1.3. 仮想マシン、イメージ、およびテンプレート
「OpenStack Bare Metal Provisioning (ironic)」
「OpenStack Orchestration (heat)」
「OpenStack Data Processing (sahara)」
1.3.1. OpenStack Compute (nova)
OpenStack Compute サービスは、オンデマンドで仮想マシンを提供する、OpenStack クラウドの中核です。Compute は、下層の仮想化メカニズムと対話するドライバーを定義し、他の OpenStack コンポーネントに機能を公開することにより、仮想マシンが一式のノード上で実行されるようにスケジュールします。
Compute は、KVM をハイパーバイザーとして使用する libvirt ドライバー libvirtd をサポートします。ハイパーバイザーは仮想マシンを作成し、ノードからノードへのライブマイグレーションを可能にします。ベアメタルマシンをプロビジョニングするには、「OpenStack Bare Metal Provisioning (ironic)」 も使用できます。
Compute は Identity サービスと対話してインスタンスおよびデータベースアクセスを認証し、Image サービスを使用してイメージにアクセスしてインスタンスを起動し、ダッシュボードサービスを使用してユーザーおよび管理インターフェイスを提供します。
プロジェクトおよびユーザーがイメージへのアクセスを制限し、プロジェクトおよびユーザーのクォータ(単一ユーザーが作成することのできるインスタンス数など)を指定できます。
Red Hat OpenStack Platform クラウドをデプロイする場合には、さまざまなカテゴリーに従ってクラウドを分類することができます。
- リージョン
Identity サービスでカタログされる各サービスは、サービスリージョン(通常は地理的な場所とサービスエンドポイント)で識別されます。複数のコンピュートノードを持つクラウドでは、リージョンはサービスを分離できるようにします。
また、リージョンを使用して、高いレベルの障害耐性を維持しながら、Compute のインストール間でインフラストラクチャーを共有することもできます。
- セル(テクノロジープレビュー)
コンピュートホストは、セルと呼ばれるグループにパーティショニングして、大規模なデプロイメントや地理的に個別のインストールを処理することができます。セルは、API セル と呼ばれるトップレベルセルであるツリーで設定されます。このツリーでは、nova-api サービスが実行されますが、nova-compute サービスはありません。
ツリーの各子セルは、nova-api サービスではなく、他のすべての一般的な nova-* サービスを実行します。各セルには、個別のメッセージキューとデータベースサービスがあり、API セルと子セル間の通信を管理する nova-cells サービスも実行します。
セルの利点は次のとおりです。
