使用して、既存の仮想マシンの永続ボリューム要求 (PVC) のクローンを作成する仮想マシンを作成できます。この方法では、ライフサイクルが元の仮想マシンから独立したデータボリュームが作成されます。
前提条件
- ソース PVC を含む仮想マシンの電源をオフにする必要があります。
-
virtctlCLI がインストールされている。 -
OpenShift CLI (
oc) がインストールされている。
手順
仮想マシンの
VirtualMachineマニフェストを作成し、YAML ファイルとして保存します。次に例を示します。virtctl create vm --name rhel-9-clone --volume-import type:pvc,src:my-project/imported-volume-q5pr9
$ virtctl create vm --name rhel-9-clone --volume-import type:pvc,src:my-project/imported-volume-q5pr9Copy to Clipboard Copied! Toggle word wrap Toggle overflow 仮想マシンの
VirtualMachineマニフェストを確認します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow PVC のクローンが作成されたデータボリュームで仮想マシンを作成します。
oc create -f <vm_manifest_file>.yaml
$ oc create -f <vm_manifest_file>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第8章 仮想マシンの管理
8.1. 仮想マシンのリスト表示
Web コンソールまたは OpenShift CLI (oc) を使用して、利用可能な仮想マシン (VM) をリスト表示できます。
8.1.1. CLI を使用して仮想マシンをリスト表示する
OpenShift CLI (oc) を使用して、クラスター内のすべての仮想マシン (VM) をリスト表示することも、指定された namespace 内の仮想マシンにリストを制限することもできます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、クラスター内のすべての仮想マシンをリスト表示します。
oc get vms -A
$ oc get vms -ACopy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して、特定の namespace 内のすべての仮想マシンをリスト表示します。
oc get vms -n <namespace>
$ oc get vms -n <namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
8.1.2. Web コンソールを使用して仮想マシンをリスト表示する
Web コンソールを使用して、クラスター内のすべての仮想マシン (VM) をリスト表示できます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックして、クラスター内のすべてのプロジェクトと仮想マシンを含むツリービューにアクセスします。
- オプション: 表示されるプロジェクトを制限するには、ツリービューの上にある Show only projects with VirtualMachines オプションを有効にします。
- オプション: 検索バーの横にある Advanced search ボタンをクリックすると、名前、所属するプロジェクト、ラベル、割り当てられた仮想 CPU およびメモリーリソースのいずれかでさらにフィルタリングできます。
8.1.3. Web コンソールを使用して仮想マシンを整理する
さまざまなプロジェクトで仮想マシン (VM) を作成することに加え、ツリービューを使用してそれらをフォルダーに分類し、さらに整理することができます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックして、クラスター内のすべてのプロジェクトと仮想マシンを含むツリービューにアクセスします。
ユースケースに応じて、次のいずれかのアクションを実行します。
仮想マシンを同じプロジェクト内の新しいフォルダーに移動するには、以下を実行します。
- ツリービューで仮想マシンの名前を右クリックします。
- メニューから Move to folder を選択します。
- "Search folder" バーに作成するフォルダーの名前を入力します。
- ドロップダウンリストで Create folder をクリックします。
- Save をクリックします。
仮想マシンを同じプロジェクト内の既存のフォルダーに移動するには、以下を実行します。
- ツリービューで仮想マシンの名前をクリックし、同じプロジェクト内のフォルダーにドラッグします。操作が許可されている場合、仮想マシンをフォルダーの上にドラッグすると、フォルダーが緑色で強調表示されます。
仮想マシンをフォルダーからプロジェクトに移動するには、以下を実行します。
- ツリービューで仮想マシンの名前をクリックし、プロジェクト名にドラッグします。操作が許可されている場合、仮想マシンをプロジェクト上にドラッグすると、プロジェクト名が緑色で強調表示されます。
8.2. QEMU ゲストエージェントと VirtIO ドライバーのインストール
QEMU ゲストエージェントは、仮想マシンで実行され、仮想マシン、ユーザー、ファイルシステム、およびセカンダリーネットワークに関する情報をホストに渡すデーモンです。
Red Hat が提供していないオペレーティングシステムイメージから作成された仮想マシンには、QEMU ゲストエージェントをインストールする必要があります。
8.2.1. QEMU ゲストエージェントのインストール
8.2.1.1. Linux 仮想マシンへの QEMU ゲストエージェントのインストール
qemu-guest-agent は、Red Hat Enterprise Linux (RHEL) 仮想マシン (VM) でデフォルトで使用できます。Running 状態の仮想マシンのスナップショットを最高の整合性で作成するには、QEMU ゲストエージェントをインストールします。
QEMU ゲストエージェントは、仮想マシンファイルシステムの静止を試みることで、一貫性のあるスナップショットを取得します。これにより、スナップショットの作成前にインフライトの I/O がディスクに書き込まれるようになります。ゲストエージェントが存在しない場合は、静止はできず、ベストエフォートスナップショットが作成されます。
スナップショットの作成条件は、Web コンソールまたは CLI に表示されるスナップショットの指示に反映されます。これらの条件が要件を満たさない場合は、スナップショットを再度作成するか、オフラインスナップショットを使用します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
- コンソールまたは SSH を使用して仮想マシンにログインします。
次のコマンドを実行して、QEMU ゲストエージェントをインストールします。
yum install -y qemu-guest-agent
$ yum install -y qemu-guest-agentCopy to Clipboard Copied! Toggle word wrap Toggle overflow サービスに永続性があることを確認し、これを起動します。
systemctl enable --now qemu-guest-agent
$ systemctl enable --now qemu-guest-agentCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
次のコマンドを実行して、
AgentConnectedが仮想マシンの spec にリストされていることを確認します。oc get vm <vm_name>
$ oc get vm <vm_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
8.2.1.2. Windows 仮想マシンへの QEMU ゲストエージェントのインストール
Windows 仮想マシンの場合には、QEMU ゲストエージェントは VirtIO ドライバーに含まれます。ドライバーは、Windows のインストール中または既存の Windows 仮想マシンにインストールできます。
Running 状態の仮想マシンのスナップショットを最高の整合性で作成するには、QEMU ゲストエージェントをインストールします。
QEMU ゲストエージェントは、仮想マシンファイルシステムの静止を試みることで、一貫性のあるスナップショットを取得します。これにより、スナップショットの作成前にインフライトの I/O がディスクに書き込まれるようになります。ゲストエージェントが存在しない場合は、静止はできず、ベストエフォートスナップショットが作成されます。
Windows ゲストオペレーティングシステムでは、静止処理には Volume Shadow Copy Service (VSS) も必要である点に注意してください。したがって、スナップショットを作成する前に、仮想マシンでも VSS が有効になっていることを確認してください。
スナップショットの作成条件は、Web コンソールまたは CLI に表示されるスナップショットの指示に反映されます。これらの条件が要件を満たさない場合は、スナップショットを再度作成するか、オフラインスナップショットを使用します。
手順
-
Windows ゲストオペレーティングシステムで、File Explorer を使用して、
virtio-winCD ドライブのguest-agentディレクトリーに移動します。 -
qemu-ga-x86_64.msiインストーラーを実行します。
検証
次のコマンドを実行して、ネットワークサービスのリストを取得します。
net start
$ net startCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
出力に
QEMU Guest Agentが含まれていることを確認します。
8.2.2. Windows 仮想マシンへの VirtIO ドライバーのインストール
VirtIO ドライバーは、Microsoft Windows 仮想マシンが OpenShift Virtualization で実行されるために必要な準仮想化デバイスドライバーです。ドライバーは残りのイメージと同梱されるされるため、個別にダウンロードする必要はありません。
container-native-virtualization/virtio-win コンテナーディスクは、ドライバーのインストールを有効にするために SATA CD ドライブとして仮想マシンに割り当てられる必要があります。VirtIO ドライバーは、Windows のインストール中にインストールすることも、既存の Windows インストールに追加することもできます。
ドライバーのインストール後に、container-native-virtualization/virtio-win コンテナーディスクは仮想マシンから削除できます。
| ドライバー名 | ハードウェア ID | 説明 |
|---|---|---|
| viostor |
VEN_1AF4&DEV_1001 | ブロックドライバー。Other devices グループの SCSI Controller としてラベル付けされる場合があります。 |
| viorng |
VEN_1AF4&DEV_1005 | エントロピーソースドライバー。Other devices グループの PCI Device としてラベル付けされる場合があります。 |
| NetKVM |
VEN_1AF4&DEV_1000 | ネットワークドライバー。Other devices グループの Ethernet Controller としてラベル付けされる場合があります。VirtIO NIC が設定されている場合にのみ利用できます。 |
8.2.2.1. インストール中に VirtIO コンテナーディスクを Windows 仮想マシンにアタッチする
必要な Windows ドライバーをインストールするには、VirtIO コンテナーディスクを Windows 仮想マシンにアタッチする必要があります。これは、仮想マシンの作成時に実行できます。
手順
- テンプレートから Windows 仮想マシンを作成する場合は、Customize VirtualMachine をクリックします。
- Mount Windows drivers disk を選択します。
- Customize VirtualMachine parameters をクリックします。
- Create VirtualMachine をクリックします。
結果
仮想マシンの作成後、virtio-win SATA CD ディスクが仮想マシンにアタッチされます。
8.2.2.2. VirtIO コンテナーディスクを既存の Windows 仮想マシンにアタッチする
必要な Windows ドライバーをインストールするには、VirtIO コンテナーディスクを Windows 仮想マシンにアタッチする必要があります。これは既存の仮想マシンに対して実行できます。
手順
- 既存の Windows 仮想マシンに移動し、Actions → Stop をクリックします。
- VM Details → Configuration → Storage に移動します。
- Mount Windows drivers disk チェックボックスを選択します。
- Save をクリックします。
- 仮想マシンを起動し、グラフィカルコンソールに接続します。
8.2.2.3. Windows インストール時の VirtIO ドライバーのインストール
仮想マシンに Windows をインストールする際に VirtIO ドライバーをインストールできます。
この手順では、Windows インストールの汎用的なアプローチを使用しますが、インストール方法は Windows のバージョンごとに異なる可能性があります。インストールする Windows のバージョンに関するドキュメントを参照してください。
前提条件
-
virtioドライバーを含むストレージデバイスを仮想マシンに接続している。
手順
-
Windows オペレーティングシステムでは、
File Explorerを使用してvirtio-winCD ドライブに移動します。 ドライブをダブルクリックして、仮想マシンに適切なインストーラーを実行します。
64 ビット仮想 CPU の場合は、
virtio-win-gt-x64インストーラーを選択します。32 ビット仮想 CPU はサポート対象外になりました。- オプション: インストーラーの Custom Setup 手順で、インストールするデバイスドライバーを選択します。デフォルトでは、推奨ドライバーセットが選択されています。
- インストールが完了したら、Finish を選択します。
- 仮想マシンを再起動します。
検証
-
PC でシステムディスクを開きます。これは通常
C:です。 - Program Files → Virtio-Win に移動します。
Virtio-Win ディレクトリーが存在し、各ドライバーのサブディレクトリーが含まれていればインストールは成功です。
8.2.2.4. 既存の Windows 仮想マシン上の SATA CD ドライブから VirtIO ドライバーのインストール
VirtIO ドライバーは、SATA CD ドライブから既存の Windows 仮想マシンにインストールできます。
この手順では、ドライバーを Windows に追加するための汎用的なアプローチを使用しています。特定のインストール手順は、お使いの Windows バージョンに関するインストールドキュメントを参照してください。
前提条件
- virtio ドライバーを含むストレージデバイスは、SATA CD ドライブとして仮想マシンに接続する必要があります。
手順
- 仮想マシンを起動し、グラフィカルコンソールに接続します。
- Windows ユーザーセッションにログインします。
Device Manager を開き、Other devices を拡張して、Unknown device をリスト表示します。
- Device Properties を開いて、不明なデバイスを特定します。
- デバイスを右クリックし、Properties を選択します。
- Details タブをクリックし、Property リストで Hardware Ids を選択します。
- Hardware Ids の Value をサポートされる VirtIO ドライバーと比較します。
- デバイスを右クリックし、Update Driver Software を選択します。
- Browse my computer for driver software をクリックし、VirtIO ドライバーが置かれている割り当て済みの SATA CD ドライブの場所に移動します。ドライバーは、ドライバーのタイプ、オペレーティングシステム、および CPU アーキテクチャー別に階層的に編成されます。
- Next をクリックしてドライバーをインストールします。
- 必要なすべての VirtIO ドライバーに対してこのプロセスを繰り返します。
- ドライバーのインストール後に、Close をクリックしてウィンドウを閉じます。
- 仮想マシンを再起動してドライバーのインストールを完了します。
8.2.2.5. SATA CD ドライブとして追加されたコンテナーディスクからの VirtIO ドライバーのインストール
Windows 仮想マシンに SATA CD ドライブとして追加するコンテナーディスクから VirtIO ドライバーをインストールできます。
コンテナーディスクがクラスター内に存在しない場合、コンテナーディスクは Red Hat レジストリーからダウンロードされるため、Red Hat エコシステムカタログ からの container-native-virtualization/virtio-win コンテナーディスクのダウンロードは必須ではありません。ただし、ダウンロードするとインストール時間が短縮されます。
前提条件
-
制限された環境では、Red Hat レジストリー、またはダウンロードされた
container-native-virtualization/virtio-winコンテナーディスクにアクセスできる必要があります。 -
virtctlCLI がインストールされている。 -
OpenShift CLI (
oc) がインストールされている。
手順
VirtualMachineマニフェストを編集して、container-native-virtualization/virtio-winコンテナーディスクを CD ドライブとして追加します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- OpenShift Virtualization は、
VirtualMachineマニフェストで定義された順序で仮想マシンディスクを起動します。container-native-virtualization/virtio-winコンテナーディスクの前に起動する他の仮想マシンディスクを定義するか、オプションのbootOrderパラメーターを使用して仮想マシンが正しいディスクから起動するようにすることができます。ディスクのブート順序を設定する場合は、他のディスクのブート順序も設定する必要があります。
変更を適用します。
仮想マシンを実行していない場合は、次のコマンドを実行します。
virtctl start <vm> -n <namespace>
$ virtctl start <vm> -n <namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 仮想マシンが実行中の場合は、仮想マシンを再起動するか、次のコマンドを実行します。
oc apply -f <vm.yaml>
$ oc apply -f <vm.yaml>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- 仮想マシンが起動したら、SATA CD ドライブから VirtIO ドライバーをインストールします。
8.2.3. VirtIO ドライバーの更新
8.2.3.1. Windows 仮想マシンでの VirtIO ドライバーの更新
Windows Update サービスを使用して、Windows 仮想マシン (VM) 上の virtio ドライバーを更新できます。
前提条件
- クラスターはインターネットに接続されている必要があります。切断されたクラスターは Windows Update サービスにアクセスできません。
手順
- Windows ゲストオペレーティングシステムで、Windows キーをクリックし、Settings を選択します。
- Windows Update → Advanced Options → Optional Updates に移動します。
- Red Hat, Inc. からのすべての更新をインストールします。
- 仮想マシンを再起動します。
検証
- Windows 仮想マシンで、Device Manager に移動します。
- デバイスを選択します。
- Driver タブを選択します。
-
Driver Details をクリックし、
virtioドライバーの詳細に正しいバージョンが表示されていることを確認します。
8.3. 仮想マシンコンソールへの接続
次のコンソールに接続して、実行中の仮想マシンにアクセスできます。
8.3.1. VNC コンソールへの接続
Red Hat OpenShift Service on AWS Web コンソールまたは virtctl コマンドラインツールを使用して、仮想マシンの VNC コンソールに接続できます。
8.3.1.1. Web コンソールを使用した VNC コンソールへの接続
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想マシン (VM) の VNC コンソールに接続できます。
vGPU が仲介デバイスとして割り当てられている Windows 仮想マシンに接続すると、デフォルトの表示と vGPU 表示を切り替えることができます。
手順
- Virtualization → VirtualMachines ページで仮想マシンをクリックして、VirtualMachine details ページを開きます。
- Console タブをクリックします。VNC コンソールセッションが自動的に開始します。
オプション: Windows 仮想マシンの仮想 GPU 表示に切り替えるには、Send key リストから Ctl + Alt + 2 を選択します。
- デフォルトの表示に戻すには、Send key リストから Ctl + Alt + 1 を選択します。
- コンソールセッションを終了するには、コンソールペインの外側をクリックし、Disconnect をクリックします。
8.3.1.2. virtctl を使用した VNC コンソールへの接続
virtctl コマンドラインツールを使用して、実行中の仮想マシンの VNC コンソールに接続できます。
SSH 接続経由でリモートマシン上で virtctl vnc コマンドを実行する場合は、-X フラグまたは -Y フラグを指定して ssh コマンドを実行して、X セッションをローカルマシンに転送する必要があります。
前提条件
-
virt-viewerパッケージをインストールする必要があります。
手順
次のコマンドを実行して、コンソールセッションを開始します。
virtctl vnc <vm_name>
$ virtctl vnc <vm_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 接続に失敗した場合は、次のコマンドを実行してトラブルシューティング情報を収集します。
virtctl vnc <vm_name> -v 4
$ virtctl vnc <vm_name> -v 4Copy to Clipboard Copied! Toggle word wrap Toggle overflow
8.3.1.3. VNC コンソールの一時トークンの生成
Kubernetes API が仮想マシン (VM) の VNC にアクセスするための一時的な認証ベアラートークンを生成します。
Kubernetes は、curl コマンドを変更することで、ベアラートークンの代わりにクライアント証明書を使用した認証もサポートします。
前提条件
-
OpenShift Virtualization 4.14 以降および
ssp-operator4.14 以降を搭載した実行中の仮想マシン。 -
OpenShift CLI (
oc) がインストールされている。
手順
HyperConverged (
HCO) カスタムリソース (CR) のdeployVmConsoleProxyフィールド値をtrueに設定します。oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv --type json -p '[{"op": "replace", "path": "/spec/deployVmConsoleProxy", "value": true}]'$ oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv --type json -p '[{"op": "replace", "path": "/spec/deployVmConsoleProxy", "value": true}]'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを入力してトークンを生成します。
curl --header "Authorization: Bearer ${TOKEN}" \ "https://api.<cluster_fqdn>/apis/token.kubevirt.io/v1alpha1/namespaces/<namespace>/virtualmachines/<vm_name>/vnc?duration=<duration>"$ curl --header "Authorization: Bearer ${TOKEN}" \ "https://api.<cluster_fqdn>/apis/token.kubevirt.io/v1alpha1/namespaces/<namespace>/virtualmachines/<vm_name>/vnc?duration=<duration>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow <duration>パラメーターは時間と分で設定でき、最小期間は 10 分です。たとえば、5h30mです。このパラメーターが設定されていない場合、トークンはデフォルトで 10 分間有効です。出力サンプル
{ "token": "eyJhb..." }{ "token": "eyJhb..." }Copy to Clipboard Copied! Toggle word wrap Toggle overflow オプション: 出力で提供されたトークンを使用して変数を作成します。
export VNC_TOKEN="<token>"
$ export VNC_TOKEN="<token>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow これで、トークンを使用して、仮想マシンの VNC コンソールにアクセスできるようになります。
検証
次のコマンドを入力してクラスターにログインします。
oc login --token ${VNC_TOKEN}$ oc login --token ${VNC_TOKEN}Copy to Clipboard Copied! Toggle word wrap Toggle overflow virtctlコマンドを使用して、仮想マシンの VNC コンソールへのアクセスをテストします。virtctl vnc <vm_name> -n <namespace>
$ virtctl vnc <vm_name> -n <namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
現在、特定のトークンを取り消すことはできません。
トークンを取り消すには、トークンの作成に使用したサービスアカウントを削除する必要があります。ただし、これにより、サービスアカウントを使用して作成された他のすべてのトークンも取り消されます。次のコマンドは注意して使用してください。
virtctl delete serviceaccount --namespace "<namespace>" "<vm_name>-vnc-access"
$ virtctl delete serviceaccount --namespace "<namespace>" "<vm_name>-vnc-access"8.3.1.3.1. クラスターロールを使用して VNC コンソールにトークン生成パーミッションを付与する
クラスター管理者は、クラスターロールをインストールし、それをユーザーまたはサービスアカウントにバインドして、VNC コンソールのトークンを生成するエンドポイントへのアクセスを許可できます。
手順
クラスターロールをユーザーまたはサービスアカウントにバインドすることを選択します。
クラスターロールをユーザーにバインドするには、次のコマンドを実行します。
kubectl create rolebinding "${ROLE_BINDING_NAME}" --clusterrole="token.kubevirt.io:generate" --user="${USER_NAME}"$ kubectl create rolebinding "${ROLE_BINDING_NAME}" --clusterrole="token.kubevirt.io:generate" --user="${USER_NAME}"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下のコマンドを実行してクラスターロールをサービスアカウントにバインドします。
kubectl create rolebinding "${ROLE_BINDING_NAME}" --clusterrole="token.kubevirt.io:generate" --serviceaccount="${SERVICE_ACCOUNT_NAME}"$ kubectl create rolebinding "${ROLE_BINDING_NAME}" --clusterrole="token.kubevirt.io:generate" --serviceaccount="${SERVICE_ACCOUNT_NAME}"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
8.3.2. シリアルコンソールへの接続
Red Hat OpenShift Service on AWS Web コンソールまたは virtctl コマンドラインツールを使用して、仮想マシンのシリアルコンソールに接続できます。
単一の仮想マシンに対する同時 VNC 接続の実行は、現在サポートされていません。
8.3.2.1. Web コンソールを使用したシリアルコンソールへの接続
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想マシン (VM) のシリアルコンソールに接続できます。
vGPU が仲介デバイスとして割り当てられている Windows 仮想マシンに接続すると、デフォルトの表示と仮想 GPU 表示を切り替えることができます。
手順
- Virtualization → VirtualMachines ページで仮想マシンをクリックして、VirtualMachine details ページを開きます。
- Console タブをクリックします。VNC コンソールセッションが自動的に開始します。
- Disconnect をクリックして、VNC コンソールセッションを終了します。それ以外の場合、VNC コンソールセッションは引き続きバックグラウンドで実行されます。
- コンソールリストから Serial console を選択します。
オプション: Windows 仮想マシンの仮想 GPU 表示に切り替えるには、Send key リストから Ctl + Alt + 2 を選択します。
- デフォルトの表示に戻すには、Send key リストから Ctl + Alt + 1 を選択します。
- コンソールセッションを終了するには、コンソールペインの外側をクリックし、Disconnect をクリックします。
8.3.2.2. virtctl を使用したシリアルコンソールへの接続
virtctl コマンドラインツールを使用して、実行中の仮想マシンのシリアルコンソールに接続できます。
SSH 接続経由でリモートマシン上で virtctl vnc コマンドを実行する場合は、-X フラグまたは -Y フラグを指定して ssh コマンドを実行して、X セッションをローカルマシンに転送する必要があります。
前提条件
-
virt-viewerパッケージをインストールする必要があります。
手順
次のコマンドを実行して、コンソールセッションを開始します。
virtctl console <vm_name>
$ virtctl console <vm_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Ctrl+]を押してコンソールセッションを終了します。virtctl vnc <vm_name>
$ virtctl vnc <vm_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 接続に失敗した場合は、次のコマンドを実行してトラブルシューティング情報を収集します。
virtctl vnc <vm_name> -v 4
$ virtctl vnc <vm_name> -v 4Copy to Clipboard Copied! Toggle word wrap Toggle overflow
8.3.3. デスクトップビューアーに接続する
デスクトップビューアーとリモートデスクトッププロトコル (RDP) を使用して、Windows 仮想マシンに接続できます。
8.3.3.1. Web コンソールを使用したデスクトップビューアーへの接続
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想マシン (VM) のデスクトップビューアーに接続できます。
Red Hat OpenShift Service on AWS Web コンソールを使用して、Windows 仮想マシン (VM) のデスクトップビューアーに接続できます。
vGPU が仲介デバイスとして割り当てられている Windows 仮想マシンに接続すると、デフォルトの表示と仮想 GPU 表示を切り替えることができます。
前提条件
- QEMU ゲストエージェントが Windows 仮想マシンにインストールされている。
- RDP クライアントがインストールされている。
手順
- Virtualization → VirtualMachines ページで仮想マシンをクリックして、VirtualMachine details ページを開きます。
- Console タブをクリックします。VNC コンソールセッションが自動的に開始します。
- Disconnect をクリックして、VNC コンソールセッションを終了します。それ以外の場合、VNC コンソールセッションは引き続きバックグラウンドで実行されます。
- コンソールのリストから Desktop viewer を選択します。
- RDP サービスの作成 をクリックして、RDP サービス ダイアログを開きます。
- Expose RDP Service を選択し、Save をクリックしてノードポートサービスを作成します。
-
Launch Remote Desktop をクリックして
.rdpファイルをダウンロードし、デスクトップビューアーを起動します。 オプション: Windows 仮想マシンの仮想 GPU 表示に切り替えるには、Send key リストから Ctl + Alt + 2 を選択します。
- デフォルトの表示に戻すには、Send key リストから Ctl + Alt + 1 を選択します。
- コンソールセッションを終了するには、コンソールペインの外側をクリックし、Disconnect をクリックします。
8.4. 仮想マシンへの SSH アクセスの設定
次の方法を使用して、仮想マシンへの SSH アクセスを設定できます。
SSH 鍵ペアを作成し、公開鍵を仮想マシンに追加し、秘密鍵を使用して
virtctl sshコマンドを実行して仮想マシンに接続します。cloud-init データソースを使用して設定できるゲストオペレーティングシステムを使用して、実行時または最初の起動時に Red Hat Enterprise Linux (RHEL) 9 仮想マシンに SSH 公開鍵を追加できます。
virtctl port-fowardコマンドを.ssh/configファイルに追加し、OpenSSH を使用して仮想マシンに接続します。サービスを作成し、そのサービスを仮想マシンに関連付け、サービスによって公開されている IP アドレスとポートに接続します。
セカンダリーネットワークを設定し、仮想マシンをセカンダリーネットワークインターフェイスに接続し、DHCP によって割り当てられた IP アドレスに接続します。
8.4.1. アクセス設定の考慮事項
仮想マシンへのアクセスを設定する各方法には、トラフィックの負荷とクライアントの要件に応じて利点と制限があります。
サービスは優れたパフォーマンスを提供するため、クラスターの外部からアクセスされるアプリケーションに推奨されます。
内部クラスターネットワークがトラフィック負荷を処理できない場合は、セカンダリーネットワークを設定できます。
virtctl sshおよびvirtctl port-forwardingコマンド- 設定が簡単。
- 仮想マシンのトラブルシューティングに推奨されます。
-
Ansible を使用した仮想マシンの自動設定には、
virtctl port-forwardingが推奨されます。 - 動的 SSH 公開鍵を使用して、Ansible で仮想マシンをプロビジョニングできます。
- API サーバーに負担がかかるため、Rsync やリモートデスクトッププロトコルなどの高トラフィックのアプリケーションには推奨されません。
- API サーバーはトラフィック負荷を処理できる必要があります。
- クライアントは API サーバーにアクセスできる必要があります。
- クライアントはクラスターへのアクセス認証情報を持っている必要があります。
- クラスター IP サービス
- 内部クラスターネットワークはトラフィック負荷を処理できる必要があります。
- クライアントは内部クラスター IP アドレスにアクセスできる必要があります。
- ノードポートサービス
- 内部クラスターネットワークはトラフィック負荷を処理できる必要があります。
- クライアントは少なくとも 1 つのノードにアクセスできる必要があります。
- ロードバランサーサービス
- ロードバランサーを設定する必要があります。
- 各ノードは、1 つ以上のロードバランサーサービスのトラフィック負荷を処理できなければなりません。
- セカンダリーネットワーク
- トラフィックが内部クラスターネットワークを経由しないため、優れたパフォーマンスが得られます。
- ネットワークトポロジーへの柔軟なアプローチを可能にします。
- 仮想マシンはセカンダリーネットワークに直接公開されるため、ゲストオペレーティングシステムは適切なセキュリティーを備えて設定する必要があります。仮想マシンが侵害されると、侵入者がセカンダリーネットワークにアクセスする可能性があります。
8.4.2. virtctl ssh の使用
virtctl ssh コマンドを実行することで、仮想マシン (VM) に SSH 公開鍵を追加し、仮想マシンに接続できます。
この方法の設定は簡単です。ただし、API サーバーに負担がかかるため、トラフィック負荷が高い場合には推奨されません。
8.4.2.1. 静的および動的 SSH 鍵の管理について
SSH 公開鍵は、最初の起動時に静的に、または実行時に動的に仮想マシン (VM) に追加できます。
Red Hat Enterprise Linux (RHEL) 9 のみが動的キーインジェクションをサポートしています。
8.4.2.1.1. 静的 SSH 鍵の管理
cloud-init データソースを使用した設定をサポートするゲストオペレーティングシステムを搭載した仮想マシンに、静的に管理される SSH 鍵を追加できます。鍵は最初の起動時に仮想マシン (VM) に追加されます。
次のいずれかの方法を使用して鍵を追加できます。
- Web コンソールまたはコマンドラインを使用して単一の仮想マシンを作成する場合は、その仮想マシンに鍵を追加します。
- Web コンソールを使用してプロジェクトに鍵を追加します。その後、このプロジェクトで作成した仮想マシンに鍵が自動的に追加されます。
使用例:
- 仮想マシンの所有者は、新しく作成したすべての仮想マシンを 1 つの鍵でプロビジョニングできます。
8.4.2.1.2. 動的 SSH 鍵の管理
Red Hat Enterprise Linux (RHEL) 9 がインストールされている仮想マシンに対して、動的 SSH 鍵の管理を有効にできます。その後、実行時に鍵を更新できます。鍵は、Red Hat ブートソースとともにインストールされる QEMU ゲストエージェントによって追加されます。
動的鍵の管理が無効になっている場合、仮想マシンのデフォルトの鍵管理設定は、その仮想マシンに使用されるイメージによって決まります。
使用例:
-
仮想マシンへのアクセスの付与または取り消し: クラスター管理者は、namespace 内のすべての仮想マシンに適用される
Secretオブジェクトに個々のユーザーのキーを追加または削除することで、リモート仮想マシンアクセスを付与または取り消すことができます。 - ユーザーアクセス: 作成および管理するすべての仮想マシンにアクセス認証情報を追加できます。
Ansible プロビジョニング:
- 運用チームのメンバーは、Ansible プロビジョニングに使用されるすべてのキーを含む 1 つのシークレットを作成できます。
- 仮想マシン所有者は、仮想マシンを作成し、Ansible プロビジョニングに使用されるキーをアタッチできます。
キーのローテーション:
- クラスター管理者は、namespace 内の仮想マシンによって使用される Ansible プロビジョナーキーをローテーションできます。
- ワークロード所有者は、管理する仮想マシンのキーをローテーションできます。
8.4.2.2. 静的キー管理
Red Hat OpenShift Service on AWS Web コンソールまたはコマンドラインを使用して仮想マシン (VM) を作成するときに、静的に管理される公開 SSH 鍵を追加できます。このキーは、仮想マシンが初めて起動するときに、cloud-init データソースとして追加されます。
Web コンソールを使用して仮想マシンを作成するときに、公開 SSH 鍵をプロジェクトに追加することもできます。鍵はシークレットとして保存され、作成するすべての仮想マシンに自動的に追加されます。
シークレットは namespace リソースであるため、シークレットをプロジェクトに追加し、その後仮想マシンを削除しても、シークレットは保持されます。シークレットは、手動で削除する必要があります。
8.4.2.2.1. テンプレートから仮想マシンを作成するときにキーを追加する
Red Hat OpenShift Service on AWS Web コンソールを使用して仮想マシン (VM) を作成するときに、静的に管理される公開 SSH 鍵を追加できます。キーは、最初の起動時に cloud-init データソースとして仮想マシンに追加されます。この方法は、cloud-init ユーザーデータには影響しません。
オプション: プロジェクトにキーを追加できます。その後、このキーはプロジェクトで作成した仮想マシンに自動的に追加されます。
前提条件
-
ssh-keygenコマンドを実行して、SSH 鍵ペアを生成しました。
手順
- Web コンソールで Virtualization → Catalog に移動します。
テンプレートタイルをクリックします。
ゲストオペレーティングシステムは、cloud-init データソースからの設定をサポートする必要があります。
- Customize VirtualMachine をクリックします。
- Next をクリックします。
- Scripts タブをクリックします。
プロジェクトに SSH 公開鍵をまだ追加していない場合は、Authorized SSH key の横にある編集アイコンをクリックし、次のいずれかのオプションを選択します。
- Use existing: シークレットリストからシークレットを選択します。
Add new:
- SSH 鍵ファイルを参照するか、ファイルを鍵のフィールドに貼り付けます。
- シークレット名を入力します。
- オプション: Automatically apply this key to any new VirtualMachine you create in this project を選択します。
- Save をクリックします。
Create VirtualMachine をクリックします。
VirtualMachine details ページには、仮想マシン作成の進行状況が表示されます。
検証
Configuration タブの Scripts タブをクリックします。
シークレット名は Authorized SSH key セクションに表示されます。
8.4.2.2.2. Web コンソールを使用したインスタンスタイプからの仮想マシンの作成
Red Hat OpenShift Service on AWS Web コンソールを使用して、インスタンスタイプから仮想マシン (VM) を作成できます。Web コンソールを使用して、既存のスナップショットをコピーするか仮想マシンを複製して、仮想マシンを作成することもできます。
使用可能な起動可能なボリュームのリストから仮想マシンを作成できます。Linux ベースまたは Windows ベースのボリュームをリストに追加できます。
Red Hat OpenShift Service on AWS Web コンソールを使用してインスタンスタイプから仮想マシン (VM) を作成するときに、静的に管理される SSH 鍵を追加できます。キーは、最初の起動時に cloud-init データソースとして仮想マシンに追加されます。この方法は、cloud-init ユーザーデータには影響しません。
手順
Web コンソールで、Virtualization → Catalog に移動します。
InstanceTypes タブがデフォルトで開きます。
注記仮想マシン設定を使用する IBM Z® システムで downward-metrics デバイスを設定する場合は、
spec.preference.name値をrhel.9.s390xに設定するか、*.s390xという形式の使用可能な別の設定を指定する必要があります。- 異種クラスターのみ: 提供されているオプションを使用して起動可能なボリュームをフィルタリングするには、Architecture をクリックします。
次のオプションのいずれかを選択します。
リストから適切な起動可能なボリュームを選択します。リストが切り捨てられている場合は、Show all ボタンをクリックしてリスト全体を表示します。
注記ブート可能ボリュームテーブルには、
openshift-virtualization-os-imagesnamespace 内のinstancetype.kubevirt.io/default-preferenceラベルを持つボリュームのみリストされます。- オプション: 星アイコンをクリックして、ブート可能ボリュームをお気に入りとして指定します。星付きのブート可能ボリュームは、ボリュームリストの最初に表示されます。
新しいボリュームをアップロードするか、既存の永続ボリューム要求 (PVC)、ボリュームスナップショット、または
containerDiskボリュームを使用するには Add volume をクリックします。Save をクリックします。クラスターで使用できないオペレーティングシステムのロゴは、リストの下部に表示されます。Add volume リンクをクリックすると、必要なオペレーティングシステムのボリュームを追加できます。
さらに、Windows の起動可能なボリュームを作成する クイックスタートへのリンクもあります。Select volume to boot from の横にある疑問符アイコンの上にポインターを置くと、ポップオーバーに同じリンクが表示されます。
環境をインストールした直後、または環境が切断された直後は、起動元のボリュームのリストは空になります。その場合、Windows、RHEL、Linux の 3 つのオペレーティングシステムのロゴが表示されます。Add volume ボタンをクリックすると、要件を満たす新しいボリュームを追加できます。
- インスタンスタイプのタイルをクリックし、ワークロードに適したリソースサイズを選択します。Red Hat が提供する M および CX シリーズのインスタンスタイプでは、huge page を選択できます。huge page オプションは、1gi で終わる名前で識別されます。
オプション: 起動元のボリュームに適用される仮想マシンの詳細 (仮想マシンの名前を含む) を選択します。
Linux ベースのボリュームの場合は、次の手順に従って SSH を設定します。
- プロジェクトに SSH 公開鍵をまだ追加していない場合は、VirtualMachine details セクションの Authorized SSH key の横にある編集アイコンをクリックします。
以下のオプションのいずれかを選択します。
- Use existing: シークレットリストからシークレットを選択します。
Add new: 以下の手順に従ってください。
- SSH 公開鍵ファイルを参照するか、ファイルを鍵のフィールドに貼り付けます。
- シークレット名を入力します。
- オプション: Automatically apply this key to any new VirtualMachine you create in this project を選択します。
- Save をクリックします。
Windows ボリュームの場合は、次のいずれかの手順に従って sysprep オプションを設定します。
Windows ボリュームに sysprep オプションをまだ追加していない場合は、次の手順に従います。
- VirtualMachine details セクションの Sysprep の横にある編集アイコンをクリックします。
- Autoattend.xml アンサーファイルを追加します。
- Unattend.xml アンサーファイルを追加します。
- Save をクリックします。
Windows ボリュームに既存の sysprep オプションを使用する場合は、次の手順に従います。
- 既存の sysprep を添付 をクリックします。
- 既存の sysprep Unattend.xml アンサーファイルの名前を入力します。
- Save をクリックします。
オプション: Windows 仮想マシンを作成する場合は、Windows ドライバーディスクをマウントできます。
- Customize VirtualMachine ボタンをクリックします。
- VirtualMachine details ページで、Storage をクリックします。
- Mount Windows drivers disk チェックボックスを選択します。
- オプション: View YAML & CLI をクリックして YAML ファイルを表示します。CLI をクリックして CLI コマンドを表示します。YAML ファイルの内容または CLI コマンドをダウンロードまたはコピーすることもできます。
- Create VirtualMachine をクリックします。
結果
仮想マシンの作成後、VirtualMachine details ページでステータスを監視できます。
8.4.2.2.3. CLI を使用して仮想マシンを作成するときに鍵を追加する
コマンドラインを使用して仮想マシン (VM) を作成するときに、静的に管理される SSH 公開鍵を追加できます。鍵は最初の起動時に仮想マシンに追加されます。
鍵は、cloud-init データソースとして仮想マシンに追加されます。この方法では、cloud-init ユーザーデータ内のアプリケーションデータからアクセス認証情報が分離されます。この方法は、cloud-init ユーザーデータには影響しません。
前提条件
-
ssh-keygenコマンドを実行して、SSH 鍵ペアを生成しました。 -
OpenShift CLI (
oc) がインストールされている。
手順
VirtualMachineオブジェクトとSecretオブジェクトのマニフェストファイルを作成します。マニフェストの例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して、
VirtualMachineオブジェクトとSecretオブジェクトを作成します。oc create -f <manifest_file>.yaml
$ oc create -f <manifest_file>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して仮想マシンを起動します。
virtctl start vm example-vm -n example-namespace
$ virtctl start vm example-vm -n example-namespaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
仮想マシン設定を取得します。
oc describe vm example-vm -n example-namespace
$ oc describe vm example-vm -n example-namespaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
8.4.2.3. 動的なキー管理
Red Hat OpenShift Service on AWS Web コンソールまたはコマンドラインを使用して、仮想マシン (VM) の動的キーインジェクションを有効にできます。その後、実行時にキーを更新できます。
Red Hat Enterprise Linux (RHEL) 9 のみが動的キーインジェクションをサポートしています。
動的キーインジェクションを無効にすると、仮想マシンは作成元のイメージのキー管理方法を継承します。
8.4.2.3.1. テンプレートから仮想マシンを作成するときに動的キーインジェクションを有効にする
Red Hat OpenShift Service on AWS Web コンソールを使用してテンプレートから仮想マシン (VM) を作成するときに、動的な公開 SSH 鍵インジェクションを有効化できます。その後、実行時にキーを更新できます。
Red Hat Enterprise Linux (RHEL) 9 のみが動的キーインジェクションをサポートしています。
鍵は、RHEL 9 とともにインストールされる QEMU ゲストエージェントによって仮想マシンに追加されます。
前提条件
-
ssh-keygenコマンドを実行して、SSH 鍵ペアを生成しました。
手順
- Web コンソールで Virtualization → Catalog に移動します。
- Red Hat Enterprise Linux 9 VM タイルをクリックします。
- Customize VirtualMachine をクリックします。
- Next をクリックします。
- Scripts タブをクリックします。
プロジェクトに SSH 公開鍵をまだ追加していない場合は、Authorized SSH key の横にある編集アイコンをクリックし、次のいずれかのオプションを選択します。
- Use existing: シークレットリストからシークレットを選択します。
Add new:
- SSH 鍵ファイルを参照するか、ファイルを鍵のフィールドに貼り付けます。
- シークレット名を入力します。
- オプション: Automatically apply this key to any new VirtualMachine you create in this project を選択します。
- Dynamic SSH key injection をオンに設定します。
- Save をクリックします。
Create VirtualMachine をクリックします。
VirtualMachine details ページには、仮想マシン作成の進行状況が表示されます。
検証
Configuration タブの Scripts タブをクリックします。
シークレット名は Authorized SSH key セクションに表示されます。
8.4.2.3.2. Web コンソールを使用したインスタンスタイプからの仮想マシンの作成
Red Hat OpenShift Service on AWS Web コンソールを使用して、インスタンスタイプから仮想マシン (VM) を作成できます。Web コンソールを使用して、既存のスナップショットをコピーするか仮想マシンを複製して、仮想マシンを作成することもできます。
使用可能な起動可能なボリュームのリストから仮想マシンを作成できます。Linux ベースまたは Windows ベースのボリュームをリストに追加できます。
Red Hat OpenShift Service on AWS Web コンソールを使用して、インスタンスタイプから仮想マシン (VM) を作成するときに、動的 SSH 鍵インジェクションを有効化できます。その後、実行時にキーを追加または取り消すことができます。
Red Hat Enterprise Linux (RHEL) 9 のみが動的キーインジェクションをサポートしています。
鍵は、RHEL 9 とともにインストールされる QEMU ゲストエージェントによって仮想マシンに追加されます。
手順
Web コンソールで、Virtualization → Catalog に移動します。
InstanceTypes タブがデフォルトで開きます。
注記仮想マシン設定を使用する IBM Z® システムで downward-metrics デバイスを設定する場合は、
spec.preference.name値をrhel.9.s390xに設定するか、*.s390xという形式の使用可能な別の設定を指定する必要があります。- 異種クラスターのみ: 提供されているオプションを使用して起動可能なボリュームをフィルタリングするには、Architecture をクリックします。
次のオプションのいずれかを選択します。
リストから適切な起動可能なボリュームを選択します。リストが切り捨てられている場合は、Show all ボタンをクリックしてリスト全体を表示します。
注記ブート可能ボリュームテーブルには、
openshift-virtualization-os-imagesnamespace 内のinstancetype.kubevirt.io/default-preferenceラベルを持つボリュームのみリストされます。- オプション: 星アイコンをクリックして、ブート可能ボリュームをお気に入りとして指定します。星付きのブート可能ボリュームは、ボリュームリストの最初に表示されます。
新しいボリュームをアップロードするか、既存の永続ボリューム要求 (PVC)、ボリュームスナップショット、または
containerDiskボリュームを使用するには Add volume をクリックします。Save をクリックします。クラスターで使用できないオペレーティングシステムのロゴは、リストの下部に表示されます。Add volume リンクをクリックすると、必要なオペレーティングシステムのボリュームを追加できます。
さらに、Windows の起動可能なボリュームを作成する クイックスタートへのリンクもあります。Select volume to boot from の横にある疑問符アイコンの上にポインターを置くと、ポップオーバーに同じリンクが表示されます。
環境をインストールした直後、または環境が切断された直後は、起動元のボリュームのリストは空になります。その場合、Windows、RHEL、Linux の 3 つのオペレーティングシステムのロゴが表示されます。Add volume ボタンをクリックすると、要件を満たす新しいボリュームを追加できます。
- インスタンスタイプのタイルをクリックし、ワークロードに適したリソースサイズを選択します。Red Hat が提供する M および CX シリーズのインスタンスタイプでは、huge page を選択できます。huge page オプションは、1gi で終わる名前で識別されます。
