托管 control plane
在 OpenShift Container Platform 中使用托管 control plane
摘要
第 1 章 托管 control plane 概述
您可以使用两个不同的 control plane 配置部署 OpenShift Container Platform 集群:独立或托管的 control plane。独立配置使用专用虚拟机或物理机器来托管 control plane。通过为 OpenShift Container Platform 托管 control plane,您可以在托管集群中创建 pod 作为 control plane,而无需为每个 control plane 使用专用虚拟机或物理机器。
1.1. 托管 control plane 简介(技术预览)
您可以使用 Red Hat OpenShift Container Platform 托管 control plane 来降低管理成本,优化集群部署时间,并分离管理和工作负载问题,以便专注于应用程序。
您可以使用 multicluster engine for Kubernetes operator 版本 2.0 或更高版本 在 Amazon Web Services (AWS) 上启用托管的 control plane 作为技术预览功能,使用 Agent 供应商或 OpenShift Virtualization。
托管的 control plane 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
1.1.1. 托管 control plane 的架构
OpenShift Container Platform 通常以组合或独立部署,集群由 control plane 和数据平面组成。control plane 包括 API 端点、存储端点、工作负载调度程序和确保状态的指示器。data plane 包括运行工作负载的计算、存储和网络。
独立的 control plane 由一组专用的节点(可以是物理或虚拟)托管,最小数字来确保仲裁数。网络堆栈被共享。对集群的管理员访问权限提供了对集群的 control plane、机器管理 API 和有助于对集群状态贡献的其他组件的可见性。
虽然独立模式运行良好,但在某些情况下需要与 control plane 和数据平面分离的架构。在这些情况下,data plane 位于带有专用物理托管环境的独立网络域中。control plane 使用 Kubernetes 原生的高级别原语(如部署和有状态集)托管。control plane 被视为其他工作负载。
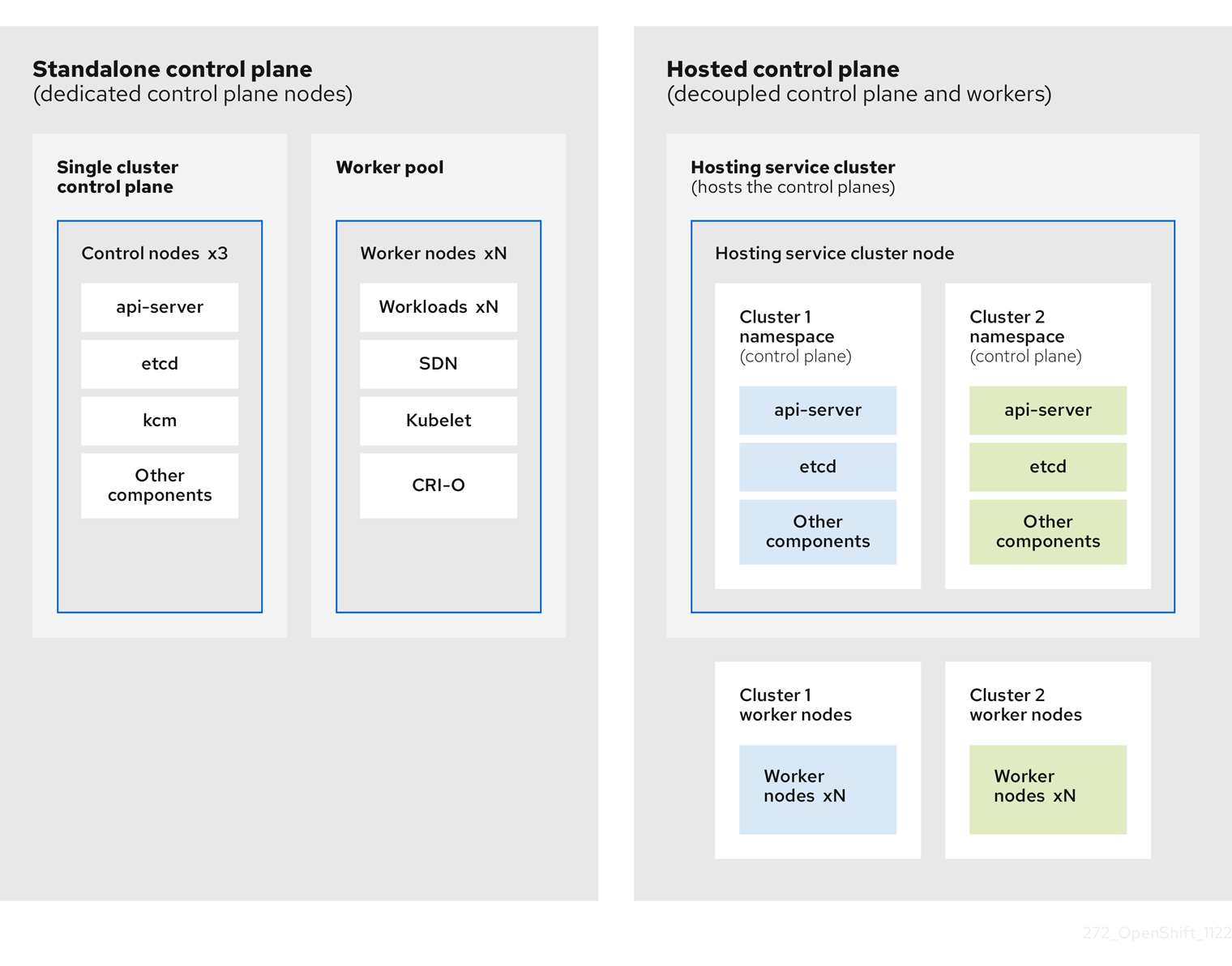
1.1.2. 托管 control plane 的优点
使用托管 OpenShift Container Platform 的 control plane,您可以为真正的混合云方法打下基础,并享受一些其他优势。
- 管理和工作负载之间的安全界限很强大,因为 control plane 分离并在专用的托管服务集群中托管。因此,您无法将集群的凭证泄漏到其他用户。因为基础架构 secret 帐户管理也已被分离,所以集群基础架构管理员无法意外删除 control plane 基础架构。
- 使用托管 control plane,您可以在较少的节点上运行多个 control plane。因此,集群更为经济。
- 因为 control plane 由 OpenShift Container Platform 上启动的 pod 组成,所以 control planes 快速启动。同样的原则适用于 control plane 和工作负载,如监控、日志记录和自动扩展。
- 从基础架构的角度来看,您可以将 registry、HAProxy、集群监控、存储节点和其他基础架构组件推送到租户的云供应商帐户,将使用情况隔离到租户。
- 从操作的角度来看,多集群管理更为集中,从而减少了影响集群状态和一致性的外部因素。站点可靠性工程师具有调试问题并进入集群的数据平面的中心位置,这可能会导致更短的时间解析 (TTR) 并提高生产效率。
1.2. 托管 control plane、多集群引擎 Operator 和 RHACM 之间的关系
您可以使用 Kubernetes Operator 的多集群引擎配置托管的 control plane。多集群引擎是 Red Hat Advanced Cluster Management (RHACM) 的一个集成部分,它在 RHACM 中默认启用。multicluster engine Operator 集群生命周期定义了在不同基础架构云供应商、私有云和内部数据中心的创建、导入、管理和销毁 Kubernetes 集群的过程。
multicluster engine operator 是集群生命周期 Operator,它为 OpenShift Container Platform 和 RHACM hub 集群提供集群管理功能。multicluster engine Operator 增强了集群管理功能,并支持跨云和数据中心的 OpenShift Container Platform 集群生命周期管理。