- 単一の API サーバーを使用して、複数の Compute インストールへのアクセスを制御することができます。
- セルレベルでの追加のスケジューリングレベルを利用すると、ホストのスケジューリングとは異なり、仮想マシンの実行時に柔軟性と制御性が向上します。
この機能は、本リリースでは テクノロジープレビュー として提供しているため、Red Hat では全面的にはサポートしていません。これは、テスト用途にのみご利用いただく機能です。実稼働環境にはデプロイしないでください。テクノロジープレビュー機能の詳細は、対象範囲の詳細 を参照してください。
- Host Aggregates and Availability Zone
1 つの Compute デプロイメントを論理グループにパーティション分割することができます。ストレージやネットワークなどの共通のリソースを共有するホストの複数のグループや、信頼済みコンピューティングハードウェアなどの特別なプロパティーを共有するグループを複数作成できます。
管理者に、グループは割り当てられたコンピュートノードと関連するメタデータと共にホストアグリゲートとして表示されます。Host Aggregate メタデータは、通常、特定のフレーバーやイメージをホストのサブセットに制限するなど、openstack-nova-scheduler アクションの情報を提供するために使用されます。
ユーザーに、グループはアベイラビリティーゾーンとして表示されます。ユーザーは、グループメタデータを表示したり、ゾーン内のホストの一覧を表示したりできません。
集約値またはゾーンの利点は次のとおりです。
- 負荷分散とインスタンスの分散。
- ゾーン間の物理的な分離と冗長性。別の電源供給またはネットワーク機器で実装されます。
- 共通の属性を持つサーバーのグループにラベリング。
- 異なるハードウェアのクラスの分離
| コンポーネント | 説明 |
|---|---|
| openstack-nova-api | 要求を処理し、インスタンスの起動等の Compute サービスへのアクセスを提供します。 |
| openstack-nova-cert | 証明書マネージャーを提供します。 |
| openstack-nova-compute | 各ノードで実行され、仮想インスタンスを作成および終了します。Compute サービスはハイパーバイザーと対話して新規インスタンスを起動し、インスタンスの状態がコンピュートデータベースで維持されるようにします。 |
| openstack-nova-conductor | コンピュートノードのデータベースアクセスをサポートし、セキュリティー上のリスクを軽減します。 |
| openstack-nova-consoleauth | コンソール認証を処理します。 |
| openstack-nova-network | OpenStack Networking の代わりに機能でき、プライベートおよびパブリックアクセスの基本的なネットワークトラフィックを処理することができるネットワークサービス。OpenStack Networking と Compute Networking を比較するには、2章Networking In-Depthを参照してください。 |