- Red Hat Enterprise Linux 9 VM タイルをクリックします。
オプション: 起動元のボリュームに適用される仮想マシンの詳細 (仮想マシンの名前を含む) を選択します。
Linux ベースのボリュームの場合は、次の手順に従って SSH を設定します。
- プロジェクトに SSH 公開鍵をまだ追加していない場合は、VirtualMachine details セクションの Authorized SSH key の横にある編集アイコンをクリックします。
以下のオプションのいずれかを選択します。
- Use existing: シークレットリストからシークレットを選択します。
Add new: 以下の手順に従ってください。
- SSH 公開鍵ファイルを参照するか、ファイルを鍵のフィールドに貼り付けます。
- シークレット名を入力します。
- オプション: Automatically apply this key to any new VirtualMachine you create in this project を選択します。
- Save をクリックします。
Windows ボリュームの場合は、次のいずれかの手順に従って sysprep オプションを設定します。
Windows ボリュームに sysprep オプションをまだ追加していない場合は、次の手順に従います。
- VirtualMachine details セクションの Sysprep の横にある編集アイコンをクリックします。
- Autoattend.xml アンサーファイルを追加します。
- Unattend.xml アンサーファイルを追加します。
- Save をクリックします。
Windows ボリュームに既存の sysprep オプションを使用する場合は、次の手順に従います。
- 既存の sysprep を添付 をクリックします。
- 既存の sysprep Unattend.xml アンサーファイルの名前を入力します。
- Save をクリックします。
- VirtualMachine details セクションで Dynamic SSH key injection をオンに設定します。
オプション: Windows 仮想マシンを作成する場合は、Windows ドライバーディスクをマウントできます。
- Customize VirtualMachine ボタンをクリックします。
- VirtualMachine details ページで、Storage をクリックします。
- Mount Windows drivers disk チェックボックスを選択します。
- オプション: View YAML & CLI をクリックして YAML ファイルを表示します。CLI をクリックして CLI コマンドを表示します。YAML ファイルの内容または CLI コマンドをダウンロードまたはコピーすることもできます。
- Create VirtualMachine をクリックします。
結果
仮想マシンの作成後、VirtualMachine details ページでステータスを監視できます。
8.4.2.3.3. Web コンソールを使用した動的 SSH キーインジェクションの有効化
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想マシン (VM) の動的キーインジェクションを有効にできます。その後、実行時に SSH 公開鍵を更新できます。
鍵は、Red Hat Enterprise Linux (RHEL) 9 とともにインストールされる QEMU ゲストエージェントによって仮想マシンに追加されます。
前提条件
- ゲストオペレーティングシステムは RHEL 9 です。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Configuration タブで、Scripts をクリックします。
プロジェクトに SSH 公開鍵をまだ追加していない場合は、Authorized SSH key の横にある編集アイコンをクリックし、次のいずれかのオプションを選択します。
- Use existing: シークレットリストからシークレットを選択します。
Add new:
- SSH 鍵ファイルを参照するか、ファイルを鍵のフィールドに貼り付けます。
- シークレット名を入力します。
- オプション: Automatically apply this key to any new VirtualMachine you create in this project を選択します。
- Dynamic SSH key injection をオンに設定します。
- Save をクリックします。
8.4.2.3.4. CLI を使用して動的キーインジェクションを有効にする
コマンドラインを使用して、仮想マシンの動的キーインジェクションを有効にすることができます。その後、実行時に SSH 公開鍵を更新できます。
Red Hat Enterprise Linux (RHEL) 9 のみが動的キーインジェクションをサポートしています。
キーは QEMU ゲストエージェントによって仮想マシンに追加され、RHEL 9 とともに自動的にインストールされます。
前提条件
-
ssh-keygenコマンドを実行して、SSH 鍵ペアを生成しました。 -
OpenShift CLI (
oc) がインストールされている。
手順
VirtualMachineオブジェクトとSecretオブジェクトのマニフェストファイルを作成します。マニフェストの例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して、
VirtualMachineオブジェクトとSecretオブジェクトを作成します。oc create -f <manifest_file>.yaml
$ oc create -f <manifest_file>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して仮想マシンを起動します。
virtctl start vm example-vm -n example-namespace
$ virtctl start vm example-vm -n example-namespaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
仮想マシン設定を取得します。
oc describe vm example-vm -n example-namespace
$ oc describe vm example-vm -n example-namespaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
8.4.2.4. virtctl ssh コマンドの使用
virtcl ssh コマンドを使用して、実行中の仮想マシンにアクセスできます。
前提条件
-
virtctlコマンドラインツールがインストールされている。 - 仮想マシンに SSH 公開鍵が追加されている。
- SSH クライアントがインストールされている。
-
virtctlツールをインストールした環境に、仮想マシンにアクセスするために必要なクラスター権限がある。たとえば、oc loginを実行するか、KUBECONFIG環境変数を設定します。
手順
virtctl sshコマンドを実行します。virtctl -n <namespace> ssh <username>@example-vm -i <ssh_key>
$ virtctl -n <namespace> ssh <username>@example-vm -i <ssh_key>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- namespace、ユーザー名、SSH 秘密鍵を指定します。デフォルトの SSH 鍵の場所は
/home/user/.sshです。キーを別の場所に保存する場合は、パスを指定する必要があります。
以下に例を示します。
virtctl -n my-namespace ssh cloud-user@example-vm -i my-key
$ virtctl -n my-namespace ssh cloud-user@example-vm -i my-keyCopy to Clipboard Copied! Toggle word wrap Toggle overflow
VirtualMachines ページの仮想マシンの横にあるオプション
メニューから、Copy SSH command を選択すると、Web コンソールで virtctl ssh コマンドをコピーできます。
または、ツリービューで仮想マシンを右クリックし、ポップアップメニューから Copy SSH command を選択して、virtctl ssh コマンドをコピーします。
8.4.3. virtctl port-forward コマンドの使用
ローカルの OpenSSH クライアントと virtctl port-forward コマンドを使用して、実行中の仮想マシン (VM) に接続できます。Ansible でこの方法を使用すると、VM の設定を自動化できます。
ポート転送トラフィックはコントロールプレーン経由で送信されるため、この方法はトラフィックの少ないアプリケーションに推奨されます。ただし、API サーバーに負荷が大きいため、Rsync や Remote Desktop Protocol などのトラフィックの高いアプリケーションには推奨されません。
前提条件
-
virtctlクライアントをインストールしている。 - アクセスする仮想マシンが実行されている。
-
virtctlツールをインストールした環境に、仮想マシンにアクセスするために必要なクラスター権限がある。たとえば、oc loginを実行するか、KUBECONFIG環境変数を設定します。
手順
以下のテキストをクライアントマシンの
~/.ssh/configファイルに追加します。Host vm/* ProxyCommand virtctl port-forward --stdio=true %h %p
Host vm/* ProxyCommand virtctl port-forward --stdio=true %h %pCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して、仮想マシンに接続します。
ssh <user>@vm/<vm_name>.<namespace>
$ ssh <user>@vm/<vm_name>.<namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
8.4.4. SSH アクセス用のサービスを使用する
仮想マシンのサービスを作成し、サービスによって公開される IP アドレスとポートに接続できます。
サービスは優れたパフォーマンスを提供するため、クラスターの外部またはクラスター内からアクセスされるアプリケーションに推奨されます。受信トラフィックはファイアウォールによって保護されます。
クラスターネットワークがトラフィック負荷を処理できない場合は、仮想マシンアクセスにセカンダリーネットワークを使用することを検討してください。
8.4.4.1. サービスについて
Kubernetes サービスは一連の Pod で実行されているアプリケーションへのクライアントのネットワークアクセスを公開します。サービスは抽象化、負荷分散を提供し、タイプ NodePort と LoadBalancer の場合は外部世界への露出を提供します。
- ClusterIP
-
内部 IP アドレスでサービスを公開し、クラスター内の他のアプリケーションに DNS 名として公開します。1 つのサービスを複数の仮想マシンにマッピングできます。クライアントがサービスに接続しようとすると、クライアントのリクエストは使用可能なバックエンド間で負荷分散されます。
ClusterIPはデフォルトのサービスタイプです。 - NodePort
-
クラスター内の選択した各ノードの同じポートでサービスを公開します。
NodePortは、ノード自体がクライアントから外部にアクセスできる限り、クラスターの外部からポートにアクセスできるようにします。 - LoadBalancer
- 現在のクラウドに外部ロードバランサーを作成し (サポートされている場合)、固定の外部 IP アドレスをサービスに割り当てます。
Red Hat OpenShift Service on AWS では、ライブマイグレーション中のネットワークのダウンタイムを最小限に抑えるために、負荷分散サービスを設定するときに externalTrafficPolicy: Cluster を使用する必要があります。
8.4.4.2. サービスの作成
Red Hat OpenShift Service on AWS Web コンソール、virtctl コマンドラインツール、または YAML ファイルを使用して、仮想マシン (VM) を公開するサービスを作成できます。
8.4.4.2.1. Web コンソールを使用したロードバランサーサービスの作成の有効化
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想マシン (VM) のロードバランサーサービスの作成を有効にできます。
前提条件
- クラスターのロードバランサーが設定されました。
-
cluster-adminロールを持つユーザーとしてログインしている。 - ネットワークの network attachment definition を作成している。
手順
- Virtualization → Overview に移動します。
- Settings タブで、Cluster をクリックします。
- Expand General settings と SSH configuration を展開します。
- SSH over LoadBalancer service をオンに設定します。
8.4.4.2.2. Web コンソールを使用したサービスの作成
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想マシン (VM) のノードポートまたはロードバランサーサービスを作成できます。
前提条件
- ロードバランサーまたはノードポートをサポートするようにクラスターネットワークが設定されている。
- ロードバランサーサービスを作成するためにロードバランサーサービスの作成が有効化されている。
手順
- VirtualMachines に移動し、仮想マシンを選択して、VirtualMachine details ページを表示します。
- Details タブで、SSH service type リストから SSH over LoadBalancer を選択します。
-
オプション: コピーアイコンをクリックして、
SSHコマンドをクリップボードにコピーします。
検証
- Details タブの Services ペインをチェックして、新しいサービスを表示します。
8.4.4.2.3. virtctl を使用したサービスの作成
virtctl コマンドラインツールを使用して、仮想マシン (VM) のサービスを作成できます。
前提条件
-
virtctlコマンドラインツールがインストールされている。 - サービスをサポートするようにクラスターネットワークを設定しました。
-
virtctlをインストールした環境には、仮想マシンにアクセスするために必要なクラスター権限があります。たとえば、oc loginを実行するか、KUBECONFIG環境変数を設定します。
手順
次のコマンドを実行してサービスを作成します。
virtctl expose vm <vm_name> --name <service_name> --type <service_type> --port <port>
$ virtctl expose vm <vm_name> --name <service_name> --type <service_type> --port <port>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
ClusterIP、NodePort、またはLoadBalancerサービスタイプを指定します。
以下に例を示します。
virtctl expose vm example-vm --name example-service --type NodePort --port 22
$ virtctl expose vm example-vm --name example-service --type NodePort --port 22Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
以下のコマンドを実行してサービスを確認します。
oc get service
$ oc get serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
次のステップ
virtctl を使用してサービスを作成した後、VirtualMachine マニフェストの spec.template.metadata.labels スタンザに special: key を追加する必要があります。コマンドラインを使用したサービスの作成 を参照してください。
8.4.4.2.4. CLI を使用したサービスの作成
コマンドラインを使用して、サービスを作成し、それを仮想マシンに関連付けることができます。
前提条件
- サービスをサポートするようにクラスターネットワークを設定しました。
-
OpenShift CLI (
oc) がインストールされている。
手順
VirtualMachineマニフェストを編集して、サービス作成のラベルを追加します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
special: keyをspec.template.metadata.labelsスタンザに追加します。
注記仮想マシンのラベルは Pod に渡されます。
special: keyラベルは、Serviceマニフェストのspec.selector属性のラベルと一致する必要があります。-
VirtualMachineマニフェストファイルを保存して変更を適用します。 仮想マシンを公開するための
Serviceマニフェストを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
Serviceマニフェストファイルを保存します。 以下のコマンドを実行してサービスを作成します。
oc create -f example-service.yaml
$ oc create -f example-service.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 仮想マシンを再起動して変更を適用します。
検証
Serviceオブジェクトをクエリーし、これが利用可能であることを確認します。oc get service -n example-namespace
$ oc get service -n example-namespaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
8.4.4.3. SSH を使用してサービスによって公開される仮想マシンに接続する
SSH を使用して、サービスによって公開されている仮想マシンに接続できます。
前提条件
- 仮想マシンを公開するサービスを作成しました。
- SSH クライアントがインストールされている。
- クラスターにログインしている。
手順
次のコマンドを実行して仮想マシンにアクセスします。
ssh <user_name>@<ip_address> -p <port>
$ ssh <user_name>@<ip_address> -p <port>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- クラスター IP サービスの場合はクラスター IP、ノードポートサービスの場合はノード IP、またはロードバランサーサービスの場合は外部 IP アドレスを指定します。
8.4.5. SSH アクセスにセカンダリーネットワークを使用する
SSH を使用して、セカンダリーネットワークを設定し、仮想マシンをセカンダリーネットワークインターフェイスに接続し、DHCP によって割り当てられた IP アドレスに接続できます。
セカンダリーネットワークは、トラフィックがクラスターネットワークスタックによって処理されないため、優れたパフォーマンスを提供します。ただし、仮想マシンはセカンダリーネットワークに直接公開されており、ファイアウォールによって保護されません。仮想マシンが侵害されると、侵入者がセカンダリーネットワークにアクセスする可能性があります。この方法を使用する場合は、仮想マシンのオペレーティングシステム内で適切なセキュリティーを設定する必要があります。
ネットワークオプションの詳細は OpenShift Virtualization Tuning & Scaling Guide の Multus および SR-IOV ドキュメントを参照してください。
前提条件
- セカンダリーネットワーク を設定した。
- ネットワークアタッチメント定義 を作成した。
8.4.5.1. Web コンソールを使用した仮想マシンネットワークインターフェイスの設定
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想マシン (VM) のネットワークインターフェイスを設定できます。
前提条件
- ネットワークの network attachment definition を作成している。
手順
- Virtualization → VirtualMachines に移動します。
- 仮想マシンをクリックして、VirtualMachine details ページを表示します。
- Configuration タブで、Network interfaces タブをクリックします。
- Add network interface をクリックします。
- インターフェイス名を入力し、Network リストから network attachment definition を選択します。
- Save をクリックします。
- 仮想マシンを再起動またはライブマイグレーションして、変更を適用します。
8.4.5.2. SSH を使用したセカンダリーネットワークに接続された仮想マシンへの接続
SSH を使用して、セカンダリーネットワークに接続されている仮想マシンに接続できます。
前提条件
- DHCP サーバーを使用して仮想マシンをセカンダリーネットワークに接続しました。
- SSH クライアントがインストールされている。
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、仮想マシンの IP アドレスを取得します。
oc describe vm <vm_name> -n <namespace>
$ oc describe vm <vm_name> -n <namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して、仮想マシンに接続します。
ssh <user_name>@<ip_address> -i <ssh_key>
$ ssh <user_name>@<ip_address> -i <ssh_key>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
ssh cloud-user@10.244.0.37 -i ~/.ssh/id_rsa_cloud-user
$ ssh cloud-user@10.244.0.37 -i ~/.ssh/id_rsa_cloud-userCopy to Clipboard Copied! Toggle word wrap Toggle overflow
8.5. 仮想マシンの編集
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想マシン (VM) 設定を更新できます。YAML ファイルまたは VirtualMachine details ページを更新できます。
コマンドラインを使用して仮想マシンを編集することもできます。
8.5.1. Web コンソールを使用して仮想マシンのインスタンスタイプを変更する
Web コンソールを使用して、実行中の仮想マシン (VM) に関連付けられているインスタンスタイプを変更できます。変更は即座に有効になります。
前提条件
- インスタンスタイプを使用して仮想マシンを作成している。
手順
- Red Hat OpenShift Service on AWS Web コンソールで、Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Configuration タブをクリックします。
- Details タブで、インスタンスタイプテキストをクリックして Edit Instancetype ダイアログを開きます。たとえば、1 CPU | 2 GiB Memory をクリックします。
Series および Size リストを使用して、インスタンスタイプを編集します。
- Series リストからアイテムを選択して、そのシリーズに関連するサイズを表示します。たとえば、General Purpose を選択します。
- Size リストから仮想マシンの新しいインスタンスタイプを選択します。たとえば、medium: 1 CPUs, 4Gi Memory を選択します。これは、General Purpose シリーズで利用できます。
- Save をクリックします。
検証
- YAML タブをクリックします。
- Reload をクリックします。
- 仮想マシン YAML を確認し、インスタンスタイプが変更されたことを確認します。
8.5.2. 仮想マシン上でのメモリーのホットプラグ
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想マシン (VM) を再起動することなく、仮想マシンに割り当てられるメモリーの量を追加または削除できます。
手順
- Virtualization → VirtualMachines に移動します。
- 目的の仮想マシンを選択して、VirtualMachine details ページを開きます。
- Configuration タブで、Edit CPU|Memory をクリックします。
必要なメモリー量を入力し、Save をクリックします。
注記仮想マシンのデフォルト初期メモリー量の最大 3 倍までホットプラグできます。この制限を超えると再起動が必要になります。
システムはこれらの変更をすぐに適用します。仮想マシンが移行可能な場合は、ライブマイグレーションがトリガーされます。そうでない場合、または変更をライブ更新できない場合は、
RestartRequired条件が仮想マシンに追加されます。注記仮想マシンのメモリーのホットプラグを実行するには、
virtio-memドライバーに対するゲストオペレーティングシステムのサポートが必要です。このサポートは、特定のアップストリームのカーネルバージョンではなく、ゲストオペレーティングシステム内に含まれる有効なドライバーに依存します。サポートされているゲストオペレーティングシステム:
- RHEL 9.4 以降
- RHEL 8.10 以降 (ホットアンプラグはデフォルトで無効)
-
その他の Linux ゲストには、カーネルバージョン 5.16 以降と
virtio-memカーネルモジュールが必要です。 -
Windows ゲストには、
virtio-memドライバーバージョン 100.95.104.26200 以降が必要です。
8.5.3. 仮想マシン上での CPU のホットプラグ
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想マシン (VM) を再起動することなく、仮想マシンに割り当てられる CPU ソケットの数を増減できます。
手順
- Virtualization → VirtualMachines に移動します。
- 目的の仮想マシンを選択して、VirtualMachine details ページを開きます。
- Configuration タブで、Edit CPU|Memory をクリックします。
- vCPU ラジオボタンを選択します。
必要な仮想 CPU ソケットの数を入力し、Save をクリックします。
注記仮想マシンの仮想 CPU ソケットのデフォルト初期数の最大 3 倍までホットプラグできます。この制限を超えると再起動が必要になります。
仮想マシンが移行可能な場合は、ライブマイグレーションがトリガーされます。そうでない場合、または変更をライブ更新できない場合は、
RestartRequired条件が仮想マシンに追加されます。注記仮想マシンで
spec.template.spec.domain.devices.networkInterfaceMultiQueueフィールドが有効になっていて、CPU がホットプラグされている場合、次の動作が発生します。- CPU のホットプラグ前に割り当てた既存のネットワークインターフェイスは、仮想 CPU (vCPU) を追加した後でも元のキューカウントを保持します。この動作は正常なものであり、基盤となる仮想化テクノロジーによって発生します。
- 新しい仮想 CPU 設定に合わせて既存のインターフェイスのキュー数を更新するには、仮想マシンを再起動します。再起動は、更新によってパフォーマンスが向上する場合にのみ必要です。
- CPU のホットプラグ後にホットプラグした新しい VirtIO ネットワークインターフェイスには、新しい仮想 CPU 設定と同じキューカウントが自動的に反映されます。
8.5.4. CLI を使用した仮想マシンの編集
コマンドラインを使用して仮想マシンを編集できます。
前提条件
-
ocCLI がインストールされている。
手順
次のコマンドを実行して、仮想マシンの設定を取得します。
oc edit vm <vm_name>
$ oc edit vm <vm_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - YAML 設定を編集します。
実行中の仮想マシンを編集する場合は、以下のいずれかを実行する必要があります。
- 仮想マシンを再起動します。
新規の設定を有効にするために、以下のコマンドを実行します。
oc apply vm <vm_name> -n <namespace>
$ oc apply vm <vm_name> -n <namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
8.5.5. 仮想マシンへのディスクの追加
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想ディスクを仮想マシン (VM) に追加できます。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Disks タブで、Add disk をクリックします。
Source、Name、Size、Type、Interface、および Storage Class を指定します。
- オプション: 空のディスクソースを使用し、データボリュームの作成時に最大の書き込みパフォーマンスが必要な場合に、事前割り当てを有効にできます。そのためには、Enable preallocation チェックボックスをオンにします。
-
オプション: Apply optimized StorageProfile settings をクリアして、仮想ディスクの Volume Mode と Access Mode を変更できます。これらのパラメーターを指定しない場合、システムは
kubevirt-storage-class-defaultsconfig map のデフォルト値を使用します。
Add をクリックします。
注記仮想マシンが実行中の場合は、仮想マシンを再起動して変更を適用する必要があります。
8.5.5.1. ストレージフィールド
| フィールド | 説明 |
|---|---|
| 空白 (PVC の作成) | 空のディスクを作成します。 |
| URL を使用したインポート (PVC の作成) | URL (HTTP または HTTPS エンドポイント) を介してコンテンツをインポートします。 |
| 既存 PVC の使用 | クラスターですでに利用可能な PVC を使用します。 |
| 既存の PVC のクローン作成 (PVC の作成) | クラスターで利用可能な既存の PVC を選択し、このクローンを作成します。 |
| レジストリーを使用したインポート (PVC の作成) | コンテナーレジストリーを使用してコンテンツをインポートします。 |
| コンテナー (一時的) | クラスターからアクセスできるレジストリーにあるコンテナーからコンテンツをアップロードします。コンテナーディスクは、CD-ROM や一時的な仮想マシンなどの読み取り専用ファイルシステムにのみ使用する必要があります。 |
| Name |
ディスクの名前。この名前には、小文字 ( |
| Size | ディスクのサイズ (GiB 単位)。 |
| 型 | ディスクのタイプ。例: Disk または CD-ROM |
| Interface | ディスクデバイスのタイプ。サポートされるインターフェイスは、virtIO、SATA、および SCSI です。 |
| Storage Class | ディスクの作成に使用されるストレージクラス。 |
ストレージの詳細設定
以下のストレージの詳細設定はオプションであり、Blank、Import via URL、および Clone existing PVC ディスクで利用できます。
これらのパラメーターを指定しない場合、システムはデフォルトのストレージプロファイル値を使用します。
| パラメーター | オプション | パラメーターの説明 |
|---|---|---|
| ボリュームモード | Filesystem | ファイルシステムベースのボリュームで仮想ディスクを保存します。 |
| Block |
ブロックボリュームで仮想ディスクを直接保存します。基礎となるストレージがサポートしている場合は、 | |
| アクセスモード | ReadWriteOnce (RWO) | ボリュームはシングルノードで読み取り/書き込みとしてマウントできます。 |
| ReadWriteMany (RWX) | ボリュームは、一度に多くのノードで読み取り/書き込みとしてマウントできます。 注記 このモードはライブマイグレーションに必要です。 |
8.5.6. 仮想マシンに Windows ドライバーディスクをマウントする
Red Hat OpenShift Service on AWS Web コンソールを使用して、Windows ドライバーディスクを仮想マシンにマウントできます。
手順
- Virtualization → VirtualMachines に移動します。
- 目的の仮想マシンを選択して、VirtualMachine details ページを開きます。
- Configuration タブで、Storage をクリックします。
Mount Windows drivers disk チェックボックスを選択します。
マウント済みディスクのリストに、Windows ドライバーディスクが表示されます。
8.5.7. シークレット、設定マップ、またはサービスアカウントの仮想マシンへの追加
Red Hat OpenShift Service on AWS Web コンソールを使用して、シークレット、設定マップ、またはサービスアカウントを仮想マシンに追加できます。
これらのリソースは、ディスクとして仮想マシンに追加されます。他のディスクをマウントするように、シークレット、設定マップ、またはサービスアカウントをマウントします。
仮想マシンが実行中の場合、仮想マシンを再起動するまで、変更は有効になりません。新しく追加されたリソースは、ページの上部で保留中の変更としてマークされます。
前提条件
- 追加するシークレット、設定マップ、またはサービスアカウントは、ターゲット仮想マシンと同じ namespace に存在する必要がある。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Configuration → Environment をクリックします。
- Add Config Map, Secret or Service Account をクリックします。
- Select a resource をクリックし、リストから resource を選択します。6 文字のシリアル番号が、選択したリソースに対して自動的に生成されます。
- オプション: Reload をクリックして、環境を最後に保存した状態に戻します。
- Save をクリックします。
検証
- VirtualMachine details ページで、Configuration → Disks をクリックし、リソースがディスクのリストに表示されていることを確認します。
- Actions → Restart をクリックして、仮想マシンを再起動します。
他のディスクをマウントするように、シークレット、設定マップ、またはサービスアカウントをマウントできるようになりました。
8.5.8. 複数の仮想マシンを更新する
コマンドラインインターフェイス (CLI) を使用して、複数の仮想マシンを同時に更新できます。
前提条件
-
ocCLI がインストールされている。 -
Red Hat OpenShift Service on AWS クラスターにアクセスでき、
cluster-admin権限を持っている。
手順
次のコマンドを実行して、特権付きサービスアカウントを作成します。
oc adm new-project kubevirt-api-lifecycle-automation
$ oc adm new-project kubevirt-api-lifecycle-automationCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc create sa kubevirt-api-lifecycle-automation -n kubevirt-api-lifecycle-automation
$ oc create sa kubevirt-api-lifecycle-automation -n kubevirt-api-lifecycle-automationCopy to Clipboard Copied! Toggle word wrap Toggle overflow oc create clusterrolebinding kubevirt-api-lifecycle-automation --clusterrole=cluster-admin --serviceaccount=kubevirt-api-lifecycle-automation:kubevirt-api-lifecycle-automation
$ oc create clusterrolebinding kubevirt-api-lifecycle-automation --clusterrole=cluster-admin --serviceaccount=kubevirt-api-lifecycle-automation:kubevirt-api-lifecycle-automationCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して、
kubevirt-api-lifecycleイメージのプル URL を決定します。oc get csv -n openshift-cnv -l=operators.coreos.com/kubevirt-hyperconverged.openshift-cnv -ojson | jq '.items[0].spec.relatedImages[] | select(.name|test(".*kubevirt-api-lifecycle-automation.*")) | .image'$ oc get csv -n openshift-cnv -l=operators.coreos.com/kubevirt-hyperconverged.openshift-cnv -ojson | jq '.items[0].spec.relatedImages[] | select(.name|test(".*kubevirt-api-lifecycle-automation.*")) | .image'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 次の例に示すように、ジョブオブジェクトを作成して
Kubevirt-Api-Lifecycle-Automationをデプロイします。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- 1
- イメージの値は、イメージのプル URL に置き換えます。
- 2
MACHINE_TYPE_GLOB値は、独自のパターンに置き換えます。このパターンは、アップグレードが必要な非推奨のマシンタイプを検出するために使用されます。- 3
RESTART_REQUIRED環境変数がtrueに設定されている場合、マシンタイプの更新後に仮想マシンが再起動されます。仮想マシンを再起動したくない場合は、値をfalseに設定します。- 4
namespace環境値は、仮想マシンを検索する namespace を示します。ジョブがクラスター内のすべての namespace を調べるようにするには、パラメーターを空のままにします。- 5
LABEL_SELECTOR環境変数を使用して、ジョブアクションを受信する仮想マシンを選択できます。ジョブをクラスター内のすべての仮想マシンに適用する場合は、パラメーターに値を割り当てないでください。
8.5.8.1. 仮想マシンでの一括操作の実行
Web コンソールの VirtualMachines リストビューを使用して、複数の仮想マシン (VM) に対して同時に一括操作を実行できます。これにより、最小限の手間で仮想マシンのグループを効率的に管理できます。
利用可能な一括操作
- Label VMs - 選択した仮想マシン全体に適用されるラベルを追加、編集、または削除します。
- Delete VMs - 削除する複数の仮想マシンを選択します。確認ダイアログに、削除対象として選択した仮想マシンの数が表示されます。
- Move VMs to folder - 選択した仮想マシンをフォルダーに移動します。すべての仮想マシンは同じ namespace に属している必要があります。
8.5.9. 高速ストレージアクセス用の複数の IOThreads の設定
ソリッドステートドライブ (SSD) や不揮発性メモリーエクスプレス (NVMe) などの高速ストレージを使用する仮想マシン (VM) に対して複数の IOThreads を設定することで、ストレージパフォーマンスを向上させることができます。この設定オプションは、仮想マシンの YAML を編集することによってのみ使用できます。
複数の IOThreads は、blockMultiQueue が有効になっていて、ディスクバスが virtio に設定されている場合にのみサポートされます。この構成を正しく機能させるには、この設定を行う必要があります。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- YAML タブをクリックして、仮想マシンマニフェストを開きます。
YAML エディターで、
spec.template.spec.domainセクションを見つけて、次のフィールドを追加または変更します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow Save をクリックします。
重要仮想マシンの実行中は、
spec.template.spec.domain設定を変更できません。変更を適用するには、仮想マシンを停止してから、新しい設定を有効にするために仮想マシンを再起動する必要があります。
config map、シークレット、サービスアカウントの追加リソース
8.6. ブート順序の編集
Web コンソールまたは CLI を使用して、ブート順序リストの値を更新できます。
Virtual Machine Overview ページの Boot Order で、以下を実行できます。
- ディスクまたはネットワークインターフェイスコントローラー (NIC) を選択し、これをブート順序のリストに追加します。
- ブート順序の一覧でディスクまたは NIC の順序を編集します。
- ブート順序のリストからディスクまたは NIC を削除して、起動可能なソースのインベントリーに戻します。
8.6.1. Web コンソールでのブート順序リストへの項目の追加
Web コンソールを使用して、ブート順序リストに項目を追加できます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Details タブをクリックします。
- Boot Order の右側にある鉛筆アイコンをクリックします。YAML 設定が存在しない場合や、これがブート順序リストの初回作成時の場合、以下のメッセージが表示されます。No resource selected.仮想マシンは、YAML ファイルでの出現順にディスクからの起動を試行します。
- Add Source をクリックして、仮想マシンのブート可能なディスクまたはネットワークインターフェイスコントローラー (NIC) を選択します。
- 追加のディスクまたは NIC をブート順序一覧に追加します。
Save をクリックします。
注記仮想マシンが実行されている場合、Boot Order への変更は仮想マシンを再起動するまで反映されません。
Boot Order フィールドの右側にある View Pending Changes をクリックして、保留中の変更を表示できます。ページ上部の Pending Changes バナーには、仮想マシンの再起動時に適用されるすべての変更のリストが表示されます。
8.6.2. Web コンソールでのブート順序リストの編集
Web コンソールでブート順序リストを編集できます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Details タブをクリックします。
- Boot Order の右側にある鉛筆アイコンをクリックします。
ブート順序リストで項目を移動するのに適した方法を選択します。
- スクリーンリーダーを使用しない場合、移動する項目の横にある矢印アイコンにカーソルを合わせ、項目を上下にドラッグし、選択した場所にドロップします。
- スクリーンリーダーを使用する場合は、上矢印キーまたは下矢印を押して、ブート順序リストで項目を移動します。次に Tab キーを押して、選択した場所に項目をドロップします。
Save をクリックします。
注記仮想マシンが実行されている場合、ブート順序の変更は仮想マシンが再起動されるまで反映されません。
Boot Order フィールドの右側にある View Pending Changes をクリックして、保留中の変更を表示できます。ページ上部の Pending Changes バナーには、仮想マシンの再起動時に適用されるすべての変更のリストが表示されます。
8.6.3. YAML 設定ファイルでのブート順序リストの編集
CLI を使用して、YAML 設定ファイル内のブート順序リストを編集できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、仮想マシンの YAML 設定ファイルを開きます。
oc edit vm <vm_name> -n <namespace>
$ oc edit vm <vm_name> -n <namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow YAML ファイルを編集し、ディスクまたはネットワークインターフェイスコントローラー (NIC) に関連付けられたブート順序の値を変更します。以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - YAML ファイルを保存します。
8.6.4. Web コンソールでのブート順序リストからの項目の削除
Web コンソールを使用して、ブート順序のリストから項目を削除します。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Details タブをクリックします。
- Boot Order の右側にある鉛筆アイコンをクリックします。
項目の横にある Remove アイコン
 をクリックします。この項目はブート順序のリストから削除され、使用可能なブートソースのリストに保存されます。ブート順序リストからすべての項目を削除する場合、以下のメッセージが表示されます。No resource selected.仮想マシンは、YAML ファイルでの出現順にディスクからの起動を試行します。
注記
をクリックします。この項目はブート順序のリストから削除され、使用可能なブートソースのリストに保存されます。ブート順序リストからすべての項目を削除する場合、以下のメッセージが表示されます。No resource selected.仮想マシンは、YAML ファイルでの出現順にディスクからの起動を試行します。
注記仮想マシンが実行されている場合、Boot Order への変更は仮想マシンを再起動するまで反映されません。
Boot Order フィールドの右側にある View Pending Changes をクリックして、保留中の変更を表示できます。ページ上部の Pending Changes バナーには、仮想マシンの再起動時に適用されるすべての変更のリストが表示されます。
8.7. 仮想マシンの削除
Web コンソールまたは oc コマンドラインインターフェイスを使用して、仮想マシンを削除できます。
8.7.1. Web コンソールの使用による仮想マシンの削除
仮想マシン (VM) を削除すると、クラスターから完全に削除されます。
仮想マシンが削除保護されている場合、仮想マシンの Actions メニューで Delete 操作は無効化されます。
前提条件
- 仮想マシンの削除保護設定を無効にした。
- 仮想マシンを停止した。
手順
Red Hat OpenShift Service on AWS Web コンソールから、ビューを選択します。
- 仮想化に重点を置いたビューの場合は、Administrator → Virtualization → VirtualMachines を選択します。
- 一般的なビューは、Virtualization → VirtualMachines に移動します。
仮想マシンの横にある オプション メニュー
をクリックし、Delete を選択します。
または、仮想マシンの名前をクリックして VirtualMachine details ページを開き、Actions → Delete をクリックします。
ツリービューで仮想マシンを右クリックし、ポップアップメニューから Delete を選択することもできます。
- オプション: With grace period を選択するか、Delete disks をクリアします。
- 仮想マシンを完全に削除するには、Delete をクリックします。
8.7.2. CLI の使用による仮想マシンの削除
oc コマンドラインインターフェイス (CLI) を使用して仮想マシン (VM) を削除できます。oc クライアントを使用すると、複数の仮想マシンに対してアクションを実行できます。
前提条件
- 仮想マシンの削除保護設定を無効にした。
- 仮想マシンを停止した。
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して仮想マシンを削除します。
oc delete vm <vm_name>
$ oc delete vm <vm_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記このコマンドは、現在のプロジェクト内の VM のみを削除します。削除する仮想マシンが別のプロジェクトまたは namespace にある場合は、
-n <project_name>オプションを指定します。
8.8. 仮想マシンのエクスポート
仮想マシンを別のクラスターにインポートしたり、フォレンジック目的でボリュームを分析したりするために、仮想マシン (VM) とそれに関連付けられたディスクをエクスポートできます。
コマンドラインインターフェイスを使用して、VirtualMachineExport カスタムリソース (CR) を作成します。
または、virtctl vmexport コマンド を使用して VirtualMachineExport CR を作成し、エクスポートされたボリュームをダウンロードすることもできます。
Migration Toolkit for Virtualization を使用して、OpenShift Virtualization クラスター間で仮想マシンを移行できます。
8.8.1. VirtualMachineExport カスタムリソースの作成
VirtualMachineExport カスタムリソース (CR) を作成して、VirtualMachine、VirtualMachineSnapshot、または PersistentVolumeClaim CR から永続ボリューム要求 (PVC) をエクスポートできます。
エクスポートできるオブジェクトは次のとおりです。
- 仮想マシン: 指定した仮想マシンの永続ボリューム要求をエクスポートします。
-
VM スナップショット:
VirtualMachineSnapshotCR に含まれる PVC をエクスポートします。 -
PVC: PVC をエクスポートします。PVC が
virt-launcherPod などの別の Pod で使用されている場合、エクスポートは PVC が使用されなくなるまでPending状態のままになります。
VirtualMachineExport CR は、エクスポートされたボリュームの内部および外部リンクを作成します。内部リンクはクラスター内で有効です。外部リンクには、Ingress または Route を使用してアクセスできます。
エクスポートサーバーは、次のファイル形式をサポートしています。
-
raw: raw ディスクイメージファイル。 -
gzip: 圧縮されたディスクイメージファイル。 -
dir: PVC ディレクトリーとファイル。 -
tar.gz: 圧縮された PVC ファイル。
前提条件
- 仮想マシンをエクスポートするために、仮想マシンがシャットダウンされている。
-
OpenShift CLI (
oc) がインストールされている。
手順
次の例に従って、
VirtualMachine、VirtualMachineSnapshot、またはPersistentVolumeClaimCR からボリュームをエクスポートするためのVirtualMachineExportマニフェストを作成し、example-export.yamlとして保存します。VirtualMachineExportの例:Copy to Clipboard Copied! Toggle word wrap Toggle overflow VirtualMachineExportCR を作成します。oc create -f example-export.yaml
$ oc create -f example-export.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow VirtualMachineExportCR を取得します。oc get vmexport example-export -o yaml
$ oc get vmexport example-export -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow エクスポートされたボリュームの内部および外部リンクは、
statusスタンザに表示されます。出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
8.8.2. エクスポートされた仮想マシンマニフェストへのアクセス
仮想マシン (VM) またはスナップショットをエクスポートすると、エクスポートサーバーから VirtualMachine マニフェストと関連情報を取得できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 VirtualMachineExportカスタムリソース (CR) を作成して、仮想マシンまたは VM スナップショットをエクスポートしている。注記spec.source.kind: PersistentVolumeClaimパラメーターを持つVirtualMachineExportオブジェクトは、仮想マシンマニフェストを生成しません。
手順
マニフェストにアクセスするには、まず証明書をソースクラスターからターゲットクラスターにコピーする必要があります。
- ソースクラスターにログインします。
次のコマンドを実行して、証明書を
cacert.crtファイルに保存します。oc get vmexport <export_name> -o jsonpath={.status.links.external.cert} > cacert.crt$ oc get vmexport <export_name> -o jsonpath={.status.links.external.cert} > cacert.crt1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
<export_name>を、VirtualMachineExportオブジェクトのmetadata.name値に置き換えます。
-
cacert.crtファイルをターゲットクラスターにコピーします。
次のコマンドを実行して、ソースクラスター内のトークンをデコードし、
token_decodeファイルに保存します。oc get secret export-token-<export_name> -o jsonpath={.data.token} | base64 --decode > token_decode$ oc get secret export-token-<export_name> -o jsonpath={.data.token} | base64 --decode > token_decode1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
<export_name>を、VirtualMachineExportオブジェクトのmetadata.name値に置き換えます。
-
token_decodeファイルをターゲットクラスターにコピーします。 次のコマンドを実行して、
VirtualMachineExportカスタムリソースを取得します。oc get vmexport <export_name> -o yaml
$ oc get vmexport <export_name> -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow status.linksスタンザを確認します。このスタンザはexternalセクションとinternalセクションに分かれています。各セクション内のmanifests.urlフィールドに注意してください。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
VirtualMachineマニフェスト、存在する場合はDataVolumeマニフェスト、外部 URL の Ingress またはルートの公開証明書を含むConfigMapマニフェストが含まれます。- 2
- Containerized Data Importer (CDI) と互換性のあるヘッダーを含むシークレットが含まれます。ヘッダーには、エクスポートトークンのテキストバージョンが含まれています。
- 3
VirtualMachineマニフェスト、存在する場合はDataVolumeマニフェスト、および内部 URL のエクスポートサーバーの証明書を含むConfigMapマニフェストが含まれます。
- ターゲットクラスターにログインします。
次のコマンドを実行して
Secretマニフェストを取得します。curl --cacert cacert.crt <secret_manifest_url> -H \ "x-kubevirt-export-token:token_decode" -H \ "Accept:application/yaml"
$ curl --cacert cacert.crt <secret_manifest_url> -H \1 "x-kubevirt-export-token:token_decode" -H \2 "Accept:application/yaml"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
curl --cacert cacert.crt https://vmexport-proxy.test.net/api/export.kubevirt.io/v1beta1/namespaces/example/virtualmachineexports/example-export/external/manifests/secret -H "x-kubevirt-export-token:token_decode" -H "Accept:application/yaml"