图 1.1. 集群生命周期和基础
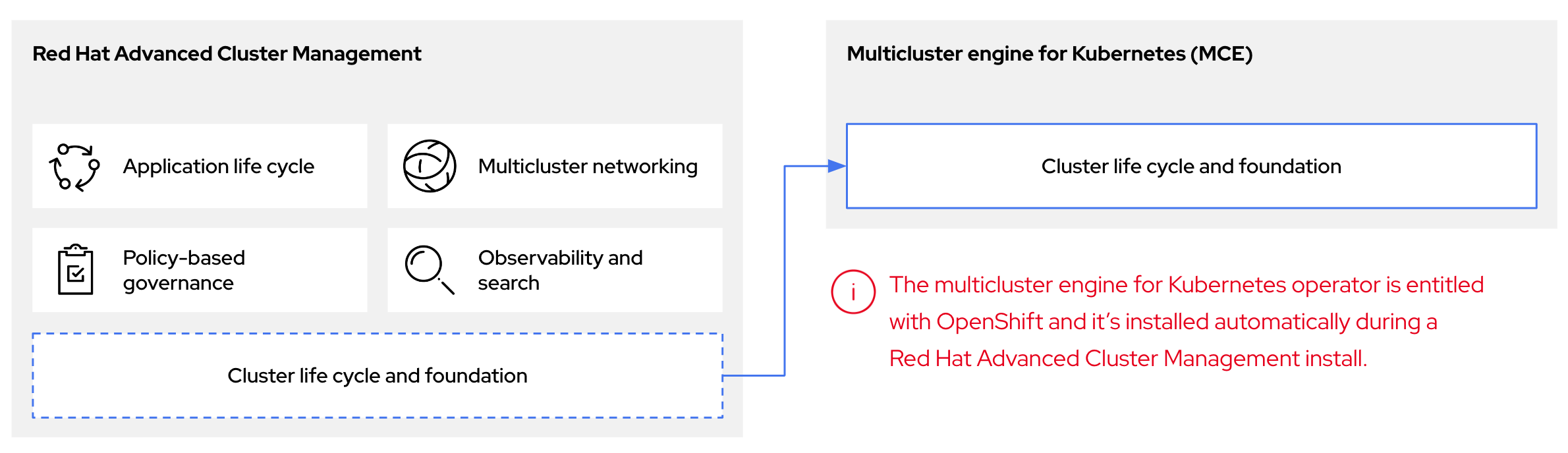
您可以将 multicluster engine Operator 与 OpenShift Container Platform 用作一个独立的集群管理器,或作为 RHACM hub 集群的一部分。
管理集群也称为托管集群。
您可以使用两个不同的 control plane 配置部署 OpenShift Container Platform 集群:独立或托管的 control plane。独立配置使用专用虚拟机或物理机器来托管 control plane。通过为 OpenShift Container Platform 托管 control plane,您可以在托管集群中创建 pod 作为 control plane,而无需为每个 control plane 使用专用虚拟机或物理机器。
图 1.2. RHACM 和多集群引擎 Operator 简介图
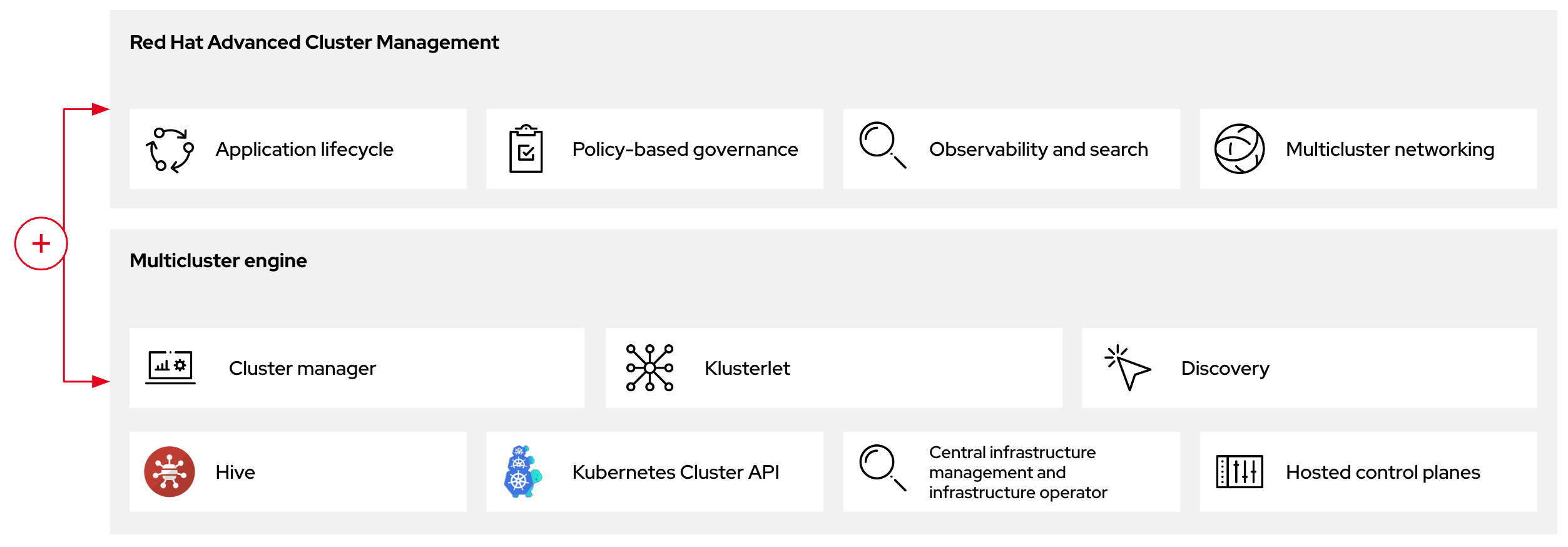
1.3. 托管 control plane 的版本控制
对于 OpenShift Container Platform 的每个主要、次版本或补丁版本,会发布两个托管的 control plane 组件:
- HyperShift Operator
- 命令行界面 (CLI)
HyperShift Operator 管理由 HostedCluster API 资源表示的托管集群的生命周期。HyperShift Operator 会随每个 OpenShift Container Platform 发行版本一起发布。在安装了 HyperShift Operator 后,它会在 HyperShift 命名空间中创建一个名为 supported-versions 的配置映射,如下例所示。配置映射描述了可以部署的 HostedCluster 版本。
apiVersion: v1
data:
supported-versions: '{"versions":["4.13","4.12","4.11"]}'
kind: ConfigMap
metadata:
labels:
hypershift.openshift.io/supported-versions: "true"
name: supported-versions
namespace: hypershiftCLI 是用于开发目的的帮助程序。CLI 作为任何 HyperShift Operator 发行版本的一部分发布。无法保证兼容性策略。
API hypershift.openshift.io 提供了以大规模创建和管理轻量级、灵活、异构的 OpenShift Container Platform 集群的方法。API 会公开两个面向用户的资源:HostedCluster 和 NodePool。HostedCluster 资源封装 control plane 和通用数据平面配置。当您创建 HostedCluster 资源时,您有一个完全正常工作的 control plane,没有附加的节点。NodePool 资源是一组可扩展的 worker 节点,附加到 HostedCluster 资源。
API 版本策略通常与 Kubernetes API 版本 的策略一致。
第 2 章 配置托管的 control plane
要开始使用 OpenShift Container Platform 的托管 control plane,首先需要在您要使用的供应商上配置托管集群。然后,完成几个管理任务。
托管的 control plane 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
您可以选择以下供应商来查看相关的步骤:
2.1. Amazon Web Services (AWS)
- 在 AWS 上配置托管集群(技术预览):在 AWS 上配置托管集群的任务包括,创建 AWS S3 OIDC secret、创建可路由的公共区、启用外部 DNS、启用 AWS PrivateLink、启用托管的 control plane 功能并安装托管的 control plane CLI。
- 在 AWS 上管理托管的 control plane 集群(技术预览) :管理任务包括创建、导入、访问或删除 AWS 上的托管集群。
2.2. 裸机
- 在裸机上配置托管集群(技术预览): 在创建托管集群前配置 DNS。
-
管理裸机上的托管 control plane 集群(技术预览) :创建一个托管集群,创建一个
InfraEnv资源、添加代理、访问托管集群、扩展NodePool对象、处理 Ingress、启用节点自动扩展或删除托管集群。
2.3. OpenShift Virtualization
- 在 OpenShift Virtualization 上管理托管的 control plane 集群(技术预览 ):使用 KubeVirt 虚拟机托管的 worker 节点创建 OpenShift Container Platform 集群。