| openstack-nova-novncproxy | VNC コンソールで仮想マシンにアクセスできるようにするブラウザー用の VNC プロキシーを提供します。 |
| openstack-nova-scheduler | 設定された重みおよびフィルターに基づいて、新しい仮想マシンのリクエストを正しいノードにディスパッチします。 |
| nova | Compute API にアクセスするためのコマンドラインクライアント。 |
以下の図は、Compute サービスと他の OpenStack コンポーネントの関係を示しています。

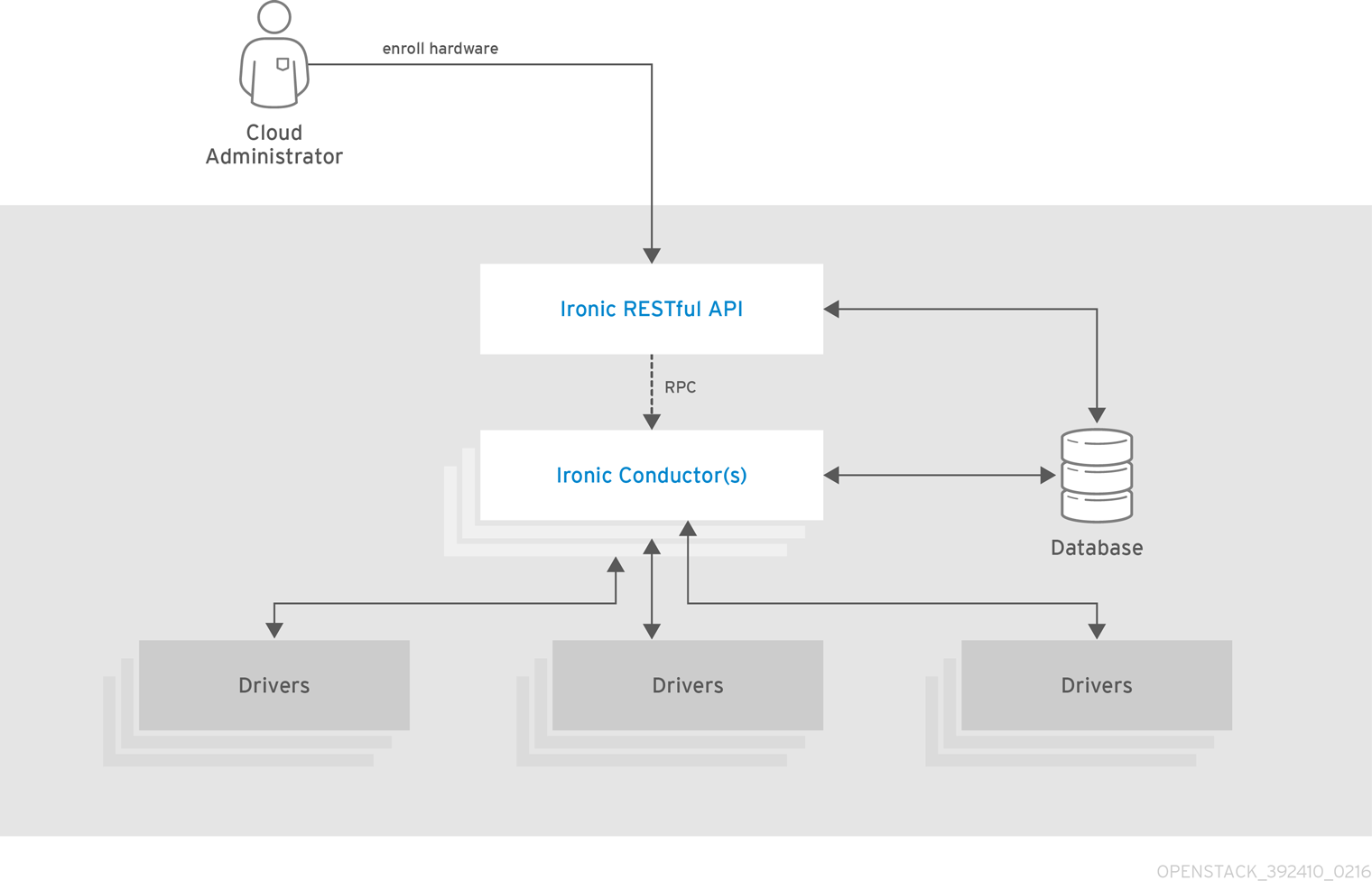
1.3.2. OpenStack Bare Metal Provisioning (ironic)
OpenStack Bare Metal Provisioning により、ハードウェア固有のドライバーを使用するさまざまなハードウェアベンダーの製品で物理マシンまたはベアメタルマシンのプロビジョニングを行うことができます。Bare Metal Provisioning は Compute サービスと統合して、仮想マシンのプロビジョニングと同じ方法で、ベアメタルマシンのプロビジョニングを行い、bare-metal-to-trusted-tenant のユースケースの解決策を提供します。
OpenStack Baremetal Provisioning には、以下のような利点があります。
- Hadoop クラスターはベアメタルマシンにデプロイすることができます。
- ハイパースケールおよび高パフォーマンスコンピューティング(HPC)クラスターをデプロイすることができます。
- 仮想マシンに敏感であるアプリケーションのデータベースホストを使用できます。
Bare Metal Provisioning は、スケジューリングとクォータの管理に Compute サービスを使用し、認証に Identity サービスを使用します。インスタンスイメージは、KVM ではなく Bare Metal Provisioning をサポートするように設定する必要があります。
以下の図は、物理サーバーがプロビジョニングされているときに Ironic と他の OpenStack サービスがどのように対話するかを示しています。

| コンポーネント | 説明 |
|---|---|
| openstack-ironic-api | 要求を処理し、ベアメタルノード上のコンピュートリソースへのアクセスを提供します。 |
| openstack-ironic-conductor | ハードウェアおよび ironic データベースと直接対話し、要求されたアクションおよび定期的なアクションを処理します。複数のコンダクターを作成して、異なるハードウェアドライバーと対話できます。 |