$ curl --cacert cacert.crt https://vmexport-proxy.test.net/api/export.kubevirt.io/v1beta1/namespaces/example/virtualmachineexports/example-export/external/manifests/secret -H "x-kubevirt-export-token:token_decode" -H "Accept:application/yaml"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して、
ConfigMapマニフェストやVirtualMachineマニフェストなどのtype: allマニフェストを取得します。curl --cacert cacert.crt <all_manifest_url> -H \ "x-kubevirt-export-token:token_decode" -H \ "Accept:application/yaml"
$ curl --cacert cacert.crt <all_manifest_url> -H \1 "x-kubevirt-export-token:token_decode" -H \2 "Accept:application/yaml"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
curl --cacert cacert.crt https://vmexport-proxy.test.net/api/export.kubevirt.io/v1beta1/namespaces/example/virtualmachineexports/example-export/external/manifests/all -H "x-kubevirt-export-token:token_decode" -H "Accept:application/yaml"
$ curl --cacert cacert.crt https://vmexport-proxy.test.net/api/export.kubevirt.io/v1beta1/namespaces/example/virtualmachineexports/example-export/external/manifests/all -H "x-kubevirt-export-token:token_decode" -H "Accept:application/yaml"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
次のステップ
-
エクスポートしたマニフェストを使用して、ターゲットクラスター上に
ConfigMapオブジェクトとVirtualMachineオブジェクトを作成できます。
8.9. 仮想マシンインスタンスの管理
OpenShift Virtualization 環境の外部で独立して作成されたスタンドアロン仮想マシンインスタンス (VMI) がある場合、Web コンソールを使用するか、コマンドラインインターフェイス (CLI) から oc または virtctl コマンドを使用してそれらを管理できます。
virtctl コマンドは、oc コマンドよりも多くの仮想化オプションを提供します。たとえば、virtctl を使用して仮想マシンを一時停止したり、ポートを公開したりできます。
8.9.1. 仮想マシンインスタンスについて
仮想マシンインスタンス (VMI) は、実行中の仮想マシンを表します。VMI が仮想マシンまたは別のオブジェクトによって所有されている場合、Web コンソールで、または oc コマンドラインインターフェイス (CLI) を使用し、所有者を通してこれを管理します。
スタンドアロンの VMI は、自動化または CLI で他の方法により、スクリプトを使用して独立して作成され、起動します。お使いの環境では、OpenShift Virtualization 環境外で開発され、起動されたスタンドアロンの VMI が存在する可能性があります。CLI を使用すると、引き続きそれらのスタンドアロン VMI を管理できます。スタンドアロン VMI に関連付けられた特定のタスクに Web コンソールを使用することもできます。
- スタンドアロン VMI とそれらの詳細をリスト表示します。
- スタンドアロン VMI のラベルとアノテーションを編集します。
- スタンドアロン VMI を削除します。
仮想マシンを削除する際に、関連付けられた VMI は自動的に削除されます。仮想マシンまたは他のオブジェクトによって所有されていないため、スタンドアロン VMI を直接削除します。
OpenShift Virtualization をアンインストールする前に、CLI または Web コンソールを使用してスタンドアロンの VMI のリストを表示します。次に、未処理の VMI を削除します。
仮想マシンを編集すると、一部の設定が再起動なしで VMI に動的に適用される場合があります。VMI に動的に適用できない仮想マシンオブジェクトを変更すると、RestartRequired 仮想マシン条件がトリガーされます。変更は次回の再起動時に有効になり、条件は削除されます。
8.9.2. CLI を使用した仮想マシンインスタンスのリスト表示
oc コマンドラインインターフェイス (CLI) を使用して、スタンドアロンおよび仮想マシンによって所有されている VMI を含むすべての仮想マシンのリストを表示できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、すべての VMI のリストを表示します。
oc get vmis -A
$ oc get vmis -ACopy to Clipboard Copied! Toggle word wrap Toggle overflow
8.9.3. Web コンソールを使用したスタンドアロン仮想マシンインスタンスのリスト表示
Web コンソールを使用して、仮想マシンによって所有されていないクラスター内のスタンドアロンの仮想マシンインスタンス (VMI) のリストを表示できます。
仮想マシンまたは他のオブジェクトが所有する VMI は、Web コンソールには表示されません。Web コンソールは、スタンドアロンの VMI のみを表示します。クラスター内のすべての VMI をリスト表示するには、CLI を使用する必要があります。
手順
サイドメニューから Virtualization → VirtualMachines をクリックします。
スタンドアロン VMI は、名前の横にある濃い色のバッジで識別できます。
8.9.4. Web コンソールを使用してスタンドアロン仮想マシンインスタンスを検索する
VirtualMachines ページの検索バーを使用して、仮想マシンインスタンス (VMI) を検索できます。追加のフィルターを適用するには、詳細検索を使用します。
手順
- Red Hat OpenShift Service on AWS コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
- ページ上部の検索バーに、仮想マシン名、ラベル、または IP アドレスを入力します。
候補リストで、次のいずれかのオプションを選択します。
- 仮想マシン名をクリックすると詳細ページが開きます。
- 専用ページで結果を表示するには All search results found for … をクリックします。
- 関連する提案をクリックすると、検索フィルターが事前に入力されます。
- オプション: 詳細な検索オプションを開くには、検索バーの横にあるスライダーアイコンをクリックします。Details セクションを展開し、使用可能なフィルター (Name、Project、Description、Labels、Date created、vCPU、Memory) を 1 つ以上指定します。
- オプション: Network セクションを展開し、フィルタリングする IP アドレスを入力します。
- Search をクリックします。
- オプション: Advanced Cluster Management (ACM) がインストールされている場合は、Cluster ドロップダウンを使用して複数のクラスターを検索します。
-
オプション: Save search アイコンをクリックして、検索を
kubevirt-user-settingsConfigMap に保存します。
8.9.5. Web コンソールを使用したスタンドアロン仮想マシンインスタンスの編集
Web コンソールを使用して、スタンドアロン仮想マシンインスタンスのアノテーションおよびラベルを編集できます。他のフィールドは編集できません。
手順
- Red Hat OpenShift Service on AWS コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
- スタンドアロン VMI を選択して、VirtualMachineInstance details ページを開きます。
- Details タブで、Annotations または Labels の横にある鉛筆アイコンをクリックします。
- 関連する変更を加え、Save をクリックします。
8.9.6. CLI を使用したスタンドアロン仮想マシンインスタンスの削除
oc コマンドラインインターフェイス (CLI) を使用してスタンドアロン仮想マシンインスタンス (VMI) を削除できます。
前提条件
- 削除する必要のある VMI の名前を特定している。
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して VMI を削除します。
oc delete vmi <vmi_name>
$ oc delete vmi <vmi_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
8.9.7. Web コンソールを使用したスタンドアロン仮想マシンインスタンスの削除
Web コンソールからスタンドアロン仮想マシンインスタンス (VMI) を削除できます。
手順
- Red Hat OpenShift Service on AWS Web コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
- Actions → Delete VirtualMachineInstance をクリックします。
- 確認のポップアップウィンドウで、Delete をクリックし、スタンドアロン VMI を永続的に削除します。
8.10. 仮想マシンの状態の制御
virtctl を使用して仮想マシンの状態を管理し、CLI から他のアクションを実行できます。たとえば、virtctl を使用して仮想マシンを強制停止したり、ポートを公開したりできます。
Web コンソールから仮想マシンを停止、起動、再起動、一時停止、一時停止解除できます。
8.10.1. Web コンソールを使用して仮想マシンの状態を管理するための RBAC 権限を設定する
Red Hat OpenShift Service on AWS Web コンソールを使用して仮想マシン(VM)の状態を管理できるようにするには、RBAC クラスターロールとクラスターのロールバインディングを作成する必要があります。クラスターロールは、subresources.kubevirt.io API を使用して、特定のユーザーまたはグループが制御できるリソースを定義します。
前提条件
- OpenShift Virtualization がインストールされている Red Hat OpenShift Service on AWS クラスターにクラスター管理者としてアクセスできる。
-
OpenShift CLI (
oc) がインストールされている。
手順
ターゲットユーザーまたはグループが仮想マシンの状態を管理できるようにする
ClusterRoleオブジェクトを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターロールを適用するには、次のコマンドを実行します。
oc apply -f <filename>.yaml
$ oc apply -f <filename>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して出力をチェックし、クラスターロールが作成されたことを確認します。
oc get clusterrole <name>
$ oc get clusterrole <name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
NAME AGE vm-manager-access 15s
NAME AGE vm-manager-access 15sCopy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターロールの詳細を検査し、
subresources.kubevirt.ioの目的のルール (具体的には、virtualmachines/startおよびvirtualmachines/stopサブリソース) が存在することを確認します。次のコマンドを実行し、出力を確認します。
oc describe clusterrole <name>
$ oc describe clusterrole <name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 作成したクラスターロールをターゲットユーザーまたはグループにバインドするための
ClusterRoleBindingオブジェクトを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターロールバインディングを適用するには、次のコマンドを実行します。
oc apply -f <filename>.yaml
$ oc apply -f <filename>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して出力をチェックし、クラスターロールバインディングが作成されたことを確認します。
oc get clusterrolebinding <name>
$ oc get clusterrolebinding <name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
NAME AGE vm-manager-access-binding 15s
NAME AGE vm-manager-access-binding 15sCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
次のコマンドを実行して、ユーザーが仮想マシンを起動できるかどうかを確認します。
oc auth can-i update virtualmachines/start --namespace=<namespace> --as=<user_name> --subresource=subresources.kubevirt.io
$ oc auth can-i update virtualmachines/start --namespace=<namespace> --as=<user_name> --subresource=subresources.kubevirt.ioCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
yes
yesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して、ユーザーが仮想マシンを停止できるかどうかを確認します。
oc auth can-i update virtualmachines/stop --namespace=<namespace> --as=<user_name> --group=subresources.kubevirt.io
$ oc auth can-i update virtualmachines/stop --namespace=<namespace> --as=<user_name> --group=subresources.kubevirt.ioCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
yes
yesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
8.10.2. 仮想マシンの動作の確認を有効にする
確認が有効になっている場合、Stop、Restart、Pause のアクションで確認ダイアログを表示できます。デフォルトでは、確認は無効になっています。
手順
- Red Hat OpenShift Service on AWS Web コンソールの Virtualization セクションで、Overview → Settings → Cluster → General settings に移動します。
- VirtualMachine actions confirmation 設定をオンに切り替えます。
8.10.3. 仮想マシンの起動
Web コンソールから仮想マシン (VM) を起動できます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- ツリービューで、起動する仮想マシンを含むプロジェクトを選択します。
ユースケースに応じて適切なメニューに移動します。
このページに留まり、複数の仮想マシンに対してアクションを実行するには、次の手順を実行します。
-
行の右端にある Options メニュー
をクリックして、Start VirtualMachine をクリックします。
-
行の右端にある Options メニュー
ツリービューから仮想マシンを起動するには、以下を実行します。
- プロジェクト名の横にある > アイコンをクリックして、仮想マシンのリストを開きます。
- 仮想マシンの名前を右クリックし、Start を選択します。
選択した仮想マシンを起動する前に、その仮想マシンに関する包括的な情報を表示するには、以下を実行します。
- 仮想マシンの名前をクリックして、VirtualMachine details ページにアクセスします。
Actions → Start をクリックします。
注記URLソースからプロビジョニングされた仮想マシンを初めて起動すると、OpenShift Virtualization が URL エンドポイントからコンテナーをインポートする間、仮想マシンのステータスは Importing になります。このプロセスは、イメージのサイズによって数分の時間がかかる可能性があります。
8.10.4. 仮想マシンの停止
Web コンソールから仮想マシン (VM) を停止できます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- ツリービューで、停止する仮想マシンを含むプロジェクトを選択します。
ユースケースに応じて適切なメニューに移動します。
このページに留まり、複数の仮想マシンに対してアクションを実行するには、次の手順を実行します。
-
行の右端にある Options メニュー
をクリックして、Stop VirtualMachine をクリックします。
- アクションの確認が有効になっている場合は、確認ダイアログで Stop をクリックします。
-
行の右端にある Options メニュー
ツリービューから仮想マシンを停止するには、以下を実行します。
- プロジェクト名の横にある > アイコンをクリックして、仮想マシンのリストを開きます。
- 仮想マシンの名前を右クリックし、Stop を選択します。
- アクションの確認が有効になっている場合は、確認ダイアログで Stop をクリックします。
選択した仮想マシンを停止する前にその包括的な情報を表示するには、以下を実行します。
- 仮想マシンの名前をクリックして、VirtualMachine details ページにアクセスします。
- Actions → Stop をクリックします。
- アクションの確認が有効になっている場合は、確認ダイアログで Stop をクリックします。
8.10.5. 仮想マシンの再起動
実行中の仮想マシン (VM) を Web コンソールから再起動できます。
エラーを回避するには、ステータスが Importing の間は仮想マシンを再起動しないでください。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- ツリービューで、再起動する仮想マシンを含むプロジェクトを選択します。
ユースケースに応じて適切なメニューに移動します。
このページに留まり、複数の仮想マシンに対してアクションを実行するには、次の手順を実行します。
-
行の右端にある Options メニュー
をクリックして、Restart をクリックします。
- アクションの確認が有効になっている場合は、確認ダイアログで Restart をクリックします。
-
行の右端にある Options メニュー
ツリービューから仮想マシンを再起動するには、以下を実行します。
- プロジェクト名の横にある > アイコンをクリックして、仮想マシンのリストを開きます。
- 仮想マシンの名前を右クリックし、Restart を選択します。
- アクションの確認が有効になっている場合は、確認ダイアログで Restart をクリックします。
選択した仮想マシンを再起動する前に、その仮想マシンに関する包括的な情報を表示するには、以下を実行します。
- 仮想マシンの名前をクリックして、VirtualMachine details ページにアクセスします。
- Actions → Restart をクリックします。
- アクションの確認が有効になっている場合は、確認ダイアログで Restart をクリックします。
8.10.6. 仮想マシンの一時停止
Web コンソールから仮想マシン (VM) を一時停止できます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- ツリービューで、一時停止する仮想マシンを含むプロジェクトを選択します。
ユースケースに応じて適切なメニューに移動します。
このページに留まり、複数の仮想マシンに対してアクションを実行するには、次の手順を実行します。
-
行の右端にある Options メニュー
をクリックして、Pause VirtualMachine をクリックします。
- アクションの確認が有効になっている場合は、確認ダイアログで Pause をクリックします。
-
行の右端にある Options メニュー
ツリービューから仮想マシンを一時停止するには、以下を実行します。
- プロジェクト名の横にある > アイコンをクリックして、仮想マシンのリストを開きます。
- 仮想マシンの名前を右クリックし、Pause を選択します。
- アクションの確認が有効になっている場合は、確認ダイアログで Pause をクリックします。
選択した仮想マシンを一時停止する前に、その仮想マシンに関する包括的な情報を表示するには、以下を実行します。
- 仮想マシンの名前をクリックして、VirtualMachine details ページにアクセスします。
- Actions → Pause をクリックします。
- アクションの確認が有効になっている場合は、確認ダイアログで Pause をクリックします。
8.10.7. 仮想マシンの一時停止の解除
一時停止中の仮想マシン (VM) を Web コンソールから一時停止解除できます。
前提条件
- 少なくとも 1 つの仮想マシンのステータスが Paused である必要があります。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- ツリービューで、一時停止を解除する仮想マシンを含むプロジェクトを選択します。
ユースケースに応じて適切なメニューに移動します。
このページに留まり、複数の仮想マシンに対してアクションを実行するには、次の手順を実行します。
-
行の右端にある Options メニュー
をクリックして、Unpause VirtualMachine をクリックします。
-
行の右端にある Options メニュー
ツリービューから仮想マシンの一時停止を解除するには、以下を実行します。
- プロジェクト名の横にある > アイコンをクリックして、仮想マシンのリストを開きます。
- 仮想マシンの名前を右クリックし、Unpause を選択します。
選択した仮想マシンの一時停止を解除する前に、その仮想マシンに関する包括的な情報を表示するには、以下を実行します。
- 仮想マシンの名前をクリックして、VirtualMachine details ページにアクセスします。
- Actions → Unpause をクリックします。
8.10.8. 複数の仮想マシンの状態を制御する
Web コンソールから複数の仮想マシン (VM) を起動、停止、再起動、一時停止、一時停止解除できます。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
- オプション: 表示されるプロジェクトを制限するには、ツリービューの上にある Show only projects with VirtualMachines オプションを有効にします。
- ツリービューから関連するプロジェクトを選択します。
ユースケースに応じて適切なメニューに移動します。
選択したプロジェクト内のすべての仮想マシンの状態を変更するには、以下を実行します。
- ツリービューでプロジェクトの名前を右クリックし、メニューから目的のアクションを選択します。
- アクションの確認が有効になっている場合は、確認ダイアログでアクションを確認します。
特定の仮想マシンの状態を変更するには、以下を実行します。
- 使用する仮想マシンの横にあるチェックボックスを選択します。すべての仮想マシンを選択するには、VirtualMachines テーブルヘッダーのチェックボックスをクリックします。
- Actions をクリックし、メニューから目的のアクションを選択します。
- アクションの確認が有効になっている場合は、確認ダイアログでアクションを確認します。
8.11. 仮想 Trusted Platform Module デバイスの使用
VirtualMachine (VM) または VirtualMachineInstance (VMI) マニフェストを編集して、仮想 Trusted Platform Module (vTPM) デバイスを新規または既存の仮想マシンに追加します。
OpenShift Virtualization 4.18 以降では、vTPM デバイスがアタッチされた 仮想マシン (VM) をエクスポート し、これらの仮想マシンのスナップショットを作成 して、これらのスナップショットから仮想マシンを復元 できます。ただし、vTPM デバイスがアタッチされた仮想マシンのクローン作成や、そのスナップショットからの新しい仮想マシンの作成はサポートされていません。
8.11.1. vTPM デバイスについて
仮想トラステッドプラットフォームモジュール (vTPM) デバイスは、物理トラステッドプラットフォームモジュール (TPM) ハードウェアチップのように機能します。vTPM デバイスはどのオペレーティングシステムでも使用できますが、Windows 11 をインストールまたは起動するには TPM チップが必要です。
vTPM デバイスを使用すると、Windows 11 イメージから作成された VM を物理 TPM チップなしで機能させることができます。
OpenShift Virtualization は、仮想マシンの永続ボリューム要求 (PVC) を使用して、vTPM デバイス状態の永続化をサポートします。この PVC のストレージクラスを指定しない場合、OpenShift Virtualization は仮想化ワークロードのデフォルトのストレージクラスを使用します。仮想化ワークロードのデフォルトのストレージクラスが設定されていない場合、OpenShift Virtualization はクラスターのデフォルトのストレージクラスを使用します。
仮想化ワークロードのデフォルトとしてマークされているストレージクラスには、storageclass.kubevirt.io/is-default-virt-class のアノテーションが "true" に設定されています。このストレージクラスは、次のコマンドを実行すると見つかります。
oc get sc -o jsonpath='{range .items[?(.metadata.annotations.storageclass\.kubevirt\.io/is-default-virt-class=="true")]}{.metadata.name}{"\n"}{end}'
$ oc get sc -o jsonpath='{range .items[?(.metadata.annotations.storageclass\.kubevirt\.io/is-default-virt-class=="true")]}{.metadata.name}{"\n"}{end}'
同様に、クラスターのデフォルトのストレージクラスでは、storageclass.kubernetes.io/is-default-class のアノテーションが "true" に設定されています。このストレージクラスを見つけるには、次のコマンドを実行します。
oc get sc -o jsonpath='{range .items[?(.metadata.annotations.storageclass\.kubernetes\.io/is-default-class=="true")]}{.metadata.name}{"\n"}{end}'
$ oc get sc -o jsonpath='{range .items[?(.metadata.annotations.storageclass\.kubernetes\.io/is-default-class=="true")]}{.metadata.name}{"\n"}{end}'一貫した動作を確保するには、仮想化ワークロードとクラスターに対して、デフォルトのストレージクラスをそれぞれ 1 つずつ設定します。
HyperConverged カスタムリソース (CR) で vmStateStorageClass 属性を設定することで、ストレージクラスを明示的に指定することが推奨されます。
vTPM を有効にしないと、ノードに TPM デバイスがある場合でも、VM は TPM デバイスを認識しません。
8.11.2. 仮想マシンへの vTPM デバイスの追加
仮想トラステッドプラットフォームモジュール (vTPM) デバイスを仮想マシン (VM) に追加すると、物理 TPM デバイスなしで Windows 11 イメージから作成された仮想マシンを実行できます。vTPM デバイスには、その仮想マシンのシークレットも保存されます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、仮想マシン設定を更新します。
oc edit vm <vm_name> -n <namespace>
$ oc edit vm <vm_name> -n <namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 仮想マシン仕様を編集して vTPM デバイスを追加します。以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 変更を適用するには、エディターを保存し、終了します。
- オプション: 実行中の仮想マシンを編集している場合は、変更を有効にするためにこれを再起動する必要があります。
8.12. OpenShift Pipelines を使用した仮想マシンの管理
Red Hat OpenShift Pipelines は、開発者が独自のコンテナーで CI/CD パイプラインの各ステップを設計および実行できるようにする、Kubernetes ネイティブの CI/CD フレームワークです。
OpenShift Pipelines タスクとサンプルパイプラインを使用すると、以下を実行できます。
- 仮想マシン (VM)、永続ボリューム要求 (PVC)、データボリューム、およびデータソースを作成および管理する。
- 仮想マシンでコマンドを実行する。
-
libguestfsツールを使用してディスクイメージを操作する。
タスクは タスクカタログ (ArtifactHub) にあります。
サンプルの Windows パイプラインは、パイプラインカタログ (ArtifactHub) にあります。
8.12.1. 前提条件
-
cluster-admin権限で Red Hat OpenShift Service on AWS クラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。 - OpenShift Pipelines がインストールされている。
8.12.2. サポートされている仮想マシンタスク
次の表に、サポートされているタスクを示します。
| タスク | 説明 |
|---|---|
|
|
提供されたマニフェストから、または |
|
| テンプレートからの仮想マシンの作成 |
|
| 仮想マシンテンプレートをコピーします。 |
|
| 仮想マシンテンプレートを変更します。 |
|
| データボリュームまたはデータソースを作成または削除します。 |
|
| 仮想マシンでスクリプトまたはコマンドを実行し、後で仮想マシンを停止または削除します。 |
|
|
|
|
|
|
|
| 仮想マシンインスタンスの特定のステータスを待機し、ステータスに基づいて失敗または成功します。 |
パイプラインでの仮想マシンの作成では、非推奨になったテンプレートベースのタスクではなく、ClusterInstanceType と ClusterPreference が使用されるようになりました。create-vm-from-template、copy-template、および modify-vm-template コマンドは引き続き使用できますが、デフォルトのパイプラインタスクでは使用されません。
8.12.3. Windows EFI インストーラーパイプライン
Web コンソールまたは CLI を使用して、Windows EFI installer pipeline を実行できます。
Windows EFI インストーラーパイプラインは、Windows インストールイメージ (ISO ファイル) から Windows 10、Windows 11、または Windows Server 2022 を新しいデータボリュームにインストールします。インストールプロセスの実行には、カスタムアンサーファイルが使用されます。
Windows EFI インストーラーパイプラインは、Red Hat OpenShift Service on AWS によって事前定義され、Microsoft ISO ファイルに適した sysprep を含む config map ファイルを使用します。さまざまな Windows エディションに関連する ISO ファイルの場合は、システム固有の sysprep 定義を使用して新しい config map ファイルを作成することが必要になる場合があります。
8.12.3.1. Web コンソールを使用してサンプルパイプラインを実行する
サンプルパイプラインは、Web コンソールの Pipelines メニューから実行できます。
手順
- サイドメニューの Pipelines → Pipelines をクリックします。
- パイプラインを選択して、Pipeline details ページを開きます。
- Actions リストから、Start を選択します。Start Pipeline ダイアログが表示されます。
- パラメーターのデフォルト値を保持し、Start をクリックしてパイプラインを実行します。Details タブでは、各タスクの進行状況が追跡され、パイプラインのステータスが表示されます。
8.12.3.2. CLI を使用してサンプルパイプラインを実行する
PipelineRun リソースを使用して、サンプルパイプラインを実行します。PipelineRun オブジェクトは、パイプラインの実行中のインスタンスです。これは、クラスター上の特定の入力、出力、および実行パラメーターで実行されるパイプラインをインスタンス化します。また、パイプライン内のタスクごとに TaskRun オブジェクトを作成します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
Microsoft Windows 11 インストーラーパイプラインを実行するには、次の
PipelineRunマニフェストを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow PipelineRunマニフェストを適用します。oc apply -f windows11-customize-run.yaml
$ oc apply -f windows11-customize-run.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
8.12.4. 非推奨または未使用のリソースの削除
Red Hat OpenShift Pipelines Operator に関連付けられた非推奨または未使用のリソースをクリーンアップできます。
手順
次のコマンドを実行して、クラスターから残っている OpenShift Pipelines リソースをすべて削除します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat OpenShift Pipelines Operator のカスタムリソース定義 (CRD) がすでに削除されている場合、コマンドはエラーを返す可能性があります。他の一致するリソースは引き続きすべて削除されるため、これを無視しても問題ありません。
8.13. 高度な仮想マシン管理
8.13.1. 仮想マシンのリソースクォータの使用
仮想マシンのリソースクォータの作成および管理
8.13.1.1. 仮想マシンのリソースクォータ制限の設定
デフォルトでは、OpenShift Virtualization は、制限を設定する必要があるリソースクォータを namespace が強制する場合、仮想マシン (VM) の CPU およびメモリー制限を自動的に管理します。メモリー制限は要求されたメモリーの 2 倍に自動的に設定され、CPU 制限は仮想 CPU ごとに 1 に設定されます。
alpha.kubevirt.io/auto-memory-limits-ratio ラベルを namespace に追加することで、特定の namespace のメモリー制限比率をカスタマイズできます。たとえば、次のコマンドはメモリー制限比率を 1.2 に設定します。
oc label ns/my-virtualization-project alpha.kubevirt.io/auto-memory-limits-ratio=1.2
$ oc label ns/my-virtualization-project alpha.kubevirt.io/auto-memory-limits-ratio=1.2リソースクォータ制限を手動で管理することは避けてください。誤った設定やスケジュールの問題を防ぐには、デフォルトをオーバーライドする必要がある場合を除き、OpenShift Virtualization が提供する自動リソース制限管理を利用してください。
requests のみを使用するリソースクォータは、仮想マシンで自動的に機能します。リソースクォータで制限を使用する場合は、仮想マシンに手動でリソース制限を設定する必要があります。リソース limits は、リソース requests より少なくとも 100 MiB 大きくする必要があります。
手順
VirtualMachineマニフェストを編集して、VM の制限を設定します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- この設定がサポートされるのは、
limits.memory値がrequests.memory値より少なくとも100Mi大きいためです。
-
VirtualMachineマニフェストを保存します。
8.13.2. 仮想マシンのノードの指定
ノードの配置ルールを使用して、仮想マシン (VM) を特定のノードに配置することができます。
8.13.2.1. 仮想マシンのノード配置について
仮想マシン (VM) が適切なノードで実行されるようにするには、ノードの配置ルールを設定できます。
以下の場合にこれを行うことができます。
- 仮想マシンが複数ある。フォールトトレランスを確保するために、これらを異なるノードで実行する必要がある。
- 2 つの相互間のネットワークトラフィックの多い chatty VM がある。冗長なノード間のルーティングを回避するには、仮想マシンを同じノードで実行します。
- 仮想マシンには、利用可能なすべてのノードにない特定のハードウェア機能が必要です。
- 機能をノードに追加する Pod があり、それらの機能を使用できるように仮想マシンをそのノードに配置する必要があります。
仮想マシンの配置は、ワークロードの既存のノードの配置ルールに基づきます。ワークロードがコンポーネントレベルの特定のノードから除外される場合、仮想マシンはそれらのノードに配置できません。
以下のルールタイプは、VirtualMachine マニフェストの spec フィールドで使用できます。
nodeSelector- このフィールドで指定したキーと値のペアでラベル付けされたノード上で仮想マシンをスケジュールできるようにします。ノードには、リスト表示されたすべてのペアに一致するラベルがなければなりません。
affinity-
より表現的な構文を使用して、ノードと仮想マシンに一致するルールを設定できます。たとえば、ルールがハード要件ではなく基本設定になるように指定し、ルールの条件が満たされない場合も仮想マシンがスケジュールされるようにすることができます。Pod のアフィニティー、Pod のアンチアフィニティー、およびノードのアフィニティーは仮想マシンの配置でサポートされます。Pod のアフィニティーは仮想マシンに対して動作します。
VirtualMachineワークロードタイプはPodオブジェクトに基づくためです。 tolerations一致する taint を持つノードに仮想マシンをスケジュールすることを許容します。ノードに taint が適用されると、そのノードはその taint を許容する仮想マシンのみを受け入れます。
注記アフィニティールールは、スケジューリング時にのみ適用されます。Red Hat OpenShift Service on AWS は、制約が満たされなくなった場合、実行中のワークロードを再スケジュールしません。
8.13.2.2. ノード配置の例
以下の YAML スニペットの例では、nodePlacement、affinity、および tolerations フィールドを使用して仮想マシンのノード配置をカスタマイズします。
8.13.2.2.1. 例: nodeSelector を使用した仮想マシンノードの配置
この例では、仮想マシンに example-key-1 = example-value-1 および example-key-2 = example-value-2 ラベルの両方が含まれるメタデータのあるノードが必要です。
この説明に該当するノードがない場合、仮想マシンはスケジュールされません。
例8.1 仮想マシンマニフェストの例
8.13.2.2.2. 例: Pod のアフィニティーおよび Pod のアンチアフィニティーによる仮想マシンノードの配置
この例では、仮想マシンはラベル example-key-1 = example-value-1 を持つ実行中の Pod のあるノードでスケジュールされる必要があります。このようなノードで実行中の Pod がない場合、仮想マシンはスケジュールされません。
可能な場合に限り、仮想マシンはラベル example-key-2 = example-value-2 を持つ Pod のあるノードではスケジュールされません。ただし、すべての候補となるノードにこのラベルを持つ Pod がある場合、スケジューラーはこの制約を無視します。
8.13.2.2.3. 例: ノードのアフィニティーによる仮想マシンノードの配置
この例では、仮想マシンはラベル example.io/example-key = example-value-1 またはラベル example.io/example-key = example-value-2 を持つノードでスケジュールされる必要があります。この制約は、ラベルのいずれかがノードに存在する場合に満たされます。いずれのラベルも存在しない場合、仮想マシンはスケジュールされません。
可能な場合、スケジューラーはラベル example-node-label-key = example-node-label-value を持つノードを回避します。ただし、すべての候補となるノードにこのラベルがある場合、スケジューラーはこの制約を無視します。
8.13.2.2.4. 例: toleration を使用した仮想マシンノードの配置
この例では、仮想マシン用に予約されているノードに、すでに key=virtualization:NoSchedule taint のラベルが付けられています。この仮想マシンには一致する tolerations があるため、この仮想マシンを taint を持つノードにスケジュールできます。
taint を許容する仮想マシンを、その taint を持つノードにスケジュールする必要はありません。
例8.4 仮想マシンマニフェストの例
8.13.3. デフォルトの CPU モデルの設定
HyperConverged カスタムリソース (CR) の defaultCPUModel 設定を使用して、クラスター全体のデフォルト CPU モデルを定義します。
仮想マシン (VM) の CPU モデルは、仮想マシンおよびクラスター内の CPU モデルの可用性によって異なります。
仮想マシンに定義された CPU モデルがない場合:
-
defaultCPUModelは、クラスター全体のレベルで定義された CPU モデルを使用して自動的に設定されます。
-
仮想マシンとクラスターの両方に CPU モデルが定義されている場合:
- 仮想マシンの CPU モデルが優先されます。
仮想マシンにもクラスターにも CPU モデルが定義されていない場合:
- ホストモデルは、ホストレベルで定義された CPU モデルを使用して自動的に設定されます。
8.13.3.1. デフォルトの CPU モデルの設定
HyperConverged カスタムリソース (CR) を更新することで、defaultCPUModel を設定できます。OpenShift Virtualization の実行中に、defaultCPUModel を変更できます。
defaultCPUModel では、大文字と小文字が区別されます。
前提条件
- OpenShift CLI (oc) のインストール。
手順
以下のコマンドを実行して
HyperConvergedCR を開きます。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow CR に
defaultCPUModelフィールドを追加し、値をクラスター内に存在する CPU モデルの名前に設定します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - YAML ファイルをクラスターに適用します。
8.13.4. 仮想マシンに UEFI モードを使用する
Unified Extensible Firmware Interface (UEFI) モードで仮想マシン (VM) を起動できます。
8.13.4.1. 仮想マシンの UEFI モードについて
レガシー BIOS などの Unified Extensible Firmware Interface (UEFI) は、コンピューターの起動時にハードウェアコンポーネントやオペレーティングシステムのイメージファイルを初期化します。UEFI は BIOS よりも最新の機能とカスタマイズオプションをサポートするため、起動時間を短縮できます。
これは、.efi 拡張子を持つファイルに初期化と起動に関する情報をすべて保存します。このファイルは、EFI System Partition (ESP) と呼ばれる特別なパーティションに保管されます。ESP には、コンピューターにインストールされるオペレーティングシステムのブートローダープログラムも含まれます。
8.13.4.2. UEFI モードでの仮想マシンの起動
VirtualMachine マニフェストを編集して、UEFI モードで起動するように仮想マシンを設定できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
VirtualMachineマニフェストファイルを編集または作成します。spec.firmware.bootloaderスタンザを使用して UEFI モードを設定します。セキュアブートを有効にして UEFI モードでブートする場合:
- 1
- OpenShift Virtualization では、UEFI モードでセキュアブートを実行するために
SMM(System Management Mode) を有効にする必要があります。 - 2
- OpenShift Virtualization は、UEFI モードを使用する場合に、セキュアブートの有無に関わらず、仮想マシンをサポートします。セキュアブートが有効な場合には、UEFI モードが必要です。ただし、セキュアブートを使用せずに UEFI モードを有効にできます。
以下のコマンドを実行して、マニフェストをクラスターに適用します。
oc create -f <file_name>.yaml
$ oc create -f <file_name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
8.13.4.3. 永続的な EFI の有効化
クラスターレベルで RWX ストレージクラスを設定し、仮想マシンの EFI セクションで設定を調整することで、仮想マシンで EFI 永続性を有効にできます。
前提条件
- クラスター管理者の権限がある。
- RWX アクセスモードと FS ボリュームモードをサポートするストレージクラスが必要です。
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、
VMPersistentStateフィーチャーゲートを有効にします。oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv \ --type json -p '[{"op":"replace","path":"/spec/featureGates/VMPersistentState", "value": true}]'$ oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv \ --type json -p '[{"op":"replace","path":"/spec/featureGates/VMPersistentState", "value": true}]'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
8.13.4.4. 永続的な EFI を使用した仮想マシンの設定
マニフェストファイルを編集して、EFI の永続性を有効にするように仮想マシンを設定できます。
前提条件
-
VMPersistentStateフィーチャーゲートが有効になっている。
手順
仮想マシンマニフェストファイルを編集して保存し、設定を適用します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
8.13.5. 仮想マシンの PXE ブートの設定
PXE ブートまたはネットワークブートは OpenShift Virtualization で利用できます。ネットワークブートにより、ローカルに割り当てられたストレージデバイスなしにコンピューターを起動し、オペレーティングシステムまたは他のプログラムを起動し、ロードすることができます。たとえば、これにより、新規ホストのデプロイ時に PXE サーバーから必要な OS イメージを選択できます。
8.13.5.1. MAC アドレスを指定した PXE ブート
まず、管理者は PXE ネットワークの NetworkAttachmentDefinition オブジェクトを作成し、ネットワーク経由でクライアントを起動できます。次に、仮想マシンインスタンスの設定ファイルで network attachment definition を参照して仮想マシンインスタンスを起動します。
また PXE サーバーで必要な場合には、仮想マシンインスタンスの設定ファイルで MAC アドレスを指定することもできます。
前提条件
- Linux ブリッジが接続されている。
- PXE サーバーがブリッジとして同じ VLAN に接続されている。
-
OpenShift CLI (
oc) がインストールされている。
手順
クラスターに PXE ネットワークを設定します。
PXE ネットワーク
pxe-net-confの network attachment definition ファイルを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
NetworkAttachmentDefinitionオブジェクトの名前。- 2
- 設定の名前。設定名を network attachment definition の
name値に一致させることが推奨されます。 - 3
- この network attachment definition のネットワークを提供する Container Network Interface (CNI) プラグインの実際の名前。この例では、Linux bridge CNI プラグインを使用します。OVN-Kubernetes localnet または SR-IOV CNI プラグインを使用することもできます。
- 4
- ノードに設定される Linux ブリッジの名前。
- 5
- オプション: MAC スプーフィングチェックを有効にするフラグ。
trueに設定すると、Pod またはゲストインターフェイスの MAC アドレスを変更できません。この属性により、Pod から出ることができる MAC アドレスは 1 つだけになり、MAC スプーフィング攻撃に対するセキュリティーが確保されます。 - 6
- オプション: VLAN タグ。Node Network Configuration Policy では、追加の VLAN 設定は必要ありません。
- 7
- オプション: 仮想マシンがデフォルト VLAN 経由でブリッジに接続するかどうかを示します。デフォルト値は
trueです。
直前の手順で作成したファイルを使用して network attachment definition を作成します。
oc create -f pxe-net-conf.yaml
$ oc create -f pxe-net-conf.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 仮想マシンインスタンス設定ファイルを、インターフェイスおよびネットワークの詳細を含めるように編集します。
PXE サーバーで必要な場合には、ネットワークおよび MAC アドレスを指定します。MAC アドレスが指定されていない場合、値は自動的に割り当てられます。
bootOrderが1に設定されており、インターフェイスが最初に起動することを確認します。この例では、インターフェイスは<pxe-net>というネットワークに接続されています。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記複数のインターフェイスおよびディスクのブートの順序はグローバル順序になります。
オペレーティングシステムのプロビジョニング後に起動が適切に実行されるよう、ブートデバイス番号をディスクに割り当てます。
ディスク
bootOrderの値を2に設定します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 直前に作成された network attachment definition に接続されるネットワークを指定します。このシナリオでは、
<pxe-net>は<pxe-net-conf>という network attachment definition に接続されます。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
仮想マシンインスタンスを作成します。
oc create -f vmi-pxe-boot.yaml
$ oc create -f vmi-pxe-boot.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
virtualmachineinstance.kubevirt.io "vmi-pxe-boot" created
virtualmachineinstance.kubevirt.io "vmi-pxe-boot" createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow 仮想マシンインスタンスの実行を待機します。
oc get vmi vmi-pxe-boot -o yaml | grep -i phase phase: Running
$ oc get vmi vmi-pxe-boot -o yaml | grep -i phase phase: RunningCopy to Clipboard Copied! Toggle word wrap Toggle overflow VNC を使用して仮想マシンインスタンスを表示します。
virtctl vnc vmi-pxe-boot
$ virtctl vnc vmi-pxe-bootCopy to Clipboard Copied! Toggle word wrap Toggle overflow - ブート画面で、PXE ブートが正常に実行されていることを確認します。
仮想マシンインスタンスにログインします。
virtctl console vmi-pxe-boot
$ virtctl console vmi-pxe-bootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
仮想マシンのインターフェイスおよび MAC アドレスを確認し、ブリッジに接続されたインターフェイスに MAC アドレスが指定されていることを確認します。この場合、PXE ブートには IP アドレスなしに
eth1を使用しています。もう 1 つのインターフェイスeth0は、Red Hat OpenShift Service on AWS から IP アドレスを取得しています。ip addr
$ ip addrCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
... 3. eth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether de:00:00:00:00:de brd ff:ff:ff:ff:ff:ff
... 3. eth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether de:00:00:00:00:de brd ff:ff:ff:ff:ff:ffCopy to Clipboard Copied! Toggle word wrap Toggle overflow
8.13.5.2. OpenShift Virtualization ネットワークの用語集
以下の用語は、OpenShift Virtualization ドキュメント全体で使用されています。
- Container Network Interface (CNI)
- コンテナーのネットワーク接続に重点を置く Cloud Native Computing Foundation プロジェクト。OpenShift Virtualization は CNI プラグインを使用して基本的な Kubernetes ネットワーク機能を強化します。
- Multus
- 複数の CNI の存在を可能にし、Pod または仮想マシンが必要なインターフェイスを使用できるようにする "メタ" CNI プラグイン。
- カスタムリソース定義 (CRD)
- カスタムリソースの定義を可能にする Kubernetes API リソース、または CRD API リソースを使用して定義されるオブジェクト。
NetworkAttachmentDefinition- Multus プロジェクトによって導入された CRD。Pod、仮想マシン、および仮想マシンインスタンスを 1 つ以上のネットワークに接続できるようにします。