第 3 章 管理托管的 control plane
为托管 control plane 配置环境并创建托管集群后,您可以进一步管理集群和节点。
托管的 control plane 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
3.1. 托管 control plane 的更新
托管 control plane 的更新涉及更新托管集群和节点池。要使集群在更新过程中完全正常工作,您必须在完成 control plane 和节点更新时满足 Kubernetes 版本偏移策略的要求。
3.1.1. 托管集群的更新
spec.release 值决定了 control plane 的版本。HostedCluster 对象将预期的 spec.release 值传送到 HostedControlPlane.spec.release 值,并运行适当的 Control Plane Operator 版本。
托管的 control plane 会管理 control plane 组件的新版本的推出,以及任何 OpenShift Container Platform 组件通过 Cluster Version Operator (CVO) 的新版本。
3.1.2. 节点池的更新
使用节点池,您可以通过公开 spec.release 和 spec.config 值来配置在节点上运行的软件。您可以使用以下方法启动滚动节点池更新:
-
更改
spec.release或spec.config值。 - 更改任何特定于平台的字段,如 AWS 实例类型。结果是一组带有新类型的新实例。
- 如果要将更改传播到节点,修改集群配置。
节点池支持替换更新和原位升级。nodepool.spec.release 值指定任何特定节点池的版本。NodePool 对象根据 .spec.management.upgradeType 值完成替换或原位滚动更新。
创建节点池后,您无法更改更新类型。如果要更改更新类型,您必须创建一个节点池并删除另一个节点池。
3.1.2.1. 替换节点池的更新
一个替换(replace)更新会在新版本中创建实例,并从以前的版本中删除旧的实例。对于这个级别的不可变性具有成本效率的云环境中,这个更新类型会非常有效。
替换更新不会保留任何手动更改,因为节点会被完全重新置备。
3.1.2.2. 节点池的原位更新
原位(in-place)会直接更新实例的操作系统。这个类型适用于对于基础架构的限制比较高的环境(如裸机)。
原位升级可保留手动更改,但在对集群直接关键的任何文件系统获操作系统配置(如 kubelet 证书)进行手工修改时会报告错误。
3.2. 为托管 control plane 更新节点池
在托管的 control plane 上,您可以通过更新节点池来更新 OpenShift Container Platform 的版本。节点池版本不能超过托管的 control plane 版本。
流程
要启动升级到 OpenShift Container Platform 的新版本,请输入以下命令来更改节点池的
spec.release.image值:$ oc -n NAMESPACE patch HC HCNAME --patch '{"spec":{"release":{"image": "example"}}}' --type=merge
验证
-
要验证新版本是否已推出,请检查
.status.version值和状态条件。
3.3. 为托管的 control plane 配置节点池
在托管的 control plane 上,您可以通过在管理集群中的配置映射中创建 MachineConfig 对象来配置节点池。
流程
要在管理集群中的配置映射中创建
MachineConfig对象,请输入以下信息:apiVersion: v1 kind: ConfigMap metadata: name: <configmap-name> namespace: clusters data: config: | apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: <machineconfig-name> spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:... mode: 420 overwrite: true path: ${PATH}1 - 1
- 在存储
MachineConfig对象的节点上设置路径。
将对象添加到配置映射后,您可以将配置映射应用到节点池,如下所示:
$ oc edit nodepool <nodepool_name> --namespace <hosted_cluster_namespace>apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: config: - name: ${configmap-name} # ...