| ironic | Bare Metal Provisioning API にアクセスするためのコマンドラインクライアント。 |
Ironic API を以下の図に示します。
1.3.3. OpenStack Image (glance)
OpenStack Image は、仮想ディスクイメージのレジストリーとして機能します。ユーザーは、新規イメージを追加したり、既存のサーバーのスナップショットを作成して直ちに保存したりすることができます。スナップショットはバックアップ用、またはサーバーを新規作成するためのテンプレートとして使用できます。
登録されたイメージは、Object Storage サービスや、単純なファイルシステムや外部の Web サーバーなどの他の場所に保存できます。
次のイメージディスク形式がサポートされています。
- Aki/ami/ari (Amazon カーネル、ramdisk、またはマシンイメージ)
- ISO (CD などの光ディスク用のアーカイブ形式)
- qcow2 (Qemu/KVM、Copy on Write をサポートしています)
- raw (非構造化形式)
- VHD (Hyper-V)、VMware、Xen、Microsoft、VirtualBox などのベンダーの仮想マシンモニターに共通です。
- VDI (Qemu/VirtualBox)
- VMDK (VMware)
コンテナーの形式は、Image サービスで登録することもできます。コンテナー形式は、イメージに保存する仮想マシンメタデータのタイプおよび詳細レベルを決定します。
以下のコンテナー形式がサポートされています。
- ベアメタル(メタデータなし)
- OVA (OVA tar アーカイブ)
- OVF (OVF 形式)
- Aki/ami/ari (Amazon カーネル、ramdisk、またはマシンイメージ)
| コンポーネント | 説明 |
|---|---|
| openstack-glance-api | ストレージバックエンドと対話して、イメージ取得およびストレージのリクエストを処理します。API は openstack-glance-registry を使用してイメージ情報を取得します。レジストリーサービスに直接アクセスすることはできません。 |
| openstack-glance-registry | 各イメージのすべてのメタデータを管理します。 |
| glance | Image API にアクセスするためのコマンドラインクライアント。 |
以下の図は、Image サービスが Image データベースからイメージを登録して取得するために使用する主なインターフェイスを示しています。

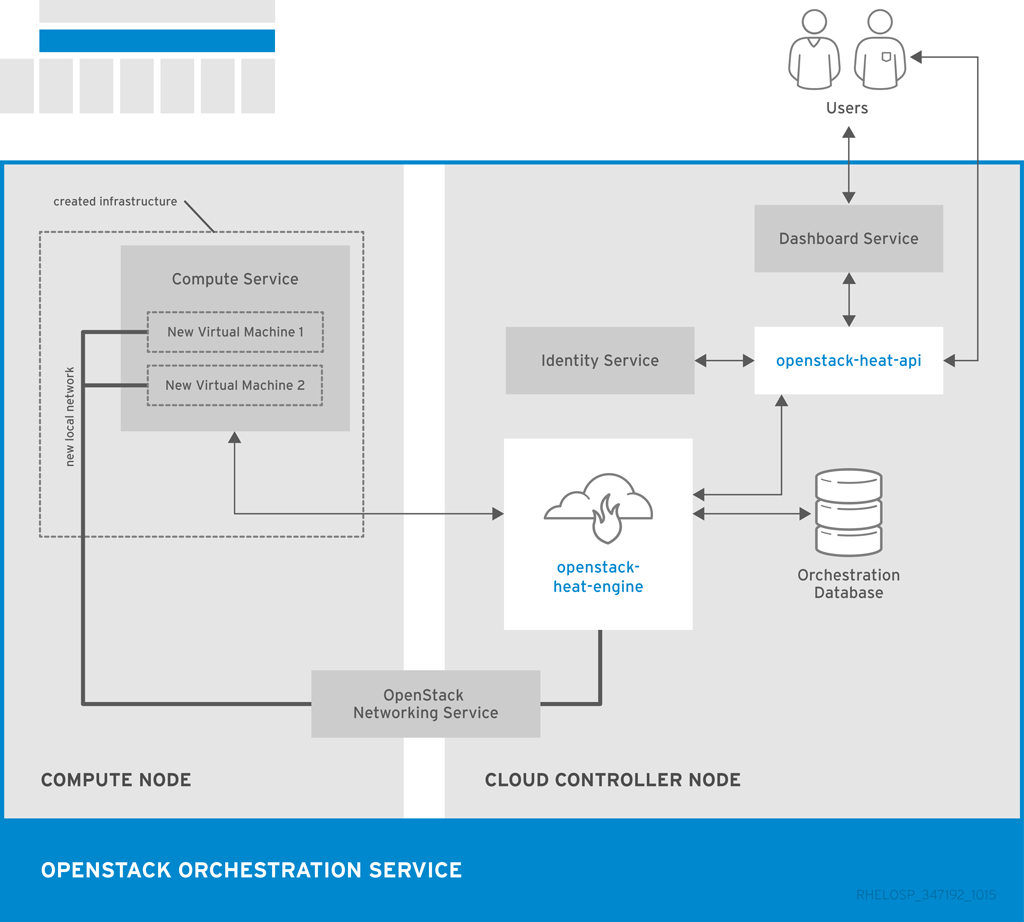
1.3.4. OpenStack Orchestration (heat)
OpenStack Orchestration は、ストレージ、ネットワーク、インスタンス、アプリケーションなどのクラウドリソースを作成および管理するためのテンプレートを提供します。テンプレートは、リソースのコレクションであるスタックの作成に使用されます。