UserDefinedNetwork- ユーザー定義ネットワーク (UDN) API によって導入された namespace スコープの CRD。これを使用して、テナント namespace を他の namespace から分離するテナントネットワークを作成できます。
ClusterUserDefinedNetwork- ユーザー定義ネットワーク API によって導入されたクラスタースコープの CRD。これは、クラスター管理者が複数の namespace 全体で共有ネットワークを作成するために使用できます。
- Node Network Configuration Policy (NNCP)
-
nmstate プロジェクトによって導入された CRD。ノード上で要求されるネットワーク設定を表します。
NodeNetworkConfigurationPolicyマニフェストをクラスターに適用して、インターフェイスの追加および削除など、ノードネットワーク設定を更新します。
8.13.6. 仮想マシンのスケジュール
仮想マシンの CPU モデルとポリシー属性が、ノードがサポートする CPU モデルおよびポリシー属性との互換性に対して一致することを確認して、ノードで仮想マシン (VM) をスケジュールできます。
8.13.6.1. ポリシー属性
仮想マシン (VM) をスケジュールするには、ポリシー属性と、仮想マシンがノードでスケジュールされる際の互換性について一致する CPU 機能を指定します。仮想マシンに指定されるポリシー属性は、その仮想マシンをノードにスケジュールする方法を決定します。
| ポリシー属性 | 説明 |
|---|---|
| force | 仮想マシンは強制的にノードでスケジュールされます。これは、ホストの CPU が仮想マシンの CPU に対応していない場合でも該当します。 |
| require | 仮想マシンが特定の CPU モデルおよび機能仕様で設定されていない場合に仮想マシンに適用されるデフォルトのポリシー。このデフォルトポリシー属性または他のポリシー属性のいずれかを持つ CPU ノードの検出をサポートするようにノードが設定されていない場合、仮想マシンはそのノードでスケジュールされません。ホストの CPU が仮想マシンの CPU をサポートしているか、ハイパーバイザーが対応している CPU モデルをエミュレートできる必要があります。 |
| optional | 仮想マシンがホストの物理マシンの CPU でサポートされている場合は、仮想マシンがノードに追加されます。 |
| disable | 仮想マシンは CPU ノードの検出機能と共にスケジュールすることはできません。 |
| forbid | この機能がホストの CPU でサポートされ、CPU ノード検出が有効になっている場合でも、仮想マシンはスケジュールされません。 |
8.13.6.2. ポリシー属性および CPU 機能の設定
それぞれの仮想マシン (VM) にポリシー属性および CPU 機能を設定して、これがポリシーおよび機能に従ってノードでスケジュールされるようにすることができます。設定する CPU 機能は、ホストの CPU によってサポートされ、またはハイパーバイザーがエミュレートされることを確認するために検証されます。
8.13.6.3. サポートされている CPU モデルでの仮想マシンのスケジューリング
仮想マシン (VM) の CPU モデルを設定して、CPU モデルがサポートされるノードにこれをスケジュールできます。
手順
仮想マシン設定ファイルの
domainspec を編集します。以下の例は、VM 向けに定義された特定の CPU モデルを示しています。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- VM の CPU モデル。
8.13.6.4. ホストモデルでの仮想マシンのスケジューリング
仮想マシン (VM) の CPU モデルが host-model に設定されている場合、仮想マシンはスケジュールされているノードの CPU モデルを継承します。
手順
仮想マシン設定ファイルの
domainspec を編集します。以下の例は、仮想マシンに指定されるhost-modelを示しています。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- スケジュールされるノードの CPU モデルを継承する仮想マシン。
8.13.6.5. カスタムスケジューラーを使用した仮想マシンのスケジュール設定
カスタムスケジューラーを使用して、ノード上の仮想マシンをスケジュールできます。
前提条件
- セカンダリースケジューラーがクラスター用に設定されています。
-
OpenShift CLI (
oc) がインストールされている。
手順
VirtualMachineマニフェストを編集して、カスタムスケジューラーを仮想マシン設定に追加します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- カスタムスケジューラーの名前。
schedulerName値が既存のスケジューラーと一致しない場合、virt-launcherPod は、指定されたスケジューラーが見つかるまでPending状態のままになります。
検証
virt-launcherPod イベントをチェックして、仮想マシンがVirtualMachineマニフェストで指定されたカスタムスケジューラーを使用していることを確認します。次のコマンドを入力して、クラスター内の Pod のリストを表示します。
oc get pods
$ oc get podsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
NAME READY STATUS RESTARTS AGE virt-launcher-vm-fedora-dpc87 2/2 Running 0 24m
NAME READY STATUS RESTARTS AGE virt-launcher-vm-fedora-dpc87 2/2 Running 0 24mCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して Pod イベントを表示します。
oc describe pod virt-launcher-vm-fedora-dpc87
$ oc describe pod virt-launcher-vm-fedora-dpc87Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力の
Fromフィールドの値により、スケジューラー名がVirtualMachineマニフェストで指定されたカスタムスケジューラーと一致することが検証されます。出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
8.13.7. 仮想マシンの高可用性について
修復ノードを設定することで、仮想マシン (VM) の高可用性を有効化できます。
ソフトウェアカタログから Self Node Remediation Operator または Fence Agents Remediation Operator をインストールし、マシンのヘルスチェックまたはノードの修復チェックを有効にすることで、修復ノードを設定できます。
ノードの修復、フェンシング、メンテナンスの詳細は、Red Hat OpenShift のワークロードの可用性 を参照してください。
8.13.8. 仮想マシンのコントロールプレーンのチューニング
OpenShift Virtualization は、コントロールプレーンレベルで次のチューニングオプションを提供します。
-
highBurstプロファイルは、固定QPSとburstレートを使用して、1 つのバッチで数百の仮想マシンを作成します。 - ワークロードの種類に基づいた移行設定の調整
8.13.8.1. highBurst プロファイルの設定
highBurst プロファイルを使用すると、1 つのクラスター内に多数の仮想マシン (VM) を作成して管理できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
次のパッチを適用して、
highBurstチューニングポリシープロファイルを有効にします。oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv \ --type=json -p='[{"op": "add", "path": "/spec/tuningPolicy", \ "value": "highBurst"}]'$ oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv \ --type=json -p='[{"op": "add", "path": "/spec/tuningPolicy", \ "value": "highBurst"}]'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
次のコマンドを実行して、
highBurstチューニングポリシープロファイルが有効になっていることを確認します。oc get kubevirt.kubevirt.io/kubevirt-kubevirt-hyperconverged \ -n openshift-cnv -o go-template --template='{{range $config, \ $value := .spec.configuration}} {{if eq $config "apiConfiguration" \ "webhookConfiguration" "controllerConfiguration" "handlerConfiguration"}} \ {{"\n"}} {{$config}} = {{$value}} {{end}} {{end}} {{"\n"}}$ oc get kubevirt.kubevirt.io/kubevirt-kubevirt-hyperconverged \ -n openshift-cnv -o go-template --template='{{range $config, \ $value := .spec.configuration}} {{if eq $config "apiConfiguration" \ "webhookConfiguration" "controllerConfiguration" "handlerConfiguration"}} \ {{"\n"}} {{$config}} = {{$value}} {{end}} {{end}} {{"\n"}}Copy to Clipboard Copied! Toggle word wrap Toggle overflow
8.14. 仮想マシンディスク
8.14.1. 仮想マシンディスクのホットプラグ
仮想マシン (VM) または仮想マシンインスタンス (VMI) を停止することなく、仮想ディスクを追加または削除できます。
データボリュームおよび永続ボリューム要求 (PVC) のみをホットプラグおよびホットアンプラグできます。コンテナーディスクのホットプラグおよびホットアンプラグはできません。
ホットプラグされたディスクは、再起動後も仮想マシンに接続されたままになります。仮想マシンからディスクを削除するには、ディスクを取り外す必要があります。
各仮想マシンは、ホットプラグされたディスクが SCSI バスを使用できるように、virtio-scsi コントローラーを備えています。virtio-scsi コントローラーは、パフォーマンス上の利点を維持しながら、VirtIO の制限を克服します。スケーラビリティーが高く、400 万台を超えるディスクのホットプラグをサポートします。
ディスクを VirtIO (virtio-blk) バスにホットプラグすると、各ディスクは仮想マシン内の PCI Express (PCIe) スロットを使用します。PCIe スロットの数は制限されており、使用可能な VirtIO ポート テーブルで指定されているとおりに仮想マシン作成時に自動的に事前設定されます。したがって、使用可能なスロットの数を超えない少数のディスクに対して virtio-blk を使用できます。
8.14.1.1. Web コンソールを使用したディスクのホットプラグとホットアンプラグ
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想マシン (VM) の実行中にディスクを仮想マシンに接続して、ディスクをホットプラグできます。
ホットプラグされたディスクは、アンプラグするまで仮想マシンに接続されたままになります。
前提条件
- ホットプラグに使用できるデータボリュームまたは永続ボリュームクレーム (PVC) が必要です。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
- 実行中の仮想マシンを選択して、その詳細を表示します。
- VirtualMachine details ページで、Configuration → Storage をクリックします。
ホットプラグされたディスクを追加します。
- Add をクリックします。
- Add disk (hot plugged) ウィンドウで、Source リストからディスクを選択し、Save をクリックします。
- オプション: インターフェイスバスのタイプを選択します。オプションは VirtIO と SCSI です。デフォルトのバスタイプは VirtIO です。
オプション: 既存のホットプラグディスクのインターフェイスバスのタイプを変更します。
-
ディスクの横にある Options メニュー
をクリックし、Edit を選択します。
- Interface フィールドで、任意のオプションを選択します。
-
ディスクの横にある Options メニュー
オプション: ホットプラグされたディスクを取り外します。
-
ディスクの横にある Options メニュー
をクリックし、Detach を選択します。
- Detach をクリックします。
-
ディスクの横にある Options メニュー
8.14.1.2. CLI を使用したディスクのホットプラグとホットアンプラグ
コマンドラインを使用して、仮想マシンの実行中にディスクのホットプラグおよびホットアンプラグを行うことができます。
ホットプラグされたディスクは、アンプラグするまで仮想マシンに接続されたままになります。
前提条件
- ホットプラグ用に 1 つ以上のデータボリュームまたは永続ボリューム要求 (PVC) が利用可能である必要があります。
手順
次のコマンドを実行して、ディスクをホットプラグします。
virtctl addvolume <virtual-machine|virtual-machine-instance> \ --volume-name=<datavolume|PVC> \ [--bus <bus_type>] [--serial=<label_name>]
$ virtctl addvolume <virtual-machine|virtual-machine-instance> \ --volume-name=<datavolume|PVC> \ [--bus <bus_type>] [--serial=<label_name>]Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
オプションの
--busフラグを使用すると、追加されたディスクのバスタイプを指定できます。オプションはvirtioとscsiです。デフォルトのバスタイプはvirtioです。 -
オプションの
--serialフラグを使用すると、選択した英数字の文字列ラベルを追加できます。これは、ゲスト仮想マシンでホットプラグされたディスクを特定するのに役立ちます。このオプションを指定しない場合、ラベルはデフォルトでホットプラグされたデータボリュームまたは PVC の名前に設定されます。
-
オプションの
次のコマンドを実行して、ディスクをホットアンプラグします。
virtctl removevolume <virtual-machine|virtual-machine-instance> \ --volume-name=<datavolume|PVC>
$ virtctl removevolume <virtual-machine|virtual-machine-instance> \ --volume-name=<datavolume|PVC>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
8.14.2. 仮想マシンディスクの拡張
ディスクの永続ボリューム要求 (PVC) を拡張することで、仮想マシンディスクのサイズを増やすことができます。
ストレージプロバイダーがボリューム拡張をサポートしていない場合は、空のデータボリュームを追加することで、仮想マシンの利用可能な仮想ストレージを拡張できます。
仮想マシンディスクのサイズを減らすことはできません。
8.14.2.1. ディスクの PVC を拡張して仮想マシンディスクサイズを増やす
ディスクの永続ボリューム要求 (PVC) を拡張することで、仮想マシンディスクのサイズを増やすことができます。増加した PVC ボリュームを指定するには、仮想マシンを実行した状態で Web コンソールを使用できます。または、CLI で PVC マニフェストを編集することもできます。
PVC がファイルシステムボリュームモードを使用する場合、ディスクイメージファイルは、ファイルシステムのオーバーヘッド用にスペースを確保しながら、利用可能なサイズまで拡張されます。
8.14.2.1.1. Web コンソールで仮想マシンディスク PVC を拡張する
VirtualMachines ページを離れずに仮想マシンを実行している状態でも、Web コンソールで仮想マシンディスク PVC のサイズを増やすことができます。
手順
- Administrator または Virtualization パースペクティブで、VirtualMachines ページを開きます。
- 実行中の仮想マシンを選択して、Details ページを開きます。
- Configuration タブを選択し、Storage をクリックします。
拡張したいディスクの横にあるオプションメニュー
をクリックします。Edit オプションを選択します。
Edit disk ダイアログが開きます。
- PersistentVolumeClaim size フィールドに、希望のサイズを入力します。
- Save をクリックします。
現在の値より大きい任意の値を入力できます。ただし、新しい値が使用可能なサイズを超える場合は、エラーが表示されます。
8.14.2.1.2. マニフェストを編集して仮想マシンディスク PVC を拡張する
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
拡張する必要のある仮想マシンディスクの
PersistentVolumeClaimマニフェストを編集します。oc edit pvc <pvc_name>
$ oc edit pvc <pvc_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow ディスクサイズを更新します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 新しいディスクサイズを指定します。
8.14.2.2. 空のデータボリュームを追加して利用可能な仮想ストレージを拡張する
空のデータボリュームを追加することで、仮想マシンの利用可能なストレージを拡張できます。
前提条件
- 少なくとも 1 つの永続ボリュームが必要です。
-
OpenShift CLI (
oc) がインストールされている。
手順
次の例に示すように、
DataVolumeマニフェストを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下のコマンドを実行してデータボリュームを作成します。
oc create -f <blank-image-datavolume>.yaml
$ oc create -f <blank-image-datavolume>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
8.14.3. 仮想マシンディスクを別のストレージクラスに移行する
仮想マシン (VM) または仮想マシンインスタンス (VMI) を停止せずに、1 つ以上の仮想ディスクを別のストレージクラスに移行できます。
8.14.3.1. Web コンソールを使用して仮想マシンディスクを別のストレージクラスに移行する
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想マシン (VM) に接続された 1 つ以上のディスクを別のストレージクラスに移行できます。実行中の仮想マシンでこのアクションを実行すると、仮想マシンの操作は中断されず、移行されたディスク上のデータに引き続きアクセスできます。
OpenShift Virtualization Operator では、一度に 1 つの仮想マシンのストレージクラスの移行のみを開始でき、その仮想マシンは実行中である必要があります。一度に複数の仮想マシンを移行する必要がある場合、または実行中の仮想マシンと停止中の仮想マシンを混在して移行する必要がある場合は、Migration Toolkit for Containers (MTC) の使用を検討してください。
Migration Toolkit for Containers は OpenShift Virtualization には含まれていないため、別途インストールする必要があります。
前提条件
- ストレージクラスの移行には、データボリュームまたは永続ボリューム要求 (PVC) が使用可能である必要がある。
- クラスターにはライブマイグレーションに使用できるノードが必要である。ストレージクラスの移行の一環として、仮想マシンが別のノードにライブマイグレーションされている。
- 仮想マシンが実行されている必要がある。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
仮想マシンの横にあるオプションメニュー
をクリックし、Migration → Storage を選択します。
このオプションには、VirtualMachine details ページで Actions → Migration → Storage を選択してアクセスすることもできます。
または、ツリービューで仮想マシンを右クリックし、ポップアップメニューから Migration を選択します。
- Migration details ページで、仮想マシンストレージ全体を移行するか、選択したボリュームのみを移行するかを選択します。Selected volumes をクリックする場合は、移行するディスクを選択します。Next をクリックして先に進みます。
- Destination StorageClass ページの利用可能なオプションのリストから、移行先のストレージクラスを選択します。Next をクリックして先に進みます。
- Review ページで、影響を受けるディスクのリストとターゲットストレージクラスを確認します。移行を開始するには、Migrate VirtualMachine storage をクリックします。
- Migrate VirtualMachine storage ページに留まり、進行状況を監視し、移行が正常に完了したことの確認を待ちます。
検証
- VirtualMachine details ページから、Configuration → Storage に移動します。
- すべてのディスクに Storage class 列にリストされている必要なストレージクラスがあることを確認します。
第9章 ネットワーク
9.1. ネットワークの概要
OpenShift Virtualization は、カスタムリソースおよびプラグインを使用して高度なネットワーク機能を提供します。仮想マシン (VM) は、Red Hat OpenShift Service on AWS ネットワークおよびそのエコシステムと統合されています。
シングルスタック IPv6 クラスターに対する OpenShift Virtualization のサポートは、OVN-Kubernetes localnet および Linux ブリッジ Container Network Interface (CNI) プラグインに限定されています。
シングルスタック IPv6 クラスターへの OpenShift Virtualization のデプロイは、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、以下のリンクを参照してください。
次の図は、OpenShift Virtualization の一般的なネットワーク設定を示しています。他の設定も可能です。
図9.1 OpenShift Virtualization ネットワークの概要

![]() Pod と仮想マシンは同じネットワークインフラストラクチャー上で実行するため、コンテナー化されたワークロードと仮想化されたワークロードを簡単に接続できます。
Pod と仮想マシンは同じネットワークインフラストラクチャー上で実行するため、コンテナー化されたワークロードと仮想化されたワークロードを簡単に接続できます。
![]() 仮想マシンをデフォルトの Pod ネットワークおよび任意の数のセカンダリーネットワークに接続できます。
仮想マシンをデフォルトの Pod ネットワークおよび任意の数のセカンダリーネットワークに接続できます。
![]() デフォルトの Pod ネットワークは、すべてのメンバー間の接続、サービス抽象化、IP 管理、マイクロセグメンテーション、およびその他の機能を提供します。
デフォルトの Pod ネットワークは、すべてのメンバー間の接続、サービス抽象化、IP 管理、マイクロセグメンテーション、およびその他の機能を提供します。
![]() Multus は、互換性のある他の CNI プラグインを使用して、Pod または仮想マシンが追加のネットワークインターフェイスに接続できるようにする "メタ" CNI プラグインです。
Multus は、互換性のある他の CNI プラグインを使用して、Pod または仮想マシンが追加のネットワークインターフェイスに接続できるようにする "メタ" CNI プラグインです。
![]() デフォルトの Pod ネットワークはオーバーレイベースであり、基盤となるマシンネットワークを介してトンネリングされます。
デフォルトの Pod ネットワークはオーバーレイベースであり、基盤となるマシンネットワークを介してトンネリングされます。
![]() マシンネットワークは、選択したネットワークインターフェイスコントローラー (NIC) のセットを介して定義できます。
マシンネットワークは、選択したネットワークインターフェイスコントローラー (NIC) のセットを介して定義できます。
![]() セカンダリー仮想マシンネットワークは通常、VLAN カプセル化の有無にかかわらず、物理ネットワークに直接ブリッジされます。セカンダリーネットワーク用の仮想オーバーレイネットワークを作成することも可能です。
セカンダリー仮想マシンネットワークは通常、VLAN カプセル化の有無にかかわらず、物理ネットワークに直接ブリッジされます。セカンダリーネットワーク用の仮想オーバーレイネットワークを作成することも可能です。
仮想マシンをアンダーレイネットワークに直接接続することは、Red Hat OpenShift Service on AWS、Azure for Red Hat OpenShift Service on AWS、Google Cloud または Oracle® Cloud Infrastructure (OCI) ではサポートされていません。
パブリッククラウドでは、layer2 トポロジーを使用して仮想マシンをユーザー定義ネットワークに接続することを推奨します。
![]() セカンダリー仮想マシンネットワークは、図 1 に示すように専用の NIC セットで定義することも、マシンネットワークを使用することもできます。
セカンダリー仮想マシンネットワークは、図 1 に示すように専用の NIC セットで定義することも、マシンネットワークを使用することもできます。
9.1.1. OpenShift Virtualization ネットワークの用語集
以下の用語は、OpenShift Virtualization ドキュメント全体で使用されています。
- Container Network Interface (CNI)
- コンテナーのネットワーク接続に重点を置く Cloud Native Computing Foundation プロジェクト。OpenShift Virtualization は CNI プラグインを使用して基本的な Kubernetes ネットワーク機能を強化します。
- Multus
- 複数の CNI の存在を可能にし、Pod または仮想マシンが必要なインターフェイスを使用できるようにする "メタ" CNI プラグイン。
- カスタムリソース定義 (CRD)
- カスタムリソースの定義を可能にする Kubernetes API リソース、または CRD API リソースを使用して定義されるオブジェクト。
NetworkAttachmentDefinition- Multus プロジェクトによって導入された CRD。Pod、仮想マシン、および仮想マシンインスタンスを 1 つ以上のネットワークに接続できるようにします。
UserDefinedNetwork- ユーザー定義ネットワーク (UDN) API によって導入された namespace スコープの CRD。これを使用して、テナント namespace を他の namespace から分離するテナントネットワークを作成できます。
ClusterUserDefinedNetwork- ユーザー定義ネットワーク API によって導入されたクラスタースコープの CRD。これは、クラスター管理者が複数の namespace 全体で共有ネットワークを作成するために使用できます。
- Node Network Configuration Policy (NNCP)
-
nmstate プロジェクトによって導入された CRD。ノード上で要求されるネットワーク設定を表します。
NodeNetworkConfigurationPolicyマニフェストをクラスターに適用して、インターフェイスの追加および削除など、ノードネットワーク設定を更新します。
9.1.2. デフォルトの Pod ネットワークの使用
- 仮想マシンをデフォルトの Pod ネットワークに接続する
- 各仮想マシンは、デフォルトの内部 Pod ネットワークにデフォルトで接続されます。仮想マシン仕様を編集することで、ネットワークインターフェイスを追加または削除できます。
- 仮想マシンをサービスとして公開する
-
Serviceオブジェクトを作成することで、クラスター内またはクラスター外に仮想マシンを公開できます。
9.1.3. プライマリーユーザー定義ネットワークの設定
- 仮想マシンをプライマリーユーザー定義ネットワークに接続する
仮想マシン (VM) を、仮想マシンのプライマリーインターフェイス上のユーザー定義ネットワーク (UDN) に接続できます。プライマリー UDN は、デフォルトの Pod ネットワークを置き換えて、選択した namespace 内の Pod と仮想マシンを接続します。
クラスター管理者は、プライマリー
UserDefinedNetworkCRD を設定して、ネットワークポリシーを必要とせずに、テナント namespace を他の namespace から分離するテナントネットワークを作成できます。さらに、クラスター管理者はClusterUserDefinedNetworkCRD を使用して、複数の namespace にわたって共有 OVNlayer2ネットワークを作成できます。layer2オーバーレイトポロジーを使用したユーザー定義ネットワークは、仮想マシンのワークロードに役立ち、物理ネットワークアクセスが制限されている環境 (例: パブリッククラウド) では、セカンダリーネットワークの適切な代替手段となります。layer2トポロジーにより、ネットワークアドレス変換 (NAT) を必要とせずに仮想マシンをシームレスに移行できるほか、再起動後やライブマイグレーション中に保持される永続的な IP アドレスも提供されます。
9.1.4. 仮想マシンのセカンダリーネットワークインターフェイスの設定
OVN-Kubernetes Container Network Interface (CNI) プラグインを使用して、仮想マシンをセカンダリーネットワークに接続できます。セカンダリーネットワークインターフェイスに接続する場合、仮想マシン仕様でプライマリー Pod ネットワークを指定する必要はありません。
- OVN-Kubernetes セカンダリーネットワークへの仮想マシンの接続
仮想マシンは Open Virtual Network (OVN)-Kubernetes セカンダリーネットワークに接続できます。OpenShift Virtualization は、OVN-Kubernetes の
layer2トポロジーをサポートします。layer2トポロジーは、クラスター全体の論理スイッチによってワークロードを接続します。OVN-Kubernetes CNI プラグインは、Geneve (Generic Network Virtualization Encapsulation) プロトコルを使用して、ノード間にオーバーレイネットワークを作成します。このオーバーレイネットワークを使用すると、追加の物理ネットワークインフラストラクチャーを設定することなく、さまざまなノード上の仮想マシンを接続できます。OVN-Kubernetes セカンダリーネットワークを設定し、そのネットワークに仮想マシンを接続するには、次の手順を実行します。
- ネットワークアタッチメント定義 (NAD) を作成して、OVN-Kubernetes セカンダリーネットワークの設定 を行います。
- ネットワークの詳細を仮想マシン仕様に追加して、仮想マシンを OVN-Kubernetes セカンダリーネットワークに接続 します。
- ホットプラグ対応のセカンダリーネットワークインターフェイス
-
仮想マシンを停止せずに、セカンダリーネットワークインターフェイスを追加または削除できます。OpenShift Virtualization は、ブリッジバインディングおよび OVN-Kubernetes
layer2トポロジーを使用するセカンダリーインターフェイスのホットプラグとホットアンプラグをサポートしています。
- IP アドレスの設定と表示
- 仮想マシンを作成するときに、セカンダリーネットワークインターフェイスの IP アドレスを設定できます。IP アドレスは、cloud-init でプロビジョニングされます。仮想マシンの IP アドレスは、Red Hat OpenShift Service on AWS Web コンソールまたはコマンドラインを使用して表示できます。ネットワーク情報は QEMU ゲストエージェントによって収集されます。
9.1.5. OpenShift Service Mesh との統合
- 仮想マシンのサービスメッシュへの接続
- OpenShift Virtualization は OpenShift Service Mesh と統合されています。Pod と仮想マシン間のトラフィックを監視、視覚化、制御できます。
9.1.6. MAC アドレスプールの管理
- ネットワークインターフェイスの MAC アドレスプールの管理
- KubeMacPool コンポーネントは、共有 MAC アドレスプールから仮想マシンネットワークインターフェイスの MAC アドレスを割り当てます。これにより、各ネットワークインターフェイスに一意の MAC アドレスが確実に割り当てられます。その仮想マシンから作成された仮想マシンインスタンスは、再起動後も割り当てられた MAC アドレスを保持します。
9.1.7. SSH アクセスの設定
- 仮想マシンへの SSH アクセスの設定
次の方法を使用して、仮想マシンへの SSH アクセスを設定できます。
SSH 鍵ペアを作成し、公開鍵を仮想マシンに追加し、秘密鍵を使用して
virtctl sshコマンドを実行して仮想マシンに接続します。cloud-init データソースを使用して設定できるゲストオペレーティングシステムを使用して、実行時または最初の起動時に Red Hat Enterprise Linux (RHEL) 9 仮想マシンに SSH 公開鍵を追加できます。
virtctl port-fowardコマンドを.ssh/configファイルに追加し、OpenSSH を使用して仮想マシンに接続します。サービスを作成し、そのサービスを仮想マシンに関連付け、サービスによって公開されている IP アドレスとポートに接続します。
セカンダリーネットワークを設定し、仮想マシンをセカンダリーネットワークインターフェイスに接続し、割り当てられた IP アドレスに接続します。
9.2. 仮想マシンをデフォルトの Pod ネットワークに接続する
masquerade バインディングモードを使用するようにネットワークインターフェイスを設定することで、仮想マシンをデフォルトの内部 Pod ネットワークに接続できます。
ネットワークインターフェイスを通過してデフォルトの Pod ネットワークに到達するトラフィックは、ライブマイグレーション中に中断されます。
9.2.1. CLI でのマスカレードモードの設定
マスカレードモードを使用し、仮想マシンの送信トラフィックを Pod IP アドレスの背後で非表示にすることができます。マスカレードモードは、ネットワークアドレス変換 (NAT) を使用して仮想マシンを Linux ブリッジ経由で Pod ネットワークバックエンドに接続します。
仮想マシンの設定ファイルを編集して、マスカレードモードを有効にし、トラフィックが仮想マシンに到達できるようにします。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - 仮想マシンは、IPv4 アドレスを取得するために DHCP を使用できるように設定される必要がある。
手順
仮想マシン設定ファイルの
interfacesspec を編集します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記ポート 49152 および 49153 は libvirt プラットフォームで使用するために予約され、これらのポートへの他のすべての受信トラフィックは破棄されます。
仮想マシンを作成します。
oc create -f <vm-name>.yaml
$ oc create -f <vm-name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.2.2. デュアルスタック (IPv4 および IPv6) でのマスカレードモードの設定
cloud-init を使用して、新規仮想マシン (VM) を、デフォルトの Pod ネットワークで IPv6 と IPv4 の両方を使用するように設定できます。
仮想マシンインスタンス設定の Network.pod.vmIPv6NetworkCIDR フィールドは、VM の静的 IPv6 アドレスとゲートウェイ IP アドレスを決定します。これらは IPv6 トラフィックを仮想マシンにルーティングするために virt-launcher Pod で使用され、外部では使用されません。Network.pod.vmIPv6NetworkCIDR フィールドは、Classless Inter-Domain Routing (CIDR) 表記で IPv6 アドレスブロックを指定します。デフォルト値は fd10:0:2::2/120 です。この値は、ネットワーク要件に基づいて編集できます。
仮想マシンが実行されている場合、仮想マシンの送受信トラフィックは、virt-launcher Pod の IPv4 アドレスと固有の IPv6 アドレスの両方にルーティングされます。次に、virt-launcher Pod は IPv4 トラフィックを仮想マシンの DHCP アドレスにルーティングし、IPv6 トラフィックを仮想マシンの静的に設定された IPv6 アドレスにルーティングします。
前提条件
- Red Hat OpenShift Service on AWS クラスターで、デュアルスタック用に設定された OVN-Kubernetes Container Network Interface (CNI) ネットワークプラグインを使用する。
-
OpenShift CLI (
oc) がインストールされている。
手順
新規の仮想マシン設定では、
masqueradeを指定したインターフェイスを追加し、cloud-init を使用して IPv6 アドレスとデフォルトゲートウェイを設定します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow namespace で仮想マシンインスタンスを作成します。
oc create -f example-vm-ipv6.yaml
$ oc create -f example-vm-ipv6.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
- IPv6 が設定されていることを確認するには、仮想マシンを起動し、仮想マシンインスタンスのインターフェイスステータスを表示して、これに IPv6 アドレスがあることを確認します。
oc get vmi <vmi-name> -o jsonpath="{.status.interfaces[*].ipAddresses}"
$ oc get vmi <vmi-name> -o jsonpath="{.status.interfaces[*].ipAddresses}"9.2.3. ジャンボフレームのサポートについて
OVN-Kubernetes CNI プラグインを使用すると、デフォルトの Pod ネットワークに接続されている 2 つの仮想マシン (VM) 間でフラグメント化されていないジャンボフレームパケットを送信できます。ジャンボフレームの最大伝送単位 (MTU) 値は 1500 バイトを超えています。
VM は、クラスター管理者が設定したクラスターネットワークの MTU 値を、次のいずれかの方法で自動的に取得します。
-
libvirt: ゲスト OS に VirtIO ドライバーの最新バージョンがあり、エミュレーションされたデバイスの Peripheral Component Interconnect (PCI) 設定レジスターを介して着信データを解釈できる場合。 - DHCP: ゲスト DHCP クライアントが DHCP サーバーの応答から MTU 値を読み取ることができる場合。
VirtIO ドライバーを持たない Windows VM の場合、netsh または同様のツールを使用して MTU を手動で設定する必要があります。これは、Windows DHCP クライアントが MTU 値を読み取らないためです。
9.3. 仮想マシンをプライマリーユーザー定義ネットワークに接続する
Red Hat OpenShift Service on AWS Web コンソールまたは CLI を使用して、仮想マシン (VM) を仮想マシンのプライマリーインターフェイス上のユーザー定義ネットワーク (UDN) に接続できます。プライマリーのユーザー定義ネットワークは、指定された namespace 内のデフォルトの Pod ネットワークを置き換えます。Pod ネットワークとは異なり、プロジェクトごとにプライマリー UDN を定義でき、各プロジェクトは特定のサブネットとトポロジーを使用できます。
OpenShift Virtualization は、namespace スコープの UserDefinedNetwork とクラスタースコープの ClusterUserDefinedNetwork カスタムリソース定義 (CRD) をサポートします。
クラスター管理者は、プライマリー UserDefinedNetwork CRD を設定して、ネットワークポリシーを必要とせずに、テナント namespace を他の namespace から分離するテナントネットワークを作成できます。さらに、クラスター管理者は ClusterUserDefinedNetwork CRD を使用して、複数の namespace にわたる共有 OVN ネットワークを作成できます。
ユーザー定義ネットワークで使用する namespace を作成する場合は、k8s.ovn.org/primary-user-defined-network ラベルを追加する必要があります。
レイヤー 2 トポロジーでは、OVN-Kubernetes はノード間にオーバーレイネットワークを作成します。このオーバーレイネットワークを使用すると、追加の物理ネットワークインフラストラクチャーを設定することなく、さまざまなノード上の仮想マシンを接続できます。
レイヤー 2 トポロジーでは、ライブマイグレーション中に永続的な IP アドレスがクラスターノード間で保持されるため、ネットワークアドレス変換 (NAT) を必要とせずに仮想マシンをシームレスに移行できます。
プライマリー UDN を実装する前に、次の制限を考慮する必要があります。
-
virtctl sshコマンドを使用して仮想マシンへの SSH アクセスを設定できません。 -
oc port-forwardコマンドを使用してポートを仮想マシンに転送できません。 - ヘッドレスサービスを使用して仮想マシンにアクセスできません。
9.3.1. Web コンソールを使用したプライマリーユーザー定義ネットワークの作成
Red Hat OpenShift Service on AWS Web コンソールを使用して、プライマリー namespace スコープの UserDefinedNetwork またはクラスタースコープの ClusterUserDefinedNetwork CRD を作成できます。UDN は、ネットワークに関連付けられた namespace で作成する Pod と仮想マシンのデフォルトのプライマリーネットワークとして機能します。
9.3.1.1. Web コンソールを使用したユーザー定義ネットワークの namespace の作成
Red Hat OpenShift Service on AWS Web コンソールを使用して、プライマリーユーザー定義ネットワーク (UDN) で使用する namespace を作成できます。
前提条件
-
cluster-admin権限を持つユーザーとして、Red Hat OpenShift Service on AWS Web コンソールにログインする。
手順
- Administrator パースペクティブから、Administration → Namespaces をクリックします。
- Create Namespace をクリックします。
- Name フィールドに、namespace の名前を指定します。名前は、小文字の英数字または '-' で構成される必要があり、先頭と末尾は英数字でなければなりません。
-
Labels フィールドに、
k8s.ovn.org/primary-user-defined-networkラベルを追加します。 -
オプション: namespace を既存のクラスタースコープ UDN で使用する場合は、
ClusterUserDefinedNetworkカスタムリソースのspec.namespaceSelectorフィールドで定義されている適切なラベルを追加します。 - オプション: デフォルトのネットワークポリシーを指定します。
- namespace を作成するには、Create をクリックします。
9.3.1.2. Web コンソールを使用したプライマリー namespace スコープのユーザー定義ネットワークの作成
Red Hat OpenShift Service on AWS Web コンソールで UserDefinedNetwork カスタムリソースを作成することにより、プロジェクト namespace に分離されたプライマリーネットワークを作成できます。
前提条件
-
cluster-admin権限を持つユーザーとして Red Hat OpenShift Service on AWS Web コンソールにアクセスできる。 -
namespace を作成し、
k8s.ovn.org/primary-user-defined-networkラベルを適用している。詳細は、「Web コンソールを使用したユーザー定義ネットワークの namespace の作成」を参照してください。
手順
- Administrator パースペクティブから、Networking → UserDefinedNetworks をクリックします。
- Create UserDefinedNetwork をクリックします。
- Project name リストから、以前に作成した namespace を選択します。
- Subnet フィールドに値を指定します。
- Create をクリックします。ユーザー定義ネットワークは、この namespace で作成する Pod と仮想マシンのデフォルトのプライマリーネットワークとして機能します。
9.3.1.3. Web コンソールを使用したプライマリークラスタースコープのユーザー定義ネットワークの作成
Red Hat OpenShift Service on AWS Web コンソールで ClusterUserDefinedNetwork カスタムリソースを作成することで、複数の namespace を同じプライマリーユーザー定義ネットワーク (UDN) に接続できます。
前提条件
-
cluster-admin権限を持つユーザーとして Red Hat OpenShift Service on AWS Web コンソールにアクセスできる。
手順
- Administrator パースペクティブから、Networking → UserDefinedNetworks をクリックします。
- Create リストから、ClusterUserDefinedNetwork を選択します。
- Name フィールドで、クラスタースコープの UDN の名前を指定します。
- Subnet フィールドに値を指定します。
- Project(s) Match Labels フィールドに適切なラベルを追加して、クラスター UDN が適用される namespace を選択します。
- Create をクリックします。クラスタースコープの UDN は、ステップ 5 で指定したラベルが含まれる namespace にある Pod および仮想マシンのデフォルトのプライマリーネットワークとして機能します。
9.3.2. CLI を使用したプライマリーユーザー定義ネットワークの作成
CLI を使用して、プライマリー UserDefinedNetwork または ClusterUserDefinedNetwork CRD を作成できます。
9.3.2.1. CLI を使用したユーザー定義ネットワークの namespace の作成
OpenShift CLI (oc) を使用して、プライマリーユーザー定義ネットワーク (UDN) で使用される namespace を作成できます。
前提条件
-
cluster-admin権限を持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
次の例のような YAML ファイルとして
Namespaceオブジェクトを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- namespace を UDN に関連付けるには、このラベルが必要です。namespace を既存のクラスター UDN で使用する場合は、
ClusterUserDefinedNetworkカスタムリソースのspec.namespaceSelectorフィールドで定義されている適切なラベルも追加する必要があります。
次のコマンドを実行して、
Namespaceマニフェストを適用します。oc apply -f <filename>.yaml
$ oc apply -f <filename>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3.2.2. CLI を使用したプライマリー namespace スコープのユーザー定義ネットワークの作成
CLI を使用して、プロジェクト namespace に分離されたプライマリーネットワークを作成できます。仮想マシンライブマイグレーションのサポートを確保にするには、OVN-Kubernetes レイヤー 2 トポロジーを使用し、ユーザー定義ネットワーク (UDN) 設定で永続的な IP アドレスの割り当てを有効にする必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
namespace を作成し、
k8s.ovn.org/primary-user-defined-networkラベルを適用している。
手順
カスタムネットワーク設定を指定するために、
UserDefinedNetworkオブジェクトを作成します。UserDefinedNetworkマニフェストの例:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
UserDefinedNetworkカスタムリソースの名前を指定します。- 2
- 仮想マシンが配置されている namespace を指定します。namespace には
k8s.ovn.org/primary-user-defined-networkラベルが必要です。namespace としてdefault、openshift-*namespace は使用できません。また Cluster Network Operator (CNO) によって定義されたグローバル namespace と同じにすることはできません。 - 3
- ネットワークのトポロジー設定を指定します。必要な値は
Layer2です。Layer2トポロジーは、すべてのノードで共有される論理スイッチを作成します。 - 4
- UDN がプライマリーかセカンダリーかを指定します。
Primaryロールとは、UDN が仮想マシンのプライマリーネットワークとして機能し、すべてのデフォルトトラフィックがこのネットワークを通過することを意味します。 - 5
- 仮想ワークロードが再起動および移行後も、同じ IP アドレスが使用されるように指定します。
ipam.lifecycle: Persistentが指定されている場合は、spec.layer2.subnetsフィールドが必須です。
次のコマンドを実行して、
UserDefinedNetworkマニフェストを適用します。oc apply -f --validate=true <filename>.yaml
$ oc apply -f --validate=true <filename>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3.2.3. CLI を使用したプライマリークラスタースコープのユーザー定義ネットワークの作成
CLI を使用して、複数の namespace を同じプライマリーユーザー定義ネットワーク (UDN) に接続して、ネイティブテナント分離を実現できます。
前提条件
-
cluster-admin権限を持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
カスタムネットワーク設定を指定するために、
ClusterUserDefinedNetworkオブジェクトを作成します。ClusterUserDefinedNetworkマニフェストの例:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
ClusterUserDefinedNetworkカスタムリソースの名前を指定します。- 2
- クラスター UDN が適用される namespace のセットを指定します。namespace セレクターは、
default、openshift-*namespace、または Cluster Network Operator (CNO) によって定義されたグローバル namespace を参照できません。 - 3
- セレクターのタイプを指定します。この例では、
matchExpressionsセレクターは、kubernetes.io/metadata.nameラベルと、値がred-namespaceまたはblue-namespaceのオブジェクトを選択します。 - 4
- 演算子の種類を指定します。可能な値は
In、NotIn、Existsです。 - 5
- ネットワークのトポロジー設定を指定します。必要な値は
Layer2です。Layer2トポロジーは、すべてのノードで共有される論理スイッチを作成します。 - 6
- UDN がプライマリーかセカンダリーかを指定します。
Primaryロールとは、UDN が仮想マシンのプライマリーネットワークとして機能し、すべてのデフォルトトラフィックがこのネットワークを通過することを意味します。
次のコマンドを実行して、
ClusterUserDefinedNetworkマニフェストを適用します。oc apply -f --validate=true <filename>.yaml
$ oc apply -f --validate=true <filename>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3.3. 仮想マシンをプライマリーユーザー定義ネットワークに接続する
Pod ネットワークの割り当てを要求し、インターフェイスバインディングを設定することで、仮想マシン (VM) をプライマリーユーザー定義ネットワーク (UDN) に接続できます。
OpenShift Virtualization は、ネットワークインターフェイスを仮想マシンに接続するために次のネットワークバインディングプラグインをサポートしています。
- Layer 2 bridge
- Layer 2 bridge バインディングは、仮想マシンの仮想インターフェイスと UDN の仮想スイッチの間に直接の Layer 2 接続を作成します。
- Passt
Plug a Simple Socket Transport (passt) バインディングは、Pod ネットワークとシームレスに統合されるユーザー空間ネットワークソリューションを提供し、Red Hat OpenShift Service on AWS を適切に統合します。
Passt バインディングには次の利点があります。
- readiness および liveness HTTP プローブを定義して、VM ヘルスチェックを設定できます。
- Red Hat Advanced Cluster Security を使用すると、詳細にわたるインサイトでクラスター内の TCP トラフィックを監視できます。
passt バインディングプラグインを使用して仮想マシンをプライマリー UDN に接続する機能は、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、以下のリンクを参照してください。
9.3.3.1. Web コンソールを使用して仮想マシンをプライマリーユーザー定義ネットワークに接続する
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想マシン (VM) をプライマリーユーザー定義ネットワーク (UDN) に接続できます。プライマリー UDN が設定された namespace で作成される仮想マシンは、Layer 2 bridge ネットワークバインディングプラグインで UDN に自動的に割り当てられます。
Plug a Simple Socket Transport (passt) バインディングを使用して仮想マシンをプライマリー UDN に接続するには、プラグインを有効にし、Web コンソールで仮想マシンネットワークインターフェイスを設定します。
passt バインディングプラグインを使用して仮想マシンをプライマリー UDN に接続する機能は、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、以下のリンクを参照してください。
前提条件
- Red Hat OpenShift Service on AWS Web コンソールにログインしている。
手順
passt ネットワークバインディングプラグインのテクノロジープレビュー機能を有効にするには、次の手順に従います。
- Virtualization パースペクティブから、Overview をクリックします。
- Virtualization ページで、Settings タブをクリックします。
- Preview features をクリックし、Enable Passt binding for primary user-defined networks を on に設定します。
- Virtualization パースペクティブから、VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Configuration タブをクリックします。
- Network をクリックします。
-
Network interfaces ページの Options メニュー
をクリックし、Edit を選択します。