3.4. 在托管集群中配置节点性能优化
托管的 control plane 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
要在托管集群中的节点上设置节点级别性能优化,您可以使用 Node Tuning Operator。在托管的 control plane 中,您可以通过创建包含 Tuned 对象并在节点池中引用这些配置映射的配置映射来配置节点调整。
流程
创建包含有效 tuned 清单的配置映射,并引用节点池中的清单。在以下示例中,
Tuned清单定义了一个配置文件,在包含tuned-1-node-label节点标签的节点上将vm.dirty_ratio设为 55。将以下ConfigMap清单保存到名为tuned-1.yaml的文件中:apiVersion: v1 kind: ConfigMap metadata: name: tuned-1 namespace: clusters data: tuning: | apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: tuned-1 namespace: openshift-cluster-node-tuning-operator spec: profile: - data: | [main] summary=Custom OpenShift profile include=openshift-node [sysctl] vm.dirty_ratio="55" name: tuned-1-profile recommend: - priority: 20 profile: tuned-1-profile注意如果您没有将任何标签添加到 Tuned spec 的
spec.recommend部分中的条目中,则假定基于 node-pool 的匹配,因此spec.recommend部分中的最高优先级配置集应用于池中的节点。虽然您可以通过在 Tuned.spec.recommend.match部分中设置标签值来实现更精细的节点标记匹配,除非您将节点池的.spec.management.upgradeType值设置为InPlace。在管理集群中创建
ConfigMap对象:$ oc --kubeconfig="$MGMT_KUBECONFIG" create -f tuned-1.yaml通过编辑节点池或创建节点池的
spec.tuningConfig字段中引用ConfigMap对象。在本例中,假设您只有一个NodePool,名为nodepool-1,它含有 2 个节点。apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: ... name: nodepool-1 namespace: clusters ... spec: ... tuningConfig: - name: tuned-1 status: ...注意您可以在多个节点池中引用同一配置映射。在托管的 control plane 中,Node Tuning Operator 会将节点池名称和命名空间的哈希值附加到 Tuned CR 的名称中,以区分它们。在这种情况下,请不要为同一托管集群在不同的 Tuned CR 中创建多个名称相同的 TuneD 配置集。
验证
现在,您已创建包含 Tuned 清单的 ConfigMap 对象并在 NodePool 中引用它,Node Tuning Operator 会将 Tuned 对象同步到托管集群中。您可以验证定义了 Tuned 对象,以及将 TuneD 配置集应用到每个节点。
列出托管的集群中的
Tuned对象:$ oc --kubeconfig="$HC_KUBECONFIG" get tuned.tuned.openshift.io -n openshift-cluster-node-tuning-operator输出示例
NAME AGE default 7m36s rendered 7m36s tuned-1 65s列出托管的集群中的
Profile对象:$ oc --kubeconfig="$HC_KUBECONFIG" get profile.tuned.openshift.io -n openshift-cluster-node-tuning-operator输出示例
NAME TUNED APPLIED DEGRADED AGE nodepool-1-worker-1 tuned-1-profile True False 7m43s nodepool-1-worker-2 tuned-1-profile True False 7m14s注意如果没有创建自定义配置集,则默认应用
openshift-node配置集。要确认正确应用了调整,请在节点上启动一个 debug shell,并检查 sysctl 值:
$ oc --kubeconfig="$HC_KUBECONFIG" debug node/nodepool-1-worker-1 -- chroot /host sysctl vm.dirty_ratio输出示例
vm.dirty_ratio = 55
3.5. 为托管 control plane 部署 SR-IOV Operator
托管的 control plane 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
配置和部署托管服务集群后,您可以在托管集群中创建 SR-IOV Operator 订阅。SR-IOV pod 在 worker 机器上运行而不是在 control plane 上运行。
先决条件
您必须在 AWS 上配置和部署托管集群。如需更多信息,请参阅在 AWS 上配置托管集群(技术预览)。
流程
创建命名空间和 Operator 组:
apiVersion: v1 kind: Namespace metadata: name: openshift-sriov-network-operator --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: sriov-network-operators namespace: openshift-sriov-network-operator spec: targetNamespaces: - openshift-sriov-network-operator创建 SR-IOV Operator 的订阅:
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: sriov-network-operator-subsription namespace: openshift-sriov-network-operator spec: channel: "4.13" name: sriov-network-operator config: nodeSelector: node-role.kubernetes.io/worker: "" source: s/qe-app-registry/redhat-operators sourceNamespace: openshift-marketplace
验证
要验证 SR-IOV Operator 是否已就绪,请运行以下命令并查看生成的输出:
$ oc get csv -n openshift-sriov-network-operator输出示例
NAME DISPLAY VERSION REPLACES PHASE sriov-network-operator.4.13.0-202211021237 SR-IOV Network Operator 4.13.0-202211021237 sriov-network-operator.4.13.0-202210290517 Succeeded要验证 SR-IOV pod 是否已部署,请运行以下命令:
$ oc get pods -n openshift-sriov-network-operator
3.6. 删除托管的集群
删除托管的集群的具体步骤会因您使用的供应商而异。
流程
- 如果集群位于 AWS 上,请按照在 AWS 上销毁托管集群的说明进行操作。
- 如果集群位于裸机上,请按照在裸机上销毁托管集群的说明进行操作。
- 如果集群位于 OpenShift Virtualization 上,请按照在 OpenShift Virtualization 上销毁托管集群的说明进行操作。
后续步骤
如果要禁用托管的 control plane 功能,请参阅禁用托管的 control plane 功能。
第 4 章 托管的 control plane 的备份、恢复和灾难恢复
如果您需要在托管集群中备份和恢复 etcd,或为托管集群提供灾难恢复,请参阅以下步骤。
托管的 control plane 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
4.1. 在托管集群中备份和恢复 etcd
如果您在 OpenShift Container Platform 上使用托管的 control plane,则备份和恢复 etcd 的过程与通常的 etcd 备份过程不同。
4.1.1. 在托管集群中执行 etcd 快照
作为为托管集群备份 etcd 的过程的一部分,您需要执行 etcd 的快照。在进行了快照后,您可以恢复快照,例如作为灾难恢复操作的一部分。
此流程需要 API 停机时间。
流程
输入以下命令暂停托管集群的协调:
$ oc patch -n clusters hostedclusters/${CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge输入以下命令停止所有 etcd-writer 部署:
$ oc scale deployment -n ${HOSTED_CLUSTER_NAMESPACE} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver使用每个 etcd 容器中的