たとえば、インスタンス、フローティング IP、ボリューム、セキュリティーグループ、またはユーザーのテンプレートを作成できます。Orchestration は、1 つのモジュラーテンプレートや、自動スケーリングや基本的な高可用性などの機能を使用して、すべての OpenStack コアサービスへのアクセスを提供します。
OpenStack Orchestration には、以下のような利点があります。
- 単一のテンプレートは、基盤となるすべてのサービス API へのアクセスを提供します。
- テンプレートはモジュール式およびリソース指向です。
- テンプレートは、ネストされたスタックなど、再帰的に定義し、再利用することができます。その後、クラウドインフラストラクチャーは、モジュール式な方法で定義および再利用できます。
- リソース実装はプラグ可能で、カスタムリソースを許可します。
- リソースは自動スケーリングを行うことができるため、使用状況に基づいてクラスターから追加または削除できます。
- 基本的な高可用性機能を利用できます。
| コンポーネント | 説明 |
|---|---|
| openstack-heat-api | RPC 経由で openstack-heat-engine サービスにリクエストを送信して API リクエストを処理する OpenStack-native REST API |
| openstack-heat-api-cfn | RPC 経由で openstack-heat-engine サービスに要求を送信することにより、API 要求を処理する AWS CloudFormation と互換性のあるオプションの AWS-Query API。 |
| openstack-heat-engine | テンプレートの起動をオーケストレーションし、API コンシューマーのイベントを生成します。 |
| openstack-heat-cfntools | メタデータの更新を処理し、カスタムフックを実行する cfn-hup などのヘルパースクリプトのパッケージ化。 |
| heat | Orchestration API と通信して AWS CloudFormation API を実行するコマンドラインツールです。 |
次の図は、2 つの新規インスタンスとローカルネットワークの新規スタックを作成するために Orchestration サービスが使用する主なインターフェイスを示しています。
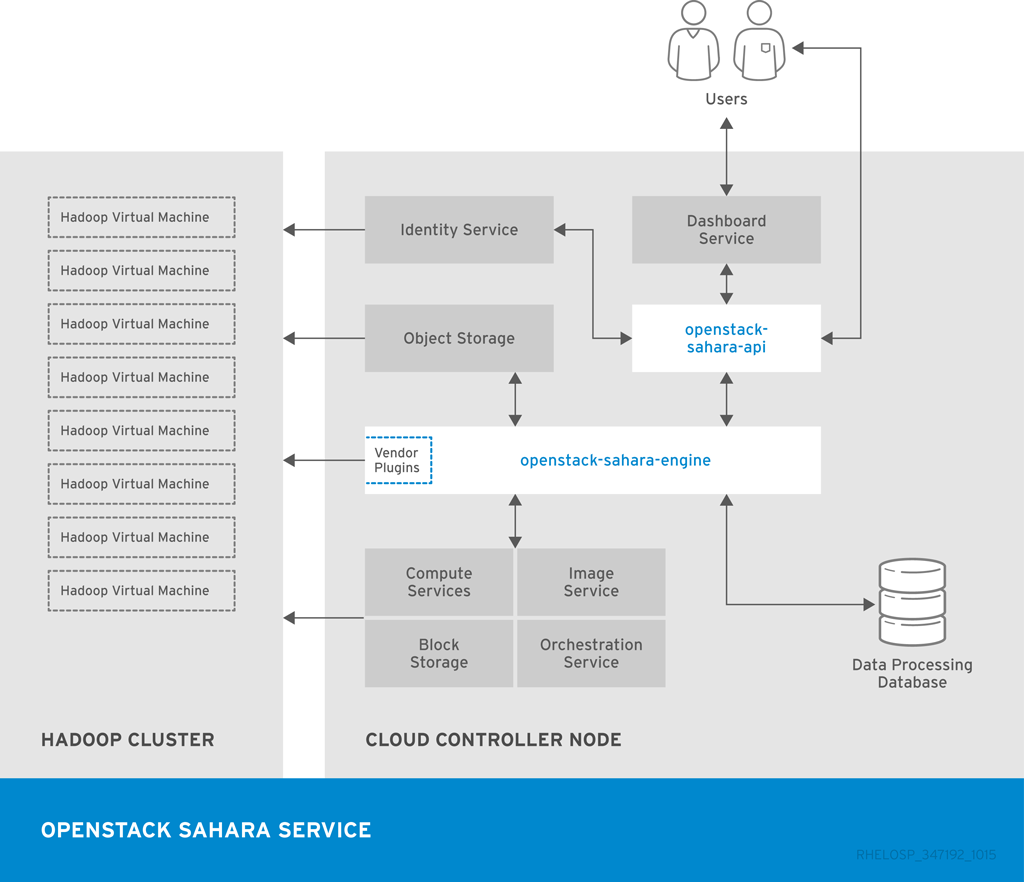
1.3.5. OpenStack Data Processing (sahara)
OpenStack Data Processing により、OpenStack 上の Hadoop クラスターのプロビジョニングと管理を行うことができます。Hadoop は、クラスター内の大量の構造化/非構造化データを保管および分析します。