- Edit network interface ダイアログで、Network リストからデフォルトの Pod ネットワーク割り当てを選択します。
- Advanced を展開し、Passt バインディングを選択します。
- Save をクリックします。
- 仮想マシンが実行中の場合は、再起動して変更を適用します。
9.3.3.2. CLI を使用して仮想マシンをプライマリーユーザー定義ネットワークにアタッチする
CLI を使用して、仮想マシン (VM) をプライマリーユーザー定義ネットワーク (UDN) に接続できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
次の例のように、
VirtualMachineマニフェストを編集して UDN インターフェイスの詳細を追加します。VirtualMachineマニフェストの例:Copy to Clipboard Copied! Toggle word wrap Toggle overflow オプション: Plug a Simple Socket Transport (passt) ネットワークバインディングプラグインを使用している場合は、次のコマンドを実行して、
HyperConvergedカスタムリソース (CR) でhco.kubevirt.io/deployPasstNetworkBindingアノテーションをtrueに設定します。oc annotate hco kubevirt-hyperconverged -n kubevirt-hyperconverged hco.kubevirt.io/deployPasstNetworkBinding=true --overwrite
$ oc annotate hco kubevirt-hyperconverged -n kubevirt-hyperconverged hco.kubevirt.io/deployPasstNetworkBinding=true --overwriteCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重要passt バインディングプラグインを使用して仮想マシンをプライマリー UDN に接続する機能は、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、以下のリンクを参照してください。
次のコマンドを実行して、
VirtualMachineマニフェストを適用します。oc apply -f <filename>.yaml
$ oc apply -f <filename>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.4. サービスを使用して仮想マシンを公開する
Service オブジェクトを作成して、クラスター内またはクラスターの外部に仮想マシンを公開することができます。
9.4.1. サービスについて
Kubernetes サービスは一連の Pod で実行されているアプリケーションへのクライアントのネットワークアクセスを公開します。サービスは抽象化、負荷分散を提供し、タイプ NodePort と LoadBalancer の場合は外部世界への露出を提供します。
- ClusterIP
-
内部 IP アドレスでサービスを公開し、クラスター内の他のアプリケーションに DNS 名として公開します。1 つのサービスを複数の仮想マシンにマッピングできます。クライアントがサービスに接続しようとすると、クライアントのリクエストは使用可能なバックエンド間で負荷分散されます。
ClusterIPはデフォルトのサービスタイプです。 - NodePort
-
クラスター内の選択した各ノードの同じポートでサービスを公開します。
NodePortは、ノード自体がクライアントから外部にアクセスできる限り、クラスターの外部からポートにアクセスできるようにします。 - LoadBalancer
- 現在のクラウドに外部ロードバランサーを作成し (サポートされている場合)、固定の外部 IP アドレスをサービスに割り当てます。
Red Hat OpenShift Service on AWS では、ライブマイグレーション中のネットワークのダウンタイムを最小限に抑えるために、負荷分散サービスを設定するときに externalTrafficPolicy: Cluster を使用する必要があります。
9.4.2. デュアルスタックサポート
IPv4 および IPv6 のデュアルスタックネットワークがクラスターに対して有効にされている場合、Service オブジェクトに spec.ipFamilyPolicy および spec.ipFamilies フィールドを定義して、IPv4、IPv6、またはそれら両方を使用するサービスを作成できます。
spec.ipFamilyPolicy フィールドは以下の値のいずれかに設定できます。
- SingleStack
- コントロールプレーンは、最初に設定されたサービスクラスターの IP 範囲に基づいて、サービスのクラスター IP アドレスを割り当てます。
- PreferDualStack
- コントロールプレーンは、デュアルスタックが設定されたクラスターのサービス用に IPv4 および IPv6 クラスター IP アドレスの両方を割り当てます。
- RequireDualStack
-
このオプションは、デュアルスタックネットワークが有効にされていないクラスターの場合には失敗します。デュアルスタックが設定されたクラスターの場合、その値が
PreferDualStackに設定されている場合と同じになります。コントロールプレーンは、IPv4 アドレスと IPv6 アドレス範囲の両方からクラスター IP アドレスを割り当てます。
単一スタックに使用する IP ファミリーや、デュアルスタック用の IP ファミリーの順序は、spec.ipFamilies を以下のアレイ値のいずれかに設定して定義できます。
-
[IPv4] -
[IPv6] -
[IPv4, IPv6] -
[IPv6, IPv4]
9.4.3. CLI を使用したサービスの作成
コマンドラインを使用して、サービスを作成し、それを仮想マシンに関連付けることができます。
前提条件
- サービスをサポートするようにクラスターネットワークを設定しました。
-
OpenShift CLI (
oc) がインストールされている。
手順
VirtualMachineマニフェストを編集して、サービス作成のラベルを追加します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
special: keyをspec.template.metadata.labelsスタンザに追加します。
注記仮想マシンのラベルは Pod に渡されます。
special: keyラベルは、Serviceマニフェストのspec.selector属性のラベルと一致する必要があります。-
VirtualMachineマニフェストファイルを保存して変更を適用します。 仮想マシンを公開するための
Serviceマニフェストを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
Serviceマニフェストファイルを保存します。 以下のコマンドを実行してサービスを作成します。
oc create -f example-service.yaml
$ oc create -f example-service.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 仮想マシンを再起動して変更を適用します。
検証
Serviceオブジェクトをクエリーし、これが利用可能であることを確認します。oc get service -n example-namespace
$ oc get service -n example-namespaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.5. 仮想マシンを OVN-Kubernetes レイヤー 2 セカンダリーネットワークに接続する
仮想マシンは Open Virtual Network (OVN)-Kubernetes セカンダリーネットワークに接続できます。OpenShift Virtualization は、OVN-Kubernetes の layer2 トポロジーをサポートします。
layer2 トポロジーは、クラスター全体の論理スイッチによってワークロードを接続します。OVN-Kubernetes Container Network Interface (CNI) プラグインは、Geneve (Generic Network Virtualization Encapsulation) プロトコルを使用して、ノード間にオーバーレイネットワークを作成します。このオーバーレイネットワークを使用すると、追加の物理ネットワークインフラストラクチャーを設定することなく、さまざまなノード上の仮想マシンを接続できます。
OVN-Kubernetes layer2 セカンダリーネットワークを設定し、そのネットワークに仮想マシンを接続するには、次の手順を実行します。
9.5.1. OVN-Kubernetes レイヤー 2 NAD の作成
Red Hat OpenShift Service on AWS Web コンソールまたは CLI を使用して、レイヤー 2 ネットワークトポロジーの OVN-Kubernetes ネットワークアタッチメント定義 (NAD) を作成できます。
仮想マシンのネットワークアタッチメント定義で spec.config.ipam.subnet 属性を指定して IP アドレス管理 (IPAM) を設定することはサポートされていません。
9.5.1.1. CLI を使用してレイヤー 2 トポロジーの NAD を作成する
Pod をレイヤー 2 オーバーレイネットワークに接続する方法を説明する network attachment definition (NAD) を作成できます。
前提条件
-
cluster-admin権限を持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
NetworkAttachmentDefinitionオブジェクトを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- Container Network Interface (CNI) 仕様のバージョン。必要な値は
0.3.1です。 - 2
- ネットワークの名前。この属性には namespace がありません。たとえば、
l2-networkという名前のネットワークを、2 つの異なる namespace に存在する 2 つの異なるNetworkAttachmentDefinitionオブジェクトから参照させることができます。この機能は、異なる namespace の仮想マシンを接続する場合に役立ちます。 - 3
- CNI プラグインの名前。必要な値は
ovn-k8s-cni-overlayです。 - 4
- ネットワークのトポロジー設定。必要な値は
layer2です。 - 5
- オプション: 最大伝送単位 (MTU) の値。この値を設定しなかった場合、Cluster Network Operator (CNO) が、プライマリーネットワークインターフェイスのアンダーレイ MTU、Geneve (Generic Network Virtualization Encapsulation) などの Pod ネットワークのオーバーレイ MTU、および IPsec などの有効な機能のバイト容量の差を計算して、デフォルトの MTU 値を設定します。
- 6
NetworkAttachmentDefinitionオブジェクトのmetadataスタンザ内のnamespaceおよびnameフィールドの値。
注記前の例では、サブネットを定義せずにクラスター全体のオーバーレイを設定します。これは、ネットワークを実装する論理スイッチがレイヤー 2 通信のみを提供することを意味します。仮想マシンの作成時に、静的 IP アドレスを設定するか、動的 IP アドレス用にネットワーク上に DHCP サーバーをデプロイすることによって、IP アドレスを設定する必要があります。
次のコマンドを実行してマニフェストを適用します。
oc apply -f <filename>.yaml
$ oc apply -f <filename>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.5.1.2. Web コンソールを使用してレイヤー 2 トポロジーの NAD を作成する
Pod をレイヤー 2 オーバーレイネットワークに接続する方法を記述した network attachment definition (NAD) を作成できます。
前提条件
-
cluster-admin権限を持つユーザーとしてクラスターにアクセスできる。
手順
- Web コンソールで、Networking → NetworkAttachmentDefinitions に移動します。
- Create Network Attachment Definition をクリックします。network attachment definition は、それを使用する Pod または仮想マシンと同じ namespace にある必要があります。
- 一意の Name およびオプションの Description を入力します。
- Network Type リストで OVN Kubernetes L2 overlay network を選択します。
- Create をクリックします。
9.5.2. OVN-Kubernetes レイヤー 2 セカンダリーネットワークに仮想マシンを接続する
Red Hat OpenShift Service on AWS Web コンソールまたは CLI を使用して、仮想マシン (VM) を OVN-Kubernetes レイヤー 2 セカンダリーネットワークインターフェイスに接続できます。
9.5.2.1. CLI を使用した OVN-Kubernetes セカンダリーネットワークへの仮想マシンの接続
仮想マシン設定にネットワークの詳細を含めることで、仮想マシンを OVN-Kubernetes セカンダリーネットワークに接続できます。
前提条件
-
cluster-admin権限を持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
次の例のように、
VirtualMachineマニフェストを編集して OVN-Kubernetes セカンダリーネットワークインターフェイスの詳細を追加します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow VirtualMachineマニフェストを適用します。oc apply -f <filename>.yaml
$ oc apply -f <filename>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow - オプション: 実行中の仮想マシンを編集している場合は、変更を有効にするためにこれを再起動する必要があります。
9.6. ホットプラグ対応のセカンダリーネットワークインターフェイス
仮想マシンを停止せずに、セカンダリーネットワークインターフェイスを追加または削除できます。OpenShift Virtualization は、ブリッジバインディングおよび VirtIO デバイスドライバーを使用するセカンダリーインターフェイスのホットプラグとホットアンプラグをサポートしています。
9.6.1. VirtIO の制限事項
各 VirtIO インターフェイスは、仮想マシン内の限られたペリフェラル接続インターフェイス (PCI) スロットの 1 つを使用します。合計 32 個のスロットが利用可能です。PCI スロットは他のデバイスでも使用され、事前に予約する必要があるため、オンデマンドでスロットを利用できない場合があります。OpenShift Virtualization は、ホットプラグインターフェイス用に最大 4 つのスロットを予約します。これには、接続されている既存のネットワークインターフェイスが含まれます。たとえば、仮想マシンにプラグインされた既存のインターフェイスが 2 つある場合は、さらに 2 つのネットワークインターフェイスをホットプラグできます。
ホットプラグに使用できる実際のスロット数もマシンのタイプによって異なります。たとえば、q35 マシンタイプのデフォルトの PCI トポロジーは、1 台の追加 PCIe デバイスのホットプラグをサポートしています。PCI トポロジーとホットプラグのサポートの詳細は、libvirt のドキュメント を参照してください。
インターフェイスをホットプラグした後に仮想マシンを再起動すると、そのインターフェイスは標準ネットワークインターフェイスの一部になります。
9.6.2. CLI を使用したセカンダリーネットワークインターフェイスのホットプラグ
仮想マシン (VM) の実行中に、セカンダリーネットワークインターフェイスを仮想マシンにホットプラグできます。
前提条件
- ネットワークアタッチメント定義が、仮想マシンと同じ namespace に設定されている。
- ネットワークインターフェイスをホットプラグする仮想マシンが実行中です。
-
OpenShift CLI (
oc) がインストールされている。
手順
次の例に示すように、好みのテキストエディターを使用して
VirtualMachineマニフェストを編集します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 変更を保存し、エディターを終了します。
新しい設定を有効にするには、次のコマンドを実行して変更を適用します。変更を適用すると、自動仮想マシンライブマイグレーションがトリガーされ、実行中の仮想マシンにネットワークインターフェイスがアタッチされます。
oc apply -f <filename>.yaml
$ oc apply -f <filename>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow ここでは、以下のようになります。
- <filename>
-
VirtualMachineマニフェスト YAML ファイルの名前を指定します。
検証
次のコマンドを使用して、仮想マシンのライブマイグレーションが成功したことを確認します。
oc get VirtualMachineInstanceMigration -w
$ oc get VirtualMachineInstanceMigration -wCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 仮想マシンインスタンス (VMI) のステータスを確認して、新しいインターフェイスが仮想マシンに追加されたことを確認します。
oc get vmi vm-fedora -ojsonpath="{ @.status.interfaces }"$ oc get vmi vm-fedora -ojsonpath="{ @.status.interfaces }"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- ホットプラグされたインターフェイスが VMI ステータスに表示されます。
9.6.3. CLI を使用したセカンダリーネットワークインターフェイスのホットアンプラグ
実行中の仮想マシンから、セカンダリーネットワークインターフェイスを削除できます。
ホットアンプラグは、Single Root I/O Virtualization (SR-IOV) インターフェイスではサポートされていません。
前提条件
- 仮想マシンが実行している必要があります。
- 仮想マシンは、OpenShift Virtualization 4.14 以降を実行しているクラスター上に作成する必要があります。
- 仮想マシンにはブリッジネットワークインターフェイスが接続されている必要があります。
-
OpenShift CLI (
oc) がインストールされている。
手順
好みのテキストエディターを使用して、
VirtualMachineマニフェストファイルを編集し、インターフェイスの状態をabsentに設定します。インターフェイスの状態をabsentに設定すると、ネットワークインターフェイスがゲストから切り離されますが、そのインターフェイスは Pod 内にまだ存在しています。仮想マシン設定の例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- インターフェイスの状態を
absentに設定して、実行中の仮想マシンから切り離します。仮想マシン仕様からインターフェイスの詳細を削除しても、セカンダリーネットワークインターフェイスはホットアンプラグされません。
- 変更を保存し、エディターを終了します。
新しい設定を有効にするには、次のコマンドを実行して変更を適用します。変更を適用すると、自動仮想マシンライブマイグレーションがトリガーされ、Pod からインターフェイスが削除されます。
oc apply -f <filename>.yaml
$ oc apply -f <filename>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow ここでは、以下のようになります。
- <filename>
-
VirtualMachineマニフェスト YAML ファイルの名前を指定します。
9.7. 仮想マシンのサービスメッシュへの接続
OpenShift Virtualization が OpenShift Service Mesh に統合されるようになりました。IPv4 を使用してデフォルトの Pod ネットワークで仮想マシンのワークロードを実行する Pod 間のトラフィックのモニター、可視化、制御が可能です。
9.7.1. サービスメッシュへの仮想マシンの追加
仮想マシン (VM) ワークロードをサービスメッシュに追加するには、sidecar.istio.io/inject アノテーションを true に設定して、仮想マシン設定ファイルでサイドカーの自動注入を有効にします。次に、仮想マシンをサービスとして公開し、メッシュでアプリケーションを表示します。
ポートの競合を回避するには、Istio サイドカープロキシーが使用するポートを使用しないでください。これには、ポート 15000、15001、15006、15008、15020、15021、および 15090 が含まれます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - Service Mesh Operator がインストールされました。
手順
仮想マシン設定ファイルを編集し、
sidecar.istio.io/inject: "true"アノテーションを追加します。設定ファイルの例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 仮想マシン設定を適用します。
oc apply -f <vm_name>.yaml
$ oc apply -f <vm_name>.yaml1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 仮想マシン YAML ファイルの名前。
Serviceオブジェクトを作成し、仮想マシンをサービスメッシュに公開します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- サービスの対象となる Pod セットを判別するサービスセレクターです。この属性は、仮想マシン設定ファイルの
spec.metadata.labelsフィールドに対応します。上記の例では、vm-istioという名前のServiceオブジェクトは、ラベルがapp=vm-istioの Pod の TCP ポート 8080 をターゲットにします。
サービスを作成します。
oc create -f <service_name>.yaml
$ oc create -f <service_name>.yaml1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- サービス YAML ファイルの名前。
9.8. ライブマイグレーション用の専用ネットワークの設定
ライブマイグレーション用に専用の セカンダリーネットワーク を設定できます。専用ネットワークは、ライブマイグレーション中のテナントワークロードに対するネットワークの飽和状態の影響を最小限に抑えます。
9.8.1. ライブマイグレーション用の専用セカンダリーネットワークの設定
ライブマイグレーション用に専用のセカンダリーネットワークを設定するには、まず CLI を使用してブリッジ network attachment definition (NAD) を作成する必要があります。次に、NetworkAttachmentDefinition オブジェクトの名前を HyperConverged カスタムリソース(CR)に追加できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにログインしている。 - 各ノードには少なくとも 2 つのネットワークインターフェイスカード (NIC) があります。
- ライブマイグレーション用の NIC は同じ VLAN に接続されます。
手順
次の例に従って、
NetworkAttachmentDefinitionマニフェストを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow ここでは、以下のようになります。
metadata.name-
NetworkAttachmentDefinitionオブジェクトの名前を指定します。 config.master- ライブマイグレーションに使用する NIC の名前を指定します。
config.type- NAD にネットワークを提供する CNI プラグインの名前を指定します。
config.range- セカンダリーネットワークの IP アドレス範囲を指定します。この範囲は、メインネットワークの IP アドレスと重複してはなりません。
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow NetworkAttachmentDefinitionオブジェクトの名前をHyperConvergedCR のspec.liveMigrationConfigスタンザに追加します。HyperConvergedマニフェストの例:Copy to Clipboard Copied! Toggle word wrap Toggle overflow ここでは、以下のようになります。
network-
ライブマイグレーションに使用される Multus
NetworkAttachmentDefinitionオブジェクトの名前を指定します。
-
変更を保存し、エディターを終了します。
virt-handlerPod が再起動し、セカンダリーネットワークに接続されます。
検証
仮想マシンが実行されるノードがメンテナンスモードに切り替えられると、仮想マシンは自動的にクラスター内の別のノードに移行します。仮想マシンインスタンス (VMI) メタデータのターゲット IP アドレスを確認して、デフォルトの Pod ネットワークではなく、セカンダリーネットワーク上で移行が発生したことを確認できます。
oc get vmi <vmi_name> -o jsonpath='{.status.migrationState.targetNodeAddress}'$ oc get vmi <vmi_name> -o jsonpath='{.status.migrationState.targetNodeAddress}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.8.2. Web コンソールを使用して専用ネットワークを選択する
Red Hat OpenShift Service on AWS Web コンソールを使用して、ライブマイグレーション用の専用ネットワークを選択できます。
前提条件
- ライブマイグレーション用に Multus ネットワークが設定されている。
- ネットワークの network attachment definition を作成している。
手順
- Red Hat OpenShift Service on AWS Web コンソールで Virtualization > Overview に移動します。
- Settings タブをクリックし、Live migration をクリックします。
- Live migration network リストからネットワークを選択します。
9.9. IP アドレスの設定と表示
仮想マシンを作成するときに IP アドレスを設定できます。IP アドレスは、cloud-init でプロビジョニングされます。
仮想マシンの IP アドレスは、Red Hat OpenShift Service on AWS Web コンソールまたはコマンドラインを使用して表示できます。ネットワーク情報は QEMU ゲストエージェントによって収集されます。
9.9.1. 仮想マシンの IP アドレスの設定
Web コンソールまたはコマンドラインを使用して仮想マシンを作成するときに、静的 IP アドレスを設定できます。
コマンドラインを使用して仮想マシンを作成するときに、動的 IP アドレスを設定できます。
IP アドレスは、cloud-init でプロビジョニングされます。
9.9.1.1. CLI を使用して仮想マシンを作成するときに IP アドレスを設定する
仮想マシンを作成するときに、静的または動的 IP アドレスを設定できます。IP アドレスは、cloud-init でプロビジョニングされます。
VM が Pod ネットワークに接続されている場合、更新しない限り、Pod ネットワークインターフェイスがデフォルトルートになります。
前提条件
- 仮想マシンはセカンダリーネットワークに接続されている。
- 仮想マシンの動的 IP を設定するために、セカンダリーネットワーク上で使用できる DHCP サーバーがある。
手順
仮想マシン設定の
spec.template.spec.volumes.cloudInitNoCloud.networkDataスタンザを編集します。
9.9.2. 仮想マシンの IP アドレスの表示
仮想マシンの IP アドレスは、Red Hat OpenShift Service on AWS Web コンソールまたはコマンドラインを使用して表示できます。
ネットワーク情報は QEMU ゲストエージェントによって収集されます。
9.9.2.1. Web コンソールを使用した仮想マシンの IP アドレスの表示
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想マシン (VM) の IP アドレスを表示できます。
セカンダリーネットワークインターフェイスの IP アドレスを表示するには、仮想マシンに QEMU ゲストエージェントをインストールする必要があります。Pod ネットワークインターフェイスには QEMU ゲストエージェントは必要ありません。
手順
- Red Hat OpenShift Service on AWS コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Details タブをクリックして IP アドレスを表示します。
9.9.2.2. CLI を使用した仮想マシンの IP アドレスの表示
コマンドラインを使用して、仮想マシンの IP アドレスを表示できます。
セカンダリーネットワークインターフェイスの IP アドレスを表示するには、仮想マシンに QEMU ゲストエージェントをインストールする必要があります。Pod ネットワークインターフェイスには QEMU ゲストエージェントは必要ありません。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、仮想マシンインスタンスの設定を取得します。
oc describe vmi <vmi_name>
$ oc describe vmi <vmi_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.10. ネットワークインターフェイスの MAC アドレスプールの管理
KubeMacPool コンポーネントは、共有 MAC アドレスプールから仮想マシンネットワークインターフェイスの MAC アドレスを割り当てます。これにより、各ネットワークインターフェイスに一意の MAC アドレスが確実に割り当てられます。
その仮想マシンから作成された仮想マシンインスタンスは、再起動後も割り当てられた MAC アドレスを保持します。
KubeMacPool は、仮想マシンから独立して作成される仮想マシンインスタンスを処理しません。
9.10.1. CLI を使用した KubeMacPool の管理
コマンドラインを使用して、KubeMacPool を無効にしたり、再度有効にしたりできます。
KubeMacPool はデフォルトで有効になっています。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
2 つの namespace で KubeMacPool を無効にするには、次のコマンドを実行します。
oc label namespace <namespace1> <namespace2> mutatevirtualmachines.kubemacpool.io=ignore
$ oc label namespace <namespace1> <namespace2> mutatevirtualmachines.kubemacpool.io=ignoreCopy to Clipboard Copied! Toggle word wrap Toggle overflow 2 つの namespace で KubeMacPool を再度有効にするには、次のコマンドを実行します。
oc label namespace <namespace1> <namespace2> mutatevirtualmachines.kubemacpool.io-
$ oc label namespace <namespace1> <namespace2> mutatevirtualmachines.kubemacpool.io-Copy to Clipboard Copied! Toggle word wrap Toggle overflow
第10章 ストレージ
10.1. ストレージ設定の概要
デフォルトのストレージクラス、ストレージプロファイル、Containerized Data Importer (CDI)、データボリューム、および自動ブートソース更新を設定できます。
10.1.1. ストレージ
次のストレージ設定タスクは必須です。
- ストレージプロファイルを設定する
- ストレージプロバイダーが CDI によって認識されない場合は、ストレージプロファイルを設定する必要があります。ストレージプロファイルは、関連付けられたストレージクラスに基づいて推奨されるストレージ設定を提供します。
次のストレージ設定タスクはオプションです。
- ファイルシステムのオーバーヘッドのために追加の PVC スペースを予約する
- デフォルトでは、ファイルシステム PVC の 5.5% がオーバーヘッド用に予約されており、その分仮想マシンディスクに使用できるスペースが減少します。別のオーバーヘッド値を設定できます。
- ホストパスプロビジョナーを使用してローカルストレージを設定する
- ホストパスプロビジョナー (HPP) を使用して、仮想マシンのローカルストレージを設定できます。OpenShift Virtualization Operator をインストールすると、HPP Operator が自動的にインストールされます。
- namespace 間でデータボリュームのクローンを作成するためのユーザー権限を設定する
- RBAC ロールを設定して、ユーザーが namespace 間でデータボリュームのクローンを作成できるようにすることができます。
10.1.2. コンテナー化されたデータインポーター
次の Containerized Data Importer (CDI) 設定タスクを実行できます。
- namespace のリソース要求制限をオーバーライドする
- CPU およびメモリーリソースの制限を受ける namespace に仮想マシンディスクをインポート、アップロード、およびクローン作成するように CDI を設定できます。
- CDI スクラッチスペースを設定する
- CDI では、仮想マシンイメージのインポートやアップロードなどの一部の操作を完了するためにスクラッチスペース (一時ストレージ) が必要です。このプロセスで、CDI は、宛先データボリューム (DV) をサポートする PVC のサイズと同じサイズのスクラッチ領域 PVC をプロビジョニングします。
10.1.3. データボリューム
次のデータボリューム設定タスクを実行できます。
- データボリュームの事前割り当てを有効にする
- CDI は、データボリュームの作成時の書き込みパフォーマンスを向上させるために、ディスク領域を事前に割り当てることができます。特定のデータボリュームの事前割り当てを有効にできます。
- データボリュームのアノテーションを管理する
- データボリュームアノテーションを使用して Pod の動作を管理できます。1 つ以上のアノテーションをデータボリュームに追加してから、作成されたインポーター Pod に伝播できます。
10.1.4. ブートソースの更新
次のブートソース更新設定タスクを実行できます。
- ブートソースの自動更新を管理する
- ブートソースにより、ユーザーは仮想マシン (VM) をよりアクセスしやすく効率的に作成できるようになります。ブートソースの自動更新が有効になっている場合、CDI はイメージをインポート、ポーリング、更新して、新しい仮想マシン用にクローンを作成できるようにします。デフォルトでは、CDI は Red Hat ブートソースを自動的に更新します。次に、カスタムブートソースの自動更新を有効にできます。
10.2. ストレージプロファイルの設定
ストレージプロファイルは、関連付けられたストレージクラスに基づいて推奨されるストレージ設定を提供します。ストレージクラスごとにストレージクラスが割り当てられます。
Containerized Data Importer (CDI) は、ストレージプロバイダーの機能を識別し、対話するように設定されている場合はストレージプロバイダーを認識します。
認識されたストレージタイプの場合、CDI は PVC の作成を最適化する値を提供します。ストレージプロファイルをカスタマイズして、ストレージクラスの自動設定を行うこともできます。CDI がストレージプロバイダーを認識しない場合は、ユーザーがストレージプロファイルを設定する必要があります。
10.2.1. ストレージプロファイルのカスタマイズ
プロビジョナーのストレージクラスの StorageProfile オブジェクトを編集してデフォルトパラメーターを指定できます。これらのデフォルトパラメーターは、DataVolume オブジェクトで設定されていない場合にのみ永続ボリューム要求 (PVC) に適用されます。
ストレージクラスのパラメーターは変更できません。変更する必要がある場合は、ストレージクラスを削除して再作成します。その後、ストレージプロファイルに適用していたカスタマイズを再適用する必要があります。
ストレージプロファイルの空の status セクションは、ストレージプロビジョナーが Containerized Data Importer (CDI) によって認識されないことを示します。CDI で認識されないストレージプロビジョナーがある場合、ストレージプロファイルをカスタマイズする必要があります。この場合、管理者はストレージプロファイルに適切な値を設定し、割り当てが正常に実行されるようにします。
仮想マシンのスナップショットを作成する場合、ディスクのストレージクラスに複数の VolumeSnapshotClass が関連付けられていると警告が表示されます。その場合、ボリュームスナップショットクラスを 1 つ指定する必要があります。そうしないと、複数のボリュームスナップショットクラスを持つディスクはスナップショットリストから除外されます。
データボリュームを作成し、YAML 属性を省略し、これらの属性がストレージプロファイルで定義されていない場合は、要求されたストレージは割り当てられず、基礎となる永続ボリューム要求 (PVC) は作成されません。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - 計画した設定がストレージクラスとそのプロバイダーでサポートされていることを確認してください。ストレージプロファイルに互換性のない設定を指定すると、ボリュームのプロビジョニングに失敗します。
手順
ストレージプロファイルを編集します。この例では、プロビジョナーは CDI によって認識されません。
oc edit storageprofile <storage_class>
$ oc edit storageprofile <storage_class>Copy to Clipboard Copied! Toggle word wrap Toggle overflow ストレージプロファイルに設定する
accessModesおよびvolumeModeの値を指定します。以下に例を示します。ストレージプロファイルの例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
10.2.1.1. Web コンソールを使用してボリュームスナップショットクラスを指定する
仮想マシンのスナップショットを作成する場合、ディスクのストレージクラスに複数のボリュームスナップショットクラスが関連付けられていると警告が表示されます。その場合、ボリュームスナップショットクラスを 1 つ指定する必要があります。そうしないと、複数のボリュームスナップショットクラスを持つディスクはスナップショットリストから除外されます。
Red Hat OpenShift Service on AWS の Web コンソールで、デフォルトのボリュームスナップショットクラスを指定できます。
手順
- Virtualization に重点を置いたビューから、Storage を選択します。
- VolumeSnapshotClasses をクリックします。
- リストからボリュームスナップショットクラスを選択します。
- Annotations の鉛筆アイコンをクリックします。
-
次の キー を入力します:
snapshot.storage.kubernetes.io/is-default-class。 -
次の 値 を入力します:
true。 - Save をクリックします。
10.2.1.2. CLI を使用してボリュームスナップショットクラスを指定する
仮想マシンのスナップショットを作成する場合、ディスクのストレージクラスに複数のボリュームスナップショットクラスが関連付けられていると警告が表示されます。その場合、ボリュームスナップショットクラスを 1 つ指定する必要があります。そうしないと、複数のボリュームスナップショットクラスを持つディスクはスナップショットリストから除外されます。
使用するボリュームスナップショットクラスは、次のいずれかの方法で選択できます。
-
ストレージプロファイルの
spec.snapshotClassを設定します。 - デフォルトのボリュームスナップショットクラスを設定します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
使用する
VolumeSnapshotClassを設定します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow または、次のコマンドを実行して、デフォルトのボリュームスナップショットクラスを設定します。
oc patch VolumeSnapshotClass ocs-storagecluster-cephfsplugin-snapclass --type=merge -p '{"metadata":{"annotations":{"snapshot.storage.kubernetes.io/is-default-class":"true"}}}'# oc patch VolumeSnapshotClass ocs-storagecluster-cephfsplugin-snapclass --type=merge -p '{"metadata":{"annotations":{"snapshot.storage.kubernetes.io/is-default-class":"true"}}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
10.2.1.3. 自動的に作成されたストレージプロファイルの表示
システムは、各ストレージクラスのストレージプロファイルを自動的に作成します。これらのストレージクラスのプロファイルは、oc コマンドを使用して表示できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
ストレージプロファイルのリストを表示するには、次のコマンドを実行します。
oc get storageprofile
$ oc get storageprofileCopy to Clipboard Copied! Toggle word wrap Toggle overflow 特定のストレージプロファイルの詳細を取得するには、次のコマンドを実行します。
oc describe storageprofile <name>
$ oc describe storageprofile <name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow ストレージプロファイルの詳細の例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
10.2.1.4. ストレージプロファイルを使用してデフォルトのクローン作成ストラテジーを設定する
ストレージプロファイルを使用してストレージクラスのデフォルトクローン作成メソッドを設定して、クローンストラテジーを作成できます。これは、たとえば、ストレージベンダーが特定のクローン作成方法のみをサポートしている場合に役立ちます。また、リソースの使用の制限やパフォーマンスの最大化を実現する手法を選択することもできます。
クローン作成ストラテジーは、ストレージプロファイルの cloneStrategy 属性を以下の値のいずれかに設定して指定できます。
-
snapshotが設定されている場合、デフォルトでスナップショットが使用されます。Containerized Data Importer (CDI) がストレージプロバイダーを認識し、プロバイダーが Container Storage Interface (CSI) スナップショットをサポートする場合、CDI はスナップショットメソッドを使用します。このクローン作成ストラテジーは、一時的なボリュームスナップショットを使用してボリュームのクローンを作成します。 -
copyは、ソース Pod とターゲット Pod を使用して、ソースボリュームからターゲットボリュームにデータをコピーします。ホスト支援型でのクローン作成は、最も効率的な方法です。 -
csi-cloneは、CSI クローン API を使用して、中間ボリュームスナップショットを使用せずに、既存のボリュームのクローンを効率的に作成します。ストレージプロファイルが定義されていない場合にデフォルトで使用されるsnapshotまたはcopyとは異なり、CSI ボリュームのクローンは、プロビジョナーのストレージクラスのStorageProfileオブジェクトに指定した場合にだけ使用されます。
YAML spec セクションのデフォルトの claimPropertySets を変更せずに、CLI でクローン作成ストラテジーを設定できます。
ストレージプロファイルの例:
10.3. ブートソースの自動更新の管理
次のブートソースの自動更新を管理できます。
ブートソースにより、ユーザーは仮想マシン (VM) をよりアクセスしやすく効率的に作成できるようになります。ブートソースの自動更新が有効になっている場合、コンテナー化データインポーター (CDI) はイメージをインポート、ポーリング、更新して、新しい仮想マシン用にクローンを作成できるようにします。デフォルトでは、CDI は Red Hat ブートソースを自動的に更新します。
10.3.1. Red Hat ブートソースの更新の管理
enableCommonBootImageImport フィールドの値を false に設定することで、すべてのシステム定義のブートソースの自動更新をオプトアウトできます。値を false に設定すると、すべての DataImportCron オブジェクトが削除されます。ただし、これによって、オペレーティングシステムイメージを格納する、以前にインポートされたブートソースオブジェクトが削除されるわけではありません。管理者は、これらを手動で削除できます。
enableCommonBootImageImport フィールドの値が false に設定されている場合、DataSource オブジェクトはリセットされ、元のブートソースをポイントしなくなります。管理者は、DataSource オブジェクトの新しい永続ボリューム要求 (PVC) またはボリュームスナップショットを作成し、それにオペレーティングシステムイメージを設定することで、ブートソースを手動で提供できます。
10.3.1.1. すべてのシステム定義のブートソースの自動更新の管理
ブートソースの自動インポートと更新を無効にすると、リソースの使用量が削減される可能性があります。切断された環境では、ブートソースの自動更新を無効にすると、CDIDataImportCronOutdated アラートがログをいっぱいにするのを防ぎます。
すべてのシステム定義のブートソースの自動更新を無効にするには、enableCommonBootImageImport フィールドの値を false に設定します。この値を true に設定すると、自動更新が再びオンになります。
カスタムブートソースは、この設定の影響を受けません。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
HyperConvergedカスタムリソース (CR) を編集して、自動ブートソース更新を有効または無効にします。自動ブートソース更新を無効にするには、
HyperConvergedCR のspec.enableCommonBootImageImportフィールド値をfalseに設定します。以下に例を示します。oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv \ --type json -p '[{"op": "replace", "path": \ "/spec/enableCommonBootImageImport", \ "value": false}]'$ oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv \ --type json -p '[{"op": "replace", "path": \ "/spec/enableCommonBootImageImport", \ "value": false}]'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 自動ブートソース更新を再度有効にするには、
HyperConvergedCR のspec.enableCommonBootImageImportフィールド値をtrueに設定します。以下に例を示します。oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv \ --type json -p '[{"op": "replace", "path": \ "/spec/enableCommonBootImageImport", \ "value": true}]'$ oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv \ --type json -p '[{"op": "replace", "path": \ "/spec/enableCommonBootImageImport", \ "value": true}]'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
10.3.2. カスタムブートソースの更新の管理
OpenShift Virtualization によって提供されていない カスタム ブートソースは、機能ゲートによって制御されません。HyperConverged カスタムリソース (CR) を編集して、それらを個別に管理する必要があります。
ストレージプロファイルを設定する必要があります。そうしないと、クラスターはカスタムブートソースの自動更新を受信できません。詳細は、ストレージプロファイルの設定 を参照してください。
10.3.2.1. デフォルトおよび virt-default ストレージクラスの設定
ストレージクラスは、ワークロードに対して永続ストレージをプロビジョニングする方法を決定します。OpenShift Virtualization では、virt-default ストレージクラスがクラスターのデフォルトストレージクラスよりも優先され、仮想化ワークロード専用に使用されます。
virt-default またはクラスターのデフォルトとして一度に設定できるストレージクラスは 1 つだけです。複数のストレージクラスがデフォルトとしてマークされている場合、virt-default ストレージクラスがクラスターのデフォルトをオーバーライドします。一貫した動作を確保するには、仮想化ワークロードのデフォルトとして 1 つのストレージクラスのみを設定します。
ブートソースは、デフォルトのストレージクラスを使用して作成されます。デフォルトのストレージクラスが変更されると、古いブートソースは新しいデフォルトのストレージクラスを使用して自動的に更新されます。クラスターにデフォルトのストレージクラスがない場合は、定義する必要があります。
ブートソースイメージがボリュームスナップショットとして保存され、クラスターのデフォルトと virt-default ストレージクラスの両方が設定解除されている場合、ボリュームスナップショットはクリーンアップされ、新しいデータボリュームが作成されます。ただし、新しく作成されたデータボリュームは、デフォルトのストレージクラスが設定されるまでインポートを開始しません。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
現在の virt-default またはクラスターのデフォルトストレージクラスを false にパッチします。
次のコマンドを実行して、現在 virt-default としてマークされているすべてのストレージクラスを識別します。
oc get sc -o json| jq '.items[].metadata|select(.annotations."storageclass.kubevirt.io/is-default-virt-class"=="true")|.name'
$ oc get sc -o json| jq '.items[].metadata|select(.annotations."storageclass.kubevirt.io/is-default-virt-class"=="true")|.name'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 返されたストレージクラスごとに、次のコマンドを実行して virt-default アノテーションを削除します。
oc patch storageclass <storage_class_name> -p '{"metadata": {"annotations": {"storageclass.kubevirt.io/is-default-virt-class": "false"}}}'$ oc patch storageclass <storage_class_name> -p '{"metadata": {"annotations": {"storageclass.kubevirt.io/is-default-virt-class": "false"}}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して、現在クラスターのデフォルトとしてマークされているすべてのストレージクラスを識別します。
oc get sc -o json| jq '.items[].metadata|select(.annotations."storageclass.kubernetes.io/is-default-class"=="true")|.name'
$ oc get sc -o json| jq '.items[].metadata|select(.annotations."storageclass.kubernetes.io/is-default-class"=="true")|.name'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 返されたストレージクラスごとに、次のコマンドを実行してクラスターのデフォルトアノテーションを削除します。
oc patch storageclass <storage_class_name> -p '{"metadata": {"annotations": {"storageclass.kubernetes.io/is-default-class": "false"}}}'$ oc patch storageclass <storage_class_name> -p '{"metadata": {"annotations": {"storageclass.kubernetes.io/is-default-class": "false"}}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
新しいデフォルトのストレージクラスを設定します。
次のコマンドを実行して、virt-default ロールをストレージクラスに割り当てます。
oc patch storageclass <storage_class_name> -p '{"metadata": {"annotations": {"storageclass.kubevirt.io/is-default-virt-class": "true"}}}'$ oc patch storageclass <storage_class_name> -p '{"metadata": {"annotations": {"storageclass.kubevirt.io/is-default-virt-class": "true"}}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow または、次のコマンドを実行して、クラスターのデフォルトロールをストレージクラスに割り当てます。
oc patch storageclass <storage_class_name> -p '{"metadata": {"annotations": {"storageclass.kubernetes.io/is-default-class": "true"}}}'$ oc patch storageclass <storage_class_name> -p '{"metadata": {"annotations": {"storageclass.kubernetes.io/is-default-class": "true"}}}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
10.3.2.2. ブートソースイメージのストレージクラスの設定
HyperConverged リソースで特定のストレージクラスを設定できます。
安定した動作を確保し、不要な再インポートを回避するには、HyperConverged リソースの dataImportCronTemplates セクションで storageClassName を指定します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow HyperConvergedリソースの spec セクションにdataImportCronTemplateを追加し、storageClassNameを設定します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow For the custom image to be detected as an available boot source, the value of the `spec.dataVolumeTemplates.spec.sourceRef.name` parameter in the VM template must match this value.