exec命令生成 etcd 快照:$ oc exec -it etcd-0 -n ${HOSTED_CLUSTER_NAMESPACE} -- env ETCDCTL_API=3 /usr/bin/etcdctl --cacert /etc/etcd/tls/client/etcd-client-ca.crt --cert /etc/etcd/tls/client/etcd-client.crt --key /etc/etcd/tls/client/etcd-client.key --endpoints=localhost:2379 snapshot save /var/lib/data/snapshot.db$ oc exec -it etcd-0 -n ${HOSTED_CLUSTER_NAMESPACE} -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/data/snapshot.db将快照数据复制到稍后检索它的位置,如 S3 存储桶,如下例所示。
注意以下示例使用签名版本 2。如果您位于支持签名版本 4 的区域,如 us-east-2 区域,请使用签名版本 4。否则,如果您使用签名版本 2 将快照复制到 S3 存储桶,上传会失败,签名版本 2 已被弃用。
Example
BUCKET_NAME=somebucket FILEPATH="/${BUCKET_NAME}/${CLUSTER_NAME}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" ACCESS_KEY=accesskey SECRET_KEY=secret SIGNATURE_HASH=`echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac ${SECRET_KEY} -binary | base64` oc exec -it etcd-0 -n ${HOSTED_CLUSTER_NAMESPACE} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${CLUSTER_NAME}-snapshot.db如果要稍后在新集群中恢复快照,请保存托管集群引用的加密 secret,如下例所示:
Example
oc get hostedcluster $CLUSTER_NAME -o=jsonpath='{.spec.secretEncryption.aescbc}' {"activeKey":{"name":"CLUSTER_NAME-etcd-encryption-key"}} # Save this secret, or the key it contains so the etcd data can later be decrypted oc get secret ${CLUSTER_NAME}-etcd-encryption-key -o=jsonpath='{.data.key}'
后续步骤
恢复 etcd 快照。
4.1.2. 在托管集群中恢复 etcd 快照
如果从托管集群中有 etcd 快照,可以恢复它。目前,您只能在集群创建过程中恢复 etcd 快照。
要恢复 etcd 快照,您需要修改 create cluster --render 命令的输出,并在 HostedCluster 规格的 etcd 部分中定义 restoreSnapshotURL 值。
hcp create 命令中的 --render 标志不会呈现 secret。要呈现 secret,您必须在 hcp create 命令中使用 --render 和 --render-sensitive 标志。
先决条件
在托管集群中执行 etcd 快照。
流程
在
aws命令行界面 (CLI) 中,创建一个预签名的 URL,以便您可以从 S3 下载 etcd 快照,而无需将凭证传递给 etcd 部署:ETCD_SNAPSHOT=${ETCD_SNAPSHOT:-"s3://${BUCKET_NAME}/${CLUSTER_NAME}-snapshot.db"} ETCD_SNAPSHOT_URL=$(aws s3 presign ${ETCD_SNAPSHOT})修改
HostedCluster规格以引用 URL:spec: etcd: managed: storage: persistentVolume: size: 4Gi type: PersistentVolume restoreSnapshotURL: - "${ETCD_SNAPSHOT_URL}" managementType: Managed-
确保从
spec.secretEncryption.aescbc值引用的 secret 包含您在前面的步骤中保存的相同 AES 密钥。
4.2. AWS 区域托管的集群的灾难恢复
对于托管集群需要灾难恢复 (DR) 的情况,您可以将托管集群恢复到 AWS 中的同一区域。例如,当升级管理集群时,需要 DR,托管的集群处于只读状态。
托管的 control plane 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
DR 进程涉及三个主要步骤:
- 在源集群中备份托管集群
- 在目标管理集群中恢复托管集群
- 从源管理集群中删除托管的集群
您的工作负载在此过程中保持运行。集群 API 可能会在一段时间内不可用,但不会影响 worker 节点上运行的服务。
源管理集群和目标管理集群必须具有 --external-dns 标志才能维护 API 服务器 URL,如下例所示:
示例:外部 DNS 标记
--external-dns-provider=aws \
--external-dns-credentials=<AWS Credentials location> \
--external-dns-domain-filter=<DNS Base Domain>
这样,服务器 URL 以 https://api-sample-hosted.sample-hosted.aws.openshift.com 结尾。
如果没有包含 --external-dns 标志来维护 API 服务器 URL,则无法迁移托管集群。
4.2.1. 环境和上下文示例
假设您有三个集群需要恢复的情况。两个是管理集群,一个是托管的集群。您只能恢复 control plane 或 control plane 和节点。开始前,您需要以下信息:
- 源 MGMT 命名空间:源管理命名空间
- Source MGMT ClusterName :源管理集群名称
-
源 MGMT Kubeconfig :源管理
kubeconfig文件 -
Destination MGMT Kubeconfig :目标管理
kubeconfig文件 -
HC Kubeconfig :托管的集群
kubeconfig文件 - SSH 密钥文件:SSH 公钥
- Pull secret:用于访问发行镜像的 pull secret 文件
- AWS 凭证
- AWS 区域
- Base domain:用作外部 DNS 的 DNS 基域
- S3 bucket name:计划上传 etcd 备份的 AWS 区域中的存储桶
此信息显示在以下示例环境变量中。
环境变量示例
SSH_KEY_FILE=${HOME}/.ssh/id_rsa.pub
BASE_PATH=${HOME}/hypershift
BASE_DOMAIN="aws.sample.com"
PULL_SECRET_FILE="${HOME}/pull_secret.json"
AWS_CREDS="${HOME}/.aws/credentials"
AWS_ZONE_ID="Z02718293M33QHDEQBROL"
CONTROL_PLANE_AVAILABILITY_POLICY=SingleReplica
HYPERSHIFT_PATH=${BASE_PATH}/src/hypershift
HYPERSHIFT_CLI=${HYPERSHIFT_PATH}/bin/hypershift
HYPERSHIFT_IMAGE=${HYPERSHIFT_IMAGE:-"quay.io/${USER}/hypershift:latest"}
NODE_POOL_REPLICAS=${NODE_POOL_REPLICAS:-2}
# MGMT Context
MGMT_REGION=us-west-1
MGMT_CLUSTER_NAME="${USER}-dev"
MGMT_CLUSTER_NS=${USER}
MGMT_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT_CLUSTER_NS}-${MGMT_CLUSTER_NAME}"
MGMT_KUBECONFIG="${MGMT_CLUSTER_DIR}/kubeconfig"
# MGMT2 Context
MGMT2_CLUSTER_NAME="${USER}-dest"
MGMT2_CLUSTER_NS=${USER}
MGMT2_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT2_CLUSTER_NS}-${MGMT2_CLUSTER_NAME}"
MGMT2_KUBECONFIG="${MGMT2_CLUSTER_DIR}/kubeconfig"
# Hosted Cluster Context
HC_CLUSTER_NS=clusters
HC_REGION=us-west-1
HC_CLUSTER_NAME="${USER}-hosted"
HC_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}"
HC_KUBECONFIG="${HC_CLUSTER_DIR}/kubeconfig"
BACKUP_DIR=${HC_CLUSTER_DIR}/backup
BUCKET_NAME="${USER}-hosted-${MGMT_REGION}"
# DNS
AWS_ZONE_ID="Z07342811SH9AA102K1AC"
EXTERNAL_DNS_DOMAIN="hc.jpdv.aws.kerbeross.com"4.2.2. 备份和恢复过程概述
备份和恢复过程按如下方式工作:
在管理集群 1 中,您可以将其视为源管理集群,control plane 和 worker 使用 ExternalDNS API 进行交互。可以访问外部 DNS API,并且一个负载均衡器位于管理集群之间。

您为托管集群执行快照,其中包括 etcd、control plane 和 worker 节点。在此过程中,worker 节点仍然会尝试访问外部 DNS API,即使无法访问它,工作负载正在运行,control plane 存储在本地清单文件中,etcd 会备份到 S3 存储桶。data plane 处于活跃状态,control plane 已暂停。