Hadoop クラスター は、Hadoop Distributed File System (HDFS)、Hadoop の MapReduce (MR)フレームワークを実行しているコンピュートサーバー、またはその両方を実行するストレージサーバーとして機能するサーバーのグループです。
Hadoop クラスター内のサーバーは同じネットワークに置く必要がありますが、メモリーやディスクを共有する必要はありません。したがって、既存のサーバーの互換性に影響を与えることなく、サーバーおよびクラスターを追加または削除できます。
Hadoop のコンピューティングサーバーとストレージサーバーは共存するため、保存されたデータの高速分析が可能になります。すべてのタスクはサーバー全体で分割され、ローカルサーバーリソースを使用します。
OpenStack データ処理の利点には、以下が含まれます。
- Identity サービスはユーザーを認証し、Hadoop クラスターでユーザーセキュリティーを提供できます。
- Compute サービスはクラスターインスタンスをプロビジョニングできます。
- Image サービスはクラスターインスタンスを保管することができます。この場合、各インスタンスにはオペレーティングシステムと HDFS が含まれます。
- オブジェクトストレージサービスを使用して、Hadoop ジョブプロセスのデータを保存できます。
- テンプレートを使用すると、クラスターの作成と設定を行うことができます。ユーザーは、カスタムテンプレートを作成するか、クラスターの作成中にパラメーターを上書きすることで、設定パラメーターを変更できます。ノードは Node Group テンプレートを使用してグループ化され、クラスターテンプレートは Node Groups を組み合わせます。
- ジョブは、Hadoop クラスターでタスクを実行するために使用できます。ジョブバイナリーは実行可能なコードを保存し、データソースは入出力の場所と必要な認証情報を保存します。
データ処理は、Cloudera (CDH)と Hortonworks Data Platform (HDP)ディストリビューションと、Apache Ambari などのベンダー固有の管理ツールをサポートしています。OpenStack Dashboard またはコマンドラインツールを使用して、クラスターをプロビジョニングおよび管理できます。
| コンポーネント | 説明 |
|---|---|
| openstack-sahara-all | API およびエンジンサービスを処理するレガシーパッケージ。 |
| openstack-sahara-api | API 要求を処理し、Data Processing サービスへのアクセスを提供します。 |
| openstack-sahara-engine | クラスター要求とデータ配信を処理するプロビジョニングエンジン。 |
| sahara | Data Processing API にアクセスするためのコマンドラインクライアント。 |
次の図は、Data Processing サービスが Hadoop クラスターのプロビジョニングと管理に使用する主なインターフェイスを示しています。