For the custom image to be detected as an available boot source, the value of the `spec.dataVolumeTemplates.spec.sourceRef.name` parameter in the VM template must match this value.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - HyperConverged Operator (HCO) と Scheduling、Scale、および Performance (SSP) リソースのリコンシリエーションが完了するまで待ちます。
次のコマンドを実行して、
openshift-virtualization-os-imagesnamespace から古くなったDataVolumeおよびVolumeSnapshotオブジェクトを削除します。oc delete DataVolume,VolumeSnapshot -n openshift-virtualization-os-images --selector=cdi.kubevirt.io/dataImportCron
$ oc delete DataVolume,VolumeSnapshot -n openshift-virtualization-os-images --selector=cdi.kubevirt.io/dataImportCronCopy to Clipboard Copied! Toggle word wrap Toggle overflow すべての
DataSourceオブジェクトが "Ready - True" ステータスに達するまで待機します。データソースは、PersistentVolumeClaim (PVC) または VolumeSnapshot のいずれかを参照できます。予想されるソース形式を確認するには、次のコマンドを実行します。oc get storageprofile <storage_class_name> -o json | jq .status.dataImportCronSourceFormat
$ oc get storageprofile <storage_class_name> -o json | jq .status.dataImportCronSourceFormatCopy to Clipboard Copied! Toggle word wrap Toggle overflow
10.3.2.3. カスタムブートソースの自動更新を有効にする
OpenShift Virtualization は、デフォルトでシステム定義のブートソースを自動的に更新しますが、カスタムブートソースは自動的に更新しません。HyperConverged カスタムリソース (CR) を編集して、自動更新を手動で有効にする必要があります。
前提条件
- クラスターにはデフォルトのストレージクラスがあります。
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 適切なテンプレートおよびブートソースを
dataImportCronTemplatesセクションで追加して、HyperConvergedCR を編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- このアノテーションは、
volumeBindingModeがWaitForFirstConsumerに設定されたストレージクラスに必要です。 - 2
- cron 形式で指定されるジョブのスケジュール。
- 3
- レジストリーソースからデータボリュームを作成するのに使用します。
nodedocker キャッシュに基づくデフォルトのnodepullMethodではなく、デフォルトのpodpullMethodを使用します。nodedocker キャッシュはレジストリーイメージがContainer.Imageで利用可能な場合に便利ですが、CDI インポーターはこれにアクセスすることは許可されていません。 - 4
- 利用可能なブートソースとして検出するカスタムイメージの場合、イメージの
managedDataSourceの名前が、仮想マシンテンプレート YAML ファイルのspec.dataVolumeTemplates.spec.sourceRef.nameにあるテンプレートのDataSourceの名前に一致する必要があります。
- ファイルを保存します。
10.3.2.4. ボリュームスナップショットのブートソースを有効にする
オペレーティングシステムのベースイメージを格納するストレージクラスに関連付けられている StorageProfile でパラメーターを設定することで、ボリュームスナップショットのブートソースを有効にできます。
DataImportCron は、元々 PVC ソースのみを維持するように設計されていましたが、特定のストレージタイプでは VolumeSnapshot ソースの方が PVC ソースよりも拡張性に優れています。
ストレージプロファイルでは、単一のスナップショットからクローンを作成する場合により適切に拡張できることが証明されているボリュームスナップショットを使用してください。
前提条件
- オペレーティングシステムイメージを含むボリュームスナップショットにアクセスできる。
- ストレージはスナップショットをサポートしている。
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、ブートソースのプロビジョニングに使用されるストレージクラスに対応するストレージプロファイルオブジェクトを開きます。
oc edit storageprofile <storage_class>
$ oc edit storageprofile <storage_class>Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
StorageProfileのdataImportCronSourceFormat仕様を確認して、仮想マシンがデフォルトで PVC またはボリュームスナップショットを使用しているか確認します。 必要に応じて、
dataImportCronSourceFormat仕様をsnapshotに更新して、ストレージプロファイルを編集します。ストレージプロファイルの例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
ブートソースのプロビジョニングに使用されるストレージクラスに対応するストレージプロファイルオブジェクトを開きます。
oc get storageprofile <storage_class> -oyaml
$ oc get storageprofile <storage_class> -oyamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
StorageProfileのdataImportCronSourceFormat仕様が 'snapshot' に設定されていること、およびDataImportCronが指すDataSourceオブジェクトがボリュームスナップショットを参照していることを確認します。
これで、これらのブートソースを使用して仮想マシンを作成できるようになりました。
10.3.3. 単一ブートソースの自動更新を無効にする
HyperConverged カスタムリソース (CR) を編集することで、カスタムブートソースかシステム定義ブートソースかに関係なく、個々のブートソースの自動更新を無効にできます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow spec.dataImportCronTemplatesフィールドを編集して、個々のブートソースの自動更新を無効にします。- カスタムブートソース
-
spec.dataImportCronTemplatesフィールドからブートソースを削除します。カスタムブートソースの自動更新はデフォルトで無効になっています。
-
- システム定義のブートソース
ブートソースを
spec.dataImportCronTemplatesに追加します。注記システム定義のブートソースの自動更新はデフォルトで有効になっていますが、これらのブートソースは追加しない限り CR にリストされません。
dataimportcrontemplate.kubevirt.io/enableアノテーションの値を'false'に設定します。以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- ファイルを保存します。
10.3.4. ブートソースのステータスの確認
HyperConverged カスタムリソース (CR) を表示することで、ブートソースがシステム定義であるかカスタムであるかを判断できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、
HyperConvergedCR の内容を表示します。oc get hyperconverged kubevirt-hyperconverged -n openshift-cnv -o yaml
$ oc get hyperconverged kubevirt-hyperconverged -n openshift-cnv -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow status.dataImportCronTemplates.statusフィールドを確認して、ブートソースのステータスを確認します。-
フィールドに
commonTemplate: trueが含まれている場合、それはシステム定義のブートソースです。 -
status.dataImportCronTemplates.statusフィールドの値が{}の場合、それはカスタムブートソースです。
-
フィールドに
10.4. ファイルシステムオーバーヘッドの PVC 領域の確保
Filesystem ボリュームモードを使用する永続ボリューム要求 (PVC) に仮想マシンディスクを追加する場合は、仮想マシンディスクおよびファイルシステムのオーバーヘッド (メタデータなど) 用に十分なスペースが PVC 上にあることを確認する必要があります。
デフォルトでは、OpenShift Virtualization は PVC 領域の 5.5% をオーバーヘッド用に予約し、その分、仮想マシンディスクに使用できる領域を縮小します。
HCO オブジェクトを編集して、別のオーバーヘッド値を設定できます。値はグローバルに変更でき、特定のストレージクラスの値を指定できます。
10.4.1. デフォルトのファイルシステムオーバーヘッド値のオーバーライド
HCO オブジェクトの spec.filesystemOverhead 属性を編集することで、OpenShift Virtualization がファイルシステムオーバーヘッド用に予約する永続ボリューム要求 (PVC) 領域の量を変更します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、
HCOオブジェクトを編集用に開きます。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow spec.filesystemOverheadフィールドを編集して、選択した値でデータを設定します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
エディターを保存して終了し、
HCOオブジェクトを更新します。
検証
次のいずれかのコマンドを実行して、
CDIConfigステータスを表示し、変更を確認します。CDIConfigへの変更を全般的に確認するには、以下を実行します。oc get cdiconfig -o yaml
$ oc get cdiconfig -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 上記の手順で行った
CDIConfigへの変更を表示するには、以下を実行します。oc get cdiconfig -o jsonpath='{.items..status.filesystemOverhead}'$ oc get cdiconfig -o jsonpath='{.items..status.filesystemOverhead}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
10.5. ホストパスプロビジョナーを使用したローカルストレージの設定
ホストパスプロビジョナー (HPP) を使用して、仮想マシンのローカルストレージを設定できます。
OpenShift Virtualization Operator のインストール時に、Hostpath Provisioner Operator は自動的にインストールされます。HPP は、Hostpath Provisioner Operator によって作成される OpenShift Virtualization 用に設計されたローカルストレージプロビジョナーです。HPP を使用するには、基本ストレージプールを使用して HPP カスタムリソース (CR) を作成します。
10.5.1. 基本ストレージプールを使用したホストパスプロビジョナーの作成
storagePools スタンザを使用して HPP カスタムリソース (CR) を作成することにより、基本ストレージプールを使用してホストパスプロビジョナー (HPP) を設定します。ストレージプールは、CSI ドライバーが使用する名前とパスを指定します。
オペレーティングシステムと同じパーティションにストレージプールを作成しないでください。そうしないと、オペレーティングシステムのパーティションがいっぱいになり、パフォーマンスに影響を与えたり、ノードが不安定になったり、使用できなくなったりする可能性があります。
前提条件
-
spec.storagePools.pathで指定されたディレクトリーには、読み取り/書き込みアクセス権が必要です。 -
OpenShift CLI (
oc) がインストールされている。
手順
次の例のように、
storagePoolsスタンザを含むhpp_cr.yamlファイルを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - ファイルを保存して終了します。
次のコマンドを実行して HPP を作成します。
oc create -f hpp_cr.yaml
$ oc create -f hpp_cr.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
10.5.1.1. ストレージクラスの作成について
ストレージクラスの作成時に、ストレージクラスに属する永続ボリューム (PV) の動的プロビジョニングに影響するパラメーターを設定します。StorageClass オブジェクトの作成後には、このオブジェクトのパラメーターを更新できません。
ホストパスプロビジョナー (HPP) を使用するには、storagePools スタンザで CSI ドライバーの関連付けられたストレージクラスを作成する必要があります。
仮想マシンは、ローカル PV に基づくデータボリュームを使用します。ローカル PV は特定のノードにバインドされます。ディスクイメージは仮想マシンで使用するために準備されますが、ローカルストレージ PV がすでに固定されたノードに仮想マシンをスケジュールすることができない可能性があります。
この問題を解決するには、Kubernetes Pod スケジューラーを使用して、永続ボリューム要求 (PVC) を正しいノードの PV にバインドします。volumeBindingMode パラメーターが WaitForFirstConsumer に設定された StorageClass 値を使用することにより、PV のバインディングおよびプロビジョニングは、Pod が PVC を使用して作成されるまで遅延します。
10.5.1.2. storagePools スタンザを使用した CSI ドライバーのストレージクラスの作成
ホストパスプロビジョナー (HPP) を使用するには、コンテナーストレージインターフェイス (CSI) ドライバーに関連するストレージクラスを作成する必要があります。
ストレージクラスの作成時に、ストレージクラスに属する永続ボリューム (PV) の動的プロビジョニングに影響するパラメーターを設定します。StorageClass オブジェクトの作成後には、このオブジェクトのパラメーターを更新できません。
仮想マシンは、ローカル PV に基づくデータボリュームを使用します。ローカル PV は特定のノードにバインドされます。ディスクイメージは仮想マシンで使用するために準備されますが、ローカルストレージ PV がすでに固定されたノードに仮想マシンをスケジュールすることができない可能性があります。
この問題を解決するには、Kubernetes Pod スケジューラーを使用して、永続ボリューム要求 (PVC) を正しいノードの PV にバインドします。volumeBindingMode パラメーターが WaitForFirstConsumer に設定された StorageClass 値を使用することにより、PV のバインディングおよびプロビジョニングは、Pod が PVC を使用して作成されるまで遅延します。
手順
storageclass_csi.yamlファイルを作成して、ストレージクラスを定義します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
reclaimPolicyには、DeleteおよびRetainの 2 つの値があります。値を指定しない場合、デフォルト値はDeleteです。- 2
volumeBindingModeパラメーターは、動的プロビジョニングとボリュームのバインディングが実行されるタイミングを決定します。WaitForFirstConsumerを指定して、永続ボリューム要求 (PVC) を使用する Pod が作成されるまで PV のバインディングおよびプロビジョニングを遅延させます。これにより、PV が Pod のスケジュール要件を満たすようになります。- 3
- HPP CR で定義されているストレージプールの名前を指定します。
- ファイルを保存して終了します。
次のコマンドを実行して、
StorageClassオブジェクトを作成します。oc create -f storageclass_csi.yaml
$ oc create -f storageclass_csi.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
10.5.2. PVC テンプレートで作成されたストレージプールについて
単一の大きな永続ボリューム (PV) がある場合は、ホストパスプロビジョナー (HPP) カスタムリソース (CR) で PVC テンプレートを定義することにより、ストレージプールを作成できます。
PVC テンプレートで作成されたストレージプールには、複数の HPP ボリュームを含めることができます。PV を小さなボリュームに分割すると、データ割り当ての柔軟性が向上します。
PVC テンプレートは、PersistentVolumeClaim オブジェクトの spec スタンザに基づいています。
- 1
- この値は、ブロックボリュームモードの PV にのみ必要です。
HPP CR の pvcTemplate 仕様を使用してストレージプールを定義します。Operator は、HPP CSI ドライバーを含む各ノードの pvcTemplate 仕様から PVC を作成します。PVC テンプレートから作成される PVC は単一の大きな PV を消費するため、HPP は小規模な動的ボリュームを作成できます。
基本的なストレージプールを、PVC テンプレートから作成されたストレージプールと組み合わせることができます。
10.5.2.1. PVC テンプレートを使用したストレージプールの作成
HPP カスタムリソース (CR) で PVC テンプレートを指定することにより、複数のホストパスプロビジョナー (HPP) ボリューム用のストレージプールを作成できます。
オペレーティングシステムと同じパーティションにストレージプールを作成しないでください。そうしないと、オペレーティングシステムのパーティションがいっぱいになり、パフォーマンスに影響を与えたり、ノードが不安定になったり、使用できなくなったりする可能性があります。
前提条件
-
spec.storagePools.pathで指定されたディレクトリーには、読み取り/書き込みアクセス権が必要です。 -
OpenShift CLI (
oc) がインストールされている。
手順
次の例に従って、
storagePoolsスタンザで永続ボリューム (PVC) テンプレートを指定する HPP CR のhpp_pvc_template_pool.yamlファイルを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
storagePoolsスタンザは、基本ストレージプールと PVC テンプレートストレージプールの両方を含むことができるアレイです。- 2
- このノードパスの下にストレージプールディレクトリーを指定します。
- 3
- オプション:
volumeModeパラメーターは、プロビジョニングされたボリューム形式と一致する限り、BlockまたはFilesystemのいずれかにすることができます。値が指定されていない場合、デフォルトはFilesystemです。volumeModeがBlockの場合、Pod をマウントする前にブロックボリュームに XFS ファイルシステムが作成されます。 - 4
storageClassNameパラメーターを省略すると、デフォルトのストレージクラスを使用して PVC を作成します。storageClassNameを省略する場合、HPP ストレージクラスがデフォルトのストレージクラスではないことを確認してください。- 5
- 静的または動的にプロビジョニングされるストレージを指定できます。いずれの場合も、要求されたストレージサイズが仮想的に分割する必要のあるボリュームに対して適切になるようにしてください。そうしないと、PVC を大規模な PV にバインドすることができません。使用しているストレージクラスが動的にプロビジョニングされるストレージを使用する場合、典型的な要求のサイズに一致する割り当てサイズを選択します。
- ファイルを保存して終了します。
次のコマンドを実行して、ストレージプールを使用して HPP を作成します。
oc create -f hpp_pvc_template_pool.yaml
$ oc create -f hpp_pvc_template_pool.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
10.6. 複数の namespace 間でデータボリュームをクローン作成するためのユーザーパーミッションの有効化
namespace には相互に分離する性質があるため、ユーザーはデフォルトでは namespace をまたがってリソースのクローンを作成することができません。
ユーザーが仮想マシンのクローンを別の namespace に作成できるようにするには、cluster-admin ロールを持つユーザーが新規のクラスターロールを作成する必要があります。このクラスターロールをユーザーにバインドし、それらのユーザーが仮想マシンのクローンを宛先 namespace に対して作成できるようにします。
10.6.1. データボリュームのクローン作成のための RBAC リソースの作成
datavolumes リソースのすべてのアクションの権限を有効にする新しいクラスターロールを作成できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - クラスター管理者権限がある。
ソース namespace とターゲット namespace の両方の管理者である非管理者ユーザーの場合は、必要に応じて ClusterRole の代わりに Role を作成できます。
手順
ClusterRoleマニフェストを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- クラスターロールの一意の名前。
クラスターにクラスターロールを作成します。
oc create -f <datavolume-cloner.yaml>
$ oc create -f <datavolume-cloner.yaml>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 直前の手順で作成された
ClusterRoleマニフェストのファイル名です。
移行元および宛先 namespace の両方に適用される
RoleBindingマニフェストを作成し、直前の手順で作成したクラスターロールを参照します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターにロールバインディングを作成します。
oc create -f <datavolume-cloner.yaml>
$ oc create -f <datavolume-cloner.yaml>1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 直前の手順で作成された
RoleBindingマニフェストのファイル名です。
10.7. CPU およびメモリークォータをオーバーライドするための CDI の設定
Containerized Data Importer (CDI) を設定して、CPU およびメモリーリソースの制限が適用される namespace に仮想マシンディスクをインポートし、アップロードし、そのクローンを作成できるようになりました。
10.7.1. namespace の CPU およびメモリークォータについて
ResourceQuota オブジェクトで定義される リソースクォータ は、その namespace 内のリソースが消費できるコンピュートリソースの全体量を制限する制限を namespace に課します。
HyperConverged カスタムリソース (CR) は、Containerized Data Importer (CDI) のユーザー設定を定義します。CPU とメモリーの要求値と制限値は、デフォルト値の 0 に設定されています。これにより、コンピュートリソース要件を指定しない CDI によって作成される Pod にデフォルト値が付与され、クォータで制限される namespace での実行が許可されます。
10.7.2. CPU およびメモリーのデフォルトのオーバーライド
ユースケースに合わせて CPU とメモリーの requests および limits のデフォルト設定を変更するには、spec.resourceRequirements.storageWorkloads スタンザを HyperConverged カスタムリソース (CR) に追加します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、
HyperConvergedCR を編集します。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow spec.resourceRequirements.storageWorkloadsスタンザを CR に追加し、ユースケースに基づいて値を設定します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
エディターを保存して終了し、
HyperConvergedCR を更新します。
10.8. CDI のスクラッチ領域の用意
10.8.1. スクラッチ領域について
Containerized Data Importer (CDI) では、仮想マシンイメージのインポートやアップロードなどの、一部の操作を実行するためにスクラッチ領域 (一時ストレージ) が必要になります。このプロセスで、CDI は、宛先データボリューム (DV) をサポートする PVC のサイズと同じサイズのスクラッチ領域 PVC をプロビジョニングします。
スクラッチ領域 PVC は操作の完了または中止後に削除されます。
HyperConverged カスタムリソースの spec.scratchSpaceStorageClass フィールドで、スクラッチ領域 PVC をバインドするために使用されるストレージクラスを定義できます。
定義されたストレージクラスがクラスターのストレージクラスに一致しない場合、クラスターに定義されたデフォルトのストレージクラスが使用されます。クラスターで定義されたデフォルトのストレージクラスがない場合、元の DV または PVC のプロビジョニングに使用されるストレージクラスが使用されます。
CDI では、元のデータボリュームをサポートする PVC の種類を問わず、file ボリュームモードが設定されているスクラッチ領域が必要です。元の PVC が block ボリュームモードでサポートされる場合、file ボリュームモード PVC をプロビジョニングできるストレージクラスを定義する必要があります。
10.8.1.1. 手動プロビジョニング
ストレージクラスがない場合、CDI はイメージのサイズ要件に一致するプロジェクトの PVC を使用します。これらの要件に一致する PVC がない場合、CDI インポート Pod は適切な PVC が利用可能になるまで、またはタイムアウト機能が Pod を強制終了するまで Pending 状態になります。
10.8.2. スクラッチ領域を必要とする CDI 操作
| 型 | 理由 |
|---|---|
| レジストリーのインポート | CDI はイメージをスクラッチ領域にダウンロードし、イメージファイルを見つけるためにレイヤーを抽出する必要があります。その後、raw ディスクに変換するためにイメージファイルが QEMU-IMG に渡されます。 |
| イメージのアップロード | QEMU-IMG は STDIN の入力を受け入れません。代わりに、アップロードするイメージは、変換のために QEMU-IMG に渡される前にスクラッチ領域に保存されます。 |
| アーカイブされたイメージの HTTP インポート | QEMU-IMG は、CDI がサポートするアーカイブ形式の処理方法を認識しません。イメージが QEMU-IMG に渡される前にアーカイブは解除され、スクラッチ領域に保存されます。 |
| 認証されたイメージの HTTP インポート | QEMU-IMG が認証を適切に処理しません。イメージが QEMU-IMG に渡される前にスクラッチ領域に保存され、認証されます。 |
| カスタム証明書の HTTP インポート | QEMU-IMG は HTTPS エンドポイントのカスタム証明書を適切に処理しません。代わりに CDI は、ファイルを QEMU-IMG に渡す前にイメージをスクラッチ領域にダウンロードします。 |
10.8.3. ストレージクラスの定義
spec.scratchSpaceStorageClass フィールドを HyperConverged カスタムリソース (CR) に追加することにより、スクラッチ領域を割り当てる際に、Containerized Data Importer (CDI) が使用するストレージクラスを定義できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、
HyperConvergedCR を編集します。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow spec.scratchSpaceStorageClassフィールドを CR に追加し、値をクラスターに存在するストレージクラスの名前に設定します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- ストレージクラスを指定しない場合、CDI は設定されている永続ボリューム要求のストレージクラスを使用します。
-
デフォルトのエディターを保存して終了し、
HyperConvergedCR を更新します。
10.8.4. CDI がサポートする操作マトリックス
このマトリックスにはエンドポイントに対してコンテンツタイプのサポートされる CDI 操作が表示されます。これらの操作にはスクラッチ領域が必要です。
| コンテンツタイプ | HTTP | HTTPS | HTTP Basic 認証 | レジストリー | アップロード |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) | ✓ QCOW2 ✓ GZ* ✓ XZ* | ✓ QCOW2** ✓ GZ* ✓ XZ* | ✓ QCOW2 ✓ GZ* ✓ XZ* | ✓ QCOW2* □ GZ □ XZ | ✓ QCOW2* ✓ GZ* ✓ XZ* |
| KubeVirt (RAW) | ✓ RAW ✓ GZ ✓ XZ | ✓ RAW ✓ GZ ✓ XZ | ✓ RAW ✓ GZ ✓ XZ | ✓ RAW* □ GZ □ XZ | ✓ RAW* ✓ GZ* ✓ XZ* |
| ✓ | サポートされている操作 |
| □ | サポートされていない操作 |
| * | スクラッチ領域が必要 |
| ** | カスタム認証局が必要な場合にスクラッチ領域が必要 |
10.9. データボリュームの事前割り当ての使用
Containerized Data Importer は、データボリュームの作成時に書き込みパフォーマンスを向上させるために、ディスク領域を事前に割り当てることができます。
特定のデータボリュームの事前割り当てを有効にできます。
10.9.1. 事前割り当てについて
Containerized Data Importer (CDI) は、データボリュームに QEMU 事前割り当てモードを使用し、書き込みパフォーマンスを向上できます。操作のインポートおよびアップロードには、事前割り当てモードを使用できます。また、空のデータボリュームを作成する際にも使用できます。
事前割り当てが有効化されている場合、CDI は基礎となるファイルシステムおよびデバイスタイプに応じて、より適切な事前割り当て方法を使用します。
fallocate-
ファイルシステムがこれをサポートする場合、CDI は
posix_fallocate関数を使用して領域を事前に割り当てるためにオペレーティングシステムのfallocate呼び出しを使用します。これは、ブロックを割り当て、それらを未初期化としてマークします。 full-
fallocateモードを使用できない場合は、基礎となるストレージにデータを書き込むことで、fullモードがイメージの領域を割り当てます。ストレージの場所によっては、空の割り当て領域がすべてゼロになる場合があります。
10.9.2. データボリュームの事前割り当ての有効化
データボリュームマニフェストに spec.preallocation フィールドを含めることにより、特定のデータボリュームの事前割り当てを有効にできます。Web コンソールで、または OpenShift CLI (oc) を使用して、事前割り当てモードを有効化することができます。
事前割り当てモードは、すべての CDI ソースタイプでサポートされます。
10.10. データボリュームアノテーションの管理
データボリューム (DV) アノテーションを使用して Pod の動作を管理できます。1 つ以上のアノテーションをデータボリュームに追加してから、作成されたインポーター Pod に伝播できます。
10.10.1. 例: データボリュームアノテーション
以下の例は、インポーター Pod が使用するネットワークを制御するためにデータボリューム (DV) アノテーションを設定する方法を示しています。v1.multus-cni.io/default-network: bridge-network アノテーションにより、Pod は bridge-network という名前の multus ネットワークをデフォルトネットワークとして使用します。
インポーター Pod にクラスターからのデフォルトネットワークとセカンダリー multus ネットワークの両方を使用させる必要がある場合は、k8s.v1.cni.cncf.io/networks: <network_name> アノテーションを使用します。
例10.1 Multus ネットワークアノテーションの例
- 1
- Multus ネットワークアノテーション
第11章 ライブマイグレーション
11.1. ライブマイグレーションについて
ライブマイグレーションは、仮想ワークロードに支障を与えることなく、実行中の仮想マシンをクラスター内の別のノードに移行するプロセスです。ライブマイグレーションにより、クラスターのアップグレード中や、メンテナンスや設定の変更のためにノードの drain (Pod の退避) を実行する必要があるときに、スムーズな移行が可能になります。
デフォルトでは、ライブマイグレーショントラフィックは Transport Layer Security (TLS) を使用して暗号化されます。
11.1.1. ライブマイグレーションの要件
ライブマイグレーションには次の要件があります。
-
クラスターには、
ReadWriteMany(RWX) アクセスモードの共有ストレージが必要です。 クラスターには十分な RAM とネットワーク帯域幅が必要です。
注記ノードの drain に伴うライブマイグレーションを実行できるように、クラスター内に十分なメモリーリクエスト容量があることを確認する必要があります。以下の計算を使用して、必要な予備のメモリーを把握できます。
Product of (Maximum number of nodes that can drain in parallel) and (Highest total VM memory request allocations across nodes)
Product of (Maximum number of nodes that can drain in parallel) and (Highest total VM memory request allocations across nodes)Copy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターで並行して実行できるデフォルトの移行数は 5 です。
- 仮想マシンがホストモデル CPU を使用する場合、ノードはその CPU をサポートする必要があります。
- ライブマイグレーション用に 専用の Multus ネットワークを設定すること を強く推奨します。専用ネットワークは、移行中のテナントワークロードに対するネットワークの飽和状態の影響を最小限に抑えます。
11.1.2. ライブマイグレーションのパーミッションについて
OpenShift Virtualization 4.19 以降では、ライブマイグレーション操作は、kubevirt.io:migrate クラスターロールが明示的に付与されたユーザーに制限されています。このロールを持つユーザーは、仮想マシン (VM) のライブマイグレーション要求を作成、削除、更新できます。
ライブマイグレーション要求は、VirtualMachineInstanceMigration (VMIM) カスタムリソースによって表されます。クラスター管理者は、namespace またはクラスターレベルのいずれかで、信頼できるユーザーまたはグループに kubevirt.io:migrate ロールをバインドできます。
OpenShift Virtualization 4.19 より前では、namespace 管理者にはデフォルトでライブマイグレーションのパーミッションが与えられていました。これは、インフラストラクチャーにとって重要な移行操作に対する意図しない、または悪意のある中断を防ぐために、バージョン 4.19 で変更されました。
クラスター管理者は、更新前に一時的なクラスターロールを作成することで、古い動作を維持できます。新しいロールをユーザーに割り当てた後、より制限の厳しいパーミッションを適用するために一時的なロールを削除します。すでに更新している場合でも、kubevirt.io:migrate ロールを admin クラスターロールに集約することで、以前の動作に戻すことができます。
11.1.3. 更新中に 4.19 より前のライブマイグレーションのパーミッションを保持する
OpenShift Virtualization 4.20 へ更新する前に、より制限の厳しいデフォルトのパーミッションを有効にする準備ができるまで、以前のライブマイグレーションのパーミッションを保持するための一時的なクラスターロールを作成できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - クラスター管理者の権限がある。
手順
OpenShift Virtualization 4.20 に更新する前に、一時的な
ClusterRoleオブジェクトを作成します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- OpenShift Virtualization を更新する前に、このクラスターロールは
adminロールに集約されます。更新プロセスでは変更されず、以前の動作が維持されます。
次のコマンドを実行して、クラスターロールマニフェストをクラスターに追加します。
oc apply -f <cluster_role_file_name>.yaml
$ oc apply -f <cluster_role_file_name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow - OpenShift Virtualization をバージョン 4.20 に更新します。
次のコマンドのいずれかを実行し、
kubevirt.io:migrateクラスターロールを信頼できるユーザーまたはグループにバインドし、<namespace>、<first_user>、<second_user>、および<group_name>を独自の値に置き換えます。namespace レベルでロールをバインドするには、次のコマンドを実行します。
oc create -n <namespace> rolebinding kvmigrate --clusterrole=kubevirt.io:migrate --user=<first_user> --user=<second_user> --group=<group_name>
$ oc create -n <namespace> rolebinding kvmigrate --clusterrole=kubevirt.io:migrate --user=<first_user> --user=<second_user> --group=<group_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターレベルでロールをバインドするには、次のコマンドを実行します。
oc create clusterrolebinding kvmigrate --clusterrole=kubevirt.io:migrate --user=<first_user> --user=<second_user> --group=<group_name>
$ oc create clusterrolebinding kvmigrate --clusterrole=kubevirt.io:migrate --user=<first_user> --user=<second_user> --group=<group_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
kubevirt.io:migrateロールを必要なすべてのユーザーにバインドしたら、次のコマンドを実行して、一時的なClusterRoleオブジェクトを削除します。oc delete clusterrole kubevirt.io:upgrademigrate
$ oc delete clusterrole kubevirt.io:upgrademigrateCopy to Clipboard Copied! Toggle word wrap Toggle overflow 一時的なクラスターロールを削除すると、
kubevirt.io:migrateロールを持つユーザーのみがライブマイグレーション要求を作成、削除、更新できるようになります。
11.1.4. ライブマイグレーションのパーミッションの付与
信頼できるユーザーまたはグループに、ライブマイグレーションインスタンスを作成、削除、更新する権限を付与できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - クラスター管理者の権限がある。
手順
(オプション) namespace 管理者が常にライブマイグレーションを作成、削除、更新するパーミッションを持つようにデフォルトの動作を変更するには、次のコマンドを実行して、
kubevirt.io:migrateロールをadminクラスターロールに集約します。oc label --overwrite clusterrole kubevirt.io:migrate rbac.authorization.k8s.io/aggregate-to-admin=true
$ oc label --overwrite clusterrole kubevirt.io:migrate rbac.authorization.k8s.io/aggregate-to-admin=trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドのいずれかを実行し、
kubevirt.io:migrateクラスターロールを信頼できるユーザーまたはグループにバインドし、<namespace>、<first_user>、<second_user>、および<group_name>を独自の値に置き換えます。namespace レベルでロールをバインドするには、次のコマンドを実行します。
oc create -n <namespace> rolebinding kvmigrate --clusterrole=kubevirt.io:migrate --user=<first_user> --user=<second_user> --group=<group_name>
$ oc create -n <namespace> rolebinding kvmigrate --clusterrole=kubevirt.io:migrate --user=<first_user> --user=<second_user> --group=<group_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターレベルでロールをバインドするには、次のコマンドを実行します。
oc create clusterrolebinding kvmigrate --clusterrole=kubevirt.io:migrate --user=<first_user> --user=<second_user> --group=<group_name>
$ oc create clusterrolebinding kvmigrate --clusterrole=kubevirt.io:migrate --user=<first_user> --user=<second_user> --group=<group_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
11.1.5. 仮想マシン移行のチューニング
ワークロードのタイプと移行シナリオに基づき、クラスター全体のライブマイグレーション設定を調整できます。
これにより、同時に移行する仮想マシンの数、各移行に使用するネットワーク帯域幅、プロセスをキャンセルするまでに OpenShift Virtualization が移行を完了しようと試みる時間を制御できます。これらの設定は、HyperConverged カスタムリソース (CR) で行います。
ノードごとに複数の仮想マシンを同時に移行する場合は、bandwidthPerMigration 制限を設定して、大規模またはビジー状態の仮想マシンがノードのネットワーク帯域幅の大部分を使用しないようにします。デフォルトでは、bandwidthPerMigration の値は 0 で、無制限を意味します。
メモリーのダーティー率が高く、負荷の高いワークロード (データベース処理など) を実行する大規模な仮想マシンでは、移行を完了するためにより高い帯域幅が必要になります。
ポストコピーモードを有効にすると、定義されたタイムアウト内に最初のプレコピーフェーズが完了しない場合にトリガーされます。ポストコピーの期間において、必要最小限のメモリーページの転送中に仮想マシン CPU はソースホスト上で一時停止します。その後、仮想マシン CPU が宛先ホスト上でアクティブになり、実行時に残りのメモリーページが宛先ノードに転送されます。これにより、転送中のパフォーマンスに影響が出る可能性があります。
ポストコピーモードは、重要なデータや不安定なネットワークで使用しないでください。
11.1.6. 一般的なライブマイグレーションタスク
次のライブマイグレーションタスクを実行できます。
- ライブマイグレーションの設定
- 負荷の高いワークロード向けのライブマイグレーション設定
- ライブマイグレーションの開始とキャンセル
- Red Hat OpenShift Service on AWS Web コンソールの Migrations タブで、すべてのライブマイグレーションの進行状況を監視します。
- Web コンソールの Metrics タブで仮想マシン移行メトリクスを表示する。
11.1.7. 関連情報
11.2. ライブマイグレーションの設定
ライブマイグレーション設定を行い、移行プロセスがクラスターに負荷を与えないようにすることができます。
ライブマイグレーションポリシーを設定して、さまざまな移行設定を仮想マシンのグループに適用できます。
11.2.1. ライブマイグレーションの制限およびタイムアウトの設定
openshift-cnv namespace にある HyperConverged カスタムリソース (CR) を更新して、クラスターのライブマイグレーションの制限およびタイムアウトを設定します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
HyperConvergedCR を編集し、必要なライブマイグレーションパラメーターを追加します。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 設定ファイルの例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 各マイグレーションの帯域幅制限。値は 1 秒あたりのバイト数です。たとえば、値
2048Miは 2048 MiB/s を意味します。デフォルト:0(無制限)。 - 2
- 移行がこの時間内に終了しない場合 (単位はメモリーの GiB あたりの秒数)、移行は取り消されます。たとえば、6 GiB メモリーを搭載した仮想マシンは、4800 秒以内に移行が完了しないとタイムアウトになります。
Migration MethodがBlockMigrationの場合、移行するディスクのサイズは計算に含められます。 - 3
- クラスターで並行して実行される移行の数。デフォルトは
5です。 - 4
- ノードごとのアウトバウンド移行の最大数。デフォルトは
2です。 - 5
- メモリーのコピーの進捗がこの時間内 (秒単位) に見られない場合に、移行は取り消されます。デフォルトは
150です。 - 6
- 仮想マシンが負荷の高いワークロードを実行しており、メモリーのダーティー率が高すぎる場合、あるノードから別のノードへの移行が収束しない可能性があります。これを防ぐには、ポストコピーモードを有効にします。デフォルトでは、
allowPostCopyはfalseに設定されています。
注記キー/値のペアを削除し、ファイルを保存して、
spec.liveMigrationConfigフィールドのデフォルト値を復元できます。たとえば、progressTimeout: <value>を削除してデフォルトのprogressTimeout: 150を復元します。
11.2.2. 負荷の高いワークロード向けのライブマイグレーション設定
メモリーのダーティー率が高く、負荷の高いワークロード (データベース処理など) を実行している仮想マシンを移行する場合、移行を完了するにはより高い帯域幅が必要です。
ダーティー率が高すぎる場合、あるノードから別のノードへの移行は収束しません。これを防ぐには、ポストコピーモードを有効にします。
ポストコピーモードは、定義されたタイムアウト内に最初のプレコピーフェーズが完了しない場合にトリガーされます。ポストコピーの期間において、必要最小限のメモリーページの転送中に仮想マシン CPU はソースホスト上で一時停止します。その後、仮想マシン CPU が宛先ホスト上でアクティブになり、実行時に残りのメモリーページが宛先ノードに転送されます。
openshift-cnv namespace にある HyperConverged カスタムリソース (CR) を更新して、負荷の高いワークロードのライブマイグレーションを設定します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
HyperConvergedCR を編集し、負荷の高いワークロードを移行するために必要なパラメーターを追加します。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 設定ファイルの例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 各マイグレーションの帯域幅制限。値は 1 秒あたりのバイト数です。デフォルトは
0で、無制限です。 - 2
- この時間内に完了しない移行はキャンセルされ、ポストコピーが有効な場合はポストコピーモードがトリガーされます。この値は、メモリー 1 GiB あたりの秒数で測定されます。移行プロセスの早い段階でポストコピーモードをトリガーするには、
completionTimeoutPerGiBを減らします。また、移行プロセスの後半でポストコピーモードをトリガーするには、completionTimeoutPerGiBを増やします。 - 3
- クラスターで並行して実行される移行の数。デフォルトは
5です。負荷の高いワークロードを移行する場合は、parallelMigrationsPerCluster設定を低くします。 - 4
- ノードごとのアウトバウンド移行の最大数。負荷の高いワークロード用に、ノードごとに仮想マシンを 1 つ設定します。
- 5
- この時間内 (秒単位) にメモリーコピーが進捗しない場合、移行は取り消されます。この値は秒単位で測定されます。大きなメモリーサイズで負荷の高いワークロードを実行する場合は、このパラメーターを増やします。
- 6
- メモリーのダーティー率が高い場合は、移行が確実に収束するように、ポストコピーモードを使用します。ポストコピーモードを有効にするには、
allowPostCopyをtrueに設定します。
オプション: メインネットワークがビジー状態で移行できない場合は、移行専用のセカンダリーネットワークを設定します。
注記ポストコピーモードは転送中のパフォーマンスに影響を与える可能性があるため、重要なデータや不安定なネットワークでは使用しないでください。
11.2.4. ライブマイグレーションポリシー
ライブマイグレーションポリシーを作成して、仮想マシンまたはプロジェクトラベルによって定義された仮想マシンのグループにさまざまな移行設定を適用できます。
Red Hat OpenShift Service on AWS Web コンソールを使用してライブマイグレーションポリシーを作成できます。
11.2.4.1. CLI を使用したライブマイグレーションポリシーの作成
コマンドラインを使用してライブマイグレーションポリシーを作成できます。
KubeVirt は、任意のラベルの組み合わせを使用して、選択した仮想マシン (VM) にライブマイグレーションポリシーを適用します。
-
size、os、gpuなどの仮想マシンラベル -
priority、bandwidth、またはhpc-workloadなどのプロジェクトラベル
ポリシーを特定の仮想マシングループに適用するには、仮想マシングループのすべてのラベルがポリシーのラベルと一致する必要があります。
複数のライブマイグレーションポリシーが仮想マシンに適用される場合は、一致するラベルの数が最も多いポリシーが優先されます。
複数のポリシーがこの基準を満たす場合、ポリシーは一致するラベルキーのアルファベット順に並べ替えられ、その順序の最初のポリシーが優先されます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
ライブマイグレーションポリシーを適用する仮想マシンオブジェクトを編集し、対応する仮想マシンラベルを追加します。
リソースの YAML 設定を開きます。
oc edit vm <vm_name>
$ oc edit vm <vm_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 設定の
.spec.template.metadata.labelsセクションで必要なラベル値を調整します。たとえば、移行ポリシーの目的で仮想マシンをproduction仮想マシンとしてマークするには、kubevirt.io/environment: production行を追加します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 設定を保存して終了します。
対応するラベルを使用して
MigrationPolicyオブジェクトを設定します。次の例では、productionというラベルが付けられたすべての仮想マシンに適用されるポリシーを設定します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して、移行ポリシーを作成します。
oc create -f <migration_policy>.yaml
$ oc create -f <migration_policy>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
11.2.5. 仮想マシンを特定のノードに移行する
VirtualMachineInstanceMigration オブジェクトの addedNodeSelector フィールドを使用して、実行中の仮想マシン (VM) を特定のノードのサブセットに移行できます。
addedNodeSelector フィールドを使用すると、仮想マシン設定や将来の移行に影響を与えずに、1 回限り の移行の試行に対して追加のノード選択ルールを適用できます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - 移行する仮想マシンは実行中です。
-
ターゲットノードのラベルを識別しました。複数のラベルを指定でき、論理
ANDで結合されます。 -
ocCLI ツールがインストールされている。
手順
移行マニフェスト YAML ファイルを作成します。以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow ここでは、以下のようになります。
vmiName-
実行中の仮想マシンの名前を指定します (例:
vmi-fedora)。 addedNodeSelector- ターゲットノードを選択するための追加の制約を指定します。
以下のコマンドを実行して、マニフェストをクラスターに適用します。
oc apply -f <file_name>.yaml
$ oc apply -f <file_name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 制約を満たすノードがない場合、タイムアウト後に移行は失敗と宣言されます。仮想マシンは影響を受けません。
11.3. ライブマイグレーションの開始とキャンセル
Red Hat OpenShift Service on AWS Web コンソール または コマンドライン を使用して、仮想マシン (VM) の別のノードへのライブマイグレーションを開始できます。
ライブマイグレーションは、Web コンソール または コマンドライン を使用してキャンセルできます。仮想マシンは元のノードに残ります。
virtctl migrate <vm_name> コマンドおよび virtctl migrate-cancel <vm_name> コマンドを使用して、ライブマイグレーションを開始およびキャンセルすることもできます。
11.3.1. ライブマイグレーションの開始
11.3.1.1. Web コンソールを使用したライブマイグレーションの開始
Red Hat OpenShift Service on AWS Web コンソールを使用して、実行中の仮想マシン (VM) をクラスター内の別のノードにライブマイグレーションできます。
Migrate アクションはすべてのユーザーに表示されますが、ライブマイグレーションを開始できるのはクラスター管理者のみです。
前提条件
-
kubevirt.io:migrateRBAC ロールを持っているか、クラスター管理者である。 - 仮想マシンが移行可能である。
- 仮想マシンがホストモデル CPU で設定されている場合、クラスターには CPU モデルをサポートする使用可能なノードがある。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
次のいずれかの手順を実行します。
-
移行する仮想マシンの横にある Options メニュー
をクリックし、Migrate オプションにマウスを移動し、Compute を選択します。
- 移行する仮想マシンの VM details ページを開いて Actions メニューをクリックし、Migrate オプションにマウスを移動して、Compute を選択します。
-
移行する仮想マシンの横にある Options メニュー
Migrate Virtual Machine to a different Node ダイアログボックスで、Automatically Selected Node または Specific Node を選択します。
- Specific Node オプションを選択した場合は、リストからノードを選択します。
- Migrate Virtual Machine をクリックします。
11.3.1.2. CLI を使用したライブマイグレーションの開始
コマンドラインを使用して仮想マシンの VirtualMachineInstanceMigration オブジェクトを作成することで、実行中の仮想マシンのライブマイグレーションを開始できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
kubevirt.io:migrateRBAC ロールを持っているか、クラスター管理者である。
手順
移行する仮想マシンの
VirtualMachineInstanceMigrationマニフェストを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下のコマンドを実行してオブジェクトを作成します。
oc create -f <migration_name>.yaml
$ oc create -f <migration_name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow VirtualMachineInstanceMigrationオブジェクトは、仮想マシンのライブマイグレーションをトリガーします。このオブジェクトは、手動で削除されない場合、仮想マシンインスタンスが実行中である限りクラスターに存在します。
検証
次のコマンドを実行して、仮想マシンのステータスを取得します。
oc describe vmi <vm_name> -n <namespace>
$ oc describe vmi <vm_name> -n <namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
11.3.2. ライブマイグレーションのキャンセル
11.3.2.1. Web コンソールを使用したライブマイグレーションのキャンセル
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想マシン (VM) のライブマイグレーションをキャンセルできます。
前提条件
-
kubevirt.io:migrateRBAC ロールを持っているか、クラスター管理者である。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
-
仮想マシンの横にあるオプションメニュー
で Cancel Migration を選択します。
11.3.2.2. CLI を使用したライブマイグレーションのキャンセル
移行に関連付けられた VirtualMachineInstanceMigration オブジェクトを削除して、仮想マシンのライブマイグレーションを取り消します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
kubevirt.io:migrateRBAC ロールを持っているか、クラスター管理者である。
手順
ライブマイグレーションをトリガーした
VirtualMachineInstanceMigrationオブジェクトを削除します。この例では、migration-jobが使用されています。oc delete vmim migration-job
$ oc delete vmim migration-jobCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第12章 Nodes
12.1. ノードのメンテナンス
oc adm ユーティリティーまたは NodeMaintenance カスタムリソース (CR) を使用してノードをメンテナンスモードにすることができます。
node-maintenance-operator (NMO) は OpenShift Virtualization に同梱されなくなりました。これは、Red Hat OpenShift Service on AWS Web コンソールのソフトウェアカタログから、または OpenShift CLI (oc) を使用してスタンドアロン Operator としてデプロイされます。
ノードの修復、フェンシング、メンテナンスの詳細は、Red Hat OpenShift のワークロードの可用性 を参照してください。
仮想マシンでは、共有 ReadWriteMany (RWX) アクセスモードを持つ永続ボリューム要求 (PVC) のライブマイグレーションが必要です。
Node Maintenance Operator は、新規または削除された NodeMaintenance CR をモニタリングします。新規の NodeMaintenance CR が検出されると、新規ワークロードはスケジュールされず、ノードは残りのクラスターから cordon されます。退避できるすべての Pod はノードから退避されます。NodeMaintenance CR が削除されると、CR で参照されるノードは新規ワークロードで利用可能になります。
ノードメンテナンスタスクに NodeMaintenance CR を使用すると、標準の Red Hat OpenShift Service on AWS カスタムリソース処理を使用した oc adm cordon および oc adm drain コマンドと同じ結果が得られます。
12.1.1. エビクションストラテジー
ノードがメンテナンス状態になると、ノードにはスケジュール対象外のマークが付けられ、ノードからすべての仮想マシンおよび Pod の drain (Pod の退避) が実行されます。
仮想マシン (VM) またはクラスターの退避ストラテジーを設定できます。
- 仮想マシン退避ストラテジー
仮想マシンの
LiveMigrate退避ストラテジーは、ノードがメンテナンス状態になるか、drain (Pod の退避) が実行される場合に仮想マシンインスタンスが中断されないようにします。この退避ストラテジーを持つ VMI は、別のノードにライブマイグレーションされます。Red Hat OpenShift Service on AWS Web コンソールまたは コマンドライン を使用して、仮想マシン (VM) の退避ストラテジーを設定できます。
重要デフォルトの退避ストラテジーは
LiveMigrateです。移行不可能な仮想マシンがLiveMigrate退避ストラテジーを使用していると、ノードの drain が妨げられたり、インフラストラクチャーのアップグレードがブロックされたりする可能性があります。これは、その仮想マシンがノードから退避されないためです。この状況では、仮想マシンを手動でシャットダウンしない限り、移行はPendingまたはScheduling中の状態のままになります。移行不可能な仮想マシンの退避ストラテジーを、アップグレードをブロックしない
LiveMigrateIfPossibleに設定する必要があります。移行すべきでない仮想マシンの場合は、Noneに設定する必要があります。
- クラスター退避ストラテジー
- ワークロードの継続性またはインフラストラクチャーのアップグレードを優先するために、クラスターの退避ストラテジーを設定できます。
| 退避ストラテジー | 説明 | ワークフローを中断する | アップグレードをブロックする |
|---|---|---|---|
|
| アップグレードよりもワークロードの継続性を優先します。 | いいえ | はい 2 |
|
| ワークロードの継続性よりもアップグレードを優先して、環境が確実に更新されるようにします。 | はい | いいえ |
|
| 退避ストラテジーを使用せずに仮想マシンをシャットダウンします。 | はい | いいえ |
- マルチノードクラスターのデフォルトの退避ストラテジー。
- 仮想マシンがアップグレードをブロックする場合は、仮想マシンを手動でシャットダウンする必要があります。
- シングルノード OpenShift のデフォルトの退避ストラテジー。
12.1.1.1. CLI を使用した仮想マシンの退避ストラテジーの設定
コマンドラインを使用して、仮想マシン (VM) の退避ストラテジーを設定できます。
デフォルトの退避ストラテジーは LiveMigrate です。移行不可能な仮想マシンが LiveMigrate 退避ストラテジーを使用していると、ノードの drain が妨げられたり、インフラストラクチャーのアップグレードがブロックされたりする可能性があります。これは、その仮想マシンがノードから退避されないためです。この状況では、仮想マシンを手動でシャットダウンしない限り、移行は Pending または Scheduling 中の状態のままになります。
移行不可能な仮想マシンの退避ストラテジーを、アップグレードをブロックしない LiveMigrateIfPossible に設定する必要があります。移行すべきでない仮想マシンの場合は、None に設定する必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、
VirtualMachineリソースを編集します。oc edit vm <vm_name> -n <namespace>
$ oc edit vm <vm_name> -n <namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 退避ストラテジーの例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 退避ストラテジーを指定します。デフォルト値は
LiveMigrateです。
仮想マシンを再起動して変更を適用します。
virtctl restart <vm_name> -n <namespace>
$ virtctl restart <vm_name> -n <namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
12.1.1.2. CLI を使用したクラスターの退避ストラテジーの設定
コマンドラインを使用して、クラスターの退避ストラテジーを設定できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、
hyperconvergedリソースを編集します。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次の例に示すように、クラスターの退避ストラテジーを設定します。
クラスターの退避ストラテジーの例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
12.1.2. 実行ストラテジー
spec.runStrategy キーは、特定の条件下での仮想マシンの動作を決定します。
12.1.2.1. 実行ストラテジー
spec.runStrategy キーには、Always、RerunOnFailure、Manual、Halted の 4 つの値があります。
Always- 仮想マシンインスタンス (VMI) は、仮想マシンが別のノードに作成されるときに常に存在します。元の VMI が何らかの理由で停止した場合、新しい VMI が作成されます。
RerunOnFailure- 以前のインスタンスに障害が発生した場合、VMI は別のノードで再作成されます。仮想マシンがシャットダウンされた場合など、仮想マシンが正常に停止した場合、インスタンスは再作成されません。
Manual-
VMI 状態は、virtctl クライアントコマンドの
start、stop、およびrestartを使用して手動で制御します。仮想マシンは自動的には再起動されません。 Halted- 仮想マシンの作成時には VMI は存在しません。
virtctl start、stop、および restart コマンドのさまざまな組み合わせが、実行ストラテジーに影響します。
次の表では、仮想マシンの状態間の遷移を説明します。最初の列には、仮想マシンの初期実行ストラテジーを示します。残りの列には、virtctl コマンドと、そのコマンドを実行した後の新しい実行ストラテジーを示します。
| 初期実行ストラテジー | Start | Stop | Restart |
|---|---|---|---|
| Always | - | Halted | Always |
| RerunOnFailure | RerunOnFailure | RerunOnFailure | RerunOnFailure |
| Manual | Manual | Manual | Manual |
| Halted | Always | - | - |
インストーラーによってプロビジョニングされたインフラストラクチャーを使用してインストールされたクラスター内のノードがマシンの健全性チェックに失敗して使用できない場合は、runStrategy: Always または runStrategy: RerunOnFailure を持つ仮想マシンが新しいノードで再スケジュールされます。
12.1.2.2. CLI を使用した仮想マシン実行ストラテジーの設定
コマンドラインを使用して、仮想マシン (VM) の実行ストラテジーを設定できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、
VirtualMachineリソースを編集します。oc edit vm <vm_name> -n <namespace>
$ oc edit vm <vm_name> -n <namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 実行ストラテジーの例:
apiVersion: kubevirt.io/v1 kind: VirtualMachine spec: runStrategy: Always # ...