在管理集群 2 中,您可以将其视为目标管理集群,您可以从 S3 存储桶中恢复 etcd,并从本地清单文件恢复 control plane。在此过程中,外部 DNS API 会停止,托管集群 API 变得不可访问,任何使用 API 的 worker 都无法更新其清单文件,但工作负载仍在运行。

外部 DNS API 可以再次访问,worker 节点使用它来移至管理集群 2。外部 DNS API 可以访问指向 control plane 的负载均衡器。

在管理集群 2 中,control plane 和 worker 节点使用外部 DNS API 进行交互。资源从管理集群 1 中删除,但 etcd 的 S3 备份除外。如果您尝试在 mangagement 集群 1 上再次设置托管集群,它将无法正常工作。

您可以手动备份和恢复托管集群,也可以运行脚本来完成这个过程。有关脚本的更多信息,请参阅"运行脚本以备份和恢复托管集群"。
4.2.3. 备份托管集群
要在目标管理集群中恢复托管集群,首先需要备份所有相关数据。
流程
输入以下命令创建 configmap 文件来声明源管理集群:
$ oc create configmap mgmt-parent-cluster -n default --from-literal=from=${MGMT_CLUSTER_NAME}输入这些命令,在托管集群和节点池中关闭协调:
$ PAUSED_UNTIL="true" $ oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge $ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator$ PAUSED_UNTIL="true" $ oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge $ oc patch -n ${HC_CLUSTER_NS} nodepools/${NODEPOOLS} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge $ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator运行此 bash 脚本备份 etcd 并将数据上传到 S3 存储桶:
提示将此脚本嵌套在函数中,并从主功能调用它。
# ETCD Backup ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi for POD in ${ETCD_PODS}; do # Create an etcd snapshot oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl --cacert /etc/etcd/tls/client/etcd-client-ca.crt --cert /etc/etcd/tls/client/etcd-client.crt --key /etc/etcd/tls/client/etcd-client.key --endpoints=localhost:2379 snapshot save /var/lib/data/snapshot.db oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/data/snapshot.db FILEPATH="/${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" set +x ACCESS_KEY=$(grep aws_access_key_id ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SECRET_KEY=$(grep aws_secret_access_key ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SIGNATURE_HASH=$(echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac "${SECRET_KEY}" -binary | base64) set -x # FIXME: this is pushing to the OIDC bucket oc exec -it etcd-0 -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${HC_CLUSTER_NAME}-${POD}-snapshot.db done有关备份 etcd 的更多信息,请参阅 "Backing and restore etcd on a hosted cluster"。
输入以下命令备份 Kubernetes 和 OpenShift Container Platform 对象。您需要备份以下对象:
-
来自 HostedCluster 命名空间的
HostedCluster和NodePool对象 -
来自 HostedCluster 命名空间中的
HostedClustersecret -
来自 Hosted Control Plane 命名空间中的
HostedControlPlane -
来自 Hosted Control Plane 命名空间的
Cluster -
来自 Hosted Control Plane 命名空间的
AWSCluster,AWSMachineTemplate, 和AWSMachine -
来自 Hosted Control Plane 命名空间的
MachineDeployments,MachineSets, 和Machines。 来自 Hosted Control Plane 命名空间的
ControlPlane$ mkdir -p ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS} ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $ chmod 700 ${BACKUP_DIR}/namespaces/ # HostedCluster $ echo "Backing Up HostedCluster Objects:" $ oc get hc ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml $ echo "--> HostedCluster" $ sed -i '' -e '/^status:$/,$d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml # NodePool $ oc get np ${NODEPOOLS} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml $ echo "--> NodePool" $ sed -i '' -e '/^status:$/,$ d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml # Secrets in the HC Namespace $ echo "--> HostedCluster Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS} | grep "^${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-${s}.yaml done # Secrets in the HC Control Plane Namespace $ echo "--> HostedCluster ControlPlane Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} | egrep -v "docker|service-account-token|oauth-openshift|NAME|token-${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-${s}.yaml done # Hosted Control Plane $ echo "--> HostedControlPlane:" $ oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-${HC_CLUSTER_NAME}.yaml # Cluster $ echo "--> Cluster:" $ CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) $ oc get cluster ${CL_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-${HC_CLUSTER_NAME}.yaml # AWS Cluster $ echo "--> AWS Cluster:" $ oc get awscluster ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-${HC_CLUSTER_NAME}.yaml # AWS MachineTemplate $ echo "--> AWS Machine Template:" $ oc get awsmachinetemplate ${NODEPOOLS} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-${HC_CLUSTER_NAME}.yaml # AWS Machines $ echo "--> AWS Machine:" $ CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) for s in $(oc get awsmachines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --no-headers | grep ${CL_NAME} | cut -f1 -d\ ); do oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} awsmachines $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-${s}.yaml done # MachineDeployments $ echo "--> HostedCluster MachineDeployments:" for s in $(oc get machinedeployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do mdp_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-${mdp_name}.yaml done # MachineSets $ echo "--> HostedCluster MachineSets:" for s in $(oc get machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do ms_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-${ms_name}.yaml done # Machines $ echo "--> HostedCluster Machine:" for s in $(oc get machine -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do m_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-${m_name}.yaml done
-
来自 HostedCluster 命名空间的
输入以下命令清理
ControlPlane路由:$ oc delete routes -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all输入该命令,您可以启用 ExternalDNS Operator 来删除 Route53 条目。
运行该脚本验证 Route53 条目是否清理:
function clean_routes() { if [[ -z "${1}" ]];then echo "Give me the NS where to clean the routes" exit 1 fi # Constants if [[ -z "${2}" ]];then echo "Give me the Route53 zone ID" exit 1 fi ZONE_ID=${2} ROUTES=10 timeout=40 count=0 # This allows us to remove the ownership in the AWS for the API route oc delete route -n ${1} --all while [ ${ROUTES} -gt 2 ] do echo "Waiting for ExternalDNS Operator to clean the DNS Records in AWS Route53 where the zone id is: ${ZONE_ID}..." echo "Try: (${count}/${timeout})" sleep 10 if [[ $count -eq timeout ]];then echo "Timeout waiting for cleaning the Route53 DNS records" exit 1 fi count=$((count+1)) ROUTES=$(aws route53 list-resource-record-sets --hosted-zone-id ${ZONE_ID} --max-items 10000 --output json | grep -c ${EXTERNAL_DNS_DOMAIN}) done } # SAMPLE: clean_routes "<HC ControlPlane Namespace>" "<AWS_ZONE_ID>" clean_routes "${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" "${AWS_ZONE_ID}"
验证
检查所有 OpenShift Container Platform 对象和 S3 存储桶,以验证所有内容是否如预期。
后续步骤
恢复托管集群。
4.2.4. 恢复托管集群
收集您备份和恢复目标管理集群中的所有对象。
先决条件
您已从源集群备份数据。
确保目标管理集群的 kubeconfig 文件放置在 KUBECONFIG 变量中,或者在 MGMT2_KUBECONFIG 变量中设置。使用 export KUBECONFIG=<Kubeconfig FilePath>,或者使用 export KUBECONFIG=${MGMT2_KUBECONFIG}。
流程
输入以下命令验证新管理集群是否不包含您要恢复的集群中的任何命名空间:
$ export KUBECONFIG=${MGMT2_KUBECONFIG}$ BACKUP_DIR=${HC_CLUSTER_DIR}/backup目标管理集群中的命名空间删除
$ oc delete ns ${HC_CLUSTER_NS} || true$ oc delete ns ${HC_CLUSTER_NS}-{HC_CLUSTER_NAME} || true输入以下命令重新创建已删除的命名空间:
命名空间创建命令
$ oc new-project ${HC_CLUSTER_NS}$ oc new-project ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}输入以下命令恢复 HC 命名空间中的 secret:
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-*输入以下命令恢复
HostedClustercontrol plane 命名空间中的对象:恢复 secret 命令
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-*集群恢复命令
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-*如果您要恢复节点和节点池来重复利用 AWS 实例,请输入以下命令恢复 HC control plane 命名空间中的对象:
AWS 命令
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-*机器的命令
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-*运行此 bash 脚本恢复 etcd 数据和托管集群:
ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi HC_RESTORE_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-restore.yaml HC_BACKUP_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml HC_NEW_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-new.yaml cat ${HC_BACKUP_FILE} > ${HC_NEW_FILE} cat > ${HC_RESTORE_FILE} <<EOF restoreSnapshotURL: EOF for POD in ${ETCD_PODS}; do # Create a pre-signed URL for the etcd snapshot ETCD_SNAPSHOT="s3://${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" ETCD_SNAPSHOT_URL=$(AWS_DEFAULT_REGION=${MGMT2_REGION} aws s3 presign ${ETCD_SNAPSHOT}) # FIXME no CLI support for restoreSnapshotURL yet cat >> ${HC_RESTORE_FILE} <<EOF - "${ETCD_SNAPSHOT_URL}" EOF done cat ${HC_RESTORE_FILE} if ! grep ${HC_CLUSTER_NAME}-snapshot.db ${HC_NEW_FILE}; then sed -i '' -e "/type: PersistentVolume/r ${HC_RESTORE_FILE}" ${HC_NEW_FILE} sed -i '' -e '/pausedUntil:/d' ${HC_NEW_FILE} fi HC=$(oc get hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} -o name || true) if [[ ${HC} == "" ]];then echo "Deploying HC Cluster: ${HC_CLUSTER_NAME} in ${HC_CLUSTER_NS} namespace" oc apply -f ${HC_NEW_FILE} else echo "HC Cluster ${HC_CLUSTER_NAME} already exists, avoiding step" fi如果您要恢复节点和节点池来重复利用 AWS 实例,请输入以下命令恢复节点池:
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-*
验证
要验证节点是否已完全恢复,请使用此功能:
timeout=40 count=0 NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 while [ ${NODE_POOL_REPLICAS} != ${NODE_STATUS} ] do echo "Waiting for Nodes to be Ready in the destination MGMT Cluster: ${MGMT2_CLUSTER_NAME}" echo "Try: (${count}/${timeout})" sleep 30 if [[ $count -eq timeout ]];then echo "Timeout waiting for Nodes in the destination MGMT Cluster" exit 1 fi count=$((count+1)) NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 done