apiVersion: kubevirt.io/v1 kind: VirtualMachine spec: runStrategy: Always # ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow
12.1.3. ベアメタルノードのメンテナンス
Red Hat OpenShift Service on AWS をベアメタルインフラストラクチャーにデプロイする場合は、クラウドインフラストラクチャーにデプロイする場合と比べて、考慮すべき追加の事項があります。
クラスターノードが一時的とみなされるクラウド環境とは異なり、ベアメタルノードを再プロビジョニングするには、メンテナンスタスクにより多くの時間と作業が必要になります。
致命的なカーネルエラーが発生したり、NIC カードのハードウェア障害が発生する場合などにベアメタルノードに障害が発生した場合には、障害のあるノードが修復または置き換えられている間に、障害が発生したノード上のワークロードをクラスターの別の場所で再起動する必要があります。ノードのメンテナンスモードにより、クラスター管理者はノードの電源をグレースフルに停止し、ワークロードをクラスターの他の部分に移動させ、ワークロードが中断されないようにします。詳細な進捗とノードのステータスの詳細は、メンテナンス時に提供されます。
12.2. 古い CPU モデルのノードラベルの管理
VM CPU モデルおよびポリシーがノードでサポートされている限り、ノードで仮想マシン (VM) をスケジュールできます。
12.2.1. 古い CPU モデルのノードラベリングについて
OpenShift Virtualization Operator は、古い CPU モデルの事前定義されたリストを使用して、ノードがスケジュールされた仮想マシンの有効な CPU モデルのみをサポートするようにします。
デフォルトでは、以下の CPU モデルはノード用に生成されたラベルのリストから削除されます。
例12.1 古い CPU モデル
この事前定義された一覧は HyperConverged CR には表示されません。このリストから CPU モデルを 削除 できませんが、HyperConverged CR の spec.obsoleteCPUs.cpuModels フィールドを編集してリストに追加することはできます。
12.2.2. 古い CPU モデルの設定
HyperConverged カスタムリソース (CR) を編集して、古い CPU モデルのリストを設定できます。
手順
古い CPU モデルを
obsoleteCPUs配列で指定して、HyperConvergedカスタムリソースを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
cpuModels配列のサンプル値を、古くなった CPU モデルに置き換えます。指定した値はすべて、古くなった CPU モデルの事前定義リストに追加されます。事前定義されたリストは CR に表示されません。
12.3. ノードのリコンシリエーションの防止
skip-node アノテーションを使用して、node-labeller がノードを調整できないようにします。
12.3.1. skip-node アノテーションの使用
node-labeller でノードを省略するには、oc CLI を使用してそのノードにアノテーションを付けます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、スキップするノードにアノテーションを付けます。
oc annotate node <node_name> node-labeller.kubevirt.io/skip-node=true
$ oc annotate node <node_name> node-labeller.kubevirt.io/skip-node=true1 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
<node_name>は、スキップする関連ノードの名前に置き換えます。
ノードのアノテーションが削除されるか、false に設定された後に、次のサイクルでリコンシリエーションが再開されます。
第13章 モニタリング
13.1. モニタリングの概要
次のツールを使用して、クラスターと仮想マシン (VM) の正常性を監視できます。
- OpenShift Virtualization 仮想マシンの健全性ステータスのモニタリング
- Red Hat OpenShift Service on AWS Web コンソールの Home → Overview ページに移動して、Web コンソールで OpenShift Virtualization 環境の全体的な健全性を確認します。Status カードには、アラートと条件に基づいて OpenShift Virtualization の全体的な健全性が表示されます。
- 仮想リソースの Prometheus クエリー
- 仮想 CPU、ネットワーク、ストレージ、およびゲストメモリースワッピングの使用状況とライブマイグレーションの進行状況をクエリーします。
- VM カスタムメトリクス
-
内部 VM メトリクスとプロセスを公開するように、
node-exporterサービスを設定します。 - VM ヘルスチェック
- レディネス、ライブネス、ゲストエージェントの ping プローブ、および VM のウォッチドッグを設定します。
- runbook
13.2. 仮想リソースの Prometheus クエリー
Red Hat OpenShift Service on AWS モニタリングダッシュボードを使用して、仮想化メトリクスをクエリーします。OpenShift Virtualization は、ネットワーク、ストレージ、ゲストメモリースワッピングなどのクラスターインフラストラクチャーリソースの消費を監視するために使用できるメトリクスを提供します。メトリクスを使用して、ライブマイグレーションのステータスを照会することもできます。
13.2.1. 前提条件
- ゲストメモリースワップクエリーがデータを返すには、仮想ゲストでメモリースワップを有効にする必要があります。
13.2.2. Red Hat OpenShift Service on AWS Web コンソールを使用してすべてのプロジェクトのメトリクスを取得する
Red Hat OpenShift Service on AWS メトリクスクエリーブラウザーを使用して Prometheus Query Language (PromQL) でクエリーを実行し、グラフでメトリクスを可視化して検証できます。この機能により、クラスターの状態と、モニターしているユーザー定義のワークロードに関する情報が提供されます。
dedicated-admin またはすべてのプロジェクトの表示パーミッションを持つユーザーとして、メトリクス UI ですべてのデフォルト Red Hat OpenShift Service on AWS およびユーザー定義プロジェクトのメトリクスにアクセスできます。
専任の管理者のみが、Red Hat OpenShift Service on AWS モニタリングで提供されるサードパーティーの UI にアクセスできます。
メトリクス UI には、すべてのプロジェクトの CPU、メモリー、帯域幅、ネットワークパケットなどの定義済みクエリーが含まれています。カスタムの Prometheus Query Language (PromQL) クエリーを実行することもできます。
前提条件
-
dedicated-adminロールまたはすべてのプロジェクトの表示パーミッションを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
- Red Hat OpenShift Service on AWS Web コンソールで、Observe → Metrics をクリックします。
1 つ以上のクエリーを追加するために、次のいずれかの操作を実行します。
Expand オプション 説明 既存のクエリーを選択する
Select query ドロップダウンリストから、既存のクエリーを選択します。
カスタムクエリーを作成する
Prometheus Query Language (PromQL) クエリーを Expression フィールドに追加します。
PromQL 式を入力すると、オートコンプリートの提案がドロップダウンリストに表示されます。これらの提案には、関数、メトリクス、ラベル、および時間トークンが含まれます。キーボードの矢印を使用して、提案された項目の中から 1 つを選択し、Enter キーを押して、その項目を式に追加します。提案された項目の上にマウスポインターを移動すると、その項目の簡単な説明が表示されます。
複数のクエリーを追加する
Add query をクリックします。
既存のクエリーを複製する
クエリーの横にあるオプションメニュー
をクリックし、Duplicate query を選択します。
クエリーの実行を無効する
クエリーの横にあるオプションメニュー
をクリックし、Disable query を選択します。
作成したクエリーを実行するために、Run queries をクリックします。クエリーからのメトリクスはプロットで可視化されます。クエリーが無効な場合は、UI にエラーメッセージが表示されます。
注記- 時系列グラフを描画する場合、大量のデータを操作するクエリーにより、タイムアウトが発生したり、ブラウザーに過負荷がかかったりする可能性があります。これを回避するには、Hide graph をクリックし、メトリクステーブルのみを使用してクエリーを調整してください。次に、使用できるクエリーを確認した後に、グラフを描画できるようにプロットを有効にします。
- デフォルトでは、クエリーテーブルに、すべてのメトリクスとその現在の値をリスト表示する拡張ビューが表示されます。クエリーの拡張ビューを最小化するには、下矢印 (˅) をクリックします。
- オプション: このクエリーのセットを今後再度使用するには、ページの URL を保存します。
視覚化されたメトリクスを調べます。最初に、有効な全クエリーの全メトリクスがプロットに表示されます。次のいずれかの操作を実行して、表示するメトリクスを選択します。
Expand オプション 説明 クエリーのすべてのメトリクスを非表示にする
クエリーのオプションメニュー
をクリックし、Hide all series をクリックします。
特定のメトリクスを非表示にする
クエリーテーブルに移動し、メトリクス名の近くにある色付きの四角形をクリックします。
プロットを拡大し、時間範囲を変更する
次のいずれかの操作を実行します。
- プロットを水平にクリックし、ドラッグして、時間範囲を視覚的に選択します。
- メニューを使用して時間範囲を選択します。
時間範囲をリセットする
Reset zoom をクリックします。
特定の時点におけるすべてのクエリーの出力を表示する
プロット上の目的のポイントにマウスを移動します。クエリーの出力がポップアップボックスに表示されます。
プロットを非表示にする
Hide graph をクリックします。
13.2.3. Red Hat OpenShift Service on AWS Web コンソールを使用してユーザー定義プロジェクトのメトリクスを取得する
Red Hat OpenShift Service on AWS メトリクスクエリーブラウザーを使用して Prometheus Query Language (PromQL) でクエリーを実行し、グラフでメトリクスを可視化して検証できます。この機能により、モニタリングしているユーザー定義ワークロードに関する情報が提供されます。
開発者として、メトリクスのクエリー時にプロジェクト名を指定する必要があります。選択したプロジェクトのメトリクスを表示するには、必要な権限が必要です。
メトリクス UI には、CPU、メモリー、帯域幅、ネットワークパケットなどの定義済みクエリーが含まれています。これらのクエリーは、選択したプロジェクトに制限されています。プロジェクト用のカスタムの Prometheus Query Language (PromQL) クエリーを実行することもできます。
開発者は Red Hat OpenShift Service on AWS モニタリングで提供されるサードパーティーの UI にアクセスできません。
前提条件
- 開発者として、またはメトリクスで表示しているプロジェクトの表示権限を持つユーザーとしてクラスターへのアクセスがある。
- ユーザー定義プロジェクトのモニタリングが有効化されている。
- ユーザー定義プロジェクトにサービスをデプロイしている。
-
サービスのモニター方法を定義するために、サービスの
ServiceMonitorカスタムリソース定義 (CRD) を作成している。
手順
- Red Hat OpenShift Service on AWS Web コンソールで、Observe → Metrics をクリックします。
1 つ以上のクエリーを追加するために、次のいずれかの操作を実行します。
Expand オプション 説明 既存のクエリーを選択する
Select query ドロップダウンリストから、既存のクエリーを選択します。
カスタムクエリーを作成する
Prometheus Query Language (PromQL) クエリーを Expression フィールドに追加します。
PromQL 式を入力すると、オートコンプリートの提案がドロップダウンリストに表示されます。これらの提案には、関数、メトリクス、ラベル、および時間トークンが含まれます。キーボードの矢印を使用して、提案された項目の中から 1 つを選択し、Enter キーを押して、その項目を式に追加します。提案された項目の上にマウスポインターを移動すると、その項目の簡単な説明が表示されます。
複数のクエリーを追加する
Add query をクリックします。
既存のクエリーを複製する
クエリーの横にあるオプションメニュー
をクリックし、Duplicate query を選択します。
クエリーの実行を無効する
クエリーの横にあるオプションメニュー
をクリックし、Disable query を選択します。
作成したクエリーを実行するために、Run queries をクリックします。クエリーからのメトリクスはプロットで可視化されます。クエリーが無効な場合は、UI にエラーメッセージが表示されます。
注記- 時系列グラフを描画する場合、大量のデータを操作するクエリーにより、タイムアウトが発生したり、ブラウザーに過負荷がかかったりする可能性があります。これを回避するには、Hide graph をクリックし、メトリクステーブルのみを使用してクエリーを調整してください。次に、使用できるクエリーを確認した後に、グラフを描画できるようにプロットを有効にします。
- デフォルトでは、クエリーテーブルに、すべてのメトリクスとその現在の値をリスト表示する拡張ビューが表示されます。クエリーの拡張ビューを最小化するには、下矢印 (˅) をクリックします。
- オプション: このクエリーのセットを今後再度使用するには、ページの URL を保存します。
視覚化されたメトリクスを調べます。最初に、有効な全クエリーの全メトリクスがプロットに表示されます。次のいずれかの操作を実行して、表示するメトリクスを選択します。
Expand オプション 説明 クエリーのすべてのメトリクスを非表示にする
クエリーのオプションメニュー
をクリックし、Hide all series をクリックします。
特定のメトリクスを非表示にする
クエリーテーブルに移動し、メトリクス名の近くにある色付きの四角形をクリックします。
プロットを拡大し、時間範囲を変更する
次のいずれかの操作を実行します。
- プロットを水平にクリックし、ドラッグして、時間範囲を視覚的に選択します。
- メニューを使用して時間範囲を選択します。
時間範囲をリセットする
Reset zoom をクリックします。
特定の時点におけるすべてのクエリーの出力を表示する
プロット上の目的のポイントにマウスを移動します。クエリーの出力がポップアップボックスに表示されます。
プロットを非表示にする
Hide graph をクリックします。
13.2.4. 仮想化メトリクス
以下のメトリクスの記述には、Prometheus Query Language (PromQL) クエリーのサンプルが含まれます。これらのメトリクスは API ではなく、バージョン間で変更される可能性があります。仮想化メトリクスの完全なリストは、KubeVirt components metrics を参照してください。
以下の例では、期間を指定する topk クエリーを使用します。その期間中に仮想マシン (VM) が削除された場合でも、クエリーの出力に依然として表示されます。
13.2.4.1. 仮想 CPU メトリクス
以下のクエリーは、入出力 I/O) を待機している仮想マシンを特定します。
kubevirt_vmi_vcpu_wait_seconds_total- 仮想マシンの仮想 CPU の I/O の待機時間 (秒単位) を返します。タイプ: カウンター。
'0' より大きい値は、仮想 CPU は実行する用意ができているが、ホストスケジューラーがこれをまだ実行できないことを意味します。実行できない場合には I/O に問題があることを示しています。
仮想 CPU メトリクスをクエリーするには、最初に schedstats=enable カーネル引数を MachineConfig オブジェクトに適用する必要があります。このカーネル引数を使用すると、デバッグとパフォーマンスチューニングに使用されるスケジューラーの統計が有効になり、スケジューラーに小規模な負荷を追加できます。
kubevirt_vmi_vcpu_delay_seconds_total- 仮想 CPU がホストスケジューラーによってキューに入れられたが、すぐに実行できなかった累積時間 (秒単位) を返します。この遅延は、仮想マシンには スチールタイム と表示されます。これは、ホストが他のワークロードを実行している間に失われた CPU 時間です。スチールタイムは、パフォーマンスに影響を与える可能性があり、多くの場合、ホスト上の CPU のオーバーコミットメントまたは競合を示します。タイプ: カウンター。
仮想 CPU 遅延クエリーの例
以下のクエリーは、5 分間の平均遅延を返します。値が大きい場合は、ノードでの CPU のオーバーコミットまたは競合を示している可能性があります。
irate(kubevirt_vmi_vcpu_delay_seconds_total[5m]) > 0.05
irate(kubevirt_vmi_vcpu_delay_seconds_total[5m]) > 0.05仮想 CPU 待機時間クエリーの例
以下のクエリーは、6 分間の任意のタイミングで I/O を待機する上位 3 の仮想マシンを返します。
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_vcpu_wait_seconds_total[6m]))) > 0
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_vcpu_wait_seconds_total[6m]))) > 013.2.4.2. ネットワークメトリクス
以下のクエリーは、ネットワークを飽和状態にしている仮想マシンを特定できます。
kubevirt_vmi_network_receive_bytes_total- 仮想マシンのネットワークで受信したトラフィックの合計量 (バイト単位) を返します。タイプ: カウンター。
kubevirt_vmi_network_transmit_bytes_total- 仮想マシンのネットワーク上で送信されるトラフィックの合計量 (バイト単位) を返します。タイプ: カウンター。
ネットワークトラフィッククエリーの例
以下のクエリーは、6 分間の任意のタイミングで最大のネットワークトラフィックを送信する上位 3 の仮想マシンを返します。
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_network_receive_bytes_total[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_network_transmit_bytes_total[6m]))) > 0
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_network_receive_bytes_total[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_network_transmit_bytes_total[6m]))) > 013.2.4.3. ストレージメトリクス
13.2.4.3.1. ストレージ関連のトラフィック
以下のクエリーは、大量のデータを書き込んでいる仮想マシンを特定できます。
kubevirt_vmi_storage_read_traffic_bytes_total- 仮想マシンのストレージ関連トラフィックの合計量 (バイト単位) を返します。タイプ: カウンター。
kubevirt_vmi_storage_write_traffic_bytes_total- 仮想マシンのストレージ関連トラフィックのストレージ書き込みの合計量 (バイト単位) を返します。タイプ: カウンター。
ストレージ関連のトラフィッククエリーの例
以下のクエリーは、6 分間の任意のタイミングで最大のストレージトラフィックを送信する上位 3 の仮想マシンを返します。
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_storage_read_traffic_bytes_total[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_storage_write_traffic_bytes_total[6m]))) > 0
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_storage_read_traffic_bytes_total[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_storage_write_traffic_bytes_total[6m]))) > 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 次のクエリーは、6 分間の任意のタイミングで平均読み取りレイテンシーが最も高い上位 3 の仮想マシンを返します。
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_storage_read_times_seconds_total{name='${name}',namespace='${namespace}'${clusterFilter}}[6m]) / rate(kubevirt_vmi_storage_iops_read_total{name='${name}',namespace='${namespace}'${clusterFilter}}[6m]) > 0)) > 0topk(3, sum by (name, namespace) (rate(kubevirt_vmi_storage_read_times_seconds_total{name='${name}',namespace='${namespace}'${clusterFilter}}[6m]) / rate(kubevirt_vmi_storage_iops_read_total{name='${name}',namespace='${namespace}'${clusterFilter}}[6m]) > 0)) > 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
13.2.4.3.2. ストレージスナップショットデータ
kubevirt_vmsnapshot_disks_restored_from_source- ソース仮想マシンから復元された仮想マシンディスクの総数を返します。タイプ: ゲージ。
kubevirt_vmsnapshot_disks_restored_from_source_bytes- ソース仮想マシンから復元された容量をバイト単位で返します。タイプ: ゲージ。
ストレージスナップショットデータクエリーの例
以下のクエリーは、ソース仮想マシンから復元された仮想マシンディスクの総数を返します。
kubevirt_vmsnapshot_disks_restored_from_source{vm_name="simple-vm", vm_namespace="default"}kubevirt_vmsnapshot_disks_restored_from_source{vm_name="simple-vm", vm_namespace="default"}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下のクエリーは、ソース仮想マシンから復元された容量をバイト単位で返します。
kubevirt_vmsnapshot_disks_restored_from_source_bytes{vm_name="simple-vm", vm_namespace="default"}kubevirt_vmsnapshot_disks_restored_from_source_bytes{vm_name="simple-vm", vm_namespace="default"}Copy to Clipboard Copied! Toggle word wrap Toggle overflow
13.2.4.3.3. I/O パフォーマンス
以下のクエリーで、ストレージデバイスの I/O パフォーマンスを判別できます。
kubevirt_vmi_storage_iops_read_total- 仮想マシンが実行している 1 秒あたりの書き込み I/O 操作の量を返します。タイプ: カウンター。
kubevirt_vmi_storage_iops_write_total- 仮想マシンが実行している 1 秒あたりの読み取り I/O 操作の量を返します。タイプ: カウンター。
I/O パフォーマンスクエリーの例
次のクエリーは、6 分間の任意のタイミングで最も大きな I/O 操作を実行している上位 3 の仮想マシンを返します。
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_storage_iops_read_total[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_storage_iops_write_total[6m]))) > 0
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_storage_iops_read_total[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_storage_iops_write_total[6m]))) > 013.2.4.4. ゲストメモリーのスワップメトリクス
以下のクエリーにより、メモリースワップを最も多く実行しているスワップ対応ゲストを特定できます。
kubevirt_vmi_memory_swap_in_traffic_bytes- 仮想ゲストがスワップされているメモリーの合計量 (バイト単位) を返します。タイプ: ゲージ。
kubevirt_vmi_memory_swap_out_traffic_bytes- 仮想ゲストがスワップアウトされているメモリーの合計量 (バイト単位) を返します。タイプ: ゲージ。
メモリースワップクエリーの例
以下のクエリーは、6 分間の任意のタイミングでゲストが最も大きなメモリースワップを実行している上位 3 の仮想マシンを返します。
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_memory_swap_in_traffic_bytes[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_memory_swap_out_traffic_bytes[6m]))) > 0 +
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_memory_swap_in_traffic_bytes[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_memory_swap_out_traffic_bytes[6m]))) > 0
+メモリースワップは、仮想マシンがメモリー不足の状態にあることを示します。仮想マシンのメモリー割り当てを増やすと、この問題を軽減できます。
13.2.4.5. AAQ Operator メトリクスの監視
リソースクォータを監視するために、Application Aware Quota (AAQ) コントローラーによって次のメトリクスが公開されます。
kube_application_aware_resourcequota- AAQ Operator リソースによって適用されている現在のクォータ使用量と CPU およびメモリーの制限を返します。タイプ: ゲージ。
kube_application_aware_resourcequota_creation_timestamp- AAQ Operator リソースが作成された時刻を UNIX タイムスタンプ形式で返します。タイプ: ゲージ。
13.2.4.6. ライブマイグレーションのメトリクス
次のメトリクスを照会して、ライブマイグレーションのステータスを表示できます。
kubevirt_vmi_migration_data_processed_bytes- 新しい仮想マシン (VM) に移行されたゲストオペレーティングシステムデータの量。タイプ: ゲージ。
kubevirt_vmi_migration_data_remaining_bytes- 移行されていないゲストオペレーティングシステムデータの量。タイプ: ゲージ。
kubevirt_vmi_migration_memory_transfer_rate_bytes- ゲストオペレーティングシステムでメモリーがダーティーになる速度。ダーティメモリーとは、変更されたがまだディスクに書き込まれていないデータです。タイプ: ゲージ。
kubevirt_vmi_migrations_in_pending_phase- 保留中の移行の数。タイプ: ゲージ。
kubevirt_vmi_migrations_in_scheduling_phase- スケジュール移行の数。タイプ: ゲージ。
kubevirt_vmi_migrations_in_running_phase- 実行中の移行の数。タイプ: ゲージ。
kubevirt_vmi_migration_succeeded- 正常に完了した移行の数。タイプ: ゲージ。
kubevirt_vmi_migration_failed- 失敗した移行の数。タイプ: ゲージ。
13.3. 仮想マシンのカスタムメトリクスの公開
Red Hat OpenShift Service on AWS には、コアプラットフォームコンポーネントのモニタリングを提供する事前に設定され、事前にインストールされた自己更新型のモニタリングスタックが組み込まれています。このモニタリングスタックは、Prometheus モニタリングシステムをベースにしています。Prometheus は Time Series を使用するデータベースであり、メトリクスのルール評価エンジンです。
Red Hat OpenShift Service on AWS 監視スタックの使用に加えて、CLI を使用してユーザー定義プロジェクトの監視を有効にし、node-exporter サービスで仮想マシンに公開されるカスタムメトリクスをクエリーできます。
13.3.1. ノードエクスポーターサービスの設定
node-exporter エージェントは、メトリクスを収集するクラスター内のすべての仮想マシンにデプロイされます。node-exporter エージェントをサービスとして設定し、仮想マシンに関連付けられた内部メトリクスおよびプロセスを公開します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。 -
cluster-monitoring-configConfigMapオブジェクトをopenshift-monitoringプロジェクトに作成する。 -
enableUserWorkloadをtrueに設定して、user-workload-monitoring-configConfigMapオブジェクトをopenshift-user-workload-monitoringプロジェクトに設定する。
手順
ServiceYAML ファイルを作成します。以下の例では、このファイルはnode-exporter-service.yamlという名前です。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 仮想マシンからメトリクスを公開する node-exporter サービス。
- 2
- サービスが作成される namespace。
- 3
- サービスのラベル。
ServiceMonitorはこのラベルを使用してこのサービスを照会します。 - 4
ClusterIPサービスのポート 9100 でメトリクスを公開するポートに指定された名前。- 5
- リクエストをリッスンするために
node-exporter-serviceによって使用されるターゲットポート。 - 6
monitorラベルが設定された仮想マシンの TCP ポート番号。- 7
- 仮想マシンの Pod を照会するために使用されるラベル。この例では、ラベル
monitorのある仮想マシンの Pod と、metricsの値がマッチします。
node-exporter サービスを作成します。
oc create -f node-exporter-service.yaml
$ oc create -f node-exporter-service.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
13.3.2. ノードエクスポーターサービスが設定された仮想マシンの設定
node-exporter ファイルを仮想マシンにダウンロードします。次に、仮想マシンの起動時に node-exporter サービスを実行する systemd サービスを作成します。
前提条件
-
コンポーネントの Pod は
openshift-user-workload-monitoringプロジェクトで実行されます。 -
このユーザー定義プロジェクトをモニターする必要のあるユーザーに
monitoring-editロールを付与します。
手順
- 仮想マシンにログインします。
node-exporterファイルのバージョンに適用されるディレクトリーパスを使用して、node-exporterファイルを仮想マシンにダウンロードします。wget https://github.com/prometheus/node_exporter/releases/download/<version>/node_exporter-<version>.linux-<architecture>.tar.gz
$ wget https://github.com/prometheus/node_exporter/releases/download/<version>/node_exporter-<version>.linux-<architecture>.tar.gzCopy to Clipboard Copied! Toggle word wrap Toggle overflow 実行ファイルを展開して、
/usr/binディレクトリーに配置します。sudo tar xvf node_exporter-<version>.linux-<architecture>.tar.gz \ --directory /usr/bin --strip 1 "*/node_exporter"$ sudo tar xvf node_exporter-<version>.linux-<architecture>.tar.gz \ --directory /usr/bin --strip 1 "*/node_exporter"Copy to Clipboard Copied! Toggle word wrap Toggle overflow ディレクトリーのパス
/etc/systemd/systemにnode_exporter.serviceファイルを作成します。このsystemdサービスファイルは、仮想マシンの再起動時に node-exporter サービスを実行します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow systemdサービスを有効にし、起動します。sudo systemctl enable node_exporter.service
$ sudo systemctl enable node_exporter.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow sudo systemctl start node_exporter.service
$ sudo systemctl start node_exporter.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
node-exporter エージェントが仮想マシンからのメトリクスを報告していることを確認します。
curl http://localhost:9100/metrics
$ curl http://localhost:9100/metricsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
go_gc_duration_seconds{quantile="0"} 1.5244e-05 go_gc_duration_seconds{quantile="0.25"} 3.0449e-05 go_gc_duration_seconds{quantile="0.5"} 3.7913e-05go_gc_duration_seconds{quantile="0"} 1.5244e-05 go_gc_duration_seconds{quantile="0.25"} 3.0449e-05 go_gc_duration_seconds{quantile="0.5"} 3.7913e-05Copy to Clipboard Copied! Toggle word wrap Toggle overflow
13.3.3. 仮想マシンのカスタムモニタリングラベルの作成
単一のサービスから複数の仮想マシンへの照会を有効にするには、仮想マシンの YAML ファイルにカスタムラベルを追加します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。 - 仮想マシンを停止および再起動するための Web コンソールへのアクセス権限がある。
手順
仮想マシン設定ファイルの
templatespec を編集します。この例では、ラベルmonitorの値がmetricsになります。spec: template: metadata: labels: monitor: metricsspec: template: metadata: labels: monitor: metricsCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
仮想マシンを停止して再起動し、
monitorラベルに指定されたラベル名を持つ新しい Pod を作成します。
13.3.3.1. メトリクスを取得するための node-exporter サービスのクエリー
仮想マシンのメトリクスは、/metrics の正規名の下に HTTP サービスエンドポイント経由で公開されます。メトリクスのクエリー時に、Prometheus は仮想マシンによって公開されるメトリクスエンドポイントからメトリクスを直接収集し、これらのメトリクスを確認用に表示します。
前提条件
-
cluster-admin権限を持つユーザーまたはmonitoring-editロールを持つユーザーとしてクラスターにアクセスできる。 - node-exporter サービスを設定して、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
OpenShift CLI (
oc) がインストールされている。
手順
サービスの namespace を指定して、HTTP サービスエンドポイントを取得します。
oc get service -n <namespace> <node-exporter-service>
$ oc get service -n <namespace> <node-exporter-service>Copy to Clipboard Copied! Toggle word wrap Toggle overflow node-exporter サービスの利用可能なすべてのメトリクスを一覧表示するには、
metricsリソースをクエリーします。curl http://<172.30.226.162:9100>/metrics | grep -vE "^#|^$"
$ curl http://<172.30.226.162:9100>/metrics | grep -vE "^#|^$"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
13.3.4. ノードエクスポーターサービスの ServiceMonitor リソースの作成
Prometheus クライアントライブラリーを使用し、/metrics エンドポイントからメトリクスを収集して、node-exporter サービスが公開するメトリクスにアクセスし、表示できます。ServiceMonitor カスタムリソース定義 (CRD) を使用して、ノードエクスポーターサービスをモニターします。
前提条件
-
cluster-admin権限を持つユーザーまたはmonitoring-editロールを持つユーザーとしてクラスターにアクセスできる。 - node-exporter サービスを設定して、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
OpenShift CLI (
oc) がインストールされている。
手順
ServiceMonitorリソース設定の YAML ファイルを作成します。この例では、サービスモニターはラベルmetricsが指定されたサービスとマッチし、30 秒ごとにexmetポートをクエリーします。Copy to Clipboard Copied! Toggle word wrap Toggle overflow node-exporter サービスの
ServiceMonitor設定を作成します。oc create -f node-exporter-metrics-monitor.yaml
$ oc create -f node-exporter-metrics-monitor.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
13.3.4.1. クラスター外のノードエクスポーターサービスへのアクセス
クラスター外の node-exporter サービスにアクセスし、公開されるメトリクスを表示できます。
前提条件
-
cluster-admin権限を持つユーザーまたはmonitoring-editロールを持つユーザーとしてクラスターにアクセスできる。 - node-exporter サービスを設定して、ユーザー定義プロジェクトのモニタリングを有効にしている。
-
OpenShift CLI (
oc) がインストールされている。
手順
node-exporter サービスを公開します。
oc expose service -n <namespace> <node_exporter_service_name>
$ oc expose service -n <namespace> <node_exporter_service_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow ルートの FQDN(完全修飾ドメイン名) を取得します。
oc get route -o=custom-columns=NAME:.metadata.name,DNS:.spec.host
$ oc get route -o=custom-columns=NAME:.metadata.name,DNS:.spec.hostCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
NAME DNS node-exporter-service node-exporter-service-dynamation.apps.cluster.example.org
NAME DNS node-exporter-service node-exporter-service-dynamation.apps.cluster.example.orgCopy to Clipboard Copied! Toggle word wrap Toggle overflow curlコマンドを使用して、node-exporter サービスのメトリクスを表示します。curl -s http://node-exporter-service-dynamation.apps.cluster.example.org/metrics
$ curl -s http://node-exporter-service-dynamation.apps.cluster.example.org/metricsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
go_gc_duration_seconds{quantile="0"} 1.5382e-05 go_gc_duration_seconds{quantile="0.25"} 3.1163e-05 go_gc_duration_seconds{quantile="0.5"} 3.8546e-05 go_gc_duration_seconds{quantile="0.75"} 4.9139e-05 go_gc_duration_seconds{quantile="1"} 0.000189423go_gc_duration_seconds{quantile="0"} 1.5382e-05 go_gc_duration_seconds{quantile="0.25"} 3.1163e-05 go_gc_duration_seconds{quantile="0.5"} 3.8546e-05 go_gc_duration_seconds{quantile="0.75"} 4.9139e-05 go_gc_duration_seconds{quantile="1"} 0.000189423Copy to Clipboard Copied! Toggle word wrap Toggle overflow
13.4. 仮想マシンのヘルスチェック
VirtualMachine リソースで readiness プローブと liveness プローブを定義することにより、仮想マシン (VM) のヘルスチェックを設定できます。
13.4.1. readiness および liveness プローブについて
readiness プローブと liveness プローブを使用して、異常な仮想マシン (VM) を検出および処理します。VM の仕様に 1 つ以上のプローブを含めて、準備ができていない VM にトラフィックが到達しないようにし、VM が応答しなくなったときに新しい VM が作成されるようにすることができます。
readiness プローブ は、VM がサービス要求を受け入れることができるかどうかを判断します。プローブが失敗すると、VM は、準備状態になるまで、利用可能なエンドポイントのリストから削除されます。
liveness プローブ は、VM が応答しているかどうかを判断します。プローブが失敗すると、VM は削除され、応答性を復元するために、新しい VM が作成されます。
VirtualMachine オブジェクトの spec.readinessProbe フィールドと spec.livenessProbe フィールドを設定することで、readiness プローブと liveness プローブを設定できます。これらのフィールドは、以下のテストをサポートします。
- HTTP GET
- プローブは、Web フックを使用して VM の正常性を判断します。このテストは、HTTP の応答コードが 200 から 399 までの値の場合に正常と見なされます。完全に初期化されている場合に、HTTP ステータスコードを返すアプリケーションで HTTP GET テストを使用できます。
- TCP ソケット
- プローブは、VM へのソケットを開こうとします。プローブが接続を確立できる場合のみ、VM は正常であると見なされます。TCP ソケットテストは、初期化が完了するまでリスニングを開始しないアプリケーションで使用できます。
- ゲストエージェントの ping
-
プローブは、
guest-pingコマンドを使用して、QEMU ゲストエージェントが仮想マシンで実行されているかどうかを判断します。
13.4.1.1. HTTP readiness プローブの定義
仮想マシン (VM) 設定の spec.readinessProbe.httpGet フィールドを設定することで、HTTP readiness プローブを定義できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
VM 設定ファイルに readiness プローブの詳細を含めます。
HTTP GET テストを使用した readiness プローブの例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- VM に接続するために実行する HTTP GET 要求。
- 2
- プローブがクエリーする VM のポート。上記の例では、プローブはポート 1500 をクエリーします。
- 3
- HTTP サーバーでアクセスするパス。上記の例では、サーバーの /healthz パスのハンドラーが成功コードを返した場合、VM は正常であると見なされます。ハンドラーが失敗コードを返した場合、VM は使用可能なエンドポイントのリストから削除されます。
- 4
- VM が起動してから準備プローブが開始されるまでの時間 (秒単位)。
- 5
- プローブの実行間の遅延 (秒単位)。デフォルトの遅延は 10 秒です。この値は
timeoutSecondsよりも大きくなければなりません。 - 6
- プローブがタイムアウトになり、VM が失敗したと見なされるまでの非アクティブな秒数。デフォルト値は 1 です。この値は
periodSeconds未満である必要があります。 - 7
- プローブが失敗できる回数。デフォルトは 3 です。指定された試行回数になると、Pod には
Unreadyというマークが付けられます。 - 8
- 成功とみなされるまでにプローブが失敗後に成功を報告する必要のある回数。デフォルトでは 1 回です。
次のコマンドを実行して VM を作成します。
oc create -f <file_name>.yaml
$ oc create -f <file_name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
13.4.1.2. TCP readiness プローブの定義
仮想マシン (VM) 設定の spec.readinessProbe.tcpSocket フィールドを設定することで、TCP readiness プローブを定義できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
TCP readiness プローブの詳細を VM 設定ファイルに追加します。
TCP ソケットテストを使用した readiness プローブの例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して VM を作成します。
oc create -f <file_name>.yaml
$ oc create -f <file_name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
13.4.1.3. HTTP liveness プローブの定義
仮想マシン (VM) 設定の spec.livenessProbe.httpGet フィールドを設定して、HTTP liveness プローブを定義します。readiness プローブと同様に、liveness プローブの HTTP および TCP テストの両方を定義できます。この手順では、HTTP GET テストを使用して liveness プローブのサンプルを設定します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
VM 設定ファイルに HTTP liveness プローブの詳細を含めます。
HTTP GET テストを使用した liveness プローブの例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- VM が起動してから liveness プローブが開始されるまでの時間 (秒単位)。
- 2
- プローブの実行間の遅延 (秒単位)。デフォルトの遅延は 10 秒です。この値は
timeoutSecondsよりも大きくなければなりません。 - 3
- VM に接続するために実行する HTTP GET 要求。
- 4
- プローブがクエリーする VM のポート。上記の例では、プローブはポート 1500 をクエリーします。VM は、cloud-init を介してポート 1500 に最小限の HTTP サーバーをインストールして実行します。
- 5
- HTTP サーバーでアクセスするパス。上記の例では、サーバーの
/healthzパスのハンドラーが成功コードを返した場合、VM は正常であると見なされます。ハンドラーが失敗コードを返した場合、VM は削除され、新しい VM が作成されます。 - 6
- プローブがタイムアウトになり、VM が失敗したと見なされるまでの非アクティブな秒数。デフォルト値は 1 です。この値は
periodSeconds未満である必要があります。
次のコマンドを実行して VM を作成します。
oc create -f <file_name>.yaml
$ oc create -f <file_name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
13.4.2. ウォッチドッグの定義
次の手順を実行して、ゲストオペレーティングシステムの健全性を監視するウォッチドッグを定義できます。
- 仮想マシン (VM) のウォッチドッグデバイスを設定します。
- ゲストにウォッチドッグエージェントをインストールします。
ウォッチドッグデバイスはエージェントを監視し、ゲストオペレーティングシステムが応答しない場合、次のいずれかのアクションを実行します。
-
poweroff: VM の電源がすぐにオフになります。spec.runStrategyがmanualに設定されていない場合、仮想マシンは再起動します。 reset: VM はその場で再起動し、ゲストオペレーティングシステムは反応できません。注記再起動時間が原因で liveness プローブがタイムアウトする場合があります。クラスターレベルの保護が liveness プローブの失敗を検出すると、VM が強制的に再スケジュールされ、再起動時間が長くなる可能性があります。
-
shutdown: すべてのサービスを停止することで、VM の電源がグレースフルにオフになります。
ウォッチドッグは、Windows VM では使用できません。
13.4.2.1. 仮想マシンのウォッチドッグデバイスの設定
仮想マシン (VM) のウォッチドッグデバイスを設定するとします。
前提条件
-
x86システムの場合、仮想マシンはi6300esbウォッチドッグデバイスで動作するカーネルを使用する必要があります。s390xアーキテクチャーを使用する場合は、カーネルでdiag288を有効にする必要があります。Red Hat Enterprise Linux (RHEL) イメージは、i6300esbとdiag288をサポートします。 -
OpenShift CLI (
oc) がインストールされている。
手順
次の内容で
YAMLファイルを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記の例では、
poweroffアクションを使用して仮想マシン上のウォッチドッグデバイスを設定し、デバイスを/dev/watchdogとして公開します。このデバイスは、ウォッチドッグバイナリーで使用できるようになりました。
以下のコマンドを実行して、YAML ファイルをクラスターに適用します。
$ oc apply -f <file_name>.yaml
$ oc apply -f <file_name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
この手順は、ウォッチドッグ機能をテストするためにのみ提供されており、実稼働マシンでは実行しないでください。
以下のコマンドを実行して、VM がウォッチドッグデバイスに接続されていることを確認します。
lspci | grep watchdog -i
$ lspci | grep watchdog -iCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下のコマンドのいずれかを実行して、ウォッチドッグがアクティブであることを確認します。
カーネルパニックをトリガーします。
echo c > /proc/sysrq-trigger
# echo c > /proc/sysrq-triggerCopy to Clipboard Copied! Toggle word wrap Toggle overflow ウォッチドッグサービスを停止します。
pkill -9 watchdog
# pkill -9 watchdogCopy to Clipboard Copied! Toggle word wrap Toggle overflow
13.4.2.2. ゲストへのウォッチドッグエージェントのインストール
ゲストにウォッチドッグエージェントをインストールし、watchdog サービスを起動できます。
手順
- root ユーザーとして仮想マシンにログインします。
この手順は、IBM Z® (
s390x) にインストールする場合にのみ必要です。次のコマンドを実行して、watchdogを有効にします。modprobe diag288_wdt
# modprobe diag288_wdtCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して、仮想マシンに
/dev/watchdogファイルパスが存在することを確認します。ls /dev/watchdog
# ls /dev/watchdogCopy to Clipboard Copied! Toggle word wrap Toggle overflow watchdogドッグパッケージとその依存関係をインストールします。yum install watchdog
# yum install watchdogCopy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/watchdog.confファイルの次の行のコメントを外し、変更を保存します。#watchdog-device = /dev/watchdog
#watchdog-device = /dev/watchdogCopy to Clipboard Copied! Toggle word wrap Toggle overflow 起動時に
watchdogサービスを開始できるようにします。systemctl enable --now watchdog.service
# systemctl enable --now watchdog.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
13.5. OpenShift Virtualization の runbook
OpenShift Virtualization の アラート を引き起こしている問題を診断して解決するには、OpenShift Virtualization Operator の runbook にある手順に従います。トリガーされた OpenShift Virtualization アラートは、Web コンソールのメインの Observe → Alerts タブ、および Virtualization → Overview タブに表示されます。
OpenShift Virtualization Operator の runbook は、openshift/runbooks Git リポジトリーで管理されており、GitHub で表示できます。
13.5.1. CDIDataImportCronOutdated
-
CDIDataImportCronOutdatedアラートの runbook を表示 します。
13.5.2. CDIDataVolumeUnusualRestartCount
-
CDIDataVolumeUnusualRestartCountアラートの runbook を表示 します。
13.5.3. CDIDefaultStorageClassDegraded
-
CDIDefaultStorageClassDegradedアラートの runbook を表示 します。
13.5.4. CDIMultipleDefaultVirtStorageClasses
-
CDIMultipleDefaultVirtStorageClassesアラートの runbook を表示 します。
13.5.5. CDINoDefaultStorageClass
-
CDINoDefaultStorageClassアラートの runbook を表示 します。
13.5.6. CDINotReady
-
CDINotReadyアラートの runbook を表示 します。
13.5.7. CDIOperatorDown
-
CDIOperatorDownアラートの runbook を表示 します。
13.5.8. CDIStorageProfilesIncomplete
-
CDIStorageProfilesIncompleteアラートの runbook を表示 します。
13.5.9. CnaoDown
-
CnaoDownアラートの runbook を表示 します。
13.5.10. CnaoNMstateMigration
-
CnaoNMstateMigrationアラートの runbook を表示 します。
13.5.11. HAControlPlaneDown
-
HAControlPlaneDownアラートの runbook を表示 します。
13.5.12. HCOInstallationIncomplete
-
HCOInstallationIncompleteアラートの runbook を表示 します。
13.5.13. HCOMisconfiguredDescheduler
-
HCOMisconfiguredDeschedulerアラートの runbook を表示 します。
13.5.14. HPPNotReady
-
HPPNotReadyアラートの runbook を表示します。
13.5.15. HPPOperatorDown
-
HPPOperatorDownアラートの runbook を表示 します。
13.5.16. HPPSharingPoolPathWithOS
-
HPPSharingPoolPathWithOSアラートの runbook を表示 します。
13.5.17. HighCPUWorkload
-
HighCPUWorkloadアラートの runbook を表示 します。
13.5.18. KubemacpoolDown
-
KubemacpoolDownアラートの runbook を表示 します。
13.5.19. KubeMacPoolDuplicateMacsFound
-
KubeMacPoolDuplicateMacsFoundアラートの runbook を表示 します。
13.5.20. KubeVirtComponentExceedsRequestedCPU
-
KubeVirtComponentExceedsRequestedCPUアラートが 非推奨 になりました。
13.5.21. KubeVirtComponentExceedsRequestedMemory
-
KubeVirtComponentExceedsRequestedMemoryアラートは 非推奨 になりました。
13.5.22. KubeVirtCRModified
-
KubeVirtCRModifiedアラートの runbook を表示 します。
13.5.23. KubeVirtDeprecatedAPIRequested
-
KubeVirtDeprecatedAPIRequestedアラートの runbook を表示 します。
13.5.24. KubeVirtNoAvailableNodesToRunVMs
-
KubeVirtNoAvailableNodesToRunVMsアラートの runbook を表示 します。
13.5.25. KubevirtVmHighMemoryUsage
-
KubevirtVmHighMemoryUsageアラートの runbook を表示 します。
13.5.26. KubeVirtVMIExcessiveMigrations
-
KubeVirtVMIExcessiveMigrationsアラートの runbook を表示 します。
13.5.27. LowKVMNodesCount
-
LowKVMNodesCountアラートの runbook を表示 します。
13.5.28. LowReadyVirtControllersCount
-
LowReadyVirtControllersCountアラートの runbook を表示 します。
13.5.29. LowReadyVirtOperatorsCount
-
LowReadyVirtOperatorsCountアラートの runbook を表示 します。
13.5.30. LowVirtAPICount
-
LowVirtAPICountアラートの runbook を表示 します。
13.5.31. LowVirtControllersCount
-
LowVirtControllersCountアラートの runbook を表示 します。
13.5.32. LowVirtOperatorCount
-
LowVirtOperatorCountアラートの runbook を表示 します。
13.5.33. NetworkAddonsConfigNotReady
-
NetworkAddonsConfigNotReadyアラートの runbook を表示 します。
13.5.34. NoLeadingVirtOperator
-
NoLeadingVirtOperatorアラートの runbook を表示 します。
13.5.35. NoReadyVirtController
-
NoReadyVirtControllerアラートの runbook を表示 します。
13.5.36. NoReadyVirtOperator
-
NoReadyVirtOperatorアラートの runbook を表示 します。
13.5.37. NodeNetworkInterfaceDown
-
NodeNetworkInterfaceDownアラートの runbook を表示 します。
13.5.38. OperatorConditionsUnhealthy
-
OperatorConditionsUnhealthyアラートは 非推奨 となりました。
13.5.39. OrphanedVirtualMachineInstances
-
OrphanedVirtualMachineInstancesアラートの runbook を表示 します。
13.5.40. OutdatedVirtualMachineInstanceWorkloads
-
OutdatedVirtualMachineInstanceWorkloadsアラートの runbook を表示 します。
13.5.41. SingleStackIPv6Unsupported
-
SingleStackIPv6Unsupportedアラートの runbook を表示 します。
13.5.42. SSPCommonTemplatesModificationReverted
-
SSPCommonTemplatesModificationRevertedアラートの runbook を表示 します。
13.5.43. SSPDown
-
SSPDownアラートの runbook を表示 します。
13.5.44. SSPFailingToReconcile
-
SSPFailingToReconcileアラートの runbook を表示します。
13.5.45. SSPHighRateRejectedVms
-
SSPHighRateRejectedVmsアラートの runbook を表示 します。
13.5.46. SSPOperatorDown
-
SSPOperatorDownアラートの runbook を表示 します。
13.5.47. SSPTemplateValidatorDown
-
SSPTemplateValidatorDownアラートの runbook を表示 します。
13.5.48. UnsupportedHCOModification
-
UnsupportedHCOModificationアラートの runbook を表示 します。
13.5.49. VirtAPIDown
-
VirtAPIDownアラートの runbook を表示 します。
13.5.50. VirtApiRESTErrorsBurst
-
VirtApiRESTErrorsBurstアラートの runbook を表示 します。
13.5.51. VirtApiRESTErrorsHigh
-
VirtApiRESTErrorsHighアラートの runbook を表示 します。
13.5.52. VirtControllerDown
-
VirtControllerDownアラートの runbook を表示 します。
13.5.53. VirtControllerRESTErrorsBurst
-
VirtControllerRESTErrorsBurstアラートの runbook を表示 します。
13.5.54. VirtControllerRESTErrorsHigh
-
VirtControllerRESTErrorsHighアラートの runbook を表示 します。
13.5.55. VirtHandlerDaemonSetRolloutFailing
-
VirtHandlerDaemonSetRolloutFailingアラートの runbook を表示 します。
13.5.56. VirtHandlerRESTErrorsBurst
-
VirtHandlerRESTErrorsBurstアラートの runbook を表示 します。
13.5.57. VirtHandlerRESTErrorsHigh
-
VirtHandlerRESTErrorsHighアラートの runbook を表示 します。
13.5.58. VirtOperatorDown
-
VirtOperatorDownアラートの runbook を表示 します。
13.5.59. VirtOperatorRESTErrorsBurst
-
VirtOperatorRESTErrorsBurstアラートの runbook を表示 します。
13.5.60. VirtOperatorRESTErrorsHigh
-
VirtOperatorRESTErrorsHighアラートの runbook を表示 します。
13.5.61. VirtualMachineCRCErrors
VirtualMachineCRCErrorsアラートは 非推奨 となりました。アラートの名前は
VMStorageClassWarningになりました。
13.5.62. VMCannotBeEvicted
-
VMCannotBeEvictedアラートの runbook を表示 します。
13.5.63. VMStorageClassWarning
-
VMStorageClassWarningアラートの runbook を表示 します。
第14章 サポート
14.1. サポートの概要
次のツールを使用して、Red Hat サポートへの支援リクエスト、バグの報告、環境に関するデータの収集、クラスターと仮想マシンの状態監視を行えます。
14.1.1. サポートチケットを作成する
Red Hat サポートからの支援を即時に必要とする問題が発生した場合は、サポートケースを作成できます。
バグを報告するには、Jira 課題を直接作成できます。
14.1.1.1. サポートケースの作成
Red Hat サポートにサポートを依頼するには、サポートケースの作成手順 に従ってください。
サポートリクエストに含めるデバッグデータを収集すると役立ちます。
14.1.1.1.1. Red Hat サポート用のデータ収集
次の手順を実行して、デバッグ情報を収集できます。
- 環境に関するデータの収集
-
Prometheus と Alertmanager を設定し、AWS および OpenShift Virtualization 上の Red Hat OpenShift Service の
must-gatherデータを収集します。
14.1.1.2. Jira 課題の作成
バグを報告するには、Create Issue ページのフォームに入力して、直接 Jira 課題を作成できます。
14.1.2. Web コンソールの監視
Red Hat OpenShift Service on AWS Web コンソールを使用して、クラスターと仮想マシンの健全性を監視できます。Web コンソールには、クラスターと OpenShift Virtualization コンポーネントおよびリソースのリソース使用量、アラート、イベント、および傾向が表示されます。
| ページ | 説明 |
|---|---|
| Overview ページ | クラスターの詳細、ステータス、アラート、インベントリー、およびリソースの使用状況 |
| Virtualization → Overview タブ | OpenShift 仮想化のリソース、使用状況、アラート、およびステータス |
| Virtualization → Top consumers タブ | CPU、メモリー、およびストレージの上位コンシューマー |
| Virtualization → Migrations タブ | ライブマイグレーションの進捗 |
| Virtualization → VirtualMachines タブ | CPU、メモリー、ストレージの使用状況の概要 |
| Virtualization → VirtualMachines → VirtualMachine details → Metrics タブ | VM リソースの使用状況、ストレージ、ネットワーク、および移行 |
| Virtualization → VirtualMachines → VirtualMachine details → Events タブ | VM イベントリスト |
| Virtualization → VirtualMachines → VirtualMachine details → Diagnostics タブ | 仮想マシンのステータス条件とボリュームスナップショットのステータス |
14.2. Red Hat サポート用のデータ収集
Red Hat サポートに サポートケース を送信するときは、次のツールを使用して、Red Hat OpenShift Service on AWS および OpenShift Virtualization のデバッグ情報を提供すると役立ちます。
- Prometheus
- Prometheus は時系列データベースであり、メトリクスのルール評価エンジンです。Prometheus は処理のためにアラートを Alertmanager に送信します。
- Alertmanager
- Alertmanager サービスは、Prometheus から送信されるアラートを処理します。また、Alertmanager は外部の通知システムにアラートを送信します。
14.2.1. 環境に関するデータの収集
環境に関するデータを収集すると、根本原因の分析および特定に必要な時間が最小限に抑えられます。
前提条件
- 影響を受けるノードおよび仮想マシンの正確な数を記録する。
14.2.2. 仮想マシンに関するデータの収集
手順
仮想マシン (VM) の誤動作に関するデータを収集することで、根本原因の分析および特定に必要な時間を最小限に抑えることができます。
前提条件
- Linux VM: 最新の QEMU ゲストエージェントをインストール します。
Windows 仮想マシン:
- Windows パッチ更新の詳細を記録します。
- 最新の VirtIO ドライバーをインストール します。
- 最新の QEMU ゲストエージェントをインストール します。
- Remote Desktop Protocol (RDP) が有効になっている場合は、デスクトップビューアー を使用して接続し、接続ソフトウェアに問題があるかどうかを確認します。
手順
- VM を再起動する 前 に、クラッシュした VM のスクリーンショットを収集します。
- 修復を試みる 前 に、VM からメモリーダンプを収集 します。
- 誤動作している仮想マシンに共通する要因を記録します。たとえば、仮想マシンには同じホストまたはネットワークがあります。
14.2.3. 仮想マシンメモリーダンプの生成
仮想マシン (VM) が予期せず終了した場合は、virtctl memory-dump を使用してメモリーダンプコマンドを生成し、仮想マシンメモリーダンプを出力して永続ボリューム要求 (PVC) に保存できます。その後、メモリーダンプを分析して、仮想マシン上の問題を診断およびトラブルシューティングできます。
前提条件
HyperConvergedカスタムリソースでホットプラグフィーチャーゲートが有効化されている。これには以下のコマンドを実行します。oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv \ --type json -p '[{"op": "add", "path": "/spec/featureGates", \ "value": "HotplugVolumes"}]'$ oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv \ --type json -p '[{"op": "add", "path": "/spec/featureGates", \ "value": "HotplugVolumes"}]'Copy to Clipboard Copied! Toggle word wrap Toggle overflow オプション: メモリーダンプを保存する既存の PVC がある。
-
PVC ボリュームモードは
FileSystemである必要があります。 PVC は、メモリーダンプを格納するのに十分な大きさである必要があります。
PVC サイズの計算式は
(VMMemorySize + 100Mi) * FileSystemOverheadです。ここで、100Miはメモリーダンプのオーバーヘッドで、FileSystemOverheadはHCOオブジェクトで定義されています。
-
PVC ボリュームモードは
手順
必要な仮想マシンのメモリーダンプを作成します。
メモリーダンプを保存する既存の PVC を選択している場合:
virtctl memory-dump get <vm_name> --claim-name=<pvc_name>
$ virtctl memory-dump get <vm_name> --claim-name=<pvc_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow メモリーダンプ用に新しい PVC を作成する場合:
virtctl memory-dump get <vm_name> --claim-name=<new_pvc_name> --create-claim
$ virtctl memory-dump get <vm_name> --claim-name=<new_pvc_name> --create-claimCopy to Clipboard Copied! Toggle word wrap Toggle overflow
メモリーダンプをダウンロードします。
virtctl memory-dump download <vm_name> --output=<output_file>
$ virtctl memory-dump download <vm_name> --output=<output_file>Copy to Clipboard Copied! Toggle word wrap Toggle overflow メモリーダンプを Red Hat サポートケースに添付します。
または、たとえば volatility3 ツール を使用して、メモリーダンプを検査することもできます。
オプション: メモリーダンプを削除します。
virtctl memory-dump remove <vm_name>
$ virtctl memory-dump remove <vm_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
14.3. トラブルシューティング
OpenShift Virtualization は、仮想マシンと仮想化コンポーネントのトラブルシューティングに使用するツールとログを提供します。
OpenShift Virtualization コンポーネントのトラブルシューティングは、Web コンソールで提供されるツールまたは oc CLI ツールを使用して実行できます。
14.3.1. Events
Red Hat OpenShift Service on AWS イベント は、重要なライフサイクル情報の記録であり、仮想マシン、namespace、リソースの問題の監視とトラブルシューティングに役立ちます。
仮想マシンイベント: Web コンソールで VirtualMachine details ページの Events タブに移動します。
- namespace イベント
namespace イベントを表示するには、次のコマンドを実行します。
oc get events -n <namespace>
$ oc get events -n <namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 特定のイベントの詳細は、イベントのリスト を参照してください。
- リソースイベント
リソースイベントを表示するには、次のコマンドを実行します。
oc describe <resource> <resource_name>
$ oc describe <resource> <resource_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
14.3.2. Pod ログ
Web コンソールまたは CLI を使用して、OpenShift Virtualization Pod のログを表示できます。Web コンソールで LokiStack を使用して、集約ログ を表示することもできます。
14.3.2.1. OpenShift Virtualization Pod ログの詳細レベルの設定
HyperConverged カスタムリソース (CR) を編集することで、OpenShift Virtualization Pod ログの詳細レベルを設定できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
特定のコンポーネントのログの詳細度を設定するには、次のコマンドを実行して、デフォルトのテキストエディターで
HyperConvergedCR を開きます。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow spec.logVerbosityConfigスタンザを編集して、1 つ以上のコンポーネントのログレベルを設定します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- ログの詳細度の値は
1–9の範囲の整数である必要があります。数値が大きいほどログの詳細度が高くなります。この例では、virtAPIコンポーネントのログは、優先度が5以上の場合に公開されます。
- エディターを保存して終了し、変更を適用します。
14.3.2.2. Web コンソールを使用して virt-launcher Pod のログを表示する
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想マシンの virt-launcher Pod ログを表示できます。
手順
- Virtualization → VirtualMachines に移動します。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- General タイルで、Pod 名をクリックして Pod details ページを開きます。
- Logs タブをクリックして、ログを表示します。
14.3.2.3. CLI を使用した OpenShift Virtualization Pod ログの表示
oc CLI ツールを使用して、OpenShift Virtualization Pod のログを表示できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、OpenShift Virtualization の namespace 内の Pod のリストを表示します。
oc get pods -n openshift-cnv
$ oc get pods -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Pod ログを表示するには、次のコマンドを実行します。
oc logs -n openshift-cnv <pod_name>
$ oc logs -n openshift-cnv <pod_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記Pod の起動に失敗した場合は、
--previousオプションを使用して、最後の試行からのログを表示できます。ログ出力をリアルタイムで監視するには、
-fオプションを使用します。出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
14.3.3. ゲストシステムログ
仮想マシンゲストのブートログを表示すると、問題の診断に役立ちます。ゲストのログへのアクセスを設定し、Red Hat OpenShift Service on AWS Web コンソールまたは oc CLI を使用してログを表示できます。
この機能はデフォルトでは無効にされています。仮想マシンでこの設定が明示的に有効または無効になっていない場合、クラスター全体のデフォルト設定が継承されます。
認証情報やその他の個人を特定できる情報 (PII) などの機密情報がシリアルコンソールに書き込まれている場合、他の表示されるすべてのテキストと一緒にそれらもログに記録されます。Red Hat では、機密データの送信にはシリアルコンソールではなく SSH を使用することを推奨しています。
14.3.3.1. Web コンソールを使用して仮想マシンゲストシステムログへのデフォルトアクセスを有効にする
Web コンソールを使用して、仮想マシンゲストシステムログへのデフォルトアクセスを有効にできます。
手順
- サイドメニューから、Virtualization → Overview をクリックします。
- Settings タブをクリックします。
- Cluster → Guest management をクリックします。
- Enable guest system log access をオンに設定します。
14.3.3.2. CLI を使用して仮想マシンゲストシステムログへのデフォルトアクセスを有効にする
HyperConverged カスタムリソース (CR) を編集して、仮想マシンゲストシステムログへのデフォルトアクセスを有効にできます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvCopy to Clipboard Copied! Toggle word wrap Toggle overflow disableSerialConsoleLogの値を更新します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- 仮想マシン上でシリアルコンソールアクセスをデフォルトで有効にする場合は、
disableSerialConsoleLogの値をfalseに設定します。
14.3.3.3. Web コンソールを使用して単一仮想マシンのゲストシステムログアクセスを設定する
Web コンソールを使用して、単一仮想マシンの仮想マシンゲストシステムログへのアクセスを設定できます。この設定は、クラスター全体のデフォルト設定よりも優先されます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Configuration タブをクリックします。
- Guest system log access をオンまたはオフに設定します。
14.3.3.4. CLI を使用して単一仮想マシンのゲストシステムログアクセスを設定する
VirtualMachine CR を編集することで、単一仮想マシンの仮想マシンゲストシステムログへのアクセスを設定できます。この設定は、クラスター全体のデフォルト設定よりも優先されます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、仮想マシンのマニフェストを編集します。
oc edit vm <vm_name>
$ oc edit vm <vm_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow logSerialConsoleフィールドの値を更新します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- ゲストのシリアルコンソールログへのアクセスを有効にするには、
logSerialConsoleの値をtrueに設定します。
次のコマンドを実行して、新しい設定を仮想マシンに適用します。
oc apply vm <vm_name>
$ oc apply vm <vm_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow オプション: 実行中の仮想マシンを編集した場合は、仮想マシンを再起動して新しい設定を適用します。以下に例を示します。
virtctl restart <vm_name> -n <namespace>
$ virtctl restart <vm_name> -n <namespace>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
14.3.3.5. Web コンソールを使用してゲストシステムログを表示する
Web コンソールを使用して、仮想マシンゲストのシリアルコンソールログを表示できます。
前提条件
- ゲストシステムログアクセスが有効になっている。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Diagnostics タブをクリックします。
- Guest system logs をクリックしてシリアルコンソールをロードします。
14.3.3.6. CLI を使用してゲストシステムログを表示する
oc logs コマンドを実行して、仮想マシンゲストのシリアルコンソールログを表示できます。
前提条件
- ゲストシステムログアクセスが有効になっている。
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行してログを表示します。その場合、
<namespace>と<vm_name>を独自の値に置き換えます。oc logs -n <namespace> -l kubevirt.io/domain=<vm_name> --tail=-1 -c guest-console-log
$ oc logs -n <namespace> -l kubevirt.io/domain=<vm_name> --tail=-1 -c guest-console-logCopy to Clipboard Copied! Toggle word wrap Toggle overflow
14.3.4. ログアグリゲーション
ログを集約してフィルタリングすることで、容易にトラブルシューティングを行えます。
14.3.4.1. LokiStack を使用した OpenShift Virtualization 集約ログの表示
Web コンソールで LokiStack を使用すると、OpenShift Virtualization Pod およびコンテナーの集約ログを表示できます。
前提条件
- LokiStack をデプロイしている。
手順
- Web コンソールで Observe → Logs に移動します。
-
ログタイプのリストから、
virt-launcherPod ログの場合は application を選択し、OpenShift Virtualization コントロールプレーン Pod およびコンテナーの場合は infrastructure を選択します。 - Show Query をクリックしてクエリーフィールドを表示します。
- クエリーフィールドに LogQL クエリーを入力し、Run Query をクリックしてフィルタリングされたログを表示します。
14.3.4.2. OpenShift Virtualization LogQL クエリー
Web コンソールの Observe → Logs ページで Loki Query Language (LogQL) クエリーを実行することで、OpenShift Virtualization コンポーネントの集約ログを表示およびフィルタリングできます。
デフォルトのログタイプは infrastructure です。virt-launcher のログタイプは application です。
オプション: 行フィルター式を使用して、文字列または正規表現の追加や除外を行えます。
クエリーが多数のログに一致する場合、クエリーがタイムアウトになる可能性があります。
| コンポーネント | LogQL クエリー |
|---|---|
| すべて |
{log_type=~".+"}|json
|kubernetes_labels_app_kubernetes_io_part_of="hyperconverged-cluster"
|
|
|
{log_type=~".+"}|json
|kubernetes_labels_app_kubernetes_io_part_of="hyperconverged-cluster"
|kubernetes_labels_app_kubernetes_io_component="storage"
|
|
|
{log_type=~".+"}|json
|kubernetes_labels_app_kubernetes_io_part_of="hyperconverged-cluster"
|kubernetes_labels_app_kubernetes_io_component="deployment"
|
|
|
{log_type=~".+"}|json
|kubernetes_labels_app_kubernetes_io_part_of="hyperconverged-cluster"
|kubernetes_labels_app_kubernetes_io_component="network"
|
|
|
{log_type=~".+"}|json
|kubernetes_labels_app_kubernetes_io_part_of="hyperconverged-cluster"
|kubernetes_labels_app_kubernetes_io_component="compute"
|
|
|
{log_type=~".+"}|json
|kubernetes_labels_app_kubernetes_io_part_of="hyperconverged-cluster"
|kubernetes_labels_app_kubernetes_io_component="schedule"
|
| Container |
{log_type=~".+",kubernetes_container_name=~"<container>|<container>"}
|json|kubernetes_labels_app_kubernetes_io_part_of="hyperconverged-cluster"
|
|
| このクエリーを実行する前に、ログタイプのリストから application を選択する必要があります。 {log_type=~".+", kubernetes_container_name="compute"}|json
|!= "custom-ga-command"
|
行フィルター式を使用して、文字列や正規表現を追加または除外するようにログ行をフィルタリングできます。
| 行フィルター式 | 説明 |
|---|---|
|
| ログ行に文字列が含まれています |
|
| ログ行に文字列は含まれていません |
|
| ログ行に正規表現が含まれています |
|
| ログ行に正規表現は含まれていません |
例14.1 行フィルター式の例
{log_type=~".+"}|json
|kubernetes_labels_app_kubernetes_io_part_of="hyperconverged-cluster"
|= "error" != "timeout"
{log_type=~".+"}|json
|kubernetes_labels_app_kubernetes_io_part_of="hyperconverged-cluster"
|= "error" != "timeout"14.3.5. 一般的なエラーメッセージ
OpenShift Virtualization のログには、次のエラーメッセージが表示される場合があります。
ErrImagePullまたはImagePullBackOff- デプロイメント設定が正しくないか、参照されているイメージに問題があることを示します。
14.3.6. データボリュームのトラブルシューティング
DataVolume オブジェクトの Conditions および Events セクションを確認して、問題を分析および解決できます。
14.3.6.1. データボリュームの条件とイベントについて
oc describe コマンド出力の Conditions および Events セクションを調べることで、データボリュームの問題を診断できます。
データボリュームを調べるには、次のコマンドを実行します。
oc describe dv <DataVolume>
$ oc describe dv <DataVolume>
Conditions セクションには、次の Types が表示されます。
-
Bound -
Running -
Ready
Events セクションでは、以下の追加情報を提供します。
-
イベントの
Type -
ロギングの
Reason -
イベントの
Source -
追加の診断情報が含まれる
Message
oc describe からの出力には常に Events が含まれるとは限りません。
Status、Reason、または Message が変化すると、イベントが生成されます。状態およびイベントはどちらもデータボリュームの状態の変更に対応します。
たとえば、インポート操作中に URL のスペルを誤ると、インポートにより 404 メッセージが生成されます。メッセージの変更により、理由と共にイベントが生成されます。Conditions セクションの出力も更新されます。
14.3.6.2. データボリュームの状態とイベントの分析
describe コマンドで生成される Conditions セクションおよび Events セクションを検査することにより、永続ボリューム要求 (PVC) に関連してデータボリュームの状態を判別します。また、操作がアクティブに実行されているか、または完了しているかどうかを判断します。
また、データボリュームのステータスに関する特定の詳細、およびどのように現在の状態になったかに関する情報を提供するメッセージを受信する可能性があります。
状態の組み合わせは多数あります。それぞれは一意のコンテキストで評価される必要があります。
各種の組み合わせの例を以下に示します。
Bound- この例では、正常にバインドされた PVC が表示されます。TypeはBoundであるため、StatusはTrueになります。PVC がバインドされていない場合、StatusはFalseになります。PVC がバインドされると、PVC がバインドされていることを示すイベントが生成されます。この場合、
ReasonはBoundで、StatusはTrueです。Messageはデータボリュームを所有する PVC を示します。EventsセクションのMessageには、PVC がバインドされている期間 (Age) や、どのリソース (From) (この場合はdatavolume-controller) によってバインドされているかなどの詳細が示されます。出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Running- この場合、TypeがRunningで、StatusがFalseであることに注意してください。これは、試行された操作が失敗する原因となったイベントが発生し、Status がTrueからFalseに変化したことを示しています。ただし、
ReasonがCompletedであり、MessageフィールドにはImport Completeが表示されることに注意してください。Eventsセクションには、ReasonおよびMessageに失敗した操作に関する追加のトラブルシューティング情報が含まれます。この例では、Eventsセクションの最初のWarningに一覧表示されるMessageに、404によって接続できないことが示唆されます。この情報から、インポート操作が実行中であり、データボリュームにアクセスしようとしている他の操作との競合が発生したと結論付けることができます。
出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Ready:TypeがReadyであり、StatusがTrueの場合、以下の例のようにデータボリュームは使用可能な状態になります。データボリュームがまだ使用できない状態の場合、StatusはFalseになります。出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
第15章 バックアップおよび復元
15.1. 仮想マシンスナップショットを使用したバックアップと復元
スナップショットを使用して、仮想マシンをバックアップおよび復元できます。スナップショットは、次のストレージプロバイダーによってサポートされています。
- Kubernetes Volume Snapshot API をサポートする Container Storage Interface (CSI) ドライバーを備えたクラウドストレージプロバイダー
Running 状態の仮想マシンのスナップショットを最高の整合性で作成するには、QEMU ゲストエージェントをインストールします (使用中のオペレーティングシステムに含まれていない場合)。QEMU ゲストエージェントは、デフォルトの Red Hat テンプレートに含まれています。
オンラインスナップショットは、ホットプラグされた仮想ディスクを持つ仮想マシンでサポートされます。ただし、仮想マシンの仕様に含まれていないホットプラグされたディスクは、スナップショットに含まれません。
QEMU ゲストエージェントは、仮想マシンファイルシステムの静止を試みることで、一貫性のあるスナップショットを取得します。これにより、スナップショットの作成前にインフライトの I/O がディスクに書き込まれるようになります。ゲストエージェントが存在しない場合は、静止はできず、ベストエフォートスナップショットが作成されます。
スナップショットの作成条件は、Web コンソールまたは CLI に表示されるスナップショットの指示に反映されます。これらの条件が要件を満たさない場合は、スナップショットを再度作成するか、オフラインスナップショットを使用します。
15.1.1. スナップショット
スナップショット は、特定の時点における仮想マシン (VM) の状態およびデータを表します。スナップショットを使用して、バックアップおよび障害復旧のために既存の仮想マシンを (スナップショットで表される) 以前の状態に復元したり、以前の開発バージョンに迅速にロールバックしたりできます。
仮想マシンのスナップショットは、電源がオフ (停止状態) またはオン (実行状態) の仮想マシンから作成されます。
実行中の仮想マシンのスナップショットを作成する場合には、コントローラーは QEMU ゲストエージェントがインストールされ、実行中であることを確認します。その場合、スナップショットを取得する前に仮想マシンファイルシステムをフリーズし、スナップショットを取得した後にファイルシステムをフリーズ解除します。
スナップショットは、仮想マシンに割り当てられた各 Container Storage Interface (CSI) ボリュームのコピーと、仮想マシンの仕様およびメタデータのコピーを保存します。スナップショットは作成後に変更できません。
次のスナップショットアクションを実行できます。
- 新しいスナップショットを作成する
スナップショットから仮想マシンのクローンを作成する
重要vTPM デバイスがアタッチされた仮想マシンのクローン作成や、そのスナップショットからの新しい仮想マシンの作成は、サポートされていません。
- 特定の仮想マシンに割り当てられているすべてのスナップショットのリスト表示
- スナップショットからの仮想マシンの復元
- 既存の仮想マシンスナップショットの削除
15.1.1.1. 仮想マシンスナップショットコントローラーとカスタムリソース
仮想マシンスナップショット機能では、スナップショットを管理するためのカスタムリソース定義 (CRD) として定義される 3 つの新しい API オブジェクトが導入されています。
-
VirtualMachineSnapshot: スナップショットを作成するユーザー要求を表します。これには、仮想マシンの現在の状態に関する情報が含まれます。 -
VirtualMachineSnapshotContent: クラスター上のプロビジョニングされたリソース (スナップショット) を表します。これは、仮想マシンのスナップショットコントローラーによって作成され、仮想マシンの復元に必要なすべてのリソースへの参照が含まれます。 -
VirtualMachineRestore: スナップショットから仮想マシンを復元するユーザー要求を表します。
仮想マシンスナップショットコントローラーは、1 対 1 のマッピングで、VirtualMachineSnapshotContent オブジェクトを、この作成に使用した VirtualMachineSnapshot オブジェクトにバインドします。
15.1.2. アプリケーションコンシステントなスナップショットとバックアップについて
フリーズとフリーズ解除のサイクルにより、Linux または Windows 仮想マシン (VM) のアプリケーションコンシステントなスナップショットおよびバックアップを設定できます。任意のアプリケーションに対して、スナップショットまたはバックアップの開始予定時に通知を受け取るように、Linux 仮想マシン上でスクリプトを設定したり、Windows 仮想マシン上で登録したりすることができます。
Linux 仮想マシンでは、たとえばスナップショットが取得されたり、Velero や別のバックアップベンダーのプラグインを使用してバックアップが開始されたりすると、フリーズおよびフリーズ解除プロセスが自動的にトリガーされます。QEMU Guest Agent (QEMU GA) のフリーズフックによって実行されるフリーズプロセスにより、仮想マシンのスナップショットまたはバックアップが実行される前に、仮想マシンのすべてのファイルシステムがフリーズされ、適切に設定された各アプリケーションにスナップショットまたはバックアップが開始されることが通知されます。この通知により、各アプリケーションに状態を静止させる機会が与えられます。アプリケーションによっては、休止に伴い、新しいリクエストの一時的な拒否、進行中の操作の終了、データのディスクへのフラッシュが実行される場合があります。その後、オペレーティングシステムが、未処理の書き込みをディスクにフラッシュし、新しい書き込みアクティビティーをフリーズすることによって、ファイルシステムを静止させるように指示されます。新しい接続要求はすべて拒否されます。すべてのアプリケーションが非アクティブになると、QEMU GA がファイルシステムをフリーズし、スナップショットが取得されるか、バックアップが開始されます。スナップショットの取得またはバックアップの開始後、フリーズ解除プロセスが開始します。ファイルシステムの書き込みが再アクティブ化され、アプリケーションが通常の操作を再開するための通知を受け取ります。
Windows 仮想マシンでも、同様のフリーズおよびフリーズ解除のサイクルを利用できます。アプリケーションが Volume Shadow Copy Service (VSS) に登録され、バックアップまたはスナップショットの実行が近づいているため、データをフラッシュする必要があるという通知を受け取ります。バックアップまたはスナップショットの完了後にアプリケーションがフリーズ解除されると、アプリケーションはアクティブな状態に戻ります。詳細は、Volume Shadow Copy Service に関する Windows Server のドキュメントを参照してください。
15.1.3. スナップショットの作成
Red Hat OpenShift Service on AWS Web コンソールまたはコマンドラインを使用して、仮想マシン (VM) のスナップショットを作成できます。
15.1.3.1. Web コンソールを使用したスナップショットを作成する
Red Hat OpenShift Service on AWS Web コンソールを使用して、仮想マシン (VM) のスナップショットを作成できます。
前提条件
-
snapshotフィーチャーゲートは、kubevirtCR の YAML 設定で有効になっています。 仮想マシンスナップショットには、以下の要件を満たすディスクが含まれます。
- ディスクはデータボリュームまたは永続ボリューム要求です。
- ディスクは、Container Storage Interface (CSI) ボリュームスナップショットをサポートするストレージクラスに属しています。
- ディスクは、永続ボリューム (PV) に バインド され、データソースが 入力 されます。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
Snapshots タブをクリックしてから Take Snapshot をクリックします。
または、仮想マシンを右クリックし、ポップアップメニューから Create snapshot を選択します。
- スナップショット名を入力します。
- Disks included in this Snapshot を拡張し、スナップショットに組み込むストレージボリュームを表示します。
- 仮想マシンにスナップショットに含めることができないディスクがあり、続行する場合は、I am aware of this warning and wish to proceed を選択します。
- Save をクリックします。
15.1.3.2. CLI を使用したスナップショットの作成
VirtualMachineSnapshot オブジェクトを作成し、オフラインまたはオンラインの仮想マシンの仮想マシン (VM) スナップショットを作成できます。
前提条件
次のコマンドを使用して、
kubevirtCR に対してSnapshotフィーチャーゲートが有効になっていることを確認します。oc get kubevirt kubevirt-hyperconverged -n openshift-cnv -o yaml
$ oc get kubevirt kubevirt-hyperconverged -n openshift-cnv -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力 (一部のみ記載):
spec: developerConfiguration: featureGates: - Snapshotspec: developerConfiguration: featureGates: - SnapshotCopy to Clipboard Copied! Toggle word wrap Toggle overflow 仮想マシンスナップショットに、次の要件を満たすディスクが含まれていることを確認します。
- ディスクはデータボリュームまたは永続ボリューム要求です。
- ディスクは、Container Storage Interface (CSI) ボリュームスナップショットをサポートするストレージクラスに属しています。
- ディスクは、永続ボリューム (PV) に バインド され、データソースが 入力 されます。
-
OpenShift CLI (
oc) がインストールされている。 - オプション: スナップショットを作成する仮想マシンの電源を切っている。
手順
次の例のように、YAML ファイルを作成して、新しい
VirtualMachineSnapshotの名前とソース仮想マシンの名前を指定するVirtualMachineSnapshotオブジェクトを定義します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow VirtualMachineSnapshotオブジェクトを作成します。oc create -f <snapshot_name>.yaml
$ oc create -f <snapshot_name>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow スナップコントローラーは
VirtualMachineSnapshotContentオブジェクトを作成し、これをVirtualMachineSnapshotにバインドし、VirtualMachineSnapshotオブジェクトのstatusおよびreadyToUseフィールドを更新します。
検証
オプション: スナップショットの作成プロセス中に、
waitコマンドを使用してスナップショットのステータスを監視し、使用可能になるまで待機できます。以下のコマンドを実行します。
oc wait <vm_name> <snapshot_name> --for condition=Ready
$ oc wait <vm_name> <snapshot_name> --for condition=ReadyCopy to Clipboard Copied! Toggle word wrap Toggle overflow スナップショットのステータスを確認します。
-
InProgress- スナップショット操作はまだ進行中です。 -
Succeeded- スナップショット操作が正常に完了しました。 Failed- スナップショット操作が失敗しました。注記オンラインスナップショットのデフォルト期限は 5 分 (
5m) です。スナップショットが 5 分後に正常に完了しない場合には、ステータスがfailedに設定されます。その後、ファイルシステムと仮想マシンのフリーズが解除され、失敗したスナップショットイメージが削除されるまで、ステータスはfailedのままになります。デフォルトの期限を変更するには、仮想マシンスナップショット spec に
FailureDeadline属性を追加して、スナップショット操作がタイムアウトするまでの時間を分単位 (m) または秒単位 (s) で指定します。期限を指定しない場合は、
0を指定できますが、仮想マシンが応答しなくなる可能性があるため、通常は推奨していません。mまたはsなどの時間の単位を指定しない場合、デフォルトは秒 (s) です。
-
VirtualMachineSnapshotオブジェクトが作成され、VirtualMachineSnapshotContentにバインドされていることと、readyToUseフラグがtrueに設定されていることを確認します。oc describe vmsnapshot <snapshot_name>
$ oc describe vmsnapshot <snapshot_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
Progressing状態のstatusフィールドは、スナップショットが作成中であるかどうかを指定します。- 2
Ready状態のstatusフィールドは、スナップショットの作成プロセスが完了しているかどうかを指定します。- 3
- スナップショットを使用する準備ができているかどうかを指定します。
- 4
- スナップショットが、スナップショットコントローラーで作成される
VirtualMachineSnapshotContentオブジェクトにバインドされるように指定します。 - 5
- スナップショットがオンラインスナップショットであるかどうか、または QEMU ゲストエージェントの実行中に作成されたかどうかなど、スナップショットに関する追加情報を指定します。
- 6
- スナップショットの一部であるストレージボリュームとそのパラメーターをリスト表示します。
-
スナップショットの説明の
includedVolumesセクションをチェックして、予想される PVC がスナップショットに含まれていることを確認します。
15.1.4. スナップショット指示を使用したオンラインスナップショットの検証
スナップショットの表示は、オンライン仮想マシン (VM) スナップショット操作に関するコンテキスト情報です。オフラインの仮想マシン (VM) スナップショット操作では、指示は利用できません。イベントは、オンラインスナップショット作成の詳説する際に役立ちます。
前提条件
- オンライン仮想マシンスナップショットを作成しようとしている必要があります。
手順
次のいずれかの操作を実行して、スナップショット指示からの出力を表示します。
-
コマンドラインを使用して、
VirtualMachineSnapshotオブジェクト YAML のstatusスタンザのインジケーター出力を表示します。 - Web コンソールの Snapshot details 画面で、VirtualMachineSnapshot → Status をクリックします。
-
コマンドラインを使用して、
status.indicationsパラメーターの値を表示して、オンラインの仮想マシンスナップショットのステータスを確認します。-
Onlineは、オンラインスナップショットの作成中に仮想マシンが実行されていたことを示します。 -
GuestAgentは、QEMU ゲストエージェントがアクティブであり、オンラインスナップショット作成時にゲストファイルシステムが正常に静止したことを示します。これにより、アプリケーションの整合性のあるスナップショットが作成され、アプリケーションがグレースフルにシャットダウンされた場合と同様にデータの整合性が維持されます。 -
NoGuestAgentは、QEMU ゲストエージェントがインストールされていないか、オンラインスナップショット作成時にファイルシステムを静止させる準備ができていなかったことを示します。これにより、クラッシュ整合性のあるスナップショットが作成されます。これは、仮想マシンの電源が突然切れたときのような状態をキャプチャーしたものです。その結果、アプリケーションの整合性が確保されず、重要なアプリケーションでデータの問題が発生するリスクが生じます。信頼性を高めるには、ゲストエージェントをインストールして実行するか、スナップショット作成を再試行してください。 -
QuiesceFailedは、オンラインスナップショット作成中にファイルシステムを静止させる試みが失敗したことを示します。これは、スナップショットは作成されたが、必ずしもアプリケーションの整合性が保たれているわけではないことを意味します。適切な整合性を確保するには、スナップショット作成を再試行してください。
-
15.1.5. スナップショットからの仮想マシンの復元
Red Hat OpenShift Service on AWS Web コンソールまたはコマンドラインを使用して、スナップショットから仮想マシン (VM) を復元できます。
15.1.5.1. Web コンソールを使用したスナップショットからの仮想マシンの復元
Red Hat OpenShift Service on AWS Web コンソールのスナップショットで表される以前の設定に仮想マシン (VM) を復元できます。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
-
仮想マシンが実行中の場合は、Options メニュー
をクリックし、Stop を選択して電源を切ります。
- Snapshots タブをクリックして、仮想マシンに関連付けられたスナップショットのリストを表示します。
- スナップショットを選択して、Snapshot Details 画面を開きます。
-
Options メニュー
をクリックし、Restore VirtualMachine from snapshot を選択します。
- Restore をクリックします。
オプション: スナップショットに基づいて新しい仮想マシンを作成することもできます。これを行うには、以下を行います。
-
スナップショットのオプションメニュー
から、Create VirtualMachine from Snapshot を選択します。
- 新しい仮想マシンの名前を指定します。
- Create をクリックします。
-
スナップショットのオプションメニュー
15.1.5.2. CLI を使用したスナップショットからの仮想マシンの復元
コマンドラインを使用して、既存の仮想マシンを以前の設定に復元できます。オフラインの仮想マシンスナップショットからしか復元できません。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - 復元する仮想マシンの電源を切ります。
オプション: ターゲット仮想マシンが完全に停止 (ready) しない場合の動作を調整します。これを行うには、
vmrestoreYAML 設定のtargetReadinessPolicyパラメーターを次のいずれかの値に設定します。-
FailImmediate- 仮想マシンの準備ができていない場合、復元プロセスは直ちに失敗します。 -
StopTarget- 仮想マシンの準備ができていない場合、仮想マシンは停止され、復元プロセスが開始されます。 -
WaitGracePeriod 5- 復元プロセスは、仮想マシンの準備ができるまで、設定された時間 (分単位) 待機します。これはデフォルトの設定であり、デフォルト値は 5 分に設定されています。 -
WaitEventually- 復元プロセスは、仮想マシンの準備が整うまで無制限に待機します。
-
手順
次の例のように、復元する仮想マシンの名前およびソースとして使用されるスナップショットの名前を指定する
VirtualMachineRestoreオブジェクトを定義するために YAML ファイルを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow VirtualMachineRestoreオブジェクトを作成します。oc create -f <vm_restore>.yaml
$ oc create -f <vm_restore>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow スナップショットコントローラーは、
VirtualMachineRestoreオブジェクトのステータスフィールドを更新し、既存の仮想マシン設定をスナップショットのコンテンツに置き換えます。
検証
仮想マシンがスナップショットで表される以前の状態に復元されていること、および
completeフラグがtrueに設定されていることを確認します。oc get vmrestore <vm_restore>
$ oc get vmrestore <vm_restore>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
15.1.6. スナップショットの削除
Red Hat OpenShift Service on AWS Web コンソールまたはコマンドラインを使用して、仮想マシン (VM) のスナップショットを削除できます。
15.1.6.1. Web コンソールを使用してスナップショットを削除する
Web コンソールを使用して既存の仮想マシンスナップショットを削除できます。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Snapshots タブをクリックして、仮想マシンに関連付けられたスナップショットのリストを表示します。
-
スナップショットの横にある Options メニュー
をクリックし、Delete snapshot を選択します。
- Delete をクリックします。
15.1.6.2. CLI での仮想マシンのスナップショットの削除
適切な VirtualMachineSnapshot オブジェクトを削除して、既存の仮想マシン (VM) スナップショットを削除できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
VirtualMachineSnapshotオブジェクトを削除します。oc delete vmsnapshot <snapshot_name>
$ oc delete vmsnapshot <snapshot_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow スナップショットコントローラーは、
VirtualMachineSnapshotを、関連付けられたVirtualMachineSnapshotContentオブジェクトと共に削除します。
検証
スナップショットが削除され、この仮想マシンに割り当てられていないことを確認します。
oc get vmsnapshot
$ oc get vmsnapshotCopy to Clipboard Copied! Toggle word wrap Toggle overflow
15.2. 仮想マシンのバックアップと復元
Red Hat は、OADP 1.3.x 以降で OpenShift Virtualization 4.14 以降を使用することをサポートしています。
OADP 1.3.0 より前のバージョンでは、OpenShift Virtualization のバックアップと復元ではサポートされていません。
OpenShift API for Data Protection を使用して仮想マシンをバックアップおよび復元します。
OADP Operator をインストールし、バックアップの場所を設定することで、OpenShift Virtualization を使用した OpenShift API for Data Protection (OADP) をインストールできます。その後、Data Protection Application をインストールできます。
OpenShift Virtualization を使用した OpenShift API for Data Protection は、バックアップおよび復元のストレージオプションとして次のものをサポートしています。
- Container Storage Interface (CSI) バックアップ
- DataMover による Container Storage Interface (CSI) バックアップ
次のストレージオプションは対象外です。
- ファイルシステムのバックアップと復元
- ボリュームスナップショットのバックアップと復元
制限されたネットワーク環境に OADP Operator をインストールするには、まずデフォルトのソフトウェアカタログソースを無効にし、Operator カタログをミラーリングする必要があります。
15.2.1. OpenShift Virtualization を使用した OADP のインストールと設定
クラスター管理者は、OADP Operator をインストールして OADP をインストールします。
最新バージョンの OADP Operator は、Velero 1.16 をインストールします。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
- ストレージプロバイダーの指示に従って、OADP Operator をインストールします。
-
kubevirtおよびopenshiftOADP プラグインを使用して Data Protection Application (DPA) をインストールします。 Backupカスタムリソース (CR) を作成して、仮想マシンをバックアップします。警告Red Hat のサポート対象は、次のオプションに限られています。
- CSI バックアップ
- DataMover による CSI バックアップ
Restore CR を作成して Backup CR を復元します。
15.2.2. Data Protection Application のインストール
DataProtectionApplication API のインスタンスを作成して、Data Protection Application (DPA) をインストールします。
前提条件
- OADP Operator をインストールする。
- オブジェクトストレージをバックアップロケーションとして設定する必要がある。
- スナップショットを使用して PV をバックアップする場合、クラウドプロバイダーはネイティブスナップショット API または Container Storage Interface (CSI) スナップショットのいずれかをサポートする必要がある。
バックアップとスナップショットの場所で同じ認証情報を使用する場合は、デフォルトの名前である
cloud-credentialsを使用してSecretを作成する必要がある。注記インストール中にバックアップまたはスナップショットの場所を指定したくない場合は、空の
credentials-veleroファイルを使用してデフォルトのSecretを作成できます。デフォルトのSecretがない場合、インストールは失敗します。
手順
- Ecosystem → Installed Operators をクリックし、OADP Operator を選択します。
- Provided APIs で、DataProtectionApplication ボックスの Create instance をクリックします。
YAML View をクリックして、
DataProtectionApplicationマニフェストのパラメーターを更新します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- OADP のデフォルトの namespace は
openshift-adpです。namespace は変数であり、設定可能です。 - 2
kubevirtプラグインは OpenShift Virtualization に必須です。- 3
- バックアッププロバイダーのプラグインがある場合には、それを指定します (例:
gcp)。 - 4
- CSI スナップショットを使用して PV をバックアップするには、
csiプラグインが必須です。csiプラグインは、Velero CSI ベータスナップショット API を使用します。スナップショットの場所を設定する必要はありません。 - 5
openshiftプラグインは必須です。- 6
- Velero CRD の可用性、volumeSnapshot の削除、バックアップリポジトリーの可用性など、タイムアウトが発生するまでに複数の Velero リソースを待機する時間を分単位で指定します。デフォルトは 10m です。
- 7
- 管理要求をサーバーにルーティングする管理エージェント。
- 8
nodeAgentを有効にして File System Backup を実行する場合は、この値をtrueに設定します。- 9
- 組み込み DataMover を使用するには、アップローダーとして
kopiaと入力します。nodeAgentはデーモンセットをデプロイします。これは、nodeAgentPod が各ワーキングノード上で実行されることを意味します。File System Backup を設定するには、spec.defaultVolumesToFsBackup: trueをBackupCR に追加します。 - 10
- Kopia が利用可能なノードを指定します。デフォルトでは、Kopia はすべてのノードで実行されます。
- 11
- バックアッププロバイダーを指定します。
- 12
- バックアッププロバイダーにデフォルトのプラグインを使用する場合は、
Secretの正しいデフォルト名を指定します (例:cloud-credentials-gcp)。カスタム名を指定すると、そのカスタム名がバックアップの場所に使用されます。Secret名を指定しない場合は、デフォルトの名前が使用されます。 - 13
- Backup Storage Location としてバケットを指定します。バケットが Velero バックアップ専用のバケットでない場合は、接頭辞を指定する必要があります。
- 14
- バケットが複数の目的で使用される場合は、Velero バックアップの接頭辞を指定します (例:
velero)。
- Create をクリックします。
検証
次のコマンドを実行して OpenShift API for Data Protection (OADP) リソースを表示し、インストールを検証します。
oc get all -n openshift-adp
$ oc get all -n openshift-adpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 次のコマンドを実行して、
DataProtectionApplication(DPA) が調整されていることを確認します。oc get dpa dpa-sample -n openshift-adp -o jsonpath='{.status}'$ oc get dpa dpa-sample -n openshift-adp -o jsonpath='{.status}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例
{"conditions":[{"lastTransitionTime":"2023-10-27T01:23:57Z","message":"Reconcile complete","reason":"Complete","status":"True","type":"Reconciled"}]}{"conditions":[{"lastTransitionTime":"2023-10-27T01:23:57Z","message":"Reconcile complete","reason":"Complete","status":"True","type":"Reconciled"}]}Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
typeがReconciledに設定されていることを確認します。 次のコマンドを実行して、Backup Storage Location を確認し、
PHASEがAvailableであることを確認します。oc get backupstoragelocations.velero.io -n openshift-adp
$ oc get backupstoragelocations.velero.io -n openshift-adpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例
NAME PHASE LAST VALIDATED AGE DEFAULT dpa-sample-1 Available 1s 3d16h true
NAME PHASE LAST VALIDATED AGE DEFAULT dpa-sample-1 Available 1s 3d16h trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.