后续步骤
关闭并删除集群。
4.2.5. 从源集群中删除托管集群
备份托管集群并将其恢复到目标管理集群后,您将关闭并删除源管理集群中的托管集群。
先决条件
您备份了数据并将其恢复到源管理集群。
确保目标管理集群的 kubeconfig 文件放置在 KUBECONFIG 变量中,或者在 MGMT_KUBECONFIG 变量中设置。使用 export KUBECONFIG=<Kubeconfig FilePath> 或使用脚本,请使用 export KUBECONFIG=${MGMT_KUBECONFIG}。
流程
输入以下命令来扩展
deployment和statefulset对象:$ export KUBECONFIG=${MGMT_KUBECONFIG}缩减部署命令
$ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all$ oc scale statefulset.apps -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all$ sleep 15输入以下命令来删除
NodePool对象:NODEPOOLS=$(oc get nodepools -n ${HC_CLUSTER_NS} -o=jsonpath='{.items[?(@.spec.clusterName=="'${HC_CLUSTER_NAME}'")].metadata.name}') if [[ ! -z "${NODEPOOLS}" ]];then oc patch -n "${HC_CLUSTER_NS}" nodepool ${NODEPOOLS} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' oc delete np -n ${HC_CLUSTER_NS} ${NODEPOOLS} fi输入以下命令删除
machine和machineset对象:# Machines for m in $(oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done$ oc delete machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all || true输入以下命令删除集群对象:
$ C_NAME=$(oc get cluster -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name)$ oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${C_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'$ oc delete cluster.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all输入这些命令来删除 AWS 机器 (Kubernetes 对象)。不用担心删除实际的 AWS 机器。云实例不会受到影响。
for m in $(oc get awsmachine.infrastructure.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name) do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done输入以下命令删除
HostedControlPlane和ControlPlaneHC 命名空间对象:删除 HCP 和 ControlPlane HC NS 命令
$ oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} hostedcontrolplane.hypershift.openshift.io ${HC_CLUSTER_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'$ oc delete hostedcontrolplane.hypershift.openshift.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all$ oc delete ns ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} || true输入以下命令删除
HostedCluster和 HC 命名空间对象:删除 HC 和 HC 命名空间命令
$ oc -n ${HC_CLUSTER_NS} patch hostedclusters ${HC_CLUSTER_NAME} -p '{"metadata":{"finalizers":null}}' --type merge || true$ oc delete hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} || true$ oc delete ns ${HC_CLUSTER_NS} || true
验证
要验证所有内容是否正常工作,请输入以下命令:
验证命令
$ export KUBECONFIG=${MGMT2_KUBECONFIG}$ oc get hc -n ${HC_CLUSTER_NS}$ oc get np -n ${HC_CLUSTER_NS}$ oc get pod -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}$ oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}HostedCluster 内的命令
$ export KUBECONFIG=${HC_KUBECONFIG}$ oc get clusterversion$ oc get nodes
后续步骤
删除托管的集群中的 OVN pod,以便您可以连接到新管理集群中运行的新 OVN control plane:
-
使用托管的集群的 kubeconfig 路径加载
KUBECONFIG环境变量。 输入这个命令:
$ oc delete pod -n openshift-ovn-kubernetes --all
4.2.6. 运行脚本来备份和恢复托管集群
要加快进程来备份托管集群并在 AWS 上的同一区域恢复它,您可以修改并运行脚本。
流程
将以下脚本中的变量替换为您的信息:
# Fill the Common variables to fit your environment, this is just a sample SSH_KEY_FILE=${HOME}/.ssh/id_rsa.pub BASE_PATH=${HOME}/hypershift BASE_DOMAIN="aws.sample.com" PULL_SECRET_FILE="${HOME}/pull_secret.json" AWS_CREDS="${HOME}/.aws/credentials" CONTROL_PLANE_AVAILABILITY_POLICY=SingleReplica HYPERSHIFT_PATH=${BASE_PATH}/src/hypershift HYPERSHIFT_CLI=${HYPERSHIFT_PATH}/bin/hypershift HYPERSHIFT_IMAGE=${HYPERSHIFT_IMAGE:-"quay.io/${USER}/hypershift:latest"} NODE_POOL_REPLICAS=${NODE_POOL_REPLICAS:-2} # MGMT Context MGMT_REGION=us-west-1 MGMT_CLUSTER_NAME="${USER}-dev" MGMT_CLUSTER_NS=${USER} MGMT_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT_CLUSTER_NS}-${MGMT_CLUSTER_NAME}" MGMT_KUBECONFIG="${MGMT_CLUSTER_DIR}/kubeconfig" # MGMT2 Context MGMT2_CLUSTER_NAME="${USER}-dest" MGMT2_CLUSTER_NS=${USER} MGMT2_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT2_CLUSTER_NS}-${MGMT2_CLUSTER_NAME}" MGMT2_KUBECONFIG="${MGMT2_CLUSTER_DIR}/kubeconfig" # Hosted Cluster Context HC_CLUSTER_NS=clusters HC_REGION=us-west-1 HC_CLUSTER_NAME="${USER}-hosted" HC_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" HC_KUBECONFIG="${HC_CLUSTER_DIR}/kubeconfig" BACKUP_DIR=${HC_CLUSTER_DIR}/backup BUCKET_NAME="${USER}-hosted-${MGMT_REGION}" # DNS AWS_ZONE_ID="Z026552815SS3YPH9H6MG" EXTERNAL_DNS_DOMAIN="guest.jpdv.aws.kerbeross.com"- 将脚本保存到本地文件系统中。
输入以下命令运行脚本:
source <env_file>其中:
env_file是保存脚本的文件的名称。迁移脚本在以下软件仓库中维护:https://github.com/openshift/hypershift/blob/main/contrib/migration/migrate-hcp.sh。
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.